
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
aramanujam-git/TDI_Coding_Challenge_ARamanujam | https://github.com/aramanujam-git/TDI_Coding_Challenge_ARamanujam | 39e53b06a2789dd0f586980ae25574a0351a1ac8 | 01d6675418b5c702af93bd0edd8b9a9dd3e05b54 | b8e630610fa84186fa8ceb61b312b7b791c03d0a | refs/heads/master | 2022-11-22T07:20:35.239926 | 2020-07-26T16:13:14 | 2020-07-26T16:13:14 | 282,483,960 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7289256453514099,
"alphanum_fraction": 0.7395660877227783,
"avg_line_length": 45.095237731933594,
"blob_id": "ed0dd2ad34cb872653cfcd118cc6dd1210095479",
"content_id": "e684d4cd421150a6df4f3007709c817ea5fa28c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9680,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 210,
"path": "/Section2_TDI_Coding_Challenge.py",
"repo_name": "aramanujam-git/TDI_Coding_Challenge_ARamanujam",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom datetime import datetime\nfrom scipy.stats import chisquare\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom plotly.subplots import make_subplots\nfrom sklearn.linear_model import LinearRegression\nimport requests\nfrom bs4 import BeautifulSoup\nimport math\nimport statistics\n\n############################ SECTION 2 ############################\n\n# The City Record is the official journal of New York City, and provides information provided by city agencies. \n# This data is available in searchable form online at the City Record Online (CROL). For this challenge, \n# we will use a subset of the CROL data consisting only of procurement notices for goods and services.\n\n## MAIN PROGRAM STARTS HERE ##\n\n# Reading the CSV file\nCROL_AllData = pd.read_csv('Recent_Contract_Awards.csv')\n\n# %%\n# Q1: \n# Keep only rows with a StartDate occurring from 2010 to 2019, inclusive. \n# Next, remove all rows for which the ContractAmount field is less than or equal to zero, or is missing entirely. \n# Use this filtered data for the rest of the challenge, as well. For the remaining data, what is the total sum of contract amounts?\n\nCROL_AllData['StartDate'] = pd.to_datetime(CROL_AllData['StartDate'])\nCROL_AllData['EndDate'] = pd.to_datetime(CROL_AllData['EndDate'])\nCROL_FiltDate = CROL_AllData[(CROL_AllData['StartDate'].dt.year > 2009) & (CROL_AllData['StartDate'].dt.year < 2020)]\nCROL_FiltDateAmount = CROL_FiltDate[(CROL_FiltDate.ContractAmount.notnull()) & (\n CROL_FiltDate['ContractAmount'] > 0)].reset_index()\nTotSum_ContAmounts = CROL_FiltDateAmount['ContractAmount'].sum()\n\n# %%\n# Q2:\n# Determine the number of contracts awarded by each agency. \n# For the top 5 agencies in terms the number of contracts, \n# compute the mean ContractAmount per contract. Among these values, \n# what is the ratio of the highest mean contract amount to the second highest?\n\nContractsPerAgency = CROL_FiltDateAmount['AgencyName'].value_counts().index.tolist() # This already sorts the data in descending order\n\nTop5_MeanContAmounts = []\nfor nm in ContractsPerAgency[:5]:\n df = CROL_FiltDateAmount[CROL_FiltDateAmount['AgencyName'] == nm]\n Top5_MeanContAmounts.append(df['ContractAmount'].mean())\n\nTop5_MeanContAmounts.sort(reverse=True)\nRatio_MeanContAmount = Top5_MeanContAmounts[0]/Top5_MeanContAmounts[1]\n\n# %%\n# Q3:\n# Consider only procurements made by the Citywide Administrative Services (CAS) agency \n# and compute the sum contract amount awarded to each unique vendor. \n# What proportion of the total number of contracts in the data set were awarded \n# to the top 50 vendors?\n\nCROL_FiltDateAmount_CAS = CROL_FiltDateAmount[CROL_FiltDateAmount['AgencyName']\n == 'Citywide Administrative Services']\nSumContAmount_CASbyVendor = CROL_FiltDateAmount_CAS.groupby(['VendorName'])[['ContractAmount']].sum()\nCAS_Vendors = SumContAmount_CASbyVendor.sort_values('ContractAmount',ascending=False).index.tolist()\nCROL_FiltDateAmount_CAS_Top50 = CROL_FiltDateAmount_CAS[CROL_FiltDateAmount_CAS['VendorName'].isin(CAS_Vendors[:50])]\nPropContracts_Top50 = len(CROL_FiltDateAmount_CAS_Top50)/len(CROL_FiltDateAmount_CAS)\n\n# %%\n# Q4:\n# Do agencies publish procurement notices uniformly throughout the week? \n# As an example, consider the agency of Parks and Recreation (PnR). For this agency, \n# compute the weekday for which each notice was published, and perform a \n# Chi-squared test on the null hypothesis that each weekday occurs equally often. \n# Report the value of the test statistic.\n\nCROL_FiltDateAmount_PnR = CROL_FiltDateAmount[CROL_FiltDateAmount['AgencyName'] \n == 'Parks and Recreation']\nWeekday_PnR_Notices = []\nfor val in CROL_FiltDateAmount_PnR['StartDate']:\n wkday = datetime(val.year,val.month,val.day).weekday()\n Weekday_PnR_Notices.append(wkday)\n\nfig = go.Figure()\nfig.add_trace(go.Histogram(x=Weekday_PnR_Notices))\nfig.update_traces(opacity=0.75) # Reduce opacity\nfig.show()\n\nWeekday_counts = pd.Series(Weekday_PnR_Notices).value_counts().sort_index()\nWeekday_counts_ChiSq = chisquare(Weekday_counts)\n\n# %%\n# Q5:\n# For this question, consider only contracts with in the categories of \n# Construction Related Services and Construction/Construction Services (CS). \n# The ShortTitle field contains a description of the procured goods/services \n# for each contract. Compute the sum contract amount for contracts whose \n# ShortTitle refer to 'CENTRAL PARK' and for those which refer to \n# 'WASHINGTON SQUARE PARK'. What is the ratio of total construction and \n# contruction-related expenditure for the Central Park contracts compared to the \n# Washington Square Park contracts? Note: you should ensure that 'PARK' \n# appears on its own and not as the beginning of another word.\n\nCROL_FiltDateAmount_CatCS = CROL_FiltDateAmount[CROL_FiltDateAmount['CategoryDescription'].isin(\n ['Construction Related Services','Construction/Construction Services'])]\nCROL_FiltDateAmount_CatCS.reset_index(inplace=True)\n\nContAmount_CatCS_CP = []\nContAmount_CatCS_WSP = []\nfor i, nm in enumerate(CROL_FiltDateAmount_CatCS['ShortTitle']):\n if 'CENTRAL PARK' in nm.upper(): # Case insensitive\n ContAmount_CatCS_CP.append(CROL_FiltDateAmount_CatCS.loc[i,'ContractAmount'])\n if 'WASHINGTON SQUARE PARK' in nm.upper(): # Case insensitive\n ContAmount_CatCS_WSP.append(CROL_FiltDateAmount_CatCS.loc[i, 'ContractAmount'])\n\nRatio_CPtoWSP_Contracts = sum(ContAmount_CatCS_CP)/sum(ContAmount_CatCS_WSP)\n\n# %%\n# Q6:\n# Is there a predictable, yearly pattern of spending for certain agencies? \n# As an example, consider the Environmental Protection agency (EPA). For each month \n# from 2010 through the end of 2019, compute the monthly expenditure for each agency. \n# Once again, use StartDate for the contract date. Then, with a lag of 12 months, \n# report the autocorrelation for total monthly expenditure.\n\nCROL_FiltDateAmount_EPA = CROL_FiltDateAmount[CROL_FiltDateAmount['AgencyName']\n == 'Environmental Protection']\n\nCROL_EPA_MonthlyExp = pd.pivot_table(CROL_FiltDateAmount_EPA, values='ContractAmount', \n index=[CROL_FiltDateAmount_EPA['StartDate'].dt.year, CROL_FiltDateAmount_EPA['StartDate'].dt.month], \n columns=None, aggfunc='sum', fill_value=0)\n\nCROL_EPA_MonthlyExp.index = CROL_EPA_MonthlyExp.index.set_names(['Year', 'Month'])\nCROL_EPA_MonthlyExp.reset_index(inplace=True)\n\nACorr_EPA_MonthlyExp = CROL_EPA_MonthlyExp['ContractAmount'].autocorr(lag=12)\npd.plotting.autocorrelation_plot(CROL_EPA_MonthlyExp['ContractAmount'])\n\n# %%\n# Q7:\n# Consider only contracts awarded by the Citywide Administrative Services (CAS) agency \n# in the category Goods. Compute the total yearly expenditure (using StartDate) \n# for these contracts and fit a linear regression model to these values. \n# What is the R^2 value for this model?\n\nCROL_FiltDateAmount_CAS_Goods = CROL_FiltDateAmount_CAS[CROL_FiltDateAmount_CAS['CategoryDescription'] == 'Goods']\nCROL_CASgoods_YearlyExp = pd.pivot_table(CROL_FiltDateAmount_CAS_Goods, values='ContractAmount',\n index=None, columns=CROL_FiltDateAmount_CAS_Goods['StartDate'].dt.year,\n aggfunc='sum', fill_value=0)\n\nRegModel_list = list(zip(list(CROL_CASgoods_YearlyExp),list(CROL_CASgoods_YearlyExp.loc['ContractAmount'])))\nRegModel_df = pd.DataFrame(RegModel_list, columns=['Year','YearlyExp'])\n\nfig = px.scatter(RegModel_df, x=\"Year\", y=\"YearlyExp\")\nfig.show()\n\nx_vals = np.array(list(CROL_CASgoods_YearlyExp)).reshape((-1, 1))\ny_vals = np.array(list(CROL_CASgoods_YearlyExp.loc['ContractAmount']))\n\nmodel = LinearRegression().fit(x_vals, y_vals)\nr_sq = model.score(x_vals, y_vals)\n\n# %%\n# Q8:\n# In this question, we will examine whether contract expenditure goes to companies \n# located within or outside of New York City. To do so, we will extract the ZIP codes \n# from the VendorAddress field. The ZIP codes pertaining to New York City can be found \n# at the following URL: https: // www.health.ny.gov/statistics/cancer/registry/appendix/neighborhoods.htm. \n# Looking only at contracts with a StartDate in 2018, compute the total expenditure for contracts awarded \n# to vendors listing NYC addresses and those located elsewhere. Report the proportion of the total \n# expenditures awarded to the NYC vendors.\n\nCROL_FiltDateAmount_2018 = CROL_FiltDateAmount[CROL_FiltDateAmount['StartDate'].dt.year == 2018]\nCROL_FiltDateAmount_2018.reset_index(inplace=True)\n\nZipcodes = []\nfor addr in CROL_FiltDateAmount_2018['VendorAddress']:\n zcode = addr.split(\" \")\n Zipcodes.append(zcode[-1])\n\nfor i, zc in enumerate(Zipcodes):\n zcode = zc.split(\"-\")\n Zipcodes[i] = zcode[0]\n\nfor i, zc in enumerate(Zipcodes):\n zcode = zc.split(\",\")\n Zipcodes[i] = zcode[-1]\n\nURL = 'https://www.health.ny.gov/statistics/cancer/registry/appendix/neighborhoods.htm'\npage = requests.get(URL)\nsoup = BeautifulSoup(page.content, 'html.parser')\nresults = soup.find(id='content')\nzcode_elements = results.find_all('td', headers=\"header3\")\nNYzcodes = pd.Series()\nfor zc in zcode_elements:\n zc_split = pd.Series(zc.text.split(\",\"))\n NYzcodes = NYzcodes.append(zc_split, ignore_index=True)\n\nfor i, zc in enumerate(NYzcodes):\n zc_split = zc.split(\" \")\n NYzcodes[i] = zc_split[-1]\n\nNYC_ContExp = []\nfor i in range(len(CROL_FiltDateAmount_2018)):\n if Zipcodes[i] in list(NYzcodes):\n NYC_ContExp.append(CROL_FiltDateAmount_2018.loc[i, 'ContractAmount'])\n\nProp_ExpNYCvendors = sum(NYC_ContExp)/CROL_FiltDateAmount_2018['ContractAmount'].sum()\n"
},
{
"alpha_fraction": 0.5937274098396301,
"alphanum_fraction": 0.6303656697273254,
"avg_line_length": 43.638710021972656,
"blob_id": "71ad6dae7812a85a5decc4f63f84d57c3b3764f4",
"content_id": "bbec64bd266df26cc943734062fcbede577fc201",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13838,
"license_type": "no_license",
"max_line_length": 263,
"num_lines": 310,
"path": "/Section1_TDI_Capstone_Cricket.py",
"repo_name": "aramanujam-git/TDI_Coding_Challenge_ARamanujam",
"src_encoding": "UTF-8",
"text": "import warnings\nimport zipfile\nimport os\nimport pandas as pd \nimport numpy as np\nimport matplotlib.pyplot as plt \nimport seaborn as sns\nimport csv\nimport glob\nfrom datetime import datetime\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom plotly.subplots import make_subplots\nimport math\nimport cufflinks as cf\nimport chart_studio.plotly as py\nsns.set_style(\"darkgrid\")\nwarnings.filterwarnings(\"ignore\")\n\n# %%\n# Function to read all CSV files and parse data\ndef ReadCSVfiles(csv_fpath, game_type):\n with zipfile.ZipFile(csv_fpath + game_type + \"\\CSVfiles.zip\", \"r\") as zip_ref:\n zip_ref.extractall(csv_fpath + game_type)\n filenames = glob.glob(csv_fpath + game_type + \"\\*.csv\")\n CSVnames = []\n csv_data = []\n fname_list = []\n for filename in filenames:\n name = filename.split(\"\\\\\")\n CSVnames.append(name[-1])\n with open(filename) as csvfile:\n readCSV = csv.reader(csvfile, delimiter=',')\n for row in readCSV:\n csv_data.append(row)\n fname = filename.split(\"\\\\\")\n fname_list.append(fname[-1])\n\n games_data_ALL = pd.DataFrame(csv_data, columns=['ball', 'inning', 'over', 'team', 'striker', 'non_striker', 'bowler', 'runs', 'extras', 'wicket', 'player_out'])\n games_data_ALL['CSVfname'] = fname_list\n return games_data_ALL, len(filenames), CSVnames\n\n# Function to compute details for Team 1 and Team 2\ndef MatchInsights(games_data, games_tot, games_ind, games_fnames):\n cols_team1 = ['T1_TeamName', 'T1_TotalScore', 'T1_Wickets', 'T1_TotalOvers',\n 'T1_Score_10overs','T1_TotalRR','T1_10ovRR']\n cols_team2 = ['T2_TeamName', 'T2_TotalScore', 'T2_Wickets', 'T2_TotalOvers',\n 'T2_Score_10overs', 'T2_TotalRR', 'T2_10ovRR']\n team1_data = pd.DataFrame(index=None, columns=cols_team1)\n team2_data = pd.DataFrame(index=None, columns=cols_team2)\n match_date = []\n match_MoM = []\n team1_scores, team1_overs, team1_names, team1_10scores, team1_totRR, team1_10ovRR, team1_wickets = [], [], [], [], [], [], []\n team2_scores, team2_overs, team2_names, team2_10scores, team2_totRR, team2_10ovRR, team2_wickets = [], [], [], [], [], [], []\n \n for i in range(games_tot):\n st = games_ind[i]\n en = games_ind[i+1]\n temp = games_data.iloc[st:en] \n\n # Match date\n date_id = temp[temp['inning'].isin(['date'])]\n full_date = date_id.iloc[0][\"over\"]\n match_date.append(datetime.strptime(full_date,'%Y/%m/%d'))\n\n # Player of the match: MoM\n MoM_id = temp[temp['inning'].isin(['player_of_match'])]\n if MoM_id.empty:\n match_MoM.append('No MoM')\n else:\n MoM_name = MoM_id.iloc[0][\"over\"]\n match_MoM.append(MoM_name)\n\n ## COLLECTING QUANTITATIVE INSIGHTS FOR TEAM1 ##\n temp1 = temp[temp['inning'] == '1']\n if temp1.empty:\n team1_scores.append(0)\n team1_overs.append(0)\n team1_names.append('NR')\n team1_10scores.append(0)\n team1_totRR.append(0)\n team1_10ovRR.append(0)\n team1_wickets.append(-1)\n else:\n # Total Score\n temp1_score = temp1['runs'].apply(pd.to_numeric).sum() + temp1['extras'].apply(pd.to_numeric).sum()\n team1_scores.append(temp1_score)\n # Total overs faced\n temp1 = temp1.reset_index()\n temp1_overs = float(temp1.loc[len(temp1)-1, \"over\"])\n team1_overs.append(temp1_overs) \n # Team1 name\n temp1_name = temp1.loc[0, \"team\"]\n team1_names.append(temp1_name)\n # Total runs scored in first 10 overs: Relevant only for ODIs\n if temp1_overs > 10:\n temp1_10ov = temp1[temp1['over'].apply(pd.to_numeric) <= 10]\n temp1_10score = temp1_10ov['runs'].apply(pd.to_numeric).sum() + temp1_10ov['extras'].apply(pd.to_numeric).sum()\n team1_10scores.append(temp1_10score)\n else:\n team1_10scores.append(0)\n # Total Run-Rate (RR)\n temp1_ovsplit = math.modf(temp1_overs)\n temp1_balls = temp1_ovsplit[1]*6 + min(round(temp1_ovsplit[0]*10),6) # Eliminating extra balls bowled > 6\n team1_totRR.append(temp1_score/temp1_balls*6)\n # 10overs Run-Rate\n if temp1_overs > 10:\n team1_10ovRR.append(temp1_10score/10)\n else:\n team1_10ovRR.append(0)\n # Wickets\n temp1_wkts = [wkts1 for wkts1 in temp1[\"wicket\"] if wkts1]\n team1_wickets.append(len(temp1_wkts)) \n \n ## COLLECTING QUANTITATIVE INSIGHTS FOR TEAM2 ##\n temp2 = temp[temp['inning'] == '2']\n if temp2.empty:\n team2_scores.append(0)\n team2_overs.append(0)\n team2_names.append('NR')\n team2_10scores.append(0)\n team2_totRR.append(0)\n team2_10ovRR.append(0)\n team2_wickets.append(-1)\n else:\n # Total Score\n temp2_score = temp2['runs'].apply(pd.to_numeric).sum() + temp2['extras'].apply(pd.to_numeric).sum()\n team2_scores.append(temp2_score)\n # Total overs faced\n temp2 = temp2.reset_index()\n temp2_overs = float(temp2.loc[len(temp2)-1, \"over\"])\n team2_overs.append(temp2_overs) \n # Team2 name\n temp2_name = temp2.loc[0, \"team\"]\n team2_names.append(temp2_name)\n # Total runs scored in first 10 overs: Relevant only for ODIs\n if temp2_overs > 10:\n temp2_10ov = temp2[temp2['over'].apply(pd.to_numeric) <= 10]\n temp2_10score = temp2_10ov['runs'].apply(pd.to_numeric).sum() + temp2_10ov['extras'].apply(pd.to_numeric).sum()\n team2_10scores.append(temp2_10score)\n else:\n team2_10scores.append(0)\n # Total Run-Rate (RR)\n temp2_ovsplit = math.modf(temp2_overs)\n temp2_balls = temp2_ovsplit[1]*6 + min(round(temp2_ovsplit[0]*10),6) # Eliminating extra balls bowled > 6\n team2_totRR.append(temp2_score/temp2_balls*6)\n # 10overs Run-Rate\n if temp2_overs > 10:\n team2_10ovRR.append(temp2_10score/10)\n else:\n team2_10ovRR.append(0)\n # Wickets\n temp2_wkts = [wkts2 for wkts2 in temp2[\"wicket\"] if wkts2]\n team2_wickets.append(len(temp2_wkts))\n \n # CSV Filenames\n team1_data = team1_data.assign(T1_TeamName=list(team1_names), T1_TotalScore=list(team1_scores), T1_Wickets=list(team1_wickets), T1_TotalOvers=list(team1_overs), T1_Score_10overs=list(team1_10scores), T1_TotalRR=list(team1_totRR), T1_10ovRR=list(team1_10ovRR))\n team2_data = team2_data.assign(T2_TeamName=list(team2_names), T2_TotalScore=list(team2_scores), T2_Wickets=list(team2_wickets), T2_TotalOvers=list(team2_overs), T2_Score_10overs=list(team2_10scores), T2_TotalRR=list(team2_totRR), T2_10ovRR=list(team2_10ovRR))\n\n return team1_data, team2_data, match_date, match_MoM\n\n# Function to get match information\ndef MatchInfo(AllData, Flag, *ColInfo):\n ColInfo = list(ColInfo)\n info_id = AllData[AllData[\"inning\"].isin(ColInfo)].reset_index()\n if Flag:\n ODI_info = list(info_id[\"over\"])\n else:\n ODI_info = list(info_id[\"inning\"])\n return ODI_info\n\n# %%\n## MAIN PROGRAM\n\npath = os.getcwd()\n\n# Parsing data for ODI matches\nODI_games, ODI_tot, ODI_CSVfnames = ReadCSVfiles(path, '\\TDI_Cricket_CSVdata\\ODI')\nODI_games_ind = ODI_games[ODI_games['ball'] == \"version\"].index.tolist()\nODI_games_ind.append(len(ODI_games))\nODI_Team1_AllData, ODI_Team2_AllData, ODI_Dates, ODI_MoMs = MatchInsights(ODI_games, ODI_tot, ODI_games_ind, ODI_CSVfnames)\n\n# Initializing DataFrame for specific match info for ODIs\ncols_games = ['Date', 'Venue', 'City', 'TossWinner',\n 'TossDecision', 'MoM', 'Winner', 'WinMargin', 'WinMarginType']\nODI_game_info = pd.DataFrame(index=None, columns=cols_games)\n\nODI_Venues = MatchInfo(ODI_games, True, 'venue')\nODI_Cities = MatchInfo(ODI_games, True, 'city')\nODI_TossWinners = MatchInfo(ODI_games, True, 'toss_winner')\nODI_TossDecisions = MatchInfo(ODI_games, True, 'toss_decision')\nODI_Winners = MatchInfo(ODI_games, True, 'winner', 'outcome')\nODI_WinMargins = MatchInfo(ODI_games, True, 'winner_runs', 'winner_wickets', 'outcome')\nODI_WinMarginsType = MatchInfo(ODI_games, False, 'winner_runs', 'winner_wickets', 'outcome')\n\nfor i, WinBy in enumerate(ODI_WinMarginsType):\n str_split = WinBy.split('_')\n ODI_WinMarginsType[i] = str_split[-1]\n \nODI_game_info = ODI_game_info.assign(Date=ODI_Dates, Venue=ODI_Venues, City=ODI_Cities, TossWinner=ODI_TossWinners,\n TossDecision=ODI_TossDecisions, MoM=ODI_MoMs, Winner=ODI_Winners, WinMargin=ODI_WinMargins, WinMarginType=ODI_WinMarginsType)\n\nODIs_AllInfo = pd.concat([ODI_game_info, ODI_Team1_AllData, ODI_Team2_AllData], axis=1, sort=False)\nODIs_AllInfo = ODIs_AllInfo.assign(CSVfnames=ODI_CSVfnames)\n\n## FILTERING DATASETS ##\nODIs_AllInfo_WithResult = ODIs_AllInfo[~ODIs_AllInfo['WinMargin'].isin(['no result', 'tie'])].reset_index()\nODIs_AllInfo_WithResult[\"Year\"] = [yr.year for yr in ODIs_AllInfo_WithResult[\"Date\"]]\nODIs_AllInfo_WithResult[\"WinMargin\"]=ODIs_AllInfo_WithResult[\"WinMargin\"].apply(pd.to_numeric)\n\nfor i, nm in enumerate(ODIs_AllInfo_WithResult[\"Winner\"]):\n if nm == ODIs_AllInfo_WithResult.loc[i,\"T1_TeamName\"]:\n ODIs_AllInfo_WithResult.loc[i, \"T1_W/L\"] = 'W'\n else:\n ODIs_AllInfo_WithResult.loc[i, \"T1_W/L\"] = 'L'\n\nfor i, nm in enumerate(ODIs_AllInfo_WithResult[\"Winner\"]):\n if nm == ODIs_AllInfo_WithResult.loc[i, \"T2_TeamName\"]:\n ODIs_AllInfo_WithResult.loc[i, \"T2_W/L\"] = 'W'\n else:\n ODIs_AllInfo_WithResult.loc[i, \"T2_W/L\"] = 'L'\n\nODIs_AllInfo_T1_50ov = ODIs_AllInfo_WithResult[ODIs_AllInfo_WithResult[\"T1_TotalOvers\"] > 49.5]\n\n\n# %% TDI CODING CHALLENGE - EXPLORATORY PLOTS\n\n# PLOT 1\n# Filtering data for Team batting first i.e. Team 1, completing 50 overs and winning the game.\n# X-axis is the total score after 50 overs, Y-axis shows the win margin\n# This is to check the hypothesis that the more you score, the more convincingly you win the game (i.e. greater win margin)\nsns.set(style=\"white\", palette=\"muted\", color_codes=True)\n\ndf1 = ODIs_AllInfo_T1_50ov[ODIs_AllInfo_T1_50ov['T1_W/L'] == 'W']\nfig1_1 = sns.jointplot(\n x=df1[\"T1_TotalScore\"], y=df1[\"WinMargin\"], kind='hex', color='b')\nfig1_1.savefig(\"PLOT1_1.png\")\nplt.show()\n\n# Same data with a regression model\nfig1_2 = sns.jointplot(\n x=df1[\"T1_TotalScore\"], y=df1[\"WinMargin\"], kind='reg', color='b')\nfig1_2.savefig(\"PLOT1_2.png\")\nplt.show()\n\n# PLOT 2\n# Filtering data for Team batting first i.e. Team 1, and completing 50 overs regardless of the outcome.\n# X-axis is the total score after the first 10 overs, Y-axis shows the total score after 50 overs.\n# Does scoring heavily in the first 10 overs with fielding restrictions have an effect on the final score after 50 overs?\nfig2_1 = sns.jointplot(\n x=ODIs_AllInfo_T1_50ov[\"T1_Score_10overs\"], y=ODIs_AllInfo_T1_50ov[\"T1_TotalScore\"],\n kind='hex', color='r')\nfig2_1.savefig(\"PLOT2_1.png\")\nplt.show()\n\n# Same data with a regression model\nfig2_2 = sns.jointplot(\n x=ODIs_AllInfo_T1_50ov[\"T1_Score_10overs\"], y=ODIs_AllInfo_T1_50ov[\"T1_TotalScore\"],\n kind='reg', color='r')\nfig2_2.savefig(\"PLOT2_2.png\")\nplt.show()\n\n# PLOT 3\n# Filtering data for Team batting first i.e. Team 1, and completing 50 overs\n# Computing the win% for range of scores in steps of 25 runs. \n# At what total score can you ensure you have atleast 50% chance of winning the game?\n# The box plot indicates that if the team scores atleast 250, their win% is >50% \n# while scoring >350 runs almost guarantees you a win.\nstep = 25\nScore_range = list(np.arange(225, 425, step))\nT1scores_YearlyWinPct = pd.DataFrame(index=Score_range)\nT1_YrScoreWinpt = []\nfor yr in range(2006, 2021):\n T1scores_WinPct = []\n for i in Score_range:\n df = ODIs_AllInfo_T1_50ov[(ODIs_AllInfo_T1_50ov['T1_TotalScore'] <= i) &\n (ODIs_AllInfo_T1_50ov['T1_TotalScore'] > i-step) &\n (ODIs_AllInfo_T1_50ov['Date'].dt.year == yr)]\n if df.empty:\n T1scores_WinPct.append('')\n T1_YrScoreWinpt.append(['', '', ''])\n else:\n df_WinPct = len(df[df['T1_W/L'] == 'W'])/len(df)*100\n T1scores_WinPct.append(df_WinPct)\n T1_YrScoreWinpt.append([yr, str(i-step)+'-'+str(i), df_WinPct])\n T1scores_YearlyWinPct[str(yr)] = list(T1scores_WinPct)\n\nT1_YrScoreWinpt = pd.DataFrame(T1_YrScoreWinpt, columns=[\n 'Year', 'Score Range', 'Win Pct'])\nT1_YrScoreWinpt = T1_YrScoreWinpt[T1_YrScoreWinpt['Year'] != '']\n\n# Box Plot\nfig3 = go.Figure()\nfig3 = px.box(T1_YrScoreWinpt, x=\"Score Range\", y=\"Win Pct\", points=\"all\")\nfig3.update_layout(title='Win Percentages for Range of Scores - Team Batting First',\n xaxis_title='Score Range',\n yaxis_title='Win Percentage')\nfig3.show()\n\n# PLOT 4\n# History of ODI wins - The best teams between 2006-2020\nTotWins_byCountry = ODIs_AllInfo_WithResult['Winner'].value_counts()\nTotWins_byCountry = pd.DataFrame(TotWins_byCountry).reset_index()\nTotWins_byCountry.columns = [\"Country\", \"Total ODI Wins\"]\nfig4 = px.bar(TotWins_byCountry, x=\"Country\",\n y=\"Total ODI Wins\", color=\"Total ODI Wins\", \n text='Total ODI Wins', color_continuous_scale=px.colors.sequential.Cividis_r)\nfig4.update_traces(textposition='outside')\nfig4.update_layout(uniformtext_minsize=8, uniformtext_mode='hide')\nfig4.show()\n"
},
{
"alpha_fraction": 0.6015999913215637,
"alphanum_fraction": 0.6413333415985107,
"avg_line_length": 29.487804412841797,
"blob_id": "346892447d6a145c451798bc039b76e052c79594",
"content_id": "a542effb027af69405517f8f8b313a854b3c15a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3754,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 123,
"path": "/Section3_TDI_Codin_Challenge.py",
"repo_name": "aramanujam-git/TDI_Coding_Challenge_ARamanujam",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport math\nimport statistics\n\n############################ SECTION 3 ############################\n\n# Consider a chess knight moving on the first quadrant of the plane. It starts at (0,0),\n# and at each step will move two units in one direction and one unit in the other, such\n# that x≥0 and y≥0. At each step the knight randomly selects a valid move, with uniform\n# probability. For example, from (0,1), the knight will move to (1,3), (2,2), or (2,0),\n# each with probability one-third.\n\n# %%\n# Q1:\n# After 10 moves, what is the expected Euclidean distance of the knight from the origin?\n# (If the knight is at (2,1), its distance is sqrt(2**2 + 1**2) = 2.24\n\nx, y = [], []\n\n# Initializing pseudo-random number generator\nnp.random.seed(123)\n\n# This is the constant distance between consecutive knight moves in any possible direction\ndist = math.sqrt(2**2 + 1**2)\n\n# Initializing starting position of X and Y\nx.append(0)\ny.append(0)\n\nmoves = 0\nwhile moves < 10:\n # Computing possible locations where the knight can move from current location\n Pos_X = []\n Pos_Y = []\n for i in range(4): # Within (0,0) to (3,3) quadrant\n for j in range(4): # Within (0,0) to (3,3) quadrant\n EuclDist = math.sqrt((i - x[-1])**2 + (j - y[-1])**2)\n if EuclDist == dist:\n Pos_X.append(i)\n Pos_Y.append(j)\n\n # Picking a possible random move based on equal probability\n RandMove = np.random.randint(0, len(Pos_X))\n x.append(Pos_X[RandMove])\n y.append(Pos_Y[RandMove])\n moves += 1\n\nKnightXYlocs10 = list(zip(x, y))\nFinalEuclDist10 = math.sqrt(x[-1]**2 + y[-1]**2)\n\n# %%\n# Q2:\n# What is the expected standard deviation in this distance?\n\nEuclDists = []\nfor i in range(10):\n EuclDists.append(math.sqrt(x[i+1]**2 + y[i+1]**2))\n\nSD10 = statistics.stdev(EuclDists)\n\n# %%\n# Q3:\n# If the knight made it a distance of at least 10 from the origin some time during\n# those 10 moves, what is its expected Euclidean distance at the end of the 10 moves?\n\n# Computing cumulative distance traveled by the Knight after 10 moves\nCumEuclDist = 0\nfor i in range(10):\n CumEuclDist = CumEuclDist + \\\n math.sqrt((x[i+1] - x[i])**2 + (y[i+1] - y[i])**2)\n\n# %%\n# Q4:\n# What is the expected standard deviation in this distance?\n\n# Answer: The total cumulative distance after 10 moves will be the same every time\n# (i.e. 22.36) since the Knight travels a distance of 2.236 each move regardless\n# of the direction. Hence, the standard deviation will be 0.\n\n# %%\n# Q5:\n# After 100 moves, what is the expected Euclidean distance of the knight from the origin?\n\nx, y = [], []\n\n# This is the constant distance between consecutive knight moves in any possible direction\ndist = math.sqrt(2**2 + 1**2)\n\n# Initializing starting position of X and Y\nx.append(0)\ny.append(0)\n\nmoves = 0\nwhile moves < 100:\n # Computing possible locations where the knight can move from current location\n Pos_X = []\n Pos_Y = []\n for i in range(4): # Within (0,0) to (3,3) quadrant\n for j in range(4): # Within (0,0) to (3,3) quadrant\n EuclDist = math.sqrt((i - x[-1])**2 + (j - y[-1])**2)\n if EuclDist == dist:\n Pos_X.append(i)\n Pos_Y.append(j)\n\n # Picking a possible random move based on equal probability\n RandMove = np.random.randint(0, len(Pos_X))\n x.append(Pos_X[RandMove])\n y.append(Pos_Y[RandMove])\n moves += 1\n\nKnightXYlocs100 = list(zip(x, y))\nFinalEuclDist100 = math.sqrt(x[-1]**2 + y[-1]**2)\n\n# %%\n# Q6:\n# What is the expected standard deviation in this distance?\n\nEuclDists = []\nfor i in range(100):\n EuclDists.append(math.sqrt(x[i+1]**2 + y[i+1]**2))\n\nSD100 = statistics.stdev(EuclDists)\n"
},
{
"alpha_fraction": 0.8214285969734192,
"alphanum_fraction": 0.8214285969734192,
"avg_line_length": 27,
"blob_id": "ccd9f0f0980b35b23144a97dc94827c0b5203452",
"content_id": "929e8bcb0eeb42d2d46638bf04ddfc73dfc33d2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/README.md",
"repo_name": "aramanujam-git/TDI_Coding_Challenge_ARamanujam",
"src_encoding": "UTF-8",
"text": "# TDI_Coding_Challenge_ARamanujam\n TDI_Coding_Challenge\n"
}
] | 4 |
edwkar/marrow | https://github.com/edwkar/marrow | d6e06712d14012afa3c1bc8ff0d6c9ba580bd159 | 8138b44eff2cbcb8f7139cab27f57e6dc263df85 | bb3c3e00f337a0333e9e63d5ce52c49250b7794c | refs/heads/master | 2021-03-24T12:41:34.751721 | 2015-06-19T15:24:35 | 2015-06-19T15:24:35 | 37,729,236 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49753695726394653,
"alphanum_fraction": 0.5123152732849121,
"avg_line_length": 18.519229888916016,
"blob_id": "cef165ed8cae2d643ebfd9c751df51fe0934b504",
"content_id": "31e823bed0e95c49039d0607da6621888a109855",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1015,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 52,
"path": "/test1.py",
"repo_name": "edwkar/marrow",
"src_encoding": "UTF-8",
"text": "import ast\nimport codegen\nfrom ast import *\n\nclass ExprDecorator(ast.NodeTransformer):\n def visit_Num(self, node):\n node.n = 12\n return node\n\n def visit_Assign(self, node):\n return [\n self.generic_visit(node),\n Call(\n func=Name(id=\"__report_assign\", ctx=Load(),), \n args=[], \n keywords=[],\n starargs=None,\n kwargs=None\n )\n ]\n\n def visit_Name(self, node):\n print dir(node)\n print node.ctx\n print node.lineno\n print node.col_offset\n #node.n = 12\n #print dir(node)\n return node\n\n\nexpr=\"\"\"\ndef foo():\n x = 3\n x = y\n y = 3\n print(\"hello world\")\n\ndef foo():\n x = report_assign(pos, v, 3)\n x = report_assign(pos, v, 3) \n y = report_assign(lineno, col, 3)\n print(\"hello world\")\n\n\nreport_call(231, 232, foo, *args, **args)\n\n\"\"\"\np = ast.parse(expr)\np = ExprDecorator().visit(p)\n\nprint(codegen.to_source(p))\n"
},
{
"alpha_fraction": 0.4779411852359772,
"alphanum_fraction": 0.5220588445663452,
"avg_line_length": 18.428571701049805,
"blob_id": "5e0fcdaaddfa77fbfb97f36256f5d824010bd2a2",
"content_id": "ff473bea0ab54b3db0252443c6401db2224d1f9b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 14,
"path": "/test2.py",
"repo_name": "edwkar/marrow",
"src_encoding": "UTF-8",
"text": "def foo(a, b):\n x = a * b\n y = 3\n return y\n\ndef foo(a, b):\n x = __report_assign(7, 8, 3)\n x = __report_assign(pos, v, 3) \n y = __report_assign(lineno, col, 3)\n print(\"hello world\")\n\nfoo(3, 2)\n\nreport_call(0, 3, foo, (report_eval(3), report_eval(2),))\n"
},
{
"alpha_fraction": 0.7090592384338379,
"alphanum_fraction": 0.7212543487548828,
"avg_line_length": 29.210525512695312,
"blob_id": "ca5b4d145de83e56855fa9abfb8aeb7d818c0935",
"content_id": "46eeca7d1e8bed6a0b667966d3009e4161a9aad7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 574,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 19,
"path": "/README.md",
"repo_name": "edwkar/marrow",
"src_encoding": "UTF-8",
"text": "# marrow\n\n\nSee what happens inside a Python program.\n\n## Strategy\nGiven input file `foo.py`...\n\n1. Parse `foo.py` using `ast` module \n2. Generate two versions of `foo.py`\n 1. Tracing version, calling `marrow_report` for each expr.\n Basically rewrite each expr so that it is wrapped in a call\n with line num and pos.\n 2. Decorated version for pygments? \n3. Run tracing version, publish updates on web server (+trace console as well)\n4. Run web site, pygmentize output, flash updates over file \n \n## Steps\n1. Only trace simple expressions. `Name` in context `Load`.\n"
}
] | 3 |
adrianbarwicki/instacard-kaggle-competition | https://github.com/adrianbarwicki/instacard-kaggle-competition | f93632f78ac4389e18aa3f658ec41b54f74d01b2 | 5881d240bead78019216369eea8e4fab4338dd28 | b96078c2a6ac053187319de094669979d3a9a5ea | refs/heads/master | 2021-01-21T14:53:29.155145 | 2017-06-25T12:11:17 | 2017-06-25T12:11:17 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6747404932975769,
"alphanum_fraction": 0.6782007217407227,
"avg_line_length": 31.22222137451172,
"blob_id": "829bc7678bd1db03d35360f11bd075db3297f487",
"content_id": "62b82815a27db48ab2589574ad70b53bc0a6adb1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 289,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 9,
"path": "/main.py",
"repo_name": "adrianbarwicki/instacard-kaggle-competition",
"src_encoding": "UTF-8",
"text": "import numpy as numpy\nimport pandas as pd\n\n## Reading data\ncols_names = [ 'order_id', 'user_id', 'eval_set', 'order_number', 'order_dow', 'order_hour_of_day', 'days_since_prior_order' ]\n\norders = pd.read_csv('./data/orders.csv', sep=',', names=cols_names, encoding='latin-1')\n\nprint orders"
},
{
"alpha_fraction": 0.7651006579399109,
"alphanum_fraction": 0.7785235047340393,
"avg_line_length": 49,
"blob_id": "c21d43a639dd104d18e4c51894041c57bbc3e5e0",
"content_id": "c276244c5523ea8b6ae292800fa553f95199ef58",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 3,
"path": "/download_data.py",
"repo_name": "adrianbarwicki/instacard-kaggle-competition",
"src_encoding": "UTF-8",
"text": "import urllib\n\nurllib.urlretrieve ('https://s3.eu-central-1.amazonaws.com/instacard-kaggle-competition-data/orders.csv.zip', \"./data/orders.csv.zip\")"
}
] | 2 |
ulimy/Study_Django | https://github.com/ulimy/Study_Django | 20ad7e3cd9cd00b034a47b2d571be1f83d4e117b | 43c0fb9da73b6a2403c11ed93d7e6a85b9523797 | d872690aa898ead2dbb241578da5f771b1c38fa7 | refs/heads/master | 2020-04-19T05:08:00.622744 | 2019-05-15T08:13:26 | 2019-05-15T08:13:26 | 167,979,101 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6809391975402832,
"alphanum_fraction": 0.689226508140564,
"avg_line_length": 29.16666603088379,
"blob_id": "11d1724339e056db3d4af74a5a5896b9acb7b6db",
"content_id": "518b4bb97538f2628e9773427b0ad291b0de436d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 24,
"path": "/ClassLion/DjangoProject/blog/views.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render,get_object_or_404,redirect\nfrom .models import Blog\nfrom django.utils import timezone\n\n# Create your views here.\ndef home(request):\n # query set\n blogs = Blog.objects\n return render (request,'blog/home.html',{'blogs' : blogs})\n\ndef detail(request,blog_pk):\n blog_detail = get_object_or_404(Blog,pk=blog_pk)\n return render(request,'blog/detail.html',{'blog' : blog_detail})\n\ndef new(request):\n return render(request,'blog/new.html')\n\ndef create(request):\n blog = Blog()\n blog.title = request.POST['title']\n blog.body = request.POST['body']\n blog.pub_date = timezone.datetime.now()\n blog.save()\n return render(request,'blog/detail.html',{'blog' : blog})\n"
},
{
"alpha_fraction": 0.6533864736557007,
"alphanum_fraction": 0.6533864736557007,
"avg_line_length": 26.88888931274414,
"blob_id": "0737e9d1c600b062e16aa8858c0cb683771965a3",
"content_id": "22ca41e1bffe555be0806b9662ef5931071b5fe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 251,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 9,
"path": "/ClassLion/DjangoProject/blog/urls.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\nurlpatterns =[\n path('',views.home,name=\"home\"),\n path('detail/<int:blog_pk>',views.detail,name=\"detail\"),\n path('new/',views.new,name='new'),\n path('create/',views.create,name=\"create\")\n]\n"
},
{
"alpha_fraction": 0.41421568393707275,
"alphanum_fraction": 0.44117647409439087,
"avg_line_length": 17.545454025268555,
"blob_id": "df9f56885636b4ab37bce721a1bbdb100213e962",
"content_id": "23b0453007c16085811ba6ba4b3e3a3d7b00925d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 22,
"path": "/ClassLion/DjangoProject/wordcount/templates/wordcount/result.html",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "<!-- DOCTYPE html -->\n<html lang=\"en\" dir=\"ltr\">\n <head>\n <meta charset=\"utf-8\">\n <title></title>\n </head>\n <body>\n <a href=\"{%url 'home'%}\">다시하기</a>\n <h1>당신이 입력한 글자 수는 {{count}}개입니다.</h1>\n\n <h2>입력한 텍스트 : </h2>\n <h3>{{text}}</h3>\n\n <h2>단어 카운트 :</h2>\n <h3>\n {% for key,value in detail %}\n {{key}} : {{value}} <br />\n {%endfor%}\n </h3>\n <br />\n </body>\n</html>\n"
},
{
"alpha_fraction": 0.6251851916313171,
"alphanum_fraction": 0.6385185122489929,
"avg_line_length": 30.395349502563477,
"blob_id": "f36f73204de738c6305391823b46efb4a54fd45d",
"content_id": "3e5a0895d767d5bb6a507369479dd8fc6be5ccf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1350,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 43,
"path": "/LikeLion/DjangoProject/restapi/views.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import get_object_or_404\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.http import JsonResponse,HttpResponse\nfrom django.http import QueryDict\nfrom .forms import PostForm\nfrom .models import Post\n\n# Create your views here.\n\n@csrf_exempt\ndef post_list(request):\n if request.method == 'GET':\n rs = Post.objects.all()\n data = [{'pk':post.pk, 'message':post.message} for post in rs]\n return JsonResponse(data,safe=False)\n elif request.method == 'POST':\n form = PostForm(request.POST)\n if form.is_valid():\n post = form.save()\n return HttpResponse(status=201)\n data = form.errors\n return JsonResponse(data,status=400)\n\n\n@csrf_exempt\ndef post_detail(request,pk):\n post = get_object_or_404(Post,pk=pk)\n\n if request.method == 'GET':\n return JsonResponse({'pk':post.pk, 'message':post.message})\n\n elif request.method == 'PUT':\n put = QueryDict(request.body)\n form = PostForm(put,instance=post)\n if form.is_valid():\n post=form.save();\n data = {'pk': post.pk , 'message': post.message}\n return JsonResponse(data=data,status=201)\n return JsonResponse(form.errors)\n\n elif request.method == 'DELETE':\n post.delete();\n return HttpResponse('',status=204)\n"
},
{
"alpha_fraction": 0.7617647051811218,
"alphanum_fraction": 0.7617647051811218,
"avg_line_length": 27.33333396911621,
"blob_id": "8679b440ae5e27f7cb52610f1168d6a2d40d5fcd",
"content_id": "e37781437d286d8e0801bb927a026dcc71f55eef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 12,
"path": "/ClassLion/DjangoProject/portfolio/urls.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from . import views\nfrom django.urls import path\n# media 사용을 위해 settings 필요\nfrom django.conf import settings\nfrom django.conf.urls.static import static\n\nurlpatterns =[\n path('',views.portfolio,name=\"portfolio\"),\n]\n\n# 이미 setting.py 에서 url을 정의 했으므로 이를 더하기만 하면 됨\nurlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n"
},
{
"alpha_fraction": 0.6595744490623474,
"alphanum_fraction": 0.6595744490623474,
"avg_line_length": 22.5,
"blob_id": "d8181287ba1806ccbc6b25d3064d6332d75796fb",
"content_id": "234455bff5d8fc54047b2cad5ccc3e65c7153d7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 4,
"path": "/ClassLion/Readme.md",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "# wordcount : 단어 수 세는 페이지\n# blog : 글 등록 및 조회 기능을 가진 블로그\n# portfolio : static image file 띄우기\n#\n"
},
{
"alpha_fraction": 0.6614173054695129,
"alphanum_fraction": 0.6732283234596252,
"avg_line_length": 35.28571319580078,
"blob_id": "7f547daf2b2cdf7d3ec1bc93ec821ceaf057754d",
"content_id": "beebb6cd9a0dc3147bb5e5fb5a20cad336d782f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 7,
"path": "/LikeLion/Readme.md",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "# LikeLion Django Study\n=======================\n## Polls : Django documentation 따라하기\n참고: [link](https://docs.djangoproject.com/en/2.1/)\n\n## Snippets : Django-rest-framework 따라하기\n참고: [link](https://www.django-rest-framework.org/tutorial/1-serialization/)\n"
},
{
"alpha_fraction": 0.7902163863182068,
"alphanum_fraction": 0.7902163863182068,
"avg_line_length": 33.290321350097656,
"blob_id": "6dd7530bd9d5c5e1d85d597dfa6a0cfbc901a8c1",
"content_id": "4ca02fd189d2012e5d9d875995aa244c27326c87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1087,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 31,
"path": "/LikeLion/DjangoProject/snippets/views.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from rest_framework import generics\nfrom .models import Snippet\nfrom .serializers import SnippetSerializer,UserSerializer\nfrom django.contrib.auth.models import User\nfrom rest_framework import permissions\nfrom snippets.permissions import IsOwnerOrReadOnly\n\n# Create your views here.\nclass snippet_List(generics.ListCreateAPIView):\n # 이 클래스가 가질 queryset과 serializer 미리 선언\n queryset = Snippet.objects.all()\n serializer_class = SnippetSerializer\n permission_classes = (permissions.IsAuthenticatedOrReadOnly,)\n\n def perform_create(self,serializer):\n serializer.save(owner=self.request.user);\n\nclass snippet_Detail(generics.RetrieveUpdateDestroyAPIView):\n\n queryset = Snippet.objects.all()\n serializer_class = SnippetSerializer\n permission_classes = (permissions.IsAuthenticatedOrReadOnly,IsOwnerOrReadOnly)\n\nclass UserList(generics.ListAPIView):\n queryset = User.objects.all()\n serializer_class = UserSerializer\n\n\nclass UserDetail(generics.RetrieveAPIView):\n queryset = User.objects.all()\n serializer_class = UserSerializer\n"
},
{
"alpha_fraction": 0.731225311756134,
"alphanum_fraction": 0.731225311756134,
"avg_line_length": 35.14285659790039,
"blob_id": "2186a53f611706aac334afad132376365ba7969b",
"content_id": "6cb483ac76918a00889d6addc78fb0fd4c3da9ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 14,
"path": "/LikeLion/DjangoProject/snippets/urls.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom snippets import views\nfrom rest_framework.urlpatterns import format_suffix_patterns\nfrom django.conf.urls import include\n\nurlpatterns =[\n path('',views.snippet_List.as_view()),\n path('detail/<int:pk>',views.snippet_Detail.as_view()),\n path('user',views.UserList.as_view()),\n path('detail/<int:pk>',views.UserDetail.as_view()),\n path('api-auth',include('rest_framework.urls',namespace='rest_framework')),\n]\n\nurlpatterns = format_suffix_patterns(urlpatterns)\n"
},
{
"alpha_fraction": 0.6891191601753235,
"alphanum_fraction": 0.6891191601753235,
"avg_line_length": 26.571428298950195,
"blob_id": "9ea8d23a7b15cb804840057b23de16cd04dfc6dc",
"content_id": "de497c3f3b7d1c6907c75758ed7449bc2bb0bc51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 7,
"path": "/LikeLion/DjangoProject/restapi/urls.py",
"repo_name": "ulimy/Study_Django",
"src_encoding": "UTF-8",
"text": "from .views import post_list,post_detail\nfrom django.urls import path\n\nurlpatterns = [\n path('post/',post_list,name='post-list'),\n path('post/<int:pk>/',post_detail,name='post-detail')\n]\n"
}
] | 10 |
Alkalit/kinopoiskparser | https://github.com/Alkalit/kinopoiskparser | 4d47f7c07a4ae8f1d3de479c3b3fc869240e2593 | 5bc704c5758fbe1de19ce348d78ef58773bb5a7c | 854b731bf2055b206fc5ad28d2095d8c1cf98b07 | refs/heads/master | 2020-03-22T20:03:31.441794 | 2018-07-28T16:51:08 | 2018-07-28T16:51:08 | 140,570,207 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8073394298553467,
"alphanum_fraction": 0.8142201900482178,
"avg_line_length": 38.6363639831543,
"blob_id": "d413e8638fb2b8e698090be5d00bb081805d514d",
"content_id": "507a4d334356ea5a34a3d9ace8d54846da008e00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 11,
"path": "/README.md",
"repo_name": "Alkalit/kinopoiskparser",
"src_encoding": "UTF-8",
"text": "# Описание\n\nПростейший парсер топа фильмов с кинопоиска. Для запуска требуется питон 3.5 и несколько зависимостей.\nЗависимости устанавливаются так:\n`pip install -r requirements.txt`\n\nДалее скрипт запускается как обычно `python parser.py`. В качестве БД используется sqlite3. Результатом работы скрипта является файл `parser.db`.\n\n---\n\nРепозиторий является реализацией тестового задания от Topface. Описание задания в прикрепленном pdf.\n"
},
{
"alpha_fraction": 0.5917503833770752,
"alphanum_fraction": 0.593865692615509,
"avg_line_length": 24.904109954833984,
"blob_id": "e41720a286de12412691704c2d682f80149bfb5f",
"content_id": "9064f0a2994016a80fc5482311405965387597f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1891,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 73,
"path": "/parser/parser.py",
"repo_name": "Alkalit/kinopoiskparser",
"src_encoding": "UTF-8",
"text": "import sqlite3\nimport requests\nfrom bs4 import BeautifulSoup\n\ndef create_connection(db_file):\n try:\n conn = sqlite3.connect(db_file)\n return conn\n except Error as e:\n print(e)\n\n return None\n\ndef create_table(conn, create_table_sql):\n try:\n c = conn.cursor()\n c.execute(create_table_sql)\n except Error as e:\n print(e)\n\ndef get_links():\n\n url = 'https://www.kinopoisk.ru/top/'\n\n response = requests.get(url)\n bs = BeautifulSoup(response.content, 'html.parser')\n\n arr = bs.select('table.js-rum-hero a.all')\n return [''.join(['https://www.kinopoisk.ru', tag.attrs['href']]) for tag in arr]\n\ndef parse_a_page(link):\n\n response = requests.get(link)\n bs = BeautifulSoup(response.content, 'html.parser')\n\n name = bs.find('h1', {'class': 'moviename-big'}).text\n likes = bs.find('li', {'class': 'pos'}).find('b').text\n dislikes = bs.find('li', {'class': 'neg'}).find('b').text\n\n return (name, link, int(likes), int(dislikes))\n\ndef main():\n database_path = 'parser.db'\n\n sql_create_film_table = \"\"\"\n CREATE TABLE IF NOT EXISTS film (\n id integer PRIMARY KEY,\n name text NOT NULL,\n url text NOT NULL,\n like text NOT NULL,\n dislike integer NOT NULL\n );\n \"\"\"\n\n conn = create_connection(database_path)\n cursor = conn.cursor()\n if conn is not None:\n create_table(conn, sql_create_film_table)\n else:\n print(\"Error! cannot create the database connection.\")\n\n links = get_links()\n\n for link in links:\n name, link, likes, dislikes = parse_a_page(link)\n print(name, link, likes, dislikes) # TODO logging\n cursor.execute(\"INSERT INTO film (name, url, like, dislike) VALUES (?,?, ?,?)\", [name, link, likes, dislikes])\n\n conn.commit()\n conn.close()\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 2 |
elisehopman/tryagain | https://github.com/elisehopman/tryagain | 9a9eae62dd0b6d49892d9abbfb7089ca1a8a5767 | 3f50f7b72a38d2774f7f424351cd691a404a5085 | 0dd6a1774e3f4eb9e4d7a3ee935900d9e26c5f14 | refs/heads/master | 2016-09-11T19:08:50.300099 | 2016-07-04T18:47:29 | 2016-07-04T18:47:29 | 62,582,002 | 0 | 0 | null | 2016-07-04T18:46:45 | 2016-07-04T18:47:29 | 2016-07-04T18:47:44 | Python | [
{
"alpha_fraction": 0.5664545297622681,
"alphanum_fraction": 0.6026363372802734,
"avg_line_length": 46.04366683959961,
"blob_id": "7bb7e27f8d2e209e3d8f2c1c5678ff2a7b1bfd4e",
"content_id": "21a14b5f5230949fc8d709eb1eb82cb2f84b58e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11000,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 229,
"path": "/functions.py",
"repo_name": "elisehopman/tryagain",
"src_encoding": "UTF-8",
"text": "def showimage(window, time, picture,pl = '1', sizeofpic = 'no', issigns = False, feedback = 'none', mic = False, green = False):\r\n \"\"\" Shows an image in a certain position for a time, picture = path to pic (including .jpg or whatever)\"\"\"\r\n p1 = visual.ImageStim(window, image = picture, pos = [0,0])\r\n if pl == '2':\r\n p1 = visual.ImageStim(window, image = picture, pos = [-200,0])\r\n p2 = visual.ImageStim(window, image = picture, pos = [200,0])\r\n if sizeofpic != 'no':\r\n p2.setSize(sizeofpic)\r\n p2.draw()\r\n if sizeofpic != 'no':\r\n p1.setSize(sizeofpic)\r\n p1.draw()\r\n if issigns == True:\r\n issign = visual.ImageStim(window, image = \"pictures/is.png\", pos = [500,-300], size = [75,45])\r\n issign.draw()\r\n isnot = visual.ImageStim(window, image = \"pictures/isnot.png\", pos = [-500,-300], size = [90,75]) \r\n isnot.draw()\r\n if feedback == 'wrong':\r\n feedb = visual.ImageStim(window, image = \"pictures/rcross.png\", pos = [0,-300], size = [75,75])\r\n feedb.draw()\r\n elif feedback == 'right':\r\n feedb = visual.ImageStim(window, image = \"pictures/gcheck.png\", pos = [0,-300], size = [75,75])\r\n feedb.draw()\r\n if mic == True:\r\n mic = visual. ImageStim(window, image = \"pictures/mic.png\", pos = [0, -300], size = [64,64])\r\n mic.draw()\r\n if green == True:\r\n left = visual.Rect(win,lineColor=\"green\",fillColor=\"green\", pos = [-400, 0] ,size=[10,1210])\r\n left.draw()\r\n right = visual.Rect(win,lineColor=\"green\",fillColor=\"green\", pos = [400, 0] ,size=[10,1210])\r\n right.draw()\r\n up = visual.Rect(win,lineColor=\"green\",fillColor=\"green\", pos = [0, 300] ,size=[1610,10])\r\n up.draw()\r\n down = visual.Rect(win,lineColor=\"green\",fillColor=\"green\", pos = [0, -300] ,size=[1610,10])\r\n down.draw()\r\n window.flip()\r\n core.wait(time)\r\ndef forcedchoiceimage(window, time, picture1, picture2, pl = '1', vid = 'no', keys = 'no'):\r\n \"\"\"shows 2 or 4 images for forced choice\"\"\"\r\n multiple = [360,270]\r\n if pl == '1':\r\n p1 = visual.ImageStim(window, image = picture1, pos = [-400,0], size = multiple)\r\n p2 = visual.ImageStim(window, image = picture2, pos = [400,0], size = multiple)\r\n elif pl == '2':\r\n multiple = [360,270]\r\n p1 = visual.ImageStim(window, image = picture1, pos = [-570,0], size = multiple)\r\n p2 = visual.ImageStim(window, image = picture2, pos = [570,0], size = multiple) \r\n p3 = visual.ImageStim(window, image = picture1, pos = [-230,0], size = multiple)\r\n p4 = visual.ImageStim(window, image = picture2, pos = [230,0], size = multiple) \r\n p3.draw()\r\n p4.draw()\r\n elif pl == '3': # two pics on left one on right \r\n multiple = [360,270]\r\n p1 = visual.ImageStim(window, image = picture1, pos = [-570,0], size = multiple)\r\n p2 = visual.ImageStim(window, image = picture2, pos = [400,0], size = multiple) \r\n p3 = visual.ImageStim(window, image = picture1, pos = [-230,0], size = multiple) \r\n p3.draw()\r\n elif pl == '4': # two pics on right one on left\r\n multiple = [360,270]\r\n p1 = visual.ImageStim(window, image = picture1, pos = [-400,0], size = multiple)\r\n p2 = visual.ImageStim(window, image = picture2, pos = [570,0], size = multiple) \r\n p3 = visual.ImageStim(window, image = picture1, pos = [230,0], size = multiple) \r\n p3.draw()\r\n p1.draw()\r\n p2.draw()\r\n showkeys = 'no'\r\n if keys == 'yes':\r\n showkeys = 'yes'\r\n key1 = visual.TextStim(window, pos = [-500,-300], text='x', color = 'black')\r\n key1.draw()\r\n key2 = visual.TextStim(window, pos = [500, -300], text = 'm', color = 'black')\r\n key2.draw()\r\n window.flip()\r\n core.wait(time)\r\n if vid == 'yes':\r\n twomovies(window, picture1, picture2, keys = showkeys)\r\ndef showfixation(window,t, position):\r\n \"\"\" This function shows a fixation cross for a specified time t at a specified position in a specified window\"\"\"\r\n cross = visual.TextStim(window,pos = position, text='+', color = 'black', height = 80)\r\n cross.draw()\r\n window.flip()\r\n core.wait(t)\r\ndef passivetrial(window, picpath, soundpath, pl = '1', vid = 'no'):\r\n \"\"\" Shows an image and plays the sound that goes with it twice. \"\"\"\r\n # show all pics in the middle of the screen for now\r\n M = [0,0]\r\n single = [480, 360] # sizeofpic trying out\r\n # trial starts with a fixation cross for 500 ms\r\n showfixation(window, 0.5, M)\r\n # put the picture on the screen for 500 ms\r\n endpic = picpath\r\n showimage(window, .5, picpath, pl, sizeofpic = single, green = True)\r\n if vid == 'yes':\r\n endpic = movie(window, picpath, sizeofpic = single, green = True)\r\n # play the sound (while freezing the screen for as long as that takes)\r\n core.wait(playsound(soundpath))\r\n # show the picture for 1.5 s\r\n showimage(window, 1.5, endpic, pl, sizeofpic = single, green = True)\r\n # quick blank screen\r\n blankscreen(window, 0.5)\r\n # and then show the picture for 500 ms\r\n showimage(window, 0.5, picpath, pl, sizeofpic = single, green = True)\r\n if vid == 'yes':\r\n movie(window, picpath, sizeofpic = single, green = True)\r\n # play the sound (while freezing the screen for as long as that takes)\r\n core.wait(playsound(soundpath))\r\n # and then show the picture for 1.5 s\r\n showimage(window, 1, endpic, pl, sizeofpic = single, green = True) \r\ndef activecomptrial(window, picpath1, picpath2, soundpath, pl = '1', vid = 'no'):\r\n \"\"\"Shows an image and plays a sound and has the participant indicate whether these match and gives them feedback\"\"\"\r\n # show all pics in the middle of the screen for now\r\n M = [0,0]\r\n single = [480, 360]\r\n endpic = picpath1\r\n # trial starts with a fixation cross for 500 ms\r\n showfixation(window, 0.5, M)\r\n # put the picture on the screen for 500 ms\r\n showimage(window, .5, picpath1, pl, sizeofpic = single)\r\n if vid == 'yes':\r\n endpic = movie(window, picpath1, sizeofpic = single)\r\n # play the sound (while freezing the screen for as long as that takes)\r\n core.wait(playsound(soundpath))\r\n # show the picture with check and crossmarks\r\n showimage(window, .01, endpic, pl, sizeofpic = single, issigns = True)\r\n response=event.waitKeys(keyList=['f','l'])[0]\r\n # right now it gives you feedback as to which one you chose, not as to whether that was the correct option. \r\n if response==\"f\":\r\n if picpath1 != picpath2:\r\n showimage(window, 1, endpic, pl, sizeofpic = single, feedback = 'right')\r\n blankscreen(window, .5)\r\n else:\r\n showimage(window, 1, endpic, pl, sizeofpic = single, feedback = 'wrong')\r\n elif response == \"l\":\r\n if picpath1 != picpath2:\r\n showimage(window, 1, endpic, pl, sizeofpic = single, feedback = 'wrong')\r\n blankscreen(window, .5)\r\n else:\r\n showimage(window, 1, endpic, pl, sizeofpic = single, feedback = 'right')\r\n # only if the picture changes because the 1st pic wasn't the correct one, there's a whitescreen in between\r\n showimage(window, .5, picpath2, pl, sizeofpic = single, green = True)\r\n endpic = picpath2\r\n if vid == 'yes':\r\n endpic = movie(window, picpath2, sizeofpic = single, green = True)\r\n core.wait(playsound(soundpath))\r\n showimage(window, 2, endpic, pl, sizeofpic = single, green = True) \r\n return response\r\ndef activeprodtrial(window, picpath, soundpath, pl = '1', vid = 'no'):\r\n \"\"\"This function shows a picture, records with a mic, then plays the sound\"\"\"\r\n # show all pics in the middle of the screen for now\r\n M = [0,0]\r\n single = [480, 360]\r\n # trial starts with a fixation cross for 500 ms\r\n showfixation(window, 0.5, M)\r\n # put the picture on the screen for 500 ms\r\n showimage(window, .01, picpath, pl, sizeofpic = single, mic = True)\r\n endpic = picpath\r\n event.clearEvents()\r\n if vid == 'yes':\r\n endpic = movie(window, picpath, sizeofpic = single, mic = True)\r\n mic = microphone.AudioCapture()\r\n recname = 'data/s'+str(subjectnr) + '/recordings/recordingtrial'+ str(trialnr) + '.wav'\r\n mic.record(60, recname, block = False)\r\n while mic.recorder.running:\r\n if 'return' in event.getKeys():\r\n core.wait(2)\r\n mic.stop()\r\n showimage(window, .5, picpath, pl, sizeofpic = single, green = True)\r\n if vid == 'yes':\r\n movie(window, picpath, sizeofpic = single, green = True)\r\n core.wait(playsound(soundpath))\r\n showimage(window, 1, endpic, pl, sizeofpic = single, green = True)\r\ndef forcedchoicetesttrial(window, picpath1, picpath2, soundpath, pl = '1', vid = 'no'): \r\n \"\"\"Shows two pictures, plays a sound, has participant choose between the two pictures. \"\"\"\r\n M = [0,0]\r\n # trial starts with a fixation cross for 500 ms\r\n showfixation(window, 0.5, M)\r\n showkey = 'yes'\r\n forcedchoiceimage(window, .5, picpath1, picpath2, pl, vid, keys = showkey)\r\n # we time how long a trial takes them.\r\n timer2 = core.MonotonicClock()\r\n sound_file = sound.Sound(soundpath)\r\n dur = sound_file.getDuration()\r\n sound_file.play()\r\n response=event.waitKeys(keyList=['x','m'])[0]\r\n reaction = timer2.getTime()\r\n if reaction < dur:\r\n sound_file.stop()\r\n out = [response, reaction]\r\n return out\r\ndef errormonitoringtesttrial(window, soundpath):\r\n \"\"\"play a sound, have participant indicate right or wrong, record time\"\"\"\r\n # show all pics in the middle of the screen for now\r\n M = [0,0]\r\n # trial starts with a fixation cross for 500 ms\r\n showfixation(window, 0.5, M)\r\n showimage(window, .001, \"pictures/empty.png\", issigns = True)\r\n timer2 = core.MonotonicClock()\r\n sound_file = sound.Sound(soundpath)\r\n dur = sound_file.getDuration()\r\n sound_file.play()\r\n response=event.waitKeys(keyList=['f','l'])[0]\r\n reaction = timer2.getTime()\r\n if reaction < dur:\r\n sound_file.stop()\r\n out = [response, reaction]\r\n return out\r\ndef movie(window, name, sizeofpic = 'no', green = False, mic = False):\r\n \"\"\"plays a movie frame by frame\"\"\"\r\n lngth = len(name)\r\n nam = name[0:lngth-5]\r\n for i in range(10):\r\n j = i+1\r\n frame = nam + '%d.png' %j\r\n showimage(window, .025, frame, sizeofpic = sizeofpic, green = green, mic = mic)\r\n return frame\r\ndef twomovies(window, name1, name2, keys = 'no'):\r\n \"\"\"plays two movies side by side for a forced choice trial\"\"\"\r\n lngth1 = len(name1)\r\n shwk = 'no'\r\n if keys == 'yes':\r\n shwk = 'yes'\r\n nam1 = name1[0:lngth1-5]\r\n lngth2 = len(name2)\r\n nam2 = name2[0:lngth2-5] \r\n for i in range(10):\r\n j = i+1\r\n frame1 = nam1 + '%d.png' %j\r\n frame2 = nam2 + '%d.png' %j\r\n forcedchoiceimage(window, 0.025, frame1, frame2, keys = shwk)"
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 4,
"blob_id": "0bb49d24f67f5117a8b2699723c3295ff62f9ae6",
"content_id": "c8b52da9017423b408143496b2ef99dee9528161",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15,
"license_type": "no_license",
"max_line_length": 10,
"num_lines": 3,
"path": "/README.md",
"repo_name": "elisehopman/tryagain",
"src_encoding": "UTF-8",
"text": "# tryagain\n\n#2\n"
}
] | 2 |
rj-james/mcmc-mh | https://github.com/rj-james/mcmc-mh | 8b4aab6fdfba0a26fabd6f59533db82097df8728 | 02f448d22ad1552a971e210ba74c992d3a0556c4 | 09f532165df05b9ca276758fbc36f9fd2c6934c5 | refs/heads/master | 2020-05-24T16:02:26.988606 | 2019-05-18T11:13:14 | 2019-05-18T11:13:14 | 187,347,585 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7824859023094177,
"alphanum_fraction": 0.799435019493103,
"avg_line_length": 43.25,
"blob_id": "8c6565dac7352b65ac40b11ef5606b0a5994140b",
"content_id": "d9312af61b9e5630f7a5eb491ecfcb7145b4dc77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 354,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 8,
"path": "/README.md",
"repo_name": "rj-james/mcmc-mh",
"src_encoding": "UTF-8",
"text": "# mcmc-mh\nMCMC - Metropolis Hastings\n\nIt uses the disease-symptom network described in the paper:\n state space of hypotheses: 256 combinations of diseases;\n evidence space: 256 combinations of symptoms\n\nIt's an implementation of queries that show just two of the biases (subadditivity and superadditivity) because I haven't got the clusters right yet.\n"
},
{
"alpha_fraction": 0.5836294889450073,
"alphanum_fraction": 0.643834114074707,
"avg_line_length": 35.555118560791016,
"blob_id": "223fbd108bff83551f5b2026edaad7065b534525",
"content_id": "4db0dc7355916796bc7a7d6537123d317fc5fd72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9285,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 254,
"path": "/metropolis_hastings.py",
"repo_name": "rj-james/mcmc-mh",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n# THE DISEASE-SYMPTOM DATASET\nstate_space = {\"lung cancer\":0, \"TB\":1, \"respiratory flu\":2, \"cold\":3, \"gastroenteritis\":4,\n \"stomach cancer\":5, \"stomach flu\":6, \"food poisining\":7}\nstate_priors = [0.001, 0.05, 0.1, 0.2, 0.1, 0.05, 0.15, 0.2]\n\nsymptoms = {\"cough\":0, \"fever\":1, \"chest pain\":2, \"short breath\":3, \"nausea\":4, \n \"fatigue\":5, \"stomach cramps\":6, \"abdominal pain\":7}\nsymptom_base = 0.01\n\nparameters = [[0.3, 0.7, 0.05, 0.5, 0.0, 0.0, 0.0, 0.0], [0.0, 0.1, 0.5, 0.3, 0.0, 0.0, 0.1, 0.2],\n [0.5, 0.5, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], [0.5, 0.2, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],\n [0.0, 0.0, 0.2, 0.1, 0.5, 0.1, 0.5, 0.7], [0.0, 0.0, 0.2, 0.3, 0.1, 0.05, 0.2, 0.4], \n [0.0, 0.0, 0.0, 0.0, 0.3, 0.05, 0.1, 0.5], [0.0, 0.0, 0.01, 0.0, 0.1, 0.5, 0.0, 0.0]]\n\n# FOCAL SPACE CLLUSTER: proposal probabilities\nr_fproposal, g_fproposal = [], []\nfor hyp in range(256):\n if (hyp & 240) != 0:\n r_fproposal.append((1-(0.002*16))/240) # respiratory disease\n else:\n r_fproposal.append(0.002) # not respiratory \nfor hyp in range(256):\n if (hyp & 15) != 0:\n g_fproposal.append((1-(0.002*16))/240) # gastrointestinal disease\n else:\n g_fproposal.append(0.002) # not gastrointestinal\n\n# NON-FOCAL SPACE CLUSTER: proposal probabilities\nr_nfproposal, g_nfproposal = [], []\nfor hyp in range(256):\n if (hyp & 240) != 0:\n r_nfproposal.append(0.25/240) # respiratory disease\n else:\n r_nfproposal.append(0.75/16) # not respiratory\nfor hyp in range(256):\n if (hyp & 15) != 0:\n g_nfproposal.append(0.25/240) # gastrointestinal disease\n else:\n g_nfproposal.append(0.75/16) # not respiratory\n \n# calculated according to the noisy-or model\ndef calculate_evidence_prob(hypothesis, symptom):\n prob = 1 - symptom_base\n for disease in range(8):\n if (hypothesis & 2 ** disease) != 0:\n prob *= (1 - parameters[symptom][disease])\n return (1 - prob)\n \ndef propose_hypothesis(current_hypothesis, g_query):\n if g_query:\n fproposal = g_fproposal\n nfproposal = g_nfproposal\n cluster_mask = 240\n else:\n fproposal = r_fproposal\n nfproposal = r_nfproposal\n cluster_mask = 15\n \n if (current_hypothesis & cluster_mask) != 0:\n proposal = np.random.choice([hypoth for hypoth in range(256)], p = fproposal)\n else:\n proposal = np.random.choice([hypoth for hypoth in range(256)], p = nfproposal)\n return proposal\n \ndef critic_function(current_hypothesis, proposed_hypothesis, symptoms_present):\n # prior of observing current and proposed hypotheses\n prob_proph, prob_curh = 1, 1\n for disease in range(8):\n if (2 ** disease & current_hypothesis) != 0:\n prob_curh *= state_priors[disease]\n if (2 ** disease & proposed_hypothesis) != 0:\n prob_proph *= state_priors[disease]\n \n # likelihood of current and proposed hypotheses\n likelihood_proph, likelihood_curh = 1, 1\n for symptom in symptoms_present:\n likelihood_curh *= calculate_evidence_prob(current_hypothesis, symptom)\n likelihood_proph *= calculate_evidence_prob(proposed_hypothesis, symptom)\n \n # Metropolis-Hastings acceptance function\n if ((prob_proph * likelihood_proph) / (prob_curh * likelihood_curh)) < 1:\n acceptance_prob = ((prob_proph * likelihood_proph) / (prob_curh * likelihood_curh))\n else:\n acceptance_prob = 1\n \n if np.random.uniform(0,1) <= acceptance_prob:\n return True\n return False\n \ndef Metropolis_Hastings(evidence, initial_hypothesis, num_samples, symptoms_present, g_query):\n if g_query:\n cluster_mask = 240\n else:\n cluster_mask = 15\n f_count, nf_count = 0, 0\n current_hypothesis = initial_hypothesis\n \n if current_hypothesis & cluster_mask != 0:\n f_count = 1\n else:\n nf_count = 1\n for sample_num in range(1, num_samples):\n proposal = propose_hypothesis(current_hypothesis, g_query)\n if critic_function(current_hypothesis, proposal, symptoms_present):\n current_hypothesis = proposal\n if current_hypothesis & cluster_mask != 0:\n f_count += 1\n else:\n nf_count += 1\n \n return current_hypothesis, f_count, nf_count\n\ndef sample_from_chain(symptoms_present, init_hypothesis, N, g_query):\n \n probabilities = []\n running_count, num_sampled = 0, 0\n\n for num_samples in N:\n current_hyp, f_count, _ = Metropolis_Hastings(symptoms_present, init_hypothesis, \n (num_samples-num_sampled), symptoms_present, g_query)\n running_count += f_count\n# print(num_samples-num_sampled, f_count)\n num_sampled = num_samples\n init_hypothesis = current_hyp\n\n # focal space: gastrointestinal diseases\n prob = running_count / num_sampled\n probabilities.append(prob)\n\n return probabilities\n\nNUM_RUNS = 100\nprint(\"\\nSubadditivity\\n\")\n\n# query: probability that specified symptoms are caused by gastrointestinal diseases\ng_query = True\nsymptoms_present = [symptoms[\"fever\"], symptoms[\"nausea\"], symptoms[\"fatigue\"]]\n\n# packed query evaluation: the probability that these symptoms are present \n# as a manifastation of a gastrointestinal disease\n\nN = [100, 500, 900, 1200, 1600, 2000, 2500, 2800, 3200, 3800]\n\nhyp_priors = [1 - sum(state_priors)] # probability of none of the diseases being present\nfor hyp in range(1, 256):\n prob = 1\n for disease in range(8):\n if (hyp & disease ** 2) != 0:\n prob *= state_priors[disease]\n hyp_priors.append(prob)\n \nnorm_constant = sum(hyp_priors)\nnprobs = [hyp_priors[hyp]/norm_constant for hyp in range(256)]\ninit_hypothesis = np.random.choice([i for i in range(256)], p = nprobs)\n\npacked_probs = []\nfor run in range(NUM_RUNS):\n packed_probs.append(sample_from_chain(symptoms_present, init_hypothesis, N, g_query))\naverage_packed = np.mean(packed_probs, axis=0)\nprint(\"packed \\n{}\".format(average_packed))\n\n# unpacked query evaluation: the probability that these symptoms are present \n# as a manifastation of a gastrointestinal disease\n\nN = [50, 250, 450, 600, 800, 1000, 1250, 1400, 1600, 1900]\n\nprompts = [state_space[\"stomach flu\"], state_space[\"food poisining\"]]\n\nunpacked_probs = []\nfor run in range(NUM_RUNS):\n prompt_prob = []\n for prompt in prompts:\n init_hypothesis = 2 ** prompt\n prompt_prob.append(sample_from_chain(symptoms_present, init_hypothesis, N, g_query))\n\n probabilities = []\n for i in range(len(N)):\n probabilities.append((prompt_prob[0][i] + prompt_prob[1][i]) / 2)\n unpacked_probs.append(probabilities)\n \naverage_unpacked = np.mean(unpacked_probs, axis=0)\nprint(\"\\nunpacked \\n{}\".format(average_unpacked))\n\nimport matplotlib.pyplot as plt\n\nypoints = average_unpacked - average_packed\nxpoints = [100, 500, 900, 1200, 1600, 2000, 2500, 2800, 3200, 3800]\nplt.plot(xpoints, ypoints)\nplt.xlabel('number of samples drawn')\nplt.ylabel('unpacked - packed')\nplt.title('Subadditivity')\nplt.show()\n\nprint(\"\\nSuperadditivity\\n\")\nNUM_RUNS = 100\n\n# query: probability that specified symptoms are caused by gastrointestinal diseases\ng_query = True\nsymptoms_present = [symptoms[\"fever\"], symptoms[\"nausea\"], symptoms[\"fatigue\"]]\n\n# packed query evaluation: the probability that these symptoms are present \n# as a manifastation of a gastrointestinal disease\n\nN = [100, 500, 900, 1200, 1600, 2000, 2500, 2800, 3200, 3800]\n\nhyp_priors = [1 - sum(state_priors)] # probability of none of the diseases being present\nfor hyp in range(1, 256):\n prob = 1\n for disease in range(8):\n if (hyp & disease ** 2) != 0:\n prob *= state_priors[disease]\n hyp_priors.append(prob)\n \nnorm_constant = sum(hyp_priors)\nnprobs = [hyp_priors[hyp]/norm_constant for hyp in range(256)]\ninit_hypothesis = np.random.choice([i for i in range(256)], p = nprobs)\n\npacked_probs = []\nfor run in range(NUM_RUNS):\n packed_probs.append(sample_from_chain(symptoms_present, init_hypothesis, N, g_query))\naverage_packed = np.mean(packed_probs, axis=0)\nprint(\"packed \\n{}\".format(average_packed))\n\n# unpacked query evaluation: the probability that these symptoms are present \n# as a manifastation of a gastrointestinal disease\n\nN = [50, 250, 450, 600, 800, 1000, 1250, 1400, 1600, 1900]\n\nprompts = [state_space[\"gastroenteritis\"], state_space[\"stomach cancer\"]]\n\nunpacked_probs = []\nfor run in range(NUM_RUNS):\n prompt_prob = []\n for prompt in prompts:\n init_hypothesis = 2 ** prompt\n prompt_prob.append(sample_from_chain(symptoms_present, init_hypothesis, N, g_query))\n\n probabilities = []\n for i in range(len(N)):\n probabilities.append((prompt_prob[0][i] + prompt_prob[1][i]) / 2)\n unpacked_probs.append(probabilities)\n \naverage_unpacked = np.mean(unpacked_probs, axis=0)\nprint(\"\\nunpacked \\n{}\".format(average_unpacked))\n\nypoints = average_unpacked - average_packed\nxpoints = [100, 500, 900, 1200, 1600, 2000, 2500, 2800, 3200, 3800]\nplt.plot(xpoints, ypoints)\nplt.xlabel('number of samples drawn')\nplt.ylabel('unpacked - packed')\nplt.title('Superadditivity')\nplt.show()\n"
}
] | 2 |
dhruva71/cpu_temp | https://github.com/dhruva71/cpu_temp | 4182477e1179b914dd77a142299d5b2e6bd44634 | b9b73f675f46a5fc8e35b8a92c4a68e3b1d4170c | 0ac5cff996afdc2b9135907b7ad00be5a259cfdf | refs/heads/master | 2017-12-17T19:49:31.279056 | 2016-12-27T11:48:20 | 2016-12-27T11:48:20 | 77,203,211 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7392784357070923,
"alphanum_fraction": 0.758338987827301,
"avg_line_length": 44.90625,
"blob_id": "eab9ed0d24283378a3812420c622933128be8642",
"content_id": "fb3fc76125b614a1b567f03fb9629abb669f93c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1469,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 32,
"path": "/README.md",
"repo_name": "dhruva71/cpu_temp",
"src_encoding": "UTF-8",
"text": "# CPU_TEMP\nCPU_TEMP allows you to watch for CPU temps and specify a temperature threshold above which, it will sound an alert.\n\n## Requirements\nThe scripts require Python 3.0+ to run. CPU temperatures are currently read from /sys/class/hwmon/hwmon1/temp1_input, and refreshed every 1 second. Sound is played with the help of aplay.\n\n## Usage\nBrowse to the directory where you have cloned the repository and provide execution rights on the script.\nThen,\n./cpu_temp <temperature> [-other misc flags]\n\nFor example: **./cpu_temp 50** would watch your CPU temperatures and play the alert.wav file each time it went above 50.\nFor more help, run **./cpu_temp -h**.\nOther flags include:\n--timestamp : to print timestamps.\n--voff : to disable printing any messages.\n--sound <soundfile> : specify a custom soundfile to play. Must be playable by aplay.\n--silent : disables any audio for alerts.\n\n## Credits\nUser 'danielnieto7' from freesound for [alert.wav](https://www.freesound.org/people/danielnieto7/sounds/135613/).\nThe sound file has been edited in Audacity to reduce the duration.\n\n---\n\n## Why I made this\nTo monitor my CPU temperatures while gaming on Wine. My laptop has a tendency to heat up a lot (thank you Crysis 2).\n\n### Other info\nTested on Arch Linux with Linux Kernel 4.8.13-1-ARCH with an Intel 3610 QM processor. \nTested on Debian 8 Jessie. \nHas some bugs, and the code could definitely use improvements. Feel free to contact me with suggestions on onlinedhruva91@gmail.com.\n"
},
{
"alpha_fraction": 0.5872690081596375,
"alphanum_fraction": 0.5995893478393555,
"avg_line_length": 26.05555534362793,
"blob_id": "b476e476f4327c3293edb8f7ce06460f375b2274",
"content_id": "628549254b3cd7570c75fac545e31c57afc1de45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 487,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/cpu_temp.py",
"repo_name": "dhruva71/cpu_temp",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nfrom sys import version_info, exit\nimport platform\n\nif __name__ == '__main__':\n if platform.system()!=\"Linux\":\n print(\"Your OS might not be supported.\")\n required_v = 3.0\n current_v = version_info\n if current_v.major >= 3:\n import mainfile\n\n mainfile.main()\n else:\n print(\"Requires atleast version \" + str(required_v))\n print(\"Found version {0}.{1}\".format(str(current_v.major), str(current_v.minor)))\n exit(1)\n"
},
{
"alpha_fraction": 0.6284987330436707,
"alphanum_fraction": 0.6321337819099426,
"avg_line_length": 30.988372802734375,
"blob_id": "f2cf2e50fb56f9cb1a8bf77dec0ca95a21d43673",
"content_id": "8f12b40f457f6e398ed9d45e0cf58f2e6a3f4e05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2751,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 86,
"path": "/mainfile.py",
"repo_name": "dhruva71/cpu_temp",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nfrom time import sleep, localtime, strftime\nimport argparse\nfrom subprocess import call\nfrom os import devnull, path\nimport sys\n\n\ndef process_arguements():\n # initialize empty dictionary to pass info\n params = {}\n\n # argument parser\n parser = argparse.ArgumentParser(\"Monitor CPU temperature and play an alert when it exceeds a threshold.\")\n\n # temp is a mandatory arguement\n parser.add_argument(\"temp\", help=\"The temperature above which alert should be played. Must be provided.\", type=int)\n parser.add_argument(\"-t\", \"--timestamp\", help=\"Print timestamps alongwith the temperatures\", action=\"store_true\")\n parser.add_argument(\"--voff\", help=\"Prevents display of all output.\", action=\"store_true\")\n\n sound_group = parser.add_mutually_exclusive_group()\n sound_group.add_argument(\"--sound\", help=\"The sound file to play when temperatures reach a threshold\")\n sound_group.add_argument(\"-s\", \"--silent\", help=\"Silent mode. No sound.\", action=\"store_true\")\n\n args = parser.parse_args()\n\n # insert temperature into dictionary\n params['temp'] = args.temp\n\n # optional arguement handling\n if args.timestamp:\n print(\"Timestamps enabled\")\n params['timestamp'] = True\n\n if args.voff:\n params['voff'] = True\n\n if args.sound:\n print(\"Custom sound file enabled\")\n params['sound'] = args.sound\n\n if args.silent:\n print(\"Silent mode enabled. No warning sounds will be played.\")\n params['silent'] = True\n\n if not args.sound and not args.silent:\n params['sound'] = path.dirname(sys.argv[0]) + \"/alert.wav\"\n\n return params\n\n\n# primary method that reads temps and does the work\ndef read_temps(params, file_handle):\n temp_file = file_handle\n while True:\n temp = temp_file.readline()\n temp = int(temp) / 1000\n\n # if temp > user provided threshold, alert!\n if temp > params['temp'] and not params.get('silent'):\n command = ['aplay', params['sound']]\n call(command, stderr=open(devnull, 'wb'))\n\n # if we don't have a voff flag,\n if not params.get('voff'):\n if params.get('timestamp', None):\n print(strftime(\"[%H:%M:%S] \", localtime()), end=' ')\n print(temp)\n sleep(1)\n temp_file.seek(0)\n\n\ndef main():\n try:\n params = process_arguements()\n try:\n file_handle = open('/sys/class/thermal/thermal_zone0/temp', 'r')\n except FileNotFoundError:\n print(\"Error: Could not find file /sys/class/thermal/thermal_zone0/temp.\")\n exit(1)\n read_temps(params, file_handle)\n\n except KeyboardInterrupt:\n print(\"Received Control-C.\")\n file_handle.close()\n"
}
] | 3 |
abdoulsn/EDA-Pima_Diabetes-NeuralNetwork | https://github.com/abdoulsn/EDA-Pima_Diabetes-NeuralNetwork | c77c771fdc25f3ecdd0b9187dcc5e6c20ca4da58 | 22502379f14bec70c605c786f19320abd59c385b | 42db9f1f6d8f59074ae275561e3a06947d2212a2 | refs/heads/master | 2020-04-29T01:10:44.963501 | 2019-03-18T17:11:17 | 2019-03-18T17:11:17 | 175,721,933 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4147360026836395,
"alphanum_fraction": 0.5092970132827759,
"avg_line_length": 27.089385986328125,
"blob_id": "6ab3c1c31f88c0a79db0b208c061150c0ba58117",
"content_id": "21c6fead4a164a1006fb60537ba63a1fff675fb7",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10080,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 358,
"path": "/PIMA.md",
"repo_name": "abdoulsn/EDA-Pima_Diabetes-NeuralNetwork",
"src_encoding": "UTF-8",
"text": "# EDA ET Creation de reseau de neurone pour PIMA Diabetes indias \nL'objectif des données est de prédire si un patient est diabétique ou non, en fonction de certaines mesures de diagnostic incluses dans l'ensemble de données. \n \nLes varaibles de la bases. \n**Grossesses**: Nombre de fois enceinte \n**Glucose**: La concentration de glucose plasmatique a 2 heures dans un test de tolérance au glucose par voie orale \n**Pression sanguine**: Tension artérielle diastolique (mm Hg) \n**SkinThickness**: Épaisseur du pli cutané des triceps (mm) \n**Insuline**: Insuline sérique 2 heures (mu U / ml) \n**IMC**: Indice de masse corporelle (poids en kg / (taille en m) ^ 2) \n**DiabetesPedigreeFunction**: Fonction pedigree du diabète \n**Âge**: Années \n**Résultat**: Variable de classe (0 ou 1) \n\n\n\n```python\n# This Python 3 environment\nimport warnings\nimport numpy as np # Algebre lineaire \nimport pandas as pd # lecture des donnees en CSV file I/O (e.g. pd.read_csv)\nimport seaborn as sns\nimport itertools \nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight')\n#plt.style.use('seaborn-white')\n#plt.style.use('seaborn')\nimport lightgbm as lgb\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import mean_squared_error\nfrom sklearn.metrics import roc_auc_score, roc_curve\nfrom sklearn.model_selection import StratifiedKFold\nwarnings.filterwarnings('ignore')\nfrom sklearn.model_selection import train_test_split\n```\n\n\n```python\n\n# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- #\n# On charge les donnees avec pandas.\ndf = pd.read_csv('pima.csv')\ndf.info()\n\ndf.isnull().sum() # Pas de donnees manquantes\n\ndiabetic=df[df['Outcome']==1] # les personne diabetiques\nnondiabetic=df[df['Outcome']==0] # les personnes non diabetics\n\n# Distribution de la variables Outcome dans le base\n\nsns.countplot(x='Outcome',data=df)\nplt.show()\ndf['Outcome'].value_counts(1) #len(df[df.Outcome == 1])/len(df['Outcome'])\n# Nous avons plus de individus sains.\n```\n\n <class 'pandas.core.frame.DataFrame'>\n RangeIndex: 768 entries, 0 to 767\n Data columns (total 9 columns):\n Pregnancies 768 non-null int64\n Glucose 768 non-null int64\n BloodPressure 768 non-null int64\n SkinThickness 768 non-null int64\n Insulin 768 non-null int64\n BMI 768 non-null float64\n DiabetesPedigreeFunction 768 non-null float64\n Age 768 non-null int64\n Outcome 768 non-null int64\n dtypes: float64(2), int64(7)\n memory usage: 54.1 KB\n\n\n\n\n\n\n\n\n\n 0 0.651042\n 1 0.348958\n Name: Outcome, dtype: float64\n\n\n\n\n```python\n# Correlation\ncorr = df.corr()\ncorr\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Pregnancies</th>\n <th>Glucose</th>\n <th>BloodPressure</th>\n <th>SkinThickness</th>\n <th>Insulin</th>\n <th>BMI</th>\n <th>DiabetesPedigreeFunction</th>\n <th>Age</th>\n <th>Outcome</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>Pregnancies</th>\n <td>1.000000</td>\n <td>0.129459</td>\n <td>0.141282</td>\n <td>-0.081672</td>\n <td>-0.073535</td>\n <td>0.017683</td>\n <td>-0.033523</td>\n <td>0.544341</td>\n <td>0.221898</td>\n </tr>\n <tr>\n <th>Glucose</th>\n <td>0.129459</td>\n <td>1.000000</td>\n <td>0.152590</td>\n <td>0.057328</td>\n <td>0.331357</td>\n <td>0.221071</td>\n <td>0.137337</td>\n <td>0.263514</td>\n <td>0.466581</td>\n </tr>\n <tr>\n <th>BloodPressure</th>\n <td>0.141282</td>\n <td>0.152590</td>\n <td>1.000000</td>\n <td>0.207371</td>\n <td>0.088933</td>\n <td>0.281805</td>\n <td>0.041265</td>\n <td>0.239528</td>\n <td>0.065068</td>\n </tr>\n <tr>\n <th>SkinThickness</th>\n <td>-0.081672</td>\n <td>0.057328</td>\n <td>0.207371</td>\n <td>1.000000</td>\n <td>0.436783</td>\n <td>0.392573</td>\n <td>0.183928</td>\n <td>-0.113970</td>\n <td>0.074752</td>\n </tr>\n <tr>\n <th>Insulin</th>\n <td>-0.073535</td>\n <td>0.331357</td>\n <td>0.088933</td>\n <td>0.436783</td>\n <td>1.000000</td>\n <td>0.197859</td>\n <td>0.185071</td>\n <td>-0.042163</td>\n <td>0.130548</td>\n </tr>\n <tr>\n <th>BMI</th>\n <td>0.017683</td>\n <td>0.221071</td>\n <td>0.281805</td>\n <td>0.392573</td>\n <td>0.197859</td>\n <td>1.000000</td>\n <td>0.140647</td>\n <td>0.036242</td>\n <td>0.292695</td>\n </tr>\n <tr>\n <th>DiabetesPedigreeFunction</th>\n <td>-0.033523</td>\n <td>0.137337</td>\n <td>0.041265</td>\n <td>0.183928</td>\n <td>0.185071</td>\n <td>0.140647</td>\n <td>1.000000</td>\n <td>0.033561</td>\n <td>0.173844</td>\n </tr>\n <tr>\n <th>Age</th>\n <td>0.544341</td>\n <td>0.263514</td>\n <td>0.239528</td>\n <td>-0.113970</td>\n <td>-0.042163</td>\n <td>0.036242</td>\n <td>0.033561</td>\n <td>1.000000</td>\n <td>0.238356</td>\n </tr>\n <tr>\n <th>Outcome</th>\n <td>0.221898</td>\n <td>0.466581</td>\n <td>0.065068</td>\n <td>0.074752</td>\n <td>0.130548</td>\n <td>0.292695</td>\n <td>0.173844</td>\n <td>0.238356</td>\n <td>1.000000</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n\n```python\n# Randomise the data \nfrom sklearn.utils import shuffle\ndf = shuffle(df)\n# Echantillon de train et de test\nseed = 123\nX_train, X_test= train_test_split(df, test_size =0.25, random_state=seed)\n\napp_X = X_train[X_train.columns[:8]]\ntest_X = X_test[X_test.columns[:8]]\n\napp_Y = X_train['Outcome']\ntest_Y = X_test['Outcome']\n```\n\n\n```python\n\n# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- #\n\n# 1 ! Neural network\n\nimport keras \nimport tensorflow as tf\nfrom keras.models import Sequential \nfrom keras.layers import Dense\nfrom keras.utils.vis_utils import plot_model\n\n# Definisons les callback sur la base de loss pour l'arrete de l'entrainement\nclass myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if(logs.get('loss') < 0.5):\n print(\"\\n Arret de l'entrainement avec car car loss est inferieur a .3\")\n self.model.stop_training = True\n \n \n# 2. Définir le modèle\n# Les modèles de Keras sont définis comme une séquence de couches. Nous créons un modèle séquentiel et ajoutons des couches \n# une par une jusqu'à ce que notre topologie de réseau nous satisfasse soit 12, 8, 8, 8, 1. \n\n\n# create m\nm = Sequential()\nm.add(Dense(12, input_dim=8, init='uniform', activation='relu'))\nm.add(Dense(8, init='uniform', activation='relu'))\nm.add(Dense(8, init='uniform', activation='relu'))\nm.add(Dense(8, init='uniform', activation='relu'))\nm.add(Dense(1, init='uniform', activation='sigmoid'))\nm.summary()\n\n# 3. compilation et execution du modele\nm.compile(loss='mean_squared_error' , optimizer='adam', metrics=['accuracy'])\ncallbacks = myCallback()\nhistory = m.fit(app_X, app_Y, epochs=300, batch_size=len(app_X), verbose=1, callbacks=[callbacks])\n\n```\n\n _________________________________________________________________\n Layer (type) Output Shape Param # \n =================================================================\n dense_26 (Dense) (None, 12) 108 \n _________________________________________________________________\n dense_27 (Dense) (None, 8) 104 \n _________________________________________________________________\n dense_28 (Dense) (None, 8) 72 \n _________________________________________________________________\n dense_29 (Dense) (None, 8) 72 \n _________________________________________________________________\n dense_30 (Dense) (None, 1) 9 \n =================================================================\n Total params: 365\n Trainable params: 365\n Non-trainable params: 0\n _________________________________________________________________\n Epoch 1/400\n 576/576 [==============================] - 0s 865us/step - loss: 0.2500 - acc: 0.3490\n Epoch 2/400\n 576/576 [==============================] - 0s 4us/step - loss: 0.2499 - acc: 0.6510\n Epoch 3/400\n 576/576 [==============================] - 0s 6us/step - loss: 0.2499 - acc: 0.6510\n Epoch 4/400\n 576/576 [==============================] - 0s 9us/step - loss: 0.2498 - acc: 0.6510\n Epoch 5/400\n 576/576 [==============================] - 0s 10us/step - loss: 0.2497 - acc: 0.6510\n Epoch 6/400\n 576/576 [==============================] - 0s 4us/step - loss: 0.2496 - acc: 0.6510\n Epoch 7/400\n ....................................................................................\n \n 576/576 [==============================] - 0s 7us/step - loss: 0.1460 - acc: 0.7830\n Epoch 399/400\n 576/576 [==============================] - 0s 6us/step - loss: 0.1461 - acc: 0.7795\n Epoch 400/400\n 576/576 [==============================] - 0s 7us/step - loss: 0.1461 - acc: 0.7917\n\n\n\n```python\n# le courbe de l'accuracy\nplt.plot(history.history['acc'])\nplt.show()\n```\n\n\n\n\n\n\n```python\n# Evaluation du modele\nscores = m.evaluate(test_X, test_Y)\nprint(\"\\n%s: %.2f%%\" % (m.metrics_names[1], scores[1]*100))\n```\n\n 192/192 [==============================] - 0s 47us/step\n \n acc: 76.56%\n\n"
},
{
"alpha_fraction": 0.6234384179115295,
"alphanum_fraction": 0.6365258693695068,
"avg_line_length": 31.960784912109375,
"blob_id": "452b1a48e53650a8d755c0fe29e1a659df8a13b3",
"content_id": "392044fe4acea8f0bfbe301b0673e85ca8de3fa5",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3372,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 102,
"path": "/pima.py",
"repo_name": "abdoulsn/EDA-Pima_Diabetes-NeuralNetwork",
"src_encoding": "UTF-8",
"text": "# This Python 3 environment\nimport warnings\nimport numpy as np # Algebre lineaire \nimport pandas as pd # lecture des donnees en CSV file I/O (e.g. pd.read_csv)\nimport seaborn as sns\nimport itertools \nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight')\n#plt.style.use('seaborn-white')\n#plt.style.use('seaborn')\nimport lightgbm as lgb\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import mean_squared_error\nfrom sklearn.metrics import roc_auc_score, roc_curve\nfrom sklearn.model_selection import StratifiedKFold\nwarnings.filterwarnings('ignore')\nfrom sklearn.model_selection import train_test_split\n\n# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- #\n# On charge les donnees avec pandas.\ndf = pd.read_csv('pima.csv')\ndf.info()\n\ndf.isnull().sum() # Pas de donnees manquantes\n\ndiabetic=df[df['Outcome']==1] # les personne diabetiques\nnondiabetic=df[df['Outcome']==0] # les personnes non diabetics\n\n# Distribution de la variables Outcome dans le base\n\nsns.countplot(x='Outcome',data=df)\nplt.show()\ndf['Outcome'].value_counts(1) #len(df[df.Outcome == 1])/len(df['Outcome'])\n# Nous avons plus de individus sains.\n\n\n\n# Correlation\ncorr = df.corr()\ncorr\n\n# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- #\n\n# Randomiser les donnees \nfrom sklearn.utils import shuffle\n\n# Echantillon de train et de test\nseed = 123\nX_train, X_test= train_test_split(df, test_size =0.25, random_state=seed)\n\napp_X = X_train[X_train.columns[:8]]\ntest_X = X_test[X_test.columns[:8]]\napp_Y = X_train['Outcome']\ntest_Y = X_test['Outcome']\n\n\n# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+- #\n\n# 1 ! Neural network\n\nimport keras \nimport tensorflow as tf\nfrom keras.models import Sequential \nfrom keras.layers import Dense\nfrom keras.utils.vis_utils import plot_model\n\n# Definisons les callback sur la base de loss pour l'arrete de l'entrainement\nclass myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if(logs.get('loss')<0.15):\n print(\"\\n Arret de l'entrainement avec car car loss est inferieur a .15\")\n self.model.stop_training = True\n \n \n# 2. Définir le modèle\n# Les modèles de Keras sont définis comme une séquence de couches. Nous créons un modèle séquentiel et ajoutons des couches \n# une par une jusqu'à ce que notre topologie de réseau nous satisfasse soit 12, 8, 8, 8, 1. \n\n\n# create m\nm = Sequential()\nm.add(Dense(12, input_dim=8, init='uniform', activation='relu'))\nm.add(Dense(8, init='uniform', activation='relu'))\nm.add(Dense(8, init='uniform', activation='relu'))\nm.add(Dense(8, init='uniform', activation='relu'))\nm.add(Dense(1, init='uniform', activation='sigmoid'))\nm.summary()\n\n# 3. compilation et execution du modele\nm.compile(loss='mean_squared_error' , optimizer='adam', metrics=['accuracy'])\ncallbacks = myCallback()\nhistory = m.fit(app_X, app_Y, epochs=400, batch_size=len(app_X), verbose=1, callbacks=[callbacks])\n\n# le courbe de l'accuracy\nplt.plot(history.history['acc'])\nplt.show()\n\n# Evaluation du modele\n\n# Evaluation du modele\nscores = m.evaluate(app_X, app_Y)\nprint(\"\\n%s: %.2f%%\" % (m.metrics_names[1], scores[1]*100))\n"
}
] | 2 |
oyamoh-brian/HotelReservation | https://github.com/oyamoh-brian/HotelReservation | 869a5c6a81eaecd8e70578de20637cdf717391ff | d0aeb0cdb8b6d0a96e100bdb155013365452cb7b | 7583d4d947721d60460369138614bbc9b65a82b8 | refs/heads/master | 2020-12-27T13:55:13.535943 | 2020-02-03T10:01:44 | 2020-02-03T10:01:44 | 237,926,130 | 0 | 0 | MIT | 2020-02-03T09:14:45 | 2020-02-03T09:41:13 | 2020-02-03T09:41:33 | Python | [
{
"alpha_fraction": 0.5965732336044312,
"alphanum_fraction": 0.6012461185455322,
"avg_line_length": 24.68000030517578,
"blob_id": "9fdf1208889c3e6832d861b93bfb3be6b352b66f",
"content_id": "0a20c772b03733ef8a003c2ff4b6418e261759f0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 25,
"path": "/app.py",
"repo_name": "oyamoh-brian/HotelReservation",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, jsonify, render_template\nimport time\nfrom datetime import datetime\nimport requests\n\n@app.route(\"/webhook\",methods=['POST'])\ndef bot():\n obj = {}\n reply = ''\n str_now = time.strftime('%H:%M:%S')\n date_time_now = datetime.strptime(str_now,'%H:%M:%S')\n str_day_week = datetime.today().strftime('%A')\n google_data = request.get_json(silent=True)\n return jsonify({'fulfillmentText':reply} if len(reply)>=1 else obj)\n\n@app.route(\"/\")\ndef hello():\n return \"\"\"\n <center>\n <h1> \n This is a Bot Find it on https://<bot_client_link> 😊😊\n </h1>\n </center>\n \n \"\"\"\n"
},
{
"alpha_fraction": 0.8031914830207825,
"alphanum_fraction": 0.8031914830207825,
"avg_line_length": 30.16666603088379,
"blob_id": "10a5396344d85ff15e2b2ea094863ee85fc0fd17",
"content_id": "eeb2b71016c3f28fff3a46357b325923722e6c79",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 188,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 6,
"path": "/README.md",
"repo_name": "oyamoh-brian/HotelReservation",
"src_encoding": "UTF-8",
"text": "This is a hotel reservation chatbot webhook \n\nThe webhook listens for POST requests from the language parser and does what it has been told to do\n\n\nIt runs on Flask Python microframework\n\n"
},
{
"alpha_fraction": 0.5301204919815063,
"alphanum_fraction": 0.7228915691375732,
"avg_line_length": 15.699999809265137,
"blob_id": "fbee42b1ad9287513992349a96f808569b29fb8d",
"content_id": "1d0f9fb6a6ebc9614daa79f5da678c776b1ee59e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 166,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 10,
"path": "/requirements.txt",
"repo_name": "oyamoh-brian/HotelReservation",
"src_encoding": "UTF-8",
"text": "click==6.7\nFlask==1.0.2\nitsdangerous==0.24\nJinja2==2.10\nMarkupSafe==1.0\nWerkzeug==0.14.1\ndialogflow==0.4.0\npython-dotenv==0.8.2\nbeautifulsoup4==4.8.2\nrequests==2.20.1"
}
] | 3 |
boxabirds/word-error-rate | https://github.com/boxabirds/word-error-rate | f4a0d50f2f7c4b379ae06b67fecc2be011efbb8e | a970df295467d5dc90fe23707cab066c97a45763 | 34d8e1d52706dea4302bfe979a19c79b5cb8c3c2 | refs/heads/master | 2022-09-24T08:02:37.807435 | 2022-09-05T16:52:46 | 2022-09-05T16:52:46 | 142,654,674 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5541862845420837,
"alphanum_fraction": 0.5636100172996521,
"avg_line_length": 35.7599983215332,
"blob_id": "1ca9b0ac0697476791ee7fb43345af5803e29b9a",
"content_id": "bac64df1e5135a49436b28baa3bbf449174172ad",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2759,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 75,
"path": "/levenstein.py",
"repo_name": "boxabirds/word-error-rate",
"src_encoding": "UTF-8",
"text": "# levenstein distance calculator\n# Word Error Rate (WER) = Subsitutions + Deletions + Insertions / Num Words\n\n#\n#\ndef levenstein(reference,hypothesis):\n norm_ref = reference.split()\n norm_hyp = hypothesis.split()\n\n # if one of them is an empty string then the distance is simply the number of words\n # of the other\n if (len(norm_ref) == 0) or (len(norm_hyp) == 0):\n return abs(len(norm_ref) - len(norm_hyp))\n\n substitutions = 0\n deletions = 0\n insertions = 0\n print(f\"Reference: '{reference}'; hypothesis: '{hypothesis}'\")\n\n # reference index and hypothesis index. They're tracked separately\n # because there may be deletions or insertions\n hi= 0\n ri = 0\n num_hyp_words= len(norm_hyp)\n num_ref_words = len(norm_ref)\n while (ri < num_ref_words) and (hi < num_hyp_words):\n print(f\" -- ri: {ri}; hi: {hi}, \")\n print(f\"comparing '{norm_ref[ri]}' with hypothesis '{norm_hyp[hi]}'\")\n\n # our words don't match\n if norm_ref[ri] != norm_hyp[hi]:\n\n # we're at the last hypothesis word\n if hi == num_hyp_words-1:\n # we're at the last reference word too so don't look ahead\n if ri == num_ref_words-1:\n print(\" -- subtitution case 1\")\n substitutions += 1\n\n elif norm_hyp[hi] == norm_ref[ri+1]:\n print(f\" -- matches reference word at index {ri+1} so it's a deletion case 1\")\n deletions += 1\n ri += 1\n\n else:\n print(\" -- subtitution case 2\")\n substitutions += 1\n\n # deletion: hypothesis matches our NEXT reference word (e.g. r:\"one two three\", h:\"one three\"\n elif norm_ref[ri+1] == norm_hyp[hi]:\n print( \" -- deletion case 2\")\n deletions += 1\n ri += 1\n\n # substitution: NEXT hypothesis word matches NEXT reference word\n # e.g. \"one two three\" vs \"one four three\"\n else:\n print(\" -- subtitution case 3\")\n substitutions +=1\n ri += 1\n hi += 1\n\n # any extra words in the hypothesis are insertions\n hyp_insertions_at_end = num_hyp_words - hi\n print(f\" -- number of hypothesis words left over: {hyp_insertions_at_end}\")\n insertions += hyp_insertions_at_end\n\n # any extra words in reference are deletions\n hyp_deletions_at_end = num_ref_words - ri\n print(f\" -- number of reference words left over: {hyp_deletions_at_end}\")\n deletions += hyp_deletions_at_end\n\n score = substitutions + deletions + insertions\n print(f\"Conclusion: for '{reference}' vs '{hypothesis}': score {score}\\n\")\n return score\n\n\n"
},
{
"alpha_fraction": 0.6716911792755127,
"alphanum_fraction": 0.679411768913269,
"avg_line_length": 35.253334045410156,
"blob_id": "0720250a5cfbfc255688e0209180b36acedcb6bf",
"content_id": "5ade7f8f5cbbd243bcacae250183896078d281c8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2720,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 75,
"path": "/wer.py",
"repo_name": "boxabirds/word-error-rate",
"src_encoding": "UTF-8",
"text": "import sys\nimport argparse\n\nimport jiwer as j\n# uses https://github.com/jitsi/jiwer\n# https://www.researchgate.net/publication/221478089_From_WER_and_RIL_to_MER_and_WIL_improved_evaluation_measures_for_connected_speech_recognition\n# WER: Word Error Rate \n# WIL: Word Information Lost\n# MER: Match Error Rate\n# \"The commonly used WER measure is ideally suited only to\n#CSR applications where output errors can be corrected by\n# typing. For almost any other type of speech recognition system \n# a measure based on the proportion of information communicated would be more useful.\"\n\n\n# file io\nfrom pathlib import Path\n\ndef test_jiwer():\n ground_truth = \"hello world\"\n hypothesis = \"hello duck\"\n\n\n wer_val = j.wer(ground_truth, hypothesis)\n print( f\"wer = {wer_val}\")\n mer_val = j.mer(ground_truth, hypothesis)\n print( f\"mer = {mer_val}\")\n wil_val = j.wil(ground_truth, hypothesis)\n print( f\"wil = {wil_val}\")\n\n # faster, because `compute_measures` only needs to perform the heavy lifting once:\n measures = j.compute_measures(ground_truth, hypothesis)\n wer = measures['wer']\n mer = measures['mer']\n wil = measures['wil']\n\n\n\ndef import_and_compare_two_files(reference = \"reference.txt\", hypothesis = \"hypothesis.txt\"):\n # read files\n with open(reference, \"r\") as ref:\n reference = ref.read()\n with open(hypothesis, \"r\") as hyp:\n hypothesis = hyp.read()\n\n # we want to heavily normalise the text -- none of these things are significant\n # when it comes to comparing the text\n transformation = j.Compose([\n j.ToLowerCase(),\n j.RemoveWhiteSpace(replace_by_space=True),\n j.RemoveMultipleSpaces(),\n j.RemovePunctuation(),\n j.ReduceToListOfListOfWords(word_delimiter=\" \")\n ]) \n\n # compare\n measures = j.compute_measures(reference, hypothesis, transformation, transformation)\n wer = measures['wer']\n mer = measures['mer']\n wil = measures['wil']\n return(wer, mer, wil)\n\nif __name__ == \"__main__\":\n print( \"=== Word error rate / word information lost / match error rate test ===\" )\n # extract reference and hypothesis files from command line arguments\n parser = argparse.ArgumentParser(description='Compare two text files.')\n parser.add_argument('--reference', type=str, help='reference file')\n parser.add_argument('--hypothesis', type=str, help='hypothesis file')\n args = parser.parse_args()\n reference = args.reference\n hypothesis = args.hypothesis\n (wer, mer, wil) = import_and_compare_two_files(reference, hypothesis)\n print( f\"Word Error Rate = {wer*100:.2f}%\")\n print( f\"Match Error Rate = {mer*100:.2f}%\")\n print( f\"Word Information Loss = {wil*100:.2f}%\")\n\n"
},
{
"alpha_fraction": 0.6354220509529114,
"alphanum_fraction": 0.6452615261077881,
"avg_line_length": 40.9782600402832,
"blob_id": "4d912f2e67b0e50d448aa1242c1ac0ea30be71df",
"content_id": "3b55ce6ccf4a817bd5c9a2ea7849b302e32f3442",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1931,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 46,
"path": "/test_levenstein.py",
"repo_name": "boxabirds/word-error-rate",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom levenstein import levenstein\n\n\nclass LevensteinTestCase(unittest.TestCase):\n def test_zero(self):\n self.assertEqual(0, levenstein(\"\", \"\"))\n self.assertEqual(0, levenstein(\"one\", \"one\"))\n self.assertEqual(0, levenstein(\"one two\", \"one two\"))\n self.assertEqual(0, levenstein(\"one two\", \"one two\"))\n\n def test_insertions(self):\n self.assertEqual(1, levenstein(\"\", \"one\"))\n self.assertEqual(1, levenstein(\"one\", \"one two\"))\n\n def test_substitutions(self):\n self.assertEqual(1, levenstein(\"one two\", \"one too\"))\n self.assertEqual(1,levenstein(\"one two three\", \"one four three\"))\n self.assertEqual(1, levenstein(\"one two three\", \"one two free\"))\n self.assertEqual(1, levenstein(\"one two three four five\", \"one two free four five\"))\n self.assertEqual(2, levenstein(\"one two three four five\", \"one two free for five\"))\n\n def test_deletions(self):\n self.assertEqual(1, levenstein(\"one\", \"\"))\n self.assertEqual(1, levenstein(\"one two three \", \"one three\"))\n self.assertEqual(1, levenstein(\"one two three four\", \"one three four\"))\n self.assertEqual(1, levenstein(\"one two three\", \"two three\"))\n\n # this could be interpreted as:\n # substitution + 5 insertions\n # 5 deletions\n # the second doesn't make any sense in the context of speech as the same word\n # could occur more than once so it's best to only evaluate the next token\n # for comparison\n self.assertEqual(6,levenstein(\"one two three four five six seven\", \"one seven\"))\n\n\n def test_deletions_and_insertions(self):\n # there are two ways to interpret this, but both produce the same score:\n # substitution and subsitution\n # deletion and insertion\n self.assertEqual(2,levenstein(\"one two three\", \"one three four\"))\n\n\nif __name__ == \"__main__\":\n unittest.main()\n"
}
] | 3 |
georgantasp/Python_Class_send_Text | https://github.com/georgantasp/Python_Class_send_Text | 21d0ab3946359ddc237bb82c2eb64b7c8fccb7c5 | 566b2e6992ace5616da4673f19eb0b1c3b785ca2 | 1b2e67651d49c6cdd72f4f3fce7ce82d4e2f0ecd | refs/heads/master | 2017-05-20T14:00:00.212631 | 2014-12-26T07:24:54 | 2014-12-26T07:24:54 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7195571660995483,
"alphanum_fraction": 0.7822878360748291,
"avg_line_length": 40.69230651855469,
"blob_id": "0aad77973b6adfb567f6e9478f0120be68cb45aa",
"content_id": "e6be88ec8825988e6c826da9b064b5a89ae17651",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 13,
"path": "/send_text.py",
"repo_name": "georgantasp/Python_Class_send_Text",
"src_encoding": "UTF-8",
"text": "from twilio.rest import TwilioRestClient\n\n# Your Account Sid and Auth Token from twilio.com/user/account\naccount_sid = \"ACfa453efad70b9e86ad8f9fe7cdc6feab\" # Create account on twilio websit and copy and paste your acc_sid and aut_token\nauth_token = \"f2cab17213ec8362179caf091600a8f5\"\n\nclient = TwilioRestClient(account_sid, auth_token)\n\nmessage = client.messages.create(body=\"Pandey if you get this message then please inform Rohan )\",\nto=\"+16602382434\", # Replace with your phone number\nfrom_=\"+16602624892\") # Replace with your Twilio number\n\nprint message.sid\n"
}
] | 1 |
paapu88/TrainSVM | https://github.com/paapu88/TrainSVM | 9cf5ff79cd52eb7e342c6eb118c7975e589545b8 | 01e53d4f8d5ff7c24c2c9f998fca5c0dfe8cb288 | 2d47e01a779897e201f924b30b2f7284c0532241 | refs/heads/master | 2021-01-19T18:32:50.426349 | 2017-04-20T13:34:32 | 2017-04-20T13:34:32 | 88,363,484 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6035805344581604,
"alphanum_fraction": 0.6287521719932556,
"avg_line_length": 29.19512176513672,
"blob_id": "1d44251cedfba76a0509ae46e0d488054cef4e66",
"content_id": "2dd8769f6ddd426171ab1d861d648aae738ed0d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7432,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 246,
"path": "/character.py",
"repo_name": "paapu88/TrainSVM",
"src_encoding": "UTF-8",
"text": "\n'''\nSVM and KNearest digit recognition.\n\nSample loads a dataset of characters as image and tehir labels as a txt file\nThen it trains a SVM and KNearest classifiers on it and evaluates\ntheir accuracy.\n\nFollowing preprocessing is applied to the dataset:\n - Moment-based image deskew (see deskew())\n - Digit images are split into cells and 16-bin\n histogram of oriented gradients is computed for each\n cell\n - Transform histograms to space with Hellinger metric (see [1] (RootSIFT))\n\n\n[1] R. Arandjelovic, A. Zisserman\n \"Three things everyone should know to improve object retrieval\"\n http://www.robots.ox.ac.uk/~vgg/publications/2012/Arandjelovic12/arandjelovic12.pdf\n\nUsage:\n\tpython3 ./character.py allSVM.tif allSVM.txt\n\n allSVM.tif contains images of positive (and negative if binary) samples\n allSVM.txt contains labels\n\n'''\n\n\n# Python 2/3 compatibility\nfrom __future__ import print_function\n\n# built-in modules\nfrom multiprocessing.pool import ThreadPool\n\nimport cv2\n\nimport numpy as np\nfrom numpy.linalg import norm\n\n# local modules\nfrom common import clock, mosaic\n\n\n\nSH = 18 # height of a character\nSW = 12 # width of a character\n\n# CLASS_N = 33 #number of characters (missing IOQÅÄÖ, digits one and zero are used instead of I and O in Fin plates)\n\n\ndef split2d(img, cell_size, flatten=True):\n h, w = img.shape[:2]\n sx, sy = cell_size\n cells = [np.hsplit(row, w//sx) for row in np.vsplit(img, h//sy)]\n cells = np.array(cells)\n if flatten:\n cells = cells.reshape(-1, sy, sx)\n return cells\n\ndef str2int(x):\n return ord(x)\n\ndef load_digits(fndata, fnlabels):\n import json\n print('loading \"%s\" ...' % fndata)\n digits_img = cv2.imread(fndata, 0)\n #n_one_char = int(round(digits_img.size[1]/SW)) # number of samples in one row, one row is for one char\n digits = split2d(digits_img, (SW, SH))\n with open(fnlabels, 'r') as f:\n lines = f.readlines()\n labels=[]\n for line in lines:\n labels.append(ord(line.split()[0]))\n\n labels = np.asarray(labels)\n # map ascii codes of characters to integers 0..34\n icount = 0\n labels_dict = {}\n for key in labels:\n if not(key in labels_dict.keys()):\n labels_dict[key]=icount\n icount = icount + 1\n # return labels as an mp array of numbers from 0 to 34\n labels = [labels_dict[l] for l in labels]\n labels = np.asarray(labels)\n\n # write dictionary to disc, so we get asciis of characters\n\n\n # load dict from file:\n #with open('/path/to/my_file.json', 'r') as f:\n #try:\n # data = json.load(f)\n ## if the file is empty the ValueError will be thrown\n #except ValueError:\n # data = {}\n\n # save to file:\n print(labels_dict)\n with open(fnlabels + '.dict', 'w') as f:\n for (key, value) in labels_dict.items():\n f.write(str(key)+' '+str(value)+'\\n')\n #json.dump(labels_dict, f)\n\n #print(labels[0:222])\n #print(labels_dict)\n\n return digits, labels, labels_dict\n\ndef deskew(img):\n m = cv2.moments(img)\n if abs(m['mu02']) < 1e-2:\n return img.copy()\n skew = m['mu11']/m['mu02']\n M = np.float32([[1, skew, -0.5*0.5*(SH+SW)*skew], [0, 1, 0]])\n img = cv2.warpAffine(img, M, (SW, SH), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR)\n return img\n\nclass StatModel(object):\n def load(self, fn):\n self.model.load(fn) # Known bug: https://github.com/opencv/opencv/issues/4969\n def save(self, fn):\n self.model.save(fn)\n\nclass KNearest(StatModel):\n def __init__(self, k = 3):\n self.k = k\n self.model = cv2.ml.KNearest_create()\n\n def train(self, samples, responses):\n self.model.train(samples, cv2.ml.ROW_SAMPLE, responses)\n\n def predict(self, samples):\n retval, results, neigh_resp, dists = self.model.findNearest(samples, self.k)\n return results.ravel()\n\nclass SVM(StatModel):\n def __init__(self, C = 1, gamma = 0.5):\n self.model = cv2.ml.SVM_create()\n self.model.setGamma(gamma)\n self.model.setC(C)\n self.model.setKernel(cv2.ml.SVM_RBF)\n self.model.setType(cv2.ml.SVM_C_SVC)\n\n def train(self, samples, responses):\n self.model.train(samples, cv2.ml.ROW_SAMPLE, responses)\n\n def predict(self, samples):\n return self.model.predict(samples)[1].ravel()\n\n\ndef evaluate_model(model, digits, samples, labels):\n CLASS_N = len(labels)\n resp = model.predict(samples)\n err = (labels != resp).mean()\n print('error: %.2f %%' % (err*100))\n\n confusion = np.zeros((CLASS_N, CLASS_N), np.int32)\n for i, j in zip(labels, resp):\n confusion[i, j] += 1\n print('confusion matrix:')\n print(confusion)\n print()\n\n vis = []\n for img, flag in zip(digits, resp == labels):\n img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)\n if not flag:\n img[...,:2] = 0\n vis.append(img)\n return mosaic(25, vis)\n\ndef preprocess_simple(digits):\n samples = []\n for img in digits:\n samples.append(np.reshape(digits, (-1, SH*SW))/255.0)\n return samples.astype(np.float32)\n\n#def preprocess_simple(digits):\n# return np.float32(digits).reshape(-1, SH*SW) / 255.0\n\ndef preprocess_hog(digits):\n samples = []\n for img in digits:\n gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)\n gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)\n mag, ang = cv2.cartToPolar(gx, gy)\n bin_n = 16\n bin = np.int32(bin_n*ang/(2*np.pi))\n bin_cells = bin[:10,:10], bin[10:,:10], bin[:10,10:], bin[10:,10:]\n mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]\n hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]\n hist = np.hstack(hists)\n\n # transform to Hellinger kernel\n eps = 1e-7\n hist /= hist.sum() + eps\n hist = np.sqrt(hist)\n hist /= norm(hist) + eps\n\n samples.append(hist)\n return np.float32(samples)\n\n\nif __name__ == '__main__':\n import sys\n print(__doc__)\n\n digits, labels, labels_dict = load_digits(sys.argv[1], sys.argv[2]) # filename for image containing data, filename for labels\n\n print('preprocessing...', digits.shape, labels.shape)\n # shuffle digits\n rand = np.random.RandomState(321)\n shuffle = rand.permutation(len(digits))\n digits, labels = digits[shuffle], labels[shuffle]\n\n #digits2 = list(map(deskew, digits))\n #samples = preprocess_hog(digits2)\n samples = preprocess_hog(digits)\n #samples = preprocess_simple(digits)\n\n\n train_n = int(0.9*len(samples))\n cv2.imshow('test set', mosaic(25, digits[train_n:]))\n #digits_train, digits_test = np.split(digits2, [train_n])\n digits_train, digits_test = np.split(digits, [train_n])\n samples_train, samples_test = np.split(samples, [train_n])\n labels_train, labels_test = np.split(labels, [train_n])\n\n\n print('training KNearest...')\n model = KNearest(k=4)\n model.train(samples_train, labels_train)\n vis = evaluate_model(model, digits_test, samples_test, labels_test)\n cv2.imshow('KNearest test', vis)\n\n print('training SVM...')\n model = SVM(C=2.67, gamma=5.383)\n print(\"SIZES, data, labels\",samples_train.shape, labels_train.shape)\n model.train(samples_train, labels_train)\n vis = evaluate_model(model, digits_test, samples_test, labels_test)\n cv2.imshow('SVM test', vis)\n print('saving SVM as \"digits_svm.dat\"...')\n model.save('digits_svm.dat')\n\n cv2.waitKey(0)\n"
}
] | 1 |
bratkovskiy/test_items | https://github.com/bratkovskiy/test_items | 1ca21ea11372ce7c0692611b5a0e3e1e9bb29804 | 3ba2e7a866c1bf0928b538e9480c6c28ec94743b | 35a8a3a17f33cef840f9c9363e2c1bbd9553fce2 | refs/heads/main | 2023-01-18T17:42:27.287781 | 2020-12-01T18:29:22 | 2020-12-01T18:29:22 | 317,631,803 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7088607549667358,
"alphanum_fraction": 0.7088607549667358,
"avg_line_length": 37.5,
"blob_id": "371a67998a7050d8c2133ad2cb7a8d7f6a77c727",
"content_id": "4efc2bf1f64e25f2e516b3499115db898e6bbe53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 4,
"path": "/test_items.py",
"repo_name": "bratkovskiy/test_items",
"src_encoding": "UTF-8",
"text": "def test_items(browser):\n\n button = browser.find_elements_by_class_name(\"btn-add-to-basket\")\n assert button, \"Кнопка ДОБАВИТЬ В КОРЗИНУ не найдена\"\n\n\n\n\n"
}
] | 1 |
vnck/EvoTopic | https://github.com/vnck/EvoTopic | 5a0fcd901b02d0cd836f759efad8850417bd979a | 0ffc995bb28de8c78720ab2ba3fa1a60260398c6 | 59f7e004f1fa0a63ad7be2a2e8b435d06ec78b78 | refs/heads/master | 2020-09-10T01:19:40.942709 | 2019-12-20T12:33:53 | 2019-12-20T12:33:53 | 221,614,198 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5988854765892029,
"alphanum_fraction": 0.6079257130622864,
"avg_line_length": 35.70909118652344,
"blob_id": "622e6a84173bfe89ae3ca00a25726c3d3b01a841",
"content_id": "fd83916e11cdd60e7e9a296767b754fb9f3353aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8079,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 220,
"path": "/source/Gene2.py",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "import random\nimport numpy as np\nimport copy\n\nclass Gene:\n \"\"\"\n A class used to represent an individual in the population. It contains the hyperparameters for LDA algorithm.\n Attributes\n ----------\n n : int\n the number of topic clusters to be generated by LDA\n a : list\n 1D array of length equal to number of topic clusters (n), that expresses our a-priori belief for the each topics’ probability.\n b : list\n 1D array of length equal to vocab_size, that expresses our a-priori belief for each word.\n fitness : float\n fitness score of the gene\n vocab_size : int\n the size of the vocabulary of corpus.\n N_MIN : int\n minimum value of n\n N_MAX : int\n maximum value of n\n Methods\n -------\n set_vocab_size(vocab_size)\n static method that sets the value of static variable vocab_size.\n mutate()\n mutates values of n, a, and b.\n set_fitness()\n sets the fitness score of a gene.\n get_fitness()\n returns the fitness score of a gene.\n \"\"\"\n\n n = 1\n N_MIN = 1\n N_MAX = 1\n a = []\n b = []\n vocab_size = 0\n fitness = -1\n\n def __init__(self, n=None, a=None, b=None):\n \"\"\"\n Parameters\n ----------\n n : int, optional\n the number of topic clusters to be generated by LDA. Default value is a\n randomly generated integer between N_MIN and N_MAX.\n a : list, optional\n 1D array of length equal to number of topic clusters (n), that expresses\n our a-priori belief for the each topics’ probability. Default value is a \n randomly generated 1D array.\n b : list, optional\n 1D array of length equal to vocab_size, that expresses our a-priori belief\n for each word. Default value is a randomly generated 1D array.\n \"\"\"\n\n if Gene.vocab_size < 1 or not isinstance(Gene.vocab_size,int):\n raise ValueError('vocab_size should be a positive integer. Set vocab_size using set_vocab_size method. The value of vocab_size was: {}'.format(Gene.vocab_size))\n \n if n is None or a is None or b is None:\n self.n = np.random.randint(self.N_MIN,self.N_MAX)\n self.a = np.random.dirichlet(np.ones(self.n), size=1)[0].tolist()\n self.b = np.random.dirichlet(np.ones(Gene.vocab_size), size=1)[0].tolist()\n else:\n if not isinstance(n, int):\n raise Exception('n should be a positive integer. \\\n The value of n was: {}'.format(n))\n self.n = n\n self.a = a\n self.b = b\n\n @staticmethod\n def set_vocab_size(vocab_size):\n \"\"\"Sets the value of vocab_size. Must be set to a positive integer before a Gene instance can be created.\n Parameters\n ----------\n vocab_size : int\n size of vocabulary of corpus.\n \"\"\"\n Gene.vocab_size = vocab_size\n\n @staticmethod\n def set_doc_size(doc_size):\n \"\"\"Sets the value of doc_size. Must be set to a positive integer before a Gene instance can be created.\n Parameters\n ----------\n doc_size : int\n size of documents of corpus.\n \"\"\"\n Gene.N_MAX = doc_size\n\n def partition_float(self, a, n):\n assert a > 0, \"Gene.py partition_float: a should be positive number a= {}\".format(a)\n if n == 1:\n return [a]\n pieces = []\n for i in range(n):\n # pieces.append(random.uniform(0.0001,a-sum(pieces)-0.0001))\n pieces.append(random.uniform(0.0001, 1))\n # pieces.append(a-sum(pieces))\n # normalize pieces\n pieces = [float(i)/sum(pieces) for i in pieces]\n # set sum of pieces to a\n for i in range(n):\n pieces[i] = pieces[i]*a\n return pieces\n\n def mutate(self, mutation_rate):\n if(random.random() < mutation_rate):\n \"\"\" mutate n \"\"\"\n self.n = random.randint(1, self.N_MAX)\n \n \"\"\" then mutate a \"\"\"\n if len(self.a) > self.n:\n # print('n:{} < a:{}'.format(self.n, len(self.a)))\n # randomly drop probabilities\n n_diff = len(self.a) - self.n\n leftover_prob = 0.0\n for i in range(n_diff):\n leftover_prob += self.a.pop(random.randrange(len(self.a)))\n # print(len(self.a))\n # randomly add probabilities until sum to 1\n n_distribute = random.randrange(len(self.a))\n spare_prob = self.partition_float(leftover_prob, n_distribute)\n for p in spare_prob:\n idx = random.randrange(len(self.a))\n self.a[idx] += p\n # print(\"Gene.py case a > n : sum of self.a = \", sum(self.a))\n\n elif len(self.a) < self.n:\n # print('n:{} > a:{}'.format(self.n, len(self.a)))\n # randomly remove probabilities from original\n n_diff = self.n - len(self.a)\n remove_portion = random.random()\n leftover_prob = 0\n for i in range(len(self.a)):\n leftover_prob += self.a[i]*remove_portion\n self.a[i] = self.a[i]*(1-remove_portion)\n # redistribute leftover_prob\n spare_prob = self.partition_float(leftover_prob, n_diff)\n # append self.a\n self.a += spare_prob\n '''\n # randomly add probabilities\n n_diff = self.n - len(self.a)\n for i in range(n_diff):\n # self.a.insert(random.randrange(len(self.a)), random.random())\n self.a.insert(random.randrange(len(self.a)), random.uniform(0.00000001, 0.99999999))\n # randomly remove probabilities until sum to 1\n n_distribute = random.randrange(len(self.a))\n spare_prob = self.partition_float(sum(self.a) - 1, n_distribute)\n for p in spare_prob:\n idx = random.randrange(len(self.a))\n while(self.a[idx] - p <= 0):\n idx = random.randrange(len(self.a))\n self.a[idx] -= p\n '''\n # print(\"Gene.py case a < n : sum of self.a = \", sum(self.a))\n \n\n elif (random.random() < mutation_rate):\n \"\"\" maybe mutate a if n does not change \"\"\"\n # print('n:{} == a:{}'.format(self.n, len(self.a)))\n if len(self.a) != 1:\n n_choice = random.sample([i for i in range(len(self.a))], random.randrange(1,len(self.a)))\n leftover_prob = 0.0\n for i in sorted(n_choice, reverse = True):\n leftover_prob += self.a.pop(i)\n spare_prob = self.partition_float(1 - sum(self.a), len(n_choice))\n for p in spare_prob:\n self.a.insert(n_choice.pop(random.randrange(len(n_choice))),p)\n else:\n print (\"No mutation since a has only one element!\")\n\n # # Randomly sample probabilities of topics in a\n # genes_a = random.sample(self.a, random.randint(2, len(self.n)))\n \n # # Calculate the sum of probabilities of topics sampled\n # sum_p_a = sum([self.a[genes_a.index(i)] for i in genes_a])\n \n # # Redistribute the probabilities among the topics sampled\n # leftover_p_a = sum_p_a\n # count_a = 0\n # for i in genes_a:\n # if count_a == len(genes_a) - 1:\n # # Assign the leftover probability to the last one sampled\n # self.a[genes_a.index(i)] = leftover_p_a\n # else: \n # # Generate random float between 0 and 1\n # ra = random.random()\n # # Assign the value in range of sum_p_a to the ith probability of topic sampled\n # self.a[genes_a.index(i)] = leftover_p_a * ra\n # # Update leftover_p_a\n # leftover_p_a -= self.a[genes_a.index(i)]\n # count_a += 1\n\n if(random.random() < mutation_rate):\n \"\"\" maybe mutate b \"\"\"\n # Randomly sample probabilities of words in b\n genes_b = random.sample(self.b, random.randint(2, len(self.b)))\n # Calculate the sum of sampled probabilities of words\n sum_p_b = sum(genes_b)\n # Redistribute the probabilities among the sampled probabilities of words \n distribute_list = []\n for i in range(len(genes_b)):\n distribute_list.append(random.random())\n distribute_list = [float(i)/sum(distribute_list) for i in distribute_list]\n for i in range(len(genes_b)):\n self.b[self.b.index(genes_b[i])] = distribute_list[i]*sum_p_b\n \n assert self.n == len(self.a), \"n: {}, a:{}\".format(self.n, len(self.a))\n assert len(self.b) == self.vocab_size, \"b: {}, v:{}\".format(len(self.b), self.vocab_size)\n new_gene = copy.deepcopy(self)\n return new_gene\n\n def set_fitness(self,f):\n self.fitness = f"
},
{
"alpha_fraction": 0.6944444179534912,
"alphanum_fraction": 0.7094017267227173,
"avg_line_length": 21.285715103149414,
"blob_id": "d89a7d69b4662c59172ff9e76a8307141248d00d",
"content_id": "053f75e8240f103ef3b48fa240c2108f60f3efe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 468,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 21,
"path": "/README.md",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "# Evolutionary Topic Modelling For User Issues\n\n## TODO:\n- [ ] Scrape issues from a Github open source project page. (e.g. facebook/React)\n- [ ] Construct Document Class\n- [ ] Construct GA Class\n- [ ] Construct Gene Class \n\n## Class Diagram\n\n\n## How to run\n- Minimum python3 version required is 3.6.2\n- pip3 is required\n```\nsudo apt-get install python3-pip\n```\n- Install requirements.txt\n```\npip3 install -r requirements.txt\n```\n"
},
{
"alpha_fraction": 0.6255592107772827,
"alphanum_fraction": 0.6341179013252258,
"avg_line_length": 31.33333396911621,
"blob_id": "c78b3554bd48c075428525b04071d82824e7abba",
"content_id": "7766c793b5facbe1fe6f3b3c93abeb488aae2d16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5145,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 159,
"path": "/source/Gene.py",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "import random\nimport numpy as np\nimport copy\n\nclass Gene:\n \"\"\"\n A class used to represent an individual in the population. It contains the hyperparameters for LDA algorithm.\n\n Attributes\n ----------\n n : int\n the number of topic clusters to be generated by LDA\n\n a : list\n 1D array of length equal to number of topic clusters (n), that expresses our a-priori belief for the each topics’ probability.\n\n b : list\n 1D array of length equal to vocab_size, that expresses our a-priori belief for each word.\n\n fitness : float\n fitness score of the gene\n\n vocab_size : int\n the size of the vocabulary of corpus.\n\n N_MIN : int\n minimum value of n\n\n N_MAX : int\n maximum value of n\n\n Methods\n -------\n set_vocab_size(vocab_size)\n static method that sets the value of static variable vocab_size.\n\n mutate()\n mutates values of n, a, and b.\n\n set_fitness()\n sets the fitness score of a gene.\n\n get_fitness()\n returns the fitness score of a gene.\n\n \"\"\"\n\n n = 1\n N_MIN = 4\n N_MAX = 1\n a = []\n b = []\n vocab_size = 0\n fitness = -1\n\n def __init__(self, n=None, a=None, b=None):\n \"\"\"\n Parameters\n ----------\n n : int, optional\n the number of topic clusters to be generated by LDA. Default value is a\n randomly generated integer between N_MIN and N_MAX.\n\n a : list, optional\n 1D array of length equal to number of topic clusters (n), that expresses\n our a-priori belief for the each topics’ probability. Default value is a \n randomly generated 1D array.\n\n b : list, optional\n 1D array of length equal to vocab_size, that expresses our a-priori belief\n for each word. Default value is a randomly generated 1D array.\n \"\"\"\n\n if Gene.vocab_size < 1 or not isinstance(Gene.vocab_size,int):\n raise ValueError('vocab_size should be a positive integer. Set vocab_size using set_vocab_size method. The value of vocab_size was: {}'.format(Gene.vocab_size))\n \n if n is None or a is None or b is None:\n self.n = np.random.randint(self.N_MIN,self.N_MAX)\n self.a = np.random.dirichlet(np.ones(self.n), size=1)[0].tolist()\n self.b = np.random.dirichlet(np.ones(Gene.vocab_size), size=1)[0].tolist()\n else:\n if not isinstance(n, int):\n raise Exception('n should be a positive integer. \\\n The value of n was: {}'.format(n))\n self.n = n\n self.a = a\n self.b = b\n\n @staticmethod\n def set_vocab_size(vocab_size):\n \"\"\"Sets the value of vocab_size. Must be set to a positive integer before a Gene instance can be created.\n\n Parameters\n ----------\n vocab_size : int\n size of vocabulary of corpus.\n \"\"\"\n Gene.vocab_size = vocab_size\n\n @staticmethod\n def set_doc_size(doc_size):\n \"\"\"Sets the value of doc_size. Must be set to a positive integer before a Gene instance can be created.\n\n Parameters\n ----------\n doc_size : int\n size of documents of corpus.\n \"\"\"\n Gene.N_MAX = max(int(doc_size * .2),50)\n\n def partition_float(self, a, n):\n assert a > 0, \"Gene.py partition_float: a should be positive number a= {}\".format(a)\n if n == 1:\n return [a]\n pieces = []\n for i in range(n-1):\n # Assign random portion of the leftover probability to p\n p = round(random.uniform(0.00001,a-sum(pieces)-0.00001),5)\n pieces.append(p)\n # Append pieces with whatever probability left as the last element to ensure probability sum to 1\n pieces.append(a-sum(pieces))\n return pieces\n\n def mutate(self, mr):\n if (random.random() < mr):\n self.n = random.randint(self.N_MIN, self.N_MAX)\n # Ensure n and the size of a are the same\n if self.n != len(self.a):\n # Extract random values from dirichlet distribution for n times and form a.\n self.a = np.random.dirichlet(np.ones(self.n), size=1)[0].tolist()\n elif (random.random() < mr):\n choices = random.sample([i for i in range(len(self.a))], random.randrange(2,len(self.a),1))\n probs = []\n for i in sorted(choices, reverse = True):\n probs.append(self.a.pop(i))\n probs = random.sample(probs, len(probs))\n for i,v in enumerate(sorted(choices)):\n self.a.insert(v,probs[i])\n if (random.random() < mr):\n choices = random.sample([i for i in range(len(self.b))], random.randrange(2,len(self.b),1))\n probs = []\n # Pop elements of choices in decreasing order and append it to probs list\n for i in sorted(choices, reverse = True):\n probs.append(self.b.pop(i))\n probs = random.sample(probs, len(probs))\n for i,v in enumerate(sorted(choices)):\n self.b.insert(v,probs[i])\n elif (random.random() < mr):\n # Extract random values from dirichlet distribution for Gene.vocab_size times and form b.\n self.b = np.random.dirichlet(np.ones(Gene.vocab_size), size=1)[0].tolist()\n\n assert self.n == len(self.a), \"n: {}, a:{}\".format(self.n, len(self.a))\n assert len(self.b) == self.vocab_size, \"b: {}, v:{}\".format(len(self.b), self.vocab_size)\n \n new_gene = copy.deepcopy(self)\n return new_gene\n\n def set_fitness(self,f):\n self.fitness = f\n"
},
{
"alpha_fraction": 0.627862811088562,
"alphanum_fraction": 0.6392547488212585,
"avg_line_length": 32.18110275268555,
"blob_id": "0820945a1a31df1e7a21836a11cb25c370b8df68",
"content_id": "a6b85be4deab274907e6a14a477a4aea3cb0a289",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8427,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 254,
"path": "/source/GA.py",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "from Gene import Gene\nimport random \nfrom sklearn import metrics\nfrom sklearn.metrics import pairwise_distances\nfrom gensim.test.utils import common_texts\nfrom gensim.corpora.dictionary import Dictionary\nfrom gensim.models import LdaModel\nimport gensim\nfrom tqdm.notebook import tqdm\nfrom gensim.models.coherencemodel import CoherenceModel\nimport math\nimport pprint\nimport numpy as np\nimport copy\nimport pyLDAvis.gensim\nimport matplotlib.pyplot as plt\n\n\nimport warnings\nwarnings.filterwarnings(\"error\")\n\nMUTATION_RATIO = 0.3\nSELECT_RATIO = 0.2\nELITISM_RATIO = 0.1\n\nclass GA:\n \"\"\"\n A class used to contain our genetic algorithm.\n\n Attributes\n ----------\n docs : Document\n Document class object containing document to evaluate fitness on.\n \n population : list\n list of Gene class objects to perform selection, crossover, and mutation on.\n \n population_size : int\n size of the population.\n \n fitness_budget : float\n the number of evaluations remaining before the GA halts.\n \n fittest : Gene\n the fittest Gene class object.\n \n fitness : float\n fitness score of the best Gene class object.\n\n Methods\n -------\n initialise_population()\n randomly generates an initial population.\n\n evolve()\n calls selection, crossover, and mutation loop while fitness budget > 0.\n \n selection()\n performs selection on the current population.\n\n crossover()\n performs crossover between two Gene objects in the population with a probability.\n\n mutate()\n calls the mutate method of each Gene class given a probability.\n\n calculate_fitness(gene)\n calculates the fitness of a gene.\n\n update_population_fitness()\n updates fitness of all genes in the new population and updates the fittest individual.\n\n get_fittest()\n returns the fittest gene.\n\n \"\"\"\n\n def __init__(self,docs,dictionary,pop_size=100,fitness_budget=10000, objective='silhouette'):\n # initial setting\n self.corpus = docs\n self.docs_size = len(self.corpus)\n self.dictionary = dictionary\n self.vocab_size = len(self.dictionary)\n Gene.set_vocab_size(self.vocab_size)\n Gene.set_doc_size(self.docs_size)\n self.population = []\n self.old_population = []\n self.population_size = pop_size\n self.fitness_budget = fitness_budget\n self.fitness = -999.0\n self.bestGene = Gene()\n self.iteration = 0\n assert objective == 'coherence' or objective == 'silhouette', \"Objective must be either: 'silhouette' or 'cohesion'\"\n self.objective = objective\n self.n_record = []\n self.score_record = []\n\n def initialise_population(self):\n \"\"\"Random initialisation of population\"\"\"\n print('Initialising Population...')\n self.population = [Gene() for i in range(self.population_size)]\n self.update_population_fitness()\n # print('{}: Fitness: {} Fitness Budget: {} '.format(self.iteration,self.fitness,self.fitness_budget))\n # print('{}: Gene.n: {} Gene.a: {} Gene.b: {} '.format(self.iteration, self.bestGene.n, len(self.bestGene.a), len(self.bestGene.b)))\n \n def evolve(self):\n print('Evolving Population...')\n while(self.fitness_budget > 0):\n self.old_population = copy.deepcopy(self.population)\n self.population = []\n self.selection()\n self.crossover()\n self.mutate()\n self.update_population_fitness()\n self.iteration += 1\n # print('{}: Gene.n: {} Gene.a: {} Gene.b: {} '.format(self.iteration, self.bestGene.n, len(self.bestGene.a), len(self.bestGene.b)))\n if self.objective == 'coherence':\n if round(self.fitness,15) == 0:\n break\n elif self.objective == 'silhouette':\n if round(self.fitness,15) == 1:\n break\n \n def selection(self):\n \"\"\"Top 20% of population will be selected\"\"\"\n # Sort population\n self.old_population = sorted(self.old_population, key=lambda gene: gene.fitness, reverse=True)\n # Get top 20% from population\n self.old_population = self.old_population[:int(self.population_size*SELECT_RATIO)]\n # elitism keeps top 10% of population\n self.population = self.old_population[:int(len(self.old_population)*ELITISM_RATIO)]\n \n\n def __crossover2genes(self, gene1, gene2):\n \"\"\"Crossover two genes\"\"\"\n new_gene_n = 0\n new_gene_a = []\n new_gene_b = []\n # Which part do you want to crossover? \n crossover_part = random.choice([\"n\", \"b\"])\n if crossover_part == \"n\":\n # Average of two genes\n new_gene_n = math.ceil((gene1.n+gene2.n)/2)\n for i in range(new_gene_n):\n if ((len(gene1.a)-1) < i):\n new_gene_a.append(gene2.a[i])\n elif ((len(gene2.a)-1) < i):\n new_gene_a.append(gene1.a[i])\n else :\n new_gene_a.append((gene1.a[i]+gene2.a[i])/2)\n new_gene_b = gene1.b[:]\n else:\n # Average of two genes\n for i in range(self.vocab_size):\n new_gene_b.append((gene1.b[i]+gene2.b[i])/2)\n new_gene_n = gene1.n\n new_gene_a = gene1.a[:]\n # normalization\n new_gene_a = [float(i)/sum(new_gene_a) for i in new_gene_a]\n new_gene_b = [float(i)/sum(new_gene_b) for i in new_gene_b]\n new_gene = Gene(new_gene_n, new_gene_a, new_gene_b)\n return new_gene\n\n def crossover(self):\n \"\"\"Generate new population using crossover\"\"\"\n while(len(self.population) < self.population_size):\n #Randomly select two genes\n # gene1, gene2 = random.sample(self.population[:int(self.population_size*SELECT_RATIO)], 2)\n gene1, gene2 = random.sample(self.old_population, 2)\n new_gene = self.__crossover2genes(gene1, gene2)\n self.population.append(new_gene)\n\n def mutate(self):\n new_population = [p.mutate(MUTATION_RATIO) for p in self.population]\n self.population = new_population\n\n def update_population_fitness(self):\n # calls calculate_fitness on all genes in the new population and updates the fittest individual\n pop_fitness = -99\n pop_gene = []\n for p in tqdm(self.population):\n score = self.calculate_fitness(p)\n if score > pop_fitness:\n pop_fitness = score\n pop_gene = p\n self.n_record.append(pop_gene.n)\n self.score_record.append(pop_fitness)\n if pop_fitness > self.fitness:\n self.fitness = pop_fitness\n self.bestGene = pop_gene\n# else:\n# self.population = self.old_population\n print('{}: Fitness: {:.15f}, Best Fitness: {:.15f}, Num Topics: {}, Fitness Budget: {} '.format(self.iteration,pop_fitness,self.fitness,self.bestGene.n,self.fitness_budget))\n\n def calculate_fitness(self,gene):\n # Make LDA model\n self.fitness_budget -= 1\n lda = LdaModel(corpus = self.corpus,\n id2word = self.dictionary,\n num_topics = gene.n,\n alpha = gene.a)\n \n if self.objective == 'coherence':\n cm = CoherenceModel(model=lda, corpus=self.corpus, coherence='u_mass')\n result = cm.get_coherence()\n\n elif self.objective == 'silhouette':\n labels = []\n word_cntLst = []\n if(len(self.corpus)<2):\n gene.set_fitness(-99)\n return -99\n for text in self.corpus:\n # Make label list\n topic_probLst = lda.get_document_topics(text)\n if (len(topic_probLst) == 0):\n print(\"LDA is fucked\")\n print(\"GA.py gene.a = \", gene.a)\n if (0 in gene.a) :\n print(\"calculate fitness: Zero in a\")\n if (0 in gene.b) :\n print(\"calculate fitness: Zero in b\")\n gene.set_fitness(-99)\n return -99\n labels.append(max(topic_probLst, key=lambda tup: tup[1])[0])\n # Make word count list\n words = [0]*self.vocab_size\n for tup in text:\n words[tup[0]] = tup[1]\n word_cntLst.append(words[:])\n # Calculate silhouette score\n if(len(np.unique(labels)) < 2):\n gene.set_fitness(-99)\n return -99\n result = metrics.silhouette_score(word_cntLst, labels, metric='cosine')\n \n gene.set_fitness(result)\n return result\n\n def get_fittest(self):\n return self.bestGene\n\n def get_model(self):\n lda = LdaModel(corpus = self.corpus,\n id2word = self.dictionary,\n num_topics = self.bestGene.n,\n alpha = self.bestGene.a,\n eta = self.bestGene.b)\n return lda\n\n def visualise_progress(self):\n plt.plot(list(range(len(self.n_record))),self.n_record)\n plt.plot(list(range(len(self.score_record))),self.score_record)\n plt.show()"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.7051281929016113,
"avg_line_length": 25.030303955078125,
"blob_id": "5a57bf11948b5535c67dc350ad7e2a1ed3305191",
"content_id": "e11aaae090c203a6c861fd024834a87d7ce88e4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 858,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 33,
"path": "/source/main.py",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "from Documents import Documents\nfrom GA import GA\nimport pandas as pd\nimport pickle\nfrom os import path\n\nloadit = False\n\nif loadit:\n docs = pickle.load(open('docs.pkl', 'rb'))\nelse:\n data_path = '../data/github_issues.csv'\n df = pd.read_csv(data_path)\n docs = Documents()\n# docs.load(list(df['description'])[:300])\n docs.load(list(df['description']))\n docs.vectorise()\n pickle.dump(docs, open('docs.pkl', 'wb+'))\n\nprint(\"No. of documents loaded: {}\".format(docs.get_doc_size()))\n\ncorpus = docs.get_vectors()\ndictionary = docs.get_dictionary()\n\nGA = GA(corpus,dictionary,pop_size=30,fitness_budget=10000,objective='coherence')\nGA.initialise_population()\nGA.evolve()\n\nfittest_gene = GA.get_fittest()\n# model = GA.get_model()\n# docs.assign_labels(model)\n\nprint('Fittest Gene discovered {} topics with score of {:.8f}'.format(fittest_gene.n,GA.fitness))"
},
{
"alpha_fraction": 0.6654699444770813,
"alphanum_fraction": 0.670039176940918,
"avg_line_length": 25.88596534729004,
"blob_id": "17700e36de7a344bb3e3a354b2413f0f7409aebe",
"content_id": "559649e891429a1ed9ff55fdda3b72e57e585697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3064,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 114,
"path": "/source/Documents.py",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom nltk.tokenize import RegexpTokenizer\nfrom nltk.stem.wordnet import WordNetLemmatizer\nfrom nltk.corpus import stopwords\nfrom gensim.models import Phrases\nfrom gensim.corpora import Dictionary\n\nclass Documents:\n \"\"\"\n A class to store documents and document vectors.\n\n Attributes\n ----------\n docs : dataframe\n a dataframe containing text and vectors\n\n doc_size : int\n number of docs in corpus\n\n vocab_size : int\n size of vocabulary of corpus\n \n\n Methods\n -------\n load(path)\n reads files and stores text data in a dataframe\n\n vectorise()\n converts textual format to vectorised format\n\n get_raw()\n returns list of documents in raw textual format\n\n get_tokens()\n returns list of documents in tokenised format\n\n get_vectors()\n returns list of documents in vectorised format\n\n get_doc_size()\n returns number of documents\n\n get_vocab_size()\n returns number of unique words in corpus\n\n get_vocab()\n returns list of corpus vocabulary\n \"\"\"\n\n def __init__(self):\n self.df = pd.DataFrame()\n\n self.tokenizer = RegexpTokenizer(r'\\w+')\n self.lemmatizer = WordNetLemmatizer()\n self.stopwords = set(stopwords.words('english'))\n\n def load(self, text):\n self.df['raw'] = text\n\n def __preprocessing_pipeline(self, doc):\n doc = doc.lower()\n tokens = self.tokenizer.tokenize(doc)\n tokens = [t for t in tokens if not t.isnumeric()]\n tokens = [t for t in tokens if t not in self.stopwords]\n tokens = [t for t in tokens if len(t) > 2]\n tokens = [self.lemmatizer.lemmatize(t) for t in tokens]\n return tokens\n\n def __add_bigrams(self, doc):\n for token in self.bigrams[doc]:\n if '_' in token:\n doc.append(token)\n return doc\n\n def __argmax(self,ls):\n return max(ls, key = lambda item: item[1])\n\n def vectorise(self):\n self.df['tokens'] = self.df['raw'].apply(self.__preprocessing_pipeline)\n self.bigrams = Phrases(self.get_tokens(), min_count=20)\n self.df['tokens'] = self.df['tokens'].apply(self.__add_bigrams)\n self.dictionary = Dictionary(self.get_tokens())\n self.dictionary.filter_extremes(no_below=20, no_above=0.5)\n self.df['vectors'] = self.df['tokens'].apply(self.dictionary.doc2bow)\n self.df = self.df[self.df['vectors'].map(len) > 0]\n\n def assign_labels(self, model):\n self.df['topic'] = self.df['vectors'].apply(lambda x : self.__argmax(model.get_document_topics(x))[0])\n self.df['topic_confidence'] = self.df['vectors'].apply(lambda x : self.__argmax(model.get_document_topics(x))[1])\n \n def get_doc_text(self,label=-1):\n if label == -1:\n return self.df['raw']\n else:\n return self.df[self.df['topic'] == label]['raw']\n \n def get_vectors(self):\n return list(self.df['vectors'])\n\n def get_tokens(self):\n return list(self.df['tokens'])\n\n def get_doc_size(self):\n return self.dictionary.num_docs\n\n def get_dictionary(self):\n return self.dictionary\n\n def get_vocab_size(self):\n return len(self.dictionary.num_nnz)\n\n def get_vocab(self):\n return list(self.dictionary.values())"
},
{
"alpha_fraction": 0.6012402176856995,
"alphanum_fraction": 0.6058236956596375,
"avg_line_length": 34.9900016784668,
"blob_id": "dfe68b6a7f895a70e2b25e11e481258ed063eac5",
"content_id": "37c66829cf7f529cb1e3502bb1f66f7b9222348a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3709,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 100,
"path": "/source/web_scraper.py",
"repo_name": "vnck/EvoTopic",
"src_encoding": "UTF-8",
"text": "from requests import get\r\nfrom requests.exceptions import RequestException\r\nfrom contextlib import closing\r\nfrom bs4 import BeautifulSoup\r\nfrom tqdm import tqdm\r\nimport csv\r\n\r\ndef get_html(url):\r\n '''\r\n Accepts a single URL argument and makes an HTTP GET request to that URL. If nothing goes wrong and\r\n the content-type of the response is some kind of HTMl/XML, return the raw HTML content for the\r\n requested page. However, if there were problems with the request, return None.\r\n '''\r\n try:\r\n with closing(get(url, stream=True)) as resp:\r\n if quality_response(resp):\r\n return resp.content\r\n else:\r\n return None\r\n except RequestException as re:\r\n print(f\"There was an error during requests to {url} : {str(re)}\")\r\n return None\r\n\r\ndef quality_response(resp):\r\n '''\r\n Returns true if response seems to be HTML, false otherwise.\r\n '''\r\n content_type = resp.headers[\"Content-Type\"].lower()\r\n return (resp.status_code == 200 and content_type is not None and content_type.find(\"html\") > - 1)\r\n\r\n\r\ndef get_title_description(url):\r\n ''' \r\n Downloads the webpage, Finds the title, description and puts it into a list\r\n '''\r\n #url = \"https://github.com/facebook/react/issues/17399\"\r\n response = get_html(url)\r\n title_desc_small_list = []\r\n if response is not None:\r\n soup = BeautifulSoup(response, \"html.parser\")\r\n #get title of the issue\r\n title = soup.title.get_text()\r\n #create a list of titles\r\n title_desc_small_list.append(title)\r\n bottom_description = soup.find_all('task-lists')\r\n description = bottom_description[0].get_text().replace(\"\\n\", \" \")\r\n title_desc_small_list.append(description)\r\n return title_desc_small_list\r\n \r\n\r\ndef write_to_csv(big_list):\r\n ''' \r\n Accepts a single item list as an argument, proceses through the list and writes all the products into\r\n a single CSV data file.\r\n '''\r\n headers = [\"title\", \"description\"]\r\n filename = \"github_issues_test.csv\"\r\n try:\r\n with open(filename, \"w\") as csvFile:\r\n writer = csv.writer(csvFile)\r\n writer.writerow(headers)\r\n for row in big_list:\r\n writer.writerow(row) \r\n csvFile.close()\r\n except:\r\n print(\"There was an error writing to the CSV data file.\")\r\n\r\ndef get_all_issues():\r\n \r\n all_links = []\r\n #the range here changes depending on the number of pages in the github issue page\r\n #iterates through all the pages in the facebook react issues.\r\n for i in range(1,313):\r\n \t#you can just change this url to any other url you want to web scrape from.\r\n url = \"https://github.com/facebook/react/issues?page=\"+str(i)+\"&q=is%3Aissue+is%3Aclosed\"\r\n print(url)\r\n response = get_html(url)\r\n\r\n #list to store links\r\n if response is not None:\r\n soup = BeautifulSoup(response, \"html.parser\") #Parse html file\r\n #accessing the data that we interested in\r\n links = soup.find_all('a', attrs={'data-hovercard-type':'issue'})\r\n for link in links:\r\n all_links.append(link.get('href'))\r\n\r\n big_data_list = []\r\n for link in tqdm(all_links):\r\n print(link)\r\n one_issue_url = \"http://github.com\"+str(link)\r\n #print(\"HERES THE URL:\", one_issue_url)\r\n title_desc = get_title_description(one_issue_url)\r\n big_data_list.append(title_desc)\r\n\r\n ##WRITE TO CSV HERE WITH BIG LIST.\r\n print(\"writing\")\r\n write_to_csv(big_data_list)\r\n\r\nif __name__ == \"__main__\":\r\n get_all_issues()\r\n\r\n \r\n\r\n"
}
] | 7 |
kayutenko/ProductInfoAnalyser | https://github.com/kayutenko/ProductInfoAnalyser | 2a4876746b328392e32a0e5176dd85d428939325 | 3e4090463092395837121f1c3740a272ad74c2b6 | 6bbdf51f2eca1bc781ca992865e1f3d44a9da87e | refs/heads/master | 2021-06-17T01:49:01.277581 | 2017-05-28T23:02:21 | 2017-05-28T23:02:21 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7052826881408691,
"alphanum_fraction": 0.7154772877693176,
"avg_line_length": 29.828571319580078,
"blob_id": "2fd554ba461abfd96eb159f4ba123469f8bb6353",
"content_id": "bf41517a6f256d363a63d8181a56b1041a50e26a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1079,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 35,
"path": "/expectations_meter/sentiment_analysis/sentiment_analysis.py",
"repo_name": "kayutenko/ProductInfoAnalyser",
"src_encoding": "UTF-8",
"text": "from pprint import pprint as pp\nimport numpy as np\nimport pandas as pd\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.tree import DecisionTreeClassifier\nfrom nltk.corpus import stopwords as sp\nfrom nltk.stem import SnowballStemmer\nfrom string import punctuation\n\nwith open('../english_stopwords.txt', 'r', encoding='utf-8') as f:\n stopwords = [word.strip('\\n') for word in f.readlines()]\n\nstemmer = SnowballStemmer('english')\n\ndef preprocess(text):\n tokens = [word.strip(punctuation) for word in text.lower().split() if not word in stopwords]\n stems = [stemmer.stem(token) for token in tokens]\n return stems\nprint('Reading df...')\ndf = pd.read_csv('Amazon.csv')\n# bodies = list(df.body)\n# pp(bodies)\n# print('Preprocessing...')\ntexts = [preprocess(text) for text in list(df.body)[:10] if not pd.isnull(text)]\nvectorizer = TfidfVectorizer(lowercase=False, max_df=0.4, min_df = 20)\nX = vectorizer.fit_transform([' '.join(text) for text in texts])\nprint(X)\n\n#\n#\n#\n#\n# y = pd.DataFrame([1 if int(star[0]) >= 4 else 0 for star in df.stars])\n#\n#\n"
},
{
"alpha_fraction": 0.5200080275535583,
"alphanum_fraction": 0.5290341973304749,
"avg_line_length": 39.209678649902344,
"blob_id": "a4c6a11ddc02aebc88f6fee017e0753de48e3a1c",
"content_id": "b76ad1dbaea5655aeb358447c66ec741f6273303",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9971,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 248,
"path": "/expectations_meter/website_parsers/base_parser.py",
"repo_name": "kayutenko/ProductInfoAnalyser",
"src_encoding": "UTF-8",
"text": "import re\nimport requests\nimport pandas as pd\nimport json\nfrom bs4 import BeautifulSoup\nfrom pprint import pprint as pp\nfrom collections import OrderedDict\nfrom time import sleep\nimport os\nfrom selenium import webdriver\n\n\nclass Parser:\n def __init__(self, output):\n if os.path.exists(output):\n output = ''.join(output.split('.')[:-1]) + '_1' + '.xlsx'\n # self.output = pd.ExcelWriter(output, engine='openpyxl')\n self.output = output\n self.urls_parsed = 0\n pass\n\n def get_element(self, source, path):\n element = source.select(path)\n if element:\n return element[0].get_text()\n else:\n return ''\n\n @staticmethod\n def get_data(url):\n web_page = requests.get(url).text\n html = BeautifulSoup(web_page, 'html.parser').html\n return html\n\n def article_parser(self, data):\n yield data\n\n def urls_collector(self):\n return []\n\n def write_data(self, data):\n data = pd.DataFrame([list(data.values())], columns=list(data.keys()))\n if self.urls_parsed == 0:\n try:\n data.to_csv(self.output, index=False)\n # self.output.save()\n except Exception as e:\n print('csv saving error', e)\n else:\n try:\n data.to_csv(self.output, mode='a', header=False, index=False)\n # self.output.save()\n except Exception as e:\n print('csv saving error', e)\n\n def parse(self):\n urls = self.urls_collector()\n for url in urls:\n try:\n data = self.article_parser(self.get_data(url))\n self.write_data(data)\n self.urls_parsed += 1\n print(self.urls_parsed, url)\n except KeyboardInterrupt:\n user_answer = input('Parsing paused. Continue? (Y/N) ')\n while True:\n if user_answer == 'Y':\n break\n elif user_answer == 'N':\n # self.output.close()\n quit()\n else:\n user_answer = input('Parsing paused. Continue? (Y/N) ')\n except Exception as e:\n print('An Error occurred with url: {} {}'.format(url, e))\n # self.output.save()\n # self.output.close()\n # self.output.save()\n # self.output.close()\n\n\nclass MacrumorsParser(Parser):\n def urls_collector(self):\n urls = []\n for year in range(2009, 2018):\n for month in range(1, 13):\n if month < 10:\n month = '0' + str(month)\n url = 'https://www.macrumors.com/archive/{year}/{month}/'.format(year=year, month=month)\n html = self.get_data(url)\n content = html.select('#contentContainer #content .wrapper')[0]\n urls_found = ['http:' + a.get('href') for a in content.find_all('a')]\n print(year, month, 'URL: ', url, \"URLS found:\", len(urls_found))\n urls.extend(urls_found)\n return urls\n\n def article_parser(self, data):\n output = OrderedDict()\n article = data.select('.article')[0]\n output['title'] = self.get_element(article, 'h1.title')\n if output['title'] == '':\n output['title'] = self.get_element(article, 'h1.header-title')\n output['body'] = self.get_element(article, '.content')\n if output['body'] == '':\n output['body'] = self.get_element(article, '#content .body')\n output['author'] = self.get_element(article, '.byline > a.author-url')\n byline = self.get_element(article, '.byline')\n output['datetime'] = byline[:byline.find('by')-1]\n if '' in list(output.values()):\n raise Exception('Something went wrong and one var is empty')\n return output\n\n\nclass AppleInsiderParser(Parser):\n def urls_collector(self):\n urls = []\n for year in range(9, 18):\n if year < 10: year = '0' + str(year)\n for month in range(1, 13):\n if month < 10: month = '0' + str(month)\n for day in range(1, 32):\n if day < 10: day = '0' + str(day)\n url = \"http://appleinsider.com/archives/{year}/{month}/{day}/page/1\".format(year=year, month=month, day=day)\n html = self.get_data(url)\n content = html.select('#content')[0]\n urls_found = ['http:' + a.get('href') for a in content.select('.post a')]\n print(year, month, 'URL: ', url, \"URLS found:\", len(urls_found))\n urls.extend(urls_found)\n with open('AppleInsiderUrls', 'w', encoding='utf-8') as f:\n [f.write(i + '\\n') for i in urls]\n return urls\n\n def article_parser(self, data):\n output = OrderedDict()\n article_data = json.loads(self.get_element(data, \"script[type='application/ld+json']\"))\n output['title'] = article_data['headline']\n body = BeautifulSoup(str(BeautifulSoup(article_data['articleBody'], 'html.parser').get_text()), 'lxml').get_text()\n output['body'] = re.sub('\\n{2,}|\\r\\n','\\n', body)\n output['author'] = article_data['author']['name']\n output['datetime'] = article_data['datePublished']\n return output\n\n\nclass NineToFiveMacParser(Parser):\n def urls_collector(self):\n urls = []\n for year in range(2009, 2018):\n for month in range(1, 13):\n if month < 10: month = '0' + str(month)\n for day in range(1, 31):\n if day < 10: day = '0' + str(day)\n url = \"https://9to5mac.com/{year}/{month}/{day}/\".format(year=year, month=month, day=day)\n html = self.get_data(url)\n content = html.select('#content')[0]\n urls_found = [a.get('href') for a in content.select('.post-title a')]\n print(year, month, 'URL: ', url, \"URLS found:\", len(urls_found))\n urls.extend(urls_found)\n # sleep(2)\n with open('NineToFiveMacUrls', 'w', encoding='utf-8') as f:\n [f.write(i + '\\n') for i in urls]\n return urls\n\n def article_parser(self, data):\n output = OrderedDict()\n article = data.select('.post-content')[0]\n output['title'] = self.get_element(article, 'h1.post-title a')\n output['body'] = self.get_element(article, '.post-body').strip()\n output['author'] = self.get_element(article, 'p[itemprop=author]').strip()\n output['datetime'] = article.select('meta[itemprop=datePublished]')[0]['content']\n if '' in list(output.values()):\n raise Exception('Something went wrong and one var is empty')\n # sleep(2)\n return output\n\n\nclass AmazonParser(Parser):\n def __init__(self, output):\n super().__init__(output)\n self.driver = webdriver.Chrome()\n\n def get_data(self, url):\n print(url)\n for n in range(1, 1000):\n current_url = url.format(n)\n print(current_url)\n self.driver.get(current_url)\n reviews = self.driver.find_element_by_id('cm_cr-review_list').get_attribute('innerHTML')\n if 'Sorry, no reviews match your current selections.' not in reviews:\n yield BeautifulSoup(reviews, 'html.parser')\n else:\n break\n\n def get_reviews(self, bs_data):\n reviews = bs_data.select('.a-section.review > .celwidget')\n return reviews\n\n def review_parser(self, bs_review):\n output = OrderedDict()\n output['stars'] = self.get_element(bs_review, 'i[data-hook=review-star-rating] > span.a-icon-alt')\n output['title'] = self.get_element(bs_review, 'a.review-title')\n output['body'] = self.get_element(bs_review, 'span.review-text').strip()\n output['author'] = self.get_element(bs_review, 'a.author').strip()\n output['date'] = self.get_element(bs_review, 'span.review-date').strip()\n # if '' in list(output.values()):\n # raise Exception('Something went wrong and one var is empty')\n # # sleep(2)\n return output\n\n def parse(self, start_urls):\n for url in start_urls:\n for page in self.get_data(url):\n for review in self.get_reviews(page):\n try:\n review_data = self.review_parser(review)\n self.write_data(review_data)\n self.urls_parsed += 1\n except KeyboardInterrupt:\n user_answer = input('Parsing paused. Continue? (Y/N) ')\n while True:\n if user_answer == 'Y':\n break\n elif user_answer == 'N':\n quit()\n else:\n user_answer = input('Parsing paused. Continue? (Y/N) ')\n except Exception as e:\n print('An Error occurred with url: {} {}'.format(url, e))\n\n\nif __name__ == '__main__':\n # test = AppleInsiderParser('AppleInsider_6.xlsx')\n # test.parse()\n\n # test = NineToFiveMacParser('NineToFiveMac.xlsx')\n # test.parse()\n\n # test = MacrumorsParser('MacRummors5.csv')\n # test.parse()\n with open('..\\\\sentiment_analysis\\\\seed_urls_ipads', 'r', encoding='utf-8') as f:\n start_urls = [url.strip('\\n') for url in f.readlines()]\n test = AmazonParser('AmazonAppleiPads.csv')\n test.parse(start_urls)\n del(test)\n\n with open('..\\\\sentiment_analysis\\\\seed_urls_macs', 'r', encoding='utf-8') as f:\n start_urls = [url.strip('\\n') for url in f.readlines()]\n test2 = AmazonParser('AmazonAppleMacs.csv')\n test2.parse(start_urls)"
},
{
"alpha_fraction": 0.7372881174087524,
"alphanum_fraction": 0.7542372941970825,
"avg_line_length": 28.75,
"blob_id": "2a39908298a038e865c5046b251aec3d763bb95a",
"content_id": "70b4e6abb2f0a16ae19b414e76de1e80cea58ade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 118,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 4,
"path": "/expectations_meter/csv_to_excel.py",
"repo_name": "kayutenko/ProductInfoAnalyser",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndata = pd.read_csv('AppleInsider_6_1.csv')\ndata.to_excel('AppleInsider_latest.xlsx', index=False)"
}
] | 3 |
dimitrismistriotis/general_assembly_data_science_class | https://github.com/dimitrismistriotis/general_assembly_data_science_class | 39eefea1364f60a4ade8c1ac3db2fe2ecf23de1a | 02fe2855d66925d398619b00c656666f9f0acbfb | 1a0d84a661ae7c3fffac91bd40a177842eb7f339 | refs/heads/master | 2020-12-02T23:53:02.921131 | 2017-08-08T06:26:46 | 2017-08-08T06:26:46 | 95,956,856 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7150077819824219,
"alphanum_fraction": 0.7212285995483398,
"avg_line_length": 46.62963104248047,
"blob_id": "8701c8a4f94c7df73db308cfa883acfca2ba823a",
"content_id": "eac1f7bfb05cdd5522104d0bd9aa58585af2968e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2572,
"license_type": "no_license",
"max_line_length": 230,
"num_lines": 54,
"path": "/week_02/Review_Statistics/assignments/assignment_1_summary_stats.md",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "# Assignment: Summary metrics\n\n## Objectives\n\nWe want to describe a dataset thanks to some key summary metrics. We will be\n\n - implementing mean, median and mode as well as when to use each summary metric\n - investigating range, interquartile range and outliers\n\nRemember that plotting out data is still the best way to understand it. Checkout [Anscombe's quartet](https://en.wikipedia.org/wiki/Anscombe's_quartet).\n\n_______________________________________\n\n## Questions & Answers\n\nBrief recap: notice the `if __name__ == '__main__':` block in the `.py` file. The code in this block will run when you type in the command prompt `python assignment_1_summary_stats.py`. Here it is mostly a check for our functions.\n\n1. Mean, median, mode\n\n (a) Fill in the functions `get_mean`, `get_median`, and `get_mode` in [assignment_1.py](../code/assignment_1.py). For the sake of practice, do not use `np.mean`, `np.median` and `scs.mode`.\n\n (b) Brief dataset description\n - dataset_1 : prices from used cars in my price range.\n - dataset_2 : prices of used cars I can afford and my dream car, a brand new Audi A8L.\n - dataset_3 : prices from used and new cars on Craiglist.\n\n Which summary metric would you choose to best describe datasets 1 to 3?\n\n YOUR ANSWER: Median\n\n YOUR EXPLANATION: So that I could get a feeling on where prices are about.\n I have a feeling that car prices would have many outliers both in the top\n of the market (ultra expensive custom-made) as well as in the bottom (cars\n that can be used for parts/scrap).\n\n2. Range vs interquartile range\n Fill in the functions `get_range`, `get_IQR`, and `remove_outliers` in [assignment_1.py](../code/assignment_1.py). Look up how to use `np.percentile`.\n\n How are range and interquartile range similar? How are they different?\n\n YOUR ANSWER: Interquartile range would remove the outliers and maybe some\n high and low variables. Range has more information but is sensitive to\n very high and very low values.\n\n If there are outliers in your dataset, how do you decide if you are going to ignore them or keep them in your analysis?\n\n YOUR ANSWER: Intuition and needs of the problem? How many are they? How far\n away from the \"body\" data-set? Could they be partly because of chance or\n errors in measurement?\n\n_______________________________________\n## Extra resources\n\n- These are relatively basic notions, they are defined in Khan Academy (https://www.khanacademy.org/math/statistics-probability/displaying-describing-data) and Udacity (https://classroom.udacity.com/courses/st101/) courses.\n"
},
{
"alpha_fraction": 0.33596837520599365,
"alphanum_fraction": 0.529644250869751,
"avg_line_length": 27.11111068725586,
"blob_id": "42e1f0de124a70cc8b182f906fd89ea2063d520e",
"content_id": "40eaf2a52b9188512fd6e502b680e43caea58fa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 253,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 9,
"path": "/adventure_in_statistics_book/page_71_ex4.py",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport math as math\n\ndf = pd.DataFrame({\"Price\": [10, 10, 10, 15, 15, 15, 20, 20, 20, 25, 25, 25],\n \"Design\": [0, 5, 10, 0, 5, 10, 0, 5, 10, 0, 5, 10]})\n\ndf['Sales'] = 20.0 + (df['Design']**2 / (df['Price'] + 10.0)**0.5)\n\nprint(df)\n"
},
{
"alpha_fraction": 0.41258740425109863,
"alphanum_fraction": 0.5209790468215942,
"avg_line_length": 25,
"blob_id": "b128365491c6d7e8fa8bf85a4630ca71b132227a",
"content_id": "71c3603330f7e279a49f82e182ae4f8861e923d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/adventure_in_statistics_book/page_72_ex8.py",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndf = pd.DataFrame({\n \"Person\": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],\n \"Mood Score\": [2, 6, 7, 10, 4, 2, 3, 5, 5, 7]})\n\nsum1 = sum(df[df[\"Person\"] >= 2][\"Mood Score\"]**3)\nprint(sum1)\n\nsum2 = sum(df[(df[\"Person\"] >= 2)&(df[\"Person\"] <= 9)][\"Mood Score\"]**2)\nprint(sum2)\n"
},
{
"alpha_fraction": 0.7927461266517639,
"alphanum_fraction": 0.7927461266517639,
"avg_line_length": 31,
"blob_id": "d5a2a81143b1c4e3cc9e2d28c0800237cc94d619",
"content_id": "8cf7829c0886c7a7d3175f86413c5188b429d274",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 6,
"path": "/LISENCE.md",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "# Lisence\n\nThis is released under the Dimitrios Mistriotis do your own homework lisence.\n\nRead it but do not copy/paste blindly, there is Google and StackOverflow for\nthat. Inspiration is OK.\n\n"
},
{
"alpha_fraction": 0.731216311454773,
"alphanum_fraction": 0.7453926801681519,
"avg_line_length": 41.49397659301758,
"blob_id": "94c17935f100f508c53a1f292a3569dcf0feba3f",
"content_id": "581f5f7519c7994b7c5187e423df16b4fffc275e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3527,
"license_type": "no_license",
"max_line_length": 265,
"num_lines": 83,
"path": "/week_02/Review_Statistics/assignments/assignment_3_estimation.md",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "# Assignment: Estimation\n\n## Objectives\nThis is first glimpse into inference.\n\n- computing confidence intervals for population proportions\n- computing confidence intervals for population means\n- choosing the appropriate test statistics\n\n_______________________________________\n\n## Questions & Answers\n\nA\tconfidence\tinterval\t(CI)\tis\tan\tinterval\testimate\tof\ta\tpopulation\tparameter.\n\n### 1. Estimating population proportion\n\nLet us consider polling. We want to survey a population size of N=12000. We randomly select people to survey to form a sample n=300 members strong and submit a yes(1)/no(0) question. p=140 people answered positively.\n\n - What is the sample mean? Its variance?\n\n YOUR ANSWER:\n\n YOUR EXPLANATION: \n\n - I want to estimate the proportion of people who answered positively, what is the point estimate? the margin of error for a 95% confidence interval? (Justify your choice of test statistics.)\n\n YOUR ANSWER:\n\n YOUR EXPLANATION:\n\n### 2. Estimating a population mean\n\nIn [assignment_3.py](../code/assignment_3.py), notice how the functions `load_pickle`, `draw_sample`, `get_mean` and `get_sem` from your completed version of [assignment_2.py](../code/assignment_2.py) were imported. You will use them in this part of the assignment.\n\n ```python\n from assignment_2 import load_pickle, draw_sample, get_mean, get_sem\n ```\n\n1. Implement `get_confidence_interval` to calculate the confidence intervals of the 100 sample and 1000 sample using confidence of `.95`.\n Use `scs.t.ppf(percentile)` to get a value at a given percentile in a t-distribution\n\n2. Define the variables `ci_100` and `ci_1000` and apply the function.\nPrint the variables.\n\n - Does the confidence intervals include the population mean? Can you explain\n why that is?\n\n YOUR ANSWER: In my case it does.\n\n YOUR EXPLANATION: From the definition of the confidence interval: if\n we sample a number of samples 95% of them will have their mean within\n the calculated CI range. We are within that 95%.\n\n3. Modifying function arguments:\n - Try lowering the confidence to `.70` instead of `.95`. What does it do to the range of the confidence interval?\n\n YOUR ANSWER: Smaller range\n\n YOUR EXPLANATION: Now we are less confident on a more narrow range.\n\n - Try increasing the sample size. What does it do to the range of the confidence interval?\n\n YOUR ANSWER: Narrows it\n\n YOUR EXPLANATION: Sqrt of n in the denominator or more data\n brings us closer to the real value.\n\n4. Assumptions: What assumption are we making about the distribution of the population when we apply the confidence interval? Why are we able to make this assumption here without visualizing any plot?\n\n YOUR ANSWER: That the population mean follows a normal distribution.\n\n YOUR EXPLANATION: As far as I remember from reading but not certain,\n Central Limit Theorem ensures that.\n\n_______________________________________\n## Extra resources\n\n- Khan Academy explains how to build confidence intervals to give an interval estimate of a population parameter (https://www.khanacademy.org/math/statistics-probability/confidence-intervals-one-sample).\n\n- JBStatistics material: these are videos that introduce you to the notion and the building of confidence intervals (http://www.jbstatistics.com/confidence-intervals/)\n\n- a [cheatsheet](../resources/CI.pdf) is available in the resources directory with compared/contrasted formulas for confidence intervals depending on whether the population standard deviation is known or not.\n"
},
{
"alpha_fraction": 0.5738681554794312,
"alphanum_fraction": 0.6469420194625854,
"avg_line_length": 30.0864200592041,
"blob_id": "69f33d07e8f8f03f7987f70057e6dd640814876d",
"content_id": "d07e9ef880402ab6f555263057d2c1f164ed4319",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2518,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 81,
"path": "/week_02/Review_Statistics/code/assignment_3.py",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport scipy.stats as scs\nfrom assignment_2 import load_pickle, draw_sample, get_mean, get_sem\n\n# Don't change this. This fixes the randomness in sampling\nnp.random.seed(seed=1234)\n\n\ndef get_confidence_interval(sample, confidence=.95):\n \"\"\"Returns the confidence interval for a population mean based on the\n given sample\n\n Parameters\n ----------\n sample : numpy arry\n confidence : float, the confidence of the ci from 0 to 1, defaults to .95\n\n Returns\n -------\n [sample mean, sample mean - margin_error, sample mean + margin_error],\n estimation of a population mean, with unknown population standard deviation\n\n Hint: use scs.t.ppf(percentile)\n \"\"\"\n if confidence < 0 or confidence > 1:\n return None\n\n t_a_div_2_parameter = ((1 - confidence) / 2) + confidence\n t_value = scs.t.ppf(t_a_div_2_parameter, len(sample))\n sem = get_sem(sample)\n margin_error = t_value * sem\n\n sample_mean = get_mean(sample)\n\n return (sample_mean - margin_error, sample_mean + margin_error)\n\n\nif __name__ == '__main__':\n population = load_pickle('../data/population.pkl')\n # draw the samples\n sample_100 = draw_sample(population, 100)\n sample_1000 = draw_sample(population, 1000)\n # population parameter: mean\n population_mean = get_mean(population)\n print '*' * 20\n print 'Population mean:', population_mean\n print '*' * 20\n # sample statistics: sample mean\n sample_100_mean = get_mean(sample_100)\n sample_1000_mean = get_mean(sample_1000)\n\n # on sample: SEM\n sem_100 = get_sem(sample_100)\n sem_1000 = get_sem(sample_1000)\n print '*' * 20\n print 'Sample 100 sem:', sem_100\n print 'Sample 1000 sem:', sem_1000\n print '*' * 20\n # confidence intervals\n ci_100 = get_confidence_interval(sample_100)\n ci_1000 = get_confidence_interval(sample_1000)\n print '*' * 20\n print 'Sample 100 mean ci, alpha .95', ci_100\n print 'Sample 1000 mean ci, alpha .95', ci_1000\n print '*' * 20\n\n ci_100_seventy = get_confidence_interval(sample_100, .7)\n ci_1000_seventy = get_confidence_interval(sample_1000, .7)\n print '*' * 20\n print 'Sample 100 mean ci, alpha .7', ci_100_seventy\n print 'Sample 1000 mean ci, alpha .7', ci_1000_seventy\n print '*' * 20\n\n #\n # Assignment question 3\n #\n sample_2000 = draw_sample(population, 2000)\n ci_2000 = get_confidence_interval(sample_2000)\n print '-' * 20\n print 'Sample 1000 mean ci, alpha .95', ci_2000\n print '-' * 20\n"
},
{
"alpha_fraction": 0.8399999737739563,
"alphanum_fraction": 0.8399999737739563,
"avg_line_length": 36.5,
"blob_id": "cee85993c14e7a9d699b74af19e533e0757461f4",
"content_id": "4f9ca0b73a68f3e4390d958e06219c9ed3626f3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 2,
"path": "/README.md",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "# general_assembly_data_science_class\nHomework from General Assembly class\n"
},
{
"alpha_fraction": 0.6015723943710327,
"alphanum_fraction": 0.6373319625854492,
"avg_line_length": 29.330768585205078,
"blob_id": "1f0bae4dfb026bbe75add69d3799be331cfbeeaa",
"content_id": "07284b2891d205f8713cd05401e22a0872400c18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3943,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 130,
"path": "/week_02/Review_Statistics/code/assignment_2.py",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "import pickle\nimport numpy as np\nimport scipy.stats as scs\n\n# Don't change this. This fixes the randomness in sampling\nnp.random.seed(seed=1234)\n\n\n# This loads in the list of numbers you are going to deal with\ndef load_pickle(file_name):\n \"\"\"INPUT:\n - file_name(STR) [The name of the file]\n\n OUTPUT:\n - population(NUMPY ARRAY) [A array of numbers for the exercise]\n \"\"\"\n return pickle.load(open(file_name))\n\n\ndef draw_sample(population, n):\n \"\"\"INPUT:\n - population(NUMPY ARRAY) [The array containing all the numbers]\n - n(INT) [The number of sample you wanna draw]\n\n OUTPUT:\n - sample(NUMPY ARRAY) [A array that contains a subset of the population]\n\n Hint: Use np.random.choice(). Google it. Google is your best friend\n \"\"\"\n # random_positions = np.random.choice(len(population), n)\n # return population[random_positions]\n # One liner:\n return population[np.random.choice(len(population), n)]\n\n\ndef get_mean(lst):\n \"\"\"INPUT:\n - lst(NUMPY ARRAY) [The array of numbers where we find the mean of]\n\n OUTPUT:\n - mean_value(FLOAT)\n\n Hint: Don't use np.mean().\n Then use np.mean(arr) to see if you got the same value\n \"\"\"\n l = len(lst)\n return float(sum(lst)) / l if l != 0 else None\n\n\ndef get_variance(lst, sample=True):\n \"\"\"INPUT:\n - lst(NUMPY ARRAY) [Either the sample or the population]\n - sample(BOOL) [True if sample variance, False if population variance]\n\n OUTPUT:\n - lst_variance(FLOAT) [Sample or population variance depending]\n \"\"\"\n n = len(lst)\n if n == 0 or (n == 1 and sample == True):\n return None\n\n denominator = n - 1 if sample else n\n m = get_mean(lst)\n\n return float(sum([(x - m)**2 for x in lst])) / denominator\n\n\ndef get_sem(sample):\n \"\"\"INPUT:\n - sample(NUMPY ARRAY)\n\n OUTPUT:\n - sem(FLOAT) [Standard Error Mean]\n \"\"\"\n variance = get_variance(sample, True)\n\n if variance == -1: # Error value\n return -1\n return float(np.sqrt(variance)) / np.sqrt(float(len(sample) - 1))\n\n\nif __name__ == '__main__':\n population = load_pickle('../data/population.pkl')\n print 'First 10 element of the population: ', population[:5]\n\n #\n # Assignment, checking functions:\n #\n print('Population mean from custom function: %f, and from np.mean: %f' %\n (get_mean(population), np.mean(population)))\n\n print('Selecting %d random elements: %s' % (5, draw_sample(population, 5)))\n\n print('Variance of population: %f' % get_variance(population, False))\n one_pct_sample = draw_sample(population, (len(population) / 100))\n print('Variance of 1%% sample of population: %f' %\n get_variance(one_pct_sample, True))\n print('Standard Error of Mean of 1%% sample of population: %f' %\n get_sem(one_pct_sample))\n print('-' * 80)\n\n #\n # Assignment parts 2 to 4\n #\n\n # Part 2\n sample_100 = draw_sample(population, 100)\n sample_1000 = draw_sample(population, 1000)\n\n # Part 3\n sem_100 = get_sem(sample_100)\n sem_1000 = get_sem(sample_1000)\n print('Standard Error of Mean of 100 sample of population: %f' % sem_100)\n print('Standard Error of Mean of 1000 sample of population: %f' % sem_1000)\n\n print('Population mean from custom function: %f, and from np.mean: %f' %\n (get_mean(population), np.mean(population)))\n print(\"Sample mean of 100-sample: %f\" % get_mean(sample_100))\n print(\"Sample mean of 1000-sample: %f\" % get_mean(sample_1000))\n\n print(\"Variance of population: %f\" % get_variance(population))\n variance_100 = get_variance(sample_100)\n print(\"Variance of 100-sample: %f\" % variance_100)\n variance_1000 = get_variance(sample_1000)\n print(\"Variance of 1000-sample: %f\" % variance_1000)\n print(\"Variance pcf difference: %f\" % (\n ((variance_1000 - variance_100) * 100) / variance_1000))\n\n # Part 4\n print(\"Sem pct difference: %f\" % (((sem_1000 - sem_100) * 100) / sem_1000))\n"
},
{
"alpha_fraction": 0.5264464616775513,
"alphanum_fraction": 0.5423392057418823,
"avg_line_length": 23.113773345947266,
"blob_id": "e11b8ec030e9fa5d47804566e682f026df3d7548",
"content_id": "fba3e152f030429c86f08cba37ce7ee57dd422b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4027,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 167,
"path": "/week_02/Review_Statistics/code/assignment_1.py",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport scipy.stats as scs\n\n\ndef get_mean(lst):\n \"\"\"Return the mean of all the values in lst\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n float, mean value of the input list\n\n Do not use np.mean().\n \"\"\"\n if len(lst) == 0:\n return None\n else:\n return float(sum(lst)) / len(lst) \n\n\ndef get_median(lst):\n \"\"\"Return the median of all the values in lst\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n float, median value of the input list\n\n Do not use np.median().\n \"\"\"\n l = len(lst)\n if l == 0:\n return None\n\n slst = sorted(lst)\n if l % 2 == 0:\n return (float(slst[(l/2) - 1]) + float(slst[(l/2)])) / 2\n else:\n return float(slst[(l/2)])\n\ndef get_mode(lst):\n \"\"\"Return the mode of all the values in lst\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n float, mode value of the input list (FLOAT)\n\n Do not use scs.mode().\n \"\"\"\n freq = {}\n for i in lst:\n if i in freq:\n freq[i] += 1\n else:\n freq[i] = 1\n\n return max(freq, key=lambda f: freq[f])\n\n\ndef get_range(lst):\n \"\"\"Return the range of all the values in lst\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n float, range of the input list\n \"\"\"\n return float(max(lst)) - float(min(lst))\n\n\ndef get_IQR(lst):\n \"\"\"Return the interquartile range of all the values in lst\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n float, interquartile range of the input list (FLOAT)\n\n Hint: you may use np.percentile\n \"\"\"\n return (float(np.percentile(lst, 75)) - float(np.percentile(lst, 25)))\n\n\ndef remove_outliers(lst):\n \"\"\"Return all the values in lst in sorted order without the outliers\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n list, sorted lst with any data points 3 interquartile range below Q1\n (25th percentile) or 3 interquartile range above Q3 (75th percentile)\n \"\"\"\n slst = sorted(lst)\n three_iqr = 3 * get_IQR(lst)\n low_boundary = float(np.percentile(lst, 25)) - three_iqr\n high_boundary = float(np.percentile(lst, 75)) + three_iqr\n\n return filter(lambda x: x >= low_boundary and x <= high_boundary, slst)\n\n\ndef run_check(lst):\n \"\"\"Check the output of functions implemented (mean, median and mode)\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n None, prints out the results of the test comparing hand implemented\n functions to corresponding 'np' or 'scs' methods.\n \"\"\"\n print('Mean: ', get_mean(lst) == np.mean(lst))\n print('Median: ', get_median(lst) == np.median(lst))\n print('Mode: ', get_mode(lst) == scs.mode(lst).mode[0])\n\n\ndef print_summary_metrics(lst):\n \"\"\"Print an overview of all summary statistics mentioned in this exercise\n\n Parameters\n ----------\n lst : list of ints/floats\n\n Returns\n -------\n None, prints out the values of the summary statistics studied in\n this exercise.\n \"\"\"\n print('*' * 50)\n print(' ' * 16 + 'Summary statistics')\n print('*' * 50)\n print('mean: {} | median: {} | mode: {}'.format(get_mean(lst),\n get_median(lst),\n get_mode(lst)))\n print('range: {} | IQR: {}'.format(get_range(list_nums),\n get_IQR(list_nums)))\n print('\\n')\n print('original list: \\n {}'.format(lst))\n print('sorted list: \\n {}'.format(sorted(lst)))\n print('List without outliers: \\n {}'.format(\n remove_outliers(list_nums)))\n\n\nif __name__ == '__main__':\n list_nums = [100, 9, 4, 7, 22, 37, 44, 22, 79, 88, 200, 37, 22, 1000]\n run_check(list_nums)\n print_summary_metrics(list_nums)\n"
},
{
"alpha_fraction": 0.6857798099517822,
"alphanum_fraction": 0.71100914478302,
"avg_line_length": 23.22222137451172,
"blob_id": "cc1be344c4afe5c0435e988c11937b1032f55ff8",
"content_id": "ee6c1b3a552e1799981a1bd9e9ccad2ae2288ada",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 872,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 36,
"path": "/Homework_for_lesson_5/individual_answers.md",
"repo_name": "dimitrismistriotis/general_assembly_data_science_class",
"src_encoding": "UTF-8",
"text": "# Individual Answers\n\n## Part 1: Hypothesis Testing recap - Question (1)\n\nFor the first example my Null Hypothesis (**H0**) would be:\n```\nmean_of_dog_weight = mean_of_cat_weight\n```\n\n\nwith the Alternative Hypothesis (**H1**) being\n```\nmean_of_dog_weight != mean_of_cat_weight\n```\n\n\nFor the second example the Null Hypothesis (**H0**) would be:\n```\npct_of_fans_in_sf = pct_of_fans_in_ok\n```\n\nThe Alternative Hypothesis (**H1**) here would be:\n```\npct_of_fans_in_sf > pct_of_fans_in_ok\n```\n\nsince it makes sense for a SF team to be more popular in SF.\n\nI would use a chi-square test for these two cases, with the H0/H1 as stated\nabove.\n\n## Part 1: Hypothesis Testing recap - Question (2)\n\nFor statistical significance of 0.05 two tailed Hypothesis the value to\ncompare with is 2.240 of which the 0.026 calculated rejects the H0 that Pisces\nhas higher failure rate than Leo.\n"
}
] | 10 |
AntonCoon/HA | https://github.com/AntonCoon/HA | 8fcf458e72cca080c81ac2630df9c02dcf37f7b5 | 7062eb8905c0d97f627c380236219e39ab64b570 | 8626d319d03951eacf4de46dd09151ed18bb1206 | refs/heads/master | 2020-07-09T00:01:10.610714 | 2020-05-14T15:33:08 | 2020-05-14T15:33:08 | 203,816,437 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5693730711936951,
"alphanum_fraction": 0.5878725647926331,
"avg_line_length": 29.40625,
"blob_id": "d98faecf3f88e83dc5d51d8a2da1cc1ab141d5d1",
"content_id": "427fd6fc4266ab3770ebe87b582a0aee761f304d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 32,
"path": "/cases/analyze.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from src import Util\nfrom os import path\n\n\nnames = [\n 'base_case_1_1',\n 'base_case_2_2',\n 'base_case_3_3',\n 'base_case_4_2',\n 'base_case_8_2',\n 'base_case_8_4',\n 'base_case_81_3',\n 'base_case_81_6',\n 'gattaca'\n]\n\n\nfor name in names:\n print(name)\n gt = Util.read_ground_truth(path.join('./input/', name, 'reads_gt.txt'))\n my = Util.read_ground_truth(path.join(\n './my_output', name, 'haplotypes.txt'))\n savage = Util.read_vgflow(path.join(\n './savage+vg-flow', name, 'haps.final.fasta'))\n print('my score: {}'.format(Util.earth_mover_distance(gt, my)))\n print('savage score: {}'.format(Util.earth_mover_distance(gt, savage)))\n gt_set = set([h for h, _ in gt])\n get_set = set([h for h, _ in my])\n savage_set = set([h for h, _ in savage])\n print('whole reconstructed', len(gt_set) - len(gt_set - get_set))\n print('whole reconstructed by savage', len(gt_set) - len(gt_set - savage_set))\n print()\n"
},
{
"alpha_fraction": 0.6611694097518921,
"alphanum_fraction": 0.6660419702529907,
"avg_line_length": 26.224489212036133,
"blob_id": "87714a795f207d944198641c447952f15b265bf2",
"content_id": "770b694156fda83e713e9ac931f8e9f3c1cc4ee7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2668,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 98,
"path": "/cases/assembling.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from src import DeBruijnBuildNetwork\nfrom src import ILPInputPreprocessor\nfrom src import ILPMinimizer\nfrom src import DeBruijnNetworkAligner\nfrom src import Util\nfrom os import path\nfrom os import mkdir\nimport numpy as np\n\n\ncase_name = 'gattaca'\ninput_path = path.join('./input', case_name)\noutput_path = path.join('./my_output', case_name)\n# mkdir(output_path)\nfile_path = path.join(input_path, 'reads.fastq')\n\nhandmade_alpha = 0.5\nk_mer_len = 61\n\nfile_extension = 'fastq'\ndb_graph = DeBruijnBuildNetwork.DBGraph(\n file_path,\n file_extension,\n k_mer_len)\ndb_graph.build()\ndb_graph.compression()\n\nheaviest_path = db_graph.get_heaviest_path()\nhap = Util.get_haplotype_by_path(db_graph, heaviest_path)\n\n# # ----Plot graph\n# import networkx as nx\n# from matplotlib import pyplot as plt\n# pos = nx.layout.kamada_kawai_layout(db_graph)\n# plt.figure(figsize=(8, 6))\n# nx.draw_networkx_edges(db_graph, pos, alpha=0.4)\n# nx.draw_networkx_nodes(db_graph, pos, node_size=60)\n# plt.axis('off')\n# plt.show()\n\naligner = DeBruijnNetworkAligner.NetworkAligner(db_graph)\naligner.align_db_graph()\n\nprint()\nprint(hap)\nfor e, (start, end) in aligner.edge_alignment.items():\n print(\n '_' * start + db_graph.get_edge_substring(e) + '_' * (len(hap) - end),\n start,\n end\n )\n\n\naligner.align_reads_with_bwa()\naligner.split_db_graph()\naligner.unite_same_edges_in_buckets()\naligner.calculate_coverage()\n\ntrial_preproc = ILPInputPreprocessor.DataPreprocessor(db_graph)\nprint('initial path amount')\nprint(len(trial_preproc.find_haplotypes()[0]))\nprint()\n\npreproc = ILPInputPreprocessor.DataPreprocessor(aligner.aligned_db_graph)\nhaps, _ = preproc.find_haplotypes()\nprint('haplotype amount', len(set(haps)))\n\nminimizer = ILPMinimizer.ILPMinimizer(\n aligner.aligned_db_graph, preproc.haplotypes_edges)\nhps_thr_e = minimizer.edges_haplotypes\nh_ids = {h: idx for idx, h in enumerate(haps)}\n\nfor e, v in hps_thr_e.items():\n coverage = aligner.aligned_db_graph.edges[e]['coverage']\n if len(v) != len(set(haps)):\n print(\n str(\n round(coverage, 5)\n ) + ' -',\n ' - '.join(['F_' + str(h_ids[h]) for h in v])\n )\n\nminimizer.find_alpha(handmade_alpha)\nbig_val, freqs = minimizer.find_frequencies_square()\nnon_zero = sum(np.array(list(freqs.values())) != 0)\nprint(\n 'huge alpha = {}\\nnonzero frequencies amount = {}\\nphi = {}'.format(\n handmade_alpha,\n non_zero,\n big_val\n )\n)\n\n# with open(path.join(output_path, 'haplotypes' + '.txt'), 'w') as my_out:\nfor h, p in freqs.items():\n if p:\n print('{} {}\\n'.format(h, p))\n # my_out.write('{} {}\\n'.format(h, p))\n"
},
{
"alpha_fraction": 0.46453043818473816,
"alphanum_fraction": 0.4770253896713257,
"avg_line_length": 38.380950927734375,
"blob_id": "576616840c1cc80ca3374916f42201226fe052e4",
"content_id": "ff9a38f6d35576bd52f070245d59e2405a984a4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4962,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 126,
"path": "/src/AlignedDB.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from Bio import SeqIO\nimport networkx as nx\nfrom src import Util\nfrom itertools import product\nfrom collections import defaultdict\nfrom tqdm import tqdm\n\n\nclass AlignedDB(nx.DiGraph):\n def __init__(\n self,\n path_to_reads: list,\n path_to_reference: str,\n read_format: str,\n k_mer_len: int = 61,\n **attr):\n super().__init__(**attr)\n self.path_to_reads = path_to_reads\n self.path_to_reference = path_to_reference\n self.format = read_format\n self.k = k_mer_len\n self.read_len = 0\n self.ref = SeqIO.parse(self.path_to_reference, \"fasta\")\n self.ref = str(next(self.ref).seq)\n self.baskets = dict()\n self.haplotypes = []\n self.ref_edges = set()\n\n def get_edge_substring(self, edge: tuple) -> str:\n u, v = edge\n in_degree = self.in_degree(u)\n out_degree = self.out_degree(v)\n k = self.k\n if in_degree == 0 and out_degree == 0:\n # |0--->0|\n return self.edges[edge]['contig']\n elif out_degree == 0:\n # ...0--->0|\n return self.edges[edge]['contig'][k // 2:]\n elif in_degree == 0:\n # |0--->0...\n return self.edges[edge]['contig'][:-k // 2]\n else:\n # |...0--->0...|\n return self.edges[edge]['contig'][k // 2: -k // 2]\n\n def build_ref(self):\n for i, (kmer1, kmer2) in enumerate(Util.k_mer_pairs(self.ref, self.k)):\n kmer1, kmer2 = Util.KMer(kmer1, i), Util.KMer(kmer2, i + 1)\n contig = kmer1.seq + kmer2.seq[-1]\n self.add_edge(kmer1, kmer2)\n self.edges[(kmer1, kmer2)]['coverage'] = 1\n self.edges[(kmer1, kmer2)]['contig'] = contig\n self.baskets[(i, i + 1)] = {(kmer1, kmer2)}\n self.ref_edges.add((kmer1, kmer2))\n\n def build(self):\n self.build_ref()\n with Util.BWAContextManager(self.path_to_reads, self.ref) as bwa:\n for read_object in tqdm(bwa.sam_file):\n read = read_object.seq\n read = \"\".join(\n [read[i] if i is not None else \"_\"\n for i, _ in read_object.aligned_pairs]\n )\n start, end = read_object.pos, read_object.aend\n # take just whole aligned data\n if start is None or end is None or read is None:\n continue\n if end - start != len(read):\n continue\n posed_kmers = [\n (km1, km2, start + i) for i, (km1, km2) in enumerate(\n Util.k_mer_pairs(read, self.k))\n ]\n new_edges = [\n (Util.KMer(km1, i), Util.KMer(km2, i + 1))\n for km1, km2, i in posed_kmers\n ]\n for u, v in new_edges:\n contig = u.seq + v.seq[-1]\n if (u, v) in self.edges:\n self.edges[(u, v)]['coverage'] += 1\n self.baskets[(u.pos, v.pos)].add((u, v))\n else:\n self.add_edge(u, v)\n self.edges[(u, v)]['coverage'] = 1\n self.edges[(u, v)]['contig'] = contig\n self.baskets[(u.pos, v.pos)].add((u, v))\n\n def build_by_sam(self):\n # to do\n pass\n\n def find_haplotypes(self) -> tuple:\n self.haplotypes = []\n haplotypes_edges = dict()\n srcs = []\n dsts = []\n for vertex in self.nodes:\n indeg = self.in_degree(vertex)\n outdeg = self.out_degree(vertex)\n if indeg == 0:\n srcs.append(vertex)\n elif outdeg == 0:\n dsts.append(vertex)\n if len(srcs) * len(dsts) > 200:\n print(len(srcs) * len(dsts))\n print(\"light version [to many possible paths]\")\n for src, dst in tqdm(product(srcs, dsts)):\n if nx.has_path(self, src, dst):\n path = nx.shortest_path(self, src, dst, weight=\"coverage\")\n # for path in nx.all_simple_paths(self, src, dst):\n edge_path = list(zip(path[:-1], path[1:]))\n haplotype = Util.get_haplotype_by_path(self, edge_path)\n self.haplotypes.append(haplotype)\n haplotypes_edges[haplotype] = edge_path\n else:\n print(\"by all possible paths\")\n for src, dst in tqdm(product(srcs, dsts)):\n for path in nx.all_simple_paths(self, src, dst):\n edge_path = list(zip(path[:-1], path[1:]))\n haplotype = Util.get_haplotype_by_path(self, edge_path)\n self.haplotypes.append(haplotype)\n haplotypes_edges[haplotype] = edge_path\n return self.haplotypes, haplotypes_edges\n"
},
{
"alpha_fraction": 0.5492333769798279,
"alphanum_fraction": 0.5526405572891235,
"avg_line_length": 36.628204345703125,
"blob_id": "0c71bfb27a9985d91a3de93495ab48fa2f0872e3",
"content_id": "ee2856bf5067957ad10bb43aa6d0c02e82a6052c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2935,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 78,
"path": "/src/AlignedDBPreprocessor.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from src import AlignedDB\nfrom src import Util\nfrom Bio import SeqIO\nfrom math import log\nfrom tqdm import tqdm\n\n\nclass AlignedDBPreprocessor(object):\n def __init__(\n self,\n aligned_db: AlignedDB.AlignedDB,\n probability: float):\n self.aligned_db = aligned_db\n self.probability = probability\n self.reference_size = len(self.aligned_db.ref)\n self.read_len = 0\n self.reads_amount = 0\n self.eriksson_threshold = None\n\n def normalize_parallel(self):\n for basket, edges in self.aligned_db.baskets.items():\n basket_norm = sum(\n [self.aligned_db.get_edge_data(*e)[\"coverage\"] for e in edges]\n )\n for e in edges:\n self.aligned_db.edges[e][\"coverage\"] /= basket_norm\n # if e not in self.aligned_db.ref_edges:\n # self.aligned_db.edges[e][\"coverage\"] /= basket_norm\n # else:\n # self.aligned_db.edges[e][\"coverage\"] = 1\n basket_norm = sum(\n [self.aligned_db.get_edge_data(*e)[\"coverage\"] for e in edges]\n )\n for e in edges:\n self.aligned_db.edges[e][\"coverage\"] /= basket_norm\n\n def mean_by_path_parallel(self):\n paths_decomposition = Util.split_graph_by_paths(self.aligned_db)\n for path in paths_decomposition:\n mean = sum(\n self.aligned_db.get_edge_data(*e)[\"coverage\"] for e in path\n ) / len(path)\n for e in path:\n self.aligned_db.edges[e][\"coverage\"] = mean\n\n def __calculate_parameters(self):\n whole_len = 0\n for path in self.aligned_db.path_to_reads:\n file_with_reads = SeqIO.parse(path, self.aligned_db.format)\n for read in file_with_reads:\n whole_len += len(read)\n self.reads_amount += 1\n self.read_len = whole_len / self.reads_amount\n\n def eriksson_clear(self):\n self.__calculate_parameters()\n # Eriksson threshold on distinguishable haplotype\n n = self.reference_size\n p = self.probability\n L = self.read_len\n N = self.reads_amount\n self.eriksson_threshold = - n * log(1 - p ** (1 / n)) / (L * N)\n targeted_edges = set()\n for e, info in tqdm(self.aligned_db.edges.items()):\n if info[\"coverage\"] < self.eriksson_threshold:\n targeted_edges.add(e)\n for e in targeted_edges:\n self.aligned_db.remove_edge(*e)\n basket_key = (e[0].pos, e[1].pos)\n self.aligned_db.baskets[basket_key].remove(e)\n self.normalize_parallel()\n self.mean_by_path_parallel()\n removable = []\n for v in self.aligned_db:\n if self.aligned_db.degree(v) == 0:\n removable.append(v)\n for v in removable:\n self.aligned_db.remove_node(v)\n"
},
{
"alpha_fraction": 0.5960233211517334,
"alphanum_fraction": 0.6204310059547424,
"avg_line_length": 26.6282901763916,
"blob_id": "4376f8c5d4ac30a2aa08527fcede7fc11b32fbdb",
"content_id": "7ea95e5dc7d33f10c70cae80c8e5597b3bede58b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8399,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 304,
"path": "/debug.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from src import DeBruijnBuildNetwork\nfrom src import ILPInputPreprocessor\nfrom src import ILPMinimizer\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport networkx as nx\nfrom collections import defaultdict\nfrom itertools import product\nfrom tqdm import tqdm\nfrom src import DeBruijnNetworkAligner\nfrom src import Util\nfrom bisect import bisect_left\nfrom bisect import bisect_right\nimport pickle\nfrom Bio import SeqIO\nfrom time import time\nfrom src import AlignedDB\nfrom src import AlignedDBPreprocessor\n\npath_to_ref = \"test/ref.fa\"\n\naligned_db = AlignedDB.AlignedDB(\n [\n \"../data/small_simul/u1.5e-5_s40_Ne1000/sequences00001/read1.fq\",\n \"../data/small_simul/u1.5e-5_s40_Ne1000/sequences00001/read2.fq\"\n ],\n path_to_ref,\n \"fastq\",\n k_mer_len=61\n)\n\naligned_db.build_ref()\naligned_db.build()\n\nprep = AlignedDBPreprocessor.AlignedDBPreprocessor(aligned_db, 0.9999999999)\nprep.normalize_parallel()\nprep.mean_by_path_parallel()\nprep.eriksson_clear()\n\naligned_db = prep.aligned_db\n\nprint(aligned_db.number_of_edges())\n\nilp_prep = ILPInputPreprocessor.DataPreprocessor(aligned_db)\nhaplotypes, _ = ilp_prep.find_haplotypes()\nprint('haplotype amount', len(set(haplotypes)))\n\nminimizer = ILPMinimizer.ILPMinimizer(\n aligned_db, ilp_prep.haplotypes_edges)\n\nminimizer.find_alpha(prep.eriksson_threshold / 10)\nbig_val, result = minimizer.find_frequencies()\n\n\n# complete to reference\nindexes = dict()\nfor k, v in ilp_prep.haplotypes_edges.items():\n indexes[k] = (v[0][0].pos, v[-1][-1].pos + aligned_db.k)\n\nassembled = []\nfor h, f in result.items():\n if f > prep.eriksson_threshold / 10:\n h = aligned_db.ref[:indexes[h][0]] + h + aligned_db.ref[indexes[h][1]:]\n assembled.append((h, f))\n\nprint()\nresult = Util.get_normalize_pair_list(assembled)\n\nprint([(len(h), f) for h, f in result])\ngt = Util.read_ground_truth(\n \"../data/small_simul/u1.5e-5_s40_Ne1000/sequences00001/gt.txt\"\n)\nprint(\"ref\", Util.earth_mover_distance([(aligned_db.ref, 1)], gt))\nprint(len(result), len(gt))\nprint(\"result\", Util.earth_mover_distance(result, gt))\n\n# predict_path = \"../sandbox/predicthaplo_results/smallest_global_8_1617.fas\"\n# predict_result = []\n# predict_result_file = SeqIO.parse(predict_path, \"fasta\")\n# for seq in predict_result_file:\n# content = seq.seq.split(\"EndOfComments\")\n# h = str(content[-1])\n# f = float(str(content[0].split(\";\")[1].split(\":\")[1]))\n# predict_result.append((h, f))\n# print(len(predict_result))\n# print(\"result\", Util.earth_mover_distance(predict_result, gt))\n\n# path = '../data/simulations/u1.5e-5_s200_Ne1000/sequences00001/read1.fq'\n#\n#\n# k_mer_len = 60\n# file_extension = 'fastq'\n# file_with_reads = SeqIO.parse(path, file_extension)\n#\n# # init = time()\n# # amount = 0\n# # for _ in file_with_reads:\n# # amount += 1\n# #\n# # print(amount)\n#\n#\n# db_graph = DeBruijnBuildNetwork.DBGraph(\n# path,\n# file_extension,\n# k_mer_len)\n# db_graph.build()\n# # db_graph.compression()\n#\n# with open(\"db_graph.pickle\", \"wb\") as file:\n# pickle.dump(db_graph, file)\n\n# path = db_graph.get_heaviest_path()\n# hap = Util.get_haplotype_by_path(db_graph, path)\n#\n# aligner = DeBruijnNetworkAligner.NetworkAligner(db_graph)\n# aligner.align_db_graph()\n#\n# print()\n# print(hap)\n# for e, (start, end) in aligner.edge_alignment.items():\n# print(\n# '_' * start + db_graph.get_edge_substring(e) + '_' * (len(hap) - end),\n# start,\n# end\n# )\n\n# aligner.align_reads()\n# aligner.split_db_graph()\n# aligner.unite_same_edges_in_buckets()\n# aligner.calculate_coverage()\n#\n# preproc = ILPInputPreprocessor.DataPreprocessor(aligner.aligned_db_graph)\n# haps, _ = preproc.find_haplotypes()\n# print('haplotype amount', len(set(haps)))\n#\n# minimizer = ILPMinimizer.ILPMinimizer(\n# aligner.aligned_db_graph, preproc.haplotypes_edges)\n# hps_thr_e = minimizer.edges_haplotypes\n# h_ids = {h: idx for idx, h in enumerate(haps)}\n#\n# # # ----Plot graph\n# # pos = nx.layout.kamada_kawai_layout(db_graph)\n# # plt.figure(figsize=(8, 6))\n# # nx.draw_networkx_edges(db_graph, pos, alpha=0.4)\n# # nx.draw_networkx_nodes(db_graph, pos, node_size=60)\n# # plt.axis('off')\n# # plt.show()\n# # # ----Plot graph\n# # pos = nx.layout.kamada_kawai_layout(aligner.aligned_db_graph)\n# # plt.figure(figsize=(8, 6))\n# # nx.draw_networkx_edges(aligner.aligned_db_graph, pos, alpha=0.4)\n# # nx.draw_networkx_nodes(aligner.aligned_db_graph, pos, node_size=60)\n# # plt.axis('off')\n# # plt.show()\n# # #\n# # ----Print equation\n# for e, v in hps_thr_e.items():\n# # length = len(db_graph.edges[e]['contig'])\n# coverage = aligner.aligned_db_graph.edges[e]['coverage']\n# print(\n# # length,\n# \"*\" if len(v) == len(set(haps)) else \"-\",\n# str(\n# round(coverage, 5)\n# ) + ' -',\n# ' - '.join(['F_' + str(h_ids[h]) for h in v])\n# )\n#\n# # ----Test huge alpha\n# big_alpha = 0.02\n# minimizer.find_alpha(big_alpha)\n# big_val, freqs = minimizer.find_frequencies()\n# non_zero = sum(np.array(list(freqs.values())) != 0)\n# big_val -= big_alpha * non_zero\n# print(\n# 'huge alpha = {}\\nnonzero frequencies amount = {}\\nphi = {}'.format(\n# big_alpha,\n# non_zero,\n# big_val\n# )\n# )\n#\n# reconstructed = [(k, v) for k, v in freqs.items() if v > 0]\n# for k, v in reconstructed:\n# print(k, v)\n#\n# # ----Different alphas\n# lmbds = np.linspace(0, .04, 20)\n# freqs = []\n# targets = []\n# phis = []\n# reconstructed = []\n# for lmbd in tqdm(lmbds):\n# minimizer.find_alpha(lmbd)\n# val, freq = minimizer.find_frequencies()\n# reconstructed.append([(k, v) for k, v in freq.items() if v > 0])\n# freqs.append(np.array(list(freq.values())))\n# targets.append(val)\n# non_zero = sum(freqs[-1] > 10**-5)\n# phis.append(val - lmbd * non_zero)\n#\n# # ----Plot nonzero frequencies\n# p = plt.plot(\n# lmbds,\n# np.array(\n# [len([x_rez for x_rez in rez if x_rez > 10**-5]) for rez in freqs]\n# ),\n# '-o'\n# )\n# plt.xlabel('importance of zeros')\n# plt.ylabel('nonzero amount')\n# plt.savefig('./tmp_plots/nonzero_amount.jpg')\n# plt.show()\n#\n# # ----Plot target value\n# p_tv = plt.plot(\n# lmbds,\n# np.array(\n# targets\n# ),\n# '-o'\n# )\n# # plt.plot(\n# # lmbds,\n# # lmbds + big_val,\n# # '--r'\n# # )\n# plt.xlabel('importance of zeros')\n# plt.ylabel('objective function')\n# plt.savefig('./tmp_plots/objective_function.jpg')\n# plt.show()\n#\n# # ----Plot error value\n# p_phi = plt.plot(\n# lmbds,\n# np.array(\n# phis\n# ),\n# '-o'\n# )\n# plt.xlabel('importance of zeros')\n# plt.ylabel('error')\n# plt.savefig('./tmp_plots/errors.jpg')\n# plt.show()\n#\n# gt = Util.read_ground_truth('./cases/input/base_case_81_3/reads_gt.txt')\n# # with open('./example/pigtail_32_gt.txt', 'r') as gt_file:\n# # for line in gt_file:\n# # h, p = line.strip().split()\n# # gt.append((h, float(p)))\n#\n# emd = [Util.earth_mover_distance(ansver, gt) for ansver in reconstructed]\n# # ----Plot error value\n# plt.plot(\n# lmbds,\n# emd,\n# '-o'\n# )\n# plt.xlabel('importance of zeros')\n# plt.ylabel('EMD')\n# plt.savefig('./tmp_plots/EMD.jpg')\n# plt.show()\n#\n# # # ----Test something\n# # example = nx.MultiDiGraph()\n# # example.add_edge(1, 2)\n# # example.edges[(1, 2, 0)]['w'] = 1\n# # example.add_edge(2, 3)\n# # example.edges[(2, 3, 0)]['w'] = .9\n# # example.add_edge(2, 3)\n# # example.edges[(2, 3, 1)]['w'] = .1\n# # example.add_edge(3, 4)\n# # example.edges[(3, 4, 0)]['w'] = 1\n# # example.add_edge(4, 5)\n# # example.edges[(4, 5, 0)]['w'] = .9\n# # example.add_edge(4, 5)\n# # example.edges[(4, 5, 1)]['w'] = .1\n# # example.add_edge(5, 6)\n# # example.edges[(5, 6, 0)]['w'] = 1\n# # example.add_edge(6, 7)\n# # example.edges[(6, 7, 0)]['w'] = .9\n# # example.add_edge(6, 7)\n# # example.edges[(6, 7, 1)]['w'] = .1\n# # example.add_edge(7, 8)\n# # example.edges[(7, 8, 0)]['w'] = 1\n# #\n# # print(example.out_edges(2, keys=True))\n# # print(example.in_edges(3, keys=True))\n# #\n# # paths = nx.all_simple_paths(example, 1, 8)\n# # for path in map(nx.utils.pairwise, paths):\n# # print(list(path))\n#\n# # ----Plot graph\n# # pos = nx.layout.kamada_kawai_layout(example)\n# # plt.figure(figsize=(8, 6))\n# # nx.draw_networkx_edges(example, pos, alpha=0.4)\n# # nx.draw_networkx_nodes(example, pos, node_size=60)\n# # plt.axis('off')\n# # plt.show()\n#\n# # print(Util.get_in_edges(example, 5))\n# # example.remove_node(5)\n"
},
{
"alpha_fraction": 0.6126482486724854,
"alphanum_fraction": 0.6176787614822388,
"avg_line_length": 25.00934600830078,
"blob_id": "230b771f2afa09390216da8d79f6831a3e9eeffb",
"content_id": "74ac67945764cf602429747a698c069a9494f968",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2783,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 107,
"path": "/HA.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "import argparse\nfrom src import AlignedDB\nfrom src import AlignedDBPreprocessor\nfrom src import ILPInputPreprocessor\nfrom src import ILPMinimizer\nfrom src import Util\n\n\nparser = argparse.ArgumentParser(\n description=\"Simple maximum parsimony Haplotype Assembler\")\n\nparser.add_argument(\n \"--ref\",\n help=\"path to reference genome\",\n type=str\n)\n\nparser.add_argument(\n \"--reads\",\n nargs=\"+\",\n help=\"path to origin read\",\n type=str\n)\n\nparser.add_argument(\n \"--format\",\n help=\"reads file format\",\n type=str,\n default=\"fasta\"\n)\n\nparser.add_argument(\n \"--k\",\n help=\"length of k-mer for De Bruijn graph\",\n default=61,\n type=int\n)\n\nparser.add_argument(\n \"--o\",\n help=\"path to my_output file\",\n type=str,\n default=\"./haplotypes\"\n)\n\n\nif __name__ == '__main__':\n args = vars(parser.parse_args())\n\n path_to_reference = args[\"ref\"]\n paths_to_reads = args[\"reads\"]\n file_extension = args[\"format\"]\n k = args['k']\n out_path = args['o']\n\n # Build aligned De Bruijn graph by reference genome and reads\n aligned_db = AlignedDB.AlignedDB(\n path_to_reference=path_to_reference,\n path_to_reads=paths_to_reads,\n read_format=file_extension,\n k_mer_len=k\n )\n aligned_db.build()\n\n # Make normalization of aligned De Bruijn graph\n prep = AlignedDBPreprocessor.AlignedDBPreprocessor(aligned_db, 1 - 10**-4)\n prep.normalize_parallel()\n prep.mean_by_path_parallel()\n prep.eriksson_clear()\n print(prep.aligned_db.number_of_edges())\n aligned_db = prep.aligned_db\n\n # Find optimized system\n ilp_prep = ILPInputPreprocessor.DataPreprocessor(aligned_db)\n haplotypes, _ = ilp_prep.find_haplotypes()\n\n print(len(ilp_prep.haplotypes_edges))\n\n # Find optimal frequencies\n minimizer = ILPMinimizer.ILPMinimizer(\n aligned_db, ilp_prep.haplotypes_edges)\n print(prep.eriksson_threshold)\n minimizer.find_alpha(prep.eriksson_threshold)\n _, result = minimizer.find_frequencies()\n\n indexes = dict()\n for k, v in ilp_prep.haplotypes_edges.items():\n indexes[k] = (v[0][0].pos, v[-1][-1].pos + aligned_db.k)\n\n assembled = []\n for h, f in result.items():\n if f > prep.eriksson_threshold / 10:\n left, right = indexes[h][0], indexes[h][1]\n h = aligned_db.ref[:left] + h + aligned_db.ref[right:]\n assembled.append((h, f))\n\n result = Util.get_normalize_pair_list(assembled)\n\n with open('{}.fa'.format(out_path), 'w') as haplotypes_file:\n for idx, (haplotype, frequency) in enumerate(result):\n haplotypes_file.write(\n '>{} freq={}\\n{}\\n'.format(\n str(idx),\n frequency,\n haplotype\n )\n )\n"
},
{
"alpha_fraction": 0.47206735610961914,
"alphanum_fraction": 0.48276254534721375,
"avg_line_length": 35.46887969970703,
"blob_id": "da4aa61340b1e327f4252f249ddc34cbe8b91b90",
"content_id": "265ed6ddc4cb0614c552446f250d6154649e17e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8789,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 241,
"path": "/src/DeBruijnBuildNetwork.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from Bio import SeqIO\nimport networkx as nx\nfrom copy import deepcopy\nfrom collections import Counter\nfrom src import Util\n\n\n# noinspection PyCallingNonCallable\nclass DBGraph(nx.MultiDiGraph):\n def __init__(\n self,\n file_path: str,\n read_format: str,\n k_mer_len: int = 55,\n **attr):\n super().__init__(**attr)\n self.file_path = file_path\n self.format = read_format\n self.k_mer_len = k_mer_len\n self.read_len = 0\n self.coded_nodes = {}\n\n def build(self):\n file_with_reads = SeqIO.parse(self.file_path, self.format)\n read = ''\n for read in file_with_reads:\n read = str(read.seq)\n if len(read) <= self.k_mer_len:\n continue\n if set(read.lower()) != set('atgc'):\n continue\n for k_mer_1, k_mer_2 in Util.k_mer_pairs(read, self.k_mer_len):\n contig = k_mer_1 + k_mer_2[-1]\n if (k_mer_1, k_mer_2) in self.edges:\n self.edges[(k_mer_1, k_mer_2, 0)]['coverage'] += 1\n else:\n self.add_edge(k_mer_1, k_mer_2)\n self.edges[(k_mer_1, k_mer_2, 0)]['coverage'] = 1\n self.edges[(k_mer_1, k_mer_2, 0)]['contig'] = contig\n for _, info in self.edges.items():\n info['coverage'] *= len(info['contig'])\n if read:\n self.read_len = len(read)\n\n self.coded_nodes = {v: idx for idx, v in enumerate(self.nodes)}\n\n def get_edge_substring(self, edge: tuple) -> str:\n u, v, _ = edge\n in_degree = self.in_degree(u)\n out_degree = self.out_degree(v)\n k = self.k_mer_len\n if in_degree == 0 and out_degree == 0:\n # |0--->0|\n return self.edges[edge]['contig']\n elif out_degree == 0:\n # ...0--->0|\n return self.edges[edge]['contig'][k // 2:]\n elif in_degree == 0:\n # |0--->0...\n return self.edges[edge]['contig'][:-k // 2]\n else:\n # |...0--->0...|\n return self.edges[edge]['contig'][k // 2: -k // 2]\n\n def get_mean_cover(self) -> float:\n sum_covers, amount = 0, 0\n for e, info in self.edges:\n coverage = info['coverage']\n sum_covers += len(info['contig']) * coverage\n amount += 1\n return sum_covers / amount\n\n def compression(self) -> None:\n k_mer_len = self.k_mer_len\n while True:\n is_simplified = False\n all_verts = list(self.adj.keys())\n for vertex in all_verts:\n out_degree = self.in_degree(vertex)\n in_degree = self.out_degree(vertex)\n if (in_degree == 1) and (out_degree == 1):\n is_simplified = True\n prev_vert = list(self.in_edges(vertex))[0][0]\n next_vert = list(self.out_edges(vertex))[0][1]\n cov_1 = self.edges[(prev_vert, vertex, 0)]['coverage']\n cov_2 = self.edges[(vertex, next_vert, 0)]['coverage']\n contig_1 = self.edges[(prev_vert, vertex, 0)]['contig']\n contig_2 = self.edges[(vertex, next_vert, 0)]['contig']\n edge_idx = self.add_edge(prev_vert, next_vert)\n new_edge = self.edges[(prev_vert, next_vert, edge_idx)]\n new_edge['coverage'] = cov_1 + cov_2\n new_edge['contig'] = contig_1 + contig_2[k_mer_len:]\n self.remove_node(vertex)\n if not is_simplified:\n break\n\n def delete_zero_deg(self) -> None:\n vertices = list(self.nodes)\n for vertex in vertices:\n if self.degree(vertex) == 0:\n self.remove_node(vertex)\n\n def simplify_tails(self) -> None:\n lbnd = .1\n while True:\n mean_cover = self.get_mean_cover()\n target_tails = []\n for e, info in self.edges.items():\n is_start = (self.in_degree(e[0]) + self.out_degree(e[0])) == 1\n is_end = (self.out_degree(e[1]) + self.in_degree(e[1])) == 1\n if is_start or is_end and info['coverage'] < lbnd * mean_cover:\n target_tails.append(e)\n if not target_tails:\n break\n for u, v, key in target_tails:\n self.remove_edge(u, v, key)\n self.compression()\n\n self.delete_zero_deg()\n\n def simplify_bad_cover(self) -> None:\n lbnd = 0.1\n while True:\n mean_cover = self.get_mean_cover()\n target_edges = []\n for e, info in self.edges.items():\n if info['coverage'] < lbnd * mean_cover:\n target_edges.append(e)\n if not target_edges:\n break\n for u, v, key in target_edges:\n self.remove_edge(u, v, key)\n self.compression()\n\n self.delete_zero_deg()\n\n def __get_length_coefficients(self) -> dict:\n result = dict()\n for edge, info in self.edges.items():\n from_vertex, to_vertex, _ = edge\n out_degree = self.out_degree(to_vertex)\n in_degree = self.in_degree(from_vertex)\n result[edge] = 1\n if (in_degree == 0) or (out_degree == 0):\n # for uniform coverage\n length = len(info['contig'])\n result[edge] -= 1 / 2 * (self.read_len - 1) / length\n return result\n\n def __get_expected_bridges_cover(self) -> float:\n db_cpy = deepcopy(self)\n all_src = []\n all_dst = []\n for u in self.nodes:\n in_deg = self.in_degree(u)\n out_deg = self.out_degree(u)\n if in_deg == 0:\n all_src.append(u)\n if out_deg == 0:\n all_dst.append(u)\n for u in all_src:\n db_cpy.add_edge('src', u)\n for v in all_dst:\n db_cpy.add_edge(v, 'dst')\n\n repeats_of_edges = Counter([e[:2] for e in db_cpy.edges])\n # multi edge is not bridge\n db_undirected = nx.Graph()\n for e in repeats_of_edges:\n db_undirected.add_edge(*e)\n bridges = list(nx.bridges(db_undirected))\n sum_bridge_cover, bridges_amount, amount = 0, 0, 0\n for e in bridges:\n if repeats_of_edges[e] > 1 or repeats_of_edges[e[::-1]] > 1:\n continue\n\n if 'dst' in e or 'src' in e:\n continue\n # bridge is not multi-edge, so key=0\n e = (*e, 0)\n if e not in self.edges:\n e = list(e)\n e[0], e[1] = e[1], e[0]\n e = tuple(e)\n sum_bridge_cover += self.edges[e]['coverage']\n bridges_amount += 1\n\n return sum_bridge_cover / bridges_amount if bridges_amount else 1\n\n def normalize_coverage(self) -> None:\n norm_length = self.__get_length_coefficients()\n\n for e, info in self.edges.items():\n info['coverage'] /= norm_length[e]\n\n def get_heaviest_path(self) -> list:\n path = []\n all_src = []\n for u in self.nodes:\n in_deg = self.in_degree(u)\n if in_deg == 0:\n all_src.append(u)\n\n all_start_edges = list()\n for src in all_src:\n for u in self.adj[src]:\n for idx, info in self.adj[src][u].items():\n edge, cov = (src, u, idx), info['coverage']\n all_start_edges.append((cov, edge))\n\n _, current_edge = max(all_start_edges)\n visited = set()\n while current_edge:\n path.append(current_edge)\n visited.add(current_edge)\n _, current_node, idx = current_edge\n possible_next_edges = list()\n for next_node in self.adj[current_node]:\n for idx, info in self.adj[current_node][next_node].items():\n edge = (current_node, next_node, idx)\n cov = info['coverage']\n possible_next_edges.append((cov, edge))\n if possible_next_edges:\n _, current_edge = max(possible_next_edges)\n if current_edge in visited:\n break\n\n return path\n\n def print_encoded_adjacency_list(self):\n cod = self.coded_nodes\n for v, neighbours in self.adj.items():\n print(cod[v], ': ', end='')\n all_neighbours = []\n for u, items in neighbours.items():\n all_neighbours.extend([cod[u]] * len(items))\n print(\n '{' +\n ', '.join(map(str, [u for u in all_neighbours])) +\n '}'\n )\n"
},
{
"alpha_fraction": 0.5009784698486328,
"alphanum_fraction": 0.514350950717926,
"avg_line_length": 26.872726440429688,
"blob_id": "416a0c2935a2734fcab17fff62aa5d7d627bb66a",
"content_id": "d5a0a3e4f9aef770c1a6ffe482e34082fc159bb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6132,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 220,
"path": "/unittests.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "import unittest\nimport networkx as nx\nfrom src import AlignedDB\nfrom src import AlignedDBPreprocessor\nfrom Bio import SeqIO\nfrom src import Util\n\n\n# Build Aligned De Bruijn graph tests\nclass BuildRefTest(unittest.TestCase):\n\n def test_nodes_amount(self):\n self.path_to_ref = \"test/ref.fa\"\n\n db = AlignedDB.AlignedDB(\n [\"test/read1.fq\", \"test/read2.fq\"],\n self.path_to_ref,\n \"fastq\",\n k_mer_len=5\n )\n\n db.build_ref()\n\n self.ref = SeqIO.parse(self.path_to_ref, \"fasta\")\n self.ref = str(next(self.ref).seq)\n\n self.assertEqual(len(self.ref) - db.k + 1, db.number_of_nodes())\n\n def test_ref_reconstruction(self):\n self.path_to_ref = \"test/ref.fa\"\n\n db = AlignedDB.AlignedDB(\n [\"test/read1.fq\", \"test/read2.fq\"],\n self.path_to_ref,\n \"fastq\",\n k_mer_len=5\n )\n\n db.build_ref()\n\n self.ref = SeqIO.parse(self.path_to_ref, \"fasta\")\n self.ref = str(next(self.ref).seq)\n\n kmer = list(enumerate(Util.k_mer_pairs(self.ref, db.k)))\n graph_path = list(\n (Util.KMer(s1, i), Util.KMer(s2, i + 1)) for i, (s1, s2) in kmer\n )\n self.assertEqual(self.ref, Util.get_haplotype_by_path(db, graph_path))\n\n\nclass BuildTest(unittest.TestCase):\n\n def test_graph(self):\n self.path_to_ref = \"test/minimal_test/ref.fa\"\n\n db = AlignedDB.AlignedDB(\n [\"test/minimal_test/reads.fa\"],\n self.path_to_ref,\n \"fasta\",\n k_mer_len=51\n )\n\n db.build_ref()\n db.build()\n\n gt = set()\n with open(\"test/minimal_test/gt.txt\", \"r\") as file:\n for line in file:\n [h, _] = line.strip().split()\n gt.add(h)\n\n res, _ = db.find_haplotypes()\n res = set(res)\n self.assertTrue(gt.issubset(res))\n\n\nclass DeletionsTest(unittest.TestCase):\n\n def test_graph_with_gaps(self):\n self.path_to_ref = \"test/gap_test/ref.fa\"\n\n db = AlignedDB.AlignedDB(\n [\"test/gap_test/reads.fa\"],\n self.path_to_ref,\n \"fasta\",\n k_mer_len=51\n )\n\n db.build_ref()\n db.build()\n\n gt = set()\n with open(\"test/gap_test/gt.txt\", \"r\") as file:\n for line in file:\n [h, _] = line.strip().split()\n gt.add(h)\n\n res, _ = db.find_haplotypes()\n res = [\"\".join([ch for ch in h if ch != \"_\"]) for h in res]\n for h in res:\n print(h)\n res = set(res)\n self.assertTrue(gt.issubset(res))\n\n\n# Util function tests\nclass SplitTest(unittest.TestCase):\n\n def test_split_graph(self):\n graph = nx.DiGraph()\n graph.add_edge(1, 2)\n graph.add_edge(2, 3)\n graph.add_edge(3, 5)\n graph.add_edge(2, 4)\n graph.add_edge(4, 5)\n graph.add_edge(4, 6)\n graph.add_edge(6, 7)\n graph.add_edge(7, 8)\n graph.add_edge(8, 4)\n graph.add_edge(8, 5)\n graph.add_edge(8, 2)\n graph.add_edge(1, 8)\n\n paths_decomposition = [\n [(1, 2)],\n [(2, 3), (3, 5)],\n [(2, 4)],\n [(4, 5)],\n [(4, 6), (6, 7), (7, 8)],\n [(8, 4)],\n [(8, 5)],\n [(8, 2)],\n [(1, 8)]]\n\n self.assertEqual(\n sorted(Util.split_graph_by_paths(graph)),\n sorted(paths_decomposition)\n )\n\n graph = nx.DiGraph()\n graph.add_edge(1, 2)\n self.assertEqual(\n sorted(Util.split_graph_by_paths(graph)),\n [[(1, 2)]]\n )\n\n\n# Preprocessor test\nclass PreprocessorTest(unittest.TestCase):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.path_to_ref = \"test/ref.fa\"\n\n db = AlignedDB.AlignedDB(\n [\"test/read1.fq\", \"test/read2.fq\"],\n self.path_to_ref,\n \"fastq\",\n k_mer_len=61\n )\n\n db.build_ref()\n db.build()\n self.prep = AlignedDBPreprocessor.AlignedDBPreprocessor(db, .9)\n\n def test_normalization(self):\n\n self.prep.normalize_parallel()\n\n sums = []\n for edges in self.prep.aligned_db.baskets.values():\n sums.append(\n sum(\n [self.prep.aligned_db.edges[e][\"coverage\"] for e in edges]\n )\n )\n for s in sums:\n self.assertAlmostEqual(s, 1, delta=10**-6)\n\n def test_mean(self):\n # Check that coverage in paths from decomposition is equal\n self.prep.mean_by_path_parallel()\n paths_decomposition = Util.split_graph_by_paths(self.prep.aligned_db)\n for path in paths_decomposition:\n if path:\n cov = self.prep.aligned_db.edges[path[0]][\"coverage\"]\n for e in path:\n self.assertEqual(\n cov, self.prep.aligned_db.edges[e][\"coverage\"]\n )\n\n def test_clearing(self):\n srcs_before, dsts_before = set(), set()\n for vertex in self.prep.aligned_db.nodes:\n indeg = self.prep.aligned_db.in_degree(vertex)\n outdeg = self.prep.aligned_db.out_degree(vertex)\n if indeg == 0:\n srcs_before.add(vertex)\n elif outdeg == 0:\n dsts_before.add(vertex)\n n_edge_before = len(self.prep.aligned_db.edges)\n\n self.prep.eriksson_clear()\n\n srcs_after, dsts_after = set(), set()\n for vertex in self.prep.aligned_db.nodes:\n indeg = self.prep.aligned_db.in_degree(vertex)\n outdeg = self.prep.aligned_db.out_degree(vertex)\n if indeg == 0:\n srcs_after.add(vertex)\n elif outdeg == 0:\n dsts_after.add(vertex)\n n_edge_after = len(self.prep.aligned_db.edges)\n\n self.assertEqual(srcs_before, srcs_after)\n self.assertEqual(dsts_before, dsts_after)\n self.assertGreaterEqual(n_edge_before, n_edge_after)\n\n\nif __name__ == \"__main__\":\n unittest.main()\n"
},
{
"alpha_fraction": 0.5965346693992615,
"alphanum_fraction": 0.5990098714828491,
"avg_line_length": 35.25640869140625,
"blob_id": "570808176b1c7d926377c0c12fbb06faadc3d3f0",
"content_id": "1b4bfb01acae4d3fe28a938b965d1e43e73b0326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2828,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 78,
"path": "/src/ILPInputPreprocessor.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from src import Util\nfrom collections import defaultdict\nfrom itertools import product\nimport networkx as nx\nfrom src import AlignedDB\nfrom src import DeBruijnBuildNetwork\n\n\n# noinspection PyCallingNonCallable\nclass DataPreprocessor(object):\n def __init__(self, db_graph):\n self.db_graph = db_graph\n self.haplotypes = list()\n self.haplotypes_edges = dict()\n\n @staticmethod\n def __multiply_paths(edge_repeats: defaultdict, paths: list) -> list:\n original_path = paths[0]\n edge_repeats_subset = dict()\n for edge in original_path:\n edge_repeats_subset[edge] = edge_repeats[edge]\n\n all_masks = []\n for edge in original_path:\n all_masks.append(list(range(edge_repeats_subset[edge])))\n\n all_masks = product(*all_masks)\n\n modified_paths = []\n for mask, path in zip(all_masks, paths):\n new_path = []\n for edge, idx in zip(path, mask):\n new_path.append((*edge, idx))\n modified_paths.append(new_path)\n return modified_paths\n\n def __find_haplotypes_in_simple_db(self) -> tuple:\n self.haplotypes = []\n srcs = []\n dsts = []\n for vertex in self.db_graph.nodes:\n indeg = self.db_graph.in_degree(vertex)\n outdeg = self.db_graph.out_degree(vertex)\n if indeg == 0:\n srcs.append(vertex)\n elif outdeg == 0:\n dsts.append(vertex)\n\n edges_amount = defaultdict(int)\n for e in self.db_graph.edges:\n edges_amount[e[:2]] += 1\n\n all_paths = defaultdict(list)\n for src, dst in product(srcs, dsts):\n for path in nx.all_simple_paths(self.db_graph, src, dst):\n edge_path = list(zip(path[:-1], path[1:]))\n all_paths[tuple(path)].append(edge_path)\n\n for _, paths in all_paths.items():\n paths = self.__multiply_paths(edges_amount, paths)\n for path in paths:\n haplotype = Util.get_haplotype_by_path(self.db_graph, path)\n self.haplotypes.append(haplotype)\n self.haplotypes_edges[haplotype] = path\n return self.haplotypes, self.haplotypes_edges\n\n def __find_haplotypes_in_aligned_db(self) -> tuple:\n haps, edges = self.db_graph.find_haplotypes()\n self.haplotypes, self.haplotypes_edges = haps, edges\n return self.haplotypes, self.haplotypes_edges\n\n def find_haplotypes(self):\n if isinstance(self.db_graph, AlignedDB.AlignedDB):\n return self.__find_haplotypes_in_aligned_db()\n elif isinstance(self.db_graph, DeBruijnBuildNetwork.DBGraph):\n return self.__find_haplotypes_in_simple_db()\n else:\n raise ValueError(\"graph should have type AlignedDB or DBGraph\")\n"
},
{
"alpha_fraction": 0.49804168939590454,
"alphanum_fraction": 0.5003497004508972,
"avg_line_length": 44.10409927368164,
"blob_id": "aa009c3939dffeb0c16622f0ec8c83cda7591ff0",
"content_id": "8d06b9b8b1f9fe561f9de0af32eeb6caae79572d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14298,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 317,
"path": "/src/DeBruijnNetworkAligner.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from src import DeBruijnBuildNetwork\nfrom src import Util\nfrom networkx import MultiDiGraph\n# from Bio import SeqIO\nfrom bisect import bisect_left\nfrom bisect import bisect_right\nfrom collections import defaultdict\nfrom tqdm import tqdm\n\n\nclass AlignedDBNetwork(MultiDiGraph):\n def __init__(self):\n super().__init__()\n\n def get_edge_substring(self, edge: tuple) -> str:\n return self.edges[edge]['contig']\n\n def get_edge_coverage(self, edge: tuple) -> str:\n return self.edges[edge]['coverage']\n\n\nclass NetworkAligner(object):\n def __init__(self, db_graph: DeBruijnBuildNetwork.DBGraph):\n self.db_graph = db_graph\n self.edge_alignment = dict()\n self.read_alignment = dict()\n self.aligned_db_graph = None\n self.reference = str()\n self.encoded_nodes = None\n self.__buckets = list()\n self.__positions = list()\n self.__edges_in_bucket = None\n\n @staticmethod\n def align(ref: str, contig: str) -> tuple:\n arg_max = 0\n max_value = 0\n for start in range(len(ref) - len(contig) + 1):\n score = sum([ri == ci for ri, ci in zip(ref[start:], contig)])\n max_value, arg_max = max([(max_value, arg_max), (score, start)])\n return arg_max, arg_max + len(contig)\n\n def align_db_graph(self) -> None:\n reference_path = self.db_graph.get_heaviest_path()\n reference = Util.get_haplotype_by_path(self.db_graph, reference_path)\n self.reference = reference\n title = 'edge alignment'\n for edge, info in tqdm(self.db_graph.edges.items(), desc=title):\n # align whole contig from edge but set position according to rules\n # in get_edge_substring function\n contig = info['contig']\n start, end = self.align(reference, contig)\n u, v, _ = edge\n in_degree = self.db_graph.in_degree(u)\n out_degree = self.db_graph.out_degree(v)\n k = self.db_graph.k_mer_len\n if in_degree == 0 and out_degree == 0:\n # |0--->0|\n pass\n elif out_degree == 0:\n # ...0--->0|\n start += k // 2\n elif in_degree == 0:\n # |0--->0...\n end -= (k // 2 + k % 2)\n else:\n # |...0--->0...|\n start += k // 2\n end -= (k // 2 + k % 2)\n self.edge_alignment[edge] = (start, end)\n\n def align_reads_with_bwa(self):\n coordinates = []\n for e, (start, end) in self.edge_alignment.items():\n coordinates.append(start)\n coordinates.append(end)\n positions = sorted(set(coordinates))\n self.__positions = positions\n self.__buckets = list(zip(positions[:-1], positions[1:]))\n self.read_alignment = {k: defaultdict(int) for k in self.__buckets}\n # align and split reads by buckets\n path_to_reads = self.db_graph.file_path\n with Util.BWAContextManager(path_to_reads, self.reference) as bwa:\n for read_object in bwa.sam_file:\n read = read_object.seq\n start, end = read_object.pos, read_object.aend\n if read_object.rlen != end - start:\n continue\n first_bucket_idx = bisect_right(positions, start) - 1\n last_bucket_idx = bisect_left(positions, end)\n for bucket_id in range(first_bucket_idx, last_bucket_idx):\n if bucket_id >= len(self.__buckets):\n # should be fixed\n continue\n bucket = self.__buckets[bucket_id]\n start_substring = max(bucket[0], start) - start\n end_substring = min(bucket[1], end) - start\n sub_read = read[start_substring: end_substring]\n self.read_alignment[bucket][sub_read] += 1\n\n def split_db_graph(self):\n positions = self.__positions\n self.aligned_db_graph = AlignedDBNetwork()\n encoded_nodes = {kmer: str(n) for n, kmer in enumerate(self.db_graph)}\n self.encoded_nodes = encoded_nodes\n self.__edges_in_bucket = defaultdict(set)\n # create topologically same as De Bruijn graph\n for e in self.db_graph.edges:\n u, v, idx = e\n new_u, new_v = encoded_nodes[u], encoded_nodes[v]\n self.aligned_db_graph.add_edge(new_u, new_v, idx)\n new_e = (new_u, new_v, idx)\n contig = self.db_graph.get_edge_substring(e)\n self.aligned_db_graph.edges[new_e]['contig'] = contig\n\n # Split edges of created graph and divide by buckets\n for e, (start, end) in self.edge_alignment.items():\n first_bucket_idx = bisect_right(positions, start) - 1\n last_bucket_idx = bisect_left(positions, end)\n u, v, idx = e\n new_u, new_v = encoded_nodes[u], encoded_nodes[v]\n old_edge_in_new_graph = (new_u, new_v, idx)\n contig = self.aligned_db_graph.edges[(new_u, new_v, idx)]['contig']\n self.aligned_db_graph.remove_edge(*old_edge_in_new_graph)\n for bucket_id in range(first_bucket_idx, last_bucket_idx):\n bucket = self.__buckets[bucket_id]\n bucket_start, bucket_end = bucket\n update_new_u, update_new_v = new_u, new_v\n if bucket_start != start:\n # we should split edge in new graph\n update_new_u = new_u + '_' + str(bucket_start)\n if bucket_end != end:\n # first vertex again\n update_new_v = new_u + '_' + str(bucket_end)\n new_contig = contig[bucket_start - start: bucket_end - start]\n\n new_idx = self.aligned_db_graph.add_edge(\n update_new_u, update_new_v\n )\n new_e = (update_new_u, update_new_v, new_idx)\n self.aligned_db_graph.edges[new_e]['contig'] = new_contig\n self.__edges_in_bucket[bucket].add(new_e)\n\n def unite_same_edges_in_buckets(self):\n bucket_by_edge = dict()\n for bucket, edges in self.__edges_in_bucket.items():\n for e in edges:\n bucket_by_edge[e] = bucket\n id_edge = {e: idx for idx, e in enumerate(self.aligned_db_graph.edges)}\n edge_by_id = {idx: e for e, idx in id_edge.items()}\n\n for bucket in self.__buckets:\n # find groups of edges in bucket with same sub-sting\n e_groups = defaultdict(set)\n for e in self.__edges_in_bucket[bucket]:\n e_groups[self.aligned_db_graph.get_edge_substring(e)].add(\n id_edge[e]\n )\n # for each group join duplicated edges and update\n # bucket_by_edge, code_by_edge and edge_by_code\n for substring, edges_codes in e_groups.items():\n if len(edges_codes) < 2:\n continue\n all_u, all_v = set(), set()\n for code in edges_codes:\n e = edge_by_id[code]\n u, v, idx = e\n all_u.add(u)\n all_v.add(v)\n united_u = '_' + '_'.join(all_u)\n united_v = '_' + '_'.join(all_v)\n\n # Work with first node (united_u)\n # Input edges\n u_in = []\n for u in all_u:\n u_in.extend(self.aligned_db_graph.in_edges(u, keys=True))\n for u_in_edge in u_in:\n e_id = id_edge[u_in_edge]\n from_node, u, idx = u_in_edge\n substring = self.aligned_db_graph.get_edge_substring(\n u_in_edge)\n idx = self.aligned_db_graph.add_edge(from_node, united_u)\n new_edge = (from_node, united_u, idx)\n self.aligned_db_graph.edges[new_edge]['contig'] = substring\n # update all maps and buckets\n bucket = bucket_by_edge[u_in_edge]\n bucket_by_edge[new_edge] = bucket\n self.__edges_in_bucket[bucket] -= {u_in_edge}\n self.__edges_in_bucket[bucket].add(new_edge)\n id_edge[new_edge] = e_id\n edge_by_id[e_id] = new_edge\n\n # Output edges\n u_out = []\n for u in all_u:\n u_out.extend(self.aligned_db_graph.out_edges(u, keys=True))\n for u_out_edge in u_out:\n e_id = id_edge[u_out_edge]\n u, to_node, idx = u_out_edge\n substring = self.aligned_db_graph.get_edge_substring(\n u_out_edge)\n idx = self.aligned_db_graph.add_edge(united_u, to_node)\n new_edge = (united_u, to_node, idx)\n self.aligned_db_graph.edges[new_edge]['contig'] = substring\n # update all maps and buckets\n bucket = bucket_by_edge[u_out_edge]\n bucket_by_edge[new_edge] = bucket\n self.__edges_in_bucket[bucket] -= {u_out_edge}\n self.__edges_in_bucket[bucket].add(new_edge)\n id_edge[new_edge] = e_id\n edge_by_id[e_id] = new_edge\n\n # Work with second node (united_v)\n # Input edges\n v_in = []\n for v in all_v:\n v_in.extend(self.aligned_db_graph.in_edges(v, keys=True))\n for v_in_edge in v_in:\n e_id = id_edge[v_in_edge]\n from_node, v, idx = v_in_edge\n if from_node in all_u:\n continue\n substring = self.aligned_db_graph.get_edge_substring(\n v_in_edge)\n idx = self.aligned_db_graph.add_edge(from_node, united_v)\n new_edge = (from_node, united_v, idx)\n self.aligned_db_graph.edges[new_edge]['contig'] = substring\n # update all maps and buckets\n bucket = bucket_by_edge[v_in_edge]\n bucket_by_edge[new_edge] = bucket\n self.__edges_in_bucket[bucket] -= {v_in_edge}\n self.__edges_in_bucket[bucket].add(new_edge)\n id_edge[new_edge] = e_id\n edge_by_id[e_id] = new_edge\n\n # Output edges\n v_out = []\n for v in all_v:\n v_out.extend(self.aligned_db_graph.out_edges(v, keys=True))\n for v_out_edge in v_out:\n e_id = id_edge[v_out_edge]\n v, to_node, idx = v_out_edge\n if to_node in all_u:\n continue\n substring = self.aligned_db_graph.get_edge_substring(\n v_out_edge)\n idx = self.aligned_db_graph.add_edge(united_v, to_node)\n new_edge = (united_v, to_node, idx)\n self.aligned_db_graph.edges[new_edge]['contig'] = substring\n # update all maps and buckets\n bucket = bucket_by_edge[v_out_edge]\n bucket_by_edge[new_edge] = bucket\n self.__edges_in_bucket[bucket] -= {v_out_edge}\n self.__edges_in_bucket[bucket].add(new_edge)\n id_edge[new_edge] = e_id\n edge_by_id[e_id] = new_edge\n\n for v in all_v:\n self.aligned_db_graph.remove_node(v)\n for u in all_u:\n self.aligned_db_graph.remove_node(u)\n edges_codes.pop()\n for e_id in edges_codes:\n removed_edge = edge_by_id[e_id]\n self.aligned_db_graph.remove_edge(*removed_edge)\n\n def calculate_coverage(self):\n for e in self.aligned_db_graph.edges:\n self.aligned_db_graph.edges[e]['coverage'] = 0\n for bucket, edges in self.__edges_in_bucket.items():\n for read, amount in self.read_alignment[bucket].items():\n edge_inqlude_read = set()\n for e in edges:\n if e in self.aligned_db_graph.edges:\n sub = self.aligned_db_graph.get_edge_substring(e)\n start, end = self.align(sub, read)\n if sub[start: end] == read:\n edge_inqlude_read.add(e)\n # needed improve\n if len(edge_inqlude_read) > 1:\n break\n # lol\n if len(edge_inqlude_read) > 1:\n continue\n for e in edge_inqlude_read:\n sub = self.aligned_db_graph.get_edge_substring(e)\n coverage = amount * len(read) / len(sub)\n self.aligned_db_graph.edges[e]['coverage'] += coverage\n\n for bucket, edges in self.__edges_in_bucket.items():\n normalize = 0\n for e in edges:\n if e in self.aligned_db_graph.edges:\n normalize += self.aligned_db_graph.edges[e]['coverage']\n for e in edges:\n if e in self.aligned_db_graph.edges:\n self.aligned_db_graph.edges[e]['coverage'] /= normalize\n\n # multi-edge index normalization\n updated_aligned_db_graph = AlignedDBNetwork()\n for e, info in self.aligned_db_graph.edges.items():\n u, v, key = e\n idx = updated_aligned_db_graph.add_edge(u, v)\n contig = info['contig']\n cover = info['coverage']\n updated_aligned_db_graph.edges[(u, v, idx)]['contig'] = contig\n updated_aligned_db_graph.edges[(u, v, idx)]['coverage'] = cover\n self.aligned_db_graph = updated_aligned_db_graph\n\n def get_aligned_db_graph(self) -> DeBruijnBuildNetwork.DBGraph:\n self.align_db_graph()\n self.align_reads_with_bwa()\n self.split_db_graph()\n self.calculate_coverage()\n\n return self.aligned_db_graph\n"
},
{
"alpha_fraction": 0.4763832688331604,
"alphanum_fraction": 0.49527665972709656,
"avg_line_length": 20.171428680419922,
"blob_id": "13fe024d4ad441415e17baef0d0c19e583eaed1e",
"content_id": "ca85c09fab14d7a54c9871a2b4068570c5152183",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 35,
"path": "/test/minimal_test/make_data.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from random import choices\n\nnuc = \"ATGC\"\n\nr_lean = 100\n\n\ndef rst():\n return \"\".join(choices(nuc, k=120))\n\n\nleft, right = rst(), rst()\n\nhaps = [\n (\"ATGTCT\", 1),\n (\"ATGCAT\", 1),\n (\"ATACAT\", 3)\n]\nhaps = [(left + h + right, c) for h, c in haps]\n\nwith open(\"reads.fa\", 'w') as reads_file:\n idx = 0\n for h, count in haps:\n for _ in range(count):\n for i in range(len(h) - r_lean + 1):\n idx += 1\n reads_file.write(\">{}\\n\".format(idx))\n reads_file.write(\"{}\\n\".format(h[i: i + r_lean]))\n\nwith open(\"gt.txt\", 'w') as gt:\n for h, count in haps:\n gt.write(\"{} {}\\n\".format(h, count))\n\nwith open(\"ref.fa\", 'w') as gt:\n gt.write(\">ref\\n{}\".format(haps[-1][0]))\n"
},
{
"alpha_fraction": 0.5060913562774658,
"alphanum_fraction": 0.5073603987693787,
"avg_line_length": 29.78125,
"blob_id": "d32adbfb87b8915726cc9bb15ea7a20a54de5ae6",
"content_id": "d9e81450a5e8b38e052a2d12d8cc818e3696a5fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3940,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 128,
"path": "/src/ILPMinimizer.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "import gurobipy as gb\nimport numpy as np\n\n\nclass ILPMinimizer(object):\n def __init__(\n self,\n db_graph,\n haplotypes_edges: dict):\n self.db_graph = db_graph\n self.haplotypes_edges = haplotypes_edges\n self.edges_haplotypes = {e: [] for e in db_graph.edges}\n for haplotype, edges in haplotypes_edges.items():\n for e in edges:\n self.edges_haplotypes[e].append(haplotype)\n self.alpha = None\n\n def find_alpha(self, alpha):\n self.alpha = alpha\n\n def find_frequencies(self) -> tuple:\n alpha = self.alpha\n ord_haplotypes = list(self.haplotypes_edges.keys())\n haplotypes_id = {\n haplotype: idx for idx, haplotype in enumerate(ord_haplotypes)\n }\n\n m = gb.Model(\"mip1\")\n u = list()\n for e in self.db_graph.edges:\n e_id = '_'.join(map(str, e))\n ui = m.addVar(\n vtype=gb.GRB.CONTINUOUS, name='u_{}'.format(str(e_id)))\n u.append((e, ui))\n\n f, b = list(), list()\n for idx, _ in enumerate(ord_haplotypes):\n fi = m.addVar(\n vtype=gb.GRB.CONTINUOUS, name='F_{}'.format(str(idx)))\n bi = m.addVar(\n vtype=gb.GRB.BINARY, name='B_{}'.format(str(idx)))\n f.append(fi)\n b.append(bi)\n\n # Set ILP objective function\n m.setObjective(\n sum([ui for _, ui in u]) + alpha * sum(b), gb.GRB.MINIMIZE\n )\n\n # Set ILP restrictions\n for e, ui in u:\n idxs = [haplotypes_id[hap] for hap in self.edges_haplotypes[e]]\n freqs = [f[idx] for idx in idxs]\n e_id = '_'.join(map(str, e))\n m.addConstr(\n ui >= self.db_graph.edges[e]['coverage'] - sum(freqs),\n name='c_pos_{}'.format(str(e_id)))\n m.addConstr(\n ui >= sum(freqs) - self.db_graph.edges[e]['coverage'],\n name='c_neg_{}'.format(str(e_id)))\n\n m.addConstr(sum(f) == 1, name='normalization')\n\n for fi, bi in zip(f, b):\n m.addConstr(bi >= fi)\n\n m.params.LogToConsole = False\n m.optimize()\n\n final_freq = np.array([fi.x for fi in f])\n\n rez = (\n m.objVal,\n {hap: final_freq[idx] for idx, hap in enumerate(ord_haplotypes)}\n )\n\n return rez\n\n def find_frequencies_square(self) -> tuple:\n alpha = self.alpha\n ord_haplotypes = list(self.haplotypes_edges.keys())\n haplotypes_id = {\n haplotype: idx for idx, haplotype in enumerate(ord_haplotypes)\n }\n\n m = gb.Model(\"mip1\")\n\n f, b = list(), list()\n for idx, _ in enumerate(ord_haplotypes):\n fi = m.addVar(\n vtype=gb.GRB.CONTINUOUS, name='F_{}'.format(str(idx)))\n bi = m.addVar(\n vtype=gb.GRB.BINARY, name='B_{}'.format(str(idx)))\n f.append(fi)\n b.append(bi)\n\n # join sums together\n sums = []\n for e in self.db_graph.edges:\n if self.db_graph.edges[e]['coverage'] == 1:\n continue\n idxs = [haplotypes_id[hap] for hap in self.edges_haplotypes[e]]\n freqs = [f[idx] for idx in idxs]\n sums.append(self.db_graph.edges[e]['coverage'] - sum(freqs))\n\n # Set ILP objective function\n m.setObjective(\n sum([error * error for error in sums]) + alpha * sum(b),\n gb.GRB.MINIMIZE\n )\n\n # Set ILP restrictions\n m.addConstr(sum(f) == 1, name='normalization')\n\n for fi, bi in zip(f, b):\n m.addConstr(bi >= fi)\n\n m.params.LogToConsole = False\n m.optimize()\n\n final_freq = np.array([fi.x for fi in f])\n\n rez = (\n m.objVal,\n {hap: final_freq[idx] for idx, hap in enumerate(ord_haplotypes)}\n )\n\n return rez\n"
},
{
"alpha_fraction": 0.5570827722549438,
"alphanum_fraction": 0.5769822597503662,
"avg_line_length": 29.276397705078125,
"blob_id": "628bc3e682b7a53bd647d072e7f14465cdb481fb",
"content_id": "7b5cb604439b881a271aac9cb1bd4d4652f9f4c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9749,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 322,
"path": "/cases/case_generation.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "from numpy.random import uniform\n# from numpy.random import normal\nfrom numpy.random import dirichlet\nfrom numpy.random import choice as np_choice\nfrom typing import List\nfrom typing import Callable\nfrom matplotlib import pyplot as plt\nfrom os import path, mkdir\nfrom itertools import product\n\n\nclass Haplotype(object):\n def __init__(self, hap: str, freq: float):\n self.hap = hap\n self.freq = freq\n\n\nHaplotypes = List[Haplotype]\n\n\nclass ReadMaker(object):\n def __init__(self, distribution: Callable, read_len=150, save_path='.'):\n self.read_len = read_len\n self.distribution = distribution\n self.read_positions = None\n self.path = save_path\n\n def make_reads(self, name: str, gt: Haplotypes, amount=1000) -> None:\n gt_path = path.join(self.path, '{}_gt.txt'.format(name))\n with open(gt_path, 'w') as gt_file:\n for hap in gt:\n gt_file.write('{} {}\\n'.format(hap.hap, hap.freq))\n frequencies = [h.freq for h in gt]\n gt_len = len(gt[0].hap)\n read_file = path.join(self.path, '{}.fastq'.format(name))\n with open(read_file, 'w') as reads:\n low = 0\n high = gt_len - self.read_len + 1\n self.read_positions = self.distribution(low, high, amount)\n for idx, pos in enumerate(self.read_positions):\n pos = int(pos)\n haplotype = np_choice(gt, 1, p=frequencies)[0]\n read = haplotype.hap[pos: pos + self.read_len]\n reads.write('@{}\\n{}\\n'.format(str(idx), read))\n reads.write('+\\n{}\\n'.format('I' * self.read_len))\n\n\ndef hap_gen(ref: List[str], pos: List[int], nucls: List[list]) -> List[str]:\n haps = []\n for substitutions in product(*nucls):\n haplotype = ref[:]\n for idx, nucl in zip(pos, substitutions):\n haplotype[idx] = nucl\n haps.append(''.join(haplotype))\n\n return haps\n\n\ndef special_hap_gen(ref: List[str], pos: List[int], nucls: List[list]) -> List:\n haps = []\n for substitutions in nucls:\n haplotype = ref[:]\n for idx, nucl in zip(pos, substitutions):\n haplotype[idx] = nucl\n haps.append(''.join(haplotype))\n\n return haps\n\n\ndef read_ref(ref_path: str) -> List[str]:\n ref = []\n with open(ref_path, 'r') as ref_file:\n ref.extend(next(ref_file).strip())\n\n return ref\n\n\ndef bone_uniform_example():\n bone_name = 'bone_uniform_7_3'\n # classic bone example\n ref = read_ref('./input/ref.txt')\n first, second = len(ref) // 10, len(ref) - len(ref) // 10\n h1 = ''.join(\n ref[:first] + ['T'] + ref[first:second] + ['T'] + ref[second:]\n )\n h2 = ''.join(\n ref[:first] + ['A'] + ref[first:second] + ['A'] + ref[second:]\n )\n\n freqs = [.7, .3]\n grt = [Haplotype(h, f) for h, f in zip([h1, h2], freqs)]\n\n uniform_read_maker = ReadMaker(uniform, read_len=200, save_path='./input')\n uniform_read_maker.make_reads(bone_name, grt, amount=1000)\n\n plt.hist(uniform_read_maker.read_positions)\n plt.xlabel('read start position')\n plt.savefig(path.join('./input', bone_name + '.jpg'))\n\n\ndef pigtail_uniform_example():\n bone_name = 'pigtail_32'\n # pigtail example with 2^5 possible paths and 8 in ground truth\n # 'GTTTGCCAGGA_GATGGAAACCA_AAATGATAGGG_GAATTGGAGGT_TTATCAAAGTA_GACAGTAT'\n haps = [\n 'GTTTGCCAGGATGATGGAAACCATAAATGATAGGGAGAATTGGAGGTATTATCAAAGTAAGACAGTAT',\n 'GTTTGCCAGGAAGATGGAAACCATAAATGATAGGGAGAATTGGAGGTATTATCAAAGTATGACAGTAT',\n 'GTTTGCCAGGATGATGGAAACCATAAATGATAGGGAGAATTGGAGGTTTTATCAAAGTAAGACAGTAT',\n 'GTTTGCCAGGAAGATGGAAACCAAAAATGATAGGGAGAATTGGAGGTTTTATCAAAGTATGACAGTAT',\n 'GTTTGCCAGGAAGATGGAAACCAAAAATGATAGGGTGAATTGGAGGTATTATCAAAGTAAGACAGTAT',\n 'GTTTGCCAGGATGATGGAAACCAAAAATGATAGGGTGAATTGGAGGTATTATCAAAGTATGACAGTAT',\n 'GTTTGCCAGGAAGATGGAAACCAAAAATGATAGGGTGAATTGGAGGTTTTATCAAAGTAAGACAGTAT',\n 'GTTTGCCAGGATGATGGAAACCAAAAATGATAGGGTGAATTGGAGGTTTTATCAAAGTATGACAGTAT'\n ]\n freqs = dirichlet([1] * len(haps), 1)[0]\n\n grt = [Haplotype(h, f) for h, f in zip(haps, freqs)]\n\n uniform_read_maker = ReadMaker(\n uniform, read_len=20, save_path='../example'\n )\n uniform_read_maker.make_reads(bone_name, grt, amount=30000)\n\n plt.hist(uniform_read_maker.read_positions)\n plt.xlabel('read start position')\n plt.savefig(path.join(uniform_read_maker.path, bone_name + '.jpg'))\n\n\ndef big_pigtail_uniform_example():\n bone_name = 'pigtail_uniform_6_3_1'\n # pigtail example with 2x2x3 possible paths\n ref = read_ref('./input/ref.txt')\n first, second = len(ref) // 10, len(ref) - len(ref) // 10\n third = len(ref) // 2\n h1 = ''.join(\n ref[:first] + ['T'] +\n ref[first:second] + ['T'] +\n ref[second:third] + ['T'] +\n ref[third:]\n )\n h2 = ''.join(\n ref[:first] + ['T'] +\n ref[first:second] + ['A'] +\n ref[second:third] + ['A'] +\n ref[third:]\n )\n\n h3 = ''.join(\n ref[:first] + ['G'] +\n ref[first:second] + ['T'] +\n ref[second:third] + ['G'] +\n ref[third:]\n )\n\n freqs = [.6, .3, .1]\n grt = [Haplotype(h, f) for h, f in zip([h1, h2, h3], freqs)]\n\n uniform_read_maker = ReadMaker(uniform, read_len=200, save_path='./input')\n uniform_read_maker.make_reads(bone_name, grt, amount=3000)\n\n plt.hist(uniform_read_maker.read_positions)\n plt.xlabel('read start position')\n plt.savefig(path.join('./input', bone_name + '.jpg'))\n\n\ndef full_case_generator(case_name: str, pos_n: int, subs: List[list]) -> None:\n save_path = path.join('./input', case_name)\n mkdir(save_path)\n\n ref = read_ref('./input/ref.txt')\n pos = [len(ref) // (pos_n + 1) * idx for idx in range(1, pos_n + 1)]\n haps = hap_gen(ref, pos, subs)\n\n freqs = dirichlet([1] * len(haps), 1)[0]\n\n grt = [Haplotype(h, f) for h, f in zip(haps, freqs)]\n\n uniform_read_maker = ReadMaker(uniform, read_len=200, save_path=save_path)\n uniform_read_maker.make_reads('reads', grt, amount=3000)\n\n plt.hist(uniform_read_maker.read_positions)\n plt.xlabel('read start position')\n plt.savefig(path.join(save_path, 'hist.jpg'))\n\n\ndef part_case_generator(name: str, subs: List) -> None:\n save_path = path.join('./input', name)\n mkdir(save_path)\n\n pos_n = len(subs[0])\n ref = read_ref('./input/ref.txt')\n pos = [len(ref) // (pos_n + 1) * idx for idx in range(1, pos_n + 1)]\n haps = special_hap_gen(ref, pos, subs)\n freqs = dirichlet([1] * len(haps), 1)[0]\n\n grt = [Haplotype(h, f) for h, f in zip(haps, freqs)]\n\n uniform_read_maker = ReadMaker(uniform, read_len=200, save_path=save_path)\n uniform_read_maker.make_reads('reads', grt, amount=10000)\n\n plt.hist(uniform_read_maker.read_positions)\n plt.xlabel('read start position')\n plt.savefig(path.join(save_path, 'hist.jpg'))\n\n\ndef case_generator_with_freqs(name: str, subs: List, freqs: List) -> None:\n save_path = path.join('./input', name)\n mkdir(save_path)\n\n pos_n = len(subs[0])\n ref = read_ref('./input/ref.txt')\n pos = [len(ref) // (pos_n + 1) * idx for idx in range(1, pos_n + 1)]\n haps = special_hap_gen(ref, pos, subs)\n\n grt = [Haplotype(h, f) for h, f in zip(haps, freqs)]\n\n uniform_read_maker = ReadMaker(uniform, read_len=200, save_path=save_path)\n uniform_read_maker.make_reads('reads', grt, amount=3000)\n\n plt.hist(uniform_read_maker.read_positions)\n plt.xlabel('read start position')\n plt.savefig(path.join(save_path, 'hist.jpg'))\n\n\ndef base_case_1_1():\n case_name = 'base_case_1_1'\n full_case_generator(case_name, 1, [['A']])\n\n\ndef base_case_2_2():\n case_name = 'base_case_2_2'\n full_case_generator(case_name, 1, [['A', 'T']])\n\n\ndef base_case_3_3():\n case_name = 'base_case_3_3'\n full_case_generator(case_name, 1, [['A', 'T', 'G']])\n\n\ndef base_case_4_2():\n case_name = 'base_case_4_2'\n subs = [\n ['A', 'A'],\n ['T', 'T']\n ]\n part_case_generator(case_name, subs)\n\n\ndef base_case_4_4():\n case_name = 'base_case_4_4'\n subs = [['A', 'T']] * 2\n full_case_generator(case_name, 2, subs)\n\n\ndef base_case_8_2():\n case_name = 'base_case_8_2'\n subs = [\n ['A', 'A', 'A'],\n ['T', 'T', 'T']\n ]\n part_case_generator(case_name, subs)\n\n\ndef base_case_8_4():\n case_name = 'base_case_8_4'\n subs = [\n ['A', 'A', 'A'],\n ['A', 'A', 'T'],\n ['A', 'T', 'T'],\n ['T', 'T', 'T']\n ]\n part_case_generator(case_name, subs)\n\n\ndef base_case_81_3():\n # maximum of nonzero frequency amount = 4 * (3 - 1) + 1\n case_name = 'base_case_81_3'\n subs = [\n ['A', 'A', 'A', 'A'],\n ['T', 'T', 'T', 'T'],\n ['G', 'G', 'G', 'G']\n ]\n part_case_generator(case_name, subs)\n\n\ndef base_case_81_6():\n # maximum of nonzero frequency amount = 4 * (3 - 1) + 1\n case_name = 'base_case_81_6'\n subs = [\n ['ATG', 'ATG', 'ATG', 'ATG'],\n ['ATG', 'ATG', 'TGC', 'TGC'],\n ['TGC', 'TGC', 'TGC', 'TGC'],\n ['TGC', 'TGC', 'GCT', 'GCT'],\n ['GCT', 'GCT', 'GCT', 'GCT'],\n ['GCT', 'GCT', 'ATG', 'ATG']\n ]\n part_case_generator(case_name, subs)\n\n\ndef case_gattaca():\n # maximum of nonzero frequency amount = 4 * (3 - 1) + 1\n case_name = 'gattaca'\n subs = [\n ['G', 'A', 'T', 'T', 'A', 'C', 'A'],\n ['G', 'T', 'T', 'A', 'C', 'A', 'T'],\n ['C', 'C', 'C', 'A', 'G', 'A', 'T']\n ]\n case_generator_with_freqs(case_name, subs, [.4, .35, .25])\n\n\nif __name__ == '__main__':\n\n # base_case_1_1()\n # base_case_2_2()\n # base_case_3_3()\n # base_case_4_4()\n # base_case_4_4()\n # base_case_8_2()\n # base_case_8_4()\n # base_case_81_3()\n # base_case_81_6()\n case_gattaca()\n"
},
{
"alpha_fraction": 0.5795634984970093,
"alphanum_fraction": 0.5839285850524902,
"avg_line_length": 28.647058486938477,
"blob_id": "290b478b22bc0ecac91d6815ffcb8119569ccbca",
"content_id": "927c56406d10587d642b136165e09823f67feff8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5040,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 170,
"path": "/src/Util.py",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "import editdistance\nimport subprocess\nimport tempfile\nimport shutil\nimport pysam\nimport networkx as nx\nfrom os import path\nfrom collections import defaultdict\nfrom ortools.linear_solver import pywraplp\nfrom networkx import MultiDiGraph\nfrom networkx import DiGraph\n\n\ndef get_haplotype_by_path(db_graph, edge_path: list) -> str:\n return ''.join([db_graph.get_edge_substring(e) for e in edge_path])\n\n\ndef get_in_edges(graph: MultiDiGraph, node) -> list:\n return graph.in_edges(node, keys=True)\n\n\ndef get_out_edges(graph: MultiDiGraph, node) -> list:\n return graph.out_edges(node, keys=True)\n\n\ndef flatten(nested_list: list) -> list:\n return [elem for sublist in nested_list for elem in sublist]\n\n\ndef k_mer_pairs(read, k):\n size = len(read)\n if size < k:\n return None, None\n for i in range(size - k):\n yield read[i:(i + k)], read[(i + 1):(i + k + 1)]\n\n\ndef earth_mover_distance(dist1: list, dist2: list) -> float:\n solver = pywraplp.Solver(\n 'earth_mover_distance',\n pywraplp.Solver.GLOP_LINEAR_PROGRAMMING)\n\n variables = dict()\n\n dirt_leaving_constraints = defaultdict(lambda: 0)\n dirt_filling_constraints = defaultdict(lambda: 0)\n\n objective = solver.Objective()\n objective.SetMinimization()\n\n for x, dirt_at_x in dist1:\n for y, capacity_of_y in dist2:\n amount_to_move_x_y = solver.NumVar(0, solver.infinity(),\n 'z_{%s, %s}' % (x, y))\n variables[(x, y)] = amount_to_move_x_y\n dirt_leaving_constraints[x] += amount_to_move_x_y\n dirt_filling_constraints[y] += amount_to_move_x_y\n objective.SetCoefficient(amount_to_move_x_y,\n editdistance.eval(x, y))\n\n dist1 = {k: v for k, v in dist1}\n dist2 = {k: v for k, v in dist2}\n for x, linear_combination in dirt_leaving_constraints.items():\n solver.Add(linear_combination == dist1[x])\n\n for y, linear_combination in dirt_filling_constraints.items():\n solver.Add(linear_combination == dist2[y])\n\n status = solver.Solve()\n if status not in [solver.OPTIMAL, solver.FEASIBLE]:\n raise Exception('Unable to find feasible solution')\n\n return objective.Value()\n\n\ndef get_normalize_pair_list(list_of_pair: list) -> list:\n total_count = sum([count for _, count in list_of_pair])\n\n return [(k, count / total_count) for k, count in list_of_pair]\n\n\ndef read_ground_truth(path_to_file: str) -> list:\n haplos_repr = []\n with open(path_to_file, 'r') as haplos:\n for line in haplos:\n haplo, count = line.strip().split()\n haplos_repr.append((haplo, float(count)))\n\n return get_normalize_pair_list(haplos_repr)\n\n\ndef read_vgflow(path_to_file: str) -> list:\n sh_frecs = []\n sh_hapls = []\n with open(path_to_file, 'r') as reconstructed:\n for line in reconstructed:\n line = line.strip()\n if line[0] == '>':\n sh_frecs.append(float(line.split('=')[-1]))\n else:\n sh_hapls.append(line)\n return get_normalize_pair_list(list(zip(sh_hapls, sh_frecs)))\n\n\nclass BWAContextManager(object):\n def __init__(self, path_to_reads: list, ref: str):\n self.ref = ref\n self.path_to_reads = path_to_reads\n self.tmp_dir = tempfile.mkdtemp(dir='.')\n self.sam_file = None\n\n def __run_bwa_mem(self):\n command = [\n 'bwa',\n 'mem',\n path.join(self.tmp_dir, 'ref.fasta'),\n *self.path_to_reads,\n '-o',\n path.join(self.tmp_dir, 'align.sam')\n ]\n subprocess.run(\n ['bwa', 'index', path.join(self.tmp_dir, 'ref.fasta')],\n stdout=subprocess.DEVNULL,\n stderr=subprocess.DEVNULL\n )\n subprocess.run(\n command,\n stdout=subprocess.DEVNULL,\n stderr=subprocess.DEVNULL\n )\n\n def __enter__(self):\n with open(path.join(self.tmp_dir, 'ref.fasta'), 'w') as ref_fie:\n ref_fie.write('>ref\\n')\n ref_fie.write(self.ref)\n self.__run_bwa_mem()\n self.sam_file = pysam.AlignmentFile(\n path.join(self.tmp_dir, 'align.sam'))\n\n return self\n\n def __exit__(self, exc_type, exc_value, exc_traceback):\n shutil.rmtree(self.tmp_dir)\n\n\nclass KMer(object):\n def __init__(self, seq, position):\n self.seq = seq\n self.pos = position\n\n def __hash__(self):\n return hash((self.seq, str(self.pos)))\n\n def __eq__(self, other):\n return self.__hash__() == other.__hash__()\n\n def __repr__(self):\n return \"{} {}\".format(self.seq, self.pos)\n\n\ndef split_graph_by_paths(graph: DiGraph) -> list:\n paths = [[]]\n dfs_result = nx.edge_dfs(graph)\n for e in dfs_result:\n paths[-1].append(e)\n indeg, outdeg = graph.in_degree(e[1]), graph.out_degree(e[1])\n if indeg != 1 or outdeg != 1:\n paths.append([])\n paths = [p for p in paths if p]\n return paths\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 32,
"blob_id": "c25d686b30c381ecddb6f26265425b7a7dcd09d9",
"content_id": "db615d6fbc7c200ed912e21e4c54dc05531cacf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 2,
"path": "/README.md",
"repo_name": "AntonCoon/HA",
"src_encoding": "UTF-8",
"text": "# HA\nSimple maximum parsimony De novo **H**aplotype **A**ssembler\n"
}
] | 15 |
4m1t0/performance-dashboard | https://github.com/4m1t0/performance-dashboard | c10992c0deb13cdae420842235234ace3e1fe240 | 6efbc57212a49e4adf9e94f5f4e32e58e5e96147 | fbfade32404a2f8e0374e81918b9e120b83e39f1 | refs/heads/master | 2022-07-09T03:48:43.543502 | 2020-05-10T13:30:02 | 2020-05-10T13:30:02 | 215,800,707 | 0 | 0 | MIT | 2019-10-17T13:34:40 | 2020-05-10T13:30:06 | 2022-07-20T16:15:20 | Python | [
{
"alpha_fraction": 0.47239452600479126,
"alphanum_fraction": 0.4937590956687927,
"avg_line_length": 37.86606979370117,
"blob_id": "d11644c8705b488e4044affd851f3a43e0a162a7",
"content_id": "ab91f946dafacc946a40a9fcea80993298f1238c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13063,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 336,
"path": "/src/python/scripts/modules/PerformanceReport.py",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "import datetime\nimport logging\nimport pandas as pd\nimport plotly.offline as offline\nimport plotly.graph_objs as go\nimport sys\n\n\nclass PerformanceReport:\n\n def __init__(self, reports):\n \"\"\"Performance Report as pandas DataFrame.\n\n Args:\n reports [pandas.DataFrame]: Having performance test reports and \\\n following columns.\n 1. Name: test target.\n 2. # requests: number of requests.\n 3. 99%: 99%tile Latency. any %tile Latency is available \\\n because you have to assign key when plotting charts.\n 4. Median response time: 50%tile Latency.\n 5. Average response time: ditto.\n 6. Min response time: ditto.\n 7. Max response time: ditto.\n 8. # failures: number of failures.\n 9. Requests/s: requests per second.\n 10: DateTime [pandas.TimeStamp]: date executed test.\n \"\"\"\n self.fontsize = 11\n self.reports = reports\n self.reports.sort_values('DateTime', ascending=True, inplace=True)\n\n def percentilePlot(self, name=None, key=None, filename=None):\n if key is None or filename is None:\n logging.critical(\n 'Invalid Usage: Please assign both key and filename.')\n sys.exit(1)\n\n data = []\n if name is None:\n names = sorted(self.reports['Name'].unique(), reverse=False)\n for name in names:\n data.append(self._Scatter(name, key, 'Latency'))\n else:\n data.append(self._Scatter(name, key, 'Latency'))\n\n key = key + 'tile' if '%' in key else key.split(' ')[0]\n\n layout = go.Layout(\n title=key + ' Latency Timeline Chart',\n xaxis=dict(gridcolor='#2B3D59', zeroline=False),\n yaxis=dict(title='Latency (ms)',\n gridcolor='#2B3D59', zeroline=False),\n paper_bgcolor=\"rgba(0,0,0,0)\",\n plot_bgcolor=\"rgba(0,0,0,0)\",\n font=dict(color=\"#F2F2F2\", size=self.fontsize),\n legend=dict(x=1, y=0.5),\n margin=dict(pad=2))\n\n fig = go.Figure(data=data, layout=layout)\n offline.plot(fig, filename=filename, auto_open=False)\n\n def _Scatter(self, name, key, label):\n text = [\n 'DateTime: ' +\n d.astype('M8[ms]').astype('O').isoformat().replace('T', ' ')\n + '<br>' + label + ': ' + str(l)\n for d, l in zip(\n self.reports[self.reports['Name'] == name]['DateTime'].values,\n self.reports[self.reports['Name'] == name][key].values)]\n return go.Scatter(\n x=self.reports[self.reports['Name'] == name]['DateTime'],\n y=self.reports[self.reports['Name'] == name][key],\n name=name,\n text=text,\n hoverinfo='text+name'\n )\n\n def rpsTimelineChart(self, name=None, filename=None):\n if filename is None:\n logging.critical(\n 'Invalid Usage: Please assign both name and filename.')\n sys.exit(1)\n\n data = []\n if name is None:\n names = sorted(self.reports['Name'].unique(), reverse=False)\n for name in names:\n data.append(self._Scatter(name, 'Requests/s', 'Requests/s'))\n else:\n data.append(self._Scatter(name, 'Requests/s', 'Requests/s'))\n\n layout = go.Layout(\n title='Rps Timeline Chart',\n xaxis=dict(gridcolor='#2B3D59', zeroline=False),\n yaxis=dict(gridcolor='#2B3D59', zeroline=False),\n paper_bgcolor=\"rgba(0,0,0,0)\",\n plot_bgcolor=\"rgba(0,0,0,0)\",\n font=dict(color=\"#F2F2F2\", size=self.fontsize),\n legend=dict(x=1, y=0.5),\n margin=dict(pad=2))\n\n fig = go.Figure(data=data, layout=layout)\n offline.plot(fig, filename=filename, auto_open=False)\n\n def requestsTimelineChart(self, key=None, title=None, filename=None):\n if key is None or title is None or filename is None:\n logging.critical(\n 'Invalid Usage: Please assign both key and filename.')\n sys.exit(1)\n\n names = sorted(self.reports['Name'].unique(), reverse=False)\n data = []\n for name in names:\n t = key.split(' ')\n text = [\n 'DateTime: ' +\n d.astype('M8[ms]').astype('O').isoformat().replace('T', ' ')\n + '<br>' + t[0] + ' of ' + t[1] + ': ' + str(l)\n for d, l in zip(\n self.reports[self.reports['Name']\n == name]['DateTime'].values,\n self.reports[self.reports['Name'] == name][key].values)]\n data.append(go.Scatter(\n x=self.reports[self.reports['Name'] == name]['DateTime'],\n y=self.reports[self.reports['Name'] == name][key],\n name=name,\n text=text,\n hoverinfo='text+name'\n ))\n layout = go.Layout(\n title=title,\n xaxis=dict(gridcolor='#2B3D59', zeroline=False),\n yaxis=dict(gridcolor='#2B3D59', zeroline=False),\n paper_bgcolor='rgba(0,0,0,0)',\n plot_bgcolor='rgba(0,0,0,0)',\n font=dict(color='#F2F2F2', size=self.fontsize),\n legend=dict(x=1, y=0.5),\n margin=dict(pad=2))\n\n fig = go.Figure(data=data, layout=layout)\n offline.plot(fig, filename=filename, auto_open=False)\n\n def activityChart(self, filename=None):\n now = datetime.datetime.now()\n d_now = datetime.date(now.year, now.month, now.day)\n\n offset = 0\n delta = 365 + offset\n\n pre_d_last_year = d_now - datetime.timedelta(days=delta)\n if pre_d_last_year.weekday():\n offset = pre_d_last_year.weekday()\n\n d_last_year = d_now - datetime.timedelta(days=delta)\n\n # gives me a list with datetimes for each day a year\n dates_in_year = [d_last_year +\n datetime.timedelta(i) for i in range(delta+1)]\n\n # gives [0,1,2,3,4,5,6,0,1,2,3,4,5,6,…] (ticktext in xaxis dict translates this to weekdays\n weekdays_in_year = [-1 * i.weekday() for i in dates_in_year]\n # gives [1,1,1,1,1,1,1,2,2,2,2,2,2,2,…] name is self-explanatory\n start_dates_of_week = [\n d - datetime.timedelta(days=d.weekday()) if d.weekday() else d\n for d in dates_in_year]\n # z = np.random.randint(3, size=(len(dates_in_year))) / 2\n\n df = pd.DataFrame({\n 'start_date': start_dates_of_week,\n 'weekday': weekdays_in_year,\n 'z': 0,\n 'commits': 0\n })\n\n # count contributions per a day\n for report in self.reports['DateTime'].unique():\n report_date = report.astype('M8[D]').astype('O')\n weekday = report_date.weekday()\n start_date_of_week = report_date - \\\n datetime.timedelta(days=weekday)\n\n target_record = df[\n (df['start_date'] == start_date_of_week) &\n (df['weekday'] == -1 * weekday)]\n\n if not target_record.empty:\n df.loc[(df['start_date'] == start_date_of_week) &\n (df['weekday'] == -1 * weekday), ['z']] \\\n = target_record['z'] + 1 \\\n if target_record['z'].values[0] < 2 else 2\n df.loc[(df['start_date'] == start_date_of_week) &\n (df['weekday'] == -1 * weekday), ['commits']] \\\n = target_record['commits'] + 1\n\n # gives something like list of strings like '2018-01-25' for each date. Used in data trace to make good hovertext.\n text = []\n for date in dates_in_year:\n start_date_of_week = date - \\\n datetime.timedelta(days=date.weekday())\n commit = df[\n (df['start_date'] == start_date_of_week) &\n (df['weekday'] == -1 * date.weekday())]['commits']\n s = 'date: ' + str(date) + '<br>commits: ' + str(commit.values[0])\n text.append(s)\n\n data = [\n go.Heatmap(\n x=df['start_date'],\n y=df['weekday'],\n z=df['z'],\n text=text,\n hoverinfo='text',\n xgap=3, # this\n ygap=3, # and this is used to make the grid-like apperance\n showscale=False,\n colorscale=[\n [0, '#223147'],\n [0.5, '#00CC69'],\n [1, '#66FA16']]\n )\n ]\n\n layout = go.Layout(\n title='Activity Chart',\n height=380,\n yaxis=dict(\n showline=False, showgrid=False, zeroline=False,\n tickmode='array',\n ticktext=['Sun', 'Sat', 'Fri', 'Thu', 'Wed', 'Tue', 'Mon'],\n tickvals=[-6, -5, -4, -3, -2, -1, 0]\n ),\n xaxis=dict(\n showline=False, showgrid=False, zeroline=False,\n side='top'\n ),\n paper_bgcolor='rgba(0,0,0,0)',\n plot_bgcolor='rgba(0,0,0,0)',\n font=dict(color='#F2F2F2', size=11),\n margin=dict(t=150, b=0, pad=5)\n )\n\n fig = go.Figure(data=data, layout=layout)\n offline.plot(fig, filename=filename, auto_open=False)\n\n def distributedDotPlot(self, name=None, filename=None):\n if name is None or filename is None:\n logging.critical(\n 'Invalid Usage: Please assign both key and filename.')\n sys.exit(1)\n\n df = self.reports[self.reports['Name'] == name].sort_values(\n 'DateTime', ascending=True, inplace=False)\n\n keys = [\n '50%',\n '66%',\n '75%',\n '80%',\n '90%',\n '95%',\n '98%',\n '99%',\n 'Average response time',\n 'Min response time',\n 'Max response time'\n ]\n data = []\n for d in df['DateTime'].values:\n date = d.astype('M8[ms]').astype('O')\n date_for_label = date.isoformat().replace('T', ' ')\n for key in keys:\n if 'time' in key:\n df[key.split(' ')[0].lower()] = df[key]\n key = key.split(' ')[0].lower()\n color = '#FF1744' if key == '99%' else '#7986CB'\n data.append(go.Scatter(\n x=df[df['DateTime'] == d][key],\n y=[date.isoformat().replace('T', '<br>')],\n text=['DateTime: ' + date_for_label + '<br>Latency: ' + str(l)\n for l in df[df['DateTime'] == d][key].values],\n name=key,\n hoverinfo='text+name',\n marker=dict(color=color)\n ))\n\n layout = go.Layout(\n title='Distribution of Latency',\n xaxis=dict(title='Latency (ms)',\n gridcolor='#2B3D59', zeroline=False),\n yaxis=dict(gridcolor='#2B3D59', zeroline=False),\n paper_bgcolor='rgba(0,0,0,0)',\n plot_bgcolor='rgba(0,0,0,0)',\n font=dict(color='#F2F2F2', size=11),\n showlegend=False,\n margin=dict(pad=3))\n\n fig = go.Figure(data=data, layout=layout)\n offline.plot(fig, filename=filename, auto_open=False)\n\n def degradationPlot(self, name=None, key=None, filename=None):\n if name is None or key is None or filename is None:\n logging.critical(\n 'Invalid Usage: Please assign name, key and filename.')\n sys.exit(1)\n\n df = self.reports[self.reports['Name'] == name]\n df_new = df.assign(diff=df[key].diff().fillna(0))\n text = ['DateTime: ' +\n d.astype('M8[ms]').astype('O').isoformat().replace('T', ' ')\n + '<br>Degraded Latency: ' + str(r)\n for d, r in zip(\n df_new['DateTime'].values, df_new['diff']\n )]\n data = [go.Scatter(\n x=df_new['DateTime'],\n y=df_new['diff'],\n name=name,\n mode='lines+markers',\n text=text,\n hoverinfo='text+name'\n )]\n\n layout = go.Layout(\n title=key + 'tile Latency Degradation Timeline Chart',\n xaxis=dict(gridcolor='#2B3D59', zeroline=False),\n yaxis=dict(title='Latency (ms)',\n gridcolor='#2B3D59', zeroline=False),\n paper_bgcolor=\"rgba(0,0,0,0)\",\n plot_bgcolor=\"rgba(0,0,0,0)\",\n font=dict(color=\"#F2F2F2\", size=self.fontsize),\n legend=dict(x=1, y=0.5),\n margin=dict(pad=2))\n\n fig = go.Figure(data=data, layout=layout)\n offline.plot(fig, filename=filename, auto_open=False)\n"
},
{
"alpha_fraction": 0.5635519623756409,
"alphanum_fraction": 0.5687754154205322,
"avg_line_length": 41.024391174316406,
"blob_id": "ef5e035212fd59d3b772174f85868adac32fa9f3",
"content_id": "937fa9179b195c3e3c4effa5571330d7f038bae6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3446,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 82,
"path": "/src/python/scripts/modules/PreProcessor.py",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "import datetime\nimport logging\nimport pandas as pd\nimport os\nimport sys\nfrom .processors import LocustResourceProcessor\n\n\nclass PreProcessor:\n RESOURCES = ['LOCUST']\n\n def __init__(self, resource, time_formatter, *args, **kwargs):\n if resource not in PreProcessor.RESOURCES:\n logging.critical(\n 'Invalid Usage: Please assign a resource defined in '\n + 'PreProcessor.RESOURCES.')\n sys.exit(1)\n if resource == 'LOCUST':\n if 'distribution_filename' in kwargs \\\n and 'requests_filename' in kwargs:\n self.resource_processor = LocustResourceProcessor. \\\n LocustResourceProcessor(\n distribution_filename=kwargs['distribution_filename'],\n requests_filename=kwargs['requests_filename'])\n elif 'distribution_filename' in kwargs:\n self.resource_processor = LocustResourceProcessor. \\\n LocustResourceProcessor(\n distribution_filename=kwargs['distribution_filename'])\n elif 'requests_filename' in kwargs:\n self.resource_processor = LocustResourceProcessor. \\\n LocustResourceProcessor(\n requests_filename=kwargs['requests_filename'])\n else:\n self.resource_processor = LocustResourceProcessor. \\\n LocustResourceProcessor()\n self.time_formatter = time_formatter\n\n def process(self, reports_path):\n \"\"\"Performance Report as pandas DataFrame.\n\n Args:\n reports_dir: directory having directory \\\n which includes locust reports.\n\n Returns:\n reports [pandas.DataFrame]: Having performance test reports and \\\n following columns.\n 1. Name: test target.\n 2. # requests: number of requests.\n 3. 99%: 99%tile Latency. any %tile Latency is available \\\n because you have to assign key when plotting charts.\n 4. Median response time: 50%tile Latency.\n 5. Average response time: ditto.\n 6. Min response time: ditto.\n 8. Max response time: ditto.\n 4. # failures: number of failures.\n 9. Requests/s: requests per second.\n 10: DateTime [pandas.TimeStamp]: date executed test.\n \"\"\"\n report_dirs = [f for f in os.listdir(reports_path) if os.path.isdir(\n os.path.join(reports_path, f))]\n\n reports_df = None\n for report_dir in report_dirs:\n tmp_df = self._process(reports_path, report_dir)\n if reports_df is None:\n reports_df = tmp_df\n else:\n reports_df = pd.concat([reports_df, tmp_df], ignore_index=True)\n\n return reports_df\n\n def _process(self, reports_path, report_dir):\n year, month, day, hour, minute, second = self.time_formatter.format(\n report_dir)\n report_df = self.resource_processor.process(reports_path + report_dir)\n report_df['DateTime'] = datetime.datetime(\n year=year, month=month, day=day,\n hour=hour, minute=minute, second=second)\n report_df.sort_values('DateTime', ascending=True, inplace=True)\n\n return report_df\n"
},
{
"alpha_fraction": 0.526566207408905,
"alphanum_fraction": 0.5340999364852905,
"avg_line_length": 36.64179229736328,
"blob_id": "bb5dd3cd2ab567cf403928dfc92cc378469f97fd",
"content_id": "99a694ff6add9ce0966bcdb501bf8b2ea9458aaf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2522,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 67,
"path": "/src/python/scripts/modules/processors/LocustResourceProcessor.py",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "import logging\nimport pandas as pd\nimport os\nimport sys\n\n\nclass LocustResourceProcessor:\n\n def __init__(\n self,\n distribution_filename='distribution.csv',\n requests_filename='requests.csv'):\n self.reports = dict(\n distribution=distribution_filename,\n requests=requests_filename\n )\n\n def process(self, report_dir):\n \"\"\"Return processed reports as DataFrame.\n\n Args:\n report_dir: directory having locust reports.\n\n Returns:\n reports [pandas.DataFrame]: Having performance test reports and \\\n following columns.\n 1. Name: test target.\n 2. # requests: number of requests.\n 3. 99%: 99%tile Latency. ny %tile Latency is available \\\n because you have to assign key when plotting charts.\n 4. Median response time: 50%tile Latency.\n 5. Average response time: ditto.\n 6. Min response time: ditto.\n 7. Max response time: ditto.\n 8. # failures: number of failures.\n 9. Requests/s: requests per second.\n \"\"\"\n reports = os.listdir(report_dir)\n self._validateDir(reports)\n\n distribution_df = pd.read_csv(os.path.join(\n report_dir, './' + self.reports['distribution']))\n requests_df = pd.read_csv(os.path.join(\n report_dir, './' + self.reports['requests']))\n\n # format Name for merging\n for index, row in requests_df.iterrows():\n if row['Name'] == 'Total':\n requests_df.at[index, 'tmp_name'] = row['Name']\n else:\n requests_df.at[index, 'tmp_name'] = row['Method'] + \\\n ' ' + row['Name']\n\n return pd.merge(\n distribution_df,\n # Because distribution_df has Name and # requests.\n requests_df.drop(['Name', '# requests'], axis=1),\n how='inner', left_on=['Name'], right_on=['tmp_name']\n ).drop('tmp_name', axis=1) # Drop the tmp name\n\n def _validateDir(self, reports):\n if self.reports['distribution'] not in reports or \\\n self.reports['requests'] not in reports:\n logging.critical(\n 'Invalid Usage: locust generates 2 csv files, distribution.csv \\\n and requests.csv. Please set the files in the report_dir.')\n sys.exit(1)\n"
},
{
"alpha_fraction": 0.5178236365318298,
"alphanum_fraction": 0.525015652179718,
"avg_line_length": 32.66315841674805,
"blob_id": "2aba9d8f085ef4dda270477285ad796de3c77b85",
"content_id": "a781b8fb94a967d3e38dc7af20aef281442fca06",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3198,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 95,
"path": "/src/python/scripts/PerformanceVisualizer.py",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "from modules import PerformanceReport, PreProcessor, TimeFormatter\nimport os\n\n\nclass PerformanceVisualizer:\n\n def __init__(self, preprocessor):\n self.preprocessor = preprocessor\n self.keys = [\n '50%',\n '66%',\n '75%',\n '80%',\n '90%',\n '95%',\n '98%',\n '99%',\n 'Average response time',\n 'Min response time',\n 'Max response time'\n ]\n\n def visualize(self, path):\n reports = self.preprocessor.process(path)\n\n static_dir = os.path.join(\n os.path.dirname(__file__),\n '../../javascript/static')\n if not os.path.isdir(static_dir + '/shared'):\n os.makedirs(static_dir + '/shared')\n\n performance_report = PerformanceReport.PerformanceReport(reports)\n\n performance_report.percentilePlot(\n key='99%',\n filename=static_dir +\n '/shared/99percentiles.html')\n performance_report.rpsTimelineChart(\n filename=static_dir\n + '/shared/rps-timeline-chart.html')\n performance_report.requestsTimelineChart(\n key='# requests',\n title='# of requests',\n filename=static_dir +\n '/shared/num-of-requests.html')\n performance_report.requestsTimelineChart(\n key='# failures',\n title='# of failures',\n filename=static_dir +\n '/shared/num-of-errors.html')\n performance_report.activityChart(\n filename=static_dir +\n '/shared/activity-chart.html')\n\n uniq_reports = sorted(reports['Name'].unique())\n for uniq_report in uniq_reports:\n additional_path = 'total/' if uniq_report == 'Total' \\\n else ''.join(\n uniq_report.split(' ')).lower() + '/'\n\n plot_path = static_dir + '/' + additional_path\n if not os.path.isdir(plot_path):\n os.makedirs(plot_path)\n\n performance_report.distributedDotPlot(\n name=uniq_report,\n filename=plot_path\n + 'distributed-dot-plot.html')\n\n performance_report.rpsTimelineChart(\n name=uniq_report,\n filename=plot_path\n + 'rps-timeline-chart.html')\n\n for key in self.keys:\n prefix = key.split(' ')[0].lower(\n ) if 'time' in key else key[:2] + 'percentile'\n\n performance_report.percentilePlot(\n name=uniq_report,\n key=key,\n filename=plot_path\n + prefix + '-timeline-chart.html')\n performance_report.degradationPlot(\n name=uniq_report,\n key=key,\n filename=plot_path\n + prefix + '-degradation-timeline-chart.html')\n\n\ntime_formatter = TimeFormatter.TimeFormatter('YYYYMMDD_HHMMSS1')\nvisualizer = PerformanceVisualizer(\n PreProcessor.PreProcessor('LOCUST', time_formatter))\nvisualizer.visualize(\n os.path.join(os.path.dirname(__file__), '../resources/reports/'))\n"
},
{
"alpha_fraction": 0.7150097489356995,
"alphanum_fraction": 0.7161793112754822,
"avg_line_length": 33.20000076293945,
"blob_id": "b8225408126b0669211ae7cc81ab9a24f88b43ff",
"content_id": "69b05a119d0e2ea514ead7e697fb6df1acec6108",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2565,
"license_type": "permissive",
"max_line_length": 658,
"num_lines": 75,
"path": "/README.md",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "# Performance Dashboard\n\n## Table of Contents\n\n- [Introductions](#introductions)\n- [Requirements](#requirements)\n- [Build Setup](#build-setup)\n\n## Introductions\n\nThis is a simple tool for monitoring your web service performance.\n\n\n\nAll web developers are interested in your service performance, so we test services with performance tools like [JMeter](https://github.com/apache/jmeter), [Vegeta](https://github.com/tsenart/vegeta), [Locust](https://github.com/locustio/locust) and so on. Now, with growing container services, we can do performance test more easier because they provide exact same environments and scalability. It means we can monitor our service performance more easier continuously.\n\nThis tool is for monitoring performance based on [Locust](https://github.com/locustio/locust) reports. Although using a database and a visualization tool (e.g. [Elasticsearch](https://github.com/elastic/elasticsearch) and [Kibana](https://github.com/elastic/kibana), [MySQL](https://github.com/mysql) and [ReDash](https://github.com/getredash/redash)) is a option, but you may think preparing those just for monitoring performance is more expensive than developing a simple performance monitoring tool. If you think in a similar way, this tool is suitable because this requires storing reports in github repository and generates plots when starting the tool.\n\nOf course you can use other performance tool reports by developing scripts for formatting its for plotting charts and adding it as a processor.\n\n## Requirements\n\nThis tool requires you basic knowledge about the following:\n\n<table>\n <thead>\n <th>Technology</th>\n <th>Usage</th>\n </thead>\n <tbody>\n <tr>\n <td>Python 3</td>\n <td rowspan=\"3\">For plotting charts and processing test reports.</td>\n </tr>\n <tr>\n <td>Pandas</td>\n </tr>\n <tr>\n <td>Plotly</td>\n </tr>\n <tr>\n <td>javascript</td>\n <td rowspan=\"4\">For developing web pages.</td>\n </tr>\n <tr>\n <td>Nuxt.js</td>\n </tr>\n <tr>\n <td>Vue.js</td>\n </tr>\n <tr>\n <td>Vuetify</td>\n </tr>\n </tbody>\n</table>\n\n## Build Setup\n\n```bash\n# install dependencies\n$ yarn install\n$ pip install -r python-requirements.txt\n\n# generate plots and serve with hot reload\n$ yarn run dev\n\n# generate plots, build for production and launch server\n$ yarn run build\n$ yarn run start\n\n# generate plots and static project\n$ yarn run generate\n```\n\nFor detailed explanation on how things work, check out [Nuxt.js docs](https://nuxtjs.org).\n"
},
{
"alpha_fraction": 0.4137931168079376,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 13.5,
"blob_id": "c4190797fb2b1e8f50833e8f1a86a600c1741eac",
"content_id": "3547ed1b71849aec281d9af11f830cc0cceae296",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 29,
"license_type": "permissive",
"max_line_length": 14,
"num_lines": 2,
"path": "/python-requirements.txt",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "pandas==0.24.2\nplotly==4.1.1\n"
},
{
"alpha_fraction": 0.5239726305007935,
"alphanum_fraction": 0.5399543642997742,
"avg_line_length": 32.69230651855469,
"blob_id": "7e09a25b0008085dc9994f4526c5a99a2b2fb187",
"content_id": "c37b2fedfa851609fe00e9bf8df63d3816d64a69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 876,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 26,
"path": "/src/python/scripts/modules/TimeFormatter.py",
"repo_name": "4m1t0/performance-dashboard",
"src_encoding": "UTF-8",
"text": "import logging\nimport sys\n\n\nclass TimeFormatter:\n TIME_STYLE = dict(\n YYYYMMDD_HHMMSS1='YYYYMMDD-HHMMSS'\n )\n\n def __init__(self, style):\n if style not in TimeFormatter.TIME_STYLE:\n logging.critical(\n 'Invalid Usage: Please assign a style defined in'\n + 'TimeFormatter.TIME_STYLE.')\n sys.exit(1)\n if style == 'YYYYMMDD_HHMMSS1':\n self._style = TimeFormatter.TIME_STYLE[style]\n\n def format(self, s):\n if self._style == TimeFormatter.TIME_STYLE['YYYYMMDD_HHMMSS1']:\n tmp = s.split('-')\n _date, _time = tmp[0], tmp[1]\n year, month, day = int(_date[:4]), int(_date[4:6]), int(_date[6:])\n hour, minute, second = int(_time[:2]), int(\n _time[2:4]), int(_time[4:])\n return year, month, day, hour, minute, second\n"
}
] | 7 |
mario21ic/odoo_vps | https://github.com/mario21ic/odoo_vps | 738d7c55ea3e0732626c105ce79bdbd2ccb14a71 | b18e4adf879ca781334042b546f2e3d065e90349 | 8ebd987600fa13c0ade25c7f711a39e74eaf9cbd | refs/heads/master | 2016-09-08T01:42:39.061327 | 2015-07-23T22:23:05 | 2015-07-23T22:23:05 | 33,608,822 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5679082870483398,
"alphanum_fraction": 0.5862464308738708,
"avg_line_length": 29.59649085998535,
"blob_id": "36917d3fff6eb21a7837817d4fd4192215862631",
"content_id": "d5857176a259b075124bf9e126886c26db59d064",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1745,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 57,
"path": "/odoo_vps/pdg/pdg.py",
"repo_name": "mario21ic/odoo_vps",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport time\n\nfrom openerp.osv import fields, osv\nfrom openerp.tools.translate import _\nfrom openerp import workflow\nfrom openerp.tools import DEFAULT_SERVER_DATE_FORMAT, DEFAULT_SERVER_DATETIME_FORMAT\n\nclass pdg_contract(osv.osv):\n _name = 'pdg.contract'\n _columns = {\n #'order_id': fields.many2one('sale.order', 'Order Reference'),\n 'partner_id': fields.many2one('res.partner', 'Cliente'),\n 'name': fields.char('Nombre', size=120),\n 'date_start': fields.date('Inicio'),\n 'date_end': fields.date('Fin'),\n\n 'vps_online': fields.boolean('Online'),\n 'vps_server': fields.many2one('pdg.vps', 'VPS'),\n 'vps_access': fields.many2one('pdg.vps.access', 'VPS Access'),\n\n 'cms_name': fields.many2one('pdg.cms', 'CMS'),\n 'cms_access': fields.many2one('pdg.cms.access', 'CMS Access'),\n 'cms_version': fields.char('CMS Version', size=10)\n }\n\nclass pdg_vps(osv.osv):\n _name = 'pdg.vps'\n _columns = {\n 'name': fields.char('Nombre', size=30),\n 'ip': fields.char('Ip', size=30),\n }\n\nclass pdg_vps_access(osv.osv):\n _name = 'pdg.vps.access'\n _columns = {\n 'username': fields.char('User', size=30),\n 'password': fields.char('Password', size=30),\n }\n\n\nclass pdg_cms(osv.osv):\n _name = 'pdg.cms'\n _columns = {\n 'name': fields.char('Nombre', size=30),\n 'web': fields.char('Web', size=30),\n }\n\nclass pdg_cms_access(osv.osv):\n _name = 'pdg.cms.access'\n _columns = {\n 'database': fields.char('Database', size=30),\n 'name': fields.char('Nombre', size=30),\n 'password': fields.char('Password', size=30),\n 'prefix': fields.char('Prefix', size=30),\n }\n\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 14,
"blob_id": "7fcbcc176f7ad999c71388f2d1e69186bb914d4f",
"content_id": "029669fb1c907cfc00872204ba351fb30da19646",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 2,
"path": "/odoo_vps/__init__.py",
"repo_name": "mario21ic/odoo_vps",
"src_encoding": "UTF-8",
"text": "import res_partner\nimport pdg\n"
},
{
"alpha_fraction": 0.6897374987602234,
"alphanum_fraction": 0.6945107579231262,
"avg_line_length": 25.1875,
"blob_id": "19e7bf4c9335018c2413ff576e3b0b286b90357b",
"content_id": "2060ec160e9020de0400d257949636422a92b0f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 16,
"path": "/odoo_vps/res_partner/res_partner.py",
"repo_name": "mario21ic/odoo_vps",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport time\n\nfrom openerp.osv import fields, osv\nfrom openerp.tools.translate import _\nfrom openerp import workflow\nfrom openerp.tools import DEFAULT_SERVER_DATE_FORMAT, DEFAULT_SERVER_DATETIME_FORMAT\n\n\nclass res_partner(osv.osv):\n _name = 'res.partner'\n _inherit = 'res.partner'\n _columns = {\n 'pdg_contract': fields.one2many('pdg.contract', 'partner_id', 'Contractos'),\n }\n"
},
{
"alpha_fraction": 0.4694444537162781,
"alphanum_fraction": 0.47777777910232544,
"avg_line_length": 17.947368621826172,
"blob_id": "fe783b959c507605149d154713bca8df8888696c",
"content_id": "9ea6da9fcbca4fd6ffecdd244f7ceefbad2d2fb8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 19,
"path": "/odoo_vps/__openerp__.py",
"repo_name": "mario21ic/odoo_vps",
"src_encoding": "UTF-8",
"text": "# coding= utf-8\n{\n \"name\": \"VPS Manager\",\n \"version\": \"1.0\",\n \"depends\": [\n \"base\"\n ],\n \"author\": \"Mario Inga Cahuana\",\n \"website\": \"\",\n \"category\": \"clients\",\n \"description\": '''\n Modulo para manejar servidor VPS\n ''',\n 'data': [\n \"res_partner/res_partner_view.xml\"\n ],\n 'installable': True,\n 'active': False\n}\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 32,
"blob_id": "15f3ea8e7ed4cf45afd8183bd5d0181f1801d2ef",
"content_id": "e928367366196b2d822c0908db6e376a4293baea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 33,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 1,
"path": "/odoo_vps/tests/__init__.py",
"repo_name": "mario21ic/odoo_vps",
"src_encoding": "UTF-8",
"text": "from . import test_foo, test_bar\n"
}
] | 5 |
shashankgpt98/YoutubeVideosDetailScraping | https://github.com/shashankgpt98/YoutubeVideosDetailScraping | 98cacf75a047767a6cec4fc9a01f25f14ba64851 | de5ee8644a4e25a48d6dd3bef82e9cd42fc417e4 | b10b6e28c860c054cabfab7159010514504e8178 | refs/heads/master | 2022-02-21T09:47:28.077867 | 2019-08-06T13:38:26 | 2019-08-06T13:38:26 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.656559407711029,
"alphanum_fraction": 0.6591893434524536,
"avg_line_length": 27.97757911682129,
"blob_id": "7456a0c871caac18662a8e2d68e70e4dad129de2",
"content_id": "cdfb1e74da7081cdf2d3c644a6c6dacf766707bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6464,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 223,
"path": "/youtube _videos_detail_scrabing.py",
"repo_name": "shashankgpt98/YoutubeVideosDetailScraping",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver \nimport pandas as pd \nfrom selenium.webdriver.common.by import By \nfrom selenium.webdriver.support.ui import WebDriverWait \nfrom selenium.webdriver.support import expected_conditions as EC\n#import time, os\nimport argparse\nfrom getpass import getpass\nimport json\nimport requests\n\ndriver = webdriver.Chrome()\ndriver.get(\"http://www.youtube.com\")\n\n\nsearch_query = input(\"Enter the search query ---> \")\n\nprint(search_query)\n\ndriver.find_element_by_xpath('//*[@id=\"search\"]').send_keys(search_query)\ndriver.find_element_by_xpath('//*[@id=\"search-icon-legacy\"]').click()\n\n\nuser_data = driver.find_elements_by_xpath('//*[@id=\"video-title\"]')\n\n#store all links in a list\n\nlinks = []\nIds = []\ntitle = []\nviews = []\ndates = []\nsubs = []\nn_comments = []\nn_likes = []\nn_dislikes = []\n\n\nfor i in user_data:\n links.append(i.get_attribute('href'))\n\n\n\nwait = WebDriverWait(driver, 30)\n\n'''f= open(\"filename.txt\",\"a\")\nf.write('\\n')\nf.write(\"THIS STORE INFORMATION OF A VIDEOS OF A PAGE THAT OPEN AFTER YOU ENTER INPUT ('select filter to video only ')\")\nf.write(\"AND PRINT INFORMATION TO A CONSOLE ('you can also syore this information to a text file, I put on comment that part of code')\")\nf.write('\\n')\nf.write('your input -->')\nf.write(search_query)\nf.close()'''\n\n\t\t\t\t\t# iterate till last link\n\nfor x in links:\n\tprint(\"link--> \",x)\n\t\n\tdriver.get(x)\n\t'''f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write('links ')\n\tf.write(x)\n\tf.close()\n\t'''\n\t# find id of video\n\tv_id = x.strip('https://www.youtube.com/watch?v=')\n\tprint(\"Id of Video --> \",v_id)\n\tIds.append(v_id)\n\t\n\t\t\t\t\t# find title of video \n\tv_title = wait.until(EC.presence_of_element_located(\n\t\t(By.CSS_SELECTOR,\"h1.title yt-formatted-string\"))).text\n\tprint(\"Title--> \",v_title)\n\ttitle.append(v_title)\n\t'''f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write(v_title)\n\tf.close()\n\t'''\n\t\t\t\t\t# find description of video\n\tv_description = wait.until(EC.presence_of_element_located(\n\t\t(By.CSS_SELECTOR,\"div#description yt-formatted-string\"))).text\n\t#print(v_description)\n\t#f= open(\"filename.txt\",\"a\")\n\t#f.write('\\n')\n\t#f.write(v_description)\n\t#f.close()\n\t\n\t\t\t\t\t# find number of views\n\tview = wait.until(EC.presence_of_element_located(\n\t\t(By.XPATH,'//*[@id=\"count\"]/yt-view-count-renderer/span[1]'))).text\n\tprint(\"Views--> \",view)\n\tviews.append(view)\n\t'''f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write(view)\n\tf.close()\n\t'''\n\t\t\t\t\t# find data on which video is uploaded\n\tdate = wait.until(EC.presence_of_element_located(\n\t\t(By.XPATH,'//*[@id=\"upload-info\"]/span'))).text\n\tprint(\"Date-->\",date)\n\tdates.append(date)\n\t'''f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write(date)\n\tf.close()\n\t'''\n\t\t\t\t\t# find subscriber\n\ts = wait.until(EC.presence_of_element_located(\n\t\t(By.XPATH,'//*[@id=\"text\"]/span'))).text\n\tprint(\"subs-->\",s)\n\tsubs.append(s)\n\t'''f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write('Subscriber ')\n\tf.write(s)\n\tf.close()\n\t'''\n\t\t\t\t# maximize window to full size\n\tdriver.maximize_window()\n\t\n\tdriver.execute_script(\"window.scrollBy(0,500)\",\"\") # scroll page to 700 pixels\n\t\n\t\t\t\t\t# find total numbers od comments\n\tcomments = wait.until(EC.presence_of_element_located(\n\t\t(By.XPATH,'//*[@id=\"count\"]/yt-formatted-string'))).text\n\tprint(\"comments--> \",comments)\n\tn_comments.append(comments)\n\n\t'''f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write(comments)\n\tf.write('\\n')\n\t\n\tf.close()\n\t'''\n\t\t\t\t\t# to find total number of like \n\troot = driver.find_element_by_id('content')\n\tpgmgr = root.find_element_by_id('page-manager')\n\twatchflexy = pgmgr.find_element_by_tag_name('ytd-watch-flexy') \n\tcol = watchflexy.find_element_by_id('columns')\n\tprimary = col.find_element_by_id('primary')\n\tinner_primary = col.find_element_by_id('primary-inner')\n\tinfo = inner_primary.find_element_by_id('info')\n\tinfo_content = info.find_element_by_id('info-contents')\n\t# print(info_content)\n\trenderer = info_content.find_element_by_tag_name('ytd-video-primary-info-renderer')\n\tcontainer = renderer.find_element_by_id('container')\n\tinfo2 = container.find_element_by_id('info')\n\tmenu_container = info2.find_element_by_id('menu-container')\n\tmenu = menu_container.find_element_by_id('menu')\n\tmenu_renderer = menu.find_element_by_tag_name('ytd-menu-renderer')\n\ttop = menu_renderer.find_element_by_id('top-level-buttons')\n\tbutton = top.find_element_by_tag_name('ytd-toggle-button-renderer')\n\ta = button.find_element_by_tag_name('a')\n \n\tlike_button = a.find_element_by_id('button')\n\tres = a.find_element_by_id('text')\n\tprint(\"like -->\",res.text)\n\tn_likes.append(res.text)\n\n\t'''f= f= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write('likes ')\n\tf.write(res.text)\n\t#f.write('\\n')\n\n\tf.close()\n\t'''\n\n\t\t\t\t\t# to find number total of dislike \n\troot = driver.find_element_by_id('content')\n\tpgmgr = root.find_element_by_id('page-manager')\n\twatchflexy = pgmgr.find_element_by_tag_name('ytd-watch-flexy') \n\tcol = watchflexy.find_element_by_id('columns')\n\tprimary = col.find_element_by_id('primary')\n\tinner_primary = col.find_element_by_id('primary-inner')\n\tinfo = inner_primary.find_element_by_id('info')\n\tinfo_content = info.find_element_by_id('info-contents')\n\t# print(info_content)\n\trenderer = info_content.find_element_by_tag_name('ytd-video-primary-info-renderer')\n\tcontainer = renderer.find_element_by_id('container')\n\tinfo2 = container.find_element_by_id('info')\n\tmenu_container = info2.find_element_by_id('menu-container')\n\tmenu = menu_container.find_element_by_id('menu')\n\tmenu_renderer = menu.find_element_by_tag_name('ytd-menu-renderer')\n\ttop = menu_renderer.find_element_by_id('top-level-buttons')\n\tbutton = menu_renderer.find_element_by_xpath('//*[@id=\"top-level-buttons\"]/ytd-toggle-button-renderer[2]')\n\ta = button.find_element_by_xpath('//*[@id=\"top-level-buttons\"]/ytd-toggle-button-renderer[2]/a')\n\tres = a.find_element_by_id('text')\n\tprint(\"dislike --> \",res.text)\n\tn_dislikes.append(res.text)\n\tprint(\"\\n\")\n\t'''\n\tf= open(\"filename.txt\",\"a\")\n\tf.write('\\n')\n\tf.write('dislikes ')\n\tf.write(res.text)\n\tf.write('\\n')\n\tf.write('\\n')\n\tf.write('------------_____________------------')\n\tf.close()\n\n\t'''\ndetails = {'Link':links,\n 'Id':Ids,\n 'Title':title,\n 'number_of_views':views,\n 'Uploaded_Date':dates,\n 'Subscribers':subs,\n 'number_of_comments':n_comments,\n 'number_of_likes':n_likes,\n 'number_of_dislikes':n_dislikes\n }\n\ndf = pd.DataFrame(details)\ndf.to_csv('data.csv')\n#print(df.head())\n#print(Ids)\ndriver.quit()\n\n\n"
}
] | 1 |
liuw123/MLSpark | https://github.com/liuw123/MLSpark | e00b71eafbbcdd462d86b60f033aa5e1cbc965a6 | 7efe4c1b49411ce546fdf92f3a06565e09062bdb | 2027cf6ec6e63b410fdf89ed4e67c3ae9b5b92e4 | refs/heads/master | 2021-01-21T12:50:13.223726 | 2017-05-19T12:24:11 | 2017-05-19T12:24:11 | 91,802,699 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6745108962059021,
"alphanum_fraction": 0.683867335319519,
"avg_line_length": 34.279998779296875,
"blob_id": "4877509a7255b6273cd512bda1ec67cea29c6dd7",
"content_id": "88089b8af86e47fb91471012828bcad3c712e19d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3527,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 100,
"path": "/Apriori_Spark_v2.1.py",
"repo_name": "liuw123/MLSpark",
"src_encoding": "UTF-8",
"text": "from operator import add\nfrom pyspark import SparkContext, SparkConf\nimport argparse\nimport os\nimport shutil\nimport time\n\nTRANS_NUM = 0\nSUPPORT_NUM = 0.0\n\ndef parseLine(line):\n\tbit_list = line[0].split(args.marker)\n\tbit_list = bit_list[0:len(bit_list)-1]\n\trecord = frozenset(bit_list)\n\treturn (record, line[1])\n\ndef mineOneItem(x):\n\t_item_list = []\n\tfor bit in x[0]:\n\t\t_item_list.append((frozenset(bit.split(\",\")),x[1]))\n\treturn _item_list\n\ndef mineItem(x):\n\t_item_list = []\n\tfor cand in broadcast_pattern.value:\n\t\tif cand.issubset(x[0]):\n\t\t\t_item_list.append((cand, x[1]))\n\treturn _item_list\n\ndef subsetCheck(input_set,parent_set):\n\ttest_set = set(input_set)\n\tfor item in test_set:\n\t\ttest_set.remove(item)\n\t\tif test_set not in parent_set:\n\t\t\treturn False\n\t\ttest_set.add(item)\n\treturn True\n\ndef getChildPattern(parent_pattern,ite):\n\tchild_list = frozenset([i.union(j) for i in parent_pattern for j in parent_pattern if (len(i.union(j))==ite and subsetCheck(i.union(j),parent_pattern))])\n\treturn child_list\n\nif __name__ == '__main__':\n\tparser = argparse.ArgumentParser()\n\tparser.add_argument('--input', type=str, nargs='+', help=\"Input data path.\")\n\tparser.add_argument('--support', type=float, help=\"The support rate.\",\n default=0.85)\n\tparser.add_argument('--k', type=int, help=\"The number of frequent pattern.\",\n default=7)\n\tparser.add_argument('--output', type=str,\n help=\"Output result path.\", default=\"Apriori_Result\")\n\tparser.add_argument('--verbose', action='store_true')\n\tparser.add_argument('--master', type=str,\n help=\"The master of spark.\", default=\"local\")\n\tparser.add_argument('--marker', type=str,\n help=\"The marker in each line.\", default=\" \")\n\tparser.add_argument('--numPartition', type=int,\n help=\"The marker in each line.\", default=16)\n\tglobal args \n\targs = parser.parse_args()\n\tconf = SparkConf().setAppName(\"Apriori\").setMaster(args.master)\n\tsc = SparkContext(conf=conf)\n\tstart = time.time()\n\n\t#To get transaction from input file\n\t_trans = sc.textFile(args.input[0],args.numPartition).map(lambda line:(line, 1))\n\tTRANS_NUM = _trans.count()\n\tSUPPORT_NUM = TRANS_NUM*args.support\n\tif args.verbose:\n\t\tprint \"Total Transactions Number: \"+str(TRANS_NUM)\n\t\tprint \"Support Transactions Number: \"+str(SUPPORT_NUM)\n\t#To remove duplicated \n\t_trans = _trans.reduceByKey(add).map(parseLine).cache()\n\n\t#To get 1-item frequent pattern\n\tone_item = _trans.flatMap(mineOneItem).reduceByKey(add).filter(lambda x:x[1]>SUPPORT_NUM).cache()\n\tresult_buffer = one_item.map(lambda x:str(x[0])+\":\"+str(float(x[1])/TRANS_NUM))\n\tif args.verbose:\n\t\tprint \"1-item pattern:\"\n\t\tprint result_buffer.collect()\n\t#result_buffer.saveAsTextFile(args.output+\"/1_item.out\")\n\n\t#To get 2-k item frequent pattern\n\tfrequent_pattern = one_item\n\tfor i in range(2,args.k+1):\n\t\tchild_pattern = getChildPattern(frequent_pattern.map(lambda x:x[0]).collect(),i)\n\t\t#print child_pattern\n\t\tif len(child_pattern)==0:\n\t\t\tbreak\n\t\tbroadcast_pattern = sc.broadcast(child_pattern)\n\t\tfrequent_pattern = _trans.flatMap(mineItem).reduceByKey(add).filter(lambda x:x[1]>SUPPORT_NUM).cache()\n\t\tresult_buffer = frequent_pattern.map(lambda x:str(x[0])+\":\"+str(float(x[1])/TRANS_NUM))\n\t\tif args.verbose:\n\t\t\tprint str(i)+\"-item pattern:\"\n\t\t\tprint result_buffer.collect()\n\t\t#result_buffer.saveAsTextFile(args.output+\"/\"+str(i)+\"_item.out\")\n\t\tbroadcast_pattern.unpersist()\n\tstop = time.time()\n\tif args.verbose:\n\t\tprint \"Complete! Time cost: {}\".format(stop - start)"
},
{
"alpha_fraction": 0.8032786846160889,
"alphanum_fraction": 0.8032786846160889,
"avg_line_length": 29.5,
"blob_id": "824c60293aa1b60dbbcea3a8332c7bf1c86cfff2",
"content_id": "e0ba2d5a2898cb9799a1f30ab5b32ed7c8584399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 2,
"path": "/README.md",
"repo_name": "liuw123/MLSpark",
"src_encoding": "UTF-8",
"text": "# MLSpark\nA Machine Learning Library in Python Base on Spark\n"
}
] | 2 |
ivogeorg/py3 | https://github.com/ivogeorg/py3 | 3ccaf3f9c674c7f83d1d9b61d97eda552f7d9709 | ca296da1712a1e841abbd6255f4bcfd9b25a2e19 | aa9f1b64d83b40f3527b5bd97e2ffdcc6a3c53a9 | refs/heads/master | 2021-01-13T10:48:24.473723 | 2016-11-08T19:53:31 | 2016-11-08T19:53:31 | 72,290,791 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.47058823704719543,
"alphanum_fraction": 0.48739495873451233,
"avg_line_length": 22.799999237060547,
"blob_id": "0e5fe2fe1cfa40b238c9fcf6512e89203c7c3169",
"content_id": "76fb8be22bf18ce3f13d753847bbe5070e5ae0d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/04prime.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "from sys import argv\n\n# assumes an integer argument\nfor n in range(2, int(argv[1])):\n for i in range(2, n):\n if n % i == 0:\n # print(n, 'equals', i, '*', n//i)\n break\n else:\n print(n, 'is prime')\n"
},
{
"alpha_fraction": 0.5058547854423523,
"alphanum_fraction": 0.5831381678581238,
"avg_line_length": 26.255319595336914,
"blob_id": "a8ebcdb30c4ddee23b57ee05c5bd1056bb7ae61a",
"content_id": "4c4d8f11ad8536e3827dfccf4d3d15df13e7963e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1281,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 47,
"path": "/05listcomp.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# a map is not directly printable, only sequences (lists, tuples) and iterables\nsquares1 = list(map(lambda x: x**2, range(10)))\nprint(squares1, ' ')\n\n# 0.\n# readability\nsquares2 = [x**2 for x in range(10)]\nprint(squares2, ' ')\n\n# 1.\n# succinctness\n# note: tuple expressions have to be in parentheses [(x, y) for ...]\nprint([(x, y) for x in [1,2,3] for y in [3,1,4] if x != y])\n# is equivalent to\ncombs = []\nfor x in [1,2,3]:\n for y in [3,1,4]:\n if x != y:\n combs.append((x, y))\nprint(combs)\n\n# 2.\n# flatten a list with two 'for'\nvec = [[1,2,3], [4,5,6], [7,8,9]]\nprint([num for elem in vec for num in elem])\n\n# unravel left to right (outer to inner)\nvec = [[[1,2,3], [4,5,6], [7,8,9]], [[1,2,3], [4,5,6], [7,8,9]]]\nprint([num for outer in vec for inner in outer for num in inner])\n\n# 3.\n# nested list comprehensions\nmatrix = [\n [1, 2, 3, 4],\n [5, 6, 7, 8],\n [9, 10, 11, 12],\n]\n# the first list comp is evaluated in the context of the following 'for'\nprint([[row[i] for row in matrix] for i in range(4)])\n# a list of LISTS\n# [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]\n\n# elegantly equivalent to the above is\nprint(list(zip(*matrix)))\n\n# notice that this is a list of TUPLES! (zip produces tuples)\n# [(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]\n"
},
{
"alpha_fraction": 0.5860927104949951,
"alphanum_fraction": 0.6258277893066406,
"avg_line_length": 19.133333206176758,
"blob_id": "83c9b786f8e7ce31942f6bce75953067190087e5",
"content_id": "febcf64d53b4338af934a3a1a5cf36f9895ef633",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 15,
"path": "/04lambdas.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# 0.\n# lambdas - returning functions\ndef make_incrementor(n):\n return lambda x: x + n\n\ninc = make_incrementor(13)\n\nprint(inc(4))\nprint(inc(50))\n\n# 1.\n# lambdas - passing a small function\npairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]\npairs.sort(key = lambda pair: pair[1])\nprint(pairs)\n"
},
{
"alpha_fraction": 0.5887483358383179,
"alphanum_fraction": 0.6284343600273132,
"avg_line_length": 28.384614944458008,
"blob_id": "faa286e6b9472da75045d8357f382feda513b4e8",
"content_id": "71acc3508af0a6a0826fd7ba77239af97249662f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2293,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 78,
"path": "/07strform.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# miscellaneous string formatting\n\n# 0.\n# tables w/ justification\nfor x in range(1, 11):\n print(repr(x).rjust(2), repr(x*x).rjust(3), end= \" \")\n print(repr(x*x*x).rjust(4))\n\n# or, equivalently\nif __name__ == '__main__':\n for x in range(1, 11):\n print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))\n\n# 1.\n# fill numerics with leading zeros\nprint(repr(-3.14).zfill(5))\nprint(repr(-3.14).zfill(7))\nprint(repr(-3.14).zfill(9))\n\n# also\nprint('-3.14'.zfill(5))\nprint('-3.14'.zfill(7))\nprint('-3.14'.zfill(9))\n\n# 2.\n# using '.format()'\nprint('We are the {} who say {}.'.format('spacepeople', '\"Hail to the commets!\"'))\n\nprint('{0} and {1}'.format('Earth', 'Mars'))\nprint('{1} and {0}'.format('Earth', 'Mars'))\n\nprint('The terminator over {land_form} was {adjective}.'.format(\n land_form='Acidalia Planitia', adjective='stunning'\n))\n\nimport math\nprint('The value of pi is approximately {0:.3f}'.format(math.pi))\nprint('The value of pi is approximately {:.5f}'.format(math.pi))\nprint('The value of pi is approximately {0:.13f}'.format(math.pi))\n\n# let's play with planets\nnear_planets = {\n 'Mercury': 2440,\n 'Venus': 6052,\n 'Earth': 6378,\n 'Mars': 3397\n}\n\n# this is a dictionary: notice the unpredictable order of the elements!\nfor planet, radius in near_planets.items():\n print('{0:10} ==> {1:10d}'.format(planet, radius))\nfor planet, radius in near_planets.items():\n print('{0:7} ==> {1:4d}'.format(planet, radius))\n\n# dictionary with [] key access (pass dict)\nprint('The radii of the 4 Solar System planets nearest to the Sun are as follows: '\n 'Mercury: {0[Mercury]:d}, '\n 'Venus: {0[Venus]:d}, '\n 'Earth: {0[Earth]:d}, '\n 'Mars: {0[Mars]:d}.'.format(near_planets))\n\n# dictionary with keyword access (pass **dict)\nprint('The radii of the 4 Solar System planets nearest to the Sun are as follows: '\n 'Mercury: {Mercury:d}, '\n 'Venus: {Venus:d}, '\n 'Earth: {Earth:d}, '\n 'Mars: {Mars:d}.'.format(**near_planets))\n\n# currently defined variables with vars()\nprint(vars())\n\n# NOTE: need to make a copy if we want to iterate\n# as the dictionary will change during iteration\nlocal_vars = dict(vars())\n# or\n# local_vars = vars().copy()\nfor var, val in local_vars.items():\n print('{0:20s} ==> {1:200s}'.format(var, repr(val)))\n\n"
},
{
"alpha_fraction": 0.548365592956543,
"alphanum_fraction": 0.5830553770065308,
"avg_line_length": 21.35820960998535,
"blob_id": "fcb07306e8d7d43810001ffca4762d5df7c00984",
"content_id": "b69a74099dbb1c336471d9008d8e313e08f9c67d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1499,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 67,
"path": "/05deque.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "from collections import deque\nfrom itertools import islice\n\n# double-ended queues\n# pronounced like 'deck'\n\n# 0.\n# lists are inefficient as queues, so use collections.deque\nd = deque(['Kili', 'Fili', 'Oin', 'Gloin', 'Bifur', 'Bofur'])\nd.append('Thorin')\nprint(d.popleft())\nprint(d.popleft())\nprint(d.popleft())\nprint(d.popleft())\n\n# 1.\n# tail functionality with deque\ndef tail(filename, n=10):\n with open(filename) as f:\n return deque(f, n)\n\nfor line in tail('04args.py', n=5):\n print(line, end='')\n\nfor line in tail('04args.py'):\n print(line, end=\"\")\n\n\n# 2.\n# running average with deque\ndef moving_average(iterable, n=3):\n # moving_average([40, 30, 50, 46, 39, 44]) --> 40.0 42.0 45.0 43.0\n # http://en.wikipedia.org/wiki/Moving_average\n it = iter(iterable)\n d = deque(islice(it, n-1))\n print(\"Deque init:\", d)\n d.appendleft(0)\n print(\"Deque appendleft(0):\", d)\n s = sum(d)\n print(\"Sum init:\", s)\n for elem in it:\n print(\"Elem\", elem)\n s += elem - d.popleft()\n print(\"Sum:\", s)\n print(\"Deque:\", d)\n d.append(elem)\n print(\"Deque append elem:\", d)\n print(\"Yield s/n:\", s/n)\n yield s / n\n\n\nif __name__ == '__main__':\n for mav in moving_average([40, 30, 50, 46, 39, 44]):\n print(mav)\n\n\n# 3.\n# deque slicing and deletion\ndef delete_nth(d, n):\n d.rotate(-n)\n d.popleft()\n d.rotate(n)\n\nd = deque(['Kili', 'Fili', 'Oin', 'Gloin', 'Bifur', 'Bofur'])\nprint(d)\ndelete_nth(d, 3)\nprint(d)\n\n"
},
{
"alpha_fraction": 0.721238911151886,
"alphanum_fraction": 0.7243362665176392,
"avg_line_length": 32.7164192199707,
"blob_id": "f5a518df838190d2e530c80a59003ee2cc7a43e9",
"content_id": "11a6e4941ec859107f7479ef140c8fa0f860bf3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2264,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 67,
"path": "/09classes.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "'''\nPYTHON CLASSES (from 3.5.1 tutorial):\n\nCompared with other programming languages, Python’s class mechanism adds classes with a minimum of new syntax and\nsemantics. It is a mixture of the class mechanisms found in C++ and Modula-3.\n\nPython classes provide all the standard features of Object Oriented Programming:\n - the class inheritance mechanism allows multiple base classes,\n - a derived class can override any methods of its base class or classes, and\n - a method can call the method of a base class with the same name.\n\nObjects can contain arbitrary amounts and kinds of data. As is true for modules, classes partake of the dynamic\nnature of Python: they are created at runtime, and can be modified further after creation.\n\nIn C++ terminology,\n - normally class members (including the data members) are public (except see below Private Variables), and\n - all member functions are virtual.\n\nAs in Modula-3,\n - there are no shorthands for referencing the object’s members from its methods:\n - the method function is declared with an explicit first argument representing the object, which is provided\n implicitly by the call.\n\nAs in Smalltalk,\n - classes themselves are objects. This provides semantics for importing and renaming.\n\nUnlike C++ and Modula-3,\n - built-in types can be used as base classes for extension by the user.\n\nAlso, like in C++,\n - most built-in operators with special syntax (arithmetic operators, subscripting etc.) can be redefined for class\n instances.\n'''\n\n# 0.\n# scope example\ndef scope_test():\n def do_local():\n spam = \"local spam\"\n\n def do_nonlocal():\n nonlocal spam\n spam = \"nonlocal spam\"\n\n def do_global():\n global spam\n spam = \"global spam\"\n\n spam = \"test spam\"\n # doesn't change the current scope binding\n do_local()\n print(\"After local assignment:\", spam)\n # changes the current (outer) scope binding\n do_nonlocal()\n print(\"After nonlocal assignment:\", spam)\n # changes the global scope binding\n do_global()\n print(\"After global assignment:\", spam)\n\n# no global scope binding for 'spam'\ntry:\n print(\"In global scope:\", spam)\nexcept NameError:\n print(\"No global scope binding for 'spam'\")\n\nscope_test()\nprint(\"In global scope:\", spam)\n\n"
},
{
"alpha_fraction": 0.6021563410758972,
"alphanum_fraction": 0.6105121374130249,
"avg_line_length": 23.569536209106445,
"blob_id": "545c45e379ff9654b0b695eb7b40c3cb8c354810",
"content_id": "444e6dbec9ebc99f1a8a1dba35a6aec7ec414382",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3710,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 151,
"path": "/08errors.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# errors and exceptions\n\n# 0.\n# a sampling of built-in exceptions\n# all end no 'Error'\ntry:\n print(10 * (1/0))\n print(4 + spam*3)\n print('2' + 2)\nexcept (ZeroDivisionError, NameError, TypeError) as inst:\n print(type(inst)) # the exception instance\n # note the trailing comma disambiguating a\n # 1-tuple from an expression in parentheses\n print(inst.args) # arguments stored in .args\n print(inst) # __str__ allows args to be printed directly,\n\n# 1.\n# handling\nwhile True:\n try:\n x = int(input(\"Please enter a number: \"))\n break\n except ValueError:\n print(\"Oops! That was no valid number. Try again...\")\n\n# 2.\n# re-raising\nimport sys\n\ntry:\n f = open('myfile.txt')\n s = f.readline()\n i = int(s.strip())\nexcept OSError as err:\n print(\"OS error: {0}\".format(err))\nexcept ValueError:\n print(\"Could not convert data to an integer.\")\nexcept:\n print(\"Unexpected error:\", sys.exc_info()[0])\n raise\n\n# 3.\n# else clause\n# NOTE: need to execute file as script with a file argument\nfor arg in sys.argv[1:]:\n if __name__ == '__main__':\n try:\n f = open(arg, 'r')\n except IOError:\n print('cannot open', arg)\n else:\n print(arg, 'has', len(f.readlines()), 'lines')\n f.close()\n\n# 4.\n# exception arguments\nif __name__ == '__main__':\n try:\n raise Exception('spam', 'eggs')\n except Exception as inst:\n print(type(inst)) # the exception instance\n print(inst.args) # arguments stored in .args\n print(inst) # __str__ allows args to be printed directly,\n # but may be overridden in exception subclasses\n x, y = inst.args # unpack args\n print('x =', x)\n print('y =', y)\n\n# 5.\n# exceptions caught from any call depth\ndef this_fails():\n x = 1/0\n\ntry:\n this_fails()\nexcept ZeroDivisionError as err:\n print('Handling run-time error:', err)\n\n# 6.\n# raising\ntry:\n raise NameError('HiThere')\nexcept NameError:\n print('An exception flew by!')\n # if want to know about the exception but\n # don't intend to handle it...\n # raise\n\n# 7.\n# user-defined module exception hierarchy\nclass Error(Exception):\n \"\"\"Base class for exceptions in this module.\"\"\"\n pass\n\nclass InputError(Error):\n \"\"\"Exception raised for errors in the input.\n\n Attributes:\n expression -- input expression in which the error occurred\n message -- explanation of the error\n \"\"\"\n\n def __init__(self, expression, message):\n self.expression = expression\n self.message = message\n\nclass TransitionError(Error):\n \"\"\"Raised when an operation attempts a state transition that's not\n allowed.\n\n Attributes:\n previous -- state at beginning of transition\n next -- attempted new state\n message -- explanation of why the specific transition is not allowed\n \"\"\"\n\n def __init__(self, previous, next, message):\n self.previous = previous\n self.next = next\n self.message = message\n\n# 8.\n# cleanup actions with finally (always executed)\ntry:\n raise KeyboardInterrupt\nexcept KeyboardInterrupt:\n print('Caught it!')\nfinally:\n print('Goodbye, world!')\n\n# the whole 9 yards! :)\ndef divide(x, y):\n try:\n result = x / y\n except ZeroDivisionError:\n print(\"division by zero!\")\n else:\n print(\"result is\", result)\n finally:\n print(\"executing finally clause\")\n\nprint(divide(2, 1))\nprint(divide(2, 0))\n# unhandled exception...\n#print(divide(\"2\", \"1\"))\n\n# 9.\n# classes with predefined cleanup actions => use 'with'\nwith open(\"json.txt\") as f:\n for line in f:\n print(line, end=\"\")\n"
},
{
"alpha_fraction": 0.5605966448783875,
"alphanum_fraction": 0.5686761736869812,
"avg_line_length": 25.799999237060547,
"blob_id": "2714f7e0873149715c66763386e8970364da79b1",
"content_id": "c808722a3a897c8281322fb0fd94e78372c3ef2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1609,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 60,
"path": "/04args.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# 0.\n# default arguments evaluated only once\n# this matters when they are mutable objects, like a list\n# even flagged by the front end\ndef f(a, L=[]):\n L.append(a) # append more efficient than +\n return L\n\nprint(f(1))\nprint(f(2))\nprint(f(3))\n\n# 1.\n# preventing the default being shared across calls\ndef g(a, L=None):\n if L is None:\n L = []\n L.append(a)\n return L\n\nprint(g(1))\nprint(g(2))\nprint(g(3))\n\n# 2.\n# formal, positional, and keyword parameters\ndef cheeseshop(kind, *arguments, **keywords):\n print(\"-- Do you have any\", kind, \"?\")\n print(\"-- I'm sorry, we're all out of\", kind)\n for arg in arguments:\n print(arg)\n print(\"-\" * 40)\n keys = sorted(keywords.keys())\n for kw in keys:\n print(kw, \":\", keywords[kw])\n\ncheeseshop(\"Limburger\", # matches kind\n \"It's very runny, sir.\", # pos (tuple)\n \"It's really very, VERY runny, sir.\",\n shopkeeper=\"Michael Palin\", # kw (dict)\n client=\"John Cleese\",\n sketch=\"Cheese Shop Sketch\")\n\n# 3.\n# variading paratemer lists\ndef concat(*args, sep = '/'):\n return sep.join(args)\n\nprint(concat('andy', 'murray', 'kills', 'at', 'wimbledon'))\nprint(concat('andy', 'murray', 'kills', 'at', 'wimbledon', sep = '-'))\n\n# 4.\n# unpacking\ndef parrot(voltage, state='a stiff', action='voom'):\n print(\"-- This parrot wouldn't\", action, end=' ')\n print(\"if you put\", voltage, \"volts through it.\", end=' ')\n print(\"E's\", state, \"!\")\n\nd = {\"voltage\": \"four million\", \"state\": \"bleedin' demised\", \"action\": \"VOOM\"}\nparrot(**d)\n\n"
},
{
"alpha_fraction": 0.5634675025939941,
"alphanum_fraction": 0.5727553963661194,
"avg_line_length": 13.636363983154297,
"blob_id": "543de48d2746ddb2ec0b1e5e5785765b486cbe68",
"content_id": "6bbb6ad6d94b1cb65ac1b46808e68cf516d22954",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 22,
"path": "/05sets.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# 0.\n# creation\ns = {'baby', 'face', 'doll', 'house', 'angel', 'smile', 'baby', 'angel'}\nprint(s)\n\nt = set()\nprint(t)\n\n# 1.\n# set operations\na = set('abracadabra')\nb = set('alacazam')\n\nprint(a - b)\nprint(a | b)\nprint(a & b)\nprint(a ^ b)\n\n# 2.\n# set comprehensions\nc = {x for x in 'abracadabra' if x not in 'abc'}\nprint(c)\n\n"
},
{
"alpha_fraction": 0.6474226713180542,
"alphanum_fraction": 0.6876288652420044,
"avg_line_length": 25.97222137451172,
"blob_id": "1913b242187346bbee6d1becfd4a7ff69816dcdd",
"content_id": "71658f5a320946e80bd789d8251f7e91e0de02cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 970,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 36,
"path": "/07files.py",
"repo_name": "ivogeorg/py3",
"src_encoding": "UTF-8",
"text": "# briefly on files\n\n# 0.\n# binary files are manipulated through byte objects\nf = open('workfile', 'wb+')\nf.write(b'0123456789abcdef')\nf.seek(5) # Go to the 6th byte in the file\nf.read(1)\nf.seek(-3, 2) # Go to the 3rd byte before the end\nf.read(1)\nf.close()\n\n# 1.\n# using 'with' for automatic file closing\nwith open('workfile', 'r') as f:\n print(str(f.read()))\n\n# verify that file object is closed\nprint('File is closed?', repr(f.closed))\n\n# 2.\n# serializing to and desearializing from JSON\nimport json\nwith open('json.txt', 'w') as outfile:\n # mind the order of the arguments of dump ;)\n json.dump([1, 'simple', 'list'], outfile)\n\nwith open('json.txt', 'r') as infile:\n print(json.load(infile))\n\n# NOTE: JSON format matches Python dicts and lists\nwith open('sample.json', 'r') as infile:\n print(json.load(infile))\n\n# see https://www.safaribooksonline.com/library/view/python-cookbook-3rd/9781449357337/ch06s02.html\n# and http://json.org/example.html"
}
] | 10 |
rserbitar/gabaros | https://github.com/rserbitar/gabaros | f37072088e275b9c6192656062101ce42bb6cb3e | 937def500d7b7622cda793ad46eefa6cc23acdfc | 909186ab5c93fa541250bd1a48075c60e9e2c183 | refs/heads/master | 2021-01-21T04:27:47.072453 | 2016-04-07T18:39:14 | 2016-04-07T18:39:14 | 22,469,834 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6126925349235535,
"alphanum_fraction": 0.6147874593734741,
"avg_line_length": 54.965518951416016,
"blob_id": "7315fe9a496fe0ed38f4cb43a3204d4dff5f355f",
"content_id": "19e540b61691e15cc347a785ae9131732b9d8821",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8115,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 145,
"path": "/models/x10_character.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\nimport data\nimport rules\n\ndescriptiondefault = \"\"\"\nAge:\n\nGeneral Appearance: What is the general appearance of the character?\n\nClothing Style: How does the character dress?\n\nPersonality: What pesonality, traits and quirks does the character have?\n\nGood: What are the characters strong points?\n\nWeak: What are the characters week points?\n\nSpecial_ what makes the character special?\n\nEducation: What ist the eductaiton of the character?\n\nFormer Occupation: What did he do for a living before runnig?\n\nFamily: Who is the characters family (names) and what are the charactes ties now?\n\nFree time: How does the character spend his free time?\n\nSocial ties: Whom does the character spend his free time with?\n\nWorldview: How does the character see the world and his place in it?\n\nMoral Code: What is the moral code of the character? Will he do, what won't he do? Has he hought about it?\n\nGoals: What are the characters goals in life?\n\nThe Reason: Why does the character start running the shadows? Whe does he still run the shadows?\n\"\"\"\n\ndb.define_table('chars', Field('player', type='reference auth_user', label=T('Player'), default=auth.user_id,\n update=auth.user_id, writable=False),\n Field('master', type='reference auth_user', label=T('Master'),\n requires=IS_IN_DB(db, db.auth_user.id, '%(username)s')),\n Field('name', type='string', label=T('Name')),\n Field('gender', type='string', label=T('Gender'), requires=IS_IN_SET(data.gendermods_dict.keys())),\n Field('race', type='string', label=T('Race'), requires=IS_IN_SET(data.races_dict.keys())),\n Field('descrption', type='text', label=T('Description'), default=descriptiondefault),\n format=lambda x: x.name)\n\ndb.define_table('char_attributes', Field('char', type='reference chars', label=T('Character')),\n Field('attribute', type='string', label=T('Attribute'),\n requires=IS_IN_SET(data.attributes_dict.keys())),\n Field('value', type='double', label=T('Value'), default=30))\n\ndb.define_table('char_skills', Field('char', type='reference chars', label=T('Character')),\n Field('skill', type='string', label=T('Skill'), requires=IS_IN_SET(data.skills_dict.keys())),\n Field('value', type='double', label=T('Value'), default=30))\n\ndb.define_table('char_locations', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('name', type='string', label=T('Name')), format=lambda x: x.name)\n\ndb.define_table('char_items', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('item', type='string', label=T('Item'), requires=IS_IN_SET(data.gameitems_dict.keys())),\n Field('rating', type='integer', label=T('Rating')),\n #Field('form_factor', type='string', label=T('Form Factor'), requires=IS_IN_SET(data.form_factors.keys())),\n Field('location', type='reference char_locations', label=T('Location')),\n Field('loadout', type='list:integer', label=T('Loadout'),\n requires=IS_IN_SET([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], multiple=True), default=0),\n format=lambda x: x.item)\n\ndb.define_table('item_upgrades', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('item', type='reference char_items', label=T('Item')),\n Field('upgrade', type='reference char_items', label=T('Upgrade')))\n\ndb.define_table('char_ware', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('ware', type='string', label=T('Ware'), requires=IS_IN_SET(data.ware_dict.keys())),\n Field('active', type='boolean', label=T('Active'), default=True))\n\ndb.define_table('char_ware_stats', Field('ware', type='reference char_ware', label=T('Ware')),\n Field('stat', type='string', label=T('Stat')), Field('value', type='double', label=T('Value')))\n\ndb.define_table('char_fixtures', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('fixture', type='string', label=T('Fixture'), requires=IS_IN_SET(data.fixtures_dict.keys())))\n\ndb.define_table('char_adept_powers', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('power', type='string', label=T('Power'), requires=IS_IN_SET(data.adept_powers_dict.keys())),\n Field('value', type='double', label=T('Value'), default=0),\n )\n\ndb.define_table('char_computers', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('item', type='reference char_items', label=T('Item'), unique=True),\n Field('firewall', type='double', label=T('Firewall')),\n Field('current_uplink', type='double', label=T('Current Uplink')),\n Field('damage', type='double', label=T('Damage')))\n\ndb.define_table('char_programmes', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('programme', type='string', label=T('Programme'),\n requires=IS_IN_SET(data.programmes_dict.keys())),\n Field('deck', type='reference char_items', label=T('Deck'),\n requires=IS_IN_DB(db, db.char_items.id, '%(item)s')),\n Field('rating', type='double', label=T('Rating')))\n\ndb.define_table('char_sins', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('name', type='string', label=T('SIN Name')),\n Field('rating', type='integer', label=T('Rating')),\n Field('permits', type='string', label=T('Permits'), requires=IS_IN_SET(data.permits_dict.keys())),\n Field('locations',type='list:reference char_locations', label=T('Locations')),\n Field('money', type='float', label='Money'),\n Field('cost', compute = lambda row: rules.get_sin_cost(row.rating, data.permits_dict.get(row.permits).cost_multiplier), label='Cost'),\n fake_migrate=True)\n\ndb.define_table('char_spells', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('spell', type='string', label=T('Spell Name'), requires=IS_IN_SET(data.spells_dict.keys())))\n\ndb.define_table('char_metamagic', Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('metamagic', type='string', label=T('Metamagic Name'), requires=IS_IN_SET(data.metamagic_dict.keys())))\n\ncontactsdefault = \"\"\"\nSize:\nAge:\nAppearance:\nClothing Style:\nWare:\nSpecialties:\nCharacter:\n\"\"\"\n\ndb.define_table('contacts',\n Field('master', type='reference auth_user', label=T('Master'),\n requires=IS_IN_DB(db, db.auth_user.id, '%(username)s'), writable=False),\n Field('name', type='string', label=T('Name')),\n Field('gender', type='string', label=T('Gender'), requires=IS_IN_SET(data.gendermods_dict.keys())),\n Field('race', type='string', label=T('Race'), requires=IS_IN_SET(data.races_dict.keys())),\n Field('occupation', type='string', label=T('Occupation')),\n Field('rating', type='integer', label=T('Rating')),\n Field('description', type='text', label=T('Description'), default=contactsdefault),\n format=lambda x: x.name),\n\n\ndb.define_table('char_contacts',\n Field('char', type='reference chars', label=T('Character'), writable=False),\n Field('name', type='reference contacts', label=T('Contact')),\n Field('loyalty', type='integer', label=T('Loyalty')),\n Field('starting', type='boolean', label=T('Starting'), default = True),\n Field('relationship', type='text', label=T('Relationship'), default = 'More in-depth description of the relationship with the contact.')\n )\n"
},
{
"alpha_fraction": 0.6416846513748169,
"alphanum_fraction": 0.6663066744804382,
"avg_line_length": 68.10447692871094,
"blob_id": "0980111d93e99695904725d6397e5ad039e70e69",
"content_id": "7eeb1cbdb74910d9ca906879b6a9794e4fd427de",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4630,
"license_type": "permissive",
"max_line_length": 180,
"num_lines": 67,
"path": "/modules/spirit.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom gluon import *\nfrom collections import namedtuple, OrderedDict\nimport rules\n\ndef spirit_scaling(force):\n return 2**((force-30)/20.)*30\n\nspirit_stats = [\n ['class_', 'charisma', 'intuition', 'logic', 'willpower', 'base_skills', 'standard_skills', 'exceptional_skills', 'powers', 'optional_powers'],\n ['creation', 1.25, 1, 0.8, 1, ['Orientation', 'Athletics', 'Acrobatics', 'Metamagic'], ['Assensing', 'Astral Combat', 'Unarmed Combat'], [],\n ['Concealment', 'Protection'], ['Skill: Counterspelling', 'Innate Spell: Creation', 'Metamagic: Shielding']],\n ['destruction', 0.8, 1, 1, 1.25, ['Orientation', 'Atheletics', 'Assensing', 'Metamagic'], ['Unarmed Combat', 'Acrobatics'], ['Astral Combat'],\n ['Ranged Attack'], ['Innate Spell: Destruction', 'Metmamagic: Transfusion']],\n ['detection', 1, 1.25, 1, 0.8, ['Athletics', 'Acrobatics', 'Astral Combat', 'Metamagic'], ['Orientation'], ['Assensing'],\n ['Search', 'Enlightenment'], ['Skill: Judge Person', 'Innate Spell: Detection', 'Metmamagic: Divination']],\n ['manipulation', 1, 0.8, 1.25, 1, ['Orientation', 'Athletics', 'Unarmed Combat', 'Acrobatics', 'Metamagic'], ['Assensing', 'Astral Combat'], [],\n ['Movement', 'Confusion'], ['Skill: Stealth', 'Skill: Interaction', 'Skill: Discussion','Innate Spell: Manipulation', 'Metmamagic: Masking', 'Metmamagic: Flexible Signature']]\n]\n\nspirit_stats_nt = namedtuple('spirit_stat', ['id'] + spirit_stats[0])\nspirit_stats_dict = OrderedDict([(entry[0], spirit_stats_nt(*([i] + entry))) for i, entry in enumerate(spirit_stats[1:])])\n\nmanifestation_stats = [\n ['class_', 'agility', 'constitution', 'coordination', 'strength', 'size', 'weight', 'life', 'armor', 'damage', 'penetration', 'powers', 'physical_powers'],\n ['ethereal', 90, 1, 1, 0.5, 0.8, 0.05, 0.1, 1, 0, 0, ['Ethereal', 'Vulnerabiliy to Magic Weapons'], ['Aura']],\n ['fluid', 60, 1, 1, 1, 1, 1., 0.5, 1.5, 0.5, 0.5, ['Fluid', 'Sensitivity to Magic Weapons'], ['Engulf']],\n ['solid', 30, 1, 1, 1.5, 1.2, 1.5, 1, 2, 1, 1, ['Structureless'], ['Increased Armor']],\n]\n\nmanifestation_stats_nt = namedtuple('manifestation_stat', ['id'] + manifestation_stats[0])\nmanifestation_stats_dict = OrderedDict([(entry[0], manifestation_stats_nt(*([i] + entry))) for i, entry in enumerate(manifestation_stats[1:])])\n\nclass Spirit(object):\n\n def __init__(self, force, class_, manifestation):\n self.force = force\n self.class_ = class_\n self.manifestation = manifestation\n self.agility = manifestation_stats_dict[manifestation].agility\n self.strength = manifestation_stats_dict[manifestation].strength * spirit_scaling(force)\n self.coordination = manifestation_stats_dict[manifestation].coordination * spirit_scaling(force)\n self.constitution = manifestation_stats_dict[manifestation].constitution * spirit_scaling(force)\n self.size = manifestation_stats_dict[manifestation].size * force**0.5 * 1.75 / (30)**0.5\n self.weight = manifestation_stats_dict[manifestation].weight * rules.calc_base_weight(rules.baseweight, self.size, 1.75)\n self.logic = spirit_stats_dict[class_].logic * spirit_scaling(force)\n self.intuition = spirit_stats_dict[class_].intuition * spirit_scaling(force)\n self.willpower = spirit_stats_dict[class_].willpower * spirit_scaling(force)\n self.charisma = spirit_stats_dict[class_].charisma * spirit_scaling(force)\n self.magic = self.force\n self.armor = manifestation_stats_dict[manifestation].armor * spirit_scaling(force)\n self.life = spirit_scaling(force)/30.*100 * manifestation_stats_dict[manifestation].life\n self.base_skill = self.force\n self.skills = {}\n self.damage = spirit_scaling(force) * 20 * manifestation_stats_dict[manifestation].damage\n self.penetration = spirit_scaling(force) * 10 * manifestation_stats_dict[manifestation].penetration\n for skill in spirit_stats_dict[class_].base_skills:\n self.skills[skill] = self.force * 0.75\n for skill in spirit_stats_dict[class_].standard_skills:\n self.skills[skill] = self.force\n for skill in spirit_stats_dict[class_].exceptional_skills:\n self.skills[skill] = self.force * 1.25\n self.metamagic = []\n self.powers = ['Manifestation', 'Immunity to Drugs and Toxins'] + spirit_stats_dict[class_].powers + manifestation_stats_dict[manifestation].powers\n self.optional_powers = spirit_stats_dict[class_].optional_powers\n self.physical_powers = manifestation_stats_dict[manifestation].physical_powers\n"
},
{
"alpha_fraction": 0.5275303721427917,
"alphanum_fraction": 0.5323886871337891,
"avg_line_length": 57.80952453613281,
"blob_id": "3009acacbe1e33de9ad2bff7b53910d67a347ced",
"content_id": "9a1fd09c21f6c156675520001c16a787872d9685",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2470,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 42,
"path": "/models/x30_state.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\nfrom datetime import datetime\nimport data\n\n\ndb.define_table('char_state',\n Field('char', type='reference chars', label=T('Character'), writable=False,\n requires=IS_IN_DB(db, db.chars.id, '%(name)s')),\n Field('stat', type='string', label=T('Stat')), Field('value', type='double', label=T('Value')))\n\ndb.define_table('char_wounds',\n Field('char', type='reference chars', label=T('Character'),\n requires=IS_IN_DB(db, db.chars.id, '%(name)s'), writable=False),\n Field('bodypart', type='string', requires=IS_IN_SET(data.bodyparts_dict.keys()), label=T('Body Part')),\n Field('damagekind', type='string', requires=IS_IN_SET(data.damagekinds_dict.keys()), label=T('Damage Kind')),\n Field('value', type='double', label=T('Value')))\n\ndb.define_table('char_damage',\n Field('char', type='reference chars', label=T('Character'),\n requires=IS_IN_DB(db, db.chars.id, '%(name)s'), writable=False),\n Field('damagekind', type='string', requires=IS_IN_SET(data.damagekinds_dict.keys()), label=T('Damage Kind')),\n Field('value', type='double', label=T('Value')))\n\ndb.define_table('char_xp',\n Field('char', type='reference chars', label=T('Character'),\n requires=IS_IN_DB(db, db.chars.id, '%(name)s'), writable=False),\n Field('xp', type='float'),\n Field('usage', type='string', requires=IS_IN_SET(['rewards', 'money', 'hand of god', 'other']), default = 'other'),\n Field('timestamp', type='date'))\n\ndb.define_table('char_money',\n Field('char', type='reference chars', label=T('Character'),\n requires=IS_IN_DB(db, db.chars.id, '%(name)s'), writable=False),\n Field('money', type='float'),\n Field('usage', type='string', requires=IS_IN_SET(['income', 'lifestyle', 'other']), default = 'other'),\n Field('timestamp', type='date')\n )\n\ndb.define_table('char_loadout',\n Field('char', type='reference chars', label=T('Character'),\n requires=IS_IN_DB(db, db.chars.id, '%(name)s'), writable=False),\n Field('value', type='integer', requires=IS_IN_SET([0,1,2,3,4,5,6,7,8,9]), default=0))\n"
},
{
"alpha_fraction": 0.5917350649833679,
"alphanum_fraction": 0.6300309300422668,
"avg_line_length": 25.819494247436523,
"blob_id": "2317bcce9d618c022cff62d8b7ea25e389dfff7a",
"content_id": "4e45817ab4bc0491b7dde57f507489eb2d6a9d0d",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14858,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 554,
"path": "/modules/rules.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf8\n#from gluon.html import *\n#from gluon.http import *\n#from gluon.validators import *\n#from gluon.sqlhtml import *\nfrom collections import OrderedDict\nfrom math import log, e, atan\nfrom math import erf\nfrom random import gauss, random\n# request, response, session, cache, T, db(s)\n# must be passed and cannot be imported!\n\n\ndouble_attrib_mod_val = 10\nattrib_mod_norm = 30\nsubskill_exp = 0.25\nsubskill_norm = 1 / 3.\nskill_exp = 1.5\nbaselife = 100.\nbaseweight = 75.\nbaseagility = attrib_mod_norm\nbaseconstitution = attrib_mod_norm\nbaseintuition = attrib_mod_norm\nbaselogic = attrib_mod_norm\nbasemagic = attrib_mod_norm\nbaseuplink = attrib_mod_norm\nwound_exp = 200.\ncyberhalf = 20\nshoot_base_difficulty = 20\nspell_xp_cost = 200\nmetamagic_xp_cost = 400\nmoney_to_xp = 1/(50*2**0.5)\nxp_to_money = 50/(2**0.5)\nstarting_money = 150000\nstarting_xp = 10000\n\nmovement_mods = OrderedDict([\n ('standing', 0),\n ('crouching', 5),\n ('walking', -5),\n ('running', -10),\n ('sprinting', -20),\n ('crouch walking', 0),\n ('crawling', -20),\n])\n\nlighting_conditions = ['clear', 'badly lit office', 'streetlight', 'city glow', 'moonlight', 'starlight',\n 'overcast moonless night']\nparticle_conditions = ['clear', 'drizzle', 'light rain', 'heavy rain', 'thunderstorm', 'light fog (100m)',\n 'medium fog (50m)', 'heavy fog (10m)', 'light smoke', 'heavy smoke']\n\n\ngas_vent_recoil = 2/3.\n\n\ndef die_roll():\n return gauss(0,10)\n\n\ndef attrib_mod(attribute, base):\n if not attribute or attribute < 0:\n return float('-infinity')\n else:\n return double_attrib_mod_val * log(attribute / base) / log(2)\n\n\ndef calc_base_weight(weight_base, size, size_base):\n return (float(size) / size_base) ** 3 * weight_base\n\n\ndef calc_base_strength(strength_base, size, size_base, weight, weight_base):\n return (2 * (float(size) / size_base) ** 2 + (float(weight) / weight_base) ** (2 / 3.)) * strength_base / 3\n\n\ndef calc_agility_base(agility_base, weight, weight_base):\n return (float(weight) / weight_base) ** (-1 / 3.) * agility_base\n\n\ndef get_skill_xp_cost(value):\n return (2**abs(value/10.)-1)*25\n\n\ndef get_attrib_xp_cost(attrib):\n val = (attrib)/30.\n if val >= 1:\n sign = 1\n else:\n sign = -1\n val = 1./val\n return (2**abs(val-1)-1)*1000*sign\n\n\ndef exp_cost_attribute(attribute, value, base, factor, signmod):\n if value == 0:\n return 0\n val = float(value)/base\n if val >= 1:\n sign = 1\n else:\n sign = -1 * signmod\n val = 1./val\n val = (val -1)\n val = (2**val-1)*factor*sign\n if val < -factor/2.:\n val = -factor/2.\n if attribute == 'Magic':\n val += factor\n return val\n\n\ndef get_spell_xp_cost(spells):\n return (2**(len(spells)/10.)-1)*spell_xp_cost/(2**0.1-1)\n\n\ndef get_metamagic_xp_cost(magics):\n return (2**(len(magics)/2.)-1)*metamagic_xp_cost/(2**0.5-1)\n\n\ndef calc_charisma_degrade(cyberindex):\n return 1 / (1. + (cyberindex / cyberhalf) ** 2)\n\n\ndef life(weight, constitution):\n return (weight/baseweight) ** (2 / 3.) * constitution / baseconstitution * baselife\n\n\ndef woundlimit(weight, constitution):\n percent = 5 * (erf((1.0123 ** constitution ** 0.4))) - 4.21\n lifeval = life(weight, constitution)\n return percent *lifeval\n\n\ndef wounds_for_incapacitated_thresh(weight, constitution, bodypart):\n wounds = 3\n if bodypart.lower() == 'body':\n wounds *= 7\n return wounds\n\n\ndef wounds_for_destroyed_thresh(weight, constitution, bodypart):\n wounds = 5\n if bodypart.lower() == 'body':\n wounds *= 7\n return wounds\n\n \ndef woundeffect(attribute, wounds, weight, constitution, bodypart):\n return attribute * (0.5)**(wounds * wounds_for_incapacitated_thresh(weight, constitution, bodypart)/3.)\n\n\ndef action_cost(kind, actionmult):\n action_cost_dict = {'Free': 5,\n 'Simple': 10,\n 'Complex': 20}\n return round(action_cost_dict.get(kind, 20) * actionmult ,0)\n\ndef physical_actionmult(agility_mod, coordination_mod, intuition_mod):\n return 2**((agility_mod+coordination_mod+intuition_mod)/-60.)\n\n\ndef matrix_actionmult(uplink_mod, logic_mod, intuition_mod):\n return 2**((uplink_mod + logic_mod + intuition_mod)/-60.)\n\n\ndef astral_actionmult(magic_mod, charisma_mod, intuition_mod):\n return 2**((magic_mod + charisma_mod + intuition_mod)/-60.)\n\n\ndef physical_reaction(agility_mod, intuition_mod):\n return (agility_mod + intuition_mod) / 2.\n\n\ndef matrix_reaction(logic_mod, uplink_mod):\n return (logic_mod + uplink_mod) / 2.\n\n\ndef astral_reaction(intuition_mod, magic_mod):\n return (intuition_mod + magic_mod) / 2.\n\n\n#load modifier on speed/agility depending on load, strength, and weight\ndef loadeffect(load, strength=30, weight=75):\n mod = (strength - weight ** (2 / 3.))\n if mod < 1:\n mod = 1\n load /= mod\n percent = 1 - erf((load / 5.) ** 1.5)\n return percent\n\n\ndef loadeffect_inv(percent, strength=30, weight=75):\n #load = erfinv(1 - percent) ** (1 / 1.5) * 5\n load = 0\n mod = (strength - weight ** (2 / 3.))\n if mod < 1:\n mod = 1\n load *= mod\n return load\n\n\n#standing horizontal jump\n#running horizontal jump\n#standing vertical jump\n#running vertical jump\ndef jumplimit(weight, strength, size):\n result = [0.8 * strength * weight ** (-0.7) * size / 1.75,\n 3 * strength * weight ** (-0.75) * size / 1.75,\n 0.5 * strength * weight ** (-0.8) * size / 1.75,\n 1.5 * strength * weight ** (-0.9) * size / 1.75]\n return result\n\n\n#speed depending on agility, weight, strength and size\ndef speed(agility, weight=75., strength=30., size=1.75):\n speed = (agility / 30.) ** 0.2\n speed *= 4. ** min(0, (-weight ** (2 / 3.) / strength * 30. / 75 ** (2 / 3.) + 1))\n speed *= size / 1.75 * 1.5\n return [speed, speed * 3, speed * 5]\n\n\n#speed depending on load carried\ndef loadspeed(agility, weight, strength, size, load):\n effect = loadeffect(load, strength, weight)\n loadspeed = speed(agility * effect, weight, strength, size)\n loadspeed = [i * effect for i in loadspeed]\n return loadspeed\n\n\n# calculate ral awareness/time cost per action\ndef combatresource_by_attribute(value, attribute, frac, attribute2):\n if value == -1:\n cost = 10\n elif value == -2:\n cost = \"variable\"\n elif value == -3:\n cost = \"feet only\"\n elif value is None:\n cost = None\n else:\n cost = round(max(30 / attribute, 30 / frac / attribute2) * value, 2)\n return cost\n\n\ndef lifemod_absolute(life, maxlife):\n if life <= 0:\n return -float('inf')\n return log(max(1, maxlife / float(life)))/log(2)*-10\n\ndef lifemod_relative(life, maxlife):\n if life <= 0:\n return 0\n return min(1, float(life)/maxlife)**(1/3.)\n\n#def warecostmult(effectmult=1, charmodmult=1, weightmult=1, kind=\"cyberware\"):\n# mult = 2.5 ** (effectmult - 1.)\n# mult /= (charmodmult - 0.3) ** 2.2 * 2.191716170991387\n# if kind == \"bioware\":\n# mult *= (0.6 * atan(4 * (charmodmult - 1.1 + (effectmult - 1) / 3.)) + 1.23)\n# return mult\n\n\ndef warecost(cost, effectmult = 1, essencemult = 1., kind = 'cyberware'):\n finalcost = 0\n if kind == 'cyberware':\n finalcost = cost * 5**(effectmult-1.) * 10**(1./essencemult-1.)\n elif kind == 'bioware':\n finalcost = cost * 7**(effectmult-1.) * 5**(1./essencemult-1)\n return finalcost\n\n\n#def warecost(basecost, cost, attributes, effectsmult, charmodmult=1, weightmult=1, kind='cyber'):\n# return basecost + sum([attributes[i] * warecostmult(effectsmult[i], charmodmult, weightmult, kind)\n# for i in range(len(attributes))]) * 5000 + cost * warecostmult(1, charmodmult, weightmult,\n# kind)\n\ndef essence_charisma_mult(essence):\n mult = max(0, 0.5 + essence/200.)\n return mult\n\ndef essence_magic_mult(essence):\n mult = max(0,essence/100.)\n return mult\n\ndef essence_psycho_thresh(essence):\n return log(1./(1-(essence/100.)))/log(2)*10+5 if essence < 100 else float('inf')\n\n\ndef spomod_max(logic):\n return logic/2.\n\n\ndef damage_location():\n value = random()\n result = 'Body'\n if value < .05:\n result = 'Head'\n elif value < .40:\n result = 'Upper Torso'\n elif value < .60:\n result = 'Lower Torso'\n elif value < .70:\n result = 'Right Arm'\n elif value < .80:\n result = 'Left Arm'\n elif value < .9:\n result = 'Right Leg'\n elif value < 1:\n result = 'Left Leg'\n return result\n\n\ndef weapondamage(damage, testresult):\n if testresult > 60:\n testresult = 60\n if testresult > 0:\n result = damage * 2 ** (testresult / 10.)\n else:\n result = 0\n return result\n\n\ndef auto_fire_damage(basedamage, recoil, testresult, numbullets=float('inf')):\n damage = []\n while testresult >= 0 and numbullets >= 1:\n damage += [weapondamage(basedamage, testresult)]\n testresult -= recoil\n numbullets -= 1\n return damage\n\n\ndef bleedingdamage_per_round(wounds, woundlimit):\n return wounds ** 3 * woundlimit / 20.\n\n\n# healing time in days\ndef healingtime(damagepercent, base_healtime, test):\n return damagepercent ** 1.5 * base_healtime / scale(test)\n\n\ndef healingtime_wounds(wounds, base_healtime, test):\n return wounds**2 * base_healtime/2. / scale(test)\n\n\ndef damage_heal_after_time(damage, days, healtime):\n return damage * (days / healtime) ** 1.5\n\n\ndef wound_heal_after_time(wounds, days, healtime):\n return int(wounds * (days / healtime) ** 1.5)\n\n\ndef healing_mod(damagepercent):\n return damagepercent ** 2. * 30\n\n\ndef firt_aid(test_value):\n if test_value > 0:\n healed = 0.05*scale(test_value)\n elif test_value > -10:\n healed = 0\n else:\n healed = -0.05*scale(-test_value+10)\n return healed\n\n\ndef resist_damage(damage, attribute_mod, roll, resistmod = 0):\n resist = attribute_mod - resistmod + roll\n return damage * 2 ** (-resist / 10.)\n\n\ndef drain_resist(willpower_mod, magic_mod):\n return (willpower_mod + magic_mod)/2.\n\n\ndef summoning_services(force, resistroll, skill, summonroll):\n forcemod = attrib_mod(force, 30)\n result = (skill + summonroll - forcemod - resistroll) / 10.\n if result > 0:\n result = 1 + int(result / 10.)\n else:\n result = 0\n return result\n\n\ndef summoning_drain(force):\n return force\n\n\ndef distance_modifier(distance):\n return log(distance)/log(2.)*10 -30\n\n\ndef size_modifier(size):\n return log(size)/log(2.)*-10 -20\n\n\ndef visible_perception_mod(size, distance, zoom):\n distance_mod = distance_modifier(distance)\n size_mod = size_modifier(size*zoom)\n return distance_mod + size_mod\n\n\ndef percept_time(time):\n return log(time) / log(2) * 10\n\n\ndef percept_intens_sens(sensitivity, intensity, background):\n return min(0, intensity + sensitivity)\n\n\ndef percept_blind(sensitivity, background):\n return -min(0, background + sensitivity)\n\n\ndef shooting_difficulty(weaponrange, magnification, distance, size=2., wide_burst_bullets=0):\n sightmod = visible_perception_mod(size, distance, magnification)\n rangemod = shoot_rangemod(weaponrange, distance)\n bulletmod = wide_burst_bullets\n return shoot_base_difficulty + sightmod + rangemod + wide_burst_bullets\n\ndef shoot_rangemod(weaponrange, distance):\n if distance < 1:\n distance = 1\n rangemod = log(distance / float(weaponrange)) / log(2) * 10\n if rangemod < 0:\n rangemod = 0\n return rangemod\n\n\ndef weapon_minstr_mod(minimum_strength, strength):\n return max(0, log(minimum_strength/strength)/log(2) * 20)\n\n\ndef matrix_action_rating(program_rating, matrix_attribute, skill):\n return negative_square_avg([(matrix_attribute + program_rating) / 2, skill])\n\n\ndef processor_cost(processor, volume):\n return 11**(processor/10.-log(volume)/5.)/200.\n\n\ndef uplink_cost(uplink, volume):\n return 6**(uplink/10.+log(volume)/10.+1.)/2.\n\n\ndef signal_cost(signal, volume):\n return 20**(signal/10.-log((volume)**(1/3.))/3.-2.5)\n\n\ndef size_cost(volume):\n return volume * 1000\n\n\ndef system_cost(system, processor):\n result = 0\n if system > processor:\n result = 6**(((system**10+processor**10)/2.)**(1/10.)/10.)*2\n elif system <= processor:\n result = 6**((system+processor)/20.)*2\n return result\n\n#def system_cost2(system, processor):\n# return 6**((system+processor)/20.)*2.\n\ndef maintain_cost(size):\n return size ** 1.5 * 100\n\n\ndef deck_cost(processor, system, uplink, signal, volume):\n cprocessor = processor_cost(processor, volume)\n csystem = system_cost(system, processor)\n cuplink = uplink_cost(uplink, volume)\n cvolume = size_cost(volume)\n csignal = signal_cost(signal, volume)\n return cprocessor, csystem, cuplink, csignal, cvolume, sum([cprocessor, csystem, csignal, cuplink, cvolume])\n\n\ndef cost_by_rating(cost, basecost, rating):\n if cost and rating:\n cost = 5**(rating/10.)/125. * cost + basecost\n else:\n cost = basecost\n return cost\n\n\ndef firewall_rating(time, skill, system, users):\n #time in hours per week\n return log(skill ** 3 / (system + 50) ** 3 * time / 8. / users) * 10 + skill - 50\n\n\ndef negative_square_avg(values):\n result = float('inf')\n if not all(values):\n result = 0\n elif values:\n result = (1./sum([(1./i)**2 for i in values]))**0.5\n result *= len(values)**0.5\n return result\n\n\ndef square_avg(values):\n return sum([i**2 for i in values])**0.5/len(values)**0.5\n\n\ndef square_add(values):\n return sum([i**2 for i in values])**0.5\n\n\ndef negative_square_add(values):\n result = float('inf')\n if values:\n result = (1./sum([(1./i)**2 for i in values]))**0.5\n return result\n\n\ndef get_armor_agility(agility, max_agility):\n if isinstance(max_agility, list):\n max_agility = negative_square_add(max_agility)\n return min(agility, max_agility)\n\n\ndef get_armor_coordination(coordination, coordination_multiplier):\n if isinstance(coordination_multiplier, list):\n coordination_multiplier = reduce(lambda x, y: x * y, [1] + coordination_multiplier)\n return coordination * coordination_multiplier\n\n\ndef get_stacked_armor_value(values):\n return square_add(values)\n\n\ndef scale(x):\n return 2**(x/10.)\n\n\ndef price_by_rating(baseprice, rating):\n return (1+(2**(rating/10.)))/9.*baseprice\n\n\ndef contact_costs(loyalty, rating):\n return 2**((loyalty/30.)**2+(30/30.)**2)*50\n\n\ndef contacts_free_value(charisma):\n return charisma*charisma\n\n\ndef recoil_by_strength(recoil, strength, min_strength):\n return recoil/(strength/min_strength)\n\n\ndef get_sin_cost(rating, permit_mult):\n return 2000*5**(rating/10.-3)*permit_mult\n"
},
{
"alpha_fraction": 0.6440467238426208,
"alphanum_fraction": 0.6474176049232483,
"avg_line_length": 44.47262954711914,
"blob_id": "5fb38c93e89e1010dd202807ac6583aecddb4e80",
"content_id": "807dcaac0b6d99dd8372d240d2575728bf7836fb",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24919,
"license_type": "permissive",
"max_line_length": 170,
"num_lines": 548,
"path": "/controllers/manage_char.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\n# versuche so etwas wie\nimport basic\nimport data\nimport rules\n\ndef index():\n redirect(URL('manage_chars'))\n\n@auth.requires_login()\ndef insert_button():\n table = request.args(0)\n name = request.args(1)\n value = request.vars['value']\n reload = request.vars['reload']\n #db[table].bulk_insert([{'char':get_char(), name:value}])\n response.flash = '{} was added'.format(value)\n #if reload:\n # redirect(URL(reload), client_side=True)\n return dict()\n\ndef my_ondelete(function):\n def func(table, id):\n db(table[table._id.name] == id).delete()\n redirect(URL(function), client_side=True)\n return func\n\ndef select_char(id):\n session.char=int(id)\n return A(id, _href=URL(\"edit_char\", args=(id)))\n\ndef get_table(table_name, insert_table=False, insert_value=False, reload = False):\n dictionary = getattr(data, table_name + '_dict')\n first = list(dictionary[dictionary.keys()[0]]._fields)\n if insert_table:\n first.append('insert')\n dict_data = []\n for entry in dictionary.values():\n dict_data.append(list(entry))\n if insert_table:\n dict_data[-1].append(A('Insert', callback=URL('insert_button', args = [insert_table, insert_value], vars={'value':dict_data[-1][1], 'reload':reload})))\n for i, row in enumerate(dict_data):\n for j, entry in enumerate(row):\n if isinstance(entry,list):\n dict_data[i][j] = ', '.join([str(k) for k in entry])\n if isinstance(entry,float):\n dict_data[i][j] = round(entry, 2)\n table = [first]\n table.extend(dict_data)\n return table\n\n@auth.requires_login()\ndef manage_chars():\n table = db.chars\n query = db.chars.player == auth.user.id or db.chars.master == auth.user.id\n table.id.represent = select_char\n table.player.represent = lambda player: db.auth_user[player].username\n create = crud.create(table)\n form = crud.select(table, query=query, fields=[\"id\", \"name\"])\n return dict(form=form, create=create)\n\n\n@auth.requires_login()\ndef edit_char():\n char = request.args(0)\n session.char = int(char)\n if not db.chars[char] or (db.chars[char].player != auth.user.id\n and db.chars[char].master != auth.user.id):\n redirect(URL(f='index'))\n table = db.chars\n table.player.writable = False\n table.player.represent = lambda player: db.auth_user[player].username\n basic.Char(db, char)\n form = crud.update(table, char)\n return dict(form=form)\n\n\n@auth.requires_login()\ndef edit_attributes():\n char_id = get_char()\n fields = []\n attributes = []\n rows = db(db.char_attributes.char == char_id).select(db.char_attributes.ALL)\n for row in rows:\n fields += [Field(row.attribute, 'double', default=row.value)]\n form = SQLFORM.factory(*fields, ondelete=my_ondelete('edit_attributes'))\n if form.accepts(request.vars, session):\n response.flash = 'form accepted'\n for entry in form.vars:\n db((db.char_attributes.char == char_id) & (db.char_attributes.attribute == entry)).update(value=form.vars[entry])\n db.commit()\n elif form.errors:\n response.flash = 'form has errors'\n rows = db(db.char_attributes.char == char_id).select(db.char_attributes.ALL)\n base = {}\n xp = {}\n total_attribute_xp = 0\n char = basic.Char(db, char_id)\n getter_base = basic.CharPropertyGetter(char, 'base')\n getter_unaugmented = basic.CharPropertyGetter(basic.Char(db, char_id), 'unaugmented')\n for row in rows:\n attribute = row.attribute\n form.custom.widget[attribute]['value'] = row.value\n form.custom.widget[attribute]['_style'] = 'width:50px'\n form.custom.widget[attribute]._postprocessing()\n base[attribute] = getter_base.get_attribute_value(attribute)\n xp[attribute] = round(getter_unaugmented.get_attribute_xp_cost(attribute))\n total_attribute_xp += xp[attribute]\n char_property_getter = basic.CharPropertyGetter(char, modlevel='augmented')\n char_xp = char_property_getter.get_xp()\n total_xp = sum(char_property_getter.get_total_exp().values())\n return dict(form=form, attributes=data.attributes_dict.keys(),\n xp=xp, base=base, total_attribute_xp=total_attribute_xp, total_xp=total_xp, char_xp = char_xp)\n\n\n@auth.requires_login()\ndef edit_skills():\n char_id = get_char()\n fields = []\n skills = []\n rows = db(db.char_skills.char == char_id).select(db.char_skills.ALL)\n for row in rows:\n fields += [Field(row.skill.replace(' ', '_'), 'double', default=row.value, label=row.skill)]\n form = SQLFORM.factory(*fields, ondelete=my_ondelete('edit_skills'))\n if form.accepts(request.vars, session):\n response.flash = 'form accepted'\n for entry in form.vars:\n db((db.char_skills.char == char_id) & (db.char_skills.skill == entry.replace('_', ' '))).update(value=form.vars[entry])\n db.commit()\n elif form.errors:\n response.flash = 'form has errors'\n rows = db(db.char_skills.char == char_id).select(db.char_skills.ALL)\n base = {}\n weight = {}\n xp = {}\n total_skill_xp = 0\n char = basic.Char(db, char_id)\n getter = basic.CharPropertyGetter(char, 'unaugmented')\n for row in rows:\n skillfield = row.skill.replace(' ', '_')\n skill = row.skill\n form.custom.widget[skillfield]['value'] = row.value\n form.custom.widget[skillfield]['_style'] = 'width:50px'\n form.custom.widget[skillfield]._postprocessing()\n parent = data.skills_dict[skill].parent\n base_val = 0\n if parent:\n base_val = getter.get_skill_value(parent)\n base[skillfield] = base_val\n weight[skillfield] = data.skills_dict[skill].expweight\n xp[skillfield] = round(getter.get_skill_xp_cost(skill))\n total_skill_xp += xp[skillfield]\n char_property_getter = basic.CharPropertyGetter(char, modlevel='augmented')\n char_xp = char_property_getter.get_xp()\n total_xp = sum(char_property_getter.get_total_exp().values())\n return dict(form=form, skills=[i.replace(\" \", \"_\") for i in data.skills_dict.keys()],\n xp=xp, base=base, total_skill_xp=total_skill_xp, weight = weight, char_xp = char_xp, total_xp = total_xp)\n\n@auth.requires_login()\ndef manage_powers():\n char_id = get_char()\n table = db.char_adept_powers\n table.value.show_if = (table.power.belongs([power.name for power in data.adept_powers_dict.values() if power.cost == 'X']))\n table.char.default = char_id\n query = (table.char == char_id)\n maxtextlength = {'char_adept_powers.power': 50, 'char_adept_powers.value': 100}\n table.value.represent = lambda value, row: basic.CharAdeptPower(db, row.power, basic.Char(db, char_id)).get_description()\n form = SQLFORM.grid(query, fields = [table.power, table.value], csv = False, maxtextlengths = maxtextlength, ondelete=my_ondelete('manage_powers'))\n table = get_table('adept_powers', 'char_adept_powers', 'power', 'manage_powers')\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='augmented')\n cost = char_property_getter.get_power_cost()\n magic = char_property_getter.get_attribute_value('Magic')\n return dict(form=form, table=table, cost=cost, magic=magic)\n\n\n@auth.requires_login()\ndef manage_ware():\n char_id = get_char()\n table = db.char_ware\n table.char.default = char_id\n query = (table.char == char_id)\n table.ware.represent = lambda ware, row: A(ware, _href=URL(\"edit_ware\", args=(row.id)))\n maxtextlength = {'table.ware': 50}\n char = basic.Char(db, char_id)\n links = [dict(header='Cost', body=lambda row: int(round(basic.CharWare(db, row.ware, row.id, char, True).get_cost()))),\n dict(header='Essence', body=lambda row: round(basic.CharWare(db, row.ware, row.id, char, True).get_essence_cost(),2))]\n form = SQLFORM.grid(query, fields = [table.id, table.ware], csv = False,\n maxtextlength = maxtextlength,\n links = links,\n ondelete=my_ondelete('manage_ware'),\n oncreate = (lambda form: basic.CharWare(db, form.vars.ware, form.vars.id, basic.Char(db, char_id), True)))\n table = get_table('ware', 'char_ware', 'ware', 'manage_ware')\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='augmented')\n cost = char_property_getter.get_total_cost()\n total_cost = sum(cost.values())\n money = char_property_getter.get_money()\n essence = char_property_getter.get_attribute_value('Essence')\n return dict(form=form, table=table, total_cost = total_cost, money = money, essence = essence)\n\n\n@auth.requires_login()\ndef manage_fixtures():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), 'augmented')\n bodyparts = []\n for bodypart in data.bodyparts_dict:\n capacity = char_property_getter.char_body.bodyparts[bodypart].get_capacity()\n if capacity:\n used = char_property_getter.char_body.bodyparts[bodypart].get_used_capacity()\n bodyparts.append([bodypart, round(capacity,2), round(used,2)])\n table = db.char_fixtures\n table.char.default = char_id\n query = (table.char == char_id)\n maxtextlength = {'table.fixture' : 50}\n char = basic.Char(db, char_id)\n links = [dict(header='Cost', body=lambda row: data.fixtures_dict[row.fixture].cost),\n dict(header='Capacity', body=lambda row: {key:round(value,2) for key,value in basic.CharFixture(row.fixture, char).get_capacity_dict().items()})]\n form = SQLFORM.grid(query, fields = [table.id, table.fixture], csv = False, maxtextlength=maxtextlength, links=links, ondelete=my_ondelete('manage_fixtures'))\n table = get_table('fixtures', 'char_fixtures', 'fixture', 'manage_fixtures')\n cost = char_property_getter.get_total_cost()\n total_cost = sum(cost.values())\n money = char_property_getter.get_money()\n return dict(form=form, bodyparts=bodyparts, table=table, total_cost = total_cost, money = money)\n\n\n@auth.requires_login()\ndef manage_upgrades():\n char_id = get_char()\n table = db.item_upgrades\n table.char.default = char_id\n query = (table.char == char_id)\n char = basic.Char(db, char_id)\n form = SQLFORM.grid(query, fields = [table.id, table.item, table.upgrade], csv = False, ondelete=my_ondelete('manage_upgrades'))\n return dict(form=form)\n\n@auth.requires_login()\ndef upgrade_item():\n char_id = get_char()\n char_gameitem_id = int(request.args(0))\n table = db.char_items\n gameitem_name = table[char_gameitem_id].item\n if not table[char_gameitem_id].char == char_id:\n redirect(URL('manage_chars'))\n gameitem = data.gameitems_dict[gameitem_name]\n capacity = gameitem.capacity\n upgradeables = gameitem.upgradeables[:]\n if gameitem.clas == 'Ranged Weapon':\n capacity = []\n ranged_weapon = data.rangedweapons_dict[gameitem.name]\n if ranged_weapon.top:\n upgradeables.extend(data.rangedweapon_upgrades['top'])\n capacity.append('top')\n if ranged_weapon.barrel:\n upgradeables.extend(data.rangedweapon_upgrades['barrel'])\n capacity.append('barrel')\n if ranged_weapon.under:\n upgradeables.extend(data.rangedweapon_upgrades['under'])\n capacity.append('under')\n fields = [Field('upgrade', 'string', requires=IS_IN_SET(upgradeables))]\n upgradeables = [data.gameitems_dict[i] for i in upgradeables]\n if gameitem.clas not in ['Ranged Weapon']:\n upgradeables = [(i.name, i.absolute_capacity+i.relative_capacity*capacity) for i in upgradeables]\n else:\n upgradeables = [(i.name) for i in upgradeables]\n form = SQLFORM.factory(*fields)\n if form.accepts(request.vars, session):\n response.flash = 'form accepted'\n upgrade = form.vars.upgrade\n id = db.char_items.insert(char=char_id, item=upgrade, location = None, loadout = None, rating = None)\n db.item_upgrades.insert(char=char_id, item = char_gameitem_id, upgrade = id)\n elif form.errors:\n response.flash = 'form has errors'\n upgrades = db(db.item_upgrades.item==char_gameitem_id).select(db.item_upgrades.id, db.item_upgrades.upgrade)\n if gameitem.clas not in ['Ranged Weapon']:\n upgrades = [(A(i.upgrade.item, _href=URL(\"upgrade_item\", args=(i.upgrade.id))),\n data.gameitems_dict[i.upgrade.item].absolute_capacity+data.gameitems_dict[i.upgrade.item].relative_capacity*capacity,\n A(\"Unlink\", callback=URL('unlink_upgrade', args=[i.id, char_gameitem_id]), _class='btn'),\n A(\"Delete\", callback=URL('delete_upgrade', args=[i.upgrade.id, i.id, char_gameitem_id]), _class='btn'))\n for i in upgrades]\n else:\n upgrades = [(A(i.upgrade.item, _href=URL(\"upgrade_item\", args=(i.upgrade.id))),\n data.rangedweapon_upgrades_reverse[i.upgrade.item],\n A(\"Unlink\", callback=URL('unlink_upgrade', args=[i.id, char_gameitem_id]), _class='btn'),\n A(\"Delete\", callback=URL('delete_upgrade', args=[i.upgrade.id, i.id, char_gameitem_id]), _class='btn'))\n for i in upgrades]\n if isinstance(capacity, float) or isinstance(capacity, int):\n free_capacity = capacity - sum([i[1] for i in upgrades])\n else:\n free_capacity = set(capacity) - set([i[1] for i in upgrades])\n return dict(name = gameitem_name, form=form, upgrades=upgrades, upgradeables=upgradeables, capacity=capacity, free_capacity=free_capacity)\n\n@auth.requires_login()\ndef unlink_upgrade():\n char_id = get_char()\n id = int(request.args(0))\n char_gameitem_id = int(request.args(1))\n db(db.item_upgrades.id == id).delete()\n redirect(URL('upgrade_item', args=[char_gameitem_id]), client_side=True)\n\n\n@auth.requires_login()\ndef delete_upgrade():\n char_id = get_char()\n item_id = int(request.args(0))\n unlink_id = int(request.args(1))\n char_gameitem_id = int(request.args(2))\n db(db.item_upgrades.id == unlink_id).delete()\n db(db.char_items.id == item_id).delete()\n redirect(URL('upgrade_item', args=[char_gameitem_id]), client_side=True)\n\n\n@auth.requires_login()\ndef edit_ware():\n char_id = get_char()\n char_ware_id = request.args(0)\n ware = db.char_ware[char_ware_id].ware\n fields = []\n attributes = []\n rows = db(db.char_ware_stats.ware == char_ware_id).select(db.char_ware_stats.ALL)\n for row in rows:\n fields += [Field(row.stat, 'double', default=row.value)]\n form = SQLFORM.factory(*fields, ondelete=my_ondelete('edit_ware'))\n if form.accepts(request.vars, session):\n response.flash = 'form accepted'\n for entry in form.vars:\n db((db.char_ware_stats.ware == char_ware_id) & (db.char_ware_stats.stat == entry)).update(value=form.vars[entry])\n db.commit()\n elif form.errors:\n response.flash = 'form has errors'\n rows = db(db.char_ware_stats.ware == char_ware_id).select(db.char_ware_stats.ALL)\n# base = {}\n# xp = {}\n# modified = {}\n for row in rows:\n stat = row.stat\n form.custom.widget[stat]['value'] = row.value\n form.custom.widget[stat]['_style'] = 'width:50px'\n form.custom.widget[stat]._postprocessing()\n# base[attribute] = database.get_attrib_xp_base(db, cache, char, attribute)\n# xp[attribute] = database.get_attrib_xpcost(db, cache, char, attribute)\n# modified[attribute] = database.get_attribute_value(db, cache, attribute, char, mod='modified')\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), 'augmented')\n cost = char_property_getter.get_total_cost()\n total_cost = sum(cost.values())\n money = char_property_getter.get_money()\n return dict(ware=ware, total_cost = total_cost, money = money,\n form=form, stats=[key for key, value in data.attributes_dict.items()\n if value.kind == 'physical' or value.name == 'Weight'] + ['Essence'])\n\n\n@auth.requires_login()\ndef edit_damage():\n char_id = get_char()\n table = db.char_damage\n table.char.default = char_id\n query = db.char_damage.char == char_id\n form = SQLFORM.grid(query, fields = [table.damagekind, table.value], csv = False)\n return dict(form=form)\n\n\n@auth.requires_login()\ndef edit_wounds():\n char_id = get_char()\n table = db.char_wounds\n table.char.default = char_id\n query = db.char_wounds.char == char_id\n form = SQLFORM.grid(query, fields = [table.bodypart, table.damagekind, table.value], csv = False)\n return dict(form=form)\n\n\n@auth.requires_login()\ndef edit_items():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), 'augmented')\n table = db.char_items\n table.rating.show_if = (table.item.belongs([item.name for item in data.gameitems_dict.values() if item.rating]))\n table.char.default = char_id\n table.item.represent = lambda item, row: A(item, _href=URL(\"upgrade_item\", args=(row.id)))\n query = table.char == char_id\n links = [dict(header='Cost', body=lambda row: int(round(rules.cost_by_rating(data.gameitems_dict[row.item].rating, data.gameitems_dict[row.item].cost, row.rating))))]\n form = SQLFORM.grid(query, fields = [table.item, table.rating, table.loadout, table.location], csv = False, ondelete=my_ondelete('edit_items'), links=links )\n table = get_table('gameitems', 'char_items', 'item', 'edit_items')\n cost = char_property_getter.get_total_cost()\n total_cost = sum(cost.values())\n money = char_property_getter.get_money()\n return dict(form=form, table=table, total_cost = total_cost, money = money)\n\n@auth.requires_login()\ndef manage_spells():\n char_id = get_char()\n char = basic.Char(db, char_id)\n char_property_getter = basic.CharPropertyGetter(char, modlevel='augmented')\n next_spell_cost = char_property_getter.get_next_spell_xp_cost()\n total_spells_xp_cost = char_property_getter.get_spell_xp_cost()\n char_xp = char_property_getter.get_xp()\n total_xp = sum(char_property_getter.get_total_exp().values())\n table = db.char_spells\n table.char.default = char_id\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.spell], csv = False)\n return dict(form=form, next_spell_cost=next_spell_cost, total_spells_xp_cost=total_spells_xp_cost,\n char_xp=char_xp, total_xp=total_xp)\n\n@auth.requires_login()\ndef manage_metamagic():\n char_id = get_char()\n char = basic.Char(db, char_id)\n char_property_getter = basic.CharPropertyGetter(char, modlevel='augmented')\n next_metamagic_cost = char_property_getter.get_next_metamagic_xp_cost()\n total_metamagic_xp_cost = char_property_getter.get_metamagic_xp_cost()\n char_xp = char_property_getter.get_xp()\n total_xp = sum(char_property_getter.get_total_exp().values())\n table = db.char_metamagic\n table.char.default = char_id\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.metamagic], csv = False)\n return dict(form=form, next_metamagic_cost=next_metamagic_cost, total_metamagic_xp_cost=total_metamagic_xp_cost,\n char_xp=char_xp, total_xp=total_xp)\n\n\n@auth.requires_login()\ndef edit_sins():\n char_id = get_char()\n table = db.char_sins\n table.locations.requires = IS_IN_DB(db(db.char_locations.char == char_id), 'char_locations.id', '%(name)s', multiple=True)\n table.char.default = char_id\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.name, table.rating, table.permits, table.locations], csv = False)\n return dict(form=form)\n\n\n@auth.requires_login()\ndef edit_locations():\n char_id = get_char()\n table = db.char_locations\n table.char.default = char_id\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.name], csv = False)\n return dict(form=form)\n\n@auth.requires_login()\ndef edit_contacts():\n char_id = get_char()\n master_id = db(db.chars.id==char_id).select(db.chars.master).first().master\n table1 = db.contacts\n table1.master.default = master_id\n query1 = (table1.master == master_id)\n form1 = SQLFORM.grid(query1, fields = [table1.name], csv = False)\n return dict(form=form1)\n\n@auth.requires_login()\ndef edit_char_contacts():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='augmented')\n xp = char_property_getter.get_contacts_xp_cost()\n charisma_xp = char_property_getter.get_free_contacts_xp()\n char_xp = char_property_getter.get_xp()\n total_xp = sum(char_property_getter.get_total_exp().values())\n master_id = db(db.chars.id==char_id).select(db.chars.master).first().master\n table2 =db.char_contacts\n table2.char.default = char_id\n query2 = (table2.char == char_id)\n form2 = SQLFORM.grid(query2, fields = [table2.name], csv = False)\n return dict(form=form2, xp=xp, charisma_xp=charisma_xp, char_xp = char_xp, total_xp = total_xp)\n\n\n@auth.requires_login()\ndef manage_contacts():\n char_id = get_char()\n master_id = db(db.chars.id==char_id).select(db.chars.master).first().master\n return dict()\n\n@auth.requires_login()\ndef edit_loadout():\n char_id = get_char()\n query = (db.char_loadout.char==char_id)\n\n if request.vars.get('loadout'):\n db.char_loadout.update_or_insert(query, value=request.vars.get('loadout'), char = char_id)\n val = db(query).select(db.char_loadout.value).first()\n if not val:\n val = 0\n else:\n val = int(val.value)\n fields1 = [Field('loadout', 'integer', default=val, label = 'Loadout', requires=IS_IN_SET(list(range(10))))]\n form1 = SQLFORM.factory(*fields1)\n\n if form1.process(formname='form_one').accepted:\n if form1.vars.get('loadout') is not None:\n db.char_loadout.update_or_insert(query, value=form1.vars.get('loadout'), char = char_id)\n form1.custom.widget['loadout']['value'] = form1.vars.get('loadout')\n form1.custom.widget['loadout']._postprocessing()\n\n items = db(db.char_items.char == char_id).select(db.char_items.id, db.char_items.item, db.char_items.loadout)\n fields2 = [Field('item_{}_{}'.format(i.id,j), 'boolean', default=True if j in i.loadout else False) for i in items for j in range(10)]\n form2 = SQLFORM.factory(*fields2)\n if form2.process(formname='form_two').accepted:\n for item in items:\n templist = []\n for j in range(10):\n if form2.vars['item_{}_{}'.format(item.id, j)]:\n templist.append(j)\n form2.custom.widget['item_{}_{}'.format(item.id, j)]['value'] = form2.vars['item_{}_{}'.format(item.id, j)]\n form2.custom.widget['item_{}_{}'.format(item.id, j)]._postprocessing()\n db(db.char_items.id == item.id).update(loadout = templist)\n return dict(form1 = form1, form2=form2, items=[(i.id, i.item) for i in items])\n\n\n@auth.requires_login()\ndef edit_computers():\n char_id = get_char()\n table = db.char_computers\n table.char.default = char_id\n owned_decks =db((db.char_items.char == char_id) &\n (db.char_items.item.belongs(data.computer_dict.keys()))\n )\n table.item.requires = IS_IN_DB(owned_decks, 'char_items.id', '%(item)s')\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.item, table.firewall, table.current_uplink, table.damage], csv = False)\n return dict(form=form)\n\n@auth.requires_login()\ndef manage_money():\n char_id = get_char()\n table = db.char_money\n table.char.default = char_id\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.money, table.usage, table.timestamp], csv = False, ondelete=my_ondelete('manage_money'))\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='augmented')\n cost = char_property_getter.get_total_cost()\n total_cost = sum(cost.values())\n money = char_property_getter.get_money()\n return dict(form=form, total_cost = total_cost, money=money)\n\n@auth.requires_login()\ndef manage_xp():\n char_id = get_char()\n table = db.char_xp\n table.char.default = char_id\n query = table.char == char_id\n form = SQLFORM.grid(query, fields = [table.xp, table.usage, table.timestamp], csv = False, ondelete=my_ondelete('manage_xp'))\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='augmented')\n char_xp = char_property_getter.get_xp()\n total_xp = sum(char_property_getter.get_total_exp().values())\n cost = char_property_getter.get_total_cost()\n total_cost = sum(cost.values())\n money = char_property_getter.get_money()\n return dict(form=form, total_cost = total_cost, money=money, total_xp = total_xp, char_xp = char_xp)\n"
},
{
"alpha_fraction": 0.6222648620605469,
"alphanum_fraction": 0.6245681643486023,
"avg_line_length": 41.01612854003906,
"blob_id": "dc4dcb33681c402e00633d6e90b8f8ea1bdc52b5",
"content_id": "d18dbb77f41b2d2d904176adea9ae0fbad707abf",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2605,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 62,
"path": "/controllers/game.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\nimport collections\nimport applications.gabaros.modules.data as data\nimport spirit\nimport vehicle\n\ndef gametables():\n table_name = request.args(0)\n if table_name:\n table_name = table_name.replace('_',' ')\n table = ''\n tablename=''\n dictionaries = {i[:-5].replace('_', ' ').capitalize():getattr(data,i) for i in dir(data) if i[-5:] == '_dict'}\n fields = Field('table', type='str', requires=IS_IN_SET(sorted(dictionaries.keys())), label = 'Table')\n form=SQLFORM.factory(fields)\n if form.process().accepted:\n table_name = form.vars.table\n tablename=form.vars.table\n if table_name:\n if not tablename:\n tablename = table_name.replace('_', ' ')\n dictionary = dictionaries[table_name]\n first = dictionary[dictionary.keys()[0]]\n dict_data = []\n for entry in dictionary.values():\n dict_data.append(list(entry))\n for i, row in enumerate(dict_data):\n for j, entry in enumerate(row):\n if isinstance(entry,list):\n dict_data[i][j] = ', '.join([str(k) for k in entry])\n if isinstance(entry,float):\n dict_data[i][j] = round(entry, 2)\n table = [first._fields]\n table.extend(dict_data)\n elif form.errors:\n response.flash = 'form has errors'\n else:\n response.flash = 'Please select a table'\n\n return dict(form=form, table=table, tablename=tablename)\n\n\ndef view_spirit():\n fields = [Field('force', type='int', label = 'Force'),\n Field('class_', type='str', requires=IS_IN_SET(['creation', 'destruction', 'detection', 'manipulation']), label = 'Class'),\n Field('manifestation', type='str', requires=IS_IN_SET(['ethereal', 'fluid', 'solid']), label = 'Manifestation')]\n summoned = None\n form=SQLFORM.factory(*fields)\n if form.process().accepted:\n force, class_, manifestation = float(form.vars.force), form.vars.class_, form.vars.manifestation\n summoned = spirit.Spirit(force, class_, manifestation)\n return dict(form=form, summoned=summoned)\n\n\ndef view_vehicle():\n fields = [Field('vehicle', type='str', requires=IS_IN_SET(data.vehicles_dict.keys()), label = 'Vehicle')]\n this_vehicle = None\n form=SQLFORM.factory(*fields)\n if form.process().accepted:\n this_vehicle = data.vehicles_dict[form.vars.vehicle]\n this_vehicle = vehicle.Vehicle(this_vehicle.chassis, this_vehicle.agent, this_vehicle.computer, this_vehicle.sensors_package, this_vehicle.equipment)\n return dict(form=form, vehicle=this_vehicle)\n"
},
{
"alpha_fraction": 0.48248669505119324,
"alphanum_fraction": 0.4901679754257202,
"avg_line_length": 45.71770477294922,
"blob_id": "2b84c76c8037993720ed831b880f5c1f8cccd2d1",
"content_id": "723cb7f8efd056579f92316dfde799eca748de86",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9764,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 209,
"path": "/models/menu.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# this file is released under public domain and you can use without limitations\n\n#########################################################################\n## Customize your APP title, subtitle and menus here\n#########################################################################\n\nresponse.logo = A(B('web',SPAN(2),'py'),XML('™ '),\n _class=\"navbar-brand\",_href=\"http://www.web2py.com/\",\n _id=\"web2py-logo\")\nresponse.title = request.application.replace('_',' ').title()\nresponse.subtitle = ''\n\n## read more at http://dev.w3.org/html5/markup/meta.name.html\nresponse.meta.author = 'Serbitar <serbita@sessionmob.de>'\nresponse.meta.description = 'a cool new app'\nresponse.meta.keywords = 'web2py, python, framework'\nresponse.meta.generator = 'Web2py Web Framework'\n\n## your http://google.com/analytics id\nresponse.google_analytics_id = None\n\n#########################################################################\n## this is the main application menu add/remove items as required\n#########################################################################\nresponse.menu = [\n (T('Home'), False, URL('default', 'index'), []),\n (T('Manage Char'), False, '#', [\n (T('Create/Select'), False, URL('manage_char', 'index')),\n LI(_class=\"divider\"),\n (T('XP'), False, URL('manage_char', 'manage_xp')),\n (T('Money'), False, URL('manage_char', 'manage_money')),\n LI(_class=\"divider\"),\n (T('Attributes'), False, URL('manage_char', 'edit_attributes')),\n (T('Skills'), False, URL('manage_char', 'edit_skills')),\n LI(_class=\"divider\"),\n (T('Adept Powers'), False, URL('manage_char', 'manage_powers')),\n (T('Spells'), False, URL('manage_char', 'manage_spells')),\n (T('Metamagic'), False, URL('manage_char', 'manage_metamagic')),\n LI(_class=\"divider\"),\n (T('Ware'), False, URL('manage_char', 'manage_ware')),\n (T('Fixtures'), False, URL('manage_char', 'manage_fixtures')),\n LI(_class=\"divider\"),\n (T('Damage'), False, URL('manage_char', 'edit_damage')),\n (T('Wounds'), False, URL('manage_char', 'edit_wounds')),\n LI(_class=\"divider\"),\n (T('Contacts'), False, URL('manage_char', 'manage_contacts')),\n (T('Items'), False, URL('manage_char', 'edit_items')),\n (T('Upgrades'), False, URL('manage_char', 'manage_upgrades')),\n (T('Loadout'), False, URL('manage_char', 'edit_loadout')),\n (T('Computers'), False, URL('manage_char', 'edit_computers')),\n (T('Sins'), False, URL('manage_char', 'edit_sins')),\n (T('Locations'), False, URL('manage_char', 'edit_locations')),\n ]),\n (T('View Char'), False, '#', [\n (T('Attributes'), False, URL('view_char', 'view_attributes')),\n (T('Stats'), False, URL('view_char', 'view_stats')),\n (T('Skills'), False, URL('view_char', 'view_skills')),\n (T('Skills ABC'), False, URL('view_char', 'view_skills_alphabetical')),\n (T('XP'), False, URL('view_char', 'view_xp')),\n (T('Cost'), False, URL('view_char', 'view_cost')),\n (T('Bodyparts'), False, URL('view_char', 'view_bodyparts')),\n (T('Actions'), False, URL('view_char', 'view_actions')),\n (T('Gear'), False, URL('view_char', 'view_items')),\n (T('Weapons'), False, URL('view_char', 'view_weapons')),\n (T('Armor'), False, URL('view_char', 'view_armor')),\n LI(_class=\"divider\"),\n (T('Computer'), False, URL('view_char', 'view_computer')),\n (T('Magic'), False, URL('view_char', 'view_magic')),\n (T('Combat'), False, URL('view_char', 'combat')),\n (T('Damage'), False, URL('view_char', 'damage')),\n ]),\n (T('Gameinformation'), False, '#', [\n (T('Wiki'), False, A('Wiki', _href='http://gabaros.sessionmob.de')),\n (T('Spirit'), False, URL('game', 'view_spirit')),\n (T('Gametables'), False, URL('game', 'gametables')),\n ]),\n (T('Toggle Sidebar'), False, A('Toggle Sidebar', _href=\"#menu-toggle\", _id=\"menu-toggle\"), []),\n]\n\nDEVELOPMENT_MENU = False\n\n#########################################################################\n## provide shortcuts for development. remove in production\n#########################################################################\n\ndef _():\n # shortcuts\n app = request.application\n ctr = request.controller\n # useful links to internal and external resources\n response.menu += [\n (T('My Sites'), False, URL('admin', 'default', 'site')),\n (T('This App'), False, '#', [\n (T('Design'), False, URL('admin', 'default', 'design/%s' % app)),\n LI(_class=\"divider\"),\n (T('Controller'), False,\n URL(\n 'admin', 'default', 'edit/%s/controllers/%s.py' % (app, ctr))),\n (T('View'), False,\n URL(\n 'admin', 'default', 'edit/%s/views/%s' % (app, response.view))),\n (T('DB Model'), False,\n URL(\n 'admin', 'default', 'edit/%s/models/db.py' % app)),\n (T('Menu Model'), False,\n URL(\n 'admin', 'default', 'edit/%s/models/menu.py' % app)),\n (T('Config.ini'), False,\n URL(\n 'admin', 'default', 'edit/%s/private/appconfig.ini' % app)),\n (T('Layout'), False,\n URL(\n 'admin', 'default', 'edit/%s/views/layout.html' % app)),\n (T('Stylesheet'), False,\n URL(\n 'admin', 'default', 'edit/%s/static/css/web2py-bootstrap3.css' % app)),\n (T('Database'), False, URL(app, 'appadmin', 'index')),\n (T('Errors'), False, URL(\n 'admin', 'default', 'errors/' + app)),\n (T('About'), False, URL(\n 'admin', 'default', 'about/' + app)),\n ]),\n ('web2py.com', False, '#', [\n (T('Download'), False,\n 'http://www.web2py.com/examples/default/download'),\n (T('Support'), False,\n 'http://www.web2py.com/examples/default/support'),\n (T('Demo'), False, 'http://web2py.com/demo_admin'),\n (T('Quick Examples'), False,\n 'http://web2py.com/examples/default/examples'),\n (T('FAQ'), False, 'http://web2py.com/AlterEgo'),\n (T('Videos'), False,\n 'http://www.web2py.com/examples/default/videos/'),\n (T('Free Applications'),\n False, 'http://web2py.com/appliances'),\n (T('Plugins'), False, 'http://web2py.com/plugins'),\n (T('Recipes'), False, 'http://web2pyslices.com/'),\n ]),\n (T('Documentation'), False, '#', [\n (T('Online book'), False, 'http://www.web2py.com/book'),\n LI(_class=\"divider\"),\n (T('Preface'), False,\n 'http://www.web2py.com/book/default/chapter/00'),\n (T('Introduction'), False,\n 'http://www.web2py.com/book/default/chapter/01'),\n (T('Python'), False,\n 'http://www.web2py.com/book/default/chapter/02'),\n (T('Overview'), False,\n 'http://www.web2py.com/book/default/chapter/03'),\n (T('The Core'), False,\n 'http://www.web2py.com/book/default/chapter/04'),\n (T('The Views'), False,\n 'http://www.web2py.com/book/default/chapter/05'),\n (T('Database'), False,\n 'http://www.web2py.com/book/default/chapter/06'),\n (T('Forms and Validators'), False,\n 'http://www.web2py.com/book/default/chapter/07'),\n (T('Email and SMS'), False,\n 'http://www.web2py.com/book/default/chapter/08'),\n (T('Access Control'), False,\n 'http://www.web2py.com/book/default/chapter/09'),\n (T('Services'), False,\n 'http://www.web2py.com/book/default/chapter/10'),\n (T('Ajax Recipes'), False,\n 'http://www.web2py.com/book/default/chapter/11'),\n (T('Components and Plugins'), False,\n 'http://www.web2py.com/book/default/chapter/12'),\n (T('Deployment Recipes'), False,\n 'http://www.web2py.com/book/default/chapter/13'),\n (T('Other Recipes'), False,\n 'http://www.web2py.com/book/default/chapter/14'),\n (T('Helping web2py'), False,\n 'http://www.web2py.com/book/default/chapter/15'),\n (T(\"Buy web2py's book\"), False,\n 'http://stores.lulu.com/web2py'),\n ]),\n (T('Community'), False, None, [\n (T('Groups'), False,\n 'http://www.web2py.com/examples/default/usergroups'),\n (T('Twitter'), False, 'http://twitter.com/web2py'),\n (T('Live Chat'), False,\n 'http://webchat.freenode.net/?channels=web2py'),\n ]),\n ]\nif DEVELOPMENT_MENU: _()\n\nif \"auth\" in locals(): auth.wikimenu()\n\ndef get_char():\n char = session.char\n if not db.chars[char] or (db.chars[char].player != auth.user.id\n and db.chars[char].master != auth.user.id):\n redirect(URL(f='index'))\n return char\n\ndef get_char_name():\n name = ''\n char = session.char\n if char:\n name = db.chars[char].name\n return name\n\ndef wikify(links):\n baselink = 'http://gabaros.sessionmob.de'\n sidebar = [A('Wiki', _href=baselink, _target='_blank')]\n for link in links:\n sidebar.append(A(link, _href=baselink + '/index.php/' +link.replace(' ', '_'), _target='_blank'))\n return sidebar\n"
},
{
"alpha_fraction": 0.5848915576934814,
"alphanum_fraction": 0.5908509492874146,
"avg_line_length": 45.992061614990234,
"blob_id": "afcb4860c2715389de3d485f01bbb63e8996ef98",
"content_id": "02e0c75144d69b238610ed6a840f1157a9524180",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 41447,
"license_type": "permissive",
"max_line_length": 246,
"num_lines": 882,
"path": "/controllers/view_char.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\n# versuche so etwas wie\nimport datetime\nimport basic\nimport data\nfrom random import gauss\nimport rules\nfrom collections import OrderedDict\nfrom math import log\n\ndef index():\n redirect(URL('view_chars'))\n\n\ndef roll(char_id, value, name, visible, psythresh=100.):\n roll = int(rules.die_roll())\n if value is None:\n value = -100\n else:\n value = float(value)\n if name is None:\n name = ''\n name = name.replace('_', ' ')\n result = int(round(value + roll))\n psyval = int(round(max(0, abs(roll) - psythresh)))\n db.rolls.insert(char=char_id, name=name, value=value, roll=roll, result=result, visible=visible, psyval=psyval)\n return result\n\n\ndef roll_button():\n value = request.args(2)\n char_id = int(request.args(0))\n psythresh = float(request.args(4))\n name = request.args(1)\n visible = int(request.args(3))\n result = roll(char_id, value, name, visible, psythresh)\n roll_val = result - float(value)\n psyval = int(round(max(0, abs(roll_val) - psythresh)))\n if visible:\n if psyval:\n response.js = 'jQuery(\".flash\").html(\"{}: {} (Psyco: {})\").slideDown();'.format(name, result, psyval)\n else:\n response.js = 'jQuery(\".flash\").html(\"{}: {}\").slideDown();'.format(name, result)\n else:\n response.js = 'jQuery(\".flash\").html(\"{} roll was sent!\").slideDown();'.format(name)\n\n\n@auth.requires_login()\ndef view_items():\n char_id = get_char()\n table = db.char_items\n table2 = db.item_upgrades\n itemdata = db(table.char==char_id).select(table.id, table.item, table.rating, table.location, table.loadout)\n upgrades = db(table2.char==char_id).select(table2.id, table2.item, table2.upgrade)\n upgrades = {row.upgrade.id: (row.item.item, row.item.id) for row in upgrades}\n itemdata2 = [['Item', 'Rating', 'Weight', 'Visible Stealth', 'Scan Stealth', 'Location', 'Loadout']]\n for row in itemdata:\n item = data.gameitems_dict[row.item]\n if row.id not in upgrades:\n itemdata2.append([row.item, row.rating, item.weight, item.vis_stealth, item.scan_stealth, row.location.name if row.location else '', row.loadout])\n if item.clas == 'Ranged Weapon':\n special = data.rangedweapons_dict[item.name].special\n if special and 'upgrades' in special:\n for upgrade in special['upgrades']:\n upgrade = data.gameitems_dict[upgrade]\n itemdata2.append(['{} - {}'.format(row.item, upgrade.name), None, upgrade.weight, upgrade.vis_stealth, upgrade.scan_stealth, None, None])\n else:\n if upgrades[row.id][1] not in upgrades:\n itemdata2.append(['{} - {}'.format(upgrades[row.id][0], row.item), row.rating, item.weight, item.vis_stealth, item.scan_stealth, row.location.name if row.location else '', row.loadout])\n else:\n itemdata2.append(['{} - {} - {}'.format(upgrades[upgrades[row.id][1]][0], upgrades[row.id][0], row.item), row.rating, item.weight, item.vis_stealth, item.scan_stealth, row.location.name if row.location else '', row.loadout])\n table = itemdata2\n return dict(table=table)\n\n@auth.requires_login()\ndef view_chars():\n table = db.chars\n query = db.chars.player == auth.user.id or db.chars.master == auth.user.id\n table.id.represent = lambda id: A(id, _href=URL(\"view_char\", args=(id)))\n table.player.represent = lambda player: db.auth_user[player].username\n form = crud.select(table, query=query, fields=[\"id\", \"name\"])\n return dict(form=form)\n\n\n@auth.requires_login()\ndef view_char():\n char_id = get_char()\n table = db.chars\n table.player.writable = False\n table.player.represent = lambda player: db.auth_user[player].username\n linklist = [A(\"attributes\", _href=URL('view_attributes')),\n A(\"skills\", _href=URL('view_skills')),\n A(\"computer\", _href=URL('view_computer')),\n A(\"weapons\", _href=URL('view_weapons')),\n A(\"combat\", _href=URL('combat')),\n ]\n return dict(linklist=linklist)\n\n\n@auth.requires_login()\ndef view_skills():\n char_id = get_char()\n skills = [[\"Skill\", \"Test\", \"Secret\"]]\n skilldepth_dict = {}\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id))\n psythresh = char_property_getter.get_psycho_thresh()\n for skill, skilldata in data.skills_dict.items():\n skillname = skill\n skilldepth = skilldepth_dict.get(skilldata.parent, 0)\n skilldepth_dict[skill] = skilldepth + 1\n val = char_property_getter.get_skilltest_value(skill)\n button1 = A(\"{:.0f}\".format(val),\n callback=URL('roll_button', args=[char_id, skillname, val, 1, psythresh]), _class='btn')\n button2 = A(\"{:.0f}\".format(val),\n callback=URL('roll_button', args=[char_id, skillname, val, 0, psythresh]), _class='btn')\n if skilldepth == 0:\n skilltext = H3(skillname)\n elif skilldepth == 1:\n skilltext = H4(skillname)\n else:\n skilltext = skillname\n skills += [[skilltext, button1, button2]]\n sidebar = wikify(['Task Resolution', 'Skill'])\n return dict(skills=skills, sidebar=sidebar)\n\ndef view_skills_alphabetical():\n char_id = get_char()\n skills = [[\"Skill\", \"Test\", \"Secret\"]]\n skilldepth_dict = {}\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id))\n psythresh = char_property_getter.get_psycho_thresh()\n for skill, skilldata in data.skills_dict.items():\n skillname = skill\n skilldepth = skilldepth_dict.get(skilldata.parent, 0)\n skilldepth_dict[skill] = skilldepth + 1\n val = char_property_getter.get_skilltest_value(skill)\n button1 = A(\"{:.0f}\".format(val),\n callback=URL('roll_button', args=[char_id, skillname, val, 1, psythresh]), _class='btn')\n button2 = A(\"{:.0f}\".format(val),\n callback=URL('roll_button', args=[char_id, skillname, val, 0, psythresh]), _class='btn')\n if skilldepth == 0:\n skilltext = H3(skillname)\n elif skilldepth == 1:\n skilltext = H4(skillname)\n else:\n skilltext = skillname\n skills += [[skillname, skilltext, button1, button2]]\n temp = sorted(skills[1:], key = lambda x: x[0])\n skills = [skills[0]] + [i[1:] for i in temp]\n sidebar = wikify(['Task Resolution', 'Skill'])\n return dict(skills=skills, sidebar=sidebar)\n\n\n@auth.requires_login()\ndef view_attributes():\n char_id = get_char()\n attributes = [[\"Attribute\", \"Unaugmented\", \"Augmented\", \"Temporary\", \"Value\", \"Mod\", \"Test\", \"Secret\"]]\n char = basic.Char(db, char_id)\n\n char_property_getter = basic.CharPropertyGetter(char, modlevel = 'unaugmented')\n char_property_getter2 = basic.CharPropertyGetter(char, modlevel = 'augmented')\n char_property_getter3 = basic.CharPropertyGetter(char, modlevel = 'temporary')\n char_property_getter4 = basic.CharPropertyGetter(char, modlevel = 'stateful')\n psythresh = char_property_getter4.get_psycho_thresh()\n for attribute in data.attributes_dict.keys()+ ['Essence']:\n unaugmented = round(char_property_getter.get_attribute_value(attribute),2)\n augmented = round(char_property_getter2.get_attribute_value(attribute),2)\n temporary = round(char_property_getter3.get_attribute_value(attribute),2)\n value = round(char_property_getter4.get_attribute_value(attribute),2)\n modval = round(char_property_getter4.get_attribute_test_value(attribute),2)\n button1= A(\"{:.0f}\".format(modval),\n callback=URL('roll_button', args=[char_id, attribute, modval, 1, psythresh]), _class='btn')\n button2 = A(\"{:.0f}\".format(modval),\n callback=URL('roll_button', args=[char_id, attribute, modval, 0, psythresh]), _class='btn')\n attributes += [[attribute, unaugmented, augmented, temporary, value, modval, button1, button2]]\n return dict(attributes=attributes)\n\n\n@auth.requires_login()\ndef view_matrix_actions():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(char)\n psythresh = char_property_getter.get_psycho_thresh()\n computer_id = request.args(0)\n computer = basic.Computer(db, computer_id, basic.Char(db, char_id))\n actions = [[\"Action\", \"Prerequisite\", \"Test\", \"Secret\"]]\n for action, item in sorted(data.matrix_actions_dict.items()):\n value = computer.get_action_value(action)\n prerequisite = item.prerequisite\n if value is not None:\n button1 = A(\"{:.0f}\".format(value),\n callback=URL('roll_button', args=[char_id, action, value, 1, psythresh]), _class='btn')\n button2 = A(\"{:.0f}\".format(value),\n callback=URL('roll_button', args=[char_id, action, value, 0, psythresh]), _class='btn')\n else:\n button1 = ''\n button2 = ''\n actions += [[action, prerequisite, button1, button2]]\n sidebar = wikify(['Matrix Actions'])\n return dict(actions=actions, computer = computer.name, sidebar=sidebar)\n\n\n@auth.requires_login()\ndef view_computer():\n char_id = get_char()\n computers = [row.id for row in db(db.char_computers.char == char_id).select(db.char_computers.id)]\n char = basic.Char(db, char_id)\n table = [['Computer', 'Processor', 'System', 'Signal', 'Firewall', 'Uplink', 'Current Uplink', 'Damage']]\n at_least_one_computer = False\n for computer_id in computers:\n at_least_one_computer = True\n row = []\n computer = basic.Computer(db, computer_id, char)\n row.append(A(computer.name, _href=URL('view_matrix_actions', args = [computer_id])))\n row.append(computer.attributes['Processor'])\n row.append(computer.attributes['System'])\n row.append(computer.attributes['Signal'])\n row.append(computer.attributes['Firewall'])\n row.append(computer.attributes['Uplink'])\n row.append(computer.attributes['Current Uplink'])\n row.append(computer.damage)\n table.append(row)\n programmes = [['Programmes','Values']]\n if at_least_one_computer:\n char_programmes = computer.programmes\n for programme in sorted(data.programmes_dict.keys()):\n programmes.append([programme, char_programmes.get(programme)])\n sidebar = wikify(['Matrix Attributes', 'Programs'])\n return dict(computer=table, programmes=programmes, sidebar=sidebar)\n\n\ndef combat():\n char_id = get_char()\n char = basic.Char(db, char_id)\n insert_situation_mod = LOAD('view_char','insert_situation_mod.load',ajax=True, target = 'insert_situation_mod')\n view_weapons = LOAD('view_char','view_weapons.load',ajax=True, target = 'view_weapons')\n view_actions = LOAD('view_char','view_actions.load',ajax=True, target = 'view_actions')\n view_cc_weapons = LOAD('view_char','view_cc_weapons.load',ajax=True, target = 'view_cc_weapons')\n sidebar = wikify(['Actions', 'Combat Resolution', 'Task Modifier'])\n return dict(view_weapons=view_weapons, insert_situation_mod=insert_situation_mod, view_actions=view_actions,\n view_cc_weapons=view_cc_weapons, sidebar=sidebar)\n\ndef damage():\n char_id = get_char()\n char = basic.Char(db, char_id)\n view_damage_state = LOAD('view_char','view_damage_state.load',ajax=True, target = 'view_damage_state')\n apply_damage = LOAD('view_char','apply_damage.load',ajax=True, target = 'apply_damage')\n heal_damage = LOAD('view_char','heal_damage.load',ajax=True, target = 'heal_damage')\n sidebar = wikify(['Damage'])\n return dict(view_damage_state=view_damage_state, apply_damage=apply_damage, heal_damage=heal_damage)\n\n\ndef get_net_shoottest_val(char_id, weapon_name):\n char = basic.Char(db, char_id)\n weapon = basic.RangedWeapon(weapon_name, char)\n rows = db((db.state_mods.char==char_id) & (db.state_mods.name.belongs(['situation_mod', 'shoot_distance', 'magnification', 'braced', 'burst']))\n ).select(db.state_mods.name, db.state_mods.value, db.state_mods.type)\n resultdict = {'situation_mod': 0.,\n 'shoot_distance': 10.,\n 'magnification': 1.,\n 'braced': False,\n 'burst': 'None'}\n for row in rows:\n resultdict[row.name] = convert(row.value, row.type)\n roll = gauss(0, 10)\n situation_mod = resultdict['situation_mod']\n net_value = situation_mod - roll\n damage, result = weapon.get_damage(net_value, resultdict['shoot_distance'], resultdict['magnification'], 2., resultdict['braced'], resultdict['burst'])\n result['roll'] = roll\n result['other mods'] = situation_mod\n test_val = (-result['difficulty'] - result['other mods'] - result['minimum strength mod']\n - result['weapon range mod'] - result['sight range mod'] + result['skill'] - result['wide burst mod'])\n return int(round(test_val))\n\ndef get_net_cc_test_val(char_id, weapon_name):\n char = basic.Char(db, char_id)\n weapon = basic.CloseCombatWeapon(weapon_name, char)\n rows = db((db.state_mods.char==char_id) & (db.state_mods.name.belongs(['situation_mod']))\n ).select(db.state_mods.name, db.state_mods.value, db.state_mods.type)\n resultdict = {'situation_mod': 0.}\n for row in rows:\n resultdict[row.name] = convert(row.value, row.type)\n roll = gauss(0, 10)\n situation_mod = resultdict['situation_mod']\n net_value = situation_mod - roll\n damage, result = weapon.get_damage(net_value)\n result['roll'] = roll\n result['other mods'] = situation_mod\n test_val = (result['weapon skill mod'] - result['other mods'] - result['minimum strength mod']\n + result['skill'])\n return int(round(test_val))\n\n\n@auth.requires_login()\ndef view_weapons():\n char_id = get_char()\n char = basic.Char(db, char_id)\n weapons = basic.CharPropertyGetter(char).get_ranged_weapons()\n table = [['Weapon', 'Skill', 'Val', 'Net Val', 'Dam', 'Type', 'Pen', 'Range', 'Bullets', 'Rec', 'Mag', 'Type', 'Hands', 'Shoot', 'Upgrades', 'Special']]\n for weapon in weapons:\n row = []\n row.append(weapon.name)\n row.append(weapon.skill)\n row.append('{:.0f}'.format(weapon.get_net_skill_value()))\n row.append(get_net_shoottest_val(char_id, weapon.name))\n row.append(weapon.damage)\n row.append(weapon.damagetype)\n row.append(weapon.penetration)\n row.append(weapon.range)\n row.append('{}/{}/{}'.format(weapon.shot, weapon.burst, weapon.auto))\n row.append(weapon.recoil)\n row.append(weapon.mag)\n row.append(weapon.magtype)\n row.append(weapon.hands)\n row.append(A('Shoot', callback=URL('shoot_weapon', args=[weapon.name]),\n target = 'attack_result', _class='btn'))\n row.append(', '.join([i.name for i in weapon.upgrades]))\n row.append([(key, value) for key,value in weapon.special.items() if key != 'upgrades'])\n table.append(row)\n #fields = [Field('val', 'integer', default=0, label = 'Modifications')]\n #form = SQLFORM.factory(*fields, table_name = 'weapons', buttons=[], _method = '', _action = None)\n #form.element(_name='val')['_onblur']=\"ajax('/gabaros/view_char/insert_state_mod/{}/shoot', \" \\\n # \"['val'], '')\".format(char_id)\n #form.element(_name='val')['_onkeypress']=\"ajax('/gabaros/view_char/insert_state_mod/{}/shoot', \" \\\n # \"['val'], '')\".format(char_id)\n return dict(weapons=table)\n\n\ndef convert(value, type_indicator):\n if type_indicator == 'str':\n result = value\n elif type_indicator == 'float':\n result = float(value)\n elif type_indicator == 'bool':\n if value == 'False':\n result = False\n else:\n result = True\n else:\n result = value\n return result\n\n@auth.requires_login()\ndef shoot_weapon():\n char_id = get_char()\n weapon_name = request.args(0).replace('_', ' ')\n char = basic.Char(db, char_id)\n weapon = basic.RangedWeapon(weapon_name, char)\n rows = db((db.state_mods.char==char_id) & (db.state_mods.name.belongs(['situation_mod', 'shoot_distance', 'magnification', 'braced', 'burst']))\n ).select(db.state_mods.name, db.state_mods.value, db.state_mods.type)\n resultdict = {'situation_mod': 0.,\n 'shoot_distance': 10.,\n 'magnification': 1.,\n 'braced': False,\n 'burst': 'None'}\n for row in rows:\n resultdict[row.name] = convert(row.value, row.type)\n roll = gauss(0, 10)\n situation_mod = resultdict['situation_mod']\n net_value = situation_mod - roll\n damage, result = weapon.get_damage(net_value, resultdict['shoot_distance'], resultdict['magnification'], 2., resultdict['braced'], resultdict['burst'])\n result['roll'] = roll\n result['other mods'] = situation_mod\n difficulty = -(result['difficulty'] + result['other mods'] + result['minimum strength mod']\n + result['weapon range mod'] + result['sight range mod'] - result['skill'] + result['wide burst mod'])\n text = \"\"\"\n <table class='table table-striped table-condensed'>\n <tr>\n <th>Stat</th>\n <th>Value</th>\n <th>Stat</th>\n <th>Value</th>\n </tr>\n <tr>\n <th>Damage</td>\n <td>{damage}</td>\n <th>Weapon Range Mod</td>\n <td>{weapon_range_mod}</td>\n </tr>\n <tr>\n <th>Result</td>\n <td>{result}</td>\n <th>Sight Mod</td>\n <td>{sight_range_mod}</td>\n </tr>\n <tr>\n <th>Roll</td>\n <td>{roll}</td>\n <th>Min Strength mod</td>\n <td>{minimum_strength_mod}</td>\n </tr>\n <tr>\n <th>Skill</td>\n <td>{skill}</td>\n <th>Wide Burst Mod</td>\n <td>{wide_burst_mod}</td>\n </tr>\n <tr>\n <th>Difficulty</td>\n <td>{difficulty}</td>\n <th>Other Mods</td>\n <td>{other_mods}</td>\n </tr>\n </table>\n \"\"\"\n if damage:\n damage = damage\n else:\n damage = 0.\n text = text.format(damage=[(int(i[0]), i[1]) for i in damage],\n weapon_range_mod = int(round(result['weapon range mod'])),\n sight_range_mod = int(round(result['sight range mod'])),\n minimum_strength_mod = int(round(result['minimum strength mod'])),\n wide_burst_mod = int(round(result['wide burst mod'])),\n other_mods =int(round( result['other mods'])),\n result = int(round(result['result'])),\n roll = int(round(result['roll'])),\n skill = int(round(result['skill'])),\n difficulty = int(round(result['difficulty'])))\n db.rolls.insert(char=char_id, name='shoot', value=difficulty, roll=roll, result=result['result'], visible=True)\n return text\n\n\n@auth.requires_login()\ndef view_cc_weapons():\n char_id = get_char()\n char = basic.Char(db, char_id)\n weapons = basic.CharPropertyGetter(char).get_close_combat_weapons()\n table = [['Weapon', 'Skill', 'Val', 'Net Val', 'Dam', 'Type', 'Pen', 'Hands', 'Swing']]\n for weapon in weapons:\n row = []\n row.append(weapon.name)\n row.append(weapon.skill)\n row.append('{:.0f}'.format(weapon.get_net_skill_value()))\n row.append(get_net_cc_test_val(char_id, weapon.name))\n row.append(weapon.damage)\n row.append(weapon.damagetype)\n row.append(weapon.penetration)\n row.append(weapon.hands)\n row.append(A('Swing', callback=URL('swing_weapon', args=[weapon.name]),\n target = 'attack_result', _class='btn'))\n table.append(row)\n #fields = [Field('val', 'integer', default=0, label = 'Modifications')]\n #form = SQLFORM.factory(*fields, table_name = 'weapons', buttons=[], _method = '', _action = None)\n #form.element(_name='val')['_onblur']=\"ajax('/gabaros/view_char/insert_state_mod/shoot', \" \\\n # \"['val'], '')\".format(char_id)\n #form.element(_name='val')['_onkeypress']=\"ajax('/gabaros/view_char/insert_state_mod/shoot', \" \\\n # \"['val'], '')\".format(char_id)\n return dict(weapons=table)\n\n\n@auth.requires_login()\ndef swing_weapon():\n char_id = get_char()\n weapon_name = request.args(0).replace('_', ' ')\n char = basic.Char(db, char_id)\n weapon = basic.CloseCombatWeapon(weapon_name, char)\n rows = db((db.state_mods.char==char_id) & (db.state_mods.name.belongs(['situation_mod']))\n ).select(db.state_mods.name, db.state_mods.value, db.state_mods.type)\n resultdict = {'situation_mod': 0.}\n for row in rows:\n resultdict[row.name] = convert(row.value, row.type)\n roll = gauss(0, 10)\n situation_mod = resultdict['situation_mod']\n net_value = situation_mod - roll\n damage, result = weapon.get_damage(net_value)\n result['roll'] = roll\n result['other mods'] = situation_mod\n difficulty = -(-result['weapon skill mod'] + result['other mods'] + result['minimum strength mod'] - result['skill'])\n text = \"\"\"\n <table class='table table-striped table-condensed'>\n <tr>\n <th>Stat</th>\n <th>Value</th>\n <th>Stat</th>\n <th>Value</th>\n </tr>\n <tr>\n <th>Damage</td>\n <td>{damage}</td>\n <th>Min Strength mod</td>\n <td>{minimum_strength_mod}</td>\n </tr>\n <tr>\n <th>Result</td>\n <td>{result}</td>\n <th>Weapon Skill Mod</td>\n <td>{weapon_skill_mod}</td>\n </tr>\n <tr>\n <th>Roll</td>\n <td>{roll}</td>\n <th>Other Mods</td>\n <td>{other_mods}</td>\n </tr>\n <tr>\n <th>Skill</td>\n <td>{skill}</td>\n </tr>\n <tr>\n <th>Difficulty</td>\n <td>{difficulty}</td>\n </tr>\n </table>\n \"\"\"\n if damage:\n damage = damage\n else:\n damage = 0.\n text = text.format(damage=[(int(i[0]), i[1]) for i in damage],\n weapon_skill_mod = int(round(result['weapon skill mod'])),\n minimum_strength_mod = int(round(result['minimum strength mod'])),\n other_mods =int(round( result['other mods'])),\n result = int(round(result['result'])),\n roll = int(round(result['roll'])),\n skill = int(round(result['skill'])),\n difficulty = int(round(result['difficulty'])))\n db.rolls.insert(char=char_id, name='swing', value=difficulty, roll=roll, result=result['result'], visible=True)\n return text\n\n@auth.requires_login()\ndef insert_state_mod():\n char_id = get_char()\n name = request.args[0]\n db.state_mods.update_or_insert(((db.state_mods.char==char) &\n (db.state_mods.name==name)),\n value=request.vars.val, char = char, name = name)\n\n\n@auth.requires_login()\ndef insert_situation_mod():\n char_id = get_char()\n if not db.chars[char_id] or (db.chars[char_id].player != auth.user.id\n and db.chars[char_id].master != auth.user.id):\n redirect(URL(f='index'))\n situation_mod_types = {'shoot_distance': 'float',\n 'situation_mod': 'float',\n 'magnification': 'float',\n 'braced': 'bool',\n 'burst': 'str'}\n vars = situation_mod_types.keys()\n query = [((db.state_mods.char==char_id) & (db.state_mods.name==i)) for i in vars]\n\n for i, var in enumerate(vars):\n if request.vars.get(var):\n db.state_mods.update_or_insert(query[i],\n value=request.vars.get(var), char = char_id, name = var, type = situation_mod_types[var])\n response.js = \"jQuery('#view_weapons').get(0).reload()\"\n fields = [Field('shoot_distance', 'integer', default=0, label = 'Distance', requires=IS_NOT_EMPTY())]\n fields.append(Field('situation_mod', 'integer', default=0, label = 'Situation Mod', requires=IS_NOT_EMPTY()))\n fields.append(Field('magnification', 'integer', default=1, label = 'Magnification', requires=IS_IN_SET([1, 2, 4, 8])))\n fields.append(Field('braced', 'boolean', default=False, label = 'Braced'))\n fields.append(Field('burst', 'string', default='None', label = 'Burst', requires=IS_IN_SET(['None','Narrow Shot','Wide Shot','Narrow Burst','Wide Burst','Narrow Auto','Wide Auto'])))\n form = SQLFORM.factory(*fields)\n for var in vars:\n form.element(_name=var)['_onblur']=\"ajax('/gabaros/view_char/insert_situation_mod', \" \\\n \"['{}'], '')\".format(var)\n if form.process().accepted:\n for i, var in enumerate(vars):\n if form.vars.get(var) is not None:\n db.state_mods.update_or_insert(query[i],\n value=form.vars.get(var), char = char_id, name = var, type = situation_mod_types[var])\n response.js = \"jQuery('#view_weapons').get(0).reload()\"\n for i,var in enumerate(vars):\n valpair = db(query[i]).select(db.state_mods.value, db.state_mods.type).first()\n if valpair:\n val = convert(valpair.value, valpair.type)\n form.element(_name=var).update(_value=val)\n return dict(form = form)\n\n\n@auth.requires_login()\ndef view_actions():\n char_id = get_char()\n char_property_getter = basic.CharPhysicalPropertyGetter(basic.Char(db, char_id))\n psythresh = char_property_getter.get_psycho_thresh()\n combat = db(db.actions.char==char_id).select(db.actions.combat).last()\n if combat:\n combat = combat.combat\n if session.combat:\n combat = session.combat\n else:\n combat = 1\n fields = [Field('combat', type = 'reference combats', requires = IS_IN_DB(db,db.combats.id,'%(name)s'), default = combat)]\n form = SQLFORM.factory(*fields)\n if form.process().accepted:\n combat = int(form.vars.combat)\n session.combat = combat\n combat_name = None\n rows = db(db.combats.id == combat).select(db.combats.name).first()\n if rows:\n combat_name = rows.name\n reaction = int(round(char_property_getter.get_reaction()))\n actions = ['Free', 'Simple', 'Complex']\n action_costs = {i: int(round(char_property_getter.get_actioncost(i))) for i in actions}\n action_buttons = {i: A(i, callback=URL('perform_action', args=[i, combat]),\n target = 'next_action', _class='btn') for i in actions}\n reaction_button = A(\"Reaction ({})\".format(reaction),\n callback=URL('roll_button', args=[char_id, 'Reaction', reaction, 1, psythresh]), _class='btn', _title = 'test')\n action_history = get_action_history(char_id, combat)\n return dict(reaction_button=reaction_button, actions=actions, action_costs=action_costs, action_buttons=action_buttons, action_history = action_history, form=form, combat_name = combat_name)\n\n\ndef get_action_history(char_id, combat):\n data = db((db.actions.char==char_id) & (db.actions.combat==combat)).select(db.actions.action, db.actions.cost)\n action_history = [['Action ', 'Cost ', 'Phase ']]\n phase = 0\n for row in data:\n action_history.append([row.action, int(round(row.cost)), int(round(phase))])\n phase += int(round(row.cost))\n return CAT(H3('Next Action: ', B('{}'.format(int(round(phase))))), P(), TABLE(*([TR(*[TH(i) for i in rows]) for rows in action_history[:1]]+[TR(*rows) for rows in reversed(action_history[1:])]),_class = 'table table-striped table-condensed'))\n\n\n@auth.requires_login()\ndef perform_action():\n char_id = get_char()\n action = request.args(0)\n combat = request.args(1)\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id))\n action_cost = char_property_getter.get_actioncost(action)\n db.actions.insert(char=int(char_id), combat=combat, action=action, cost=action_cost)\n action_history = get_action_history(char_id, combat)\n return action_history\n\n\n@auth.requires_login()\ndef view_bodyparts():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id))\n table = char_property_getter.get_bodypart_table()\n return dict(table=table)\n\n\n@auth.requires_login()\ndef view_stats():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='stateful')\n char_physical_property_getter = basic.CharPhysicalPropertyGetter(basic.Char(db, char_id), modlevel='stateful')\n stats = OrderedDict()\n stats['Maximum Life'] = int(round(char_property_getter.get_maxlife()))\n stats['Action Multiplier'] = round(char_physical_property_getter.get_actionmult(),2)\n stats['Physical Reaction'] = int(round(char_physical_property_getter.get_reaction()))\n stats['Standing Jump Distance'] = round(char_physical_property_getter.get_jump_distance(False),2)\n stats['Running Jump Distance'] = round(char_physical_property_getter.get_jump_distance(True),2)\n stats['Standing Jump Height'] = round(char_physical_property_getter.get_jump_height(False),2)\n stats['Running Jump Height'] = round(char_physical_property_getter.get_jump_height(True),2)\n speed = [round(i,2) for i in char_physical_property_getter.get_speed()]\n stats['Walk Speed'] = speed[0]\n stats['Run Speed'] = speed[1]\n stats['Sprint Speed'] = speed[2]\n stats['Psychological Threshold'] = round(char_property_getter.get_psycho_thresh(),2)\n drain_resist = round(char_property_getter.get_drain_resist(),2)\n drain_percent = round(rules.resist_damage(100., drain_resist, 0),2)\n stats['Sponataneous Modification Maximum'] = round(char_property_getter.get_spomod_max(),2)\n stats['Drain Resistance'] = \"{} / {}%\".format(drain_resist, drain_percent)\n for part in ['Body', 'Head', 'Upper Torso', 'Lower Torso', 'Right Arm', 'Left Arm', 'Right Leg', 'Left Leg']:\n stats['Wound Limit {}'.format(part)] = round(char_physical_property_getter.char_body.bodyparts[part].get_woundlimit(),2)\n return dict(stats=stats)\n\n\n@auth.requires_login()\ndef view_armor():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='stateful')\n armors = char_property_getter.get_armor()\n armor_table = [['Bodypart'] + [armor.name for armor in armors] + ['Total']]\n bodyparts = data.main_bodyparts\n damage_types = ['ballistic','impact']\n for bodypart in bodyparts:\n template = [bodypart]\n for armor in armors:\n template.append('{}/{}'.format(int(round(armor.get_protection(bodypart, damage_types[0]))),\n int(round(armor.get_protection(bodypart, damage_types[1])))))\n template.append('{}/{}'.format(int(round(char_property_getter.get_protection(bodypart, damage_types[0]))),\n int(round(char_property_getter.get_protection(bodypart, damage_types[1])))))\n armor_table.append(template)\n return dict(armor_table=armor_table)\n\n\n@auth.requires_login()\ndef view_damage_state():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='stateful')\n wounds = char_property_getter.char.wounds\n damage = char_property_getter.char.damage\n maxlife = char_property_getter.get_maxlife()\n damage_attribute_mod = char_property_getter.get_damagemod('relative')\n damage_skill_mod = char_property_getter.get_damagemod('absolute')\n return dict(wounds=wounds, damage=damage, maxlife=maxlife, damage_attribute_mod = damage_attribute_mod, damage_skill_mod=damage_skill_mod)\n\n\n@auth.requires_login()\ndef apply_damage():\n char_id = get_char()\n fields = [Field('kind', 'string', requires=IS_IN_SET(data.damagekinds_dict.keys()), default = 'physical',\n label = 'Damage Kind'),\n Field('damage', 'integer', default=0, label = 'Damage'),\n Field('penetration', 'integer', default=0, label = 'Penetration'),\n Field('bodypart', 'string', requires=IS_IN_SET(['Body'] + data.main_bodyparts), default = 'Body'),\n Field('typ', 'string', requires=IS_IN_SET(['ballistic','impact', 'none']), default = 'ballistic'),\n Field('percent', 'boolean', default = False),\n Field('resist', 'str', requires=IS_IN_SET(['', 'Willpower', 'Body']), default = ''),\n Field('wounding', 'boolean', default = True)]\n form = SQLFORM.factory(*fields, table_name = 'damage_apply')\n if form.process().accepted:\n char = basic.Char(db, char_id)\n char_property_putter = basic.CharPropertyPutter(char)\n if form.vars.resist or form.vars.kind in ['drain stun', 'drain physical']:\n die_roll = roll(char_id, 0, 'Resist', True)\n resist = form.vars.resist\n resist_roll = die_roll\n else:\n resist = form.vars.resist\n resist_roll = None\n damage_text = char_property_putter.put_damage(form.vars.damage,\n form.vars.penetration,\n form.vars.bodypart,\n form.vars.kind,\n form.vars.typ,\n form.vars.percent,\n resist,\n resist_roll,\n form.vars.wounding\n )\n response.flash = damage_text\n response.js = \"jQuery('#view_damage_state').get(0).reload()\"\n elif form.errors:\n response.flash = 'form has errors'\n return dict(form=form)\n\n\n@auth.requires_login()\ndef heal_damage():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='stateful')\n wounds = char_property_getter.char.wounds\n wounds = ['{},{}'.format(location, kind) for location, values in wounds.items() for kind in values]\n damage = char_property_getter.char.damage\n damage = damage.keys()\n fields = [Field('heal_time', 'string',\n label = 'Healing Time'),\n Field('med_test', 'integer', default=0, label = 'Medical Care Test'),]\n form = SQLFORM.factory(*fields, table_name = 'rest')\n fields2 = [Field('damage_healed', 'float', default = 0, label = 'Damage Healed'),\n Field('damage_kind', 'string', requires=IS_IN_SET(damage), label = 'Damage Kind'),]\n form2 = SQLFORM.factory(*fields2, table_name = 'heal_damage')\n fields3 = [Field('wounds_healed', 'integer', requires=IS_IN_SET([1,2,3,4,5]), default = 1, label = 'Wounds Healed'),\n Field('location', 'string', requires=IS_IN_SET(wounds), label = 'Location and Damage Kind')]\n form3 = SQLFORM.factory(*fields3, table_name = 'heal_wounds')\n fields4 = [Field('first_aid_test', 'float',label = 'First Aid Test')]\n form4 = SQLFORM.factory(*fields4, table_name = 'first_aid')\n if form.process(formname='form_one').accepted:\n char = basic.Char(db, char_id)\n char_property_putter = basic.CharPropertyPutter(char)\n die_roll = roll(char_id, 0, 'Rest', True)\n text = char_property_putter.rest(form.vars.heal_time,\n form.vars.med_test,\n die_roll\n )\n response.flash = text\n response.js = \"jQuery('#view_damage_state').get(0).reload()\"\n elif form.errors:\n response.flash = 'form has errors'\n\n\n if form2.process(formname='form_two').accepted:\n char = basic.Char(db, char_id)\n char_property_putter = basic.CharPropertyPutter(char)\n text = char_property_putter.heal_damage(form2.vars.damage_healed,\n form2.vars.damage_kind\n )\n response.flash = text\n response.js = \"jQuery('#view_damage_state').get(0).reload()\"\n elif form.errors:\n response.flash = 'form has errors'\n\n\n if form3.process(formname='form_three').accepted:\n char = basic.Char(db, char_id)\n char_property_putter = basic.CharPropertyPutter(char)\n text = char_property_putter.heal_wounds(int(form3.vars.wounds_healed),\n form3.vars.location\n )\n response.flash = text\n response.js = \"jQuery('#view_damage_state').get(0).reload()\"\n elif form.errors:\n response.flash = 'form has errors'\n\n if form4.process(formname='form_four').accepted:\n char = basic.Char(db, char_id)\n char_property_putter = basic.CharPropertyPutter(char)\n text = char_property_putter.first_aid(form4.vars.first_aid\n )\n response.flash = text\n response.js = \"jQuery('#view_damage_state').get(0).reload()\"\n elif form.errors:\n response.flash = 'form has errors'\n return dict(form=form, form2 = form2, form3=form3, form4=form4)\n\n\n@auth.requires_login()\ndef chat():\n char_id = get_char()\n player = db.chars[char_id].name\n form=LOAD('view_char', 'ajax_form', args=char_id, ajax=True)\n script=SCRIPT(\"\"\"\n var text = ''\n jQuery(document).ready(function(){\n var callback = function(e){alert(e.data);\n text = e.data + '<br>' + text;\n document.getElementById('text').innerHTML = text;};\n if(!$.web2py.web2py_websocket('ws://127.0.0.1:8888/realtime/\"\"\" + str(player) + \"\"\"', callback))\n alert(\"html5 websocket not supported by your browser, try Google Chrome\");\n });\"\"\")\n return dict(form=form, script=script)\n\n\n@auth.requires_login()\ndef ajax_form():\n char_id = get_char()\n master = db.chars[char_id].master\n charname = db.chars[char_id].name\n now = datetime.datetime.now().time()\n form=SQLFORM.factory(Field('message'))\n if form.accepts(request,session):\n from gluon.contrib.websocket_messaging import websocket_send\n message = '{}:{} <b>{}</b>: {}'.format(now.hour, now.minute, charname, form.vars.message)\n websocket_send('http://127.0.0.1:8888', message, 'mykey', master)\n return form\n\n\n@auth.requires_login()\ndef view_xp():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='unaugmented')\n xp = char_property_getter.get_total_exp()\n totalxp = sum(xp.values())\n return dict(totalxp=totalxp, xp=xp)\n\n\n@auth.requires_login()\ndef view_cost():\n char_id = get_char()\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id), modlevel='stateful')\n cost = char_property_getter.get_total_cost()\n totalcost = sum(cost.values())\n return dict(totalcost=totalcost, cost=cost)\n\ndef view_magic():\n char_id = get_char()\n char = basic.Char(db, char_id)\n\n skills = [[\"Skill\", \"Test\", \"Secret\"]]\n magicskills = ['Assensing', 'Astral Combat', 'Sorcery', 'Spellcasting', 'Counterspelling', 'Ritual Magic',\n 'Invocation', 'Binding', 'Banishing', 'Summoning', 'Alchemy', 'Metamagic']\n skilldepth_dict = {}\n char_property_getter = basic.CharPropertyGetter(basic.Char(db, char_id))\n psythresh = char_property_getter.get_psycho_thresh()\n for skill, skilldata in data.skills_dict.items():\n if skill in magicskills:\n skillname = skill\n skilldepth = skilldepth_dict.get(skilldata.parent, 0)\n skilldepth_dict[skill] = skilldepth + 1\n val = char_property_getter.get_skilltest_value(skill)\n button1 = A(\"{:.0f}\".format(val),\n callback=URL('roll_button', args=[char_id, skillname, val, 1, psythresh]), _class='btn')\n button2 = A(\"{:.0f}\".format(val),\n callback=URL('roll_button', args=[char_id, skillname, val, 0, psythresh]), _class='btn')\n if skilldepth == 0:\n skilltext = H3(skillname)\n elif skilldepth == 1:\n skilltext = H4(skillname)\n else:\n skilltext = skillname\n skills += [[skilltext, button1, button2]]\n \n view_damage_state = LOAD('view_char','view_damage_state.load',ajax=True, target = 'view_damage_state')\n apply_damage = LOAD('view_char','apply_damage.load',ajax=True, target = 'apply_damage')\n sidebar = wikify(['Spellcasting', 'Summoning'])\n return dict(skills=skills,\n view_damage_state=view_damage_state, \n apply_damage=apply_damage, sidebar=sidebar)\n"
},
{
"alpha_fraction": 0.6109036803245544,
"alphanum_fraction": 0.6112770438194275,
"avg_line_length": 17.217687606811523,
"blob_id": "54f4be14d1d1b9ad98984cbeffe44afe563459a4",
"content_id": "6190ffba13ebc349cea2a544c64873328ba48fe9",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2678,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 147,
"path": "/modules/tests/test_basic.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "import pytest\nimport basic\nimport data\n\n@pytest.fixture()\ndef db():\n\n class DBFunc():\n\n def generic(self, *args, **kwargs):\n pass\n\n def __getattr__(self, generic):\n return self.generic\n\n class DB(object):\n\n def generic(self, *args, **kwargs):\n pass\n\n def __getattr__(self, generic):\n self.db = DBFunc()\n return self.db\n\n db = DB()\n return db\n\n@pytest.fixture(params = ['base', 'unaugmented', 'augmented', 'temporary', 'stateful'])\ndef modlevel(request):\n return request.param\n\n@pytest.fixture(params = data.attributes_dict.keys())\ndef attribute(request):\n return request.param\n\n\n@pytest.fixture()\ndef load_char(charname = 'Testman', gender = 'Male', race = 'Human'):\n\n def load_char(self):\n self.name = charname\n self.gender = gender\n self.race = race\n char_property_getter = basic.CharPropertyGetter(self, 'base')\n for attribute in data.attributes_dict.keys():\n value = char_property_getter.get_attribute_value(attribute)\n self.attributes[attribute] = value\n\n for name, skill in data.skills_dict.items():\n self.skills[name] = 0\n\n\n return load_char\n\n\n@pytest.fixture()\ndef char(db, load_char, monkeypatch):\n\n monkeypatch.setattr(basic.Char, 'load_char', load_char)\n\n char = basic.Char(db, None)\n\n char.init_attributes()\n char.init_skills()\n\n return char\n\n\nclass TestChar():\n\n def test_init(self, db, load_char, monkeypatch):\n\n monkeypatch.setattr(basic.Char, 'load_char', load_char)\n\n char = basic.Char(db, None)\n\n char.init_attributes()\n char.init_skills()\n\n assert char.name == 'Testman'\n print(char.attributes)\n\n\nclass Computer():\n\n def test_init(self):\n pass\n\n\nclass Weapons():\n\n def test_init(self):\n pass\n\n\nclass Armor():\n\n def test_init(self):\n pass\n\n\nclass Ware():\n\n def test_init(self):\n pass\n\n\nclass CharWare():\n\n def test_init(self):\n pass\n\n\nclass Body():\n\n def test_init(self):\n pass\n\n\nclass CharBody():\n\n def test_init(self):\n pass\n\n\nclass Bodypart():\n\n def test_init(self):\n pass\n\n\nclass CharBodyoart():\n\n def test_init(self):\n pass\n\n\nclass TestCharPropertyGetter():\n\n def test_init(self, char, modlevel):\n charpropertygetter = basic.CharPropertyGetter(char, modlevel)\n assert charpropertygetter\n\n def test_get_attribute(self, char, modlevel, attribute):\n charpropertygetter = basic.CharPropertyGetter(char, modlevel)\n value = charpropertygetter.get_attribute_value(attribute)\n assert value\n"
},
{
"alpha_fraction": 0.5733025670051575,
"alphanum_fraction": 0.5764679908752441,
"avg_line_length": 40.245155334472656,
"blob_id": "6cbac0184b6abe04758a45554d7c87432eb21cd7",
"content_id": "d69513c583c0bab7310288596c985d2c4f273bf0",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72344,
"license_type": "permissive",
"max_line_length": 194,
"num_lines": 1754,
"path": "/modules/basic.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# !/usr/bin/env python\n# coding: utf8\n\nfrom gluon.debug import dbg\nimport collections\nimport data\nimport rules\nimport math\nimport logging\nlogger = logging.getLogger(\"web2py.app.gabaros\")\nlogger.setLevel(logging.DEBUG)\n\nclass Char(object):\n \"\"\"\n Basic character class,\n handles database access\n \"\"\"\n\n def __init__(self, db, char_id):\n \"\"\"\n :param char_id: the character id from the database\n \"\"\"\n self.db = db\n self.char_id = char_id\n self.name = None\n self.gender = None\n self.race = None\n self.attributes = {}\n self.skills = {}\n self.ware = []\n self.fixtures = []\n self.foci = []\n self.adept_powers = []\n self.items = []\n self.all_items = []\n self.all_items_dict = {}\n self.damage = {}\n self.wounds = {}\n self.spells = []\n self.metamagic = []\n self.money = []\n self.xp = []\n self.contacts = []\n self.sins = []\n self.load_char()\n\n def init_attributes(self):\n char_property_getter = CharPropertyGetter(self, 'base')\n for attribute in data.attributes_dict.keys():\n value = char_property_getter.get_attribute_value(attribute)\n self.attributes[attribute] = value\n self.db.char_attributes.bulk_insert([{'char': self.char_id, 'attribute': attribute, 'value': value}])\n\n def init_skills(self):\n for name, skill in data.skills_dict.items():\n self.db.char_skills.bulk_insert([{'char': self.char_id, 'skill': name, 'value': 0}])\n\n def load_char(self):\n \"\"\"\n\n Load all character data from database\n \"\"\"\n row = self.db.chars[self.char_id]\n self.name = row.name\n self.gender = row.gender\n self.race = row.race\n self.load_attributes()\n self.load_skills()\n self.load_ware()\n self.load_fixtures()\n self.load_damage()\n self.load_wounds()\n self.load_items()\n self.load_upgrades()\n self.load_foci()\n self.load_spells()\n self.load_metamagic()\n self.load_adept_powers()\n self.load_xp()\n self.load_money()\n self.load_contacts()\n self.load_sins()\n\n def load_xp(self):\n db_cx = self.db.char_xp\n for row in self.db(db_cx.char == self.char_id).select(db_cx.xp, db_cx.usage, db_cx.timestamp):\n self.xp.append([row.xp, row.usage, row.timestamp])\n\n def load_money(self):\n db_cm = self.db.char_money\n for row in self.db(db_cm.char == self.char_id).select(db_cm.money, db_cm.usage, db_cm.timestamp):\n self.money.append([row.money, row.usage, row.timestamp])\n for entry in self.xp:\n if entry[1] == 'money':\n self.money.append([entry[0]*(-1)/rules.money_to_xp if entry[0] > 1 else entry[0] *(-1) *rules.xp_to_money , 'xp', entry[2]])\n\n def load_spells(self):\n db_cs = self.db.char_spells\n for row in self.db(db_cs.char == self.char_id).select(db_cs.spell):\n self.spells.append(row.spell)\n\n def load_metamagic(self):\n db_cm = self.db.char_metamagic\n for row in self.db(db_cm.char == self.char_id).select(db_cm.metamagic):\n self.metamagic.append(row.metamagic)\n\n def load_attributes(self):\n \"\"\"\n\n Load character attributes from database, if not present, use 30\n \"\"\"\n db_ca = self.db.char_attributes\n if not self.db(db_ca.char == self.char_id).select().first():\n self.init_attributes()\n for row in self.db(db_ca.char == self.char_id).select(db_ca.attribute, db_ca.value):\n self.attributes[row.attribute] = row.value\n\n def load_skills(self):\n \"\"\"\n\n Load char skills from database, if not present, use 0\n \"\"\"\n db_cs = self.db.char_skills\n if not self.db(db_cs.char == self.char_id).select().first():\n self.init_skills()\n for row in self.db(db_cs.char == self.char_id).select(db_cs.skill, db_cs.value):\n self.skills[row.skill] = row.value\n\n def load_damage(self):\n db_cd = self.db.char_damage\n self.damage = {}\n for row in self.db(db_cd.char == self.char_id).select(db_cd.damagekind, db_cd.value):\n self.damage[row.damagekind] = row.value\n\n def load_wounds(self):\n db_cw = self.db.char_wounds\n self.wounds = collections.defaultdict(dict)\n for row in self.db(db_cw.char == self.char_id).select(db_cw.bodypart, db_cw.damagekind, db_cw.value):\n self.wounds[row.bodypart].update({row.damagekind: row.value})\n\n def load_ware(self):\n \"\"\"\n\n Load character ware\n \"\"\"\n db_cw = self.db.char_ware\n for row in self.db(db_cw.char == self.char_id).select(db_cw.ware, db_cw.id, db_cw.active):\n self.ware.append(CharWare(self.db, row.ware, row.id, self, row.active))\n\n def load_fixtures(self):\n \"\"\"\n\n Load character fixtures\n \"\"\"\n db_cf = self.db.char_fixtures\n for row in self.db(db_cf.char == self.char_id).select(db_cf.fixture):\n self.fixtures.append(CharFixture(row.fixture, self))\n\n def load_adept_powers(self):\n db_cap = self.db.char_adept_powers\n for row in self.db(db_cap.char == self.char_id).select(db_cap.power):\n self.adept_powers.append(CharAdeptPower(self.db, row.power, self))\n\n def get_loadout(self):\n loadout = self.db(self.db.char_loadout.char == self.char_id).select(self.db.char_loadout.value).first()\n if loadout:\n self.loadout = loadout.value\n else:\n self.loadout = 0\n\n def load_items(self):\n db_ci = self.db.char_items\n for row in self.db(db_ci.char == self.char_id).select(db_ci.id, db_ci.item, db_ci.rating):\n self.all_items.append(Item(row.item, row.id, row.rating))\n self.all_items_dict[row.id] = self.all_items[-1]\n else:\n self.get_loadout()\n for row in self.db((db_ci.char == self.char_id) & (db_ci.loadout.contains(self.loadout))).select(db_ci.id):\n self.items.append(self.all_items_dict[row.id])\n\n def load_upgrades(self):\n db_iu = self.db.item_upgrades\n for row in self.db(db_iu.char == self.char_id).select(db_iu.item, db_iu.upgrade):\n item_id = row.item\n upgrade_id = row.upgrade\n self.all_items_dict[item_id].upgrades.append(self.all_items_dict[upgrade_id])\n\n def load_foci(self):\n foci = [item.name for item in self.items if data.gameitems_dict[item.name].clas == 'Focus']\n self.foci = [CharFocus(self.db, name, self) for name in foci]\n\n def load_contacts(self):\n db_cc = self.db.char_contacts\n for row in self.db(db_cc.char == self.char_id).select(db_cc.loyalty, db_cc.name, db_cc.starting):\n if row.starting:\n self.contacts.append((row.loyalty, row.name.rating))\n\n def load_sins(self):\n db_cs = self.db.char_sins\n for row in self.db(db_cs.char == self.char_id).select(db_cs.rating, db_cs.permits):\n self.sins.append((row.rating, row.permits))\n\n def write_attribute(self, attribute, value):\n db_ca = self.db.char_attributes\n self.db((db_ca.char == self.char_id) & (db_ca.attribute == attribute)).update(value=value)\n\n def write_skill(self, skill, value):\n db_cs = self.db.char_skills\n self.db((db_cs.char == self.char_id) & (db_cs.skill == skill)).update(value=value)\n\n def write_damage(self, kind, value):\n db_cd = self.db.char_damage\n if value:\n db_cd.update_or_insert((db_cd.char == self.char_id) & (db_cd.damagekind == kind),\n value=value,\n char = self.char_id,\n damagekind = kind)\n else:\n self.db((db_cd.char == self.char_id) & (db_cd.damagekind == kind)).delete()\n\n def write_wounds(self, number, bodypart, kind):\n db_cw = self.db.char_wounds\n if number:\n db_cw.update_or_insert((db_cw.char == self.char_id) & (db_cw.damagekind == kind) &\n (db_cw.bodypart == bodypart),\n value=number,\n char = self.char_id,\n damagekind = kind,\n bodypart = bodypart)\n else:\n self.db((db_cw.char == self.char_id) & (db_cw.damagekind == kind) & (db_cw.bodypart == bodypart)).delete()\n\n @staticmethod\n def write_ware(ware):\n ware.write()\n\n @staticmethod\n def delete_ware(ware):\n ware.delete()\n\n def delete_damage(self, damage, value):\n pass\n\n def ware_fix_power_effect(self, primary, secondary, value, func = None, modlevel = 'augmented'):\n for adept_power in self.adept_powers:\n for effect in adept_power.effects:\n if effect[0] == primary and effect[1] == secondary:\n magic = CharPropertyGetter(self, 'stateful').get_attribute_value('Magic')\n formula = effect[2].format(Value = adept_power.value, Magic = magic)\n if not func:\n value = eval('value {}'.format(formula))\n else:\n value = eval(func.format(formula))\n for ware in self.ware:\n if ware.active:\n for effect in ware.effects:\n if effect[0] == primary and effect[1] == secondary:\n if not func:\n value = eval('value {}'.format(effect[2]))\n else:\n value = eval(func.format(effect[2]))\n for fixture in self.fixtures:\n for effect in fixture.effects:\n if effect[0] == primary and effect[1] == secondary:\n if not func:\n value = eval('value {}'.format(effect[2]))\n else:\n value = eval(func.format(effect[2]))\n if modlevel in ('temporary', 'stateful'):\n for focus in self.foci:\n for effect in focus.effects:\n if effect[0] == primary and effect[1] == secondary:\n if not func:\n value = eval('value {}'.format(effect[2].format(Rating=focus.rating)))\n else:\n value = eval(func.format(effect[2].format(Rating=focus.rating)))\n return value\n\n\nclass Item(object):\n def __init__(self, name, db_id, rating = None):\n self.name = name\n self.rating = rating\n self.upgrades = []\n\n def get_cost(self):\n ratingcost = 0\n if self.rating:\n cost = data.gameitems_dict[self.name].rating\n ratingcost = rules.price_by_rating(cost,self.rating)\n return data.gameitems_dict[self.name].cost + ratingcost\n\nclass Computer(object):\n def __init__(self, db, computer_id, char):\n self.db = db\n self.char = char\n self.computer_id = computer_id\n self.name = ''\n self.attributes = {}\n self.programmes = {}\n self.damage = []\n self.mode = None\n self.actions = data.matrix_actions_dict\n self.load_attributes()\n self.load_programmes()\n self.char_property_getter = CharPropertyGetter(self.char)\n\n def load_attributes(self):\n db_cc = self.db.char_computers\n row = self.db(db_cc.id == self.computer_id).select(db_cc.item,\n db_cc.firewall,\n db_cc.current_uplink,\n db_cc.damage).first()\n self.attributes['Current Uplink'] = row.current_uplink\n self.attributes['Firewall'] = row.firewall\n self.damage = row.damage\n self.name = row.item.item\n self.attributes['System'] = data.computer_dict[self.name].System\n self.attributes['Processor'] = data.computer_dict[self.name].Processor\n self.attributes['Signal'] = data.computer_dict[self.name].Signal\n self.attributes['Uplink'] = data.computer_dict[self.name].Uplink\n\n def load_programmes(self):\n db_cg = self.db.char_items\n rows = self.db((db_cg.char == self.char.char_id) &\n (db_cg.item in data.programmes_dict.keys())).select(db_cg.item,db_cg.rating)\n for row in rows:\n self.programmes[row.item] = row.rating\n\n def load_damage(self):\n db_cc = self.db.char_computers\n row = self.db(db_cc.id == self.computer_id).select(db_cc.damage).first()\n self.damage = row.damage\n\n def get_action_value(self, action):\n programme = self.actions[action].programme\n if programme:\n programme_value = self.programmes.get(programme,0)\n attribute = data.programmes_dict[programme].attribute\n attribute_value = self.attributes[attribute]\n skill = data.programmes_dict[programme].skill\n skill_value = self.char_property_getter.get_skilltest_value(skill)\n value = rules.matrix_action_rating(programme_value, attribute_value, skill_value)\n else:\n value = None\n return value\n\n\nclass CloseCombatWeapon(object):\n def __init__(self, name, char):\n self.char = char\n self.name = name\n self.char_property_getter = CharPropertyGetter(self.char)\n self.skill = ''\n self.skillmod = 0\n self.minstr = 0\n self.recoil = 0\n self.damage = 0\n self.penetration = 0\n self.get_attributes()\n\n def get_attributes(self):\n weapon_tuple = data.closecombatweapons_dict[self.name]._asdict()\n for key, value in weapon_tuple.items():\n setattr(self, key, value)\n for attribute in ('damage', 'penetration'):\n if isinstance(getattr(self, attribute), str):\n setattr(self, attribute,\n round(eval(getattr(self, attribute).format(Strength=self.char_property_getter.get_attribute_value('Strength')))))\n\n def get_net_skill_value(self):\n minstr_mod = rules.weapon_minstr_mod(self.minstr, self.char_property_getter.get_attribute_value('Strength'))\n net_skill_value = self.char_property_getter.get_skill_value(self.skill) + self.skillmod - minstr_mod\n return net_skill_value\n\n def get_damage(self, cc_mod):\n damage = []\n skill = self.char_property_getter.get_skilltest_value(self.skill)\n minstr_mod = rules.weapon_minstr_mod(self.minstr, self.char_property_getter.get_attribute_value('Strength'))\n net_value = skill - minstr_mod - cc_mod + self.skillmod\n result = net_value\n if net_value > 0:\n damage.append((rules.weapondamage(self.damage, net_value), rules.damage_location()))\n return damage, {'minimum strength mod': minstr_mod, 'weapon skill mod': self.skillmod,\n 'skill': skill, 'other mods': cc_mod, 'result': result, 'difficulty': 0.}\n\n\nclass RangedWeapon(object):\n def __init__(self, name, char, upgrades=None):\n self.char = char\n self.name = name\n self.char_property_getter = CharPropertyGetter(self.char)\n self.range = 0\n self.skill = ''\n self.skillmod = 0\n self.minstr = 0\n self.recoil = 0\n self.damage = 0\n self.penetration = 0\n self.shot = None\n self.burst = None\n self.auto = None\n self.special = {}\n if not upgrades:\n self.upgrades = []\n else:\n self.upgrades = upgrades\n self.get_attributes()\n self.get_standard_upgrades()\n\n def get_standard_upgrades(self):\n if self.special:\n upgrades = self.special.get('upgrades', [])\n else:\n upgrades = []\n upgrades = [Item(i, None, None) for i in upgrades]\n self.upgrades.extend(upgrades)\n self.upgrade_names = [i.name for i in self.upgrades]\n if 'Gas Vent' in self.upgrade_names:\n self.recoil *= rules.gas_vent_recoil\n\n\n def get_attributes(self):\n weapon_tuple = data.rangedweapons_dict[self.name]._asdict()\n for key, value in weapon_tuple.items():\n setattr(self, key, value)\n for attribute in ('damage', 'penetration', 'range'):\n if isinstance(getattr(self, attribute), str):\n setattr(self, attribute,\n round(eval(getattr(self, attribute).format(Strength=self.char_property_getter.get_attribute_value('Strength')))))\n self.recoil = rules.recoil_by_strength(self.recoil, self.char_property_getter.get_attribute_value('Strength'), self.minstr)\n if not self.special:\n self.special = {}\n\n def get_shooting_difficulty(self, distance, magnification=1., burst = False):\n if burst == 'Wide Shot':\n wide_burst_bullets = self.shot\n elif burst == 'Wide Burst':\n wide_burst_bullets = self.burst\n elif burst == 'Wide Auto':\n wide_burst_bullets = self.auto\n else:\n wide_burst_bullets = 0\n return rules.shooting_difficulty(self.range, magnification, distance, 2, wide_burst_bullets)\n\n def get_net_skill_value(self, braced = False):\n if not braced:\n minstr_mod = rules.weapon_minstr_mod(self.minstr, self.char_property_getter.get_attribute_value('Strength'))\n else:\n minstr_mod = 0\n net_skill_value = self.char_property_getter.get_skilltest_value(self.skill) + self.skillmod - minstr_mod\n return net_skill_value\n\n def get_damage(self, shoot_mod, distance, magnification = 1., size = 2., braced = False, burst=False):\n damage = []\n range_mod = rules.shoot_rangemod(self.range, distance)\n sight_mod = rules.visible_perception_mod(size, distance, magnification)\n skill = self.char_property_getter.get_skilltest_value(self.skill)\n if not braced:\n minstr_mod = rules.weapon_minstr_mod(self.minstr, self.char_property_getter.get_attribute_value('Strength'))\n else:\n minstr_mod = 0\n if burst == 'Wide Shot':\n wide_burst_mod = self.shot\n elif burst == 'Wide Burst':\n wide_burst_mod = self.burst\n elif burst == 'Wide Auto':\n wide_burst_mod = self.auto\n else:\n wide_burst_mod = 0\n net_value = -rules.shoot_base_difficulty + skill - minstr_mod - range_mod - sight_mod - shoot_mod + self.skillmod - wide_burst_mod\n result = net_value\n if burst == 'Narrow Shot':\n bullets = self.shot\n elif burst == 'Narrow Burst':\n bullets = self.burst\n elif burst == 'Narrow Auto':\n bullets = self.auto\n else:\n bullets = 1\n while net_value >= 0 and bullets:\n damage.append(((rules.weapondamage(self.damage, net_value)), rules.damage_location()))\n net_value -= self.recoil\n bullets -= 1\n return damage, {'difficulty': rules.shoot_base_difficulty, 'weapon range mod': range_mod,\n 'sight range mod': sight_mod, 'minimum strength mod': minstr_mod,\n 'skill': skill, 'other mods': shoot_mod, 'result': result, 'wide burst mod': wide_burst_mod}\n\n\nclass Armor(object):\n def __init__(self, name):\n self.name = name\n\n def get_locations(self):\n return data.armor_dict[self.name].locations\n\n def get_max_agi(self):\n return data.armor_dict[self.name].maxagi\n\n def get_coordination_mult(self):\n return data.armor_dict[self.name].coordmult\n\n def get_protection(self, bodypart, typ = 'ballistic'):\n map_dict = {'ballistic': 0,\n 'impact': 1}\n locations = data.armor_dict[self.name].locations\n index = locations.index(bodypart) if bodypart in locations else None\n protection = 0\n if index is not None:\n protection = data.armor_dict[self.name].protections[index][map_dict[typ]]\n return protection\n\n#class CharMatrix(Char):\n# def __init__(self, db, char, computer=None):\n# Char.__init__(self, db, char)\n# self.computer = Computer(computer)\n#\n#\n#class CharAstral(Char):\n# def __init__(self, db, char):\n# \"\"\"\"\n#\n# :param char: the character for witch to get the attribute\n# \"\"\"\n# Char.__init__(self, db, char)\n#\n#\nclass Loadout(Char):\n def __init__(self, db, char):\n \"\"\"\"\n\n :param char: the character for witch to get the attribute\n \"\"\"\n Char.__init__(self, db, char)\n\n\nclass SkillTree(object):\n def __init__(self):\n self.tree_dict = {}\n\n def load_data(self):\n pass\n\n def get_skill(self, name):\n pass\n\n\nclass Skill(object):\n def __init__(self, name, parent, attribmods):\n self.name = name\n self.parent = parent\n self.attribmods = attribmods\n\n\nclass Fixture(object):\n def __init__(self, name):\n self.name = name\n self.location = None\n self.relative_capacity = None\n self.absolute_capacity = None\n self.weight = None\n self.description = None\n self.cost = None\n self.effects = None\n self.load_basic_data()\n\n def load_basic_data(self):\n fixture = data.fixtures_dict[self.name]\n self.location = fixture.location\n self.relative_capacity = fixture.relative_capacity\n self.absolute_capacity = fixture.absolute_capacity\n self.weight = fixture.weight\n self.cost = fixture.cost\n self.effects = fixture.effects\n self.description = fixture.description\n\n def get_cost(self):\n return self.cost\n\nclass CharFixture(Fixture):\n def __init__(self, fixture_name, char):\n Fixture.__init__(self, fixture_name)\n self.char = char\n\n def get_capacity_dict(self):\n capacity = {}\n char_body = CharBody(self.char)\n for location in self.location:\n capacity[location] = (self.absolute_capacity +\n self.relative_capacity *\n char_body.bodyparts[location].get_attribute_absolute('Weight', 'augmented'))\n return capacity\n\n\n\nclass Ware(object):\n def __init__(self, db, name):\n self.db = db\n self.name = name\n self.kind = None\n self.essence = None\n self.part_weight = None\n self.additional_weight = None\n self.description = None\n self.basecost = None\n self.cost = None\n self.parts = None\n self.effects = None\n self.location = None\n self.capacity = None\n self.load_basic_data()\n\n def load_basic_data(self):\n ware_nt = data.ware_dict[self.name]\n self.kind = ware_nt.kind\n self.essence = ware_nt.essence\n self.part_weight = ware_nt.part_weight\n self.additional_weight = ware_nt.additional_weight\n self.description = ware_nt.description\n self.basecost = ware_nt.basecost\n self.effectcost = ware_nt.effectcost\n self.partcost = ware_nt.partcost\n self.parts = ware_nt.parts\n self.effects = ware_nt.effects\n self.location = ware_nt.location\n self.capacity = ware_nt.capacity\n\nclass CharWare(Ware):\n def __init__(self, db, ware_name, db_id, char, active):\n Ware.__init__(self, db, ware_name)\n self.db_id = db_id\n self.char = char\n self.stats = {}\n self.load_extra_data()\n self.active = active\n #self.weight = self.calc_absolute_weight()\n\n def init_stats(self):\n char_property_getter = CharPropertyGetter(self.char, 'base')\n for name, attribute in data.attributes_dict.items():\n if attribute.kind == 'physical' or attribute.name == 'Weight':\n value = char_property_getter.get_attribute_value(attribute.name)\n self.db.char_ware_stats.bulk_insert([{'ware': self.db_id, 'stat': attribute.name, 'value': value}])\n essence_value = data.essence_by_ware[self.kind]\n self.db.char_ware_stats.bulk_insert([{'ware': self.db_id, 'stat': 'Essence', 'value': essence_value}])\n\n def load_extra_data(self):\n db_cws = self.db.char_ware_stats\n if not self.db(db_cws.ware == self.db_id).select().first():\n self.init_stats()\n for row in self.db(db_cws.ware == self.db_id).select(db_cws.stat, db_cws.value):\n self.stats[row.stat] = row.value\n\n def write(self):\n db_cw = self.db.char_ware\n if self.db_id is not None:\n self.db_id = db_cw.insert(char=self.char.char_id, ware=self.name)\n else:\n self.db(db_cw.id == self.db_id).update(char=self.char.char_id, ware=self.name)\n\n def delete(self):\n db_cw = self.db.char_ware\n self.db(db_cw.id == self.db_id).delete()\n\n# def calc_absolute_weight(self):\n# if '%' in str(self.additional_weight):\n# weight = getter_functions.CharPhysicalPropertyGetter(self.char, 'unaugmented').get_attribute_mod('weight')\n# weight *= float(self.additional_weight[:-1])\n# else:\n# weight = self.additional_weight\n# return weight\n\n def get_cost(self):\n essencemult = 1 - self.stats['Essence']/100.\n cost = rules.warecost(self.basecost, kind = self.kind)\n cost += rules.warecost(self.effectcost, essencemult=essencemult )\n if self.parts:\n char_property_getter = CharPropertyGetter(self.char, modlevel='base')\n size = char_property_getter.get_attribute_value('Size')\n weight_base = data.attributes_dict['Weight'].base\n size_base = data.attributes_dict['Size'].base\n weight = rules.calc_base_weight(weight_base, size, size_base)\n for part in self.parts:\n bodypart = char_property_getter.char_body.bodyparts[part].bodypart\n for attribute in ['Agility', 'Constitution', 'Coordination', 'Strength']:\n base = 30.\n if attribute == 'Agility':\n agility_base = data.attributes_dict['Agility'].base\n base = rules.calc_agility_base(agility_base, weight, weight_base)\n elif attribute == 'Strength':\n strength_base = data.attributes_dict['Strength'].base\n size_racemod = data.races_dict[char_property_getter.char.race].Weight**(1/3.)\n base = rules.calc_base_strength(strength_base, size*size_racemod, size_base, weight, weight_base)\n value = self.stats[attribute]\n frac = bodypart.get_fraction(attribute)\n cost += frac * rules.warecost(self.partcost,\n effectmult=value/base,\n essencemult=essencemult,\n kind=self.kind)\n return cost\n\n def get_essence_cost(self):\n cost = self.essence\n if self.parts:\n char_body = CharBody(self.char)\n for part in self.parts:\n cost += char_body.bodyparts[part].get_attribute_absolute('Essence', modlevel = 'basic')\n cost *= (1-self.stats['Essence']/100.)\n return cost\n\n def get_non_located_essence_cost(self):\n cost = self.essence\n cost *= (1-self.stats['Essence']/100.)\n return cost\n\n\nclass AdeptPower(object):\n def __init__(self, db, name):\n self.db = db\n self.name = name\n self.description = None\n self.cost = None\n self.effects = None\n self.formdescription = None\n self.load_basic_data()\n\n def load_basic_data(self):\n adept_powers_nt = data.adept_powers_dict[self.name]\n self.description = adept_powers_nt.description\n self.cost = adept_powers_nt.cost\n self.effects = adept_powers_nt.effects\n self.formdescription = adept_powers_nt.formdescription\n\nclass CharAdeptPower(AdeptPower):\n def __init__(self, db, adept_power_name, char):\n AdeptPower.__init__(self, db, adept_power_name)\n self.char = char\n self.value = None\n self.load_extra_data()\n\n def load_extra_data(self):\n db_cap = self.db.char_adept_powers\n for row in self.db((db_cap.char == self.char.char_id) & (db_cap.power == self.name)).select(db_cap.value):\n self.value = row.value\n\n def write(self):\n db_cap = self.db.char_adept_powers\n if self.db_id is not None:\n self.db_id = db_cap.insert(char=self.char.char_id, power=self.name, value=self.value)\n else:\n self.db((db_cap.char == self.char.char_id) & (db_cap.power == self.name)).update(char=self.char.char_id,\n power=self.name,\n value=self.value)\n def delete(self):\n db_cap = self.db.char_adept_powers\n self.db((db_cap.char == self.char.char_id) & (db_cap.power == self.name)).delete()\n\n def get_description(self):\n magic = CharPropertyGetter(self.char, 'augmented').get_attribute_value('Magic')\n formdesc = '{}: '.format(self.value)\n for entry in self.formdescription:\n formdesc += entry[0]\n formdesc += str(eval(entry[1].format(Magic = magic, Value = self.value)))\n formdesc += ' '\n return formdesc\n\n# def calc_absolute_weight(self):\n# if '%' in str(self.additional_weight):\n# weight = getter_functions.CharPhysicalPropertyGetter(self.char, 'unaugmented').get_attribute_mod('weight')\n# weight *= float(self.additional_weight[:-1])\n# else:\n# weight = self.additional_weight\n# return weight\n\n\nclass Focus(object):\n def __init__(self, db, name):\n self.db = db\n self.name = name\n self.effects = None\n self.load_basic_data()\n\n def load_basic_data(self):\n foci_nt = data.foci_dict[self.name]\n self.effects = foci_nt.effects\n\n\nclass CharFocus(Focus):\n def __init__(self, db, focus_name, char):\n Focus.__init__(self, db, focus_name)\n self.char = char\n self.rating = None\n self.load_extra_data()\n\n def load_extra_data(self):\n db_ci = self.db.char_items\n for row in self.db((db_ci.char == self.char.char_id) & (db_ci.item == self.name)).select(db_ci.rating):\n self.rating = row.rating\n\n\nclass Body(object):\n def __init__(self):\n self.bodyparts = {}\n for bodypart in data.bodyparts_dict:\n self.bodyparts[bodypart] = Bodypart(self, bodypart)\n for bodypart in self.bodyparts.values():\n bodypart.set_children()\n\n\nclass CharBody():\n def __init__(self, char):\n self.char = char\n self.bodyparts = {}\n self.body = Body()\n self.init_body()\n self.place_ware()\n self.place_fixtures()\n\n def init_body(self):\n self.place_bodypart(self.body.bodyparts['Body'], None)\n for part in data.bodyparts_dict:\n part = self.body.bodyparts[part]\n self.bodyparts[part.name] = CharBodypart(self.char,self, part, None, None)\n\n def place_ware(self):\n for ware in self.char.ware:\n if ware.parts:\n for part in ware.parts:\n self.place_bodypart(part, ware)\n\n def place_fixtures(self):\n for fixture in self.char.fixtures:\n for location in fixture.location:\n self.bodyparts[location].fixtures.append(fixture)\n\n def place_bodypart(self, part, ware):\n if isinstance(part, basestring):\n part = self.body.bodyparts[part]\n self.bodyparts[part.name] = CharBodypart(self.char, self, part, ware, None)\n for child in part.children:\n self.place_bodypart(child, ware)\n\n def get_bodypart_composition(self, name):\n pass\n\n def get_location_ware(self, name):\n pass\n\n def get_essence(self):\n pass\n\nBodyFractions = collections.namedtuple('BodyFraction',\n ['Weight', 'Size', 'Essence', 'Agility',\n 'Coordination', 'Strength', 'Constitution'])\n\n\nclass Bodypart(object):\n def __init__(self, body, name):\n self.body = body\n self.name = name\n self.template = None\n self.parent = None\n self.body_fractions = None\n self.children = []\n self.level = 0\n self.load_data()\n\n def load_data(self):\n bodypart_nt = data.bodyparts_dict[self.name]\n self.level = bodypart_nt.level\n self.template = bodypart_nt.template\n self.parent = self.body.bodyparts.get(bodypart_nt.parent, None)\n self.relative_body_fractions = BodyFractions(Weight=bodypart_nt.weightfrac,\n Size=bodypart_nt.sizefrac,\n Essence=bodypart_nt.essencefrac,\n Agility=bodypart_nt.agilityfrac,\n Coordination=bodypart_nt.coordinationfrac,\n Strength=bodypart_nt.strengthfrac,\n Constitution=bodypart_nt.constitutionfrac)\n if self.parent is None:\n self.body_fractions = self.relative_body_fractions\n else:\n self.body_fractions = BodyFractions(*[i*j for i,j in zip(self.relative_body_fractions, self.parent.body_fractions)])\n\n def set_children(self):\n self.children = [self.body.bodyparts[i.name] for i in data.bodyparts_dict.values() if i.parent == self.name]\n\n def get_fraction(self, attribute):\n return getattr(self.body_fractions, attribute)\n\n def get_kind(self):\n return 'unaugmented', 0., 0.\n\n\nclass CharBodypart():\n def __init__(self, char, char_body, bodypart, ware, fixtures):\n self.char_body = char_body\n self.char = char\n self.bodypart = bodypart\n self.ware = ware\n if fixtures:\n self.fixtures = fixtures\n else:\n self.fixtures = []\n self.wounds = char.wounds.get(bodypart.name, {})\n self.attributes = {}\n\n def get_capacity(self):\n capacity = 0\n if self.ware and self.ware.kind == 'cyberware':\n weight = self.get_attribute_absolute('Weight', 'augmented')\n capacity = weight * self.ware.capacity if self.ware.capacity else 0\n return capacity\n\n def get_used_capacity(self):\n used = 0\n if self.fixtures:\n weight = self.get_attribute_absolute('Weight', 'augmented')\n for fixture in self.fixtures:\n used += fixture.absolute_capacity + weight*fixture.relative_capacity\n for child in self.bodypart.children:\n used += self.char_body.bodyparts[child.name].get_used_capacity()\n return used\n\n def get_kind(self):\n if self.ware:\n if self.ware.kind == 'cyberware':\n return self.ware.kind, 1., 0.\n elif self.ware.kind == 'bioware':\n return self.ware.kind, 0., 1.\n elif self.bodypart.children:\n child_char_bodyparts = [self.char_body.bodyparts[child.name] for child in self.bodypart.children]\n weights = [part.get_attribute_absolute('Weight', modlevel='augmented') for part in child_char_bodyparts]\n kinds = [part.get_kind() for part in child_char_bodyparts]\n cyberweight = sum([weights[i]*kind[1] for i,kind in enumerate(kinds)])\n bioweight = sum([weights[i]*kind[2] for i,kind in enumerate(kinds)])\n cyberfrac = cyberweight/sum(weights)\n biofrac = bioweight/sum(weights)\n if cyberfrac > 0.5:\n kind = 'cyberware'\n elif biofrac > 0.5:\n kind = 'bioware'\n else:\n kind = 'unaugmented'\n return kind, cyberfrac, biofrac\n else:\n return self.bodypart.get_kind()\n\n def get_attribute_absolute(self, attribute, modlevel='stateful'):\n value = self.attributes.get((attribute, modlevel))\n if value:\n return value\n fraction = self.bodypart.get_fraction(attribute)\n if not fraction:\n return 0\n if self.bodypart.children:\n child_char_bodyparts = [self.char_body.bodyparts[child.name] for child in self.bodypart.children]\n value = sum([part.get_attribute_absolute(attribute, modlevel) for part in child_char_bodyparts])\n # calculate armor modifications\n if modlevel in ('stateful', 'temporary'):\n char_property_getter = CharPropertyGetter(self.char, modlevel = modlevel)\n if attribute == 'Agility':\n max_agis = []\n for armor in char_property_getter.get_armor(self.bodypart.name):\n max_agis.append(armor.get_max_agi())\n value /= fraction\n value = rules.get_armor_agility(value, max_agis)\n value *= fraction\n if attribute == 'Coordination':\n coord_mults = []\n for armor in char_property_getter.get_armor(self.bodypart.name):\n coord_mults.append(armor.get_coordination_mult())\n value = rules.get_armor_coordination(value, coord_mults)\n if modlevel == 'stateful':\n if self.wounds and attribute not in ('Size', 'Weight', 'Constitution', 'Essence'):\n weight = self.get_attribute_relative('Weight')\n constitution = self.get_attribute_relative('Constitution')\n value = rules.woundeffect(value, sum(self.wounds.values()), weight, constitution, self.bodypart.name)\n return value\n else:\n if attribute == 'Essence':\n value = 100.\n else:\n value = self.char.attributes[attribute]\n if modlevel in ('augmented', 'temporary', 'stateful'):\n if self.ware:\n value = self.ware.stats[attribute]\n if attribute != 'Magic':\n value = self.char.ware_fix_power_effect('attributes', attribute, value, modlevel=modlevel)\n if modlevel == 'stateful':\n if self.wounds and attribute not in ('Size', 'Weight', 'Constitution', 'Essence'):\n weight = self.get_attribute_relative('Weight')\n constitution = self.get_attribute_relative('Constitution')\n value = rules.woundeffect(value, sum(self.wounds.values()), weight, constitution, self.bodypart.name)\n value *= fraction\n self.attributes[(attribute, modlevel)] = value\n return value\n\n def get_life(self):\n if self.bodypart.children:\n child_char_bodyparts = [self.char_body.bodyparts[child.name] for child in self.bodypart.children]\n return sum([part.get_life() for part in child_char_bodyparts])\n else:\n kind, cyberfraction, biofraction = self.get_kind()\n weight = self.get_attribute_relative('Weight')\n constitution = self.get_attribute_relative('Constitution')\n fraction = self.bodypart.get_fraction('Weight')\n life = fraction * rules.life(weight, constitution) * (1.-cyberfraction)\n return life\n\n def get_woundlimit(self, modlevel = 'stateful'):\n constitution = self.get_attribute_relative('Constitution', modlevel)\n weight = self.get_attribute_relative('Weight', 'temporary')\n woundlimit = rules.woundlimit(weight, constitution)\n return woundlimit\n\n def get_wounds_incapacitated_thresh(self, modlevel = 'stateful'):\n constitution = self.get_attribute_relative('Constitution', modlevel)\n weight = self.get_attribute_relative('Weight', 'temporary')\n thresh = rules.wounds_for_incapacitated_thresh(weight, constitution)\n return thresh\n\n def get_wounds_destroyed_thresh(self, modlevel = 'stateful'):\n constitution = self.get_attribute_relative('Constitution', modlevel)\n weight = self.get_attribute_relative('Weight', 'temporary')\n thresh = rules.wounds_for_destroyed_thresh(weight, constitution, self.bodypart.name)\n return thresh\n\n def get_attribute_relative(self, attribute, modlevel = 'stateful'):\n absolute_value = self.get_attribute_absolute(attribute, modlevel)\n fraction = self.bodypart.get_fraction(attribute)\n return absolute_value/fraction if fraction else 0\n\n\nmodlevels = ['base', 'unaugmented', 'augmented', 'temporary', 'stateful']\ninterfaces = ['basic', 'ar', 'cold-sim', 'hot-sim']\n\n\nclass CharPropertyGetter():\n def __init__(self, char, modlevel='stateful'):\n \"\"\"\"\n :param modlevel: the modlevel: ['base', 'unaugmented', 'augmented', 'temporary', 'stateful']\n \"\"\"\n self.char = char\n self.modlevel = modlevel\n self.char_body = CharBody(self.char)\n self.attributes = {}\n self.skills = {}\n self.stats = {}\n self.maxlife = {}\n\n def get_bodypart_table(self):\n attributes = ['Essence', 'Agility', 'Constitution', 'Coordination', 'Strength', 'Weight']\n table = [['Name'] + attributes + ['Ware', 'Woundlimit', 'Wounds']]\n for bodypartname in data.bodyparts_dict:\n templist = []\n bodypart = self.char_body.bodyparts[bodypartname]\n level = bodypart.bodypart.level\n templist.append('<b style=\"margin-left:{}em;\">{}</b>'.format(level*1, bodypartname))\n for attribute in attributes:\n augmented = int(round(bodypart.get_attribute_relative(attribute, modlevel='augmented')))\n stateful = int(round(bodypart.get_attribute_relative(attribute, modlevel='stateful')))\n frac = round(bodypart.bodypart.get_fraction(attribute),2)\n templist.append('{}/{}/{}'.format(augmented, stateful, frac))\n ware = bodypart.ware.name if bodypart.ware else ''\n kind,cyberfrac,_ = bodypart.get_kind()\n templist.append('{}({})/{}'.format(kind, cyberfrac, ware))\n woundlimit = int(round(bodypart.get_woundlimit()))\n templist.append(woundlimit)\n wounds = int(sum([i for i in bodypart.wounds.values()]))\n templist.append(wounds)\n table.append(templist)\n return table\n\n def get_skill_xp_cost(self, skill):\n parent = data.skills_dict[skill].parent\n base_value = 0\n if parent:\n base_value = self.get_skill_value(parent)\n value = self.get_skill_value(skill)\n base_value_xp = rules.get_skill_xp_cost(base_value)\n value_xp = rules.get_skill_xp_cost(value)\n result = (value_xp - base_value_xp) * data.skills_dict[skill].expweight\n if result < 0:\n result = 0\n return result\n\n def get_attribute_xp_cost(self, attribute):\n factor = data.attributes_dict[attribute].factor\n signmod = data.attributes_dict[attribute].signmod\n base = CharPropertyGetter(self.char, 'base').get_attribute_value(attribute)\n value = CharPropertyGetter(self.char, 'unaugmented').get_attribute_value(attribute)\n result = rules.exp_cost_attribute(attribute, value, base, factor, signmod)\n return result\n\n def get_spell_xp_cost(self):\n return rules.get_spell_xp_cost(self.char.spells)\n\n def get_next_spell_xp_cost(self):\n return rules.get_spell_xp_cost(self.char.spells + [1]) - rules.get_spell_xp_cost(self.char.spells)\n\n def get_metamagic_xp_cost(self):\n return rules.get_metamagic_xp_cost(self.char.metamagic)\n\n def get_next_metamagic_xp_cost(self):\n return rules.get_metamagic_xp_cost(self.char.metamagic + [1]) - rules.get_metamagic_xp_cost(self.char.metamagic)\n\n def get_contacts_xp_cost(self):\n return sum([i**2*j**2/5000 for i,j in self.char.contacts])\n\n def get_free_contacts_xp(self):\n return CharPropertyGetter(self.char, 'unaugmented').get_attribute_value('Charisma')**4*2/5000 + 300\n\n def get_attribute_value(self, attribute):\n \"\"\"\n Calculate a specific attribute of the given character\n\n :param attribute: the attribute to get\n :returns: the value of the requested attribute\n :rtype: float\n \"\"\"\n value = self.attributes.get(attribute)\n # use value if already calculated\n if value:\n return value\n # base modlevel returns the basic average attribute value of a given gender/race combination\n if self.modlevel == 'base':\n value = data.attributes_dict[attribute].base\n if attribute == 'Weight':\n size = CharPropertyGetter(self.char, 'unaugmented').get_attribute_value('Size')\n size_base = data.attributes_dict['Size'].base\n value = rules.calc_base_weight(value, size, size_base)\n elif attribute in ['Strength', 'Agility']:\n size = CharPropertyGetter(self.char, 'unaugmented').get_attribute_value('Size')\n size_base = data.attributes_dict['Size'].base\n weight = CharPropertyGetter(self.char, 'unaugmented').get_attribute_value('Weight')\n weight_base = data.attributes_dict['Weight'].base\n if attribute == 'Strength':\n value = rules.calc_base_strength(value, size, size_base, weight, weight_base)\n elif attribute == 'Agility':\n value = rules.calc_agility_base(value, weight, weight_base)\n if self.char.gender and self.char.race:\n value *= getattr(data.gendermods_dict[self.char.gender], attribute)\n value *= getattr(data.races_dict[self.char.race], attribute)\n # unaugmented modlevel includes basic attribute values without any modifiers\n elif self.modlevel == 'unaugmented':\n if attribute == 'Essence':\n value = 100.\n else:\n value = self.char.attributes[attribute]\n # augmented modlevel includes permanent modifications including cyberware, bioware, adept powers and more\n # temporary modlevel includes drugs, spells, encumbrance\n # stateful modlevel includes damage\n elif self.modlevel in ('augmented', 'temporary', 'stateful'):\n # calculate body part contribution to attribute\n if attribute == 'Weight':\n #implicitly includes wounds\n value = self.char_body.bodyparts['Body'].get_attribute_absolute(attribute, self.modlevel)\n elif attribute == 'Essence' or data.attributes_dict[attribute].kind == 'physical':\n #implicitly includes wounds\n value = self.char_body.bodyparts['Body'].get_attribute_absolute(attribute, self.modlevel)\n else:\n value = self.char.attributes[attribute]\n #subtract Essence from non located ware\n if attribute == 'Essence':\n for ware in self.char.ware:\n essence_cost = ware.get_non_located_essence_cost()\n essence_cost = self.char.ware_fix_power_effect('Essence Cost', ware.location, essence_cost, modlevel=self.modlevel)\n value -= essence_cost\n elif attribute == 'Charisma':\n essence = self.get_attribute_value('Essence')\n value *= rules.essence_charisma_mult(essence)\n elif attribute == 'Magic':\n essence = self.get_attribute_value('Essence')\n value *= rules.essence_magic_mult(essence)\n # add ware effects to attribute\n if attribute not in ('Constitution', 'Strength', 'Agility', 'Coordindation', 'Weight', 'Size'):\n value = self.char.ware_fix_power_effect('attributes', attribute, value, modlevel=self.modlevel)\n if self.modlevel in ('stateful', 'temporary'):\n pass\n if self.modlevel == 'stateful' and attribute not in ('Size', 'Weight', 'Constitution', 'Essence', 'Magic'):\n value *= self.get_damagemod('relative')\n # store calculated value\n self.attributes[attribute] = value\n return value\n\n def get_attribute_mod(self, attribute):\n \"\"\"\n\n :param attribute: the attribute to get\n \"\"\"\n value = self.get_attribute_value(attribute)\n if attribute == 'Essence':\n base = 100.\n else:\n base = data.attributes_dict[attribute].base\n return rules.attrib_mod(value, base)\n\n def get_attribute_test_value(self, attribute):\n\n value = self.get_attribute_mod(attribute) + rules.attrib_mod_norm\n if self.modlevel == 'stateful':\n value += self.get_damagemod('absolute')\n return value\n\n def get_skill_value(self, skill, base = False):\n \"\"\"\n\n :param skill: the skill to get\n \"\"\"\n if not base:\n value = self.skills.get(skill)\n if value:\n return value\n if self.modlevel == 'base':\n value = self.char.skills[skill]\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = self.char.skills.get(skill,0)\n parent = data.skills_dict[skill].parent\n if parent:\n parent_value = self.get_skill_value(parent, base=True)\n if value < parent_value:\n value = parent_value\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('skills', skill, value, modlevel=self.modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n if not base:\n self.skills[skill] = value\n return value\n\n def get_skilltest_value(self, skill):\n \"\"\"\n\n :param skill: the skill to get\n \"\"\"\n value = self.get_skill_value(skill)\n mod = 0\n skill_attribmods = data.skills_attribmods_dict[skill]\n for attribute in data.attributes_dict.keys():\n weight = getattr(skill_attribmods, attribute, None)\n if weight:\n mod += weight * self.get_attribute_mod(attribute)\n value += mod\n if self.modlevel == 'stateful':\n value += self.get_damagemod('absolute')\n return value\n\n\n def get_armor(self, bodypart = None):\n armor = [item.name for item in self.char.items if data.gameitems_dict[item.name].clas == 'Armor']\n armor = [Armor(name) for name in armor]\n if bodypart:\n armor = [i for i in armor if bodypart in i.get_locations()]\n return armor\n\n\n def get_protection(self, bodypart, typ):\n protection = []\n if bodypart == 'Body':\n protections = []\n for bodypart in data.main_bodyparts:\n protections.append(self.get_protection(bodypart, typ))\n protection = rules.negative_square_avg(protections)\n else:\n for armor in self.get_armor():\n protection.append(armor.get_protection(bodypart, typ))\n protection.append(self.char.ware_fix_power_effect(typ + ' armor', bodypart, 0, func = '(value**2 + {}**2)**0.5', modlevel=self.modlevel))\n protection = rules.get_stacked_armor_value(protection)\n return protection\n\n def get_ranged_weapons(self):\n weapons = [item for item in self.char.items if data.gameitems_dict[item.name].clas == 'Ranged Weapon']\n weapons = [RangedWeapon(item.name, self.char, item.upgrades) for item in weapons]\n return weapons\n\n def get_close_combat_weapons(self):\n weapons = [item.name for item in self.char.items if data.gameitems_dict[item.name].clas == 'Close Combat Weapon']\n weapons = [CloseCombatWeapon(name, self.char) for name in weapons]\n return weapons\n\n def get_maxlife(self, bodypart = 'Body'):\n value = self.maxlife.get(bodypart)\n if value:\n return value\n value = self.char_body.bodyparts['Body'].get_life()\n if self.modlevel in ('augmented', 'temporary', 'stateful'):\n value = self.char.ware_fix_power_effect('stats', 'life', value, modlevel=self.modlevel)\n self.maxlife[bodypart] = value\n return value\n\n def get_damagemod(self, kind):\n \"\"\"\n kind = ['absolute', 'relative']\n\n \"\"\"\n totaldamage = sum([i for i in self.char.damage.values()])\n if not totaldamage:\n totaldamage = 0\n statname = 'Pain Resistance'\n pain_resistance = 0\n pain_resistance = self.char.ware_fix_power_effect('stats', statname, pain_resistance, func = 'value + (1-value) * {}', modlevel=self.modlevel)\n max_life = self.get_maxlife()\n life = max_life - max(0, totaldamage - pain_resistance * max_life)\n if kind == 'relative':\n damagemod = rules.lifemod_relative(life, max_life)\n elif kind == 'absolute':\n damagemod = rules.lifemod_absolute(life, max_life)\n else:\n damagemod = 0\n return damagemod\n\n\n def get_reaction(self):\n \"\"\"\n\n\n \"\"\"\n statname = 'Reaction'\n value = self.stats.get(statname)\n if value:\n return value\n if self.modlevel == 'base':\n value = 0\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = rules.physical_reaction(self.get_attribute_mod('Agility'),\n self.get_attribute_mod('Intuition'))\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('stats', statname, value, modlevel=self.modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n if self.modlevel == 'stateful':\n value += self.get_damagemod('absolute')\n self.stats[statname] = value\n return value\n\n def get_actionmult(self):\n \"\"\"\n\n \"\"\"\n statname = 'Action Multiplier'\n value = self.stats.get(statname)\n if value:\n return value\n if self.modlevel == 'base':\n value = 0\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = rules.physical_actionmult(self.get_attribute_mod('Agility'),\n self.get_attribute_mod('Coordination'),\n self.get_attribute_mod('Intuition'))\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('stats', statname, value, modlevel=self.modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n if self.modlevel == 'stateful':\n value /= self.get_damagemod('relative')\n self.stats[statname] = value\n return value\n\n def get_actioncost(self, kind):\n actionmult = self.get_actionmult()\n cost = rules.action_cost(kind, actionmult)\n return cost\n\n def get_psycho_thresh(self):\n essence = self.get_attribute_value('Essence')\n thresh = rules.essence_psycho_thresh(essence)\n return thresh\n\n def get_total_exp(self):\n \"\"\"\n\n \"\"\"\n xp = {}\n xp['Attributes'] = 0\n for attribute in data.attributes_dict:\n xp['Attributes'] += self.get_attribute_xp_cost(attribute)\n xp['Skills'] = 0\n for skill in data.skills_dict:\n xp['Skills'] += self.get_skill_xp_cost(skill)\n xp['Contacts'] = max(0, self. get_contacts_xp_cost() - self.get_free_contacts_xp())\n xp['Spells'] = self.get_spell_xp_cost()\n xp['Metamagic'] = self.get_metamagic_xp_cost()\n xp['Contacts']\n return xp\n\n def get_total_cost(self):\n cost = {}\n warecost = 0\n for ware in self.char.ware:\n warecost += ware.get_cost()\n cost['Ware'] = warecost\n fixturecost = 0\n for fixture in self.char.fixtures:\n fixturecost += fixture.get_cost()\n cost['Fixtures'] = fixturecost\n itemcost = 0\n for item in self.char.all_items:\n itemcost += item.get_cost()\n cost['Items'] = itemcost\n sincost = 0\n for sin in self.char.sins:\n sincost += rules.get_sin_cost(sin[0], data.permits_dict.get(sin[1]).cost_multiplier)\n cost['SINs'] = sincost\n return cost\n\n def get_spomod_max(self):\n logic = self.get_attribute_value('Logic')\n spomod_max = rules.spomod_max(logic)\n return spomod_max\n\n def get_drain_resist(self):\n willpower_mod = self.get_attribute_mod('Willpower')\n magic_mod = self.get_attribute_mod('Magic')\n drain_resist = rules.drain_resist(willpower_mod, magic_mod)\n return drain_resist\n\n def get_money(self):\n return sum([i[0] for i in self.char.money]) + rules.starting_money\n\n def get_xp(self):\n return sum([i[0] for i in self.char.xp]) + rules.starting_xp\n\n def get_power_cost(self):\n cost = 0\n for power in self.char.adept_powers:\n cost += power.cost if power.cost != 'X' else power.value\n return cost\n\nclass LoadoutPropertyGetter(Loadout):\n def __init__(self,db, char):\n \"\"\"\"\n :param char: the character for witch to get the attribute\n \"\"\"\n Loadout.__init__(self, db, char)\n\n\nclass CharPhysicalPropertyGetter(CharPropertyGetter):\n def __init__(self, char, modlevel='stateful', bodypart='all'):\n \"\"\"\"\n :param char: the character for witch to get the attribute\n :param modlevel: the modlevel: ['unaugmented', 'augmented', 'temporary', 'stateful']\n :param bodypart: the bodypart(s) that are used calculating the attributes\n \"\"\"\n CharPropertyGetter.__init__(self, char, modlevel)\n self.bodypart = bodypart\n\n def get_jump_distance(self, movement):\n weight = self.get_attribute_value('Weight')\n size = self.get_attribute_value('Size')\n strength = self.get_attribute_value('Strength')\n if movement:\n distance = rules.jumplimit(weight, strength, size)[1]\n else:\n distance = rules.jumplimit(weight, strength, size)[0]\n return distance\n\n def get_jump_height(self, movement):\n weight = self.get_attribute_value('Weight')\n size = self.get_attribute_value('Size')\n strength = self.get_attribute_value('Strength')\n if movement:\n distance = rules.jumplimit(weight, strength, size)[3]\n else:\n distance = rules.jumplimit(weight, strength, size)[2]\n return distance\n\n def get_speed(self):\n weight = self.get_attribute_value('Weight')\n size = self.get_attribute_value('Size')\n strength = self.get_attribute_value('Strength')\n agility = self.get_attribute_value('Agility')\n return rules.speed(agility, weight, strength, size)\n\n def get_reaction(self):\n \"\"\"\n\n\n \"\"\"\n statname = 'Physical Reaction'\n value = self.stats.get(statname)\n if value:\n return value\n if self.modlevel == 'base':\n value = 0\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = rules.physical_reaction(self.get_attribute_mod('Agility'),\n self.get_attribute_mod('Intuition'))\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('stats', statname, value, modlevel=self.modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n self.stats[statname] = value\n return value\n\n def get_actionmult(self):\n \"\"\"\n\n \"\"\"\n statname = 'Physical Action Multiplyer'\n value = self.stats.get(statname)\n if value:\n return value\n if self.modlevel == 'base':\n value = 0\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = rules.physical_actionmult(self.get_attribute_mod('Agility'),\n self.get_attribute_mod('Coordination'),\n self.get_attribute_mod('Intuition'))\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('stats', statname, value, modlevel=self.modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n self.stats[statname] = value\n return value\n\nclass CharMatrixPropertyGetter(CharPropertyGetter):\n def __init__(self, char, modlevel='stateful', interface='ar'):\n \"\"\"\"\n\n :param char: the character for witch to get the attribute\n :param modlevel: the modlevel: ['unaugmented', 'augmented', 'temporary', 'stateful']\n :param interface: the matrix access interface: ['basic', 'ar', 'cold-sim', 'hot-sim']\n \"\"\"\n CharPropertyGetter.__init__(self, char, modlevel)\n self.interface = interface\n\n def get_attribute_value(self, attribute):\n\n conversion_dict = {'Strength': 'Processing',\n 'Agility': 'Uplink',\n 'Body': 'Firewall',\n 'Coordination': 'Logic',\n 'Weight': 75,\n 'Size': 1.75}\n converted_attribute = attribute\n if attribute in conversion_dict:\n converted_attribute = conversion_dict[attribute]\n if isinstance(converted_attribute, str):\n value = CharPropertyGetter.get_attribute_value(self, converted_attribute)\n else:\n value = converted_attribute\n return value\n\n def get_reaction(self):\n \"\"\"\n\n\n \"\"\"\n statname = 'Matrix Reaction'\n value = self.stats.get(statname)\n if value:\n return value\n if self.modlevel == 'base':\n value = 0\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = rules.matrix_reaction(self.get_attribute_mod('Agility'),\n self.get_attribute_mod('Intuition'))\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('stats', statname, value, modlevel=self.modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n self.stats[statname] = value\n return value\n\n\nclass CharAstralPropertyGetter(CharPropertyGetter):\n def __init__(self, char, modlevel):\n \"\"\"\"\n\n :param char: the character for witch to get the attribute\n :param modlevel: the modlevel: ['unaugmented', 'augmented', 'temporary', 'stateful']\n \"\"\"\n CharPropertyGetter.__init__(self, char, modlevel)\n\n def get_attribute_value(self, attribute):\n\n conversion_dict = {'Strength': 'Charisma',\n 'Agility': 'Logic',\n 'Body': 'Willpower',\n 'Coordination': 'Intuition',\n 'Weight': 'Magic',\n 'Size': 'Magic'}\n converted_attribute = attribute\n if attribute in conversion_dict:\n converted_attribute = conversion_dict[attribute]\n if isinstance(converted_attribute, str):\n value = CharPropertyGetter.get_attribute_value(self, converted_attribute)\n else:\n value = converted_attribute\n return value\n\n def get_reaction(self):\n \"\"\"\n\n\n \"\"\"\n statname = 'Astral Reaction'\n value = self.stats.get(statname)\n if value:\n return value\n if self.modlevel == 'base':\n value = 0\n if self.modlevel in ('unaugmented', 'augmented','temporary','stateful'):\n value = rules.astral_reaction(self.get_attribute_mod('Agility'),\n self.get_attribute_mod('Intuition'))\n if self.modlevel in ('augmented','temporary','stateful'):\n value = self.char.ware_fix_power_effect('stats', statname, value, modlevel=modlevel)\n if self.modlevel in ('temporary','stateful'):\n pass\n self.stats[statname] = value\n return value\n\n\nclass CharPropertyPutter():\n def __init__(self, char):\n self.char = char\n\n def first_aid(self, test_value):\n char_property_getter = CharPropertyGetter(self.char, modlevel='stateful')\n max_life = char_property_getter.get_maxlife()\n damage = char_property_getter.char.damage.get('physical', 0)\n damagepercent = damage/float(maxlife)\n healing_mod = rules.healing_mod()\n test_value -= healing_mod\n healed_damage = min(damage, rules.first_aid(test_value)*damagepercent*max_life)\n self.heal_damage(healed_damage, 'physical')\n return 'Healed {} physical damage'.format(healed_damage)\n\n def rest(self, total_time, medic_test, die_roll):\n timedict = {'m': 1./24./60., 's': 1/24./60./60., 'h': 1/24., 'd': 1, 'w': 7,}\n result = 'Heal Roll: {}\\n'.format(die_roll)\n if isinstance(total_time, str):\n splits = total_time.split(',')\n total_time = 0\n for i in splits:\n value, id = float(i.strip()[:-1]), i.strip()[-1]\n total_time += value * timedict.get(id.lower(), 0)\n total_wound_time = total_time\n char_property_getter = CharPropertyGetter(self.char, modlevel='stateful')\n max_life = char_property_getter.get_maxlife()\n test = die_roll + char_property_getter.get_attribute_mod('Constitution')\n test += medic_test if medic_test > 0 else 0\n for damage_kind in sorted(data.damagekinds_dict.values(), key = lambda x: x.priority):\n damage = char_property_getter.char.damage.get(damage_kind.name, 0)\n if damage:\n damagepercent = float(damage)/max_life\n healing_time = rules.healingtime(damagepercent, damage_kind.healing_time, test)\n if total_time >= healing_time:\n total_time -= healing_time\n self.heal_damage(damage, damage_kind.name)\n result += 'Healed all {} {} damage in {} hours\\n'.format(damage, damage_kind.name, healing_time * 24.)\n else:\n damage = rules.damage_heal_after_time(damage, total_time, healing_time)\n self.heal_damage(damage, damage_kind.name)\n result += 'Healed {} {} damage in {} hours\\n'.format(damage, damage_kind.name, total_time * 24.)\n break\n wounds = char_property_getter.char.wounds\n for location, wounds_by_location in wounds.items():\n for damage_kind, wound_num in wounds_by_location.items():\n base_time = data.damagekinds_dict[damage_kind].healing_time\n healing_time = rules.healingtime_wounds(wound_num, base_time, test)\n if total_wound_time < healing_time:\n wound_num = rules.wound_heal_after_time(wound_num, total_wound_time, healing_time)\n result += 'Healed {} {} wounds at {} in {} hours\\n'.format(wound_num, damage_kind, location, total_wound_time * 24.)\n else:\n result += 'Healed all {} {} wounds at {} in {} hours\\n'.format(wound_num, damage_kind, location, healing_time * 24.)\n self.heal_wounds(wound_num, location, damage_kind)\n return result\n\n def heal_wounds(self, healed_wounds, location, damage_kind=None):\n char_property_getter = CharPropertyGetter(self.char, modlevel='stateful')\n if not damage_kind:\n location, damage_kind = location.split(',')\n wounds = char_property_getter.char.wounds.get(location, {}).get(damage_kind,0)\n wounds = wounds - healed_wounds\n if wounds < 0:\n wounds = 0\n self.char.write_wounds(wounds, location, damage_kind)\n\n def heal_damage(self, healed_damage, damage_kind):\n char_property_getter = CharPropertyGetter(self.char, modlevel='stateful')\n damage = char_property_getter.char.damage.get(damage_kind, 0)\n damage = damage - healed_damage\n if damage < 0:\n damage = 0\n self.char.write_damage(damage_kind, damage)\n\n def put_damage(self, value, penetration, bodypart='Body', kind='physical', typ='ballistic',\n percent=False, resist=False, resistroll=None, wounding = True):\n logging.debug('value: {}'.format(value))\n charpropertygetter = CharPropertyGetter(self.char, 'stateful')\n if kind in ['drain stun', 'drain physical']:\n percent = True\n typ = 'direct'\n resist = 'drain'\n bodypart = 'Body'\n wounding = False\n if not typ or typ == 'direct':\n armor = 0\n else:\n armor = charpropertygetter.get_protection(bodypart, typ)\n if percent:\n value = charpropertygetter.get_maxlife(bodypart)*value/100.\n damageval = value\n if resist:\n if resist == 'drain':\n attribute_mod = charpropertygetter.get_drain_resist()\n else:\n attribute_mod = charpropertygetter.get_attribute_mod(resist)\n value = rules.resist_damage(value, attribute_mod, resistroll, 0)\n damage = float(max(0, value - max(0, armor-penetration)))\n bodykind, cyberfraction, biofraction = charpropertygetter.char_body.bodyparts[bodypart].get_kind()\n max_life = charpropertygetter.get_maxlife()\n woundlimit = charpropertygetter.char_body.bodyparts[bodypart].get_woundlimit()\n destroy_thresh = charpropertygetter.char_body.bodyparts[bodypart].get_wounds_destroyed_thresh()\n calc_wounds = float('inf')\n wounds = 0\n if wounding:\n wounds = int(damage/woundlimit)\n calc_wounds = wounds + 1\n old_wounds = self.char.wounds.get(bodypart, 0)\n if old_wounds:\n old_wounds = old_wounds.get(kind, 0)\n else:\n old_wounds = 0\n if bodykind != 'cyberware' or kind in ('physical'):\n wounds = min(wounds, destroy_thresh-old_wounds)\n calc_wounds = min(calc_wounds, destroy_thresh-old_wounds)\n if wounds:\n new_wounds = wounds + old_wounds\n self.char.write_wounds(new_wounds, bodypart, kind)\n if cyberfraction != 1.:\n damage = min(damage, woundlimit*(calc_wounds))\n if not percent:\n damage *= (1.-cyberfraction)\n old_damage = self.char.damage.get(kind, 0)\n new_damage = old_damage + damage\n new_damage = min(new_damage, 2*max_life)\n self.char.write_damage(kind, new_damage)\n logging.debug('value: {}'.format(value))\n logging.debug('calc_wounds: {}'.format(calc_wounds))\n logging.debug('damage: {}'.format(damage))\n logging.debug('armor: {}'.format(armor))\n logging.debug('cyberfraction: {}'.format(cyberfraction))\n result = 'damage: {:.0f}, wounds: {:.0f} (armor: {:.0f}, cyberfraction: {:.0%}, maximum destruction limit: {:.0f})'.format(damage, wounds, armor, cyberfraction, woundlimit*(calc_wounds))\n if resistroll:\n result += '; resistroll:{}'.format(resistroll)\n return result\n\n\nif __name__ == '__main__':\n body = Body()\n"
},
{
"alpha_fraction": 0.4745972752571106,
"alphanum_fraction": 0.5074349641799927,
"avg_line_length": 23.409090042114258,
"blob_id": "2e0334adb0eefe7d58eb59fc24407a6227313f97",
"content_id": "7cfe5a99a275bdf7dc6eda59f4895d3ff5d3df7f",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1614,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 66,
"path": "/modules/weapon.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom gluon import *\nfrom collections import namedtuple, OrderedDict\nimport rules\n\nclass Weapon():\n\n def __init__(self):\n self.name = ''\n self.skill = ''\n\n self.minimum_strength = 0\n self.hands = 0\n\n self.damage = 0\n self.damage_type = ''\n self.penetration = 0\n\n self.range = 0\n\n self.shot = 0\n self.burst = 0\n self.auto = 0\n self.recoil = 0\n\n self.magazine_size = 0\n self.magazine_kind = 0\n self.size = 0\n self.visible_stealth = 0\n self.scan_stealth = 0\n\n self.weight = 0\n self.cost = 0\n\n def basic_by_strength(self, strength):\n self.shot = 1\n self.burst = 3\n self.auto = 8\n\n self.damage = strength/3.\n self.penetration = strength/1.8\n self.range = strength*2.\n self.calc_rest()\n\n\n def calc_rest(self):\n self.weight = ((self.damage/12. * self.penetration/20.)**0.5 * 2 +\n (self.damage / 12. * self.penetration / 20.) ** 0.5 * max(self.auto, self.burst)/8. * 0.5 +\n (self.damage / 12. * self.penetration / 20. * self.range/72.)**(1/3.)*1.)\n self.minimum_strength = self.weight/3.5*36\n\n def __repr__(self):\n result = \"\"\"Weapon:\nDamage: {},\nPenetration: {},\nRange: {}m,\nWeight: {}kg,\nMininum Strength: {}\n\"\"\".format(self.damage,\n self.penetration,\n self.range,\n self.weight,\n self.minimum_strength)\n return result\n\n\n\n"
},
{
"alpha_fraction": 0.611940324306488,
"alphanum_fraction": 0.6231343150138855,
"avg_line_length": 37.28571319580078,
"blob_id": "c0bfc3241d2e31a02a2727980732fddd9323a75c",
"content_id": "9c560c2626065906df456d913bafe5e528fbf709",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 7,
"path": "/controllers/maintainance.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Versuchen Sie so etwas wie\ndef index(): return dict(message=\"hello from maintainance.py\")\n\ndef add_skill():\n for row in db().select(db.chars.id):\n db['char_skills'].insert(**{\"char\": row.id, \"skill\": \"Astral Combat\", \"value\": 0.0})\n"
},
{
"alpha_fraction": 0.6746987700462341,
"alphanum_fraction": 0.6867470145225525,
"avg_line_length": 14.199999809265137,
"blob_id": "9c2979469fae5b81f147de7be5630133a5376ec7",
"content_id": "c9320b29ee26f9d35680e25d91d85d981f15f644",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 5,
"path": "/modules/getter_functions.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\r\n# coding: utf8\r\nimport data\r\nimport basic\r\nimport rules\r\n\r\n"
},
{
"alpha_fraction": 0.6245303153991699,
"alphanum_fraction": 0.6325818300247192,
"avg_line_length": 39.5,
"blob_id": "4f3944787fdad4d2db643d961b33160dd6c977cc",
"content_id": "362d46ed82a1dc6d1dd38104cfd04bbfe03874f1",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3726,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 92,
"path": "/modules/vehicle.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom gluon import *\nfrom collections import namedtuple, OrderedDict\nimport rules\nimport data\n\nclass Vehicle(object):\n\n def __init__(self, chassis, agent, computer, sensors_package, upgrade_list):\n self.chassis = chassis\n self.agent = agent\n self.computer = computer\n self.sensors_package = sensors_package\n self.upgrade_list = upgrade_list\n\n self.locomotion = ''\n self.weight = 0\n self.handling = 0\n self.max_speed = 0\n self.acceleration = 0\n self.load = 0\n self.used_load = 0\n self.capacity = 0\n self.used_capacity = 0\n self.size = 0\n self.constitution = 0\n self.armor = 0\n self.visibility = 0\n self.signature = 0\n self.sensors = []\n self.System = 0\n self.Processor = 0\n self.Firewall = 0\n self.Signal = 0\n self.Uplink = 0\n self.agent_rating = 0\n self.upgrades = []\n self.skills = {}\n\n self.structure = 0\n\n self.fill_initials()\n self.calc_stats()\n\n def fill_initials(self):\n self.weight = data.vehicle_chassis_dict[self.chassis].weight\n self.locomotion = data.vehicle_chassis_dict[self.chassis].locomotion\n self.handling = data.vehicle_chassis_dict[self.chassis].handling\n self.max_speed = data.vehicle_chassis_dict[self.chassis].max_speed\n self.acceleration = data.vehicle_chassis_dict[self.chassis].acceleration\n self.load = data.vehicle_chassis_dict[self.chassis].load\n self.capacity = data.vehicle_chassis_dict[self.chassis].capacity\n self.size = data.vehicle_chassis_dict[self.chassis].size\n self.constitution = data.vehicle_chassis_dict[self.chassis].constitution\n self.armor = data.vehicle_chassis_dict[self.chassis].armor\n self.visibility = data.vehicle_chassis_dict[self.chassis].visibility\n self.signature = data.vehicle_chassis_dict[self.chassis].signature\n self.cost = data.vehicle_chassis_dict[self.chassis].cost\n\n self.System = data.computer_dict[self.computer].System\n self.Processor = data.computer_dict[self.computer].Processor\n self.Signal = data.computer_dict[self.computer].Signal\n self.Uplink = data.computer_dict[self.computer].Uplink\n self.used_capacity += data.computer_dict[self.computer].Volume*1000\n self.used_load += data.computer_dict[self.computer].Volume*500\n self.cost += data.gameitems_dict[self.computer].cost\n\n self.agent_rating = data.agents_dict[self.agent].rating\n self.skills = data.agents_dict[self.agent].skills\n\n self.sensors = data.sensor_packages_dict[self.sensors_package].content\n for i in self.sensors:\n self.used_capacity += data.gameitems_dict[i].absolute_capacity\n self.used_load += data.gameitems_dict[i].weight\n self.cost += data.gameitems_dict[i].cost\n for upgrade in self.upgrade_list:\n upgrade = data.vehicle_upgrades_dict[upgrade]\n self.cost += upgrade.cost\n self.cost += upgrade.square_weight_cost * self.weight**0.5\n if isinstance(upgrade.capacity, str):\n self.used_capacity += eval('{}'.format(self.weight)+upgrade.capacity)\n else:\n self.used_capacity += upgrade.capacity\n if isinstance(upgrade.weight, str):\n self.used_load += eval('{}'.format(self.weight)+upgrade.weight)\n else:\n self.used_load += upgrade.weight\n self.upgrades.append(upgrade)\n\n def calc_stats(self):\n self.structure = rules.life(self.weight, self.constitution)\n"
},
{
"alpha_fraction": 0.6063535809516907,
"alphanum_fraction": 0.6138121485710144,
"avg_line_length": 46.01298522949219,
"blob_id": "d24c6e66f15fa648160140fd8ad8f65bef0e0812",
"content_id": "49c6e7a0e1a2873b218de33b85f53232f5c80159",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10860,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 231,
"path": "/controllers/master.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\nimport collections\nimport applications.gabaros.modules.data as data\nimport applications.gabaros.modules.rules as rules\nfrom random import gauss\n\n@auth.requires_login()\ndef index():\n return dict()\n\n\n@auth.requires_login()\ndef chat():\n form=LOAD('master', 'ajax_form', ajax=True)\n script=SCRIPT(\"\"\"\n var text = ''\n jQuery(document).ready(function(){\n var callback = function(e){alert(e.data);\n text = e.data + '<br>' + text;\n document.getElementById('text').innerHTML = text;};\n if(!$.web2py.web2py_websocket('ws://127.0.0.1:8888/realtime/\"\"\" + str(auth.user.id) + \"\"\"', callback))\n alert(\"html5 websocket not supported by your browser, try Google Chrome\");\n });\n \"\"\")\n return dict(form=form, script=script)\n\n@auth.requires_login()\ndef ajax_form():\n players = db(db.chars.master==auth.user.id).select(db.chars.name)\n players = [i.name for i in players]\n form=SQLFORM.factory(Field('message'),\n Field('players',\n type='list',\n requires=IS_IN_SET(players)))\n if form.accepts(request,session):\n from gluon.contrib.websocket_messaging import websocket_send\n players = form.vars.players\n if not isinstance(players, list):\n players = [players]\n for player in players:\n websocket_send(\n 'http://127.0.0.1:8888', form.vars.message, 'mykey', player)\n return form\n\n\n@auth.requires_login()\ndef livedata():\n db.rolls.char.represent = lambda char: db.chars[char].name\n db.rolls.roll.represent = lambda val: int(round(val))\n db.rolls.value.represent = lambda val: int(round(val))\n db.rolls.result.represent = lambda val: int(round(val))\n rows = db(db.rolls.char.belongs(db(db.chars.master == auth.user.id)._select(db.chars.id))).select(db.rolls.ALL, orderby=~db.rolls.id,\n limitby=(0, 10), distinct=True)\n table = SQLTABLE(rows, headers='labels', _class = 'table table-striped')\n return dict(rows=rows, table=table)\n\n@auth.requires_login()\ndef live():\n db.rolls.char.represent = lambda char: db.chars[char].name\n db.rolls.roll.represent = lambda val: int(round(val))\n db.rolls.value.represent = lambda val: int(round(val))\n db.rolls.result.represent = lambda val: int(round(val))\n rows = db(db.rolls.char.belongs(db(db.chars.master == auth.user.id)._select(db.chars.id))).select(db.rolls.ALL, orderby=~db.rolls.id,\n limitby=(0, 10), distinct=True)\n table = SQLTABLE(rows, headers='labels', _class = 'table table-striped')\n return dict(rows=rows, table=table)\n\n@auth.requires_login()\ndef combat():\n initiative = [None, None]\n combats = []\n combat = session.master_current_combat\n rows = db(db.combats.master==auth.user.id).select(db.combats.name)\n for row in rows:\n combats.append(row.name)\n form = SQLFORM.factory(Field('combat', requires=IS_IN_SET(combats), label = 'Combat'))\n if form.process().accepted:\n response.flash = 'form accepted'\n combat = form.vars.combat\n session.master_current_combat = combat\n elif form.errors:\n response.flash = 'form has errors'\n else:\n response.flash = 'please fill out the form'\n if combat:\n db.actions.char.represent = lambda char: db.chars[char].name\n rows = db((db.actions.combat==db.combats.id) & (db.combats.name == combat)).select(db.actions.char, db.actions.cost)\n if rows:\n initiative = collections.defaultdict(int)\n for row in rows:\n char = row.char.name\n cost = row.cost\n initiative[char] += cost\n initiative = [[key, value] for key, value in initiative.items()]\n initiative = sorted(initiative, key = lambda x: x[1], reverse = True)\n tempinitiative = [['Char', 'Initiative']]\n tempinitiative.extend(initiative)\n initiative = tempinitiative\n\n return dict(initiative=initiative, form=form, combat = combat)\n\n#@auth.requires_login()\n#def combat():\n# fields = []\n# combatants = []\n# rows = db(db.chars.master == auth.user.id).select(db.chars.name)\n# for row in rows:\n# combatants += [row.name]\n# combatants += [\"\"]\n# combatants = sorted(combatants)\n# fields += [Field(\"name\", type='string', label=T('Name'))]\n# fields += [Field(\"combatant1\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 1'), default=None)]\n# fields += [Field(\"combatant2\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 2'), default=None)]\n# fields += [Field(\"combatant3\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 3'), default=None)]\n# fields += [Field(\"combatant4\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 4'), default=None)]\n# fields += [Field(\"combatant5\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 5'), default=None)]\n# fields += [Field(\"combatant6\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 6'), default=None)]\n# fields += [Field(\"combatant7\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 7'), default=None)]\n# fields += [Field(\"combatant8\", type='string', requires=IS_IN_SET(combatants), label=T('Combatant 8'), default=None)]\n# form = SQLFORM.factory(*fields)\n# if form.process(formname='form_one').accepted:\n# response.flash = 'form accepted'\n# id = db.combat.bulk_insert([{'name': form.vars.name, 'round': 1, 'master': auth.user.id}])[0]\n# for i in range(1, 9):\n# if form.vars['combatant' + str(i)]:\n# row = db(db.chars.name == form.vars['combatant' + str(i)]).select(db.chars.id).first()\n# combatant = row.id\n# db.combatants.bulk_insert([{'combat': id, 'char': combatant}])\n# initiative = database.get_initiative(db, cache, combatant) + gauss(0, 10)\n# db.combat_initiative.bulk_insert(\n# [{'combat': id, 'round': 1, 'char': combatant, 'initiative': initiative}])\n# elif form.errors:\n# response.flash = 'form has errors'\n# form2 = SQLFORM.factory(*[Field('add', type='boolean', label=T('Add Round'), default=True, readable=False)],\n# submit_button='Next Round')\n# combat = database.get_current_combat(db, auth.user.id)\n# if form2.process(formname='form_two').accepted:\n# response.flash = 'form accepted'\n# database.add_combat_round(db, auth.user.id)\n# round = db(db.combat.id == combat).select(db.combat.round).first().round\n# rows = db(db.combatants.combat == combat).select(db.combatants.char)\n# for row in rows:\n# combatant = row.char.id\n# initiative = database.get_initiative(db, cache, combatant) + gauss(0, 10)\n# db.combat_initiative.bulk_insert(\n# [{'combat': combat, 'round': round, 'char': combatant, 'initiative': initiative}])\n# elif form2.errors:\n# response.flash = 'form has errors'\n# cname = None\n# cround = None\n# row = db(db.combat.id == combat).select(db.combat.round, db.combat.name).first()\n# if row:\n# cname = row.name\n# cround = row.round\n# rows = db(db.combatants.combat == combat).select(db.combatants.char)\n# combatants = []\n# for row in rows:\n# charid = row.char.id\n# charname = row.char.name\n# awarecount, timecount = database.get_ccab(db, charid)\n# initiative = db((db.combat_initiative.combat == combat) & (db.combat_initiative.char == charid) & (\n# db.combat_initiative.round == cround)).select(db.combat_initiative.initiative).first()\n# if initiative:\n# initiative = initiative.initiative\n# else:\n# initiative = None\n# combatants += [[charid, charname, initiative, awarecount, timecount]]\n# combatants = sorted(combatants, key=lambda x: x[2], reverse=True)\n# return dict(form=form, form2=form2, cname=cname, cround=cround, combatants=combatants)\n\n\n@auth.requires_login()\ndef calc_deck():\n fields = [Field(\"processor\", 'float', default=0)]\n fields += [Field(\"system\", 'float', default=0)]\n fields += [Field(\"uplink\", 'float', default=0)]\n fields += [Field(\"size\", 'float', default=0)]\n fields += [Field(\"hours_per_week\", 'float', default=0)]\n fields += [Field(\"skill\", 'float', default=0)]\n fields += [Field(\"users\", 'float', default=0)]\n form = SQLFORM.factory(*fields)\n maintainance = 0\n cost = 0\n firewall = 0\n system = 0\n processor = 0\n uplink = 0\n if form.process().accepted:\n response.flash = 'form accepted'\n processor = form.vars[\"processor\"]\n system = form.vars[\"system\"]\n uplink = form.vars[\"uplink\"]\n size = form.vars[\"size\"]\n skill = form.vars[\"skill\"]\n users = form.vars[\"users\"]\n hours_per_week = form.vars[\"hours_per_week\"]\n cost = (rules.processor_cost(processor, size) +\n rules.uplink_cost(uplink, size) +\n rules.system_cost(system, processor) +\n rules.size_cost(size))\n maintainance = rules.maintain_cost(size)\n firewall = rules.firewall_rating(hours_per_week, skill,\n system, users)\n\n elif form.errors:\n response.flash = 'form has errors'\n return dict(form=form, firewall=firewall, cost=cost, maintainance=maintainance, system=system, processor=processor,\n uplink=uplink)\n\ndef calc_vehicle():\n fields = [Field(\"chassis\", 'string', requires=IS_IN_SET(data.vehicle_chassis_dict.keys()))]\n fields += [Field(\"computer\", 'string', requires=IS_IN_SET(data.computer_dict.keys()))]\n fields += [Field(\"sensors\", 'string', requires=IS_IN_SET([i[0] for i in data.sensor_packages_dict.keys()]))]\n fields += [Field(\"agent\", 'string', requires=IS_IN_SET([data.agents_dict.keys()]))]\n form = SQLFORM.factory(*fields)\n chassis = []\n computer = []\n sensors = []\n agent = None\n capacity = 0\n used_capacity = 0\n free_capacity = 0\n\n if form.process().accepted:\n chassis = data.vehicle_chassis_dict[form.vars.chassis]\n computer = data.gameitems_dict[form.vars.computer]\n sensors = data.sensor_packages_dict[form.vars.sensors]\n capacity = chassis.capacity\n used_capacity = computer.absolute_capacity + sum([data.gameitems_dict[i].absolute_capacity for i in sensors.content])\n return dict(form=form, chassis=chassis, agent = agent, computer=computer, sensors=sensors, capacity=capacity, used_capacity=used_capacity,\n free_capacity = capacity-used_capacity)\n"
},
{
"alpha_fraction": 0.5066371560096741,
"alphanum_fraction": 0.5221238732337952,
"avg_line_length": 27.25,
"blob_id": "48cc0d4b3e0d503ebc74c54ef670f154a40b6a94",
"content_id": "5c527eae4f89bb0d81ceff5cf490731ec5fe9b6d",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 452,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 16,
"path": "/views/view_char/view_weapons.html",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "{{extend 'layout.html'}}\n\n<table class = 'table table-striped'>\n <tr>\n {{for entry in weapons[0]:}}\n {{=TH(entry, _style=\"padding-right:10px;text-align:left;\")}}\n {{pass}}\n </tr>\n {{for row in weapons[1:]:}}\n <tr>\n {{for entry in row:}}\n {{=TD('{:.0f}'.format(entry) if isinstance(entry, float) else entry, _style=\"padding-right:10px;text-align:left;\")}}\n {{pass}}\n </tr>\n {{pass}}\n</table>\n"
},
{
"alpha_fraction": 0.5516014099121094,
"alphanum_fraction": 0.5800711512565613,
"avg_line_length": 45.83333206176758,
"blob_id": "f6a3a457855ab8d9dafbd69eec8d674211c38132",
"content_id": "ba6e50017e7988a07fec7ffafc7afce80057bb8a",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 281,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 6,
"path": "/views/manage_char/edit_char_contacts.html",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "{{extend 'layout.html'}}\n{{=H4('XP: {:,.2f}'.format(float(char_xp)))}}\n{{=H4('Free Cost: {:,.2f}'.format(float(char_xp - total_xp)))}}\n{{=H4('Free XP for contacts from charisma: {:,.2f}'.format(float(charisma_xp)))}}\n{{=H4('XP for Contacts: {:,.2f}'.format(float(xp)))}}\n{{=form}}\n"
},
{
"alpha_fraction": 0.5873544216156006,
"alphanum_fraction": 0.5879090428352356,
"avg_line_length": 38.19565200805664,
"blob_id": "ed77f998a2d69c20990719c8a76d3463cbb780ca",
"content_id": "bd72e0cd8f0b2702e903b4a57ea307d895f13c2b",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1803,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 46,
"path": "/models/x50_live.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# coding: utf8\nfrom datetime import datetime\n\ndb.define_table('rolls',\n Field('char', type='reference chars', label=T('Char'),\n writable=False,\n requires = IS_IN_DB(db,db.chars.id,'%(name)s')),\n Field('name', type = 'string', label = T('Name')),\n Field('value', type = 'double', label = T('Value')),\n Field('roll', type = 'double', label = T('Roll')),\n Field('result', type = 'double', label = T('Result')),\n Field('visible', type = 'boolean', label = T('Visible')),\n Field('psyval', type = 'double', label = T('Psyco Value')),\n Field('time', type = 'datetime', label = T('Time'),\n writable = False, default = datetime.now()),\n )\n\n\ndb.define_table('state_mods',\n Field('char', type='reference chars', label=T('Char'),\n writable=False,\n requires = IS_IN_DB(db,db.chars.id,'%(name)s')),\n Field('name', type = 'string', label = T('Name')),\n Field('value', type = 'string', label = T('Value')),\n Field('type', type = 'string', label = T('Type')),\n )\n\n\ndb.define_table('combats',\n Field('master', type='reference auth_user', label=T('Master'),\n writable=False,\n requires=IS_IN_DB(db, db.auth_user.id, '%(username)s')),\n Field('name', type = 'string', label = T('Name')),\n Field('lighting', type = 'string', label = T('Lighting')),\n Field('noise', type = 'string', label = T('Noise')),\n Field('environment', type = 'string', label = T('Environment')))\n\n\ndb.define_table('actions',\n Field('char', type='reference chars', label=T('Char'),\n writable=False,\n requires = IS_IN_DB(db,db.chars.id,'%(name)s')),\n Field('combat', type = 'reference combats', requires = IS_IN_DB(db,db.combats.id,'%(name)s')),\n Field('action', type = 'string', label = T('Value')),\n Field('cost', type = 'double', label = T('Roll')),\n )\n"
},
{
"alpha_fraction": 0.5457413196563721,
"alphanum_fraction": 0.5467928647994995,
"avg_line_length": 20.636363983154297,
"blob_id": "22a81623b6905ea4b65a575f8b35b74d79b7418d",
"content_id": "b10f67cd7484d151ed15ae325760c3d5a59eb76b",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 951,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 44,
"path": "/modules/setter_functions.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# coding: utf8\nimport basic\n\n\nclass CharPropertySetter(basic.Char):\n def __init__(self, char):\n \"\"\"\"\n :param char: the character for witch to get the attribute\n \"\"\"\n\n basic.Char.__init__(self, char)\n\n def set_attribute(self, attribute, payexp=True):\n \"\"\"\n\n :param attribute: the attribute to set\n :param payexp: weather to pay experience points\n \"\"\"\n pass\n\n def set_skill(self, skill, payexp=True):\n \"\"\"\n\n :param skill: the skill to set\n :param payexp: weather to pay experience points\n \"\"\"\n pass\n\n def apply_damage(self, damage, kind):\n \"\"\"\n\n :param damage: the ammount of damage, if 'x%' percent damage is used\n :param kind: the damage kind\n \"\"\"\n pass\n\n def heal_damage(self, time, treatment):\n \"\"\"\n\n :param time:\n :param treatment:\n \"\"\"\n pass"
},
{
"alpha_fraction": 0.45572006702423096,
"alphanum_fraction": 0.5519344806671143,
"avg_line_length": 71.66922760009766,
"blob_id": "03b4234296aaad65782d6512fa8aa0d950d79aba",
"content_id": "866e643924bacee3a6e3ff991d4ef3bd8d2a48c6",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151152,
"license_type": "permissive",
"max_line_length": 242,
"num_lines": 2080,
"path": "/modules/data.py",
"repo_name": "rserbitar/gabaros",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf8\n# from gluon import *\n\n#!/usr/bin/env python\n# coding: utf8\n# request, response, session, cache, T, db(s)\n# must be passed and cannot be imported!\n\nfrom collections import namedtuple, OrderedDict\nimport rules\n\ndef replace_stars(data):\n for i, v in enumerate(data):\n for i2, v2 in enumerate(v):\n if isinstance(v2, str) and \"*\" in v2:\n data[i][i2] = v2.replace(\"*\", data[i][data[0].index(\"parent\")])\n\n\nconverted = ['attributes', 'bodyparts', 'stats', 'skill_attribmods']\n\nstates = [\"Physical Damage\",\n \"Stun Damage\",\n \"Head Wounds\",\n \"Upper Torso Wounds\",\n \"Lower Torso Wounds\",\n \"Left Arm Wounds\",\n \"Right Arm Wounds\",\n \"Left Leg Wounds\",\n \"Right Leg Wounds\",\n \"Stunned\",\n \"Unconscious\"]\n\npermits = [\n [\"name\", \"cost_multiplier\"],\n ['none', 1],\n ['civilian', 1.5],\n ['security', 2.5],\n ['military', 5]\n]\n\npermits_nt = namedtuple('permits', ['id'] + permits[0])\npermits_dict = OrderedDict([(entry[0], permits_nt(*([i] + entry))) for i, entry in enumerate(permits[1:])])\n\nform_factors = [\n [\"name\", \"accessory\", \"size\", 'description'],\n ['commlink', True, 1.5, ''],\n ['lenses', True, 1.5, ''],\n ['glasses', True, 1.5, ''],\n ['goggles', True, 1.5, ''],\n ['helmet', True, 1.5, ''],\n ['micro sensors', True, 1.5, ''],\n ['mini sensors', True, 1.5, ''],\n ['basic sensors', True, 1.5, ''],\n ['macro sensors', True, 1.5, ''],\n ['commlink', True, 1.5, ''],\n ['cyberdeck', True, 2, ''],\n ['gun', True, 1, ''],\n ['ciggaret_box', False, 3, ''],\n ['match_box', False, 3, ''],\n ['ciggaret_box', False, 3, ''],\n ['one_litre_box', False, 3, ''],\n]\n\nform_factors_nt = namedtuple('form_factors', ['id'] + form_factors[0])\nform_factors_dict = OrderedDict([(entry[0], form_factors_nt(*([i] + entry))) for i, entry in enumerate(form_factors[1:])])\n\ndamagekinds = [\n [\"name\", \"healing_time\", \"description\", \"priority\"],\n [\"fatigue\", 1 / 24., \"Damage gained by physical exertion\", 1],\n [\"stun\", 1 / 24. * 5, \"Bruises,...\", 10],\n [\"physical\", 30, \"\", 100],\n [\"drain stun\", 1 / 24. * 5, \"Drain Stun\", 5],\n [\"drain physical\", 30, \"Drain Physical\", 50]\n]\n\ndamagekinds_nt = namedtuple('damagekind', ['id'] + damagekinds[0])\ndamagekinds_dict = OrderedDict([(entry[0], damagekinds_nt(*([i] + entry))) for i, entry in enumerate(damagekinds[1:])])\n\nstatclasses = [\n [\"name\", \"parent\"],\n [\"Char\", None],\n [\"Item\", None],\n [\"Attributes\", \"Char\"],\n [\"Ware\", \"Item\"],\n [\"Cyberware\", \"Ware\"],\n [\"Bioware\", \"Ware\"],\n [\"Nanoware\", \"Ware\"],\n [\"Genetech\", \"Ware\"],\n [\"Weapon\", \"Item\"],\n [\"Ranged Weapon\", \"Weapon\"],\n [\"Melee Weapon\", \"Weapon\"],\n [\"Armor\", \"Item\"],\n [\"Sensor\", \"Item\"],\n [\"Cyberdeck\", \"Item\"]\n]\n\nstats = [\n [\"name\", \"clas\", \"parent\", \"type\"],\n [\"Action Costs\", \"Char\", None, \"float\"],\n [\"Awareness Costs\", \"Char\", \"Action Costs\", \"float\"],\n [\"Time Costs\", \"Char\", \"Action Costs\", \"float\"],\n [\"Physical Awareness\", \"Char\", \"Awareness Costs\", \"float\"],\n [\"Physical Time\", \"Char\", \"Time Costs\", \"float\"],\n [\"Move Awareness\", \"Char\", \"Physical Awareness Costs\", \"float\"],\n [\"Move Time\", \"Char\", \"Physical Time Costs\", \"float\"],\n [\"Shift Awareness\", \"Char\", \"Physical Awareness Costs\", \"float\"],\n [\"Shift Time\", \"Char\", \"Physical Time Costs\", \"float\"],\n [\"Meta Awareness\", \"Char\", \"Awareness Costs\", \"float\"],\n [\"Meta Time\", \"Char\", \"Time Costs\", \"float\"],\n [\"General Awareness\", \"Char\", \"Awareness Costs\", \"float\"],\n [\"General Time\", \"Char\", \"Time Costs\", \"float\"],\n [\"Combat Awareness\", \"Char\", \"Physical Awareness Costs\", \"float\"],\n [\"Combat Time\", \"Char\", \"Physical Time Costs\", \"float\"],\n [\"Melee Combat Awareness\", \"Char\", \"Combat Awareness\", \"float\"],\n [\"Melee Combat Time\", \"Char\", \"Combat Time\", \"float\"],\n [\"Ranged Combat Awareness\", \"Char\", \"Combat Awareness\", \"float\"],\n [\"Ranged Combat Time\", \"Char\", \"Combat Time\", \"float\"],\n [\"Astral Awareness\", \"Char\", \"Awareness Costs\", \"float\"],\n [\"Astral Time\", \"Char\", \"Time Costs\", \"float\"],\n [\"Matrix Awareness\", \"Char\", \"Awareness Costs\", \"float\"],\n [\"Matrix Time\", \"Char\", \"Time Costs\", \"float\"],\n [\"Name\", \"Char\", None, \"str\"],\n [\"Streetname\", \"Char\", None, \"str\"],\n [\"Date of Birth\", \"Char\", None, \"date\"],\n [\"Skintone\", \"Char\", None, \"str\"],\n [\"Eyecolor\", \"Char\", None, \"str\"],\n [\"Hairstyle\", \"Char\", None, \"str\"],\n [\"Haircolor\", \"Char\", None, \"str\"],\n [\"Loadout\", \"Char\", None, \"int\"],\n [\"Woundlimit\", \"Char\", None, \"float\"],\n [\"Life\", \"Char\", None, \"float\"],\n [\"Carriing Capacity\", \"Char\", None, \"float\"],\n [\"Initiative\", \"Char\", None, \"float\"],\n [\"Reaction\", \"Char\", None, \"float\"],\n [\"Physical Initiative\", \"Char\", \"Initiative\", \"float\"],\n [\"Physical Reaction\", \"Char\", \"Reaction\", \"float\"],\n [\"Matrix Initiative\", \"Char\", \"Initiative\", \"float\"],\n [\"Matrix Reaction\", \"Char\", \"Reaction\", \"float\"],\n [\"Astral Initiative\", \"Char\", \"Initiative\", \"float\"],\n [\"Astral Reaction\", \"Char\", \"Reaction\", \"float\"],\n [\"Legality\", \"Item\", None, \"float\"],\n [\"Visible Stealth Rating\", \"Item\", None, \"float\"],\n [\"Scan Stealth Rating\", \"Item\", None, \"float\"],\n [\"Ballistic Armor\", \"Armor\", None, \"float\"],\n [\"Impact Armor\", \"Armor\", None, \"float\"],\n [\"Shielding\", \"Armor\", None, \"float\"],\n [\"Insulation\", \"Armor\", None, \"float\"],\n [\"Agility Cap\", \"Armor\", None, \"float\"],\n [\"Coordination Multiplier\", \"Armor\", None, \"float\"],\n [\"Damage\", \"Weapon\", None, \"float\"],\n [\"Damagetype\", \"Weapon\", None, \"str\"],\n [\"Penetration\", \"Weapon\", None, \"float\"],\n [\"Range\", \"Weapon\", None, \"float\"],\n [\"Single Shot Rate\", \"Weapon\", None, \"integer\"],\n [\"Burst Shot Rate\", \"Weapon\", None, \"integer\"],\n [\"Auto Shot Rate\", \"Weapon\", None, \"integer\"],\n]\n\nstats_nt = namedtuple('stat', ['id'] + stats[0])\nstats_dict = OrderedDict([(entry[0], stats_nt(*([i] + entry))) for i, entry in enumerate(stats[1:])])\n\nraces = [\n [\"name\", \"Size\", \"Weight\", \"Agility\", \"Constitution\", \"Coordination\", \"Strength\", \"Charisma\", \"Intuition\", \"Logic\",\n \"Willpower\", \"Magic\", \"Edge\", \"xpcost\"],\n [\"Human\", 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],\n [\"Troll\", 1.3, 1.3, 0.9, 1.3, 0.7, 1.1, 0.8, 1.1, 0.7, 0.9, 1, 1, 0],\n [\"Orc\", 1.1, 1.2, 1.2, 1.2, 1, 1.1, 0.7, 1.1, 0.7, 1.2, 1, 1, 0],\n [\"Elf\", 1.1, 0.8, 1.3, 0.8, 1.2, 0.8, 1.2, 1.1, 0.9, 1, 1, 1, 0],\n [\"Dwarf\", 0.75, 1.5, 0.8, 1.3, 1.2, 1.5, 1, 0.9, 1.1, 1.2, 1, 1, 0],\n]\n\nraces_nt = namedtuple('race', ['id'] + races[0])\nraces_dict = OrderedDict([(entry[0], races_nt(*([i] + entry))) for i, entry in enumerate(races[1:])])\n\ngendermods = [\n [\"name\", \"Size\", \"Weight\", \"Agility\", \"Constitution\", \"Coordination\", \"Strength\", \"Charisma\", \"Intuition\", \"Logic\",\n \"Willpower\", \"Magic\", \"Edge\"],\n [\"Male\", 1.05, 1, 1, 1, 1, 1.1, 0.9, 1, 1, 1, 1, 1],\n [\"Female\", 0.95, 1, 1, 1, 1, 0.9, 1.1, 1, 1, 1, 1, 1],\n]\n\ngendermods_nt = namedtuple('gendermod', ['id'] + gendermods[0])\ngendermods_dict = OrderedDict([(entry[0], gendermods_nt(*([i] + entry))) for i, entry in enumerate(gendermods[1:])])\n\nattributes = [\n [\"name\", \"base\", \"description\", \"factor\", \"signmod\", \"kind\"],\n [\"Size\", 1.75, \"size of a character in meteres\", 5000, -1, \"special\"],\n [\"Weight\", 75, \"weight of the character in kg\", 1000, -1, \"special\"],\n [\"Agility\", 30, \"speed of muscle movement, dexterity of limbs..\", 3000, 1, \"physical\"],\n [\"Constitution\", 30, \"ability to endure fatigue, bodily toughness, resistance to poinson and disease\", 3000, 1,\n \"physical\"],\n [\"Coordination\", 30, \"ability to coordinate agility and strength\", 3000, 1, \"physical\"],\n [\"Strength\", 30, \"raw physical strength\", 3000, 1, \"physical\"],\n [\"Charisma\", 30, \"empathy, ability to influence others\", 3000, 1, \"mental\"],\n [\"Intuition\", 30, \"unconsciousness thinking, ability to recognize patterns\", 3000, 1, \"mental\"],\n [\"Logic\", 30, \"raw mental processing power\", 3000, 1, \"mental\"],\n [\"Willpower\", 30, \"ability to resist temptations and influence of others\", 3000, 1, \"mental\"],\n [\"Magic\", 30, \"the ability to channel magic\", 3000, 1, \"special\"],\n [\"Edge\", 30, \"luck, the ability to excel in dangerous situations\", 3000, 1, \"special\"],\n]\n\nattributes_nt = namedtuple('attribute', ['id'] + attributes[0])\nattributes_dict = OrderedDict([(entry[0], attributes_nt(*([i] + entry))) for i, entry in enumerate(attributes[1:])])\n\nskills = [\n [\"name\", \"parent\", \"expweight\", 'kind'],\n [\"Combat\", None, 8.44, None],\n [\"Armed Combat\", \"Combat\", 2.25, None],\n [\"Impact Weapons\", \"Armed Combat\", 1, 'active'],\n [\"Piercing Weapons\", \"Armed Combat\", 1, 'active'],\n [\"Slashing Weapons\", \"Armed Combat\", 1, 'active'],\n [\"Unarmed Combat\", \"Combat\", 1.5, None],\n [\"Brawling\", \"Unarmed Combat\", 1, 'active'],\n [\"Wrestling\", \"Unarmed Combat\", 1, 'active'],\n [\"Thrown Weapons\", \"Combat\", 2.25, None],\n [\"Aerodynamics\", \"Thrown Weapons\", 1, 'active'],\n [\"Axes\", \"Thrown Weapons\", 1, 'active'],\n [\"Balls\", \"Thrown Weapons\", 1, 'active'],\n [\"Ranged Weapons\", \"Combat\", 5.25, None],\n [\"Archery\", \"Ranged Weapons\", 1, 'active'],\n [\"Pistols\", \"Ranged Weapons\", 1, 'active'],\n [\"Automatics\", \"Ranged Weapons\", 1, 'active'],\n [\"Long Rifles\", \"Ranged Weapons\", 1, 'active'],\n [\"Indirect Fire\", \"Ranged Weapons\", 1, 'active'],\n [\"Launch Weapons\", \"Ranged Weapons\", 1, 'active'],\n [\"Spray Weapons\", \"Ranged Weapons\", 1, 'active'],\n [\"Physical\", None, 8.44, None],\n [\"Acrobatics\", \"Physical\", 2.5, None],\n [\"Balance\", \"Acrobatics\", 1, 'active'],\n [\"Dodge\", \"Acrobatics\", 1, 'active'],\n [\"Athletics\", \"Physical\", 2., None],\n [\"Climbing\", \"Athletics\", 0.5, 'active'],\n [\"Jumping\", \"Athletics\", 0.5, 'active'],\n [\"Lifting\", \"Athletics\", 0.5, 'active'],\n [\"Running\", \"Athletics\", 0.5, 'active'],\n [\"Swimming\", \"Athletics\", 0.5, 'active'],\n [\"Carouse\", \"Physical\", 0.75, None],\n [\"Perform\", \"Physical\", 1.5, None],\n [\"Dancing\", \"Perform\", 1, 'active'],\n [\"Singing\", \"Perform\", 1, 'active'],\n [\"Stealth\", \"Physical\", 2.25, None],\n [\"Hideing\", \"Stealth\", 1, 'active'],\n [\"Shadowing\", \"Stealth\", 1, 'active'],\n [\"Sneaking\", \"Stealth\", 1, 'active'],\n [\"Sleight of Hand\", \"Physical\", 2.25, None],\n [\"Lockpicking\", \"Sleight of Hand\", 1, 'active'],\n [\"Pickpocketing\", \"Sleight of Hand\", 1, 'active'],\n [\"Quickdrawing\", \"Sleight of Hand\", 1, 'active'],\n [\"Processing\", None, 7.31, None],\n [\"Art\", \"Processing\", 1.5, None],\n [\"Painting\", \"Art\", 1, 'active'],\n [\"Sculpting\", \"Art\", 1, 'active'],\n [\"Composure\", \"Processing\", 1.5, None],\n [\"Mental Composure\", \"Composure\", 1, None],\n [\"Physical Composure\", \"Composure\", 1, None],\n [\"Memory\", \"Processing\", 1, None],\n [\"Navigation\", \"Processing\", 2.25, None],\n [\"Orientation\", \"Navigation\", 1, 'passive'],\n [\"Land\", \"Navigation\", 0.5, 'passive'],\n [\"Sea\", \"Navigation\", 0.5, 'passive'],\n [\"Space\", \"Navigation\", 0.5, 'passive'],\n [\"Air\", \"Navigation\", 0.5, 'passive'],\n [\"Perception\", \"Processing\", 2.25, None],\n [\"Aural\", \"Perception\", 1, 'passive'],\n [\"Olfactorial\", \"Perception\", 0.5, 'passive'],\n [\"Tactile\", \"Perception\", 0.5, 'passive'],\n [\"Visual\", \"Perception\", 1, 'passive'],\n [\"Judge Person\", \"Processing\", 2.25, None],\n [\"Guess Intentions\", 'Judge Person', 1, 'passive'],\n [\"Detect Deceit\", \"Judge Person\", 1, 'passive'],\n [\"Interrogation\", \"Judge Person\", 1, 'passive'],\n [\"Empathy\", None, 8.44, None],\n [\"Act\", \"Empathy\", 1.5, None],\n [\"Theatrical\", \"Act\", 1, 'active'],\n [\"Impersonation\", \"Act\", 1, 'active'],\n [\"Animal Controll\", \"Empathy\", 1.5, None],\n [\"Animal Training\", \"Animal Controll\", 1, 'passive'],\n [\"Animal Riding\", \"Animal Controll\", 1, 'active'],\n [\"Discussion\", \"Empathy\", 2.25, None],\n [\"Convince\", \"Discussion\", 1, 'passive'],\n [\"Instruction\", \"Discussion\", 1, 'passive'],\n [\"Negotiation\", \"Discussion\", 1, 'passive'],\n [\"Interaction\", \"Empathy\", 3.75, None],\n [\"Deception\", \"Interaction\", 1, 'passive'],\n [\"Intimidation\", \"Interaction\", 1, 'passive'],\n [\"Leadership\", \"Interaction\", 1, 'passive'],\n [\"Persuasion\", \"Interaction\", 1, 'passive'],\n [\"Oratory\", \"Interaction\", 1, 'passive'],\n [\"Etiquette\", \"Empathy\", 2.25, None],\n [\"Academic\", \"Etiquette\", 0.5, 'passive'],\n [\"Corporate\", \"Etiquette\", 0.5, 'passive'],\n [\"Criminals\", \"Etiquette\", 0.5, 'passive'],\n [\"Scene\", \"Etiquette\", 0.5, 'passive'],\n [\"Security\", \"Etiquette\", 0.5, 'passive'],\n [\"Street\", \"Etiquette\", 0.5, 'passive'],\n [\"Magic\", None, 8.46, None],\n [\"Assensing\", \"Magic\", 1, 'magic'],\n [\"Astral Combat\", \"Magic\", 1, 'magic'],\n [\"Sorcery\", \"Magic\", 3, 'magic'],\n [\"Spellcasting\", \"Sorcery\", 2, 'magic'],\n [\"Counterspelling\", \"Sorcery\", 1, 'magic'],\n [\"Ritual Magic\", \"Sorcery\", 1, 'magic'],\n [\"Invocation\", \"Magic\", 2.25, 'magic'],\n [\"Binding\", \"Invocation\", 1, 'magic'],\n [\"Banishing\", \"Invocation\", 1, 'magic'],\n [\"Summoning\", \"Invocation\", 1, 'magic'],\n [\"Alchemy\", \"Magic\", 1, 'magic'],\n [\"Metamagic\", \"Magic\", 3, 'magic'],\n [\"Matrix\", None, 5.63, None],\n [\"Computers\", \"Matrix\", 3, None],\n [\"Data Search\", \"Computers\", 1, 'passive'],\n [\"Programming\", \"Computers\", 1, 'passive'],\n [\"Computer Use\", \"Computers\", 2, 'passive'],\n [\"Hacking\", \"Matrix\", 4.5, None],\n [\"Cracking\", \"Hacking\", 2, 'passive'],\n [\"Cybercombat\", \"Hacking\", 1, 'passive'],\n [\"Decryption\", \"Hacking\", 1, 'passive'],\n [\"Matrix Security\", \"Hacking\", 2, 'passive'],\n [\"Technical\", None, 7.88, None],\n [\"Chemistry\", \"Technical\", 1.5, None],\n [\"Toxins\", \"Chemistry\", 1, 'passive'],\n [\"Demolitions\", \"Chemistry\", 1, 'passive'],\n [\"Electronics\", \"Technical\", 3, None],\n [\"Maglocks\", \"Electronics\", 1, 'passive'],\n [\"Sensors\", \"Electronics\", 1, 'passive'],\n [\"Optical Computers\", \"Electronics\", 1, 'passive'],\n [\"Electronic Warfare\", \"Electronics\", 1, 'passive'],\n [\"Mechanics\", \"Technical\", 2.25, None],\n [\"Locks\", \"Mechanics\", 1, 'passive'],\n [\"Weapons\", \"Mechanics\", 1, 'passive'],\n [\"Traps\", \"Mechanics\", 1, 'passive'],\n [\"Medics\", \"Technical\", 2.25, 'passive'],\n [\"Cybernetics\", \"Medics\", 1, 'passive'],\n [\"Extended Care\", \"Medics\", 1, 'passive'],\n [\"First Aid\", \"Medics\", 1, 'passive'],\n [\"Social\", \"Technical\", 1.5, None],\n [\"Disguise\", \"Social\", 1, 'passive'],\n [\"Forgery\", \"Social\", 1, 'passive'],\n ['Locomotion', None, 6.19, None],\n ['Vehicle Mechanics', 'Locomotion', 3, None],\n [\"Ground Vehicle Mechanics\", \"Vehicle Mechanics\", 1, 'passive'],\n [\"Airborne Vehicle Mechanics\", \"Vehicle Mechanics\", 1, 'passive'],\n [\"Spacecraft Mechanics\", \"Vehicle Mechanics\", 1, 'passive'],\n [\"Watercraft Mechanics\", \"Vehicle Mechanics\", 1, 'passive'],\n [\"Pilot\", \"Locomotion\", 5.25, None],\n [\"Airplane\", \"Pilot\", 1, 'active'],\n [\"Hovercraft\", \"Pilot\", 1, 'active'],\n [\"Helicopter\", \"Pilot\", 1, 'active'],\n [\"Submarine\", \"Pilot\", 1, 'active'],\n [\"Thrust\", \"Pilot\", 1, 'active'],\n [\"Watercraft\", \"Pilot\", 1, 'active'],\n [\"Wheeled\", \"Pilot\", 1, 'active'],\n]\n\nskills_nt = namedtuple('skill', ['id'] + skills[0])\nskills_dict = OrderedDict([(entry[0], skills_nt(*([i] + entry))) for i, entry in enumerate(skills[1:])])\n\nskill_attribmods = [['skill', 'Agility', 'Constitution', 'Coordination', 'Strength', 'Weight',\n 'Charisma', 'Intuition', 'Logic', 'Willpower', 'Magic', 'Size'],\n [\"Combat\", 0.333, 0, 0.333, 0, 0, 0, 0.333, 0, 0, 0, 0],\n [\"Armed Combat\", 0.333, 0, 0.333, 0, 0, 0, 0.333, 0, 0, 0, 0],\n [\"Impact Weapons\", 0.5, 0, 0.5, 0, 0, 0, 0., 0, 0, 0, 0],\n [\"Piercing Weapons\", 0.25, 0, 0.25, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Slashing Weapons\", 0.333, 0, 0.333, 0, 0, 0, 0.333, 0, 0, 0, 0],\n [\"Unarmed Combat\", 0.25, 0, 0.5, 0.25, 0, 0, 0., 0, 0, 0, 0],\n [\"Brawling\", 0.5, 0, 0.25, 0.25, 0, 0, 0.0, 0, 0, 0, 0],\n [\"Wrestling\", 0.0, 0, 0.5, 0.5, 0, 0, 0.0, 0, 0, 0, 0],\n [\"Thrown Weapons\", 0.25, 0, 0.375, 0, 0, 0, 0.375, 0, 0, 0, 0],\n [\"Aerodynamics\", 0.25, 0, 0.375, 0, 0, 0, 0.375, 0, 0, 0, 0],\n [\"Axes\", 0.5, 0, 0.25, 0, 0, 0, 0.25, 0, 0, 0, 0],\n [\"Balls\", 0.333, 0, 0.333, 0, 0, 0, 0.333, 0, 0, 0, 0],\n [\"Ranged Weapons\", 0.25, 0, 0.375, 0, 0, 0, 0.375, 0, 0, 0, 0],\n [\"Archery\", 0.5, 0, 0.25, 0, 0, 0, 0.25, 0, 0, 0, 0],\n [\"Pistols\", 0.125, 0, 0.5, 0, 0, 0, 0.375, 0, 0, 0, 0],\n [\"Automatics\", 0, 0, 0.75, 0, 0, 0, 0.25, 0, 0, 0, 0],\n [\"Long Rifles\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Indirect Fire\", 0, 0, 0.25, 0, 0, 0, 0.25, 0.5, 0, 0, 0],\n [\"Launch Weapons\", 0, 0, 0, 0, 0, 0, 0.25, 0.75, 0, 0, 0],\n [\"Spray Weapons\", 0, 0, 0, 0, 0, 0, 0, 1.0, 0, 0, 0],\n [\"Physical\", 0.5, 0, 0.5, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Acrobatics\", 0.5, 0, 0.5, 1, -1, 0, 0, 0, 0, 0, 0],\n [\"Balance\", 0.5, 0, 0.5, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Dodge\", 0.5, 0, 0., 1, -1, 0, 0.5, 0, 0, 0, 0],\n [\"Athletics\", 0.75, 0, 0.25, 1, -1, 0, 0, 0, 0, 0, 0],\n [\"Climbing\", 0, 0.5, 0.5, 1.5, -1.5, 0, 0, 0, 0, 0, 0],\n [\"Jumping\", 0.75, 0, 0.25, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Lifting\", 0, 0.5, 0.5, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Running\", 0.5, 0.5, 0, 1, -1, 0, 0, 0, 0, 0, 0],\n [\"Swimming\", 0.25, 0.5, 0.25, 1, -1, 0, 0, 0, 0, 0, 0],\n [\"Carouse\", 0, 1., 0, 0, 0.5, 0, 0, 0, 0, 0, 0],\n [\"Perform\", 0, 0, 0, 0.25, 0, 0.75, 0, 0, 0, 0, 0],\n [\"Dancing\", 0.25, 0, 0.25, 0., 0, 0.5, 0, 0, 0, 0, 0],\n [\"Singing\", 0, 0, 0.25, 0, 0, 0.75, 0, 0, 0, 0, 0],\n [\"Stealth\", 0, 0, .75, 0, 0, 0, 0.25, 0, 0, 0, 0],\n [\"Hideing\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Shadowing\", 0.25, 0, 0.25, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Sneaking\", 0.25, 0, 0.75, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Sleight of Hand\", 0.25, 0, 0.75, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Lockpicking\", 0.25, 0, 0.75, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Pickpocketing\", 0.25, 0, 0.5, 0, 0, 0, 0.25, 0, 0, 0, 0],\n [\"Quickdrawing\", 0.75, 0, 0.25, 0, 0, 0, 0, 0, 0, 0, 0],\n [\"Processing\", 0, 0, 0, 0, 0, 0, .75, 0, 0.25, 0, 0],\n [\"Art\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Painting\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Sculpting\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0, 0],\n [\"Composure\", 0, 0, 0.25, 0, 0, 0, 0., 0, 0.75, 0, 0],\n [\"Mental Composure\", 0, 0, 0, 0, 0, 0, 0., 0, 1, 0, 0],\n [\"Physical Composure\", 0, 0, 0.5, 0, 0, 0, 0., 0, 0.5, 0, 0],\n [\"Memory\", 0, 0, 0, 0, 0, 0, 0.25, 0.5, 0.25, 0, 0],\n [\"Navigation\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Orientation\", 0, 0, 0, 0, 0, 0, 0.75, 0.25, 0, 0, 0],\n [\"Land\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Sea\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Space\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Air\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Perception\", 0, 0, 0, 0, 0, 0, 1., 0, 0, 0, 0],\n [\"Aural\", 0, 0, 0, 0, 0, 0, 1., 0, 0, 0, 0],\n [\"Olfactorial\", 0, 0, 0, 0, 0, 0, 1., 0, 0, 0, 0],\n [\"Tactile\", 0, 0, 0, 0, 0, 0, 1., 0, 0, 0, 0],\n [\"Visual\", 0, 0, 0, 0, 0, 0, 1., 0, 0, 0, 0],\n [\"Assensing\", 0, 0, 0, 0, 0, 0, 0.5, 0, 0, 0.5, 0],\n [\"Judge Person\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Guess Intentions\", 0, 0, 0, 0, 0, 0, .5, 0.5, 0, 0, 0],\n [\"Detect Deceit\", 0, 0, 0, 0, 0, 0, .25, 0.75, 0, 0, 0],\n [\"Interrogation\", 0, 0, 0, 0, 0, 0, .25, 0.75, 0, 0, 0],\n [\"Empathy\", 0, 0, 0, 0, 0, 1., 0, 0, 0, 0, 0],\n [\"Act\", 0, 0, 0.25, 0, 0, 0.75, 0, 0, 0, 0, 0],\n [\"Theatrical\", 0, 0, 0.25, 0, 0, 0.5, 0, 0.25, 0, 0, 0],\n [\"Impersonation\", 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0, 0],\n [\"Animal Controll\", 0, 0, 0, 0, 0, 0.75, 0.25, 0, 0, 0, 0],\n [\"Animal Training\", 0, 0, 0, 0, 0, 0.5, 0.25, 0.25, 0, 0, 0],\n [\"Animal Riding\", 0, 0, 0.5, 0, 0, 0.5, 0., 0, 0, 0, 0],\n [\"Discussion\", 0, 0, 0, 0, 0, 0.5, 0, 0.5, 0, 0, 0],\n [\"Convince\", 0, 0, 0, 0, 0, 0.5, 0, 0.5, 0, 0, 0],\n [\"Instruction\", 0, 0, 0, 0, 0, 0.25, 0, 0.75, 0, 0, 0],\n [\"Negotiation\", 0, 0, 0, 0, 0, 0.25, 0, 0.25, 0.5, 0, 0],\n [\"Interaction\", 0, 0, 0, 0, 0, 0.75, 0.25, 0, 0, 0, 0],\n [\"Deception\", 0, 0, 0, 0, 0, .5, 0.25, 0.25, 0, 0, 0],\n [\"Intimidation\", 0, 0, 0, 0, 0, .25, 0, 0, 0.75, 0, 0],\n [\"Leadership\", 0, 0, 0, 0, 0, 0.75, 0., 0, 0.25, 0, 0],\n [\"Persuasion\", 0, 0, 0, 0, 0, .75, 0., 0.25, 0, 0, 0],\n [\"Oratory\", 0, 0, 0, 0, 0, .5, 0, 0.5, 0, 0, 0],\n [\"Etiquette\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Academic\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Corporate\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Criminals\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Scene\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Security\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Street\", 0, 0, 0, 0, 0, 0, 0.5, 0.5, 0, 0, 0],\n [\"Magic\", 0, 0, 0, 0, 0, 0, 0, 0, 0, 1., 0],\n [\"Astral Combat\", 0, 0, 0, 0, 0, 0, 0.5, 0, 0, 0.5, 0],\n [\"Sorcery\", 0, 0, 0, 0, 0, 0, 0.25, 0.25, 0, .5, 0],\n [\"Spellcasting\", 0, 0, 0, 0, 0, 0, 0.5, 0., 0, .5, 0],\n [\"Counterspelling\", 0, 0, 0, 0, 0, 0, 0.5, 0., 0, .5, 0],\n [\"Ritual Magic\", 0, 0, 0, 0, 0, 0, 0., .5, 0, .5, 0],\n [\"Invocation\", 0, 0, 0, 0, 0, 0.25, 0, 0, 0.25, .5, 0],\n [\"Binding\", 0, 0, 0, 0, 0, 0.25, 0, 0, 0.25, .5, 0],\n [\"Banishing\", 0, 0, 0, 0, 0, 0, 0, 0, .5, .5, 0],\n [\"Summoning\", 0, 0, 0, 0, 0, .5, 0, 0, 0, .5, 0],\n [\"Alchemy\", 0, 0, 0, 0, 0, 0, 0, .5, 0, 0.5, 0],\n [\"Metamagic\", 0, 0, 0, 0, 0, 0, 0, 0., 0, 0., 0],\n [\"Matrix\", 0, 0, 0, 0, 0, 0, 0.25, 0.75, 0, 0., 0],\n [\"Computers\", 0, 0, 0, 0, 0, 0, 0.25, 0.75, 0, 0., 0],\n [\"Data Search\", 0, 0, 0, 0, 0, 0, 0.5, .5, 0, 0., 0],\n [\"Programming\", 0, 0, 0, 0, 0, 0, 0.25, .75, 0, 0., 0],\n [\"Computer Use\", 0, 0, 0, 0, 0, 0, 0.25, .75, 0, 0., 0],\n [\"Hacking\", 0, 0, 0, 0, 0, 0, 0.25, 0.5, 0.25, 0, 0],\n [\"Cracking\", 0, 0, 0, 0, 0, 0, 0.25, 0.75, 0, 0., 0],\n [\"Cybercombat\", 0, 0, 0, 0, 0, 0, 0., .75, 0.25, 0., 0],\n [\"Decryption\", 0, 0, 0, 0, 0, 0, 0., 1., 0, 0., 0],\n [\"Matrix Security\", 0, 0, 0, 0, 0, 0, 0.25, 0.75, 0, 0., 0],\n [\"Technical\", 0, 0, 0.25, 0, 0, 0, 0.25, 0.5, 0, 0., 0],\n [\"Chemistry\", 0, 0, 0.25, 0, 0, 0, 0.25, .5, 0, 0., 0],\n [\"Toxins\", 0, 0, 0, 0, 0, 0, 0.25, .75, 0, 0., 0],\n [\"Demolitions\", 0, 0, 0.25, 0, 0, 0, 0.25, .5, 0, 0., 0],\n [\"Electronics\", 0, 0, 0.25, 0, 0, 0, 0.25, .5, 0, 0., 0],\n [\"Maglocks\", 0, 0, 0.5, 0, 0, 0, 0.25, .25, 0, 0., 0],\n [\"Sensors\", 0, 0, 0.5, 0, 0, 0, 0.25, .25, 0, 0., 0],\n [\"Optical Computers\", 0, 0, 0.25, 0, 0, 0, 0.25, .5, 0, 0., 0],\n [\"Electronic Warfare\", 0, 0, 0, 0, 0, 0, 0.5, .5, 0, 0., 0],\n [\"Mechanics\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Locks\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Weapons\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Traps\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Medics\", 0, 0, 0.25, 0, 0, 0, 0, 0.75, 0, 0., 0],\n [\"Cybernetics\", 0, 0, 0.25, 0, 0, 0, 0, 0.75, 0, 0., 0],\n [\"Extended Care\", 0, 0, 0., 0, 0, 0, 0.25, 0.75, 0, 0., 0],\n [\"First Aid\", 0, 0, 0.5, 0, 0, 0, 0.25, 0.25, 0, 0., 0],\n [\"Social\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Disguise\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Forgery\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Locomotion\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Vehicle Mechanics\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Ground Vehicle Mechanics\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Airborne Vehicle Mechanics\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Spacecraft Mechanics\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Watercraft Mechanics\", 0, 0, 0.5, 0, 0, 0, 0, 0.5, 0, 0., 0],\n [\"Pilot\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Airplane\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Hovercraft\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Helicopter\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Submarine\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Thrust\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Watercraft\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n [\"Wheeled\", 0, 0, 0.5, 0, 0, 0, 0.5, 0, 0, 0., 0],\n]\n\nskill_attribmods_nt = namedtuple('skill_attribmod', ['id'] + skill_attribmods[0])\nskills_attribmods_dict = OrderedDict(\n [(entry[0], skill_attribmods_nt(*([i] + entry))) for i, entry in enumerate(skill_attribmods[1:])])\n\nactions = [\n [\"name\", \"category\", \"cost\", \"reaction\"],\n [\"Walk\", \"move\", 'No', False],\n [\"Run\", \"move\", 'No', False],\n [\"Sprint\", \"move\", 'Complex', False],\n [\"Jump\", \"move\", 'Simple', False],\n [\"Climb\", \"move\", 'Complex', False],\n [\"Swim\", \"move\", 'Complex', False],\n [\"Crouch Walk\", 'move', 'No', False],\n [\"Crawl\", \"move\", 'Complex', False],\n [\"Jump for Cover\", \"move\", 'Simple', True],\n\n [\"Dodge\", \"move\", 'Free', True],\n [\"Crouch\", \"shift\", 'Free', False],\n [\"Stand\", \"shift\", 'Simple', False],\n [\"Stand Up\", \"shift\", 'Complex', False],\n [\"Jump Up\", \"shift\", 'Simple', False],\n [\"Drop Down\", \"shift\", 'Free', True],\n [\"Get Down\", \"shift\", 'Simple', False],\n [\"Turn\", \"shift\", 'Free', False],\n [\"Peek\", \"shift\", 'Free', False],\n [\"Duck Back\", \"shift\", 'Free', True],\n [\"Take Cover\", \"shift\", 'Simple', False],\n\n [\"Interrupt\", \"meta\", 'Free', False],\n [\"Postpone\", \"meta\", 'Simple', False],\n [\"Delay\", \"meta\", 'Complex', False],\n [\"Overwatch\", \"meta\", 'Complex', False],\n\n [\"Melee Attack\", \"melee combat\", 'Complex', False],\n [\"Parry\", \"melee combat\", 'Free', True],\n\n [\"Single Shot\", \"ranged combat\", 'Simple', False],\n [\"Fast Shots\", \"ranged combat\", 'Complex', False],\n [\"Burst Shot\", \"ranged combat\", 'Simple', False],\n [\"Short FA Burst\", \"ranged combat\", 'Simple', False],\n [\"Long FA Burst\", \"ranged combat\", 'Complex', False],\n [\"Brace Weapon\", \"ranged combat\", 'Simple', False],\n [\"Throw Weapon\", \"ranged combat\", 'Simple', False],\n [\"Evasive Action\", \"ranged combat\", 'Simple', False],\n\n [\"Target\", \"ranged combat\", 'Free', False],\n [\"Sight\", \"ranged combat\", 'Simple', False],\n [\"Aim\", \"ranged combat\", 'Simple', False],\n\n [\"Evade\", \"combat\", 'Free', False],\n [\"Draw Weapon\", \"combat\", 'Simple', False],\n [\"Reload\", \"combat\", 'Complex', False],\n\n [\"Observe\", \"general\", 'Complex', False],\n\n [\"Cast\", \"astral\", 'Complex', False],\n [\"Counterspell\", \"astral\", 'Simple', True],\n [\"Banish\", \"astral\", 'Complex', False],\n [\"Sustain\", \"astral\", 'No', False],\n\n [\"Matrix Action\", \"matrix\", 'Complex', False],\n]\n\nmatrix_attributes = [\n [\"name\", \"description\"],\n [\"Processor\", \"Raw processing power\"],\n [\"System\", \"System quality\"],\n [\"Firewall\", \"Ability to resist illegal action\"],\n [\"Uplink\", \"Maximal bandwidth and latency\"],\n [\"Signal\", \"Strength of wireless signal\"],\n]\n\nprogrammes = [\n [\"name\", \"skill\", \"attribute\"],\n [\"Search\", \"Data Search\", \"Processor\"],\n [\"Stealth\", \"Cracking\", \"System\"],\n [\"Scan\", \"Electronic Warfare\", \"Signal\"],\n [\"Analyze\", \"Computer Use\", \"System\"],\n [\"Access\", \"Computer Use\", \"System\"],\n [\"Exploit\", \"Cracking\", \"System\"],\n [\"Crypt\", \"Computer Use\", \"System\"],\n [\"Break\", \"Decryption\", \"Processor\"],\n [\"Edit\", \"Computer Use\", \"System\"],\n [\"Control\", \"Computer Use\", \"System\"],\n [\"Find\", \"Computer Use\", \"Uplink\"],\n [\"Corrupt\", \"Cybercombat\", \"Processor\"],\n [\"Medic\", \"Programming\", \"System\"],\n]\n\nprogrammes_nt = namedtuple('programme', ['id'] + programmes[0])\nprogrammes_dict = OrderedDict([(entry[0], programmes_nt(*([i] + entry))) for i, entry in enumerate(programmes[1:])])\n\nmatrix_actions = [\n [\"name\", \"programme\", \"prerequisite\"],\n [\"Find Node\", \"Find\", \"AID\"],\n [\"Find Wireless Node\", \"Scan\", \"\"],\n [\"Find Process\", \"Find\", \"Node Access\"],\n [\"Find File\", \"Find\", \"Node Access\"],\n [\"Find Stream\", \"Find\", \"Node Access\"],\n [\"Find Wireless Stream\", \"Scan\", \"\"],\n [\"Analyze Node\", \"Analyze\", \"Found Node\"],\n [\"Analyze Process\", \"Analyze\", \"Found Process\"],\n [\"Analyze File\", \"Analyze\", \"Found File\"],\n [\"Analyze Stream\", \"Analyze\", \"Found Stream\"],\n [\"Access Node\", \"Access\", \"Found Node\"],\n [\"Access Process\", \"Access\", \"Found Process\"],\n [\"Access File\", \"Access\", \"Found File\"],\n [\"Access Stream\", \"Access\", \"Found Stream\"],\n [\"Encrypt File\", \"Crypt\", \"File Access\"],\n [\"Decrypt File\", \"Crypt\", \"File Access, Key\"],\n [\"Break File\", \"Break\", \"File Access\"],\n [\"Encrypt Stream\", \"Crypt\", \"Stream Access\"],\n [\"Decrypt Stream\", \"Crypt\", \"Stream Access, Key\"],\n [\"Break Stream\", \"Break\", \"Stream Access\"],\n [\"Edit Account\", \"Edit\", \"Node Access\"],\n [\"Edit Subscription List\", \"Edit\", \"Node Access\"],\n [\"Edit Log\", \"Edit\", \"Node Access\"],\n [\"Edit Process Account\", \"Edit\", \"Process Access\"],\n [\"Edit File\", \"Edit\", \"File Access\"],\n [\"Edit Stream\", \"Edit\", \"Stream Access\"],\n [\"Start Process\", \"Control\", \"Node Access\"],\n [\"Stop Process\", \"Control\", \"Found process\"],\n [\"Shutdown Node\", \"Control\", \"Node Access\"],\n [\"Change Alarm Status\", \"Edit\", \"Node Access\"],\n [\"Create File\", \"Control\", \"Node Access\"],\n [\"Delete File\", \"Control\", \"Found File\"],\n [\"Control Process\", \"Control\", \"Process Access\"],\n [\"Change Stream Path\", \"Control\", \"Relay Node Access\"],\n [\"Terminate Stream\", \"Control\", \"Relay Node Access\"],\n [\"Slow Node\", \"Corrupt\", \"Found Node\"],\n [\"Crash Node\", \"Corrupt\", \"Found Node\"],\n [\"Slow Process\", \"Corrupt\", \"Found Process\"],\n [\"Crash Process\", \"Corrupt\", \"Found Process\"],\n [\"Corrupt File\", \"Corrupt\", \"Found File\"],\n [\"Corrupt Stream\", \"Corrupt\", \"Found Stream\"],\n [\"Repair Process\", \"Medic\", \"Process Access\"],\n [\"Repair Node\", \"Medic\", \"Node Access\"],\n [\"Jam Stream\", \"Scan\", \"Found Stream in Signal Range\"],\n [\"Exploit\", \"Exploit\", \"None\"]\n]\n\nmatrix_actions_nt = namedtuple('matrix_action', ['id'] + matrix_actions[0])\nmatrix_actions_dict = OrderedDict(\n [(entry[0], matrix_actions_nt(*([i] + entry))) for i, entry in enumerate(matrix_actions[1:])])\n\nmain_bodyparts = ['Head', 'Upper Torso', 'Lower Torso', 'Left Arm', 'Right Arm', 'Left Leg', 'Right Leg']\n\nbodyparts = [\n [\"name\", \"template\", \"parent\", \"level\", \"weightfrac\", \"sizefrac\", \"essencefrac\",\n \"agilityfrac\", \"coordinationfrac\", \"strengthfrac\", \"constitutionfrac\"],\n [\"Body\", \"human\", None, 0, 1., 1., 1, 1., 1., 1., 1., ],\n [\"Head\", \"human\", \"Body\", 1, 1/11., 1/11., 0.25, 0.255, 0.2, 0., 0.1, ],\n [\"Brain\", \"human\", \"Head\", 2, 0.2, 0.2, 0., 0., 0., 0., 0., ],\n [\"Vertebrae\", \"human\", \"Head\", 2, 0.2, 0.2, 0.45, 1., 0.5, 0., 0., ],\n [\"Eyes\", \"human\", \"Head\", 2, 0.05, 0.05, 0.2, 0., 0., 0., 0., ],\n [\"Ears\", \"human\", \"Head\", 2, 0.05, 0.05, 0.1, 0., 0.5, 0., 0., ],\n [\"Olfactory System\", \"human\", \"Head\", 2, 0.05, 0.05, 0.05, 0., 0., 0., 0., ],\n [\"Tongue\", \"human\", \"Head\", 2, 0.05, 0.05, 0.05, 0., 0., 0., 0., ],\n [\"* Bones\", \"human\", \"Head\", 2, 0.3, 0.4, 0.1, 0., 0., 0., 1., ],\n [\"* Skin\", \"human\", \"Head\", 2, 0.1, 0., 0.05, 0., 0., 0., 0., ],\n [\"Upper Torso\", \"human\", \"Body\", 1, 2/11., 2/11., 0.15, 0.125, 0.0, 0.2, 0.3, ],\n [\"Lungs\", \"human\", \"Upper Torso\", 2, 0.1, 0.1, 0.1, 0., 0., 0.0, 0.3, ],\n [\"Heart\", \"human\", \"Upper Torso\", 2, 0.1, 0.1, 0.2, 0., 0., 0.0, 0.2, ],\n [\"* Muscles\", \"human\", \"Upper Torso\", 2, 0.3, 0.3, 0.3, 0.4, 0.2, 0.9, 0.3, ],\n [\"* Bones\", \"human\", \"Upper Torso\", 2, 0.3, 0.5, 0.2, 0., 0., 0.1, 0.2, ],\n [\"* Nerves\", \"human\", \"Upper Torso\", 2, 0., 0., 0.1, 0.6, 0.8, 0., 0., ],\n [\"* Skin\", \"human\", \"Upper Torso\", 2, 0.2, 0., 0.1, 0., 0., 0., 0., ],\n [\"Lower Torso\", \"human\", \"Body\", 1, 2/11., 2/11., 0.15, 0.05, 0.0, 0.05, 0.1, ],\n [\"Intestines\", \"human\", \"Lower Torso\", 2, 0.5, 0.4, 0.3, 0.0, 0.0, 0.0, 0.3, ],\n [\"* Muscles\", \"human\", \"Lower Torso\", 2, 0.25, 0.3, 0.3, 0.4, 0.2, 0.9, 0.2, ],\n [\"* Bones\", \"human\", \"Lower Torso\", 2, 0.1, 0.3, 0.2, 0., 0., 0.1, 0.5, ],\n [\"* Nerves\", \"human\", \"Lower Torso\", 2, 0., 0, 0.1, 0.6, 0.8, 0., 0., ],\n [\"* Skin\", \"human\", \"Lower Torso\", 2, 0.15, 0., 0.1, 0., 0., 0., 0., ],\n [\"Left Arm\", \"human\", \"Body\", 1, 1/11., 1/11., 0.125, 0.15, 0.3, 0.225, 0.1, ],\n [\"* Muscles\", \"human\", \"Left Arm\", 2, 0.6, 0.6, 0.4, 0.4, 0.2, 0.9, 0.5, ],\n [\"* Bones\", \"human\", \"Left Arm\", 2, 0.2, 0.4, 0.2, 0., 0., 0.1, 0.5, ],\n [\"* Nerves\", \"human\", \"Left Arm\", 2, 0., 0., 0.3, 0.6, 0.8, 0., 0., ],\n [\"* Skin\", \"human\", \"Left Arm\", 2, 0.2, 0., 0.1, 0., 0., 0., 0., ],\n [\"Right Arm\", \"human\", \"Body\", 1, 1/11., 1/11., 0.125, 0.15, 0.3, 0.225, 0.1, ],\n [\"* Muscles\", \"human\", \"Right Arm\", 2, 0.6, 0.6, 0.4, 0.4, 0.2, 0.9, 0.5, ],\n [\"* Bones\", \"human\", \"Right Arm\", 2, 0.2, 0.4, 0.2, 0., 0., 0.1, 0.5, ],\n [\"* Nerves\", \"human\", \"Right Arm\", 2, 0., 0., 0.3, 0.6, 0.8, 0., 0., ],\n [\"* Skin\", \"human\", \"Right Arm\", 2, 0.2, 0., 0.1, 0., 0., 0., 0., ],\n [\"Left Leg\", \"human\", \"Body\", 1, 2/11., 2/11., 0.1, 0.15, 0.1, 0.15, 0.15, ],\n [\"* Muscles\", \"human\", \"Left Leg\", 2, 0.6, 0.6, 0.4, 0.4, 0.2, 0.9, 0.5, ],\n [\"* Bones\", \"human\", \"Left Leg\", 2, 0.2, 0.4, 0.2, 0., 0., 0.1, 0.5, ],\n [\"* Nerves\", \"human\", \"Left Leg\", 2, 0., 0., 0.3, 0.6, 0.8, 0., 0., ],\n [\"* Skin\", \"human\", \"Left Leg\", 2, 0.2, 0., 0.1, 0., 0., 0., 0., ],\n [\"Right Leg\", \"human\", \"Body\", 1, 2/11., 2/11., 0.1, 0.15, 0.1, 0.15, 0.15, ],\n [\"* Muscles\", \"human\", \"Right Leg\", 2, 0.6, 0.6, 0.4, 0.4, 0.2, 0.9, 0.5, ],\n [\"* Bones\", \"human\", \"Right Leg\", 2, 0.2, 0.4, 0.2, 0., 0., 0.1, 0.5, ],\n [\"* Nerves\", \"human\", \"Right Leg\", 2, 0., 0., 0.3, 0.6, 0.8, 0., 0., ],\n [\"* Skin\", \"human\", \"Right Leg\", 2, 0.2, 0., 0.1, 0., 0., 0., 0., ],\n]\n\nbodyparts_nt = namedtuple('bodypart', ['id'] + bodyparts[0])\nreplace_stars(bodyparts)\nbodyparts_dict = OrderedDict([(entry[0], bodyparts_nt(*([i] + entry))) for i, entry in enumerate(bodyparts[1:])])\n\n\ncomputer = [\n [\"name\", \"Processor\", \"System\", \"Uplink\", \"Signal\", \"Volume\"],\n ['Nano Drone Computer I', 1, 20, 35, 20, 0.0000000002],\n ['Nano Drone Computer II', 5, 30, 40, 25, 0.0000000002],\n ['Nano Drone Computer III', 10, 40, 50, 30, 0.0000000002],\n ['Mini Drone Computer I', 15, 25, 35, 25, 0.0000001],\n ['Mini Drone Computer II', 20, 30, 40, 30, 0.0000001],\n ['Mini Drone Computer III', 25, 40, 50, 35, 0.0000001],\n [\"Meta Link\", 15, 15, 20, 20, 0.00005],\n [\"Sony Emperor\", 20, 25, 30, 30, 0.00005],\n [\"Renraku Sensei\", 30, 30, 30, 30, 0.00005],\n [\"Erika Elite\", 30, 40, 40, 40, 0.00005],\n [\"Transys Avalon\", 40, 50, 50, 40, 0.00005],\n [\"Fairlight Caliban\", 45, 60, 60, 45, 0.00005],\n [\"Erika MCD-1\", 30, 30, 30, 40, 0.005],\n [\"Hermes Chariot\", 40, 40, 40, 40, 0.005],\n [\"Novatech Navigator\", 45, 45, 45, 45, 0.005],\n [\"Renraku Tsurugi\", 50, 50, 50, 50, 0.005],\n [\"Sony CIY-720\", 55, 55, 55, 50, 0.005],\n [\"Fairlight Excalibur\", 65, 65, 60, 50, 0.005],\n [\"Small Business Tower\", 40, 30, 30, 0, 0.128],\n [\"Medium Business Tower\", 50, 40, 40, 0, 0.128],\n [\"Cheap Mainframe\", 60, 30, 40, 0, 2],\n [\"Expensive Mainframe\", 60, 40, 50, 0, 2],\n [\"Super Cluster\", 100, 60, 60, 0, 5000],\n]\n\ncomputer_nt = namedtuple('computer', ['id'] + computer[0])\ncomputer_dict = OrderedDict([(entry[0], computer_nt(*([i] + entry))) for i, entry in enumerate(computer[1:])])\n\n\nsensor_packages = [\n ['name', 'content',],\n ['Nano Drone', ['Nano Camera', 'Nano Microphone']],\n ['Micro Drone', ['Micro Camera', 'Mini Microphone']],\n ['Mini Drone', ['Mini Camera', 'Microphone', 'Micro Laser Sensor 50m']],\n ['Civilian Drone', ['Camera', 'Studio Microphone', 'Mini Laser Sensor 150m', 'Micro Radar 50m']],\n ['Civilian Vehicle', ['Camera', 'Studio Microphone', 'Laser Sensor 500m', 'Mini Radar 500m']],\n ['Security Vehicle', ['Camera Suite', 'Microphone Suite', 'Large Laser Sensor 2000m', 'Mini Radar 500m']],\n ['Military Vehicle', ['Camera Suite', 'Microphone Suite', 'Large Laser Sensor 2000m', 'Radar 5000m']],\n]\n\nsensor_packages_nt = namedtuple('sensor_package', ['id'] + sensor_packages[0])\nsensor_packages_dict = OrderedDict([(entry[0], sensor_packages_nt(*([i] + entry))) for i, entry in enumerate(sensor_packages[1:])])\n\n#Rigger Adaption:\n# Compass, Gyro, Acceleration\n\n#Legality: AAA: 10, AA: 20, A: 30, B: 40, C: 50, D: 60, E: 70, Z: Any\n#Licenced 40+\n#restricted 50+\n#Forbidden 70+\nAvailability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating, capacity, upgradeables, relative_capacity, aboslute_capacity = 0,0,0,0,0,0,False, 0, [], 0, 0\ngameitems = [\n [\"name\", \"clas\", \"availability\", \"cost\", \"weight\", \"vis_stealth\", \"scan_stealth\", \"legality\", 'rating', 'capacity', 'upgradeables', 'relative_capacity', 'absolute_capacity'],\n [\"Combat Knife\", \"Close Combat Weapon\", 0, 50, 0.25, 35, 10, 20, False, 0, [], 0, 0],\n [\"Sword\", \"Close Combat Weapon\", 10, 200, 0.7, 0, -25, 50, False, 0, [], 0, 0],\n [\"Scimitar\", \"Close Combat Weapon\", 15, 300, 0.6, 3, -21, 50, False, 0, [], 0, 0],\n [\"Rapier\", \"Close Combat Weapon\", 15, 300, 0.5, 5, -20, 30, False, 0, [], 0, 0],\n [\"Hammer\", \"Close Combat Weapon\", 0, 100, 2.5, 5, -15, 25, False, 0, [], 0, 0],\n [\"Spear\", \"Close Combat Weapon\", 20, 300, 1.0, -10, -10, 50, False, 0, [], 0, 0],\n [\"Snap Blades\", \"Close Combat Weapon\", 10, 500, 0.5, 25, 0, 40, False, 0, [], 0, 0],\n [\"Mono Whip\", \"Close Combat Weapon\", 60, 5000, 0.2, 40, 70, 80, False, 0, [], 0, 0],\n [\"Mono Chainsaw\", \"Close Combat Weapon\", 10, 2100, 3.0, 0, -30, 60, False, 0, [], 0, 0],\n [\"Axe\", \"Close Combat Weapon\", 20, 100, 2.0, 3, -20, 40, False, 0, [], 0, 0],\n [\"Stun Baton\", \"Close Combat Weapon\", 10, 400, 1, 15, -20, 30, False, 0, [], 0, 0],\n [\"Shock Gloves\", \"Close Combat Weapon\", 20, 500, 0.3, 50, 10, 40, False, 0, [], 0, 0],\n [\"Extendeable Baton\", \"Close Combat Weapon\", 0, 100, 0.5, 15, 40, 30, False, 0, [], 0, 0],\n [\"Katana\", \"Close Combat Weapon\", 15, 500, 1.2, -5, -30, 60, False, 0, [], 0, 0],\n [\"Defiance EX Shocker\", \"Ranged Weapon\", 0, 200, 0.5, 30, 10, 10, False, 0, [], 0, 0],\n [\"Yamaha Pulsar\", \"Ranged Weapon\", 10, 200, 0.5, 30, 10, 10, False, 0, [], 0, 0],\n [\"Streeline Special\", \"Ranged Weapon\", 5, 200, 0.4, 35, 5, 15, False, 0, [], 0, 0],\n [\"Raecor Sting\", \"Ranged Weapon\", 40, 500, 0.3, 40, 50, 50, False, 0, [], 0, 0],\n [\"Colt America L36\", \"Ranged Weapon\", 0, 150, 0.6, 30, 5, 20, False, 0, [], 0, 0],\n [\"Fichetti Security 600\", \"Ranged Weapon\", 10, 450, 0.9, 27, 0, 20, False, 0, [], 0, 0],\n [\"Hammerli 620S\", \"Ranged Weapon\", 20, 650, 0.8, 23, 2, 25, False, 0, [], 0, 0],\n [\"Yamaha Sakura Fubuki\", \"Ranged Weapon\", 40, 2000, 0.7, 24, -5, 40, False, 0, [], 0, 0],\n [\"Ares Predator\", \"Ranged Weapon\", 5, 500, 2.0, 20, -5, 40, False, 0, [], 0, 0],\n [\"Ares Viper Slivergun\", \"Ranged Weapon\", 15, 700, 2.2, 20, 10, 40, False, 0, [], 0, 0],\n [\"Colt Manhunter\", \"Ranged Weapon\", 5, 350, 2.0, 20, -5, 40, False, 0, [], 0, 0],\n [\"Remington Roomsweeper\", \"Ranged Weapon\", 15, 500, 2.0, 18, -5, 40, False, 0, [], 0, 0],\n [\"Ruger Super Warhawk\", \"Ranged Weapon\", 5, 300, 2.5, 15, -5, 40, False, 0, [], 0, 0],\n [\"Ceska Black Scorpion\", \"Ranged Weapon\", 35 , 550, 1.5, 25, -3, 40, False, 0, [], 0, 0],\n [\"Steyr TMP\", \"Ranged Weapon\", 30 , 600, 1.4, 20, 22, 40, False, 0, [], 0, 0],\n [\"AK-97 Carbine\", \"Ranged Weapon\", 15, 500, 3.0, 15, -10, 50, False, 0, [], 0, 0],\n [\"HK-227X\", \"Ranged Weapon\", 35, 900, 3.0, 15, -10, 50, False, 0, [], 0, 0],\n [\"HK MP-5 TX\", \"Ranged Weapon\", 15, 600, 3.0, 15, -10, 50, False, 0, [], 0, 0],\n [\"Ingram Smartgun X\", \"Ranged Weapon\", 25, 750, 3.0, 15, -10, 50, False, 0, [], 0, 0],\n [\"Uzi IV\", \"Ranged Weapon\", 15, 500, 3.0, 18, -10, 50, False, 0, [], 0, 0],\n [\"Mossberg AM-CMDT\", \"Ranged Weapon\", 5, 1200, 4.5, 0, -25, 50, False, 0, [], 0, 0],\n [\"Remington 990\", \"Ranged Weapon\", 5, 600, 4.0, 5, -20, 40, False, 0, [], 0, 0],\n [\"Battle Rifle\", \"Ranged Weapon\", 35, 2000, 4.0, -3, -28, 65, False, 0, [], 0, 0],\n [\"AK-97\", \"Ranged Weapon\", 15, 500, 3.5, 0, -25, 60, False, 0, [], 0, 0],\n [\"Ares Alpha\", \"Ranged Weapon\", 45, 2500, 4.5, -5, -30, 70, False, 0, [], 0, 0],\n [\"FN HAR\", \"Ranged Weapon\", 25, 1200, 3.5, 0, -25, 60, False, 0, [], 0, 0],\n [\"Ruger 100\", \"Ranged Weapon\", 15, 1500, 3.0, -4, 8, 50, False, 0, [], 0, 0],\n [\"PJSS Elephant Rifle\", \"Ranged Weapon\", 15, 6000, 5.0, -8, 0, 50, False, 0, [], 0, 0],\n [\"Ranger Arms SM-4\", \"Ranged Weapon\", 55, 9200, 3.5, -6, 10, 70, False, 0, [], 0, 0],\n [\"Walter MA-2100\", \"Ranged Weapon\", 45, 8000, 3.5, -6, 10, 70, False, 0, [], 0, 0],\n [\"Ingram White Knight\", \"Ranged Weapon\", 40, 3000, 5.5, -10, -35, 70, False, 0, [], 0, 0],\n [\"GE Vindicator Minigun\", \"Ranged Weapon\", 70, 15000, 9.5, -10, -45, 80, False, 0, [], 0, 0],\n [\"Stoner-Ares 202\", \"Ranged Weapon\", 60, 4500, 8.0, -15, -40, 75, False, 0, [], 0, 0],\n [\"Ultimax HMG-2\", \"Ranged Weapon\", 65, 12000, 25.0, -20, -45, 80, False, 0, [], 0, 0],\n [\"Panther XXL\", \"Ranged Weapon\", 60, 9000, 12.0, -20, -45, 80, False, 0, [], 0, 0],\n [\"Ares Thunderstruck Gauss Rifle\", \"Ranged Weapon\", 80, 25000, 14.0, -25, -55, 90, False, 0, [], 0, 0],\n [\"Ares Antioch\", \"Ranged Weapon\", 40, 500, 3.0, 0, -15, 70, False, 0, [], 0, 0],\n [\"Enfield GL-67\", \"Ranged Weapon\", 40, 4000, 6.0, -10, -25, 75, False, 0, [], 0, 0],\n [\"Shuriken\", \"Ranged Weapon\", 20, 100, 0.08, 50, 35, 35, False, 0, [], 0, 0],\n [\"Throwing Knife\", \"Ranged Weapon\", 10, 80, 0.1, 40, 30, 25, False, 0, [], 0, 0],\n [\"High Explosive Grenade\", \"Ranged Weapon\", 50, 50, 0.5, 30, -10, 70, False, 0, [], 0, 0],\n [\"Fragmentation Grenade\", \"Ranged Weapon\", 60, 60, 0.5, 30, -5, 80, False, 0, [], 0, 0],\n [\"Flash-Bang\", \"Ranged Weapon\", 30, 40, 0.3, 40, 20, 50, False, 0, [], 0, 0],\n [\"Smoke Grenade\", \"Ranged Weapon\", 20, 35, 0.3, 40, 20, 40, False, 0, [], 0, 0],\n [\"Thermal Smoke Grenade\", \"Ranged Weapon\", 25, 65, 0.4, 40, 20, 45, False, 0, [], 0, 0],\n [\"Multispectrum Smoke Grenade\", \"Ranged Weapon\", 50, 150, 0.4, 40, 20, 50, False, 0, [], 0, 0],\n [\"Gas Grenade\", \"Ranged Weapon\", 25, 40, 0.1, 40, 30, 50, False, 1, ['Neuro-Stun', 'Neuro-Stun X', 'Nausea-Gas'], 0, 0],\n [\"Bow\", \"Ranged Weapon\", 10, 500, 0.0, -5, 20, 30, False, 0, [], 0, 0],\n [\"Orc Bow\", \"Ranged Weapon\", 20, 1000, 30.0, -8, 18, 45, False, 0, [], 0, 0],\n [\"Troll Bow\", \"Ranged Weapon\", 30, 2000, 30.0, -10, 15, 50, False, 0, [], 0, 0],\n [\"Pistol Crossbow\", \"Ranged Weapon\", 5, 200, 30.0, 20, 0, 35, False, 0, [], 0, 0],\n [\"Light Crossbow\", \"Ranged Weapon\", 7, 500, 30.0, 10, -10, 40, False, 0, [], 0, 0],\n [\"Heavy Crossbow\", \"Ranged Weapon\", 10, 1000, 30.0, 0, -20, 45, False, 0, [], 0, 0],\n [\"Armored Clothing\", \"Armor\", 0, 300, 3.0, 40, 40, 5, False, 0, [], 0, 0],\n [\"Armored Pants\", \"Armor\", 0, 200, 2.0, 40, 40, 5, False, 0, [], 0, 0],\n [\"Explorer Jumpsuit\", \"Armor\", 0, 400, 4.0, 10, 10, 0, False, 0, [], 0, 0],\n [\"Form Fitting Body Armor\", \"Armor\", 40, 5000, 4.0, 60, 50, 15, False, 0, [], 0, 0],\n [\"Flak Vest\", \"Armor\", 20, 1000, 3.0, 20, 15, 20, False, 0, [], 0, 0],\n [\"Flak Vest with Plates\", \"Armor\", 30.0, 3000, 6.0, 10, -10, 40, False, 0, [], 0, 0],\n [\"Armor Jacket\", \"Armor\", 10, 1000, 5.0, 20, 20, 35, False, 0, [], 0, 0],\n [\"Armor Pants\", \"Armor\", 10, 500, 3.0, 20, 20, 35, False, 0, [], 0, 0],\n [\"Lined Coat\", \"Armor\", 5, 500, 4.0, 35, 35, 25, False, 0, [], 0, 0],\n [\"Light Carapace\", \"Armor\", 40, 4000, 9.0, -10, -30, 40, False, 0, [], 0, 0],\n [\"Heavy Carapace\", \"Armor\", 45, 6000, 15.0, -20, -40, 50, False, 0, [], 0, 0],\n [\"Ballistic Mask\", \"Armor\", 20, 200, .5, -5, 10, 30, False, 0, [], 0, 0],\n [\"Biker Helmet\", \"Armor\", 5, 500, 1.0, -10, -20, 0, False, 0, [], 0, 0],\n [\"Light Helmet\", \"Armor\", 20, 1000, 1.0, -10, -20, 40, False, 0, [], 0, 0],\n [\"Heavy Helmet\", \"Armor\", 30, 1500, 1.50, -15, -25, 50, False, 0, [], 0, 0],\n ['Nano Drone Computer I', \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Nano Drone Computer I\"][2:])[-1],0), 2.0, -5, 10, 25, False, 0, [], 0, 0.00000004],\n ['Nano Drone Computer II', \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Nano Drone Computer II\"][2:])[-1],0), 2.0, -5, 10, 25, False, 0, [], 0, 0.00000004],\n ['Nano Drone Computer III', \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Nano Drone Computer III\"][2:])[-1],0), 2.0, -5, 10, 25, False, 0, [], 0, 0.00000004],\n ['Mini Drone Computer I', \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Mini Drone Computer I\"][2:])[-1],0), 2.0, -5, 10, 25, False, 0, [], 0, 0.0002],\n ['Mini Drone Computer II', \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Mini Drone Computer II\"][2:])[-1],0), 2.0, -5, 10, 25, False, 0, [], 0, 0.0002],\n ['Mini Drone Computer III', \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Mini Drone Computer III\"][2:])[-1],0), 2.0, -5, 10, 25, False, 0, [], 0, 0.0002],\n [\"Erika MCD-1\", \"Computer\", 30, round(rules.deck_cost(*computer_dict[\"Erika MCD-1\"][2:])[-1],0), 5.0, -5, 10, 25, False, 0, [], 0, 7],\n [\"Hermes Chariot\", \"Computer\", 35, round(rules.deck_cost(*computer_dict[\"Hermes Chariot\"][2:])[-1],0), 5.0, -5, 10, 25, False, 0, [], 0, 7],\n [\"Novatech Navigator\", \"Computer\", 40, round(rules.deck_cost(*computer_dict[\"Novatech Navigator\"][2:])[-1],0), 5.0, -5, 10, 25, False, 0, [], 0, 7],\n [\"Renraku Tsurugi\", \"Computer\", 50, round(rules.deck_cost(*computer_dict[\"Renraku Tsurugi\"][2:])[-1],0), 5.0, -5, 10, 25, False, 0, [], 0, 7],\n [\"Sony CIY-720\", \"Computer\", 60, round(rules.deck_cost(*computer_dict[\"Sony CIY-720\"][2:])[-1],0), 5.0, -5, 10, 25, False, 0, [], 0, 7],\n [\"Fairlight Excalibur\", \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Fairlight Excalibur\"][2:])[-1],0), 5.0, -5, 10, 25, False, 0, [], 0, 7],\n [\"Meta Link\", \"Computer\", 0, round(rules.deck_cost(*computer_dict[\"Meta Link\"][2:])[-1],0), .1, 40, 40, 0, False, 0, [], 0, 0.1],\n [\"Sony Emperor\", \"Computer\", 5, round(rules.deck_cost(*computer_dict[\"Sony Emperor\"][2:])[-1],0), .1, 40, 40, 0, False, 0, [], 0, 0.1],\n [\"Renraku Sensei\", \"Computer\", 10, round(rules.deck_cost(*computer_dict[\"Renraku Sensei\"][2:])[-1],0), .1, 40, 40, 0, False, 0, [], 0, 0.1],\n [\"Erika Elite\", \"Computer\", 15, round(rules.deck_cost(*computer_dict[\"Erika Elite\"][2:])[-1],0), .1, 40, 40, 0, False, 0, [], 0, 0.1],\n [\"Transys Avalon\", \"Computer\", 30, round(rules.deck_cost(*computer_dict[\"Transys Avalon\"][2:])[-1],0), .1, 40, 40, 0, False, 0, [], 0, 0.1],\n [\"Fairlight Caliban\", \"Computer\", 40, round(rules.deck_cost(*computer_dict[\"Fairlight Caliban\"][2:])[-1],0), .1, 40, 40, 0, False, 0, [], 0, 0.1],\n [\"Small Business Tower\", \"Computer\", 0, round(rules.deck_cost(*computer_dict[\"Small Business Tower\"][2:])[-1],0), 10.0, None, None, 0, False, 0, [], 0, 0],\n [\"Medium Business Tower\", \"Computer\", 10, round(rules.deck_cost(*computer_dict[\"Medium Business Tower\"][2:])[-1],0), 10.0, None, None, 0, False, 0, [], 0, 0],\n [\"Cheap Mainframe\", \"Computer\", 20, round(rules.deck_cost(*computer_dict[\"Cheap Mainframe\"][2:])[-1],0), 200.0, None, None, 0, False, 0, [], 0, 0],\n [\"Expensive Mainframe\", \"Computer\", 30, round(rules.deck_cost(*computer_dict[\"Expensive Mainframe\"][2:])[-1],0), 200.0, None, None, 0, False, 0, [], 0, 0],\n [\"Super Cluster\", \"Computer\", 80, round(rules.deck_cost(*computer_dict[\"Super Cluster\"][2:])[-1],0), None, None, None, 0, False, 0, [], 0, 0],\n [\"Optotronics Kit\", \"Tools\", 0, 1000, 3, 10, 50, 0, False, 0, [], 0, 5.],\n [\"Vibropicker\", \"Anti-Security Tools\", 30, 500, 0.1, 35, 40, 40, False, 0, [], 0, 0.2],\n [\"Mini Welder\", \"Anti-Security Tools\", 0, 250, 0.5, 15, 40, 20, False, 0, [], 0, 1],\n [\"Sequencer\", \"Anti-Security Tools\", 30, 30, 0.1, 35, 70, 60, 270, 0, [], 0, 0.2],\n [\"Maglock Passkey\", \"Anti-Security Tools\", 30, 30, 0.1, 35, 70, 60, 270, 0, [], 0, 0.2],\n [\"Voice Emulator\", \"Anti-Security Tools\", 30, 30, 0.1, 35, 70, 60, 270, 0, [], 0, 0.2],\n [\"Fingerprint Emulator\", \"Anti-Security Tools\", 30, 40, 0.2, 35, 70, 60, 360, 0, [], 0, 0.4],\n [\"Retina Emulator\", \"Anti-Security Tools\", 40, 80, 0.5, 30, 70, 60, 720, 0, [], 0, 1],\n [\"Bio Replicator\", \"Anti-Security Tools\", 40, 100, 0.5, 25, 70, 70, 900, 0, [], 0, 1],\n [\"Microfone Deceiver\", \"Anti-Security Tools\", 20, 20, 0.2, 35, 70, 40, 80, 0, [], 0, 0.4],\n [\"Camera Deceiver\", \"Anti-Security Tools\", 20, 20, 0.1, 30, 70, 50, 80, 0, [], 0, 0.2],\n [\"Nano Case Breaker\", \"Anti-Security Tools\", 40, 500, 0.00075, 30, 70, 50, False, 0, [], 0, 0.0015],\n [\"Nano Camera\", \"Sensors\", 0, 100, 0.001, 80, 60, 0, False, 0., [], 0, 0.0002],\n [\"Micro Camera\", \"Sensors\", 0, 500, 0.02, 30, 20, 0, False, 0.02,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0.04],\n [\"Mini Camera\", \"Sensors\", 0, 150, 0.2, 30, 20, 0, False, 0.2,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0.4],\n [\"Camera\", \"Sensors\", 0, 50, 0.5, 30, 20, 0, False, 0.5,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 1.2],\n [\"Camera Suite\", \"Sensors\", 0, 2500, 5, None, None, 0, False, 0.5,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0.01, 10],\n [\"Nano Microphone\", \"Sensors\", 0, 100, 0.001, 90, 60, 0, False, 0.001, [], 0, 0.0002],\n [\"Mini Microphone\", \"Sensors\", 0, 150, 0.01, 70, 40, 0, False, 0.01,\n [\"Enhanced Hearing I\", \"Enhanced Hearing II\", \"Enhanced Hearing III\", \"Select Sound Filter I\", \"Select Sound Filter II\", \"Select Sound Filter III\", \"Damper\", \"Wide Frequency Adaption\"], 0, 0.02],\n [\"Microphone\", \"Sensors\", 0, 50, 0.1, 60, 30, 0, False, 0.1,\n [\"Enhanced Hearing I\", \"Enhanced Hearing II\", \"Enhanced Hearing III\", \"Select Sound Filter I\", \"Select Sound Filter II\", \"Select Sound Filter III\", \"Damper\", \"Wide Frequency Adaption\"], 0, 0.2],\n [\"Studio Microphone\", \"Sensors\", 0, 250, 0.5, 40, 20, 0, False, 0.5,\n [\"Enhanced Hearing I\", \"Enhanced Hearing II\", \"Enhanced Hearing III\", \"Select Sound Filter I\", \"Select Sound Filter II\", \"Select Sound Filter III\", \"Damper\", \"Wide Frequency Adaption\"], 0, 1],\n [\"Microphone Suite\", \"Sensors\", 0, 3000, 0.5, None, None, 0, False, 0.5,\n [\"Enhanced Hearing I\", \"Enhanced Hearing II\", \"Enhanced Hearing III\", \"Select Sound Filter I\", \"Select Sound Filter II\", \"Select Sound Filter III\", \"Damper\", \"Wide Frequency Adaption\"], 0.005, 5],\n [\"Weapon/Cyberware Detector\", \"Sensors\", 20, 250, 2., 0, 20, 50, 250, 0, [], 0, 4.],\n [\"Ultrasound Generator\", \"Sensors\", 10, 100, 0, 0, 0, 0, True, 0, [], 0, 0.2],\n [\"Micro Laser Sensor 50m\", \"Sensors\", 0, 100, 0.025, 0, 0, 10, True, 0, [], 0, 0.05],\n [\"Mini Laser Sensor 150m\", \"Sensors\", 10, 300, 0.1, 0, 0, 10, True, 0, [], 0, 0.2],\n [\"Laser Sensor 500m\", \"Sensors\", 20, 1000, 0.5, 0, 0, 10, True, 0, [], 0, 1.],\n [\"Large Laser Sensor 2000m\", \"Sensors\",30, 3000, 2, 0, 0, 10, True, 0, [], 0, 4.],\n [\"Micro Radar 50m\", \"Sensors\", 40, 2000, 0.5, 0, 0, 30, False, 0, [], 0., 1],\n [\"Mini Radar 500m\", \"Sensors\", 30, 1000, 2.5, 0, 0, 40, False, 0, [], 0., 5],\n [\"Radar 5000m\", \"Sensors\", 30, 0, 3000, 25, 0, 50, False, 0, [], 0., 50],\n [\"Large Radar 50000m\", \"Sensors\", 50, 10000, 250, 0, 0, 60, False, 0, [], 0., 500],\n [\"Chem Sniffer\", \"Sensors\", 30, 50, 1., 10, 10, 30, 450, 0, [], 0, 2.],\n [\"Light 25m\", \"Sensors\", 0, 200, 0.1, 0, 0, 0, False, 0, [], 0, 0.2],\n [\"Light 100m\", \"Sensors\", 0, 100, 0.5, 0, 0, 0, False, 0, [], 0, 1],\n [\"Light 400m\", \"Sensors\", 0, 500, 2, 0, 0, 0, False, 0, [], 0, 4.],\n [\"Light 2000m\", \"Sensors\", 0, 5000, 20, 0, 0, 0, False, 0, [], 0, 40.],\n [\"Flashlight\", \"Survival\", 0, 50, 0.3, 40, 40, 0, False, 0, [], 0, 0],\n [\"Flashlight Infrared\", \"Survival\", 20, 200, 0.3, 40, 40, 0, False, 0, [], 0, 0],\n [\"Flashlight Low Light\", \"Survival\", 20, 150, 0.3, 40, 40, 0, False, 0, [], 0, 0],\n [\"Respirator\", \"Survival\", 30, 50, 0.2, 40, 40, 0, 500, 0, [], 0, 0],\n [\"Rebreather\", \"Survival\", 20, 200, 2, 10, 10, 0, False, 0, [], 0, 0],\n [\"Climbing Gear\", \"Survival\", 0, 500, 3, 0, 0, 0, False, 0, [], 0, 0],\n [\"Diving Gear\", \"Survival\", 10, 1000, 10, -10, -10, 0, False, 0, [], 0, 0],\n [\"Urban Survival Kit\", \"Survival\", 0, 500, 2, 10, 10, 10, False, 0, [], 0, 0],\n [\"Outdoors Survival Kit\", \"Survival\", 0, 500, 2, 10, 10, 10, False, 0, [], 0, 0],\n [\"Micro Winch (10kg)\", \"Survival\", 0, 100, 0.2, 30, 30, 0, False, 0, [], 0, 0],\n [\"Standard Winch (100kg)\", \"Survival\", 200, 1, 15, 15, 0, 0, False, 0, [], 0, 0],\n [\"Large Winch (250kg)\", \"Survival\", 0, 300, 2, 5, 5, 0, False, 0, [], 0, 0],\n [\"XXL Winch (500kg)\", \"Survival\", 0, 500, 5, -5, -5, 0, False, 0, [], 0, 0],\n [\"Microwire (20m)\", \"Survival\", 20, 100, 0.5, 40, 70, 0, False, 0, [], 0, 0],\n [\"Stealth Wire (20m)\", \"Survival\", 30, 500, 0.75, 30, 70, 40, False, 0, [], 0, 0],\n [\"Myomeric Rope (20m)\", \"Survival\", 50, 1000, 1, 20, 70, 0, False, 0, [], 0, 0],\n [\"Medkit\", \"Biotech\", 10, 50, 3, 10, 30, 0, 450, 0, [], 0, 0],\n [\"Bio Monitor\", \"Biotech\", 20, 500, 1, 30, 30, 0, False, 0, [], 0, 0],\n [\"Chem Patch\", \"Biotech\", 0, 50, 0.1, 50, 100, 0, False, 0.01,\n ['Antidote I', 'Antidote II', 'Antidote III', 'Stim', 'Elysium', 'Oblivion', 'Joy', 'Truth', 'Narcojet', 'Gamma-Skopolamine'], 0, 0],\n [\"Search\", \"Programmes\", 0, 0, 0, None, None, 0, 100, 0, [], 0, 0],\n [\"Stealth\", \"Programmes\", 30, 0, 0, None, None, 40, 500, 0, [], 0, 0],\n [\"Scan\", \"Programmes\", 0, 0, 0, None, None, 0, 200, 0, [], 0, 0],\n [\"Analyze\", \"Programmes\", 0, 0, 0, None, None, 0, 200, 0, [], 0, 0],\n [\"Access\", \"Programmes\", 0, 0, 0, None, None, 0, 50, 0, [], 0, 0],\n [\"Exploit\", \"Programmes\", 40, 0, 0, None, None, 80, 1000, 0, [], 0, 0],\n [\"Crypt\", \"Programmes\", 0, 0, 0, None, None, 20, 100, 0, [], 0, 0],\n [\"Break\", \"Programmes\", 40, 0, 0, None, None, 70, 200, 0, [], 0, 0],\n [\"Edit\", \"Programmes\", 0, 0, 0, None, None, 0, 100, 0, [], 0, 0],\n [\"Control\", \"Programmes\", 0, 0, 0, None, None, 0, 50, 0, [], 0, 0],\n [\"Find\", \"Programmes\", 0, 0, 0, None, None, 0, 100, 0, [], 0, 0],\n [\"Corrupt\", \"Programmes\", 30, 0, 0, None, None, 60, 500, 0, [], 0, 0],\n [\"Medic\", \"Programmes\", 10, 0, 0, None, None, 10, 150, 0, [], 0, 0],\n\n [\"Small Backpack\", \"Carrying Gear\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Large Backpack\", \"Carrying Gear\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Tactical Backpack\", \"Carrying Gear\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Combat Harness\", \"Carrying Gear\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Smart Combat Harness\", \"Carrying Gear\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"AR GLoves\", \"Input Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Nano Trodes\", \"Input Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Contact Lenses\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.04,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Glasses\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.1,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Goggles\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.3,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Binoculars, small\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.4,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Binoculars, large\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.8,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Pistol Scope\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.2,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Rifle Scope\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.4,\n [\"Video Enhancement I\", \"Video Enhancement II\", \"Video Enhancement III\", \"Flare Compensation\", \"Vision Magnification 4x\", \"Infrared Vision\", \"Low Light Vision\", \"Microscopic Vision\"], 0, 0],\n [\"Earbuds\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.04,\n [\"Enhanced Hearing I\", \"Enhanced Hearing II\", \"Enhanced Hearing III\", \"Select Sound Filter I\", \"Select Sound Filter II\", \"Select Sound Filter III\", \"Damper\", \"Wide Frequency Adaption\"], 0, 0],\n [\"Headphones\", \"Output Devices\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0.3,\n [\"Enhanced Hearing I\", \"Enhanced Hearing II\", \"Enhanced Hearing III\", \"Select Sound Filter I\", \"Select Sound Filter II\", \"Select Sound Filter III\", \"Damper\", \"Wide Frequency Adaption\"], 0, 0],\n [\"Tag Eraser\", \"Electronics\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"White Noise Generator\", \"Electronics\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, 1, 0, [], 0, 0],\n [\"Data Chip\", \"Electronics\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Holo Projector\", \"Electronics\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, 1, 0, [], 0, 0],\n [\"Polygraph\", \"Electronics\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, 1, 0, [], 0, 0],\n [\"Restraints Metal\", \"Survival\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Restraints Plasteel\", \"Survival\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Restraints Plastic\", \"Survival\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, False, 0, [], 0, 0],\n [\"Fake SIN\", \"Category\", 50, Cost, Weight, Wis_stealth, Scan_stealth, 70, 5000, 0, [], 0, 0],\n [\"Fake SIN with Security License\", \"Category\", 55, Cost, Weight, Wis_stealth, Scan_stealth, 80, 7500, 0, [], 0, 0],\n [\"Fake SIN with Military License\", \"Category\", 60, Cost, Weight, Wis_stealth, Scan_stealth, 90, 10000, 0, [], 0, 0],\n\n [\"Antidode I\", \"Drugs & Toxins\", 0, 100, 0.02, 50, 10, 0, False, 0, [], 0, 0.01],\n [\"Antidode II\", \"Drugs & Toxins\", 30, 1000, 0.02, 50, 10, 0, False, 0, [], 0, 0.01],\n [\"Antidode III\", \"Drugs & Toxins\", 60, 5000, 0.02, 50, 10, 0, False, 0, [], 0, 0.01],\n [\"Stim\", \"Drugs & Toxins\", 20, 200, 0.02, 50, 10, 20, False, 0, [], 0, 0.01],\n [\"Elysium\", \"Drugs & Toxins\", 40, 300, 0.02, 50, 70, 60, False, 0, [], 0, 0.01],\n [\"Oblivion\", \"Drugs & Toxins\", 30, 200, 0.02, 50, 10, 50, False, 0, [], 0, 0.01],\n [\"Joy\", \"Drugs & Toxins\", 40, 500, 0.02, 50, 60, 60, False, 0, [], 0, 0.01],\n [\"Truth\", \"Drugs & Toxins\", 50, 1000, 0.02, 50, 30, 40, False, 0, [], 0, 0.01],\n\n [\"Neuro-Stun\", \"Drugs & Toxins\", 30, 200, 0.02, 50, 40, 40, False, 0, [], 0, 0.01],\n [\"Neuro-Stun X\", \"Drugs & Toxins\", 35, 400, 0.02, 50, 30, 50, False, 0, [], 0, 0.01],\n [\"Narcojet\", \"Drugs & Toxins\", 20, 50, 0.02, 50, 20, 30, False, 0, [], 0, 0.01],\n [\"Seven-7\", \"Drugs & Toxins\", 60, 1000, 0.02, 50, 40, 70, False, 0, [], 0, 0.01],\n [\"Gamma-Skopolamine\", \"Drugs & Toxins\", 60, 2000, 0.02, 50, 0, 50, False, 0, [], 0, 0.01],\n [\"Nausea-Gas\", \"Drugs & Toxins\", 10, 50, 0.02, 50, 20, 10, False, 0, [], 0, 0.01],\n\n [\"C-4 100g\", \"Explosives\", 40, 10, 0.1, 30, 20, 60, False, 0, [], 0, 0],\n [\"C-4 1kg\", \"Explosives\", 50, 100, 1., 10, 10, 60, False, 0, [], 0, 0],\n [\"C-4 10kg\", \"Explosives\", 60, 1000, 10., -10, 0, 60, False, 0, [], 0, 0],\n [\"Radio Detonator\", \"Explosives\", 20, 50, 0.05, 40, 20, 50, False, 0, [], 0, 0],\n [\"Security Radio Detonator\", \"Explosives\", 40, 500, 0.05, 40, 20, 60, False, 0, [], 0, 0],\n [\"Timer Detonator\", \"Explosives\", 20, 20, 0.05, 40, 20, 50, False, 0, [], 0, 0],\n\n [\"Latex Face Mask\", \"Deception\", 40, 200, 0.2, 40, 60, 60, False, 0, [], 0, 0],\n [\"Nanopaste Face Mask\", \"Deception\", 50, 2000, 0.2, 40, 70, 70, False, 0, [], 0, 0],\n\n [\"Image Link\", \"Upgrade\", 0, 0, None, None, None, 0, False, 0, [], 0., 0.],\n [\"Video Enhancement I\", \"Upgrade\", 10, 2000, None, None, None, 0, False, 0, [], 0.08, 0.02],\n [\"Video Enhancement II\", \"Upgrade\", 30, 10000, None, None, None, 0, False, 0, [], 0.12, 0.03],\n [\"Video Enhancement III\", \"Upgrade\", 50, 25000, None, None, None, 0, False, 0, [], 0.16, 0.04],\n [\"Flare Compensation\", \"Upgrade\", 0, 750, None, None, None, 0, False, 0, [], 0.1, 0.02],\n [\"Laser System\", \"Upgrade\", 0, 5000, None, None, None, 0, False, 0, [], 0.0, 0.05],\n [\"Laser System Range Finder\", \"Upgrade\", 0, 500, None, None, None, 0, False, 0, [], 0.0, 0.005],\n [\"Laser System Microphone\", \"Upgrade\", 0, 2000, None, None, None, 0, False, 0, [], 0.0, 0.01],\n [\"Vision Magnification 4x\", \"Upgrade\", 0, 1000, None, None, None, 0, False, 0, [], 0.15, 0.05],\n [\"Vision Magnification 8x\", \"Upgrade\", 0, 2500, None, None, None, 0, False, 0, [], 0.15, 0.15],\n [\"Vision Magnification 16x\", \"Upgrade\", 0, 5000, None, None, None, 0, False, 0, [], 0.15, 0.5],\n [\"Vision Magnification 32x\", \"Upgrade\", 0, 10000, None, None, None, 0, False, 0, [], 0.15, 1.5],\n [\"Infrared Vision\", \"Upgrade\", 10, 4000, None, None, None, 20, False, 0, [], 0.1, 0.03],\n [\"Low Light Vision\", \"Upgrade\", 10, 2500, None, None, None, 20, False, 0, [], 0.15, 0.015],\n [\"Microscopic Vision\", \"Upgrade\", 10, 3000, None, None, None, 20, False, 0, [], 0.2, 0.06],\n [\"Enhanced Hearing I\", \"Upgrade\", 10, 1500, None, None, None, 20, False, 0, [], 0.1, 0.02],\n [\"Enhanced Hearing II\", \"Upgrade\", 30, 7500, None, None, None, 20, False, 0, [], 0.15, 0.03],\n [\"Enhanced Hearing III\", \"Upgrade\", 50, 37500, None, None, None, 20, False, 0, [], 0.2, 0.04],\n [\"Select Sound Filter I\", \"Upgrade\", 10, 1000, None, None, None, 20, False, 0, [], 0.05, 0.015],\n [\"Select Sound Filter II\", \"Upgrade\", 30, 5000, None, None, None, 20, False, 0, [], 0.075, 0.02],\n [\"Select Sound Filter III\", \"Upgrade\", 50, 2500, None, None, None, 20, False, 0, [], 0.1, 0.03],\n [\"Damper\", \"Upgrade\", 10, 750, None, None, None, 20, False, 0, [], 0.1, 0.02],\n [\"Wide Frequency Adaption\", \"Upgrade\", 10, 6000, None, None, None, 20, False, 0, [], 0.2, 0.06],\n [\"Ultra Wideband Radar\", \"Upgrade\", 10, 15000, None, None, None, 20, False, 0, [], 0.3, 1.],\n [\"Silencer\", \"Upgrade\", 10, 200, None, None, None, 20, False, 0, [], 1, 0],\n [\"Gas Vent\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Shock Pad\", \"Upgrade\", 10, 100, None, None, None, 20, False, 0, [], 1, 0],\n [\"External Smartgun\", \"Upgrade\", 10, 1500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Smartlink\", \"Upgrade\", 10, 0, None, None, None, 20, False, 0, [], 1, 0],\n [\"Laser Sight 50m\", \"Upgrade\", 0, 100, None, None, None, 0, False, 0, [], 0.0, 0.07],\n [\"Laser Sight 150m\", \"Upgrade\", 0, 150, None, None, None, 0, False, 0, [], 0.0, 0.3],\n [\"Laser Sight 500m\", \"Upgrade\", 0, 200, None, None, None, 0, False, 0, [], 0.0, 1],\n [\"Gun Weight\", \"Upgrade\", 10, 100, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Grenadelauncher\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Flamethrower\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Shotgun\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Bayonet\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Flashlight\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Infrared Flashlight\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Ultrasound\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Underbarrel Gun Cam\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n\n [\"Insulation I\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Insulation II\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Insulation III\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Fire Proofing I\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Fire Proofing II\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Fire Proofing III\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Chem Seal I\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Chem Seal II\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n [\"Chem Seal III\", \"Upgrade\", 10, 500, None, None, None, 20, False, 0, [], 1, 0],\n\n [\"Sustaining Focus Creation\", \"Focus\", 30, 8000, 0.3, 80, None, 20, 2000, 0, [], 0, 0],\n [\"Sustaining Focus Destruction\", \"Focus\", 30, 8000, 0.3, 80, None, 50, 2000, 0, [], 0, 0],\n [\"Sustaining Focus Detection\", \"Focus\", 30, 8000, 0.3, 80, None, 40, 2000, 0, [], 0, 0],\n [\"Sustaining Focus Manipulation\", \"Focus\", 30, 8000, 0.3, 80, None, 40, 2000, 0, [], 0, 0],\n [\"Weapon Focus\", \"Focus\", 40, 10000, None, None, None, 0, 1000000, 50, [], 0, 0],\n [\"Spell Focus Creation\", \"Focus\", 40, 5000, 0.3, 80, None, 20, 1000000, 0, [], 0, 0],\n [\"Spell Focus Destruction\", \"Focus\", 40, 5000, 0.3, 80, None, 50, 1000000, 0, [], 0, 0],\n [\"Spell Focus Detection\", \"Focus\", 40, 5000, 0.3, 80, None, 40, 1000000, 0, [], 0, 0],\n [\"Spell Focus Manipulation\", \"Focus\", 40, 5000, 0.3, 80, None, 40, 1000000, 0, [], 0, 0],\n [\"Power Focus\", \"Focus\", 50, 20000, None, None, None, 0, 200000, 40, [], 0, 0],\n [\"Spirit Focus Creation\", \"Focus\", 35, 8000, 0.3, 80, None, 20, 800000, 0, [], 0, 0],\n [\"Spirit Focus Destruction\", \"Focus\", 35, 8000, 0.3, 80, None, 50, 800000,0, [], 0, 0],\n [\"Spirit Focus Detection\", \"Focus\", 35, 8000, 0.3, 80, None, 40, 800000, 0, [], 0, 0],\n [\"Spirit Focus Manipulation\", \"Focus\", 35, 8000, 0.3, 80, None, 40, 800000, 0, [], 0, 0],\n [\"Banishing Focus\", \"Focus\", 20, 1000, 0.3, 80, None, 20, 500000, 0, [], 0, 0],\n [\"Counterspelling Focus\", \"Focus\", 20, 1000, 0.3, 80, None, 20, 500000, 0, [], 0, 0],\n\n ['Civilian Driver Class I', 'Agent', 0, 200, None, None, None, 0, None, 0, [], 0, 0],\n ['Civilian Driver Class II', 'Agent', 10, 1000, None, None, None, 0, None, 0, [], 0, 0],\n ['Civilian Driver Class III', 'Agent', 20, 5000, None, None, None, 0, None, 0, [], 0, 0],\n ['Security Driver Class I', 'Agent', 30, 1400, None, None, None, 0, None, 50, [], 0, 0],\n ['Security Driver Class II', 'Agent', 40, 7000, None, None, None, 0, None, 50, [], 0, 0],\n ['Military Driver Class I', 'Agent', 50, 16000, None, None, None, 0, None, 70, [], 0, 0],\n ['Civilian Drone Pilot Class I', 'Agent', 0, 240, None, None, None, 0, None, 0, [], 0, 0],\n ['Civilian Drone Pilot Class II', 'Agent', 10, 1200, None, None, None, 0, None, 0, [], 0, 0],\n ['Civilian Drone Pilot Class III', 'Agent', 20, 6000, None, None, None, 0, None, 0, [], 0, 0],\n ['Security Drone Pilot Class I', 'Agent', 30, 2000, None, None, None, 0, None, 50, [], 0, 0],\n ['Security Drone Pilot Class II', 'Agent', 40, 10000, None, None, None, 0, None, 50, [], 0, 0],\n ['Military Drone Pilot Class I', 'Agent', 50, 23000, None, None, None, 0, None, 70, [], 0, 0],\n\n\n]\n\ngameitems.extend([[\"Activesoft: {}\".format(key), \"Skillsoft\", 30, 0, None, None, None, 40, 4000*value.expweight, 0, [], 0, 0] for key, value in skills_dict.items() if value.kind == 'active'])\ngameitems.extend([[\"Passivesoft: {}\".format(key), \"Skillsoft\".format, 30, 0, None, None, None, 40, 6000*value.expweight, 0, [], 0, 0] for key, value in skills_dict.items() if value.kind == 'passive'])\ngameitems.extend([\n [\"Knowsoft\", \"Skillsoft\", 10, 0, None, None, None, 0, 3000, 0, [], 0, 0],\n [\"Linguasoft\", \"Skillsoft\", 10, 0, None, None, None, 0, 2000, 0, [], 0, 0],\n#small-armspistol: 30/-\n#small-arms light: 45/30\n#small-arms medium: 55/40\n#small-arms heavy: 70/60\n#light: 80\n#medium: 120\n#heavy: 180\n#apc\n#tank\n [\"Small-Arms Pistol Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Light Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Medium Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Heavy Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Light Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Medium Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Heavy Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Assault Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Tank Fixed Weapon Mount\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n\n [\"Small-Arms Pistol Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Light Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Medium Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Heavy Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Light Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Medium Turrret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Heavy Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Assault Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Tank Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n\n [\"Small-Arms Pistol Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Light Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Medium Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Small-Arms Heavy Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Light Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Medium Retracteable Turrret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Heavy Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Assault Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n [\"Tank Retracteable Turret\", \"Vehicle Upgrade\", Availability, Cost, Weight, Wis_stealth, Scan_stealth, legality, rating,capacity, upgradeables, relative_capacity, aboslute_capacity],\n])\ngameitems_nt = namedtuple('gameitem', ['id'] + gameitems[0])\ngameitems_dict = OrderedDict([(entry[0], gameitems_nt(*([i] + entry))) for i, entry in enumerate(gameitems[1:])])\n\nfoci = [[\"item\", \"effects\"],\n [\"Sustaining Focus Creation\", []],\n [\"Sustaining Focus Destruction\", []],\n [\"Sustaining Focus Detection\", []],\n [\"Sustaining Focus Manipulation\", []],\n [\"Weapon Focus\", []],\n [\"Spell Focus Creation\", []],\n [\"Spell Focus Destruction\", []],\n [\"Spell Focus Detection\", []],\n [\"Spell Focus Manipulation\", []],\n [\"Power Focus\", [['attributes','Magic','+{Rating}']]],\n [\"Spirit Focus Creation\", []],\n [\"Spirit Focus Destruction\", []],\n [\"Spirit Focus Detection\", []],\n [\"Spirit Focus Manipulation\", []],\n [\"Banishing Focus\", [['skills','Banishing','+{Rating}']]],\n [\"Counterspelling Focus\", [['skills','Counterspelling','+{Rating}']]],\n]\n\nfoci_nt = namedtuple('focus', ['id'] + foci[0])\nfoci_dict = OrderedDict([(entry[0], foci_nt(*([i] + entry))) for i, entry in enumerate(foci[1:])])\n\nrangedweapon_upgrades = {\n 'top': ['External Smartgun', 'Pistol Scope', 'Rifle Scope'],\n 'barrel': ['Silencer', 'Gas Vent'],\n 'under': ['Underbarrel Grenadelauncher', 'Underbarrel Flamethrower', 'Underbarrel Heavy Pistol', 'Underbarrel Bayonet', 'Underbarrel Flashlight', 'Underbarrel Infrared Flashlight',\n 'Underbarrel Ultrasound', 'Underbarrel Gun Cam', 'Gun Weight']}\n\nrangedweapon_upgrades_reverse = {i:key for key, value in rangedweapon_upgrades.items() for i in value}\n# effective strength = strength *1.5 if two handed\n# kind damage penetration\n# slashing minstr/3 + str/6 minstr/3 + str/6\n# impact minstr/2.5 + str/5 minstr/4 + str/8\n# penetration minstr/3.5 + str/7 minstr/2 + str/4\n\nclosecombatweapons = [\n [\"item\", \"skill\", \"skillmod\", \"damage\", \"damagetype\", \"damagekind\", \"penetration\", \"minstr\", \"hands\", \"special\"],\n [\"Brawling\", \"Brawling\", 0., '{Strength}/10.', \"impact\", \"stun\", '{Strength}/20.', 0., 2, None],\n [\"Wrestling\", \"Wrestling\", 0., '{Strength}/20.', \"impact\", \"stun\", '{Strength}/40.', 0., 2, None],\n [\"Scimitar\", \"Slashing Weapons\", 5., '10.+{Strength}/6.', \"impact\", \"physical\", '3.33+{Strength}/18.', 30., 1, None],\n [\"Axe\", \"Impact Weapons\", 3., '15.28+{Strength}/6.55', \"impact\", \"physical\", '12.22+{Strength}/8.18', 50., 1, None],\n [\"Rapier\", \"Piercing Weapons\", 7., '5.+{Strength}/10.', \"impact\", \"physical\", '7.5.+{Strength}/6.67.', 25., 1, None],\n [\"Extendeable Baton\", \"Impact Weapons\", 5., '6.94+{Strength}/7.20', \"impact\", \"physical\", '5.56+{Strength}/9.', 30., 1, None],\n [\"Stun Baton\", \"Impact Weapons\", 4., 30., \"electricity\", \"stun\", 10., 15., 1, [('upscale_limit', 15)]],\n [\"Shock Gloves\", \"Wrestling\", 0., 20., \"electricity\", \"stun\", 7, 0., 2, [('upscale_limit', 15)]],\n [\"Combat Knife\", \"Piercing Weapons\", 0., '3.33+{Strength}/9.', \"impact\", \"physical\", '5.+{Strength}/6.', 15., 1, None],\n [\"Katana\", \"Slashing Weapons\", 7., '13.5+{Strength}/4.44', \"impact\", \"physical\", '4.5.+{Strength}/13.33', 30., 2, None],\n [\"Sword\", \"Slashing Weapons\", 5., '12.21+{Strength}/6.55', \"impact\", \"physical\", '6.67+{Strength}/12.', 40., 1, None],\n [\"Hammer\", \"Impact Weapons\", 0., '15.+{Strength}/6.67', \"impact\", \"physical\", '16.67+{Strength}/6.', 50., 1, None],\n [\"Spear\", \"Piercing Weapons\", 10., '8.+{Strength}/7.5', \"impact\", \"physical\", '12.+{Strength}/5.', 30., 2, None],\n [\"Snap Blades\", \"Piercing Weapons\", 0., '4.44+{Strength}/9.', \"impact\", \"physical\", '6.67+{Strength}/6.', 20., 1, None],\n [\"Mono Whip\", \"Slashing Weapons\", 10., 20, \"impact\", \"physical\", 20, 20., 1, None],\n [\"Mono Chainsaw\", \"Slashing Weapons\", 0., '18.+{Strength}/5.', \"impact\", \"physical\", '6.+{Strength}/15.', 45., 1, None],\n]\n\nclosecombatweapons_nt = namedtuple('rangedweapon', ['id'] + closecombatweapons[0])\nclosecombatweapons_dict = OrderedDict(\n [(entry[0], closecombatweapons_nt(*([i] + entry))) for i, entry in enumerate(closecombatweapons[1:])])\n\n\n#flechette: damage + 20%, penetration so dass bei verdreifachung gleicher schaden\nrangedweapons = [\n [\"item\", \"skill\", \"skillmod\", \"damage\", \"damagetype\", \"damagekind\", \"penetration\", \"range\", \"shot\", \"burst\", \"auto\",\n \"minstr\", \"recoil\", \"mag\", \"magtype\", \"top\", \"under\", \"barrel\", \"special\", \"hands\"],\n [\"Defiance EX Shocker\", \"Pistols\", 0., 20., \"electricity\", \"stun\", 7., 5., 1, 0, 0, 20, 2, 4, \"\", 1, 0, 0, {'upscale_limit': 15}, 1],\n [\"Yamaha Pulsar\", \"Pistols\", 0., 15., \"electricity\", \"stun\", 5., 10., 2, 0, 0, 20, 4, 4, \"\", 1, 0, 0, {'upscale_limit': 15}, 1],\n [\"Streetline Special\", \"Pistols\", 0., 8., \"ballistic\", \"physical\", 10., 5., 1, 0, 0, 25, 15, 6, \"\", 0, 0, 0, None, 1],\n [\"Raecor Sting\", \"Pistols\", 0., 10., \"ballistic\", \"physical\", 4., 5., 1, 0, 0, 25, 15, 5, \"\", 0, 0, 0, None, 1],\n [\"Colt America L36\", \"Pistols\", 0., 8., \"ballistic\", \"physical\", 10., 10., 2, 0, 0, 30, 15, 11, \"\", 1, 0, 1, {'upgrades': ['Laser Sight 50m']}, 1],\n [\"Fichetti Security 600\", \"Pistols\", 0., 8., \"ballistic\", \"physical\", 10., 10., 2, 0, 0, 30, 15, 20, \"\", 1, 0, 1, {'upgrades': ['Laser Sight 50m']}, 1],\n [\"Hammerli 620S\", \"Pistols\", 0., 8., \"ballistic\", \"physical\", 10., 12., 2, 0, 0, 30, 15, 6, \"\", 1, 0, 1, {'upgrades': ['Smartlink', 'Gas Vent']}, 1],\n [\"Yamaha Sakura Fubuki\", \"Pistols\", 0., 8., \"ballistic\", \"physical\", 10., 9., 4, 0, 0, 30, 8, 40, \"\", 1, 0, 1, {'upgrades': ['Smartlink']}, 1],\n [\"Ceska Black Scorpion\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 10, 2, 3, 0, 40, 15, 36, \"\", 1, 0, 1, None, 1],\n [\"Steyr TMP\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 10, 2, 3, 8, 40, 15, 32, \"\", 1, 0, 1, None, 1],\n [\"Ares Predator\", \"Pistols\", 0., 16., \"ballistic\", \"physical\", 15., 12., 2, 0, 0, 50, 15, 15, \"\", 1, 0, 1, {'upgrades': ['Smartlink']}, 1],\n [\"Ares Viper Slivergun\", \"Pistols\", 0., 20., \"ballistic\", \"physical\", 6., 11., 2, 3, 0, 45, 15, 20, \"\", 1, 0, 1, {'upgrades': ['Silencer']}, 1],\n [\"Colt Manhunter\", \"Pistols\", 0., 16., \"ballistic\", \"physical\", 15., 12., 2, 0, 0, 50, 15, 16, \"\", 1, 0, 1, {'upgrades': ['Laser Sight 50m']}, 1],\n [\"Remington Roomsweeper\", \"Pistols\", 0., 16., \"ballistic\", \"physical\", 15., 12., 2, 0, 0, 50, 20, 8, \"\", 1, 0, 1, None, 1],\n [\"Ruger Super Warhawk\", \"Pistols\", 0., 18., \"ballistic\", \"physical\", 20., 13., 1, 0, 0, 60, 20, 6, \"\", 1, 0, 1, None, 1],\n [\"AK-97 Carbine\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 20, 2, 3, 7, 25, 15, 30, \"\", 1, 0, 1, None, 2],\n [\"HK-227X\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 20, 2, 3, 8, 25, 15, 28, \"\", 1, 0, 1, {'upgrades': ['Silencer', 'Smartlink', \"Gas Vent\"]}, 2],\n [\"HK MP-5 TX\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 20, 2, 3, 7, 25, 15, 20, \"\", 1, 0, 1, {'upgrades': ['Laser Sight 50m', \"Gas Vent\"]}, 2],\n [\"Ingram Smartgun X\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 20, 0, 3, 8, 25, 15, 32, \"\", 1, 0, 1, {'upgrades': ['Silencer', 'Smartlink']}, 2],\n [\"Uzi IV\", \"Automatics\", 0., 8., \"ballistic\", \"physical\", 10., 20, 0, 3, 0, 25, 15, 24, \"\", 1, 0, 1, {'upgrades': ['Laser Sight 50m']}, 2],\n [\"Mossberg AM-CMDT\", \"Long Rifles\", 0., 22., \"ballistic\", \"physical\", 8., 30, 2, 2, 5, 40, 20, 6, \"\", 1, 1, 1, None, 2],\n [\"Remington 990\", \"Automatics\", 0., 18., \"ballistic\", \"physical\", 20., 30, 2, 0, 0, 40, 20, 6, \"\", 1, 1, 1, None, 2],\n [\"Battle Rifle\", \"Automatics\", 0., 18., \"ballistic\", \"physical\", 30., 100, 4, 10, 20, 54, 15, 20, \"\", 1, 1, 1, None, 2],\n [\"AK-97\", \"Automatics\", 0., 12., \"ballistic\", \"physical\", 20., 80, 2, 3, 8, 36, 15, 38, \"\", 1, 1, 1, None, 2], #g36\n [\"Ares Alpha\", \"Automatics\", 0., 12., \"ballistic\", \"physical\", 20., 80, 2, 3, 8, 36, 12, 42, \"\", 1, 1, 1, {'upgrades': ['Underbarrel Grenadelauncher', 'Smartlink']}, 2],\n [\"FN HAR\", \"Automatics\", 0., 12., \"ballistic\", \"physical\", 20., 80, 2, 3, 8, 36, 15, 35, \"\", 1, 1, 1, {'upgrades': ['Laser Sight 150m', 'Gas Vent']}, 2],\n [\"Ruger 100\", \"Long Rifles\", 0., 12., \"ballistic\", \"physical\", 20., 120, 2, 0, 0, 45, 25, 5, \"\", 0, 1, 1, {'upgrades': ['Shock Pad']}, 2],\n [\"PJSS Elephant Rifle\", \"Long Rifles\", 0., 18., \"ballistic\", \"physical\", 30., 100, 1, 2, 0, 50, 25, 2, \"\", 1, 1, 1, {'upgrades': ['Shock Pad']}, 2],\n [\"Ranger Arms SM-4\", \"Long Rifles\", 0., 16., \"ballistic\", \"physical\", 24., 160, 2, 0, 0, 60, 25, 15, \"\", 0, 1, 0, {'upgrades': ['Silencer', 'Shock Pad'], 'assembly': (3,3)}, 2],\n [\"Walter MA-2100\", \"Long Rifles\", 0., 18., \"ballistic\", \"physical\", 30., 160, 2, 0, 0, 60, 25, 10, \"\", 1, 1, 1, {'upgrades': ['Smartlink', 'Shock Pad']}, 2],\n [\"Ingram White Knight\", \"Automatics\", 0., 12., \"ballistic\", \"physical\", 20., 120, 2, 4, 12, 55, 15, 100, \"\", 0, 0, 0, {'upgrades': ['Smartlink', 'Gas Vent', 'Shock Pad']}, 2],\n [\"GE Vindicator Minigun\", \"Automatics\", 0., 12., \"ballistic\", \"physical\", 20., 120, 0, 0, 16, 85, 10, 100, \"\", 0, 0, 0, {'upgrades': ['Smartlink', 'Gas Vent', 'Shock Pad'], 'power-up': 1}, 2],\n [\"Stoner-Ares M202\", \"Automatics\", 0., 18., \"ballistic\", \"physical\", 30., 150, 0, 0, 12, 80, 15, 100, \"\", 1, 1, 1, {'upgrades': ['Smartlink']}, 2],\n [\"Ultimax HMG-2\", \"Automatics\", 0., 36., \"ballistic\", \"physical\", 60., 300, 0, 0, 12, 140, 15, 100, \"\", 1, 1, 1, {'upgrades': ['Smartlink', 'Tripod', 'Gas Vent']}, 2], #browning m2\n [\"Panther XXL\", \"Long Rifles\", 0., 36., \"ballistic\", \"physical\", 60., 300, 1, 0, 0, 100, 25, 15, \"\", 1, 1, 1, {'upgrades': ['Smartlink']}, 2], #light fifty\n [\"Ares Thunderstruck Gauss Rifle\", \"Long Rifles\", 0., 30., \"ballistic\", \"physical\", 72., 320, 2, 0, 0, 100, 20, 10, \"\", 1, 1, 1, {'upgrades': ['Smartlink', 'Shock Pad']}, 2], #light fifty\n [\"Throwing Knife\",\"Aerodynamics\", 0., '3+{Strength}/15.', \"impact\", \"physical\", '3+{Strength}/15.', 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0, None, 1],\n [\"Shuriken\",\"Aerodynamics\", 0., '2+{Strength}/20.', \"impact\", \"physical\", '2+{Strength}/20.', 8, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0, None, 1],\n [\"High Explosive Grenade\", \"Balls\", 0., 200, \"impact\", \"physical\", 30, 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Fall-Off Length': 1, 'Scatter Length': 2}, 1],\n [\"Fragmentation Grenade\", \"Balls\", 0., 100, \"impact\", \"physical\", 5, 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Fall-Off Length': 4, 'Scatter Length': 2}, 1],\n [\"Flash-Bang\", \"Balls\", 0., 50,\"impact\", \"stun\", 5, 5, 5, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Fall-Off Length': 1, 'Scatter Length': 2, 'Maximum Lnegth': 8}, 1],\n [\"Smoke Grenade\", \"Balls\", 0., 0, \"impact\", \"physical\", 0, 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Maximum Length': 8}, 1],\n [\"Thermal Smoke Grenade\", \"Balls\", 0., 0, \"impact\", \"physical\", 0, 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Maximum Length': 8}, 1],\n [\"Multispectrum Smoke Grenade\", \"Balls\", 0., 0, \"impact\", \"physical\", 0, 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Maximum Length': 4}, 1],\n [\"Gas Grenade\", \"Balls\", 0., 0, \"impact\", \"physical\", 0, 5, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0,\n {'Maximum Length': 4}, 1],\n [\"Bow\", \"Archery\", 0., '5+{Strength}/10.', \"impact\", \"physical\", '5+{Strength}/10.', 30, 1, 0, 0, 30, 0, 0, \"\", 1, 0, 0, None, 2],\n [\"Orc Bow\", \"Archery\", 0., '10+{Strength}/10.', \"impact\", \"physical\", '10+{Strength}/10.', 50, 1, 0, 0, 60, 0, 0, \"\", 1, 0, 0, None, 2],\n [\"Troll Bow\", \"Archery\", 0., '15+{Strength}/10.', \"impact\", \"physical\", '15+{Strength}/10.', 60, 1, 0, 0, 90, 0, 0, \"\", 1, 0, 0, None, 2],\n [\"Pistol Crossbow\", \"Archery\", 0., 6., \"impact\", \"physical\", 6., 10, 1, 0, 0, 26, 0, 0, \"\", 1, 1, 0, None, 1],\n [\"Light Crossbow\", \"Archery\", 0., 10., \"impact\", \"physical\", 10., 30, 1, 0, 0, 30, 0, 0, \"\", 1, 1, 0, None, 2],\n [\"Heavy Crossbow\", \"Archery\", 0., 16., \"impact\", \"physical\", 16., 48, 1, 0, 0, 40, 0, 0, \"\", 1, 1, 0, None, 2],\n [\"Ares Antioch\", \"Indirect Fire\", 0., 0., \"impact\", \"physical\", 0., 40, 1, 0, 0, 40, 0, 1, \"\", 1, 1, 0, {'upgrades': ['Smartlink']}, 2],\n [\"Enfield GL-67\", \"Indirect Fire\", 0., 0., \"impact\", \"physical\", 0., 30, 1, 0, 0, 60, 0, 8, \"\", 1, 1, 0, {'upgrades': ['Smartlink']}, 2],\n]\n\nrangedweapons_nt = namedtuple('rangedweapon', ['id'] + rangedweapons[0])\nrangedweapons_dict = OrderedDict(\n [(entry[0], rangedweapons_nt(*([i] + entry))) for i, entry in enumerate(rangedweapons[1:])])\n\narmor = [\n [\"item\", \"locations\", \"protections\", \"maxagi\", \"coordmult\"],\n [\"Armored Clothing\",\n [\"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\", \"Right Leg\", \"Left Leg\"],\n [[20.,0.], [20.,0.], [20.,0.], [20.,0.], [20.,0.], [20.,0.]],\n 45, 0.95],\n [\"Armored Pants\",\n [\"Right Leg\", \"Left Leg\"],\n [[20.,0.], [20.,0.]],\n 45, 0.95],\n [\"Explorer Jumpsuit\",\n [\"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\", \"Right Leg\", \"Left Leg\"],\n [[10.,30.], [10.,30.], [10.,30.], [10.,30.], [10.,30.], [10.,30.]],\n 70, 0.90],\n [\"Flak Vest\",\n [\"Upper Torso\", \"Lower Torso\"],\n [[50.,20.],[50.,20.]],\n 30, 0.9],\n [\"Flak Vest with Plates\",\n [\"Upper Torso\", \"Lower Torso\"],\n [[70.,40.],[70.,40.]],\n 25, 0.75],\n [\"Form Fitting Body Armor\",\n [\"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\", \"Right Leg\", \"Left Leg\"],\n [[25.,0.], [25.,0.], [25.,0.], [25.,0.], [25.,0.], [25.,0.]],\n 50, 0.95],\n [\"Lined Coat\",\n [\"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\", \"Right Leg\", \"Left Leg\"],\n [[30.,0.], [30.,0.], [30.,0.], [30.,0.], [20.,0.], [20.,0.]],\n 45, 0.9],\n [\"Armor Jacket\",\n [\"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\"],\n [[40., 15.],[30., 10.],[40., 15.],[40., 15.]],\n 35, 0.85],\n [\"Armor Pants\",\n [\"Right Leg\", \"Left Leg\"],\n [[30., 10.],[30., 10.]],\n 35, 0.85],\n [\"Ballistic Mask\",\n [\"Head\", ], [[20., 0.],], 60, 0.9],\n [\"Biker Helmet\",\n [\"Head\", ], [[10., 30.],], 40, 0.85],\n [\"Light Helmet\",\n [\"Head\", ], [[30., 15.],], 30, 0.8],\n [\"Heavy Helmet\",\n [\"Head\", ], [[40., 20.],], 20, 0.75],\n [\"Light Carapace\",\n [\"Head\", \"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\", \"Right Leg\", \"Left Leg\"],\n [[30., 15.], [50., 30.], [50., 30.], [40., 20.], [40., 20.], [40.,20.], [40.,20.]],\n 30, 0.8],\n [\"Heavy Carapace\",\n [\"Head\", \"Upper Torso\", \"Lower Torso\", \"Right Arm\", \"Left Arm\", \"Right Leg\", \"Left Leg\"],\n [[40., 20.], [70., 40.], [70., 40.], [50., 25.], [50., 25.], [50.,25.], [50.,25.]],\n 20, 0.75],\n]\n\narmor_nt = namedtuple('armor', ['id'] + armor[0])\narmor_dict = OrderedDict(\n [(entry[0], armor_nt(*([i] + entry))) for i, entry in enumerate(armor[1:])])\n\nessence_by_ware = {'cyberware': 0.,\n 'bioware': 0.}\n\nware = [\n [\"name\", \"kind\", \"essence\", \"capacity\", \"part_weight\", \"additional_weight\", \"description\", \"basecost\", \"effectcost\", \"partcost\", \"parts\",\n \"effects\", \"location\"],\n [\"Smartgun Processor\", \"cyberware\", 3, None, 0, 0, \"Requires Additional Image Link, and connection\", 0, 0, 5000, [], [], 'Brain'],\n [\"Cybereyes\", \"cyberware\", 0, 0.33, 0, 0, \"Cybernetic Eye Replacement, Includes Image Link\", 0, 2000, 6000, [\"Eyes\"], [], ''],\n [\"High Capcity Cybereyes\", \"cyberware\", 2, 1, 0, 0, \"High Capacity Cybernetic Eye Replacement, includes Image Link\", 0, 10000, 6000, [\"Eyes\"], [], ''],\n [\"Cyberears\", \"cyberware\", 0, 0.33, 0, 0, \"Cybernetic Ear Replacement, includes Audio Link\", 0, 2000, 6000, [\"Ears\"], [], ''],\n [\"High Capacity Cyberears\", \"cyberware\", 2, 1, 0, 0, \"High Capacity Cybernetic Ear Replacement, includes Audio Link\", 0, 10000, 6000, [\"Ears\"], [], ''],\n [\"Brain Gateway Storage\", \"cyberware\", 3, None, 0, 0, \"Internal storage that can only be accessed with a mental command of the owner\", 0, 5000, 0, [], [], 'Brain'],\n [\"Datajack\", \"cyberware\", 1, None, 0, 0, \"A wired and wireless connection to headware. Wired: Unlimited Uplink. Wireless: Signal 10, Uplink 40.\", 0, 250, 0, [], [], 'Brain'],\n [\"Internal Datajack\", \"cyberware\", 2, None, 0, 0, \"A hidden wireless connection to headware. Signal 2, Uplink 50.\", 0, 2000, 0, [], [], 'Brain'],\n [\"Image Link\", \"cyberware\", 2, None, 0, 0, \"Machine to Video Sense Interface\", 0, 1000, 0, [], [], 'Brain'],\n [\"Sound Link\", \"cyberware\", 2, None, 0, 0, \"Machine to Audio Sense Interface\", 0, 1000, 0, [], [], 'Brain'],\n [\"Tactile Link\", \"cyberware\", 2, None, 0, 0, \"Machine to Tactile Sense Interface\", 0, 1000, 0, [], [], 'Brain'],\n [\"Olfactorial Link\", \"cyberware\", 2, None, 0, 0, \"Machine to Olfactorial Sense Interface\", 0, 1000, 0, [], [], 'Brain'],\n [\"Taste Link\", \"cyberware\", 2, None, 0, 0, \"Machine to Taste Sense Interface\", 0, 1000, 0, [], [], 'Brain'],\n [\"Internal Simsense Module\", \"cyberware\", 6, None, 0, 0, \"Machine to Multisense Interface\", 0, 5000, 0, [], [], 'Brain'],\n [\"Knowledge-Link\", \"cyberware\", 12, None, 0, 0, \"Machine to Raw Thoughts/Knowledge Interface, allowes 1 concurrent Knowsofts of unlimited Rating\", 0, 30000, 0, [],\n [['attributes', 'Logic', '+5'], ['skills', 'Data Search', '+10']], 'Brain'],\n [\"Skillsoft Driver 25\", \"cyberware\", 10, None, 0, 0, \"Skill Driver System, allowes a maximum of 2 concurrent Passivesofts with Rating 25\", 3000, 3000, 0,\n [], [], 'Brain'],\n [\"Skillsoft Driver 35\", \"cyberware\", 15, None, 0, 0, \"Skill Driver System, allowes a maximum of 2 concurrent Passivesofts with Rating 35\", 3000, 15000, 0,\n [], [], 'Brain'],\n [\"Skillsoft Driver 45\", \"cyberware\", 20, None, 0, 0, \"Skill Driver System, allowes a maximum of 2 concurrent Passivesofts with Rating 45\", 3000, 75000, 0,\n [], [], 'Brain'],\n [\"Skillsoft Expert System\", \"cyberware\", 10, None, 0, 0, \"Skill Expert System, adds +5 Rating to all Active/Passive/Knowsoft Ratings, allow use of Edge with these rolls\", 5000, 50000, 0,\n [], [], 'Brain'],\n [\"Skillsoft Compression System\", \"cyberware\", 3, None, 0, 0, \"Skill Compression System, allows 2 more concurrent of each Active/Passive/Knowsoft\", 5000, 5000, 0,\n [], [], 'Brain'],\n [\"Transducer\", \"cyberware\", 3, None, 0, 0, \"Vocal Thoughts to Machine Interface\", 0, 1000, 0, [], [], 'Brain'],\n [\"Simrig\", \"cyberware\", 4, None, 0, 0, \"Senses/Motoric Triggers to Machine Interface\", 0, 5000, 0, [], [], 'Brain'],\n [\"Transscriber\", \"cyberware\", 6, None, 0, 0, \"Raw Thoughts to Machine Interface\", 0, 20000, 0, [], [], 'Brain'],\n [\"Encephalon I\", \"cyberware\", 6, None, 0, 0, \"Cybernetic Logic-Processing Unit\", 0, 6000, 0, [],\n [[\"attributes\", \"Logic\", \"+10\"]], 'Brain'],\n [\"Encephalon II\", \"cyberware\", 11, None, 0, 0, \"Cybernetic Logic-Processing Unit\", 0, 30000, 0, [],\n [[\"attributes\", \"Logic\", \"+20\"]], 'Brain'],\n [\"Encephalon III\", \"cyberware\", 15, None, 0, 0, \"Cybernetic Logic-Processing Unit\", 0, 150000, 0, [],\n [[\"attributes\", \"Logic\", \"+30\"]], 'Brain'],\n [\"Sensor Coprocessor I\", \"cyberware\", 6, None, 0, 0, \"Cybernetic Sensor Coprocessor\", 0, 6000, 0, [],\n [[\"attributes\", \"Intuition\", \"+10\"]], 'Brain'],\n [\"Sensor Coprocessor II\", \"cyberware\", 11, None, 0, 0, \"Cybernetic Sensor Coprocessor\", 0, 30000, 0, [],\n [[\"attributes\", \"Intuition\", \"+20\"]], 'Brain'],\n [\"Sensor Coprocessor III\", \"cyberware\", 15, None, 0, 0, \"Cybernetic Sensor Coprocessor\", 0, 150000, 0, [],\n [[\"attributes\", \"Intuition\", \"+30\"]], 'Brain'],\n [\"Emotion Control Filter I\", \"cyberware\", 6, None, 0, 0, \"Cybernetic Processing Filter\", 0, 6000, 0, [],\n [[\"attributes\", \"Willpower\", \"+10\"]], 'Brain'],\n [\"Emotion Control Filter II\", \"cyberware\", 11, None, 0, 0, \"Cybernetic Processing Filter\", 0, 30000, 0, [],\n [[\"attributes\", \"Willpower\", \"+20\"]], 'Brain'],\n [\"Emotion Control Filter III\", \"cyberware\", 15, None, 0, 0, \"Cybernetic Processing Filter\", 0, 150000, 0, [],\n [[\"attributes\", \"Willpower\", \"+30\"]], 'Brain'],\n [\"Cerebral Booster I\", \"bioware\", 6, None, 0, 0, \"Bionetic Cortex Enhancement\", 6000, 6000, 0, [],\n [[\"attributes\", \"Logic\", \"+10\"]], 'Brain'],\n [\"Cerebral Booster II\", \"bioware\",11, None, 0, 0, \"Bionetic Cortex Enhancement\", 6000, 48000, 0, [],\n [[\"attributes\", \"Logic\", \"+20\"]], 'Brain'],\n [\"Cerebral Booster III\", \"bioware\", 15, None, 0, 0, \"Bionetic Cortex Enhancement\", 6000, 294000, 0, [],\n [[\"attributes\", \"Logic\", \"+30\"]], 'Brain'],\n [\"Thalamus Enhancer I\", \"bioware\", 6, None, 0, 0, \"Bionetic Thalamus Enhancement\", 6000, 6000, 0, [],\n [[\"attributes\", \"Intuition\", \"+10\"]], 'Brain'],\n [\"Thalamus Enhancer II\", \"bioware\", 11, None, 0, 0, \"Bionetic Thalamus Enhancement\", 6000, 42000, 0, [],\n [[\"attributes\", \"Intuition\", \"+20\"]], 'Brain'],\n [\"Thalamus Enhancer III\", \"bioware\", 15, None, 0, 0, \"Bionetic Thalamus Enhancement\", 6000, 294000, 0, [],\n [[\"attributes\", \"Intuition\", \"+30\"]], 'Brain'],\n [\"Lymbic Filter I\", \"bioware\", 6, None, 0, 0, \"Bionetic Lymbic Filter System\", 6000, 6000, 0, [],\n [[\"attributes\", \"Willpower\", \"+10\"]], 'Brain'],\n [\"Lymbic Filter II\", \"bioware\", 11, None, 0, 0, \"Bionetic Lymbic Filter System\", 6000, 42000, 0, [],\n [[\"attributes\", \"Willpower\", \"+20\"]], 'Brain'],\n [\"Lymbic Filter III\", \"bioware\", 15, None, 0, 0, \"Bionetic Lymbic Filter System\", 6000, 294000, 0, [],\n [[\"attributes\", \"Willpower\", \"+30\"]], 'Brain'],\n [\"Pain Editor\", \"cyberware\", 10, None, 0, 0, \"Cybernetic Pain Gateway\", 0, 20000, 0, [],\n [[\"stats\", \"Pain Resistance\", \"+1.\"], [\"attributes\", \"Willpower\", \"+10\"], [\"attributes\", \"Intuition\", \"-10\"]], 'Brain'],\n [\"Emo-Pattern Sub-Processor\", \"cyberware\", 10, None, 0, 0, \"Cybernetic Emotion Detection Sub-Processor.\", 0, 12000, 0, [],\n [[\"skills\", \"Judge Person\", \"+10.\"]], 'Brain'],\n [\"Sleep Regulator\", \"bioware\", 5, None, 0, 0, \"Sleep Regulator\", 2500, 5000, 0, [],\n [], 'Brain'],\n [\"Trauma Damper\", \"bioware\", 7, None, 0, 0, \"Reduce effective stun damage by 30%\", 4000, 26000, 0, [],\n [['stats', 'Stun Damage Reduction', '*0.70']], 'Brain'],\n [\"Voice Modulator\", \"cyberware\", 3, None, 0, 0, \"Enables the user to change the tone of his voice\", 0, 5000, 0, [],\n [['skills', 'Act', '+5'], ['skills', 'Discussion', '+5'], ['skills', 'Interaction', '+5'], ['skills', 'Singing', '+10']], 'Vocal Chords'],\n [\"Tailored Pheromones\", \"bioware\", 10, None, 0, 0, \"Enables the user emmit tailored pheromones. +10 on Discussion and Interaction Skill Tests if appropriate (Manual) \", 10000, 20000, 0, [],\n [], 'Upper Torso'],\n [\"Nano Repair Bots I\", \"cyberware\", 4, None, 0, 0, \"Divide healing time of all damage by 4, wounds by 2\", 0, 6000, 0, [],\n [['stats', 'Damage Heal Time', '*0.25'], ['stats', 'Wound Heal Time', '*0.5']], 'Bloodstream'],\n [\"Nano Repair Bots II\", \"cyberware\", 6, None, 0, 0, \"Divide healing time of all damage by 8, wounds by 4\", 0, 30000, 0, [],\n [['stats', 'Damage Heal Time', '*0.125'], ['stats', 'Wound Heal Time', '*0.25']], 'Bloodstream'],\n [\"Nano Repair Bots III\", \"cyberware\", 8, None, 0, 0, \"Divide healing time of all damage by 16, wounds by 8\", 0, 150000, 0, [],\n [['stats', 'Damage Heal Time', '*0.0625'], ['stats', 'Wound Heal Time', '*0.125']], 'Bloodstream'],\n [\"Symbiotes I\", \"bioware\", 3, None, 0, 0, \"Divide healing time of all damage (not wounds) by 2\", 3000, 3000, 0, [],\n [['stats', 'Damage Heal Time', '*0.5']], 'Bloodstream'],\n [\"Symbiotes II\", \"bioware\", 4, None, 0, 0, \"Divide healing time for all damage (not wounds) by 4\", 3000, 22000, 0, [],\n [['stats', 'Damage Heal Time', '*0.25']], 'Bloodstream'],\n [\"Symbiotes III\", \"bioware\", 6, None, 0, 0, \"Divide healing time of all damage (not wounds) by 8\", 3000, 147000, 0, [],\n [['stats', 'Damage Heal Time', '*0.125']], 'Bloodstream'],\n [\"Platelet Factory I\", \"bioware\", 5, None, 0, 0, \"Reduce bleeding by 1 wound\", 3000, 4000, 0, [],\n [['stats', 'Bleeding Wounds' '-1']], 'Bloodstream'],\n [\"Platelet Factory II\", \"bioware\", 8, None, 0, 0, \"Reduces bleeding by 2 wounds, reduce effective physical damage by 15%\", 3000, 28250, 0, [],\n [['stats', 'Bleeding Wounds', '-2'], ['stats', 'Physical Damage Reduction', '*0.85']], 'Bloodstream'],\n [\"Platelet Factory III\", \"bioware\", 10, None, 0, 0, \"Reduces bleeding by 3 wounds, reduce effective physical damage by 30%\", 3000, 184500, 0, [],\n [['stats', 'Bleeding Wounds', '-3'], ['stats', 'Physical Damage Reduction', '*0.70']], 'Bloodstream'],\n [\"Auto Injector\", \"cyberware\", 3, None, 0, 0, \"Can inject up to 6 doses of drugs/toxins on defined triggers. Halve the speed of the compound.\", 0, 1000, 0, [],\n [], 'Neck'],\n [\"Skinlink\", \"cyberware\", 3, None, 0, 0, \"Allowes low bandwidth connections over skin. Uplink 10.\", 0, 3000, 0, [],\n [], 'Skin'],\n [\"Biomonitor\", \"cyberware\", 5, None, 0, 0, \"Detailed bio information of the user. +10 on Medic, +5 on Judge Person Tests if user is target. (Manual)\", 0, 3000, 0, [],\n [], 'Torso'],\n [\"Tracheal Filter\", \"bioware\", 3, None, 0, 0, \"+10 on Resist Rolls against Inhalation Vector Drugs and Toxins. (Manual)\", 2500, 5000, 0, [],\n [], 'Trachea'],\n [\"Blood Filter\", \"bioware\", 5, None, 0, 0, \"+10 on Resist Rolls agains Drugs and Toxins. (Manual)\", 5000, 10000, 0, [],\n [], 'Blood'],\n [\"Nano Tox-Bots\", \"cyberware\", 5, None, 0, 0, \"+15 on Resist Rolls agains Drugs and Toxins. (Manual)\", 0, 10000, 0, [],\n [], 'Blood'],\n [\"Vehicle Control Rig I\", \"cyberware\", 5, None, 0, 0, \"Enables user to interface with rigged Vehicles. Requires Simrig and Internal Simsense Module\", 5000, 3000, 6000, [\"Vertebrae\"],\n [], ''],\n [\"Vehicle Control Rig II\", \"cyberware\", 7, None, 0, 0, \"Enables user to interface with rigged Vehicles. Requires Simrig and Internal Simsense Module\", 5000, 30000, 6000, [\"Vertebrae\"],\n [], ''],\n [\"Vehicle Control Rig III\", \"cyberware\", 10, None, 0, 0, \"Enables user to interface with rigged Vehicles. Requires Simrig and Internal Simsense Module\", 5000, 150000, 6000, [\"Vertebrae\"],\n [], ''],\n [\"Left Cyberarm\", \"cyberware\", 0, 0.65, 0, 0, \"Artificial cyberlimb\", 0, 1000, 6000, [\"Left Arm\"], [], ''],\n [\"Right Cyberarm\", \"cyberware\", 0, 0.65, 0, 0, \"Artificial cyberlimb\", 0, 1000, 6000, [\"Right Arm\"], [], ''],\n [\"Left Cyberleg\", \"cyberware\", 0, 0.65, 0, 0, \"Artificial cyberlimb\", 0, 1000, 6000, [\"Left Leg\"], [], ''],\n [\"Right Cyberleg\", \"cyberware\", 0, 0.65, 0, 0, \"Artificial cyberlimb\", 0, 1000, 6000, [\"Right Leg\"], [], ''],\n [\"High Capacity Left Cyberarm\", \"cyberware\", 1, 1, 0, 0, \"Artificial cyberlimb\", 5000, 2000, 7000, [\"Left Arm\"], [], ''],\n [\"High Capacity Right Cyberarm\", \"cyberware\", 1, 1, 0, 0, \"Artificial cyberlimb\", 5000, 2000, 7000, [\"Right Arm\"], [], ''],\n [\"High Capacity Left Cyberleg\", \"cyberware\", 1, 1, 0, 0, \"Artificial cyberlimb\", 5000, 2000, 7000, [\"Left Leg\"], [], ''],\n [\"High Capacity Right Cyberleg\", \"cyberware\", 1, 1, 0, 0, \"Artificial cyberlimb\", 5000, 2000, 7000, [\"Right Leg\"], [], ''],\n [\"Left Raptor Cyberleg\", \"cyberware\", 2, 0.8, 0, 0, \"Artificial cyberlimb\", 5000, 2000, 6000, [\"Left Leg\"],\n [['stats', 'Running Speed', '*1.5'], ['stats', 'Sprinting Speed', '*1.5'], ['stats','Running Jump Vertical', '*1.5'], ['stats','Running Jump Horizontal', '*1.5']], ''],\n [\"Right Raptor Cyberleg\", \"cyberware\", 2, 0.8, 0, 0, \"Artificial cyberlimb\", 5000, 2000, 6000, [\"Right Leg\"],\n [['stats', 'Running Speed', '*1.5'], ['stats', 'Sprinting Speed', '*1.5'], ['stats','Running Jump Vertical', '*1.5'], ['stats','Running Jump Horizontal', '*1.5']], ''],\n [\"Torso Shell\", \"cyberware\", 0, 0.65, 0, 0, \"Artificial Cybertorso\", 0, 5000, 6000,\n [\"Upper Torso Bones\", \"Upper Torso Muscles\", \"Upper Torso Nerves\", \"Upper Torso Skin\",\n \"Lower Torso Bones\", \"Lower Torso Muscles\", \"Lower Torso Nerves\", \"Lower Torso Skin\",], [], ''],\n [\"High Capacity Torso Shell\", \"cyberware\", 2, 1, 0, 0, \"Artificial Cybertorso\", 5000, 8000, 7000,\n [\"Upper Torso Bones\", \"Upper Torso Muscles\", \"Upper Torso Nerves\", \"Upper Torso Skin\",\n \"Lower Torso Bones\", \"Lower Torso Muscles\", \"Lower Torso Nerves\", \"Lower Torso Skin\",], [], ''],\n [\"Cyberskull\", \"cyberware\", 0, 1, 0, 0, \"Artificial Cyberskull, Reduces Essence Cost for Headware\", 0, 5000, 6000, [\"Head Bones\", \"Head Skin\"], [['Essence Cost', 'Brain', '*0.9']], ''],\n [\"Muscle Augmentation Upper\", \"bioware\", 0, None, 0, 0, \"Biological muscle replacement\", 6000, 0, 6000,\n [\"Left Arm Muscles\", \"Right Arm Muscles\", \"Upper Torso Muscles\"], [], ''],\n [\"Muscle Augmentation Lower\", \"bioware\", 0, None, 0, 0, \"Biological muscle replacement\", 6000, 0, 6000,\n [\"Left Leg Muscles\", \"Right Leg Muscles\", \"Lower Torso Muscles\"], [], ''],\n [\"Muscle Augmentation Total\", \"bioware\", 0, None, 0, 0, \"Biological muscle replacement\", 6000, 0, 6000,\n [\"Left Leg Muscles\", \"Right Leg Muscles\", \"Lower Torso Muscles\",\n \"Left Arm Muscles\", \"Right Arm Muscles\", \"Upper Torso Muscles\"], [], ''],\n [\"Muscle Replacement Upper\", \"cyberware\", 0, None, 0, 0, \"Cybernetic muscle replacement\", 0, 0, 6000,\n [\"Left Arm Muscles\", \"Right Arm Muscles\", \"Upper TorsoMuscles\"], [], ''],\n [\"Muscle Replacement Lower\", \"cyberware\", 0, None, 0, 0, \"Cybernetic muscle replacement\", 0, 0, 6000,\n [\"Left Leg Muscles\", \"Right Leg Muscles\", \"Lower Torso Muscles\"], [], ''],\n [\"Muscle Replacement Total\", \"cyberware\", 0, None, 0, 0, \"Cybernetic muscle replacement\", 0, 0, 6000,\n [\"Left Leg Muscles\", \"Right Leg Muscles\", \"Lower Torso Muscles\",\n \"Left Arm Muscles\", \"Right Arm Muscles\", \"Upper Torso Muscles\"], [], ''],\n [\"Bone Density Upper\", \"bioware\", 0, None, 0, 0, \"Biological bone strengthening\", 6000, 0, 6000,\n [\"Left Arm Bones\", \"Right Arm Bones\", \"Upper Torso Bones\"], [], ''],\n [\"Bone Density Lower\", \"bioware\", 0, None, 0, 0, \"Biological bone strengthening\", 6000, 0, 6000,\n [\"Left Leg Bones\", \"Right Leg Bones\", \"Lower Torso Bones\"], [], ''],\n [\"Bone Density Total\", \"bioware\", 0, None, 0, 0, \"Biological bone strengthening\", 6000, 0, 6000,\n [\"Left Leg Bones\", \"Right Leg Bones\", \"Lower Torso Bones\",\n \"Left Arm Bones\", \"Right Arm Bones\", \"Upper Torso Bones\"], [], ''],\n [\"Bone Lacing Upper\", \"cyberware\", 0, None, 0, 0, \"Cybernetic bone lacing\", 0, 0, 6000,\n [\"Left Arm Bones\", \"Right Arm Bones\", \"Upper Torso Bones\"], [], ''],\n [\"Bone Lacing Lower\", \"cyberware\", 0, None, 0, 0, \"Cybernetic bone lacing\", 0, 0, 6000,\n [\"Left Leg Bones\", \"Right Leg Bones\", \"Lower Torso Bones\"], [], ''],\n [\"Bone Lacing Total\", \"cyberware\", 0, None, 0, 0, \"Cybernetic bone lacing\", 0, 0, 6000,\n [\"Left Leg Bones\", \"Right Leg Bones\", \"Lower Torso Bones\",\n \"Left Arm Bones\", \"Right Arm Bones\", \"Upper Torso Bones\"], [], ''],\n [\"Wired Reflexes I\", \"cyberware\", 8, None, 0, 0, \"Cybernetic nerve replacement\", 5000, 5000, 6000,\n [\"Vertebrae\"], [['stats', 'Physical Reaction', '+10'], ['stats', 'Physical Action Multiplyer', '*0.9']], ''],\n [\"Wired Reflexes II\", \"cyberware\", 15, None, 0, 0, \"Cybernetic nerve replacement\", 5000, 25000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\"],\n [['stats', 'Physical Reaction', '+20'], ['stats', 'Physical Action Multiplyer', '*0.8']], ''],\n [\"Wired Reflexes III\", \"cyberware\", 20, None, 0, 0, \"Cybernetic nerve replacement\", 5000, 125000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\", \"Lower Torso Nerves\", \"Left Leg Nerves\",\n \"Right Leg Nerves\"],\n [['stats', 'Physical Reaction', '+30'], ['stats', 'Physical Action Multiplyer', '*0.7']], ''],\n [\"Skillwires 25\", \"cyberware\", 8, None, 0, 0, \"Skill Driver System, allowes a maximum of 2 concurrent Activesofts with Rating 25\", 4000, 4000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\", \"Lower Torso Nerves\", \"Left Leg Nerves\",\n \"Right Leg Nerves\"], [], ''],\n [\"Skillwires 35\", \"cyberware\", 10, None, 0, 0, \"Skill Driver System, allowes a maximum of 2 concurrent Activesofts with Rating 35\", 4000, 20000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\", \"Lower Torso Nerves\", \"Left Leg Nerves\",\n \"Right Leg Nerves\"], [], ''],\n [\"Skillwires 45\", \"cyberware\", 12, None, 0, 0, \"Skill Driver System, allowes a maximum of 2 concurrent Activesofts with Rating 45\", 4000, 100000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\", \"Lower Torso Nerves\", \"Left Leg Nerves\",\n \"Right Leg Nerves\"], [], ''],\n [\"Skillwire Auto Driver\", \"cyberware\", 3, None, 0, 0, \"Allowes automation of basic tasks like looking arround and standing. Requires Skillwires 25 or greater.\", 0, 5000, 0,\n [], [], 'Brain'],\n [\"Skillwire Auto Driver II\", \"cyberware\", 5, None, 0, 0, \"Allowes automation of basic tasks like orientation and walking. Requires Skillwires 35 or greater.\", 0, 15000, 0,\n [], [], 'Brain'],\n [\"Synaptic Accelerator I\", \"bioware\", 8, None, 0, 0, \"Bionetic nerve replacement\", 15000, 5000, 6000,\n [\"Vertebrae\"], [ ['stats', 'Physical Reaction', '+10'], ['stats', 'Physical Action Multiplyer', '*0.9']], ''],\n [\"Synaptic Accelerator II\", \"bioware\", 15, None, 0, 0, \"Bionetic nerve replacement\",15000, 35000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\"],\n [['stats', 'Physical Reaction', '+20'], ['stats', 'Physical Action Multiplyer', '*0.8']], ''],\n [\"Synaptic Accelerator III\", \"bioware\", 20, None, 0, 0, \"Bionetic nerve replacement\", 15000, 245000, 6000,\n [\"Vertebrae\", \"Upper Torso Nerves\", \"Left Arm Nerves\", \"Right Arm Nerves\", \"Lower Torso Nerves\", \"Left Leg Nerves\",\n \"Right Leg Nerves\"],\n [['stats', 'Physical Reaction', '+30'], ['stats', 'Physical Action Multiplyer', '*0.7']], ''],\n [\"Damage Compensator 33%\", \"cyberware\", 2, None, 0, 0, \"Cybernetic Pain Stimulus Filter\", 0, 2500, 6000, [\"Vertebrae\"],\n [[\"stats\", \"Pain Resistance\", \"+0.33\"]], ''],\n [\"Damage Compensator 66%\", \"cyberware\", 3, None, 0, 0, \"Cybernetic Pain Stimulus Filter\", 0, 12500, 6000, [\"Vertebrae\"],\n [[\"stats\", \"Pain Resistance\", \"+0.66\"]], ''],\n [\"Damage Compensator 100%\", \"cyberware\", 4, None, 0, 0, \"Cybernetic Pain Stimulus Filter\", 0, 62500, 6000, [\"Vertebrae\"],\n [[\"stats\", \"Pain Resistance\", \"+1.\"]], ''],\n [\"Damage Regulator 33%\", \"bioware\", 2, None, 0, 0, \"Bilogical Pain Stimulus Filter\", 2500, 2500, 6000, [\"Vertebrae\"],\n [[\"stats\", \"Pain Resistance\", \"+0.33\"]], ''],\n [\"Damage Regulator 66%\", \"bioware\", 3, None, 0, 0, \"Cybernetic Pain Stimulus Filter\", 2500, 17500, 6000, [\"Vertebrae\"],\n [[\"stats\", \"Pain Resistance\", \"+0.66\"]], ''],\n [\"Damage Regulator 100%\", \"bioware\", 4, None, 0, 0, \"Cybernetic Pain Stimulus Filter\", 2500, 122500, 6000, [\"Vertebrae\"],\n [[\"stats\", \"Pain Resistance\", \"+1.\"]], ''],\n [\"Cyberheart\", \"cyberware\", 1, None, 0, 0, \"Cybernetic Heart\", 0, 5000, 6000, [\"Heart\"],\n [[\"skills\", \"Athletics\", \"+10\"]], ''],\n [\"Synthacardium\", \"bioware\", 1, None, 0, 0, \"Bionic Heart\", 6000, 2000, 6000, [\"Heart\"],\n [[\"skills\", \"Athletics\", \"+5\"]], ''],\n [\"Cybernetic Lungs\", \"cyberware\", 2, 1, 0, 0, \"Cybernetic Lungs. \", 0, 0, 6000, [\"Lungs\"],\n [], ''],\n [\"Bionetic Lungs\", \"bioware\", 0, None, 0, 0, \"Bionic Lungs.\", 2000, 0, 6000, [\"Lungs\"],\n [], ''],\n [\"Torso Dermal Plating\", \"cyberware\", 8, None, 0, 0, \"Subdermal Armor Plates\", 0, 10000, 0, [],\n [[\"ballistic armor\", \"Upper Torso\", \"20\"],[\"ballistic armor\", \"Lower Torso\", \"20\"],\n [\"impact armor\", \"Upper Torso\", \"20\"],[\"impact armor\", \"Lower Torso\", \"20\"],\n ],\n 'Torso'],\n [\"Upper Body Dermal Plating\", \"cyberware\", 12, None, 0, 0, \"Subdermal Armor Plates\", 0, 15000, 0, [],\n [[\"ballistic armor\", \"Upper Torso\", \"30\"],[\"ballistic armor\", \"Lower Torso\", \"30\"],\n [\"ballistic armor\", \"Right Arm\", \"30\"],[\"ballistic armor\", \"Left Arm\", \"30\"],\n [\"impact armor\", \"Upper Torso\", \"30\"],[\"impact armor\", \"Lower Torso\", \"30\"],\n [\"impact armor\", \"Right Arm\", \"30\"],[\"impact armor\", \"Left Arm\", \"30\"],\n ],\n 'Torso and Arms'],\n [\"Total Body Dermal Plating\", \"cyberware\", 16, None, 0, 0, \"Subdermal Armor Plates\", 0, 20000, 0, [],\n [[\"ballistic armor\", \"Upper Torso\", \"30\"],[\"ballistic armor\", \"Lower Torso\", \"30\"],\n [\"ballistic armor\", \"Right Arm\", \"30\"],[\"ballistic armor\", \"Left Arm\", \"30\"],\n [\"ballistic armor\", \"Right Leg\", \"30\"],[\"ballistic armor\", \"Left Leg\", \"30\"],\n [\"ballistic armor\", \"Head\", \"30\"],\n [\"impact armor\", \"Upper Torso\", \"30\"],[\"impact armor\", \"Lower Torso\", \"30\"],\n [\"impact armor\", \"Right Arm\", \"30\"],[\"impact armor\", \"Left Arm\", \"30\"],\n [\"impact armor\", \"Right Leg\", \"30\"],[\"impact armor\", \"Left Leg\", \"30\"],\n [\"impact armor\", \"Head\", \"30\"]\n ],\n 'Body'],\n [\"Dermal Sheath\", \"cyberware\", 0, 0.2, 0, 0, \"Cybernetic Dermal Armor\", 0, 20000, 6000,\n [\"Upper Torso Skin\", \"Left Arm Skin\", \"Right Arm Skin\", \"Lower Torso Skin\", \"Left Leg Skin\",\n \"Right Leg Skin\", \"Head Skin\"],\n [[\"ballistic armor\", \"Upper Torso\", \"20\"],[\"ballistic armor\", \"Lower Torso\", \"20\"],\n [\"ballistic armor\", \"Right Arm\", \"20\"],[\"ballistic armor\", \"Left Arm\", \"20\"],\n [\"ballistic armor\", \"Right Leg\", \"20\"],[\"ballistic armor\", \"Left Leg\", \"20\"],\n [\"ballistic armor\", \"Head\", \"20\"],\n ],\n ''],\n [\"Orthoskin\", \"bioware\", 0, None, 0, 0, \"Bionetic Dermal Armor\", 20000, 20000, 6000,\n [\"Upper Torso Skin\", \"Left Arm Skin\", \"Right Arm Skin\", \"Lower Torso Skin\", \"Left Leg Skin\",\n \"Right Leg Skin\", \"Head Skin\"],\n [[\"ballistic armor\", \"Upper Torso\", \"20\"],[\"ballistic armor\", \"Lower Torso\", \"20\"],\n [\"ballistic armor\", \"Right Arm\", \"20\"],[\"ballistic armor\", \"Left Arm\", \"20\"],\n [\"ballistic armor\", \"Right Leg\", \"20\"],[\"ballistic armor\", \"Left Leg\", \"20\"],\n [\"ballistic armor\", \"Head\", \"20\"],\n ],\n ''],\n [\"Cybernetic Balance Tail\", \"cyberware\", 5, None, 0, 0, \"Cybernetic tail\", 0, 5000, 0,\n [], [['skills', 'Balance', '+20']], 'Spine'],\n [\"Bionetic Balance Tail\", \"cyberware\", 5, None, 0, 0, \"Bionetic tail\", 5000, 5000, 0,\n [], [['skills', 'Balance', '+20']], 'Spine'],\n]\n\nware.extend([[\"Reflex Recorder I: {}\".format(key), \"cyberware\", 3, None, 0, 0, \"Skill increase\", 0, 12000*value.expweight, 6000, [\"Vertebrae\"], [['skills', key, '+5']], ''] for key, value in skills_dict.items() if value.kind == 'active'])\nware.extend([[\"Reflex Recorder II: {}\".format(key), \"cyberware\", 4, None, 0, 0, \"Skill increase\", 0, 36000*value.expweight, 6000, [\"Vertebrae\"], [['skills', key, '+10']], ''] for key, value in skills_dict.items() if value.kind == 'active'])\nware.extend([[\"Reflex Recorder III: {}\".format(key), \"cyberware\", 5, None, 0, 0, \"Skill increase\", 0, 108000*value.expweight, 6000, [\"Vertebrae\"], [['skills', key, '+15']], ''] for key, value in skills_dict.items() if value.kind == 'active'])\n\nware_nt = namedtuple('ware', ['id'] + ware[0])\nware_dict = OrderedDict([(entry[0], ware_nt(*([i]+ entry))) for i, entry in enumerate(ware[1:])])\n\nfixtures = [\n [\"name\", 'location', 'relative_capacity', 'absolute_capacity', 'weight', 'description', 'effects', 'cost'],\n ['Image Link', ['Eyes'], 0, 0, 0, \"Machine to Video Sense Interface\", [], 0 ],\n ['Video Enhancement I', ['Eyes'], 0.08, 0.02, 0, \"Add +5 to Visual Perception skill\", [['skills', 'Visual', '+5']], 2000],\n ['Video Enhancement II', ['Eyes'], 0.12, 0.03, 0, \"Add +10 to Visual Perception skill\", [['skills', 'Visual', '+10']], 10000],\n ['Video Enhancement III', ['Eyes'], 0.16, 0.04, 0, \"Add +15 to Visual Perception skill\", [['skills', 'Visual', '+15']], 50000],\n ['Flare Compensation', ['Eyes'], 0.05, 0.01, 0, \"Reduce Glare Modifiers by 20 (Manual).\", [], 750],\n ['Vision Magnification 4x', ['Eyes'], 0.15, 0.05, 0, \"Enables user to zoom in and out\", [], 1000],\n ['Vision Magnification 8x', ['Eyes'], 0.15, 0.15, 0, \"Enables user to zoom in and out\", [], 2500],\n ['Infrared Vision', ['Eyes'], 0.1, 0.03, 0, \"Enables infrared vision\", [], 4000],\n ['Low Light Vision', ['Eyes'], 0.15, 0.015, 0, \"Enables low light vision\", [], 2500 ],\n ['Microscopic Vision', ['Eyes'], 0.2, 0.05, 0, \"Enables microscopic vision\", [], 3000 ],\n ['Eye Laser System', ['Eyes'], 0, 0.03, 0., \"Allows for installation of Eye-Laser subsystems\", [], 5000],\n ['Eye Laser Microphone', ['Eyes'], 0, 0.01, 0, \"Requires Eye Laser System, works like a Laser Microphone (Range 20 Meters)\", [], 2000],\n ['Eye Laser Designator', ['Eyes'], 0, 0.01, 0., \"Requires Eye Laser System, works like a Laser Designator (Range 30 Meters)\", [], 1500],\n ['Eye Laser Range Finder', ['Eyes'], 0, 0.005, 0, \"Requires Eye Laser System, works like a Range Finder (Range 50 Meters)\", [], 500],\n ['Eye Laser Power Increase', ['Eyes'], 0, 0.07, 0, \"Requires Eye Laser System, triples all ranges and allowes to work as a Tool Laser\", [], 5000],\n ['Eye Light System', ['Eyes'], 0., 0.05, 0, \"Provides Perfect Vison with Low Light Vision for up to 25 Meters\", [], 3000],\n ['Ocular Drones', ['Eyes'], 0.3, 0.2, 0, \"Transforms both eyes into ocular drones\", [], 20000],\n ['Sound Link', ['Ears'], 0, 0, 0, \"Machine to Audio Sense Interface\", [], 0],\n ['Enhanced Hearing I', ['Ears'], 0.1, 0.02, 0, \"Add +5 to Aural Perception skill\", [['skills', 'Aural', '+5']], 1500],\n ['Enhanced Hearing II', ['Ears'], 0.15, 0.03, 0, \"Add +10 to Aural Perception skill\", [['skills', 'Aural', '+10']], 7500],\n ['Enhanced Hearing III', ['Ears'], 0.2, 0.04, 0, \"Add +15 to Aural Perception skill\", [['skills', 'Aural', '+15']], 37500],\n ['Select Sound Filter I', ['Ears'], 0.05, 0.015, 0, \"Subtract 5 from Environmental Noise Modifiers (manual)\", [], 1000],\n ['Select Sound Filter II', ['Ears'], 0.075, 0.02, 0, \"Subtract 10 from Environmental Noise Modifiers (manual)\", [], 5000],\n ['Select Sound Filter III', ['Ears'], 0.1, 0.03, 0, \"Subtract 15 from Environmental Noise Modifiers (manual)\", [], 25000],\n ['Damper', ['Ears'], 0.1, 0.02, 0, \"Reduce Modifiers due to intense noise by 20 (Manual).\", [], 750],\n ['Wide Frequency Adaption', ['Ears'], 0.2, 0.06, 0, \"Allows users to hear Ultra- and Infrasound, needed for Ultrasound system\", [], 6000],\n ['Balance Augmentor', ['Ears'], 0.1, 0.1, 0, \"Add +10 to Balance skill\", [['skills', 'Balance', '+10']], 10000],\n ['Ultrasound Generator', ['Head Bones'], 0.1, 0.2, 0, \"Generates Ultrasound waves. Needed for Ultrasound system.\", [], 1000],\n ['Ultra Wideband Radar', ['Head Bones'], 0.3, 1, 0, \"Radar that also allowes to see through walls in a limited way.\", [], 15000],\n ['Nano-Tox Filters', ['Lungs'], 0.3, 0.0, 0, \"Optional +20 on Resist Rolls against Inhalation Vector Toxins (Manual).\", [], 7500],\n ['Oxy-Stash I', ['Lungs'], 0.5, 0.0, 0, \"4/1 Minute Air Reservoir (No exertion, exertion)\", [], 2000],\n ['Oxy-Stash II', ['Lungs'], 0.7, 0.0, 0, \"12/3 Minute Air Reservoir (No exertion, exertion)\", [], 5000],\n ['Cyber Gills', ['Lungs'], 0.3, 0.0, 0, \"Enables user to breath water\", [], 7500],\n ['Hydraulick Jacks', ['Left Leg', 'Right Leg'], 0.5, 0, 0, 'Allows higher and farther jumps using hydraulic technics',\n [['stat', 'Jumping Distance', '*4']], 10000],\n ['Retractable Cyberskates', ['Left Leg', 'Right Leg'], 0.3, 0, 0, 'Doubles Running and Sprinting Speed on paved surfaces (Manual). Complex Action to deploy/retract.',\n [], 4000],\n ['Ruthenium Polymer Coating',\n ['Head Skin', 'Upper Torso Skin', 'Lower Torso Skin', 'Left Arm Skin', 'Right Arm Skin', 'Left leg Skin', 'Right Leg Skin'],\n 0.2, 0, 0, 'Allows user to change skin colour at will', [], 10000],\n ['Chamaeleon Modification', [], 0, 0, 0,\n 'Requires Ruthenium Polymer Coating, adds +20 to Stealth tests if no armor and minimal clothing is worn (manual)',[], 20000],\n ['Light Armor Cover Head', ['Head Skin'], 0.15, 0, 0, '',[['ballistic armor', 'Head', '10']], 500],\n ['Light Armor Cover Torso', ['Upper Torso Skin', 'Lower Torso Skin'], 0.15, 0, 0, 'Provides Ballistic Armor of 10',\n [['ballistic armor', 'Upper Torso', '10'],['ballistic armor', 'Lower Torso', '10']],\n 1000],\n ['Light Armor Cover Right Arm', ['Right Arm Skin'], 0.2, 0, 0, 'Provides Ballistic Armor of 10',\n [['ballistic armor', 'Right Arm', '10']], 500],\n ['Light Armor Cover Left Arm', ['Left Arm Skin'], 0.2, 0, 0, 'Provides Ballistic Armor of 10',\n [['ballistic armor', 'Left Arm', '10']], 500],\n ['Light Armor Cover Right Leg', ['Right Leg Skin'], 0.2, 0, 0, 'Provides Ballistic Armor of 10',\n [['ballistic armor', 'Right Leg', '10']], 500],\n ['Light Armor Cover Left Leg', ['Left Leg Skin'], 0.2, 0, 0, 'Provides Ballistic Armor of 10',\n [['ballistic armor', 'Left Leg', '10']], 500],\n ['Medium Armor Cover Head', ['Head Skin'], 0.8, 0, 0, 'Provides Ballistic Armor of 20',\n [['ballistic armor', 'Head', '20']], 1000],\n ['Medium Armor Cover Torso', ['Upper Torso Skin', 'Lower Torso Skin'], 0.8, 0, 0, 'Provides Ballistic Armor of 20',\n [['ballistic armor', 'Upper Torso', '20'],['ballistic armor', 'Lower Torso', '20']],1000],\n ['Medium Armor Cover Right Arm', ['Right Arm Skin'], 0.8, 0, 0, 'Provides Ballistic Armor of 20',\n [['ballistic armor', 'Right Arm', '20']], 1000],\n ['Medium Armor Cover Left Arm', ['Left Arm Skin'], 0.8, 0, 0, 'Provides Ballistic Armor of 20',\n [['ballistic armor', 'Left Arm', '20']], 1000],\n ['Medium Armor Cover Right Leg', ['Right Leg Skin'], 0.8, 0, 0, 'Provides Ballistic Armor of 20',\n [['ballistic armor', 'Right Leg', '20']], 1000],\n ['Medium Armor Cover Left Leg', ['Left Leg Skin'], 0.8, 0, 0, 'Provides Ballistic Armor of 20',\n [['ballistic armor', 'Left Leg', '20']], 1000],\n ['Armor Plating Head', ['Head Skin'], 0.4, 0.3, 0, 'Provides Ballistic and Impact Armor of 30',\n [['ballistic armor', 'Head', '30'],['impact armor', 'Head', '30']], 2000],\n ['Armor Plating Torso', ['Upper Torso Skin', 'Lower Torso Skin'], 0.4, 1., 0, 'Provides Ballistic and Impact Armor of 30',\n [['ballistic armor', 'Upper Torso', '30'], ['impact armor', 'Upper Torso', '30'],\n ['ballistic armor', 'Lower Torso', '30'], ['impact armor', 'Lower Torso', '30']], 4000],\n ['Armor Plating Right Arm', ['Right Arm Skin'], 0.4, 0.75, 0, 'Provides Ballistic and Impact Armor of 30',\n [['ballistic armor', 'Right Arm', '30'],['impact armor', 'Right Arm', '30']], 2000],\n ['Armor Plating Left Arm', ['Left Arm Skin'], 0.4, 0.75, 0, 'Provides Ballistic and Inpact Armor of 30',\n [['ballistic armor', 'Left Arm', '30'], ['impact armor', 'Left Arm', '30']], 2000],\n ['Armor Plating Right Leg', ['Right Leg Skin'], 0.4, 1.5, 0, 'Provides Ballistic and Impact Armor of 30',\n [['ballistic armor', 'Right Leg', '30'], ['impact armor', 'Right Leg', '30']], 2000],\n ['Armor Plating Left Leg', ['Left Leg Skin'], 0.4, 1.5, 0, 'Provides Ballistic and Impact Armor of 30',\n [['ballistic armor', 'Left Leg', '30'], ['impact armor', 'Left Leg', '30']], 2000],\n ['Heavy Armor Plating Head', ['Head Skin'], 0.7, 0.5, 0, 'Provides Ballistic and Impact Armor of 40',\n [['ballistic armor', 'Head', '40'],['impact armor', 'Head', '40']], 4000],\n ['Heavy Armor Plating Torso', ['Upper Torso Skin', 'Lower Torso Skin'], 0.7, 1.5, 0, 'Provides Ballistic and Impact Armor of 40',\n [['ballistic armor', 'Upper Torso', '40'], ['impact armor', 'Upper Torso', '40'],\n ['ballistic armor', 'Lower Torso', '40'], ['impact armor', 'Lower Torso', '40']], 8000],\n ['Heavy Armor Plating Right Arm', ['Right Arm Skin'], 0.7, 1., 0, 'Provides Ballistic and Impact Armor of 40',\n [['ballistic armor', 'Right Arm', '40'],['impact armor', 'Right Arm', '40']], 4000],\n ['Heavy Armor Plating Left Arm', ['Left Arm Skin'], 0.7, 1., 0, 'Provides Ballistic and Inpact Armor of 40',\n [['ballistic armor', 'Left Arm', '40'], ['impact armor', 'Left Arm', '40']], 4000],\n ['Heavy Armor Plating Right Leg', ['Right Leg Skin'], 0.7, 2., 0, 'Provides Ballistic and Impact Armor of 40',\n [['ballistic armor', 'Right Leg', '40'], ['impact armor', 'Right Leg', '40']], 4000],\n ['Heavy Armor Plating Left Leg', ['Left Leg Skin'], 0.7, 2., 0, 'Provides Ballistic and Impact Armor of 40',\n [['ballistic armor', 'Left Leg', '40'], ['impact armor', 'Left Leg', '40']], 4000],\n ['Drone Hand Right', ['Right Arm'], .2, 0, 0, '',[], 5000],\n ['Drone Hand Left', ['Left Arm'], .2, 0, 0, '',[], 5000],\n ['Retracteable Cyberspurs Right', ['Right Arm'], 0.2, 0, 0, '',[], 1000],\n ['Retracteable Cyberspurs Left', ['Left Arm'], 0.2, 0, 0, '',[], 1000],\n ['Retracteable Cyberclaws Right', ['Right Arm'], 0.05, 0, 0, '',[], 500],\n ['Retracteable Cyberclaws Left', ['Left Arm'], 0.05, 0, 0, '',[], 500],\n ['Hold-Out Cyberpistol Right', ['Right Arm'], 0, 3., 0, '',[], 1000],\n ['Hold-Out Cyberpistol Left', ['Left Arm'], 0, 3., 0, '',[], 1000],\n ['Light Cyberpistol Right', ['Right Arm'], 0, 4.5, 0, '',[], 1500],\n ['Light Cyberpistol Left', ['Left Arm'], 0, 4.5, 0, '',[], 1500],\n ['Heavy Cyberpistol Right', ['Right Arm'], 0, 6., 0, '',[], 3000],\n ['Heavy Cyberpistol Left', ['Left Arm'], 0, 6., 0, '',[], 3000],\n ['Cybershotgun Right', ['Right Arm'], 0, 9., 0, '',[], 5000],\n ['Cybershotgun Left', ['Left Arm'], 0, 9., 0, '',[], 5000],\n\n ['Light Torso External Weapon Mount', ['Upper Torso Bones'], 0, 2., 0, 'Can equip weapons with 1-handed minimum strength of 40. 120 degree FOV.',[], 4000],\n ['Medium Torso External Weapon Mount', ['Upper Torso Bones'], 0, 3., 0, 'Can equip weapons with 1/2-handed minimum strength of 55/40. 120 degree FOV.',[], 6000],\n ['Heavy Torso External Weapon Mount', ['Upper Torso Bones'], 0, 4., 0, 'Can equip weapons with 1/2-handed minimum strength of 70/55. 120 degree FOV.',[], 8000],\n ['Light Articulated Weapon Arm', ['Upper Torso Bones'], 0, 3, 0, 'Can equip weapons with 1-handed minimum strength of 40. 360 degree FOV.',[], 6000],\n ['Medium Articulated Weapon Arm', ['Upper Torso Bones'], 0, 4.5, 0, 'Can equip weapons with 1/2-handed minimum strength of 55/40. 360 degree FOV.',[], 9000],\n ['Heavy Articulated Weapon Arm', ['Upper Torso Bones'], 0, 6., 0, 'Can equip weapons with 1/2-handed minimum strength of 70/55. 360 degree FOV.',[], 12000],\n ['Hold-Out Cyberholster Right', ['Right Leg'], 0, 6., 0, '',[], 500],\n ['Hold-Out Cyberholster Left', ['Left Leg'], 0, 6., 0, '',[], 500],\n ['Light Pistol Cyberholster Right', ['Right Leg'], 0, 9., 0, '',[], 750],\n ['Light Pistol Cyberholster Left', ['Left Leg'], 0, 9, 0, '',[], 750],\n ['Heavy Pistol Cyberholster Right', ['Right Leg'], 0, 12., 0, '',[], 1000],\n ['Heavy Pistol Cyberholster Left', ['Left Leg'], 0, 12., 0, '',[], 1000],\n ['Internal Cyberdeck Right Arm', ['Right Arm'], 0, 7., 0, 'Deck has to be purchased seperately',[], 5000],\n ['Internal Cyberdeck Left Arm', ['Left Arm'], 0, 7., 0, 'Deck has to be purchased seperately',[], 5000],\n ['Internal Cyberdeck Right Leg', ['Right Leg'], 0, 7., 0, 'Deck has to be purchased seperately',[], 5000],\n ['Internal Cyberdeck Left Leg', ['Left Leg'], 0, 7., 0, 'Deck has to be purchased seperately',[], 5000],\n ['Internal Commlink Right Arm', ['Right Arm'], 0, .1, 0, 'Commlink has to be purchased seperately',[], 1000],\n ['Internal Commlink Left Arm', ['Left Arm'], 0, .1, 0, 'Commlink has to be purchased seperately',[], 1000],\n ['Internal Commlink Right Leg', ['Right Leg'], 0, .1, 0, 'Commlink has to be purchased seperately',[], 1000],\n ['Internal Commlink Left Leg', ['Left Leg'], 0, .1, 0, 'Commlink has to be purchased seperately',[], 1000],\n ]\n\nfixtures_nt = namedtuple('fixtures', ['id'] + fixtures[0])\nfixtures_dict = OrderedDict([(entry[0], fixtures_nt(*([i]+ entry))) for i, entry in enumerate(fixtures[1:])])\n\nadept_powers = [\n [\"name\", \"cost\", \"description\", \"formdescription\", \"effects\"],\n [\"Combat Sense\", 'X', 'Enhance Reaction', [['Physical Reaction +', '{Value}**0.5*{Magic}/10.']], [['stats', 'Physical Reaction', '+{Value}**0.5*{Magic}/10.']]],\n [\"Danger Sense\", 'X', 'Enhance Reaction for suprise tests (Manual). Reduce Distraction Modifier (Manual). Allow for Dodge Test even if not aware of attack.',\n [['Physical Reaction in Surprise Tests +', '{Value}**0.5*{Magic}/6.'],\n ['Distraction Modifier -', '{Value}**0.5*{Magic}/12.'],\n ['Unaware Dodge Mod', '30 - 30*math.erf({Value}*{Magic}/1000.)'],],\n [['test', 'Surprise', '+{Value}**0.5*{Magic}/6.'],\n ['stats', 'Distraction Modifier', '-{Value}**0.5*{Magic}/12.'],\n ]],\n [\"Astral Sight\", 10, 'Allow Adept to perceive astrally', [], []],\n [\"Low Light Vision\", 2, 'Low Light Vision', [], []],\n [\"Infrared Vision\", 2, 'Infrared Vision', [], []],\n [\"Flare Compensation\", 1, 'Reduce Glare Modifiers by 20 (Manual).', [], []],\n [\"Wide Frequency Adaption\", 3, 'Allows users to hear Ultra- and Infrasound.', [], []],\n [\"Damper\", 1, 'Reduce Modifiers due to intense noise by 20 (Manual).', [], []],\n [\"Blindsight\", 3, 'With closed eyes, the adept can use ambient sounds for an Ultrasound like Vision. Requires Wide Frequency adaption. Range 8m. Can be increased to full Ultrasound ranges with an Ultrasound generator.', [], []],\n [\"Traceless Walk\", 5, 'Leave no traces when walking. Does not trigger pressure sensors. (Manual)',[], []],\n [\"Wall Running\", 10, 'Allow Adept to run on a wall as long as he is sprinting',[], []],\n [\"Mystic Armor\", 'X', 'Add Ballistic and Impact Armor', [['additional armor', '{Value}**0.5*{Magic}/8.']],\n [['ballistic armor', 'Upper Torso', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Upper Torso', '{Value}**0.5*{Magic}/8.'],\n ['ballistic armor', 'Lower Torso', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Lower Torso', '{Value}**0.5*{Magic}/8.'],\n ['ballistic armor', 'Right Arm', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Right Arm', '{Value}**0.5*{Magic}/8.'],\n ['ballistic armor', 'Left Arm', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Left Arm', '{Value}**0.5*{Magic}/8.'],\n ['ballistic armor', 'Right Leg', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Right Leg', '{Value}**0.5*{Magic}/8.'],\n ['ballistic armor', 'Left Leg', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Left Leg', '{Value}**0.5*{Magic}/8.'],\n ['ballistic armor', 'Head', '{Value}**0.5*{Magic}/8.'], ['impact armor', 'Head', '{Value}**0.5*{Magic}/8.'],\n ]],\n [\"Killing Hands\", 5, 'Cause Physical Damage in Combat',[], []],\n [\"Critical Strike\", 'X', 'Multiply Unarmed Combat Damage (Manual)', [['Unarmed Combat Damage *', '(1+{Value}**0.5*{Magic}/400.)']], [['stat', 'Unarmed Combat Damage', '*(1+{Value}**0.5*{Magic}/400.)']]],\n [\"Spirit Claw\", 'X', 'Multiply Unarmed Combat Damage to dual/astral targets (Manual)', [['Unarmed Combat Damage *', '(1+{Value}**0.5*{Magic}/200.)']],\n [['stat', 'Unarmed Combat Damage', '*(1+{Value}**0.5*{Magic}/200.)']]],\n [\"Penetrating Strike\", 'X', 'Multiply Unarmed Combat Penetration (Manual)', [['Unarmed Combat Penetration *', '(1+{Value}**0.5*{Magic}/40.)']],\n [['stat', 'Unarmed Combat Penetration', '*(1+{Value}**0.5*{Magic}/40.)']]],\n [\"Elemental Strike\", 5, 'Add elemental Effect to Unarmed Combat Damage (Manual)', [], []],\n [\"Elemental Aura\", 'X', 'Elemental Aura that deals damage on Contact (successfull attack of being successfully attacked in (un)armed combat). (Manual)',\n [['Elemental Aura Damage ', '{Value}**0.5*{Magic}/6.'], ['Elemental Aura Penetration ', '{Value}**0.5*{Magic}/20.']], []],\n [\"Elemental Resistance\", 'X', 'Armor against specific elemental effects (Manual)', [['Elemental Armor', '{Value}**0.5*{Magic}/3.']], []],\n [\"Freefall\", 'X', 'Gain no damage for falling a given distance (Manual)', [['Free falling Distance in meters ', '{Value}**0.5*{Magic}/6.']], []],\n [\"Great Leap\", 'X', 'Jump further', [['Jumping Distance *', '(1+{Value}**0.5*{Magic}/200.)']], [['stat', 'Jumping Distance', '*(1+{Value}**0.5*{Magic}/200.)']]],\n [\"Improved Running\", 'X', 'Run faster', [['Run Speed *', '(1+{Value}**0.5*{Magic}/200.)']], [['stat', 'Run Speed', '*(1+{Value}**0.5*{Magic}/200.)']]],\n [\"Improved Swimming\", 'X', 'Swim faster', [['Swim Speed *', '(1+{Value}**0.5*{Magic}/200.)']], [['stat', 'Swim Speed', '*(1+{Value}**0.5*{Magic}/200.)']]],\n [\"Rapid Healing\", 'X', 'Decrease Heal Time (Manual)', [['Heal Time /', '(1+{Value}**0.5*{Magic}/50.)']], [['stat', 'Heal Time', '/(1+{Value}**0.5*{Magic}/50.)']]],\n [\"Kinesics\", 10, 'Change Face. Same Gender and Metatype. Change time 5 min, Perception Test with a Test Difficulty Equal to Magic is needed to find faults. (Manual)',[], []],\n [\"Melain Control\", 5, 'Change Hair Color (only natural colors). Change time 1min. Perception Test with a Test Difficulty Equal to Magic is needed to find faults. (Manual)',[], []],\n [\"Voice Control\", 5, 'Change Voice. change time 1 min. Perception Test with a Test Difficulty Equal to Magic is needed to find faults. (Manual)',[], []],\n [\"Pain Resistance\", 'X', 'Ignore low life penalties', [['Ignore percentage of damage', '{Value}**0.5*{Magic}/2.']], [['stat', 'Pain Resistance', '+ (1-value)**0.5 * {Value}*{Magic}/200.']]],\n ] + [\n [\"Enhanced Attribute {}\".format(i.name), 'X', 'Enhance {}'.format(i.name),\n [['{} *'.format(i.name), '(1+{Value}**0.5*{Magic}/600.)']],\n [['attributes', '{}'.format(i.name), '*(1+{Value}**0.5*{Magic}/600.)']]]\n for i in attributes_dict.values() if i.kind != 'special'\n ] + [\n [\"Improved Skill {}\".format(i.name), 'X', 'Improve {}'.format(i.name),\n [['{} +'.format(i.name), '+{Value}**0.5*{Magic}/10./' + str(i.expweight)]],\n [['skills', '{}'.format(i.name), '+{Value}**0.5*{Magic}/10./'+ str(i.expweight)]]]\n for i in skills_dict.values()\n ]\n\n\nadept_powers_nt = namedtuple('adept_power', ['id'] + adept_powers[0])\nadept_powers_dict = OrderedDict([(entry[0], adept_powers_nt(*([i] + entry))) for i, entry in enumerate(adept_powers[1:])])\n\n\n\nspells = [\n ['name', 'category', 'difficulty', 'cast_time', 'resist', 'effect', 'drain', 'range', 'volume', 'anchor',\n 'duration'],\n ['Astral Barrier', '', '', '', '', '', '', '', '', '', ''],\n ['Astral Armor', '', '', '', '', '', '', '', '', '', ''],\n ['Healing', '', '', '', '', '', '', '', '', '', ''],\n ['First Aid', '', '', '', '', '', '', '', '', '', ''],\n ['Heal Wounds', '', '', '', '', '', '', '', '', '', ''],\n ['Increase Physical Attribute', '', '', '', '', '', '', '', '', '', ''],\n ['Increase Reaction', '', '', '', '', '', '', '', '', '', ''],\n ['Mana Barrier', '', '', '', '', '', '', '', '', '', ''],\n ['Barrier', '', '', '', '', '', '', '', '', '', ''],\n ['Armor', '', '', '', '', '', '', '', '', '', ''],\n ['Animate', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Magic', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Enemies', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Emotions', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Individual', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Life', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Thoughts', '', '', '', '', '', '', '', '', '', ''],\n ['Mindprobe', '', '', '', '', '', '', '', '', '', ''],\n ['Clairaudience', '', '', '', '', '', '', '', '', '', ''],\n ['Clairvoyance', '', '', '', '', '', '', '', '', '', ''],\n ['Mindprobe', '', '', '', '', '', '', '', '', '', ''],\n ['Catalog', '', '', '', '', '', '', '', '', '', ''],\n ['Detect Sensors', '', '', '', '', '', '', '', '', '', ''],\n ['Control Thoughts', '', '', '', '', '', '', '', '', '', ''],\n ['Mana Illusion', '', '', '', '', '', '', '', '', '', ''],\n ['Possession', '', '', '', '', '', '', '', '', '', ''],\n ['Fear', '', '', '', '', '', '', '', '', '', ''],\n ['Shapechange', '', '', '', '', '', '', '', '', '', ''],\n ['Physical Illusion', '', '', '', '', '', '', '', '', '', ''],\n ['Physical Mask', '', '', '', '', '', '', '', '', '', ''],\n ['Physical Invisibility', '', '', '', '', '', '', '', '', '', ''],\n ['Physical Silence', '', '', '', '', '', '', '', '', '', ''],\n ['Levitation', '', '', '', '', '', '', '', '', '', ''],\n ['Magic Fingers', '', '', '', '', '', '', '', '', '', ''],\n ['Astral Weapon', '', '', '', '', '', '', '', '', '', ''],\n ['Powerbolt', '', '', '', '', '', '', '', '', '', ''],\n ['Manabolt', '', '', '', '', '', '', '', '', '', ''],\n ['Sterilize', '', '', '', '', '', '', '', '', '', ''],\n ['Firebolt', '', '', '', '', '', '', '', '', '', ''],\n ['Fireball', '', '', '', '', '', '', '', '', '', ''],\n ['Wreck Vehicle', '', '', '', '', '', '', '', '', '', ''],\n ['Melt Structure', '', '', '', '', '', '', '', '', '', ''],\n]\n\nspells_nt = namedtuple('spell', ['id'] + spells[0])\nspells_dict = OrderedDict([(entry[0], spells_nt(*([i] + entry))) for i, entry in enumerate(spells[1:])])\n\nmetamagic = [\n [\"name\"],\n ['Centering'],\n ['Divination'],\n ['Masking'],\n ['Shielding'],\n ['Flexible Aura'],\n ['Inner Binding'],\n ['Inner Power'],\n ['Infusion'],\n ['Transfusion'],\n ['Extended Masking'],\n ['Flux'],\n ['Ally Formula'],\n ['Quickening'],\n ['Absorption'],\n ['Reflection'],\n ['Search'],\n ['Shrouding'],\n ['Spell Moding'],\n ]\n\nmetamagic_nt = namedtuple('metamagic', ['id'] + metamagic[0])\nmetamagic_dict = OrderedDict([(entry[0], metamagic_nt(*([i] + entry))) for i, entry in enumerate(metamagic[1:])])\n\n\n#weight:payloads:\n# cars: 1:1\n# rotorcraft 1:1\n# vector thrust: 2:1\n# jets: 3:1\n# bike 2:1\nvehicle_chassis = [\n [\"name\", \"locomotion\", \"handling\", \"weight\", \"max_speed\", \"acceleration\", \"load\", 'capacity', 'size', 'constitution', 'armor', 'visibility','signature', 'cost'],\n ['Lady Bug', ['insect flight', 'walk'], 0, 0.0005, 10, 3, 0.0005, 0.0005, 0.01, 20, 1, 45, 45, 600],\n ['Bug', 'walk', 0, 0.0005, 0.2, 0.2, 0.01, 0.001, 0.01, 30, 1, 45, 45, 200],\n ['Hummel', ['insect flight', 'walk'], 0, 0.002, 12, 4, 0.002, 0.002, 0.025, 20, 1, 35, 35, 300],\n ['Dragonfly', ['insect flight', 'walk'], 0, 0.005, 13, 5, 0.005, 0.005, 0.1, 15, 1, 15, 15, 300],\n ['Roach', 'walk', 0, 0.01, 1, 1, 0.1, 0.01, 0.05, 40, 3, 25, 25, 100], #American Roach\n ['Spider', 'walk', 0, 0.1, 4, 4, 0.5, 0.05, 0.3, 30, 1, 5, 5, 200], #Vogelspinne\n ['Flying Football', 'rotor flight', 0, 5, 25, 4, 5, 5, 0.5, 30, 30, -10, -10, 500],\n ['Rolling Ball', 'roll', 0, 0.5, 10, 3, 0.5, 0.5, 0.1, 40, 5, 10, 10, 100],\n ['Blimp', 'lta flight', 0, 10, 15, 1, 10, 10, 2, 20, 0, -30, -30, 450],\n ['Cat', 'walk', 0, 4, 10, 5, 1, 0.4, 0.3, 30, 1, -5, -5, 2000],\n ['Small Patrol Drone', 'wheeled', 0, 20, 20, 2, 20, 20, 0.5, 40, 40, -10, -10, 1000],\n ['Medium Patrol Drone', 'wheeled', 0, 100, 35, 3, 100, 100, 1, 40, 50, -20, -20, 2500],\n ['Large Patrol Drone', 'wheeled', 0, 250, 40, 4, 250, 250, 2, 40, 50, -30, -30, 5000],\n ['Vector Thrust Drone', 'thrust flight', 0, 100, 60, 4, 50, 50, 1, 30, 40, -20, -20, 8000],\n ['Mini Plane Drone', 'fixed-wing flight', 0, 3, 40, 5, 2, 1, 1, 20, 1, -20, -20, 2500],\n ['Jet Drone', 'fixed-wing flight', 0, 20, 100, 10, 30, 30, 2, 20, 20, -30, -30, 32000],\n ['Hover Drone', 'hover', 0, 2, 30, 2, 2, 2, 0.5, 30, 3, -10, -10, 300],\n ['Segway', 'dual-wheeled', 0, 30, 12, 1, 100, 100, 1., 30, 0, -20, -20, 800],\n ['Personal Mobility Vehicle', 'three-wheeled', 0, 100, 20, 2, 100, 100, 2., 30, 5, -30, -30, 3000],\n ['Google Car', 'wheeled', 0, 500, 30, 2, 300, 300, 2.5, 40, 10, -35, -35, 6000],\n ['Subcompact', 'wheeled', 0, 750, 50, 3, 350, 350, 4.5, 40, 10, -40, -40, 12000], # opel insignia\n ['Speed Car', 'wheeled', 0, 1500, 75, 5, 300, 500, 4.5, 40, 10, -40, -40, 80000],\n ['Sedan', 'wheeled', 0, 1500, 50, 2, 500, 500, 5, 40, 15, -45, -45, 25000], # opel insignia\n ['Medium Van', 'wheeled', 0, 2000, 40, 2, 1500, 1500, 5.5, 40, 15, -45, -45, 30000], #sprinter kurz\n ['Large Van', 'wheeled', 0, 2500, 30, 1.5, 2500, 2500, 7, 40, 15, -50, -50, 35000], #sprinter lang\n ['Monocycle', 'monocycle', 0, 150, 60, 5, 100, 100, 1., 30, 10, -20, -20, 4000],\n ['Enclosed Monocycle', 'monocycle', 0, 400, 50, 4, 200, 200, 2, 40, 15, -30, -30, 7500],\n ['Speedbike', 'cycle', 0, 200, 75, 6, 120, 120, 2, 30, 10, -30, -30, 8000], # ducati 1199\n ['Chopper', 'rotor flight', 0, 350, 50, 4, 200, 200, 2.5, 40, 15, -35, -35, 6500], # harley davidson breakout\n ['Combat Helicopter', 'rotor flight', 0, 5000, 80, 6, 3000, 3000, 15, 40, 50, -60, -60, 750000], # apache\n #['Commuting Helicopter', '', '', '', '', '', '', ''],\n ['APC', 'wheeled', 0, 10000, 30, 1, 5000, 5000, 7, 50, 150, -50, -50, 58000], # LAV\n ['IFV', 'tracked', 0, 15000, 15, 1, 15000, 15000, 7, 50, 200, -50, -50, 130000], # Bradley\n ['Tank', 'tracked', 0, 30000, 20, 2, 30000, 30000, 9, 50, 500, -50, -50, 420000], # Leopard 2a6\n #['', '', '', '', '', '', ''],\n]\n\nvehicle_chassis_nt = namedtuple('vehicle', ['id'] + vehicle_chassis[0])\nvehicle_chassis_dict = OrderedDict([(entry[0], vehicle_chassis_nt(*([i] + entry))) for i, entry in enumerate(vehicle_chassis[1:])])\n\nagents = [\n [\"name\", \"rating\", \"skills\"],\n ['Civilian Driver Class I', 15, {'Pilot': 20}],\n ['Civilian Driver Class II', 20, {'Pilot': 30}],\n ['Civilian Driver Class III', 25, {'Pilot': 40}],\n ['Security Driver Class I', 20, {'Pilot': 30, 'Electronic Warfare': 20, 'Ranged Combat': 20}],\n ['Security Driver Class II', 25, {'Pilot': 40, 'Electronic Warfare': 30, 'Ranged Combat': 30}],\n ['Military Driver Class I', 25, {'Pilot': 40, 'Electronic Warfare': 40, 'Ranged Combat': 40, 'Cracking': 30}],\n ['Civilian Drone Pilot Class I', 15, {'Pilot': 20, \"Perception\": 10}],\n ['Civilian Drone Pilot Class II', 20, {'Pilot': 30, \"Perception\": 20}],\n ['Civilian Drone Pilot Class III', 25, {'Pilot': 40, \"Perception\": 30}],\n ['Security Drone Pilot Class I', 20, {'Pilot': 30, 'Perception': 20, 'Electronic Warfare': 20, 'Ranged Combat': 20, 'Dodge': 20, 'Stealth': 20}],\n ['Security Drone Pilot Class II', 25, {'Pilot': 40, 'Perception': 30, 'Electronic Warfare': 30, 'Ranged Combat': 30, 'Dodge': 30, 'Stealth': 30}],\n ['Military Drone Pilot Class I', 25, {'Pilot': 40, 'Perception': 40, 'Electronic Warfare': 40, 'Ranged Combat': 40, 'Dodge': 30, 'Stealth': 30, 'Cracking': 30}],\n ]\n\n\nagents_nt = namedtuple('agent', ['id'] + agents[0])\nagents_dict = OrderedDict([(entry[0], agents_nt(*([i] + entry))) for i, entry in enumerate(agents[1:])])\n\n\ndef get_vehicle_stats(chassis, agent, computer, sensors_package, equipment, cost, availability):\n chassis = vehicle_chassis_dict[chassis]\n agent = gameitems_dict[agent]\n computer = gameitems_dict[computer]\n sensors = [gameitems_dict[i] for i in sensor_packages_dict[sensors_package].content]\n equipment = [gameitems_dict[i] for i in equipment]\n\n cost = chassis.cost + agent.cost + computer.cost + sum([i.cost for i in sensors]) + sum([i.cost for i in equipment])\n availability = max([agent.availability, computer.availability, max([i.cost for i in sensors]) + max([i.cost for i in equipment]) if equipment else 0])\n capacity = chassis.capacity\n used_capacity = computer.absolute_capacity + capacity * computer.relative_capacity + sum([i.absolute_capacity + capacity * i.relative_capacity for i in sensors]) + \\\n sum([i.absolute_capacity + capacity * i.relative_Capacity for i in equipment])\n\n return [cost, availability, capacity, used_capacity]\n\nvehicles = [\n [\"name\", \"chassis\", \"agent\", \"computer\", \"sensors_package\", \"equipment\", \"cost\", \"availability\"],\n [\"Shiawase Kanmushi\", \"Bug\", \"Civilian Drone Pilot Class I\", \"Nano Drone Computer I\", \"Nano Drone\", [], 0, 0, ],\n [\"MCT Fly-Spy\", \"Dragonfly\", \"Civilian Drone Pilot Class I\", \"Mini Drone Computer I\", \"Nano Drone\", [], 0, 0, ],\n [\"Lone Star iBall\", \"Rolling Ball\", \"Civilian Drone Pilot Class I\", \"Mini Drone Computer I\", \"Micro Drone\", [], 0, 0, ],\n [\"Lockheed Optic-X\", \"Mini Plane Drone\", \"Security Drone Pilot Class I\", \"Erika Elite\", \"Mini Drone\", [], 0, 0, ],\n [\"GM-Nissan Doberman\", \"Small Patrol Drone\", \"Security Drone Pilot Class I\", \"Renraku Sensei\", \"Civilian Drone\", [], 0, 0, ],\n [\"Steel Lynx\", \"Medium Patrol Drone\", \"Security Drone Pilot Class II\", \"Erika Elite\", \"Civilian Drone\", [\"Small-Arms Medium (6kg) Turret\"], 0, 0, ],\n [\"MCT-Nissan Roto-drone\", \"Flying Football\", \"Security Drone Pilot Class I\", \"Renraku Sensei\", \"Mini Drone\", [], 0, 0, ],\n [\"Renraku Stormcloud\", \"Blimp\", \"Security Drone Pilot Class I\", \"Renraku Sensei\", \"Civilian Vehicle\", [], 0, 0, ],\n [\"McDonnel-Douglas Nimrod\", \"Jet Drone\", \"Military Drone Pilot Class I\", \"Erika Elite\", \"Civilian Vehicle\", [], 0, 0, ],\n]\n\n#for i, vehicle in enumerate(vehicles[1:]):\n# vehicles[i+1].extend(get_vehicle_stats(*vehicle[1:]))\n\nvehicles_nt = namedtuple('vehicle', ['id'] + vehicles[0])\nvehicles_dict = OrderedDict([(entry[0], vehicles_nt(*([i] + entry))) for i, entry in enumerate(vehicles[1:])])\n\nvehicle_upgrades = [\n ['name', 'category', 'weight', 'capacity', 'cost', 'square_weight_cost'],\n ['Seat','basic', 80, 200, 500, 0],\n\n ['Seat Ejection','basic', 100, 250, 3000, 0],\n ['Seat, Troll', 'basic', 240, 575, 1000, 0],\n ['Seat Ejection, Troll', 'basic', 300, 750, 5000, 0],\n ['Bench', 'basic', 230, 500, 500, 0],\n ['Gridlink', 'basic', '*0.02', '*0.02', 300, 100],\n ['Manual Controls', 'basic', 20, 50, 3000, 0],\n ['Passenger Protection', 'security', 20, 30, 1000, 0],\n ['Passenger Protection, Troll', 'security', 60, 90, 2000, 0],\n ['Life Support I', 'security', 50, 50, 5000, 20],\n ['Life Support II', 'security', 200, 200, 10000, 100],\n ['Zapper System I', 'security', 2, 2, 500, 5],\n ['Zapper System II', 'security', 5, 5, 1000, 10],\n ['Zapper System III', 'security', 20, 20, 5000, 50],\n ['External Armor', 'security', 0, 0, 0, 0],\n ['Internal Armor', 'security', 0, 0, 0, 0],\n ['Signature Masking', 'security', '*0.01', '*0.04', 200, 100],\n ['Signature Masking II', 'security', '*0.02', '*0.08', 500, 300],\n ['Ruthenium Polymer Coating', 'security', '*0.01', '*0.01', 1000, 150],\n ['Oil-Slick Sprayer', 'security', 20, 20, 500, 0],\n ['Ram Plate', 'security', '*0.03', '*0.03', 0, 20],\n ['Drone Rack Mini', 'cargo', 0.5, 1, 100, 0],\n ['Drone Rack Multi Mini', 'cargo', 5, 10, 500, 0],\n ['Drone Rack Small', 'cargo', 20, 25, 500, 0],\n ['Drone Rack Medium', 'cargo', 100, 125, 800, 0],\n ['Drone Rack Large', 'cargo', 250, 300, 1000, 0],\n ['Drone Rack Airborne Small', 'cargo', 10, 25, 750, 0],\n ['Drone Rack Airborne Medium', 'cargo', 50, 125, 1250, 0],\n ['Drone Rack Airborne Large', 'cargo', 100, 250, 2000, 0],\n\n ['Engine Customization I', 'performance', '*0.03', '*0.03', 200, 50],\n ['Engine Customization II', 'performance', '*0.05', '*0.05', 1000, 150],\n ['Improved Economy I', 'performance', '*0.01', '*0.01', 100, 30],\n ['Improved Economy II', 'performance', '*0.015', '*0.01.5', 300, 50],\n ['Handling Upgrade I', 'performance', '*0.02', '*0.02', 200, 100],\n ['Handling Upgrade II', 'performance', '*0.03', '*0.03', 600, 300],\n ['Offroad Suspension', 'performance', '*0.03', '*0.03', 200, 50],\n ['Grapple', 'utility', 10, 10, 500, 0],\n ['Micro Mechanical Arm', 'utility', 0.01, 0.01, 300, 0],\n ['Mini Mechanical Arm', 'utility', 0.1, 0.1, 500, 0],\n ['Small Mechanical Arm', 'utility', 1, 1, 500, 0],\n ['Mechanical Arm', 'utility', 15, 15, 2000, 0],\n ['Rigger Adaption', 'utility', '*0.05', '*0.05', 500, 200],\n ['Nanomaintainance System', 'utility', '*0.02', '*0.02', 2000, 500],\n ['Rigger Cocoon', 'basic', 100, 300, 5000, 0],\n ['Rigger Cocoon II', 'basic', 150, 350, 20000, 0],\n ['Road Strip Ejector', 'security', 5, 5, 300, 0],\n ['Mounted Searchlight', 'security', 10, 30, 1000, 0],\n ['Smoke Projector', 'security', '*0.01', '*0.01', 100, 20],\n ['Smuggling Compartment Small', 'security', 5, 20, 500, 0],\n ['Smuggling Compartment Medium', 'security', 25, 100, 1000, 0],\n ['Smuggling Compartment Large', 'security', 100, 400, 2000, 0],\n\n [\"Small-Arms Micro (0.5kg) Fixed Weapon Mount\", \"weapon\", 0.75, 1.5, 100, 0],\n [\"Small-Arms Light (2kg) Fixed Weapon Mount\", \"weapon\", 3, 6, 150, 0],\n [\"Small-Arms Medium (6kg) Fixed Weapon Mount\", \"weapon\", 9, 18, 200, 0],\n [\"Small-Arms Heavy (15kg) Fixed Weapon Mount\", \"weapon\", 22.5, 45, 300, 0],\n [\"Light (40kg) Fixed Weapon Mount\", \"weapon\", 60, 120, 100, 0],\n [\"Medium (100kg) Fixed Weapon Mount\", \"weapon\", 150, 300, 100, 0],\n [\"Heavy (250kg) Fixed Weapon Mount\", \"weapon\", 375, 750, 100, 0],\n [\"Assault (500kg) Fixed Weapon Mount\", \"weapon\", 750, 1500, 100, 0],\n [\"Tank (1500kg) Fixed Weapon Mount\", \"weapon\", 2250, 4500, 100, 0],\n\n [\"Small-Arms Micro (0.5kg) Turret\", \"weapon\", 1.5, 1.5, 100, 0],\n [\"Small-Arms Light (2kg) Turret\", \"weapon\", 6, 6, 100, 0],\n [\"Small-Arms Medium (6kg) Turret\", \"weapon\", 18, 18, 100, 0],\n [\"Small-Arms Heavy (15kg) Turret\", \"weapon\", 45, 45, 100, 0],\n [\"Light (40kg) Turret\", \"weapon\", 120, 120, 100, 0],\n [\"Medium (100kg) Turrret\", \"weapon\", 300, 300, 100, 0],\n [\"Heavy (250kg) Turret\", \"weapon\", 750, 750, 100, 0],\n [\"Assault (500kg) Turret\", \"weapon\", 1500, 1500, 100, 0],\n [\"Tank (1500kg) Turret\", \"weapon\", 4500, 4500, 100, 0],\n\n [\"Small-Arms Micro (0.5kg) Retracteable Turret\", \"weapon\", 1.5, 3, 100, 0],\n [\"Small-Arms Light (2kg) Retracteable Turret\", \"weapon\", 6, 16, 100, 0],\n [\"Small-Arms Medium (6kg) Retracteable Turret\", \"weapon\", 12, 24, 100, 0],\n [\"Small-Arms Heavy (15kg) Retracteable Turret\", \"weapon\", 45, 90, 100, 0],\n [\"Light (40kg) Retracteable Turret\", \"weapon\", 120, 240, 100, 0],\n [\"Medium (100kg) Retracteable Turrret\", \"weapon\", 300, 600, 100, 0],\n [\"Heavy (250kg) Retracteable Turret\", \"weapon\", 750, 1500, 100, 0],\n [\"Assault (500kg) Retracteable Turret\", \"weapon\", 1500, 3000, 100, 0],\n [\"Tank (1500kg) Retracteable Turret\", \"weapon\", 4500, 9000, 100, 0],\n\n ]\n\nvehicle_upgrades_nt = namedtuple('vehicle_upgrade', ['id'] + vehicle_upgrades[0])\nvehicle_upgrades_dict = OrderedDict([(entry[0], vehicle_upgrades_nt(*([i] + entry))) for i, entry in enumerate(vehicle_upgrades[1:])])\n\n# single automatic minigun\n#5.56 = 12/20 3.5kg 10kg\n#7.62 = 18/30 4.5kg 20kg\n#0.5 = 36/60 12kg 25kg 50kg\n#20mm 120kg\n#25mm 120 kg\n#30mm 250kg\n#105mm 1200kg\n"
}
] | 20 |
heathbm/Misc-Code | https://github.com/heathbm/Misc-Code | be41bfce70ccf24d9febe03a7b8b1126a9834ab8 | 0974bee511530c3a4c31c9f2e3aea5cfe05b233d | aed703fb0a27004ac750552fe42ba92c044fe6cc | refs/heads/master | 2021-01-11T08:41:38.112527 | 2017-02-13T21:00:45 | 2017-02-13T21:00:45 | 76,646,766 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6616314053535461,
"alphanum_fraction": 0.6631419658660889,
"avg_line_length": 19.6875,
"blob_id": "7e8eefb486dd4b9ad3d3480c4942949f8d552f02",
"content_id": "ae4b3ff758d1993b0fe70d555c4fdca8ae6b2ed7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 662,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 32,
"path": "/Algorithms and Data structures/Java/Data Structures/Generic-Queue/GenQueue.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "//generic fixed size queue \npublic class GenQueue<T> implements IGenQ<T> {\n\t\n\tprivate T q[]; // this array holds the queue\n\tprivate int putloc, getloc; // the get and put indices \n\t\n\t// construct an empty queue with the given array\n\tpublic GenQueue(T[] aRef) {\n\t\tq = aRef;\n\t\tputloc = getloc = 0;\n\t}\n\t\n\t//put amn item into the queue \n\tpublic void put(T obj) throws QueueFullException {\n\t\t\n\t\tif(putloc == q.length)\n\t\t\tthrow new QueueFullException(q.length);\n\t\t\n\t\tq[putloc++] = obj;\n\t}\n\t\n\t// get a character from the queue\n\tpublic T get()\n\tthrows QueueEmptyException {\n\t\t\n\t\tif(getloc == putloc)\n\t\t\tthrow new QueueEmptyException();\n\t\t\n\t\treturn q[getloc++];\n\t}\n\t\t\t\n}\n"
},
{
"alpha_fraction": 0.7232704162597656,
"alphanum_fraction": 0.7232704162597656,
"avg_line_length": 21.714284896850586,
"blob_id": "631532f2a3d24fb8c0db1d01f925b6ca1c3d9612",
"content_id": "0132749c355e595c1d8b91a5df87e0c5010084ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 159,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 7,
"path": "/Algorithms and Data structures/Java/Data Structures/Generic-Queue/QueueEmptyException.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "// an exception for queue empty errors \npublic class QueueEmptyException extends Exception {\t\n\t\n\tpublic String toString() {\n\t\treturn \"\\nQueue is empty.\";\n\t}\n}\n"
},
{
"alpha_fraction": 0.7606837749481201,
"alphanum_fraction": 0.7606837749481201,
"avg_line_length": 38,
"blob_id": "fcfb941f95339d5c081cab7c3d2dd2f38ae10f18",
"content_id": "c50ba617a64cb920b71b64fb22c4d7426c0dd640",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 117,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 3,
"path": "/README.md",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "# Misc-Code\n\nA library of useful code snippets (Sorting algorithms, Data structures, ADTs, Concurrency, GUI apps...)\n"
},
{
"alpha_fraction": 0.6157137751579285,
"alphanum_fraction": 0.6165696382522583,
"avg_line_length": 18.091503143310547,
"blob_id": "73fe4a5bbc4388492b3be5ab3e3c0fa4445eb102",
"content_id": "4742e1c02fb3110d117c412f798a021ace24df1b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5842,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 306,
"path": "/Algorithms and Data structures/Java/Data Structures/Binary_Search_Tree/Bst.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "public class Bst {\n\n\tNode root;\n\t\n\tBst(){\n\t\troot = null;\n\t}\n\t\n\tpublic void insert(int key, String data) {\n\t\t\n\t\tNode newNode = new Node(key, data);\n\t\tif(root == null){\n\t\t\troot = newNode;\n\t\t\treturn;\n\t\t}\n\t\t\n\t\tNode current = root;\n\t\tNode parent = null;\n\t\t\n\t\twhile(true) {\n\t\t\t\n\t\t\tparent = current;\n\t\t\tif(key < current.getKey()) {\t\t\t\t\n\t\t\t\tcurrent = current.left;\n\t\t\t\tif(current == null) {\n\t\t\t\t\tparent.left = newNode;\n\t\t\t\t\treturn;\n\t\t\t\t}\n\t\t\t\t\n\t\t\t} else if (key > current.getKey()) {\n\t\t\t\t\n\t\t\t\tcurrent = current.right;\n\t\t\t\tif(current == null) {\n\t\t\t\t\tparent.right = newNode;\n\t\t\t\t\treturn;\n\t\t\t\t}\n\t\t\t\t\n\t\t\t} else { // Stopped duplicate data\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t}\n\t\n\n\tpublic boolean isKeyPresent(int key) {\n\t\tNode currentNode = root;\n\t\t\n\t\twhile(currentNode != null) {\n\t\t\tif(key == currentNode.getKey()) {\n\t\t\t\treturn true;\n\t\t\t} else if(key > currentNode.getKey()) {\n\t\t\t\tcurrentNode = currentNode.right;\n\t\t\t} else if(key < currentNode.getKey()) {\n\t\t\t\tcurrentNode = currentNode.left;\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn false;\n\t}\n\t\n\tpublic String getDataForKey(int key) {\n\t\tNode currentNode = root;\n\t\t\n\t\twhile(currentNode != null) {\n\t\t\tif(key == currentNode.getKey()) {\n\t\t\t\treturn currentNode.getData();\n\t\t\t} else if(key > currentNode.getKey()) {\n\t\t\t\tcurrentNode = currentNode.right;\n\t\t\t} else if(key < currentNode.getKey()) {\n\t\t\t\tcurrentNode = currentNode.left;\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn \"KEY NOT FOUND\";\n\t}\n\t\n\tpublic boolean deleteKey(int key) {\n\t\tNode parent = root;\n\t\tNode current = root;\n\t\tboolean isLeftChild = false;\n\t\t\n\t\twhile(key != current.getKey()) {\n\t\t\tparent = current;\n\t\t\tif(key < current.getKey()) {\n\t\t\t\tisLeftChild = true;\n\t\t\t\tcurrent = current.left;\n\t\t\t} else {\n\t\t\t\tisLeftChild = false;\n\t\t\t\tcurrent = current.right;\n\t\t\t}\n\t\t\t\n\t\t\tif(current ==null){\n\t\t\t\treturn false;\n\t\t\t}\n\t\t}\n\t\t\n\t\t//if i am here that means we have found the node\n\t\t//Case 1: if node to be deleted has no children\n\t\t\n\t\tif(current.left == null && current.right == null) {\n\t\t\tif(current == root) {\n\t\t\t\troot = null;\n\t\t\t}\n\t\t\t\n\t\t\tif(isLeftChild ==true){\n\t\t\t\tparent.left = null;\n\t\t\t} else {\n\t\t\t\tparent.right = null;\n\t\t\t}\n\t\t}\n\t\t\n\t\t//Case 2 : if node to be deleted has only one child\n\t\telse if(current.right == null) {\n\t\t\tif(current == root) {\n\t\t\t\troot = current.left;\n\t\t\t} else if(isLeftChild) {\n\t\t\t\tparent.left = current.left;\n\t\t\t} else { \n\t\t\t\tparent.right = current.left;\n\t\t\t}\n\t\t}\n\t\t\n\t\telse if(current.left == null) {\n\t\t\tif(current == root){\n\t\t\t\troot = current.right;\n\t\t\t} else if(isLeftChild) {\n\t\t\t\tparent.left = current.right;\n\t\t\t} else{\n\t\t\t\tparent.right = current.right;\n\t\t\t}\n\t\t\t\n\t\t//Case 3 : if node has left and right children\t\n\t\t} else if(current.left != null && current.right != null) {\n\t\t\t\n\t\t\t//now we have found the minimum element in the right sub tree\n\t\t\tNode successor = getSuccessor(current);\n\t\t\tif(current == root) {\n\t\t\t\troot = successor;\n\t\t\t} else if(isLeftChild) {\n\t\t\t\tparent.left = successor;\n\t\t\t} else {\n\t\t\t\tparent.right = successor;\n\t\t\t}\t\t\t\n\t\t\tsuccessor.left = current.left;\n\t\t}\t\t\n\t\treturn true;\t\t\n\t}\n\t\n\tpublic Node getSuccessor(Node deleleNode) {\n\t\tNode successsor = null;\n\t\tNode successsorParent = null;\n\t\tNode current = deleleNode.right;\n\t\t\n\t\twhile(current != null) {\n\t\t\tsuccesssorParent = successsor;\n\t\t\tsuccesssor = current;\n\t\t\tcurrent = current.left;\n\t\t}\n\t\t\n\t\t//check if successor has the right child, it cannot have left child for sure\n\t\t// if it does have the right child, add it to the left of successorParent.\n\t\t// successsorParent\n\t\tif(successsor != deleleNode.right) {\n\t\t\tsuccesssorParent.left = successsor.right;\n\t\t\tsuccesssor.right = deleleNode.right;\n\t\t}\n\t\treturn successsor;\n\t}\n\t\n\t// Min and max keys and data\n\t\n\tpublic int getMin() {\n\t\tif(root == null) {\n\t\t\treturn -1;\n\t\t}\n\t\t\n\t\tNode currentNode = root;\n\t\t\n\t\twhile(currentNode.left != null) {\n\t\t\tcurrentNode = currentNode.left;\n\t\t}\n\t\t\n\t\treturn currentNode.getKey();\n\t}\n\t\n\tpublic int getMax() {\n\t\tif(root == null) {\n\t\t\treturn -1;\n\t\t}\n\t\t\n\t\tNode currentNode = root;\n\t\t\n\t\twhile(currentNode.right != null) {\n\t\t\tcurrentNode = currentNode.right;\n\t\t}\n\t\t\n\t\treturn currentNode.getKey();\n\t}\n\t\n\t// display order of data\n\t\n\tpublic void dataInOrder(){\n\t\tdataInOrder(root);\n\t\tSystem.out.println(\"\");\n\t}\n\t\n\tprivate void dataInOrder(Node root) {\n\t\tif(root!=null) {\n\t\t\tdataInOrder(root.left);\n\t\t\tSystem.out.print(\" \" + root.getData());\n\t\t\tdataInOrder(root.right);\n\t\t}\n\t}\n\t\n\tpublic void dataPreOrder() {\n\t\tdataPreOrder(root);\n\t\tSystem.out.println(\"\");\n\t}\n\t\n\tprivate void dataPreOrder(Node root) {\n\t\tif(root!=null) {\n\t\t\tSystem.out.print(\" \" + root.getData());\n\t\t\tdataPreOrder(root.left);\n\t\t\tdataPreOrder(root.right);\n\t\t}\n\t}\n\t\n\tpublic void dataPostOrder() {\n\t\tdataPostOrder(root);\n\t\tSystem.out.println(\"\");\n\t}\n\t\n\tprivate void dataPostOrder(Node root) {\n\t\tif(root!=null) {\n\t\t\tdataPostOrder(root.left);\n\t\t\tdataPostOrder(root.right);\n\t\t\tSystem.out.print(\" \" + root.getData());\n\t\t}\n\t}\n\t\n\t// display order of keys\n\t\n\tpublic void keysInOrder(){\n\t\tkeysInOrder(root);\n\t\tSystem.out.println(\"\");\n\t}\n\t\n\tprivate void keysInOrder(Node root) {\n\t\tif(root!=null) {\n\t\t\tkeysInOrder(root.left);\n\t\t\tSystem.out.print(\" \" + root.getKey());\n\t\t\tkeysInOrder(root.right);\n\t\t}\n\t}\n\t\n\tpublic void keysPreOrder() {\n\t\tkeysPreOrder(root);\n\t\tSystem.out.println(\"\");\n\t}\n\t\n\tprivate void keysPreOrder(Node root) {\n\t\tif(root!=null) {\n\t\t\tSystem.out.print(\" \" + root.getKey());\n\t\t\tkeysPreOrder(root.left);\n\t\t\tkeysPreOrder(root.right);\n\t\t}\n\t}\n\t\n\tpublic void keysPostOrder() {\n\t\tkeysPostOrder(root);\n\t\tSystem.out.println(\"\");\n\t}\n\t\n\tprivate void keysPostOrder(Node root) {\n\t\tif(root!=null) {\n\t\t\tkeysPostOrder(root.left);\n\t\t\tkeysPostOrder(root.right);\n\t\t\tSystem.out.print(\" \" + root.getKey());\n\t\t}\n\t}\n\t\n}\n\nclass Node {\n\t\n\tprivate int key;\n\tprivate String data;\n\tNode left;\n\tNode right;\t\n\t\n\tNode(int key, String data){\n\t\tthis.key = key;\n\t\tthis.data = data;\n\t\tleft = null;\n\t\tright = null;\n\t}\n\t\n\tpublic int getKey() {\n\t\treturn key;\n\t}\n\t\n\tpublic String getData() {\n\t\treturn data;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5520833134651184,
"alphanum_fraction": 0.5677083134651184,
"avg_line_length": 16.066667556762695,
"blob_id": "45fbc174c45a3f724f657eec81f5ded5490572a1",
"content_id": "2bf37e5d67e21214e5e6588daf2421323be6544f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 768,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 45,
"path": "/Basics/Java/Generics-Method2/Core.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "public class Core {\n\t\n\t// void method\n\tpublic static <T> void methodName (T i) {\n\tSystem.out.println(i);\n}\n\t\n\t//return method |this T is the return type\n\tpublic static <T extends Comparable<T>> T max(T a, T b, T c) {\n\t\tT m = a;\n\t\t\n\t\tif(b.compareTo(m) > 0)\n\t\t\tm = b;\n\t\t\n\t\tif(c.compareTo(m) > 0)\n\t\t\tm = c;\n\t\t\n\t\treturn m;\n\t}\n\t\n\tpublic static void main(String[] args) {\n\t\t\n\t\tint i = 10;\n\t\tdouble d = 2.2;\n\t\tString str = \"Hello\";\n\t\t\n\t\t// method that return void \n\t\t\n\t\tSystem.out.println(\"Void method\\n\");\n\t\t\n\t\tmethodName(i);\n\t\tmethodName(d);\n\t\tmethodName(str);\n\t\t\n\t\t\n\t\t// method that return generic data\n\t\t\n\t\tSystem.out.println(\"\\nReturn method\");\n\t\t\n\t\tSystem.out.println(max(10, 20, 30));\n\t\t\n\t\tSystem.out.println(max(\"aaa\", \"bbb\", \"ccc\"));\n\t\t\n\t}\n}\n"
},
{
"alpha_fraction": 0.5869565010070801,
"alphanum_fraction": 0.6005434989929199,
"avg_line_length": 22.365079879760742,
"blob_id": "1c34055e7ddcbd5b0553cdcf1c6151a80de30592",
"content_id": "78f1c78f92b5571726f378d2635df8cdb02b38b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1472,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 63,
"path": "/Algorithms and Data structures/Java/Data Structures/Generic-Queue/GenQDemo.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "//demonstrate a generic queue class \npublic class GenQDemo {\n\tpublic static void main(String[] args) {\n\t\t\n\t\t//create an integer queue\n\t\t\n\t\tInteger iStore[] = new Integer[10];\n\t\tGenQueue<Integer> q = new GenQueue<Integer>(iStore);\n\t\t\n\t\tInteger iVal;\n\t\t\n\t\tSystem.out.println(\"Demonstrate a queue of Integers.\");\n\t\ttry {\n\t\t\tfor(int i = 0; i < 5; i++) {\n\t\t\t\tSystem.out.println(\"Adding \" + i + \" to q.\");\n\t\t\t\tq.put(i); // add integer value to q\n\t\t\t}\n\t\t} catch (QueueFullException exc) {\n\t\t\tSystem.out.println(exc);\n\t\t}\n\t\tSystem.out.println();\n\t\t\n\t\ttry {\n\t\t\tfor(int i = 0; i < 5; i++) {\n\t\t\t\tSystem.out.println(\"Getting next Integer from q: \");\n\t\t\t\tiVal = q.get();\n\t\t\t\tSystem.out.println(iVal);\n\t\t\t}\n\t\t} catch (QueueEmptyException exc){\n\t\t\tSystem.out.println(exc);\n\t\t}\n\t\t\n\t\tSystem.out.println();\n\t\t\n\t\t// create a double queue\n\t\tDouble dStore[] = new Double[10];\n\t\tGenQueue<Double> q2 = new GenQueue<Double>(dStore);\n\t\t\n\t\tDouble dVal;\n\t\t\n\t\tSystem.out.println(\"Demonstrate a queue of Doubles.\");\n\t\ttry {\n\t\t\tfor(int i = 0; i < 5; i++) {\n\t\t\t\tSystem.out.println(\"Adding \" + (double) i/2 + \" to q2.\");\n\t\t\t\tq2.put((double)i/2); // add double value to q2\n\t\t\t}\n\t\t} catch(QueueFullException exc) {\n\t\t\tSystem.out.println(exc);\n\t\t}\n\t\t\n\t\tSystem.out.println();\n\t\t\n\t\ttry {\n\t\t\tfor(int i = 0; i < 5; i++) {\n\t\t\t\tSystem.out.println(\"Getting next double from q2: \");\n\t\t\t\tdVal = q2.get();\n\t\t\t\tSystem.out.println(dVal);\n\t\t\t}\n\t\t} catch (QueueEmptyException exc) {\n\t\t\tSystem.out.println(exc);\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.6877636909484863,
"alphanum_fraction": 0.6877636909484863,
"avg_line_length": 17.230770111083984,
"blob_id": "6b5a986782f7b8bd425a2444c1a690587215c30c",
"content_id": "9dd945451e1fd20907fabbbd47b276dc815f22dc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 237,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 13,
"path": "/Algorithms and Data structures/Java/Data Structures/Generic-Queue/QueueFullException.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "// an exception for queue-full errors\npublic class QueueFullException extends Exception {\n\t\n\tint size;\n\t\n\tQueueFullException(int s) {\n\t\tsize = s;\n\t}\n\t\n\tpublic String toString() {\n\t\treturn \"\\nQueue is full. Maximum size is \" + size;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6183673739433289,
"alphanum_fraction": 0.6530612111091614,
"avg_line_length": 15.931034088134766,
"blob_id": "1019925e47c24c3f18a229e46b2c75cbdc4ff888",
"content_id": "aa5159959a375b651a507a841ef99553a206eb75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 490,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 29,
"path": "/Concurrency/Java/TrafficLight-With_ENums/App.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "// Enumeration of the colors of a traffic light\nenum TrafficLightColor {\n\tRED(3200), GREEN(2000), YELLOW(500);\n\t\n\tprivate int delay;\n\t\n\tTrafficLightColor(int t) {\n\t\tdelay = t;\n\t}\n\t\n\tint getDelay() {\n\t\treturn delay;\n\t}\n}\n\npublic class App {\n\tpublic static void main(String[] args) {\n\t\t\n\t\tTrafficLightSimulator t1 = new TrafficLightSimulator(TrafficLightColor.GREEN);\n\t\t\n\t\tfor(int i = 0; i < 9; i++) {\n\t\t\tSystem.out.println(t1.getColor());\n\t\t\tt1.waitForChange();\n\t\t}\n\t\t\n\t\tt1.cancel();\n\t\t\n\t}\n}"
},
{
"alpha_fraction": 0.4278438091278076,
"alphanum_fraction": 0.47198641300201416,
"avg_line_length": 19.814815521240234,
"blob_id": "a195fda6338d233bc00f01a115fd2d9e863ffa06",
"content_id": "29d287b64f67d901bdfbac838399b4c5f954adc2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 589,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 27,
"path": "/Algorithms and Data structures/Java/Algorithms/BinaryShift/ShiftDemo.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "public class ShiftDemo {\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\tint val = 1;\r\n\t\t\r\n\t\tfor(int i = 0; i < 9; i++){\r\n\t\t\tfor(int t = 256; t > 0;t = t/2){\r\n\t\t\t\tif((val & t) != 0) System.out.print(\"1 \");\r\n\t\t\t\telse System.out.print(\"0 \");\t\t\r\n\t\t\t}\r\n\t\t\tSystem.out.println();\r\n\t\t\tval = val << 1; // left shift\r\n\t\t}\r\n\t\tSystem.out.println();\r\n\t\t\r\n\t\tval = 128;\r\n\t\tfor(int i = 0; i < 8; i++){\r\n\t\t\tfor(int t = 128; t > 0; t = t/2){\r\n\t\t\t\tif((val & t) != 0) System.out.print(\"1 \");\r\n\t\t\t\telse System.out.print(\"0 \");\r\n\t\t\t}\r\n\t\t\tSystem.out.println();\r\n\t\t\tval = val >> 1; // right shift\r\n\t\t}\r\n\t}\r\n\r\n}\r\n"
},
{
"alpha_fraction": 0.6044260263442993,
"alphanum_fraction": 0.6210235357284546,
"avg_line_length": 21.59375,
"blob_id": "dd31d195c5bbbf48bbd0ba36cd216d494cf12a61",
"content_id": "469dd21df290f6a0d2c31b3164f3218a3df99d01",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 723,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 32,
"path": "/Basics/Java/Lambda-Blocks/BlockLambdaDemo.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "//a block lambda that finds the smallest positive factors of an int\n\ninterface NumericFunc {\n\tint func(int n);\n}\n\npublic class BlockLambdaDemo {\n\tpublic static void main(String[] args) {\n\t\t\n\t\t// this block lambda returns the smallest positive factor of a value \n\t\tNumericFunc smallestF = (n) -> {\n\t\t\n\t\tint result = 1;\n\t\t\n\t\t// get an absolute value of n\n\t\tSystem.out.println(n);\n\t\tn = n < 0 ? -n : n; // this is pointless here\n\t\tSystem.out.println(n);\n\t\t\n\t\tfor(int i = 2; i < n/i; i++) \n\t\t\tif((n % i) == 0) {\n\t\t\t result = i;\n\t\t\t break;\n\t\t\t}\n\t\t\n\t\treturn result;\n\t\t};\n\t\t\n\t\tSystem.out.println(\"Smallest factor of 12 is \" + smallestF.func(12));\n\t\tSystem.out.println(\"Smallest factor of 11 is \" + smallestF.func(11));\n\t}\n}\n"
},
{
"alpha_fraction": 0.7219512462615967,
"alphanum_fraction": 0.7219512462615967,
"avg_line_length": 21.77777862548828,
"blob_id": "dca84f91642cdbcecc2e79e5510f24d9c6009083",
"content_id": "60edb540f0d3bd48285f8a310b93f5178c819b1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 205,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 9,
"path": "/Algorithms and Data structures/Java/Data Structures/Generic-Queue/IGenQ.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "//a generic queue interface\npublic interface IGenQ<T> {\n\t// put an item in to the queue\n\t\n\tvoid put(T ch) throws QueueFullException;\n\t\n\t// get an item from the queue\n\tT get() throws QueueEmptyException;\n}\n"
},
{
"alpha_fraction": 0.6478617191314697,
"alphanum_fraction": 0.6669699549674988,
"avg_line_length": 28.70270347595215,
"blob_id": "f55d1d84d84e5d76b673b583c5328cd5333d96bd",
"content_id": "f53d66f3c214c94e7d34a8bb26bf1124f3af099f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1099,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 37,
"path": "/Basics/Java/Lambda-Generic-Functional-Interface/GenericFuctionalInterfaceDemo.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "//use a generic fuctional interface\n\n// a generic functional interface with two parameters that returns a boolean result\ninterface SomeTest <T> {\n\tboolean test(T n, T m);\n}\n\npublic class GenericFuctionalInterfaceDemo {\n\tpublic static void main(String[] args) {\n\t\t\n\t\t//this lambda expression determines if one integer is a factor of another\n\t\tSomeTest<Integer> isFactor = (n, d) -> (n % d) == 0;\n\t\t\n\t\tif(isFactor.test(10,2))\n\t\t\tSystem.out.println(\"2 is a factor of 10\");\n\t\tSystem.out.println();\n\t\t\n\t\t// the next lambda expression determines if one Double is a factor of another\n\t\tSomeTest<Double> isFactorD = (n, d) -> (n % d) == 0;\n\t\t\n\t\tif(isFactorD.test(212.0, 4.0))\n\t\t\tSystem.out.println(\"4.0 is a factor of 212.0\");\n\t\tSystem.out.println();\n\t\t\n\t\t// this lambda determines if one string is part of another \n\t\tSomeTest<String> isIn = (a, b) -> a.indexOf(b) != -1;\n\t\t\n\t\tString str = \"Generic Functional Interface\";\n\t\t\n\t\tSystem.out.println(\"Testing string: \" + str);\n\t\t\n\t\tif(isIn.test(str, \"face\"))\n\t\t\tSystem.out.println(\"'face' is found.\");\n\t\telse\n\t\t\tSystem.out.println(\"'face' is not found.\");\n\t}\n}\n"
},
{
"alpha_fraction": 0.44536083936691284,
"alphanum_fraction": 0.4886597990989685,
"avg_line_length": 22.25,
"blob_id": "31b9c5f46976e3e1fcdc119f35de0c98e52d78cf",
"content_id": "34ae1fbde235c9f6d057bb6eeff9331c87f8bab2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 970,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 40,
"path": "/Algorithms and Data structures/Java/Sorting/BubbleSort/Bubble.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "public class Bubble {\r\n\tpublic static void main(String args[]){\r\n\t\t\r\n\t\tint nums[] = { 99, -10, 100123, 18, -978, 5623, 463, -9, 287, 49};\r\n\t\t\r\n\t\t//display original array\r\n\t\tSystem.out.print(\"Original array is:\");\r\n\t\tfor(int i = 0; i < nums.length; i++)\r\n\t\t\tSystem.out.println(\" \" + nums[i]);\r\n\t\tSystem.out.println();\r\n\t\t\t\t\r\n\t\tint swaps = -1;\r\n\t\t\r\n\t\t//This is bubble sort\r\n\t\twhile(swaps != 0) {\r\n\t\t\t\r\n\t\t\tswaps = 0;\r\n\t\t\t\r\n\t\t\tfor(int j = 0; j < nums.length - 1; j++) {\r\n\t\t\t\r\n\t\t\t\tSystem.out.println(\"at: \" + j + \" Is \" + nums[j] + \" > \" + nums[j+1] + \r\n\t\t\t\t\t\t\" at: \" + (j+1) + \" \" + (nums[j]>nums[j+1]));\r\n\t\t\t\t\r\n\t\t\t\tif(nums[j] > nums[j+1]) { // compare adjacent pairs\r\n\t\t\t\t\tswaps += 1;\r\n\t\t\t\t\tint temp = nums[j+1];\r\n\t\t\t\t\tnums[j+1] = nums[j];\r\n\t\t\t\t\tnums[j] = temp;\r\n\t\t\t\t}\r\n\t\t\t\t\r\n\t\t\t}\r\n\t\t}\r\n\t\t\r\n\t\t//display sorted array\r\n\t\tSystem.out.println(\"Sorted array is:\");\r\n\t\tfor(int i = 0; i < nums.length; i++)\r\n\t\t\tSystem.out.println(\" \" + nums[i]);\r\n\t\tSystem.out.println();\r\n\t}\r\n}\r\n"
},
{
"alpha_fraction": 0.6588835716247559,
"alphanum_fraction": 0.6666151285171509,
"avg_line_length": 27.870534896850586,
"blob_id": "cf31dc59624026a9777a38c96dd6afac27a324c9",
"content_id": "252e0fe105085a5c22e0bac70fdc7fa82cd9b491",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6467,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 224,
"path": "/GUI/JavaFX-DesktopApp/src/application/mainPageCOntroller.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "package application;\n\nimport java.net.URL;\nimport java.text.DecimalFormat;\nimport java.util.ResourceBundle;\n\nimport javafx.application.Platform;\nimport javafx.beans.value.ChangeListener;\nimport javafx.beans.value.ObservableValue;\nimport javafx.collections.FXCollections;\nimport javafx.collections.ObservableList;\nimport javafx.fxml.FXML;\nimport javafx.fxml.Initializable;\nimport javafx.scene.control.Label;\nimport javafx.scene.control.ListView;\nimport javafx.scene.control.MultipleSelectionModel;\nimport javafx.scene.control.TextField;\nimport javafx.scene.control.Toggle;\nimport javafx.scene.control.ToggleButton;\nimport javafx.scene.control.ToggleGroup;\nimport javafx.scene.layout.AnchorPane;\n\npublic class mainPageCOntroller implements Initializable {\n\n\tboolean calcStarted = false;\n\tString time = \"Seconds\";\n\tint timeValue = 1;\n\tboolean distanceType = true; // true = km false = miles\n\tdouble distTypeValue = 340.29;\n\tString Distance = \"KM\";\n\tint divider = 1000;\n\tboolean distError = false;\n\tboolean timeError = false;\n\t\n\t@FXML\n\tprivate Label response;\n\t@FXML\n\tprivate ListView<String> listView;\n\t@FXML\n\tprivate Label shortAnswer;\n\t@FXML\n\tprivate Label longAnswer;\n\t@FXML\n\tprivate TextField timeInput;\n\t@FXML \n\tprivate AnchorPane speedOfSound;\n\t@FXML \n\tprivate AnchorPane temperatureConversion;\n\t@FXML\n\tprivate Label longAnswer1;\n\t@FXML\n\tprivate Label shortAnswer1;\n\t@FXML\n\tprivate TextField celsuis;\n\t@FXML\n\tprivate ToggleButton secondsToggle;\n\t@FXML\n\tprivate ToggleButton minutesToggle;\n\t@FXML\n\tprivate ToggleButton hoursToggle;\n\t@FXML\n\tprivate ToggleButton kmToggle;\n\t@FXML\n\tprivate ToggleButton milesToggle;\n\t\n\tToggleGroup groupTime = new ToggleGroup();\n\n\tpublic void distancemeth() {\n\t\t\n\t\t\ttry {\n\t\t\t\tif(groupTime.getSelectedToggle().equals(kmToggle)) {\n\t\t\t\t\tif(distError = true) {\n\t\t\t\t\t\tdistError = false;\n\t\t\t\t\t\tif(calcStarted == true) {\n\t\t\t\t\t\t\tcalcSpeedOfSound(); } else {\n\t\t\t\t\t\t\t\tlongAnswer.setText(\"Enter the amount of time to calculate the distance\");\n\t\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\tDistance = \"KM\";\n\t\t\t\t\tdistTypeValue = 340.29;\n\t\t\t\t\tdivider = 1000;\n\t\t\t\t\tif(calcStarted == true)\n\t\t\t\t\t\tcalcSpeedOfSound();\n\t\t\t\t } else if(groupTime.getSelectedToggle().equals(milesToggle)) {\n\t\t\t\t\t if(distError = true) {\n\t\t\t\t\t\t\tdistError = false;\n\t\t\t\t\t\t\tif(calcStarted == true) {\n\t\t\t\t\t\t\t\tcalcSpeedOfSound(); } else {\n\t\t\t\t\t\t\t\t\tlongAnswer.setText(\"Enter the amount of time to calculate the distance\");\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t\tDistance = \"Miles\";\n\t\t\t\t\tdistTypeValue = 1116;\n\t\t\t\t\tdivider = 5280;\n\t\t\t\t\tif(calcStarted == true)\n\t\t\t\t\t\tcalcSpeedOfSound();\n\t\t\t\t\t}\n\t\t\t} catch (Exception e) {\n\t\t\t\tdistError = true;\n\t\t\t\tSystem.out.println(\"HBM Exception : NullPointerException at DistanceTypeSelector\");\n\t\t\t\tlongAnswer.setText(\"Please select a distance type\");\n\t\t\t} \n\t\t\t}\n\t\n\tToggleGroup group = new ToggleGroup();\n\t\n\tpublic void timeMeth() {\n\t\t\n\t\ttry {\n\t\t\t if(group.getSelectedToggle().equals(secondsToggle)) {\n\t\t\t \t if(timeError = true) {\n\t\t\t\t\t\t\t\ttimeError = false;\n\t\t\t\t\t\t\t\tif(calcStarted == true) {\n\t\t\t\t\t\t\t\t\tcalcSpeedOfSound(); } else {\n\t\t\t\t\t\t\t\t\t\tlongAnswer.setText(\"Enter the amount of time to calculate the distance\");\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t}\n\t\t\t \t\ttime = \"Seconds\";\n\t\t\t \t\ttimeValue = 1;\n\t\t\t \t\tif(calcStarted == true)\n\t\t\t \t\t\tcalcSpeedOfSound();\n\t\t\t } else if(group.getSelectedToggle().equals(minutesToggle)) {\n\t\t\t \t if(timeError = true) {\n\t\t\t\t\t\t\t\ttimeError = false;\n\t\t\t\t\t\t\t\tif(calcStarted == true) {\n\t\t\t\t\t\t\t\t\tcalcSpeedOfSound(); } else {\n\t\t\t\t\t\t\t\t\t\tlongAnswer.setText(\"Enter the amount of time to calculate the distance\");\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t}\n\t\t\t \t time = \"Minutes\";\n\t\t\t \t\ttimeValue = 60;\n\t\t\t \t\tif(calcStarted == true)\n\t\t\t \t\t calcSpeedOfSound();\n\t\t\t } else if(group.getSelectedToggle().equals(hoursToggle)) {\n\t\t\t \t if(timeError = true) {\n\t\t\t\t\t\t\t\ttimeError = false;\n\t\t\t\t\t\t\t\tif(calcStarted == true) {\n\t\t\t\t\t\t\t\t\tcalcSpeedOfSound(); } else {\n\t\t\t\t\t\t\t\t\t\tlongAnswer.setText(\"Enter the amount of time to calculate the distance\");\n\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t}\n\t\t\t \t time = \"Hours\";\n\t\t\t \t\ttimeValue = 3600;\n\t\t\t \t\tif(calcStarted == true)\n\t\t\t \t\t calcSpeedOfSound();\n\t\t\t }\n\t\t\t \t \n\t\t} catch (NullPointerException exc) {\n\t\t\ttimeError = true;\n\t\t\tSystem.out.println(\"HBM Exception : NullPointerException at TimeTypeSelector\");\n\t\t\tlongAnswer.setText(\"Please select a time type\");\n\t\t}\n\t}\n\t\n\tpublic void disableOld() {\n\t\tMultipleSelectionModel<String> lvSelModel = listView.getSelectionModel();\n\t\tlvSelModel.selectedItemProperty().addListener((changed, oldVal, newVal) -> {\n\t\t\n switch(oldVal) {\n\t\tcase \"Speed of sound\":\n\t\t\tspeedOfSound.setVisible(false);\n\t\t\tSystem.out.println(\"speed off\");\n\t\t\tbreak;\n\t\tcase \"Temperature conversion\":\n\t\t\ttemperatureConversion.setVisible(false);\n\t\t\tSystem.out.println(\"Temp off\");\n\t\t\tbreak;\n\t\t}\n });\n\t}\n\t\n\tpublic void listSelection() {\t\t\n\t\tString selection = listView.getSelectionModel().getSelectedItem();\n\t\tswitch(selection) {\n\t\tcase \"Speed of sound\":\n\t\t\tdisableOld();\n\t\t\tresponse.setText(\"Speed of sound conversion\");\n\t\t\tspeedOfSound.setVisible(true);\t\n\t\t\tbreak;\n\t\tcase \"Temperature conversion\":\n\t\t\tdisableOld();\n\t\t\tresponse.setText(\"Temperature conversion\");\n\t\t\ttemperatureConversion.setVisible(true);\t\t\n\t\t\tbreak;\n\t\t}\n\t}\n\t\n\tpublic void closeApp() {\n\t\tPlatform.exit();\n\t}\n\t\n\tpublic void calcTemperature() {\n\t\tdouble temp = Double.parseDouble(celsuis.getText());\n\t\tdouble result = (temp * 1.8) + 32;\n\t\tDecimalFormat df = new DecimalFormat(\"0.000\");\n\t\tshortAnswer1.setText(df.format(result) + \" F\");\n\t\tlongAnswer1.setText(temp + \" Celsuis is \" + result + \" fahrenheit\");\n\t}\n\t\n\tpublic void calcSpeedOfSound() {\n\t\tcalcStarted = true;\n\t\tdouble userInput = Double.parseDouble(timeInput.getText());\n\t\tdouble result = ((userInput * timeValue) * distTypeValue) / divider;\n\t\tDecimalFormat df = new DecimalFormat(\"0.000\");\n\t\tshortAnswer.setText(df.format(result) + \" \" + Distance);\n\t\tlongAnswer.setText(\"In \" + userInput + \" \" + time + \", sound will travel \" + df.format(result) + \" \" + Distance);\n\t}\n\t\n\t@Override\n\tpublic void initialize(URL location, ResourceBundle resources) {\n\n\t\tkmToggle.setToggleGroup(groupTime);\n\t\tmilesToggle.setToggleGroup(groupTime);\n\t\tsecondsToggle.setToggleGroup(group);\n\t\tminutesToggle.setToggleGroup(group);\n\t\thoursToggle.setToggleGroup(group);\n\t\t\n\t\tObservableList<String> data = FXCollections.observableArrayList(\n\t\t\"Speed of sound\", \"Temperature conversion\");\n\t\tlistView.setItems(data);\n\t\t\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.4871891438961029,
"alphanum_fraction": 0.5177091360092163,
"avg_line_length": 23.794391632080078,
"blob_id": "8a7b4bae7df36eae8c76e41a6d333168bd9bb3f2",
"content_id": "7e6a412ebde699190ad9df3149e7351efd9db7f0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2654,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 107,
"path": "/Algorithms and Data structures/Java/Sorting/InsertionSort/InsertionSort.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "import java.time.Duration;\nimport java.time.Instant;\n\nclass sort{\n\t\n\tpublic static void insertionSort(int array[]) {\n for (int i = 1; i < array.length; i++) {\n int key = array[i];\n int j = i-1;\n while ( (j > -1) && ( array[j] > key ) ) {\n array[j+1] = array[j];\n j--;\n }\n array[j+1] = key;\n }\n }\n\t\n\tpublic static void insertionSort(char array[]) {\n for (int i = 1; i < array.length; i++) {\n char key = array[i];\n int j = i-1;\n while ( (j > -1) && ( array[j] > key ) ) {\n array[j+1] = array[j];\n j--;\n }\n array[j+1] = key;\n }\n\t}\n\t\n\tpublic static void simpleInsertionSort(int list[]) {\n\t\tfor (int i = 1; i < list.length; i++) {\n\t\t\tint j = i;\n\t\t\twhile(j != 0 && list[j] < list[j-1]) {\n\t\t\t\t\t\t\t\t\n\t\t\t\tint temp = list[j-1];\n\t\t\t\tlist[j-1] = list[j];\n\t\t\t\tlist[j] = temp;\n\t\t\t\t\n\t\t\t\tj--;\n\t\t\t}\n\t\t}\n\t}\n}\n\npublic class InsertionSort {\n\tpublic static void main(String[] args) {\n\t\t\n\t\tint a[] = { 76,4,43,131,566,585,321,13,31,34,5,645,654};\n\t\tchar b[] = { 'f', 'j', 'a', 'r', 'h', 'j', 'w', 'n', 'e', 't', 'z', 'b', 'o'};\n\t\tint c[] = { 76,4,43,131,566,585,321,13,31,34,5,645,654};\n\t\t\n\t\tSystem.out.println(\"Original array: \");\n\t\tfor(int \ti = 0; i < a.length; i++)\n\t\t\tSystem.out.print(a[i] + \",\");\n\t\t\n\t\tSystem.out.println(\"\\n\");\n\t\t\n\t\tInstant startTime = Instant.now();\n\n\t\tsort.insertionSort(a);\n\t\t\n\t\tInstant endTime = Instant.now();\n\t\t\n\t\tSystem.out.println(\"Sorted array: \");\n\t\tfor(int i = 0; i < a.length; i++)\n\t\t\tSystem.out.println(a[i]);\n\t\t\n\t\tSystem.out.println(\"\");\n\t\tSystem.out.println(\"Original array: \");\n\t\tfor(int \ti = 0; i < b.length; i++)\n\t\t\tSystem.out.print(b[i] + \",\");\n\t\t\n\t\tSystem.out.println(\"Time taken: \" + Duration.between(endTime, startTime) + \"\\n\");\n\t\t\t\t\n\t\tstartTime = Instant.now();\n\t\t\n\t\tsort.insertionSort(b);\n\t\t\n\t\tendTime = Instant.now();\n\t\t\n\t\tSystem.out.println(\"Sorted array: \");\n\t\tfor(int i = 0; i < b.length; i++)\n\t\t\tSystem.out.println(b[i]);\n\t\t\n\t\tSystem.out.println(\"Time taken: \" + Duration.between(endTime, startTime));\n\t\t\n\t\tSystem.out.println(\"\");\n\t\tSystem.out.println(\"Original array: \");\n\t\tfor(int i = 0; i < c.length; i++)\n\t\t\tSystem.out.print(c[i] + \",\");\n\t\t\n\t\tSystem.out.println(\"Time taken: \" + Duration.between(endTime, startTime) + \"\\n\");\n\t\t\t\t\n\t\tstartTime = Instant.now();\n\t\t\n\t\tsort.simpleInsertionSort(c);\n\t\t\n\t\tendTime = Instant.now();\n\t\t\n\t\tSystem.out.println(\"Sorted array: \");\n\t\tfor(int i = 0; i < c.length; i++)\n\t\t\tSystem.out.println(c[i]);\n\t\t\n\t\tSystem.out.println(\"Time taken: \" + Duration.between(endTime, startTime));\n\t\t\n\t\t}\n}\n\n"
},
{
"alpha_fraction": 0.5185891389846802,
"alphanum_fraction": 0.5786463022232056,
"avg_line_length": 19.85416603088379,
"blob_id": "bb7088871d494ad5490441cfd2e7c52e39a417ed",
"content_id": "45cca570c417778d3d05d4b1497ca39b36febef7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1049,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 48,
"path": "/Algorithms and Data structures/Java/Algorithms/Integer-To-Binary/ShowBitsDemo.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "class ShowBits {\r\n\tint numbits;\r\n\t\r\n\tShowBits(int n){\r\n\t\tnumbits = n;\r\n\t}\r\n\t\r\n\tvoid show(long val){\r\n\t\tlong mask = 1;\r\n\t\t\r\n\t\t//left-shift a 1 into a proper position \r\n\t\tmask <<= numbits-1;\r\n\t\t\r\n\t\tint spacer = 0;\r\n\t\tfor(;mask != 0; mask >>>=1){\r\n\t\t\tif((val & mask) != 0) System.out.print(\"1\");\r\n\t\t\telse System.out.print(\"0\");\r\n\t\t\tspacer++; //This makes the numbers have a space every 8 digits\r\n\t\t\tif((spacer % 8) == 0) {\r\n\t\t\t\tSystem.out.print(\" \");\r\n\t\t\t\tspacer = 0;\r\n\t\t\t}\r\n\t\t}\r\n\t\tSystem.out.println();\r\n\t}\r\n}\r\n\r\npublic class ShowBitsDemo {\r\n\tpublic static void main(String args []){\r\n\t\t\r\n\t\tShowBits b = new ShowBits(8);\r\n\t\tShowBits i = new ShowBits(32);\r\n\t\tShowBits li = new ShowBits(64);\r\n\t\t\r\n\t\tSystem.out.println(\"123 in binary: \");\r\n\t\tb.show(123);\r\n\t\t\r\n\t\tSystem.out.println(\"\\n87987 in binary: \");\r\n\t\ti.show(87987);\r\n\t\t\r\n\t\tSystem.out.println(\"\\n237658768 in binary: \");\r\n\t\tli.show(237658768);\r\n\t\t\r\n\t\t//you can also show low-order bits of any interger \r\n\t\tSystem.out.println(\"\\nLow order 8 bits of 87987 in binary: \");\r\n\t\tb.show(87987);\r\n\t}\r\n}\r\n"
},
{
"alpha_fraction": 0.6047689914703369,
"alphanum_fraction": 0.6169895529747009,
"avg_line_length": 17.228260040283203,
"blob_id": "e1a845752e22a8b517b4402ea03226f68b20c00b",
"content_id": "aad3d56ab883ec0b0e3fec50e60bcce08e604d62",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3355,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 184,
"path": "/Algorithms and Data structures/Java/Data Structures/LinkedList/LinkedList.java",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "public class LinkedList {\n\t\n\tpublic static void main(String[] args) {\n\t\t\n\t\t List linkedList = new List();\n\t\t \n\t\t linkedList.addAtStart(1);\n\t\t linkedList.addAtStart(2);\n\t\t linkedList.addAtStart(3);\n\t\t linkedList.addAtStart(4);\n\t\t linkedList.addAtStart(5);\n\t\t \n\t\t System.out.println(\"Added 5 values\");\n\t\t linkedList.display();\n\t\t System.out.println(\"\\n\");\n\t\t \n\t\t linkedList.addAtEnd(10);\n\t\t linkedList.addAtEnd(11);\n\t\t linkedList.addAtEnd(12);\n\t\t linkedList.addAtEnd(13);\n\t\t linkedList.addAtEnd(14);\n\t\t linkedList.addAtEnd(15);\n\t\t \n\t\t System.out.println(\"Added 5 more values\");\n\t\t linkedList.display();\n\t\t System.out.println(\"\\n\");\n\t\t \n\t\t System.out.println(\"Deleted index 10\");\n\t\t linkedList.deleteIndex(10);\n\t\t linkedList.display();\n\t\t \n\t\t System.out.println(\"\\n\");\n\t\t System.out.println(\"Is index 9 present: \" + linkedList.findIndex(9));\n\t\t \n\t\t System.out.println();\n\t\t System.out.println(\"Is data value 14 present: \" + linkedList.findData(14));\n\t\t \n\t\t System.out.println();\n\t\t System.out.println(\"Deleted value 14: \" + linkedList.deleteData(14) + \"\\n\");\n\t\t \n\t\t System.out.println(\"Displaying the dataSet\");\n\t\t linkedList.display();\n\t}\n\t\n}\n\nclass Node {\n\tpublic int data;\n\tpublic Node nextNode;\n\t\n\tNode(int newData) {\n\t\tnextNode = null;\n\t\tdata = newData;\n\t}\n}\n\nclass List {\n\t\n\tNode root;\n\tpublic int size = 0;\n\t\n\tList() {\n\t\troot = null;\n\t}\n\t\n\tpublic int getSize() {\n\t\treturn size;\n\t}\n\t\n\tpublic void addAtStart(int newData) {\n\t\tNode tempNode = new Node(newData);\n\t\t\n\t\tif (root == null) {\n\t\t\troot = tempNode;\n\t\t} else {\n\n\t\t\ttempNode.nextNode = root;\n\t\t\troot = tempNode;\n\t\t}\n\t\t\n\t\tsize++;\n\t}\n\t\n\tpublic void addAtEnd(int newData) {\n\t\tNode tempNode = new Node(newData);\n\t\t\n\t\tif (root == null) {\n\t\t\troot = tempNode;\n\t\t} else {\n\n\t\t\tNode parentNode = root;\n\t\t\tfor (int i = 0; i < size - 1; i++) {\n\t\t\t\tparentNode = parentNode.nextNode;\n\t\t\t}\n\n\t\t\tparentNode.nextNode = tempNode;\n\t\t}\n\t\t\n\t\tsize++;\n\t}\n\t\n\tpublic boolean deleteIndex(int index) {\n\t\t\n\t\tif(index > size) {\n\t\t\treturn false;\n\t\t} else if (index == 0) {\n\t\t\troot = root.nextNode;\n\t\t\tsize--;\n\t\t\treturn true;\n\t\t}\n\t\t\n\t\tNode parentNode = null;\n\t\tNode currentNode = root;\n\t\tfor (int i = 0; i < index; i++) {\n\t\t\tparentNode = currentNode;\n\t\t\tcurrentNode = parentNode.nextNode;\n\t\t}\n\t\t\n\t\tif(index == size) {\n\t\t\tparentNode.nextNode = null;\n\t\t} else {\n\t\t\tparentNode.nextNode = currentNode.nextNode;\n\t\t}\n\t\t\n\t\tsize--;\n\t\treturn true;\n\t}\n\t\n\tpublic boolean deleteData(int data) {\n\t\t\n\t\tNode parentNode = null;\n\t\tNode currentNode = root;\n\t\tint i;\n\t\tfor (i = 0; i < size; i++) {\n\t\t\tif(currentNode.data == data) {\n\t\t\t\tbreak;\n\t\t\t}\n\t\t\tparentNode = currentNode;\n\t\t\tcurrentNode = parentNode.nextNode;\n\t\t}\n\t\t\n\t\tif(currentNode == root) {\n\t\t\troot = root.nextNode;\n\t\t\tsize--;\n\t\t\treturn true;\n\t\t}\n\t\t\n\t\tif(currentNode.data != data) {\n\t\t\treturn false;\n\t\t}\n\t\t\n\t\tparentNode.nextNode = currentNode.nextNode;\n\t\t\n\t\tsize--;\n\t\treturn true;\n\t}\n\t\n\tpublic boolean findData(int data) {\n\t\tNode currentNode = root;\n\t\tfor (int i = 0; i < size; i++) {\n\t\t\tif(data == currentNode.data) {\n\t\t\t\treturn true;\n\t\t\t}\n\t\t\tcurrentNode = currentNode.nextNode;\n\t\t}\n\t\treturn false;\n\t}\n\t\n\tpublic boolean findIndex(int index) {\n\t\tif(index <= size) {\n\t\t\treturn true;\n\t\t}\n\t\treturn false;\n\t}\n\t\n\tpublic void display() {\n\t\tNode currentNode = root;\n\t\tfor (int i = 0; i < size; i++) {\n\t\t\tSystem.out.print(currentNode.data + \",\");\n\t\t\tcurrentNode = currentNode.nextNode;\n\t\t}\n\t}\n\t\n}\n\n"
},
{
"alpha_fraction": 0.5840276479721069,
"alphanum_fraction": 0.594391405582428,
"avg_line_length": 31.156862258911133,
"blob_id": "9445dd33c3039ce23f7c3ef77a954df17bf82ad2",
"content_id": "d54d21387933129bf00226a44a3a9a145e0ec184",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4921,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 153,
"path": "/Algorithms and Data structures/Python/Recursive_BinarySearch.py",
"repo_name": "heathbm/Misc-Code",
"src_encoding": "UTF-8",
"text": "# Heath Baron-Morgan\n\nimport random\nimport time\n \ndef linearInsertionSort(aList):\n '''\n Standard insertion sort (using linear search)\n '''\n start = time.time()\n for currentPosition in range(1, len(aList)):\n currentValue = aList[currentPosition]\n position = currentPosition\n while position > 0 and aList[position - 1] > currentValue:\n aList[position] = aList[position - 1]\n position = position - 1\n aList[position] = currentValue\n elapsed = time.time() - start\n print('linearInsertionSort:', len(aList), 'items =', \"%.4f\" % elapsed,\n 'seconds')\n\n\ndef testSortPerformance(sortFunction, noOfSamples):\n print()\n print('Testing sorting performance at different sample sizes')\n print()\n \n sampleSize = 200\n for sample in range(noOfSamples):\n\n # Create an unsorted list of random integers \n testList = []\n for i in range(sampleSize):\n testList.append(random.randrange(0, sampleSize))\n \n sortFunction(testList)\n \n sampleSize = sampleSize * 2 # the next sample has double the size\n\nnoOfSamples = 1\ntestSortPerformance(linearInsertionSort, noOfSamples)\n\n# --------------\n\ndef recursiveBinarySearch(aList, first, last, target):\n assert 0 <= first < len(aList) # Checks if first is valid\n assert last < len(aList) # Checks if last is valid\n assert sorted(aList) == aList # Checks if the list is in assending order\n \n pos = (first + last) // 2 # Aquire new pos\n\n if first > last: # Return appropriate pos in a first and last crossover (DEFENSIVE)\n if aList[pos] > target:\n return pos \n else:\n return pos + 1\n else:\n if aList[pos] == target:\n return pos # Target found, return pos\n elif len(aList[first:last]) == 0: # Target not found, return appropriate pos\n if aList[pos] > target:\n return pos \n else:\n return pos + 1\n else:\n if aList[pos] < target:\n return recursiveBinarySearch(aList, pos+1, last, target) # Target is larger of pos\n else:\n return recursiveBinarySearch(aList, first, pos, target) # Target is smaller than pos\n \n\ndef testBinarySearch(search):\n testList = [2, 8, 17, 42, 79, 85]\n\n listSize = len(testList)\n\n print()\n print('Checking output for values that are present:')\n for i in range(0, listSize):\n target = testList[i]\n foundAt = search(testList, 0, listSize-1, target)\n if foundAt == i:\n print('Found value ', target, ' at index ', foundAt,\n ' as expected')\n else: \n print('Found value ', target, ' at index ', foundAt,\n ' instead of expected value', i)\n\n print()\n print('Checking output for values that are not present:')\n for i in range(0, listSize):\n target = testList[i]+1 # no consecutive integers in test list\n foundAt = search(testList, 0, listSize-1, target)\n if foundAt == i+1:\n print('Searching for value ', target, ' returned index ',\n i+1, ' as expected')\n else: \n print('Searching for value ', target, ' returned index ',\n foundAt, ' instead of expected value', i)\n \n print()\n print('Checking output for value that precedes all present:')\n target = testList[0]-1\n foundAt = search(testList, 0, listSize-1, target)\n if foundAt == 0:\n print('Searching for value ', target, ' returned index ',\n foundAt, ' as expected')\n else: \n print('Searching for value ', target, ' returned index ',\n foundAt, ' instead of expected value 0')\n \nprint()\nprint('Testing recursive binary search')\n\ntestBinarySearch(recursiveBinarySearch)\n\n# --------------\n\ndef iterativeBinarySearch(aList, first, last, target): \n found = False\n \n while first <= last and not found: \n midpoint = (first + last) // 2 \n if aList[midpoint] == target: \n found = True \n else: \n if target < aList[midpoint]: \n last = midpoint-1 \n else: \n first = midpoint+1 \n \n if first > last: # i.e. target not found\n return first\n else:\n return midpoint # i.e. target found\n\n\ndef binaryInsertionSort(aList):\n '''\n Insertion sort (using binary search)\n '''\n start = time.time()\n\n for currentPosition in range(1, len(aList)):\n currentValue = aList[currentPosition]\n position = recursiveBinarySearch(aList[0:currentPosition], 0, currentPosition-1, currentValue)\n aList.pop(currentPosition)\n aList.insert(position, currentValue)\n \n elapsed = time.time() - start\n print('binaryInsertionSort: ', len(aList), 'items =', \"%.4f\" % elapsed,'seconds')\n\ntestSortPerformance(binaryInsertionSort, noOfSamples)\n\n"
}
] | 18 |
samarthraizada/Supervised-and-Unsupervised-ML--Classification-using-Random-Forest | https://github.com/samarthraizada/Supervised-and-Unsupervised-ML--Classification-using-Random-Forest | d4d941c4867b026f5732a97e3f229305589cc271 | d2bde1ecffeb9fdfedf1e724e9d8b275d4bdf29d | 856e279d3a69ad4d649eeb4fe2f292225a2a17b7 | refs/heads/master | 2020-12-22T15:19:32.001252 | 2020-01-28T20:54:13 | 2020-01-28T20:54:13 | 236,838,772 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.8484848737716675,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 98,
"blob_id": "0d6d6e1a67b3ba16450e0187207934e7cffac018",
"content_id": "18556e0767c1d3cb3ba996b67919829537be3aed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 2,
"path": "/README.md",
"repo_name": "samarthraizada/Supervised-and-Unsupervised-ML--Classification-using-Random-Forest",
"src_encoding": "UTF-8",
"text": "# Classification-using-Decision-Tree-and-Ranfdom-Forest-Supervised-and-Unsupervised-ML-\nUsing Decision Trees and Random Forest for classification of labeled and unlabeled data and tuning parameters\n"
},
{
"alpha_fraction": 0.5007385611534119,
"alphanum_fraction": 0.536189079284668,
"avg_line_length": 29.81818199157715,
"blob_id": "84b52478dc311cd44ace382c77c5c978d44d2ab2",
"content_id": "764d98c5e28475c2220490655322a6d454a17582",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 22,
"path": "/utils.py",
"repo_name": "samarthraizada/Supervised-and-Unsupervised-ML--Classification-using-Random-Forest",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\nfrom matplotlib.colors import ListedColormap\n\n\ndef visualize_2d_data(df, h=0.02):\n y = df[\"y\"].values\n x = df.drop(\"y\", axis=1).values\n x_min, x_max = x[:, 0].min() - .5, x[:, 0].max() + .5\n y_min, y_max = x[:, 1].min() - .5, x[:, 1].max() + .5\n xx, yy = np.meshgrid(np.arange(x_min, x_max, h),\n np.arange(y_min, y_max, h))\n\n cm_bright = ListedColormap(['#FF0000', '#0000FF'])\n f = plt.figure()\n plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cm_bright)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n plt.tight_layout()\n ax = f.get_axes()\n return f, ax[0]"
}
] | 2 |
tsmaselyna/GUI-MINI-PROJECT | https://github.com/tsmaselyna/GUI-MINI-PROJECT | c213a68544c81cf30424e8d26bf155b942dbef3f | f48feb2d566b02b88dd46f68866c748a0de89bf4 | 3b7b37b68feb0547eee13facabf86bea231bfcc6 | refs/heads/master | 2022-12-14T05:40:56.210709 | 2020-08-23T17:06:32 | 2020-08-23T17:06:32 | 289,727,722 | 0 | 0 | null | 2020-08-23T16:48:58 | 2020-08-23T14:03:51 | 2020-08-23T14:03:49 | null | [
{
"alpha_fraction": 0.5359891057014465,
"alphanum_fraction": 0.6011015772819519,
"avg_line_length": 27.421730041503906,
"blob_id": "13c32d72b65d0fe5816111bba800eb381efa4655",
"content_id": "a70370453dfd7c10ad6287fceafb4875caae4311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39762,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 1399,
"path": "/Coding.py",
"repo_name": "tsmaselyna/GUI-MINI-PROJECT",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGood luck guys\n\"\"\"\n\n#Assign Variable\nx = 0\nSumGrade = 0\nSumCredit = 0\nCount = int(input(\"Enter Number Of Subject: \"))\n\n#While Loop\nwhile x < Count:\n Subject = input(\"Enter Subject: \")\n Credit = int(input(\"Enter Credit: \"))\n SumCredit = SumCredit + Credit\n Grade = float(input(\"Enter Grade: \"))\n SumGrade = SumGrade + (Grade * Credit)\n\n #Increment\n x +=1\n\n #Formula\n Formula = SumGrade / SumCredit\n\n#Function \ndef Cal_Value(Formula):\n \"This function calculate CGPA by input user\"\n if Formula >= 3.67 and Formula <=4.00: return \"Dean List\"\n elif Formula >= 2.75 and Formula <=3.66: return \"Pass\"\n elif Formula >= 2.00 and Formula <=2.74: return \"Conditional Pass\"\n else : return \"Fail\"\n\n#Output\nprint(\"CGPA is {:0.2f} and Result is {}. Total Credit is {}\".format(Formula,Cal_Value(Formula),SumCredit))\n\n\n\n#Coding Combine With Python tkinter\nimport tkinter as tk\n\n# Assign Tkinter\nwd = tk.Tk()\n\n# Window Size\nwd.geometry(\"850x250\")\n\n# Assign Title\nwd.title(\"MINI PROJECT\")\ntitle1=tk.Label(text=\"CGPA CALCULATOR\",bg=\"#80ff00\")\ntitle1.grid(column=2,row=0)\n\n# Function Grade\ndef Display():\n\n # Declare Objects For Entering Data \n D0 = tk.Entry(wd) # Name\n D1 = tk.Entry(wd) # Matric\n D2 = tk.Entry(wd) # Number Of Subject\n D3 = tk.Entry(wd) # Subject\n D4 = tk.Entry(wd) # Credit\n D5 = tk.Entry(wd) # Grade\n D6 = tk.Entry(wd) # Total Credit // Entry Location\n D7 = tk.Entry(wd) # Total CGPA // Entry Location\n D8 = tk.Entry(wd) # Result // Entry Location\n\n # Assign Variables\n x = 0\n SumGrade = 0\n SumCredit = 0\n Credit = 0\n Grade = 0.00\n while x == D2:\n #Subject = input(\"Enter Subject: \") *D3\n #Credit = int(input(\"Enter Credit: \")) *D4\n #SumCredit = SumCredit + D4\n #Grade = float(input(\"Enter Grade: \")) *D5\n ## SumGrade = SumGrade + (D5 * D4) *Location Entry *D7 ##\n x +=1\n ## Formula = SumGrade / SumCredit *Location Entry ##\n \n # D2 [NUMBER OF SUBJECT]\n if D2.get() == D2 :\n tk.Label(wd, text = D2).grid(row=5, column=4) \n D2 = D2\n \n # D4 [CREDIT]\n if D4.get() == D4 : \n tk.Label(wd, text = SumCredit).grid(row=5, column=4) \n SumCredit = SumCredit + Credit\n\n # D5 [GRADE]\n if D5.get() == \"A\": \n tk.Label(wd, text =4.00).grid(row=5, column=4) \n SumGrade += 4.00\n if D5.get() == \"A-\": \n tk.Label(wd, text =3.75).grid(row=5, column=4) \n SumGrade += 3.75\n if D5.get() == \"B+\": \n tk.Label(wd, text =3.50).grid(row=5, column=4) \n SumGrade += 3.50\n if D5.get() == \"B\": \n tk.Label(wd, text =3.00).grid(row=5, column=4) \n SumGrade += 3.00\n if D5.get() == \"B-\": \n tk.Label(wd, text =2.75).grid(row=5, column=4) \n SumGrade += 2.75\n if D5.get() == \"C+\": \n tk.Label(wd, text =2.50).grid(row=5, column=4) \n SumGrade += 250\n if D5.get() == \"C\": \n tk.Label(wd, text =2.00).grid(row=5, column=4) \n SumGrade += 2.00\n if D5.get() == \"C-\": \n tk.Label(wd, text =1.75).grid(row=5, column=4) \n SumGrade += 1.75\n if D5.get() == \"D\": \n tk.Label(wd, text =1.50).grid(row=5, column=4) \n SumGrade += 1.50\n if D5.get() == \"E\": \n tk.Label(wd, text =1.00).grid(row=5, column=4) \n SumGrade += 1.00\n if D5.get() == \"F\": \n tk.Label(wd, text =0.00).grid(row=5, column=4) \n SumGrade += 0.00\n \n # Label [CREDIT]\n tk.Label(wd, text=\"Credit\").grid(row=3, column=0)\n D4 = tk.Entry(wd).grid(row=3, column=1)\n\n # Label [GRADE]\n tk.Label(wd, text=\"Grade\").grid(row=4, column=0)\n D5 = tk.Entry(wd).grid(row=4, column=1)\n\n # Label [TOTAL CREDIT]\n tk.Label(wd, text=\"Total Credit :\").grid(row=3, column=3)\n tk.Label(wd, text=SumCredit + Credit).grid(row=3, column=4)\n #D6 = tk.Entry(wd).grid(row=3, column=4)\n\n # Label [TOTAL CGPA]\n tk.Label(wd, text=\"Total CGPA :\").grid(row=4, column=3)\n tk.Label(wd, text=SumGrade + Grade).grid(row=4, column=4)\n #D7 = tk.Entry(wd).grid(row=4, column=4)\n\n # Label [RESULT]\n tk.Label(wd, text=\"Result :\").grid(row=5, column=3)\n tk.Label(wd, text=(SumGrade/SumCredit)).grid(row=5, column=4)\n #D8 = tk.Entry(wd).grid(row=5, column=4)\n\n#Function Result\n#def Cal_Value():\n #\"This function calculate CGPA by input user\"\n #if SumGrade/SumCredit >= 3.67 and SumGrade/SumCredit <=4.00: return \"Dean List\"\n #elif SumGrade/SumCredit >= 2.75 and SumGrade/SumCredit <=3.66: return \"Pass\"\n #elif SumGrade/SumCredit >= 2.00 and SumGrade/SumCredit <=2.74: return \"Conditional Pass\"\n #else : return \"Fail\"\n\n# Label [NAME]\ntk.Label(wd, text=\"Name\").grid(row=1, column=0)\nD0 = tk.Entry(wd).grid(row=1, column=1)\n\n# Label [MATRIC]\ntk.Label(wd, text=\"Matric\").grid(row=1, column=3)\nD1 = tk.Entry(wd).grid(row=1, column=4)\n\n# Label [NUMBER OF SUBJECT]\ntk.Label(wd, text=\"Number of Subject\").grid(row=2, column=0)\nD2 = tk.Entry(wd).grid(row=2, column=1)\n\n# Label [BUTTON]\nbutton=tk.Button(wd, text=\"submit\", bg=\"#ffbf00\", command=Display) \nbutton.grid(row=9, column=5)\n\n# Label [BUTTON1]\nbutton1=tk.Button(wd, text=\"Exit\", bg=\"#E74C3C\", command=exit) \nbutton1.grid(row=9, column=7)\n\n# Label [BUTTON2]\n#button2=tk.Button(wd, text=\"Back\", bg=\"#FF00FF\", command=) \n#button2.grid(row=9, column=6)\n\nwd.mainloop()\n\n\n#helmy latest update 3 button with 3windows\nfrom tkinter import*\nimport tkinter.messagebox\nfrom tkinter import ttk\nimport random\nimport time\nimport datetime\n\ndef main():\n root = Tk()\n application=Rental_Inventory(root)\n root.mainloop()\n\n#blank windows 1\nclass Window1:\n def __init__ (self,master):\n self.master.title(\"CGPA Calculator\")\n self.master.geometry(\"1350x750+0+0\")\n self.master.config(bg=\"powder blue\")\n self.frame = Frame(self.master, bg=\"powder blue\")\n self.frame.pack()\n\n#3 buttons \n self.btnLogin = Button(self.frame,text =\"login\", width =17, command =self.new_windows)\n self.btnlogin.grid(row=3,column=0)\n\n self.btnReset = Button(self.frame,text =\"login\", width =17, command =self.new_windows)\n self.btnReset.grid(row=3,column=0)\n\n self.btnExit = Button(self.frame,text =\"login\", width =17, command =self.new_windows)\n self.btnExit.grid(row=3,column=0)\n\n def new_window(self):\n self.newWindow = Toplevel(self.master)\n self.app = Window2(self.newWindow)\n\n\nclass Window2:\n def __init__ (self,master):\n self.master.title(\"CGPA Calculator\")\n self.master.geometry(\"1350x750+0+0\")\n self.master.config(bg=\"cadet blue\")\n self.frame = Frame(self.master, bg=\"powder blue\")\n self.frame.pack()\n\nif __name__ == \"_main_\":\n main()\n\n\n#latest update 19/8/20 at 4.14 P.M.\n#by helmy\n\n#from tkinter import*\nimport tkinter as tk\nimport tkinter.messagebox \n#from tkinter import tk\n\n\ndef main ():\n root =tk.Tk()\n app = Window1(root)\n #application = Rental_Inventory(root)\n #root.mainloop()\n\n \n \n#blank windows 1\nclass Window1:\n def __init__ (self, master):\n self.master = master\n self.master.title(\"MINI PROJECT\")\n self.master.geometry(\"1350x750+0+0\")\n self.master.config(bg=\"powder blue\")\n self.frame = tk.Frame(self.master, bg=\"powder blue\")\n self.frame.pack()\n\n#2 buttons will pop up\n# buttons about us and cgpa calculator\n\n self.lblTitle = tk.Label(self.frame, text= \" WELCOME TO CGPA CALCULATOR\", font=(\"arial\",50,\"bold\"), bg=\"powder blue\", fg=\"black\")\n self.lblTitle.grid(row=0, columnspan=3, pady=40)\n\n\n self.btncgpa = tk.Button(self.frame,text =\"CGPA CALCULATOR\", width =17, command =self.new_window2)\n self.btncgpa.grid(row=2,column=1)\n \n def new_window2(self):\n self.newWindow = tk.Toplevel(self.master)\n self.app = Window2(self.newWindow)\n\n#this windows will be open if the button click\nclass Window2:\n def __init__ (self, master):\n self.master = master\n self.master.title(\"MINI PROJECT\")\n self.master.geometry(\"1350x750+0+0\")\n self.master.config(bg=\"cadet blue\")\n self.frame = tk.Frame(self.master, bg=\"powder blue\") \n self.frame.pack()\n\n\n\n\n#suspect this is might be the error\nif __name__ == \"__main__\":\n\n main()\n\n\n\n#Calculate Credit Code 19/8/2020 @ 5:01 PM\nfrom tkinter import *\n \ndef cal_credit():\n res=int(r9.get())+int(r10.get())+int(r11.get())+int(r12.get())+int(r13.get())\n count.set(res)\n \nwindow = Tk()\ncount=StringVar();\nLabel(window, text=\"Credit Input 1\").grid(row=0, column=0)\nLabel(window, text=\"Credit Input 2\").grid(row=1, column=0)\nLabel(window, text=\"Credit Input 3\").grid(row=2, column=0)\nLabel(window, text=\"Credit Input 4\").grid(row=3, column=0)\nLabel(window, text=\"Credit Input 5\").grid(row=4, column=0)\nLabel(window, text=\"Total Credit: \").grid(row=5, column=0)\nresult=Label(window, text=\"\", textvariable=count).grid(row=6, column=0)\n \nr9 = Entry(window)\nr10 = Entry(window)\nr11 = Entry(window)\nr12 = Entry(window)\nr13 = Entry(window)\n \nr9.grid(row=0, column=1)\nr10.grid(row=1, column=1)\nr11.grid(row=2, column=1)\nr12.grid(row=3, column=1)\nr13.grid(row=4, column=1)\n \nb = Button(window, text=\"Calculate\", command=cal_credit)\nb.grid(row=0, column=2,columnspan=2, rowspan=2,sticky=W+E+N+S, padx=5, pady=5)\n \n \nwindow.mainloop()\n\n\n#Latest Update: Full Coding CGPA [Long Coding] @22/8/2020 @17:46\n#But did not show the result\n\nfrom tkinter import*\n\n#Assign Tk As Window\nwindow = Tk()\nwindow.title(\"MINI PROJECT\")\nwindow.geometry(\"1200x700\")\n\n#Total Credit Label\ncount = IntVar()\nGrade = 0\nInvert = count.get()\n\nLabel(window, text=\"Number\").grid(row=0, column=0)\nLabel(window, text=\"1\").grid(row=1, column=0)\nLabel(window, text=\"2\").grid(row=3, column=0)\nLabel(window, text=\"3\").grid(row=5, column=0)\nLabel(window, text=\"4\").grid(row=7, column=0)\nLabel(window, text=\"5\").grid(row=9, column=0)\nLabel(window, text=\"6\").grid(row=11, column=0)\nLabel(window, text=\"7\").grid(row=13, column=0)\nLabel(window, text=\"8\").grid(row=15, column=0)\n\n#Entry Credit\nr0=Entry(window)\nr8=Entry(window)\nr9=Entry(window)\nr10=Entry(window) \nr11=Entry(window) \nr12=Entry(window) \nr13=Entry(window)\nr15=Entry(window)\n\n#Entry Grade\nr1=Entry(window) \nr2=Entry(window)\nr3=Entry(window) \nr4=Entry(window) \nr5=Entry(window) \nr6=Entry(window) \nr7=Entry(window)\nr14=Entry(window)\n\n#Entry Subject\nr16 = Entry(window)\nr17 = Entry(window)\nr18 = Entry(window)\nr19 = Entry(window)\nr20 = Entry(window)\nr21 = Entry(window)\nr22 = Entry(window)\nr23 = Entry(window)\n\n#Entry Boarder\nr24 = Entry(window)\nr25 = Entry(window)\nr26 = Entry(window)\n\n#Grade Value\nr27 = Entry(window)\nr28 = Entry(window)\nr29 = Entry(window)\nr30 = Entry(window)\nr31 = Entry(window)\nr32 = Entry(window)\nr33 = Entry(window)\nr34 = Entry(window)\n\n\ndef calculate():\n global Grade\n \n #Grade [r1]\n if r1.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r1.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r1.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r1.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r1.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r1.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r1.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r1.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r1.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r1.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r1.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r1.get() == \"F\": \n Label(window) \n Grade += 0.00\n\n #Grade [r2]\n if r2.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r2.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r2.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r2.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r2.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r2.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r2.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r2.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r2.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r2.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r2.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r2.get() == \"F\": \n Label(window) \n Grade += 0.00\n\n #Grade [r3]\n if r3.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r3.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r3.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r3.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r3.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r3.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r3.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r3.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r3.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r3.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r3.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r3.get() == \"F\": \n Label(window) \n Grade += 0.00\n\n #Grade [r4]\n if r4.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r4.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r4.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r4.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r4.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r4.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r4.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r4.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r4.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r4.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r4.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r4.get() == \"F\": \n Label(window) \n Grade += 0.00\n\n #Grade [r5]\n if r5.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r5.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r5.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r5.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r5.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r5.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r5.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r5.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r5.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r5.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r5.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r5.get() == \"F\": \n Label(window) \n Grade += 0.00\n\n #Grade [r6]\n if r6.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r6.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r6.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r6.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r6.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r6.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r6.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r6.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r6.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r6.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r6.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r6.get() == \"F\": \n Tk.Label(window) \n Grade += 0.00\n\n #Grade [r7]\n if r7.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r7.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r7.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r7.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r7.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r7.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r7.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r7.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r7.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r7.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r7.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r7.get() == \"F\": \n Label(window) \n Grade += 0.00\n \n #Grade [r14]\n if r14.get() == \"A\": \n Label(window)\n Grade += 4.00\n if r14.get() == \"A-\": \n Label(window)\n Grade += 3.75\n if r14.get() == \"B+\": \n Label(window)\n Grade += 3.50\n if r14.get() == \"B\": \n Label(window)\n Grade += 3.00\n if r14.get() == \"B-\": \n Label(window) \n Grade += 2.75\n if r14.get() == \"C+\": \n Label(window) \n Grade += 2.50\n if r14.get() == \"C\": \n Label(window)\n Grade += 2.00\n if r14.get() == \"C-\": \n Label(window)\n Grade += 1.75\n if r14.get() == \"D+\": \n Label(window) \n Grade += 1.50\n if r14.get() == \"D\": \n Label(window) \n Grade += 1.00\n if r14.get() == \"D-\": \n Label(window) \n Grade += 0.75\n if r14.get() == \"F\": \n Label(window) \n Grade += 0.00\n\n #Boarder\n #displayGrade = StringVar()\n #displayCredit = StringVar()\n #displayStatus = StringVar()\n\n #Boarder Entry\n #Total Credit\n #r24 = Entry(window, width=10, state=DISABLED, textvariable=displayCredit)\n #r24.grid(row=17, column=4)\n\n #Total Grade\n #r25 = Entry(window,width=10, state=DISABLED, textvariable=displayGrade)\n #r25.grid(row=18, column=4)\n\n #Status\n #r26 = Entry(window,width=10, state=DISABLED, textvariable=displayStatus)\n #r26.grid(row=19, column=4)\n \n\n #Display Grade\n Label(window, text=\"Total Grade :\").grid(row=18,column=2)\n Label(window, text=str(Grade)).grid(row=18, column=4)\n\n #Display Credit\n Label(window, text=\" Total Unit :\").grid(row=17, column=2)\n Label(window, text=\"\", textvariable=count).grid(row=17, column=4)\n \n #Convert\n \n \"This function calculate CGPA by input user\"\n #elif (Grade*counter)/counter >= 2.75 and (Grade*counter)/counter <=3.66: return \"Pass\"\n #elif (Grade*counter)/counter >= 2.00 and (Grade*counter)/counter <=2.74: return \"Conditional Pass\"\n #else : return \"Fail\"\n\n #Display Status\n Label(window, text=\" Status :\").grid(row=19, column=2)\n Label(window, text=(Score)).grid(row=19, column=4) \n\n #Total Credit\n total=int(r0.get())+int(r8.get())+int(r9.get())+int(r10.get())+int(r11.get())+int(r12.get())+int(r13.get())+int(r15.get())\n count.set(total)\n\n #Button [EXIT]\n button2=Button(window, text=\"Exit\", bg=\"lightgreen\", command=exit) \n button2.grid(row=21, column=15)\n\n#Entry Credit\nr0 = Entry(window)\nr8 = Entry(window)\nr9 = Entry(window)\nr10 = Entry(window)\nr11 = Entry(window)\nr12 = Entry(window)\nr13 = Entry(window)\nr15 = Entry(window)\n\n#Entry Grade\nr1 = Entry(window)\nr2 = Entry(window)\nr3 = Entry(window)\nr4 = Entry(window)\nr5 = Entry(window)\nr6 = Entry(window)\nr7 = Entry(window)\nr14 = Entry(window)\n\n#Entry Subject\nr16 = Entry(window)\nr17 = Entry(window)\nr18 = Entry(window)\nr19 = Entry(window)\nr20 = Entry(window)\nr21 = Entry(window)\nr22 = Entry(window)\nr23 = Entry(window)\n\n#Grade Value\nr27 = Entry(window)\nr28 = Entry(window)\nr29 = Entry(window)\nr30 = Entry(window)\nr31 = Entry(window)\nr32 = Entry(window)\nr33 = Entry(window)\nr34 = Entry(window)\n\n#Guideline\nLabel(window, text=\"Guideline Grade \\n& Grade Value\").grid(row=0,column=13)\nLabel(window, text=\"Grade:\").grid(row=2,column=11)\nLabel(window, text=\"Grade:\").grid(row=3,column=11)\nLabel(window, text=\"Grade:\").grid(row=4,column=11)\nLabel(window, text=\"Grade:\").grid(row=5,column=11)\nLabel(window, text=\"Grade:\").grid(row=6,column=11)\nLabel(window, text=\"Grade:\").grid(row=7,column=11)\nLabel(window, text=\"Grade:\").grid(row=8,column=11)\nLabel(window, text=\"Grade:\").grid(row=9, column=11)\nLabel(window, text=\"Grade:\").grid(row=10, column=11)\nLabel(window, text=\"Grade:\").grid(row=11, column=11)\nLabel(window, text=\"Grade:\").grid(row=12, column=11)\nLabel(window, text=\"Grade:\").grid(row=13, column=11)\n\nLabel(window, text=\"A \").grid(row=2,column=12)\nLabel(window, text=\"A-\").grid(row=3,column=12)\nLabel(window, text=\"B+\").grid(row=4,column=12)\nLabel(window, text=\"B \").grid(row=5,column=12)\nLabel(window, text=\"B-\").grid(row=6,column=12)\nLabel(window, text=\"C+\").grid(row=7,column=12)\nLabel(window, text=\"C \").grid(row=8,column=12)\nLabel(window, text=\"C-\").grid(row=9, column=12)\nLabel(window, text=\"D+\").grid(row=10, column=12)\nLabel(window, text=\"D \").grid(row=11, column=12)\nLabel(window, text=\"D-\").grid(row=12, column=12)\nLabel(window, text=\"F \").grid(row=13, column=12)\n\nLabel(window, text=\"Grade Value:\").grid(row=2,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=3,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=4,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=5,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=6,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=7,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=8,column=14)\nLabel(window, text=\"Grade Value:\").grid(row=9, column=14)\nLabel(window, text=\"Grade Value:\").grid(row=10, column=14)\nLabel(window, text=\"Grade Value:\").grid(row=11, column=14)\nLabel(window, text=\"Grade Value:\").grid(row=12, column=14)\nLabel(window, text=\"Grade Value:\").grid(row=13, column=14)\n\nLabel(window, text=\"4.00\").grid(row=2,column=15)\nLabel(window, text=\"3.75\").grid(row=3,column=15)\nLabel(window, text=\"3.50\").grid(row=4,column=15)\nLabel(window, text=\"3.00\").grid(row=5,column=15)\nLabel(window, text=\"2.75\").grid(row=6,column=15)\nLabel(window, text=\"2.50\").grid(row=7,column=15)\nLabel(window, text=\"2.00\").grid(row=8,column=15)\nLabel(window, text=\"1.75\").grid(row=9, column=15)\nLabel(window, text=\"1.50\").grid(row=10, column=15)\nLabel(window, text=\"1.00\").grid(row=11, column=15)\nLabel(window, text=\"0.75\").grid(row=12, column=15)\nLabel(window, text=\"0.00\").grid(row=13, column=15)\n\n#Organizing [Grade Value]\nLabel(window, text=\"Grade Value\").grid(row=0,column=8)\nr27.grid(row=1, column=8)\nr28.grid(row=3, column=8)\nr29.grid(row=5, column=8)\nr30.grid(row=7, column=8)\nr31.grid(row=9, column=8)\nr32.grid(row=11, column=8)\nr33.grid(row=13, column=8)\nr34.grid(row=15, column=8)\n\n#Organizing [Unit]\nLabel(window, text=\"Unit\").grid(row=0,column=6)\nr0.grid(row=1, column=6)\nr8.grid(row=3, column=6)\nr9.grid(row=5, column=6)\nr10.grid(row=7, column=6)\nr11.grid(row=9, column=6)\nr12.grid(row=11, column=6)\nr13.grid(row=13, column=6)\nr15.grid(row=15, column=6)\n\n#Orgainizing [Grade]\nLabel(window, text=\"Grade\").grid(row=0,column=4)\nr1.grid(row=1, column=4)\nr2.grid(row=3, column=4)\nr3.grid(row=5, column=4)\nr4.grid(row=7, column=4)\nr5.grid(row=9, column=4)\nr6.grid(row=11, column=4)\nr7.grid(row=13, column=4)\nr14.grid(row=15, column=4)\n\n#Organizing [Subject]\nLabel(window, text=\"Subject\").grid(row=0,column=2)\nr16.grid(row=1, column=2)\nr17.grid(row=3, column=2)\nr18.grid(row=5, column=2)\nr19.grid(row=7, column=2)\nr20.grid(row=9, column=2)\nr21.grid(row=11, column=2)\nr22.grid(row=13, column=2)\nr23.grid(row=15, column=2)\n\n#Gap\nLabel(window, text=\" \").grid(row=2,column=3)\nLabel(window, text=\" \").grid(row=4,column=3)\nLabel(window, text=\" \").grid(row=6,column=3)\nLabel(window, text=\" \").grid(row=8,column=3)\nLabel(window, text=\" \").grid(row=10,column=3)\nLabel(window, text=\" \").grid(row=12,column=3)\nLabel(window, text=\" \").grid(row=14,column=3)\nLabel(window, text=\" \").grid(row=16, column=3)\nLabel(window, text=\" \").grid(row=2,column=5)\nLabel(window, text=\" \").grid(row=4,column=5)\nLabel(window, text=\" \").grid(row=6,column=5)\nLabel(window, text=\" \").grid(row=8,column=5)\nLabel(window, text=\" \").grid(row=10,column=5)\nLabel(window, text=\" \").grid(row=12,column=5)\nLabel(window, text=\" \").grid(row=14,column=5)\nLabel(window, text=\" \").grid(row=16, column=5)\nLabel(window, text=\" \").grid(row=2,column=7)\nLabel(window, text=\" \").grid(row=4,column=7)\nLabel(window, text=\" \").grid(row=6,column=7)\nLabel(window, text=\" \").grid(row=8,column=7)\nLabel(window, text=\" \").grid(row=10,column=7)\nLabel(window, text=\" \").grid(row=12,column=7)\nLabel(window, text=\" \").grid(row=14,column=7)\nLabel(window, text=\" \").grid(row=16, column=7)\nLabel(window, text=\" \").grid(row=2,column=10)\nLabel(window, text=\" \").grid(row=3,column=10)\nLabel(window, text=\" \").grid(row=4,column=10)\nLabel(window, text=\" \").grid(row=5,column=10)\nLabel(window, text=\" \").grid(row=6,column=10)\nLabel(window, text=\" \").grid(row=7,column=10)\nLabel(window, text=\" \").grid(row=8,column=10)\nLabel(window, text=\" \").grid(row=9,column=10)\nLabel(window, text=\" \").grid(row=10, column=10)\nLabel(window, text=\" \").grid(row=11,column=10)\nLabel(window, text=\" \").grid(row=12,column=10)\nLabel(window, text=\" \").grid(row=13,column=10)\n\n\n#Button [SUBMIT]\nbutton1=Button(window, text=\"Submit\", bg=\"yellow\", command=calculate) \nbutton1.grid(row=21, column=14)\n\n#button3 = Button(window, text=\"Calculate\", command=addNumbers)\n#button3.grid(row=0, column=2,columnspan=2, rowspan=2,sticky=W+E+N+S, padx=5, pady=5)\n\nwindow.mainloop()\n\n\n#Latest Update: Full Coding CGPA [Short Coding] @22/8/2020 @17:48\n#Still did not get the result/status\nfrom tkinter import*\nwindow = Tk()\n\nwindow.geometry(\"1200x500\")\n\n#Unit\nr0 = Entry (window) \nr8 = Entry (window) \nr9 = Entry (window) \nr10 = Entry (window) \nr11 = Entry (window) \nr12 = Entry (window) \nr13 = Entry (window) \nr15 = Entry (window) \n\n#Value Grade\nr27 = Entry (window) \nr28 = Entry (window) \nr29 = Entry (window) \nr30 = Entry (window) \nr31 = Entry (window) \nr32 = Entry (window) \nr33 = Entry (window) \nr34 = Entry (window)\n\ndef answer(): \n #Value Grade\n v1 = r27.get()\n v2 = r28.get()\n v3 = r29.get()\n v4 = r30.get()\n v5 = r31.get()\n v6 = r32.get()\n v7 = r33.get()\n v8 = r34.get()\n\n #Unit\n v9 = r0.get()\n v10 = r8.get()\n v11 = r9.get()\n v12 = r10.get()\n v13 = r11.get()\n v14 = r12.get()\n v15 = r13.get()\n v16 = r15.get()\n\n Answer = (float(v1)*int(v9)) + (float(v2)*int(v10)) + (float(v3)*int(v11)) + (float(v4)*int(v12)) + (float(v5)*int(v13)) + (float(v6)*int(v14)) + (float(v7)*int(v15)) + (float(v8)*int(v16))\n Total_Unit = int(v9) + int(v10) + int(v11) + int(v12) + int(v13) + int(v14) + int(v15) + int(v16)\n Total_Grade = float(v1) + float(v2) + float(v3) + float(v4) + float(v5) + float(v6) + float(v7) + float(v8)\n Status = Answer / Total_Unit\n\n Label(window, text=\"Total Grade:\").grid(row=16,column=1)\n Label(window, text=(Total_Grade)).grid(row=16, column=3)\n\n Label(window, text=\"Total Unit:\").grid(row=17,column=1)\n Label(window, text=(Total_Unit)).grid(row=17, column=3)\n\n Label(window, text=\"CGPA:\").grid(row=18,column=1)\n Label(window, text=(Status)).grid(row=18, column=3)\n\n Label(window, text=\"Status:\").grid(row=19,column=1)\n #Label(window, text=(result)).grid(row=19, column=3)\n\n#Organizing [Grade Value]\nLabel(window, text=\"Grade Value\").grid(row=0,column=1)\nr27.grid(row=1, column=1)\nr28.grid(row=3, column=1)\nr29.grid(row=5, column=1)\nr30.grid(row=7, column=1)\nr31.grid(row=9, column=1)\nr32.grid(row=11, column=1)\nr33.grid(row=13, column=1)\nr34.grid(row=15, column=1)\n\n#Organizing [Unit]\nLabel(window, text=\"Unit\").grid(row=0,column=3)\nr0.grid(row=1, column=3)\nr8.grid(row=3, column=3)\nr9.grid(row=5, column=3)\nr10.grid(row=7, column=3)\nr11.grid(row=9, column=3)\nr12.grid(row=11, column=3)\nr13.grid(row=13, column=3)\nr15.grid(row=15, column=3)\n\nbutton1=Button(window, text=\"Submit\", bg=\"yellow\", command=answer) \nbutton1.grid(row=21, column=3)\n\nwindow.mainloop()\n\n#Latest Code Updated [23/08/2020 @12:45AM]\n\n#Import Tkinter\nfrom tkinter import*\n\n#Assign Tk\nwindow = Tk()\n\n#Assign Window Title\nwindow.title(\"MINI PROJECT VGT123\")\n\n#Set Window Size\nwindow.geometry(\"1200x700\")\n\n#Assign Application Name\nLabel(window, text=\"CGPA CALCULATOR\", bg=\"#ffff33\", font=\"bold\").grid(row=0,column=7)\n\n#Unit\nr0 = Entry (window) \nr8 = Entry (window) \nr9 = Entry (window) \nr10 = Entry (window) \nr11 = Entry (window) \nr12 = Entry (window) \nr13 = Entry (window) \nr15 = Entry (window) \n\n#Subject\nr16 = Entry (window)\nr17 = Entry (window)\nr18 = Entry (window)\nr19 = Entry (window)\nr20 = Entry (window)\nr21 = Entry (window)\nr22 = Entry (window)\nr23 = Entry (window)\n\n#Value Grade\nr27 = Entry (window) \nr28 = Entry (window) \nr29 = Entry (window) \nr30 = Entry (window) \nr31 = Entry (window) \nr32 = Entry (window) \nr33 = Entry (window) \nr34 = Entry (window)\n\n#Function [CLEAR]\ndef clear():\n r0.delete(0,END)\n r8.delete(0,END) \n r9.delete(0,END) \n r10.delete(0,END) \n r11.delete(0,END) \n r12.delete(0,END) \n r13.delete(0,END) \n r15.delete(0,END) \n r16.delete(0,END) \n r17.delete(0,END) \n r18.delete(0,END) \n r19.delete(0,END) \n r20.delete(0,END) \n r21.delete(0,END) \n r22.delete(0,END) \n r23.delete(0,END) \n r27.delete(0,END) \n r28.delete(0,END) \n r29.delete(0,END) \n r30.delete(0,END) \n r31.delete(0,END) \n r32.delete(0,END) \n r33.delete(0,END) \n r34.delete(0,END)\n\n#Function [CALCULATION]\ndef answer(): \n #Value Grade\n v1 = r27.get()\n v2 = r28.get()\n v3 = r29.get()\n v4 = r30.get()\n v5 = r31.get()\n v6 = r32.get()\n v7 = r33.get()\n v8 = r34.get()\n\n #Unit\n v9 = r0.get()\n v10 = r8.get()\n v11 = r9.get()\n v12 = r10.get()\n v13 = r11.get()\n v14 = r12.get()\n v15 = r13.get()\n v16 = r15.get()\n\n #Calculation\n Answer = (float(v1)*int(v9)) + (float(v2)*int(v10)) + (float(v3)*int(v11)) + (float(v4)*int(v12)) + (float(v5)*int(v13)) + (float(v6)*int(v14)) + (float(v7)*int(v15)) + (float(v8)*int(v16))\n Total_Unit = int(v9) + int(v10) + int(v11) + int(v12) + int(v13) + int(v14) + int(v15) + int(v16)\n Total_Grade = float(v1) + float(v2) + float(v3) + float(v4) + float(v5) + float(v6) + float(v7) + float(v8)\n Status = Answer / Total_Unit\n\n #Covert Decimal Place\n con_answer = float(\"{0:.2f}\".format(Status))\n\n #Display Total Grade \n Label(window, text=\"Total Grade :\").grid(row=19,column=3)\n Label(window, text=(Total_Grade)).grid(row=19, column=5)\n\n #Display Total Unit\n Label(window, text=\" Total Unit :\").grid(row=20,column=3)\n Label(window, text=(Total_Unit)).grid(row=20, column=5)\n\n #Display CGPA\n Label(window, text=\" CGPA :\").grid(row=21,column=3)\n Label(window, text=(con_answer)).grid(row=21, column=5)\n\n #Display Status Result\n Label(window, text=\" Status :\").grid(row=22,column=3)\n\n #Codition ResultS\n \"This function calculate CGPA by input user\"\n if Status >= 3.67 and Status <=4.00:\n Label(window, text=\"Dean List\", fg=\"#0000ff\", font=\"bold\").grid(row=22, column=5)\n elif Status >= 2.75 and Status <=3.66:\n Label(window, text=\"Pass\", fg=\"#ff9900\", font=\"bold\").grid(row=22, column=5)\n elif Status >= 2.00 and Status <=2.74:\n Label(window, text=\"Conditional Pass\", fg=\"#00ff00\", font=\"bold\").grid(row=22,column=5)\n else :\n Label(window, text=\"Fail\", fg=\"#ff3300\", font=\"bold\").grid(row=22,column=5)\n\n#Entry Subject\nr16 = Entry(window)\nr17 = Entry(window)\nr18 = Entry(window)\nr19 = Entry(window)\nr20 = Entry(window)\nr21 = Entry(window)\nr22 = Entry(window)\nr23 = Entry(window)\n\n#Organizing [NUMBER]\nLabel(window, text=\"Number\",bg=\"#1a8cff\").grid(row=2,column=1)\nLabel(window, text=\"1\").grid(row=3,column=1)\nLabel(window, text=\"2\").grid(row=5,column=1)\nLabel(window, text=\"3\").grid(row=7,column=1)\nLabel(window, text=\"4\").grid(row=9,column=1)\nLabel(window, text=\"5\").grid(row=11,column=1)\nLabel(window, text=\"6\").grid(row=13,column=1)\nLabel(window, text=\"7\").grid(row=15,column=1)\nLabel(window, text=\"8\").grid(row=17,column=1)\n\n#Organizing [SUBJECT]\nLabel(window, text=\"Subject\", bg=\"#d279d2\").grid(row=2,column=3)\nr16.grid(row=3, column=3)\nr17.grid(row=5, column=3)\nr18.grid(row=7, column=3)\nr19.grid(row=9, column=3)\nr20.grid(row=11, column=3)\nr21.grid(row=13, column=3)\nr22.grid(row=15, column=3)\nr23.grid(row=17, column=3)\n\n#Organizing [GRADE VALUE]\nLabel(window, text=\"Grade Value\", bg=\"#dfff80\").grid(row=2,column=5)\nr27.grid(row=3, column=5)\nr28.grid(row=5, column=5)\nr29.grid(row=7, column=5)\nr30.grid(row=9, column=5)\nr31.grid(row=11, column=5)\nr32.grid(row=13, column=5)\nr33.grid(row=15, column=5)\nr34.grid(row=17, column=5)\n\n#Organizing [UNIT]\nLabel(window, text=\"Unit\", bg=\"#ffb84d\").grid(row=2,column=7)\nr0.grid(row=3, column=7)\nr8.grid(row=5, column=7)\nr9.grid(row=7, column=7)\nr10.grid(row=9, column=7)\nr11.grid(row=11, column=7)\nr12.grid(row=13, column=7)\nr13.grid(row=15, column=7)\nr15.grid(row=17, column=7)\n\n#Guideline [GRADE]\nLabel(window, text=\"Guideline\",bg=\"#d98cb3\").grid(row=2,column=11)\nLabel(window, text=\"Grade :\").grid(row=3,column=9)\nLabel(window, text=\"Grade :\").grid(row=4,column=9)\nLabel(window, text=\"Grade :\").grid(row=5,column=9)\nLabel(window, text=\"Grade :\").grid(row=6,column=9)\nLabel(window, text=\"Grade :\").grid(row=7,column=9)\nLabel(window, text=\"Grade :\").grid(row=8,column=9)\nLabel(window, text=\"Grade :\").grid(row=9,column=9)\nLabel(window, text=\"Grade :\").grid(row=10, column=9)\nLabel(window, text=\"Grade :\").grid(row=11, column=9)\nLabel(window, text=\"Grade :\").grid(row=12, column=9)\nLabel(window, text=\"Grade :\").grid(row=13, column=9)\nLabel(window, text=\"Grade :\").grid(row=14, column=9)\n\n#Guideline [LETTER]\nLabel(window, text=\"A \").grid(row=3,column=10)\nLabel(window, text=\"A-\").grid(row=4,column=10)\nLabel(window, text=\"B+\").grid(row=5,column=10)\nLabel(window, text=\"B \").grid(row=6,column=10)\nLabel(window, text=\"B-\").grid(row=7,column=10)\nLabel(window, text=\"C+\").grid(row=8,column=10)\nLabel(window, text=\"C \").grid(row=9,column=10)\nLabel(window, text=\"C-\").grid(row=10, column=10)\nLabel(window, text=\"D+\").grid(row=11, column=10)\nLabel(window, text=\"D \").grid(row=12, column=10)\nLabel(window, text=\"D-\").grid(row=13, column=10)\nLabel(window, text=\"F \").grid(row=14, column=10)\n\n#Guideline [GRADE VALUE]\nLabel(window, text=\"Grade Value :\").grid(row=3,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=4,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=5,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=6,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=7,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=8,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=9,column=12)\nLabel(window, text=\"Grade Value :\").grid(row=10, column=12)\nLabel(window, text=\"Grade Value :\").grid(row=11, column=12)\nLabel(window, text=\"Grade Value :\").grid(row=12, column=12)\nLabel(window, text=\"Grade Value :\").grid(row=13, column=12)\nLabel(window, text=\"Grade Value :\").grid(row=14, column=12)\n\n#Guideline [FLOATING VALUE]\nLabel(window, text=\"4.00\").grid(row=3,column=13)\nLabel(window, text=\"3.75\").grid(row=4,column=13)\nLabel(window, text=\"3.50\").grid(row=5,column=13)\nLabel(window, text=\"3.00\").grid(row=6,column=13)\nLabel(window, text=\"2.75\").grid(row=7,column=13)\nLabel(window, text=\"2.50\").grid(row=8,column=13)\nLabel(window, text=\"2.00\").grid(row=9,column=13)\nLabel(window, text=\"1.75\").grid(row=10, column=13)\nLabel(window, text=\"1.50\").grid(row=11, column=13)\nLabel(window, text=\"1.00\").grid(row=12, column=13)\nLabel(window, text=\"0.75\").grid(row=13, column=13)\nLabel(window, text=\"0.00\").grid(row=14, column=13)\n\n#Gap\nLabel(window, text=\" \").grid(row=18,column=3)\n\n\n#Column 0\nLabel(window, text=\" \").grid(row=2,column=0)\nLabel(window, text=\" \").grid(row=4,column=0)\nLabel(window, text=\" \").grid(row=6,column=0)\nLabel(window, text=\" \").grid(row=8,column=0)\nLabel(window, text=\" \").grid(row=10,column=0)\nLabel(window, text=\" \").grid(row=12,column=0)\nLabel(window, text=\" \").grid(row=14,column=0)\nLabel(window, text=\" \").grid(row=16, column=0)\n\n#Column 2\nLabel(window, text=\" \").grid(row=2,column=2)\nLabel(window, text=\" \").grid(row=4,column=2)\nLabel(window, text=\" \").grid(row=6,column=2)\nLabel(window, text=\" \").grid(row=8,column=2)\nLabel(window, text=\" \").grid(row=10,column=2)\nLabel(window, text=\" \").grid(row=12,column=2)\nLabel(window, text=\" \").grid(row=14,column=2)\nLabel(window, text=\" \").grid(row=16, column=2)\n\n#Column 4\nLabel(window, text=\" \").grid(row=2,column=4)\nLabel(window, text=\" \").grid(row=4,column=4)\nLabel(window, text=\" \").grid(row=6,column=4)\nLabel(window, text=\" \").grid(row=8,column=4)\nLabel(window, text=\" \").grid(row=10,column=4)\nLabel(window, text=\" \").grid(row=12,column=4)\nLabel(window, text=\" \").grid(row=14,column=4)\nLabel(window, text=\" \").grid(row=16, column=4)\n\n#Column 6\nLabel(window, text=\" \").grid(row=2,column=6)\nLabel(window, text=\" \").grid(row=3,column=6)\nLabel(window, text=\" \").grid(row=4,column=6)\nLabel(window, text=\" \").grid(row=5,column=6)\nLabel(window, text=\" \").grid(row=6,column=6)\nLabel(window, text=\" \").grid(row=7,column=6)\nLabel(window, text=\" \").grid(row=8,column=6)\nLabel(window, text=\" \").grid(row=9,column=6)\n\n#Column 8\nLabel(window, text=\" \").grid(row=10, column=8)\nLabel(window, text=\" \").grid(row=11,column=8)\nLabel(window, text=\" \").grid(row=12,column=8)\nLabel(window, text=\" \").grid(row=13,column=8)\nLabel(window, text=\" \").grid(row=10, column=8)\nLabel(window, text=\" \").grid(row=11,column=8)\nLabel(window, text=\" \").grid(row=12,column=8)\nLabel(window, text=\" \").grid(row=13,column=8)\n\n#Button [CALCULATE]\nbutton1=Button(window, text=\"Calculate\", bg=\"#00ff00\", command=answer) \nbutton1.grid(row=25, column=14)\n\n#Button [CLEAR]\nbutton2=Button(window, text=\"Clear\", bg=\"#00ffff\", command=clear) \nbutton2.grid(row=25, column=15)\n\n#Button [EXIT]\nbutton3=Button(window, text=\"Exit\", bg=\"#ff1a1a\", command=exit) \nbutton3.grid(row=25, column=16)\n\nwindow.mainloop()\n\n\n#from tkinter import*\nimport tkinter as tk\nimport tkinter.messagebox \n#from tkinter import tk\n#using import tkinter as tk\n\n\ndef main ():\n root =tk.Tk()\n app = Window1(root)\n #application = Rental_Inventory(root)\n #root.mainloop()\n\n \n \n#blank windows 1\nclass Window1:\n def __init__ (self, master):\n self.master = master\n self.master.title(\"MINI PROJECT\")\n self.master.geometry(\"1350x750+0+0\")\n self.master.config(bg=\"powder blue\")\n self.frame = tk.Frame(self.master, bg=\"powder blue\")\n self.frame.pack()\n\n#2 buttons will pop up\n# buttons about us and cgpa calculator\n\n self.lblTitle = tk.Label(self.frame, text= \" WELCOME TO CGPA CALCULATOR\", font=(\"arial\",50,\"bold\"), bg=\"powder blue\", fg=\"black\")\n self.lblTitle.grid(row=0, columnspan=3, pady=40)\n\n\n self.btncgpa = tk.Button(self.frame,text =\"CGPA CALCULATOR\", width =17, command =self.new_window2)\n self.btncgpa.grid(row=2,column=1)\n \n def new_window2(self):\n self.newWindow = tk.Toplevel(self.master)\n self.app = Window2(self.newWindow)\n\n#this windows will be open if the button click\nclass Window2:\n def __init__ (self, master):\n self.master = master\n self.master.title(\"MINI PROJECT\")\n self.master.geometry(\"1350x750+0+0\")\n self.master.config(bg=\"cadet blue\")\n self.frame = tk.Frame(self.master, bg=\"powder blue\") \n self.frame.pack()\n\n\n\n\n#suspect this is might be the error\nif __name__ == \"__main__\":\n\n main()\n"
}
] | 1 |
DianaCrainic/Partition-Statistics | https://github.com/DianaCrainic/Partition-Statistics | 6a1bed3a800b0aad3842e1d6664b6df6dda0a20e | 219ef80e88aaf59586f121da3bc73f29aa4d24e3 | c58fb60cb01c91f6f41eff68e258e218ca490720 | refs/heads/main | 2023-01-23T08:20:29.461458 | 2020-12-08T10:42:06 | 2020-12-08T10:42:06 | 316,979,017 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6602316498756409,
"alphanum_fraction": 0.6647740006446838,
"avg_line_length": 34.796749114990234,
"blob_id": "6dda57b994676c0d2e34b1efd1040f826e64ab72",
"content_id": "e2f440d140732264dad39b89c52f486811355ac7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4403,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 123,
"path": "/analyze_partition.py",
"repo_name": "DianaCrainic/Partition-Statistics",
"src_encoding": "UTF-8",
"text": "import math\nimport os\nimport pprint\nimport sys\n\nfrom cutecharts.charts import Bar\nfrom cutecharts.charts import Pie\nfrom cutecharts.components import Page\n\n\ndef create_chart_dir_files(dictionary_of_dir_files):\n labels = list(dictionary_of_dir_files.keys())\n values = list(dictionary_of_dir_files.values())\n chart = Pie(\"The chart for the number of directories and files\")\n chart.set_options(labels=labels, inner_radius=0, colors=['#FFE07F', '#5AD2EC'])\n chart.add_series(values)\n return chart\n\n\ndef create_chart_extension_dict(extension_dict):\n extension_dict = dict(sorted(extension_dict.items(), key=lambda item: item[1]))\n labels = list(extension_dict.keys())\n values = list(extension_dict.values())\n chart = Bar(\"The chart for the number of file extensions\")\n chart.set_options(labels=labels, x_label=\"Extensions\", y_label=\"Number of extensions\",\n colors=['#E09DE1' for _ in range(len(labels))])\n chart.add_series(\"The number of extensions\", values)\n return chart\n\n\ndef create_chart_file_size_dict(file_size_dict):\n file_size_dict = dict(sorted(file_size_dict.items(), key=lambda item: item[1]))\n labels = list(file_size_dict.keys())\n values = list(file_size_dict.values())\n chart = Bar(\"The chart for the distribution of file sizes of each extension\")\n chart.set_options(labels=labels, x_label=\"Extensions\", y_label=\"Sum of file sizes\",\n colors=['#1EAFAE' for _ in range(len(labels))])\n chart.add_series(\"The Sum of sizes\", values)\n return chart\n\n\ndef number_of_elements(number_of_directories, directories, number_of_files, files):\n number_of_directories += len(directories)\n number_of_files += len(files)\n return number_of_directories, number_of_files\n\n\ndef print_number_of_elements(dictionary_of_dir_files):\n print(\"Number of directories: {}\".format(list(dictionary_of_dir_files.values())[0]))\n print(\"Number of files: {}\".format(list(dictionary_of_dir_files.values())[1]))\n print()\n\n\ndef get_extensions(extension, extensions, extension_dict):\n if extension != '':\n extensions.add(extension)\n if extension not in extension_dict.keys():\n extension_dict[extension] = 1\n else:\n extension_dict[extension] += 1\n\n return extensions, extension_dict\n\n\ndef print_extensions_info(extensions, extension_dict):\n print(\"The sorted extensions are: \")\n pprint.pprint(sorted(extensions))\n print()\n print(\"The dictionary of extensions is: \")\n pprint.pprint(extension_dict)\n print()\n\n\ndef get_file_sizes(full_path, extension, file_size_dict):\n file_size = os.path.getsize(full_path)\n if extension != '':\n if extension not in file_size_dict.keys():\n file_size_dict[extension] = file_size\n else:\n file_size_dict[extension] += file_size\n return file_size_dict\n\n\ndef print_file_sizes_info(file_size_dict):\n print(\"The dictionary of files with their sizes is: \")\n pprint.pprint(file_size_dict)\n\n\ndef partition_analysis(partition_name):\n dictionary_of_dir_files = {}\n extensions = set()\n extension_dict = {}\n file_size_dict = {}\n number_of_files = 0\n number_of_directories = 0\n\n for (root, directories, files) in os.walk(partition_name):\n\n number_of_directories, number_of_files = number_of_elements(number_of_directories, directories, number_of_files,\n files)\n dictionary_of_dir_files = {'directories': number_of_directories, 'files': number_of_files}\n\n for file_name in files:\n extension = (os.path.splitext(file_name)[1][1:]).lower()\n extensions, extension_dict = get_extensions(extension, extensions, extension_dict)\n\n full_path = os.path.abspath(os.path.join(root, file_name))\n file_size_dict = get_file_sizes(full_path, extension, file_size_dict)\n\n print_number_of_elements(dictionary_of_dir_files)\n print_extensions_info(extensions, extension_dict)\n print_file_sizes_info(file_size_dict)\n\n page = Page()\n page.add(create_chart_dir_files(dictionary_of_dir_files), create_chart_extension_dict(extension_dict),\n create_chart_file_size_dict(file_size_dict))\n page.render()\n\n\nif __name__ == '__main__':\n partition = sys.argv[1]\n partition = partition + \":\"\n partition_analysis(partition)\n"
},
{
"alpha_fraction": 0.7854406237602234,
"alphanum_fraction": 0.7988505959510803,
"avg_line_length": 103.5999984741211,
"blob_id": "8eb330d76604daaab0d9dabc8a1187001521f1a5",
"content_id": "e17722119b62d1b084adfd781a7ba24946005866",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 548,
"license_type": "no_license",
"max_line_length": 397,
"num_lines": 5,
"path": "/README.md",
"repo_name": "DianaCrainic/Partition-Statistics",
"src_encoding": "UTF-8",
"text": "# Partition-Statistics\n\nRealizați o aplicație care primește ca parametru o partiție și analizează toate directoarele și fișierele de acolo. La final, aceasta va afișa numărul de directoare și de fișiere, proporția fiecărui tip de fișier (.zip, .exe etc.) atât ca număr cât și ca size. Toate aceste informații vor fi afișate sub forma de charturi (pie chart, bar chart etc.) astfel încât să fie cât mai ușor de intepretat.\n\n[Proiecte propuse Python](https://drive.google.com/drive/folders/1IPWjN5g_h9VebR6I8xEH4-VCg7ZGZ-nb)"
}
] | 2 |
rkstan1985/imessagedb2 | https://github.com/rkstan1985/imessagedb2 | e7bb4f9b92cacc613268ce5dba65ee8796134040 | f3795198820604fc3c241ca55ebb742acfe1318c | c29c197d71f3f9dc1dd4adaa9dae566555f6f112 | refs/heads/master | 2020-12-25T14:22:41.959754 | 2016-09-10T23:53:25 | 2016-09-10T23:53:25 | 67,900,004 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5928618907928467,
"alphanum_fraction": 0.6201806664466858,
"avg_line_length": 28.66891860961914,
"blob_id": "938e2237099a59b7b547de7a527a02bc5fe46064",
"content_id": "fde8f3d0ce21fe5f73bb1f897de13fbc3b924722",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4539,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 148,
"path": "/rationew/rationew.py",
"repo_name": "rkstan1985/imessagedb2",
"src_encoding": "UTF-8",
"text": "import sqlite3\r\nimport datetime\r\nimport mysql.connector\r\n\r\nsqlite_file = '/Users/BConn/Library/Messages/chat.db'\r\ntable_name = 'message' #iMessage history\r\n\r\nid_column = 'ROWID'\r\ntext_column = 'text'\r\nhandle_column = 'handle_id'\r\ndistro_column = 'cache_roomnames'\r\ndistro_id = 'chat644931494225636'\r\n\r\n# connecting to the database file\r\nconn = sqlite3.connect(sqlite_file)\r\nc = conn.cursor()\r\n\r\n#Get the total number of messages in the group chat\r\nc.execute('SELECT COUNT(*) {coi2} FROM {tn} WHERE {coi2}=\"chat644931494225636\"'.\\\r\n format(coi2=distro_column, tn=table_name, cn=handle_column))\r\ntotal_distro_messages = c.fetchall()\r\n\r\n#Remove the extra second item that is put in the tuple\r\ndenominator = []\r\nfor x in total_distro_messages:\r\n for y in x:\r\n denominator.append(y)\r\n\r\ntotal_distro_messages = str(denominator[0])\r\n\r\nprint('The Distro has sent a total of ' + total_distro_messages + ' messages since December 2014.')\r\nprint(\"\")\r\nprint('Individal contributions are as follows:')\r\nprint(\"\")\r\n\r\n# Obtaining each members messages of the distro\r\n# 0 - Bryan, 2 - Crandall, 3 - Jim, 4 - Cole, 5 - Kenny, 6 - Jack, 7 - Kydes, 8 - Zach, 9 - Evan, 10 - Scotty, 11 - Greg\r\nmembers = ['Bryan', 'Brant', 'Jimmy Mole', 'Cole', 'Kenny', 'Jack', 'Kydes', 'Fennius', 'Evan', 'Scotty', 'Greg']\r\nresults = []\r\nfor x in range(0,12):\r\n c.execute('SELECT COUNT(*) {coi2},{coi1} FROM {tn} WHERE {coi2}=\"chat644931494225636\" AND {coi1}={a}'.\\\r\n format(coi2=distro_column, coi1=handle_column, tn=table_name, cn=handle_column, a=x))\r\n total_messages = c.fetchall()\r\n results.append(total_messages)\r\n\r\n#Remove the empty list that is encountered because of the '1' variable\r\nresults.pop(1)\r\n\r\n#Replace the handle_id's with the actual names of people\r\nlist2 = []\r\nlist1 = results\r\n\r\n#Converts List of Lists of Tuples to List of Tuples\r\nfor x in list1:\r\n for y in x:\r\n list2.append(y)\r\n\r\n#Convert List of Tuples to List of Lists\r\nlist3 = [list(elem) for elem in list2]\r\n\r\n#Switch items in each list so it's handle_id, messages\r\nfor x in list3:\r\n x.reverse()\r\n\r\n#Replace handle_ids with names of actual distro members\r\nu = 0\r\nfor x in list3:\r\n x[0] = members[u]\r\n u = u+1\r\n\r\n#Separating names and messages sent into two separate lists\r\nname_list, message_list = zip(*list3)\r\n\r\n#Calculating the Ratio of each individual\r\nratio_list4 = []\r\nfor x in list3:\r\n ratio = float(x[1]) / float(total_distro_messages)\r\n ratio_list4.append(ratio)\r\n\r\n#Rounding the ratios\r\nlist5 = []\r\nfor x in ratio_list4:\r\n \r\n y = round(x, 3)\r\n list5.append(y)\r\n\r\n#Print on separte lines\r\nfor item in list3:\r\n print(' has sent a total of '.join(map(str, item)) + ' messages')\\\r\n\r\nconn.close()\r\n\r\n#AWS variables and settings\r\naws_host = 'ratios.cfy6bgj8jv5o.us-west-2.rds.amazonaws.com'\r\naws_user = 'brohmo'\r\naws_password = 'aaaoooooohhhhhhhhhh'\r\naws_database = 'ratios'\r\n\r\n#method to update the time table\r\ndef updatetime(cur, db):\r\n f = '%Y-%m-%d %H:%M:%S'\r\n dt = datetime.datetime.now().strftime(f)\r\n query =\"UPDATE `ratios`.`updated` SET `updated` = '\" + dt + \"' WHERE `index` = '1';\"\r\n print(dt)\r\n try:\r\n cur.execute(query)\r\n db.commit()\r\n print(\"Successfully updated time\")\r\n except:\r\n db.rollback()\r\n print(\"Rolled back with an exception\")\r\n\r\n#method to update the ratio column within the table on AWS\r\ndef updateratios( cur, db ):\r\n for num in range(0, 11):\r\n rt = list5[num]\r\n nm = members[num]\r\n q1 = \"UPDATE `ratios`.`ratios` SET `Ratio` = '\" + str(rt) + \"' WHERE `Name` = '\" + nm + \"';\"\r\n try:\r\n cur.execute(q1)\r\n db.commit()\r\n print(\"Successfully...\" + q1 )\r\n except:\r\n db.rollback()\r\n print(\"UN-successfully...\" + q1 )\r\n\r\n#method to update the message column within the table on AWS\r\ndef updatemessages(cur, db):\r\n for num in range(0, 11):\r\n rt = message_list[num]\r\n nm = members[num]\r\n q1 = \"UPDATE `ratios`.`ratios` SET `Total` = '\" + str(rt) + \"' WHERE `Name` = '\" + nm + \"';\"\r\n try:\r\n cur.execute(q1)\r\n db.commit()\r\n print(\"Successfully...\" + q1 )\r\n except:\r\n db.rollback()\r\n print(\"UN-successfully...\" + q1 )\r\n\r\n#main method\r\ndb = mysql.connector.connect(host='ratios.cfy6bgj8jv5o.us-west-2.rds.amazonaws.com',database='ratios',user='brohmo',password='aaaoooooohhhhhhhhhh')\r\ncur = db.cursor()\r\nupdateratios(cur, db)\r\nupdatemessages(cur, db)\r\nupdatetime(cur, db)\r\n\r\ndb.close()\r\n"
},
{
"alpha_fraction": 0.8222222328186035,
"alphanum_fraction": 0.8222222328186035,
"avg_line_length": 32.75,
"blob_id": "ee51392f68e513599b78abcf38d62553ba07f6dc",
"content_id": "a9e50acb269cbf181e23c1098400227c5b707db9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 4,
"path": "/README.md",
"repo_name": "rkstan1985/imessagedb2",
"src_encoding": "UTF-8",
"text": "# imessagedb\niMessage Database Analysis\n\nBryan and Ricky's python code for the imessage database file stored locally on Mac computers.\n"
}
] | 2 |
Morena96/Complex-admin-interface | https://github.com/Morena96/Complex-admin-interface | 900159bad207dce2fd35ef92ec90d999373d3a12 | 7f0d501a617dfe57aebd674626b8fa2bea68e305 | 0a2e3b35c4304a4ed1f74f7fea7a8fb44e60e091 | refs/heads/master | 2023-05-04T07:02:30.986456 | 2022-04-14T11:41:39 | 2022-04-14T11:41:39 | 229,714,932 | 8 | 1 | null | 2019-12-23T08:58:46 | 2022-04-14T11:41:44 | 2023-04-21T20:44:10 | JavaScript | [
{
"alpha_fraction": 0.5883108377456665,
"alphanum_fraction": 0.6043673753738403,
"avg_line_length": 33.599998474121094,
"blob_id": "5bad82e2611a46f57ca4f72160eb3076a2597c2f",
"content_id": "1de3cac89cc3ea197d28da820e120c88b69a18dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1561,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 45,
"path": "/Dokument_Dolanysygy/migrations/0002_auto_20191223_0016.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-23 00:16\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='ulanyjy',\n name='ady',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='ulanyjy',\n name='bölümi',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, to='Dokument_Dolanysygy.Bolumler'),\n ),\n migrations.AlterField(\n model_name='ulanyjy',\n name='döreden',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n migrations.AlterField(\n model_name='ulanyjy',\n name='edarasy',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, to='Dokument_Dolanysygy.Edaralar'),\n ),\n migrations.AlterField(\n model_name='ulanyjy',\n name='mac_adresi',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AlterField(\n model_name='ulanyjy',\n name='welaýaty',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, to='Dokument_Dolanysygy.Welayatlar'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5524957180023193,
"alphanum_fraction": 0.585197925567627,
"avg_line_length": 24.2608699798584,
"blob_id": "e5ac4a1ae9ef1cb5938e77498bf628a8477fe80d",
"content_id": "a002d06a1b2f95b55f6ee44ec93fcc57a856df3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 585,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 23,
"path": "/Dokument_Dolanysygy/migrations/0007_auto_20191223_1307.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-23 13:07\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0006_remove_file_welaýaty'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='file',\n name='döredilen_senesi',\n field=models.DateTimeField(auto_now_add=True),\n ),\n migrations.AlterField(\n model_name='file',\n name='üýgedilen_senesi',\n field=models.DateTimeField(auto_now=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6484509706497192,
"alphanum_fraction": 0.6574870944023132,
"avg_line_length": 35.904762268066406,
"blob_id": "9af5aff8b12c8d795981a9e5168c07694daba923",
"content_id": "75374815d6404a054c3b1bbf805a4d5c2a768e73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2340,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 63,
"path": "/Dokument_Dolanysygy/models.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\nfrom django.db import models\nfrom django.contrib.auth.models import AbstractUser\n# Create your models here.\nclass Welayatlar(models.Model):\n ady = models.CharField(max_length=200)\n class Meta:\n verbose_name_plural =(\"Welayatlar\")\n def __str__(self):\n return self.ady\n\nclass Edaralar(models.Model):\n ady = models.CharField(max_length=200)\n welaýaty= models.ForeignKey(Welayatlar,models.CASCADE)\n class Meta:\n verbose_name_plural =(\"Edaralar\")\n def __str__(self):\n return self.ady\n\nclass Bolumler(models.Model):\n ady = models.CharField(max_length=200)\n\n class Meta:\n verbose_name_plural =(\"Bolumler\")\n def __str__(self):\n return self.ady\n\nclass Hasabat(models.Model):\n ady = models.CharField(max_length=200)\n bölümi = models.ForeignKey(Bolumler,on_delete=models.CASCADE)\n class Meta:\n verbose_name_plural =(\"Hasabat\")\n def __str__(self):\n return self.ady\n\nclass Ulanyjy(AbstractUser):\n ady = models.CharField(max_length=200,null=True,blank=True)\n edarasy = models.ForeignKey(Edaralar,on_delete=models.CASCADE,null=True,blank=True)\n bölümi = models.ForeignKey(Bolumler,on_delete=models.CASCADE,null=True,blank=True)\n mac_adresi = models.CharField(max_length=200,null=True,blank=True)\n döreden = models.ForeignKey('self',on_delete=models.CASCADE,null=True,blank=True)\n class Meta:\n verbose_name_plural =(\"Ulanyjylar\")\n def __str__(self):\n return self.username\n\nclass File(models.Model):\n ady = models.CharField(max_length=200)\n eýesi = models.ForeignKey(Ulanyjy,on_delete=models.CASCADE)\n edarasy = models.ForeignKey(Edaralar,on_delete=models.CASCADE)\n bölümi = models.ForeignKey(Bolumler,on_delete=models.CASCADE)\n dokument = models.FileField()\n görnüşi = models.ForeignKey(Hasabat,on_delete=models.CASCADE)\n mazmuny = models.TextField(blank=True,null=True)\n döredilen_senesi = models.DateTimeField(auto_now_add=True)\n üýgedilen_senesi = models.DateTimeField(auto_now=True)\n\n class Meta:\n verbose_name_plural =(\"Faýl\")\n def __str__(self):\n return self.ady"
},
{
"alpha_fraction": 0.49635037779808044,
"alphanum_fraction": 0.7080292105674744,
"avg_line_length": 16.125,
"blob_id": "17c465533845739407f0046f469e746123dce4c1",
"content_id": "0dfd0084a0faf81d2855bf8d894691bf00d7beb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "asgiref==3.2.3\nDjango==3.0.1\ndjango-modeltranslation==0.14.1\ngunicorn==20.0.4\npytz==2019.3\nsix==1.13.0\nsqlparse==0.3.0\nwhitenoise==5.0.1\n"
},
{
"alpha_fraction": 0.5824176073074341,
"alphanum_fraction": 0.6410256624221802,
"avg_line_length": 26.299999237060547,
"blob_id": "9a9d5fd34d63f48108cb3da45c7e5f6fbb1106be",
"content_id": "6fc8b277af25b39252708f3a73fb4b45ff96b6b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 20,
"path": "/Dokument_Dolanysygy/migrations/0011_auto_20191226_0124.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-26 01:24\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0010_auto_20191225_1607'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='ulanyjy',\n name='edarasy',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to='Dokument_Dolanysygy.Edaralar'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.7965517044067383,
"alphanum_fraction": 0.7965517044067383,
"avg_line_length": 28,
"blob_id": "674f7f3ea8c76362ea889e463a41295e0993d914",
"content_id": "8020cd717167dc95bb3732b524911146e941f870",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 290,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 10,
"path": "/Dokument_Dolanysygy/translation.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "from modeltranslation.translator import register, TranslationOptions\nfrom .models import File,Hasabat\n\n@register(File)\nclass NewsTranslationOptions(TranslationOptions):\n fields = ('mazmuny',)\n\n@register(Hasabat)\nclass HasabatTranslationOptions(TranslationOptions):\n fields = ('ady',)\n"
},
{
"alpha_fraction": 0.529940128326416,
"alphanum_fraction": 0.5868263244628906,
"avg_line_length": 18.647058486938477,
"blob_id": "26aeaa22d9640458124f5b357866ec4b29cb0f7b",
"content_id": "6aff65393f0f3b91020e450a97ddf2e89f1069fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 17,
"path": "/Dokument_Dolanysygy/migrations/0006_remove_file_welaýaty.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-23 02:35\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0005_file_mazmuny'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='file',\n name='welaýaty',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5061082243919373,
"alphanum_fraction": 0.5706806182861328,
"avg_line_length": 23.913043975830078,
"blob_id": "8411b99b90cb90b349791417b277bf974fb2bc14",
"content_id": "ed6661d2d3ae7f2b85d87072007ba0b9e921c9c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/Dokument_Dolanysygy/migrations/0010_auto_20191225_1607.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-25 16:07\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0009_auto_20191225_1547'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='hasabat',\n name='ady_ru',\n field=models.CharField(max_length=200, null=True),\n ),\n migrations.AddField(\n model_name='hasabat',\n name='ady_tr',\n field=models.CharField(max_length=200, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6447486877441406,
"alphanum_fraction": 0.6454693078994751,
"avg_line_length": 37.28965377807617,
"blob_id": "95e3b139453b0c02c2cb601b73d57b163c98e721",
"content_id": "8f3bb4b8d2757e5917b5504501e2ffa4cb1fde15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5608,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 145,
"path": "/Dokument_Dolanysygy/admin.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "from django.db.models.signals import post_save\nfrom django.dispatch import receiver\nfrom django.contrib import admin\nfrom .models import *\nfrom django.contrib.auth.models import Group\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.admin import UserAdmin\nfrom django.utils.translation import gettext_lazy as _\n# Register your models here.\n\nadmin.site.site_header = \"asd\"\n#admin.site.index_title = \"Stan\"\nadmin.site.site_title = \"Edara\"\n\nclass WelayatlarAdmin(admin.ModelAdmin):\n pass\n\nadmin.site.register(Welayatlar,WelayatlarAdmin)\n\nclass EdaralarAdmin(admin.ModelAdmin):\n list_display = ['ady','welaýaty']\n list_filter= ('welaýaty',)\n list_per_page=30\nadmin.site.register(Edaralar,EdaralarAdmin)\n\nclass BolumlerAdmin(admin.ModelAdmin):\n list_display = ['ady']\n\nadmin.site.register(Bolumler,BolumlerAdmin)\n\nclass FileAdmin(admin.ModelAdmin):\n list_display = ['ady','eýesi','welayaty','edarasy','bölümi','görnüşi','dokument'\n ,'döredilen_senesi','üýgedilen_senesi']\n fields = ('ady','görnüşi','dokument','mazmuny_tr','mazmuny_ru')\n date_hierarchy = 'döredilen_senesi'\n def formfield_for_foreignkey(self, db_field, request, **kwargs):\n# if db_field.name == \"welaýaty\" and (not request.user.is_superuser):\n# print(request.user.welaýaty)\n# kwargs[\"initial\"] = request.user.welaýaty\n# kwargs['disabled'] = True\n if db_field.name == \"görnüşi\":\n kwargs[\"queryset\"] = Hasabat.objects.filter(bölümi=request.user.bölümi)\n return super().formfield_for_foreignkey(db_field, request, **kwargs)\n def get_queryset(self, request):\n qs = super().get_queryset(request)\n if request.user.is_superuser or request.user.groups.filter(name='Gozegci').exists:\n return qs\n if(request.user.groups.filter(name='Ulanyjy').exists()):\n return qs.filter(eýesi=request.user)\n if(request.user.groups.filter(name='Admin').exists()):\n return qs.filter(eýesi__döreden=request.user)\n return qs.filter(edarasy=request.user.edarasy)\n\n def save_model(self, request, obj, form, change):\n obj.eýesi = request.user\n obj.edarasy=request.user.edarasy\n obj.bölümi=request.user.bölümi\n super().save_model(request, obj, form, change)\n\n def welayaty(self,obj):\n if obj.edarasy:\n return obj.edarasy.welaýaty\n \n def has_delete_permission(self, request, obj=None):\n if(request.user.groups.filter(name='Ulanyjy').exists()):\n return True\n return False\n\n def has_add_permission(self,request):\n if(request.user.groups.filter(name='Ulanyjy').exists()):\n return True\n return False\n def has_change_permission(self,request, obj=None):\n if(request.user.groups.filter(name='Ulanyjy').exists()):\n return True\n return False\n\n\n# empty_value_display = '-empty-'\nadmin.site.register(File,FileAdmin)\n\nclass HasabatAdmin(admin.ModelAdmin):\n list_display = ['ady','bölümi']\n fields=['ady_tr','ady_ru','bölümi']\nadmin.site.register(Hasabat,HasabatAdmin)\n\n#@receiver(post_save, sender=Ulanyjy)\n#def create_user_profile(sender, instance, created, **kwargs):\n# if created:\n# if instance.döreden.is_superuser:\n# instance.groups.add(Group.objects.get(name='Admin'))\n# else:\n# print('bb')\n# instance.groups.add(Group.objects.get(name='Ulanyjy'))\n\nclass UlanyjyAdmin(UserAdmin):\n list_display = ['username','ady','edarasy','welayaty','bölümi','döreden','mac_adresi']#\n fieldsets = (\n (None, {\n 'fields': ( 'username','ady','edarasy','bölümi','password','mac_adresi','groups')\n }),\n ('Goşmaça Maglumatlar', {\n 'classes': ('collapse',),\n 'fields': ('first_name', 'last_name'),\n }),\n )\n\n def formfield_for_foreignkey(self, db_field, request, **kwargs):\n# if db_field.name == \"welaýaty\" and (not request.user.is_superuser):\n# print(request.user.welaýaty)\n# kwargs[\"initial\"] = request.user.welaýaty\n# kwargs['disabled'] = True\n\n if db_field.name == \"edarasy\" and (not request.user.is_superuser):\n kwargs['disabled'] = True\n return super().formfield_for_foreignkey(db_field, request, **kwargs)\n def formfield_for_manytomany(self, db_field, request, **kwargs):\n if db_field.name == \"groups\":\n if(not request.user.is_superuser):\n kwargs['queryset']=Group.objects.filter(name='Ulanyjy')\n else:\n kwargs['queryset']=Group.objects.exclude(name='Ulanyjy')\n return super().formfield_for_manytomany(db_field, request, **kwargs)\n def get_queryset(self, request):\n qs = super().get_queryset(request)\n if request.user.is_superuser:\n return qs\n return qs.filter(döreden=request.user)\n\n def save_model(self, request, obj, form, change):\n if not obj.döreden:\n obj.döreden = request.user\n obj.is_staff=True\n if request.user.edarasy:\n obj.edarasy=request.user.edarasy\n if not obj.edarasy and request.user.is_superuser:\n obj.edarasy=Edaralar.objects.all()[0]\n if not obj.bölümi and request.user.groups.filter(name='Admin').exists():\n obj.bölümi=Bolumler.objects.all()[0]\n super().save_model(request, obj, form, change)\n def welayaty(self,obj):\n if obj.edarasy:\n return obj.edarasy.welaýaty\n\nadmin.site.register(Ulanyjy,UlanyjyAdmin)"
},
{
"alpha_fraction": 0.5481651425361633,
"alphanum_fraction": 0.5917431116104126,
"avg_line_length": 21.947368621826172,
"blob_id": "bb2435e915b3eae7ef6fddee01e571e7ec5626f2",
"content_id": "d056dac0188b07c3e727b2e7791873b0c7ebcc8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/Dokument_Dolanysygy/migrations/0005_file_mazmuny.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-23 02:16\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0004_remove_ulanyjy_welaýaty'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='file',\n name='mazmuny',\n field=models.TextField(default='sad'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5209876298904419,
"alphanum_fraction": 0.5975308418273926,
"avg_line_length": 21.5,
"blob_id": "e6146bb4047127b9a5875be2bf7059b74c5e1ee8",
"content_id": "597d78d71ecd3bd51f1690881439096ec2fe397e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 18,
"path": "/Dokument_Dolanysygy/migrations/0008_auto_20191225_1545.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.1 on 2019-12-25 15:45\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('Dokument_Dolanysygy', '0007_auto_20191223_1307'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='file',\n name='mazmuny',\n field=models.TextField(blank=True, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7602739930152893,
"alphanum_fraction": 0.7602739930152893,
"avg_line_length": 23.33333396911621,
"blob_id": "593f358071d5b2dea542da0fdb586c3d5cc35ae6",
"content_id": "7f822d8ba4421f0efdf7d0b3bc313e70676c5c79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 6,
"path": "/Dokument_Dolanysygy/apps.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass DokumentDolanysygyConfig(AppConfig):\n name = 'Dokument_Dolanysygy'\n verbose_name = \"admin paneli\"\n"
},
{
"alpha_fraction": 0.7278732061386108,
"alphanum_fraction": 0.7463672161102295,
"avg_line_length": 22.6875,
"blob_id": "497a0e7aa2511713dc1f9096463e3a32072834f8",
"content_id": "3ab363c1675c092450357fd5d80d411294e731b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/README.md",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "# Complex-admin-interface\nFile share system implemented in Django Framework.\n\n## Setup\n\nThe first thing to do is to clone the repository:\n\n```sh\n$ git clone https://github.com/Morena96/Complex-admin-interface.git\n$ cd Complex-admin-interface\n```\n\nCreate a virtual environment to install dependencies in and activate it:\n\n```sh\n$ virtualenv2 --no-site-packages env\n$ source env/bin/activate\n```\n\nThen install the dependencies:\n\n```sh\n(env)$ pip install -r requirements.txt\n```\nNote the `(env)` in front of the prompt. This indicates that this terminal\nsession operates in a virtual environment set up by `virtualenv2`.\n\nOnce `pip` has finished downloading the dependencies:\n```sh\n(env)$ python manage.py runserver\n```\nAnd navigate to `http://127.0.0.1:8000`."
},
{
"alpha_fraction": 0.8611111044883728,
"alphanum_fraction": 0.8611111044883728,
"avg_line_length": 72,
"blob_id": "80aa63197d700f41595b247f10f89c41597b643f",
"content_id": "464cef505f9fd268fa71f0ee5eb33c4780b42a2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 1,
"path": "/Dokument_Dolanysygy/__init__.py",
"repo_name": "Morena96/Complex-admin-interface",
"src_encoding": "UTF-8",
"text": "default_app_config = 'Dokument_Dolanysygy.apps.DokumentDolanysygyConfig'"
}
] | 14 |
AbdurRahman111/SonMon_ShoppingZone | https://github.com/AbdurRahman111/SonMon_ShoppingZone | 355f7f097be313fedcc2e9335770e925bbe359f4 | 22982dc5fabbf3a1bad49d3bdecbd3a2b53cc725 | e23d352afa63ca6b2490a1ec037260379d2c932b | refs/heads/master | 2023-01-01T00:59:44.593095 | 2020-10-27T17:30:14 | 2020-10-27T17:30:14 | 307,680,655 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6244897842407227,
"alphanum_fraction": 0.6244897842407227,
"avg_line_length": 35.75,
"blob_id": "a5574e2f436db224318624647cb972331542b810",
"content_id": "4b65f911e410c2615f56162fe646a858fef56387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 735,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 20,
"path": "/SonMon/monsonapp/urls.py",
"repo_name": "AbdurRahman111/SonMon_ShoppingZone",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\nurlpatterns = [\n path('', views.index, name='index'),\n path('index', views.index, name='index'),\n path('mens', views.mens, name='mens'),\n path('men', views.men, name='men'),\n path('women', views.women, name='women'),\n path('womens', views.womens, name='womens'),\n path('boys', views.boys, name='boys'),\n path('girls', views.girls, name='girls'),\n path('about', views.about, name='about'),\n path('blog', views.blog, name='blog'),\n path('contact', views.contact, name='contact'),\n path('checkout', views.checkout, name='checkout'),\n path('checkout.html', views.checkout, name='checkout'),\n path('payment', views.payment, name='payment'),\n \n]\n"
},
{
"alpha_fraction": 0.7634408473968506,
"alphanum_fraction": 0.7634408473968506,
"avg_line_length": 17.600000381469727,
"blob_id": "e8e0665bb57df5ad1b57d2f74d06219b3c15ea5d",
"content_id": "ce5996832770a163276c9365a5a1cc5ef26a286c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/SonMon/monsonapp/apps.py",
"repo_name": "AbdurRahman111/SonMon_ShoppingZone",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass MonsonappConfig(AppConfig):\n name = 'monsonapp'\n"
},
{
"alpha_fraction": 0.7523364424705505,
"alphanum_fraction": 0.7523364424705505,
"avg_line_length": 18.454545974731445,
"blob_id": "b75baefa778556d5d7f575bd6fef7515fe2a6302",
"content_id": "fcab1a349303d8a7430465b706ac6ec1c9003f3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 11,
"path": "/SonMon/monsonapp/admin.py",
"repo_name": "AbdurRahman111/SonMon_ShoppingZone",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import register\n\n# Register your models here.\n\nclass register_dis(admin.ModelAdmin):\n list_display = ['name','email']\n\n\n\nadmin.site.register(register, register_dis)\n"
},
{
"alpha_fraction": 0.6745283007621765,
"alphanum_fraction": 0.6745283007621765,
"avg_line_length": 16.081632614135742,
"blob_id": "0a9397262f65153203ba8c0f60b1d4f827d1b641",
"content_id": "1965606016adb1a3807326fc207480c173c1525f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 49,
"path": "/SonMon/monsonapp/views.py",
"repo_name": "AbdurRahman111/SonMon_ShoppingZone",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n# Create your views here.\n\n\ndef index(request):\n return render(request, 'index.html')\n\n\ndef men(request):\n return render(request, 'men.html')\n\n\ndef mens(request):\n return render(request, 'mens.html') \n\n\ndef women(request):\n return render(request, 'women.html')\n\ndef womens(request):\n return render(request, 'womens.html') \n\n\ndef boys(request):\n return render(request, 'boys.html')\n\n\ndef girls(request):\n return render(request, 'girls.html') \n \n\ndef about(request):\n\treturn render(request, 'about.html') \n\n\ndef blog(request):\n\treturn render(request, 'blog.html') \n\ndef contact(request):\n\treturn render(request, 'contact.html') \n\n\ndef checkout(request):\n return render(request, 'checkout.html') \n\n\ndef payment(request):\n return render(request, 'payment.html') \n\n"
},
{
"alpha_fraction": 0.7179487347602844,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 26.399999618530273,
"blob_id": "4d011cc7bbe0b2b27943c9d705cc55ce5ed27080",
"content_id": "378312c273f69b3244a03f45160fba2589006643",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/SonMon/monsonapp/models.py",
"repo_name": "AbdurRahman111/SonMon_ShoppingZone",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\n\nclass register(models.Model):\n name=models.CharField(max_length=200)\n email=models.CharField(max_length=200)\n password=models.CharField(max_length=200)\n confirm_password=models.CharField(max_length=200)"
}
] | 5 |
gavinatthu/Parttern-Recognition | https://github.com/gavinatthu/Parttern-Recognition | a9cf047b1c394e825c5b3b3cc817c74566fdca94 | c62d434202787b5e0e34baf1a6a6276ecac0c572 | 2213e645045e8bef5d3806de9a6cf8e818593dce | refs/heads/main | 2023-04-30T01:48:31.368816 | 2021-05-25T12:51:31 | 2021-05-25T12:51:31 | 351,312,134 | 3 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7413793206214905,
"alphanum_fraction": 0.7413793206214905,
"avg_line_length": 28,
"blob_id": "3540c0dd230a6fa5b4c02790b966bbeeb767cdae",
"content_id": "6927d25b152a28998b1eb23ab282691fb44204db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 2,
"path": "/HW3/readme.md",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "## EM Method \nEM Method for GMM is implemented by matlab\n"
},
{
"alpha_fraction": 0.6888889074325562,
"alphanum_fraction": 0.6888889074325562,
"avg_line_length": 20.5,
"blob_id": "013bfef731a5cdcd8c8a3b81ceefac31e105ddf8",
"content_id": "e84fcefa1fd35dea1005e8c9b71eddc0ed7292a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 2,
"path": "/HW4/readme.md",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "## Parzen Window \n## Perception Algorithm \n"
},
{
"alpha_fraction": 0.5017555952072144,
"alphanum_fraction": 0.5121137499809265,
"avg_line_length": 28.821989059448242,
"blob_id": "b3c02321d2d22a2dc7d0c1d9f4925e83cc997eea",
"content_id": "672528c6d451c34fce9d8c48a97bad7447dee64a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5698,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 191,
"path": "/HW12/adaboost.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nfrom numpy.core.numeric import Inf\nimport scipy.io as scio\nimport matplotlib.pyplot as plt\nimport time\n\ndef adaboost(X, y, X_test, y_test, maxIter):\n '''\n adaboost: carry on adaboost on the data for maxIter loops\n Input \n X : n * p matirx, training data\n y : (n, ) vector, training label\n X_test : m * p matrix, testing data\n y_test : (m, ) vector, testing label\n maxIter : number of loops\n Output\n e_train : (maxIter, ) vector, errors on training data\n e_test : (maxIter, ) vector, errors on testing data\n '''\n\n w = np.ones(y.shape, dtype='float') / y.shape[0]\n\n k = np.zeros(maxIter, dtype='int')\n a = np.zeros(maxIter)\n d = np.zeros(maxIter)\n alpha = np.zeros(maxIter)\n\n e_train = np.zeros(maxIter)\n e_test = np.zeros(maxIter)\n\n for i in range(maxIter):\n k[i], a[i], d[i] = decision_stump(X, y, w)\n print('new decision stump k:%d a:%f, d:%d' % (k[i], a[i], d[i]))\n \n e = decision_stump_error(X, y, k[i], a[i], d[i], w)\n #alpha[i] = np.log((1 - e) / e)\n alpha[i] = 0.5 * np.log((1 - e) / e)\n w = update_weights(X, y, k[i], a[i], d[i], w, alpha[i])\n \n e_train[i] = adaboost_error(X, y, k, a, d, alpha)\n e_test[i] = adaboost_error(X_test, y_test, k, a, d, alpha)\n print('weak learner error rate: %f\\nadaboost error rate: %f\\ntest error rate: %f\\n' % (e, e_train[i], e_test[i]))\n\n return e_train, e_test\n\ndef plot_error(e_train, e_test):\n plt.figure()\n plt.plot(e_train, label = 'train')\n plt.plot(e_test, label = 'test')\n plt.legend(loc = 'upper right')\n plt.title('Error vs iters')\n plt.xlabel('Iters')\n plt.ylabel('Error')\n plt.savefig('adaboost01.png', dpi=300)\n plt.show()\n\n\ndef decision_stump(X, y, w):\n '''\n decision_stump returns a rule ...\n h(x) = d if x(k) <= a, −d otherwise,\n Input\n X : n * p matrix, each row a sample\n y : (n, ) vector, each row a label\n w : (n, ) vector, each row a weight\n Output\n k : the optimal dimension\n a : the optimal threshold\n d : the optimal d, 1 or -1\n '''\n\n # total time complexity required to be O(p*n*logn) or less\n ### Your Code Here ###\n\n num_step = 100\n min_error = Inf\n\n for i in range(X.shape[1]):\n step = (np.max(X[:, i]) - np.min(X[:, i]))/num_step\n temp_stump = np.min(X[:, i])\n for j in range(num_step):\n for temp_d in [1, -1]:\n E = decision_stump_error(X, y, i, temp_stump, temp_d, w)\n if E < min_error:\n min_error = E\n #print('update E=', E)\n k, a, d = i, temp_stump, temp_d\n #print(k, a, d)\n\n temp_stump += step\n \n ### Your Code Here ###\n return k, a, d\n\n\ndef decision_stump_error(X, y, k, a, d, w):\n '''\n decision_stump_error returns error of the given stump\n Input\n X : n * p matrix, each row a sample\n y : (n, ) vector, each row a label\n k : selected dimension of features\n a : selected threshold for feature-k\n d : 1 or -1\n Output\n e : number of errors of the given stump \n '''\n #p = ((X[:, k] <= a).astype('float') - 0.5) * 2 * d # predicted label\n p = np.where(X[:, k] <= a, d, -d)\n e = np.sum((p.astype('int') != y) * w)\n\n return e\n\n\ndef update_weights(X, y, k, a, d, w, alpha):\n '''\n update_weights update the weights with the recent classifier\n \n Input\n X : n * p matrix, each row a sample\n y : (n, ) vector, each row a label\n k : selected dimension of features\n a : selected threshold for feature-k\n d : 1 or -1\n w : (n, ) vector, old weights\n alpha : weights of the classifiers\n \n Output\n w_update : (n, ) vector, the updated weights\n '''\n\n ### Your Code Here ###\n p = np.where(X[:, k] <= a, d, -d)\n #p = ((X[:, k] <= a).astype('float') - 0.5) * 2 * d\n w_update = w * np.exp(- alpha * y * p )\n w_update = w_update / np.sum(w_update)\n\n ### Your Code Here ###\n \n return w_update\n\n\n\ndef adaboost_error(X, y, k, a, d, alpha):\n '''\n adaboost_error: returns the final error rate of a whole adaboost\n \n Input\n X : n * p matrix, each row a sample\n y : (n, ) vector, each row a label\n k : (iter, ) vector, selected dimension of features\n a : (iter, ) vector, selected threshold for feature-k\n d : (iter, ) vector, 1 or -1\n alpha : (iter, ) vector, weights of the classifiers\n Output\n e : error rate\n '''\n\n ### Your Code Here ###\n\n n, _ = X.shape\n pre_label = []\n sum = np.zeros_like(y)\n for i in range(len(k)):\n #p = ((X[:, k[i]] <= a[i]).astype('float') - 0.5) * 2 * d[i]\n p = np.where(X[:, k[i]] <= a[i], d[i], -d[i])\n temp = alpha[i] * p\n sum = sum + temp\n\n pre_label.append(np.sign(sum))\n e = np.sum(pre_label!=y) / n\n ### Your Code Here ###\n return e\n\nif __name__ == '__main__':\n\n dataFile = 'ada_data.mat'\n data = scio.loadmat(dataFile)\n X_train = data['X_train'] #(1000, 25), float\n X_test = data['X_test'] #(1000, 25)\n y_train = data['y_train'].ravel() #(1000, ), +1 or -1\n y_test = data['y_test'].ravel() #(1000, )\n \n ### Your Code Here ###\n start = time.time()\n e_train, e_test = adaboost(X_train, y_train, X_test, y_test, 300)\n print('time =', time.time() - start)\n plot_error(e_train, e_test)\n\n ### Your Code Here ###\n"
},
{
"alpha_fraction": 0.5789473652839661,
"alphanum_fraction": 0.5789473652839661,
"avg_line_length": 16,
"blob_id": "96cd3618166ee5fa6e0341577493ad54dd5268a1",
"content_id": "d5481d718e05e03e4302ed922d940cdf768919c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 1,
"path": "/HW6/readme.md",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "## KNN for MNIST \n"
},
{
"alpha_fraction": 0.6190926432609558,
"alphanum_fraction": 0.6663516163825989,
"avg_line_length": 23.85365867614746,
"blob_id": "38d4be6da329fe2eb23d3a16914af1c1983ab404",
"content_id": "c5a590b59b9c6a9bd2781d227638adbf339c2bbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1058,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 41,
"path": "/HW8/hw10.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\r\nfrom sklearn import manifold\r\nfrom utils import *\r\n\r\nn_points = 500\r\nX, color = make_w_curve(n_points, random_state=0)\r\nn_neighbors = 30\r\nn_components = 2\r\n\r\n\r\nmy_isomap = My_Isomap(n_neighbors, n_components)\r\ndata_1 = my_isomap.isomap(X)\r\nmy_isomap.scatter_3d(color)\r\ndata_2 = manifold.Isomap(n_neighbors, n_components).fit_transform(X)\r\n\r\n\r\nmy_lle = My_LLE(n_neighbors, n_components)\r\ndata_3 = my_lle.lle(X)\r\ndata_4 = manifold.LocallyLinearEmbedding(n_components=2, n_neighbors = 30).fit_transform(X)\r\n\r\n\r\nplt.figure(figsize=(10,10))\r\nplt.subplot(221)\r\nplt.title(\"my_Isomap\")\r\nplt.scatter(data_1[:, 0], data_1[:, 1], c = color)\r\nplt.subplot(222)\r\nplt.title(\"sklearn_Isomap\")\r\nplt.scatter(data_2[:, 0], data_2[:, 1], c = color)\r\n#plt.savefig(\"Isomap.png\")\r\n#plt.show()\r\n\r\n\r\n#plt.figure(figsize=(10,5))\r\nplt.subplot(223)\r\nplt.title(\"My_LLW\")\r\nplt.scatter(data_3[:, 0], data_3[:, 1], c = color)\r\nplt.subplot(224)\r\nplt.title(\"sklearn_LLE\")\r\nplt.scatter(data_4[:, 0], data_4[:, 1], c = color)\r\nplt.savefig(\"LLE.png\")\r\nplt.show()"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.7115384340286255,
"avg_line_length": 24.5,
"blob_id": "64f15443c1fc8c0034d0c15849c0cbe542823cdb",
"content_id": "93023733afba59b8e42a38ca78a11b4baa0c5592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/HW5/readme.md",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "## 2-class SVD \nUsing sklearn for svd classifier. \n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.4285714328289032,
"avg_line_length": 8.5,
"blob_id": "02e57691a08ccb09b6532c89f767f3b009904e2d",
"content_id": "509fb7304fed2edb4c3ece1139e0a3eaa155fca6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 21,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 2,
"path": "/HW8/readme.md",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "## ISOMAP \n## LLE \n"
},
{
"alpha_fraction": 0.46261486411094666,
"alphanum_fraction": 0.4887218177318573,
"avg_line_length": 31.690141677856445,
"blob_id": "c8241f9e826c1189d83cc7fa6c832b0e6dc59460",
"content_id": "99860c4a211501ddf16c7eb87dadbb229f9d2db1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4788,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 142,
"path": "/HW8/utils.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\n\r\nimport matplotlib.pyplot as plt\r\ndef make_z_curve(n_samples=100, *, noise=0.0, random_state=None):\r\n\r\n t = 3 * np.pi * (np.random.rand(1, n_samples) - 0.5)\r\n x = -np.sin(t)\r\n y = 2.0 * np.random.rand(1, n_samples)\r\n z = np.sign(t) * (np.cos(t) - 1)\r\n\r\n X = np.concatenate((x, y, z))\r\n X += noise * np.random.randn(3, n_samples)\r\n X = X.T\r\n t = np.squeeze(t)\r\n return X, t\r\n\r\ndef make_w_curve(n_samples=100, *, noise=0.0, random_state=None):\r\n x = 4.0 * np.random.rand(1, n_samples) - 2\r\n z = np.cos(np.pi * x)\r\n y = 2.0 * np.random.rand(1, n_samples)\r\n\r\n X = np.concatenate((x, y, z))\r\n X += noise * np.random.randn(3, n_samples)\r\n X = X.T\r\n return X, x\r\n\r\n\r\nclass My_Isomap():\r\n def __init__(self, n_neighbors=30, n_components=2):\r\n self.n_neighbors = n_neighbors\r\n self.n_components = n_components\r\n\r\n def isomap(self, input):\r\n self.input = input\r\n dist = self.cal_pairwise_dist()\r\n dist[dist < 0] = 0\r\n dist = dist**0.5\r\n dist_floyd = self.floyd(dist)\r\n data_n = self.my_mds(dist_floyd, n_dims=self.n_components)\r\n return data_n\r\n\r\n def cal_pairwise_dist(self):\r\n x = self.input\r\n sum_x = np.sum(np.square(x), 1)\r\n dist = np.add(np.add(-2 * np.dot(x, x.T), sum_x).T, sum_x)\r\n return dist\r\n\r\n def floyd(self, D):\r\n Max = np.max(D)*1000\r\n n1,_ = D.shape\r\n k = self.n_neighbors\r\n D1 = np.ones((n1,n1))*Max\r\n D_arg = np.argsort(D,axis=1)\r\n for i in range(n1):\r\n D1[i,D_arg[i,0:k+1]] = D[i,D_arg[i,0:k+1]]\r\n for k in range(n1):\r\n for i in range(n1):\r\n for j in range(n1):\r\n if D1[i,k]+D1[k,j]<D1[i,j]:\r\n D1[i,j] = D1[i,k]+D1[k,j]\r\n return D1\r\n\r\n def my_mds(self, dist, n_dims):\r\n # dist (n_samples, n_samples)\r\n dist = dist**2\r\n n = dist.shape[0]\r\n T1 = np.ones((n,n))*np.sum(dist)/n**2\r\n T2 = np.sum(dist, axis = 1)/n\r\n T3 = np.sum(dist, axis = 0)/n\r\n B = -(T1 - T2 - T3 + dist)/2\r\n eig_val, eig_vector = np.linalg.eig(B)\r\n index_ = np.argsort(-eig_val)[:n_dims]\r\n picked_eig_val = eig_val[index_].real\r\n picked_eig_vector = eig_vector[:, index_]\r\n\r\n return picked_eig_vector*picked_eig_val**(0.5)\r\n\r\n def scatter_3d(self, y):\r\n X = self.input\r\n fig = plt.figure(figsize=(12, 10))\r\n fig.suptitle(\"Manifold Learning with %i points, %i neighbors\"\r\n % (1000, self.n_neighbors), fontsize=18)\r\n ax = fig.add_subplot(111, projection='3d')\r\n ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=y, cmap=plt.cm.Spectral)\r\n ax.view_init(10, -70)\r\n ax.set_xlabel(\"$X$\", fontsize=18)\r\n ax.set_ylabel(\"$Y$\", fontsize=18)\r\n ax.set_zlabel(\"$Z$\", fontsize=18)\r\n plt.show()\r\n plt.savefig(\"scatter_3d.png\")\r\n\r\nclass My_LLE():\r\n def __init__(self, n_neighbors, n_components):\r\n self.n_neighbors = n_neighbors\r\n self.n_components = n_components\r\n\r\n def cal_pairwise_dist(self):\r\n x = self.input\r\n sum_x = np.sum(np.square(x), 1)\r\n dist = np.add(np.add(-2 * np.dot(x, x.T), sum_x).T, sum_x)\r\n return dist\r\n\r\n def get_n_neighbors(self):\r\n dist = self.cal_pairwise_dist()\r\n dist[dist < 0] = 0\r\n dist = dist**0.5\r\n n = dist.shape[0]\r\n N = np.zeros((n, self.n_neighbors))\r\n for i in range(n):\r\n index_ = np.argsort(dist[i])[1:self.n_neighbors+1]\r\n N[i] = N[i] + index_\r\n return N.astype(np.int32)\r\n\r\n def lle(self, input):\r\n self.input = input\r\n N = self.get_n_neighbors()\r\n n, D = self.input.shape\r\n if self.n_neighbors > D:\r\n tol = 1e-3\r\n else:\r\n tol = 0\r\n W = np.zeros((self.n_neighbors, n))\r\n I = np.ones((self.n_neighbors, 1))\r\n for i in range(n):\r\n Xi = np.tile(self.input[i], (self.n_neighbors, 1)).T\r\n Ni = self.input[N[i]].T\r\n Si = np.dot((Xi-Ni).T, (Xi-Ni))\r\n Si = Si+np.eye(self.n_neighbors)*tol*np.trace(Si)\r\n Si_inv = np.linalg.pinv(Si)\r\n wi = (np.dot(Si_inv, I))/(np.dot(np.dot(I.T, Si_inv), I)[0,0])\r\n W[:, i] = wi[:,0]\r\n W_y = np.zeros((n, n))\r\n for i in range(n):\r\n index = N[i]\r\n for j in range(self.n_neighbors):\r\n W_y[index[j],i] = W[j,i]\r\n I_y = np.eye(n)\r\n M = np.dot((I_y - W_y), (I_y - W_y).T)\r\n eig_val, eig_vector = np.linalg.eig(M)\r\n index_ = np.argsort(np.abs(eig_val))[1:self.n_components+1]\r\n Y = eig_vector[:, index_]\r\n return Y\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.599452555179596,
"alphanum_fraction": 0.6186131238937378,
"avg_line_length": 19.115385055541992,
"blob_id": "cf4bffb076e73a736765cfd499cfa68cba64f4fb",
"content_id": "5fffb981c36f3d75b5bd8f7681c006b6edcb3591",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1096,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 52,
"path": "/HW11/hw11_GCN.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport networkx as nx\r\nimport matplotlib.pyplot as plt\r\n\r\n\r\nzkc = nx.karate_club_graph()\r\n\r\nG = nx.karate_club_graph()\r\nprint(\"Node Degree\")\r\nfor v in G:\r\n print(f\"{v:4} {G.degree(v):6}\")\r\nnx.draw_circular(G, with_labels=True)\r\nplt.show()\r\n\r\n\r\norder = sorted(list(zkc.nodes()))\r\n\r\n\r\ndef ReLU(input):\r\n output = np.maximum(0,input)\r\n return output\r\n\r\n\r\ndef gcn_layer(A_hat, D_hat, X, W):\r\n return ReLU(np.linalg.inv(D_hat) * A_hat * X * W)\r\n\r\n\r\nA = nx.to_numpy_matrix(zkc, nodelist=order)\r\nI = np.eye(zkc.number_of_nodes())\r\nA_hat = A + I\r\n\r\nD_hat = np.array(np.sum(A_hat, axis=0))\r\nD_hat = np.diag(D_hat[0])\r\n\r\n# initialize the weights randomly\r\nW_1 = np.random.normal(\r\n loc=0, scale=1, size=(zkc.number_of_nodes(), 4))\r\nW_2 = np.random.normal(\r\n loc=0, size=(W_1.shape[1], 2))\r\n\r\n# propagation\r\nH_1 = gcn_layer(A_hat, D_hat, I, W_1)\r\noutput = gcn_layer(A_hat, D_hat, H_1, W_2)\r\n\r\n\r\n\r\nnx.draw(zkc,node_color=order,cmap=plt.cm.Blues, with_labels=True)\r\nplt.show\r\n\r\nplt.figure(2)\r\nplt.scatter([output[:,0]],[output[:,1]],c= order, cmap=plt.cm.Blues)\r\nplt.show"
},
{
"alpha_fraction": 0.5346378684043884,
"alphanum_fraction": 0.5445794463157654,
"avg_line_length": 35.50887680053711,
"blob_id": "8077a06655b4809c3eb00d17ba01ac51fcaa1adf",
"content_id": "f16dff73a1c3e0a3e56646c1e1246bc66bb62570",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6583,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 169,
"path": "/HW11/test.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport scipy.io as sio\r\nimport math\r\nimport time\r\n\r\nclass MyTree(object):\r\n def __init__(self, data, datalabel, depth):\r\n self.leftchild = None\r\n self.rightchild = None\r\n self.label = 0\t\t\t#判断这一类属于什么文档类型\r\n self.keynumber = -1\t\t#作为该节点继续向下分的关键词编号,叶子结点为-1\r\n self.delta_entropy = 0.0\r\n self.entropy = 0.0\t\t#该节点的熵\r\n self.data = data\r\n self.datalabel = datalabel\r\n self.count = dict()\r\n self.depth = depth\r\n self.error_num = 0\r\n\r\n def Impurity(self):\r\n '''不纯度采用Shannon Entropy进行计算'''\r\n num = len(self.datalabel)\r\n for i in range(num):\r\n ind = self.datalabel[i][0]\r\n if ind not in self.count:\r\n self.count[ind] = 1\r\n else:\r\n self.count[ind] += 1\r\n\r\n maxv = 0\r\n self.entropy = 0.0\r\n for i in self.count:\r\n p = self.count[i]/num\r\n self.entropy -= p*math.log2(p)\r\n if self.count[i] > maxv:\r\n maxv = self.count[i]\r\n self.label = i\r\n\r\n def SelectFeature(self):\r\n '''在当前节点选择待分特征:具有最大信息增益的特征'''\r\n keyamount = len(self.data[0])\r\n docamount = len(self.data)\r\n for k in range(keyamount):\r\n leftdata = []\r\n leftdatalabel = []\r\n rightdata = []\r\n rightdatalabel = []\r\n for i in range(docamount):\r\n if self.data[i][k]:\r\n leftdata.append(self.data[i])\r\n leftdatalabel.append(self.datalabel[i])\r\n else:\r\n rightdata.append(self.data[i])\r\n rightdatalabel.append(self.datalabel[i])\r\n\r\n templeftchild = Tree(leftdata, leftdatalabel, self.depth + 1)\r\n temprightchild = Tree(rightdata, rightdatalabel, self.depth + 1)\r\n templeftchild.Impurity()\r\n temprightchild.Impurity()\r\n tempde = self.entropy - (len(leftdata)*templeftchild.entropy/docamount +\r\n len(rightdata)*temprightchild.entropy/docamount)\r\n if tempde > self.delta_entropy:\r\n self.delta_entropy = tempde\r\n self.leftchild = templeftchild\r\n self.rightchild = temprightchild\r\n self.keynumber = k\r\n\r\n def SplitNode(self, de_threshold, depth_threshold):\r\n if self.delta_entropy > de_threshold and self.depth < depth_threshold:\r\n self.data = None\r\n self.datalabel = None\r\n self.count = dict()\r\n self.delta_entropy = 0.0\r\n self.entropy = 0.0\r\n return True\r\n else:\r\n self.leftchild = None\r\n self.rightchild = None\r\n self.keynumber = -1\r\n self.data = None\r\n self.datalabel = None\r\n self.count = dict()\r\n self.delta_entropy = 0.0\r\n self.entropy = 0.0\r\n return False\r\n\r\n def GenerateTree(self, de_threshold, depth_threshold):\r\n self.SelectFeature()\r\n if self.SplitNode(de_threshold, depth_threshold):\r\n self.leftchild.GenerateTree(de_threshold, depth_threshold)\r\n self.rightchild.GenerateTree(de_threshold, depth_threshold)\r\n\r\n def Refresh(self, data, datalabel):\r\n '''计算当前节点下的错误个数'''\r\n self.error_num = 0\r\n leftdata = []\r\n leftdatalabel = []\r\n rightdata = []\r\n rightdatalabel = []\r\n for i in range(len(data)):\r\n if datalabel[i][0] != self.label:\r\n self.error_num += 1\r\n if self.keynumber >= 0:\r\n if data[i][self.keynumber]:\r\n leftdata.append(data[i])\r\n leftdatalabel.append(datalabel[i])\r\n else:\r\n rightdata.append(data[i])\r\n rightdatalabel.append(datalabel[i])\r\n data = None\r\n datalabel = None\r\n if self.keynumber >= 0:\r\n self.leftchild.Refresh(leftdata, leftdatalabel)\r\n self.rightchild.Refresh(rightdata, rightdatalabel)\r\n\r\n def sum_error_num(self):\r\n '''递归计算总错误个数'''\r\n if self.keynumber < 0:\r\n return self.error_num\r\n return self.leftchild.sum_error_num() + self.rightchild.sum_error_num()\r\n\r\n def Decision(self, testdata, testlabel):\r\n '''使用生成的树 GenerateTree,对样本 XToBePredicted 进行预测'''\r\n amount = len(testlabel)\r\n self.Refresh(testdata, testlabel)\r\n error = self.sum_error_num()\r\n accuracy = (amount - error)/amount\r\n return accuracy\r\n\r\n\r\ndef Dataloader(path):\r\n '''数据文件读取,数据集划分'''\r\n np.random.seed(24)\r\n data = sio.loadmat(path)\r\n wordmat = data['wordMat']\r\n label = data['doclabel']\r\n num_total = wordmat.shape[0]\r\n shuffled_indices = np.random.permutation(num_total)\r\n train_indices = shuffled_indices[:int(num_total*0.6)]\r\n valid_indices = shuffled_indices[int(num_total*0.6):int(num_total*0.8)]\r\n test_indices = shuffled_indices[int(num_total*0.8):]\r\n train_data, train_label = wordmat[train_indices], label[train_indices]\r\n valid_data, valid_label = wordmat[valid_indices], label[valid_indices]\r\n test_data, test_label = wordmat[test_indices], label[test_indices]\r\n return train_data, train_label, valid_data, valid_label, test_data, test_label\r\n\r\n\r\ndef main():\r\n\r\n # 超参数设置\r\n de_threshold = 0.001\r\n depth_threshold = 100\r\n PATH = './Sogou_data/Sogou_webpage.mat'\r\n traindata, trainlabel, crossdata, crosslabel, testdata, testlabel = Dataloader(PATH)\r\n time_start = time.time()\r\n mytree = MyTree(traindata, trainlabel, 0)\r\n de_threshold = 0.01\r\n depth_threshold = 100\r\n mytree.Impurity()\r\n mytree.GenerateTree(de_threshold, depth_threshold)\r\n #mytree.Prune(crossdata, crosslabel)\r\n Test_acc = mytree.Decision(testdata, testlabel)\r\n Train_acc = mytree.Decision(traindata, trainlabel)\r\n print(\"de_threshold={0}, depth_threshold={1}, Train_acc = {2}, Test_acc = {3}, Time = {4}s\".format(de_threshold,\r\n depth_threshold, Train_acc, Test_acc,\r\n time.time() - time_start))\r\n\r\nif __name__ == \"__main__\":\r\n main()"
},
{
"alpha_fraction": 0.44035911560058594,
"alphanum_fraction": 0.4595981240272522,
"avg_line_length": 26.901233673095703,
"blob_id": "1fd2fac834ad1942f5a545ca8a56fd0a7101f98b",
"content_id": "a53299a4ca265a34bcbc4f64fa3580d75f4b1fdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2587,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 81,
"path": "/HW7/HW7.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport pandas as pd\r\n\r\ndef getdata():\r\n dataset = pd.read_csv('./watermelon_3.csv')\r\n \r\n Map = {}\r\n del dataset['编号']\r\n #\r\n \r\n Map['浅白'],Map['青绿'],Map['乌黑']=0, 0.5, 1\r\n Map['蜷缩'],Map['稍蜷'],Map['硬挺']=0, 0.5, 1\r\n Map['沉闷'],Map['浊响'],Map['清脆']=0, 0.5, 1\r\n Map['模糊'],Map['稍糊'],Map['清晰']=0, 0.5, 1\r\n Map['凹陷'],Map['稍凹'],Map['平坦']=0, 0.5, 1\r\n Map['硬滑'],Map['软粘']=0, 1\r\n Map['否'],Map['是']=0, 1\r\n '''\r\n Python 字典类没法实现多对一\r\n Map = {\r\n ('浅白','蜷缩','沉闷','模糊','凹陷','硬滑','否'): int(0),\r\n ('青绿', '稍蜷', '浊响','稍糊','稍凹') : int(0.5),\r\n ('乌黑', '硬挺', '清脆','清晰','平坦','软粘','是') :int(1),\r\n }\r\n '''\r\n data = dataset.values\r\n \r\n for i in range(data.shape[0]):\r\n for j in range(data.shape[1]):\r\n #data[i] = list(Map(int, dataset.values[:,i]))\r\n if data[i, j] in Map:\r\n data[i, j] = Map[data[i, j]]\r\n #data = Map[dataset.values[0,1 ]]\r\n features = dataset.columns.values\r\n return data, features\r\n\r\n\r\ndef diff(dataSet, i, j, mode=\"\"):\r\n exDataSet = None\r\n if mode == 'nh':\r\n exDataSet = dataSet[dataSet[:, -1] == dataSet[i][-1]]\r\n if mode == 'nm':\r\n exDataSet = dataSet[dataSet[:, -1] != dataSet[i][-1]]\r\n dist = np.inf\r\n if j < 6:\r\n dist = 1 # 对于离散型数据,初始dist为1,当遇到相同的j属性值时,置零。\r\n for k in range(len(exDataSet)):\r\n if k == i: # 遇到第i个样本跳过。\r\n continue\r\n if exDataSet[k][j] == dataSet[i][j]:\r\n dist = 0\r\n break\r\n else:\r\n for k in range(len(exDataSet)):\r\n if k == i:\r\n continue\r\n sub = abs(float(exDataSet[k][j]) - float(dataSet[i][j]))\r\n if sub < dist:\r\n dist = sub\r\n return dist\r\n\r\n\r\ndef Relief(input):\r\n n_samples, n_features = input.shape\r\n relief = []\r\n for j in range(n_features - 1):\r\n rj = 0\r\n for i in range(n_samples):\r\n diff_nh = diff(input, i, j, mode='nh')\r\n diff_nm = diff(input, i, j, mode='nm') \r\n rj += diff_nm**2 - diff_nh**2\r\n relief.append(rj)\r\n return relief\r\n\r\n\r\nif __name__ == '__main__':\r\n data, features = getdata()\r\n relief = Relief(data)\r\n #print(relief)\r\n print(\"特征排序:\",features[np.array(relief).argsort()])\r\n print(relief)"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5163571834564209,
"avg_line_length": 26.607595443725586,
"blob_id": "307e49c36e93092ad36ce21017c4cece0d55f29a",
"content_id": "d3918ba344eba642237d9538bed8734fbd13907a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2262,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 79,
"path": "/HW6/KNN_HW6.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport mnist_data_loader\r\nimport tensorflow as tf\r\nimport time\r\n\r\nclass KNN():\r\n def __init__(self, batch_size, k, metrics):\r\n self.batch_size = batch_size\r\n self.k = k\r\n self.metrics = metrics\r\n\r\n\r\n def dataload(self):\r\n\r\n # Data Preprocessing\r\n mnist_dataset = mnist_data_loader.read_data_sets(\"./MNIST_data/\")\r\n train_set = mnist_dataset.train\r\n test_set = mnist_dataset.test\r\n\r\n # train dataset\r\n train_set = train_set.next_batch(self.batch_size)\r\n self.input, self.label = train_set\r\n \r\n # test dataset\r\n test_set = test_set.next_batch(1000)\r\n self.test_input, self.test_label = test_set\r\n\r\n\r\n\r\n def find_labels(self, num):\r\n test = self.test_input[num]\r\n dis_list = []\r\n labels = []\r\n for i in range(self.batch_size):\r\n dis = np.linalg.norm(self.input[i] - test, ord = self.metrics)\r\n dis_list.append(dis)\r\n sorted_dis = np.argsort(dis_list)\r\n for j in range(self.k):\r\n labels.append(self.label[sorted_dis[j]])\r\n max_labels = max(labels, key=labels.count)\r\n return max_labels\r\n\r\n\r\n def classifier(self):\r\n result = []\r\n acc = 0\r\n\r\n # Training and test\r\n for i in range(self.test_label.shape[0]):\r\n knn_labels = self.find_labels(i)\r\n result.append(knn_labels)\r\n if knn_labels == self.test_label[i]:\r\n acc += 1\r\n #print(acc)\r\n \r\n # Accurate rate\r\n acc_rate = acc/1000\r\n return result, acc_rate\r\n\r\nres = []\r\nacc = []\r\n\r\nfor num in [100, 300, 1000, 3000, 10000]:\r\n for k in [1, 2, 5, 10]:\r\n for m in[ np.inf ,2, 1]:\r\n start = time.perf_counter()\r\n print(\"Training sample =\", num, \"; k =\", k, \"; metrics =\", m)\r\n\r\n KNN_obj = KNN(num, k, m)\r\n KNN_obj.dataload()\r\n result, acc_rate = KNN_obj.classifier()\r\n res.append(result)\r\n acc.append(acc_rate)\r\n\r\n end = time.perf_counter()\r\n Time = end - start\r\n print(\"Accuracy =\", acc_rate)\r\n print(\"CPU time =\", Time, '\\n')\r\n\r\n"
},
{
"alpha_fraction": 0.34925374388694763,
"alphanum_fraction": 0.45298507809638977,
"avg_line_length": 32.842105865478516,
"blob_id": "227768524124f4112e134ec961abc72731e77492",
"content_id": "aeadc12d8403ca315db6c2c6ae5b60c140b28a5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1340,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 38,
"path": "/HW5/SVM_hw5.py",
"repo_name": "gavinatthu/Parttern-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom sklearn.svm import SVC\r\n\r\n\r\n\r\nx = np.array([[-3.0, -2.9], [0.5, 8.7], [2.9, 2.1], [-0.1, 5.2], [-4.0, 2.2], [-1.3, 3.7], [-3.4, 6.2], [-4.1, 3.4], [-5.1, 1.6], [1.9, 5.1],\r\n [-2.0, -8.4], [-8.9, 0.2], [-4.2, -7.7], [-8.5, -3.2], [-6.7, -4.0], [-0.5, -9.2], [-5.3, -6.7], [-8.7, -6.4], [-7.1, -9.7], [-8.0, -6.3]])\r\n\r\ny = np.array([0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1])\r\nprint('step = ', 0)\r\nplt.scatter(x[:, 0], x[:, 1], c=y)\r\nplt.show()\r\n\r\n#########################################\r\nclf = SVC(kernel='linear')\r\nx_train = np.empty([0,2])\r\ny_train = np.empty([0])\r\nfor i in range (0, 10):\r\n x_train = np.concatenate((x_train, x[[i, i + 10]]), axis=0)\r\n y_train = np.concatenate((y_train, y[[i, i + 10]]), axis=0)\r\n clf.fit(x_train, y_train)\r\n w = clf.coef_\r\n b = clf.intercept_\r\n margin = 2 / np.linalg.norm(w)\r\n print(margin)\r\n xx = np.arange(-10,4,0.01)\r\n yy = (w[0][0] * xx + b) / (-1 * w[0][1])\r\n fig = plt.figure()\r\n ax = fig.add_subplot(111)\r\n ax.set_title('2-Class SVM')\r\n plt.xlabel('X1')\r\n plt.ylabel('X2')\r\n ax.scatter(x[:, 0], x[:, 1], c=y)\r\n ax.scatter(x_train[:, 0], x_train[:, 1], c = y_train, cmap = 'cool')\r\n ax.scatter(xx, yy, s=1, marker = 'h')\r\n print('step = ', i + 1)\r\n plt.show()\r\n \r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 13 |
lukynmatuska/purkiada | https://github.com/lukynmatuska/purkiada | 0d908fab86b43a52fc23990dcdd09f87771a7c2c | 8f0ca64b97b6effe99c7e962addf604ca0166c4a | 064f6515123dd5fb9015f72ced45293c150dc25a | refs/heads/master | 2020-12-07T20:52:06.486000 | 2020-01-09T07:26:18 | 2020-01-09T07:26:18 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4135802388191223,
"alphanum_fraction": 0.5140292048454285,
"avg_line_length": 32.01852035522461,
"blob_id": "c62f061c565d9453de48ae9ac3445b3db88adabf",
"content_id": "58f828e5587c79885f83a05fe5dc3747665ad240",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1803,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 54,
"path": "/templates/quest2.html",
"repo_name": "lukynmatuska/purkiada",
"src_encoding": "UTF-8",
"text": "{% extends \"layout.html\" %}\n{% block title %}Úkol č. 2{% endblock %}\n{% block body %}\n\n <!--CONTENT BODY-->\n\n <h1>Úkol č. 2</h1>\n\n <div class = \"body-cell\">\n\n <div class = \"green-box\">\n <p>\n <h3>Zadání:</h3>\n </p>\n\n <p>\n ButterBot se rozbil. Ví jak se má opravit, ale nemůže nám to říct. Mluví pouze v jedničkách a nulách. Dokážeš zjistit, jak ho máme opravit?\n </p>\n\n <p>\n <input id=\"answer\" type=\"text\" class=\"answer-input\">\n </p>\n </div>\n\n <div class = \"nav\">\n <form method = \"post\" action = \"/quest1\">\n <button type = \"submit\" class=\"left\" onclick=\"setCookie('answer2')\"><i class=\"fas fa-arrow-circle-left\"></i></button>\n </form>\n\n <form method = \"post\" action = \"/quest3\">\n <button type = \"submit\" class=\"right\" onclick=\"setCookie('answer2')\"><i class=\"fas fa-arrow-circle-right\"></i></button>\n </form>\n </div>\n\n <div class = \"pics\" style=\"justify-content: center;\">\n <img src='{{ url_for(\"static\", filename=\"img/robotRick.png\") }}' class=\"img1\" width=\"200px\">\n <div class=\"cypher\">\n 00110111 00110010 00100000 00110110 00110101 00100000 00110111 00110011 <br>\n 00100000 00110111 00110100 00100000 00110110 00110001 00100000 00110111 <br>\n 00110010 00100000 00110111 00110100 \n </div>\n <img src='{{ url_for(\"static\", filename=\"img/robot.png\") }}' class=\"img1\" style=\"height: 200px;\">\n <!--MRKNI SE DO KONSOLE xd-->\n </div>\n \n </div>\n\n <script>\n setValue(\"answer2\");\n </script>\n\n <!--CONTENT BODY-->\n\n{% endblock %}"
},
{
"alpha_fraction": 0.6000689268112183,
"alphanum_fraction": 0.6150663495063782,
"avg_line_length": 32.72674560546875,
"blob_id": "71d3775e86636bc35790921394ccb7ed5f006eba",
"content_id": "123808b6ed1bd8f7d2bac0174e03330e7956a97d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5801,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 172,
"path": "/app.py",
"repo_name": "lukynmatuska/purkiada",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom flask import Flask, render_template, url_for, request, redirect, session, g, jsonify\nfrom flask_wtf import FlaskForm\nfrom flask_sqlalchemy import SQLAlchemy\nimport os\nimport json\n\napplication = Flask(__name__)\napplication.config.update(dict(SECRET_KEY=\"LOPDEWQUN25x\", WTF_CSRF_SECRET_KEY=\"LOPDEWQUN25x\")) #key for sending forms\napplication.config[\"SQLALCHEMY_TRACK_MODIFICATIONS\"] = False\napplication.config[\"SQLALCHEMY_DATABASE_URI\"] = \"sqlite:///db/student.db\"\napplication.config[\"SECRET_KEY\"] = \"SQUOIMD1892xe\"\n\ndb = SQLAlchemy(application)\n\nclass Student(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(80))\n username = db.Column(db.String(80))\n password = db.Column(db.String(80))\n school = db.Column(db.String(80))\n\ndef calculate(ans1, ans2, ans3, ans4, ans5, egg):\n points = 0\n if ans1 == \"Wubba-Lubba-Dub-Dub!\":\n points += 2\n if ans2 == \"restart\":\n points += 2\n if ans3 == \"jablko\":\n points += 3\n if ans4 == \"morseovka\":\n points += 3\n if ans5 == \"eelworm\":\n points += 6\n if egg == \"1\":\n points += 2\n return points\n\n@application.route(\"/\", methods = [\"GET\", \"POST\"])\ndef index():\n #delete last student in session\n session.pop(\"student\", None)\n\n if request.method == \"POST\":\n #get data from form\n username = request.form[\"id\"]\n password = request.form[\"password\"]\n\n #Authorization\n student = Student.query.filter_by(username = username, password = password).first()\n \n if student:\n #correct password\n student = {\"name\":student.name, \"username\":student.username, \"school\": student.school}\n session[\"student\"] = student\n return redirect(url_for(\"info\"))\n else:\n #bad password\n return render_template(\"index.html\", status = \"no\")\n\n #GET METHOD \n else:\n #rewrite easteregg js file & load page\n url = request.host_url + \"helloworldKominik123\"\n with open(\"static/scripts/scriptLog.js\", 'w') as file:\n file.write(\"for(i = 0; i <10; i++){console.log( ' \" + url + \" '); console.log('');}\")\n return render_template(\"index.html\", status = \"yes\")\n \n@application.route(\"/info\", methods=[\"GET\", \"POST\"]) \ndef info():\n if request.method == \"POST\":\n return redirect(url_for(\"quest1\"))\n else:\n if g.student:\n return render_template(\"info.html\", name = session[\"student\"][\"name\"], school = session[\"student\"][\"school\"])\n else:\n return redirect(url_for(\"index\"))\n\n@application.route(\"/quest1\", methods = [\"GET\", \"POST\"])\ndef quest1():\n if g.student:\n return render_template(\"quest1.html\", name = session[\"student\"][\"name\"], school = session[\"student\"][\"school\"])\n else:\n return redirect(url_for(\"index\"))\n\n@application.route(\"/quest2\", methods=[\"GET\", \"POST\"])\ndef quest2():\n if g.student:\n return render_template(\"quest2.html\", name = session[\"student\"][\"name\"], school = session[\"student\"][\"school\"])\n else:\n return redirect(url_for(\"index\"))\n\n@application.route(\"/quest3\", methods = [\"GET\", \"POST\"])\ndef quest3():\n if g.student:\n return render_template(\"quest3.html\", name = session[\"student\"][\"name\"], school = session[\"student\"][\"school\"])\n else:\n return redirect(url_for(\"index\"))\n\n@application.route(\"/quest4\", methods = [\"GET\", \"POST\"])\ndef quest4():\n if g.student:\n return render_template(\"quest4.html\", name = session[\"student\"][\"name\"], school = session[\"student\"][\"school\"])\n else:\n return redirect(url_for(\"index\"))\n\n@application.route(\"/quest5\", methods = [\"GET\", \"POST\"])\ndef quest5():\n if g.student:\n return render_template(\"quest5.html\", name = session[\"student\"][\"name\"], school = session[\"student\"][\"school\"])\n else:\n return redirect(url_for(\"index\"))\n\n@application.route(\"/end\", methods = [\"GET\", \"POST\"])\ndef end():\n #get score-data\n answer1 = request.cookies[\"answer1\"]\n answer2 = request.cookies[\"answer2\"]\n answer3 = request.cookies[\"answer3\"]\n answer4 = request.cookies[\"answer4\"]\n answer5 = request.cookies[\"answer5\"]\n try:\n easteregg = request.cookies[\"easteregg\"]\n except KeyError:\n easteregg=\"\"\n finally:\n #calculate score-data\n points = calculate(answer1, answer2, answer3, answer4, answer5, easteregg)\n session[\"student\"].update({\"score\" : int(points), \"cipher\" : \"true\"})\n jsonData = session[\"student\"]\n\n #jsonify and write all data\n with open('output.txt', 'a', encoding=\"utf8\") as file:\n json.dump(jsonData, file, ensure_ascii=False)\n file.write(\"\\n\")\n \n #REDIRECT TO SIGNPOST\n g.student = None\n return redirect(\"https://www.purkiada.cz/rick-and-morty\")\n\n@application.route(\"/helloworldKominik123\")\ndef easteregg():\n if g.student:\n return render_template(\"easteregg.html\")\n else:\n return redirect(url_for(\"index\"))\n\n@application.before_request\ndef before_request():\n g.student = None\n if \"student\" in session:\n g.student = session[\"student\"]\n\n@application.errorhandler(404)\ndef error404(error):\n return render_template(\"error404.html\")\n\n@application.context_processor\ndef override_url_for():\n return dict(url_for=dated_url_for)\n\ndef dated_url_for(endpoint, **values):\n if endpoint == 'static':\n filename = values.get('filename', None)\n if filename:\n file_path = os.path.join(application.root_path,\n endpoint, filename)\n values['q'] = int(os.stat(file_path).st_mtime)\n return url_for(endpoint, **values)\n\nif __name__ == \"__main__\":\n application.run(debug=\"true\", host = \"0.0.0.0\", port = 5207)\n"
}
] | 2 |
Thomas-Elder/py.cc-ass2 | https://github.com/Thomas-Elder/py.cc-ass2 | f16463fc723808d7b103e6427f231bdc2b2d2069 | cf781a43a15d96e514fa233bb5c475fe11ed4a6a | 0ff0a757f22a31ccf7875fd3807134857f0018c9 | refs/heads/master | 2023-07-01T04:00:59.020102 | 2021-08-06T00:18:15 | 2021-08-06T00:18:15 | 385,122,712 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.716284990310669,
"alphanum_fraction": 0.7188295125961304,
"avg_line_length": 28.148147583007812,
"blob_id": "64115b730b66c5bfdfbbbc8ab85687020749632a",
"content_id": "90a71fe91d597c92a58fd01279ef4b2ea5c45fe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 27,
"path": "/music/__init__.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom flask import Flask\nfrom flask_login import login_manager, login_user, logout_user, login_required, current_user, LoginManager\n\ndef create_app(test_config=None):\n # create and configure the app\n app = Flask(__name__, instance_relative_config=True)\n app.config.from_mapping(SECRET_KEY='dev')\n\n loginManager = LoginManager(app)\n loginManager.login_view = 'authentication/login'\n\n from .routes import authentication, subscription, index\n app.register_blueprint(authentication.bp)\n app.register_blueprint(subscription.bp)\n app.register_blueprint(index.bp)\n\n from .db import dynamodb, s3\n dynamodb.init_app(app)\n s3.init_app(app) \n\n @loginManager.user_loader\n def load_user(id):\n return dynamodb.get_user(id)\n\n return app"
},
{
"alpha_fraction": 0.678372323513031,
"alphanum_fraction": 0.6789297461509705,
"avg_line_length": 32.24074172973633,
"blob_id": "24bcab1c2adef9644ed4225c44068eeaec1a5449",
"content_id": "15f4b52746fe9bd5065db46a838e81bb8a77e070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1794,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 54,
"path": "/music/routes/forms.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "from boto3.docs.docstring import AttributeDocstring\nfrom flask_wtf import FlaskForm\nfrom wtforms import StringField, SubmitField, TextAreaField, PasswordField\nfrom flask_wtf.file import FileField, FileRequired\nfrom wtforms.validators import DataRequired\n\nfrom ..db.authentication import check_email_unique, check_password\n\nclass PostForm(FlaskForm):\n subject = StringField('Subject', validators=[DataRequired()])\n message = TextAreaField('Message', validators=[DataRequired()])\n image = FileField('Image', validators=[FileRequired()])\n submit = SubmitField('Post')\n\nclass RegisterForm(FlaskForm):\n email = StringField('email', validators=[DataRequired()])\n username = StringField('username', validators=[DataRequired()])\n password = PasswordField('password', validators=[DataRequired()])\n submit = SubmitField('register')\n\n def validate(self):\n\n if not FlaskForm.validate(self):\n return False\n else:\n\n if not check_email_unique(self.email.data):\n self.email.errors.append('The email already exists')\n return False\n\n return True\n\nclass LoginForm(FlaskForm):\n email = StringField('email', validators=[DataRequired()])\n password = PasswordField('password', validators=[DataRequired()])\n submit = SubmitField('login')\n\n def validate(self):\n\n if not FlaskForm.validate(self):\n return False\n else:\n\n if check_password(self.email.data, self.password.data):\n return True\n\n self.password.errors.append('email or password is invalid')\n return False\n\nclass QueryForm(FlaskForm):\n artist = StringField('artist') \n title = StringField('title')\n year = StringField('year')\n search = SubmitField('query')"
},
{
"alpha_fraction": 0.6419616341590881,
"alphanum_fraction": 0.6467551589012146,
"avg_line_length": 31.68674659729004,
"blob_id": "6c4445ab355589aaa21b4547ca72b1d1eda6c4fe",
"content_id": "7554a0276fb137a89bf01229961d8a78e3f2e493",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2712,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 83,
"path": "/music/routes/subscription.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom flask import Blueprint, flash, g, redirect, render_template, request, session, url_for\nfrom flask_login import current_user\n\nfrom ..db.s3 import get_img\nfrom ..db.dynamodb import get_songs, get_user_songs, rm_user_song, put_user_song\nfrom .forms import QueryForm\n\nbp = Blueprint('subscription', __name__, url_prefix='/subscription')\n\n#@bp.route('/music/<query_songs>', methods=[\"GET\"])\n@bp.route('/music', methods=[\"GET\"])\ndef music():\n form = QueryForm()\n\n # set up query_songs\n #query_songs = []\n #get_songs()\n # get user songs and images:\n user_songs = get_user_songs(current_user.email) #list\n\n # If we're local, use place holder images.\n if os.environ['FLASK_ENV'] == \"dev\":\n for song in user_songs:\n song.img_url = \"https://upload.wikimedia.org/wikipedia/commons/thumb/1/11/Test-Logo.svg/783px-Test-Logo.svg.png\"\n else:\n for song in user_songs:\n song.img_url = get_img(song.artist)\n\n return render_template('subscription/music.html', current_user=current_user, user_songs=user_songs, form=form)\n\n\n@bp.route('/music/remove', methods=[\"POST\"])\ndef remove():\n\n # parse request\n print(f\"Removing: {request.form['artist']}:{request.form['title']}\")\n\n # remove song \n rm_user_song(current_user.email, request.form['artist'], request.form['title'])\n\n # redirect to music\n return redirect(url_for('subscription.music'))\n\n@bp.route('/music/subscribe', methods=[\"POST\"])\ndef subscribe():\n\n # parse request\n print(f\"Subscribing: {request.form['artist']}:{request.form['title']}\")\n\n # add song \n put_user_song(current_user.email, request.form['artist'], request.form['title']) \n\n # redirect to music \n return redirect(url_for('subscription.music'))\n\n@bp.route('/music/query', methods=[\"POST\"])\ndef query():\n\n # parse request\n print(f\"Querying: {request.form['artist']}:{request.form['title']}:{request.form['year']}\")\n\n # query db\n songs = get_songs(artist=request.form['artist'], title=request.form['title'], year=request.form['year'])\n\n # If we're local, use place holder images.\n if os.environ['FLASK_ENV'] == \"dev\":\n for song in songs:\n song.img_url = \"https://upload.wikimedia.org/wikipedia/commons/thumb/1/11/Test-Logo.svg/783px-Test-Logo.svg.png\"\n else:\n for song in songs:\n song.img_url = get_img(song.artist)\n\n query_songs = []\n\n for song in songs:\n query_songs.append({'artist': song.artist, 'title': song.title, 'year': song.year, 'web_url': song.web_url, 'img_url': song.img_url})\n\n session['query_songs'] = query_songs\n\n # redirect to music \n return redirect(url_for('subscription.music'))"
},
{
"alpha_fraction": 0.7487708926200867,
"alphanum_fraction": 0.7674533128738403,
"avg_line_length": 25.428571701049805,
"blob_id": "42255f99a21972d4c9476944be5fcab3b05cc579",
"content_id": "de5b591a3ff1832b87f9d258fd12c04346fe5df9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2034,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 77,
"path": "/README.md",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "# Music\nA simple application allowing users to register, log in and query a list of music. They can then subscribe to any song and view a list of a subscribed items. \n\n## Running locally\n### Dynamodb \nFirst run docker-compose script to get dynamodb running locally:\n\ndocker-compose -f dynamodb/docker-compose.yaml up -d\n\n### Then initialise the dbs:\nflask init_db\n\n### Initialise s3\nflask init_s3\nThis only needs to be done once. Also this only runs from the ec2 instance, permissions are not set for this to be run from the local instance.\n\n### Then run the flask app:\nflask run\n\n## Deploying to EC2\n### package app\npy setup.py bdist_wheel\n\n### ssh cmd\nssh -i [your_key_file_location]/[your_key_filename].pem ubuntu@[your_ec2_instance_public_dns]\n\n### stfp\nNeed to stfp the wheel via filezilla\ndist\\music-1.0.0-py3-none-any.whl\n\n### setup\nFirst update:\napt-get update\n\n#### python and pip\nDouble check python is there:\npython3 --version\n\nInstall pip, first dl and install package\ncurl -O https://bootstrap.pypa.io/get-pip.py\npython3 get-pip.py --user\n\n.profile has a script that exports LOCAL_PATH to PATH to make pip available for use:\nsource ~/PROFILE_SCRIPT\n\nThen install and activate venv:\nsudo apt-get install python3-venv\npython3 -m venv venv\nsource venv/bin/activate\n\n### install\npip install music-1.0.0-py3-none-any.whl\nNote that music is install by default in venv/lib/python3.8/site-packages/music\n\n### init\nThese commands only need running once. \nflask init_s3\nflask init_db\n\n### run \nflask run\n\n## Tutorials/References\nDocker for local dynamodb container:\nhttps://betterprogramming.pub/how-to-set-up-a-local-dynamodb-in-a-docker-container-and-perform-the-basic-putitem-getitem-38958237b968\n\nFlask layout:\nhttps://flask.palletsprojects.com/en/2.0.x/tutorial/\n\nDynamodb crud ops:\nhttps://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GettingStarted.Python.html\n\nDynamodb ref:\nhttps://dynobase.dev/dynamodb-python-with-boto3/\n\ns3 ref:\nhttps://boto3.amazonaws.com/v1/documentation/api/latest/guide/migrations3.html"
},
{
"alpha_fraction": 0.5218198895454407,
"alphanum_fraction": 0.5277004241943359,
"avg_line_length": 22.155502319335938,
"blob_id": "99810bc18db18a0657f61fb88ba7ac63177510f2",
"content_id": "51d093ca4af6281e8a1cc66f4b3ae6635988e956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9693,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 418,
"path": "/music/db/dynamodb.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "\nimport os, json, sys\n\nfrom pathlib import Path\n\nimport boto3, botocore\n\nimport click\n\nfrom flask import current_app, g\nfrom flask.cli import with_appcontext\n\nfrom ..models.user import User\nfrom ..models.song import Song\n\n\"\"\"\nDyanamoDB functions\n\"\"\"\ndef get_db():\n \"\"\"\n get_db\n \n Gets the database. \n \"\"\"\n\n if 'db' not in g:\n\n if os.environ['FLASK_ENV'] == \"dev\":\n g.db = boto3.resource('dynamodb', endpoint_url=\"http://localhost:8042\")\n\n else:\n g.db = boto3.resource(\n 'dynamodb', \n region_name=\"us-east-1\")\n\n return g.db\n\ndef close_db(e=None):\n \"\"\"\n close_db\n\n Closes the database.\n \"\"\"\n db = g.pop('db', None)\n\n if db is not None:\n #db.close()\n pass\n\n\"\"\"\nInitialisation functions.\n\"\"\"\ndef init_app(app):\n \"\"\"\n init_app\n\n Registers the db with the flask application\n \"\"\"\n app.teardown_appcontext(close_db)\n app.cli.add_command(init_db)\n\n@click.command('init_db')\n@with_appcontext\ndef init_db():\n \"\"\"\n init_db\n\n Initialises the database.\n \"\"\"\n print('Initialising the database... ')\n\n base_path = Path(__file__).parent\n songfile = (base_path / \"a2.json\").resolve()\n\n init_loginTable()\n init_musicTable()\n\n init_users()\n init_songs(songfile) \n\n for user in get_users():\n print(user)\n\n print('Database initialised.')\n\ndef init_loginTable():\n \"\"\"\n init_loginTable\n\n Initialises the login table.\n \"\"\"\n db = get_db()\n \n # Get the table if it exists. \n table = db.Table(\"login\")\n\n print('Creating log in table...')\n\n try: \n\n # Create table.\n table = db.create_table(\n TableName='login',\n KeySchema=[\n {\n 'AttributeName': 'email',\n 'KeyType': 'HASH' # Partition key\n },\n ],\n AttributeDefinitions=[\n {\n 'AttributeName': 'email',\n 'AttributeType': 'S'\n },\n \n ],\n ProvisionedThroughput={\n 'ReadCapacityUnits': 10,\n 'WriteCapacityUnits': 10\n }\n )\n\n except Exception as error:\n print(f'Table exists already: {error}')\n\n print('Initialized the login table.')\n return table\n\ndef init_musicTable():\n \"\"\"\n init_musicTable\n\n Initialises the music table.\n \"\"\"\n\n db = get_db()\n\n # title, artist, year, web_url, image_url\n # Get the table\n table = db.Table(\"music\")\n\n print('Creating music table...')\n\n try:\n\n # Create table.\n table = db.create_table(\n TableName='music',\n KeySchema=[\n {\n 'AttributeName': 'artist',\n 'KeyType': 'HASH' # Partition key\n },\n {\n 'AttributeName': 'title',\n 'KeyType': 'RANGE' # Sort key\n },\n ],\n AttributeDefinitions=[\n {\n 'AttributeName': 'artist',\n 'AttributeType': 'S'\n },\n {\n 'AttributeName': 'title',\n 'AttributeType': 'S'\n },\n ],\n ProvisionedThroughput={\n 'ReadCapacityUnits': 10,\n 'WriteCapacityUnits': 10\n }\n )\n \n except Exception as error:\n print(f'Table exists already: {error}')\n\n print('Initialized the music table.')\n return table\n\ndef init_users():\n \"\"\"\n init_users\n\n Adds the default users to the Users table.\n \"\"\"\n emails = ['s33750870@student.rmit.edu.au', 's33750871@student.rmit.edu.au', 's33750872@student.rmit.edu.au', 's33750873@student.rmit.edu.au', 's33750874@student.rmit.edu.au', 's33750875@student.rmit.edu.au', 's33750876@student.rmit.edu.au', 's33750877@student.rmit.edu.au','s33750878@student.rmit.edu.au','s33750879@student.rmit.edu.au']\n usernames = ['Tom Elder0', 'Tom Elder1', 'Tom Elder2', 'Tom Elder3', 'Tom Elder4', 'Tom Elder5', 'Tom Elder6', 'Tom Elder7', 'Tom Elder8', 'Tom Elder9']\n passwords = ['012345', '123456', '234567', '345678', '456789', '567890', '678901', '789012', '890123', '901234']\n usersongs = []\n\n # users\n for email, username, password in zip(emails, usernames, passwords):\n put_user(email, username, password, usersongs)\n\ndef init_songs(songfile):\n \"\"\"\n init_songs\n\n Reads songs from json and adds them to music table\n \"\"\"\n\n with open(songfile) as file:\n data = json.load(file)\n\n for song in data['songs']:\n put_song(song['artist'], song['title'], song['year'], song['web_url'], song['img_url'])\n\n\"\"\"\nUSER CRUD Operations\n\"\"\"\ndef put_user(email, username, password, usersongs):\n \"\"\"\n put_user\n\n Adds the passed user details to the Login table.\n \"\"\"\n db = get_db()\n table = db.Table(\"login\")\n\n try:\n response = table.put_item(\n TableName='login',\n Item=\n {\n 'email' : email,\n 'username' : username,\n 'password': password,\n 'usersongs': usersongs\n\n }\n )\n\n return response\n\n except Exception as error:\n print(f'Error putting user: {error}')\n\n print(f'User added: {email}:{username}:{password}')\n\n # return response\n\ndef get_user(email=None):\n \"\"\"\n get_user\n\n Gets the user with the specified email.\n\n Parameters\n ----------\n email: the email of the user to return.\n\n Returns\n -------\n user\n \"\"\"\n db = get_db()\n table = db.Table(\"login\")\n\n try:\n response = table.get_item(Key={'email': email})\n except Exception as error:\n print(f'Error getting user: {error}')\n else:\n if 'Item' in response:\n\n return User(response['Item']['email'], response['Item']['email'], response['Item']['username'], response['Item']['password'], response['Item']['usersongs'])\n\n else:\n return None\n\ndef get_users():\n \"\"\"\n get_users\n \n Gets all users in the login table\n \"\"\"\n db = get_db()\n table = db.Table(\"login\")\n\n try:\n response = table.scan()['Items']\n except Exception as error:\n print(f'Error getting users: {error}')\n else:\n users = []\n for record in response:\n users.append(User(record['email'], record['email'], record['username'], record['password'], record['usersongs']))\n\n return users\n\n\"\"\"\nMUSIC CRUD Operations\n\"\"\"\ndef put_song(artist, title, year, web_url, img_url):\n \"\"\"\n put_song\n\n Adds the passed song details to the music table.\n \"\"\"\n\n db = get_db()\n table = db.Table(\"music\")\n\n try:\n response = table.put_item(\n TableName='music',\n Item=\n {\n 'artist' : artist,\n 'title' : title,\n 'year' : year,\n 'web_url' : web_url,\n 'img_url' : img_url\n }\n )\n\n return response\n\n except Exception as error:\n print(f'Error putting song: {error}')\n\ndef get_song(artist=None, title=None):\n \"\"\"\n get_song\n\n Gets the song with the specified title and artist.\n\n Parameters\n ----------\n title: the title of the song\n artist: the artist of the song\n\n Returns\n -------\n song\n \"\"\"\n\n db = get_db()\n table = db.Table(\"music\")\n\n try:\n response = table.get_item(Key={'artist': artist, 'title': title})\n except Exception as error:\n print(f'Error getting song: {error}')\n else:\n if 'Item' in response:\n #print(response['Item'])\n return Song(response['Item']['artist'], response['Item']['title'], response['Item']['year'], response['Item']['web_url'])\n else:\n return None\n\ndef get_songs(artist=None, title=None, year=None):\n \"\"\"\n get_songs\n \n Gets all songs in the music table\n \"\"\"\n\n db = get_db()\n table = db.Table(\"music\")\n\n try:\n response = table.scan()['Items']\n except Exception as error:\n print(f'Error getting songs: {error}')\n else:\n songs = []\n\n for record in response:\n songs.append(Song(record['artist'], record['title'], record['year'], record['web_url']))\n \n if artist != \"\":\n print(f'querying on artist:{artist}')\n songs = list(filter(lambda song: song.artist == artist, songs))\n\n if title != \"\":\n print(f'querying on title:{title}')\n songs = list(filter(lambda song: song.title == title, songs))\n\n if year != \"\":\n print(f'querying on year:{year}')\n songs = list(filter(lambda song: song.year == year, songs))\n\n return songs\n\n\"\"\"\nSUBSCRIPTION CRUD Operations\n\"\"\"\ndef get_user_songs(useremail):\n \"\"\"\n Returns the list of songs the user has subscribed to.\n \"\"\"\n user = get_user(useremail)\n\n songs = []\n for record in user.usersongs:\n song = get_song(artist=record['artist'], title=record['title'])\n songs.append(song)\n\n return songs\n\ndef put_user_song(useremail, songartist, songtitle):\n \"\"\"\n Adds the given song to the users usersong table entry.\n \"\"\"\n user = get_user(useremail)\n user.usersongs.append({'artist': songartist, 'title': songtitle})\n put_user(user.email, user.username, user.password, user.usersongs)\n\ndef rm_user_song(useremail, songartist, songtitle):\n \"\"\"\n Removes the given song to the users usersong table entry.\n \"\"\"\n user = get_user(useremail)\n\n temp = list(filter(lambda song: song['title'] != songtitle and song['artist'] != songartist, user.usersongs))\n\n put_user(user.email, user.username, user.password, temp)\n \n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.6304348111152649,
"avg_line_length": 26.600000381469727,
"blob_id": "13978e8f25a012c3b9a116f7e6bf88e10acf0870",
"content_id": "bfe311e457d5ceef20e10d77c61979bac3adc22b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 10,
"path": "/music/models/user.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "from flask_login import UserMixin\n\nclass User(UserMixin):\n\n def __init__(self, id, email, username, password, usersongs):\n self.id = id\n self.email = email\n self.username = username\n self.password = password\n self.usersongs = usersongs\n"
},
{
"alpha_fraction": 0.5623342394828796,
"alphanum_fraction": 0.5763925909996033,
"avg_line_length": 20.63793182373047,
"blob_id": "256c1f68aa3e5df4000b5ada56e5aca82379c1a8",
"content_id": "28b3375edcd20ec57fc048213f8cab57d7fd613a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3770,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 174,
"path": "/music/db/s3.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "import os, json, sys\nfrom pathlib import Path\nimport requests\n\nimport boto3, botocore\n\nimport click\nfrom flask import current_app, g\nfrom flask.cli import with_appcontext\n\n\"\"\"\nS3 functions\n\"\"\"\ndef get_s3():\n \"\"\"\n get_s3\n \n Gets the database. \n \"\"\"\n\n if 's3' not in g:\n\n g.s3 = boto3.resource(\n 's3', \n region_name=\"us-east-1\")\n \n return g.s3\n\ndef close_s3(e=None):\n \"\"\"\n close_s3\n\n Closes the database.\n \"\"\"\n s3 = g.pop('s3', None)\n\n if s3 is not None:\n #s3.close()\n pass\n\n\"\"\"\nInitialisation functions\n\"\"\"\ndef init_app(app):\n \"\"\"\n init_app\n\n Registers the db with the flask application\n \"\"\"\n app.teardown_appcontext(close_s3)\n app.cli.add_command(init_s3)\n\n@click.command('init_s3')\n@with_appcontext\ndef init_s3():\n \"\"\"\n init_s3\n\n Initialises the s3 database.\n \"\"\"\n print('Initialising the s3 database... ')\n\n # Set up bucket\n bucket_name = \"assignment2images\"\n create_bucket(bucket_name)\n\n # DL/Upload images\n base_path = Path(__file__).parent\n filename = (base_path / \"a2.json\").resolve()\n\n # Set up tmp_img dir\n os.mkdir(os.path.join(Path(__file__).parent, 'tmp_img')) \n\n init_imgs(filename, bucket_name) \n\n print('s3 Database initialised.')\n\ndef create_bucket(bucket_name):\n \"\"\"\n create_bucket\n\n Creates an s3 bucket\n \"\"\"\n\n s3 = get_s3()\n\n if s3.Bucket(bucket_name) in s3.buckets.all():\n print(f'{bucket_name} already exists.')\n return s3.Bucket(bucket_name)\n\n else: \n\n try:\n print(f'Creating new bucket:{bucket_name}')\n bucket = s3.create_bucket(Bucket=bucket_name)\n\n bucket.wait_until_exists()\n print(f'Bucket successfully created as {bucket_name} in \"us-east-1\"')\n\n except Exception as error:\n print(f'Error creating bucket: {error}')\n\n else:\n return bucket\n \ndef init_imgs(filename, bucket_name):\n \"\"\"\n init_imgs\n\n Reads data from json and adds images to the s3 bucket\n \"\"\"\n\n with open(filename) as file:\n data = json.load(file)\n\n for song in data['songs']:\n response = requests.get(song['img_url'])\n\n if response.status_code == 200:\n\n filename = os.path.split(song['img_url'])[1]\n print(filename)\n with open(os.path.join('tmp_img/', filename), 'wb') as file:\n file.write(response.content)\n\n put_img('tmp_img/', filename, bucket_name)\n\n else:\n print(f'Error downloading image error: {response.status_code}')\n\n\"\"\"\nIMG CRUD Operations\n\"\"\"\ndef put_img(path, filename, bucket_name):\n \"\"\"\n put_imgs\n\n Uploads the passed img to the s3 bucket\n \"\"\"\n s3 = get_s3()\n print(path)\n print(filename)\n s3.Object(bucket_name, filename).put(Body=open(os.path.join(path, filename), 'rb'))\n\ndef get_img(artist=None):\n \"\"\"\n get_img\n\n Returns the public url of the image matching the passed artist-string. \n If no artist is passed then returns all img urls\n \"\"\"\n s3 = get_s3()\n\n bucket_name = 'assignment2images'\n my_bucket = s3.Bucket(bucket_name)\n\n if artist is not None:\n artist_key = artist + '.jpg'\n params = {'Bucket': bucket_name, 'Key': artist_key}\n url = s3.meta.client.generate_presigned_url('get_object', params)\n final_url = url.split('?')[0].replace(\"%20\", \"\")\n return final_url\n\n \n else: \n\n urls = []\n \n for file in my_bucket.objects.all():\n params = {'Bucket': bucket_name, 'Key': file.key}\n url = s3.meta.client.generate_presigned_url('get_object', params)\n urls.append(url.split('?')[0])\n\n return urls\n \n"
},
{
"alpha_fraction": 0.6628989577293396,
"alphanum_fraction": 0.6628989577293396,
"avg_line_length": 30.33333396911621,
"blob_id": "a39e3e946934ee0c74919614bd7252ecc3cb25f4",
"content_id": "655058e4e146148327d22eb11ffb8f517a36a15f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1504,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 48,
"path": "/music/routes/authentication.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "\nfrom flask import Blueprint, flash, g, redirect, render_template, request, session, url_for\nfrom flask_login import login_user, logout_user, login_required, current_user\n\nfrom ..db.dynamodb import get_user, put_user\nfrom .forms import LoginForm, RegisterForm\n\nbp = Blueprint('authentication', __name__, url_prefix='/authentication')\n\n@bp.route('/register', methods=('GET', 'POST'))\ndef register():\n\n form = RegisterForm()\n\n if request.method == 'POST':\n\n if form.validate_on_submit():\n put_user(form.email.data, form.username.data, form.password.data, [])\n return redirect(url_for('authentication.login'))\n\n else:\n return render_template('authentication/register.html', current_user=current_user, form=form)\n\n else:\n return render_template('authentication/register.html', current_user=current_user, form=form)\n\n\n@bp.route('/login', methods=['GET', 'POST'])\ndef login():\n\n form = LoginForm()\n\n if request.method == 'POST':\n\n if form.validate_on_submit():\n login_user(get_user(form.email.data))\n return redirect(url_for('subscription.music'))\n\n else:\n return render_template('authentication/login.html', current_user=current_user, form=form) \n\n else:\n return render_template('authentication/login.html', current_user=current_user, form=form) \n\n@bp.route('/logout', methods=['GET', 'POST'])\n@login_required\ndef logout():\n logout_user()\n return redirect(url_for('index'))"
},
{
"alpha_fraction": 0.6282528042793274,
"alphanum_fraction": 0.6282528042793274,
"avg_line_length": 21.41666603088379,
"blob_id": "98e1e3f5c531a1fc807077ad674d6d5c8134a180",
"content_id": "7dffee0e2de82735f91d24e48f025033282ee34f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 24,
"path": "/music/db/authentication.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "\nfrom .dynamodb import get_user, get_users\n\ndef check_password(email: str, password: str) -> bool:\n \"\"\"\n check_password\n\n Returns true if the password stored with the email matches.\n \"\"\"\n user = get_user(email=email)\n \n if user is None:\n return False\n else:\n return user.password == password\n\ndef check_email_unique(email: str) -> bool:\n \"\"\"\n check_email_unique\n \n Returns true if the given email is not already in the database.\n \"\"\"\n user = get_user(email)\n\n return user is None"
},
{
"alpha_fraction": 0.6486486196517944,
"alphanum_fraction": 0.7837837934494019,
"avg_line_length": 17.75,
"blob_id": "e2713b7f86356eb9c259985548de651a73aaabae",
"content_id": "2381d694db1ca4ff8d2cc6028fa5d720f009d4e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 4,
"path": "/.flaskenv",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "FLASK_APP=music\nFLASK_ENV=dev\nFLASK_RUN_PORT=8181\nFLASK_RUN_HOST=127.0.0.1"
},
{
"alpha_fraction": 0.375,
"alphanum_fraction": 0.47894737124443054,
"avg_line_length": 23.54838752746582,
"blob_id": "be196aac00a627cc7298939a00b91abf0a095319",
"content_id": "a7e6698ecca91b4a64f60c8b7fc4edc9a1dd7ad5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 31,
"path": "/setup.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "from setuptools import find_packages, setup\n\nsetup(\n name='music',\n version='1.0.0',\n packages=find_packages(),\n include_package_data=True,\n zip_safe=False,\n install_requires=[\n 'boto3==1.17.110',\n 'botocore==1.20.110',\n 'click==8.0.1',\n 'colorama==0.4.4',\n 'Flask==2.0.1',\n 'Flask-Login==0.5.0',\n 'Flask-WTF==0.15.1',\n 'itsdangerous==2.0.1',\n 'Jinja2==3.0.1',\n 'jmespath==0.10.0',\n 'MarkupSafe==2.0.1',\n 'python-dateutil==2.8.1',\n 's3transfer==0.4.2',\n 'six==1.16.0',\n 'urllib3==1.26.6',\n 'waitress==2.0.0',\n 'Werkzeug==2.0.1',\n 'WTForms==2.3.3',\n 'python-dotenv==0.18.0',\n 'requests==2.26.0'\n ],\n)"
},
{
"alpha_fraction": 0.5630630850791931,
"alphanum_fraction": 0.5630630850791931,
"avg_line_length": 30.85714340209961,
"blob_id": "d716dd8c1dd453132d474036aa1a8f60efa57639",
"content_id": "4d536577e2a15fe279344327321924c29949c8a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 7,
"path": "/music/models/song.py",
"repo_name": "Thomas-Elder/py.cc-ass2",
"src_encoding": "UTF-8",
"text": "class Song:\n def __init__(self, artist, title, year, web_url, img_url=None):\n self.artist = artist\n self.title = title\n self.year = year\n self.web_url = web_url\n self.img_url = img_url"
}
] | 12 |
lujiean/PythonStudy | https://github.com/lujiean/PythonStudy | 46f00bfe2945288229eda241dc4e1f2f9856804f | fcdc9961a78f9127dcb4df098f781a33bacad04c | d349caf6962ddb7dcec27becc8ddc5fca28e4024 | refs/heads/master | 2020-05-30T03:33:38.953945 | 2020-02-19T09:59:03 | 2020-02-19T09:59:03 | 189,518,077 | 0 | 0 | null | 2019-05-31T03:01:35 | 2019-10-20T02:39:31 | 2020-02-19T09:59:04 | Python | [
{
"alpha_fraction": 0.5286179780960083,
"alphanum_fraction": 0.5490925908088684,
"avg_line_length": 33.77669906616211,
"blob_id": "490fe97f22d3299fa5a3ce8c94c2598af6772111",
"content_id": "9d004d0e19c06ca6e4cce4c6a4323d1d2622e8d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10745,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 309,
"path": "/spider.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "# pa chong https://pan.baidu.com/share/init?surl=pUZRD5wJOM7iUA4_O-TRSw fptt\n# https://pan.baidu.com/s/1pUZRD5wJOM7iUA4_O-TRSw fptt\n\nimport sys\nimport requests\nimport time\nimport execjs\nimport json\nimport os\nimport smtplib\nimport logging\nimport re\n\nfrom bs4 import BeautifulSoup\nfrom urllib import parse\nfrom utils import spiderutils\nfrom email.mime.text import MIMEText\nfrom email.header import Header\n\ndef TestSpider1():\n # proxy={'http':'http://127.0.0.1:8888', 'https':'https://127.0.0.1:8888'}\n proxy={}\n # url=\"https://pan.baidu.com/s/1pUZRD5wJOM7iUA4_O-TRSw\"\n url=\"https://www.baidu.com\"\n ret = requests.get(url=url, proxies=proxy,verify=False)\n ret.encoding = 'UTF-8'\n print(ret.text)\n\n print(\"------\")\n soup = BeautifulSoup(ret.text, \"html.parser\")\n print(soup.prettify())\n\n print(\"------\")\n links = soup.find_all(name=\"a\")\n for l in links:\n print(l.get_text())\n\ndef TestSpider2(configFile):\n\n #read config file\n if len(configFile) == 0:\n print(\"input root path as arg 2\")\n return\n else:\n cfgFile=configFile\n # cfgFile = \"./config/spider.cfg\"\n # cfgFile = cwd + \"/config/usr/spider.json\"\n if not os.path.isfile(cfgFile):\n with open(cfgFile, \"w\", encoding=\"UTF-8\") as f:\n f.write(\"\")\n print(\"not found config file. setup as /config/usr/README do\")\n return\n else:\n with open(cfgFile,\"r\", encoding=\"UTF-8\") as f:\n cfgText = json.load(f)\n title = cfgText[\"title\"]\n url = cfgText[\"url\"]\n pick_up_code = cfgText[\"pickup\"]\n username = cfgText[\"email\"][\"username\"]\n passwd = cfgText[\"email\"][\"passwd\"]\n receiver = cfgText[\"email\"][\"receiver\"]\n jsPath = cfgText[\"jsPath\"]\n logFile = cfgText[\"logFile\"]\n configFile = cfgText[\"configFile\"]\n outFile = cfgText[\"outFile\"]\n\n #log file\n if not os.path.isdir(os.path.dirname(logFile)):\n os.makedirs(os.path.dirname(logFile))\n fh = logging.FileHandler(filename=logFile, encoding=\"UTF-8\")\n logging.basicConfig(level=logging.INFO, handlers=[fh])\n\n #pan.baidu.com config\n with open(configFile, \"r\", encoding='UTF-8') as f:\n dupanConfig = json.load(f)\n #--\n logging.info(\"===\" + title +\" start===\")\n logging.info(time.asctime())\n logging.info(\"logFile: \" + logFile)\n logging.info(\"outFile: \" + outFile)\n\n # proxy={'http':'http://127.0.0.1:8888', 'https':'https://127.0.0.1:8888'}\n\n # --s1 first request\n curStep = \"step1\"\n if curStep in dupanConfig:\n dupanConfig[curStep][\"url\"] = url\n resp = requests.get(url=dupanConfig[curStep][\"url\"], \n proxies=dupanConfig[\"proxy\"], \n headers=dupanConfig[curStep][\"headers\"], \n allow_redirects=dupanConfig[curStep][\"allow_redirects\"])\n resp.encoding = 'UTF-8'\n\n # set redirect url\n if resp.status_code == 302 and 'Location' in resp.headers:\n url3=resp.headers['Location']\n cookieDict = spiderutils.GetCookieDict(resp)\n cookie = spiderutils.GetCookieStrFromDict(cookieDict)\n logging.info(resp.status_code)\n else:\n logging.info(\"No \"+curStep)\n # --\n\n # --s2\n curStep=\"step2\"\n if curStep in dupanConfig:\n\n dupanConfig[curStep][\"url\"]=url3\n dupanConfig[curStep][\"headers\"][\"Cookie\"]=cookie\n \n resp = requests.get(url=dupanConfig[curStep][\"url\"], \n proxies=dupanConfig[\"proxy\"], \n headers=dupanConfig[curStep][\"headers\"], \n allow_redirects=dupanConfig[curStep][\"allow_redirects\"])\n resp.encoding = 'UTF-8'\n\n logging.info(resp.status_code)\n else:\n logging.info(\"No \"+curStep)\n # --\n\n # --s3: post pick_up_code request\n curStep=\"step3\"\n if curStep in dupanConfig:\n \n surl = parse.parse_qs(parse.urlparse(url3).query)['surl'][0]\n ts13 = str(int(time.time()*1000))\n ts10 = str(int(time.time()))\n\n with open(jsPath + \"/boot.js\", \"r\", encoding=\"UTF-8\") as f:\n content = f.read()\n ctx = execjs.compile(content)\n logid = ctx.call(\"Getlogid\", cookieDict[\"BAIDUID\"])\n\n #params\n dupanConfig[curStep][\"params\"][\"surl\"]=surl\n dupanConfig[curStep][\"params\"][\"t\"]=ts13\n dupanConfig[curStep][\"params\"][\"logid\"]=logid\n\n #headers\n cookieDict[\"Hm_lvt_7a3960b6f067eb0085b7f96ff5e660b0\"]=ts10\n cookieDict[\"Hm_lpvt_7a3960b6f067eb0085b7f96ff5e660b0\"]=ts10\n cookie = spiderutils.GetCookieStrFromDict(cookieDict)\n dupanConfig[curStep][\"headers\"][\"Referer\"]=url3\n dupanConfig[curStep][\"headers\"][\"Cookie\"]=cookie\n\n #data\n dupanConfig[curStep][\"data\"][\"pwd\"]=pick_up_code\n\n resp = requests.post(url=dupanConfig[curStep][\"url\"], \n proxies=dupanConfig[\"proxy\"], \n params=dupanConfig[curStep][\"params\"], \n headers=dupanConfig[curStep][\"headers\"],\n data=dupanConfig[curStep][\"data\"])\n resp.encoding = 'UTF-8'\n \n randsk=json.loads(resp.text, encoding='UTF-8').get('randsk')\n logging.info(resp.status_code)\n else:\n logging.info(\"No \"+curStep)\n # --\n\n # s4--\n cookieDict[\"BDCLND\"] = randsk\n cookie = spiderutils.GetCookieStrFromDict(cookieDict)\n\n curStep=\"step4\"\n if curStep in dupanConfig:\n # cookieDict[\"BDCLND\"] = randsk\n # cookie = spiderutils.GetCookieStrFromDict(cookieDict)\n dupanConfig[curStep][\"url\"]=url\n dupanConfig[curStep][\"headers\"][\"Referer\"]=url3\n dupanConfig[curStep][\"headers\"][\"Cookie\"]=cookie\n \n resp = requests.get(url=dupanConfig[curStep][\"url\"], \n proxies=dupanConfig[\"proxy\"], \n headers=dupanConfig[curStep][\"headers\"])\n resp.encoding = 'UTF-8'\n logging.info(resp.status_code)\n\n #--\n soup = BeautifulSoup(resp.text, \"html.parser\")\n links = soup.find_all(name=\"script\", attrs={\"type\": \"text/javascript\"})\n jsAssignDict={}\n for l in links:\n li=re.findall(r'yunData.SHARE_UK = .*;',l.get_text())\n if len(li) > 0:\n li = li[0].replace(\"=\",\"\").replace(\"\\\\\",\"\").split('\"')\n jsAssignDict[li[0].strip()]=li[1].strip()\n li=re.findall(r'yunData.SHARE_ID = .*;',l.get_text())\n if len(li) > 0:\n li = li[0].replace(\"=\",\"\").replace(\"\\\\\",\"\").split('\"')\n jsAssignDict[li[0].strip()]=li[1].strip()\n li=re.findall(r'yunData.PATH = .*;',l.get_text())\n if len(li) > 0:\n # li = li[0].replace(\"=\",\"\").replace(\"\\\\\",\"\").split('\"')\n li = li[0].replace(\"=\",\"\").replace(\"\\\\\",\"\").replace(\"x27\",\"'\").split('\"')\n jsAssignDict[li[0].strip()]=li[1].strip()\n\n # print(jsAssignDict)\n else:\n logging.info(\"No \"+curStep)\n # --\n\n # s5--list all files.\n curStep=\"step5\"\n if curStep in dupanConfig:\n #--params\n logid2 = ctx.call(\"Getlogid\", cookieDict[\"BAIDUID\"])\n dupanConfig[curStep][\"params\"][\"logid\"]=logid2\n\n dupanConfig[curStep][\"params\"][\"uk\"]=jsAssignDict[\"yunData.SHARE_UK\"]\n dupanConfig[curStep][\"params\"][\"shareid\"]=jsAssignDict[\"yunData.SHARE_ID\"]\n dupanConfig[curStep][\"params\"][\"dir\"]=jsAssignDict[\"yunData.PATH\"]\n\n #--headers\n cookieDict[\"cflag\"] = \"13%3A3\"\n ts10_2 = str(int(time.time()))\n cookieDict[\"Hm_lpvt_7a3960b6f067eb0085b7f96ff5e660b0\"]=ts10_2\n cookie = spiderutils.GetCookieStrFromDict(cookieDict)\n dupanConfig[curStep][\"headers\"][\"Referer\"]=url\n dupanConfig[curStep][\"headers\"][\"Cookie\"]=cookie\n\n resp = requests.get(url=dupanConfig[curStep][\"url\"],\n proxies=dupanConfig[\"proxy\"],\n params=dupanConfig[curStep][\"params\"],\n headers=dupanConfig[curStep][\"headers\"])\n resp.encoding = 'UTF-8'\n logging.info(resp.status_code)\n else:\n logging.info(\"No \"+curStep)\n #--\n\n #-- save JSON\n jsonDict = json.loads(resp.text,encoding=\"UTF-8\")\n\n if not os.path.exists(os.path.dirname(outFile)):\n os.makedirs(os.path.dirname(outFile))\n\n # check old list\n if os.path.isfile(outFile):\n # file exists\n with open(outFile, \"r\", encoding=\"UTF-8\") as f:\n jloadDict = json.load(f)\n #compare different\n difflist = []\n # for i in jsonDict[\"list\"]:\n for i in range(jsonDict[\"list\"].__len__()):\n i_new_server_filename=jsonDict[\"list\"][i][\"server_filename\"]\n # if i not in jloadDict[\"list\"]:\n for j in range(jloadDict[\"list\"].__len__()):\n if i_new_server_filename == jloadDict[\"list\"][j][\"server_filename\"]:\n break\n else:\n difflist.append(i_new_server_filename)\n #--\n \n if difflist.__len__() == 0:\n # print(\"No change\")\n logging.info(\"No change\")\n else:\n # print(\"Been changed\")\n logging.info(\"Been changed:{0}\".format(difflist.__str__()))\n subject = \"\"\n for i in difflist:\n # subject = subject + i[\"path\"] + \",\"\n if len(subject) == 0:\n subject = i\n else:\n subject = subject + \",\" + i\n #send notification email\n # try:\n smtp = smtplib.SMTP_SSL(\"smtp.163.com\", 465)\n smtp.login(username, passwd)\n sender = username\n\n msg = MIMEText(difflist.__str__(),'plain','utf-8')\n msg['From'] = 'z136604<'+ sender + '>'\n msg['To'] = 'pyto<'+ receiver + '>'\n subject = 'DuPanUpdate: ' + subject\n msg['Subject'] = Header(subject,'utf-8') \n\n smtp.sendmail(sender, receiver, msg.as_string())\n smtp.quit()\n\n #update file\n with open(outFile, \"w\", encoding=\"UTF-8\") as f:\n json.dump(jsonDict, f)\n else:\n # file not exists\n with open(outFile, \"w\", encoding=\"UTF-8\") as f:\n json.dump(jsonDict, f)\n\n # --\n logging.info(\"===\" + title + \" end===\")\n logging.info(time.asctime())\n return\n\nif __name__ == \"__main__\":\n \n if sys.argv.__len__() > 1:\n if sys.argv[1] == \"1\":\n TestSpider1()\n elif sys.argv[1] == \"2\":\n TestSpider2(sys.argv[2])\n else:\n print(\"need input paramers\") \nelse:\n pass"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6875,
"avg_line_length": 31.5,
"blob_id": "d1c13cc8dd8bc2bdf2e4bc2ac3ffc76f4ab69a27",
"content_id": "ba46e9f09c8a4a30d6e66bfbf2043cb4982ad35f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 2,
"path": "/pkg1/innerpkg1/pkg1utils2.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "def pkg2Commfunc2(a):\n print(\"this is in pkg2Commfunc2: \", a)"
},
{
"alpha_fraction": 0.6262626051902771,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 19,
"blob_id": "10c6053e0bf62d2dc0bccb54a9810fcc63c8cd1c",
"content_id": "87968baf7003aca2fe1174055d08a60961f7bd8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 99,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 5,
"path": "/pkg1/innerpkg1/__init__.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "# Initialize \n# innerpkg1 is a package folder\n\n# use import *\n__all__ = [\"pkg1utils\", \"pkg1utils2\"]"
},
{
"alpha_fraction": 0.581818163394928,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 27,
"blob_id": "72d73a37fccffdd9ace075d309dfcf8ab2b0d941",
"content_id": "07f10b195256c31fd8eb6f9ca9af94501ba32ba1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/pkg1/innerpkg1/pkg1utils.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "def pkg1CommFunc1(a):\n print(\"you are in pkg1: \", a)"
},
{
"alpha_fraction": 0.7182053923606873,
"alphanum_fraction": 0.787170946598053,
"avg_line_length": 33.57692337036133,
"blob_id": "affc7d4be7c04001c18cce4e1dc7d7920a4248a4",
"content_id": "684ab04f966e008caca272634e2e442953454e59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3149,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 78,
"path": "/README.md",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "# PythonStudy\nPython Study\n\ncurrent learning chapter:\nhttps://docs.python.org/3/tutorial/inputoutput.html\n\nNote:\n1. upgread pythone pip\n\nYou are using pip version 9.0.3, however version 19.1.1 is available.\nYou should consider upgrading via the 'python -m pip install --upgrade pip' command.\n\n2. install request package\nPS C:\\Users\\sqpz\\Documents\\PythonStudy> pip --trusted-host pypi.org --trusted-host files.pythonhosted.org install requests\n\n3. install pylint\nPS C:\\Users\\sqpz\\Documents\\PythonStudy> pip --trusted-host pypi.org --trusted-host files.pythonhosted.org install pylint\n\n4. when catch SSLerror, the reason is fiddler is opening using proxy[for item 3,4]\n\n5. 在爬虫中使用proxy 可以同时使用Fiddler4 和爬虫\nhttp://baijiahao.baidu.com/s?id=1599906763166379926&wfr=spider&for=pc\n\n6. test case\n链接: https://pan.baidu.com/s/1MtzzoarNAZbQGv92zlZyCg 提取码: rxks 复制这段内容后打开百度网盘手机App,操作更方便哦\n\n7. flow\n发送request\n—> \n收到response,分析获取数据\n-> \n再发送request\n-> \n再收到response,分析获取数据\n...\n直到获取了自己需要的信息\n\n8. avoid requests auto redirect.\nret = requests.get(url=url, headers=headers, allow_redirects=False)\n\n9. Python获取URL中参数的方法\nhttps://blog.csdn.net/weixin_34179762/article/details/86943489\n\n10. File \"C:\\Users\\jiean.a.lu\\AppData\\Local\\Programs\\Python\\Python37\\lib\\subprocess.py\", line 939, in communicate\n stdout, stderr = self._communicate(input, endtime, timeout)\n File \"C:\\Users\\jiean.a.lu\\AppData\\Local\\Programs\\Python\\Python37\\lib\\subprocess.py\", line 1261, in _communicate\n self._stdin_write(input)\n File \"C:\\Users\\jiean.a.lu\\AppData\\Local\\Programs\\Python\\Python37\\lib\\subprocess.py\", line 873, in _stdin_write\n self.stdin.write(input)\n File \"C:\\Users\\jiean.a.lu\\AppData\\Local\\Programs\\Python\\Python37\\lib\\encodings\\cp1252.py\", line 19, in encode\n return codecs.charmap_encode(input,self.errors,encoding_table)[0]\nUnicodeEncodeError: 'charmap' codec can't encode character '\\uff01' in position 1324: character maps to <undefined>\n\nhttps://blog.csdn.net/sergiojune/article/details/88423694\n原因是有一个程序在使用TextIOWrapper 类创建对象时默认使用了cp936的编码,也就是gbk编码,读取不了utf-8的字符,\n所以我们可以修改下 subprocess.py 文件的默认编码方式为utf-8即可\n\n在代码行656有个初始化,直接修改默认即可,如下\n\n11. python读写json文件\nhttps://www.cnblogs.com/bigberg/p/6430095.html\n\n12. python--自动创建文件和创建目录的方法\nhttps://blog.csdn.net/liuyingying0418/article/details/84633603\nhttps://www.cnblogs.com/jhao/p/7243043.html\n\n13. python自动发邮件总结及实例说明\nhttps://www.cnblogs.com/yufeihlf/p/5726619.html\nhttps://blog.csdn.net/weixin_41789943/article/details/82348946\n\n14.\nhttps://blog.csdn.net/wudj810818/article/details/50403424 \n\n15.\n链接: https://pan.baidu.com/s/1NHDs_vH1AD9FWSscQMO5uQ 提取码: vmwk 复制这段内容后打开百度网盘手机App,操作更方便哦\n\nReference Dic\n1. https://2.python-requests.org/en/master/user/quickstart/#make-a-request\n"
},
{
"alpha_fraction": 0.5917107462882996,
"alphanum_fraction": 0.631393313407898,
"avg_line_length": 29.675676345825195,
"blob_id": "631a2f83ad756a7b54c6f9128031831fe04643bf",
"content_id": "3815a94e080341f5272c33b1bc09a3855981baa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1134,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 37,
"path": "/test2.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "import requests\n\nfrom bs4 import BeautifulSoup\n\nheader={\n \"Host\": \"www.ktkkt.com\",\n \"Connection\": \"keep-alive\",\n \"Cache-Control\": \"max-age=0\",\n \"Upgrade-Insecure-Requests\": \"1\",\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36\",\n \"Accept\": \"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\",\n \"Accept-Encoding\": \"gzip, deflate\",\n \"Accept-Language\": \"zh-CN,zh;q=0.9\"\n}\n\nresp = requests.get(\n url=\"http://www.ktkkt.com/y/index.html\",\n headers=header\n)\nresp.encoding = 'gb2312'\n# print(resp.text)\n\nsoup = BeautifulSoup(resp.text, \"html.parser\")\nprint(soup.prettify())\nprint(\"------\")\n# print(soup.find_all('ul')[0].find_all('a'))\nfor r in soup.find_all('ul'):\n for s in r.find_all('strong'):\n for t in s.find_all('a'):\n print(t.get('title'))\nprint(\"------\")\n# l=soup.find_all('ul')\n# htext=l[0]\n# soup1 = BeautifulSoup(htext, \"html.parser\")\n# print(soup1.find_all('ul'))\n# for i in soup.find_all('a', 'class'):\n# print(i.get('title'))"
},
{
"alpha_fraction": 0.4251824915409088,
"alphanum_fraction": 0.4574209153652191,
"avg_line_length": 41.8125,
"blob_id": "ffb0f9ef9ce4eaba131a7aadb909e2cc00aa6205",
"content_id": "ed6c772cbbe1cd5971c9da9b4c184e785837b047",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 8228,
"license_type": "no_license",
"max_line_length": 220,
"num_lines": 192,
"path": "/js/boot.js",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "// !function() {\n // function e(e, n, t) {\n // var o = new Image;\n // o.onload = function(e) {\n // \"function\" == typeof n && n.call(null, e)\n // }\n // ,\n // o.onerror = function(e) {\n // \"function\" == typeof t && t.call(null, e)\n // }\n // ,\n // o.src = e\n // }\n // var n = window\n // , t = n.document\n // , o = require(\"disk-share:widget/data/yunData.js\").get()\n // , i = require(\"system-core:context/context.js\")\n // , r = i.instanceForSystem.libs.JQuery\n // , a = i.instanceForSystem.libs.underscore\n // , c = i.instanceForSystem.message\n // , s = i.instanceForSystem.tools.baseService;\n // !function(e) {\n // void 0 === e && (e = n.disk = {}),\n // e.DEBUG = function() {\n // var e = n.location.host;\n // return n.console ? \"pan.baidu.com\" === e || \"lab.pan.baidu.com\" === e ? !1 : !0 : !1\n // }(),\n // e.uniqueId = 0,\n // e.obtainId = function() {\n // return \"_disk_id_\" + ++e.uniqueId\n // }\n // ,\n // e.common = {}\n // }(n.disk);\n var u = \"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/~!@#¥%……&\"\n , l = String.fromCharCode\n , d = function(e) {\n if (e.length < 2) {\n var n = e.charCodeAt(0);\n return 128 > n ? e : 2048 > n ? l(192 | n >>> 6) + l(128 | 63 & n) : l(224 | n >>> 12 & 15) + l(128 | n >>> 6 & 63) + l(128 | 63 & n)\n }\n var n = 65536 + 1024 * (e.charCodeAt(0) - 55296) + (e.charCodeAt(1) - 56320);\n return l(240 | n >>> 18 & 7) + l(128 | n >>> 12 & 63) + l(128 | n >>> 6 & 63) + l(128 | 63 & n)\n }\n , f = /[\\uD800-\\uDBFF][\\uDC00-\\uDFFFF]|[^\\x00-\\x7F]/g\n , g = function(e) {\n return (e + \"\" + Math.random()).replace(f, d)\n }\n , h = function(e) {\n var n = [0, 2, 1][e.length % 3]\n , t = e.charCodeAt(0) << 16 | (e.length > 1 ? e.charCodeAt(1) : 0) << 8 | (e.length > 2 ? e.charCodeAt(2) : 0)\n , o = [u.charAt(t >>> 18), u.charAt(t >>> 12 & 63), n >= 2 ? \"=\" : u.charAt(t >>> 6 & 63), n >= 1 ? \"=\" : u.charAt(63 & t)];\n return o.join(\"\")\n }\n , m = function(e) {\n return e.replace(/[\\s\\S]{1,3}/g, h)\n }\n , p = function() {\n return m(g((new Date).getTime()))\n }\n , w = function(e, n) {\n return n ? p(String(e)).replace(/[+\\/]/g, function(e) {\n return \"+\" == e ? \"-\" : \"_\"\n }).replace(/=/g, \"\") : p(String(e))\n };\n // !function() {\n function Getlogid(baiduid) {\n // r(document).ajaxSend(function(e, n, t) {\n // var i = w(s.getCookie(\"BAIDUID\"));\n var i = w(baiduid);\n return i;\n // t.url += /\\?/.test(t.url) ? \"&channel=chunlei&web=1&app_id=250528\" : \"?channel=chunlei&web=1&app_id=250528\",\n // (\"script\" !== t.dataType || t.cache !== !0) && (t.url += \"&bdstoken=\" + o.bdstoken + \"&logid=\" + i),\n // t.url += \"/disk/plugin\" === location.pathname ? \"&clienttype=8&version=4.9.9.9\" : \"132\" === s.getParam(\"msg\") && s.getParam(\"devuid\") ? \"&clienttype=8\" : \"&clienttype=0\"\n // })\n // }(),\n // }()\n }\n // function(e) {\n // var n = e.async;\n // e.async = function(e, t, o) {\n // n(e, function() {\n // \"function\" == typeof t && t.apply(this, arguments)\n // }, function() {\n // \"function\" == typeof o && o.apply(this, arguments)\n // })\n // }\n // }(require),\n // function() {\n // r.browser.msie && 6 === parseInt(r.browser.version, 10) && t.execCommand(\"backgroundimagecache\", !1, !0)\n // }(),\n // function(e) {\n // e.trim || (e.trim = function() {\n // return this.replace(/^\\s+|\\s+$/g, \"\")\n // }\n // )\n // }(String.prototype),\n // function(e) {\n // e.indexOf || (e.indexOf = function(e) {\n // return a.indexOf(this, e)\n // }\n // ,\n // e.forEach || (e.forEach = function(e) {\n // return a.each(this, e)\n // }\n // ))\n // }(Array.prototype),\n // function() {\n // r.browser.msie === !0 && 6 == r.browser.version && r(\"body\").addClass(\"fixbug-ie6\")\n // }(),\n // function() {\n // c.once(\"after-list-loaded\", function() {\n // require.async(\"disk-share:static/js/pcsDownloadUtil.js\", function(e) {\n // e.initPcsDownloadCdnConnectivity(function(e) {\n // e && i.instanceForSystem.file.watchCDNOfPCS(e)\n // })\n // })\n // })\n // }(),\n // function() {\n // Object.defineProperty && (Object.defineProperty(window, \"navigator\", {\n // configurable: !1,\n // writable: !1,\n // value: window.navigator\n // }),\n // Object.defineProperty(window.navigator, \"platform\", {\n // configurable: !1,\n // writable: !1,\n // value: window.navigator.platform\n // }),\n // Object.defineProperty(window.navigator, \"userAgent\", {\n // configurable: !1,\n // writable: !1,\n // value: window.navigator.userAgent\n // }))\n // }(),\n // window.location.origin || (window.location.origin = window.location.protocol + \"//\" + window.location.hostname + (window.location.port ? \":\" + window.location.port : \"\")),\n // function() {\n // for (var e = [\"Hm_lvt_773fea2ac036979ebb5fcc768d8beb67\", \"Hm_lvt_b181fb73f90936ebd334d457c848c8b5\", \"Hm_lvt_adf736c22cd6bcc36a1d27e5af30949e\"], n = \".\" + location.hostname, t = 0; t < e.length; t++)\n // s.setCookie(e[t], \"\", -1, \"/\", n)\n // }();\n // var v = s.client();\n // if (\"/disk/home\" === location.pathname) {\n // var b = null\n // , y = v.browserString\n // , S = 30\n // , k = 0\n // , x = 2e3;\n // (-1 !== y.indexOf(\"chrome\") || -1 !== y.indexOf(\"firefox\") || -1 !== y.indexOf(\"safari\")) && (b = setInterval(function() {\n // var e = r(\"script\")\n // , n = e[e.length - 1].src;\n // (-1 !== n.indexOf(\"mjaenbjdjmgolhoafkohbhhbaiedbkno\") || -1 !== n.indexOf(\"acgotaku311\") || -1 !== n.indexOf(\"BaiduExporter\")) && (i.instanceForSystem.log.send({\n // name: \"chrome-extension\",\n // sendServerLog: !0,\n // value: y\n // }),\n // clearInterval(b)),\n // ++k > S && clearInterval(b)\n // }, x),\n // r(document).delegate(\"#export_menu\", \"click\", function() {\n // i.instanceForSystem.log.send({\n // name: \"chrome-used\",\n // sendServerLog: !0,\n // value: y\n // })\n // }))\n // }\n // \"http:\" !== location.protocol || !v.engine || null == v.engine.ie || \"ie11\" !== v.browserString && \"edge\" !== v.browserString || e(\"https://\" + location.host + \"/yun-static/common/images/default.gif\", function() {\n // s.setCookie(\"secu\", 1, 365, \"/\"),\n // i.instanceForSystem.log.send({\n // type: \"httpsAccess\" + v.browserString\n // })\n // }),\n // \"https:\" === location.protocol && \"serviceWorker\"in navigator && navigator.userAgent.indexOf(\"Firefox\") <= -1 && navigator.serviceWorker.register(\"/disk/serviceworker.js\", {\n // scope: \"/disk/home\"\n // }).then(function(e) {\n // e.installing ? console.log(\"Service worker installing\") : e.waiting ? console.log(\"Service worker installed\") : e.active && console.log(\"Service worker active\")\n // }, function(e) {\n // console.log(e)\n // });\n // var C = function() {\n // var e = document.referrer;\n // if (\"string\" == typeof e && e.length > 0) {\n // var n = \"fm_self\"\n // , t = /(http|https):\\/\\/(tieba|hao123)\\.baidu\\.com/gi\n // , o = /(http|https):\\/\\/www\\.hao123\\.com/gi;\n // t.test(e) ? n = \"fm_\" + RegExp.$2 : o.test(e) ? n = \"fm_hao123\" : -1 !== e.indexOf(\"http://www.baidu.com/s?wd=\") && (n = \"fm_baidups\")\n // }\n // return n\n // }();\n // i.instanceForSystem.log.sendUserReport(C)\n// }();\n"
},
{
"alpha_fraction": 0.7128713130950928,
"alphanum_fraction": 0.7722772359848022,
"avg_line_length": 50,
"blob_id": "9efc5b7920b7740fd931d21fbfb62fd027096aa3",
"content_id": "e2b105c7621735f8542c44e52683dd203c8950d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 2,
"path": "/spider.sh",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "DIRNAME=`dirname $0`\npython ${DIRNAME}/spider.py 2 ${DIRNAME}/config/usr/1pUZRD5wJOM7iUA4_O-TRSw.json"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.5874999761581421,
"avg_line_length": 26,
"blob_id": "87def1edf2bc7a468a34fc133be715385df33879",
"content_id": "8cd89e15812ebf1e6c1f1e4d4d16fb0fab65ebd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 3,
"path": "/js/test.js",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "function testJSFunc1(a, b) {\n return \"Calling testJSFunc1: \" + a + \" \" + b;\n}"
},
{
"alpha_fraction": 0.574999988079071,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 19.25,
"blob_id": "498c81821396ac071e1d7a3c7cdc7bf53dbec825",
"content_id": "1b83c8f55df589c4175401714b69290dc464a5bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 4,
"path": "/testutils.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "# moudule utils.py\n\ndef CommFunc1(a,b):\n print(\"Call CommFunc1: \", a, \"+\", b)"
},
{
"alpha_fraction": 0.5351351499557495,
"alphanum_fraction": 0.5441441535949707,
"avg_line_length": 25.4761905670166,
"blob_id": "ef6e3485c8c83130e3e065283bb6fba4229d4c05",
"content_id": "3926e281c75f174afffe6f89608953140b2f288e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 21,
"path": "/utils/spiderutils.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "def PrintHttpDetails(ret):\n print(\"------response status code-------\")\n print(ret.status_code)\n print(\"-------response headers-----\")\n print(ret.headers)\n print(\"-------response text-----\")\n print(ret.text)\n\ndef GetCookieStrFromDict(dict):\n str=''\n # print(resp.cookies)\n for k,v in dict.items():\n str = str + k + \"=\" + v + \";\"\n # str = print(\"{0}{1}={2};\".format(str, k, v))\n return str[0:len(str)-1]\n\ndef GetCookieDict(resp):\n dict={}\n for i in resp.cookies:\n dict[i.name]=i.value\n return dict"
},
{
"alpha_fraction": 0.707317054271698,
"alphanum_fraction": 0.7317073345184326,
"avg_line_length": 19.5,
"blob_id": "96f79d459b95b7e40910696ab7a8b81ec047502f",
"content_id": "7cfd1c7c67fd3bc6105b3b396aceb00bc2bed2b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 2,
"path": "/pkg1/__init__.py",
"repo_name": "lujiean/PythonStudy",
"src_encoding": "UTF-8",
"text": "# Initialize \n# pkg1 is a package folder\n"
}
] | 12 |
paulovictor/cricri | https://github.com/paulovictor/cricri | 52f6b164d9cd18334465143fa353c15a78714bc2 | c37ad01fc00b5d55317e27925f2f18946f3b6858 | a7353f2713c2d57731335ed4dba311489be48e53 | refs/heads/master | 2019-11-17T12:09:25.517848 | 2014-09-04T17:20:00 | 2014-09-04T17:20:00 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 21.75,
"blob_id": "f89904a33d877c53886bd2a340491fde56215e84",
"content_id": "686257749c76271a0f393c53d14aca45fe7b2a7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 4,
"path": "/candidato/eleitores/admin.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Eleitor\n\nadmin.site.register(Eleitor)"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6396104097366333,
"avg_line_length": 37.5625,
"blob_id": "b3bbe413b2c2d4efe57c829a252a2e1d4842563b",
"content_id": "966b77e7ca04efd0d2916b0e791d4ce13c9c8e51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 16,
"path": "/candidato/agendas/serializers.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.forms import widgets\nfrom rest_framework import serializers\nfrom .models import Agenda\n\n\nclass AgendaSerializer(serializers.Serializer):\n pk = serializers.Field() # Note: `Field` is an untyped read-only field.\n data = serializers.DateTimeField()\n title = serializers.CharField(required=False,\n max_length=100)\n description = serializers.CharField(required=False,\n max_length=100)\n\n created_at = serializers.DateTimeField()\n local = serializers.CharField(required=False,\n max_length=100)"
},
{
"alpha_fraction": 0.6014492511749268,
"alphanum_fraction": 0.6057971119880676,
"avg_line_length": 42.125,
"blob_id": "b778f5c522caaa8559f2fa7a40397d28d2b70c99",
"content_id": "4ad6c7fdd47f90017bc7fe116e0224aec3ce677a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 690,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 16,
"path": "/candidato/noticias/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, include, url\n\nurlpatterns = patterns('candidato.noticias.views',\n\turl(r'^$', 'noticias', name='noticias'),\n\turl(r'^detail/(?P<pk>\\d+)$', 'noticia_detail', name='noticia_detail'),\n\turl(r'^edit/(?P<pk>\\d+)$', 'noticia_edit', name='noticia_edit'),\n\turl(r'^excluir/(?P<pk>\\d+)$', 'noticia_excluir', name='noticia_excluir'),\n\turl(r'^nova/$', 'noticia_create', name='noticia_create'),\n\turl(r'^api/$', 'api', name='api'),\n\turl(r'^api/(?P<pk>[0-9]+)/$', 'api_noticia_detail'),\n\turl(r'^api/(?P<slug>[-\\w\\d]+)/$', 'api_todas_noticias_detail'),\n\turl(r'^api/(?P<slug>[-\\w\\d]+)/site/$', 'api_todas_noticias_site'),\n)\n"
},
{
"alpha_fraction": 0.670258641242981,
"alphanum_fraction": 0.681034505367279,
"avg_line_length": 27.875,
"blob_id": "ecc747adf5133894d6176142469ef742ee9e01cf",
"content_id": "a87bb31c14d66fda49a45866746ed53cb14c9a66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 464,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 16,
"path": "/candidato/agendas/forms.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nfrom django import forms\n\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext as _\nfrom django.db import IntegrityError\nfrom candidato.agendas.models import Agenda\n\nclass AgendaForm(forms.ModelForm):\n class Meta:\n model = Agenda\n fields = ['title','description','data','local']\n widgets = {\n 'description': forms.Textarea(attrs={'cols': 100, 'rows': 5}),\n }\n\n\n"
},
{
"alpha_fraction": 0.5973253846168518,
"alphanum_fraction": 0.5988112688064575,
"avg_line_length": 41.0625,
"blob_id": "617a2e19980a0d5adb0f0a4e2550ef7e99db4e40",
"content_id": "6fd01b1418f6592f87248b420d53d53051dc33e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 16,
"path": "/candidato/agendas/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, include, url\n\nurlpatterns = patterns('candidato.agendas.views',\n\turl(r'^$', 'agendas', name='agendas'),\n\turl(r'^nova/$', 'agenda_create', name='agenda_create'),\n\turl(r'^detail/(?P<pk>\\d+)$', 'agenda_detail', name='agenda_detail'),\n\turl(r'^excluir/(?P<pk>\\d+)$', 'agenda_excluir', name='agenda_excluir'),\n\turl(r'^edit/(?P<pk>\\d+)$', 'agenda_edit', name='agenda_edit'),\n\turl(r'^api/$', 'api', name='api'),\n\turl(r'^api/(?P<pk>\\d+)/$', 'api_agenda_detail'),\n\turl(r'^api/(?P<slug>[-\\w\\d]+)/$', 'api_todas_agendas_detail'),\n\turl(r'^api/(?P<slug>[-\\w\\d]+)/site/$', 'api_todas_agendas_site'),\n)\n"
},
{
"alpha_fraction": 0.7003745436668396,
"alphanum_fraction": 0.7071161270141602,
"avg_line_length": 34.157894134521484,
"blob_id": "8d282d7cd3c83de7956073365ddea690e527010f",
"content_id": "6f8d756cf74ec4d755a2dd1c93852f310b40ba89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 38,
"path": "/candidato/places/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from rest_framework.renderers import JSONRenderer\nfrom rest_framework.parsers import JSONParser\nfrom .serializers import BairroSerializer,CidadeSerializer\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.views.decorators.csrf import csrf_exempt\nfrom .models import Cidade,Bairro\nclass JSONResponse(HttpResponse):\n \"\"\"\n An HttpResponse that renders its content into JSON.\n \"\"\"\n def __init__(self, data, **kwargs):\n content = JSONRenderer().render(data)\n kwargs['content_type'] = 'application/json'\n super(JSONResponse, self).__init__(content, **kwargs)\n\n@csrf_exempt\ndef cidades(request):\n \"\"\"\n List all code snippets, or create a new snippet.\n \"\"\"\n if request.method == 'GET':\n cidades = Cidade.objects.all()\n serializer = CidadeSerializer(cidades, many=True)\n return JSONResponse(serializer.data)\n@csrf_exempt\ndef api_todos_bairros(request,pk):\n try:\n cidade = get_object_or_404(Cidade,pk=pk)\n \n bairros = Bairro.objects.filter(cidade=cidade)\n except Bairro.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = CidadeSerializer(bairros)\n return JSONResponse(serializer.data)"
},
{
"alpha_fraction": 0.6519337296485901,
"alphanum_fraction": 0.7624309659004211,
"avg_line_length": 19.11111068725586,
"blob_id": "896ffdd994275b4f926eab283c8aff15d123ce32",
"content_id": "75905272ed4bdad6ea15b33503039196feea3be9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/requirements.txt",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "django==1.6.2\ndj-database-url==0.3.0\nUnipath==1.0\ngunicorn==18.0\ndjango-admin-honeypot==0.3.0\ndjangorestframework\nPillow==2.5.1\ndjango-push-notifications==1.1.0\ndjango-cors-headers\n"
},
{
"alpha_fraction": 0.6141176223754883,
"alphanum_fraction": 0.6211764812469482,
"avg_line_length": 37.6363639831543,
"blob_id": "05950662e73d05565e17d13ff75201480c7539fe",
"content_id": "d2d5ac927d868e1a29dc920bf3104460d3f87853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/candidato/politicos/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, include, url\nurlpatterns = patterns('candidato.politicos.views',\n\turl(r'^novo/$', 'politico_create', name='politico_create'),\n\turl(r'^api/$', 'api', name='api'),\n\turl(r'^api/(?P<pk>[0-9]+)/$', 'api_politico_detail'),\n\turl(r'^(?P<slug>[-\\w\\d]+)/$', 'politico_detail', name='politico_detail'),\n\turl(r'^$', 'politicos', name='politicos'),\n\t)\n"
},
{
"alpha_fraction": 0.7342799305915833,
"alphanum_fraction": 0.7363083362579346,
"avg_line_length": 22.5238094329834,
"blob_id": "6ff021378b98533d934aec87ca2638af430e74be",
"content_id": "0a35ea59f4ead9a79b24746bf6beaec9faab9815",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 21,
"path": "/candidato/politicos/api.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from tastypie.resources import ModelResource\nfrom tastypie import fields, utils\nfrom tastypie.constants import ALL\nfrom .models import Politico\nfrom candidato.noticias.models import Noticia\n\n\n\nclass PoliticoResource(ModelResource):\n\t\n\tclass Meta:\n\t\tqueryset = Politico.objects.all()\n\t\tresource_name = 'politicos'\n\t\tdetail_uri_name = 'slug'\n\nclass NoticiaResource(ModelResource):\n \n class Meta:\n queryset = Noticia.objects.all()\n resource_name = 'noticias'\n limit = 0"
},
{
"alpha_fraction": 0.6854838728904724,
"alphanum_fraction": 0.6995967626571655,
"avg_line_length": 32.13333511352539,
"blob_id": "b39b49fb5a77438fb915cf829f7bbc34b8b9e36f",
"content_id": "847f6832463a33ca53903171c2546ccfac5905e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 15,
"path": "/candidato/places/models.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.auth.models import User\n\nclass Cidade(models.Model):\n nome = models.CharField(max_length=100,verbose_name='Nome')\n def __str__(self):\n return self.nome\n\nclass Bairro(models.Model):\n nome = models.CharField(max_length=100,verbose_name='Nome')\n cidade = models.ForeignKey(Cidade,related_name='bairros')\n def __str__(self):\n return self.nome"
},
{
"alpha_fraction": 0.6859196424484253,
"alphanum_fraction": 0.6901783347129822,
"avg_line_length": 31.11111068725586,
"blob_id": "07debed7c8777ffa6f2fc3e97b9ac92a8b0d3cbd",
"content_id": "6c7c27fb5c6c724df4c0bf7fce0cd66f8fec4795",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3758,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 117,
"path": "/candidato/politicos/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\nfrom django.shortcuts import render\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponseRedirect\nfrom .forms import PoliticoForm\nfrom .models import Politico\n#comment\nimport random\nfrom django.http import HttpResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.parsers import JSONParser\nfrom .serializers import PoliticoSerializer\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.admin.views.decorators import staff_member_required\n\n\nclass JSONResponse(HttpResponse):\n \"\"\"\n An HttpResponse that renders its content into JSON.\n \"\"\"\n def __init__(self, data, **kwargs):\n content = JSONRenderer().render(data)\n kwargs['content_type'] = 'application/json'\n super(JSONResponse, self).__init__(content, **kwargs)\n\n@csrf_exempt\ndef api(request):\n \"\"\"\n List all code snippets, or create a new snippet.\n \"\"\"\n if request.method == 'GET':\n politicos = Politico.objects.all()\n serializer = PoliticoSerializer(politicos, many=True)\n return JSONResponse(serializer.data)\n\n@csrf_exempt\ndef api_politico_detail(request, pk):\n \"\"\"\n Retrieve, update or delete a code snippet.\n \"\"\"\n try:\n politico = Politico.objects.get(pk=pk)\n except Politico.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = PoliticoSerializer(politico)\n return JSONResponse(serializer.data)\n\ndef politicos(request):\n politicos = Politico.objects.all().select_related().order_by('first_name')\n return render(request,'politicos/politicos.html',{'politicos':politicos}) \n\ndef politico_edit(request,id): \n '''\n @politico_edit: View para determinar se é um GET ou POST para editar um politico\n '''\n politico = get_object_or_404(Politico,id=id)\n if request.method == 'POST':\n return edit_politico(request,politico)\n else:\n return request_politico(request,politico)\n\n@login_required\ndef edit_politico(request,politico):\n '''\n @edit_politico: View para alterar os dados de um politico\n ''' \n form = PoliticoForm(request.POST,instance=politico)\n if form.is_valid():\n politico = form.save(commit=False)\n politico.save()\n return HttpResponseRedirect(politico.detail())\n else:\n return render(request,'politicos/politico_edit.html',{'form':form})\n@login_required\ndef request_politico(request,politico):\n '''\n @request_politico: View para obter os dados de um determinado politico\n ''' \n form = PoliticoForm(instance=politico)\n return render(request, 'politicos/politico_edit.html', {'form': form,'politico':politico})\n\ndef politico_detail(request,slug):\n\n politico = get_object_or_404(Politico,slug=slug)\n politicos = Politico.objects.all()\n politicos = politicos[:30]\n politicos = sorted(politicos, key=lambda x: random.random())\n return render(request,'politicos/politico_detail.html',\n {'politico':politico,'politicos':politicos[:4]}\n )\n\n@staff_member_required\ndef politico_create(request):\n if request.method == 'POST': \n return create_politico(request)\n else:\n return new_politico(request)\n \n@staff_member_required\ndef new_politico(request):\n\n return render(request, 'politicos/politico_form.html',\n {'form': PoliticoForm()})\n\n@staff_member_required\ndef create_politico(request):\n\n form = PoliticoForm(request.POST)\n if not form.is_valid():\n return render(request, 'politicos/politico_form.html',\n {'form': form})\n obj = form.save()\n obj.save()\n return HttpResponseRedirect('/')\n"
},
{
"alpha_fraction": 0.672771692276001,
"alphanum_fraction": 0.6862027049064636,
"avg_line_length": 36.272727966308594,
"blob_id": "7a6cc1cb44956bb29cc1e55ef65383fac4429cf2",
"content_id": "6f21a51d2e8ad5bfad547edff41f803723af731a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 819,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 22,
"path": "/candidato/agendas/models.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.auth.models import User\n\nclass Agenda(models.Model):\n title = models.CharField(max_length=100,verbose_name='Titulo')\n description = models.CharField(max_length=2500,verbose_name='Descricao')\n data = models.DateTimeField()\n created_at = models.DateTimeField(auto_now_add=True)\n local = models.CharField(max_length=100,verbose_name='Local')\n politico = models.ForeignKey('politicos.Politico',related_name='agendas')\n def __str__(self):\n return self.title\n\n @models.permalink\n def detail(self):\n return ('agendas:agenda_detail', (), {'pk': self.id})\n\n @models.permalink\n def edit(self):\n return ('agendas:agenda_edit', (), {'pk': self.id})"
},
{
"alpha_fraction": 0.665228009223938,
"alphanum_fraction": 0.6740476489067078,
"avg_line_length": 31.699386596679688,
"blob_id": "7154b35aceace5bc96a2585d79d315d597ee8a19",
"content_id": "336e75a9588c7ac9366100470ca9de4f36607e56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5331,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 163,
"path": "/candidato/agendas/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\nfrom django.shortcuts import render\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponseRedirect\nfrom .forms import AgendaForm\nfrom .models import Agenda\nfrom candidato.politicos.models import Politico\nfrom django.http import Http404\nimport random\nfrom django.http import HttpResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.parsers import JSONParser\nfrom .serializers import AgendaSerializer\nfrom django.contrib.auth.decorators import login_required\n\n\nclass JSONResponse(HttpResponse):\n \"\"\"\n An HttpResponse that renders its content into JSON.\n \"\"\"\n def __init__(self, data, **kwargs):\n content = JSONRenderer().render(data)\n kwargs['content_type'] = 'application/json'\n super(JSONResponse, self).__init__(content, **kwargs)\n\n@csrf_exempt\ndef api(request):\n \"\"\"\n List all code snippets, or create a new snippet.\n \"\"\"\n if request.method == 'GET':\n agendas = Agenda.objects.all()\n serializer = AgendaSerializer(agendas, many=True)\n return JSONResponse(serializer.data)\n\nimport json\n\n@csrf_exempt\ndef api_todas_agendas_detail(request,slug):\n try:\n politico = get_object_or_404(Politico,slug=slug)\n \n agenda = Agenda.objects.filter(politico=politico)\n except Agenda.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = AgendaSerializer(agenda)\n return JSONResponse(serializer.data)\n\n\ndef api_todas_agendas_site(request,slug):\n politico = get_object_or_404(Politico,slug=slug)\n agenda = Agenda.objects.filter(politico=politico)\n\n ag_list = []\n for a in agenda:\n ag_dict = {}\n ag_dict['id'] = a.id\n ag_dict['title'] = a.title\n ag_dict['description'] = a.description\n ag_dict['data'] = a.data.strftime(\"%d/%m/%Y às %H:%M:%S\")\n ag_list.append(ag_dict)\n \n response = HttpResponse(json.dumps(ag_list))\n response[\"Access-Control-Allow-Origin\"] = \"*\"\n response[\"Access-Control-Allow-Methods\"] = \"POST,GET,OPTIONS\"\n response[\"Access-Control-Max-Age\"] = \"1000\"\n response[\"Access-Control-Allow-Headers\"] = \"*\"\n return response\n\n\n@csrf_exempt\ndef api_agenda_detail(request, pk):\n \"\"\"\n Retrieve, update or delete a code snippet.\n \"\"\"\n try:\n agenda = Agenda.objects.get(pk=pk)\n except Agenda.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = AgendaSerializer(agenda)\n return JSONResponse(serializer.data)\n\ndef agenda_detail(request,pk):\n pol = get_object_or_404(Politico,user=request.user)\n agenda = get_object_or_404(Agenda,id=pk,politico=pol)\n return render(request,'agendas/agenda_detail.html',\n {'agenda':agenda}\n )\n@login_required\ndef agenda_edit(request,pk): \n '''\n @politico_edit: View para determinar se é um GET ou POST para editar um politico\n '''\n pol = get_object_or_404(Politico,user=request.user)\n agenda = get_object_or_404(Agenda,id=pk,politico=pol)\n if request.method == 'POST':\n return edit_agenda(request,agenda)\n else:\n return request_agenda(request,agenda)\n\n@login_required\ndef edit_agenda(request,agenda):\n '''\n @edit_politico: View para alterar os dados de um politico\n ''' \n form = AgendaForm(request.POST,instance=agenda)\n if form.is_valid():\n agenda = form.save(commit=False)\n agenda.save()\n return HttpResponseRedirect(agenda.detail())\n else:\n return render(request,'agendas/agenda_edit.html',{'form':form})\n\ndef request_agenda(request,agenda):\n '''\n @request_politico: View para obter os dados de um determinado politico\n ''' \n form = AgendaForm(instance=agenda)\n return render(request, 'agendas/agenda_edit.html', {'form': form,'agenda':agenda})\n\ndef agendas(request):\n pol = get_object_or_404(Politico,user=request.user)\n agendas = Agenda.objects.filter(politico=pol).select_related().order_by('-created_at')\n return render(request,'agendas/agendas_geral.html',{'agendas':agendas})\n\ndef agenda_geral(request):\n agendas = Agenda.objects.filter().select_related().order_by('-created_at')\n return render(request,'agendas/agendas_geral.html',{'agendas':agendas})\n \n@login_required\ndef agenda_create(request):\n if request.method == 'POST': \n return create_agenda(request)\n else:\n return new_agenda(request)\n@login_required\ndef new_agenda(request):\n return render(request, 'agendas/agenda_form.html',\n {'form': AgendaForm()})\n@login_required\ndef create_agenda(request):\n if not request.user.is_authenticated():\n raise Http404\n form = AgendaForm(request.POST)\n if not form.is_valid():\n return render(request, 'agendas/agenda_form.html',\n {'form': form})\n obj = form.save(commit=False)\n pol = get_object_or_404(Politico,user=request.user)\n obj.politico = pol\n obj.save()\n return HttpResponseRedirect('/agenda/')\n\n@login_required\ndef agenda_excluir(request,pk):\n pol = get_object_or_404(Politico,user=request.user)\n u = Agenda.objects.get(id=pk,politico=pol).delete()\n return HttpResponseRedirect('/agenda/')"
},
{
"alpha_fraction": 0.6708497405052185,
"alphanum_fraction": 0.6794549822807312,
"avg_line_length": 33.64596176147461,
"blob_id": "d04c8a2f96c35d9fa9c05b617fa6e27d660722a8",
"content_id": "1622cd3114b0f42ddd32efe0e3cb517c78d1616c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5579,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 161,
"path": "/candidato/noticias/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\nfrom django.shortcuts import render\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponseRedirect\nfrom .forms import NoticiaForm\nfrom .models import Noticia\nfrom candidato.politicos.models import Politico\nfrom django.http import Http404\nimport random\nfrom django.http import HttpResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.parsers import JSONParser\nfrom .serializers import NoticiaSerializer\nfrom django.contrib.auth.decorators import login_required\nimport json\nclass JSONResponse(HttpResponse):\n \"\"\"\n An HttpResponse that renders its content into JSON.\n \"\"\"\n def __init__(self, data, **kwargs):\n content = JSONRenderer().render(data)\n kwargs['content_type'] = 'application/json'\n super(JSONResponse, self).__init__(content, **kwargs)\n\n@csrf_exempt\ndef api(request):\n \"\"\"\n List all code snippets, or create a new snippet.\n \"\"\"\n if request.method == 'GET':\n noticias = Noticia.objects.all()\n serializer = NoticiaSerializer(noticias, many=True)\n return JSONResponse(serializer.data)\n@csrf_exempt\ndef api_todas_noticias_detail(request,slug):\n try:\n politico = get_object_or_404(Politico,slug=slug)\n \n noticia = Noticia.objects.filter(politico=politico)\n except Noticia.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = NoticiaSerializer(noticia)\n return JSONResponse(serializer.data)\n\ndef api_todas_noticias_site(request,slug):\n politico = get_object_or_404(Politico,slug=slug)\n noticia = Noticia.objects.filter(politico=politico).order_by('-created_at')\n\n ag_list = []\n for n in noticia:\n ag_dict = {}\n ag_dict['id'] = n.id\n ag_dict['title'] = n.title\n ag_dict['description'] = n.description\n ag_dict['photo'] = str(n.photo)\n ag_dict['created_at'] = n.created_at.strftime(\"%d/%m/%Y\")\n ag_list.append(ag_dict)\n \n response = HttpResponse(json.dumps(ag_list))\n response[\"Access-Control-Allow-Origin\"] = \"*\"\n response[\"Access-Control-Allow-Methods\"] = \"POST,GET,OPTIONS\"\n response[\"Access-Control-Max-Age\"] = \"1000\"\n response[\"Access-Control-Allow-Headers\"] = \"*\"\n return response\n\n@csrf_exempt\ndef api_noticia_detail(request, pk):\n \"\"\"\n Retrieve, update or delete a code snippet.\n \"\"\"\n try:\n noticia = Noticia.objects.get(pk=pk)\n except Noticia.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = NoticiaSerializer(noticia)\n return JSONResponse(serializer.data)\n\ndef todas_noticias(request):\n noticias = Noticia.objects.all().order_by('-created_at')\n return render(request,'noticias/noticias.html',{'noticias':noticias})\n\ndef noticias(request):\n pol = get_object_or_404(Politico,user=request.user)\n noticias = Noticia.objects.filter(politico=pol).select_related().order_by('-created_at')\n return render(request,'noticias/noticias.html',{'noticias':noticias})\n\n@login_required\ndef noticia_edit(request,pk):\n '''\n @noticia_edit: View para determinar se é um GET ou POST para editar uma noticia\n '''\n pol = get_object_or_404(Politico,user=request.user)\n noticia = get_object_or_404(Noticia,id=pk,politico=pol)\n if request.method == 'POST':\n return edit_noticia(request,noticia)\n else:\n return request_noticia(request,noticia)\n\n@login_required\ndef edit_noticia(request,noticia):\n '''\n @edit_noticia: View para alterar os dados de uma noticia\n ''' \n form = NoticiaForm(request.POST,instance=noticia)\n if form.is_valid():\n noticia = form.save(commit=False)\n noticia.save()\n return HttpResponseRedirect(noticia.detail())\n else:\n return render(request,'noticias/noticia_edit.html',{'form':form})\n\ndef request_noticia(request,noticia):\n '''\n @request_noticia: View para obter os dados de uma determinada noticia\n ''' \n form = NoticiaForm(instance=noticia)\n return render(request, 'noticias/noticia_edit.html', {'form': form,'noticia':noticia})\n\n\ndef noticia_detail(request,pk):\n pol = get_object_or_404(Politico,user=request.user)\n noticia = get_object_or_404(Noticia,id=pk,politico=pol)\n noticias = Noticia.objects.filter(politico=pol).order_by('-created_at').exclude(pk=noticia.pk)\n return render(request,'noticias/noticia_detail.html',\n {'noticia':noticia,'noticias':noticias[:5]}\n )\n\n@login_required\ndef noticia_create(request):\n if request.method == 'POST': \n return create_noticia(request)\n else:\n return new_noticia(request)\n@login_required\ndef new_noticia(request):\n return render(request, 'noticias/noticia_form.html',\n {'form': NoticiaForm()})\n@login_required\ndef create_noticia(request):\n if not request.user.is_authenticated():\n raise Http404\n form = NoticiaForm(request.POST,request.FILES)\n if not form.is_valid():\n return render(request, 'noticias/noticia_form.html',\n {'form': form})\n obj = form.save(commit=False)\n pol = get_object_or_404(Politico,user=request.user)\n obj.politico = pol\n obj.save()\n return HttpResponseRedirect('/noticia/')\n\n@login_required\ndef noticia_excluir(request,pk):\n pol = get_object_or_404(Politico,user=request.user)\n u = Noticia.objects.get(id=pk,politico=pol).delete()\n return HttpResponseRedirect('/noticia/')\n"
},
{
"alpha_fraction": 0.7536656856536865,
"alphanum_fraction": 0.7565982341766357,
"avg_line_length": 25,
"blob_id": "b0eceadd2329b4f20d22bd79d13391dc1be06687",
"content_id": "d1ef2a1c9a81b3607f1e76ef44256a5680334832",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 13,
"path": "/candidato/messages/forms.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nfrom django import forms\n\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext as _\nfrom django.db import IntegrityError\nfrom candidato.messages.models import Message\n\nclass MessageForm(forms.ModelForm):\n class Meta:\n model = Message\n fields = ['description']\n\n\n\n"
},
{
"alpha_fraction": 0.718199610710144,
"alphanum_fraction": 0.7338551878929138,
"avg_line_length": 41.66666793823242,
"blob_id": "49a588c5877452f1a2d9508e006b9a053a941721",
"content_id": "45fe30ce93161ff97d2b537a7a33ae359c0864f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 511,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 12,
"path": "/candidato/messages/models.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.auth.models import User\n\nclass Message(models.Model):\n title = models.CharField(max_length=100,verbose_name='Titulo')\n description = models.CharField(max_length=2500,verbose_name='Descricao')\n created_at = models.DateTimeField(auto_now_add=True)\n politico = models.ForeignKey('politicos.Politico',related_name='messages')\n def __str__(self):\n return self.title"
},
{
"alpha_fraction": 0.6417322754859924,
"alphanum_fraction": 0.6456692814826965,
"avg_line_length": 27.22222137451172,
"blob_id": "cd58539cbbb75971bbd010272525cac5ab25d0ca",
"content_id": "338ce74aaa4bb64022f24031789f38f0232d6a2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 254,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 9,
"path": "/candidato/places/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, include, url\n\nurlpatterns = patterns('candidato.places.views',\n\turl(r'^api/cidades/$', 'cidades', name='cidades'),\n\turl(r'^api/(?P<pk>\\d+)/$', 'api_todos_bairros'),\n\t)\n"
},
{
"alpha_fraction": 0.6181398034095764,
"alphanum_fraction": 0.6181398034095764,
"avg_line_length": 39.25581359863281,
"blob_id": "28aeda66b23c201b554712470f4d77240829ed78",
"content_id": "612612b5d2ab06e228c0628100c4bc1ffacbf3ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1731,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 43,
"path": "/candidato/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import patterns, include, url\n\nfrom django.contrib import admin\nadmin.autodiscover()\nfrom django.conf import settings\n\n\nurlpatterns = patterns('',\n\n )\n\n\nif settings.CANDIDATO_SLUG=='servidor':\n urlpatterns += patterns('',\n url(r'^login/','django.contrib.auth.views.login',{\"template_name\":'login.html'}),\n url(r'^logout/','django.contrib.auth.views.logout_then_login',{'login_url': '/'}),\n url(r'^admin/', include('admin_honeypot.urls')),\n url(r'^politico/', include('candidato.politicos.urls',namespace='politicos')),\n url(r'^noticia/', include('candidato.noticias.urls',namespace='noticias')),\n url(r'^agenda/', include('candidato.agendas.urls',namespace='agendas')),\n url(r'^eleitor/', include('candidato.eleitores.urls',namespace='eleitores')),\n url(r'^message/', include('candidato.messages.urls',namespace='messages')),\n url(r'^places/', include('candidato.places.urls',namespace='places')),\n url(r'^secret/', include(admin.site.urls)),\n url(r'^change_password/$', 'candidato.core.views.alterar_senha', name='alterar_senha'),\n url(r'^$', 'candidato.core.views.index', name='index'),\n )\nif settings.CANDIDATO_SLUG == 'taylor':\n urlpatterns += patterns('',\n url(r'^$', 'candidato.core.views.taylor', name='taylor'),\n )\n\n\nif settings.CANDIDATO_SLUG == 'silas':\n urlpatterns += patterns('',\n url(r'^$', 'candidato.core.views.silas', name='silas'),\n )\n\nfrom django.conf import settings\nurlpatterns +=patterns('',\n (r'^media/(?P<path>.*)$','django.views.static.serve',\n {'document_root':settings.MEDIA_ROOT}),\n)\n"
},
{
"alpha_fraction": 0.6550387740135193,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 35.92856979370117,
"blob_id": "bb7de2ba2cd24f109222d43575d780b6d4f21320",
"content_id": "4250f890f4384090ac1191f0c26629711c9bc26c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 14,
"path": "/candidato/noticias/serializers.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.forms import widgets\nfrom rest_framework import serializers\nfrom .models import Noticia\n\n\nclass NoticiaSerializer(serializers.Serializer):\n pk = serializers.Field() # Note: `Field` is an untyped read-only field.\n\n title = serializers.CharField(required=False,\n max_length=100)\n description = serializers.CharField(required=False,\n max_length=100)\n photo = serializers.ImageField()\n created_at = serializers.DateTimeField()"
},
{
"alpha_fraction": 0.6209813952445984,
"alphanum_fraction": 0.6362097859382629,
"avg_line_length": 35.9375,
"blob_id": "79ee3cda6326b74bd53804846f066e8ad679da67",
"content_id": "29cfaa7ab81997aad6bc7a066827a6316b3b39cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 591,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 16,
"path": "/candidato/politicos/serializers.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.forms import widgets\nfrom rest_framework import serializers\nfrom .models import Politico\n\n\nclass PoliticoSerializer(serializers.Serializer):\n pk = serializers.Field() # Note: `Field` is an untyped read-only field.\n\n first_name = serializers.CharField(required=False,\n max_length=100)\n last_name = serializers.CharField(required=False,\n max_length=100)\n slug = serializers.CharField(required=False,\n max_length=100)\n\n noticias = serializers.RelatedField(many=True)\n"
},
{
"alpha_fraction": 0.672245442867279,
"alphanum_fraction": 0.6820083856582642,
"avg_line_length": 34.849998474121094,
"blob_id": "844da7522c2af8366852611c5a4d517e1048603b",
"content_id": "978906592a20f803faf8d7947dc77a250dd77726",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 717,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 20,
"path": "/candidato/politicos/models.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.auth.models import User\n\n\nclass Politico(models.Model):\n user = models.ForeignKey(User,related_name='politico')\n first_name = models.CharField(max_length=80,verbose_name='Primeiro ')\n last_name = models.CharField(max_length=80,verbose_name='Sobrenome')\n slug = models.SlugField(max_length=80,verbose_name='Slug',unique=True)\n created_at = models.DateTimeField(auto_now_add=True)\n \n class Meta:\n verbose_name = _('Politico')\n verbose_name_plural = _('Politicos')\n ordering = ('-created_at',)\n\n def __str__(self):\n return self.first_name\n"
},
{
"alpha_fraction": 0.5331230163574219,
"alphanum_fraction": 0.57413250207901,
"avg_line_length": 23.384614944458008,
"blob_id": "11780a67a21ba0a51fed7521b5b57be7a223e508",
"content_id": "6e7ef2fac39dae50063f48ae3885ef3009ae335b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 13,
"path": "/crivella_uwsgi.ini",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "[uwsgi]\nsocket = /tmp/uwsgi2.sock\nvirtualenv = /work/crivella\nchdir = /work/crivella/candidato\nmodule = candidato.wsgi\nmaster = True\nworkers = 8\npidfile = /tmp/uwsgi-master.pid\nmax-requests = 5000\nchmod-socket = 777\nvacuum = true\nuid = 33\ngid = 33\n"
},
{
"alpha_fraction": 0.5651628971099854,
"alphanum_fraction": 0.5709273219108582,
"avg_line_length": 29.090909957885742,
"blob_id": "d69874eb2f95333149f02e1dd7af7ab92de2a610",
"content_id": "7856b53bb24a41233c06c73a0d73635a717d3ae4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3990,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 132,
"path": "/candidato/eleitores/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponseRedirect\nfrom candidato.politicos.models import Politico\nfrom django.http import Http404\nimport random\nfrom django.http import HttpResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.parsers import JSONParser\nfrom .serializers import EleitorSerializer\nfrom django.contrib.auth.decorators import login_required\nfrom .models import Eleitor\n\n\nclass JSONResponse(HttpResponse):\n \"\"\"\n An HttpResponse that renders its content into JSON.\n \"\"\"\n def __init__(self, data, **kwargs):\n content = JSONRenderer().render(data)\n kwargs['content_type'] = 'application/json'\n super(JSONResponse, self).__init__(content, **kwargs)\n\n@csrf_exempt\ndef api_todos_eleitores(request,slug):\n try:\n politico = get_object_or_404(Politico,slug=slug)\n eleitores = Eleitor.objects.filter(politico=politico)\n except Eleitor.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = EleitorSerializer(eleitores)\n return JSONResponse(serializer.data)\n\nfrom push_notifications.models import APNSDevice, GCMDevice\n\n@csrf_exempt\ndef sem_eleitor(request):\n apn = None\n gcm = None\n\n try:\n apn = request.POST['apn']\n except:\n pass\n\n try:\n gcm = request.POST['gcm']\n except:\n pass\n\n if apn:\n nova_a = APNSDevice.objects.create(registration_id=apn)\n print \"apn registrada\"\n return HttpResponse('ok')\n if gcm:\n nova_g = GCMDevice.objects.create(registration_id=gcm)\n print \"gcm registrada\"\n return HttpResponse('ok')\n return HttpResponse('nenhum')\n\n\n@csrf_exempt\ndef criar_eleitor(request):\n '''\n @rem_disc: View para remover uma disciplina nao mais lecionada do professor via ajax\n '''\n if request.POST :\n # do some stuff\n\n nome = request.POST['nome']\n cidade = request.POST['cidade']\n bairro = request.POST['bairro']\n email = request.POST['email']\n politico = request.POST['politico']\n pol = get_object_or_404(Politico,slug=politico)\n ele = None\n gcm = None\n apn = None\n try :\n gcm = request.POST['gcm']\n except:\n pass\n try:\n apn = request.POST['apn']\n except:\n pass\n print \"1\"\n try:\n ele = Eleitor.objects.get(email=email,politico=pol)\n if gcm:\n print \"2\"\n a , b = GCMDevice.objects.get_or_create(registration_id=gcm)\n if a:\n ele.devicesGCM.add(a)\n if b:\n ele.devicesGCM.add(b)\n if apn:\n a , b = APNSDevice.objects.get_or_create(registration_id=apn)\n if a:\n ele.devicesAPN.add(a)\n if b:\n ele.devicesAPN.add(b) \n except:\n pass\n print \"3\"\n if not ele:\n novo_eleitor = Eleitor(nome=nome,cidade=cidade,bairro=bairro,email=email,politico=pol)\n novo_eleitor.save()\n print \"4\"\n if gcm:\n print \"5\"\n g , b = GCMDevice.objects.get_or_create(registration_id=gcm)\n if b:\n print \"6\"\n novo_eleitor.devicesGCM.add(b)\n if g:\n print \"7\"\n novo_eleitor.devicesGCM.add(g) \n if apn:\n a , b = APNSDevice.objects.get_or_create(registration_id=apn)\n if a:\n novo_eleitor.devicesAPN.add(a)\n if b:\n novo_eleitor.devicesAPN.add(b)\n print \"8\"\n return HttpResponse('ok')\n\n else:\n return HttpResponse('somente post')\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7162725925445557,
"alphanum_fraction": 0.734353244304657,
"avg_line_length": 50.42856979370117,
"blob_id": "6a005daaacca9e385e503615bdcad64f473a79b8",
"content_id": "d5e9f3ff2e40c170cde3bb9514fe271b01f7808a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 719,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 14,
"path": "/candidato/eleitores/models.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db import models\nfrom push_notifications.models import APNSDevice, GCMDevice\nclass Eleitor(models.Model):\n nome = models.CharField(max_length=100,verbose_name='Nome')\n cidade = models.CharField(max_length=100,verbose_name='Cidade')\n bairro = models.CharField(max_length=100,verbose_name='Bairro')\n email = models.EmailField(max_length=100,verbose_name='Email')\n politico = models.ForeignKey('politicos.Politico',related_name='eleitores')\n created_at = models.DateTimeField(auto_now_add=True)\n devicesGCM = models.ManyToManyField(GCMDevice,null=True)\n devicesAPN = models.ManyToManyField(APNSDevice,null=True)\n def __str__(self):\n return self.nome"
},
{
"alpha_fraction": 0.7372093200683594,
"alphanum_fraction": 0.765116274356842,
"avg_line_length": 34.58333206176758,
"blob_id": "82ce55936ce5585340a5a34881c7ae1267283837",
"content_id": "77d2a285c373e30c9b542bb1b100f66f3078cdf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 430,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 12,
"path": "/candidato/eleitores/serializers.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.forms import widgets\nfrom rest_framework import serializers\nfrom .models import Eleitor\n\n\nclass EleitorSerializer(serializers.Serializer):\n pk = serializers.Field()\n nome = serializers.CharField(max_length=100)\n cidade = serializers.CharField(max_length=100)\n bairro = serializers.CharField(max_length=100)\n email = serializers.EmailField(max_length=100)\n created_at = serializers.DateTimeField()\n "
},
{
"alpha_fraction": 0.6048780679702759,
"alphanum_fraction": 0.6121951341629028,
"avg_line_length": 33.16666793823242,
"blob_id": "8688f2cad29d337a2f16152e23f8a61ecf0bf6ed",
"content_id": "537d4f3174732de3c103246300c54db36aac6b37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 12,
"path": "/candidato/messages/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, include, url\n\nurlpatterns = patterns('candidato.messages.views',\n\turl(r'^nova/$', 'message_create', name='message_create'),\n\turl(r'^api/$', 'api', name='api'),\n\turl(r'^api/(?P<pk>[0-9]+)/$', 'api_message_detail'),\n\turl(r'^api/(?P<slug>[-\\w\\d]+)/$', 'api_todas_messages_detail'),\n\turl(r'^$', 'messages', name='messages'),\n\t)\n"
},
{
"alpha_fraction": 0.6746203899383545,
"alphanum_fraction": 0.6854663491249084,
"avg_line_length": 27.6875,
"blob_id": "523c9e18b054fe799e074b054e65c46cb2ea0f63",
"content_id": "4074b67dd0cd45472cdf06e2ebad6f6de9cca2a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 461,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 16,
"path": "/candidato/noticias/forms.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nfrom django import forms\n\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext as _\nfrom django.db import IntegrityError\nfrom candidato.noticias.models import Noticia\n\nclass NoticiaForm(forms.ModelForm):\n class Meta:\n model = Noticia\n fields = ['title','description','photo']\n widgets = {\n 'description': forms.Textarea(attrs={'cols': 100, 'rows': 5}),\n }\n\n\n"
},
{
"alpha_fraction": 0.7845304012298584,
"alphanum_fraction": 0.8011049628257751,
"avg_line_length": 29.25,
"blob_id": "7d85b09a8b8248fa78c105f40cf84d00028b891e",
"content_id": "f2650b5cc7fb8f0c196adae15a1f0b9e44243ecd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 362,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 12,
"path": "/candidato/places/serializers.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "from django.forms import widgets\nfrom rest_framework import serializers\nfrom .models import Bairro,Cidade\n\n\nclass CidadeSerializer(serializers.Serializer):\n pk = serializers.Field()\n nome = serializers.CharField(required=False,max_length=100)\n\n\nclass BairroSerializer(serializers.Serializer):\n nome = serializers.CharField(required=False,max_length=100)"
},
{
"alpha_fraction": 0.6349278092384338,
"alphanum_fraction": 0.7251996994018555,
"avg_line_length": 57.52178955078125,
"blob_id": "2accafedb667d4e1a76714f99bb8c33c48353f16",
"content_id": "20507fec8359e1005f872bf2260fc77a63355447",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 153770,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 2616,
"path": "/candidato/eleitores/sql/eleitor.sql",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "INSERT INTO places_cidade VALUES (1, 'Angra dos Reis');\nINSERT INTO places_cidade VALUES (2, 'Aperibé');\nINSERT INTO places_cidade VALUES (3, 'Araruama');\nINSERT INTO places_cidade VALUES (4, 'Areal');\nINSERT INTO places_cidade VALUES (5, 'Armação dos Búzios');\nINSERT INTO places_cidade VALUES (6, 'Arraial do Cabo');\nINSERT INTO places_cidade VALUES (7, 'Barra do Piraí');\nINSERT INTO places_cidade VALUES (8, 'Barra Mansa');\nINSERT INTO places_cidade VALUES (9, 'Belford Roxo');\nINSERT INTO places_cidade VALUES (10, 'Bom Jardim');\nINSERT INTO places_cidade VALUES (11, 'Bom Jesus do Itabapoana');\nINSERT INTO places_cidade VALUES (12, 'Cabo Frio');\nINSERT INTO places_cidade VALUES (13, 'Cachoeiras de Macacu');\nINSERT INTO places_cidade VALUES (14, 'Cambuci');\nINSERT INTO places_cidade VALUES (15, 'Campos dos Goytacazes');\nINSERT INTO places_cidade VALUES (16, 'Cantagalo');\nINSERT INTO places_cidade VALUES (17, 'Carapebus');\nINSERT INTO places_cidade VALUES (18, 'Cardoso Moreira');\nINSERT INTO places_cidade VALUES (19, 'Carmo');\nINSERT INTO places_cidade VALUES (20, 'Casimiro de Abreu');\nINSERT INTO places_cidade VALUES (21, 'Comendador Levy Gasparia');\nINSERT INTO places_cidade VALUES (22, 'Conceição de Macabu');\nINSERT INTO places_cidade VALUES (23, 'Cordeiro');\nINSERT INTO places_cidade VALUES (24, 'Duas Barras');\nINSERT INTO places_cidade VALUES (25, 'Duque de Caxias');\nINSERT INTO places_cidade VALUES (26, 'Engenheiro Paulo de Fronti');\nINSERT INTO places_cidade VALUES (27, 'Guapimirim');\nINSERT INTO places_cidade VALUES (28, 'Iguaba Grande');\nINSERT INTO places_cidade VALUES (29, 'Itaboraí');\nINSERT INTO places_cidade VALUES (30, 'Itaguaí');\nINSERT INTO places_cidade VALUES (31, 'Italva');\nINSERT INTO places_cidade VALUES (32, 'Itaocara');\nINSERT INTO places_cidade VALUES (33, 'Itaperuna');\nINSERT INTO places_cidade VALUES (34, 'Itatiaia');\nINSERT INTO places_cidade VALUES (35, 'Japeri');\nINSERT INTO places_cidade VALUES (36, 'Laje do Muriaé');\nINSERT INTO places_cidade VALUES (37, 'Macaé');\nINSERT INTO places_cidade VALUES (38, 'Macuco');\nINSERT INTO places_cidade VALUES (39, 'Magé');\nINSERT INTO places_cidade VALUES (40, 'Mangaratiba');\nINSERT INTO places_cidade VALUES (41, 'Maricá');\nINSERT INTO places_cidade VALUES (42, 'Mendes');\nINSERT INTO places_cidade VALUES (43, 'Mesquita');\nINSERT INTO places_cidade VALUES (44, 'Miguel Pereira');\nINSERT INTO places_cidade VALUES (45, 'Miracema');\nINSERT INTO places_cidade VALUES (46, 'Natividade');\nINSERT INTO places_cidade VALUES (47, 'Nilópolis');\nINSERT INTO places_cidade VALUES (48, 'Niterói');\nINSERT INTO places_cidade VALUES (49, 'Nova Friburgo');\nINSERT INTO places_cidade VALUES (50, 'Nova Iguaçu');\nINSERT INTO places_cidade VALUES (51, 'Paracambi');\nINSERT INTO places_cidade VALUES (52, 'Paraíba do Sul');\nINSERT INTO places_cidade VALUES (53, 'Parati');\nINSERT INTO places_cidade VALUES (54, 'Paty do Alferes');\nINSERT INTO places_cidade VALUES (55, 'Petrópolis');\nINSERT INTO places_cidade VALUES (56, 'Pinheiral');\nINSERT INTO places_cidade VALUES (57, 'Piraí');\nINSERT INTO places_cidade VALUES (58, 'Porciúncula');\nINSERT INTO places_cidade VALUES (59, 'Porto Real');\nINSERT INTO places_cidade VALUES (60, 'Quatis');\nINSERT INTO places_cidade VALUES (61, 'Queimados');\nINSERT INTO places_cidade VALUES (62, 'Quissamã');\nINSERT INTO places_cidade VALUES (63, 'Resende');\nINSERT INTO places_cidade VALUES (64, 'Rio Bonito');\nINSERT INTO places_cidade VALUES (65, 'Rio Claro');\nINSERT INTO places_cidade VALUES (66, 'Rio das Flores');\nINSERT INTO places_cidade VALUES (67, 'Rio das Ostras');\nINSERT INTO places_cidade VALUES (68, 'Rio de Janeiro');\nINSERT INTO places_cidade VALUES (69, 'Santa Maria Madalena');\nINSERT INTO places_cidade VALUES (70, 'Santo Antônio de Pádua');\nINSERT INTO places_cidade VALUES (71, 'São Fidélis');\nINSERT INTO places_cidade VALUES (72, 'São Francisco de Itabapoana');\nINSERT INTO places_cidade VALUES (73, 'São Gonçalo');\nINSERT INTO places_cidade VALUES (74, 'São João da Barra');\nINSERT INTO places_cidade VALUES (75, 'São João de Meriti');\nINSERT INTO places_cidade VALUES (76, 'São José de Ubá');\nINSERT INTO places_cidade VALUES (77, 'São José do Vale do Rio Preto');\nINSERT INTO places_cidade VALUES (78, 'São Pedro da Aldeia');\nINSERT INTO places_cidade VALUES (79, 'São Sebastião do Alto');\nINSERT INTO places_cidade VALUES (80, 'Sapucaia');\nINSERT INTO places_cidade VALUES (81, 'Saquarema');\nINSERT INTO places_cidade VALUES (82, 'Seropédica');\nINSERT INTO places_cidade VALUES (83, 'Silva Jardim');\nINSERT INTO places_cidade VALUES (84, 'Sumidouro');\nINSERT INTO places_cidade VALUES (85, 'Tanguá');\nINSERT INTO places_cidade VALUES (86, 'Teresópolis');\nINSERT INTO places_cidade VALUES (87, 'Trajano de Morais');\nINSERT INTO places_cidade VALUES (88, 'Três Rios');\nINSERT INTO places_cidade VALUES (89, 'Valença');\nINSERT INTO places_cidade VALUES (90, 'Varre-Sai');\nINSERT INTO places_cidade VALUES (91, 'Vassouras');\nINSERT INTO places_cidade VALUES (92, 'Volta Redonda');\n\n\nINSERT INTO places_bairro VALUES (1, 'Vila do Abraão', 1);\nINSERT INTO places_bairro VALUES (2, 'Afonso Arinos', 21);\nINSERT INTO places_bairro VALUES (3, 'Centro', 91);\nINSERT INTO places_bairro VALUES (4, 'Centro', 1);\nINSERT INTO places_bairro VALUES (5, 'Morro da Fortaleza', 1);\nINSERT INTO places_bairro VALUES (6, 'Morro do Abel', 1);\nINSERT INTO places_bairro VALUES (7, 'Morro da Carioca', 1);\nINSERT INTO places_bairro VALUES (8, 'Morro do Bulé', 1);\nINSERT INTO places_bairro VALUES (9, 'Morro do Santo Antônio', 1);\nINSERT INTO places_bairro VALUES (10, 'Morro do Carmo', 1);\nINSERT INTO places_bairro VALUES (11, 'Morro da Caixa D''Água', 1);\nINSERT INTO places_bairro VALUES (12, 'Praia do Anil', 1);\nINSERT INTO places_bairro VALUES (13, 'Morro do Tatu', 1);\nINSERT INTO places_bairro VALUES (14, 'Morro do Perez', 1);\nINSERT INTO places_bairro VALUES (15, 'Morro da Glória', 1);\nINSERT INTO places_bairro VALUES (16, 'Morro da Glória II', 1);\nINSERT INTO places_bairro VALUES (17, 'Morro da Cruz', 1);\nINSERT INTO places_bairro VALUES (18, 'Enseada (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (19, 'Encruzo da Enseada (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (20, 'Balneário', 1);\nINSERT INTO places_bairro VALUES (21, 'Parque das Palmeiras', 1);\nINSERT INTO places_bairro VALUES (22, 'Praia da Chácara', 1);\nINSERT INTO places_bairro VALUES (23, 'Praia do Jardim', 1);\nINSERT INTO places_bairro VALUES (24, 'Marinas', 1);\nINSERT INTO places_bairro VALUES (25, 'Colégio Naval', 1);\nINSERT INTO places_bairro VALUES (26, 'Bonfim', 1);\nINSERT INTO places_bairro VALUES (27, 'Praia Grande', 1);\nINSERT INTO places_bairro VALUES (28, 'Vila Velha', 1);\nINSERT INTO places_bairro VALUES (29, 'Tanguá', 1);\nINSERT INTO places_bairro VALUES (30, 'Ponta da Ribeira (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (31, 'Retiro (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (32, 'Ponta do Sapê (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (33, 'Grataú (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (34, 'Frade (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (35, 'Piraquara (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (36, 'Usina Nuclear (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (37, 'Praia Brava (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (38, 'Praia Vermelha (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (39, 'Praia das Goiabas (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (40, 'Vila Histórica de Mambucaba (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (41, 'Morro da Boa Vista (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (42, 'Parque Perequê (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (43, 'Parque Mambucaba (Mambucaba);', 1);\nINSERT INTO places_bairro VALUES (44, 'Gambôa do Bracuí (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (45, 'Santa Rita do Bracuí (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (46, 'Bracuí (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (47, 'Pontal (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (48, 'Pontal do Partido (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (49, 'Ariró (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (50, 'Itanema (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (51, 'Serra D''Água (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (52, 'Praia da Ribeira (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (53, 'Gambôa do Belém (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (54, 'Parque Belém (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (55, 'Aeroporto (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (56, 'Japuíba (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (57, 'Nova Angra (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (58, 'Banqueta (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (59, 'Areal (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (60, 'Campo Belo (Cunhambebe);', 1);\nINSERT INTO places_bairro VALUES (61, 'Sapinhatuba I', 1);\nINSERT INTO places_bairro VALUES (62, 'Monte Castelo', 1);\nINSERT INTO places_bairro VALUES (63, 'Sapinhatuba III', 1);\nINSERT INTO places_bairro VALUES (64, 'Mombaça', 1);\nINSERT INTO places_bairro VALUES (65, 'Camorim Pequeno', 1);\nINSERT INTO places_bairro VALUES (66, 'Camorim', 1);\nINSERT INTO places_bairro VALUES (67, 'Lambicada', 1);\nINSERT INTO places_bairro VALUES (68, 'Morro do Moreno', 1);\nINSERT INTO places_bairro VALUES (69, 'BNH', 1);\nINSERT INTO places_bairro VALUES (70, 'Village', 1);\nINSERT INTO places_bairro VALUES (71, 'Verolme', 1);\nINSERT INTO places_bairro VALUES (72, 'Vila da Petrobrás', 1);\nINSERT INTO places_bairro VALUES (73, 'Água Santa', 1);\nINSERT INTO places_bairro VALUES (74, 'Caputera I', 1);\nINSERT INTO places_bairro VALUES (75, 'Caputera II', 1);\nINSERT INTO places_bairro VALUES (76, 'Monsuaba', 1);\nINSERT INTO places_bairro VALUES (77, 'Paraíso', 1);\nINSERT INTO places_bairro VALUES (78, 'Biscaia', 1);\nINSERT INTO places_bairro VALUES (79, 'Ponta Leste', 1);\nINSERT INTO places_bairro VALUES (80, 'Maciéis', 1);\nINSERT INTO places_bairro VALUES (81, 'Portogalo', 1);\nINSERT INTO places_bairro VALUES (82, 'Caetés', 1);\nINSERT INTO places_bairro VALUES (83, 'Vila dos Pescadores', 1);\nINSERT INTO places_bairro VALUES (84, 'Garatucaia', 1);\nINSERT INTO places_bairro VALUES (85, 'Cidade da Bíblia', 1);\nINSERT INTO places_bairro VALUES (86, 'Cantagalo', 1);\nINSERT INTO places_bairro VALUES (87, 'Centro', 80);\nINSERT INTO places_bairro VALUES (88, 'Centro', 2);\nINSERT INTO places_bairro VALUES (89, 'Ponte Seca', 2);\nINSERT INTO places_bairro VALUES (90, 'Porto das Barcas', 2);\nINSERT INTO places_bairro VALUES (91, 'Praia Seca', 3);\nINSERT INTO places_bairro VALUES (92, 'Centro', 3);\nINSERT INTO places_bairro VALUES (93, 'Morro Grande', 3);\nINSERT INTO places_bairro VALUES (94, 'Areal', 4);\nINSERT INTO places_bairro VALUES (95, 'Centro', 5);\nINSERT INTO places_bairro VALUES (96, 'Rasa', 5);\nINSERT INTO places_bairro VALUES (97, 'Cem Braças', 5);\nINSERT INTO places_bairro VALUES (98, 'Centro', 6);\nINSERT INTO places_bairro VALUES (99, 'Monte Alto', 6);\nINSERT INTO places_bairro VALUES (100, 'Figueira', 6);\nINSERT INTO places_bairro VALUES (101, 'Arrozal', 57);\nINSERT INTO places_bairro VALUES (102, 'Centro', 54);\nINSERT INTO places_bairro VALUES (103, 'Bacaxá', 81);\nINSERT INTO places_bairro VALUES (104, 'Rio de Areia', 81);\nINSERT INTO places_bairro VALUES (105, 'Vilatur', 81);\nINSERT INTO places_bairro VALUES (106, 'Madressilva', 81);\nINSERT INTO places_bairro VALUES (107, 'Centro', 70);\nINSERT INTO places_bairro VALUES (108, 'Centro', 10);\nINSERT INTO places_bairro VALUES (109, 'Centro', 89);\nINSERT INTO places_bairro VALUES (110, 'Centro', 74);\nINSERT INTO places_bairro VALUES (111, 'Centro', 10);\nINSERT INTO places_bairro VALUES (112, 'Côrrego de Santo Antonio', 10);\nINSERT INTO places_bairro VALUES (113, 'Corrego do Ouro', 37);\nINSERT INTO places_bairro VALUES (114, 'Barra de São João', 20);\nINSERT INTO places_bairro VALUES (115, 'Boca do Mato', 57);\nINSERT INTO places_bairro VALUES (116, 'Areal', 57);\nINSERT INTO places_bairro VALUES (117, 'Arthur Catalddi', 57);\nINSERT INTO places_bairro VALUES (118, 'Belvedere da Taquara', 57);\nINSERT INTO places_bairro VALUES (119, 'Boa Sorte', 57);\nINSERT INTO places_bairro VALUES (120, 'Caieira São Pedro', 57);\nINSERT INTO places_bairro VALUES (121, 'Caieira Velha', 57);\nINSERT INTO places_bairro VALUES (122, 'Caixa D''Água Velha', 57);\nINSERT INTO places_bairro VALUES (123, 'Campo Bom', 57);\nINSERT INTO places_bairro VALUES (124, 'Cantão', 57);\nINSERT INTO places_bairro VALUES (125, 'Carvão', 57);\nINSERT INTO places_bairro VALUES (126, 'Centro', 57);\nINSERT INTO places_bairro VALUES (127, 'Chácara Farani', 57);\nINSERT INTO places_bairro VALUES (128, 'Chalet', 57);\nINSERT INTO places_bairro VALUES (129, 'Coimbra', 57);\nINSERT INTO places_bairro VALUES (130, 'Lago Azul', 57);\nINSERT INTO places_bairro VALUES (131, 'Maracanã', 57);\nINSERT INTO places_bairro VALUES (132, 'Matadouro', 57);\nINSERT INTO places_bairro VALUES (133, 'Metalúrgica', 57);\nINSERT INTO places_bairro VALUES (134, 'Morro da Gama', 57);\nINSERT INTO places_bairro VALUES (135, 'Muqueca', 57);\nINSERT INTO places_bairro VALUES (136, 'Nossa Senhora de Santana', 57);\nINSERT INTO places_bairro VALUES (137, 'Oficinas Velhas', 57);\nINSERT INTO places_bairro VALUES (138, 'Parque Almirante', 57);\nINSERT INTO places_bairro VALUES (139, 'Parque Santana', 57);\nINSERT INTO places_bairro VALUES (140, 'Parque São Joaquim', 57);\nINSERT INTO places_bairro VALUES (141, 'Parque São José', 57);\nINSERT INTO places_bairro VALUES (142, 'Ponte do Andrade', 57);\nINSERT INTO places_bairro VALUES (143, 'Ponte Preta', 57);\nINSERT INTO places_bairro VALUES (144, 'Ponte Vermelha', 57);\nINSERT INTO places_bairro VALUES (145, 'Química', 57);\nINSERT INTO places_bairro VALUES (146, 'Represa', 57);\nINSERT INTO places_bairro VALUES (147, 'Roseira', 57);\nINSERT INTO places_bairro VALUES (148, 'Santana da Barra', 57);\nINSERT INTO places_bairro VALUES (149, 'Santo Antônio', 57);\nINSERT INTO places_bairro VALUES (150, 'Santo Cristo', 57);\nINSERT INTO places_bairro VALUES (151, 'São João', 57);\nINSERT INTO places_bairro VALUES (152, 'São Luís', 57);\nINSERT INTO places_bairro VALUES (153, 'Vargem Grande', 57);\nINSERT INTO places_bairro VALUES (154, 'Vila Helena', 57);\nINSERT INTO places_bairro VALUES (155, 'Vila Suíça', 57);\nINSERT INTO places_bairro VALUES (156, 'Abelhas', 8);\nINSERT INTO places_bairro VALUES (157, 'Água Comprida', 8);\nINSERT INTO places_bairro VALUES (158, 'Ano Bom', 8);\nINSERT INTO places_bairro VALUES (159, 'Antônio Rocha', 8);\nINSERT INTO places_bairro VALUES (160, 'Apóstolo Paulo', 8);\nINSERT INTO places_bairro VALUES (161, 'Assunção', 8);\nINSERT INTO places_bairro VALUES (162, 'Barbara', 8);\nINSERT INTO places_bairro VALUES (163, 'Boa Sorte', 8);\nINSERT INTO places_bairro VALUES (164, 'Boa Vista', 8);\nINSERT INTO places_bairro VALUES (165, 'Boa Vista I', 8);\nINSERT INTO places_bairro VALUES (166, 'Boa Vista II', 8);\nINSERT INTO places_bairro VALUES (167, 'Boa Vista III', 8);\nINSERT INTO places_bairro VALUES (168, 'Bocaininha', 8);\nINSERT INTO places_bairro VALUES (169, 'Bom Pastor', 8);\nINSERT INTO places_bairro VALUES (170, 'Cajueiro', 8);\nINSERT INTO places_bairro VALUES (171, 'Cantagalo', 8);\nINSERT INTO places_bairro VALUES (172, 'Centro', 8);\nINSERT INTO places_bairro VALUES (173, 'Colônia Santo Antônio', 8);\nINSERT INTO places_bairro VALUES (174, 'Cotiara', 8);\nINSERT INTO places_bairro VALUES (175, 'Floriano', 8);\nINSERT INTO places_bairro VALUES (176, 'Getúlio Vargas', 8);\nINSERT INTO places_bairro VALUES (177, 'Goiabal', 8);\nINSERT INTO places_bairro VALUES (178, 'Jardim Alvorada', 8);\nINSERT INTO places_bairro VALUES (179, 'Jardim América', 8);\nINSERT INTO places_bairro VALUES (180, 'Jardim Boa Vista', 8);\nINSERT INTO places_bairro VALUES (181, 'Jardim Central', 8);\nINSERT INTO places_bairro VALUES (182, 'Jardim Guanabara', 8);\nINSERT INTO places_bairro VALUES (183, 'Jardim Marilu', 8);\nINSERT INTO places_bairro VALUES (184, 'Jardim Ponte Alta', 8);\nINSERT INTO places_bairro VALUES (185, 'Jardim Primavera', 8);\nINSERT INTO places_bairro VALUES (186, 'Jardim Redentor', 8);\nINSERT INTO places_bairro VALUES (187, 'Jardim Santo Antônio', 8);\nINSERT INTO places_bairro VALUES (188, 'Km - 4', 8);\nINSERT INTO places_bairro VALUES (189, 'Loteamento Aiuruoca', 8);\nINSERT INTO places_bairro VALUES (190, 'Loteamento Belo Horizonte', 8);\nINSERT INTO places_bairro VALUES (191, 'Loteamento Boa Vista', 8);\nINSERT INTO places_bairro VALUES (192, 'Loteamento Chinês', 8);\nINSERT INTO places_bairro VALUES (193, 'Loteamento Cristo Redentor', 8);\nINSERT INTO places_bairro VALUES (194, 'Loteamento da Chácara', 8);\nINSERT INTO places_bairro VALUES (195, 'Loteamento Jardim Monique', 8);\nINSERT INTO places_bairro VALUES (196, 'Loteamento Morada da Colonia', 8);\nINSERT INTO places_bairro VALUES (197, 'Loteamento Primavera', 8);\nINSERT INTO places_bairro VALUES (198, 'Loteamento São Sebastião', 8);\nINSERT INTO places_bairro VALUES (199, 'Loteamento São Vicente', 8);\nINSERT INTO places_bairro VALUES (200, 'Loteamento Sofia', 8);\nINSERT INTO places_bairro VALUES (201, 'Mangueira', 8);\nINSERT INTO places_bairro VALUES (202, 'Metalúrgico', 8);\nINSERT INTO places_bairro VALUES (203, 'Minerlândia', 8);\nINSERT INTO places_bairro VALUES (204, 'Moinho de Vento', 8);\nINSERT INTO places_bairro VALUES (205, 'Monte Cristo', 8);\nINSERT INTO places_bairro VALUES (206, 'Morada da Colonia I', 8);\nINSERT INTO places_bairro VALUES (207, 'Morada da Granja', 8);\nINSERT INTO places_bairro VALUES (208, 'Morada da Granja II', 8);\nINSERT INTO places_bairro VALUES (209, 'Morada do Vale', 8);\nINSERT INTO places_bairro VALUES (210, 'Morada Verde', 8);\nINSERT INTO places_bairro VALUES (211, 'Nossa Senhora Aparecida', 8);\nINSERT INTO places_bairro VALUES (212, 'Nossa Senhora de Fátima', 8);\nINSERT INTO places_bairro VALUES (213, 'Nossa Senhora de Lourdes', 8);\nINSERT INTO places_bairro VALUES (214, 'Nossa Senhora do Amparo', 8);\nINSERT INTO places_bairro VALUES (215, 'Nossa Senhora dos Remédios', 8);\nINSERT INTO places_bairro VALUES (216, 'Nova Esperança', 8);\nINSERT INTO places_bairro VALUES (217, 'Novo Horizonte', 8);\nINSERT INTO places_bairro VALUES (218, 'Paraíso', 8);\nINSERT INTO places_bairro VALUES (219, 'Parque Independência', 8);\nINSERT INTO places_bairro VALUES (220, 'Piteiras', 8);\nINSERT INTO places_bairro VALUES (221, 'Pombal', 8);\nINSERT INTO places_bairro VALUES (222, 'Ponte Alta', 8);\nINSERT INTO places_bairro VALUES (223, 'Recanto do Sol', 8);\nINSERT INTO places_bairro VALUES (224, 'Rialto', 8);\nINSERT INTO places_bairro VALUES (225, 'Roberto Silveira', 8);\nINSERT INTO places_bairro VALUES (226, 'Roselândia', 8);\nINSERT INTO places_bairro VALUES (227, 'Santa Clara', 8);\nINSERT INTO places_bairro VALUES (228, 'Santa Ines', 8);\nINSERT INTO places_bairro VALUES (229, 'Santa Izabel', 8);\nINSERT INTO places_bairro VALUES (230, 'Santa Lúcia', 8);\nINSERT INTO places_bairro VALUES (231, 'Santa Maria I', 8);\nINSERT INTO places_bairro VALUES (232, 'Santa Maria II', 8);\nINSERT INTO places_bairro VALUES (233, 'Santa Maria III', 8);\nINSERT INTO places_bairro VALUES (234, 'Santa Rita', 8);\nINSERT INTO places_bairro VALUES (235, 'Santa Rita de Cássia', 8);\nINSERT INTO places_bairro VALUES (236, 'Santa Rosa', 8);\nINSERT INTO places_bairro VALUES (237, 'São Carlos', 8);\nINSERT INTO places_bairro VALUES (238, 'São Domingos', 8);\nINSERT INTO places_bairro VALUES (239, 'São Francisco de Assis', 8);\nINSERT INTO places_bairro VALUES (240, 'São Genaro', 8);\nINSERT INTO places_bairro VALUES (241, 'São Judas Tadeu', 8);\nINSERT INTO places_bairro VALUES (242, 'São Lucas', 8);\nINSERT INTO places_bairro VALUES (243, 'São Luís', 8);\nINSERT INTO places_bairro VALUES (244, 'São Luiz', 8);\nINSERT INTO places_bairro VALUES (245, 'São Paulo', 8);\nINSERT INTO places_bairro VALUES (246, 'São Pedro', 8);\nINSERT INTO places_bairro VALUES (247, 'São Sebastião', 8);\nINSERT INTO places_bairro VALUES (248, 'São Silvestre', 8);\nINSERT INTO places_bairro VALUES (249, 'Saudade', 8);\nINSERT INTO places_bairro VALUES (250, 'Siderlandia', 8);\nINSERT INTO places_bairro VALUES (251, 'Vale do Paraíba', 8);\nINSERT INTO places_bairro VALUES (252, 'Verbo Divino', 8);\nINSERT INTO places_bairro VALUES (253, 'Vila Coringa', 8);\nINSERT INTO places_bairro VALUES (254, 'Vila Elmira', 8);\nINSERT INTO places_bairro VALUES (255, 'Vila Independência', 8);\nINSERT INTO places_bairro VALUES (256, 'Vila Maria', 8);\nINSERT INTO places_bairro VALUES (257, 'Vila Nova', 8);\nINSERT INTO places_bairro VALUES (258, 'Vila Orlandelia', 8);\nINSERT INTO places_bairro VALUES (259, 'Vila Principal', 8);\nINSERT INTO places_bairro VALUES (260, 'Vila Santa Maria', 8);\nINSERT INTO places_bairro VALUES (261, 'Vila Ursulino', 8);\nINSERT INTO places_bairro VALUES (262, 'Village do Sol', 8);\nINSERT INTO places_bairro VALUES (263, 'Vista Alegre', 8);\nINSERT INTO places_bairro VALUES (264, '9 de Abril', 8);\nINSERT INTO places_bairro VALUES (265, 'Albuquerque', 9);\nINSERT INTO places_bairro VALUES (266, 'Ambai', 9);\nINSERT INTO places_bairro VALUES (267, 'Amélia', 9);\nINSERT INTO places_bairro VALUES (268, 'Andrade Araujo', 9);\nINSERT INTO places_bairro VALUES (269, 'Andreia', 9);\nINSERT INTO places_bairro VALUES (270, 'Apolo XI', 9);\nINSERT INTO places_bairro VALUES (271, 'Arco-Iris', 9);\nINSERT INTO places_bairro VALUES (272, 'Areia Branca', 9);\nINSERT INTO places_bairro VALUES (273, 'Babi', 9);\nINSERT INTO places_bairro VALUES (274, 'Bela Vista', 9);\nINSERT INTO places_bairro VALUES (275, 'Belford Roxo', 9);\nINSERT INTO places_bairro VALUES (276, 'Benfica', 9);\nINSERT INTO places_bairro VALUES (277, 'Boa Esperança', 9);\nINSERT INTO places_bairro VALUES (278, 'Boa Sorte', 9);\nINSERT INTO places_bairro VALUES (279, 'Boa Ventura', 9);\nINSERT INTO places_bairro VALUES (280, 'Buriti', 9);\nINSERT INTO places_bairro VALUES (281, 'Centro', 9);\nINSERT INTO places_bairro VALUES (282, 'Chácara Santo Antônio', 9);\nINSERT INTO places_bairro VALUES (283, 'Dois Irmãos', 9);\nINSERT INTO places_bairro VALUES (284, 'Doze de Maio', 9);\nINSERT INTO places_bairro VALUES (285, 'Frei Fabiano', 9);\nINSERT INTO places_bairro VALUES (286, 'Graças', 9);\nINSERT INTO places_bairro VALUES (287, 'Heliópolis', 9);\nINSERT INTO places_bairro VALUES (288, 'Hiterland', 9);\nINSERT INTO places_bairro VALUES (289, 'Itaipu', 9);\nINSERT INTO places_bairro VALUES (290, 'Jardim Almo', 9);\nINSERT INTO places_bairro VALUES (291, 'Jardim Amapa', 9);\nINSERT INTO places_bairro VALUES (292, 'Jardim América', 9);\nINSERT INTO places_bairro VALUES (293, 'Jardim Boa Vista', 9);\nINSERT INTO places_bairro VALUES (294, 'Jardim Bom Pastor', 9);\nINSERT INTO places_bairro VALUES (295, 'Jardim Brasil', 9);\nINSERT INTO places_bairro VALUES (296, 'Jardim Caxias', 9);\nINSERT INTO places_bairro VALUES (297, 'Jardim das Acácias', 9);\nINSERT INTO places_bairro VALUES (298, 'Jardim das Estrelas', 9);\nINSERT INTO places_bairro VALUES (299, 'Jardim Dimas Filho', 9);\nINSERT INTO places_bairro VALUES (300, 'Jardim Glaucia', 9);\nINSERT INTO places_bairro VALUES (301, 'Jardim Ideal', 9);\nINSERT INTO places_bairro VALUES (302, 'Jardim Imperial', 9);\nINSERT INTO places_bairro VALUES (303, 'Jardim Cristina', 9);\nINSERT INTO places_bairro VALUES (304, 'Jardim Itaipu', 9);\nINSERT INTO places_bairro VALUES (305, 'Jardim Laranjeiras', 9);\nINSERT INTO places_bairro VALUES (306, 'Jardim Limeira', 9);\nINSERT INTO places_bairro VALUES (307, 'Jardim Lisboa', 9);\nINSERT INTO places_bairro VALUES (308, 'Jardim Marajó', 9);\nINSERT INTO places_bairro VALUES (309, 'Jardim Maringá', 9);\nINSERT INTO places_bairro VALUES (310, 'Jardim Marques de Pombal', 9);\nINSERT INTO places_bairro VALUES (311, 'Jardim Meu Retiro', 9);\nINSERT INTO places_bairro VALUES (312, 'Jardim Nova Esperança', 9);\nINSERT INTO places_bairro VALUES (313, 'Jardim Patricia', 9);\nINSERT INTO places_bairro VALUES (314, 'Jardim Piedade', 9);\nINSERT INTO places_bairro VALUES (315, 'Jardim Portugal', 9);\nINSERT INTO places_bairro VALUES (316, 'Redentor', 9);\nINSERT INTO places_bairro VALUES (317, 'Jardim Santa Marta', 9);\nINSERT INTO places_bairro VALUES (318, 'Jardim São Bento', 9);\nINSERT INTO places_bairro VALUES (319, 'Jardim São Francisco', 9);\nINSERT INTO places_bairro VALUES (320, 'Jardim Tonalegre', 9);\nINSERT INTO places_bairro VALUES (321, 'Jardim Tupiara', 9);\nINSERT INTO places_bairro VALUES (322, 'Jardim Universo', 9);\nINSERT INTO places_bairro VALUES (323, 'Jardim Xavantes', 9);\nINSERT INTO places_bairro VALUES (324, 'Ligia', 9);\nINSERT INTO places_bairro VALUES (325, 'Lisboa', 9);\nINSERT INTO places_bairro VALUES (326, 'Lote XV', 9);\nINSERT INTO places_bairro VALUES (327, 'Luzes', 9);\nINSERT INTO places_bairro VALUES (328, 'Malhapão', 9);\nINSERT INTO places_bairro VALUES (329, 'Martins Ribeiro', 9);\nINSERT INTO places_bairro VALUES (330, 'Meu Cantinho', 9);\nINSERT INTO places_bairro VALUES (331, 'Miguel Couto', 9);\nINSERT INTO places_bairro VALUES (332, 'Nossa Senhora das Graças', 9);\nINSERT INTO places_bairro VALUES (333, 'Nossa Senhora de Fátima', 9);\nINSERT INTO places_bairro VALUES (334, 'Nova Aurora', 9);\nINSERT INTO places_bairro VALUES (335, 'Novo Eldorado', 9);\nINSERT INTO places_bairro VALUES (336, 'Núcleo Colonial São Bento', 9);\nINSERT INTO places_bairro VALUES (337, 'Orquídeas', 9);\nINSERT INTO places_bairro VALUES (338, 'Outeiro', 9);\nINSERT INTO places_bairro VALUES (339, 'Parque Afonso', 9);\nINSERT INTO places_bairro VALUES (340, 'Parque Aida', 9);\nINSERT INTO places_bairro VALUES (341, 'Parque Alvorada', 9);\nINSERT INTO places_bairro VALUES (342, 'Parque Ambai', 9);\nINSERT INTO places_bairro VALUES (343, 'Parque Americano', 9);\nINSERT INTO places_bairro VALUES (344, 'Parque Amorim', 9);\nINSERT INTO places_bairro VALUES (345, 'Parque Boa Sorte', 9);\nINSERT INTO places_bairro VALUES (346, 'Parque Colonial', 9);\nINSERT INTO places_bairro VALUES (347, 'Parque das Flores', 9);\nINSERT INTO places_bairro VALUES (348, 'Parque dos Califas', 9);\nINSERT INTO places_bairro VALUES (349, 'Parque Esperança', 9);\nINSERT INTO places_bairro VALUES (350, 'Parque Floresta', 9);\nINSERT INTO places_bairro VALUES (351, 'Parque Fluminense', 9);\nINSERT INTO places_bairro VALUES (352, 'Parque Glória', 9);\nINSERT INTO places_bairro VALUES (353, 'Parque Jordão', 9);\nINSERT INTO places_bairro VALUES (354, 'Parque Jupiranguai', 9);\nINSERT INTO places_bairro VALUES (355, 'Parque Laranjeiras', 9);\nINSERT INTO places_bairro VALUES (356, 'Parque Martinho', 9);\nINSERT INTO places_bairro VALUES (357, 'Parque Nossa Senhora Aparecida', 9);\nINSERT INTO places_bairro VALUES (358, 'Parque Nova Aurea', 9);\nINSERT INTO places_bairro VALUES (359, 'Parque Real', 9);\nINSERT INTO places_bairro VALUES (360, 'Parque Renascenca', 9);\nINSERT INTO places_bairro VALUES (361, 'Parque Roseiral', 9);\nINSERT INTO places_bairro VALUES (362, 'Parque Santa Amélia', 9);\nINSERT INTO places_bairro VALUES (363, 'Parque Santa Branca', 9);\nINSERT INTO places_bairro VALUES (364, 'Parque Santa Rita', 9);\nINSERT INTO places_bairro VALUES (365, 'Jardim Silvana', 9);\nINSERT INTO places_bairro VALUES (366, 'Parque São Bernardo', 9);\nINSERT INTO places_bairro VALUES (367, 'Parque São José', 9);\nINSERT INTO places_bairro VALUES (368, 'Parque São Lucas', 9);\nINSERT INTO places_bairro VALUES (369, 'São Vicente', 9);\nINSERT INTO places_bairro VALUES (370, 'Parque Saxonia', 9);\nINSERT INTO places_bairro VALUES (371, 'Parque Umari', 9);\nINSERT INTO places_bairro VALUES (372, 'Parque União', 9);\nINSERT INTO places_bairro VALUES (373, 'Parque União 4', 9);\nINSERT INTO places_bairro VALUES (374, 'Parque Veneza', 9);\nINSERT INTO places_bairro VALUES (375, 'Peixoto', 9);\nINSERT INTO places_bairro VALUES (376, 'Penápolis', 9);\nINSERT INTO places_bairro VALUES (377, 'Piam', 9);\nINSERT INTO places_bairro VALUES (378, 'Prata', 9);\nINSERT INTO places_bairro VALUES (379, 'Primus', 9);\nINSERT INTO places_bairro VALUES (380, 'Retiro dos Califas', 9);\nINSERT INTO places_bairro VALUES (381, 'Retiro Santa Isabel', 9);\nINSERT INTO places_bairro VALUES (382, 'Ribaslandia', 9);\nINSERT INTO places_bairro VALUES (383, 'Rocha Sobrinho', 9);\nINSERT INTO places_bairro VALUES (384, 'Santa Cecília', 9);\nINSERT INTO places_bairro VALUES (385, 'Santa Emilia', 9);\nINSERT INTO places_bairro VALUES (386, 'Santa Helena', 9);\nINSERT INTO places_bairro VALUES (387, 'Santa Maria', 9);\nINSERT INTO places_bairro VALUES (388, 'Santo Tirco', 9);\nINSERT INTO places_bairro VALUES (389, 'Santos Reis', 9);\nINSERT INTO places_bairro VALUES (390, 'São Bernardo', 9);\nINSERT INTO places_bairro VALUES (391, 'São Jorge', 9);\nINSERT INTO places_bairro VALUES (392, 'São Leopoldo', 9);\nINSERT INTO places_bairro VALUES (393, 'Shangli-lá', 9);\nINSERT INTO places_bairro VALUES (394, 'Sicelândia', 9);\nINSERT INTO places_bairro VALUES (395, 'Sitio Floresta Linda', 9);\nINSERT INTO places_bairro VALUES (396, 'Sitio Retiro Feliz', 9);\nINSERT INTO places_bairro VALUES (397, 'Sublime', 9);\nINSERT INTO places_bairro VALUES (398, 'Vergel dos Felix', 9);\nINSERT INTO places_bairro VALUES (399, 'Vila Borgerth', 9);\nINSERT INTO places_bairro VALUES (400, 'Vila Claudia', 9);\nINSERT INTO places_bairro VALUES (401, 'Vila Dagmar', 9);\nINSERT INTO places_bairro VALUES (402, 'Vila Entre Rios', 9);\nINSERT INTO places_bairro VALUES (403, 'Vila Era', 9);\nINSERT INTO places_bairro VALUES (404, 'Vila Esperança', 9);\nINSERT INTO places_bairro VALUES (405, 'Vila Esteves', 9);\nINSERT INTO places_bairro VALUES (406, 'Vila Fluminense', 9);\nINSERT INTO places_bairro VALUES (407, 'Vila Heliopolis', 9);\nINSERT INTO places_bairro VALUES (408, 'Vila Herminia Maia', 9);\nINSERT INTO places_bairro VALUES (409, 'Vila Joana', 9);\nINSERT INTO places_bairro VALUES (410, 'Vila João Lima', 9);\nINSERT INTO places_bairro VALUES (411, 'Vila João Rodrigues', 9);\nINSERT INTO places_bairro VALUES (412, 'Vila Joema', 9);\nINSERT INTO places_bairro VALUES (413, 'Vila Jola', 9);\nINSERT INTO places_bairro VALUES (414, 'Vila Luz', 9);\nINSERT INTO places_bairro VALUES (415, 'Vila Madalena', 9);\nINSERT INTO places_bairro VALUES (416, 'Vila Maia', 9);\nINSERT INTO places_bairro VALUES (417, 'Vila Mangueiras', 9);\nINSERT INTO places_bairro VALUES (418, 'Vila Maria Céu', 9);\nINSERT INTO places_bairro VALUES (419, 'Vila Marquesa de Santos', 9);\nINSERT INTO places_bairro VALUES (420, 'Vila Medeiros', 9);\nINSERT INTO places_bairro VALUES (421, 'Vila Monjardim', 9);\nINSERT INTO places_bairro VALUES (422, 'Vila Pauline', 9);\nINSERT INTO places_bairro VALUES (423, 'Vila Rica', 9);\nINSERT INTO places_bairro VALUES (424, 'Vila Sagres', 9);\nINSERT INTO places_bairro VALUES (425, 'Vila Santa Rita', 9);\nINSERT INTO places_bairro VALUES (426, 'Vila Santa Teresa', 9);\nINSERT INTO places_bairro VALUES (427, 'Vila Santo Antônio', 9);\nINSERT INTO places_bairro VALUES (428, 'Vila Santo Antônio da Prata', 9);\nINSERT INTO places_bairro VALUES (429, 'Vila São Luís', 9);\nINSERT INTO places_bairro VALUES (430, 'Vila São Sebastião', 9);\nINSERT INTO places_bairro VALUES (431, 'Vila São Teodoro', 9);\nINSERT INTO places_bairro VALUES (432, 'Vila Seabra', 9);\nINSERT INTO places_bairro VALUES (433, 'Vila Sousa', 9);\nINSERT INTO places_bairro VALUES (434, 'Vila Tamoios', 9);\nINSERT INTO places_bairro VALUES (435, 'Vila Verde', 9);\nINSERT INTO places_bairro VALUES (436, 'Vila Viçosa', 9);\nINSERT INTO places_bairro VALUES (437, 'Vila Vitorio', 9);\nINSERT INTO places_bairro VALUES (438, 'Vilar Novo', 9);\nINSERT INTO places_bairro VALUES (439, 'Vilarinho', 9);\nINSERT INTO places_bairro VALUES (440, 'Xavante', 9);\nINSERT INTO places_bairro VALUES (441, 'Santa Tereza', 9);\nINSERT INTO places_bairro VALUES (442, 'Bemposta', 88);\nINSERT INTO places_bairro VALUES (443, 'Centro', 64);\nINSERT INTO places_bairro VALUES (444, 'Centro', 16);\nINSERT INTO places_bairro VALUES (445, 'Centro', 33);\nINSERT INTO places_bairro VALUES (446, 'Centro', 10);\nINSERT INTO places_bairro VALUES (447, 'Centro', 11);\nINSERT INTO places_bairro VALUES (448, 'Serrinha', 11);\nINSERT INTO places_bairro VALUES (449, 'Pirapetinga', 11);\nINSERT INTO places_bairro VALUES (450, 'Usina Santa Isabel', 11);\nINSERT INTO places_bairro VALUES (451, 'Usina Santa Maria', 11);\nINSERT INTO places_bairro VALUES (452, 'Centro', 46);\nINSERT INTO places_bairro VALUES (453, 'Algodoal', 12);\nINSERT INTO places_bairro VALUES (454, 'Braga', 12);\nINSERT INTO places_bairro VALUES (455, 'Canaã', 12);\nINSERT INTO places_bairro VALUES (456, 'Célula Mater', 12);\nINSERT INTO places_bairro VALUES (457, 'Centro', 12);\nINSERT INTO places_bairro VALUES (458, 'Dunas', 12);\nINSERT INTO places_bairro VALUES (459, 'Gamboa', 12);\nINSERT INTO places_bairro VALUES (460, 'Guarani', 12);\nINSERT INTO places_bairro VALUES (461, 'Itajuru', 12);\nINSERT INTO places_bairro VALUES (462, 'Jardim Caiçara', 12);\nINSERT INTO places_bairro VALUES (463, 'Jardim Esperança', 12);\nINSERT INTO places_bairro VALUES (464, 'Jardim Excelcior', 12);\nINSERT INTO places_bairro VALUES (465, 'Jardim Flamboyant', 12);\nINSERT INTO places_bairro VALUES (466, 'Jardim Machado', 12);\nINSERT INTO places_bairro VALUES (467, 'Jardim Olinda', 12);\nINSERT INTO places_bairro VALUES (468, 'Peró', 12);\nINSERT INTO places_bairro VALUES (469, 'Jardim Náutilus', 12);\nINSERT INTO places_bairro VALUES (470, 'Juscelino Kubitschek de Oliveira', 12);\nINSERT INTO places_bairro VALUES (471, 'Manoel Correa', 12);\nINSERT INTO places_bairro VALUES (472, 'Ogiva', 12);\nINSERT INTO places_bairro VALUES (473, 'Palmeiras', 12);\nINSERT INTO places_bairro VALUES (474, 'Parque Burle', 12);\nINSERT INTO places_bairro VALUES (475, 'Parque Central', 12);\nINSERT INTO places_bairro VALUES (476, 'Parque Riviera', 12);\nINSERT INTO places_bairro VALUES (477, 'Praia do Siqueira', 12);\nINSERT INTO places_bairro VALUES (478, 'Passagem', 12);\nINSERT INTO places_bairro VALUES (479, 'Portinho', 12);\nINSERT INTO places_bairro VALUES (480, 'Porto do Carro', 12);\nINSERT INTO places_bairro VALUES (481, 'Recanto das Dunas', 12);\nINSERT INTO places_bairro VALUES (482, 'São Bento', 12);\nINSERT INTO places_bairro VALUES (483, 'São Cristóvão', 12);\nINSERT INTO places_bairro VALUES (484, 'Vila Blanche', 12);\nINSERT INTO places_bairro VALUES (485, 'Vila Nova', 12);\nINSERT INTO places_bairro VALUES (486, 'Jardim Peró', 12);\nINSERT INTO places_bairro VALUES (487, 'Agrisa', 12);\nINSERT INTO places_bairro VALUES (488, 'Jacaré', 12);\nINSERT INTO places_bairro VALUES (489, 'Vila do Sol', 12);\nINSERT INTO places_bairro VALUES (490, 'Miguel Couto', 12);\nINSERT INTO places_bairro VALUES (491, 'Parque Balneário São Francisco', 12);\nINSERT INTO places_bairro VALUES (492, 'Centro', 29);\nINSERT INTO places_bairro VALUES (493, 'Centro', 13);\nINSERT INTO places_bairro VALUES (494, 'Areia Branca', 37);\nINSERT INTO places_bairro VALUES (495, 'Centro', 11);\nINSERT INTO places_bairro VALUES (496, 'Cambiasca', 71);\nINSERT INTO places_bairro VALUES (497, 'Centro', 14);\nINSERT INTO places_bairro VALUES (498, 'Cruzeiro', 14);\nINSERT INTO places_bairro VALUES (499, 'Parque Bandeirantes', 15);\nINSERT INTO places_bairro VALUES (500, 'Bosque das Acácias', 15);\nINSERT INTO places_bairro VALUES (501, 'Caju', 15);\nINSERT INTO places_bairro VALUES (502, 'Calabouço', 15);\nINSERT INTO places_bairro VALUES (503, 'Centro', 15);\nINSERT INTO places_bairro VALUES (504, 'Codim', 15);\nINSERT INTO places_bairro VALUES (505, 'Custodópolis', 15);\nINSERT INTO places_bairro VALUES (506, 'Horto Municipal', 15);\nINSERT INTO places_bairro VALUES (507, 'Ips', 15);\nINSERT INTO places_bairro VALUES (508, 'Jardim Carioca', 15);\nINSERT INTO places_bairro VALUES (509, 'Jardim Ceasa', 15);\nINSERT INTO places_bairro VALUES (510, 'Jardim Lagoa das Pedras', 15);\nINSERT INTO places_bairro VALUES (511, 'Lapa', 15);\nINSERT INTO places_bairro VALUES (512, 'Nova Campos', 15);\nINSERT INTO places_bairro VALUES (513, 'Parque Aeroporto', 15);\nINSERT INTO places_bairro VALUES (514, 'Parque Aldeia', 15);\nINSERT INTO places_bairro VALUES (515, 'Parque Alvorada', 15);\nINSERT INTO places_bairro VALUES (516, 'Parque Aurora', 15);\nINSERT INTO places_bairro VALUES (517, 'Parque Bela Vista', 15);\nINSERT INTO places_bairro VALUES (518, 'Parque Boa Vista', 15);\nINSERT INTO places_bairro VALUES (519, 'Parque Bonsucesso', 15);\nINSERT INTO places_bairro VALUES (520, 'Parque Brasília', 15);\nINSERT INTO places_bairro VALUES (521, 'Parque Caju', 15);\nINSERT INTO places_bairro VALUES (522, 'Parque Calabouço', 15);\nINSERT INTO places_bairro VALUES (523, 'Parque Califórnia', 15);\nINSERT INTO places_bairro VALUES (524, 'Parque Ceasa', 15);\nINSERT INTO places_bairro VALUES (525, 'Parque Céu Azul', 15);\nINSERT INTO places_bairro VALUES (526, 'Parque Cidade Luz', 15);\nINSERT INTO places_bairro VALUES (527, 'Parque Corrientes', 15);\nINSERT INTO places_bairro VALUES (528, 'Parque Eldorado', 15);\nINSERT INTO places_bairro VALUES (529, 'Parque Esplanada', 15);\nINSERT INTO places_bairro VALUES (530, 'Parque Flamboyant', 15);\nINSERT INTO places_bairro VALUES (531, 'Parque Fundão', 15);\nINSERT INTO places_bairro VALUES (532, 'Parque Guarus', 15);\nINSERT INTO places_bairro VALUES (533, 'Parque Imperial', 15);\nINSERT INTO places_bairro VALUES (534, 'Vila Industrial', 15);\nINSERT INTO places_bairro VALUES (535, 'Parque Jardim Carioca', 15);\nINSERT INTO places_bairro VALUES (536, 'Parque João Maria', 15);\nINSERT INTO places_bairro VALUES (537, 'Parque Jóquei Club', 15);\nINSERT INTO places_bairro VALUES (538, 'Parque Leopoldina', 15);\nINSERT INTO places_bairro VALUES (539, 'Parque Maciel', 15);\nINSERT INTO places_bairro VALUES (540, 'Parque Novo Mundo', 15);\nINSERT INTO places_bairro VALUES (541, 'Parque Pecuária', 15);\nINSERT INTO places_bairro VALUES (542, 'Parque Penha', 15);\nINSERT INTO places_bairro VALUES (543, 'Parque Prazeres', 15);\nINSERT INTO places_bairro VALUES (544, 'Parque Presidente Vargas', 15);\nINSERT INTO places_bairro VALUES (545, 'Parque Rodoviário', 15);\nINSERT INTO places_bairro VALUES (546, 'Parque Rosário', 15);\nINSERT INTO places_bairro VALUES (547, 'Parque Salo Brand', 15);\nINSERT INTO places_bairro VALUES (548, 'Parque Santa Clara', 15);\nINSERT INTO places_bairro VALUES (549, 'Parque Santa Helena', 15);\nINSERT INTO places_bairro VALUES (550, 'Parque Santa Maria', 15);\nINSERT INTO places_bairro VALUES (551, 'Parque Santa Rosa', 15);\nINSERT INTO places_bairro VALUES (552, 'Parque Santo Amaro', 15);\nINSERT INTO places_bairro VALUES (553, 'Parque Santo Antônio', 15);\nINSERT INTO places_bairro VALUES (554, 'Parque Santos Dumont', 15);\nINSERT INTO places_bairro VALUES (555, 'Parque São Benedito', 15);\nINSERT INTO places_bairro VALUES (556, 'Parque São Caetano', 15);\nINSERT INTO places_bairro VALUES (557, 'Parque São Domingos', 15);\nINSERT INTO places_bairro VALUES (558, 'Parque São José', 15);\nINSERT INTO places_bairro VALUES (559, 'Parque São Mateus', 15);\nINSERT INTO places_bairro VALUES (560, 'Parque São Silvestre', 15);\nINSERT INTO places_bairro VALUES (561, 'Parque Tamandaré', 15);\nINSERT INTO places_bairro VALUES (562, 'Parque Tarcisio Miranda', 15);\nINSERT INTO places_bairro VALUES (563, 'Parque Tropical', 15);\nINSERT INTO places_bairro VALUES (564, 'Parque Turf Club', 15);\nINSERT INTO places_bairro VALUES (565, 'Parque Varanda do Visconde', 15);\nINSERT INTO places_bairro VALUES (566, 'Parque Vera Cruz', 15);\nINSERT INTO places_bairro VALUES (567, 'Parque Vicente Gonçalves Dias', 15);\nINSERT INTO places_bairro VALUES (568, 'Parque Visconde de Ururaí', 15);\nINSERT INTO places_bairro VALUES (569, 'Parque Zuza Mota', 15);\nINSERT INTO places_bairro VALUES (570, 'Santa Cruz', 15);\nINSERT INTO places_bairro VALUES (571, 'Tapera', 15);\nINSERT INTO places_bairro VALUES (572, 'Ururaí', 15);\nINSERT INTO places_bairro VALUES (573, 'Vila da Rainha', 15);\nINSERT INTO places_bairro VALUES (574, 'Parque Julião Nogueira', 15);\nINSERT INTO places_bairro VALUES (575, 'Centro', 16);\nINSERT INTO places_bairro VALUES (576, 'Centro', 11);\nINSERT INTO places_bairro VALUES (577, 'Mutum', 11);\nINSERT INTO places_bairro VALUES (578, 'Centro', 17);\nINSERT INTO places_bairro VALUES (579, 'Centro', 18);\nINSERT INTO places_bairro VALUES (580, 'Outeiro', 18);\nINSERT INTO places_bairro VALUES (581, 'Doutor Matos', 18);\nINSERT INTO places_bairro VALUES (582, 'Centro', 19);\nINSERT INTO places_bairro VALUES (583, 'Barra de São Francisco', 19);\nINSERT INTO places_bairro VALUES (584, 'Influência', 19);\nINSERT INTO places_bairro VALUES (585, 'Professor Souza', 20);\nINSERT INTO places_bairro VALUES (586, 'Centro', 20);\nINSERT INTO places_bairro VALUES (587, 'Rio Dourado', 20);\nINSERT INTO places_bairro VALUES (588, 'Colônia', 71);\nINSERT INTO places_bairro VALUES (589, 'Centro', 21);\nINSERT INTO places_bairro VALUES (590, 'Centro', 33);\nINSERT INTO places_bairro VALUES (591, 'Centro', 40);\nINSERT INTO places_bairro VALUES (592, 'Centro', 22);\nINSERT INTO places_bairro VALUES (593, 'Centro', 44);\nINSERT INTO places_bairro VALUES (594, 'Centro', 89);\nINSERT INTO places_bairro VALUES (595, 'Centro', 23);\nINSERT INTO places_bairro VALUES (596, 'Lavrinhas', 23);\nINSERT INTO places_bairro VALUES (597, 'Retiro Poético', 23);\nINSERT INTO places_bairro VALUES (598, 'Centro', 19);\nINSERT INTO places_bairro VALUES (599, 'Córrego do Ouro', 37);\nINSERT INTO places_bairro VALUES (600, 'Frade', 1);\nINSERT INTO places_bairro VALUES (601, 'Centro', 57);\nINSERT INTO places_bairro VALUES (602, 'Dores de Macabu', 15);\nINSERT INTO places_bairro VALUES (603, 'Ponta da Lama', 15);\nINSERT INTO places_bairro VALUES (604, 'Monte Café', 87);\nINSERT INTO places_bairro VALUES (605, 'Serra das Almas', 87);\nINSERT INTO places_bairro VALUES (606, 'Centro', 69);\nINSERT INTO places_bairro VALUES (607, 'Centro', 24);\nINSERT INTO places_bairro VALUES (608, 'Barro Branco', 25);\nINSERT INTO places_bairro VALUES (609, 'Bom Retiro', 25);\nINSERT INTO places_bairro VALUES (610, 'Carolina', 25);\nINSERT INTO places_bairro VALUES (611, 'Centro', 25);\nINSERT INTO places_bairro VALUES (612, 'Chácaras Arcampo', 25);\nINSERT INTO places_bairro VALUES (613, 'Chácaras Maria Helena', 25);\nINSERT INTO places_bairro VALUES (614, 'Chácaras Rio-Petrópolis', 25);\nINSERT INTO places_bairro VALUES (615, 'Chacrinha', 25);\nINSERT INTO places_bairro VALUES (616, 'Circular', 25);\nINSERT INTO places_bairro VALUES (617, 'Coriolano', 25);\nINSERT INTO places_bairro VALUES (618, 'Divino', 25);\nINSERT INTO places_bairro VALUES (619, 'Doutor Laureano', 25);\nINSERT INTO places_bairro VALUES (620, 'Engenho do Porto', 25);\nINSERT INTO places_bairro VALUES (621, 'Fonseca', 25);\nINSERT INTO places_bairro VALUES (622, 'Graças', 25);\nINSERT INTO places_bairro VALUES (623, 'Gramacho', 25);\nINSERT INTO places_bairro VALUES (624, 'Imbariê', 25);\nINSERT INTO places_bairro VALUES (625, 'Itatiaia', 25);\nINSERT INTO places_bairro VALUES (626, 'Jardim Anhangá', 25);\nINSERT INTO places_bairro VALUES (627, 'Jardim Balneário Ana Clara', 25);\nINSERT INTO places_bairro VALUES (628, 'Jardim Barro Branco', 25);\nINSERT INTO places_bairro VALUES (629, 'Jardim Califórnia', 25);\nINSERT INTO places_bairro VALUES (630, 'Jardim das Oliveiras', 25);\nINSERT INTO places_bairro VALUES (631, 'Jardim Fim de Semana', 25);\nINSERT INTO places_bairro VALUES (632, 'Jardim Glória', 25);\nINSERT INTO places_bairro VALUES (633, 'Jardim Gramacho', 25);\nINSERT INTO places_bairro VALUES (634, 'Jardim Guanabara', 25);\nINSERT INTO places_bairro VALUES (635, 'Jardim Imbariê', 25);\nINSERT INTO places_bairro VALUES (636, 'Jardim Leal', 25);\nINSERT INTO places_bairro VALUES (637, 'Jardim Líder', 25);\nINSERT INTO places_bairro VALUES (638, 'Jardim Mariana', 25);\nINSERT INTO places_bairro VALUES (639, 'Jardim Marice', 25);\nINSERT INTO places_bairro VALUES (640, 'Jardim Nossa Senhora de Fátima', 25);\nINSERT INTO places_bairro VALUES (641, 'Jardim Nossa Senhora do Carmo', 25);\nINSERT INTO places_bairro VALUES (642, 'Jardim Olavo Bilac', 25);\nINSERT INTO places_bairro VALUES (643, 'Jardim Olimpo', 25);\nINSERT INTO places_bairro VALUES (644, 'Jardim Panamá', 25);\nINSERT INTO places_bairro VALUES (645, 'Jardim Piratininga', 25);\nINSERT INTO places_bairro VALUES (646, 'Jardim Porangaba', 25);\nINSERT INTO places_bairro VALUES (647, 'Jardim Portugal', 25);\nINSERT INTO places_bairro VALUES (648, 'Jardim Primavera', 25);\nINSERT INTO places_bairro VALUES (649, 'Jardim Rosário', 25);\nINSERT INTO places_bairro VALUES (650, 'Jardim Rotse', 25);\nINSERT INTO places_bairro VALUES (651, 'Jardim Santa Rita', 25);\nINSERT INTO places_bairro VALUES (652, 'Jardim Santana do Pilar', 25);\nINSERT INTO places_bairro VALUES (653, 'Jardim Santos Meira', 25);\nINSERT INTO places_bairro VALUES (654, 'Jardim São Lourenço', 25);\nINSERT INTO places_bairro VALUES (655, 'Jardim Taquara', 25);\nINSERT INTO places_bairro VALUES (656, 'Jardim Três Marias', 25);\nINSERT INTO places_bairro VALUES (657, 'Jardim Vila Nova', 25);\nINSERT INTO places_bairro VALUES (658, 'Jardim Vinte e Cinco de Agosto', 25);\nINSERT INTO places_bairro VALUES (659, 'Jardim Vista Alegre', 25);\nINSERT INTO places_bairro VALUES (660, 'Loteamento Cachoeira', 25);\nINSERT INTO places_bairro VALUES (661, 'Mantiquira', 25);\nINSERT INTO places_bairro VALUES (662, 'Nossa Senhora das Graças', 25);\nINSERT INTO places_bairro VALUES (663, 'Nossa Senhora do Carmo', 25);\nINSERT INTO places_bairro VALUES (664, 'Nova Campinas', 25);\nINSERT INTO places_bairro VALUES (665, 'Parada Angélica', 25);\nINSERT INTO places_bairro VALUES (666, 'Parque Alvorada', 25);\nINSERT INTO places_bairro VALUES (667, 'Parque Barão do Amapá', 25);\nINSERT INTO places_bairro VALUES (668, 'Parque Beira Mar', 25);\nINSERT INTO places_bairro VALUES (669, 'Parque Boa Vista I', 25);\nINSERT INTO places_bairro VALUES (670, 'Parque Boa Vista II', 25);\nINSERT INTO places_bairro VALUES (671, 'Parque Bom Retiro', 25);\nINSERT INTO places_bairro VALUES (672, 'Parque Capivari', 25);\nINSERT INTO places_bairro VALUES (673, 'Parque Centenário', 25);\nINSERT INTO places_bairro VALUES (674, 'Parque Chuno', 25);\nINSERT INTO places_bairro VALUES (675, 'Parque Comercial', 25);\nINSERT INTO places_bairro VALUES (676, 'Parque do Carmo', 25);\nINSERT INTO places_bairro VALUES (677, 'Parque Duque', 25);\nINSERT INTO places_bairro VALUES (678, 'Parque Eldorado', 25);\nINSERT INTO places_bairro VALUES (679, 'Parque A Equitativa', 25);\nINSERT INTO places_bairro VALUES (680, 'Parque Esperança', 25);\nINSERT INTO places_bairro VALUES (681, 'Parque Estrela', 25);\nINSERT INTO places_bairro VALUES (682, 'Parque Felicidade', 25);\nINSERT INTO places_bairro VALUES (683, 'Parque Fluminense', 25);\nINSERT INTO places_bairro VALUES (684, 'Parque Guararapes', 25);\nINSERT INTO places_bairro VALUES (685, 'Parque Império', 25);\nINSERT INTO places_bairro VALUES (686, 'Parque Independência', 25);\nINSERT INTO places_bairro VALUES (687, 'Parque João Pessoa', 25);\nINSERT INTO places_bairro VALUES (688, 'Parque Lafaiete', 25);\nINSERT INTO places_bairro VALUES (689, 'Parque Laguna e Dourados', 25);\nINSERT INTO places_bairro VALUES (690, 'Parque Marilandia', 25);\nINSERT INTO places_bairro VALUES (691, 'Parque Moderno', 25);\nINSERT INTO places_bairro VALUES (692, 'Parque Muísa', 25);\nINSERT INTO places_bairro VALUES (693, 'Parque Nossa Senhora da Penha', 25);\nINSERT INTO places_bairro VALUES (694, 'Parque Nova Esperança', 25);\nINSERT INTO places_bairro VALUES (695, 'Parque Panorama', 25);\nINSERT INTO places_bairro VALUES (696, 'Parque Paulicéia', 25);\nINSERT INTO places_bairro VALUES (697, 'Parque Paulista', 25);\nINSERT INTO places_bairro VALUES (698, 'Parque Redentor', 25);\nINSERT INTO places_bairro VALUES (699, 'Parque Samirópolis', 25);\nINSERT INTO places_bairro VALUES (700, 'Parque Santa Lúcia', 25);\nINSERT INTO places_bairro VALUES (701, 'Parque Santa Marta', 25);\nINSERT INTO places_bairro VALUES (702, 'Parque Santa Rosa', 25);\nINSERT INTO places_bairro VALUES (703, 'Parque Santo Antônio', 25);\nINSERT INTO places_bairro VALUES (704, 'Parque São Bento', 25);\nINSERT INTO places_bairro VALUES (705, 'Parque São Carlos', 25);\nINSERT INTO places_bairro VALUES (706, 'Parque São João', 25);\nINSERT INTO places_bairro VALUES (707, 'Parque São Pedro de Alcantara', 25);\nINSERT INTO places_bairro VALUES (708, 'Parque Senhor do Bonfim', 25);\nINSERT INTO places_bairro VALUES (709, 'Parque Uruguaiana', 25);\nINSERT INTO places_bairro VALUES (710, 'Parque Vitória', 25);\nINSERT INTO places_bairro VALUES (711, 'Parque Xerém', 25);\nINSERT INTO places_bairro VALUES (712, 'Quatorze de Julho', 25);\nINSERT INTO places_bairro VALUES (713, 'Santa Alice', 25);\nINSERT INTO places_bairro VALUES (714, 'Santa Lúcia', 25);\nINSERT INTO places_bairro VALUES (715, 'Santo Antônio', 25);\nINSERT INTO places_bairro VALUES (716, 'Santo Antônio da Serra', 25);\nINSERT INTO places_bairro VALUES (717, 'São Bento', 25);\nINSERT INTO places_bairro VALUES (718, 'Saracuruna', 25);\nINSERT INTO places_bairro VALUES (719, 'Sarapuí', 25);\nINSERT INTO places_bairro VALUES (720, 'Silva', 25);\nINSERT INTO places_bairro VALUES (721, 'Silva Cardoso', 25);\nINSERT INTO places_bairro VALUES (722, 'Taquara', 25);\nINSERT INTO places_bairro VALUES (723, 'Trevo das Missões', 25);\nINSERT INTO places_bairro VALUES (724, 'Vila Actura', 25);\nINSERT INTO places_bairro VALUES (725, 'Vila Amélia', 25);\nINSERT INTO places_bairro VALUES (726, 'Vila Angélica', 25);\nINSERT INTO places_bairro VALUES (727, 'Vila Araci', 25);\nINSERT INTO places_bairro VALUES (728, 'Vila Bela Vista', 25);\nINSERT INTO places_bairro VALUES (729, 'Vila Bernadete', 25);\nINSERT INTO places_bairro VALUES (730, 'Vila Bonança', 25);\nINSERT INTO places_bairro VALUES (731, 'Vila Caetano Madeira', 25);\nINSERT INTO places_bairro VALUES (732, 'Vila Campanaro', 25);\nINSERT INTO places_bairro VALUES (733, 'Vila Canaa', 25);\nINSERT INTO places_bairro VALUES (734, 'Vila Capixaba', 25);\nINSERT INTO places_bairro VALUES (735, 'Vila Centenário', 25);\nINSERT INTO places_bairro VALUES (736, 'Vila Cocota', 25);\nINSERT INTO places_bairro VALUES (737, 'Vila Constança de Calvos', 25);\nINSERT INTO places_bairro VALUES (738, 'Vila Ema', 25);\nINSERT INTO places_bairro VALUES (739, 'Vila Esperança', 25);\nINSERT INTO places_bairro VALUES (740, 'Vila Flávia', 25);\nINSERT INTO places_bairro VALUES (741, 'Vila Guanabara', 25);\nINSERT INTO places_bairro VALUES (742, 'Vila Ideal', 25);\nINSERT INTO places_bairro VALUES (743, 'Vila Irene', 25);\nINSERT INTO places_bairro VALUES (744, 'Vila Itamarati', 25);\nINSERT INTO places_bairro VALUES (745, 'Vila Leopoldina', 25);\nINSERT INTO places_bairro VALUES (746, 'Vila Maria Helena', 25);\nINSERT INTO places_bairro VALUES (747, 'Vila Meriti', 25);\nINSERT INTO places_bairro VALUES (748, 'Vila Nossa Senhora das Graças', 25);\nINSERT INTO places_bairro VALUES (749, 'Vila Oito de Maio', 25);\nINSERT INTO places_bairro VALUES (750, 'Vila Operária', 25);\nINSERT INTO places_bairro VALUES (751, 'Vila Ouro Preto', 25);\nINSERT INTO places_bairro VALUES (752, 'Vila Paula', 25);\nINSERT INTO places_bairro VALUES (753, 'Vila Rosário', 25);\nINSERT INTO places_bairro VALUES (754, 'Vila Santa Alice', 25);\nINSERT INTO places_bairro VALUES (755, 'Vila Santa Cruz', 25);\nINSERT INTO places_bairro VALUES (756, 'Vila Santo Antônio', 25);\nINSERT INTO places_bairro VALUES (757, 'Vila São João', 25);\nINSERT INTO places_bairro VALUES (758, 'Vila São Judas Tadeu', 25);\nINSERT INTO places_bairro VALUES (759, 'Vila São Luís', 25);\nINSERT INTO places_bairro VALUES (760, 'Vila São Pedro', 25);\nINSERT INTO places_bairro VALUES (761, 'Vila São Sebastião', 25);\nINSERT INTO places_bairro VALUES (762, 'Vila Sapê', 25);\nINSERT INTO places_bairro VALUES (763, 'Vila Sarapuí', 25);\nINSERT INTO places_bairro VALUES (764, 'Vila Sheila', 25);\nINSERT INTO places_bairro VALUES (765, 'Vila Sossego', 25);\nINSERT INTO places_bairro VALUES (766, 'Vila Teresa', 25);\nINSERT INTO places_bairro VALUES (767, 'Vila Urussaí', 25);\nINSERT INTO places_bairro VALUES (768, 'Xerém', 25);\nINSERT INTO places_bairro VALUES (769, 'Campos Elíseos', 25);\nINSERT INTO places_bairro VALUES (770, 'Cidade dos Meninos', 25);\nINSERT INTO places_bairro VALUES (771, 'Pilar', 25);\nINSERT INTO places_bairro VALUES (772, 'Parada Morabi', 25);\nINSERT INTO places_bairro VALUES (773, 'Cangulo', 25);\nINSERT INTO places_bairro VALUES (774, 'Centro', 63);\nINSERT INTO places_bairro VALUES (775, 'Centro', 26);\nINSERT INTO places_bairro VALUES (776, 'Morro Azul do Tinguá', 26);\nINSERT INTO places_bairro VALUES (777, 'Centro', 32);\nINSERT INTO places_bairro VALUES (778, 'Euclidelândia', 16);\nINSERT INTO places_bairro VALUES (779, 'Portozil', 16);\nINSERT INTO places_bairro VALUES (780, 'Córrego Frio', 16);\nINSERT INTO places_bairro VALUES (781, 'Ponte do Ismério', 16);\nINSERT INTO places_bairro VALUES (782, 'Centro', 63);\nINSERT INTO places_bairro VALUES (783, 'Funil', 14);\nINSERT INTO places_bairro VALUES (784, 'Centro', 83);\nINSERT INTO places_bairro VALUES (785, 'Centro', 65);\nINSERT INTO places_bairro VALUES (786, 'Frade', 37);\nINSERT INTO places_bairro VALUES (787, 'Centro', 37);\nINSERT INTO places_bairro VALUES (788, 'Trapiche', 37);\nINSERT INTO places_bairro VALUES (789, 'Goytacazes', 15);\nINSERT INTO places_bairro VALUES (790, 'Poço Gordo', 15);\nINSERT INTO places_bairro VALUES (791, 'Governador Portela', 44);\nINSERT INTO places_bairro VALUES (792, 'Centro', 27);\nINSERT INTO places_bairro VALUES (793, 'Ipiranga', 39);\nINSERT INTO places_bairro VALUES (794, 'Centro', 70);\nINSERT INTO places_bairro VALUES (795, 'Ibitioca', 15);\nINSERT INTO places_bairro VALUES (796, 'Lagoa de Cima', 15);\nINSERT INTO places_bairro VALUES (797, 'Centro', 28);\nINSERT INTO places_bairro VALUES (798, 'Iguaba Grande', 28);\nINSERT INTO places_bairro VALUES (799, 'Cidade Nova', 28);\nINSERT INTO places_bairro VALUES (800, 'Sardoal', 52);\nINSERT INTO places_bairro VALUES (801, 'Inconfidência', 52);\nINSERT INTO places_bairro VALUES (802, 'Fragoso', 39);\nINSERT INTO places_bairro VALUES (803, 'Inoã', 41);\nINSERT INTO places_bairro VALUES (804, 'São José do Imbassaí', 41);\nINSERT INTO places_bairro VALUES (805, 'Ipiabás', 57);\nINSERT INTO places_bairro VALUES (806, 'Centro', 71);\nINSERT INTO places_bairro VALUES (807, 'Centro', 72);\nINSERT INTO places_bairro VALUES (808, 'Batelão da Barra', 72);\nINSERT INTO places_bairro VALUES (809, 'Cidade Gebara', 29);\nINSERT INTO places_bairro VALUES (810, 'Centro', 29);\nINSERT INTO places_bairro VALUES (811, 'Muriqui', 29);\nINSERT INTO places_bairro VALUES (812, 'São José', 29);\nINSERT INTO places_bairro VALUES (813, 'Pacheco', 29);\nINSERT INTO places_bairro VALUES (814, 'Engenho Velho', 29);\nINSERT INTO places_bairro VALUES (815, 'Visconde de Itaboraí', 29);\nINSERT INTO places_bairro VALUES (816, 'Manilha', 29);\nINSERT INTO places_bairro VALUES (817, 'Posse do Coutinhos', 29);\nINSERT INTO places_bairro VALUES (818, 'Marambaia', 29);\nINSERT INTO places_bairro VALUES (819, 'Grande Rio', 29);\nINSERT INTO places_bairro VALUES (820, 'Morada do Sol', 29);\nINSERT INTO places_bairro VALUES (821, 'Outeiro das Pedras', 29);\nINSERT INTO places_bairro VALUES (822, 'Itacurussá', 40);\nINSERT INTO places_bairro VALUES (823, 'Centro', 40);\nINSERT INTO places_bairro VALUES (824, 'Águas Lindas', 30);\nINSERT INTO places_bairro VALUES (825, 'Amendoeira', 30);\nINSERT INTO places_bairro VALUES (826, 'Boa Esperança', 30);\nINSERT INTO places_bairro VALUES (827, 'Brisa Mar', 30);\nINSERT INTO places_bairro VALUES (828, 'Cabral', 30);\nINSERT INTO places_bairro VALUES (829, 'Caçador', 30);\nINSERT INTO places_bairro VALUES (830, 'Califórnia', 30);\nINSERT INTO places_bairro VALUES (831, 'Campo Lindo', 30);\nINSERT INTO places_bairro VALUES (832, 'Centro', 30);\nINSERT INTO places_bairro VALUES (833, 'Chaperó', 30);\nINSERT INTO places_bairro VALUES (834, 'Cidade Industrial', 30);\nINSERT INTO places_bairro VALUES (835, 'Cidade Nova', 30);\nINSERT INTO places_bairro VALUES (836, 'Coroa Grande', 30);\nINSERT INTO places_bairro VALUES (837, 'Dom Bosco', 30);\nINSERT INTO places_bairro VALUES (838, 'Ecologia', 30);\nINSERT INTO places_bairro VALUES (839, 'Engenho', 30);\nINSERT INTO places_bairro VALUES (840, 'Estrela do Céu', 30);\nINSERT INTO places_bairro VALUES (841, 'Fazenda Caxias', 30);\nINSERT INTO places_bairro VALUES (842, 'Fonte Limpa', 30);\nINSERT INTO places_bairro VALUES (843, 'Ibituporanga', 30);\nINSERT INTO places_bairro VALUES (844, 'Ilha da Madeira', 30);\nINSERT INTO places_bairro VALUES (845, 'Itimirim', 30);\nINSERT INTO places_bairro VALUES (846, 'Jardim Acácias', 30);\nINSERT INTO places_bairro VALUES (847, 'Jardim América', 30);\nINSERT INTO places_bairro VALUES (848, 'Jardim Central', 30);\nINSERT INTO places_bairro VALUES (849, 'Jardim Laia', 30);\nINSERT INTO places_bairro VALUES (850, 'Jardim Maracanã', 30);\nINSERT INTO places_bairro VALUES (851, 'Jardim Veda', 30);\nINSERT INTO places_bairro VALUES (852, 'Leandro', 30);\nINSERT INTO places_bairro VALUES (853, 'Mazomba', 30);\nINSERT INTO places_bairro VALUES (854, 'Monte Serrat', 30);\nINSERT INTO places_bairro VALUES (855, 'Nazare', 30);\nINSERT INTO places_bairro VALUES (856, 'Parque Campo Lindo', 30);\nINSERT INTO places_bairro VALUES (857, 'Parque Dom Bosco', 30);\nINSERT INTO places_bairro VALUES (858, 'Parque Independência', 30);\nINSERT INTO places_bairro VALUES (859, 'Parque Jocimar', 30);\nINSERT INTO places_bairro VALUES (860, 'Parque Paraíso', 30);\nINSERT INTO places_bairro VALUES (861, 'Parque Primavera', 30);\nINSERT INTO places_bairro VALUES (862, 'Parque São Jorge', 30);\nINSERT INTO places_bairro VALUES (863, 'Parque Vera Cruz', 30);\nINSERT INTO places_bairro VALUES (864, 'Pau Cheiroso', 30);\nINSERT INTO places_bairro VALUES (865, 'Piranema', 30);\nINSERT INTO places_bairro VALUES (866, 'Ponte Preta', 30);\nINSERT INTO places_bairro VALUES (867, 'Santa Alice', 30);\nINSERT INTO places_bairro VALUES (868, 'Santa Cândida', 30);\nINSERT INTO places_bairro VALUES (869, 'Santa Sofia', 30);\nINSERT INTO places_bairro VALUES (870, 'Santana', 30);\nINSERT INTO places_bairro VALUES (871, 'São José', 30);\nINSERT INTO places_bairro VALUES (872, 'São Miguel', 30);\nINSERT INTO places_bairro VALUES (873, 'São Salvador', 30);\nINSERT INTO places_bairro VALUES (874, 'Seropedica', 30);\nINSERT INTO places_bairro VALUES (875, 'Somel', 30);\nINSERT INTO places_bairro VALUES (876, 'Teixeiras', 30);\nINSERT INTO places_bairro VALUES (877, 'Vila Geny', 30);\nINSERT INTO places_bairro VALUES (878, 'Vila Ibirapitanga', 30);\nINSERT INTO places_bairro VALUES (879, 'Vila Margarida', 30);\nINSERT INTO places_bairro VALUES (880, 'Vila Paraíso', 30);\nINSERT INTO places_bairro VALUES (881, 'Vila Sonia', 30);\nINSERT INTO places_bairro VALUES (882, 'Vista Alegre', 30);\nINSERT INTO places_bairro VALUES (883, 'Centro', 33);\nINSERT INTO places_bairro VALUES (884, 'Centro', 31);\nINSERT INTO places_bairro VALUES (885, 'Sambra Guarniere', 31);\nINSERT INTO places_bairro VALUES (886, 'Cimento Paraíso', 31);\nINSERT INTO places_bairro VALUES (887, 'São Pedro do Paraíso', 31);\nINSERT INTO places_bairro VALUES (888, 'Doutor Matos', 31);\nINSERT INTO places_bairro VALUES (889, 'Bairro Amaral', 29);\nINSERT INTO places_bairro VALUES (890, 'Centro', 29);\nINSERT INTO places_bairro VALUES (891, 'João Caetano', 29);\nINSERT INTO places_bairro VALUES (892, 'Centro', 32);\nINSERT INTO places_bairro VALUES (893, 'Engenho Central', 32);\nINSERT INTO places_bairro VALUES (894, 'Coronel Teixeira', 32);\nINSERT INTO places_bairro VALUES (895, 'Presidente Costa e Silva', 33);\nINSERT INTO places_bairro VALUES (896, 'Aeroporto', 33);\nINSERT INTO places_bairro VALUES (897, 'Centro', 33);\nINSERT INTO places_bairro VALUES (898, 'Vinhosa', 33);\nINSERT INTO places_bairro VALUES (899, 'Niterói', 33);\nINSERT INTO places_bairro VALUES (900, 'Centro', 34);\nINSERT INTO places_bairro VALUES (901, 'Centro', 32);\nINSERT INTO places_bairro VALUES (902, 'Centro', 80);\nINSERT INTO places_bairro VALUES (903, 'Alecrim', 35);\nINSERT INTO places_bairro VALUES (904, 'Austi', 35);\nINSERT INTO places_bairro VALUES (905, 'Carlos Sampaio', 35);\nINSERT INTO places_bairro VALUES (906, 'Carmo', 35);\nINSERT INTO places_bairro VALUES (907, 'Cidade Jardim Marajoara', 35);\nINSERT INTO places_bairro VALUES (908, 'Cidade Senhor do Bonfim', 35);\nINSERT INTO places_bairro VALUES (909, 'Citrópolis', 35);\nINSERT INTO places_bairro VALUES (910, 'Colinas', 35);\nINSERT INTO places_bairro VALUES (911, 'Cosme e Damião', 35);\nINSERT INTO places_bairro VALUES (912, 'Engenheiro Pedreira', 35);\nINSERT INTO places_bairro VALUES (913, 'Esperança', 35);\nINSERT INTO places_bairro VALUES (914, 'Granja Copacabana', 35);\nINSERT INTO places_bairro VALUES (915, 'Granja Iguaçu', 35);\nINSERT INTO places_bairro VALUES (916, 'Irmãos Unidos', 35);\nINSERT INTO places_bairro VALUES (917, 'Jaceruba', 35);\nINSERT INTO places_bairro VALUES (918, 'Japeri', 35);\nINSERT INTO places_bairro VALUES (919, 'Jardim Aljezur', 35);\nINSERT INTO places_bairro VALUES (920, 'Jardim Americano', 35);\nINSERT INTO places_bairro VALUES (921, 'Jardim Delamare', 35);\nINSERT INTO places_bairro VALUES (922, 'Jardim Emília', 35);\nINSERT INTO places_bairro VALUES (923, 'Jardim Esperança', 35);\nINSERT INTO places_bairro VALUES (924, 'Jardim Normandia', 35);\nINSERT INTO places_bairro VALUES (925, 'Jardim Paraíso', 35);\nINSERT INTO places_bairro VALUES (926, 'Jardim Real', 35);\nINSERT INTO places_bairro VALUES (927, 'Jardim Rio D''Ouro', 35);\nINSERT INTO places_bairro VALUES (928, 'Jardim Santa Branca', 35);\nINSERT INTO places_bairro VALUES (929, 'Jardim São Geraldo', 35);\nINSERT INTO places_bairro VALUES (930, 'Jardim São João', 35);\nINSERT INTO places_bairro VALUES (931, 'Jardim São Sebastião', 35);\nINSERT INTO places_bairro VALUES (932, 'Jardim Transmontano', 35);\nINSERT INTO places_bairro VALUES (933, 'Jardim Tri-Campeão', 35);\nINSERT INTO places_bairro VALUES (934, 'Jardim Willis', 35);\nINSERT INTO places_bairro VALUES (935, 'Julima', 35);\nINSERT INTO places_bairro VALUES (936, 'Laranjal Santo Antônio', 35);\nINSERT INTO places_bairro VALUES (937, 'Linda Vista', 35);\nINSERT INTO places_bairro VALUES (938, 'Luis de Camões', 35);\nINSERT INTO places_bairro VALUES (939, 'Mactube', 35);\nINSERT INTO places_bairro VALUES (940, 'Madeira', 35);\nINSERT INTO places_bairro VALUES (941, 'Mantiqueira', 35);\nINSERT INTO places_bairro VALUES (942, 'Maria José', 35);\nINSERT INTO places_bairro VALUES (943, 'Nossa Senhora da Penha', 35);\nINSERT INTO places_bairro VALUES (944, 'Nossa Senhora de Fátima', 35);\nINSERT INTO places_bairro VALUES (945, 'Nova Belém', 35);\nINSERT INTO places_bairro VALUES (946, 'Parque Amaro', 35);\nINSERT INTO places_bairro VALUES (947, 'Parque dos Feirantes', 35);\nINSERT INTO places_bairro VALUES (948, 'Parque Engenheiro Pedreira', 35);\nINSERT INTO places_bairro VALUES (949, 'Parque Guandu', 35);\nINSERT INTO places_bairro VALUES (950, 'Parque Itaguare', 35);\nINSERT INTO places_bairro VALUES (951, 'Parque Luis Gonzaga', 35);\nINSERT INTO places_bairro VALUES (952, 'Parque Macaiba', 35);\nINSERT INTO places_bairro VALUES (953, 'Parque Marabá', 35);\nINSERT INTO places_bairro VALUES (954, 'Parque Mucaja', 35);\nINSERT INTO places_bairro VALUES (955, 'Parque Professor João de Maria', 35);\nINSERT INTO places_bairro VALUES (956, 'Parque Santo Antônio', 35);\nINSERT INTO places_bairro VALUES (957, 'Parque São Bartolomeu', 35);\nINSERT INTO places_bairro VALUES (958, 'Parque São Benedito', 35);\nINSERT INTO places_bairro VALUES (959, 'Parque Sarandi', 35);\nINSERT INTO places_bairro VALUES (960, 'Parque Triunfo', 35);\nINSERT INTO places_bairro VALUES (961, 'Paz', 35);\nINSERT INTO places_bairro VALUES (962, 'Pedra Lisa', 35);\nINSERT INTO places_bairro VALUES (963, 'Ponte Preta', 35);\nINSERT INTO places_bairro VALUES (964, 'Queimados', 35);\nINSERT INTO places_bairro VALUES (965, 'Recreio dos Jornalistas', 35);\nINSERT INTO places_bairro VALUES (966, 'Redentor', 35);\nINSERT INTO places_bairro VALUES (967, 'Rio D''Ouro', 35);\nINSERT INTO places_bairro VALUES (968, 'Roncador', 35);\nINSERT INTO places_bairro VALUES (969, 'Santa Inês', 35);\nINSERT INTO places_bairro VALUES (970, 'Santa Sofia', 35);\nINSERT INTO places_bairro VALUES (971, 'Santa Terezinha', 35);\nINSERT INTO places_bairro VALUES (972, 'Santo Antônio', 35);\nINSERT INTO places_bairro VALUES (973, 'São Bernardo', 35);\nINSERT INTO places_bairro VALUES (974, 'São Bras', 35);\nINSERT INTO places_bairro VALUES (975, 'São Jorge', 35);\nINSERT INTO places_bairro VALUES (976, 'Teofilo Cunha', 35);\nINSERT INTO places_bairro VALUES (977, 'Três Fontes', 35);\nINSERT INTO places_bairro VALUES (978, 'Vila Bom Jardim', 35);\nINSERT INTO places_bairro VALUES (979, 'Vila Carmelita', 35);\nINSERT INTO places_bairro VALUES (980, 'Vila Central', 35);\nINSERT INTO places_bairro VALUES (981, 'Vila Coqueiros', 35);\nINSERT INTO places_bairro VALUES (982, 'Vila Cristine Maria', 35);\nINSERT INTO places_bairro VALUES (983, 'Vila Japeri', 35);\nINSERT INTO places_bairro VALUES (984, 'Vila Maricá', 35);\nINSERT INTO places_bairro VALUES (985, 'Vila Maringá', 35);\nINSERT INTO places_bairro VALUES (986, 'Vila Nossa Senhora da Conceição', 35);\nINSERT INTO places_bairro VALUES (987, 'Vila Nossa Senhora do Rosário', 35);\nINSERT INTO places_bairro VALUES (988, 'Vila Planetária', 35);\nINSERT INTO places_bairro VALUES (989, 'Vila Santa Amélia', 35);\nINSERT INTO places_bairro VALUES (990, 'Vila Santa Helena', 35);\nINSERT INTO places_bairro VALUES (991, 'Vila São Francisco', 35);\nINSERT INTO places_bairro VALUES (992, 'Vila São João', 35);\nINSERT INTO places_bairro VALUES (993, 'Vilar Grande', 35);\nINSERT INTO places_bairro VALUES (994, 'Vitória', 35);\nINSERT INTO places_bairro VALUES (995, 'Centro de Japeri', 35);\nINSERT INTO places_bairro VALUES (996, 'Chacrinha', 35);\nINSERT INTO places_bairro VALUES (997, 'Centro', 13);\nINSERT INTO places_bairro VALUES (998, 'Centro', 36);\nINSERT INTO places_bairro VALUES (999, 'Centro', 32);\nINSERT INTO places_bairro VALUES (1000, 'Centro', 65);\nINSERT INTO places_bairro VALUES (1001, 'Centro', 22);\nINSERT INTO places_bairro VALUES (1002, 'Alto Cajueiros', 37);\nINSERT INTO places_bairro VALUES (1003, 'Aroeiras', 37);\nINSERT INTO places_bairro VALUES (1004, 'Barra', 37);\nINSERT INTO places_bairro VALUES (1005, 'Barra de Macaé', 37);\nINSERT INTO places_bairro VALUES (1006, 'Barreto', 37);\nINSERT INTO places_bairro VALUES (1007, 'Bela Vista', 37);\nINSERT INTO places_bairro VALUES (1008, 'Botafogo', 37);\nINSERT INTO places_bairro VALUES (1009, 'Cajueiros', 37);\nINSERT INTO places_bairro VALUES (1010, 'Campo do Oeste', 37);\nINSERT INTO places_bairro VALUES (1011, 'Cancela Preta', 37);\nINSERT INTO places_bairro VALUES (1012, 'Cavaleiros', 37);\nINSERT INTO places_bairro VALUES (1013, 'Centro', 37);\nINSERT INTO places_bairro VALUES (1014, 'Costa do Sol', 37);\nINSERT INTO places_bairro VALUES (1015, 'Glória', 37);\nINSERT INTO places_bairro VALUES (1016, 'Granja dos Cavaleiros', 37);\nINSERT INTO places_bairro VALUES (1017, 'Imbetiba', 37);\nINSERT INTO places_bairro VALUES (1018, 'Jardim Aeroporto', 37);\nINSERT INTO places_bairro VALUES (1019, 'Jardim Carioca', 37);\nINSERT INTO places_bairro VALUES (1020, 'Jardim Maringá', 37);\nINSERT INTO places_bairro VALUES (1021, 'Jardim Santo Antônio', 37);\nINSERT INTO places_bairro VALUES (1022, 'Lagoa', 37);\nINSERT INTO places_bairro VALUES (1023, 'Lagomar', 37);\nINSERT INTO places_bairro VALUES (1024, 'Malvinas', 37);\nINSERT INTO places_bairro VALUES (1025, 'Maringá', 37);\nINSERT INTO places_bairro VALUES (1026, 'Miramar', 37);\nINSERT INTO places_bairro VALUES (1027, 'Morada das Garças', 37);\nINSERT INTO places_bairro VALUES (1028, 'Morro Santana', 37);\nINSERT INTO places_bairro VALUES (1029, 'Morro São Jorge', 37);\nINSERT INTO places_bairro VALUES (1030, 'Nossa Senhora da Ajuda -Imburo', 37);\nINSERT INTO places_bairro VALUES (1031, 'Nova Aroeiras', 37);\nINSERT INTO places_bairro VALUES (1032, 'Nova Holanda', 37);\nINSERT INTO places_bairro VALUES (1033, 'Nova Macaé', 37);\nINSERT INTO places_bairro VALUES (1034, 'Novo Cavaleiro', 37);\nINSERT INTO places_bairro VALUES (1035, 'Novo Visconde', 37);\nINSERT INTO places_bairro VALUES (1036, 'Paraíso', 37);\nINSERT INTO places_bairro VALUES (1037, 'Parque Aeroporto', 37);\nINSERT INTO places_bairro VALUES (1038, 'Parque Atlântico', 37);\nINSERT INTO places_bairro VALUES (1039, 'Parque Duque de Caxias', 37);\nINSERT INTO places_bairro VALUES (1040, 'Praia Campista', 37);\nINSERT INTO places_bairro VALUES (1041, 'Riviera Dois', 37);\nINSERT INTO places_bairro VALUES (1042, 'Riviera Fluminense', 37);\nINSERT INTO places_bairro VALUES (1043, 'Santa Mônica', 37);\nINSERT INTO places_bairro VALUES (1044, 'Santa Rosa Lagomar', 37);\nINSERT INTO places_bairro VALUES (1045, 'São José do Barreto', 37);\nINSERT INTO places_bairro VALUES (1046, 'Sol e Mar', 37);\nINSERT INTO places_bairro VALUES (1047, 'Vale Encantado', 37);\nINSERT INTO places_bairro VALUES (1048, 'Vilage Parque Aeroporto', 37);\nINSERT INTO places_bairro VALUES (1049, 'Visconde de Araújo', 37);\nINSERT INTO places_bairro VALUES (1050, 'Vivenda da Lagoa', 37);\nINSERT INTO places_bairro VALUES (1051, 'Imboassica', 37);\nINSERT INTO places_bairro VALUES (1052, 'Centro', 38);\nINSERT INTO places_bairro VALUES (1053, 'Centro', 39);\nINSERT INTO places_bairro VALUES (1054, 'Praia Brava', 1);\nINSERT INTO places_bairro VALUES (1055, 'Centro', 40);\nINSERT INTO places_bairro VALUES (1056, 'Serra do Piloto', 40);\nINSERT INTO places_bairro VALUES (1057, 'Ponta Negra', 41);\nINSERT INTO places_bairro VALUES (1058, 'Guarabira', 41);\nINSERT INTO places_bairro VALUES (1059, 'Espraiado', 41);\nINSERT INTO places_bairro VALUES (1060, 'Bambuí', 41);\nINSERT INTO places_bairro VALUES (1061, 'Três Ilhas', 66);\nINSERT INTO places_bairro VALUES (1062, 'Centro', 66);\nINSERT INTO places_bairro VALUES (1063, 'Centro', 70);\nINSERT INTO places_bairro VALUES (1064, 'Centro', 41);\nINSERT INTO places_bairro VALUES (1065, 'Espraiado', 41);\nINSERT INTO places_bairro VALUES (1066, 'São Bento da Lagoa', 41);\nINSERT INTO places_bairro VALUES (1067, 'Jardim Atlântico', 41);\nINSERT INTO places_bairro VALUES (1068, 'Barra de Guaratiba', 41);\nINSERT INTO places_bairro VALUES (1069, 'Rio Fundo', 41);\nINSERT INTO places_bairro VALUES (1070, 'Bambuí', 41);\nINSERT INTO places_bairro VALUES (1071, 'Recanto de Itaipuaçu', 41);\nINSERT INTO places_bairro VALUES (1072, 'Ponta Negra', 41);\nINSERT INTO places_bairro VALUES (1073, 'Itapeba', 41);\nINSERT INTO places_bairro VALUES (1074, 'Centro', 42);\nINSERT INTO places_bairro VALUES (1075, 'Edson Passos', 43);\nINSERT INTO places_bairro VALUES (1076, 'Jacutinga', 43);\nINSERT INTO places_bairro VALUES (1077, 'Juscelino', 43);\nINSERT INTO places_bairro VALUES (1078, 'Rocha Sobrinho', 43);\nINSERT INTO places_bairro VALUES (1079, 'Santa Terezinha', 43);\nINSERT INTO places_bairro VALUES (1080, 'Centro', 43);\nINSERT INTO places_bairro VALUES (1081, 'Coréia', 43);\nINSERT INTO places_bairro VALUES (1082, 'Santo Elias', 43);\nINSERT INTO places_bairro VALUES (1083, 'Banco de Areia', 43);\nINSERT INTO places_bairro VALUES (1084, 'Vila Emil', 43);\nINSERT INTO places_bairro VALUES (1085, 'Cosmorama', 43);\nINSERT INTO places_bairro VALUES (1086, 'Chatuba', 43);\nINSERT INTO places_bairro VALUES (1087, 'Centro', 44);\nINSERT INTO places_bairro VALUES (1088, 'Vera Cruz', 44);\nINSERT INTO places_bairro VALUES (1089, 'Centro', 45);\nINSERT INTO places_bairro VALUES (1090, 'Centro', 24);\nINSERT INTO places_bairro VALUES (1091, 'Centro', 70);\nINSERT INTO places_bairro VALUES (1092, 'Centro', 14);\nINSERT INTO places_bairro VALUES (1093, 'Cruzeiro', 14);\nINSERT INTO places_bairro VALUES (1094, 'Monumento', 57);\nINSERT INTO places_bairro VALUES (1095, 'Morangaba', 15);\nINSERT INTO places_bairro VALUES (1096, 'Centro', 15);\nINSERT INTO places_bairro VALUES (1097, 'Saturnino Braga', 15);\nINSERT INTO places_bairro VALUES (1098, 'Centro', 15);\nINSERT INTO places_bairro VALUES (1099, 'Centro', 46);\nINSERT INTO places_bairro VALUES (1100, 'Nhunguaçu', 86);\nINSERT INTO places_bairro VALUES (1101, 'Cabral', 47);\nINSERT INTO places_bairro VALUES (1102, 'Cabuis', 47);\nINSERT INTO places_bairro VALUES (1103, 'Centro', 47);\nINSERT INTO places_bairro VALUES (1104, 'Nossa Senhora de Fátima', 47);\nINSERT INTO places_bairro VALUES (1105, 'Nova Cidade', 47);\nINSERT INTO places_bairro VALUES (1106, 'Olinda', 47);\nINSERT INTO places_bairro VALUES (1107, 'Paiol de Pólvora', 47);\nINSERT INTO places_bairro VALUES (1108, 'Atalaia', 48);\nINSERT INTO places_bairro VALUES (1109, 'Badu', 48);\nINSERT INTO places_bairro VALUES (1110, 'Baldeador', 48);\nINSERT INTO places_bairro VALUES (1111, 'Barreto', 48);\nINSERT INTO places_bairro VALUES (1112, 'Boa Viagem', 48);\nINSERT INTO places_bairro VALUES (1113, 'Camboinhas', 48);\nINSERT INTO places_bairro VALUES (1114, 'Cantagalo', 48);\nINSERT INTO places_bairro VALUES (1115, 'Caramujo', 48);\nINSERT INTO places_bairro VALUES (1116, 'Centro', 48);\nINSERT INTO places_bairro VALUES (1117, 'Charitas', 48);\nINSERT INTO places_bairro VALUES (1118, 'Cubango', 48);\nINSERT INTO places_bairro VALUES (1119, 'Engenhoca', 48);\nINSERT INTO places_bairro VALUES (1120, 'Fátima', 48);\nINSERT INTO places_bairro VALUES (1121, 'Figueira', 48);\nINSERT INTO places_bairro VALUES (1122, 'Fonseca', 48);\nINSERT INTO places_bairro VALUES (1123, 'Gragoatá', 48);\nINSERT INTO places_bairro VALUES (1124, 'Icaraí', 48);\nINSERT INTO places_bairro VALUES (1125, 'Ilha da Conceição', 48);\nINSERT INTO places_bairro VALUES (1126, 'Ingá', 48);\nINSERT INTO places_bairro VALUES (1127, 'Itacoatiara', 48);\nINSERT INTO places_bairro VALUES (1128, 'Itaipu', 48);\nINSERT INTO places_bairro VALUES (1129, 'Ititioca', 48);\nINSERT INTO places_bairro VALUES (1130, 'Jurujuba', 48);\nINSERT INTO places_bairro VALUES (1131, 'Largo da Batalha', 48);\nINSERT INTO places_bairro VALUES (1132, 'Largo do Barradas', 48);\nINSERT INTO places_bairro VALUES (1133, 'Engenho do Mato', 48);\nINSERT INTO places_bairro VALUES (1134, 'Maravista', 48);\nINSERT INTO places_bairro VALUES (1135, 'Maceió', 48);\nINSERT INTO places_bairro VALUES (1136, 'Maralegre', 48);\nINSERT INTO places_bairro VALUES (1137, 'Marazul', 48);\nINSERT INTO places_bairro VALUES (1138, 'Maria Paula', 48);\nINSERT INTO places_bairro VALUES (1139, 'Mata Paca', 48);\nINSERT INTO places_bairro VALUES (1140, 'Muriqui', 48);\nINSERT INTO places_bairro VALUES (1141, 'Pe Pequeno', 48);\nINSERT INTO places_bairro VALUES (1142, 'Pendotiba', 48);\nINSERT INTO places_bairro VALUES (1143, 'Piratininga', 48);\nINSERT INTO places_bairro VALUES (1144, 'Ponta D''Areia', 48);\nINSERT INTO places_bairro VALUES (1145, 'Santana', 48);\nINSERT INTO places_bairro VALUES (1146, 'Rio do Ouro', 48);\nINSERT INTO places_bairro VALUES (1147, 'Santa Bárbara', 48);\nINSERT INTO places_bairro VALUES (1148, 'Santa Rosa', 48);\nINSERT INTO places_bairro VALUES (1149, 'São Domingos', 48);\nINSERT INTO places_bairro VALUES (1150, 'São Francisco', 48);\nINSERT INTO places_bairro VALUES (1151, 'São Lourenço', 48);\nINSERT INTO places_bairro VALUES (1152, 'Sape', 48);\nINSERT INTO places_bairro VALUES (1153, 'Tenente Jardim', 48);\nINSERT INTO places_bairro VALUES (1154, 'Várzea das Moças', 48);\nINSERT INTO places_bairro VALUES (1155, 'Venda da Cruz', 48);\nINSERT INTO places_bairro VALUES (1156, 'Vila Progresso', 48);\nINSERT INTO places_bairro VALUES (1157, 'Vital Brasil', 48);\nINSERT INTO places_bairro VALUES (1158, 'Serra Grande', 48);\nINSERT INTO places_bairro VALUES (1159, 'Centro', 80);\nINSERT INTO places_bairro VALUES (1160, 'Centro', 33);\nINSERT INTO places_bairro VALUES (1161, 'Are', 33);\nINSERT INTO places_bairro VALUES (1162, 'Amparo', 49);\nINSERT INTO places_bairro VALUES (1163, 'Aprazível', 49);\nINSERT INTO places_bairro VALUES (1164, 'Bela Vista', 49);\nINSERT INTO places_bairro VALUES (1165, 'Braunes', 49);\nINSERT INTO places_bairro VALUES (1166, 'Campo do Coelho', 49);\nINSERT INTO places_bairro VALUES (1167, 'Cascatinha', 49);\nINSERT INTO places_bairro VALUES (1168, 'Catarcione', 49);\nINSERT INTO places_bairro VALUES (1169, 'Centro', 49);\nINSERT INTO places_bairro VALUES (1170, 'Chácara Paraíso', 49);\nINSERT INTO places_bairro VALUES (1171, 'Cônego', 49);\nINSERT INTO places_bairro VALUES (1172, 'Conselheiro Paulino', 49);\nINSERT INTO places_bairro VALUES (1173, 'Cordoeira', 49);\nINSERT INTO places_bairro VALUES (1174, 'Córrego D''Antas', 49);\nINSERT INTO places_bairro VALUES (1175, 'Debossa', 49);\nINSERT INTO places_bairro VALUES (1176, 'Duas Pedras', 49);\nINSERT INTO places_bairro VALUES (1177, 'Jardim Califórnia', 49);\nINSERT INTO places_bairro VALUES (1178, 'Jardim Ouro Preto', 49);\nINSERT INTO places_bairro VALUES (1179, 'Jardinlândia', 49);\nINSERT INTO places_bairro VALUES (1180, 'Lagoinha', 49);\nINSERT INTO places_bairro VALUES (1181, 'Loteamento Floresta', 49);\nINSERT INTO places_bairro VALUES (1182, 'Loteamento Nosso Sonho', 49);\nINSERT INTO places_bairro VALUES (1183, 'Loteamento Santa Teresinha', 49);\nINSERT INTO places_bairro VALUES (1184, 'Loteamento São João', 49);\nINSERT INTO places_bairro VALUES (1185, 'Loteamento São José', 49);\nINSERT INTO places_bairro VALUES (1186, 'Loteamento São Sebastião', 49);\nINSERT INTO places_bairro VALUES (1187, 'Loteamento Sitio Jacina', 49);\nINSERT INTO places_bairro VALUES (1188, 'Lumiar', 49);\nINSERT INTO places_bairro VALUES (1189, 'Mury', 49);\nINSERT INTO places_bairro VALUES (1190, 'Olaria', 49);\nINSERT INTO places_bairro VALUES (1191, 'Parque Dom João VI', 49);\nINSERT INTO places_bairro VALUES (1192, 'Parque Maria Teresa', 49);\nINSERT INTO places_bairro VALUES (1193, 'Parque Residencial Solares', 49);\nINSERT INTO places_bairro VALUES (1194, 'Parque São Clemente', 49);\nINSERT INTO places_bairro VALUES (1195, 'Perissê', 49);\nINSERT INTO places_bairro VALUES (1196, 'Ponte da Saudade', 49);\nINSERT INTO places_bairro VALUES (1197, 'Prado', 49);\nINSERT INTO places_bairro VALUES (1198, 'Riograndina', 49);\nINSERT INTO places_bairro VALUES (1199, 'Rui Sanglard', 49);\nINSERT INTO places_bairro VALUES (1200, 'Sans Souci', 49);\nINSERT INTO places_bairro VALUES (1201, 'Santa Elisa', 49);\nINSERT INTO places_bairro VALUES (1202, 'São Geraldo', 49);\nINSERT INTO places_bairro VALUES (1203, 'São Pedro da Serra', 49);\nINSERT INTO places_bairro VALUES (1204, 'Serraville', 49);\nINSERT INTO places_bairro VALUES (1205, 'Suíço', 49);\nINSERT INTO places_bairro VALUES (1206, 'Tingly', 49);\nINSERT INTO places_bairro VALUES (1207, 'Vale do Sol', 49);\nINSERT INTO places_bairro VALUES (1208, 'Vale dos Pinheiros', 49);\nINSERT INTO places_bairro VALUES (1209, 'Vargem Grande', 49);\nINSERT INTO places_bairro VALUES (1210, 'Varginha', 49);\nINSERT INTO places_bairro VALUES (1211, 'Vila Amélia', 49);\nINSERT INTO places_bairro VALUES (1212, 'Vila Guarani', 49);\nINSERT INTO places_bairro VALUES (1213, 'Vila Nova', 49);\nINSERT INTO places_bairro VALUES (1214, 'Vilage', 49);\nINSERT INTO places_bairro VALUES (1215, 'Ypu', 49);\nINSERT INTO places_bairro VALUES (1216, 'Adrianópolis', 50);\nINSERT INTO places_bairro VALUES (1217, 'Aero Clube', 50);\nINSERT INTO places_bairro VALUES (1218, 'Afonso Celso', 50);\nINSERT INTO places_bairro VALUES (1219, 'Alto da Posse', 50);\nINSERT INTO places_bairro VALUES (1220, 'Alvarez', 50);\nINSERT INTO places_bairro VALUES (1221, 'Ambaí', 50);\nINSERT INTO places_bairro VALUES (1222, 'Andrade Araújo', 50);\nINSERT INTO places_bairro VALUES (1223, 'Argenta', 50);\nINSERT INTO places_bairro VALUES (1224, 'Austi', 50);\nINSERT INTO places_bairro VALUES (1225, 'Autódromo', 50);\nINSERT INTO places_bairro VALUES (1226, 'Barão de Amapá', 50);\nINSERT INTO places_bairro VALUES (1227, 'Barão de Guandu', 50);\nINSERT INTO places_bairro VALUES (1228, 'Bela Vista', 50);\nINSERT INTO places_bairro VALUES (1229, 'Belmonte', 50);\nINSERT INTO places_bairro VALUES (1230, 'Belterra', 50);\nINSERT INTO places_bairro VALUES (1231, 'Bernardo Kelner', 50);\nINSERT INTO places_bairro VALUES (1232, 'Boa Esperança', 50);\nINSERT INTO places_bairro VALUES (1233, 'Boa Vista', 50);\nINSERT INTO places_bairro VALUES (1234, 'Bom Jesus', 50);\nINSERT INTO places_bairro VALUES (1235, 'Botafogo', 50);\nINSERT INTO places_bairro VALUES (1236, 'Brasil', 50);\nINSERT INTO places_bairro VALUES (1237, 'Cachoeiras', 50);\nINSERT INTO places_bairro VALUES (1238, 'Caioaba', 50);\nINSERT INTO places_bairro VALUES (1239, 'Califórnia', 50);\nINSERT INTO places_bairro VALUES (1240, 'Carolina', 50);\nINSERT INTO places_bairro VALUES (1241, 'Centenário', 50);\nINSERT INTO places_bairro VALUES (1242, 'Centro', 50);\nINSERT INTO places_bairro VALUES (1243, 'Cerâmica', 50);\nINSERT INTO places_bairro VALUES (1244, 'Chacrinha', 50);\nINSERT INTO places_bairro VALUES (1245, 'Chavascal', 50);\nINSERT INTO places_bairro VALUES (1246, 'Ponto Chic', 50);\nINSERT INTO places_bairro VALUES (1247, 'Cidade Jardim Montevidéu', 50);\nINSERT INTO places_bairro VALUES (1248, 'Cidade Jardim Parque Estoril', 50);\nINSERT INTO places_bairro VALUES (1249, 'Cobrex', 50);\nINSERT INTO places_bairro VALUES (1250, 'Conjunto Residencial Redenção', 50);\nINSERT INTO places_bairro VALUES (1251, 'Cruzeiro do Sul', 50);\nINSERT INTO places_bairro VALUES (1252, 'Cuiabá', 50);\nINSERT INTO places_bairro VALUES (1253, 'Dano', 50);\nINSERT INTO places_bairro VALUES (1254, 'Diana', 50);\nINSERT INTO places_bairro VALUES (1255, 'Dois Irmãos', 50);\nINSERT INTO places_bairro VALUES (1256, 'Dom Rodrigo', 50);\nINSERT INTO places_bairro VALUES (1257, 'Dona Neli', 50);\nINSERT INTO places_bairro VALUES (1258, 'Duque Estrada', 50);\nINSERT INTO places_bairro VALUES (1259, 'Engenheiro Rocha Freire', 50);\nINSERT INTO places_bairro VALUES (1260, 'Essolandia', 50);\nINSERT INTO places_bairro VALUES (1261, 'Figueiras', 50);\nINSERT INTO places_bairro VALUES (1262, 'Flores', 50);\nINSERT INTO places_bairro VALUES (1263, 'Floresta', 50);\nINSERT INTO places_bairro VALUES (1264, 'Fraternidade', 50);\nINSERT INTO places_bairro VALUES (1265, 'Grajau', 50);\nINSERT INTO places_bairro VALUES (1266, 'Grama', 50);\nINSERT INTO places_bairro VALUES (1267, 'Guarani', 50);\nINSERT INTO places_bairro VALUES (1268, 'Hiterland', 50);\nINSERT INTO places_bairro VALUES (1269, 'Ida', 50);\nINSERT INTO places_bairro VALUES (1270, 'Iguaçu Velho', 50);\nINSERT INTO places_bairro VALUES (1271, 'Imperador', 50);\nINSERT INTO places_bairro VALUES (1272, 'Imperial', 50);\nINSERT INTO places_bairro VALUES (1273, 'Independência', 50);\nINSERT INTO places_bairro VALUES (1274, 'Industrial', 50);\nINSERT INTO places_bairro VALUES (1275, 'Iolanda', 50);\nINSERT INTO places_bairro VALUES (1276, 'Jardim Alvorada', 50);\nINSERT INTO places_bairro VALUES (1277, 'Jardim Belo Horizonte', 50);\nINSERT INTO places_bairro VALUES (1278, 'Jardim Cachoeira', 50);\nINSERT INTO places_bairro VALUES (1279, 'Jardim Canaã', 50);\nINSERT INTO places_bairro VALUES (1280, 'Jardim Carioca', 50);\nINSERT INTO places_bairro VALUES (1281, 'Jardim Continental', 50);\nINSERT INTO places_bairro VALUES (1282, 'Jardim Corumbá', 50);\nINSERT INTO places_bairro VALUES (1283, 'Jardim da Posse', 50);\nINSERT INTO places_bairro VALUES (1284, 'Jardim da Viga', 50);\nINSERT INTO places_bairro VALUES (1285, 'Jardim Emilia', 50);\nINSERT INTO places_bairro VALUES (1286, 'Jardim Esplanada', 50);\nINSERT INTO places_bairro VALUES (1287, 'Jardim Felix', 50);\nINSERT INTO places_bairro VALUES (1288, 'Jardim Fonte São Miguel', 50);\nINSERT INTO places_bairro VALUES (1289, 'Jardim Iara', 50);\nINSERT INTO places_bairro VALUES (1290, 'Jardim Ideal', 50);\nINSERT INTO places_bairro VALUES (1291, 'Jardim Iguaçu', 50);\nINSERT INTO places_bairro VALUES (1292, 'Jardim Império', 50);\nINSERT INTO places_bairro VALUES (1293, 'Jardim Jasmim', 50);\nINSERT INTO places_bairro VALUES (1294, 'Jardim Javari', 50);\nINSERT INTO places_bairro VALUES (1295, 'Jardim Lumar', 50);\nINSERT INTO places_bairro VALUES (1296, 'Jardim Marambaia', 50);\nINSERT INTO places_bairro VALUES (1297, 'Jardim Marilice', 50);\nINSERT INTO places_bairro VALUES (1298, 'Jardim Mato Grosso', 50);\nINSERT INTO places_bairro VALUES (1299, 'Jardim Monte Castelo', 50);\nINSERT INTO places_bairro VALUES (1300, 'Jardim Nacional', 50);\nINSERT INTO places_bairro VALUES (1301, 'Jardim Natal', 50);\nINSERT INTO places_bairro VALUES (1302, 'Jardim Nazaré', 50);\nINSERT INTO places_bairro VALUES (1303, 'Jardim Nossa Senhora das Graças', 50);\nINSERT INTO places_bairro VALUES (1304, 'Jardim Nova Era', 50);\nINSERT INTO places_bairro VALUES (1305, 'Jardim Palmares', 50);\nINSERT INTO places_bairro VALUES (1306, 'Jardim Pernambuco', 50);\nINSERT INTO places_bairro VALUES (1307, 'Jardim Pitoresco', 50);\nINSERT INTO places_bairro VALUES (1308, 'Jardim Real', 50);\nINSERT INTO places_bairro VALUES (1309, 'Jardim Sagrado Coração de Jesus', 50);\nINSERT INTO places_bairro VALUES (1310, 'Jardim Santa Eugênia', 50);\nINSERT INTO places_bairro VALUES (1311, 'Jardim Santa Fé', 50);\nINSERT INTO places_bairro VALUES (1312, 'Jardim Santa Rita', 50);\nINSERT INTO places_bairro VALUES (1313, 'Jardim Santo Inácio', 50);\nINSERT INTO places_bairro VALUES (1314, 'Jardim São João', 50);\nINSERT INTO places_bairro VALUES (1315, 'Jardim São Vicente', 50);\nINSERT INTO places_bairro VALUES (1316, 'Jardim Tropical', 50);\nINSERT INTO places_bairro VALUES (1317, 'Jardim Vila Rica', 50);\nINSERT INTO places_bairro VALUES (1318, 'Jardim Willis', 50);\nINSERT INTO places_bairro VALUES (1319, 'Joana D''Arc', 50);\nINSERT INTO places_bairro VALUES (1320, 'José Bulhões', 50);\nINSERT INTO places_bairro VALUES (1321, 'Juriti', 50);\nINSERT INTO places_bairro VALUES (1322, 'Kennedy', 50);\nINSERT INTO places_bairro VALUES (1323, 'Lafaiete', 50);\nINSERT INTO places_bairro VALUES (1324, 'Lambert', 50);\nINSERT INTO places_bairro VALUES (1325, 'Ligia', 50);\nINSERT INTO places_bairro VALUES (1326, 'Lisboa', 50);\nINSERT INTO places_bairro VALUES (1327, 'Luz', 50);\nINSERT INTO places_bairro VALUES (1328, 'Maio', 50);\nINSERT INTO places_bairro VALUES (1329, 'Marco II', 50);\nINSERT INTO places_bairro VALUES (1330, 'Margarida', 50);\nINSERT INTO places_bairro VALUES (1331, 'Maria da Luz', 50);\nINSERT INTO places_bairro VALUES (1332, 'Maria José', 50);\nINSERT INTO places_bairro VALUES (1333, 'Martins Ribeiro', 50);\nINSERT INTO places_bairro VALUES (1334, 'Metrópole', 50);\nINSERT INTO places_bairro VALUES (1335, 'Miguel Couto', 50);\nINSERT INTO places_bairro VALUES (1336, 'Monte Castelo', 50);\nINSERT INTO places_bairro VALUES (1337, 'Monte Líbano', 50);\nINSERT INTO places_bairro VALUES (1338, 'Moqueta', 50);\nINSERT INTO places_bairro VALUES (1339, 'Comendador Soares', 50);\nINSERT INTO places_bairro VALUES (1340, 'Nazaré', 50);\nINSERT INTO places_bairro VALUES (1341, 'Nossa Senhora das Graças', 50);\nINSERT INTO places_bairro VALUES (1342, 'Nossa Senhora de Fátima', 50);\nINSERT INTO places_bairro VALUES (1343, 'Nova América', 50);\nINSERT INTO places_bairro VALUES (1344, 'Nova Brasília', 50);\nINSERT INTO places_bairro VALUES (1345, 'Nova Luz', 50);\nINSERT INTO places_bairro VALUES (1346, 'Oliveira', 50);\nINSERT INTO places_bairro VALUES (1347, 'Ouro Preto', 50);\nINSERT INTO places_bairro VALUES (1348, 'Palmeiras', 50);\nINSERT INTO places_bairro VALUES (1349, 'Parada Amaral', 50);\nINSERT INTO places_bairro VALUES (1350, 'Parque Alvorada', 50);\nINSERT INTO places_bairro VALUES (1351, 'Parque Ambai', 50);\nINSERT INTO places_bairro VALUES (1352, 'Parque Antártica', 50);\nINSERT INTO places_bairro VALUES (1353, 'Parque Bárbara', 50);\nINSERT INTO places_bairro VALUES (1354, 'Parque do Laranjal', 50);\nINSERT INTO places_bairro VALUES (1355, 'Parque Engenho Pequeno', 50);\nINSERT INTO places_bairro VALUES (1356, 'Parque Flora', 50);\nINSERT INTO places_bairro VALUES (1357, 'Parque Geneciano Luz', 50);\nINSERT INTO places_bairro VALUES (1358, 'Parque Horizonte', 50);\nINSERT INTO places_bairro VALUES (1359, 'Parque Maria da Fonte', 50);\nINSERT INTO places_bairro VALUES (1360, 'Parque Princesa Isabel', 50);\nINSERT INTO places_bairro VALUES (1361, 'Parque Renascença', 50);\nINSERT INTO places_bairro VALUES (1362, 'Parque Residencial Gisela', 50);\nINSERT INTO places_bairro VALUES (1363, 'Parque Residencial Guadalajara', 50);\nINSERT INTO places_bairro VALUES (1364, 'Parque Rodilar', 50);\nINSERT INTO places_bairro VALUES (1365, 'Parque Rosa do Sertão', 50);\nINSERT INTO places_bairro VALUES (1366, 'Parque Rosário', 50);\nINSERT INTO places_bairro VALUES (1367, 'Parque São Carlos', 50);\nINSERT INTO places_bairro VALUES (1368, 'Parque São Vicente de Paulo', 50);\nINSERT INTO places_bairro VALUES (1369, 'Parque Saudade', 50);\nINSERT INTO places_bairro VALUES (1370, 'Parque Três Corações', 50);\nINSERT INTO places_bairro VALUES (1371, 'Parque Ulisses', 50);\nINSERT INTO places_bairro VALUES (1372, 'Pau Rolou', 50);\nINSERT INTO places_bairro VALUES (1373, 'Peixoto', 50);\nINSERT INTO places_bairro VALUES (1374, 'Pioneiro', 50);\nINSERT INTO places_bairro VALUES (1375, 'Ponte Branca', 50);\nINSERT INTO places_bairro VALUES (1376, 'Posse', 50);\nINSERT INTO places_bairro VALUES (1377, 'Prata', 50);\nINSERT INTO places_bairro VALUES (1378, 'Primavera', 50);\nINSERT INTO places_bairro VALUES (1379, 'Quartéis', 50);\nINSERT INTO places_bairro VALUES (1380, 'Quatro Irmãos do Prata', 50);\nINSERT INTO places_bairro VALUES (1381, 'Quinta da Piedade', 50);\nINSERT INTO places_bairro VALUES (1382, 'Rancho Alegre', 50);\nINSERT INTO places_bairro VALUES (1383, 'Rancho Fundo', 50);\nINSERT INTO places_bairro VALUES (1384, 'Recanto Santo Antônio', 50);\nINSERT INTO places_bairro VALUES (1385, 'Recreio Itapoã', 50);\nINSERT INTO places_bairro VALUES (1386, 'Recreio Paco da Marambaia', 50);\nINSERT INTO places_bairro VALUES (1387, 'Rosa dos Ventos', 50);\nINSERT INTO places_bairro VALUES (1388, 'Sacopa', 50);\nINSERT INTO places_bairro VALUES (1389, 'Santa Catarina', 50);\nINSERT INTO places_bairro VALUES (1390, 'Santa Cecília', 50);\nINSERT INTO places_bairro VALUES (1391, 'Santa Eufenia', 50);\nINSERT INTO places_bairro VALUES (1392, 'Santa Eugênia', 50);\nINSERT INTO places_bairro VALUES (1393, 'Santa Isabel', 50);\nINSERT INTO places_bairro VALUES (1394, 'Santa Lúcia', 50);\nINSERT INTO places_bairro VALUES (1395, 'Santa Rita', 50);\nINSERT INTO places_bairro VALUES (1396, 'Santos Neves', 50);\nINSERT INTO places_bairro VALUES (1397, 'São Benedito', 50);\nINSERT INTO places_bairro VALUES (1398, 'São Bosco', 50);\nINSERT INTO places_bairro VALUES (1399, 'São Francisco Xavier', 50);\nINSERT INTO places_bairro VALUES (1400, 'São Gabriel', 50);\nINSERT INTO places_bairro VALUES (1401, 'São Geraldo', 50);\nINSERT INTO places_bairro VALUES (1402, 'São Jorge', 50);\nINSERT INTO places_bairro VALUES (1403, 'São José', 50);\nINSERT INTO places_bairro VALUES (1404, 'São Luiz Gonzaga', 50);\nINSERT INTO places_bairro VALUES (1405, 'Silvania', 50);\nINSERT INTO places_bairro VALUES (1406, 'Sitio Novo Oriente', 50);\nINSERT INTO places_bairro VALUES (1407, 'Tinguá', 50);\nINSERT INTO places_bairro VALUES (1408, 'Tiradentes', 50);\nINSERT INTO places_bairro VALUES (1409, 'Triangulo', 50);\nINSERT INTO places_bairro VALUES (1410, 'Vila Abolição', 50);\nINSERT INTO places_bairro VALUES (1411, 'Vila Anita', 50);\nINSERT INTO places_bairro VALUES (1412, 'Vila Avelina', 50);\nINSERT INTO places_bairro VALUES (1413, 'Vila Bandeirantes', 50);\nINSERT INTO places_bairro VALUES (1414, 'Vila Bom Jardim', 50);\nINSERT INTO places_bairro VALUES (1415, 'Vila Borgerth', 50);\nINSERT INTO places_bairro VALUES (1416, 'Vila Borges', 50);\nINSERT INTO places_bairro VALUES (1417, 'Vila Brasília', 50);\nINSERT INTO places_bairro VALUES (1418, 'Vila Camari', 50);\nINSERT INTO places_bairro VALUES (1419, 'Vila Carlota', 50);\nINSERT INTO places_bairro VALUES (1420, 'Vila Catia', 50);\nINSERT INTO places_bairro VALUES (1421, 'Vila Catulina', 50);\nINSERT INTO places_bairro VALUES (1422, 'Vila Cosme e Damião', 50);\nINSERT INTO places_bairro VALUES (1423, 'Vila Crista', 50);\nINSERT INTO places_bairro VALUES (1424, 'Vila de Cava', 50);\nINSERT INTO places_bairro VALUES (1425, 'Vila do Tinguá', 50);\nINSERT INTO places_bairro VALUES (1426, 'Vila Esperança', 50);\nINSERT INTO places_bairro VALUES (1427, 'Vila Fátima', 50);\nINSERT INTO places_bairro VALUES (1428, 'Vila Fluminense', 50);\nINSERT INTO places_bairro VALUES (1429, 'Vila Formosa', 50);\nINSERT INTO places_bairro VALUES (1430, 'Vila Gaúcha', 50);\nINSERT INTO places_bairro VALUES (1431, 'Vila Guarita', 50);\nINSERT INTO places_bairro VALUES (1432, 'Vila Iguaçuana', 50);\nINSERT INTO places_bairro VALUES (1433, 'Vila Iracema', 50);\nINSERT INTO places_bairro VALUES (1434, 'Vila Itaci', 50);\nINSERT INTO places_bairro VALUES (1435, 'Vila José', 50);\nINSERT INTO places_bairro VALUES (1436, 'Vila Maia', 50);\nINSERT INTO places_bairro VALUES (1437, 'Vila Maranhão', 50);\nINSERT INTO places_bairro VALUES (1438, 'Vila Marilia', 50);\nINSERT INTO places_bairro VALUES (1439, 'Vila Marines', 50);\nINSERT INTO places_bairro VALUES (1440, 'Vila Marpiza', 50);\nINSERT INTO places_bairro VALUES (1441, 'Vila Martins', 50);\nINSERT INTO places_bairro VALUES (1442, 'Vila Matilde', 50);\nINSERT INTO places_bairro VALUES (1443, 'Vila Morro Agudo', 50);\nINSERT INTO places_bairro VALUES (1444, 'Vila Nossa Senhora da Conceição', 50);\nINSERT INTO places_bairro VALUES (1445, 'Vila Nova do Couto', 50);\nINSERT INTO places_bairro VALUES (1446, 'Vila Olorum', 50);\nINSERT INTO places_bairro VALUES (1447, 'Vila Omega', 50);\nINSERT INTO places_bairro VALUES (1448, 'Vila Operaria', 50);\nINSERT INTO places_bairro VALUES (1449, 'Vila Pacheco da Rocha', 50);\nINSERT INTO places_bairro VALUES (1450, 'Vila Palmeiras', 50);\nINSERT INTO places_bairro VALUES (1451, 'Vila Paulista', 50);\nINSERT INTO places_bairro VALUES (1452, 'Vila Pedro', 50);\nINSERT INTO places_bairro VALUES (1453, 'Vila Pedro I', 50);\nINSERT INTO places_bairro VALUES (1454, 'Vila Posse', 50);\nINSERT INTO places_bairro VALUES (1455, 'Vila Rancho Novo', 50);\nINSERT INTO places_bairro VALUES (1456, 'Vila Sacra Família', 50);\nINSERT INTO places_bairro VALUES (1457, 'Vila Santa Teresinha de Jesus', 50);\nINSERT INTO places_bairro VALUES (1458, 'Vila Santo Antônio', 50);\nINSERT INTO places_bairro VALUES (1459, 'Vila Santos Neto', 50);\nINSERT INTO places_bairro VALUES (1460, 'Vila São Domingos', 50);\nINSERT INTO places_bairro VALUES (1461, 'Vila São Gabriel', 50);\nINSERT INTO places_bairro VALUES (1462, 'Vila São Jorge', 50);\nINSERT INTO places_bairro VALUES (1463, 'Vila São Luis', 50);\nINSERT INTO places_bairro VALUES (1464, 'Vila São Teodoro', 50);\nINSERT INTO places_bairro VALUES (1465, 'Vila Sergipe', 50);\nINSERT INTO places_bairro VALUES (1466, 'Vila Sueli', 50);\nINSERT INTO places_bairro VALUES (1467, 'Vila Três Corações', 50);\nINSERT INTO places_bairro VALUES (1468, 'Vila Treze de Maio', 50);\nINSERT INTO places_bairro VALUES (1469, 'Vila Zulmira', 50);\nINSERT INTO places_bairro VALUES (1470, 'Vista Alegre', 50);\nINSERT INTO places_bairro VALUES (1471, 'Caonze', 50);\nINSERT INTO places_bairro VALUES (1472, 'Santa Clara', 50);\nINSERT INTO places_bairro VALUES (1473, 'Vila Nova', 50);\nINSERT INTO places_bairro VALUES (1474, 'Centro', 46);\nINSERT INTO places_bairro VALUES (1475, 'Papucaia', 13);\nINSERT INTO places_bairro VALUES (1476, 'Lages', 51);\nINSERT INTO places_bairro VALUES (1477, 'Centro', 51);\nINSERT INTO places_bairro VALUES (1478, 'Centro', 52);\nINSERT INTO places_bairro VALUES (1479, 'Centro', 45);\nINSERT INTO places_bairro VALUES (1480, 'Centro', 70);\nINSERT INTO places_bairro VALUES (1481, 'Campelo', 70);\nINSERT INTO places_bairro VALUES (1482, 'Centro', 89);\nINSERT INTO places_bairro VALUES (1483, 'Centro', 53);\nINSERT INTO places_bairro VALUES (1484, 'Centro', 53);\nINSERT INTO places_bairro VALUES (1485, 'Centro', 65);\nINSERT INTO places_bairro VALUES (1486, 'Centro', 54);\nINSERT INTO places_bairro VALUES (1487, 'Centro', 63);\nINSERT INTO places_bairro VALUES (1488, 'Visconde de Mauá', 63);\nINSERT INTO places_bairro VALUES (1489, 'Centro', 89);\nINSERT INTO places_bairro VALUES (1490, 'Alto da Serra', 55);\nINSERT INTO places_bairro VALUES (1491, 'Araras', 55);\nINSERT INTO places_bairro VALUES (1492, 'Binge', 55);\nINSERT INTO places_bairro VALUES (1493, 'Bonsucesso', 55);\nINSERT INTO places_bairro VALUES (1494, 'Capela', 55);\nINSERT INTO places_bairro VALUES (1495, 'Carangola', 55);\nINSERT INTO places_bairro VALUES (1496, 'Cascatinha', 55);\nINSERT INTO places_bairro VALUES (1497, 'Castelanea', 55);\nINSERT INTO places_bairro VALUES (1498, 'Castrioto', 55);\nINSERT INTO places_bairro VALUES (1499, 'Caxambu', 55);\nINSERT INTO places_bairro VALUES (1500, 'Centro', 55);\nINSERT INTO places_bairro VALUES (1501, 'Chácara Flora', 55);\nINSERT INTO places_bairro VALUES (1502, 'Coronel Veiga', 55);\nINSERT INTO places_bairro VALUES (1503, 'Corrêas', 55);\nINSERT INTO places_bairro VALUES (1504, 'Cuiabá', 55);\nINSERT INTO places_bairro VALUES (1505, 'Duarte Silveira', 55);\nINSERT INTO places_bairro VALUES (1506, 'Duchas', 55);\nINSERT INTO places_bairro VALUES (1507, 'Duques', 55);\nINSERT INTO places_bairro VALUES (1508, 'Estrada da Saudade', 55);\nINSERT INTO places_bairro VALUES (1509, 'Fazenda Inglesa', 55);\nINSERT INTO places_bairro VALUES (1510, 'Floresta', 55);\nINSERT INTO places_bairro VALUES (1511, 'Gloria', 55);\nINSERT INTO places_bairro VALUES (1512, 'Independência', 55);\nINSERT INTO places_bairro VALUES (1513, 'Itaipava', 55);\nINSERT INTO places_bairro VALUES (1514, 'Itamarati', 55);\nINSERT INTO places_bairro VALUES (1515, 'Mori', 55);\nINSERT INTO places_bairro VALUES (1516, 'Mosela', 55);\nINSERT INTO places_bairro VALUES (1517, 'Nogueira', 55);\nINSERT INTO places_bairro VALUES (1518, 'Oswaldo Cruz', 55);\nINSERT INTO places_bairro VALUES (1519, 'Pedro do Rio', 55);\nINSERT INTO places_bairro VALUES (1520, 'Posse', 55);\nINSERT INTO places_bairro VALUES (1521, 'Provisória', 55);\nINSERT INTO places_bairro VALUES (1522, 'Quarteirão Brasileiro', 55);\nINSERT INTO places_bairro VALUES (1523, 'Quarteirão Ingelhei', 55);\nINSERT INTO places_bairro VALUES (1524, 'Quissama', 55);\nINSERT INTO places_bairro VALUES (1525, 'Quitandinha', 55);\nINSERT INTO places_bairro VALUES (1526, 'Retiro', 55);\nINSERT INTO places_bairro VALUES (1527, 'Roseiral', 55);\nINSERT INTO places_bairro VALUES (1528, 'Saldanha Marinho', 55);\nINSERT INTO places_bairro VALUES (1529, 'Samambaia', 55);\nINSERT INTO places_bairro VALUES (1530, 'São Sebastião', 55);\nINSERT INTO places_bairro VALUES (1531, 'Simeria', 55);\nINSERT INTO places_bairro VALUES (1532, 'Valparaíso', 55);\nINSERT INTO places_bairro VALUES (1533, 'Vila Militar', 55);\nINSERT INTO places_bairro VALUES (1534, 'Vinte e Quatro de Maio', 55);\nINSERT INTO places_bairro VALUES (1535, 'Piabetá', 39);\nINSERT INTO places_bairro VALUES (1536, 'Vila do Pião', 80);\nINSERT INTO places_bairro VALUES (1537, 'Centro', 56);\nINSERT INTO places_bairro VALUES (1538, 'Pipeiras', 74);\nINSERT INTO places_bairro VALUES (1539, 'Água Preta', 74);\nINSERT INTO places_bairro VALUES (1540, 'Sabonete', 74);\nINSERT INTO places_bairro VALUES (1541, 'Centro', 57);\nINSERT INTO places_bairro VALUES (1542, 'Rosa Machado', 57);\nINSERT INTO places_bairro VALUES (1543, 'Ribeirão das Lajes', 57);\nINSERT INTO places_bairro VALUES (1544, 'Centro', 58);\nINSERT INTO places_bairro VALUES (1545, 'Portela', 32);\nINSERT INTO places_bairro VALUES (1546, 'Centro', 29);\nINSERT INTO places_bairro VALUES (1547, 'Centro', 59);\nINSERT INTO places_bairro VALUES (1548, 'Bulhões', 59);\nINSERT INTO places_bairro VALUES (1549, 'Centro', 19);\nINSERT INTO places_bairro VALUES (1550, 'Centro', 71);\nINSERT INTO places_bairro VALUES (1551, 'Centro', 58);\nINSERT INTO places_bairro VALUES (1552, 'Barrinha', 60);\nINSERT INTO places_bairro VALUES (1553, 'Bela Vista', 60);\nINSERT INTO places_bairro VALUES (1554, 'Centro', 60);\nINSERT INTO places_bairro VALUES (1555, 'Falcão', 60);\nINSERT INTO places_bairro VALUES (1556, 'Jardim Independência', 60);\nINSERT INTO places_bairro VALUES (1557, 'Jardim Polastri', 60);\nINSERT INTO places_bairro VALUES (1558, 'Loteamento Bondarovshy', 60);\nINSERT INTO places_bairro VALUES (1559, 'Mirandópolis', 60);\nINSERT INTO places_bairro VALUES (1560, 'Nossa Senhora do Rosário', 60);\nINSERT INTO places_bairro VALUES (1561, 'Pilotos', 60);\nINSERT INTO places_bairro VALUES (1562, 'Quatis', 60);\nINSERT INTO places_bairro VALUES (1563, 'Ribeirão de São Joaquim', 60);\nINSERT INTO places_bairro VALUES (1564, 'São Benedito', 60);\nINSERT INTO places_bairro VALUES (1565, 'São Francisco de Assis', 60);\nINSERT INTO places_bairro VALUES (1566, 'Vila Santo Antônio', 60);\nINSERT INTO places_bairro VALUES (1567, 'A Noite', 61);\nINSERT INTO places_bairro VALUES (1568, 'Albuquerque', 61);\nINSERT INTO places_bairro VALUES (1569, 'Aliança', 61);\nINSERT INTO places_bairro VALUES (1570, 'Arcampo', 61);\nINSERT INTO places_bairro VALUES (1571, 'Arruda Negreiros', 61);\nINSERT INTO places_bairro VALUES (1572, 'Austi', 61);\nINSERT INTO places_bairro VALUES (1573, 'Belmonte', 61);\nINSERT INTO places_bairro VALUES (1574, 'Bertioga', 61);\nINSERT INTO places_bairro VALUES (1575, 'Boa Esperança', 61);\nINSERT INTO places_bairro VALUES (1576, 'Boa Vista', 61);\nINSERT INTO places_bairro VALUES (1577, 'Bom Jesus', 61);\nINSERT INTO places_bairro VALUES (1578, 'Bruno Lecini', 61);\nINSERT INTO places_bairro VALUES (1579, 'Cabuçu', 61);\nINSERT INTO places_bairro VALUES (1580, 'Cacuia', 61);\nINSERT INTO places_bairro VALUES (1581, 'Campo Alegre', 61);\nINSERT INTO places_bairro VALUES (1582, 'Carlos Sampaio', 61);\nINSERT INTO places_bairro VALUES (1583, 'Cidade Jardim Cabuçu', 61);\nINSERT INTO places_bairro VALUES (1584, 'Civilização', 61);\nINSERT INTO places_bairro VALUES (1585, 'Coqueiros', 61);\nINSERT INTO places_bairro VALUES (1586, 'Cruzeiro', 61);\nINSERT INTO places_bairro VALUES (1587, 'Dois Irmãos', 61);\nINSERT INTO places_bairro VALUES (1588, 'Esperança', 61);\nINSERT INTO places_bairro VALUES (1589, 'Eurico Miranda', 61);\nINSERT INTO places_bairro VALUES (1590, 'Fabio Gimenes', 61);\nINSERT INTO places_bairro VALUES (1591, 'Fazenda Cabuçu', 61);\nINSERT INTO places_bairro VALUES (1592, 'Fazenda do Tingui', 61);\nINSERT INTO places_bairro VALUES (1593, 'Flesmam', 61);\nINSERT INTO places_bairro VALUES (1594, 'Fluminense', 61);\nINSERT INTO places_bairro VALUES (1595, 'Granja Mônica', 61);\nINSERT INTO places_bairro VALUES (1596, 'Granja Napoleão', 61);\nINSERT INTO places_bairro VALUES (1597, 'Granja Rancho Alegre', 61);\nINSERT INTO places_bairro VALUES (1598, 'Granja Rosalina', 61);\nINSERT INTO places_bairro VALUES (1599, 'Guarani', 61);\nINSERT INTO places_bairro VALUES (1600, 'Jardim Aimorés', 61);\nINSERT INTO places_bairro VALUES (1601, 'Jardim Alzira', 61);\nINSERT INTO places_bairro VALUES (1602, 'Jardim Antônio Seixas', 61);\nINSERT INTO places_bairro VALUES (1603, 'Jardim Campo Alegre', 61);\nINSERT INTO places_bairro VALUES (1604, 'Jardim Campo Belo', 61);\nINSERT INTO places_bairro VALUES (1605, 'Jardim Capuaçu', 61);\nINSERT INTO places_bairro VALUES (1606, 'Jardim Ceci', 61);\nINSERT INTO places_bairro VALUES (1607, 'Jardim Continental', 61);\nINSERT INTO places_bairro VALUES (1608, 'Jardim Europa', 61);\nINSERT INTO places_bairro VALUES (1609, 'Jardim Faturista', 61);\nINSERT INTO places_bairro VALUES (1610, 'Jardim Guanabara', 61);\nINSERT INTO places_bairro VALUES (1611, 'Jardim Guandu', 61);\nINSERT INTO places_bairro VALUES (1612, 'Jardim Himalaia', 61);\nINSERT INTO places_bairro VALUES (1613, 'Jardim Laranjeiras', 61);\nINSERT INTO places_bairro VALUES (1614, 'Jardim Magnólia', 61);\nINSERT INTO places_bairro VALUES (1615, 'Jardim Mirassol', 61);\nINSERT INTO places_bairro VALUES (1616, 'Jardim Palmira', 61);\nINSERT INTO places_bairro VALUES (1617, 'Jardim Paquetá', 61);\nINSERT INTO places_bairro VALUES (1618, 'Jardim Paraíso', 61);\nINSERT INTO places_bairro VALUES (1619, 'Jardim Passa Vinte', 61);\nINSERT INTO places_bairro VALUES (1620, 'Jardim Queimados', 61);\nINSERT INTO places_bairro VALUES (1621, 'Jardim Riachão', 61);\nINSERT INTO places_bairro VALUES (1622, 'Jardim São Silvestre', 61);\nINSERT INTO places_bairro VALUES (1623, 'Lagoinha', 61);\nINSERT INTO places_bairro VALUES (1624, 'Lili', 61);\nINSERT INTO places_bairro VALUES (1625, 'Linda Vista', 61);\nINSERT INTO places_bairro VALUES (1626, 'Lucie Dano', 61);\nINSERT INTO places_bairro VALUES (1627, 'Marapicu', 61);\nINSERT INTO places_bairro VALUES (1628, 'Meu Ranchinho', 61);\nINSERT INTO places_bairro VALUES (1629, 'Morro Agudo', 61);\nINSERT INTO places_bairro VALUES (1630, 'Nossa Senhora das Graças', 61);\nINSERT INTO places_bairro VALUES (1631, 'Nossa Senhora de Fátima', 61);\nINSERT INTO places_bairro VALUES (1632, 'Nova Atlântica', 61);\nINSERT INTO places_bairro VALUES (1633, 'Novo Eldorado', 61);\nINSERT INTO places_bairro VALUES (1634, 'Olaria', 61);\nINSERT INTO places_bairro VALUES (1635, 'Pacaembu', 61);\nINSERT INTO places_bairro VALUES (1636, 'Palhada', 61);\nINSERT INTO places_bairro VALUES (1637, 'Parada Amaral', 61);\nINSERT INTO places_bairro VALUES (1638, 'Parque Bandeiras', 61);\nINSERT INTO places_bairro VALUES (1639, 'Parque Biquinha', 61);\nINSERT INTO places_bairro VALUES (1640, 'Parque Boa Ventura', 61);\nINSERT INTO places_bairro VALUES (1641, 'Parque Central', 61);\nINSERT INTO places_bairro VALUES (1642, 'Parque Coqueiros', 61);\nINSERT INTO places_bairro VALUES (1643, 'Parque da Conceição', 61);\nINSERT INTO places_bairro VALUES (1644, 'Parque Eldorado', 61);\nINSERT INTO places_bairro VALUES (1645, 'Parque Farias', 61);\nINSERT INTO places_bairro VALUES (1646, 'Parque Grande Rio', 61);\nINSERT INTO places_bairro VALUES (1647, 'Parque Imperial', 61);\nINSERT INTO places_bairro VALUES (1648, 'Parque Ipanema', 61);\nINSERT INTO places_bairro VALUES (1649, 'Parque Ipiranga', 61);\nINSERT INTO places_bairro VALUES (1650, 'Parque Laranjal', 61);\nINSERT INTO places_bairro VALUES (1651, 'Parque Luzitana', 61);\nINSERT INTO places_bairro VALUES (1652, 'Parque Marau', 61);\nINSERT INTO places_bairro VALUES (1653, 'Parque Palmeiras', 61);\nINSERT INTO places_bairro VALUES (1654, 'Parque Paulicéia', 61);\nINSERT INTO places_bairro VALUES (1655, 'Parque Peraflor', 61);\nINSERT INTO places_bairro VALUES (1656, 'Parque Presidente Dutra', 61);\nINSERT INTO places_bairro VALUES (1657, 'Parque Rodilandia', 61);\nINSERT INTO places_bairro VALUES (1658, 'Parque Rodilvania', 61);\nINSERT INTO places_bairro VALUES (1659, 'Parque Santa Eugenia', 61);\nINSERT INTO places_bairro VALUES (1660, 'Parque Santiago', 61);\nINSERT INTO places_bairro VALUES (1661, 'Parque São Carlos', 61);\nINSERT INTO places_bairro VALUES (1662, 'Parque São José', 61);\nINSERT INTO places_bairro VALUES (1663, 'Parque São Marcelo', 61);\nINSERT INTO places_bairro VALUES (1664, 'Parque São Tiago', 61);\nINSERT INTO places_bairro VALUES (1665, 'Parque Todos os Santos', 61);\nINSERT INTO places_bairro VALUES (1666, 'Parque Tupiara', 61);\nINSERT INTO places_bairro VALUES (1667, 'Parque Valdairosa', 61);\nINSERT INTO places_bairro VALUES (1668, 'Penápolis', 61);\nINSERT INTO places_bairro VALUES (1669, 'Piabas', 61);\nINSERT INTO places_bairro VALUES (1670, 'Prados Verdes', 61);\nINSERT INTO places_bairro VALUES (1671, 'Primavera', 61);\nINSERT INTO places_bairro VALUES (1672, 'Quarto Centenário', 61);\nINSERT INTO places_bairro VALUES (1673, 'Queimados', 61);\nINSERT INTO places_bairro VALUES (1674, 'Rancho Alegre', 61);\nINSERT INTO places_bairro VALUES (1675, 'Recreio dos Laranjais', 61);\nINSERT INTO places_bairro VALUES (1676, 'Retiro Consuelo', 61);\nINSERT INTO places_bairro VALUES (1677, 'Rodoviário', 61);\nINSERT INTO places_bairro VALUES (1678, 'Santa Clara do Guandu', 61);\nINSERT INTO places_bairro VALUES (1679, 'Santa Isabel', 61);\nINSERT INTO places_bairro VALUES (1680, 'Santa Rosa', 61);\nINSERT INTO places_bairro VALUES (1681, 'Santo Antônio', 61);\nINSERT INTO places_bairro VALUES (1682, 'São Carlos', 61);\nINSERT INTO places_bairro VALUES (1683, 'São Cristóvão', 61);\nINSERT INTO places_bairro VALUES (1684, 'São Francisco', 61);\nINSERT INTO places_bairro VALUES (1685, 'São Humberto', 61);\nINSERT INTO places_bairro VALUES (1686, 'São Manuel', 61);\nINSERT INTO places_bairro VALUES (1687, 'São Simão', 61);\nINSERT INTO places_bairro VALUES (1688, 'Siag', 61);\nINSERT INTO places_bairro VALUES (1689, 'Sio', 61);\nINSERT INTO places_bairro VALUES (1690, 'Sítio Bela Esperança', 61);\nINSERT INTO places_bairro VALUES (1691, 'Sítio Floresta', 61);\nINSERT INTO places_bairro VALUES (1692, 'Turístico Serra de Madureira', 61);\nINSERT INTO places_bairro VALUES (1693, 'Vale do Sol', 61);\nINSERT INTO places_bairro VALUES (1694, 'Varges', 61);\nINSERT INTO places_bairro VALUES (1695, 'Vila Aida', 61);\nINSERT INTO places_bairro VALUES (1696, 'Vila Alto Lindo', 61);\nINSERT INTO places_bairro VALUES (1697, 'Vila Amélia', 61);\nINSERT INTO places_bairro VALUES (1698, 'Vila Apolo', 61);\nINSERT INTO places_bairro VALUES (1699, 'Vila Aurora', 61);\nINSERT INTO places_bairro VALUES (1700, 'Vila Avante', 61);\nINSERT INTO places_bairro VALUES (1701, 'Vila Belga', 61);\nINSERT INTO places_bairro VALUES (1702, 'Vila Bonanza', 61);\nINSERT INTO places_bairro VALUES (1703, 'Vila Caiçaras', 61);\nINSERT INTO places_bairro VALUES (1704, 'Vila Coqueiros', 61);\nINSERT INTO places_bairro VALUES (1705, 'Vila das Mangueiras', 61);\nINSERT INTO places_bairro VALUES (1706, 'Vila das Porteiras', 61);\nINSERT INTO places_bairro VALUES (1707, 'Vila do Tinguá', 61);\nINSERT INTO places_bairro VALUES (1708, 'Vila Dona Branca', 61);\nINSERT INTO places_bairro VALUES (1709, 'Vila Eros', 61);\nINSERT INTO places_bairro VALUES (1710, 'Vila Floresta', 61);\nINSERT INTO places_bairro VALUES (1711, 'Vila Floriano', 61);\nINSERT INTO places_bairro VALUES (1712, 'Vila Gomes', 61);\nINSERT INTO places_bairro VALUES (1713, 'Vila Gratidão', 61);\nINSERT INTO places_bairro VALUES (1714, 'Vila João Correia', 61);\nINSERT INTO places_bairro VALUES (1715, 'Vila Josefina', 61);\nINSERT INTO places_bairro VALUES (1716, 'Vila Jurema', 61);\nINSERT INTO places_bairro VALUES (1717, 'Vila Leonora', 61);\nINSERT INTO places_bairro VALUES (1718, 'Vila Lina', 61);\nINSERT INTO places_bairro VALUES (1719, 'Vila Maricá', 61);\nINSERT INTO places_bairro VALUES (1720, 'Vila Marileia', 61);\nINSERT INTO places_bairro VALUES (1721, 'Vila Marina', 61);\nINSERT INTO places_bairro VALUES (1722, 'Vila Martins', 61);\nINSERT INTO places_bairro VALUES (1723, 'Vila Nanci', 61);\nINSERT INTO places_bairro VALUES (1724, 'Vila Nascente', 61);\nINSERT INTO places_bairro VALUES (1725, 'Vila Olimpio Alves', 61);\nINSERT INTO places_bairro VALUES (1726, 'Vila Paula Zander', 61);\nINSERT INTO places_bairro VALUES (1727, 'Vila Quita', 61);\nINSERT INTO places_bairro VALUES (1728, 'Vila Resende', 61);\nINSERT INTO places_bairro VALUES (1729, 'Vila Santa Catarina', 61);\nINSERT INTO places_bairro VALUES (1730, 'Vila Santa Luzia', 61);\nINSERT INTO places_bairro VALUES (1731, 'Vila Santa Maria', 61);\nINSERT INTO places_bairro VALUES (1732, 'Vila Santo Antônio', 61);\nINSERT INTO places_bairro VALUES (1733, 'Vila São Francisco', 61);\nINSERT INTO places_bairro VALUES (1734, 'Vila São João', 61);\nINSERT INTO places_bairro VALUES (1735, 'Vila São Joaquim', 61);\nINSERT INTO places_bairro VALUES (1736, 'Vila São Jorge', 61);\nINSERT INTO places_bairro VALUES (1737, 'Vila São José', 61);\nINSERT INTO places_bairro VALUES (1738, 'Vila São Michel', 61);\nINSERT INTO places_bairro VALUES (1739, 'Vila São Roque', 61);\nINSERT INTO places_bairro VALUES (1740, 'Vila Scintila', 61);\nINSERT INTO places_bairro VALUES (1741, 'Vila Tarumã', 61);\nINSERT INTO places_bairro VALUES (1742, 'Vila Valverde', 61);\nINSERT INTO places_bairro VALUES (1743, 'Vila Vista Alegre de Austi', 61);\nINSERT INTO places_bairro VALUES (1744, 'Vila Zenith', 61);\nINSERT INTO places_bairro VALUES (1745, 'Vilar Grande', 61);\nINSERT INTO places_bairro VALUES (1746, 'Vista Alegre', 61);\nINSERT INTO places_bairro VALUES (1747, 'Jardim Palmares', 61);\nINSERT INTO places_bairro VALUES (1748, 'Prq', 61);\nINSERT INTO places_bairro VALUES (1749, 'Vila Camarim', 61);\nINSERT INTO places_bairro VALUES (1750, 'Quissamâ', 62);\nINSERT INTO places_bairro VALUES (1751, 'Barra do Furado', 62);\nINSERT INTO places_bairro VALUES (1752, 'Santa Catarina', 62);\nINSERT INTO places_bairro VALUES (1753, 'Centro', 33);\nINSERT INTO places_bairro VALUES (1754, 'Centro', 69);\nINSERT INTO places_bairro VALUES (1755, 'Alambari', 63);\nINSERT INTO places_bairro VALUES (1756, 'Alegria', 63);\nINSERT INTO places_bairro VALUES (1757, 'Alvorada', 63);\nINSERT INTO places_bairro VALUES (1758, 'Boca do Leão', 63);\nINSERT INTO places_bairro VALUES (1759, 'Cabral', 63);\nINSERT INTO places_bairro VALUES (1760, 'Campos Elíseos', 63);\nINSERT INTO places_bairro VALUES (1761, 'Casa da Lua', 63);\nINSERT INTO places_bairro VALUES (1762, 'Castelo Branco', 63);\nINSERT INTO places_bairro VALUES (1763, 'Centro', 63);\nINSERT INTO places_bairro VALUES (1764, 'Cidade Alegria', 63);\nINSERT INTO places_bairro VALUES (1765, 'Comercial', 63);\nINSERT INTO places_bairro VALUES (1766, 'Elite', 63);\nINSERT INTO places_bairro VALUES (1767, 'Eucaliptal', 63);\nINSERT INTO places_bairro VALUES (1768, 'Fazenda da Barra', 63);\nINSERT INTO places_bairro VALUES (1769, 'Fazenda da Barra 2', 63);\nINSERT INTO places_bairro VALUES (1770, 'Fazenda da Barra 3', 63);\nINSERT INTO places_bairro VALUES (1771, 'Fazenda Penedo', 63);\nINSERT INTO places_bairro VALUES (1772, 'Formigueiro', 63);\nINSERT INTO places_bairro VALUES (1773, 'Granja Minas Gerais', 63);\nINSERT INTO places_bairro VALUES (1774, 'Guararapes', 63);\nINSERT INTO places_bairro VALUES (1775, 'Independência', 63);\nINSERT INTO places_bairro VALUES (1776, 'Itapuca', 63);\nINSERT INTO places_bairro VALUES (1777, 'Jardim Brasília', 63);\nINSERT INTO places_bairro VALUES (1778, 'Jardim Brasília 2', 63);\nINSERT INTO places_bairro VALUES (1779, 'Jardim das Rosas', 63);\nINSERT INTO places_bairro VALUES (1780, 'Jardim Martinelli', 63);\nINSERT INTO places_bairro VALUES (1781, 'Jardim Tropical', 63);\nINSERT INTO places_bairro VALUES (1782, 'Lava-pés', 63);\nINSERT INTO places_bairro VALUES (1783, 'Liberdade', 63);\nINSERT INTO places_bairro VALUES (1784, 'Manejo', 63);\nINSERT INTO places_bairro VALUES (1785, 'Monte Castelo', 63);\nINSERT INTO places_bairro VALUES (1786, 'Montese', 63);\nINSERT INTO places_bairro VALUES (1787, 'Morada da Colina', 63);\nINSERT INTO places_bairro VALUES (1788, 'Nova Liberdade', 63);\nINSERT INTO places_bairro VALUES (1789, 'Novo Surubi', 63);\nINSERT INTO places_bairro VALUES (1790, 'Paraíso', 63);\nINSERT INTO places_bairro VALUES (1791, 'Parque Embaixador', 63);\nINSERT INTO places_bairro VALUES (1792, 'Parque Ipiranga', 63);\nINSERT INTO places_bairro VALUES (1793, 'Jardim Jalisco', 63);\nINSERT INTO places_bairro VALUES (1794, 'Santa Isabel', 63);\nINSERT INTO places_bairro VALUES (1795, 'Santo Amaro', 63);\nINSERT INTO places_bairro VALUES (1796, 'São Caetano', 63);\nINSERT INTO places_bairro VALUES (1797, 'Surubi', 63);\nINSERT INTO places_bairro VALUES (1798, 'Vale dos Reis', 63);\nINSERT INTO places_bairro VALUES (1799, 'Vicentina', 63);\nINSERT INTO places_bairro VALUES (1800, 'Vila Adelaide', 63);\nINSERT INTO places_bairro VALUES (1801, 'Vila Santa Cecília', 63);\nINSERT INTO places_bairro VALUES (1802, 'Vila Central', 63);\nINSERT INTO places_bairro VALUES (1803, 'Vila Hulda Rocha', 63);\nINSERT INTO places_bairro VALUES (1804, 'Vila Julieta', 63);\nINSERT INTO places_bairro VALUES (1805, 'Vila Moderna', 63);\nINSERT INTO places_bairro VALUES (1806, 'Vila Verde', 63);\nINSERT INTO places_bairro VALUES (1807, 'Monet', 63);\nINSERT INTO places_bairro VALUES (1808, 'Boa Vista II', 63);\nINSERT INTO places_bairro VALUES (1809, 'Boa Vista I', 63);\nINSERT INTO places_bairro VALUES (1810, 'Barbosa Lima', 63);\nINSERT INTO places_bairro VALUES (1811, 'Mirante de Serra', 63);\nINSERT INTO places_bairro VALUES (1812, 'Jardim do Sol', 63);\nINSERT INTO places_bairro VALUES (1813, 'Jardim Primavera III', 63);\nINSERT INTO places_bairro VALUES (1814, 'Mirante das Agulhas', 63);\nINSERT INTO places_bairro VALUES (1815, 'Jardim Beira Rio', 63);\nINSERT INTO places_bairro VALUES (1816, 'Centro', 33);\nINSERT INTO places_bairro VALUES (1817, 'Centro', 64);\nINSERT INTO places_bairro VALUES (1818, 'Basílio', 64);\nINSERT INTO places_bairro VALUES (1819, 'Centro', 65);\nINSERT INTO places_bairro VALUES (1820, 'Fazenda da Grama', 65);\nINSERT INTO places_bairro VALUES (1821, 'Centro', 66);\nINSERT INTO places_bairro VALUES (1822, 'Centro', 67);\nINSERT INTO places_bairro VALUES (1823, 'Nova Esperança', 67);\nINSERT INTO places_bairro VALUES (1824, 'Rocha Leão', 67);\nINSERT INTO places_bairro VALUES (1825, 'Cantagalo', 67);\nINSERT INTO places_bairro VALUES (1826, 'Praia Âncora', 67);\nINSERT INTO places_bairro VALUES (1827, 'Abolição', 68);\nINSERT INTO places_bairro VALUES (1828, 'Acari', 68);\nINSERT INTO places_bairro VALUES (1829, 'Água Santa', 68);\nINSERT INTO places_bairro VALUES (1830, 'Alto da Boa Vista', 68);\nINSERT INTO places_bairro VALUES (1831, 'Anchieta', 68);\nINSERT INTO places_bairro VALUES (1832, 'Andaraí', 68);\nINSERT INTO places_bairro VALUES (1833, 'Anil', 68);\nINSERT INTO places_bairro VALUES (1834, 'Araújo de Cosmos', 68);\nINSERT INTO places_bairro VALUES (1835, 'Baia de Guanabara', 68);\nINSERT INTO places_bairro VALUES (1836, 'Bancários', 68);\nINSERT INTO places_bairro VALUES (1837, 'Bangu', 68);\nINSERT INTO places_bairro VALUES (1838, 'Barra da Tijuca', 68);\nINSERT INTO places_bairro VALUES (1839, 'Barra de Guaratiba', 68);\nINSERT INTO places_bairro VALUES (1840, 'Barros Filho', 68);\nINSERT INTO places_bairro VALUES (1841, 'Benfica', 68);\nINSERT INTO places_bairro VALUES (1842, 'Bento Ribeiro', 68);\nINSERT INTO places_bairro VALUES (1843, 'Bonsucesso', 68);\nINSERT INTO places_bairro VALUES (1844, 'Botafogo', 68);\nINSERT INTO places_bairro VALUES (1845, 'Brás de Pina', 68);\nINSERT INTO places_bairro VALUES (1846, 'Cachambi', 68);\nINSERT INTO places_bairro VALUES (1847, 'Cacuia', 68);\nINSERT INTO places_bairro VALUES (1848, 'Caju', 68);\nINSERT INTO places_bairro VALUES (1849, 'Camorim', 68);\nINSERT INTO places_bairro VALUES (1850, 'Campinho', 68);\nINSERT INTO places_bairro VALUES (1851, 'Campo dos Afonsos', 68);\nINSERT INTO places_bairro VALUES (1852, 'Campo Grande', 68);\nINSERT INTO places_bairro VALUES (1853, 'Cascadura', 68);\nINSERT INTO places_bairro VALUES (1854, 'Catete', 68);\nINSERT INTO places_bairro VALUES (1855, 'Catumbi', 68);\nINSERT INTO places_bairro VALUES (1856, 'Cavalcanti', 68);\nINSERT INTO places_bairro VALUES (1857, 'Centro', 68);\nINSERT INTO places_bairro VALUES (1858, 'Cidade de Deus', 68);\nINSERT INTO places_bairro VALUES (1859, 'Cidade Nova', 68);\nINSERT INTO places_bairro VALUES (1860, 'Cidade Universitária', 68);\nINSERT INTO places_bairro VALUES (1861, 'Cocotá', 68);\nINSERT INTO places_bairro VALUES (1862, 'Coelho Neto', 68);\nINSERT INTO places_bairro VALUES (1863, 'Colégio', 68);\nINSERT INTO places_bairro VALUES (1864, 'Copacabana', 68);\nINSERT INTO places_bairro VALUES (1865, 'Cordovil', 68);\nINSERT INTO places_bairro VALUES (1866, 'Cosme Velho', 68);\nINSERT INTO places_bairro VALUES (1867, 'Cosmos', 68);\nINSERT INTO places_bairro VALUES (1868, 'Costa Barros', 68);\nINSERT INTO places_bairro VALUES (1869, 'Curicica', 68);\nINSERT INTO places_bairro VALUES (1870, 'Curral Falso', 68);\nINSERT INTO places_bairro VALUES (1871, 'Del Castilho', 68);\nINSERT INTO places_bairro VALUES (1872, 'Dendê', 68);\nINSERT INTO places_bairro VALUES (1873, 'Deodoro', 68);\nINSERT INTO places_bairro VALUES (1874, 'Dumas', 68);\nINSERT INTO places_bairro VALUES (1875, 'Encantado', 68);\nINSERT INTO places_bairro VALUES (1876, 'Engenheiro Leal', 68);\nINSERT INTO places_bairro VALUES (1877, 'Engenho da Rainha', 68);\nINSERT INTO places_bairro VALUES (1878, 'Engenho de Dentro', 68);\nINSERT INTO places_bairro VALUES (1879, 'Engenho Novo', 68);\nINSERT INTO places_bairro VALUES (1880, 'Estácio', 68);\nINSERT INTO places_bairro VALUES (1881, 'Flamengo', 68);\nINSERT INTO places_bairro VALUES (1882, 'Freguesia (Ilha do Governador);', 68);\nINSERT INTO places_bairro VALUES (1883, 'Galeão', 68);\nINSERT INTO places_bairro VALUES (1884, 'Gamboa', 68);\nINSERT INTO places_bairro VALUES (1885, 'Gardênia Azul', 68);\nINSERT INTO places_bairro VALUES (1886, 'Gávea', 68);\nINSERT INTO places_bairro VALUES (1887, 'Glória', 68);\nINSERT INTO places_bairro VALUES (1888, 'Grajaú', 68);\nINSERT INTO places_bairro VALUES (1889, 'Grumari', 68);\nINSERT INTO places_bairro VALUES (1890, 'Guadalupe', 68);\nINSERT INTO places_bairro VALUES (1891, 'Guarabu', 68);\nINSERT INTO places_bairro VALUES (1892, 'Guaratiba', 68);\nINSERT INTO places_bairro VALUES (1893, 'Higienópolis', 68);\nINSERT INTO places_bairro VALUES (1894, 'Honório Gurgel', 68);\nINSERT INTO places_bairro VALUES (1895, 'Humaitá', 68);\nINSERT INTO places_bairro VALUES (1896, 'Inhaúma', 68);\nINSERT INTO places_bairro VALUES (1897, 'Inhoaíba', 68);\nINSERT INTO places_bairro VALUES (1898, 'Ipanema', 68);\nINSERT INTO places_bairro VALUES (1899, 'Irajá', 68);\nINSERT INTO places_bairro VALUES (1900, 'Itacolomi', 68);\nINSERT INTO places_bairro VALUES (1901, 'Itanhangá', 68);\nINSERT INTO places_bairro VALUES (1902, 'Jacaré', 68);\nINSERT INTO places_bairro VALUES (1903, 'Jacarepaguá', 68);\nINSERT INTO places_bairro VALUES (1904, 'Jardim América', 68);\nINSERT INTO places_bairro VALUES (1905, 'Jardim Botânico', 68);\nINSERT INTO places_bairro VALUES (1906, 'Jardim Carioca', 68);\nINSERT INTO places_bairro VALUES (1907, 'Jardim Guanabara', 68);\nINSERT INTO places_bairro VALUES (1908, 'Jardim Sulacap', 68);\nINSERT INTO places_bairro VALUES (1909, 'Joá', 68);\nINSERT INTO places_bairro VALUES (1910, 'Lagoa', 68);\nINSERT INTO places_bairro VALUES (1911, 'Laranjeiras', 68);\nINSERT INTO places_bairro VALUES (1912, 'Leblo', 68);\nINSERT INTO places_bairro VALUES (1913, 'Leme', 68);\nINSERT INTO places_bairro VALUES (1914, 'Lins de Vasconcelos', 68);\nINSERT INTO places_bairro VALUES (1915, 'Loteamento Madea', 68);\nINSERT INTO places_bairro VALUES (1916, 'Madureira', 68);\nINSERT INTO places_bairro VALUES (1917, 'Magalhães Bastos', 68);\nINSERT INTO places_bairro VALUES (1918, 'Mangueira', 68);\nINSERT INTO places_bairro VALUES (1919, 'Manguinhos', 68);\nINSERT INTO places_bairro VALUES (1920, 'Maracanã', 68);\nINSERT INTO places_bairro VALUES (1921, 'Marechal Hermes', 68);\nINSERT INTO places_bairro VALUES (1922, 'Maria da Graça', 68);\nINSERT INTO places_bairro VALUES (1923, 'Méier', 68);\nINSERT INTO places_bairro VALUES (1924, 'Moneró', 68);\nINSERT INTO places_bairro VALUES (1925, 'Nossa Senhora das Graças', 68);\nINSERT INTO places_bairro VALUES (1926, 'Olaria', 68);\nINSERT INTO places_bairro VALUES (1927, 'Oswaldo Cruz', 68);\nINSERT INTO places_bairro VALUES (1928, 'Paciência', 68);\nINSERT INTO places_bairro VALUES (1929, 'Padre Miguel', 68);\nINSERT INTO places_bairro VALUES (1930, 'Paquetá', 68);\nINSERT INTO places_bairro VALUES (1931, 'Parada de Lucas', 68);\nINSERT INTO places_bairro VALUES (1932, 'Parque Anchieta', 68);\nINSERT INTO places_bairro VALUES (1933, 'Pavuna', 68);\nINSERT INTO places_bairro VALUES (1934, 'Pechincha', 68);\nINSERT INTO places_bairro VALUES (1935, 'Pedra de Guaratiba', 68);\nINSERT INTO places_bairro VALUES (1936, 'Penha', 68);\nINSERT INTO places_bairro VALUES (1937, 'Penha Circular', 68);\nINSERT INTO places_bairro VALUES (1938, 'Piedade', 68);\nINSERT INTO places_bairro VALUES (1939, 'Pilares', 68);\nINSERT INTO places_bairro VALUES (1940, 'Pitangueiras', 68);\nINSERT INTO places_bairro VALUES (1941, 'Portuguesa', 68);\nINSERT INTO places_bairro VALUES (1942, 'Praça da Bandeira', 68);\nINSERT INTO places_bairro VALUES (1943, 'Praça Seca', 68);\nINSERT INTO places_bairro VALUES (1944, 'Praia da Bandeira', 68);\nINSERT INTO places_bairro VALUES (1945, 'Quintino Bocaiúva', 68);\nINSERT INTO places_bairro VALUES (1946, 'Ramos', 68);\nINSERT INTO places_bairro VALUES (1947, 'Realengo', 68);\nINSERT INTO places_bairro VALUES (1948, 'Recreio dos Bandeirantes', 68);\nINSERT INTO places_bairro VALUES (1949, 'Riachuelo', 68);\nINSERT INTO places_bairro VALUES (1950, 'Ribeira', 68);\nINSERT INTO places_bairro VALUES (1951, 'Ricardo de Albuquerque', 68);\nINSERT INTO places_bairro VALUES (1952, 'Rio Comprido', 68);\nINSERT INTO places_bairro VALUES (1953, 'Rocha', 68);\nINSERT INTO places_bairro VALUES (1954, 'Rocha Miranda', 68);\nINSERT INTO places_bairro VALUES (1955, 'Rocinha', 68);\nINSERT INTO places_bairro VALUES (1956, 'Sampaio', 68);\nINSERT INTO places_bairro VALUES (1957, 'Santa Cruz', 68);\nINSERT INTO places_bairro VALUES (1958, 'Santa Teresa', 68);\nINSERT INTO places_bairro VALUES (1959, 'Santíssimo', 68);\nINSERT INTO places_bairro VALUES (1960, 'Santo Cristo', 68);\nINSERT INTO places_bairro VALUES (1961, 'São Conrado', 68);\nINSERT INTO places_bairro VALUES (1962, 'São Cristóvão', 68);\nINSERT INTO places_bairro VALUES (1963, 'São Francisco Xavier', 68);\nINSERT INTO places_bairro VALUES (1964, 'Saúde', 68);\nINSERT INTO places_bairro VALUES (1965, 'Senador Camará', 68);\nINSERT INTO places_bairro VALUES (1966, 'Senador Vasconcelos', 68);\nINSERT INTO places_bairro VALUES (1967, 'Sepetiba', 68);\nINSERT INTO places_bairro VALUES (1968, 'Tanque', 68);\nINSERT INTO places_bairro VALUES (1969, 'Taquara', 68);\nINSERT INTO places_bairro VALUES (1970, 'Tauá', 68);\nINSERT INTO places_bairro VALUES (1971, 'Tijuca', 68);\nINSERT INTO places_bairro VALUES (1972, 'Todos os Santos', 68);\nINSERT INTO places_bairro VALUES (1973, 'Tomás Coelho', 68);\nINSERT INTO places_bairro VALUES (1974, 'Tubiacanga', 68);\nINSERT INTO places_bairro VALUES (1975, 'Turiaçu', 68);\nINSERT INTO places_bairro VALUES (1976, 'Urca', 68);\nINSERT INTO places_bairro VALUES (1977, 'Vargem Grande', 68);\nINSERT INTO places_bairro VALUES (1978, 'Vargem Pequena', 68);\nINSERT INTO places_bairro VALUES (1979, 'Vaz Lobo', 68);\nINSERT INTO places_bairro VALUES (1980, 'Vicente de Carvalho', 68);\nINSERT INTO places_bairro VALUES (1981, 'Vidigal', 68);\nINSERT INTO places_bairro VALUES (1982, 'Vigário Geral', 68);\nINSERT INTO places_bairro VALUES (1983, 'Vila da Penha', 68);\nINSERT INTO places_bairro VALUES (1984, 'Vila Isabel', 68);\nINSERT INTO places_bairro VALUES (1985, 'Vila Kosmos', 68);\nINSERT INTO places_bairro VALUES (1986, 'Vila Militar', 68);\nINSERT INTO places_bairro VALUES (1987, 'Vila Valqueire', 68);\nINSERT INTO places_bairro VALUES (1988, 'Vista Alegre', 68);\nINSERT INTO places_bairro VALUES (1989, 'Zumbi', 68);\nINSERT INTO places_bairro VALUES (1990, 'Freguesia (Jacarepaguá);', 68);\nINSERT INTO places_bairro VALUES (1991, 'Maré', 68);\nINSERT INTO places_bairro VALUES (1992, 'Centro', 11);\nINSERT INTO places_bairro VALUES (1993, 'Centro', 52);\nINSERT INTO places_bairro VALUES (1994, 'Centro', 29);\nINSERT INTO places_bairro VALUES (1995, 'Centro', 81);\nINSERT INTO places_bairro VALUES (1996, 'Centro', 37);\nINSERT INTO places_bairro VALUES (1997, 'Sana', 37);\nINSERT INTO places_bairro VALUES (1998, 'Centro', 58);\nINSERT INTO places_bairro VALUES (1999, 'Centro', 70);\nINSERT INTO places_bairro VALUES (2000, 'Santa Luzia', 70);\nINSERT INTO places_bairro VALUES (2001, 'Santa Isabel do Rio Preto', 89);\nINSERT INTO places_bairro VALUES (2002, 'Santa Maria', 15);\nINSERT INTO places_bairro VALUES (2003, 'Centro', 15);\nINSERT INTO places_bairro VALUES (2004, 'Centro', 69);\nINSERT INTO places_bairro VALUES (2005, 'Centro', 16);\nINSERT INTO places_bairro VALUES (2006, 'Centro', 57);\nINSERT INTO places_bairro VALUES (2007, 'Centro', 39);\nINSERT INTO places_bairro VALUES (2008, 'Baixa Grande', 15);\nINSERT INTO places_bairro VALUES (2009, 'Centro', 15);\nINSERT INTO places_bairro VALUES (2010, 'São Martinho', 15);\nINSERT INTO places_bairro VALUES (2011, 'Farol de São Tomé', 15);\nINSERT INTO places_bairro VALUES (2012, 'Campo Limpo', 15);\nINSERT INTO places_bairro VALUES (2013, 'Centro', 70);\nINSERT INTO places_bairro VALUES (2014, 'São Pedro de Alcântara', 70);\nINSERT INTO places_bairro VALUES (2015, 'Centro', 69);\nINSERT INTO places_bairro VALUES (2016, 'Centro', 15);\nINSERT INTO places_bairro VALUES (2017, 'Centro', 71);\nINSERT INTO places_bairro VALUES (2018, 'Praia dos Sonhos', 72);\nINSERT INTO places_bairro VALUES (2019, 'Praia de Santa Clara', 72);\nINSERT INTO places_bairro VALUES (2020, 'Travessão da Barra', 72);\nINSERT INTO places_bairro VALUES (2021, 'Ponto de Cacimbas', 72);\nINSERT INTO places_bairro VALUES (2022, 'Praça João Pessoa', 72);\nINSERT INTO places_bairro VALUES (2023, 'Guaxindiba', 72);\nINSERT INTO places_bairro VALUES (2024, 'Pingo D'' Água', 72);\nINSERT INTO places_bairro VALUES (2025, 'Imburi', 72);\nINSERT INTO places_bairro VALUES (2026, 'Amontoado Brejo Grande', 72);\nINSERT INTO places_bairro VALUES (2027, 'Centro', 72);\nINSERT INTO places_bairro VALUES (2028, 'Buena', 72);\nINSERT INTO places_bairro VALUES (2029, 'Gargau', 72);\nINSERT INTO places_bairro VALUES (2030, 'Barra do Itabapoana', 72);\nINSERT INTO places_bairro VALUES (2031, 'Estreito', 72);\nINSERT INTO places_bairro VALUES (2032, 'Santa Rita', 72);\nINSERT INTO places_bairro VALUES (2033, 'Floresta', 72);\nINSERT INTO places_bairro VALUES (2034, 'Alcântara', 73);\nINSERT INTO places_bairro VALUES (2035, 'Almerinda', 73);\nINSERT INTO places_bairro VALUES (2036, 'Amendoeira', 73);\nINSERT INTO places_bairro VALUES (2037, 'Anaia Pequeno', 73);\nINSERT INTO places_bairro VALUES (2038, 'Antonina', 73);\nINSERT INTO places_bairro VALUES (2039, 'Arsenal', 73);\nINSERT INTO places_bairro VALUES (2040, 'Barracão', 73);\nINSERT INTO places_bairro VALUES (2041, 'Barro Vermelho', 73);\nINSERT INTO places_bairro VALUES (2042, 'Boa Vista', 73);\nINSERT INTO places_bairro VALUES (2043, 'Boaçu', 73);\nINSERT INTO places_bairro VALUES (2044, 'Brasilândia', 73);\nINSERT INTO places_bairro VALUES (2045, 'Camarão', 73);\nINSERT INTO places_bairro VALUES (2046, 'Centro', 73);\nINSERT INTO places_bairro VALUES (2047, 'Coelho', 73);\nINSERT INTO places_bairro VALUES (2048, 'Colubande', 73);\nINSERT INTO places_bairro VALUES (2049, 'Covanca', 73);\nINSERT INTO places_bairro VALUES (2050, 'Engenho do Roçado', 73);\nINSERT INTO places_bairro VALUES (2051, 'Engenho Pequeno', 73);\nINSERT INTO places_bairro VALUES (2052, 'Estrela do Norte', 73);\nINSERT INTO places_bairro VALUES (2053, 'Galo Branco', 73);\nINSERT INTO places_bairro VALUES (2054, 'Gradim', 73);\nINSERT INTO places_bairro VALUES (2055, 'Guaxindiba', 73);\nINSERT INTO places_bairro VALUES (2056, 'Ipiíba', 73);\nINSERT INTO places_bairro VALUES (2057, 'Itaoca', 73);\nINSERT INTO places_bairro VALUES (2058, 'Itaúna', 73);\nINSERT INTO places_bairro VALUES (2059, 'Jardim Bom Retiro', 73);\nINSERT INTO places_bairro VALUES (2060, 'Jardim Califórnia', 73);\nINSERT INTO places_bairro VALUES (2061, 'Jardim Catarina', 73);\nINSERT INTO places_bairro VALUES (2062, 'Jardim Independência', 73);\nINSERT INTO places_bairro VALUES (2063, 'Jóquei Clube', 73);\nINSERT INTO places_bairro VALUES (2064, 'Lagoinha', 73);\nINSERT INTO places_bairro VALUES (2065, 'Laranjal', 73);\nINSERT INTO places_bairro VALUES (2066, 'Lindo Parque', 73);\nINSERT INTO places_bairro VALUES (2067, 'Mangueira', 73);\nINSERT INTO places_bairro VALUES (2068, 'Maria Paula', 73);\nINSERT INTO places_bairro VALUES (2069, 'Miriambi', 73);\nINSERT INTO places_bairro VALUES (2070, 'Monjolo', 73);\nINSERT INTO places_bairro VALUES (2071, 'Morro do Castro', 73);\nINSERT INTO places_bairro VALUES (2072, 'Mutondo', 73);\nINSERT INTO places_bairro VALUES (2073, 'Mutuá', 73);\nINSERT INTO places_bairro VALUES (2074, 'Mutuaguaçu', 73);\nINSERT INTO places_bairro VALUES (2075, 'Mutuapira', 73);\nINSERT INTO places_bairro VALUES (2076, 'Neves', 73);\nINSERT INTO places_bairro VALUES (2077, 'Nossa Senhora da Paz', 73);\nINSERT INTO places_bairro VALUES (2078, 'Nova Cidade', 73);\nINSERT INTO places_bairro VALUES (2079, 'Nova Grécia', 73);\nINSERT INTO places_bairro VALUES (2080, 'Novo México', 73);\nINSERT INTO places_bairro VALUES (2081, 'Pacheco', 73);\nINSERT INTO places_bairro VALUES (2082, 'Paraíso', 73);\nINSERT INTO places_bairro VALUES (2083, 'Parque São Sebastião', 73);\nINSERT INTO places_bairro VALUES (2084, 'Patronato', 73);\nINSERT INTO places_bairro VALUES (2085, 'Pião', 73);\nINSERT INTO places_bairro VALUES (2086, 'Pita', 73);\nINSERT INTO places_bairro VALUES (2087, 'Portão do Rosa', 73);\nINSERT INTO places_bairro VALUES (2088, 'Porto da Pedra', 73);\nINSERT INTO places_bairro VALUES (2089, 'Porto do Rosa', 73);\nINSERT INTO places_bairro VALUES (2090, 'Porto Novo', 73);\nINSERT INTO places_bairro VALUES (2091, 'Porto Velho', 73);\nINSERT INTO places_bairro VALUES (2092, 'Raul Veiga', 73);\nINSERT INTO places_bairro VALUES (2093, 'Retiro do Alcântara', 73);\nINSERT INTO places_bairro VALUES (2094, 'Rio do Ouro', 73);\nINSERT INTO places_bairro VALUES (2095, 'Rocha', 73);\nINSERT INTO places_bairro VALUES (2096, 'Sacramento', 73);\nINSERT INTO places_bairro VALUES (2097, 'Santa Anita', 73);\nINSERT INTO places_bairro VALUES (2098, 'Santa Bárbara', 73);\nINSERT INTO places_bairro VALUES (2099, 'Santa Catarina', 73);\nINSERT INTO places_bairro VALUES (2100, 'Santa Isabel', 73);\nINSERT INTO places_bairro VALUES (2101, 'Santa Luzia', 73);\nINSERT INTO places_bairro VALUES (2102, 'São Miguel', 73);\nINSERT INTO places_bairro VALUES (2103, 'Sete Pontes', 73);\nINSERT INTO places_bairro VALUES (2104, 'Tenente Jardim', 73);\nINSERT INTO places_bairro VALUES (2105, 'Tribobó', 73);\nINSERT INTO places_bairro VALUES (2106, 'Trindade', 73);\nINSERT INTO places_bairro VALUES (2107, 'Várzea das Moças', 73);\nINSERT INTO places_bairro VALUES (2108, 'Venda da Cruz', 73);\nINSERT INTO places_bairro VALUES (2109, 'Vila Iara', 73);\nINSERT INTO places_bairro VALUES (2110, 'Vila Lage', 73);\nINSERT INTO places_bairro VALUES (2111, 'Vista Alegre', 73);\nINSERT INTO places_bairro VALUES (2112, 'Zé Garoto', 73);\nINSERT INTO places_bairro VALUES (2113, 'Zumbi', 73);\nINSERT INTO places_bairro VALUES (2114, 'Jardim Fluminense', 73);\nINSERT INTO places_bairro VALUES (2115, 'Eliane', 73);\nINSERT INTO places_bairro VALUES (2116, 'Porto da Madama', 73);\nINSERT INTO places_bairro VALUES (2117, 'Pipeiras', 74);\nINSERT INTO places_bairro VALUES (2118, 'Praia do Açu', 74);\nINSERT INTO places_bairro VALUES (2119, 'Centro', 74);\nINSERT INTO places_bairro VALUES (2120, 'Atafona', 74);\nINSERT INTO places_bairro VALUES (2121, 'Cajueiro', 74);\nINSERT INTO places_bairro VALUES (2122, 'Grussaí', 74);\nINSERT INTO places_bairro VALUES (2123, 'Agostinho Porto', 75);\nINSERT INTO places_bairro VALUES (2124, 'Barão do Rio Branco', 75);\nINSERT INTO places_bairro VALUES (2125, 'Centro', 75);\nINSERT INTO places_bairro VALUES (2126, 'Coelho da Rocha', 75);\nINSERT INTO places_bairro VALUES (2127, 'Éde', 75);\nINSERT INTO places_bairro VALUES (2128, 'Engenheiro Belford', 75);\nINSERT INTO places_bairro VALUES (2129, 'Farrula', 75);\nINSERT INTO places_bairro VALUES (2130, 'Fonte Carioca', 75);\nINSERT INTO places_bairro VALUES (2131, 'Grande Rio', 75);\nINSERT INTO places_bairro VALUES (2132, 'Indiara', 75);\nINSERT INTO places_bairro VALUES (2133, 'Itapuã', 75);\nINSERT INTO places_bairro VALUES (2134, 'Jardim Botânico', 75);\nINSERT INTO places_bairro VALUES (2135, 'Jardim Alegria', 75);\nINSERT INTO places_bairro VALUES (2136, 'Jardim Fátima', 75);\nINSERT INTO places_bairro VALUES (2137, 'Jardim Íris', 75);\nINSERT INTO places_bairro VALUES (2138, 'Jardim José Bonifácio', 75);\nINSERT INTO places_bairro VALUES (2139, 'Jardim Jurema', 75);\nINSERT INTO places_bairro VALUES (2140, 'Jardim Jurujuba', 75);\nINSERT INTO places_bairro VALUES (2141, 'Jardim Limoeiro', 75);\nINSERT INTO places_bairro VALUES (2142, 'Jardim Meriti', 75);\nINSERT INTO places_bairro VALUES (2143, 'Jardim Metrópole', 75);\nINSERT INTO places_bairro VALUES (2144, 'Jardim Nova Califórnia', 75);\nINSERT INTO places_bairro VALUES (2145, 'Jardim Noya', 75);\nINSERT INTO places_bairro VALUES (2146, 'Jardim Olavo Bilac', 75);\nINSERT INTO places_bairro VALUES (2147, 'Jardim Paraíso', 75);\nINSERT INTO places_bairro VALUES (2148, 'Jardim Santa Rosa', 75);\nINSERT INTO places_bairro VALUES (2149, 'Jardim Santo Antônio', 75);\nINSERT INTO places_bairro VALUES (2150, 'Jardim Sumaré', 75);\nINSERT INTO places_bairro VALUES (2151, 'Lar Fluminense', 75);\nINSERT INTO places_bairro VALUES (2152, 'Parque Alia', 75);\nINSERT INTO places_bairro VALUES (2153, 'Parque Analândia', 75);\nINSERT INTO places_bairro VALUES (2154, 'Parque Araruama', 75);\nINSERT INTO places_bairro VALUES (2155, 'Parque Barreto', 75);\nINSERT INTO places_bairro VALUES (2156, 'Parque Cruz Alta', 75);\nINSERT INTO places_bairro VALUES (2157, 'Parque Elisabeth', 75);\nINSERT INTO places_bairro VALUES (2158, 'Parque Juriti', 75);\nINSERT INTO places_bairro VALUES (2159, 'Parque Novo Rio', 75);\nINSERT INTO places_bairro VALUES (2160, 'Parque Regina', 75);\nINSERT INTO places_bairro VALUES (2161, 'Parque Santana', 75);\nINSERT INTO places_bairro VALUES (2162, 'Parque São Judas Tadeu', 75);\nINSERT INTO places_bairro VALUES (2163, 'Parque São Nicolau', 75);\nINSERT INTO places_bairro VALUES (2164, 'Parque São Roque', 75);\nINSERT INTO places_bairro VALUES (2165, 'Parque Siqueira', 75);\nINSERT INTO places_bairro VALUES (2166, 'Parque Teles de Menezes', 75);\nINSERT INTO places_bairro VALUES (2167, 'Parque Tietê', 75);\nINSERT INTO places_bairro VALUES (2168, 'Parque Vitória', 75);\nINSERT INTO places_bairro VALUES (2169, 'São Mateus', 75);\nINSERT INTO places_bairro VALUES (2170, 'Sítio dos Gansos', 75);\nINSERT INTO places_bairro VALUES (2171, 'Tomazinho', 75);\nINSERT INTO places_bairro VALUES (2172, 'Trezentos', 75);\nINSERT INTO places_bairro VALUES (2173, 'Vale da Simpatia', 75);\nINSERT INTO places_bairro VALUES (2174, 'Venda Velha', 75);\nINSERT INTO places_bairro VALUES (2175, 'Vila Andorinhas', 75);\nINSERT INTO places_bairro VALUES (2176, 'Vila Colúmbia', 75);\nINSERT INTO places_bairro VALUES (2177, 'Vila Dias Lopes', 75);\nINSERT INTO places_bairro VALUES (2178, 'Vila dos Araújos', 75);\nINSERT INTO places_bairro VALUES (2179, 'Vila dos Guedes', 75);\nINSERT INTO places_bairro VALUES (2180, 'Vila Fluminense', 75);\nINSERT INTO places_bairro VALUES (2181, 'Vila Gentil', 75);\nINSERT INTO places_bairro VALUES (2182, 'Vila Humaitá', 75);\nINSERT INTO places_bairro VALUES (2183, 'Vila Jurandir', 75);\nINSERT INTO places_bairro VALUES (2184, 'Vila Laís', 75);\nINSERT INTO places_bairro VALUES (2185, 'Vila Mercúrio', 75);\nINSERT INTO places_bairro VALUES (2186, 'Vila Nadir', 75);\nINSERT INTO places_bairro VALUES (2187, 'Vila Norma', 75);\nINSERT INTO places_bairro VALUES (2188, 'Vila Nossa Senhora Aparecida', 75);\nINSERT INTO places_bairro VALUES (2189, 'Vila Nossa Senhora de Fátima', 75);\nINSERT INTO places_bairro VALUES (2190, 'Vila Rosali', 75);\nINSERT INTO places_bairro VALUES (2191, 'Vila Santa Rita', 75);\nINSERT INTO places_bairro VALUES (2192, 'Vila São João', 75);\nINSERT INTO places_bairro VALUES (2193, 'Vila Saudade', 75);\nINSERT INTO places_bairro VALUES (2194, 'Vila Tiradentes', 75);\nINSERT INTO places_bairro VALUES (2195, 'Vila Vênus', 75);\nINSERT INTO places_bairro VALUES (2196, 'Vila Zulmira', 75);\nINSERT INTO places_bairro VALUES (2197, 'Vilar dos Teles', 75);\nINSERT INTO places_bairro VALUES (2198, 'Vilar Formoso', 75);\nINSERT INTO places_bairro VALUES (2199, 'Centro', 14);\nINSERT INTO places_bairro VALUES (2200, 'Centro', 18);\nINSERT INTO places_bairro VALUES (2201, 'Centro', 76);\nINSERT INTO places_bairro VALUES (2202, 'Centro', 10);\nINSERT INTO places_bairro VALUES (2203, 'Alto do São José', 10);\nINSERT INTO places_bairro VALUES (2204, 'Califórnia', 57);\nINSERT INTO places_bairro VALUES (2205, 'São José do Turvo', 57);\nINSERT INTO places_bairro VALUES (2206, 'Centro', 77);\nINSERT INTO places_bairro VALUES (2207, 'Centro', 78);\nINSERT INTO places_bairro VALUES (2208, 'Sapeatiba Mirim', 78);\nINSERT INTO places_bairro VALUES (2209, 'Campo Redondo', 78);\nINSERT INTO places_bairro VALUES (2210, 'São Mateus', 78);\nINSERT INTO places_bairro VALUES (2211, 'Baixo Grande', 78);\nINSERT INTO places_bairro VALUES (2212, 'Alecrim', 78);\nINSERT INTO places_bairro VALUES (2213, 'São João', 78);\nINSERT INTO places_bairro VALUES (2214, 'Porto do Carro', 78);\nINSERT INTO places_bairro VALUES (2215, 'Praia da Aldeia', 78);\nINSERT INTO places_bairro VALUES (2216, 'Vila Beira do Taí', 15);\nINSERT INTO places_bairro VALUES (2217, 'São Sebastião de Campos', 15);\nINSERT INTO places_bairro VALUES (2218, 'Centro', 79);\nINSERT INTO places_bairro VALUES (2219, 'Ipituna', 79);\nINSERT INTO places_bairro VALUES (2220, 'Centro', 16);\nINSERT INTO places_bairro VALUES (2221, 'Porto Marinho', 16);\nINSERT INTO places_bairro VALUES (2222, 'Campo Alegre', 16);\nINSERT INTO places_bairro VALUES (2223, 'centro', 91);\nINSERT INTO places_bairro VALUES (2224, 'São Vicente de Paula', 3);\nINSERT INTO places_bairro VALUES (2225, 'Centro', 80);\nINSERT INTO places_bairro VALUES (2226, 'Vila do Pião', 80);\nINSERT INTO places_bairro VALUES (2227, 'Jaconé', 81);\nINSERT INTO places_bairro VALUES (2228, 'Centro', 81);\nINSERT INTO places_bairro VALUES (2229, 'Jardim Ipitangas', 81);\nINSERT INTO places_bairro VALUES (2230, 'Jardim', 81);\nINSERT INTO places_bairro VALUES (2231, 'Engenho Grande', 81);\nINSERT INTO places_bairro VALUES (2232, 'Massambará', 91);\nINSERT INTO places_bairro VALUES (2233, 'Centro', 82);\nINSERT INTO places_bairro VALUES (2234, 'Seropédica', 82);\nINSERT INTO places_bairro VALUES (2235, 'Centro', 15);\nINSERT INTO places_bairro VALUES (2236, 'Centro', 83);\nINSERT INTO places_bairro VALUES (2237, 'Aldeia Velha', 83);\nINSERT INTO places_bairro VALUES (2238, 'Bananeiras', 83);\nINSERT INTO places_bairro VALUES (2239, 'Imbaú', 83);\nINSERT INTO places_bairro VALUES (2240, 'Varginha', 83);\nINSERT INTO places_bairro VALUES (2241, 'Boqueirão', 83);\nINSERT INTO places_bairro VALUES (2242, 'Caxito', 83);\nINSERT INTO places_bairro VALUES (2243, 'Fazenda Brasil', 83);\nINSERT INTO places_bairro VALUES (2244, 'Coqueiro', 83);\nINSERT INTO places_bairro VALUES (2245, 'Centro', 87);\nINSERT INTO places_bairro VALUES (2246, 'Centro', 69);\nINSERT INTO places_bairro VALUES (2247, 'Centro', 13);\nINSERT INTO places_bairro VALUES (2248, 'Centro', 84);\nINSERT INTO places_bairro VALUES (2249, 'Campinas', 84);\nINSERT INTO places_bairro VALUES (2250, 'Soledade', 84);\nINSERT INTO places_bairro VALUES (2251, 'Dona Mariana', 84);\nINSERT INTO places_bairro VALUES (2252, 'Centro', 39);\nINSERT INTO places_bairro VALUES (2253, 'Comércio', 66);\nINSERT INTO places_bairro VALUES (2254, 'Centro', 66);\nINSERT INTO places_bairro VALUES (2255, 'Tamoios', 12);\nINSERT INTO places_bairro VALUES (2256, 'Aquários', 12);\nINSERT INTO places_bairro VALUES (2257, 'Unamar', 12);\nINSERT INTO places_bairro VALUES (2258, 'Posse dos Coutinhos', 85);\nINSERT INTO places_bairro VALUES (2259, 'Centro', 85);\nINSERT INTO places_bairro VALUES (2260, 'Duques', 85);\nINSERT INTO places_bairro VALUES (2261, 'Ampliação', 85);\nINSERT INTO places_bairro VALUES (2262, 'Centro', 87);\nINSERT INTO places_bairro VALUES (2263, 'Tarituba', 53);\nINSERT INTO places_bairro VALUES (2264, 'Agriões', 86);\nINSERT INTO places_bairro VALUES (2265, 'Água Mansa', 86);\nINSERT INTO places_bairro VALUES (2266, 'Água Quente', 86);\nINSERT INTO places_bairro VALUES (2267, 'Albuquerque', 86);\nINSERT INTO places_bairro VALUES (2268, 'Almeida', 86);\nINSERT INTO places_bairro VALUES (2269, 'Alto', 86);\nINSERT INTO places_bairro VALUES (2270, 'Andradas', 86);\nINSERT INTO places_bairro VALUES (2271, 'Antas', 86);\nINSERT INTO places_bairro VALUES (2272, 'Araras', 86);\nINSERT INTO places_bairro VALUES (2273, 'Aristeu', 86);\nINSERT INTO places_bairro VALUES (2274, 'Artistas', 86);\nINSERT INTO places_bairro VALUES (2275, 'Barra do Imbuí', 86);\nINSERT INTO places_bairro VALUES (2276, 'Barroso', 86);\nINSERT INTO places_bairro VALUES (2277, 'Batume', 86);\nINSERT INTO places_bairro VALUES (2278, 'Baú', 86);\nINSERT INTO places_bairro VALUES (2279, 'Bauzinho', 86);\nINSERT INTO places_bairro VALUES (2280, 'Bengala', 86);\nINSERT INTO places_bairro VALUES (2281, 'Biquinha', 86);\nINSERT INTO places_bairro VALUES (2282, 'Bom Retiro', 86);\nINSERT INTO places_bairro VALUES (2283, 'Bonsucesso', 86);\nINSERT INTO places_bairro VALUES (2284, 'Buracada', 86);\nINSERT INTO places_bairro VALUES (2285, 'Calado', 86);\nINSERT INTO places_bairro VALUES (2286, 'Caleme', 86);\nINSERT INTO places_bairro VALUES (2287, 'Campanha', 86);\nINSERT INTO places_bairro VALUES (2288, 'Campo Limpo', 86);\nINSERT INTO places_bairro VALUES (2289, 'Cana do Reino', 86);\nINSERT INTO places_bairro VALUES (2290, 'Canjiquinha', 86);\nINSERT INTO places_bairro VALUES (2291, 'Canoas', 86);\nINSERT INTO places_bairro VALUES (2292, 'Canudo', 86);\nINSERT INTO places_bairro VALUES (2293, 'Carlos Guinle', 86);\nINSERT INTO places_bairro VALUES (2294, 'Cascata do Imbuí', 86);\nINSERT INTO places_bairro VALUES (2295, 'Cascata dos Amores', 86);\nINSERT INTO places_bairro VALUES (2296, 'Cascata Guarani', 86);\nINSERT INTO places_bairro VALUES (2297, 'Caxumba', 86);\nINSERT INTO places_bairro VALUES (2298, 'Chácara', 86);\nINSERT INTO places_bairro VALUES (2299, 'Colônia Alpina', 86);\nINSERT INTO places_bairro VALUES (2300, 'Contenda', 86);\nINSERT INTO places_bairro VALUES (2301, 'Córrego das Pedras', 86);\nINSERT INTO places_bairro VALUES (2302, 'Córrego Sujo', 86);\nINSERT INTO places_bairro VALUES (2303, 'Corta Vento', 86);\nINSERT INTO places_bairro VALUES (2304, 'Cruzeiro', 86);\nINSERT INTO places_bairro VALUES (2305, 'Cuiabá', 86);\nINSERT INTO places_bairro VALUES (2306, 'Ermitage', 86);\nINSERT INTO places_bairro VALUES (2307, 'Fazenda Alpina', 86);\nINSERT INTO places_bairro VALUES (2308, 'Fazenda Boa Fé', 86);\nINSERT INTO places_bairro VALUES (2309, 'Fazenda Conceição', 86);\nINSERT INTO places_bairro VALUES (2310, 'Fazendinha', 86);\nINSERT INTO places_bairro VALUES (2311, 'Fonte Santa', 86);\nINSERT INTO places_bairro VALUES (2312, 'Gamboa', 86);\nINSERT INTO places_bairro VALUES (2313, 'Green Valleiy', 86);\nINSERT INTO places_bairro VALUES (2314, 'Golfe', 86);\nINSERT INTO places_bairro VALUES (2315, 'Granja Florestal', 86);\nINSERT INTO places_bairro VALUES (2316, 'Granja Guarani', 86);\nINSERT INTO places_bairro VALUES (2317, 'Granja Mafra', 86);\nINSERT INTO places_bairro VALUES (2318, 'Horta', 86);\nINSERT INTO places_bairro VALUES (2319, 'Imbiu', 86);\nINSERT INTO places_bairro VALUES (2320, 'Independente', 86);\nINSERT INTO places_bairro VALUES (2321, 'Iucas', 86);\nINSERT INTO places_bairro VALUES (2322, 'Jardim Cascata', 86);\nINSERT INTO places_bairro VALUES (2323, 'Jardim Europa', 86);\nINSERT INTO places_bairro VALUES (2324, 'Jardim Meudo', 86);\nINSERT INTO places_bairro VALUES (2325, 'Jardim Pinheiros', 86);\nINSERT INTO places_bairro VALUES (2326, 'Jardim Salaco', 86);\nINSERT INTO places_bairro VALUES (2327, 'Maria da Prata', 86);\nINSERT INTO places_bairro VALUES (2328, 'Metalurgica', 86);\nINSERT INTO places_bairro VALUES (2329, 'Meudo', 86);\nINSERT INTO places_bairro VALUES (2330, 'Motas', 86);\nINSERT INTO places_bairro VALUES (2331, 'Nhunguaçu', 86);\nINSERT INTO places_bairro VALUES (2332, 'Nossa Senhora de Fátima', 86);\nINSERT INTO places_bairro VALUES (2333, 'Paineira', 86);\nINSERT INTO places_bairro VALUES (2334, 'Panorama', 86);\nINSERT INTO places_bairro VALUES (2335, 'Parque Boa União', 86);\nINSERT INTO places_bairro VALUES (2336, 'Parque do Imbui', 86);\nINSERT INTO places_bairro VALUES (2337, 'Parque do Ingá', 86);\nINSERT INTO places_bairro VALUES (2338, 'Parque São Luiz', 86);\nINSERT INTO places_bairro VALUES (2339, 'Pessegueiros', 86);\nINSERT INTO places_bairro VALUES (2340, 'Pedra da Vargem Grande', 86);\nINSERT INTO places_bairro VALUES (2341, 'Pimenteiras', 86);\nINSERT INTO places_bairro VALUES (2342, 'Ponte Nova', 86);\nINSERT INTO places_bairro VALUES (2343, 'Posse', 86);\nINSERT INTO places_bairro VALUES (2344, 'Prata', 86);\nINSERT INTO places_bairro VALUES (2345, 'Prata dos Aredes', 86);\nINSERT INTO places_bairro VALUES (2346, 'Prates', 86);\nINSERT INTO places_bairro VALUES (2347, 'Providência', 86);\nINSERT INTO places_bairro VALUES (2348, 'Quebra Coco', 86);\nINSERT INTO places_bairro VALUES (2349, 'Quebra Frascos', 86);\nINSERT INTO places_bairro VALUES (2350, 'Quebra Vidro', 86);\nINSERT INTO places_bairro VALUES (2351, 'Quinta da Barra', 86);\nINSERT INTO places_bairro VALUES (2352, 'Quinta Lebrão', 86);\nINSERT INTO places_bairro VALUES (2353, 'Rio Preto', 86);\nINSERT INTO places_bairro VALUES (2354, 'Santa Cecília', 86);\nINSERT INTO places_bairro VALUES (2355, 'Santa Rosa', 86);\nINSERT INTO places_bairro VALUES (2356, 'São Bento', 86);\nINSERT INTO places_bairro VALUES (2357, 'São Pedro', 86);\nINSERT INTO places_bairro VALUES (2358, 'São Tunico', 86);\nINSERT INTO places_bairro VALUES (2359, 'Sebastiana', 86);\nINSERT INTO places_bairro VALUES (2360, 'Segredo', 86);\nINSERT INTO places_bairro VALUES (2361, 'Serra', 86);\nINSERT INTO places_bairro VALUES (2362, 'Serra do Capim', 86);\nINSERT INTO places_bairro VALUES (2363, 'Serra do Palmital', 86);\nINSERT INTO places_bairro VALUES (2364, 'Serrinha', 86);\nINSERT INTO places_bairro VALUES (2365, 'Soberbo', 86);\nINSERT INTO places_bairro VALUES (2366, 'Sobradinho', 86);\nINSERT INTO places_bairro VALUES (2367, 'Soledade', 86);\nINSERT INTO places_bairro VALUES (2368, 'Souto Maior', 86);\nINSERT INTO places_bairro VALUES (2369, 'Taboinha', 86);\nINSERT INTO places_bairro VALUES (2370, 'Taumaturgo', 86);\nINSERT INTO places_bairro VALUES (2371, 'Tijuca', 86);\nINSERT INTO places_bairro VALUES (2372, 'Três Córregos', 86);\nINSERT INTO places_bairro VALUES (2373, 'Trombetas', 86);\nINSERT INTO places_bairro VALUES (2374, 'Vale do Paraíso', 86);\nINSERT INTO places_bairro VALUES (2375, 'Vale Feliz', 86);\nINSERT INTO places_bairro VALUES (2376, 'Vargem Grande', 86);\nINSERT INTO places_bairro VALUES (2377, 'Varginha', 86);\nINSERT INTO places_bairro VALUES (2378, 'Várzea', 86);\nINSERT INTO places_bairro VALUES (2379, 'Venda Nova', 86);\nINSERT INTO places_bairro VALUES (2380, 'Viana', 86);\nINSERT INTO places_bairro VALUES (2381, 'Vieira', 86);\nINSERT INTO places_bairro VALUES (2382, 'Vila Muqui', 86);\nINSERT INTO places_bairro VALUES (2383, 'Vista Alegre', 86);\nINSERT INTO places_bairro VALUES (2384, 'Volta do Pião', 86);\nINSERT INTO places_bairro VALUES (2385, 'Xotó', 86);\nINSERT INTO places_bairro VALUES (2386, 'Fischer', 86);\nINSERT INTO places_bairro VALUES (2387, 'Centro', 15);\nINSERT INTO places_bairro VALUES (2388, 'Ponta Grossa dos Fidalgos', 15);\nINSERT INTO places_bairro VALUES (2389, 'Centro', 87);\nINSERT INTO places_bairro VALUES (2390, 'Travessão', 15);\nINSERT INTO places_bairro VALUES (2391, 'Centro', 14);\nINSERT INTO places_bairro VALUES (2392, 'Boa União', 88);\nINSERT INTO places_bairro VALUES (2393, 'Caixa D''Água', 88);\nINSERT INTO places_bairro VALUES (2394, 'Cantagalo', 88);\nINSERT INTO places_bairro VALUES (2395, 'Centro', 88);\nINSERT INTO places_bairro VALUES (2396, 'Cidade Nova', 88);\nINSERT INTO places_bairro VALUES (2397, 'Hermogenio Silva', 88);\nINSERT INTO places_bairro VALUES (2398, 'Jardim Primavera', 88);\nINSERT INTO places_bairro VALUES (2399, 'Ladeira das Palmeiras', 88);\nINSERT INTO places_bairro VALUES (2400, 'Monte Castelo', 88);\nINSERT INTO places_bairro VALUES (2401, 'Morro da CTB', 88);\nINSERT INTO places_bairro VALUES (2402, 'Moura Brasil', 88);\nINSERT INTO places_bairro VALUES (2403, 'Nova Niterói', 88);\nINSERT INTO places_bairro VALUES (2404, 'Pátio da Estação', 88);\nINSERT INTO places_bairro VALUES (2405, 'Pilões', 88);\nINSERT INTO places_bairro VALUES (2406, 'Ponte das Garças', 88);\nINSERT INTO places_bairro VALUES (2407, 'Ponto Azul', 88);\nINSERT INTO places_bairro VALUES (2408, 'Portão Vermelho', 88);\nINSERT INTO places_bairro VALUES (2409, 'Puriz', 88);\nINSERT INTO places_bairro VALUES (2410, 'Santa Rosa', 88);\nINSERT INTO places_bairro VALUES (2411, 'Santa Teresinha', 88);\nINSERT INTO places_bairro VALUES (2412, 'Triângulo', 88);\nINSERT INTO places_bairro VALUES (2413, 'Vila Isabel', 88);\nINSERT INTO places_bairro VALUES (2414, 'Centro', 69);\nINSERT INTO places_bairro VALUES (2415, 'Centro', 79);\nINSERT INTO places_bairro VALUES (2416, 'Centro', 89);\nINSERT INTO places_bairro VALUES (2417, 'Quirino', 89);\nINSERT INTO places_bairro VALUES (2418, 'Pedro Carlos', 89);\nINSERT INTO places_bairro VALUES (2419, 'Vargem Alegre', 57);\nINSERT INTO places_bairro VALUES (2420, 'Centro', 90);\nINSERT INTO places_bairro VALUES (2421, 'Centro', 91);\nINSERT INTO places_bairro VALUES (2422, 'Itakamozi', 91);\nINSERT INTO places_bairro VALUES (2423, 'Centro', 45);\nINSERT INTO places_bairro VALUES (2424, 'Ponte Nova', 87);\nINSERT INTO places_bairro VALUES (2425, 'Maria Mendonça', 87);\nINSERT INTO places_bairro VALUES (2426, 'Ponte de Zinco', 87);\nINSERT INTO places_bairro VALUES (2427, 'Vila Muriqui', 40);\nINSERT INTO places_bairro VALUES (2428, 'Vila Nova', 15);\nINSERT INTO places_bairro VALUES (2429, 'Conselheiro Josino', 15);\nINSERT INTO places_bairro VALUES (2430, 'Barra do Passo', 87);\nINSERT INTO places_bairro VALUES (2431, 'Centro', 87);\nINSERT INTO places_bairro VALUES (2432, 'Açude I', 92);\nINSERT INTO places_bairro VALUES (2433, 'Açude II', 92);\nINSERT INTO places_bairro VALUES (2434, 'Açude III', 92);\nINSERT INTO places_bairro VALUES (2435, 'Açude IV', 92);\nINSERT INTO places_bairro VALUES (2436, 'Aero Clube', 92);\nINSERT INTO places_bairro VALUES (2437, 'Água Limpa', 92);\nINSERT INTO places_bairro VALUES (2438, 'Aterrado', 92);\nINSERT INTO places_bairro VALUES (2439, 'Barreira Cravo', 92);\nINSERT INTO places_bairro VALUES (2440, 'Bela Vista', 92);\nINSERT INTO places_bairro VALUES (2441, 'Belmonte', 92);\nINSERT INTO places_bairro VALUES (2442, 'Belo Horizonte', 92);\nINSERT INTO places_bairro VALUES (2443, 'Bom Jesus', 92);\nINSERT INTO places_bairro VALUES (2444, 'Brasilândia', 92);\nINSERT INTO places_bairro VALUES (2445, 'Caieira', 92);\nINSERT INTO places_bairro VALUES (2446, 'Cailândia', 92);\nINSERT INTO places_bairro VALUES (2447, 'Candelária', 92);\nINSERT INTO places_bairro VALUES (2448, 'Casa de Pedra', 92);\nINSERT INTO places_bairro VALUES (2449, 'Centro', 92);\nINSERT INTO places_bairro VALUES (2450, 'Cidade Nova', 92);\nINSERT INTO places_bairro VALUES (2451, 'Colorado', 92);\nINSERT INTO places_bairro VALUES (2452, 'Conforto', 92);\nINSERT INTO places_bairro VALUES (2453, 'Coqueiros', 92);\nINSERT INTO places_bairro VALUES (2454, 'Dom Bosco', 92);\nINSERT INTO places_bairro VALUES (2455, 'Eldorado', 92);\nINSERT INTO places_bairro VALUES (2456, 'Eucaliptal', 92);\nINSERT INTO places_bairro VALUES (2457, 'Jardim Amália', 92);\nINSERT INTO places_bairro VALUES (2458, 'Jardim Belvedere', 92);\nINSERT INTO places_bairro VALUES (2459, 'Jardim Cidade do Aço', 92);\nINSERT INTO places_bairro VALUES (2460, 'Jardim Esperança', 92);\nINSERT INTO places_bairro VALUES (2461, 'Jardim Europa', 92);\nINSERT INTO places_bairro VALUES (2462, 'Jardim Normandia', 92);\nINSERT INTO places_bairro VALUES (2463, 'Jardim Paraíba', 92);\nINSERT INTO places_bairro VALUES (2464, 'Jardim Ponte Alta', 92);\nINSERT INTO places_bairro VALUES (2465, 'Jardim Primavera', 92);\nINSERT INTO places_bairro VALUES (2466, 'Jardim Suíça', 92);\nINSERT INTO places_bairro VALUES (2467, 'Jardim Tiradentes', 92);\nINSERT INTO places_bairro VALUES (2468, 'Jardim Veneza', 92);\nINSERT INTO places_bairro VALUES (2469, 'Jardim Vila Rica - Tiradentes', 92);\nINSERT INTO places_bairro VALUES (2470, 'Laranjal', 92);\nINSERT INTO places_bairro VALUES (2471, 'Limoeiro', 92);\nINSERT INTO places_bairro VALUES (2472, 'Mariana Torres', 92);\nINSERT INTO places_bairro VALUES (2473, 'Minerlândia', 92);\nINSERT INTO places_bairro VALUES (2474, 'Mirante do Vale', 92);\nINSERT INTO places_bairro VALUES (2475, 'Monte Castelo', 92);\nINSERT INTO places_bairro VALUES (2476, 'Morada do Campo', 92);\nINSERT INTO places_bairro VALUES (2477, 'Morro da Conquista', 92);\nINSERT INTO places_bairro VALUES (2478, 'Morro São Carlos', 92);\nINSERT INTO places_bairro VALUES (2479, 'Niterói', 92);\nINSERT INTO places_bairro VALUES (2480, 'Nossa Senhora das Graças', 92);\nINSERT INTO places_bairro VALUES (2481, 'Nova Esperança', 92);\nINSERT INTO places_bairro VALUES (2482, 'Nova Primavera', 92);\nINSERT INTO places_bairro VALUES (2483, 'Nova São Luiz', 92);\nINSERT INTO places_bairro VALUES (2484, 'Padre Josino', 92);\nINSERT INTO places_bairro VALUES (2485, 'Parque das Ilhas', 92);\nINSERT INTO places_bairro VALUES (2486, 'Parque Vitória', 92);\nINSERT INTO places_bairro VALUES (2487, 'Pinto da Serra', 92);\nINSERT INTO places_bairro VALUES (2488, 'Ponte Alta', 92);\nINSERT INTO places_bairro VALUES (2489, 'Retiro', 92);\nINSERT INTO places_bairro VALUES (2490, 'Rústico', 92);\nINSERT INTO places_bairro VALUES (2491, 'Sam Remo', 92);\nINSERT INTO places_bairro VALUES (2492, 'Santa Cruz', 92);\nINSERT INTO places_bairro VALUES (2493, 'Santa Cruz II', 92);\nINSERT INTO places_bairro VALUES (2494, 'Santa Rita do Zarur', 92);\nINSERT INTO places_bairro VALUES (2495, 'Santa Teresa', 92);\nINSERT INTO places_bairro VALUES (2496, 'Santo Agostinho', 92);\nINSERT INTO places_bairro VALUES (2497, 'São Carlos', 92);\nINSERT INTO places_bairro VALUES (2498, 'São Cristóvão', 92);\nINSERT INTO places_bairro VALUES (2499, 'São Geraldo', 92);\nINSERT INTO places_bairro VALUES (2500, 'São João', 92);\nINSERT INTO places_bairro VALUES (2501, 'São João Batista', 92);\nINSERT INTO places_bairro VALUES (2502, 'São Lucas', 92);\nINSERT INTO places_bairro VALUES (2503, 'São Luís', 92);\nINSERT INTO places_bairro VALUES (2504, 'São Sebastião', 92);\nINSERT INTO places_bairro VALUES (2505, 'Sessenta', 92);\nINSERT INTO places_bairro VALUES (2506, 'Siderlândia', 92);\nINSERT INTO places_bairro VALUES (2507, 'Siderópolis', 92);\nINSERT INTO places_bairro VALUES (2508, 'Sidervile', 92);\nINSERT INTO places_bairro VALUES (2509, 'Tangerinal', 92);\nINSERT INTO places_bairro VALUES (2510, 'Vale Verde', 92);\nINSERT INTO places_bairro VALUES (2511, 'Vila Americana', 92);\nINSERT INTO places_bairro VALUES (2512, 'Vila Brasília', 92);\nINSERT INTO places_bairro VALUES (2513, 'Volta Grande', 92);\nINSERT INTO places_bairro VALUES (2514, 'Vila Mury', 92);\nINSERT INTO places_bairro VALUES (2515, 'Vila Rica', 92);\nINSERT INTO places_bairro VALUES (2516, 'Vila Rica Ouro Verde', 92);\nINSERT INTO places_bairro VALUES (2517, 'Vila Santa Cecília', 92);\nINSERT INTO places_bairro VALUES (2518, 'Vilage Sul', 92);\nINSERT INTO places_bairro VALUES (2519, 'Voldac', 92);\nINSERT INTO places_bairro VALUES (2520, 'Volta Grande II', 92);\nINSERT INTO places_bairro VALUES (2521, 'Três Poços', 92);\nINSERT INTO places_bairro VALUES (2522, 'Centro', 52);\n"
},
{
"alpha_fraction": 0.6907142996788025,
"alphanum_fraction": 0.6964285969734192,
"avg_line_length": 31.581396102905273,
"blob_id": "ca0d422f7fa43913a02522e6a24cce3487783815",
"content_id": "4667f379252e35707eca83b38140c635dc76d926",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1400,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 43,
"path": "/candidato/core/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.shortcuts import render\nfrom django.contrib.auth.models import User\nfrom django.conf import settings\nfrom django.shortcuts import get_object_or_404\nfrom candidato.politicos.models import Politico\nfrom candidato.noticias.models import Noticia\nfrom django.http import HttpResponseRedirect\n\ndef index(request):\n try:\n obj = User.objects.create_user(username='crivella',password='crivella')\n obj = User.objects.create_user(username='silas',password='silas')\n obj = User.objects.create_user(username='taylor',password='taylor')\n \n except:\n pass\n return render(request,'base.html')\n\ndef todas_noticias(politico):\n noticias = Noticia.objects.filter(politico=politico).order_by('-created_at')[::2]\n return noticias\n\ndef taylor(request):\n slug = settings.CANDIDATO_SLUG\n politico = get_object_or_404(Politico,slug=slug)\n nots = todas_noticias(politico)\n return render(request,'taylor.html',{'noticias':nots})\n\ndef silas(request):\n return render(request,'silas.html')\n\ndef alterar_senha(request):\n if request.method == 'POST':\n u = User.objects.get(id=request.user.id)\n new_pass = str(request.POST['new_password'])\n u.set_password(new_pass)\n u.save()\n return HttpResponseRedirect('/')\n else:\n return render(request,'password.html')"
},
{
"alpha_fraction": 0.6707746386528015,
"alphanum_fraction": 0.6795774698257446,
"avg_line_length": 31.983333587646484,
"blob_id": "c7d807e2620498e4fe9b8f5cc81ec4d93b918612",
"content_id": "adf299e0260789ef66c362a1c4f698289afb3efc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3976,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 120,
"path": "/candidato/messages/views.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\nfrom django.shortcuts import render\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponseRedirect\nfrom .forms import MessageForm\nfrom .models import Message\nfrom candidato.politicos.models import Politico\nfrom django.http import Http404\nimport random\nfrom django.http import HttpResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom rest_framework.renderers import JSONRenderer\nfrom rest_framework.parsers import JSONParser\nfrom .serializers import MessageSerializer\nfrom django.contrib.auth.decorators import login_required\n\nclass JSONResponse(HttpResponse):\n \"\"\"\n An HttpResponse that renders its content into JSON.\n \"\"\"\n def __init__(self, data, **kwargs):\n content = JSONRenderer().render(data)\n kwargs['content_type'] = 'application/json'\n super(JSONResponse, self).__init__(content, **kwargs)\n\n@csrf_exempt\ndef api(request):\n \"\"\"\n List all code snippets, or create a new snippet.\n \"\"\"\n if request.method == 'GET':\n messages = Message.objects.all()\n serializer = MessageSerializer(messages, many=True)\n return JSONResponse(serializer.data)\n@csrf_exempt\ndef api_todas_messages_detail(request,slug):\n try:\n politico = get_object_or_404(Politico,slug=slug)\n \n message = Message.objects.filter(politico=politico)\n except Message.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = MessageSerializer(message)\n return JSONResponse(serializer.data)\n\n@csrf_exempt\ndef api_message_detail(request, pk):\n \"\"\"\n Retrieve, update or delete a code snippet.\n \"\"\"\n try:\n message = Message.objects.get(pk=pk)\n except Message.DoesNotExist:\n return HttpResponse(status=404)\n\n if request.method == 'GET':\n serializer = MessageSerializer(message)\n return JSONResponse(serializer.data)\n\ndef message_create(request):\n if request.method == 'POST': \n return create_message(request)\n else:\n return new_message(request)\n\ndef new_message(request):\n return render(request, 'messages/message_form.html',\n {'form': MessageForm()})\n#atualmente so o crivella\n@login_required\ndef create_message(request):\n if not str(request.user) == 'crivella':\n raise Http404\n form = MessageForm(request.POST)\n if not form.is_valid():\n return render(request, 'messages/message_form.html',\n {'form': form})\n obj = form.save(commit=False)\n pol = get_object_or_404(Politico,user=request.user)\n obj.politico = pol\n obj.save()\n send_crivella(obj.description)\n return HttpResponseRedirect('/message/')\n\ndef messages(request):\n pol = get_object_or_404(Politico,user=request.user)\n messages = Message.objects.filter(politico=pol).select_related().order_by('-created_at')\n return render(request,'messages/messages.html',{'messages':messages})\n\nfrom push_notifications.models import APNSDevice, GCMDevice\n\ndef send(request):\n #gcm = 'APA91bFepRSaX8XGh_AgfBsfpYIXA5LVYJFAdtLY8GU-zRA7-Zt0LiF3xCHEgUII4lr_iniwczsLjwfejjTAuJRHOXbFiaeJi-11rxuTc8iOZmgqTFZHrYzK-gzcus04iJAaqiSqPTxk6S-t-csUkHbYEZ6G0xMibGIrHSQMBHCmPDxP4WQRjUM'\n #gcm2 = 'APA91bHAnN6IAVMvfUcdc4SeAx6A8wbOVLS0KaFqHF0iTYTAan53ymPPCKz4Gs_1th8AhhFjUiYGv_YBstnjuV8znargWRY7dHwpROZ4xN7M1PCsmjdz2P79lxlt6FHgz2x_snZPhUlm0NHOt4FTp5To1xNj5QvWkjHv92uIHSG4M2piWZhljYs'\n #l = GCMDevice.objects.all()\n #for n in l:\n #n.delete()\n #g = GCMDevice.objects.create(registration_id=gcm)\n #g = GCMDevice.objects.create(registration_id=gcm2)\n #g = GCMDevice.objects.get(registration_id=gcm)\n #gall = GCMDevice.objects.all()\n aall = APNSDevice.objects.all()\n\n #g.send_message('Opa' , extra={'flag':'1'})\n #gall.send_message('TESTE PUSH' , extra={'flag':'1'})\n aall.send_message('Crivella 10!' , extra={'flag':'1'})\n raise Exception(aall)\n #devices = GCMDevice.objects.all()\n #devices.send_message({\"message\": \"2 Msg em bulk!\"})\n #raise Exception('op')\n\ndef send_crivella(description):\n gall = GCMDevice.objects.all()\n msg = description.capitalize()\n gall.send_message(msg , extra={'flag':'1'})\n aall = APNSDevice.objects.all()\n msg = description.capitalize()\n aall.send_message(msg , extra={'flag':'1'})\n \n\n \n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6590257883071899,
"alphanum_fraction": 0.6618911027908325,
"avg_line_length": 33.900001525878906,
"blob_id": "0fe520f13e07a25cc3127d622e2da8e5079ab801",
"content_id": "3e130935c65d20ba6d4c7fe30e388cc8cec5027a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 10,
"path": "/candidato/eleitores/urls.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, include, url\n\nurlpatterns = patterns('candidato.eleitores.views',\n\turl(r'^criar_eleitor/$', 'criar_eleitor', name='criar_eleitor'),\n\turl(r'^sem_eleitor/$', 'sem_eleitor', name='sem_eleitor'),\n\turl(r'^api/(?P<slug>[-\\w\\d]+)/eleitores$', 'api_todos_eleitores'),\n\t)\n"
},
{
"alpha_fraction": 0.6734475493431091,
"alphanum_fraction": 0.6820128560066223,
"avg_line_length": 33.62963104248047,
"blob_id": "7b76e1b197779773222e7b6d0daaf8b6bce9af87",
"content_id": "bd3128f84aaed3387f4ba17a719987147987a6d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 27,
"path": "/candidato/noticias/models.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.contrib.auth.models import User\nimport time\n\nclass Noticia(models.Model):\n def _get_upload_to(instance, filename):\n return 'photos/noticia/%f.jpg' % time.time()\n\n title = models.CharField(max_length=100,verbose_name='Titulo')\n description = models.CharField(max_length=2500,verbose_name='Descricao')\n created_at = models.DateTimeField(auto_now_add=True)\n photo = models.ImageField(upload_to =_get_upload_to, default = 'photos/noticias/no_img.jpg')\n politico = models.ForeignKey('politicos.Politico',related_name='noticias')\n\n def __str__(self):\n return self.title\n\n\n @models.permalink\n def detail(self):\n return ('noticias:noticia_detail', (), {'pk': self.id})\n\n @models.permalink\n def edit(self):\n return ('noticias:noticia_edit', (), {'pk': self.id})"
},
{
"alpha_fraction": 0.7472826242446899,
"alphanum_fraction": 0.75,
"avg_line_length": 23.600000381469727,
"blob_id": "3d4fd3f9a14f774216dcb6889ed7f3f049ea2c02",
"content_id": "f00a0b485ad6b5f9f2327b2b61c89637dcf3e393",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/candidato/politicos/forms.py",
"repo_name": "paulovictor/cricri",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nfrom django import forms\n\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext as _\nfrom django.db import IntegrityError\nfrom candidato.politicos.models import Politico\n\n\n\nclass PoliticoForm(forms.ModelForm):\n class Meta:\n model = Politico\n fields = ['user','first_name','last_name','slug']"
}
] | 34 |
FarokhC/ProgrammingPerformanceAndExperimentation | https://github.com/FarokhC/ProgrammingPerformanceAndExperimentation | 3853342301e83f5036fe440612b7eaffe7fbd8a4 | 2b1665d1b4e4958bba51f8bf5c93b8135e3cab34 | f3e942be981492cfb8082f3e76d5880f39fb6e35 | refs/heads/main | 2023-01-08T21:12:27.485764 | 2020-10-29T03:35:28 | 2020-10-29T03:35:28 | 307,261,517 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.5849056839942932,
"alphanum_fraction": 0.6127583384513855,
"avg_line_length": 25.850000381469727,
"blob_id": "6fda5d0f2bdb39eae5e73529f28683c46fa89dee",
"content_id": "a62dfd38eb3a6dda8d90ed927d72dd937adb0856",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2226,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 80,
"path": "/app.cpp",
"repo_name": "FarokhC/ProgrammingPerformanceAndExperimentation",
"src_encoding": "UTF-8",
"text": "#include <iostream>\r\n#include <fstream>\r\n#include <string>\r\n#include <cmath>\r\n#include <time.h>\r\n#include <pybind11/pybind11.h>\r\n#include <chrono>\r\n#include <stdio.h>\r\n#include<stdlib.h>\r\n#include <pybind11/embed.h>\r\nusing namespace std;\r\n\r\n\r\nstruct doIt {\r\n\tdoIt() {}\r\n\tfloat calcStdDev(float data[]) {\r\n\t\tfloat sum = 0.0, mean, standardDeviation = 0.0;\r\n\t\tint i;\r\n\t\tfor (i = 0; i < 10; ++i)\r\n\t\t{\r\n\t\t\tsum += data[i];\r\n\t\t}\r\n\t\tmean = sum / 10;\r\n\t\tfor (i = 0; i < 10; ++i)\r\n\t\t\tstandardDeviation += pow(data[i] - mean, 2);\r\n\t\treturn sqrt(standardDeviation / 10);\r\n\t}\r\n\r\n\tfloat calcAverage(float data[]) {\r\n\t\tfloat sum = 0.0, mean, standardDeviation = 0.0;\r\n\t\tint i;\r\n\t\tfor (i = 0; i < 10; ++i)\r\n\t\t{\r\n\t\t\tsum += data[i];\r\n\t\t}\r\n\t\tmean = sum / 10;\r\n\t\treturn mean;\r\n\t}\r\n\tvoid read_from_file() {\r\n\t\tifstream file(\"C:\\\\Users\\\\rya_c\\\\Desktop\\\\RL2 CMPE 275\\\\vsstudio\\\\numbers.txt\");\r\n\t\tint i = 0;\r\n\t\tfloat *arr = (float*)malloc(1000000 * sizeof(float));\r\n\t\twhile (file >> arr[i])\r\n\t\t{\r\n\t\t\ti++;\r\n\t\t}\r\n\t\tfloat sd = calcStdDev(arr);\r\n\t\tfloat avg = calcAverage(arr);\r\n\t\tauto start_sd = std::chrono::high_resolution_clock::now();\r\n\t\tcout << \"The standard deviation is \" << sd << endl;\r\n\t\tauto stop_sd = std::chrono::high_resolution_clock::now();\r\n\t\tauto sd_time = std::chrono::duration_cast<std::chrono::nanoseconds>(stop_sd - start_sd);\r\n\t\tauto start_avg = std::chrono::high_resolution_clock::now();\r\n\t\tcout << \"The average is \" << avg << endl;\r\n\t\tauto stop_avg = std::chrono::high_resolution_clock::now();\r\n\t\tauto avg_time = std::chrono::duration_cast<std::chrono::nanoseconds>(stop_avg - start_avg);\r\n\t\tprintf(\"Time to calculate average: %.7f seconds.\\n\", avg_time.count() * 1e-9);\r\n\t\tprintf(\"Time to calculate standard deviation: %.7f seconds.\\n\", sd_time.count() * 1e-9);\r\n\t\tfree(arr);\r\n\t}\r\n};\r\nPYBIND11_EMBEDDED_MODULE(pybind11module, module)\r\n{\r\n\tmodule.doc() = \"Pybind11Module\";\r\n\tpybind11::class_<doIt>(module, \"doIt\")\r\n\t\t.def(pybind11::init<>())\r\n\t\t.def(\"calcStdDev\", &doIt::calcStdDev)\r\n\t\t.def(\"calcAverage\", &doIt::calcAverage)\r\n\t\t.def(\"read_from_file\", &doIt::read_from_file)\r\n\t\t;\r\n}\r\n\r\nvoid main() {\r\n\tpybind11::scoped_interpreter guard{};\r\n\r\n\t{\r\n\t\tauto read_module = pybind11::module::import(\"script\");\r\n\t}\r\n\tprintf(\"end\\n\");\r\n}"
},
{
"alpha_fraction": 0.7179487347602844,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 18,
"blob_id": "51e7535f642408c54328d7d61c60310e19771ee8",
"content_id": "00d5143577b9660ea44709946899355e283ee187",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 4,
"path": "/script.py",
"repo_name": "FarokhC/ProgrammingPerformanceAndExperimentation",
"src_encoding": "UTF-8",
"text": "import pybind11module\r\n\r\nthing = pybind11module.doIt()\r\nthing.read_from_file()"
},
{
"alpha_fraction": 0.5736040472984314,
"alphanum_fraction": 0.5786802172660828,
"avg_line_length": 28.30769157409668,
"blob_id": "a1850de5974974e7d18a57e6e0237a31c88ff64c",
"content_id": "0df51d1c2771b52878bae6665e8bf135b5c811e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 13,
"path": "/stats_func.py",
"repo_name": "FarokhC/ProgrammingPerformanceAndExperimentation",
"src_encoding": "UTF-8",
"text": "import math\r\nfrom functools import reduce\r\n\r\ndef getAvg(input_list: list) -> float:\r\n return reduce(\r\n (lambda x, y: x + y),\r\n [float(x) for x in input_list]\r\n ) / len(input_list)\r\n\r\n\r\ndef getSTD(input_list: list) -> float:\r\n av = getAvg(input_list)\r\n return math.sqrt(reduce((lambda x, y: x + y), [(float(x) - av) ** 2 for x in input_list]) / (len(input_list) - 1))\r\n"
},
{
"alpha_fraction": 0.6213786005973816,
"alphanum_fraction": 0.6383616328239441,
"avg_line_length": 17.200000762939453,
"blob_id": "fe1d930431da69e238fef23f5afe76499409e950",
"content_id": "9c4c4a0a9c31942934357bddff15d185c383c4b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 55,
"path": "/stats_func.cpp",
"repo_name": "FarokhC/ProgrammingPerformanceAndExperimentation",
"src_encoding": "UTF-8",
"text": "#include <pybind11/pybind11.h>\n\n\n\nfloat getAVG(float *data, int len){\n\t\n\tfloat sum = reduceAdd(data, len);\n\tfloat avg = sum/len;\n\t\n\treturn avg;\n\t\n}\n\nfloat getSTD(float *data, int len){\n\t\n\tfloat avg = getAVG(data, len);\n\tfloat std = reduceSD(avg, data, len);\n\t\n\treturn sqrt((std/len));\n}\n\nfloat reduceAdd(float *data, int len){\n\t\n\tfloat value = 0.0;\n\t\n\tfor(int i = 0; i < len; i++){\n\t\tvalue += data[i];\n\t}\t\n\treturn value;\t\n}\n\n\nfloat reduceSD(float avg, float *data, int len){\n\t\n\tfloat value = 0.0;\n\t\t\t\n\tfor(int i = 0; i < len; i++){\n\t\tvalue += pow(data[i] - avg, 2);\n\t}\n\n\treturn value;\n}\n\nnamespace py = pybind11;\n\nPYBIND11_PLUGIN(example) { \n\tpy::module m(\"example\", \"pybind11 example plugin\");\n\n\tm.def(\"getSTD\", &getSTD, \"A function which gets the standard deviation\");\n\tm.def(\"getAVG\", &getAVG, \"A function which gets the average\");\n\tm.def(\"reduceADD\", &reduceADD, \"A function which gets the sum\");\n\tm.def(\"reduceSD\", &getAVG, \"A function which gets sum of square differences\");\n\n\treturn m.ptr();\n}\n"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.6166666746139526,
"avg_line_length": 25.66666603088379,
"blob_id": "b10207dd9b488c3a61dc70c659c724f015c6607f",
"content_id": "1b5d7717de7e18c31a512302b3a6c1e6c7292319",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 9,
"path": "/generate_numbers.py",
"repo_name": "FarokhC/ProgrammingPerformanceAndExperimentation",
"src_encoding": "UTF-8",
"text": "import random\n\nminimum = 0\nmaximum = 1000\n\nwith open(\"numbers.txt\", \"w\") as file:\n for i in range(0, 1000000):\n random_number = int(minimum + (random.random() * (maximum - minimum)))\n file.write(str(random_number) + \"\\n\")\n"
},
{
"alpha_fraction": 0.7305577397346497,
"alphanum_fraction": 0.7321288585662842,
"avg_line_length": 30.04878044128418,
"blob_id": "c07fe5ada92d4cdd2d9db29f4981ee80abd0569c",
"content_id": "09b1101bf42c077195a93b90f49016d84c260e06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1273,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 41,
"path": "/pybind_test.py",
"repo_name": "FarokhC/ProgrammingPerformanceAndExperimentation",
"src_encoding": "UTF-8",
"text": "import stats_func\nimport time\n\nnumbers = []\nlines = None\n\n#Read lines and get time\nread_lines_start_time = time.time()\nwith open(\"numbers.txt\", 'r') as file:\n lines = file.readlines()\nnumbers = [int(line) for line in lines]\nread_lines_end_time = time.time()\nread_lines_time = read_lines_end_time - read_lines_start_time\n\n#Compute time to get average\npython_avg_start_time = time.time()\npython_avg = stats_func.getAvg(numbers)\npython_avg_end_time = time.time()\npython_avg_time = python_avg_end_time - python_avg_start_time\n\n#Compute time to get std\npython_std_start_time = time.time()\npython_std = stats_func.getSTD(numbers)\npython_std_end_time = time.time()\npython_std_time = python_std_end_time - python_std_start_time\n\n#Print results\nprint(\"Python time to read file: \" + str(read_lines_time))\n\nprint(\"Python computational average: \" + str(python_avg))\nprint(\"Python computational average time: \" + str(python_avg_time))\n\nprint(\"Python computaitonal standard deviation: \" + str(python_std))\nprint(\"Python computaitonal standard deviation time: \" + str(python_std_time))\n\n\n\n# TODO: Call C++ average and standard deviation (using pybind11) code and compare results\n\n# TODO: Add more cases (small list, large list, etc...)\n# so we have more data to investigate and report\n"
}
] | 6 |
Syangmay/MyntraHack | https://github.com/Syangmay/MyntraHack | 86fa48a76681b5f0da9a9b09ab7e00e8141baa95 | aab825d296ee6e8de1f14c2c0be5668251d534e3 | 286329387d6de314e225bf60ed07ce54e62d64a3 | refs/heads/main | 2023-01-05T13:16:02.773459 | 2020-11-01T18:04:45 | 2020-11-01T18:04:45 | 308,985,896 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6003710627555847,
"alphanum_fraction": 0.6111317276954651,
"avg_line_length": 38.632354736328125,
"blob_id": "6342c7c77a4ca2ae0162fa82b3f3222ec9245644",
"content_id": "fd46c79964d2491eb56fdee82eb3a5b48d40bacc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2695,
"license_type": "no_license",
"max_line_length": 198,
"num_lines": 68,
"path": "/jacket.py",
"repo_name": "Syangmay/MyntraHack",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\n\ndef getjackets(attr, count):\n dfjackets = pd.read_csv('data/mjackets.csv')\n\n del dfjackets['Waist Rise']\n del dfjackets['Fit']\n del dfjackets['Brand Fit Name']\n del dfjackets['Type of Pleat']\n del dfjackets['Weave Type']\n del dfjackets['Fly Type']\n del dfjackets['Distress']\n del dfjackets['Hemline']\n del dfjackets['Occasion']\n del dfjackets['Features']\n\n\n dfjackets['Print or Pattern Type']=dfjackets['Print or Pattern Type'].fillna(value='Solid')\n dfjackets['Closure']=dfjackets['Closure'].fillna(value='Zip')\n dfjackets['Number of Pockets']=dfjackets['Number of Pockets'].fillna(value='0')\n\n\n #attr=['Quilted Jacket', 'Bomber', 'Puffer', 'Padded Jacket', 'Leather Jacket', 'Long Sleeves', 'Sporty Jacket']\n #count=[2, 3.0, 2, 2, 3.0, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0]\n dfjackets.insert(13,'Score', 1)\n\n for ind in dfjackets.index:\n if dfjackets['Type'][ind] in attr:\n a=attr.index(dfjackets['Type'][ind])\n dfjackets['Score'][ind]+=count[a]\n\n if dfjackets['Sleeve Length'][ind] in attr:\n a=attr.index(dfjackets['Sleeve Length'][ind])\n dfjackets['Score'][ind]+=count[a]\n\n if dfjackets['Print or Pattern Type'][ind] in attr:\n a=attr.index(dfjackets['Print or Pattern Type'][ind])\n dfjackets['Score'][ind]+=count[a]\n\n if dfjackets['Closure'][ind] in attr:\n a=attr.index(dfjackets['Closure'][ind])\n dfjackets['Score'][ind]+=count[a]\n\n if dfjackets['Lining Fabric'][ind] in attr:\n a=attr.index(dfjackets['Lining Fabric'][ind])\n dfjackets['Score'][ind]+=count[a]\n\n if dfjackets['Number of Pockets'][ind] in attr:\n a=attr.index(dfjackets['Number of Pockets'][ind])\n dfjackets['Score'][ind]+=count[a]\n\n\n\n td=dfjackets['Score'].mean()\n #for final in dfjackets.index:\n # if dfjackets['Score'][final] >= int(td):\n# print(dfjackets['title'][final],dfjackets['name'][final],dfjackets['price'][final])\n# print(td)\n dfjackets = dfjackets.sort_values(['Score'], ascending=[False])\n\n return dfjackets['title'].tolist()[:60], dfjackets['productId'].tolist()[:60], dfjackets['name'].tolist()[:60], dfjackets['price'].tolist()[:60]\n\n #dfjackets['Print or Pattern Type'].value_counts()\n\n\n#att=['Zip','Button','Solid','Colourblocked','Self Design','Bomber','Sporty Jacket','Padded Jacket','Denim Jacket','Tailored Jacket','Puffer Jacket','Quilted Jacket','Biker Jacket','Leather Jacket',\n #'Polyester','Unlined','Cotton','Fleece','Nylon','Polycotton','Sleeveless ','Long Sleeves']\n"
},
{
"alpha_fraction": 0.6252129673957825,
"alphanum_fraction": 0.6375638842582703,
"avg_line_length": 36.870967864990234,
"blob_id": "d3c92c619bb60adaa124d436c4d2a0f83f6e6773",
"content_id": "c731e7e1d665251544ec438c018397a3e8dcdaa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2348,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 62,
"path": "/data/retrieval.py",
"repo_name": "Syangmay/MyntraHack",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport urllib.request\nimport os\nimport json\nimport time\nimport pandas as pd\n\nlink = \"https://www.myntra.com/jackets/campus-sutra/campus-sutra-men-off-white-solid-tailored-jacket/10890976/buy\"\ndriver = webdriver.Chrome('chromedriver')\ndfl = pd.read_csv(\"data/links/womenskirtlinks.csv\")\n\ncolumn_names = [\"title\", \"name\", \"price\", \"Waist Rise\", \"Length\", \"Fit\", \"Brand Fit Name\", \"Print or Pattern Type\", \"Closure\", \"Type of Pleat\", \"Weave Type\", \"Fly Type\", \"productId\"]\n\ndf = pd.DataFrame(columns = column_names)\n\ni=0\n\nfor link in dfl[\"link\"].tolist():\n if i==350:\n break\n\n try:\n metadata = {}\n driver.get(link)\n metadata['title'] = driver.find_element_by_class_name('pdp-title').get_attribute(\"innerHTML\")\n metadata['name'] = driver.find_element_by_class_name('pdp-name').get_attribute(\"innerHTML\")\n metadata['price'] = driver.find_element_by_class_name('pdp-price').find_element_by_xpath('./strong').get_attribute(\"innerHTML\")\n\n try:\n driver.find_element_by_class_name('index-showMoreText').click()\n except:\n j = 0;\n metadata['specifications'] = {}\n\n #commmment\n for index_row in driver.find_element_by_class_name('index-tableContainer').find_elements_by_class_name('index-row'):\n metadata[index_row.find_element_by_class_name('index-rowKey').get_attribute(\"innerHTML\")] = index_row.find_element_by_class_name('index-rowValue').get_attribute(\"innerHTML\")\n metadata['productId'] = driver.find_element_by_class_name('supplier-styleId').get_attribute(\"innerHTML\")\n\n df = df.append(metadata, ignore_index=True)\n #neech ka images ke liye hai\n\n base = \"C:\\\\Users\\\\Ipshita\\\\Desktop\\\\github\\\\Myntra\"\n itr = 1\n\n for image_tags in driver.find_elements_by_class_name('image-grid-image'):\n image_path = os.path.join(\"images//wskirts//\" + metadata['productId'] + '_'+str(itr)+\".jpg\")\n urllib.request.urlretrieve( image_tags.get_attribute('style').split(\"url(\\\"\")[1].split(\"\\\")\")[0], image_path)\n itr +=1\n\n #print(metadata)\n i = i+1\n print(str(i) + \" of 17,000 products\")\n\n except:\n i = i+1\n print(str(i) + \" of 17,000 products - error\")\n\ndf.to_csv(\"data/wskirts.csv\")\n\ndriver.close()\ndriver.quit()\n"
},
{
"alpha_fraction": 0.6041209101676941,
"alphanum_fraction": 0.6171948313713074,
"avg_line_length": 25.632312774658203,
"blob_id": "8057cbe20adf14c6efac07bf518a7777664ff567",
"content_id": "884620d6afe8eee17896772523e5b4564c940577",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9561,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 359,
"path": "/app.py",
"repo_name": "Syangmay/MyntraHack",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, render_template, render_template_string\nfrom jacket import getjackets\n\nimport pandas as pd\n\nmjackets = {}\nmjeans = {}\nmshirts = {}\nmtshirts = {}\n\njackets = []\njacketcount = [0] * 15\n\n\napp = Flask(__name__)\n\n@app.route('/')\ndef index():\n return render_template(\"index.html\")\n\n@app.route('/begin')\ndef begin():\n return render_template(\"page1.html\")\n\n@app.route('/gender')\ndef gender():\n return render_template(\"gender.html\")\n\n@app.route('/products')\ndef products():\n title, productid, name, price = getjackets(jackets, jacketcount)\n productId = [str(i) for i in productid]\n length = len(title)\n print(title)\n\n return render_template(\"productlist.html\", title=title, productid=productId, name=name, price=price, length=length)\n\n\n@app.route('/men')\ndef men():\n return render_template(\"men.html\")\n\n\n\n@app.route('/menjackets', methods=['get','post'])\ndef menjackets():\n\n return render_template(\"menjackets.html\")\n\n@app.route('/menjackets2', methods=['get','post'])\ndef menjackets2():\n if request.method == 'POST':\n images = request.form.getlist('image[]')\n print(images)\n attribute = []\n if \"jacket1\" in images:\n attribute.append(\"Leather\")\n if \"jacket2\" in images:\n attribute.append(\"Puffer\")\n attribute.append(\"Padded\")\n if \"jacket3\" in images:\n attribute.append(\"Denim\")\n if \"jacket4\" in images:\n attribute.append(\"Tailored\")\n if \"jacket5\" in images:\n attribute.append(\"Bomber\")\n attribute.append(\"Biker\")\n if \"jacket6\" in images:\n attribute.append(\"Sporty\")\n\n for i in range(len(attribute)):\n if attribute[i] not in jackets:\n jackets.append(attribute[i])\n jacketcount[jackets.index(attribute[i])] += 1\n\n return render_template(\"menjackets2.html\")\n\n@app.route('/menjackets3', methods=['get','post'])\ndef menjackets3():\n if request.method == 'POST':\n weather = request.form.get('gender')\n\n if weather == \"yes\" :\n attributes = [\"Quilted\" , \"Bomber\", \"Puffer\" , \"Padded\" , \"Leather\", \"Full Sleeve\"]\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 1\n print(\"weather:\")\n print(jackets)\n print(jacketcount)\n\n return render_template(\"menjackets3.html\")\n\n@app.route('/menjackets4', methods=['get','post'])\ndef menjackets4():\n if request.method == 'POST':\n biking = request.form.get('biking')\n attributes = [\"Bomber\", \"Leather\"]\n\n if biking == \"often\" :\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 1\n elif biking==\"sometimes\":\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 0.5\n print(\"biking:\")\n print(jackets)\n print(jacketcount)\n return render_template(\"menjackets4.html\")\n\n@app.route('/menjackets5', methods=['get','post'])\ndef menjackets5():\n if request.method == 'POST':\n sports = request.form.get('sports')\n\n if sports == \"yes\" :\n attributes = [\"Sporty\"]\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 1\n\n print(\"sports:\")\n print(jackets)\n print(jacketcount)\n\n return render_template(\"menjackets5.html\")\n\n@app.route('/menjackets6', methods=['get','post'])\ndef menjackets6():\n\n if request.method == 'POST':\n party = request.form.get('party')\n attributes = [\"Tailored\" , \"Bomber\", \"Denim\", \"Leather\"]\n\n if party == \"often\" :\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 1\n elif party==\"sometimes\":\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 0.5\n elif party==\"rarely\":\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 0.25\n\n print(\"party:\")\n print(jackets)\n print(jacketcount)\n return render_template(\"menjackets6.html\")\n\n@app.route('/menjackets7', methods=['get','post'])\ndef menjackets7():\n\n\n return render_template(\"menjackets7.html\")\n\n@app.route('/menjackets8', methods=['get','post'])\ndef menjackets8():\n return render_template(\"menjackets8.html\")\n\n@app.route('/menjackets9', methods=['get','post'])\ndef menjackets9():\n if request.method == 'POST':\n formal = request.form.get('formal')\n\n if formal == \"yes\" :\n attributes = [\"Puffer\", \"Padded\", \"Bomber\"]\n for i in range(len(attributes)):\n if attributes[i] not in jackets:\n jackets.append(attributes[i])\n jacketcount[jackets.index(attributes[i])] += 1\n print(\"daily:\")\n print(jackets)\n print(jacketcount)\n return render_template(\"menjackets9.html\")\n\n@app.route('/menjackets10', methods=['get','post'])\ndef menjackets10():\n if request.method == 'POST':\n closure = request.form.get('prefer')\n\n if closure not in jackets:\n jackets.append(closure)\n jacketcount[jackets.index(closure)] += 1\n\n print(\"closure:\")\n print(jackets)\n print(jacketcount)\n return render_template(\"menjackets10.html\")\n\n@app.route('/bodytype', methods=['get','post'])\ndef bodytype():\n if request.method == 'POST':\n pockets = request.form.get('pockets')\n attributes = [\"Tailored\" , \"Bomber\", \"Denim\", \"Leather\"]\n\n if pockets == \"lots\" :\n if \"Pockets\" not in jackets:\n jackets.append(\"Pockets\")\n jacketcount[jackets.index(\"Pockets\")] += 2\n elif pockets==\"few\":\n if \"Pockets\" not in jackets:\n jackets.append(\"Pockets\")\n jacketcount[jackets.index(\"Pockets\")] += 1\n\n print(\"pockets:\")\n print(jackets)\n print(jacketcount)\n return render_template(\"bodytype.html\")\n\n@app.route('/end')\ndef end():\n attr = []\n count = []\n return render_template(\"end.html\")\n\n\n\n\n\n\n@app.route('/menjeans')\ndef menjeans():\n return render_template(\"menjeans.html\")\n\n@app.route('/menjeans1')\ndef menjeans1():\n return render_template(\"menjeans1.html\")\n\n@app.route('/menjeans2')\ndef menjeans2():\n return render_template(\"menjeans2.html\")\n\n@app.route('/menjeans3')\ndef menjeans3():\n return render_template(\"menjeans3.html\")\n\n@app.route('/menjeans4')\ndef menjeans4():\n return render_template(\"menjeans4.html\")\n\n@app.route('/menjeans5')\ndef menjeans5():\n return render_template(\"menjeans5.html\")\n\n@app.route('/menjeans6')\ndef menjeans6():\n return render_template(\"menjeans6.html\")\n\n\n\n\n\n\n@app.route('/menshirt')\ndef menshirt():\n return render_template(\"menshirt.html\")\n\n@app.route('/menshirt1')\ndef menshirt1():\n return render_template(\"menshirt1.html\")\n\n@app.route('/menshirt2')\ndef menshirt2():\n return render_template(\"menshirt2.html\")\n\n@app.route('/menshirt3')\ndef menshirt3():\n return render_template(\"menshirt3.html\")\n\n@app.route('/menshirt4')\ndef menshirt4():\n return render_template(\"menshirt4.html\")\n\n@app.route('/menshirt5')\ndef menshirt5():\n return render_template(\"menshirt5.html\")\n\n\n\n\n\n@app.route('/women')\ndef women():\n return render_template(\"women.html\")\n\n@app.route('/womenjumpsuit')\ndef womenjumpsuit():\n return render_template(\"womenjumpsuit.html\")\n\n@app.route('/womenjeans')\ndef womenjeans():\n return render_template(\"womenjeans.html\")\n\n@app.route('/womenjumpsuit1')\ndef womenjumpsuit1():\n return render_template(\"womenjumpsuit1.html\")\n\n@app.route('/womenjumpsuit2')\ndef womenjumpsuit2():\n return render_template(\"womenjumpsuit2.html\")\n\n@app.route('/womenjumpsuit3')\ndef womenjumpsuit3():\n return render_template(\"womenjumpsuit3.html\")\n\n@app.route('/womenjumpsuit4')\ndef womenjumpsuit4():\n return render_template(\"womenjumpsuit4.html\")\n\n@app.route('/womenjumpsuit5')\ndef womenjumpsuit5():\n return render_template(\"womenjumpsuit5.html\")\n\n@app.route('/womenjumpsuit6')\ndef womenjumpsuit6():\n return render_template(\"womenjumpsuit6.html\")\n\n@app.route('/mentshirt')\ndef mentshirt():\n return render_template(\"mentshirt.html\")\n\n@app.route('/mentshirt1')\ndef mentshirt1():\n return render_template(\"mentshirt1.html\")\n\n@app.route('/mentshirt2')\ndef mentshirt2():\n return render_template(\"mentshirt2.html\")\n\n@app.route('/mentshirt3')\ndef mentshirt3():\n return render_template(\"mentshirt3.html\")\n\n@app.route('/mentshirt4')\ndef mentshirt4():\n return render_template(\"mentshirt4.html\")\n\n@app.route('/mentshirt5')\ndef mentshirt5():\n return render_template(\"mentshirt5.html\")\n\n@app.route('/mentshirt6')\ndef mentshirt6():\n return render_template(\"mentshirt6.html\")\n\nif __name__ == \"__main__\":\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.6347717046737671,
"alphanum_fraction": 0.6397748589515686,
"avg_line_length": 28.61111068725586,
"blob_id": "255e6fe883e05f32cb9c117b8b0e147b29304b1e",
"content_id": "3f0cde0b0243f4bbff43ffe9b6c51d77043e6d1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1599,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 54,
"path": "/data/datacollection.py",
"repo_name": "Syangmay/MyntraHack",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport urllib.request\nimport os\nimport json\nimport time\nimport pandas as pd\n\ndef products(driver, links, itr):\n time.sleep(5)\n for product_base in driver.find_elements_by_class_name('product-base'):\n try:\n links.append( product_base.find_element_by_xpath('./a').get_attribute(\"href\"))\n itr = itr+1\n print(itr)\n\n except:\n print(\"Error occured with \", product_base)\n\n return links, itr\n\ndef getlinks(search_string):\n links=[]\n itr = 0\n driver = webdriver.Chrome('chromedriver')\n #driver.get('https://www.myntra.com/')\n driver.get('https://www.myntra.com/women-shorts-skirts')\n time.sleep(4)\n\n #driver.find_element_by_class_name('desktop-searchBar').send_keys(search_string)\n #driver.find_element_by_class_name('desktop-submit').click()\n\n while(True):\n if itr>500:\n break\n links, itr = products(driver, links, itr)\n time.sleep(5)\n try:\n driver.find_element_by_class_name('pagination-next').click()\n except:\n driver.close()\n driver.quit()\n break\n\n print(links)\n print(len(links))\n return links\n\nsearch_string = \"Women Tops, T-Shirts & Shirts\"\nlinks = getlinks(search_string)\n#find_element_by_class_name('pdp-name').get_attribute(\"innerHTML\")metadata['price'] = driver.find_element_by_class_name('pdp-price').find_element_by_xpath('./strong').get_attribute(\"innerHTML\")\n\ndf = pd.DataFrame(links,columns=['link'])\nprint(df)\ndf.to_csv('data/links/womenskirtlinks.csv', index=False)\n"
}
] | 4 |
amiacoder/leetcode | https://github.com/amiacoder/leetcode | 4e44588eed63b60f0aab2f850c558686907d4f27 | 3a3a21c72b93857f5e3954874ec7c3d915350ded | de8d8381a4c98aed87a90d4be9344a67ed1bea19 | refs/heads/master | 2022-11-18T11:24:15.469572 | 2020-07-17T15:11:57 | 2020-07-17T15:11:57 | 256,767,774 | 1 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.3017142713069916,
"alphanum_fraction": 0.328000009059906,
"avg_line_length": 45.05263137817383,
"blob_id": "a56bfb0c1e2067df47b0e3990c14e53a7f1c3424",
"content_id": "4888a6482432b09d9d523c9fa56abd15c4d6bb87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 19,
"path": "/leet_code_59.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution:\n def generateMatrix(self, n):\n list0 = [j for j in range(1,n**2 + 1)] # 生成长列表\n x = y = 0\n dx = [0,1,0,-1] # 方向坐标\n dy = [1,0,-1,0]\n di = 0\n visited = set() # 初始化集合,用于记录已走过坐标\n list1 = [[None for k in range(n)] for k in range(n)] # 生成空矩阵\n for i in range(n**2):\n list1[x][y] = list0[i] \n visited.add((x,y))\n nx,ny = x + dx[di],y+dy[di] # 记录下一步操作\n if 0<=nx<n and 0<=ny<n and (nx,ny) not in visited: # 判断是否越界,未曾走过的路\n x,y = nx,ny\n else:\n di = (di+1)%4\n x,y= x+dx[di],y+dy[di]\n return list1\n"
},
{
"alpha_fraction": 0.45390069484710693,
"alphanum_fraction": 0.4609929025173187,
"avg_line_length": 27.200000762939453,
"blob_id": "08dca7e0532cd7d7ae7fa649c70cf88a88fcc278",
"content_id": "c2f94169ccc26e52e634967d9e47dcf6c81e90d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 15,
"path": "/remove_duplicates_num_in_sorted_list.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def removeDuplicates(self, nums):\n \"\"\"\n :type nums: List[int]\n :rtype: int\n \"\"\"\n index = len(nums) - 1\n last_value = None\n while index >= 0:\n if last_value != None and nums[index] == last_value:\n del(nums[index])\n else:\n last_value = nums[index]\n index -= 1\n return len(nums)\n"
},
{
"alpha_fraction": 0.5095541477203369,
"alphanum_fraction": 0.5276008248329163,
"avg_line_length": 31.482759475708008,
"blob_id": "bffb6d0d3da7f954c177a61fd04b667c24e0e5c3",
"content_id": "5244ae543719f5ed0cf7135f8452da278df5b623",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 942,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 29,
"path": "/divide.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def divide(self, dividend, divisor):\n \"\"\"\n :type dividend: int\n :type divisor: int\n :rtype: int\n \"\"\"\n if divisor == 0:\n return 0\n if divisor == 1:\n return dividend\n if divisor == -1:\n return -dividend if dividend > 0 else min(-dividend, 2**31-1)\n if (divisor > 0 and dividend > 0) or (divisor < 0 and dividend < 0):\n return self.getResult(abs(dividend), abs(divisor))\n else:\n return -self.getResult(abs(dividend), abs(divisor))\n\n def getResult(self, dividend, divisor):\n i = 0\n origin_divisor = divisor\n last_divisor = divisor\n while dividend - divisor >= 0:\n i = 2**i\n last_divisor = divisor\n divisor += divisor\n if i < 1:\n return i\n return i + self.getResult(dividend-last_divisor, origin_divisor)\n"
},
{
"alpha_fraction": 0.42397475242614746,
"alphanum_fraction": 0.4321766495704651,
"avg_line_length": 31.32653045654297,
"blob_id": "0d924204f9c4e2cf13bf44ebd77e811da89904cd",
"content_id": "5193669f33380bb24be9617804dda0420a8d6b01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1765,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 49,
"path": "/three_sum.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def threeSum(self, nums):\n \"\"\"\n :type nums: List[int]\n :rtype: List[List[int]]\n \"\"\"\n if len(nums) < 3:\n return []\n nums = self.quickSort(nums)\n n = len(nums)\n ans = []\n # 枚举 a\n for first in range(n):\n # 需要和上一次枚举的数不相同\n if first > 0 and nums[first] == nums[first - 1]:\n continue\n # c 对应的指针初始指向数组的最右端\n third = n - 1\n target = -nums[first]\n # 枚举 b\n for second in range(first + 1, n):\n # 需要和上一次枚举的数不相同\n if second > first + 1 and nums[second] == nums[second - 1]:\n continue\n # 需要保证 b 的指针在 c 的指针的左侧\n while second < third and nums[second] + nums[third] > target:\n third -= 1\n # 如果指针重合,随着 b 后续的增加\n # 就不会有满足 a+b+c=0 并且 b<c 的 c 了,可以退出循环\n if second == third:\n break\n if nums[second] + nums[third] == target:\n ans.append([nums[first], nums[second], nums[third]])\n return ans\n\n def quickSort(self, nums):\n if len(nums) < 2:\n return nums\n ref = nums[0]\n i = 1\n left_arr = []\n right_arr = []\n while i < len(nums):\n if nums[i] < ref:\n left_arr.append(nums[i])\n else:\n right_arr.append(nums[i])\n i += 1\n return self.quickSort(left_arr) + [ref] + self.quickSort(right_arr)\n\n"
},
{
"alpha_fraction": 0.3871733844280243,
"alphanum_fraction": 0.3931116461753845,
"avg_line_length": 32.68000030517578,
"blob_id": "a21e8c8e5d6dea8b6fc4c8fb8a66b1ac4eef0c33",
"content_id": "b75c5fe9e0e0cda18672e1fe110927c4ff382947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 842,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 25,
"path": "/isvalid_brackets.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def isValid(self, s):\n \"\"\"\n :type s: str\n :rtype: bool\n \"\"\"\n v_map = {'(': ')', '{': '}', '[': ']'}\n list_to_remove = []\n start = 0\n is_valid_str = True\n while start < len(s):\n if s[start] not in v_map:\n if s[start] not in list_to_remove:\n is_valid_str = False\n break\n else:\n if list_to_remove[len(list_to_remove)-1] == s[start]:\n del(list_to_remove[len(list_to_remove)-1])\n else:\n is_valid_str = False\n break\n else:\n list_to_remove.append(v_map[s[start]])\n start += 1\n return (is_valid_str and len(list_to_remove) == 0)\n"
},
{
"alpha_fraction": 0.3655914068222046,
"alphanum_fraction": 0.3851417303085327,
"avg_line_length": 28.794116973876953,
"blob_id": "7115de88de619a298f11ab36cf21e829e4f6b19e",
"content_id": "760895979d2f53a81afb6d3bb3f9706e9c71138c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1023,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 34,
"path": "/atoi.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "c1ass Solution(object):\n def myAtoi(self, str):\n \"\"\"\n :type str: str\n :rtype: int\n \"\"\"\n if not str or len(str) == 0:\n return 0\n valid_char = None\n for char in str:\n if not valid_char:\n if char == ' ':\n continue\n elif char == '-' or char == '+' or char.isdigit():\n valid_char = char\n else:\n return 0\n else:\n if char.isdigit():\n valid_char += char\n else:\n break\n #print valid_char\n if not valid_char:\n return 0\n if valid_char[0] == '-':\n if len(valid_char) == 1:\n return 0;\n return -min(int(valid_char[1:]), 2**31)\n elif valid_char[0] == '+':\n valid_char = valid_char[1:]\n if len(valid_char) == 0:\n return 0;\n return min(int(valid_char), 2**31-1)\n \n\n"
},
{
"alpha_fraction": 0.5231350064277649,
"alphanum_fraction": 0.5231350064277649,
"avg_line_length": 30.147058486938477,
"blob_id": "e964997455d87989f61ffdbb87ae6c668168f12e",
"content_id": "3da4609990e8dc8ea1f57b1774bee1eb36753a94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1059,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 34,
"path": "/swap_nebour_node_in_link_list.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "# Definition for singly-linked list.\n# class ListNode(object):\n# def __init__(self, x):\n# self.val = x\n# self.next = None\n\nclass Solution(object):\n def swapPairs(self, head):\n \"\"\"\n :type head: ListNode\n :rtype: ListNode\n \"\"\"\n if not head or not head.next:\n return head\n result_head = None\n cursor = head\n next_cursor = cursor.next\n last_node = None\n while cursor and next_cursor:\n # print 'test', cursor.val, next_cursor.val\n temp_cursor = next_cursor.next\n next_cursor.next = cursor\n cursor.next = temp_cursor\n if last_node:\n last_node.next = next_cursor\n last_node = cursor\n if not result_head:\n result_head = next_cursor\n if not cursor.next or not cursor.next.next:\n break\n cursor = cursor.next\n next_cursor = cursor.next\n # print cursor.val, next_cursor.val\n return result_head\n"
},
{
"alpha_fraction": 0.33227992057800293,
"alphanum_fraction": 0.3553047478199005,
"avg_line_length": 35.91666793823242,
"blob_id": "aad7d8dee58b441850adc7deda97cf841fe10c0f",
"content_id": "2ff61506a906291c47ffa539dcea784fdbb57ec8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2309,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 60,
"path": "/zigzag.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def convert(self, s, numRows):\n \"\"\"\n :type s: str\n :type numRows: int\n :rtype: str\n \"\"\"\n if numRows == 1:\n return s\n if len(s) < 3:\n return s\n l = [[s[0]]]\n last_position = [0, 0, 0] # 第几个字数组,第几个位置,是否z 平字边\n i = 1\n while i < len(s):\n if last_position[2] == 0:\n # z 横字边\n if last_position[1] == numRows - 1:\n # 上次已经填满z 横字边\n last_position[0] = last_position[0] + 1\n last_position[1] = numRows - 2\n last_position[2] = 1\n sub_l = []\n l.append(sub_l)\n for j in range(0, numRows):\n if j == numRows - 2:\n sub_l.append(s[i])\n else:\n sub_l.append(-1)\n else:\n sub_l = l[last_position[0]]\n sub_l.append(s[i])\n last_position[1] = last_position[1] + 1\n else:\n # 上次不是z 横字边\n if last_position[1] == 0:\n #刚好填到下一个 z 字横边\n l[last_position[0]] = l[last_position[0]][0:1]\n sub_l = l[last_position[0]]\n last_position[1] = last_position[1] + 1\n last_position[2] = 0\n sub_l.append(s[i])\n else:\n last_position[0] = last_position[0] + 1\n last_position[1] = last_position[1] - 1\n last_position[2] = 1\n sub_l = []\n l.append(sub_l)\n for j in range(0, numRows):\n if j == last_position[1]:\n sub_l.append(s[i])\n else:\n sub_l.append(-1)\n i = i + 1\n final_s = ''\n for j in range(0, numRows):\n for i in range(0, len(l)):\n if j < len(l[i]) and not isinstance(l[i][j], int):\n final_s = final_s + l[i][j]\n return final_s\n"
},
{
"alpha_fraction": 0.38787877559661865,
"alphanum_fraction": 0.40909090638160706,
"avg_line_length": 24.384614944458008,
"blob_id": "e5cf5d0ab66801aac934fc8975a91b88c35fdd91",
"content_id": "2daf166abac1cc906a1487ea7a337d4633211ab6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 13,
"path": "/reverse_int.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def reverse(self, x):\n \"\"\"\n :type x: int\n :rtype: int\n \"\"\"\n flag = True if x < 0 else False\n s = str(x)[::-1]\n if flag:\n s = str(x)[1:][::-1]\n if len(bin(int(s))) > 33:\n return 0\n return (-int(s) if flag else int(s))\n"
},
{
"alpha_fraction": 0.3983606696128845,
"alphanum_fraction": 0.41147541999816895,
"avg_line_length": 26.727272033691406,
"blob_id": "6c960afb03982473f47e712f504e6db3637c2e4f",
"content_id": "df3b7bbacac7f4a8d523cf6b23d8f55605578eef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 22,
"path": "/longest_unrepeated_substr.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def lengthOfLongestSubstring(self, s):\n \"\"\"\n :type s: str\n :rtype: int\n \"\"\"\n if not s:\n return 0\n start = 0\n cur_len = 0\n max_length = 0\n look_up = set()\n for i in range(0, len(s)):\n cur_len += 1\n if s[i] in look_up:\n while s[i] in look_up:\n look_up.remove(s[start])\n start += 1\n cur_len -= 1\n look_up.add(s[i])\n if cur_len > max_length: max_length = cur_len\n return max_length\n"
},
{
"alpha_fraction": 0.41550523042678833,
"alphanum_fraction": 0.4216027855873108,
"avg_line_length": 44.91999816894531,
"blob_id": "eab3987970e70e639ca2005a3e24a0709fd2470c",
"content_id": "84a914b5a6e5b0fac5144e29f8349c65fe940506",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1148,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 25,
"path": "/valid_sodu.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def isValidSudoku(self, board):\n \"\"\"\n :type board: List[List[str]]\n :rtype: bool\n \"\"\"\n temp_map = {}\n for i in range(0, 9):\n if 'row' + str(i) not in temp_map:\n temp_map['row' + str(i)] = []\n for j in range(0, 9):\n if 'column' + str(j) not in temp_map:\n temp_map['column' + str(j)] = []\n sub_board = (i / 3) * 3 + j / 3\n if 'board' + str(sub_board) not in temp_map:\n temp_map['board' + str(sub_board)] = []\n if board[i][j] in temp_map['row' + str(i)] or board[i][j] in temp_map['column' + str(j)] or board[i][j] in temp_map['board' + str(sub_board)]:\n # print temp_map, i, j, sub_board\n return False\n else:\n if board[i][j] != '.':\n temp_map['board' + str(sub_board)].append(board[i][j])\n temp_map['row' + str(i)].append(board[i][j])\n temp_map['column' + str(j)].append(board[i][j])\n return True\n"
},
{
"alpha_fraction": 0.5324909687042236,
"alphanum_fraction": 0.5324909687042236,
"avg_line_length": 31.558822631835938,
"blob_id": "70fc5d40f993437679fc0d4d35ad8e2788c6e3df",
"content_id": "9aa90c401b7aea597d60ba47284bf48869d9dcb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 34,
"path": "/lowest_common_ancestor.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "# Definition for a binary tree node.\n# class TreeNode(object):\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nresult = None\n\nclass Solution(object):\n def lowestCommonAncestor(self, root, p, q):\n \"\"\"\n :type root: TreeNode\n :type p: TreeNode\n :type q: TreeNode\n :rtype: TreeNode\n \"\"\"\n def current_branch_contains_destination(node, p, q):\n if not node:\n return False\n global result\n left_result = current_branch_contains_destination(node.left, p, q)\n right_result = current_branch_contains_destination(node.right, p, q)\n if node.val == p.val or node.val == q.val:\n if left_result or right_result:\n result = node\n return True\n if left_result and right_result:\n result = node\n return True\n if left_result or right_result:\n return True\n current_branch_contains_destination(root, p, q)\n return result\n\n"
},
{
"alpha_fraction": 0.48446327447891235,
"alphanum_fraction": 0.4887005686759949,
"avg_line_length": 25.22222137451172,
"blob_id": "c5eaec0e5d3f1577b8882bf5a9700d78b29bf674",
"content_id": "955c32315ab9b9532d29e7aa485e900db5e6af21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 27,
"path": "/remove_link_list_node.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "tion for singly-linked list.\n# class ListNode(object):\n# def __init__(self, x):\n# self.val = x\n# self.next = None\n\nclass Solution(object):\n def removeNthFromEnd(self, head, n):\n \"\"\"\n :type head: ListNode\n :type n: int\n :rtype: ListNode\n \"\"\"\n start = -n + 1\n end_node = head\n start_node = head\n pre_node = None\n while end_node.next:\n end_node = end_node.next\n start += 1\n if start > 0:\n pre_node = start_node\n start_node = start_node.next\n if not pre_node:\n return head.next\n pre_node.next = start_node.next\n return head\n"
},
{
"alpha_fraction": 0.40111732482910156,
"alphanum_fraction": 0.4111731946468353,
"avg_line_length": 26.65625,
"blob_id": "6492e4acb875b8aab5ac1196569a6b1639008332",
"content_id": "8692a8fd6ddd2919ee57e81bf380b4e1651d5c82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 895,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/next_permutation.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def nextPermutation(self, nums):\n \"\"\"\n :type nums: List[int]\n :rtype: None Do not return anything, modify nums in-place instead.\n \"\"\"\n if len(nums) < 2:\n return None\n left = len(nums) - 2\n right = len(nums) - 1\n while left >= 0:\n if nums[right] > nums[left]:\n break\n else:\n right -= 1\n left -= 1\n i = len(nums) - 1\n\n while i >= right:\n if nums[i] > nums[left]:\n temp = nums[left]\n nums[left] = nums[i]\n nums[i] = temp\n break\n i -= 1\n right_arr = nums[right:len(nums)]\n right_arr.sort()\n i = right\n while i < len(nums):\n nums[i] = right_arr[i-right]\n i += 1\n return nums\n\n \n"
},
{
"alpha_fraction": 0.36347198486328125,
"alphanum_fraction": 0.39421337842941284,
"avg_line_length": 25.33333396911621,
"blob_id": "95f7288d606de2013460aa711778070d6eb03199",
"content_id": "2306dd79b7dc89fdbfd3f0970903d1da2a1eed4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 21,
"path": "/palindrome_number.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution:\n def isPalindrome(self, x):\n # if x == 0:\n # return True\n # elif x < 0:\n # return False\n # else:\n # return str(x)[::-1] == str(x)\n\n if x < 0:\n return False\n elif x == 0:\n return True\n elif x%10 == 0:\n return False\n else:\n revert_num = 0\n while x > revert_num:\n revert_num = revert_num * 10 + x%10\n x //= 10\n return x == revert_num or x == revert_num // 10\n"
},
{
"alpha_fraction": 0.3551483452320099,
"alphanum_fraction": 0.36823734641075134,
"avg_line_length": 28.384614944458008,
"blob_id": "f95da93019475ef8b74fb96174c43022f7e69a88",
"content_id": "79eab2d1a8371e89da1a7d9469e699dd071a16d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1154,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 39,
"path": "/search_rotated_list_to_find_target.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def search(self, nums, target):\n \"\"\"\n :type nums: List[int]\n :type target: int\n :rtype: int\n \"\"\"\n if not nums or len(nums) == 0:\n return -1\n if target > nums[-1]:\n # 正序\n destination = -1\n i = 0\n while target > nums[i] and i < len(nums) - 2:\n if target == nums[i]:\n destination = i\n break\n if nums[i+1] < nums[i]:\n break\n i += 1\n if target == nums[i]:\n destination = i\n return destination\n elif target < nums[-1]:\n # 倒序\n destination = -1\n i = len(nums) - 1\n while target < nums[i] and i > 0:\n if target == nums[i]:\n destination = i\n break\n if nums[i-1] > nums[i]:\n break\n i -= 1\n if target == nums[i]:\n destination = i\n return destination\n else:\n return len(nums) - 1\n"
},
{
"alpha_fraction": 0.4336372911930084,
"alphanum_fraction": 0.43971630930900574,
"avg_line_length": 35.33333206176758,
"blob_id": "6b25c372e9e53692dcaf306d0f52cedc5db95cad",
"content_id": "93d69aac361ac0781afdf1429ca69126b2f30e15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 27,
"path": "/three_sum_closest.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def threeSumClosest(self, nums, target):\n \"\"\"\n :type nums: List[int]\n :type target: int\n :rtype: int\n \"\"\"\n nums.sort()\n result = None\n gap = None\n for i in range(0, len(nums)-2):\n left = i + 1\n right = len(nums) - 1\n if not gap:\n gap = abs(target-nums[i]-nums[left]-nums[right])\n result = nums[i] + nums[left] + nums[right]\n while left < right:\n if abs(target-nums[i]-nums[left]-nums[right]) < gap:\n gap = abs(target-nums[i]-nums[left]-nums[right])\n result = nums[i] + nums[left] + nums[right]\n if nums[left] + nums[right] > target - nums[i]:\n right -= 1\n elif nums[left] + nums[right] < target - nums[i]:\n left += 1\n else:\n return target\n return result\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.33243000507354736,
"alphanum_fraction": 0.34688347578048706,
"avg_line_length": 29.75,
"blob_id": "7164aa9e081d95d42203b4b8659d108df738fd61",
"content_id": "9878d66c740707e0064dfd655868ec7095480fed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1107,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 36,
"path": "/search_range.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def searchRange(self, nums, target):\n \"\"\"\n :type nums: List[int]\n :type target: int\n :rtype: List[int]\n \"\"\"\n if len(nums) < 1:\n return [-1, -1]\n start = 0\n end = len(nums) - 1\n result = [-1, -1]\n while start <= end:\n mid = start + (end - start) / 2\n if nums[mid] == target:\n des_start = mid\n des_end = mid\n while des_start >= start:\n if nums[des_start] == target:\n result[0] = des_start\n des_start -= 1\n else:\n break\n while des_end <= end:\n if nums[des_end] == target:\n result[1] = des_end\n des_end += 1\n else:\n break\n return result\n elif target > nums[mid]:\n start = mid + 1\n else:\n end = mid - 1\n \n return [-1, -1]\n"
},
{
"alpha_fraction": 0.37217599153518677,
"alphanum_fraction": 0.3781212866306305,
"avg_line_length": 26.46666717529297,
"blob_id": "5267fdce54d761c123fd245184010120fa8436cb",
"content_id": "f317d66e44f3f1cc7940888214212e6ed79cd2a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 841,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 30,
"path": "/longest_public_prefix_in_strlist.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def longestCommonPrefix(self, strs):\n \"\"\"\n :type strs: List[str]\n :rtype: str\n \"\"\"\n if not strs or strs.count == 0:\n return ''\n if strs.count < 2:\n return strs[1]\n i = 0\n publis_str = ''\n while True:\n pre_str = None\n is_public_str = False\n for s in strs:\n if i >= len(s):\n is_public_str = False\n else:\n is_public_str = (not pre_str or pre_str == s[i])\n pre_str = s[i]\n if not is_public_str:\n break\n if is_public_str:\n publis_str += pre_str\n i += 1\n else:\n break\n\n return publis_str\n \n"
},
{
"alpha_fraction": 0.44485634565353394,
"alphanum_fraction": 0.46802595257759094,
"avg_line_length": 37.53571319580078,
"blob_id": "6921ed83c2e3ac02ef063bec83609d13aa13f386",
"content_id": "2d5f05d0bc999013018f545c9b43fe614d793f9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1079,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 28,
"path": "/generate_matrix.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution:\n def generateMatrix(self, n):\n column_deltas = [1, 0, -1, 0]\n row_deltas = [0, 1, 0, -1]\n result = [[None for _ in range(0, n)] for _ in range(0, n)]\n i = 1\n row = 0\n column = 0\n corner = 0\n while i <= n**2:\n result[row][column] = i\n column_delta = column_deltas[corner%4]\n row_delta = row_deltas[corner%4]\n next_row = row + row_delta\n next_column = column + column_delta\n # print row, column, next_row, next_column\n if (column_delta == 0 and row == n - 1) or (row_delta == 0 and column == n - 1) or result[next_row][next_column] != None:\n corner += 1\n column_delta = column_deltas[corner%4]\n row_delta = row_deltas[corner%4]\n row = row + row_delta\n column = column + column_delta\n # print 'test', row, column\n else:\n row = next_row\n column = next_column\n i += 1\n return result\n"
},
{
"alpha_fraction": 0.3689168095588684,
"alphanum_fraction": 0.38461539149284363,
"avg_line_length": 27.954545974731445,
"blob_id": "223f38afc19251749b5923e2b835901c6483a31d",
"content_id": "c0e2db09050228ba0d2123de8196b90a0bdb953e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 22,
"path": "/longest_palindrome_substr.py",
"repo_name": "amiacoder/leetcode",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def longestPalindrome(self, s):\n \"\"\"\n :type s: str\n :rtype: str\n \"\"\"\n if len(s) < 2:\n return s\n test = '#'+'#'.join(s)+'#'\n max_len = 0\n for i in range(len(test)):\n left = i - 1\n right = i + 1\n step = 0\n while left >= 0 and right < len(test) and test[left] == test[right]:\n left -= 1\n right += 1\n step += 1\n if step > max_len:\n max_len = step\n start = (i - max_len) // 2\n return s[start: start + max_len]\n"
}
] | 21 |
monkeydnoya/roundrobin | https://github.com/monkeydnoya/roundrobin | a19cd14616754bf8ac0b43f319e1b060368e6a67 | 706232a0aa599cab772ee2f924a6ade2c5f8629a | 010b187106e49955ed6d76959d07a1026e225e95 | refs/heads/main | 2022-12-24T06:15:56.714374 | 2020-10-02T17:08:02 | 2020-10-02T17:08:02 | 300,643,428 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7674418687820435,
"alphanum_fraction": 0.8023256063461304,
"avg_line_length": 16.200000762939453,
"blob_id": "4e7e4176441f19fd00bf262c6d5a67ea8784539c",
"content_id": "5452ba97631e73c95792b6b10d6c412ceae27c42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/README.md",
"repo_name": "monkeydnoya/roundrobin",
"src_encoding": "UTF-8",
"text": "# roundrobin\nRound Robin algorithm\n\nВыполенение алгоритма RoundRobin\nШукуров Алмаз, АиУ 18-8\n"
},
{
"alpha_fraction": 0.5201452970504761,
"alphanum_fraction": 0.5402905941009521,
"avg_line_length": 26.5181827545166,
"blob_id": "9a1caaa84c973897ae282e55dea06ab91e84e360",
"content_id": "a09bc24cd4ea6ce066b478b99a7008492103869d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3251,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 110,
"path": "/roundrobin.py",
"repo_name": "monkeydnoya/roundrobin",
"src_encoding": "UTF-8",
"text": "chart = [] # Шукуров Алмаз, АиУ 18-8 \n\nclass Process:\n def __init__(self, pid, AT, BT, WT, TT, CT):\n self.pid = pid\n self.arrival = AT\n self.burst = BT\n self.waitingTime = WT\n self.turnarroundtime = TT\n self.completion = CT\n\ndef shiftCL(alist):\n wt = []\n temp = alist[0]\n for i in range(len(alist)-1):\n alist[i] = alist[i+1]\n alist[len(alist)-1] = temp\n return alist\n\ndef takeburstatStart(alist):\n blist = [] * len(alist)\n for i in range(len(alist)):\n blist.append(alist[i].burst)\n return blist\n\ndef calculateWaitingTime(plist, blist):\n allwaitingTime = 0\n print('----------------------------')\n for i in range(len(plist)):\n plist[i].turnarroundtime = plist[i].completion - plist[i].arrival\n plist[i].waitingTime = plist[i].turnarroundtime - blist[i]\n print(\"Process \"+ str(plist[i].pid) + \" үшін күту уақыты: \" + str(plist[i].waitingTime))\n allwaitingTime += plist[i].waitingTime\n midleWaitingTime = allwaitingTime / len(plist)\n print('----------------------------')\n print(\"Орташа күту уақыты: \" + str(midleWaitingTime))\n\n\ndef RoundRobin(tq,plist,capacity):\n global chart\n queue = []\n time = 0\n ap = 0 #Прибывший процесс\n rp = 0 #готовые\n done = 0\n q = tq\n start = False\n while (done<capacity):\n for i in range(ap, capacity):\n if time >= plist[i].arrival:\n queue.append(plist[i])\n ap += 1\n rp += 1\n\n\n\n if start:\n queue = shiftCL(queue)\n\n if queue[0].burst>0:\n if queue[0].burst>q:\n for g in range(time, time+q):\n chart.append(queue[0].pid)\n time += q\n queue[0].burst -= q\n else:\n for g in range(time, time+queue[0].burst):\n chart.append(queue[0].pid)\n time += queue[0].burst\n queue[0].burst = 0\n queue[0].completion = time\n done += 1\n rp -= 1\n\n start = True\n\n#main function\nplist = []\n\nplist.append(Process(\"A\",0,3,0,0,0)) #plist.append <- append plist списогіна соңына қосу үшін list классынының методы\nplist.append(Process(\"B\",2,6,0,0,0)) #Process('process name', 'bastaluyi', 'oryndalu uakiti', 'kutu uakiti', ) Process деп аталатын класстын обьектісі\nplist.append(Process(\"C\",4,4,0,0,0))\nplist.append(Process(\"D\",6,5,0,0,0))\nplist.append(Process(\"E\",8,2,0,0,0))\n\nsavedBT = takeburstatStart(plist)\n\nquantumTime = 1\n\nRoundRobin(quantumTime, plist, len(plist))\n\nprint(chart)\ncalculateWaitingTime(plist, savedBT)\n\n\n\n\n\n\"\"\"RESULT Есептің жауабы\n['A', 'A', 'B', 'A', 'B', 'C', 'B', 'D', 'C', 'B', 'E', 'D', 'C', 'B', 'E', 'D', 'C', 'B', 'D', 'D']\n----------------------------\nProcess A үшін күту уақыты: 1\nProcess B үшін күту уақыты: 10\nProcess C үшін күту уақыты: 9\nProcess D үшін күту уақыты: 9\nProcess E үшін күту уақыты: 5\n----------------------------\nОрташа күту уақыты: 6.8\n\n\"\"\"\n\n"
}
] | 2 |
munaeem77/dataviz-final-project-group4 | https://github.com/munaeem77/dataviz-final-project-group4 | d0a66a0601b96d7841eddc10032cd082476c693a | 521cda44356b33428e54ad095764f7639e8c6c49 | 15507967944f538db31779d3387fe6ba3cb3bbce | refs/heads/main | 2023-02-01T16:48:38.764140 | 2020-12-18T03:14:27 | 2020-12-18T03:14:27 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7620915174484253,
"alphanum_fraction": 0.7686274647712708,
"avg_line_length": 33.59090805053711,
"blob_id": "699b7d57a918b289f4f1c296511f75689eaa8785",
"content_id": "722422d8d3e58c1420ddc92b27110664418a4378",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 22,
"path": "/README.md",
"repo_name": "munaeem77/dataviz-final-project-group4",
"src_encoding": "UTF-8",
"text": "# dataviz-final-project-group4\nFinal project for the McCombs Data and Visualization Bootcamp\n\n## Project\n### Selected topic: COVID-19 Data Analysis to Predict New Cases across country\n### Reason they selected the topic: \n### Description of the source of data: https://github.com/owid/covid-19-data/tree/master/public/data\n### Questions hoping to be answered with the data: \n- To analyze impact of covid on economy (some relationship between covid cases vs GDP)\n- To analyze relationship between underlying health conditions and deaths\n- Recovery rate vs country\n- Predict new cases\n\n### Description of the communication protocols: Slack, Team meetings every other day.\n\n### Overview\n\n### Machine Learning Model\n\n### Database Integration\n\n### Data Visualization\n\n\n\n\n"
},
{
"alpha_fraction": 0.593069314956665,
"alphanum_fraction": 0.6168316602706909,
"avg_line_length": 11.897436141967773,
"blob_id": "3fffb3c7fc082ea7f58d90451c6affc66a9fd007",
"content_id": "be4e53c4d0e2906c7a04ef35c31d83ea2cd44594",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 78,
"path": "/dataviz_fp_gp4_covid_analysis.py",
"repo_name": "munaeem77/dataviz-final-project-group4",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\nimport pandas as pd\nimport os\n\n\n# In[2]:\n\n\nos.getcwd()\n\n\n# In[6]:\n\n\ndf = pd.read_csv('owid-covid-data.csv')\n\n\n# In[4]:\n\n\nusa_df = df[df.location=='United States']\nusa_df.columns\n\n\n# In[9]:\n\n\nimport seaborn as sns\nsns.heatmap(df.isnull())\n\n\n# In[10]:\n\n\nsns.heatmap(usa_df.isnull())\n\n\n# In[13]:\n\n\ndf.isnull().sum()\n\n\n# In[19]:\n\n\ncols = ['reproduction_rate', 'new_cases','new_tests', 'new_deaths', 'icu_patients', \n 'positive_rate', 'stringency_index', 'population', 'population_density', \n 'median_age', 'aged_65_older', 'aged_70_older','gdp_per_capita','extreme_poverty', \n 'cardiovasc_death_rate', 'diabetes_prevalence', 'female_smokers', 'male_smokers', \n 'handwashing_facilities','hospital_beds_per_thousand', 'life_expectancy', 'human_development_index'] \n\n\n# In[20]:\n\n\nnew_df = df[cols]\n\n\n# In[21]:\n\n\nnew_df.head()\n\n\n# In[27]:\n\n\nfig = pd.plotting.scatter_matrix(new_df, alpha=0.2)\nplt.savefig('scatterPlot.png')\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 2 |
MProx/UsefulCode | https://github.com/MProx/UsefulCode | e6ea48de9bcbf1893384f7bf150a810d05a9606f | 1861b8c6a9d5cb385516fc404db7cd2859275da7 | cd2f11894c3d16fed81d87472dcd22236f2fe78e | refs/heads/master | 2020-03-15T20:18:53.415623 | 2018-09-25T19:19:20 | 2018-09-25T19:19:20 | 132,329,707 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.624821662902832,
"alphanum_fraction": 0.6576319336891174,
"avg_line_length": 21.612903594970703,
"blob_id": "e1f0f57391a21a506933dcfb61e7d107393624d1",
"content_id": "0b28cc200634447332336d993731c4df4818b376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 31,
"path": "/TCP_socket_server.py",
"repo_name": "MProx/UsefulCode",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport socket, time\nimport random\n\nimport sys\n\nif (len(list(sys.argv)) < 2):\n print(\"Usage: {} <Server Port>\\n\".format(list(sys.argv)[0]));\n exit(1);\n\nTCP_IP = '192.168.1.142'\nTCP_PORT = int(sys.argv[1])\nBUFFER_SIZE = 100 # Normally 1024, but we want fast response\n\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ns.bind((TCP_IP, TCP_PORT))\ns.listen(1)\nprint(\"Socket created, listening on port {}\".format(TCP_PORT))\n\nconn, addr = s.accept()\nprint('Connection address: {}'.format(addr))\nwhile 1:\n data = conn.recv(BUFFER_SIZE)\n if not data: break\n\n print(\"Received data: {}\".format(data))\n\n #To return a string, use conn.send(\"String\")\n \nconn.close()\n"
},
{
"alpha_fraction": 0.36749210953712463,
"alphanum_fraction": 0.554344892501831,
"avg_line_length": 40.90565872192383,
"blob_id": "f58fae866fc0e53b231d188ff8a6d0afad0c02c1",
"content_id": "c7545df6db0ed76bcf159da5a00a956f349abef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11105,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 265,
"path": "/Lopy_SSD1306.py",
"repo_name": "MProx/UsefulCode",
"src_encoding": "UTF-8",
"text": "'''\nA Microython class (lested with the Pycom Lopy module) to display text on a SSD1306 OLED display\n'''\nfrom machine import I2C\nimport time\n\nclass SSD1306():\n def __init__(self, i2c, SSD1306_I2C_ADDRESS = 0x3c, displayType = '128x32'):\n\n self.i2c = i2c\n self.SSD1306_I2C_ADDRESS = SSD1306_I2C_ADDRESS\n if displayType == \"128x32\":\n self.disptype = 1\n elif displayType == \"128x64\":\n self.disptype = 2\n else:\n raise Exception('Please select \"128x32\" or \"128x64\" as display type')\n\n # LCD Control constants\n self.SSD1306_SETCONTRAST = 0x81\n self.SSD1306_DISPLAYALLON_RESUME = 0xA4\n self.SSD1306_DISPLAYALLON = 0xA5\n self.SSD1306_NORMALDISPLAY = 0xA6\n self.SSD1306_INVERTDISPLAY = 0xA7\n self.SSD1306_DISPLAYOFF = 0xAE\n self.SSD1306_DISPLAYON = 0xAF\n self.SSD1306_SETDISPLAYOFFSET = 0xD3\n self.SSD1306_SETCOMPINS = 0xDA\n self.SSD1306_SETVCOMDETECT = 0xDB\n self.SSD1306_SETDISPLAYCLOCKDIV = 0xD5\n self.SSD1306_SETPRECHARGE = 0xD9\n self.SSD1306_SETMULTIPLEX = 0xA8\n self.SSD1306_SETLOWCOLUMN = 0x00\n self.SSD1306_SETHIGHCOLUMN = 0x10\n self.SSD1306_SETSTARTLINE = 0x40\n self.SSD1306_MEMORYMODE = 0x20\n self.SSD1306_COLUMNADDR = 0x21\n self.SSD1306_PAGEADDR = 0x22\n self.SSD1306_COMSCANINC = 0xC0\n self.SSD1306_COMSCANDEC = 0xC8\n self.SSD1306_SEGREMAP = 0xA0\n self.SSD1306_CHARGEPUMP = 0x8D\n self.SSD1306_EXTERNALVCC = 0x1\n self.SSD1306_SWITCHCAPVCC = 0x2\n\n # Scrolling constants\n self.SSD1306_ACTIVATE_SCROLL = 0x2F\n self.SSD1306_DEACTIVATE_SCROLL = 0x2E\n self.SSD1306_SET_VERTICAL_SCROLL_AREA = 0xA3\n self.SSD1306_RIGHT_HORIZONTAL_SCROLL = 0x26\n self.SSD1306_LEFT_HORIZONTAL_SCROLL = 0x27\n self.SSD1306_VERTICAL_AND_RIGHT_HORIZONTAL_SCROLL = 0x29\n self.SSD1306_VERTICAL_AND_LEFT_HORIZONTAL_SCROLL = 0x2A\n\n # Font data. Taken from https://github.com/hsmptg/lcd/blob/master/font.py\n self.font = [\n 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x5F, 0x00, 0x00,\n 0x00, 0x07, 0x00, 0x07, 0x00,\n 0x14, 0x7F, 0x14, 0x7F, 0x14,\n 0x24, 0x2A, 0x7F, 0x2A, 0x12,\n 0x23, 0x13, 0x08, 0x64, 0x62,\n 0x36, 0x49, 0x56, 0x20, 0x50,\n 0x00, 0x08, 0x07, 0x03, 0x00,\n 0x00, 0x1C, 0x22, 0x41, 0x00,\n 0x00, 0x41, 0x22, 0x1C, 0x00,\n 0x2A, 0x1C, 0x7F, 0x1C, 0x2A,\n 0x08, 0x08, 0x3E, 0x08, 0x08,\n 0x00, 0x80, 0x70, 0x30, 0x00,\n 0x08, 0x08, 0x08, 0x08, 0x08,\n 0x00, 0x00, 0x60, 0x60, 0x00,\n 0x20, 0x10, 0x08, 0x04, 0x02,\n 0x3E, 0x51, 0x49, 0x45, 0x3E,\n 0x00, 0x42, 0x7F, 0x40, 0x00,\n 0x72, 0x49, 0x49, 0x49, 0x46,\n 0x21, 0x41, 0x49, 0x4D, 0x33,\n 0x18, 0x14, 0x12, 0x7F, 0x10,\n 0x27, 0x45, 0x45, 0x45, 0x39,\n 0x3C, 0x4A, 0x49, 0x49, 0x31,\n 0x41, 0x21, 0x11, 0x09, 0x07,\n 0x36, 0x49, 0x49, 0x49, 0x36,\n 0x46, 0x49, 0x49, 0x29, 0x1E,\n 0x00, 0x00, 0x14, 0x00, 0x00,\n 0x00, 0x40, 0x34, 0x00, 0x00,\n 0x00, 0x08, 0x14, 0x22, 0x41,\n 0x14, 0x14, 0x14, 0x14, 0x14,\n 0x00, 0x41, 0x22, 0x14, 0x08,\n 0x02, 0x01, 0x59, 0x09, 0x06,\n 0x3E, 0x41, 0x5D, 0x59, 0x4E,\n 0x7C, 0x12, 0x11, 0x12, 0x7C,\n 0x7F, 0x49, 0x49, 0x49, 0x36,\n 0x3E, 0x41, 0x41, 0x41, 0x22,\n 0x7F, 0x41, 0x41, 0x41, 0x3E,\n 0x7F, 0x49, 0x49, 0x49, 0x41,\n 0x7F, 0x09, 0x09, 0x09, 0x01,\n 0x3E, 0x41, 0x41, 0x51, 0x73,\n 0x7F, 0x08, 0x08, 0x08, 0x7F,\n 0x00, 0x41, 0x7F, 0x41, 0x00,\n 0x20, 0x40, 0x41, 0x3F, 0x01,\n 0x7F, 0x08, 0x14, 0x22, 0x41,\n 0x7F, 0x40, 0x40, 0x40, 0x40,\n 0x7F, 0x02, 0x1C, 0x02, 0x7F,\n 0x7F, 0x04, 0x08, 0x10, 0x7F,\n 0x3E, 0x41, 0x41, 0x41, 0x3E,\n 0x7F, 0x09, 0x09, 0x09, 0x06,\n 0x3E, 0x41, 0x51, 0x21, 0x5E,\n 0x7F, 0x09, 0x19, 0x29, 0x46,\n 0x26, 0x49, 0x49, 0x49, 0x32,\n 0x03, 0x01, 0x7F, 0x01, 0x03,\n 0x3F, 0x40, 0x40, 0x40, 0x3F,\n 0x1F, 0x20, 0x40, 0x20, 0x1F,\n 0x3F, 0x40, 0x38, 0x40, 0x3F,\n 0x63, 0x14, 0x08, 0x14, 0x63,\n 0x03, 0x04, 0x78, 0x04, 0x03,\n 0x61, 0x59, 0x49, 0x4D, 0x43,\n 0x00, 0x7F, 0x41, 0x41, 0x41,\n 0x02, 0x04, 0x08, 0x10, 0x20,\n 0x00, 0x41, 0x41, 0x41, 0x7F,\n 0x04, 0x02, 0x01, 0x02, 0x04,\n 0x40, 0x40, 0x40, 0x40, 0x40,\n 0x00, 0x03, 0x07, 0x08, 0x00,\n 0x20, 0x54, 0x54, 0x78, 0x40,\n 0x7F, 0x28, 0x44, 0x44, 0x38,\n 0x38, 0x44, 0x44, 0x44, 0x28,\n 0x38, 0x44, 0x44, 0x28, 0x7F,\n 0x38, 0x54, 0x54, 0x54, 0x18,\n 0x00, 0x08, 0x7E, 0x09, 0x02,\n 0x18, 0xA4, 0xA4, 0x9C, 0x78,\n 0x7F, 0x08, 0x04, 0x04, 0x78,\n 0x00, 0x44, 0x7D, 0x40, 0x00,\n 0x20, 0x40, 0x40, 0x3D, 0x00,\n 0x7F, 0x10, 0x28, 0x44, 0x00,\n 0x00, 0x41, 0x7F, 0x40, 0x00,\n 0x7C, 0x04, 0x78, 0x04, 0x78,\n 0x7C, 0x08, 0x04, 0x04, 0x78,\n 0x38, 0x44, 0x44, 0x44, 0x38,\n 0xFC, 0x18, 0x24, 0x24, 0x18,\n 0x18, 0x24, 0x24, 0x18, 0xFC,\n 0x7C, 0x08, 0x04, 0x04, 0x08,\n 0x48, 0x54, 0x54, 0x54, 0x24,\n 0x04, 0x04, 0x3F, 0x44, 0x24,\n 0x3C, 0x40, 0x40, 0x20, 0x7C,\n 0x1C, 0x20, 0x40, 0x20, 0x1C,\n 0x3C, 0x40, 0x30, 0x40, 0x3C,\n 0x44, 0x28, 0x10, 0x28, 0x44,\n 0x4C, 0x90, 0x90, 0x90, 0x7C,\n 0x44, 0x64, 0x54, 0x4C, 0x44,\n 0x00, 0x08, 0x36, 0x41, 0x00,\n 0x00, 0x00, 0x77, 0x00, 0x00,\n 0x00, 0x41, 0x36, 0x08, 0x00,\n 0x02, 0x01, 0x02, 0x04, 0x02,\n 0x3C, 0x26, 0x23, 0x26, 0x3C]\n\n # Display data\n self.width = None\n self.height = None\n self.pages = None\n self.buffer = None\n\n self.initialize(self.disptype)\n self.set_contrast(128) # 1-255\n self.displayOn()\n\n def command1(self, c):\n self.i2c.writeto(self.SSD1306_I2C_ADDRESS, bytearray([0, c]))\n\n def command2(self, c1, c2):\n self.i2c.writeto(self.SSD1306_I2C_ADDRESS, bytearray([0, c1, c2]))\n\n def command3(self, c1, c2, c3):\n self.i2c.writeto(self.SSD1306_I2C_ADDRESS, bytearray([0, c1, c2, c3]))\n\n def initialize(self, type):\n if type == 1:\n #128x32 I2C OLED Display\n self.width = 128\n self.height = 32\n self.pages = 4 # height/8\n self.buffer = [0]*512 # 128*32/8\n self.initialize_128x32()\n if type == 2:\n #128x64 I2C OLED Display\n self.width = 128\n self.height = 64\n self.pages = 8 # height/8\n self.buffer = [0]*1024 # 128*64/8\n self.initialize_128x64()\n\n def initialize_128x32(self):\n self.command1(self.SSD1306_DISPLAYOFF) # 0xAE\n self.command2(self.SSD1306_SETDISPLAYCLOCKDIV, 0x80) # 0xD5\n self.command2(self.SSD1306_SETMULTIPLEX, 0x1F) # 0xA8\n self.command2(self.SSD1306_SETDISPLAYOFFSET, 0x0) # 0xD3\n self.command1(self.SSD1306_SETSTARTLINE | 0x0) # line #0\n self.command2(self.SSD1306_CHARGEPUMP, 0x14) # 0x8D\n self.command2(self.SSD1306_MEMORYMODE, 0x00) # 0x20\n self.command3(self.SSD1306_COLUMNADDR, 0, self.width-1)\n self.command3(self.SSD1306_PAGEADDR, 0, self.pages-1)\n self.command1(self.SSD1306_SEGREMAP | 0x1)\n self.command1(self.SSD1306_COMSCANDEC)\n self.command2(self.SSD1306_SETCOMPINS, 0x02) # 0xDA\n self.command2(self.SSD1306_SETCONTRAST, 0x8F) # 0x81\n self.command2(self.SSD1306_SETPRECHARGE, 0xF1) # 0xd9\n self.command2(self.SSD1306_SETVCOMDETECT, 0x40) # 0xDB\n self.command1(self.SSD1306_DISPLAYALLON_RESUME) # 0xA4\n self.command1(self.SSD1306_NORMALDISPLAY) # 0xA6\n\n def initialize_128x64(self):\n self.command1(self.SSD1306_DISPLAYOFF) # 0xAE\n self.command1(self.SSD1306_DISPLAYALLON_RESUME) # 0xA4\n self.command2(self.SSD1306_SETDISPLAYCLOCKDIV, 0x80) # 0xD5\n self.command2(self.SSD1306_SETMULTIPLEX, 0x3F) # 0xA8\n self.command2(self.SSD1306_SETDISPLAYOFFSET, 0x0) # 0xD3\n self.command1(self.SSD1306_SETSTARTLINE | 0x0) # line #0\n self.command2(self.SSD1306_CHARGEPUMP, 0x14) # 0x8D\n self.command2(self.SSD1306_MEMORYMODE, 0x00) # 0x20\n self.command3(self.SSD1306_COLUMNADDR, 0, self.width-1)\n self.command3(self.SSD1306_PAGEADDR, 0, self.pages-1)\n self.command1(self.SSD1306_SEGREMAP | 0x1)\n self.command1(self.SSD1306_COMSCANDEC)\n self.command2(self.SSD1306_SETCOMPINS, 0x12) # 0xDA\n self.command2(self.SSD1306_SETCONTRAST, 0xCF) # 0x81\n self.command2(self.SSD1306_SETPRECHARGE, 0xF1) # 0xd9\n self.command2(self.SSD1306_SETVCOMDETECT, 0x40) # 0xDB\n self.command1(self.SSD1306_NORMALDISPLAY) # 0xA6\n self.command1(self.SSD1306_DISPLAYON)\n\n def set_contrast(self, contrast):\n # Sets the contrast of the display. Contrast should be a value between 0 and 255.\n if contrast < 0 or contrast > 255:\n print('Contrast must be a value from 0 to 255 (inclusive).')\n self.command2(self.SSD1306_SETCONTRAST, contrast)\n\n def displayOff(self):\n self.command1(self.SSD1306_DISPLAYOFF)\n\n def displayOn(self):\n self.command1(self.SSD1306_DISPLAYON)\n\n def clearBuffer(self):\n for i in range(0, len(self.buffer)):\n self.buffer[i] = 0\n\n def addString(self, x, y, str):\n symPos = self.width*y + 6*x\n for i in range(0, len(str)):\n c = 5*(ord(str[i]) - 32)\n self.buffer[symPos] = self.font[c]\n self.buffer[symPos + 1] = self.font[c+1]\n self.buffer[symPos + 2] = self.font[c+2]\n self.buffer[symPos + 3] = self.font[c+3]\n self.buffer[symPos + 4] = self.font[c+4]\n symPos += 6\n\n def drawBuffer(self):\n self.command1(self.SSD1306_SETLOWCOLUMN)\n self.command1(self.SSD1306_SETHIGHCOLUMN)\n self.command1(self.SSD1306_SETSTARTLINE)\n\n line = [0]*17\n line[0] = 0x40\n for i in range(0, len(self.buffer), 16):\n for p in range(0, 16):\n line[p+1] = self.buffer[i + p]\n self.i2c.writeto(self.SSD1306_I2C_ADDRESS, bytearray(line))\n"
},
{
"alpha_fraction": 0.629041314125061,
"alphanum_fraction": 0.6548308730125427,
"avg_line_length": 24.00467300415039,
"blob_id": "ab40b6f0ccde1d8930fc86ec5e643325e3108e2f",
"content_id": "19842661383b7d6f1174d4ef26ca0e27db39d7e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5351,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 214,
"path": "/GPS+Compass.ino",
"repo_name": "MProx/UsefulCode",
"src_encoding": "UTF-8",
"text": "/*\n * This Arduino sketch captures raw GPS data from the hardware serial port and displays \n * it on an OLED display. Note that the SoftwareSerial library is too fussy about timing \n * so the recieved GPS messages are garbled. As such, the output must be displayed on a \n * display, since the serial monitor cannot share the serial port.\n * \n * GPS Settings:\n * Outputs the $GPGGA message at a minimum (see http://freenmea.net/docs)\n * Baud rate at 38400\n * \n * Possible outputs functions listed at the bottom of this file\n */\n\n#include <TinyGPS++.h>\n#include <SoftwareSerial.h>\n#include <SPI.h>\n#include <Wire.h>\n#include <Adafruit_GFX.h>\n#include <Adafruit_SSD1306.h>\n#include <math.h>\n\n#define OLED_RESET 4\n\n// OLED display object\nAdafruit_SSD1306 display(OLED_RESET);\n// The TinyGPS++ object\nTinyGPSPlus gps;\n// Compass i2c address:\nint addr = 0x1e;\nint x,y,z; //triple axis data\nint i; // index for loops\n\n// Calibration data (collected empirically)\nint x_cal_pos = 308, x_cal_neg = -226;\nint y_cal_pos = 104, y_cal_neg = -425;\nint z_cal_pos = 250, z_cal_neg = -223;\nint offset_x, offset_y, offset_z;\nbool calibated = false;\n\nvoid setup()\n{\n Serial.begin(38400);\n display.begin(SSD1306_SWITCHCAPVCC, 0x3C); // initialize with the I2C addr 0x3C (for the 128x32)\n display.clearDisplay();\n display.setTextSize(1);\n display.setTextColor(WHITE);\n display.display();\n\n offset_x = (x_cal_pos + x_cal_neg)/2;\n offset_y = (y_cal_pos + y_cal_neg)/2;\n offset_z = (z_cal_pos + z_cal_neg)/2;\n \n compass_init();\n delay(10); // warm up \n\n display.clearDisplay();\n display.setTextSize(1);\n display.setTextColor(WHITE); \n}\n\nvoid loop()\n{\n // This sketch displays information every time a new sentence is correctly encoded.\n while (Serial.available() > 0)\n if (gps.encode(Serial.read()))\n displayInfo();\n\n if (millis() > 5000 && gps.charsProcessed() < 10)\n {\n display.print(\"No GPS\");\n while(true);\n }\n}\n\nvoid displayInfo()\n{\n if (gps.location.isValid())\n {\n display.clearDisplay();\n display.setCursor(0,0);\n display.print(\"UTC Time: \");\n display.print(gps.time.hour());\n display.print(\":\");\n display.print(gps.time.minute());\n display.print(\":\");\n display.print(gps.time.second());\n\n display.setCursor(0,8);\n display.print(\"Lat: \");\n display.print(gps.location.rawLat().negative ? \"-\" : \"+\");\n display.print(gps.location.rawLat().deg);\n display.print('.');\n display.print(gps.location.rawLat().billionths);\n\n display.setCursor(0,16);\n display.print(\"Lon: \");\n display.print(gps.location.rawLng().negative ? \"-\" : \"+\");\n display.print(gps.location.rawLng().deg);\n display.print('.');\n display.print(gps.location.rawLng().billionths);\n\n display.setCursor(0,24);\n display.print(\"sats:\");\n display.print(gps.satellites.value());\n display.print(\" heading:\");\n display.print(getHeading(), 1);\n\n display.display(); \n }\n \n else\n {\n display.clearDisplay();\n display.setCursor(0,0);\n display.print(F(\"INVALID\"));\n\n display.setCursor(0,24);\n display.print(\"sats:\");\n display.print(gps.satellites.value());\n display.print(\" heading:\");\n display.print(getHeading(), 1);\n display.display(); \n }\n}\n\nfloat getHeading(void){\n\n //Tell the HMC what regist to begin writing data into\n Wire.beginTransmission(addr);\n Wire.write(0x03); //start with register 3.\n Wire.endTransmission();\n \n \n //Read the data.. 2 bytes for each axis.. 6 total bytes\n Wire.requestFrom(addr, 6);\n if(Wire.available() >= 6){\n x = Wire.read()<<8; //MSB x \n x |= Wire.read(); //LSB x\n z = Wire.read()<<8; //MSB z\n z |= Wire.read(); //LSB z\n y = Wire.read()<<8; //MSB y\n y |= Wire.read(); //LSB y\n }\n\n x -= offset_x;\n y -= offset_y;\n z -= offset_z;\n\n // use arctan2 to take the signs of x and y into account\n float heading = atan2(float(y), float(-x))*180/PI;\n\n if (heading < 0)\n heading += 360;\n \n return heading;\n}\n\nint compass_init(){\n Wire.beginTransmission(addr);\n byte MA = 0b11; // average 8x samples for each reading\n byte DO = 0b100; // set data output rate to 15 Hz\n byte MS = 0b00; // No bias\n byte CRA = (MA << 5) + (DO << 2) + MS;\n Wire.write(0x00); // Set the Register\n Wire.write(CRA); // Set averaging, data rate, bias mode\n Wire.endTransmission();\n\n Wire.beginTransmission(addr);\n byte GN = 0b001; // Gain is 1\n byte CRB = GN << 5;\n Wire.write(0x01); // Set the Register\n Wire.write(CRB); // Set device gain\n Wire.endTransmission();\n\n Wire.beginTransmission(addr);\n byte MD = 0b00; // Continuous data capture mode\n Wire.write(0x02); // Set the Register\n Wire.write(MD); // Select continuously Measure\n Wire.endTransmission();\n\n}\n\n/*\nGPS output options:\n\ngps.location.lat()\ngps.location.lng()\ngps.location.rawLat().negative ? \"-\" : \"+\"gps.location.rawLat().billionths\ngps.location.rawLng().negative ? \"-\" : \"+\"gps.location.rawLng().billionths\ngps.date.value\ngps.date.year()\ngps.date.month()\ngps.date.day()\ngps.time.value()\ngps.time.hour()\ngps.time.minute()\ngps.time.second()\ngps.time.centisecond()\ngps.speed.value()\ngps.speed.knots()\ngps.speed.mph()\ngps.speed.mps()\ngps.speed.kmph()\ngps.course.value()\ngps.course.deg()\ngps.altitude.value()\ngps.altitude.meters()\ngps.altitude.miles()\ngps.altitude.kilometers()\ngps.altitude.feet()\ngps.satellites.value()\ngps.hdop.value()\n\n*/\n"
},
{
"alpha_fraction": 0.5618181824684143,
"alphanum_fraction": 0.5709090828895569,
"avg_line_length": 28.39285659790039,
"blob_id": "cd14a1b01ced2bd941f4add8870de3ccf5bd7dd0",
"content_id": "231a304719223902c25c2765faac51eaf62f6ba6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1650,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 56,
"path": "/TensorFlow/Keras/ANN.py",
"repo_name": "MProx/UsefulCode",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport keras\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nimport data_loader\n\n#==================================\n# Parameters:\n\ninput_layer_nodes = 784\nhidden_layer_nodes = 30\noutput_layer_nodes = 10\nbatch_size = 10\nepochs = 30\n\n#==================================\n# Import data and pre-process here: \n# X_train, X_test, y_train, y_test all should be numpy arrays, containing numpy arrays of data.\n\nX_train, X_test, y_train, y_test = data_loader.load_data() #preprocessing done in separate file\n\n#==================================\nprint(\"Building model\")\nclassifier = Sequential()\n\nclassifier.add(Dense(activation=\"relu\", \n input_dim=input_layer_nodes, \n units=hidden_layer_nodes, \n kernel_initializer=\"uniform\")) \n\nclassifier.add(Dense(activation=\"relu\", \n units=hidden_layer_nodes, \n kernel_initializer=\"uniform\"))\n\nclassifier.add(Dense(activation=\"sigmoid\",\n units=output_layer_nodes, \n kernel_initializer=\"uniform\")) \n\nclassifier.compile(optimizer = 'adam',\n loss = 'categorical_crossentropy',\n metrics = ['accuracy'])\n\nprint(\"Training model\")\nclassifier.fit(x = X_train, \n y = y_train,\n batch_size = batch_size,\n epochs = epochs, \n verbose = 1,\n validation_data=(X_test, y_test))\n\npred = classifier.predict(X_test)\n\nscore = classifier.evaluate(X_test, y_test, verbose=0)\nprint(\"Loss: \", score[0]) \nprint(\"Accuracy: \", score[1]) \n"
},
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 55,
"blob_id": "15071f1b5998ac82a2719e8f972478f8e5b95539",
"content_id": "cf6de6756045fbcb7a0c4a03b72e66475fd6a2d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 2,
"path": "/README.md",
"repo_name": "MProx/UsefulCode",
"src_encoding": "UTF-8",
"text": "# UsefulCode\nA collection of short scripts and code snippets that I use often. Small for now, will be expanded.\n"
},
{
"alpha_fraction": 0.4483024775981903,
"alphanum_fraction": 0.5262345671653748,
"avg_line_length": 29.13953399658203,
"blob_id": "4db685ee2ae196f3c2534d6037264c3732a93c71",
"content_id": "995d4bd1adb0f747fda4a3160768ee2b94e92d19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1296,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 43,
"path": "/Lopy_HMC5883L.py",
"repo_name": "MProx/UsefulCode",
"src_encoding": "UTF-8",
"text": "'''\nA micropython class for operation of the HMC5883L digital compass module. \n'''\n\nimport time\nfrom machine import UART, I2C\nimport math\n\nclass HMC5883l():\n def __init__(self, i2c, addr = 0x1e):\n self.addr = addr\n self.i2c = i2c\n self.MA = 0b11 << 5 # average 8x samples for each reading\n self.DO = 0b100 << 2 # set data output rate to 15 Hz\n self.MS = 0b00 # No bias\n i2c.writeto_mem(addr, 0x00, bytes([self.MS | self.MA | self.DO]))\n self.GN = 0b001 << 5 # Gain is 1\n i2c.writeto_mem(addr, 0x01, bytes([self.GN]))\n self.MD = 0b00 # Continuous data capture mode\n i2c.writeto_mem(addr, 0x02, bytes([self.MD]))\n\n self.buffer = bytearray(6)\n\n def read(self):\n self.i2c.readfrom_mem_into(self.addr, 0x03, self.buffer)\n x = self.buffer[0]<<8 | self.buffer[1]\n z = self.buffer[2]<<8 | self.buffer[3]\n y = self.buffer[4]<<8 | self.buffer[5]\n if (x & (1 << 16 - 1)):\n x-= (1<<16)\n if (y & (1 << 16 - 1)):\n y-= (1<<16)\n if (z & (1 << 16 - 1)):\n z-= (1<<16)\n\n # Offsets measured empirically:\n x -= 147\n y -= 63\n z -= 23\n\n heading = math.atan2(float(y), float(-x))*180/3.1416\n\n return heading\n"
}
] | 6 |
azizur77/smartwebapps | https://github.com/azizur77/smartwebapps | 755b11691046039a988ce8064ce67c6744e22ecc | 19dcd2440cab5675708ddc0c3e1dad037e9f90cb | 2b02d96b7281e6d319a723eeecc016a1b9c4ea48 | refs/heads/master | 2021-01-18T04:31:29.296269 | 2011-06-22T16:21:31 | 2011-06-22T16:21:31 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6716417670249939,
"alphanum_fraction": 0.6716417670249939,
"avg_line_length": 25.799999237060547,
"blob_id": "ebdb135698f52c3fa19fb2baeca60cb6ce126925",
"content_id": "36f67378094dcd378a3b87f98e186690629d7a8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 5,
"path": "/apps/emoter/urls.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.conf.urls.defaults import *\n\nurlpatterns = patterns('',\n url(r'^$', 'apps.emoter.views.index', name='emoter-index'),\n)\n"
},
{
"alpha_fraction": 0.8203592896461487,
"alphanum_fraction": 0.8203592896461487,
"avg_line_length": 22.85714340209961,
"blob_id": "a346c8ba3df77ec60cdc720cedf7743bca102ca7",
"content_id": "b523d90e5f2eee3426805dbf23965d6cfdc266d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 167,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 7,
"path": "/apps/news/admin.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom models import Cluster, News, NewsSource\n\nadmin.site.register(NewsSource)\nadmin.site.register(Cluster)\nadmin.site.register(News)\n"
},
{
"alpha_fraction": 0.660756528377533,
"alphanum_fraction": 0.660756528377533,
"avg_line_length": 35.78260803222656,
"blob_id": "9972961927ec5b1a48459c264a9be4c677255021",
"content_id": "c12cf6bb2a1fa47e987031bd5447f116e471509c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 846,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 23,
"path": "/urls.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.conf.urls.defaults import *\nfrom django.views.generic.simple import direct_to_template\n\n# Uncomment the next two lines to enable the admin:\nfrom django.contrib import admin\nadmin.autodiscover()\n\nurlpatterns = patterns('',\n # Example:\n # (r'^webapp/', include('webapp.foo.urls')),\n\n # Uncomment the admin/doc line below and add 'django.contrib.admindocs' \n # to INSTALLED_APPS to enable admin documentation:\n # (r'^admin/doc/', include('django.contrib.admindocs.urls')),\n\n # Uncomment the next line to enable the admin:\n (r'^$', direct_to_template, {'template': 'home.html'}),\n (r'^emoter/', include('apps.emoter.urls')),\n (r'^news/', include('apps.news.urls')),\n (r'^admin/', include(admin.site.urls)),\n (r'^static/(?P<path>.*)$', 'django.views.static.serve',\n {'document_root': 'static/'}),\n)\n"
},
{
"alpha_fraction": 0.515853226184845,
"alphanum_fraction": 0.5333095788955688,
"avg_line_length": 33.62963104248047,
"blob_id": "249951250a3056d654a0b8411828851dcd72b487",
"content_id": "2835db3da3521a008cb06678f920964955cc945b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2807,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 81,
"path": "/apps/ai/clustering.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "\"\"\"\nClustering class\n\"\"\"\nimport re\nimport random\n\nfrom django.utils.stopwords import strip_stopwords\n\ndef jaccard_distance(item1, item2):\n \"\"\"\n A simple distance function (curse of dimentionality applies)\n distance(A, B) = 1 - n(A intersection B) / n(A union B) or\n distance(A, B) = 1 - n(A intersection B) / n(A) + n(B) - n(A intersection B)\n text1 and text2 are our features\n \"\"\"\n feature1 = set(re.findall('\\w+', strip_stopwords(\"%s %s\" % (item1.title.lower(), item1.body.lower())))[:100])\n feature2 = set(re.findall('\\w+', strip_stopwords(\"%s %s\" % (item2.title.lower(), item2.body.lower())))[:100])\n\n if len(feature1) == 0 and len(feature2) == 0:\n return 1# max distance\n similarity = 1.0*len(feature1.intersection(feature2))/len(feature1.union(feature2))\n return 1 - similarity\n\n \nclass Cluster(object):\n \"\"\"\n Clustering class\n \"\"\"\n def __init__(self, items, distance_function=jaccard_distance):\n self.distance = distance_function\n self.items = items\n \n def kmeans(self, k=10, threshold=0.80):\n \"k is number of clusters, threshold is minimum acceptable distance\"\n \n #pick n random stories and make then centroid\n centroids = random.sample(self.items, k)\n \n #remove centroid from collection\n items = list(set(self.items) - set(centroids))\n \n last_matches = None\n # Max. 50 iterations for convergence.\n for t in range(50):\n # Make k empty clusters\n best_matches = [[] for c in centroids]\n min_distance = 1 # it's max value of distance\n \n # Find which centroid is the closest for each row\n for item in items:\n best_center = 0\n min_distance = 1.1\n minima = -1\n for centroid in centroids:\n minima+=1\n distance = self.distance(item, centroid) \n if distance <= min_distance:\n best_center = minima\n min_distance = distance\n # maintain quality of your cluster\n if min_distance <= threshold:#threshold\n best_matches[best_center].append(item)\n \n # If the results are the same as last time, this is complete\n if best_matches == last_matches:\n break\n last_matches = best_matches\n \n ret = []\n cnt = 0\n for c in best_matches:\n tmp = []\n seen = 0\n for i in c:\n seen = 1\n tmp.append(i)\n if seen:\n tmp.append(centroids[cnt])\n ret.append(tmp)\n cnt += 1\n return ret\n "
},
{
"alpha_fraction": 0.6933333277702332,
"alphanum_fraction": 0.6933333277702332,
"avg_line_length": 29.714284896850586,
"blob_id": "18cb2643a7c3ad3b6746315a07bae722646a309b",
"content_id": "936a1d2a2a8bb0e722916f3416deae85e4353c9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 225,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 7,
"path": "/apps/emoter/views.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render_to_response\n\nfrom models import Tweet\n\ndef index(request):\n tweets = Tweet.objects.all().order_by('-pk')\n return render_to_response(\"emoter/index.html\", {\"tweets\": tweets})\n \n \n"
},
{
"alpha_fraction": 0.6615384817123413,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 25,
"blob_id": "575a814eb10fc27e6f7130a2a7bd78bc9f3450be",
"content_id": "e470bb0dc6d8aa4fe3bf56fb1b496a9c31fd2da4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 5,
"path": "/apps/news/urls.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.conf.urls.defaults import *\n\nurlpatterns = patterns('',\n url(r'^$', 'apps.news.views.index', name='news-index'),\n)\n"
},
{
"alpha_fraction": 0.6258603930473328,
"alphanum_fraction": 0.6293018460273743,
"avg_line_length": 29.28358268737793,
"blob_id": "41ecd545990768bcfd4c4387ecec9c3c18656f97",
"content_id": "e8a311750f78c02b3e33d775139dc580a16277f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2034,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 67,
"path": "/apps/news/models.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\nfrom django.utils.html import strip_tags\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom contrib.feedparser import feedparser\n\n# Create your models here.\n\nclass Cluster(models.Model):\n created = models.DateTimeField()\n \n def save(self, *args, **kwargs):\n if not self.id:\n self.created = datetime.datetime.now()\n super(Cluster, self).save()\n \n def get_items(self):\n return News.objects.filter(cluster=self)\n \n def __unicode__(self):\n return u'%d' % self.pk\n\n\nclass NewsSource(models.Model):\n name = models.CharField(_(\"Name\"), max_length=200)\n url = models.URLField(verify_exists=False)\n \n def __unicode__(self):\n return self.name\n \nclass News(models.Model):\n url = models.URLField(_(\"URL\"), verify_exists=False)\n title = models.CharField(_(\"Title\"), max_length=200)\n body = models.TextField(null=True, blank=True)\n date = models.DateTimeField()\n source = models.ForeignKey(NewsSource)\n cluster = models.ForeignKey(Cluster, null=True, blank=True)\n \n class Meta:\n verbose_name = _(\"News\")\n verbose_name_plural = _(\"News\")\n\n \n def __unicode__(self):\n return self.title\n \n\n@receiver(post_save, sender=NewsSource)\ndef create_news_items(sender, instance, created, **kwargs):\n \"\"\"Create a news items from source\"\"\"\n #if created:\n feed = feedparser.parse(instance.url)\n for item in feed.entries:\n try:\n news = News.objects.get(url=item.link)\n except News.DoesNotExist:\n if not hasattr(item, 'updated_parsed'):\n date = datetime.datetime.now()\n else:\n date = datetime.datetime(*item.updated_parsed[:6])\n news = News(url=item.link, title=item.title, body=strip_tags(item.summary),\n date=date, source=instance)\n news.save()\n \n"
},
{
"alpha_fraction": 0.7119341492652893,
"alphanum_fraction": 0.7119341492652893,
"avg_line_length": 32.42856979370117,
"blob_id": "9cfac8063a2c478b98efb364530f0433ef6dbbd3",
"content_id": "d7db95aed4caf03ca7f7cc545753757ae452bad9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 7,
"path": "/apps/news/views.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render_to_response\n\nfrom models import Cluster, News\n\ndef index(request):\n clusters = Cluster.objects.all().order_by('-created')\n return render_to_response(\"news/index.html\", {\"clusters\": clusters})\n \n "
},
{
"alpha_fraction": 0.8244274854660034,
"alphanum_fraction": 0.8244274854660034,
"avg_line_length": 20.83333396911621,
"blob_id": "16b120aceb4e2752737321abc2dc3fae33e6771f",
"content_id": "eb183b1df6700a59700cda8233753532be15fad3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 131,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 6,
"path": "/apps/emoter/admin.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom models import SearchTerm, Tweet\n\nadmin.site.register(Tweet)\nadmin.site.register(SearchTerm)\n"
},
{
"alpha_fraction": 0.631267786026001,
"alphanum_fraction": 0.6359826326370239,
"avg_line_length": 36.270572662353516,
"blob_id": "e82a3b2eafbc5c6089effe78f7bf7c289e1ffc91",
"content_id": "ea0df6618dd119eb10b1cc97ace301f0a8089b1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26724,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 717,
"path": "/apps/ai/bayes.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "import operator\nimport re\nimport math\n\nPOSITIVE = \"H\" #Happy\nNEGATIVE = \"S\" #Sad\nNEUTRAL = \"N\" #Neutral\n\n\nclass BayesianClassifier(object):\n\n POSITIVE = POSITIVE\n NEGATIVE = NEGATIVE\n NEUTRAL = NEUTRAL\n\n THRESHHOLD = 0.05\n guesser = None\n\n def __init__(self):\n self.guesser = Bayes()\n self.guesser.train(POSITIVE, \"cool\")\n self.guesser.train(POSITIVE, \"Woo\")\n self.guesser.train(POSITIVE, \"quite amazing\")\n self.guesser.train(POSITIVE, \"thks\")\n self.guesser.train(POSITIVE, \"looking forward to\")\n self.guesser.train(POSITIVE, \"damn good\")\n self.guesser.train(POSITIVE, \"frickin ruled\")\n self.guesser.train(POSITIVE, \"frickin rules\")\n self.guesser.train(POSITIVE, \"Way to go\")\n self.guesser.train(POSITIVE, \"cute\")\n self.guesser.train(POSITIVE, \"comeback\")\n self.guesser.train(POSITIVE, \"not suck\")\n self.guesser.train(POSITIVE, \"prop\")\n self.guesser.train(POSITIVE, \"kinda impressed\")\n self.guesser.train(POSITIVE, \"props\")\n self.guesser.train(POSITIVE, \"come on\")\n self.guesser.train(POSITIVE, \"congratulation\")\n self.guesser.train(POSITIVE, \"gtd\")\n self.guesser.train(POSITIVE, \"proud\")\n self.guesser.train(POSITIVE, \"thanks\")\n self.guesser.train(POSITIVE, \"can help\")\n self.guesser.train(POSITIVE, \"thanks!\")\n self.guesser.train(POSITIVE, \"pumped\")\n self.guesser.train(POSITIVE, \"integrate\")\n self.guesser.train(POSITIVE, \"really like\")\n self.guesser.train(POSITIVE, \"loves it\")\n self.guesser.train(POSITIVE, \"yay\")\n self.guesser.train(POSITIVE, \"amazing\")\n self.guesser.train(POSITIVE, \"epic flail\")\n self.guesser.train(POSITIVE, \"flail\")\n self.guesser.train(POSITIVE, \"good luck\")\n self.guesser.train(POSITIVE, \"fail\")\n self.guesser.train(POSITIVE, \"life saver\")\n self.guesser.train(POSITIVE, \"piece of cake\")\n self.guesser.train(POSITIVE, \"good thing\")\n self.guesser.train(POSITIVE, \"hawt\")\n self.guesser.train(POSITIVE, \"hawtness\")\n self.guesser.train(POSITIVE, \"highly positive\")\n self.guesser.train(POSITIVE, \"my hero\")\n self.guesser.train(POSITIVE, \"yummy\")\n self.guesser.train(POSITIVE, \"awesome\")\n self.guesser.train(POSITIVE, \"congrats\")\n self.guesser.train(POSITIVE, \"would recommend\")\n self.guesser.train(POSITIVE, \"intellectual vigor\")\n self.guesser.train(POSITIVE, \"really neat\")\n self.guesser.train(POSITIVE, \"yay\")\n self.guesser.train(POSITIVE, \"ftw\")\n self.guesser.train(POSITIVE, \"I want\")\n self.guesser.train(POSITIVE, \"best looking\")\n self.guesser.train(POSITIVE, \"imrpessive\")\n self.guesser.train(POSITIVE, \"positive\")\n self.guesser.train(POSITIVE, \"thx\")\n self.guesser.train(POSITIVE, \"thanks\")\n self.guesser.train(POSITIVE, \"thank you\")\n self.guesser.train(POSITIVE, \"endorse\")\n self.guesser.train(POSITIVE, \"clearly superior\")\n self.guesser.train(POSITIVE, \"superior\")\n self.guesser.train(POSITIVE, \"really love\")\n self.guesser.train(POSITIVE, \"woot\")\n self.guesser.train(POSITIVE, \"w00t\")\n self.guesser.train(POSITIVE, \"super\")\n self.guesser.train(POSITIVE, \"wonderful\")\n self.guesser.train(POSITIVE, \"leaning towards\")\n self.guesser.train(POSITIVE, \"rally\")\n self.guesser.train(POSITIVE, \"incredible\")\n self.guesser.train(POSITIVE, \"the best\")\n self.guesser.train(POSITIVE, \"is the best\")\n self.guesser.train(POSITIVE, \"strong\")\n self.guesser.train(POSITIVE, \"would love\")\n self.guesser.train(POSITIVE, \"rally\")\n self.guesser.train(POSITIVE, \"very quickly\")\n self.guesser.train(POSITIVE, \"very cool\")\n self.guesser.train(POSITIVE, \"absolutely love\")\n self.guesser.train(POSITIVE, \"very exceptional\")\n self.guesser.train(POSITIVE, \"so proud\")\n self.guesser.train(POSITIVE, \"funny\")\n self.guesser.train(POSITIVE, \"recommend\")\n self.guesser.train(POSITIVE, \"so proud\")\n self.guesser.train(POSITIVE, \"so great\")\n self.guesser.train(POSITIVE, \"so cool\")\n self.guesser.train(POSITIVE, \"cool\")\n self.guesser.train(POSITIVE, \"wowsers\")\n self.guesser.train(POSITIVE, \"plus\")\n self.guesser.train(POSITIVE, \"liked it\")\n self.guesser.train(POSITIVE, \"make a difference\")\n self.guesser.train(POSITIVE, \"moves me\")\n self.guesser.train(POSITIVE, \"inspired\")\n self.guesser.train(POSITIVE, \"OK\")\n self.guesser.train(POSITIVE, \"love it\")\n self.guesser.train(POSITIVE, \"LOL\")\n self.guesser.train(POSITIVE, \":)\")\n self.guesser.train(POSITIVE, \";)\")\n self.guesser.train(POSITIVE, \":-)\")\n self.guesser.train(POSITIVE, \";-)\")\n self.guesser.train(POSITIVE, \":D\")\n self.guesser.train(POSITIVE, \";]\")\n self.guesser.train(POSITIVE, \":]\")\n self.guesser.train(POSITIVE, \":p\")\n self.guesser.train(POSITIVE, \";p\")\n self.guesser.train(POSITIVE, \"voting for\")\n self.guesser.train(POSITIVE, \"great\")\n self.guesser.train(POSITIVE, \"agreeable\")\n self.guesser.train(POSITIVE, \"amused\")\n self.guesser.train(POSITIVE, \"brave\")\n self.guesser.train(POSITIVE, \"calm\")\n self.guesser.train(POSITIVE, \"charming\")\n self.guesser.train(POSITIVE, \"cheerful\")\n self.guesser.train(POSITIVE, \"comfortable\")\n self.guesser.train(POSITIVE, \"cooperative\")\n self.guesser.train(POSITIVE, \"courageous\")\n self.guesser.train(POSITIVE, \"delightful\")\n self.guesser.train(POSITIVE, \"determined\")\n self.guesser.train(POSITIVE, \"eager\")\n self.guesser.train(POSITIVE, \"elated\")\n self.guesser.train(POSITIVE, \"enchanting\")\n self.guesser.train(POSITIVE, \"encouraging\")\n self.guesser.train(POSITIVE, \"energetic\")\n self.guesser.train(POSITIVE, \"enthusiastic\")\n self.guesser.train(POSITIVE, \"excited\")\n self.guesser.train(POSITIVE, \"exuberant\")\n self.guesser.train(POSITIVE, \"excellent\")\n self.guesser.train(POSITIVE, \"I like\")\n self.guesser.train(POSITIVE, \"fine\")\n self.guesser.train(POSITIVE, \"fair\")\n self.guesser.train(POSITIVE, \"faithful\")\n self.guesser.train(POSITIVE, \"fantastic\")\n self.guesser.train(POSITIVE, \"fine\")\n self.guesser.train(POSITIVE, \"friendly\")\n self.guesser.train(POSITIVE, \"fun \")\n self.guesser.train(POSITIVE, \"funny\")\n self.guesser.train(POSITIVE, \"gentle\")\n self.guesser.train(POSITIVE, \"glorious\")\n self.guesser.train(POSITIVE, \"good\")\n self.guesser.train(POSITIVE, \"pretty good\")\n self.guesser.train(POSITIVE, \"happy\")\n self.guesser.train(POSITIVE, \"healthy\")\n self.guesser.train(POSITIVE, \"helpful\")\n self.guesser.train(POSITIVE, \"high\")\n self.guesser.train(POSITIVE, \"agile\")\n self.guesser.train(POSITIVE, \"responsive\")\n self.guesser.train(POSITIVE, \"hilarious\")\n self.guesser.train(POSITIVE, \"jolly\")\n self.guesser.train(POSITIVE, \"joyous\")\n self.guesser.train(POSITIVE, \"kind\")\n self.guesser.train(POSITIVE, \"lively\")\n self.guesser.train(POSITIVE, \"lovely\")\n self.guesser.train(POSITIVE, \"lucky\")\n self.guesser.train(POSITIVE, \"nice\")\n self.guesser.train(POSITIVE, \"nicely\")\n self.guesser.train(POSITIVE, \"obedient\")\n self.guesser.train(POSITIVE, \"perfect\")\n self.guesser.train(POSITIVE, \"pleasant\")\n self.guesser.train(POSITIVE, \"proud\")\n self.guesser.train(POSITIVE, \"relieved\")\n self.guesser.train(POSITIVE, \"silly\")\n self.guesser.train(POSITIVE, \"smiling\")\n self.guesser.train(POSITIVE, \"splendid\")\n self.guesser.train(POSITIVE, \"successful\")\n self.guesser.train(POSITIVE, \"thankful\")\n self.guesser.train(POSITIVE, \"thoughtful\")\n self.guesser.train(POSITIVE, \"victorious\")\n self.guesser.train(POSITIVE, \"vivacious\")\n self.guesser.train(POSITIVE, \"witty\")\n self.guesser.train(POSITIVE, \"wonderful\")\n self.guesser.train(POSITIVE, \"zealous\")\n self.guesser.train(POSITIVE, \"zany\")\n self.guesser.train(POSITIVE, \"rocks\")\n self.guesser.train(POSITIVE, \"comeback\")\n self.guesser.train(POSITIVE, \"pleasantly surprised\")\n self.guesser.train(POSITIVE, \"pleasantly\")\n self.guesser.train(POSITIVE, \"surprised\")\n self.guesser.train(POSITIVE, \"love\")\n self.guesser.train(POSITIVE, \"glad\")\n self.guesser.train(POSITIVE, \"yum\")\n self.guesser.train(POSITIVE, \"interesting\")\n\n\n\n self.guesser.train(NEGATIVE, \"FTL\")\n self.guesser.train(NEGATIVE, \"irritating\")\n self.guesser.train(NEGATIVE, \"not that good\")\n self.guesser.train(NEGATIVE, \"suck\")\n self.guesser.train(NEGATIVE, \"lying\")\n self.guesser.train(NEGATIVE, \"duplicity\")\n self.guesser.train(NEGATIVE, \"angered\")\n self.guesser.train(NEGATIVE, \"dumbfounding\")\n self.guesser.train(NEGATIVE, \"dumbifying\")\n self.guesser.train(NEGATIVE, \"not as good\")\n self.guesser.train(NEGATIVE, \"not impressed\")\n self.guesser.train(NEGATIVE, \"stomach it\")\n self.guesser.train(NEGATIVE, \"pw\")\n self.guesser.train(NEGATIVE, \"pwns\")\n self.guesser.train(NEGATIVE, \"pwnd\")\n self.guesser.train(NEGATIVE, \"pwning\")\n self.guesser.train(NEGATIVE, \"in a bad way\")\n self.guesser.train(NEGATIVE, \"horrifying\")\n self.guesser.train(NEGATIVE, \"wrong\")\n self.guesser.train(NEGATIVE, \"flailing\")\n self.guesser.train(NEGATIVE, \"failing\")\n self.guesser.train(NEGATIVE, \"fallen way behind\")\n self.guesser.train(NEGATIVE, \"fallen behind\")\n self.guesser.train(NEGATIVE, \"lose\")\n self.guesser.train(NEGATIVE, \"fallen\")\n self.guesser.train(NEGATIVE, \"self-deprecating\")\n self.guesser.train(NEGATIVE, \"hunker down\")\n self.guesser.train(NEGATIVE, \"duh\")\n self.guesser.train(NEGATIVE, \"get killed by\")\n self.guesser.train(NEGATIVE, \"got killed by\")\n self.guesser.train(NEGATIVE, \"hated us\")\n self.guesser.train(NEGATIVE, \"only works in safari\")\n self.guesser.train(NEGATIVE, \"must have ie\")\n self.guesser.train(NEGATIVE, \"fuming and frothing\")\n self.guesser.train(NEGATIVE, \"heavy\")\n self.guesser.train(NEGATIVE, \"buggy\")\n self.guesser.train(NEGATIVE, \"unusable\")\n self.guesser.train(NEGATIVE, \"nothing is\")\n self.guesser.train(NEGATIVE, \"is great until\")\n self.guesser.train(NEGATIVE, \"don't support\")\n self.guesser.train(NEGATIVE, \"despise\")\n self.guesser.train(NEGATIVE, \"pos\")\n self.guesser.train(NEGATIVE, \"hindrance\")\n self.guesser.train(NEGATIVE, \"sucks\")\n self.guesser.train(NEGATIVE, \"problems\")\n self.guesser.train(NEGATIVE, \"not working\")\n self.guesser.train(NEGATIVE, \"fuming\")\n self.guesser.train(NEGATIVE, \"annoying\")\n self.guesser.train(NEGATIVE, \"frothing\")\n self.guesser.train(NEGATIVE, \"poorly\")\n self.guesser.train(NEGATIVE, \"headache\")\n self.guesser.train(NEGATIVE, \"completely wrong\")\n self.guesser.train(NEGATIVE, \"sad news\")\n self.guesser.train(NEGATIVE, \"didn't last\")\n self.guesser.train(NEGATIVE, \"lame\")\n self.guesser.train(NEGATIVE, \"pet peeves\")\n self.guesser.train(NEGATIVE, \"pet peeve\")\n self.guesser.train(NEGATIVE, \"can't send\")\n self.guesser.train(NEGATIVE, \"bullshit\")\n self.guesser.train(NEGATIVE, \"fail\")\n self.guesser.train(NEGATIVE, \"so terrible\")\n self.guesser.train(NEGATIVE, \"negative\")\n self.guesser.train(NEGATIVE, \"anooying\")\n self.guesser.train(NEGATIVE, \"an issue\")\n self.guesser.train(NEGATIVE, \"drop dead\")\n self.guesser.train(NEGATIVE, \"trouble\")\n self.guesser.train(NEGATIVE, \"brainwashed\")\n self.guesser.train(NEGATIVE, \"smear\")\n self.guesser.train(NEGATIVE, \"commie\")\n self.guesser.train(NEGATIVE, \"communist\")\n self.guesser.train(NEGATIVE, \"anti-women\")\n self.guesser.train(NEGATIVE, \"WTF\")\n self.guesser.train(NEGATIVE, \"anxiety\")\n self.guesser.train(NEGATIVE, \"STING\")\n self.guesser.train(NEGATIVE, \"nobody spoke\")\n self.guesser.train(NEGATIVE, \"yell\")\n self.guesser.train(NEGATIVE, \"Damn\")\n self.guesser.train(NEGATIVE, \"aren't\")\n self.guesser.train(NEGATIVE, \"anti\")\n self.guesser.train(NEGATIVE, \"i hate\")\n self.guesser.train(NEGATIVE, \"hate\")\n self.guesser.train(NEGATIVE, \"dissapointing\")\n self.guesser.train(NEGATIVE, \"doesn't recommend\")\n self.guesser.train(NEGATIVE, \"the worst\")\n self.guesser.train(NEGATIVE, \"worst\")\n self.guesser.train(NEGATIVE, \"expensive\")\n self.guesser.train(NEGATIVE, \"crap\")\n self.guesser.train(NEGATIVE, \"socialist\")\n self.guesser.train(NEGATIVE, \"won't\")\n self.guesser.train(NEGATIVE, \"wont\")\n self.guesser.train(NEGATIVE, \":(\")\n self.guesser.train(NEGATIVE, \":-(\")\n self.guesser.train(NEGATIVE, \"Thanks\")\n self.guesser.train(NEGATIVE, \"smartass\")\n self.guesser.train(NEGATIVE, \"don't like\")\n self.guesser.train(NEGATIVE, \"too bad\")\n self.guesser.train(NEGATIVE, \"frickin\")\n self.guesser.train(NEGATIVE, \"snooty\")\n self.guesser.train(NEGATIVE, \"knee jerk\")\n self.guesser.train(NEGATIVE, \"jerk\")\n self.guesser.train(NEGATIVE, \"reactionist\")\n self.guesser.train(NEGATIVE, \"MUST DIE\")\n self.guesser.train(NEGATIVE, \"no more\")\n self.guesser.train(NEGATIVE, \"hypocrisy\")\n self.guesser.train(NEGATIVE, \"ugly\")\n self.guesser.train(NEGATIVE, \"too slow\")\n self.guesser.train(NEGATIVE, \"not reliable\")\n self.guesser.train(NEGATIVE, \"noise\")\n self.guesser.train(NEGATIVE, \"crappy\")\n self.guesser.train(NEGATIVE, \"horrible\")\n self.guesser.train(NEGATIVE, \"bad quality\")\n self.guesser.train(NEGATIVE, \"angry\")\n self.guesser.train(NEGATIVE, \"annoyed\")\n self.guesser.train(NEGATIVE, \"anxious\")\n self.guesser.train(NEGATIVE, \"arrogant\")\n self.guesser.train(NEGATIVE, \"ashamed\")\n self.guesser.train(NEGATIVE, \"awful\")\n self.guesser.train(NEGATIVE, \"bad\")\n self.guesser.train(NEGATIVE, \"bewildered\")\n self.guesser.train(NEGATIVE, \"blues\")\n self.guesser.train(NEGATIVE, \"bored\")\n self.guesser.train(NEGATIVE, \"clumsy\")\n self.guesser.train(NEGATIVE, \"combative\")\n self.guesser.train(NEGATIVE, \"condemned\")\n self.guesser.train(NEGATIVE, \"confused\")\n self.guesser.train(NEGATIVE, \"crazy\")\n self.guesser.train(NEGATIVE, \"flipped-out\")\n self.guesser.train(NEGATIVE, \"creepy\")\n self.guesser.train(NEGATIVE, \"cruel\")\n self.guesser.train(NEGATIVE, \"dangerous\")\n self.guesser.train(NEGATIVE, \"defeated\")\n self.guesser.train(NEGATIVE, \"defiant\")\n self.guesser.train(NEGATIVE, \"depressed\")\n self.guesser.train(NEGATIVE, \"disgusted\")\n self.guesser.train(NEGATIVE, \"disturbed\")\n self.guesser.train(NEGATIVE, \"dizzy\")\n self.guesser.train(NEGATIVE, \"dull\")\n self.guesser.train(NEGATIVE, \"embarrassed\")\n self.guesser.train(NEGATIVE, \"envious\")\n self.guesser.train(NEGATIVE, \"evil\")\n self.guesser.train(NEGATIVE, \"fierce\")\n self.guesser.train(NEGATIVE, \"foolish\")\n self.guesser.train(NEGATIVE, \"frantic\")\n self.guesser.train(NEGATIVE, \"frightened\")\n self.guesser.train(NEGATIVE, \"grieving\")\n self.guesser.train(NEGATIVE, \"grumpy\")\n self.guesser.train(NEGATIVE, \"helpless\")\n self.guesser.train(NEGATIVE, \"homeless\")\n self.guesser.train(NEGATIVE, \"hungry\")\n self.guesser.train(NEGATIVE, \"hurt\")\n self.guesser.train(NEGATIVE, \"ill\")\n self.guesser.train(NEGATIVE, \"itchy\")\n self.guesser.train(NEGATIVE, \"jealous\")\n self.guesser.train(NEGATIVE, \"jittery\")\n self.guesser.train(NEGATIVE, \"lazy\")\n self.guesser.train(NEGATIVE, \"lonely\")\n self.guesser.train(NEGATIVE, \"mysterious\")\n self.guesser.train(NEGATIVE, \"nasty\")\n self.guesser.train(NEGATIVE, \"rape\")\n self.guesser.train(NEGATIVE, \"naughty\")\n self.guesser.train(NEGATIVE, \"nervous\")\n self.guesser.train(NEGATIVE, \"nutty\")\n self.guesser.train(NEGATIVE, \"obnoxious\")\n self.guesser.train(NEGATIVE, \"outrageous\")\n self.guesser.train(NEGATIVE, \"panicky\")\n self.guesser.train(NEGATIVE, \"fucking up\")\n self.guesser.train(NEGATIVE, \"repulsive\")\n self.guesser.train(NEGATIVE, \"scary\")\n self.guesser.train(NEGATIVE, \"selfish\")\n self.guesser.train(NEGATIVE, \"sore\")\n self.guesser.train(NEGATIVE, \"tense\")\n self.guesser.train(NEGATIVE, \"terrible\")\n self.guesser.train(NEGATIVE, \"testy\")\n self.guesser.train(NEGATIVE, \"thoughtless\")\n self.guesser.train(NEGATIVE, \"tired\")\n self.guesser.train(NEGATIVE, \"troubled\")\n self.guesser.train(NEGATIVE, \"upset\")\n self.guesser.train(NEGATIVE, \"uptight\")\n self.guesser.train(NEGATIVE, \"weary\")\n self.guesser.train(NEGATIVE, \"wicked\")\n self.guesser.train(NEGATIVE, \"worried\")\n self.guesser.train(NEGATIVE, \"is a fool\")\n self.guesser.train(NEGATIVE, \"painful\")\n self.guesser.train(NEGATIVE, \"pain\")\n self.guesser.train(NEGATIVE, \"gross\") \n\n\n def classify(self, sentence):\n guess = self.guesser.guess(sentence)\n if len(guess) == 0:\n return NEUTRAL\n\n if len(guess) == 1:\n (sentiment, probabitily) = guess[0]\n return sentiment\n\n (max_sentiment, max_value) = guess[0]\n (min_sentiment, min_value) = guess[1]\n if max_value - min_value > self.THRESHHOLD:\n return max_sentiment\n\n\n return NEUTRAL\n\n\n\nclass BayesData(dict):\n\n def __init__(self, name='', pool=None):\n self.name = name\n self.training = []\n self.pool = pool\n self.tokenCount = 0\n self.trainCount = 0\n\n def trainedOn(self, item):\n return item in self.training\n\n def __repr__(self):\n return '<BayesDict: %s, %s tokens>' % (self.name, self.tokenCount)\n\nclass Bayes(object):\n\n def __init__(self, tokenizer=None, combiner=None, dataClass=None):\n if dataClass is None:\n self.dataClass = BayesData\n else:\n self.dataClass = dataClass\n self.corpus = self.dataClass('__Corpus__')\n self.pools = {}\n self.pools['__Corpus__'] = self.corpus\n self.trainCount = 0\n self.dirty = True\n # The tokenizer takes an object and returns\n # a list of strings\n if tokenizer is None:\n self._tokenizer = Tokenizer()\n else:\n self._tokenizer = tokenizer\n # The combiner combines probabilities\n if combiner is None:\n self.combiner = self.robinson\n else:\n self.combiner = combiner\n\n def commit(self):\n self.save()\n\n def newPool(self, poolName):\n \"\"\"Create a new pool, without actually doing any\n training.\n \"\"\"\n self.dirty = True # not always true, but it's simple\n return self.pools.setdefault(poolName, self.dataClass(poolName))\n\n def removePool(self, poolName):\n del(self.pools[poolName])\n self.dirty = True\n\n def renamePool(self, poolName, newName):\n self.pools[newName] = self.pools[poolName]\n self.pools[newName].name = newName\n self.removePool(poolName)\n self.dirty = True\n\n def mergePools(self, destPool, sourcePool):\n \"\"\"Merge an existing pool into another.\n The data from sourcePool is merged into destPool.\n The arguments are the names of the pools to be merged.\n The pool named sourcePool is left in tact and you may\n want to call removePool() to get rid of it.\n \"\"\"\n sp = self.pools[sourcePool]\n dp = self.pools[destPool]\n for tok, count in sp.items():\n if dp.get(tok):\n dp[tok] += count\n else:\n dp[tok] = count\n dp.tokenCount += 1\n self.dirty = True\n\n def poolData(self, poolName):\n \"\"\"Return a list of the (token, count) tuples.\n \"\"\"\n return self.pools[poolName].items()\n\n def poolTokens(self, poolName):\n \"\"\"Return a list of the tokens in this pool.\n \"\"\"\n return [tok for tok, count in self.poolData(poolName)]\n\n def save(self, fname='bayesdata.dat'):\n from cPickle import dump\n fp = open(fname, 'wb')\n dump(self.pools, fp)\n fp.close()\n\n def load(self, fname='bayesdata.dat'):\n from cPickle import load\n fp = open(fname, 'rb')\n self.pools = load(fp)\n fp.close()\n self.corpus = self.pools['__Corpus__']\n self.dirty = True\n\n def poolNames(self):\n \"\"\"Return a sorted list of Pool names.\n Does not include the system pool '__Corpus__'.\n \"\"\"\n pools = self.pools.keys()\n pools.remove('__Corpus__')\n pools = [pool for pool in pools]\n pools.sort()\n return pools\n\n def buildCache(self):\n \"\"\" merges corpora and computes probabilities\n \"\"\"\n self.cache = {}\n for pname, pool in self.pools.items():\n # skip our special pool\n if pname == '__Corpus__':\n continue\n\n poolCount = pool.tokenCount\n themCount = max(self.corpus.tokenCount - poolCount, 1)\n cacheDict = self.cache.setdefault(pname, self.dataClass(pname))\n\n for word, totCount in self.corpus.items():\n # for every word in the copus\n # check to see if this pool contains this word\n thisCount = float(pool.get(word, 0.0))\n if (thisCount == 0.0):\n continue\n otherCount = float(totCount) - thisCount\n\n if not poolCount:\n goodMetric = 1.0\n else:\n goodMetric = min(1.0, otherCount/poolCount)\n badMetric = min(1.0, thisCount/themCount)\n f = badMetric / (goodMetric + badMetric)\n\n # PROBABILITY_THRESHOLD\n if abs(f-0.5) >= 0.1 :\n # GOOD_PROB, BAD_PROB\n cacheDict[word] = max(0.0001, min(0.9999, f))\n\n def poolProbs(self):\n if self.dirty:\n self.buildCache()\n self.dirty = False\n return self.cache\n\n def getTokens(self, obj):\n \"\"\"By default, we expect obj to be a screen and split\n it on whitespace.\n\n Note that this does not change the case.\n In some applications you may want to lowecase everthing\n so that \"king\" and \"King\" generate the same token.\n\n Override this in your subclass for objects other\n than text.\n\n Alternatively, you can pass in a tokenizer as part of\n instance creation.\n \"\"\"\n return self._tokenizer.tokenize(obj)\n\n def getProbs(self, pool, words):\n \"\"\" extracts the probabilities of tokens in a message\n \"\"\"\n probs = [(word, pool[word]) for word in words if word in pool]\n probs.sort(lambda x,y: cmp(y[1],x[1]))\n return probs[:2048]\n\n def train(self, pool, item, uid=None):\n \"\"\"Train Bayes by telling him that item belongs\n in pool. uid is optional and may be used to uniquely\n identify the item that is being trained on.\n \"\"\"\n tokens = self.getTokens(item)\n pool = self.pools.setdefault(pool, self.dataClass(pool))\n self._train(pool, tokens)\n self.corpus.trainCount += 1\n pool.trainCount += 1\n if uid:\n pool.training.append(uid)\n self.dirty = True\n\n def untrain(self, pool, item, uid=None):\n tokens = self.getTokens(item)\n pool = self.pools.get(pool, None)\n if not pool:\n return\n self._untrain(pool, tokens)\n # I guess we want to count this as additional training?\n self.corpus.trainCount += 1\n pool.trainCount += 1\n if uid:\n pool.training.remove(uid)\n self.dirty = True\n\n\n def _train(self, pool, tokens):\n wc = 0\n for token in tokens:\n count = pool.get(token, 0)\n pool[token] = count + 1\n count = self.corpus.get(token, 0)\n self.corpus[token] = count + 1\n wc += 1\n pool.tokenCount += wc\n self.corpus.tokenCount += wc\n\n def _untrain(self, pool, tokens):\n for token in tokens:\n count = pool.get(token, 0)\n if count:\n if count == 1:\n del(pool[token])\n else:\n pool[token] = count - 1\n pool.tokenCount -= 1\n\n count = self.corpus.get(token, 0)\n if count:\n if count == 1:\n del(self.corpus[token])\n else:\n self.corpus[token] = count - 1\n self.corpus.tokenCount -= 1\n\n def trainedOn(self, msg):\n for p in self.cache.values():\n if msg in p.training:\n return True\n return False\n\n def guess(self, msg):\n tokens = set(self.getTokens(msg))\n pools = self.poolProbs()\n\n res = {}\n for pname, pprobs in pools.items():\n p = self.getProbs(pprobs, tokens)\n if len(p) != 0:\n res[pname]=self.combiner(p, pname)\n res = res.items()\n res.sort(lambda x,y: cmp(y[1], x[1]))\n return res\n\n def robinson(self, probs, ignore):\n \"\"\" computes the probability of a message being spam (Robinson's method)\n P = 1 - prod(1-p)^(1/n)\n Q = 1 - prod(p)^(1/n)\n S = (1 + (P-Q)/(P+Q)) / 2\n Courtesy of http://christophe.delord.free.fr/en/index.html\n \"\"\"\n\n nth = 1./len(probs)\n P = 1.0 - reduce(operator.mul, map(lambda p: 1.0-p[1], probs), 1.0) ** nth\n Q = 1.0 - reduce(operator.mul, map(lambda p: p[1], probs)) ** nth\n S = (P - Q) / (P + Q)\n return (1 + S) / 2\n\n\n def robinsonFisher(self, probs, ignore):\n \"\"\" computes the probability of a message being spam (Robinson-Fisher method)\n H = C-1( -2.ln(prod(p)), 2*n )\n S = C-1( -2.ln(prod(1-p)), 2*n )\n I = (1 + H - S) / 2\n Courtesy of http://christophe.delord.free.fr/en/index.html\n \"\"\"\n n = len(probs)\n try: H = chi2P(-2.0 * math.log(reduce(operator.mul, map(lambda p: p[1], probs), 1.0)), 2*n)\n except OverflowError: H = 0.0\n try: S = chi2P(-2.0 * math.log(reduce(operator.mul, map(lambda p: 1.0-p[1], probs), 1.0)), 2*n)\n except OverflowError: S = 0.0\n return (1 + H - S) / 2\n\n def __repr__(self):\n return '<Bayes: %s>' % [self.pools[p] for p in self.poolNames()]\n\n def __len__(self):\n return len(self.corpus)\n\nclass Tokenizer:\n \"\"\"A simple regex-based whitespace tokenizer.\n It expects a string and can return all tokens lower-cased\n or in their existing case.\n \"\"\"\n\n WORD_RE = re.compile('\\\\w+', re.U)\n\n def __init__(self, lower=False):\n self.lower = lower\n\n def tokenize(self, obj):\n for match in self.WORD_RE.finditer(obj):\n if self.lower:\n yield match.group().lower()\n else:\n yield match.group()\n\ndef chi2P(chi, df):\n \"\"\" return P(chisq >= chi, with df degree of freedom)\n\n df must be even\n \"\"\"\n assert df & 1 == 0\n m = chi / 2.0\n sum = term = math.exp(-m)\n for i in range(1, df/2):\n term *= m/i\n sum += term\n return min(sum, 1.0)\n\n"
},
{
"alpha_fraction": 0.43577003479003906,
"alphanum_fraction": 0.44144782423973083,
"avg_line_length": 35.842105865478516,
"blob_id": "31f9ffbda65549ac3aa8e62cf509a534af6c5f16",
"content_id": "ce38e3e40cc2ba1ad935a6915618d72a04a95c56",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1409,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 38,
"path": "/apps/news/management/commands/clusternews.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from optparse import make_option\nfrom django.core.management.base import BaseCommand, CommandError\n\nfrom apps.news.models import News, Cluster\nfrom apps.ai.clustering import Cluster as Clustering\n\nclass Command(BaseCommand):\n option_list = BaseCommand.option_list + (\n make_option('--iteration',\n '-i',\n dest='iteration',\n default=10,\n help='Specify number of interations'),\n )\n help = 'Cluster news items'\n\n def handle(self, *args, **options):\n items = News.objects.all()[:1000]\n cluster = Clustering(items)\n for i in xrange(options.get('iteration')):\n print \"Iteration %d ...\" % i\n ret = cluster.kmeans()\n for item in ret:\n if len(item) > 1:\n for i in item:\n if not i.cluster is None:\n for b in item:\n if b.cluster is None:\n b.cluster = i.cluster\n b.save()\n continue\n if item[0].cluster is None: \n c = Cluster()\n c.save()\n for i in item:\n if i.cluster is None:\n i.cluster = c\n i.save()\n \n"
},
{
"alpha_fraction": 0.6632583737373352,
"alphanum_fraction": 0.6680299639701843,
"avg_line_length": 29.375,
"blob_id": "f664bcbee19fc4c77c814d166f654acb9348bc3a",
"content_id": "108e5ee48b8e327de1ceeab97de6866989ae0db6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1467,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 48,
"path": "/apps/emoter/models.py",
"repo_name": "azizur77/smartwebapps",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\n\nfrom apps.ai.bayes import BayesianClassifier\nfrom contrib.feedparser import feedparser\n\nSTATUS_DEFAULT = 'N'\nSTATUS_POSITIVE = 'H'\nSTATUS_NEGATIVE = 'S'\nSTATUS_CHOICES = (\n (STATUS_DEFAULT, _(\"Neutral\")),\n (STATUS_POSITIVE, _(\"Positive\")),\n (STATUS_NEGATIVE, _(\"Negative\"))\n)\n\nclass SearchTerm(models.Model):\n search = models.CharField(_(\"Search Term\"), max_length=100)\n\n def __unicode__(self):\n return self.search\n\n\nclass Tweet(models.Model):\n text = models.CharField(_(\"Message\"), max_length=140)\n polarity = models.CharField(_(\"Polarity\"), choices=STATUS_CHOICES, max_length=1, default=STATUS_DEFAULT)\n \n def save(self, *args, **kwargs):\n if not self.id:\n classifier = BayesianClassifier()\n self.polarity = classifier.classify(self.text)\n super(Tweet, self).save()\n \n def __unicode__(self):\n return self.text\n \n\n@receiver(post_save, sender=SearchTerm)\ndef create_tweets(sender, instance, created, **kwargs):\n \"\"\"Create a news items from source\"\"\"\n #if created:\n classifier = BayesianClassifier()\n url = \"feed://search.twitter.com/search.atom?q=\" + instance.search\n feed = feedparser.parse(url)\n for item in feed.entries:\n news = Tweet(text=item.summary)\n news.save()\n \n"
}
] | 12 |
SemyonDyachenko/biquadtelebot | https://github.com/SemyonDyachenko/biquadtelebot | 33efa44034963f8da472e6d03549593afd014bd7 | 26ae3257a6d9476a44c9f16da3eddf0fff3824dc | e0f1271fbb428af870d60d876fac6eda8f029aa0 | refs/heads/master | 2022-11-30T04:20:47.388004 | 2020-08-19T15:47:15 | 2020-08-19T15:47:15 | 288,771,831 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6702954769134521,
"alphanum_fraction": 0.6710730791091919,
"avg_line_length": 29.64285659790039,
"blob_id": "dbd3a55f29ce3167922b5e1b77f8d6ae7124df7f",
"content_id": "1d1930e347d19898d1b1ee0c4853c08d4db65019",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1286,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 42,
"path": "/Bot.py",
"repo_name": "SemyonDyachenko/biquadtelebot",
"src_encoding": "UTF-8",
"text": "import telebot\nimport requests\nimport random\nimport _config_\nfrom telebot import apihelper\nimport unittest\n\n\ntelegram_bot = telebot.TeleBot(_config_.telegram_token)\n\n#receive messages from website chat\ndef on_receiving(chat_id):\n pass\n\n\n@telegram_bot.message_handler(commands=['start'])\ndef _bot_start(message):\n if message.chat.type == \"group\":\n admins = apihelper.get_chat_administrators(_config_.telegram_token,message.chat.id)\n for user in admins:\n if user['user']['id'] == apihelper.get_me(_config_.telegram_token)['id']:\n telegram_bot.send_message(message.chat.id,\"Set unique id with /setid\")\n break\n else:\n telegram_bot.send_message(message.chat.id,\"Please promote me to admin\") \n else:\n telegram_bot.send_message(message.chat.id,\"Please add me to group\")\n\n@telegram_bot.message_handler(commands=['setid'])\ndef _set_id(message):\n pass\n \n\n#check for non-existent commands\n@telegram_bot.message_handler(content_types=['text'])\ndef _message_handle(message):\n if message.text[0] == \"/\": #first symbol\n if message.text != \"/start\":\n telegram_bot.send_message(message.chat.id,\"Warning ! Bot understood only commands\")\n\n\ntelegram_bot.polling(none_stop = True)"
}
] | 1 |
omerkap/bulboard | https://github.com/omerkap/bulboard | 6852909193184a72c9de4d73cd79e992f37ccd2b | 88eecd013d4037962478c61266ac21d6edd4c22c | 90cb119c2a12a5439922d1e640f7f30cf2c41d63 | refs/heads/master | 2021-01-09T05:20:01.305387 | 2018-04-20T18:30:56 | 2018-04-20T18:30:56 | 80,753,434 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3177599012851715,
"alphanum_fraction": 0.4900990128517151,
"avg_line_length": 30.37864112854004,
"blob_id": "4271cf07fb1d8c7de3fe3ed2abcea6e72f26de46",
"content_id": "16b34e92b400ee11b49e7d7fc5abe3dcb18e7a27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3240,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 103,
"path": "/runners/static_sov_n_txt_runner.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf8 -*-\nimport sys\nsys.path.append(r'../')\nfrom SR_Board.sr_driver import SRDriver\nfrom screen_usages.sovsov import Sovsov\nimport time\nimport os\nimport numpy as np\n\nfrom screen_usages.messages_writer import MessagesWriter\ntry:\n import matplotlib.pyplot as plt\nexcept ImportError as ex:\n print ex\n\n\nclass StaticSovNTextRunner(object):\n def __init__(self):\n nun_sov = [[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,1,1,1,1,1,1,1,0,0,0],\n[0,0,1,0,0,0,0,0,1,0,0,0],\n[0,0,1,0,0,1,1,0,1,0,0,0],\n[0,0,1,0,0,0,1,0,1,0,0,0],\n[0,0,1,0,0,0,1,0,1,0,0,0],\n[0,0,1,0,1,1,1,0,1,0,0,0],\n[0,0,0,1,0,0,0,1,0,0,0,0],\n[0,0,0,0,1,0,1,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0]]\n gimel_sov = [[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,1,1,1,1,1,1,1,0,0,0],\n[0,0,1,0,0,0,0,0,1,0,0,0],\n[0,0,1,0,1,1,1,0,1,0,0,0],\n[0,0,1,0,0,0,1,0,1,0,0,0],\n[0,0,1,0,0,1,1,0,1,0,0,0],\n[0,0,1,0,1,0,1,0,1,0,0,0],\n[0,0,0,1,0,0,0,1,0,0,0,0],\n[0,0,0,0,1,0,1,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0]]\n he_sov = [[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,1,1,1,1,1,1,1,0,0,0],\n[0,0,1,0,0,0,0,0,1,0,0,0],\n[0,0,1,0,1,1,1,0,1,0,0,0],\n[0,0,1,0,0,0,1,0,1,0,0,0],\n[0,0,1,0,1,0,1,0,1,0,0,0],\n[0,0,1,0,1,0,1,0,1,0,0,0],\n[0,0,0,1,0,0,0,1,0,0,0,0],\n[0,0,0,0,1,0,1,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0]]\n pe_sov = [[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0],\n[0,0,1,1,1,1,1,1,1,0,0,0],\n[0,0,1,0,0,0,0,0,1,0,0,0],\n[0,0,1,0,1,1,1,0,1,0,0,0],\n[0,0,1,0,1,0,1,0,1,0,0,0],\n[0,0,1,0,0,0,1,0,1,0,0,0],\n[0,0,1,0,1,1,1,0,1,0,0,0],\n[0,0,0,1,0,0,0,1,0,0,0,0],\n[0,0,0,0,1,0,1,0,0,0,0,0],\n[0,0,0,0,0,1,0,0,0,0,0,0]]\n self.sovim = [nun_sov,gimel_sov,he_sov,pe_sov]\n self.sr_driver = SRDriver(board_num_of_regs=56,\n num_of_boards=4,\n clk_pin=11,\n store_pin=12,\n data_pin=13,\n index_map_file=os.path.join('..', 'SR_Board', 'index_map.csv'),\n is_simulated=True)\n self.mw = MessagesWriter(font_path, 10, (7, 11))\n self.mw.load_text(self.mw.mirror_string(u'חנוכה שמח!'), True)\n\n def start(self):\n #plt.ion()\n #f = plt.figure()\n counter = 0\n while (True):\n if (counter >= 28):\n counter = 0\n sov_index = counter / 7\n sov = self.sovim[sov_index]\n counter += 1\n\n a = self.mw.get_next_step()\n a = a[1:7, :]\n a = np.asarray(a)\n sov = np.asarray(sov)\n sov = sov[:,0:11]\n b = np.concatenate([sov,a],0)\n self.sr_driver.draw(pic=b.astype(int))\n # f.clf()\n # plt.imshow(b, cmap='hot')\n # f.canvas.draw()\n time.sleep(0.2)\n\nif __name__ == '__main__':\n #font_path = r'/home/netanel/PycharmProjects/bulboard/screen_usages/fonts/arcade/ARCADE.TTF'\n #font_path = r'/usr/share/fonts/truetype/freefont/FreeSans.ttf'\n font_path = r'/usr/share/fonts/truetype/msttcorefonts/Arial.ttf'\n #font_path = r'C:\\Windows\\Fonts\\Arial.ttf'\n runner = StaticSovNTextRunner()\n runner.start()\n"
},
{
"alpha_fraction": 0.6316925883293152,
"alphanum_fraction": 0.6424870491027832,
"avg_line_length": 45.220001220703125,
"blob_id": "c9262b6ee8f0fb940e463f210bf18d5917daa4ed",
"content_id": "8ec20dbe016b48333dcd1fd18a504cef13f4a4d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2316,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 50,
"path": "/screen_usages/dual_line_message_writer.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "import logging\nfrom abstract_screen_usage import AbstractScreenUsage\nfrom screen_usages.messages_writer import MessagesWriter\nimport numpy as np\n\n\nclass DualLineMessageWriter(AbstractScreenUsage):\n\n def __init__(self, font_path, font_size=8, half_screen_size=(8, 11), bdf_font=True):\n super(DualLineMessageWriter, self).__init__()\n self._logger = logging.getLogger(self.__class__.__name__)\n self._line_1_mw = MessagesWriter(font_path=font_path, font_size=font_size, screen_size=half_screen_size, bdf=bdf_font)\n self._line_2_mw = MessagesWriter(font_path=font_path, font_size=font_size, screen_size=half_screen_size, bdf=bdf_font)\n\n self._current_frame = None\n self.set_text()\n self._logger.info('initialized {}'.format(self.__class__.__name__))\n\n def set_text(self, first_line=' ', second_line=' ', first_line_rtl=False, second_line_rtl=False):\n\n self._logger.info(u'in set_text, first_line: {}, second_line: {}, first_line_rtl: {}, second_line_rtl: {}'\n .format(first_line, second_line, first_line_rtl, second_line_rtl))\n if first_line_rtl is True:\n first_line = MessagesWriter.mirror_string(first_line)\n if second_line_rtl is True:\n second_line = MessagesWriter.mirror_string(second_line)\n\n self._line_1_mw.load_text(text=first_line, rtl=first_line_rtl)\n self._line_2_mw.load_text(text=second_line, rtl=second_line_rtl)\n\n def get_next_step(self):\n first_row_m = self._line_1_mw.get_next_step()\n second_row_m = self._line_2_mw.get_next_step()\n seperator = np.zeros((1, first_row_m.shape[1]))\n\n m = np.concatenate([first_row_m, seperator, second_row_m], 0)\n self._logger.debug('calculated frame with shape: {}'.format(m.shape))\n return m.astype(dtype=int)\n\n def serialize_state(self):\n container = dict()\n line_1_data = self._line_1_mw.serialize_state()\n line_2_data = self._line_2_mw.serialize_state()\n container['line_1_data'] = line_1_data\n container['line_2_data'] = line_2_data\n return container\n\n def load_state(self, serialized_state):\n self._line_1_mw.load_state(serialized_state['line_1_data'])\n self._line_2_mw.load_state(serialized_state['line_2_data'])\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5297845602035522,
"alphanum_fraction": 0.5416138768196106,
"avg_line_length": 37.16128921508789,
"blob_id": "d224bcca9374910100fe8c7d31f698106b8f4e6f",
"content_id": "350cd2be907045de0907d326388b6bf4e748ff04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2367,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 62,
"path": "/screen_usages/matrix_scroller.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom abstract_screen_usage import AbstractScreenUsage\n\n\nclass MatrixScroller(AbstractScreenUsage):\n def __init__(self, screen_size=(17, 11)):\n self._screen_size = screen_size\n self._data_matrix = None\n self._rtl = None\n self._scrolling_step = 0\n\n def set_data_matrix(self, matrix, rtl=False):\n self._data_matrix = matrix\n self._rtl = rtl\n self._scrolling_step = 0\n\n def get_next_step(self):\n \"\"\"\n Roll the text in one pixel to the wanted direction (RTL: right, LTR: left) and return the next viewable matrix\n :return:\n \"\"\"\n if not self._rtl:\n if self._scrolling_step + self._screen_size[1] <= self._data_matrix.shape[1]:\n result = self._data_matrix[:, self._scrolling_step: self._scrolling_step + self._screen_size[1]]\n else:\n result = np.concatenate([\n self._data_matrix[:, self._scrolling_step: self._data_matrix.shape[1]],\n self._data_matrix[:, 0: self._screen_size[1] - (self._data_matrix.shape[1] - self._scrolling_step)]\n ], 1)\n\n if self._scrolling_step < self._data_matrix.shape[1]:\n self._scrolling_step += 1\n else:\n self._scrolling_step = 0\n\n else:\n if self._scrolling_step - self._screen_size[1] >= 0:\n result = self._data_matrix[:, self._scrolling_step - self._screen_size[1]: self._scrolling_step]\n else:\n result = np.concatenate([\n self._data_matrix[:,\n self._data_matrix.shape[1] - (self._screen_size[1] - self._scrolling_step): self._data_matrix.shape[\n 1]],\n self._data_matrix[:, 0: self._scrolling_step]\n ], 1)\n\n if self._scrolling_step == 0:\n self._scrolling_step = self._data_matrix.shape[1]\n else:\n self._scrolling_step -= 1\n\n return result\n\n def load_state(self, serialized_state):\n self._data_matrix = serialized_state['data_matrix']\n self._rtl = serialized_state['rtl']\n\n def serialize_state(self):\n container = dict()\n container['data_matrix'] = self._data_matrix\n container['rtl'] = self._rtl\n return container\n\n"
},
{
"alpha_fraction": 0.4958692193031311,
"alphanum_fraction": 0.5125681161880493,
"avg_line_length": 30.782123565673828,
"blob_id": "095374a5d009a3931b9580bd00360707e39fcf74",
"content_id": "3c09c61dff7c6f63be7bd4ff3a3a0b0317abf860",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5689,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 179,
"path": "/SR_Board/sr_driver.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "try:\n import RPi.GPIO as GPIO\nexcept ImportError as ex:\n print ex\nfrom time import sleep\nimport re\nimport pprint\n\n\nclass SRDriver(object):\n\n # Usage example:\n # For a 17*11 board use total_num_of_regs = 187\n # For a bus of 50 wires connected to a board use board_num_of_active_regs = 50\n # If we soldered the board in such a way that the first wire is connected to\n # the 7th reg, use board_starting_reg = 6\n def __init__(self, board_num_of_regs, num_of_boards,\n clk_pin, store_pin, data_pin, index_map_file, is_simulated=False):\n self._index_map = self._read_csv(index_map_file)\n self._num_of_boards = num_of_boards\n self._board_num_of_regs = board_num_of_regs\n self.clk_pin = clk_pin\n self.store_pin = store_pin\n self.data_pin = data_pin\n self.num_of_lines = len(self._index_map)\n self.num_of_columns = len(self._index_map[0])\n self.simulated = is_simulated\n self.data = [0] * (self._num_of_boards * self._board_num_of_regs)\n for i in range(0, len(self.data)):\n self.data[i] = 0\n\n if is_simulated is False:\n GPIO.setmode(GPIO.BOARD)\n GPIO.setup(self.data_pin, GPIO.OUT)\n GPIO.setup(self.store_pin, GPIO.OUT)\n GPIO.setup(self.clk_pin, GPIO.OUT)\n\n GPIO.output(self.data_pin, 0)\n GPIO.output(self.store_pin, 0)\n GPIO.output(self.clk_pin, 0)\n\n def _read_csv(self,index_map_file):\n file = open(index_map_file)\n index_map = []\n line_format_str = \"(\\d+),(\\d+),(\\d+),(\\d+),(\\d+),(\\d+),(\\d+),(\\d+),(\\d+),(\\d+),(\\d+)\"\n line_format = re.compile(line_format_str)\n for line in file:\n re_result = line_format.match(line)\n index_map_line = []\n for i in range(1, 12):\n index_map_line.extend([int(re_result.group(i))])\n index_map.append(index_map_line)\n return index_map\n\n def load_array(self,picture):\n for i in range(0,self.num_of_lines):\n for j in range(0,self.num_of_columns):\n self.data[self._index_map[i][j]] = picture[i][j]\n\n def shift_data(self, data):\n \"\"\"\n shift data into register, data should be 0, 1\n :param data:\n :return:\n \"\"\"\n if self.simulated is False:\n GPIO.output(self.data_pin, data)\n sleep(0.00005)\n GPIO.output(self.clk_pin, 1)\n sleep(0.00001)\n GPIO.output(self.clk_pin, 0)\n sleep(0.00001)\n\n def load_output(self):\n \"\"\"\n load shift register data into output latches\n :return:\n \"\"\"\n if self.simulated is False:\n GPIO.output(self.store_pin, 1)\n sleep(0.00001)\n GPIO.output(self.store_pin, 0)\n sleep(0.00001)\n\n def write_data(self):\n for d in self.data:\n self.shift_data(data=d)\n self.load_output()\n\n def draw(self, pic):\n self.load_array(picture=pic)\n self.write_data()\n\n def test_board(self):\n for i in range(0, self.num_of_lines):\n for j in range(0, self.num_of_columns):\n pic = [self.num_of_columns * [0] for k in range(0, self.num_of_lines)]\n pic[i][j] = 1\n self.load_array(picture=pic)\n self.write_data()\n print '{},{}'.format(i,j)\n sleep(0.5)\n\n def test_board_no_pic(self):\n for d in range(2):\n for i in range(0, self._board_num_of_regs * self._num_of_boards):\n print 'line {}'.format(i)\n self.shift_data(d)\n \n self.load_output()\n sleep(2)\n\n def test_blink(self): \n pic = [self.num_of_columns * [0] for k in range(0, self.num_of_lines)]\n self.load_array(picture=pic)\n self.write_data()\n sleep(0.2)\n pic = [self.num_of_columns * [1] for k in range(0, self.num_of_lines)]\n self.load_array(picture=pic)\n self.write_data()\n sleep(0.2)\n\n def light_line(self, line):\n pic = []\n for i in range(self.num_of_lines):\n if i == line:\n pic.append(self.num_of_columns * [1])\n else:\n pic.append(self.num_of_columns * [0])\n return pic\n\n def light_column(self, c):\n pic = []\n for i in range(self.num_of_lines):\n line = [0] * self.num_of_columns\n line[c] = 1\n pic.append(line)\n return pic\n \n def test_columns(self):\n for i in range(self.num_of_columns):\n pic = self.light_column(i)\n self.load_array(pic)\n self.write_data()\n sleep(1)\n \n def test_lines(self):\n for i in range(self.num_of_lines):\n print 'line: {}'.format(i)\n\n pic = self.light_line(line=i)\n pprint.pprint(pic)\n self.load_array(pic)\n self.write_data()\n sleep(1)\n\n\nif __name__ == '__main__':\n driver = SRDriver(board_num_of_regs=56,\n num_of_boards=4,\n clk_pin=11,\n store_pin=12,\n data_pin=13,\n index_map_file=\"index_map.csv\")\n\n \n while True: # for testing just start running the pixel\n #driver.test_board()\n #driver.test_lines()\n #driver.test_columns() \n driver.test_board_no_pic()\n '''\n while True:\n a = raw_input(\"press 'd' for demo, 'q' for quit\")\n if a == 'd':\n driver.test_board()\n elif a == 'q':\n exit(0)\n '''\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 18,
"blob_id": "4f99437c7d84b8642db8c5a309315017a3ca1f15",
"content_id": "472d63e4828df1fa99c012170db3baa2a48cc5b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/run_bulboard.sh",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncd /home/pi/bulboard/runners\npython static_sov_n_txt_runner.py\n"
},
{
"alpha_fraction": 0.5912600159645081,
"alphanum_fraction": 0.6050030589103699,
"avg_line_length": 36.212642669677734,
"blob_id": "dc1a95e3e12f4e104a3a286513dd0eb9bff04e14",
"content_id": "fe6b1f3c94f1a3d32dd5742ca97e2153a3128cc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6486,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 174,
"path": "/screen_usages/messages_writer.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf8 -*-\nfrom __future__ import print_function\nimport logging\nfrom disk_sapce_file_handlers import DiskSpaceRotatingFileHandler\nfrom datetime import datetime\nimport os\nimport time\nfrom bdf_font import BdfFont\nfrom PIL import Image\nfrom PIL import ImageFont\nfrom PIL import ImageDraw\nimport numpy as np\nfrom abstract_screen_usage import AbstractScreenUsage\nfrom matrix_scroller import MatrixScroller\ntry:\n import matplotlib.pyplot as plt\n from matplotlib import animation\nexcept ImportError as ex:\n print(ex)\nimport sys\nsys.path.append(r'../')\n\n\nclass MessagesWriter(MatrixScroller):\n def __init__(self, font_path, font_size, screen_size=(17, 11), bdf=False):\n self._logger = logging.getLogger(self.__class__.__name__)\n self._logger.info('initializing {}'.format(self.__class__.__name__))\n self._logger.info('screen size: {}'.format(screen_size))\n super(MessagesWriter, self).__init__(screen_size=screen_size)\n self._screen_size = screen_size\n self._font = None\n self._is_bdf = False\n self._font_size = None\n self.set_font(font_path=font_path, font_size=font_size, bdf=bdf)\n self._logger.info('finished initializing MessagesWriter')\n\n def set_font(self, font_path, font_size, bdf=False):\n \"\"\"\n Set the current used font of MessagesWriter\n :param font_path: path to used font\n :param font_size: size\n :return:\n \"\"\"\n self._logger.info('setting new font, {}'.format(font_path))\n if bdf is False:\n self._font = ImageFont.truetype(font_path, font_size)\n self._font_size = font_size\n else:\n self._logger.info('bdf font is used, size is taken from Font parameters')\n self._font = BdfFont(font_file=font_path)\n self._font_size = self._font.get_font_size()[1]\n self._is_bdf = True\n\n def load_text(self, text, rtl=False):\n \"\"\"\n Set the current shown text of MessagesWriter\n :param text: the text string\n :param rtl: should the text be interpreted as RTL (scroll the other direction)\n :return: the length of the full text matrix\n \"\"\"\n self._rtl = rtl\n self._logger.info(u'trying to load text: {}'.format(text))\n text_matrix = self._str_to_pixels(string=text)\n if text_matrix.shape[0] < self._screen_size[0]:\n self._logger.debug('text is shorter than screen, padding towards downside')\n a, b = divmod(self._screen_size[0] - text_matrix.shape[0], 2)\n top_size = self._screen_size[0] - text_matrix.shape[0] - a\n bottom_size = a\n top_padding_matrix = np.zeros([top_size, text_matrix.shape[1]])\n bottom_padding_matrix = np.zeros([bottom_size, text_matrix.shape[1]])\n text_matrix = np.concatenate([top_padding_matrix, text_matrix, bottom_padding_matrix], 0)\n\n # add to text matrix an 'empty' matrix with the screen size, so when we move the text we start from clean screen\n self._data_matrix = np.concatenate([np.zeros(self._screen_size, dtype=int), text_matrix], 1)\n self._logger.debug('text size: {}'.format(self._data_matrix.shape))\n return self._data_matrix.shape[1]\n\n def _str_to_pixels(self, string):\n string_array = np.zeros((self._font_size, 1), dtype=int) # 0 column\n #chars_matrixs = []\n for c in string:\n arr = self._char_to_pixels(c)\n #chars_matrixs.append(arr)\n string_array = np.concatenate([string_array, arr], 1)\n #print(1)\n return self._trim(string_array)\n\n def _char_to_pixels(self, char):\n \"\"\"\n Based on https://stackoverflow.com/a/27753869/190597 (jsheperd)\n \"\"\"\n if self._is_bdf:\n return self._font.char_to_matrix(char)\n w, h = self._font.getsize(char)\n self._logger.debug(u'char: {}, w: {}, h: {}'.format(char, w, h))\n image = Image.new('L', (w, h), 1)\n draw = ImageDraw.Draw(image)\n draw.text((0, 0), char, font=self._font)\n arr = np.asarray(image)\n arr = np.where(arr, 0, 1) # replace 1's and 0's\n if arr.shape[0] < self._font_size:\n return np.concatenate([np.zeros([self._font_size - arr.shape[0], arr.shape[1]], dtype=int), arr], 0)\n else:\n return arr\n\n @staticmethod\n def _trim(matrix):\n i = j = 0\n for i in range(matrix.shape[0]):\n if np.sum(matrix[i:i+1, :], 1) > 0:\n break\n\n for j in range(matrix.shape[0], 0, -1):\n if np.sum(matrix[j:j+1, :], 1) > 0:\n break\n\n return matrix[i:j+1, :]\n\n @staticmethod\n def mirror_string(string):\n \"\"\"\n Mirror string, can be used for mirroring Hebrew text\n :param string:\n :return:\n \"\"\"\n s = ''\n for i in range(len(string) - 1, -1, -1):\n s = s + string[i]\n return s\n\n\ndef init_logging(level):\n root_logger = logging.getLogger()\n root_logger.setLevel(level=level)\n try:\n os.mkdir('logs')\n except Exception:\n pass\n file_name = os.path.join('logs', 'GameOfLife_{}'.format(datetime.now().strftime('%d_%m_%y__%H_%M_%S')))\n file_handler = DiskSpaceRotatingFileHandler(folder_max_size=10E6, filename=file_name, maxBytes=1E6, backupCount=10000)\n formatter = logging.Formatter(fmt=r'%(asctime)s:%(name)s:%(levelname)s:%(message)s')\n file_handler.setFormatter(formatter)\n\n console_handler = logging.StreamHandler()\n console_handler.setFormatter(formatter)\n\n root_logger.addHandler(hdlr=file_handler)\n root_logger.addHandler(hdlr=console_handler)\n\n\nif __name__ == '__main__':\n init_logging(level=logging.DEBUG)\n #font_path = r'/home/netanel/PycharmProjects/bulboard/screen_usages/fonts/arcade/ARCADE.TTF'\n font_path = r'/usr/share/fonts/truetype/freefont/FreeSans.ttf'\n #font_path = r'C:\\Windows\\Fonts\\Arial.ttf'\n font_path = r'fonts/bdf/5x8.bdf'\n font_path = r'fonts/bdf/7x14B.bdf'\n font_path = r'fonts/bdf/helvR12.bdf'\n\n mw = MessagesWriter(font_path, 17, (17, 11), True)\n #steps = mw.load_text(mw.mirror_string(u'חג שמח!'), True)\n steps = mw.load_text(u'חג שמח!')\n\n plt.ion()\n f = plt.figure()\n #plt.show()\n for k in range(2 * steps):\n a = mw.get_next_step()\n f.clf()\n plt.imshow(a, cmap='hot')\n f.canvas.draw()\n time.sleep(0.01)\n\n# plt.show()\n\n"
},
{
"alpha_fraction": 0.6185330748558044,
"alphanum_fraction": 0.6198428273200989,
"avg_line_length": 36.69135665893555,
"blob_id": "f4174d741e9383afa4a2df4bc081dd2eaf96d639",
"content_id": "668d302602ee1a244d0ca27d6b2cb5702781c0b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3054,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 81,
"path": "/runners/screen_usages_orchestrator.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "import logging\nimport time\nimport threading\nimport cPickle\nimport pickle\nfrom screen_usages.abstract_screen_usage import AbstractScreenUsage\n\n\nclass ScreenUsagesOrchestrator(threading.Thread):\n def __init__(self, sr_driver, screen_scroll_delay=0.2, runners={}):\n super(ScreenUsagesOrchestrator, self).__init__()\n self._logger = logging.getLogger(self.__class__.__name__)\n self._sr_driver = sr_driver\n self._screen_scroll_delay = screen_scroll_delay\n self._current_frame = None\n\n for runner_name, runner in runners.items():\n assert isinstance(runner, AbstractScreenUsage)\n\n self._runners = runners\n # default runner is the first one\n self._active_runner = self._runners[self._runners.keys()[0]]\n self._active_runner_name = self._runners.keys()[0]\n try:\n self._logger.info('trying to load previously saved state')\n self.load_state_from_file()\n except Exception as ex:\n self._logger.exception(ex)\n\n self._should_run = False\n\n def set_active_runner(self, runner_name):\n self._logger.info('setting active runner to: {}'.format(runner_name))\n try:\n self._active_runner = self._runners[runner_name]\n self._active_runner_name = runner_name\n self._logger.info('runner {} was set successfully'.format(runner_name))\n except KeyError:\n self._logger.error('runner {} not found, runners names: {}'.format(runner_name, self._runners.keys()))\n\n def get_active_runner(self):\n return self._active_runner\n\n def kill_runner(self):\n self._should_run = False\n\n def calc_next_frame(self):\n return self._active_runner.get_next_step()\n\n def get_current_frame(self):\n return self._current_frame\n\n def save_state_to_file(self):\n with open('orchestrator_back_up_file.pickle', 'w') as f:\n current_runner_data = self._active_runner.serialize_state()\n container = dict()\n container['runner_data'] = current_runner_data\n container['runner_name'] = self._active_runner_name\n cPickle.dump(container, f, pickle.HIGHEST_PROTOCOL)\n\n self._logger.info('saved state to file')\n\n def load_state_from_file(self):\n with open('orchestrator_back_up_file.pickle', 'r') as f:\n container = cPickle.load(f)\n self._active_runner_name = container['runner_name']\n self._active_runner = self._runners[self._active_runner_name]\n self._active_runner.load_state(container['runner_data'])\n\n self._logger.info('loaded state, active runner: {}'.format(self._active_runner_name))\n\n def run(self):\n self._should_run = True\n while self._should_run:\n try:\n self._current_frame = self.calc_next_frame()\n self._sr_driver.draw(pic=self._current_frame)\n except Exception as ex:\n self._logger.exception(ex)\n\n time.sleep(self._screen_scroll_delay)\n\n"
},
{
"alpha_fraction": 0.5766977071762085,
"alphanum_fraction": 0.5884177684783936,
"avg_line_length": 35.26250076293945,
"blob_id": "d37bab3057ee57db5de604e562b128cc1c41558f",
"content_id": "bf5b4ad303925c15cd9c1db38bc73cfa09c20263",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2901,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 80,
"path": "/runners/gol_runner.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom screen_usages.disk_sapce_file_handlers import DiskSpaceRotatingFileHandler\nimport logging\nimport os\nimport time\nfrom screen_usages.gol_calculator import GameOfLife\nimport numpy as np\n\ntry:\n import matplotlib.pyplot as plt\n from matplotlib import animation\nexcept ImportError as ex:\n print ex\nimport sys\n\nsys.path.append(r'../')\nfrom SR_Board.sr_driver import SRDriver\n\n\nclass GameOfLifeRunner(object):\n def __init__(self, initial_pattern, steps):\n self._steps = steps\n self._logger = logging.getLogger(self.__class__.__name__)\n self._initial_pattern = initial_pattern\n\n @staticmethod\n def create(pattern_str, steps):\n try:\n return GameOfLifeRunner(np.asarray(np.matrix(pattern_str.encode('ascii', 'ignore'))), steps)\n except Exception:\n return None\n\n @staticmethod\n def init_logging(level):\n root_logger = logging.getLogger()\n root_logger.setLevel(level=level)\n try:\n os.mkdir('logs')\n except Exception:\n pass\n file_name = os.path.join('logs', 'GameOfLife_{}'.format(datetime.now().strftime('%d_%m_%y__%H_%M_%S')))\n # file_handler = RotatingFileHandler(filename=file_name, maxBytes=10e6, backupCount=5)\n file_handler = DiskSpaceRotatingFileHandler(folder_max_size=10E6, filename=file_name, maxBytes=1E6,\n backupCount=10000)\n formatter = logging.Formatter(fmt=r'%(asctime)s:%(name)s:%(levelname)s:%(message)s')\n file_handler.setFormatter(formatter)\n root_logger.addHandler(hdlr=file_handler)\n\n def start(self):\n self.init_logging(logging.INFO)\n logger = logging.getLogger()\n p = np.zeros((17, 11))\n pattern_x_size, pattern_y_size = self._initial_pattern.shape\n p[0:pattern_x_size, 0:pattern_y_size] = self._initial_pattern\n gol_obj = GameOfLife(initial_pattern=p)\n screen_writer = SRDriver(board_num_of_regs=56,\n num_of_boards=4,\n clk_pin=11,\n store_pin=12,\n data_pin=13,\n index_map_file=os.path.join('..', 'SR_Board', 'index_map.csv'),\n is_simulated=True)\n\n plt.ion()\n f = plt.figure()\n\n for i in range(self._steps):\n state = gol_obj.state\n step = gol_obj.step\n logger.info('step: {}'.format(step))\n screen_writer.draw(pic=state.astype(int))\n gol_obj.visualize_state(state=state, step=step, figure=f)\n gol_obj.get_next_step()\n time.sleep(0.1)\n\n\nif __name__ == '__main__':\n initial_beacon = GameOfLife.get_demo_glider()\n gol_runner = GameOfLifeRunner(initial_beacon, 100)\n gol_runner.start()\n"
},
{
"alpha_fraction": 0.589798092842102,
"alphanum_fraction": 0.6057385802268982,
"avg_line_length": 25.13888931274414,
"blob_id": "53c84a6a6f126ed9cf39c7277804156255f086a4",
"content_id": "01332e08ecea1128f6e0bc483972c03399c0e1d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 36,
"path": "/camera.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport os\nimport pygame\n\nfrom pygame.locals import *\nimport pygame.camera\n\nclass picture_taker():\n\n def __init__(self):\n #initialise pygame\n width = 640\n height = 480\n pygame.init()\n pygame.camera.init()\n self.cam = pygame.camera.Camera(\"/dev/video0\",(width,height))\n self.windowSurfaceObj = pygame.display.set_mode((width,height),1,16)\n \n def take_picture(self, pic_name):\n #take a picture\n self.cam.start()\n image = self.cam.get_image()\n self.cam.stop()\n catSurfaceObj = image\n self.windowSurfaceObj.blit(catSurfaceObj,(0,0))\n #save picture\n pygame.image.save(self.windowSurfaceObj,pic_name)\n\n def take_many_pics(self,target_val):\n for i in range(target_val):\n pic_name = 'picture' + str(i) + '.jpg'\n self.take_picture(pic_name)\n\n\npt = picture_taker()\npt.take_many_pics(100)\n"
},
{
"alpha_fraction": 0.5410740375518799,
"alphanum_fraction": 0.5500725507736206,
"avg_line_length": 32.44660186767578,
"blob_id": "b61a748dbbfa62307fa11da0e4a6137a5c1ec092",
"content_id": "c886f26b83d11fba46b717f92673cd7dea1a711c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3446,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 103,
"path": "/screen_usages/bdf_font.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf8 -*-\nimport logging\nimport os\nfrom disk_sapce_file_handlers import DiskSpaceRotatingFileHandler\nfrom datetime import datetime\nimport numpy as np\n\n\nclass BdfFont(object):\n # some bdf file parameters\n STARTCHAR = 'STARTCHAR'\n ENDCHAR = 'ENDCHAR'\n BBX = 'BBX'\n ENCODING = 'ENCODING'\n BITMAP = 'BITMAP'\n FONTBOUNDINGBOX = 'FONTBOUNDINGBOX'\n\n def __init__(self, font_file):\n self._logger = logging.getLogger(self.__class__.__name__)\n self._logger.info('creating BdfFont object with font: {}'.format(font_file))\n self._chars_dict = {}\n self._font_size = (0, 0)\n self._parse_file(font_file)\n\n def _parse_file(self, file_name):\n with open(file_name) as f:\n for line in f:\n try:\n line = line.split(' ')\n if line[0] == self.STARTCHAR:\n char_name = line[1].strip()\n self._parse_char(f, char_name)\n\n elif line[0] == self.FONTBOUNDINGBOX:\n self._font_size = [int(v) for v in line[1:3]]\n\n except Exception as ex:\n self._logger.error('ex in line: {}'.format(line))\n self._logger.exception(ex)\n\n self._logger.info('parsed {} characters'.format(len(self._chars_dict)))\n\n def _parse_char(self, file_iterator, char_name):\n char_data = {'name': char_name}\n enc = 0\n bitmap = []\n\n bitmap_reading_started = False\n for line in file_iterator:\n line = line.strip('\\n')\n line = line.split(' ')\n\n if line[0] == self.ENCODING and bitmap_reading_started is False:\n enc = line[1]\n\n elif line[0] == self.BBX and bitmap_reading_started is False:\n char_data['bbx'] = [int(v) for v in line[1:]]\n\n elif line[0] == self.BITMAP and bitmap_reading_started is False:\n bitmap_reading_started = True\n continue\n\n if bitmap_reading_started:\n if line[0] != self.ENDCHAR:\n bitmap.append(line[0])\n else:\n char_data['bitmap'] = self._hex_list_to_ndarray(l=bitmap)\n self._chars_dict[enc] = char_data\n return\n\n def _hex_list_to_ndarray(self, l):\n #arr = np.zeros(self._font_size, dtype=int)\n arr = np.zeros((self._font_size[1], 8), dtype=int)\n for row_num, row in enumerate(l):\n bin_str = '{:08b}'.format(int(row, 16))\n bin_int = [int(c) for c in bin_str]\n arr[row_num, :] = bin_int\n\n return arr #arr[0:size[1], 0:size[0]]\n\n def char_to_matrix(self, c):\n char_str_val = str(ord(c))\n return self._chars_dict[char_str_val]['bitmap']\n\n def get_font_size(self):\n return self._font_size\n\n\ndef init_logging(level):\n root_logger = logging.getLogger()\n root_logger.setLevel(level=level)\n formatter = logging.Formatter(fmt=r'%(asctime)s:%(name)s:%(levelname)s:%(message)s')\n console_handler = logging.StreamHandler()\n console_handler.setFormatter(formatter)\n root_logger.addHandler(hdlr=console_handler)\n\n\nif __name__ == '__main__':\n init_logging(level=logging.DEBUG)\n font_path = r'fonts/bdf/5x8.bdf'\n font_path = r'fonts/bdf/6x10.bdf'\n bdf = BdfFont(font_file=font_path)\n print(bdf.char_to_matrix(u'ק'))\n"
},
{
"alpha_fraction": 0.48699840903282166,
"alphanum_fraction": 0.5223113894462585,
"avg_line_length": 36.07143020629883,
"blob_id": "30d0b88a9ec097371439e3b2448e9553bfdddf57",
"content_id": "7c680113ba64da477c75e024b05b2c4e0597dc1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3115,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 84,
"path": "/screen_usages/sovsov.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport math\nfrom abstract_screen_usage import AbstractScreenUsage\ntry:\n import matplotlib.pyplot as plt\nexcept ImportError as ex:\n print ex\n\n\nclass Sovsov(AbstractScreenUsage):\n SCALE = 100\n BOARD_SIZE = [17,11]\n DRAW_ORIGIN = [8, 5]\n\n def __init__(self, phi, dtheta_self, dtheta_inclined, shift_origin):\n self.a= np.asarray(([-1., 1., 1.],\n [-1, -1, 1],\n [1, -1, 1],\n [1, 1, 1],\n [-1,1,-1],\n [-1,-1,-1],\n [1,-1,-1],\n [1,1,-1]))\n self.a *= 3 * self.SCALE\n print self.a\n self.lines = ([0,1],[1,2],[2,3],[3,0],\n [4,5],[5,6],[6,7],[7,4],\n [0,4],[1,5],[2,6],[3,7])\n self.shift(shift_origin[0], shift_origin[1], shift_origin[2])\n self.a = np.transpose(self.a)\n self.phi = phi\n self.theta_inclined = 0\n self.dtheta_self = np.deg2rad(dtheta_self)\n self.dtheta_inclined = np.deg2rad(dtheta_inclined)\n self.spin_y(self.phi)\n\n # screen horizontal is x, vertical is y and depth is z\n def shift(self,x,y,z):\n self.a[:, 0] += x\n self.a[:, 1] += y\n self.a[:, 2] += z\n\n def spin_x(self,theta):\n spin = ([1,0,0],[0,np.cos(theta),-np.sin(theta)],[0,np.sin(theta),np.cos(theta)])\n self.a = np.dot(spin,self.a)\n\n def spin_y(self,theta):\n spin = ([np.cos(theta),0,np.sin(theta)],[0,1,0],[-np.sin(theta),0,np.cos(theta)])\n self.a = np.dot(spin,self.a)\n\n def spin_z(self,theta):\n spin = ([np.cos(theta),-np.sin(theta),0],[np.sin(theta),np.cos(theta),0],[0,0,1])\n self.a = np.dot(spin,self.a)\n\n def get_next_step(self):\n self.spin_z(-self.theta_inclined)\n self.spin_y(-self.phi)\n self.spin_z(self.dtheta_self)\n self.spin_y(self.phi)\n self.theta_inclined = self.theta_inclined + self.dtheta_inclined\n self.spin_z(self.theta_inclined)\n return self.get_drawable(render_lines= 1)\n\n def get_drawable(self, render_lines):\n projected_a = self.a[:2]\n projected_a = np.transpose(projected_a)\n drawable = np.zeros((self.BOARD_SIZE[0]*self.SCALE,self.BOARD_SIZE[1]*self.SCALE))\n if (render_lines == 0):\n for point in projected_a:\n drawable[int(round(point[0] + self.DRAW_ORIGIN[0]*self.SCALE)),\n int(round(point[1] + self.DRAW_ORIGIN[1]*self.SCALE))] = 1\n else:\n res_enhance = 2\n for line in self.lines:\n p0 = projected_a[line[0]]\n p1 = projected_a[line[1]]\n vector = p1 - p0\n vector_length = math.sqrt(vector[0]**2 + vector[1]**2)\n vector /= vector_length #normalized\n for step in range(0,int(math.floor(vector_length*res_enhance))):\n next_p = p0 + vector/res_enhance*step\n drawable[int(self.DRAW_ORIGIN[0] * self.SCALE + next_p[0]),\n int(self.DRAW_ORIGIN[1] * self.SCALE + next_p[1])] = 1\n return drawable\n\n"
},
{
"alpha_fraction": 0.48362892866134644,
"alphanum_fraction": 0.49727147817611694,
"avg_line_length": 31.600000381469727,
"blob_id": "cf081bfea577651ec7f7bfb18e9e6ff764eaccba",
"content_id": "3d568909b6df5022b5b680621958a1770928bd9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1466,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 45,
"path": "/runners/hanukkah_runner.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(r'../')\nfrom SR_Board.sr_driver import SRDriver\nfrom screen_usages.sovsov import Sovsov\nfrom time import sleep\nimport os\ntry:\n import matplotlib.pyplot as plt\nexcept ImportError as ex:\n print ex\n\n\nclass HanukkahRunner(object):\n def __init__(self):\n self.phi = 40\n self.dtheta_self = 5\n self.dtheta_inclined = 10\n self.shift_origin = (0,0,0)\n self.delay = 0.01\n self.sr_driver = SRDriver(board_num_of_regs=56,\n num_of_boards=4,\n clk_pin=11,\n store_pin=12,\n data_pin=13,\n index_map_file=os.path.join('..', 'SR_Board', 'index_map.csv'),\n is_simulated=True)\n self.sovsov = Sovsov(phi = self.phi,\n dtheta_self = self.dtheta_self,\n dtheta_inclined = self.dtheta_inclined,\n shift_origin = self.shift_origin)\n\n def start(self):\n plt.ion()\n f = plt.figure()\n while True:\n sovsov_data = self.sovsov.get_next_step()\n self.sr_driver.draw(sovsov_data)\n f.clf()\n plt.imshow(sovsov_data, cmap='hot')\n f.canvas.draw()\n sleep(self.delay)\n\nif __name__ == '__main__':\n hanukkah_runner = HanukkahRunner()\n hanukkah_runner.start()"
},
{
"alpha_fraction": 0.6430266499519348,
"alphanum_fraction": 0.6498813629150391,
"avg_line_length": 33.321266174316406,
"blob_id": "f67cd5bf41ece3683af711b4d1517dad59fb1591",
"content_id": "f6ccc2487f122872ed1233222545399762fe4bec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7586,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 221,
"path": "/runners/bulboard_server_runner.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf8 -*-\nimport os\nimport StringIO\nfrom datetime import datetime\nimport numpy as np\nimport logging\nimport json\nfrom flask import Flask, url_for, render_template, request, make_response\n\nfrom screen_usages_orchestrator import ScreenUsagesOrchestrator\nfrom screen_usages.dual_line_message_writer import DualLineMessageWriter\nfrom screen_usages.messages_writer import MessagesWriter\nfrom screen_usages.matrix_scroller import MatrixScroller\nfrom screen_usages.gol_calculator import GameOfLife\n\nfrom SR_Board.sr_driver import SRDriver\nfrom screen_usages.disk_sapce_file_handlers import DiskSpaceRotatingFileHandler\n\ntry:\n from matplotlib.backends.backend_agg import FigureCanvasAgg\n from matplotlib.figure import Figure\nexcept ImportError as ex:\n print ex\n\n\napp = Flask(__name__)\n\n# TODO: move to config file sometime\nONE_LINE_FONT_FILE = r'/usr/share/fonts/truetype/msttcorefonts/Arial.ttf'\nFONT_PATH = r'../screen_usages/fonts/arcade/ARCADE.TTF' #['..', 'screen_usages', 'fonts', 'arcade', 'ARCADE.TTF'])\nFONT_PATH = r'../screen_usages/fonts/Ozone.ttf'\nONE_LINE_FONT_FILE = r'../screen_usages/fonts/bdf/8x13.bdf'\nFONT_PATH = r'../screen_usages/fonts/bdf/6x9.bdf'\n\nDELAY_BETWEEN_PIXEL_SCROLL = 0.2 #[S]\nLOG_LEVEL = logging.INFO\n\n\n@app.route(\"/\")\ndef index():\n return render_template('index.html')\n\n\n@app.route(\"/two_line_message\")\ndef two_line_message(first_line_text='line1', first_line_rtl='', second_line_text='line2', second_line_rtl=''):\n return render_template('2_line_message.html',\n first_line_text=first_line_text,\n first_line_rtl=first_line_rtl,\n second_line_text=second_line_text,\n second_line_rtl=second_line_rtl)\n\n\n@app.route(\"/horizontal_pixel_message\")\ndef horizontal_pixel_message():\n return render_template('horizontal_pixel_message.html', row_number=17, col_number=11 * 10)\n\n\n@app.route(\"/game_of_life\")\ndef game_of_life():\n return render_template('game_of_life.html', row_number=17, col_number=11)\n\n\n@app.route(\"/one_line_message\")\ndef one_line_message(message='demo message', message_rtl=''):\n return render_template('one_line_message.html',\n message=message,\n message_rtl=message_rtl)\n\n\n@app.route(\"/set_one_line_message_text\")\ndef set_one_line_message_text():\n message = request.values['FirstLine']\n try:\n rtl = bool(request.values['FirstLineRtl'])\n except Exception:\n rtl = False\n\n try:\n runner.set_active_runner(runner_name='OneMessagesWriter')\n r = runner.get_active_runner()\n if rtl:\n message = r.mirror_string(message)\n r.load_text(text=message, rtl=rtl)\n message_rtl = 'checked' if rtl is True else ''\n return one_line_message(message=message, message_rtl=message_rtl)\n\n except Exception as ex:\n logging.exception(ex)\n\n return one_line_message()\n\n\n@app.route(\"/save_current_state\")\ndef save_current_state():\n runner.save_state_to_file()\n return index()\n\n\n@app.route(\"/set_two_line_message_text\")\ndef set_two_line_message_text():\n first_line_text = request.values['FirstLine']\n try:\n first_line_rtl = bool(request.values['FirstLineRtl'])\n except Exception:\n first_line_rtl = False\n second_line_text = request.values['SecondLine']\n try:\n second_line_rtl = bool(request.values['SecondLineRtl'])\n except Exception:\n second_line_rtl = False\n\n try:\n runner.set_active_runner(runner_name='DualLineMessageWriter')\n r = runner.get_active_runner()\n r.set_text(first_line=first_line_text, second_line=second_line_text,\n first_line_rtl=first_line_rtl, second_line_rtl=second_line_rtl)\n first_checked = 'checked' if first_line_rtl is True else ''\n second_checked = 'checked' if second_line_rtl is True else ''\n return two_line_message(first_line_text=first_line_text,\n first_line_rtl=first_checked,\n second_line_text=second_line_text,\n second_line_rtl=second_checked)\n\n except Exception as ex:\n logging.exception(ex)\n\n return two_line_message()\n\n\n@app.route(\"/set_horizontal_pixel_message\", methods=['POST'])\ndef set_horizontal_pixel_message():\n logging.info('in set_horizontal_pixel_message')\n data = request.data\n parsed_pixel_message = json.loads(data)\n logging.debug(parsed_pixel_message)\n rtl = True if parsed_pixel_message['rtl'] == 1 else False\n try:\n runner.set_active_runner(runner_name='MatrixScroller')\n r = runner.get_active_runner()\n m = np.array(parsed_pixel_message['outputArray'], dtype=int)\n r.set_data_matrix(m, rtl=rtl)\n except Exception as ex:\n logging.exception(ex)\n\n return make_response()\n\n\n@app.route(\"/set_game_of_life_initial_state\", methods=['POST'])\ndef set_game_of_life_initial_state():\n logging.info('in set_game_of_life_initial_state')\n data = request.data\n parsed_pixel_message = json.loads(data)\n logging.debug(parsed_pixel_message)\n\n try:\n runner.set_active_runner(runner_name='GameOfLife')\n r = runner.get_active_runner()\n m = np.array(parsed_pixel_message['outputArray'], dtype=int)\n r.reset_initial_pattern(m)\n except Exception as ex:\n logging.exception(ex)\n\n return make_response()\n\n\n@app.route(\"/cur_img\", methods=['GET', 'POST'])\ndef cur_img():\n c = runner.get_current_frame()\n fig = Figure()\n ax = fig.add_subplot(111)\n ax.imshow(c, cmap='hot')\n canvas = FigureCanvasAgg(fig)\n png_output = StringIO.StringIO()\n canvas.print_png(png_output)\n response = make_response(png_output.getvalue())\n response.headers['Content-Type'] = 'image/png'\n return response\n\n\ndef init_logging(level):\n root_logger = logging.getLogger()\n root_logger.setLevel(level=level)\n try:\n os.mkdir('logs')\n except Exception:\n pass\n file_name = os.path.join('logs', 'BulboardServer_{}'.format(datetime.now().strftime('%d_%m_%y__%H_%M_%S')))\n file_handler = DiskSpaceRotatingFileHandler(folder_max_size=10E6, filename=file_name, maxBytes=1E6, backupCount=10000)\n formatter = logging.Formatter(fmt=u'%(asctime)s:%(name)s:%(levelname)s:%(message)s')\n file_handler.setFormatter(formatter)\n\n console_handler = logging.StreamHandler()\n console_handler.setFormatter(formatter)\n\n logging._defaultFormatter = logging.Formatter(u\"%(message)s\") # so utf8 messages will not crash the logging\n root_logger.addHandler(hdlr=file_handler)\n root_logger.addHandler(hdlr=console_handler)\n\n\nif __name__ == '__main__':\n init_logging(level=LOG_LEVEL)\n sr = SRDriver(board_num_of_regs=56,\n num_of_boards=4,\n clk_pin=11,\n store_pin=12,\n data_pin=13,\n index_map_file=os.path.join('..', 'SR_Board', 'index_map.csv'),\n is_simulated=True)\n\n runners = {\n 'DualLineMessageWriter': DualLineMessageWriter(font_path=FONT_PATH),\n 'OneMessagesWriter': MessagesWriter(font_path=ONE_LINE_FONT_FILE, font_size=1, screen_size=(17, 11), bdf=True),\n 'MatrixScroller': MatrixScroller(),\n 'GameOfLife': GameOfLife()\n }\n\n runner = ScreenUsagesOrchestrator(sr_driver=sr,\n screen_scroll_delay=0.2,\n runners=runners)\n runner.start()\n app.run() # don't do that, use FLASK_APP env\n\n"
},
{
"alpha_fraction": 0.7049180269241333,
"alphanum_fraction": 0.7049180269241333,
"avg_line_length": 23.399999618530273,
"blob_id": "78827d2c7d4cbfb9e8a7ef8862c13e12f2db64a7",
"content_id": "02f335b0209f7273dd758743a8e2cf2956e8f3fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 10,
"path": "/screen_usages/abstract_screen_usage.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "class AbstractScreenUsage(object):\n\n def get_next_step(self):\n raise NotImplementedError\n\n def serialize_state(self):\n raise NotImplementedError\n\n def load_state(self, serialized_state):\n raise NotImplementedError\n"
},
{
"alpha_fraction": 0.571374237537384,
"alphanum_fraction": 0.5906440019607544,
"avg_line_length": 31.73029136657715,
"blob_id": "41d3daf4f2e67d613be6fb1bfaca7c6fa958663c",
"content_id": "f3cb0e0445986c12a5e0ff787995430ae73472b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7888,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 241,
"path": "/screen_usages/gol_calculator.py",
"repo_name": "omerkap/bulboard",
"src_encoding": "UTF-8",
"text": "import logging\nimport numpy as np\nfrom datetime import datetime\nimport os\nimport time\n\nfrom disk_sapce_file_handlers import DiskSpaceRotatingFileHandler\nfrom abstract_screen_usage import AbstractScreenUsage\n\ntry:\n import matplotlib.pyplot as plt\n from matplotlib import animation\nexcept ImportError as ex:\n print ex\nimport sys\nsys.path.append(r'../')\nfrom SR_Board.sr_driver import SRDriver\n\n\nclass GameOfLife(AbstractScreenUsage):\n def __init__(self, initial_pattern=np.zeros((17, 11))):\n self._logger = logging.getLogger(self.__class__.__name__)\n self._logger.info('initialized Game Of Life')\n self._logger.info('size: {}'.format(initial_pattern.shape))\n self._initial_pattern = initial_pattern\n self._state = self._initial_pattern\n self._size = self._state.shape\n self._step = 0\n\n def reset_initial_pattern(self, initial_pattern):\n self._logger.warning('resetting initial pattern, new size: {}'.format(initial_pattern.shape))\n self._state = initial_pattern\n self._initial_pattern = initial_pattern\n self._size = self._state.shape\n self._step = 0\n\n def get_next_step(self):\n \"\"\"\n Advance the state 1 step\n :return:\n \"\"\"\n t0 = time.time()\n next_state = np.zeros(self._size)\n v_bloated = np.concatenate((self._state, self._state, self._state), axis=0)\n bloated = np.concatenate((v_bloated, v_bloated, v_bloated), axis=1)\n self._logger.debug('bloated shape: {}'.format(bloated.shape))\n\n for index, x in np.ndenumerate(self._state):\n next_state[index] = self._calculate_one_cell(index=index, bloated=bloated)\n\n self._state = np.copy(next_state)\n self._step += 1\n t1 = time.time()\n self._logger.debug('step calculation time: {}'.format(t1 - t0))\n return self._state\n\n def _calculate_one_cell(self, index, bloated):\n \"\"\"\n Calculate next state of one cell, from the current states of neighbors\n :param index: index of calculated cell\n :param bloated: a matrix that is bigger than state, that has sequences of state, this helps with indexing\n neighbors without wraparounds\n :return: next value of cell in index\n \"\"\"\n current_value = self._state[index]\n neighbors_data = self._get_neighbors_data(index, bloated)\n sum_of_neighbors = np.sum(neighbors_data)\n self._logger.debug(current_value)\n\n if current_value == 1:\n if sum_of_neighbors < 2:\n return 0\n if sum_of_neighbors > 3:\n return 0\n else:\n return 1\n elif current_value == 0:\n if sum_of_neighbors == 3:\n return 1\n else:\n return 0\n\n self._logger.error('in _calculate_one_cell, none of rules matched,'\\\n '\\n index: {}, current value: {}'.format(index, current_value))\n\n def _get_neighbors_data(self, index, bloated):\n x = index[0]\n y = index[1]\n\n bloated_x = x + self._size[0]\n bloated_y = y + self._size[1]\n\n neighbors_matrix = np.copy(bloated[bloated_x - 1: bloated_x + 2, bloated_y - 1: bloated_y + 2])\n flattened = neighbors_matrix.ravel()\n\n return np.concatenate((flattened[0:4], flattened[5:9]))\n\n def load_state(self, serialized_state):\n self._initial_pattern = serialized_state['initial_pattern']\n self._state = self._initial_pattern\n self._step = 0\n\n def serialize_state(self):\n container = dict()\n container['initial_pattern'] = self._initial_pattern\n return container\n\n @property\n def state(self):\n return np.copy(self._state)\n\n @property\n def step(self):\n return self._step\n\n @staticmethod\n def visualize_state(state, step, figure):\n t_start_vis = time.time()\n figure.clf()\n plt.title('Step: {}'.format(step))\n plt.imshow(state, cmap='hot')\n figure.canvas.draw()\n t_end_vis = time.time()\n logging.debug('visualizing time: {}'.format(t_end_vis - t_start_vis))\n return figure\n\n @staticmethod\n def get_demo_blinker():\n blinker = np.ones((3, 1))\n return blinker\n\n @staticmethod\n def get_demo_beacon():\n beacon = np.zeros((4, 4))\n beacon[0:2, 0:2] = 1\n beacon[2:4, 2:4] = 1\n return beacon\n\n @staticmethod\n def get_demo_glider():\n glider = np.zeros((3, 3))\n glider[0:3, 2:3] = 1\n glider[1:2, 0:1] = 1\n glider[2:3, 1:2] = 1\n return glider\n\n @staticmethod\n def get_demo_pentadecathlon():\n pentadecathlon = np.zeros((10, 3))\n pentadecathlon[0:10, 1:2] = 1\n pentadecathlon[2:3, 0:3] = 1\n pentadecathlon[7:8, 0:3] = 1\n pentadecathlon[2:3, 1:2] = 0\n pentadecathlon[7:8, 1:2] = 0\n return pentadecathlon\n\n\ndef init_logging(level):\n root_logger = logging.getLogger()\n root_logger.setLevel(level=level)\n try:\n os.mkdir('logs')\n except Exception:\n pass\n file_name = os.path.join('logs', 'GameOfLife_{}'.format(datetime.now().strftime('%d_%m_%y__%H_%M_%S')))\n #file_handler = RotatingFileHandler(filename=file_name, maxBytes=10e6, backupCount=5)\n file_handler = DiskSpaceRotatingFileHandler(folder_max_size=10E6, filename=file_name, maxBytes=1E6, backupCount=10000)\n formatter = logging.Formatter(fmt=r'%(asctime)s:%(name)s:%(levelname)s:%(message)s')\n file_handler.setFormatter(formatter)\n\n #console_handler = logging.StreamHandler()\n #console_handler.setFormatter(formatter)\n\n root_logger.addHandler(hdlr=file_handler)\n #root_logger.addHandler(hdlr=console_handler)\n\n\nif __name__ == '__main__':\n init_logging(logging.INFO)\n l = logging.getLogger()\n p = np.zeros((17, 11))\n\n # blinker = GameOfLife.get_demo_blinker()\n # blinker_x_size, blinker_y_size = blinker.shape\n # p[1:1+blinker_x_size, 1:1+blinker_y_size] = blinker\n #\n # beacon = GameOfLife.get_demo_beacon()\n # beacon_x_size, beacon_y_size = beacon.shape\n # p[7:7 + beacon_x_size, 7:7 + beacon_y_size] = beacon\n\n glider = GameOfLife.get_demo_glider()\n glider_x_size, glider_y_size = glider.shape\n p[2:2 + glider_x_size, 4:4 + glider_y_size] = glider\n\n # pentadecathlon = GameOfLife.get_demo_pentadecathlon()\n # pentadecathlon_x_size, pentadecathlon_y_size = pentadecathlon.shape\n # p[3:3 + pentadecathlon_x_size, 4:4 + pentadecathlon_y_size] = pentadecathlon\n\n l.info('\\n{}'.format(p))\n\n gol_obj = GameOfLife(initial_pattern=p)\n screen_writer = SRDriver(board_num_of_regs=56,\n num_of_boards=4,\n clk_pin=11,\n store_pin=12,\n data_pin=13,\n index_map_file=os.path.join('..', 'SR_Board', 'index_map.csv'),\n is_simulated=True)\n\n plt.ion()\n f = plt.figure()\n\n for i in range(200):\n state = gol_obj.state\n step = gol_obj.step\n l.info('step: {}'.format(step))\n t0 = time.time()\n screen_writer.load_array(picture=state.astype(int))\n screen_writer.write_data()\n gol_obj.visualize_state(state=state, step=step, figure=f)\n gol_obj.calc_next_step()\n time.sleep(0.1)\n\n\n\n ## Create GIF\n\n # def animate(i):\n # state = g.state\n # step = g.step\n # l.info(f'step: {step}')\n # a = g.visualize_state(state=state, step=step, figure=f)\n # g.calc_next_step()\n # return (a,)\n #\n #\n # def init():\n # return (f,)\n #\n # anim = animation.FuncAnimation(f, animate, init_func=init, frames=15, interval=150, blit=True)\n # anim.save('pentadecathlon.gif', writer='imagemagick', fps=5)\n"
}
] | 15 |
shahar603/manim | https://github.com/shahar603/manim | 3493a9257ffdd9acdce0935f3c008fca86a00de1 | 1467e02d188c508ad6908a9eab0082a8c1d0ff66 | ba2a1e9117d02492643e9c55822eb157fa76630d | refs/heads/master | 2018-02-07T10:11:10.998890 | 2017-06-29T11:33:01 | 2017-06-29T11:33:01 | 95,771,106 | 0 | 0 | null | 2017-06-29T11:32:27 | 2017-06-29T09:50:10 | 2017-06-22T17:22:20 | null | [
{
"alpha_fraction": 0.535732626914978,
"alphanum_fraction": 0.5428341627120972,
"avg_line_length": 30.359878540039062,
"blob_id": "31dcc2f212801b56e136d28315a0fa5b1a3e8721",
"content_id": "5b443bdd2627d4c0866a287cbd4907d8f106d7f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 31120,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 992,
"path": "/crypto.py",
"repo_name": "shahar603/manim",
"src_encoding": "UTF-8",
"text": "from helpers import *\n\nfrom mobject.tex_mobject import TexMobject\nfrom mobject import Mobject\nfrom mobject.image_mobject import ImageMobject\nfrom mobject.vectorized_mobject import *\n\nfrom animation.animation import Animation\nfrom animation.transform import *\nfrom animation.simple_animations import *\nfrom animation.playground import *\nfrom topics.geometry import *\nfrom topics.characters import *\nfrom topics.functions import *\nfrom topics.fractals import *\nfrom topics.number_line import *\nfrom topics.combinatorics import *\nfrom topics.numerals import *\nfrom topics.three_dimensions import *\nfrom topics.objects import *\nfrom topics.probability import *\nfrom topics.complex_numbers import *\nfrom topics.common_scenes import *\nfrom scene import Scene\nfrom scene.reconfigurable_scene import ReconfigurableScene\nfrom scene.zoomed_scene import *\nfrom camera import Camera\nfrom mobject.svg_mobject import *\nfrom mobject.tex_mobject import *\n\n#force_skipping\n#revert_to_original_skipping_status\n\nBITCOIN_COLOR = \"#f7931a\"\n\ndef get_cursive_name(name):\n result = TextMobject(\"\\\\normalfont\\\\calligra %s\"%name)\n result.set_stroke(width = 0.5)\n return result\n\n##################\n\nclass AskQuestion(Scene):\n CONFIG = {\n \"time_per_char\" : 0.06,\n }\n def construct(self):\n strings = [\n \"What\", \"does\", \"it\", \"mean \", \"to\", \n \"have \", \"a\", \"Bitcoin?\"\n ]\n question = TextMobject(*strings)\n question.highlight_by_tex(\"have\", YELLOW)\n self.dither()\n for word, part in zip(strings, question):\n n_chars = len(word.strip())\n n_spaces = len(word) - n_chars\n self.play(\n LaggedStart(FadeIn, part),\n run_time = self.time_per_char * len(word),\n rate_func = squish_rate_func(smooth, 0, 0.5)\n )\n self.dither(self.time_per_char*n_spaces)\n self.dither(2)\n\nclass BitcoinPaperHighlightTitle(ExternallyAnimatedScene):\n pass\n\nclass TimeBitcoinCover(ExternallyAnimatedScene):\n pass\n\nclass ListOfAttributes(Scene):\n def construct(self):\n logo = BitcoinLogo()\n\n digital = TextMobject(\"Digital\")\n government, bank = buildings = [\n SVGMobject(\n file_name = \"%s_building\"%word,\n height = 2,\n fill_color = LIGHT_GREY,\n fill_opacity = 1,\n stroke_width = 0,\n )\n for word in \"government\", \"bank\"\n ]\n attributes = VGroup(digital, *buildings)\n attributes.arrange_submobjects(RIGHT, buff = LARGE_BUFF)\n for building in buildings:\n building.cross = Cross(building)\n building.cross.set_stroke(width = 12)\n\n self.play(DrawBorderThenFill(logo))\n self.play(\n logo.to_corner, UP+LEFT,\n Write(digital, run_time = 2)\n )\n for building in buildings:\n self.play(FadeIn(building))\n self.play(ShowCreation(building.cross))\n self.dither()\n\nclass UnknownAuthor(Scene):\n CONFIG = {\n \"camera_config\" : {\n \"background_image\" : \"bitcoin_paper\"\n }\n }\n def construct(self):\n rect = Rectangle(height = 0.4, width = 2.5)\n rect.shift(2.45*UP)\n question = TextMobject(\"Who is this?\")\n question.next_to(rect, RIGHT, buff = 1.5)\n arrow = Arrow(question, rect, buff = SMALL_BUFF)\n VGroup(question, arrow, rect).highlight(RED_D)\n\n self.play(ShowCreation(rect))\n self.play(\n Write(question),\n ShowCreation(arrow)\n )\n self.dither()\n\nclass NameCryptoCurrencies(TeacherStudentsScene):\n def construct(self):\n words = TextMobject(\"It's called a\", \"``cryptocurrency''\")\n words.highlight_by_tex(\"cryptocurrency\", YELLOW)\n self.teacher_says(words)\n self.change_student_modes(*[\"pondering\"]*3)\n self.dither()\n\nclass CryptocurrencyMarketCaps(ExternallyAnimatedScene):\n pass\n\nclass Hype(TeacherStudentsScene):\n def construct(self):\n self.teacher.change_mode(\"guilty\")\n phrases = map(TextMobject, [\n \"I want some!\",\n \"I'll get rich, right?\",\n \"Buy them all!\"\n ])\n modes = [\"hooray\", \"conniving\", \"surprised\"]\n for student, phrase, mode in zip(self.students, phrases, modes):\n bubble = SpeechBubble()\n bubble.set_fill(BLACK, 1)\n bubble.add_content(phrase)\n bubble.resize_to_content()\n bubble.pin_to(student)\n bubble.add(phrase)\n self.play(\n student.change_mode, mode,\n FadeIn(bubble),\n )\n self.dither(3)\n\nclass AskQuestionCopy(AskQuestion):\n pass\n\nclass LedgerScene(PiCreatureScene):\n CONFIG = {\n \"ledger_width\" : 6,\n \"ledger_height\" : 7,\n \"denomination\" : \"USD\",\n \"ledger_line_height\" : 0.4,\n }\n def setup(self):\n PiCreatureScene.setup(self)\n self.remove(self.pi_creatures)\n\n def add_ledger_and_network(self):\n self.add(self.get_ledger(), self.get_network())\n\n def get_ledger(self):\n title = TextMobject(\"Ledger\")\n rect = Rectangle(\n width = self.ledger_width, \n height = self.ledger_height\n )\n title.next_to(rect.get_top(), DOWN)\n h_line = Line(rect.get_left(), rect.get_right())\n h_line.scale(0.8)\n h_line.set_stroke(width = 2)\n h_line.next_to(title, DOWN)\n content = VGroup(h_line)\n\n self.ledger = VGroup(rect, title, h_line, content)\n self.ledger.content = content\n self.ledger.to_corner(UP+LEFT)\n return self.ledger\n\n def add_line_to_ledger(self, string_or_mob):\n if isinstance(string_or_mob, str):\n mob = TextMobject(string_or_mob)\n elif isinstance(string_or_mob, Mobject):\n mob = string_or_mob\n else:\n raise Exception(\"Invalid input\")\n\n mob.scale_to_fit_height(self.ledger_line_height)\n mob.next_to(\n self.ledger.content[-1], DOWN, \n buff = MED_SMALL_BUFF, \n aligned_edge = LEFT\n )\n self.ledger.content.add(mob)\n return mob\n\n def add_payment_line_to_ledger(self, from_name, to_name, amount):\n amount_str = str(amount)\n if self.denomination == \"USD\":\n amount_str = \"\\\\$\" + amount_str\n else:\n amount_str += \" \" + self.denomination\n line = TextMobject(\n from_name.capitalize(), \n \"pays\" if from_name.lower() != \"you\" else \"pay\",\n to_name.capitalize(),\n amount_str\n )\n for name in from_name, to_name:\n color = self.get_color_from_name(name)\n line.highlight_by_tex(name.capitalize(), color)\n if self.denomination == \"USD\":\n line.highlight_by_tex(amount_str, GREEN_D)\n elif self.denomination == \"BTC\":\n line.highlight_by_tex(amount_str, BITCOIN_COLOR)\n\n return self.add_line_to_ledger(line)\n\n def get_color_from_name(self, name):\n if hasattr(self, name.lower()):\n creature = getattr(self, name.lower())\n color = creature.get_color()\n if np.mean(color.get_rgb()) < 0.5:\n color = average_color(color, color, WHITE)\n return color\n return WHITE\n\n def animate_payment_addition(self, *args, **kwargs):\n line = self.add_payment_line_to_ledger(*args, **kwargs)\n self.play(LaggedStart(\n FadeIn, \n VGroup(*it.chain(*line)),\n run_time = 1\n ))\n\n def get_network(self):\n creatures = self.pi_creatures\n lines = VGroup(*[\n Line(\n VGroup(pi1, pi1.label), VGroup(pi2, pi2.label),\n buff = MED_SMALL_BUFF,\n stroke_width = 2,\n )\n for pi1, pi2 in it.combinations(creatures, 2)\n ])\n labels = VGroup(*[pi.label for pi in creatures])\n self.network = VGroup(creatures, labels, lines)\n return self.network\n\n def create_pi_creatures(self):\n creatures = VGroup(*[\n PiCreature(color = color, height = 1).shift(2*vect)\n for color, vect in zip(\n [BLUE_C, MAROON_D, GREY_BROWN, BLUE_E],\n [UP+LEFT, UP+RIGHT, DOWN+LEFT, DOWN+RIGHT],\n )\n ])\n creatures.to_edge(RIGHT)\n names = self.get_names()\n for name, creature in zip(names, creatures):\n setattr(self, name, creature)\n label = TextMobject(name.capitalize())\n label.scale(0.75)\n label.next_to(creature, DOWN, SMALL_BUFF)\n creature.label = label\n if (creature.get_center() - creatures.get_center())[0] > 0:\n creature.flip()\n creature.look_at(creatures.get_center())\n\n return creatures\n\n def get_names(self):\n return [\"alice\", \"bob\", \"charlie\", \"you\"]\n\nclass LayOutPlan(LedgerScene):\n def construct(self):\n self.ask_question()\n self.show_ledger()\n self.become_skeptical()\n\n def ask_question(self):\n btc = BitcoinLogo()\n group = VGroup(btc, TexMobject(\"= ???\"))\n group.arrange_submobjects(RIGHT)\n\n self.play(\n DrawBorderThenFill(btc),\n Write(group[1], run_time = 2)\n )\n self.dither()\n self.play(\n group.scale, 0.7,\n group.next_to, ORIGIN, RIGHT,\n group.to_edge, UP\n )\n\n def show_ledger(self):\n network = self.get_network()\n ledger = self.get_ledger()\n payments = [\n (\"Alice\", \"Bob\", 20),\n (\"Bob\", \"Charlie\", 40),\n (\"Alice\", \"You\", 50),\n ]\n\n self.play(*map(FadeIn, [network, ledger]))\n for payment in payments:\n new_line = self.add_payment_line_to_ledger(*payment)\n from_name, to_name, amount = payment\n from_pi = getattr(self, from_name.lower())\n to_pi = getattr(self, to_name.lower())\n cash = TexMobject(\"\\\\$\"*(amount/10))\n cash.scale(0.5)\n cash.move_to(from_pi)\n cash.highlight(GREEN)\n\n self.play(\n cash.move_to, to_pi,\n to_pi.change_mode, \"hooray\"\n )\n self.play(\n FadeOut(cash),\n Write(new_line, run_time = 1)\n )\n self.dither()\n\n def become_skeptical(self):\n creatures = self.pi_creatures\n\n self.play(*[\n ApplyMethod(pi.change_mode, \"sassy\")\n for pi in creatures\n ])\n for k in range(3):\n self.play(*[\n ApplyMethod(\n creatures[i].look_at,\n creatures[k*(i+1)%4]\n )\n for i in range(4)\n ])\n self.dither(2)\n\nclass UnderlyingSystemVsUserFacing(Scene):\n def construct(self):\n underlying = TextMobject(\"Underlying \\\\\\\\ system\")\n underlying.shift(DOWN).to_edge(LEFT)\n user_facing = TextMobject(\"User-facing\")\n user_facing.next_to(underlying, UP, LARGE_BUFF, LEFT)\n\n protocol = TextMobject(\"Bitcoin protocol\")\n protocol.next_to(underlying, RIGHT, MED_LARGE_BUFF)\n protocol.highlight(BITCOIN_COLOR)\n banking = TextMobject(\"Banking system\")\n banking.next_to(protocol, RIGHT, MED_LARGE_BUFF)\n banking.highlight(GREEN)\n\n phone = SVGMobject(\n file_name = \"phone\",\n fill_color = WHITE,\n fill_opacity = 1,\n height = 1,\n stroke_width = 0,\n )\n phone.next_to(protocol, UP, LARGE_BUFF)\n card = SVGMobject(\n file_name = \"credit_card\",\n fill_color = LIGHT_GREY,\n fill_opacity = 1,\n stroke_width = 0,\n height = 1\n )\n card.next_to(banking, UP, LARGE_BUFF)\n\n btc = BitcoinLogo()\n btc.next_to(phone, UP, MED_LARGE_BUFF)\n dollar = TexMobject(\"\\\\$\")\n dollar.scale_to_fit_height(1)\n dollar.highlight(GREEN)\n dollar.next_to(card, UP, MED_LARGE_BUFF)\n card.save_state()\n card.shift(2*RIGHT)\n card.set_fill(opacity = 0)\n\n\n h_line = Line(underlying.get_left(), banking.get_right())\n h_line.next_to(underlying, DOWN, MED_SMALL_BUFF, LEFT)\n h_line2 = h_line.copy()\n h_line2.next_to(user_facing, DOWN, MED_LARGE_BUFF, LEFT)\n h_line3 = h_line.copy()\n h_line3.next_to(user_facing, UP, MED_LARGE_BUFF, LEFT)\n v_line = Line(5*UP, ORIGIN)\n v_line.next_to(underlying, RIGHT, MED_SMALL_BUFF)\n v_line.shift(1.7*UP)\n v_line2 = v_line.copy()\n v_line2.next_to(protocol, RIGHT, MED_SMALL_BUFF)\n v_line2.shift(1.7*UP)\n\n self.add(h_line, h_line2, h_line3, v_line, v_line2)\n self.add(underlying, user_facing, btc)\n self.play(Write(protocol))\n self.dither(2)\n self.play(\n card.restore,\n Write(dollar)\n )\n self.play(Write(banking))\n self.dither(2)\n self.play(DrawBorderThenFill(phone))\n self.dither(2)\n \nclass CryptoPrefix(Scene):\n def construct(self):\n cryptocurrency = TextMobject(\n \"Crypto\", \"currency\",\n arg_separator = \"\"\n )\n crypto = cryptocurrency.get_part_by_tex(\"Crypto\")\n brace = Brace(crypto, UP)\n explanation = TextMobject(\n \"Built using the math \\\\\\\\ from cryptography\"\n )\n explanation.next_to(brace, UP)\n\n self.add(cryptocurrency)\n self.play(\n crypto.highlight, YELLOW,\n GrowFromCenter(brace)\n )\n self.play(Write(explanation))\n self.dither(3)\n\nclass IntroduceLedgerSystem(LedgerScene):\n CONFIG = {\n \"payments\" : [\n (\"Alice\", \"Bob\", 20),\n (\"Bob\", \"Charlie\", 40),\n (\"Charlie\", \"You\", 30),\n (\"You\", \"Alice\", 10),\n ]\n }\n def construct(self):\n self.add(self.get_network())\n self.exchange_money()\n self.add_ledger()\n self.tally_it_all_up()\n\n\n def exchange_money(self):\n for from_name, to_name, num in self.payments:\n from_pi = getattr(self, from_name.lower())\n to_pi = getattr(self, to_name.lower())\n cash = TexMobject(\"\\\\$\"*(num/10)).highlight(GREEN)\n cash.scale_to_fit_height(0.5)\n cash.move_to(from_pi)\n self.play(\n cash.move_to, to_pi,\n to_pi.change_mode, \"hooray\"\n )\n self.play(FadeOut(cash))\n self.dither()\n\n def add_ledger(self):\n ledger = self.get_ledger()\n\n self.play(\n Write(ledger),\n *[\n ApplyMethod(pi.change, \"pondering\", ledger)\n for pi in self.pi_creatures\n ]\n )\n for payment in self.payments:\n self.animate_payment_addition(*payment)\n self.dither(3)\n\n def tally_it_all_up(self):\n accounts = dict()\n names = \"alice\", \"bob\", \"charlie\", \"you\"\n for name in names:\n accounts[name] = 0\n for from_name, to_name, amount in self.payments:\n accounts[from_name.lower()] -= amount\n accounts[to_name.lower()] += amount\n\n results = VGroup()\n debtors = VGroup()\n creditors = VGroup()\n for name in names:\n amount = accounts[name]\n creature = getattr(self, name)\n creature.cash = TexMobject(\"\\\\$\"*abs(amount/10))\n creature.cash.next_to(creature, UP+LEFT, SMALL_BUFF)\n creature.cash.highlight(GREEN)\n if amount < 0:\n verb = \"Owes\"\n debtors.add(creature)\n else:\n verb = \"Gets\"\n creditors.add(creature)\n if name == \"you\":\n verb = verb[:-1]\n result = TextMobject(\n verb, \"\\\\$%d\"%abs(amount)\n )\n result.highlight_by_tex(\"Owe\", RED)\n result.highlight_by_tex(\"Get\", GREEN)\n result.add_background_rectangle()\n result.scale(0.7)\n result.next_to(creature.label, DOWN)\n results.add(result)\n\n brace = Brace(VGroup(*self.ledger.content[1:]), RIGHT)\n tally_up = brace.get_text(\"Tally up\")\n tally_up.add_background_rectangle()\n\n self.play(\n GrowFromCenter(brace), \n FadeIn(tally_up)\n )\n self.play(\n LaggedStart(FadeIn, results),\n *[\n ApplyMethod(pi.change, \"happy\")\n for pi in creditors\n ] + [\n ApplyMethod(pi.change, \"plain\")\n for pi in debtors\n ]\n )\n self.dither()\n debtor_cash, creditor_cash = [\n VGroup(*it.chain(*[pi.cash for pi in group]))\n for group in debtors, creditors\n ]\n self.play(FadeIn(debtor_cash))\n self.play(\n debtor_cash.arrange_submobjects, RIGHT, SMALL_BUFF,\n debtor_cash.move_to, self.pi_creatures,\n )\n self.dither()\n self.play(ReplacementTransform(\n debtor_cash, creditor_cash\n ))\n self.dither(2)\n\nclass InitialProtocol(Scene):\n def construct(self):\n title = TextMobject(\"Protocol\")\n title.scale(1.5)\n title.to_edge(UP)\n h_line = Line(LEFT, RIGHT).scale(4)\n h_line.next_to(title, DOWN)\n\n items = VGroup(*map(TextMobject, [\n \"$\\\\cdot$ Anyone can add lines to the Ledger\",\n \"$\\\\cdot$ Settle up with real money each month\"\n ]))\n items.arrange_submobjects(\n DOWN, \n buff = MED_LARGE_BUFF, \n aligned_edge = LEFT\n )\n items.next_to(h_line, DOWN, MED_LARGE_BUFF)\n\n\n self.add(title, h_line)\n for item in items:\n self.dither()\n self.play(LaggedStart(FadeIn, item))\n self.dither(2)\n\n self.title = title\n self.items = items\n\nclass AddFraudulentLine(LedgerScene):\n def construct(self):\n self.add_ledger_and_network()\n self.bob_adds_lines()\n self.alice_reacts()\n\n def bob_adds_lines(self):\n line = self.add_payment_line_to_ledger(\"Alice\", \"Bob\", 100)\n line.save_state()\n line.scale(0.001)\n line.move_to(self.bob)\n\n self.play(self.bob.change, \"conniving\")\n self.play(line.restore)\n self.dither()\n\n def alice_reacts(self):\n bubble = SpeechBubble(\n height = 1.5, width = 2, direction = LEFT,\n )\n bubble.next_to(self.alice, UP+RIGHT, buff = 0)\n bubble.write(\"Hey!\")\n self.play(\n Animation(self.bob.pupils),\n self.alice.change, \"angry\",\n FadeIn(bubble),\n Write(bubble.content, run_time = 1)\n )\n self.dither(3)\n self.play(\n FadeOut(bubble),\n FadeOut(bubble.content),\n self.alice.change_mode, \"pondering\"\n )\n\nclass AnnounceDigitalSignatures(TeacherStudentsScene):\n def construct(self):\n words = TextMobject(\"Digital \\\\\\\\ signatures!\")\n words.scale(1.5)\n self.force_skipping()\n self.teacher_says(\n words,\n target_mode = \"hooray\",\n )\n self.revert_to_original_skipping_status()\n\n self.change_student_modes(*[\"hooray\"]*3)\n self.dither(2)\n\nclass IntroduceSignatures(LedgerScene):\n CONFIG = {\n \"payments\" : [\n (\"Alice\", \"Bob\", 100),\n (\"Charlie\", \"You\", 20),\n (\"Bob\", \"You\", 30),\n ],\n }\n def construct(self):\n self.add_ledger_and_network()\n self.add_transactions()\n self.add_signatures()\n\n def add_transactions(self):\n transactions = VGroup(*[\n self.add_payment_line_to_ledger(*payment)\n for payment in self.payments\n ])\n self.play(LaggedStart(FadeIn, transactions))\n self.dither()\n\n def add_signatures(self):\n signatures = VGroup(*[\n get_cursive_name(payments[0].capitalize())\n for payments in self.payments\n ])\n for signature, transaction in zip(signatures, self.ledger.content[1:]):\n signature.next_to(transaction, RIGHT)\n signature.highlight(transaction[0].get_color())\n self.play(Write(signature, run_time = 2))\n transaction.add(signature)\n self.dither(2)\n\n rect = SurroundingRectangle(self.ledger.content[1])\n self.play(ShowCreation(rect))\n self.play(FadeOut(rect))\n self.dither()\n self.play(Indicate(signatures[0]))\n self.dither()\n\nclass AskHowDigitalSignaturesArePossible(TeacherStudentsScene):\n def construct(self):\n signature = get_cursive_name(\"Alice\")\n signature.scale(1.5)\n signature.highlight(BLUE_C)\n signature.to_corner(UP+LEFT)\n signature_copy = signature.copy()\n signature_copy.shift(3*RIGHT)\n\n bits = TexMobject(\"01100001\")\n bits.next_to(signature, DOWN)\n bits.shift_onto_screen()\n bits_copy = bits.copy()\n bits_copy.next_to(signature_copy, DOWN)\n\n\n self.add(signature)\n\n self.student_says(\n \"Couldn't you just \\\\\\\\ copy the signature?\",\n target_mode = \"confused\",\n run_time = 1\n )\n self.change_student_modes(\"pondering\", \"confused\", \"erm\")\n self.play(LaggedStart(FadeIn, bits, run_time = 1))\n self.dither()\n self.play(ReplacementTransform(\n bits.copy(), bits_copy,\n path_arc = np.pi/2\n ))\n self.play(Write(signature_copy))\n self.dither(3)\n\nclass DescribeDigitalSignatures(LedgerScene):\n CONFIG = {\n \"public_color\" : GREEN,\n \"private_color\" : RED,\n \"signature_color\" : BLUE_C,\n }\n def construct(self):\n self.reorganize_pi_creatures()\n self.generate_key_pairs()\n self.keep_secret_key_secret()\n self.show_handwritten_signatures()\n self.show_digital_signatures()\n self.show_signing_functions()\n\n def reorganize_pi_creatures(self):\n self.pi_creatures.remove(self.you)\n creature_groups = VGroup(*[\n VGroup(pi, pi.label).scale(1.7)\n for pi in self.pi_creatures\n ])\n creature_groups.arrange_submobjects(RIGHT, buff = 2)\n creature_groups.to_edge(DOWN)\n self.add(creature_groups)\n for pi in self.pi_creatures:\n if pi.is_flipped():\n pi.flip()\n\n def generate_key_pairs(self):\n title = TextMobject(\"Private\", \"key /\", \"Public\", \"key\")\n title.to_edge(UP)\n private, public = map(title.get_part_by_tex, [\"Private\", \"Public\"])\n private.highlight(self.private_color)\n public.highlight(self.public_color)\n secret = TextMobject(\"Secret\")\n secret.move_to(private, RIGHT)\n secret.highlight(self.private_color)\n\n names = self.get_names()[:-1]\n public_key_strings = [\n bin(256+ord(name[0].capitalize()))[3:]\n for name in names\n ]\n private_key_strings = [\n bin(hash(name))[2:10]\n for name in names\n ]\n public_keys, private_keys = [\n VGroup(*[\n TextMobject(key_name+\":\",\" $%s\\\\dots$\"%key)\n for key in keys\n ])\n for key_name, keys in [\n (\"pk\", public_key_strings),\n (\"sk\", private_key_strings)\n ]\n ]\n key_pairs = [\n VGroup(*pair).arrange_submobjects(DOWN, aligned_edge = LEFT)\n for pair in zip(public_keys, private_keys)\n ]\n for key_pair, pi in zip(key_pairs, self.pi_creatures):\n key_pair.next_to(pi, UP, MED_LARGE_BUFF)\n for key in key_pair:\n key.highlight_by_tex(\"sk\", self.private_color)\n key.highlight_by_tex(\"pk\", self.public_color)\n\n self.play(Write(title, run_time = 2))\n self.play(ReplacementTransform(\n VGroup(VGroup(public.copy())),\n public_keys\n ))\n self.play(ReplacementTransform(\n VGroup(VGroup(private.copy())),\n private_keys\n ))\n self.dither()\n self.play(private.shift, DOWN)\n self.play(FadeIn(secret))\n self.play(FadeOut(private))\n self.dither()\n\n title.remove(private)\n title.add(secret)\n self.title = title\n self.private_keys = private_keys\n self.public_keys = public_keys\n\n def keep_secret_key_secret(self):\n keys = self.private_keys\n rects = VGroup(*map(SurroundingRectangle, keys))\n rects.highlight(self.private_color)\n lock = SVGMobject(\n file_name = \"lock\",\n height = rects.get_height(),\n fill_color = LIGHT_GREY,\n fill_opacity = 1,\n stroke_width = 0,\n )\n locks = VGroup(*[\n lock.copy().next_to(rect, LEFT, SMALL_BUFF)\n for rect in rects\n ])\n\n self.play(ShowCreation(rects))\n self.play(LaggedStart(DrawBorderThenFill, locks))\n self.dither()\n\n self.private_key_rects = rects\n self.locks = locks\n\n def show_handwritten_signatures(self):\n lines = VGroup(*[Line(LEFT, RIGHT) for x in range(5)])\n lines.arrange_submobjects(DOWN)\n last_line = lines[-1]\n last_line.scale(0.7, about_point = last_line.get_left())\n\n signature_line = lines[0].copy()\n signature_line.set_stroke(width = 2)\n signature_line.next_to(lines, DOWN, LARGE_BUFF)\n ex = TexMobject(\"\\\\times\")\n ex.scale(0.7)\n ex.next_to(signature_line, UP, SMALL_BUFF, LEFT)\n lines.add(ex, signature_line)\n\n rect = SurroundingRectangle(\n lines, \n color = LIGHT_GREY, \n buff = MED_SMALL_BUFF\n )\n document = VGroup(rect, lines)\n documents = VGroup(*[\n document.copy()\n for x in range(2)\n ])\n documents.arrange_submobjects(RIGHT, buff = MED_LARGE_BUFF)\n documents.to_corner(UP+LEFT)\n\n signatures = VGroup()\n for document in documents:\n signature = get_cursive_name(\"Alice\")\n signature.highlight(self.signature_color)\n line = document[1][-1]\n signature.next_to(line, UP, SMALL_BUFF)\n signatures.add(signature)\n\n self.play(\n FadeOut(self.title),\n LaggedStart(FadeIn, documents, run_time = 1)\n )\n self.play(Write(signatures))\n self.dither()\n\n self.signatures = signatures\n self.documents = documents\n\n def show_digital_signatures(self):\n rect = SurroundingRectangle(VGroup(\n self.public_keys[0],\n self.private_key_rects[0],\n self.locks[0]\n ))\n digital_signatures = VGroup()\n for i, signature in enumerate(self.signatures):\n bits = bin(hash(str(i)))[-8:]\n digital_signature = TexMobject(bits + \"\\\\dots\")\n digital_signature.scale(0.7)\n digital_signature.highlight(signature.get_color())\n digital_signature.move_to(signature, DOWN)\n digital_signatures.add(digital_signature)\n\n arrows = VGroup(*[\n Arrow(\n rect.get_corner(UP), sig.get_bottom(),\n tip_length = 0.15,\n color = WHITE\n )\n for sig in digital_signatures\n ])\n\n words = VGroup(*map(\n TextMobject,\n [\"Different messages\", \"Completely different signatures\"]\n ))\n words.arrange_submobjects(DOWN, aligned_edge = LEFT)\n words.scale(1.3)\n words.next_to(self.documents, RIGHT)\n\n self.play(FadeIn(rect))\n self.play(*map(ShowCreation, arrows))\n self.play(Transform(self.signatures, digital_signatures))\n self.play(*[\n ApplyMethod(pi.change, \"pondering\", digital_signatures)\n for pi in self.pi_creatures\n ])\n for word in words:\n self.play(FadeIn(word))\n self.dither()\n self.play(FadeOut(words))\n\n def show_signing_functions(self):\n sign = TextMobject(\n \"Sign(\", \"Message\", \", \", \"sk\", \") = \", \"Signature\",\n arg_separator = \"\"\n )\n sign.to_corner(UP+RIGHT)\n verify = TextMobject(\n \"Verify(\", \"Message\", \", \", \"Signature\", \", \", \"pk\", \") = \", \"T/F\",\n arg_separator = \"\"\n )\n for mob in sign, verify:\n mob.highlight_by_tex(\"sk\", self.private_color)\n mob.highlight_by_tex(\"pk\", self.public_color)\n mob.highlight_by_tex(\n \"Signature\", self.signature_color,\n )\n for name in \"Message\", \"sk\", \"Signature\", \"pk\":\n part = mob.get_part_by_tex(name)\n if part is not None:\n setattr(mob, name.lower(), part)\n verify.next_to(sign, DOWN, MED_LARGE_BUFF, LEFT)\n VGroup(sign, verify).to_corner(UP+RIGHT)\n\n private_key = self.private_key_rects[0]\n public_key = self.public_keys[0]\n message = self.documents[0]\n signature = self.signatures[0]\n\n self.play(*[\n FadeIn(part)\n for part in sign\n if part not in [sign.message, sign.sk, sign.signature]\n ])\n self.play(ReplacementTransform(\n message.copy(), VGroup(sign.message)\n ))\n self.dither()\n self.play(ReplacementTransform(\n private_key.copy(), sign.sk\n ))\n self.dither()\n self.play(ReplacementTransform(\n VGroup(sign.sk, sign.message).copy(),\n VGroup(sign.signature)\n ))\n self.dither()\n self.play(Indicate(sign.sk))\n self.dither()\n self.play(Indicate(sign.message))\n self.dither()\n self.play(*[\n FadeIn(part)\n for part in verify\n if part not in [\n verify.message, verify.signature, \n verify.pk, verify[-1]\n ]\n ])\n self.dither()\n self.play(\n ReplacementTransform(\n sign.message.copy(), verify.message\n ),\n ReplacementTransform(\n sign.signature.copy(), verify.signature\n )\n )\n self.dither()\n self.play(ReplacementTransform(\n public_key.copy(), VGroup(verify.pk)\n ))\n self.dither()\n self.play(Write(verify[-1]))\n self.dither()\n\n\nclass TryGuessingDigitalSignature(Scene):\n def construct(self):\n pass\n\n\nclass SupplementVideoWrapper(Scene):\n def construct(self):\n pass\n\n\n\n\n\n\n\n\n\n\n\n"
}
] | 1 |
Gerdid/INFINICO | https://github.com/Gerdid/INFINICO | 725f07868b8c3ca88f32b636f77e85d8dbcdc5e2 | 0036aaed8af3e7c98e56f7312f2911b3fda698c5 | 169a18892a1a752c3e180f7eb8550ddc8361923b | refs/heads/master | 2021-02-08T23:36:27.173590 | 2020-03-16T02:17:05 | 2020-03-16T02:17:05 | 244,211,320 | 0 | 0 | null | 2020-03-01T19:35:11 | 2020-03-07T19:42:44 | 2020-03-08T18:26:34 | C++ | [
{
"alpha_fraction": 0.5525709986686707,
"alphanum_fraction": 0.636224091053009,
"avg_line_length": 21.084745407104492,
"blob_id": "d59d23e72dc526545b329a39d6e75244daeccba3",
"content_id": "3aea7d82ce6e5dcbb69a88536d4ffe2a4beee83b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1304,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 59,
"path": "/ReadTag/ReadTag.ino",
"repo_name": "Gerdid/INFINICO",
"src_encoding": "UTF-8",
"text": "#include <NfcAdapter.h>\n#include <PN532/PN532/PN532.h>\n\n#if 0 // use SPI\n#include <SPI.h>\n#include <PN532/PN532_SPI/PN532_SPI.h>\nPN532_SPI pn532spi(SPI, 9);\nNfcAdapter nfc = NfcAdapter(pn532spi);\n#elif 1 // use hardware serial\n\n#include <PN532/PN532_HSU/PN532_HSU.h>\nPN532_HSU pn532hsu(Serial1);\nNfcAdapter nfc(pn532hsu);\n#elif 0 // use software serial\n\n#include <PN532/PN532_SWHSU/PN532_SWHSU.h>\n#include \"SoftwareSerial.h\"\nSoftwareSerial SWSerial(2, 3);\nPN532_SWHSU pn532swhsu(SWSerial);\nNfcAdapter nfc(pn532swhsu);\n#else //use I2C\n\n#include <Wire.h>\n#include <PN532/PN532_I2C/PN532_I2C.h>\n\nPN532_I2C pn532_i2c(Wire);\nNfcAdapter nfc = NfcAdapter(pn532_i2c);\n#endif\n\nvoid setup(void) {\n Serial.begin(9600);\n Serial.println(\"NDEF Reader\");\n nfc.begin();\n pinMode(9, OUTPUT);\n}\n\nint incomingByte = 0;\nint i=0;\n\nvoid loop(void) {\n digitalWrite(9, LOW);\n if (Serial.available() > 0) {\n incomingByte = Serial.read();\n if (incomingByte == 49) { //Si se recibe el número 1\n while (1) {\n digitalWrite(9, HIGH); \n //Serial.println(\"\\nEscanee tarjeta NFC\\n\");\n if (nfc.tagPresent()) {\n NfcTag tag = nfc.read();\n String UID=tag.getUidString();\n Serial.println(UID);\n \n break;\n }\n delay(5);\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.7701149582862854,
"alphanum_fraction": 0.7873563170433044,
"avg_line_length": 86,
"blob_id": "7da3c3898bf53d0060b115f156af394b56591fca",
"content_id": "fc567b7ab424b4e376ccef5d10bbd0f31d2eb4b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 2,
"path": "/ReadTag/Readme.txt",
"repo_name": "Gerdid/INFINICO",
"src_encoding": "UTF-8",
"text": "This file is intended to be run on an Arduino and a PN532 NFC Module (From DFRobot on this project) connected to a serial port.\nIt uses the Seeed_Ardunio_NFC-master library.\n"
},
{
"alpha_fraction": 0.4976303279399872,
"alphanum_fraction": 0.5959715843200684,
"avg_line_length": 41.20000076293945,
"blob_id": "7415a81a804afd6be949ab25e1279253a77bd192",
"content_id": "8413b346800cf384696d2c1567c42118e6ba98bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1688,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 40,
"path": "/Infinico.sql",
"repo_name": "Gerdid/INFINICO",
"src_encoding": "UTF-8",
"text": "-- --------------------------------------------------------\n-- Host: 127.0.0.1\n-- Server version: 10.4.12-MariaDB - mariadb.org binary distribution\n-- Server OS: Win64\n-- HeidiSQL Version: 10.3.0.5771\n-- --------------------------------------------------------\n\n/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;\n/*!40101 SET NAMES utf8 */;\n/*!50503 SET NAMES utf8mb4 */;\n/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;\n/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;\n\n\n-- Dumping database structure for test\nCREATE DATABASE IF NOT EXISTS `test` /*!40100 DEFAULT CHARACTER SET latin1 */;\nUSE `test`;\n\n-- Dumping structure for table test.cliente\nCREATE TABLE IF NOT EXISTS `cliente` (\n `uid` varchar(20) NOT NULL DEFAULT '',\n `points` int(10) unsigned DEFAULT 0,\n `balance` int(10) unsigned DEFAULT 0,\n `card_no` int(10) unsigned DEFAULT NULL,\n PRIMARY KEY (`uid`)\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n-- Dumping data for table test.cliente: ~4 rows (approximately)\n/*!40000 ALTER TABLE `cliente` DISABLE KEYS */;\nINSERT INTO `cliente` (`uid`, `points`, `balance`, `card_no`) VALUES\n\t('02 E2 00 14 2A E5 A2', 0, 0, 4),\n\t('02 E2 00 14 3F 0C C4', 0, 0, 2),\n\t('02 E2 00 14 4D 9F EF', 0, 0, 3),\n\t('02 E2 00 14 51 72 42', 0, 100, 1),\n\t('02 E2 00 22 B3 A9 7B', 3, 5921, 0);\n/*!40000 ALTER TABLE `cliente` ENABLE KEYS */;\n\n/*!40101 SET SQL_MODE=IFNULL(@OLD_SQL_MODE, '') */;\n/*!40014 SET FOREIGN_KEY_CHECKS=IF(@OLD_FOREIGN_KEY_CHECKS IS NULL, 1, @OLD_FOREIGN_KEY_CHECKS) */;\n/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;\n"
},
{
"alpha_fraction": 0.6941037774085999,
"alphanum_fraction": 0.707783043384552,
"avg_line_length": 29.482013702392578,
"blob_id": "3ef292bae426f4b2591053bbd0d394d5a70507ea",
"content_id": "ea692b4cef7eb33c24ea48c18950239ffd284466",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4240,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 139,
"path": "/Tienda-1.py",
"repo_name": "Gerdid/INFINICO",
"src_encoding": "UTF-8",
"text": "\n\"\"\"\nPROYECTO INTEGRADOR\nINFINICO\n8-Mar-2020\n\nAuthors:\nSandra Cristina Sixtos Barrera\nGerhard Didier de la Mora\n\"\"\"\n\n#module imports\nimport mariadb\nimport sys\nimport serial\nimport re\n\nser=serial.Serial('/dev/ttyACM1',9600)\n\n#variable que almacena el arreglo con el valor tipo byte 49 (ASCII 1)\nvalue=bytearray([49])\n#Cuando se envia el valor 49 por el puerto serial se le manda decir a la terminal que lea la tarjeta\n\n#Conexion a servidor\ntry:\n conn=mariadb.connect(\n user=\"root\",\n password=\"root\",\n host='192.168.137.1',\n port=3306)\nexcept mariadb.Error as e:\n print(f\"Error connecting to MariaDB Platform: {e}\")\n sys.exit(1)\n#To interact with and manage databases on MariaDB Platform, we must instantiate a cursor \n#The cursor provides methods for interacting with data from Python code. The cursor provides two\n#methods for executing SQL code: execute() and executemany()\ncursor=conn.cursor()\n\ndef get_balance(cursor,uid):\n\tclient=[]\n\tuid_string=uid\n\tcursor.execute(\"SELECT balance FROM test.cliente WHERE uid=?\",(uid,))\n\tfor(uid) in cursor:\n\t\tclient=(f\"{uid}\")\n\tbalance=int(re.search(r'\\d+',client).group(0))\n\tprint(\"El saldo de la tarjeta \",uid_string,\" es de:\",balance)\n\treturn uid_string,balance\n\ndef read_balance(cursor,uid):\n\t#client=[]\n\t#uid=read_card()\n\tuid_string=uid\n\tcursor.execute(\"SELECT balance FROM test.cliente WHERE uid=?\",(uid,))\n\tfor(uid) in cursor:\n\t\tclient=(f\"{uid}\")\n\tbalance=int(re.search(r'\\d+',client).group(0))\n\treturn balance\n\ndef read_points(cursor,uid):\n\t#uid_string=uid\n\tcursor.execute(\"SELECT points FROM test.cliente WHERE uid=?\",(uid,))\n\tfor(uid) in cursor:\n\t\tclient=(f\"{uid}\")\n\tpoints=int(re.search(r'\\d+',client).group(0))\n\treturn points\n\ndef read_balance_and_points(cursor,uid):\n\tbalance=read_balance(cursor,uid)\n\tpoints=read_points(cursor,uid)\n\treturn uid,balance,points\n\ndef recharge(cursor,uid):\n\tuid_string,balance=get_balance(cursor,uid)\n\tprint(\"Introduzca el monto a recargar: \")\n\ttoCharge=int(input())\n\tnew_balance=balance+toCharge\n\tupdate_balance(cursor,uid_string,new_balance)\n\ndef update_balance(cursor,uid_string,new_balance):\n\t#Actualiza el saldo del uid correspondiente\n\tcursor.execute(\"UPDATE test.cliente SET balance=? WHERE uid=?\",(new_balance,uid_string))\n\ndef update_points(cursor,uid_string,new_points):\n\t#Actualiza los puntos del uid correspondiente\n\tcursor.execute(\"UPDATE test.cliente SET points=? WHERE uid=?\",(new_points,uid_string))\n\ndef cobrar(cursor,uid):\n\tprint(\"Ingrese total a cobrar: \")\n\tammount=int(input())\n\tbalance=read_balance(cursor,uid)\n\tif(balance>=ammount):\n\t\tnew_balance=balance-ammount\n\t\tupdate_balance(cursor,uid,new_balance)\n\telse:\n\t\tprint(\"Saldo insuficiente, use otro metodo de pago\")\n\ndef points_to_balance(cursor,uid):\n\t#10 puntos= $1\n\tpoints=read_points(cursor,uid)\n\tbalance=read_balance(cursor,uid)\n\tbalance_to_add=balance+points//10\n\trem_points=points%10\n\tupdate_balance(cursor,uid,balance_to_add)\n\tupdate_points(cursor,uid,rem_points)\n\ndef display_card_summary(cursor,uid):\n\tbalance=read_balance(cursor,uid)\n\tpoints=read_points(cursor,uid)\n\tprint(\"-------------------------------------\")\n\tprint(\"------------Tarjeta No.--------------\")\n\tprint(\"-------\",uid,\"--------\")\n\tprint(\"SALDO:$ \",balance)\n\tprint(\"PUNTOS: \",points)\n\tprint(\"-------------------------------------\")\n\ndef read_card():\n\t#Se abre el puerto serial para el ordenar a terminal y recepcion de datos de terminal\n\t#Serial toma dos parametros: dispositivo serial y el baudrate\n\tprint(\"Escanee tarjeta\")\n\tser=serial.Serial('/dev/ttyACM1',9600)\n\tser.write(value) #Escribe los bytes al puerto. Este debe de ser tipo byte (o compatible como bytearray)\n\tser.flush() #Espera a que todos los datos esten escritos\n\tuid=ser.readline() #lee una linea terminada por '\\n'. En nuestro caso despues de recibir el UID de la terminal\n\tuid=str(uid) #Convierte el UID a tipo string\n\tuid=uid[2:22] #Y se extra los caracteres basura\n\tser.close() #Se cierra el puerto\n\treturn uid\n\nwhile True:\n\tprint(\"Introduzca operacion: \\n 1.Resumen de tarjeta \\n 2.Recargar saldo \\n 3.Cobrar \\n 4.Convertir puntos a saldo\")\n\top=input()\n\tuid=read_card()\n\tif(op=='1'):\n\t\tdisplay_card_summary(cursor,uid)\n\tif(op=='2'):\n\t\trecharge(cursor,uid)\n\tif(op=='3'):\n\t\tcobrar(cursor,uid)\n\tif(op=='4'):\n\t\tpoints_to_balance(cursor,uid)\n\n\n"
}
] | 4 |
mihsamusev/pylidarlib | https://github.com/mihsamusev/pylidarlib | 3b656119fc39237ec7f8323357dff6af31b33e81 | 58fd22bb0f36c5f04ac628f31245c5138b8841cb | c02f41d457e70eadd93101d8dcfca47532982ff1 | refs/heads/main | 2023-07-28T09:22:39.767669 | 2021-09-15T13:45:17 | 2021-09-15T13:45:17 | 346,120,661 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5104808807373047,
"alphanum_fraction": 0.5608596205711365,
"avg_line_length": 32.98203659057617,
"blob_id": "6542367a83ebb7885e0ab68c792aeb82b5810bc7",
"content_id": "5a5b8ab81c9720bd498f7e394bb178f7e49a477b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5677,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 167,
"path": "/pylidarlib/io.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\nfrom typing import List, Tuple, Iterator\nimport numpy as np\nfrom pylidarlib import PointCloud\n\n\nt_packet_stream = List[Tuple[float, bytes]] # (timestam, databuffer)\n\n\n@dataclass\nclass HDL32eLaserFiring:\n \"\"\"\n inputs are 1x32 arrays for data from a single HDL32e firing\n contents are (32,) numpy arrays\n \"\"\"\n azimuth: np.ndarray\n distance: np.ndarray\n intensity: np.ndarray\n\n\nclass HDL32e:\n \"\"\"\n Each HDL32e UDP packet is 1248 bytes consists of:\n 42 byte packet header\n 12x100 byte blocks of data, each with [\n timestamp(uint),\n azimuth(uint) * 100,\n 32x[distance(uint) * 500, intensity(byte)]\n ]\n 4 byte timestamp, 2 byte factory\n \"\"\"\n LASERS = 32\n BLOCKS = 12\n ELE_LUT = [\n -30.67, -9.33, -29.33,\n -8.00, -28.00, -6.66,\n -26.66, -5.33, -25.33,\n -4.00, -24.00, -2.67,\n -22.67, -1.33, -21.33,\n 0.00, -20.00, 1.33,\n -18.67, 2.67, -17.33,\n 4.00, -16.00, 5.33,\n -14.67, 6.67, -13.33,\n 8.00, -12.00, 9.33,\n -10.67, 10.67\n ]\n ELE_ARRAY = np.asarray(ELE_LUT)\n ELE_ARRAY_RAD = np.deg2rad(ELE_ARRAY)\n ELE_ARRAY_COS = np.cos(ELE_ARRAY_RAD)\n ELE_ARRAY_SIN = np.sin(ELE_ARRAY_RAD)\n AZIMUTH_RES = 0.01\n DISTANCE_RES = 0.002\n HEADER_SIZE = 42\n PACKET_SIZE = 1248\n\n @staticmethod\n def parse_data_packet(buffer: bytes):\n \"\"\"\n Parses HDL32e strongest return mode data packet\n Fast parsing from\n # https://stackoverflow.com/questions/36797088/speed-up-pythons-struct-unpakc\n using details of np.ndarray(\n shape - output array shape\n dtype - <H little-endian unsigned short aka np.uint16,\n <B little-endian unsigned byte aka np.uint8\n buffer - the placeholder of the data itself\n offset - from header\n strides - that type re-appears every th)\n \"\"\"\n azimuth = np.ndarray(\n (HDL32e.BLOCKS,), np.uint16, buffer, 2, (100, )\n ) * HDL32e.AZIMUTH_RES\n azimuth = np.repeat(azimuth, HDL32e.LASERS).reshape(\n HDL32e.BLOCKS, HDL32e.LASERS)\n\n distance = np.ndarray(\n (HDL32e.BLOCKS, HDL32e.LASERS), np.uint16, buffer, 4, (100, 3)\n ) * HDL32e.DISTANCE_RES\n\n intensity = np.ndarray(\n (HDL32e.BLOCKS, HDL32e.LASERS), np.uint8, buffer, 6, (100, 3))\n return azimuth, distance, intensity\n\n @staticmethod\n def yield_firings(buffer: bytes) -> Iterator[HDL32eLaserFiring]:\n \"\"\"\n Generator for HDL32e lidar firings from data packets\n Only supports strongest return mode\n \"\"\"\n azimuth, distance, intensity = HDL32e.parse_data_packet(buffer)\n for i in range(HDL32e.BLOCKS):\n firing = HDL32eLaserFiring(\n azimuth[i],\n distance[i],\n intensity[i]\n )\n yield firing\n\n @staticmethod\n def yield_clouds(packet_stream: t_packet_stream) -> Iterator[PointCloud]:\n \"\"\"\n Generator for point clouds from HDL32e pcap data\n packet stream\n \"\"\"\n prev_azi = 0\n firings_buffer: List[HDL32eLaserFiring] = []\n for timestamp, packet in packet_stream:\n if len(packet) != HDL32e.PACKET_SIZE:\n continue\n\n for firing in HDL32e.yield_firings(packet[42:]):\n if prev_azi > firing.azimuth[0]:\n xyzi = HDL32e.firings_to_xyzi(firings_buffer)\n xyzi = xyzi[np.where(np.count_nonzero(xyzi[:, :3], axis=1))]\n pc = PointCloud.from_numpy(xyzi)\n firings_buffer = []\n yield pc\n\n firings_buffer.append(firing)\n prev_azi = firing.azimuth[0]\n \n xyzi = HDL32e.firings_to_xyzi(firings_buffer)\n xyzi = xyzi[np.where(np.count_nonzero(xyzi[:, :3], axis=1))]\n pc = PointCloud.from_numpy(xyzi)\n yield pc\n\n @staticmethod\n def firings_to_xyzi(firings: List[HDL32eLaserFiring]) -> np.ndarray:\n \"\"\"\n converts list of HDL32eLaserFiring to xyzi nuy\n \"\"\"\n n = len(firings)\n xyzi = np.zeros((n * HDL32e.LASERS, 4))\n for i, firing in enumerate(firings): \n azi_rad = np.deg2rad(firing.azimuth)\n rcos_ele = firing.distance * HDL32e.ELE_ARRAY_COS\n\n i_start = HDL32e.LASERS * i\n i_end = i_start + HDL32e.LASERS\n xyzi[i_start:i_end, 0] = rcos_ele * np.sin(azi_rad)\n xyzi[i_start:i_end, 1] = rcos_ele * np.cos(azi_rad)\n xyzi[i_start:i_end, 2] = firing.distance * HDL32e.ELE_ARRAY_SIN\n xyzi[i_start:i_end, 3] = firing.intensity\n return xyzi\n\n @staticmethod\n def count_rotations(packet_stream: t_packet_stream) -> int:\n \"\"\"\n Counts full rotations (number of point clouds)\n of a HDL32e rounded up, new rotation is registered\n after crossing 0 .Accounts for new rotation starting\n both within packet but also from one packet to another\n \"\"\"\n count = 1\n prev_max_azi = 0\n\n for timestamp, packet in packet_stream:\n if len(packet) != HDL32e.PACKET_SIZE:\n continue\n # use same binary parsing as in parse_data_packet()\n min_azi, max_azi = np.ndarray(\n (2,), np.uint16, packet, HDL32e.HEADER_SIZE + 2, (1100,))\n if (max_azi < min_azi or prev_max_azi > min_azi):\n count += 1\n prev_max_azi = max_azi\n\n return count\n\n\n"
},
{
"alpha_fraction": 0.5329341292381287,
"alphanum_fraction": 0.5403592586517334,
"avg_line_length": 27.595890045166016,
"blob_id": "0995cb3a54576e5e2ad219e1e271723a3e894966",
"content_id": "1de238579e3462d675d6da0f9eaa0bc22a035a8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4175,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 146,
"path": "/pylidarlib/transforms.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy.spatial.transform import Rotation as ScipyRotation\nfrom skimage.measure import points_in_poly\nfrom sklearn.neighbors import BallTree\n\nfrom pylidarlib import PointCloud\n\n\nclass Compose:\n def __init__(self, transforms):\n self.transforms = transforms\n\n def apply(self, pc: PointCloud):\n for t in self.transforms:\n pc = t.apply(pc)\n return pc\n\n\nclass Translate:\n def __init__(self, x=0, y=0, z=0):\n self.x = x\n self.y = y\n self.z = z\n\n def apply(self, pc: PointCloud):\n \"\"\"translate .xyz of the point cloud, this\n implementation creates outputs\n \"\"\"\n new_data = pc.data + np.array([self.x, self.y, self.z, 0])\n return PointCloud.from_numpy(\n new_data,\n capacity=new_data.shape[0])\n\n\nclass CartesianClip:\n def __init__(\n self,\n x_range=[-np.inf, np.inf],\n y_range=[-np.inf, np.inf],\n z_range=[-np.inf, np.inf],\n inverse=False):\n self.x_range = x_range\n self.y_range = y_range\n self.z_range = z_range\n self.inverse = inverse\n\n def apply(self, pc: PointCloud):\n \"\"\"\n Points that lay right at the boundary are not included\n \"\"\"\n x, y, z = pc.xyz.T\n x_mask = (x > self.x_range[0]) & (x < self.x_range[1])\n y_mask = (y > self.y_range[0]) & (y < self.y_range[1])\n z_mask = (z > self.z_range[0]) & (z < self.z_range[1])\n mask = x_mask & y_mask & z_mask\n\n if self.inverse:\n mask = np.invert(mask)\n\n new_data = pc.data[mask, :]\n return PointCloud.from_numpy(\n new_data,\n capacity=new_data.shape[0])\n\n\nclass PolygonCrop:\n def __init__(\n self,\n polygon,\n z_range=[-np.inf, np.inf],\n inverse=False):\n self.polygon = polygon\n self.z_range = z_range\n self.inverse = inverse\n\n def apply(self, pc: PointCloud):\n \"\"\"\n Clip the point cloud outside the given polygon\n \"\"\"\n xy_mask = points_in_poly(pc.data[:, :2], self.polygon)\n mask = xy_mask\n if self.z_range[0] < self.z_range[1]:\n z = pc.data[:, 2]\n z_mask = (z > self.z_range[0]) & (z < self.z_range[1])\n mask = xy_mask & z_mask\n\n if self.inverse:\n mask = np.invert(mask)\n\n new_data = pc.data[mask, :]\n return PointCloud.from_numpy(\n new_data,\n capacity=new_data.shape[0])\n\n\nclass AxisRotate:\n def __init__(self, axis, angle):\n self.axis = np.asarray(axis)\n self.axis = self.axis / np.linalg.norm(self.axis)\n self.angle = angle\n\n def _get_matrix(self):\n \"\"\"\n Get rotation matrix from quaterion defined by\n axis and CCW rotation angle\n \"\"\"\n qw = np.cos(self.angle / 2)\n qx, qy, qz = np.sin(self.angle / 2) * self.axis\n return ScipyRotation.from_quat([qx, qy, qz, qw])\n\n def apply(self, pc: PointCloud):\n \"\"\"\n Rotate around axis using quaternion\n \"\"\"\n R = self._get_matrix()\n new_xyz = R.apply(pc.xyz)\n new_data = np.hstack([new_xyz, pc.intensity])\n return PointCloud.from_numpy(\n new_data,\n capacity=new_data.shape[0])\n\n\nclass CloudSubtractor:\n def __init__(self, subtracted: PointCloud, radius: float=0.2, leaf_size: np.uint=10):\n if subtracted.size == 0:\n raise ValueError(\"Cant use empty point cloud for subtraction.\")\n if radius <= 0:\n raise ValueError(\"Cant use nonpositive KD-tree search radius.\")\n\n self.subtracted_kdtree = BallTree(subtracted.xyz, leaf_size)\n self.radius = radius\n\n def apply(self, pc: PointCloud):\n if pc.size == 0:\n return pc\n\n intersection_count = self.subtracted_kdtree.query_radius(\n pc.xyz,\n r=self.radius,\n count_only=True\n )\n new_data = pc.data[intersection_count==0, :]\n return PointCloud.from_numpy(\n new_data,\n capacity=new_data.shape[0]\n )\n"
},
{
"alpha_fraction": 0.6610169410705566,
"alphanum_fraction": 0.685230016708374,
"avg_line_length": 25.44871711730957,
"blob_id": "02dccba2139a03db7452a3e0067dac7f24e04081",
"content_id": "2a7f5522dd0d4fbcbf9cbe7d494933023216caa3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2065,
"license_type": "permissive",
"max_line_length": 198,
"num_lines": 78,
"path": "/README.md",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "# pylidarlib\nUtilities for LIDAR data reading and transformation\n\n## Repo status\n\n[](https://github.com/mihsamusev/pylidarlib/actions/workflows/build.yml)\n\nSee which OS and Python versions combinations are supported [here](https://github.com/mihsamusev/pylidarlib/actions).\n\n## Getting started\n\n### Quick demo - PCAP to KITTI format\nConvert your `.pcap` file collected with Velodyne HDL32e to KITTI compatiable format. Useful for using your own data with one of the KITTI benchmark algorithms for 3D object detection /segmentation.\n\n```python\nimport dpkt\nfrom pylidarlib.io import HDL32e\nimport pylidarlib.transforms as PT\n\n# compose a transformation pipeline PyTorch style\npipeline = PT.Compose([\n PT.AxisRotate(\n axis=[0, 0, 1],\n angle=0.7070\n ),\n PT.PolygonCrop(polygon=[\n [0.0, -10.0],\n [-4.0, 0.0],\n [-4.0, 5.0],\n [-20.0, 10.0],\n [-20.0, -12.0],\n [0.0, -32.0]\n ]),\n PT.Translate(x=5, y=-10)\n])\n\n# read UDP stream using any package you like, here dpkg is shown\nwith open(\"file.pcap\", \"rb\") as fin:\n packet_stream = dpkt.pcap.Reader(fin)\n\n # feed the stream into cloud generator\n pc_generator = HDL32e.yield_clouds(packet_stream)\n\n # do something with the clouds\n for i, pc in enumerate(pc_generator):\n pc = pipeline.apply(pc)\n pc.data.astype(np.float32).tofile(f\"data/cloud_{i}.bin\")\n```\n\n## Installation\n\nClone and install `pylidarlib` to your environment\n\n```sh\ngit clone https://github.com/mihsamusev/pylidarlib.git\ncd pylidarlib\n```\n\n\nOptionally create a conda environment\n```sh\nconda env create -f environment.yml\n```\n\nOr install requirements to an existing environment\n```sh\npip install -r requirements.txt\n\n```\nInstall the module itself using `setup.py`\n```\npip install -e .\n```\n\nRun tests.\n```sh\npytest\n```\n\n\n"
},
{
"alpha_fraction": 0.5886398553848267,
"alphanum_fraction": 0.6130921840667725,
"avg_line_length": 33.438594818115234,
"blob_id": "4064691786d7454d9dccc8c26a143ad8594f275f",
"content_id": "bf9d9e5e7708f74be6d4bf8eb971279b6fac6606",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3926,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 114,
"path": "/test/test_dataobjects.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport unittest\nfrom pylidarlib import PointCloud, RangeImage\nimport numpy as np\n\n\nclass TestDataObjects(unittest.TestCase):\n \"\"\"Test cases for dataobjects.py\n \"\"\"\n\n def test_empty_cloud_construction(self):\n pc = PointCloud()\n np.testing.assert_array_equal(pc.data, np.zeros((pc.size, 4)))\n np.testing.assert_array_equal(pc.xyz, np.zeros((pc.size, 3)))\n np.testing.assert_array_equal(pc.intensity, np.zeros((pc.size, 1)))\n\n pc = PointCloud(capacity=55)\n self.assertEqual(pc.capacity, 55)\n\n def test_cloud_construction_from_numpy(self):\n # wrong dimensions\n data = np.random.rand(4, 3)\n self.assertRaises(ValueError, PointCloud.from_numpy, data)\n\n # wrong type\n data = [[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]\n self.assertRaises(ValueError, PointCloud.from_numpy, data)\n\n # all correct\n data = np.random.rand(2, 4)\n pc = PointCloud.from_numpy(data)\n np.testing.assert_array_equal(pc.xyz, data[:, :3])\n np.testing.assert_array_equal(pc.intensity, data[:, 3:4])\n self.assertEqual(pc.size, 2)\n\n def test_cloud_extend_within_capacity(self):\n pc = PointCloud(capacity=10)\n\n data_chunk1 = np.random.rand(2, 4)\n pc.extend(data_chunk1)\n self.assertEqual(pc.size, 2)\n\n data_chunk2 = np.random.rand(3, 4)\n pc.extend(data_chunk2)\n self.assertEqual(pc.size, 5)\n\n expected = np.vstack([data_chunk1, data_chunk2])\n np.testing.assert_array_equal(pc.data, expected)\n\n def test_cloud_extend_past_capacity(self):\n # past 1x capacity\n pc = PointCloud(capacity=2)\n data_chunk = np.random.rand(3, 4)\n pc.extend(data_chunk)\n self.assertEqual(pc.capacity, 4)\n self.assertEqual(pc.size, 3)\n\n # past 2x capacity\n pc = PointCloud(capacity=2)\n data_chunk = np.random.rand(5, 4)\n pc.extend(data_chunk)\n self.assertEqual(pc.capacity, 8)\n self.assertEqual(pc.size, 5)\n\n expected_data = np.zeros((8, 4))\n expected_data[:5, :] = data_chunk\n np.testing.assert_array_equal(pc._data, expected_data)\n\n def test_cloud_shrink(self):\n # normal\n data_chunk = np.random.rand(3, 4)\n pc = PointCloud.from_numpy(data_chunk)\n pc.shrink()\n self.assertEqual(pc.size, pc.capacity)\n np.testing.assert_array_equal(pc._data, data_chunk)\n\n # after extend\n data_chunk = np.random.rand(3, 4)\n pc = PointCloud(capacity=2)\n pc.extend(data_chunk)\n pc.shrink()\n self.assertEqual(pc.size, pc.capacity)\n np.testing.assert_array_equal(pc._data, data_chunk)\n\n def test_cloud_construct_from_numpy_past_capacity(self):\n # past 1x capacity\n data_chunk = np.random.rand(15, 4)\n pc = PointCloud.from_numpy(data_chunk, capacity=10)\n self.assertEqual(pc.capacity, 16)\n self.assertEqual(pc.size, 15)\n\n # past 2x capacity\n data_chunk = np.random.rand(30, 4)\n pc = PointCloud.from_numpy(data_chunk, capacity=10)\n self.assertEqual(pc.capacity, 32)\n self.assertEqual(pc.size, 30)\n\n expected_data = np.zeros((32, 4))\n expected_data[:30, :] = data_chunk\n np.testing.assert_array_equal(pc._data, expected_data)\n\n def test_empty_rangeimage_construction(self):\n ri = RangeImage()\n np.testing.assert_array_equal(ri.data, np.zeros((ri.size, 4)))\n np.testing.assert_array_equal(ri.radius, np.zeros((ri.size, 1)))\n np.testing.assert_array_equal(ri.azimuth, np.zeros((ri.size, 1)))\n np.testing.assert_array_equal(ri.elevation, np.zeros((ri.size, 1)))\n np.testing.assert_array_equal(ri.intensity, np.zeros((ri.size, 1)))\n\n ri = RangeImage(capacity=55)\n self.assertEqual(ri.capacity, 55)\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.6725663542747498,
"alphanum_fraction": 0.6814159154891968,
"avg_line_length": 25.076923370361328,
"blob_id": "fddcd29fdbc15f12180dc22022f6bea1449334d1",
"content_id": "bff38cb1bfc14cdda3d25d55314d77d9dd058dc7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 339,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 13,
"path": "/setup.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup\nfrom setuptools import find_packages\n\nsetup(\n name=\"pylidarlib\",\n packages=find_packages(),\n version=\"0.0.1\",\n license=\"MIT\",\n description=\"Python library for simple lidar data operations\",\n author=\"Mihhail Samusev\",\n url=\"https://github.com/mihsamusev\",\n keywords=[\"pointcloud\", \"lidar\"]\n)\n"
},
{
"alpha_fraction": 0.5138142704963684,
"alphanum_fraction": 0.566769003868103,
"avg_line_length": 34.380088806152344,
"blob_id": "b6da213d5a2cb6616a5a6f2c00ba01f295c6da08",
"content_id": "699e509b729782b5e4ddeebeb97593449919cd8e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7818,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 221,
"path": "/test/test_io.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport unittest\nimport itertools\nimport numpy as np\n\nfrom pylidarlib.io import HDL32e\nfrom test.testdoubles import HDL32ePcapDouble\n\nnp.random.seed(seed=42) # deterministic tests\n\n\nclass TestHDL32PcapIO(unittest.TestCase):\n \"\"\"Test cases for readers / writters\n \"\"\"\n def setUp(self):\n \"\"\"\n Generate lidar data at different levels\n \"\"\"\n self.test_azi_1rot = self._get_azimuth_block_single_rotation()\n self.test_azi_2rot = self._get_azimuth_block_double_rotation()\n self.test_elev = self._get_elevations_block()\n self.test_dist, self.test_intens = self._get_random_dist_and_intens()\n self.test_packet1 = HDL32ePcapDouble.build_single_return_packet(\n self.test_azi_1rot, self.test_dist, self.test_intens\n )\n self.test_packet2 = HDL32ePcapDouble.build_single_return_packet(\n self.test_azi_2rot, self.test_dist, self.test_intens\n )\n self.test_numpy_block_1rot = np.dstack([\n self.test_azi_1rot,\n self.test_elev,\n self.test_dist,\n self.test_intens\n ])\n self.test_numpy_block_2rot = np.dstack([\n self.test_azi_2rot,\n self.test_elev,\n self.test_dist,\n self.test_intens\n ])\n self.test_xyzi_block_1rot = self._get_xyzi_datablock(\n self.test_azi_1rot,\n self.test_elev,\n self.test_dist,\n self.test_intens\n )\n self.test_xyzi_block_2rot = self._get_xyzi_datablock(\n self.test_azi_2rot,\n self.test_elev,\n self.test_dist,\n self.test_intens\n )\n\n def _get_elevations_block(self):\n elevations = np.asarray([\n -30.67, -9.33, -29.33, -8.00, -28.00, -6.66,\n -26.66, -5.33, -25.33, -4.00, -24.00, -2.67,\n -22.67, -1.33, -21.33, 0.00, -20.00, 1.33,\n -18.67, 2.67, -17.33, 4.00, -16.00, 5.33,\n -14.67, 6.67, -13.33, 8.00, -12.00, 9.33,\n -10.67, 10.67\n ])\n return np.repeat(elevations, 12).reshape(32, 12).T\n\n def _get_azimuth_block_single_rotation(self):\n azimuths = np.array([\n 345.5, 346.5, 347.5, 348.5,\n 349.5, 350.5, 351.5, 352.5,\n 353.5, 354.5, 355.5, 356.5\n ])\n return np.repeat(azimuths, 32).reshape(12, 32)\n\n def _get_azimuth_block_double_rotation(self):\n azimuths = np.array([\n 356.5, 357.5, 358.5, 359.5,\n 1.5, 2.5, 3.5, 4.5,\n 5.5, 6.5, 7.5, 8.5\n ])\n return np.repeat(azimuths, 32).reshape(12, 32)\n\n def _get_random_dist_and_intens(self):\n \"\"\"\n generates (12, 32) arrays for each\n azimuth, elevations, distances, intesities\n only nonzero distances unlike real-lidar\n \"\"\"\n distances = np.random.randint(1, 70, (12, 32))\n intensities = np.random.randint(0, 100, (12, 32))\n return distances, intensities\n\n def _get_xyzi_datablock(self, azi, elev, dist, intens):\n \"\"\"\n Returns (12, 32, 4) array where for each 12 firngs\n there is a (32, 4) array with cartiesian coordinates\n and intensity\n \"\"\"\n azi_rad = np.deg2rad(azi)\n ele_rad = np.deg2rad(elev)\n rcos_ele = dist * np.cos(ele_rad)\n xyzi = np.dstack([\n rcos_ele * np.sin(azi_rad),\n rcos_ele * np.cos(azi_rad),\n dist * np.sin(ele_rad),\n intens\n ])\n return xyzi\n\n def test_HDL32e_pcap_packet_parser(self):\n payload = self.test_packet1[42:] # remove header\n p_azi, p_dist, p_intens = HDL32e.parse_data_packet(payload)\n\n np.testing.assert_array_equal(\n p_azi, self.test_azi_1rot)\n np.testing.assert_array_almost_equal(\n p_dist, self.test_dist, decimal=2)\n np.testing.assert_array_equal(\n p_intens, self.test_intens)\n\n def test_HDL32e_pcap_firing_generator(self):\n payload = self.test_packet1[42:] # remove header\n firings = HDL32e.yield_firings(payload)\n index = 8 # firing at this index is tested\n f = next(itertools.islice(firings, index, None))\n\n np.testing.assert_array_equal(\n f.azimuth, self.test_azi_1rot[index, :])\n np.testing.assert_array_almost_equal(\n f.distance, self.test_dist[index, :], decimal=2)\n np.testing.assert_array_equal(\n f.intensity, self.test_intens[index, :])\n\n def test_HDL32e_pcap_count_rotations(self):\n # acts as a mock to dpkt.pcap.Reader generator\n packets = [\n (\"timestamp1\", self.test_packet1),\n (\"timestamp2\", self.test_packet2)\n ]\n packet_stream = (p for p in packets)\n\n r = HDL32e.count_rotations(packet_stream)\n self.assertEqual(r, 2)\n\n def test_HDL32e_firings_to_xyzi(self):\n payload = self.test_packet1[42:]\n firings = HDL32e.yield_firings(payload)\n firings_list = [f for f in firings]\n xyzi = HDL32e.firings_to_xyzi(firings_list)\n\n self.assertEqual(xyzi.shape[0], 12 * 32)\n expected = self.test_xyzi_block_1rot.reshape((12 * 32, 4))\n np.testing.assert_array_almost_equal(\n xyzi, expected, decimal=2\n )\n\n def test_HDL32e_pcap_yield_clouds(self):\n # acts as a mock to dpkt.pcap.Reader generator\n packets = [\n (\"timestamp1\", self.test_packet1),\n (\"timestamp2\", self.test_packet2)\n ]\n \n # standart start_angle\n packet_stream = (p for p in packets)\n\n clouds = []\n cloud_gen = HDL32e.yield_clouds(packet_stream)\n for c in cloud_gen:\n clouds.append(c)\n\n self.assertEqual(len(clouds), 2)\n self.assertEqual(clouds[0].size, 16 * 32)\n self.assertEqual(clouds[1].size, 8 * 32)\n\n expected1 = self.test_xyzi_block_1rot.reshape(12 * 32, 4)\n expected2 = self.test_xyzi_block_2rot.reshape(12 * 32, 4)\n expected = np.vstack([expected1, expected2])\n split_idx = (12 + 4) * 32\n expected_pc1 = expected[:split_idx, :]\n np.testing.assert_array_almost_equal(\n clouds[0].data, expected_pc1, decimal=2)\n expected_pc2 = expected[split_idx:,:]\n np.testing.assert_array_almost_equal(\n clouds[1].data, expected_pc2, decimal=2)\n\n self.assertTrue(\n np.all(np.count_nonzero(clouds[0].xyz, axis=1)))\n self.assertTrue(\n np.all(np.count_nonzero(clouds[1].xyz, axis=1)))\n\n def test_HDL32e_pcap_yield_clouds_without_zeros(self):\n test_dist_w_zeros = self.test_dist\n rand_column = np.random.randint(0, 32, 3)\n \n test_dist_w_zeros[0, rand_column] = np.zeros(3)\n test_dist_w_zeros[3, rand_column] = np.zeros(3)\n test_dist_w_zeros[4, rand_column] = np.zeros(3)\n test_dist_w_zeros[11,rand_column] = np.zeros(3)\n\n test_packet1 = HDL32ePcapDouble.build_single_return_packet(\n self.test_azi_1rot, test_dist_w_zeros, self.test_intens\n )\n test_packet2 = HDL32ePcapDouble.build_single_return_packet(\n self.test_azi_2rot, test_dist_w_zeros, self.test_intens\n )\n \n # acts as a mock to dpkt.pcap.Reader generator\n packets = [\n (\"timestamp1\", test_packet1),\n (\"timestamp2\", test_packet2)\n ]\n \n # standart start_angle\n packet_stream = (p for p in packets)\n clouds = []\n cloud_gen = HDL32e.yield_clouds(packet_stream)\n for c in cloud_gen:\n clouds.append(c)\n\n self.assertEqual(len(clouds), 2)\n self.assertEqual(clouds[0].size, 10 * 32 + 6 * 29)\n self.assertEqual(clouds[1].size, 6 * 32 + 2 * 29)"
},
{
"alpha_fraction": 0.47343817353248596,
"alphanum_fraction": 0.5478113293647766,
"avg_line_length": 29.960525512695312,
"blob_id": "e35482242beaebec479e80886585aac6f5a775e4",
"content_id": "607b3cb944ee5859b49751fbf07ba34e58fcfd9e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2353,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 76,
"path": "/test/testdoubles.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "from pylidarlib.io import HDL32e\nimport numpy as np\n\n\nclass HDL32ePcapDouble:\n \"\"\"\n generates packets and pcap files with given data\n \"\"\"\n @classmethod\n def get_pcap_header(cls):\n \"\"\"\n Copied from a valid PCAP file\n \"\"\"\n pcap_header = bytes.fromhex((\n \"d4c3b2a1020004000000000000000000\"\n \"ffff00000100000085adc750ac970500\"\n \"e0040000e0040000\"\n ))\n return pcap_header\n\n @classmethod\n def get_packet_header(cls, port=2368):\n \"\"\"\n Copied from a valid PCAP file\n bytes 36-38\n port_hex = port.to_bytes(2, 'big').hex()\n \"\"\"\n header = bytes.fromhex((\n \"ffffffffffff6076\"\n \"8820126e08004500\"\n \"04d200004000ff11\"\n \"b4a9c0a801c9ffff\"\n \"ffff0940\"\n \"0940\"\n \"04be0000\"\n ))\n return header\n\n @classmethod\n def build_firing_from_numpy(cls, azi, dist_row, int_row):\n \"\"\"\n builds 2 + 2 + 32 * (2 + 1) = 100 bytes datablock\n corresponding to azimuth data + dist, intensity from firing\n of 32 laser channels\n \"\"\"\n dist_bytes = [dist_row.tobytes()[i:i+2] for i in range(0, 2*32, 2)]\n int_bytes = [int_row.tobytes()[i:i+1] for i in range(0, 32, 1)]\n firing = np.random.bytes(2) + azi.tobytes() # 2 byte flag first\n for d, i in zip(dist_bytes, int_bytes):\n firing += d + i\n return firing\n\n @classmethod\n def build_single_return_packet(\n cls, azi, dist, intens, port=2368, timestamp=0):\n header = cls.get_packet_header(port)\n payload = cls.numpy_data_to_packet_payload(\n azi, dist, intens)\n ts = timestamp.to_bytes(4, 'little')\n factory = np.random.bytes(2)\n return header + payload + ts + factory\n\n @classmethod\n def numpy_data_to_packet_payload(cls, azi, dist, intens):\n azi_pcap = (azi / HDL32e.AZIMUTH_RES).astype(np.uint16)\n dist_pcap = (dist / HDL32e.DISTANCE_RES).astype(np.uint16)\n intens_pcap = intens.astype(np.uint8)\n\n payload = b''\n for i in range(0, 12):\n payload += cls.build_firing_from_numpy(\n azi_pcap[i, 0],\n dist_pcap[i, :],\n intens_pcap[i, :]\n )\n return payload\n"
},
{
"alpha_fraction": 0.5560623407363892,
"alphanum_fraction": 0.57012540102005,
"avg_line_length": 25.31999969482422,
"blob_id": "12bb2dcb7cb178e6bbc7e60443458b86f2fd9d92",
"content_id": "6e856a03167758c68844a36dd5f985ad452002af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2631,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 100,
"path": "/pylidarlib/dataobjects.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\ndef is_valid_numpy(arr: np.ndarray):\n \"\"\"\n test if input has same numpy type and right size\n \"\"\"\n out = False\n if isinstance(arr, np.ndarray):\n out = arr.shape[1] == 4\n return out\n\nclass Container3D:\n pass\n\nclass PointCloud:\n \"\"\"\n Cartesian coordinate representation of point could data \n containing X Y Z and Intensity\n \"\"\"\n def __init__(self, capacity: np.uint=32768):\n self.capacity = capacity\n self.size = 0\n self._data = np.zeros((self.capacity, 4))\n\n @property\n def data(self) -> np.ndarray:\n return self._data[:self.size]\n\n @property\n def xyz(self) -> np.ndarray:\n return self._data[:self.size, :3]\n\n @property\n def intensity(self) -> np.ndarray:\n return self._data[:self.size, 3:4]\n\n @staticmethod\n def from_numpy(arr: np.ndarray, **kwargs):\n \"\"\"\n Constructs a PointCloud using [N x 4] numpy array\n \"\"\"\n if is_valid_numpy(arr):\n pc = PointCloud(**kwargs)\n pc.extend(arr)\n return pc\n else:\n raise ValueError(\n \"Input array should be 'numpy.ndarray' of size [N x 4]\")\n\n def extend(self, arr: np.ndarray):\n \"\"\"\n Extends the _data array with a [N x 4] numpy array\n \"\"\"\n next_size = self.size + arr.shape[0]\n if next_size > self.capacity:\n next_pow2 = np.ceil(np.log2(next_size))\n self.capacity = int(np.power(2, next_pow2))\n\n extended_data = np.zeros((self.capacity, 4))\n extended_data[:self.size, :] = self.data\n self._data = extended_data\n\n self._data[self.size:next_size, :] = arr\n self.size = next_size\n\n def shrink(self):\n self.capacity = self.size\n self._data = self._data[:self.size, :]\n\n\nclass RangeImage:\n \"\"\"\n Cyllindrical coordinate representation of point could data \n containing Azimuth Elevation Radius and Intensity\n \"\"\"\n def __init__(self, capacity: np.uint=32768):\n self.capacity = capacity\n self.size = 0\n self._data = np.zeros((self.capacity, 4))\n\n @property\n def data(self) -> np.ndarray:\n return self._data[:self.size]\n\n @property\n def azimuth(self) -> np.ndarray:\n return self._data[:self.size, 0:1]\n \n @property\n def elevation(self) -> np.ndarray:\n return self._data[:self.size, 1:2]\n \n @property\n def radius(self) -> np.ndarray:\n return self._data[:self.size, 2:3]\n\n @property\n def intensity(self) -> np.ndarray:\n return self._data[:self.size, 3:4]"
},
{
"alpha_fraction": 0.4023866355419159,
"alphanum_fraction": 0.45813843607902527,
"avg_line_length": 28.671388626098633,
"blob_id": "8a5d406725474b93623448709abb3e31d3505938",
"content_id": "e73d233996c95b8815afb85e8660d6b6569c2f5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10475,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 353,
"path": "/test/test_transforms.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport unittest\nfrom pylidarlib import PointCloud\nimport pylidarlib.transforms as T\nimport numpy as np\n\n\nclass TestTransforms(unittest.TestCase):\n \"\"\"Test cases for transforms\n \"\"\"\n def test_translation(self):\n data = np.random.random((6, 4))\n pc = PointCloud.from_numpy(data)\n\n t = T.Translate(x=1, y=-2.5, z=3)\n pc = t.apply(pc)\n expected = np.add(data, np.array([1.0, -2.5, 3.0, 0]))\n np.testing.assert_array_equal(pc.data, expected)\n\n def test_pointcloud_is_copied_during_transform(self):\n data = np.random.random((6, 4))\n pc1 = PointCloud.from_numpy(data)\n\n t = T.Translate(x=1)\n pc2 = t.apply(pc1)\n self.assertNotEqual(pc1, pc2)\n\n def test_cartesian_clip_non_empty_output_1d(self):\n data = np.asarray([\n [1, 0, 0, 1],\n [1, 2, 0, 1],\n [0, 0, 3, 1],\n ])\n pc = PointCloud.from_numpy(data)\n clipper = T.CartesianClip(\n x_range=[-1.0, 1.0]\n )\n pc_test = clipper.apply(pc)\n self.assertEqual(pc_test.size, 1)\n np.testing.assert_array_equal(pc_test.data, data[2:3, :])\n\n def test_cartesian_clip_non_empty_output_2d(self):\n data = np.asarray([\n [1, 0, 0, 1],\n [1, 2, 0, 1],\n [0, 0, 3, 1],\n ])\n pc = PointCloud.from_numpy(data)\n clipper = T.CartesianClip(\n x_range=[-1.0, 1.5],\n z_range=[-1.0, 1.0]\n )\n pc_test = clipper.apply(pc)\n self.assertEqual(pc_test.size, 2)\n np.testing.assert_array_equal(pc_test.data, data[:2, :])\n\n def test_cartesian_clip_non_empty_output_2d_inverse(self):\n data = np.asarray([\n [1, 0, 0, 1],\n [1, 2, 0, 1],\n [0, 0, 3, 1],\n ])\n pc = PointCloud.from_numpy(data)\n clipper = T.CartesianClip(\n x_range=[-1.0, 1.5],\n z_range=[-1.0, 1.0],\n inverse=True\n )\n pc_test = clipper.apply(pc)\n self.assertEqual(pc_test.size, 1)\n np.testing.assert_array_equal(pc_test.data, data[2:3, :])\n\n def test_cartesian_clip_empty_output(self):\n data = np.asarray([\n [1, 0, 0, 1],\n [1, 2, 0, 1],\n [0, 0, 3, 1],\n ])\n\n # only 1 dim\n pc = PointCloud.from_numpy(data)\n clipper = T.CartesianClip(\n inverse=True\n )\n pc_test = clipper.apply(pc)\n self.assertEqual(pc_test.size, 0)\n np.testing.assert_array_equal(pc_test.data, data[:0, :])\n\n def test_quaternion_rotate_30_around_z(self):\n data = np.asarray([\n [-1, -1, 0, 1],\n [1, -1, 0, 1],\n [1, 1, 0, 1],\n [-1, 1, 0, 1],\n ])\n pc = PointCloud.from_numpy(data)\n\n # rotate 30 degrees around Z\n rotator = T.AxisRotate(\n axis=[0.0, 0.0, 1.0],\n angle=np.pi / 6\n )\n pc = rotator.apply(pc)\n expected = np.asarray([\n [-0.3660254, -1.3660254, 0.0, 1.0],\n [1.3660254, -0.3660254, 0.0, 1.0],\n [0.3660254, 1.3660254, 0.0, 1.0],\n [-1.3660254, 0.3660254, 0.0, 1.0]\n ])\n np.testing.assert_array_almost_equal(pc.data, expected)\n\n # rotate 30 degrees, axis not normalized\n pc = PointCloud.from_numpy(data)\n rotator = T.AxisRotate(\n axis=[0.0, 0.0, 1.1],\n angle=np.pi / 6\n )\n pc = rotator.apply(pc)\n np.testing.assert_array_almost_equal(pc.data, expected)\n\n def test_compose_2_translates(self):\n data = np.random.random((6, 4))\n pc = PointCloud.from_numpy(data)\n\n pipe = T.Compose([\n T.Translate(1.1, 2.2, 3.3),\n T.Translate(-1.1, -2.2, -3.3)\n ])\n pc = pipe.apply(pc)\n np.testing.assert_array_almost_equal(pc.data, data)\n\n def test_compose_rotate_translate(self):\n data = np.asarray([\n [0, 0, 2, 1],\n [2, 0, 2, 1],\n [2, 2, 2, 1],\n [0, 2, 2, 1],\n ])\n pc = PointCloud.from_numpy(data)\n pipe = T.Compose([\n T.Translate(0, 0, -2),\n T.AxisRotate([1, 0, 0], np.pi / 2)\n ])\n pc = pipe.apply(pc)\n expected = np.asarray([\n [0.0, 0.0, 0.0, 1.0],\n [2.0, 0.0, 0.0, 1.0],\n [2.0, 0.0, 2.0, 1.0],\n [0.0, 0.0, 2.0, 1.0]\n ])\n np.testing.assert_array_almost_equal(pc.data, expected)\n\n def test_polygon_clipper_clips_entire_pc(self):\n data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 2, 1],\n [1, 1, 3, 1],\n [-1, 1, 4, 1],\n ])\n pc = PointCloud.from_numpy(data)\n poly = [\n [-2, -2],\n [2, -2],\n [2, 2],\n [-2, 2],\n ]\n clipper = T.PolygonCrop(\n polygon=poly,\n inverse=True\n )\n new_pc = clipper.apply(pc)\n self.assertEqual(new_pc.size, 0)\n np.testing.assert_array_equal(new_pc.data.shape, (0, 4))\n\n def test_polygon_clipper_positive(self):\n data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 2, 1],\n [1, 1, 3, 1],\n [-1, 1, 4, 1],\n ])\n pc = PointCloud.from_numpy(data)\n poly = [\n [-2, -2],\n [0, -2],\n [0, 0],\n [2, 0],\n [2, 2],\n [-2, 2],\n ]\n clipper = T.PolygonCrop(\n polygon=poly\n )\n pc = clipper.apply(pc)\n self.assertEqual(pc.size, 3)\n np.testing.assert_array_equal(pc.data, data[[0, 2, 3], :])\n\n def test_polygon_clipper_inverse(self):\n data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 2, 1],\n [1, 1, 3, 1],\n [-1, 1, 4, 1],\n ])\n pc = PointCloud.from_numpy(data)\n poly = [\n [-2, -2],\n [0, -2],\n [0, 0],\n [2, 0],\n [2, 2],\n [-2, 2],\n ]\n clipper = T.PolygonCrop(\n polygon=poly,\n inverse=True\n )\n pc = clipper.apply(pc)\n self.assertEqual(pc.size, 1)\n np.testing.assert_array_equal(pc.data, data[[1], :])\n\n def test_polygon_clipper_z_range(self):\n data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 2, 1],\n [1, 1, 3, 1],\n [-1, 1, 4, 1],\n ])\n pc = PointCloud.from_numpy(data)\n poly = [\n [-2, -2],\n [0, -2],\n [0, 0],\n [2, 0],\n [2, 2],\n [-2, 2],\n ]\n clipper = T.PolygonCrop(\n polygon=poly,\n z_range=[2, 5],\n )\n pc = clipper.apply(pc)\n self.assertEqual(pc.size, 2)\n np.testing.assert_array_equal(pc.data, data[[2, 3], :])\n\n def test_polygon_clipper_poly_nparray(self):\n data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 2, 1],\n [1, 1, 3, 1],\n [-1, 1, 4, 1],\n ])\n pc = PointCloud.from_numpy(data)\n poly = np.asarray([\n [-2, -2],\n [0, -2],\n [0, 0],\n [2, 0],\n [2, 2],\n [-2, 2],\n ])\n clipper = T.PolygonCrop(\n polygon=poly,\n z_range=[2, 5],\n )\n pc = clipper.apply(pc)\n self.assertEqual(pc.size, 2)\n np.testing.assert_array_equal(pc.data, data[[2, 3], :])\n\n def test_cloud_subtractor_empty_subtracted_cloud_error(self):\n subtracted_data = np.empty((0, 4))\n subtracted_pc = PointCloud.from_numpy(subtracted_data)\n self.assertRaises(ValueError, T.CloudSubtractor, subtracted_pc)\n\n def test_cloud_subtractor_nonpositive_radius_error(self):\n subtracted_data = np.zeros((1, 4))\n subtracted_pc = PointCloud.from_numpy(subtracted_data)\n self.assertRaises(ValueError, T.CloudSubtractor, subtracted_pc, radius=0)\n self.assertRaises(ValueError, T.CloudSubtractor, subtracted_pc, radius=-0.5)\n\n def test_cloud_subtractor_partial_subtraction(self):\n source_data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 1, 1],\n [1, 1, 1, 1],\n [-1, 1, 1, 1],\n ])\n subtracted_data = np.asarray([\n [0.9, -0.9, 1.1, 1],\n [1.9, -0.9, 1.1, 1],\n [1.9, 1.1, 1.1, 1],\n [0.9, 1.1, 1.1, 1],\n ])\n expected = np.asarray([\n [-1, -1, 1, 1],\n [-1, 1, 1, 1],\n ])\n source_pc = PointCloud.from_numpy(source_data)\n subtracted_pc = PointCloud.from_numpy(subtracted_data)\n subtractor = T.CloudSubtractor(\n subtracted=subtracted_pc,\n radius=0.2\n )\n new_pc = subtractor.apply(source_pc)\n\n self.assertEqual(new_pc.size, 2)\n np.testing.assert_array_equal(new_pc.data, expected)\n\n def test_cloud_subtractor_complete_subtraction(self):\n source_data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 1, 1],\n [1, 1, 1, 1],\n [-1, 1, 1, 1],\n ])\n source_pc = PointCloud.from_numpy(source_data)\n subtracted_pc = PointCloud.from_numpy(source_data)\n subtractor = T.CloudSubtractor(\n subtracted=subtracted_pc,\n radius=0.2\n )\n new_pc = subtractor.apply(source_pc)\n\n self.assertEqual(new_pc.size, 0)\n np.testing.assert_array_equal(new_pc.data.shape, (0, 4))\n\n def test_cloud_subtractor_no_subtraction(self):\n source_data = np.asarray([\n [-1, -1, 1, 1],\n [1, -1, 1, 1],\n [1, 1, 1, 1],\n [-1, 1, 1, 1],\n ])\n subtracted_data = np.asarray([\n [0.9, -0.9, 1.1, 1],\n [1.9, -0.9, 1.1, 1],\n [1.9, 1.1, 1.1, 1],\n [0.9, 1.1, 1.1, 1],\n ])\n expected = np.asarray([\n [-1, -1, 1, 1],\n [-1, 1, 1, 1],\n ])\n source_pc = PointCloud.from_numpy(source_data)\n subtracted_pc = PointCloud.from_numpy(subtracted_data)\n subtractor = T.CloudSubtractor(\n subtracted=subtracted_pc,\n radius=0.05\n )\n new_pc = subtractor.apply(source_pc)\n\n self.assertEqual(new_pc.size, 4)\n np.testing.assert_array_equal(new_pc.data, source_pc.data)\n\n"
},
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7884615659713745,
"avg_line_length": 25,
"blob_id": "efa96bf95c744145b825941d65cda57b78afc6a2",
"content_id": "db977701204521ea781db296ce597624495ced32",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 52,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 2,
"path": "/pylidarlib/__init__.py",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "# flake8: noqa\nfrom pylidarlib.dataobjects import *\n"
},
{
"alpha_fraction": 0.8571428656578064,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 7.333333492279053,
"blob_id": "a25f507e6606426dfda8753ee71d5f55c5ea2e48",
"content_id": "3d452aa1ae2c0e0fdb6e79b75fce34e0698b67cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 49,
"license_type": "permissive",
"max_line_length": 12,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "mihsamusev/pylidarlib",
"src_encoding": "UTF-8",
"text": "numpy\npytest\ndpkt\nscikit-image\nscikit-learn\nscipy"
}
] | 11 |
linalizeth/Parcial1 | https://github.com/linalizeth/Parcial1 | de7471b9584b6f97c71ded2e94d2adbb9cf14f49 | a10525b4285322daad197eee87d38330824222c6 | 71dceab9e9dd5ff9d78c302e42fa07e44a22f1df | refs/heads/main | 2023-04-02T06:54:29.460313 | 2021-03-18T21:29:46 | 2021-03-18T21:29:46 | 349,220,952 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6184738874435425,
"alphanum_fraction": 0.6265060305595398,
"avg_line_length": 18.230770111083984,
"blob_id": "0c5d2553330cefcbb2676be3116ae1db3f420b45",
"content_id": "5bffb55fa1c6bb2d2b8a9a4b806ad24f3866c329",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 13,
"path": "/src/models/modelo1.py",
"repo_name": "linalizeth/Parcial1",
"src_encoding": "UTF-8",
"text": "import src.config.globals as globals\n\nclass modelo1:\n def metodo1(self):\n cursor = globals.DB.cursor()\n\n cursor.execute('SELECT * FROM products')\n\n products = cursor.fetchall()\n\n cursor.close()\n\n return products"
},
{
"alpha_fraction": 0.7132530212402344,
"alphanum_fraction": 0.7132530212402344,
"avg_line_length": 25,
"blob_id": "056c2a0083cba4fc2202e2fbc268da3a0fc151fa",
"content_id": "43a532d02cb9bcb1218894411033b3b75fca4caf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 16,
"path": "/src/controllers/home.py",
"repo_name": "linalizeth/Parcial1",
"src_encoding": "UTF-8",
"text": "import src.config.globals as globals\nfrom src.config.db import createDB\nfrom flask import render_template\nfrom src import app\nfrom os import path\n\nCONEXION_PATH = path.abspath('src/config/conexion.json')\n\n@app.route('/')\ndef index():\n if path.exists(CONEXION_PATH):\n createDB()\n elif globals.DB == False:\n return render_template('configuracion.html')\n \n return render_template('home.html')"
},
{
"alpha_fraction": 0.6041666865348816,
"alphanum_fraction": 0.6041666865348816,
"avg_line_length": 23.16666603088379,
"blob_id": "65924729994741c35217428c51c2ef474dab8ac5",
"content_id": "714db53785588e2e0bbf8a871bb4091166027b2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 6,
"path": "/src/views/home.html",
"repo_name": "linalizeth/Parcial1",
"src_encoding": "UTF-8",
"text": "{% extends 'layout/base.html' %}\n{% block titulo %} Inicio {% endblock %}\n\n{% block contenido %} \n <p>aqui va el contenido</p>\n{% endblock %}"
}
] | 3 |
nirmaltudu/moviebuzz | https://github.com/nirmaltudu/moviebuzz | fb06f3770ef14f2a7e9189500561e42607e01a73 | 68229de2a5d399880274e163a1a6eff716845618 | fb134bc8140adbe59dda409cb81b28414412c2f3 | refs/heads/master | 2021-01-01T05:06:18.426466 | 2016-05-19T06:17:21 | 2016-05-19T06:17:21 | 59,178,757 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6510066986083984,
"alphanum_fraction": 0.6548417806625366,
"avg_line_length": 27.589040756225586,
"blob_id": "1f3555156a23c4f7379f3f45dfbc381257e2e4e2",
"content_id": "2911e6d45d146887128b0bc0619d397739c27cfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2086,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 73,
"path": "/lib/stats.py",
"repo_name": "nirmaltudu/moviebuzz",
"src_encoding": "UTF-8",
"text": "import time\nfrom apiclient.discovery import build \nimport mongo\nfrom datetime import datetime\nfrom collections import defaultdict\n\nDEVELOPER_KEY = \"AIzaSyCW9a_Dq3EtJFisysq5rtiQ3iFI_2OZkPU\" \nYOUTUBE_API_SERVICE_NAME = \"youtube\" \nYOUTUBE_API_VERSION = \"v3\"\n\n_yt_client = None\ndef _youtube_client():\n\tglobal _yt_client, YOUTUBE_API_VERSION, YOUTUBE_API_SERVICE_NAME, DEVELOPER_KEY\n\tif _yt_client is None:\n\t\t_yt_client = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION,\n \t\t\t\t\tdeveloperKey=DEVELOPER_KEY)\n\treturn _yt_client\n\n\ndef stats():\n\tkey_data = mongo.data_youtube_movie_trailers()\n\tdata = dict()\n\tfor vid in key_data.keys():\n\t\tdata[vid] = get_stat(vid)\n\treturn data\n\ndef write_stats():\n\tdata = stats()\n\treturn mongo.write_youtube_statistics(data)\n\ndef get_stat(vid):\n\tstats_list = _youtube_client().videos().list(id=vid,\n part='id,statistics').execute()\n\ttry:\n\t stat = stats_list['items'][0]['statistics']\n\t stat['timestamp'] = str(datetime.now())\n\texcept KeyError:\n\t\treturn {}\n\treturn stat\n\ndef get_comment_threads():\n\tmov = mongo._collection_youtube_movie_trailers().find_one()\n\tnames = dict()\n\tfor k in mov.keys():\n\t\tif k == '_id':\n\t\t\tcontinue\t\n\t\tnames[k] = mov[k]['name']\n\n\tallComments = defaultdict(str)\n\ttempComments = list()\n\tfor video in names.keys():\n\t\ttime.sleep(1.0)\n \t\tresults = _youtube_client().commentThreads().list(\n \t\tpart=\"snippet\",\n \t\tvideoId=video,\n \t\ttextFormat=\"plainText\",\n \t\tmaxResults=20,\n \t\torder='relevance'\n \t\t).execute()\n\n \t\t\n \t\tfor item in results[\"items\"]:\n \t\t\tcomment = item[\"snippet\"][\"topLevelComment\"]\n \t\t\ttempComment = dict(videoId=video, videoName=names[video],\n \t\t\t\t\t\t\t\tnbrReplies = item[\"snippet\"][\"totalReplyCount\"],\n \t\t\t\t\t\t\t\tauthor = comment[\"snippet\"][\"authorDisplayName\"],\n \t\t\t\t\t\t\t\tlikes = comment[\"snippet\"][\"likeCount\"],\n \t\t\t\t\t\t\t\tpublishedAt=comment[\"snippet\"][\"publishedAt\"],\n \t\t\t\t\t\t\t\ttext = comment[\"snippet\"][\"textDisplay\"].encode('utf-8').strip())\n \t\t\tallComments[video] += tempComment['text'].lower().decode('utf-8').strip(\":,.!?\")\n \t\t\ttempComments.append(tempComment)\n \t\n \treturn allComments"
},
{
"alpha_fraction": 0.460829496383667,
"alphanum_fraction": 0.4677419364452362,
"avg_line_length": 42.5,
"blob_id": "dfade8ae37ec80db201150a5ff95fc8114426583",
"content_id": "c66ed635be08026e11e059e881fb1f5cee9bfab9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 10,
"path": "/lib/tconfig.py",
"repo_name": "nirmaltudu/moviebuzz",
"src_encoding": "UTF-8",
"text": "#--------------------------------------------------------------------------------\n# These tokens are needed for user authentication.\n# Credentials can be generates via Twitter's Application Management:\n#\thttps://apps.twitter.com/app/new\n#--------------------------------------------------------------------------------\n\nconsumer_key = \"RmY0MXwzMq4gTntH8oSmJOpOu\"\nconsumer_secret = \"BLU3xlSnYTHw6pfpPBwhhRQOzMhqigWxmk3n74ssmJdvrrwSnK\"\naccess_key = \" 92949260-ZXQqHICrqzM7qnQPdtw8duXXNATFLXNr5L47mpqYl\"\naccess_secret = \"EYzMMUikuEYgFAe2nmjR4JQTODOHB5wwRMDqReCApdPws\""
},
{
"alpha_fraction": 0.6539368033409119,
"alphanum_fraction": 0.6690240502357483,
"avg_line_length": 21.817203521728516,
"blob_id": "89b866d62d0fedec285d5ee51fafb3462c872c70",
"content_id": "2fd213fea861563718e98e50f504089bbf324147",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2121,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 93,
"path": "/lib/mongo.py",
"repo_name": "nirmaltudu/moviebuzz",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport pymongo\nfrom collections import defaultdict\nimport json\n\nURI = \"mongodb://writer:writer123@ds019482.mlab.com:19482/analytics\"\n\n_client = None\ndef _mongoclient():\n\tglobal _client, URI\n\tif _client is None:\n\t\t_client = pymongo.MongoClient(URI)\n\treturn _client\n\n\n_database = None\ndef _database_analytics():\n\tglobal _database\n\tif _database is None:\n\t\t_database = _mongoclient()['analytics']\n\treturn _database\n\n_collection_1 = None\ndef _collection_youtube_movie_trailers():\n\tglobal _collection_1\n\tif _collection_1 is None:\n\t\t_collection_1 = _database_analytics()['youtube_movie_trailers']\n\treturn _collection_1\n\n_collection_2 = None\ndef _collection_youtube_statistics():\n\tglobal _collection_2\n\tif _collection_2 is None:\n\t\t_collection_2 = _database_analytics()['youtube_statistics']\n\treturn _collection_2\n\n_data_1 = None\ndef data_youtube_movie_trailers():\n\tglobal _data_1\n\tif _data_1 is None:\n\t\t_data_1 = _collection_youtube_movie_trailers().find_one()\n\t\tif _data_1 is not None:\n\t\t\t_data_1.pop('_id')\n\treturn _data_1\n\n_data_2 = None\ndef data_youtube_statistics():\n\tglobal _data_2\n\tif _data_2 is None:\n\t\t_data_2 = _collection_youtube_statistics().find_one()\n\t\tif _data_2 is not None:\n\t\t\t_data_2.pop('_id')\n\treturn _data_2\n\ndef write_youtube_statistics(data):\n\ttry:\n\t\t_collection_youtube_statistics().insert_one(data)\n\texcept Exception:\n\t\treturn False\n\treturn True\n\ndef get_graph_data():\n\tmov = _collection_youtube_movie_trailers().find_one()\n\tnames = dict()\n\tfor k in mov.keys():\n\t\tif k == '_id':\n\t\t\tcontinue\t\n\t\tnames[k] = mov[k]['name']\n\n\tview_counts = list()\n\tdiff_counts = list()\n\trecs = [i for i in _collection_youtube_statistics().find()]\n\t# return recs\n\tc = 0\n\tfor rec in recs:\n\t\trr = dict()\n\t\tfor k in rec.keys():\n\t\t\tif k == '_id':\n\t\t\t\tcontinue\n\t\t\tname = names[k]\n\t\t\trr['timestamp'] = rec[k]['timestamp']\n\t\t\t# rr[name] = rec[k]['viewCount']\n\t\t\tdiff = int(rec[k]['viewCount']) - int(recs[c-1][k]['viewCount'])\n\t\t\trr[name] = diff\n\t\tview_counts.append(rr)\n\t\tc += 1\n\tret = dict()\n\tret['data'] = view_counts\n\tret['xkey'] = 'timestamp'\n\tret['ykeys'] = names.values()\n\tret['labels'] = names.values()\n\treturn json.dumps(ret)"
}
] | 3 |
FrostyBonny/MSDevoDevelop | https://github.com/FrostyBonny/MSDevoDevelop | 6d3cc54f6a34506c4713118b9a9168308270a79e | 9e6f0685806c26d3e294fb976e422f67ab581124 | f8834762614b295859e6a400e428fc261d13d282 | refs/heads/master | 2020-05-19T00:12:33.020716 | 2019-05-20T07:18:12 | 2019-05-20T07:18:12 | 184,729,107 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6724137663841248,
"alphanum_fraction": 0.7413793206214905,
"avg_line_length": 18.66666603088379,
"blob_id": "f4612da2406bd4dfe4e3b6f6cc0b32fa4a0ea41d",
"content_id": "8b3d21eab0c748482456cab300d3f6bd61616f0f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 3,
"path": "/utils/config.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "# this is app config\nDEBUG = True\n# TOKEN_EXPIRATION=6000"
},
{
"alpha_fraction": 0.7155963182449341,
"alphanum_fraction": 0.7155963182449341,
"avg_line_length": 21,
"blob_id": "6a7bb76799b3e2ec092fae01756239030e6fafc7",
"content_id": "417d8c7ebffb998583346c1988e18513af9159f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 5,
"path": "/src/veiws/course/__init__.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint\n\ncourse = Blueprint('course', __name__, url_prefix='/course')\n\nfrom . import veiw"
},
{
"alpha_fraction": 0.7053571343421936,
"alphanum_fraction": 0.7053571343421936,
"avg_line_length": 21.600000381469727,
"blob_id": "0eb1f7696b9e8097ec4630d2c1988a47f62070b8",
"content_id": "0a5c83c4be12fa9f752e3cfe67bf7fbbc340826f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 5,
"path": "/src/veiws/class/__init__.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint\n\nmy_class = Blueprint('my_class', __name__, url_prefix='/class')\n\nfrom . import veiw"
},
{
"alpha_fraction": 0.7372881174087524,
"alphanum_fraction": 0.7372881174087524,
"avg_line_length": 22.799999237060547,
"blob_id": "d8e1e0d2a1a45ab1a7e906f1a747520fbcb885b4",
"content_id": "e019dbd7d1603f89b3740e29bb4089b44c9918b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 118,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 5,
"path": "/src/veiws/classRoom/__init__.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint\n\nclassRoom = Blueprint('classRoom', __name__, url_prefix='/classRoom')\n\nfrom . import veiw"
},
{
"alpha_fraction": 0.5622956156730652,
"alphanum_fraction": 0.5631131529808044,
"avg_line_length": 36.07272720336914,
"blob_id": "5d1a822a204c883278c0d77b7291782dc3c6e63d",
"content_id": "80bd218a18e45c8e8119f7d1120bc51449762773",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6264,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 165,
"path": "/src/veiws/user/veiw.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask_restful import Api, Resource, url_for, abort\nfrom . import user\n# from .parser import putPaeser, getParser\nfrom . import parser as allParser\n# from ... import dbclient\nfrom src import dbclient\nfrom flask import jsonify,request\nfrom utils.code import Code\nfrom utils.function import make_result, make_token, verify_token, encode_password,dbclient_decorate,pagenation\n\ntable = 'm_user'\napi = Api(user)\nclass Login(Resource):\n # 登录\n @dbclient_decorate\n def post(self):\n args = allParser.postLoginParser.parse_args()\n m_user = dbclient.list_one(table,{\"username\":args[\"username\"]})\n if not m_user:\n return make_result(code=Code.ERROR, msg=\"没有该用户\")\n m_user = m_user[0] \n if m_user['password'] == encode_password(args['password']):\n token = make_token()\n dbclient.update(table,token,{\"username\":args[\"username\"]})\n # token[\"username\"]\n back = {}\n back[\"name\"] = m_user[\"name\"]\n back[\"token\"] = token[\"token\"]\n back[\"role\"] = m_user[\"role\"]\n back['id'] = m_user['id']\n response = make_result(data=back,code=Code.SUCCESS)\n else:\n response = make_result(code=Code.ERROR, msg=\"账户密码不一致\")\n return response\n \n @dbclient_decorate\n def get(self):\n args = allParser.getLoginParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if verify_result:\n return make_result(code=Code.SUCCESS, msg=\"成功\")\n else:\n return make_result(code=Code.ERROR, msg=\"token无效\")\n\n\napi.add_resource(Login, '/login',endpoint='userLogin')\n\nclass Login_Out(Resource):\n @dbclient_decorate\n def post(self):\n args = allParser.getLoginOutParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.SUCCESS, msg=\"token已失效\")\n else:\n new_token = make_token()\n result = dbclient.update(table,new_token,{\"token\":args[\"token\"]})\n if result:\n return make_result(code=Code.SUCCESS)\n else:\n return make_result(code=Code.ERROR,msg=\"登出失败\")\n\napi.add_resource(Login_Out, '/loginout',endpoint='userLoginOut')\n\nclass User(Resource):\n # 获取\n @dbclient_decorate\n def get(self):\n args = allParser.getUserParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR, msg=\"token错误\")\n args.pop('token')\n if args['type'] == 'all':\n m_result = dbclient.list_all(table)\n if not m_result:\n return make_result(code=Code.ERROR, msg=\"查询错误\")\n for index,i in enumerate(m_result):\n m_result[index] = {\n \"id\":i[\"id\"],\n \"username\":i[\"username\"],\n \"name\":i['name'],\n \"phone\":i['phone'],\n \"role\":i['role'],\n \"class\":i[\"class\"]\n }\n length = len(m_result)\n m_result = pagenation(m_result,args[\"page\"] - 1,args[\"limit\"])\n response = make_result(m_result,code=Code.SUCCESS,count=length)\n else:\n if args['username']:\n m_result = dbclient.list_one(table,{\"username\":args[\"username\"]})\n if len(m_result) == 0:\n return make_result(code=Code.ERROR, msg=\"没有该用户\")\n m_result = m_result[0]\n m_result.pop('endtime')\n m_result.pop('token')\n response = make_result(m_result,code=Code.SUCCESS)\n elif args['id']:\n m_result = dbclient.list_one(table,{\"id\":args[\"id\"]})\n m_result = m_result[0]\n if not m_result:\n return make_result(code=Code.ERROR, msg=\"没有该用户\")\n m_result.pop('endtime')\n m_result.pop('token')\n response = make_result(m_result,code=Code.SUCCESS)\n return response\n\n\n # 更新\n @dbclient_decorate\n def post(self):\n args = allParser.postUserParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR, msg=\"token无效\")\n args.pop('token')\n # 去空\n values_keys = ['username','password','name','role']\n condition_keys = ['id']\n values = {key: value for key, value in args.items() if key in values_keys and args[key]}\n condition = {key: value for key, value in args.items() if key in condition_keys}\n values[\"password\"] = encode_password(values[\"password\"])\n m_result = dbclient.update(table,values,condition)\n if m_result:\n response = make_result(code=Code.SUCCESS)\n else:\n response = make_result(code=Code.ERROR, msg=\"更新失败\")\n return response\n\n\n # 删除\n @dbclient_decorate\n def delete(self):\n args = allParser.deleteUserParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR, msg=\"token无效\")\n args.pop('token')\n m_result = dbclient.delete(table,args)\n if m_result:\n response = make_result(code=Code.SUCCESS)\n else:\n response = make_result(code=Code.ERROR, msg=\"删除失败\")\n return response\n\n\n # 新增\n @dbclient_decorate\n def put(self):\n args = allParser.putUserParser.parse_args()\n m_users = dbclient.list_column(table,['username'])\n if args['username'] in m_users:\n return make_result(code=Code.ERROR, msg=\"已经存在此用户\")\n args[\"password\"] = encode_password(args[\"password\"])\n # print(args)\n m_result = dbclient.insert(table,args)\n if m_result:\n response = make_result(code=Code.SUCCESS)\n else:\n response = make_result(code=Code.ERROR, msg=\"新增失败\")\n return response\n \n\napi.add_resource(User, '/user',endpoint='user')"
},
{
"alpha_fraction": 0.5453523993492126,
"alphanum_fraction": 0.5470373630523682,
"avg_line_length": 33.89215850830078,
"blob_id": "e94b206941a233b82503e552408362402d9f4d10",
"content_id": "b6117aea4a8d8c67833b40aaf881057436a09e8b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3689,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 102,
"path": "/src/veiws/sc/veiw.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask_restful import Api, Resource, url_for, abort\nfrom . import sc\n# from .parser import putPaeser, getParser\nfrom . import parser as allParser\nfrom ... import dbclient\nfrom flask import jsonify, request\nfrom utils.code import Code\nfrom utils.function import make_result, verify_token, pagenation, dbclient_decorate\n\ntable = 'sc'\napi = Api(sc)\nclass SC(Resource):\n # 获取数据\n @dbclient_decorate\n def get(self):\n args = allParser.getParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR,msg=\"token失效\")\n args.pop('token')\n if args[\"type\"] == \"all\":\n data = dbclient.list_all(table)\n length = len(data)\n data = pagenation(data,args[\"page\"] - 1,args[\"limit\"])\n if data:\n response = make_result(data,Code.SUCCESS,count=length)\n elif data == False:\n response = make_result(code=Code.ERROR,msg='获取数据失败')\n return response\n else:\n if args['id']:\n data = dbclient.list_one(table,{\"id\":args['id']})\n \n data = data[0]\n if not data:\n return make_result(data,Code.ERROR,msg='查询失败或者没有信息') \n elif args['student']:\n data = dbclient.list_one(table,{\"student\":args['student']})\n if len(data) == 0:\n return make_result(data,Code.ERROR,msg='查询失败或者没有信息')\n return make_result(data,Code.SUCCESS,msg='成功')\n \n # print(len(data))\n \n \n # 新增数据\n @dbclient_decorate\n def put(self):\n args = allParser.putParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR)\n args.pop('token')\n result = dbclient.insert(table,args)\n if result:\n response = make_result(code=Code.SUCCESS, msg='新增成功')\n else:\n response = make_result(code=Code.ERROR, msg='新增失败')\n return response\n\n # 更新数据\n @dbclient_decorate\n def post(self):\n args = allParser.postParser.parse_args()\n if args.id == None:\n _t = str(request.get_data(), encoding = \"utf-8\")\n _t = _t.split(\"&\")\n for i in _t:\n _l = i.split(\"=\")\n args[_l[0]] = _l[1]\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR,msg=\"token失效\")\n args.pop('token')\n for i in list(args.keys()):\n if args[i] == None:\n del args[i]\n result = dbclient.update(table,args,{\"id\":args[\"id\"]})\n if result:\n response = make_result(code=Code.SUCCESS)\n else:\n response = make_result(code=Code.ERROR,msg=\"修改失败\")\n return response\n return make_response(jsonify({\"test\":\"Ttest\"}))\n\n \n # 删除数据\n @dbclient_decorate\n def delete(self):\n args = allParser.deleteParser.parse_args()\n verify_result = verify_token(args[\"token\"])\n if not verify_result:\n return make_result(code=Code.ERROR)\n args.pop('token')\n result = dbclient.delete(table,{\"id\":args['id']})\n if result:\n response = make_result(code=Code.SUCCESS)\n else:\n response = make_result(code=Code.ERROR,msg='删除失败')\n return response\n\napi.add_resource(SC, '/',endpoint='SC')\n\n\n"
},
{
"alpha_fraction": 0.7789255976676941,
"alphanum_fraction": 0.7789255976676941,
"avg_line_length": 51.630435943603516,
"blob_id": "079e598befc357587f5f36f64ee5eb984f0119d6",
"content_id": "549b731111748e9c4d59b52f706fa74a3224e29e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2420,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 46,
"path": "/src/veiws/user/parser.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask_restful import reqparse\n\ngetUserParser = reqparse.RequestParser()\ngetUserParser.add_argument('id', type=int, help='please enter id')\ngetUserParser.add_argument('username', type=str, help='please enter username')\ngetUserParser.add_argument('type', type=str, help='please enter type')\ngetUserParser.add_argument('token', type=str, location='headers')\ngetUserParser.add_argument('page', type=int, help='please enter page')\ngetUserParser.add_argument('limit', type=int, help='please enter limit')\n\ndeleteUserParser = reqparse.RequestParser()\ndeleteUserParser.add_argument('id', type=int, help='please enter id', required=True)\ndeleteUserParser.add_argument('token', type=str, location='headers')\n\n\nputUserParser = reqparse.RequestParser()\nputUserParser.add_argument('username', type=str, help='please enter username', required=True)\nputUserParser.add_argument('password', type=str, help='please enter password', required=True)\nputUserParser.add_argument('role', type=str, help='please enter role', required=True)\nputUserParser.add_argument('name', type=str, help='please enter name', required=True)\nputUserParser.add_argument('class', type=str, help='please enter name', required=True)\nputUserParser.add_argument('phone', type=str, help='please enter name', required=True)\n\n\n\npostUserParser = reqparse.RequestParser()\npostUserParser.add_argument('id', type=str, help='please enter id', required=True)\npostUserParser.add_argument('username', type=str, help='please enter username', required=True)\npostUserParser.add_argument('role', type=str, help='please enter role', required=True)\npostUserParser.add_argument('name', type=str, help='please enter name', required=True)\npostUserParser.add_argument('password', type=str, help='please enter password', required=True)\npostUserParser.add_argument('phone', type=str, help='please enter phone', required=True)\npostUserParser.add_argument('token', type=str, location='headers')\n\n\npostLoginParser = reqparse.RequestParser()\npostLoginParser.add_argument('username', type=str, help='please enter username', required=True)\npostLoginParser.add_argument('password', type=str, help='please enter password', required=True)\n\ngetLoginParser = reqparse.RequestParser()\ngetLoginParser.add_argument('token', type=str, location='headers')\n\ngetLoginOutParser = reqparse.RequestParser()\ngetLoginOutParser.add_argument('token', type=str, location='headers')\n\n# args = parser.parse_args()"
},
{
"alpha_fraction": 0.6455696225166321,
"alphanum_fraction": 0.6962025165557861,
"avg_line_length": 15,
"blob_id": "37811084eefe52ad6f3891193fd21f4a7a1e4622",
"content_id": "8116eb21eb2ea22b8fd022eba7023a1849ed6006",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 79,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/app.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from src import creatapp\n\n\napp = creatapp()\napp.run(host='0.0.0.0', debug=True)"
},
{
"alpha_fraction": 0.7113401889801025,
"alphanum_fraction": 0.7113401889801025,
"avg_line_length": 16.727272033691406,
"blob_id": "56123915d5ee6b98015a70446242c1638ee0d3f9",
"content_id": "0469fd71d5f4325f978bd01f366aaefdc1682e1f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 316,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 11,
"path": "/README.md",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "# MSDevelop\npython的flask后台,用于信息系统开发课程\n\n\n### 使用\n\n需要在utils目录下创建一个SQLconfig并且在里面填入你自己的数据库信息。\nSQL_ADDRESS = '' # 数据库ip\nSQL_DATABASE = '' # 数据库名字\nSQL_USERNAME = '' # 数据库账号\nSQL_PASSWORD = '' # 数据库密码"
},
{
"alpha_fraction": 0.6605350971221924,
"alphanum_fraction": 0.6605350971221924,
"avg_line_length": 21.11111068725586,
"blob_id": "1438a524ddac3a0b92afc1cb8588b58e5adf173c",
"content_id": "1680d2d906f8f5c5d35416ab74ba7a206aa9bce6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 27,
"path": "/src/__init__.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom werkzeug.utils import import_string\nfrom utils import mysql\nfrom flask_cors import *\n\n# import utils.mysql as mysql\n\n\nblueprints = [\n 'src.veiws.classRoom:classRoom',\n 'src.veiws.user:user',\n 'src.veiws.class:my_class',\n 'src.veiws.sc:sc',\n 'src.veiws.course:course',\n]\n\ndbclient = mysql.MySqldb()\n\n# __all__ = [dbclient]\ndef creatapp():\n app = Flask(__name__)\n CORS(app, supports_credentials=True)\n app.config['DEBUG'] = True\n for bp_name in blueprints:\n bp = import_string(bp_name)\n app.register_blueprint(bp)\n return app\n\n"
},
{
"alpha_fraction": 0.5413989424705505,
"alphanum_fraction": 0.5430512428283691,
"avg_line_length": 32.219512939453125,
"blob_id": "6d5b3c06957f8ca6048d0be722d8932c15242128",
"content_id": "474c3319887a7f0de6a50cfababdbbfed554d2d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5697,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 164,
"path": "/utils/mysql.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "import pymysql\nfrom .function import create_insert_sql_values, create_update_sql, create_insert_sql_column\nfrom . import SQLConfig\n\n\nclass MySqldb(object):\n def __init__(self):\n self.SQLConfig = SQLConfig\n # self.db = pymysql.connect(SQLConfig.SQL_ADDRESS,SQLConfig.SQL_USERNAME,\\\n # SQLConfig.SQL_PASSWORD,SQLConfig.SQL_DATABASE)\n\n def connect(self):\n self.db = pymysql.connect(self.SQLConfig.SQL_ADDRESS,self.SQLConfig.SQL_USERNAME,\\\n self.SQLConfig.SQL_PASSWORD,self.SQLConfig.SQL_DATABASE)\n # 一共就四个方法,增删改查。\n # 增,也就是insert\n # 增加一共有两个变量,一个是需要增加到哪个表里面去,另一个是数据。\n # 数据必须是一个dict\n def insert(self, table, values):\n if not isinstance(values,dict):\n raise TypeError('values must be dict')\n if not isinstance(table,str):\n raise TypeError('table must be str')\n cursor = self.db.cursor()\n # 创建sql\n sql = \"INSERT INTO %s%s VALUES %s\"%(table,\\\n create_insert_sql_column(values),create_insert_sql_values(values))\n # print(sql)\n try:\n cursor.execute(sql)\n self.db.commit()\n return True\n except Exception as e:\n print(\"reason:{}\".format(e))\n print('insert fail')\n return False\n\n # 删除,变量只有两个\n # 表名, 条件\n def delete(self, table, condition):\n if not isinstance(condition,dict):\n raise TypeError('condition must be dict')\n if not isinstance(table,str):\n raise TypeError('table must be str')\n cursor = self.db.cursor()\n sql = \"DELETE FROM %s WHERE %s = '%s'\" % \\\n (table,list(condition.keys())[0],condition[list(condition.keys())[0]])\n # print(sql)\n try:\n cursor.execute(sql)\n self.db.commit()\n return True\n except Exception as e:\n print(\"reason:{}\".format(e))\n print(\"delete fail\") \n return False\n\n\n # 改\n # 传入参数依次为,表名,需要修改的值, 寻找条件\n def update(self, table, values, condition):\n if not isinstance(condition,dict):\n raise TypeError('condition must be dict')\n if not isinstance(values,dict):\n raise TypeError('values must be dict')\n if not isinstance(table,str):\n raise TypeError('table must be str')\n cursor = self.db.cursor()\n sql = \"UPDATE %s SET %s WHERE %s = '%s'\"%\\\n (table,create_update_sql(values),list(condition.keys())[0],condition[list(condition.keys())[0]])\n try:\n # print(sql)\n cursor.execute(sql)\n self.db.commit()\n return True\n except Exception as e:\n print(\"reason:{}\".format(e))\n print(\"update fail\") \n return False\n\n\n # 全查\n # 传入参数依次:表名\n def list_all(self, table):\n if not isinstance(table,str):\n raise TypeError('table must be str')\n cursor = self.db.cursor()\n # 获取当前表头\n sql = \"select COLUMN_NAME from information_schema.COLUMNS where table_name = '%s'\"%(table)\n cursor.execute(sql)\n table_name = cursor.fetchall()\n table_column = []\n for i in table_name:\n table_column.append(i[0])\n \n sql = \"SELECT * FROM %s\" % (table)\n try:\n cursor.execute(sql)\n table_data = []\n data = cursor.fetchall()\n for i in data:\n table_data.append(dict(zip(table_column,list(i))))\n return table_data\n except Exception as e:\n print(\"reason:{}\".format(e))\n print('get fail')\n return False\n\n\n def list_one(self, table, condition):\n if not isinstance(condition,dict):\n raise TypeError('condition must be dict')\n if not isinstance(table,str):\n raise TypeError('table must be str')\n cursor = self.db.cursor()\n # 获取当前表头\n sql = \"select COLUMN_NAME from information_schema.COLUMNS where table_name = '%s'\"%(table)\n cursor.execute(sql)\n table_name = cursor.fetchall()\n table_column = []\n for i in table_name:\n table_column.append(i[0])\n \n sql = \"SELECT * FROM %s WHERE %s = '%s'\" % (table,\\\n list(condition.keys())[0], condition[list(condition.keys())[0]])\n \n try:\n cursor.execute(sql)\n table_data = []\n data = cursor.fetchall()\n for i in data:\n table_data.append(dict(zip(table_column,list(i))))\n return table_data\n except Exception as e:\n print(\"reason:{}\".format(e))\n print(\"list one fail\")\n return False\n\n\n def list_column(self, table, columns):\n if not isinstance(table,str):\n raise TypeError('table must be str')\n if not isinstance(columns,list):\n raise TypeError('columns must be list')\n cursor = self.db.cursor()\n sql = \"SELECT %s FROM %s\" % (\",\".join(columns),table)\n # print(sql)\n try:\n cursor.execute(sql)\n data = cursor.fetchall()\n columnData = []\n for i in data:\n columnData.append(i[0])\n return columnData\n except Exception as e:\n print(\"reason:{}\".format(e))\n print(\"list column fail\")\n return False\n\n\n\n\n def close(self):\n self.db.close()"
},
{
"alpha_fraction": 0.5407969355583191,
"alphanum_fraction": 0.5939279198646545,
"avg_line_length": 51.75,
"blob_id": "96d42373d6f274aa937b20272eb45052832aec94",
"content_id": "daf668c47d339dc651855acb1bad54f0d0a4d52b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1068,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 20,
"path": "/test.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "#\n# INSERT INTO `ClassTest`.`m_user`(`password`, `username`, `name`, `phone`, `role`, `class`) \n# VALUES ('202cb962ac59075b964b07152d234b70', 'user2', '用户2', '13120184444', 'student', 12)\nfrom random import choice,randint\nuserInedx = 3\nindex2 = 20\nclassIndex = [1,8,9,10,12,13,14,15,16]\nfor i in range(7):\n # print(\"INSERT INTO `ClassTest`.`m_user`(`password`, `username`, `name`, `phone`, `role`, `class`)\" + \n # \"VALUES (\\'202cb962ac59075b964b07152d234b70\\', \\'user%s\\', \\'用户%s\\', \\'13120184444\\', \\'student\\', %s);\"%(\\\n # userInedx,userInedx,choice(classIndex)))\n # print(\"INSERT INTO `ClassTest`.`sc`(`score`, `student`, `course`) VALUES (%s, %s, %s);\"%(\n # randint(70,101),randint(27,45),randint(1,13)))\n print(\"UPDATE `ClassTest`.`m_user` SET `name` = '班主任%s' WHERE `id` = %s;\"%(userInedx,index2))\n userInedx = userInedx + 1\n index2 = index2 + 1\n# sql = \"INSERT INTO %s%s VALUES %s\"%(table,\\\n # create_insert_sql_column(values),create_insert_sql_values(values))\n\n# INSERT INTO `ClassTest`.`sc`(`score`, `student`, `course`) VALUES (88, 1, 1)"
},
{
"alpha_fraction": 0.44999998807907104,
"alphanum_fraction": 0.46875,
"avg_line_length": 15.100000381469727,
"blob_id": "9c60f63a46e47963682840a72b976e3761c51ea7",
"content_id": "b3ecc3ee63dae6cc8672eb847f01768004c3d1e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 10,
"path": "/utils/code.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "class Code:\n SUCCESS = 0\n NO_PARAM = 1\n ERROR =-1\n\n msg = {\n SUCCESS: \"success\",\n NO_PARAM: \"param error\",\n ERROR:\"error\"\n }"
},
{
"alpha_fraction": 0.6804123520851135,
"alphanum_fraction": 0.6804123520851135,
"avg_line_length": 18.600000381469727,
"blob_id": "375c74063c5e0d3fe16ad739502c8eedf19b86ae",
"content_id": "d980549bd777e5583c0c740a1b5bf5ba3b719cde",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 5,
"path": "/src/veiws/sc/__init__.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint\n\nsc = Blueprint('sc', __name__, url_prefix='/sc')\n\nfrom . import veiw"
},
{
"alpha_fraction": 0.755859375,
"alphanum_fraction": 0.755859375,
"avg_line_length": 47.03125,
"blob_id": "9f4ffb56357e0e8f230405b4c188e4499e22e71a",
"content_id": "794cc2b6a77d0b20456ade1ebfc64e113e0bb6b4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1536,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 32,
"path": "/src/veiws/class/parser.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask_restful import reqparse\n\ngetParser = reqparse.RequestParser()\ngetParser.add_argument('name', type=str, help='please enter name')\ngetParser.add_argument('id', type=str, help='please enter id')\ngetParser.add_argument('type', type=str, help='please enter type')\ngetParser.add_argument('page', type=int, help='please enter page')\ngetParser.add_argument('limit', type=int, help='please enter limit')\ngetParser.add_argument('token', type=str, location='headers')\n\n\ndeleteParser = reqparse.RequestParser()\ndeleteParser.add_argument('id', type=int, help='please enter id', required=True)\ndeleteParser.add_argument('token', type=str, location='headers')\n\npostParser = reqparse.RequestParser()\npostParser.add_argument('id', type=str, help='please enter id', required=True)\npostParser.add_argument('name', type=str, help='please enter name')\npostParser.add_argument('header', type=str, help='please enter header')\npostParser.add_argument('token', type=str, location='headers')\n# putParser.add_argument('id',required=True)\n# putParser.add_argument('total')\n# putParser.add_argument('arrived')\n# putParser.add_argument('name')\n# putParser.add_argument('token')\n\nputParser = reqparse.RequestParser()\n# postParser.add_argument('id', type=int, help='please enter id', required=True)\nputParser.add_argument('name', type=str, help='please enter name', required=True)\nputParser.add_argument('header', type=str, help='please enter header', required=True)\nputParser.add_argument('token', type=str, location='headers')\n# args = parser.parse_args()"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 48.24242401123047,
"blob_id": "0b21c3b7316ebebd2f90dae9f2a6a7248c8d1c0d",
"content_id": "72cff924cdaa45107de6662f5c59554dc0b8db37",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1624,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 33,
"path": "/src/veiws/sc/parser.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask_restful import reqparse\n\ngetParser = reqparse.RequestParser()\ngetParser.add_argument('student', type=str, help='please enter student')\ngetParser.add_argument('id', type=str, help='please enter id')\ngetParser.add_argument('type', type=str, help='please enter type')\ngetParser.add_argument('page', type=int, help='please enter page')\ngetParser.add_argument('limit', type=int, help='please enter limit')\ngetParser.add_argument('token', type=str, location='headers')\n\n\ndeleteParser = reqparse.RequestParser()\ndeleteParser.add_argument('id', type=int, help='please enter id', required=True)\ndeleteParser.add_argument('token', type=str, location='headers')\n\npostParser = reqparse.RequestParser()\npostParser.add_argument('id', type=str, help='please enter id', required=True)\npostParser.add_argument('student', type=str, help='please enter student')\npostParser.add_argument('course', type=str, help='please enter course')\npostParser.add_argument('score', type=str, help='please enter score')\npostParser.add_argument('token', type=str, location='headers')\n# putParser.add_argument('id',required=True)\n# putParser.add_argument('total')\n# putParser.add_argument('arrived')\n# putParser.add_argument('name')\n# putParser.add_argument('token')\n\nputParser = reqparse.RequestParser()\n# postParser.add_argument('id', type=int, help='please enter id', required=True)\nputParser.add_argument('student', type=str, help='please enter student', required=True)\nputParser.add_argument('course', type=str, help='please enter course', required=True)\nputParser.add_argument('token', type=str, location='headers')\n# args = parser.parse_args()"
},
{
"alpha_fraction": 0.5656370520591736,
"alphanum_fraction": 0.5689464807510376,
"avg_line_length": 26.477272033691406,
"blob_id": "659bc94dabef351228a5c9abedd08162e03f94e9",
"content_id": "2d7012ff21bf6f129fbc8d6a40c5a0ba8f1f98d5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3790,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 132,
"path": "/utils/function.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from .code import Code\nfrom flask import jsonify, make_response\nimport string\nimport random\nimport src\nimport time\nimport hashlib\n\n\n# 公用的function\ndef create_insert_sql_values(values):\n result = \"(\"\n # result += \",\".join([ str(values[i]) for i in values])\n first = True\n for i in values:\n if first:\n first = False\n if isinstance(values[i],str):\n result += \"'\" + str(values[i]) + \"'\"\n else:\n result += str(values[i])\n else:\n if isinstance(values[i],str):\n result += \",'\" + str(values[i]) + \"'\"\n else:\n result += \",\" + str(values[i])\n result += \")\"\n return result\n\n\ndef create_insert_sql_column(values):\n result = \"(\"\n # result += \",\".join([ str(values[i]) for i in values])\n first = True\n for i in values:\n if first:\n first = False\n result += str(i)\n else:\n result += \",\" + str(i)\n result += \")\"\n return result\n\n\ndef create_update_sql(values):\n result = ''\n first = True\n for i in values:\n if first:\n first = False\n result += str(i) + \" = '%s'\"%(values[i])\n else:\n result += \",\" + str(i) + \" = '%s'\"%(values[i]) \n return result\n\n\n'''\ndata: 返回的数据\ncode:返回的状态码\nmsg:返回的消息\ncount:分页时用到的数据\n'''\ndef make_result(data=None, code=Code.SUCCESS, msg=\"成功\",count=None):\n # if not isinstance(data,dict) and data != None:\n # raise TypeError('data must be dict')\n if not isinstance(msg,str) and data != None:\n raise TypeError('msg must be str')\n if count:\n jsonData = jsonify({\"code\": code, \"data\": data, \"msg\": msg, \"count\":count})\n else:\n jsonData = jsonify({\"code\": code, \"data\": data, \"msg\": msg})\n response = make_response(jsonData)\n # response.headers['Access-Control-Allow-Origin'] = '*'\n response.headers['Access-Control-Allow-Methods'] = 'OPTIONS,HEAD,GET,POST'\n response.headers['Access-Control-Allow-Headers'] = 'x-requested-with'\n response.headers['Content-Type'] = 'application/json' \n return response\n\n\ndef make_token():\n result = {}\n result['token'] = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(10))\n return result\n\n# 验证token\ndef verify_token(token):\n if token == \"ASDFGHJKL\":\n return True\n m_result = src.dbclient.list_one('m_user',{\"token\":token})\n if m_result:\n m_result = m_result[0]\n current_time = int(time.time())\n token_end_time = int(time.mktime(time.strptime(str(m_result['endtime']), \"%Y-%m-%d %H:%M:%S\")))\n # print(current_time,token_end_time)\n # 此处报错\n differ = current_time - token_end_time\n if 0 < differ and differ < 7200:\n return True \n else:\n return False\n else:\n return False\n\n\n# md5加密\ndef encode_password(password):\n hl = hashlib.md5()\n # 此处必须声明encode\n # 若写法为hl.update(str) 报错为: Unicode-objects must be encoded before hashing\n hl.update(password.encode())\n return hl.hexdigest()\n\n\n# 用于分页\n# data->数据\n# page->第几页\n# limit->页的大小\ndef pagenation(data,page,limit):\n # split = lambda a:map(lambda b:a[b:b+int(limit)],range(0,len(a),int(limit)))\n data = [data[i:i+int(limit)] for i in range(0,len(data),int(limit))]\n # data = split(data)\n return data[page]\n # print(data[page])\n\n# 自动连接以及关闭数据库的装饰器\ndef dbclient_decorate(func):\n def inner(*args,**kwargs):\n src.dbclient.connect()\n result = func(*args,**kwargs)\n src.dbclient.close()\n return result\n return inner"
},
{
"alpha_fraction": 0.7571351528167725,
"alphanum_fraction": 0.7571351528167725,
"avg_line_length": 49.216217041015625,
"blob_id": "acb5ca7c7eb54ffe3c81d30307799c8f0834c399",
"content_id": "7447bff19968d3f02df6d3109b901bf691fd5a0e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1857,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 37,
"path": "/src/veiws/classRoom/parser.py",
"repo_name": "FrostyBonny/MSDevoDevelop",
"src_encoding": "UTF-8",
"text": "from flask_restful import reqparse\n\ngetParser = reqparse.RequestParser()\ngetParser.add_argument('name', type=str, help='please enter name')\ngetParser.add_argument('type', type=str, help='please enter type')\ngetParser.add_argument('page', type=int, help='please enter page')\ngetParser.add_argument('limit', type=int, help='please enter limit')\ngetParser.add_argument('token', type=str, location='headers')\n\n\ndeleteParser = reqparse.RequestParser()\ndeleteParser.add_argument('id', type=int, help='please enter id', required=True)\ndeleteParser.add_argument('token', type=str, location='headers')\n\npostParser = reqparse.RequestParser()\n# putParser =\npostParser.add_argument('id', type=str, help='please enter id', required=True)\npostParser.add_argument('name', type=str, help='please enter name')\npostParser.add_argument('arrived', type=str, help='please enter arrived')\npostParser.add_argument('arriveNum', type=int, help='please enter arriveNum')\npostParser.add_argument('total', type=int, help='please enter total')\npostParser.add_argument('col', type=int, help='please enter col')\npostParser.add_argument('row', type=int, help='please enter row')\npostParser.add_argument('token', type=str, location='headers')\n# putParser.add_argument('id',required=True)\n# putParser.add_argument('total')\n# putParser.add_argument('arrived')\n# putParser.add_argument('name')\n# putParser.add_argument('token')\n\nputParser = reqparse.RequestParser()\n# postParser.add_argument('id', type=int, help='please enter id', required=True)\nputParser.add_argument('name', type=str, help='please enter name', required=True)\nputParser.add_argument('total', type=int, help='please enter total', required=True)\nputParser.add_argument('arriveNum', type=int, help='please enter arrived', required=True)\nputParser.add_argument('token', type=str, location='headers')\n# args = parser.parse_args()"
}
] | 18 |
itmo-wad/HW4-Appiah_Prince | https://github.com/itmo-wad/HW4-Appiah_Prince | 8cdea03a08da1250b5d5871e585ea2f7d133a44e | 9140eac54fadac6d89ddc292fd34994e42468d3d | e374525a27ccb836ae2e0a0370c630289ed64d95 | refs/heads/master | 2023-04-11T09:21:00.652365 | 2021-04-29T05:48:11 | 2021-04-29T05:48:11 | 362,702,953 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6201404929161072,
"alphanum_fraction": 0.6262295246124268,
"avg_line_length": 26.824323654174805,
"blob_id": "b78020b5c8a329425e0ce6f8b7ed88e684e6ae74",
"content_id": "3ad06a336088660bdf426e9cc29319ed0e105625",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2135,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 74,
"path": "/appdb.py",
"repo_name": "itmo-wad/HW4-Appiah_Prince",
"src_encoding": "UTF-8",
"text": "from flask import flash, redirect,url_for,Flask, send_from_directory, render_template, request\r\nfrom flask_login import login_required, logout_user,login_user, LoginManager, UserMixin\r\nimport random \r\nfrom flask_pymongo import PyMongo\r\n\r\napp = Flask(__name__)\r\napp.secret_key = b'mylittlsecretewrwegiweug093gewjgjoiew'\r\nlogin_manager = LoginManager()\r\nlogin_manager.init_app(app)\r\nfrom pymongo import MongoClient\r\n\r\nclient = MongoClient('localhost', 27017)\r\ndb = client.users\r\n\r\n\r\nclass User(UserMixin):\r\n def __init__(self, username, password):\r\n self.id = random.randint(1,1000)\r\n self.password = password\r\n self.username = username\r\n\r\n def is_active(self):\r\n return True\r\n \r\n\r\n def get_id(self):\r\n return self.username\r\n\r\ncurrent_users = {\r\n}\r\nactivated_users = {}\r\n@app.route('/', methods=['GET', 'POST'])\r\ndef index():\r\n if request.method == 'POST':\r\n username = request.form.get('username')\r\n password = request.form.get('password')\r\n user = db.my_users.find_one({\"username\": username})\r\n if user and password == user['password']:\r\n user = User(username,password)\r\n login_user(user)\r\n activated_users[username] = user\r\n return redirect(url_for('cabinet'))\r\n else:\r\n flash('Invalid username or password')\r\n return render_template('index.html', title='My Image Gallery')\r\n if request.method == 'GET':\r\n return render_template('index.html', title='My Image Gallery')\r\n \r\n\r\n@login_manager.user_loader\r\ndef load_user(username):\r\n return activated_users.get(username)\r\n\r\n@app.route('/cabinet')\r\n@login_required\r\ndef cabinet():\r\n return render_template('cabinet.html')\r\n \r\n \r\n\r\n\r\n@app.route('/img/<path:path>')\r\ndef send_img(path):\r\n return send_from_directory('img', path)\r\n@app.route('/static/css/<path:path>')\r\ndef send_css(path):\r\n return send_from_directory('css', path)\r\n@app.route('/static/js/<path:path>')\r\ndef send_js(path):\r\n return send_from_directory('js', path)\r\n \r\n \r\nif __name__ == \"__main__\":\r\n app.run(debug=True)\r\n\r\n"
},
{
"alpha_fraction": 0.6849315166473389,
"alphanum_fraction": 0.767123281955719,
"avg_line_length": 17.25,
"blob_id": "02f58291a0318cf018a9c0529f38a1e8121fa48d",
"content_id": "f7ac8c6ce6aea259d916dd789a370738c1c43f21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 4,
"path": "/README.md",
"repo_name": "itmo-wad/HW4-Appiah_Prince",
"src_encoding": "UTF-8",
"text": "# HW4-Appiah_Prince\n# Group: N41503c\n\n# Database Connection with MongoDB\n"
}
] | 2 |
Jomen034/etl-cloud-batch-processing | https://github.com/Jomen034/etl-cloud-batch-processing | 44ffa43f7f8132aa25dcac6c2fd4c4d1a6cf6a05 | 450cc5c4dbae4ca41378d2b74d6ed7ba5f59f143 | 1090e551968ff48575da1e9c27c3ad9df7df6c5f | refs/heads/master | 2023-04-13T23:05:04.623860 | 2021-05-08T07:30:34 | 2021-05-08T07:30:34 | 361,437,168 | 1 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6271480917930603,
"alphanum_fraction": 0.6333268880844116,
"avg_line_length": 49.7843132019043,
"blob_id": "264afc79345018ee032c9cd6c6aead9280a114ce",
"content_id": "56857268c1d3a5553cd57dbbd32b7f2ab912204d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5179,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 102,
"path": "/dags/transaction_data.py",
"repo_name": "Jomen034/etl-cloud-batch-processing",
"src_encoding": "UTF-8",
"text": "from datetime import datetime, timedelta\n\nfrom airflow import models\nfrom airflow.contrib.operators.bigquery_operator import BigQueryOperator\nfrom airflow.operators.python_operator import PythonOperator\nimport numpy as np\nfrom google.cloud import bigquery\nfrom google.oauth2 import service_account\n\nproject_id = models.Variable.get(\"project_id\")\ndata_source_project_id = models.Variable.get(\"data_source_project_id\")\ncredentials_path = models.Variable.get(\"credentials_path\")\nbucket_path = models.Variable.get(\"bucket_path\")\n\ncredentials_source = service_account.Credentials.from_service_account_file(credentials_path+\"data_source_project.json\")\nclient_source = bigquery.Client(credentials= credentials_source,project=data_source_project_id)\n\n\ndef pull_from_bq(**kwargs):\n sql = f\"\"\"SELECT * FROM pkl-playing-fields.unified_events.event WHERE event_name = 'purchase_item'\n AND DATE(event_datetime) between '{kwargs.get('ds')}' and DATE_ADD('{kwargs.get('ds')}', INTERVAL 2 DAY)\"\"\"\n event_table = client_source.query(sql).result().to_dataframe()\n event_table['transaction_id'], event_table['transaction_detail_id'], event_table['transaction_number'] = '', '', ''\n event_table['purchase_quantity'], event_table['purchase_amount'], event_table['purchase_payment_method'] = '', '', ''\n event_table['purchase_source'], event_table['product_id'] = '', ''\n for i in range(len(event_table)):\n try:\n if len(event_table['event_params'][i]) == 21:\n event_table['transaction_id'][i] = event_table['event_params'][i][0]\n event_table['transaction_detail_id'][i] = event_table['event_params'][i][1]\n event_table['transaction_number'][i] = event_table['event_params'][i][2]\n event_table['purchase_quantity'][i] = event_table['event_params'][i][3]\n event_table['purchase_amount'][i] = event_table['event_params'][i][4]\n event_table['purchase_payment_method'][i] = event_table['event_params'][i][5]\n event_table['purchase_source'][i] = event_table['event_params'][i][6]\n event_table['product_id'][i] = event_table['event_params'][i][7]\n else:\n event_table['transaction_id'][i] = np.NaN\n event_table['transaction_detail_id'][i] = np.NaN\n event_table['transaction_number'][i] = event_table['event_params'][i][0]\n event_table['purchase_quantity'][i] = np.NaN\n event_table['purchase_amount'][i] = np.NaN\n event_table['purchase_payment_method'][i] = np.NaN\n event_table['purchase_source'][i] = np.NaN\n event_table['product_id'][i] = event_table['event_params'][i][1]\n except ValueError:\n pass\n event_table = event_table.drop('event_params', axis=1)\n job_config = bigquery.LoadJobConfig(write_disposition=\"WRITE_TRUNCATE\")\n table_id = project_id + \".transactions.raw\"\n credentials_my = service_account.Credentials.from_service_account_file(credentials_path+\"my_project.json\")\n client_target = bigquery.Client(credentials=credentials_my, project=project_id)\n client_target.load_table_from_dataframe(event_table, table_id, job_config=job_config)\n\nsql_store = \"\"\" SELECT transaction_id.value.int_value `transaction_id`,\n transaction_detail_id.value.int_value `transaction_detail_id`,\n transaction_number.value.string_value `transaction_number`,\n event_datetime `transaction_datetime`,\n purchase_quantity.value.int_value `purchase_quantity`,\n purchase_amount.value.float_value `purchase_amount`,\n purchase_payment_method.value.string_value `purchase_payment_method`,\n purchase_source.value.string_value `purchase_source`,\n product_id.value.int_value `product_id`,\n user_id, state, city, created_at, '{{ ds }}' `ext_created_at`\n FROM `academi-cloud-etl.transactions.raw`\n WHERE DATE(event_datetime) BETWEEN '{{ ds }}' AND DATE_ADD('{{ ds }}', INTERVAL 2 DAY)\"\"\"\n\ndefault_args = {\n \"start_date\": datetime(2021,3,21),\n \"end_date\": datetime(2021,3,27),\n \"depends_on_past\": True,\n \"dataflow_default_options\": {\n \"project\": project_id,\n \"temp_location\": bucket_path + \"/tmp/\",\n \"numWorkers\": 1,\n },\n}\n\n\nwith models.DAG(\n # The id you will see in the DAG airflow page\n \"transactions_table_dag\",\n default_args=default_args,\n # The interval with which to schedule the DAG\n schedule_interval=timedelta(days=3), # Override to match your needs\n) as dag:\n\n preprocessed = PythonOperator(\n task_id='storing_preprocessed_data',\n python_callable=pull_from_bq,\n provide_context=True\n )\n\n store = BigQueryOperator(\n task_id='storing_final_table',\n sql=sql_store,\n write_disposition='WRITE_APPEND',\n destination_dataset_table=project_id + \":transactions.transactions_table\",\n use_legacy_sql=False,\n )\n\n preprocessed >> store"
},
{
"alpha_fraction": 0.7005826234817505,
"alphanum_fraction": 0.7711194157600403,
"avg_line_length": 47.53535461425781,
"blob_id": "cbb74bd237ed5c1746e9f54436b0801acefc279f",
"content_id": "359b3a24d16fe7883f4b54cbfaad3f1f1504439c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4808,
"license_type": "no_license",
"max_line_length": 413,
"num_lines": 99,
"path": "/README.md",
"repo_name": "Jomen034/etl-cloud-batch-processing",
"src_encoding": "UTF-8",
"text": "# ETL Cloud and Batch Processing Case\n\n## Overview\nTech companies used to require having their own on-premise servers to operate ETLs on their data. Of course, numerous companies would have to face issues on scalability, data loss, hardware failure, etc. With the appearance of cloud services offered by major tech companies, this was changed, as they provided shared-computing resources on the cloud which is able to solve most issues found on on-premise servers.\nThis repo is to set up a Google Cloud Composer environment and solve several batch-processing cases by creating DAGs to run ETL jobs in the cloud. The data processing consists of ETLs with data going in and from GCS and BigQuery\n\n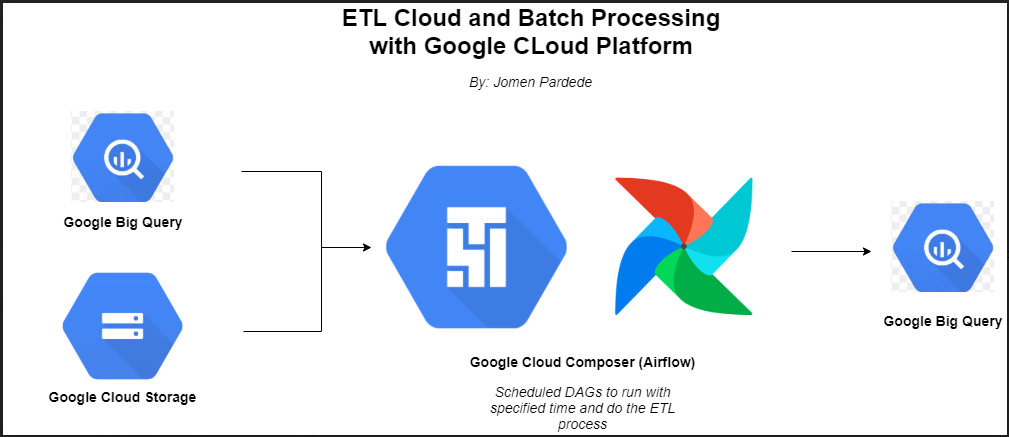\n\n\n## ETL Cloud\nCloud ETL entails extracting data from diverse source systems, transforming it to a common format, and loading the consolidated data into the data warehouse platform to best serve the needs of enterprise business intelligence, reporting and analytics.\n\n## Batch Processing\nBatch processing is a method of running high-volume, repetitive data jobs. The batch method allows users to process data when computing resources are available, and with little or no user interaction.\n\n# Installation\n\n## GCP Setup\nIf you don't have GCP acoount yet, create one with the free trial from [Google Cloud Platform](https://cloud.google.com/composer). After you have acces to your GCP, let's do some following setup:\n1. **Service Account**\n * go to `IAM & Admin`\n * choose `Service Accounts`, and create your service account.\n\n2. **Environment Set Up**\n * go to `Composer`\n * enable the `Cloud Composer API`\n * create your environment. I used this set up for this task\n\n```\nLocation : us-central1\nZone : us-central1-f\nNode count : 3\nDisk size (GB) : 20\nMachine type : n1-standard-1\nCloud SQL machine type : db-n1-standard-2 (2 vCPU, 7.5 GB memory)\nWeb server machine type : composer-n1-webserver-2 (2 vCPU, 1.6 GB memory)\n```\n\n3. **Create Bucket**\n * go to `Cloud Storage`\n * create your bucket\n\n4. **Variable Set Up**\n * go to `composer`\n * click your env\n * go to `Environment Variables` and set up your variables\n\n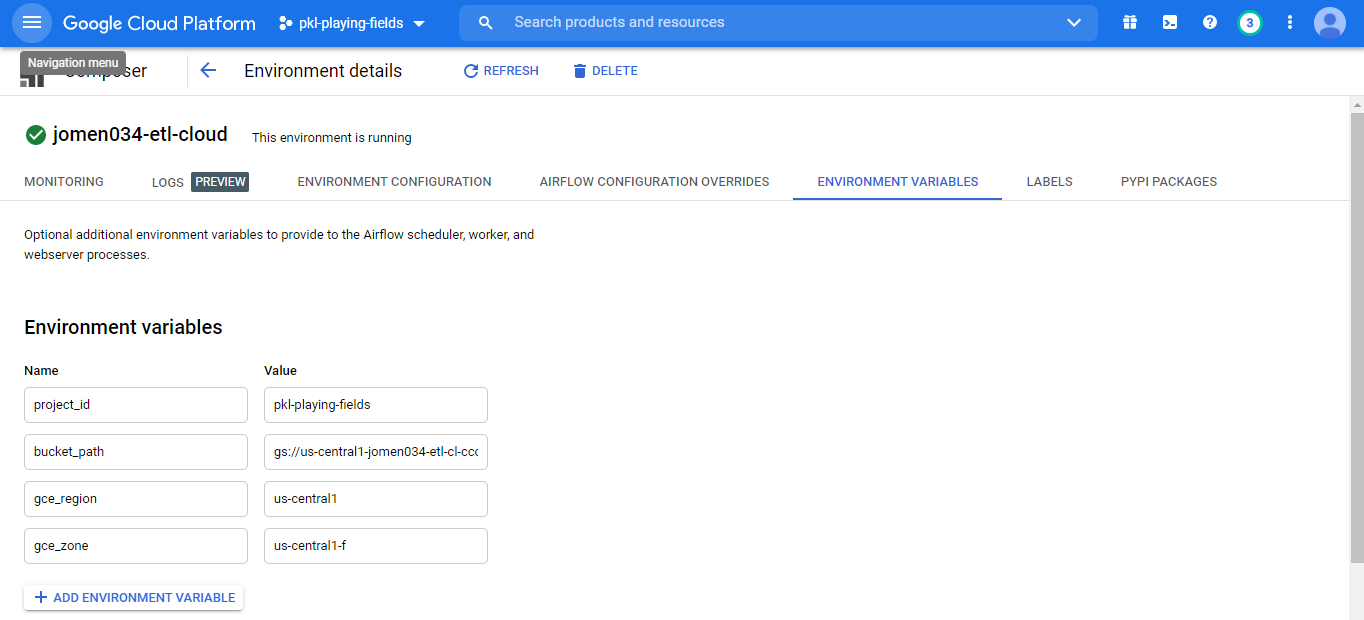\n\n\n## Google Composer Airflow\nOpen the `Airflow Web UI` by clicking `Airflow` section on your list of environments\n\n\n\n**Define Airflow Variables**\n\n\n**Define Airflow COnnections**\n\n\n\n## Writing DAGs\nWhen creating your DAGs, make sure you do this 5 actions:\n1. Import module\n2. Define the `default_args`\n3. Instantiate DAG\n4. Define your task\n5. Define the dependencies\n\n## ETL Cloud & Batch Processing Case\n**Integrate daily search history**\n\n*Case : A website has been keeping track of their user’s search history. They process their data day-by-day and upload it into a GCS bucket.*\n\n1. Run Dataflow job on CSV into a Bigquery table. Make the BQ schema the same as the csv.\n2. Create another Bigquery table that reports the most searched keyword for each day. Schema is up to you as long as it solves the task.\n3. The DAG is scheduled to run day-by-day for each csv.\n\nLoad the `daily_search_history.py` to the `dags` folder on the bucket object. After loading the file, the Airflow Web UI will be update\n\n\n\n## Result\nIf all is clear, the Airflow Web UI will show following information\n\n\n\n**All the scheduler task are done**\n\nIn the Google Cloud Big Query, the result is\n\n\n\n# Conclusion\n* ETL in traditional way was made use of physical warehouses to store the integrated data from various sources. \n* **With Cloud ETL, both, the sources from where companies bring in the data and the destination data warehouses are purely online.** \n* There is no physical data warehouse or any other hardware that a business needs to maintain. \n* **Cloud ETL** manages these dataflows with the help of robust Cloud ETL Tools that **allows users to create and monitor automated ETL data pipelines, also allowing users to use diverse data for analysis all through a single user interface.** \n"
},
{
"alpha_fraction": 0.6129779815673828,
"alphanum_fraction": 0.6216685771942139,
"avg_line_length": 36.129032135009766,
"blob_id": "5474f6addb0bbf5b5b4cdef383275b2d36bd19f2",
"content_id": "7a8d929be645c46f659d4689883c43b356736081",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3452,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 93,
"path": "/dags/daily_search_history.py",
"repo_name": "Jomen034/etl-cloud-batch-processing",
"src_encoding": "UTF-8",
"text": "\"\"\"A liveness prober dag for monitoring composer.googleapis.com/environment/healthy.\"\"\"\nimport airflow\nfrom airflow import DAG, models\nfrom datetime import timedelta, datetime\nfrom airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator\nfrom airflow.contrib.operators.bigquery_operator import BigQueryOperator\n\n\nbucket_path = models.Variable.get(\"bucket_path\")\nproject_id = models.Variable.get(\"project_id\")\n\n\ndefault_args = {\n # Tell airflow to start one day ago, so that it runs as soon as you upload it\n \"start_date\": datetime(2021,3,10),\n \"end_date\": datetime(2021,3,15),\n \"depends_on_past\": True,\n \"dataflow_default_options\": {\n \"project\": project_id,\n # This is a subfolder for storing temporary files, like the staged pipeline job.\n \"temp_location\": bucket_path + \"/tmp/\",\n \"numWorkers\": 1,\n },\n}\n\n# Define a DAG (directed acyclic graph) of tasks.\n# Any task you create within the context manager is automatically added to the\n# DAG object.\nwith models.DAG(\n # The id you will see in the DAG airflow page\n \"dailiy_search_history\",\n default_args=default_args,\n # The interval with which to schedule the DAG\n schedule_interval= \"00 21 * * *\", # Override to match your needs\n) as dag:\n\n store_to_bq = GoogleCloudStorageToBigQueryOperator(\n task_id=\"gcs_to_bq\",\n bucket='week_2_bs',\n source_objects= [\"keyword_search/search_{{ ds_nodash }}.csv\"],\n destination_project_dataset_table= \"daily_search_history.daily_search_keyword_history\",\n source_format=\"csv\",\n skip_leading_rows=1,\n schema_fields=[\n {'name': 'user_id', 'type': 'STRING', 'mode': 'REQUIRED'},\n {'name': 'search_keyword', 'type': 'STRING', 'mode': 'REQUIRED'},\n {'name': 'search_result_count', 'type': 'STRING', 'mode': 'REQUIRED'},\n {'name': 'created_at', 'type': 'STRING', 'mode': 'REQUIRED'},\n ],\n write_disposition=\"WRITE_TRUNCATE\",\n wait_for_downstream=True,\n depends_on_past=True\n )\n\n convert_data_type = BigQueryOperator(\n task_id='collect_n_update_data',\n sql = \"\"\"\n SELECT \n SAFE_CAST(user_id AS INT64 ) user_id,\n search_keyword,\n SAFE_CAST(search_result_count AS INT64 ) search_result_count,\n created_at\n FROM \n `pkl-playing-fields.daily_search_history.daily_search_keyword_history`\n \"\"\",\n write_disposition='WRITE_APPEND',\n destination_dataset_table=project_id + \":daily_search_history.daily_search_results\",\n use_legacy_sql=False,\n dag =dag\n )\n\n get_most_searched_keyword = BigQueryOperator(\n task_id='most_searched_keywords',\n sql = \"\"\"\n SELECT \n user_id, \n search_keyword, \n search_result_count, \n SAFE_CAST(LEFT(created_at, 10) AS DATE) AS `created_date` \n FROM \n `pkl-playing-fields.daily_search_history.daily_search_results` \n WHERE \n SAFE_CAST(LEFT(created_at, 10) AS DATE) = '{{ ds }}'\n ORDER BY search_result_count DESC\n LIMIT 1\n \"\"\",\n write_disposition='WRITE_APPEND',\n destination_dataset_table=project_id + \":daily_search_history.most_search_keyword_history\",\n use_legacy_sql=False,\n dag = dag\n )\n\n store_to_bq >> convert_data_type >> get_most_searched_keyword"
}
] | 3 |
yiyue-zhang/30DayCodingChallenge-Hackerrank | https://github.com/yiyue-zhang/30DayCodingChallenge-Hackerrank | d8422e2a3209e296e2be6d2a15140f9dd38ed1cf | 5659c19e4b0161a12aafe77a0b1b4fe9fb2d2d92 | 5690b184579b1a5257379569d68895decd72958a | refs/heads/main | 2023-06-14T01:23:47.632367 | 2021-07-02T14:44:49 | 2021-07-02T14:44:49 | 372,006,224 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5651214122772217,
"alphanum_fraction": 0.5916115045547485,
"avg_line_length": 18.68181800842285,
"blob_id": "d0ee5544eaeb3b0ceeab0fba1cf39351df1c258e",
"content_id": "5f298dfc0ca74dcfe0342323c2cf7ac564aef45e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 22,
"path": "/Day 8 Dictionaries and maps solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Jun 9 13:53:07 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nn = int(input(\"Enter the number of pairs\"))\r\n\r\nt = []\r\nfor i in range(n):\r\n a = str(input(\"Enter the name of the contact\"))\r\n b = int(input(\"Enter their phone number\"))\r\n t.append((a, b))\r\nprint(t)\r\n \r\nphoneBook = {}\r\nphoneBook.update(t)\r\nprint(phoneBook)\r\n\r\nfor i in range(n):\r\n print(phoneBook.get(str(input(\"Enter the name you want to access\"))))"
},
{
"alpha_fraction": 0.47803616523742676,
"alphanum_fraction": 0.4806201457977295,
"avg_line_length": 19.61111068725586,
"blob_id": "3cd47fdb85d8e3de1418fb26127f2d60bc893121",
"content_id": "1905875ad8b7d9ce16d6a1856b9639361160e874",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 18,
"path": "/Day 24 More linked list solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nSpyder Editor\r\n\r\nThis is a temporary script file.\r\n\"\"\"\r\n\r\ndef removeDuplicates(self,head):\r\n node = head\r\n while node:\r\n if node.next:\r\n if node.data == node.next.data:\r\n node.next = node.next.next\r\n else:\r\n node = node.next\r\n else:\r\n node = node.next\r\n return head"
},
{
"alpha_fraction": 0.4911660850048065,
"alphanum_fraction": 0.554770290851593,
"avg_line_length": 21.25,
"blob_id": "5d6cfb5e3c8e3a93404b59323c3542eb9d85126e",
"content_id": "a4ee257d84ba506d9a284f01c689b0d6d29ed760",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 283,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 12,
"path": "/Day 5 Loops solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jun 3 13:18:30 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nn = int(input(\"Enter an interger that is bigger than or equal to 2 and smaller than or equal to 20\"))\r\n\r\nfor i in range(1, 11):\r\n results = n * i\r\n print(n, \" x \", i, \" = \", results)\r\n "
},
{
"alpha_fraction": 0.6173184514045715,
"alphanum_fraction": 0.6620111465454102,
"avg_line_length": 25.69230842590332,
"blob_id": "b100428ad51e0fb6702daac779863020d362d888",
"content_id": "7cac8aa49486f09a3ecac20a967bc8779b99d0a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 13,
"path": "/Day 22 Binary search trees solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jul 1 17:35:25 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\n# I did not write those codes because I did not understand binary\r\n\r\ndef getHeight(self,root):\r\n leftH = self.getHeight(root.left) if root.left else -1\r\n rightH = self.getHeight(root.right) if root.right else -1\r\n return leftH+1 if leftH > rightH else rightH+1"
},
{
"alpha_fraction": 0.5174418687820435,
"alphanum_fraction": 0.5784883499145508,
"avg_line_length": 19.625,
"blob_id": "367b722b4aec9eb43d6838c455b381152bc83613",
"content_id": "262c1d1c879cdf1bebe9998ce709a4db3c7d8c5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 16,
"path": "/Day 6 Lets review solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jun 4 10:57:20 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nt = int(input(\"Please enter the number of test case\"))\r\n\r\nl = []\r\nfor i in range(t):\r\n l.append(str(input(\"Please enter a string that is less than 10000 letters but more than 2 letters\")))\r\n\r\nfor i in range(t):\r\n s = l[i]\r\n print(s[::2], s[1::2])"
},
{
"alpha_fraction": 0.4440227746963501,
"alphanum_fraction": 0.4762808382511139,
"avg_line_length": 19.040000915527344,
"blob_id": "06efab48e7543a348bae53ee592f460865e318f7",
"content_id": "101fb6d9a7739fa843fdddd256bed60f778709b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 25,
"path": "/Day 17 More exceptions solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jun 24 10:44:10 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nclass myCalculator:\r\n def power(self,n,p):\r\n if n < 0 or p < 0:\r\n raise ValueError(\"n and p should be non-negative\")\r\n elif p == 0:\r\n return 1\r\n else:\r\n pp = pow(n, p)\r\n return pp\r\n\r\nT=int(input())\r\nfor i in range(T):\r\n n,p = map(int, input().split())\r\n try:\r\n ans=myCalculator.power(n,p)\r\n print(ans)\r\n except Exception as e:\r\n print(e) "
},
{
"alpha_fraction": 0.5156695246696472,
"alphanum_fraction": 0.5811966061592102,
"avg_line_length": 18.764705657958984,
"blob_id": "e46d9dfd8928f5370e6e20d03abb1d835953095c",
"content_id": "66904f2a0b705fcf2688b6dfb03e2492c3b02299",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 17,
"path": "/Day 3 Intro to conditional statements solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jun 1 15:06:35 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nn = int(input('Enter an interger that is bigger than or equal to 1 but smaller than or equal to 100'))\r\n\r\nif n % 2 != 0:\r\n print(\"Weird\")\r\nelif n in range(2,6):\r\n print(\"Not weird\")\r\nelif n in range(6,21):\r\n print(\"Weird\")\r\nelse:\r\n print(\"Not weird\")"
},
{
"alpha_fraction": 0.4241379201412201,
"alphanum_fraction": 0.44712644815444946,
"avg_line_length": 19.774999618530273,
"blob_id": "cc4d22b77b2f951f211d3c4118dacfda963cce79",
"content_id": "ccff73a2747f164db9ad656b5a4a898936cf6235",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 40,
"path": "/Day 29 Bitwise and solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jul 2 10:43:55 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nimport sys\r\n\r\n\r\nt = int(input().strip())\r\nfor a0 in range(t):\r\n n,k = input().strip().split(' ')\r\n n,k = [int(n),int(k)]\r\n\r\n # Check k\r\n # Start iterating at beginning\r\n max_and = 0\r\n starting_point = n\r\n i = starting_point\r\n largest_possible = k - 1\r\n max_reached = False\r\n while i > 1:\r\n j = i - 1\r\n while j > 0:\r\n iteration_and = j & i\r\n print(\"{} {} {}\".format(i, j, iteration_and))\r\n\r\n if iteration_and > max_and and iteration_and < k: \r\n max_and = iteration_and\r\n if max_and == largest_possible: \r\n max_reached = True\r\n break\r\n\r\n j -= 1\r\n\r\n if max_reached:\r\n break\r\n i -= 1\r\n print(max_and) "
},
{
"alpha_fraction": 0.46451613306999207,
"alphanum_fraction": 0.5612903237342834,
"avg_line_length": 12.272727012634277,
"blob_id": "10d182dc40f879efb93c2c9098fde0558c2233a6",
"content_id": "614e06dc5e416beb6a286114aa5e740145bc2baa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 11,
"path": "/Day 0 Hello world solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sat May 29 11:19:33 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\na = \"Welcome to 30 Day of Code\"\r\n\r\nprint(\"Hello, World\")\r\nprint(a)"
},
{
"alpha_fraction": 0.4519999921321869,
"alphanum_fraction": 0.515999972820282,
"avg_line_length": 13.75,
"blob_id": "d1dc1432875e12a5bfd24925d990127ec77d0a07",
"content_id": "e73a5ff4e94a22ad53f3151ae10b4ac8008bb86d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 16,
"path": "/Day 9 Recursion solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jun 10 13:14:30 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\n\r\ndef factorial(x):\r\n if x == 1:\r\n return 1\r\n else:\r\n return(x * factorial(x - 1))\r\n\r\nN = int(input(\"Enter an integer\"))\r\nprint(factorial(N))"
},
{
"alpha_fraction": 0.5512820482254028,
"alphanum_fraction": 0.6282051205635071,
"avg_line_length": 17.75,
"blob_id": "ea5ef7434200c0f32a4e22258acb153eb54ba1e5",
"content_id": "4e2c933d0872dafef83c44f29a3452b3d1f2b777",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 8,
"path": "/Day 21 Generics solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jul 1 16:56:38 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\n# Unable to do this challenge because it is not supported in Python"
},
{
"alpha_fraction": 0.5372670888900757,
"alphanum_fraction": 0.5869565010070801,
"avg_line_length": 19.46666717529297,
"blob_id": "43043a4a83e77a2fa72fabdf850c7445ea7788d2",
"content_id": "7fc858b9c26b8f7df0f8f1237bd8369577a8a369",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 15,
"path": "/Day 1 Data type solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon May 31 15:07:26 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\ni = input('Enter an integer')\r\nd = input('Enter a double d')\r\ns = input('Enter a string s')\r\nsum_i = int(i) + 4\r\nsum_s = float(d) + 4.0\r\nprint(sum_i)\r\nprint(sum_s)\r\nprint(str(s) + \" is the best place to learn and practice coding!\")\r\n"
},
{
"alpha_fraction": 0.5370370149612427,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 16.700000762939453,
"blob_id": "b866cfeedb9328cb070059ac31d80e91d47560c7",
"content_id": "c4939f563ce58043ac1fd1547edb325728d66285",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 20,
"path": "/Day 28 RegEx patterns and intro to database solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jul 2 10:42:57 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nimport sys, re\r\n\r\nnames = []\r\npattern = re.compile('@gmail.com$')\r\n\r\nN = int(input().strip())\r\nfor a0 in range(N):\r\n firstName,emailID = input().strip().split(' ')\r\n if pattern.search(emailID):\r\n names.append(firstName)\r\nnames.sort()\r\nfor name in names:\r\n print(name)\r\n "
},
{
"alpha_fraction": 0.473347544670105,
"alphanum_fraction": 0.5245202779769897,
"avg_line_length": 19.409090042114258,
"blob_id": "db26e6913fa3505e2da4872fb88bfea279da1612",
"content_id": "7e0392b159f9b671e2d22342a39d4adab6591fbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 22,
"path": "/Day 20 Sorting solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jun 25 17:14:31 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n#I did not write those codes\r\n\r\nimport sys\r\n\r\nn = int(input().strip())\r\na = list(map(int, input().strip().split(' ')))\r\nnofswap = 0\r\nfor i in range(0,n-1):\r\n for i in range(0,n-1):\r\n if a[i]>a[i+1]:\r\n a[i],a[i+1] = a[i+1],a[i]\r\n nofswap +=1\r\n\r\nprint(\"Array is sorted in\", nofswap, \"swaps.\")\r\nprint(\"First Element:\",a[0])\r\nprint(\"Last Element:\",a[-1])"
},
{
"alpha_fraction": 0.7925925850868225,
"alphanum_fraction": 0.8222222328186035,
"avg_line_length": 66.5,
"blob_id": "9d21a6d04a72f9dece5b73467d6cf9f0400f9cac",
"content_id": "575ec010962c3440ca1d8e20d5c83c4546b315c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 2,
"path": "/README.md",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# 30DayCodingChallenge-Hackerrank\nHere I post my (and occasionally others') solutions to 30 days of coding challenge on hackerrank.com\n"
},
{
"alpha_fraction": 0.5018315315246582,
"alphanum_fraction": 0.553113579750061,
"avg_line_length": 17.64285659790039,
"blob_id": "e69dca7117702d2712b5df25238bbddc0bc04350",
"content_id": "bcf62f8982e4dc02fe8061824ae80ebcb4c8ed7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 14,
"path": "/Day 7 Arrays solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon Jun 7 10:38:50 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nN = int(input(\"Enter the number of integers in an array\"))\r\nS = input(\"Enter all integers in the array\")\r\n\r\nA = []\r\nfor i in range(1, N + 1):\r\n A.append(S[-i])\r\nprint(*A, sep = '')"
},
{
"alpha_fraction": 0.517671525478363,
"alphanum_fraction": 0.5509355664253235,
"avg_line_length": 21,
"blob_id": "81add9a66a8322153454244996140b985dde8a54",
"content_id": "48b806999677cb86b2bf999eb833de0140015483",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 21,
"path": "/Day 13 Abstract classes solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jun 22 12:03:42 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nfrom abc import ABCMeta\r\n\r\nclass book(object):\r\n def __init__(self, title, author, price):\r\n self.title = str(title)\r\n self.author = str(author)\r\n self.price = int(price)\r\n def display(self): \r\n print(\"Title: \", self.title)\r\n print(\"Author: \", self.author)\r\n print(\"Price: \", self.price)\r\n\r\na = book(\"The Alchemist\", \"Paulo Coelho\", 248)\r\na.display()"
},
{
"alpha_fraction": 0.5180723071098328,
"alphanum_fraction": 0.5518072247505188,
"avg_line_length": 22.52941131591797,
"blob_id": "a86db1351ee77e3fcc2cb3ec6ac440cb353e14e7",
"content_id": "191bcec57acbd6047ef893d5cd569e1684811fed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 17,
"path": "/Day 23 BST level-order traversal solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jul 1 17:38:08 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n# I did not write those codes because I did not understand binary\r\n\r\ndef levelOrder(self,root):\r\n leafs = [root]\r\n while len(leafs) > 0:\r\n leaf = leafs.pop(0)\r\n print(leaf.data, end=\" \")\r\n if leaf.left:\r\n leafs.append(leaf.left)\r\n if leaf.right:\r\n leafs.append(leaf.right)"
},
{
"alpha_fraction": 0.4719271659851074,
"alphanum_fraction": 0.512898325920105,
"avg_line_length": 19.25806427001953,
"blob_id": "5c841033bd9cd982fe34d31b7f6a97c311bb8c84",
"content_id": "7baebc9e249ef1beca80390a7d770e9f755f3d41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 659,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 31,
"path": "/Day 11 2D array solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jun 15 13:02:35 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\n#Again, I did not write those codes because I could not figure it out\r\n\r\nimport math\r\nimport os\r\nimport random\r\nimport re\r\nimport sys\r\n\r\narr = []\r\n\r\nfor arr_i in range(6):\r\n arr_t = [int(arr_temp) for arr_temp in input().strip().split(' ')]\r\n arr.append(arr_t)\r\n \r\nmaxi = 0\r\n\r\nfor i in range(4):\r\n for j in range(4):\r\n current = arr[i][j] + arr[i][j+1] + arr[i][j+2] + \\\r\n arr[i+1][j+1] + \\\r\n arr[i+2][j] + arr[i+2][j+1] + arr[i+2][j+2]\r\n if maxi == 0 or current > maxi:\r\n maxi = current\r\nprint(maxi)\r\n"
},
{
"alpha_fraction": 0.47795823216438293,
"alphanum_fraction": 0.5104408264160156,
"avg_line_length": 25.0625,
"blob_id": "ae2479641c7b1abe557f82c8dd0b8a9085967578",
"content_id": "84d09749e56b291603842ddb91096e7e2daf8bf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 16,
"path": "/Day 14 Scope solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Jun 23 12:25:02 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nclass Difference:\r\n def __init__(self, a):\r\n self.__elements = a\r\n def computeDifference(self):\r\n self.maximumDifference = 0\r\n for x in range(len(a)):\r\n for y in range(x,len(a)):\r\n if abs(a[x] - a[y]) > self.maximumDifference:\r\n self.maximumDifference = abs(a[x] - a[y])"
},
{
"alpha_fraction": 0.4317673444747925,
"alphanum_fraction": 0.46532437205314636,
"avg_line_length": 23.600000381469727,
"blob_id": "a3f5cd7f63b092350ba3d81360adff243bbf9cba",
"content_id": "78ea7e9bfa8c0fe517ce84a63f1c979aad317b77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 35,
"path": "/Day 4 Class vs instance solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Jun 2 13:40:32 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nclass Person:\r\n def __init__(self, initialAge):\r\n if initialAge < 0:\r\n print(\"Age is not valid, setting age to 0.\")\r\n self.age = 0 \r\n else:\r\n self.age = initialAge\r\n \r\n def amIOld(self):\r\n if self.age < 13:\r\n return(\"You are young.\")\r\n elif (self.age >= 13) & (self.age < 18):\r\n return(\"You are a teenager.\")\r\n else:\r\n return(\"You are old.\")\r\n \r\n def yearPasses(self):\r\n self.age += 1 \r\n if self.age < 13:\r\n return(\"You are young.\")\r\n elif (self.age >= 13) & (self.age < 18):\r\n return(\"You are a teenager.\")\r\n else:\r\n return(\"You are old.\")\r\n\r\ni = Person(17)\r\nprint(Person.amIOld(i))\r\nprint(Person.yearPasses(i))"
},
{
"alpha_fraction": 0.5076141953468323,
"alphanum_fraction": 0.5736040472984314,
"avg_line_length": 13.307692527770996,
"blob_id": "dc570e8b666b55209aef451448cbb4180870a72d",
"content_id": "29eaa728b9ac9c70bcab82681ac017cb54700f87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 13,
"path": "/Day 16 Exceptions - String to intergers solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jun 24 10:40:03 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\ns = input(\"Please enter an integer\")\r\n\r\ntry:\r\n print(int(s))\r\nexcept ValueError:\r\n print(\"Bad String\")"
},
{
"alpha_fraction": 0.5394594669342041,
"alphanum_fraction": 0.5772972702980042,
"avg_line_length": 21.769229888916016,
"blob_id": "3664961e3e6c289cfa5b2e2c4e2f743dbd263d3e",
"content_id": "4df09278c62d36bfcc9283d49c09616a7ce9971c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 39,
"path": "/Day 12 Inheritance solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Jun 16 14:16:45 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nclass Person:\r\n\tdef __init__(self, firstName, lastName, idNumber):\r\n\t\tself.firstName = firstName\r\n\t\tself.lastName = lastName\r\n\t\tself.idNumber = idNumber\r\n\tdef printPerson(self):\r\n\t\tprint(\"Name:\", self.lastName + \",\", self.firstName)\r\n\t\tprint(\"ID:\", self.idNumber)\r\n \r\nclass Student(Person):\r\n def __init__(self, firstName, lastName, idNumber, scores): \r\n Person.__init__(self, firstName, lastName, idNumber)\r\n self.Scores = []\r\n for i in Scores:\r\n self.score.append(int(i))\r\n \tdef calgrade(self):\r\n\t\ta = float(sum(self.scores)) / len(self.scores)\r\n\t\tif a < 40:\r\n\t\t\treturn 'T'\r\n\t\telif a < 55:\r\n\t\t\treturn 'D'\r\n\t\telif a < 70:\r\n\t\t\treturn 'P'\r\n\t\telif a < 80:\r\n\t\t\treturn 'A'\r\n\t\telif a < 90:\r\n\t\t\treturn 'E'\r\n\t\telse:\r\n\t\t\treturn 'O'\r\n\r\na = Student(Heraldo, Memelli, 8135627, [100, 80])\r\ncalgrade(a)"
},
{
"alpha_fraction": 0.45148515701293945,
"alphanum_fraction": 0.4891089200973511,
"avg_line_length": 16.77777862548828,
"blob_id": "b195a0334b0abbea5af49555900739a092103bb1",
"content_id": "2b61cbe74a703b354b062c4c0065550b9e17891a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 505,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 27,
"path": "/Day 25 Running time and complexity solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jul 2 10:37:11 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nimport math\r\n\r\ndef prime(value):\r\n if value == 2:\r\n return True\r\n if value < 2:\r\n return False\r\n if value % 2 == 0:\r\n return False\r\n stop = math.sqrt(value)\r\n i = 3\r\n while i <= stop:\r\n if value % i == 0:\r\n return False\r\n i += 2\r\n return True\r\n\r\nN = int(input())\r\nfor _ in range(N):\r\n print(\"Prime\") if prime(int(input())) else print(\"Not prime\")"
},
{
"alpha_fraction": 0.6396588683128357,
"alphanum_fraction": 0.6801705956459045,
"avg_line_length": 37.08333206176758,
"blob_id": "af65cf2c78222a17e9e755f85fa6a29fc90b26a4",
"content_id": "1d7954738a4fbe5cfd7e5478b9d3875642177128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 12,
"path": "/Day 2 Operators solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon May 31 15:17:18 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nmealCost = float(input('Enter the cost of the meal before tax and tip'))\r\ntipPercent = int(input('Enter the percentage of the cost of the meal being added as tip'))\r\ntaxPercent = int(input('Enter the percentage of the tax of the meal being added as tax'))\r\nx = round(mealCost + mealCost * tipPercent / 100 + mealCost * taxPercent / 100)\r\nprint('The total cost of a meal is ', x)\r\n"
},
{
"alpha_fraction": 0.42657342553138733,
"alphanum_fraction": 0.4755244851112366,
"avg_line_length": 13.962963104248047,
"blob_id": "462ca1765d39ac69cfd13389b2a9d64efd277a89",
"content_id": "1216cf64fbed4c60413fdfd7f8a3dbd0d8947862",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 27,
"path": "/Day 10 Binary numbers solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jun 11 14:17:34 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\n#Disclaimer: I did not write those codes because I do not understand binaries...\r\n\r\nimport sys, math\r\n\r\nn = int(input(\"Please enter an integer\"))\r\nc = 0\r\nm = 0\r\n\r\nwhile n > 0:\r\n if n % 2 == 1:\r\n c += 1\r\n else:\r\n if c > m:\r\n m = c\r\n c = 0\r\n n = math.floor(n / 2)\r\nif c > m:\r\n m = c\r\n \r\nprint(m)"
},
{
"alpha_fraction": 0.5349887013435364,
"alphanum_fraction": 0.5665914416313171,
"avg_line_length": 21.421052932739258,
"blob_id": "a9d2159ba64460d05ae265d14f2f0e7a33ef624d",
"content_id": "4afe23789a8760597516e596e4dfef4b27d54bdf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 19,
"path": "/Day 18 Queues and stacks solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jun 25 17:05:53 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\nclass Solution:\r\n def __init__(self):\r\n self.queue = []\r\n self.stack = []\r\n def pushCharacter(self,obj):\r\n self.stack.append(obj)\r\n def enqueueCharacter(self,obj):\r\n self.queue.append(obj)\r\n def popCharacter(self):\r\n return self.stack.pop()\r\n def dequeueCharacter(self):\r\n return self.queue.pop(0)"
},
{
"alpha_fraction": 0.5116822719573975,
"alphanum_fraction": 0.5268691778182983,
"avg_line_length": 21.08108139038086,
"blob_id": "2d197db6b6bb8151482217b925beaed4d0d77a29",
"content_id": "71fa2989d59e8c6db9a18ba4709460d438348894",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 856,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 37,
"path": "/Day 15 Linked list solution.py",
"repo_name": "yiyue-zhang/30DayCodingChallenge-Hackerrank",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jun 24 10:37:37 2021\r\n\r\n@author: Yi\r\n\"\"\"\r\n\r\n#I did not write this solution because I did not understand the prompt\r\n\r\nclass Node:\r\n def __init__(self,data):\r\n self.data = data\r\n self.next = None \r\nclass Solution: \r\n def display(self,head):\r\n current = head\r\n while current:\r\n print(current.data,end=' ')\r\n current = current.next\r\n def insert(self,head,data): \r\n n = Node(data)\r\n if head:\r\n current = head\r\n while current.next:\r\n current = current.next\r\n current.next = n\r\n return head\r\n else:\r\n return n\r\n\r\nmylist= Solution()\r\nT=int(input())\r\nhead=None\r\nfor i in range(T):\r\n data=int(input())\r\n head=mylist.insert(head,data) \r\nmylist.display(head); \t "
}
] | 28 |
SSA111/CPRGenerator | https://github.com/SSA111/CPRGenerator | c938cf9a683f07e303eb938cae83c32465bd8c2b | 8bf3112395493fa7f4d710295678276aec3f82bb | 752e1df618d03cdc1073a860b93807a337e0ec08 | refs/heads/master | 2020-12-24T15:49:31.914567 | 2014-12-06T23:46:23 | 2014-12-06T23:46:23 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49819493293762207,
"alphanum_fraction": 0.5480144619941711,
"avg_line_length": 33.625,
"blob_id": "c0bf2c5541b50a61653da52c0d7bc5fb13711a36",
"content_id": "799590cd7f5b540e595eb8cf17a57db282ca7f10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1385,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 40,
"path": "/CPR/CPRGenerator.py",
"repo_name": "SSA111/CPRGenerator",
"src_encoding": "UTF-8",
"text": "__author__ = 'SebastianA'\n\nclass CPRGenerator:\n\n def __init__(self, DateOfBirth, Gender):\n self.dateOfBirth = DateOfBirth\n self.gender = Gender\n\n self.CPRPossibilites = [[1, 2, 3, 0], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]\n self.CPRList = []\n\n\n def searchCPRPossibilities(self, depth = 0, partialCPR = \"\"):\n\n if self.gender is \"Male\":\n self.CPRPossibilites[3] = [1, 3, 5, 7, 9]\n elif self.gender is \"Female\":\n self.CPRPossibilites[3] = [0, 2, 4, 6, 8]\n\n for i in self.CPRPossibilites[depth]:\n\n if depth < 3:\n nextPartialCPR = str(partialCPR) + \"\" + str(self.CPRPossibilites[depth][i])\n nextDepth = depth + 1\n self.searchCPRPossibilities(nextDepth, nextPartialCPR)\n else:\n validCPR = str(partialCPR) + \"\" + str(self.CPRPossibilites[2][i])\n\n if self.isCPRValid(validCPR):\n self.CPRList.append(self.dateOfBirth + \"-\" + validCPR)\n\n return self.CPRList\n\n def isCPRValid(self, CPR):\n fullCPR = self.dateOfBirth + CPR\n factors = [4, 3, 2, 7, 6, 5, 4, 3, 2, 1]\n return sum(int(digit) * factor for digit, factor in zip(fullCPR, factors)) % 11 == 0\n\n\nprint(CPRGenerator(\"240788\", \"Male\").searchCPRPossibilities())\n"
},
{
"alpha_fraction": 0.7464788556098938,
"alphanum_fraction": 0.7558685541152954,
"avg_line_length": 25.625,
"blob_id": "2e31f9368883dfde2fda07a019640958feea8581",
"content_id": "d07132858892a537d41adedad31d49a98d9df3e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 8,
"path": "/README.md",
"repo_name": "SSA111/CPRGenerator",
"src_encoding": "UTF-8",
"text": "CPRGenerator\n============\n\nDanish Valid Personal Number Generator\n\nGenerates Valid Personal Numbers (CPR) with the Modulos 11 test. \n\nCreated based on the description here: http://da.wikipedia.org/wiki/CPR-nummer\n"
}
] | 2 |
gsx0/Feature-Generating-Networks | https://github.com/gsx0/Feature-Generating-Networks | 80e6cb645521676b45604c37b2e25ba1ad7e7966 | 95264ef627128b45695e21f0c4bda17e8f87dbf9 | 74d44bd786c3df16550a43ec30f4d2c0beaba8fc | refs/heads/master | 2020-04-27T06:49:05.148789 | 2019-03-04T03:00:21 | 2019-03-04T03:00:21 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7489361763000488,
"alphanum_fraction": 0.7773049473762512,
"avg_line_length": 53.230770111083984,
"blob_id": "f36b290d1122b56836db31e8d1971aa9f8bf531f",
"content_id": "5daab21b186f881ddfb5aec463fef2319cfef3fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 705,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 13,
"path": "/README.md",
"repo_name": "gsx0/Feature-Generating-Networks",
"src_encoding": "UTF-8",
"text": "## Feature Generating Networks for Zero Shot Learning\n\nPyTorch implementation of paper: <https://arxiv.org/abs/1712.00981>\n\nCurrently, only Animals With Attributes 2 dataset is supported(<https://cvml.ist.ac.at/AwA2/>)\n\n<!--Accuracy obtained: 96.1%-->\nRemarks:\n* For training the model, use ``python3 main.py --n_epochs 20 --use_cls_loss --visualize``\n* Using MLPClassifier instead of a linear Softmax classifier yields much better results.\n\nNote: \nThe dataset has to be downloaded and extracted into proper numpy arrays of specified shapes for training/testing the model. All relevant files except the Resnet101 feature matrix have been uploaded in this repo. See comments in datautils.py for more info.\n"
},
{
"alpha_fraction": 0.566146731376648,
"alphanum_fraction": 0.5774118900299072,
"avg_line_length": 34.32653045654297,
"blob_id": "5362dd9cec787aff8dbf07d9739a7d6c44a51150",
"content_id": "1386ac410f0d4bb89fb39e2ff80f7816df184616",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3462,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 98,
"path": "/datautils.py",
"repo_name": "gsx0/Feature-Generating-Networks",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch.utils.data.dataset import Dataset\nfrom torchvision import transforms\nfrom torch.autograd import Variable\n\nimport numpy as np\n\nclass AwA2Dataset(Dataset):\n def __init__(self, device, n_train, n_test, train=True, synthetic=False, syn_dataset=None):\n '''\n Dataset for Animals with Attributes consists of 37322 images of 50 animals\n Args:\n device: torch.device object to use GPU/CPU\n '''\n super(AwA2Dataset, self).__init__()\n self.device = device\n self.n_train = n_train\n self.n_test = n_test\n\n # a np array of size (37322, 2048)\n self.features = np.load('./data/features.npy')\n # a np array of size (37322,)\n self.labels = np.load('./data/labels.npy')\n # a np array of size (50, 85)\n self.attributes = np.load('./data/attributes.npy')\n\n # file with all class names for deciding train/test split\n self.class_names = './data/classes.txt'\n\n self.synthetic = synthetic\n if self.synthetic:\n assert syn_dataset is not None\n self.syn_dataset = syn_dataset\n else:\n self.train_dataset, self.test_dataset = self.create_orig_dataset()\n if train:\n self.dataset = self.train_dataset\n else:\n self.dataset = self.test_dataset\n\n def get_label_maps(self):\n '''\n Returns the labels of all classes to be used as test set\n as described in proposed split\n '''\n test_classes = ['sheep','dolphin','bat','seal','blue+whale', 'rat','horse','walrus','giraffe','bobcat']\n with open(self.class_names) as fp:\n all_classes = fp.readlines()\n\n test_count = 0\n train_count = 0\n\n train_labels = dict()\n test_labels = dict()\n for line in all_classes:\n idx, name = [i.strip() for i in line.split(' ')]\n if name in test_classes:\n test_labels[int(idx)] = test_count\n test_count += 1\n else:\n train_labels[int(idx)] = train_count\n train_count += 1\n\n return train_labels, test_labels\n\n def create_orig_dataset(self):\n '''\n Partitions all 37322 image features into train/test based on proposed split\n Returns 2 lists, train_set & test_set: each entry of list is a 3-tuple\n (feature, label_in_dataset, label_for_classification)\n '''\n self.train_labels, self.test_labels = self.get_label_maps()\n train_set, test_set = [], []\n\n for feat, label in zip(self.features, self.labels):\n if label in self.test_labels.keys():\n test_set.append((feat, label, self.test_labels[label]))\n else:\n train_set.append((feat, label, self.train_labels[label]))\n\n return train_set, test_set\n\n def __getitem__(self, index):\n if self.synthetic:\n # choose an example from synthetic dataset\n img_feature, orig_label, label_idx = self.syn_dataset[index]\n else:\n # choose an example from original dataset\n img_feature, orig_label, label_idx = self.dataset[index]\n\n label_attr = self.attributes[orig_label - 1]\n return img_feature, label_attr, label_idx\n\n def __len__(self):\n if self.synthetic:\n return len(self.syn_dataset)\n else:\n return len(self.dataset)\n"
},
{
"alpha_fraction": 0.5940755605697632,
"alphanum_fraction": 0.6053115129470825,
"avg_line_length": 34.47101593017578,
"blob_id": "0046172129e672ecd263411d277e214452365c3a",
"content_id": "2423aab609bc510bf6ffaf738a29bbf723fe8927",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4895,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 138,
"path": "/main.py",
"repo_name": "gsx0/Feature-Generating-Networks",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch.utils.data import DataLoader\nimport argparse\n\nfrom datautils import AwA2Dataset\nfrom trainer import Trainer\n\nparser = argparse.ArgumentParser()\n\nparser.add_argument('--dataset', type=str, default='awa2')\nparser.add_argument('--latent_dim', type=int, default=128)\nparser.add_argument('--n_critic', type=int, default=5)\nparser.add_argument('--lmbda', type=float, default=10.0)\nparser.add_argument('--beta', type=float, default=0.01)\nparser.add_argument('--batch_size', type=int, default=128)\nparser.add_argument('--n_epochs', type=int, default=10)\nparser.add_argument('--use_cls_loss', action='store_true', default=False)\nparser.add_argument('--visualize', action='store_true', default=False)\n\nargs = parser.parse_args()\n\nif args.dataset == 'awa2':\n x_dim = 2048\n attr_dim = 85\n train_classes = 40\n test_classes = 10\nelse:\n raise NotImplementedError\n\nn_epochs = args.n_epochs\n\n# trainer object for mini batch training\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\ntrain_agent = Trainer(\n device, x_dim, args.latent_dim, attr_dim,\n train_classes, test_classes,\n args.n_critic, args.lmbda, args.beta,\n args.batch_size\n)\n\nparams = {\n 'batch_size': args.batch_size,\n 'shuffle': True,\n 'num_workers': 0,\n 'drop_last': True\n}\n\ntrain_dataset = AwA2Dataset(device, train_classes, test_classes)\ntrain_generator = DataLoader(train_dataset, **params)\n\n# =============================================================\n# PRETRAIN THE SOFTMAX CLASSIFIER\n# =============================================================\nmodel_name = \"disc_classifier\"\nsuccess = train_agent.load_model(model=model_name)\nif success:\n print(\"Discriminative classifier parameters loaded...\")\nelse:\n print(\"Training the discriminative classifier...\")\n for ep in range(1, n_epochs + 1):\n loss = 0\n for idx, (img_features, label_attr, label_idx) in enumerate(train_generator):\n l = train_agent.fit_classifier(img_features, label_attr, label_idx)\n loss += l\n\n print(\"Loss for epoch: %3d - %.4f\" %(ep, loss))\n\n train_agent.save_model(model=model_name)\n\n# =============================================================\n# TRAIN THE GANs\n# =============================================================\nmodel_name = \"gan\"\nsuccess = train_agent.load_model(model=model_name)\nif success:\n print(\"\\nGAN parameters loaded....\")\nelse:\n print(\"\\nTraining the GANS...\")\n for ep in range(1, n_epochs + 1):\n loss_dis = 0\n loss_gan = 0\n for idx, (img_features, label_attr, label_idx) in enumerate(train_generator):\n l_d, l_g = train_agent.fit_GAN(img_features, label_attr, label_idx, args.use_cls_loss)\n loss_dis += l_d\n loss_gan += l_g\n\n print(\"Loss for epoch: %3d - D: %.4f | G: %.4f\"\\\n %(ep, loss_dis, loss_gan))\n\n train_agent.save_model(model=model_name)\n\n# =============================================================\n# TRAIN FINAL CLASSIFIER ON SYNTHETIC DATASET\n# =============================================================\n\n# create new synthetic dataset using trained Generator\nsyn_dataset = train_agent.create_syn_dataset(train_dataset.test_labels, train_dataset.attributes)\nsynthetic_train_dataset = AwA2Dataset(device, train_classes, test_classes, synthetic=True, syn_dataset=syn_dataset)\nsyn_train_generator = DataLoader(synthetic_train_dataset, **params)\n\nmodel_name = \"final_classifier\"\nsuccess = train_agent.load_model(model=model_name)\nif success:\n print(\"\\nFinal classifier parameters loaded....\")\nelse:\n print(\"\\nTraining the final classifier on the synthetic dataset...\")\n for ep in range(1, n_epochs + 1):\n syn_loss = 0\n for idx, (img, label_attr, label_idx) in enumerate(syn_train_generator):\n l = train_agent.fit_final_classifier(img, label_attr, label_idx)\n syn_loss += l\n\n # print losses on real and synthetic datasets\n print(\"Loss for epoch: %3d - %.4f\" %(ep, syn_loss))\n\n train_agent.save_model(model=model_name)\n\n# =============================================================\n# TESTING PHASE\n# =============================================================\ntest_dataset = AwA2Dataset(device, train_classes, test_classes, train=False)\ntest_generator = DataLoader(test_dataset, **params)\n\nprint(\"\\nFinal Accuracy on ZSL Task: %.3f\" % train_agent.test(test_generator))\n\nif args.visualize:\n # TSNE visualizations for generated data\n from sklearn.manifold import TSNE\n import numpy as np\n import matplotlib.pyplot as plt\n\n D = [(x.detach().cpu().numpy(), i) for x, _, i in syn_dataset]\n X_embedded = TSNE(n_components=2).fit_transform(np.asarray([d[0] for d in D]))\n colors = np.asarray([d[1] for d in D])\n\n plt.scatter(X_embedded[:, 0], X_embedded[:, 1], c=colors)\n plt.savefig('tsne_plot.pdf')\n plt.show()\n"
},
{
"alpha_fraction": 0.5618411302566528,
"alphanum_fraction": 0.5669554471969604,
"avg_line_length": 35.70881271362305,
"blob_id": "d6259cc95f11637bf002cf37278b027a3747ed1b",
"content_id": "70c0cc0f19058d329437baa4f1cec7e23232b511",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9581,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 261,
"path": "/trainer.py",
"repo_name": "gsx0/Feature-Generating-Networks",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.autograd as autograd\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nfrom torch.distributions import uniform, normal\n\nimport os\nimport numpy as np\nfrom sklearn.metrics import accuracy_score\n\nfrom models import Generator, Discriminator, MLPClassifier, Resnet101\n\nclass Trainer:\n def __init__(self, device, x_dim, z_dim, attr_dim, train_out, test_out, n_critic, lmbda, beta, bs):\n self.device = device\n\n self.x_dim = x_dim\n self.z_dim = z_dim\n self.attr_dim = attr_dim\n\n self.n_critic = n_critic\n self.lmbda = lmbda\n self.beta = beta\n self.bs = bs\n\n self.eps_dist = uniform.Uniform(0, 1)\n self.Z_dist = normal.Normal(0, 1)\n\n self.eps_shape = torch.Size([bs, 1])\n self.z_shape = torch.Size([bs, z_dim])\n\n self.net_G = Generator(z_dim, attr_dim).to(self.device)\n self.optim_G = optim.Adam(self.net_G.parameters(), lr=1e-4)\n\n self.net_D = Discriminator(x_dim, attr_dim).to(self.device)\n self.optim_D = optim.Adam(self.net_D.parameters(), lr=1e-4)\n\n # classifier for judging the output of generator\n self.classifier = MLPClassifier(x_dim, attr_dim, train_out).to(self.device)\n self.optim_cls = optim.Adam(self.classifier.parameters(), lr=1e-4)\n\n # Final classifier trained on augmented data for GZSL\n self.final_classifier = MLPClassifier(x_dim, attr_dim, test_out).to(self.device)\n self.optim_final_cls = optim.Adam(self.final_classifier.parameters(), lr=1e-4)\n\n self.criterion_cls = nn.CrossEntropyLoss()\n\n self.model_save_dir = \"saved_models\"\n if not os.path.exists(self.model_save_dir):\n os.mkdir(self.model_save_dir)\n\n def get_conditional_input(self, X, C_Y):\n new_X = torch.cat([X, C_Y], dim=1).float()\n return autograd.Variable(new_X).to(self.device)\n\n def fit_classifier(self, img_features, label_attr, label_idx):\n '''\n Train the classifier in supervised manner on a single\n minibatch of available data\n Args:\n img : bs X 2048\n label_attr : bs X 85\n label_idx : bs\n Returns:\n loss for the minibatch\n '''\n img_features = autograd.Variable(img_features).to(self.device)\n label_attr = autograd.Variable(label_attr).to(self.device)\n label_idx = autograd.Variable(label_idx).to(self.device)\n\n X_inp = self.get_conditional_input(img_features, label_attr)\n Y_pred = self.classifier(X_inp)\n\n self.optim_cls.zero_grad()\n loss = self.criterion_cls(Y_pred, label_idx)\n loss.backward()\n self.optim_cls.step()\n\n return loss.item()\n\n def get_gradient_penalty(self, X_real, X_gen):\n eps = self.eps_dist.sample(self.eps_shape).to(self.device)\n X_penalty = eps * X_real + (1 - eps) * X_gen\n\n X_penalty = autograd.Variable(X_penalty, requires_grad=True).to(self.device)\n critic_pred = self.net_D(X_penalty)\n grad_outputs = torch.ones(critic_pred.size()).to(self.device)\n gradients = autograd.grad(\n outputs=critic_pred, inputs=X_penalty,\n grad_outputs=grad_outputs,\n create_graph=True, retain_graph=True, only_inputs=True\n )[0]\n\n grad_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()\n return grad_penalty\n\n def fit_GAN(self, img_features, label_attr, label_idx, use_cls_loss=True):\n L_gen = 0\n L_disc = 0\n total_L_disc = 0\n\n img_features = autograd.Variable(img_features.float()).to(self.device)\n label_attr = autograd.Variable(label_attr.float()).to(self.device)\n label_idx = label_idx.to(self.device)\n\n # =============================================================\n # optimize discriminator\n # =============================================================\n X_real = self.get_conditional_input(img_features, label_attr)\n for _ in range(self.n_critic):\n Z = self.Z_dist.sample(self.z_shape).to(self.device)\n Z = self.get_conditional_input(Z, label_attr)\n\n X_gen = self.net_G(Z)\n X_gen = self.get_conditional_input(X_gen, label_attr)\n\n # calculate normal GAN loss\n L_disc = (self.net_D(X_gen) - self.net_D(X_real)).mean()\n\n # calculate gradient penalty\n grad_penalty = self.get_gradient_penalty(X_real, X_gen)\n L_disc += self.lmbda * grad_penalty\n\n # update critic params\n self.optim_D.zero_grad()\n L_disc.backward()\n self.optim_D.step()\n\n total_L_disc += L_disc.item()\n\n # =============================================================\n # optimize generator\n # =============================================================\n Z = self.Z_dist.sample(self.z_shape).to(self.device)\n Z = self.get_conditional_input(Z, label_attr)\n\n X_gen = self.net_G(Z)\n X = torch.cat([X_gen, label_attr], dim=1).float()\n L_gen = -1 * torch.mean(self.net_D(X))\n\n if use_cls_loss:\n self.classifier.eval()\n Y_pred = F.softmax(self.classifier(X), dim=0)\n log_prob = torch.log(torch.gather(Y_pred, 1, label_idx.unsqueeze(1)))\n L_cls = -1 * torch.mean(log_prob)\n L_gen += self.beta * L_cls\n\n self.optim_G.zero_grad()\n L_gen.backward()\n self.optim_G.step()\n\n return total_L_disc, L_gen.item()\n\n def fit_final_classifier(self, img_features, label_attr, label_idx):\n img_features = autograd.Variable(img_features.float()).to(self.device)\n label_attr = autograd.Variable(label_attr.float()).to(self.device)\n label_idx = label_idx.to(self.device)\n\n X_inp = self.get_conditional_input(img_features, label_attr)\n Y_pred = self.final_classifier(X_inp)\n\n self.optim_final_cls.zero_grad()\n loss = self.criterion_cls(Y_pred, label_idx)\n loss.backward()\n self.optim_final_cls.step()\n\n return loss.item()\n\n def create_syn_dataset(self, test_labels, attributes, n_examples=200):\n syn_dataset = []\n\n for test_cls, idx in test_labels.items():\n attr = attributes[test_cls - 1]\n z = self.Z_dist.sample(torch.Size([n_examples, self.z_dim]))\n c_y = torch.stack([torch.FloatTensor(attr) for _ in range(n_examples)])\n\n z_inp = self.get_conditional_input(z, c_y)\n X_gen = self.net_G(z_inp)\n\n syn_dataset.extend([(X_gen[i], test_cls, idx) for i in range(n_examples)])\n\n return syn_dataset\n\n def test(self, generator, pretrained=False):\n if pretrained:\n model = self.classifier\n else:\n model = self.final_classifier\n\n # eval mode\n model.eval()\n batch_accuracies = []\n for idx, (img_features, label_attr, label_idx) in enumerate(generator):\n img_features = img_features.to(self.device)\n label_attr = label_attr.to(self.device)\n\n X_inp = self.get_conditional_input(img_features, label_attr)\n with torch.no_grad():\n Y_probs = model(X_inp)\n _, Y_pred = torch.max(Y_probs, dim=1)\n\n Y_pred = Y_pred.cpu().numpy()\n Y_real = label_idx.cpu().numpy()\n\n acc = accuracy_score(Y_pred, Y_real)\n batch_accuracies.append(acc)\n\n model.train()\n return np.mean(batch_accuracies)\n\n def save_model(self, model=None):\n if model == \"disc_classifier\":\n ckpt_path = os.path.join(self.model_save_dir, model + \".pth\")\n torch.save(self.classifier.state_dict(), ckpt_path)\n\n elif model == \"gan\":\n g_ckpt_path = os.path.join(self.model_save_dir, \"generator.pth\")\n torch.save(self.net_G.state_dict(), g_ckpt_path)\n\n d_ckpt_path = os.path.join(self.model_save_dir, \"discriminator.pth\")\n torch.save(self.net_D.state_dict(), d_ckpt_path)\n\n elif model == \"final_classifier\":\n ckpt_path = os.path.join(self.model_save_dir, model + \".pth\")\n torch.save(self.final_classifier.state_dict(), ckpt_path)\n\n else:\n raise Exception(\"Trying to save unknown model: %s\" % model)\n\n def load_model(self, model=None):\n if model == \"disc_classifier\":\n ckpt_path = os.path.join(self.model_save_dir, model + \".pth\")\n if os.path.exists(ckpt_path):\n self.classifier.load_state_dict(torch.load(ckpt_path))\n return True\n\n elif model == \"gan\":\n f1, f2 = False, False\n g_ckpt_path = os.path.join(self.model_save_dir, \"generator.pth\")\n if os.path.exists(g_ckpt_path):\n self.net_G.load_state_dict(torch.load(g_ckpt_path))\n f1 = True\n\n d_ckpt_path = os.path.join(self.model_save_dir, \"discriminator.pth\")\n if os.path.exists(d_ckpt_path):\n self.net_D.load_state_dict(torch.load(d_ckpt_path))\n f2 = True\n\n return f1 and f2\n\n elif model == \"final_classifier\":\n ckpt_path = os.path.join(self.model_save_dir, model + \".pth\")\n if os.path.exists(ckpt_path):\n self.final_classifier.load_state_dict(torch.load(ckpt_path))\n return True\n\n else:\n raise Exception(\"Trying to load unknown model: %s\" % model)\n\n return False\n"
}
] | 4 |
chaishi/problems | https://github.com/chaishi/problems | 8345e9d4c6c5586ab80a7174c1e96fbf635e6436 | 0f8134411221ee9d825326dd97b58a3884d06174 | 05eb21c64c7cdfa9073eb87391645cba84bd7691 | refs/heads/master | 2021-01-12T20:06:47.153562 | 2015-04-14T01:57:49 | 2015-04-14T01:57:49 | 34,092,434 | 1 | 0 | null | 2015-04-17T02:34:50 | 2015-04-14T01:58:11 | 2015-04-14T01:58:11 | null | [
{
"alpha_fraction": 0.4916711449623108,
"alphanum_fraction": 0.5260612368583679,
"avg_line_length": 23.16883087158203,
"blob_id": "9f7f65b8da364d2305feb4c2fc823613db362b04",
"content_id": "28d5460076660cb5eb5d8ed163727b603f99c9f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1861,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 77,
"path": "/leetcode/src/sumroot2leaf.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary tree containing digits from 0-9. each root-to-leaf could represent a number.\n * an example is 1->2->3 which represents the number 123.\n * */\n\n#include \"../include/preliminary.h\"\n\nint sumStackAsNumber(stack<TreeNode*>& stk){\n int sum=0;\n stack<TreeNode*> stk2;\n int d = 1;\n while(!stk.empty()){\n stk2.push(stk.top());\n sum += d * stk.top()->val;\n stk.pop();\n d *= 10;\n }\n while(!stk2.empty()){\n stk.push(stk2.top());\n stk2.pop();\n }\n return sum;\n}\n\nint sumNumbers(TreeNode *root){\n if(root==NULL) return 0;\n stack<TreeNode*> stk;\n stk.push(root);\n int res=0;\n stack<TreeNode*> snums;\n while(!stk.empty()){\n TreeNode *p = stk.top();\n stk.pop();\n while(!snums.empty() && snums.top()->left != p && snums.top()->right != p){\n snums.pop();\n }\n snums.push(p);\n if(p->left == NULL && p->right == NULL){ //reach leaf\n res += sumStackAsNumber(snums);\n snums.pop();\n }\n if(p->right != NULL) stk.push(p->right);\n if(p->left != NULL) stk.push(p->left);\n }\n return res;\n}\n\nvoid test_01(){\n TreeNode *p0 = new TreeNode(1);\n TreeNode *p1 = new TreeNode(2);\n TreeNode *p2 = new TreeNode(3);\n p0->left = p1;\n p0->right = p2;\n printf(\"%d\\n \", sumNumbers(p0));\n}\n\nvoid test_02(){\n TreeNode *p0 = new TreeNode(1);\n TreeNode *p1 = new TreeNode(2);\n TreeNode *p2 = new TreeNode(3);\n p0->left = p1;\n p0->right = p2;\n TreeNode *p3 = new TreeNode(1);\n p1->left = p3;\n TreeNode *p4 = new TreeNode(0);\n p1->right = p4;\n TreeNode *p5 = new TreeNode(4);\n p2->left = p5;\n TreeNode *p6 = new TreeNode(5);\n p2->right = p6;\n printf(\"%d\\n \", sumNumbers(p0));\n}\n\nint main(int, char**){\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40185731649398804,
"alphanum_fraction": 0.44744616746902466,
"avg_line_length": 22.690000534057617,
"blob_id": "e532caeb92f20f71fc451eff78b504c1051af2d6",
"content_id": "ff7792951a6107c4c129c6563f766d2c7a01dfe6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2369,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 100,
"path": "/leetcode/src/romannumeral.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * write functions to convert integer2roman and roman2integer\n * \n * note: in Roman numeral's definition, integer >= 3999 is invalid\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include \"stdlib.h\"\n\nusing namespace std;\n\nconst int MaxSize = 50;\nint digits[] = {1,4,5,9,10,40,50,90,100,400,500,900,1000}; // for int a[] initialization, OK for C code, local var in C++, but not for data member in C++ class\nchar alphas[][13] = {\n \"I\", //1\n \"IV\", //4\n \"V\", //5\n \"IX\", //9\n \"X\", //10\n \"XL\", //40\n \"L\", //50\n \"XC\", //90\n \"C\", //100\n \"CD\", //400\n \"D\", //500\n \"CM\", //900\n \"M\" //1000\n};\n\n/*\n * method 1, direct strategy\n * */\nstring int2Roman_01(int num){\n char *res = new char[MaxSize];\n memset(res, 0, sizeof(char)*MaxSize);\n int j=0, i=12;\n while(num > 0){\n if(num < digits[i]){\n --i;\n }else{\n res[j++] = alphas[i][0];\n if(i & 1){ // i%2 == 1\n res[j++] = alphas[i][1];\n }\n num -= digits[i];\n }\n }\n res[j] = '\\0';\n string str(res);\n delete[] res;\n return str;\n}\n\nint roman2Int(const string& str){ //split string by fixed segment, plus to sum \n int res = 0, n = str.size(), i=0, j=12;\n while(i<n && j>=0){\n if(j & 1){ // to match 2 chars\n if(i<n-1 && str[i]==alphas[j][0] && str[i+1] == alphas[j][1]){\n res += digits[j];\n i += 2;\n }else{\n --j;\n }\n }else{ // to match 1 char \n if(str[i] == alphas[j][0]){\n res += digits[j];\n ++i;\n }else{\n --j;\n }\n }\n }\n return res;\n}\n\nvoid test_int2roman(){\n string str;\n while(1){\n printf(\"please input integer:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int n = atoi(str.c_str());\n printf(\"%s\\n\", int2Roman_01(n).c_str());\n }\n}\n\nvoid test_roman2int(){\n string str;\n while(1){\n printf(\"please input roman numeral in upper case:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n printf(\"%d\\n\", roman2Int(str));\n }\n}\n\nint main(int, char**){\n test_roman2int();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4634397625923157,
"alphanum_fraction": 0.47785788774490356,
"avg_line_length": 21.06818199157715,
"blob_id": "7010441f712342d5bea505860052373079415e62",
"content_id": "b348241ba5d6dc8383796987d20a092786aed206",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1942,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 88,
"path": "/leetcode/src/removeDuplicatesSLL.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * remove duplicates in a SLL\n *\n * 1->1->2->2->2->3 1->2->3\n * */\n\n#include \"../include/preliminary.h\"\n\n/*\n * for duplicate nodes, remove them other than one\n * input: 1->1->2\n * output: 1->2\n * */\nListNode* remove(ListNode *head){\n if(!head) return NULL;\n ListNode *pre = NULL, *curr = head, *post = curr->next;\n while(curr && post){\n if(curr->val == post->val){\n if(!pre){\n head = post;\n }else{\n pre->next = post;\n }\n curr->next = NULL;\n delete curr;\n }else{\n pre = curr;\n }\n curr = post;\n post = curr->next;\n }\n return head;\n}\n\n/*\n * given a sorted SLL, remove all the nodes with duplicates\n * input: 1->1->2\n * output: 2\n * */\nListNode* delPart(ListNode *pre, ListNode *start, ListNode *end){\n if(pre) pre->next = end->next;\n for(ListNode *h = start; h != end;){\n ListNode *after = h->next;\n delete h;\n h = after;\n }\n delete end;\n return pre;\n}\n\nListNode* removeII(ListNode *head){\n if(!head || !(head->next)) return head;\n ListNode *pre = NULL, *curr = head, *post = head->next;\n ListNode *start = NULL, *end = NULL;\n while(curr){\n post = curr->next;\n end = curr;\n if(!post || curr->val != post->val){\n if(start){\n if(head == start) head = post;\n pre = delPart(pre, start, end);\n start = NULL;\n }else{\n pre = curr;\n }\n }else{\n if(!start) start = curr;\n }\n curr = post;\n }\n if(pre) pre->next = NULL;\n return head;\n}\n\nvoid test_01(){\n int arr[6] = {1,1,1,2,3,3};\n ListNode *head = createSLL(arr, sizeof(arr)/sizeof(int));\n displaySLL(head);\n head = removeII(head);\n displaySLL(head);\n\n delSLL(head);\n return;\n}\n\nint main(){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.42672809958457947,
"alphanum_fraction": 0.4350230395793915,
"avg_line_length": 26.820512771606445,
"blob_id": "3fe0985e56ca58912ea5d89e155bb32a56e7432c",
"content_id": "3cae44216da70f8f25e4f4aabeaeb74e9b7de3f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 39,
"path": "/topics/binarytree/src/MorrisInorder.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\n/*\n* transform whole binary tree to one tree of single right line via append root to rightmost of left subtree \n*/\ntemplate<typename TreeNode>\nvoid MorrisInorder(TreeNode* root){\n TreeNode *p = root, *tmp;\n while(p != 0){\n if(p->left == 0){ //root of transformation completed tree, or just with no left child\n visit(p);\n p = p->right;\n }\n else{\n tmp = p->left; //right most node of left half\n while(tmp->right != 0 && \n tmp->right != p){\n tmp = tmp->right;\n }\n \n if(tmp->right == 0){ //go to rightmost leaf (of left subtree), append p to it\n tmp->right = p; \n p = p->left;\n }\n else{\n visit(p); //tmp->right == p, this link is appended\n tmp->right = 0;\n p = p->right;\n } \n }\n } \n}\n\nvoid test_01(){\n}\n\nint main(int, char**){\n test_01();\n}\n"
},
{
"alpha_fraction": 0.43022602796554565,
"alphanum_fraction": 0.44461050629615784,
"avg_line_length": 30.488235473632812,
"blob_id": "dfbbf3c2b637c9e66cb27e994d29dd737348eeef",
"content_id": "4e96009d3db078c1f7371f7aa7d103a36643e439",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5353,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 170,
"path": "/leetcode/src/substringConcatAllWords.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * substring with concatenation of all words\n * given a string S, and a list of words L, that are all of the same length. Find all starting indices of substring in S\n * that is a concatenation of each word in L exactly.\n * e.g.\n * S=\"barfoothefoobarfoo\", L=[\"foo\", \"bar\"], return 0,9,12,15\n * S=\"abaababbaba\", L=[\"ab\", \"ba\", \"ab\", \"ba\"], return 1,3\n * S=\"abababab\", L=[\"ab\", \"ba\"], return null\n * S=\"mississippi\", L=[\"is\", \"si\"], return 1,4\n *\n * a question can be asked: if words in L has different length?\n * */\n#include \"../include/preliminary.h\"\n\nbool isfull(int *arr, int n){\n for(int i=0; i<n; i++){\n if(arr[i] == 0) return false;\n }\n return true;\n}\n\nvoid checkOnce(string str, vector<string>& L, int *used, vector<int> *headpos, \n int start, vector<int>& res){\n if(isfull(used, L.size())){\n res.push_back(start);\n return;\n }\n if(str.empty()) return;\n vector<int> options = headpos[(int)str[0]];\n int n = str.size();\n for(size_t i=0; i<options.size(); i++){\n int t = options[i]; // index in L\n if(used[t] == 1) continue; // if used already\n string src = L[t];\n int m = src.size();\n if(n < m) continue; // if length overflow\n int j = m-1;\n while(j>=0 && src[j] == str[j]) j--;\n if(j>=0) continue;\n used[t] = 1;\n checkOnce(str.substr(m, n-m), L, used, headpos, start, res);\n used[t] = 0;\n }\n return;\n}\n\nvector<int> findSubstring(string S, vector<string>& L){\n vector<int> res;\n if(S.empty() || L.empty() || L[0].empty()) return res;\n int l = L.size(), m = L[0].size(), n = S.size();\n if(n < l * m) return res;\n vector<int> headpos[256];\n for(int i=0; i<256; i++){\n headpos[i] = vector<int>();\n }\n int used[l];\n memset(used, 0, sizeof(used));\n for(int i=0; i<l; i++){\n if(L[i].empty()) continue;\n headpos[(int)L[i][0]].push_back(i);\n }\n for(int i=0; i<n; i++){\n checkOnce(S.substr(i, n-i), L, used, headpos, i, res);\n }\n return res;\n}\n\nclass Solution{\npublic:\n vector<int> findSubstring(string S, vector<string>& L){\n vector<int> res;\n int m = L.size(), n = S.size();\n if(m==0 || n==0) return res;\n int l = L[0].size();\n if(n < l*m) return res;\n map<string, int> need2Find, hasFound; // string is used as key for search in O(1)\n for(int i=0; i<m; i++){\n if(need2Find.count(L[i]) == 0){\n need2Find[L[i]] = 1;\n }else{\n need2Find[L[i]]++;\n }\n }\n int cnt = 0;\n int used[n]; // store beginning j\n memset(used, 0, sizeof(used));\n set<int> st; // store result for search duplicate\n for(int k = 0;k <= n-l*m; k++){\n if(used[k] == 1) continue;\n hasFound.clear();\n for(int i=0; i<m; i++){\n hasFound[L[i]] = 0;\n }\n cnt = 0;\n\n for(int i=k, j=k; j <= n-l;){\n if(used[j] == 0) used[j] = 1;\n string str = S.substr(j, l);\n if(need2Find.count(str) == 0){\n j++;\n continue;\n }\n hasFound[str]++;\n if(hasFound[str] <= need2Find[str]) cnt++;\n if(cnt == m && j+l-i >= l*m){\n for(;;){\n string tmp = S.substr(i, l);\n if(need2Find.count(tmp) == 0){\n i++;\n continue;\n }\n if(hasFound[tmp] > need2Find[tmp]){\n hasFound[tmp]--;\n i += l;\n }else{\n break;\n }\n }\n if(j+l-i == l*m && st.count(i) == 0){ // NOTE: check if length valid and not found yet\n st.insert(i);\n res.push_back(i);\n }\n }\n j += l;\n }\n }\n return res;\n }\n\n void test_01(){\n const string arr[] = {\"bar\", \"foo\"};\n vector<string> L(arr, arr + sizeof(arr)/sizeof(string));\n string S(\"foobarfoo\");\n vector<int> res = findSubstring(S, L);\n displayVector(res);\n }\n\n void test_02(){\n const string arr[] = {\"ab\", \"ba\", \"ab\", \"ba\"};\n vector<string> L(arr, arr + sizeof(arr)/sizeof(string));\n string S(\"abaababbaba\");\n vector<int> res = findSubstring(S, L);\n displayVector(res);\n }\n\n void test_03(){\n const string arr[] = {\"ab\", \"ba\"};\n vector<string> L(arr, arr + sizeof(arr)/sizeof(string));\n string S(\"abababab\");\n vector<int> res = findSubstring(S, L);\n displayVector(res);\n }\n\n void test_04(){\n const string arr[] = {\"is\", \"si\"};\n vector<string> L(arr, arr + sizeof(arr)/sizeof(string));\n string S(\"mississippi\");\n vector<int> res = findSubstring(S, L);\n displayVector(res);\n }\n};\n\nint main(){\n Solution s;\n s.test_01();\n s.test_02();\n s.test_03();\n s.test_04();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.36903563141822815,
"alphanum_fraction": 0.4091000556945801,
"avg_line_length": 26.44198989868164,
"blob_id": "8bea5d4fea676baf7fe48d66c7ac3befef0bd295",
"content_id": "7f36d0b8cfd2cd77f67e17102ec12029ca27c0fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4967,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 181,
"path": "/leetcode/src/validSudoku.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * determine if a Sudoku is valid. null cell is char '.'\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <vector>\n#include <set>\n#include <algorithm>\n#include <cmath> //double abs()\n\nusing namespace std;\n\nvoid displayVector(const vector<char>& vec){\n int n = vec.size();\n for(int i=0;i<n;i++){\n printf(\"%c \", vec[i]);\n }\n printf(\"\\n\");\n}\n\nbool check(const vector<char>& vec){\n set<int> st;\n char cstr[2];\n cstr[1] = '\\0';\n for(size_t i=0; i<vec.size();i++){\n if(vec[i] == '.') continue;\n cstr[0] = vec[i];\n int d = atoi(cstr);\n if(d>9 || d<0 || st.find(d) != st.end()){\n //displayVector(vec);\n return false;\n }\n st.insert(d);\n }\n return true;\n}\n\nbool isValidSudoku(const vector<vector<char> > &board){\n int n = board.size();\n if(n != 9) return false;\n vector<char> block;\n for(int i=0;i<n;++i){ //row\n block.clear();\n for(int j=0;j<n;++j){\n block.push_back(board[i][j]);\n }\n if(!check(block)) return false;\n }\n \n for(int j=0;j<n;++j){ //column\n block.clear();\n for(int i=0;i<n;++i){\n block.push_back(board[i][j]);\n }\n if(!check(block)) return false;\n }\n\n for(int i=0,j=0;i<=6;j+=3){\n if(j>6){\n j=0;\n i+=3;\n }\n if(i>6) break;\n block.clear();\n for(int t=i, k=j;t <= 2+i; ++k){\n if(k > 2+j){\n k=j;\n ++t;\n }\n if(t > 2+i) break;\n //printf(\"d=%d, k=%d\\n\", t, k);\n block.push_back(board[t][k]);\n }\n if(!check(block)) return false;\n }\n /*\n for(int s=0;s<=12;s+=3){ //3*3 square\n for(int i=0, j=s-i; j>=0; i+=3, j-=3){\n if(max(i,j) > 6) continue;\n block.clear();\n for(int d=0; d<=4; ++d){\n for(int t=i, k=j+d-(t-i); k>=j; t++, k--){ //init: t-i=0, k-j=d-(t-i); determine: k-j >=0\n if(max(t-i, k-j) > 2) continue;\n block.push_back(board[t][k]);\n }\n }\n if(!check(block)) return false;\n }\n }\n */\n return true;\n}\n\nvoid test_01(){\n vector<vector<char> > board;\n char row0[] = {'5', '3', '.', '.', '7', '.', '.', '.', '.'};\n vector<char> vec0(row0, row0 + 9);\n board.push_back(vec0);\n\n char row1[] = {'6', '.', '.', '1', '9', '5', '.', '.', '.'};\n vector<char> vec1(row1, row1 + 9);\n board.push_back(vec1);\n\n char row2[] = {'.', '9', '8', '.', '.', '.', '.', '6', '.'};\n vector<char> vec2(row2, row2 + 9);\n board.push_back(vec2);\n\n char row3[] = {'8', '.', '.', '.', '6', '.', '.', '.', '3'};\n vector<char> vec3(row3, row3 + 9);\n board.push_back(vec3);\n \n char row4[] = {'4', '.', '.', '8', '.', '3', '.', '.', '1'};\n vector<char> vec4(row4, row4 + 9);\n board.push_back(vec4);\n\n char row5[] = {'7', '.', '.', '.', '2', '.', '.', '.', '6'};\n vector<char> vec5(row5, row5 + 9);\n board.push_back(vec5);\n\n char row6[] = {'.', '6', '.', '.', '.', '.', '2', '8', '.'};\n vector<char> vec6(row6, row6 + 9);\n board.push_back(vec6);\n\n char row7[] = {'.', '.', '.', '4', '1', '9', '.', '.', '5'};\n vector<char> vec7(row7, row7 + 9);\n board.push_back(vec7);\n\n char row8[] = {'.', '.', '.', '.', '8', '.', '.', '7', '9'};\n vector<char> vec8(row8, row8 + 9);\n board.push_back(vec8);\n\n printf(\"%s\\n\", isValidSudoku(board) ? \"true\" : \"false\");\n}\n\nvoid test_02(){\n vector<vector<char> > board;\n char row0[] = {'.', '.', '.', '.', '.', '.', '5', '.', '.'};\n vector<char> vec0(row0, row0 + 9);\n board.push_back(vec0);\n\n char row1[] = {'.', '.', '.', '.', '.', '.', '.', '.', '.'};\n vector<char> vec1(row1, row1 + 9);\n board.push_back(vec1);\n\n char row2[] = {'.', '.', '.', '.', '.', '.', '.', '.', '.'};\n vector<char> vec2(row2, row2 + 9);\n board.push_back(vec2);\n\n char row3[] = {'9', '3', '.', '.', '2', '.', '4', '.', '.'};\n vector<char> vec3(row3, row3 + 9);\n board.push_back(vec3);\n \n char row4[] = {'.', '.', '7', '.', '.', '.', '3', '.', '.'};\n vector<char> vec4(row4, row4 + 9);\n board.push_back(vec4);\n\n char row5[] = {'.', '.', '.', '.', '.', '.', '.', '.', '.'};\n vector<char> vec5(row5, row5 + 9);\n board.push_back(vec5);\n\n char row6[] = {'.', '.', '.', '3', '4', '.', '.', '.', '.'};\n vector<char> vec6(row6, row6 + 9);\n board.push_back(vec6);\n\n char row7[] = {'.', '.', '.', '.', '.', '3', '.', '.', '.'};\n vector<char> vec7(row7, row7 + 9);\n board.push_back(vec7);\n\n char row8[] = {'.', '.', '.', '.', '.', '5', '2', '.', '.'};\n vector<char> vec8(row8, row8 + 9);\n board.push_back(vec8);\n\n printf(\"%s\\n\", isValidSudoku(board) ? \"true\" : \"false\");\n}\n\nint main(int, char**){\n test_01();\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.548682689666748,
"alphanum_fraction": 0.5612829327583313,
"avg_line_length": 32.57692337036133,
"blob_id": "abce6dc36627ae2a8a5260cc94175bb992978f02",
"content_id": "f4a52d2c839c12b3d37cb60cf2883377b05a5f0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2619,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 78,
"path": "/topics/modematch/src/KMP.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * one copy of implementation of KMP string match algorithm\n * for string match problem that match a string T with pattern P, the KMP(Knuth-Morris-Pratt) algorithm is popular at its linear time O(n)\n * \n * test data: pattern/string\n * abab/abbaabbaabab\n * ababa/abaaba\n * aaaaa/aabaaaabaaaaa\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n\nusing namespace std;\n\ninline int max(int a, int b){\n return a>b ? a : b;\n}\n/*\n * for KMP algorithm, the most important part is the preprocess of pattern P, to get int prefix[P]\n * it means for P[0...i], the greatest k that prefix of P(P[0..k-1]) matches suffix of P(P[i-k+1, i])\n * generally, this pattern preprocess is in time O(P)\n * */\nvoid setPrefix(const string& pattern, int *prefix){ //prefix should be [n]\n const int n = pattern.size();\n prefix[0] = 0;\n for(int i=1;i<n;i++){\n int k=prefix[i-1]; //because index is 0-based, and length is 1-based. so k=prefix[i-1] is just the next potential matched char\n for(;pattern[k] != pattern[i] && k>0; k=prefix[k-1]);\n if(pattern[k] == pattern[i]) prefix[i] = k+1; //here k is index of 0-based, prefix[i] should be 1-based, prefix[i]<=i\n else prefix[i] = 0;\n }\n return;\n}\n\n/*\n * in total, KMP is in time O(n+m) while n is length of string to match, m is length of pattern\n * */\nbool isMatchKMP(const string& str, const string& pattern){\n int n=str.size(), m=pattern.size();\n if(n<m) return false;\n if(n==0 && m==0) return true;\n if(m==0) return false;\n int *prefix = new int[m]();\n setPrefix(pattern, prefix); //get prefix array\n int i=0, s=0;\n bool bfind = false;\n while(i<n){\n int k=i-s; //k is 0-based\n if(k<0||(k<m && pattern[k] == str[i])){\n ++i;\n }else if(k==m){\n bfind=true;\n break;\n }else{ //prefix[k] <=k\n s += (k<1)? 1 : k - prefix[k-1]; //note, shift pattern either 1 or k-prefix[k-1] !!!\n }\n }\n delete[] prefix;\n //printf(\"i=%d, s=%d\\n\", i, s);\n return bfind || i-s==m; //note if i reaches n, it must be detected as well\n}\n\nint main(int, char**){\n while(1){\n string pat;\n cout<<\"please input matching pattern:\"<<endl;\n if(getline(cin, pat)==0 || pat.empty())\n break;\n string str;\n cout<<\"please input string to match in:\"<<endl;\n if(getline(cin, str)==0 || str.empty())\n break;\n printf(\"%s\\n\", isMatchKMP(str, pat) ? \"true\" : \"false\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5154827237129211,
"alphanum_fraction": 0.5373406410217285,
"avg_line_length": 26.424999237060547,
"blob_id": "a06a9aea145d6d4c744d5a8968922175641dad9e",
"content_id": "7e1b594d34ac56cfd0a6cea8b291aaeb794707dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 40,
"path": "/leetcode/src/maxstockprofit.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * Best Time to Buy and Sell Stock\n * III.Given an array for which the ith element is the price of a given stock on day i. Find the maximum profit with at most two transactions\n * test data: \n * gas{1,2,3,4,5}, cost{3,4,5,1,2}\n * */\n#include \"../include/preliminary.h\"\n\nusing namespace std;\n\nclass Solution{\n\npublic:\n int maxProfitIII(const vector<int> &prices){\n const int n = prices.size();\n if(n < 2) return 0;\n\n int history[n];\n memset(history, 0, sizeof(history));\n int future[n];\n memset(future, 0, sizeof(future));\n\n int valley = prices[0];\n for(int i = 1;i < n; ++i){\n valley = min(valley, prices[i]);\n\n history[i] = max(history[i-1], prices[i] - valley); // max profit for days [0, i]\n }\n\n int peak = prices[n-1], sum = 0;\n for(int i = n-2;i >= 0; --i){\n peak = max(peak, prices[i]);\n future[i] = max(future[i+1], peak - prices[i]); // max profit for days [i, n-1]\n\n sum = max(sum, history[i] + future[i]);\n }\n\n return sum;\n }\n};\n\n"
},
{
"alpha_fraction": 0.26787739992141724,
"alphanum_fraction": 0.37400680780410767,
"avg_line_length": 21.810810089111328,
"blob_id": "09e5511d39285d5184dc3668fd33129d190a7fff",
"content_id": "7770cf9c587699ddb705329a4e97085d1480afc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1762,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 74,
"path": "/leetcode/src/sqrt.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * sqrt(1) = 1 , N = 1\r\n * sqrt(10) = 3 , N = 2\r\n * sqrt(100) = 10 , N = 3\r\n * sqrt(1000) = 31 , N = 4\r\n * sqrt(10000) = 100 , N = 5\r\n * sqrt(100000) = 316 , N = 6\r\n * sqrt(1000000) = 1000 , N = 7\r\n * sqrt(10000000) = 3162 , N = 8\r\n * sqrt(100000000) = 10000 , N = 9\r\n * sqrt(1000000000) = 31622 , N = 10\r\n * 2^31 = 2147483648,\r\n * 46340^2 = 2147395600\r\n * 2^30 = 1073741824\r\n * 2^15 = 32768\r\n */\r\n\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <cstring>\r\n#include <string>\r\n#include \"stdlib.h\"\r\n#include <algorithm>\r\nusing namespace std;\r\n\r\nclass Sqrt{\r\npublic:\r\n int mysqrt(int x){\r\n if(x <= 0) return 0;\r\n if(x >= 2147395600) return 46340;\r\n int a = 1, b = 2;\r\n while(b * b < x){\r\n a = b;\r\n b *= 2;\r\n if(b > 46340){ // it has to code hard :(\r\n b = 46340;\r\n break;\r\n }\r\n }\r\n if(b * b == x) return b;\r\n int m = 0;\r\n while(a < b){\r\n m = (a+b)/2;\r\n if(m * m == x){\r\n return m;\r\n }else if(m * m < x){\r\n if(m == b-1) return m;\r\n a = m;\r\n }else{\r\n b = m;\r\n }\r\n }\r\n return a;\r\n }\r\n\r\n void test_01(){\r\n string str;\r\n while(1){\r\n cout << \"please input integer x:\" << endl;\r\n if(getline(cin, str)==0 || str.empty()) break;\r\n int x = atoi(str.c_str());\r\n printf(\"sqrt is %d\\n\", mysqrt(x));\r\n }\r\n return;\r\n }\r\n};\r\n\r\nint main(){\r\n Sqrt *st = new Sqrt();\r\n st->test_01();\r\n delete st;\r\n st = 0;\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.33212077617645264,
"alphanum_fraction": 0.35394689440727234,
"avg_line_length": 21.161291122436523,
"blob_id": "05d00574b1bc98c0013066cf886420befd122902",
"content_id": "d7b00fede1c4f6f782b79fda78612857e60437dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2749,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 124,
"path": "/leetcode/src/searchRange.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a sorted array of integers, find the starting and ending position of a given target\n *\n * test case:\n * 1,1 x=1, x=0, x=2\n * 1,2,2,3,4, x=3, x=2, x=4\n * 1, x=1,0,2\n * */\n\n#include \"../include/preliminary.h\"\n\nvector<int> searchRange(int A[], int n, int x){\n vector<int> res;\n if(n==0 || (n==1 && x != A[0])){\n res.push_back(-1);\n res.push_back(-1);\n return res;\n }\n if(n==1 && x==A[0]){\n res.push_back(0);\n res.push_back(0);\n return res;\n }\n \n int v=0, u=n, m;\n while(v<u){\n m = (v+u)>>1;\n if(A[m]==x){\n break;\n }else if(A[m] > x){\n u=m;\n }else{\n v=m+1;\n }\n }\n if(v >= u){\n res.push_back(-1);\n res.push_back(-1);\n return res; \n }\n int mid = m;\n if(m==0 || A[m-1]<x){\n res.push_back(m);\n }\n if(res.size() < 1){\n u=m;\n while(v<u){\n m = (v+u) >> 1;\n if(A[m] < x){\n if(A[m+1]==x){\n res.push_back(m+1);\n break;\n }else{\n v = m+1;\n }\n }else{\n if(A[m-1]<x){\n res.push_back(m);\n break;\n }else{\n u=m;\n }\n }\n }\n }\n if(res.size()<1){\n res.push_back(m);\n }\n\n if(mid==n-1 || A[mid+1] > x){\n res.push_back(mid);\n return res;\n }\n if(res.size()<2){\n v=mid, u=n;\n while(v<u){\n m = (v+u)>>1;\n if(A[m] > x){\n if(A[m-1]==x){\n res.push_back(m-1);\n break;\n }else{\n u=m-1;\n }\n }else{\n if(A[m+1]>x){\n res.push_back(m);\n break;\n }else{\n v=m+1;\n }\n }\n }\n }\n if(res.size()<2){\n res.push_back(m);\n }\n return res;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input sorted integer array:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n \n printf(\"please input sorted integer array:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int target = atoi(str.c_str());\n vector<int> res = searchRange(arr, n, target);\n for(size_t i=0;i<res.size();i++){\n printf(\"%d \", res[i]);\n }\n printf(\"\\n\");\n delete[] arr;\n }\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.5356371402740479,
"alphanum_fraction": 0.5831533670425415,
"avg_line_length": 21.047618865966797,
"blob_id": "6c51c0a34691c9b75553576b8a0e80cc755f5ab5",
"content_id": "a187d4c95b501c4acd0adc5988c14d5a8c1648ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 21,
"path": "/leetcode/cpp_unittest/candy_unittest/candy_unittest.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include \"candy.cpp\"\n#include \"gtest/gtest.h\"\n\n/* int Solution::candy(vector<int>&) */\n\n// Test case: candyTest\n// Test name: Positive\nTEST(candyTest, Positive01){\n Solution s;\n\n\tint arr[] = {1, 2, 4, 4, 4, 2, 2, 2, 1};\n\tint candies[] = {1, 2, 3, 1, 2, 1, 1, 2, 1};\n\tint expected = 0;\n\tint n = sizeof(arr) / sizeof(int);\n\tfor(int i=0; i < n; i++){\n\t\texpected += candies[i];\n\t}\n\n\tvector<int> ratings(arr, arr + n);\n\tEXPECT_EQ(expected, s.candy(ratings));\n}\n"
},
{
"alpha_fraction": 0.48681673407554626,
"alphanum_fraction": 0.4971061050891876,
"avg_line_length": 22.560606002807617,
"blob_id": "00fba5ccaffda4df8febb4036919b5a8ece039c4",
"content_id": "8cb2ceec6a5a6e0cdd9a2075b37ddd4be4d44c14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1555,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 66,
"path": "/topics/graph/src/genGraph.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*****************genGraph.cpp*********************/\n#include \"genGraph.h\"\n\ntemplate<typename pT>\nvoid swapLocal(pT& lhd, pT&rhd){\n pT tmp = rhd;\n rhd = lhd;\n lhd = tmp;\n tmp = 0;\n}\n\ngenGraph::genGraph(int vN, int eN, int mtx[BoundMax][BoundMax])\n :vNum(vN)\n ,eNum(eN)\n ,edgeArray(new genEdge*[BoundMax]()) \n{\n //memset(edgeArray, 0, sizeof(genEdge*)*BoundMax);\n int k=0;\n for(int i=0; i<vNum; i++)\n for(int j=0;j<vNum;j++){\n adjaMtx[i][j] = mtx[i][j];\n if(k<eNum && mtx[i][j] != MAX && mtx[i][j]!=MIN){ // j>i limit it to undigraph\n if(findEdge(i,j) == -1){\n edgeArray[k] = new genEdge(mtx[i][j], i, j);\n ++k;\n }\n }\n }\n}\n\ngenGraph::~genGraph(){\n delete[] edgeArray;\n}\n\nint genGraph::findEdge(int u, int v){\n if(u>v)\n swapLocal<int>(u, v);\n for(int i=0;edgeArray[i]!= 0;i++)\n if(edgeArray[i]->v1 == u \n && edgeArray[i]->v2 == v)\n return i;\n return -1;\n}\n\n\n//not completed\nvoid quickSort(genEdge* arr[BoundMax], int start, int length){\n //int mid = start+length/2;\n \n}\n\nvoid genGraph::sortEdges(){ //bumble \n for(int i=0;i<eNum-1;i++)\n for(int j=i+1;j<eNum;j++){\n if(edgeArray[i]->compare(edgeArray[j])){ //greater than return true\n swapLocal<genEdge*>(edgeArray[i], edgeArray[j]);\n }\n }\n}\n\nvoid genGraph::outputEdges(){\n for(int i=0;i<eNum;i++){\n printf(\"%d \", edgeArray[i]->weight);\n }\n printf(\"\\n\");\n}\n"
},
{
"alpha_fraction": 0.44690266251564026,
"alphanum_fraction": 0.47050148248672485,
"avg_line_length": 20.171875,
"blob_id": "048509e67adb6b6283acc81134d97ed175cd4d5d",
"content_id": "87df636fd16e97f6a90661014d4761daa87fd372",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1356,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 64,
"path": "/leetcode/src/pascalTriangleII.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given an index k, return kth row of Pascal's triangle.\n * e.g, given k=3, return: 1,3,3,1\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include \"stdlib.h\"\n#include <vector>\n\nusing namespace std;\n\nvector<int> getRow(int k){ //kth row, has k+1 elements\n vector<int> res;\n if(k<0) return res;\n int **dp = new int*[2];\n for(int i=0;i<2;i++){\n dp[i] = new int[k+1]();\n }\n int last = 0;\n dp[last][0] = 1;\n for(int i=1;i<=k;i++){\n int now = 1-last;\n memset(dp[now], 0, sizeof(int)*(k+1));\n dp[now][0] = dp[last][0];\n for(int j=1;j<i;++j){\n dp[now][j] = dp[last][j-1] + dp[last][j];\n }\n dp[now][i] = dp[last][i-1];\n last = now;\n }\n for(int i=0;i<=k;i++){\n res.push_back(dp[last][i]);\n }\n\n for(int i=0;i<2;i++){\n delete[] dp[i];\n dp[i] = 0;\n }\n delete[] dp;\n dp=0;\n return res;\n}\n\nvoid show(const vector<int>& vec){\n int n = vec.size();\n for(int i=0;i<n;++i){\n printf(\"%d \", vec[i]);\n }\n printf(\"\\n\");\n}\n\nint main(int, char**){\n string str;\n while(1){\n printf(\"please input numRows:\\n\");\n if(getline(cin, str)==0 || str.empty()) \n break;\n int n = atoi(str.c_str());\n show(getRow(n));\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.45941686630249023,
"alphanum_fraction": 0.4728132486343384,
"avg_line_length": 24.87755012512207,
"blob_id": "9dabeec6d5a74d1d9c5107d7f3a225aa9e22e98b",
"content_id": "4f11a351ff816078a37535ccf4363e40b5e73d93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1269,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 49,
"path": "/leetcode/src/searchInsert.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a sorted array and a target value, return index if it is found. if not, return the index where it would be inserted in order\n * assume array is in ascending order without duplicates.\n * */\n#include \"../include/preliminary.h\"\n\nint searchInsert(int A[], int n, int x){\n int v=0, u=n, m;\n while(v<u){\n m = (v+u)>>1;\n if(A[m]==x){\n return m;\n }else if(A[m] > x){\n if(m==0 || A[m-1] < x){\n return m;\n }else{\n u=m;\n }\n }else{\n if(m == n-1 || A[m+1] >= x){\n return m+1;\n }else{\n v=m+1;\n }\n }\n }\n return v;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input sorted integer array:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n\n printf(\"please input target value to seach:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int target = atoi(str.c_str());\n printf(\"position to insert: %d\\n\", searchInsert(arr, n, target));\n delete[] arr;\n }\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.5447394251823425,
"alphanum_fraction": 0.5506391525268555,
"avg_line_length": 28.05714225769043,
"blob_id": "9d358f1fd25b3e2d96cabf4743a1ae7d134c47b9",
"content_id": "0027cac8bb80cdb9634377c327ac0f0412a6b93a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1017,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 35,
"path": "/topics/modematch/src/wordbreak.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * from oj.leetcode\n * */\n#include \"../header/preliminary.h\"\n\nvoid collect(vector<list<int> > &mark, int ind, const string &s, string path, vector<string>& result){\n for(auto& stop: mark[ind]){\n string sub = s.substr(ind,stop-ind);\n string newpath = path + (ind==0 ? sub : \" \"+sub);\n if(stop==s.length()){\n result.push_back(newpath);\n }else{\n collect(mark,stop,s,newpath,result);\n }\n }\n}\n\nvector<string> wordBreak(string s, unordered_set<string> &dict){\n vector<list<int>> mark(s.length(),list<int>());\n for(int stop=s.length();stop>=0;stop--){\n if(stop < s.length() && mark[stop].empty()) //most smart statement !!!!\n continue;\n for(int start=stop-1;start>=0;start--){\n if(dict.count(s.substr(start,stop-start)))\n mark[start].push_back(stop);\n }\n vector<string> result;\n collect(mark,0,s,\"\",result);\n return result;\n }\n}\n\nint main(int, char**){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3619367182254791,
"alphanum_fraction": 0.39525407552719116,
"avg_line_length": 23.397661209106445,
"blob_id": "aac04f3abff18afbba5996b7e7a0d43adad80688",
"content_id": "b03c493bc3ea2f74e423fa0885a4ffff2b88a14c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4172,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 171,
"path": "/leetcode/src/spiralmatrix.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a matrix of mx x n elements(m rows, n columns), return all elements of the matrix in spiral order\n *\n * test case:\n * 1 2 3 4 \n * 5 6 7 8\n * 9 10 11 12\n * output in spiral order: 1,2,3,4,8,12,11,10,9,5,6,7\n * */\n#include \"../include/preliminary.h\"\n\nvector<int> spiralOrder(vector<vector<int> >& matrix){\n vector<int> res;\n int d = matrix.size();\n if(d==0) return res;\n int w = matrix[0].size();\n if(w==0) return res;\n \n int step[] = {1,-1,-1,1};\n int i=0, j=0, k=0;\n while(w>0 && d>0){\n if((k & 1) == 0){ // k == 0, 2\n if(k==0){\n for(int cnt=0; cnt<w; ++cnt, ++j){\n res.push_back(matrix[i][j]);\n }\n --j;\n }else if(k==2){\n for(int cnt=0; cnt<w; ++cnt, --j){\n res.push_back(matrix[i][j]);\n }\n ++j;\n }\n i += step[k];\n --d;\n }else{\n if(k==1){\n for(int cnt=0; cnt<d; ++cnt, ++i){\n res.push_back(matrix[i][j]);\n }\n --i;\n }else if(k==3){\n for(int cnt=0; cnt<d; ++cnt, --i){\n res.push_back(matrix[i][j]);\n }\n ++i;\n }\n j += step[k];\n --w; \n }\n k = (k+1)%4;\n }\n return res;\n}\n\nvoid fillMatrix(vector<vector<int> >& matrix, int n){\n if(n<1) return;\n for(int i=0; i<n; ++i){\n vector<int> vec;\n for(int j=0; j<n; ++j){\n vec.push_back(0);\n }\n matrix.push_back(vec);\n }\n return;\n}\n\n/*\n * Spiral Matrix II\n * */\nvector<vector<int> > generateMatrix(int n){\n vector<vector<int> > matrix;\n if(n<1) return matrix;\n int d = n, w = n;\n fillMatrix(matrix, n);\n \n int step[] = {1,-1,-1,1};\n int i=0, j=0, k=0, a=1;\n bool horizon = true;\n while(w>0 && d>0){\n if(horizon){\n if(k==0){\n for(int cnt=0; cnt<w; ++cnt, ++j){\n matrix[i][j] = a++;\n }\n --j;\n }else if(k==2){\n for(int cnt=0; cnt<w; ++cnt, --j){\n matrix[i][j] = a++;\n }\n ++j;\n }else{\n break;\n }\n i += step[k];\n --d;\n }else{\n if(k==1){\n for(int cnt=0; cnt<d; ++cnt, ++i){\n matrix[i][j] = a++;\n }\n --i;\n }else if(k==3){\n for(int cnt=0; cnt<d; ++cnt, --i){\n matrix[i][j] = a++;\n }\n ++i;\n }else{\n break;\n }\n j += step[k];\n --w; \n }\n k = (k+1)%4;\n horizon = !horizon;\n }\n return matrix;\n}\n\nvoid displayVector(const vector<int>& nums){\n for(vector<int>::const_iterator iter = nums.begin(); iter != nums.end(); ++iter){\n cout << (*iter) << \" \";\n }\n cout << endl;\n return;\n}\n\nvoid displayMatrix(const vector<vector<int> >& matrix){\n int n = matrix.size();\n for(int i=0; i<n; ++i){\n for(int j=0; j<n; ++j){\n printf(\"%d \", matrix[i][j]);\n }\n printf(\"\\n\");\n }\n return;\n}\n\nvoid test_01(){\n int arr0[] = {1,2,3,4};\n vector<int> vec0(arr0, arr0 + 4);\n int arr1[] = {5,6,7,8};\n vector<int> vec1(arr1, arr1 + 4);\n int arr2[] = {9,10,11,12};\n vector<int> vec2(arr2, arr2 + 4);\n int arr3[] = {13,14,15,16};\n vector<int> vec3(arr3, arr3 + 4);\n vector<vector<int> > matrix;\n matrix.push_back(vec0);\n matrix.push_back(vec1);\n matrix.push_back(vec2);\n matrix.push_back(vec3);\n displayVector(spiralOrder(matrix));\n return;\n}\n\nvoid test_02(){\n string str;\n while(1){\n printf(\"please input integer n:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int n = atoi(str.c_str());\n displayMatrix(generateMatrix(n));\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.42461782693862915,
"alphanum_fraction": 0.47944122552871704,
"avg_line_length": 26.897058486938477,
"blob_id": "c9328385b03dfe2881cf8f9c6eaee7cac7659eed",
"content_id": "ef86b2940377c0792ffa3dc9ff4e2f55442d72cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3794,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 136,
"path": "/leetcode/src/largestX.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a matrix of 0/1, find the largest X made up of 1\n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <vector>\n#include <string>\n\nusing namespace std;\n\nbool check(const vector<vector<char> >& board, int cx, int cy, int d){\n if(board[cx][cy] != '1') return false;\n for(int k=d;k >= 1;k--){\n if(board[cx-k][cy-k] != '1' //NW\n || board[cx-k][cy+k] != '1' //NE\n || board[cx+k][cy-k] != '1' //SW\n || board[cx+k][cy+k] != '1'){ //SE\n return false;\n }\n }\n return true;\n}\n\nint solve(const vector<vector<char> >& board){\n int m = board.size();\n int n = board.size();\n if(m<3 || n<3) return 0;\n int d=1;\n for(int cx=d, cy=d; cx+d<m && cy+d<n;){\n if(check(board, cx, cy, d)){\n ++d;\n cx=d;\n cy=d;\n }else{\n ++cy;\n if(cy+d >= m){\n ++cx;\n cy=d;\n }\n }\n }\n return d-1;\n}\n\nvoid display(const vector<vector<char> >& board){\n int m=board.size();\n int n=board.size();\n for(int i=0;i<m;++i){\n for(int j=0;j<n;++j){\n printf(\"%c \", board[i][j]);\n }\n printf(\"\\n\");\n }\n}\n\nvoid display(const vector<char>& line){\n int m = line.size();\n for(int i=0;i<m;i++){\n printf(\"%c \", line[i]);\n }\n printf(\"\\n\");\n}\n\nvoid test_01(){\n vector<vector<char> > board;\n char arr0[] = {'1', '0', '1', '1', '1', '0', '1'};\n vector<char> vec0(arr0, arr0 + sizeof(arr0)/sizeof(char));\n board.push_back(vec0);\n\n char arr1[] = {'0', '1', '0', '1', '1', '1', '0'};\n vector<char> vec1(arr1, arr1 + sizeof(arr1)/sizeof(char));\n board.push_back(vec1);\n \n char arr2[] = {'1', '0', '1', '0', '1', '0', '1'};\n vector<char> vec2(arr2, arr2 + sizeof(arr2)/sizeof(char));\n board.push_back(vec2);\n \n char arr3[] = {'1', '1', '1', '1', '0', '1', '1'};\n vector<char> vec3(arr3, arr3 + sizeof(arr3)/sizeof(char));\n board.push_back(vec3);\n \n char arr4[] = {'1', '1', '1', '0', '1', '1', '0'};\n vector<char> vec4(arr4, arr4 + sizeof(arr4)/sizeof(char));\n board.push_back(vec4);\n \n char arr5[] = {'1', '0', '1', '1', '0', '1', '1'};\n vector<char> vec5(arr5, arr5 + sizeof(arr5)/sizeof(char));\n board.push_back(vec5);\n \n char arr6[] = {'1', '1', '1', '1', '1', '0', '1'};\n vector<char> vec6(arr6, arr6 + sizeof(arr6)/sizeof(char));\n board.push_back(vec6);\n \n display(board);\n printf(\"largest x is leg of %d\\n\", solve(board));\n}\n\nvoid test_02(){\n vector<vector<char> > board;\n char arr0[] = {'1', '0', '0', '0', '0', '0', '1'};\n vector<char> vec0(arr0, arr0 + sizeof(arr0)/sizeof(char));\n board.push_back(vec0);\n\n char arr1[] = {'0', '1', '0', '0', '0', '1', '0'};\n vector<char> vec1(arr1, arr1 + sizeof(arr1)/sizeof(char));\n board.push_back(vec1);\n \n char arr2[] = {'1', '0', '1', '0', '1', '0', '1'};\n vector<char> vec2(arr2, arr2 + sizeof(arr2)/sizeof(char));\n board.push_back(vec2);\n \n char arr3[] = {'0', '0', '0', '1', '0', '0', '0'};\n vector<char> vec3(arr3, arr3 + sizeof(arr3)/sizeof(char));\n board.push_back(vec3);\n \n char arr4[] = {'0', '0', '1', '0', '1', '1', '0'};\n vector<char> vec4(arr4, arr4 + sizeof(arr4)/sizeof(char));\n board.push_back(vec4);\n \n char arr5[] = {'0', '1', '0', '0', '0', '1', '1'};\n vector<char> vec5(arr5, arr5 + sizeof(arr5)/sizeof(char));\n board.push_back(vec5);\n \n char arr6[] = {'1', '0', '0', '0', '0', '0', '1'};\n vector<char> vec6(arr6, arr6 + sizeof(arr6)/sizeof(char));\n board.push_back(vec6);\n \n display(board);\n printf(\"largest x is leg of %d\\n\", solve(board));\n}\nint main(int, char**){\n test_01();\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4784998297691345,
"alphanum_fraction": 0.5053346157073975,
"avg_line_length": 26.616071701049805,
"blob_id": "1bd5cb98309f80d5c2c42b6f1a20c015690540eb",
"content_id": "6b5d47347d29348707685b66a9db0d6050c01461",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3093,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 112,
"path": "/leetcode/src/maxsubarray.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * find the contiguous subarray within an array(containing at least one number) which has the largest sum.\n * Furthermore, if you have figured out O(n) solution, try coding another using divide-and-conquer approach.\n *\n * test case:\n * [-1], -1\n * [-2, -3, -4, -1, -2], -1 //as subsrray has one element at least, test case of all negative elements needs careful process\n * [-1, 4, -2, 3, 1, -2], 6\n * [2, 2, -4, 1, 2, -1], 4\n * */\n#include \"../include/preliminary.h\"\n\n/*\n * linear scan in O(n)\n * */\nint maxSubArray_01(int A[], int n){ \n int sum = 0, msm = 0, t = n-1, mx = A[n-1];\n for(int i=n-1; i>=0; --i){\n mx = max(mx, A[i]); //save the max element of all\n if(A[i] <= 0){\n if(t == i){\n t = i-1;\n continue;\n }else if(A[i] + sum <= 0){\n sum = 0;\n t = i-1;\n continue;\n }else{\n sum += A[i];\n }\n }else{\n sum += A[i];\n msm = max(msm, sum);\n }\n }\n return mx<0 ? mx : msm; //msm is 0 at least, so return value depends on mx\n}\n\n/*\n * from discussion on oj.leetcode\n * */\nint maxSubArray_02(int A[], int n){\n int mSum = A[0]; //max sum\n int cSum = max(A[0], 0); //current sum\n for(int i=1; i<n; ++i){\n cSum += A[i];\n mSum = max(mSum, cSum);\n cSum = max(cSum, 0);\n }\n return mSum;\n}\n\n/*\n * from discussion on oj.leetcode\n * */\nint maxSubArray_03(int A[], int n){\n int best = A[0]; //max sum\n int curr = A[0]; //current sum\n for(int i=1; i<n; ++i){\n curr = max(curr, 0) + A[i];\n best = max(curr, best);\n }\n return best;\n}\n\n/*\n * divide-and-conquer, worse than linear solution, in time O(nlgn)\n * */\nint split(int A[], int n){ //return max sum among the range of A[]\n if(n==1) return A[0];\n int l = n >> 1;\n int lmx = split(A, l);\n int rmx = split(A+l, n-l);\n int lhalf=A[l-1], rhalf=A[l]; //initial value of lhalf and rhalf is critical important to avoid returning 0 when negative\n int tmp = lhalf;\n for(int i=l-2; i>=0; --i){ //leftward from middle line\n tmp += A[i];\n lhalf = max(lhalf, tmp);\n }\n tmp = rhalf;\n for(int i=l+1; i<n; ++i){\n tmp += A[i];\n rhalf = max(rhalf, tmp);\n }\n return max(max(lmx, rmx), lhalf + rhalf);\n}\n\nint maxSubArray_04(int A[], int n){\n if(n==1) return A[0];\n return split(A, n);\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input integer array:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n printf(\"solution1: result is %d\\n\", maxSubArray_01(arr, n));\n printf(\"solution2: result is %d\\n\", maxSubArray_02(arr, n));\n printf(\"solution3: result is %d\\n\", maxSubArray_03(arr, n));\n printf(\"solution3: result is %d\\n\", maxSubArray_04(arr, n));\n delete[] arr;\n arr=0;\n }\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5164579153060913,
"alphanum_fraction": 0.5345179438591003,
"avg_line_length": 29.380531311035156,
"blob_id": "024c07752d0551c150de1d3b9d02f78c2e163ff7",
"content_id": "3df01ef72f08c2f1284b98d161f28a08559462d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3433,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 113,
"path": "/topics/linear/src/bestBuySellStock.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * from oj.leetcode. \n * given an integer array for which the ith element is price of a given stock on day i, find solution to get maximum benefit for below constraints:\n * 1). if you were only permitted to buy one share and sell one share\n * 2). if you can keep buying and selling\n *\n * obviously, the brute force in time O(n^2).we have to find a better solution\n * \n * test data:\n * 2,1,3,5,4,0,6. b-0, s-6\n * 2,1,3,5,4,0,1. b-1, s-5\n * 6,5,4,3,2,1. no buy-sell solution at all\n * */\n#include \"../header/preliminary.h\"\n#include <queue>\n#include <vector>\n\n/*\n * problem 1, solution 1:\n * deque is good structure for this problem: only one element(lower) at head and one(higher) at tail need to consider\n * in time O(n), space O(n)\n * disadvantage: deque store elements all time, but only the one at front and back possible useful. this structure is overused absolutely\n * */\nint bestbuysellstock01_01(const int *A, int n, int& buy, int& sell){\n if(n<2) return 0;\n deque<int> q; //store index of price\n for(int i=0;i<n;++i){\n if(q.empty()){\n q.push_back(i);\n }else if(A[i] < A[q.front()]){ //store index of lower price in front\n q.push_front(i);\n }else if(A[i] > A[q.back()]){ //store index of higher price in back\n if(q.size() > 1){ //pop abandoned potential sell price\n q.pop_back();\n }\n q.push_back(i);\n }\n }\n\n while(q.size() > 2 && q.front() > q.back()){\n q.pop_front();\n }\n if(q.back() < q.front()){ //q.back() is supposed to be later than q.front()\n return 0; //no sell price higher than bit, no operation to do\n }\n sell = q.back();\n buy = q.front();\n q.clear();\n int res = A[sell] - A[buy];\n return res;\n}\n\n/*\n * problem 1, solution 2: mention as i traverse from left(earlier) to right(later), we just need to update index of min, and max diff\n * remain time O(n) without data strucure. \n * */\nint bestbuysellstock01_02(const int *A, int n, int& buy, int& sell){\n int min=0, maxDiff=0;\n buy = sell = 0;\n for(int i=1;i<n;++i){\n if(A[i] < A[min]){\n min = i;\n }else{\n int diff = A[i] - A[min];\n if(diff > maxDiff){\n maxDiff = diff;\n buy = min;\n sell = i;\n }\n }\n }\n return maxDiff;\n}\n\n/*\n * problem 2: if permit keep buying and selling\n * as a personal investor, this is easy. ideal solution is buying at all lowest and selling at all highest\n * */\nint keepbuysellstock(int *A, int n){\n int sum=0, buy=0, sell=0;\n for(int i=1;i<n;++i){\n if(A[i] >= A[i-1]){ //increasing\n if(buy == sell){\n buy = i-1;\n }\n sell = i;\n }else{ //falling down\n if(sell > buy){\n sum += A[sell] - A[buy];\n sell = buy = i-1;\n }\n }\n }\n if(sell > buy)\n sum += A[sell] - A[buy];\n return sum;\n}\n\nint main(int, char**){\n string str;\n while(1){\n cout<<\"please input integer array of stock price:\"<<endl;\n if(getline(cin, str)==0 || str.empty())\n break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n printf(\"the max profit is %d\\n\", keepbuysellstock(arr, n));\n\n delete[] arr;\n arr=0;\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5460030436515808,
"alphanum_fraction": 0.5475113391876221,
"avg_line_length": 33.894737243652344,
"blob_id": "f1f6822c1dc6f0a0d4a0347863c79debe064057d",
"content_id": "33363f1c725b5a5166e482f9a5af64397cfff9e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1326,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 38,
"path": "/leetcode/src/validateBST.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary tree, validate whether it is a binary search tree\n * NOTE: the idea beneath the solution is \"bottom-up\": when a subtree with root A is not BST, its parent with A as left/right child\n * will not be BST definitely\n * */\n#include \"../include/preliminary.h\"\n\nclass Solution{\npublic:\n bool isValidBST(TreeNode *root){\n int ml = 0, mr = 0;\n return valid(root, mk, mr);\n }\n\n /*\n * @param lfoot: most leaf leaf value\n * @param rfoot: most right leaf value\n * */\n bool valid(TreeNode *root, int lfoot, int rfoot){\n if(!root) return true;\n if(!(root->left) && !(root->right)){\n lfoot = rfoot = root->val;\n }\n if(root->left && !(root->left->val < root->val)) return false;\n if(root->right && !(root->right->val > root->val)) return false;\n int ll = lr = root->val; // default value of ll and lr if without left child\n int rl = rr = root->val; // default value of rl and rr if without right child\n if(root->left){\n if(!valid(root->left, ll, lr) || !(lr < root->val)) return false;\n }\n if(root->right){\n if(!valid(root->right. rl, rr) || !(rl > root->val)) return false;\n }\n lfoot = ll;\n rfoot = rr;\n return true;\n }\n};\n"
},
{
"alpha_fraction": 0.4305657744407654,
"alphanum_fraction": 0.43975019454956055,
"avg_line_length": 31.023529052734375,
"blob_id": "c69555f55decd1a0fd0135b4d30157fae614b625",
"content_id": "80f4054b0b0cbdab85f6e029795f0b796ae12d3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2722,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 85,
"path": "/leetcode/java/maxPoints.java",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given n points on 2D plane, find maximum number of points on one straight line\n * */\nimport java.io.*;\nimport java.util.*;\n\nclass Point{\n int x;\n int y;\n Point(){x=0; y=0;}\n Point(int a, int b){x=a; y=b;}\n}\n\npublic class maxPoints{\n public int mPoints(Point[] points){\n if(points == null) return 0;\n if(points.length <= 2) return points.length;\n\n Map<Integer, Map<Integer, Integer>> map\n = new HashMap<Integer, Map<Integer, Integer>>();\n int result = 0;\n for(int i=0; i < points.length; i++){\n map.clear();\n int overlap = 0, max = 0;\n for(int j = i+1; j < points.length; j++){\n int x = points[j].x - points[i].x;\n int y = points[j].y - points[i].y;\n if(x==0 && y==0){ // find duplicate of [i] with [j], so that no need to sort in advance\n overlap++;\n continue;\n }\n int gcd = getGCD(x, y);\n if(gcd != 0){\n x /= gcd;\n y /= gcd;\n }\n\n if(map.containsKey(x)){ // (x,y) confirms the line, y/x is its slope\n if(map.get(x).containsKey(y)){\n map.get(x).put(y, map.get(x).get(y)+1);\n }else{\n map.get(x).put(y,1);\n }\n }else{\n Map<Integer, Integer> m = new HashMap<Integer, Integer>();\n m.put(y, 1);\n map.put(x, m);\n }\n max = Math.max(max, map.get(x).get(y));\n }\n result = Math.max(result, max + overlap+1);\n }\n return result;\n }\n\n private int getGCD(int a, int b){\n if(b == 0) return a;\n else return getGCD(b, a%b);\n }\n\n public void test(){\n Scanner scan = new Scanner(System.in);\n while(true){\n System.out.println(\"please input string: \");\n String s = scan.nextLine().trim();\n if(s.isEmpty()) break;\n StringTokenizer t = new StringTokenizer(s, \" ,\");\n int[] arr = new int[t.countTokens()];\n int n=0;\n while(t.hasMoreTokens()){\n arr[n++] = Integer.parseInt(t.nextToken());\n }\n Point[] points = new Point[n/2];\n for(int i=0; i<n/2; i++){\n points[i] = new Point(arr[i*2], arr[i*2+1]);\n }\n System.out.println(\"max points on one line: \" + mPoints(points));\n }\n }\n\n public static void main(String[] args){\n maxPoints mp = new maxPoints();\n mp.test();\n }\n}\n"
},
{
"alpha_fraction": 0.5553206205368042,
"alphanum_fraction": 0.586328387260437,
"avg_line_length": 21.171875,
"blob_id": "951d3eb004eff4fd4cd2de4d2be29fab51b8f8d1",
"content_id": "6ed532ab598443bb40a1149f876d95bc68545a41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1419,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 64,
"path": "/leetcode/src/plusOne.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a non-negative number represented as an array of digits, plus one to the number\n * the digits are stored such that the most significant digit is at the head of the list\n * test data:\n * 9\n * 899\n * 8791238989123\n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <vector>\nusing namespace std;\n\n/*\n * as argument integer is represented in vector, the transmission to int is risky of overflow\n * */\nvector<int> plusOne(vector<int>& digits){\n int m = digits.size();\n if(m == 0) return vector<int>();\n int n = m + 1;\n int arr[n];\n int i=m-1, j=n-1, over=1;\n for(; i>=0; --i, --j){\n int curr = digits[i] + over;\n arr[j] = curr % 10;\n over = curr / 10;\n }\n if(over){\n arr[j--] = 1; // [j] is next significant digit to write, so j+1 is current valid most significant\n }\n return vector<int>(arr+j+1, arr+n);\n}\n\nvoid displayVector(vector<int>& vec){\n for(size_t i=0; i<vec.size(); ++i){\n printf(\"%d\", vec[i]);\n }\n printf(\"\\n\");\n return;\n}\n\nvoid test_01(){\n vector<int> input;\n input.push_back(9);\n vector<int> res = plusOne(input);\n displayVector(res);\n}\n\nvoid test_02(){\n vector<int> input;\n input.push_back(8);\n input.push_back(9);\n input.push_back(9);\n vector<int> res = plusOne(input);\n displayVector(res);\n}\n\nint main(int, char**){\n test_01();\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4167797267436981,
"alphanum_fraction": 0.4291044771671295,
"avg_line_length": 29.920578002929688,
"blob_id": "53b7aab3776131716897dda5c6ced33dbc236942",
"content_id": "4c4423c01c761bad4642a6d7391755c83fe1603a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8844,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 277,
"path": "/topics/dynamicprogramming/src/beanMan.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n* BeanMan game: moving in a M*N matrix and try to eat the most beans with his path\r\n* Problem I : one man starts from [0,0] to [M-1][N-1], only downward and rightward movement is allowed\r\n* Problem II: two men start from [0,0] to [M-1][N-1], only downward and rightward movement is allowed\r\n* -- Date: Jan, 2013\r\n*/\r\n\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <string>\r\n#include <cstring>\r\n#include \"stdlib.h\"\r\n#include <stack>\r\n\r\nusing namespace std;\r\n\r\nconst int Rows = 6;\r\nconst int Columns = 6;\r\n//it should be enum \r\nconst int EMove = 1;\r\nconst int WMove = 2;\r\nconst int NMove = 3;\r\nconst int SMove = 4;\r\n\r\nint beanMan(int pool[Rows][Columns], int prev[Rows][Columns], int beginX, int beginY, int destRow, int destCol){\r\n cout << \"The bean pool is: \" <<endl; \r\n for(int i=0;i<Rows; i++){\r\n for(int j=0; j<Columns; j++){\r\n cout << pool[i][j] << \" \";\r\n }\r\n cout << endl;\r\n }\r\n\r\n int score[Rows][Columns];\r\n memset(score, 0, sizeof(score));\r\n\r\n for(int i=beginX; i < destRow+1; i++){\r\n for(int j = beginY; j < destCol+1; j++){\r\n int preVal = 0;\r\n if(i == beginX && j == beginY){\r\n preVal = 0;\r\n }else if(i == beginX){\r\n preVal = score[i][j-1];\r\n prev[i][j] = WMove;\r\n }else if(j == beginY){\r\n preVal = score[i-1][j];\r\n prev[i][j] = NMove;\r\n }else{\r\n if(score[i-1][j] > score[i][j-1]){\r\n preVal = score[i-1][j];\r\n prev[i][j] = NMove;\r\n }else if(score[i-1][j] < score[i][j-1]){\r\n preVal = score[i][j-1];\r\n prev[i][j] = WMove;\r\n }else{\r\n int tmpi = i-1;\r\n int tmpj = j-1;\r\n while(tmpi-1 >= beginX && tmpj-1 >= beginY ){\r\n if(score[tmpi-1][j] < score[i][tmpj-1]){\r\n preVal = score[i][j-1];\r\n prev[i][j] = WMove;\r\n break;\r\n }else if(score[tmpi-1][j] > score[i][tmpj-1]){\r\n preVal = score[i-1][j];\r\n prev[i][j] = NMove;\r\n break;\r\n }else{\r\n tmpi--;\r\n tmpj--;\r\n continue;\r\n }\r\n }\r\n\r\n if(tmpi -1 < beginX && tmpj - 1 >= beginY){\r\n preVal = score[i][j-1];\r\n prev[i][j] = WMove;\r\n }else if(tmpi -1 >= beginX && tmpj -1 < beginY){ \r\n preVal = score[i-1][j];\r\n prev[i][j] = NMove;\r\n }\r\n\r\n if(prev[i][j] != NMove){\r\n prev[i][j] = WMove;\r\n preVal = score[i][j-1];\r\n }\r\n }\r\n }\r\n score[i][j] = preVal + pool[i][j];\r\n }\r\n }\r\n\r\n cout << \"The score array is: \" <<endl; \r\n for(int i=beginX;i<=destRow; i++){\r\n for(int j=beginY; j<=destCol; j++){\r\n cout << score[i][j] << \" \";\r\n }\r\n cout << endl;\r\n }\r\n return score[destRow][destCol];\r\n}\r\n\r\n//recurse\r\nvoid trace(int prev[Rows][Columns], int beginX, int beginY, int dR, int dC){\r\n int r = dR;\r\n int c = dC;\r\n if(r == beginX && c == beginY){\r\n cout << \"(\" << r << \", \" << c << \")\";\r\n return;\r\n }else{\r\n switch (prev[r][c]){\r\n case NMove:\r\n r--;\r\n break;\r\n case WMove:\r\n c--;\r\n break;\r\n default:\r\n r--;\r\n c--;\r\n break; \r\n }\r\n trace(prev, beginX, beginY, r, c);\r\n }\r\n cout << \" --> \" << \"(\" << dR << \", \" << dC << \")\" ;\r\n}\r\n\r\n/*\r\n * for double bean man problem.\r\n */\r\n\r\n/* \r\n * trace the best path from begin point to destination point backwards\r\n * */\r\nvoid backTrace(int prev[Rows][Columns], int boundary[Rows], int sR, int sC, int dR, int dC, bool bResetUpper){\r\n if(bResetUpper){\r\n for(int i=0; i<Rows; i++){\r\n boundary[i] = Columns;\r\n }\r\n }else{\r\n for(int i=0; i<Rows; i++){\r\n boundary[i] = -1;\r\n } \r\n }\r\n \r\n int r = dR;\r\n int c = dC;\r\n while(r >= sR && c >= sC){\r\n cout << \"(\" << r << \", \" << c << \") <<\" ; \r\n if(bResetUpper){\r\n if(c < boundary[r]) boundary[r] = c;\r\n }else{\r\n if(c > boundary[r]) boundary[r] = c;\r\n }\r\n\r\n switch (prev[r][c]){\r\n case NMove:\r\n r--;\r\n break;\r\n case WMove:\r\n c--;\r\n break;\r\n default:\r\n r--;\r\n c--;\r\n break; \r\n }\r\n continue; \r\n }\r\n cout << endl << \"-----------------------------------\" << endl;\r\n}\r\n\r\n/* \r\n * based on an existing boundary and up/down direction, update the pool matrix \r\n * */\r\nvoid updatePool(int pool[Rows][Columns], int boundary[Rows], bool bResetUpper){\r\n cout << \"The boundary array is: \" << endl;\r\n for(int i = 0; i < Rows; ++i){ \r\n int j = boundary[i];\r\n cout << \"[\" << i << \", \" << boundary[i] << \"] --> \";\r\n if(bResetUpper){\r\n if(j >= Columns) continue;\r\n while(j < Columns){\r\n pool[i][j] = 0;\r\n j++;\r\n }\r\n }else{\r\n if(j < 0) continue; \r\n while(j >= 0){\r\n pool[i][j] = 0;\r\n j--;\r\n } \r\n } \r\n }\r\n cout<<endl;\r\n}\r\n\r\nvoid cpArray(int src[Rows][Columns], int dest[Rows][Columns]){\r\n memset(dest, 0, sizeof(dest));\r\n for(int i=0; i<Rows; i++){\r\n for(int j=0; j<Columns; j++){\r\n dest[i][j] = src[i][j];\r\n }\r\n }\r\n}\r\n\r\n/*\r\n * plan A, independent best path from [0,1] to [N-2, N-1], and dependent best path from [1,0] to [N-1, N-2]\r\n * plan B, independetn best path from [1,0] to [N-1, N-2], and dependent best path from [0,1] to [N-2, N-1]\r\n * */\r\nvoid beanMan2(int pool[Rows][Columns], int prev[Rows][Columns], int sR, int sC, int dR, int dC){\r\n memset(prev, 0, sizeof(prev));\r\n \r\n int tmpPool[Rows][Columns];\r\n cpArray(pool, tmpPool);\r\n\r\n int boundary[Rows];\r\n for(int i=0; i<Rows; i++){\r\n boundary[i] = Columns-1;\r\n }\r\n\r\n //independent best path from [0,1] to [N-2, N-1]\r\n int beginX = sR;\r\n int beginY = sC + 1;\r\n int endX = dR - 1;\r\n int endY = dC;\r\n \r\n int UpScoreA = beanMan(pool, prev, beginX, beginY, endX, endY);\r\n cout << \"Plan A, independent best path scores: \" << UpScoreA << endl;\r\n backTrace(prev, boundary, beginX, beginY, endX, endY, true);\r\n\r\n //dependent best path from [1,0] to [N-1,N-2]\r\n updatePool(tmpPool, boundary, true);\r\n memset(prev, 0, sizeof(prev));\r\n beginX = sR + 1;\r\n beginY = sC;\r\n endX = dR;\r\n endY = dC -1;\r\n int DownScoreA = beanMan(tmpPool, prev, beginX, beginY, endX, endY);\r\n cout << \"Plan A, dependent best path scores: \" << DownScoreA << endl;\r\n backTrace(prev, boundary, beginX, beginY, endX, endY, false);\r\n int scoreA = pool[sR][sC] + UpScoreA + DownScoreA + pool[dR][dC];\r\n cout << \"In total, Plan A scores: \" << scoreA <<endl;\r\n cout << \"===========================================================\" << endl; \r\n \r\n\r\n //plan B:\r\n memset(prev, 0, sizeof(prev));\r\n cpArray(pool, tmpPool);\r\n\r\n //independent best path from [1,0] to [N-1, N-2]\r\n beginX = sR + 1;\r\n beginY = sC;\r\n endX = dR;\r\n endY = dC - 1;\r\n int DownScoreB = beanMan(pool, prev, beginX, beginY, endX, endY);\r\n cout << \"Plan B, independent best path scores: \" << DownScoreB << endl;\r\n backTrace(prev, boundary, beginX, beginY, endX, endY, false);\r\n\r\n //dependent best path from [0,1] to [N-2,N-1]\r\n updatePool(tmpPool, boundary, false);\r\n memset(prev, 0, sizeof(prev));\r\n beginX = sR;\r\n beginY = sC + 1;\r\n endX = dR - 1;\r\n endY = dC;\r\n int UpScoreB = beanMan(tmpPool, prev, beginX, beginY, endX, endY);\r\n cout << \"Plan B, dependent best path scores: \" << UpScoreB << endl;\r\n backTrace(prev, boundary, beginX, beginY, endX, endY, true);\r\n int scoreB = pool[sR][sC] + UpScoreB + DownScoreB + pool[dR][dC];\r\n cout << \"In total, Plan B scores: \" << scoreB <<endl;\r\n cout << \"Among Plan A and B, the better is \" << (scoreB > scoreA ? 'B':'A') << endl;\r\n cout << \"******************************************************************************\" << endl;\r\n}\r\n\r\nint main(int, char**){\r\n return 0;\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.47550034523010254,
"alphanum_fraction": 0.483091801404953,
"avg_line_length": 27.41176414489746,
"blob_id": "cc4e26a31b0301e8bbe6350042979c38fc826142",
"content_id": "0dfb65f0f3cdc23c028a3af4b8d295096688097b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1449,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 51,
"path": "/leetcode/src/recoverBST.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * two elements of a BST are swapped by mistake. find them and recover the tree without changing the structure\n * use space O(1)\n * */\n#include \"../include/preliminary.h\"\n\nvoid swap(int &a, int &b){\n int tmp = a;\n a = b;\n b = tmp;\n}\n\n/*\n * idea: Morris inorder to traverse BST in ascending order. store the swapped nodes\n * */\nvoid recoverTree(TreeNode *root){\n TreeNode *p = root, *tmp = NULL, *pred = NULL;\n TreeNode *cur1 = NULL, *cur2 = NULL; // two swapped nodes to recover\n while(p){\n if(p->left == NULL){\n pred = p; // visit p\n p = p->right;\n }else{\n tmp = p->left; // find the right most leaf of left half\n while(tmp->right != NULL\n && tmp->right != p){\n tmp = tmp->right;\n }\n\n if(tmp->right == NULL){\n tmp->right = p; // extra link up\n p = p->left;\n }else{\n pred = p; // visit p\n tmp->right = NULL; // release the extra link up\n p = p->right;\n }\n }\n\n if(pred && p && pred->val > p->val){ // in normal, pred should be greater then p\n if(!cur1) cur1 = pred; // 1st swapped node\n cur2 = p; // anyway, it must be the 2nd swapped node\n pred = NULL; // defensive coding\n }\n }\n swap(cur1->val, cur2->val);\n}\n\nint main(){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4638054370880127,
"alphanum_fraction": 0.4755364954471588,
"avg_line_length": 27.61864471435547,
"blob_id": "9fd6915bbea55e2234a4532d4177d48fd4056a70",
"content_id": "700ba15b48421995da446ff36becaea2c351d1c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3495,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 118,
"path": "/leetcode/src/zigzagLevelOrder.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given a binary tree,\r\n * 1. return zigzag level order traversal of its nodes' values.\r\n * (ie, firstly from left to right, then right to left for the next level and alternate between)\r\n * --->\r\n * <---\r\n * --->\r\n * <---\r\n *\r\n * 2. return level order traversal\r\n * --->\r\n * --->\r\n * --->\r\n * */\r\n\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <vector>\r\n#include <stack>\r\n\r\nusing namespace std;\r\n\r\nstruct TreeNode{\r\n int val;\r\n TreeNode *left;\r\n TreeNode *right;\r\n TreeNode(int x): val(x), left(NULL), right(NULL){}\r\n};\r\n\r\nclass Solution{\r\npublic:\r\n vector<vector<int> > zigzagLevelOrder(TreeNode* root){\r\n vector<vector<int> > res;\r\n if(!root) return res;\r\n stack<TreeNode*> stks[2]; // key structure for zigzag level order\r\n bool isl2r = true;\r\n int i = 0;\r\n stks[i].push(root);\r\n while(!stks[i].empty()){\r\n vector<int> level;\r\n while(!stks[i].empty()){\r\n TreeNode* rt = stks[i].top();\r\n if(isl2r){\r\n if(rt->left) stks[1-i].push(rt->left);\r\n if(rt->right) stks[1-i].push(rt->right);\r\n }else{\r\n if(rt->right) stks[1-i].push(rt->right); \r\n if(rt->left) stks[1-i].push(rt->left);\r\n }\r\n level.push_back(rt->val);\r\n stks[i].pop();\r\n }\r\n if(!level.empty()) res.push_back(level);\r\n isl2r = !isl2r;\r\n i = 1-i;\r\n }\r\n return res;\r\n }\r\n\r\n vector<vector<int> > levelOrder(TreeNode* root){\r\n vector<vector<int> > res;\r\n if(!root) return res;\r\n vector<TreeNode*> arr[2]; // key structure for primary level order\r\n int i=0;\r\n arr[i].push_back(root);\r\n while(!arr[i].empty()){\r\n vector<int> level;\r\n int n = arr[i].size();\r\n for(int j=0; j<n; j++){\r\n TreeNode *curr = arr[i][j];\r\n if(curr->left) arr[1-i].push_back(curr->left);\r\n if(curr->right) arr[1-i].push_back(curr->right);\r\n level.push_back(curr->val);\r\n }\r\n res.push_back(level);\r\n arr[i].clear();\r\n i = 1-i;\r\n }\r\n return res;\r\n }\r\n\r\n void test_01(){\r\n TreeNode* root = new TreeNode(1);\r\n root->left = new TreeNode(2);\r\n root->right = new TreeNode(3);\r\n root->left->left = new TreeNode(0);\r\n root->left->right = new TreeNode(4);\r\n root->right->left = new TreeNode(5);\r\n root->right->right = new TreeNode(7);\r\n root->right->left->left = new TreeNode(6);\r\n root->right->left->right = new TreeNode(10);\r\n root->right->right->left = new TreeNode(9);\r\n root->right->right->right = new TreeNode(8);\r\n vector<vector<int> > res1 = zigzagLevelOrder(root);\r\n displayVectorOfVector(res1);\r\n vector<vector<int> > res2 = levelOrder(root);\r\n displayVectorOfVector(res2);\r\n }\r\n\r\n void displayVector(vector<int>& vec){\r\n int n = vec.size();\r\n for(int i=0; i<n; i++){\r\n cout << vec[i] << \" \";\r\n }\r\n cout << endl;\r\n }\r\n\r\n void displayVectorOfVector(vector<vector<int> >& matrix){\r\n for(int i=0; i < (int)matrix.size(); i++){\r\n displayVector(matrix[i]);\r\n }\r\n }\r\n};\r\n\r\nint main(){\r\n Solution s;\r\n s.test_01();\r\n}\r\n"
},
{
"alpha_fraction": 0.5663129687309265,
"alphanum_fraction": 0.5857648253440857,
"avg_line_length": 31.314285278320312,
"blob_id": "0634e52c27884c059b31580d9ccb6103ebdd522d",
"content_id": "e11817016c1cb3a6aa3435fe9b41a30be4b45804",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2262,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 70,
"path": "/leetcode/src/longestconsecutive.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given an unsorted array of integers, find the length of the longest consecutive elements sequence. complete it in time O(n)\n * \n * test case:\n * [100, 4, 200, 1, 3, 2], the longest consecutive sequence is [1,2,3,4], length is 4\n *\n * */\n\n#include \"../include/preliminary.h\"\n#include <unordered_map>\n\n/*\n * hash_map<>(unordered_map<>) will be used definitely, but how to enable map[i] present consecutive sequence length covering it? how to \n * process upper(right)/lower(left) bound?\n * */\nint longestConsecutive(vector<int> &num){\n if(num.size()==0) return 0;\n unordered_map<int, int> uii;\n int maxlen{1};\n for(auto &val : num){\n if(uii[val] != 0) continue; //NOTE: operator[] is overused, while key not in, after operator[] is called, size increases by 1\n uii[val] = 1;\n int leftbound{uii[val-1]}, rightbound{uii[val+1]};\n uii[val-leftbound] = uii[val+rightbound] = 1 + leftbound + rightbound;\n maxlen = max(maxlen, 1+leftbound+rightbound);\n }\n return maxlen;\n}\n\n/*\n * modified version which call find() instead of operator[]\n * */\nint longestConsecutive_02(vector<int> &num){\n if(num.size()==0) return 0;\n unordered_map<int, int> uii;\n int maxlen{1};\n unordered_map<int, int>::const_iterator it = uii.end();\n for(auto &val : num){\n it = uii.find(val);\n if(it != uii.end()) continue;\n uii[val] = 1;\n\n int leftbound = 0;\n it = uii.find(val-1);\n if(it != uii.end()) leftbound = it->second;\n int rightbound = 0;\n it = uii.find(val+1);\n if(it != uii.end()) rightbound = it->second;\n \n uii[val-leftbound] = uii[val+rightbound] = 1 + leftbound + rightbound;\n maxlen = max(maxlen, 1+leftbound+rightbound);\n }\n return maxlen;\n}\n\nint main(int, char**){\n string str;\n while(1){\n printf(\"input int array:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n vector<int> vec;\n for(int i=0;i<n;i++){\n vec.push_back(arr[i]);\n }\n printf(\"length of longest consecutive sequence is %d\\n\", longestConsecutive_02(vec));\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5340050458908081,
"alphanum_fraction": 0.5491183996200562,
"avg_line_length": 21.05555534362793,
"blob_id": "fe06dda8a18a2bf455aa614484c4e6ea358326ee",
"content_id": "8f6ef4b9c900b1b4a5b6fdcad80afe4013b8cdc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 794,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 36,
"path": "/leetcode/src/longestcommonprefix.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * find the longest common prefix string amongst an array of strings\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <vector>\n#include <algorithm>\n\nusing namespace std;\n\nstring longestCommonPrefix(const vector<string>& strs){\n int n = strs.size();\n if(n==0) return string();\n if(n==1) return string(strs[0]);\n size_t length = strs[0].size();\n for(int i=1;i<n;i++){\n length = min(length, strs[i].size());\n }\n char *res = new char[length+1];\n size_t i=0;\n for(;i<length;++i){\n int j=1;\n for(;j<n && strs[j][i] == strs[j-1][i];++j);\n if(j<n) break;\n res[i] = strs[0][i];\n }\n res[i] = '\\0';\n string prefix(res);\n delete[] res;\n return prefix;\n}\n\nint main(int, char**){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3838028311729431,
"alphanum_fraction": 0.41109153628349304,
"avg_line_length": 22.64583396911621,
"blob_id": "82cb76e78b6e011fbfda20581fbeb64a6906fc44",
"content_id": "dcc491ece8aab204abe900d4eafbd33575d350e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1136,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 48,
"path": "/leetcode/src/setZeroes.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * set matrix zeroes. given a m*n matrix, if an element is 0, set its entire row and column to 0. do it in place\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <vector>\nusing namespace std;\n\nvoid setZeroes(vector<vector<int> >& grid){\n int m = grid.size();\n if(m==0) return;\n int n = grid[0].size();\n if(n==0) return;\n bool row = false, col = false;\n \n for(int i=0; i<m; ++i){\n for(int j=0; j<n; ++j){\n if(grid[i][j] == 0){\n if(i==0) row = true;\n if(j==0) col = true;\n grid[i][0] = 0; // projection to column 0\n grid[0][j] = 0; // projection to row 0\n }\n }\n }\n for(int i=1; i<m; ++i){\n for(int j=1; j<n; ++j){\n if(grid[i][0] == 0 || grid[0][j] == 0){\n grid[i][j] = 0;\n }\n }\n }\n if(row){ // set row 0 to all zeroes\n for(int j=0; j<n; ++j){\n grid[0][j] = 0;\n }\n }\n if(col){\n for(int i=0; i<m; ++i){\n grid[i][0] = 0;\n }\n }\n return;\n}\n\nint main(){\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.5968421101570129,
"alphanum_fraction": 0.6126315593719482,
"avg_line_length": 23.35897445678711,
"blob_id": "d857256fabcfae98b0d1583fb7a3e4e489a3c29a",
"content_id": "7848d8a9aef8f6614f615ca671f5da50b412afe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 950,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 39,
"path": "/leetcode/src/sameTree.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * givena two binary trees, write a function to check it they are equal or not. The concept \"equal\" means they are structually\n * identical and the nodes have the same value.\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n\nusing namespace std;\n\nstruct TreeNode{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x) : val(x), left(NULL), right(NULL){}\n};\n\nbool isSameTree(TreeNode *p, TreeNode *q){\n if(!p && !q) return true;\n if(!p || !q) return false;\n if(p->val != q->val) return false;\n return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);\n}\n\nvoid test_01(){\n TreeNode *node1 = new TreeNode(1);\n node1->right = new TreeNode(2);\n\n TreeNode *node2 = new TreeNode(1);\n node2->right = new TreeNode(2);\n\n printf(\"%s\\n\", isSameTree(node1, node2) ? \"true\" : \"false\");\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4560260474681854,
"alphanum_fraction": 0.49837133288383484,
"avg_line_length": 20.543859481811523,
"blob_id": "6cd7734dc09656abadec6e5e998f5b0507d99170",
"content_id": "82b9f57f80b465ca07fcdce16c39816373bda56e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1228,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 57,
"path": "/leetcode/src/removeDuplicatesArray.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a sorted array, remove the duplicates from it in-place, return the new array size.\n * */\n#include \"../include/preliminary.h\"\n\n/*\n * problem I: every value is allowed to appear only once\n * input: 1,1,2,2\n * output: 1,2\n * */\nint remove(int A[], int n){ // best solution\n if(n < 2) return n;\n int len = 1, itor = 1;\n while(itor < n){\n if(A[itor] != A[len-1]){\n if(len < itor) A[len] = A[itor];\n len++;\n }\n itor++;\n }\n return len;\n}\n\n/*\n * problem II: every value is allowed to appear twice at most.\n * input: 1,1,1,2,2,3\n * output: 1,1,2,2,3\n * */\nint removeII(int A[], int n){ // best solution\n if(n <= 2) return n;\n int len = 2, itor = 2;\n while(itor < n){\n if(A[itor] != A[len-2]){\n if(len < itor) A[len] = A[itor];\n len++;\n }\n itor++;\n }\n return len;\n}\n\nvoid test_01(){\n int arr[] = {1,1,2,3,3,3,4,5,5,};\n int m = sizeof(arr) / sizeof(int);\n showarray(arr, remove(arr, m));\n}\n\nvoid test_02(){\n int arr[] = {1,1,2,3,3,3,4,5,5,5,6};\n int m = sizeof(arr) / sizeof(int);\n showarray(arr, removeII(arr, m));\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.488571435213089,
"alphanum_fraction": 0.5044897794723511,
"avg_line_length": 24.24742317199707,
"blob_id": "4643ee344c10c48322fb4e459641206c9eac2a4b",
"content_id": "0d89ef3bf2f92b9c0ec13605ef222a309ed67180",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2450,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 97,
"path": "/leetcode/src/letterCombinationNumber.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a digit string,return all possible letter combinations that the number could represent.\n * A mapping of digit to letters is just like the telephone buttons\n *\n * several questions need to ask during interview:\n * 1. how to process 0 and 1?\n * 2. what should the result is when no result? empty vector<> or empty string in vector<>?\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include \"stdlib.h\"\n#include <vector>\n\nusing namespace std;\n\n/*\n * solution same to <BeautyOfProgramming>, it uses iteration instead of recurse, with changing index\n * */\nvector<string> letterCombinations(const string& digits){\n vector<string> res;\n if(digits.empty()){\n res.push_back(string());\n return res;\n }\n char character[10][5]={ //digit is 0-based as well\n \" \", //space for 0\n \"\",\n \"abc\",\n \"def\",\n \"ghi\",\n \"jkl\",\n \"mno\",\n \"pqrs\",\n \"tuv\",\n \"wxyz\"\n };\n int count[10] = {1,0,3,3,3,3,3,4,3,4};\n int n = digits.size();\n int *number = new int[n]();\n bool canParse=true;\n for(int i=0;i<n;i++){\n char ch = digits[i];\n if(!isdigit(ch)){\n canParse = false;\n break;\n }\n number[i] = atoi(&ch);\n }\n if(!canParse){\n delete[] number;\n res.push_back(string());\n return res;\n }\n int *index = new int[n](); //initialize to all 0\n \n while(1){\n char cstr[n+1];\n memset(cstr, 0, sizeof(char)*n);\n for(int i=0; i<n;i++){\n if(number[i]==1) continue;\n cstr[i] = character[number[i]][index[i]];\n }\n cstr[n] = '\\0'; //necessary\n res.push_back(string(cstr));\n int k = n-1;\n if(index[k] < count[number[k]] - 1){\n index[k]++;\n continue;\n }\n while(k>=0 && index[k] >= count[number[k]]-1){\n index[k] = 0;\n k--;\n }\n if(k<0) break;\n index[k]++;\n }\n delete[] number;\n delete[] index;\n return res;\n}\n\nint main(int, char**){\n string str;\n while(1){\n printf(\"please input digits:\\n\");\n if(getline(cin, str)==0 || str.empty())\n break;\n vector<string> res = letterCombinations(str);\n for(size_t i=0; i<res.size();i++){\n printf(\"%s, \", res[i].c_str());\n }\n printf(\"\\n\");\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.6917808055877686,
"alphanum_fraction": 0.7089040875434875,
"avg_line_length": 31.44444465637207,
"blob_id": "992cd983435cb22a1a4725820c225c8276d09a23",
"content_id": "92d24959ebbe357ee839f35f04ca2fb8ad9c8b27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 9,
"path": "/leetcode/sql/secondHighestSalary.sql",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "-- database problem #176\n--\n-- query to get the second highest salary from the Employee table\n-- +--- Employee --+\n-- 0|Id|int\n-- 1|Salary|int\n-- Note: if there is no second highest salary, then return null\n\nselect max(Salary) from Employee where Salary < (select max(salary) from Employee);\n"
},
{
"alpha_fraction": 0.4502599537372589,
"alphanum_fraction": 0.5188907980918884,
"avg_line_length": 30.02150535583496,
"blob_id": "ab61673e22499df9bebe9fdff150978586767509",
"content_id": "dcf00e75d407bc6bdf9b380498d978e0902dc5fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2885,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 93,
"path": "/leetcode/cpp_unittest/dungeonGame_unittest/DungeonGame_unittest.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include \"DungeonGame.cpp\"\n#include \"gtest/gtest.h\"\n\n// Test case: Function_Test\n// Test name: Positive01\nTEST(Function_Test, Positive01){\n Solution s;\n int arr1[] = {-2, -3, 3};\n int arr2[] = {-5, -10, 1};\n int arr3[] = {10, 30, -5};\n vector<vector<int> > dungeon;\n dungeon.push_back(vector<int>(arr1, arr1 + sizeof(arr1)/sizeof(int)));\n dungeon.push_back(vector<int>(arr2, arr2 + sizeof(arr2)/sizeof(int)));\n dungeon.push_back(vector<int>(arr3, arr3 + sizeof(arr3)/sizeof(int)));\n int hp = s.calculateMinimumHP(dungeon);\n EXPECT_EQ(7, hp);\n}\n\n// Test case: Function_Test\n// Test name: Positive02\nTEST(Function_Test, Positive02){\n Solution s;\n int arr[][3] = {{ 3, -20, 30},\n { -3, 4, 0}};\n vector<vector<int> > dungeon;\n for(int i=0; i<2; i++){\n dungeon.push_back(vector<int>(arr[i], arr[i] + sizeof(arr[i])/sizeof(int)));\n }\n int hp = s.calculateMinimumHP(dungeon);\n EXPECT_EQ(1, hp);\n}\n\n// Test case: Function_Test\n// Test name: Positive03\nTEST(Function_Test, Positive03){\n Solution s;\n int arr[][3] = {{ 1, -3, 3},\n { 0, -2, 0},\n {-3, -3, -3}};\n vector<vector<int> > dungeon;\n for(int i=0; i<3; i++){\n dungeon.push_back(vector<int>(arr[i], arr[i] + sizeof(arr[i])/sizeof(int)));\n }\n int hp = s.calculateMinimumHP(dungeon);\n EXPECT_EQ(3, hp);\n}\n\n\n// Test case: Function_Test\n// Test name: Positive03\nTEST(Function_Test, Positive04){\n Solution s;\n int arr[][7] = {{ 0, -74, -47, -20, -23, -39, -48},\n { 37, -30, 37, -65, -82, 28, -27},\n {-76, -33, 7, 42, 3, 49, -93},\n { 37, -41, 35, -16, -96, -56, 38},\n {-52, 19, -37, 14, -65, -42, 9},\n { 5, -26, -30, -65, 11, 5, 16},\n {-60, 9, 36, -36, 41, -47, -86},\n {-22, 19, -5, -41, -8, -96, -95}};\n vector<vector<int> > dungeon;\n for(int i=0; i<8; i++){\n dungeon.push_back(vector<int>(arr[i], arr[i] + sizeof(arr[i])/sizeof(int)));\n }\n int hp = s.calculateMinimumHP(dungeon);\n EXPECT_EQ(30, hp);\n}\n\n// Test case: Function_Test\n// Test name: Positive05\nTEST(Function_Test, Positive05){\n Solution s;\n int arr[][3] = {{ 1, 2, 1},\n {-2, -3, -3},\n { 3, 2, -2}};\n vector<vector<int> > dungeon;\n for(int i=0; i<3; i++){\n dungeon.push_back(vector<int>(arr[i], arr[i] + sizeof(arr[i])/sizeof(int)));\n }\n int hp = s.calculateMinimumHP(dungeon);\n EXPECT_EQ(1, hp);\n}\n\n// Test case: Edge_Test\n// Test name: single\nTEST(Edge_Test, single){\n Solution s;\n int arr1[] = {10};\n vector<vector<int> > dungeon;\n dungeon.push_back(vector<int>(arr1, arr1 + sizeof(arr1)/sizeof(int)));\n int hp = s.calculateMinimumHP(dungeon);\n EXPECT_EQ(1, hp);\n}\n"
},
{
"alpha_fraction": 0.5588957071304321,
"alphanum_fraction": 0.5638036727905273,
"avg_line_length": 23.696969985961914,
"blob_id": "30208b0e2917f4caf5b8a99cd0919b3cfb0903b2",
"content_id": "bba984be02e282ae20d3c25ef744b18a083e084a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1630,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 66,
"path": "/leetcode/src/pathsum.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary and a sum\n * I. determine if the tree has a root-to-leaf path such that adding up all the values of path equals the sum\n * II. find all root-to-leaf paths where each path's sum equals the given sum\n * */\n#include \"../include/preliminary.h\"\n\n/*\n * I\n * */\nbool hasPathSum(TreeNode *root, int sum){\n if(!root) return false;\n if(root->left == NULL && root->right == NULL && sum == 0) return true;\n sum -= root->val;\n if(root->left != NULL && hasPathSum(root->left, sum)) return true;\n if(root->right != NULL && hasPathSum(root->right, sum)) return true;\n return false;\n}\n\n/*\n * II\n * */\nvoid addStk(vector<vector<int> >& res, stack<int>& stk){\n stack<int> stk2;\n while(!stk.empty()){\n stk2.push(stk.top());\n stk.pop();\n }\n vector<int> vec;\n while(!stk2.empty()){\n stk.push(stk2.top());\n vec.push_back(stk.top());\n stk2.pop();\n }\n res.push_back(vec);\n return;\n}\n\nvoid branchSum(vector<vector<int> >& res, stack<int>& stk, int sum, TreeNode *par){\n if(!par) return;\n stk.push(par->val);\n sum -= par->val;\n if(par->left != NULL){\n branchSum(res, stk, sum, par->left);\n }\n if(par->right != NULL){\n branchSum(res, stk, sum, par->right);\n }\n if(par->left == NULL && par->right == NULL && sum==0){\n addStk(res, stk);\n }\n stk.pop();\n return;\n}\n\nvector<vector<int> > pathSum(TreeNode *root, int sum){\n vector<vector<int> > res;\n if(!root) return res;\n stack<int> stk;\n branchSum(res, stk, sum, root);\n return res;\n}\n\nint main(int, char**){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4280259609222412,
"alphanum_fraction": 0.46697211265563965,
"avg_line_length": 28.430233001708984,
"blob_id": "df439317ab314ae8668d088d286a34de6a47725f",
"content_id": "2a02eb1de18f5a86f0aa8fe96fabcb46806fe3b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2619,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 86,
"path": "/leetcode/src/largestRectangleArea.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given n non-negative integers representing the histogram's bar height where the width of each is 1, find area of\r\n * largest rectangle in the histogram\r\n *\r\n * e.g. {2,1,5,6,2,3}, output 5*2=10\r\n * */\r\n\r\n#include \"../include/preliminary.h\"\r\n\r\nint largestRectangleArea_01(const vector<int>& height){ // time limit error for array with extreme peak\r\n int n = height.size();\r\n int res = n == 0 ? 0 : height[0];\r\n if(n==0 || n==1) return res;\r\n int m = 0;\r\n for(int i=0; i<n; i++) m = max(m, height[i]); // m is the height of highest bar\r\n /*\r\n int dp[n][m+1]; memset(dp, 0, sizeof(dp)); // time O(n^2), space O(n^2)\r\n for(int j=1; j<=height[0]; j++) dp[0][j] = 1;\r\n for(int i=1; i<n; i++){\r\n for(int j=1; j<=height[i]; j++){\r\n dp[i][j] = 1 + dp[i-1][j];\r\n res = max(res, j * dp[i][j]);\r\n }\r\n }\r\n */\r\n int dp[m+1]; // time O(n^2), space O(n)\r\n memset(dp, 0, sizeof(dp));\r\n for(int i=0; i<n; i++){\r\n for(int j=1; j<=height[i]; j++){\r\n if(i==0 || dp[j] == 0){\r\n dp[j] = 1;\r\n }else{\r\n dp[j] += 1;\r\n }\r\n res = max(res, j * dp[j]);\r\n memset(dp + height[i] + 1, 0, sizeof(int) * (m+1 - height[i]));\r\n }\r\n }\r\n return res;\r\n}\r\n\r\n/*\r\n * time O(n) and space O(n)\r\n * */\r\nint largestRectangleArea_02(const vector<int>& height){\r\n int n = height.size(), res = 0;\r\n if(n == 0) return res;\r\n stack<int> stk; // store index\r\n for(int i=0; i<=n; i++){ // elegance in appending one bar of 0 to merge the final process following for-loop\r\n int h = i == n ? 0 : height[i];\r\n while(!stk.empty()){\r\n int p = stk.top();\r\n if(height[p] < h) break;\r\n stk.pop();\r\n int start = stk.empty() ? -1 : stk.top();\r\n res = max(res, (i - 1 - start) * height[p]);\r\n }\r\n stk.push(i);\r\n }\r\n return res;\r\n}\r\n\r\nvoid test_01(){\r\n int h[] = {2,1,3,1,4,2};\r\n vector<int> height(h, h + sizeof(h)/sizeof(int));\r\n cout << largestRectangleArea_02(height) << endl;\r\n}\r\n\r\nvoid test_02(){\r\n int h[] = {2,1,5,6,2,3};\r\n vector<int> height(h, h + sizeof(h)/sizeof(int));\r\n cout << largestRectangleArea_02(height) << endl;\r\n}\r\n\r\nvoid test_03(){\r\n int h[] = {0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,11};\r\n vector<int> height(h, h + sizeof(h)/sizeof(int));\r\n cout << largestRectangleArea_02(height) << endl;\r\n}\r\n\r\nint main(){\r\n test_01();\r\n test_02();\r\n test_03();\r\n return 0;\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.5641729831695557,
"alphanum_fraction": 0.5833905339241028,
"avg_line_length": 28.139999389648438,
"blob_id": "25498dfe32ebdab82ac361d0b0d89b37c8a2e991",
"content_id": "2e3e44f998a6c8a1980c21553a93de11c7c7ae77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2914,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 100,
"path": "/leetcode/src/maxpathsum.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * from oj.leetcode. given a binary tree, find the maximum path sum. the path may start and end at any node in the tree;\n *\n * test case:\n * 1. root has child, val may be negetive, positive, zero.\n * 2. root without child, if its val is negative, the result has to be it.\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\nusing namespace std;\n\nstruct TreeNode{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x): val(x), left(NULL), right(NULL){}\n};\n\ninline int max(int a, int b){\n return a>b ? a : b;\n}\ninline int min(int a, int b){\n return a<b ? a : b;\n}\n\n/*\n * my own solution, DFS actually\n * */\nint maxPath(TreeNode *par, int *pSum){\n if(!par) return 0;\n int leftsum = maxPath(par->left, pSum);\n int rightsum = maxPath(par->right, pSum);\n int mx = max(leftsum, rightsum); //it is key of efficiency to conclude the process of left/right to max/min \n int mn = min(leftsum, rightsum);\n\n if(mx <= 0){ //both mx/min can not contribute to max path sum beneath *par \n if(par->val > *pSum){\n *pSum = par->val;\n }\n return par->val > 0 ? par->val : 0;\n }else if(mn > 0){ //both mx/mn can contribute to max path sum beneath *par, but only mx contributes the one above *par\n if(par->val + mx + mn > *pSum){\n *pSum = par->val + mx + mn;\n }\n return (par->val + mx) > 0 ? (par->val + mx) : 0;\n }else{\n if(par->val + mx > *pSum){\n *pSum = par->val + mx;\n }\n return (par->val + mx) > 0 ? (par->val + mx) : 0;\n }\n}\n\nint maxPathSum(TreeNode *root){\n int res = root->val; //res must be initialized by root's val!!! for test case that negative root without child\n maxPath(root, &res);\n return res;\n}\n\n/*\n * from intenet, Geek style. Implement same algorithm with much less and simple code\n * */\nint DFS(TreeNode *root, int &ret){\n if(!root) return 0;\n int maxl = DFS(root->left, ret);\n int maxr = DFS(root->right, ret);\n ret = max(ret, root->val + max(0, maxl) + max(0, maxr)); //elegent code, worth to follow\n return max(0, root->val + max(0, max(maxl, maxr)));\n}\n\nint maxPathSum_02(TreeNode *root){\n if(!root) return 0;\n int res = root->val;\n DFS(root, res);\n return res;\n}\n\nint main(int, char**){\n TreeNode *p0 = new TreeNode(3);\n TreeNode *p1 = new TreeNode(-2);\n p0->left = p1;\n TreeNode *p2 = new TreeNode(0);\n p0->right = p2;\n TreeNode *p3 = new TreeNode(3);\n p1->left = p3;\n TreeNode *p4 = new TreeNode(4);\n p1->right = p4;\n TreeNode *p5 = new TreeNode(-1);\n p2->left = p5;\n TreeNode *p6 = new TreeNode(2);\n p2->right = p6;\n TreeNode *p7 = new TreeNode(4);\n p5->right = p7;\n\n printf(\"solution 1: the max path sum is %d\\n\", maxPathSum(p0));\n printf(\"solution 2: the max path sum is %d\\n\", maxPathSum_02(p0));\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5385647416114807,
"alphanum_fraction": 0.5613682270050049,
"avg_line_length": 27.399999618530273,
"blob_id": "bbefaaf11ac42f4101801a9aa9d0ca0ebed2a4e7",
"content_id": "5f1cde209968bd8b47b9674c080ff373d40f0bd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2982,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 105,
"path": "/leetcode/src/mergeIntervals.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * merge:\n * given a collection of intervals, merge all overlapping intervals.\n * \n * test cases:\n * given [1,3], [2,6], [8,10], [15,18]\n * return [1,6], [8,10], [15,18]\n *\n * given [1,3], [2,4]\n * */\n#include \"../include/preliminary.h\"\n\nstruct Interval{\n int start;\n int end;\n Interval():start(0), end(0){}\n Interval(int s, int e):start(s), end(e){} \n};\n\nbool cmpInterval(const Interval& i1, const Interval& i2){ //for ascending order\n if(i1.start == i2.start){\n return i1.end < i2.end;\n }else{\n return i1.start < i2.start;\n }\n}\n\nvoid displayIntervals(const vector<Interval>& intervals){\n for(vector<Interval>::const_iterator iter = intervals.begin();\n iter < intervals.end();\n ++iter){\n printf(\"[%d, %d] \", iter->start, iter->end);\n }\n printf(\"\\n\");\n}\n\ntypedef bool (cmpFcn)(const Interval&, const Interval&); //function pointer for compare function of Interval\n\nvoid my_swap(Interval& i1, Interval& i2){\n Interval tmp(i2.start, i2.end);\n i2.start = i1.start;\n i2.end = i1.end;\n i1.start = tmp.start;\n i1.end = tmp.end;\n return;\n}\n\nvoid my_quicksort(vector<Interval>& intervals, int s, int e, cmpFcn cmp){ // range of [s, e]\n if(s >= e) return;\n int q = s-1, p = s, t = e;\n while(p < t){\n if(cmp(intervals[p], intervals[t])){ //cmp() return true if i1 is less than i2, so i1 should be swapped to head\n ++q;\n my_swap(intervals[q], intervals[p]);\n }\n ++p;\n }\n ++q;\n my_swap(intervals[q], intervals[p]);\n my_quicksort(intervals, s, q-1, cmp);\n my_quicksort(intervals, q+1, e, cmp);\n}\n\nvector<Interval> merge(vector<Interval>& intervals){\n //sort(intervals.begin(), intervals.end(), cmpInterval); //std::sort(), <algorithm>. not accepted by oj.leetcode\n my_quicksort(intervals, 0, intervals.size()-1, cmpInterval);\n displayIntervals(intervals);\n vector<Interval> res;\n for(vector<Interval>::const_iterator iter = intervals.begin();\n iter != intervals.end();\n ++iter){\n if(res.empty()){\n res.push_back(Interval(iter->start, iter->end));\n continue;\n }\n int m = res.size();\n if(res[m-1].end >= iter->start){\n res[m-1].end = max(res[m-1].end, iter->end);\n }else{\n res.push_back(Interval(iter->start, iter->end));\n }\n }\n return res;\n}\n\nvoid test_01(){ // test merge()\n string str;\n while(1){\n cout << \"please input integer start/end of intervals in pairs:\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n vector<Interval> intervals;\n for(int i=0; i < (n>>1); ++i){\n intervals.push_back(Interval(arr[i<<1], arr[(i<<1) + 1]));\n }\n displayIntervals(merge(intervals));\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.40200889110565186,
"alphanum_fraction": 0.4218640625476837,
"avg_line_length": 28.12244987487793,
"blob_id": "431c5a2e604e042316ed86bd7e9c9b42d9e96273",
"content_id": "6cf429f9b69f1163686ed3434fe67288b0fef24f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4281,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 147,
"path": "/leetcode/src/rotatedSortedArray.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * search in a sorted(ascending) array which is rotated somewhere, assume it is ascending order initially\n *\n * test case:\n * 5,1,3, x=4, return -1\n * 5,6,1,2,3, x=5, return 0\n * */\n#include \"../include/preliminary.h\"\n\nclass Solution{\npublic:\n\nint search(int A[], int n, int key){ // problem I: no duplicate\n int l=0, r=n-1;\n while(l <= r){\n int m = l + (r-l)/2;\n if(key == A[m]) return m;\n if(A[l] < A[m]){ // left half is sorted\n if(A[l] <= key && key < A[m]){ // if in [l, m)\n r = m-1;\n }else{\n l = m+1;\n }\n }else if(A[l] > A[m]){ // right half is sorted\n if(A[m] < key && key <= A[r]){ // if in (m, r]\n l = m+1;\n }else{\n r = m-1;\n }\n }else{ // l == m, r == m+1\n l = m+1;\n }\n }\n return -1;\n}\n\nint searchII(int A[], int n, int key){ // probelm II: with duplicates\n int l = 0, r = n-1;\n while(l <= r){\n int m = l + (r-l)/2;\n if(A[m] == key) return m;\n if(A[l] < A[m]){ // left half is sorted\n if(A[l] <= key && key < A[m]){ // if in [l, m)\n r = m-1;\n }else{\n l = m+1;\n }\n }else if(A[l] > A[m]){ // right half is sorted\n if(A[m] < key && key <= A[r]){ // if in (m, r]\n l = m+1;\n }else{\n r = m-1;\n }\n }else{ // e.g.{1,1,5,1,1,1} with key=5, no idea where it is. so the time is O(n) in the worst\n l++;\n }\n }\n return -1;\n}\n\nint findMin(vector<int>& nums){ // find minimum of a rotated sorted array\n int n = nums.size();\n if(n == 0) return 0;\n int l = 0, r = n-1;\n while(l <= r){\n int m = l + (r-l)/2;\n if((m == 0 || nums[m-1] > nums[m])\n &&(m == n-1 || nums[m] < nums[m+1])) return nums[m]; // exit criteria\n if(nums[l] < nums[m]){ // left half is sorted\n if(nums[l] > nums[r]) l = m+1;\n else r = m-1;\n }else if(nums[l] > nums[m]){ // right half is sorted while left half is not\n r = m-1;\n }else{ // l == m\n l = m+1;\n }\n }\n return 0;\n}\n\nint findMinII(vector<int>& nums){ // duplicate exists in array\n int n = nums.size();\n if(n == 0) return 0;\n int l = 0, r = n-1;\n while(l <= r){\n int m = l + (r-l)/2;\n if(m != 0 && m != n-1 \n && nums[m-1] == nums[m] && nums[m] == nums[m+1]){ // [m-1] == [m] == [m+1]\n if(nums[l] > nums[r]) l++;\n else r--;\n continue;\n }\n if((m == 0 || nums[m-1] > nums[m])\n &&(m == n-1 || nums[m+1] >= nums[m])) return nums[m]; // exit case, note the '>=' for right side\n if(nums[l] < nums[m]){ // left half is sorted\n if(nums[l] >= nums[r]) l = m+1;\n else r = m-1;\n }else if(nums[l] > nums[m]){ // right half is sorted while left is not\n r = m-1;\n }else{ // nums[l] == nums[m]\n if(l < m) l++;\n else return min(nums[l], nums[r]);\n }\n }\n return 0;\n}\n\n};\n\n/*\nvoid test_01(){\n string str;\n printf(\"please input sorted ascending array which is rotated in some where\\n\");\n if(getline(cin, str)==0 || str.empty()) return;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n Solution s;\n while(1){ \n printf(\"please input target to search:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int target = atoi(str.c_str());\n printf(\"index of target is %d\\n\", s.search(arr, n, target));\n }\n delete[] arr;\n return;\n}\n\nvoid test_02(){\n Solution s;\n while(1){\n string str;\n printf(\"please input rotated integer array\\n\");\n if(getline(cin, str) == 0 || str.empty()) break;\n int arr[str.size()];\n int n = splitStr2IntArray(str, arr);\n vector<int> vec;\n for(int i=0; i<n; i++) vec.push_back(arr[i]);\n printf(\"%d\\n\", s.findMinII(vec));\n }\n return;\n}\n\nint main(int, char**){\n test_02();\n return 0;\n}\n*/\n"
},
{
"alpha_fraction": 0.5158001780509949,
"alphanum_fraction": 0.538226306438446,
"avg_line_length": 21.295454025268555,
"blob_id": "b9b3624c6826f70a5a2ee8eb296fb3fc6e5de15c",
"content_id": "84b5727b9cae70e4ced33efd8dee4da20558980c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 981,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 44,
"path": "/leetcode/src/uniqueBST.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * problem 1:\n * given n, how many structurally unique BST's(binary search tree) that store values 1...n?\n * e.g. n=3, there are a total of 5 unique BST's\n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include \"stdlib.h\"\n\nusing namespace std;\n\nint numTrees(int n){\n if(n<1) return 0;\n int *subs = new int[n+1]();\n subs[0] = subs[1] = 1;\n for(int i=2; i<=n; ++i){ // i is 1-based\n for(int r=1; r<=i; ++r){ // r is root of the i numbers\n subs[i] += subs[r-1] * subs[i-r];\n }\n }\n int total = subs[n];\n delete[] subs;\n subs=0;\n return total;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input positive integer n:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int n = atoi(str.c_str());\n printf(\"total count of unique BST is %d\\n\", numTrees(n));\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5167509317398071,
"alphanum_fraction": 0.5360303521156311,
"avg_line_length": 22.094890594482422,
"blob_id": "50637a604da5cb07f39dfcc6563d4bacb11a17cc",
"content_id": "dfef5a61eb7bde3a637d74533f9d4f5ca07def3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3164,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 137,
"path": "/leetcode/src/symmetricTree.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary tree, check whether it is a mirror of itself(symmetric around its center)\n * e.g\n * 1\n * / \\\n * 2 2\n * / \\ / \\\n * 3 4 4 3 is true\n *\n * test case:\n * 1\n * 1 # 2\n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include <stack>\n#include <queue>\n#include <vector>\n\nusing namespace std;\n\nstruct TreeNode{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x) : val(x), left(NULL), right(NULL){}\n};\n\n/*\n * solution 1, space O(n), time O(n)\n * */\nvoid pushChildren(TreeNode *root, vector<TreeNode*>& vec, bool l2r){ // NULL is pushed as well to take place\n if(!root) return;\n if(l2r){\n vec.push_back(root->left);\n }\n vec.push_back(root->right);\n if(!l2r){\n vec.push_back(root->left);\n }\n return;\n}\n\nbool isSymmetric_01(TreeNode *root){\n if(!root) return true;\n vector<TreeNode*> vecArr[2];\n int idx = 0;\n vecArr[idx].push_back(root);\n \n while(!vecArr[idx].empty()){\n int n=vecArr[idx].size();\n bool l2r = (idx==0);\n int i = l2r ? 0 : n-1; // next level push in positive order, curr level push in reverse order, and curr level pop in positive order\n for(; i < n && i >= 0; l2r ? ++i : --i){\n TreeNode *curr = vecArr[idx][i], *oppo = vecArr[idx][n-1-i];\n if(!curr && !oppo) continue;\n if( !curr || ! oppo || (curr->val != oppo->val)){\n break; \n }\n pushChildren(curr, vecArr[1-idx], l2r);\n }\n if(i >=0 && i<n) return false;\n vecArr[idx].clear();\n idx = 1-idx;\n }\n return true;\n}\n\n/*\n * solution 2, elegant recurse !!!\n * */\nbool helper(TreeNode *a, TreeNode *b){\n if(!a && !b) return true;\n if(!a || !b) return false;\n if(a->val != b->val) return false;\n return helper(a->left, b->right) && helper(a->right, b->left);\n}\n\nbool isSymmetric_02(TreeNode *root){\n if(!root) return true;\n return helper(root->left, root->right);\n}\n\n/*\n * solution 3, compare a vector by inorder traverse with NULL node saved as well\n * */\nvoid inorderTraversal(TreeNode *root, vector<char>& vec){\n if(!root){\n vec.push_back('#');\n return;\n }\n if(!root->left && !root->right){\n vec.push_back('0' + root->val);\n }else{\n inorderTraversal(root->left, vec);\n vec.push_back('0' + root->val);\n inorderTraversal(root->right, vec);\n }\n return;\n}\n\nbool isSymmetric_03(TreeNode *root){\n if(!root) return true;\n vector<char> vec;\n inorderTraversal(root, vec);\n\n int i=0, j=vec.size()-1;\n while(i<j){\n if(vec[i] != vec[j]) return false;\n ++i;\n --j;\n }\n return true;\n}\n\n/****** test ******/\nvoid test_01(){\n TreeNode *node1 = new TreeNode(1);\n printf(\"%s\\n\", isSymmetric_03(node1) ? \"true\" : \"false\");\n return;\n}\n\nvoid test_02(){\n TreeNode *node1 = new TreeNode(1);\n node1->left = new TreeNode(2);\n printf(\"%s\\n\", isSymmetric_03(node1) ? \"true\" : \"false\");\n return;\n}\n\nint main(int, char**){\n test_01();\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5043778419494629,
"alphanum_fraction": 0.5287874937057495,
"avg_line_length": 26.107913970947266,
"blob_id": "a334825c2d4b3c50101aaabe4ea25ca18698aee2",
"content_id": "d7e3eadbaf838d9d17c447b8e9016e8a044fcd72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3769,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 139,
"path": "/leetcode/src/triangle.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a triangle, find the minimum path sum from top to bottom. Each step you may move to adjacent numbers on the row below.\n * 2\n * 3,4\n * 6,5,7\n * 4,1,8,3\n * the answer is 2+3+5+1\n * */\n#include \"../include/preliminary.h\"\n#include <algorithm>\n#include <fstream>\n\nusing namespace std;\n\nint sumPath(const vector<vector<int> >& triangle, int* indice){\n int n = triangle.size();\n int sum=0;\n for(int i=0;i<n;++i){\n sum += triangle[i][indice[i]];\n }\n return sum;\n}\n\nvoid copyArray(int *src, int *dst, int n){\n for(int i=0;i<n;i++){\n dst[i] = src[i];\n }\n return;\n}\n\n/*\n * permutation of all the indice, inefficient causing Time Limit Exceed\n * */\nint minimumTotal_01(vector<vector<int> >& triangle){\n int n = triangle.size();\n int *indice = new int[n](); //start from {0,0,0,0...} the most left path\n int res = sumPath(triangle, indice);\n while(1){\n int i=n-1;\n while(i>0){\n if(indice[i] == indice[i-1]){\n indice[i]++;\n break;\n }\n --i;\n }\n if(i==0) break;\n int k = indice[i];\n for(int j=i+1;j<n;j++){ //take care the permutation, reset the following integers eqaul to indice[i]\n indice[j] = k;\n }\n res = min(res, sumPath(triangle, indice));\n }\n delete[] indice;\n return res;\n}\n\n/*\n * correct answer from others, using DP.\n * in row [i], for column [j] where j=(0,i-1), dp[i][j] = triangle[i][j] + min(dp[i-1][j-1], dp[i-1][j]), it means current row is just dependent on last row. so define a 2-array of two rows, \n * */\nint minimumTotal_02(vector<vector<int> >& tri){\n int n = tri.size();\n int** dp = new int*[2];\n for(int i=0;i<2;i++){\n dp[i] = new int[n]();\n }\n int last = 0;\n dp[0][0] = tri[0][0];\n for(int i=1;i<n;++i){ //for row [i], the last element is column [i]\n int now = 1 - last; //rotating the two rows for use\n memset(dp[now], 0, sizeof(int)*n);\n dp[now][0] = tri[i][0] + dp[last][0]; //most left path\n dp[now][i] = tri[i][i] + dp[last][i-1]; //most right path\n for(int j=1;j<i;++j){\n dp[now][j] = tri[i][j] + min(dp[last][j-1], dp[last][j]);\n }\n last = now;\n }\n int ans = dp[last][0];\n for(int i=1;i<n;++i){\n ans = min(ans, dp[last][i]);\n }\n\n for(int i=0;i<2;i++){\n delete[] dp[i];\n dp[i] = 0;\n }\n delete[] dp;\n return ans;\n}\n\nvoid test_01(){\n vector<vector<int> > triangle;\n triangle.push_back(vector<int>());\n triangle[0].push_back(2);\n triangle.push_back(vector<int>());\n triangle[1].push_back(3);\n triangle[1].push_back(4);\n triangle.push_back(vector<int>());\n triangle[2].push_back(6);\n triangle[2].push_back(5);\n triangle[2].push_back(7);\n triangle.push_back(vector<int>());\n triangle[3].push_back(4);\n triangle[3].push_back(1);\n triangle[3].push_back(8);\n triangle[3].push_back(3);\n printf(\"the minimum path sum is %d\\n\", minimumTotal_02(triangle));\n}\n\nvoid test_02(){\n ifstream ifs;\n ifs.open(\"../testdata\", ifstream::in);\n if(ifs == NULL) return;\n vector<vector<int> > triangle;\n string str;\n while(ifs.good()){\n getline(ifs, str);\n if(str.empty()) break;\n int* arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n printf(\"%s ---- %d\\n\", str.c_str(), n);\n vector<int> vec;\n for(int i=0;i<n;i++){\n vec.push_back(arr[i]);\n }\n triangle.push_back(vec);\n delete[] arr;\n str.clear();\n }\n printf(\"the minimum path sum is %d\\n\", minimumTotal_01(triangle));\n ifs.close();\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.5713707804679871,
"alphanum_fraction": 0.6283865571022034,
"avg_line_length": 25.308509826660156,
"blob_id": "fccd55aa66c4f5c86cf6574090c526c2c68bac4e",
"content_id": "dfa696af4dcaa451766062e52aadb0beed210dc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2473,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 94,
"path": "/leetcode/cpp_unittest/largestNum_unittest/largestNum_unittest.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include \"largestNum.cpp\"\n#include \"gtest/gtest.h\"\n\n// Test case: Function_Test\n// Test name: Positive01\nTEST(Function_Test, Positive01){\n Solution s;\n int arr[] = {3, 30, 34, 5, 9};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"9534330\", str);\n}\n\n// Test case: Function_Test\n// Test name: Positive02\nTEST(Function_Test, Positive02){\n Solution s;\n int arr[] = {824, 8247};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"8248247\", str);\n}\n\n// Test case: Function_Test\n// Test name: Positive03\nTEST(Function_Test, Positive03){\n Solution s;\n int arr[] = {12, 121};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"12121\", str);\n}\n\n// Test case: Function_Test\n// Test name: Positive04\nTEST(Function_Test, Positive04){\n Solution s;\n int arr[] = {12, 121, 122};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"12212121\", str);\n}\n\n// Test case: Function_Test\n// Test name: Positive05\n// very good unit test case which is not in scope of oj.leetcode judge :)\nTEST(Function_Test, Positive05){\n Solution s;\n int arr[] = {121, 12113};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"12113121\", str);\n}\n\n// Test case: Function_Test\n// Test name: Positive05\n// spawned case of Positive05\nTEST(Function_Test, Positive06){\n Solution s;\n int arr[] = {121, 1211212};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"1211212121\", str);\n}\n\n// Test case: Edge_Test\n// Test name: Zero\nTEST(Edge_Test, Zero){\n Solution s;\n int arr[] = {1, 2, 0, 0, 3};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"32100\", str);\n}\n\n// Test case: Edge_Test\n// Test name: AllZero\nTEST(Edge_Test, AllZero){\n Solution s;\n int arr[] = {0, 0, 0, 0};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"0\", str);\n}\n\n// Test case: Edge_Test\n// Test name: MultiZero\nTEST(Edge_Test, MultiZero){\n Solution s;\n int arr[] = {0, 0, 0, 1, 0};\n vector<int> num(arr, arr + sizeof(arr)/sizeof(int));\n string str = s.largestNumber(num);\n EXPECT_EQ(\"10000\", str);\n}\n"
},
{
"alpha_fraction": 0.42380085587501526,
"alphanum_fraction": 0.4408014714717865,
"avg_line_length": 20.389610290527344,
"blob_id": "c90ac8fe36892ea507a0f96fafd980db4abbe97b",
"content_id": "70cfd97d346461943e2f71c2be913829a0dafa81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1647,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 77,
"path": "/leetcode/src/mergeSortedArray.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given two sorted integer arrays A and B, merge B into A as one sorted array\n * assume A has enough space with size of m+n at least\n *\n * test case:\n * 3,4,5 | 1, 2\n * 1,2,2,5 | 0,2,3\n * */\n#include \"../include/preliminary.h\"\n\nvoid swap(int *pa, int *pb){\n int tmp = *pb;\n *pb = *pa;\n *pa = tmp;\n}\n\nvoid sortHead(int A[], int n){\n if(n < 2) return;\n for(int *p = A+1; p < A+n; ++p){\n if(*(p-1) > *p){\n swap(p-1, p);\n }\n }\n return;\n}\n\n/*\n * point of solution is to sort the swapped *q to make it in order with following values \n * */\nvoid merge(int A[], int m, int B[], int n){\n if(n==0) return;\n for(int i=0; i<n; ++i){\n A[m+i] = B[i];\n }\n if(m==0) return;\n int *p = A, *q = A + m;\n while(p < q && q < A+m+n){\n if(*p > *q){\n swap(p, q);\n sortHead(q, A+m+n - q);\n continue;\n }\n ++p;\n }\n return;\n}\n\nvoid test(){\n string str;\n while(1){\n cout << \"please input sorted array B[]:\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int *B = new int[str.size()]();\n int n = splitStr2IntArray(str, B);\n \n cout << \"please input sorted array A[]:\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int *A = new int[str.size() + n]();\n int m = splitStr2IntArray(str, A);\n \n merge(A, m, B, n);\n for(int i=0; i<m+n; ++i){\n cout << A[i] << \", \";\n }\n cout << endl;\n\n delete A;\n A = 0;\n delete B;\n B = 0;\n }\n}\n\nint main(){\n test();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.47517040371894836,
"alphanum_fraction": 0.5238558650016785,
"avg_line_length": 20.851064682006836,
"blob_id": "e856eebdaa51ebb48816abf14478ccc7ec54a9b9",
"content_id": "193a28a473bc9caa80dc621bede3d1ef857d03c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2054,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 94,
"path": "/leetcode/src/removeNthFromEnd.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a SLL, remove the Nth node from the end of list and return its head.\n *\n * test data:\n * 1->2->3->4->5, n=2, after the removal, the SLL becomes 1->2->3->5\n * 1, 1,\n * 1->2, 2\n * 1->2, 1\n * */\n\n#include \"../include/preliminary.h\"\n\nListNode* removeNth2End(ListNode *head, int n){\n if(!head) return NULL;\n if(n==1){ //n==1 must be processed specially\n ListNode *pr = NULL, *l = head;\n while(l->next != NULL){\n pr = l;\n l = l->next;\n }\n if(pr) pr->next = NULL;\n delete l;\n return !pr ? NULL : head;\n }\n\n ListNode *p1 = head;\n for(int i=1;i<n && p1 != NULL;i++){ //n>1 so p1 and p2 cannot be same node\n p1 = p1->next;\n }\n if(!p1) return NULL;\n ListNode *p2 = head, *prev = NULL;\n while(p1->next != NULL){\n prev = p2;\n p2 = p2->next; //p2 is Nth node ahead of p1\n p1 = p1->next;\n }\n ListNode *h = head; //define another node pointer instead\n if(prev != NULL){\n prev->next = p2->next;\n }else{\n h = p2->next;\n }\n p2->next = NULL;\n delete p2;\n return h;\n}\n\nvoid test_01(){\n ListNode *p0 = new ListNode(0);\n ListNode *p1 = new ListNode(1);\n p0->next = p1;\n ListNode *p2 = new ListNode(2);\n p1->next = p2;\n displaySLL(p0);\n ListNode *h = removeNth2End(p0, 2);\n displaySLL(h);\n delSLL(h);\n}\n\nvoid test_02(){\n ListNode *p0 = new ListNode(0);\n ListNode *p1 = new ListNode(1);\n p0->next = p1;\n displaySLL(p0);\n ListNode *h = removeNth2End(p0, 1);\n displaySLL(h);\n delSLL(h);\n}\n\nvoid test_03(){\n ListNode *p0 = new ListNode(0);\n ListNode *p1 = new ListNode(1);\n p0->next = p1;\n displaySLL(p0);\n ListNode *h = removeNth2End(p0, 2);\n displaySLL(h);\n delSLL(h);\n}\n\nvoid test_04(){\n ListNode *p0 = new ListNode(0);\n displaySLL(p0);\n ListNode *h = removeNth2End(p0, 1);\n displaySLL(h);\n delSLL(h);\n}\n\nint main(int, char**){\n test_01();\n test_02();\n test_03();\n test_04();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3716157078742981,
"alphanum_fraction": 0.3829694390296936,
"avg_line_length": 22.89130401611328,
"blob_id": "618576b4392de3870acd26bc69b8136fb0322455",
"content_id": "6801604b4d0a228fb9ee6070dee2f40f6c6dd9da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2290,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 92,
"path": "/leetcode/src/simplifyPath.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given a path, simplify it\r\n *\r\n * test case:\r\n * /a/b/../../c/, /c\r\n * /../, / \r\n * /a//b/../, /a\r\n * //, /\r\n */\r\n\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <cstring>\r\n#include <string>\r\n#include <vector>\r\nusing namespace std;\r\n\r\n\r\nclass SimplifyPath{\r\npublic:\r\n string simplifyPath(string path){\r\n int n = path.size();\r\n if(n == 0) return string();\r\n int i = 0 , j = 1, length = 0;\r\n vector<string> vec;\r\n while(j <= n){\r\n if(j == n || path[j] == '/'){\r\n if(path[i] == '/'){\r\n if(i < j-1){\r\n length += process(path.substr(i+1, j-(i+1)), vec);\r\n }\r\n i = j;\r\n }\r\n }\r\n ++j;\r\n }\r\n return generate(vec, length);\r\n }\r\n\r\n void test_01(){\r\n string str;\r\n while(1){\r\n cout << \"please input path to simplify:\" << endl;\r\n getline(cin, str); // ASCII 13 is Carriage Return character\r\n if(str.empty()) break;\r\n cout << simplifyPath(str) << endl;\r\n str.clear();\r\n }\r\n }\r\n\r\nprivate:\r\n int process(string str, vector<string>& vec){\r\n int length = 0;\r\n if(str.size() == 0 || str == \".\" || str == \"/\") return length;\r\n if(str == \"..\"){\r\n if(!vec.empty()){\r\n length = vec[vec.size()-1].size();\r\n vec.pop_back();\r\n return -length;\r\n }else{\r\n return 0;\r\n }\r\n }\r\n length = str.size();\r\n vec.push_back(str);\r\n return length;\r\n }\r\n\r\n string generate(const vector<string>& chips, int len){\r\n int n = chips.size();\r\n if(n == 0) return string(\"/\");\r\n len += n + 1;\r\n char arr[len];\r\n int t = 0;\r\n for(int i = 0; i<n; ++i){\r\n arr[t++] = '/';\r\n for(size_t j = 0; j < chips[i].size(); ++j){\r\n arr[t++] = chips[i][j];\r\n }\r\n }\r\n arr[t] = '\\0';\r\n return string(arr);\r\n }\r\n};\r\n\r\nint main(int, char**){\r\n SimplifyPath *sp = new SimplifyPath();\r\n sp->test_01();\r\n delete sp;\r\n sp = 0;\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.4403790533542633,
"alphanum_fraction": 0.4588049352169037,
"avg_line_length": 27.1407413482666,
"blob_id": "9675542c24a112c5472df8331b4bcc8e451855c3",
"content_id": "dee4998ec69cb8acbe49942770a454294869c0e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3799,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 135,
"path": "/leetcode/src/maxPoints.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given n points on a 2D plane, find maximum number of points on one straight line\n *\n * cases:\n * 1. if calculating slope, process p1.x == p2.x\n * 2. if there is duplicate points\n * 3. all points are duplicate\n * */\n#include \"../include/preliminary.h\"\n\nusing namespace std;\n\nstruct Point{\n int x;\n int y;\n Point() : x(0), y(0){}\n Point(int a, int b) : x(a), y(b){}\n};\n\nstruct Line{\n int start;\n int end;\n Line(int s=0, int e=0) : start(s), end(e){}\n};\n\nbool point_cmp(Point p1, Point p2){\n if(p1.x < p2.x){\n return true;\n }else if(p1.x > p2.x){\n return false;\n }else{\n return p1.y <= p2.y;\n }\n}\n\nclass Solution{\npublic:\n int maxPoints(vector<Point> &points){\n sort(points.begin(), points.end(), point_cmp); // sorted\n int n = points.size();\n if(n <= 2) return n;\n /*\n for(int i=0; i<n; i++){\n cout << \"(\" << points[i].x << \", \" << points[i].y << \"),\";\n }\n cout << endl;\n */\n vector<Point> upoints; // unique points without duplicate\n int dups[n]; // duplicate count of unique point\n upoints.push_back(points[0]);\n int m = 1; // m is count of all unique points\n dups[m-1] = 1;\n for(int i=1; i<n; i++){\n if(points[i].x == points[i-1].x\n && points[i].y == points[i-1].y){\n dups[m-1]++;\n }else{\n m++;\n dups[m-1] = 1;\n upoints.push_back(points[i]);\n }\n }\n /*\n for(int i=0; i<m; i++){\n cout << \"(\" << upoints[i].x << \", \" << upoints[i].y << \"),\";\n }\n cout << endl;\n for(int i=0; i<m; i++){\n cout << dups[i] << \", \";\n }\n cout << endl;\n */\n if(m==1) return n; //only 1 unique point, unnecessary to get slope any more!\n map<float, vector<Line> > slopes;\n for(int i=0; i<m-1; ++i){ // calculate slope within unique points\n for(int j=i+1; j<n; ++j){\n float f = slope(upoints[i], upoints[j]);\n if(slopes.count(f) == 0){\n vector<Line> vec;\n slopes[f] = vec;\n }\n slopes[f].push_back(Line(i, j));\n }\n }\n\n int res = 2;\n for(map<float, vector<Line> >::iterator iter = slopes.begin();\n iter != slopes.end(); ++iter){\n res = max(res, maxNodesOnLine(iter->second, dups));\n }\n return res;\n }\n\nprivate:\n float slope(Point &p1, Point &p2){ // slope of two unique points, take care of p1.x == p2.x\n return p1.x == p2.x ? 0xffff : (float)(p1.y - p2.y) / (float)(p1.x - p2.x);\n }\n\n int maxNodesOnLine(vector<Line> &lines, int dups[]){\n int n = lines.size();\n int res = 2, curr = 2;\n for(int i=1; i<=n; ++i){ // implicit tip: process the edge i==n !\n if(i == n || lines[i].start != lines[i-1].start){\n curr += dups[lines[i-1].start] - 1; // complement the duplicate points\n res = max(res, curr);\n curr = 2;\n }else{\n curr++;\n }\n }\n return res;\n }\n};\n\nvoid test_01(){\n string str;\n while(1){\n cout << \"please input points of integer x and y\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int arr[str.size()];\n int n = splitStr2IntArray(str, arr);\n vector<Point> points;\n for(int i=0; i<n/2; i++){\n points.push_back(Point(arr[2*i], arr[2*i+1]));\n }\n Solution s;\n cout << \"maximum points on one line: \" << s.maxPoints(points) << endl;\n }\n return;\n}\n\nint main(){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.568976879119873,
"alphanum_fraction": 0.5775577425956726,
"avg_line_length": 29.918367385864258,
"blob_id": "b45adefbbd3646ca64e82b44f0f4a04af898eb04",
"content_id": "e8c19b76a33a640b2b34532a62ced9f3a6665849",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 49,
"path": "/leetcode/src/combinationsum.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a set of candidate numbers (C) and a target number (T), find all unique combinations in C where candidate number sum to T.\n * ps, the same number can be chosen from C unlimited number of times.\n * all numbers are positive integers, and elements in a combination must be non-decending order without duplicate combinations.\n *\n * test case:\n * S=[2,3,7], target=7\n * output: [2,2,3], [7]\n * */\n#include \"../include/preliminary.h\"\n#include <algorithm>\n\nclass Solution{\n\npublic:\n vector<vector<int> > combinationSum(vector<int>& candidates, int target){\n sort(candidates.begin(), candidates.end()); //sort candidates in ascending order \n vector<vector<int> > res;\n vector<int> vec;\n\n plusSum(res, candidates, vec, -1, target);\n return res;\n }\n\nprivate:\n void plusSum(vector<vector<int> >& res, const vector<int>& candidates,\n vector<int>& vec, int lastIdx, int target){\n if(target == 0){\n res.push_back(vec);\n return;\n }\n\n int n = candidates.size();\n int start = lastIdx < 0 ? 0 : lastIdx;\n for(int i = start; i < n; ++i){\n int d = candidates[i];\n if(target < d) break;\n\n //if(!vec.empty() && vec[vec.size() - 1] > d) continue;\n\n vec.push_back(d);\n plusSum(res, candidates, vec, i, target - d);\n vec.pop_back();\n }\n return;\n }\n\n /* unit test is in ../cpp_unittest/combinationsum_unittest */\n};\n"
},
{
"alpha_fraction": 0.5987951755523682,
"alphanum_fraction": 0.6222891807556152,
"avg_line_length": 27.620689392089844,
"blob_id": "96249d9e9728e23b312ff252116d65ff757c109e",
"content_id": "606560b6c22a616016e0981ee8aaf59cf5083057",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1660,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 58,
"path": "/topics/binarytree/src/maxpathsum.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * from oj.leetcode. given a binary tree, find the maximum path sum. the path may start and end at any node in the tree;\n *\n * test case:\n * 1. root has child, val may be negetive, positive, zero.\n * 2. root without child, if its val is negative, the result has to be it.\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include <algorithm>\nusing namespace std;\n\nstruct TreeNode{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x): val(x), left(NULL), right(NULL){}\n};\n\nint maxPath(TreeNode *par, int *pSum){\n if(!par) return 0;\n int leftsum = maxPath(par->left, pSum);\n int rightsum = maxPath(par->right, pSum);\n int mx = max(leftsum, rightsum); //it is key of efficiency to conclude the process of left/right to max/min \n int mn = min(leftsum, rightsum);\n\n *pSum = max(par->val + max(mx,0) + max(mn,0), *pSum);\n return max(par->val + max(mx,0), 0);\n}\n\nint maxPathSum(TreeNode *root){\n int res = root->val; //res must be initialized by root's val!!! for test case that negative root without child\n maxPath(root, &res);\n return res;\n}\n\nint main(int, char**){\n TreeNode *p0 = new TreeNode(3);\n TreeNode *p1 = new TreeNode(-2);\n p0->left = p1;\n TreeNode *p2 = new TreeNode(0);\n p0->right = p2;\n TreeNode *p3 = new TreeNode(3);\n p1->left = p3;\n TreeNode *p4 = new TreeNode(4);\n p1->right = p4;\n TreeNode *p5 = new TreeNode(-1);\n p2->left = p5;\n TreeNode *p6 = new TreeNode(2);\n p2->right = p6;\n TreeNode *p7 = new TreeNode(4);\n p5->right = p7;\n\n printf(\"the max path sum is %d\\n\", maxPathSum(p0));\n return 0;\n}\n"
},
{
"alpha_fraction": 0.41914892196655273,
"alphanum_fraction": 0.457446813583374,
"avg_line_length": 28.375,
"blob_id": "ead65d5af9413c7dfdf06f4fcd0ac52c0a6c622a",
"content_id": "6cb89cc27ce069b72b17cea9dd5c771ddb54aab9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1410,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 48,
"path": "/leetcode/src/multiplyStrings.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given two numbers represented as strings, return multiplication of the two numbers as string\n * */\n#include \"../include/preliminary.h\"\n\nstring multiply(string num1, string num2){\n int m = num1.size();\n int n = num2.size();\n if(m==0 || n==0) return string();\n if(num1 == \"0\" || num2 == \"0\") return string(\"0\");\n char arr[m+n+1];\n for(int i=0; i<m+n+1; ++i){\n arr[i] = '0';\n }\n arr[m+n] = '\\0';\n int t = m+n-1; // index in result string\n for(int j=n-1; j>=0; --j){\n int b = num2[j] - '0', over = 0;\n t = (m+n-1) - (n-1-j);\n for(int i=m-1; i>=0; --i){\n int a = num1[i] - '0';\n int c = arr[t] - '0';\n int s = a*b + c + over;\n //printf(\"a=%d, b=%d, c=%d, s=%d, index t=%d\\n\", a, b, c, s, t);\n arr[t--] = '0' + s % 10;\n over = s/10;\n }\n if(over > 0) arr[t--] = '0' + over;\n }\n return string(arr+t+1, arr+m+n); // tail char '\\0' no need to initialize the string\n}\n\nvoid test(){\n while(1){\n cout << \"input num1 as string:\" << endl;\n string num1;\n if(getline(cin, num1)==0 || num1.size()==0) break;\n cout << \"input num2 as string:\" << endl;\n string num2;\n if(getline(cin, num2)==0 || num2.size()==0) break;\n cout << multiply(num1, num2) << endl;\n }\n}\n\nint main(){\n test();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3564789593219757,
"alphanum_fraction": 0.3849097788333893,
"avg_line_length": 21.862499237060547,
"blob_id": "e1fb513794323d6ea9a6b6884fd1607c6f6bbe94",
"content_id": "fc911cfdee471a85b3eec4d413aee0c9de28d36d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1829,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 80,
"path": "/topics/sort/src/waterjug.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * <IntroductionToAlgorithm> exercise 8-4\n * given n red jugs and n blue jugs, all of different shapes and sizes. For each red jug, there is blue jug mapping it with the same\n * capacity of water. Assume you have a unit operation of selecting one red jug and pour its water into another blue jug.\n *\n * Q: group all the red jugs and blue jugs in time O(nlgn)\n *\n * test data:\n * 1,3,10,8,12,5,15,7,2,11\n * 5,2,11,3,8,12,1,15,10,7\n * */\n#include \"../header/preliminary.h\"\n\ntemplate<typename T>\nvoid swap(T* pa, T* pb){\n T tmp = *pb;\n *pb = *pa;\n *pa = tmp;\n tmp = 0;\n}\n\nvoid sortjugs(int *A, int *B, int n){\n if(n < 2) return;\n\n int *p = B, *q = B-1, t = A[n-1], *S = 0;\n while(p < B+n){ // quick sort B[] with sentinel of A[n-1]\n while(p < B+n && *p > t){\n p++;\n }\n if(p < B+n){\n if(*p == t){\n S = p;\n }else{ //*p < t\n q++;\n if(S == q)\n q++;\n swap<int>(p,q);\n }\n p++;\n }\n }\n\n if(S < q){\n while(S < q){\n *S = *(S + 1);\n S++;\n }\n *S = t; //S moves to q+1\n q = S-1;\n }else{\n while(S > q+1){ //S moves to q+1\n *S = *(S-1);\n S--;\n }\n *S = t;\n }\n \n p = A; // quick sort A[] with sentinel of B[S]\n q = A - 1;\n t = *S;\n while(p < A + n - 1){\n while(p < A+n-1 && *p > t){\n p++;\n }\n if(p < A+n-1){\n q++;\n swap<int>(p,q);\n p++;\n }\n }\n q++;\n swap<int>(p, q);\n if(S-B != q-A){\n printf(\"error!!!\\n\");\n return;\n }\n sortjugs(A,B,S-B);\n sortjugs(q+1,S+1,n-1-(S-B));\n p=0,q=0,S=0;\n}\n"
},
{
"alpha_fraction": 0.5029636025428772,
"alphanum_fraction": 0.5105136632919312,
"avg_line_length": 36.6888313293457,
"blob_id": "338f6874588b21cc992012135d2a2a2874872125",
"content_id": "b4a476b9f6bc0ba16389f73095caa0ab0807c7d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 14172,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 376,
"path": "/topics/graph/java/findladders.java",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * from oj.leetcode.\n * given two words(start and end), and a dictionary, find all shortest transformation sequence(s) from start to end, such that:\n * 1.only one letter can be chanegd at a time\n * 2.each intermediate word must exist in the dictionary\n *\n * test data:\n * start=\"hit\", end=\"cog\", dict=[hot,dot,dog,lot,log,hat,bit,big,dit,dig,cat,hak,cak,cok,dok]\n * return:\n * [hit,hot,dot,dog,cog]\n * [hit,hot,lot,log,cog]\n * [hit,dit,dig,dog,cog]\n * [hit,hot,dot,dog,cog]\n * */\n\nimport java.lang.*;\nimport java.io.*;\nimport java.util.*;\n\npublic class findladders{\n private final int X = 0xffff;\n /*\n * Dijkstra algorithm. basically it is correct.in case the dict the conversion is unavailable, and the \"start\" is long, this solution is\n * good. But if in case the \"start\" is not long while dict has too much redundent string, this is worse than _02. after all, it is not\n * worth to create a adjcent matrix of all string in dict\n * */\n public int ladderLength_01(String start, String end, HashSet<String> dict){\n if(start.equals(end)){\n return 1;\n }else if(canConvert(start, end)){\n return 2;\n }\n\n if(dict.isEmpty()){\n return 0;\n }\n if(dict.contains(start)){\n dict.remove(start);\n }\n if(dict.contains(end)){\n dict.remove(end);\n }\n ArrayList<String> strArr = new ArrayList<String>();\n strArr.add(start);\n for(String s : dict){\n strArr.add(s);\n }\n strArr.add(end);\n ArrayList<ArrayList<Integer>> adjMtx = getAdjMatrix(strArr);\n\n final int n = strArr.size();\n int[] dist = new int[n];\n for(int i=0;i<n;i++){\n dist[i] = X;\n }\n LinkedList<Integer> q = new LinkedList<Integer>(); //used as queue\n boolean[] cover = new boolean[n];\n for(boolean b : cover){\n b = false;\n }\n q.addFirst(0);\n dist[0] = 0;\n \n while(!q.isEmpty()){ //Dijkstra algorithm, shortest path from src vertex to dst\n int u = q.pollLast();\n cover[u] = true;\n for(int v=0;v<n;v++){\n if(v==u || adjMtx.get(u).get(v) != 1) continue;\n if(dist[u] + 1 < dist[v]){\n dist[v] = dist[u] + 1;\n }\n if(!q.contains(v) && cover[v] == false) q.addFirst(v);\n }\n }\n if(dist[n-1]==X) return 0; //dict[n-1]+1 is the ladder length\n return dist[n-1]+1;\n }\n \n public ArrayList<ArrayList<String>> findall_01(String start, String end, HashSet<String> dict){\n ArrayList<ArrayList<String>> res = new ArrayList<ArrayList<String>>(); \n if(start.equals(end) || canConvert(start, end)){\n ArrayList<String> arr = new ArrayList<String>();\n arr.add(start);\n arr.add(end);\n res.add(arr);\n return res;\n }\n if(dict.isEmpty()){\n return res;\n }\n if(dict.contains(start)){\n dict.remove(start);\n }\n if(dict.contains(end)){\n dict.remove(end);\n }\n ArrayList<String> strArr = new ArrayList<String>();\n strArr.add(start);\n for(String s : dict){\n strArr.add(s);\n }\n strArr.add(end);\n ArrayList<ArrayList<Integer>> adjMtx = getAdjMatrix(strArr);\n\n final int n = strArr.size();\n ArrayList<HashSet<Integer>> prevPos = new ArrayList<HashSet<Integer>>();\n for(int i=0;i<n;i++){\n prevPos.add(new HashSet<Integer>());\n }\n int[] dist = new int[n];\n for(int i=0;i<n;i++){\n dist[i] = X;\n }\n LinkedList<Integer> q = new LinkedList<Integer>(); //used as queue\n boolean[] cover = new boolean[n];\n for(boolean b : cover){\n b = false;\n }\n q.addFirst(0);\n dist[0] = 0;\n \n while(!q.isEmpty()){\n int u = q.pollLast();\n cover[u] = true;\n for(int v=0;v<n;v++){\n if(v==u || adjMtx.get(u).get(v) != 1) continue;\n if(dist[u] + 1 < dist[v]){\n dist[v] = dist[u] + 1;\n prevPos.get(v).clear();\n prevPos.get(v).add(u);\n }else if(dist[u] + 1 == dist[v] && !prevPos.get(v).contains(u)){\n prevPos.get(v).add(u);\n }\n if(!q.contains(v) && cover[v] == false) q.addFirst(v);\n }\n }\n if(dist[n-1]==X) return res; //dict[n-1]+1 is the ladder length\n \n LinkedList<Integer> stk = new LinkedList<Integer>(); //as stack\n replayPath(prevPos, strArr, n-1, stk, res);\n return res;\n }\n\n public ArrayList<ArrayList<Integer>> getAdjMatrix(ArrayList<String> strArr){ //assume src vertex is [0] and dest is [n-1]\n final int n = strArr.size();\n ArrayList<ArrayList<Integer>> adjMtx = new ArrayList<ArrayList<Integer>>();\n for(int i=0;i<n;++i){\n adjMtx.add(new ArrayList<Integer>(n));\n for(int j=0;j<n;++j){\n if(i==j){\n adjMtx.get(i).add(0);\n }else{\n adjMtx.get(i).add(X);\n }\n }\n }\n for(int u=0;u<n;++u){\n for(int v=u+1;v<n;++v){\n if(canConvert(strArr.get(u), strArr.get(v))){\n adjMtx.get(u).set(v,1);\n adjMtx.get(v).set(u,1);\n }else{\n adjMtx.get(u).set(v,X);\n adjMtx.get(v).set(u,X);\n }\n }\n }\n return adjMtx;\n }\n\n public boolean canConvert(String s1, String s2){\n if(s1.length() != s2.length()) return false;\n int diff=0;\n for(int i=0;i < s1.length();++i){\n if(s1.charAt(i) != s2.charAt(i))\n diff++;\n }\n return diff==1;\n }\n\n public void replayPath(ArrayList<HashSet<Integer>> prevPos, ArrayList<String> strArr, int ind, \n LinkedList<Integer> stk1, ArrayList<ArrayList<String>> res){\n if(ind==0){\n ArrayList<String> ladder = new ArrayList<String>();\n ladder.add(strArr.get(0));\n LinkedList<Integer> stk2 = new LinkedList<Integer>();\n while(!stk1.isEmpty()){\n int i = stk1.pop();\n stk2.push(i);\n ladder.add(strArr.get(i));\n }\n res.add(ladder);\n while(!stk2.isEmpty()){\n stk1.push(stk2.pop());\n }\n return;\n }else{\n stk1.push(ind);\n for(int i : prevPos.get(ind)){\n replayPath(prevPos, strArr, i, stk1, res);\n }\n stk1.pop();\n }\n return;\n }\n\n private static HashSet<String> parseStrArray(String str){\n HashSet<String> st = new HashSet<String>();\n StringTokenizer t = new StringTokenizer(str, \" ,\");\n while(t.hasMoreTokens()){\n String s = t.nextToken().toString();\n if(!st.contains(s)){\n st.add(s);\n }\n }\n return st;\n }\n\n /*\n * this solution considers every candicate which changes one char for once.\n * 1. in case the dict has too much redundent string, and the size of \"start\" is not large, this is more efficient than _01\n * 2. in frequent use, char[] is faster than String manipulation\n * 3. Java Doc suggests ArrayDeque is faster than LinkedList in most cases\n *\n * note: this is accepted on oj. but actually, the structure steps can be replaced by several variables... \n * */\n public int ladderLength_02(String start, String end, HashSet<String> dict){\n if(start.equals(end)) return 1;\n if(canConvert(start, end)) return 2;\n if(dict.isEmpty()) return 0;\n\n Set<String> visited = new HashSet<String>();\n Queue<String> q = new ArrayDeque<String>();\n q.add(start);\n Queue<Integer> steps = new LinkedList<Integer>();\n steps.add(0);\n final int N = start.length();\n\n while(!q.isEmpty()){\n String word = q.poll();\n visited.add(word);\n int stp = steps.poll();\n char[] wordChar = word.toCharArray(); //it is faster than manipulation of String\n for(int i=0;i<N;++i){\n char saved = wordChar[i];\n for(char c='a';c <= 'z';++c){\n int st = stp;\n wordChar[i] = c;\n String str = new String(wordChar);\n if(str.equals(end)) return st+2;\n if(dict.contains(str) && !visited.contains(str) && !q.contains(str)){\n q.add(str);\n st++;\n steps.add(st);\n }\n }\n wordChar[i] = saved;\n }\n }\n return 0;\n }\n\n /*\n * correct and accepted by oj.leetcode. \n * BFS to get next ladder\n * */\n public ArrayList<ArrayList<String>> findLadders_02(String start, String end, HashSet<String> dict){\n HashMap<String, Queue<String>> adjMap = new HashMap<String, Queue<String>>();//contains all the adjacent words discovered in its prev\n int currLen=0;\n boolean found=false;\n ArrayList<ArrayList<String>> r = new ArrayList<ArrayList<String>>();//results\n Queue<String> queue = new LinkedList<String>(); //Queue for BFS\n Set<String> unVisited = new HashSet<String>(dict); //unvisited words\n unVisited.add(end);\n Set<String> visitedThisLev = new HashSet<String>();\n \n queue.offer(start);\n int currLev=1; //ladders count at current level\n int nextLev=0; //ladders count of next level\n for(String word : unVisited){\n adjMap.put(word, new LinkedList<String>());\n }\n unVisited.remove(start); //nobody tells whether start is in dict\n \n while(!queue.isEmpty()){//BFS, every time change one char of it among a-z 26 characters\n String currLadder = queue.poll();\n for(String nextLadder : getNextLadder(currLadder, unVisited)){\n if(visitedThisLev.add(nextLadder)){\n nextLev++; //every new nextLadder converted from currLadder contributes to nextLev\n queue.offer(nextLadder);\n }\n adjMap.get(nextLadder).offer(currLadder); //save in map: nextLadder-->currLadder \n if(nextLadder.equals(end) && !found){\n found=true;\n currLen += 2;\n } \n }\n System.out.println(\"currLen=\" + currLev + \" , nextLev=\" + nextLev + \", currLadder=\" + currLadder + \", unVisited=\" + unVisited.toString() + \", visitedThisLev=\" + visitedThisLev.toString());\n if(--currLev==0){\n if(found) break;\n unVisited.removeAll(visitedThisLev); //expand in BFS from start to further, so current visited word does not need later\n visitedThisLev.clear();\n currLev = nextLev;\n nextLev=0;\n currLen++;\n }\n }\n if(found){\n LinkedList<String> p = new LinkedList<String>();\n p.addFirst(end); //from end to start\n getLadders(start, end, p, r, adjMap, currLen);\n }\n return r;\n }\n\n private ArrayList<String> getNextLadder(String currLadder, Set<String> unVisited){//\n ArrayList<String> nextLadder = new ArrayList<String>();\n StringBuffer replace = new StringBuffer(currLadder);\n for(int i=0;i<currLadder.length();i++){\n char old = replace.charAt(i);\n for(char ch='a'; ch<='z';ch++){\n if(ch==old) continue;\n replace.setCharAt(i, ch);\n String replaced = replace.toString();\n if(unVisited.contains(replaced)){\n nextLadder.add(replaced);\n }\n }\n replace.setCharAt(i, old);\n }\n return nextLadder;\n }\n\n //DFS to get all possible path from start to end\n //@params p: choose LinkedList<> to push/pop like stack, and initialize ArrayList<> like queue\n private void getLadders(String start, String currLadder, LinkedList<String> p, ArrayList<ArrayList<String>> solu,\n HashMap<String, Queue<String>> adjMap, int len){\n if(currLadder.equals(start)){\n solu.add(new ArrayList<String>(p));\n }else if(len>0){\n Queue<String> adjs = adjMap.get(currLadder);\n for(String lad : adjs){\n p.addFirst(lad);\n getLadders(start, lad, p, solu, adjMap, len-1);\n p.pollFirst();\n }\n }\n }\n\n public static void main(String[] args){\n Scanner scan = new Scanner(System.in);\n findladders lad = new findladders();\n while(true){ \n System.out.println(\"input start string:\");\n String start = scan.nextLine().trim();\n if(start.length()==0) break;\n \n System.out.println(\"input end string:\");\n String end = scan.nextLine().trim();\n if(end.length()==0) break;\n \n System.out.println(\"input dictionary strings:\");\n String dictStr = scan.nextLine();\n if(dictStr.length()==0) break;\n HashSet<String> dict = parseStrArray(dictStr);\n \n int steps = lad.ladderLength_02(start, end, dict);\n System.out.println(\"the shortest ladder is \" + steps);\n \n ArrayList<ArrayList<String>> result = lad.findLadders_02(start, end, dict);\n for(int i=0;i<result.size(); i++){\n System.out.println(result.get(i).toString());\n }\n }\n }\n}\n\n"
},
{
"alpha_fraction": 0.4338521361351013,
"alphanum_fraction": 0.48638132214546204,
"avg_line_length": 19.979591369628906,
"blob_id": "e8fc331c21caaadae2ff3c2c3d61099a4cb0fe28",
"content_id": "097ade564f07dab6b369c1aefaa2db6a62ce3e5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1028,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 49,
"path": "/leetcode/src/swapNodesInPairs.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a SLL, swap every two adjacent nodes and return its head\n * e.g. 1->2->3->4->5 => 2->1->4->3->5\n *\n * test case:\n * 1\n * 1->2\n * 1->2->3\n *\n * */\n#include \"../include/preliminary.h\"\n\nListNode *swapPairs(ListNode *head){\n if(!head || !(head->next)) return head;\n ListNode *pre = 0, *l1 = head, *l2 = head->next, \n *post = l2->next, *h=l2;\n while(1){\n if(pre) pre->next = l2; //swap\n l2->next = l1;\n l1->next = post;\n \n pre = l1; //move forward\n l1 = post;\n if(!l1) break;\n l2 = l1->next;\n if(!l2) break;\n post = l2->next;\n }\n return h;\n}\n\nvoid test_01(){\n ListNode *l1 = new ListNode(1);\n l1->next = new ListNode(2);\n displaySLL(swapPairs(l1));\n}\n\nvoid test_02(){\n ListNode *l1 = new ListNode(1);\n l1->next = new ListNode(2);\n l1->next->next = new ListNode(3);\n displaySLL(swapPairs(l1));\n}\n\nint main(int, char**){\n test_01();\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.49613258242607117,
"alphanum_fraction": 0.5171270966529846,
"avg_line_length": 21.600000381469727,
"blob_id": "13f450a91b2b6da64680cf660f540b835a426b9f",
"content_id": "706e5fa52170356f669c0729a1f270a4b2bd45b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 905,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 40,
"path": "/topics/graph/header/genGraph.h",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "//*************************genGraph.h*******************************\n//\n#include <stdio.h>\n#include \"string.h\"\n#include \"graphConst.h\"\n\nstruct genEdge{\n int weight;\n int v1;\n int v2;\n genEdge()\n :weight(0)\n ,v1(0)\n ,v2(0){}\n genEdge(int w, int d1, int d2)\n :weight(w)\n ,v1(d1<d2 ? d1:d2)\n ,v2(d1<d2 ? d2:d1){}\n ~genEdge(){}\n bool compare(genEdge* rh){\n return this->weight > rh->weight;\n }\n};\n\n/*\n * undigraph\n * */\nstruct genGraph{\n const int vNum;\n const int eNum;\n int adjaMtx[BoundMax][BoundMax]; //adjacent matrix, a V*V matrix\n genEdge** edgeArray; \n \n genGraph(int, int, int[BoundMax][BoundMax]);\n ~genGraph();\n void sortEdges(); //sort edges by weight\n void quickSort(genEdge* arr[BoundMax], int start, int length);\n void outputEdges();\n int findEdge(int, int);\n};\n\n"
},
{
"alpha_fraction": 0.526393711566925,
"alphanum_fraction": 0.5426738858222961,
"avg_line_length": 35.19643020629883,
"blob_id": "b04a4f8e4cca0033eb36472cfd82ab04861220a1",
"content_id": "6b455026016cfd0e8642d12badac96ceda81ee54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2027,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 56,
"path": "/topics/recursion/src/regexpre.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * regular expression matching, from leetcode\n * Q: implement regular expression matching with support for '.' and '*'. The matching should cover entire input string(not partial)\n * '.': matches any single char\n * '*': matches 0+ times of preceding single char(instead of '*' in wild char)\n * bool isMatch(const char *s, const char *p)\n * isMatch(\"aa\", \"a\") false\n * isMatch(\"ab\", \".*\") true !!!\n * isMatch(\"abcbcd\", \"a.*c.*d\") true\n *\n * I want to explain further more about s=\"aa\", p='a*'\n * its idea is when p[1] == '*', so it compares s[0] and p[0] firstly. when it succeeds, move s one char, to compare s[1] and p[0].\n * As a result, isMatch(\"aa\", \"a*\") is true.\n * with the same idea, isMatch(\"ab\", \"a*\") is false\n * Let's take a look at s=\"ab\" and p=\".*\". as p[1]=='*', we compare s[0] and p[0], then s[1] and p[0]... finally, it is TRUE!\n * besides, any string of s, even empty string, can match \".*\" successfully\n * */\n\n#include \"stdio.h\"\n#include \"assert.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\nusing namespace std;\n\n/*\n * recursion breaks down to two cases: the next char is '*' or not\n * */\nbool isMatch(const char *s, const char *p){\n assert(s && p);\n if(*p == '\\0') return *s == '\\0';\n if(*(p+1) != '*'){ // p[1] is not '*', so s[0] must match p[0]\n assert(*p != '*');\n return ((*p == *s) || (*p == '.' && *s != '\\0')) && isMatch(s+1, p+1);\n }\n while((*p == *s) || (*p == '.' && *s != '\\0')){ // p[1] is '*', match s[0] and p[0] recursely with moving s\n if(isMatch(s, p+2)) return true; // p[1] '*' evaluates 0 occurance of p[0]\n s++;\n }\n return isMatch(s, p+2);\n}\n\nint main(int, char**){\n string s, p;\n while(1){\n printf(\"source:\\n\");\n if(getline(cin, s)==0 || s.empty())\n break;\n printf(\"pattern:\\n\");\n if(getline(cin, p)==0 || p.empty())\n break;\n bool res = isMatch(s.c_str(), p.c_str());\n printf(\"result is %s\\n\", res ? \"true\" : \"false\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5105663537979126,
"alphanum_fraction": 0.533389687538147,
"avg_line_length": 26.091602325439453,
"blob_id": "6f2ed5545d52a66a20b6285817d6467c7784e021",
"content_id": "4385fe53843253b9e62f65a2b1f063282703e609",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3549,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 131,
"path": "/leetcode/src/removekdigits.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a string of integer, ask to remove k from it to keep the left integers becomes the least without destroying their interactive order\n *\n * test data:\n * 13243221, k=5, result is 121\n * */\n\n#include \"../include/preliminary.h\"\n#include <queue>\n\n/*\n * solution: begin from remove 1st char, iterate from left to right, it is the one as head of first decending(str[i] > str[i+1])\n * time O(n*k), with some duplicate iteration\n * */\nstring removechar_01(const string& str, int k){\n string res(str);\n int len=res.size();\n while(k){ //IMPORTANT: start scanning from left(i=0) every time \n int i=0;\n for(;i<len-1;i++){\n if(res[i] > res[i+1])\n break;\n }\n for(;i<len-1;i++){\n res[i] = res[i+1];\n }\n res[len-1] = '\\0';\n --k;\n --len;\n }\n return res.substr(0, str.size());\n}\n\n/*\n * based on previous solution, eliminate the duplicate\n * time O(n+k)\n * */\nvoid removechar_02(string& str, int k){\n int len = str.size();\n if(k > len) return;\n if(k == len){\n str.clear();\n return;\n }\n int i=0;\n while(k){\n if(i<0) i=0;\n for(;i<len-1;i++){\n if(str[i] > str[i+1])\n break;\n }\n for(int j=i;j<len-1;j++){ //remove str[i]\n str[j] = str[j+1];\n }\n str[len-1] = '\\0';\n --k;\n --i; //IMPORTANT: go back by 1, start scanning from [i-1] as [i] is removed \n --len;\n }\n return;\n}\n\n/*\n * solution 3 in use of priority_queue\n * */\nstruct element{\n char ch;\n int index;\npublic:\n element(char c, int i): ch(c), index(i){}\n};\n\nclass mycomparision{\n bool reverse;\npublic:\n mycomparision(const bool& b = false): reverse(b){}\n bool operator() (const element& lhs, const element& rhs){\n if(reverse) return (lhs.ch > rhs.ch);\n else return (lhs.ch < rhs.ch);\n }\n};\n\ntypedef priority_queue<element, vector<element>, mycomparision> pq_element;\n\n/*\n * str: 13524682, k:4\n * push 1,3,5,2 to priority_queue, each element is value with index\n * push 4, save top(), then pop() if index of top() is less than index of saved\n * this method utilizes priority_queue for sort() so it is less efficient than method2 \n * */\nstring removechar_03(const string& str, int k){\n int n = str.size();\n if(k>=n) return string();\n char cstr[n-k+1];\n memset(cstr, 0, sizeof(char)*(n-k+1));\n pq_element pq(mycomparision(true)); //greater-than returns true and put in back, top is minimum\n for(int i=0;i<k;i++){\n pq.push(element(str[i], i)); \n }\n for(int i=k;i<n;i++){\n pq.push(element(str[i], i));\n cstr[i-k] = pq.top().ch;\n int curr = pq.top().index;\n pq.pop();\n while(!pq.empty() && pq.top().index < curr){\n pq.pop();\n }\n }\n cstr[n-k] = '\\0';\n return string(cstr);\n}\n\nint main(int argc, char* argv[]){\n string str;\n while(1){\n printf(\"input string:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n string kstr;\n printf(\"input k:\\n\");\n if(getline(cin, kstr)==0 || kstr.empty()) break;\n int a = atoi(kstr.c_str());\n string res1 = removechar_01(str, a);\n printf(\"solution1: %s\\n\", res1.c_str());\n string str2(str);\n removechar_02(str2, a);\n printf(\"solution2: %s\\n\", str2.c_str());\n string res3 = removechar_03(str, a);\n printf(\"solution3: %s\\n\", res3.c_str());\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5406162738800049,
"alphanum_fraction": 0.5518207550048828,
"avg_line_length": 20,
"blob_id": "4cf0846d74b571a90b90b98af709cca6c4bcc1f0",
"content_id": "2ba1aab78bbf8b5b3cf4b4dcb5e4abb5f5adcbec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 357,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 17,
"path": "/leetcode/src/removeElement.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given an array and a value, remove all instances of that value in place and return the new length\n * */\n#include \"../include/preliminary.h\"\n\nint removeElement(int A[], int n, int elem){\n int i=-1, j=0;\n for(; j<n; ++j){\n if(A[j] == elem) continue;\n A[++i] = A[j];\n }\n return i+1;\n}\n\nint main(int, char**){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4357384443283081,
"alphanum_fraction": 0.4554678797721863,
"avg_line_length": 23.63888931274414,
"blob_id": "1cdd751fb6639cc242f2f4702256a36efc993d75",
"content_id": "c4db3cc026cd5510f4509ccba6adbfefefcb14e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1774,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 72,
"path": "/leetcode/src/partitionpalindromeII.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a string s, partition s such that every substring of partition is a palindrome\n * return the minimum cuts needed for a palindrome partitioning of s\n *\n * test data:\n * cbbcc\n * aaaaaaaaaab\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include <algorithm>\nusing namespace std;\n\nint minCut(const string& s){\n int n = s.size();\n if(n<2) return 0;\n int **dp = new int*[n]; //dp[start][end] ==1 means substring [) is palindrome\n for(int i=0;i<n;++i){\n dp[i] = new int[n+1]();\n dp[i][i+1] = 1;\n }\n for(int len=2;len<=n;++len){\n for(int start=0;start+len<=n;++start){\n if(len<4 || dp[start+1][start+len-1]==1){\n if(s[start] == s[start+len-1]){\n dp[start][start+len] = 1;\n }\n }\n }\n }\n int *mc = new int[n+1](); //mc[i] means min cuts of substring [0,i) of length i\n for(int i=2;i<=n;++i){\n if(dp[0][i]==1){\n mc[i] = 0;\n }else{\n int ic = i-2; //minimize ic and mc[i] is ic+1 at least\n for(int j=i-1;j>0;--j){\n if(dp[j][i]==1){\n ic = min(ic, mc[j]);\n }\n }\n mc[i] = ic + 1;\n }\n }\n for(int i=0;i<=n;++i){\n printf(\"%d \", mc[i]);\n }\n printf(\"\\n\");\n int res = mc[n];\n \n for(int i=0;i<n;++i){\n delete[] dp[i];\n dp[i]=0;\n }\n delete[] dp;\n dp=0;\n delete[] mc;\n mc=0;\n return res;\n}\n\nint main(int, char**){\n string str;\n while(1){\n printf(\"please input string: \\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n printf(\"min cuts is %d\\n\", minCut(str));\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4918323755264282,
"alphanum_fraction": 0.5134943127632141,
"avg_line_length": 22.86440658569336,
"blob_id": "359495fbb209280caf1b8f91b5b87465bba7f951",
"content_id": "df0ea07c647c9a11bf0ee580567bbd3fface4ce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2816,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 118,
"path": "/leetcode/src/subsets.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * problem I:\n * given a set of distinct integers S, return all possible subsets.\n * e.g. S = [1,2,3]\n * output: \n * [], [1], [1,2], [1,2,3], [1,3], [2], [2,3], [3] \n *\n * problem II:\n * given a set with duplicate integers\n * e.g. S = [1,2,2]\n * output:\n * [], [1], [1,2], [1,2,2], [2], [2,2]\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include <vector>\n#include <algorithm>\n#include \"stdlib.h\"\nusing namespace std;\n\n/*\n * for problem I that S of distinct integers\n * */\nvoid helper(const vector<int>& src, int i, vector<int>& pipe, vector<vector<int> >& res){\n if(i<0) return;\n res.push_back(pipe);\n int n = src.size();\n if(i==n) return;\n for(; i<n; ++i){\n pipe.push_back(src[i]);\n helper(src, i+1, pipe, res);\n pipe.pop_back();\n }\n return;\n}\n\nvector<vector<int> > subsets(vector<int>& S){\n sort(S.begin(), S.end());\n vector<vector<int> > result;\n vector<int> pipe;\n helper(S, 0, pipe, result);\n return result;\n}\n\n/*\n * for problem II that S with duplicate integers\n * */\nvector<int> index2Value(const vector<int>& src, const vector<int>& indexes){\n vector<int> values;\n for(size_t i=0; i < indexes.size(); ++i){\n values.push_back(src[indexes[i]]);\n }\n return values;\n}\n\nvoid helper_II(const vector<int>& src, int i, vector<int>& vec, vector<vector<int> >& res){\n res.push_back(index2Value(src, vec));\n int n = src.size();\n for(; i<n; ++i){\n int m = vec.size();\n if(i>0 && (m==0 || i > vec[m-1] + 1) && (src[i-1] == src[i])) continue;\n vec.push_back(i); // vec to save index of src instead of value\n helper_II(src, i+1, vec, res);\n vec.pop_back();\n }\n}\n\nvector<vector<int> > subsets_II(vector<int>& S){\n sort(S.begin(), S.end());\n vector<vector<int> > result;\n vector<int> vec;\n\n helper_II(S, 0, vec, result);\n return result;\n}\n\n/*****************test****************/\nvoid output(const vector<vector<int> >& res){\n for(size_t i=0; i<res.size(); ++i){\n printf(\"[\");\n if(res[i].size() > 0){\n printf(\"%d\", res[i][0]);\n }\n for(size_t j=1; j<res[i].size(); ++j){\n printf(\", %d\", res[i][j]);\n }\n printf(\"]\\n\");\n }\n return;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input integer between 1 and 9:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int n = atoi(str.c_str());\n \n vector<int> S;\n for(int i=0; i<n; ++i){\n S.push_back(n-i);\n }\n output(subsets(S));\n }\n}\n\nvoid test_02(){\n int a[] = {1,2,2,2,1};\n vector<int> S(a, a + sizeof(a)/sizeof(int));\n output(subsets_II(S));\n}\n\nint main(int, char**){\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5876534581184387,
"alphanum_fraction": 0.5958390235900879,
"avg_line_length": 33.904762268066406,
"blob_id": "469b59f9b02cc4dddf714960592040fc821437c6",
"content_id": "09b9ac4a04c8ae10c611f095c7a7d28689d91c10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2932,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 84,
"path": "/leetcode/src/largestBSTInBT.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary tree, find the largest BST.\n * Note: the result BST may not be balanced; and it may or may not include all of its descendants\n * idea of this solution looks like \"top-down\". if root p's value breaks BST(compare with min and max), it cannot contribute\n * to parent as subtree. it has to consider as an independent subtree.\n * */\n\n#include \"../include/preliminary.h\"\n\nclass Solution{\npublic:\n /*\n * since result BST may or may not include all of its descendants, we need to create copy of nodes dynamically.\n * but the release operation is not involved here.\n * @param p: in,\n * min: in\n * max: in\n * maxNodes: inout\n * largestBST: out,\n * child: out\n * */\n int findLargestBST(TreeNode *p, int min, int max, int &maxNodes,\n TreeNode* &largestBST, TreeNode* &child){\n if(!p) return 0;\n if(!(min < p->val) || !(max > p->val)){ // p's value breaks BST definition\n findLargestBST(p, INT_MIN, INT_MAX, maxNodes, largestBST, child); // consider p an independent subtree\n return 0; // return 0 means p cannot contribute to parent as subtree of BST\n }\n\n int totalNodes = 1;\n int leftNodes = findLargestBST(p->left, min, p->val, maxNodes, largestBST, child);\n TreeNode *leftChild = NULL;\n if(leftNodes > 0){\n leftChild = child;\n totalNodes += leftNodes;\n }\n int rightNodes = findLargestBST(p->right, p->val, max, maxNodes, largestBST, child);\n TreeNode *rightChild = NULL;\n if(rightNodes > 0){\n rightChild = child;\n totalNodes += rightNodes;\n }\n\n TreeNode *curr = new TreeNode(p->val); // create copy to update child\n curr->left = leftChild;\n curr->right = rightChild;\n child = curr; // pass curr as child to above tree\n\n if(maxNodes < totalNodes){ // update maxNodes and largestBST\n maxNodes = totalNodes;\n largestBST = curr;\n }\n return totalNodes;\n }\n\n TreeNode* findLargestBST(TreeNode* root){\n TreeNode* largestBST= NULL, *child = NULL;\n int maxNodes = INT_MIN;\n findLargestBST(root, INT_MIN, INT_MAX, maxNodes, largestBST, child);\n return largestBST;\n }\n};\n\nvoid test_01(){\n TreeNode *root = new TreeNode(15);\n root->right = new TreeNode(20);\n root->left = new TreeNode(10);\n root->left->left = new TreeNode(5);\n root->left->right = new TreeNode(7);\n root->left->right->left = new TreeNode(2);\n root->left->right->right = new TreeNode(5);\n root->left->right->left->left = new TreeNode(0);\n root->left->right->left->right = new TreeNode(8);\n root->left->right->right->left = new TreeNode(3);\n Solution s;\n TreeNode *p = s.findLargestBST(root);\n showPre(p);\n showIn(p);\n}\n\nint main(){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5684210658073425,
"alphanum_fraction": 0.6296650767326355,
"avg_line_length": 28.02777862548828,
"blob_id": "ce49e8282cce5d1a2869fffa7983bfbcfae5675c",
"content_id": "5e3e322da4e0803806c0d07dc03bb0a1017d586d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1045,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 36,
"path": "/leetcode/cpp_unittest/rotatedSortedArray_unittest/rotatedSortedArray_unittest.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include \"rotatedSortedArray.cpp\"\n#include \"gtest/gtest.h\"\n\n// Test case: rotatedSortedArrayTest\n// Test name: positive\nTEST(rotatedSortedArrayTest, Positive){\n Solution s;\n int arr1[] = {1,3,3,3};\n vector<int> vec1(arr1, arr1 + sizeof(arr1)/sizeof(int));\n EXPECT_EQ(1, s.findMinII(vec1));\n\n int arr2[] = {2,2,2,1,1};\n vector<int> vec2(arr2, arr2 + sizeof(arr2)/sizeof(int));\n EXPECT_EQ(1, s.findMinII(vec2));\n\n int arr3[] = {1,1,3};\n vector<int> vec3(arr3, arr3 + sizeof(arr3)/sizeof(int));\n EXPECT_EQ(1, s.findMinII(vec3));\n}\n\n// Test case: rotatedSortedArrayTest\n// Test name: edge\nTEST(rotatedSortedArrayTest, Edge){\n Solution s;\n int arr1[] = {1,1};\n vector<int> vec1(arr1, arr1 + sizeof(arr1)/sizeof(int));\n EXPECT_EQ(1, s.findMinII(vec1));\n\n int arr2[] = {1,2,2,0,1,1};\n vector<int> vec2(arr2, arr2 + sizeof(arr2)/sizeof(int));\n EXPECT_EQ(0, s.findMinII(vec2));\n\n int arr3[] = {3,1};\n vector<int> vec3(arr3, arr3 + sizeof(arr3)/sizeof(int));\n EXPECT_EQ(1, s.findMinII(vec3));\n}\n"
},
{
"alpha_fraction": 0.5661271214485168,
"alphanum_fraction": 0.5759968161582947,
"avg_line_length": 33.698631286621094,
"blob_id": "54358a63f17639790fd9241b13619dc510baab67",
"content_id": "5df1a6566950df49c1c87187391bc4586a4a730a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2533,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 73,
"path": "/leetcode/src/largestSubtreeIsBST.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary tree, find the largest subtree which is BST. Note, a subtree all of its descendants.\n * Idea: 'bottom-up' solution. when subtree with node A is validated not BST, and node above A with A as child will not be BST definitely\n * NOTE: recurse method calling is 'top-down' from root to child with no doubt. \"bottom-up\" means denying child as BST will deny parent immediately\n * */\n#include \"../include/preliminary.h\"\n\nclass Solution{\npublic:\n /*\n * @param p: in, current node to handle\n * @return : node count of largest subtree with root of p\n * @param min, inout: minimum value of subtree with root of p\n * max, inout: maximum ...\n * maxNodes, inout: global largest subtree node count\n * largestBST, inout: root of global largest subtree\n * */\n int findLargestBSTSubtree(TreeNode *p, int &min, int &max,\n int &maxNodes, TreeNode* &largestBST){\n if(!p) return 0;\n bool isBST = true;\n int leftNodes = findLargestBSTSubtree(p->left, min, max, maxNodes, largestBST);\n int currMin = (leftNodes == 0) ? p->val : min;\n if(leftNodes == -1 ||\n (leftNodes != 0 && p->val <= min)){\n isBST = false;\n }\n int rightNodes = findLargestBSTSubtree(p->right, min, max, maxNodes, largestBST);\n int currMax = (rightNodes == 0) ? p->val : max;\n if(rightNodes == -1 ||\n (rightNodes != 0 && p->val >= min)){\n isBST = false;\n }\n if(isBST){\n min = currMin;\n max = currMax;\n int totalNodes = leftNodes + rightNodes + 1;\n if(totalNodes > maxNodes){\n maxNodes = totalNodes;\n largestBST = p;\n }\n return totalNodes;\n }else{\n return -1; // this subtree with root of p is not BST\n }\n }\n\n TreeNode *findLargestBSTSubtree(TreeNode *root){\n TreeNode *largestBST = NULL;\n int min = 0, max = 0;\n int maxNodes = 0;\n findLargestBSTSubtree(root, min, max, maxNodes, largestBST);\n return largestBST;\n }\n};\n\nvoid test_01(){\n TreeNode* root = new TreeNode(10);\n root->left = new TreeNode(5);\n root->right = new TreeNode(15);\n root->left->left = new TreeNode(1);\n root->left->right = new TreeNode(8);\n root->right->right = new TreeNode(7);\n Solution s;\n TreeNode *p = s.findLargestBSTSubtree(root);\n showPre(p);\n showIn(p);\n}\n\nint main(){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.28807947039604187,
"alphanum_fraction": 0.41059601306915283,
"avg_line_length": 21.641666412353516,
"blob_id": "966aae97a2f2a1e64121dbf41b7faeb5bb281ad6",
"content_id": "fce15bd21c37c028c9e4b924d1a1fb277b6f4a99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2718,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 120,
"path": "/topics/dynamicprogramming/src/beanMan_test.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * test code for beanMan\n * */\nvoid runBeanMan(int pool[Rows][Columns]){\n int Prev[Rows][Columns];\n memset(Prev, 0, sizeof(Prev));\n\n int destR = Rows-1;\n int destC = Columns -1;\n int srcR = 0;\n int srcC = 0;\n int har = beanMan(pool, Prev, srcR, srcC, destR, destC);\n \n cout << \"The best path is: \" <<endl; \n trace(Prev, srcR, srcC, destR, destC);\n cout << endl;\n cout << \"I can eat most beans of \"<< har << endl<< \"**************************\"<< endl ; \n}\n\nvoid test_01(){\n int BeanPool1[Rows][Columns] ={\n {1, 0, 1, 0, 0, 1}, \n {1, 0, 0, 1, 0, 1},\n {0, 1, 0, 1, 0, 0}, \n {1, 0, 1, 1, 1, 0},\n {0, 0, 1, 0, 1, 1},\n {0, 1, 1, 1, 0, 0}\n }; \n \n int BeanPool2[Rows][Columns]={\n {0,1,0,0,0,0},\n {0,1,1,0,0,0},\n {1,0,1,1,0,0},\n {1,1,0,1,1,0},\n {0,0,0,0,1,0},\n {1,0,1,0,0,1}\n };\n\n int BeanPool3[Rows][Columns] ={\n {0, 0, 0, 0, 0, 0}, \n {0, 0, 0, 0, 0, 1},\n {0, 0, 0, 0, 0, 0}, \n {0, 0, 0, 0, 0, 0},\n {0, 0, 0, 0, 0, 1},\n {0, 1, 1, 1, 0, 0}\n }; \n\n int BeanPool4[Rows][Columns] ={\n {0, 0, 0, 1, 0, 0}, \n {0, 0, 0, 0, 1, 1},\n {0, 0, 0, 0, 0, 1}, \n {0, 0, 0, 0, 0, 0},\n {0, 0, 0, 0, 0, 1},\n {1, 1, 1, 1, 0, 0}\n }; \n \n runBeanMan(BeanPool1);\n runBeanMan(BeanPool2);\n runBeanMan(BeanPool3);\n runBeanMan(BeanPool4);\n}\n\nvoid runBeanMan_02(int pool[Rows][Columns]){\n int prev[Rows][Columns];\n memset(prev, 0, sizeof(prev));\n \n int beginR = 0;\n int beginC = 0;\n int destR = Rows - 1;\n int destC = Columns -1;\n beanMan2(pool, prev, beginR, beginC, destR, destC);\n}\n\nvoid test_02(){\n int BeanPool1[Rows][Columns] ={\n {1, 0, 1, 0, 0, 1}, \n {1, 0, 0, 1, 0, 1},\n {0, 1, 0, 1, 0, 0}, \n {1, 0, 1, 1, 1, 0},\n {0, 0, 1, 0, 1, 1},\n {0, 1, 1, 1, 0, 0}\n }; \n \n int BeanPool2[Rows][Columns]={\n {0,1,0,0,0,0},\n {0,1,1,0,0,0},\n {1,0,1,1,0,0},\n {1,1,0,1,1,0},\n {0,0,0,0,1,0},\n {1,0,1,0,0,1}\n };\n \n int BeanPool3[Rows][Columns]={\n {0,1,0,1,0,0},\n {1,1,0,0,1,0},\n {1,0,1,1,0,0},\n {0,0,1,1,0,0},\n {0,0,0,0,1,0},\n {0,0,1,1,0,0}\n };\n\n int BeanPool4[Rows][Columns]={\n {1,0,0,0,0,0},\n {0,1,0,0,0,0},\n {0,0,1,0,0,0},\n {0,0,0,1,1,1},\n {0,0,0,1,0,1},\n {0,0,0,1,1,0}\n };\n \n runBeanMan_02(BeanPool1, dbmp);\n runBeanMan_02(BeanPool2, dbmp);\n runBeanMan_02(BeanPool3, dbmp);\n runBeanMan_02(BeanPool4, dbmp);\n}\n\nint main(int, char**){\n test_01();\n //test_02();\n}\n\n"
},
{
"alpha_fraction": 0.41895604133605957,
"alphanum_fraction": 0.4306318759918213,
"avg_line_length": 27.1200008392334,
"blob_id": "42fa67d4200c8a722fb531eb7ba958248a5ece22",
"content_id": "4512bad9c7eec20ed7f4273db018f923f2a5ab5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1456,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 50,
"path": "/leetcode/src/solveSudoku.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * solve a sudoku of 9*9 board. null cell is marked as '.'\r\n * */\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <string>\r\n#include <vector>\r\n\r\nusing namespace std;\r\n\r\nclass Solution{\r\npublic:\r\n void solveSudoku(vector<vector<char> >& board){\r\n dfs(board, 0);\r\n }\r\n\r\n bool dfs(vector<vector<char> >& board, int pos){\r\n int n = board.size();\r\n if(pos == n*n) return true;\r\n int x = pos / n, y = pos % n;\r\n if(board[x][y] == '.'){\r\n for(char ch = '1'; ch <= '9'; ch++){\r\n board[x][y] = ch;\r\n if(validate(board, pos) && dfs(board, pos+1)) return true;\r\n }\r\n board[x][y] = '.';\r\n }else{\r\n if(dfs(board, pos+1)) return true;\r\n }\r\n return false;\r\n }\r\n\r\n bool validate(vector<vector<char> >& board, int pos){\r\n int n = board.size();\r\n int x = pos/n, y = pos%n;\r\n char ch = board[x][y];\r\n for(int i=0; i<n; i++){\r\n if(i != x && board[i][y] == ch) return false;\r\n if(i != y && board[x][i] == ch) return false;\r\n }\r\n int cx = x/3 * 3; // 3 is the height and width of the 3*3 cubic of sudoku\r\n int cy = y/3 * 3;\r\n for(int i=cx; i<cx+3; i++){\r\n for(int j=cy; j<cy+3; j++){\r\n if(i != x && j != y && board[i][j] == ch) return false;\r\n }\r\n }\r\n return true;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.44929245114326477,
"alphanum_fraction": 0.46639150381088257,
"avg_line_length": 22.55555534362793,
"blob_id": "4f960dd53b65d2588db5c2df63967d119528dc20",
"content_id": "55cf7d99e8fc4881a41c91f3da65ca0e8cae1e31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1696,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 72,
"path": "/leetcode/src/rotateImage.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given an n*n 2D matrix, rotate the image by 90 degrees clockwisely in place.\n * */\n#include \"../include/preliminary.h\"\n\nvoid swap(int &a, int &b){\n int tmp = b;\n b = a;\n a = tmp;\n return;\n}\n\nvoid rotateClockwiseQuarter(vector<vector<int> >& matrix){\n int n = matrix.size();\n if(n==0) return;\n for(int i=0;i<n;i++){\n for(int j=0;j<(n>>1);j++){\n swap(matrix[i][j], matrix[i][n-1-j]);\n }\n }\n \n for(int i=0;i<n-1;i++){\n for(int j=0;j<n-1-i;j++){\n swap(matrix[i][j], matrix[n-1-j][n-1-i]);\n }\n }\n return;\n}\n\nvoid showMatrix(const vector<vector<int> >& matrix){\n int n = matrix.size();\n for(int i=0;i<n;i++){\n for(int j=0;j<n;j++){\n printf(\"%d \", matrix[i][j]);\n }\n printf(\"\\n\");\n }\n printf(\"------------------\\n\");\n return;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input positive n:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int n = atoi(str.c_str());\n if(n<1) continue;\n vector<vector<int> > matrix;\n for(int i=0;i<n;i++){\n if(getline(cin, str)==0 || str.empty()) return;\n int *row = new int[str.size()]();\n int m = splitStr2IntArray(str, row);\n vector<int> vec;\n for(int j=0;j<m;j++){\n vec.push_back(row[j]);\n }\n matrix.push_back(vec);\n delete[] row;\n row=0;\n }\n printf(\"matrix input completed\\n\");\n rotateClockwiseQuarter(matrix);\n showMatrix(matrix);\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5232067704200745,
"alphanum_fraction": 0.5316455960273743,
"avg_line_length": 29.580644607543945,
"blob_id": "0b006676886c79502a8c662bb14dc1e863133833",
"content_id": "6573fa9c37e843c03fef2f72f18c7c8241ac4746",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2844,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 93,
"path": "/leetcode/src/insertIntervals.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a set of non-overlapping intervals, insert a new interval into the intervals. \n * You can assume that the intervals were initially sorted according to their start time.\n *\n * \n * */\n\n#include \"../include/preliminary.h\"\n\nstruct Interval{\n int start;\n int end;\n Interval():start(0), end(0){}\n Interval(int s, int e):start(s), end(e){} \n};\n\nvoid displayIntervals(const vector<Interval>& intervals){\n for(vector<Interval>::const_iterator iter = intervals.begin();\n iter < intervals.end();\n ++iter){\n printf(\"[%d, %d] \", iter->start, iter->end);\n }\n printf(\"\\n\");\n}\n\n/*\n * linear solution, time in O(n)\n * */\nvector<Interval> insert(vector<Interval>& intervals, Interval newInterval){\n vector<Interval> res;\n bool inserted = false;\n for(vector<Interval>::const_iterator iter = intervals.begin();\n iter != intervals.end();\n ++iter){\n if(!inserted){\n bool overlapped = (iter->end >= newInterval.start) && (newInterval.end >= iter->start);\n if(overlapped){\n int a = min(newInterval.start, iter->start);\n int b = max(newInterval.end, iter->end);\n res.push_back(Interval(a, b));\n inserted = true;\n }else{\n if(newInterval.end < iter->start){\n res.push_back(Interval(newInterval.start, newInterval.end));\n inserted = true;\n }\n res.push_back(Interval(iter->start, iter->end));\n }\n }else{\n int m = res.size();\n if(res[m-1].end < iter->start){\n res.push_back(Interval(iter->start, iter->end));\n }else{\n res[m-1].end = max(res[m-1].end, iter->end);\n }\n }\n }\n if(!inserted){ //don't forget insert it if not yet\n res.push_back(Interval(newInterval.start, newInterval.end));\n }\n return res;\n}\n\nvoid test_01(){\n string str;\n while(1){\n cout << \"please input integer start/end of intervals in pairs:\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n vector<Interval> intervals;\n for(int i=0; i < (n>>1); ++i){\n intervals.push_back(Interval(arr[i<<1], arr[(i<<1) + 1]));\n }\n delete[] arr;\n arr=0;\n\n cout << \"please input new Interval to insert:\" << endl;\n if(getline(cin, str)==0 || str.empty()) continue;\n arr = new int[str.size()]();\n n = splitStr2IntArray(str, arr);\n if(n < 2) continue;\n Interval added(arr[0], arr[1]);\n \n displayIntervals(insert(intervals, added));\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4680028259754181,
"alphanum_fraction": 0.497538685798645,
"avg_line_length": 29.913043975830078,
"blob_id": "9510bd17995b6838e6cbbfc91a4bd0835cf62b75",
"content_id": "34c926e03157dfef8c792dd01f18de696371ca57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2844,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 92,
"path": "/leetcode/src/candy.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * there are N children standing in a line. Everyone is assigned a rating value.\n * you are giving candies to these children subjectd to the following requirements:\n * 1.each child must have at least one candy\n * 2.children with a higher rating get more candies than their neighbors.\n * what is the minimum candies you must give?\n *\n * hidden point: for 4 4 3, the minimum candies can be 1+2+1 = 4 \n *\n * test data:\n * 2 5 7 6 5 4 2 3 6 9 4 2\n * 4 4 5 7 6 5 4 4 3 3 2 1 4 6 9 3 2 \n * */\n#include \"../include/preliminary.h\"\n\nclass Solution{\n\npublic:\n/*\n * key: \n * 1. do not start backtrack until the decending range closes\n * 2. if [i]=[i-1], neighbor's candy can be 1 in minimum\n * */\n int candy(vector<int>& ratings){\n int n = ratings.size();\n if(n < 2) return n; // 0 or 1\n int *candies = new int[n]();\n candies[0] = 1;\n int sum = 1, ki = -1;\n for(int i = 1; i < n; ++i){\n if(ratings[i] == ratings[i-1]){\n if(ki > -1) continue; // within decending range\n candies[i] = 1;\n }else if(ratings[i] > ratings[i-1]){\n if(ki > -1){ // [i-1] is start of previous preceding range\n sum += backtrack(ratings, ki, i-1, candies);\n ki = -1;\n }\n candies[i] = candies[i-1] + 1;\n }else{\n if(ki == -1) ki = i-1; // [i-1] is start of preceding range\n }\n sum += candies[i];\n }\n if(ki > -1){\n sum += backtrack(ratings, ki, n-1, candies);\n }\n delete[] candies;\n candies = NULL;\n return sum;\n }\n\nprivate:\n /*\n * note:\n * 1. candies[l] > [r], while [r-1] >= [r]\n * 2. candies[l] has been set already\n * */\n int backtrack(vector<int>& ratings, int l, int r, int *candies){\n if(l >= r) return 0;\n candies[r] = 1;\n int sum = 1;\n for(int i = r-1; i > l; --i){ // process candies[l] later\n candies[i] = (ratings[i] > ratings[i+1] ? candies[i+1] : 0) + 1;\n sum += candies[i];\n }\n int tmp = candies[l+1] + 1;\n if(tmp > candies[l]){ // complement candies[l]\n sum += tmp - candies[l];\n candies[l] = tmp;\n }\n return sum;\n }\n};\n /* unit test code is in ../cpp_unittest/candy_unittest */\n/*\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input rating values of children in a row:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n vector<int> ratings;\n for(int i=0;i<n;i++){\n ratings.push_back(arr[i]);\n }\n printf(\"minimum sum is %d\\n\", candy(ratings));\n }\n return;\n}\n*/\n"
},
{
"alpha_fraction": 0.317401260137558,
"alphanum_fraction": 0.34688037633895874,
"avg_line_length": 24.881481170654297,
"blob_id": "13091717903d21ed43f3059a372de30ad6081eb7",
"content_id": "69a6914074004c46357211e88405efdb062b2e0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3494,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 135,
"path": "/topics/sort/src/shellsort.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * shell sort:\n * one progression sort based on insertion sort.in-place, not stable\n * generally it is thought to be better than direct insert sort, around time O(n(lgn)^2)\n *\n * different implementation differs in choice of group step only\n * */\n#include \"../include/preliminary.h\"\n\nclass Solution{\n\npublic:\n /*\n * D.Shell initial version\n * */\n void shellSort_Sh(int *p, int n){\n for(int h = n/2; h > 0;h /= 2){ // different group step\n for(int i = h; i < n; i++){\n int temp = p[i];\n int j = 0;\n\n for(j = i-h; j >= 0 && p[j] > temp; j -= h){ // insert temp(p[i], search in reverse order\n p[j+h] = p[j];\n }\n p[j+h] = temp;\n }\n }\n return;\n }\n\n /*\n * Lazarus-Frank, 1960'\n * */\n void shellSort_LF(int *p, int n){\n for(int h = n/2; h > 0; h /= 2){ // different group step\n if(h % 2 == 0) h--;\n\n for(int i = h; i < n; i++){\n int temp = p[i];\n int j = 0;\n\n for(j = i-h; j >= 0 && p[j] > temp; j -= h){\n p[j+h] = p[j];\n }\n p[j+h] = temp;\n }\n }\n return;\n }\n\n /*\n * Hibband, 1963\n * */\n void shellSort_Hb(int *p, int n){\n int h;\n for(h = 1; h <= n/4; h = h*2 + 1);\n\n for(; h > 0;h = (h-1) / 2){\n /* 1,3,7,15,31,...2^i-1*/\n for(int i = h; i < n; i++){\n int temp = p[i];\n int j = 0;\n for(j = i-h; j >= 0 && p[j] > temp; j -= h){\n p[j+h] = p[j];\n }\n p[j+h] = temp;\n }\n }\n return;\n }\n\n /*\n * Papernov-Stasevich, 1965. this is nearly reach the performance of Knuth's\n * */\n void shellSort_PS(int *p, int n){\n int h;\n for(h = 2; h <= n/4; h = h*2 - 1);\n\n for(; h > 1;){ // different group step\n h = (h == 3) ? 1 : (h+1)/2;\n /* h=1,3,5,9,17,33...2^i+1 */\n for(int i = h; i < n; i++){\n int temp = p[i];\n int j = 0;\n for(j = i-h; j >= 0 && p[j] > temp; j -= h){\n p[j+h] = p[j];\n }\n p[j+h] = temp;\n }\n }\n return;\n }\n\n /*\n * Knuth, suggest in case n<1000. till now, this is nearly the best\n * */\n void shellSort_Kn(int *p, int n){\n int h;\n for(h = 1;h <= n/9; h = h*3 + 1);\n\n for(; h > 0; h = h/3){ // different group step\n /* h = 1,4,13,40,121,364...3^h+1*/\n for(int i = h;i < n; i++){\n int temp = p[i];\n int j = 0;\n for(j = i-h; j >= 0 && p[j] > temp; j -= h){\n p[j+h] = p[j];\n }\n p[j+h] = temp;\n }\n }\n return;\n }\n\n /*\n * Gonnet's, 1991\n * */\n void shellSort_Go(int *p, int n){\n int h;\n for(h = n; h > 1;){ // different group step\n h = (h < 5) ? 1 : (h*5 - 1) / 11;\n for(int i=h;i<n;i++){\n int temp = p[i];\n int j = 0;\n for(j = i-h; j >= 0 && p[j] > temp; j -= h){\n p[j+h] = p[j];\n }\n p[j+h] = temp;\n }\n }\n return;\n }\n};\n\n/* unit test is in ../unittest/shellsort_unittest/ */\n"
},
{
"alpha_fraction": 0.373620867729187,
"alphanum_fraction": 0.4267803430557251,
"avg_line_length": 31.200000762939453,
"blob_id": "3eaa317e109f8bc8e722485057ba44ca56a1dbf8",
"content_id": "45588fad75135c0fb1f78748f7b985f2ef532111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1994,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 60,
"path": "/leetcode/src/interleaveString.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given string s1, s2, s3, ask if s1 and s2 interleave s3\r\n */\r\n#include \"../include/preliminary.h\"\r\n\r\nclass InterleaveString{\r\npublic:\r\n bool isInterleave(string s1, string s2, string s3){\r\n if(s1.size() + s2.size() != s3.size()) return false; // check length\r\n int m = s1.size(), n = s2.size();\r\n int arr1[256], arr2[256];\r\n memset(arr1, 0, sizeof(arr1));\r\n memset(arr2, 0, sizeof(arr2));\r\n for(int i=0; i<m; i++) arr1[(int)s1[i]]++;\r\n for(int i=0; i<n; i++) arr1[(int)s2[i]]++;\r\n for(int i=0; i<m+n; i++) arr2[(int)s3[i]]++;\r\n for(int i=0; i < m+n; i++){ // check set of s1+s2 and s3\r\n if(arr1[i] != arr2[i]) return false;\r\n }\r\n\r\n int dp[m+1][n+1]; // dp[i][j] == 1 means s1.sub(0,i) and s2.sub(0,j) interleaves s3.sub(0, i+j), both of i and j are lengths\r\n memset(dp, 0, sizeof(dp));\r\n dp[0][0] = 1;\r\n for(int i=1; i<=m; i++){\r\n if(s1[i-1] != s3[i-1]) break;\r\n dp[i][0] = 1;\r\n }\r\n for(int j=1; j<=n; j++){\r\n if(s2[j-1] != s3[j-1]) break;\r\n dp[0][j] = 1;\r\n }\r\n for(int i=1; i<=m; i++){\r\n for(int j=1; j<=n; j++){\r\n dp[i][j] = (dp[i][j-1] == 1 && s2[j-1] == s3[i+j-1])\r\n || (dp[i-1][j] == 1 && s1[i-1] == s3[i+j-1]) ? 1 : 0;\r\n }\r\n }\r\n return dp[m][n] == 1;\r\n }\r\n\r\n void test_01(){\r\n string s1(\"aabcc\");\r\n string s2(\"dbbca\");\r\n cout << (isInterleave(s1, s2, string(\"aadbbcbcac\")) ? \"true\" : \"false\") << endl;\r\n cout << (isInterleave(s1, s2, string(\"aadbbbaccc\")) ? \"true\" : \"false\") << endl;\r\n }\r\n\r\n void test_02(){\r\n string s1(\"\");\r\n string s2(\"b\");\r\n cout << (isInterleave(s1, s2, string(\"b\")) ? \"true\" : \"false\") << endl;\r\n }\r\n};\r\n\r\nint main(){\r\n InterleaveString ils;\r\n ils.test_01();\r\n ils.test_02();\r\n return 0;\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.4371534287929535,
"alphanum_fraction": 0.4722735583782196,
"avg_line_length": 20.215686798095703,
"blob_id": "2dd66e87c67068cacd409ad3ce455eaa6eccf4f4",
"content_id": "142c8cdd52123b2cc33f6e6cce22741a455e2414",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1082,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 51,
"path": "/leetcode/src/mergeKSortedList.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * merge k sorted linked lists and return it as one sorted list. Analyze its complexity\n * */\n#include \"../include/preliminary.h\"\n\nusing namespace std;\n\nListNode* merge(ListNode *l1, ListNode *l2, ListNode* &tail){\n ListNode *h=0, *head=0;\n if(!l1) return l2;\n if(!l2) return l1;\n if(l1->val < l2->val){\n h = head = l1;\n l1 = l1->next;\n }else{\n h = head = l2;\n l2 = l2->next;\n }\n while(l1 || l2){\n if(!l2 || (l1 && l1->val < l2->val)){\n h->next = l1;\n l1 = l1->next;\n }else{\n h->next = l2;\n l2 = l2->next;\n }\n h = h->next;\n }\n tail = h;\n return head;\n}\n\nListNode* mergeKLists(vector<ListNode*>& lists){\n int n = lists.size();\n if(n<1) return NULL;\n int i=0;\n while(i<n && lists[i]==NULL){\n i++;\n }\n if(i==n) return NULL;\n ListNode *l1 = lists[i++];\n for(;i<n;i++){\n ListNode *l2 = lists[i], *tail = 0;\n l1 = merge(l1, l2, tail);\n }\n return l1;\n}\n\nint main(int, char**){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.43809524178504944,
"alphanum_fraction": 0.4752834439277649,
"avg_line_length": 25.5625,
"blob_id": "16e62d14ac6924e3a65de5bf6d532461a2b35e07",
"content_id": "960e849a328ed8c1327283a92d3c015ab91f9e61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2205,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 80,
"path": "/leetcode/src/minimumEditDistance.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given two words in string, find the minimum edit distance for converting word1 to word2. once conversion must be one of below:\r\n * 1.delete one letter\r\n * 2.insert one letter\r\n * 3.replace one letter with another\r\n *\r\n * solution: DP\r\n * dp[i][j] = min{\r\n * dp[i-1][j] + 1, // delete\r\n * dp[i][j-1] + 1, // insert\r\n * dp[i-1][j-1] + word1[i] == word2[j] ? 1 : 0 // substution\r\n * }\r\n */\r\n\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <cstring>\r\n#include <string>\r\n#include <vector>\r\n#include <algorithm>\r\nusing namespace std;\r\n\r\nclass EditDistance{\r\npublic:\r\n int minDistance(const string& word1, const string& word2){\r\n int m = word1.size();\r\n int n = word2.size();\r\n if(m==0 || n==0) return max(m, n);\r\n int dp[m+1][n+1]; //define one more row and column to facilitate processing [i-1][] and [][j-1]\r\n memset(dp, 0, sizeof(dp));\r\n for(int i=0; i<=m; ++i){\r\n dp[i][0] = i;\r\n }\r\n for(int j=0; j<=n; ++j){\r\n dp[0][j] = j;\r\n }\r\n for(int i=1; i<=m; ++i){ // i-1 is index of argument\r\n for(int j=1; j<=n; ++j){\r\n dp[i][j] = min(1 + min(dp[i-1][j], dp[i][j-1]),\r\n dp[i-1][j-1] + (word1[i-1] == word2[j-1] ? 0 : 1));\r\n }\r\n }\r\n return dp[m][n];\r\n }\r\n\r\n void test_01(){ // 1 operation\r\n string word1(\"\");\r\n string word2(\"a\");\r\n cout << minDistance(word1, word2) << endl;\r\n }\r\n\r\n void test_02(){ // 1 operation\r\n string word1(\"a\");\r\n string word2(\"b\");\r\n cout << minDistance(word1, word2) << endl;\r\n }\r\n\r\n void test_03(){ // 2 operations\r\n string word1(\"abc\");\r\n string word2(\"acd\");\r\n cout << minDistance(word1, word2) << endl;\r\n }\r\n\r\n void test_04(){ // 1 substitution\r\n string word1(\"abc\");\r\n string word2(\"adc\");\r\n cout << minDistance(word1, word2) << endl;\r\n }\r\n};\r\n\r\nint main(int, char**){\r\n EditDistance *ed = new EditDistance();\r\n ed->test_01();\r\n ed->test_02();\r\n ed->test_03();\r\n ed->test_04();\r\n delete ed;\r\n ed = 0;\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.45665237307548523,
"alphanum_fraction": 0.466094434261322,
"avg_line_length": 24.866666793823242,
"blob_id": "8400dcca050e47f27a3e85e7fe7c39d2e3eb7a4a",
"content_id": "b89c5f3de1b66d157e4c6bd7acc53209814e0798",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1165,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 45,
"path": "/leetcode/src/trapWater.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining.\n *\n * */\n#include \"../include/preliminary.h\"\n\n/*\n * one-pass solution: scan leftward and rightward at the same time, start from lower of the two. \n * */\nint trap(int A[], int n){\n if(n <= 2) return 0;\n int l=0, r=n-1, sum=0;\n while(l < r){\n bool leftMove = A[l] < A[r];\n int w = 0;\n if(leftMove){\n int h = A[l++];\n while(h > A[l]){\n w += h - A[l];\n ++l;\n }\n }else{\n int h = A[r--];\n while(h > A[r]){\n w += h - A[r];\n --r;\n }\n }\n sum += w;\n }\n return sum;\n}\n\nint main(){\n string str;\n while(1){\n cout << \"please input non-negative integer array as wall:\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n printf(\"trapped water is %d\\n\", trap(arr, n));\n delete[] arr;\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.507311999797821,
"alphanum_fraction": 0.5142757892608643,
"avg_line_length": 24.64285659790039,
"blob_id": "5979fa6df02086836f1c5084006bd65cf84098c3",
"content_id": "55cf36718125f1fac11d66261922247110636cf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2872,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 112,
"path": "/leetcode/src/NQueens.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * problem 1. put N queens on a N*N square board. output all the options\n *\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <vector>\n#include \"stdlib.h\"\n\nusing namespace std;\n\n/*\n * columnForRow[i] means column x possessed for queen stands on row i.\n * 1. conflict in column: ColumnsForRow[i] = ColumnForRow[j]\n * 2. conflict in diagonal: ColumnForRow[i] - ColumnForRow[j] == i-j || ColumnForRow[i] - ColumnForRow[j] == j-i\n * */\n\nclass NQueens{\n\npublic:\n NQueens(int n): N(n), total(0){\n columnForRow = new int[N]();\n }\n\n virtual ~NQueens(){\n delete[] columnForRow;\n columnForRow = NULL;\n }\n\n /*\n * return board which has placed N queens\n * */\n vector<vector<string> > solve(){\n vector<vector<string> > res;\n placeQueen(0, res);\n return res;\n }\n\n /*\n * return total options count\n * */\n int totalNQueens(){\n total = 0;\n solve();\n return total;\n }\n\nprivate:\n /*\n * in the return vector<vector<string> >\n * string is N chars, 'Q' for queen, '.' for space\n * vector<string> is N string, which compose a N*N board which places N queens\n * vector<vector<string> > are all of the optional boards\n * */\n void printBoard(vector<vector<string> >& res){\n vector<string> board;\n for(int i = 0; i < N; i++){ // row i\n char *row = new char[N+1];\n for(int j = 0; j < N; j++){ // column j\n row[j] = (j == columnForRow[i] ? 'Q' : '.');\n }\n row[N] = '\\0';\n board.push_back(string(row));\n delete[] row;\n }\n res.push_back(board);\n ++total;\n return;\n }\n\n /*\n * if queen put in (r, columnForRow[r]), whether will conflict with all the placed queens in rows [0, r)\n * */\n bool check(int r){\n for(int i = 0; i < r; i++){ // avoid check of same row\n int tmp = columnForRow[i] - columnForRow[r];\n if(tmp == 0 // same column\n ||tmp == (i-r) // '/' diagnol\n ||tmp == (r-i)){ // '\\' diagnol, same to r1 + c1 = r2 + c2\n return false;\n }\n }\n return true;\n }\n\n /*\n * try to put queen on row r, r is 0-based\n * */\n void placeQueen(int r, vector<vector<string> >& res){\n if(r == N){\n printBoard(res);\n return;\n }\n\n for(int i = 0; i < N; i++){\n columnForRow[r] = i; // try any column of this row to put queen\n if(check(r)){\n placeQueen(r + 1, res);\n }\n }\n }\n\n int N; // dimension size of board\n\n int total; // total valid options\n\n // columnForRow[i] = x means column x possessed for queen stands on row i.\n int *columnForRow;\n};\n\n/* unit test is in ../cpp_unittest/NQueens_unittest */\n"
},
{
"alpha_fraction": 0.46995994448661804,
"alphanum_fraction": 0.48064085841178894,
"avg_line_length": 22.77777862548828,
"blob_id": "4a489244f1f3b26e54bc76ba9720f5fa58bd9710",
"content_id": "18212364ae0896242a4ba2a00b39091fe4eec6f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1498,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 63,
"path": "/leetcode/src/zigzaggame.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * the string \"paypalistring\" is written in a zigzag pattern on a given number of rows like this:\n * p a t g\n * a p l s r n\n * y i i \n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include \"stdlib.h\"\n#include <vector>\nusing namespace std;\n\nstring zigzag(const string& str, int rows){\n if(rows==0) return string();\n if(rows==1) return string(str);\n int n = str.size();\n vector<char> pvec[rows];\n bool up=false;\n for(int i=0, r=0; i<n;i++){\n pvec[r].push_back(str[i]);\n if(up) r--;\n else r++;\n \n if(r==-1){\n r = 1;\n up = false;\n }\n if(r==rows){\n r = rows-2;\n up = true;\n }\n }\n string res;\n for(int i=0;i<rows;i++){ //take care of the string build and output\n int l = pvec[i].size();\n char cstr[l+1];\n memset(cstr, 0, sizeof(char)*(l+1));\n for(int j=0;j<l;j++){\n cstr[j] = pvec[i][j];\n }\n res.append(string(cstr));\n }\n return res;\n}\n\nint main(int, char**){\n string str;\n while(1){\n cout<<\"please input rows:\"<<endl;\n if(getline(cin, str)==0 || str.empty()) \n break;\n int rows = atoi(str.c_str());\n \n cout<<\"please input string:\"<<endl;\n if(getline(cin, str)==0 || str.empty()) \n break;\n printf(\"ZigZag game: %s\\n\", zigzag(str, rows).c_str());\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4616432189941406,
"alphanum_fraction": 0.47571492195129395,
"avg_line_length": 31.89230728149414,
"blob_id": "4056826b4d4aad89f435645119ddccc24d694292",
"content_id": "728dd9f37e11ea63a2de4e8ca95dd118fe0d4a5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2203,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 65,
"path": "/leetcode/src/max2DRectangle.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * a matrix is made up of '1' and '0', find the maximum rectangle which ONLY contains '1'\r\n *\r\n * [1, 2, 4, 0, 2], every int has one unit of width. max area is 4\r\n */\r\n\r\n#include \"../include/preliminary.h\"\r\n\r\nclass Solution{\r\npublic:\r\n int maximumRectangle(vector<vector<char> >& matrix){ //to project 2D matrix to 1D array eventually\r\n if(matrix.empty()) return 0;\r\n\r\n const int m = matrix.size();\r\n const int n = matrix[0].size();\r\n int res = 0;\r\n if(n == 0) return 0;\r\n\r\n int horizon[n];\r\n memset(horizon, 0, sizeof(horizon));\r\n\r\n for(int i = 0; i < m; i++){ // each row\r\n for(int j = 0; j < n; j++){\r\n if(matrix[i][j] == '1'){\r\n horizon[j] += 1;\r\n }else{\r\n horizon[j] = 0;\r\n }\r\n }\r\n vector<int> height(horizon, horizon + n);\r\n int tmp = largestRectangleArea(height);\r\n res = max(res, tmp);\r\n\r\n height.clear();\r\n }\r\n return res;\r\n }\r\n\r\n int largestRectangleArea(const vector<int>& heights){ //max rectangle in one array, time is O(n)\r\n const int n = heights.size();\r\n if(n == 0) return 0;\r\n\r\n int res = 0;\r\n stack<int> stk; // store index\r\n\r\n for(int i = 0; i <= n; i++){ // include i == n avoids the appendix process\r\n int h = (i == n ? 0 : heights[i]);\r\n while(!stk.empty() && heights[stk.top()] > h){ // before lower height push to stack, pop higher height\r\n int p = stk.top(); // and calculate their rectangle\r\n stk.pop();\r\n\r\n if(!stk.empty() && heights[stk.top()] == heights[p]) continue;\r\n\r\n int start = (stk.empty() ? -1 : stk.top()); // start is exclusive left index\r\n\r\n int tmp = (i-1 - start) * heights[p]; // i-1 is inclusive right index\r\n res = max(res, tmp);\r\n }\r\n stk.push(i); // push height which is greater than or equal to [stk.top()]\r\n }\r\n return res;\r\n }\r\n};\r\n\r\n/* unit test is in ../cpp_unittest/max2DRectangle_unittest */\r\n"
},
{
"alpha_fraction": 0.5116666555404663,
"alphanum_fraction": 0.5316666960716248,
"avg_line_length": 30.986665725708008,
"blob_id": "1ba4e733bcb41cd2ee6aa87f6d48fca5b3ce2dcc",
"content_id": "e1723ae41849e74a49eb7a4109ac1523663dd1ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2400,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 75,
"path": "/leetcode/src/searchWord.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a matrix composed of char, search another word whether exist in the matrix\n *\n * [ABCD,\n * DEFC]\n * ABE, true\n * DF: flase\n * */\n#include \"../include/preliminary.h\"\n\nbool searchOneChar(vector<int> pos[], string s, int currpos, int *used, int rows, int cols){\n if(s.empty()) return true;\n char ch = s[0];\n int l = s.size();\n int r = currpos / cols, c = currpos % cols;\n vector<int> options = pos[(int)ch];\n for(int i=0; i<(int)options.size(); i++){\n int nr = options[i] / cols;\n int nc = options[i] % cols;\n if(abs(nr - r) + abs(nc - c) != 1 || used[options[i]] == 1) // check if not successive, if used already\n continue;\n used[options[i]] = 1;\n if(searchOneChar(pos, s.substr(1, l-1), options[i], used, rows, cols))\n return true;\n used[options[i]] = 0;\n }\n return false;\n}\n\nbool exist(vector<vector<char> >& board, string word){\n if(word.empty()) return true;\n if(board.size() == 0 || board[0].size() == 0) return false;\n int m = board.size(), n = board[0].size(), l= word.size();\n if(l > m*n) return false; // length exceed\n\n vector<int> pos[256];\n for(int i=0; i < 256; i++){ // to support char search in O(1)\n pos[i] = vector<int>();\n }\n for(int i=0; i < m; i++){\n for(int j=0; j < n; j++){\n pos[(int)board[i][j]].push_back(i * n + j);\n }\n }\n\n int used[m*n];\n memset(used, 0, sizeof(used));\n vector<int> options = pos[(int)word[0]];\n for(int i=0; i<(int)options.size();i++){\n used[options[i]] = 1;\n if(searchOneChar(pos, word.substr(1, l-1), options[i], used, m, n))\n return true;\n used[options[i]] = 0;\n }\n return false;\n}\n\nvoid test(){\n vector<vector<char> > board;\n char row0[] = {'A', 'B', 'C', 'D'};\n board.push_back(vector<char>(row0, row0 + sizeof(row0)/sizeof(char)));\n char row1[] = {'E', 'F', 'G', 'H'};\n board.push_back(vector<char>(row1, row1 + sizeof(row1)/sizeof(char)));\n char row2[] = {'D', 'E', 'B', 'A'};\n board.push_back(vector<char>(row2, row2 + sizeof(row2)/sizeof(char)));\n string word1(\"BCE\");\n printf(\"%s, %s\\n\", word1.c_str(), exist(board, word1) ? \"true\" : \"false\");\n string word2(\"ABC\");\n printf(\"%s, %s\\n\", word2.c_str(), exist(board, word2) ? \"true\" : \"false\");\n}\n\nint main(){\n test();\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.42577841877937317,
"alphanum_fraction": 0.4641564190387726,
"avg_line_length": 26.72916603088379,
"blob_id": "0285dd57f3387c5211756e39dffb63a47eabc884",
"content_id": "e72e8bb59f840982955587fc02ef98cf5e32970d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1381,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 48,
"path": "/leetcode/src/scrambleString.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * scrambleString.h\r\n */\r\n\r\n#include \"../include/preliminary.h\"\r\n\r\nclass ScrambleString{\r\npublic:\r\n bool isScramble(string s1, string s2){\r\n if(s1.empty() || s2.empty() || s1.length() != s2.length()) return false;\r\n if(s1 == s2) return true;\r\n int n = s1.length();\r\n const char* arr1 = s1.c_str();\r\n const char* arr2 = s2.c_str();\r\n vector<char> vec1(arr1, arr1 + n);\r\n vector<char> vec2(arr2, arr2 + n);\r\n sort(vec1.begin(), vec1.end());\r\n sort(vec2.begin(), vec2.end());\r\n vector<char>::iterator it1 = vec1.begin(), it2 = vec2.begin();\r\n while(it1 != vec1.end()){\r\n if(*(it1++) != *(it2++)) return false;\r\n }\r\n\r\n for(int i=1; i<n; i++){\r\n if(isScramble(s1.substr(0, i), s2.substr(0, i))\r\n && isScramble(s1.substr(i, n-i), s2.substr(i, n-i))){\r\n return true;\r\n }\r\n if(isScramble(s1.substr(0, i), s2.substr(n-i, i))\r\n && isScramble(s1.substr(i, n-i), s2.substr(0, n-i))){\r\n return true;\r\n }\r\n }\r\n return false;\r\n }\r\n\r\n void test_01(){\r\n string s1(\"great\");\r\n string s2(\"agtre\");\r\n cout << (isScramble(s1, s2) ? \"true\" : \"false\") << endl;\r\n }\r\n};\r\n\r\nint main(){\r\n ScrambleString s;\r\n s.test_01();\r\n return 0;\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.38746437430381775,
"alphanum_fraction": 0.43304842710494995,
"avg_line_length": 16.549999237060547,
"blob_id": "e71e79bb0b18746b2c030fbefce6e8a800383c40",
"content_id": "db7cdf5007e12edd207122dbbbb66f4f56b445bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 20,
"path": "/leetcode/src/pow.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * implement pow(x, n)\n * */\n\ndouble pow(double x, int n){\n if(n==0) return 1;\n if(x==0) return 0;\n if(x==1) return 1;\n if(x == -1) return n % 2 ? -1 : 1;\n if(n<0) return (double)1/pow(x, -n);\n if(n % 2){\n return pow(x*x, n/2)*x;\n }else{\n return pow(x*x, n/2);\n }\n}\n\nint main(){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4429023563861847,
"alphanum_fraction": 0.4721207618713379,
"avg_line_length": 23.01754379272461,
"blob_id": "17241812d357c63b2f8ad479d1f51ba6ed73103a",
"content_id": "24a698a1c3e8f91936b926c19f7f2ffb99dff26a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4107,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 171,
"path": "/leetcode/src/surroundedregions.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a 2D board containing 'x' and '0', capture all regions surrounded by 'x'. A region is captured by flipping all '0's into 'x's in\n * that surrounded region.\n * For example:\n * x x x x\n * x 0 0 x //can be captured\n * x x 0 x //can be captured\n * x 0 x x\n *\n * solution: very smart!\n * mark all '0's can be iterated from 4 walls(up/down/left/right), then flip all '0's without being marked\n * */\n#include \"../include/preliminary.h\"\n#include <queue>\n\nconst int rs[4]={-1,0,0,1};\nconst int cs[4]={0,1,-1,0};\n\nvoid bfs(int r, int c, const vector<vector<char> >& board, int **covered){\n int n = board.size(); //row count\n int m = board[0].size(); //column count\n covered[r][c] = 1;\n queue<pair<int, int> > q;\n q.push(make_pair(r, c));\n while(!q.empty()){ //iterate '0' in board starting from [r][c] in BFS\n r = q.front().first;\n c = q.front().second;\n q.pop();\n for(int i=0;i<4;i++){\n int nr = r + rs[i];\n int nc = c + cs[i];\n if(nr >= 0 && nr < n && nc >= 0 && nc < m){\n if(board[nr][nc] != 'x' && !covered[nr][nc]){\n covered[nr][nc] = 1;\n q.push(make_pair(nr,nc));\n }\n }\n }\n }\n return;\n}\n\nvoid solve(vector<vector<char> > &board){\n int n = board.size(); //row count\n if(n<3) return; //at least it must be a 3*3 board\n int m = board[0].size(); //column count\n if(m<3) return;\n int **covered = new int*[n];\n for(int i=0;i<n;i++){\n covered[i] = new int[m]();\n }\n\n for(int j=0;j<m;j++){ //iterate from up wall\n if(board[0][j] != 'x' && !covered[0][j]){\n bfs(0,j, board, covered);\n }\n }\n for(int j=0;j<m;j++){ //iterate from low wall\n if(board[n-1][j] != 'x' && !covered[n-1][j]){\n bfs(n-1, j, board, covered);\n }\n }\n for(int i=0;i<n;i++){ //iterate from left wall\n if(board[i][0] != 'x' && !covered[i][0]){\n bfs(i,0, board, covered);\n }\n }\n for(int i=0;i<n;i++){ //iterate from right wall\n if(board[i][m-1] != 'x' && !covered[i][m-1]){\n bfs(i, m-1, board, covered);\n }\n }\n\n for(int i=1;i<n-1;i++){ //flip all '0's inside the 4 walls in board\n for(int j=1;j<m-1;j++){\n if(board[i][j] != 'x' && !covered[i][j]){\n board[i][j] = 'x';\n }\n }\n }\n\n for(int i=0;i<n;i++){\n delete[] covered[i];\n covered[i] = 0;\n }\n delete[] covered;\n return;\n}\n\nvoid display(const vector<vector<char> >& vec){\n printf(\"-------------------\\n\");\n for(size_t i=0;i<vec.size();i++){\n for(size_t j=0;j<vec[i].size();j++){\n printf(\"%c \", vec[i][j]);\n }\n printf(\"\\n\");\n }\n}\n\n/*\n * x x x\n * x 0 x\n * x x x\n * */\nvoid test_01(){\n vector<vector<char> > vec;\n vector<char> v0;\n v0.push_back('x');\n v0.push_back('x');\n v0.push_back('x');\n vec.push_back(v0);\n vector<char> v1;\n v1.push_back('x');\n v1.push_back('0');\n v1.push_back('x');\n vec.push_back(v1);\n vector<char> v2;\n v2.push_back('x');\n v2.push_back('x');\n v2.push_back('x');\n vec.push_back(v2);\n display(vec);\n\n solve(vec);\n display(vec);\n return;\n}\n\n/*\n * x x x 0\n * x 0 0 x\n * x 0 x 0\n * x x 0 x\n * */\nvoid test_02(){\n vector<vector<char> > vec;\n vector<char> v0;\n v0.push_back('x');\n v0.push_back('x');\n v0.push_back('x');\n v0.push_back('0');\n vec.push_back(v0);\n vector<char> v1;\n v1.push_back('x');\n v1.push_back('0');\n v1.push_back('0');\n v1.push_back('x');\n vec.push_back(v1);\n vector<char> v2;\n v2.push_back('x');\n v2.push_back('0');\n v2.push_back('x');\n v2.push_back('0');\n vec.push_back(v2);\n vector<char> v3;\n v3.push_back('x');\n v3.push_back('x');\n v3.push_back('0');\n v3.push_back('x');\n vec.push_back(v3);\n display(vec);\n\n solve(vec);\n display(vec);\n return;\n}\n\nint main(int, char**){\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4615384638309479,
"alphanum_fraction": 0.4865616261959076,
"avg_line_length": 23.247190475463867,
"blob_id": "c29fce534af1c73732a00afe344b04151cbb32d0",
"content_id": "69084ea4cf594e3ab240dbe6c6cad98e572abce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2158,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 89,
"path": "/topics/binarysearch/src/maxdistance.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n* from leetcode. given an integer array A, find maximum j-i subjected to the constraint of A[i] < A[j]\n* solution 1: binary search with linear scan\n* solution 2: twice linear scan, key is the Rmax[]\n* \n* test data:\n* 1 4 3 5 2 7 5 4\n* 6 5 4 3 2 1\n* 1 2 3 4 5 6\n*/\n\n#include \"../header/preliminary.h\"\n\n/*\n * in time O(nlgn)\n * */\nbool distanceExist(int *A, int n, int k, int& begin){ //k=j-i\n for(int i=0;i+k<n;++i){\n if(A[i] < A[i+k]){\n begin = i;\n return true;\n }\n }\n return false;\n}\n\nint maxDistance_01(int *A, int n, int& begin){\n int u=n, v=0, m=0;\n while(v<u){\n m = (u+v)/2;\n if(distanceExist(A, n, m, begin)){\n v = m+1; //enlarge m\n }else{ //reduce m to try smaller m\n u = m;\n }\n }\n return m;\n}\n\n/*\n * achieve linear search, in time O(n) and space O(n)\n * */\nint maxDistance_02(int *A, int n, int& left){\n if(n<2) return 0;\n int Rmax[n]; // Rmax[i] is the maximum value on right side of A[i], inclusive of A[i]\n Rmax[n-1] = A[n-1];\n for(int i = n-2; i >= 0; i--){ // in time O(n)\n Rmax[i] = max(A[i], Rmax[i+1]);\n } \n \n int i=0, j=1, maxDiff=0;\n while(i<n && j<n){ // in time O(n)\n if(A[i] < Rmax[j]){\n maxDiff = max(maxDiff, j-i);\n if(maxDiff == j-i) left = i;\n }else{\n ++i;\n }\n ++j; // resume to scane from the potential distance remaining j-i\n }\n return maxDiff;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input integer array:\\n\");\n if(getline(cin, str)==0 || str.empty())\n break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n int begin = 0;\n int res = maxDistance_02(arr, n, begin);\n if(res<1){\n printf(\"no result\\n\");\n }else{\n printf(\"the max distanace is %d from A[%d]=%d to A[%d]=%d\\n\", \n res, begin, arr[begin], begin+res, arr[begin+res]);\n }\n delete[] arr;\n arr = 0;\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4223988950252533,
"alphanum_fraction": 0.43415141105651855,
"avg_line_length": 23.310924530029297,
"blob_id": "7f8cff2708109374fd9daf38217af6bb2ab882ad",
"content_id": "a8c13a9edb5815e49fc476c1605010ab3143e01f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2893,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 119,
"path": "/topics/sort/src/selectionsort.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * bubble sort:\n * time O(n^2), in place. excessive swap in every time internal iteration\n *\n * selection sort:\n * time O(n^2), in place\n * improvement on bubble sort by reducing swap to once in each internal iteration.\n * its average efficiency is a little worse than insertionsort\n *\n * insertion sort:\n * in internal iteration, stops till finding its correct postion.\n * improvement on selection sort with copy instead of swap.\n * for linked list sort, it is very efficient.\n *\n * merge sort:\n * divide-and-conquer\n *\n * */\n#include \"../include/preliminary.h\"\n\nstatic const int MAXIM = 0xffff;\n\nclass Solution{\n\npublic:\n void bubbleSort(int *A, int n){ //in descending order\n for(int i = 0; i < n-1; i++){\n for(int j = n-1; j > i; j--){ // bottom up, compare two adjacent elements and swap\n if(A[j-1] > A[j]){\n swapInt(A[j-1], A[j]); // the minimum during [i,n) rises to [i] like bubble\n }\n }\n }\n return;\n }\n\n void selectionSort(int *A, int n){\n for (int i = 0; i < n-1; i++){\n int sel = i;\n for(int j = n-1; j > i; j--){\n if(A[j] < A[sel]) sel = j; // find the minimum [sel] among (i,n)\n }\n\n if(sel != i) swapInt(A[i], A[sel]); // only swap in need\n }\n return;\n }\n\n void insertionSort(int *A, int n){\n for(int i = 1; i < n; i++){\n int temp = A[i];\n int j = i-1;\n for(; j >= 0 && A[j] > temp; j--){\n A[j+1] = A[j];\n }\n A[j+1] = temp;\n }\n return;\n }\n\n void mergeSort(int *A, int n){\n mergesort(A, 0, n-1);\n }\n\nprivate:\n /*\n * divide-and-conquer\n * */\n void mergesort(int *A, int p, int r){ // p,r are inclusivea\n if(p < r){\n int q = (p + r) / 2;\n mergesort(A, p, q);\n mergesort(A, q + 1, r);\n\n merge(A, p, q, r);\n }\n }\n\n /*\n * trick: use one appendix sentinel at tail to avoid checking which sub array is empty\n * */\n void merge(int *A, int p, int q, int r){\n int n1 = q - p + 1;\n int n2 = r - q;\n\n int AL[n1 + 1];\n memset(AL, 0, sizeof(AL));\n\n for(int i = p; i <= q; i++){\n AL[i - p] = A[i];\n }\n AL[q - p + 1] = MAXIM;\n\n int AR[n2 + 1];\n memset(AR, 0, sizeof(AR));\n\n for(int i = q + 1; i <= r; i++){\n AR[i - q - 1] = A[i];\n }\n AR[r - q] = MAXIM;\n\n int i = 0, j = 0;\n for(int k = p; k <= r; k++){\n if(AL[i] <= AR[j]){\n A[k] = AL[i];\n i++;\n }else{\n A[k] = AR[j];\n j++;\n }\n }\n }\n\n void swapInt(int& a, int& b){\n int tmp = a;\n a = b;\n b = tmp;\n }\n};\n"
},
{
"alpha_fraction": 0.5189292430877686,
"alphanum_fraction": 0.543021023273468,
"avg_line_length": 24.388349533081055,
"blob_id": "bf8beabdc9429351876d0ff96e9eb1579bdc83b9",
"content_id": "597feda33573d69fd85a1eead803e619f3002d85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2615,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 103,
"path": "/topics/graph/src/DFS01.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * personal implemenation of DFS\n * Note: the data structure can be tree or array. But as linked list does not support random access, array is easier.\n * date: Feb03, 2013\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include <queue>\n#include <stack>\n\nusing namespace std;\n\nenum CoveredEnum {\n NoProbed = 0,\n Probed,\n Covered\n};\n\nstruct Point{\n Point(int val): \n value(val), Left(0), Mid(0), Right(0), Cov(NoProbed){}\n int value;\n Point *Left;\n Point *Mid;\n Point *Right;\n CoveredEnum Cov;\n};\n\nPoint* FindNextChild(Point* pParent){\n if(pParent->Cov == Covered) return 0;\n if(pParent->Left != 0 && pParent->Left->Cov == NoProbed){\n return pParent->Left;\n }else if(pParent->Mid != 0 && pParent->Mid->Cov == NoProbed){\n return pParent->Mid;\n }else if(pParent->Right != 0 && pParent->Right->Cov == NoProbed){\n return pParent->Right;\n }\n return NULL;\n}\n\nvoid DFS02(Point* begin){\n stack<Point*> _stack;\n Point* parent = begin;\n\n _stack.push(parent);\n cout << parent->value << ' ';\n while(!_stack.empty()){\n Point* child = FindNextChild(parent);\n if(child != 0){\n _stack.push(child);\n cout << child->value << ' ';\n child->Cov = Probed;\n parent = child;\n }else{\n _stack.top()->Cov = Covered;\n _stack.pop();\n if(!_stack.empty()){\n parent = _stack.top();\n }\n }\n }\n cout << endl;\n return;\n}\n\nvoid test_01(){\n Point* pp = new Point(1);\n pp->Left = new Point(2);\n pp->Mid = new Point(3);\n pp->Right = new Point(4);\n\n pp->Left->Left = new Point(5);\n pp->Left->Right = new Point(6);\n pp->Mid->Left = new Point(7);\n pp->Mid->Right = new Point(8);\n pp->Right->Left = new Point(9);\n pp->Right->Mid = new Point(10);\n pp->Right->Right = new Point(11);\n\n pp->Left->Left->Left = new Point(12);\n pp->Left->Left->Right = new Point(13);\n pp->Left->Right->Left = new Point(14);\n pp->Mid->Left->Left = new Point(15);\n pp->Mid->Left->Right = new Point(16);\n pp->Mid->Right->Left = new Point(17);\n pp->Mid->Right->Right = new Point(18);\n pp->Right->Left->Left = new Point(19);\n pp->Right->Left->Right = new Point(20);\n pp->Right->Mid->Left = new Point(21);\n pp->Right->Mid->Right = new Point(22);\n pp->Right->Right->Left = new Point(23);\n pp->Right->Right->Right = new Point(24);\n\n DFS02(pp);\n return;\n}\n\nint main(){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6090651750564575,
"alphanum_fraction": 0.643059492111206,
"avg_line_length": 24.214284896850586,
"blob_id": "ba67c3c2b34e32efa0bbc99a1816e24a117d2217",
"content_id": "9ddf0f08fb3df3ef3878f6e3807bb9c184488e7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 353,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 14,
"path": "/leetcode/cpp_unittest/maxstockprofit_unittest/maxstockprofit_unittest.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include \"maxstockprofit.cpp\"\n#include \"gtest/gtest.h\"\n\n/* int Solution::maxProfitIII(const vector<int>& prices) */\n\nTEST(maxstockprofitTest, Positive01){\n Solution s;\n\n int arr[] = {1, 2, 4, 3, 1, 2, 3, 2, 5};\n vector<int> prices(arr, arr + sizeof(arr) / sizeof(int));\n\n int expected = 7;\n EXPECT_EQ(expected, s.maxProfitIII(prices));\n}\n"
},
{
"alpha_fraction": 0.5347852110862732,
"alphanum_fraction": 0.5722928047180176,
"avg_line_length": 23.671642303466797,
"blob_id": "0411d09eedb9d2b1c31dc128d0616dd74076312c",
"content_id": "d45cec11b3807b5865d78173e296156bcc2d673b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1653,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 67,
"path": "/leetcode/cpp_unittest/max2DRectangle_unittest/max2DRectangle_unittest.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include \"max2DRectangle.cpp\"\n#include \"gtest/gtest.h\"\n\n/*\n * int Solution::maximumRectangle(vector<vector<char> >&)\n *\n * int Solution::largestRectangleArea(vector<int>&)\n * */\n\nTEST(largestRectangleAreaTest, Positive01){\n Solution s;\n\n int arr[] = {1, 2, 2, 3, 2};\n vector<int> heights(arr, arr + sizeof(arr)/sizeof(int));\n\n int expected = 8;\n EXPECT_EQ(expected, s.largestRectangleArea(heights));\n}\n\nTEST(largestRectangleAreaTest, Positive02){\n Solution s;\n\n int arr[] = {1, 2, 1, 4, 3};\n vector<int> heights(arr, arr + sizeof(arr)/sizeof(int));\n\n int expected = 6;\n EXPECT_EQ(expected, s.largestRectangleArea(heights));\n}\n\nTEST(largestRectangleAreaTest, Positive03){\n Solution s;\n\n int arr[] = {1, 2, 2, 3, 2, 2, 1, 2};\n vector<int> heights(arr, arr + sizeof(arr)/sizeof(int));\n\n int expected = 10;\n EXPECT_EQ(expected, s.largestRectangleArea(heights));\n}\n\nTEST(maximumRectangleTest, Positive01){\n Solution s;\n\n char arr[][5] = {{'1', '0', '1', '1', '1'},\n {'0', '1', '1', '1', '0'},\n {'1', '0', '1', '1', '1'}};\n vector<vector<char> > matrix;\n for(int i = 0; i < 3; i++){\n matrix.push_back(vector<char>(arr[i], arr[i] + 5));\n }\n\n int expected = 6;\n EXPECT_EQ(expected, s.maximumRectangle(matrix));\n}\n\nTEST(maximumRectangleTest, Negative01){\n Solution s;\n\n char arr[][2] = {{'1', '0'},\n {'0', '1'}};\n vector<vector<char> > matrix;\n for(int i = 0; i < 2; i++){\n matrix.push_back(vector<char>(arr[i], arr[i] + 2));\n }\n\n int expected = 1;\n EXPECT_EQ(expected, s.maximumRectangle(matrix));\n}\n"
},
{
"alpha_fraction": 0.37119340896606445,
"alphanum_fraction": 0.37613168358802795,
"avg_line_length": 25.39130401611328,
"blob_id": "30cec6812ceed8399c30ee7a5ab60710ee441f79",
"content_id": "846360b8a68a821ea4b81ca145f6f8bcb8c656e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1215,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 46,
"path": "/leetcode/src/wildcardMatch.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * implememnt wildcard pattern matching with support for '?' and '*'\n * '?' macthes any single char\n * '*' macthes any sequences of char, including empty string\n * s = \"hi\", p = \"*?i\" true\n * p = \"*i\" true\n * p = \"*\" true\n * p = \"**a\" false\n * p = \"*?a\" false\n * s = \"\", p = \"*?\" false\n * */\n#include \"stdio.h\"\n\nusing namespace std;\n\nbool isMatch(const char *s, const char *p){\n if(!*p && !*s) return true;\n if(*p == *s) return isMatch(s+1, p+1);\n if(*p == '?' && *s) return isMatch(s+1, p+1);\n if(*p == '*'){\n bool ret = false;\n while(*p == '*') ++p;\n if(!*p) return true;\n while(*s){\n const char *ts = s, *tp = p;\n while(*ts && (*ts == *tp || *tp == '?')){\n if(*tp == '*') break;\n ++ts;\n ++tp;\n }\n if(!*ts && !*tp) return true; // both '\\0'\n if(*tp == '*'){\n ret |= isMatch(ts, tp);\n return ret;\n }\n if(!*ts) return false;\n ++s;\n }\n return ret;\n }else\n return false;\n}\n\nint main(){\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4747474789619446,
"alphanum_fraction": 0.4879564940929413,
"avg_line_length": 35.79411697387695,
"blob_id": "86104c76bdef9599acc55c26ad89653b31d60f8a",
"content_id": "b86a6dfa2454a227f9f29769d5c71a91b3146432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1287,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 34,
"path": "/leetcode/src/partitionList.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given a linked list and a value, partition it such that all nodes less than x come before nodes greater than or equal to x\r\n * you should preserve the original relative order of the nodes in each of the two partition\r\n * given 1->4->3->2->5->2 and x = 3\r\n * return 1->2->2->4->3->5\r\n * */\r\n#include \"../include/preliminary.h\"\r\n\r\nListNode* partition(ListNode *head, int x){\r\n if(!head || !(head->next)) return head;\r\n ListNode *curr = head, *post = head->next, *r = 0, *s = head, *toDel = 0;\r\n for(; post; curr = post, post = curr->next){\r\n if(curr->val < x && post->val < x) continue;\r\n if(curr->val >= x && post->val >= x) continue;\r\n if(curr->val < x && post->val >= x){ //position between r and s is the place to insert node less than x\r\n r = curr;\r\n s = post;\r\n }else{ // curr->val >= x and post < x, post is the node to insert ahead \r\n toDel = post;\r\n post = post->next;\r\n curr->next = post;\r\n toDel->next = 0;\r\n if(r){\r\n r->next = toDel;\r\n }else{\r\n head = toDel;\r\n }\r\n toDel->next = s;\r\n r = toDel;\r\n toDel = 0;\r\n }\r\n }\r\n return head;\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.5137895941734314,
"alphanum_fraction": 0.5178753733634949,
"avg_line_length": 22.878047943115234,
"blob_id": "1d799dab85dbc94dd8305d3c03f4e9921dba714d",
"content_id": "e400bc4cff3d878071a84a20538ddd11eb054b74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 979,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 41,
"path": "/leetcode/src/validpalindrome.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a string, determine if it is a palindrome, considering only alphanumeric char and ignoring cases.\n *\n * NOTE: it is good to ask during interview, what about empty string? here we determine empty is true\n *\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cctype>\nusing namespace std;\n\nbool isPalindrome(const string& s){\n if(s.empty()) return true;\n int i=0, j=s.size()-1;\n while(i<j){\n if(!isalpha(s[i]) && !isdigit(s[i])){\n ++i;\n continue;\n }\n if(!isalpha(s[j]) && !isdigit(s[j])){\n --j;\n continue;\n }\n char a = isalpha(s[i]) ? tolower(s[i]) : s[i];\n char b = isalpha(s[j]) ? tolower(s[j]) : s[j];\n if(a != b) break;\n ++i;\n --j;\n }\n return i>=j;\n}\n\nint main(int, char**){\n string str;\n while(1){\n getline(cin, str);\n printf(\"%s\\n\", isPalindrome(str) ? \"true\" : \"false\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.534167468547821,
"alphanum_fraction": 0.5572665929794312,
"avg_line_length": 24.341463088989258,
"blob_id": "07d9e02ba7f96ed4506af1a2b5628281b78a3e15",
"content_id": "ddb495fa38c2168d3d37ab269bc041a9d033e5a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1039,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 41,
"path": "/leetcode/src/lengthOfLastWord.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a string s consists of upper/lower-case alphabets and empty space characters ' ', return the length of last word in the string.\n * if the last word does not exist, return 0;\n * a word is defined as a character sequence without space char.\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n\nusing namespace std;\n\nint lengthOfLastWord(const char *s){ //remember save the last valid word length\n int l1 = 0, l2 = 0, n = strlen(s);\n for(int i=0; i<n; ++i){\n if(s[i] == ' '){\n if(l1 != 0){\n l2 = l1;\n l1 = 0;\n }\n continue;\n }\n ++l1;\n }\n return l1 > 0 ? l1 : l2;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input char sequence consisting of char and space\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n printf(\"length of last word is %d\\n\", lengthOfLastWord(str.c_str()));\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.513847291469574,
"alphanum_fraction": 0.5392963886260986,
"avg_line_length": 24.20754623413086,
"blob_id": "a923bca37e63cd8b92ce88f72c91c4e5a9eb6abb",
"content_id": "305b8d18d7aa4c18e957219cc1cd799ec3d87e3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2672,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 106,
"path": "/leetcode/py/perm.py",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding:utf-8 -*-\n\n# permutation and combination\n\nimport os, sys\nfrom copy import copy\n\n# generate permutation\ndef perm(items, n=None):\n if n is None:\n n = len(items)\n for i in range(len(items)):\n v = items[i:i+1]\n if n == 1:\n yield v\n else:\n rest = items[:i] + items[i+1:] # rest always has n-1 elements\n for p in perm(rest, n-1): # recurse\n yield v + p\n\n# recurse for C++ style\ndef perm_02(items):\n res = []\n res.append(copy(items)) # initial status must be processed precedingly\n recur_02(items, 0, len(items), res)\n return res\n\ndef recur_02(items, start, end, res):\n if start >= end:\n return\n recur_02(items, start+1, end, res)\n for i in range(start+1, end):\n items[start], items[i] = items[i], items[start] # swap\n res.append(copy(items)) # shallow copy\n recur_02(items, start+1, end, res)\n items[i], items[start] = items[start], items[i] # fallback\n\n# convert C++ style solution(recur_02) to python style with 'yield'\n# @return it returns a list instead of a generator !\ndef perm_03(items):\n return map(copy, recur_03(items, 0, len(items)))\n\n# @return: with 'yield', it returns generator(iterator) !\ndef recur_03(items, start, end):\n if start == 0:\n yield items\n if start < end-1:\n for x in recur_03(items, start+1, end):\n yield x\n for i in range(start+1, end):\n items[i], items[start] = items[start], items[i] # swap\n yield items\n for x in recur_03(items, start+1, end):\n yield x\n items[i], items[start] = items[start], items[i] # fallback\n\ndef comb(items, n=None):\n if n is None:\n n = len(items)\n for i in range(len(items)):\n v = items[i:i+1]\n if n == 1:\n yield v\n else:\n rest = items[i+1:] # if rest has no element, following code will not yield any more\n for c in comb(rest, n-1):\n yield v + c\n\ndef test_01():\n if len(sys.argv) < 2:\n items = '1234'\n else:\n items = sys.argv[1]\n\n if len(sys.argv) < 3:\n n = None\n else:\n n = int(sys.argv[2])\n\n ps = perm(items, n)\n print 'permutation:'\n for p in ps:\n print p\n print '-'*20\n\n cs = comb(items, n)\n print 'combination:'\n for c in cs:\n print c\n\ndef test_02():\n res = perm_02(range(4))\n for p in res:\n print p\n print len(res)\n\ndef test_03():\n res = perm_03(range(4))\n for p in res:\n print p\n print len(res)\n\nif __name__ == '__main__':\n # test_01()\n test_03()\n"
},
{
"alpha_fraction": 0.6967213153839111,
"alphanum_fraction": 0.7103825211524963,
"avg_line_length": 27.076923370361328,
"blob_id": "e04d0ea75497520d9dee67f93948c50127198d0f",
"content_id": "9e46449b73274c06b783af7882f4cb908ffa40cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 13,
"path": "/leetcode/sql/NthHighestSalary.sql",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "-- database problem #177\n--\n-- write a stored procedure(SP) to get the Nth highest salary from the Employee table\n-- note: if there is no Nth highest salary, return null\n\ncreate function getNthHighestSalary(N int) returns int\nbegin\n declare M int;\n set M=N-1;\n return{\n select distinct Salary from Employee order by Salary desc limit M,1\n };\nend\n\n"
},
{
"alpha_fraction": 0.6230216026306152,
"alphanum_fraction": 0.6345323920249939,
"avg_line_length": 21.419355392456055,
"blob_id": "8a5a0af28f56407fd3d27f9821704eec29b7a287",
"content_id": "d2e279f40f7e01716edc71ea1798b6207ecd34a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 31,
"path": "/topics/binarytree/src/minPath.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * check if a tree is balanced(binary search tree).A balanced tree is defined to be a tree that no two leaf nodes differ in distance from the root by more than one.\n * */\n\n// ideal recursion\n\ninline int Min(int x, int y){\n return x>y ? y : x;\n}\n\ninline int Max(int x, int y){\n return x>y ? x: y;\n}\n\npublic int maxPath(Node* root){\n if(root == 0) return 0;\n return 1 + Max(maxPath(root->left), maxPath(root->right));\n}\n\npublic int minPath(Node* root){\n if(root == 0) return 0;\n return 1 + Min(minPath(root->left), minPath(root->right));\n}\n\npublic bool isBalancedTree(Node* root){\n return maxPath(root) - minPath(root) <= 1;\n}\n\nint main(int, char**){\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5256003737449646,
"alphanum_fraction": 0.5387403964996338,
"avg_line_length": 24.2738094329834,
"blob_id": "dc01477037e0b792d8eaabb0cf8a40f9a4535b17",
"content_id": "a6ea126bbf0f981c35e22bd03df855d038c3306a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2207,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 84,
"path": "/leetcode/src/reverseWords.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * reverse a string word by word. besides normal question of reverse, some clarification are necessary to mention:\r\n * 1. a word is constituted of non-space characters.\r\n * 2. reversed result should not contain leading/tailing\r\n * */\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <string>\r\n#include <cstring>\r\n#include <cctype> //isspace(char)\r\n\r\nusing namespace std;\r\n\r\n/*\r\n * reduce spaces in input string\r\n * 1. eliminate the leading and tailing spaces \r\n * 2. reduce the multiple spaces between two words to one single space\r\n * */\r\nstring reduceSpaces(const string& src){\r\n int n = src.size();\r\n char *cstr = new char[n + 1];\r\n memset(cstr, 0, sizeof(char)*(n+1));\r\n int j=0;\r\n for(int i=0; i<n; ++i){\r\n if(isspace(src[i])) continue;\r\n if(i>0 && isspace(src[i-1]) \r\n && j>0 && !isspace(cstr[j-1])){ // add single space before following word\r\n cstr[j++] = ' ';\r\n }\r\n cstr[j++] = src[i];\r\n }\r\n cstr[j] = '\\0';\r\n string dst(cstr);\r\n delete[] cstr;\r\n cstr = 0;\r\n return dst;\r\n}\r\n\r\n/*\r\n * function group to reverse words\r\n * */\r\nvoid swapCharInStr(string& str, int l, int r){\r\n char tmp = str[l];\r\n str[l] = str[r];\r\n str[r] = tmp;\r\n return;\r\n}\r\n\r\nvoid reverseItem(string& src, int begin, int end){\r\n int mid = (end + begin) >> 1;\r\n for(int i = begin; i < mid; ++i){\r\n swapCharInStr(src, i, --end);\r\n }\r\n return;\r\n}\r\n\r\nvoid reverseWords(string& src){\r\n src = reduceSpaces(src);\r\n if(src.empty()) return;\r\n int n = src.size();\r\n for(int b=0, e=0; b<n && e<=n; ++e){\r\n if(e < n && !isspace(src[e])) continue;\r\n if(b < e-1) reverseItem(src, b, e);\r\n b = e+1; // after reduceSpaces(), space between words is 1 absolutely\r\n }\r\n reverseItem(src, 0, n);\r\n return;\r\n}\r\n\r\nvoid test_02(){\r\n string str;\r\n while(1){\r\n printf(\"please input string to reverse:\\n\");\r\n if(getline(cin, str) == 0 || str.empty()) break;\r\n reverseWords(str);\r\n printf(\"%s, with length is %d\\n\", str.c_str(), str.size());\r\n }\r\n return;\r\n}\r\n\r\nint main(int, char**){\r\n test_02();\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.47003626823425293,
"alphanum_fraction": 0.4811260402202606,
"avg_line_length": 22.796955108642578,
"blob_id": "c5bbbdbc4af3367f6660fe2a69f3a1424992d532",
"content_id": "b3dfbc010f76246c5fc338acfcec4bb7f6968921",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4689,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 197,
"path": "/leetcode/src/preliminary.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/******************preliminary.cpp**************************/\n#include \"../include/preliminary.h\"\n\n/*\n * 1. support any unknown delimiter(\\s,\\n,','...) except digit\n * 2. support minus integer, multiple digits but float\n * */\nint splitStr2IntArray(const string& str, int *array){\n int leng = 0;\n string::size_type pos = 0; //string::size_type and std::size_t are alternative\n int minus = 1;\n while(pos<str.size()){\n if(str[pos] == '-' && pos<(str.size()-1) && isdigit(str[pos+1])){ //support minus\n minus = -1;\n }else if(isdigit(str[pos])){\n string::size_type begin = pos;\n while(pos<str.size() && isdigit(str[pos])) //at exit, pos is the one following last digit\n pos++;\n char* tmp = new char[pos-begin+1];\n for(size_t i=0;i < pos-begin;i++){\n tmp[i] = str[i+begin];\n }\n tmp[pos-begin] = '\\0';\n array[leng++] = minus*atoi(tmp);\n minus = 1;\n delete[] tmp;\n tmp = 0;\n }\n pos++;\n }\n return leng;\n}\n\nint splitStr2IntArrayExt(const string& str, int *array){\n int leng = 0;\n string::size_type pos = 0; //string::size_type and std::size_t are alternative\n int minus = 1;\n while(pos<str.size()){\n if(str[pos] == '-' && pos<(str.size()-1) && isdigit(str[pos+1])){\n minus = -1;\n }else if(isdigit(str[pos])){\n int val = 0;\n while(pos<str.size() && isdigit(str[pos])){\n char ch = str[pos];\n val = (val==0) ? atoi(&ch) : 10*val + atoi(&ch); //it works\n pos++;\n }\n array[leng++] = minus*val;\n minus = 1;\n }\n pos++;\n }\n return leng;\n}\n\nvector<string> splitStr2Vector(const string& str){\n vector<string> res;\n int n = str.size();\n if(n<1) return res;\n int b=-1;\n for(int i=0;i<n;i++){\n if(isalpha(str[i]) || isdigit(str[i])){ //valid str segment\n if(b < 0) b = i;\n }else if(b >= 0){\n res.push_back(str.substr(b, i-b));\n b = -1;\n }\n }\n if(b>=0){\n res.push_back(str.substr(b, n-b));\n }\n return res;\n}\n\n/*\n* time O(lgm) to get index m == lgn\n*/\nint getindex(int num, int& t, int e){\n int m=1, pre_m=0, pre_t=1;\n t=e;\n while(num/t < 1 || num/t > 9){\n if(num/t > 9){\n pre_t = t;\n t *= t;\n pre_m = m;\n m *= 2;\n }else{\n t = pre_t * (int)sqrt(t/pre_t);\n m = pre_m + (m-pre_m)/2;\n }\n }\n return m;\n}\n\nvoid showarray(int *A, int n){\n for(int i=0;i<n;i++)\n printf(\"%d \", A[i]);\n printf(\"\\n\");\n}\n\nvoid copyarray(int* dst, int* src, int n){\n memset(dst, 0, sizeof(int)*n);\n for(int i=0;i<n;i++)\n dst[i] = src[i];\n return;\n}\n\nvoid displayVector(vector<int>& vec){\n if(vec.size() == 0){\n cout << \"empty\" << endl;\n return;\n }\n cout << vec[0];\n for(int i=1; i < (int)vec.size(); i++){\n cout << \", \" << vec[i];\n }\n cout << endl;\n return;\n}\n\n// struct ListNode is defined in preliminary.h\nvoid displaySLL(ListNode *head){\n printf(\"SLL is: \");\n if(!head){\n printf(\"\\n\");\n return;\n }\n printf(\"%d\", head->val);\n for(ListNode *curr = head->next;curr != NULL; curr=curr->next){\n printf(\" -> %d\", curr->val);\n }\n printf(\"\\n\");\n return;\n}\n\nListNode* createSLL(int A[], int n){\n if(n == 0) return NULL;\n ListNode *head = new ListNode(A[0]);\n ListNode *h = head;\n for(int i=1; i<n; i++, h = h->next){\n h->next = new ListNode(A[i]);\n }\n return head;\n}\n\nvoid delSLL(ListNode *head){\n if(!head){\n printf(\"NULL\\n\");\n return;\n }\n for(ListNode *nx = head; nx != NULL;){\n head = nx->next;\n delete nx;\n nx = head;\n }\n return;\n}\n\n// struct TreeNode is defined in preliminary.h\nvoid preorder(TreeNode *root){\n if(!root) return;\n printf(\"%d \", root->val);\n preorder(root->left);\n preorder(root->right);\n return;\n}\n\nvoid showPre(TreeNode *root){\n printf(\"preorder: \");\n preorder(root);\n printf(\"\\n\");\n return;\n}\n\nvoid inorder(TreeNode *root){\n if(!root) return;\n inorder(root->left);\n printf(\"%d \", root->val);\n inorder(root->right);\n return;\n}\n\nvoid showIn(TreeNode *root){\n printf(\"inorder: \");\n inorder(root);\n printf(\"\\n\");\n return;\n}\n\nvoid delTree(TreeNode *root){ //natural for post order\n if(!root) return;\n delTree(root->left);\n delTree(root->right);\n delete root;\n root = 0;\n return;\n}\n\n"
},
{
"alpha_fraction": 0.6277372241020203,
"alphanum_fraction": 0.7080292105674744,
"avg_line_length": 18.571428298950195,
"blob_id": "c73c571d03f04069f9ab2a3d0b215ddb9a06c65b",
"content_id": "03bc5613cfb43eb580de2663d29b46b821d55c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 7,
"path": "/topics/graph/header/graphConst.h",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "#include <iostream>\nusing namespace std;\n\nconst int MAX = 1000;\nconst int MIN = -1000;\nconst int NullVert = -1;\nconst int BoundMax = 20;\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5183374285697937,
"avg_line_length": 24.153846740722656,
"blob_id": "d3bcd1618a86d737fd9dfce98cfc42ddf4c4ea26",
"content_id": "3217eb4d06511ce2c83ef43b02661a1cc791329d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1636,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 65,
"path": "/leetcode/src/rotateList.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a list, rotate the list to right by k places, where K >= 0\n * \n * test case:\n * 1->2->3->4->5, k = 2, return 4->5->1->2->3\n * */\n#include \"../include/preliminary.h\" //struct ListNode, displayList()\n\nListNode* rotateRight(ListNode *head, int k){ //twice traverse \n if(head == NULL || k==0) return head;\n ListNode *curr = head;\n int n = 1;\n while(curr->next != NULL){ //1st traverse to get length of SLL\n curr = curr->next;\n ++n;\n }\n curr->next = head; //enable it loop\n int l = n - (k%n);\n \n while(l > 0){ //2nd traverse, curr starts at tail\n curr = curr->next;\n --l;\n }\n ListNode *h = curr->next;\n curr->next = NULL;\n return h;\n}\n\nListNode* generateList(int *arr, int n){\n if(n<1) return NULL;\n ListNode *head = new ListNode(arr[0]);\n ListNode *h = head;\n for(int i=1; i<n; ++i){\n h->next = new ListNode(arr[i]);\n h = h->next;\n }\n return head;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input integer array of List:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n ListNode *head = generateList(arr, n);\n delete[] arr;\n arr = 0;\n\n printf(\"input k offset to rotate right:\\n\");\n if(getline(cin, str)==0 || str.empty()) continue;\n int k = atoi(str.c_str());\n ListNode *h = rotateRight(head, k);\n displaySLL(h);\n\n delSLL(h);\n }\n return;\n}\n\nint main(int, char**){\n test_01();\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.4151061177253723,
"alphanum_fraction": 0.4350811541080475,
"avg_line_length": 22.217391967773438,
"blob_id": "b030229e2bf5cf9be506b254d18f9616480f5d70",
"content_id": "1638b20ac396300e7ab74be0af533b935b3a7cee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1602,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 69,
"path": "/leetcode/src/sortColors.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given an array of n, integers 0,1,2 for color red, white, and blue. sort it in order 0/1/2 in one-pass with space O(1)\n * \n * */\n#include \"../include/preliminary.h\"\n\nvoid swap(int *pa, int *pb){\n int tmp = *pa;\n *pa = *pb;\n *pb = tmp;\n return;\n}\n\nvoid sortColors_01(int A[], int n){\n if(n<=1) return;\n int *p = A-1, *q = A, *t = A+n;\n while(q != t){\n if(*q == 2){ // check 2 firstly\n t--;\n swap(q, t);\n continue; // NOTE: value swapped from [t] is at right of q which has not been checked yet\n }else if(*q == 0){\n p++;\n if(q > p) swap(q, p);\n }\n q++;\n }\n return;\n}\n\nvoid sortColors_02(int A[], int n){\n if(n<=1) return;\n int *p = A-1, *q = A, *t = A+n;\n while(q != t){\n if(*q == 0){ // check 0 firstly\n p++;\n if(q > p) swap(q, p);\n }else if(*q == 2){\n t--;\n swap(q, t);\n continue; //NOTE: recheck of the swapped value from *t is necessary\n }\n q++;\n }\n return;\n}\n\nvoid test(){\n string str;\n while(1){\n cout << \"please input initial integer array of 0,1,2\" << endl;\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n sortColors_02(arr, n);\n for(int i=0; i<n; ++i){\n printf(\"%d \", arr[i]);\n }\n printf(\"\\n\");\n delete arr;\n arr = 0;\n }\n return;\n}\n\nint main(){\n test();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5305164456367493,
"alphanum_fraction": 0.5474178194999695,
"avg_line_length": 24.35714340209961,
"blob_id": "217549b25066ce5bb5db9acd627c46fb180af920",
"content_id": "a6c09bb035af86175e4d275ffaf9795c392b8e2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1065,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 42,
"path": "/leetcode/src/lengthoflongestsubstr.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a string of lower case, find the length of longest substring without repeat characters\n *\n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\nusing namespace std;\n\ninline int min(int a, int b){\n return a<b ? a : b;\n}\nint lengthOfLongestSubstring(const string& s){\n if(s.empty()) return 0;\n int pos[26]; //position of 'a' to 'z'\n for(int i=0;i<26;++i){\n pos[i] = -1;\n }\n pos[s[0]-'a'] = 0;\n int *length = new int[s.size()]();\n length[0] = 1;\n int res = 1;\n for(size_t i=1; i<s.size();i++){\n length[i] = min(length[i-1]+1, i - pos[s[i]-'a']); //optimal substructure of Dynamic Programming\n pos[s[i]-'a'] = i; //don't forget it\n if(res < length[i]) res = length[i];\n }\n delete[] length;\n return res;\n}\n\nint main(int, char**){\n string str;\n while(1){\n cout<<\"please input string:\"<<endl;\n if(getline(cin, str)==0 || str.empty()) break;\n printf(\"%d\\n\", lengthOfLongestSubstring(str));\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4487284719944,
"alphanum_fraction": 0.4749794900417328,
"avg_line_length": 22.3799991607666,
"blob_id": "a1838e1651952ece2804c4e59611af21bbb9c4fa",
"content_id": "c4cae8566bc596f586a8efd69e6dbf167339f609",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 50,
"path": "/leetcode/src/uniquePaths.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * given a matrix of m*n, for a robot, it needs to walk from left top corner [0,0] to right bottom corner [m-1,n-1]\r\n * find count of the distinct walkings\r\n *\r\n */\r\n\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <cstring>\r\n#include <string>\r\nusing namespace std;\r\n\r\nclass UniquePaths{\r\npublic:\r\n int oncePath(int x, int y, int m, int n){ // recurse should be avoided here since it has too much redundancy\r\n if(x==m && y==n) return 1;\r\n if(x>m || y>n) return 0;\r\n return oncePath(x+1, y, m, n) + oncePath(x, y+1, m, n);\r\n }\r\n\r\n int uniquePaths_01(int m, int n){\r\n return oncePath(1, 1, m, n);\r\n }\r\n\r\n int uniquePaths_02(int m, int n){\r\n int dp[m][n];\r\n for(int i=0; i<m; ++i){\r\n dp[i][0] = 1;\r\n }\r\n for(int j=0; j<n; ++j){\r\n dp[0][j] = 1;\r\n }\r\n\r\n for(int i=1; i<m; ++i){\r\n for(int j=1; j<n; ++j){\r\n dp[i][j] = dp[i-1][j] + dp[i][j-1];\r\n }\r\n }\r\n return dp[m-1][n-1];\r\n }\r\n\r\n};\r\n\r\nint main(int, char**){\r\n UniquePaths *up = new UniquePaths();\r\n printf(\"%d\\n\", up->uniquePaths_02(3, 3));\r\n delete up;\r\n up = 0;\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.46331658959388733,
"alphanum_fraction": 0.5075376629829407,
"avg_line_length": 24.18987274169922,
"blob_id": "98ba97988722de28df29a4ecf89bff404a9331f9",
"content_id": "75f81bc48a2f25fdd5be55d79c6e3b64604c127b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1990,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 79,
"path": "/leetcode/src/reverseNodesInK.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a SLL, reverse the nodes of k at a time, return its modified head.if number less than k, remain them.\n * e.g 1->2->3->4->5,\n * k=2, 2->1->4->3->5\n * k=3, 3->2->1->4->5\n * {1}, k=2 => return {1}\n * */\n#include \"../include/preliminary.h\"\n\nvoid reverse(ListNode *pre, ListNode *h, ListNode *e, ListNode *post){ //pre->h->...->e->post => pre->e->...->h->post\n if(!h) return;\n ListNode *l1 = h, *l2 = h->next, *after = l2->next;\n while(l2 != post){ //l1->l2->after => l1<-l2 after\n l2->next = l1;\n if(!after) break;\n l1 = l2; //move one step forward\n l2 = after;\n after = l2->next;\n }\n if(pre) pre->next = e;\n h->next = post;\n return;\n}\n\nListNode *reverseKGroups(ListNode *head, int k){\n if(!head || k<2) return head;\n ListNode *pre=0, *h = head, *post=0;\n head = NULL;\n while(h != NULL){\n ListNode *e = h;\n int i = 0;\n for(i=1;i<k && e->next != NULL;++i){\n e = e->next;\n }\n if(i<k) break; //less than k nodes\n post = e->next;\n reverse(pre, h, e, post);\n if(!head) head = e; \n\n pre = h; //after reverse, h becomes prev of post\n h = post;\n }\n if(!head) return h;\n return head;\n}\n\nvoid test_01(){\n ListNode *l1 = new ListNode(1);\n ListNode *l2 = new ListNode(2);\n l1->next = l2;\n ListNode *l3 = new ListNode(3);\n l2->next = l3;\n ListNode *l4 = new ListNode(4);\n l3->next = l4;\n ListNode *l5 = new ListNode(5);\n l4->next = l5;\n\n displaySLL(reverseKGroups(l1, 2));\n}\n\nvoid test_02(){\n ListNode *l1 = new ListNode(1);\n ListNode *l2 = new ListNode(2);\n l1->next = l2;\n ListNode *l3 = new ListNode(3);\n l2->next = l3;\n ListNode *l4 = new ListNode(4);\n l3->next = l4;\n ListNode *l5 = new ListNode(5);\n l4->next = l5;\n\n displaySLL(reverseKGroups(l1, 3));\n}\n\nint main(int, char**){\n test_01();\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.48578596115112305,
"alphanum_fraction": 0.5150501728057861,
"avg_line_length": 19.98245620727539,
"blob_id": "1551b41532210bbaf02ee2527d2d1c8ae451d7bb",
"content_id": "1fb1ef14dd59e0edcda051e93722cdd8b5514908",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1196,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 57,
"path": "/leetcode/src/pascalTriangle.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given numRows, generate the first numRows of Pascal's triangle\n * e.g. given nRows=5, return below:\n * 1\n * 1,1\n * 1,2,1\n * 1,3,3,1\n * 1,4,6,4,1\n * */\n\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <vector>\n#include \"stdlib.h\"\n\nusing namespace std;\n\nvector<vector<int> > generate(int nRows){\n vector<vector<int> > res;\n if(nRows < 1) return res;\n vector<int> arr0;\n arr0.push_back(1);\n res.push_back(arr0);\n for(int i=1;i < nRows;++i){\n vector<int> vec;\n vec.push_back(res[i-1][0]);\n for(int j=1;j<i;++j){\n vec.push_back(res[i-1][j-1] + res[i-1][j]);\n }\n vec.push_back(res[i-1][i-1]);\n res.push_back(vec);\n }\n return res;\n}\n\nvoid show(const vector<vector<int> >& tri){\n int n=tri.size();\n for(int i=0;i<n;++i){\n for(size_t j=0;j<tri[i].size();++j){\n printf(\"%d \", tri[i][j]);\n }\n printf(\"\\n\");\n }\n}\n\nint main(int, char**){\n string str;\n while(1){\n printf(\"please input the numRows:\\n\");\n if(getline(cin, str)==0 || str.empty())\n break;\n int n = atoi(str.c_str());\n show(generate(n));\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4636148512363434,
"alphanum_fraction": 0.4846250116825104,
"avg_line_length": 22.183870315551758,
"blob_id": "6ca466e10c088062f3a3f1b60a79a2eec47e5ef4",
"content_id": "e74c49b95d025fad97bff9c2124a5b457a478c43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7187,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 310,
"path": "/topics/sort/src/youngtableau.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * \"IntroductionToAlgorithm, chapter6 heap sort, problem 6-3 YoungTableau\"\n *\n * test data input:\n * 11 10 9 8 7 6 5 4 3 2 1\n * 2 3 10 31 21 14 6 1 11 23 30 9 18 \n * */\n#include \"../header/preliminary.h\"\n\nconst static int LIMIT = 0x0fff;\n\nvoid myswap(int& a, int& b){\n int tmp = b;\n b = a;\n a = tmp;\n}\n\nclass YoungTableau{\npublic:\n YoungTableau(int m, int n):M(m), N(n), ppTab(0){\n init();\n }\n ~YoungTableau(){\n clean();\n }\n void insert(int key);\n int extract_max();\n int extract_min();\n void showAll();\n bool search(int);\nprivate:\n int M;\n int N;\n int** ppTab;\n void clean();\n void init();\n void min_heapify(int i, int j);\n void getTailer(int& tailx, int& taily);\n bool searchInBound(int x, int y, int key); \n bool searchInBoundRecur(int x, int y, int key);\n \n inline int downx(int x){\n return x+1;\n }\n\n inline int upx(int x){\n return x-1;\n }\n\n inline int lefty(int y){\n return y-1;\n }\n\n inline int righty(int y){\n return y+1;\n }\n};\n\nvoid YoungTableau::init(){\n ppTab = new int*[M];\n for(int i = 0; i < M; i++){\n ppTab[i] = new int[N]();\n for(int j = 0; j < N; j++){\n ppTab[i][j] = LIMIT;\n }\n }\n}\n\nvoid YoungTableau::clean(){\n for(int i = 0; i < M; i++){\n delete[] ppTab[i];\n ppTab[i] = 0;\n }\n delete[] ppTab;\n ppTab = 0;\n}\n\n/*\n * find tailer of the young tableau, the last valid element\n * */\nvoid YoungTableau::getTailer(int& tailx, int& taily){\n tailx = 0;\n taily = N-1;\n\n for(;tailx < M && ppTab[tailx][0] < LIMIT; tailx++);\n\n tailx--;\n if(tailx < 0) return;\n\n for(;taily > -1 && ppTab[tailx][taily] == LIMIT; taily--);\n return;\n}\n\nvoid YoungTableau::insert(int key){\n int x = 0, y = 0;\n getTailer(x,y);\n\n if(y == N-1){\n y = 0;\n x++;\n }else{\n y++;\n }\n\n if(x >= M) return; //full\n\n ppTab[x][y] = key;\n min_heapify(x, y);\n}\n\n/*\n * __| find largest element next to (i,j) and swap it to here\n * */\nvoid YoungTableau::min_heapify(int i, int j){\n if(i == 0 && j == 0) return;\n while(1){\n int largestx = i, largesty = j;\n\n if(upx(i) >= 0 && ppTab[upx(i)][j] > ppTab[i][j]){\n largestx = upx(i);\n largesty = j;\n }\n\n if(lefty(j) >= 0 && ppTab[i][lefty(j)] > ppTab[largestx][largesty]){\n largestx = i;\n largesty = lefty(j);\n }\n\n if(largestx != i || largesty != j){\n myswap(ppTab[i][j], ppTab[largestx][largesty]);\n i = largestx;\n j = largesty;\n }else{\n break;\n }\n }\n}\n\nint YoungTableau::extract_max(){\n int x = 0, y = 0;\n getTailer(x, y);\n\n if(x < 0) return -LIMIT;\n\n int max = ppTab[x][y];\n if(y < N-1 && x > 0 && ppTab[x-1][N-1] > max){ // 1.compare two options 2.compact the table if there is hole\n max = ppTab[x-1][N-1];\n myswap(ppTab[x][y], ppTab[x-1][N-1]);\n min_heapify(x-1, N-1);\n }\n ppTab[x][y] = LIMIT;\n return max;\n}\n\n/*\n * |--, find least element next to (i,j) and swap it to here\n * */\nint YoungTableau::extract_min(){\n int min = ppTab[0][0];\n int tailx = 0, taily = 0;\n getTailer(tailx, taily);\n\n if(tailx < 0) return LIMIT;\n\n myswap(ppTab[0][0], ppTab[tailx][taily]);\n ppTab[tailx][taily] = LIMIT;\n\n int x = 0, y = 0;\n while(1){ // move (x,y) downside if it larger than any element less than it\n int leastx = x, leasty = y;\n if(downx(x)<M && ppTab[downx(x)][y] < ppTab[x][y]){\n leastx = downx(x);\n leasty = y;\n }\n\n if(righty(y)<N && ppTab[x][righty(y)] < ppTab[leastx][leasty]){\n leastx = x;\n leasty = righty(y);\n }\n\n if(leastx != x || leasty != y){\n myswap(ppTab[leastx][leasty], ppTab[x][y]);\n x = leastx;\n y = leasty;\n }else{\n break;\n }\n }\n return min;\n}\n\n/*\n * this iterative function has bug.\n *\n * 1 2 5\n * 3 4 8\n * 6 7 11\n * 9 10\n * when search 5 in the box of 1<-->11, it returns false because it choose to 7's branch.\n * when 8's and 7's are all greater than 5, both should be searched\n *\n * this solution is recurse\n * */\nbool YoungTableau::searchInBound(int x, int y, int key){\n while(x > -1 && y > -1 && ppTab[x][y] >= key){\n if(ppTab[x][y] == key) return true;\n\n if(x == 0 || ppTab[x-1][y] < key){\n y = y-1;\n continue;\n }\n\n if(y == 0 || ppTab[x][y-1] < key){\n x = x-1;\n continue;\n }\n\n if(ppTab[x-1][y] > ppTab[x][y-1]){\n y = y-1;\n }else{\n x = x-1;\n } \n }\n return false;\n}\n\nbool YoungTableau::searchInBoundRecur(int x, int y, int key){\n if(x > -1 && y > -1 && ppTab[x][y] >= key){\n if(ppTab[x][y] == key) return true;\n return searchInBoundRecur(x-1, y, key) || searchInBound(x, y-1, key);\n }\n return false;\n}\n\nbool YoungTableau::search(int key){\n int tailx = 0, taily = 0;\n\n getTailer(tailx, taily);\n if(tailx < 0) return false;\n\n int i = tailx, j = taily;\n return searchInBoundRecur(i,j,key) || (taily<N-1 ? searchInBoundRecur(tailx-1, N-1, key) : false);\n}\n\nvoid YoungTableau::showAll(){\n printf(\"the Young Tableau is:\\n\");\n for(int i = 0;i < M; i++){\n for(int j = 0; j < N; j++){\n if(ppTab[i][j] == LIMIT)\n printf(\"%c \", '*');\n else\n printf(\"%d \", ppTab[i][j]);\n }\n printf(\"\\n\");\n }\n}\n\n/*\n * decompose N to around a*b which is a little greater than N\n * */\nvoid decomposeInt(int num, int& m, int& n){\n m = 2;\n for(; num/m >= m; m++);\n n = num/m + 1;\n return;\n}\n\nint main(int argc, char* argv[]){\n string str;\n while(1){\n if(getline(cin, str) == 0 || str.empty())\n break;\n int* arr = new int[str.size()](); // limited by test case, input count < 6\n int size = splitStr2IntArray(str, arr);\n int m=1, n=1;\n decomposeInt(size, m, n);\n \n YoungTableau* pYTable = new YoungTableau(m, n);\n for(int i=0; i<size;i++){\n pYTable->insert(arr[i]);\n }\n pYTable->showAll();\n \n for(int i=0;i<size;i++){\n int res = pYTable->search(arr[i]);\n printf(\"now %d should be in Young Tableau: %s\\n\", arr[i], res ? \"true\" : \"false\");\n }\n \n for(int i=0;i<3;i++){ //extract top 3 max elements\n int max = pYTable->extract_max();\n printf(\"current maximum element is %d\\n\", max);\n \n int res = pYTable->search(max);\n printf(\"now %d should not be in Young Tableau: %s\\n\", max, res ? \"true\" : \"false\");\n }\n pYTable->showAll();\n\n for(int i=0;i<2;i++){\n int min = pYTable->extract_min();\n printf(\"current minimum element is %d\\n\", min);\n pYTable->showAll();\n }\n \n delete pYTable;\n pYTable = 0;\n delete[] arr;\n arr = 0;\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.45727333426475525,
"alphanum_fraction": 0.4781474173069,
"avg_line_length": 21.217391967773438,
"blob_id": "f254075ff912c630bdf7e4b860a06a4bda8fea19",
"content_id": "a25c51e70013d181a8ccb8a0e0f56325d6c3f784",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3066,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 138,
"path": "/leetcode/src/nextPermutation.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * implement next permutation, which rearranges numbers into lexicographically next greater permutation of numbers.\n * if such arrangement is not possible, it must be in accending order. the replacement is in-place\n * e.g \n * 1,2,3 -> 1,3,2\n * 3,2,1 -> 1,2,3\n * 1,1,5 -> 1,5,1\n * \n * */\n#include \"../include/preliminary.h\"\n\nvoid swap(int& a, int & b){\n int tmp = b;\n b = a;\n a = tmp;\n return;\n}\n\nvoid reverse(vector<int>& num){\n int n = num.size();\n for(int i=0;i<(n>>1); ++i){\n swap(num[i], num[n-1-i]);\n }\n return;\n}\n\nvoid quicksort(vector<int>& vec, int b, int e){ //sort [b,e]\n if(b >= e) return;\n int p=b-1, q=b;\n while(q < e){\n if(vec[q] < vec[e]){\n ++p;\n swap(vec[p], vec[q]);\n }\n ++q;\n }\n ++p;\n swap(vec[p], vec[e]);\n quicksort(vec, b, p-1);\n quicksort(vec, p+1, e);\n}\n\nvoid nextPermutation(vector<int> &num){\n int n = num.size();\n /*\n int i=n-1, j=i-1; //abandoned code block, it is in tim O(n^2), replaced by O(n) \n for(; i>0; --i){\n j=i-1;\n for(; j>=0 && num[j] >= num[i]; --j); //stops at [j] < [i] \n if(j>=0) break;\n }\n swap(num[j], num[i]);\n */\n int i=n-2;\n for(; i>=0 && num[i] >= num[i+1]; --i);\n if(i<0){\n reverse(num);\n return;\n }\n int j=n-1;\n while(j > i+1){ //at least, j==i+1\n if(num[j] > num[i]) break;\n --j;\n }\n swap(num[i], num[j]);\n quicksort(num, i+1, n-1);\n return;\n}\n\n/*\n * another similar question which solution is based nextPermutation().\n * note: in case k >> n!\n * but it is TIME LIMIT ERROR on oj.leetcode\n * */\nstring getPermutation(int n, int k){ // k is 1-based\n vector<int> nums;\n for(int i=1; i<=n; ++i){\n nums.push_back(i);\n }\n for(int i=2; i<=k; ++i){\n nextPermutation(nums);\n }\n \n char *cstr = new char[n+1];\n cstr[n] = '\\0';\n for(int i=0; i<n; ++i){\n cstr[i] = '0' + nums[i];\n }\n \n string str(cstr);\n delete[] cstr;\n cstr = 0;\n return str;\n}\n\nvoid test_01(){\n string str;\n while(1){\n printf(\"please input integer array:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int *arr = new int[str.size()]();\n int n = splitStr2IntArray(str, arr);\n vector<int> nums;\n for(int i=0;i<n;i++){\n nums.push_back(arr[i]);\n }\n nextPermutation(nums);\n for(int i=0;i<n;i++){\n printf(\"%d \", nums[i]);\n }\n printf(\"\\n\");\n\n delete[] arr;\n arr=0;\n }\n return;\n}\n\nvoid test_02(){\n string str;\n while(1){\n printf(\"please input integer n:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int n = atoi(str.c_str());\n\n printf(\"please input integer k:\\n\");\n if(getline(cin, str)==0 || str.empty()) break;\n int k = atoi(str.c_str());\n\n printf(\"%s\\n\", getPermutation(n, k).c_str());\n }\n return;\n}\n\nint main(int, char**){\n test_02();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.48145025968551636,
"alphanum_fraction": 0.5071669220924377,
"avg_line_length": 22.475248336791992,
"blob_id": "ea06709b6d70c91ed3e11dc7f086902edff44338",
"content_id": "1262269b4f2d5589e280f130a6e9ee831fda1cee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2372,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 101,
"path": "/topics/graph/src/BFS01.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * personal implementation of BFS\n * date: Feb03, 2013\n * */\n#include \"stdio.h\"\n#include <iostream>\n#include <string>\n#include <cstring>\n#include <queue>\n#include <stack>\n\nusing namespace std;\n\nenum CoveredEnum {\n NoProbed = 0,\n Probed,\n Covered\n};\n\nstruct Point{\n Point(int val): \n value(val), Left(0), Mid(0), Right(0), Cov(NoProbed){}\n int value;\n Point *Left;\n Point *Mid;\n Point *Right;\n CoveredEnum Cov;\n};\n\nvoid PushPoint(Point* pp, queue<Point*>& q){\n q.push(pp);\n cout << pp->value << ' ';\n}\n\nvoid BFS01(Point* begin){\n queue<Point*> _q;\n\n _q.push(begin);\n cout << begin->value << ' ';\n while(!_q.empty()){\n Point *parent = _q.front();\n if(parent->Left != 0){\n PushPoint(parent->Left, _q);\n //_q.push(parent->Left);\n //cout << parent->Left->value << ' ';\n }\n \n if(parent->Mid != 0){\n PushPoint(parent->Mid, _q);\n //_q.push(parent->Mid);\n //cout << parent->Mid->value << ' ';\n }\n \n if(parent->Right != 0){\n PushPoint(parent->Right, _q);\n //_q.push(parent->Right);\n //cout << parent->Right->value << ' ';\n }\n\n _q.front()->Cov = Covered;\n _q.pop();\n }\n cout << endl;\n}\n\nvoid test_01(){\n Point* pp = new Point(1);\n pp->Left = new Point(2);\n pp->Mid = new Point(3);\n pp->Right = new Point(4);\n\n pp->Left->Left = new Point(5);\n pp->Left->Right = new Point(6);\n pp->Mid->Left = new Point(7);\n pp->Mid->Right = new Point(8);\n pp->Right->Left = new Point(9);\n pp->Right->Mid = new Point(10);\n pp->Right->Right = new Point(11);\n\n pp->Left->Left->Left = new Point(12);\n pp->Left->Left->Right = new Point(13);\n pp->Left->Right->Left = new Point(14);\n pp->Mid->Left->Left = new Point(15);\n pp->Mid->Left->Right = new Point(16);\n pp->Mid->Right->Left = new Point(17);\n pp->Mid->Right->Right = new Point(18);\n pp->Right->Left->Left = new Point(19);\n pp->Right->Left->Right = new Point(20);\n pp->Right->Mid->Left = new Point(21);\n pp->Right->Mid->Right = new Point(22);\n pp->Right->Right->Left = new Point(23);\n pp->Right->Right->Right = new Point(24);\n\n BFS01(pp);\n return;\n}\n\nint main(){\n test_01();\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.41689127683639526,
"alphanum_fraction": 0.44923630356788635,
"avg_line_length": 25.825000762939453,
"blob_id": "9f4516b21ab12b7d68bc28de24c03139b5158a7f",
"content_id": "5ff2c5f6af9a5b4d45ad558193f42902dbf6e2ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 40,
"path": "/leetcode/src/uniquePathsII.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\r\n * folloing uniquePaths\r\n * currently the matrix has some obstracle in cells. '1' for obstacle and '0' for pass.\r\n */\r\n#include \"stdio.h\"\r\n#include <iostream>\r\n#include <cstring>\r\n#include <string>\r\nusing namespace std;\r\n\r\nclass UniquePathsII{\r\npublic:\r\n int uniquePathsWithObstacles(vector<vector<int> >& obstacleGrid){\r\n int m = obstacleGrid.size();\r\n if(m == 0) return 0;\r\n int n = obstacleGrid[0].size();\r\n if(n == 0) return 0;\r\n int dp[m][n];\r\n for(int i=0; i<m; ++i){\r\n bool cannot = obstacleGrid[i][0] == 1 || (i>0 && dp[i-1][0] == 0);\r\n dp[i][0] = cannot ? 0 : 1;\r\n }\r\n for(int j=0; j<n; ++j){\r\n bool cannot = obstacleGrid[0][j] == 1 || (j>0 && dp[0][j-1] == 0);\r\n dp[0][j] = cannot ? 0 : 1;\r\n }\r\n for(int i=1; i<m; ++i){\r\n for(int j=1; j<n; ++j){\r\n dp[i][j] = \r\n obstacleGrid[i][j] == 1 ? 0 : dp[i-1][j] + dp[i][j-1];\r\n }\r\n }\r\n return dp[m-1][n-1];\r\n }\r\n\r\n};\r\n\r\nint main(int, char**){\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5223097205162048,
"alphanum_fraction": 0.5314960479736328,
"avg_line_length": 22.8125,
"blob_id": "82d2b1668d243e1dda5ef8e8099bbcbd413b405a",
"content_id": "cbae81b9e02035972aefe0f775f23a05db11a9a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 762,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 32,
"path": "/leetcode/src/maxminDepth.cpp",
"repo_name": "chaishi/problems",
"src_encoding": "UTF-8",
"text": "/*\n * given a binary tree, find the maximum depth and minimum depth\n * */\n#include \"../include/preliminary.h\"\n\nclass Solution{\npublic:\n int maxDepth(TreeNode *root){\n if(!root) return 0;\n return 1 + max(maxDepth(root->left), maxDepth(root->right));\n }\n\n int minDepth(TreeNode *root){\n if(!root) return 0;\n int childmin = 0;\n if(!(root->left) && !(root->right)){\n childmin = 0;\n }else if(!(root->left)){\n childmin = minDepth(root->right);\n }else if(!(root->right)){\n childmin = minDepth(root->left);\n }else{\n childmin = min(minDepth(root->left), minDepth(root->right));\n }\n return 1 + childmin;\n }\n\n};\n\nint main(){\n return 0;\n}\n"
}
] | 104 |
dalalsunil1986/N-TicTacToe | https://github.com/dalalsunil1986/N-TicTacToe | 2e968b4f7e12c2b7c19e4193a220c85624d53b57 | db1143e2e94012451ba590952670452431814b7b | ff46272f7094dfebfac17272f2003f677e7777ba | refs/heads/master | 2021-05-28T12:59:57.677671 | 2015-02-24T18:25:35 | 2015-02-24T18:25:35 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4856771230697632,
"alphanum_fraction": 0.4983433187007904,
"avg_line_length": 37.456451416015625,
"blob_id": "8f8244324a740b32f6abc9b4f3eea12b9ca90336",
"content_id": "b161de6456d6f8b14c33e69247fe9c0fa8b2fa93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23843,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 620,
"path": "/TicTacToe2.py",
"repo_name": "dalalsunil1986/N-TicTacToe",
"src_encoding": "UTF-8",
"text": "# N-Dimensional Tic-Tac-Toe by Thomas Lively\n\nfrom __future__ import division\nimport curses, curses.ascii, sys\n\n# logical representation of the n-dimensional board as a single list\nclass Model(object):\n def __init__(self, dimensions=2, size=0, players=2):\n if size < 3:\n size = dimensions+1\n self.dimensions = dimensions\n self.size = size\n if self.size < 3:\n self.size = 3\n self.players = players\n if self.players < 2 or self.players > 9:\n self.players = 2\n self.board = [0 for i in xrange(size**dimensions)]\n self.current_player = 1\n self.game_over = False\n self.tied_game = False\n self.moves = 0\n\n # makes the next player the active player\n def nextTurn(self):\n self.current_player += 1\n if self.current_player > self.players:\n self.current_player = 1\n return self.current_player\n\n def playAtCoordinate(self, coord):\n self.validateCoord(coord)\n self.playAtIndex(self.getIndexFromCoord(coord))\n\n # puts the current player's number into this index of the array then check game over\n def playAtIndex(self, index):\n self.validateIndex(index)\n if self.board[index] != 0:\n raise IllegalMoveError(index)\n return\n self.board[index] = self.current_player\n seqs = self.getSequencesFromIndex(index)\n for seq in seqs:\n n = 0\n for coord in seq:\n if self.board[self.getIndexFromCoord(coord)] == self.current_player:\n n += 1\n if n == self.size:\n self.game_over = True\n break\n self.moves += 1\n if self.moves == self.size ** self.dimensions:\n self.tied_game = True\n self.game_over = True\n \n\n def getIndexFromCoord(self, coord):\n self.validateCoord(coord)\n index = 0\n for i in xrange(len(coord)-1,-1,-1):\n index += coord[i]*(self.size**i)\n return index\n\n def getCoordFromIndex(self, index):\n self.validateIndex(index)\n coord_list = []\n for i in xrange(self.dimensions):\n nd = self.size**(self.dimensions-1-i)\n coord_list.append(index//nd)\n index %= nd\n coord_list.reverse()\n return tuple(coord_list)\n\n def getSequencesFromIndex(self, index):\n return self.getSequencesFromCoord(self.getCoordFromIndex(index))\n\n # returns all the possible winning sequences containing this coordinate set\n def getSequencesFromCoord(self, coord):\n # from a set of indices, return a subset with elements indicated by the ones in\n # bin_rep\n def getIndexSet(indices, bin_rep):\n iset = []\n for i in xrange(len(indices)):\n if bin_rep[i] == u\"1\":\n iset.append(indices[i])\n return iset\n\n # given a set of indices that should be varied, return the n versions of coord\n def getVariedSequences(varying_indices):\n returned_sequences = []\n for i in xrange(self.size):\n new_coord = list(coord)\n for index in varying_indices:\n if coord[index] < self.size//2:\n new_coord[index] = i\n else:\n new_coord[index] = self.size-i-1\n returned_sequences.append(new_coord)\n return returned_sequences\n \n # given a set of indices that should be varied and a binary representation of\n # the direction in which they should vary, return the n versions of coord\n def getMidVariedSequences(varying_indices, vary_dir):\n returned_sequences = []\n for i in xrange(self.size):\n new_coord = list(coord)\n for j in xrange(len(varying_indices)):\n if vary_dir[j] == u\"1\":\n new_coord[varying_indices[j]] = i\n else:\n new_coord[varying_indices[j]] = self.size-i-1\n returned_sequences.append(new_coord)\n return returned_sequences\n \n self.validateCoord(coord)\n returned_sequences = []\n # for values up to half if evenly sized, up to middle-1 if oddly sized\n for x in xrange(self.size//2+1):\n x2 = self.size-x-1\n all_indices = []\n for index in xrange(len(coord)):\n if coord[index] == x or coord[index] == x2:\n all_indices.append(index)\n for i in xrange(1, 2 ** len(all_indices)):\n bin_rep = bin(i)[2:]\n while len(bin_rep) < len(all_indices):\n bin_rep = u\"0\" + bin_rep\n iset = getIndexSet(all_indices, bin_rep)\n if x != x2:\n returned_sequences.append(getVariedSequences(iset))\n else:\n for j in xrange(2 ** (len(iset)-1)):\n dir_vary = bin(j)[2:]\n while len(dir_vary) < len(iset):\n dir_vary = u\"0\" + dir_vary\n mid_sequences = getMidVariedSequences(iset, dir_vary)\n returned_sequences.append(mid_sequences)\n return returned_sequences\n \n def validateIndex(self, index):\n if index < 0 or index >= len(self.board):\n raise ValueError(u\"Invalid index\")\n\n def validateCoord(self, coord):\n if len(coord) != self.dimensions:\n raise ValueError(u\"Coordinate needs \" + unicode(self.dimensions) + u\" dimensions\")\n return\n for i in coord:\n if i >= self.size or i < 0:\n raise ValueError(u\"0 <= coordinate < \" + unicode(self.size))\n return\n \n # xy pairs from high order to low order to model coordinates \n def XYCoordToCoord(self, xy):\n coord = []\n start = 0\n if self.dimensions % 2 == 1:\n start = 1\n for i in xrange(start+1, len(xy), 2):\n coord.insert(0, xy[i])\n if start == 1:\n coord.insert(0, xy[0])\n for i in xrange(start, len(xy), 2):\n coord.insert(0, xy[i])\n return tuple(coord)\n\nclass IllegalMoveError(Exception):\n def __init__(self, index):\n self.index = index\n\n def __str__(self):\n return u\"Illegal move at index \" + unicode(self.index)\n\n\n# A view for the model. Other views might use Curses or a graphics library \nclass PlainTextView():\n def __init__(self, model):\n self.model = model\n self.create() \n\n # returns the divider that goes between board units of the d-th horizontal order\n def getHorizontalDivider(self, d):\n if d < 0: return\n if d == 0: return [u\"|\"]\n if d == 1: return [u\" \"]\n div = [u\" \", u\" \"]\n for i in xrange(d-1):\n div.insert(1, u\"|\")\n return div\n \n # returns the divider that goes between board units of the d-th vertical order\n def getVerticalDivider(self, d):\n if d < 0: return\n if d == 0: return [u\"-\"]\n if d == 1: return [u\" \"]\n div = [u\" \", u\" \"]\n for i in xrange(d-1):\n div.insert(1, u\"-\")\n return div\n \n # recursively create the board as a matrix of characters\n def createMatrix(self, d):\n if d < 0: return\n if d == 0: return [[u\"X\"]]\n \n sub_block = self.createMatrix(d-1)\n returned = []\n \n if d % 2 == 1:\n divider = self.getHorizontalDivider(d // 2)\n for row in sub_block:\n new_row = []\n for char in row:\n new_row.append(char)\n for i in xrange(self.model.size - 1):\n for char in divider:\n new_row.append(char)\n for char in row:\n new_row.append(char)\n returned.append(new_row)\n return returned\n \n if d % 2 == 0:\n divider = self.getVerticalDivider(d // 2 - 1)\n for row in sub_block:\n new_row = []\n for char in row:\n new_row.append(char)\n returned.append(new_row)\n for i in xrange (self.model.size - 1):\n for char in divider:\n new_row = []\n for j in xrange(len(sub_block[0])):\n new_row.append(char)\n returned.append(new_row)\n for row in sub_block:\n new_row = []\n for char in row:\n new_row.append(char)\n returned.append(new_row)\n return returned\n \n # use the matrix of characters that make up the board to create maps from the\n # representation's indices to the models and vice versa, and create an str\n def create(self):\n matrix = self.createMatrix(self.model.dimensions)\n self.str_rep = u\"\"\n for row in matrix:\n for char in row:\n self.str_rep += char\n self.str_rep += u\"\\n\" \n #print(str_rep) \n self.model_to_view = dict()\n self.view_to_model = dict()\n model_index = 0\n for i in xrange(len(self.str_rep)):\n if self.str_rep[i] == u\"X\":\n self.str_rep = self.str_rep.replace(u\"X\", u\" \", 1)\n self.model_to_view[model_index] = i\n self.view_to_model[i] = model_index\n model_index += 1\n \n # given char from model, return char for display\n def getDisplayChar(self, c):\n if c == 0: return u\" \"\n if self.model.players == 2:\n if c == 1: return u\"X\"\n if c == 2: return u\"O\"\n return unicode(c)\n \n # must be called to update the view when the state of index i in the model changes\n def update(self, i):\n index = self.model_to_view[i]\n char = self.getDisplayChar(self.model.board[i])\n self.str_rep = self.str_rep[:index] + char + self.str_rep[index+1:]\n \n def __str__(self): \n return self.str_rep\n\n\n# serves as a \"Main\" class and controls user interface with model and view\nclass TextGameController():\n def __init__(self):\n dimensions = int(raw_input(u\"dimensions: \"))\n size = int(raw_input(u\"size: \"))\n players = int(raw_input(u\"players: \"))\n print u\"creating model...\"\n self.board = Model(dimensions, size, players)\n print u\"creating view...\"\n self.view = PlainTextView(self.board)\n \n while True:\n print\n print self.view\n print\n player = u\"Player \" + unicode(self.board.current_player)\n coord = self.makeMove(player + u\": \")\n self.view.update(self.board.getIndexFromCoord(coord))\n if self.board.game_over:\n if self.board.tied_game:\n print u\"It's a tie :(\"\n break\n print self.view\n print\n print player + u\" wins!\"\n break\n self.board.nextTurn()\n \n # transform user input to model coordinates\n # and coordinates through necessary checks, repeating if necessary \n def makeMove(self, prompt):\n coord = None\n while True:\n try:\n raw_in = eval(u\"(\" + raw_input(prompt) + u\")\")\n coord = self.board.XYCoordToCoord(raw_in)\n print coord\n except Exception, e:\n print u\"Unrecognizable input\"\n continue\n try:\n self.board.validateCoord(coord)\n except Exception, e:\n print e\n continue\n try:\n self.board.playAtCoordinate(coord)\n break\n except Exception, e:\n print u\"Illegal move!\"\n continue\n return coord\n\nclass CursesController(object):\n def main(self, stdscr):\n model = self.model\n view = self.view\n \n def alert():\n curses.beep()\n curses.flash()\n \n uneven = model.dimensions % 2 != 0\n locked_coords = []\n selected_x = model.size // 2\n selected_y = 0\n if not (len(locked_coords) == 0 and uneven):\n selected_y = model.size // 2\n \n def getEnclosingRectangle(coord):\n extension = xrange(model.dimensions - len(coord))\n min_xycoord = coord[:]\n min_xycoord.extend([0 for i in extension])\n min_coord = model.XYCoordToCoord(min_xycoord)\n max_xycoord = coord[:]\n max_xycoord.extend([model.size-1 for i in extension])\n max_coord = model.XYCoordToCoord(max_xycoord)\n min_index = view.model_to_view[model.getIndexFromCoord(min_coord)]\n min_index = min_index - unicode(view).count(u\"\\n\",0, min_index)\n max_index = view.model_to_view[model.getIndexFromCoord(max_coord)]\n max_index = max_index - unicode(view).count(u\"\\n\",0, max_index)\n length = unicode(view).find(u\"\\n\")\n min_x = min_index % length\n min_y = min_index // length\n max_x = max_index % length\n max_y = max_index // length\n return (min_y,min_x,max_y,max_x)\n \n def getPlayerColor(p):\n colors = {1:4,2:1,3:2,4:3,5:5,6:6,7:7,8:5,9:7}\n return int(colors[((p-1)%9)+1])\n \n curses.curs_set(0)\n win = curses.newpad(unicode(view).count(u\"\\n\")+1, unicode(view).find(u\"\\n\")+1)\n \n for i in xrange(1,8):\n curses.init_pair(i,i,0)\n\n history = []\n \n initialized = False\n \n while not model.game_over: \n stdscr.clear()\n \n # Title Box Outline\n stdscr.addch(0,0,curses.ACS_ULCORNER)\n stdscr.hline(0,1,curses.ACS_HLINE,curses.COLS-2)\n stdscr.addch(0,curses.COLS-1,curses.ACS_URCORNER)\n stdscr.vline(1,0,curses.ACS_VLINE,3)\n stdscr.vline(1,curses.COLS-1,curses.ACS_VLINE,3)\n \n panel_width = model.dimensions * 2 + 11\n \n # Board Area Outline\n stdscr.addch(4,0,curses.ACS_ULCORNER)\n stdscr.hline(4,1,curses.ACS_HLINE,curses.COLS-panel_width-1)\n stdscr.addch(curses.LINES-1,0,curses.ACS_LLCORNER)\n stdscr.hline(curses.LINES-1,1,curses.ACS_HLINE,curses.COLS-panel_width-1)\n stdscr.vline(5,0,curses.ACS_VLINE,curses.LINES-6)\n \n # Top Panel Box Outline\n stdscr.addch(4,curses.COLS-panel_width,curses.ACS_ULCORNER)\n stdscr.hline(4,curses.COLS-panel_width+1,curses.ACS_HLINE,panel_width-2)\n stdscr.addch(4,curses.COLS-1,curses.ACS_URCORNER)\n stdscr.vline(5,curses.COLS-panel_width,curses.ACS_VLINE,4)\n stdscr.vline(5,curses.COLS-1,curses.ACS_VLINE,4)\n stdscr.addch(9,curses.COLS-panel_width,curses.ACS_LLCORNER)\n stdscr.addch(9,curses.COLS-1,curses.ACS_LRCORNER)\n stdscr.hline(9,curses.COLS-panel_width+1,curses.ACS_HLINE,panel_width-2)\n \n # Bottom Panel OUTLINE\n stdscr.vline(10,curses.COLS-panel_width,curses.ACS_VLINE,curses.LINES-11)\n stdscr.vline(10,curses.COLS-1,curses.ACS_VLINE,curses.LINES-11)\n stdscr.addch(curses.LINES-1,curses.COLS-panel_width,curses.ACS_LLCORNER)\n stdscr.hline(curses.LINES-1,curses.COLS-panel_width+1,\n curses.ACS_HLINE,panel_width-2)\n try:stdscr.addch(curses.LINES-1,curses.COLS-1,curses.ACS_LRCORNER)\n except:pass\n \n title = u\"N-Dimensional Tic-Tac-Toe ({0}^{1})\"\\\n .format(model.size,model.dimensions)\n stdscr.addstr(2, curses.COLS//2 - len(title)//2, title)\n \n \n # Get input\n key = None\n curses.flushinp()\n if initialized:\n key = win.getch()\n else:\n initialized = True\n \n if key == ord(u\"w\"):\n if selected_y == 0 or len(locked_coords) == 0 and uneven:\n alert()\n else:\n selected_y -= 1\n \n if key == ord(u\"s\"):\n if selected_y == model.size-1 or len(locked_coords) == 0 and uneven:\n alert()\n else:\n selected_y += 1\n \n if key == ord(u\"a\"):\n if selected_x == 0:\n alert()\n else:\n selected_x -= 1\n \n if key == ord(u\"d\"):\n if selected_x == model.size-1:\n alert()\n else:\n selected_x += 1\n \n if key == ord(u\"\\n\"):\n locked_coords.append(selected_x)\n if not (len(locked_coords) == 1 and uneven):\n locked_coords.append(selected_y)\n selected_x = model.size // 2\n selected_y = 0\n if not (len(locked_coords) == 0 and uneven):\n selected_y = model.size // 2\n \n if len(locked_coords) == model.dimensions:\n try:\n coord = model.XYCoordToCoord(locked_coords)\n model.playAtCoordinate(coord)\n view.update(model.getIndexFromCoord(coord))\n history.insert(0, (model.current_player, locked_coords[:]))\n del locked_coords[:]\n selected_x = model.size // 2\n selected_y = 0\n if not (len(locked_coords) == 0 and uneven):\n selected_y = model.size // 2\n if not model.game_over:\n model.nextTurn()\n except Exception:\n key = curses.ascii.ESC\n \n if key == curses.ascii.ESC:\n if len(locked_coords) == 0:\n alert()\n else:\n selected_y = locked_coords[-1]\n del locked_coords[-1]\n if not (len(locked_coords) == 0):\n selected_x = locked_coords[-1]\n del locked_coords[-1]\n else:\n selected_x = selected_y\n selected_y = 0\n \n # Draw info box contents\n info_line = u\"Player {0}\".format(model.current_player)\n stdscr.addstr(6, int(curses.COLS-(panel_width + len(info_line))/2),\n info_line,\n curses.color_pair(\n getPlayerColor(\n model.current_player)))\n info_coord = locked_coords[:]\n info_coord.append(selected_x)\n if not (len(locked_coords) == 0 and uneven):\n info_coord.append(selected_y)\n info_line = unicode(info_coord)[1:-1].replace(u\" \", u\"\")\n stdscr.addstr(7, int(curses.COLS-(panel_width + len(info_line))/2),\n info_line,\n curses.color_pair(\n getPlayerColor(\n model.current_player)))\n \n \n # Draw move history\n for i, move in enumerate(history):\n if 10 + i == curses.LINES -1:\n break\n p, loc = move\n loc = unicode(loc)[1:-1].replace(u\" \", u\"\")\n stdscr.addstr(10+i, curses.COLS-panel_width+1,\n u\"Player {0}: {1}\".format(p, loc),\n curses.color_pair(getPlayerColor(p)))\n \n # Draw board\n win.addstr(0,0, unicode(view))\n \n \n # Highlight selected area \n coord = locked_coords[:]\n coord.append(selected_x)\n if not (len(locked_coords) == 0 and uneven):\n coord.append(selected_y)\n min_y,min_x,max_y,max_x = getEnclosingRectangle(coord)\n for y in xrange(min_y, max_y+1):\n win.chgat(y, min_x, max_x + 1 - min_x,\n curses.A_REVERSE |\n curses.color_pair(getPlayerColor(model.current_player)))\n \n # Highlight past moves\n for p, loc in history:\n rect = getEnclosingRectangle(loc)\n current = win.inch(rect[0], rect[1])\n if current == current | curses.A_REVERSE:\n win.chgat(rect[0], rect[1], 1, curses.color_pair(getPlayerColor(p)))\n else:\n win.chgat(rect[0], rect[1], 1,\n curses.color_pair(getPlayerColor(p)) | curses.A_REVERSE)\n \n # Calculate area of board to display\n pminrow = 0\n pmincol = 0\n pheight = unicode(view).count(u\"\\n\")-1\n pwidth = unicode(view).find(u\"\\n\")-1\n sminrow = 5\n smincol = 1\n smaxrow = curses.LINES-2\n smaxcol = curses.COLS-panel_width-1\n sheight = smaxrow - sminrow\n swidth = smaxcol - smincol\n \n if pheight <= sheight:\n dif = sheight - pheight\n sminrow += dif // 2\n else:\n pminrow1 = min_y - sheight * min_y / pheight\n pminrow2 = sheight/pheight*(pheight-max_y) + max_y - sheight\n dif1 = min_y\n dif2 = pheight - max_y\n if not (dif1 == 0 and dif2 == 0):\n pminrow = int((pminrow1 * dif2 + pminrow2 * dif1) / (dif1 + dif2)+.5)\n else:\n dif = sheight - pheight\n sminrow += dif // 2\n \n if pwidth <= swidth:\n dif = swidth - pwidth\n smincol += dif // 2\n else:\n pmincol1 = min_x - swidth * min_x / pwidth\n pmincol2 = swidth/pwidth*(pwidth-max_x) + max_x - swidth\n dif1 = min_x\n dif2 = pwidth - max_x\n if not (dif1 == 0 and dif2 == 0):\n pmincol = int((pmincol1 * dif2 + pmincol2 * dif1) / (dif1 + dif2)+.5)\n else:\n dif = swidth - pwidth\n smincol += dif // 2\n\n # Refresh the display\n stdscr.refresh()\n win.refresh(pminrow, pmincol, sminrow, smincol, smaxrow, smaxcol)\n \n \n stdscr.clear()\n win.clear() \n if not model.tied_game:\n player = model.current_player\n message = u\"PLAYER {0} WINS!\".format(player)\n stdscr.addstr(curses.LINES//2, int((curses.COLS - len(message))/2+.5), message,\n curses.A_BLINK | curses.A_REVERSE | curses.color_pair(getPlayerColor(player)))\n else:\n message = u\"IT'S A TIE :(\"\n stdscr.addstr(curses.LINES//2, int((curses.COLS - len(message))/2+.5), message,\n curses.A_BLINK | curses.A_REVERSE)\n stdscr.getch()\n \n def __init__(self, model):\n self.model = model\n self.view = PlainTextView(self.model)\n curses.wrapper(self.main)\n \n# run the game if run as a script\nif __name__ == u\"__main__\": \n #TextGameController()\n args = [int(i) for i in sys.argv[1:]]\n if args:\n CursesController(Model(*args))\n else:\n CursesController(Model(4))\n"
},
{
"alpha_fraction": 0.6881188154220581,
"alphanum_fraction": 0.7029703259468079,
"avg_line_length": 16.342857360839844,
"blob_id": "3e8c903873f5651b1acb41839e333e42edf12dee",
"content_id": "f759df283172c2f8056019e42f30114eb9394acc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 606,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 35,
"path": "/README.md",
"repo_name": "dalalsunil1986/N-TicTacToe",
"src_encoding": "UTF-8",
"text": "# N-TicTacToe\n\nAn n-dimensional tic tac toe game written in python using ncurses for graphics.\n\n### Run\n\nPlay with a 4 dimensions with board length 5 and 2 players\n```\n./TicTacToe.py\n```\n\nPlay with n dimensions with board length n+1 and 2 players\n```\n./TicTacToe.py n\n```\n\nPlay with n dimensions with board length m and 2 players\n```\n./TicTacToe.py n m\n```\n\nPlay with n dimensions with board length m and p players\n```\n./TicTacToe.py n m p\n```\n\nTo use python 2.7 instead of three, use TicTacToe2.py instead of TicTacToe.py\n\n### Play\n\nw, a, s, d - move cells\n\nenter - select a cell\n\nesc - go back up a level"
}
] | 2 |
mu1er/flaskWeb | https://github.com/mu1er/flaskWeb | 24a7aa08765664434bcc353408b929378c52dffa | a7f2d7b48a4ac283d164d8c365d4d6543f271197 | 651ee849d23628f07fc147a1bb145b0b50f31dd1 | refs/heads/master | 2018-07-07T23:32:17.724893 | 2018-06-01T01:53:53 | 2018-06-01T01:53:53 | 135,516,986 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7564102411270142,
"alphanum_fraction": 0.7948718070983887,
"avg_line_length": 25.33333396911621,
"blob_id": "6c6cf0a6fdb334f68637b3be9189033b37c11b64",
"content_id": "21f5f7f4ef7dd7d9ee44b2fb34dba5f10cfd1fe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 3,
"path": "/README.md",
"repo_name": "mu1er/flaskWeb",
"src_encoding": "UTF-8",
"text": "# python3-flaskWeb\n\n### 写了一半,差不多三分之二,感觉2 和3差别还是有的,这个应用就先放下了,发现忘记了好多python 的语法。"
},
{
"alpha_fraction": 0.612004280090332,
"alphanum_fraction": 0.6570203900337219,
"avg_line_length": 28.15625,
"blob_id": "bd56f24db286ccbb135f24530d788b01795a1ba8",
"content_id": "8efc1ecd4a5bdad422a3ed0b10903c77cf75d920",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 933,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 32,
"path": "/migrations/versions/5049153067a2_add_field.py",
"repo_name": "mu1er/flaskWeb",
"src_encoding": "UTF-8",
"text": "\"\"\"add field\n\nRevision ID: 5049153067a2\nRevises: a0e43baa84e2\nCreate Date: 2018-06-01 01:06:37.450400\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '5049153067a2'\ndown_revision = 'a0e43baa84e2'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.create_foreign_key(None, 'followers', 'user', ['follower_id'], ['id'])\n op.create_foreign_key(None, 'followers', 'user', ['followed_id'], ['id'])\n op.create_foreign_key(None, 'post', 'user', ['user_id'], ['id'])\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_constraint(None, 'post', type_='foreignkey')\n op.drop_constraint(None, 'followers', type_='foreignkey')\n op.drop_constraint(None, 'followers', type_='foreignkey')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.7348203063011169,
"alphanum_fraction": 0.7360594868659973,
"avg_line_length": 31.70833396911621,
"blob_id": "af408732ccf81d1e965449237dc399d9a8d70154",
"content_id": "8767ee7e76c5a34c47a7660a6c00efb621ed4cf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 807,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 24,
"path": "/app/email.py",
"repo_name": "mu1er/flaskWeb",
"src_encoding": "UTF-8",
"text": "from flask_mail import Message\r\nfrom app import mail,app\r\nfrom flask import render_template\r\nfrom threading import Thread\r\n\r\n\r\n\r\ndef send_async_email(app,msg):\r\n\twith app.app_context():\r\n\t\tmail.send(msg)\r\ndef send_email(subject,sender,recipients,text_body,html_body):\r\n\tmsg=Message(subject,sender=sender,recipients=recipients)\r\n\tmsg.body=text_body\r\n\tmsg.html=html_body\r\n\tThread(target=send_async_email,args=(app,msg)).start()\r\ndef send_password_reset_email(user):\r\n\ttoken = user.get_reset_password_token()\r\n\tsend_email('[Microblog] Reset Your Password',\r\n\t\tsender=app.config['ADMINS'][0],\r\n\t\trecipients=[user.email],\r\n\t\ttext_body=render_template('email/reset_password_email.txt',\r\n\t\t\tuser=user, token=token),\r\n\t\thtml_body=render_template('email/reset_password_email.html',\r\n\t\t\tuser=user, token=token))"
},
{
"alpha_fraction": 0.7168141603469849,
"alphanum_fraction": 0.7327433824539185,
"avg_line_length": 35.79999923706055,
"blob_id": "675a7dcc1facd4796718eb8f0d68fe9fadee2128",
"content_id": "e4414e70f5fc9e051f0b830760e55716ee9fa481",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 15,
"path": "/config.py",
"repo_name": "mu1er/flaskWeb",
"src_encoding": "UTF-8",
"text": "import os\r\n\r\nclass Config(object):\r\n\tSECRET_KEY=os.environ.get('SECRET_KEY') or 'flask_web_demo'\r\n\tSQLALCHEMY_DATABASE_URI='mysql+pymysql://root:root@localhost:3306/py3flask?charset=utf8'\r\n\tSQLALCHEMY_TRACK_MODIFICATIONS=True\r\n\tPOST_PRE_PAGE=3\r\n\t# SQLALCHEMY_COMMIT_ON_TEARDOWN=True\r\n\t# Email Config\r\n\tMAIL_SERVER=os.environ.get('MAIL_SERVER')\r\n\tMAIL_PORT=int(os.environ.get('MAIL_PORT') or 25)\r\n\tMAIL_USE_TLS=os.environ.get('MAIL_USE_TLS') is not None\r\n\tMAIL_USERNAME=os.environ.get('MAIL_USERNAME')\r\n\tMAIL_PASSWORD=os.environ.get('MAIL_PASSWORD')\r\n\tADMINS=['auuu@moo.fish']"
},
{
"alpha_fraction": 0.7207149863243103,
"alphanum_fraction": 0.721672534942627,
"avg_line_length": 39.23684310913086,
"blob_id": "1a5913900b9d3a8581a295e22d591c50ce8bdd53",
"content_id": "5a046f81731c60da75967700624f961aba93b126",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6266,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 152,
"path": "/app/routes.py",
"repo_name": "mu1er/flaskWeb",
"src_encoding": "UTF-8",
"text": "from flask import render_template,redirect,flash,url_for,request\r\nfrom app.translate import translate\r\nfrom app import app,db\r\nfrom app.forms import LoginForm,RegisterForm,EditProfileForm,PostForm,ResetPasswordForm,ResetPasswordEmailForm\r\nfrom flask_login import current_user,login_user,logout_user,login_required\r\nfrom werkzeug.urls import url_parse\r\nfrom app.models import User,Post\r\nfrom datetime import datetime\r\nfrom app.email import send_password_reset_email\r\n@app.route('/',methods=['GET','POST'])\r\n@app.route('/index',methods=['GET','POST'])\r\n@login_required\r\ndef index():\r\n\tform=PostForm()\r\n\tif form.validate_on_submit():\r\n\t\tpost=Post(body=form.post.data,author=current_user)\r\n\t\tdb.session.add(post)\r\n\t\tdb.session.commit()\r\n\t\tflash('Your Post is now live!')\r\n\t\treturn redirect(url_for('index'))\r\n\tpage=request.args.get('page',1,type=int)\r\n\tposts=current_user.followed_posts().paginate(page,app.config['POST_PRE_PAGE'],False)\r\n\tnext_url=url_for('index',page=posts.next_num) if posts.has_next else None\r\n\tprev_url=url_for('index',page=posts.prev_num) if posts.has_prev else None\r\n\treturn render_template('index.html',title=\"Home Page\",form=form,posts=posts.items,next_url=next_url,prev_url=prev_url)\r\n\r\n@app.route('/login',methods=['GET','POST'])\r\ndef login():\r\n\tif current_user.is_authenticated:\r\n\t\treturn redirect(url_for('index'))\r\n\tform=LoginForm()\r\n\tif form.validate_on_submit():\r\n\t\tuser=User.query.filter_by(username=form.username.data).first()\r\n\t\tif user is None or not user.check_password(form.password.data):\r\n\t\t\tflash('Invalid username or password')\r\n\t\t\treturn redirect(url_for('login'))\r\n\t\tlogin_user(user,remember=form.remember_me.data)\r\n\t\tnext_page=request.args.get('next')\r\n\t\tif not next_page or url_parse(next_page).netloc !='':\r\n\t\t\tnext_page=url_for('index')\r\n\t\treturn redirect(next_page)\r\n\treturn render_template(\"login.html\",title=\"Sign In\",form=form)\r\n@app.route('/logout')\r\ndef logout():\r\n\tlogout_user()\r\n\treturn redirect(url_for('index'))\r\n@app.route('/register',methods=['GET','POST'])\r\ndef register():\r\n\tif current_user.is_authenticated:\r\n\t\treturn redirect(url_for('index'))\r\n\tform=RegisterForm()\r\n\tif form.validate_on_submit():\r\n\t\tuser=User(username=form.username.data,email=form.email.data)\r\n\t\tuser.set_password(form.password.data)\r\n\t\tdb.session.add(user)\r\n\t\tdb.session.commit()\r\n\t\tflash(\"Congratulations, you are now a registered user!\")\r\n\t\treturn redirect(url_for('login'))\r\n\treturn render_template('register.html',title=\"Register\",form=form)\r\n@app.route('/user/<username>')\r\n@login_required\r\ndef user(username):\r\n\tuser=User.query.filter_by(username=username).first_or_404()\r\n\tpage=request.args.get('page',1,type=int)\r\n\tposts=user.posts.order_by(Post.timestamp.desc()).paginate(page,app.config['POST_PRE_PAGE'],False)\r\n\tnext_url=url_for('user',username=user.username,page=posts.next_num) if posts.has_next else None\r\n\tprev_url=url_for('user',username=user.username,page=posts.prev_num) if posts.has_prev else None\r\n\treturn render_template('user.html',user=user,posts=posts.items,next_url=next_url,prev_url=prev_url)\r\n@app.before_request\r\ndef before_request():\r\n\tif current_user.is_authenticated:\r\n\t\tcurrent_user.last_seen=datetime.utcnow()\r\n\t\tdb.session.commit()\r\n@app.route('/edit_profile',methods=['GET','POST'])\r\n@login_required\r\ndef edit_profile():\r\n\tform=EditProfileForm(current_user.username)\r\n\tif form.validate_on_submit():\r\n\t\tcurrent_user.username=form.username.data\r\n\t\tcurrent_user.about_me=form.about_me.data\r\n\t\tdb.session.commit()\r\n\t\tflash(\"Your change hava been saved\")\r\n\t\treturn redirect(url_for('edit_profile'))\r\n\telif request.method=='GET':\r\n\t\tform.username.data=current_user.username\r\n\t\tform.about_me.data=current_user.about_me\r\n\treturn render_template('editprofile.html',title=\"Edit Profile\",form=form)\r\n@app.route('/follow/<username>')\r\n@login_required\r\ndef follow(username):\r\n\tuser = User.query.filter_by(username=username).first()\r\n\tif user is None:\r\n\t\tflash('User {} not found.'.format(username))\r\n\t\treturn redirect(url_for('index'))\r\n\t\tif user == current_user:\r\n\t\t\tflash('You cannot follow yourself!')\r\n\t\t\treturn redirect(url_for('user', username=username))\r\n\t\t\tcurrent_user.follow(user)\r\n\t\t\tdb.session.commit()\r\n\t\tflash('You are following {}!'.format(username))\r\n\treturn redirect(url_for('user', username=username))\r\n\r\n@app.route('/unfollow/<username>')\r\n@login_required\r\ndef unfollow(username):\r\n\tuser = User.query.filter_by(username=username).first()\r\n\tif user is None:\r\n\t\tflash('User {} not found.'.format(username))\r\n\t\treturn redirect(url_for('index'))\r\n\t\tif user == current_user:\r\n\t\t\tflash('You cannot unfollow yourself!')\r\n\t\t\treturn redirect(url_for('user', username=username))\r\n\t\t\tcurrent_user.unfollow(user)\r\n\t\t\tdb.session.commit()\r\n\t\t\tflash('You are not following {}.'.format(username))\r\n\treturn redirect(url_for('user', username=username))\r\n\r\n@app.route('/explore')\r\n@login_required\r\ndef explore():\r\n\tpage=request.args.get('page',1,type=int)\r\n\tposts = Post.query.order_by(Post.timestamp.desc()).paginate(\r\n\t\tpage,app.config['POST_PRE_PAGE'],False)\r\n\tnext_url=url_for('index',page=posts.next_num) if posts.has_next else None\r\n\tprev_url=url_for('index',page=posts.prev_num) if posts.has_prev else None\r\n\treturn render_template('index.html', title='Explore', posts=posts.items,next_url=next_url,prev_url=prev_url)\r\n@app.route('/reset_password')\r\ndef reset_password():\r\n\tif current_user.is_authenticated:\r\n\t\treturn redirect(url_for('index'))\r\n\tform=ResetPasswordForm()\r\n\tif validate_on_submit():\r\n\t\tuser=User.query.filter_by(email=form.email.data).first()\r\n\t\tif user:\r\n\t\t\tsend_password_reset_email(user)\r\n\t\tflash('Check Your Password for you email')\r\n\t\treturn redirect(url_for('login'))\r\n\treturn render_template('reset_password.html',title='Reset Password',form=form)\r\n@app.route('/reset_password/<token>', methods=['GET', 'POST'])\r\ndef reset_password_view(token):\r\n\tif current_user.is_authenticated:\r\n\t\treturn redirect(url_for('index'))\r\n\tuser = User.verify_reset_password_token(token)\r\n\tif not user:\r\n\t\treturn redirect(url_for('index'))\r\n\tform = ResetPasswordEmailForm()\r\n\tif form.validate_on_submit():\r\n\t\tuser.set_password(form.password.data)\r\n\t\tdb.session.commit()\r\n\t\tflash('Your password has been reset.')\r\n\t\treturn redirect(url_for('login'))\r\n\treturn render_template('reset_password_view.html', form=form)"
}
] | 5 |
ProzorroUKR/robot_tests.broker.GovAuction | https://github.com/ProzorroUKR/robot_tests.broker.GovAuction | 2e11b15e3c939be8b2c26560469d0651429261e8 | bde81013a395792a8be92bc7d1f210f7be1859e3 | b0dfb5602775c8fd246ce9e876770fc60f3a4788 | refs/heads/master | 2021-01-14T18:27:03.080528 | 2020-03-03T14:50:22 | 2020-03-03T14:50:22 | 242,711,779 | 0 | 1 | Apache-2.0 | 2020-02-24T10:52:53 | 2020-02-28T10:18:23 | 2020-03-03T14:50:22 | RobotFramework | [
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 31,
"blob_id": "21b7f275071829a812bd486fe63fd87595d2a7ef",
"content_id": "0e07d1838336aa45e6a9d741af7039b3efacd7ca",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 32,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 1,
"path": "/README.md",
"repo_name": "ProzorroUKR/robot_tests.broker.GovAuction",
"src_encoding": "UTF-8",
"text": "# robot_tests.broker.GovAuction\n"
},
{
"alpha_fraction": 0.6088921427726746,
"alphanum_fraction": 0.6210681796073914,
"avg_line_length": 39.90565872192383,
"blob_id": "5231655e691c41609c9111c2646e842f0d2cb437",
"content_id": "48664323d922b0973a708f60dba5cec1b75db78a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11927,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 265,
"path": "/GovAuction_service.py",
"repo_name": "ProzorroUKR/robot_tests.broker.GovAuction",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nfrom datetime import datetime, timedelta\nfrom iso8601 import parse_date\nfrom pytz import timezone\nimport urllib\nimport json\nimport os\nimport requests\n\n\ndef convert_time(date):\n date = datetime.strptime(date, \"%d/%m/%Y %H:%M:%S\")\n return timezone('Europe/Kiev').localize(date).strftime('%Y-%m-%dT%H:%M:%S.%f%z')\n\n\ndef convert_time_item(date):\n date = datetime.strptime(date, \"%d/%m/%Y\")\n res_date = date.strftime('%Y-%m-%dT%H:%M:%S')\n return \"{}+{}\".format(res_date, \"02:00\")\n\ndef subtract_min_from_date(date, minutes, template):\n date_obj = datetime.strptime(date.split(\"+\")[0], template)\n return \"{}+{}\".format(date_obj - timedelta(minutes=minutes), date.split(\"+\")[1])\n\n\ndef convert_datetime_to_GovAuction_format(isodate):\n iso_dt = parse_date(isodate)\n day_string = iso_dt.strftime(\"%d/%m/%Y %H:%M\")\n return day_string\n\ndef convert_date_plan_to_GovAuction_format(isodate):\n iso_dt = parse_date(isodate)\n day_string = iso_dt.strftime(\"%d/%m/%Y\")\n return day_string\n\n\ndef convert_date_plan_tender_to_GovAuction_format(isodate):\n iso_dt = parse_date(isodate)\n day_string = iso_dt.strftime(\"%m/%Y\")\n return day_string\n\ndef convert_date_plan_to_GovAuction_format_year(isodate):\n iso_dt = parse_date(isodate)\n day_string = iso_dt.strftime(\"%Y\")\n return day_string\n\n\ndef convert_string_from_dict_GovAuction(string):\n return {\n u\"грн.\": u\"UAH\",\n u\"True\": u\"1\",\n u\"False\": u\"0\",\n u\"Відкриті торги\": u\"aboveThresholdUA\",\n u\"Відкриті торги з публікацією англ. мовою\": u\"aboveThresholdEU\",\n u\"Переговорна процедура для потреб оборони\": u\"aboveThresholdUA.defense\",\n u'Класифікацiя предмета закупівлi за ДК021:2015': u'ДК021',\n u'Код ДК (ДК003)': u'ДК003',\n u'Код ДК (ДК018)': u'ДК018',\n u'Код ДК (ДК015)': u'ДК015',\n u'з урахуванням ПДВ': True,\n u'без урахуванням ПДВ': False,\n u'Очiкування пропозицiй': u'active.tendering',\n u'Перiод уточнень': u'active.enquiries',\n u'Аукцiон': u'active.auction',\n u'Прекваліфікація': u'active.pre-qualification',\n u'Квалiфiкацiя переможця': u'active.qualification',\n u'Оскарження прекваліфікації': u'active.pre-qualification.stand-still',\n u'вимога': u'claim',\n u'не задоволено': u'declined',\n u'дано відповідь': u'answered',\n u'вирішено': u'resolved',\n u'відхилено': u'declined',\n u'недійсно': u'invalid',\n u'award_ignored': u'ignored',\n u'Так': True,\n u'Ні': False,\n u'на розглядi': u'pending',\n u'На розгляді': u'pending',\n u'не вирішено(обробляється)': u'pending',\n u'відмінено': u'cancelled',\n u'відмінена': u'cancelled',\n u'Переможець': u'active',\n u'ящик': u'BX',\n u'open_belowThreshold': u'belowThreshold',\n u'limited_reporting': u'reporting',\n u'open_aboveThresholdUA': u'aboveThresholdUA',\n u'Код ДК 021-2015 (CPV)': u'ДК021',\n u'Запланований': u'scheduled',\n u'(робочі)': u'working',\n u'(банківські)': u'banking',\n u'(календарні)': u'calendar',\n u'Аванс': u'prepayment',\n u'Пiсляоплата': u'postpayment',\n u'виконання робіт': u'executionOfWorks',\n u'поставка товару': u'deliveryOfGoods',\n u'надання послуг': u'submittingServices',\n u'підписання договору': u'signingTheContract',\n u'дата подання заявки': u'submissionDateOfApplications',\n u'дата виставлення рахунку': u'dateOfInvoicing',\n u'дата закінчення звітного періоду': u'endDateOfTheReportingPeriod',\n u'інша подія': u'anotherEvent',\n u'Послуги': u'services',\n u'Товари': u'goods',\n u'Роботи': u'works',\n u'Класифікацiя предмета закупівлi за ДК 021:2015': u'ДК021',\n u'Конкурентний діалог': u'competitiveDialogueUA',\n u'Конкурентний діалог з публікацією англ. мовою': u'competitiveDialogueEU',\n u'Визначення переможців': u'active.qualification',\n u'Відкриті торги для закупівлі енергосервісу': u'esco',\n u'співфінансування з бюджетних коштів': u'budget',\n u'Очікування переведення': u'active.stage2.pending',\n u'Укладання рамкової угоди': u'closeFrameworkAgreementUA',\n u'Пропозицiї розглянуто': u'active.qualification',\n u'Завершена': u'complete',\n u'відкликано скаржником': u'stopping',\n u'USA': u'Сполучені Штати Америки',\n u'Не визначено': u'Не відображене в інших розділах',\n u'без відповіді': u'ignored',\n u'відкликано скаржником': u'stopping',\n u'Без ответа': u'ignored',\n u'Укладена Рамкова угода': u'complete',\n }.get(string, string)\n\n\ndef adapt_procuringEntity(role_name, tender_data):\n if role_name == 'tender_owner':\n tender_data['data']['procuringEntity']['name'] = u\"prozorroytenderowner\"\n if tender_data['data']['procuringEntity'].has_key(\"address\"):\n tender_data['data']['procuringEntity']['address']['postalCode'] = u\"01001\"\n tender_data['data']['procuringEntity']['address']['region'] = u\"м. Київ\"\n tender_data['data']['procuringEntity']['address']['locality'] = u\"Київ\"\n tender_data['data']['procuringEntity']['address']['streetAddress'] = u\"Вулична вулиця\"\n tender_data['data']['procuringEntity']['identifier']['legalName'] = u\"prozorroytenderowner\"\n tender_data['data']['procuringEntity']['identifier']['id'] = u\"54575680\"\n if tender_data['data']['procuringEntity'].has_key(\"contactPoint\"):\n tender_data['data']['procuringEntity']['contactPoint']['name'] = u\"бла бла \"\n tender_data['data']['procuringEntity']['contactPoint']['telephone'] = u\"+38(099)353-10-28\"\n tender_data['data']['procuringEntity']['contactPoint']['url'] = u\"http://webpage.com.ua\"\n if tender_data['data'].has_key('procurementMethodType'):\n if \"above\" in tender_data['data']['procurementMethodType']:\n tender_data['data']['tenderPeriod']['startDate'] = subtract_min_from_date(\n tender_data['data']['tenderPeriod']['startDate'], 1, '%Y-%m-%dT%H:%M:%S.%f')\n for item in tender_data['data']['items']:\n if item['classification']['description'] == u\"Не відображене в інших розділах\":\n item['classification']['description'] = u\"Не визначено\"\n return tender_data\n\n\ndef adapt_delivery_data(tender_data):\n for index in range(len(tender_data['data']['items'])):\n value = tender_data['data']['items'][index]['deliveryAddress']['region']\n if value == u\"місто Київ\":\n tender_data['data']['items'][index]['deliveryAddress']['region'] = u\"Київ\"\n return tender_data\n\n\ndef adapt_view_tender_data(value, field_name):\n if 'amount' in field_name:\n value = float(value.replace(\" \", \"\"))\n elif 'currency' in field_name and 'awards' in field_name:\n value = value.split(' ')[-1]\n elif 'minimalStep.amount' in field_name:\n value = float(\"\".join(value.split(\" \")[:-4]))\n # elif 'unit.name' in field_name:\n # value = value.split(' ')[1]\n elif 'quantity' in field_name:\n value = float(value.replace(\",\", \".\"))\n elif 'questions' in field_name and '.date' in field_name:\n value = convert_time(value.split(' - ')[0])\n elif 'Date' in field_name:\n value = convert_time(value)\n elif 'NBUdiscountRate' in field_name:\n value = round(float(value[0:-1]) / 100, 5)\n elif 'minimalStepPercentage' in field_name:\n value = round(float(value[0:-1]) / 100, 5)\n elif 'maxAwardsCount' in field_name:\n value = int(value)\n elif 'agreementDuration' in field_name:\n l = value.split(\" \")\n value = \"P{}Y{}M{}D\".format(l[0], l[2], l[4] )\n elif 'yearlyPaymentsPercentageRange'in field_name:\n value = round(float(value.split(\" \")[-1][:-1]) / 100, 5)\n return convert_string_from_dict_GovAuction(value)\n\n\ndef adapt_view_lot_data(value, field_name):\n # if 'value.amount' in field_name:\n # value = float(\"\".join(value.split(' ')[:-4]))\n if 'value.amount' in field_name:\n value = float(value.replace(' ', ''))\n # elif 'minimalStep.currency' in field_name:\n # value = value.split(' ')[-1]\n # elif 'currency' in field_name:\n # value = value.split(' ')[-4]\n # elif 'valueAddedTaxIncluded' in field_name:\n # value = ' '.join(value.split(' ')[-3:]).strip()\n # elif 'minimalStep.amount' in field_name:\n # value = float(\"\".join(value.split(' ')[:-1]))\n elif 'minimalStep.amount' in field_name:\n value = float(value.replace(' ', ''))\n elif 'Date' in field_name:\n value = convert_time(value)\n return convert_string_from_dict_GovAuction(value)\n\n\ndef adapt_view_item_data(value, field_name):\n if 'unit.name' in field_name:\n value = ' '.join(value.split(' ')[1:])\n elif 'quantity' in field_name:\n value = float(value.split(' ')[0])\n elif 'Date' in field_name:\n value = convert_time(value)\n return convert_string_from_dict_GovAuction(value)\n\n\ndef adapt_view_agreement_data(value, field_name):\n if 'factor' in field_name:\n value = round(float((value + 1) / 10, 1))\n return convert_string_from_dict_GovAuction(value)\n\n\ndef get_related_elem_description(tender_data, feature, item_id):\n if item_id == \"\":\n for elem in tender_data['data']['{}s'.format(feature['featureOf'])]:\n if feature['relatedItem'] == elem['id']:\n return elem['description']\n else:\n return item_id\n\n\ndef custom_download_file(url, file_name, output_dir):\n urllib.urlretrieve(url, ('{}/{}'.format(output_dir, file_name)))\n\n\ndef add_second_sign_after_point(amount):\n amount = str(repr(amount))\n if '.' in amount and len(amount.split('.')[1]) == 1:\n amount += '0'\n return amount\n\n\ndef get_upload_file_path():\n return os.path.join(os.getcwd(), 'src/robot_tests.broker.GovAuction/testFileForUpload.txt')\n\n\ndef get_company_name_by_bid_id(bid_id, data):\n for bid in data['data']['bids']:\n if bid['id'] == bid_id:\n return bid['tenderers'][0]['name']\n\n\ndef retrieve_qaulifications_range(internal_id):\n resp_data = requests.get(\"https://lb-api-staging.prozorro.gov.ua/api/2.4/tenders/{}\".format(internal_id))\n data = json.loads(resp_data.content)\n lst = list()\n for index in range(len(data['data']['qualifications'])):\n lst.append(get_company_name_by_bid_id(data['data']['qualifications'][index]['bidID'], data))\n return lst\n\n\ndef retrive_agreement_id(internal_agreement_id):\n resp_data = requests.get(\"https://lb-api-staging.prozorro.gov.ua/api/2.4/agreements/{}\".format(internal_agreement_id))\n return json.loads(resp_data.content)['data']['agreementID']\n\n"
}
] | 2 |
jad-bend/webscraper-sentiment | https://github.com/jad-bend/webscraper-sentiment | 8fc12ea70316da0d3abf2a77addd5b25be2253f9 | 3efcc9e3aa3da780bb4f2e323f37fb1d24921d31 | c058a35608db4e37ab56b16991b1cb1e9ab80ebd | refs/heads/main | 2023-06-11T14:21:58.362758 | 2021-06-26T03:44:28 | 2021-06-26T03:44:28 | 380,401,522 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6759493947029114,
"alphanum_fraction": 0.6816455721855164,
"avg_line_length": 27.727272033691406,
"blob_id": "a36df8f623283adb701a4a705813d8c298bb58cf",
"content_id": "db9fc93cf0953047f11065784eb5aba11fe3a35d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1580,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 55,
"path": "/webscraper.py",
"repo_name": "jad-bend/webscraper-sentiment",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport time\nfrom selenium.webdriver import Chrome\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.common.keys import Keys\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.support import expected_conditions as EC\nimport pandas as pd \nimport nltk\nimport random\nfrom nltk.corpus import stopwords\nfrom nltk.tokenize import sent_tokenize, word_tokenize\n\n\ndata=[]\nfinal =[]\n\nfileObj = open(\"negative-words.txt\", \"r\") #opens the file in read mode\nnegative = fileObj.read().splitlines() #puts the file into an array\nfileObj.close()\n\nwith Chrome(executable_path=r\"/usr/local/bin/chromedriver\") as driver:\n wait = WebDriverWait(driver,5)\n driver.get(\"https://youtu.be/TMrtLsQbaok\")\n\n for item in range(3): \n wait.until(EC.visibility_of_element_located((By.TAG_NAME, \"body\"))).send_keys(Keys.END)\n time.sleep(5)\n\n for comment in wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, \"#content\"))):\n data.append(comment.text)\n\nwith open('comments.txt', 'w') as f:\n for x in data:\n f.write(x)\n f.write('\\n')\n\nfor comment in data:\n\n counter = 0\n # array to store key words\n found = []\n for word in negative:\n\n # incrementer counter by 1 if key word found in comment\n if word in comment:\n counter += 1\n found.append(word)\n\n # append domain and key words to result if 2 or more key words found\n if counter >= 10:\n final.append((comment))\n\nfor x in final:\n print( x + '\\n')\n"
},
{
"alpha_fraction": 0.7046783566474915,
"alphanum_fraction": 0.7397660613059998,
"avg_line_length": 41.625,
"blob_id": "855e8064ef235cd9420b2b3bc75a77d26a1ea2bb",
"content_id": "8b07875a71cfccf3a2224dce6b1bb36652ad9525",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 8,
"path": "/README.md",
"repo_name": "jad-bend/webscraper-sentiment",
"src_encoding": "UTF-8",
"text": "# webscraper-sentiment\nwebscraper + sentiment analysis for youtube comments\n\nnegative-words.txt citation:\n Minqing Hu and Bing Liu. \"Mining and Summarizing Customer Reviews.\" \n Proceedings of the ACM SIGKDD International Conference on Knowledge \n Discovery and Data Mining (KDD-2004), Aug 22-25, 2004, Seattle, \n Washington, USA, \n"
}
] | 2 |
odell/pyazr | https://github.com/odell/pyazr | e27ac2f4870de70c0abb80de46eeaf94b3866bc3 | 3ea6a1f28b034fb56527b1d5f33b544ea3e53893 | 83ab277fb0e4295ff916bcf3233593ab034f188f | refs/heads/main | 2023-05-31T19:18:16.765989 | 2021-06-02T19:57:18 | 2021-06-02T19:57:18 | 314,349,163 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6404958963394165,
"alphanum_fraction": 0.6574839353561401,
"avg_line_length": 28.02666664123535,
"blob_id": "f4ded07a6b1d79ffc2cdbe67f74a171847d58a0c",
"content_id": "eb601c0d6a48147becff30f78447051919fcf8e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2178,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 75,
"path": "/test/model.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nDefines the Bayesian model we will use to analyze the Vogl data.\n'''\n\nimport sys\nimport os\n\nimport numpy as np\nfrom scipy import stats\n\n# Get the current path so we can import classes defined in the parent directory.\npwd = os.getcwd()\ni = pwd.find('/test')\n# Import pyazr classes.\nsys.path.append(pwd[:i])\nfrom azr import AZR\nfrom parameter import Parameter\n########################################\n# Set up AZR object and data.\n\n# We have to tell AZURE2 which output files it should look at.\n# (This could/should be inferred from the data segments in the .azr file.)\n# R=2 => particle pair 2\noutput_files = ['AZUREOut_aa=1_R=2.out']\n\n# We have all of the information we need to instantiate our AZR object.\nazr = AZR('12C+p.azr')\nazr.root_directory = '/tmp/'\n\n# We'll read the data from the output file since it's already in the\n# center-of-mass frame.\ndata = np.loadtxt('output/' + output_files[0])\nx = data[:, 0] # energies\ny = data[:, 5] # cross sections\ndy = data[:, 6] # cross section uncertainties\n\n########################################\n# Next, let's set up the Bayesian calculation. Recall:\n# * lnP \\propto lnL + lnPi\n# where\n# * P = posterior\n# * L = likelihood\n# * Pi = prior\n\n# We'll work from right to left.\n# First, we need prior disributions for each sampled parameters.\npriors = [\n stats.uniform(0, 5),\n stats.uniform(1, 5),\n stats.uniform(0, 50000),\n stats.uniform(-100, 200),\n stats.lognorm(0.1),\n stats.lognorm(0.1)\n]\n\ndef lnPi(theta):\n return np.sum([pi.logpdf(t) for (pi, t) in zip(priors, theta)])\n\n\n# To calculate the likelihood, we generate the prediction at theta and compare\n# it to data. (Assumes data uncertainties are Gaussian and IID.)\ndef lnL(theta):\n mu = azr.predict(theta)\n capture = mu[0].xs_com_fit\n return np.sum(-np.log(np.sqrt(2*np.pi)*dy) - 0.5*((y - capture)/dy)**2)\n\n\ndef lnP(theta):\n lnpi = lnPi(theta)\n # If any of the parameters fall outside of their prior distributions, go\n # ahead and return lnPi = -infty. Don't bother running AZURE2 or risking\n # calling it with a parameter value that will throw an error.\n if lnpi == -np.inf:\n return lnpi\n return lnL(theta) + lnpi\n\n"
},
{
"alpha_fraction": 0.5642172694206238,
"alphanum_fraction": 0.5674121379852295,
"avg_line_length": 38.87261199951172,
"blob_id": "2ed3fbcbdef26b9d141128ae413b78d3350205bc",
"content_id": "b27455f64a6f0aa7caf052a1f3708e18a580e334",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6260,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 157,
"path": "/configuration.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nClass to read and write the contents of an AZURE2 input file.\nThe purpose is to remove as much of this work from AZR as possible.\n'''\n\nimport utility\nfrom data import Data\nfrom nodata import Test\nfrom parameter import Parameter\n\nclass Config:\n def __init__(self, input_filename, parameters=None):\n self.input_filename = input_filename\n self.input_filename = input_filename\n self.input_file_contents = utility.read_input_file(input_filename)\n self.initial_levels = utility.read_levels(input_filename)\n self.data = Data(self.input_filename)\n self.test = Test(self.input_filename)\n\n if parameters is None:\n self.parameters = []\n jpis = []\n for group in self.initial_levels:\n # grab the J^pi from the first row in the group\n jpi = group[0].spin*group[0].parity\n # add it to the list\n jpis.append(jpi)\n for (i, sublevel) in enumerate(group):\n spin = sublevel.spin\n parity = sublevel.parity\n rank = jpis.count(jpi)\n if i == 0:\n if not sublevel.energy_fixed:\n self.parameters.append(Parameter(spin, parity, 'energy', i+1, rank=rank))\n if not sublevel.width_fixed:\n if sublevel.energy < sublevel.separation_energy:\n self.parameters.append(\n Parameter(spin, parity, 'width', i+1, rank=rank,\n is_anc=True)\n )\n else:\n self.parameters.append(\n Parameter(spin, parity, 'width', i+1, rank=rank)\n )\n else:\n self.parameters = parameters\n\n Jpi = [l[0].spin*l[0].parity for l in self.initial_levels]\n self.addresses = []\n for p in self.parameters:\n jpi = p.spin*p.parity\n i = Jpi.index(jpi)\n i += p.rank-1 # convert from one-based count to zero-based index\n j = p.channel-1 # convert from one-based count to zero-based index\n self.addresses.append([i, j, p.kind])\n\n self.n1 = len(self.parameters)\n self.n2 = len(self.data.norm_segment_indices)\n # number of free parameters\n self.nd = self.n1 + self.n2\n\n self.labels = []\n for i in range(self.n1):\n self.labels.append(self.parameters[i].label)\n for i in self.data.norm_segment_indices:\n self.labels.append(self.data.all_segments[i].nf.label)\n\n\n def generate_levels(self, theta):\n levels = self.initial_levels.copy()\n for (theta_i, address) in zip(theta, self.addresses):\n i, j, kind = address\n if kind == 'energy':\n '''\n Set the energy for each channel in this level to the prescribed\n energy.\n '''\n for sl in levels[i]:\n sl.energy = theta_i\n else:\n setattr(levels[i][j], kind, theta_i)\n return [l for sublevel in levels for l in sublevel]\n\n\n def get_input_values(self):\n '''\n Returns the values of the sampled parameters in the input file.\n '''\n values = [getattr(self.initial_levels[i][j], kind) for (i, j, kind) in\n self.addresses]\n for i in self.data.norm_segment_indices:\n values.append(self.data.all_segments[i].norm_factor)\n return values\n\n\n def update_data_directories(self, new_dir, contents):\n '''\n The data needs to be stored in a new location (new_dir), so the input\n has to reflect that. In preparation, the contents of the input file are\n updated here.\n '''\n contents = self.data.update_all_dir(new_dir, contents)\n return self.data.write_segments(contents)\n\n\n def generate_workspace(self, theta, prepend='', mod_data=None):\n '''\n Config handles the configuration of the calculation. That includes:\n * mapping theta to the relevant values in the input file\n * setting up the appropriate workspace for AZR to operate in\n '''\n contents = self.input_file_contents.copy()\n\n new_levels = self.generate_levels(theta[:self.n1])\n contents = self.data.update_norm_factors(theta[self.n1:self.n1+self.n2],\n contents)\n\n input_filename, output_dir, data_dir = utility.random_workspace(prepend=prepend)\n\n\n if mod_data is not None:\n utility.write_input_file(contents, new_levels, input_filename,\n output_dir, data_dir=data_dir)\n self.data.update_all_dir(data_dir, contents)\n for (i, data) in mod_data:\n self.data.segments[i].update_dir(data_dir, data)\n else:\n utility.write_input_file(contents, new_levels, input_filename,\n output_dir)\n\n return input_filename, output_dir, data_dir\n\n def generate_workspace_extrap(self, theta, segment_indices=None):\n '''\n Similar to generate_workspace, except the test segments are updated\n rather than the data segments.\n '''\n contents = self.input_file_contents.copy()\n\n # Map theta to a new list of levels.\n new_levels = self.generate_levels(theta)\n\n # What extrapolation files need to be read?\n # If the user specifies the indices of the segments, then make sure\n # those are \"include\"d in the calculation and everything else is\n # excluded.\n t = Test('', contents=contents)\n if segment_indices is not None:\n for (i, test_segment) in enumerate(t.all_segments):\n test_segment.include = i in segment_indices\n t.write_segments(contents)\n\n # Write the updated contents to the input file and run.\n input_filename, output_dir = utility.random_output_dir_filename()\n utility.write_input_file(contents, new_levels, input_filename,\n output_dir)\n return input_filename, output_dir, t.get_output_files()\n"
},
{
"alpha_fraction": 0.5257452726364136,
"alphanum_fraction": 0.5349593758583069,
"avg_line_length": 31.36842155456543,
"blob_id": "a208c0e820d797572a80f8b775ca173c71aa13dc",
"content_id": "74ea1990b86c06bbe4a8b05098eaa8e5cbcb3e75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1845,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 57,
"path": "/output.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nclass Output:\n '''\n Packages AZURE2 output.\n (See the Section 8 of the AZURE2 Manual.)\n\n filename : Either the filename where the data can be read OR a NumPy array\n with the data.\n is_array : Is filename actually an array?\n\n e_com = center-of-mass energy\n e_x = excitation energy\n xs = cross section\n sf = S-factor\n com = center-of-mass\n err = error/uncertainty\n fit = AZURE2 calculation\n data = original data\n '''\n def __init__(self, filename, is_array=False):\n if is_array:\n self.contents = filename\n else:\n self.contents = np.loadtxt(filename)\n self.e_com = self.contents[:, 0]\n self.e_x = self.contents[:, 1]\n self.angle_com = self.contents[:, 2]\n self.xs_com_fit = self.contents[:, 3]\n self.sf_com_fit = self.contents[:, 4]\n self.xs_com_data = self.contents[:, 5]\n self.xs_err_com_data = self.contents[:, 6]\n self.sf_com_data = self.contents[:, 7]\n self.sf_err_com_data = self.contents[:, 8]\n\n\nclass OutputList:\n '''\n List of Output objects.\n '''\n def __init__(self, filename):\n with open(filename, 'r') as f:\n contents = f.read()\n self.data = []\n for section in contents.split('\\n\\n '):\n data_set = np.array([])\n for (i, row) in enumerate(section.split('\\n')):\n data_row = np.array(list(map(float, row.split())))\n if data_row.shape[0] > 0:\n if i == 0:\n data_set = data_row\n else:\n data_set = np.vstack((data_set, data_row))\n self.data.append(Output(data_set, is_array=True))\n\n self.ns = list(map(lambda d: d.shape[0], self.data))\n self.ntot = sum(self.ns)\n"
},
{
"alpha_fraction": 0.5805820226669312,
"alphanum_fraction": 0.5881508588790894,
"avg_line_length": 30.796680450439453,
"blob_id": "2be71a053bc72bf8b22dc47cff3a7cb189c65b46",
"content_id": "77ab3862a035c9ff45271b998a6b9dce16b33776",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7665,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 241,
"path": "/utility.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nUtility functions stored here to keep other class definitions uncluttered.\n'''\n\nimport string\nimport random\nimport os\nfrom subprocess import Popen, PIPE\nimport numpy as np\nfrom level import Level\n\n'''\nThe rows of levels in the .azr file are converted to list of strings. These\nindices make it more convenient to access the desired parameter.\n'''\nJ_INDEX = 0\nPI_INDEX = 1\nENERGY_INDEX = 2\nENERGY_FIXED_INDEX = 3\nCHANNEL_INDEX = 5\nWIDTH_INDEX = 11\nWIDTH_FIXED_INDEX = 10\nSEPARATION_ENERGY_INDEX = 21\nCHANNEL_RADIUS_INDEX = 27\nOUTPUT_DIR_INDEX = 2\nDATA_FILEPATH_INDEX = 11\n\ndef read_input_file(filename):\n '''\n Reads AZURE2 input file (.azr file) – purely for convenience.\n Takes a filename (str).\n Returns a list of strings.\n '''\n with open(filename, 'r') as f:\n contents = f.read().split('\\n')\n return contents\n\n\ndef read_level_contents(infile):\n '''\n Reads rows between <levels> and </levels>.\n '''\n contents = read_input_file(infile)\n start = contents.index('<levels>')+1\n stop = contents.index('</levels>')\n return contents[start:stop]\n\n\ndef read_levels(infile):\n '''\n Packages the contents of the input file (infile, str) into instances of\n Level.\n Takes an input filename (str).\n Returns a list of Level instances.\n '''\n level_contents = read_level_contents(infile)\n\n levels = []\n sublevels = []\n for row in level_contents:\n if row != '':\n row = row.split()\n spin = float(row[J_INDEX])\n parity = int(row[PI_INDEX])\n energy = float(row[ENERGY_INDEX])\n energy_fixed = int(row[ENERGY_FIXED_INDEX])\n width = float(row[WIDTH_INDEX])\n width_fixed = int(int(row[WIDTH_FIXED_INDEX]) or width == 0)\n radius = float(row[CHANNEL_RADIUS_INDEX])\n channel = int(row[CHANNEL_INDEX])\n separation_energy = float(row[SEPARATION_ENERGY_INDEX])\n sublevels.append(Level(spin, parity, energy, energy_fixed, width,\n width_fixed, radius, channel,\n separation_energy))\n else:\n levels.append(sublevels)\n sublevels = []\n\n return levels\n\n\nLETTERS = string.ascii_lowercase\nNUMBERS = ''.join(map(str, range(10)))\nCHARACTERS = LETTERS+NUMBERS\n\n\ndef random_string(length=8):\n return ''.join(random.choice(CHARACTERS) for i in range(length))\n\n\ndef random_output_dir_filename():\n s = 'mcazure_' + random_string()\n output_dir = 'output_' + s\n os.mkdir(output_dir)\n input_filename = s + '.azr'\n return input_filename, output_dir\n\n\ndef random_workspace(prepend=''):\n s = 'mcazure_' + random_string()\n output_dir = prepend + 'output_' + s\n data_dir = prepend + 'data_' + s\n os.mkdir(output_dir)\n os.mkdir(data_dir)\n input_filename = prepend + s + '.azr'\n return input_filename, output_dir, data_dir\n\n\ndef update_segmentsData_dir(contents0, data_dir):\n contents = contents0.copy()\n start = contents0.index('<segmentsData>')+1\n stop = contents0.index('</segmentsData>')\n\n for i in range(start, stop):\n row = contents[i].split()\n row[11] = row[11].replace('data', data_dir)\n contents[i] = ' '.join(row)\n \n return contents\n\n\ndef write_input_file(old_input_file_contents, new_levels, input_filename,\n output_dir, data_dir=None):\n '''\n Takes:\n * contents of an old .azr file (see read_input_file function)\n * list of new Levels\n Does:\n * replaces the level parameters of the old .azr files with the\n parameters of the new levels\n * generates a random filename\n * writes the new level parameters (along with everything else in the\n old .azr file) to the random filename\n * returns random filename\n '''\n start = old_input_file_contents.index('<levels>')+1\n stop = old_input_file_contents.index('</levels>')\n old_levels = old_input_file_contents[start:stop]\n nlines = len(old_levels)\n level_indices = [i for (i, line) in enumerate(old_levels) if line != '']\n nlevels = len(level_indices)\n blank_indices = [i for i in range(nlines) if i not in level_indices]\n assert (nlevels == len(new_levels)), '''\nThe number of levels passed in does not match the number of existing levels.'''\n\n # Replace the old level parameters with the new parameters.\n new_level_data = []\n j = 0\n for i in range(nlines):\n if i in blank_indices:\n new_level_data.append('')\n else:\n level = new_levels[j]\n nlevel = old_levels[i].split()\n nlevel[J_INDEX] = str(level.spin)\n nlevel[PI_INDEX] = str(level.parity)\n nlevel[ENERGY_INDEX] = str(level.energy)\n nlevel[WIDTH_INDEX] = str(level.width)\n nlevel[CHANNEL_RADIUS_INDEX] = str(level.channel_radius)\n new_level_data.append(str.join(' ', nlevel))\n j += 1\n\n # If the data directory is specified, then we'll update it.\n if data_dir is not None:\n old_input_file_contents = update_segmentsData_dir(old_input_file_contents, data_dir)\n\n # Write the new parameters to the same input file.\n with open(input_filename, 'w') as f:\n f.write(old_input_file_contents[0]+'\\n')\n f.write(old_input_file_contents[1]+'\\n')\n f.write(output_dir+'/\\n')\n for row in old_input_file_contents[OUTPUT_DIR_INDEX+1:start]:\n f.write(row+'\\n')\n for row in new_level_data:\n f.write(row+'\\n')\n f.write('</levels>\\n')\n for row in old_input_file_contents[stop+1:]:\n f.write(row+'\\n')\n\n\ndef read_rwas_alt(output_dir):\n with open(output_dir + '/parameters.out', 'r') as f:\n pars = f.read().split('\\n')\n rwas = []\n for row in pars:\n if row.find('g_int') >= 0:\n elements = row.split()\n ii = elements.index('g_int')\n rwas.append(float(elements[ii+2]))\n return rwas\n\n\ndef read_rwas_jpi(output_dir):\n with open(output_dir + '/parameters.out', 'r') as f:\n pars = f.read().split('\\n')\n rwas = []\n for row in pars:\n if row.find('J =') == 0:\n Jpi = row.split()[2]\n if row.find('g_int') >= 0:\n elements = row.split()\n ii = elements.index('g_int')\n channel = int(elements[2])\n rwas.append([Jpi, channel, float(elements[ii+2])])\n return rwas\n\n\ndef read_ext_capture_file(filename):\n ext_capture_data = []\n with open(filename, 'r') as f:\n for line in f:\n i = line.find('(')\n j = line.find(',')\n k = line.find(')')\n x = float(line[i+1:j])\n y = float(line[j+1:k])\n ext_capture_data.append([x, y])\n return np.array(ext_capture_data)\n\n\ndef write_ext_capture_file(filename, data):\n '''\n data is expected to be 2-column matrix\n '''\n with open(filename, 'w') as f:\n for row in data:\n x, y = row\n f.write(f'({x:.5e},{y:.5e})\\n')\n \n \ndef run_AZURE2(input_filename, choice=1, use_brune=False, ext_par_file='\\n',\n ext_capture_file='\\n', use_gsl=False, command='AZURE2'):\n cl_args = [command, input_filename, '--no-gui', '--no-readline']\n if use_brune:\n cl_args += ['--use-brune']\n if use_gsl:\n cl_args += ['--gsl-coul']\n p = Popen(cl_args, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n options = str(choice) + '\\n' + ext_par_file + ext_capture_file\n response = p.communicate(options.encode('utf-8'))\n return (response[0].decode('utf-8'), response[1].decode('utf-8'))\n"
},
{
"alpha_fraction": 0.5864285826683044,
"alphanum_fraction": 0.5908928513526917,
"avg_line_length": 31.183908462524414,
"blob_id": "0255dfcf5616bff5773661974ffd8ce7792a7e4c",
"content_id": "635aeb2e33a0296c7212fa45d651b62bc5172c07",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5600,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 174,
"path": "/data.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nClasses to hold Data segments as found in .azr files.\n'''\n\nimport numpy as np\nimport utility\nfrom parameter import NormFactor\n\nINCLUDE_INDEX = 0\nIN_CHANNEL_INDEX = 1\nOUT_CHANNEL_INDEX = 2\nNORM_FACTOR_INDEX = 8\nVARY_NORM_FACTOR_INDEX = 9\nFILEPATH_INDEX = 11\n\nclass Segment:\n '''\n Structure to organize the information contained in a line in the\n <segmentsData> section of an AZURE2 input file.\n '''\n def __init__(self, row, index):\n self.row = row.split()\n self.include = (int(self.row[INCLUDE_INDEX]) == 1)\n self.in_channel = int(self.row[IN_CHANNEL_INDEX])\n self.out_channel = int(self.row[OUT_CHANNEL_INDEX])\n self.norm_factor = float(self.row[NORM_FACTOR_INDEX])\n self.vary_norm_factor = int(self.row[VARY_NORM_FACTOR_INDEX])\n self.index = index\n\n self.filepath = self.row[FILEPATH_INDEX]\n i = self.filepath.find('/')\n self.filename = self.filepath[i+1:]\n\n if self.vary_norm_factor:\n self.nf = NormFactor(self.index)\n else:\n self.nf = None\n \n self.values_original = np.loadtxt(self.filepath)\n self.values = np.copy(self.values_original)\n self.n = self.values.shape[0]\n\n if self.out_channel != -1:\n self.output_filename = f'AZUREOut_aa={self.in_channel}_R={self.out_channel}.out'\n else:\n self.output_filename = f'AZUREOut_aa={self.in_channel}_TOTAL_CAPTURE.out'\n\n \n def string(self):\n '''\n Returns a string of the text in the segment line.\n '''\n row = self.row.copy()\n # Are these lines...\n row[INCLUDE_INDEX] = '1' if self.include else '0'\n row[IN_CHANNEL_INDEX] = str(self.in_channel)\n row[OUT_CHANNEL_INDEX] = str(self.out_channel)\n row[FILEPATH_INDEX] = str(self.filepath)\n row[NORM_FACTOR_INDEX] = str(self.norm_factor)\n # necessary?\n \n return ' '.join(row)\n\n\n def update_dir(self, new_dir, values=None):\n '''\n Updates the path directory of the segment.\n If modifications are made to the data, the modified data is written to\n an ephemeral directory so that multiple processes can do so\n simultaneously.\n '''\n filepath = new_dir + '/' + self.filename\n if values is not None:\n np.savetxt(filepath, values)\n else:\n np.savetxt(filepath, self.values)\n\n\n def shift_energies(self, shift):\n values = np.copy(self.values_original)\n values[:, 0] += shift\n return values\n\n\nclass Data:\n '''\n Structure to hold all of the data segments in a provided AZURE2 input file.\n '''\n def __init__(self, filename):\n self.contents = utility.read_input_file(filename)\n i = self.contents.index('<segmentsData>')+1\n j = self.contents.index('</segmentsData>')\n\n # All segments listed in the file.\n self.all_segments = []\n k = 0\n for row in self.contents[i:j]:\n if row != '':\n self.all_segments.append(Segment(row, k))\n k += 1\n\n # All segments included in the calculation.\n self.segments = []\n for seg in self.all_segments:\n if seg.include:\n self.segments.append(seg)\n\n # Indices of segments with varied normalization constants.\n self.norm_segment_indices = []\n for (i, seg) in enumerate(self.all_segments):\n if seg.include and seg.vary_norm_factor:\n self.norm_segment_indices.append(i)\n\n # Number of data points for each included segment.\n self.ns = [seg.n for seg in self.segments] \n\n # Output files that need to be read.\n self.output_files = []\n for seg in self.segments:\n self.output_files.append(seg.output_filename)\n # Eliminates repeated output files AND SORTS them:\n # (1, 2, 3, ..., TOTAL_CAPTURE)\n self.output_files = list(np.unique(self.output_files))\n\n\n def update_all_dir(self, new_dir, contents):\n '''\n Updates all the path directories of the segments.\n '''\n start = contents.index('<segmentsData>')+1\n stop = contents.index('</segmentsData>')\n\n new_contents = contents.copy()\n\n for i in range(start, stop):\n row = contents[i].split()\n old_path = row[FILEPATH_INDEX]\n j = old_path.find('/') + 1\n row[FILEPATH_INDEX] = new_dir + '/' + old_path[j:]\n new_contents[i] = ' '.join(row)\n \n for seg in self.all_segments:\n seg.update_dir(new_dir)\n\n return new_contents\n\n\n\n def write_segments(self, contents):\n '''\n Writes the segments to contents.\n \"contents\" is a representation of the .azr file (list of strings)\n This is typically done in preparation for writing a new .azr file.\n '''\n start = contents.index('<segmentsData>')+1\n stop = contents.index('</segmentsData>')\n\n for (i, segment) in zip(range(start, stop), self.all_segments):\n contents[i] = segment.string()\n\n return contents\n\n\n def update_norm_factors(self, theta_norm, contents):\n assert len(theta_norm) == len(self.norm_segment_indices), '''\nNumber of normalization factors does not match the number of data segments\nindicating the normalization factor should be varied.\n'''\n for (f, i) in zip(theta_norm, self.norm_segment_indices):\n self.all_segments[i].norm_factor = f\n\n self.write_segments(contents)\n \n return contents\n"
},
{
"alpha_fraction": 0.5746714472770691,
"alphanum_fraction": 0.5782556533813477,
"avg_line_length": 30.58490562438965,
"blob_id": "1a94bd29c3587e02adbf17741aa802684b6c31ce",
"content_id": "8503fd8c940a7dbdd457933adb6ec9cb84d91c37",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3348,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 106,
"path": "/nodata.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nClasses to hold Test segments as found in AZURE2 input files.\n'''\n\nimport numpy as np\nimport utility\n\nINCLUDE_INDEX = 0\nIN_CHANNEL_INDEX = 1\nOUT_CHANNEL_INDEX = 2\n\nclass TestSegment:\n '''\n Contains a single row within the <segmentsTest> section of a AZURE2 input\n file.\n '''\n def __init__(self, row):\n self.row = row.split()\n self.include = (int(self.row[INCLUDE_INDEX]) == 1)\n self.in_channel = int(self.row[IN_CHANNEL_INDEX])\n self.out_channel = int(self.row[OUT_CHANNEL_INDEX])\n if self.out_channel != -1:\n self.output_filename = f'AZUREOut_aa={self.in_channel}_R={self.out_channel}.extrap'\n else:\n self.output_filename = f'AZUREOut_aa={self.in_channel}_TOTAL_CAPTURE.extrap'\n\n\n def string(self):\n '''\n Returns a string of the text in the segment line.\n '''\n row = self.row.copy()\n row[INCLUDE_INDEX] = '1' if self.include else '0'\n row[IN_CHANNEL_INDEX] = str(self.in_channel)\n \n return ' '.join(row)\n\n\nclass Test:\n '''\n Structure to hold all of the test segments in a provided AZURE2 input file.\n '''\n def __init__(self, filename, contents=None):\n '''\n Takes:\n * filename : input filename (.azr)\n * contents : list of strings (generated from the input file)\n '''\n # If contents is provided, don't try to read the input file.\n if contents is not None:\n self.contents = contents.copy()\n else:\n self.contents = utility.read_input_file(filename)\n\n i = self.contents.index('<segmentsTest>')+1\n j = self.contents.index('</segmentsTest>')\n\n self.all_segments = [] # all segments in the .azr file\n for row in self.contents[i:j]:\n if row != '':\n self.all_segments.append(TestSegment(row))\n\n self.segments = [] # only the segments to be included in the calculation\n for seg in self.all_segments:\n if seg.include:\n self.segments.append(seg)\n \n self.output_files = []\n for seg in self.segments:\n self.output_files.append(seg.output_filename)\n self.output_files = list(np.unique(self.output_files))\n\n\n def write_segments(self, contents):\n '''\n Writes the segments to contents.\n \"contents\" is a representation of the .azr file (list of strings)\n This is typically done in preparation for writing a new .azr file.\n '''\n start = contents.index('<segmentsTest>')+1\n stop = contents.index('</segmentsTest>')\n\n for (i, segment) in zip(range(start, stop), self.all_segments):\n contents[i] = segment.string()\n\n return contents\n\n \n def get_output_files(self):\n segments = [] # only the segments to be included in the calculation\n for seg in self.all_segments:\n if seg.include:\n segments.append(seg)\n \n output_files = []\n for seg in segments:\n output_files.append(seg.output_filename)\n\n return list(np.unique(output_files))\n\n\n def show_test_segments(self):\n print('index | test segment')\n print('--------------------')\n for (i, seg) in enumerate(self.all_segments):\n print(i,'|', seg.string())\n"
},
{
"alpha_fraction": 0.5431222915649414,
"alphanum_fraction": 0.5480349063873291,
"avg_line_length": 34.92156982421875,
"blob_id": "02bca0e71a4b28099d0e8d4e23f16555b1863edb",
"content_id": "906a3d21c4283b50ce182a8d7e847d4822039808",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1832,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 51,
"path": "/parameter.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "class Parameter:\n '''\n Defines a sampled (or \"free\") parameter by spin, parity, channel,\n rank, and whether it's an energy or width (kind).\n kind : \"energy\" or \"width\"\n \"width\" can be the partial width or ANC (depending on how it was\n set up in AZURE2)\n channel : channel pair (defined in AZURE2; consistent with AZURE2,\n these are one-based)\n rank : Which spin^{parity} level is this? (There are frequently\n more than one. Consistent with AZURE2, these are \n one-based.)\n '''\n def __init__(self, spin, parity, kind, channel, rank=1, is_anc=False):\n self.spin = spin\n self.parity = parity\n self.kind = kind\n self.channel = int(channel)\n self.rank = rank\n \n jpi_label = '+' if self.parity == 1 else '-'\n subscript = f'{rank:d},{channel:d}'\n superscript = f'({jpi_label:s}{spin:.1f})'\n if self.kind == 'energy':\n self.label = r'$E_{%s}^{%s}$' % (subscript, superscript)\n elif self.kind == 'width':\n if is_anc:\n self.label = r'$C_{%s}^{%s}$' % (subscript, superscript)\n else:\n self.label = r'$\\Gamma_{%s}^{%s}$' % (subscript, superscript)\n else:\n print('\"kind\" attribute must be either \"energy\" or \"width\"')\n\n\n def string(self):\n parity = '+' if self.parity == 1 else '-'\n return f'{self.spin}{parity} {self.kind} (number {self.rank}) in \\\nparticle pair {self.channel}, {self.label}'\n\n\n def print(self):\n print(self.string())\n\n\nclass NormFactor:\n '''\n Defines a sampled normalization factor (n_i in the AZURE2 manual).\n '''\n def __init__(self, dataset_index):\n self.index = dataset_index\n self.label = r'$n_{%d}$' % (self.index)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6818181872367859,
"avg_line_length": 15.5,
"blob_id": "3ef73bb53e10748749109a9e2d79f004930c4303",
"content_id": "2de9dca83d7c840d54ea61ad1271f6c43d85a412",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 8,
"path": "/test/check.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append('/home/odell/pyazr')\nfrom azr import AZR\n\nazr = AZR('12C+p.azr')\n\nfor p in azr.parameters:\n p.print()\n"
},
{
"alpha_fraction": 0.7465465664863586,
"alphanum_fraction": 0.7549549341201782,
"avg_line_length": 21.200000762939453,
"blob_id": "adaefcb643ed90d8cf6d5f45b2d9aeb3b44e08f3",
"content_id": "590e3eb9d396f7360951bda774cfb30fe908cac5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1665,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 75,
"path": "/README.md",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "# pyazr\n\npyazr is a Python module that serves as an interface to AZURE2.\n\nIt _accompanies_ AZURE2. The primary goal is to provide an accessible means of\nrunning AZURE2 with a set of R-matrix parameters and reading the output.\n\n## Requirements\n\n[AZURE2](https://azure.nd.edu) must be installed and available at the command\nline via `AZURE2`.\n\n[NumPy](https://numpy.org) and [Matplotlib](https://matplotlib.org/) must be\navailable in order to run the test script in `test` directory.\n\n## Overview\n\nThe classes defined in this module are:\n\n1. AZR\n2. Parameter\n3. Level\n4. Output\n5. Segment\n6. Data\n\n### AZR\n\nHandles communication with AZURE2 and its output.\n\n### Parameter\n\nDefines a sampled or \"free\" parameter.\n\n### Level\n\nDefines an R-matrix level (a line in the `<levels>` section of the .azr file).\n\n### Output\n\nData structure for accessing output data. (I got tired of consulting the\nextremely well-documented manual for the output file format.)\n\n### Segment\n\nData structure to organize the information contained in line of the\n`<segmentsData>` section of the .azr file.\n\n### Data\n\nData structure that holds a list of Segments and provides some convenient\nfunctions for applying actions to all of them.\n\n## Example\n\nIn the `test` directory there is a Python script (`test.py`) that predicts the\n12C(p,gamma) cross section and compares it to the Vogl data.\n\nNote that the script uses NumPy and Matplotlib.\n\n## Installation\n\nOnce the repository has been cloned in `location`, the user can simply modify\nthe path and `import` the relevant modules.\n\n```\nimport sys\nsys.path.append(location)\n\nimport azr\nimport parameter\nimport utility\nimport level\nimport output\n```\n"
},
{
"alpha_fraction": 0.6208270788192749,
"alphanum_fraction": 0.6552067995071411,
"avg_line_length": 25.407894134521484,
"blob_id": "fa34f3131f7ad389a89d580a8103c865cb6d5a4f",
"content_id": "2df759043f5317ba44a33bd82e2a6859e4be25c1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2007,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 76,
"path": "/test/test.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\n Calculates the 12C(p,gamma) cross section and compares it to the Vogl data.\n \"Free\" parameters:\n * ANC (1/2-)\n * level energy (1/2+)\n * partial width (1/2+, elastic)\n * partial width (1/2+, capture)\n'''\n\nimport os\nimport sys\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# Get the current path so we can import classes defined in the parent directory.\npwd = os.getcwd()\ni = pwd.find('/test')\n\n# Import pyazr classes.\nsys.path.append(pwd[:i])\nfrom azr import AZR\nfrom parameter import Parameter\n\nparameters = [\n Parameter(1/2, -1, 'width', 1),\n Parameter(1/2, 1, 'energy', 1),\n Parameter(1/2, 1, 'width', 1),\n Parameter(1/2, 1, 'width', 2)\n]\n\nnd = len(parameters) # number of parameters\n\nlabels = [\n r'$C_{1/2-}$',\n r'$E_{1/2+}$',\n r'$\\Gamma_{1/2+,p}$',\n r'$\\Gamma_{1/2+,\\gamma}$'\n]\n\n# We have to tell AZURE2 which output files it should look at.\n# (This could/should be inferred from the data segments in the .azr file.)\n# R=2 => particle pair 2\noutput_files = ['AZUREOut_aa=1_R=2.out']\n\nazr = AZR('12C+p.azr', parameters, output_files)\n\n# Pick a point (theta) in parameter space at which we can evaluate the capture cross\n# section.\ntheta = [2.1, 2.37, 33600, -0.6325]\n\n# Calculate the capture cross section at theta (using AZURE2).\noutput = azr.predict(theta)\n\n# output is a list of Output instances. They are ordered according to the\n# output_files list. \ncapture = output[0]\n\n# Plot the data.\nplt.errorbar(1000*capture.e_com, capture.xs_com_data, yerr=capture.xs_err_com_data,\n linestyle='', label='Vogl')\n# Plot the prediction.\nplt.plot(1000*capture.e_com, capture.xs_com_fit, label=r'$Prediction$')\n\nplt.yscale('log')\nplt.xlabel(r'$E$ (keV, COM)')\nplt.ylabel(r'$\\sigma$ (b)')\nplt.legend()\n\n# Just for kicks let's compute the chi^2/nu.\nn = np.size(capture.e_com) # number of data points\nchisq = np.sum(((capture.xs_com_data - capture.xs_com_fit) /\n capture.xs_err_com_data)**2)\nprint(f'chi^2/nu = {chisq/(n-nd)}')\n\nplt.show()\n"
},
{
"alpha_fraction": 0.5993413925170898,
"alphanum_fraction": 0.6297109127044678,
"avg_line_length": 30.76744270324707,
"blob_id": "7c7e6b1c3cacae3df74beb8729654969dec8655a",
"content_id": "bcdfd5760703efa212f017a6075f5fc9cade6d10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2733,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 86,
"path": "/exam/extrapolate.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\nimport emcee\nimport corner\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport model\n\n########################################\n# 1. Read in test_mcmc.h5 and test and throw out bad walkers\n\nbackend = emcee.backends.HDFBackend('test_mcmc.h5')\n\nbackend.get_log_prob().shape\n\nns, nw, nd = backend.get_chain().shape\n\n# estimated (by eye) burn-in period\nnb = 100\n# ln(probability) = ln(posterior)\nlnp = backend.get_log_prob(discard=nb)\n# Get the indices of the walkers whose median ln(prob) is greater than 0.\nii = np.where(np.median(lnp, axis=0) > 0)[0]\n# How many walkers pass the criteria? And how many were there to start off with?\nprint(ii.size, nw)\n\ncut_chain = backend.get_chain(discard=nb)\n# Give me the walkers that meet the criteria specified.\n\nchain = cut_chain[:, ii, :].reshape(-1, len(model.labels)) #len(model.labels) is just a way to get the number of parameters\n\n########################################\n# 4. Extrapolate to low energy.\n\ndef extrapolate(theta):\n '''\n Runs AZURE2 with the single test segment in the input file. \n '''\n le_capture = model.azr.extrapolate(theta,\n extrap_files=['AZUREOut_aa=2_R=1.extrap'])[0]\n return le_capture[:,3]\n\n# Run the extrapolation for one point in the chain so we can easily read the\n# energy.\nle_capture = model.azr.extrapolate(chain[0], extrap_files=['AZUREOut_aa=2_R=1.extrap'])[0]\nenergy = le_capture[:,0]\n\nbucket = np.array([extrapolate(theta) for theta in chain])\n\n#----------------------------------------------\n#outputfile = open('bucket_contents.dat','w')\n#for stuff in bucket:\n# outputfile.write(str(stuff)+'\\n')\n#outputfile.close()\n#---------------------------------------------\n\nquant_16 = [0 for i in range(len(energy))]\nquant_50 = [0 for i in range(len(energy))]\nquant_84 = [0 for i in range(len(energy))]\nlower_range = [0 for i in range(len(energy))]\nupper_range = [0 for i in range(len(energy))]\nfig = {}\nax = {}\nquantOut = open('quantiles.dat','w')\nquantOut.write(f'Energy, Q16, Q50, Q84\\n')\nfor i in range(len(energy)):\n# print (bucket[:,i])\n quant_16[i] = np.quantile(bucket[:,i],0.16)\n quant_50[i] = np.quantile(bucket[:,i],0.5)\n quant_84[i] = np.quantile(bucket[:,i],0.84)\n\n lower_range[i] = quant_50[i] - 3*(quant_50[i]-quant_16[i])\n upper_range[i] = quant_50[i] + 3*(quant_84[i]-quant_50[i])\n\n# print(f'Quantiles: {quant_16[i]}, {quant_50[i]}, {quant_84[i]}\\n')\n quantOut.write(f'{energy[i]}, {quant_16[i]}, {quant_50[i]}, {quant_84[i]}\\n')\n\n fig, ax = plt.subplots()\n fig.patch.set_facecolor('white')\n ax.hist(bucket[:,i],bins=100,range=(lower_range[i], upper_range[i]))\n plt.title(f'E = {energy[i]}')\n plt.savefig(f'plots/sigma_hist_{energy[i]:.2e}.pdf')\n plt.close()\nquantOut.close()\n\n"
},
{
"alpha_fraction": 0.6405767202377319,
"alphanum_fraction": 0.6740473508834839,
"avg_line_length": 33.07017517089844,
"blob_id": "3f5e3c98cd5d4ec4fc7763a52556a84114c9979a",
"content_id": "b0f6587efbd582849b410c5eceab8affefd1f425",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1942,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 57,
"path": "/test/test_mcmc.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\n Calculates the 12C(p,gamma) cross section and compares it to the Vogl data.\n \"Free\" parameters:\n * ANC (1/2-)\n * level energy (1/2+)\n * partial width (1/2+, elastic)\n * partial width (1/2+, capture)\n'''\n\nimport os\nimport sys\nfrom multiprocessing import Pool\n\nimport emcee\nimport numpy as np\nfrom scipy import stats\n\nimport model\n\n########################################\n# We'll set up the sampler and get it started.\n\nnd = model.azr.config.nd\nnw = 2*nd # number of walkers = 2 * number of sampled parameters\n\n# Pick a point (theta) in parameter space around which we'll start each walker.\ntheta0 = [2.1, 2.37, 33600, -0.6325]\n# theta0 = np.array(model.azr.config.get_input_values())\n# theta0 = np.array([[pi.rvs() for pi in model.priors] for _ in range(nw)])\n# Each walkers needs its own starting position. We'll take normally distributed\n# random values centered at theta0.\np0 = np.zeros((nw, nd))\n\nmask = np.array([0.01, 0.0001, 0.01, 0.01])\nfor i in range(nw):\n mu = theta0\n sig = np.abs(theta0) * mask # 1% width\n p0[i, :] = stats.norm(mu, sig).rvs()\n\n# We'll store the chain in test_mcmc.h5. (See emcee Backends documentation.)\nbackend = emcee.backends.HDFBackend('test_mcmc.h5')\nbackend.reset(nw, nd)\n\nnsteps = 10 # How many steps should each walker take?\nnthin = 1 # How often should the walker save a step?\nnprocs = 4 # How many Python processes do you want to allocate?\n# AZURE2 and emcee are both parallelized. We'll restrict AZURE2 to 1 thread to\n# simplify things.\nos.environ['OMP_NUM_THREADS'] = '1'\n\n# emcee allows the user to specify the way the ensemble generates proposals.\nmoves = [(emcee.moves.DESnookerMove(), 0.8), (emcee.moves.DEMove(), 0.2)]\n\nwith Pool(processes=nprocs) as pool:\n sampler = emcee.EnsembleSampler(nw, nd, model.lnP, moves=moves, pool=pool,\n backend=backend)\n state = sampler.run_mcmc(p0, nsteps, thin_by=nthin, progress=True, tune=True)\n"
},
{
"alpha_fraction": 0.5862347483634949,
"alphanum_fraction": 0.5880793333053589,
"avg_line_length": 35.59915542602539,
"blob_id": "4cc301b89086ead3a217aec775a297d05e0088ac",
"content_id": "cf7e41371302bcfab0a989d695d07b98c24a5630",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8674,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 237,
"path": "/azr.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nDefines classes for interacting with AZURE2.\n'''\n\nimport os\nimport shutil\nimport numpy as np\nimport level\nimport utility\nfrom parameter import Parameter\nfrom output import Output\nfrom data import Data\nfrom nodata import Test\nfrom configuration import Config\n\nclass AZR:\n '''\n Object that manages the communication between Python and AZURE2.\n\n Attributes specified at instantiation:\n input_filename : .azr file\n parameters : list of Parameter instances (sampled parameters)\n output_filenames : Which output files (AZUREOut_*.out) are read?\n extrap_filenames : Which output files (AZUREOut_*.extrap) are read?\n\n Other attributes (given default values below):\n use_brune : Bool that indicates the use of the Brune\n parameterization.\n use_gsl : Bool that indicates the use of GSL Coulomb functions.\n ext_par_file : Filename where parameter values can be read.\n ext_capture_file : Filename where external capture integral results have\n been stored.\n command : Name of AZURE2 binary.\n '''\n def __init__(self, input_filename, parameters=None, output_filenames=None,\n extrap_filenames=None):\n # Give default values to attributes that are not specified at\n # instantiation. These values must be changed *after* instantiation.\n self.use_brune = True\n self.use_gsl = True\n self.ext_par_file = '\\n'\n self.ext_capture_file = '\\n'\n self.command = 'AZURE2'\n self.root_directory = ''\n \n self.config = Config(input_filename, parameters=parameters)\n\n '''\n If parameters are not specified, they are inferred from the input file.\n '''\n if parameters is None:\n self.parameters = self.config.parameters.copy()\n else:\n self.parameters = parameters.copy()\n\n '''\n If output files are not specified, they are inferred from the input file.\n '''\n if output_filenames is None:\n self.output_filenames = self.config.data.output_files\n else:\n self.output_filenames = output_filenames\n\n '''\n If extrapolation files are not specified, they are inferred from the input file.\n '''\n if extrap_filenames is None:\n self.extrap_filenames = self.config.test.output_files\n else:\n self.extrap_filenames = extrap_filenames\n\n\n def predict(self, theta, mod_data=None, dress_up=True, full_output=False):\n '''\n Takes:\n * a point in parameter space, theta.\n * dress_up : Use Output class.\n * full_output : Return reduced width amplitudes as well.\n * mod_data : Do any parametes in theta modify the original data?\n Does:\n * creates a random filename ([rand].azr)\n * creates a (similarly) random output directory (output_[rand]/)\n * writes the new Levels to a [rand].azr\n * writes output directory to [rand].azr\n * runs AZURE2 with [rand].azr\n * reads observable from output_[rand]/output_filename\n * deletes [rand].azr\n * deletes output_[rand]/\n * deletes data_[rand]/\n Returns:\n * predicted values and (optionally) reduced width amplitudes.\n '''\n\n workspace = self.config.generate_workspace(\n theta,\n prepend=self.root_directory,\n mod_data=mod_data\n )\n input_filename, output_dir, data_dir = workspace\n\n try:\n response = utility.run_AZURE2(input_filename, choice=1,\n use_brune=self.use_brune, ext_par_file=self.ext_par_file,\n ext_capture_file=self.ext_capture_file, use_gsl=self.use_gsl,\n command=self.command)\n except:\n shutil.rmtree(output_dir)\n shutil.rmtree(data_dir)\n os.remove(input_filename)\n print('AZURE2 did not execute properly.')\n raise\n\n try:\n if dress_up:\n output = [Output(output_dir + '/' + of) for of in\n self.output_filenames]\n else:\n output = [np.loadtxt(output_dir + '/' + of) for of in\n self.output_filenames]\n\n if full_output:\n output = (output, utility.read_rwas_jpi(output_dir))\n\n shutil.rmtree(output_dir)\n shutil.rmtree(data_dir)\n os.remove(input_filename)\n\n return output\n except:\n shutil.rmtree(output_dir)\n shutil.rmtree(data_dir)\n os.remove(input_filename)\n print('Output files were not properly read.')\n print('AZURE output:')\n print(response)\n raise\n\n\n def extrapolate(self, theta, segment_indices=None, use_brune=None,\n use_gsl=None, ext_capture_file='\\n'):\n '''\n See predict() documentation.\n '''\n workspace = self.config.generate_workspace_extrap(theta,\n segment_indices=segment_indices)\n input_filename, output_dir, output_files = workspace\n\n try:\n response = utility.run_AZURE2(input_filename, choice=3,\n use_brune=use_brune if use_brune is not None else self.use_brune,\n use_gsl=use_gsl if use_gsl is not None else self.use_gsl,\n ext_par_file=self.ext_par_file,\n ext_capture_file=ext_capture_file,\n command=self.command)\n except:\n shutil.rmtree(output_dir)\n os.remove(input_filename)\n print('AZURE2 did not execute properly.')\n raise\n\n try:\n output = [np.loadtxt(output_dir + '/' + of) for of in output_files]\n shutil.rmtree(output_dir)\n os.remove(input_filename)\n return output\n except:\n shutil.rmtree(output_dir)\n os.remove(input_filename)\n print('Output files could not be read.')\n raise\n\n\n def rwas(self, theta):\n '''\n Returns the reduced width amplitudes (rwas) and their corresponding J^pi\n at the point in parameter space, theta.\n '''\n input_filename, output_dir = utility.random_output_dir_filename()\n new_levels = self.config.generate_levels(theta)\n utility.write_input_file(self.config.input_file_contents, new_levels,\n input_filename, output_dir)\n response = utility.run_AZURE2(input_filename, choice=1,\n use_brune=self.use_brune, ext_par_file=self.ext_par_file,\n ext_capture_file=self.ext_capture_file, use_gsl=self.use_gsl,\n command=self.command)\n\n rwas = utility.read_rwas_jpi(output_dir)\n\n shutil.rmtree(output_dir)\n os.remove(input_filename)\n\n return rwas\n\n \n def ext_capture_integrals(self, use_gsl=False, mod_data=False):\n '''\n Returns the AZURE2 output of external capture integrals.\n '''\n input_filename, output_dir, data_dir = utility.random_workspace()\n\n if mod_data:\n self.config.update_data_directories(data_dir)\n\n new_levels = self.config.initial_levels.copy()\n new_levels = [l for sl in new_levels for l in sl]\n utility.write_input_file(self.config.input_file_contents, new_levels,\n input_filename, output_dir)\n response = utility.run_AZURE2(input_filename, choice=1,\n use_brune=self.use_brune, ext_par_file=self.ext_par_file,\n ext_capture_file='\\n', use_gsl=use_gsl,\n command=self.command)\n\n ec = utility.read_ext_capture_file(output_dir + '/intEC.dat')\n\n shutil.rmtree(output_dir)\n shutil.rmtree(data_dir)\n os.remove(input_filename)\n\n return ec\n\n \n def update_ext_capture_integrals(self, segment_indices, shifts, use_gsl=False):\n '''\n Takes:\n * a list of indices to identification which data segment is being\n shifted\n * a list of shifts to be applied (in the same order as the indices are\n provided)\n * Adjusts the energies of data segments (identified by index) by the\n provided shifts (MeV, lab).\n * Evaluates the external capture (EC) integrals.\n * Returns the values from the EC file.\n '''\n for (i, shift) in zip(segment_indices, shifts):\n self.config.data.segments[i].shift_energies(shift)\n\n return self.ext_capture_integrals(use_gsl=use_gsl, mod_data=True)\n"
},
{
"alpha_fraction": 0.6496428847312927,
"alphanum_fraction": 0.6650000214576721,
"avg_line_length": 28.16666603088379,
"blob_id": "bd5abf54dcc31d7d4852595d70ed12a9bca92aa6",
"content_id": "a3dc9ded7f761edeed550a9a2f7c001761e8001d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2800,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 96,
"path": "/test/analyze_mcmc.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nAnalyzes output of test_mcmc.py.\n1. Read in test_mcmc.h5.\n2. Produce a corner plot.\n3. Produce a band (or \"brush\") of curves to show the uncertainty in the capture\ncross section.\n4. Extrapolate to low energy.\n\nThe default parameters of test_mcmc.py will not produce a converged run, so\nthese plots will not look very good. The user will undoubtedly need to run\nlonger.\n'''\n\nimport os\nimport sys\n\nimport emcee\nimport corner\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport model\n\nos.environ['OMP_NUM_THREADS'] = '4'\n\n########################################\n# 1. Read in test_mcmc.h5.\n\nbackend = emcee.backends.HDFBackend('test_mcmc.h5')\nchain = backend.get_chain(flat=True)\n\n########################################\n# 2. Produce a corner plot.\n\nfig = corner.corner(chain, labels=model.labels, quantiles=[0.16, 0.5, 0.84],\n show_titles=True)\nfig.patch.set_facecolor('white')\nplt.savefig('corner.pdf')\n\n########################################\n# 3. Produce a band (or \"brush\") of curves to show the uncertainty.\n\ndef mu(theta):\n '''\n Compute the AZURE2 prediction at theta and applies the normalization factor.\n '''\n f = theta[-1] # normalization factor (applied to theory prediction)\n mu = model.azr.predict(theta[:model.nrpar]) # AZR object only wants R-matrix parameters\n capture = mu[0].xs_com_fit\n return f*capture\n\n# Run an evaluation just to read the energies.\noutput = model.azr.predict(chain[0])[0]\nenergies = output.e_com\nvogl = output.xs_com_data\nvogl_err = output.xs_err_com_data\n\n# The default parameters of test_mcmc.py produce a short chain. When analyzing a\n# longer run, one may want to do the evaluation on a subset of the chain.\nbrush = np.array([mu(theta) for theta in chain])\n\nfig, ax = plt.subplots()\nfig.patch.set_facecolor('white')\n\nfor stroke in brush:\n ax.plot(energies, stroke, color='C0', alpha=0.1)\n\nax.errorbar(energies, vogl, yerr=vogl_err, linestyle='', capsize=2, color='C1')\nax.set_xlabel(r'$E$ (MeV, COM)')\nax.set_ylabel(r'$\\sigma$ (b)')\nax.set_yscale('log')\nplt.savefig('brush.pdf')\n\n########################################\n# 4. Extrapolate to low energy.\n\ndef extrapolate(theta):\n '''\n Runs AZURE2 with the single test segment in the input file. \n Returns the cross section at 0.1 MeV (lab).\n '''\n le_capture = model.azr.extrapolate(theta,\n extrap_files=['AZUREOut_aa=1_R=1.extrap'])[0]\n return le_capture[3]\n\n# Run the extrapolation for one point in the chain so we can easily read the\n# energy.\nle_capture = model.azr.extrapolate(chain[0], extrap_files=['AZUREOut_aa=1_R=1.extrap'])[0]\nenergy = le_capture[0]\n\nbucket = np.array([extrapolate(theta) for theta in chain])\n\nfig, ax = plt.subplots()\nfig.patch.set_facecolor('white')\nax.hist(bucket)\nplt.savefig(f'sigma_{energy:.2f}_hist.pdf')\n"
},
{
"alpha_fraction": 0.4643397331237793,
"alphanum_fraction": 0.5395504832267761,
"avg_line_length": 31.46666717529297,
"blob_id": "f7715effe71cec17eba6cb12a1d236fa36e74d68",
"content_id": "5bc110d289750199723838b43a2ae7bd894dae12",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9254,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 285,
"path": "/exam/model.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\nDefines the Bayesian model we will use to analyze the Vogl data.\n'''\n\nimport sys\nimport os\n\nimport numpy as np\nfrom scipy import stats\n\n# Get the current path so we can import classes defined in the parent directory.\npwd = os.getcwd()\ni = pwd.find('/exam')\n# Import pyazr classes.\nsys.path.append(pwd[:i])\nfrom azr import AZR\nfrom parameter import Parameter\n########################################\n# Set up AZR object and data.\n\nparameters = [\n Parameter(1/2, -1, 'width', 1, 1),\n Parameter(1/2, 1, 'energy', 1, 1),\n Parameter(1/2, 1, 'width', 1, 1),\n Parameter(1/2, 1, 'width', 2, 1),\n Parameter(3/2, -1, 'energy', 1, 1),\n Parameter(3/2, -1, 'width', 1, 1),\n Parameter(3/2, -1, 'width', 2, 1),\n Parameter(5/2, 1, 'energy', 1, 1),\n Parameter(5/2, 1, 'width', 1, 1)\n]\n\n# The number of parameters = number of R-matrix parameters + 3 normalization\n# factors.\nnrpar = len(parameters)\nnd = nrpar + 30\n\nlabels = [\n r'$ANC_{1/2-,p}$',\n r'$E_{1/2+}$',\n r'$\\Gamma_{1/2+,p}$',\n r'$\\Gamma_{1/2+,\\gamma}$',\n r'$E_{3/2-}$',\n r'$\\Gamma_{3/2-,p}$',\n r'$\\Gamma_{3/2-,\\gamma}$',\n r'$E_{5/2+}$',\n r'$\\Gamma_{5/2+,p}$',\n r'$n_{Ketner}$',\n r'$n_{Ket1}$',\n r'$n_{Ket2}$',\n r'$n_{Ket3}$',\n r'$n_{Ket4}$',\n r'$n_{Ket5}$',\n r'$n_{Ket6}$',\n r'$n_{Ket7}$',\n r'$n_{Ket8}$',\n r'$n_{Ket9}$',\n r'$n_{Ket10}$',\n r'$n_{Ket11}$',\n r'$n_{Ket12}$',\n r'$n_{Ket13}$',\n r'$n_{Burt}$',\n r'$n_{Burt1}$', \n r'$n_{Burt2}$',\n r'$n_{Burt3}$',\n r'$n_{Burt4}$',\n r'$n_{Burt5}$',\n r'$n_{Burt6}$',\n r'$n_{Burt7}$',\n r'$n_{Vogl}$',\n r'$n_{Rolfs}$',\n r'$n_{Young1}$', \n r'$n_{Young2}$',\n r'$n_{Young3}$',\n r'$n_{Young4}$',\n r'$n_{Young5}$',\n r'$n_{Meyer}$'\n]\n\n# We have to tell AZURE2 which output files it should look at.\n# (This could/should be inferred from the data segments in the .azr file.)\n# R=2 => particle pair 2\noutput_files = ['AZUREOut_aa=1_R=1.out', \n 'AZUREOut_aa=1_R=2.out']\n\nECintfile = ['intEC.dat']\n\n# We have all of the information we need to instantiate our AZR object.\nazr = AZR('12C+p.azr', parameters, output_files, ECintfile)\n\n# We'll read the data from the output file since it's already in the\n# center-of-mass frame.\nscat_data = np.loadtxt('output/' + output_files[0])\ncapt_data = np.loadtxt('output/' + output_files[1])\n\nx_scat = scat_data[:, 0] # energies\ny_scat = scat_data[:, 5] # cross sections\ndy_scat = scat_data[:, 6] # cross section uncertainties\n\nx_capt = capt_data[:, 0] # energies\ny_capt = capt_data[:, 5] # cross sections\ndy_capt = capt_data[:, 6] # cross section uncertainties\n\nx = np.concatenate((x_scat,x_capt))\ny = np.concatenate((y_scat,y_capt))\ndy = np.concatenate((dy_scat,dy_capt))\n\n\n########################################\n# Next, let's set up the Bayesian calculation. Recall:\n# * lnP \\propto lnL + lnPi\n# where\n# * P = posterior\n# * L = likelihood\n# * Pi = prior\n\n# We'll work from right to left.\n# First, we need prior disributions for each sampled parameters.\npriors = [\n stats.uniform(0,5),\n stats.uniform(2.36, 0.02),\n stats.uniform(20000, 40000),\n stats.uniform(-2, 2),\n stats.uniform(3.49, 0.02),\n stats.uniform(40000, 40000),\n stats.uniform(-2, 2),\n stats.uniform(3.53, 0.03),\n stats.uniform(20000, 40000),\n stats.norm(1, 0.08),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.norm(1, 0.1),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.norm(1, 0.1),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.uniform(0.1, 2),\n stats.norm(1, 0.05)\n]\n\ndef lnPi(theta):\n return np.sum([pi.logpdf(t) for (pi, t) in zip(priors, theta)])\n\n\n# To calculate the likelihood, we generate the prediction at theta and compare\n# it to data. (Assumes data uncertainties are Gaussian and IID.)\ndef lnL(theta):\n f1 = theta[-30] # normalization factor (applied to theory prediction)\n f2 = theta[-29]\n f3 = theta[-28]\n f4 = theta[-27]\n f5 = theta[-26]\n f6 = theta[-25]\n f7 = theta[-24]\n f8 = theta[-23]\n f9 = theta[-22]\n f10 = theta[-21]\n f11 = theta[-20]\n f12 = theta[-19]\n f13 = theta[-18]\n f14 = theta[-17]\n f15 = theta[-16]\n f16 = theta[-15]\n f17 = theta[-14]\n f18 = theta[-13]\n f19 = theta[-12]\n f20 = theta[-11]\n f21 = theta[-10]\n f22 = theta[-9]\n f23 = theta[-8]\n f24 = theta[-7]\n f25 = theta[-6]\n f26 = theta[-5]\n f27 = theta[-4]\n f28 = theta[-3]\n f29 = theta[-2]\n f30 = theta[-1]\n\n mu = azr.predict(theta[:nrpar]) # AZR object only wants R-matrix parameters\n \n output_scat = mu[0]\n output_capt = mu[1]\n \n cross_sections_scat = output_scat.xs_com_fit\n cross_sections_capt = output_capt.xs_com_fit \n\n cross_sections_1 = cross_sections_scat\n cross_sections_2 = cross_sections_capt[:118]\n cross_sections_3 = cross_sections_capt[118:125]\n cross_sections_4 = cross_sections_capt[125:129]\n cross_sections_5 = cross_sections_capt[129:140]\n cross_sections_6 = cross_sections_capt[140:144]\n cross_sections_7 = cross_sections_capt[144:155]\n cross_sections_8 = cross_sections_capt[155:159]\n cross_sections_9 = cross_sections_capt[159:171]\n cross_sections_10 = cross_sections_capt[171:175]\n cross_sections_11 = cross_sections_capt[175:179]\n cross_sections_12 = cross_sections_capt[179:182]\n cross_sections_13 = cross_sections_capt[182:186]\n cross_sections_14 = cross_sections_capt[186:190]\n cross_sections_15 = cross_sections_capt[190:194]\n cross_sections_16 = cross_sections_capt[194:201]\n cross_sections_17 = cross_sections_capt[201:205]\n cross_sections_18 = cross_sections_capt[205:209]\n cross_sections_19 = cross_sections_capt[209:212]\n cross_sections_20 = cross_sections_capt[212:215]\n cross_sections_21 = cross_sections_capt[215:218]\n cross_sections_22 = cross_sections_capt[218:222]\n cross_sections_23 = cross_sections_capt[222:226]\n cross_sections_24 = cross_sections_capt[226:306]\n cross_sections_25 = cross_sections_capt[306:468]\n cross_sections_26 = cross_sections_capt[468:474]\n cross_sections_27 = cross_sections_capt[474:480]\n cross_sections_28 = cross_sections_capt[480:488]\n cross_sections_29 = cross_sections_capt[488:494]\n cross_sections_30 = cross_sections_capt[494:]\n\n \n# cross_sections_3 = cross_sections[52:]\n# cross_sections_4 = cross_sections[99:]\n\n# print(f'{cross_sections_1}, {cross_sections_2}\\n')\n\n normalized_prediction = np.hstack((f1*cross_sections_1, \n f2*cross_sections_2,\n f3*cross_sections_3,\n f4*cross_sections_4,\n f5*cross_sections_5,\n f6*cross_sections_6,\n f7*cross_sections_7,\n f8*cross_sections_8,\n f9*cross_sections_9,\n f10*cross_sections_10,\n f11*cross_sections_11,\n f12*cross_sections_12,\n f13*cross_sections_13,\n f14*cross_sections_14,\n f15*cross_sections_15,\n f16*cross_sections_16,\n f17*cross_sections_17,\n f18*cross_sections_18,\n f19*cross_sections_19,\n f20*cross_sections_20,\n f21*cross_sections_21,\n f22*cross_sections_22,\n f23*cross_sections_23,\n f24*cross_sections_24,\n f25*cross_sections_25,\n f26*cross_sections_26,\n f27*cross_sections_27,\n f28*cross_sections_28,\n f29*cross_sections_29,\n f30*cross_sections_30))\n\n return np.sum(-np.log(np.sqrt(2*np.pi)*dy) - 0.5*((y - normalized_prediction)/dy)**2)\n\n\ndef lnP(theta):\n lnpi = lnPi(theta)\n # If any of the parameters fall outside of their prior distributions, go\n # ahead and return lnPi = -infty. Don't bother running AZURE2 or risking\n # calling it with a parameter value that will throw an error.\n if lnpi == -np.inf:\n return lnpi\n return lnL(theta) + lnpi\n\n"
},
{
"alpha_fraction": 0.601571261882782,
"alphanum_fraction": 0.662177324295044,
"avg_line_length": 33.269229888916016,
"blob_id": "4cd4914558cc06daa9a140b43400da7255fcca6c",
"content_id": "047a54b42de14b71ab0ea40349265e16014ece76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1782,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 52,
"path": "/exam/test_mcmc.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "'''\n Calculates the 13C(a,n) cross section\n \"Free\" parameters:\n * partial width BGP (1/2+, neutron) \n * level energy (3/2+)\n * partial width (3/2+, neutron)\n * partial width (3/2+, alpha)\n'''\n\nimport os\nimport sys\nfrom multiprocessing import Pool\n\nimport emcee\nimport numpy as np\nfrom scipy import stats\n\nimport model\n\n########################################\n# We'll set up the sampler and get it started.\n\nnw = 4*model.nd # number of walkers = 4 * number of sampled parameters\n\n# Pick a point (theta) in parameter space around which we'll start each walker.\ntheta0 = [1.87, 2.3689, 35000, -0.61, 3.5002, 57500, -0.67, 3.5451, 45200,\n 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]\n# Each walkers needs its own starting position.\np0 = np.zeros((nw, model.nd))\nfor i in range(nw):\n mu = theta0\n sig = np.abs(theta0) * 0.01\n p0[i, :] = stats.norm(mu, sig).rvs()\n\n# We'll store the chain in test_mcmc.h5. (See emcee Backends documentation.)\nbackend = emcee.backends.HDFBackend('test_mcmc.h5')\nbackend.reset(nw, model.nd)\n\nnsteps = 1000 # How many steps should each walker take?\nnthin = 10 # How often should the walker save a step?\nnprocs = 4 # How many Python processes do you want to allocate?\n# AZURE2 and emcee are both parallelized. We'll restrict AZURE2 to 1 thread to\n# simplify things.\nos.environ['OMP_NUM_THREADS'] = '1'\n\n# emcee allows the user to specify the way the ensemble generates proposals.\nmoves = [(emcee.moves.DESnookerMove(), 0.8), (emcee.moves.DEMove(), 0.2)]\n\nwith Pool(processes=nprocs) as pool:\n sampler = emcee.EnsembleSampler(nw, model.nd, model.lnP, moves=moves, pool=pool,\n backend=backend)\n state = sampler.run_mcmc(p0, nsteps, thin_by=nthin, progress=True, tune=True)\n"
},
{
"alpha_fraction": 0.6102021336555481,
"alphanum_fraction": 0.6140519976615906,
"avg_line_length": 36.10714340209961,
"blob_id": "a0f4f733cf6c68f1e39ff3740bef1efab7627085",
"content_id": "b73291f4e75adb67b54e30eb5949248f63b01a5f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1039,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 28,
"path": "/level.py",
"repo_name": "odell/pyazr",
"src_encoding": "UTF-8",
"text": "class Level:\n '''\n Simple data structure for storing the spin (total J), parity (+/-1),\n energy (MeV, excitation), and width (eV) of a level used in an AZURE2\n calculation.\n\n channel : channel pair (defined in AZURE2)\n radius : channel radius\n index : Which spin^{parity} level is this? (There are frequently more than\n one. Consistent with the language, these are zero-based.)\n '''\n def __init__(self, spin, parity, energy, energy_fixed, width, width_fixed,\n radius, channel, separation_energy):\n self.spin = spin\n self.parity = parity\n self.energy = energy\n self.energy_fixed = energy_fixed\n self.width = width\n self.width_fixed = width_fixed\n self.channel_radius = radius\n self.channel = channel\n self.separation_energy = separation_energy\n\n\n def describe(self):\n sign = '+' if self.parity > 0 else '-'\n print(f'{self.spin}{sign} | \\\n{self.energy} MeV | {self.width} eV | channel {self.channel}')\n"
}
] | 17 |
datafibers/space-shuttle-demo | https://github.com/datafibers/space-shuttle-demo | c6e2150e9ac99e2a48cfd397623c9dc18ac34970 | 011e60051611a7426a1c2a2de06f83f9305e5b86 | 6166afddeeaf89ec4ac4ce25ed1f460d1910209e | refs/heads/master | 2020-11-30T16:22:16.238306 | 2016-06-30T14:42:41 | 2016-06-30T14:57:11 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.43878236413002014,
"alphanum_fraction": 0.44668683409690857,
"avg_line_length": 33.569766998291016,
"blob_id": "0fb1d178ebef22e4724392c3e9ed960859bfb9cc",
"content_id": "c129c199106bfe6599093c310c3ce337bc719ad7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5946,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 172,
"path": "/src/main/resources/static/js/samples-controller.js",
"repo_name": "datafibers/space-shuttle-demo",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright (c) 2015 Intel Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n(function(){\n var COLOR_NORMAL = '#0062a8',\n COLOR_ACTIVE = '#FF0000';\n\n App.controller('SamplesPopupController', ['$scope', 'ngDialog', '$q', '$http', 'appConfig', '$filter',\n function($scope, ngDialog, $q, $http, appConfig, $filter) {\n\n var charts = {};\n\n $scope.dataLoaded = false;\n\n $scope.selectSample = function (sample) {\n $scope.selectedSample = sample;\n highlightHistograms();\n };\n\n $scope.getCategory = function(id) {\n return appConfig.categories[id - 1];\n };\n\n $q.all([\n fetchSamples($scope.ngDialogData.item),\n fetchHistograms()\n ])\n .then(function(values) {\n $scope.samples = values[0];\n var histograms = values[1];\n\n charts = _.mapObject(histograms, function(v, k) {\n return drawHistogram(k, v);\n });\n\n $scope.dataLoaded = true;\n $scope.dataLoaded = true;\n\n });\n\n function highlightHistograms() {\n $scope.selectedSample.features.map(function(v, k){\n var featureChart = charts[k+1];\n var bucket = Math.floor((v + 1) * 5);\n _.each(featureChart.dataProvider, function(b){\n b.color = COLOR_NORMAL;\n });\n featureChart.dataProvider[bucket].color = COLOR_ACTIVE;\n featureChart.validateData();\n });\n }\n\n\n function drawHistogram(id, data) {\n\n var sum = _.reduce(_.pluck(data, 'value'), function(memo, num) {\n return memo + num;\n }, 0);\n\n var chart = AmCharts.makeChart(\"histogram-\" + id, {\n \"type\": \"serial\",\n \"theme\": \"black\",\n \"dataProvider\": data,\n \"startDuration\": 1,\n \"marginTop\": 0,\n \"marginRight\": 0,\n \"marginLeft\": 0,\n \"marginBottom\": 0,\n \"autoMargins\": false,\n \"graphs\": [ {\n title: \"Feature #\" + id,\n \"fillAlphas\": 0.8,\n \"lineAlpha\": 0.2,\n \"type\": \"column\",\n \"valueField\": \"value\",\n colorField: 'color',\n balloonFunction: function(arg) {\n var category = parseFloat(arg.category);\n var percent = $filter('number')(arg.values.value * 100 / sum, 1) + '%';\n var bucketEnd = $filter('number')(category + appConfig.bucketSize, 1);\n return '<b>[' + category + ', ' + bucketEnd + ']</b>: ' + percent;\n },\n } ],\n \"categoryField\": \"range\",\n categoryAxis: {\n labelsEnabled: false\n },\n valueAxes: [{\n axisAlpha: 0\n }],\n colors: [\n COLOR_NORMAL\n ]\n });\n\n return chart;\n }\n\n function fetchSamples(item) {\n var timestamp = new Date(item.timestamp).getTime();\n var deferred = $q.defer();\n\n $http.get(appConfig.restBase + 'samples', {\n params: {\n intervalStart: timestamp,\n intervalLength: appConfig.groupby\n }\n })\n .success(function onSuccess(data) {\n var samples = _.mapObject(data, function(v, k) {\n return {\n time: k,\n class: v[1],\n features: v.slice(2)\n };\n });\n samples = _.groupBy(_.sortBy(_.sortBy(samples, 'time'), 'class'), 'class');\n\n deferred.resolve(samples);\n })\n .error(function onError() {\n deferred.reject();\n });\n return deferred.promise;\n }\n\n function fetchHistograms() {\n var deferred = $q.defer();\n\n $http.get(appConfig.restBase + 'histogram')\n .success(function onSuccess(data) {\n var histograms = _.mapObject(data, function(v) {\n // fill missing values with 0\n return _.sortBy(_.mapObject(_.extend(getEmptyHistogram(), v), function(v, k){\n return {\n range: Number(k),\n value: v\n };\n }), 'range');\n });\n\n deferred.resolve(histograms);\n })\n .error(function onError() {\n deferred.reject();\n });\n return deferred.promise;\n }\n\n function getEmptyHistogram() {\n var bucketsCount = 10;\n return _.object(Array.apply(null, {length: bucketsCount})\n .map(Number.call, Number)\n .map(function(v){\n return [((v*2 - bucketsCount) / bucketsCount).toFixed(1), 0];\n }));\n }\n\n }]);\n})();\n"
},
{
"alpha_fraction": 0.5908662676811218,
"alphanum_fraction": 0.5974576473236084,
"avg_line_length": 23.136363983154297,
"blob_id": "4f309ca5f263246d79a160d57022b6a14e5fbdae",
"content_id": "5215f7ac0916d318d67fee319717853a42ca61cb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2124,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 88,
"path": "/src/main/client/client.py",
"repo_name": "datafibers/space-shuttle-demo",
"src_encoding": "UTF-8",
"text": "#\n# Copyright (c) 2015 Intel Corporation\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport websocket\nimport thread\nimport time\nimport sys\nimport os\nimport ssl\n\n\ndef on_message(ws, message):\n print \"### message ###\"\n print message\n\n\ndef on_error(ws, error):\n print \"### error ###\"\n print error\n\n\ndef on_close(ws):\n print \"### closed ###\"\n\n\ndef on_open(ws):\n print \"### open ###\"\n\n def run():\n print \"### send data ####\"\n sendData(ws)\n ws.close()\n print \"thread terminating...\"\n\n thread.start_new_thread(run, ())\n\n\ndef sendData(ws):\n with open(sys.argv[2], \"r\") as data:\n for line in data:\n print \"send: \" + line\n ws.send(\"[\" + line + \"]\")\n time.sleep(0.1)\n\n\ndef get_proxy(http_proxy):\n if not http_proxy:\n return (None, None)\n\n id = http_proxy.find('://')\n if id != -1:\n http_proxy = http_proxy[id + 3:]\n return http_proxy.split(\":\")\n\n\nif __name__ == \"__main__\":\n\n http_host, http_port = get_proxy(os.getenv(\"http_proxy\"))\n\n uri = sys.argv[1]\n\n websocket.enableTrace(True)\n ws = websocket.WebSocketApp(uri,\n on_message=on_message,\n on_error=on_error,\n on_close=on_close)\n ws.on_open = on_open\n\n sslopt = {\"cert_reqs\": ssl.CERT_NONE, \"check_hostname\": False}\n\n if http_host:\n ws.run_forever(http_proxy_host=http_host, http_proxy_port=http_port, sslopt=sslopt)\n else:\n sslopt = {\"cert_reqs\": ssl.CERT_NONE, \"check_hostname\": False}\n ws.run_forever(sslopt=sslopt)\n"
}
] | 2 |
akashgiri/medusa | https://github.com/akashgiri/medusa | e1513c16492b652b14b26ec8b3e78bf239f72198 | fe0082f26ce3cd4405f221f64e33cef858a039a2 | 4d68de2cf83f7191f206f1be55ed60745c1a5125 | refs/heads/master | 2021-01-22T14:38:52.049501 | 2014-02-26T05:58:52 | 2014-02-26T05:58:52 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6105859875679016,
"alphanum_fraction": 0.6143667101860046,
"avg_line_length": 19.384614944458008,
"blob_id": "8de1383599e4d3491325c9994527580e21e09e7f",
"content_id": "b9384f935afcce2bdcb5feddd89453198df6231c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 26,
"path": "/Makefile",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "bin=bin\ninc=inc\nsrc=src\ncflags=-O3 -Wall\nlflags=-lssl -lcrypto -lsqlite3\nCC=gcc\n\nmedusa: main.o cache.o transformer.o exec.o\n\t$(CC) -o $(bin)/medusa main.o cache.o transformer.o exec.o $(cflags) $(lflags)\n\ncache.o: $(src)/cache.c\n\t$(CC) -c $(src)/cache.c -I$(inc) $(cflags)\n\ntransformer.o: $(src)/transformer.c\n\t$(CC) -c $(src)/transformer.c -I$(inc) $(cflags)\n\nexec.o: $(src)/exec.c\n $(CC) -c $(src)/exec.c -I$(inc) $(cflags)\n\nmain.o: $(src)/main.c\n\t$(CC) -c $(src)/main.c -I$(inc) $(cflags)\n\n.PHONY: clean\n\nclean:\n\trm -f *.o"
},
{
"alpha_fraction": 0.719197690486908,
"alphanum_fraction": 0.7220630645751953,
"avg_line_length": 18.44444465637207,
"blob_id": "b30f697483e67485001f17ac0821deac008a3639",
"content_id": "3a6134492e10d33fd2fc1fab3b03093f38e71532",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 18,
"path": "/inc/cache.h",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "#ifndef CACHE_H\n#define CACHE_H\n\n#include <globals.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n#include <sqlite3.h>\n#include <openssl/sha.h>\n\nvoid makeDiffIndex();\nchar* hashFile(char* path);\nint tryInsert(char* fileName, char* hash);\nint changed(char* fileName, char* hash);\nint cached(char* fileName);\n\n#endif"
},
{
"alpha_fraction": 0.5615589022636414,
"alphanum_fraction": 0.5969884991645813,
"avg_line_length": 24.382022857666016,
"blob_id": "6a4c0ec133b8275c156b254279f1d120c1cff82e",
"content_id": "511c1e74d3a4367d30e8d703453394efbdb5d26c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2258,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 89,
"path": "/src/cache.c",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "#include <cache.h>\n\nsqlite3 *handle;\nchar hexString[128];\n\nvoid makeDiffIndex() {\n char query[125] = \"CREATE TABLE DiffIndex(InFile VARCHAR(256) PRIMARY KEY, ContentHash VARCHAR(128), OutFile VARCHAR(256))\";\n\n sqlite3_open(\"DiffIndex\", &handle);\n sqlite3_exec(handle, query, 0, 0, 0);\n}\n\nchar* hashFile(char* path) {\n int i, bytes;\n FILE *inFile = fopen(path, \"rb\");\n SHA512_CTX context;\n unsigned char digest[SHA512_DIGEST_LENGTH + 1], buffer[BUFSIZ];\n char *bufPtr;\n\n SHA512_Init(&context);\n while ((bytes = fread (buffer, 1, BUFSIZ, inFile)) != 0)\n SHA512_Update(&context, buffer, bytes);\n SHA512_Final(digest, &context);\n\n bufPtr = hexString;\n for (i = 0; i < SHA512_DIGEST_LENGTH; i++)\n bufPtr += sprintf(bufPtr, \"%02X\", digest[i]);\n *(bufPtr + 1) = 0;\n\n fclose (inFile);\n return hexString;\n}\n\nint tryInsert(char* fileName, char* hash) {\n char *query = (char *) malloc(strlen(fileName) + strlen(hash) + 41);\n int ret;\n\n sprintf(query, \"INSERT INTO DiffIndex VALUES('%s', '%s', '')\", fileName, hash);\n ret = sqlite3_exec(handle, query, 0, 0, 0);\n\n free(query);\n return ret;\n}\n\nint changed(char* fileName, char* hash) {\n char *query = (char *) malloc(strlen(fileName) + 50);\n sqlite3_stmt *stmt;\n\n sprintf(query, \"SELECT ContentHash FROM DiffIndex WHERE InFile='%s'\", fileName);\n sqlite3_prepare_v2(handle, query, -1, &stmt, 0);\n\n sqlite3_step(stmt);\n char *value = (char*) sqlite3_column_text(stmt, 0);\n free(query);\n\n if (strcmp(value, hash) != 0) {\n query = (char *) malloc(strlen(fileName) + strlen(hash) + 52);\n sprintf(query, \"UPDATE DiffIndex SET ContentHash='%s' WHERE InFile='%s'\", hash, fileName);\n sqlite3_exec(handle, query, 0, 0, 0);\n free(query);\n\n return 1;\n }\n return 0;\n}\n\nint cached(char* fileName) {\n char *hash;\n\n if (access(\"DiffIndex\", 0) == -1)\n makeDiffIndex();\n else\n sqlite3_open(\"DiffIndex\", &handle);\n\n hash = hashFile(fileName);\n\n if (tryInsert(fileName, hash)) {\n if (changed(fileName, hash))\n return 0;\n else\n return 1;\n\n sqlite3_close(handle);\n }\n else\n return 0;\n\n sqlite3_close(handle);\n}"
},
{
"alpha_fraction": 0.7538461685180664,
"alphanum_fraction": 0.7538461685180664,
"avg_line_length": 10,
"blob_id": "9fe0b23abb145405a465be143fc8f5abb1185aa3",
"content_id": "8afb213b13632202ecee68a42e41cc9ab5304d89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 6,
"path": "/inc/globals.h",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "#ifndef GLOBALS_H\n#define GLOBALS_H\n\nextern char* buffer;\n\n#endif"
},
{
"alpha_fraction": 0.5140674114227295,
"alphanum_fraction": 0.5169039964675903,
"avg_line_length": 25.950077056884766,
"blob_id": "873d9a373d8aae9401c53011630a5cc9b67ad139",
"content_id": "f485fd04be17228fdb806054e3133314267b76a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17274,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 641,
"path": "/bin/transform.py",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "\"\"\" Fast Python Transform by heisenberg, apoorv, akashgiri \"\"\"\n\nimport ast, _ast, sys, re\n\ndartImports = []\ndartLocalVars = []\ndartClassVars = []\ndartGlobalVars = []\n\npyGlobalVars = []\npyClasses = []\npyInbuilts = [\"abs\", \"all\", \"any\", \"bin\", \"input\", \"len\", \"open\", \"range\", \"raw_input\", \"str\", \"xrange\"]\n\nparsedClasses = []\nparsedFunctions = []\nparsedCode = []\n\nclassyMode = False\nfunMode = False\nbroken = False\nformats = False\nfromTest = False\nparsedType = \"\"\n\nexceptions = dict()\nexceptions['Exception'] = \"Exception\"\nexceptions['IOError'] = \"FileSystemException\"\nexceptions['ZeroDivisionError'] = \"IntegerDivisionByZeroException\"\n\nclass PyParser(ast.NodeVisitor):\n def parse(self, code):\n tree = ast.parse(code)\n self.visit(tree)\n\n def escape(self, s):\n s = s.replace('\\\\', '\\\\\\\\')\n s = s.replace('\\n', r'\\n')\n s = s.replace('\\t', r'\\t')\n s = s.replace('\\r', r'\\r')\n s = s.replace('$', '\\$')\n\n return \"'\" + s + \"'\"\n\n def addImport(self, module):\n global dartImports\n\n if module not in dartImports:\n dartImports.append(module)\n\n def visit_Module(self, stmt_module):\n global parsedType, parsedClasses, parsedFunctions, parsedCode\n\n for node in stmt_module.body:\n parsed = self.visit(node)\n #print parsed\n if parsedType is \"class\":\n parsedClasses.append(parsed)\n elif parsedType is \"function\":\n parsedFunctions.append(parsed)\n elif parsedType is \"code\":\n parsedCode.append(parsed)\n else:\n print \"Not Implemented => \", type(node)\n\n def visit_UAdd(self, stmt_uadd):\n return \"+\"\n\n def visit_USub(self, stmt_usub):\n return \"-\"\n\n def visit_Invert(self, stmt_invert):\n return \"~\"\n\n def visit_Name(self, stmt_name):\n global parsedType\n\n name = stmt_name.id\n\n if name is \"False\" or name is \"True\":\n name = name.lower()\n elif name is \"self\":\n name = \"this\"\n elif name is \"None\":\n name = \"null\"\n\n parsedType = \"code\"\n return str(name)\n\n def visit_Num(self, stmt_num):\n return str(stmt_num.n)\n\n def visit_Str(self, stmt_str):\n self.addImport(\"lib/inbuilts.dart\")\n return \"new $PyString(\" + self.escape(stmt_str.s) + \")\"\n\n def visit_Add(self, stmt_add):\n return \"+\"\n\n def visit_Sub(self, stmt_sub):\n return \"-\"\n\n def visit_Mult(self, stmt_mult):\n return \"*\"\n\n def visit_Div(self, stmt_div):\n return \"~/\"\n\n def visit_Pow(self, stmt_pow):\n self.addImport('dart:math')\n return \",\"\n\n def visit_RShift(self, stmt_rshift):\n return \">>\"\n\n def visit_LShift(self, stmt_lshift):\n return \"<<\"\n\n def visit_BitAnd(self, stmt_bitand):\n return \"&\"\n\n def visit_BitXor(self, stmt_bitxor):\n return \"^\"\n\n def visit_BitOr(self, stmt_bitor):\n return \"|\"\n\n def visit_Mod(self, stmt_mod):\n return \"%\"\n\n def visit_Eq(self, stmt_eq):\n return \"==\"\n\n def visit_Gt(self, stmt_gt):\n return \">\"\n\n def visit_Lt(self, stmt_lt):\n return \"<\"\n\n def visit_GtE(self, stmt_gte):\n return \">=\"\n\n def visit_LtE(self, stmt_lte):\n return \"<=\"\n\n def visit_NotEq(self, stmt_neq):\n return \"!=\"\n\n def visit_And(self, stmt_and):\n return \"$and([\"\n\n def visit_Or(self, stmt_or):\n return \"$or([\"\n\n def visit_In(self, stmt_in):\n return \".contains\"\n\n\n\n def visit_IfExp(self, stmt_ternary):\n global parsedType\n\n stmt = self.visit(stmt_ternary.test) + \"?\" + self.visit(stmt_ternary.body) + \":\" + self.visit(stmt_ternary.orelse)\n\n parsedType = \"code\"\n return stmt\n\n def visit_UnaryOp(self, stmt_unop):\n global parsedType\n\n data = self.visit(stmt_unop.op) + self.visit(stmt_unop.operand)\n\n parsedType = \"code\"\n return data\n\n def visit_BinOp(self, stmt_binop):\n global parsedType\n\n left = self.visit(stmt_binop.left)\n op = self.visit(stmt_binop.op)\n right = self.visit(stmt_binop.right)\n exp = \"(\" + left + op + right + \")\"\n\n if op == \",\":\n exp = \"(pow\" + exp + \")\"\n\n parsedType = \"code\"\n return exp\n\n def visit_BoolOp(self, stmt_boolop):\n global parsedType\n\n self.addImport('lib/inbuilts.dart');\n code = self.visit(stmt_boolop.op)\n alen = len(stmt_boolop.values)\n i = 0\n while i < alen:\n code += self.visit(stmt_boolop.values[i])\n if i < alen - 1:\n code += \",\"\n i += 1\n\n code += \"])\"\n\n if fromTest:\n code = \"$checkValue(\" + code + \")\"\n\n parsedType = \"code\"\n return code\n\n def visit_List(self, stmt_list):\n global parsedType\n\n code = \"[\"\n\n alen = len(stmt_list.elts)\n i = 0\n while i < alen:\n code += self.visit(stmt_list.elts[i])\n if i < alen - 1:\n code += \",\"\n i += 1\n\n code += \"]\"\n\n parsedType = \"code\"\n return code\n\n def visit_Dict(self, stmt_dict):\n global parsedType\n\n keyLen = len(stmt_dict.keys)\n valueLen = len(stmt_dict.values)\n code = \"{\"\n\n if keyLen == valueLen:\n i = 0\n while i < keyLen:\n code += self.visit(stmt_dict.keys[i]) + \":\" + self.visit(stmt_dict.values[i])\n if i < keyLen - 1:\n code += \",\"\n i += 1\n code += \"}\"\n\n parsedType = \"code\"\n return code\n else:\n print \"Invalid Dictionary\"\n exit(1)\n\n def visit_Tuple(self, stmt_tuple):\n global parsedType\n\n self.addImport('lib/inbuilts.dart')\n\n code = \"tuple([\"\n i = 0\n alen = len(stmt_tuple.elts)\n while i < alen:\n code += self.visit(stmt_tuple.elts[i])\n\n if (i + 1) < alen:\n code += \",\"\n i += 1\n code += \"])\"\n\n parsedType = \"code\"\n return code\n\n def visit_Subscript(self, stmt_Subscript):\n if isinstance(stmt_Subscript.slice, _ast.Slice):\n self.addImport('lib/slice.dart')\n listVar = self.visit(stmt_Subscript.value)\n lower = self.subsituteVisit(stmt_Subscript.slice.lower)\n upper = self.subsituteVisit(stmt_Subscript.slice.upper)\n step = self.subsituteVisit(stmt_Subscript.slice.step)\n step = 1 if step is None or step == \"None\" else int(step)\n lower = (str(listVar) + \".length,\" if step < 0 else \"0,\") if lower is None else str(lower) + \",\"\n upper = (str(listVar) + \".length,\" if step > 0 else \"0,\") if upper is None else str(upper) + \",\"\n data = \"$slice(\" + str(listVar) + \",\" + str(lower) + str(upper) + str(step) + \")\"\n return data\n elif isinstance(stmt_Subscript.slice, _ast.Index):\n listVar = self.visit(stmt_Subscript.value)\n index = self.visit(stmt_Subscript.slice.value)\n index = (str(listVar) + \".length\" + str(index)) if int(index) < 0 else index\n index = \"[\" + str(index) + \"]\"\n data = str(listVar) + index\n return data\n else:\n print \"Unimplemented TYpe =>\", type(stmt_Subscript.slice)\n exit(1)\n\n def subsituteVisit(self, node):\n if node is not None:\n return self.visit(node)\n else:\n return None\n\n def visit_Compare(self, stmt_test):\n global parsedType\n\n stmt = self.visit(stmt_test.left) + self.visit(stmt_test.ops[0]) + self.visit(stmt_test.comparators[0])\n\n parsedType = \"code\"\n return stmt\n\n def visit_ClassDef(self, stmt_class):\n global parsedType, dartLocalVars, dartClassVars, classyMode\n\n if stmt_class.name not in pyClasses:\n pyClasses.append(stmt_class.name)\n\n code = \"class \" + stmt_class.name\n if len(stmt_class.bases) == 1:\n if stmt_class.bases[0].id == \"object\":\n base = \"Object\"\n else:\n base = str(stmt_class.bases[0].id)\n code += \" extends \" + base\n elif len(stmt_class.bases) > 1:\n print \"Multiple Inheritace is unsupported at the moment :( Sorry!\"\n exit(1)\n code += \"{\"\n\n classyMode = True\n for node in stmt_class.body:\n code += self.visit(node)\n code += \"}\"\n classyMode = False\n dartClassVars = []\n\n parsedType = \"class\"\n return code\n\n def visit_Global(self, stmt_global):\n global dartLocalVars\n\n for name in stmt_global.names:\n dartLocalVars.append(name)\n\n return \"\"\n\n def visit_FunctionDef(self, stmt_function):\n global dartLocalVars, funMode, parsedType\n\n body = \"\"\n code = \"\"\n defs = \"\"\n\n funMode = True\n for node in stmt_function.body:\n body += self.visit(node)\n funMode = False\n\n if len(dartLocalVars) > 0:\n defs = \"var \" + \",\".join(dartLocalVars) + \";\"\n\n if stmt_function.name == \"__init__\":\n code = pyClasses[-1] + \"(\" + code\n else:\n code = stmt_function.name + \"(\" + code\n\n i = 0\n alen = len(stmt_function.args.args)\n while i < alen:\n if str(stmt_function.args.args[i].id) == \"self\":\n i += 1\n continue\n\n code += stmt_function.args.args[i].id\n dartLocalVars.append(stmt_function.args.args[i].id)\n\n if (i + 1) < alen:\n code += \",\"\n i += 1\n code += \"){\" + defs + body + \"}\"\n\n dartLocalVars = []\n parsedType = \"function\"\n return code\n\n def visit_Call(self, stmt_call):\n global pyClasses, pyInbuilts, forceCall, parsedType, formats\n\n code = self.visit(stmt_call.func)\n keyDict = {}\n\n if code in pyInbuilts:\n self.addImport(\"lib/inbuilts.dart\")\n elif code in pyClasses:\n code = \"new \" + code\n\n alen = len(stmt_call.args)\n i = 0\n\n code += \"([\" if formats else \"(\"\n while i < alen:\n code += self.visit(stmt_call.args[i])\n\n if (i + 1) < alen:\n code += \",\"\n i += 1\n code += \"]\" if formats else \")\"\n\n for node in stmt_call.keywords:\n arg = node.arg\n value = self.visit(node.value)\n keyDict[arg] = value\n\n code += (\",\" + str(keyDict) + \")\") if formats else \"\"\n\n formats = False\n parsedType = \"code\"\n return code\n\n def visit_Expr(self, stmt_expr):\n global parsedType\n\n parsedType = \"code\"\n return self.visit(stmt_expr.value) + \";\"\n\n def visit_Return(self, stmt_return):\n global parsedType\n\n code = \"return \" + self.visit(stmt_return.value) + \";\"\n\n parsedType = \"code\"\n return code\n\n def visit_Print(self, stmt_print):\n global parsedType\n\n self.addImport(\"dart:io\")\n\n code = \"\"\n i = 0\n values = len(stmt_print.values)\n\n while (i < values):\n if (i + 1) < values:\n code += \"stdout.write(\"\n else:\n code += \"stdout.writeln(\"\n\n printee = self.visit(stmt_print.values[i])\n if printee is not None:\n code += printee\n code += \");\"\n\n if (i + 1) < values:\n code += \"stdout.write(' ');\"\n i += 1\n\n parsedType = \"code\"\n return code\n\n def visit_Assign(self, stmt_assign):\n global dartLocalVars, funMode, parsedType, pyGlobalVars, classyMode\n\n code = \"\"\n for target in stmt_assign.targets:\n if isinstance(target, _ast.Attribute):\n code += self.visit(target) + \"=\"\n else:\n if funMode and target.id not in dartLocalVars:\n dartLocalVars.append(target.id)\n elif classyMode and target.id not in dartClassVars:\n dartClassVars.append(target.id)\n code += \"var \"\n else:\n if target.id not in dartGlobalVars:\n dartGlobalVars.append(target.id)\n\n code += target.id + \"=\";\n code += self.visit(stmt_assign.value)\n code += \";\"\n\n parsedType = \"code\"\n return code\n\n def visit_AugAssign(self, stmt_aug_assign):\n global powFlag, parsedType\n\n left = self.visit(stmt_aug_assign.target)\n op = self.visit(stmt_aug_assign.op)\n right = self.visit(stmt_aug_assign.value)\n\n code = left\n if op == \",\":\n code += \"=pow(\" + left + op + right + \")\"\n else:\n code += op + \"=\" + right\n\n parsedType = \"code\"\n return code + \";\"\n\n def visit_Break(self, stmt_break):\n global broken\n\n return \"$broken=true;break;\" if broken else \"break;\"\n\n def visit_If(self, stmt_if):\n global parsedType, fromTest\n\n fromTest = True\n code = \"if(\" + self.visit(stmt_if.test) + \"){\"\n for node in stmt_if.body:\n code += self.visit(node)\n code += \"}\"\n\n if len(stmt_if.orelse) > 0:\n code += \"else{\"\n for node in stmt_if.orelse:\n code += self.visit(node)\n code += \"}\"\n\n fromTest = False\n parsedType = \"code\"\n return code\n\n def visit_While(self, stmt_while):\n global parsedType\n\n code = \"while(\" + self.visit(stmt_while.test) + \"){\"\n for node in stmt_while.body:\n code += self.visit(node)\n code += \"}\"\n\n code += \"if(!(\" + self.visit(stmt_while.test) + \")){\"\n for node in stmt_while.orelse:\n code += self.visit(node)\n code += \"}\"\n\n parsedType = \"code\"\n return code\n\n def visit_For(self, stmt_for):\n global broken, parsedType\n\n broken = True\n code = \"var $broken=false;for(var \" + stmt_for.target.id + \" in \" + self.visit(stmt_for.iter) + \"){\"\n for node in stmt_for.body:\n code += self.visit(node)\n code += \"}\"\n\n if len(stmt_for.orelse) > 0:\n code += \"if($broken==false){\"\n for node in stmt_for.orelse:\n code += self.visit(node)\n code += \"}\"\n broken = False\n\n parsedType = \"code\"\n return code\n\n def visit_Raise(self, stmt_raise):\n return \"throw \" + self.visit(stmt_raise.type) + \";\"\n\n def visit_TryExcept(self, stmt_tryexcept, final = False):\n global dartLocalVars, parsedType\n\n if not final:\n nodes = stmt_tryexcept\n else:\n nodes = stmt_tryexcept[0]\n\n code = \"var $tried=true;try{\"\n for node in nodes.body:\n code += self.visit(node)\n code += \"}\"\n\n for handler in nodes.handlers:\n try:\n code += \"on \" + exceptions[handler.type.id]\n if isinstance(handler.name, _ast.Name):\n code += \" catch(\" + handler.name.id + \")\"\n dartLocalVars.append(handler.name.id)\n\n code += \"{$tried=false;\"\n for node in handler.body:\n code += self.visit(node)\n code += \"}\"\n except KeyError:\n print \"Fatal Error: Exception handler not implemented for \" + handler.type.id\n exit(1)\n\n if not final and len(nodes.orelse) > 0:\n code += \"if($tried){\"\n for node in nodes.orelse:\n code += self.visit(node)\n code += \"}\"\n\n parsedType = \"code\"\n return code;\n\n def visit_TryFinally(self, stmt_tryfinally):\n global parsedType\n\n code = self.visit_TryExcept(stmt_tryfinally.body, True) + \"finally{\"\n for node in stmt_tryfinally.finalbody:\n code += self.visit(node)\n code += \"}\"\n\n if len(stmt_tryfinally.body[0].orelse) > 0:\n code += \"if($tried){\"\n for node in stmt_tryfinally.body[0].orelse:\n code += self.visit(node)\n code += \"}\"\n\n parsedType = \"code\"\n return code\n\n def visit_Attribute(self, stmt_attribute):\n global parsedType, formats\n\n value = self.visit(stmt_attribute.value)\n if isinstance(stmt_attribute.value, _ast.Str) and stmt_attribute.attr is \"format\":\n formats = True\n\n code = value + \".\" + stmt_attribute.attr\n parsedType = \"code\"\n return code\n\nPyParser().parse(open(sys.argv[1]).read())\n\nstitched = \"\"\nfor module in dartImports:\n stitched += \"import'\" + module + \"';\"\nif len(dartGlobalVars):\n stitched += \"var \" + \",\".join(dartGlobalVars) + \";\"\nfor parsedClass in parsedClasses:\n stitched += parsedClass\nfor parsedFunction in parsedFunctions:\n stitched += parsedFunction\nstitched += \"main(){\"\nfor code in parsedCode:\n stitched += code\nstitched += \"}\"\n\noutFile = open(\"out.dart\", 'w')\noutFile.write(stitched)\noutFile.close()"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 20,
"blob_id": "f1e4e1267eb46bec3332102e0dc01891597c0a4a",
"content_id": "3b705efc75e4b07954b1756884fb075bd285de65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 4,
"path": "/README.md",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "medusa\n======\n\nAn attempt at making Python stronger and faster like Medusa herself!\n"
},
{
"alpha_fraction": 0.7916666865348816,
"alphanum_fraction": 0.7916666865348816,
"avg_line_length": 24,
"blob_id": "1c1eec30997b3d3062579d30e36bc29876f8050a",
"content_id": "df7e9a440f35517b047c85834424321838ba7235",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/src/transformer.c",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "#include <transformer.h>"
},
{
"alpha_fraction": 0.511695921421051,
"alphanum_fraction": 0.5263158082962036,
"avg_line_length": 16.149999618530273,
"blob_id": "2bdda41a230ec7992a43075d0419a2a102c5c8cd",
"content_id": "66363fc867dccd878a6a38d7f2963010e58a5138",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 20,
"path": "/src/main.c",
"repo_name": "akashgiri/medusa",
"src_encoding": "UTF-8",
"text": "#include <globals.h>\n#include <stdio.h>\n#include <cache.h>\n\nchar* buffer;\n\nint main(int argc, char** argv) {\n if (argc != 2) {\n printf(\"Usage: %s <filename>\\n\", argv[0]);\n return 1;\n }\n\n if (cached(argv[1])) {\n printf(\"Cached, Skipping Compilation... :D\\n\");\n } else {\n }\n\n free(buffer);\n return 0;\n}"
}
] | 8 |
paleomedia/idleg_flask | https://github.com/paleomedia/idleg_flask | aae6056ba7125cadaf8b8ce6a8f4bbb7b3fed189 | 7764b25f14292b3839c9e1bb8228caf41a8767c6 | f146a29283fb444f599c4ebfe93f27b596254e1c | refs/heads/master | 2021-04-09T17:40:19.609211 | 2017-01-19T07:10:15 | 2017-01-19T07:10:15 | 44,326,719 | 5 | 1 | null | 2015-10-15T15:24:11 | 2015-12-14T02:32:13 | 2015-12-15T05:08:55 | JavaScript | [
{
"alpha_fraction": 0.5209471583366394,
"alphanum_fraction": 0.5233758091926575,
"avg_line_length": 35.61111068725586,
"blob_id": "156aa3cbfbcfe4f2b739db7c5e5760762ed17a3b",
"content_id": "d5597810b2433158810385c90e54cbb42024a5b0",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3294,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 90,
"path": "/php_archive/dash.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<div class=\"dashboard\">\n <div class=\"dashhead\" id=\"dashtop\">\n Legislative Dash\n </div>\n <div id=\"search\">\n <form>\n <input type=\"submit\" value=\"Go\">\n <div>\n <input type=\"search\" name=\"search\" placeholder=\"Search bills, legislators, etc....\" autocomplete=\"on\">\n </div>\n </form>\n </div> \n\n <div class=\"dashhead\" id=\"login\">Login</div>\n\n \t<?php if (isset($_SESSION[\"name\"])) { ?>\n \t\t <div class=\"loginbox\">\n \t\t <div class=\"dashitem\">\n \t\t\t<p>You are logged in as <?= $_SESSION[\"name\"] ?>.</p>\n \t\t</div>\n \t\t\t<form id=\"logout\" action=\"lib/logout.php\" method=\"post\">\n \t\t\t\t<input type=\"submit\" value=\"Log out\" />\n \t\t\t\t<input type=\"hidden\" name=\"logout\" value=\"true\" />\n \t\t\t</form>\n \t\t</div>\n \n <?php } elseif (isset($_SESSION[\"flash\"])) { #temp message across page redirects\n\t?>\n\t\t<script src=\"js/happy.js\"></script>\n\t\t<script src=\"js/loginval.js\"></script>\n\t\t<div class=\"dashitem\"><?= $_SESSION[\"flash\"] ?> </div>\n\t\t\t<div class=\"loginbox\">\n \t<form id=\"loginform\" action=\"lib/login.php\" method=\"POST\">\n \t\t<div class=\"loginbox\">\n \t\t<input type=\"text\" name=\"username\" id=\"username\" placeholder=\"Username\" tabindex=\"1\" />\n \t\t</div>\n \t\t\t<input type=\"submit\" value=\"Go\" tabindex=\"3\">\n \t\t<div>\n \t\t<input type=\"password\" name=\"password\" id=\"password\" placeholder=\"Password\" tabindex=\"2\">\n \t\t<label for=\"rememberme\">Remember me:</label> \n \t\t<input type=\"checkbox\" name=\"rememberme\" value=\"1\">\n \t\t</div>\n \t</form>\n <p span id=\"newuser\">or <a href=\"newaccount.php\">create new account</a>\n </p>\n </span>\n </div>\n\t\n\t<?php\n\t\tunset($_SESSION[\"flash\"]);\n\t} else { ?>\n <div class=\"loginbox\">\n \t<form id=\"loginform\" action=\"lib/login.php\" method=\"POST\">\n \t\t<div class=\"loginbox\">\n \t\t<input type=\"text\" name=\"username\" id=\"username\" placeholder=\"Username\" tabindex=\"1\" />\n \t\t</div>\n \t\t\t<input type=\"submit\" value=\"Go\" tabindex=\"3\">\n \t\t<div>\n \t\t<input type=\"password\" name=\"password\" id=\"password\" placeholder=\"Password\" tabindex=\"2\">\n \t\t</div>\n \t\t<label for=\"rememberme\">Remember me:</label> \n \t\t<input type=\"checkbox\" name=\"rememberme\" value=\"1\">\n \t</form>\n <p span id=\"newuser\">or <a href=\"newaccount.php\">create new account</a>\n </p>\n </span>\n </div>\n <?php } ?>\n \n <div class=\"dashhead\" id=\"bills\">Bills</div>\n <div class=\"dashitem\">LOGIN...to load your bills.</div>\n \n <div class=\"dashhead\" id=\"testimony\">Comments</div>\n <div class=\"dashitem\">\n \n <?php $dao = new Dao();\n $commentlist = $dao->getUserComments($_SESSION[\"name\"]);\n foreach ($commentlist as $comment) {\n echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\";\n } ?>\n \n </div>\n \n <div class=\"dashhead\" id=\"lawmakers\">Lawmakers</div>\n <div class=\"dashitem\">...to load your legislators.</div>\n <div class=\"dashhead\" id=\"topics\">Topics</div>\n <div class=\"dashitem\">...to load your topics.</div>\n\n </div>"
},
{
"alpha_fraction": 0.5958904027938843,
"alphanum_fraction": 0.5958904027938843,
"avg_line_length": 15.333333015441895,
"blob_id": "b2c16e0d751496e400b8676d904bb4668465fa89",
"content_id": "6aa31d9b65fe8133f781b68da9c3033e6d34951b",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 146,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 9,
"path": "/php_archive/topics.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n$thisPage=\"Topics\"; \ninclude 'top.php'; ?>\n\n<div class=\"maincontainer\">\n \n<?php include 'dash.php'; ?>\n \n<?php include 'footer.php'; ?>"
},
{
"alpha_fraction": 0.4646226465702057,
"alphanum_fraction": 0.4811320900917053,
"avg_line_length": 14.740740776062012,
"blob_id": "f29abafb0d79c3a742fae80ac8a2854ae360e225",
"content_id": "770f8fc238cf245bbb7dc57b72386a11d081b4ee",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 424,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 27,
"path": "/lib/sql_logins.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php \n\n// sql logins\n\n//cloud9 login\n\n $host = getenv('IP');\n $user = getenv('C9_USER');\n $password = \"\";\n $database = \"c9\";\n $dbport = 3306;\n \n//mac mini login\n\n $host = \"\";\n $user = \"\";\n $password = \"\";\n $database = \"idleg_test\";\n $dbport = \"\";\n\n// webdev login\n\n $host = \"localhost\";\n $user = \"nhoffman\";\n $password = \"Spring2015!\";\n $database = \"nhoffman\";\n $dbport = \"\";"
},
{
"alpha_fraction": 0.4979203939437866,
"alphanum_fraction": 0.5008912682533264,
"avg_line_length": 35.182796478271484,
"blob_id": "d4119dc7f27a5ecf7a9fc0233810b9dee9044f47",
"content_id": "a1ba3d7509c0dbc02598e025cd27315d94c1e67e",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3366,
"license_type": "permissive",
"max_line_length": 167,
"num_lines": 93,
"path": "/php_archive/index.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n$thisPage = 'Home'; \nrequire_once \"lib/classes/dao.php\";\ninclude 'lib/api_functions.php';\n\n $dao = new Dao();\n \ninclude 'top.php'; ?>\n\n <body>\n\n <div class=\"maincontainer\">\n \n<?php include 'dash.php'; ?>\n\n<div class=\"billmain\">\n \n <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.3/jquery.min.js\"></script>\n <script src=\"js/ajax.js\" type=\"text/javascript\"></script>\n \n Filter bills:\n <ul>\n <li>Most comments</li>\n <li>Recent bills</li>\n <li>Signed</li>\n </ul>\n \n <?php\n \n $bill_list = $dao->getBills();\n\n foreach ($bill_list as $bill) { \n $action_date = last_action($bill[\"bill_id\"]) ?>\n <div class=\"active\">\n <p>Active Bills</p>\n <div class=\"billimage\"><span><?php echo $bill[\"bill_name\"]; ?></span></div>\n <div class=\"lastaction\">Last Action: <?php echo $action_date; ?> </div>\n <div class=\"billsummary\"><?php echo $bill[\"title\"]; ?></div>\n \n <div class=\"comments\">\n <div class=\"commentbox\">\n <form name=\"commentForm\" action=\"lib/handler.php\" method=\"POST\">\n <textarea name=\"comment\" rows=\"4\" id=\"comment\" placeholder=\"Write comments or testimony here, select pro, neutral or anti, and press Submit.\"></textarea>\n <label>Yea, Nay or Neutral?</label>\n <label>\n <input type=\"radio\" name=\"vote\" value=\"pro\" id=\"pro\" /><img class=\"prolabel\" src=\"images/thumbs_up.png\" />\n </label>\n <label>\n <input type=\"radio\" name=\"vote\" value=\"anti\" id=\"anti\" /><img class=\"antilabel\" src=\"images/thumbs_down.png\" />\n </label>\n <label class=\"neutrallabel\">\n <input type=\"radio\" name=\"vote\" value=\"neutral\" id=\"neutral\" checked=\"checked\" />?</label>\n <input type=\"submit\" name=\"commentButton\" value=\"Submit\" />\n <input type=\"hidden\" name=\"form\" value=\"comment\" />\n <input type=\"hidden\" name=\"bill\" value=\"<?php echo $bill[\"bill_id\"]; ?>\" />\n </form>\n </div>\n \n <div class=\"pro\"><h3>Yea</h3>\n <?php $comments = $dao->getComments($bill[\"bill_id\"], \"pro\");\n foreach ($comments as $comment) { \n ?>\n <span><?php echo $comment[\"username\"]; ?> says:</span> <?php echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\"; ?> \n <?php } ?>\n </div> \n \n <div class=\"neutral\"><h3>Neutral</h3>\n <?php $comments = $dao->getComments($bill[\"bill_id\"], \"neutral\");\n foreach ($comments as $comment) { ?>\n <span><?php echo $comment[\"username\"]; ?> says:</span> <?php echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\"; ?>\n <?php } ?>\n </div>\n\n <div class=\"anti\"><h3>Nay</h3>\n <?php $comments = $dao->getComments($bill[\"bill_id\"], \"anti\");\n foreach ($comments as $comment) { ?>\n <span><?php echo $comment[\"username\"]; ?> says:</span> <?php echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\"; ?>\n <?php } ?>\n </div>\n </div>\n </div>\n \n <?php } ?>\n\n </div>\n</div>\n\n \n\n<?php include 'footer.php'; ?> "
},
{
"alpha_fraction": 0.6155258417129517,
"alphanum_fraction": 0.618935227394104,
"avg_line_length": 55.92537307739258,
"blob_id": "c014d3f57b98c562a35e6e877a87ebffc7fbaf00",
"content_id": "e21cec3751699b61e50bc67ffac8f229aa8b7d96",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3814,
"license_type": "permissive",
"max_line_length": 258,
"num_lines": 67,
"path": "/php_archive/newaccount.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php \n$thisPage=\"New_Account\"; \ninclude 'top.php'; ?>\n\n<div class=\"maincontainer\">\n \n<div class=\"dashboard\">\n <div class=\"dashhead\" id=\"dashtop\">\n Legislative Dash\n </div>\n \n\t<div class=\"dashhead\" id=\"login\">Create new account</div> \n\t\t<div class=\"loginbox\">\n \t<form action=\"lib/newuser.php\" method=\"POST\">\n \t\t<div class=\"loginbox\">\n \t\t<input type=\"text\" name=\"username\" id=\"username\" placeholder=\"Username\" /> \n \t\t<input type=\"email\" name=\"email\" id=\"email\" placeholder=\"Email\" /> \t\t\t\n \t\t<input type=\"password\" name=\"password\" id=\"password\" placeholder=\"Password\">\n \t\t<input type=\"password\" name=\"passconfirm\" id=\"passwordconfirm\" placeholder=\"Confirm password\">\n \t\t</div>\n \t\t<label for=\"rememberme\">Remember me:</label> \n \t\t<input type=\"checkbox\" name=\"rememberme\" value=\"1\">\n \t\t\t<input type=\"submit\" value=\"Go\">\n \t</form> \n\t\t</div>\n\t</div>\n \n <div class=\"billmain\">\n <div class=\"active\">\n <p>Most Active</p>\n <div class=\"billimage\"><span>S 1081</span></div>\n <div class=\"lastaction\">Passed Senate, 2/20/2015</div>\n <div class=\"billsummary\">Summary: HEALTH CARE - Amends existing law to provide reserves and surplus requirements of public postsecondary educational institutions with a public postsecondary educational institution plan for health care benefits.</div>\n <div class=\"comments\">\n <div class=\"commentbox\">\n <form>\n <textarea name=\"comment\" rows=\"4\" placeholder=\"Write comments or testimony here, select pro, neutral or anti, and press Go.\"></textarea>\n <label>Yea or Nay?</label>\n <label>\n <input type=\"radio\" name=\"vote\" value=\"pro\" /><img class=\"prolabel\" src=\"images/thumbs_up.png\" />\n </label>\n <label class=\"neutrallabel\">\n <input type=\"radio\" name=\"vote\" value=\"neutral\" />?</label>\n <label>\n <input type=\"radio\" name=\"vote\" value=\"anti\" /><img class=\"antilabel\" src=\"images/thumbs_down.png\" />\n </label>\n <input type=\"submit\" value=\"Go\" />\n </form>\n </div>\n <div class=\"pro\">\n <span>Conrad says:</span> Best bill ever ... Lorem ipsum dolor sit amet, nobis suavitate iracundia ei his, ad nihil eirmod quo, viris temporibus qui eu. Et idque omnes instructior usu, qui ut posse everti lobortis, id his deserunt assentior.\n Quo oratio senserit te, verterem constituto usu ut. Te pro aeque equidem maluisset, ponderum consetetur sea no. At volutpat torquatos adipiscing est, tempor temporibus in cum.\n </div>\n <div class=\"neutral\">\n <span>Sarah says:</span> Could go either way... Lorem ipsum dolor sit amet, nobis suavitate iracundia ei his, ad nihil eirmod quo, viris temporibus qui eu. Et idque omnes instructior usu, qui ut posse everti lobortis, id his deserunt assentior.\n Quo oratio senserit te, verterem constituto usu ut. Te pro aeque equidem maluisset, ponderum consetetur sea no. At volutpat torquatos adipiscing est, tempor temporibus in cum.\n </div>\n <div class=\"anti\">\n <span>José says:</span> Impeach! Impeach! Lorem ipsum dolor sit amet, nobis suavitate iracundia ei his, ad nihil eirmod quo, viris temporibus qui eu. Et idque omnes instructior usu, qui ut posse everti lobortis, id his deserunt assentior.\n Quo oratio senserit te, verterem constituto usu ut. Te pro aeque equidem maluisset, ponderum consetetur sea no. At volutpat torquatos adipiscing est, tempor temporibus in cum.\n </div>\n </div> \n </div>\n </div> \n</div>\n \n<?php include 'footer.php'; ?>"
},
{
"alpha_fraction": 0.6554757356643677,
"alphanum_fraction": 0.6709156036376953,
"avg_line_length": 34.42675018310547,
"blob_id": "d0a59190ecadfa5dd45d73799eb3e7bc6add2cc6",
"content_id": "68a1abdb0673b3d4a2051e06abe21597e0139f23",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5570,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 157,
"path": "/app/idleg/models.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "from werkzeug.security import generate_password_hash, check_password_hash\nfrom flask_wtf import Form\nfrom wtforms import TextField, PasswordField, TextAreaField, RadioField, StringField, SelectMultipleField, validators\nfrom wtforms.validators import InputRequired, EqualTo, Required\nimport datetime\nfrom app import db\n\nclass lastCall(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n lastSunlight = db.Column(db.String(10))\n \n def __init__(self, lastSunlight):\n self.lastSunlight = lastSunlight\n\nclass User(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n username = db.Column(db.String(100), unique=True)\n pwdhash= db.Column(db.String())\n email = db.Column(db.String(64), nullable=True)\n comments = db.relationship('Comment', backref='commenter', lazy='dynamic')\n \n# socialid = db.Column(db.String(64), unique=True)\n# party = db.Column(db.String(12))\n# website = db.Column(db.String(64))\n# district_cong = db.Column(db.Integer)\n# district_leg = db.Column(db.Integer)\n# date_created = db.Column(db.DateTime, default=db.func.current_timestamp())\n# verified = db.Column(db.Boolean)\n\n\n #New instance instantiation\n def __init__(self, username, password, email):\n self.username = username\n self.pwdhash = generate_password_hash(password)\n self.email = email\n \n def check_password(self, password):\n return check_password_hash(self.pwdhash, password)\n \n def is_authenticated(self):\n return True\n \n def is_active(self):\n return True\n \n def is_anonymous(self):\n return False\n \n def get_id(self):\n return unicode(self.id)\n \n def get_comments(self):\n return Comment.query.filter_by(user_id = user.id).order_by(Coment.timestamp.desc())\n \n# def __repr__(self):\n# return '<User %r>' % (self.username)\n \nclass RegistrationForm(Form):\n username = TextField('Username', [InputRequired()])\n email = StringField('Email Address', [InputRequired()])\n password = PasswordField('Password', [validators.DataRequired(), validators.EqualTo('confirm', message='Passwords must match')])\n confirm = PasswordField('Confirm Password', [InputRequired()])\n \nclass LoginForm(Form):\n username = TextField('Username', [InputRequired()])\n password = PasswordField('Password', [InputRequired()])\n\nclass Bill(db.Model):\n __searchable__ = ['bill_name','title','bill_id']\n\n bill_id = db.Column(db.String(6)) #i.e. H 572\n year = db.Column(db.String(4))\n title = db.Column(db.Text) #Title and Descrip\n bill_name = db.Column(db.String(9), primary_key=True) #unique bill ID from Sunlight\n last_updated = db.Column(db.Text)\n votes_for = db.Column(db.Integer)\n votes_against = db.Column(db.Integer)\n comments = db.relationship('Comment', backref='bill_name', lazy='dynamic')\n\n def __init__(self, bill_id, year, title, bill_name, last_updated, votes_for=0, votes_against=0):\n self.bill_id = bill_id\n self.year = year\n self.title = title\n self.bill_name = bill_name\n self.last_updated = last_updated\n self.votes_for = votes_for\n self.votes_against = votes_against\n \n def __repr__(self):\n return '<Bill %s>' % (self.bill_id)\n \n def get_comments(self):\n return Comment.query.filter_by(bill_id = bill.id).order_by(Coment.timestamp.desc())\n \nclass Comment(db.Model):\n id = db.Column(db.Integer, primary_key = True)\n body = db.Column(db.String(140))\n timestamp = db.Column(db.DateTime)\n author = db.Column(db.String, db.ForeignKey('user.id'))\n comment_type = db.Column(db.String(8))\n bill_num = db.Column(db.String(8), db.ForeignKey('bill.bill_name'))\n \n def __init__(self, comment, author, position, bill_num, timestamp=datetime.datetime.utcnow()):\n self.body = comment\n self.author = author\n self.comment_type = position\n self.bill_num = bill_num\n self.timestamp = timestamp\n\nclass CommentForm(Form):\n comment = TextAreaField('comment')\n position = RadioField(\n 'Yea, Neutral or Nay?',\n choices=[('yea','Yea'),('neutral','Neutral'),('nay','Nay')])\n \nclass SearchForm(Form):\n search = TextField('search')\n house = RadioField('houses', choices=[('lower','House only'),('upper','Senate only'),('all','All bills')], default='all', validators=[Required()])\n year = SelectMultipleField('years', choices=[('2017','2017'),('2016','2016'),('2015','2015'),('2014','2014'),('2013','2013'),('2012','2012'),('2011','2011')], default='2017')\n\nclass Lawmaker(db.Model):\n leg_id = db.Column(db.String, primary_key = True)\n first_name = db.Column(db.String)\n last_name = db.Column(db.String)\n middle_name = db.Column(db.String)\n district = db.Column(db.String)\n chamber = db.Column(db.String)\n url = db.Column(db.String)\n email = db.Column(db.String)\n party = db.Column(db.String)\n photo_url = db.Column(db.String)\n \n def __init__(self, leg_id, first_name, last_name, middle_name, district, chamber, url, email, party, photo_url):\n self.leg_id = leg_id\n self.first_name = first_name\n self.last_name = last_name\n self.middle_name = middle_name\n self.district = district\n self.chamber = chamber\n self.url = url\n self.email = email\n self.party = party\n self.photo_url = photo_url\n \n \n \n# def from_json(self, source):\n# if 'bill_id' in source:\n# self.bill_id = source['bill_id']\n# if 'session' in source:\n# self.year = source['session']\n# if 'title' in source:\n# self.completed = source['title']\n# if 'bill_name' in source:\n# self.bill_name = source['bill_name']\n# if 'last_updated' in source:\n# self.last_updated = source['last_updated']\n \n\n"
},
{
"alpha_fraction": 0.6147859692573547,
"alphanum_fraction": 0.6167315244674683,
"avg_line_length": 23.5238094329834,
"blob_id": "d6d4bd678fa08a47d1a5482e176492d6624ed24e",
"content_id": "af2be278f4330f99a7e7e9bf6cb783236ed5f0e1",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 514,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 21,
"path": "/lib/classes/api_getter.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n// api_getter.php\n// class for saving and getting info to/from API\n// not in use at the moment\n\nclass api_getter {\n\n private $api_key = \"/?apikey=bcc2a830883c4f459dbffe94b2a3e90f\";\n private $url_base = \"http://openstates.org/api/v1/\";\n\npublic function last_action($bill_id) {\n $url_base = $this->url_base\n $key = $this->api_key\n $url = $url_base . 'bills/' . $bill_id . $key;\n $bill_json = file_get_contents($url);\n $bill_detail = json_decode($bill_json, true);\n return $bill_detail[action_dates][last];\n}\n\n}\n?>"
},
{
"alpha_fraction": 0.8139534592628479,
"alphanum_fraction": 0.8139534592628479,
"avg_line_length": 42,
"blob_id": "8241d63c98d6f9f08706111610c090ffb2b52b86",
"content_id": "1074ef061b3664003f893b37764c4d78acc54201",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 43,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 1,
"path": "/app/idleg/__init__.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "# Placeholder file to create Python module\n"
},
{
"alpha_fraction": 0.6927374005317688,
"alphanum_fraction": 0.6927374005317688,
"avg_line_length": 26.15151596069336,
"blob_id": "703e827c21c692417f683303cdd49f64d39386e2",
"content_id": "b9d75ec3fab597b2f764c47d5b75978e6daf0167",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 895,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 33,
"path": "/app/idleg/helpers.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "# Get current session bills from Sunlight and add to database Bills table, then return\ndef getBills():\n import sunlight\n import json\n from sunlight import openstates\n id_bill_json = openstates.bills(\n state = 'id',\n search_window = 'session')\n id_bills = byteify(json.dumps(id_bills_json))\n for bill in id_bills_json:\n bill_adder = Bill(bill[\"bill_id\"], bill[\"session\"], bill[\"title\"], bill[\"id\"], bill[\"updated_at\"])\n db.session.add(bill_adder)\n db.session.commit()\n return id_bills\n \n# Get lawmakers from Sunlight\n\n# Get topics by bill from Sunlight\n\n# Get comments by bill by sentiment from database\n\n\n\n# Strip html tags (from milkypostman on stackoverflow)\nfrom BeautifulSoup import BeautifulSoup\n\ndef removeTags(html, *tags):\n soup = BeautifulSoup(html)\n for tag in tags:\n for tag in soup.findAll(tag):\n tag.replaceWith(\"\")\n\n return soup"
},
{
"alpha_fraction": 0.499026894569397,
"alphanum_fraction": 0.5037843585014343,
"avg_line_length": 29.29257583618164,
"blob_id": "1d1fdf5a6e9ca9d600bca090af5a6ec8308593cf",
"content_id": "798923b864637f26ed39863951286091cdea32fa",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 13873,
"license_type": "permissive",
"max_line_length": 183,
"num_lines": 458,
"path": "/php_archive/lawmakers_tester.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\nif (!isset($_SESSION)) {\n\tsession_start();\n}\n\nif (isset($_COOKIE[\"username\"])) {\n $username = $_COOKIE[\"username\"];\n $_SESSION[\"name\"] = $username;\n}\n?>\n\n<!DOCTYPE html>\n\n<html>\n\n<head>\n \n <link href='https://fonts.googleapis.com/css?family=Source+Sans+Pro:400,700' rel='stylesheet' type='text/css'>\n\n <title><?php if ($thisPage != \"\") {\n echo \"$thisPage\"; } ?> - Idaho Legislative Information Portal, Bills, Lawmakers & Data</title>\n <meta charset=\"utf-8\" />\n <meta name=\"description\" content=\"idleg: Idaho legislative bill information portal\" />\n <meta name=\"keywords\" content=\"Idaho, legislature, bills, laws, legislation\" />\n <meta name=\"author\" content=\"Nathaniel Hoffman\" /> <!-- Note: Make dynamic based on page author -->\n <meta name=\"revised\" content=\"<?php filemtime('index.php'); ?>\" /> <!-- last mod of index.html -->\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n\n <link href=\"css/styles.css\" type=\"text/scc\" rel=\"stylesheet\" />\n <link rel=\"shortcut icon\" href=\"/images/favicon.ico\" />\n \n <!-- jPList core -->\t\t\n <link href=\"/css/jplist-core.min.css\" rel=\"stylesheet\" type=\"text/css\" />\n <script src=\"/js/jplist/jplist-core.min.js\"></script>\t\n \n <!-- sort bundle -->\n <script src=\"/js/jplist/jplist.sort-bundle.min.js\"></script>\n \n <!-- textbox filter control -->\n <script src=\"/js/jplist/jplist.textbox-control.min.js\"></script>\n <link href=\"/css/jplist-textbox-control.min.css\" rel=\"stylesheet\" type=\"text/css\" />\n \n <!-- jPList pagination bundle -->\n <script src=\"/content/js/jplist/jplist.pagination-bundle.min.js\"></script>\n <link href=\"/content/css/jplist-pagination-bundle.min.css\" rel=\"stylesheet\" type=\"text/css\" />\t\t\n \n <!-- jPList history bundle -->\n <script src=\"/content/js/jplist/jplist.history-bundle.min.js\"></script>\n <link href=\"/content/css/jplist-history-bundle.min.css\" rel=\"stylesheet\" type=\"text/css\" />\n \n <!-- jPList toggle bundle -->\n <script src=\"/content/js/jplist/jplist.filter-toggle-bundle.min.js\"></script>\n <link href=\"/content/css/jplist-filter-toggle-bundle.min.css\" rel=\"stylesheet\" type=\"text/css\" />\n \n <!-- jPList views control -->\n <script src=\"/content/js/jplist/jplist.views-control.min.js\"></script>\n <link href=\"/content/css/jplist-views-control.min.css\" rel=\"stylesheet\" type=\"text/css\" />\n \n <!-- jPList preloader control -->\n <script src=\"/content/js/jplist/jplist.preloader-control.min.js\"></script>\n <link href=\"/content/css/jplist-preloader-control.min.css\" rel=\"stylesheet\" type=\"text/css\" />\n \n <!-- Handlebars Templates Library: http://handlebarsjs.com -->\n <script src=\"http://cdnjs.cloudflare.com/ajax/libs/handlebars.js/2.0.0-alpha.4/handlebars.min.js\"></script>\n \n <!-- handlebars template -->\n <script id=\"jplist-template\" type=\"text/x-handlebars-template\">\n {{#each this}}\n \n <div class=\"list-item box\">\t\n <div class=\"img left\">\n <img src=\"{{image}}\" alt=\"\" title=\"\"/>\n </div>\n \n <div class=\"block right\">\n <p class=\"title\">{{title}}</p>\n <p class=\"desc\">{{description}}</p>\n <p class=\"like\">{{likes}} Likes</p>\n <p class=\"theme\">{{keyword1}}, {{keyword2}}</p>\n </div>\n </div>\n \n {{/each}}\n </script>\t\n \n <script>\n $('document').ready(function () {\n\n var $list = $('#demo .list')\n ,template = Handlebars.compile($('#jplist-template').html());\n\n $('#demo').jplist({\n\n itemsBox: '.list'\n ,itemPath: '.list-item'\n ,panelPath: '.jplist-panel'\n\n //data source\n ,dataSource: {\n\n type: 'server'\n ,server: {\n\n //ajax settings\n ajax: {\n url: '/content/data-sources/php-mysql-demo/server-json.php'\n ,dataType: 'json'\n ,type: 'POST'\n }\n }\n\n //render function for json + templates like handlebars, xml + xslt etc.\n ,render: function (dataItem, statuses) {\n $list.html(template(dataItem.content));\n }\n }\n\n });\n });\n</script> \n\n</head>\n\n<header>\n <div class=\"tops\">\n <div id=\"topline\">\n <div class=\"socials\">\n <ul>\n <li class=\"social\">\n <a href=\"https://twitter.com/search?q=%23idleg&src=typd\"><img src=\"images/twittericon.png\" width=\"24px\" height=\"24px\">\n </a>\n </li>\n <li class=\"social\">\n <a href=\"http://idleg.info/rss\"><img src=\"images/RSS-Icon.png\" width=\"24px\" height=\"24px\">\n </a>\n </li>\n <li class=\"social\">\n <a href=\"https://github.com/paleomedia/idleg\"><img src=\"images/Github-Icon.png\" width=\"24px\" height=\"24px\">\n </a>\n </li>\n <li class=\"social\">\n <a href=\"mailto:editor@idleg.info\"><img src=\"images/Email-Icon.png\" width=\"24px\" height=\"24px\">\n </a>\n </li>\n <li class=\"social\">\n <a href=\"http://facebook.com\"><img src=\"images/Facebook-Icon.png\" width=\"24px\" height=\"24px\">\n </a>\n </li>\n </ul>\n </div>\n </div>\n\n <div id=\"logoline\">\n <div id=\"logo\">\n <h1>#IDleg</h1>\n </div>\n <div id=\"slogan\">\n <h2>An Idaho social-political network</h2>\n </div>\n </div>\n\n<?php include('menu.php'); ?>\n\n</header>\n\n<?php\n $thisPage=\"Lawmakers\"; \n // include 'top.php'; \n require_once(\"lib/classes/dao.php\"); ?>\n <!-- <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.3/jquery.min.js\"></script> -->\n \n <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js\"></script>\n <script src=\"https://ajax.googleapis.com/ajax/libs/jqueryui/1.9.1/jquery-ui.min.js\"></script>\n <!-- <script src=\"js/shapeshift.min.js\" type=\"text/javascript\"></script> -->\n \n <div class=\"maincontainer\">\n \n <?php include 'dash.php'; ?>\n\n <div class=\"billmain\">\n \n <!-- demo -->\n<div id=\"demo\">\n \n <!-- panel -->\n <div class=\"jplist-panel\">\t\t\t\t\t\t\n \n <!-- reset button -->\n <button \n type=\"button\" \n class=\"jplist-reset-btn\"\n data-control-type=\"reset\" \n data-control-name=\"reset\" \n data-control-action=\"reset\">\n Reset <i class=\"fa fa-share\"></i>\n </button>\n\n <!-- items per page dropdown -->\n <div\n class=\"jplist-drop-down\"\n data-control-type=\"items-per-page-drop-down\"\n data-control-name=\"paging\"\n data-control-action=\"paging\">\n\n <ul>\n <li><span data-number=\"3\"> 3 per page </span></li>\n <li><span data-number=\"5\"> 5 per page </span></li>\n <li><span data-number=\"10\" data-default=\"true\"> 10 per page </span></li>\n <li><span data-number=\"all\"> View All </span></li>\n </ul>\n </div>\n\n <!-- sort dropdown -->\n <div\n class=\"jplist-drop-down\"\n data-control-type=\"sort-drop-down\"\n data-control-name=\"sort\"\n data-control-action=\"sort\">\n\n <ul>\n <li><span data-path=\"default\">Sort by</span></li>\n <li><span data-path=\".title\" data-order=\"asc\" data-type=\"text\">Title A-Z</span></li>\n <li><span data-path=\".title\" data-order=\"desc\" data-type=\"text\">Title Z-A</span></li>\n <li><span data-path=\".desc\" data-order=\"asc\" data-type=\"text\">Description A-Z</span></li>\n <li><span data-path=\".desc\" data-order=\"desc\" data-type=\"text\">Description Z-A</span></li>\n <li><span data-path=\".like\" data-order=\"asc\" data-type=\"number\">Likes asc</span></li>\n <li><span data-path=\".like\" data-order=\"desc\" data-type=\"number\">Likes desc</span></li>\n </ul>\n </div>\n\n <!-- text filter by title -->\n <div class=\"text-filter-box\">\n \n <!--[if lt IE 10]>\n <div class=\"jplist-label\">Filter by Title:</div>\n <![endif]-->\n \n <input \n data-path=\".title\" \n data-button=\"#title-search-button\"\n type=\"text\" \n value=\"\" \n placeholder=\"Filter by Title\" \n data-control-type=\"textbox\" \n data-control-name=\"title-filter\" \n data-control-action=\"filter\"\n />\n \n <button \n type=\"button\" \n id=\"title-search-button\">\n <i class=\"fa fa-search\"></i>\n </button>\n </div>\n \n <!-- text filter by description -->\n <div class=\"text-filter-box\">\n \n <!--[if lt IE 10]>\n <div class=\"jplist-label\">Filter by Description:</div>\n <![endif]-->\n \n <input \n data-path=\".desc\" \n data-button=\"#desc-search-button\"\n type=\"text\" \n value=\"\" \n placeholder=\"Filter by Description\" \n data-control-type=\"textbox\" \n data-control-name=\"desc-filter\" \n data-control-action=\"filter\"\n />\t\n \n <button \n type=\"button\" \n id=\"desc-search-button\">\n <i class=\"fa fa-search\"></i>\n </button>\n </div>\n \n <!-- checkbox filters -->\n <div\n class=\"jplist-group\"\n data-control-type=\"checkbox-group-filter\"\n data-control-action=\"filter\"\n data-control-name=\"themes\">\n\n <input\n data-path=\".architecture\"\n id=\"architecture\"\n type=\"checkbox\"\n />\n\n <label for=\"architecture\">Architecture</label>\n\n <input\n data-path=\".christmas\"\n id=\"christmas\"\n type=\"checkbox\"\n />\n\n <label for=\"christmas\">Christmas</label>\n\n <input\n data-path=\".nature\"\n id=\"nature\"\n type=\"checkbox\"\n />\n\n <label for=\"nature\">Nature</label>\n\n <input\n data-path=\".lifestyle\"\n id=\"lifestyle\"\n type=\"checkbox\"\n />\n\n <label for=\"lifestyle\">Lifestyle</label>\n </div>\n\n <div\n class=\"jplist-group\"\n data-control-type=\"checkbox-group-filter\"\n data-control-action=\"filter\"\n data-control-name=\"colors\">\n\n <input\n data-path=\".red\"\n id=\"red-color\"\n type=\"checkbox\"\n />\n\n <label for=\"red-color\">Red</label>\n\n <input\n data-path=\".green\"\n id=\"green-color\"\n type=\"checkbox\"\n />\n\n <label for=\"green-color\">Green</label>\n\n <input\n data-path=\".blue\"\n id=\"blue-color\"\n type=\"checkbox\"\n />\n\n <label for=\"blue-color\">Blue</label>\n\n <input\n data-path=\".brown\"\n id=\"brown-color\"\n type=\"checkbox\"\n />\n\n <label for=\"brown-color\">Brown</label>\n \n </div>\n\n <!-- list / grid view -->\n <div \n class=\"jplist-views\" \n data-control-type=\"views\" \n data-control-name=\"views\" \n data-control-action=\"views\"\n data-default=\"jplist-list-view\">\n \n <button type=\"button\" class=\"jplist-view jplist-list-view\" data-type=\"jplist-list-view\"></button>\n <button type=\"button\" class=\"jplist-view jplist-grid-view\" data-type=\"jplist-grid-view\"></button>\n </div>\n \n <!-- pagination results -->\n <div \n class=\"jplist-label\" \n data-type=\"Page {current} of {pages}\" \n data-control-type=\"pagination-info\" \n data-control-name=\"paging\" \n data-control-action=\"paging\">\n </div>\n \n <!-- pagination -->\n <div \n class=\"jplist-pagination\" \n data-control-type=\"pagination\" \n data-control-name=\"paging\" \n data-control-action=\"paging\">\n </div>\t\n\n <!-- preloader for data sources -->\n <div \n class=\"jplist-hide-preloader jplist-preloader\"\n data-control-type=\"preloader\" \n data-control-name=\"preloader\" \n data-control-action=\"preloader\">\n <img src=\"/content/img/common/ajax-loader-line.gif\" alt=\"Loading...\" title=\"Loading...\" />\n </div>\t\t\n \n </div>\t\t\t\t \n \n <!-- HTML data --> \n <div class=\"list\">\n \n <!-- item 1 -->\n <div class=\"list-item\">\t\n ...\n </div>\n \n <!-- item 2 -->\n <div class=\"list-item\">\t\n ...\n </div>\n \n ...\n \n </div>\n \n <!-- no results found -->\n <div class=\"jplist-no-results\">\n <p>No results found</p>\n </div>\n \n</div>\n \n \n <div class=\"lawmaker\">\n\n <?php $dao = new Dao();\n $legislators = $dao->getLegislators();\n foreach ($legislators as $legislator) { ?>\n \n <div>\n <div class=\"leg_img\">\n \n <img src=\"<?php echo $legislator[\"photo_url\"]; ?>\" alt=\"<?php echo $legislator[\"last_name\"]; ?>\" />\n <h2><span><?php echo $legislator[\"first_name\"] . \" \" . $legislator[\"last_name\"] . \", \" . $legislator[\"party\"] . \" (\". $legislator[\"district\"] . \")\"; ?></span></h2>\n </div>\n \n </div> \n <?php } ?>\n </div> \n\n <script type=\"text/javascript\">\n $(document).ready(function(){\n\t$('.lawmaker').shapeshift(\n\t {\n align:'left',\n minColumns:3\n });\n $(\".ss-container\").trigger(\"ss-shuffle\")\n});</script>\n\n </div>\n </div>\n \n \n<?php include 'footer.php'; ?>"
},
{
"alpha_fraction": 0.5747126340866089,
"alphanum_fraction": 0.5747126340866089,
"avg_line_length": 11.5,
"blob_id": "ff1312c12f7721c8e28f31ce77090455098ee3e8",
"content_id": "8284b417df226f3721ba53ac02497521d0d7e63a",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 174,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 14,
"path": "/php_archive/bills.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n$thisPage=\"Bills\"; \ninclude 'top.php';\nrequire_once(\"dao.php\"); ?>\n \n<div class=\"maincontainer\">\n \n<?php include 'dash.php'; \n\n\n\n \n \ninclude 'footer.php'; ?>"
},
{
"alpha_fraction": 0.7092875242233276,
"alphanum_fraction": 0.7360050678253174,
"avg_line_length": 28.05555534362793,
"blob_id": "7fc42eda8a86d73eb3d911050be9a90207ddded4",
"content_id": "74e9ebbe5d0ed77c4887c5c72e8240ddb4737145",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1572,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 54,
"path": "/app/__init__.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_script import Manager\nfrom flask_login import LoginManager\nfrom flask_wtf import Form\nfrom flask_wtf.csrf import CsrfProtect\nfrom flask_oauth import OAuth\nfrom config import basedir\nfrom flask_restful import Api, Resource\n\napp = Flask(__name__)\napp.config.from_object(os.environ['APP_SETTINGS'])\ncsrf = CsrfProtect(app)\n\ndb = SQLAlchemy(app)\n\nlogin_manager = LoginManager()\nlogin_manager.init_app(app)\nlogin_manager.login_view = 'idleg.login'\n\noauth = OAuth()\n\ntwitter = oauth.remote_app('twitter', \\\n base_url='https://api.twitter.com/1/', \\\n request_token_url='https://api.twitter.com/oauth/request_token', \\\n access_token_url='https://api.twitter.com/oauth/access_token', \\\n authorize_url='https://api.twitter.com/oauth/authenticate', \\\n consumer_key='nZRuF6tkYBLbhUvrHfauHK88a', \\\n consumer_secret='n15RO8Xh0XgnB5ia1779cb9xKCF7pn5JKie161vSzd3lXzxh9W' \\\n)\n\nfacebook = oauth.remote_app('facebook', \\\n base_url='https://graph.facebook.com/', \\\n request_token_url=None, \\\n access_token_url='/oauth/access_token', \\\n authorize_url='https://www.facebook.com/dialog/oauth', \\\n consumer_key='1172176769479154', \\\n consumer_secret='789db0a5084f84ca460f66a9b44d2666', \\\n request_token_params={'scope': 'email'})\n\nfrom app.idleg import views, models\nfrom app.idleg.views import idleg\nfrom app.idleg import views\nfrom app.api.views import apiModule\n\napp.register_blueprint(apiModule)\napp.register_blueprint(idleg)\n\n\n# from app.auth.views import auth\n# app.register_blueprint(auth)\n\ndb.create_all()\n\n\n\n"
},
{
"alpha_fraction": 0.6892351508140564,
"alphanum_fraction": 0.6892351508140564,
"avg_line_length": 32.619049072265625,
"blob_id": "8c43f27186c6564df1a1c43a8ada2affef1be085",
"content_id": "261697ec76afcd5d705a7f9c88076abe6f0702d4",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3530,
"license_type": "permissive",
"max_line_length": 147,
"num_lines": 105,
"path": "/app/auth/views.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "from flask import request, render_template, flash, redirect, url_for \nfrom flask import session, Blueprint, g\nfrom flask.ext.login import current_user, login_user, logout_user, login_required\nfrom app import app, db\nfrom app import login_manager\nfrom app import facebook\nfrom app.auth.models import User, RegistrationForm, LoginForm\n#from flask_wtf import Form\n\nauth = Blueprint('auth', __name__)\n\n@login_manager.user_loader\ndef load_user(id):\n return User.query.get(int(id))\n \n@auth.before_request\ndef get_current_user():\n g.user = current_user\n\n#@auth.route('/')\n#@auth.route('/home')\n#def home():\n# return render_template('home.html', user=current_user)\n \n@auth.route('/register', methods=['GET', 'POST'])\ndef register():\n if session.get('username'):\n flash('Your are already logged in.', 'info')\n return redirect(url_for('idleg.home'))\n\n form = RegistrationForm(request.form)\n \n if request.method == 'POST' and form.validate():\n username = request.form.get('username')\n password = request.form.get('password')\n existing_username = User.query.filter_by(username=username).first()\n if existing_username:\n flash('This username has been already taken. Try another one.','warning')\n return render_template('register.html', form=form)\n user = User(username, password)\n db.session.add(user)\n db.session.commit()\n login_user(user)\n flash('You are now registered and logged in.', 'success')\n return redirect(url_for('idleg.home'))\n if form.errors:\n flash(form.errors, 'danger')\n return render_template('register.html', form=form)\n \n@auth.route('/login', methods=['GET', 'POST'])\ndef login():\n if current_user.is_authenticated:\n flash('You are already logged in.')\n return redirect(url_for('idleg.home'))\n\n form = LoginForm(request.form)\n \n if request.method == 'POST' and form.validate():\n username = request.form.get('username')\n password = request.form.get('password')\n existing_user = User.query.filter_by(username=username).first()\n \n if not (existing_user and existing_user.check_password(password)):\n flash('Invalid username or password. Please try again.', 'danger')\n return render_template('login.html', form=form)\n\n login_user(existing_user) \n flash('You have successfully logged in.', 'success')\n return redirect(url_for('idleg.home'))\n \n if form.errors:\n flash(form.errors, 'danger')\n \n return render_template('login.html', form=form)\n\n@auth.route('/facebook-login')\ndef facebook_login():\n return facebook.authorize(callback=url_for('auth.facebook_authorized', next=request.args.get('next') or request.referrer or None, _external=True))\n\n@auth.route('/facebook-login/authorized')\n@facebook.authorized_handler\ndef facebook_authorized(resp):\n if resp is None:\n return 'Access denied: reason=%s error=%s' % (request.args['error_reason'], request.args['error_description'])\n session['facebook_oauth_token'] = (resp['access_token'], '')\n me = facebook.get('/me')\n user = User.query.filter_by(username=me.data['email']).first()\n if not user:\n user = User(me.data['email'], '')\n db.session.add(user)\n db.session.commit()\n \n login_user(user)\n flash('Logged in as id=%s name=%s' % (me.data['id'], me.data['name']),'success')\n return redirect(request.args.get('next'))\n\n@facebook.tokengetter\ndef get_facebook_oauth_token():\n return session.get('facebook_oauth_token')\n \n@auth.route('/logout')\n@login_required\ndef logout():\n logout_user()\n return redirect(url_for('idleg.home'))\n"
},
{
"alpha_fraction": 0.643750011920929,
"alphanum_fraction": 0.643750011920929,
"avg_line_length": 16.55555534362793,
"blob_id": "1374d82b3725cd870c221213f2e26ba252ab8f7d",
"content_id": "0cd412da951e8a49c95a29c3d9e8a559d84bc3c3",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 9,
"path": "/run.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "#!./flask/bin/python\nfrom app import app\n#app.run(debug=True, threaded=True)\n\nif __name__ == \"__main__\":\n app.run()\n\n#from app import manager\n#manager.run()\n\n\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5555555820465088,
"avg_line_length": 21.387096405029297,
"blob_id": "af9c15afd6818c554eaa2ee766162d5d1cd03c09",
"content_id": "ceca7ef18a9a607ebb9a7d3f9175083a7846c804",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 693,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 31,
"path": "/lib/handler.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n// handler.php\n// handle comment posts, saving to MySQL and redirecting back to the list\n\nif (!isset($_SESSION)) {\n\tsession_start();\n}\n\nrequire_once(\"classes/dao.php\");\n\n if (isset($_SESSION[\"name\"]) && isset($_POST[\"commentButton\"])) {\n $comment = $_POST[\"comment\"];\n $comment_type = $_POST[\"vote\"];\n $bill = $_POST[\"bill\"];\n $username = $_SESSION[\"name\"];\n\n try {\n $dao = new Dao();\n $dao->saveComment($username, $comment, $bill, $comment_type);\n }\n catch (Exception $e) {\n var_dump($e);\n die;\n }\n }\n else {\n\t\t\t$dao = new Dao();\n\t\t\t$dao -> redirect(\"../index.php\", \"Please log in to comment.\");\n\t\t}\n\n header(\"Location:../index.php\");"
},
{
"alpha_fraction": 0.5413744449615479,
"alphanum_fraction": 0.5596072673797607,
"avg_line_length": 20,
"blob_id": "b2b9491924df79afd62906e1a9dff1af798c5242",
"content_id": "9eed8d2cc33b091f3ce1a107bb7ab4ff821fe95c",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 713,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 34,
"path": "/lib/login.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\nif (!isset($_SESSION)) {\n\tsession_start();\n}\n\nrequire_once(\"classes/dao.php\");\n\nif (isset($_POST[\"username\"]) && isset($_POST[\"password\"])) {\n\t$name = $_POST[\"username\"];\n\t$password = $_POST[\"password\"];\n\n\ttry {\n\t\t$dao = new Dao();\n\t\tif ($dao -> check_login($name, $password)) {\n\t\t\t$_SESSION[\"name\"] = $name;\n\t\t\t\n\t\t\tif ($_POST['rememberme']=1) {\n\t\t\t\t$expireTime = time() + 60*60*24*180; # 180 days from now\n\t\t\t\tsetcookie(\"username\", $_SESSION[\"name\"], $expireTime); }\n\t\t\t\t\n\t\t\t$dao -> redirect(\"../index.php\", \"Login successful! Welcome back, $name.\");\n\t\t}\n\t\telse {\n\t\t\t$dao -> redirect(\"../index.php\", \"Incorrect user name and/or password.\");\n\t\t}\n\t}\n\tcatch (Exception $e) {\n\t\tvar_dump($e);\n\t\tdie;\n\t}\n}\n\n?>"
},
{
"alpha_fraction": 0.6182432174682617,
"alphanum_fraction": 0.6182432174682617,
"avg_line_length": 20.214284896850586,
"blob_id": "2df6cc68143ff1f5bc72e0f8f9e0c27fe21bf669",
"content_id": "6169482801a47f72130c03471053dcf1aa6f2437",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 296,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 14,
"path": "/lib/granted.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\nsession_start();\n\nif (isset($_SESSION[\"access_granted\"]) && !$_SESSION[\"access_granted\"] ||\n !isset($_SESSION[\"access_granted\"])) {\n $_SESSION[\"status\"] = \"You need to log in first\";\n header(\"Location:index.php\");\n}\nelse {\necho \"ACCESS GRANTED\"; }\n?>\n \n<a href=\"logout.php\">Logout</a>"
},
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 33,
"blob_id": "9dbeca74482dd4e24d4e4847e5dd7056cb9daaa9",
"content_id": "003d8bb569b5390b5bd992d61ad12e0a46cb4e6e",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 102,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 3,
"path": "/MANIFEST.ini",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "recursive-include app/templates *\nrecursive-include app/static *\nrecursive-include app/translations *\n"
},
{
"alpha_fraction": 0.49024391174316406,
"alphanum_fraction": 0.6939024329185486,
"avg_line_length": 15.399999618530273,
"blob_id": "baec2ad387e26fe08244aa4a71e28248cc57a668",
"content_id": "1787556fed34bbc8463d313357e85177d3f8b336",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 820,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 50,
"path": "/app/static/js/requirements.txt",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "aniso8601==1.1.0\nargs==0.1.0\nBeautifulSoup==3.2.1\nblinker==1.4\nclint==0.5.1\ncoverage==4.0.1\ndecorator==4.0.4\ndocopt==0.6.2\nenum34==1.1.4\nFlask==0.10.1\nFlask-Cache==0.13.1\nFlask-Login==0.3.2\nFlask-OAuth==0.12\nFlask-RESTful==0.3.5\nFlask-Script==2.0.5\nFlask-SQLAlchemy==2.1\nFlask-WTF==0.12\nflipflop==1.0\ngoogle-api-python-client==1.4.2\ngunicorn==19.6.0\nhttplib2==0.9.2\nidna==2.1\nipaddress==1.0.16\nitsdangerous==0.24\nJinja2==2.8\nMako==1.0.3\nMarkupSafe==0.23\noauth==1.0.1\noauth2==1.9.0.post1\noauth2client==1.5.1\noauthlib==1.0.3\npasslib==1.6.5\npbr==1.8.1\npipreqs==0.3.3\npyasn1==0.1.9\npyasn1-modules==0.0.8\npycparser==2.14\npython-dateutil==2.5.3\npytz==2016.6.1\nrequests==2.10.0\nrsa==3.2\nsimplejson==3.8.1\nsix==1.10.0\nSQLAlchemy==1.0.9\nsunlight==1.2.9\nuritemplate==0.6\nWerkzeug==0.11.10\nWhoosh==2.7.0\nWTForms==2.0.2\nyarg==0.1.9\n"
},
{
"alpha_fraction": 0.49325627088546753,
"alphanum_fraction": 0.6994219422340393,
"avg_line_length": 15.741935729980469,
"blob_id": "0e384a7a2b55df1c9a765a1adc89bc2dc39bd0f3",
"content_id": "44f9cf305996dee351295c22fd68ea3d8597b584",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 519,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 31,
"path": "/requirements.txt",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "aniso8601==1.2.0\nargs==0.1.0\nBabel==2.3.4\nblinker==1.4\nclick==6.6\nclint==0.5.1\ndpath==1.4.0\nFlask==0.12\nFlask-Babel==0.11.1\nFlask-Cache==0.13.1\nFlask-Login==0.4.0\nFlask-OAuth==0.12\nFlask-RESTful==0.3.5\nFlask-Script==2.0.5\nFlask-SQLAlchemy==2.1\nFlask-WhooshAlchemy==0.56\nFlask-WTF==0.13.1\ngunicorn==19.4.5\nhttplib2==0.9.2\nitsdangerous==0.24\nJinja2==2.8.1\nMarkupSafe==0.23\noauth2==1.9.0.post1\npython-dateutil==2.6.0\npytz==2016.10\nsix==1.10.0\nSQLAlchemy==1.1.4\nsunlight==1.2.9\nWerkzeug==0.11.13\nWhoosh==2.7.4\nWTForms==2.1\n"
},
{
"alpha_fraction": 0.5351400971412659,
"alphanum_fraction": 0.5378962159156799,
"avg_line_length": 32.5076904296875,
"blob_id": "71242807bab511f557d9db9d38e287ff2fb01fa0",
"content_id": "0a95cebfc91db263b7670da2a12f66e280a44988",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2177,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 65,
"path": "/lib/cron_functions.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\n\n/* get list of lawmakers and insert into lawmakers table\nread the json file contents */\n\nrequire_once(\"lib/classes/dao.php\");\n \n $jsondata = file_get_contents('http://openstates.org/api/v1/legislators/?apikey=bcc2a830883c4f459dbffe94b2a3e90f&state=id'); \n\n//convert json object to php associative array\n $legislators = json_decode($jsondata, true);\n \n // echo \"<pre>\" . print_r($legislators, 1) . \"</pre>\";\n\n $dao = new Dao();\n $connection = $dao->getConnection();\n $i = 1;\n foreach ($legislators as $legislator) {\n $sql = \"INSERT INTO lawmakers(leg_id, last_name, first_name, middle_name, district, party, active, chamber, photo_url)\n VALUES('\" . $legislator['leg_id'] . \"', \" .\n \"'\" . $legislator['last_name'] . \"', \" .\n \"'\" . $legislator['first_name'] . \"', \" .\n \"'\" . $legislator['middle_name'] . \"', \" .\n $legislator['district'] . \", \" .\n \"'\" . $legislator['party'] . \"', \" .\n $legislator['active'] . \", \" .\n \"'\" . $legislator['chamber'] . \"', \" .\n \"'\" . $legislator['photo_url'] . \"')\";\n echo \"inserting record $i<br/>\";\n $i++;\n \n $count = $connection->exec($sql) or die(print_r($connection->errorInfo(), true));\n echo \"rows actually inserted $count </br>\";\n }\n \n /* Save new bill information to bills table */\n \n /* read the json file contents */\n \n $jsondata = file_get_contents('http://openstates.org/api/v1/bills/?apikey=bcc2a830883c4f459dbffe94b2a3e90f&state=id&search_window=session'); \n\n//convert json object to php associative array\n $bills = json_decode($jsondata, true);\n \n // echo \"<pre>\" . print_r($bills, 1) . \"</pre>\";\n\n $dao = new Dao();\n $connection = $dao->getConnection();\n $i = 1;\n foreach ($bills as $bill) {\n $bill_name = $bill['bill_id'];\n $year = $bill['session'];\n $title = $bill['title'];\n $bill_id = $bill['id'];\n \n echo \"inserting record $i<br/>\";\n $i++;\n \n $dao->saveBills($bill_id, $year, $title, $bill_name, $connection) or die(print_r($connection->errorInfo(), true));\n echo \"$bill_name actually inserted</br>\";\n } \n \n \n ?>"
},
{
"alpha_fraction": 0.6037735939025879,
"alphanum_fraction": 0.606918215751648,
"avg_line_length": 17.764705657958984,
"blob_id": "34ef4415afd89255e1203afd619369c95cd0f0eb",
"content_id": "3f35bd6ef5be7a516236067078218f59ecaa46e3",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 318,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 17,
"path": "/lib/api_functions.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\nfunction last_action($bill_id) {\n\n$api_key = \"/?apikey=bcc2a830883c4f459dbffe94b2a3e90f\";\n$url_base = \"http://openstates.org/api/v1/\";\n$url = $url_base . 'bills/' . $bill_id . $api_key;\n$bill_json = file_get_contents($url);\n$bill_detail = json_decode($bill_json, true);\n\nreturn strtok($bill_detail['action_dates']['last'], \" \") ;\n\n}\n\n\n\n?>"
},
{
"alpha_fraction": 0.6944444179534912,
"alphanum_fraction": 0.6944444179534912,
"avg_line_length": 36,
"blob_id": "f39d844ca88f1dfc63cb9878b10c959cfe0b3b89",
"content_id": "20de4688aeeeee228be9a3667d33f20d30734914",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 36,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 1,
"path": "/app/static/js/lawmakers.js",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "$('.legislators-main').shapeshift();"
},
{
"alpha_fraction": 0.6470146179199219,
"alphanum_fraction": 0.6492677330970764,
"avg_line_length": 29.272727966308594,
"blob_id": "a24736fd554844ee598b48bc0b8057c48b27462b",
"content_id": "564f5a4468f590068ad9218a1e106f27f5e25363",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2663,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 88,
"path": "/app/api/views.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask, Blueprint, jsonify, g, session\nfrom app import app,api, db, csrf\nfrom app.idleg.models import User, Bill, Comment\nfrom flask_restful import Resource, Api, reqparse, fields\nfrom app.cache import cache\n\n\nfrom flask.views import MethodView\n\napiModule = Blueprint('apiModule', __name__)\napi = Api(app, decorators=[csrf.exempt])\n\nparser = reqparse.RequestParser()\nparser.add_argument('comment', type=str)\nparser.add_argument('author', type=int)\nparser.add_argument('position', type=str)\nparser.add_argument('bill', type=str)\n\nclass commentApi(Resource):\n#@login_required\n def get(self, id):\n if not id:\n abort(404)\n comment = [Comment.query.get(id)]\n result = []\n for c in comment:\n result.append({\n 'comment': c.body,\n 'timestamp': c.timestamp,\n 'author': c.commenter.username,\n 'position': c.comment_type,\n 'bill': c.bill_num\n })\n return jsonify(results=result)\n \n def post(self):\n args = parser.parse_args()\n comment = args['comment']\n #author = args['current_user.id'] - need to authenticate API caller\n author = args['author']\n position = args['position']\n bill = args['bill']\n newComment = Comment(comment, author, position, bill)\n db.session.add(newComment)\n db.session.commit()\n cache.clear()\n \n return jsonify({'comment': comment, 'author': author, 'position' : position, 'bill': bill})\n \napi.add_resource(commentApi, '/api/comment','/api/comment/<int:id>')\n\n\n#add optional position parameter\nclass commentsApi(Resource):\n def get(self, bill_deet, position=None):\n if not bill_deet:\n abort(404)\n else:\n #query for comments on current bill\n billComments = [Bill.query.get(bill_deet)]\n if not billComments:\n billComments = 'No comments yet'\n\n #return json sting of comment for current bill\n result = []\n for billComment in billComments:\n for comment in billComment.comments:\n result.append({\n \"commentId\": comment.id,\n \"commentBody\": comment.body,\n \"timeStamp\": comment.timestamp,\n \"author\": comment.author,\n \"commentType\": comment.comment_type,\n \"bill\": comment.bill_num,\n \"bill_id\": bill_deet\n })\n if not position:\n return jsonify(results=result)\n else:\n filtered_result = []\n for i in result:\n if i['commentType'] == position:\n filtered_result.append(i)\n print i['commentType']\n print position\n return jsonify(results=filtered_result)\n \napi.add_resource(commentsApi, '/api/comments/<string:bill_deet>', '/api/comments/<string:bill_deet>/<string:position>')"
},
{
"alpha_fraction": 0.7425742745399475,
"alphanum_fraction": 0.7425742745399475,
"avg_line_length": 32.66666793823242,
"blob_id": "65ba8b1d3e0000dbd052675677bc0f51c184f3c9",
"content_id": "1e0b2604dc9424fa23c05057ef0b50bd045a5889",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 3,
"path": "/app/cache.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "from flask_cache import Cache\nfrom app import app\ncache = Cache(app,config={'CACHE_TYPE': 'simple'})\n"
},
{
"alpha_fraction": 0.7455871105194092,
"alphanum_fraction": 0.7513430714607239,
"avg_line_length": 40.36507797241211,
"blob_id": "c492bfcbb30356eafa21b9810a842c0eb82866d7",
"content_id": "a7122ec068808bb1b0fc22a460fd1efb7f179a35",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2606,
"license_type": "permissive",
"max_line_length": 212,
"num_lines": 63,
"path": "/README.md",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "# IDleg\nBeing a spinoff of the #idleg Twitter hashtag, pronounced by some as Idle-G.\n\n## Interactive Portal to Idaho Legislature - BETA RELEASE\n### In development, i.e. use at your own risk\n\nThis project is part of a master's degree in \"Data Journalism\" at Boise State University. I'm building an alternative legislative portal for the state of Idaho that:\n\n- Uses data from the Sunlight Foundation [Open States Project API] (https://sunlightlabs.github.io/openstates-api/) to provide a rich dataset of state legislative data\n- Provides social tools for bills and other legislative actions, allowing constituents to \"testify\" on bills online\n- Provides some basic statistics on legislative actions\n- Provides a means to parse votes in various ways - by bill, lawmaker, party, etc.\n- Demonstrates the type of information that hacker-journalists can access\n- Demonstrates the cross-over between \"open government\" and \"open news\" initiatives\n\n- In this idleg_flask repo, I'm refactoring and building out the project with Python Flask\n\nYou can read more about my [MA project on my blog] (http://www.paleomedia.org/2013/09/30/data-journalism/) and look for beta releases and other updates [at idleg.info](http://idleg.info/) soon.\n\n## Setup for Developers\n\n### Requirements\n- Python 2.6 or higher\n- A [Sunlight Labs API Key](http://sunlightfoundation.com/api/accounts/register/) - Read their instructions to [install the key and use the Python library](http://python-sunlight.readthedocs.org/en/latest/#usage)\n- Recommend installing in [virtualenv](http://flask.pocoo.org/docs/0.10/installation/) and [virtualenvwrapper](http://virtualenvwrapper.readthedocs.io/en/latest/install.html)\n\n```python\n $ pip install virtualenv\n $ virtualenv idleg_flask\n $ cd idleg_flask\n $ source bin/activate\n $ pip install flask\n```\n\n- Then [fork the repository](https://github.com/paleomedia/idleg_flask#fork-destination-box) if you want or just clone it to your virtualenv:\n\n```python\n $ git clone https://github.com/paleomedia/idleg_flask.git\n```\n\n- Finally, install dependencies (note: requirements.txt contains some bloat... will clean up dependencies at a later date)\n\n```python\n $ pip install -r requirements.txt\n```\n\nI think that will work... but please let us know if you run into problems getting it running. And remember, the app is still in development...\n\n### How to run\n\n```python\n python run.py\n```\nor\n```python\n ./run.py\n```\n## Contributors\n[@paleomedia](http://twitter.com/paleomdia)\n\n##Technical Advisors\n[@nilabmm](http://twitter.com/nilabmm)\n[@jwoodsy1](http://twitter.com/jwoodsy1)\n"
},
{
"alpha_fraction": 0.7224199175834656,
"alphanum_fraction": 0.7224199175834656,
"avg_line_length": 25.761905670166016,
"blob_id": "3457cb0dc7d5fdf9951b0edda9d2e0563ce1e5f6",
"content_id": "7d2da3849319a89707d109daec6328d255abe3ed",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 562,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 21,
"path": "/config.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "import os\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\nclass Config(object):\n SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(basedir, 'app.db')\n SQLALCHEMY_MIGRATE_REPO = os.path.join(basedir, 'db_repository')\n SQLALCHEMY_TRACK_MODIFICATIONS = False\n WTF_CSRF_ENABLED = True\n SECRET_KEY = 'aG45!geB8593423)fkFrd4C'\n DEBUG= False\n TESTING = False\n\nclass ProductionConfig(Config):\n 'Production specific config'\n DEBUG = False\n\nclass DevelopmentConfig(Config):\n 'Development environment specific config'\n DEVELOPMENT = True\n DEBUG = True\n TESTING = True\n"
},
{
"alpha_fraction": 0.49802109599113464,
"alphanum_fraction": 0.5059366822242737,
"avg_line_length": 31.276596069335938,
"blob_id": "e383b9a3b1f3238a52d435aeac6969009b5e72b0",
"content_id": "7122d099d6c2dd148989133e5dbd24ff6cbe3ced",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1516,
"license_type": "permissive",
"max_line_length": 183,
"num_lines": 47,
"path": "/php_archive/lawmakers.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n $thisPage=\"Lawmakers\"; \n include 'top.php'; \n require_once(\"lib/classes/dao.php\"); ?>\n <!-- <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.3/jquery.min.js\"></script> -->\n \n <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/1.8.2/jquery.min.js\"></script>\n <script src=\"https://ajax.googleapis.com/ajax/libs/jqueryui/1.9.1/jquery-ui.min.js\"></script>\n <script src=\"js/shapeshift.min.js\" type=\"text/javascript\"></script> \n \n <div class=\"maincontainer\">\n \n <?php include 'dash.php'; ?>\n\n <div class=\"billmain\">\n <div class=\"lawmaker\">\n\n <?php $dao = new Dao();\n $legislators = $dao->getLegislators();\n foreach ($legislators as $legislator) { ?>\n \n <div>\n <div class=\"leg_img\">\n \n <img src=\"<?php echo $legislator[\"photo_url\"]; ?>\" alt=\"<?php echo $legislator[\"last_name\"]; ?>\" />\n <h2><span><?php echo $legislator[\"first_name\"] . \" \" . $legislator[\"last_name\"] . \", \" . $legislator[\"party\"] . \" (\". $legislator[\"district\"] . \")\"; ?></span></h2>\n </div>\n \n </div> \n <?php } ?>\n </div> \n\n <script type=\"text/javascript\">\n $(document).ready(function(){\n\t$('.lawmaker').shapeshift(\n\t {\n align:'left',\n minColumns:3\n });\n $(\".ss-container\").trigger(\"ss-shuffle\")\n});</script>\n\n </div>\n </div>\n \n \n<?php include 'footer.php'; ?>"
},
{
"alpha_fraction": 0.4764898121356964,
"alphanum_fraction": 0.479507178068161,
"avg_line_length": 30.307086944580078,
"blob_id": "f8f468bbfc82faff4c23ae1db6f380ba379a4471",
"content_id": "7274eece22721a72419c20bfdd6065fdcd404898",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3977,
"license_type": "permissive",
"max_line_length": 167,
"num_lines": 127,
"path": "/php_archive/index.1.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n$thisPage = 'Home'; \nrequire_once \"lib/classes/dao.php\";\ninclude 'lib/api_functions.php';\n\n $dao = new Dao();\n \ninclude 'top.php'; ?>\n\n <body>\n\n <div class=\"maincontainer\">\n \n<?php include 'dash.php'; ?>\n\n<div class=\"billmain\">\n \n <script src=\"https://ajax.googleapis.com/ajax/libs/jquery/2.1.3/jquery.min.js\"></script>\n <script src=\"js/ajax.js\" type=\"text/javascript\"></script>\n \n <!-- demo -->\n<div id=\"demo\">\n \n <!-- panel -->\n <div class=\"jplist-panel\">\t\t\t\t\t\t\n \n <!-- ios button: show/hide panel -->\n <div class=\"jplist-ios-button\">\n <i class=\"fa fa-sort\"></i>\n jPList Actions\n </div>\n \n <!-- add here jPList controls and bundles -->\n ...\n \n </div>\t\t\t\t \n \n <!-- HTML data --> \n <div class=\"list\">\n \n <!-- item 1 -->\n <div class=\"list-item\">\t\n ...\n </div>\n\n <!-- item 2 -->\n <div class=\"list-item\">\t\n ...\n </div>\n\n ...\n \n </div>\n \n <!-- no results found -->\n <div class=\"jplist-no-results\">\n <p>No results found</p>\n </div>\n \n</div>\t\n \n <?php\n \n $bill_list = $dao->getBills();\n\n foreach ($bill_list as $bill) { \n $action_date = last_action($bill[\"bill_id\"]) ?>\n <div class=\"active\">\n <p>Active Bills</p>\n <div class=\"billimage\"><span><?php echo $bill[\"bill_name\"]; ?></span></div>\n <div class=\"lastaction\">Last Action: <?php echo $action_date; ?> </div>\n <div class=\"billsummary\"><?php echo $bill[\"title\"]; ?></div>\n \n <div class=\"comments\">\n <div class=\"commentbox\">\n <form name=\"commentForm\" action=\"lib/handler.php\" method=\"POST\">\n <textarea name=\"comment\" rows=\"4\" id=\"comment\" placeholder=\"Write comments or testimony here, select pro, neutral or anti, and press Submit.\"></textarea>\n <label>Yea, Nay or Neutral?</label>\n <label>\n <input type=\"radio\" name=\"vote\" value=\"pro\" id=\"pro\" /><img class=\"prolabel\" src=\"images/thumbs_up.png\" />\n </label>\n <label>\n <input type=\"radio\" name=\"vote\" value=\"anti\" id=\"anti\" /><img class=\"antilabel\" src=\"images/thumbs_down.png\" />\n </label>\n <label class=\"neutrallabel\">\n <input type=\"radio\" name=\"vote\" value=\"neutral\" id=\"neutral\" checked=\"checked\" />?</label>\n <input type=\"submit\" name=\"commentButton\" value=\"Submit\" />\n <input type=\"hidden\" name=\"form\" value=\"comment\" />\n <input type=\"hidden\" name=\"bill\" value=\"<?php echo $bill[\"bill_id\"]; ?>\" />\n </form>\n </div>\n \n <div class=\"pro\"><h3>Yea</h3>\n <?php $comments = $dao->getComments($bill[\"bill_id\"], \"pro\");\n foreach ($comments as $comment) { \n ?>\n <span><?php echo $comment[\"username\"]; ?> says:</span> <?php echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\"; ?> \n <?php } ?>\n </div> \n \n <div class=\"neutral\"><h3>Neutral</h3>\n <?php $comments = $dao->getComments($bill[\"bill_id\"], \"neutral\");\n foreach ($comments as $comment) { ?>\n <span><?php echo $comment[\"username\"]; ?> says:</span> <?php echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\"; ?>\n <?php } ?>\n </div>\n\n <div class=\"anti\"><h3>Nay</h3>\n <?php $comments = $dao->getComments($bill[\"bill_id\"], \"anti\");\n foreach ($comments as $comment) { ?>\n <span><?php echo $comment[\"username\"]; ?> says:</span> <?php echo $comment[\"comment\"] . \"<br />\";\n echo \"DATE:\" . $comment[\"date\"] . \"<br />\"; ?>\n <?php } ?>\n </div>\n </div>\n </div>\n \n <?php } ?>\n\n </div>\n</div>\n\n \n\n<?php include 'footer.php'; ?> "
},
{
"alpha_fraction": 0.7142110466957092,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 20.255556106567383,
"blob_id": "9bfe43fcc727613fe0038ffe1bdf1c1c1dcfb047",
"content_id": "b792ed9597a5d15732b881831eb08d7dab45cf67",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1914,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 90,
"path": "/lib/etc/nhoffman.sql",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "CREATE TABLE IF NOT EXISTS users (\nemail VARCHAR(256) NOT NULL,\nusername VARCHAR(64) NOT NULL PRIMARY KEY,\npassword VARCHAR(64) NOT NULL,\nfirstname VARCHAR(64),\nlastname VARCHAR(64),\nparty VARCHAR(12),\nwebsite VARCHAR(64),\ndistrict_cong TINYINT,\ndistrict_leg TINYINT,\nregistered TIMESTAMP DEFAULT CURRENT_TIMESTAMP,\nverified BOOL\n);\n\nCREATE TABLE IF NOT EXISTS comments (\ncomment_id BIGINT(20) NOT NULL PRIMARY KEY AUTO_INCREMENT,\nusername VARCHAR(64),\ncomment MEDIUMBLOB,\ncomment_link VARCHAR(200),\ncomment_type VARCHAR(9),\nvotes_for TINYINT,\nvotes_against TINYINT,\nflags TINYINT,\nbill_id VARCHAR(20),\ncomment_ip VARCHAR(100),\ncomment TIMESTAMP DEFAULT CURRENT_TIMESTAMP,\ncomment_parent BIGINT(20),\napproved BOOL\n);\n\nCREATE TABLE IF NOT EXISTS topics (\ntopic_id BIGINT(20) NOT NULL PRIMARY KEY AUTO_INCREMENT,\ntopic VARCHAR(64)\n);\n\nCREATE TABLE IF NOT EXISTS bills_topics (\nbill_id BIGINT(20),\ntopic_id BIGINT(20)\n);\n\nCREATE TABLE IF NOT EXISTS bills (\nbill_id VARCHAR(15) NOT NULL PRIMARY KEY,\nyear YEAR(4),\ntitle MEDIUMBLOB,\nbill_name VARCHAR(6),\nvotes_for BIGINT(20),\nvotes_against BIGINT(20)\n);\n\nCREATE TABLE IF NOT EXISTS lawmakers (\nleg_id VARCHAR(9) NOT NULL PRIMARY KEY,\nfirst_name VARCHAR(32) NOT NULL,\nlast_name VARCHAR(32) NOT NULL,\nmiddle_name VARCHAR(32),\nsuffix VARCHAR(8),\nnickname VARCHAR(32),\ndistrict INT(2),\ntwitter VARCHAR(64),\nfacebook VARCHAR(64),\nwebsite VARCHAR(64),\nparty VARCHAR(24),\nactive BOOL,\nchamber VARCHAR(12),\nphoto_url VARCHAR(64)\n);\n\nCREATE TABLE IF NOT EXISTS leg_geo (\ndistrict INT(2) PRIMARY KEY,\npolygon POLYGON NOT NULL\n);\n\nCREATE TABLE IF NOT EXISTS user_bills (\nbill_id BIGINT(20),\nuser_id VARCHAR(64)\n);\n\nCREATE TABLE IF NOT EXISTS user_friends (\nuser_id VARCHAR(64),\nfriend_id VARCHAR(64)\n);\n\nCREATE TABLE IF NOT EXISTS user_topics (\nuser_id VARCHAR(64),\ntopic_id BIGINT(20)\n);\n\nCREATE TABLE IF NOT EXISTS user_lawmakers (\nuser_id VARCHAR(64),\nlawmaker VARCHAR(9)\n);\n\n"
},
{
"alpha_fraction": 0.5272276997566223,
"alphanum_fraction": 0.5272276997566223,
"avg_line_length": 15.875,
"blob_id": "f07b258171318224215456721402d930ddcf4d23",
"content_id": "c00731efb23b5a92558408330206699184c8d4ef",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 404,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 24,
"path": "/lib/session_start.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\nif (!isset($_SESSION)) {\nsession_start();\n}\n\nif (isset($_SESSION[\"flash\"])) {\n\t?>\n\t<div id=\"flash\"> <?= $_SESSION[\"flash\"] ?> </div>\n\t<?php\n\tunset($_SESSION[\"flash\"]);\n\t}\n\n \n \n/* if (isset($_SESSION[\"access_granted\"]) && $_SESSION[\"access_granted\"]) {\n header(\"Location:granted.php\");\n }\n\n $user = \"\";\n if (isset($_SESSION[\"user_preset\"])) {\n $user = $_SESSION[\"user_preset\"];\n } */\n?>"
},
{
"alpha_fraction": 0.5360303521156311,
"alphanum_fraction": 0.5512009859085083,
"avg_line_length": 20.405405044555664,
"blob_id": "c378d92695cfcb4d62adc3fa916569cc766d2c12",
"content_id": "41651b75777a180ac667c30c9f03a1b7cb78e5b8",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 791,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 37,
"path": "/lib/newuser.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n\nif (!isset($_SESSION)) {\n\tsession_start();\n}\n\nrequire_once(\"classes/dao.php\");\n\nif (isset($_POST[\"username\"]) && isset($_POST[\"password\"]) && isset($_POST[\"email\"])) {\n\t$username = $_POST[\"username\"];\n\t$password = $_POST[\"password\"];\n\t$email = $_POST[\"email\"];\n\n\ttry {\n\t\t$dao = new Dao();\n\t\tif ($dao -> newUser($username, $password, $email)) {\n\t\t\t$_SESSION[\"name\"] = $username;\n\t\t\t\n\t\t\tif (isset($_POST['rememberme']) && $_POST['rememberme']) {\n\t\t\t\t$expireTime = time() + 60*60*24*180; # 180 days from now\n\t\t\t\tsetcookie(\"username\", $_SESSION[\"name\"], $expireTime); }\n\t\t\t\t\n\t\t$dao -> redirect(\"../index.php\", \"Welcome to idleg, $username!\");\n\t\t\n\t\t\t\n\t\t}\n\t\telse {\n\t\t\t$dao -> redirect(\"../index.php\", \"User setup failed.\");\n\t\t}\n\t}\n\tcatch (Exception $e) {\n\t\tvar_dump($e);\n\t\tdie;\n\t}\n}\n\n?>"
},
{
"alpha_fraction": 0.5604223608970642,
"alphanum_fraction": 0.5756745934486389,
"avg_line_length": 26.5053768157959,
"blob_id": "617c3e505a14cfd08c5eb43c49bca7999780f3c2",
"content_id": "7a517ab18ac3652605e855767fa232932c16b542",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2557,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 93,
"path": "/lib/functions.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php // outputs e.g. somefile.txt was last modified: December 29 2002 22:16:23.\n\n$filename = 'index.html';\nif (file_exists($filename)) {\n echo \"$filename was last modified: \" . date (\"F d Y H:i:s.\", filemtime($filename));\n}\n\n\n\n$db = new PDO(\"mysql:host=127.0.0.1;port=8889;dbname=idleg_test\", \"root\", \"root\");\n$query = $db->prepare('SELECT * from users where username = \"paleomedia\"');\n$query->execute();\n?>\n<pre>\n<?php\nwhile($rows = $query->fetch(PDO::FETCH_ASSOC)){\n var_dump($rows); } ?>\n </pre>\n\n<?php\n \n if ($db->connect_error) {\n die(\"Connection failed: \" . $db->connect_error);\n } \n echo \"Connected successfully (\".$db->host_info.\")\";\n\n\n$db = new PDO(\"mysql:host=127.0.0.1;port=8889;dbname=idleg_test\", \"root\", \"root\");\n var_dump($db);\n \n if ($db->connect_error) {\n die(\"Connection failed: \" . $db->connect_error);\n } \n echo \"Connected successfully (\".$db->host_info.\")\";\n\n?>\n\n\n\n\n/* read the json file contents */\n\n<?php \n $jsondata = file_get_contents('http://openstates.org/api/v1/legislators/?apikey=bcc2a830883c4f459dbffe94b2a3e90f&state=id');\n var_dump($jsondata);\n \n//convert json object to php associative array\n $data = json_decode($jsondata, true);\n \n var_dump($data);\n \n//get the legislator details\n// FIXXXXXX\n// extra fields $suffix = $data['personal']['address']['streetaddress'];\n// $nickname = $data['personal']['address']['city'];\n// $website = $data['personal']['address']['postalcode']; \n\n $first_name = $data['first_name'];\n $last_name = $data['last_name'];\n $middle_name = $data['middle_name'];\n $district = $data['district'];\n $party = $data['party'];\n $active = $data['active'];\n $chamber = $data['chamber'];\n $photo_url = $data['photo_url'];\n \n \n $host = getenv('IP');\n $user = getenv('C9_USER');\n $password = \"\";\n $database = \"c9\";\n $dbport = 3306;\n\n try {\n $db = new PDO(\"mysql:dbname=$database; host=$host\", $user, $password);\n $db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);\n \n} catch (PDOException $ex) {\n print \"Error!: \" . $ex->getMessage() . \"<br/>\";\n die();\n}\n \n//insert into mysql table\n mysql_select_db(\"lawmakers\", $cxn);\n $sql = \"INSERT INTO lawmakers(first_name, last_name, middle_name, district, party, active, chamber, photo_url)\n VALUES('$first_name', '$last_name', '$middle_name', '$district', '$party', '$active', '$chamber', '$photo_url')\";\n if(!mysql_query($sql,$con))\n {\n die('Error : ' . mysql_error());\n }\n }\n\n?>"
},
{
"alpha_fraction": 0.5686220526695251,
"alphanum_fraction": 0.5727725625038147,
"avg_line_length": 29.378150939941406,
"blob_id": "6c842d639a045db80c7da6203c28735f7f758dac",
"content_id": "7c447159ea2ce50ac24c422b6137c91badf937e6",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3614,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 119,
"path": "/lib/classes/dao.php",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "<?php\n// dao.php\n// class for saving and getting info to/from MySQL\n\nclass Dao {\n\n private $dbhost = \"paleomedia-idleg-1299620\";\n private $user = \"paleomedia\";\n private $password = \"\";\n private $database = \"c9\";\n private $dbport = 3306; \n \n public function getConnection () {\n return\n new PDO(\"mysql:host={$this->dbhost};dbname={$this->database};port={$this->dbport}\", $this->user, $this->password);\n }\n \n public function check_login($name, $password) {\n $conn = $this->getConnection();\n $name = $conn->quote($name);\n $rows = $conn->query(\"SELECT password FROM users WHERE username = $name\");\n if ($rows) {\n foreach ($rows as $row) { #only one row should match \n if ($password === $row[\"password\"]) {\n return TRUE;\n }\n }\n }\n return FALSE; # user not found, or wrong password\n }\n\n public function ensure_logged_in() {\n if (!isset($_SESSION[$name])) {\n redirect(\"index.php\", \"You must login first\");\n }\n }\n\n public function redirect($url, $flash_message = NULL) {\n\t if ($flash_message) {\n\t\t$_SESSION[\"flash\"] = $flash_message;\n\t }\n\t header(\"Location: $url\");\n\t die;\n\t}\n\n public function saveComment ($username, $comment, $bill, $comment_type) {\n $conn = $this->getConnection();\n $saveQuery =\n \"INSERT INTO comments\n (username, comment, bill_id, comment_type)\n VALUES\n (:username, :comment, :bill, :comment_type)\";\n $q = $conn->prepare($saveQuery);\n $q->bindParam(\":username\", $username);\n $q->bindParam(\":comment\", $comment);\n $q->bindParam(\":bill\", $bill);\n $q->bindParam(\":comment_type\", $comment_type);\n return $q->execute();\n }\n\n public function getComments ($bill, $comment_type) {\n $conn = $this->getConnection();\n return $conn->query(\"SELECT username, comment, date FROM comments WHERE bill_id = '$bill' AND comment_type = '$comment_type'\");\n }\n \n public function getUserComments ($user) {\n $conn = $this->getConnection();\n return $conn->query(\"SELECT comment, date FROM comments\n WHERE username = '$user'\n ORDER BY date\n LIMIT 5\");\n }\n \n public function newUser ($username, $password, $email) {\n $conn = $this->getConnection();\n $saveQuery =\n \"INSERT INTO users\n (username, password, email)\n VALUES\n (:username, :password, :email)\";\n $q = $conn->prepare($saveQuery);\n $q->bindParam(\":username\", $username);\n $q->bindParam(\":password\", $password);\n $q->bindParam(\":email\", $email);\n return $q->execute();\n }\n \n public function saveBills ($bill_id, $year, $title, $bill_name, $connection) {\n \n $saveQuery =\n \"INSERT INTO bills\n (bill_id, year, title, bill_name)\n VALUES\n (:bill_id, :year, :title, :bill_name)\";\n $q = $connection->prepare($saveQuery);\n $q->bindParam(\":bill_id\", $bill_id);\n $q->bindParam(\":year\", $year);\n $q->bindParam(\":title\", $title);\n $q->bindParam(\":bill_name\", $bill_name);\n $q->execute();\n return $bill_name;\n }\n \n public function getBills () {\n $conn = $this->getConnection();\n return $conn->query(\"SELECT bill_name, bill_id, title, (votes_for + votes_against) AS total\n FROM bills\n ORDER BY total\n LIMIT 20\");\n }\n \n public function getLegislators () {\n $conn = $this->getConnection();\n return $conn->query(\"SELECT first_name, last_name, middle_name, district, party, chamber, photo_url\n FROM lawmakers\");\n }\n \n} // end Dao\n?>"
},
{
"alpha_fraction": 0.6826149821281433,
"alphanum_fraction": 0.6860021948814392,
"avg_line_length": 33.937870025634766,
"blob_id": "1058118b59f51c1d41d26da7ae1c385c442d3654",
"content_id": "3ddafe704ef4fdaba8e985e17ccf057802781146",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11809,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 338,
"path": "/app/idleg/views.py",
"repo_name": "paleomedia/idleg_flask",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request, Blueprint, jsonify, json, flash, redirect, url_for, session, send_from_directory\nfrom flask import g, session\nfrom werkzeug import abort\nfrom app import app, db\nfrom app import login_manager, facebook\nfrom app.cache import cache\nfrom flask_login import current_user, login_user, logout_user, login_required\nfrom app.idleg.models import User, RegistrationForm, LoginForm, SearchForm, Bill, Comment, CommentForm, Lawmaker, lastCall\nfrom sqlalchemy import cast, Integer, desc\n#from flask_restful import Resource, Api\n#from flask.ext.restful import reqparse\nfrom json import dumps\n\nidleg = Blueprint('idleg', __name__)\n#apiModule = Blueprint('api', __name__)\n\n@login_manager.user_loader\ndef load_user(id):\n return User.query.get(int(id))\n \n@idleg.before_request\ndef get_current_user():\n g.user = current_user\n \n# function to convert json for sqlite database\ndef byteify(input):\n if isinstance(input, dict):\n return {byteify(key):byteify(value) for key,value in input.iteritems()}\n elif isinstance(input, list):\n return [byteify(element) for element in input]\n elif isinstance(input, unicode):\n return input.encode('utf-8')\n else:\n return input\n \n# routes for login and registrations -------------------------------\n@idleg.route('/register', methods=['GET', 'POST'])\ndef register():\n if session.get('username'):\n flash('Your are already logged in.', 'info')\n return redirect(url_for('idleg.home'))\n\n r_form = RegistrationForm(request.form, prefix=\"register-form\")\n\n if request.method == 'POST' and r_form.validate():\n username = request.form.get('username')\n password = request.form.get('password')\n email= request.form.get('email')\n confirm = request.form.get('confirm')\n existing_username = User.query.filter_by(username=username).first()\n if existing_username:\n flash('This username has been already taken. Try another one.','warning')\n return render_template('register.html', rform=r_form, lform=LoginForm(), )\n user = User(username, password, email)\n db.session.add(user)\n db.session.commit()\n login_user(user)\n flash('You are now registered and logged in.', 'success')\n return redirect(url_for('idleg.home'))\n if r_form.errors:\n flash(r_form.errors, 'danger')\n return render_template('register.html', lform=LoginForm(), rform=r_form)\n\n@idleg.route('/login', methods=['GET', 'POST'])\ndef login():\n if current_user.is_authenticated:\n flash('You are already logged in.')\n return redirect(url_for('idleg.home'))\n\n l_form = LoginForm(request.form, prefix=\"login-form\")\n\n if request.method == 'POST' and l_form.validate():\n username = request.form.get('username')\n password = request.form.get('password')\n existing_user = User.query.filter_by(username=username).first()\n if not (existing_user and existing_user.check_password(password)):\n popup = True\n flash('Invalid username or password. Please try again.', 'danger')\n return render_template('login.html', lform=l_form, rform=RegistrationForm(), popup=popup)\n login_user(existing_user)\n flash('You have successfully logged in.', 'success')\n return redirect(url_for('idleg.home'))\n if l_form.errors:\n popup = True\n flash(l_form.errors, 'danger')\n return render_template('login.html',lform=l_form, rform=RegistrationForm(), popup=popup)\n \n@idleg.route('/facebook-login')\ndef facebook_login():\n return facebook.authorize(callback=url_for('idleg.facebook_authorized', next=request.args.get('next') or request.referrer or None, _external=True))\n\n@idleg.route('/facebook-login/authorized')\n@facebook.authorized_handler\ndef facebook_authorized(resp):\n if resp is None:\n return 'Access denied: reason=%s error=%s' % (request.args['error_reason'], request.args['error_description'])\n session['facebook_oauth_token'] = (resp['access_token'], '')\n me = facebook.get('/me?fields=id,name,email')\n user = User.query.filter_by(email=me.data['email']).first()\n if not user:\n user = User(username=me.data['name'], email=me.data['email'], password=me.data['id'])\n db.session.add(user)\n db.session.commit()\n \n login_user(user)\n flash('Logged in as id=%s name=%s' % (me.data['id'], me.data['name']),'success')\n return redirect(request.args.get('next'))\n \n@facebook.tokengetter\ndef get_facebook_oauth_token():\n return session.get('facebook_oauth_token')\n\n@idleg.route('/logout')\n@login_required\ndef logout():\n logout_user()\n return redirect(url_for('idleg.home'))\n \n@app.route('/favicon.ico')\ndef favicon():\n import os\n return send_from_directory(os.path.join(app.root_path, 'static', 'images'), 'favicon.ico', mimetype='image/png')\n\n# routes to download data from Sunlight <---- to be automated later\n@idleg.route('/populateBills')\ndef populateBills():\n from datetime import datetime, date\n lastSunCall = lastCall.query.order_by(lastCall.id.desc()).first()\n \n import sunlight\n import json\n from sunlight import openstates\n id_bill_json = openstates.bills(\n state = 'id',\n updated_since = '%s' % lastSunCall.lastSunlight\n )\n print id_bill_json\n id_bills = byteify(json.dumps(id_bill_json))\n\n for bill in id_bill_json:\n bill_adder = Bill(bill[\"bill_id\"], bill[\"session\"], bill[\"title\"], bill[\"id\"], bill[\"updated_at\"])\n db.session.merge(bill_adder)\n db.session.commit()\n \n lastSunCall=datetime.now().date()\n lastSunCall=lastSunCall.strftime('%Y-%m-%d')\n \n dateUpdate = lastCall(lastSunCall)\n #lastCall.query.with_entities(lastCall.lastSunlight).one()\n db.session.merge(dateUpdate)\n db.session.commit()\n \n return id_bills\n\n@idleg.route('/populateLawmakers')\ndef populateLawmakers():\n import sunlight\n import json\n from sunlight import openstates\n id_lm_json = openstates.legislators(\n state = 'id'\n# active = 'true'\n )\n print id_lm_json\n id_lm = byteify(json.dumps(id_lm_json))\n for lm in id_lm_json:\n lm_adder = Lawmaker(lm[\"leg_id\"], lm[\"first_name\"], lm[\"last_name\"], lm[\"middle_name\"], lm[\"district\"], lm[\"chamber\"], lm[\"url\"], lm[\"email\"], lm[\"party\"], lm[\"photo_url\"])\n db.session.add(lm_adder)\n db.session.commit()\n return id_lm\n \n# main app routes --------------\n@idleg.route('/', methods=['GET','POST'])\n@idleg.route('/index', methods=['GET','POST'])\n@idleg.route('/home', methods=['GET','POST'])\n@idleg.route('/index/<int:page>', methods=['GET','POST'])\n@cache.cached(timeout=60)\ndef home(page=1):\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n comment_form = CommentForm(request.form)\n search_form = SearchForm(request.form)\n \n id_bills = Bill.query.order_by(desc(Bill.last_updated)).paginate(page, 10, False)\n\n return render_template('home.html', user=current_user, id_bills=id_bills, lform=lform, comment_form=comment_form, search_form=search_form, rform=rform)\n\n# route gets more bills by year by AJAX\n'''\n@idleg.route('/loadBills', methods=['POST'])\n@cache.cached(timeout=5000)\ndef loadBills():\n # year=\"2016\"\n if request.method == 'POST':\n billyear=request.json['billyear']\n print type(billyear)\n moreBills = Bill.query.order_by(desc(Bill.last_updated)).filter_by(year=billyear)\n return moreBills\n'''\n\n@idleg.route('/search', methods=['POST', 'GET'])\ndef search(page=1):\n import sunlight\n import json\n from sunlight import openstates\n form=SearchForm(request.form)\n \n if request.method == 'POST' and form.validate():\n searchTerm = request.form.get('search')\n \n# if len(year)==1:\n# year = 'session:'+year\n# else:\n# year = 'session:'+year[-1]+'-'+year[0]\n \n house = request.form.get('house')\n if house == 'all':\n house = ''\n \n year = form.year.data\n print year\n if year == []:\n year = [2017]\n \n searchResults = []\n for session in year:\n \n searchResult_json = openstates.bills(\n state = 'id',\n active = 'true',\n chamber = '%s' % house,\n search_window = 'session:%s' % session,\n q = '%s' % searchTerm,\n fields='bill_id'\n )\n searchResults.extend(searchResult_json)\n \n idList = []\n for bill in searchResults:\n idList.append(bill['id'])\n #idList = json.dumps(idList)\n \n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n comment_form = CommentForm(request.form)\n search_form = SearchForm(request.form)\n \n id_bills = Bill.query.filter(Bill.bill_name.in_(idList)).order_by(desc(Bill.last_updated)).paginate(page, 10, False)\n\n return render_template('home.html', user=current_user, id_bills=id_bills, lform=lform, rform=rform, comment_form=comment_form, search_form=search_form)\n\n@idleg.route('/about')\ndef about():\n form = RegistrationForm(request.form)\n return render_template('about.html', user=current_user, form=form)\n\n@idleg.route('/lawmakers')\ndef lawmakers():\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n lawmakers = Lawmaker.query.order_by(cast(Lawmaker.district, Integer)).all()\n return render_template('lawmakers.html', user=current_user, lform=lform, rform=rform, lawmakers=lawmakers)\n \n@idleg.route('/lawmaker/<path:legid>')\ndef lawmaker(legid):\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n# Get lawmaker detail from Sunlight\n import sunlight\n import json\n from sunlight import openstates\n id_lm_json = openstates.legislator_detail(legid)\n lawmakers = Lawmaker.query.filter_by(leg_id=legid).first()\n\n return render_template('leg_detail.html', legid=legid, lawmakers=lawmakers, id_lm_json=id_lm_json, user=current_user, lform=lform, rform=rform)\n\n@idleg.route('/topics')\ndef topics():\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n return render_template('topics.html', user=current_user, lform=lform, rform=rform)\n\n@idleg.route('/bills/<path:bill_deet>')\ndef bills(bill_deet):\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n bill_deets = Bill.query.filter_by(bill_name=bill_deet).first_or_404()\n \n# Get bill detail from Sunlight\n import sunlight\n import json\n from sunlight import openstates\n id_bill_json = openstates.bill_detail(\n state = 'id',\n session = '%s' % bill_deets.year,\n bill_id = '%s' % bill_deets.bill_id\n )\n\n# vote_chart = {}\n# for vote in id_bill_json:\n# for yes_vote in vote.votes:\n\n# vote_chart_json = json.dumps(vote_chart)\n \n lawmakers = Lawmaker.query.order_by(cast(Lawmaker.district, Integer)).all()\n return render_template('bills.html', bill_deet = bill_deet, user=current_user, id_bill_json=id_bill_json, lawmakers=lawmakers, lform=lform, rform=rform)\n \n@idleg.route('/billyear/<path:year>')\n@cache.cached(timeout=5000)\ndef billyear(year):\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n comment_form = CommentForm(request.form)\n id_bills = Bill.query.order_by(desc(Bill.last_updated)).filter_by(year=year)\n return render_template('home.html', user=current_user, id_bills=id_bills, lform=lform, rform=rform, comment_form=comment_form)\n \n\n@app.route('/comment', methods=['POST'])\n@login_required\ndef add_comment():\n rform = RegistrationForm(request.form)\n lform = LoginForm(request.form)\n if request.method == 'POST' and form.validate():\n comment = request.form.get('comment')\n author = current_user.id\n position = request.form.get('position')\n bill_num = request.form.get('bill_num')\n newComment = Comment(comment, author, position, bill_num)\n db.session.add(newComment)\n db.session.commit()\n cache.clear()\n return jsonify({'comment': comment, 'author': author, 'position' : position, 'bill_num': bill_num})\n flash(form.errors, 'danger')\n return \"\"\n\n@idleg.errorhandler(404)\ndef page_not_found(e):\n return render_template('404.html'), 404\n"
}
] | 35 |
Vishal-exe123/JavaScript_HTML_CSS_Docker | https://github.com/Vishal-exe123/JavaScript_HTML_CSS_Docker | 88ccf83c8d2a02c1604c7e03c6cbd2c4c4fc5889 | 4770da299bc2929b611a3b694a46c92449ff4c32 | 9c1a46bade91763030ccf6a7c7a9f045c0a53276 | refs/heads/main | 2023-06-04T04:30:01.737575 | 2022-10-19T13:33:07 | 2022-10-19T13:33:07 | 381,088,148 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7753623127937317,
"alphanum_fraction": 0.7753623127937317,
"avg_line_length": 45,
"blob_id": "bca6583ea870e2abe749fb9b53e2495af35a3f54",
"content_id": "ca55055cf53f8c4817a15234b042a4f99cc3c2a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Vishal-exe123/JavaScript_HTML_CSS_Docker",
"src_encoding": "UTF-8",
"text": "# JavaScript_HTML_CSS_Docker\n# Docker Interpreter Using CSS, HTML and Java Script\n## Languages: Java Script, CSS, HTML and Bash Scripting\n"
},
{
"alpha_fraction": 0.7098039388656616,
"alphanum_fraction": 0.7137255072593689,
"avg_line_length": 17.214284896850586,
"blob_id": "f723853e254a54dfb63e5528ab41656cdca16d84",
"content_id": "146d4f63535adc632eb4c88faeb3b8a93ebbf99b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 255,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 14,
"path": "/dockerCMD.py",
"repo_name": "Vishal-exe123/JavaScript_HTML_CSS_Docker",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3\n\nimport cgi\nimport subprocess\n\nprint(\"content-type: text/html\")\nprint(\"Access-Control-Allow-Origin: *\")\nprint()\n\nvishdata = cgi.FieldStorage()\ncmd = vishdata.getvalue(\"x\")\n\noutput = subprocess.getoutput(\"sudo \"+cmd)\nprint(output)\n"
}
] | 2 |
moumen-soliman/show-me-the-data-structures | https://github.com/moumen-soliman/show-me-the-data-structures | 514abcc09e6a5117a4dbcc87096b28b5000affa3 | 0f8eba83363d0fa8378c2142468ad7cdcccbeffc | 454293bfdaae308cda45f772151ed1cc87e2b08c | refs/heads/master | 2022-04-22T22:34:19.943448 | 2020-04-18T20:35:23 | 2020-04-18T20:35:23 | 256,846,585 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.623711347579956,
"alphanum_fraction": 0.6362297534942627,
"avg_line_length": 26.15999984741211,
"blob_id": "528eebd28981f5a7c9c5d14c0d317ba03facb200",
"content_id": "b541387e2740508fa9c458f26355758c2ed5e73e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1358,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 50,
"path": "/solution_5.py",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "import hashlib\nimport datetime\nclass Block:\n\n def __init__(self, timestamp, data, previous_hash):\n self.timestamp = timestamp\n self.data = data\n self.previous_hash = previous_hash\n self.hash = self.calc_hash(data)\n\n def calc_hash(self, data):\n sha = hashlib.sha256()\n hash_str = data.encode('utf-8')\n sha.update(hash_str)\n return sha.hexdigest()\n\n# Method 0\nclass LinkedList:\n def __init__(self):\n self.head = None\n self.last = None\n\n def append(self, timestamp, data):\n if not self.head:\n self.head = Block(timestamp, data, 0)\n self.last = self.head\n else:\n temp = self.last\n self.last = Block(timestamp, data, temp)\n self.last.previous_hash = temp\n\ndef get_utc_time():\n utc = datetime.datetime.utcnow()\n return utc.strftime(\"%d/%m/%Y %H:%M:%S\")\n\n# Method 1\nblock0 = Block(get_utc_time(), \"Some Information\", 0)\nblock1 = Block(get_utc_time(), \"Another Information\", block0)\nblock2 = Block(get_utc_time(), \"Some more Information\", block1)\n\nprint(block0.data)\nprint(block0.hash)\nprint(block0.timestamp)\nprint(block1.previous_hash.data)\n\ntemp = LinkedList()\ntemp.append(get_utc_time(), \"Some Information\")\ntemp.append(get_utc_time(), \"Another Information\")\nprint(temp.last.data)\nprint(temp.last.previous_hash.data)\n"
},
{
"alpha_fraction": 0.8171428442001343,
"alphanum_fraction": 0.822857141494751,
"avg_line_length": 57.66666793823242,
"blob_id": "0164eb1de6e1ced29a3bc6c28035d121b917af6c",
"content_id": "686c5f4825897c0ad3497da97d76c6998d52793f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 3,
"path": "/README.md",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "# Show-Me-the-Data-Structure\nSolving various problems using basic data structures\nFrom Udacity's Data Structures & Algorithms Nanodegree Project 2 - Show Me the Data Structure"
},
{
"alpha_fraction": 0.7841269969940186,
"alphanum_fraction": 0.7841269969940186,
"avg_line_length": 62,
"blob_id": "c412954b6868fddccd10dd1935b8413d8828d3fa",
"content_id": "0c453249a5aeba5f19ca2c2007d7799aa8584a2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 215,
"num_lines": 5,
"path": "/explanation_2.md",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "I have written a recursive function for this question which takes input the suffix, path and the list of required files which are found till now. Each time I find a file ending with .c will be appended to this file.\n\nRun time complexity: O(depth X Avg. number of directoryin each level)\n\nSpace complexity: O(depth)\n"
},
{
"alpha_fraction": 0.7681818008422852,
"alphanum_fraction": 0.7749999761581421,
"avg_line_length": 61.85714340209961,
"blob_id": "f337571faec79ca582cefdcd6b5f70d7a88e9815",
"content_id": "4d577fd43e3298a087a07d62776c004e827870e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 440,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 7,
"path": "/explanation_1.md",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "As I have to design a data structure for a Least Recently Used (LRU) cache with O(1) operations. It's the best option to go with dictionary in python which has constant time access of values with particular key.\nTo keep track of the order of the values I have created a queue with the help of python deque, which allows constant time popleft().\n\nGet Time complexity: O(1)\nSet Time complexity: O(1)\n\nSpace complexity of the LRU: O(capacity)\n"
},
{
"alpha_fraction": 0.667735755443573,
"alphanum_fraction": 0.6786401271820068,
"avg_line_length": 37.024391174316406,
"blob_id": "af21b3bd2fa6b92a381e9866b4f333c0010570d3",
"content_id": "623b8cb7bfb2d7c30dda437055dbe105133fca9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1559,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 41,
"path": "/solution_1.py",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "'''\nDesign a a data structure for a Least Recently Used (LRU) cache with O(1) operations.\nIt holds most recently used items while staying memory constrained. Specifically, the LRU cache removes recently used items when low on memory or capacity.\nIt to support two operations, get and set\nThe get operation should retrieve the value if the key exists, otherwise it should return -1 if it does not exist.\nThe set operation will insert the value if the key is not present. If the cache is full then it should remove the oldest item before inserting a new item.\n'''\nfrom collections import deque\n\nclass LRU_Cache(object):\n\n def __init__(self, capacity):\n # Initialize class variables\n self.cache_cap = capacity\n self.cache_val = {}\n self.cache_order = deque()\n\n def get(self, key):\n # Retrieve item from provided key. Return -1 if non existant.\n if key is None:\n return -1\n\n return self.cache_val.get(key, -1)\n\n def set(self, key, value):\n # Set the value if the key is not present in the cache. If the cache is at capacity remove the oldest item.\n if len(self.cache_order) >= self.cache_cap:\n del self.cache_val[self.cache_order.popleft()]\n self.cache_order.append(key)\n self.cache_val[key] = value\n'''\nFor testing'''\nour_cache = LRU_Cache(2)\n\nour_cache.set(1, 1)\nour_cache.set(2, 2)\nour_cache.set(3, 2)\nprint(our_cache.cache_val)\nprint(our_cache.get(1)) # returns -1\nprint(our_cache.get(2)) # returns 2\nprint(our_cache.get(None)) # return -1\n"
},
{
"alpha_fraction": 0.7852760553359985,
"alphanum_fraction": 0.803680956363678,
"avg_line_length": 39.75,
"blob_id": "03f27c127d50121786fb2cb080af0b003291c202",
"content_id": "af2b0b020ad742298840c8e5ff9cf43131b69357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 326,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 8,
"path": "/explanation_3.md",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "I have implemented huffman encoding technique here with following steps:\n\ni) Calculate the occurences of each characters in a string.\nii) Character with highest occurence is encoded with minimum code length ie 1\nthen next Character as 01 and then 001 and so on.\n\nTime complexity: O(n)\nSpace complexity: O(distinct_characters)\n"
},
{
"alpha_fraction": 0.7584905624389648,
"alphanum_fraction": 0.7584905624389648,
"avg_line_length": 28.44444465637207,
"blob_id": "e991c89e16df48025ec958636d4b93997f703b20",
"content_id": "299262d62eba499472b985fc8fbdd3b1fff97d7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 9,
"path": "/explanation_6.md",
"repo_name": "moumen-soliman/show-me-the-data-structures",
"src_encoding": "UTF-8",
"text": "In this problem, first I have created a set for making union & intersection of the two linked list. Then I have created a new linked list from the set.\n\nUnion:\nTime complexity: O(n)\nSpace complexity: O(n)\n\nintersection:\nTime complexity: O(n)\nSpace complexity: O(n)\n"
}
] | 7 |
Ibrahim-Alqarni/IoT | https://github.com/Ibrahim-Alqarni/IoT | 6bb77f085d36a46fd46e81d3c9b44c03390e2513 | 5aa5bf1d80cb4b571bd453121df10944337cd40d | c02e8b2211de39d01e3208d1d717669a9c9b3a65 | refs/heads/main | 2023-04-20T20:45:52.907215 | 2021-05-14T04:36:32 | 2021-05-14T04:36:32 | 335,719,670 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7010676264762878,
"alphanum_fraction": 0.7153024673461914,
"avg_line_length": 20.69230842590332,
"blob_id": "fcd2b99515fb03b0fc2e7fb6be6187232a15844a",
"content_id": "47b4298f82cfdb92477391a261dec2bb55e9b0cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 13,
"path": "/Final Project/PIR motion sensor/parent_detector.py",
"repo_name": "Ibrahim-Alqarni/IoT",
"src_encoding": "UTF-8",
"text": "from gpiozero import MotionSensor\nfrom picamera import PiCamera\n\npir = MotionSensor(4)\ncamera = PiCamera()\nfilename = \"intruder.h264\"\n\nwhile True:\n pir.wait_for_motion()\n print(\"Motion detected!\")\n camera.start_preview()\n pir.wait_for_motion()\n camera.stop_preview()"
},
{
"alpha_fraction": 0.7101280689239502,
"alphanum_fraction": 0.7648428678512573,
"avg_line_length": 52.625,
"blob_id": "5defb205c73668563554e2174ba7fcf8a30d23f2",
"content_id": "153a0878ef53a71340814c24b923cd8a5ae25d18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 859,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 16,
"path": "/README.md",
"repo_name": "Ibrahim-Alqarni/IoT",
"src_encoding": "UTF-8",
"text": "# IoT -- EE 629\n\n## Final Project: Home Security Camera\n\n### The motivation for this project is to provide a security system powered by Python and Raspberry Pi.\n\n### To complete this project, I have used Raspberry Pi 4, 5 Megapixels 1080p Sensor Mini Camera Module, PIR Sensor Infrared (IR) Body Motion Module, and 3 female-to-female jumper wires.\n\n\n\n### For more information go to the Home Security Camera folder. \n\n## Credit\n\n### The following contributions by [AO8](https://gist.github.com/AO8/29e04da9a0410fd672d1e29b65908808#file-motion_video_alert-py) and [others](http://raspi.tv/2013/another-way-to-convert-raspberry-pi-camera-h264-output-to-mp4):\nUse Python, a PIR sensor, Raspberry Pi, and PiCamera to detect motion, record h264 video with timestamp, convert to mp4, then email video as an attachment from Gmail. \n"
},
{
"alpha_fraction": 0.6209523677825928,
"alphanum_fraction": 0.6669387817382812,
"avg_line_length": 35.02941131591797,
"blob_id": "a20e54d753fb3d819bb696b4e3a2cb4cedc3f538",
"content_id": "1c86044f5d1d1473bebed1b24a22b66c75a5304f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3677,
"license_type": "no_license",
"max_line_length": 206,
"num_lines": 102,
"path": "/Final Project/README.md",
"repo_name": "Ibrahim-Alqarni/IoT",
"src_encoding": "UTF-8",
"text": "## In motion_video_alert.py in Home Security Camera folder:\n### From line 1 to 12 cover required imports to make the script work:\n```sh\n1 from gpiozero import MotionSensor\n2 from picamera import PiCamera\n3 from datetime import datetime\n4 from email.mime.multipart import MIMEMultipart\n5 from email.mime.base import MIMEBase\n6 from email.mime.text import MIMEText\n7 import email.encoders\n8 import smtplib\n9 import os\n10 import email\n11 import sys\n12 import time\n``` \n### From line 14 to 18 establish important variables needed to make the camera and PIR sensor work properly:\n```sh\n14 camera = PiCamera()\n15 pir = MotionSensor(4)\n16 camera.rotation = 180 # delete or adjust to 90, 180, or 270 accordingly\n17 h264_video = \".h264\" \n18 mp4_video = \".mp4\"\n``` \n### Line 20 introduces some basic logic by creating a while loop:\n```sh\n20 while True:\n``` \n### From line 23 to 30 represent the sensor detecting motion. Once motion is detected, the camera will begin recording video. Once the sensor registers the absence of motion, the camera will stop recording:\n```sh\n23 pir.wait_for_motion()\n24 video_name = datetime.now().strftime(\"%m-%d-%Y_%H.%M.%S\")\n25 camera.start_recording(video_name + h264_video)\n26 pir.wait_for_no_motion()\n27 camera.stop_recording()\n28 os.system(\"MP4Box -add \" + video_name + h264_video + \" \" + video_name + mp4_video)\n29 os.system(\"rm \" + video_name + h264_video)\n30 footage = video_name + mp4_video\n``` \n### From line 33 to 39 are preparing the email we’re about to send:\n```sh\n33 f_time = datetime.now().strftime(\"%A %B %d %Y @ %H:%M:%S\")\n34 msg = MIMEMultipart()\n35 msg[\"Subject\"] = f_time\n36 msg[\"From\"] = \"...@gmail.com\"\n37 msg[\"To\"] = \"...@gmail.com\"\n38 text = MIMEText(\"WARNING! Motion Detected!\")\n39 msg.attach(text)\n``` \n\n### For sending the Video .mp4 to the email you have to do two steps in motion_video_alert.py:\n\n#### First step, you need to prepare the Email.\n##### To do that: \nIn line 36: \nThe first email is the sender email \n```sh\n36 msg[\"From\"] = \"...@gmail.com\"\n``` \nIn line 37: \nThe second email is the receiver email\n```sh\n37 msg[\"To\"] = \"...@gmail.com\"\n``` \n### From line 49 to 53 describe how to access a Gmail account and email everything:\n```sh\n49 server = smtplib.SMTP(\"smtp.gmail.com:587\")\n50 server.starttls()\n51 server.login(\"your_gmail_login\",\"your_gmail_password\")\n52 server.sendmail(\"your_address@gmail.com\", \"to_address@gmail.com\", msg.as_string())\n53 server.quit()\n``` \nSecond step, you need to access to a Gmail Address Account to send the video. \n##### To do that: \nIn line 51: first parameter \"\" should be the Gamai Address, and the second parameter \"\" should be the Google App Password.\n```sh\n51 server.login(\"....@gmail.com\",\"....\")\n``` \nIn line 52: first parameter \"\" should be the Sender Gmail Address, and the second parameter \"\" should be the Receiver Gmail Address\n```sh\n52 server.sendmail(\"....@gmail.com\", \"....@gmail.com\", msg.as_string())\n``` \n### From line 42 to 46 attach the mp4 video:\n```sh\n42 part = MIMEBase(\"application\", \"octet-stream\")\n43 part.set_payload(open(footage, \"rb\").read())\n44 email.encoders.encode_base64(part)\n45 part.add_header(\"Content-Disposition\", \"attachment; filename= %s\" % os.path.basename(footage))\n46 msg.attach(part)\n``` \n### Line 56 describes a simple Linux commands that deletes the mp4 (we already deleted the original h264 in line 29):\n```sh\n56 os.system(\"rm \" + footage)\n``` \n### To convert video.mp4 to video.gif:\n```sh\npi@raspberrypi:~ $ sudo apt install ffmpeg\n```\n```sh\npi@raspberrypi:~ $ ffmpeg -i the_video.mp4 the_video.gif\n```\n\n"
}
] | 3 |
r3ntru3w4n9/zerospeech | https://github.com/r3ntru3w4n9/zerospeech | ca378ed8754c6d7aef7e2e3e551be03557eda701 | 85cba96ea301c412f7d084f9f80d80ded8e26567 | add67d32ec9bb9a30d1b90065aa7a84d0217be6c | refs/heads/main | 2023-03-07T09:00:59.116696 | 2021-03-01T13:36:07 | 2021-03-01T13:36:07 | 170,731,419 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5580571293830872,
"alphanum_fraction": 0.5636571645736694,
"avg_line_length": 29.172412872314453,
"blob_id": "d6b652e41fe075a99e5866d067381cc47243eb5f",
"content_id": "d638ee4ca73ab7099b5998a34bc04e6d7b866a0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8750,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 290,
"path": "/main.py",
"repo_name": "r3ntru3w4n9/zerospeech",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\n\nfrom convert import get_trainer, test, test_single\nfrom dataloader import DataLoader, Dataset\nfrom discrete import discrete_main\nfrom hps.hps import Hps\nfrom preprocess import preprocess\nfrom trainer import Trainer\n\nif __name__ == \"__main__\":\n\n parser = argparse.ArgumentParser(description=\"zerospeech_project\")\n parser.add_argument(\n \"--preprocess\",\n default=False,\n action=\"store_true\",\n help=\"preprocess the zerospeech dataset\",\n )\n parser.add_argument(\n \"--train\",\n default=False,\n action=\"store_true\",\n help=\"start stage 1 and stage 2 training\",\n )\n parser.add_argument(\n \"--test\",\n default=False,\n action=\"store_true\",\n help=\"test the trained model on all testing files\",\n )\n parser.add_argument(\n \"--test_single\",\n default=False,\n action=\"store_true\",\n help=\"test the trained model on a single file\",\n )\n parser.add_argument(\n \"--discrete\",\n default=False,\n action=\"store_true\",\n help=\"train the discrete model ZeroSpeech needs\",\n )\n parser.add_argument(\n \"--load_model\",\n default=False,\n action=\"store_true\",\n help=\"whether to load training session from previous checkpoints\",\n )\n\n static_setting = parser.add_argument_group(\"static_setting\")\n static_setting.add_argument(\n \"--flag\", type=str, default=\"train\", help=\"constant flag\"\n )\n static_setting.add_argument(\n \"--remake\", type=bool, default=bool(0), help=\"whether to remake dataset.hdf5\"\n )\n static_setting.add_argument(\n \"--targeted_G\",\n type=bool,\n default=bool(1),\n help=\"G can only convert to target speakers and not all speakers\",\n )\n static_setting.add_argument(\n \"--one_hot\",\n type=bool,\n default=bool(0),\n help=\"Set the encoder to encode to symbolic discrete one-hot vectors\",\n )\n static_setting.add_argument(\n \"--binary_output\",\n type=bool,\n default=bool(1),\n help=\"Set the encoder to produce binary 1/0 output vectors\",\n )\n static_setting.add_argument(\n \"--binary_ver\",\n type=int,\n default=0,\n help=\"Set the binary type of the encoder output\",\n )\n static_setting.add_argument(\n \"--enc_only\",\n type=bool,\n default=bool(1),\n help=\"whether to predict only with stage 1 audoencoder\",\n )\n static_setting.add_argument(\n \"--s_speaker\",\n type=str,\n default=\"S015\",\n help=\"for the --test_single mode, set voice convergence source speaker\",\n )\n static_setting.add_argument(\n \"--t_speaker\",\n type=str,\n default=\"V001\",\n help=\"for the --test_single mode, set voice convergence target speaker\",\n )\n static_setting.add_argument(\n \"--n_clusters\", type=int, default=500, help=\"how many subword units to use\"\n )\n\n data_path = parser.add_argument_group(\"data_path\")\n data_path.add_argument(\n \"--source_path\",\n type=str,\n default=\"./data/english/train/unit/\",\n help=\"the zerospeech train unit dataset\",\n )\n data_path.add_argument(\n \"--target_path\",\n type=str,\n default=\"./data/english/train/voice/\",\n help=\"the zerospeech train voice dataset\",\n )\n data_path.add_argument(\n \"--test_path\",\n type=str,\n default=\"./data/english/test/\",\n help=\"the zerospeech test dataset\",\n )\n data_path.add_argument(\n \"--dataset_path\",\n type=str,\n default=\"./data/dataset.hdf5\",\n help=\"the processed train dataset (unit + voice)\",\n )\n data_path.add_argument(\n \"--index_path\",\n type=str,\n default=\"./data/index.json\",\n help=\"sample training segments from the train dataset, for stage 1 training\",\n )\n data_path.add_argument(\n \"--index_source_path\",\n type=str,\n default=\"./data/index_source.json\",\n help=\"sample training source segments from the train dataset, for stage 2 training\",\n )\n data_path.add_argument(\n \"--index_target_path\",\n type=str,\n default=\"./data/index_target.json\",\n help=\"sample training target segments from the train dataset, for stage 2 training\",\n )\n data_path.add_argument(\n \"--speaker2id_path\",\n type=str,\n default=\"./data/speaker2id.json\",\n help=\"records speaker and speaker id\",\n )\n\n model_path = parser.add_argument_group(\"model_path\")\n model_path.add_argument(\n \"--hps_path\",\n type=str,\n default=\"./hps/zerospeech.json\",\n help=\"hyperparameter path\",\n )\n model_path.add_argument(\n \"--ckpt_dir\",\n type=str,\n default=\"./ckpt\",\n help=\"checkpoint directory for training storage\",\n )\n model_path.add_argument(\n \"--result_dir\",\n type=str,\n default=\"./result\",\n help=\"result directory for generating test results\",\n )\n model_path.add_argument(\n \"--model_name\",\n type=str,\n default=\"model.pth\",\n help=\"base model name for training\",\n )\n model_path.add_argument(\n \"--load_train_model_name\",\n type=str,\n default=\"model.pth-s1-100000\",\n help=\"the model to restore for training, the command --load_model will load this model\",\n )\n model_path.add_argument(\n \"--load_test_model_name\",\n type=str,\n default=\"model.pth-s2-150000\",\n help=\"the model to restore for testing, the command --test will load this model\",\n )\n args = parser.parse_args()\n\n HPS = Hps(args.hps_path)\n hps = HPS.get_tuple()\n\n if args.preprocess:\n\n preprocess(\n args.source_path,\n args.target_path,\n args.test_path,\n args.dataset_path,\n args.index_path,\n args.index_source_path,\n args.index_target_path,\n args.speaker2id_path,\n seg_len=hps.seg_len,\n n_samples=hps.n_samples,\n dset=args.flag,\n resample=args.resample,\n )\n\n if args.train:\n\n # ---create datasets---#\n dataset = Dataset(args.dataset_path, args.index_path, seg_len=hps.seg_len)\n sourceset = Dataset(\n args.dataset_path, args.index_source_path, seg_len=hps.seg_len\n )\n targetset = Dataset(\n args.dataset_path, args.index_target_path, seg_len=hps.seg_len\n )\n\n # ---create data loaders---#\n data_loader = DataLoader(dataset, hps.batch_size)\n source_loader = DataLoader(sourceset, hps.batch_size)\n target_loader = DataLoader(targetset, hps.batch_size)\n\n # ---handle paths---#\n os.makedirs(args.ckpt_dir, exist_ok=True)\n model_path = os.path.join(args.ckpt_dir, args.model_name)\n\n # ---initialize trainer---#\n trainer = Trainer(\n hps,\n data_loader,\n args.targeted_G,\n args.one_hot,\n args.binary_output,\n args.binary_ver,\n )\n if args.load_model:\n trainer.load_model(\n os.path.join(args.ckpt_dir, args.load_train_model_name), model_all=False\n )\n\n if args.train:\n # Stage 1 pre-train: encoder-decoder reconstruction\n trainer.train(model_path, args.flag, mode=\"pretrain_AE\")\n # trainer.train(model_path, args.flag, mode='pretrain_C') # Stage 1 pre-train: classifier-1\n # trainer.train(model_path, args.flag, mode='train')\n # # Stage 1 training\n\n # trainer.add_duo_loader(source_loader, target_loader)\n # trainer.train(model_path, args.flag, mode='patchGAN') # Stage 2\n # training\n\n if args.test or args.test_single:\n\n os.makedirs(args.result_dir, exist_ok=True)\n model_path = os.path.join(args.ckpt_dir, args.load_test_model_name)\n trainer = get_trainer(\n args.hps_path,\n model_path,\n args.targeted_G,\n args.one_hot,\n args.binary_output,\n args.binary_ver,\n )\n\n if args.test:\n test(\n trainer,\n args.dataset_path,\n args.speaker2id_path,\n args.result_dir,\n args.enc_only,\n args.flag,\n )\n if args.test_single:\n test_single(\n trainer,\n args.speaker2id_path,\n args.result_dir,\n args.enc_only,\n args.s_speaker,\n args.t_speaker,\n )\n\n discrete_main(args)\n"
}
] | 1 |
Epiphane/LudumDare | https://github.com/Epiphane/LudumDare | 09d4016d4127c2c9cf2776e7885ac95d16db4c20 | 81e9f17cc8cb6d7b0d507031929c375b3934f8a0 | fbdd9fbe33ea885321e1579805b3dcb05d3ad9f0 | refs/heads/master | 2021-01-22T13:37:02.274701 | 2013-08-26T23:59:56 | 2013-08-26T23:59:56 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.533494770526886,
"alphanum_fraction": 0.5913370847702026,
"avg_line_length": 41.2386360168457,
"blob_id": "0865aa25cb81d66c6eebce4d1550e63d9bdfce71",
"content_id": "f1df5ec5ba84659971356f68c91ffd5827050475",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3717,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 88,
"path": "/character_select.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "CHARACTER_HEIGHT = 278\nCHARACTER_WIDTH = 196\n# How much room between each button?\nCHARACTER_PADDING = [100, 20]\nCHARACTER_STEP = [4, 4]\n\ncharacters = [\"Lars\", \"Buster\", \"Ted\", \"SmithWickers\", \"Pate\", \"EricStrohm\"]\ncharacterColors = [(255,255,0), (153,255,0), (166,0,0), (255,102,0), (0,51,255), (128,128,128)]\np1choice = 0\np2choice = 1\n\ndef initCharSelect():\n images[\"P1Select\"] = load_image(\"P1Select.png\", (255,191,255))\n images[\"P2Select\"] = load_image(\"P2Select.png\", (255,191,255))\n \n # Load all the menu buttons\n for i, character in enumerate(characters):\n images[character] = load_image(character + \".png\")\n images[character][0].set_colorkey(pygame.Color(\"white\"))\n # Change imagerect to where the image actually is on screen\n images[character][1].left = CHARACTER_PADDING[0] + (CHARACTER_STEP[0] + CHARACTER_WIDTH) * (i % 3)\n images[character][1].top = CHARACTER_PADDING[1] + (CHARACTER_STEP[1] + CHARACTER_HEIGHT) * math.trunc(i / 3)\n \n images[character+\"_winner\"] = load_image(character + \"_winner.png\", (255,122,122))\n # Change imagerect to where the image actually is on screen\n images[character+\"_winner\"][1].left = (SCREEN_WIDTH_PX - 800) / 2\n images[character+\"_winner\"][1].top = 0\n \n images[character+\"_loser\"] = load_image(character + \"_loser.png\", (255,122,122))\n # Change imagerect to where the image actually is on screen\n images[character+\"_loser\"][1].left = (SCREEN_WIDTH_PX - 800) / 2\n images[character+\"_loser\"][1].top = 0\n \ndef drawCharSelect(screen):\n global gameState, p1choice, p2choice\n # TODO: put an image here?\n screen.fill(pygame.Color(\"white\"))\n \n for character in characters:\n screen.blit(images[character][0], images[character][1])\n \n p1left = CHARACTER_PADDING[0] + (CHARACTER_STEP[0] + CHARACTER_WIDTH) * (p1choice % 3)\n p1top = CHARACTER_PADDING[1] + (CHARACTER_STEP[1] + CHARACTER_HEIGHT) * math.trunc(p1choice / 3)\n \n p2left = CHARACTER_PADDING[0] + (CHARACTER_STEP[0] + CHARACTER_WIDTH) * (p2choice % 3)\n p2top = CHARACTER_PADDING[1] + (CHARACTER_STEP[1] + CHARACTER_HEIGHT) * math.trunc(p2choice / 3)\n \n screen.blit(images[\"P1Select\"][0], (p1left, p1top))\n screen.blit(images[\"P2Select\"][0], (p2left, p2top))\n \ndef charSelectInput(event):\n global lastButtonClicked\n global gameState, p1choice, p2choice\n global arena, prepare, char1, char2, char1color, char2color\n \n if hasattr(event, 'key') and event.type is pygame.KEYDOWN:\n if event.key == K_SPACE or event.key == K_RETURN:\n char1, char2 = characters[p1choice], characters[p2choice]\n char1color, char2color = characterColors[p1choice], characterColors[p2choice]\n arena = Arena()\n prepare = PrepareForBattle()\n gameState = \"Prepare\"\n \n if event.key == K_UP:\n p2choice -= 3\n if p2choice < 0: p2choice += 6\n if event.key == K_DOWN: \n p2choice += 3\n if p2choice > 5: p2choice -= 6\n if event.key == K_LEFT: \n p2choice -= 1\n if p2choice < 0: p2choice = 5\n if event.key == K_RIGHT: \n p2choice += 1\n if p2choice > 5: p2choice = 0\n \n if event.key is K_w: \n p1choice -= 3\n if p1choice < 0: p1choice += 6\n if event.key is K_s: \n p1choice += 3\n if p1choice > 5: p1choice -= 6\n if event.key is K_a: \n p1choice -= 1\n if p1choice < 0: p1choice = 5\n if event.key is K_d: \n p1choice += 1\n if p1choice > 5: p1choice = 0\n"
},
{
"alpha_fraction": 0.5219227075576782,
"alphanum_fraction": 0.5365378260612488,
"avg_line_length": 38.83116912841797,
"blob_id": "15ab20a8663f232b08727578e55a433ae61a5dc8",
"content_id": "4925536b5d8f68612b4f7d6027c607aead31f4b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3079,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 77,
"path": "/effects.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "class BombDrop():\n done = False\n bombCooldown = 20\n bombs = []\n def draw(self, screen):\n # Draw the bombas\n for i,bomb in enumerate(self.bombs):\n if bomb.body is None: return\n rotAngle = bomb.body.angle\n offsetX, offsetY = arena.camera.getOffset_in_px()\n verts = vertices_with_offset(bomb, offsetX, offsetY)\n # The \"vertices\" method will return a rotated square of vertices.\n # As it turns out, if we grab the leftmost, topmost, rightmost and\n # bottommost values from these vertices, we end up with the right\n # bounding box for pygame to draw the image. Huh.\n xvals = [ x[0] for x in verts ]\n yvals = [ y[1] for y in verts ]\n left = min(xvals)\n right = max(xvals)\n top = min(yvals)\n bottom = max(yvals)\n finalRect = pygame.Rect(left, top, (right - left), (bottom - top))\n imgRot = pygame.Surface.convert_alpha(pygame.transform.rotate(images[\"bomb\"][0], rotAngle))\n screen.blit(imgRot, finalRect)\n if bomb.body.userData == \"kill me\":\n bomb.body.DestroyFixture(bomb)\n del self.bombs[i]\n \n def update(self):\n # Iterate the cooldown on bombs. If it's been long enough, drop another one!\n self.bombCooldown -= 1\n if self.bombCooldown <= 0:\n self.bombCooldown = 20\n # drop da bomb\n # Choose a random spot between 0 -> Stage Width meters\n bombX = int(random.random() * STAGE_WIDTH_M)\n # Choose a random spot in the upper half of the map to drop the bomb\n bombY = int(random.random() * SCREEN_HEIGHT_M/2 + SCREEN_HEIGHT_M)\n \n newBomb = arena.world.CreateDynamicBody(\n userData = \"bomb\",\n position = (bombX, 10),\n fixtures = b2FixtureDef(density = 5.0, shape = b2PolygonShape(box = (1,1)),\n isSensor = True))\n \n # Start with a li'l spin\n newBomb.angularVelocity = 2 - random.random() * 4\n \n self.bombs.append(newBomb.fixtures[0])\n \n def finish(self):\n self.done = True\n bombs = []\n\nclass Explosion:\n size = 5\n alpha = 255\n x = 0\n y = 0\n done = False\n def __init__(self, ex, ey):\n self.x, self.y = int(ex), int(ey)\n def draw(self, screen):\n # Transparency sucks. Make a new surface then draw the splosion onto it,\n # then draw that new surface on to the old surface.\n s = pygame.Surface((SCREEN_WIDTH_PX, SCREEN_HEIGHT_PX), HWSURFACE)\n s.set_alpha(self.alpha)\n s.set_colorkey(pygame.Color(0, 0, 0))\n pygame.draw.circle(s, pygame.Color(237, 211, 17),\n (self.x, self.y), self.size)\n \n screen.blit(s, (0,0))\n def update(self):\n self.size += 6\n self.alpha -= 15\n if self.alpha <= 0:\n self.done = True\n "
},
{
"alpha_fraction": 0.6842105388641357,
"alphanum_fraction": 0.6889952421188354,
"avg_line_length": 34,
"blob_id": "d18c0bbecb5680bdcac2c9313092192b3742f6fb",
"content_id": "e00333347575e54da3110301e4da9bb7d26b1cbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 6,
"path": "/ui_class.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "# Back is used for the scrolling image...\nclass Back(pygame.sprite.Sprite):\n\tdef __init__(self,name):\n\t\tpygame.sprite.Sprite.__init__(self)\n\t\tself.tendency = 0\n\t\tself.image, self.rect = load_image(name+'.jpg')"
},
{
"alpha_fraction": 0.5131244659423828,
"alphanum_fraction": 0.5331639647483826,
"avg_line_length": 29.765216827392578,
"blob_id": "f1417525fbb5669cd14161742cb3ef92fa3d3557",
"content_id": "05d10484942f781cd752686837bc3df04970bf81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3543,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 115,
"path": "/title.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "BTN_HEIGHT = 81\nBTN_WIDTH = 260\n# How much room between each button?\nBTN_STEP = 100\n\nbuttons = [ [\"play\",0], [\"quit\",0]]\nstates = [\"des\", \"sel\", \"cli\" ]\n\nangle = 0\nlastButtonClicked = \"\"\napp = gui.Desktop()\n\ndef initTitle():\n # Load all the menu buttons\n buttonY = SCREEN_HEIGHT_PX/2 - BTN_HEIGHT/2 - BTN_STEP\n buttonX = SCREEN_WIDTH_PX/2 - BTN_WIDTH/2\n for button in buttons:\n for state in states:\n imageName = button[0] + \"-\" + state\n images[imageName] = load_image(imageName + \".png\")\n images[imageName][0].set_colorkey(pygame.Color(\"white\"))\n # Change imagerect to where the image actually is on screen\n images[imageName][1].left = buttonX\n images[imageName][1].top = buttonY\n \n buttonY += BTN_STEP\n \n global app\n app = gui.Desktop()\n \n \ndef titleInput(event):\n # Grab mouse coords\n mousePos = pygame.mouse.get_pos()\n \n global lastButtonClicked\n global gameState\n \n # Is it just a mousemove?\n if event.type == pygame.MOUSEMOTION:\n for i, button in enumerate(buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n # Tell the button to highlight\n buttons[i][1] = 1\n else:\n # Deselect button\n buttons[i][1] = 0\n \n # Is it a new mouseclick?\n if event.type == pygame.MOUSEBUTTONDOWN:\n for i, button in enumerate(buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n lastButtonClicked = button[0]\n buttons[i][1] = 2\n \n # Is it a mouse up?\n if event.type == pygame.MOUSEBUTTONUP:\n for i, button in enumerate(buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n buttons[i][1] = 1\n if lastButtonClicked == button[0]:\n # Positive match! Rejoice!\n if button[0] == \"play\":\n global arena, prepare # Arena for minigame\n initCharSelect()\n gameState = \"CharSelect\"\n elif button[0] == \"opt\":\n makeOptions()\n elif button[0] == \"quit\":\n sys.exit()\n else:\n # Make sure we wipe the last button clicked\n lastButtonClicked = \"\"\n \ndef drawTitle(screen):\n # TODO: put an image here?\n screen.fill(pygame.Color(\"white\"))\n screen.blit(images[\"title\"][0], (SCREEN_WIDTH_PX / 2 - 500, 0))\n \n for button in buttons:\n imageName = button[0] + \"-\" + states[button[1]]\n screen.blit(images[imageName][0], images[imageName][1])\n \n# Make the Options menu out of pgu\ndef endItAll(what):\n sys.exit()\n \ndef makeOptions():\n app = gui.Desktop()\n # make sure the game closes when you hit X\n app.connect(gui.QUIT,endItAll,None)\n c = gui.Table()\n \n c.tr()\n c.td(gui.Label(\"MUSIC VOLUME:\"))\n \n c.tr()\n musicSlider = gui.HSlider(value=23,min=0,max=100,size=20,width=120)\n c.td(musicSlider)\n \n c.tr()\n c.td(gui.Label(\"SOUND VOLUME:\"))\n \n c.tr()\n soundSlider = gui.HSlider(value=23,min=0,max=100,size=20,width=120)\n c.td(soundSlider)\n \n c.tr()\n c.td(gui.Label(\"SCREEN RESOLUTION\"))\n \n c.tr()\n btn = gui.Button(\"BACK\")\n btn.connect(gui.CLICK, app.quit)\n c.td(btn,colspan=3)\n app.run(c)\n \n"
},
{
"alpha_fraction": 0.7115384340286255,
"alphanum_fraction": 0.7445054650306702,
"avg_line_length": 27.076923370361328,
"blob_id": "fefc15d4cbf23b93f9355151379331644a95843d",
"content_id": "fd3e52e18424e6b58ca9b2929a9ff6959023c503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/README.md",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "LudumDare\n=========\n\nLD 27 8/23/13-8/26/13\n\nIT IS READY.\n\nNote for developer: In order to set up the executable,\nI have made your life the epitome of easy. Run this:\n\"python makeInstaller.py\" VOILA THAT'S ALL. IT WILL\nIMPORT EVERYTHING INTO THE dist/ folder and then you\nhave to run NSIS and compile the \"installer.nsi\" file\nthat has been created and you're ready!"
},
{
"alpha_fraction": 0.575276255607605,
"alphanum_fraction": 0.5883978009223938,
"avg_line_length": 40.371429443359375,
"blob_id": "c8b4aadb00976d2194ef78455b34a6a0a5851b05",
"content_id": "9c4a9a528c1bc626ebde6b4b642c8f26d1d1008f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2896,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 70,
"path": "/camera.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "\ndef DrawPolygon(vertices, color = (0,0,0), color_2 = None):\n \"\"\" Draw a wireframe polygon given the screen vertices with the specified color.\"\"\"\n if not vertices:\n print(\"no vertices, brotha\")\n return\n \n\n if len(vertices) == 2:\n pygame.draw.aaline(screen, color, vertices[0], vertices)\n else:\n if color_2 is not None:\n pygame.draw.polygon(screen, color_2, vertices, 0)\n pygame.draw.polygon(screen, color, vertices, 2)\n\ndef DrawCircle(center, radius, color = (0,0,0), color_2 = (0,0,0)):\n \"\"\" Draw a wireframe polygon given the screen vertices with the specified color.\"\"\"\n if not center or not radius:\n return\n \n pygame.draw.circle(screen, color, center, int(radius*PPM))\n pygame.draw.circle(screen, color_2, center, int(radius*PPM), 2)\n \ndef DrawImage(vertices, userData):\n screen.blit(images[userData][0], (vertices[0], vertices[1]))\n \nclass Camera():\n def __init__(self, centerX_in_meters):\n self.background = Back(\"background\")\n self.centerX_in_meters = centerX_in_meters\n self.centerX_in_px = centerX_in_meters * PPM\n \n self.dx = 0\n \n def getOffset_in_meters(self):\n offsetX_in_meters = self.centerX_in_meters - SCREEN_WIDTH_M / 2\n offsetY_in_meters = 0\n return offsetX_in_meters, offsetY_in_meters\n \n def getOffset_in_px(self):\n offsetX_in_meters, offsetY_in_meters = self.getOffset_in_meters()\n return offsetX_in_meters * PPM, offsetY_in_meters * PPM\n \n def draw(self, screen):\n offsetX_in_meters = self.centerX_in_meters - SCREEN_WIDTH_M / 2\n screen.blit(self.background.image, (-1 * offsetX_in_meters * PPM - 200, 0))\n \n def update(self, ball):\n if abs(ball.position.x - self.centerX_in_meters) > CAMERA_PILLOW_SPACE_M:\n if abs(self.dx) + CAMERA_SPEEDUP_SPEED <= CAMERA_MAX_PAN_SPEED_PX:\n if ball.position.x - self.centerX_in_meters > 0:\n self.dx += CAMERA_SPEEDUP_SPEED\n else:\n self.dx -= CAMERA_SPEEDUP_SPEED\n \n if abs(ball.position.x - self.centerX_in_meters) <= CAMERA_MAX_PAN_SPEED_M:\n self.dx = (ball.position.x - self.centerX_in_meters) * PPM\n \n self.centerX_in_px += self.dx\n self.centerX_in_meters = self.centerX_in_px / PPM\n \n if self.centerX_in_meters < SCREEN_WIDTH_M / 2:\n self.dx = 0\n self.centerX_in_meters = SCREEN_WIDTH_M / 2\n self.centerX_in_px = self.centerX_in_meters * PPM\n if self.centerX_in_meters > STAGE_WIDTH_M - SCREEN_WIDTH_M / 2:\n self.dx = 0\n self.centerX_in_meters = STAGE_WIDTH_M - SCREEN_WIDTH_M / 2\n self.centerX_in_px = self.centerX_in_meters * PPM\n \n def stop(self): pass"
},
{
"alpha_fraction": 0.5456187725067139,
"alphanum_fraction": 0.5633845329284668,
"avg_line_length": 36.325843811035156,
"blob_id": "c511f856e0554960249a8b0e8766cdba160599d1",
"content_id": "0352eafead65d0395a26d18266ce4ae2ae6a0595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3321,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 89,
"path": "/gameOver.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "def winGame(winner):\n global gameWinner, gameLoser, gameState\n global gameWinnerColor, gameLoserColor\n gameState = \"GameOver\"\n if winner == 1:\n gameWinner = char1\n gameWinnerColor = char1color\n gameLoser = char2\n gameLoserColor = char2color\n else:\n gameWinner = char2\n gameWinnerColor = char2color\n gameLoser = char1\n gameLoserColor = char1color\n \n #arena.cleanUp()\n # Find the bomb drop and PUT A STOP TO THE MADNESS\n for ef in effects:\n if ef.__class__.__name__ == \"BombDrop\":\n ef.finish()\n \n initGameOver()\n\ngame_over_buttons = [ [\"menu\",0], [\"quit\",0]]\n\ndef initGameOver():\n # Load all the menu buttons\n buttonY = SCREEN_HEIGHT_PX/2 - BTN_HEIGHT/2 - BTN_STEP\n buttonX = SCREEN_WIDTH_PX/2 - BTN_WIDTH/2\n for button in game_over_buttons:\n for state in states:\n imageName = button[0] + \"-\" + state\n images[imageName] = load_image(imageName + \".png\")\n images[imageName][0].set_colorkey(pygame.Color(\"white\"))\n # Change imagerect to where the image actually is on screen\n images[imageName][1].left = buttonX\n images[imageName][1].top = buttonY\n \n buttonY += BTN_STEP\n \ndef gameOverInput(event):\n # Grab mouse coords\n mousePos = pygame.mouse.get_pos()\n \n global lastButtonClicked\n global gameState\n \n # Is it just a mousemove?\n if event.type == pygame.MOUSEMOTION:\n for i, button in enumerate(game_over_buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n # Tell the button to highlight\n game_over_buttons[i][1] = 1\n else:\n # Deselect button\n game_over_buttons[i][1] = 0\n \n # Is it a new mouseclick?\n if event.type == pygame.MOUSEBUTTONDOWN:\n for i, button in enumerate(game_over_buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n lastButtonClicked = button[0]\n game_over_buttons[i][1] = 2\n \n # Is it a mouse up?\n if event.type == pygame.MOUSEBUTTONUP:\n for i, button in enumerate(game_over_buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n game_over_buttons[i][1] = 1\n if lastButtonClicked == button[0]:\n # Positive match! Rejoice!\n if button[0] == \"menu\":\n gameState = \"Title\"\n elif button[0] == \"quit\":\n sys.exit()\n else:\n # Make sure we wipe the last button clicked\n lastButtonClicked = \"\"\n \ndef drawGameOver(screen):\n screen.fill(gameWinnerColor, (0,0,SCREEN_WIDTH_PX/2,SCREEN_HEIGHT_PX))\n screen.fill(gameLoserColor, (SCREEN_WIDTH_PX/2,0,SCREEN_WIDTH_PX/2,SCREEN_HEIGHT_PX))\n # TODO: put an image here?\n screen.blit(images[gameLoser+\"_loser\"][0], ((SCREEN_WIDTH_PX/2 - 400),0))\n screen.blit(images[gameWinner+\"_winner\"][0], ((SCREEN_WIDTH_PX/2 - 400),0))\n \n for button in game_over_buttons:\n imageName = button[0] + \"-\" + states[button[1]]\n screen.blit(images[imageName][0], images[imageName][1])"
},
{
"alpha_fraction": 0.6304493546485901,
"alphanum_fraction": 0.6351441740989685,
"avg_line_length": 24.70689582824707,
"blob_id": "e2d96d12b60fe5c2fde315e23a9b9c14bbd962b0",
"content_id": "f0f2cab471aff02a17e711a571ce1a941ef7457c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1491,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 58,
"path": "/makeinstaller.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "import os\n\nexec(open('exe_setup.py'))\n\ngameName = \"Kickbox\"\nversion = \"0.9\"\n\nf = open(\"dist/installer.nsi\",\"w\")\n\nmain = \"dist/\"\npath = \"\"\n\nf.write(\"Name \\\"\"+gameName+\"Installer\\\"\\n\")\nf.write(\"OutFile \\\"\"+gameName+\"_\"+version+\".exe\\\"\\n\")\nf.write(\"InstallDir $PROGRAMFILES\\\\\"+gameName+\"\\n\")\nf.write(\"DirText \\\"This will install \"+gameName+\" on your computer. Choose a directory\\\"\\n\")\nf.write(\"Section \\\"\\\" ;No components page, name is not important\\n\")\ndirs = []\n\ndef loadpics(main,path):\n\tpics = []\n\tpics_raw = os.listdir(main+path)\n\tif path != \"\":\n\t\tf.write(\"\\tCreateDirectory $INSTDIR\"+path+\"\\n\")\n\t\tglobal dirs\n\t\tdirs.append(path)\n\tf.write(\"\\tSetOutPath $INSTDIR\"+path+\"\\n\")\n\tfor pic in pics_raw:\n\t\tif pic[0] == \".\": continue\n\t\ttry:\n\t\t\tnewpics = loadpics(main,path+\"\\\\\"+pic)\n\t\t\tfor newpic in newpics:\n\t\t\t\tpics.append(newpic)\n\t\t\tf.write(\"\\tSetOutPath $INSTDIR\"+path+\"\\n\")\n\t\texcept:\n\t\t\tpics.append(path+\"\\\\\"+pic+\"\\n\")\n\t\t\tif path != \"\": f.write(\"\\tFile \"+path[1:]+\"\\\\\"+pic+\"\\n\")\n\t\t\telse:\n\t\t\t\t\tif pic != \"installer.nsi\": f.write(\"\\tFile \"+pic+\"\\n\")\n\n\treturn pics\n\npics = loadpics(main,path)\nfor pic in pics:\n\tpic = pic[1:]\nf.write(\"\\tWriteUninstaller $INSTDIR\\Uninstall.exe\\n\")\nf.write(\"SectionEnd\\n\")\nf.write(\"Section \\\"Uninstall\\\"\\n\")\nf.write(\"\\tDelete $INSTDIR\\Uninstall.exe\\n\")\nfor pic in pics:\n\tpic = pic[1:]\n\tf.write(\"\\tDelete $INSTDIR\\\\\"+pic)\nfor d in range(len(dirs)):\n\tf.write(\"\\tRMDir $INSTDIR\"+dirs[len(dirs)-1-d]+\"\\n\")\nf.write(\"\\tRMDir $INSTDIR\\n\")\nf.write(\"SectionEnd\")\n\nf.close()\n"
},
{
"alpha_fraction": 0.5652598142623901,
"alphanum_fraction": 0.5872495174407959,
"avg_line_length": 41.55849075317383,
"blob_id": "780781e7eeaddcb666d13cf198118279544524df",
"content_id": "a7c9cc3bdde56caa5af57922f0bf8834a7b8afd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11278,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 265,
"path": "/init.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "import pygame, math, random, sys, os, hashlib\nfrom Box2D import *\nimport Box2D\nimport time\nfrom pygame.locals import *\nfrom pgu import gui\n\nPPM = 16\nSTAGE_WIDTH_PX = 4000\nSTAGE_WIDTH_M = STAGE_WIDTH_PX / PPM\nSCREEN_WIDTH_PX = 1400\nSCREEN_WIDTH_M = SCREEN_WIDTH_PX / PPM\nSCREEN_HEIGHT_PX = 600\nSCREEN_HEIGHT_M = SCREEN_HEIGHT_PX / PPM\n\nSCREEN_RECT = pygame.Rect(0, 0, SCREEN_WIDTH_PX, SCREEN_HEIGHT_PX)\n\nCAMERA_MAX_PAN_SPEED_PX = 48\nCAMERA_MAX_PAN_SPEED_M = 3\nCAMERA_PILLOW_SPACE_PX = 160\nCAMERA_PILLOW_SPACE_M = 10\nCAMERA_SPEEDUP_SPEED = 3\n\n##### VARIABLES FOR GAME BALANCE ######\nBALL_DENSITY = 4\nBALL_CHANGE_DENSITY = 10\nCHAR_DENSITY = 25\nBALL_FRICTION = 0.9\nCHAR_FRICTION = 1\nCHAR_DENSITY = 5\nBALL_FRICTION = 0.95\n\nTARGET_FPS = 60\nTIME_STEP = 1.0/TARGET_FPS\n\npygame.mixer.pre_init(22050,-16, 2, 1024)\npygame.init()\n\nscreen = pygame.display.set_mode((SCREEN_WIDTH_PX, SCREEN_HEIGHT_PX), DOUBLEBUF, 32)\npygame.display.set_caption(\"LD 27: Kickbox\")\nclock = pygame.time.Clock()\n\ndef load_image(name, colorkey=None):\n fullname = os.path.join('img', name)\n try:\n image = pygame.image.load(fullname)\n except pygame.error, message:\n print 'Cannot load image:', name\n raise SystemExit, message\n image = image.convert()\n if colorkey is not None:\n if colorkey is -1:\n colorkey = image.get_at((0,0))\n image.set_colorkey(colorkey, RLEACCEL)\n return image, image.get_rect()\n \ndef loadSounds():\n result = {}\n \n ## Note- if you add a new sound, make sure to put a number at the end. The parser relies on that.\n \n # Sound effects\n sfxPath = os.path.join(\"sounds\", \"sfx\")\n result[\"boom1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"boom1.wav\"))\n result[\"boom2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"boom2.wav\"))\n result[\"hop1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"hop1.wav\"))\n result[\"hop2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"hop2.wav\"))\n result[\"hop3\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"hop3.wav\"))\n result[\"kick1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"kick1.wav\"))\n result[\"kick2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"kick2.wav\"))\n result[\"transition1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"transition1.wav\"))\n result[\"transition2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"transition2.wav\"))\n result[\"transition3\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"transition3.wav\"))\n result[\"start1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"start1.wav\"))\n result[\"score1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"score1.wav\"))\n result[\"score2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"score2.wav\"))\n result[\"score3\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"score3.wav\"))\n \n # 10 second themes\n musicPath = os.path.join(\"sounds\", \"music\")\n result[\"background1\"] = pygame.mixer.Sound(os.path.join(musicPath, \"antigravity1.wav\"))\n result[\"background2\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill1.wav\"))\n result[\"background3\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill2.wav\"))\n result[\"background4\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill3.wav\"))\n result[\"background5\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill4.wav\"))\n result[\"background6\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill5.wav\"))\n result[\"background7\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill6.wav\"))\n result[\"background8\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill7.wav\"))\n result[\"background9\"] = pygame.mixer.Sound(os.path.join(musicPath, \"lowkey1.wav\"))\n result[\"backgroundA\"] = pygame.mixer.Sound(os.path.join(musicPath, \"upbeat1.wav\"))\n result[\"backgroundB\"] = pygame.mixer.Sound(os.path.join(musicPath, \"whee1.wav\"))\n \n for sound in result.values():\n sound.set_volume(0.3)\n \n return result\n \ndef playSound(soundName, volume = 1):\n global sounds, backgroundplayer\n # Get all the sounds with the name beginning in \"soundName\"\n choices = []\n for key in sounds.keys():\n if key[:-1] == soundName:\n choices.append(sounds[key])\n \n if volume < 0:\n volume = 0\n if not volume == 1:\n print(\"volume\" + str(volume) )\n \n # dang python you sexy. Choose a random sound to play.\n soundToPlay = random.choice(choices)\n soundToPlay.set_volume(0.3 * volume)\n if soundName == \"background\":\n backgroundPlayer.play(soundToPlay)\n else:\n soundToPlay.play(loops=0, maxtime=0, fade_ms=0)\n \ndef pauseBackground():\n global backgroundPlayer\n backgroundPlayer.pause()\n \ndef resumeBackground():\n global backgroundPlayer\n backgroundPlayer.unpause()\n \ndef vertices(shapeIn):\n # Grab the old vertices from the shape\n olds = shapeIn.shape.vertices\n # Convert them (with magic) using the body.transform thing\n result = [(shapeIn.body.transform*v)*PPM for v in olds]\n \n return result\n \ndef vertices_with_offset(shapeIn, offsetX, offsetY):\n # Grab the old vertices from the shape\n olds = shapeIn.shape.vertices\n # Convert them (with magic) using the body.transform thing\n result = [(shapeIn.body.transform*v)*PPM for v in olds]\n # Fix the coordinates\n result = [(v[0] - offsetX, v[1] - offsetY) for v in result]\n \n return result\n \nclass ContactHandler(b2ContactListener):\n \"\"\"Extends the contact listener and can override the sexy, sexy event handling\n methods with its own jazz.\"\"\"\n \n def __init__(self):\n # The nonsense that's required to extend classes in Python\n super(ContactHandler, self).__init__()\n \n def __del__(self):\n pass\n \n def checkContact(self, contact, desiredName):\n \"\"\"Checks to see if one of the fixtures named by \"contact\" is a \n \"desiredName.\" Returns (desiredFixture, otherFixture) if there's a match\"\"\"\n if contact.fixtureA.body.userData == desiredName:\n return (contact.fixtureA, contact.fixtureB)\n if contact.fixtureB.body.userData == desiredName:\n return (contact.fixtureB, contact.fixtureA)\n \n return None\n \n def BeginContact(self, contact):\n \n blowUp = self.checkContact(contact, \"bomb\")\n if blowUp is not None and blowUp[1].body.userData != \"ceiling\":\n # Since you can't call DestroyFixture while the physics is iterating,\n # flag it for destruction by setting userData to \"kill me\"\n blowUp[0].body.userData = \"kill me\"\n \n # Figure out how far away it is\n explosDistance = abs(blowUp[0].body.position.x - arena.camera.centerX_in_meters)\n \n # Play a splosion sound w/ an appropriate volume\n playSound(\"boom\", (1 - explosDistance / 50) * 0.5)\n \n for shape in arena.shapes + [arena.player1.shapes[0], arena.player2.shapes[0]]:\n # See how far everyone is from the 'splosion\n distResult = b2Distance(shapeA = shape.fixtures[0].shape, shapeB = blowUp[0].shape, transformA = shape.transform, transformB = blowUp[0].body.transform)\n pointA, pointB, distance, dummy = distResult\n \n # mass > 0 implies it's not a \"Static\" object\n if distance < 6 and shape.massData.mass > 0.1 and shape.userData != \"particle\":\n xComp = int(random.random() * -5000 + 2500)\n yComp = int(random.random() * -5000 + 2500)\n \n shape.linearVelocity.x = xComp\n shape.linearVelocity.y = yComp\n shape.angularVelocity = random.random() * 5 + 5\n shape.awake = True\n \n offsetX, offsetY = arena.camera.getOffset_in_px()\n explos = Explosion(blowUp[0].body.position.x * PPM - offsetX, 37 * PPM - offsetY)\n effects.append(explos)\n \n goalLeft = self.checkContact(contact, \"ball\")\n if goalLeft is not None:\n # mass > 0 implies it's not a \"Static\" object\n if goalLeft[1].body.userData is not None or goalLeft[1].userData is not None:\n \n if goalLeft[1].body.userData == \"goal left\":\n # Pause background music\n pauseBackground()\n # Play the happy score sound\n playSound(\"score\")\n arena.score[0] += 1\n if arena.score[0] >= 5:\n winGame(1)\n arena.player1.dead = True\n arena.player2.dead = True\n arena.toInit = (STAGE_WIDTH_M / 3, 2000)\n for shape in arena.shapes:\n # mass > 0 implies it's not a \"Static\" object\n if shape.userData == \"crowd member\":\n shape.linearVelocity.y = random.random() * -15 - 5\n if goalLeft[1].body.userData == \"goal right\":\n # Pause background music\n pauseBackground()\n # Play the happy score sound\n playSound(\"score\")\n\n arena.score[1] += 1\n if arena.score[1] >= 5:\n winGame(2)\n arena.player1.dead = True\n arena.player2.dead = True\n arena.toInit = (STAGE_WIDTH_M * 2 / 3, 2000)\n for shape in arena.shapes:\n # mass > 0 implies it's not a \"Static\" object\n if shape.userData == \"crowd member\":\n shape.linearVelocity.y = random.random() * -15 - 5\n \n \n kick = self.checkContact(contact, \"player1\")\n if kick is None:\n kick = self.checkContact(contact, \"player2\")\n \n if kick is not None:\n \n # Punt the ball a little ways kick[1] is ball, kick[0] is player.\n if kick[1].body.userData == \"ball\":\n if len(kick[0].body.contacts) < 3:\n kick[1].body.linearVelocity.x = kick[0].body.linearVelocity.x * 10\n print kick[0].body.linearVelocity.x\n if abs(kick[0].body.linearVelocity.x) > 10:\n # Play kick sfx\n playSound(\"kick\", 2)\n if arena.world.gravity == (0, 0):\n kick[1].body.linearVelocity.y = kick[0].body.linearVelocity.y * 10\n else:\n kick[1].body.linearVelocity.y -= 100\n if kick[1].body.userData == \"player1\" or kick[1].body.userData == \"player2\":\n if kick[0].body.linearVelocity.y>= 25 or kick[1].body.linearVelocity.y >= 25:\n kick[0].body.linearVelocity.y = -25\n kick[1].body.linearVelocity.y = -25\n \n \n \n # If the player has touched the ball recently, they're considered\n # \"in possession,\" and have their run speed limited slightly,\n # giving a chance for the chaser to catch up\n arena.gotPossession(kick[0])\n"
},
{
"alpha_fraction": 0.5140272974967957,
"alphanum_fraction": 0.5412000417709351,
"avg_line_length": 37.34245681762695,
"blob_id": "7cf8682b07fc16d78645887d57d58c507eaedb61",
"content_id": "f11070003c691604e6d32bcfaa5d2f53bfe40139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 71432,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 1863,
"path": "/KickBox.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "\"\"\" \nLUDUM DARE 27 ENTRY\n8/23/2013 - 8/26/2013\nTHEME: 10 Seconds\nBY: Thomas Steinke, Elliot Fiske, Eli Backer\n\nMay be uploaded to http://thomassteinke.net\nor another domain later, if decided.\n\nBring it on, LD.\n\n\"\"\"\n\n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\n# INITIALIZE CLASSES AND GAME |\n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\nimport pygame, math, random, sys, os, hashlib\nfrom Box2D import *\nimport Box2D\nimport time\nfrom pygame.locals import *\nfrom pgu import gui\n\nPPM = 16\nSTAGE_WIDTH_PX = 4000\nSTAGE_WIDTH_M = STAGE_WIDTH_PX / PPM\nSCREEN_WIDTH_PX = 1400\nSCREEN_WIDTH_M = SCREEN_WIDTH_PX / PPM\nSCREEN_HEIGHT_PX = 600\nSCREEN_HEIGHT_M = SCREEN_HEIGHT_PX / PPM\n\nSCREEN_RECT = pygame.Rect(0, 0, SCREEN_WIDTH_PX, SCREEN_HEIGHT_PX)\n\nCAMERA_MAX_PAN_SPEED_PX = 48\nCAMERA_MAX_PAN_SPEED_M = 3\nCAMERA_PILLOW_SPACE_PX = 160\nCAMERA_PILLOW_SPACE_M = 10\nCAMERA_SPEEDUP_SPEED = 3\n\n##### VARIABLES FOR GAME BALANCE ######\nBALL_DENSITY = 4\nBALL_CHANGE_DENSITY = 10\nCHAR_DENSITY = 25\nBALL_FRICTION = 0.9\nCHAR_FRICTION = 1\nCHAR_DENSITY = 5\nBALL_FRICTION = 0.95\n\nTARGET_FPS = 60\nTIME_STEP = 1.0/TARGET_FPS\n\npygame.mixer.pre_init(22050,-16, 2, 1024)\npygame.init()\n\nscreen = pygame.display.set_mode((SCREEN_WIDTH_PX, SCREEN_HEIGHT_PX), DOUBLEBUF, 32)\npygame.display.set_caption(\"LD 27: Kickbox\")\nclock = pygame.time.Clock()\n\ndef load_image(name, colorkey=None):\n fullname = os.path.join('img', name)\n try:\n image = pygame.image.load(fullname)\n except pygame.error, message:\n print 'Cannot load image:', name\n raise SystemExit, message\n image = image.convert()\n if colorkey is not None:\n if colorkey is -1:\n colorkey = image.get_at((0,0))\n image.set_colorkey(colorkey, RLEACCEL)\n return image, image.get_rect()\n \ndef loadSounds():\n result = {}\n \n ## Note- if you add a new sound, make sure to put a number at the end. The parser relies on that.\n \n # Sound effects\n sfxPath = os.path.join(\"sounds\", \"sfx\")\n result[\"boom1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"boom1.wav\"))\n result[\"boom2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"boom2.wav\"))\n result[\"hop1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"hop1.wav\"))\n result[\"hop2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"hop2.wav\"))\n result[\"hop3\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"hop3.wav\"))\n result[\"kick1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"kick1.wav\"))\n result[\"kick2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"kick2.wav\"))\n result[\"transition1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"transition1.wav\"))\n result[\"transition2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"transition2.wav\"))\n result[\"transition3\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"transition3.wav\"))\n result[\"start1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"start1.wav\"))\n result[\"score1\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"score1.wav\"))\n result[\"score2\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"score2.wav\"))\n result[\"score3\"] = pygame.mixer.Sound(os.path.join(sfxPath, \"score3.wav\"))\n \n # 10 second themes\n musicPath = os.path.join(\"sounds\", \"music\")\n result[\"background1\"] = pygame.mixer.Sound(os.path.join(musicPath, \"antigravity1.wav\"))\n result[\"background2\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill1.wav\"))\n result[\"background3\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill2.wav\"))\n result[\"background4\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill3.wav\"))\n result[\"background5\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill4.wav\"))\n result[\"background6\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill5.wav\"))\n result[\"background7\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill6.wav\"))\n result[\"background8\"] = pygame.mixer.Sound(os.path.join(musicPath, \"chill7.wav\"))\n result[\"background9\"] = pygame.mixer.Sound(os.path.join(musicPath, \"lowkey1.wav\"))\n result[\"backgroundA\"] = pygame.mixer.Sound(os.path.join(musicPath, \"upbeat1.wav\"))\n result[\"backgroundB\"] = pygame.mixer.Sound(os.path.join(musicPath, \"whee1.wav\"))\n \n for sound in result.values():\n sound.set_volume(0.3)\n \n return result\n \ndef playSound(soundName, volume = 1):\n global sounds, backgroundplayer\n # Get all the sounds with the name beginning in \"soundName\"\n choices = []\n for key in sounds.keys():\n if key[:-1] == soundName:\n choices.append(sounds[key])\n \n if volume < 0:\n volume = 0\n if not volume == 1:\n print(\"volume\" + str(volume) )\n \n # dang python you sexy. Choose a random sound to play.\n soundToPlay = random.choice(choices)\n soundToPlay.set_volume(0.3 * volume)\n if soundName == \"background\":\n backgroundPlayer.play(soundToPlay)\n else:\n soundToPlay.play(loops=0, maxtime=0, fade_ms=0)\n \ndef pauseBackground():\n global backgroundPlayer\n backgroundPlayer.pause()\n \ndef resumeBackground():\n global backgroundPlayer\n backgroundPlayer.unpause()\n \ndef vertices(shapeIn):\n # Grab the old vertices from the shape\n olds = shapeIn.shape.vertices\n # Convert them (with magic) using the body.transform thing\n result = [(shapeIn.body.transform*v)*PPM for v in olds]\n \n return result\n \ndef vertices_with_offset(shapeIn, offsetX, offsetY):\n # Grab the old vertices from the shape\n olds = shapeIn.shape.vertices\n # Convert them (with magic) using the body.transform thing\n result = [(shapeIn.body.transform*v)*PPM for v in olds]\n # Fix the coordinates\n result = [(v[0] - offsetX, v[1] - offsetY) for v in result]\n \n return result\n \nclass ContactHandler(b2ContactListener):\n \"\"\"Extends the contact listener and can override the sexy, sexy event handling\n methods with its own jazz.\"\"\"\n \n def __init__(self):\n # The nonsense that's required to extend classes in Python\n super(ContactHandler, self).__init__()\n \n def __del__(self):\n pass\n \n def checkContact(self, contact, desiredName):\n \"\"\"Checks to see if one of the fixtures named by \"contact\" is a \n \"desiredName.\" Returns (desiredFixture, otherFixture) if there's a match\"\"\"\n if contact.fixtureA.body.userData == desiredName:\n return (contact.fixtureA, contact.fixtureB)\n if contact.fixtureB.body.userData == desiredName:\n return (contact.fixtureB, contact.fixtureA)\n \n return None\n \n def BeginContact(self, contact):\n \n blowUp = self.checkContact(contact, \"bomb\")\n if blowUp is not None and blowUp[1].body.userData != \"ceiling\":\n # Since you can't call DestroyFixture while the physics is iterating,\n # flag it for destruction by setting userData to \"kill me\"\n blowUp[0].body.userData = \"kill me\"\n \n # Figure out how far away it is\n explosDistance = abs(blowUp[0].body.position.x - arena.camera.centerX_in_meters)\n \n # Play a splosion sound w/ an appropriate volume\n playSound(\"boom\", (1 - explosDistance / 50) * 0.5)\n \n for shape in arena.shapes + [arena.player1.shapes[0], arena.player2.shapes[0]]:\n # See how far everyone is from the 'splosion\n distResult = b2Distance(shapeA = shape.fixtures[0].shape, shapeB = blowUp[0].shape, transformA = shape.transform, transformB = blowUp[0].body.transform)\n pointA, pointB, distance, dummy = distResult\n \n # mass > 0 implies it's not a \"Static\" object\n if distance < 6 and shape.massData.mass > 0.1 and shape.userData != \"particle\":\n xComp = int(random.random() * -5000 + 2500)\n yComp = int(random.random() * -5000 + 2500)\n \n shape.linearVelocity.x = xComp\n shape.linearVelocity.y = yComp\n shape.angularVelocity = random.random() * 5 + 5\n shape.awake = True\n \n offsetX, offsetY = arena.camera.getOffset_in_px()\n explos = Explosion(blowUp[0].body.position.x * PPM - offsetX, 37 * PPM - offsetY)\n effects.append(explos)\n \n goalLeft = self.checkContact(contact, \"ball\")\n if goalLeft is not None:\n # mass > 0 implies it's not a \"Static\" object\n if goalLeft[1].body.userData is not None or goalLeft[1].userData is not None:\n \n if goalLeft[1].body.userData == \"goal left\":\n # Pause background music\n pauseBackground()\n # Play the happy score sound\n playSound(\"score\")\n arena.score[0] += 1\n if arena.score[0] >= 5:\n winGame(1)\n arena.player1.dead = True\n arena.player2.dead = True\n arena.toInit = (STAGE_WIDTH_M / 3, 2000)\n for shape in arena.shapes:\n # mass > 0 implies it's not a \"Static\" object\n if shape.userData == \"crowd member\":\n shape.linearVelocity.y = random.random() * -15 - 5\n if goalLeft[1].body.userData == \"goal right\":\n # Pause background music\n pauseBackground()\n # Play the happy score sound\n playSound(\"score\")\n\n arena.score[1] += 1\n if arena.score[1] >= 5:\n winGame(2)\n arena.player1.dead = True\n arena.player2.dead = True\n arena.toInit = (STAGE_WIDTH_M * 2 / 3, 2000)\n for shape in arena.shapes:\n # mass > 0 implies it's not a \"Static\" object\n if shape.userData == \"crowd member\":\n shape.linearVelocity.y = random.random() * -15 - 5\n \n \n kick = self.checkContact(contact, \"player1\")\n if kick is None:\n kick = self.checkContact(contact, \"player2\")\n \n if kick is not None:\n \n # Punt the ball a little ways kick[1] is ball, kick[0] is player.\n if kick[1].body.userData == \"ball\":\n if len(kick[0].body.contacts) < 3:\n kick[1].body.linearVelocity.x = kick[0].body.linearVelocity.x * 10\n print kick[0].body.linearVelocity.x\n if abs(kick[0].body.linearVelocity.x) > 10:\n # Play kick sfx\n playSound(\"kick\", 2)\n if arena.world.gravity == (0, 0):\n kick[1].body.linearVelocity.y = kick[0].body.linearVelocity.y * 10\n else:\n kick[1].body.linearVelocity.y -= 100\n if kick[1].body.userData == \"player1\" or kick[1].body.userData == \"player2\":\n if kick[0].body.linearVelocity.y>= 25 or kick[1].body.linearVelocity.y >= 25:\n kick[0].body.linearVelocity.y = -25\n kick[1].body.linearVelocity.y = -25\n \n \n \n # If the player has touched the ball recently, they're considered\n # \"in possession,\" and have their run speed limited slightly,\n # giving a chance for the chaser to catch up\n arena.gotPossession(kick[0])\n\nBTN_HEIGHT = 81\nBTN_WIDTH = 260\n# How much room between each button?\nBTN_STEP = 100\n\nbuttons = [ [\"play\",0], [\"quit\",0]]\nstates = [\"des\", \"sel\", \"cli\" ]\n\nangle = 0\nlastButtonClicked = \"\"\napp = gui.Desktop()\n\ndef initTitle():\n # Load all the menu buttons\n buttonY = SCREEN_HEIGHT_PX/2 - BTN_HEIGHT/2 - BTN_STEP\n buttonX = SCREEN_WIDTH_PX/2 - BTN_WIDTH/2\n for button in buttons:\n for state in states:\n imageName = button[0] + \"-\" + state\n images[imageName] = load_image(imageName + \".png\")\n images[imageName][0].set_colorkey(pygame.Color(\"white\"))\n # Change imagerect to where the image actually is on screen\n images[imageName][1].left = buttonX\n images[imageName][1].top = buttonY\n \n buttonY += BTN_STEP\n \n global app\n app = gui.Desktop()\n \n \ndef titleInput(event):\n # Grab mouse coords\n mousePos = pygame.mouse.get_pos()\n \n global lastButtonClicked\n global gameState\n \n # Is it just a mousemove?\n if event.type == pygame.MOUSEMOTION:\n for i, button in enumerate(buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n # Tell the button to highlight\n buttons[i][1] = 1\n else:\n # Deselect button\n buttons[i][1] = 0\n \n # Is it a new mouseclick?\n if event.type == pygame.MOUSEBUTTONDOWN:\n for i, button in enumerate(buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n lastButtonClicked = button[0]\n buttons[i][1] = 2\n \n # Is it a mouse up?\n if event.type == pygame.MOUSEBUTTONUP:\n for i, button in enumerate(buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n buttons[i][1] = 1\n if lastButtonClicked == button[0]:\n # Positive match! Rejoice!\n if button[0] == \"play\":\n global arena, prepare # Arena for minigame\n initCharSelect()\n gameState = \"CharSelect\"\n elif button[0] == \"opt\":\n makeOptions()\n elif button[0] == \"quit\":\n sys.exit()\n else:\n # Make sure we wipe the last button clicked\n lastButtonClicked = \"\"\n \ndef drawTitle(screen):\n # TODO: put an image here?\n screen.fill(pygame.Color(\"white\"))\n screen.blit(images[\"title\"][0], (SCREEN_WIDTH_PX / 2 - 500, 0))\n \n for button in buttons:\n imageName = button[0] + \"-\" + states[button[1]]\n screen.blit(images[imageName][0], images[imageName][1])\n \n# Make the Options menu out of pgu\ndef endItAll(what):\n sys.exit()\n \ndef makeOptions():\n app = gui.Desktop()\n # make sure the game closes when you hit X\n app.connect(gui.QUIT,endItAll,None)\n c = gui.Table()\n \n c.tr()\n c.td(gui.Label(\"MUSIC VOLUME:\"))\n \n c.tr()\n musicSlider = gui.HSlider(value=23,min=0,max=100,size=20,width=120)\n c.td(musicSlider)\n \n c.tr()\n c.td(gui.Label(\"SOUND VOLUME:\"))\n \n c.tr()\n soundSlider = gui.HSlider(value=23,min=0,max=100,size=20,width=120)\n c.td(soundSlider)\n \n c.tr()\n c.td(gui.Label(\"SCREEN RESOLUTION\"))\n \n c.tr()\n btn = gui.Button(\"BACK\")\n btn.connect(gui.CLICK, app.quit)\n c.td(btn,colspan=3)\n app.run(c)\n \n\nclass BombDrop():\n done = False\n bombCooldown = 20\n bombs = []\n def draw(self, screen):\n # Draw the bombas\n for i,bomb in enumerate(self.bombs):\n if bomb.body is None: return\n rotAngle = bomb.body.angle\n offsetX, offsetY = arena.camera.getOffset_in_px()\n verts = vertices_with_offset(bomb, offsetX, offsetY)\n # The \"vertices\" method will return a rotated square of vertices.\n # As it turns out, if we grab the leftmost, topmost, rightmost and\n # bottommost values from these vertices, we end up with the right\n # bounding box for pygame to draw the image. Huh.\n xvals = [ x[0] for x in verts ]\n yvals = [ y[1] for y in verts ]\n left = min(xvals)\n right = max(xvals)\n top = min(yvals)\n bottom = max(yvals)\n finalRect = pygame.Rect(left, top, (right - left), (bottom - top))\n imgRot = pygame.Surface.convert_alpha(pygame.transform.rotate(images[\"bomb\"][0], rotAngle))\n screen.blit(imgRot, finalRect)\n if bomb.body.userData == \"kill me\":\n bomb.body.DestroyFixture(bomb)\n del self.bombs[i]\n \n def update(self):\n # Iterate the cooldown on bombs. If it's been long enough, drop another one!\n self.bombCooldown -= 1\n if self.bombCooldown <= 0:\n self.bombCooldown = 20\n # drop da bomb\n # Choose a random spot between 0 -> Stage Width meters\n bombX = int(random.random() * STAGE_WIDTH_M)\n # Choose a random spot in the upper half of the map to drop the bomb\n bombY = int(random.random() * SCREEN_HEIGHT_M/2 + SCREEN_HEIGHT_M)\n \n newBomb = arena.world.CreateDynamicBody(\n userData = \"bomb\",\n position = (bombX, 10),\n fixtures = b2FixtureDef(density = 5.0, shape = b2PolygonShape(box = (1,1)),\n isSensor = True))\n \n # Start with a li'l spin\n newBomb.angularVelocity = 2 - random.random() * 4\n \n self.bombs.append(newBomb.fixtures[0])\n \n def finish(self):\n self.done = True\n bombs = []\n\nclass Explosion:\n size = 5\n alpha = 255\n x = 0\n y = 0\n done = False\n def __init__(self, ex, ey):\n self.x, self.y = int(ex), int(ey)\n def draw(self, screen):\n # Transparency sucks. Make a new surface then draw the splosion onto it,\n # then draw that new surface on to the old surface.\n s = pygame.Surface((SCREEN_WIDTH_PX, SCREEN_HEIGHT_PX), HWSURFACE)\n s.set_alpha(self.alpha)\n s.set_colorkey(pygame.Color(0, 0, 0))\n pygame.draw.circle(s, pygame.Color(237, 211, 17),\n (self.x, self.y), self.size)\n \n screen.blit(s, (0,0))\n def update(self):\n self.size += 6\n self.alpha -= 15\n if self.alpha <= 0:\n self.done = True\n \n# Back is used for the scrolling image...\nclass Back(pygame.sprite.Sprite):\n\tdef __init__(self,name):\n\t\tpygame.sprite.Sprite.__init__(self)\n\t\tself.tendency = 0\n\t\tself.image, self.rect = load_image(name+'.jpg')\ndef changeArena(arenaNum):\n global currentArena # Midpoint\n global camera\n \n currentArena = arenaNum\n camera.panCam(arenaNum)\n camera.delay = 200\n\nchar1 = \"Lars\"\nchar2 = \"Buster\"\nclass Arena():\n def __init__(self):\n self.timeRemaining = 10000 # 10 seconds\n self.drawRed = 0\n self.bignum = 10\n self.shapes = []\n self.crowd = []\n \n self.modeName = \"none\"\n \n self.player1possession = 0\n self.player2possession = 0\n \n self.modifications = []\n \n # Initialize effects queue\n self.effects = []\n \n # Init physics \"world\", defining gravity. doSleep means that if an object\n # comes to rest, it can \"sleep\" and be ignored by the physics engine for a bit.\n self.world = b2World(gravity=(0, 25), doSleep = False)\n \n # Initialize the contact handler\n self.world.contactListener = ContactHandler()\n \n self.initWalls()\n self.ball = None\n self.startGame(STAGE_WIDTH_M / 2)\n \n self.camera = Camera(STAGE_WIDTH_M / 2)\n \n self.score = [0,0]\n \n self.toInit = False\n self.pauseTime = 0\n \n self.createCrowd(2, 24)\n self.createCrowd(227, 248)\n \n #self.bombDrop()\n #self.changeBall()\n #self.nogravity()\n #self.slowmo()\n \n def startGame(self, middle_x, delay=0):\n global char1, char2\n if delay > 0:\n self.toInit = (middle_x, delay)\n return\n resumeBackground()\n self.toInit = False\n self.pauseTime = delay\n \n if hasattr(self,'player2'):\n self.player1.materialize(middle_x - SCREEN_WIDTH_M / 4, self, 2)\n self.player2.materialize(middle_x + SCREEN_WIDTH_M / 4, self, 1)\n else:\n if char1 == \"Lars\":\n self.player1 = Lars(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"Buster\":\n self.player1 = Buster(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"SmithWickers\":\n self.player1 = SmithWickers(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"Pate\":\n self.player1 = Pate(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"EricStrohm\":\n self.player1 = EricStrohm(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n else: # char1 == \"Ted\":\n self.player1 = Ted(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n \n if char2 == \"Lars\":\n self.player2 = Lars(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"Buster\":\n self.player2 = Buster(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"SmithWickers\":\n self.player2 = SmithWickers(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"Ted\":\n self.player2 = Ted(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"EricStrohm\":\n self.player2 = EricStrohm(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n else: # char2 == \"Pate\":\n self.player2 = Pate(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n \n if self.ball is not None: self.world.DestroyBody(self.ball)\n \n self.ball = self.world.CreateDynamicBody(position = (middle_x,28),\n fixtures = b2FixtureDef(\n shape = b2CircleShape(radius=1.3),\n density=1,\n restitution=0.5,\n friction = 50),\n userData=\"ball\")\n \n self.ball.color = pygame.color.Color(128,128,128)\n self.shapes.append(self.ball)\n \n self.textAlpha = 255\n self.dispText = \"Go!\"\n \n def createCrowd(self, minx, maxx):\n numCrowd = int(math.ceil(random.random() * 10) + 10)\n width = maxx - minx\n \n for i in range(numCrowd):\n member = CrowdMember(0, minx + random.random() * width, (int(random.random()*255),int(random.random()*255),int(random.random()*255)), self)\n self.crowd.append(member)\n self.shapes.append(member.shapes[0])\n \n def initWalls(self):\n ground = self.world.CreateStaticBody(\n position = (0, 37.5),\n shapes = b2PolygonShape(box = (STAGE_WIDTH_M,1)),\n userData = \"ground\"\n )\n ground.color = pygame.color.Color(0,128,0)\n self.shapes.append(ground)\n \n ceiling = self.world.CreateStaticBody(\n position = (0, -1),\n shapes = b2PolygonShape(box = (STAGE_WIDTH_M,1)),\n userData = \"ceiling\"\n )\n self.shapes.append(ceiling)\n \n leftWall = self.world.CreateStaticBody(\n position = (25, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"left wall\"\n )\n #self.shapes.append(leftWall)\n \n rightWall = self.world.CreateStaticBody(\n position = (225, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"right wall\"\n )\n #self.shapes.append(rightWall)\n \n leftWall = self.world.CreateStaticBody(\n position = (0, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"left wall\"\n )\n #self.shapes.append(leftWall)\n \n rightWall = self.world.CreateStaticBody(\n position = (250, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"right wall\"\n )\n \n goal_left = self.world.CreateStaticBody(\n position = (223, 37),\n shapes = b2PolygonShape(box = (2,8))\n )\n goal_left.fixtures[0].sensor = True\n goal_left.userData = \"goal left\"\n self.shapes.append(goal_left)\n \n goal_right = self.world.CreateStaticBody(\n position = (29, 37),\n shapes = b2PolygonShape(box = (2,8))\n )\n goal_right.fixtures[0].sensor = True\n goal_right.userData = \"goal right\"\n self.shapes.append(goal_right)\n \n # Detects if the player is off camera and draws an arrow to them\n def playerOffCamera(self):\n # A player is off camera if all 4 of their vertices don't intersect with the screen.\n SCREEN_RECT.left = self.camera.centerX_in_meters * PPM - SCREEN_WIDTH_PX / 2\n offsetX, offsetY = self.camera.getOffset_in_px()\n verts = vertices(self.player1.shapes[0].fixtures[0])\n inside = False\n for vert in verts:\n inside = inside or SCREEN_RECT.collidepoint( (vert.x, vert.y) )\n \n if not inside:\n self.drawArrow(self.player1)\n \n verts = vertices(self.player2.shapes[0].fixtures[0])\n inside = False\n for vert in verts:\n inside = inside or SCREEN_RECT.collidepoint( (vert.x, vert.y) )\n \n if not inside:\n self.drawArrow(self.player2)\n \n # Draw an arrow to the lost, lonely player. \n def drawArrow(self, player):\n position = player.shapes[0].position\n arrowX, arrowY = 0, 0\n \n # Identify the x and y to draw the arrow in\n arrowY = position.y * PPM - 70\n if position.x < self.camera.centerX_in_meters:\n arrowX = 5\n arrowImg = pygame.transform.flip(images[\"red arrow\"][0], True, False)\n else:\n arrowImg = images[\"red arrow\"][0]\n arrowX = SCREEN_WIDTH_PX - (5 + images[\"red arrow\"][1].width)\n \n screen.blit(arrowImg, (arrowX, arrowY))\n \n # Lets the arena know that a player has touched the ball recently\n def gotPossession(self, playerFixture):\n if playerFixture.body.userData == \"player1\":\n self.player1possession = 50\n elif playerFixture.body.userData == \"player2\":\n self.player2possession = 50\n else:\n print(\"wat\")\n \n def update(self, dt):\n self.camera.update(self.ball)\n \n if self.toInit is not False:\n self.startGame(self.toInit[0], self.toInit[1] - dt)\n \n # Update a \"tick\" in physics land\n self.world.Step(TIME_STEP*2, 10, 10)\n \n # Reset forces for the next frame\n self.world.ClearForces()\n \n if(self.player1.dead):\n self.player1.dead = False\n self.player1.destroy()\n if(self.player2.dead):\n self.player2.dead = False\n self.player2.destroy()\n return\n \n self.timeRemaining -= dt\n oldbignum = self.bignum\n self.bignum = math.trunc(self.timeRemaining / 1000)\n if self.bignum != oldbignum and self.bignum < 4: self.drawRed = 128\n if(self.timeRemaining <= 0):\n self.randomEvent()\n self.timeRemaining = 10000\n \n self.player1.update(self.world.gravity == b2Vec2(0,0))\n self.player2.update(self.world.gravity == b2Vec2(0,0))\n for member in self.crowd:\n member.update(dt, self.world.gravity == b2Vec2(0,0))\n \n # Murder things that need murdering\n for i, shape in enumerate(self.shapes):\n if shape.userData == \"kill me\":\n shape.DestroyFixture(shape)\n del self.shapes[i]\n \n for i, ef in enumerate(self.effects):\n ef.update()\n ef.draw(screen)\n if ef.done:\n del self.effects[i]\n \n self.ball.linearVelocity.x *= BALL_FRICTION\n \n # Check the \"possession\" status of each character and change friction as necessary\n #if self.player1possession > 0 and self.player1possession > self.player2possession:\n # self.player1.shapes[0].friction = 10\n # print(\"fraction\", self.player1.shapes[0].friction) \n #else: \n # self.player1.shapes[0].friction = 0.3\n # \n #if self.player2possession > 0 and self.player2possession > self.player1possession:\n # self.player1.shapes[0].friction = 10\n #else: \n # self.player2.shapes[0].friction = 0.3\n \n # Decrement the possession timers\n self.player1possession -= 1\n if self.player1possession < 0: self.player1possession = 0\n self.player2possession -= 1\n if self.player2possession < 0: self.player2possession = 0\n \n # Update a \"tick\" in physics land\n self.world.Step(TIME_STEP*2, 10, 10)\n \n # Reset forces for the next frame\n self.world.ClearForces()\n \n def draw(self, screen, showTimer = True):\n \n self.camera.draw(screen)\n \n if showTimer:\n self.drawTimer(screen)\n \n offsetX, offsetY = self.camera.getOffset_in_px()\n self.player1.draw(screen, offsetX, offsetY)\n self.player2.draw(screen, offsetX, offsetY)\n for member in self.crowd: pass\n #DrawPolygon(vertices_with_offset(member.fixtures[0], offsetX, offsetY), (0,0,0), member.color)\n \n for shape in self.shapes:\n if isinstance(shape.fixtures[0].shape, b2CircleShape):\n pos = (int(shape.position.x * PPM - offsetX), int(shape.position.y * PPM + offsetY))\n if shape.userData == \"ball\":\n DrawCircle(pos, shape.fixtures[0].shape.radius, shape.color)\n else:\n DrawCircle(pos, shape.fixtures[0].shape.radius, (0,0,0))\n elif shape.userData is not None:\n if shape.userData == \"goal left\" or shape.userData == \"goal right\":\n DrawImage(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), shape.userData)\n else:\n if hasattr(shape, \"color\"):\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0), shape.color)\n else:\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0))\n else:\n if hasattr(shape, \"color\"):\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0), shape.color)\n else:\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0))\n \n # Draw arrows if the player is off screen\n self.playerOffCamera()\n \n def drawTimer(self, screen):\n color = (self.drawRed,0,0)\n \n text = time_font_lg.render(str(self.bignum), False, color)\n text_sm = time_font_sm.render(str(self.timeRemaining % 1000), False, color)\n \n if(self.drawRed > 0):\n self.drawRed -= 2\n \n if(self.bignum == 10): screen.blit(text, (SCREEN_WIDTH_PX / 2 - 1100,0))\n else: screen.blit(text, (SCREEN_WIDTH_PX / 2 - 70,0))\n screen.blit(text_sm, (SCREEN_WIDTH_PX / 2,0))\n \n text_l = time_font_lg.render(str(self.score[0]), False, (0,0,0))\n text_r = time_font_lg.render(str(self.score[1]), False, (0,0,0))\n screen.blit(text_l, (0,0))\n screen.blit(text_r, (SCREEN_WIDTH_PX - 60,0))\n \n if self.textAlpha > 0:\n self.textAlpha -= 2.5\n \n text = time_font_giant.render(self.dispText, False, (0, 0, 0), (255,255,255, 0))\n if self.dispText == \"SLOW MO!\":\n surface = pygame.Surface((text.get_width()+30, text.get_height()))\n surface.blit(text, (30,0))\n text = time_font_giant.render(self.dispText, False, (0, 0, 0), (255,255,255, 0))\n surface.blit(text, (0,0))\n surface.set_colorkey((255,255,255))\n surface.set_alpha(self.textAlpha)\n screen.blit(surface, (SCREEN_WIDTH_PX / 2 - text.get_width()/2,180))\n else:\n surface = pygame.Surface((text.get_width(), text.get_height()))\n surface.blit(text, (0,0))\n surface.set_colorkey((255,255,255))\n surface.set_alpha(self.textAlpha)\n screen.blit(surface, (SCREEN_WIDTH_PX / 2 - text.get_width()/2,180))\n\n def doAction(self, event):\n if event.key is K_a:\n self.player1.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_d:\n self.player1.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_LEFT:\n self.player2.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_RIGHT:\n self.player2.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_UP:\n self.player2.input[\"up\"] = (event.type is pygame.KEYDOWN)\n self.player2.jump(self.world.gravity)\n if event.key == K_DOWN:\n self.player2.input[\"down\"] = (event.type is pygame.KEYDOWN)\n self.player2.dive()\n if event.key is K_w:\n self.player1.input[\"up\"] = (event.type is pygame.KEYDOWN)\n self.player1.jump(self.world.gravity)\n if event.key is K_s:\n self.player1.input[\"down\"] = (event.type is pygame.KEYDOWN)\n self.player1.dive()\n \n def changeBall(self):\n print \"Changeball triggered\"\n self.shapes.remove(self.ball)\n position = self.ball.position\n self.world.DestroyBody(self.ball)\n self.ball = self.world.CreateDynamicBody(position = position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(vertices=[(-0.33,1 ),\n (-1 ,0.33),\n (-1 ,-0.33),\n (-0.33 ,-1 ),\n (0.33 ,-1 ),\n (1 ,-0.33),\n (1 ,0.33),\n (-0.33 ,1 )]),\n density=10,\n restitution=0.5,\n friction = 50),\n userData=\"ball\")\n self.ball.color = pygame.color.Color(128,128,128)\n self.shapes.append(self.ball)\n \n self.textAlpha = 255\n self.dispText = \"ROCK BALL!\"\n \n def changeBall_revert(self):\n print \"Changeball reverted\"\n self.shapes.remove(self.ball)\n position = self.ball.position\n self.world.DestroyBody(self.ball)\n \n self.ball = self.world.CreateDynamicBody(position = position,\n fixtures = b2FixtureDef(\n shape = b2CircleShape(radius=1.3),\n density=1,\n restitution=0.5,\n friction = 50),\n userData=\"ball\")\n \n self.ball.color = pygame.color.Color(128,128,128)\n self.shapes.append(self.ball)\n \n def slowmo(self):\n print \"slow mo!\"\n global TIME_STEP\n TIME_STEP /= 4\n \n self.textAlpha = 255\n self.dispText = \"SLOW MO!\"\n \n def slowmo_revert(self):\n print \"slow mo reverted\"\n global TIME_STEP\n TIME_STEP *= 4\n \n def giantMode(self):\n self.textAlpha = 255\n self.dispText = \"GET BIG!\"\n \n self.player1.toExpand = True\n self.player2.toExpand = True\n \n def giantMode_revert(self):\n self.player1.toNormalSize = True\n self.player2.toNormalSize = True\n \n def cleanUp(self):\n self.crowd = []\n while len(self.shapes) > 0:\n shape = self.shapes[0]\n self.world.DestroyBody(shape)\n self.shapes.remove(shape)\n \n def bombDrop(self):\n print \"bomb droppin time!\"\n bombs = BombDrop()\n effects.append(bombs)\n \n self.textAlpha = 255\n self.dispText = \"BOMBS!\"\n \n def bombDrop_revert(self):\n print \"bomb droppin reversion!\"\n # Find the bomb drop and PUT A STOP TO THE MADNESS\n for ef in effects:\n if ef.__class__.__name__ == \"BombDrop\":\n ef.finish()\n \n def randomEvent(self):\n randomEvents = [ [self.bombDrop, self.bombDrop_revert],\n [self.changeBall, self.changeBall_revert],\n [self.giantMode, self.giantMode_revert],\n [self.slowmo, self.slowmo_revert]]\n \n while len(self.modifications) > 0:\n mod = self.modifications[0]\n mod[1]()\n del self.modifications[0]\n \n event = math.floor(random.random() * len(randomEvents))\n \n # Grab the function from the list of events and run it\n mod = randomEvents[int(event)]\n mod[0]()\n self.modifications.append(mod)\n \n # Stop all inferior sounds\n pygame.mixer.stop()\n # Play the \"woopwoopwoop\" transition sound\n playSound(\"transition\")\n # Put on a new backtrack, DJ!\n playSound(\"background\")\n \n \nclass PrepareForBattle(Arena):\n def __init__(self):\n self.timeRemaining = 3000\n self.bignum = 3\n playSound(\"start\")\n \n def draw(self, screen):\n arena.draw(screen, False)\n \n self.drawTimer(screen)\n \n text = (time_font_lg.render(\"PREPARE\", False, (0, 0, 0)), time_font_lg.render(\"YOURSELF\", False, (0, 0, 0)))\n screen.blit(text[0], (SCREEN_WIDTH_PX / 2 - 210,180))\n screen.blit(text[1], (SCREEN_WIDTH_PX / 2 - 220,260))\n \n \n def drawTimer(self, screen):\n color = (self.drawRed,0,0)\n \n text = time_font_lg.render(str(self.bignum), False, color)\n text_sm = time_font_sm.render(str(self.timeRemaining % 1000), False, color)\n \n if(self.drawRed > 0):\n self.drawRed -= 2\n \n screen.blit(text, (SCREEN_WIDTH_PX / 2 - 70,0))\n screen.blit(text_sm, (SCREEN_WIDTH_PX / 2,0))\n \n def update(self, dt):\n self.timeRemaining -= dt\n oldbignum = self.bignum\n self.bignum = math.trunc(self.timeRemaining / 1000)\n if self.bignum != oldbignum and self.bignum < 4: self.drawRed = 128\n if(self.timeRemaining <= 0):\n global arena, gameState\n gameState = \"Arena\"\n # Play the first background\n playSound(\"background\")\n\n def doAction(self, event):\n if event.key is K_a:\n arena.player1.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_d:\n arena.player1.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_LEFT:\n arena.player2.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_RIGHT:\n arena.player2.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_UP:\n arena.player2.input[\"up\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_DOWN:\n arena.player2.input[\"down\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_w:\n arena.player1.input[\"up\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_s:\n arena.player1.input[\"down\"] = (event.type is pygame.KEYDOWN)\n\ndef DrawPolygon(vertices, color = (0,0,0), color_2 = None):\n \"\"\" Draw a wireframe polygon given the screen vertices with the specified color.\"\"\"\n if not vertices:\n print(\"no vertices, brotha\")\n return\n \n\n if len(vertices) == 2:\n pygame.draw.aaline(screen, color, vertices[0], vertices)\n else:\n if color_2 is not None:\n pygame.draw.polygon(screen, color_2, vertices, 0)\n pygame.draw.polygon(screen, color, vertices, 2)\n\ndef DrawCircle(center, radius, color = (0,0,0), color_2 = (0,0,0)):\n \"\"\" Draw a wireframe polygon given the screen vertices with the specified color.\"\"\"\n if not center or not radius:\n return\n \n pygame.draw.circle(screen, color, center, int(radius*PPM))\n pygame.draw.circle(screen, color_2, center, int(radius*PPM), 2)\n \ndef DrawImage(vertices, userData):\n screen.blit(images[userData][0], (vertices[0], vertices[1]))\n \nclass Camera():\n def __init__(self, centerX_in_meters):\n self.background = Back(\"background\")\n self.centerX_in_meters = centerX_in_meters\n self.centerX_in_px = centerX_in_meters * PPM\n \n self.dx = 0\n \n def getOffset_in_meters(self):\n offsetX_in_meters = self.centerX_in_meters - SCREEN_WIDTH_M / 2\n offsetY_in_meters = 0\n return offsetX_in_meters, offsetY_in_meters\n \n def getOffset_in_px(self):\n offsetX_in_meters, offsetY_in_meters = self.getOffset_in_meters()\n return offsetX_in_meters * PPM, offsetY_in_meters * PPM\n \n def draw(self, screen):\n offsetX_in_meters = self.centerX_in_meters - SCREEN_WIDTH_M / 2\n screen.blit(self.background.image, (-1 * offsetX_in_meters * PPM - 200, 0))\n \n def update(self, ball):\n if abs(ball.position.x - self.centerX_in_meters) > CAMERA_PILLOW_SPACE_M:\n if abs(self.dx) + CAMERA_SPEEDUP_SPEED <= CAMERA_MAX_PAN_SPEED_PX:\n if ball.position.x - self.centerX_in_meters > 0:\n self.dx += CAMERA_SPEEDUP_SPEED\n else:\n self.dx -= CAMERA_SPEEDUP_SPEED\n \n if abs(ball.position.x - self.centerX_in_meters) <= CAMERA_MAX_PAN_SPEED_M:\n self.dx = (ball.position.x - self.centerX_in_meters) * PPM\n \n self.centerX_in_px += self.dx\n self.centerX_in_meters = self.centerX_in_px / PPM\n \n if self.centerX_in_meters < SCREEN_WIDTH_M / 2:\n self.dx = 0\n self.centerX_in_meters = SCREEN_WIDTH_M / 2\n self.centerX_in_px = self.centerX_in_meters * PPM\n if self.centerX_in_meters > STAGE_WIDTH_M - SCREEN_WIDTH_M / 2:\n self.dx = 0\n self.centerX_in_meters = STAGE_WIDTH_M - SCREEN_WIDTH_M / 2\n self.centerX_in_px = self.centerX_in_meters * PPM\n \n def stop(self): pass\ndef winGame(winner):\n global gameWinner, gameLoser, gameState\n global gameWinnerColor, gameLoserColor\n gameState = \"GameOver\"\n if winner == 1:\n gameWinner = char1\n gameWinnerColor = char1color\n gameLoser = char2\n gameLoserColor = char2color\n else:\n gameWinner = char2\n gameWinnerColor = char2color\n gameLoser = char1\n gameLoserColor = char1color\n \n #arena.cleanUp()\n # Find the bomb drop and PUT A STOP TO THE MADNESS\n for ef in effects:\n if ef.__class__.__name__ == \"BombDrop\":\n ef.finish()\n \n initGameOver()\n\ngame_over_buttons = [ [\"menu\",0], [\"quit\",0]]\n\ndef initGameOver():\n # Load all the menu buttons\n buttonY = SCREEN_HEIGHT_PX/2 - BTN_HEIGHT/2 - BTN_STEP\n buttonX = SCREEN_WIDTH_PX/2 - BTN_WIDTH/2\n for button in game_over_buttons:\n for state in states:\n imageName = button[0] + \"-\" + state\n images[imageName] = load_image(imageName + \".png\")\n images[imageName][0].set_colorkey(pygame.Color(\"white\"))\n # Change imagerect to where the image actually is on screen\n images[imageName][1].left = buttonX\n images[imageName][1].top = buttonY\n \n buttonY += BTN_STEP\n \ndef gameOverInput(event):\n # Grab mouse coords\n mousePos = pygame.mouse.get_pos()\n \n global lastButtonClicked\n global gameState\n \n # Is it just a mousemove?\n if event.type == pygame.MOUSEMOTION:\n for i, button in enumerate(game_over_buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n # Tell the button to highlight\n game_over_buttons[i][1] = 1\n else:\n # Deselect button\n game_over_buttons[i][1] = 0\n \n # Is it a new mouseclick?\n if event.type == pygame.MOUSEBUTTONDOWN:\n for i, button in enumerate(game_over_buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n lastButtonClicked = button[0]\n game_over_buttons[i][1] = 2\n \n # Is it a mouse up?\n if event.type == pygame.MOUSEBUTTONUP:\n for i, button in enumerate(game_over_buttons):\n if images[button[0] + \"-des\"][1].collidepoint(mousePos):\n game_over_buttons[i][1] = 1\n if lastButtonClicked == button[0]:\n # Positive match! Rejoice!\n if button[0] == \"menu\":\n gameState = \"Title\"\n elif button[0] == \"quit\":\n sys.exit()\n else:\n # Make sure we wipe the last button clicked\n lastButtonClicked = \"\"\n \ndef drawGameOver(screen):\n screen.fill(gameWinnerColor, (0,0,SCREEN_WIDTH_PX/2,SCREEN_HEIGHT_PX))\n screen.fill(gameLoserColor, (SCREEN_WIDTH_PX/2,0,SCREEN_WIDTH_PX/2,SCREEN_HEIGHT_PX))\n # TODO: put an image here?\n screen.blit(images[gameLoser+\"_loser\"][0], ((SCREEN_WIDTH_PX/2 - 400),0))\n screen.blit(images[gameWinner+\"_winner\"][0], ((SCREEN_WIDTH_PX/2 - 400),0))\n \n for button in game_over_buttons:\n imageName = button[0] + \"-\" + states[button[1]]\n screen.blit(images[imageName][0], images[imageName][1])\n\nclass Player(pygame.sprite.Sprite):\n \n def __init__(self, direction, start_x, color, color_2, arena, playerNum):\n self.input = {\"up\": False, \"down\": False, \"left\": False, \"right\": False}\n self.direction = direction\n self.color = color\n self.color_2 = color_2\n self.shapes = []\n self.arena = arena\n \n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n self.toExpand = False\n self.toNormalSize = False\n \n self.speed = 10\n self.airspeed = 14\n self.moving = None\n \n self.dead = False\n self.materialize(start_x, arena, playerNum)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes(arena)\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction=CHAR_FRICTION,\n restitution=0\n ),\n userData = \"player\"+str(playerNum)\n )\n block.color = self.color_2\n self.shapes.append(block)\n \n w = self.size[0]\n h = self.size[1]\n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1*w-.6,-1*h-.1),(w+.6,-1*h-.1),(w+.6,h+.1),(-1*w-.6,h+.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n self.dead = False\n self.dx = 0\n \n def draw(self, screen, offsetX, offsetY):\n for shape in self.shapes:\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0), shape.color)\n \n def destroy(self):\n destructionShapes = []\n if len(self.shapes) > 1:\n for i in range(1,len(self.shapes)):\n # Grab the old vertices from the shape\n olds = self.shapes[i].fixtures[0].shape.vertices\n # Convert them (with magic) using the body.transform thing\n result = [(self.shapes[i].transform*v) for v in olds]\n for v in result:\n body = arena.world.CreateDynamicBody(position = v, userData = \"particle\")\n shape = body.CreatePolygonFixture(box = (.2,.2), density = 1, isSensor = True)\n body.color = self.shapes[i].color\n body.linearVelocity.y = -15\n body.linearVelocity.x = random.random() * 6 - 3\n destructionShapes.append(body)\n \n # Grab the old vertices from the shape\n olds = self.shapes[0].fixtures[0].shape.vertices\n for i in range(20):\n # Convert them (with magic) using the body.transform thing\n result = [(self.shapes[0].transform*v) for v in olds]\n for v in result:\n body = arena.world.CreateDynamicBody(position = (v.x + random.random()*4 - 2, v.y + random.random()*4-2), userData = \"particle\")\n shape = body.CreatePolygonFixture(box = (.2,.2), density = 1, isSensor = True)\n body.color = self.shapes[0].color\n body.linearVelocity.y = -15\n body.linearVelocity.x = random.random() * 16 - 8\n destructionShapes.append(body)\n \n self.clearShapes()\n self.shapes = destructionShapes\n \n def create(self, color):\n self.clearShapes(arena, color)\n \n body = arena.world.CreateDynamicBody(position = ((ARENA_WIDTH * (arena + 0.5)) / PPM, 34))\n box = body.CreatePolygonFixture(box = (1,2), density = CHAR_DENSITY, friction = 0.3)\n self.shapes.append(body)\n \n def clearShapes(self, a = None):\n if a is not None:\n for shape in self.shapes:\n a.world.DestroyBody(shape)\n else:\n for shape in self.shapes:\n arena.world.DestroyBody(shape)\n self.shapes = []\n \n def update(self, nogravity = False):\n if self.toExpand:\n self.expand()\n self.toExpand = False\n if self.toNormalSize:\n self.normal()\n self.toNormalSize = False\n if(self.dead):\n self.destroy()\n return\n \n self.shapes[0].awake = True\n if nogravity:\n if self.input[\"up\"]:\n self.shapes[0].linearVelocity.y -= 3\n if self.input[\"down\"]:\n self.shapes[0].linearVelocity.y += 3\n if self.input[\"left\"]:\n self.shapes[0].linearVelocity.x -= 4\n if self.input[\"right\"]:\n self.shapes[0].linearVelocity.x += 4\n \n if self.shapes[0].linearVelocity.y > 20: self.shapes[0].linearVelocity.y = 20\n if self.shapes[0].linearVelocity.y < -20: self.shapes[0].linearVelocity.y = -20\n if self.shapes[0].linearVelocity.x > 20: self.shapes[0].linearVelocity.x = 20\n if self.shapes[0].linearVelocity.x < -20: self.shapes[0].linearVelocity.x = -20\n else:\n if self.moving is not None: \n if self.moving == \"l\": \n self.shapes[0].linearVelocity.x += self.speed\n if self.moving == \"r\":\n self.shapes[0].linearVelocity.x -= self.speed\n \n if len(self.shapes[0].contacts) > 0: maxspeed = self.speed\n else: maxspeed = self.speed + self.airspeed\n if self.input[\"left\"]:\n self.shapes[0].linearVelocity.x -= maxspeed\n if self.input[\"right\"]:\n self.shapes[0].linearVelocity.x += maxspeed\n \n if self.shapes[0].linearVelocity.x > 20: self.shapes[0].linearVelocity.x = 20\n if self.shapes[0].linearVelocity.x < -20: self.shapes[0].linearVelocity.x = -20\n \n def jump(self):\n if len(self.shapes[0].contacts) > 0:\n self.shapes[0].linearVelocity.y = -15\n self.shapes[0].angularVelocity = 5.4\n \n def dive(self):\n if self.shapes[0].linearVelocity.x > 0:\n dir = \"l\"\n else:\n dir = \"r\"\n \n if len(self.shapes[0].contacts) == 0:\n self.shapes[0].linearVelocity.y = 25\n self.shapes[0].linearVelocity.x *= 2\n if dir == \"l\":\n if self.shapes[0].angle < math.pi / 4:\n self.shapes[0].angularVelocity = 0.5\n else:\n self.shapes[0].angularVelocity = -0.5\n if dir == \"r\":\n if self.shapes[0].angle < - math.pi / 4:\n self.shapes[0].angularVelocity = 0.5\n else:\n self.shapes[0].angularVelocity = -0.5\n \n def jump(self, gravity):\n if gravity == b2Vec2(0,0): pass\n else:\n if len(self.shapes[0].contacts) > 0:\n playSound(\"hop\")\n self.shapes[0].linearVelocity.y = -20 * gravity[1] / 25\n self.shapes[0].angularVelocity = -5.4 * self.direction\n \n def makeNewBlock(self, size):\n i = 0\n shape = self.shapes[i]\n s = shape.fixtures[0].shape\n \n newshape = arena.world.CreateDynamicBody(\n position = shape.position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = size),\n density=shape.fixtures[0].density,\n friction = shape.fixtures[0].friction,\n restitution=shape.fixtures[0].restitution\n ),\n userData = shape.userData\n )\n newshape.color = shape.color\n arena.world.DestroyBody(self.shapes[i])\n self.shapes[i] = newshape\n \n def expand(self):\n self.makeNewBlock(self.large)\n \n def normal(self):\n self.makeNewBlock(self.size)\n \n def shrink(self):\n self.makeNewBlock(self.small)\n\nclass Lars(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n Player.__init__(self, direction, start_x, (0, 0, 0), (255, 255, 0), arena, playerNum)\n\nclass Pate(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n self.small = (0.4,1)\n self.size = (0.8,2.3)\n self.large = (1.6,4.2)\n \n Player.__init__(self, direction, start_x, (0, 0, 0), (0, 255, 255), arena, playerNum)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes(arena)\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction = 10000,\n restitution=0),\n userData = \"player\"+str(playerNum)\n )\n block.color = self.color_2\n self.shapes.append(block)\n \n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1.6,-2.1),(1.6,-2.1),(1.6,2.1),(-1.6,2.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n self.dead = False\n\nclass Buster(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n Player.__init__(self, direction, start_x, (0, 0, 0), (153, 255, 0), arena, playerNum)\n \n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n self.materialize(start_x, arena, playerNum)\n\nclass EricStrohm(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n Player.__init__(self, direction, start_x, (0, 0, 0), (30, 30, 30), arena, playerNum)\n \n self.speed = 12\n self.airspeed = 20\n\nclass Ted(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n Player.__init__(self, direction, start_x, (0, 0, 0), (255, 0, 0), arena, playerNum)\n \n self.small = (0.7,0.7)\n self.size = (1.3,1.3)\n self.large = (2.5,2.5)\n self.clearShapes(arena) \n \n self.materialize(start_x, arena, playerNum)\n\nclass SmithWickers(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n \n self.alt_color = pygame.color.Color(255, 102, 0)\n self.alt_color_2 = pygame.color.Color(102, 51, 102)\n \n Player.__init__(self, direction, start_x, (0, 0, 0), (255, 0, 255), arena, playerNum)\n \n self.small = (0.3,0.8)\n self.size = (0.75,1.7)\n self.large = (1.5,3.5)\n \n self.materialize(start_x, arena, playerNum)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes(arena)\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction = CHAR_FRICTION,\n restitution=0),\n userData = \"player\"+str(playerNum)\n )\n block.color = self.alt_color\n self.shapes.append(block)\n \n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1.6,-2.1),(1.6,-2.1),(1.6,2.1),(-1.6,2.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n block2 = arena.world.CreateDynamicBody(\n position = (start_x - 3, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction=CHAR_FRICTION,\n restitution=0),\n userData = \"player\"+str(playerNum)\n )\n block2.color = self.alt_color_2\n self.shapes.append(block2)\n \n arena.world.CreateDistanceJoint(bodyA = block, bodyB = block2, anchorA = block.worldCenter, anchorB = block2.worldCenter, collideConnected = True)\n \n self.dead = False\n \n def expand(self):\n shape = self.shapes[0]\n s = shape.fixtures[0].shape\n block = arena.world.CreateDynamicBody(\n position = shape.position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.large),\n density=shape.fixtures[0].density,\n friction = shape.fixtures[0].friction,\n restitution=shape.fixtures[0].restitution\n ),\n userData = shape.userData\n )\n block.color = self.alt_color\n arena.world.DestroyBody(self.shapes[0])\n self.shapes[0] = block\n \n oldpos = shape.position\n shape2 = self.shapes[1]\n newpos = shape2.position\n s = shape2.fixtures[0].shape\n block2 = arena.world.CreateDynamicBody(\n position = (newpos.x + (newpos.x - oldpos.x) * 4/3, newpos.y + (newpos.y - oldpos.y) * 4/3),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.large),\n density=shape2.fixtures[0].density,\n friction = shape2.fixtures[0].friction,\n restitution=shape2.fixtures[0].restitution\n ),\n userData = shape2.userData\n )\n block2.color = self.alt_color_2\n arena.world.DestroyBody(self.shapes[1])\n self.shapes[1] = block2\n \n arena.world.CreateDistanceJoint(bodyA = block, bodyB = block2, anchorA = block.worldCenter, anchorB = block2.worldCenter, collideConnected = True)\n \n def normal(self):\n shape = self.shapes[0]\n s = shape.fixtures[0].shape\n block = arena.world.CreateDynamicBody(\n position = shape.position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=shape.fixtures[0].density,\n friction = shape.fixtures[0].friction,\n restitution=shape.fixtures[0].restitution\n ),\n userData = shape.userData\n )\n block.color = self.alt_color\n arena.world.DestroyBody(self.shapes[0])\n self.shapes[0] = block\n \n oldpos = shape.position\n shape2 = self.shapes[1]\n newpos = shape2.position\n s = shape2.fixtures[0].shape\n block2 = arena.world.CreateDynamicBody(\n position = (oldpos.x - 3, oldpos.y),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=shape2.fixtures[0].density,\n friction = shape2.fixtures[0].friction,\n restitution=shape2.fixtures[0].restitution\n ),\n userData = shape2.userData\n )\n block2.color = self.alt_color_2\n arena.world.DestroyBody(self.shapes[1])\n self.shapes[1] = block2\n \n arena.world.CreateDistanceJoint(bodyA = block, bodyB = block2, anchorA = block.worldCenter, anchorB = block2.worldCenter, collideConnected = True)\n\nclass CrowdMember(Player):\n def __init__(self, direction, start_x, color, arena):\n Player.__init__(self, direction, start_x, (0, 0, 0), color, arena, 0)\n self.timeToJump = random.random() * 10000 + 1000\n \n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes()\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction=CHAR_FRICTION,\n restitution=0,\n filter = b2Filter(\n categoryBits = 0x0010,\n maskBits = 0xFFFF ^ 0x0010\n )\n ),\n userData = \"crowd member\"\n )\n\n block.color = self.color_2\n self.shapes.append(block)\n \n w = self.size[0]\n h = self.size[1]\n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1*w-.6,-1*h-.1),(w+.6,-1*h-.1),(w+.6,h+.1),(-1*w-.6,h+.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n self.dead = False\n self.dx = 0\n \n def update(self, dt, nogravity = False):\n if(self.dead):\n self.dead = False\n return\n \n self.shapes[0].awake = True\n if nogravity: pass\n else:\n if abs(self.shapes[0].transform.angle) > 0.1 and abs(self.shapes[0].transform.angle - 180) > 0.1 and self.shapes[0].linearVelocity.y == 0:\n self.jumpBackUp()\n \n self.timeToJump -= dt\n if self.timeToJump <= 0 and self.shapes[0].linearVelocity.y == 0:\n self.jump()\n self.timeToJump = random.random() * 10000 + 1000\n maxspeed = 3\n \n if self.shapes[0].linearVelocity.x != 0 and random.random() > 0.7 and self.shapes[0].linearVelocity.y == 0:\n self.shapes[0].linearVelocity.x = 0\n \n if self.shapes[0].linearVelocity.x == 0 and random.random() > 0.7 and self.shapes[0].linearVelocity.y == 0:\n self.shapes[0].linearVelocity.x = 5 * (random.random() * 4 - 2)\n \n def jump(self):\n if len(self.shapes[0].contacts) > 0:\n self.shapes[0].linearVelocity.y -= 15\n \n def jumpBackUp(self):\n if len(self.shapes[0].contacts) > 0:\n self.shapes[0].linearVelocity.y = -10\n self.shapes[0].angularVelocity = 2\n\nCHARACTER_HEIGHT = 278\nCHARACTER_WIDTH = 196\n# How much room between each button?\nCHARACTER_PADDING = [100, 20]\nCHARACTER_STEP = [4, 4]\n\ncharacters = [\"Lars\", \"Buster\", \"Ted\", \"SmithWickers\", \"Pate\", \"EricStrohm\"]\ncharacterColors = [(255,255,0), (153,255,0), (166,0,0), (255,102,0), (0,51,255), (128,128,128)]\np1choice = 0\np2choice = 1\n\ndef initCharSelect():\n images[\"P1Select\"] = load_image(\"P1Select.png\", (255,191,255))\n images[\"P2Select\"] = load_image(\"P2Select.png\", (255,191,255))\n \n # Load all the menu buttons\n for i, character in enumerate(characters):\n images[character] = load_image(character + \".png\")\n images[character][0].set_colorkey(pygame.Color(\"white\"))\n # Change imagerect to where the image actually is on screen\n images[character][1].left = CHARACTER_PADDING[0] + (CHARACTER_STEP[0] + CHARACTER_WIDTH) * (i % 3)\n images[character][1].top = CHARACTER_PADDING[1] + (CHARACTER_STEP[1] + CHARACTER_HEIGHT) * math.trunc(i / 3)\n \n images[character+\"_winner\"] = load_image(character + \"_winner.png\", (255,122,122))\n # Change imagerect to where the image actually is on screen\n images[character+\"_winner\"][1].left = (SCREEN_WIDTH_PX - 800) / 2\n images[character+\"_winner\"][1].top = 0\n \n images[character+\"_loser\"] = load_image(character + \"_loser.png\", (255,122,122))\n # Change imagerect to where the image actually is on screen\n images[character+\"_loser\"][1].left = (SCREEN_WIDTH_PX - 800) / 2\n images[character+\"_loser\"][1].top = 0\n \ndef drawCharSelect(screen):\n global gameState, p1choice, p2choice\n # TODO: put an image here?\n screen.fill(pygame.Color(\"white\"))\n \n for character in characters:\n screen.blit(images[character][0], images[character][1])\n \n p1left = CHARACTER_PADDING[0] + (CHARACTER_STEP[0] + CHARACTER_WIDTH) * (p1choice % 3)\n p1top = CHARACTER_PADDING[1] + (CHARACTER_STEP[1] + CHARACTER_HEIGHT) * math.trunc(p1choice / 3)\n \n p2left = CHARACTER_PADDING[0] + (CHARACTER_STEP[0] + CHARACTER_WIDTH) * (p2choice % 3)\n p2top = CHARACTER_PADDING[1] + (CHARACTER_STEP[1] + CHARACTER_HEIGHT) * math.trunc(p2choice / 3)\n \n screen.blit(images[\"P1Select\"][0], (p1left, p1top))\n screen.blit(images[\"P2Select\"][0], (p2left, p2top))\n \ndef charSelectInput(event):\n global lastButtonClicked\n global gameState, p1choice, p2choice\n global arena, prepare, char1, char2, char1color, char2color\n \n if hasattr(event, 'key') and event.type is pygame.KEYDOWN:\n if event.key == K_SPACE or event.key == K_RETURN:\n char1, char2 = characters[p1choice], characters[p2choice]\n char1color, char2color = characterColors[p1choice], characterColors[p2choice]\n arena = Arena()\n prepare = PrepareForBattle()\n gameState = \"Prepare\"\n \n if event.key == K_UP:\n p2choice -= 3\n if p2choice < 0: p2choice += 6\n if event.key == K_DOWN: \n p2choice += 3\n if p2choice > 5: p2choice -= 6\n if event.key == K_LEFT: \n p2choice -= 1\n if p2choice < 0: p2choice = 5\n if event.key == K_RIGHT: \n p2choice += 1\n if p2choice > 5: p2choice = 0\n \n if event.key is K_w: \n p1choice -= 3\n if p1choice < 0: p1choice += 6\n if event.key is K_s: \n p1choice += 3\n if p1choice > 5: p1choice -= 6\n if event.key is K_a: \n p1choice -= 1\n if p1choice < 0: p1choice = 5\n if event.key is K_d: \n p1choice += 1\n if p1choice > 5: p1choice = 0\n\n\n\ndef init():\n global time_font_lg,time_font_sm,time_font_giant # Font\n global player1, player2 # Players\n global currentArena # Midpoint\n global gameState # duh\n global world # the Box2D world\n global arena, prepare # Arena for minigame\n global effects # Sort of like AwesomeRogue!\n global images # Dict of all the images we have to draw\n global sounds # Music to my ears\n global musicVolume\n global soundVolume # Shhhh\n global backgroundPlayer\n \n backgroundPlayer = pygame.mixer.Channel(7)\n \n musicVolume = soundVolume = 25\n \n effects = []\n \n time_font_sm = pygame.font.Font(\"fonts/ka1.ttf\", 30)\n time_font_lg = pygame.font.Font(\"fonts/ka1.ttf\", 60)\n time_font_giant = pygame.font.Font(\"fonts/ka1.ttf\", 120)\n \n #arena = Arena()\n #prepare = PrepareForBattle()\n gameState = \"Title\"\n \n # Load some images\n images = {}\n images[\"bomb\"] = load_image(\"bomb.png\", (255, 255, 255))\n images[\"goal left\"] = load_image(\"GOOOAL.png\", (255,255,255))\n images[\"goal right\"] = [pygame.transform.flip(images[\"goal left\"][0], True, False), images[\"goal left\"][1]]\n images[\"red arrow\"] = load_image(\"red_arrow.png\", (255,255,255))\n images[\"blue arrow\"] = load_image(\"blue_arrow.png\", (255,255,255))\n images[\"title\"] = load_image(\"title.png\")\n \n # Make sure alpha will properly render\n for key in images:\n images[key] = (images[key][0].convert_alpha(), images[key][1])\n \n pygame.mixer.init(frequency=22050, size=-16, channels=2, buffer=512)\n pygame.mixer.set_num_channels(20)\n sounds = loadSounds()\n \n \n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\n# MAIN LOOP |\n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\ninit()\ninitTitle()\nwhile 1:\n dt = clock.tick(TARGET_FPS)\n screen.fill((255,255,255))\n \n # Check user input\n for event in pygame.event.get():\n if gameState == \"Title\":\n titleInput(event)\n if gameState == \"CharSelect\":\n charSelectInput(event)\n if gameState == \"GameOver\":\n gameOverInput(event)\n if event.type is pygame.QUIT: sys.exit()\n if hasattr(event, 'key'):\n if event.key is K_ESCAPE: \n if event.type is pygame.KEYDOWN: sys.exit()\n if gameState == \"Arena\":\n arena.doAction(event)\n if gameState == \"Prepare\":\n prepare.doAction(event)\n \n if gameState == \"Title\":\n drawTitle(screen)\n if gameState == \"CharSelect\":\n drawCharSelect(screen)\n if gameState == \"Prepare\":\n prepare.update(dt)\n prepare.draw(screen)\n if gameState == \"Arena\":\n arena.update(dt)\n arena.draw(screen)\n\n for i, ef in enumerate(effects):\n ef.update()\n ef.draw(screen)\n if ef.done:\n del effects[i]\n if gameState == \"GameOver\":\n drawGameOver(screen)\n \n pygame.display.flip()\n"
},
{
"alpha_fraction": 0.46535131335258484,
"alphanum_fraction": 0.4886910617351532,
"avg_line_length": 32.78861618041992,
"blob_id": "00960c474b0f6dd7b13491fb1fcef22f10ea6460",
"content_id": "b172f27a3ba269b401565c83bffd82d9b09b3df5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4156,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 123,
"path": "/main.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "\"\"\" \nLUDUM DARE 27 ENTRY\n8/23/2013 - 8/26/2013\nTHEME: 10 Seconds\nBY: Thomas Steinke, Elliot Fiske, Eli Backer\n\nMay be uploaded to http://thomassteinke.net\nor another domain later, if decided.\n\nBring it on, LD.\n\n\"\"\"\n\n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\n# INITIALIZE CLASSES AND GAME |\n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\nexec(open('init.py'))\nexec(open('title.py'))\nexec(open('effects.py'))\nexec(open('ui_class.py'))\nexec(open('arena_mechanics.py'))\nexec(open('camera.py'))\nexec(open('gameOver.py'))\nexec(open('character_class.py'))\nexec(open('character_select.py'))\n\n\ndef init():\n global time_font_lg,time_font_sm,time_font_giant # Font\n global player1, player2 # Players\n global currentArena # Midpoint\n global gameState # duh\n global world # the Box2D world\n global arena, prepare # Arena for minigame\n global effects # Sort of like AwesomeRogue!\n global images # Dict of all the images we have to draw\n global sounds # Music to my ears\n global musicVolume\n global soundVolume # Shhhh\n global backgroundPlayer\n \n backgroundPlayer = pygame.mixer.Channel(7)\n \n musicVolume = soundVolume = 25\n \n effects = []\n \n time_font_sm = pygame.font.Font(\"fonts/ka1.ttf\", 30)\n time_font_lg = pygame.font.Font(\"fonts/ka1.ttf\", 60)\n time_font_giant = pygame.font.Font(\"fonts/ka1.ttf\", 120)\n \n #arena = Arena()\n #prepare = PrepareForBattle()\n gameState = \"Title\"\n \n # Load some images\n images = {}\n images[\"bomb\"] = load_image(\"bomb.png\", (255, 255, 255))\n images[\"goal left\"] = load_image(\"GOOOAL.png\", (255,255,255))\n images[\"goal right\"] = [pygame.transform.flip(images[\"goal left\"][0], True, False), images[\"goal left\"][1]]\n images[\"red arrow\"] = load_image(\"red_arrow.png\", (255,255,255))\n images[\"blue arrow\"] = load_image(\"blue_arrow.png\", (255,255,255))\n images[\"title\"] = load_image(\"title.png\")\n \n # Make sure alpha will properly render\n for key in images:\n images[key] = (images[key][0].convert_alpha(), images[key][1])\n \n pygame.mixer.init(frequency=22050, size=-16, channels=2, buffer=512)\n pygame.mixer.set_num_channels(20)\n sounds = loadSounds()\n \n \n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\n# MAIN LOOP |\n# -----------------------------------------------------------------------|\n# -----------------------------------------------------------------------|\ninit()\ninitTitle()\nwhile 1:\n dt = clock.tick(TARGET_FPS)\n screen.fill((255,255,255))\n \n # Check user input\n for event in pygame.event.get():\n if gameState == \"Title\":\n titleInput(event)\n if gameState == \"CharSelect\":\n charSelectInput(event)\n if gameState == \"GameOver\":\n gameOverInput(event)\n if event.type is pygame.QUIT: sys.exit()\n if hasattr(event, 'key'):\n if event.key is K_ESCAPE: \n if event.type is pygame.KEYDOWN: sys.exit()\n if gameState == \"Arena\":\n arena.doAction(event)\n if gameState == \"Prepare\":\n prepare.doAction(event)\n \n if gameState == \"Title\":\n drawTitle(screen)\n if gameState == \"CharSelect\":\n drawCharSelect(screen)\n if gameState == \"Prepare\":\n prepare.update(dt)\n prepare.draw(screen)\n if gameState == \"Arena\":\n arena.update(dt)\n arena.draw(screen)\n\n for i, ef in enumerate(effects):\n ef.update()\n ef.draw(screen)\n if ef.done:\n del effects[i]\n if gameState == \"GameOver\":\n drawGameOver(screen)\n \n pygame.display.flip()\n"
},
{
"alpha_fraction": 0.6069528460502625,
"alphanum_fraction": 0.6165306568145752,
"avg_line_length": 27.190000534057617,
"blob_id": "2d8502333b683a6bb3d8e1e69fc68697071b5acc",
"content_id": "1d980437a776e93b36886bf438d71e71330f79a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2819,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 100,
"path": "/mac_setup.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis is a setup.py script generated by py2applet\n\nUsage:\n python setup.py py2app\n\"\"\"\n\nfrom setuptools import setup\nfrom distutils.core import setup\nimport py2app\nimport pygame\nimport sys\nimport os\nimport glob, shutil\nsys.argv.append(\"py2app\")\n\nSCRIPT_MAIN = 'main.py'\ntext = open(SCRIPT_MAIN,'r')\nf = open(\"final.py\",\"w\")\ntext = text.readlines()\ndef addfile(text,tofile):\n for line in text:\n if line[0:10] == \"exec(open(\":\n string = \"\"\n for char in line[11:]:\n if char != \"'\": string += char\n else: break\n newfile = open(string,\"r\")\n newtxt = newfile.readlines()\n addfile(newtxt,tofile)\n tofile.write(\"\\n\")\n else:\n tofile.write(line)\n\naddfile(text,f)\nf.close()\n\n\nVERSION = '0.1'\nAUTHOR_NAME = 'Thomas Steinke & Elliot Fiske'\nAUTHOR_EMAIL = 'thomasteinke@gmail.com'\nAUTHOR_URL = \"http://www.thomassteinke.net\"\nPRODUCT_NAME = \"Ludum Dare 27\"\nSCRIPT_MAIN = 'final.py'\nVERSIONSTRING = PRODUCT_NAME + \" ALPHA \" + VERSION\nICONFILE = 'favicon.ico'\n\n# Remove the build tree on exit automatically\nREMOVE_BUILD_ON_EXIT = True\nPYGAMEDIR = os.path.split(pygame.base.__file__)[0]\n\nSDL_DLLS = glob.glob(os.path.join(PYGAMEDIR,'*.dll'))\n\nif os.path.exists('dist/'): shutil.rmtree('dist/')\n\nextra_files = [ (\"\",[ICONFILE]),\n (\"data\",glob.glob(os.path.join('data','*.dat'))),\n (\"gfx\",glob.glob(os.path.join('gfx','*.jpg'))),\n (\"gfx\",glob.glob(os.path.join('gfx','*.png'))),\n (\"fonts\",glob.glob(os.path.join('fonts','*.ttf'))),\n (\"music\",glob.glob(os.path.join('music','*.ogg'))),\n (\"snd\",glob.glob(os.path.join('snd','*.wav')))]\n\nINCLUDE_STUFF = ['encodings',\"encodings.latin_1\",]\n\nAPP = ['final.py']\nDATA_FILES = []\nOPTIONS = {'argv_emulation': True,\n \"optimize\": 2,\n \"includes\": INCLUDE_STUFF,\n \"compressed\": 1,\n \"excludes\": []}\n\nsetup(\n app=APP,\n data_files=DATA_FILES,\n options={'py2app': OPTIONS},\n setup_requires=['py2app'],\n name = PRODUCT_NAME,\n version = VERSION,\n zipfile = None,\n author = AUTHOR_NAME,\n author_email = AUTHOR_EMAIL,\n url = AUTHOR_URL\n )\n\n# Create the /save folder for inclusion with the installer\nshutil.copytree('img','dist/'+PRODUCT_NAME+'.app/contents/Resources/img')\nshutil.copytree('default','dist/'+PRODUCT_NAME+'.app/contents/Resources/default')\nshutil.copytree('fonts','dist/'+PRODUCT_NAME+'.app/contents/Resources/fonts')\nshutil.copytree('sounds','dist/'+PRODUCT_NAME+'.app/contents/Resources/sounds')\n\nif os.path.exists('dist/tcl'): shutil.rmtree('dist/tcl')\n\n# Remove the build tree\nif REMOVE_BUILD_ON_EXIT:\n shutil.rmtree('build/')\n\nif os.path.exists('dist/tcl84.dll'): os.unlink('dist/tcl84.dll')\nif os.path.exists('dist/tk84.dll'): os.unlink('dist/tk84.dll')\n"
},
{
"alpha_fraction": 0.49124574661254883,
"alphanum_fraction": 0.5220674872398376,
"avg_line_length": 36.95328903198242,
"blob_id": "607e8aa52a532167451725ec2349b9a074ca0999",
"content_id": "e1adebc9bc4f40231e84a32e96f1d06e3c741cad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17877,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 471,
"path": "/character_class.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "\nclass Player(pygame.sprite.Sprite):\n \n def __init__(self, direction, start_x, color, color_2, arena, playerNum):\n self.input = {\"up\": False, \"down\": False, \"left\": False, \"right\": False}\n self.direction = direction\n self.color = color\n self.color_2 = color_2\n self.shapes = []\n self.arena = arena\n \n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n self.toExpand = False\n self.toNormalSize = False\n \n self.speed = 10\n self.airspeed = 14\n self.moving = None\n \n self.dead = False\n self.materialize(start_x, arena, playerNum)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes(arena)\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction=CHAR_FRICTION,\n restitution=0\n ),\n userData = \"player\"+str(playerNum)\n )\n block.color = self.color_2\n self.shapes.append(block)\n \n w = self.size[0]\n h = self.size[1]\n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1*w-.6,-1*h-.1),(w+.6,-1*h-.1),(w+.6,h+.1),(-1*w-.6,h+.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n self.dead = False\n self.dx = 0\n \n def draw(self, screen, offsetX, offsetY):\n for shape in self.shapes:\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0), shape.color)\n \n def destroy(self):\n destructionShapes = []\n if len(self.shapes) > 1:\n for i in range(1,len(self.shapes)):\n # Grab the old vertices from the shape\n olds = self.shapes[i].fixtures[0].shape.vertices\n # Convert them (with magic) using the body.transform thing\n result = [(self.shapes[i].transform*v) for v in olds]\n for v in result:\n body = arena.world.CreateDynamicBody(position = v, userData = \"particle\")\n shape = body.CreatePolygonFixture(box = (.2,.2), density = 1, isSensor = True)\n body.color = self.shapes[i].color\n body.linearVelocity.y = -15\n body.linearVelocity.x = random.random() * 6 - 3\n destructionShapes.append(body)\n \n # Grab the old vertices from the shape\n olds = self.shapes[0].fixtures[0].shape.vertices\n for i in range(20):\n # Convert them (with magic) using the body.transform thing\n result = [(self.shapes[0].transform*v) for v in olds]\n for v in result:\n body = arena.world.CreateDynamicBody(position = (v.x + random.random()*4 - 2, v.y + random.random()*4-2), userData = \"particle\")\n shape = body.CreatePolygonFixture(box = (.2,.2), density = 1, isSensor = True)\n body.color = self.shapes[0].color\n body.linearVelocity.y = -15\n body.linearVelocity.x = random.random() * 16 - 8\n destructionShapes.append(body)\n \n self.clearShapes()\n self.shapes = destructionShapes\n \n def create(self, color):\n self.clearShapes(arena, color)\n \n body = arena.world.CreateDynamicBody(position = ((ARENA_WIDTH * (arena + 0.5)) / PPM, 34))\n box = body.CreatePolygonFixture(box = (1,2), density = CHAR_DENSITY, friction = 0.3)\n self.shapes.append(body)\n \n def clearShapes(self, a = None):\n if a is not None:\n for shape in self.shapes:\n a.world.DestroyBody(shape)\n else:\n for shape in self.shapes:\n arena.world.DestroyBody(shape)\n self.shapes = []\n \n def update(self, nogravity = False):\n if self.toExpand:\n self.expand()\n self.toExpand = False\n if self.toNormalSize:\n self.normal()\n self.toNormalSize = False\n if(self.dead):\n self.destroy()\n return\n \n self.shapes[0].awake = True\n if nogravity:\n if self.input[\"up\"]:\n self.shapes[0].linearVelocity.y -= 3\n if self.input[\"down\"]:\n self.shapes[0].linearVelocity.y += 3\n if self.input[\"left\"]:\n self.shapes[0].linearVelocity.x -= 4\n if self.input[\"right\"]:\n self.shapes[0].linearVelocity.x += 4\n \n if self.shapes[0].linearVelocity.y > 20: self.shapes[0].linearVelocity.y = 20\n if self.shapes[0].linearVelocity.y < -20: self.shapes[0].linearVelocity.y = -20\n if self.shapes[0].linearVelocity.x > 20: self.shapes[0].linearVelocity.x = 20\n if self.shapes[0].linearVelocity.x < -20: self.shapes[0].linearVelocity.x = -20\n else:\n if self.moving is not None: \n if self.moving == \"l\": \n self.shapes[0].linearVelocity.x += self.speed\n if self.moving == \"r\":\n self.shapes[0].linearVelocity.x -= self.speed\n \n if len(self.shapes[0].contacts) > 0: maxspeed = self.speed\n else: maxspeed = self.speed + self.airspeed\n if self.input[\"left\"]:\n self.shapes[0].linearVelocity.x -= maxspeed\n if self.input[\"right\"]:\n self.shapes[0].linearVelocity.x += maxspeed\n \n if self.shapes[0].linearVelocity.x > 20: self.shapes[0].linearVelocity.x = 20\n if self.shapes[0].linearVelocity.x < -20: self.shapes[0].linearVelocity.x = -20\n \n def jump(self):\n if len(self.shapes[0].contacts) > 0:\n self.shapes[0].linearVelocity.y = -15\n self.shapes[0].angularVelocity = 5.4\n \n def dive(self):\n if self.shapes[0].linearVelocity.x > 0:\n dir = \"l\"\n else:\n dir = \"r\"\n \n if len(self.shapes[0].contacts) == 0:\n self.shapes[0].linearVelocity.y = 25\n self.shapes[0].linearVelocity.x *= 2\n if dir == \"l\":\n if self.shapes[0].angle < math.pi / 4:\n self.shapes[0].angularVelocity = 0.5\n else:\n self.shapes[0].angularVelocity = -0.5\n if dir == \"r\":\n if self.shapes[0].angle < - math.pi / 4:\n self.shapes[0].angularVelocity = 0.5\n else:\n self.shapes[0].angularVelocity = -0.5\n \n def jump(self, gravity):\n if gravity == b2Vec2(0,0): pass\n else:\n if len(self.shapes[0].contacts) > 0:\n playSound(\"hop\")\n self.shapes[0].linearVelocity.y = -20 * gravity[1] / 25\n self.shapes[0].angularVelocity = -5.4 * self.direction\n \n def makeNewBlock(self, size):\n i = 0\n shape = self.shapes[i]\n s = shape.fixtures[0].shape\n \n newshape = arena.world.CreateDynamicBody(\n position = shape.position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = size),\n density=shape.fixtures[0].density,\n friction = shape.fixtures[0].friction,\n restitution=shape.fixtures[0].restitution\n ),\n userData = shape.userData\n )\n newshape.color = shape.color\n arena.world.DestroyBody(self.shapes[i])\n self.shapes[i] = newshape\n \n def expand(self):\n self.makeNewBlock(self.large)\n \n def normal(self):\n self.makeNewBlock(self.size)\n \n def shrink(self):\n self.makeNewBlock(self.small)\n\nclass Lars(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n Player.__init__(self, direction, start_x, (0, 0, 0), (255, 255, 0), arena, playerNum)\n\nclass Pate(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n self.small = (0.4,1)\n self.size = (0.8,2.3)\n self.large = (1.6,4.2)\n \n Player.__init__(self, direction, start_x, (0, 0, 0), (0, 255, 255), arena, playerNum)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes(arena)\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction = 10000,\n restitution=0),\n userData = \"player\"+str(playerNum)\n )\n block.color = self.color_2\n self.shapes.append(block)\n \n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1.6,-2.1),(1.6,-2.1),(1.6,2.1),(-1.6,2.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n self.dead = False\n\nclass Buster(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n Player.__init__(self, direction, start_x, (0, 0, 0), (153, 255, 0), arena, playerNum)\n \n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n self.materialize(start_x, arena, playerNum)\n\nclass EricStrohm(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n Player.__init__(self, direction, start_x, (0, 0, 0), (30, 30, 30), arena, playerNum)\n \n self.speed = 12\n self.airspeed = 20\n\nclass Ted(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n Player.__init__(self, direction, start_x, (0, 0, 0), (255, 0, 0), arena, playerNum)\n \n self.small = (0.7,0.7)\n self.size = (1.3,1.3)\n self.large = (2.5,2.5)\n self.clearShapes(arena) \n \n self.materialize(start_x, arena, playerNum)\n\nclass SmithWickers(Player):\n def __init__(self, direction, start_x, arena, playerNum):\n \n self.alt_color = pygame.color.Color(255, 102, 0)\n self.alt_color_2 = pygame.color.Color(102, 51, 102)\n \n Player.__init__(self, direction, start_x, (0, 0, 0), (255, 0, 255), arena, playerNum)\n \n self.small = (0.3,0.8)\n self.size = (0.75,1.7)\n self.large = (1.5,3.5)\n \n self.materialize(start_x, arena, playerNum)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes(arena)\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction = CHAR_FRICTION,\n restitution=0),\n userData = \"player\"+str(playerNum)\n )\n block.color = self.alt_color\n self.shapes.append(block)\n \n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1.6,-2.1),(1.6,-2.1),(1.6,2.1),(-1.6,2.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n block2 = arena.world.CreateDynamicBody(\n position = (start_x - 3, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction=CHAR_FRICTION,\n restitution=0),\n userData = \"player\"+str(playerNum)\n )\n block2.color = self.alt_color_2\n self.shapes.append(block2)\n \n arena.world.CreateDistanceJoint(bodyA = block, bodyB = block2, anchorA = block.worldCenter, anchorB = block2.worldCenter, collideConnected = True)\n \n self.dead = False\n \n def expand(self):\n shape = self.shapes[0]\n s = shape.fixtures[0].shape\n block = arena.world.CreateDynamicBody(\n position = shape.position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.large),\n density=shape.fixtures[0].density,\n friction = shape.fixtures[0].friction,\n restitution=shape.fixtures[0].restitution\n ),\n userData = shape.userData\n )\n block.color = self.alt_color\n arena.world.DestroyBody(self.shapes[0])\n self.shapes[0] = block\n \n oldpos = shape.position\n shape2 = self.shapes[1]\n newpos = shape2.position\n s = shape2.fixtures[0].shape\n block2 = arena.world.CreateDynamicBody(\n position = (newpos.x + (newpos.x - oldpos.x) * 4/3, newpos.y + (newpos.y - oldpos.y) * 4/3),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.large),\n density=shape2.fixtures[0].density,\n friction = shape2.fixtures[0].friction,\n restitution=shape2.fixtures[0].restitution\n ),\n userData = shape2.userData\n )\n block2.color = self.alt_color_2\n arena.world.DestroyBody(self.shapes[1])\n self.shapes[1] = block2\n \n arena.world.CreateDistanceJoint(bodyA = block, bodyB = block2, anchorA = block.worldCenter, anchorB = block2.worldCenter, collideConnected = True)\n \n def normal(self):\n shape = self.shapes[0]\n s = shape.fixtures[0].shape\n block = arena.world.CreateDynamicBody(\n position = shape.position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=shape.fixtures[0].density,\n friction = shape.fixtures[0].friction,\n restitution=shape.fixtures[0].restitution\n ),\n userData = shape.userData\n )\n block.color = self.alt_color\n arena.world.DestroyBody(self.shapes[0])\n self.shapes[0] = block\n \n oldpos = shape.position\n shape2 = self.shapes[1]\n newpos = shape2.position\n s = shape2.fixtures[0].shape\n block2 = arena.world.CreateDynamicBody(\n position = (oldpos.x - 3, oldpos.y),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=shape2.fixtures[0].density,\n friction = shape2.fixtures[0].friction,\n restitution=shape2.fixtures[0].restitution\n ),\n userData = shape2.userData\n )\n block2.color = self.alt_color_2\n arena.world.DestroyBody(self.shapes[1])\n self.shapes[1] = block2\n \n arena.world.CreateDistanceJoint(bodyA = block, bodyB = block2, anchorA = block.worldCenter, anchorB = block2.worldCenter, collideConnected = True)\n\nclass CrowdMember(Player):\n def __init__(self, direction, start_x, color, arena):\n Player.__init__(self, direction, start_x, (0, 0, 0), color, arena, 0)\n self.timeToJump = random.random() * 10000 + 1000\n \n self.small = (0.5,1)\n self.size = (1,2)\n self.large = (2,4)\n \n def materialize(self, start_x, arena, playerNum):\n self.clearShapes()\n \n block = arena.world.CreateDynamicBody(\n position = (start_x, 30),\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(box = self.size),\n density=CHAR_DENSITY,\n friction=CHAR_FRICTION,\n restitution=0,\n filter = b2Filter(\n categoryBits = 0x0010,\n maskBits = 0xFFFF ^ 0x0010\n )\n ),\n userData = \"crowd member\"\n )\n\n block.color = self.color_2\n self.shapes.append(block)\n \n w = self.size[0]\n h = self.size[1]\n foot = block.CreateFixture(\n shape = b2PolygonShape(vertices = [(-1*w-.6,-1*h-.1),(w+.6,-1*h-.1),(w+.6,h+.1),(-1*w-.6,h+.1)]),\n isSensor=True\n )\n self.foot = block.fixtures[1]\n \n self.dead = False\n self.dx = 0\n \n def update(self, dt, nogravity = False):\n if(self.dead):\n self.dead = False\n return\n \n self.shapes[0].awake = True\n if nogravity: pass\n else:\n if abs(self.shapes[0].transform.angle) > 0.1 and abs(self.shapes[0].transform.angle - 180) > 0.1 and self.shapes[0].linearVelocity.y == 0:\n self.jumpBackUp()\n \n self.timeToJump -= dt\n if self.timeToJump <= 0 and self.shapes[0].linearVelocity.y == 0:\n self.jump()\n self.timeToJump = random.random() * 10000 + 1000\n maxspeed = 3\n \n if self.shapes[0].linearVelocity.x != 0 and random.random() > 0.7 and self.shapes[0].linearVelocity.y == 0:\n self.shapes[0].linearVelocity.x = 0\n \n if self.shapes[0].linearVelocity.x == 0 and random.random() > 0.7 and self.shapes[0].linearVelocity.y == 0:\n self.shapes[0].linearVelocity.x = 5 * (random.random() * 4 - 2)\n \n def jump(self):\n if len(self.shapes[0].contacts) > 0:\n self.shapes[0].linearVelocity.y -= 15\n \n def jumpBackUp(self):\n if len(self.shapes[0].contacts) > 0:\n self.shapes[0].linearVelocity.y = -10\n self.shapes[0].angularVelocity = 2\n"
},
{
"alpha_fraction": 0.49868011474609375,
"alphanum_fraction": 0.5272079110145569,
"avg_line_length": 37.56071472167969,
"blob_id": "5ee9f896223b69e9baedaf4ce3e71cd78990066d",
"content_id": "bd78f66c104ab0f24bf63a4c160861c91ecbb358",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21593,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 560,
"path": "/arena_mechanics.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "def changeArena(arenaNum):\n global currentArena # Midpoint\n global camera\n \n currentArena = arenaNum\n camera.panCam(arenaNum)\n camera.delay = 200\n\nchar1 = \"Lars\"\nchar2 = \"Buster\"\nclass Arena():\n def __init__(self):\n self.timeRemaining = 10000 # 10 seconds\n self.drawRed = 0\n self.bignum = 10\n self.shapes = []\n self.crowd = []\n \n self.modeName = \"none\"\n \n self.player1possession = 0\n self.player2possession = 0\n \n self.modifications = []\n \n # Initialize effects queue\n self.effects = []\n \n # Init physics \"world\", defining gravity. doSleep means that if an object\n # comes to rest, it can \"sleep\" and be ignored by the physics engine for a bit.\n self.world = b2World(gravity=(0, 25), doSleep = False)\n \n # Initialize the contact handler\n self.world.contactListener = ContactHandler()\n \n self.initWalls()\n self.ball = None\n self.startGame(STAGE_WIDTH_M / 2)\n \n self.camera = Camera(STAGE_WIDTH_M / 2)\n \n self.score = [0,0]\n \n self.toInit = False\n self.pauseTime = 0\n \n self.createCrowd(2, 24)\n self.createCrowd(227, 248)\n \n #self.bombDrop()\n #self.changeBall()\n #self.nogravity()\n #self.slowmo()\n \n def startGame(self, middle_x, delay=0):\n global char1, char2\n if delay > 0:\n self.toInit = (middle_x, delay)\n return\n resumeBackground()\n self.toInit = False\n self.pauseTime = delay\n \n if hasattr(self,'player2'):\n self.player1.materialize(middle_x - SCREEN_WIDTH_M / 4, self, 2)\n self.player2.materialize(middle_x + SCREEN_WIDTH_M / 4, self, 1)\n else:\n if char1 == \"Lars\":\n self.player1 = Lars(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"Buster\":\n self.player1 = Buster(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"SmithWickers\":\n self.player1 = SmithWickers(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"Pate\":\n self.player1 = Pate(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n elif char1 == \"EricStrohm\":\n self.player1 = EricStrohm(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n else: # char1 == \"Ted\":\n self.player1 = Ted(1, middle_x - SCREEN_WIDTH_M / 4, self, 1)\n \n if char2 == \"Lars\":\n self.player2 = Lars(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"Buster\":\n self.player2 = Buster(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"SmithWickers\":\n self.player2 = SmithWickers(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"Ted\":\n self.player2 = Ted(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n elif char2 == \"EricStrohm\":\n self.player2 = EricStrohm(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n else: # char2 == \"Pate\":\n self.player2 = Pate(-1, middle_x + SCREEN_WIDTH_M / 4, self, 2)\n \n if self.ball is not None: self.world.DestroyBody(self.ball)\n \n self.ball = self.world.CreateDynamicBody(position = (middle_x,28),\n fixtures = b2FixtureDef(\n shape = b2CircleShape(radius=1.3),\n density=1,\n restitution=0.5,\n friction = 50),\n userData=\"ball\")\n \n self.ball.color = pygame.color.Color(128,128,128)\n self.shapes.append(self.ball)\n \n self.textAlpha = 255\n self.dispText = \"Go!\"\n \n def createCrowd(self, minx, maxx):\n numCrowd = int(math.ceil(random.random() * 10) + 10)\n width = maxx - minx\n \n for i in range(numCrowd):\n member = CrowdMember(0, minx + random.random() * width, (int(random.random()*255),int(random.random()*255),int(random.random()*255)), self)\n self.crowd.append(member)\n self.shapes.append(member.shapes[0])\n \n def initWalls(self):\n ground = self.world.CreateStaticBody(\n position = (0, 37.5),\n shapes = b2PolygonShape(box = (STAGE_WIDTH_M,1)),\n userData = \"ground\"\n )\n ground.color = pygame.color.Color(0,128,0)\n self.shapes.append(ground)\n \n ceiling = self.world.CreateStaticBody(\n position = (0, -1),\n shapes = b2PolygonShape(box = (STAGE_WIDTH_M,1)),\n userData = \"ceiling\"\n )\n self.shapes.append(ceiling)\n \n leftWall = self.world.CreateStaticBody(\n position = (25, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"left wall\"\n )\n #self.shapes.append(leftWall)\n \n rightWall = self.world.CreateStaticBody(\n position = (225, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"right wall\"\n )\n #self.shapes.append(rightWall)\n \n leftWall = self.world.CreateStaticBody(\n position = (0, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"left wall\"\n )\n #self.shapes.append(leftWall)\n \n rightWall = self.world.CreateStaticBody(\n position = (250, 0),\n shapes = b2PolygonShape(box = (1,37.5)),\n userData = \"right wall\"\n )\n \n goal_left = self.world.CreateStaticBody(\n position = (223, 37),\n shapes = b2PolygonShape(box = (2,8))\n )\n goal_left.fixtures[0].sensor = True\n goal_left.userData = \"goal left\"\n self.shapes.append(goal_left)\n \n goal_right = self.world.CreateStaticBody(\n position = (29, 37),\n shapes = b2PolygonShape(box = (2,8))\n )\n goal_right.fixtures[0].sensor = True\n goal_right.userData = \"goal right\"\n self.shapes.append(goal_right)\n \n # Detects if the player is off camera and draws an arrow to them\n def playerOffCamera(self):\n # A player is off camera if all 4 of their vertices don't intersect with the screen.\n SCREEN_RECT.left = self.camera.centerX_in_meters * PPM - SCREEN_WIDTH_PX / 2\n offsetX, offsetY = self.camera.getOffset_in_px()\n verts = vertices(self.player1.shapes[0].fixtures[0])\n inside = False\n for vert in verts:\n inside = inside or SCREEN_RECT.collidepoint( (vert.x, vert.y) )\n \n if not inside:\n self.drawArrow(self.player1)\n \n verts = vertices(self.player2.shapes[0].fixtures[0])\n inside = False\n for vert in verts:\n inside = inside or SCREEN_RECT.collidepoint( (vert.x, vert.y) )\n \n if not inside:\n self.drawArrow(self.player2)\n \n # Draw an arrow to the lost, lonely player. \n def drawArrow(self, player):\n position = player.shapes[0].position\n arrowX, arrowY = 0, 0\n \n # Identify the x and y to draw the arrow in\n arrowY = position.y * PPM - 70\n if position.x < self.camera.centerX_in_meters:\n arrowX = 5\n arrowImg = pygame.transform.flip(images[\"red arrow\"][0], True, False)\n else:\n arrowImg = images[\"red arrow\"][0]\n arrowX = SCREEN_WIDTH_PX - (5 + images[\"red arrow\"][1].width)\n \n screen.blit(arrowImg, (arrowX, arrowY))\n \n # Lets the arena know that a player has touched the ball recently\n def gotPossession(self, playerFixture):\n if playerFixture.body.userData == \"player1\":\n self.player1possession = 50\n elif playerFixture.body.userData == \"player2\":\n self.player2possession = 50\n else:\n print(\"wat\")\n \n def update(self, dt):\n self.camera.update(self.ball)\n \n if self.toInit is not False:\n self.startGame(self.toInit[0], self.toInit[1] - dt)\n \n # Update a \"tick\" in physics land\n self.world.Step(TIME_STEP*2, 10, 10)\n \n # Reset forces for the next frame\n self.world.ClearForces()\n \n if(self.player1.dead):\n self.player1.dead = False\n self.player1.destroy()\n if(self.player2.dead):\n self.player2.dead = False\n self.player2.destroy()\n return\n \n self.timeRemaining -= dt\n oldbignum = self.bignum\n self.bignum = math.trunc(self.timeRemaining / 1000)\n if self.bignum != oldbignum and self.bignum < 4: self.drawRed = 128\n if(self.timeRemaining <= 0):\n self.randomEvent()\n self.timeRemaining = 10000\n \n self.player1.update(self.world.gravity == b2Vec2(0,0))\n self.player2.update(self.world.gravity == b2Vec2(0,0))\n for member in self.crowd:\n member.update(dt, self.world.gravity == b2Vec2(0,0))\n \n # Murder things that need murdering\n for i, shape in enumerate(self.shapes):\n if shape.userData == \"kill me\":\n shape.DestroyFixture(shape)\n del self.shapes[i]\n \n for i, ef in enumerate(self.effects):\n ef.update()\n ef.draw(screen)\n if ef.done:\n del self.effects[i]\n \n self.ball.linearVelocity.x *= BALL_FRICTION\n \n # Check the \"possession\" status of each character and change friction as necessary\n #if self.player1possession > 0 and self.player1possession > self.player2possession:\n # self.player1.shapes[0].friction = 10\n # print(\"fraction\", self.player1.shapes[0].friction) \n #else: \n # self.player1.shapes[0].friction = 0.3\n # \n #if self.player2possession > 0 and self.player2possession > self.player1possession:\n # self.player1.shapes[0].friction = 10\n #else: \n # self.player2.shapes[0].friction = 0.3\n \n # Decrement the possession timers\n self.player1possession -= 1\n if self.player1possession < 0: self.player1possession = 0\n self.player2possession -= 1\n if self.player2possession < 0: self.player2possession = 0\n \n # Update a \"tick\" in physics land\n self.world.Step(TIME_STEP*2, 10, 10)\n \n # Reset forces for the next frame\n self.world.ClearForces()\n \n def draw(self, screen, showTimer = True):\n \n self.camera.draw(screen)\n \n if showTimer:\n self.drawTimer(screen)\n \n offsetX, offsetY = self.camera.getOffset_in_px()\n self.player1.draw(screen, offsetX, offsetY)\n self.player2.draw(screen, offsetX, offsetY)\n for member in self.crowd: pass\n #DrawPolygon(vertices_with_offset(member.fixtures[0], offsetX, offsetY), (0,0,0), member.color)\n \n for shape in self.shapes:\n if isinstance(shape.fixtures[0].shape, b2CircleShape):\n pos = (int(shape.position.x * PPM - offsetX), int(shape.position.y * PPM + offsetY))\n if shape.userData == \"ball\":\n DrawCircle(pos, shape.fixtures[0].shape.radius, shape.color)\n else:\n DrawCircle(pos, shape.fixtures[0].shape.radius, (0,0,0))\n elif shape.userData is not None:\n if shape.userData == \"goal left\" or shape.userData == \"goal right\":\n DrawImage(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), shape.userData)\n else:\n if hasattr(shape, \"color\"):\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0), shape.color)\n else:\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0))\n else:\n if hasattr(shape, \"color\"):\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0), shape.color)\n else:\n DrawPolygon(vertices_with_offset(shape.fixtures[0], offsetX, offsetY), (0,0,0))\n \n # Draw arrows if the player is off screen\n self.playerOffCamera()\n \n def drawTimer(self, screen):\n color = (self.drawRed,0,0)\n \n text = time_font_lg.render(str(self.bignum), False, color)\n text_sm = time_font_sm.render(str(self.timeRemaining % 1000), False, color)\n \n if(self.drawRed > 0):\n self.drawRed -= 2\n \n if(self.bignum == 10): screen.blit(text, (SCREEN_WIDTH_PX / 2 - 1100,0))\n else: screen.blit(text, (SCREEN_WIDTH_PX / 2 - 70,0))\n screen.blit(text_sm, (SCREEN_WIDTH_PX / 2,0))\n \n text_l = time_font_lg.render(str(self.score[0]), False, (0,0,0))\n text_r = time_font_lg.render(str(self.score[1]), False, (0,0,0))\n screen.blit(text_l, (0,0))\n screen.blit(text_r, (SCREEN_WIDTH_PX - 60,0))\n \n if self.textAlpha > 0:\n self.textAlpha -= 2.5\n \n text = time_font_giant.render(self.dispText, False, (0, 0, 0), (255,255,255, 0))\n if self.dispText == \"SLOW MO!\":\n surface = pygame.Surface((text.get_width()+30, text.get_height()))\n surface.blit(text, (30,0))\n text = time_font_giant.render(self.dispText, False, (0, 0, 0), (255,255,255, 0))\n surface.blit(text, (0,0))\n surface.set_colorkey((255,255,255))\n surface.set_alpha(self.textAlpha)\n screen.blit(surface, (SCREEN_WIDTH_PX / 2 - text.get_width()/2,180))\n else:\n surface = pygame.Surface((text.get_width(), text.get_height()))\n surface.blit(text, (0,0))\n surface.set_colorkey((255,255,255))\n surface.set_alpha(self.textAlpha)\n screen.blit(surface, (SCREEN_WIDTH_PX / 2 - text.get_width()/2,180))\n\n def doAction(self, event):\n if event.key is K_a:\n self.player1.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_d:\n self.player1.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_LEFT:\n self.player2.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_RIGHT:\n self.player2.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_UP:\n self.player2.input[\"up\"] = (event.type is pygame.KEYDOWN)\n self.player2.jump(self.world.gravity)\n if event.key == K_DOWN:\n self.player2.input[\"down\"] = (event.type is pygame.KEYDOWN)\n self.player2.dive()\n if event.key is K_w:\n self.player1.input[\"up\"] = (event.type is pygame.KEYDOWN)\n self.player1.jump(self.world.gravity)\n if event.key is K_s:\n self.player1.input[\"down\"] = (event.type is pygame.KEYDOWN)\n self.player1.dive()\n \n def changeBall(self):\n print \"Changeball triggered\"\n self.shapes.remove(self.ball)\n position = self.ball.position\n self.world.DestroyBody(self.ball)\n self.ball = self.world.CreateDynamicBody(position = position,\n fixtures = b2FixtureDef(\n shape = b2PolygonShape(vertices=[(-0.33,1 ),\n (-1 ,0.33),\n (-1 ,-0.33),\n (-0.33 ,-1 ),\n (0.33 ,-1 ),\n (1 ,-0.33),\n (1 ,0.33),\n (-0.33 ,1 )]),\n density=10,\n restitution=0.5,\n friction = 50),\n userData=\"ball\")\n self.ball.color = pygame.color.Color(128,128,128)\n self.shapes.append(self.ball)\n \n self.textAlpha = 255\n self.dispText = \"ROCK BALL!\"\n \n def changeBall_revert(self):\n print \"Changeball reverted\"\n self.shapes.remove(self.ball)\n position = self.ball.position\n self.world.DestroyBody(self.ball)\n \n self.ball = self.world.CreateDynamicBody(position = position,\n fixtures = b2FixtureDef(\n shape = b2CircleShape(radius=1.3),\n density=1,\n restitution=0.5,\n friction = 50),\n userData=\"ball\")\n \n self.ball.color = pygame.color.Color(128,128,128)\n self.shapes.append(self.ball)\n \n def slowmo(self):\n print \"slow mo!\"\n global TIME_STEP\n TIME_STEP /= 4\n \n self.textAlpha = 255\n self.dispText = \"SLOW MO!\"\n \n def slowmo_revert(self):\n print \"slow mo reverted\"\n global TIME_STEP\n TIME_STEP *= 4\n \n def giantMode(self):\n self.textAlpha = 255\n self.dispText = \"GET BIG!\"\n \n self.player1.toExpand = True\n self.player2.toExpand = True\n \n def giantMode_revert(self):\n self.player1.toNormalSize = True\n self.player2.toNormalSize = True\n \n def cleanUp(self):\n self.crowd = []\n while len(self.shapes) > 0:\n shape = self.shapes[0]\n self.world.DestroyBody(shape)\n self.shapes.remove(shape)\n \n def bombDrop(self):\n print \"bomb droppin time!\"\n bombs = BombDrop()\n effects.append(bombs)\n \n self.textAlpha = 255\n self.dispText = \"BOMBS!\"\n \n def bombDrop_revert(self):\n print \"bomb droppin reversion!\"\n # Find the bomb drop and PUT A STOP TO THE MADNESS\n for ef in effects:\n if ef.__class__.__name__ == \"BombDrop\":\n ef.finish()\n \n def randomEvent(self):\n randomEvents = [ [self.bombDrop, self.bombDrop_revert],\n [self.changeBall, self.changeBall_revert],\n [self.giantMode, self.giantMode_revert],\n [self.slowmo, self.slowmo_revert]]\n \n while len(self.modifications) > 0:\n mod = self.modifications[0]\n mod[1]()\n del self.modifications[0]\n \n event = math.floor(random.random() * len(randomEvents))\n \n # Grab the function from the list of events and run it\n mod = randomEvents[int(event)]\n mod[0]()\n self.modifications.append(mod)\n \n # Stop all inferior sounds\n pygame.mixer.stop()\n # Play the \"woopwoopwoop\" transition sound\n playSound(\"transition\")\n # Put on a new backtrack, DJ!\n playSound(\"background\")\n \n \nclass PrepareForBattle(Arena):\n def __init__(self):\n self.timeRemaining = 3000\n self.bignum = 3\n playSound(\"start\")\n \n def draw(self, screen):\n arena.draw(screen, False)\n \n self.drawTimer(screen)\n \n text = (time_font_lg.render(\"PREPARE\", False, (0, 0, 0)), time_font_lg.render(\"YOURSELF\", False, (0, 0, 0)))\n screen.blit(text[0], (SCREEN_WIDTH_PX / 2 - 210,180))\n screen.blit(text[1], (SCREEN_WIDTH_PX / 2 - 220,260))\n \n \n def drawTimer(self, screen):\n color = (self.drawRed,0,0)\n \n text = time_font_lg.render(str(self.bignum), False, color)\n text_sm = time_font_sm.render(str(self.timeRemaining % 1000), False, color)\n \n if(self.drawRed > 0):\n self.drawRed -= 2\n \n screen.blit(text, (SCREEN_WIDTH_PX / 2 - 70,0))\n screen.blit(text_sm, (SCREEN_WIDTH_PX / 2,0))\n \n def update(self, dt):\n self.timeRemaining -= dt\n oldbignum = self.bignum\n self.bignum = math.trunc(self.timeRemaining / 1000)\n if self.bignum != oldbignum and self.bignum < 4: self.drawRed = 128\n if(self.timeRemaining <= 0):\n global arena, gameState\n gameState = \"Arena\"\n # Play the first background\n playSound(\"background\")\n\n def doAction(self, event):\n if event.key is K_a:\n arena.player1.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_d:\n arena.player1.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_LEFT:\n arena.player2.input[\"left\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_RIGHT:\n arena.player2.input[\"right\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_UP:\n arena.player2.input[\"up\"] = (event.type is pygame.KEYDOWN)\n if event.key == K_DOWN:\n arena.player2.input[\"down\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_w:\n arena.player1.input[\"up\"] = (event.type is pygame.KEYDOWN)\n if event.key is K_s:\n arena.player1.input[\"down\"] = (event.type is pygame.KEYDOWN)"
},
{
"alpha_fraction": 0.5667821764945984,
"alphanum_fraction": 0.5761130452156067,
"avg_line_length": 26.992536544799805,
"blob_id": "524a58099fd29145a6616a85b456f6fad213b199",
"content_id": "9500f7e085dc9eb5b06021912bae95a02e020a86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3751,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 134,
"path": "/exe_setup.py",
"repo_name": "Epiphane/LudumDare",
"src_encoding": "UTF-8",
"text": "# py2exe setup program\nfrom distutils.core import setup\nimport py2exe\nimport pygame\nimport sys\nimport os\nimport glob, shutil\nsys.argv.append(\"py2exe\")\n\nSCRIPT_MAIN = 'main.py'\ntext = open(SCRIPT_MAIN,'r')\nf = open(\"KickBox.py\",\"w\")\ntext = text.readlines()\ndef addfile(text,tofile):\n for line in text:\n if line[0:10] == \"exec(open(\":\n string = \"\"\n for char in line[11:]:\n if char != \"'\": string += char\n else: break\n newfile = open(string,\"r\")\n newtxt = newfile.readlines()\n addfile(newtxt,tofile)\n tofile.write(\"\\n\")\n else:\n tofile.write(line)\n\naddfile(text,f)\nf.close()\n\n \nVERSION = '0.1'\nAUTHOR_NAME = 'Thomas Steinke & Elliot Fiske'\nAUTHOR_EMAIL = 'thomasteinke@gmail.com'\nAUTHOR_URL = \"http://www.thomassteinke.net\"\nPRODUCT_NAME = \"Ludum Dare 27\"\nSCRIPT_MAIN = 'Kickbox.py'\nVERSIONSTRING = PRODUCT_NAME + \" ALPHA \" + VERSION\nICONFILE = \"favicon.ico\"\n \n# Remove the build tree on exit automatically\nREMOVE_BUILD_ON_EXIT = True\nPYGAMEDIR = os.path.split(pygame.base.__file__)[0]\n \nSDL_DLLS = glob.glob(os.path.join(PYGAMEDIR,'*.dll'))\n \nif os.path.exists('dist/'): shutil.rmtree('dist/')\n \nextra_files = [ (\"\",[ICONFILE]),\n (\"data\",glob.glob(os.path.join('data','*.dat'))),\n (\"gfx\",glob.glob(os.path.join('gfx','*.jpg'))),\n (\"gfx\",glob.glob(os.path.join('gfx','*.png'))),\n (\"fonts\",glob.glob(os.path.join('fonts','*.ttf'))),\n (\"music\",glob.glob(os.path.join('music','*.ogg'))),\n (\"snd\",glob.glob(os.path.join('snd','*.wav')))]\n \n# List of all modules to automatically exclude from distribution build\n# This gets rid of extra modules that aren't necessary for proper functioning of app\n# You should only put things in this list if you know exactly what you DON'T need\n# This has the benefit of drastically reducing the size of your dist\n \nMODULE_EXCLUDES =[\n'email',\n'AppKit',\n'Foundation',\n'bdb',\n'difflib',\n'tcl',\n'Tkinter',\n'Tkconstants',\n'curses',\n'distutils',\n'setuptools',\n'urllib',\n'urllib2',\n'urlparse',\n'BaseHTTPServer',\n'_LWPCookieJar',\n'_MozillaCookieJar',\n'ftplib',\n'gopherlib',\n'_ssl',\n'htmllib',\n'httplib',\n'mimetools',\n'mimetypes',\n'rfc822',\n'tty',\n'webbrowser',\n'base64',\n'compiler',\n'pydoc']\n \nINCLUDE_STUFF = ['encodings',\"encodings.latin_1\",]\n \nsetup(windows=[\n {'script': SCRIPT_MAIN,\n 'other_resources': [(u\"VERSIONTAG\",1,VERSIONSTRING)],\n 'icon_resources': [(1,ICONFILE)]}],\n options = {\"py2exe\": {\n \"optimize\": 2,\n \"includes\": INCLUDE_STUFF,\n \"compressed\": 1,\n \"ascii\": 1,\n \"bundle_files\": 1,\n \"ignores\": ['tcl','AppKit','Numeric','Foundation'],\n \"excludes\": MODULE_EXCLUDES} },\n name = PRODUCT_NAME,\n version = VERSION,\n data_files = extra_files,\n zipfile = None,\n author = AUTHOR_NAME,\n author_email = AUTHOR_EMAIL,\n url = AUTHOR_URL)\n \n# Create the /save folder for inclusion with the installer\nshutil.copytree('img','dist/img')\nshutil.copytree('default','dist/default')\nshutil.copytree('sounds','dist/sounds')\n \nif os.path.exists('dist/tcl'): shutil.rmtree('dist/tcl') \n \n# Remove the build tree\nif REMOVE_BUILD_ON_EXIT:\n shutil.rmtree('build/')\n \nif os.path.exists('dist/tcl84.dll'): os.unlink('dist/tcl84.dll')\nif os.path.exists('dist/tk84.dll'): os.unlink('dist/tk84.dll')\n \nfor f in SDL_DLLS:\n fname = os.path.basename(f)\n try:\n shutil.copyfile(f,os.path.join('dist',fname))\n except: pass\n"
}
] | 15 |
pradiprathod76/try | https://github.com/pradiprathod76/try | d10342ed40601bc76126956a16d372dfc22207ff | c462d0002775154b3e7d0133f9cfcab939cfb8dc | e1f781c6b8c51765aadbd6df343420fdf64efda4 | refs/heads/master | 2022-10-10T15:43:31.496219 | 2020-06-08T10:46:38 | 2020-06-08T10:46:38 | 270,630,206 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5092166066169739,
"alphanum_fraction": 0.5691244006156921,
"avg_line_length": 23.11111068725586,
"blob_id": "1db950c9080361ad1b653e71326b23c136ffc07a",
"content_id": "f55ae3894dfcfd49f1aeba1a0172d4a285fc25db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 18,
"path": "/DjangoUploadModelForm/tutorials/migrations/0003_auto_20200606_1102.py",
"repo_name": "pradiprathod76/try",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-06-06 05:32\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('tutorials', '0002_tutorial_select'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='tutorial',\n name='select',\n field=models.CharField(choices=[('1', '1'), ('2', '2')], default='1', max_length=10),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6729824542999268,
"alphanum_fraction": 0.6750876903533936,
"avg_line_length": 29.978260040283203,
"blob_id": "bb5c745ef7ecc9b598e0ded7cf142bdc0a3dc2e1",
"content_id": "901f1c81904e09d729d23cd6ba82cc8eca87ceb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1425,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 46,
"path": "/DjangoUploadModelForm/tutorials/views.py",
"repo_name": "pradiprathod76/try",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect,get_object_or_404\nfrom django.http import HttpResponse\nfrom .forms import TutorialForm\nfrom .models import Tutorial\n\n\ndef tutorialList(request):\n tutorials = Tutorial.objects.all()\n return render(request, 'tutorial/list.html', { 'tutorials' : tutorials})\n\n\ndef uploadTutorial(request):\n if request.method == 'POST': \n form = TutorialForm(request.POST, request.FILES)\n\n if form.is_valid():\n form.save()\n return redirect('tutorial_list')\n else:\n form = TutorialForm()\n return render(request, 'tutorial/upload.html', {'form' : form})\n\ndef editTutorial(request,pk):\n tutorials = Tutorial.objects.get(id=pk)\n return render(request,'tutorial/update.html',{'t':tutorials})\n\n\ndef updateTutorial(request,pk):\n tutorials = Tutorial.objects.get(id=pk)\n form = TutorialForm(request.POST,request.FILES,instance=Tutorial)\n if form.is_valid():\n #form.feature_image = form.changed_data['feature_image']\n #form.attachment = form.changed_data['attachment']\n\n form.save()\n return HttpResponse('done')\n else:\n return HttpResponse('not done')\n #return render(request,'tutorial/update.html',{'t':tutorials})\n\n\ndef deleteTutorial(request, pk):\n if request.method == 'POST':\n tutorial = Tutorial.objects.get(pk=pk)\n tutorial.delete()\n return redirect('tutorial_list')\n"
},
{
"alpha_fraction": 0.6528117656707764,
"alphanum_fraction": 0.684596598148346,
"avg_line_length": 28.071428298950195,
"blob_id": "4f248affacf5ff642c4857c9d84ec506a575317f",
"content_id": "f3a2b438d9f946a2b6c5ca52f8228928d5c9c6f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 409,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 14,
"path": "/DjangoUploadModelForm/tutorials/models.py",
"repo_name": "pradiprathod76/try",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nselect = (\n ('1','1'),\n ('2','2'),\n)\n\nclass Tutorial(models.Model):\n title = models.CharField(max_length=100)\n category = models.CharField(max_length=100)\n feature_image = models.ImageField(upload_to='tutorial/images/')\n attachment = models.FileField(upload_to='tutorial/attachments/')\n select = models.CharField(max_length=10,choices=select,default='1')\n\n\n"
},
{
"alpha_fraction": 0.7341576218605042,
"alphanum_fraction": 0.7341576218605042,
"avg_line_length": 39.4375,
"blob_id": "de86346bb8c3d4ea2603460e7f6c8cc7a363064f",
"content_id": "846a439fc4f9b3d10a45e7a5f3ab0737344c8c62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 16,
"path": "/DjangoUploadModelForm/DjangoUploadModelForm/urls.py",
"repo_name": "pradiprathod76/try",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom django.conf import settings\nfrom django.conf.urls.static import static\n\nfrom tutorials import views\n\nurlpatterns = [\n path('tutorials/upload/', views.uploadTutorial, name='upload_tutorial'),\n path('tutorials/', views.tutorialList, name='tutorial_list'),\n path('tutorials/<int:pk>', views.deleteTutorial, name='tutorial'),\n path('update/<int:pk>',views.updateTutorial,name='update_tutorial'),\n path('edit/<int:pk>',views.editTutorial,name='edit')\n]\n\nif settings.DEBUG: # remember to set 'DEBUG = True' in settings.py\n urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n"
},
{
"alpha_fraction": 0.5256410241127014,
"alphanum_fraction": 0.5820512771606445,
"avg_line_length": 20.66666603088379,
"blob_id": "62d595348d189bea4f1e467032db1039c1b5bb1d",
"content_id": "67f3ba0ec9c89fea2122622ba93a14b85300dc8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 18,
"path": "/DjangoUploadModelForm/tutorials/migrations/0002_tutorial_select.py",
"repo_name": "pradiprathod76/try",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-06-06 05:25\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('tutorials', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='tutorial',\n name='select',\n field=models.CharField(default='1', max_length=10),\n ),\n ]\n"
}
] | 5 |
AlexandraMihalevschi/Instructiunea-IF | https://github.com/AlexandraMihalevschi/Instructiunea-IF | 6ddba691caf1d261ab713328a6f6867c65dd3bfd | 2e41da5785c9bbba17ed5e343aa3193572949707 | 922dd0a1d11c479bba3057b164f5c906dfae63dc | refs/heads/main | 2022-12-30T21:17:41.746195 | 2020-10-18T15:23:12 | 2020-10-18T15:23:12 | 303,621,796 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5562015771865845,
"alphanum_fraction": 0.6317829489707947,
"avg_line_length": 37.846153259277344,
"blob_id": "80b3568896fab21fb78eea87c16893895f2eb1d8",
"content_id": "506edc284b21eba0a298e2273a735b22860bf054",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 13,
"path": "/Problema_4_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Se introduc vârstele a 3 persoane. Afişaţi vârstele cuprinse între 18 şi 60 de ani. \r\nExemplu : Date de intrare 56 34 12 Date de ieşire 56 34.\"\"\"\r\na = int(input(\"Varsta primei persoane: \"))\r\nb = int(input(\"Varsta persoanei a doua: \"))\r\nc = int(input(\"Varsta persoanei a treia: \"))\r\nif (a>=18)and(a<=60):\r\n print(a)\r\nif (b>=18)and(b<=60):\r\n print(b)\r\nif (c>=18)and(c<=60):\r\n print(c)\r\nif (a<=18)and(a>=60)and(b<=18)and(b>=60)and(c<=18)and(c>=60):\r\n print(\"Toate persoanele nu sunt de varsta potrivita\")"
},
{
"alpha_fraction": 0.6920903921127319,
"alphanum_fraction": 0.7104519605636597,
"avg_line_length": 52.61538314819336,
"blob_id": "b606cfca01983a43418fe4bbd1335f513994ab22",
"content_id": "15bd69f1eb0a36f7eda206a5a13b4c2d06ca9a15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 13,
"path": "/Problema_10_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"La ferma de găini Copanul este democraţie. Fiecare găină primeşte exact acelaşi număr de boabe de porumb. Cele care nu pot\r\nfi împărţite vor fi primite de curcanul Clapon. Să se spună cine a primit mai multe boabe şi cu cât. În caz de egalitate, se va\r\nafişa numărul de boabe primite şi cuvântul \"egalitate\". Datele se vor citi în următoarea ordine: numărul de găini, iar dupa aceea\r\nnumărul de boabe de porumb. Exemplu: Date de intrare 100 4050 Date de ieşire: Curcanul mai mult cu 10 boabe.\r\n\"\"\"\r\ng = int(input(\"Numarul de gaini \"))\r\nb = int(input(\"Numarul de boabe \"))\r\nx=b//(g+1)\r\ny=b-(x*(g+1))\r\nif y==0:\r\n print(x, \"- egalitate\")\r\nelif y!=0:\r\n print(\"Curcanul a primit mai mult cu\", x, \"boabe\")"
},
{
"alpha_fraction": 0.6534273028373718,
"alphanum_fraction": 0.6604740619659424,
"avg_line_length": 48.41935348510742,
"blob_id": "fafb9247a4e643e68a0f2f5109d0e5b74bb1412a",
"content_id": "abb40bbf7b26064b9e929bba7d3180a10c6ce657",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1579,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 31,
"path": "/Problema_9_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Pe o masă de biliard sunt bile albe, roşii şi verzi. Din fiecare culoare sunt bile de două dimensiuni: mari şi mici. Să se afişeze\r\ncâte bile sunt în total pe masa de biliard. Un jucător vrea să-i spuneţi care bile sunt mai multe , cele mici sau cele mari, afişând\r\nnumărul lor. De ce culoare sunt bilele cele mai numeroase? Precizaţi numărul lor. Exemplu: Date de intrare Nr. bile albe mici: 2\r\nNr. bile albe mari: 3 Nr. bile rosii mici: 1 Nr. bile rosii mari: 4 Nr. bile verzi mici: 3 Nr. bile verzi mari: 4 Date de ieşire Totalul\r\nbilelor: 17 Mari: 11 bile Verzi: 7 bile .\"\"\"\r\nxa = int(input(\"Bile albe mici \"))\r\nya = int(input(\"Bile albe mari \"))\r\nxr = int(input(\"Bile rosii mici \"))\r\nyr = int(input(\"Bile rosii mari \"))\r\nxv = int(input(\"Bile verzi mici \"))\r\nyv = int(input(\"Bile verzi mari \"))\r\ntx = xa+xr+xv\r\nty = ya+yr+yv \r\nprint(\"In total bile sunt\", tx+ty)\r\nif tx>ty: print(tx, \" mici\")\r\nelif tx<ty: print(ty, \" mari\")\r\nelif tx==ty: print(\"sunt in numar egale\", tx)\r\nif (xa+ya>xr+yr)and(xa+ya>xv+yv):\r\n print(xa+ya, \"albe\")\r\nelif (xr+yr>xa+ya)and(xr+yr>xv+yv):\r\n print(xr+yr, \"rosii\")\r\nelif (xv+yv>xa+ya)and(xv+yv>xr+yr):\r\n print(xv+yv, \"verzi\")\r\nelif (xa+ya==xr+yr)and(xa+ya>xv+yv)and(xr+yr>xv+yv):\r\n print(\"albe si rosii sunt egale\", xa+ya)\r\nelif (xa+ya==xv+yv)and(xa+ya>xr+yr)and(xv+yv>xr+yr):\r\n print(\"albe si verzi sunt egale\", xa+ya)\r\nelif (xv+yv==xr+yr)and(xv+yv>xa+ya)and(xr+yr>xa+ya):\r\n print(\"verzi si rosii sunt egale\", xr+yr)\r\nelif (xa+ya==xv+yv)and(xa+ya==xr+yr)and(xv+yv==xr+yr):\r\n print(\"toate sunt egale\", xa+ya)"
},
{
"alpha_fraction": 0.6817593574523926,
"alphanum_fraction": 0.7192755341529846,
"avg_line_length": 62.58333206176758,
"blob_id": "1f5816d43a78129c62da93bf734ffaebcc9cd0a7",
"content_id": "724dad300d91d8ab29a41644c6c71a476e8bb085",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 792,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 12,
"path": "/Problema_2_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"La ora de matematică Gigel este scos la tablă. \r\nProfesoara îi dictează trei numere şi îi cere să verifice dacă cele trei numere pot fi laturile unui triunghi.\r\nAjutaţi-l pe Gigel să afle rezultatul. Scrieţi un program care primeşte numerele lui Gigel, care sunt mai mici\r\nca 32000, şi returnează DA sau NU. \r\nObservaţie: Trei numere pot fi laturile unui triunghi numai dacă fiecare este mai mic ca\r\nsuma celorlalte două. Exemple: Date de intrare 3 5 7 Date de ieşire Da Date de intrare 2 5 9 Date de ieşire Nu. \"\"\"\r\na = int(input(\"Dati primul numar: \"))\r\nb = int(input(\"Dati al doilea numar: \"))\r\nc = int(input(\"Dati al treilea numar: \"))\r\nif (a<b+c)and (b<a+c)and(c<a+b)and(a<32000)and(b<32000)and(c<32000)and(a>0)and(b>0)and(c>0):\r\n print(\"Da\")\r\nelse : print(\"Nu\")"
},
{
"alpha_fraction": 0.6493799090385437,
"alphanum_fraction": 0.6708004474639893,
"avg_line_length": 36.65217208862305,
"blob_id": "b827ca87db43cf04ddca269d291055915fc820ec",
"content_id": "5715fc0cf455e6859140ebdc2a3a69278b19354d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 904,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 23,
"path": "/Problema_5_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Cunoscând data curentă exprimată prin trei numere întregi reprezentând anul, luna, ziua precum şi data naşterii unei persoane,\r\nexprimată la fel, să se facă un program care să calculeze vârsta persoanei respective în număr de ani împliniţi. \r\nExemplu : Date de intrare data curenta 2005 10 25 data nasterii 1960 11 2 Date de ieşre 44 ani.\"\"\"\r\nac = int(input(\"Anul curent \"))\r\nlc = int(input(\"Luna curenta \"))\r\nzc = int(input(\"Ziua curenta \"))\r\nan = int(input(\"Anul nasterii \"))\r\nln = int(input(\"Luna nasterii \"))\r\nzn = int(input(\"Ziua nasterii \"))\r\nif ln>lc :\r\n print((ac-an)-1)\r\nelif (ln==lc)and(zn>zc):\r\n print((ac-an)-1)\r\nelif (ln==lc)and(zn<=zc):\r\n print(ac-an)\r\nelif ln>lc:\r\n print(ac-an)\r\nelif ac>an:\r\n print(ac-an)\r\nelif (ac==an)and(lc==ln)and(zc==zn):\r\n print(\"Persoana s-a nascut azi\")\r\nelif ac<an:\r\n print(\"Anul curent este mai mic decat anul nasterii\")"
},
{
"alpha_fraction": 0.5955734252929688,
"alphanum_fraction": 0.6277666091918945,
"avg_line_length": 33.64285659790039,
"blob_id": "a87cf7bf162a0b7d0fdf97ce7b5d899350f7b524",
"content_id": "0278a94fd5636b056e8d484b7bbde73087b7ff23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 14,
"path": "/Problema_11_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Se dau trei numere. Să se afişeze aceste numere unul sub altul, afişând în dreptul fiecăruia unul dintre cuvintele PAR sau\r\nIMPAR. Exemplu : Date de intrare : 45 3 24 Date de ieşire : 45 impar 3 impar 24 par.\"\"\"\r\na = int(input(\"Primul numar \"))\r\nb = int(input(\"Al doilea numar \"))\r\nc = int(input(\"Al treilea numar \"))\r\nif a%2==0:\r\n print(a, \"par\")\r\nelse : print(a, \"impar\")\r\nif b%2==0:\r\n print(b, \"par\")\r\nelse : print(b, \"impar\")\r\nif c%2==0:\r\n print(c, \"par\")\r\nelse : print(c, \"impar\")"
},
{
"alpha_fraction": 0.5649122595787048,
"alphanum_fraction": 0.6175438761711121,
"avg_line_length": 36.13333511352539,
"blob_id": "d66307f3ad71cfd6f735c9f5eb4e53bfe76f95d5",
"content_id": "77218d7aa28c68eb1007caa8d08cfd3feed3e2c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 15,
"path": "/Problema_15_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Elevii clasei a V-a se repartizează în clase câte 25 în ordinea mediilor clasei a IV-a. Radu este pe locul x în ordinea mediilor. În\r\nce clasa va fi repartizat (A, B, C, D sau E)?. Exemplu : date de intrare : x=73 date de ieşire : C.\"\"\"\r\nx = int(input(\"Locul lui Radu in ordinea mediilor este \"))\r\nif (x>0)and(x<=25):\r\n print(\"A\")\r\nelif (x>25)and(x<=50):\r\n print(\"B\")\r\nelif (x>50)and(x<=75):\r\n print(\"C\")\r\nelif (x>75)and(x<=100):\r\n print(\"D\")\r\nelif (x>100)and(x<=125):\r\n print(\"E\")\r\nelif(x<0)or(x>125):\r\n print(\"Nu a fost repartizat in nicio clasa\")"
},
{
"alpha_fraction": 0.6545166373252869,
"alphanum_fraction": 0.6767036318778992,
"avg_line_length": 43.21428680419922,
"blob_id": "3cf5a35a028dab1c498760a6d7c3e836e879cf73",
"content_id": "b7cde0ae401aa33ac8177402982af232731b2149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 657,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 14,
"path": "/Problema_6_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Andrei primeşte într-o zi trei note, nu toate bune. \r\nSe hotărăşte ca, dacă ultima notă este cel puţin 8, să le spună părinţilor toate\r\nnotele primite iar dacă este mai mică decât 8, să le comunice doar cea mai mare notă dintre primele două. Introduceţi notele\r\nluate şi afişaţi notele pe care le va comunica părinţilor. Exemple : Date de intrare 6 9 9 Date de ieşire 6 9 9 ; Date de\r\nintrare 8 5 7 Date de ieşire 8.\"\"\"\r\na = int(input(\"Prima nota \"))\r\nb = int(input(\"A doua nota \"))\r\nc = int(input(\"A treia nota \"))\r\nif c>=8 :\r\n print(a, b, c)\r\nelif c<8:\r\n if a>b: print(a)\r\n elif b>a: print(b)\r\n elif b==a: print(a)"
},
{
"alpha_fraction": 0.5727482438087463,
"alphanum_fraction": 0.5958429574966431,
"avg_line_length": 34.25,
"blob_id": "8e67e4aeef6311ddb79208b7b83e4b152ffcc51d",
"content_id": "000e4e3ca8a2048b4801a6e3d32b6dd2544a2ff8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 12,
"path": "/Problema_12_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"“Mă iubeşte un pic, mult, cu pasiune, la nebunie, de loc, un pic,…”. Rupând petalele unei margarete cu x petale, el (ea) mă\r\niubeşte …. Exemplu: Date de intrare: x=10 Date de ieşire: … de loc.\"\"\"\r\nx = int(input(\"Numarul de petale al margaretei \"))\r\nif x%5==0:\r\n print(\"...deloc\")\r\nelif x%4==0:\r\n print(\"...la nebunie\")\r\nelif x%3==0:\r\n print(\"... cu pasiune\")\r\nelif x%2==0:\r\n print(\"... mult\")\r\nelse: print(\"...un pic\")"
},
{
"alpha_fraction": 0.6570605039596558,
"alphanum_fraction": 0.6772334575653076,
"avg_line_length": 56.16666793823242,
"blob_id": "7e9ff5a5e9b5628522c9168794faedc4947a7bda",
"content_id": "8f8b479cbd898c2b55973a2a3dd98198dadd6ef9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 6,
"path": "/Problema_14_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Într-o tabără, băieţii sunt cazaţi câte 4 într-o căsuţă, în ordinea sosirii. Ionel a sosit al n-lea. În a câta căsuţă se va afla?\r\nExemplu : date de intrare : n=69 date de ieşire : casuta 17.\"\"\"\r\nn = int(input(\"Numarul de ordine a lui Ionel \"))\r\nif n>0:\r\n print(\"El a fost cazat in casuta a\", n//4)\r\nelse: print(\" Ionel nu a fost la tabara\")"
},
{
"alpha_fraction": 0.5796964168548584,
"alphanum_fraction": 0.6432637572288513,
"avg_line_length": 42,
"blob_id": "55c16fcc085a73d2309fb4dcef7f09187e639b5a",
"content_id": "4fa242760bda2ec2af09585c7325b9ebae4a7acc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1059,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 24,
"path": "/Problema_1_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Se introduc trei date de forma număr curent elev, punctaj. \r\nAfişaţi numărul elevului cu cel mai mare punctaj. \r\nExemplu: Date de intrare nr crt 7 punctaj 120 nr crt 3 punctaj 100 nr crt 4 punctaj 119 \r\nDate de ieşire punctaj maxim areelevul cu nr crt 7.\"\"\"\r\nn1 = int(input(\"Numarul elevului curent: \"))\r\nn2 = int(input(\"Numarul elevului curent: \"))\r\nn3 = int(input(\"Numarul elevului curent: \"))\r\np1 = int(input(\"Punctajul 1: \"))\r\np2 = int(input(\"Punctajul 2: \"))\r\np3 = int(input(\"Punctajul 3: \"))\r\nif (p1>p2)and(p1>p3) :\r\n print(\"Punctaj maxim la elevul\", n1)\r\nelif (p2>p3)and(p2>p1) :\r\n print(\"Punctaj maxim la elevul\", n2)\r\nelif (p3>p1)and(p3>p2) :\r\n print(\"Punctaj maxim la elevul\", n3)\r\nelif (p1==p2)and(p1==p3)and(p2==p3):\r\n print(\"Elevii au punctaje egale\")\r\nelif (p1==p2)and(p1>p3)and(p2>p3):\r\n print(\"elevii\", n1,\"si\" ,n2, \"au punctaj egal\")\r\nelif (p2==p3)and(p2>p1)and(p3>p1):\r\n print(\"elevii\", n2,\"si\" ,n3, \"au punctaj egal\")\r\nelif (p1==p3)and(p1>p2)and(p3>p2):\r\n print(\"elevii\", n1,\"si\" ,n3, \"au punctaj egal\")"
},
{
"alpha_fraction": 0.5731922388076782,
"alphanum_fraction": 0.6261022686958313,
"avg_line_length": 38.64285659790039,
"blob_id": "ac17c36e6796ab448c11599d46b879c741832031",
"content_id": "5f69ffb245c09d77b437c3c4bacf718636aa6d1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 14,
"path": "/Problema_8_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Să se afişeze cel mai mare număr par dintre doua numere introduse în calculator. Exemple : Date de intrare 23 45 Date de\r\nieşire nu exista numar par ; Date de intrare 28 14 Date de ieşire 28 ; Date de intrare 77 4 Date de ieşire 4.\"\"\"\r\na = int(input(\"Primul numar \"))\r\nb = int(input(\"Al doilea numar \"))\r\nif (a%2==0)and(b%2==0):\r\n if a>b: print(a)\r\n elif a<b: print(b)\r\n elif a==b: print(\"Numerele sunt egale\")\r\nelif (a%2==0)and(b%2!=0):\r\n print(a)\r\nelif (a%2!=0)and(b%2==0):\r\n print(b)\r\nelif (a%2!=0)and(b%2!=0):\r\n print(\"Numerele nu sunt pare\")"
},
{
"alpha_fraction": 0.6264591217041016,
"alphanum_fraction": 0.6712062358856201,
"avg_line_length": 44.90909194946289,
"blob_id": "e93b2e531dfb6a83941bd08c9a2ed7f62b980931",
"content_id": "dc628e89a880b97032a70e345ceb6a6b65709219",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 11,
"path": "/Problema_7_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"Se consideră trei numere întregi. Dacă toate sunt pozitive, să se afişeze numărul mai mare dintre al doilea şi al treilea număr, în\r\ncaz contrar să se calculeze suma primelor două numere. Exemple: Date de intrare 45 23 100 date de ieşire 100 ; Date de\r\nintrare 34 -25 10 Date de ieşire 9.\"\"\"\r\na = int(input(\"Primul numar \"))\r\nb = int(input(\"Al doilea numar \"))\r\nc = int(input(\"Al treilea numar \"))\r\nif (a>0)and(b>0)and(c>0):\r\n if b>c: print(b)\r\n elif b<c: print(c)\r\nif (a<0)or(b<0)or(c<0):\r\n print(a+b)"
},
{
"alpha_fraction": 0.6384615302085876,
"alphanum_fraction": 0.6769230961799622,
"avg_line_length": 44.57143020629883,
"blob_id": "df01a3e4bcfbbdd414473433733f7731d7c0f47e",
"content_id": "82838b20837e21446b5558cc30c4323bbcc93fa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 661,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 14,
"path": "/Problema_13_IF.py",
"repo_name": "AlexandraMihalevschi/Instructiunea-IF",
"src_encoding": "UTF-8",
"text": "\"\"\"La un concurs se dau ca premii primilor 100 de concurenţi, tricouri de culoare albă, roşie, albastră şi neagră, în această\r\nsecvenţă. Ionel este pe locul x. Ce culoare va avea tricoul pe care-l va primi? Exemplu : date de intrare : x=38 date de ieşire :\r\nrosie. \"\"\"\r\nx = int(input(\"Locul lui Ionel \"))\r\nif (x>0)and(x<=25):\r\n print(\"A primit tricou de culoare alba\")\r\nelif (x>25)and(x<=50):\r\n print(\"A primit tricou de culoare rosie\")\r\nelif (x>50)and(x<=75):\r\n print(\"A primit tricou de culoare albastra\")\r\nelif (x>75)and(x<=100):\r\n print(\"A primit tricou de culoare neagra\")\r\nelif(x<0)or(x>100):\r\n print(\"Nu a primit niciun tricou\")"
}
] | 14 |
Ritsch1/GoogleImageLoader | https://github.com/Ritsch1/GoogleImageLoader | 72d326027c741be3eaff08630ff6ee3589205b2a | 939bbce74f3dd215fdb27837b0a718297f66e51a | 02948abc1c87240175a16f04dfd399caa70e5c72 | refs/heads/master | 2023-08-04T19:16:01.089265 | 2021-09-24T12:34:00 | 2021-09-24T12:34:00 | 376,058,367 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5809937715530396,
"alphanum_fraction": 0.58444744348526,
"avg_line_length": 44.26803970336914,
"blob_id": "7d039f5aa19edb15bd1f7a25b52ecb4d33dd9495",
"content_id": "d6f23cba7204a26f8055e058160b40985074cf4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8976,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 194,
"path": "/GoogleImageLoader/Google_Image_Loader.py",
"repo_name": "Ritsch1/GoogleImageLoader",
"src_encoding": "UTF-8",
"text": "import os\r\nimport time\r\nimport multiprocessing as mp\r\nfrom selenium import webdriver\r\nfrom selenium.webdriver.common.keys import Keys\r\nfrom webdriver_manager.chrome import ChromeDriverManager\r\nimport urllib.request\r\nimport datetime\r\nimport requests\r\nimport numpy as np\r\n\r\n\r\nclass Loader:\r\n \"\"\"\r\n The central class to perform the loading of the google - images.\r\n \"\"\"\r\n\r\n def __init__(self, search_keys:[str], num_images: int = 20):\r\n \"\"\"Initialize instance of the Google_Image_Loader class\r\n\r\n Args:\r\n search_keys : List of search keys for which images shall be downloaded.\r\n If the list is empty, a ValueError is raised.\r\n num_images: The maximum number of images to download for every search-key.\r\n By default set to 20.\r\n \"\"\"\r\n if type(search_keys) != list and type(search_keys) != tuple:\r\n raise ValueError(f\"provided search_keys - value {search_keys} is not an iterable.\")\r\n elif type(num_images) != int or num_images <= 0:\r\n raise ValueError(f\"provided image-number value {num_images} must be positive.\")\r\n else:\r\n # Removing empty strings\r\n search_keys = [s for s in search_keys if len(s) > 0]\r\n if len(search_keys) == 0:\r\n raise ValueError(\"No search_key was provided.\")\r\n # Remove duplicate search_keys\r\n search_keys = list(set(search_keys))\r\n self.search_keys = search_keys\r\n self.num_images = num_images\r\n # Constants - do not change\r\n self.GOOGLE_PREFIX = \"https://www.google.com/search?q=\"\r\n self.GOOGLE_SUFFIX = \"&source=lnms&tbm=isch&sa=X&ei=0eZEVbj3IJG5uATalICQAQ&ved=0CAcQ_AUoAQ&biw=939&bih=591\"\r\n # Variable to save the current stage of the google image results for different search_keys\r\n self.page_sources = {}\r\n # Dictionary for storing the urls of images found in the page source-codes\r\n self.image_urls = {}\r\n # Directory path where directories of the search-keys and within them the images will be saved\r\n self.DIRECTORY_PREFIX = os.path.join(os.path.expanduser(\"~\"), \"GoogleImageLoads\")\r\n self.TODAY = str(datetime.date.today())\r\n\r\n def create_central_dir(self):\r\n \"\"\"\r\n Create the central folder that contains all sub - folders to search - queries and contains the\r\n corresponding images.\r\n \"\"\"\r\n if not os.path.isdir(self.DIRECTORY_PREFIX):\r\n os.mkdir(self.DIRECTORY_PREFIX)\r\n\r\n def create_image_dirs(self):\r\n \"\"\"\r\n Creates the image directories for the search-keys.\r\n \"\"\"\r\n for search_key in self.search_keys:\r\n # Check if there is already a directory with this search - key\r\n new_dir = os.path.join(self.DIRECTORY_PREFIX, search_key+ \"_\" + str(datetime.date.today()))\r\n # Skip the creation if it already exists\r\n if not os.path.isdir(new_dir):\r\n os.mkdir(new_dir)\r\n\r\n def reformat_search_keys(self):\r\n \"\"\"\r\n Reformat the search-keys to match format in the http get-query.\r\n For example: \"dogs big fluffy\" -> \"dogs+big+fluffy\"\r\n \"\"\"\r\n self.search_keys = [s.strip().replace(\" \",\"+\") for s in self.search_keys]\r\n\r\n def fetch_image_urls(self) -> list:\r\n \"\"\"\r\n This function executes scrolling through the google image search results. This\r\n is necessary as google only loads new images by scrolling down. Additionally,\r\n the \"see more\" button needs to be clicked.\r\n\r\n returns:\r\n image_urls: A list of image_url - tuples of the form (search_key, url).\r\n The first item in each tuple is always the search - key for later inference of\r\n the download directory.\r\n \"\"\"\r\n page_reload_wait = 0.05\r\n\r\n # Set selenium chrome options\r\n options = webdriver.ChromeOptions()\r\n # Suppress terminal output from selenium\r\n options.add_argument(\"--log-level=3\")\r\n # Run selenium without UI\r\n options.add_argument(\"headless\")\r\n\r\n image_urls = []\r\n for search_key in self.search_keys:\r\n driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)\r\n # Construct the target url to access\r\n url = self.GOOGLE_PREFIX + search_key + self.GOOGLE_SUFFIX\r\n # Invoke get request\r\n driver.get(url)\r\n\r\n # Accessing the page and scroll down / see - more click buttons\r\n old_height = driver.execute_script('return document.body.scrollHeight')\r\n # Click accept-cookies button if there is one\r\n cookie_btn = driver.find_element_by_class_name(\"qXTnff\")\r\n cookie_btn.click()\r\n while True:\r\n # Scroll down\r\n driver.execute_script(\"window.scrollTo(0, document.body.scrollHeight)\")\r\n time.sleep(page_reload_wait)\r\n new_height = driver.execute_script('return document.body.scrollHeight')\r\n\r\n # If the end of the page is reached\r\n if new_height == old_height:\r\n # try to find the \"see more\" button if there is one\r\n try:\r\n driver.find_element_by_class_name('mye4qd').click()\r\n time.sleep(page_reload_wait)\r\n # If there is no \"see more\" button, the end of the page is reached\r\n except Exception as e:\r\n break\r\n else:\r\n old_height = new_height\r\n\r\n # for google image result website logic\r\n is_first_image = True\r\n # Get all image results (class with multiple words separated by whitespaces are actually several\r\n # classes, use css_selector instead and prefix every class with a dot, like below\r\n images = driver.find_elements_by_css_selector('.isv-r.PNCib.MSM1fd.BUooTd')\r\n \"\"\" \r\n Go back to the top of the page, such that the little icon bar is not\r\n hiding the images and the images are thus clickable\r\n \"\"\"\r\n driver.find_element_by_tag_name('body').send_keys(Keys.CONTROL + Keys.HOME)\r\n\r\n # Click and infer the original image - url (with the original size) from each image result\r\n for image in images[:self.num_images]:\r\n image.click()\r\n if is_first_image:\r\n image_urls.append((search_key, driver.find_elements_by_class_name('n3VNCb')[0].get_attribute(\"src\")))\r\n is_first_image = False\r\n else:\r\n image_urls.append((search_key, driver.find_elements_by_class_name('n3VNCb')[1].get_attribute(\"src\")))\r\n\r\n driver.close()\r\n\r\n return image_urls\r\n\r\n def download_images(self, image_urls: list):\r\n \"\"\"\r\n Downloads all images referenced with their urls from image_urls and persists the\r\n images to disc into the corresponding directory.\r\n\r\n params:\r\n image_urls: A list of image_url - tuples of the form (search_key, url).\r\n The first item in each tuple is always the search - key for later inference of\r\n the download directory.\r\n \"\"\"\r\n\r\n # Instantiate as many processes as there are cpu - cores available\r\n pool = mp.Pool(mp.cpu_count())\r\n pool.map(self.worker, image_urls)\r\n\r\n def worker(self, image_url: tuple):\r\n \"\"\"\r\n Initiates a worker process to download images from the web and saving them to disk.\r\n This way network - delays can be mitigated and the code can be sped up.\r\n\r\n params:\r\n image_url: A tuple of the form (search_key, url).\r\n The first item in each tuple is always the search - key for later inference of\r\n the download directory.\r\n \"\"\"\r\n\r\n search_key, url = image_url\r\n # Set download directory\r\n download_dir = os.path.join(self.DIRECTORY_PREFIX, search_key + \"_\" + self.TODAY)\r\n\r\n # If url is actually an image-uri and not a image e.g. jpeg, the image must be saved as png\r\n if url[:4] == \"data\":\r\n img_data = urllib.request.urlopen(url)\r\n random_id = str(np.random.choice(self.num_images ** 2))\r\n with open(os.path.join(download_dir, search_key + \"_\" + random_id + \".jpg\"), 'wb') as f:\r\n f.write(img_data.file.read())\r\n\r\n # Normal image data e.g. jpeg or png, this type of data will be saved as jpeg by default\r\n else:\r\n img_data = requests.get(url).content\r\n random_id = str(np.random.choice(self.num_images ** 2))\r\n with open(os.path.join(download_dir, search_key + \"_\" + random_id + \".jpg\"), 'wb') as handler:\r\n handler.write(img_data)\r\n"
},
{
"alpha_fraction": 0.7453083395957947,
"alphanum_fraction": 0.7730116248130798,
"avg_line_length": 36.29999923706055,
"blob_id": "f15955632cf622863bf4a955b81bf3d23e32beae",
"content_id": "134c25f9a01f42da4ceab462e3d2da711fdeded4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 30,
"path": "/README.md",
"repo_name": "Ritsch1/GoogleImageLoader",
"src_encoding": "UTF-8",
"text": "# GoogleImageLoader\n\nThis application enables you to automatically download images from google using the selenium chrome driver.\nIn order to use this application you need to have installed the Google Chrome webbrowser on your machine.\n\nThe packages that need to be installed in order to run the application are:\n\n* numpy\n* requests\n* selenium\n\n## Usage\n\nTo use the GoogleImageLoader you have to run:\n\n`python GoogleImageLoader -n <number_of_images> -k <[\"key1\", .., \"keyN\"]>`\n\nThe argument *-n* determines how many images will maximally be downloaded for each search - key.\nIt will download the maximal available images from the Google image search-page.\nThe argument *-k* determines the search-keys that are used for an image-search each.\nThe images to each search key will be saved into a folder in *~/GoogleImageLoads/key_YYYY-MM-DD* for every key provided with -k option.\n\n## Example\n\n`python GoogleImageLoader -n 100 -k \"football\" \"volleyball\"`\n\nAssuming todays date is 2021-09-24, this will save 100 images each in the folders:\n\n* ~/GoogleImageLoads/football_2021-09-24\n* ~/GoogleImageLoads/volleyball_2021-09-24\n"
},
{
"alpha_fraction": 0.5819118022918701,
"alphanum_fraction": 0.5831992030143738,
"avg_line_length": 34.13953399658203,
"blob_id": "9631ef29b24c8b7a69fc9b59b22f4ad543ca4600",
"content_id": "97d9ea92caa2bbc7e6a862444b27e15036515dd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6214,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 172,
"path": "/Tests/test_loader.py",
"repo_name": "Ritsch1/GoogleImageLoader",
"src_encoding": "UTF-8",
"text": "import unittest\r\nimport os\r\nfrom shutil import rmtree\r\nfrom GoogleImageLoader import Google_Image_Loader\r\n\r\n# Directory path where directories of the search-keys and within them the images will be saved\r\nPREFIX = os.path.join(os.path.expanduser(\"~\"), \"GoogleImageLoads\")\r\n\r\nclass LoaderTest(unittest.TestCase):\r\n\r\n def test_init_list_two_keys(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = [\"Hello Mars\", \"Nice to meet you too\"]\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n self.assertIsInstance(gil, Google_Image_Loader.Loader)\r\n\r\n def test_init_tuple_one_key(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = (\"Hello World\", \"Nice to meet you\")\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n self.assertIsInstance(gil, Google_Image_Loader.Loader)\r\n\r\n def test_init_tuple_one_key_zero_images(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = (\"Hello World\", \"Nice to meet you\")\r\n num_images = 0\r\n self.assertRaises(ValueError, Google_Image_Loader.Loader, search_keys, num_images)\r\n\r\n def test_init_tuple_one_key_negative_images(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = (\"Hello World\", \"Nice to meet you\")\r\n num_images = -1\r\n self.assertRaises(ValueError, Google_Image_Loader.Loader, search_keys, num_images)\r\n\r\n\r\n def test_init_tuple_no_key(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = ()\r\n self.assertRaises(ValueError, Google_Image_Loader.Loader, search_keys)\r\n\r\n def test_init_list_no_key(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = []\r\n self.assertRaises(ValueError, Google_Image_Loader.Loader, search_keys)\r\n\r\n def test_init_tuple_empty_key(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = (\"\")\r\n self.assertRaises(ValueError, Google_Image_Loader.Loader, search_keys)\r\n\r\n def test_init_tuple_empty_key(self):\r\n \"\"\"\r\n Testing the __init__ method of the Google_Image_Loader - class\r\n \"\"\"\r\n search_keys = [\"\"]\r\n self.assertRaises(ValueError, Google_Image_Loader.Loader, search_keys)\r\n\r\n def test_create_image_dirs_one_search_key_list(self):\r\n \"\"\"\r\n Testing the create_image_dirs method of the Loader - class\r\n \"\"\"\r\n # Arrange\r\n global PREFIX\r\n search_keys = [\"Dogs\"]\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n # Act\r\n gil.create_image_dirs()\r\n # Assert\r\n self.assertTrue(set(search_keys).issubset(set(os.listdir(PREFIX))))\r\n # Cleaning\r\n rmtree(PREFIX)\r\n\r\n def test_create_image_dirs_two_search_keys_tuple(self):\r\n \"\"\"\r\n Testing the create_image_dirs method of the Loader - class\r\n \"\"\"\r\n # Arrange\r\n global PREFIX\r\n search_keys = (\"Cats\", \"Unicorns\")\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n # Act\r\n gil.create_image_dirs()\r\n # Assert\r\n self.assertTrue(set(search_keys).issubset(set(os.listdir(PREFIX))))\r\n # Cleaning\r\n rmtree(PREFIX)\r\n\r\n def test_reformat_search_keys_one_key_whitespaces(self):\r\n \"\"\"\r\n Testing the reformat_search_keys method of the Loader - class\r\n \"\"\"\r\n # Arrange\r\n search_key = tuple([\" fluffy Dogs \"])\r\n # Act\r\n gil = Google_Image_Loader.Loader(search_key)\r\n formatted_search_keys = gil.reformat_search_keys()\r\n # Assert\r\n self.assertEqual(gil.search_keys, [\"fluffy+Dogs\"])\r\n\r\n def test_page_scroll(self):\r\n \"\"\"\r\n Testing the scroll_through_google_images method of the Loader - class\r\n \"\"\"\r\n # Arrange\r\n search_keys = [\"fluffy Gods\", \"fluffy Hawks\"]\r\n # Act\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n gil.reformat_search_keys()\r\n gil.scroll_through_google_images()\r\n # Number of page source codes should be equal to the number of search-keys\r\n # Assert\r\n self.assertEqual(len(gil.page_sources), len(search_keys))\r\n\r\n def test_extract_picture_urls(self):\r\n \"\"\"\r\n Testing the extract_picture_url method of the Loader - class\r\n \"\"\"\r\n # Arrange\r\n search_keys = [\"fluffy Gods\", \"fluffy Hawks\"]\r\n # Act\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n gil.reformat_search_keys()\r\n gil.scroll_through_google_images()\r\n gil.extract_picture_urls()\r\n\r\n # Count number of image urls in both image - url queues.\r\n # It should equal twice the maximal number of images to retrieve if this number is not too high.\r\n num_image_urls = 0\r\n for s in gil.search_keys:\r\n while not gil.image_urls[s].empty():\r\n gil.image_urls[s].get()\r\n num_image_urls += 1\r\n # Assert\r\n self.assertEqual(len(search_keys) * gil.num_images, num_image_urls,)\r\n\r\n def test_image_download(self):\r\n \"\"\"\r\n Testing the download_images method of the Loader - class.\r\n \"\"\"\r\n # Arrange\r\n global PREFIX\r\n search_keys = [\"fluffy Gods\", \"fluffy Hawks\"]\r\n # Act\r\n gil = Google_Image_Loader.Loader(search_keys)\r\n gil.reformat_search_keys()\r\n gil.create_image_dirs()\r\n gil.scroll_through_google_images()\r\n url_queue = gil.extract_picture_urls()\r\n gil.download_images(url_queue=url_queue)\r\n\r\n #Assert that pictures have been saved\r\n self.assertTrue(len(os.listdir(os.path.join(PREFIX,gil.search_keys[0]))) > 0 and\r\n len(os.listdir(os.path.join(PREFIX,gil.search_keys[1]))) > 0)\r\n # Cleaning\r\n #rmtree(PREFIX)\r\n\r\nif __name__ == '__main__':\r\n unittest.main()"
},
{
"alpha_fraction": 0.6794871687889099,
"alphanum_fraction": 0.6794871687889099,
"avg_line_length": 24,
"blob_id": "feee38008c60077a59082fddf4adb1ad82bd314a",
"content_id": "6258bc731a8fcee97347159dc6b92f7a3152c868",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 3,
"path": "/GoogleImageLoader/__init__.py",
"repo_name": "Ritsch1/GoogleImageLoader",
"src_encoding": "UTF-8",
"text": "__all__ = [\"Google_Image_Loader\"]\r\n\r\nfrom .Google_Image_Loader import Loader\r\n"
},
{
"alpha_fraction": 0.6609880924224854,
"alphanum_fraction": 0.6635434627532959,
"avg_line_length": 37.20000076293945,
"blob_id": "e4984969a2c688e64ea985c107dd093442ea37cc",
"content_id": "2031e3e00ce92e188b22a6c50fa1e368ffdfb6ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1174,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 30,
"path": "/__main__.py",
"repo_name": "Ritsch1/GoogleImageLoader",
"src_encoding": "UTF-8",
"text": "import GoogleImageLoader.Google_Image_Loader\r\nimport os\r\nimport argparse\r\nimport timeit\r\n\r\n\r\ndef main():\r\n parser = argparse.ArgumentParser(description=\"Downloading images from google image search.\")\r\n parser.add_argument(\"--keys\" ,\"-k\", nargs=\"+\", help=\"Search - keys to download images for.\")\r\n parser.add_argument(\"--num_images\", \"-n\", default=\"20\", type=int, help=\"Maximum number of images to be downloaded for each search - key.\")\r\n args = parser.parse_args()\r\n\r\n PREFIX = os.path.join(os.path.expanduser(\"~\"), \"GoogleImageLoads\")\r\n start = timeit.default_timer()\r\n gil = GoogleImageLoader.Loader(args.keys, args.num_images)\r\n gil.reformat_search_keys()\r\n # If central directory already exists, skip creating it\r\n if not os.path.isdir(PREFIX):\r\n gil.create_central_dir()\r\n # create search - key specific image folders\r\n gil.create_image_dirs()\r\n image_urls = gil.fetch_image_urls()\r\n gil.download_images(image_urls)\r\n\r\n print(f\"Successfully downloaded images for the search - keys:\\n{','.join(x for x in args.keys)}\\nin \"\r\n f\"{timeit.default_timer()-start:.2f} s\")\r\n\r\n\r\nif __name__ == '__main__':\r\n main()"
}
] | 5 |
Pradeet/caesar_cipher_decryptor | https://github.com/Pradeet/caesar_cipher_decryptor | b0d07b0fc58a55386af84cc196f7b3d38123cbe2 | 419400096974c9585b052d32da180b43ef419634 | 5fa3674bd1f1245ac8dc106119c0b9c4aec13216 | refs/heads/master | 2016-09-13T16:59:37.150937 | 2016-04-21T14:07:49 | 2016-04-21T14:07:49 | 56,778,688 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6460278630256653,
"alphanum_fraction": 0.6556920409202576,
"avg_line_length": 39.171051025390625,
"blob_id": "0f4b034630d6dc3c6666e06d72b7e566a1880c8b",
"content_id": "21fd17aab219c0f963e04a07806f18e0a12d9349",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6105,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 152,
"path": "/mcmc.py",
"repo_name": "Pradeet/caesar_cipher_decryptor",
"src_encoding": "UTF-8",
"text": "# AIM: To Decrypt a text using MCMC approach. i.e. find decryption key which we will call cipher from now on.\nimport string\nimport math\nimport random\n\n# This function takes as input a decryption key and creates a dict for key where each letter in the decryption key\n# maps to a alphabet For example if the decryption key is \"DGHJKL....\" this function will create a dict like {D:A,G:B,H:C....} \ndef create_cipher_dict(cipher):\n cipher_dict = {}\n alphabet_list = list(string.ascii_uppercase)\n for i in range(len(cipher)):\n cipher_dict[alphabet_list[i]] = cipher[i]\n return cipher_dict\n\n# This function takes a text and applies the cipher/key on the text and returns text.\ndef apply_cipher_on_text(text,cipher):\n cipher_dict = create_cipher_dict(cipher) \n text = list(text)\n newtext = \"\"\n for elem in text:\n if elem.upper() in cipher_dict:\n newtext+=cipher_dict[elem.upper()]\n else:\n newtext+=\" \"\n return newtext\n\n# This function takes as input a path to a long text and creates scoring_params dict which contains the \n# number of time each pair of alphabet appears together\n# Ex. {'AB':234,'TH':2343,'CD':23 ..}\ndef create_scoring_params_dict(longtext_path):\n scoring_params = {}\n alphabet_list = list(string.ascii_uppercase)\n with open(longtext_path) as fp:\n for line in fp:\n data = list(line.strip())\n for i in range(len(data)-1):\n alpha_i = data[i].upper()\n alpha_j = data[i+1].upper()\n if alpha_i not in alphabet_list and alpha_i != \" \":\n alpha_i = \" \"\n if alpha_j not in alphabet_list and alpha_j != \" \":\n alpha_j = \" \"\n key = alpha_i+alpha_j\n if key in scoring_params:\n scoring_params[key]+=1\n else:\n scoring_params[key]=1\n return scoring_params\n\n# This function takes as input a text and creates scoring_params dict which contains the \n# number of time each pair of alphabet appears together\n# Ex. {'AB':234,'TH':2343,'CD':23 ..}\n\ndef score_params_on_cipher(text):\n scoring_params = {}\n alphabet_list = list(string.ascii_uppercase)\n data = list(text.strip())\n for i in range(len(data)-1):\n alpha_i =data[i].upper()\n alpha_j = data[i+1].upper()\n if alpha_i not in alphabet_list and alpha_i != \" \":\n alpha_i = \" \"\n if alpha_j not in alphabet_list and alpha_j != \" \":\n alpha_j = \" \"\n key = alpha_i+alpha_j\n if key in scoring_params:\n scoring_params[key]+=1\n else:\n scoring_params[key]=1\n return scoring_params\n\n# This function takes the text to be decrypted and a cipher to score the cipher.\n# This function returns the log(score) metric\n\ndef get_cipher_score(text,cipher,scoring_params):\n cipher_dict = create_cipher_dict(cipher)\n decrypted_text = apply_cipher_on_text(text,cipher)\n scored_f = score_params_on_cipher(decrypted_text)\n cipher_score = 0\n for k,v in scored_f.iteritems():\n if k in scoring_params:\n cipher_score += v*math.log(scoring_params[k])\n return cipher_score\n\n# Generate a proposal cipher by swapping letters at two random location\ndef generate_cipher(cipher):\n pos1 = random.randint(0, len(list(cipher))-1)\n pos2 = random.randint(0, len(list(cipher))-1)\n if pos1 == pos2:\n return generate_cipher(cipher)\n else:\n cipher = list(cipher)\n pos1_alpha = cipher[pos1]\n pos2_alpha = cipher[pos2]\n cipher[pos1] = pos2_alpha\n cipher[pos2] = pos1_alpha\n return \"\".join(cipher)\n\n# Toss a random coin with robability of head p. If coin comes head return true else false.\ndef random_coin(p):\n unif = random.uniform(0,1)\n if unif>=p:\n return False\n else:\n return True\n \n# Takes as input a text to decrypt and runs a MCMC algorithm for n_iter. Returns the state having maximum score and also\n# the last few states \ndef MCMC_decrypt(n_iter,cipher_text,scoring_params):\n current_cipher = string.ascii_uppercase # Generate a random cipher to start\n state_keeper = set()\n best_state = ''\n score = 0\n for i in range(n_iter):\n state_keeper.add(current_cipher)\n proposed_cipher = generate_cipher(current_cipher)\n score_current_cipher = get_cipher_score(cipher_text,current_cipher,scoring_params)\n score_proposed_cipher = get_cipher_score(cipher_text,proposed_cipher,scoring_params)\n acceptance_probability = min(1,math.exp(score_proposed_cipher-score_current_cipher))\n if score_current_cipher>score:\n best_state = current_cipher\n if random_coin(acceptance_probability):\n current_cipher = proposed_cipher\n if i%500==0:\n print \"iter\",i,\":\",apply_cipher_on_text(cipher_text,current_cipher)[0:99]\n return state_keeper,best_state\n\n## Run the Main Program:\n\n# scoring_params = create_scoring_params_dict('war_and_peace.txt')\nscoring_params = create_scoring_params_dict('The_DaVinci_Code.txt')\n\nplain_text = \"As gave this first proof of the free and proper action of his lungs, \\\nthe patchwork coverlet which was carelessly flung over the iron bedstead, rustled; \\\nthe pale face of a young woman was raised feebly from the pillow; and a faint voice imperfectly \\\narticulated the words, Let me see the child, and die. \\\nThe surgeon had been sitting with his face turned towards the fire: giving the palms of his hands a warm \\\nand a rub alternately. As the young woman spoke, he rose, and advancing to the bed's head, said, with more kindness \\\nthan might have been expected of him: \"\n\nencryption_key = \"XEBPROHYAUFTIDSJLKZMWVNGQC\"\ncipher_text = apply_cipher_on_text(plain_text,encryption_key)\ndecryption_key = \"ICZNBKXGMPRQTWFDYEOLJVUAHS\"\n\nprint\"Text To Decode:\", cipher_text\nprint \"\\n\"\nstates,best_state = MCMC_decrypt(10000,cipher_text,scoring_params)\nprint \"\\n\"\nprint \"Decoded Text:\",apply_cipher_on_text(cipher_text,best_state)\nprint \"\\n\"\nprint \"MCMC KEY FOUND:\",best_state\nprint \"ACTUAL DECRYPTION KEY:\",decryption_key"
}
] | 1 |
Almazishe/django-page-editor | https://github.com/Almazishe/django-page-editor | 47b1046212c8a2029803ef664a4940429f9efa1d | f7c00f5ba3f2a4ce720d05a692dde7bf7a3e9a54 | 858545d7a3c87a613d068da4752d880a84115a3f | refs/heads/main | 2023-02-11T17:49:08.000771 | 2021-01-09T02:20:01 | 2021-01-09T02:20:01 | 328,056,712 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 20,
"blob_id": "b3d914f09415aa612fdc70b57b1030bedec2f38b",
"content_id": "ebdd1a4eea174edc8deba39968896d8ab39d3ad5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 21,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Almazishe/django-page-editor",
"src_encoding": "UTF-8",
"text": "# django-page-editor\n"
},
{
"alpha_fraction": 0.6633109450340271,
"alphanum_fraction": 0.6700223684310913,
"avg_line_length": 29.827587127685547,
"blob_id": "5937d6e24c6fb49643fba31e97f7276f527b2064",
"content_id": "1dd764c0f405d2aa166bbf2d413706ae90c4b129",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 942,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 29,
"path": "/products/models.py",
"repo_name": "Almazishe/django-page-editor",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Product(models.Model):\n name = models.CharField(\"Название\", max_length=255)\n img = models.ImageField(verbose_name=\"Фото\", upload_to='product/images/', null=True, blank=True)\n\n class Meta:\n verbose_name = \"Продукт\"\n verbose_name_plural = \"Продукты\"\n\n def __str__(self):\n return self.name\n\nclass ListHeader(models.Model):\n value = models.CharField(verbose_name=\"\", max_length=255)\n product = models.ForeignKey(\n Product, verbose_name=\"Продукт\", on_delete=models.CASCADE, related_name=\"headers\")\n\n def __str__(self):\n return self.value\n\nclass ListParagraph(models.Model):\n value = models.TextField(verbose_name='Текст')\n header = models.ForeignKey(\n ListHeader, verbose_name='Заголовок', on_delete=models.CASCADE, related_name='paragraphs')\n\n def __str__(self):\n return self.value\n"
}
] | 2 |
pyzh/Zope | https://github.com/pyzh/Zope | 07af0f0034ead24623f2fb2b2550c28852d88039 | 8b22610e5e486677dccfc05e994abb252a452fbe | 19627a41079a41e07032933e5e40e42af07c7f1d | refs/heads/master | 2021-01-01T17:33:51.303691 | 2017-07-16T16:14:50 | 2017-07-16T16:14:50 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5908141732215881,
"alphanum_fraction": 0.594989538192749,
"avg_line_length": 26.634614944458008,
"blob_id": "13333d2fa712580100e9915081470a12f1b754fc",
"content_id": "85728b626095f6a0cf5bc047c1220ad369712001",
"detected_licenses": [
"ZPL-2.1"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1437,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 52,
"path": "/src/ZPublisher/tests/test_hooks.py",
"repo_name": "pyzh/Zope",
"src_encoding": "UTF-8",
"text": "##############################################################################\n#\n# Copyright (c) 2002 Zope Foundation and Contributors.\n#\n# This software is subject to the provisions of the Zope Public License,\n# Version 2.1 (ZPL). A copy of the ZPL should accompany this distribution.\n# THIS SOFTWARE IS PROVIDED \"AS IS\" AND ANY AND ALL EXPRESS OR IMPLIED\n# WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND FITNESS\n# FOR A PARTICULAR PURPOSE\n#\n##############################################################################\n\nimport unittest\n\n\nclass TestHooks(unittest.TestCase):\n\n def test_set(self):\n\n class FauxRequest(object):\n pass\n\n class FauxEvent(object):\n request = FauxRequest()\n\n event = FauxEvent()\n\n from ZPublisher.hooks import set_\n set_(event)\n\n from zope.globalrequest import getRequest\n self.assertEqual(getRequest(), event.request)\n\n def test_clear(self):\n\n class FauxRequest(object):\n pass\n\n class FauxEvent(object):\n request = FauxRequest()\n\n event = FauxEvent()\n\n from zope.globalrequest import setRequest\n setRequest(event.request)\n\n from ZPublisher.hooks import clear\n clear(event)\n\n from zope.globalrequest import getRequest\n self.assertEqual(getRequest(), None)\n"
},
{
"alpha_fraction": 0.759078860282898,
"alphanum_fraction": 0.7599645853042603,
"avg_line_length": 27.94871711730957,
"blob_id": "9b3ffba3cfd1038cd7fabc4852a96646837ef68e",
"content_id": "77c81ba76f4945e919e797581a7ac06b69dcc55e",
"detected_licenses": [
"ZPL-2.1"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1129,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 39,
"path": "/README.rst",
"repo_name": "pyzh/Zope",
"src_encoding": "UTF-8",
"text": ".. contents::\n\nIntroduction\n============\n\nZope is an open-source web application server.\n\nThis document provides some general information about Zope and provides\nlinks to other documents.\n\nInstallation information can be found in ``docs/INSTALL.rst``. Other\ndocumentation is also in the \"docs\" directory and in the Zope\ndocumentation section at https://zope.readthedocs.io .\n\nInstallation\n============\n\nFollow the instructions in ``docs/INSTALL.rst`` to install Zope.\n\nIf you do not have a source checkout with docs, you can find the latest\ninstall docs online at\nhttps://zope.readthedocs.io/en/latest/INSTALL-buildout.html\n\nNote that you *cannot* simply do ``pip install zope2``, because you need\nspecific versions of all dependencies. Follow the documentation to\nensure you get the correct versions, or else installation is very\nlikely to fail.\n\nLicense\n=======\n\nThe Zope License is included in ``LICENSE.txt``.\n\nBug tracker\n===========\n\nBugs reports should be made through the Zope bugtracker at\nhttps://github.com/zopefoundation/Zope/issues. A bug report should\ncontain detailed information about how to reproduce the bug.\n"
},
{
"alpha_fraction": 0.6957134008407593,
"alphanum_fraction": 0.7208693623542786,
"avg_line_length": 27.722543716430664,
"blob_id": "49b2fbe45cbc396eb7156204ddfafb151b703310",
"content_id": "36914ab1190e581a660206b79b75275994d7abfa",
"detected_licenses": [
"ZPL-2.1"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 14907,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 519,
"path": "/CHANGES.rst",
"repo_name": "pyzh/Zope",
"src_encoding": "UTF-8",
"text": "Changelog\n=========\n\nThis file contains change information for the current Zope release.\nChange information for previous versions of Zope can be found at\nhttps://zope.readthedocs.io/en/2.13/CHANGES.html\n\n4.0a7 (unreleased)\n------------------\n\nBugs Fixed\n++++++++++\n\n\nFeatures Added\n++++++++++++++\n\n- Updated distributions:\n\n - DocumentTemplate = 3.0a4\n - five.globalrequest = 99.1\n\n\nRestructuring\n+++++++++++++\n\n\n4.0a6 (2017-06-01)\n------------------\n\nFeatures Added\n++++++++++++++\n\n- Updated distributions:\n\n - Products.BTreeFolder2 = 4.0.0\n - Products.ZCatalog = 4.0.0\n\n\nRestructuring\n+++++++++++++\n\n- Claim support for Python 3 and update the documentation.\n\n\n4.0a5 (2017-05-22)\n------------------\n\nFeatures Added\n++++++++++++++\n\n- Many changes to support Python 3.\n\n- Updated distributions:\n\n - AccessControl = 4.0a7\n - DocumentTemplate = 3.0a3\n - Missing = 4.0\n - MultiMapping = 4.0\n - Record = 3.4\n - zExceptions = 3.6.1\n\n\n4.0a4 (2017-05-12)\n------------------\n\nBugs Fixed\n++++++++++\n\n- #116: Restore exception views for unauthorized.\n\n- Restore a `_unauthorized` hook on the response object.\n\n- Restore `HTTPResponse.redirect` behaviour of not raising an exception.\n\nFeatures Added\n++++++++++++++\n\n- Updated distributions:\n\n - AccessControl = 4.0a6\n - Acquisition = 4.4.2\n - Record = 3.3\n - zope.dottedname = 4.2.0\n - zope.i18nmessageid = 4.1.0\n\n\n4.0a3 (2017-05-03)\n------------------\n\nBugs Fixed\n++++++++++\n\n- Fixed reflective XSS in findResult.\n This applies PloneHotfix20170117. [maurits]\n\n- Patch zope.interface to remove docstrings and avoid publishing.\n From Products.PloneHotfix20161129. [maurits]\n\n- Don't copy items the user is not allowed to view.\n From Products.PloneHotfix20161129. [maurits]\n\n- Make the WSGIPublisher normalize HTTP exception classes based on name\n (for example, any exception named NotFound will be converted\n into `zExceptions.NotFound`). This restores compatibility with\n similar behavior of the old publisher.\n [davisagli]\n\n- Use unicode transaction-notes to support ZODB 5.\n [pbauer]\n\nFeatures Added\n++++++++++++++\n\n- Add support to SameSite cookie in ``ZPublisher.HTTPBaseResponse``:\n https://tools.ietf.org/html/draft-west-first-party-cookies-07\n\n- Updated distributions:\n\n - AccessControl = 4.0a4\n - Acquisition = 4.3.0\n - BTrees = 4.4.1\n - DateTime = 4.2\n - DocumentTemplate = 3.0a1\n - ExtensionClass = 4.3.0\n - Missing = 3.2\n - MultiMapping = 3.1\n - Persistence = 3.0a3\n - persistent = 4.2.2\n - Products.ZCatalog = 4.0a3\n - pytz = 2016.10\n - Record = 3.2\n - transaction = 2.1.1\n - waitress = 1.0.2\n - WebOb = 1.7.1\n - WebTest = 2.0.26\n - WSGIProxy2 = 0.4.3\n - zdaemon = 4.2.0\n - ZEO = 5.0.4\n - zExceptions = 3.6\n - ZODB = 5.2.0\n - zope.configuration = 4.1.0\n - zope.deprecation = 4.2.0\n - zope.interface = 4.3.3\n - zope.testbrowser = 5.2\n - zope.testing = 4.6.1\n - zope.testrunner = 4.6.0\n - zope.globalrequest = 1.3\n - zope.testing = 4.6.0\n - ZServer = 4.0a2\n\nRestructuring\n+++++++++++++\n\n- Integrate code from and drop dependency on `five.globalrequest`.\n\n- Remove special handling of redirect and unauthorized exceptions from\n the WSGI publisher. These are now always raised as exceptions, to\n match the behavior of all other HTTPExceptions.\n\n- Removed xml-export.\n [maurits, pbauer]\n\n- Add back ZCacheable support.\n\n- Update to zope.testbrowser 5.0 and its WebTest based implementation.\n\n- Use `@implementer` and `@adapter` class decorators.\n\n\n4.0a2 (2016-09-09)\n------------------\n\nBugs Fixed\n++++++++++\n\n- Quote variable in manage_tabs to avoid XSS.\n From Products.PloneHotfix20160830. [maurits]\n\n- Remove more HelpSys references.\n\nFeatures Added\n++++++++++++++\n\n- Add support for exception views to WSGIPublisher.\n\n- Add support for ConflictError and TransientError retry logic directly\n into WSGIPublisher.\n\n- Add support for raising HTTPOK and HTTPRedirection exceptions and\n have them result in successful transactions.\n\n- Add better blob support to HTTPRequest.ZopeFieldStorage.\n\n- Updated distributions:\n\n - AccessControl = 4.0a3\n - AuthEncoding = 4.0.0\n - Products.ZCatalog = 4.0a2\n - zExceptions = 3.3\n - ZServer = 4.0a1\n\nRestructuring\n+++++++++++++\n\n- Change the WSGIResponse exception methods to raise exceptions instead\n of returning responses. This includes notFoundError, forbiddenError,\n debugError, badRequestError, unauthorized and redirect.\n\n- Split a common HTTPBaseResponse base class out of HTTPResponse and\n WSGIResponse. Move ZServer specific logic onto HTTPResponse.\n\n- Simplified `ZPublisher.WSGIPublisher.get_module_info` contract.\n\n- Add new `ZPublisher.utils.recordMetaData` function and use default\n `transaction.manager` as the transaction manager.\n\n- Remove support for repoze.tm2.\n\n- Change Testing to use the WSGI publisher for functional and testbrowser\n based tests incl. functional doctests. Alternatives are available\n in `ZServer.Testing`.\n\n- Move `ZPublisher.Publish` module into ZServer distribution.\n\n- Remove `Globals` package, opened database are now found in\n `Zope2.opened` next to `Zope2.DB`.\n\n- Remove proxy role support from DTML documents and methods.\n\n- Remove ZCacheable logic and StandardCacheManagers dependency.\n\n- Stop mixing in `Five.bbb.AcquisitionBBB` into browser components.\n\n- Integrate `five.pt` code directly into `Products.PageTemplates`.\n\n- Move `Products.SiteAccess` into ZServer distribution.\n\n- Simplify Page Template and Scripts ZMI screens.\n\n- Change VHM id to `virtual_hosting` to match AppInitializer.\n\n- Raise BadRequest instead of returning MessageDialog.\n\n- Remove property management ZMI screens.\n\n- Remove ZMI copy/cut/paste/rename and re-ordering features.\n\n- Drop `OFS.History` functionality.\n\n- Drop ZopeUndo dependency and move undo management to the control panel.\n\n- Simplify ZMI control panel and globally available management screens.\n\n- Move ZServer related testing support into ZServer.Testing.\n\n- Split out Lifetime, webdav and ZServer packages into a ZServer project.\n\n- Move webdav's EtagSupport, Lockable and LockItem into OFS.\n\n- Split `Products.TemporaryFolder` and `Products.ZODBMountPoint` into\n one new project called `Products.TemporaryFolder`.\n\n- Split a WSGI part out of `zopeschema.xml`. This reduces the supported\n `zope.conf` directives when run under WSGI.\n\n- Remove temp_folder mount point from default configuration.\n\n- Split a WSGI part out of `Zope2.Startup.ZopeStarter`.\n\n- Add new `ZServer.Zope2.Startup.config` module to hold configuration.\n\n- Remove `Control_Panel` `/DebugInfo` and `/DavLocks`.\n\n- Remove profiling support via `publisher-profile-file` directive.\n\n- Create new `Products.Sessions` distribution including Products.Sessions\n and Products.Transience code.\n\n- Merge `Products.OFSP` project back in.\n\n- No longer test compatibility with dependencies:\n\n ``Products.ExternalMethod``\n ``Products.PythonScripts``\n ``Products.Sessions``\n ``Products.SiteErrorLog``\n ``Products.TemporaryFolder``\n ``tempstorage``\n ``zLOG``\n ``ZopeUndo``\n\n- Dropped dependency declarations for indirect dependencies:\n\n ``docutils``\n ``Missing``\n ``pytz``\n ``zLOG``\n ``zope.sendmail``\n ``zope.structuredtext``\n\n\n4.0a1 (2016-07-22)\n------------------\n\nBugs Fixed\n++++++++++\n\n- Remove `Connection` and `Transfer-Encoding` headers from WSGI responses.\n According to PEP 333 WSGI applications must not emit hop-by-hop headers.\n\n- Removed docstrings from some methods to avoid publishing them. From\n Products.PloneHotfix20160419. [maurits]\n\n- bobo_traverse of ProductDispatcher did not correctly invalidate cache\n when a product was not initializes after first access of the cache. Types\n that were added in test-profiles were not useable.\n [pbauer, jensens]\n\n- Fix pt_editForm after the help-system was removed.\n [pbauer]\n\n- Skipped ipv6 test on Travis, because Travis no longer supports this.\n\n- LP #789863: Ensure that Request objects cannot be published / traversed\n directly via a URL.\n\n- Document running Zope as a WSGI application.\n\n- Queue additional warning filters at the beginning of the queue in order to\n allow overrides.\n\n- Issue #16: prevent leaked connections when broken ``EndRequestEvent``\n subscribers raise exceptions.\n\n- Ensure that the ``WSGIPublisher`` begins and ends an *interaction*\n at the request/response barrier. This is required for instance for\n the ``checkPermission`` call to function without an explicit\n ``interaction`` parameter.\n\n- Made sure getConfiguration().default_zpublisher_encoding is set correctly.\n\n- Issue #28: Fix publishing of IStreamIterator. This interface does\n not have seek or tell.\n Introduce IUnboundStreamIterator to support publishing iterators\n of unknown length.\n\n\nFeatures Added\n++++++++++++++\n\n- Include waitress as a default WSGI app server.\n\n- Add `egg:Zope2#httpexceptions` WSGI middleware.\n\n- Update available HTTP response code, 302 is now called Found.\n\n- Add a new `runwsgi` script to serve PasteDeploy files.\n\n- Depend on and automatically set up `five.globalrequest`.\n\n- Optimized the `OFS.ObjectManager.__contains__` method to do the\n least amount of work necessary.\n\n- Optimized the `OFS.Traversable.getPhysicalPath` method to avoid excessive\n amounts of method calls.\n\n- During startup open a connection to every configured database, to ensure all\n of them can indeed be accessed. This avoids surprises during runtime when\n traversal to some database mountpoint could fail as the underlying storage\n cannot be opened at all.\n\n- Explicitly close all databases on shutdown, which ensures `Data.fs.index`\n gets written to the file system.\n\n- Always configure a `blob-dir` in the default skeleton.\n\n- ZPublisher: If `IBrowserPage` is provided by a view, form input is decoded.\n This makes it easier to use ``zope.formlib`` and ``z3c.form`` in Zope 2.\n\n- Remove `control panel` object from the ZODB.\n\n- Updated to latest versions of Zope Toolkit libraries.\n\n- Updated distributions:\n\n - AccessControl = 4.0a1\n - Acquisition = 4.2.2\n - BTrees = 4.0.8\n - DateTime = 4.1.1\n - ExtensionClass = 4.1.2\n - docutils = 0.9.1\n - five.globalrequest = 1.0\n - manuel = 1.6.0\n - Missing = 3.1\n - MultiMapping = 3.0\n - Persistence = 3.0a1\n - Products.BTreeFolder2 = 3.0\n - Products.ExternalMethod = 3.0\n - Products.MailHost = 3.0\n - Products.OFSP = 3.0\n - Products.PythonScripts = 3.0\n - Products.SiteErrorLog = 4.0\n - Products.StandardCacheManagers = 3.0\n - Products.ZCatalog = 4.0a1\n - Products.ZCTextIndex = 3.0\n - Record = 3.1\n - tempstorage = 3.0\n - zExceptions = 3.0\n - zLOG = 3.0\n - zope.globalrequest = 1.2\n - ZopeUndo = 4.1\n\nRestructuring\n+++++++++++++\n\n- Remove dependency on initgroups. Use the standard libraries os.initgroups\n instead.\n\n- Removed nt_svcutils support from zopectl.\n\n- Python 2.6 is no longer supported. Use Python 2.7.\n\n- Products.SiteErrorLog: Is now a separated package.\n\n- OFS: Removed duplicate code in ZopeFind and ZopeFindAndApply\n\n- Five: Removed obsolete metaclass.\n\n- Five: Refactored ``browser:view`` and ``browser:page`` directives.\n This makes their implementation more similar to that in ``zope.browserpage``\n and adds allowed_interface support for the ``browser:view`` directive.\n By default the `aq_*` attributes are no longer available on those\n views/pages. If you still use them, you have to mix in Five's BrowserView.\n\n- Removed the (very obsolete) thread lock around the cookie parsing code\n in HTTPRequest.py; the python `re` module is thread-safe, unlike the\n ancient `regex` module that was once used here.\n\n- Removed the special handling of `Set-Cookie` headers in\n `HTTPResponse.setHeader`. Use the `setCookie`/`appendCookie`/`expireCookie`\n methods instead, or if low-level control is needed, use `addHeader` instead\n to get the exact same effect.\n\n- Removed the `App.version_txt.getZopeVersion` API, you can use\n ``pkg_resources.get_distribution('Zope2').version`` instead.\n\n- On the application object, removed `PrincipiaTime` in favor of `ZopeTime` and\n `PrincipiaRedirect` in favor of `Redirect` or `ZopeRedirect`.\n\n- Removed `OFS.DefaultObservable` - an early predecessor of `zope.event`.\n\n- Removed `mime-types` option from `zope.conf`. You can use the `add_files`\n API from `zope.contenttype` instead.\n\n- Removed `OFS.ZDOM`. `OFS.SimpleItem.Item` now implements `getParentNode()`.\n\n- Removed the last remaining code to support `SOFTWARE_HOME` and `ZOPE_HOME`.\n\n- Removed ZMI controls for restarting the process, these no longer apply when\n managed as a WSGI application.\n\n- Removed `bobobase_modification_time` from `Persistence.Persistent`, you can\n use `DateTime(object._p_mtime)` instead.\n\n- Removed `AccessRule` and `SiteRoot` from `Products.SiteAccess`.\n\n- Removed `Products.ZReST` and the `reStructuredText` wrapper, you can use\n `docutils` directly to gain `reST` support.\n\n- Removed special code to create user folders and page templates while creating\n new `OFS.Folder` instances.\n\n- Removed persistent default code like the `error_log` and `temp_folder`.\n\n- Removed persistent default content, including the `standard_error_message`\n template.\n\n- Retired icons from the `Zope Management Interface` and various smaller\n cleanups of ZMI screens.\n\n- Removed the old help system, in favor of the current Sphinx documentation\n hosted at https://zope.readthedocs.io/. For backwards compatibility the\n `registerHelp` and `registerHelpTitle` methods are still available on the\n ProductContext used during the `initialize` function.\n\n- Removed various persistent product related code and options. The\n `enable-product-installation` `zope.conf` setting is now a no-op.\n\n- Changed the value for `default-zpublisher-encoding` and\n `management_page_charset` to `utf-8`.\n\n- Removed the `enable-ms-author-via` directive which was only required for\n very old web folder implementations from before 2007.\n\n- Changed zope.conf default settings for `zserver-threads` to `2` and\n `python-check-interval` to `1000`.\n\n- Simplified instance skeleton, removing old `Extensions`, `import`,\n `lib/python` and `Products` from the default. You can continue to manually\n add these back.\n\n- Five.browser: Marked `processInputs` and `setPageEncoding` as deprecated.\n `processInputs` was replaced by the `postProcessInputs` request method and\n the charset negotiation done by `setPageEncoding` was never fully supported.\n\n- Dropped the direct dependencies on packages that have been factored out of\n the main Zope 2 tree. Make sure you declare a dependency in your own\n distribution if you still use one of these:\n\n ``Products.BTreeFolder2``\n ``Products.ExternalMethod``\n ``Products.MailHost``\n ``Products.MIMETools``\n ``Products.PythonScripts``\n ``Products.SiteErrorLog``\n ``Products.StandardCacheManagers``\n ``Products.ZCatalog``\n ``Record``\n"
},
{
"alpha_fraction": 0.5943496823310852,
"alphanum_fraction": 0.7340085506439209,
"avg_line_length": 20.56321907043457,
"blob_id": "88f7079e89606162e9cfd17575b53715c14a0d01",
"content_id": "f48e0e4eef2eb8c4917105c04f343f965d3723a9",
"detected_licenses": [
"ZPL-2.1"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1876,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 87,
"path": "/requirements-full.txt",
"repo_name": "pyzh/Zope",
"src_encoding": "UTF-8",
"text": "-e git+https://github.com/zopefoundation/Zope.git@master#egg=Zope2\nAccessControl==4.0a7\nAcquisition==4.4.2\nAuthEncoding==4.0.0\nBTrees==4.4.1\nChameleon==3.1\nDateTime==4.2\nDocumentTemplate==3.0a4\nExtensionClass==4.3.0\nMissing==4.0\nMultiMapping==4.0\nPasteDeploy==1.5.2\nPersistence==3.0a3\nProducts.BTreeFolder2==4.0.0\nProducts.MailHost==3.0 ; python_version < '3.0'\nProducts.ZCTextIndex==4.0.2\nProducts.ZCatalog==4.0.0\nRecord==3.4\nRestrictedPython==4.0a2\nWSGIProxy2==0.4.4\nWebOb==1.7.2\nWebTest==2.0.27\nZConfig==3.1.0\nZEO==5.1\nZODB==5.2.4\nZServer==4.0a2 ; python_version < '3.0'\nfive.globalrequest==99.1\nfive.localsitemanager==3.0.1\nfuncsigs==1.0.2\nmock==2.0.0\npbr==3.0.1\npersistent==4.2.2\npytz==2017.2\nsix==1.10.0\ntransaction==2.1.2\nwaitress==1.0.2\nz3c.pt==3.0\nzExceptions==3.6.1\nzc.lockfile==1.2.1\nzdaemon==4.2.0\nzodbpickle==0.6.0\nzope.annotation==4.5\nzope.browser==2.1.0\nzope.browsermenu==4.2\nzope.browserpage==4.1.0\nzope.browserresource==4.1.0\nzope.cachedescriptors==4.2.0\nzope.component==4.3.0\nzope.componentvocabulary==2.0.0\nzope.configuration==4.1.0\nzope.container==4.1.0\nzope.contentprovider==4.0.0\nzope.contenttype==4.2.0\nzope.datetime==4.1.0\nzope.deferredimport==4.1.0\nzope.deprecation==4.2.0\nzope.dottedname==4.2.0\nzope.event==4.2.0\nzope.exceptions==4.1.0\nzope.filerepresentation==4.1.0\nzope.formlib==4.3.0\nzope.globalrequest==1.4\nzope.i18n==4.2.0\nzope.i18nmessageid==4.1.0\nzope.interface==4.4.1\nzope.lifecycleevent==4.1.0\nzope.location==4.0.3\nzope.pagetemplate==4.2.1\nzope.processlifetime==2.1.0\nzope.proxy==4.2.1\nzope.ptresource==4.0.0\nzope.publisher==4.3.2\nzope.ramcache==2.1.0\nzope.schema==4.4.2\nzope.security==4.1.1\nzope.sendmail==4.0.1\nzope.sequencesort==4.0.1\nzope.site==4.0.0\nzope.size==4.1.0\nzope.structuredtext==4.1.0\nzope.tal==4.2.0\nzope.tales==4.1.1\nzope.testbrowser==5.2\nzope.testing==4.6.1\nzope.testrunner==4.7.0\nzope.traversing==4.1.0\nzope.viewlet==4.0.0\n"
},
{
"alpha_fraction": 0.6322954297065735,
"alphanum_fraction": 0.6399624347686768,
"avg_line_length": 30.175609588623047,
"blob_id": "0eefb555fd973a1c33a5e1f62080a4d22987275d",
"content_id": "367f55fdc1a7e736f2adfa02ad885e7ec4ec9c11",
"detected_licenses": [
"ZPL-2.1"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6391,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 205,
"path": "/src/ZPublisher/tests/test_pubevents.py",
"repo_name": "pyzh/Zope",
"src_encoding": "UTF-8",
"text": "from io import BytesIO\nfrom sys import modules, exc_info\nfrom unittest import TestCase\n\nfrom ZODB.POSException import ConflictError\nfrom zope.interface.verify import verifyObject\nfrom zope.event import subscribers\n\nfrom ZPublisher.BaseRequest import BaseRequest\nfrom ZPublisher.HTTPResponse import WSGIResponse\nfrom ZPublisher.interfaces import (\n IPubStart, IPubEnd, IPubSuccess, IPubFailure,\n IPubAfterTraversal, IPubBeforeCommit,\n IPubBeforeStreaming,\n)\nfrom ZPublisher.pubevents import (\n PubStart, PubSuccess, PubFailure,\n PubAfterTraversal, PubBeforeCommit, PubBeforeAbort,\n PubBeforeStreaming,\n)\nfrom ZPublisher.WSGIPublisher import publish_module\n\n\nPUBMODULE = 'TEST_testpubevents'\n\n_g = globals()\n\n\nclass TestInterface(TestCase):\n\n def testPubStart(self):\n verifyObject(IPubStart, PubStart(_Request()))\n\n def testPubSuccess(self):\n e = PubSuccess(_Request())\n verifyObject(IPubSuccess, e)\n verifyObject(IPubEnd, e)\n\n def testPubFailure(self):\n # get some exc info\n try:\n raise ValueError()\n except Exception:\n exc = exc_info()\n e = PubFailure(_Request(), exc, False)\n verifyObject(IPubFailure, e)\n verifyObject(IPubEnd, e)\n\n def testAfterTraversal(self):\n e = PubAfterTraversal(_Request())\n verifyObject(IPubAfterTraversal, e)\n\n def testBeforeCommit(self):\n e = PubBeforeCommit(_Request())\n verifyObject(IPubBeforeCommit, e)\n\n def testBeforeStreaming(self):\n e = PubBeforeStreaming(_Response())\n verifyObject(IPubBeforeStreaming, e)\n\n\nclass TestPubEvents(TestCase):\n def setUp(self):\n self._saved_subscribers = subscribers[:]\n self.reporter = r = _Reporter()\n subscribers[:] = [r]\n modules[PUBMODULE] = __import__(__name__, _g, _g, ('__doc__', ))\n self.request = _Request()\n\n def tearDown(self):\n if PUBMODULE in modules:\n del modules[PUBMODULE]\n subscribers[:] = self._saved_subscribers\n\n def _publish(self, request, module_name):\n def start_response(status, headers):\n pass\n\n publish_module({\n 'SERVER_PROTOCOL': 'HTTP/1.1',\n 'SERVER_NAME': 'localhost',\n 'SERVER_PORT': 'localhost',\n 'REQUEST_METHOD': 'GET',\n }, start_response, _request=request, _module_name=module_name)\n\n def testSuccess(self):\n r = self.request\n r.action = 'succeed'\n self._publish(r, PUBMODULE)\n events = self.reporter.events\n self.assertIsInstance(events[0], PubStart)\n self.assertEqual(events[0].request, r)\n self.assertIsInstance(events[1], PubAfterTraversal)\n self.assertEqual(events[1].request, r)\n self.assertIsInstance(events[2], PubBeforeCommit)\n self.assertEqual(events[2].request, r)\n self.assertIsInstance(events[3], PubSuccess)\n self.assertEqual(events[3].request, r)\n\n def testFailureReturn(self):\n r = self.request\n r.action = 'fail_return'\n self.assertRaises(Exception, self._publish, r, PUBMODULE)\n events = self.reporter.events\n self.assertIsInstance(events[0], PubStart)\n self.assertEqual(events[0].request, r)\n self.assertIsInstance(events[1], PubBeforeAbort)\n self.assertEqual(events[1].request, r)\n self.assertIsInstance(events[2], PubFailure)\n self.assertEqual(events[2].request, r)\n self.assertEqual(len(events[2].exc_info), 3)\n\n def testFailureException(self):\n r = self.request\n r.action = 'fail_exception'\n self.assertRaises(Exception, self._publish, r, PUBMODULE)\n events = self.reporter.events\n self.assertIsInstance(events[0], PubStart)\n self.assertEqual(events[0].request, r)\n self.assertIsInstance(events[1], PubBeforeAbort)\n self.assertEqual(events[1].request, r)\n self.assertEqual(len(events[1].exc_info), 3)\n self.assertIsInstance(events[2], PubFailure)\n self.assertEqual(events[2].request, r)\n self.assertEqual(len(events[2].exc_info), 3)\n\n def testFailureConflict(self):\n r = self.request\n r.action = 'conflict'\n self.assertRaises(ConflictError, self._publish, r, PUBMODULE)\n events = self.reporter.events\n self.assertIsInstance(events[0], PubStart)\n self.assertEqual(events[0].request, r)\n self.assertIsInstance(events[1], PubBeforeAbort)\n self.assertEqual(events[1].request, r)\n self.assertEqual(len(events[1].exc_info), 3)\n self.assertIsInstance(events[1].exc_info[1], ConflictError)\n self.assertIsInstance(events[2], PubFailure)\n self.assertEqual(events[2].request, r)\n self.assertEqual(len(events[2].exc_info), 3)\n self.assertIsInstance(events[2].exc_info[1], ConflictError)\n\n def testStreaming(self):\n out = BytesIO()\n response = WSGIResponse(stdout=out)\n response.write(b'datachunk1')\n response.write(b'datachunk2')\n\n events = self.reporter.events\n self.assertEqual(len(events), 1)\n self.assertIsInstance(events[0], PubBeforeStreaming)\n self.assertEqual(events[0].response, response)\n\n self.assertTrue(b'datachunk1datachunk2' in out.getvalue())\n\n\ndef _succeed():\n ''' '''\n return 'success'\n\n\nclass _Application(object):\n pass\n\n\nclass _Reporter(object):\n def __init__(self):\n self.events = []\n\n def __call__(self, event):\n self.events.append(event)\n\n\nclass _Response(object):\n def setBody(*unused):\n pass\n\n\nclass _Request(BaseRequest):\n response = WSGIResponse()\n _hacked_path = False\n args = ()\n\n def __init__(self, *args, **kw):\n BaseRequest.__init__(self, *args, **kw)\n self['PATH_INFO'] = self['URL'] = ''\n self.steps = []\n\n def traverse(self, *unused, **unused_kw):\n action = self.action\n if action.startswith('fail'):\n raise Exception(action)\n if action == 'conflict':\n raise ConflictError()\n if action == 'succeed':\n return _succeed\n else:\n raise ValueError('unknown action: %s' % action)\n\n def close(self):\n # override to get rid of the 'EndRequestEvent' notification\n pass\n\n# define things necessary for publication\nbobo_application = _Application()\n"
}
] | 5 |
bopopescu/nodasf | https://github.com/bopopescu/nodasf | ea89d0332b1aecf7a9bd38357c2330787939182d | 32718c9ba606a7373b20c77710fd3706fc583396 | ebcd570c1f5734170410a0b20fa8f0b19f67b0f1 | refs/heads/master | 2022-11-21T16:04:39.302755 | 2019-12-05T20:44:47 | 2019-12-05T20:44:47 | 282,542,595 | 0 | 0 | null | 2020-07-25T23:37:20 | 2019-12-05T20:45:09 | 2020-06-05T22:02:34 | null | [
{
"alpha_fraction": 0.5351912975311279,
"alphanum_fraction": 0.5468469858169556,
"avg_line_length": 51.69291305541992,
"blob_id": "fbb1b69e3b480a4728809ecfc49d9224c4631b8b",
"content_id": "0dabdd541179fc321a908020a1fa5ad4e17d56c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13384,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 254,
"path": "/nodasf/migrations/0001_initial.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-23 18:07\n\nimport datetime\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Agency',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('picture', models.ImageField(default=' ', upload_to='media/stock')),\n ('homepage', models.CharField(default='', max_length=300)),\n ('description', models.TextField()),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='City',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('imageQ', models.BooleanField(default=False)),\n ('image', models.ImageField(blank=True, default='', upload_to='media/stock')),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='County',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='Event',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=200)),\n ('date', models.DateTimeField()),\n ('free', models.BooleanField(default=False)),\n ('cost', models.CharField(blank=True, default='', max_length=100)),\n ('homepage', models.CharField(blank=True, default='', max_length=200)),\n ('description', models.TextField()),\n ('imageQ', models.BooleanField(default=False)),\n ('image', models.ImageField(blank=True, default='', upload_to='media/stock')),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ('city', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.City')),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ],\n options={\n 'ordering': ('-date',),\n },\n ),\n migrations.CreateModel(\n name='Genre',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='Issue',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('imageQ', models.BooleanField(default=False)),\n ('image', models.ImageField(blank=True, default='', upload_to='media/stock')),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='Journalist',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=200)),\n ('contact', models.CharField(default='', max_length=200)),\n ('bio', models.TextField(default='bio goes here')),\n ('picture', models.ImageField(default=' ', upload_to='media/faces')),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n options={\n 'ordering': ('name',),\n },\n ),\n migrations.CreateModel(\n name='Level',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='Local_Link',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('url', models.CharField(default='', max_length=300)),\n ('headline', models.CharField(default='', max_length=150)),\n ('posted', models.DateTimeField(blank=True, default=datetime.datetime.now)),\n ('imageQ', models.BooleanField(default=False)),\n ('image', models.ImageField(blank=True, default='', upload_to='media/stock')),\n ('city', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.City')),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ('issue', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue')),\n ('journalist', models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Journalist')),\n ],\n options={\n 'ordering': ('-posted',),\n },\n ),\n migrations.CreateModel(\n name='Media_Org',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('home_page', models.CharField(default='', max_length=200)),\n ('date_founded', models.DateField(default='1956-02-27')),\n ('logo', models.ImageField(upload_to='media/logos')),\n ('description', models.TextField()),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ('city', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.City')),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ],\n options={\n 'ordering': ('name',),\n },\n ),\n migrations.CreateModel(\n name='Organization',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('picture', models.ImageField(default=' ', upload_to='media/stock')),\n ('homepage', models.CharField(default='', max_length=300)),\n ('description', models.TextField()),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='Party',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='Politician',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('picture', models.ImageField(default=' ', upload_to='media/faces')),\n ('homepage', models.CharField(default='', max_length=300)),\n ('description', models.TextField()),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ('level', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.Level')),\n ('party', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.Party')),\n ('upcoming', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.Event')),\n ],\n ),\n migrations.CreateModel(\n name='STF',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('headline', models.CharField(max_length=200)),\n ('image', models.ImageField(default='', upload_to='media/stock')),\n ('credit', models.CharField(default='', max_length=200)),\n ('update', models.TextField()),\n ('date_updated', models.DateTimeField()),\n ('videoQ', models.BooleanField(default=False)),\n ('video', models.CharField(blank=True, default='', max_length=500)),\n ('slug', models.SlugField(default=' ', max_length=200)),\n ('city', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.City')),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ],\n ),\n migrations.CreateModel(\n name='STF_Hub',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('banner', models.ImageField(upload_to='media/stock')),\n ('credit', models.CharField(default='', max_length=200)),\n ('date_updated', models.DateTimeField(blank=True, default=datetime.datetime.now)),\n ('description', models.TextField(blank=True, default='')),\n ('slug', models.SlugField(default=' ', max_length=200)),\n ('city', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.City')),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ],\n options={\n 'ordering': ('-date_updated',),\n },\n ),\n migrations.CreateModel(\n name='STF_Link',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('url', models.CharField(blank=True, default='', max_length=300)),\n ('title', models.CharField(blank=True, default='', max_length=150)),\n ('media', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='nodasf.Media_Org')),\n ('story', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='nodasf.STF')),\n ],\n ),\n migrations.CreateModel(\n name='Venue',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ('imageQ', models.BooleanField(default=False)),\n ('image', models.ImageField(blank=True, default='', upload_to='media/stock')),\n ('slug', models.SlugField(default=' ', max_length=100)),\n ('city', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.City')),\n ('county', models.ForeignKey(blank=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County')),\n ],\n ),\n migrations.AddField(\n model_name='stf',\n name='hub',\n field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.STF_Hub'),\n ),\n migrations.AddField(\n model_name='local_link',\n name='media',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='nodasf.Media_Org'),\n ),\n migrations.AddField(\n model_name='journalist',\n name='organization',\n field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.Media_Org'),\n ),\n migrations.AddField(\n model_name='event',\n name='genre',\n field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.Genre'),\n ),\n migrations.AddField(\n model_name='city',\n name='county',\n field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.County'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5752212405204773,
"alphanum_fraction": 0.5923672318458557,
"avg_line_length": 35.8979606628418,
"blob_id": "8b4fadb4333657b35fff7863cae9dea39228e9ed",
"content_id": "0d3cf6ac79c5b25a496dc1d28ead0b59a52eb0ce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1808,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 49,
"path": "/nodasf/migrations/0024_auto_20191010_1521.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-10-10 22:21\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0023_auto_20190904_1042'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='stf',\n name='city',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='nodasf.City'),\n ),\n migrations.AlterField(\n model_name='stf',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='nodasf.County'),\n ),\n migrations.AlterField(\n model_name='stf',\n name='hub',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='nodasf.STF_Hub'),\n ),\n migrations.AlterField(\n model_name='stf',\n name='issue',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='nodasf.Issue'),\n ),\n migrations.AlterField(\n model_name='stf_hub',\n name='city',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='nodasf.City'),\n ),\n migrations.AlterField(\n model_name='stf_hub',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='nodasf.County'),\n ),\n migrations.AlterField(\n model_name='stf_hub',\n name='issue',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='nodasf.Issue'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5863528251647949,
"alphanum_fraction": 0.5995693206787109,
"avg_line_length": 31.375,
"blob_id": "537eb70f12acd12ca20262870661a105e2547e5d",
"content_id": "f51db97e91e25d82f7dfd9d9648dbe6888929a38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13468,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 416,
"path": "/nodasf/models.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom datetime import datetime\nfrom django.db.models.aggregates import Count\n\n\nclass County(models.Model):\n name = models.CharField(max_length=100, default='')\n image = models.ImageField(upload_to='media/stock', default='', blank=True) \n description = models.TextField(default=' ') \n slug = models.SlugField(max_length=100, default=' ')\n \n def __str__(self):\n return \"{}/{}\".format(self.name, self.id) \n def get_district(self):\n return self.name\n \n class Meta:\n ordering = ('name',)\n\nclass Category(models.Model):\n name = models.CharField(max_length=100, default='')\n def __str__(self):\n return \"{}/{}\".format(self.name, self.id)\n class Meta:\n ordering = ('name',) \n \nclass Agency(models.Model):\n name = models.CharField(max_length=100, default='')\n picture = models.ImageField(upload_to='media/stock', default=\" \")\n homepage = models.CharField(max_length=300, default='')\n description = models.TextField()\n category = models.ForeignKey(\n 'Category',\n null=True,\n on_delete=models.PROTECT)\n issue = models.ForeignKey(\n 'Issue',\n null=True,\n default=1,\n on_delete=models.PROTECT) \n slug = models.SlugField(max_length=100, default=' ')\n \n def __str__(self):\n return self.name \n class Meta:\n ordering = ('name',)\n\n\nclass Genre(models.Model):\n name = models.CharField(max_length=100, default='')\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return \"{}/{}\".format(self.name, self.id)\n\nclass Issue(models.Model):\n name = models.CharField(max_length=100, default='')\n imageQ = models.BooleanField(default=False)\n image = models.ImageField(upload_to='media/stock', default='', blank=True)\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return \"{}/{}\".format(self.name, self.id) \n class Meta:\n ordering = ('name',)\n\nclass Organization(models.Model):\n name = models.CharField(max_length=100, default='')\n picture = models.ImageField(upload_to='media/stock', default=\" \")\n homepage = models.CharField(max_length=300, default='')\n description = models.TextField()\n category = models.ForeignKey(\n 'Category',\n null=True, \n on_delete=models.PROTECT)\n issue = models.ForeignKey(\n 'Issue',\n null=True,\n default=1,\n on_delete=models.PROTECT) \n slug = models.SlugField(max_length=100, default=' ')\n \n def __str__(self):\n return self.name \n class Meta:\n ordering = ('name',)\n\n\nclass City(models.Model):\n name = models.CharField(max_length=100, default='')\n homepage = models.CharField(max_length=300, default=' ') \n county = models.ForeignKey(\n 'County',\n on_delete=models.PROTECT,)\n description = models.TextField(default=' ') \n imageQ = models.BooleanField(default=False)\n image = models.ImageField(upload_to='media/stock', default='', blank=True)\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return self.name \n def get_district(self):\n return self.name \n class Meta:\n ordering = ('name',) \n\nclass Program(models.Model):\n name = models.CharField(max_length=200, default='name')\n homepage = models.CharField(max_length=300, default=' ') \n organization = models.ForeignKey(\n 'Organization',\n on_delete=models.PROTECT,)\n description = models.TextField(default=' ') \n imageQ = models.BooleanField(default=False)\n image = models.ImageField(upload_to='media/stock', default='', blank=True) \n category = models.ForeignKey(\n 'Category',\n null=True, \n on_delete=models.PROTECT)\n issue = models.ForeignKey(\n 'Issue',\n null=True,\n default=1,\n on_delete=models.PROTECT) \n def __str__(self):\n return self.name \n class Meta:\n ordering = ('name',) \n \nclass Party(models.Model):\n name = models.CharField(max_length=100, default='')\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return self.name \n\nclass Level(models.Model):\n name = models.CharField(max_length=100, default='')\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return self.name \n \nclass District(models.Model):\n name = models.CharField(max_length=100, default='')\n description = models.TextField(default=' ') \n county = models.ManyToManyField('County', related_name=\"counties\")\n city = models.ManyToManyField('City', related_name=\"cities\")\n image = models.ImageField(upload_to='media/stock', default='', blank=True) \n level = models.ForeignKey(\n 'Level',\n default=1,\n on_delete=models.PROTECT,)\n slug = models.SlugField(max_length=100, default=' ') \n \n def __str__(self):\n return self.name \n class Meta:\n ordering = ('name',) \n \nclass Venue(models.Model):\n name = models.CharField(max_length=100, default='')\n description = models.TextField(default=' ')\n homepage = models.CharField(max_length=300, default=' ') \n city = models.ForeignKey(\n 'City',\n null=True, \n on_delete=models.SET_NULL,) \n county = models.ForeignKey(\n 'County',\n blank=True,\n null=True,\n on_delete=models.SET_NULL,)\n imageQ = models.BooleanField(default=False)\n image = models.ImageField(upload_to='media/stock', default='', blank=True)\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return self.name \n class Meta:\n ordering = ('name',)\n \nclass Event(models.Model):\n name = models.CharField(max_length=200)\n date = models.DateTimeField(default=datetime.now)\n city = models.ForeignKey(\n 'City',\n null=True, \n on_delete=models.SET_NULL,) \n county = models.ForeignKey(\n 'County',\n blank=True,\n null=True, \n on_delete=models.SET_NULL,)\n free = models.BooleanField(default=False)\n cost = models.CharField(max_length=100, default='', blank=True)\n homepage = models.CharField(max_length=200, default='', blank=True)\n genre = models.ForeignKey(\n 'Genre',\n null=True, \n on_delete=models.SET_NULL,)\n description = models.TextField()\n venue = models.ForeignKey(\n 'Venue',\n default=1,\n on_delete=models.CASCADE,) \n imageQ = models.BooleanField(default=False)\n image = models.ImageField(upload_to='media/stock', default='', blank=True)\n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return self.name\n\n class Meta:\n ordering = ('-date',) \n\nclass Politician(models.Model):\n first_name = models.CharField(max_length=100, default='first')\n last_name = models.CharField(max_length=100, default='last') \n party = models.ForeignKey(\n 'Party',\n null=True, \n on_delete=models.SET_NULL,)\n level = models.ForeignKey(\n 'Level',\n null=True, \n on_delete=models.SET_NULL,)\n county = models.ForeignKey(\n 'County',\n blank=True,\n null=True,\n on_delete=models.SET_NULL,)\n district = models.ForeignKey(\n 'District',\n null=True,\n on_delete=models.SET_NULL) \n picture = models.ImageField(upload_to='media/faces', default=\" \")\n homepage = models.CharField(max_length=300, default='')\n description = models.TextField()\n upcoming = models.ForeignKey(\n 'Event',\n null=True,\n on_delete=models.SET_NULL,\n blank=True) \n candidate = models.BooleanField(default=False) \n slug = models.SlugField(max_length=100, default=' ')\n\n def __str__(self):\n return self.last_name \n \nclass Bureaucrat(models.Model):\n last_name = models.CharField(max_length=100, default='last')\n first_name = models.CharField(max_length=100, default='first')\n picture = models.ImageField(upload_to='media/faces', default=\" \")\n description = models.TextField()\n organization = models.ForeignKey(\n 'Organization',\n blank=True,\n null=True,\n on_delete=models.SET_NULL,)\n program = models.ManyToManyField(\n 'Program',\n null=True,\n blank=True,) \n def __str__(self):\n return self.last_name \n \nclass Media_Org(models.Model):\n name = models.CharField(max_length=100, default='')\n home_page = models.CharField(max_length=200, default='')\n date_founded = models.DateField(default='1956-02-27')\n logo = models.ImageField(upload_to='media/logos')\n description = models.TextField()\n city = models.ForeignKey(\n 'City',\n on_delete=models.PROTECT,) \n county = models.ForeignKey(\n 'County',\n blank=True, \n on_delete=models.PROTECT,)\n slug = models.SlugField(max_length=100, default=' ')\n\n \n def __str__(self):\n return self.name\n class Meta:\n ordering = ('name',)\n \nclass Journalist(models.Model):\n first_name = models.CharField(max_length=200, default='first') \n last_name = models.CharField(max_length=200, default='last') \n contact = models.CharField(max_length=200, default='')\n organization = models.ForeignKey(\n 'Media_Org',\n on_delete=models.PROTECT,)\n bio = models.TextField(default='bio goes here')\n picture = models.ImageField(upload_to='media/faces', default=\" \")\n slug = models.SlugField(max_length=100, default=' ')\n def __str__(self):\n return self.last_name\n class Meta:\n ordering = ('last_name',)\n\n\nclass Local_Link(models.Model):\n url = models.CharField(max_length=300, default='')\n headline = models.CharField(max_length=150, default='')\n media = models.ForeignKey(\n 'Media_Org',\n on_delete=models.CASCADE,)\n posted = models.DateTimeField(auto_now_add=True, blank=True)\n county = models.ForeignKey(\n 'County',\n blank=True,\n null=True,\n on_delete=models.PROTECT,)\n city = models.ForeignKey(\n 'City',\n null=True,\n on_delete=models.PROTECT,\n blank=True)\n issue = models.ForeignKey(\n 'Issue',\n on_delete=models.PROTECT,\n null=True, \n blank=True,) \n journalist = models.ForeignKey('Journalist',\n null=True,\n blank=True,\n on_delete=models.PROTECT,)\n imageQ = models.BooleanField(default=False)\n image = models.ImageField(upload_to='media/stock', default='', blank=True)\n\n def __str__(self):\n return \"{}/{}\".format(self.headline, self.media)\n\n class Meta:\n ordering = ('-posted',)\n\nclass STF_Hub(models.Model):\n name = models.CharField(max_length=100, default='')\n banner = models.ImageField(upload_to='media/stock')\n credit = models.CharField(max_length=200, default='')\n county = models.ForeignKey(\n 'County',\n blank=True, \n null=True, \n on_delete=models.CASCADE,)\n city = models.ForeignKey(\n 'City',\n blank=True,\n null=True, \n on_delete=models.CASCADE,) \n date_updated = models.DateTimeField(auto_now=True, blank=True)\n description = models.TextField(default='', blank=True)\n issue = models.ForeignKey(\n 'Issue',\n null=True, \n on_delete=models.CASCADE,\n blank=True,) \n slug = models.SlugField(max_length=200, default=' ') \n\n def __str__(self):\n return self.name\n class Meta:\n ordering = ('-date_updated',) \n \nclass STF(models.Model):\n headline = models.CharField(max_length=200)\n image = models.ImageField(upload_to='media/stock', default='')\n credit = models.CharField(max_length=200, default='') \n update = models.TextField()\n date_updated = models.DateTimeField(auto_now_add=True)\n videoQ = models.BooleanField(default=False)\n video = models.CharField(max_length=500, default='', blank=True) \n hub= models.ForeignKey(\n 'STF_Hub',\n on_delete=models.CASCADE)\n county = models.ForeignKey(\n 'County',\n blank=True, \n null=True, \n on_delete=models.CASCADE,)\n city = models.ForeignKey(\n 'City',\n blank=True,\n null=True, \n on_delete=models.CASCADE,)\n issue = models.ForeignKey(\n 'Issue',\n null=True, \n on_delete=models.CASCADE,\n blank=True,) \n slug = models.SlugField(max_length=200, default=' ') \n\n def __str__(self):\n return \"{}/{}\".format(self.headline, self.hub) \n class Meta:\n ordering = ('-date_updated',) \n\n\nclass STF_Link(models.Model):\n url = models.CharField(max_length=300, default='', blank=True)\n title = models.CharField(max_length=150, default='', blank=True)\n media = models.ForeignKey(\n 'Media_Org',\n on_delete=models.CASCADE,)\n story = models.ForeignKey(\n 'STF',\n on_delete=models.CASCADE,)\n journalist = models.ForeignKey('Journalist',\n null=True,\n blank=True,\n on_delete=models.PROTECT,) \n def __str__(self):\n return \"{}/{}\".format(self.title, self.story)\n"
},
{
"alpha_fraction": 0.49497488141059875,
"alphanum_fraction": 0.5829145908355713,
"avg_line_length": 21.11111068725586,
"blob_id": "7e427602220a712cc6047368ec9effe978ac723d",
"content_id": "5afe4e46670241c6d59ab282e928b3e1b4699a72",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 398,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 18,
"path": "/nodasf/migrations/0004_city_homepage.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-24 17:02\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0003_auto_20190724_0943'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='city',\n name='homepage',\n field=models.CharField(default=' ', max_length=300),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7017508745193481,
"alphanum_fraction": 0.7142282128334045,
"avg_line_length": 38.7599983215332,
"blob_id": "1c34ceea62c4966c4760e1ab2921f3fdeed134fb",
"content_id": "a8c90596a55226d97f154debb8f18797c4568a1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4969,
"license_type": "permissive",
"max_line_length": 208,
"num_lines": 125,
"path": "/nodasf/views.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import get_object_or_404, render, redirect\nfrom django.template.loader import get_template\nfrom django.template import Context\nfrom django.template.defaulttags import register\nfrom django.http import HttpResponse, Http404, HttpResponseRedirect\nfrom django.urls import reverse\nfrom django.db.models import F, Q\nfrom .models import County, Venue, Agency, Organization, Genre, Issue, City, Party, Level, Event, Politician, Media_Org, Journalist, Local_Link, STF_Hub, STF_Link, STF, District, Category, Program, Bureaucrat\n\n@register.filter\ndef get_item(dictionary, key):\n return dictionary.get(key)\n\ndef index(request):\n\tlocal_links = Local_Link.objects.all()[0:15]\n\tstfs= STF.objects.all().order_by('-date_updated') [0:10]\n\tevents= Event.objects.all().order_by('-date') [0:20]\n\treturn render(request, 'index.html', {'local_links': local_links, 'stfs': stfs, 'events': events})\n\ndef media_directory(request):\n\tmedias = Media_Org.objects.all()\n\treturn render(request, 'media-org-directory.html', {'medias': medias})\n\ndef media_org(request, id, slug):\n\tmedia = get_object_or_404(Media_Org, pk=id)\n\tjournalists = Journalist.objects.filter( organization__id = id )\n\treturn render(request, 'media-org.html', {'media': media, 'journalists': journalists})\n\t\ndef venues(request):\n\tvenues = Venue.objects.all()\n\treturn render(request, 'venues.html', {'venues': venues})\n\t\ndef venue_part(request, id, slug):\n\tvenue = get_object_or_404(Venue, pk=id)\n\tevents = Event.objects.filter( venue__id = id )\n\treturn render(request, 'venue-part.html', {'venue': venue, 'events': events})\n\t\ndef politicians(request):\n\tpoliticians = Politician.objects.all()\n\treturn render(request, 'politicians.html', {'politicians': politicians})\n\ndef politician_part(request, id, slug):\n\tpolitician = get_object_or_404(Politician, pk=id)\n\treturn render(request, 'politician-part.html', {'politician': politician})\n\ndef issues(request):\n\tissues = Issue.objects.all()\n\treturn render(request, 'issue.html', {'issues': issues})\n\ndef issue_part(request, id, slug):\n\tissue = get_object_or_404(Issue, pk=id)\n\tlocal_links = Local_Link.objects.filter( issue_id = id)\n\tstf_hubs = STF_Hub.objects.filter( issue__id = id)\n\tstfs = {\n\t\tp: STF.objects.filter(hub__id = p.id) for p in stf_hubs\n\t}\n\treturn render(request, 'issue-part.html', {'issue': issue, 'local_links': local_links, 'stf_hubs': stfs})\n\ndef agencies(request):\n\tagencies = Agency.objects.all().order_by('name')\n\treturn render(request, 'agency.html', {'agencies': agencies})\n\ndef agency_part(request, id, slug):\n\tagency = get_object_or_404(Agency, pk=id)\n\treturn render(request, 'agency-part.html', {'agency': agency})\n\t\ndef about(request):\n\treturn render(request, 'about.html')\n\ndef organizations(request):\n\torganizations = Organization.objects.all().order_by('issue')\n\treturn render(request, 'organization.html', {'organizations': organizations})\n\ndef organization_part(request, id, slug):\n\torganization = get_object_or_404(Organization, pk=id)\n\treturn render(request, 'organization-part.html', {'organization': organization})\n\t\ndef city(request, id, slug):\n\tcity = get_object_or_404(City, pk=id)\n\treturn render(request, 'city.html', {'city': city})\t\n\ndef county(request, id, slug):\n\tcounty = get_object_or_404(County, pk=id)\n\tcities = City.objects.filter( county_id = id )\n\treturn render(request, 'county.html', {'county': county, 'cities': cities})\t\n\ndef district(request, id, slug):\n\tdistrict = get_object_or_404(District, pk=id)\n\tpols = Politician.objects.filter( district_id = id )\n\treturn render(request, 'district.html', {'district': district, 'pols': pols})\t\n\ndef journalists(request):\n\tjournalists = Journalist.objects.all()\n\treturn render(request, 'journalist.html', {'journalists': journalists})\n\ndef journalist_part(request, id, slug):\n\tjournalist = get_object_or_404(Journalist, pk=id)\n\tarticles = Local_Link.objects.filter( journalist__id = id)\n\treturn render(request, 'journalist-part.html', {'journalist': journalist, 'articles': articles})\n\ndef stf_hub(request, id, slug):\n\tstf_hub = get_object_or_404(STF_Hub, pk=id)\n\tstfs = STF.objects.filter( hub__id = id)[0:7]\n\tstf_links = {\n\t\tp: STF_Link.objects.filter(story__id = p.id) for p in stfs\n\t}\t\n\treturn render(request, 'stf-hub.html', {'stf_hub': stf_hub, 'stfs': stf_links})\n\ndef stf(request, id, slug):\n\tstf = get_object_or_404(STF, pk=id)\n\tstf_links = STF_Link.objects.filter( story__id = id)\n\treturn render(request, 'stf.html', {'stf': stf, 'stf_links': stf_links})\t\n\t\ndef event(request, id, slug):\n\tevent = get_object_or_404(Event, pk=id)\n\treturn render(request, 'event.html', {'event': event})\n\ndef events_hub(request):\n\tevents = Event.objects.all().order_by('-date')\n\treturn render(request,'event-hub.html', {'events': events})\n\ndef events_genre(request, id, slug):\n\tgenre = get_object_or_404(Genre, pk=id)\n\tevents = Event.objects.filter( genre__id = id).order_by('-date')[0:20]\n\treturn render(request, 'event-genre.html', {'genre': genre, 'events': events})"
},
{
"alpha_fraction": 0.5594989657402039,
"alphanum_fraction": 0.6283924579620361,
"avg_line_length": 24.210525512695312,
"blob_id": "8369fb047e4b2ea27464c775fb9473100c7e81c5",
"content_id": "091e097ef5f6d5ffc37f726dbdffac6a32844c7a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 19,
"path": "/nodasf/migrations/0009_district_level.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-25 16:29\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0008_auto_20190725_0924'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='district',\n name='level',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Level'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5594272017478943,
"alphanum_fraction": 0.5804296135902405,
"avg_line_length": 47.72093200683594,
"blob_id": "268f0dedc19c56d13e96540874a1d5701b3d56e0",
"content_id": "13f278beb6afe633aeed5c098e763512f0863514",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2095,
"license_type": "permissive",
"max_line_length": 147,
"num_lines": 43,
"path": "/nodasf/migrations/0029_bureaucrat_program.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-12-05 20:34\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0028_auto_20191203_1044'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Program',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='name', max_length=200)),\n ('homepage', models.CharField(default=' ', max_length=300)),\n ('description', models.TextField(default=' ')),\n ('imageQ', models.BooleanField(default=False)),\n ('image', models.ImageField(blank=True, default='', upload_to='media/stock')),\n ('category', models.ForeignKey(null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Category')),\n ('issue', models.ForeignKey(default=1, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue')),\n ('organization', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='nodasf.Organization')),\n ],\n options={\n 'ordering': ('name',),\n },\n ),\n migrations.CreateModel(\n name='Bureaucrat',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('last_name', models.CharField(default='last', max_length=100)),\n ('first_name', models.CharField(default='first', max_length=100)),\n ('picture', models.ImageField(default=' ', upload_to='media/faces')),\n ('description', models.TextField()),\n ('organization', models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.Organization')),\n ('program', models.ManyToManyField(blank=True, null=True, to='nodasf.Program')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.4850136339664459,
"alphanum_fraction": 0.5722070932388306,
"avg_line_length": 19.38888931274414,
"blob_id": "a60da92d1a825d9c431cf98cf856207035cd1518",
"content_id": "412abd6916cca183680cb0458ee95ee2bb60bda9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 367,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 18,
"path": "/nodasf/migrations/0015_auto_20190730_1458.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-30 21:58\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0014_auto_20190730_1306'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='district',\n old_name='county',\n new_name='counties',\n ),\n ]\n"
},
{
"alpha_fraction": 0.482820987701416,
"alphanum_fraction": 0.5913200974464417,
"avg_line_length": 2212,
"blob_id": "9bf1fd04b52a7c9f52db41ac177baa4436ec68b4",
"content_id": "bf11f239a65e28188ddc975048117c36de98eda0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 2212,
"license_type": "permissive",
"max_line_length": 2212,
"num_lines": 1,
"path": "/.c9/metadata/environment/nodasf/templates/index.html",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "{\"filter\":false,\"title\":\"index.html\",\"tooltip\":\"/nodasf/templates/index.html\",\"undoManager\":{\"mark\":5,\"position\":5,\"stack\":[[{\"start\":{\"row\":91,\"column\":181},\"end\":{\"row\":91,\"column\":182},\"action\":\"insert\",\"lines\":[\"f\"],\"id\":43},{\"start\":{\"row\":91,\"column\":182},\"end\":{\"row\":91,\"column\":183},\"action\":\"insert\",\"lines\":[\"i\"]},{\"start\":{\"row\":91,\"column\":183},\"end\":{\"row\":91,\"column\":184},\"action\":\"insert\",\"lines\":[\"r\"]},{\"start\":{\"row\":91,\"column\":184},\"end\":{\"row\":91,\"column\":185},\"action\":\"insert\",\"lines\":[\"s\"]},{\"start\":{\"row\":91,\"column\":185},\"end\":{\"row\":91,\"column\":186},\"action\":\"insert\",\"lines\":[\"t\"]}],[{\"start\":{\"row\":91,\"column\":186},\"end\":{\"row\":91,\"column\":187},\"action\":\"insert\",\"lines\":[\"_\"],\"id\":44}],[{\"start\":{\"row\":91,\"column\":193},\"end\":{\"row\":91,\"column\":194},\"action\":\"insert\",\"lines\":[\" \"],\"id\":45}],[{\"start\":{\"row\":91,\"column\":194},\"end\":{\"row\":91,\"column\":230},\"action\":\"insert\",\"lines\":[\"{{local_link.journalist.first_name}}\"],\"id\":46}],[{\"start\":{\"row\":91,\"column\":222},\"end\":{\"row\":91,\"column\":223},\"action\":\"remove\",\"lines\":[\"t\"],\"id\":47},{\"start\":{\"row\":91,\"column\":221},\"end\":{\"row\":91,\"column\":222},\"action\":\"remove\",\"lines\":[\"s\"]},{\"start\":{\"row\":91,\"column\":220},\"end\":{\"row\":91,\"column\":221},\"action\":\"remove\",\"lines\":[\"r\"]},{\"start\":{\"row\":91,\"column\":219},\"end\":{\"row\":91,\"column\":220},\"action\":\"remove\",\"lines\":[\"i\"]},{\"start\":{\"row\":91,\"column\":218},\"end\":{\"row\":91,\"column\":219},\"action\":\"remove\",\"lines\":[\"f\"]}],[{\"start\":{\"row\":91,\"column\":218},\"end\":{\"row\":91,\"column\":219},\"action\":\"insert\",\"lines\":[\"l\"],\"id\":48},{\"start\":{\"row\":91,\"column\":219},\"end\":{\"row\":91,\"column\":220},\"action\":\"insert\",\"lines\":[\"a\"]},{\"start\":{\"row\":91,\"column\":220},\"end\":{\"row\":91,\"column\":221},\"action\":\"insert\",\"lines\":[\"s\"]},{\"start\":{\"row\":91,\"column\":221},\"end\":{\"row\":91,\"column\":222},\"action\":\"insert\",\"lines\":[\"t\"]}]]},\"ace\":{\"folds\":[],\"scrolltop\":945,\"scrollleft\":0,\"selection\":{\"start\":{\"row\":91,\"column\":222},\"end\":{\"row\":91,\"column\":222},\"isBackwards\":false},\"options\":{\"guessTabSize\":true,\"useWrapMode\":false,\"wrapToView\":true},\"firstLineState\":{\"row\":24,\"state\":\"start\",\"mode\":\"ace/mode/html\"}},\"timestamp\":1575397413490,\"hash\":\"130729cee64d1f7b11f593c89b52d8d070765b2a\"}"
},
{
"alpha_fraction": 0.5373831987380981,
"alphanum_fraction": 0.5934579372406006,
"avg_line_length": 25.75,
"blob_id": "e2711f9475591f45682e7d2fe86318331e580c3e",
"content_id": "78145eb7b7c8c8ffaa321fbaaac7856603c4d314",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 642,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 24,
"path": "/nodasf/migrations/0011_auto_20190725_1228.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-25 19:28\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0010_auto_20190725_1030'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='event',\n name='venue',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Venue'),\n ),\n migrations.AddField(\n model_name='venue',\n name='homepage',\n field=models.CharField(default=' ', max_length=300),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5654596090316772,
"alphanum_fraction": 0.5951717495918274,
"avg_line_length": 31.636363983154297,
"blob_id": "65e93a6e85dd8391f86dd482dc0090101c8fbb46",
"content_id": "d0460acc68117153d0d2ce70b676ea48f88aa511",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1077,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 33,
"path": "/nodasf/migrations/0013_auto_20190726_1201.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-26 19:01\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0012_auto_20190725_1234'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='stf',\n options={'ordering': ('-date_updated',)},\n ),\n migrations.AlterField(\n model_name='event',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County'),\n ),\n migrations.AlterField(\n model_name='local_link',\n name='city',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.City'),\n ),\n migrations.AlterField(\n model_name='local_link',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5516162514686584,
"alphanum_fraction": 0.5776851177215576,
"avg_line_length": 28.060606002807617,
"blob_id": "784008316acf4088ce99905df56786b2b8f088f4",
"content_id": "a73dddd4d67808a4b25fa63722f0d66d425f4aa0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 959,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 33,
"path": "/nodasf/migrations/0028_auto_20191203_1044.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-12-03 18:44\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0027_remove_journalist_name'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='politician',\n name='name',\n ),\n migrations.AddField(\n model_name='politician',\n name='first_name',\n field=models.CharField(default='first', max_length=100),\n ),\n migrations.AddField(\n model_name='politician',\n name='last_name',\n field=models.CharField(default='last', max_length=100),\n ),\n migrations.AlterField(\n model_name='politician',\n name='upcoming',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.Event'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5560859441757202,
"alphanum_fraction": 0.5954654216766357,
"avg_line_length": 28.928571701049805,
"blob_id": "4ca964a33464099b1e61ba655b11876306f238b1",
"content_id": "5af39ba55614959853c565c1c76366ef16bd38be",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 838,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 28,
"path": "/nodasf/migrations/0021_auto_20190806_1448.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-08-06 21:48\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0020_auto_20190806_1045'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='category',\n options={'ordering': ('name',)},\n ),\n migrations.AddField(\n model_name='agency',\n name='issue',\n field=models.ForeignKey(default=1, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue'),\n ),\n migrations.AddField(\n model_name='organization',\n name='issue',\n field=models.ForeignKey(default=1, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.635814905166626,
"avg_line_length": 25.157894134521484,
"blob_id": "0c9ffa4bdba4be50d2f78312ee4ea1312ebbccfa",
"content_id": "184dd35951570594fe3cb2c1fbe766f0896f04c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 19,
"path": "/nodasf/migrations/0016_auto_20190730_1527.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-30 22:27\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0015_auto_20190730_1458'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='politician',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.County'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5700541138648987,
"alphanum_fraction": 0.5838845372200012,
"avg_line_length": 35.15217208862305,
"blob_id": "656f357acb993c773164757b96b9565b6b7dd2b8",
"content_id": "82b7d1cdd4f5dd7ba965642374aacb297693d6a0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1663,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 46,
"path": "/nodasf/migrations/0002_auto_20190724_0903.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-24 16:03\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Category',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=100)),\n ],\n ),\n migrations.AddField(\n model_name='stf',\n name='issue',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue'),\n ),\n migrations.AddField(\n model_name='stf_hub',\n name='issue',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue'),\n ),\n migrations.AlterField(\n model_name='local_link',\n name='issue',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Issue'),\n ),\n migrations.AddField(\n model_name='agency',\n name='category',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Category'),\n ),\n migrations.AddField(\n model_name='organization',\n name='category',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.PROTECT, to='nodasf.Category'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4739745855331421,
"alphanum_fraction": 0.5615255236625671,
"avg_line_length": 4169,
"blob_id": "1dae3fc10778a236ec9e27fa8fe9a57287fa57b2",
"content_id": "d7660cf5ad367a6985ad70f1fd7da2fb726f365b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 4169,
"license_type": "permissive",
"max_line_length": 4169,
"num_lines": 1,
"path": "/.c9/metadata/environment/nodasf/templates/agency-part.html",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "{\"filter\":false,\"title\":\"agency-part.html\",\"tooltip\":\"/nodasf/templates/agency-part.html\",\"ace\":{\"folds\":[],\"scrolltop\":362.5,\"scrollleft\":0,\"selection\":{\"start\":{\"row\":46,\"column\":29},\"end\":{\"row\":46,\"column\":29},\"isBackwards\":false},\"options\":{\"guessTabSize\":true,\"useWrapMode\":false,\"wrapToView\":true},\"firstLineState\":{\"row\":25,\"state\":\"start\",\"mode\":\"ace/mode/html\"}},\"hash\":\"4dec997fef6d902f26641b28dd3777f575b024b8\",\"undoManager\":{\"mark\":16,\"position\":16,\"stack\":[[{\"start\":{\"row\":43,\"column\":64},\"end\":{\"row\":43,\"column\":69},\"action\":\"remove\",\"lines\":[\"image\"],\"id\":6},{\"start\":{\"row\":43,\"column\":64},\"end\":{\"row\":43,\"column\":65},\"action\":\"insert\",\"lines\":[\"p\"]},{\"start\":{\"row\":43,\"column\":65},\"end\":{\"row\":43,\"column\":66},\"action\":\"insert\",\"lines\":[\"i\"]},{\"start\":{\"row\":43,\"column\":66},\"end\":{\"row\":43,\"column\":67},\"action\":\"insert\",\"lines\":[\"c\"]},{\"start\":{\"row\":43,\"column\":67},\"end\":{\"row\":43,\"column\":68},\"action\":\"insert\",\"lines\":[\"t\"]}],[{\"start\":{\"row\":43,\"column\":68},\"end\":{\"row\":43,\"column\":69},\"action\":\"insert\",\"lines\":[\"u\"],\"id\":7},{\"start\":{\"row\":43,\"column\":69},\"end\":{\"row\":43,\"column\":70},\"action\":\"insert\",\"lines\":[\"r\"]},{\"start\":{\"row\":43,\"column\":70},\"end\":{\"row\":43,\"column\":71},\"action\":\"insert\",\"lines\":[\"e\"]}],[{\"start\":{\"row\":43,\"column\":87},\"end\":{\"row\":43,\"column\":88},\"action\":\"insert\",\"lines\":[\"-\"],\"id\":8},{\"start\":{\"row\":43,\"column\":88},\"end\":{\"row\":43,\"column\":89},\"action\":\"insert\",\"lines\":[\"p\"]},{\"start\":{\"row\":43,\"column\":89},\"end\":{\"row\":43,\"column\":90},\"action\":\"insert\",\"lines\":[\"a\"]},{\"start\":{\"row\":43,\"column\":90},\"end\":{\"row\":43,\"column\":91},\"action\":\"insert\",\"lines\":[\"r\"]},{\"start\":{\"row\":43,\"column\":91},\"end\":{\"row\":43,\"column\":92},\"action\":\"insert\",\"lines\":[\"t\"]}],[{\"start\":{\"row\":42,\"column\":0},\"end\":{\"row\":42,\"column\":112},\"action\":\"remove\",\"lines\":[\" <a href=\\\"https://sf.nodanews.com/agency/{{agency.id}}/{{agency.slug}}/\\\" target=\\\"_blank\\\" class=\\\"agency-name\\\">\"],\"id\":9}],[{\"start\":{\"row\":42,\"column\":0},\"end\":{\"row\":42,\"column\":2},\"action\":\"insert\",\"lines\":[\" \"],\"id\":10}],[{\"start\":{\"row\":42,\"column\":2},\"end\":{\"row\":42,\"column\":4},\"action\":\"insert\",\"lines\":[\" \"],\"id\":11}],[{\"start\":{\"row\":42,\"column\":4},\"end\":{\"row\":42,\"column\":6},\"action\":\"insert\",\"lines\":[\" \"],\"id\":12}],[{\"start\":{\"row\":42,\"column\":6},\"end\":{\"row\":42,\"column\":7},\"action\":\"insert\",\"lines\":[\"<\"],\"id\":13},{\"start\":{\"row\":42,\"column\":7},\"end\":{\"row\":42,\"column\":8},\"action\":\"insert\",\"lines\":[\"h\"]},{\"start\":{\"row\":42,\"column\":8},\"end\":{\"row\":42,\"column\":9},\"action\":\"insert\",\"lines\":[\"2\"]}],[{\"start\":{\"row\":42,\"column\":8},\"end\":{\"row\":42,\"column\":9},\"action\":\"remove\",\"lines\":[\"2\"],\"id\":14}],[{\"start\":{\"row\":42,\"column\":8},\"end\":{\"row\":42,\"column\":9},\"action\":\"insert\",\"lines\":[\"1\"],\"id\":15}],[{\"start\":{\"row\":42,\"column\":9},\"end\":{\"row\":42,\"column\":15},\"action\":\"insert\",\"lines\":[\"></h1>\"],\"id\":16}],[{\"start\":{\"row\":42,\"column\":10},\"end\":{\"row\":42,\"column\":15},\"action\":\"remove\",\"lines\":[\"</h1>\"],\"id\":17}],[{\"start\":{\"row\":42,\"column\":28},\"end\":{\"row\":42,\"column\":29},\"action\":\"remove\",\"lines\":[\">\"],\"id\":18},{\"start\":{\"row\":42,\"column\":27},\"end\":{\"row\":42,\"column\":28},\"action\":\"remove\",\"lines\":[\"a\"]},{\"start\":{\"row\":42,\"column\":26},\"end\":{\"row\":42,\"column\":27},\"action\":\"remove\",\"lines\":[\"/\"]},{\"start\":{\"row\":42,\"column\":25},\"end\":{\"row\":42,\"column\":26},\"action\":\"remove\",\"lines\":[\"<\"]}],[{\"start\":{\"row\":42,\"column\":25},\"end\":{\"row\":42,\"column\":30},\"action\":\"insert\",\"lines\":[\"</h1>\"],\"id\":19}],[{\"start\":{\"row\":44,\"column\":33},\"end\":{\"row\":44,\"column\":34},\"action\":\"remove\",\"lines\":[\"C\"],\"id\":20}],[{\"start\":{\"row\":44,\"column\":33},\"end\":{\"row\":44,\"column\":34},\"action\":\"insert\",\"lines\":[\"c\"],\"id\":21}],[{\"start\":{\"row\":44,\"column\":41},\"end\":{\"row\":44,\"column\":42},\"action\":\"insert\",\"lines\":[\".\"],\"id\":22},{\"start\":{\"row\":44,\"column\":42},\"end\":{\"row\":44,\"column\":43},\"action\":\"insert\",\"lines\":[\"n\"]},{\"start\":{\"row\":44,\"column\":43},\"end\":{\"row\":44,\"column\":44},\"action\":\"insert\",\"lines\":[\"a\"]},{\"start\":{\"row\":44,\"column\":44},\"end\":{\"row\":44,\"column\":45},\"action\":\"insert\",\"lines\":[\"m\"]},{\"start\":{\"row\":44,\"column\":45},\"end\":{\"row\":44,\"column\":46},\"action\":\"insert\",\"lines\":[\"e\"]}]]},\"timestamp\":1565713840439}"
},
{
"alpha_fraction": 0.516539454460144,
"alphanum_fraction": 0.5954198241233826,
"avg_line_length": 20.83333396911621,
"blob_id": "101ece3eabfdec80e29c4b71900b0a9271d477cc",
"content_id": "53ab20f8c44d0dabb769103295077e4ef20ace76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 18,
"path": "/nodasf/migrations/0022_politician_candidate.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-08-06 22:43\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0021_auto_20190806_1448'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='politician',\n name='candidate',\n field=models.BooleanField(default=False),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4831223487854004,
"alphanum_fraction": 0.5042194128036499,
"avg_line_length": 24.62162208557129,
"blob_id": "053229ee80d1aa72a9cfdc2820430967dab16b48",
"content_id": "84ecacc846b99aa93fb3b79fafd665bdd9ee53c8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 948,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 37,
"path": "/nodasf/migrations/0005_auto_20190724_1019.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-24 17:19\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0004_city_homepage'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='agency',\n options={'ordering': ('name',)},\n ),\n migrations.AlterModelOptions(\n name='city',\n options={'ordering': ('name',)},\n ),\n migrations.AlterModelOptions(\n name='county',\n options={'ordering': ('name',)},\n ),\n migrations.AlterModelOptions(\n name='issue',\n options={'ordering': ('name',)},\n ),\n migrations.AlterModelOptions(\n name='organization',\n options={'ordering': ('name',)},\n ),\n migrations.AlterModelOptions(\n name='venue',\n options={'ordering': ('name',)},\n ),\n ]\n"
},
{
"alpha_fraction": 0.5122548937797546,
"alphanum_fraction": 0.5502451062202454,
"avg_line_length": 25.322580337524414,
"blob_id": "606d8973c4945f13a6a61a383de82005058c50b7",
"content_id": "7bf0aae81a801f5add7ef6c3fa9e36aeaccc7ff2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 816,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 31,
"path": "/nodasf/migrations/0017_auto_20190806_0915.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-08-06 16:15\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0016_auto_20190730_1527'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='district',\n name='cities',\n ),\n migrations.RemoveField(\n model_name='district',\n name='counties',\n ),\n migrations.AddField(\n model_name='district',\n name='city',\n field=models.ManyToManyField(related_name='cities', to='nodasf.City'),\n ),\n migrations.AddField(\n model_name='district',\n name='county',\n field=models.ManyToManyField(related_name='counties', to='nodasf.County'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5792460441589355,
"alphanum_fraction": 0.5918118953704834,
"avg_line_length": 37.546875,
"blob_id": "4269234daa87e2d8a7b8abe88da9f809be521cff",
"content_id": "dd5fdb6a60f49909dca426594305a33ede7a9da9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2467,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 64,
"path": "/nodasf/migrations/0020_auto_20190806_1045.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-08-06 17:45\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0019_auto_20190806_1014'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='event',\n name='city',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.City'),\n ),\n migrations.AlterField(\n model_name='event',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.County'),\n ),\n migrations.AlterField(\n model_name='event',\n name='genre',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.Genre'),\n ),\n migrations.AlterField(\n model_name='politician',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.County'),\n ),\n migrations.AlterField(\n model_name='politician',\n name='district',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.District'),\n ),\n migrations.AlterField(\n model_name='politician',\n name='level',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.Level'),\n ),\n migrations.AlterField(\n model_name='politician',\n name='party',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.Party'),\n ),\n migrations.AlterField(\n model_name='politician',\n name='upcoming',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.Event'),\n ),\n migrations.AlterField(\n model_name='venue',\n name='city',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.City'),\n ),\n migrations.AlterField(\n model_name='venue',\n name='county',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='nodasf.County'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.47455161809921265,
"alphanum_fraction": 0.5714977979660034,
"avg_line_length": 2063,
"blob_id": "cd416ee1063c7f071d1b7f86a888c6c6f891b8ab",
"content_id": "5798f84d2de14870ba4957813ea799dc344eb958",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2063,
"license_type": "permissive",
"max_line_length": 2063,
"num_lines": 1,
"path": "/.c9/metadata/environment/requirements_org.txt",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "{\"filter\":false,\"title\":\"requirements_org.txt\",\"tooltip\":\"/requirements_org.txt\",\"undoManager\":{\"mark\":13,\"position\":13,\"stack\":[[{\"start\":{\"row\":1,\"column\":12},\"end\":{\"row\":2,\"column\":0},\"action\":\"remove\",\"lines\":[\"\",\"\"],\"id\":28}],[{\"start\":{\"row\":14,\"column\":19},\"end\":{\"row\":14,\"column\":20},\"action\":\"remove\",\"lines\":[\"6\"],\"id\":29}],[{\"start\":{\"row\":14,\"column\":19},\"end\":{\"row\":14,\"column\":20},\"action\":\"insert\",\"lines\":[\"5\"],\"id\":30}],[{\"start\":{\"row\":14,\"column\":17},\"end\":{\"row\":14,\"column\":18},\"action\":\"remove\",\"lines\":[\"2\"],\"id\":31}],[{\"start\":{\"row\":14,\"column\":17},\"end\":{\"row\":14,\"column\":18},\"action\":\"insert\",\"lines\":[\"1\"],\"id\":32}],[{\"start\":{\"row\":14,\"column\":17},\"end\":{\"row\":14,\"column\":18},\"action\":\"remove\",\"lines\":[\"1\"],\"id\":33}],[{\"start\":{\"row\":14,\"column\":17},\"end\":{\"row\":14,\"column\":18},\"action\":\"insert\",\"lines\":[\"2\"],\"id\":34}],[{\"start\":{\"row\":14,\"column\":19},\"end\":{\"row\":14,\"column\":20},\"action\":\"remove\",\"lines\":[\"5\"],\"id\":35}],[{\"start\":{\"row\":14,\"column\":19},\"end\":{\"row\":14,\"column\":20},\"action\":\"insert\",\"lines\":[\"6\"],\"id\":36}],[{\"start\":{\"row\":3,\"column\":10},\"end\":{\"row\":3,\"column\":11},\"action\":\"remove\",\"lines\":[\"1\"],\"id\":37}],[{\"start\":{\"row\":3,\"column\":10},\"end\":{\"row\":3,\"column\":11},\"action\":\"insert\",\"lines\":[\"2\"],\"id\":38}],[{\"start\":{\"row\":3,\"column\":13},\"end\":{\"row\":3,\"column\":14},\"action\":\"remove\",\"lines\":[\"0\"],\"id\":39},{\"start\":{\"row\":3,\"column\":12},\"end\":{\"row\":3,\"column\":13},\"action\":\"remove\",\"lines\":[\"1\"]}],[{\"start\":{\"row\":3,\"column\":12},\"end\":{\"row\":3,\"column\":13},\"action\":\"insert\",\"lines\":[\"2\"],\"id\":40},{\"start\":{\"row\":3,\"column\":13},\"end\":{\"row\":3,\"column\":14},\"action\":\"insert\",\"lines\":[\"4\"]}],[{\"start\":{\"row\":3,\"column\":12},\"end\":{\"row\":3,\"column\":13},\"action\":\"remove\",\"lines\":[\"2\"],\"id\":41}]]},\"ace\":{\"folds\":[],\"scrolltop\":0,\"scrollleft\":0,\"selection\":{\"start\":{\"row\":2,\"column\":6},\"end\":{\"row\":2,\"column\":6},\"isBackwards\":false},\"options\":{\"guessTabSize\":true,\"useWrapMode\":false,\"wrapToView\":true},\"firstLineState\":0},\"timestamp\":1565032557855,\"hash\":\"0cc1c3b6e675dd6c65efb66ad24523da25790dee\"}"
},
{
"alpha_fraction": 0.5433526039123535,
"alphanum_fraction": 0.6011560559272766,
"avg_line_length": 19.352941513061523,
"blob_id": "227e74a7f80ff84736e52685d6062756e0259434",
"content_id": "fcfcc9287def20ca945cfcee59e3084e12d5bf54",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 17,
"path": "/nodasf/migrations/0008_auto_20190725_0924.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-25 16:24\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0007_congressdistrict_image'),\n ]\n\n operations = [\n migrations.RenameModel(\n old_name='CongressDistrict',\n new_name='District',\n ),\n ]\n"
},
{
"alpha_fraction": 0.7456709742546082,
"alphanum_fraction": 0.7456709742546082,
"avg_line_length": 34.55769348144531,
"blob_id": "23837f5f143d28c0242d6a3392dcfeb258f5ef92",
"content_id": "d66c70055b5022cdd68a930cc5824597417e3d57",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1848,
"license_type": "permissive",
"max_line_length": 208,
"num_lines": 52,
"path": "/nodasf/admin.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom .models import County, Venue, Agency, Genre, Issue, City, Party, Level, Event, Politician, Media_Org, Journalist, Local_Link, STF, STF_Hub, STF_Link, District, Category, Organization, Program, Bureaucrat\n\nclass Media_OrgAdmin(admin.ModelAdmin):\n list_display = ['name', 'city']\n\nclass CityAdmin(admin.ModelAdmin):\n list_display = ['name', 'county', 'imageQ']\n \nclass EventAdmin(admin.ModelAdmin):\n list_display = ['name', 'venue', 'city', 'date']\n date_hierarchy= 'date'\n\nclass VenueAdmin(admin.ModelAdmin):\n list_display = ['name', 'city', 'county', ]\nclass JournalistAdmin(admin.ModelAdmin):\n list_display = ['last_name', 'first_name', 'organization',]\n\nclass AgencyAdmin(admin.ModelAdmin):\n list_display = ['name', 'category']\n\nclass OrgAdmin(admin.ModelAdmin):\n list_display = ['name', 'issue', 'category']\n\nclass PoliticianAdmin(admin.ModelAdmin):\n list_display = ['last_name','first_name', 'district', 'level', 'candidate',]\n \nclass BureaucratAdmin(admin.ModelAdmin):\n list_display = ['last_name','first_name', 'organization',] \n\nadmin.site.register(County)\nadmin.site.register(Venue, VenueAdmin)\nadmin.site.register(Agency, AgencyAdmin)\nadmin.site.register(Genre)\nadmin.site.register(Issue)\nadmin.site.register(City, CityAdmin)\nadmin.site.register(Party)\nadmin.site.register(Level)\nadmin.site.register(Event, EventAdmin)\nadmin.site.register(Politician, PoliticianAdmin)\nadmin.site.register(Media_Org, Media_OrgAdmin)\nadmin.site.register(Journalist, JournalistAdmin)\nadmin.site.register(Local_Link)\nadmin.site.register(STF)\nadmin.site.register(STF_Hub)\nadmin.site.register(STF_Link)\nadmin.site.register(District)\nadmin.site.register(Category)\nadmin.site.register(Organization, OrgAdmin)\nadmin.site.register(Bureaucrat, BureaucratAdmin)\nadmin.site.register(Program)"
},
{
"alpha_fraction": 0.6959531307220459,
"alphanum_fraction": 0.6959531307220459,
"avg_line_length": 61.63333511352539,
"blob_id": "512d7926c7f53a9b88fecf6d360ff26dbefe2857",
"content_id": "0c4ce35709634df5199dd1f2f44798821cfbeca4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1878,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 30,
"path": "/nodasf/urls.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nfrom django.urls import include, path, re_path\n\nfrom . import views\nurlpatterns = [\n\tpath('', views.index, name='index'),\n\tpath('media-org-directory/', views.media_directory, name='media org directory'),\t\n\tpath('media-org-directory/<int:id>/<slug:slug>/', views.media_org, name='media org'),\t\n\tpath('journalist/', views.journalists, name='journalist directory'),\n\tpath('journalist/<int:id>/<slug:slug>/', views.journalist_part, name='specific journalists'),\n\tpath('venues/', views.venues, name=\"venue directory\"),\n\tpath('venues/<int:id>/<slug:slug>/', views.venue_part, name='Specific venue'),\n\tpath('politicians/', views.politicians, name=\"politician directory\"),\n\tpath('politicians/<int:id>/<slug:slug>/', views.politician_part, name=\"politician particular\"),\t\n\tpath('issues/', views.issues, name=\"issue directory\"),\n\tpath('issues/<int:id>/<slug:slug>/', views.issue_part, name=\"specific issue\"),\n\tpath('agencies/', views.agencies, name=\"agency directory\"),\n\tpath('agency/<int:id>/<slug:slug>/', views.agency_part, name=\"agency particular\"),\t\n\tpath('about/', views.about, name=\"about NodaSF\"),\t\n\tpath('organizations/', views.organizations, name=\"organization directory\"),\t\n\tpath('organizations/<int:id>/<slug:slug>/', views.organization_part, name=\"organization particular\"),\t\n\tpath('story/<int:id>/<slug:slug>/', views.stf, name=\"story to follow\"),\n\tpath('hub/<int:id>/<slug:slug>/', views.stf_hub, name=\"story hub\"),\n\tpath('city/<int:id>/<slug:slug>/', views.city, name=\"city\"),\n\tpath('county/<int:id>/<slug:slug>/', views.county, name=\"county\"),\n\tpath('district/<int:id>/<slug:slug>/', views.district, name=\"district\"),\n\tpath('event/<int:id>/<slug:slug>/', views.event, name=\"event\"),\n\tpath('events/', views.events_hub, name=\"events hub\"),\n\tpath('events/genre/<int:id>/<slug:slug>/', views.events_genre, name=\"events by genre\"),\n\t]"
},
{
"alpha_fraction": 0.4935064911842346,
"alphanum_fraction": 0.5528756976127625,
"avg_line_length": 22.434782028198242,
"blob_id": "4c5df970496b9651118f6a09e919c880b68a1cfa",
"content_id": "8aadc21587f0d5de78df421d31ac673f20227fa3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 539,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 23,
"path": "/nodasf/migrations/0014_auto_20190730_1306.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-30 20:06\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0013_auto_20190726_1201'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='city',\n name='description',\n field=models.TextField(default=' '),\n ),\n migrations.AddField(\n model_name='county',\n name='description',\n field=models.TextField(default=' '),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5421686768531799,
"alphanum_fraction": 0.5629791617393494,
"avg_line_length": 25.852941513061523,
"blob_id": "6b68c8f8f46cd8d419246ab4f6ea4464feba3071",
"content_id": "00bfe7d5ec5fa94cfbb489ef66c6a708ee308a95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 913,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 34,
"path": "/nodasf/migrations/0023_auto_20190904_1042.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-09-04 17:42\n\nimport datetime\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0022_politician_candidate'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='event',\n name='date',\n field=models.DateTimeField(default=datetime.datetime.now),\n ),\n migrations.AlterField(\n model_name='local_link',\n name='posted',\n field=models.DateTimeField(auto_now_add=True),\n ),\n migrations.AlterField(\n model_name='stf',\n name='date_updated',\n field=models.DateTimeField(auto_now_add=True),\n ),\n migrations.AlterField(\n model_name='stf_hub',\n name='date_updated',\n field=models.DateTimeField(auto_now=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5851528644561768,
"alphanum_fraction": 0.6142649054527283,
"avg_line_length": 27.625,
"blob_id": "d10972e9375ac9d9a31b558259ee10b64d10e756",
"content_id": "213005956515bb5442825fe688e0cbe2c31e4657",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 687,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 24,
"path": "/nodasf/migrations/0019_auto_20190806_1014.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-08-06 17:14\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0018_stf_link_journalist'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='event',\n name='venue',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to='nodasf.Venue'),\n ),\n migrations.AlterField(\n model_name='politician',\n name='upcoming',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='nodasf.Event'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4933530390262604,
"alphanum_fraction": 0.5435745716094971,
"avg_line_length": 24.074073791503906,
"blob_id": "a45725198465cc001137d489b0272b467433c154",
"content_id": "b718b1be6c2953779e45e04667eef34ce968fed3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 27,
"path": "/nodasf/migrations/0025_auto_20191203_1004.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.4 on 2019-12-03 18:04\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0024_auto_20191010_1521'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='journalist',\n options={'ordering': ('last_name',)},\n ),\n migrations.RenameField(\n model_name='journalist',\n old_name='name',\n new_name='first_name',\n ),\n migrations.AddField(\n model_name='journalist',\n name='last_name',\n field=models.CharField(default='', max_length=200),\n ),\n ]\n"
},
{
"alpha_fraction": 0.520348846912384,
"alphanum_fraction": 0.5784883499145508,
"avg_line_length": 19.235294342041016,
"blob_id": "999c6ed473527d0dfa99e9878609679021f87c49",
"content_id": "141b95d5a88cb3f84886e452970f7e8170e10d69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 17,
"path": "/nodasf/migrations/0010_auto_20190725_1030.py",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.10 on 2019-07-25 17:30\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('nodasf', '0009_district_level'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='district',\n options={'ordering': ('name',)},\n ),\n ]\n"
},
{
"alpha_fraction": 0.5054054260253906,
"alphanum_fraction": 0.7027027010917664,
"avg_line_length": 15.1304349899292,
"blob_id": "9cc1158b8b022ab5180754b0f140ab08b6eac09d",
"content_id": "f787f08c1295567848e5d58132053b0dd95b1946",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 370,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 23,
"path": "/requirements.txt",
"repo_name": "bopopescu/nodasf",
"src_encoding": "UTF-8",
"text": "boto==2.45.0\nboto3==1.4.4\ndj-database-url==0.5.0\nDjango==2.2.8\ndjango-storages==1.7.1\ndjango-tinymce==1.5.2\ndocutils==0.13.1\nargparse==1.2.1\nfutures==3.0.5\nheroku==0.1.4\njmespath==0.9.0\nolefile==0.44\nPillow==4.0.0\npsycopg2==2.7.4\npython-dateutil==2.6.0\npytz==2019.1\nrequests==2.20.0\ns3transfer==0.1.10\nsix==1.10.0\nwaitress==1.0.1\nwhitenoise==3.2.3\ndjango-heroku\ngunicorn"
}
] | 30 |
xcytek/pruebas | https://github.com/xcytek/pruebas | d4752b307c9c23ae0b46f5774602fb54f6856b6c | f8111738fd9b26d14c0f69628add3404733dacb3 | b9921def544b44b9daa74b20d4eaeea8425b3de1 | refs/heads/master | 2016-08-02T21:06:52.013112 | 2013-05-14T22:00:50 | 2013-05-14T22:00:50 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 17,
"blob_id": "99b0164a19e292c1174fae40ba96035172d47949",
"content_id": "77e22f9dc2be4a2eca994ff0d3ef092dabb95cd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 1,
"path": "/archivo2.py",
"repo_name": "xcytek/pruebas",
"src_encoding": "UTF-8",
"text": "print 'Archivo 2'"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 17,
"blob_id": "6805c77f5925540948fda79f48bdd58503eef10e",
"content_id": "1ba0f7ade0104de972b70a9f4ad983216e8623ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 1,
"path": "/archivo1.py",
"repo_name": "xcytek/pruebas",
"src_encoding": "UTF-8",
"text": "print 'Archivo 1'"
}
] | 2 |
tabusalab/kamijima-pay-camera | https://github.com/tabusalab/kamijima-pay-camera | 2f9580e028687233de72f240b9f67d9336534338 | 23eec641fbd9610892ce6ac58de32523379b598f | 750a23857d02e918c3d967182f2ddab82af432d4 | refs/heads/master | 2021-01-06T23:15:35.299111 | 2020-05-14T05:38:49 | 2020-05-14T05:38:49 | 241,510,096 | 0 | 0 | null | 2020-02-19T01:59:33 | 2020-02-20T05:24:48 | 2020-02-20T06:57:44 | Python | [
{
"alpha_fraction": 0.559356153011322,
"alphanum_fraction": 0.5889623165130615,
"avg_line_length": 27.516393661499023,
"blob_id": "4f37829670359e2c31548d90eee724b455223681",
"content_id": "f22c9c5301819cba3ac75a46c144ac86fb87aa9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4037,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 122,
"path": "/kamijimapay-user.py",
"repo_name": "tabusalab/kamijima-pay-camera",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom time import sleep\nimport tkinter\nimport json\nimport requests\n\nimport cv2\nfrom PIL import Image, ImageTk\nfrom pyzbar import pyzbar\nimport numpy as np\nimport simpleaudio as sa\n\nfrequency = 3500\nfs = 48000\nseconds = 0.1\nt = np.linspace(0, seconds, seconds * fs, False)\nnote = np.sin(frequency * t * 2 * np.pi)\naudio = note * (2**15 - 1) / np.max(np.abs(note))\naudio = audio.astype(np.int16)\n\n\n\nroot = tkinter.Tk()\nroot.title(\"QR reader\")\nroot.geometry(\"640x480\")\nCANVAS_X = 640\nCANVAS_Y = 480\n\n# Canvas作成\ncanvas = tkinter.Canvas(root, width=CANVAS_X, height=CANVAS_Y)\ncanvas.pack()\n\n\n# VideoCaptureの引数にカメラ番号を入れる。\n# デフォルトでは0、ノートPCの内臓Webカメラは0、別にUSBカメラを接続した場合は1を入れる。\ncap = cv2.VideoCapture(0)\n\n\ndef show_frame():\n global CANVAS_X, CANVAS_Y\n\n ret, frame = cap.read()\n if ret == False:\n print('カメラから画像を取得できませんでした')\n\n image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # BGRなのでRGBに変換\n image_pil = Image.fromarray(image_rgb) # RGBからPILフォーマットへ変換\n image_tk = ImageTk.PhotoImage(image_pil) # ImageTkフォーマットへ変換\n # image_tkがどこからも参照されないとすぐ破棄される。\n # そのために下のようにインスタンスを作っておくかグローバル変数にしておく\n canvas.image_tk = image_tk\n # global image_tk\n\n # ImageTk 画像配置 画像の中心が指定した座標x,yになる\n canvas.create_image(CANVAS_X / 2, CANVAS_Y / 2, image=image_tk)\n # Canvasに現在の日時を表示\n now_time = datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")\n canvas.create_text(CANVAS_X / 2, 30, text=now_time, font=(\"Helvetica\", 18, \"bold\"))\n\n # 画像からQRコードを読み取る\n decoded_objs = pyzbar.decode(frame)\n\n # pyzbar.decode(frame)の返値\n # ('Decoded', ['data', 'type', 'rect', 'polygon'])\n # [0][0]->.data, [0][1]->.type, [0][2]->rect, [0][3]->polygon\n\n # 配列要素がある場合\n if decoded_objs != []:\n # [0][0]->.data, [0][1]->.type, [0][2]->rect\n # example\n # for obj in decoded_objs:\n # print('Type: ', obj.type)\n\n str_dec_obj = decoded_objs[0][0].decode('utf-8', 'ignore')\n print('QR cord: {}'.format(str_dec_obj))\n left, top, width, height = decoded_objs[0][2]\n play_obj = sa.play_buffer(audio, 1, 2, fs)\n # 取得したQRコードの範囲を描画\n \n canvas.create_rectangle(left, top, left + width, top + height, outline=\"green\", width=5)\n # 取得したQRの内容を表示\n canvas.create_text(left + (width / 2), top - 30, text=str_dec_obj, font=(\"Helvetica\", 20, \"bold\"))\n\n data = str_dec_obj.split(\"&\")\n shopID = data[0].split(\"=\")\n productID = data[1].split(\"=\")\n if shopID[0] == 'shopID' and productID[0] == 'productID':\n print(\"yes/no?\", end=\"\")\n var = input()\n #prin(\":{}\".format(var))\n if var == 'yes':\n #userdata = {\"data\":str_dec_obj}\n url =\"http://52.156.45.138/~db2019/kamijimapay/api/recieve.php\"\n data = str_dec_obj.split(\"&\")\n SendData = {\"userID\": \"385623\", \"shopID\": shopID[1], \"productID\": productID[1]}\n response = requests.post(url,json=SendData)\n resDatas = response.json()\n print(resDatas)\n\n if var=='no':\n pass\n else:\n root.quit()\n\n\n\n\n\n\n # QRコードを取得して、その内容をTextに書き出し、そのままTKのプログラムを終了するコード\n # with open('QR_read_data.txt', 'w') as exportFile:\n # exportFile.write(str_dec_obj)\n # sleep(1)\n # cap.release()\n #root.quit()\n\n\n # 10msごとにこの関数を呼び出す\n canvas.after(10, show_frame)\n\nshow_frame()\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.6024844646453857,
"alphanum_fraction": 0.6677018404006958,
"avg_line_length": 25.83333396911621,
"blob_id": "90a9243d4cd611e6a9b307f6c5436f78d54c29ae",
"content_id": "8668d25c60f072df90ba111e4f0f4e43a1e74dce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 12,
"path": "/sound.py",
"repo_name": "tabusalab/kamijima-pay-camera",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport simpleaudio as sa\n\nfrequency = 3500\nfs = 48000\nseconds = 0.1\nt = np.linspace(0, seconds, seconds * fs, False)\nnote = np.sin(frequency * t * 2 * np.pi)\naudio = note * (2**15 - 1) / np.max(np.abs(note))\naudio = audio.astype(np.int16)\nplay_obj = sa.play_buffer(audio, 1, 2, fs)\nplay_obj.wait_done()\n"
}
] | 2 |
bite440/friendly-sniffle | https://github.com/bite440/friendly-sniffle | eb2f4e31c46f6d944de412a2d7edcbf95fe724f4 | c329ec265604978a1322e663c607c1a5bad7f04a | 949b7b48fe3bb4475ac20d876f88c95aef2d04df | refs/heads/master | 2021-01-14T03:12:51.086888 | 2020-02-23T20:25:16 | 2020-02-23T20:25:16 | 242,582,422 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5952380895614624,
"avg_line_length": 9.5,
"blob_id": "4a3d79497cd954dbf863e67b45aa732a9081f884",
"content_id": "26d6b5496465c3040c3ce2d2c857430937f2a62d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 4,
"path": "/111.py",
"repo_name": "bite440/friendly-sniffle",
"src_encoding": "UTF-8",
"text": "#just practice\ny = 14\nx = 45\nprint(x + y)\n"
}
] | 1 |
eloitanguy/bert-grammar-tuto | https://github.com/eloitanguy/bert-grammar-tuto | 2423bab40b96170b15513080d6621ba768f30459 | 2d4e63908409853160e5c7397537ab664860d6b9 | ae184befd916cfb2fdfa60dca5ec113c545231ef | refs/heads/main | 2023-04-07T07:49:40.456226 | 2021-04-15T13:46:11 | 2021-04-15T13:46:11 | 358,273,160 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6311852931976318,
"alphanum_fraction": 0.6429804563522339,
"avg_line_length": 31.485980987548828,
"blob_id": "1aa1eb2980590c52a8c657948a9ab6647048b1c9",
"content_id": "b2d2125d013423df5a3f5ef4d159a6de0f2ad743",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6952,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 214,
"path": "/train.py",
"repo_name": "eloitanguy/bert-grammar-tuto",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch.utils.data import DataLoader\nfrom transformers import BertForSequenceClassification, AdamW, BertConfig\nfrom transformers import get_linear_schedule_with_warmup\nimport numpy as np\nimport time\nimport datetime\nimport random\nimport json\n\ntrain_dataset = torch.load('data/train_dataset.pt')\nval_dataset = torch.load('data/val_dataset.pt')\n\nbatch_size = 32\n\ntrain_dataloader = DataLoader(\n train_dataset, # The training samples.\n shuffle=True, # Select batches randomly\n batch_size=batch_size # Trains with this batch size.\n)\n\nvalidation_dataloader = DataLoader(\n val_dataset, # The validation samples.\n shuffle=False, # Pull out batches sequentially.\n batch_size=batch_size # Evaluate with this batch size.\n)\n\n# Load BertForSequenceClassification, the pretrained BERT model with a single\n# linear classification layer on top.\nmodel = BertForSequenceClassification.from_pretrained(\n \"bert-base-uncased\", # Use the 12-layer BERT model, with an uncased vocab.\n num_labels=2, # The number of output labels--2 for binary classification.\n # You can increase this for multi-class tasks.\n output_attentions=False, # Whether the model returns attentions weights.\n output_hidden_states=False, # Whether the model returns all hidden-states.\n)\n\nmodel.cuda()\n\n\ndef show_param_summary(m):\n params = list(m.named_parameters())\n\n print('The BERT model has {:} different named parameters.\\n'.format(len(params)))\n\n print('==== Embedding Layer ====\\n')\n\n for p in params[0:5]:\n print(\"{:<55} {:>12}\".format(p[0], str(tuple(p[1].size()))))\n\n print('\\n==== First Transformer (1/12) ====\\n')\n\n for p in params[5:21]:\n print(\"{:<55} {:>12}\".format(p[0], str(tuple(p[1].size()))))\n\n print('\\n==== Output Layer ====\\n')\n\n for p in params[-4:]:\n print(\"{:<55} {:>12}\".format(p[0], str(tuple(p[1].size()))))\n\n\noptimizer = AdamW(model.parameters(), lr=1e-5)\nepochs = 4\ntotal_steps = len(train_dataloader) * epochs\n\n# linearly decreasing LR schedule from the initial LR to 0\nscheduler = get_linear_schedule_with_warmup(optimizer,\n num_warmup_steps=0,\n num_training_steps=total_steps)\n\n\n# Function to calculate the accuracy of our predictions vs labels\ndef flat_accuracy(predictions, labels):\n predictions_flat = np.argmax(predictions, axis=1).flatten()\n labels_flat = labels.flatten()\n return np.sum(predictions_flat == labels_flat) / len(labels_flat)\n\n\ndef format_time(elapsed):\n \"\"\"\n Takes a time in seconds and returns a string hh:mm:ss\n \"\"\"\n # Round to the nearest second.\n elapsed_rounded = int(round(elapsed))\n\n # Format as hh:mm:ss\n return str(datetime.timedelta(seconds=elapsed_rounded))\n\n\nseed_val = 42\n\nrandom.seed(seed_val)\nnp.random.seed(seed_val)\ntorch.manual_seed(seed_val)\ntorch.cuda.manual_seed_all(seed_val)\n\n# We'll store a number of quantities such as training and validation loss,\n# validation accuracy, and timings.\ntraining_stats = []\n\n# Measure the total training time for the whole run.\ntotal_t0 = time.time()\n\nfor epoch_i in range(0, epochs):\n\n print(\"\")\n print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))\n print('Training...')\n\n t0 = time.time()\n total_train_loss = 0\n\n model.train()\n\n for step, batch in enumerate(train_dataloader):\n\n # Progress update every 40 batches.\n if step % 40 == 0 and not step == 0:\n elapsed = format_time(time.time() - t0)\n print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))\n\n b_input_ids = batch[0].cuda()\n b_input_mask = batch[1].cuda()\n b_labels = batch[2].cuda()\n\n model.zero_grad()\n\n # Perform a forward pass (evaluate the model on this training batch).\n # The documentation for this `model` function is here:\n # https://huggingface.co/transformers/v2.2.0/model_doc/bert.html#transformers.BertForSequenceClassification\n # It returns different numbers of parameters depending on what arguments\n # arge given and what flags are set. For our useage here, it returns\n # the loss (because we provided labels) and the \"logits\"--the model\n # outputs prior to activation.\n output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)\n loss = output.loss\n logits = output.logits\n\n total_train_loss += loss.item()\n loss.backward()\n torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)\n optimizer.step()\n scheduler.step()\n\n # Calculate the average loss over all of the batches.\n avg_train_loss = total_train_loss / len(train_dataloader)\n\n # Measure how long this epoch took.\n training_time = format_time(time.time() - t0)\n\n print(\"\")\n print(\" Average training loss: {0:.2f}\".format(avg_train_loss))\n print(\" Training epoch took: {:}\".format(training_time))\n print(\"\")\n print(\"Running Validation...\")\n\n t0 = time.time()\n model.eval()\n\n total_eval_accuracy = 0\n total_eval_loss = 0\n nb_eval_steps = 0\n\n for batch in validation_dataloader:\n\n b_input_ids = batch[0].cuda()\n b_input_mask = batch[1].cuda()\n b_labels = batch[2].cuda()\n\n with torch.no_grad():\n output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)\n loss = output.loss\n logits = output.logits\n\n total_eval_loss += loss.item()\n logits = logits.detach().cpu().numpy()\n label_ids = b_labels.to('cpu').numpy()\n total_eval_accuracy += flat_accuracy(logits, label_ids)\n\n # Report the final accuracy for this validation run.\n avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)\n print(\" Accuracy: {0:.2f}\".format(avg_val_accuracy))\n\n # Calculate the average loss over all of the batches.\n avg_val_loss = total_eval_loss / len(validation_dataloader)\n\n # Measure how long the validation run took.\n validation_time = format_time(time.time() - t0)\n\n print(\" Validation Loss: {0:.2f}\".format(avg_val_loss))\n print(\" Validation took: {:}\".format(validation_time))\n\n # Record all statistics from this epoch.\n training_stats.append(\n {\n 'epoch': epoch_i + 1,\n 'Training Loss': avg_train_loss,\n 'Valid. Loss': avg_val_loss,\n 'Valid. Accur.': avg_val_accuracy,\n 'Training Time': training_time,\n 'Validation Time': validation_time\n }\n )\n\n # save the current model\n torch.save(model, \"checkpoints/trained_model_ep{}.pth\".format(epoch_i+1))\n\nprint(\"\")\nprint(\"Training complete!\")\n\nprint(\"Total training took {:} (h:mm:ss)\".format(format_time(time.time() - total_t0)))\n\nwith open(\"training_stats.json\", 'w') as f:\n json.dump(training_stats, f, indent=4)\n"
},
{
"alpha_fraction": 0.7050473093986511,
"alphanum_fraction": 0.7117508053779602,
"avg_line_length": 30.6875,
"blob_id": "a7355afa18c7abe9c7451892df28bf396529fedc",
"content_id": "cfad88cb3b995eed411c65b4c0499b940f95861a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2536,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 80,
"path": "/test.py",
"repo_name": "eloitanguy/bert-grammar-tuto",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch.utils.data import DataLoader\nfrom sklearn.metrics import matthews_corrcoef\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n\nmodel = torch.load(\"checkpoints/trained_model_ep2.pth\")\nmodel.eval()\n\ntest_dataset = torch.load('data/test_dataset.pt')\nprediction_dataloader = DataLoader(test_dataset, shuffle=False, batch_size=32)\n\n# Tracking variables\npredictions, true_labels = [], []\n\n# Predict\nfor batch in prediction_dataloader:\n # Add batch to GPU\n batch = tuple(t.cuda() for t in batch)\n\n # Unpack the inputs from our dataloader\n b_input_ids, b_input_mask, b_labels = batch\n\n # Telling the model not to compute or store gradients, saving memory and\n # speeding up prediction\n with torch.no_grad():\n # Forward pass, calculate logit predictions\n outputs = model(b_input_ids, token_type_ids=None,\n attention_mask=b_input_mask)\n\n logits = outputs.logits\n\n # Move logits and labels to CPU\n logits = logits.detach().cpu().numpy()\n label_ids = b_labels.to('cpu').numpy()\n\n # Store predictions and true labels\n predictions.append(logits)\n true_labels.append(label_ids)\n\nmatthews_set = []\n\n# Evaluate each test batch using Matthew's correlation coefficient\nprint('Calculating Matthews Corr. Coef. for each batch...')\n\n# For each input batch...\nfor i in range(len(true_labels)):\n # The predictions for this batch are a 2-column ndarray (one column for \"0\"\n # and one column for \"1\"). Pick the label with the highest value and turn this\n # in to a list of 0s and 1s.\n prediction_labels_i = np.argmax(predictions[i], axis=1).flatten()\n\n # Calculate and store the coef for this batch.\n matthews = matthews_corrcoef(true_labels[i], prediction_labels_i)\n matthews_set.append(matthews)\n\n# Create a barplot showing the MCC score for each batch of test samples.\nax = sns.barplot(x=list(range(len(matthews_set))), y=matthews_set, ci=None)\n\nplt.title('MCC Score per Batch')\nplt.ylabel('MCC Score (-1 to +1)')\nplt.xlabel('Batch #')\n\nplt.show()\n\n# Combine the results across all batches.\nflat_predictions = np.concatenate(predictions, axis=0)\n\n# For each sample, pick the label (0 or 1) with the higher score.\nflat_predictions = np.argmax(flat_predictions, axis=1).flatten()\n\n# Combine the correct labels for each batch into a single list.\nflat_true_labels = np.concatenate(true_labels, axis=0)\n\n# Calculate the MCC\nmcc = matthews_corrcoef(flat_true_labels, flat_predictions)\n\nprint('Total MCC: %.3f' % mcc)\n\n"
},
{
"alpha_fraction": 0.6941580772399902,
"alphanum_fraction": 0.70561283826828,
"avg_line_length": 21.973684310913086,
"blob_id": "def813199dbdb2b6f0d9758a2ac54ab8ad4cd4aa",
"content_id": "813acd8c13cdc6cfa1bea62149cd00cd5179f618",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 38,
"path": "/statistics.py",
"repo_name": "eloitanguy/bert-grammar-tuto",
"src_encoding": "UTF-8",
"text": "import json\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nwith open('training_stats.json', 'r') as f:\n stats = json.load(f)\n\n# Display floats with two decimal places.\npd.set_option('precision', 2)\n\n# Create a DataFrame from our training statistics.\ndf_stats = pd.DataFrame(data=stats)\n\n# Use the 'epoch' as the row index.\ndf_stats = df_stats.set_index('epoch')\n\nprint(df_stats)\n\n# Use plot styling from seaborn.\nsns.set(style='darkgrid')\n\n# Increase the plot size and font size.\nsns.set(font_scale=1.5)\nplt.rcParams[\"figure.figsize\"] = (12,6)\n\n# Plot the learning curve.\nplt.plot(df_stats['Training Loss'], 'b-o', label=\"Training\")\nplt.plot(df_stats['Valid. Loss'], 'g-o', label=\"Validation\")\n\n# Label the plot.\nplt.title(\"Training & Validation Loss\")\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"Loss\")\nplt.legend()\nplt.xticks([1, 2, 3, 4])\n\nplt.show()\n"
},
{
"alpha_fraction": 0.6247766613960266,
"alphanum_fraction": 0.6307325959205627,
"avg_line_length": 33.61855697631836,
"blob_id": "c2d74b4444f252236678ff934c5c8f1557714bf4",
"content_id": "1d7c67c19c46d85f227d946a4559ec623be32bac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3358,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 97,
"path": "/dataset.py",
"repo_name": "eloitanguy/bert-grammar-tuto",
"src_encoding": "UTF-8",
"text": "import wget\nimport os\nimport pandas as pd\nfrom transformers import BertTokenizer\nimport torch\nfrom torch.utils.data import TensorDataset, random_split\n\n\ndef download():\n print('Downloading dataset...')\n\n # The URL for the dataset zip file.\n url = 'https://nyu-mll.github.io/CoLA/cola_public_1.1.zip'\n\n # Download the file (if we haven't already)\n if not os.path.exists('./cola_public_1.1.zip'):\n wget.download(url, './cola_public_1.1.zip')\n\n\ndef encode_sentences(tokenizer, sentences):\n # Tokenize all of the sentences and map the tokens to their word IDs.\n input_ids = []\n attention_masks = []\n\n # For every sentence...\n for sent in sentences:\n # `encode_plus` will:\n # (1) Tokenize the sentence.\n # (2) Prepend the `[CLS]` token to the start.\n # (3) Append the `[SEP]` token to the end.\n # (4) Map tokens to their IDs.\n # (5) Pad or truncate the sentence to `max_length`\n # (6) Create attention masks for [PAD] tokens.\n encoded_dict = tokenizer.encode_plus(\n sent, # Sentence to encode.\n add_special_tokens=True, # Add '[CLS]' and '[SEP]'\n max_length=64, # Pad & truncate all sentences.\n padding='max_length',\n truncation=True,\n return_attention_mask=True, # Construct attn. masks.\n return_tensors='pt', # Return pytorch tensors.\n )\n\n # Add the encoded sentence to the list.\n input_ids.append(encoded_dict['input_ids'])\n\n # And its attention mask (simply differentiates padding from non-padding with 0/1).\n attention_masks.append(encoded_dict['attention_mask'])\n\n # Convert the lists into tensors.\n input_ids = torch.cat(input_ids, dim=0)\n attention_masks = torch.cat(attention_masks, dim=0)\n\n return input_ids, attention_masks\n\n\ndef create_datasets():\n download()\n\n # Train + val\n df = pd.read_csv(\"./cola_public/raw/in_domain_train.tsv\",\n delimiter='\\t',\n header=None,\n names=['sentence_source', 'label', 'label_notes', 'sentence'])\n\n sentences = df.sentence.values\n labels = df.label.values\n\n # Load the BERT tokenizer.\n print('Loading BERT tokenizer...')\n tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)\n\n input_ids, attention_masks = encode_sentences(tokenizer, sentences)\n labels = torch.tensor(labels)\n\n dataset = TensorDataset(input_ids, attention_masks, labels)\n train_size = int(0.9 * len(dataset))\n val_size = len(dataset) - train_size\n train_dataset, val_dataset = random_split(dataset, [train_size, val_size])\n\n print('Saving the datasets...')\n torch.save(train_dataset, 'data/train_dataset.pt')\n torch.save(val_dataset, 'data/val_dataset.pt')\n\n # test\n df = pd.read_csv(\"./cola_public/raw/out_of_domain_dev.tsv\", delimiter='\\t', header=None,\n names=['sentence_source', 'label', 'label_notes', 'sentence'])\n sentences = df.sentence.values\n labels = torch.tensor(df.label.values)\n input_ids, attention_masks = encode_sentences(tokenizer, sentences)\n prediction_data = TensorDataset(input_ids, attention_masks, labels)\n\n torch.save(prediction_data, 'data/test_dataset.pt')\n\n\nif __name__ == '__main__':\n create_datasets()\n"
}
] | 4 |
Yonatan1P/text-classifier | https://github.com/Yonatan1P/text-classifier | 8fa70e444ba65b9f819c55701c5119c900c76892 | 15347b2c2696165f98813b3c502df9f594d478b4 | a13f93d9fa3244cdb8aa8be6788521b4545a5ad5 | refs/heads/master | 2023-02-06T00:32:26.790202 | 2020-12-30T03:25:30 | 2020-12-30T03:25:30 | 325,439,057 | 0 | 0 | null | 2020-12-30T02:53:49 | 2020-12-30T02:58:53 | 2020-12-30T03:25:31 | null | [
{
"alpha_fraction": 0.7335285544395447,
"alphanum_fraction": 0.7349926829338074,
"avg_line_length": 31.5238094329834,
"blob_id": "41ada877675bcd33b13c3df8fe89b2bffc482069",
"content_id": "a4ca5277ff85859a9b26c2f1f73a03d2d5590537",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 683,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 21,
"path": "/dataset.py",
"repo_name": "Yonatan1P/text-classifier",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom sklearn.feature_extraction.text import CountVectorizer\n\nfilepath_dict = { 'yelp': 'data/sentiment_analysis/yelp_labelled.txt',\n'amazon': 'data/sentiment_analysis/amazon_cells_labelled.txt',\n'imdb': 'data/sentiment_analysis/imdb_labelled.txt'}\n\ndf_list = []\nfor source, filepath in filepath_dict.item():\n df = pd.read_csv(filepath, names=['sentence', 'label'], sep='/t')\n df['source'] = source\n df_list.append(df)\n\ndf = pd.concat(df_list)\n\nsentences = ['John likes ice cream', 'John hates chocolate.']\n\nvectorizer = CountVectorizer(min_df=0, lowercase=False)\nvectorizer.fit(sentences)\nvectorizer.vocabulary_\nvectorizer.transform(sentences).toarray()\n"
},
{
"alpha_fraction": 0.7108969688415527,
"alphanum_fraction": 0.7220163345336914,
"avg_line_length": 31.926828384399414,
"blob_id": "e1468b2f8f5e5418e4277891caed75b31cdb36fc",
"content_id": "478cb11f9839445b6e4f281ad10427ed5f6836b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 41,
"path": "/baseline.py",
"repo_name": "Yonatan1P/text-classifier",
"src_encoding": "UTF-8",
"text": "from sklearn.model_selection import train_test_split\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.linear_model import LogisticRegression\n\ndf_yelp = df[df['source'] == 'yelp']\n\nsentences = df_yelp['sentences'].values\ny= df_yelp['label'].values\n\nsentences_train. sentences_test, y_train, y_test = test_train_split(\n sentences, y, test_size=0.25, random_state=1000)\n\nvectorizer = CountVectorizer()\nvectorizer.fit(sentences_train)\n\nX_train = vectorizer.transform(sentences_train)\nX_test = vectorizer.transform(sentences_test)\nX_train\n\nclassifier = LogisticRegression()\nclassifier.fit(X_train, y_train)\nscore = classifier.score(X_test, y_test)\n\nprint(\"Accuracy:\", score)\n\nfor source in df['source'].unique():\n df_source = df[df['source'] == source]\n sentences = df_source['sentences'].values\n y = df_source['label'].values\n\n sentences_train, sentences_test, y_train, y_test = train_test_split(\n sentences, y, test_size=0.25, random_state=1000)\n \n vectorizer = CountVectorizer()\n vectorizer.fit(sentences_train)\n X_train = vectorizer.transform(sentences_train)\n X_test = vectorizer.transform(sentences_test)\n classifier = LogisticRegression()\n classifier.fit(X_train, y_train)\n score = classifier.score(X_test, y_test)\n print('Accuracy for {} data: {:.4f}'.format(source,score))"
}
] | 2 |
hill-a/python-runtime-check | https://github.com/hill-a/python-runtime-check | a0eb8ea0749ecb63d1efa457ac76eddd27164f5a | e5b5b9ad2f9cb721c64dde5038ac01f0885e06ea | 491aa7551b9caee9845360f4e7956d2b980f8df8 | refs/heads/master | 2020-03-15T05:30:28.449128 | 2018-12-11T10:45:47 | 2018-12-11T10:45:47 | 131,990,116 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5470892190933228,
"alphanum_fraction": 0.5486626029014587,
"avg_line_length": 33.488372802734375,
"blob_id": "44fcfb8a3ad6989b97d061b1ff0bdc12f571129f",
"content_id": "a59bab0d9010accbc878db977665065e1cc47a22",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4449,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 129,
"path": "/runtime_check/check_type.py",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis module is used for type checking\n\"\"\"\n\nfrom typing import List, Union, Dict, Tuple, Any, Set, TypeVar, Callable, Mapping, Iterator, Iterable\n\nimport numpy as np\n\nDEEP = False\n\nclass _TypeCheckerMeta(type):\n \"\"\"\n Meta class used for the TypeChecker[] notation, also contains the checking code.\n \"\"\"\n\n @classmethod\n def _check_type(mcs, key, val): #TODO: add the remainding typing objects (generator, ...)\n \"\"\"\n Checks whether a value is of a specific type.\n\n :param val: (Any)\n :param key: (Type or Typing object)\n :return: (bool) is of type\n \"\"\"\n if key == Any:\n return True\n elif type(key) == type(Union):\n return any([mcs._check_type(k, val) for k in key.__args__])\n elif isinstance(key, TypeVar):\n return any([mcs._check_type(k, val) for k in key.__constraints__])\n elif issubclass(key, List):\n valid = isinstance(val, List)\n if DEEP and valid and key.__args__ is not None:\n return all([mcs._check_type(key.__args__[0], v) for v in val])\n else:\n return valid\n elif issubclass(key, Set):\n valid = isinstance(val, Set)\n if DEEP and valid and key.__args__ is not None:\n return all([mcs._check_type(key.__args__[0], v) for v in val])\n else:\n return valid\n elif issubclass(key, Dict):\n valid = isinstance(val, Dict)\n if DEEP and valid and key.__args__ is not None:\n return all([mcs._check_type(key.__args__[0], k) and\n mcs._check_type(key.__args__[1], v) for (k, v) in val.items()])\n else:\n return valid\n elif issubclass(key, Tuple):\n valid = isinstance(val, Tuple) and (key.__args__ is None or len(key.__args__) == len(val))\n if DEEP and valid and key.__args__ is not None:\n return all([mcs._check_type(k, v) for k, v in zip(key.__args__, val)])\n else:\n return valid\n elif type(key) == type(Callable): # will not do in depth checking, only shallow.\n return callable(val)\n elif issubclass(key, Mapping): # will not do in depth checking, only shallow.\n return isinstance(val, map)\n elif issubclass(key, Iterator): # will not do in depth checking, only shallow.\n return isinstance(val, Iterator)\n elif key == type(None) or key == None:\n return val is None\n elif val is None:\n return False\n else:\n try:\n return isinstance(val, key)\n except Exception as ex: # pragma: no cover\n print(\"Error: occured when comparing {} to class {}\".format(val, key))\n raise ex\n\n @classmethod\n def _validater(mcs, key):\n \"\"\"\n Returns a checking function that checks that a value in allowed by key.\n\n :param key: (Type or Typing object)\n :retrun: (callable) function that takes value and will raise an error if not valid\n \"\"\"\n def check(val):\n \"\"\"\n Checks that val is valid, will raise an error if not valid.\n\n :param val: (Any)\n \"\"\"\n if not mcs._check_type(key, val):\n raise TypeError(\"Expected {}, got {}\".format(key, val.__class__))\n return check\n\n def __getitem__(mcs, key):\n if isinstance(key, (Tuple, List, Set)):\n return mcs._validater(Union[tuple(key)])\n else:\n return mcs._validater(key)\n\n\nclass TypeChecker(object, metaclass=_TypeCheckerMeta):\n \"\"\"\n Class used to check whether a value is of a specific type.\n\n ex:\n TypeChecker[int, float](0)\n TypeChecker.array(numpy.arange(10))\n\n you may use typing.Union[int, float] for mutliple valid types\n or List[int], Dict[str, int], Optional[int].\n \"\"\"\n\n @classmethod\n def scalar(cls, val):\n \"\"\"\n Checks whether val is a number.\n \"\"\"\n cls._validater(Union[int, float])(val)\n\n @classmethod\n def numpy_array(cls, val):\n \"\"\"\n Checks whether val is a numpy array.\n \"\"\"\n cls._validater(np.ndarray)(val)\n\n @classmethod\n def iterable(cls, val):\n \"\"\"\n Checks whether val is an Iterable.\n \"\"\"\n cls._validater(Union[np.ndarray, Iterable])(val)\n"
},
{
"alpha_fraction": 0.6438356041908264,
"alphanum_fraction": 0.6506849527359009,
"avg_line_length": 25.636363983154297,
"blob_id": "0d6baf1cafe803295c979ee5988a96b27848f15f",
"content_id": "982b1a8a43e4c4030e80aa46b042441aaeb8cfe3",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 11,
"path": "/setup.py",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom distutils.core import setup\n\nsetup(name='RuntimeCheck',\n version='0.2',\n description='Python type and bounds checker for runtime',\n author='Ashley Hill',\n url='https://github.com/hill-a/python-runtime-check',\n packages=['runtime_check'],\n )"
},
{
"alpha_fraction": 0.55768221616745,
"alphanum_fraction": 0.567121148109436,
"avg_line_length": 31.598291397094727,
"blob_id": "a6ea66d641462dd0a996ed05b469774fe1d76e35",
"content_id": "f067e225f00c0a7975518ad5ba65e27db38b4c7e",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3814,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 117,
"path": "/runtime_check/check_bounds.py",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis module is used for bound checking on numbers\n\"\"\"\n\nimport operator\n\nimport numpy as np\n\nfrom runtime_check.check_type import TypeChecker\n\n\nclass _BoundCheckerMeta(type):\n \"\"\"\n Meta class used for the BoundChecker[] notation, also contains the checking code.\n \"\"\"\n\n @classmethod\n def _in_bounds(mcs, val, key):\n \"\"\"\n Checks whether a value in within specific bounds.\n\n :param val: (int, float)\n :param key: (tuples) (Lower_bound, Upper_bound, (Include_lower_bound, Include_upper_bound))\n or (Lower_bound, Upper_bound)\n :return: (bool) is in bounds\n \"\"\"\n TypeChecker.scalar(val)\n if isinstance(key, tuple) and len(key) == 2:\n TypeChecker.scalar(key[0])\n TypeChecker.scalar(key[1])\n return key[0] <= val <= key[1]\n elif isinstance(key, tuple) and len(key) == 3 and isinstance(key[2], tuple) and len(key[2]) == 2:\n TypeChecker.scalar(key[0])\n TypeChecker.scalar(key[1])\n TypeChecker[bool](key[2][0])\n TypeChecker[bool](key[2][1])\n return (operator.le if key[2][0] else operator.lt)(key[0], val) and \\\n (operator.le if key[2][1] else operator.lt)(val, key[1])\n else:\n raise ValueError(\"The bound tuple can be of structure: (Lower_bound, Upper_bound, (Include_lower_bound, \" +\n \"Include_upper_bound)) or (Lower_bound, Upper_bound)\")\n\n @classmethod\n def _validater(mcs, key):\n \"\"\"\n Returns a checking function that checks that a value in allowed by key.\n\n :param key: (tuples or [tuples]) (Lower_bound, Upper_bound, (Include_lower_bound, Include_upper_bound))\n or (Lower_bound, Upper_bound)\n :retrun: (callable) function that takes value and will raise an error if not valid\n \"\"\"\n def check(val):\n \"\"\"\n Checks that val is valid, will raise an error if not valid.\n\n :param val: (int, float)\n \"\"\"\n if isinstance(key, list) or isinstance(key, tuple) and all([isinstance(k, tuple) for k in key]):\n valid = any([mcs._in_bounds(val, k) for k in key])\n else:\n valid = mcs._in_bounds(val, key)\n if not valid:\n raise ValueError(\"Number out of bounds {}, expected bounds {}\".format(val, key))\n\n return check\n\n def __getitem__(mcs, key):\n return mcs._validater(key)\n\n\nclass BoundChecker(object, metaclass=_BoundCheckerMeta):\n \"\"\"\n Class used to check whether a number is in given bounds.\n\n ex:\n BoundChecker[(0,1)](0.5)\n BoundChecker.positive(100)\n\n the tuple defining the bounds are (Lower_bound, Upper_bound, (Include_lower_bound, Include_upper_bound))\n or (Lower_bound, Upper_bound)\n You may use lists of bounds to define discontinuous bounds.\n \"\"\"\n\n @classmethod\n def positive(cls, val):\n \"\"\"\n Checks whether val is positive.\n \"\"\"\n cls._validater((0, np.inf))(val)\n\n @classmethod\n def negative(cls, val):\n \"\"\"\n Checks whether val is negative.\n \"\"\"\n cls._validater((-np.inf, 0))(val)\n\n @classmethod\n def positive_not_zero(cls, val):\n \"\"\"\n Checks whether val is positive and not zero.\n \"\"\"\n cls._validater((0, np.inf, (False, True)))(val)\n\n @classmethod\n def negative_not_zero(cls, val):\n \"\"\"\n Checks whether val is negative and not zero.\n \"\"\"\n cls._validater((-np.inf, 0, (True, False)))(val)\n\n @classmethod\n def probability(cls, val):\n \"\"\"\n Checks whether val is bound between 0 and 1 included.\n \"\"\"\n cls._validater((0, 1))(val)\n"
},
{
"alpha_fraction": 0.6698113083839417,
"alphanum_fraction": 0.6698113083839417,
"avg_line_length": 12.125,
"blob_id": "1667d1507cbadf4970bbef180166183e2ea62086",
"content_id": "bf1f85aaa2069c0062d8056d9ab6d08a1a2987a7",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 8,
"path": "/.coveragerc",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "# .coveragerc to control coverage.py\n\n[run]\nbranch = True\nsource = ./\n\n[report]\nomit = test.py, setup.py\n\n"
},
{
"alpha_fraction": 0.45794087648391724,
"alphanum_fraction": 0.5032477974891663,
"avg_line_length": 25.093219757080078,
"blob_id": "a94c148640b6a260155687eb987c34947d7699cb",
"content_id": "7918b9a8350e025dae20b1974a514232acd2db8f",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12316,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 472,
"path": "/test.py",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "\"\"\"\nTest code\n\"\"\"\nfrom typing import Union, Any, Optional, List, Dict, Tuple, TypeVar, Set, Callable, Iterator, Mapping\n\nimport numpy\n\nimport runtime_check\nfrom runtime_check import check_type_at_run, TypeChecker, check_bound_at_run, BoundChecker, enforce_annotations\n\nruntime_check.check_type.DEEP = True\n\n\ndef test_type_decorator_union():\n \"\"\"\n test type decorator union\n \"\"\"\n\n @check_type_at_run\n def _check_union(val_a: Union[int, float]):\n return val_a + 100\n\n for val in [\"\", [1, 2, \"\"], (1, \"\", []), {\"a\": 1, 2: 'b'}]:\n # these should fail\n try:\n print(val)\n _check_union(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [0.0, 0, 1e10, -100, -1.0, 10, 1.0]:\n print(val)\n _check_union(val)\n\n\ndef test_type_decorator_simple():\n \"\"\"\n test type decorator simple\n \"\"\"\n\n @check_type_at_run\n def _check_int(val_a: int):\n return str(val_a + 10)\n\n for val in [\"\", 0.0, [1, 2, \"\"], (1, \"\", []), {\"a\": 1, 2: 'b'}]:\n # these should fail\n try:\n print(val)\n _check_int(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [0, int(1e10), -100, 10]:\n print(val)\n _check_int(val)\n\ndef test_type_decorator_complex():\n \"\"\"\n test type decorator complex\n \"\"\"\n\n @check_type_at_run\n def _check_complex(val_a, val_b: str, val_c: Optional[List[Any]] = None) -> Union[int, str]:\n if val_c is not None:\n return val_b\n else:\n return val_a\n\n for val in [(0, 0), (0, \"\", (1,)), (0, 0, None), ([], \"\"), (0.0, \"\")]:\n # these should fail\n try:\n print(val)\n _check_complex(*val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [(0, \"\"), (0, \"\", None), (0, \"\", None), ([[\"a\"], (1,)], \"\", [[\"a\"], (1,)])]:\n print(val)\n _check_complex(*val)\n\n\n\ndef test_type_union():\n \"\"\"\n test type union\n \"\"\"\n\n for val in [\"\", [1, 2, \"\"], (1, \"\", []), {\"a\": 1, 2: 'b'}]:\n # these should fail\n try:\n print(val)\n TypeChecker[int, float](val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [0.0, 0, 1e10, -100, -1.0, 10, 1.0]:\n print(val)\n TypeChecker[int, float](val)\n\ndef test_type_tuple():\n \"\"\"\n test type tuple\n \"\"\"\n\n for val in [0, 0.0, [], None, \"\", {}, (0.0, 0.0, \"\"), (0, 0, \"\"), (0, 0.0, 0), (None, 0.0, \"\"), (0, None, \"\"),\n (0, 0.0, None), (1,), (1, 1.0), (1, 1.0, \"\", 0)]:\n # these should fail\n try:\n print(val)\n TypeChecker[Tuple[int, float, str]](val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [(0, 0.0, \"\"), (10, 100.0, \"hello\"), (-10, -1.0, \"world\")]:\n print(val)\n TypeChecker[Tuple[int, float, str]](val)\n\ndef test_type_dict():\n \"\"\"\n test type dict\n \"\"\"\n\n for val in [0, 0.0, [], \"\", (0,), {\"hi\": \"bob\"}, {\"hi\": 0.0}, {0: 0}, {\"hi\": 0, 1: \"world\"}, {\"hi\": 0, None: 0},\n {\"hi\": 0, \"world\": None}]:\n # these should fail\n try:\n print(val)\n TypeChecker[Optional[Dict[str, int]]](val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [{}, {\"str\": 0}, {\"hello\": 0, \"world\": 1}]:\n print(val)\n TypeChecker[Optional[Dict[str, int]]](val)\n\ndef test_type_array():\n \"\"\"\n test type array\n \"\"\"\n\n for val in [0, 0.0, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n TypeChecker.iterable(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [[], [\"hello\", 0, (1,), [], {}], list(range(1000)), numpy.arange(1000)]:\n print(val)\n TypeChecker.iterable(val)\n\n\ndef test_bounds_decorator_discont():\n \"\"\"\n test bounds decorator discontinuous\n \"\"\"\n # val_a must be between ]-inf, 1] or [0, 1] or [2, +inf[\n\n @check_bound_at_run\n def _check_discontinuous(val_a: [(float('-inf'), -1), (0, 1), (2, float('+inf'))]):\n return val_a + 0.1\n\n for val in [-0.5, 1.5, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n _check_discontinuous(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [-1000, -100.0, -1, 0.0, 0.5, 1.0, 2, 20000]:\n print(val)\n _check_discontinuous(val)\n\ndef test_bounds_decorator_simple():\n \"\"\"\n test bounds decorator simple\n \"\"\"\n # val_a must be between [0,1]\n\n @check_bound_at_run\n def _check_simple(val_a: (0, 1)):\n return val_a + 0\n\n for val in [-10, 1000, -100.0, 1000.2, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n _check_simple(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0, 0.0, 0.5, 1, 1.0]:\n print(val)\n _check_simple(val)\n\n\ndef test_bounds_decorator_return():\n \"\"\"\n test bounds decorator return\n \"\"\"\n # return must be between [0,1]\n\n @check_bound_at_run\n def _check_return(val_a) -> (0, 1):\n return val_a\n\n for val in [-10, 1000, -100.0, 1000.2, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n _check_return(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0, 0.0, 0.5, 1, 1.0]:\n print(val)\n _check_return(val)\n\ndef test_bounds_decorator_complex():\n \"\"\"\n test bounds decorator complex\n \"\"\"\n # val_a must be between ]0, +inf[\n # val_b must be between [0, 1]\n # return must be between [0, 100]\n\n @check_bound_at_run\n def _check_complex(val_a: (0, float('+inf'), (False, True)), val_b: (0, 1)) -> (0, 100):\n if val_a < (val_b * 100):\n return val_b * 100\n else:\n return min(val_a, 100)\n\n for val in [(0.0, 0), (0, 0), (-10, 0), (100, 1.000001), (10, -0.0001), (\"\", \"\"), ((1,), (1,)), (None, None),\n ([], []), ({}, {})]:\n # these should fail\n try:\n print(val)\n _check_complex(*val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [(0.00001, 0), (1000, 1), (0.5, 0.5)]:\n print(val)\n _check_complex(*val)\n\ndef test_bounds_discontinuous():\n \"\"\"\n test bounds discontinuous\n \"\"\"\n # [0, 1] or [2, 4]\n\n for val in [-10000, -1, -1.0, 1.5, 5, 5.4, 10000, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n BoundChecker[(0, 1), (2, 4)](val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0, 0.0, 0.5, 1, 1.0, 2, 2.0, 3, 4, 4.0]:\n print(val)\n BoundChecker[(0, 1), (2, 4)](val)\n\ndef test_bounds_simple():\n \"\"\"\n test bounds simple\n \"\"\"\n # [0, 100[\n\n for val in [-10000, -1, -1.0, 100, 100.0, 10000, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n BoundChecker[(0, 100, (True, False))](val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0, 0.0, 50, 50.0, 99.9999999]:\n print(val)\n BoundChecker[(0, 100, (True, False))](val)\n\ndef test_bounds_positive():\n \"\"\"\n test bounds positive\n \"\"\"\n # [0, +inf[\n\n for val in [-10000, -1, -1.0, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n BoundChecker.positive(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0, 0.0, 50, 50.0, 99.9999999, 1e10000, float(\"inf\")]:\n print(val)\n BoundChecker.positive(val)\n\n\ndef test_enforced_dual():\n \"\"\"\n test bounds dual\n \"\"\"\n\n @enforce_annotations\n def _check_dual(val_a: [BoundChecker[(0, 1)], TypeChecker[int, float]]):\n return val_a + 0\n\n for val in [-10000, -1, -1.0, 1.001, 10, 100000, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n _check_dual(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0, 0.0, 0.5, 1.0, 1]:\n print(val)\n _check_dual(val)\n\ndef test_enforced_simple():\n \"\"\"\n test enforced simple\n \"\"\"\n\n @enforce_annotations\n def _check_simple(val_a: TypeChecker[str]):\n return val_a + \"\"\n\n for val in [0, 0.0, (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n _check_simple(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n\n print()\n for val in [\"hello\", 'world']:\n print(val)\n _check_simple(val)\n\ndef test_enforced_complex():\n \"\"\"\n test enforced simple\n \"\"\"\n\n @enforce_annotations\n def _check_complex(val_a: [BoundChecker[(0, 1)], TypeChecker[int, float]])\\\n -> [BoundChecker[(0, 1, (False, True))], TypeChecker[float]]:\n return 0.2 * val_a\n\n for val in [-10000, -1, -1.0, 1.001, 10, 100000, 0, \"\", (1,), None, [], {}, float(\"nan\")]:\n # these should fail\n try:\n print(val)\n _check_complex(val)\n raise EnvironmentError(\"Error: {} should not be valid\".format(val))\n except TypeError:\n pass\n except ValueError:\n pass\n\n print()\n for val in [0.000001, 0.5, 1.0, 1]:\n print(val)\n _check_complex(val)\n\n\ndef test_check_bounds_coverage():\n \"\"\"\n test bounds coverage\n \"\"\"\n\n BoundChecker.positive(1)\n BoundChecker.negative(-1)\n BoundChecker.positive_not_zero(1)\n BoundChecker.negative_not_zero(-1)\n BoundChecker.probability(0.5)\n\n try:\n BoundChecker[(0, 1, 0)](0.5)\n except ValueError:\n pass\n\n\ndef test_check_type_coverage():\n \"\"\"\n test type coverage\n \"\"\"\n\n TypeChecker[TypeVar('s', int, float)](1)\n TypeChecker[Set]({1})\n TypeChecker[Set[int]]({1})\n\n TypeChecker[Callable](lambda a: 1)\n TypeChecker[Mapping](map(lambda x: x+1, [1, 2, 3]))\n TypeChecker[Iterator]([1, 2, 3].__iter__())\n\n TypeChecker.numpy_array(numpy.ones(10))\n\n\ndef test_check_wrapper_coverage():\n \"\"\"\n test wrapper coverage\n \"\"\"\n\n @enforce_annotations\n def _enforce_simple_return(val_a) -> TypeChecker[str]:\n return val_a\n\n _enforce_simple_return(\"\")\n\n @check_bound_at_run\n def _check_discontinuous_return(val_a: (0, float('+inf'), (False, True)), val_b: (0, 1)) -> [(0, 100), (200, 300)]:\n if val_a < (val_b * 100):\n return val_b * 100\n else:\n return min(val_a, 100)\n\n _check_discontinuous_return(100, 0.5)\n"
},
{
"alpha_fraction": 0.6731199026107788,
"alphanum_fraction": 0.6973938941955566,
"avg_line_length": 37.371429443359375,
"blob_id": "477f05cab7b7d62ab955432ecbd7cc327c74f0a5",
"content_id": "46cbb55d28cfef41bea1a14daf4d1b92293c9d13",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6715,
"license_type": "permissive",
"max_line_length": 1083,
"num_lines": 175,
"path": "/README.md",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "# python-runtime-check\n\n[](https://travis-ci.org/hill-a/python-runtime-check) [](https://ci.appveyor.com/project/hill-a/python-runtime-check) [](https://creativecommons.org/share-your-work/public-domain/cc0/) [](https://github.com/hill-a/python-runtime-check) [](https://www.codacy.com/app/hill-a/python-runtime-check?utm_source=github.com&utm_medium=referral&utm_content=hill-a/python-runtime-check&utm_campaign=Badge_Grade) [](https://www.codacy.com/app/hill-a/python-runtime-check?utm_source=github.com&utm_medium=referral&utm_content=hill-a/python-runtime-check&utm_campaign=Badge_Coverage)\n\n## Information\n### Disclosure\n\nI did not directly come up with this. This 'blackmagic' is inspired from a talk by David Beazley. It's quite fun watch if you have an hour to spare :) \n\nVideo: \n<a href=\"http://www.youtube.com/watch?feature=player_embedded&v=5nXmq1PsoJ0\" target=\"_blank\"><img src=\"http://img.youtube.com/vi/5nXmq1PsoJ0/0.jpg\" alt=\"The 'Fun' of Reinvention by David Beazley\" width=\"480\" height=\"360\" border=\"10\" /></a> \n\nAs such, all the code in this repository is Creative Commons 0 [(CC0)](https://creativecommons.org/share-your-work/public-domain/cc0/) \n\n### What is this?\n\nThis is a python 3 only library, used for type checking and bound checking, enforced at runtime. \n\nNow before I begin, yes I am aware of python's ducktyping. However some situations have arisen in the past, where I needed to garanty that my inputs where sanitized. For example, a list `a = []` that should contain only number, if `a.append('')` occure, it will lead to undesired side effects. \nOr even with `ParseArgument`, if you need a number between 0 and 1 for probabilistic usage. \n\nAlso, I find it sad that the [annotations](https://www.python.org/dev/peps/pep-3107/) of types in methods `a: int` is not an enforced restriction at runtime (it is however very useful with [MyPy](http://mypy-lang.org/) or some IDEs). \n\nHence this library, where annotations can be enforced if present, types checked, or bounds of numbers checked. \n\n### When should I use this?\n\nPreferably, in situations where you REALLY need to. This is not designed to run on every function (you can't neglect the overhead cost), as such here are some (rather poor) examples of when to use this: \n<br/>\n```python\ndef print_information(info):\n print(\"here is the information:\" + info)\n```\nHere, we would prefere `info` to be of type string. \n<br/> \n```python\ndef print_informations(infos):\n for info in infos:\n print(\"here some of the information:\" + info)\n```\nHere, we would prefere `infos` to be of type list of string. \n<br/> \n```python\ndef dice_roll(proba):\n roll = random.random()\n if roll <= proba:\n print(\"success!\")\n return True\n else:\n print(\"failure!\")\n return False\n```\nHere, we would prefere `proba` to be of type float, but also bound between [0, 1]. \n \n\n## Installation\n\nThis library will require NumPy and python 3.5 or higher:\n```bash\npip install numpy\n```\n\nYou can install this using:\n```bash\npip install git+https://github.com/hill-a/python-runtime-check\n```\n\n## Usage\n### Type checking\n\nYou can enforce the python type annotations at call:\n```python\n # a can either be a int, or a float\n@check_type_at_run\ndef hello(a: Union[int, float]):\n pass\n\n # a has to be an int\n@check_type_at_run\ndef hello(a: int):\n pass\n\n # c can be either None, or a list composed of anything\n # the return value can either be an int, or a string\n@check_type_at_run\ndef hello(a: int, b: str, c: Optional[List[Any]] = []) -> Union[int, str]:\n if c is None:\n return b\n else: \n return a\n``` \n\nOr check them during execution:\n```python\nTypeChecker[int, float](0) # here the comma seperated types are replaced with typing.Union internaly\nTypeChecker[Tuple[int, float, str]]((0, 1.0, 'a'))\nTypeChecker[Optional[Dict[str, int]]](None)\nTypeChecker[Optional[Dict[str, int]]]({'a':1, 'b':2})\nTypeChecker.iterable(\"hello\")\nTypeChecker.numpy_array(numpy.arange(10))\n``` \n\nShould you need to check all the elements of a list, dict, set, tuple or sequence when type checking, \nset this flag `runtime_check.check_type.DEEP = True`. \n\nHere are some useful types commonly used in python:\n- `numpy.ndarray`\n- `torch.FloatTensor`\n- `torch.tensor._TensorBase`\n- `collections.Iterable`\n- `type(None)`\n- `typing.Optional[int]`\n- `typing.Union[int, float]`\n- `typing.List, typing.Dict, typing.Set, typing.Tuple, typing.Iterable`\n- `typing.Any, typing.TypeVar, typing.AnyStr` \n\npython typing annotations [here](https://docs.python.org/3/library/typing.html).\n\n### Bounds checking\n\nYou can check annotated bounds at call (however the notation is not very readable):\n```python\n # a must be between ]-inf, 1] or [0, 1] or [2, +inf[\n@check_bound_at_run\ndef hello(a: [(float('-inf'), -1), (0, 1), (2, float('+inf'))]):\n pass\n\n # a must be between [0,1]\n@check_bound_at_run\ndef hello(a: (0, 1)):\n pass\n\n # a must be between ]0, +inf[\n # b must be between [0, 1]\n # return must be between [0, 100]\n@check_bound_at_run\ndef hello(a: (0, float('+inf'), (False, True)), b: (0, 1)) -> (0, 100):\n if a < (b * 100):\n return b * 100\n else:\n return min(a, 100)\n```\n\nOr check them during execution:\n```python\nBoundChecker[(0, 1), (2, 4)](0.5) # [0, 1] or [2, 4]\nBoundChecker[(0, 100, (True, False))](20) # [0, 100[\nBoundChecker.positive(100) # [0, +inf[\n```\n\nthe tuple defining the bounds are: \n`(Lower_bound, Upper_bound, (Include_lower_bound, Include_upper_bound))` \nor: \n`(Lower_bound, Upper_bound)` \nThe bounds must be numbers (`float` or `int`), if the `Include_lower_bound` and `Include_upper_bound` are not defined, \nthey default to `True`. \n\nYou may use lists of bounds to define discontinuous bounds\n\n### Chained checking\n\nYou may also combine the previous execution checks, to validate a variable with annotations:\n```python\n@enforce_annotations\ndef hello(a: [BoundChecker[(0, 1)], TypeChecker[int, float]]):\n pass\n\n@enforce_annotations\ndef hello(a: TypeChecker[str]):\n pass\n\n@enforce_annotations\ndef hello(a: [BoundChecker[(0, 1)], TypeChecker[int, float]]) -> [BoundChecker[(0, 1, (False, True))], TypeChecker[float]]:\n return 0.2\n```\n"
},
{
"alpha_fraction": 0.5821412801742554,
"alphanum_fraction": 0.5886432528495789,
"avg_line_length": 30.16891860961914,
"blob_id": "7ad47d3e6b8aa3b4cdf0c4fe4fb705a19c94e188",
"content_id": "87ca651c910834341f9ab11e1e04e7c916f3a939",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4614,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 148,
"path": "/runtime_check/wrappers.py",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis module containes the wrappers used in the library\n\"\"\"\n\nfrom inspect import signature\nfrom collections import Iterable\nfrom functools import wraps\n\nfrom runtime_check.check_bounds import BoundChecker\nfrom runtime_check.check_type import TypeChecker\n\n\ndef _checking_annotations(func, pre_check, post_check):\n \"\"\"\n Takes a pre checker, a function and a post checker and runs them in order.\n\n :param func: (callable) the function you want to check\n :param pre_check: (callable) the check you want to run before execution\n :param post_check: (callable) the check you want to run after execution\n \"\"\"\n sig = signature(func)\n ann = func.__annotations__\n\n @wraps(func)\n def _wrapper(*args, **kwargs):\n \"\"\"\n A simple wrapper for the checking of a function\n \"\"\"\n bound = sig.bind(*args, **kwargs)\n for name, val in bound.arguments.items():\n if name in ann:\n pre_check(ann[name], val, name)\n\n return_val = func(*args, **kwargs)\n if 'return' in ann:\n post_check(ann['return'], return_val)\n return return_val\n\n return _wrapper\n\n\n\ndef enforce_annotations(func):\n \"\"\"\n An annotation used to enforce callable functions on the associated variable\n\n ex:\n @enforce_annotations\n def hello(a: [BoundChecker[(0,1)], TypeChecker[int,float]]):\n pass\n\n @enforce_annotations\n def hello(a: [BoundChecker[(0,1)], TypeChecker[int,float]]) -> [BoundChecker[(0,1,(False, True))]]:\n return 0.2\n \"\"\"\n def _pre_check(annotated, val, name):\n if isinstance(annotated, Iterable):\n for ann in annotated:\n ann(val)\n else:\n annotated(val)\n\n def _post_check(annotated, val):\n if isinstance(annotated, Iterable):\n for ann in annotated:\n ann(val)\n else:\n annotated(val)\n\n return _checking_annotations(func, _pre_check, _post_check)\n\n\ndef check_bound_at_run(func):\n \"\"\"\n Annotation used to enforce bounds on the associated variable\n\n ex:\n @check_bound_at_run\n def hello(a: [(float('-inf'), -1), (0, 1),(2, float('+inf'))]):\n pass\n\n @check_bound_at_run\n def hello(a: (0, 1)):\n pass\n\n @check_bound_at_run\n def hello(a: (0, float('+inf'),(False, True)), b: (0, 1)) -> (0,100):\n if a < (b * 100):\n return b * 100\n else:\n return min(a, 100)\n\n the tuple defining the bounds are (Lower_bound, Upper_bound, (Include_lower_bound, Include_upper_bound))\n or (Lower_bound, Upper_bound)\n You may use lists of bounds to define discontinuous bounds\n \"\"\"\n\n def _pre_check(annotated, val, name):\n if isinstance(annotated, list):\n valid = any([BoundChecker._in_bounds(val, key) for key in annotated])\n else:\n valid = BoundChecker._in_bounds(val, annotated)\n if not valid:\n raise ValueError(\"Number out of bounds {} for argument {}, expected bounds {}\".format(val, name, annotated))\n\n def _post_check(annotated, val):\n if isinstance(annotated, list):\n valid = any([BoundChecker._in_bounds(val, key) for key in annotated])\n else:\n valid = BoundChecker._in_bounds(val, annotated)\n if not valid:\n raise ValueError(\"Number out of bounds {} for return, expected bounds {}\".format(val, annotated))\n\n return _checking_annotations(func, _pre_check, _post_check)\n\n\ndef check_type_at_run(func):\n \"\"\"\n Annotation used to check the type of an associated variable\n\n ex:\n @check_type_at_run\n def hello(a: Union[int, float]):\n pass\n\n @check_type_at_run\n def hello(a: int):\n pass\n\n @check_type_at_run\n def hello(a: int, b: str, c: Optional[List[Any]] = []) -> Union[int, str]:\n if c is None:\n return b\n else:\n return a\n\n you may use typing.Union[int, float] for mutliple valid types\n or List[int], Dict[str, int], Optional[int].\n \"\"\"\n def _pre_check(annotated, val, name):\n if not TypeChecker._check_type(annotated, val):\n raise TypeError('Expected {} for argument {}, got {}'.format(annotated, name, val.__class__))\n\n def _post_check(annotated, val):\n if not TypeChecker._check_type(annotated, val):\n raise TypeError('Expected {} for return, got {}'.format(annotated, val.__class__))\n\n return _checking_annotations(func, _pre_check, _post_check)\n\n"
},
{
"alpha_fraction": 0.7931034564971924,
"alphanum_fraction": 0.7974137663841248,
"avg_line_length": 34.69230651855469,
"blob_id": "6f47b890674baa4fa2529de6bf19b3b503a29bba",
"content_id": "68a0a991b59d7471be3674f6d3a145ac0974714d",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 464,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 13,
"path": "/runtime_check/__init__.py",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "\"\"\"\nruntime_check\n\nThis library allows the checking of:\n- specific carateristics of a function on pre and post execution.\n- specific variables at call.\n\"\"\"\n# inspired blackmagic https://www.youtube.com/watch?v=Je8TcRQcUgA\n# python 3 only type and bound checking\n\nfrom runtime_check.check_type import TypeChecker, DEEP\nfrom runtime_check.check_bounds import BoundChecker\nfrom runtime_check.wrappers import check_bound_at_run, check_type_at_run, enforce_annotations\n"
},
{
"alpha_fraction": 0.7816091775894165,
"alphanum_fraction": 0.7816091775894165,
"avg_line_length": 16.600000381469727,
"blob_id": "cb5ea8dd63f1d398ef8f89c8c0dad092ee3aa92d",
"content_id": "ac99840b471ab139d2796c9bd727fdef7ae81e1f",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 87,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/report_coverage.sh",
"repo_name": "hill-a/python-runtime-check",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\ncoverage report\ncoverage xml\necho \"\"\npython-codacy-coverage -r coverage.xml"
}
] | 9 |
tomwa/cartodb_mbtiles | https://github.com/tomwa/cartodb_mbtiles | 6bec698bef978d1973bfa01a136eb23afc482258 | da5b83cfb32b27fc8d7636a1af0b89c295329d81 | e11071c985d3b944e4bd9b255d1b62ca7eb08b30 | refs/heads/master | 2020-12-02T15:07:58.823602 | 2013-10-25T16:08:09 | 2013-10-25T16:08:09 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.527845025062561,
"alphanum_fraction": 0.5548829436302185,
"avg_line_length": 35.955223083496094,
"blob_id": "97929df800c4e176b90be7180b7ac2936cf004c6",
"content_id": "064448ffa3ee85b7d9233a223c928f49595748d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2478,
"license_type": "no_license",
"max_line_length": 182,
"num_lines": 67,
"path": "/tiles.py",
"repo_name": "tomwa/cartodb_mbtiles",
"src_encoding": "UTF-8",
"text": "\nfrom landez import GoogleProjection\nfrom collections import defaultdict\nimport json\nimport urllib2, urllib\n\ndef fetch(url, data=None, headers={}):\n request = urllib2.Request(url, data, headers=headers)\n return urllib2.urlopen(request).read()\n\nclass CartoDBTiles(GoogleProjection):\n\n def __init__(self, *args, **kwargs):\n self.sql_api_url = 'http://dev.localhost.lan:8080/api/v1/sql'\n super(CartoDBTiles, self).__init__(*args, **kwargs)\n\n def tileslist(self, bbox):\n return self.tiles(bbox, self.levels[0], self.levels[-1])\n\n def containsGeometry(self, tile):\n #sql = \"select 1 from ne_10m_populated_places_simple_9 where st_contains(CDB_XYZ_Extent(%d,%d,%d), the_geom_webmercator) limit 1\" % tile\n sql = \"SELECT EXISTS ( SELECT 1 FROM ne_10m_populated_places_simple_9 WHERE ST_Contains(CDB_XYZ_Extent(%d,%d,%d),the_geom_webmercator) limit 1)\" % (tile[1], tile[2], tile[0])\n return json.loads(fetch(self.sql_api_url + \"?q=\" + urllib.quote_plus(sql), headers={'Host': 'dev.localhost.lan'}))['rows'][0]['?column?']\n\n def tilesForBBox(self, bbox, z):\n xmin, ymin, xmax, ymax = bbox\n l = []\n\n ll0 = (xmin, ymax) # left top\n ll1 = (xmax, ymin) # right bottom\n\n px0 = self.project_pixels(ll0,z)\n px1 = self.project_pixels(ll1,z)\n\n for x in range(int(px0[0]/self.tilesize),\n int(px1[0]/self.tilesize)+1):\n if (x < 0) or (x >= 2**z):\n continue\n for y in range(int(px0[1]/self.tilesize),\n int(px1[1]/self.tilesize)+1):\n if (y < 0) or (y >= 2**z):\n continue\n if self.tms_scheme:\n y = ((2**z-1) - y)\n l.append((z, x, y))\n return l\n\n def tiles(self, bbox, zoom, maxZoom):\n tiles = []\n boxtiles = self.tilesForBBox(bbox, zoom)\n tiles += boxtiles\n #print zoom, maxZoom\n if zoom < maxZoom:\n for t in boxtiles:\n if self.containsGeometry(t):\n tiles += [x for x in self.tiles(self.tile_bbox(t), zoom + 1, maxZoom) if x not in tiles]\n return tiles\n\nif __name__ == '__main__':\n p = CartoDBTiles(levels=[0, 7])\n bbox = (-180.0, -90.0, 180.0, 90.0)\n tiles = p.tileslist(bbox)\n zoom = defaultdict(int)\n for x in tiles:\n zoom[x[0]] += 1\n\n for z in sorted(zoom.items()):\n print \"%02d - %d\" % z\n\n"
},
{
"alpha_fraction": 0.6255506873130798,
"alphanum_fraction": 0.6255506873130798,
"avg_line_length": 17.83333396911621,
"blob_id": "6e32e244973760ef3741909ae6ce9ac7bf54eea2",
"content_id": "49a3eb30caa5c6c8204c706ea0e56d6c4d3fd4dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 12,
"path": "/README.md",
"repo_name": "tomwa/cartodb_mbtiles",
"src_encoding": "UTF-8",
"text": "\n# install\n ```\n virtualenv env\n . env/bin/activate\n pip install -r requirements.txt\n ```\n\n# usage\n\n ```\n python cartodb_vizz_mbtile_creator.py vizjson_url max_zoom_level file.mbtiles thread_number\n ```\n"
},
{
"alpha_fraction": 0.7678571343421936,
"alphanum_fraction": 0.7678571343421936,
"avg_line_length": 55,
"blob_id": "7470fa28f567abcf37cb984cd0a36db0129571fb",
"content_id": "5e82917a461aa9eaa2ed9b5ed12a5a7224ceac21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 1,
"path": "/requirements.txt",
"repo_name": "tomwa/cartodb_mbtiles",
"src_encoding": "UTF-8",
"text": "-e git+https://github.com/CartoDB/landez.git#egg=landez\n"
},
{
"alpha_fraction": 0.6057214140892029,
"alphanum_fraction": 0.6312189102172852,
"avg_line_length": 34.733333587646484,
"blob_id": "b124fa392129f15ec3a47d323d4b78f9c0d36aa2",
"content_id": "0fb238fb819ab214b3c4bcc67eb0556026f884f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1608,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 45,
"path": "/cartodb_vizz_mbtile_creator.py",
"repo_name": "tomwa/cartodb_mbtiles",
"src_encoding": "UTF-8",
"text": "import logging\nfrom landez import MBTilesBuilder\nimport sys\nimport urllib2\nimport urllib\nimport json\n\n\nCDN_URL = 'api.cartocdn.com'\n\ndef fetch(url, data=None, headers={}):\n if data:\n pass\n #data = urllib.quote_plus(data)\n request = urllib2.Request(url, data, headers=headers)\n return urllib2.urlopen(request).read()\n\ndef get_layergroup_url(vizjson_url):\n vizjson = vizjson_url\n username = vizjson.split('.')[0].replace('http://', '')\n\n vizjson = json.loads(fetch(sys.argv[1]))\n layerdef = vizjson['layers'][1]['options']['layer_definition']\n layers = [ { \"type\": 'cartodb', 'ttl': 3600*24*265, \"options\": x['options'] } for x in layerdef['layers'] ]\n layerdef = json.dumps({ \"version\": \"1.0.1\", \"layers\": layers })\n layerid = json.loads(fetch('http://' + username + '.cartodb.com/tiles/layergroup', layerdef, headers={ 'Content-Type': 'application/json' }))\n return 'http://' + username + \".cartodb.com/tiles/layergroup/\" + layerid['layergroupid'] + \"/{z}/{x}/{y}.png\"\n\nif __name__ == '__main__':\n if len(sys.argv) < 4:\n print \"vizsjon_url max_zoom mbtiles [nthreads]\"\n sys.exit()\n nthreads = 20\n if len(sys.argv) > 4:\n nthreads = int(sys.argv[4])\n\n logging.basicConfig(level=logging.DEBUG)\n template_url = get_layergroup_url(sys.argv[1])\n logging.info(\"%d threads\" % nthreads)\n mb = MBTilesBuilder(tiles_url=template_url, filepath=sys.argv[3], thread_number=nthreads, errors_as_warnings=True)\n mb.add_coverage(\n bbox=(-180.0, -90.0, 180.0, 90.0),\n zoomlevels=[0, int(sys.argv[2])]\n )\n mb.run()\n"
}
] | 4 |
newlybaoba/qrcode | https://github.com/newlybaoba/qrcode | 48ca166275b6b6f7931e54f3b0ed3a43069fe942 | d90f87cdb5005463cda50506dbc8066de3dd592c | 4a6a871ae91b5ec3da04a005657e52901b78f362 | refs/heads/master | 2020-05-01T04:03:21.248847 | 2019-03-23T08:38:24 | 2019-03-23T08:38:24 | 177,248,810 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.39393940567970276,
"alphanum_fraction": 0.5757575631141663,
"avg_line_length": 21.33333396911621,
"blob_id": "a0221aca18851db1dfad44ae76ce4334e5ed34db",
"content_id": "5c3b84c11407924c1c795a7722d631e7de2349cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 3,
"path": "/__init__.py",
"repo_name": "newlybaoba/qrcode",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n# Author : Niuli\n# Data : 2018/11/19 上午9:40"
},
{
"alpha_fraction": 0.5969868302345276,
"alphanum_fraction": 0.6365348696708679,
"avg_line_length": 24.238094329833984,
"blob_id": "7e3e6d8648e46e1a9a60025edb29e7164286d7da",
"content_id": "8e77ea5acb275b4d942767f71556e4adffdc57c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1300,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 42,
"path": "/QRcode.py",
"repo_name": "newlybaoba/qrcode",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n# Author : Niuli\n# Data : 2018/11/19 上午9:40\n\n# pip install pillow\n# pip install numpy\n# pip install imageio\n# pip install myqr\n\n\n\n# version, level, qr_name = myqr.run(\n# words='dhb cdfb64%vjk', # 不支持中文,支持 0~9,a~z, A~Z 以及常见的常用英文标点符号和空格\n# version=2, # 版本,从 1至 40\n# level='H', # 纠错等级,范围是L、M、Q、H,从左到右依次升高\n# picture='4e.jpg', # 文件要放在目录下\n# colorized=True, # True 为彩色,False 为黑白\n# contrast=1.0, # 对比度\n# brightness=1.0, # 亮度\n# save_name='1d6.bmp', # 命名随便都行,格式可以是 jpg,png,bmp,gif\n# save_dir=\"F:\\二维码\" # 路径要存在\n# )\n\n\n\nfrom MyQR import myqr\n\n# 普通二维码\n# myqr.run(words='should be str')\n# myqr.run(words='xxxxx' ,picture='150*150.jpg')\n\n# count = 0\n# for i in range(1,40):\n# myqr.run(words='should be str',version=i,save_name='%s.jpg'%(count))\n# count+=1\n\n\n# 动态彩色二维码\n# 先找到一个new1.gif动图做背景,picture='new1.gif',\n# 再设置为彩色:colorized=True\n# myqr.run(words='this is colourful qrcode',picture='timg.gif',colorized=True,version=5)\nmyqr.run(words='http://niuli.xyz',picture='timg.gif',colorized=True,version=5)\n\n\n"
},
{
"alpha_fraction": 0.7227784991264343,
"alphanum_fraction": 0.7565706968307495,
"avg_line_length": 23.58461570739746,
"blob_id": "3ae2597e1eef21aba414514eaac6f0de547ea9d3",
"content_id": "a733f4a025c56ed4f2cde8f47b9e87aae0a749d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2802,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 65,
"path": "/README.md",
"repo_name": "newlybaoba/qrcode",
"src_encoding": "UTF-8",
"text": "最近经常听到网站编辑妹子嚷嚷着说公众号二维码太丑了, 想要个好看的,\n\n‘要二维码? 找我啊, 我做二维码贼6! PS, AI, Coredraw, 你说你想要哪种做?’\n\n“Python吧..”\n\n‘你妹的.. 以为这个能难倒我? 来来来, 叔叔教教你! ‘\n\n今天就讲讲python怎么搞二维码的事吧.\n\n\n介绍一个好玩的库: qrcode\n\nqrcode 运行在 Python 3 上,它可以生成以下三种二维码图片:普通二维码、带图片的艺术二维码(黑白与彩色)、动态二维码(黑白与彩色)。它比较适合直接用于生成二维码图片的场景。\n\n安装 qrcode 库可以使用 pip 方式。但是该库依赖 pillow、numpy 和 imageio。因此,我们需要先安装依赖库,再安装 qrcode。最后的安装命令如下:\n\npip install pillow\npip install numpy\npip install imageio\npip install myqr\n简单的解释下\n\n数\t含义\t详细\nwords\t二维码指向链接\tstr,输入链接或者句子作为参数\nversion\t边长\tint,控制边长,范围是1到40,数字越大边长越大,默认边长是取决于你输入的信息的长度和使用的纠错等级\nlevel\t纠错等级\tstr,控制纠错水平,范围是L、M、Q、H,从左到右依次升高,默认纠错等级为’H’\npicture\t结合图片\tstr,将QR二维码图像与一张同目录下的图片相结合,产生一张黑白图片\ncolorized\t颜色\tbool,使产生的图片由黑白变为彩色的\ncontrast\t对比度\tfloat,调节图片的对比度,1.0 表示原始图片,更小的值表示更低对比度,更大反之。默认为1.0\nbrightness\t亮度\tfloat,调节图片的亮度,其余用法和取值与 contrast 相同\nsave_name\t输出文件名\tstr,默认输出文件名是”qrcode.png”\nsave_dir\t存储位置\tstr,默认存储位置是当前目录\n有40种样式吧,不过也就前面7种还行,后面的实在是,密集恐惧症莫入啊\n\n废话不多说,直接上代码\n\n-*- coding:utf-8 -*-\nAuthor : Niuli\n\nfrom MyQR import myqr\n\n普通二维码\n\\# myqr.run(words='should be str')\n\\# myqr.run(words='xxxxx' ,picture='150*150.jpg')\n\n\\# 40个版本样子方便查看选择想要的\n\\# count = 0 \n\\# for i in range(1,40):\n\\# myqr.run(words='should be str',version=i,save_name='%s.jpg'%(count))\n\\# count+=1\n\n\n\\# 动态彩色二维码\n\\# 先找到一个new1.gif动图做背景,picture='new1.gif',\n\\# 再设置为彩色:colorized=True\n\\# myqr.run(words='this is colourful qrcode',picture='timg.gif',colorized=True,version=5)\nmyqr.run(words='http://niuli.xyz',picture='timg.gif',colorized=True,version=5)\n最后,如果要自动跳转网址的话, 需要加上 word=’http://你的网址’\n\n\n\n最后..真正的二维码,,还是用作图软件做吧, 哈哈\n\n\n"
}
] | 3 |
heartbeats15/Turtle-Race | https://github.com/heartbeats15/Turtle-Race | 6652c916314395e499aa4d721a91b0c84cde36c2 | ce1e93c5ffd78232f0d9efa1e525683eb63c0bd1 | df77215ecf278ca420771d27886c9237145a4c82 | refs/heads/main | 2023-01-28T18:42:11.485652 | 2020-12-09T13:15:24 | 2020-12-09T13:15:24 | 319,961,215 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.543181836605072,
"alphanum_fraction": 0.6119318008422852,
"avg_line_length": 16.731182098388672,
"blob_id": "3e7155a450a15c44a7e8efa21a5ae4cb8da662d2",
"content_id": "dc5e9872e8b0e6847b3d8ed6667053de11530864",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1760,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 93,
"path": "/Turtle_race.py",
"repo_name": "heartbeats15/Turtle-Race",
"src_encoding": "UTF-8",
"text": "from turtle import*\r\nfrom random import randint\r\nprint(\"Created by Pratik Ledaskar\")\r\n\r\n#classic shape turtle\r\nspeed(0)\r\npenup()\r\ngoto(-140,140)\r\n\r\n#racing track\r\n\r\nfor step in range(15):\r\n write(step, align = 'center')\r\n right(90)\r\n \r\n for num in range(8):\r\n penup()\r\n forward(10)\r\n pendown()\r\n forward(10)\r\n \r\n penup()\r\n backward(160)\r\n left(90)\r\n forward(20)\r\n \r\n#player 1 details\r\nplayer_1 = Turtle()\r\nplayer_1.color('red')\r\nplayer_1.shape('turtle')\r\n\r\n# player 1 proceed to racing track\r\nplayer_1.penup()\r\nplayer_1.goto(-160,100)\r\nplayer_1.pendown()\r\n\r\n# 360 degree turn\r\nfor turn in range(10):\r\n player_1.right(36)\r\n \r\n \r\n# player 2 details\r\nplayer_2 = Turtle()\r\nplayer_2.color('blue')\r\nplayer_2.shape('turtle')\r\n\r\n# player 2 proceed to racing track\r\nplayer_2.penup()\r\nplayer_2.goto(-160,70)\r\nplayer_2.pendown()\r\n\r\n# 360 degree turn\r\nfor turn in range(30):\r\n player_2.left(12)\r\n \r\n \r\n# player 3 details\r\nplayer_3 = Turtle()\r\nplayer_3.color('green')\r\nplayer_3.shape('turtle')\r\n\r\n# player 1 proceed to racing track\r\nplayer_3.penup()\r\nplayer_3.goto(-160,40)\r\nplayer_3.pendown()\r\n\r\n# 360 degree turn\r\nfor turn in range(60):\r\n player_3.right(6)\r\n \r\n# player 4 details\r\nplayer_4 = Turtle()\r\nplayer_4.color('orange')\r\nplayer_4.shape('turtle')\r\n\r\n# player 4 proceed to racing track\r\nplayer_4.penup()\r\nplayer_4.goto(-160,10)\r\nplayer_4.pendown()\r\n\r\n# 360 degree turn\r\nfor turn in range(60):\r\n player_4.left(6)\r\n \r\n \r\n# turtles run at random speeds\r\nfor turn in range(100):\r\n player_1.forward(randint(1,5))\r\n player_2.forward(randint(1,5))\r\n player_3.forward(randint(1,5))\r\n player_4.forward(randint(1,5))\r\n\r\nprint(\"congrats , you are the winner\")\r\n \r\n \r\n \r\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 54,
"blob_id": "2f5de568cefddce019f6ceaef2f95fbc778e8bfa",
"content_id": "711734f24a66e30c3b3ed8b4e6f66dfa99f2c037",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 2,
"path": "/README.md",
"repo_name": "heartbeats15/Turtle-Race",
"src_encoding": "UTF-8",
"text": "# Turtle-Race\nAmazing animation using Python of a turtle race where we can learn how a random function works.\n"
}
] | 2 |
rodrigo-mendes/various-demos | https://github.com/rodrigo-mendes/various-demos | a71304c58eb7b668c78016edbebbe3267126ac41 | 2e8833d127388371560a951052f59f8586744f2f | a28473366a8335635e5c43e3b67153c713a5d27c | refs/heads/master | 2023-03-11T08:20:46.262097 | 2021-03-01T13:52:21 | 2021-03-01T13:52:21 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5664214491844177,
"alphanum_fraction": 0.5904370546340942,
"avg_line_length": 27.887500762939453,
"blob_id": "c4a6020e8da5f71fc98fb368f7a90712d5a12f4c",
"content_id": "4c5672a004e1952506d1cab860ec52320613cf3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Maven POM",
"length_bytes": 4622,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 160,
"path": "/iot-stream-ingestion-demo/src/truck-client/pom.xml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<project xmlns=\"http://maven.apache.org/POM/4.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n\txsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\n\n\t<modelVersion>4.0.0</modelVersion>\n\n\t<groupId>com.trivadis</groupId>\n\t<version>1.0.0</version>\n\t<artifactId>truck-client</artifactId>\n\n <properties>\n <hadoop.miniclusters.version>0.0.15-SNAPSHOT</hadoop.miniclusters.version>\n <scala.version>2.11</scala.version>\n <kafka.version>2.0.0</kafka.version>\n <akka.version>2.3.16</akka.version>\n <jpmml.version>1.0.22</jpmml.version>\n <commons.csv.version>1.2</commons.csv.version>\n <commons.lang.version>3.7</commons.lang.version>\n <slf4j.version>1.7.10</slf4j.version>\n <storm.version>0.10.0.2.3.0.0-2557</storm.version>\n <storm.hdfs.version>0.10.0.2.3.0.0-2557</storm.hdfs.version>\n\n <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>\n </properties>\n\n\n\t<dependencies>\n\t\t<dependency>\n\t\t\t<groupId>org.eclipse.paho</groupId>\n\t\t\t<artifactId>org.eclipse.paho.client.mqttv3</artifactId>\n\t\t\t<version>1.1.1</version>\n\t\t</dependency>\n\t\t\n <!-- Kafka -->\n\t\t<dependency>\n \t\t<groupId>org.apache.kafka</groupId>\n \t\t<artifactId>kafka-clients</artifactId>\n \t\t<version>${kafka.version}</version>\n\t\t</dependency>\n \n <dependency>\n <groupId>com.typesafe.akka</groupId>\n <artifactId>akka-remote_${scala.version}</artifactId>\n <version>${akka.version}</version>\n </dependency>\n\n <dependency>\n <groupId>org.jpmml</groupId>\n <artifactId>pmml-evaluator</artifactId>\n <version>${jpmml.version}</version>\n </dependency>\n\n <dependency>\n <groupId>org.slf4j</groupId>\n <artifactId>slf4j-api</artifactId>\n <version>${slf4j.version}</version>\n </dependency>\n\n <dependency>\n <groupId>org.apache.commons</groupId>\n <artifactId>commons-csv</artifactId>\n <version>${commons.csv.version}</version>\n </dependency>\n\n <dependency>\n <groupId>org.apache.commons</groupId>\n <artifactId>commons-lang3</artifactId>\n <version>${commons.lang.version}</version>\n </dependency>\n\n\t\t<dependency>\n \t\t<groupId>commons-codec</groupId>\n \t\t<artifactId>commons-codec</artifactId>\n \t\t<version>1.11</version>\n\t\t</dependency>\n\n\t\t<dependency>\n \t\t<groupId>log4j</groupId>\n \t\t<artifactId>log4j</artifactId>\n \t\t<version>1.2.17</version>\n\t\t</dependency>\n \n <dependency>\n <groupId>org.slf4j</groupId>\n <artifactId>slf4j-simple</artifactId>\n <version>${slf4j.version}</version>\n </dependency>\n\n <dependency>\n <groupId>junit</groupId>\n <artifactId>junit</artifactId>\n <version>3.8.1</version>\n <scope>test</scope>\n </dependency>\n\n <dependency>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-idea-plugin</artifactId>\n <version>2.2.1</version>\n </dependency>\n\n\t</dependencies>\n\n\t<build>\n\t\t<plugins>\n \t<plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-compiler-plugin</artifactId>\n <version>3.2</version>\n <configuration>\n <source>1.8</source>\n <target>1.8</target>\n </configuration>\n </plugin>\t\t\n\t\t\t<plugin>\n\t\t\t\t<groupId>org.codehaus.mojo</groupId>\n\t\t\t\t<artifactId>exec-maven-plugin</artifactId>\n\t\t\t\t<version>1.6.0</version>\n\t\t\t\t<executions>\n\t\t\t\t\t<execution>\n\t\t\t\t\t\t<goals>\n\t\t\t\t\t\t\t<goal>java</goal>\n\t\t\t\t\t\t</goals>\n\t\t\t\t\t</execution>\n\t\t\t\t</executions>\n\t\t\t\t<configuration>\n\t\t\t\t\t<mainClass>com.hortonworks.solution.Lab</mainClass>\n\t\t\t\t\t<arguments>\n\t\t\t\t\t\t<argument>mqtt</argument>\n\t\t\t\t\t</arguments>\n\t\t\t\t</configuration>\n\t\t\t</plugin>\n\t\t\t<plugin>\n\t\t\t\t<artifactId>maven-assembly-plugin</artifactId>\n\t\t\t\t<configuration>\n\t\t\t\t\t<descriptorRefs>\n\t\t\t\t\t\t<descriptorRef>jar-with-dependencies</descriptorRef>\n\t\t\t\t\t</descriptorRefs>\n\t\t\t\t\t<archive>\n\t\t\t\t\t\t<manifest>\n\t\t\t\t\t\t\t<mainClass>com.hortonworks.solution.Lab</mainClass>\n\t\t\t\t\t\t</manifest>\n\t\t\t\t\t</archive>\n\t\t\t\t</configuration>\n\t\t\t\t<executions>\n\t\t\t\t\t<execution>\n\t\t\t\t\t\t<id>make-assembly</id>\n\t\t\t\t\t\t<phase>package</phase>\n\t\t\t\t\t\t<goals>\n\t\t\t\t\t\t\t<goal>single</goal>\n\t\t\t\t\t\t</goals>\n\t\t\t\t\t</execution>\n\t\t\t\t</executions>\n\n\t\t\t</plugin>\n\n\t\t</plugins>\n\t</build>\n\n</project>\n"
},
{
"alpha_fraction": 0.6142534017562866,
"alphanum_fraction": 0.6583710312843323,
"avg_line_length": 26.5625,
"blob_id": "31229b4b4e3cbe0b4e2dd5397b590ebdf0d80aa6",
"content_id": "bb1b7a97f8f9efbe4869224ccb50939fb1fb544f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 3536,
"license_type": "permissive",
"max_line_length": 238,
"num_lines": 128,
"path": "/data-lake-platform/cask-cdap/docker/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# CASK CDAP\n\nversion: \"2.1\"\n\nservices:\n zookeeper:\n image: confluentinc/cp-zookeeper:5.0.0\n hostname: zookeeper\n ports:\n - \"2181:2181\"\n environment:\n ZOOKEEPER_CLIENT_PORT: 2181\n ZOOKEEPER_TICK_TIME: 2000\n restart: always\n\n broker-1:\n image: confluentinc/cp-enterprise-kafka:5.0.0\n hostname: broker-1\n depends_on:\n - zookeeper\n ports:\n - \"9092:9092\"\n environment:\n KAFKA_BROKER_ID: 1\n KAFKA_BROKER_RACK: rack-a\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9092'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9999\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9999'\n KAFKA_JMX_HOSTNAME: 'broker-1'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-1:9092\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper:2181\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n\n schema-registry:\n image: confluentinc/cp-schema-registry:5.0.0\n hostname: schema-registry\n container_name: schema-registry\n depends_on:\n - zookeeper\n - broker-1\n ports:\n - \"8081:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry\n SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper:2181'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always\n\n cdap:\n image: caskdata/cdap-sandbox:latest\n hostname: cdap\n ports: \n - \"11011:11011\"\n - \"11015:11015\"\n volumes:\n - ./volume/cdap-localfile:/Root/home/data\n restart: always\n \n adminer:\n image: adminer\n ports:\n - 38080:8080\n restart: always\n \n postgresql:\n image: mujz/pagila\n environment:\n POSTGRES_PASSWORD: sample\n POSTGRES_USER: sample\n POSTGRES_DB: sample\n restart: always\n\n mysql:\n image: mysql:5.7\n ports:\n - 3306:3306\n volumes:\n# - ./volume/mysql:/var/lib/mysql:rw\n - ./scripts/mysql/demo.sql:/docker-entrypoint-initdb.d/demo.sql:ro\n environment:\n MYSQL_ALLOW_EMPTY_PASSWORD: \"yes\"\n MYSQL_DATABASE: \"sample\"\n MYSQL_USER: \"sample\"\n MYSQL_PASSWORD: \"sample\"\n restart: always\n \n kafka-manager:\n image: trivadisbds/kafka-manager\n hostname: kafka-manager\n depends_on:\n - zookeeper\n ports:\n - \"9000:9000\"\n environment:\n ZK_HOSTS: 'zookeeper:2181'\n APPLICATION_SECRET: 'letmein' \n restart: always\n \n streamsets:\n image: trivadisbds/streamsets-kafka-hadoop-aws:3.6.0\n hostname: streamsets\n ports:\n - \"18630:18630\"\n volumes:\n - ./streamsets/user-libs:/opt/streamsets-datacollector-user-libs\n - ./streamsets/data:/data \n restart: always\n\n schema-registry-ui:\n image: landoop/schema-registry-ui\n hostname: schema-registry-ui\n depends_on:\n - broker-1\n - schema-registry\n ports:\n - \"8002:8000\"\n environment:\n SCHEMAREGISTRY_URL: 'http://${PUBLIC_IP}:8081'\n restart: always\n\n \n"
},
{
"alpha_fraction": 0.7138378620147705,
"alphanum_fraction": 0.7187640070915222,
"avg_line_length": 35.6065559387207,
"blob_id": "9229919211884aa28344d6c72de4a27129e13329",
"content_id": "82baf967a90960142a003fe7564ec448fd992d33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2233,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 61,
"path": "/iot-stream-ingestion-demo/src/truck-client/src/main/java/com/hortonworks/solution/MQTTSensorEventCollector.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.hortonworks.solution;\n\nimport org.apache.log4j.Logger;\nimport org.eclipse.paho.client.mqttv3.MqttClient;\nimport org.eclipse.paho.client.mqttv3.MqttConnectOptions;\nimport org.eclipse.paho.client.mqttv3.MqttException;\nimport org.eclipse.paho.client.mqttv3.MqttMessage;\nimport org.eclipse.paho.client.mqttv3.persist.MemoryPersistence;\n\nimport com.hortonworks.simulator.impl.domain.transport.MobileEyeEvent;\nimport com.hortonworks.simulator.impl.domain.transport.Truck;\n\nimport akka.actor.UntypedActor;\n\npublic class MQTTSensorEventCollector extends UntypedActor {\n\n private MqttClient sampleClient = null;\n private static final String TOPIC = \"truck\";\n private int qos = 2;\n private String broker = \"tcp://localhost:\" + ((Lab.port == null) ? \"1883\" : Lab.port);\n private String clientId = \"TrucksProducer\";\t\n\t\n private Logger logger = Logger.getLogger(this.getClass());\n \n public MQTTSensorEventCollector() throws MqttException {\n sampleClient = new MqttClient(broker, clientId);\n MqttConnectOptions connOpts = new MqttConnectOptions();\n connOpts.setCleanSession(true);\n System.out.println(\"Connecting to MQTT broker: \" + broker);\n sampleClient.connect(connOpts);\n\t \n }\n\n public String topicName(Truck truck) {\n\t return TOPIC + \"/\" + truck.getTruckId() + \"/\" + \"position\";\n }\n \n @Override\n public void onReceive(Object event) throws Exception {\n\tInteger eventKind = MobileEyeEvent.EVENT_KIND_BEHAVIOUR_AND_POSITION;\n\t \n MobileEyeEvent mee = (MobileEyeEvent) event;\n String eventToPass = null;\n if (Lab.format.equals(Lab.JSON)) {\n eventToPass = mee.toJSON(eventKind, Lab.timeResolution);\n } else if (Lab.format.equals(Lab.CSV)) {\n eventToPass = mee.toCSV(eventKind, Lab.timeResolution);\n }\n String driverId = String.valueOf(mee.getTruck().getDriver().getDriverId());\n \n try {\n System.out.println(\"Publishing message to MQTT: \"+eventToPass);\n MqttMessage message = new MqttMessage(eventToPass.getBytes());\n message.setQos(qos);\n sampleClient.publish(topicName(mee.getTruck()), message);\n \t\n } catch (MqttException e) {\n logger.error(\"Error sending event[\" + eventToPass + \"] to MQTT topic\", e);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.7481991052627563,
"alphanum_fraction": 0.7537655830383301,
"avg_line_length": 48.25806427001953,
"blob_id": "a5a5f1ab8f88380001b9ec5ee26eb605a76b6825",
"content_id": "9241cea7677f317a4b371288d637884c58ce4d3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3054,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 62,
"path": "/ukoug-2017-kafka/src/kafka-streams-truck/src/main/java/KafkaStreamsExample.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "import java.util.Properties;\n\nimport org.apache.kafka.clients.consumer.ConsumerConfig;\nimport org.apache.kafka.common.serialization.Serde;\nimport org.apache.kafka.common.serialization.Serdes;\nimport org.apache.kafka.streams.KafkaStreams;\nimport org.apache.kafka.streams.KeyValue;\nimport org.apache.kafka.streams.StreamsConfig;\nimport org.apache.kafka.streams.kstream.ForeachAction;\nimport org.apache.kafka.streams.kstream.KStream;\nimport org.apache.kafka.streams.kstream.KStreamBuilder;\nimport org.apache.kafka.streams.kstream.Predicate;\n\npublic class KafkaStreamsExample {\n\n\tpublic static void main(String[] args) {\n\t\t// Serializers/deserializers (serde) for String and Long types\n\t\tfinal Serde<String> stringSerde = Serdes.String();\n\t\tfinal Serde<Long> longSerde = Serdes.Long();\n\n\t final String bootstrapServers = args.length > 0 ? args[0] : \"192.168.69.134:9092\";\n\t final Properties streamsConfiguration = new Properties();\n\t // Give the Streams application a unique name. The name must be unique in the Kafka cluster\n\t // against which the application is run.\n\t streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, \"kafka-streams-example\");\n\t streamsConfiguration.put(StreamsConfig.CLIENT_ID_CONFIG, \"kafka-streams-example-client\");\n\t // Where to find Kafka broker(s).\n\t streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);\n\t streamsConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, \"latest\");\n\t // Specify default (de)serializers for record keys and for record values.\n\t streamsConfiguration.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());\n\t streamsConfiguration.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());\t\t\n\t\t\n\t \n\t\t// In the subsequent lines we define the processing topology of the Streams application.\n\t\tfinal KStreamBuilder builder = new KStreamBuilder();\n\t\t// Construct a `KStream` from the input topic \"streams-plaintext-input\", where message values\n\t\t// represent lines of text (for the sake of this example, we ignore whatever may be stored\n\t\t// in the message keys).\n\t\tKStream<String, String> source = builder.stream(stringSerde, stringSerde, \"truck_position\");\n\t\t\n\t\tKStream<String, TruckPosition> positions = source.map((key,value) -> new KeyValue<>(key, TruckPosition.create(value)));\n\t\t\n\t\tKStream<String, TruckPosition> filtered = positions.filter(TruckPosition::filterNonNORMAL);\n\t\t\n\t\tfiltered.foreach(new ForeachAction<String, TruckPosition>() {\n\t\t public void apply(String key, TruckPosition value) {\n\t\t System.out.println(key + \": \" + value);\n\t\t }\n\t\t });\n\t\t\n\t\tfiltered.map((key,value) -> new KeyValue<>(key,value._originalRecord)).to(\"dangerous_driving\");\n\n\t\tfinal KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration);\n\t\tstreams.cleanUp();\n\t streams.start();\n\n\t // Add shutdown hook to respond to SIGTERM and gracefully close Kafka Streams\n\t Runtime.getRuntime().addShutdownHook(new Thread(streams::close));\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 32,
"blob_id": "57023ec1fc94c65f940392505427383821bc913c",
"content_id": "82a1b8d8d673e6d709b09e073c4821c3104d2ef6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 2,
"path": "/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# various-demos\nVarious Demos mostly based on docker environments\n"
},
{
"alpha_fraction": 0.7194244861602783,
"alphanum_fraction": 0.7482014298439026,
"avg_line_length": 26.600000381469727,
"blob_id": "9f3dc83d3973b7ca77df799446b2a7edbe194ca5",
"content_id": "764e96096f32d3cde2590db2db34c828c9585655",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 139,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 5,
"path": "/bidirectional-integration-oracle-kafka/scripts/kafka-connect/stop-connect-jdbc-source.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"removing JDBC Source Connector\"\n\ncurl -X \"DELETE\" \"http://$DOCKER_HOST_IP:8083/connectors/jdbc-orderprocessing-source\"\n\n"
},
{
"alpha_fraction": 0.588942289352417,
"alphanum_fraction": 0.6442307829856873,
"avg_line_length": 17.130434036254883,
"blob_id": "58b510dfb7fbf93f376d8826e8207212eaed1197",
"content_id": "f2b7a973ed7d93fd3da36e42fe0c76d829b7d20f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 23,
"path": "/event-sourcing/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Event Sourcing\n\nCreate a new account\n\n```\ncurl -X POST -H 'Content-Type: application/json' -i http://analyticsplatform:8080/api/accounts --data '{\n \"id\": \"abc983\",\n \"forCustomerId\": \"983\",\n \"accountType\": \"Savings\"\n}'\n```\n\nDeposit some money\n\n```\ncurl -X PUT -H 'Content-Type: application/json' -i http://localhost:8080/api/deposit/abc983 --data '{\n \"id\": \"abc983\",\n \"amount\": \"200\"\n}'\n```\n\n\njava -jar target/"
},
{
"alpha_fraction": 0.7438111901283264,
"alphanum_fraction": 0.754749596118927,
"avg_line_length": 19.42352867126465,
"blob_id": "60d114e9cb1303d260d2a39a29059956f747232e",
"content_id": "c08d80cc195a6398716d76fdf5202de773e24b82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1737,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 85,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/model/Account.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.model;\n\nimport java.io.Serializable;\nimport java.math.BigDecimal;\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport org.springframework.data.annotation.Id;\n\n/**\n * @author saikatkar1\n *\n */\npublic class Account implements Serializable{\n\t\n\t/**\n\t * \n\t */\n\tprivate static final long serialVersionUID = -683252464592318120L;\n\n\t@Id\n\tprivate String accountNo;\n\t\n\tprivate BigDecimal balance;\n\tprivate String forCustomerId;\n\tprivate String accountType;\n\tprivate String lastUpdated;\n\t\n\tprivate List<Transaction> transactions;\n\t\n\tpublic Account(String accountNo, BigDecimal balance, String forCustomerId, String accountType,String lastUpdated) {\n\t\tsuper();\n\t\tthis.accountNo = accountNo;\n\t\tthis.balance = balance;\n\t\tthis.forCustomerId = forCustomerId;\n\t\tthis.lastUpdated = lastUpdated;\n\t\tthis.accountType = accountType;\n\t\tthis.transactions = new ArrayList<Transaction>();\n\t}\n\n\tpublic String getAccountNo() {\n\t\treturn accountNo;\n\t}\n\n\tpublic void setAccountNo(String accountNo) {\n\t\tthis.accountNo = accountNo;\n\t}\n\n\tpublic BigDecimal getBalance() {\n\t\treturn balance;\n\t}\n\n\tpublic void setBalance(BigDecimal balance) {\n\t\tthis.balance = balance;\n\t}\n\n\tpublic String getForCustomerId() {\n\t\treturn forCustomerId;\n\t}\n\n\tpublic void setForCustomerId(String forCustomerId) {\n\t\tthis.forCustomerId = forCustomerId;\n\t}\n\n\tpublic String getAccountType() {\n\t\treturn accountType;\n\t}\n\n\tpublic void setAccountType(String accountType) {\n\t\tthis.accountType = accountType;\n\t}\n\n\tpublic String getLastUpdated() {\n\t\treturn lastUpdated;\n\t}\n\n\tpublic void setLastUpdated(String lastUpdated) {\n\t\tthis.lastUpdated = lastUpdated;\n\t}\n\n\tpublic void appendTransaction(Transaction transaction) {\n\t\ttransactions.add(transaction);\n\t}\n\n}\n\n"
},
{
"alpha_fraction": 0.5722599625587463,
"alphanum_fraction": 0.5853540301322937,
"avg_line_length": 27.24657440185547,
"blob_id": "fb1ff56d51e0d6815de897dbbc7b5aec6e32b4e3",
"content_id": "b99ed84020efc09d3adc85acf87dbaea2f97cfda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2062,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 73,
"path": "/streaming-visualization/consume-json-tweet.py",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "import json\nimport requests\n\nfrom subprocess import check_output\n\nfrom confluent_kafka import Consumer, KafkaError\n\n# Get your API_KEY from your settings file ('~/.tipboard/settings-local.py').\nAPI_KEY = 'api-key-here'\n# Change '127.0.0.1:7272' to the address of your Tipboard instance.\nAPI_URL = 'http://localhost:80/api/v0.1/{}'.format(API_KEY)\nAPI_URL_PUSH = '/'.join((API_URL, 'push'))\nAPI_URL_TILECONFIG = '/'.join((API_URL, 'tileconfig'))\n\n\ndef prepare_for_text(data):\n # Listing needs data as a list of lists (whose elements are pairs\n # component-percentage), so we have to prepare it.\n # data = {\"text\": \"<text_content>\"}\n data_prepared = []\n for k in data:\n data_prepared.append(k)\n data_prepared = {'text': data_prepared}\n return data_prepared\n\n\ndef main():\n # Tile 'pie001' (pie chart)\n # (let's say we want to show issues count for project 'Tipboard' grouped by\n # issue status i.e. 'Resolved', 'In Progress', 'Open', 'Closed' etc.)\n TILE_NAME = 'text'\n TILE_KEY = 'tweet'\n\n c = Consumer({\n 'bootstrap.servers': 'streamingplatform:9092',\n 'group.id': 'test-consumer-group',\n 'default.topic.config': {\n 'auto.offset.reset': 'largest'\n }\n })\n\n c.subscribe(['DASH_TWEETS_S'])\n\n while True:\n msg = c.poll(1.0)\n\n if msg is None:\n continue\n if msg.error():\n if msg.error().code() == KafkaError._PARTITION_EOF:\n continue\n else:\n print(msg.error())\n break\n\n data = json.loads(msg.value().decode('utf-8'))\n data_selected = data.get('TEXT')\n # print (data_selected)\n data_prepared = prepare_for_text(data_selected)\n data_jsoned = json.dumps(data_prepared)\n data_to_push = {\n 'tile': TILE_NAME,\n 'key': TILE_KEY,\n 'data': data_jsoned,\n }\n resp = requests.post(API_URL_PUSH, data=data_to_push)\n if resp.status_code != 200:\n print(resp.text)\n return\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5496229529380798,
"alphanum_fraction": 0.5770739316940308,
"avg_line_length": 20.8092098236084,
"blob_id": "bc5bbedec040435588f393ed1c6009cec1c5f7d1",
"content_id": "f506cb683b956138ce69c1ccade837a7eaf17470",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3315,
"license_type": "no_license",
"max_line_length": 234,
"num_lines": 152,
"path": "/IoTHub-to-GraphQL/Azure IoT Hub to Hasura GraphQL.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Azure IoT Hub to Hasura GraphQL\n\n## IoT Simulator\n\n```\nmkdir conf\n```\n\n```\nnano conf/config-azureiothub.json\n```\n\n```\n{\n\t\"host\": \"gusiothub2.azure-devices.net\",\n\t\"deviceId\": \"test\",\n\t\"accessKey\": \"T5aTVz79LDH7kSKpyMLqSh4Fm9ChQdL2VDtQIWsnkik=\",\n\t\"clients\": 1,\n\t\"seed\": 123456\n}\n```\n\n```\nnano conf/devices-def.json\n```\n\nadd the following definition\n\n```\n[\n {\n \"type\":\"simple\",\n \"uuid\":\"\",\n \"topic\":\"sensor-reading\",\n \"partition\":\"{$uuid}\",\n \"sampling\":{\"type\":\"fixed\", \"interval\":4000},\n \"copy\":1,\n \"sensors\":[\n {\"type\":\"string\", \"name\":\"sensorType\", \"cycle\":[\"temperature\"]},\n {\"type\":\"dev.timestamp\", \"name\":\"ts\", \"format\":\"yyyy-MM-dd'T'HH:mm:ss.SSSZ\"},\n {\"type\":\"dev.uuid\", \"name\":\"uuid\"},\n {\"type\":\"double_walk\", \"name\":\"temp\", \"min\":10, \"max\":20},\n {\"type\":\"double_walk\", \"name\":\"level\", \"values\": [1.1,3.2,8.3,9.4]},\n {\"type\":\"string\", \"name\":\"category\", \"random\": [\"a\",\"b\",\"c\",\"d\",\"e\",\"f\",\"g\",\"h\",\"i\",\"j\",\"k\",\"l\",\"m\",\"n\",\"o\"]}\n ]\n }\n]\n```\n\n```\ndocker run --rm -v $PWD/conf/config-azureiothub.json:/conf/config-azureiothub.json -v $PWD/conf/devices-def.json:/conf/devices-def.json trivadis/iot-simulator -t azureiothub -cf /conf/config-azureiothub.json -df /conf/devices-def.json\n```\n\n## Avro Message\n\nRaw message\n\n```\n{\n \"sensorType\": \"temperature\",\n \"ts\": \"2021-02-08T16:49:03.218+0000\",\n \"uuid\": \"ce2730fc-f2f0-4268-bbdc-706404ee4ef2\",\n \"temp\": 11.7258,\n \"level\": 0.4966,\n \"category\": \"a\"\n}\n```\n\nThe following Avro schema for the message is available in the `src/main/meta` maven project. \n\n```\n{\n \"type\": \"record\",\n \"name\": \"SensorReadingV1\",\n \"namespace\": \"com.trivadis.demo\",\n \"doc\": \"This is a sample Avro schema for a sensor reading\",\n \"fields\": [\n {\n \"name\": \"sensorType\",\n \"type\": \"string\"\n },\n {\n \"name\": \"ts\",\n \"logicalType\": \"timestamp\",\n \"type\": \"long\"\n },\n {\n \"name\": \"uuid\",\n \"type\": \"string\"\n },\n {\n \"name\": \"temp\",\n \"type\": \"double\"\n },\n {\n \"name\": \"level\",\n \"type\": \"double\"\n },\n {\n \"name\": \"category\",\n \"type\": \"string\"\n }\n ]\n}\n```\n\nUsing maven we can easily register it in the schema registry using: \n\n```\nmvn schema:registry:register\n```\n\nFor that to work the alias `dataplatform` has to be set in `/etc/hosts`.\n\nIt is registered under subject `sensor-reading-v1-value`.\n\nUse the Schema-Registry UI to view it: <http://dataplatform:28102>\n\n## Kafka\n\nCreate the topic where the message from IoT Hub should be moved to.\n\n```\ndocker exec -ti kafka-1 kafka-topics --zookeeper zookeeper-1:2181 --create --topic sensor-reading-v1 --replication-factor 3 --partitions 8 \n```\n\n## StreamSets\n\n\nImport the StreamSets data flow in `src/streamsets`.\n\n## PostgreSQL\n\n```\nDROP TABLE IF EXISTS \"readings\";\nCREATE TABLE \"sensor_readings\".\"readings\" (\n \"uuid\" text NOT NULL,\n \"ts\" timestamptz NOT NULL,\n \"temp\" numeric NOT NULL,\n \"level\" numeric NOT NULL,\n \"category\" text NOT NULL,\n CONSTRAINT \"readings_pkey\" PRIMARY KEY (\"uuid\", \"ts\")\n) WITH (oids = false);\n\n\nDROP TABLE IF EXISTS \"sensor\";\nCREATE TABLE \"sensor_readings\".\"sensor\" (\n \"uuid\" text NOT NULL,\n \"name\" text NOT NULL,\n CONSTRAINT \"sensor_pkey\" PRIMARY KEY (\"uuid\")\n) WITH (oids = false);\n```\n"
},
{
"alpha_fraction": 0.6820831894874573,
"alphanum_fraction": 0.6972960829734802,
"avg_line_length": 30.314783096313477,
"blob_id": "aa73a175f58d685d2a36e00945ebf66d95ab4655",
"content_id": "8ffb78710c0e5bfebc6dc7d6d1893552d0ab3b72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 18014,
"license_type": "no_license",
"max_line_length": 355,
"num_lines": 575,
"path": "/streaming-visualization/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Streaming Visualization Demo\n\nThis demo shows various solutions for implementing streaming visualization applications using Kafka Connect / KSQL as the stream data integration and stream analytics stack. \n\n## Running on AWS Lightstail\n\n```\n# Install Docker \ncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -\nadd-apt-repository \"deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable edge\"\napt-get install -y docker-ce\nsudo usermod -a -G docker $USER\n\n# Install Docker Compose\ncurl -L \"https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)\" -o /usr/local/bin/docker-compose\nchmod +x /usr/local/bin/docker-compose\nln -s /usr/local/bin/docker-compose /usr/bin/docker-compose\n\n# Install wget\napt-get install -y wget\n\n# Install kafkacat\napt-get install -y kafkacat\n\n# Prepare Environment\nexport PUBLIC_IP=$(curl ipinfo.io/ip)\nexport DOCKER_HOST_IP=$(ip addr show eth0 | grep \"inet\\b\" | awk '{print $2}' | cut -d/ -f1)\nmkdir analyticsplatform\ncd analyticsplatform\nwget https://raw.githubusercontent.com/gschmutz/various-demos/master/streaming-visualization/docker/docker-compose.yml\n\n# Setup Kafka Connect Twitter Connector\nmkdir kafka-connect\ncd kafka-connect\nwget https://github.com/jcustenborder/kafka-connect-twitter/releases/download/0.2.26/kafka-connect-twitter-0.2.26.tar.gz\nmkdir kafka-connect-twitter-0.2.26\ntar -zxvf kafka-connect-twitter-0.2.26.tar.gz -C kafka-connect-twitter-0.2.26\nrm kafka-connect-jms-1.2.1-2.1.0-all.tar.gz\n\n# Startup Environment\ndocker-compose up\n```\n\n\n## Prepare\n\n### Create topics\n\nCreate the topic `tweet-raw-v1` and `tweet-term-v1`\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic tweet-raw-v1 --replication-factor 3 --partitions 8\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic tweet-term-v1 --replication-factor 3 --partitions 8\n```\n\n### Setup Kafka Connector for Twitter Source\n\nGet the Kafka Connector from here: <https://github.com/jcustenborder/kafka-connect-twitter>\n\n```\ncd kafka-connect\nmkdir kafka-connect-twitter-0.2.26\ncd kafka-connect-twitter-0.2.26\n```\n\n```\nwget https://github.com/jcustenborder/kafka-connect-twitter/releases/download/0.2.26/kafka-connect-twitter-0.2.26.tar.gz\n```\n\n```\ntar -xvzf kafka-connect-twitter-0.2.26.tar.gz\nrm kafka-connect-twitter-0.2.26.tar.gz\n```\n\nCreate the connector \n\n```\nconnector.class=com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector\nprocess.deletes=false\nfilter.keywords=#vdz19 \nkafka.status.topic=tweet-raw-v1\ntasks.max=1\ntwitter.oauth.consumerKey=wd6ohwZCiS4qI4woGqPnNhEd4\ntwitter.oauth.consumerSecret=XXXXXX\ntwitter.oauth.accessToken=18898576-2Qzx1PlhCL2ZkCBVZvX0epzKOSoOaZ9ABaeL7ndd5\ntwitter.oauth.accessTokenSecret=XXXXXX\n\n\n# do not use transform currently\n#transforms.createKey.type=org.apache.kafka.connect.transforms.ValueToKey\n#transforms=createKey,extractInt\n#transforms.extractInt.type=org.apache.kafka.connect.transforms.ExtractField$Key\n#transforms.extractInt.field=Id\n#transforms.createKey.fields=Id\n```\n\n\n```\n{\n \"connector.class\": \"com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector\",\n \"tasks.max\": \"1\",\n \"twitter.oauth.consumerKey\": \"wd6ohwZCiS4qI4woGqPnNhEd4\",\n \"twitter.oauth.consumerSecret\": \"3OUIaM4VmzDLyldB377lawzmupebgQqp7Bb5PrAPVLVUI28PRs\",\n \"twitter.oauth.accessToken\": \"18898576-2Qzx1PlhCL2ZkCBVZvX0epzKOSoOaZ9ABaeL7ndd5\",\n \"twitter.oauth.accessTokenSecret\": \"ZzAOSAVDXoojMqcViZ7q9TmOFvqPzx1WjoN0Wvd5tPYZD\",\n \"process.deletes\": \"false\",\n \"filter.keywords\": \"trump\",\n \"kafka.status.topic\": \"tweet-raw-v2\",\n \"transforms.createKey.type\": \"org.apache.kafka.connect.transforms.ValueToKey\",\n \"transforms\": \"createKey,extractInt\",\n \"transforms.createKey.fields\": \"Id\",\n \"transforms.extractInt.type\": \"org.apache.kafka.connect.transforms.ExtractField$Key\",\n \"transforms.extractInt.field\": \"Id\"\n}\n```\n\n\n\n## KSQL Stream Processing\n\nFirst let's connect to the KSQL CLI\n\n```\ndocker run --rm -it --network docker_default confluentinc/cp-ksql-cli:5.3.0 http://ksql-server-1:8088\n```\n\nnext we will create the following streams and tables\n\n* `tweet_raw_s` - the raw tweets in a hierarchical format\n* `tweet_s` - the id, text and screenName of all the tweets\n* `tweet_with_geo_s` - the raw tweets in a hierarchical format\n* `tweet_term_s` - all the terms for all the tweets (hashtag and word)\n* `tweet_terms_per_min_t` - a table with the terms per minute\n* `tweet_terms_per_hour_t` - a table with the terms per hour\n* `tweet_count_by_min_t` - the number of tweets by minute\n* `tweet_count_by_hour_t` - the number of tweets by hour\n\n### Register Raw Topic Stream\n\nFirst we create a new stream `tweet_raw_s` which holds all the raw tweets:\n\n```\nCREATE STREAM tweet_raw_s WITH (KAFKA_TOPIC='tweet-raw-v1', VALUE_FORMAT='AVRO');\n```\n\n### Tweets\n\n```\nCREATE STREAM tweet_s WITH (KAFKA_TOPIC='tweet-v1', VALUE_FORMAT='AVRO', PARTITIONS=8)\nAS SELECT id\n,\tcreatedAt\n,\ttext\n,\tuser->screenName\nFROM tweet_raw_s;\n```\n\n### Tweets with Geo Location\n\n```\nCREATE STREAM tweet_with_geo_s WITH (KAFKA_TOPIC='tweet-with-geo-v1', VALUE_FORMAT='AVRO', PARTITIONS=8)\nAS SELECT id\n,\ttext\n,\tuser->screenName\n,\tgeolocation->latitude\n,\tgeolocation->longitude\nFROM tweet_raw_s\nWHERE geolocation->latitude is not null;\n```\n\n### Create the Term Stream\n\nRegister the Avro Schema for terms as subject `tweet-term-v1-value`\n\n```\n{\n \"type\": \"record\",\n \"name\": \"TweetTerms\",\n \"namespace\": \"com.trivadis.twitter.sample\",\n \"fields\": [\n {\n \"name\": \"id\",\n \"type\": [\n \"null\",\n {\n \"type\": \"long\",\n \"connect.doc\": \"Returns the id of the status\"\n }\n ],\n \"doc\": \"Returns the id of the status\",\n \"default\": null\n },\n {\n \"name\": \"lang\",\n \"type\": [\n \"null\",\n {\n \"type\": \"string\",\n \"connect.doc\": \"The language as returned in the Tweet\"\n }\n ],\n \"doc\": \"The language as returned in the Tweet\",\n \"default\": null\n }, \n {\n \"name\": \"term\",\n \"type\": [\n \"null\",\n {\n \"type\": \"string\",\n \"connect.doc\": \"Returns the term found in the tweet\"\n }\n ],\n \"doc\": \"Returns the id of the status\",\n \"default\": null\n }, \n {\n \"name\": \"type\",\n \"type\": [\n \"null\",\n {\n \"type\": \"string\",\n \"connect.doc\": \"Returns the type of the term (hashtag, url, word, username)\"\n }\n ],\n \"doc\": \"Returns the id of the status\",\n \"default\": null\n } \n ],\n \"connect.doc\": \"Twitter Terms\"\n}\n```\n\nNow create the empty stream. We will then using multiple inserts statements to publish to the stream.\n\n```\nDROP STREAM tweet_term_s;\n\nCREATE STREAM tweet_term_s \\\nWITH (kafka_topic='tweet-term-v1', \\\nvalue_format='AVRO');\n```\n\n#### Populate Hashtags\n\nHashtags are organized as an array. Currently there is no way in KSQL to dynamically read over the arrays, all you can do is access it by index. \n\n```\nSELECT id, LCASE(hashtagentities[0]->text) from tweet_raw_s where hashtagentities[0] IS NOT NULL;\n```\n\nThe code below currently handles a max of 6 hashtags per Tweet:\n \n```\nINSERT INTO tweet_term_s \\\nSELECT id, lang, TRIM(LCASE(hashtagentities[0]->text)) as term, 'hashtag' as type from tweet_raw_s where hashtagentities[0] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, TRIM(LCASE(hashtagentities[1]->text)) as term, 'hashtag' as type from tweet_raw_s where hashtagentities[1] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, TRIM(LCASE(hashtagentities[2]->text)) as term, 'hashtag' as type from tweet_raw_s where hashtagentities[2] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, TRIM(LCASE(hashtagentities[3]->text)) as term, 'hashtag' as type from tweet_raw_s where hashtagentities[3] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, TRIM(LCASE(hashtagentities[4]->text)) as term, 'hashtag' as type from tweet_raw_s where hashtagentities[4] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, TRIM(LCASE(hashtagentities[5]->text)) as term, 'hashtag' as type from tweet_raw_s where hashtagentities[5] IS NOT NULL;\n```\n\n\n```\nselect type, collect_set (term) from tweet_term_s window tumbling (size 30 seconds) group by type;\n```\n\n```\nselect type, histogram (term) from tweet_term_s window tumbling (size 30 seconds) group by type;\n```\n\n#### Populate Words\n\n```\nCREATE STREAM tweet_words_s WITH (kafka_topic='tweet-words-v1', value_format='AVRO', PARTITIONS=8)\nAS SELECT id, lang, removestopwords(split(LCASE(text), ' ')) AS word FROM tweet_raw_s WHERE lang = 'en' or lang = 'de';\n```\n\n```\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[0]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[0] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[1]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[1] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[2]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[2] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[3]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[3] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[4]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[4] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[5]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[5] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[6]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[6] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[7]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[7] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[8]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[8] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[9]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[9] IS NOT NULL;\n\nINSERT INTO tweet_term_s \\\nSELECT id, lang, replacestring(replacestring(replacestring(replacestring(TRIM(word[10]),'#',''),'@',''),'.',''),':','') as term, 'word' as type from tweet_words_s where word[10] IS NOT NULL;\n```\n\n### Terms per 1 minute\n\n```\nDROP TABLE tweet_terms_per_min_t;\n\nCREATE TABLE tweet_terms_per_min_t AS\nSELECT windowstart() windowStart, windowend() windowEnd, type, term, count(*) terms_per_min FROM tweet_term_s window TUMBLING (SIZE 60 seconds) where lang = 'en' or lang = 'de' GROUP by type, term;\n```\n\n```\nSELECT TIMESTAMPTOSTRING(windowStart, 'yyyy-MM-dd HH:mm:ss.SSS'), TIMESTAMPTOSTRING(windowEnd, 'yyyy-MM-dd HH:mm:ss.SSS'), terms_per_min, term FROM tweet_terms_per_min_t WHERE type = 'hashtag';\n```\n\n### Terms per 1 hour\n\n```\nDROP TABLE tweet_terms_per_hour_t;\n\nCREATE TABLE tweet_terms_per_hour_t AS\nSELECT windowstart() windowStart, windowend() windowEnd, type, term, count(*) terms_per_hour FROM tweet_term_s window TUMBLING (SIZE 60 minutes) where lang = 'en' or lang = 'de' GROUP by type, term;\n```\n\n### Top 10 Terms per hour (this does not work!)\n\n\n```\nDROP STREAM tweet_terms_per_hour_s;\n\nCREATE STREAM tweet_terms_per_hour_s WITH (KAFKA_TOPIC='TWEET_TERMS_PER_HOUR_T', VALUE_FORMAT='AVRO');\n```\n\n```\nDROP TABLE tweet_hashtag_top_1hour_t;\n\nCREATE TABLE tweet_hashtag_top_1hour_t\nAS SELECT type, windowstart, topkdistinct (CONCAT(LEFTPAD(CAST(terms_per_hour AS VARCHAR),5,'0'), term),10) top_10, topkdistinct (terms_per_hour,20) top_20 from tweet_terms_per_hour_s group by type, windowstart;\n```\n\n\n\n### Tweets Total\n\nFirst we create a stream with an \"artifical\" group id so that we can count on \"one single group\" later, as KSQL does not allow an aggregate operation without a group by operation. \n\n```\nDROP STREAM tweet_count_s\n\nCREATE STREAM tweet_count_s\nAS SELECT 1 AS groupId, id, \nTIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') AS rowtimefull, SUBSTRING(TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS'),0,11) as rowtimedate, SUBSTRING(TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS'),11,6) as rowtimeHHMM\nFROM tweet_raw_s;\n```\n\nnow with this stream we can count by hour\n\n```\nDROP TABLE tweet_count_by_hour_t;\n\nCREATE TABLE tweet_count_by_hour_t\nAS SELECT groupid, windowstart() windowStart, windowend() windowEnd, COUNT(*) tweets_per_hour FROM tweet_count_s WINDOW TUMBLING (SIZE 1 HOUR) GROUP BY groupid;\n```\n\nand count by minute\n\n```\nDROP TABLE tweet_count_by_min_t;\n\nCREATE TABLE tweet_count_by_min_t\nAS SELECT groupid, windowstart() windowStart, windowend() windowEnd, count(*) tweets_per_min FROM tweet_count_s \nWINDOW TUMBLING (size 60 seconds) GROUP BY groupid; \n```\n\n\n## Tweets per user\n\nDue to <https://github.com/confluentinc/ksql/pull/2076> this is not possible (should work in 5.2):\n\n```\nSELECT user->screenname, count(*) AS tweet_count_by_user FROM tweet_raw_s GROUP BY user->screenname having count(*) > 1;\n```\n\nAs a workaround first create a stream where the user is unpacked and then used\n\n```\nDROP STREAM tweet_tweets_with_user_s;\n\nCREATE STREAM tweet_tweets_with_user_s\nAS SELECT id, text, user->screenname as user_screenname, createdat from tweet_raw_s;\n\n\nCREATE TABLE tweet_by_user_t\nAS SELECT user_screenname, COUNT(*) nof_tweets_by_user FROM tweet_tweets_with_user_s GROUP BY user_screenname having count(*) > 1;\n```\n## Arcadia Data\n\nNavigate to <http://127.0.0.1:7999/arc/apps/login?next=/arc/apps/> and login as user `admin` with password `admin`.\n\n## Tipboard Dashboard\n\n```\ndocker run --rm -it --network docker_default confluentinc/cp-ksql-cli:5.3.0 http://ksql-server-1:8088\n```\n\n<http://allegro.tech/tipboard/>\n<https://tipboard.readthedocs.io>\n\n```\nDROP TABLE dash_hashtag_top10_5min_t;\n\nCREATE TABLE dash_hashtag_top10_5min_t WITH (VALUE_FORMAT = 'JSON')\nAS SELECT TIMESTAMPTOSTRING(windowstart(), 'yyyy-MM-dd HH:mm:ss.SSS'), type, term, count(*) TOP_10 from tweet_term_s window hopping (size 5 minutes, advance by 1 minute) where lang = 'en' and type = 'hashtag' group by type, term;\n```\n\n```\nCREATE TABLE dash_tweet_count_t WITH (VALUE_FORMAT = 'JSON')\nAS SELECT groupid, COUNT(*) nof_tweets FROM tweet_count_s GROUP BY groupid;\n```\n\n```\nDROP TABLE dash_tweet_count_by_hour_t;\n\nCREATE TABLE dash_tweet_count_by_hour_t WITH (VALUE_FORMAT = 'JSON')\nAS SELECT groupid, COUNT(*) nof_tweets FROM tweet_count_s WINDOW TUMBLING (SIZE 1 HOUR) GROUP BY groupid;\n```\n\n\n\n```\nDROP STREAM dash_tweets_s;\n\nCREATE STREAM dash_tweets_s WITH (VALUE_FORMAT = 'JSON')\nAS SELECT id, user->screenName screenName, text FROM tweet_raw_s;\n```\n\n\n```\npython consume-json-nof-tweets.py \n```\n\n```\ncurl -X POST http://localhost:80/api/v0.1/api-key-here/push -d \"tile=just_value\" -d \"key=nof_tweets\" -d 'data={\"title\": \"Number of Tweets:\", \"description\": \"(1 hour)\", \"just-value\": \"23\"}'\n```\n\n```\ncurl -X POST http://localhost:80/api/v0.1/api-key-here/push -d \"tile=text\" -d \"key=tweet\" -d 'data={\"text\": \"The need for data-driven organizations and cultures isn’t going away. Firms need to take a hard look at why these initiatives are failing to gain business traction: https://t.co/V7iNuoEfB0 via @harvardbiz #BigData #DataDiscovery #DataAnalytics\"}'\n```\n\n```\ncurl -X POST http://localhost:80/api/v0.1/api-key-here/push -d \"tile=listing\" -d \"key=top_hashtags\" -d 'data={\"items\": [\"bigdata\", \"machinelearning\", \"ksql\", \"kafka\"]}'\n```\n\n\n## Slack\n\n```\ndocker run --rm -it --network docker_default confluentinc/cp-ksql-cli:5.3.0 http://ksql-server-1:8088\n```\n\n```\nDROP STREAM slack_notify_s;\n\nCREATE STREAM slack_notify_s WITH (KAFKA_TOPIC='slack-notify', VALUE_FORMAT='AVRO')\nAS SELECT id, text, user->screenname as user_screenname, createdat from tweet_raw_s\nwhere user->screenname = 'gschmutz' or user->screenname = 'JavaZone';\n```\n\n```\ncd docker/kafka-connect\n\nmkdir kafka-connect-slack\ncd kafka-connect-slack\n```\n\n```\nwget https://www.dropbox.com/s/hmfmora6yvpz9sy/kafka-connect-slack-sink-0.1-SNAPSHOT.jar?dl=0\nmv kafka-connect-slack-sink-0.1-SNAPSHOT.jar\\?dl\\=0 kafka-connect-slack-sink-0.1-SNAPSHOT.jar\n```\n\n# Demo\n\n## Slack\n\n```\nkafkacat -b analyticsplatform -t tweet-raw-v1 -o end -q\n```\n\n```\nkafkacat -b analyticsplatform -t slack-notify -o end -q\n```\n```\nTesting once more my demo for today's talk on \"Streaming Visualization\" at JavaZone 2019: showing integration between #KafkaConnect and #Slack #kafka #javazone\n```\n\n```\nLive Demo \"Streaming Visualization\": Now showing integration with #KafkaConnect and #Slack #bigdata2019 #javazone\n```\n\n## Tipboard\n\n```\nLive Demo \"Streaming Visualization\": Now showing integration with #Kafka and #Tipboard #vdz19\n```\n\n## Arcadia Data\n\n```\nSELECT * FROM tweet_raw_s;\n```\n\n```\nDESCRIBE tweet_raw_s;\n```\n\n```\nSELECT text, user->screenname FROM tweet_raw_s;\n```\n\n```\nDESCRIBE tweet_term_s;\n```\n\n```\nSELECT * FROM tweet_term_s;\n```\n\n```\nSELECT windowstart() windowStart, windowend() windowEnd, type, term, count(*) terms_per_min \nFROM tweet_term_s \nWINDOW TUMBLING (SIZE 60 seconds) \nWHERE lang = 'en' or lang = 'de' \nGROUP by type, term;\n```\n\n\n```\nLive Demo \"Streaming Visualization\": Now showing integration with #Kafka, #KSQL and #ArcadiaData #javazone\n```\n\n## REST API\n\n```\ncurl -X POST -H 'Content-Type: application/vnd.ksql.v1+json' \u000b -i http://analyticsplatform:18088/query --data '{\r\n \"ksql\": \"SELECT text FROM tweet_raw_s;\",\r\n \"streamsProperties\": {\r\n \"ksql.streams.auto.offset.reset\": \"latest\"\r\n }\r\n}'\n```\n"
},
{
"alpha_fraction": 0.658682644367218,
"alphanum_fraction": 0.7485029697418213,
"avg_line_length": 54.66666793823242,
"blob_id": "2b470415446d3350901575a3b839493f69db0ff2",
"content_id": "bd9afb6dc1b774c69f7895e09f4d272bf3803eca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 3,
"path": "/rb-dr-case/vmware/scripts/create-topic.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n/home/gus/confluent-5.0.1/bin/kafka-topics --zookeeper zookeeper-1:2181, zookeeper-4:2185 --create --topic sequence --partitions 8 --replication-factor 4\n"
},
{
"alpha_fraction": 0.7284595370292664,
"alphanum_fraction": 0.7428198456764221,
"avg_line_length": 37.20000076293945,
"blob_id": "fd03e438fef2af9db19c32134017436237117a3c",
"content_id": "10c6c96cd9c0df215a6b54e4c92034d888ffd511",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "SQL",
"length_bytes": 766,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 20,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/testdata/customer_t.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nINSERT INTO customer_t (ID,FIRST_NAME,LAST_NAME,TITLE,NOTIFICATION_ON,EMAIL,SLACK_HANDLE,TWITTER_HANDLE) \n\tVALUES (101,'Peter','Muster','Mr',NULL,'peter.muster@somecomp.com',NULL,NULL);\n\nCOMMIT;\n\n\n"
},
{
"alpha_fraction": 0.6928104758262634,
"alphanum_fraction": 0.741830050945282,
"avg_line_length": 18.70967674255371,
"blob_id": "4b4cd03012e9c6a68fec1830e553f7295f400a0d",
"content_id": "8b6cd09765c141465dad2cd15715318f30e22183",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 612,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 31,
"path": "/rb-dr-case/vmware/scripts/cleanup.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncd ../data\nrm -R *\nmkdir kafka-1\nmkdir kafka-2\nmkdir kafka-3\nmkdir kafka-4\nmkdir kafka-5\nmkdir kafka-6\n\nmkdir -p zookeeper-1/data\nmkdir -p zookeeper-2/data\nmkdir -p zookeeper-3/data\nmkdir -p zookeeper-4/data\nmkdir -p zookeeper-5/data\nmkdir -p zookeeper-6/data\n\nmkdir -p zookeeper-1/log\nmkdir -p zookeeper-2/log\nmkdir -p zookeeper-3/log\nmkdir -p zookeeper-4/log\nmkdir -p zookeeper-5/log\nmkdir -p zookeeper-6/log\n\necho 1 > zookeeper-1/data/myid\necho 2 > zookeeper-2/data/myid\necho 3 > zookeeper-3/data/myid\necho 4 > zookeeper-4/data/myid\necho 5 > zookeeper-5/data/myid\necho 6 > zookeeper-6/data/myid\n\n"
},
{
"alpha_fraction": 0.7186234593391418,
"alphanum_fraction": 0.7186234593391418,
"avg_line_length": 16.678571701049805,
"blob_id": "092dc23a3290d4195cb345d13796d1f9d393d27d",
"content_id": "4bf461d6f157e70fa371ecc5b02548c7f0e490f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 28,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/event/MoneyWithdrawnEvent.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.event;\n\nimport java.math.BigDecimal;\n\npublic class MoneyWithdrawnEvent extends BaseEvent<String> {\n\tprivate BigDecimal amount;\n\tprivate long when;\n\t\n\tpublic MoneyWithdrawnEvent(String __eventId, String id, BigDecimal amount, long when) {\n\t\tsuper(__eventId, id);\n\t\tthis.amount = amount;\n\t\tthis.when = when;\n\t}\n\t\n\tpublic MoneyWithdrawnEvent() {\n\t\t\n\t}\n\n\tpublic BigDecimal getAmount() {\n\t\treturn amount;\n\t}\n\n\tpublic long getWhen() {\n\t\treturn when;\n\t}\n\t\n\t\n}"
},
{
"alpha_fraction": 0.6200645565986633,
"alphanum_fraction": 0.6240377426147461,
"avg_line_length": 33.13559341430664,
"blob_id": "7bc7c91d3accacc06bc4bccacebc8faf027e9297",
"content_id": "db75b023d5c23a594dbace706745076a7f99507e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 4027,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 118,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/package/order_pck.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz\t@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nCREATE OR REPLACE PACKAGE order_pck \nAS\n\nPROCEDURE insert_order (in_order_obj IN order_objt);\nPROCEDURE update_status(in_order_id IN NUMBER, in_new_status IN INTEGER);\n\nEND;\n/\n\ncreate or replace PACKAGE BODY order_pck\nIS\n\nPROCEDURE send_aq_event(in_order_id IN NUMBER)\nIS\n l_enqueue_options sys.dbms_aq.enqueue_options_t;\n l_message_props sys.dbms_aq.message_properties_t;\n l_jms_message sys.aq$_jms_text_message := sys.aq$_jms_text_message.construct;\n l_msgid RAW(16);\n\n order_json CLOB;\n\n\t\tCURSOR order_sel\n\t\tIS\n\t\tSELECT json_object('orderId' VALUE po.id,\n\t\t 'orderDate' VALUE po.order_date,\n\t\t 'orderMode' VALUE po.order_mode,\n\t\t 'orderStatus' VALUE DECODE (po.order_status,2,'PROCESSING'),\n\t\t 'totalPrice' VALUE po.order_total,\n\t\t 'customer' VALUE\n\t\t json_object('firstName' VALUE cu.first_name,\n\t\t 'lastName' VALUE cu.last_name,\n\t\t 'emailAddress' VALUE cu.email),\n\t\t 'items' VALUE (SELECT json_arrayagg(\n\t\t json_object('itemNumber' VALUE li.id,\n\t\t 'Product' VALUE\n\t\t json_object('id' VALUE li.product_id,\n\t\t 'name' VALUE li.product_name,\n\t\t 'unitPrice' VALUE li.unit_price),\n\t\t 'quantity' VALUE li.quantity))\n\t\t FROM order_item_t li WHERE po.id = li.order_id),\n\t\t 'offset' VALUE TO_CHAR(po.modified_at, 'YYYYMMDDHH24MISS'))\n\t\tFROM order_t po LEFT JOIN customer_t cu ON (po.customer_id = cu.id)\n\t\tWHERE po.id = in_order_id;\n\nBEGIN\n\n OPEN order_sel;\n FETCH order_sel INTO order_json;\n\n l_jms_message.clear_properties();\n l_message_props.correlation := sys_guid;\n l_message_props.priority := 3;\n l_message_props.expiration := 5;\n l_jms_message.set_string_property('msg_type', 'test');\n l_jms_message.set_text(order_json);\n dbms_aq.enqueue(queue_name => 'order_aq',\n enqueue_options => l_enqueue_options,\n message_properties => l_message_props,\n payload => l_jms_message,\n msgid => l_msgid);\nEND send_aq_event;\n\n\nPROCEDURE insert_order (in_order_obj IN order_objt)\nIS\nBEGIN\n\tINSERT INTO order_t (id, order_date, order_mode, customer_id, order_status, order_total, promotion_id)\n\tVALUES (in_order_obj.id,\n\t\t\tin_order_obj.order_date,\n\t\t\tin_order_obj.order_mode,\n\t\t\tin_order_obj.customer_id,\n\t\t\tin_order_obj.order_status,\n\t\t\tin_order_obj.order_total,\n\t\t\tin_order_obj.promotion_id);\n\n\tFOR i IN 1 .. in_order_obj.order_item_coll.count()\n\tLOOP\n\t\tINSERT INTO order_item_t (id, order_id, product_id, product_name, unit_price, quantity)\n\t\tVALUES (in_order_obj.order_item_coll(i).id, \n\t\t\t in_order_obj.id,\n\t\t\t\tin_order_obj.order_item_coll(i).product_id, \n\t\t\t\tin_order_obj.order_item_coll(i).product_name,\n\t\t\t\tin_order_obj.order_item_coll(i).unit_price, \n\t\t\t\tin_order_obj.order_item_coll(i).quantity);\n\tEND LOOP;\n\n -- publish event to AQ\n send_aq_event(in_order_obj.id);\nEND insert_order;\n\nPROCEDURE update_status(in_order_id IN NUMBER, in_new_status IN INTEGER)\nIS\nBEGIN\n UPDATE order_t SET order_status = in_new_status\n WHERE id = in_order_id;\n\n -- publish event to AQ\n send_aq_event(in_order_id);\nEND update_status;\n\nEND;\n/"
},
{
"alpha_fraction": 0.7595959305763245,
"alphanum_fraction": 0.760606050491333,
"avg_line_length": 20.06382942199707,
"blob_id": "89dee6046ddab18957a95039a3e0595a17927aca",
"content_id": "cacf0e381cc2d7253cd7a79ff3b41b12b075ccbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 990,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 47,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/event/AccountCreatedEvent.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.event;\n\nimport java.math.BigDecimal;\n\n/**\n * @author saikatkar1\n *\n */\npublic class AccountCreatedEvent extends BaseEvent<String> {\n\n\tprivate String forCustomerId;\n\tprivate String accountType;\n\tprivate BigDecimal balance;\n\tpublic AccountCreatedEvent(String __eventId, String id,String forCustomerId,String accountType,BigDecimal balance) {\n\t\tsuper(__eventId, id);\n\t\tthis.setForCustomerId(forCustomerId);\n\t\tthis.setBalance(balance);\n\t\tthis.setAccountType(accountType);\n\t}\n\t\n\tpublic AccountCreatedEvent() {}\n\n\tpublic String getForCustomerId() {\n\t\treturn forCustomerId;\n\t}\n\n\tpublic void setForCustomerId(String forCustomerId) {\n\t\tthis.forCustomerId = forCustomerId;\n\t}\n\n\tpublic String getAccountType() {\n\t\treturn accountType;\n\t}\n\n\tpublic void setAccountType(String accountType) {\n\t\tthis.accountType = accountType;\n\t}\n\n\tpublic BigDecimal getBalance() {\n\t\treturn balance;\n\t}\n\n\tpublic void setBalance(BigDecimal balance) {\n\t\tthis.balance = balance;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6659367084503174,
"alphanum_fraction": 0.6983874440193176,
"avg_line_length": 22.688678741455078,
"blob_id": "984ffbb1e9009b3d7dc6d88ac047b2f54577440d",
"content_id": "23a9986b09ceb211bcca1b4828503c7ef5e2940a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5023,
"license_type": "no_license",
"max_line_length": 546,
"num_lines": 212,
"path": "/iot-stream-ingestion-demo/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# IoT Streaming Data Ingestion Demo\n\n## Prepare Environment\n\nThe environment we are going to use is based on docker containers. In order to easily start the multiple containers, we are going to use Docker Compose. \n\n### Docker Compose\n\nFor Kafka to work in this Docker Compose setup, two envrionment variables are necessary, which are configured with the IP address of the docker machine as well as the Public IP of the docker machine. \n\nYou can add them to `/etc/environment` (without export) to make them persistent:\n\n```\nexport DOCKER_HOST_IP=192.168.25.136\nexport PUBLIC_IP=192.168.25.136\n```\nAlso export the local folder of this GitHub project as the SAMPLE_HOME variable. \n\n```\nexport SAMPLE_HOME=/mnt/hgfs/git/gschmutz/various-demos/iot-truck-demo\n```\n\n\nAdd `streamingplatform` as an alias to the `/etc/hosts` file on the machine you are using to run the demo on. \n\n```\n192.168.25.136\tstreamingplatform\n```\n\nNow we can start the environment. Navigate to the `docker` sub-folder inside the SAMPLE_HOME folder. \n\n```\ncd $SAMPLE_HOME/docker\n```\n\nand start the vaious docker containers \n\n```\ndocker-compose up -d\n```\n\nto show the logs of the containers\n\n```\ndocker-compose logs -f\n```\n\n\n### Creating Kafka Topics\n\nThe Kafka cluster is configured with `auto.topic.create.enable` set to `false`. Therefore we first have to create all the necessary topics, using the `kafka-topics` command line utility of Apache Kafka. \n\nWe can easily get access to the `kafka-topics` CLI by navigating into one of the containers for the 3 Kafka Borkers. Let's use `broker-1`\n\n```\ndocker exec -ti docker_broker-1_1 bash\n```\n\nFirst lets see all existing topics\n\n```\nkafka-topics --zookeeper zookeeper:2181 --list\n```\n\nAnd now create the topics `truck_position` and `truck_driver`.\n\n```\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_position --partitions 8 --replication-factor 2\n\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_driver --partitions 8 --replication-factor 2 --config cleanup.policy=compact --config segment.ms=100 --config delete.retention.ms=100 --config min.cleanable.dirty.ratio=0.001\n```\n\n## Truck Client\n\n### Producing to Kafka\n\nProduce the IoT Truck events to topic `truck_position` and `truck_driving_info`.\n\nIn a new terminal window, move to the `truck-client` folder and start the truck simulator:\n\n```\ncd $SAMPLE_HOME/src/truck-client\nmvn exec:java -Dexec.args=\"-s KAFKA -f JSON -m COMBINE\"\n```\n\nFirst start the kafka-console-consumer on the Kafka topic `truck_position`:\n\n```\ndocker exec -ti docker_broker-1_1 bash\n```\n \n```\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_position\n```\n\n```\nkafkacat -b streamingplatform:9092 -t truck_position\nkafkacat -b streamingplatform:9092 -t truck_driving_info\n```\n\n### Producing to MQTT\n\nIn a new \n\n```\ncd $SAMPLE_HOME/src/truck-client\nmvn exec:java -Dexec.args=\"-s MQTT -f JSON -p 1883 -m COMBINE -t millisec\"\n```\n\nin MQTT.fx suscribe to `truck/+/position` \n\n## Apache NiFi\n\n```\nhttp://streamingplatform:28080/nifi\n```\n\nBroker URI\ntcp://192.168.69.136:1883\n\nClientID\nconsumer1\n\nTopic Filter\ntruck/+/position\n\nMessage Size\n1000\n\nKafka\n\nKafka Brokers\n192.168.69.135:9092\n\nTopic Name\ntruck_position\n\nMasking wit ReplaceText Processor\n\nSearch Value\ndriverId\":(.*?),\n\nReplacement Value\ndriverId\":NN,\n\n## StreamSets Data Collector\n\nNavigate to <http://streamingplatform:18630/>\n\nBroker URL: tcp://mosquitto:1883\nTopic Filter: truck/+/position\n\n\nSchema Registry URI: http://schema-registry:8081\nSchema ID: truck-position-value\n\nSchema Registry UI:\n\nhttp://192.168.69.136:8002\n\n\nRegister new schema\n\n```\ncurl -vs --stderr - -XPOST -i -H \"Content-Type: application/vnd.schemaregistry.v1+json\" --data '{\"schema\":\"{\\\"type\\\":\\\"record\\\",\\\"name\\\":\\\"truckMovement\\\",\\\"namespace\\\":\\\"com.landoop\\\",\\\"doc\\\":\\\"This is an Avro schema for Truck Movements\\\",\\\"fields\\\":[{\\\"name\\\":\\\"truckid\\\",\\\"type\\\":\\\"string\\\"},{\\\"name\\\":\\\"driverid\\\",\\\"type\\\":\\\"string\\\"},{\\\"name\\\":\\\"eventtype\\\",\\\"type\\\":\\\"string\\\"},{\\\"name\\\":\\\"latitude\\\",\\\"type\\\":\\\"string\\\"},{\\\"name\\\":\\\"longitude\\\",\\\"type\\\":\\\"string\\\"}]}\"}' http://streamingplatform:8081/subjects/truck-position-value/versions\n\n{\n \"type\": \"record\",\n \"name\": \"truckMovement\",\n \"namespace\": \"com.trivadis.truck\",\n \"doc\": \"This is an Avro schema for Truck Movements\",\n \"fields\": [\n {\n \"name\": \"truckid\",\n \"type\": \"string\"\n },\n {\n \"name\": \"driverid\",\n \"type\": \"string\"\n },\n {\n \"name\": \"eventtype\",\n \"type\": \"string\"\n },\n {\n \"name\": \"latitude\",\n \"type\": \"string\"\n },\n {\n \"name\": \"longitude\",\n \"type\": \"string\"\n }\n ]\n}\n```\n\n## Kafka Connect\n\nAdd and start the MQTT connector (make sure that consumer is still running):\n\n```\ncd $SAMPLE_HOME/docker\n./configure-connect-mqtt.sh\n```\n\nNavigate to the [Kafka Connect UI](http://streamingplatform:8003) to see the connector configured and running.\n\nYou can remove the connector using the following command\n\n```\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/mqtt-source\"\n```\n\n"
},
{
"alpha_fraction": 0.7876147031784058,
"alphanum_fraction": 0.7885321378707886,
"avg_line_length": 35.349998474121094,
"blob_id": "4d3cf9303ce3189ef21a3777a27a78b181b0790c",
"content_id": "bcf40a391c32aa202f21600b406aae310d91896b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2180,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 60,
"path": "/event-sourcing/kafka-streams/account-ms/src/main/java/com/trivadis/sample/kafkastreams/ms/account/api/AccountAPI.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.kafkastreams.ms.account.api;\n\nimport java.math.BigDecimal;\nimport java.text.ParseException;\nimport java.util.concurrent.CompletableFuture;\n\nimport javax.validation.Valid;\n\nimport org.slf4j.Logger;\nimport org.slf4j.LoggerFactory;\nimport org.springframework.beans.factory.annotation.Autowired;\nimport org.springframework.transaction.annotation.Transactional;\nimport org.springframework.web.bind.annotation.PathVariable;\nimport org.springframework.web.bind.annotation.PutMapping;\nimport org.springframework.web.bind.annotation.RequestBody;\nimport org.springframework.web.bind.annotation.RequestMapping;\nimport org.springframework.web.bind.annotation.RequestMethod;\nimport org.springframework.web.bind.annotation.RestController;\n\nimport com.google.common.base.Preconditions;\n\nimport com.trivadis.sample.kafkastreams.ms.account.aggregate.AccountAggregate;\nimport com.trivadis.sample.kafkastreams.ms.account.command.AccountCreateCommand;\nimport com.trivadis.sample.kafkastreams.ms.account.command.DepositMoneyCommand;\nimport com.trivadis.sample.kafkastreams.ms.account.command.WithdrawMoneyCommand;\n\n@RestController()\n@RequestMapping(\"/api\")\npublic class AccountAPI {\n\n private static final Logger LOGGER = LoggerFactory.getLogger(AccountAPI.class);\n\n @Autowired\n private AccountAggregate accountAggregate;\n \n @RequestMapping(value= \"/accounts\",\n method = RequestMethod.POST,\n consumes = \"application/json\") \n @Transactional\n public void postCustomer(@RequestBody @Valid AccountCreateCommand command) throws ParseException {\n Preconditions.checkNotNull(command);\n \n accountAggregate.performAccountCreateCommand(command);\n }\n \n\t@PutMapping(path = \"/deposit/{accountId}\")\n\tpublic void deposit(@RequestBody DepositMoneyCommand command) {\n Preconditions.checkNotNull(command);\n \n accountAggregate.performDepositMoneyCommand(command);\n\t}\n\n\t@PutMapping(path = \"/withdraw/{accountId}\")\n\tpublic void deposit(@RequestBody WithdrawMoneyCommand command) {\n Preconditions.checkNotNull(command);\n \n accountAggregate.performWithdrawMoneyCommand(command);\n\t}\n\n}"
},
{
"alpha_fraction": 0.7967644333839417,
"alphanum_fraction": 0.8003033399581909,
"avg_line_length": 41.085105895996094,
"blob_id": "ffbd5f05740fd5690adc136fad0a74f0abf5dd25",
"content_id": "9babcdf8a4c53db1c4589a41f569e879669412ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1978,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 47,
"path": "/kafka-geofencing/kafka-streams/geo-utils/src/main/java/com/thyssenkrupp/tkse/DistanceUtil.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.thyssenkrupp.tkse;\n\nimport org.geotools.geometry.jts.JTS;\nimport org.geotools.referencing.GeodeticCalculator;\nimport org.geotools.referencing.crs.DefaultGeographicCRS;\nimport org.locationtech.jts.geom.Coordinate;\nimport org.locationtech.jts.geom.Geometry;\nimport org.locationtech.jts.geom.Point;\nimport org.locationtech.jts.geom.Polygon;\nimport org.locationtech.jts.operation.distance.DistanceOp;\nimport org.opengis.referencing.crs.CoordinateReferenceSystem;\nimport org.opengis.referencing.operation.TransformException;\n\npublic class DistanceUtil {\n\n\tprivate static CoordinateReferenceSystem crs = DefaultGeographicCRS.WGS84;\n\n\tpublic static Coordinate findClosest(Point spot, Geometry geometryToFindClosest) {\n\t\tCoordinate closest = DistanceOp.nearestPoints(geometryToFindClosest, spot)[0];\n\t\treturn closest;\n\t}\n\t\n\tpublic static double calculateDistanceInMeters(Coordinate start, Coordinate end) throws TransformException {\n\t\tGeodeticCalculator gc = new GeodeticCalculator(crs);\n\t\tgc.setStartingPosition(JTS.toDirectPosition(start, crs));\n\t\tgc.setDestinationPosition(JTS.toDirectPosition(end, crs));\n\t\tdouble distanceInMeters = gc.getOrthodromicDistance();\n\t\treturn distanceInMeters;\n\t}\n\t\n\tpublic static double calculateDistanceToPolygon(Point spot, Polygon polygon) throws TransformException {\n\n\t\tCoordinate closestInBox = DistanceOp.nearestPoints(polygon, spot)[0];\n\t\tdouble distance = calculateDistanceInMeters(spot.getCoordinate(), closestInBox);\n\t\t\n\t\tif (distance == 0) {\n\t\t\t// If distance is null, the point is located inside the polygon.\n\t\t\t// We then calculate the polygon's boundary (i.e. only the outer line),...\n\t\t\tGeometry polygonBoundary = polygon.getBoundary();\n\t\t\t// ...calculate the distance to the corresponding closest points\n\t\t\tCoordinate closestOnBorder = DistanceOp.nearestPoints(polygonBoundary, spot)[0];\n\t\t\tdistance = calculateDistanceInMeters(spot.getCoordinate(), closestOnBorder);\n\t\t\tdistance = distance * -1;\n\t\t}\n\t\treturn distance;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6028382778167725,
"alphanum_fraction": 0.6500099897384644,
"avg_line_length": 27.75287437438965,
"blob_id": "deff7425b827a4a8d7bf96b27a91885cc6d0707e",
"content_id": "6e4b62217093c8b158672a92b0ad187997d19b40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 5003,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 174,
"path": "/atlas/amundsen-atlas/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "version: '2.1'\nservices:\n zookeeper-1:\n image: confluentinc/cp-zookeeper:5.3.0\n container_name: zookeeper-1\n ports:\n - \"2181:2181\"\n environment:\n ZOOKEEPER_CLIENT_PORT: 2181\n ZOOKEEPER_TICK_TIME: 2000\n restart: always\n\n broker-1:\n image: confluentinc/cp-kafka:5.3.0\n container_name: broker-1\n depends_on:\n - zookeeper-1\n ports:\n - \"9092:9092\"\n environment:\n KAFKA_BROKER_ID: 1\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9092'\n# KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9994\n restart: always\n\n kafka-setup:\n image: confluentinc/cp-kafka:5.3.0\n hostname: kafka-setup\n container_name: kafka-setup\n depends_on:\n - broker-1\n - zookeeper-1\n command: \"bash -c 'echo Waiting for Kafka to be ready... && \\\n cub kafka-ready -b broker-1:9092 1 120 && \\\n kafka-topics --create --if-not-exists --zookeeper zookeeper-1:2181 --partitions 1 --replication-factor 1 --topic ATLAS_HOOK && \\\n kafka-topics --create --if-not-exists --zookeeper zookeeper-1:2181 --partitions 1 --replication-factor 1 --topic ATLAS_ENTITIES'\"\n environment:\n # The following settings are listed here only to satisfy the image's requirements.\n # We override the image's `command` anyways, hence this container will not start a broker.\n KAFKA_BROKER_ID: ignored\n KAFKA_ZOOKEEPER_CONNECT: ignored\n \n schema-registry:\n image: confluentinc/cp-schema-registry:5.3.0\n hostname: schema-registry\n container_name: schema-registry\n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"8089:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry\n SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper-1:2181'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always\n\n schema-registry-ui:\n image: landoop/schema-registry-ui\n container_name: schema-registry-ui\n depends_on:\n - broker-1\n - schema-registry\n ports:\n - \"28002:8000\"\n environment:\n SCHEMAREGISTRY_URL: 'http://${PUBLIC_IP}:8089'\n restart: always\n\n kafka-manager:\n image: trivadis/kafka-manager\n container_name: kafka-manager\n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"29000:9000\"\n environment:\n ZK_HOSTS: 'zookeeper-1:2181'\n APPLICATION_SECRET: 'letmein'\n restart: always\n\n # Apache Atlas with Cassandra and Elasticsearch Backend Configuration (for JanusGraph)\n\n atlas:\n image: trivadis/apache-atlas:2.0.0\n container_name: atlas\n ports:\n - 21000:21000\n environment:\n - ATLAS_PROVISION_EXAMPLES=true\n volumes:\n - ./conf/atlas-application.properties:/opt/atlas/conf/atlas-application.properties\n depends_on:\n - zookeeper-1\n - broker-1\n - kafka-setup\n - cassandra\n restart: always\n\n cassandra:\n image: cassandra:3\n container_name: cassandra\n ports:\n - \"9042:9042\"\n - \"9160:9160\"\n environment:\n - CASSANDRA_START_RPC=true\n restart: always\n\n elasticsearch:\n image: docker.elastic.co/elasticsearch/elasticsearch:6.6.0\n container_name: elasticsearch\n environment:\n - \"ES_JAVA_OPTS=-Xms512m -Xmx512m\"\n - \"http.host=0.0.0.0\"\n - \"network.host=0.0.0.0\"\n - \"transport.host=127.0.0.1\"\n - \"cluster.name=docker-cluster\"\n - \"xpack.security.enabled=false\"\n - \"discovery.zen.minimum_master_nodes=1\"\n ports:\n - \"9200:9200\"\n restart: always\n\n amundsenfrontend:\n image: amundsendev/amundsen-frontend:latest\n container_name: amundsenfrontend\n depends_on:\n - amundsenmetadata\n - amundsensearch\n ports:\n - 5000:5000\n environment:\n - METADATASERVICE_BASE=http://amundsenmetadata:5000\n - SEARCHSERVICE_BASE=http://amundsensearch:5000\n restart: always\n\n amundsensearch:\n image: amundsendev/amundsen-search:latest\n container_name: amundsensearch\n ports:\n - 5001:5000\n depends_on:\n - elasticsearch\n environment:\n - CREDENTIALS_PROXY_USER=admin\n - CREDENTIALS_PROXY_PASSWORD=admin\n - PROXY_ENDPOINT=atlas:21000\n - PROXY_CLIENT=ATLAS\n restart: always\n\n amundsenmetadata:\n image: amundsendev/amundsen-metadata:latest\n container_name: amundsenmetadata\n depends_on:\n - atlas\n ports:\n - 5002:5000\n environment:\n - CREDENTIALS_PROXY_USER=admin\n - CREDENTIALS_PROXY_PASSWORD=admin\n - PROXY_HOST=atlas\n - PROXY_PORT=21000\n - PROXY_CLIENT=ATLAS\n restart: always\n"
},
{
"alpha_fraction": 0.7247371077537537,
"alphanum_fraction": 0.7331961393356323,
"avg_line_length": 29.587411880493164,
"blob_id": "5ecfa86f981a028cb4a2cd545a64646730b783ad",
"content_id": "e67113528b9f5698f8a297a56f78b3a022fbe7a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4374,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 143,
"path": "/avro-vs-protobuf/avro/java/avro-encoding/src/test/java/com/trivadis/avro/demo/TestAvroV1.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.avro.demo;\n\nimport static org.junit.Assert.assertEquals;\n\nimport java.io.ByteArrayInputStream;\nimport java.io.ByteArrayOutputStream;\nimport java.io.File;\nimport java.io.FileInputStream;\nimport java.io.FileOutputStream;\nimport java.io.IOException;\nimport java.io.Writer;\nimport java.nio.file.Files;\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport org.apache.avro.Schema;\nimport org.apache.avro.file.CodecFactory;\nimport org.apache.avro.file.DataFileConstants;\nimport org.apache.avro.file.DataFileReader;\nimport org.apache.avro.file.DataFileWriter;\nimport org.apache.avro.generic.GenericData;\nimport org.apache.avro.generic.GenericDatumReader;\nimport org.apache.avro.generic.GenericRecord;\nimport org.apache.avro.io.BinaryDecoder;\nimport org.apache.avro.io.BinaryEncoder;\nimport org.apache.avro.io.DatumReader;\nimport org.apache.avro.io.DatumWriter;\nimport org.apache.avro.io.DecoderFactory;\nimport org.apache.avro.io.EncoderFactory;\nimport org.apache.avro.io.JsonEncoder;\nimport org.apache.avro.specific.SpecificDatumReader;\nimport org.apache.avro.specific.SpecificDatumWriter;\nimport org.apache.avro.specific.SpecificRecord;\nimport org.joda.time.LocalDate;\nimport org.joda.time.format.DateTimeFormatter;\nimport org.junit.Test;\n\nimport com.trivadis.avro.person.v1.Address;\nimport com.trivadis.avro.person.v1.Person;\nimport com.trivadis.avro.person.v1.TitleEnum;\n\npublic class TestAvroV1 {\n\n\tprivate final static String CONTAINER_FILE_NAME_V1 = \"../../data/encoding_v1.0.avro\";\n\tprivate final static String BIN_FILE_NAME_V1 = \"../../data/encoding_v1.0.bin\";\n\t\t\n\t@Test\n\tpublic void testWriteToBinaryFileV1() throws IOException {\n\t\tList<CharSequence> skills = new ArrayList<>();\n\t\t\n\t\tskills.add(\"Avro\");\n\t\tskills.add(\"Protobuf\");\n\t\tskills.add(\"Kafka\");\t\n\t\t\n\t\tPerson person = Person.newBuilder().setId(1842)\n\t\t\t\t\t.setName(\"Guido Schmutz\")\n\t\t\t\t\t.setSkills(skills).build();\n\n\t\tSystem.out.println(person);\n\t\t\n\t\tFileOutputStream fos = new FileOutputStream(BIN_FILE_NAME_V1);\n\t\tByteArrayOutputStream out = new ByteArrayOutputStream();\n\t\tBinaryEncoder encoder = EncoderFactory.get().binaryEncoder(out, null);\n\t\tDatumWriter<Person> writer = new SpecificDatumWriter<Person>(Person.getClassSchema());\n\n\t\twriter.write(person, encoder);\n\t\tencoder.flush();\n\t\tout.close();\n\t\tbyte[] serializedBytes = out.toByteArray();\n\n\t\tfos.write(serializedBytes);\n\t\t\n\t}\n\t\n\t@Test\n\tpublic void testSpecificReadFromBinaryFileV1() throws IOException {\n\t\tDatumReader<Person> datumReader = new SpecificDatumReader<Person>(Person.class);\n\t\tbyte[] bytes = Files.readAllBytes(new File(BIN_FILE_NAME_V1).toPath());\n\n\t\tBinaryDecoder decoder = DecoderFactory.get().binaryDecoder(bytes, null);\n\t\tPerson person = datumReader.read(null, decoder);\n\t\t\n\t\tSystem.out.println(person);\n\t}\n\n\t@Test\n\tpublic void testWriteToContainerFileV1() throws IOException {\n\t\tList<Person> persons = new ArrayList<Person>();\n\t\tList<CharSequence> skills = new ArrayList<>();\n\t\t\n\t\tskills.add(\"Avro\");\n\t\tskills.add(\"Protobuf\");\n\t\tskills.add(\"Kafka\");\t\n\t\t\n\t\tPerson person1 = Person.newBuilder().setId(1842)\n\t\t\t\t\t.setName(\"Guido Schmutz\")\n\t\t\t\t\t.setSkills(skills).build();\n\t\tfor (int i = 1; i<100; i++) {\n\t\t\tpersons.add(person1);\n\t\t}\n\n\t\tfinal DatumWriter<Person> datumWriter = new SpecificDatumWriter<>(Person.class);\n\t\tfinal DataFileWriter<Person> dataFileWriter = new DataFileWriter<>(datumWriter);\n\n\t\ttry {\n\t\t dataFileWriter.create(persons.get(0).getSchema(), new File(CONTAINER_FILE_NAME_V1));\n\t\t \n\t\t // specify block size\n\t\t dataFileWriter.setSyncInterval(1000);\n\t\t persons.forEach(employee -> {\n\t\t try {\n\t\t dataFileWriter.append(employee);\n\t\t } catch (IOException e) {\n\t\t throw new RuntimeException(e);\n\t\t }\n\n\t\t });\n\t\t} catch (IOException e) {\n\t\t\tthrow new RuntimeException(e);\n\t\t}\n\t\tfinally {\n\t\t dataFileWriter.close();\n\t\t}\t\t\n\n\t}\n\t\t\n\t@Test\n\tpublic void testReadFromContainerFileV1() throws IOException {\n\t\tfinal File file = new File(CONTAINER_FILE_NAME_V1);\n\t\tfinal List<Person> persons = new ArrayList<>();\n\t\tfinal DatumReader<Person> personReader = new SpecificDatumReader<>(Person.SCHEMA$);\n\t\tfinal DataFileReader<Person> dataFileReader = new DataFileReader<>(file, personReader);\n\n\t\twhile (dataFileReader.hasNext()) {\n\t\t persons.add(dataFileReader.next(new Person()));\n\t\t}\n\t\t\n\t\tfor (Person person : persons) {\n\t\t\tSystem.out.println(person);\n\t\t}\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.638248860836029,
"alphanum_fraction": 0.6797235012054443,
"avg_line_length": 16.67346954345703,
"blob_id": "a03270a2cbd997f8f7c43a9b282d4869d5204040",
"content_id": "3ab64969f08d1442e23ffbc67e19370c0010177d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 49,
"path": "/event-sourcing/axon/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Event Sourcing Sample using Axon Framework\n\n## Prepare environment\n\n### Create necessary Kafka topics\n```\ndocker exec -ti broker-1 kafka-topics --zookeeper zookeeper-1:2181 --create --topic account-v1 --replication-factor 3 --partitions 3\n```\n\n### Start services\n```\ncd finance-axon-discovery\nmvn spring-boot:run\n```\n\n```\ncd finance-axon-command\nmvn spring-boot:run\n```\n\n```\ncd finance-axon-query\nmvn spring-boot:run\n```\n\n## Work with the system\n\n<http://localhost:9090/ui>\n\n\n\nCreate a new account\n\n```\ncurl -X POST -H 'Content-Type: application/json' -i http://analyticsplatform:8080/api/accounts --data '{\n \"id\": \"abc983\",\n \"forCustomerId\": \"983\",\n \"accountType\": \"Savings\"\n}'\n```\n\nDeposit some money\n\n```\ncurl -X PUT -H 'Content-Type: application/json' -i http://analyticsplatform:8080/api/deposit/abc983 --data '{\n \"id\": \"abc983\",\n \"amount\": \"200\"\n}'\n```\n\n\n"
},
{
"alpha_fraction": 0.697593092918396,
"alphanum_fraction": 0.7001645565032959,
"avg_line_length": 42.801841735839844,
"blob_id": "951bb70f448254e1c9a7f9f4525daebab83cd04b",
"content_id": "23d71ae51a7b0187e62a0a6d545911ae1a11b375",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 9722,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 217,
"path": "/graph-performance/des-graph-test/src/main/java/com/trivadis/GraphIngestStrategies.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis;\r\n\r\nimport java.io.Serializable;\r\nimport java.util.ArrayList;\r\nimport java.util.HashMap;\r\nimport java.util.List;\r\nimport java.util.Map;\r\nimport java.util.stream.Collectors;\r\n\r\nimport org.apache.commons.lang3.StringUtils;\r\n\r\nimport com.datastax.driver.core.ConsistencyLevel;\r\nimport com.datastax.driver.dse.DseCluster;\r\nimport com.datastax.driver.dse.DseSession;\r\nimport com.datastax.driver.dse.graph.Edge;\r\nimport com.datastax.driver.dse.graph.GraphOptions;\r\nimport com.datastax.driver.dse.graph.Vertex;\r\nimport com.trivadis.domain.Tweet;\r\n\r\npublic class GraphIngestStrategies implements Serializable {\r\n\r\n\tprivate static final long serialVersionUID = 4725813855174838651L;\r\n\r\n\tprivate transient DseSession session = null;\r\n\t\r\n\tprivate String cassandraHost;\r\n\tprivate String cassandraPort;\r\n\tprivate String graphName;\r\n\t\r\n\tprivate Map<Object,Vertex> cache;\r\n\t\r\n\tpublic int cacheHit = 0;\r\n\tpublic int cacheMiss = 0;\r\n\t\r\n\tprivate Object fmtKey(String label, String id) {\r\n\t\treturn label + \":\" + id;\r\n\t}\r\n\t\r\n\tprivate Vertex getFromCache(String label, String id) {\r\n\t\tVertex v = cache.get(fmtKey(label, id));\r\n\t\tif (v != null) { cacheHit++; } else { cacheMiss++; }\r\n\t\treturn v;\r\n\t}\r\n\tprivate void addToCache(String label, String id, Vertex v) {\r\n\t\tcache.put(fmtKey(label,id), v);\r\n\t}\r\n\r\n\tprivate Vertex getFromCache(String label, Long id) {\r\n\t\treturn getFromCache(label, id.toString());\r\n\t}\r\n\tprivate void addToCache(String label, Long id, Vertex v) {\r\n\t\taddToCache(label, id.toString(), v);\r\n\t}\r\n\t\r\n\tpublic void clearCache() {\r\n\t\tcache.clear();\r\n\t\tcacheHit = 0;\r\n\t\tcacheMiss = 0;\r\n\t}\r\n\t\r\n\tpublic GraphIngestStrategies(String cassandraHost, String cassandraPort, String graphName) {\r\n\t\tthis.cassandraHost = cassandraHost;\t\t\t\r\n\t\t DseCluster dseCluster = DseCluster.builder()\r\n\t\t .addContactPoints(StringUtils.split(cassandraHost,\",\"))\r\n\t\t .withGraphOptions(new GraphOptions().setGraphName(graphName)\r\n\t\t\t\t\t\t//.setReadTimeoutMillis(readTimeoutMillis)\r\n\t\t\t\t\t\t.setGraphReadConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM)\r\n\t\t\t\t\t\t.setGraphWriteConsistencyLevel(ConsistencyLevel.ONE))\r\n\t\t .build();\r\n\t\tsession = dseCluster.connect();\r\n\r\n\t\tthis.cassandraPort = cassandraPort;\r\n\t\tthis.graphName = graphName;\r\n\t\t// init cache\r\n\t\tcache = new HashMap<Object,Vertex>();\r\n\t}\r\n\r\n\tpublic DseSession getDseSession() {\r\n\t\treturn session;\r\n\t}\r\n\r\n\t/* ======================= implementation =================================*/\r\n\r\n\t/* (non-Javadoc)\r\n\t * @see com.trivadis.GraphRepository#createTweetAndUsers(com.trivadis.domain.Tweet, boolean, boolean)\r\n\t */\r\n\tpublic void createSingle(Tweet tweetDO, boolean useCustomVertexId) {\r\n\t\tString suffix = (useCustomVertexId ? \"CV\" : \"\");\r\n\r\n\t\tVertex userVertex = VertexHelper.getVertexByLabelAndPropertyKey(session,\r\n\t\t\t\tSocialGraphConstants.TWITTER_USER_VERTEX_LABEL + suffix, \r\n\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getUser().getId());\r\n\t\tif (userVertex == null) {\r\n\t\t\tuserVertex = VertexHelper.createVertex(session,\r\n\t\t\t\tSocialGraphConstants.TWITTER_USER_VERTEX_LABEL + suffix, \r\n\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getUser().getId(), \r\n\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, tweetDO.getUser().getScreenName() != null ? tweetDO.getUser().getScreenName().toLowerCase() : null,\r\n\t\t\t\tSocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getUser().getLanguage() != null ? tweetDO.getUser().getLanguage().toLowerCase() : null,\r\n\t\t\t\tSocialGraphConstants.VERIFIED_PROPERTY_KEY, tweetDO.getUser().getVerified() != null ? tweetDO.getUser().getVerified() : false);\r\n\t\t}\r\n\t\tVertex tweetVertex = VertexHelper.createVertex(session,\r\n\t\t\t\tSocialGraphConstants.TWEET_VERTEX_LABEL + suffix, \r\n\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getId(), \r\n\t\t\t\tSocialGraphConstants.TIME_PROPERTY_KEY, tweetDO.getCreatedAt().toDate().getTime(), \r\n\t\t\t\tSocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getLanguage() != null ? tweetDO.getLanguage().toLowerCase() : null);\r\n\t\t\r\n\t\tEdge publishedBy = VertexHelper.createOrUpdateEdge(session, true, SocialGraphConstants.PUBLISHES_EDGE_LABEL,\r\n\t\t\t\tuserVertex, tweetVertex);\r\n\t\t\r\n\t\tfor (String term : tweetDO.getHashtags()) {\r\n\t\t\tVertex termVertex = VertexHelper.getVertexByLabelAndPropertyKey(session,\r\n\t\t\t\t\tSocialGraphConstants.TERM_VERTEX_LABEL + suffix, \r\n\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, term.toLowerCase());\r\n\t\t\tif (termVertex == null) {\r\n\t\t\t\ttermVertex = VertexHelper.createVertex(session,\r\n\t\t\t\t\tSocialGraphConstants.TERM_VERTEX_LABEL + suffix,\r\n\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, term.toLowerCase(),\r\n\t\t\t\t\tSocialGraphConstants.TYPE_PROPERTY_KEY, \"hashtag\");\r\n\t\t\t}\r\n\t\t\t\r\n\t\t\tEdge replyToEdge = VertexHelper.createOrUpdateEdge(session, true, SocialGraphConstants.USES_EDGE_LABEL,\r\n\t\t\t\t\ttweetVertex, termVertex);\r\n\t\t}\r\n\t\t\r\n\t}\r\n\t\r\n\tpublic void createSinlgeWithCache(Tweet tweetDO, boolean useCustomVertexId) {\r\n\t\tString suffix = (useCustomVertexId ? \"CV\" : \"\");\r\n\r\n\t\tVertex userVertex = getFromCache(SocialGraphConstants.TWITTER_USER_VERTEX_LABEL, tweetDO.getUser().getId());\r\n\t\tif (userVertex == null) {\r\n\t\t\tuserVertex = VertexHelper.getVertexByLabelAndPropertyKey(session,\r\n\t\t\t\t\tSocialGraphConstants.TWITTER_USER_VERTEX_LABEL + suffix, \r\n\t\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getUser().getId());\r\n\t\t\tif (userVertex == null) {\r\n\t\t\t\tuserVertex = VertexHelper.createVertex(session,\r\n\t\t\t\t\tSocialGraphConstants.TWITTER_USER_VERTEX_LABEL + suffix, \r\n\t\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getUser().getId(), \r\n\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, tweetDO.getUser().getScreenName() != null ? tweetDO.getUser().getScreenName().toLowerCase() : null,\r\n\t\t\t\t\tSocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getUser().getLanguage() != null ? tweetDO.getUser().getLanguage().toLowerCase() : null,\r\n\t\t\t\t\tSocialGraphConstants.VERIFIED_PROPERTY_KEY, tweetDO.getUser().getVerified() != null ? tweetDO.getUser().getVerified() : false);\r\n\t\t\t}\r\n\t\t\taddToCache(SocialGraphConstants.TWITTER_USER_VERTEX_LABEL + suffix, tweetDO.getUser().getId(), userVertex);\r\n\t\t} \r\n\t\t\r\n\t\tVertex tweetVertex = VertexHelper.createVertex(session,\r\n\t\t\t\tSocialGraphConstants.TWEET_VERTEX_LABEL + suffix, \r\n\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getId(), \r\n\t\t\t\tSocialGraphConstants.TIME_PROPERTY_KEY, tweetDO.getCreatedAt().toDate().getTime(), \r\n\t\t\t\tSocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getLanguage() != null ? tweetDO.getLanguage().toLowerCase() : null);\r\n\t\t\r\n\t\tEdge publishedBy = VertexHelper.createOrUpdateEdge(session, true, SocialGraphConstants.PUBLISHES_EDGE_LABEL,\r\n\t\t\t\tuserVertex, tweetVertex);\r\n\t\t\r\n\t\tfor (String term : tweetDO.getHashtags()) {\r\n\t\t\tVertex termVertex = getFromCache(SocialGraphConstants.TERM_VERTEX_LABEL + suffix, term.toLowerCase());\r\n\t\t\tif (termVertex == null) {\r\n\t\t\t\ttermVertex = VertexHelper.getVertexByLabelAndPropertyKey(session,\r\n\t\t\t\t\t\tSocialGraphConstants.TERM_VERTEX_LABEL + suffix, \r\n\t\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, term.toLowerCase());\r\n\t\t\t\tif (termVertex == null) {\r\n\t\t\t\t\ttermVertex = VertexHelper.createVertex(session,\r\n\t\t\t\t\t\t\tSocialGraphConstants.TERM_VERTEX_LABEL + suffix,\r\n\t\t\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, term.toLowerCase(),\r\n\t\t\t\t\t\t\tSocialGraphConstants.TYPE_PROPERTY_KEY, \"hashtag\");\r\n\t\t\t\t}\r\n\t\t\t\taddToCache(SocialGraphConstants.TERM_VERTEX_LABEL + suffix, term.toLowerCase(), termVertex);\r\n\t\t\t}\r\n\t\t\t\r\n\t\t\tEdge replyToEdge = VertexHelper.createOrUpdateEdge(session, true, SocialGraphConstants.USES_EDGE_LABEL,\r\n\t\t\t\t\ttweetVertex, termVertex);\r\n\t\t}\r\n\t\t\r\n\t}\r\n\t\r\n\tpublic GraphMetrics createScripted(Tweet tweetDO, boolean useCustomVertexId) {\r\n\t\tDseGraphDynGremlinHelper dyn = new DseGraphDynGremlinHelper(session);\r\n\t\tList<Map<String,Object>> paramsList = null;\r\n\t\t\r\n\t\t// ============================= User =========================================\r\n\t\t\r\n\t\tdyn.addCreateVertex(\"user\", SocialGraphConstants.TWITTER_USER_VERTEX_LABEL\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t, SocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getUser().getIdAsString()\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t, SocialGraphConstants.NAME_PROPERTY_KEY, tweetDO.getUser().getScreenName() != null ? tweetDO.getUser().getScreenName().toLowerCase() : null\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t, SocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getUser().getLanguage() != null ? tweetDO.getUser().getLanguage().toLowerCase() : null\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t, SocialGraphConstants.VERIFIED_PROPERTY_KEY, tweetDO.getUser().getVerified() != null ? tweetDO.getUser().getVerified() : false\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t);\r\n\t\r\n\t\t// ============================= Tweet =========================================\r\n\r\n\t\tdyn.addCreateVertex(\"tweet\", SocialGraphConstants.TWEET_VERTEX_LABEL\r\n\t\t\t\t, SocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getId().toString() \r\n\t\t\t\t, SocialGraphConstants.TIME_PROPERTY_KEY, tweetDO.getCreatedAt().toDate().getTime() \r\n\t\t\t\t, SocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getLanguage() != null ? tweetDO.getLanguage().toLowerCase() : null);\r\n\t\tdyn.addCreateEdge(\"publishes\", \"user\", \"tweet\", SocialGraphConstants.PUBLISHES_EDGE_LABEL);\r\n\t\t\t\t\t\t\t//\t\t, SocialGraphConstants.TIME_PROPERTY_KEY, new DateTime().toDate().getTime());\r\n\r\n\t\t// ============================= Hashtags ======================================\r\n\t\t\r\n\t\tdyn.addCreateVertices(\"term\", \r\n\t\t\t\t\t\t\t\t\tSocialGraphConstants.TERM_VERTEX_LABEL, \r\n\t\t\t\t\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, \r\n\t\t\t\t\t\t\t\t\tnew ArrayList<Object>(tweetDO.getHashtags().stream().map(String::toLowerCase).collect(Collectors.toList())), \r\n\t\t\t\t\t\t\t\t\tSocialGraphConstants.TYPE_PROPERTY_KEY, \"hashtag\");\r\n\t\t\t\r\n\t\tdyn.addCreateEdges(\"usesTerm\", \r\n\t\t\t\t\t\t\t\t\"tweet\", 1, \r\n\t\t\t\t\t\t\t\t\"term\", tweetDO.getHashtags().size(),\r\n\t\t\t\t\t\t\t\tSocialGraphConstants.USES_EDGE_LABEL);\r\n\r\n\t\tdyn.execute(\"createTweetAndUsersImpl\");\r\n\t\t\r\n\t\treturn dyn.getGraphMetrics();\r\n\t}\r\n\r\n\r\n}\r\n"
},
{
"alpha_fraction": 0.732582688331604,
"alphanum_fraction": 0.7543982863426208,
"avg_line_length": 24.836362838745117,
"blob_id": "ac57279742500790752681fc4a5d1bacb7c467c1",
"content_id": "f741b5cdeacabd196fb15878a850e6c6f12f2eb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1421,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 55,
"path": "/data-lake-platform/zaloni/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Zaloni ZDP\n\n## Setup\n\nDeployment Name = trivadiszdp \nDeployment Location = westeurope\n\nTo login to the Azure VM provisioned before:\n\n```\nssh zaloni@zdp502trivadiszdp.westeurope.cloudapp.azure.com\n```\n\nStart ZDP services\n\n```\ncd startup-scripts\n./start-zdp.sh\n```\n\nAfter you are in the azure vm shell you would have to ssh again for ZDP using the following command. \n\n```\nssh root@sandbox-hdp\n```\n\n## Using Zaloni\n\n* ZDP URL: <http://zdp502trivadiszdp.westeurope.cloudapp.azure.com:9090> \n* Ambari URL: <http://zdp502trivadiszdp.westeurope.cloudapp.azure.com:8080> \n* <http://sandbox-hdp.hortonworks.com:18081/>\n\n\n## Open Issues / Questions\n\n### Wizard File Ingest\n\n2. File Wizard can only create a new Entity? \n3. No Lineage shown in File Wizard Ingestion?\n\n### Manual File Ingest\n\n3. If using the Manual File Ingest, I have to create the Entity manually first? What is the correct approach to create an Entity, when using the Manul Ingestion\n4. What is the purpose of Ingesting without an Entity? Does it make sense?\n5. Can I manually ingest from let's say CSV and directly store it as Parquet? Transformation while ingesting? \n\n### Stream Ingestion\n\n1. Stream Ingestion is through Flume? How to configure it?\n2. Stream Ingestion is not \"Entity-based\"?\n2. Sink in a Stream Ingestion can only be SequenceFile?\n\n### Entity Definition\n\n6. Why is an HCatalog_Table Name not changeable on the Entity Technical Information?\n"
},
{
"alpha_fraction": 0.6879505515098572,
"alphanum_fraction": 0.7178167104721069,
"avg_line_length": 34.85185241699219,
"blob_id": "884c4ac9bcc3cf9415e9fc561c2307fb0f77f873",
"content_id": "65889dd3c4f8b50fcbcfc179d08244a9daee99ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 971,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 27,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/table/address_t.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nCREATE TABLE address_t (\n id NUMBER(12) \t\tCONSTRAINT pk_address PRIMARY KEY,\n customer_id NUMBER(12)\t\tNOT NULL CONSTRAINT fk_customer REFERENCES customer_t,\n street VARCHAR2(50) \t\tNOT NULL,\n nr VARCHAR2(10),\n city VARCHAR2(50),\t\t\n postcode VARCHAR2(10),\n country VARCHAR2(50),\n created_at TIMESTAMP(0)\t\t\tNOT NULL,\n modified_at TIMESTAMP(0)\t\tNOT NULL\n);\n\n\n\n"
},
{
"alpha_fraction": 0.6282978057861328,
"alphanum_fraction": 0.6727502942085266,
"avg_line_length": 34.022151947021484,
"blob_id": "28973e10d87b35f292ab57c85a3959dfb499d58a",
"content_id": "d1dbd216c3b106f641b40e65770aacfb2bfe88aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 11068,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 316,
"path": "/streaming-visualization/docker/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "version: \"2.1\"\n\nservices:\n zookeeper-1:\n image: confluentinc/cp-zookeeper:5.3.1\n container_name: zookeeper-1\n ports:\n - \"2181:2181\"\n environment:\n ZOOKEEPER_CLIENT_PORT: 2181\n ZOOKEEPER_TICK_TIME: 2000\n restart: always\n\n broker-1:\n image: confluentinc/cp-kafka:5.3.1\n container_name: broker-1\n depends_on:\n - zookeeper-1\n ports:\n - \"9092:9092\"\n environment:\n KAFKA_BROKER_ID: 1\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${PUBLIC_IP}:9092'\n# KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9994\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9994'\n KAFKA_JMX_HOSTNAME: 'broker-1' \n restart: always\n\n broker-2:\n image: confluentinc/cp-kafka:5.3.1\n container_name: broker-2\n depends_on:\n - zookeeper-1\n ports:\n - \"9093:9093\"\n environment:\n KAFKA_BROKER_ID: 2\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${PUBLIC_IP}:9093'\n# KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9993\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9993'\n KAFKA_JMX_HOSTNAME: 'broker-2' \n restart: always\n\n broker-3:\n image: confluentinc/cp-kafka:5.3.1\n container_name: broker-3\n depends_on:\n - zookeeper-1\n ports:\n - \"9094:9094\"\n environment:\n KAFKA_BROKER_ID: 3\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${PUBLIC_IP}:9094'\n# KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9992\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9992'\n KAFKA_JMX_HOSTNAME: 'broker-3'\n restart: always\n \n schema-registry-1:\n image: confluentinc/cp-schema-registry:5.3.1\n hostname: schema-registry-1\n container_name: schema-registry-1\n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"28030:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry-1\n SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper-1:2181'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always\n \n \n connect-1:\n image: confluentinc/cp-kafka-connect:5.3.1\n container_name: connect-1\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry-1\n ports:\n - \"28013:8083\"\n environment:\n CONNECT_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONNECT_REST_ADVERTISED_HOST_NAME: connect-1\n CONNECT_REST_PORT: 8083\n CONNECT_GROUP_ID: compose-connect-group\n CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs\n CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000\n CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets\n CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status\n CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONNECT_PLUGIN_PATH: \"/usr/share/java,/etc/kafka-connect/custom-plugins\"\n CONNECT_LOG4J_ROOT_LOGLEVEL: INFO\n CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-4.0.0.jar\n AWS_ACCESS_KEY_ID: V42FCGRVMK24JJ8DHUYG\n AWS_SECRET_ACCESS_KEY: bKhWxVF3kQoLY9kFmt91l+tDrEoZjqnWXzY9Eza\n volumes:\n - $PWD/kafka-connect:/etc/kafka-connect/custom-plugins\n restart: always\n\n connect-2:\n image: confluentinc/cp-kafka-connect:5.3.1\n container_name: connect-2\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry-1\n ports:\n - \"28014:8084\"\n environment:\n CONNECT_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONNECT_REST_ADVERTISED_HOST_NAME: connect-2\n CONNECT_REST_PORT: 8084\n CONNECT_GROUP_ID: compose-connect-group\n CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs\n CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000\n CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets\n CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status\n CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONNECT_PLUGIN_PATH: \"/usr/share/java,/etc/kafka-connect/custom-plugins\"\n CONNECT_LOG4J_ROOT_LOGLEVEL: INFO\n CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-4.0.0.jar\n AWS_ACCESS_KEY_ID: V42FCGRVMK24JJ8DHUYG\n AWS_SECRET_ACCESS_KEY: bKhWxVF3kQoLY9kFmt91l+tDrEoZjqnWXzY9Eza\n volumes:\n - $PWD/kafka-connect:/etc/kafka-connect/custom-plugins\n restart: always\n\n ksqldb-server-1:\n image: confluentinc/ksqldb-server:0.6.0\n# image: confluentinc/cp-ksql-server:5.3.1\n hostname: ksqldb-server-1\n container_name: ksqldb-server-1\n ports:\n - \"28031:8088\"\n depends_on:\n - broker-1\n - schema-registry-1\n environment:\n KSQL_CONFIG_DIR: \"/etc/ksql-server\"\n KSQL_APPLICATION_ID: \"tweet-ksql\"\n KSQL_KSQL_EXTENSION_DIR: \"/etc/ksql-server/ext\"\n KSQL_LOG4J_OPTS: \"-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties\"\n KSQL_BOOTSTRAP_SERVERS: \"broker-1:9092,broker-2:9093\"\n KSQL_HOST_NAME: ksqldb-server-1\n KSQL_LISTENERS: http://0.0.0.0:8088\n KSQL_KSQL_SCHEMA_REGISTRY_URL: \"http://schema-registry-1:8081\"\n KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: \"true\"\n KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: \"true\"\n KSQL_KSQL_CONNECT_URL: http://connect-1:8083,http://connect-2:8084\n KSQL_CACHE_MAX_BYTES_BUFFERING: 0\n volumes:\n - $PWD/ksql:/etc/ksql-server/ext \n restart: always\n\n ksqldb-server-2:\n image: confluentinc/ksqldb-server:0.6.0\n# image: confluentinc/cp-ksql-server:5.3.1\n hostname: ksqldb-server-2\n container_name: ksqldb-server-2\n ports:\n - \"28032:8088\"\n depends_on:\n - broker-1\n - schema-registry-1\n environment:\n KSQL_CONFIG_DIR: \"/etc/ksql-server\"\n KSQL_APPLICATION_ID: \"tweet-ksql\"\n KSQL_KSQL_EXTENSION_DIR: \"/etc/ksql-server/ext\"\n KSQL_LOG4J_OPTS: \"-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties\"\n KSQL_BOOTSTRAP_SERVERS: \"broker-1:9092,broker-2:9093\"\n KSQL_HOST_NAME: ksqldb-server-2\n KSQL_LISTENERS: http://0.0.0.0:8088\n KSQL_KSQL_SCHEMA_REGISTRY_URL: \"http://schema-registry-1:8081\"\n KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: \"true\"\n KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: \"true\"\n KSQL_KSQL_CONNECT_URL: http://connect-1:8083,http://connect-2:8084\n KSQL_CACHE_MAX_BYTES_BUFFERING: 0\n volumes:\n - $PWD/ksql:/etc/ksql-server/ext \n restart: always\n\n ksqldb-cli:\n image: confluentinc/ksqldb-cli:0.6.0\n# image: confluentinc/cp-ksql-cli:5.3.1\n container_name: ksqldb-cli\n depends_on:\n - ksqldb-server-1\n - ksqldb-server-2\n entrypoint: /bin/sh\n tty: true\n\n streamsets:\n image: trivadisbds/streamsets-kafka-hadoop-aws\n container_name: streamsets\n ports:\n - \"28029:18630\"\n restart: always\n\n schema-registry-ui:\n image: landoop/schema-registry-ui \n container_name: schema-registry-ui\n depends_on:\n - broker-1\n - schema-registry-1\n ports:\n - \"28039:8000\"\n environment:\n SCHEMAREGISTRY_URL: 'http://${PUBLIC_IP}:28030'\n restart: always\n\n kafka-connect-ui:\n image: landoop/kafka-connect-ui:0.9.7\n container_name: kafka-connect-ui\n ports:\n - \"28038:8000\"\n environment:\n CONNECT_URL: \"http://${PUBLIC_IP}:28013/,http://${PUBLIC_IP}:28014/\"\n PROXY: \"true\"\n depends_on:\n - connect-1\n restart: always\n\n kafka-manager:\n image: trivadis/kafka-manager\n container_name: kafka-manager\n hostname: kafka-manager\n depends_on:\n - zookeeper-1\n - broker-1\n - broker-2\n - broker-3\n ports:\n - \"28044:9000\"\n environment:\n ZK_HOSTS: 'zookeeper-1:2181'\n APPLICATION_SECRET: 'letmein'\n restart: always\n \n kafkahq:\n image: tchiotludo/kafkahq\n container_name: kafkahq\n ports:\n - 28042:8080\n environment:\n KAFKAHQ_CONFIGURATION: |\n kafkahq:\n connections:\n docker-kafka-server:\n properties:\n bootstrap.servers: \"broker-1:9092,broker-2:9093\"\n schema-registry:\n url: \"http://schema-registry-1:8081\"\n connect:\n url: \"http://connect-1:8083\"\n depends_on:\n - broker-1\n restart: always\n\n\n \n adminer:\n image: adminer\n container_name: adminer\n ports:\n - 28081:8080\n\n postgresql:\n image: mujz/pagila\n container_name: postgresql\n environment:\n - POSTGRES_PASSWORD=sample\n - POSTGRES_USER=sample\n - POSTGRES_DB=sample\n\n"
},
{
"alpha_fraction": 0.5987379550933838,
"alphanum_fraction": 0.6455085277557373,
"avg_line_length": 18.057554244995117,
"blob_id": "87a1412ec48164584c19a8ac7281d4ce7dd07ddd",
"content_id": "3268650953b1950fb940a05995c1a42d3ee87242",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2699,
"license_type": "no_license",
"max_line_length": 284,
"num_lines": 139,
"path": "/various-datastores/ README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Various Datastores\n\n\n## RDBMS\n\n```\nSELECT o.order_id, o.customer_id, ol.product_id, ol.quantity\nFROM order_t o\nLEFT JOIN order_line_t ol\nON (o.order_id = ol.order_id)\n```\n\n\n```\nselect SUM(quantity * item_price) from order_line_t\n```\n\n## Redis\n\n```\nSET \"product:1 \" \"{\r\nproductId: 1\r\n, name: 'SAMSUNG UE65MU8000'\r\n, description: 'Samsung TV'\r\n, price: 1396.90\r\n, category: 'Electronics'\r\n}\"\n```\r\n\n```\r\nSET \"product:2 \" \"{\r\nproductId: 2\r\n, name: 'APPLE iPhone X 64 GB Space Grau'\r\n, description: 'Beim iPhone X ist das Gerät das Display. Das Super-Retina-Display füllt die ganze Hand aus und lässt die Augen nicht mehr los. Auf kleinstem Raum arbeiten hier die fortschrittlichen Technologien. Dazu gehören auch die Kameras und Sensoren, die Face ID möglich machen.'\r\n, price: 829.00\r\n, category: 'Electronics'\r\n}\"\n```\n\nAdd customers\n\n```\nSET \"customer:1\" \"{\r\ncustomerId: 1\r\n, firstName: 'Peter'\r\n, lastName: 'Muster'\r\n, gender: 'male'\n, addresses: [1,2]\r\n}\n\"\r\n```\r\nAdd addresses\n\n```\nSET \"address:1\" \"{\r\nid: 1\r\n, street: 'Musterstrasse'\r\n, nr: '5'\r\n, zipCode: '3001'\r\n, city: 'Bern'\r\n, country: 'Switzerland'\r\n}\n\"\r\n```\n\n```\nSET \"address:2\" \"{\r\nid: 2\r\n, street: 'Seeweg'\r\n, nr: '15'\r\n, zipCode: '3700'\r\n, city: 'Spiez'\r\n, country: 'Switzerland'\r\n}\n\"\r\n```\n\n```\nSET \"order:1\" \"{\r\norderId: 1\r\n, customerId: 1\r\n, deliveryAddressId: 1\r\n, billingAddressId: 1\r\n, orderDetails: [ { productid: 1, quantity: 1, price: 1396.90 },\r\n\t { productid: 2 quantity: 2, price: 829.00 } \r\n ]\r\n}\r\n\"\n```\n\n<http://localhost:5001>\n\n## Cassandra\n\n```\nCREATE KEYSPACE order_processing\n WITH REPLICATION = { \n 'class' : 'SimpleStrategy', \n 'replication_factor' : 1 \n };\n```\n\n\n```\nDROP TABLE IF EXISTS order_t;\nCREATE TABLE order_t (\n\torder_id int\n\t, order_date text STATIC\n\t, customer_id int STATIC\n\t, delivery_street text STATIC\n\t, delivery_city text STATIC\n\t, billing_street text STATIC\n\t, billing_city text STATIC\n\t, order_line_id int\n\t, product_id int\n\t, quantity int\n\t, price double\n\t, PRIMARY KEY (order_id, order_line_id))\n\tWITH CLUSTERING ORDER BY (order_line_id ASC);\n```\n```\nINSERT INT order_t (order_id, order_date, customer_id, delivery_street,\n \t\t\t\tdelivery_city, billing_street, billing_city, order_line_id,\n \t\t\t\tproduct_id, quantity, price)\n \t\t\tVALUES (1, '10.1.2018', 1, 'Musterstrasse 5', '3000 Bern', \t\t\t\t\t'Musterstrasse 5', '3000 Bern', 1, 1001, 1, 483.65);\n```\n\n## Mongo DB\n\n```\n{\norderId: 1\n, customerId: 1\n, deliveryAddress: { id:1, street:'Musterstrasse',nr:5, city:'Bern', zipCode:'3015'}\n, billingAddress: { id:1, street: 'Musterstrasse',nr:5, city:'Bern', zipCode:'3015'}\n, orderDetails: [ { productid: 1, quantity: 1, price: 110.00 },\n\t { productid: 10, quantity: 1, price: 110.00 } ]\n}\n```"
},
{
"alpha_fraction": 0.65625,
"alphanum_fraction": 0.726190447807312,
"avg_line_length": 20,
"blob_id": "ca5701c121fa2bf48537b7c8f84ce091d234da3e",
"content_id": "81cd74d3715315b0a763431d7ed014908193da3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 32,
"path": "/imply/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Working with Imply\n\nDocumentation: <https://github.com/implydata/distribution-docker>\n\n```\ngit clone https://github.com/implydata/distribution-docker.git\n```\n\n```\ncd distribution-docker \nexport implyversion=2.7.2\nwget https://static.imply.io/release/imply-2.7.2.tar.gz\ntar -xzf imply-$implyversion.tar.gz\nrm *.tar.gz\ndocker build -t imply:$implyversion --build-arg implyversion=$implyversion .\n```\n\n\n\n```\ndocker run -p 28081-28110:8081-8110 -p 28200:8200 -p 29095:9095 -d --name imply imply:$implyversion\n```\n\n```\ndocker exec -it imply bin/post-index-task -f quickstart/wikipedia-index.json\n```\n\n```\ndocker exec -it imply /bin/bash\n```\n\n<http://streamingplatform:29095>\n"
},
{
"alpha_fraction": 0.7697346806526184,
"alphanum_fraction": 0.7697346806526184,
"avg_line_length": 37.64556884765625,
"blob_id": "586dc4103d4c516b5abbebcdbb7722da6e4d8f14",
"content_id": "c2daed1590757a730d9cd9d014511e7024d681ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3053,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 79,
"path": "/event-sourcing/kafka-streams/account-ms/src/main/java/com/trivadis/sample/kafkastreams/ms/account/kafka/AccountCommandEventProducer.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.kafkastreams.ms.account.kafka;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport org.apache.kafka.clients.producer.ProducerRecord;\nimport org.apache.kafka.common.header.Header;\nimport org.apache.kafka.common.header.internals.RecordHeader;\nimport org.springframework.beans.factory.annotation.Autowired;\nimport org.springframework.beans.factory.annotation.Value;\nimport org.springframework.kafka.core.KafkaTemplate;\nimport org.springframework.stereotype.Component;\n\nimport com.fasterxml.jackson.core.JsonParser;\nimport com.fasterxml.jackson.core.JsonProcessingException;\nimport com.fasterxml.jackson.databind.ObjectMapper;\nimport com.fasterxml.jackson.databind.node.JsonNodeFactory;\nimport com.fasterxml.jackson.databind.node.ObjectNode;\nimport com.trivadis.sample.kafkastreams.ms.account.command.AccountCreateCommand;\nimport com.trivadis.sample.kafkastreams.ms.account.command.DepositMoneyCommand;\nimport com.trivadis.sample.kafkastreams.ms.account.command.WithdrawMoneyCommand;\n\n\n@Component\npublic class AccountCommandEventProducer {\n\t@Autowired\n\tprivate KafkaTemplate<String, String> kafkaTemplate;\n\t\n\t@Value(\"${kafka.topic.account.command}\")\n\tString kafkaTopicAccountCommand;\n\t\n\t@Value(\"${kafka.topic.account-created}\")\n\tString kafkaTopicAccountCreated;\n\n\tpublic void produce(AccountCreateCommand accountCreateCommand) {\n\t\tfinal ObjectMapper objectMapper = new ObjectMapper();\n\t\t\n\t\ttry {\n\t\t\tProducerRecord<String, String> record = new ProducerRecord<> (kafkaTopicAccountCommand,\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\taccountCreateCommand.getId().toString(), \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\tobjectMapper.writeValueAsString(accountCreateCommand));\n\t\t\trecord.headers().add(new RecordHeader(\"command\", \"AccountCreateCommand\".getBytes()));\n\t\t\tkafkaTemplate.send(record);\n\t\t} catch (JsonProcessingException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t}\n\n\tpublic void produce(DepositMoneyCommand depositMoneyCommand) {\n\t\tfinal ObjectMapper objectMapper = new ObjectMapper();\n\t\t\n\t\ttry {\n\t\t\tProducerRecord<String, String> record = new ProducerRecord<> (kafkaTopicAccountCommand,\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\tdepositMoneyCommand.getId().toString(), \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\tobjectMapper.writeValueAsString(depositMoneyCommand));\n\t\t\trecord.headers().add(new RecordHeader(\"command\", \"DepositMoneyCommand\".getBytes()));\n\t\t\tkafkaTemplate.send(record);\n\t\t} catch (JsonProcessingException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t}\n\t\n\tpublic void produce(WithdrawMoneyCommand withdrawMoneyCommand) {\n\t\tfinal ObjectMapper objectMapper = new ObjectMapper();\n\t\t\n\t\ttry {\n\t\t\tProducerRecord<String, String> record = new ProducerRecord<> (kafkaTopicAccountCommand,\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\twithdrawMoneyCommand.getId().toString(), \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\tobjectMapper.writeValueAsString(withdrawMoneyCommand));\n\t\t\trecord.headers().add(new RecordHeader(\"command\", \"WithdrawMoneyCommand\".getBytes()));\n\t\t\tkafkaTemplate.send(record);\n\t\t} catch (JsonProcessingException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t}\t\n}\n"
},
{
"alpha_fraction": 0.6854220032691956,
"alphanum_fraction": 0.7180306911468506,
"avg_line_length": 19.5657901763916,
"blob_id": "6b3273b73e607e68dad0683352b444e9475b8a7d",
"content_id": "62d99e59169955ee2765925c40bc6766f838fa90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1564,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 76,
"path": "/oracle-stream-analytics/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Using Oracle Stream Analytics (18.1)\n\n```\ncd /mnt/hgfs/git/gschmutz/various-demos/oracle-stream-analytics\n```\n\n\n```\ndocker-compose up -d\n```\n\nCopy the spark-osa.jar into the two spark workers (workaround)\n\n```\ndocker cp spark-osa.jar oracle-stream-analytics_worker-1_1:/usr/spark-2.2.1/jars\ndocker cp spark-osa.jar oracle-stream-analytics_worker-2_1:/usr/spark-2.2.1/jars\n```\n\n## Create the Kafka Topics\n\nlist topics and create the new topics\n\n```\ndocker exec -ti oracle-stream-analytics_broker-1_1 bash\n```\n\n\n```\nkafka-topics --zookeeper zookeeper:2181 --list\n\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_position --partitions 8 --replication-factor 2\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_driving_info --partitions 8 --replication-factor 2\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_geofencing --partitions 8 --replication-factor 2\n```\n\n## Starting Kafka Truck Simulation\n\n```\ncd $SAMPLE_HOME/src/truck-client\n```\n\n```\nmvn exec:java -Dexec.args=\"-s KAFKA -p 9092 -f JSON -m COMBINE -t sec\"\n```\n\n## Starting OSA\n\nmake sure that the IP address is current\n\n```\nsudo nano ../etc/jetty-osa-datasource.xml\n```\n\nStart the shell script\n\n```\ncd /home/gus/OSA-18.1.0.0.1/osa-base/bin\n```\n\n```\n./start-osa.sh dbroot=root dbroot_password=root\n```\n\n```\ntail -f ../nohup.out \n```\n\nEnter the password to be used for the osaadmin user. \n\n## Using OSA\n\nNavigate to <http://streamingplatform:9080/osa>\n\nLogin using the osaadmin user and the password specified above. \n\nNavigate to System Settings and enter "
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6302851438522339,
"avg_line_length": 19.34000015258789,
"blob_id": "0f66fd793000f4efc68c19efcf8fabe6eb0e4979",
"content_id": "4c47acafa94a12ce013d567ff60aded96395d8ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 1017,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 50,
"path": "/rb-dr-case/vmware/docker-management/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Kafka Disaster Recovery Test\n\nversion: \"2.1\"\n\nservices:\n kafka-manager:\n image: trivadisbds/kafka-manager\n hostname: kafka-manager\n ports:\n - \"9000:9000\"\n environment:\n ZK_HOSTS: 'zookeeper-1:2181'\n APPLICATION_SECRET: 'letmein'\n restart: always\n\n web:\n image: elkozmon/zoonavigator-web:0.5.0\n container_name: zoonavigator-web\n ports:\n - \"8010:8010\"\n environment:\n WEB_HTTP_PORT: 8010\n API_HOST: \"api\"\n API_PORT: 9010\n depends_on:\n - api\n restart: always\n api:\n image: elkozmon/zoonavigator-api:0.5.0\n container_name: zoonavigator-api\n environment:\n API_HTTP_PORT: 9010\n restart: always\n\n kafka-offset-monitor:\n image: jpodeszwik/kafka-offset-monitor:0.2.1\n ports:\n - \"8080:8080\"\n environment:\n ZK: zookeeper-1:2181\n restart: always\n\n kafdrop:\n image: thomsch98/kafdrop:latest\n ports:\n - \"9020:9020\"\n environment:\n ZK_HOSTS: zookeeper-1:2181\n LISTEN: 9020\n restart: always\n"
},
{
"alpha_fraction": 0.6828047037124634,
"alphanum_fraction": 0.6828047037124634,
"avg_line_length": 23,
"blob_id": "6d2179525f526b0ccbe286f353be2ca8cb7c6d3c",
"content_id": "fbcbf171d3982dbd1bbc8cc30ddc4e7bc04c08a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 25,
"path": "/event-sourcing/axon/finance-axon-command/src/main/java/com/trivadis/sample/axon/account/command/WithdrawMoneyCommand.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.command;\n\nimport java.math.BigDecimal;\n\npublic class WithdrawMoneyCommand extends BaseCommand<String> {\n\tprivate BigDecimal amount;\n\n\tpublic WithdrawMoneyCommand(String id, BigDecimal amount) {\n\t\tsuper(id);\n\t\tthis.amount = amount;\n\t}\n\tpublic WithdrawMoneyCommand() {}\n\t\n\tpublic BigDecimal getAmount() {\n\t\treturn amount;\n\t}\n\t\n\t@Override\n\tpublic String toString() {\n\t\treturn \"WithdrawMoneyCommand [amount=\" + amount + \", getId()=\" + getId() + \", getClass()=\" + getClass()\n\t\t\t\t+ \", hashCode()=\" + hashCode() + \", toString()=\" + super.toString() + \"]\";\n\t}\n\t\n\t\n}"
},
{
"alpha_fraction": 0.6883525848388672,
"alphanum_fraction": 0.7072402834892273,
"avg_line_length": 34.185184478759766,
"blob_id": "16d438d1d0f6126ad01b4e545d2746c6af7ea34c",
"content_id": "e86206a997184c79896703fae223053f8bedc935",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 953,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 27,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/table/order_t.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nCREATE TABLE order_t (\n id NUMBER(12) \t\tCONSTRAINT pk_order PRIMARY KEY,\n order_date DATE \t\t\tNOT NULL,\n order_mode VARCHAR2(8) \tNOT NULL,\n customer_id NUMBER(12),\n order_status NUMBER(2) NOT NULL,\n order_total NUMBER(8,2)\t\tNOT NULL,\n promotion_id NUMBER(6),\n created_at TIMESTAMP\t\t\tNOT NULL,\n modified_at TIMESTAMP\t\tNOT NULL\n);\n\n\n\n"
},
{
"alpha_fraction": 0.6483622193336487,
"alphanum_fraction": 0.6719653010368347,
"avg_line_length": 24.317073822021484,
"blob_id": "de42fb03153e9da83f6ed59c9cb91e64270ee449",
"content_id": "49b281b18cf9d25821b41591040e91a96ee33bdf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Maven POM",
"length_bytes": 2076,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 82,
"path": "/graph-performance/des-graph-test/pom.xml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "<project xmlns=\"http://maven.apache.org/POM/4.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n\txsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\n\t<modelVersion>4.0.0</modelVersion>\n\n\t<groupId>com.trivadis.graph</groupId>\n\t<artifactId>dse-graph-test</artifactId>\n\t<packaging>jar</packaging>\n\t<version>1.0.0-SNAPSHOT</version>\n\t<name>DSE Graph Tests</name>\n\n\t<properties>\n\t\t<maven.compiler.source>1.8</maven.compiler.source>\n\t\t<maven.compiler.target>1.8</maven.compiler.target>\n\t</properties>\n\n\t<dependencies>\n\t\t<!-- https://mvnrepository.com/artifact/com.datastax.cassandra/dse-driver -->\n\t\t<dependency>\n \t\t<groupId>com.datastax.dse</groupId>\n \t\t<artifactId>dse-java-driver-core</artifactId>\n \t\t<version>1.7.0</version>\n\t\t</dependency>\n\t\t\n\t\t<dependency>\n \t\t<groupId>com.datastax.dse</groupId>\n \t\t<artifactId>dse-java-driver-graph</artifactId>\n \t\t<version>1.7.0</version>\n\t\t</dependency>\n\n\t\t<dependency>\n\t\t <groupId>joda-time</groupId>\n\t\t <artifactId>joda-time</artifactId>\n\t\t <version>2.9.7</version>\n\t\t</dependency>\n\n\t\t<dependency>\n\t\t\t<groupId>org.apache.commons</groupId>\n\t\t\t<artifactId>commons-math3</artifactId>\n\t\t\t<version>3.6.1</version>\n\t\t</dependency>\n\n\t\t<dependency>\n \t\t<groupId>junit</groupId>\n \t\t<artifactId>junit</artifactId>\n \t\t<version>4.12</version>\n\t\t</dependency>\n<!--\n\t\t<dependency>\n\t\t\t<groupId>org.apache.tinkerpop</groupId>\n\t\t\t<artifactId>gremlin-driver</artifactId>\n\t\t\t<version>3.2.0-incubating</version>\n\t\t</dependency>\n-->\n\t</dependencies>\n\n\t<build>\n\t\t<plugins>\n\t\t\t<plugin>\n\t\t\t\t<artifactId>maven-compiler-plugin</artifactId>\n\t\t\t\t<version>3.1</version>\n\t\t\t\t<configuration>\n\t\t\t\t\t<source>1.8</source>\n\t\t\t\t\t<target>1.8</target>\n\t\t\t\t</configuration>\n\t\t\t</plugin>\n\n\t\t\t<plugin>\n\t\t\t\t<groupId>org.apache.maven.plugins</groupId>\n\t\t\t\t<artifactId>maven-jar-plugin</artifactId>\n\t\t\t</plugin>\n\n\t\t</plugins>\n\t</build>\n\n\t<repositories>\n\t\t<repository>\n\t\t\t<id>lib</id>\n\t\t\t<name>lib</name>\n\t\t\t<url>file:${project.basedir}/repo</url>\n\t\t</repository>\n\t</repositories>\n</project>\n"
},
{
"alpha_fraction": 0.6917024254798889,
"alphanum_fraction": 0.7174534797668457,
"avg_line_length": 13.11111068725586,
"blob_id": "d301448d6112f7f792d6b05519018a430ace13b8",
"content_id": "18ccf8f4b16e20efc461ec8c5d6d0f1e9a3dfe8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "AsciiDoc",
"length_bytes": 1398,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 99,
"path": "/asciidoc/test.adoc",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "\n:TOC:\n\n= Ueberschrift 1\n\n\n== Ueberschrift 2\n\nText\n\n=== Ueberschrift 3.1\n=== Ueberschrift 3.2\n\n==== Ueberschrift 4\n\n===== Ueberschrift 5\n\nnormal, _italic_, *bold*, +mono typed+\n\nCommand: `ls -l`\n\n\n.Labeled\nTerm 1::\n Definition 1 dfklsdjflksdjfklj dsfdsjlkfjdlkj fdafdlj fdsfdsf sflskfjslkdjfklj dflsdkjfjsdlkj fsklajflksdjfs dsdfdsfsdlks dlfjlksdjfklsdjfkljdsklfj\nTerm 2::\n Definition 2\n\n\nThis is a bullet list\n\n* bullet\n** bullet 2\n*** bullet 3\n\nThis is a numbered list:\n\n. One\n. Two\n. Three: lfjkslfjklfjlj flsdfj djflsdjk dfsakfldjsa afdfs dfsdklfldf saddfds sdffsdfd ldfdfdd fdfdsafsdf dfsdsdff sfsdfdfds sdfdsffdfd fdsfsdsdfds\n\n+\nimage:2019-10-24_16-20-40.png[alt=\"not bad.\",width=1024,height=1024]\n\n. *Three*: lfjkslfjklfjlj flsdfj djflsdjk dfsakfldjsa afdfs dfsdklfldf saddfds sdffsdfd ldfdfdd fdfdsafsdf dfsdsdff sfsdfdfds sdfdsffdfd fdsfsdsdfds\n\nType some *text* which is rendered on the *right*.\n\nTIP: there are\n\nIMPORTANT: this is important\n\nWARNING: be careful\n\nCAUTION: do not use\n\n[source,java]\n----\npublic class Test {\n public void main() {\n system.out.println(\"test\");\n }\n}\n----\n\n\n\n\n(C)\n(R)\n\nhttp://google.com\n\n---\n\n\n\n\n\n\n\n.this block title\n=====\nContent in block\n=====\n\n.this block title\n=====\nContent in block\n=====\n\ntest\n\n\n\n\n\nThis is some text about an object{wj}footnote:[This is the first footnote] is found.\n\nBig Name footnote:[This is another footnote] is found.\n"
},
{
"alpha_fraction": 0.6462157964706421,
"alphanum_fraction": 0.6879227161407471,
"avg_line_length": 34.0819206237793,
"blob_id": "6407c9a5d6165756351dbf2c0763677e14d63c85",
"content_id": "e89dd2066c56ef079cff83189588abe27b7e8641",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 12420,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 354,
"path": "/iot-truck-demo/docker/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# IoT Truck Demo\n\nversion: \"2.1\"\n\nservices:\n zookeeper-1:\n image: confluentinc/cp-zookeeper:5.2.1\n hostname: zookeeper-1\n container_name: zookeeper-1\n ports:\n - \"2181:2181\"\n environment:\n ZOOKEEPER_CLIENT_PORT: 2181\n ZOOKEEPER_TICK_TIME: 2000\n restart: always\n\n broker-1:\n image: confluentinc/cp-enterprise-kafka:5.2.1\n hostname: broker-1\n container_name: broker-1\n depends_on:\n - zookeeper-1\n ports:\n - \"9092:9092\"\n environment:\n KAFKA_BROKER_ID: 1\n KAFKA_BROKER_RACK: rack-a\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9092'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9999\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9999'\n KAFKA_JMX_HOSTNAME: 'broker-1'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-1:9092\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n\n broker-2:\n image: confluentinc/cp-enterprise-kafka:5.2.1\n hostname: broker-2\n container_name: broker-2\n depends_on:\n - zookeeper-1\n ports:\n - \"9093:9093\"\n environment:\n KAFKA_BROKER_ID: 2\n KAFKA_BROKER_RACK: rack-a\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9093'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9998\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9998'\n KAFKA_JMX_HOSTNAME: 'broker-2'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-2:9093\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n\n broker-3:\n image: confluentinc/cp-enterprise-kafka:5.2.1\n hostname: broker-3\n container_name: broker-3\n depends_on:\n - zookeeper-1\n ports:\n - \"9094:9094\"\n environment:\n KAFKA_BROKER_ID: 3\n KAFKA_BROKER_RACK: rack-a\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9094'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9997\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9997'\n KAFKA_JMX_HOSTNAME: 'broker-3'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-3:9094\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n \n connect-1:\n image: confluentinc/cp-kafka-connect:5.2.1\n container_name: connect-1\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry\n ports:\n - \"8083:8083\"\n environment:\n CONNECT_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONNECT_REST_ADVERTISED_HOST_NAME: connect-1\n CONNECT_REST_PORT: 8083\n CONNECT_GROUP_ID: compose-connect-group\n CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs\n CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000\n CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets\n CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status\n CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'\n CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'\n CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONNECT_PLUGIN_PATH: \"/usr/share/java,/etc/kafka-connect/custom-plugins\"\n CONNECT_LOG4J_ROOT_LOGLEVEL: INFO\n CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-4.0.0.jar\n volumes:\n - $PWD/kafka-connect:/etc/kafka-connect/custom-plugins\n restart: always\n\n connect-2:\n image: confluentinc/cp-kafka-connect:5.2.1\n container_name: connect-2\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry\n ports:\n - \"8084:8084\"\n environment:\n CONNECT_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONNECT_REST_ADVERTISED_HOST_NAME: connect-2\n CONNECT_REST_PORT: 8084\n CONNECT_GROUP_ID: compose-connect-group\n CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs\n CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000\n CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets\n CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status\n CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'\n CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'\n CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONNECT_PLUGIN_PATH: \"/usr/share/java,/etc/kafka-connect/custom-plugins\"\n CONNECT_LOG4J_ROOT_LOGLEVEL: INFO\n CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-4.0.0.jar\n volumes:\n - $PWD/kafka-connect:/etc/kafka-connect/custom-plugins\n restart: always\n\n ksql-server-1:\n image: confluentinc/cp-ksql-server:5.2.1\n container_name: ksql-server-1\n ports:\n - '8088:8088'\n depends_on:\n - broker-1\n - schema-registry\n environment:\n KSQL_CONFIG_DIR: \"/etc/ksql\"\n KSQL_LOG4J_OPTS: \"-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties\"\n KSQL_BOOTSTRAP_SERVERS: \"broker-1:9092\"\n KSQL_HOST_NAME: ksql-server\n KSQL_APPLICATION_ID: \"kafka-demo\"\n KSQL_LISTENERS: \"http://0.0.0.0:8088\"\n KSQL_CACHE_MAX_BYTES_BUFFERING: 0\n # Schema Registry using HTTPS\n KSQL_KSQL_SCHEMA_REGISTRY_URL: \"http://schema_registry:8081\"\n KSQL_KSQL_SERVICE_ID: \"kafka-demo\"\n KSQL_PRODUCER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor\n KSQL_CONSUMER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor\n KSQL_KSQL_SERVER_UI_ENABLED: \"true\"\n restart: always\n\n schema-registry:\n image: confluentinc/cp-schema-registry:5.2.1\n hostname: schema-registry\n container_name: schema-registry\n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"8081:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry\n SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper-1:2181'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always\n \n mqtt-1:\n image: eclipse-mosquitto:latest\n hostname: mqtt-1\n container_name: mqtt-1\n ports: \n - \"1883:1883\"\n - \"9001:9001\"\n volumes:\n - ./mosquitto/mosquitto-1.conf:/mosquitto/config/mosquitto.conf\n restart: always\n\n adminer:\n image: adminer\n container_name: adminer\n ports:\n - 38080:8080\n restart: always\n \n postgresql:\n image: mujz/pagila\n container_name: postgresql\n environment:\n - POSTGRES_PASSWORD=sample\n - POSTGRES_USER=sample\n - POSTGRES_DB=sample\n restart: always\n \n # the services following below are optional, if you have not enough resources, you can remove them\n mqtt-proxy:\n image: confluentinc/cp-kafka-mqtt:5.2.1\n hostname: mqtt-proxy\n container_name: mqtt-proxy\n ports:\n - \"1884:1884\"\n environment:\n KAFKA_MQTT_TOPIC_REGEX_LIST: 'truck_position:.*position,truck_engine:.*engine'\n KAFKA_MQTT_LISTENERS: 0.0.0.0:1884\n KAFKA_MQTT_BOOTSTRAP_SERVERS: PLAINTEXT://broker-1:9092,broker-2:9093\n KAFKA_MQTT_CONFLUENT_TOPIC_REPLICATIN_FACTOR: 1\n restart: always\n\n control-center:\n image: confluentinc/cp-enterprise-control-center:5.2.1\n hostname: control-center\n container_name: control-center\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry\n - connect-1\n ports:\n - \"9021:9021\"\n environment:\n CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONTROL_CENTER_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONTROL_CENTER_CONNECT_CLUSTER: 'connect:8083'\n CONTROL_CENTER_KSQL_URL: \"http://ksql-server:8088\"\n CONTROL_CENTER_KSQL_ADVERTISED_URL: \"http://localhost:8088\"\n CONTROL_CENTER_SCHEMA_REGISTRY_URL: \"http://schema-registry:8081\"\n CONTROL_CENTER_REPLICATION_FACTOR: 1\n CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1\n CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1\n CONFLUENT_METRICS_TOPIC_REPLICATION: 1\n PORT: 9021\n restart: always\n \n kafka-manager:\n image: trivadis/kafka-manager\n hostname: kafka-manager\n container_name: kafka-manager\n depends_on:\n - zookeeper-1\n ports:\n - \"9000:9000\"\n environment:\n ZK_HOSTS: 'zookeeper-1:2181'\n APPLICATION_SECRET: 'letmein' \n restart: always\n \n kafkahq:\n image: tchiotludo/kafkahq\n container_name: kafkahq\n ports:\n - 28082:8080\n environment:\n KAFKAHQ_CONFIGURATION: |\n kafkahq:\n connections:\n docker-kafka-server:\n properties:\n bootstrap.servers: \"broker-1:9092\"\n schema-registry: \"http://schema-registry:8085\"\n depends_on:\n - broker-1\n restart: always \n \n streamsets:\n image: trivadis/streamsets-kafka-nosql:3.8.1\n hostname: streamsets\n container_name: streamsets\n ports:\n - \"18630:18630\"\n restart: always\n\n kafka-connect-ui:\n image: landoop/kafka-connect-ui:latest\n hostname: kafka-connect-ui\n container_name: kafka-connect-ui\n ports:\n - \"8003:8000\"\n environment:\n CONNECT_URL: \"http://${PUBLIC_IP}:8083/\"\n PROXY: \"true\"\n depends_on:\n - connect-1\n restart: always\n \n ksqlui:\n image: matsumana/tsujun:0.0.1\n hostname: ksqlui\n container_name: ksqlui\n ports: \n - \"28083:8080\"\n environment:\n - KSQL_SERVER=http://ksql-server-1:8088\n restart: always\n\n schema-registry-ui:\n image: landoop/schema-registry-ui:latest\n hostname: schema-registry-ui\n container_name: schema-registry-ui\n depends_on:\n - broker-1\n - schema-registry\n ports:\n - \"8002:8000\"\n environment:\n SCHEMAREGISTRY_URL: 'http://${PUBLIC_IP}:8081'\n restart: always\n \n mqtt-ui:\n image: vergissberlin/hivemq-mqtt-web-client\n hostname: mqtt-ui\n container_name: mqtt-ui\n restart: always\n ports:\n - \"29080:80\"\n\n"
},
{
"alpha_fraction": 0.6690821051597595,
"alphanum_fraction": 0.7198067903518677,
"avg_line_length": 14.884614944458008,
"blob_id": "ef6311ae2938f548a13548e4060c78bc527468e0",
"content_id": "96caf8b06db1e0438c7aa45f73e889515afc3743",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 26,
"path": "/rb-dr-case/vmware/scripts/cleanup-dc2.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncd ../data\nrm -R kafka-4\nrm -R kafka-5\nrm -R kafka-6\n\nrm -R zookeeper-4\nrm -R zookeeper-5\nrm -R zookeeper-6\n\nmkdir kafka-4\nmkdir kafka-5\nmkdir kafka-6\n\nmkdir -p zookeeper-4/data\nmkdir -p zookeeper-5/data\nmkdir -p zookeeper-6/data\n\nmkdir -p zookeeper-4/log\nmkdir -p zookeeper-5/log\nmkdir -p zookeeper-6/log\n\necho 4 > zookeeper-4/data/myid\necho 5 > zookeeper-5/data/myid\necho 6 > zookeeper-6/data/myid\n\n"
},
{
"alpha_fraction": 0.43785151839256287,
"alphanum_fraction": 0.44206973910331726,
"avg_line_length": 32.86274337768555,
"blob_id": "c471ccb940138849341dd070a17f2911c2206e76",
"content_id": "ff2f0383a3f3b733e5021b299823082983fbddd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 3556,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 102,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/install.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\r\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\r\n*\r\n* Licensed under the Apache License, Version 2.0 (the \"License\");\r\n* you may not use this file except in compliance with the License.\r\n* You may obtain a copy of the License at\r\n*\r\n* http://www.apache.org/licenses/LICENSE-2.0\r\n*\r\n* Unless required by applicable law or agreed to in writing, software\r\n* distributed under the License is distributed on an \"AS IS\" BASIS,\r\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n* See the License for the specific language governing permissions and\r\n* limitations under the License.\r\n*/\r\n\r\nSET DEFINE OFF\r\nSET SCAN OFF\r\nSET ECHO OFF\r\nSET SERVEROUTPUT ON SIZE 1000000\r\nSPOOL install.log\r\n\r\nPROMPT ======================================================================\r\nPROMPT This script installs Oracle database objects for emptracker.\r\nPROMPT\r\nPROMPT Connect to the target user (schema) of your choice.\r\nPROMPT See user/emptracker.sql for required privileges.\r\nPROMPT ======================================================================\r\nPROMPT\r\n\r\nPROMPT ======================================================================\r\nPROMPT create order and customer queue tables\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./queue_table/order_qt.sql\r\n@./queue_table/customer_qt.sql\r\n\r\nPROMPT ======================================================================\r\nPROMPT create order and customer queues and enable enqueue/dequeue ops\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./queue/order_aq.sql\r\n@./queue/customer_aq.sql\r\n\r\n\r\nPROMPT ======================================================================\r\nPROMPT create object types\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./object/order_objt.sql\r\n\r\nPROMPT ======================================================================\r\nPROMPT create PL/SQL packages\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./package/order_pck.sql\r\n\r\nPROMPT ======================================================================\r\nPROMPT create monitoring views\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./view/monitor_order_v.sql\r\n@./view/monitor_customer_v.sql\r\n\r\nPROMPT ======================================================================\r\nPROMPT create tables\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./table/order_t.sql\r\n@./table/order_item_t.sql\r\n\r\n@./table/customer_t.sql\r\n@./table/address_t.sql\r\n\r\nPROMPT ======================================================================\r\nPROMPT create trigger to enqueue sal changes\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./trigger/order_biu_trg.sql\r\n@./trigger/order_item_biu_trg.sql\r\n\r\n@./trigger/customer_biu_trg.sql\r\n@./trigger/address_biu_trg.sql\r\n\r\nPROMPT ======================================================================\r\nPROMPT create ORDS structures\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./ords/ords-order-orderdetail.sql\r\n@./ords/ords-customer.sql\r\n\r\n\r\nPROMPT ======================================================================\r\nPROMPT insert test data to order_t and order_item_t\r\nPROMPT ======================================================================\r\nPROMPT\r\n@./testdata/customer_t.sql\r\n@./testdata/order_t.sql\r\n@./testdata/order_item_t.sql\r\n\r\n\r\nSPOOL OFF\r\n"
},
{
"alpha_fraction": 0.7105262875556946,
"alphanum_fraction": 0.7105262875556946,
"avg_line_length": 38,
"blob_id": "7e72f645b9a99866b6975b8204c6039af307e4e0",
"content_id": "62e8b32c3496b03b9d0561036326ab250e3b6e1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 1,
"path": "/kafka-geofencing/docker/ksql/readme.txt",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "Place ksql extensions (UDFs) here ...."
},
{
"alpha_fraction": 0.7763578295707703,
"alphanum_fraction": 0.7763578295707703,
"avg_line_length": 17.41176414489746,
"blob_id": "af06cf4e9f7d5143a59c58f7c54424805c27616e",
"content_id": "bcdce5307135e951f76d8d0426dc1c1266501977",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 17,
"path": "/avro-vs-protobuf/datagenerator/java/datagenerator/src/test/java/com/trivadis/datagenerator/TestPersonData.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.datagenerator;\n\nimport java.io.IOException;\nimport java.util.List;\n\nimport org.junit.Test;\n\nimport com.trivadis.datagenerator.domain.PersonDO;\n\npublic class TestPersonData {\n\n\t@Test\n\tpublic void testGetPersons() throws IOException {\n\t\tList<PersonDO> persons = PersonData.getPersons();\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.8198830485343933,
"alphanum_fraction": 0.8233917951583862,
"avg_line_length": 36.173912048339844,
"blob_id": "06e994947fe7493ced032ffbbac482e0f238c01d",
"content_id": "9c38c315a029020a885d41e70176f7561b58b243",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 855,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 23,
"path": "/event-sourcing/kafka-streams/account-ms/src/main/java/com/trivadis/sample/kafkastreams/ms/account/kafka/AccountCommandEventConsumer.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.kafkastreams.ms.account.kafka;\n\nimport org.apache.kafka.clients.consumer.ConsumerRecord;\nimport org.slf4j.Logger;\nimport org.slf4j.LoggerFactory;\nimport org.springframework.beans.factory.annotation.Autowired;\nimport org.springframework.kafka.annotation.KafkaListener;\nimport org.springframework.stereotype.Component;\n\nimport com.trivadis.avro.command.account.v1.AccountCreateCommand;\n\n@Component\npublic class AccountCommandEventConsumer {\n\tprivate static final Logger LOGGER = LoggerFactory.getLogger(AccountCommandEventConsumer.class);\n\n\t@KafkaListener(topics = \"${kafka.topic.account.command}\")\n\tpublic void receive(ConsumerRecord<String, String> accountCreateCommand) {\n\t\tString accountCreateCommandValue = accountCreateCommand.value();\n\t\tLOGGER.info(\"received payload='{}'\", accountCreateCommandValue.toString());\n\t\t\n\n\t}\n}\n"
},
{
"alpha_fraction": 0.6276127099990845,
"alphanum_fraction": 0.6489406824111938,
"avg_line_length": 27,
"blob_id": "7cad0f6126b05b92f9da9eed955d1e40592cefea",
"content_id": "485252e3619cfa8a1b3442a9aa00c6f75b25ad77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7033,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 251,
"path": "/bidirectional-integration-oracle-kafka/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Bi-Directional Communication between Oracle RDBMS and Kafka\n\n## Setup Oracle XE 18 database\nSetup a docker \n\n### Setup Sample schema\n\n```\ncd /mnt/hgfs/git/gschmutz/various-demos/bidirectional-integration-oracle-kafka/scripts/oracle\n``` \n\n```\n/mnt/hgfs/Downloads/sqlcl/bin/sql sys/manager as sysdba\n```\n\n```\nalter session set container= XEPDB1;\n```\n\n```\n@order-processing/user/order-processing.sql\n```\n\n```\nconnect order_processing/order_processing@//localhost:1521/XEPDB1\n```\n\n```\n@order-processing/install.sql\n```\n\n\n\n```\nDECLARE\n PRAGMA AUTONOMOUS_TRANSACTION;\nBEGIN\n\n ORDS.ENABLE_SCHEMA(p_enabled => TRUE,\n p_schema => 'ORDER_PROCESSING',\n p_url_mapping_type => 'BASE_PATH',\n p_url_mapping_pattern => 'order_processing',\n p_auto_rest_auth => FALSE);\n\n commit;\n\nEND;\n/\n```\n\nDECLARE\n PRAGMA AUTONOMOUS_TRANSACTION;\nBEGIN\n\n ORDS.ENABLE_OBJECT(p_enabled => TRUE,\n p_schema => 'ORDER_PROCESSING',\n p_object => 'ORDER_T',\n p_object_type => 'TABLE',\n p_object_alias => 'orders',\n p_auto_rest_auth => FALSE);\n\n commit;\n\nEND;\n\n\n### Create Kafka Topics\n\nCreate the necessary Kafka topics\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic order --replication-factor 3 --partitions 8\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic order-item --replication-factor 3 --partitions 8\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic customer --replication-factor 3 --partitions 8\n```\n\n\n## RDBMS => Kafka\n\n\n\n### Kafka Connect JDBC\n\n```\n./scripts/kafka-connect/start-connect-jdbc-source.sh\n```\n\n### StreamSets REST Polling\n\n### Kafka Connect JMS\n\nThe following connectors are available for JMS:\n\n * Confluent: <https://docs.confluent.io/current/connect/kafka-connect-jms/index.html> (Source & Sink)\n * Bikeholik: <https://github.com/bikeholik/jms-kafka-connector>\n * Landoop: <https://github.com/Landoop/stream-reactor/releases> (Source & Sink)\n\nInstall the Kafka JMS Connect from Landoop into the `kafka-connect folder\n\n```\ncd kafka-connect\nmkdir kafka-connect-jms-1.2.1-2.1.0-all\ncd kafka-connect-jms-1.2.1-2.1.0-all\n\nwget https://github.com/Landoop/stream-reactor/releases/download/1.2.1/kafka-connect-jms-1.2.1-2.1.0-all.tar.gz\n\ntar -xvzf kafka-connect-jms-1.2.1-2.1.0-all.tar.gz\n```\n\nDownload the necessary AQ jars into the `kafka-connect-jms-1.2.1-2.1.0-all` folder\n\n```\nwget https://github.com/PhilippSalvisberg/emptracker/blob/master/lib/aqapi.jar\nwget https://github.com/PhilippSalvisberg/emptracker/blob/master/lib/jmscommon.jar\nwget https://github.com/PhilippSalvisberg/emptracker/blob/master/lib/ojdbc8.jar\nwget https://github.com/PhilippSalvisberg/emptracker/blob/master/lib/orai18n-collation.jar\nwget https://github.com/PhilippSalvisberg/emptracker/blob/master/lib/orai18n-mapping.jar\nwget https://github.com/PhilippSalvisberg/emptracker/blob/master/lib/ucp.jar\n```\n\n\nConsume from the Kafka topic\n\n```\ndocker exec -ti schema-registry kafka-avro-console-consumer --bootstrap-server broker-1:9092 --topic order \n```\n\n\t\n```\n#!/bin/bash\n\necho \"creating JMS Source Connector\"\n\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n --data '{\n \"name\": \"jms-source\",\n \"config\": {\n \"name\": \"jms-source\",\n \"connector.class\": \"com.datamountaineer.streamreactor.connect.jms.source.JMSSourceConnector\",\n \"connect.jms.initial.context.factory\": \"oracle.jms.AQjmsInitialContextFactory\",\n \"connect.jms.initial.context.extra.params\": \"db_url=jdbc:oracle:thin:@//192.168.73.86:1521/XEPDB1,java.naming.security.principal=order_processing,java.naming.security.credentials=order_processing\",\n \"tasks.max\": \"1\",\n \"connect.jms.connection.factory\": \"ConnectionFactory\",\n \"connect.jms.url\": \"jdbc:oracle:thin:@//192.168.73.86:1521/XEPDB1\",\n \"connect.jms.kcql\": \"INSERT INTO order SELECT * FROM order_aq WITHTYPE QUEUE WITHCONVERTER=`com.datamountaineer.streamreactor.connect.converters.source.JsonSimpleConverter`\"\n }\n}'\n```\n\nGenerate a message\n\n```\nDECLARE\n l_enqueue_options sys.dbms_aq.enqueue_options_t;\n l_message_props sys.dbms_aq.message_properties_t;\n l_jms_message sys.aq$_jms_text_message := sys.aq$_jms_text_message.construct;\n l_msgid RAW(16);\n \n order_json CLOB;\n \n\t\tCURSOR order_sel\n\t\tIS\n\t\tSELECT json_object('orderId' VALUE po.id,\n\t\t 'orderDate' VALUE po.order_date,\n\t\t 'orderMode' VALUE po.order_mode,\n\t\t 'customer' VALUE\n\t\t json_object('firstName' VALUE cu.first_name,\n\t\t 'lastName' VALUE cu.last_name),\n\t\t 'lineItems' VALUE (SELECT json_arrayagg(\n\t\t json_object('ItemNumber' VALUE li.id,\n\t\t 'Product' VALUE\n\t\t json_object('productId' VALUE li.product_id,\n\t\t 'unitPrice' VALUE li.unit_price),\n\t\t 'quantity' VALUE li.quantity))\n\t\t FROM order_item_t li WHERE po.id = li.order_id),\n\t\t 'offset' VALUE TO_CHAR(po.modified_at, 'YYYYMMDDHH24MISS'))\n\t\tFROM order_t po LEFT JOIN customer_t cu ON (po.customer_id = cu.id)\n\t\tWHERE po.modified_at > TO_DATE('20190313000000', 'YYYYMMDDHH24MISS');\n \nBEGIN\n\t OPEN order_sel;\n\t\tFETCH order_sel INTO order_json;\n\t\tdbms_output.put_line(order_json);\n\n\n l_jms_message.clear_properties();\n l_message_props.correlation := sys_guid;\n l_message_props.priority := 3;\n l_message_props.expiration := 5;\n l_jms_message.set_string_property('msg_type', 'test');\n l_jms_message.set_text(order_json);\n dbms_aq.enqueue(queue_name => 'order_aq',\n enqueue_options => l_enqueue_options,\n message_properties => l_message_props,\n payload => l_jms_message,\n msgid => l_msgid);\n COMMIT;\nEND;\n```\n\n### Notification Service\n \nFirst let's connect to the KSQL CLI\n\n```\ndocker run --rm -it --network analyticsplatform_default confluentinc/cp-ksql-cli:5.1.2 http://ksql-server-1:8088\n```\n\nFirst let's connect to the KSQL CLI\n\n```\nCREATE STREAM order_s WITH (KAFKA_TOPIC='order', VALUE_FORMAT='AVRO');\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic notify-twitter --replication-factor 3 --partitions 8\n```\n\n\n```\nCREATE STREAM notify_twitter_s WITH (KAFKA_TOPIC='notify', VALUE_FORMAT='AVRO', PARTITIONS=8)\nAS SELECT * \nFROM order_s\nWHERE order_status = 1;\n```\n\n\n## Kafka => RDBMS\n\n### JDBC Connector\n\n\n\n```\n\"transforms\": \"flatten\",\n\"transforms.flatten.type\": \"org.apache.kafka.connect.transforms.Flatten$Value\",\n\"transforms.flatten.delimiter\": \"_\"\n```\n\n### StreamSets to REST API\n\n\n\n### Kafka Connect to AQ\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6667240262031555,
"alphanum_fraction": 0.6784300208091736,
"avg_line_length": 26.799043655395508,
"blob_id": "a90b391ac2aa1e9a1df80b0335f8575a143847ec",
"content_id": "47d6e71df9c468ade05b74cedb6d822536c544bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Maven POM",
"length_bytes": 5809,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 209,
"path": "/event-sourcing/kafka-streams/account-ms/pom.xml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<project xmlns=\"http://maven.apache.org/POM/4.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n\txsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\n\t<modelVersion>4.0.0</modelVersion>\n\n\t<parent>\n\t\t<groupId>org.springframework.boot</groupId>\n\t\t<artifactId>spring-boot-starter-parent</artifactId>\n\t\t<version>2.1.3.RELEASE</version>\n\t\t<relativePath /> <!-- lookup parent from repository -->\n\t</parent>\n\n\n\t<groupId>com.trivadis.demo.ms.account</groupId>\n\t<artifactId>account-ms</artifactId>\n\t<version>1.0-SNAPSHOT</version>\n\n\t<properties>\n\t\t<java.version>1.8</java.version>\n\t\t<confluent.version>5.1.0</confluent.version>\n\t</properties>\n\n\t<repositories>\n\t\t<repository>\n\t\t\t<id>confluent</id>\n\t\t\t<url>https://packages.confluent.io/maven/</url>\n\t\t</repository>\n\t</repositories>\n\t\n\t<dependencies>\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.boot</groupId>\n\t\t\t<artifactId>spring-boot-starter</artifactId>\n\t\t</dependency>\n\t\t\t\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.boot</groupId>\n\t\t\t<artifactId>spring-boot-starter-web</artifactId>\n\t\t</dependency>\n\t\t\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.boot</groupId>\n\t\t\t<artifactId>spring-boot-starter-actuator</artifactId>\n\t\t</dependency>\n\t\t\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.kafka</groupId>\n\t\t\t<artifactId>spring-kafka</artifactId>\n\t\t</dependency>\t\t\n\t\t\t\n\t\t<dependency>\n\t\t\t<groupId>com.google.guava</groupId>\n\t\t\t<artifactId>guava</artifactId>\n\t\t\t<version>24.0-jre</version>\n\t\t</dependency>\n\t\t\n\t\t<dependency>\n\t\t\t<groupId>io.confluent</groupId>\n\t\t\t<artifactId>kafka-avro-serializer</artifactId>\n\t\t\t<version>${confluent.version}</version>\n\t\t</dependency>\n\t\t\n\t\t<dependency>\n\t\t\t<groupId>com.fasterxml.jackson.core</groupId>\n\t\t\t<artifactId>jackson-core</artifactId>\n\t\t\t<version>2.9.4</version>\n\t\t</dependency>\n\t\t\n\t\t<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->\n\t\t<dependency>\n\t\t\t<groupId>com.fasterxml.jackson.core</groupId>\n\t\t\t<artifactId>jackson-databind</artifactId>\n\t\t\t<version>2.9.4</version>\n\t\t</dependency>\n\t\t\n\t\t<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-annotations -->\n\t\t<dependency>\n\t\t\t<groupId>com.fasterxml.jackson.core</groupId>\n\t\t\t<artifactId>jackson-annotations</artifactId>\n\t\t\t<version>2.9.4</version>\n\t\t</dependency>\n\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.kafka</groupId>\n\t\t\t<artifactId>spring-kafka</artifactId>\n\t\t</dependency>\n\n\t\t<!-- jstl tag lib -->\n\t\t<dependency>\n\t\t\t<groupId>jstl</groupId>\n\t\t\t<artifactId>jstl</artifactId>\n\t\t\t<version>${jstl.version}</version>\n\t\t</dependency>\n\t\t\n\t\t<!-- avro -->\n\t\t<dependency>\n\t\t\t<groupId>org.apache.avro</groupId>\n\t\t\t<artifactId>avro</artifactId>\n\t\t\t<version>1.8.2</version>\n\t\t</dependency>\t\t\n\t\t\n\t\t<!-- kafka streams -->\n\t\t<dependency>\n\t\t\t<groupId>org.apache.kafka</groupId>\n\t\t\t<artifactId>kafka-streams</artifactId>\n\t\t</dependency>\t\t\n\t\t\n\t\t<dependency>\n\t\t\t<groupId>io.confluent</groupId>\n\t\t\t<artifactId>kafka-avro-serializer</artifactId>\n\t\t\t<version>${confluent.version}</version>\n\t\t</dependency>\n\t\t<dependency>\n\t\t\t<groupId>io.confluent</groupId>\n\t\t\t<artifactId>kafka-streams-avro-serde</artifactId>\n\t\t\t<version>${confluent.version}</version>\n\t\t</dependency>\n\t\t\t\t\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.boot</groupId>\n\t\t\t<artifactId>spring-boot-starter-test</artifactId>\n\t\t\t<scope>test</scope>\n\t\t</dependency>\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.kafka</groupId>\n\t\t\t<artifactId>spring-kafka-test</artifactId>\n\t\t\t<scope>test</scope>\n\t\t</dependency>\n\t\t<dependency>\n\t\t\t<groupId>org.springframework.kafka</groupId>\n\t\t\t<artifactId>spring-kafka-test</artifactId>\n\t\t\t<scope>test</scope>\n\t\t</dependency>\t\t\n\t</dependencies>\n\n\t<build>\n\t\t<plugins>\n\t\t\t<plugin>\n\t\t\t\t<groupId>org.springframework.boot</groupId>\n\t\t\t\t<artifactId>spring-boot-maven-plugin</artifactId>\n\t\t\t</plugin>\n\t\t\t<plugin>\n\t\t\t\t<groupId>com.spotify</groupId>\n\t\t\t\t<artifactId>dockerfile-maven-plugin</artifactId>\n\t\t\t\t<version>1.3.6</version>\n\t\t\t\t<configuration>\n\t\t\t\t\t<repository>${user.name}/${project.artifactId}</repository>\n\t\t\t\t\t<tag>${project.version}</tag>\n\t\t\t\t\t<buildArgs>\n\t\t\t\t\t\t<JAR_FILE>${project.build.finalName}.jar</JAR_FILE>\n\t\t\t\t\t</buildArgs>\n\t\t\t\t</configuration>\n\t\t\t</plugin>\n\n\t\t\t<plugin>\n\t\t\t\t<groupId>org.apache.avro</groupId>\n\t\t\t\t<artifactId>avro-maven-plugin</artifactId>\n\t\t\t\t<version>1.8.2</version>\n\t\t\t\t<executions>\n\t\t\t\t\t<execution>\n\t\t\t\t\t\t<id>schemas</id>\n\t\t\t\t\t\t<phase>generate-sources</phase>\n\t\t\t\t\t\t<goals>\n\t\t\t\t\t\t\t<goal>schema</goal>\n\t\t\t\t\t\t</goals>\n\t\t\t\t\t\t<configuration>\n\t\t\t\t\t\t\t<excludes>\n\t\t\t\t\t\t\t\t<exclude>**/mapred/tether/**</exclude>\n\t\t\t\t\t\t\t</excludes>\n\t\t\t\t\t\t\t<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>\n\t\t\t\t\t\t\t<testSourceDirectory>${project.basedir}/src/test/avro/</testSourceDirectory>\n\t\t\t\t\t\t</configuration>\n\t\t\t\t\t</execution>\n\t\t\t\t</executions>\n\t\t\t</plugin>\n\t\t\t<plugin>\n\t\t\t\t<groupId>org.apache.maven.plugins</groupId>\n\t\t\t\t<artifactId>maven-compiler-plugin</artifactId>\n\t\t\t\t<configuration>\n\t\t\t\t\t<source>1.8</source>\n\t\t\t\t\t<target>1.8</target>\n\t\t\t\t</configuration>\n\t\t\t</plugin>\n\t\t\t<plugin>\n \t\t\t\t<groupId>io.confluent</groupId>\n \t\t\t\t<artifactId>kafka-schema-registry-maven-plugin</artifactId>\n \t\t\t\t<version>4.0.0</version>\n\t\t\t\t<configuration>\n\t\t\t\t\t<schemaRegistryUrls>\n\t\t\t\t\t\t<param>http://analyticsplatform:8081</param>\n\t\t\t\t\t</schemaRegistryUrls>\n\t\t\t\t\t<subjects>\n\t\t\t\t\t\t<customer-v1-value>src/main/avro/command/AccountCreateCommand-v1.avsc</customer-v1-value>\n\t\t\t\t\t\t<order-v1-value>src/main/avro/aggregate/Account-v1.avsc</order-v1-value>\n\t\t\t\t\t</subjects>\n\t\t\t\t</configuration>\n\t\t\t\t<goals>\n\t\t\t\t\t<goal>register</goal>\n\t\t\t\t</goals>\n\n\t\t\t</plugin>\n\t\t\t<plugin>\n\t\t\t\t<groupId>org.apache.maven.plugins</groupId>\n\t\t\t\t<artifactId>maven-jar-plugin</artifactId>\n\t\t\t</plugin>\n\t\t</plugins>\n\t</build>\n\t\n</project>"
},
{
"alpha_fraction": 0.7108333110809326,
"alphanum_fraction": 0.7183333039283752,
"avg_line_length": 27.629629135131836,
"blob_id": "4d4e70fd43caeee802023637d49e181322f209c9",
"content_id": "be62abdb46f76aa6cb3a05f6aaf558d1dce69a80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2400,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 81,
"path": "/tkse-2018-kafka/src/kafka-producer/src/main/java/kafka/sample/producer/AvroSensorGroupProducer.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package kafka.sample.producer;\r\n\r\nimport java.io.ByteArrayOutputStream;\r\nimport java.io.IOException;\r\nimport java.util.Properties;\r\nimport java.util.Random;\r\nimport java.util.concurrent.Future;\r\n\r\nimport org.apache.kafka.clients.producer.KafkaProducer;\r\nimport org.apache.kafka.clients.producer.Producer;\r\nimport org.apache.kafka.clients.producer.ProducerRecord;\r\nimport org.apache.kafka.clients.producer.RecordMetadata;\r\nimport org.apache.avro.io.DatumWriter;\r\nimport org.apache.avro.io.Encoder;\r\nimport org.apache.avro.io.EncoderFactory;\r\nimport org.apache.avro.specific.SpecificDatumWriter;\r\n\r\nimport de.tkse.sample.SensorGroupOne;\r\n\r\npublic class AvroSensorGroupProducer {\r\n\tprivate Producer<String, SensorGroupOne> producer = null;\r\n\tprivate String kafkaTopicSensorGroupOne = \"sensor-group-1-v1\";\r\n\r\n\tprivate Producer<String, SensorGroupOne> connect() {\r\n\t\tProducer<String, SensorGroupOne> producer = null;\r\n\r\n\t\tProperties props = new Properties();\r\n\t\tprops.put(\"bootstrap.servers\", \"localhost:9092\");\r\n\t\tprops.put(\"acks\", \"all\");\r\n\t\tprops.put(\"retries\", 0);\r\n\t\tprops.put(\"key.serializer\", \"io.confluent.kafka.serializers.KafkaAvroSerializer\");\r\n\t\tprops.put(\"value.serializer\", \"io.confluent.kafka.serializers.KafkaAvroSerializer\");\r\n\t\tprops.put(\"schema.registry.url\", \"http://localhost:8081\");\r\n\r\n\t\ttry {\r\n\t\t\tproducer = new KafkaProducer<String, SensorGroupOne>(props);\r\n\t\t} catch (Exception e) {\r\n\t\t\te.printStackTrace();\r\n\t\t}\r\n\t\treturn producer;\r\n\t}\r\n\r\n\tpublic void produce(SensorGroupOne value) throws IOException {\r\n\t\tfinal Random rnd = new Random();\r\n\r\n\t\tByteArrayOutputStream out = new ByteArrayOutputStream();\r\n\r\n\t\tif (producer == null) {\r\n\t\t\tproducer = connect();\r\n\t\t}\r\n\r\n\t\tInteger key = rnd.nextInt(255);\r\n\r\n\t\tProducerRecord<String, SensorGroupOne> record = new ProducerRecord<String, SensorGroupOne>(\r\n\t\t\t\tkafkaTopicSensorGroupOne, null, value);\r\n\r\n\t\tif (producer != null) {\r\n\t\t\ttry {\r\n\t\t\t\tFuture<RecordMetadata> future = producer.send(record);\r\n\t\t\t\tRecordMetadata metadata = future.get();\r\n\t\t\t} catch (Exception e) {\r\n\t\t\t\tSystem.err.println(e.getMessage());\r\n\t\t\t\te.printStackTrace();\r\n\t\t\t}\r\n\r\n\t\t}\r\n\r\n\t}\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\tAvroSensorGroupProducer producer = new AvroSensorGroupProducer();\r\n\r\n\t\tSensorGroupOne value = new SensorGroupOne(0.1d, 0.2d);\r\n\t\ttry {\r\n\t\t\tproducer.produce(value);\r\n\t\t} catch (IOException e) {\r\n\t\t\te.printStackTrace();\r\n\t\t}\r\n\t}\r\n\r\n}\r\n"
},
{
"alpha_fraction": 0.46946150064468384,
"alphanum_fraction": 0.4882544279098511,
"avg_line_length": 33.96104049682617,
"blob_id": "2a3e148206d211092137c48293e36b98f4455491",
"content_id": "01524edba71f593fc070216a0ec5637b8791ab2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 2767,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 77,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/ords/ords-customer.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "-- Generated by Oracle SQL Developer REST Data Services 18.3.0.277.2354\r\n-- Exported REST Definitions from ORDS Schema Version 18.4.0.r3541002\r\n-- Schema: ORDER_PROCESSING Date: Wed Mar 13 12:41:10 PDT 2019\r\n--\r\nBEGIN\r\n ORDS.ENABLE_SCHEMA(\r\n p_enabled => TRUE,\r\n p_schema => 'ORDER_PROCESSING',\r\n p_url_mapping_type => 'BASE_PATH',\r\n p_url_mapping_pattern => 'order_processing',\r\n p_auto_rest_auth => FALSE); \r\n\r\n ORDS.DEFINE_MODULE(\r\n p_module_name => 'customer',\r\n p_base_path => '/customers/',\r\n p_items_per_page => 25,\r\n p_status => 'PUBLISHED',\r\n p_comments => NULL); \r\n ORDS.DEFINE_TEMPLATE(\r\n p_module_name => 'customer',\r\n p_pattern => 'customer',\r\n p_priority => 0,\r\n p_etag_type => 'HASH',\r\n p_etag_query => NULL,\r\n p_comments => NULL);\r\n ORDS.DEFINE_HANDLER(\r\n p_module_name => 'customer',\r\n p_pattern => 'customer',\r\n p_method => 'POST',\r\n p_source_type => 'plsql/block',\r\n p_items_per_page => 0,\r\n p_mimes_allowed => '',\r\n p_comments => NULL,\r\n p_source => \r\n'DECLARE\r\n L_CU CLOB := :body_text;\r\nBEGIN\r\ninsert into debug_t values (l_cu);\r\n--INSERT INTO customer_t (id, first_name, last_name, title) values (29, ''a'', ''b'', ''c'');\r\n\r\nINSERT INTO customer_t (id, first_name, last_name, title, notification_on, email, slack_handle, twitter_handle)\r\n SELECT * FROM json_table(L_CU, ''$''\r\n COLUMNS (\r\n id \tNUMBER PATH ''$.id'',\r\n first_name VARCHAR2 PATH ''$.firstName'',\r\n last_name \tVARCHAR2 PATH ''$.lastName'',\r\n title \t\tVARCHAR2 PATH ''$.title'',\r\n notification_on VARCHAR2 PATH ''$.notificationOn'',\r\n email \t\t\tVARCHAR2 PATH ''$.email'',\r\n slack_handle \t\tVARCHAR2 PATH ''$.slackHandle'',\r\n twitter_handle \t\tVARCHAR2 PATH ''$.twitterHandle''\r\n));\r\n\r\nINSERT INTO address_t (customer_id, id, street, nr, city, postcode, country)\r\nSELECT * FROM json_table(L_CU , ''$''\r\n COLUMNS (\r\n customer_id Number PATH ''$.id'',\r\n NESTED PATH ''$.addresses[*]''\r\n COLUMNS (\r\n id \t\tNUMBER PATH ''$.id'',\r\n street \t\t\tVARCHAR2 PATH ''$.street'',\r\n nr \t\t\t\tVARCHAR2 PATH ''$.number'',\r\n city \t\t\tVARCHAR2 PATH ''$.city'',\r\n postcode \t\tVARCHAR2 PATH ''$.postcode'',\r\n country \t\tVARCHAR2 PATH ''$.country''\r\n)));\r\n\r\n\r\nCOMMIT;\r\n\r\nEND;'\r\n );\r\n\r\n\r\n COMMIT; \r\nEND;\r\n/"
},
{
"alpha_fraction": 0.6234416961669922,
"alphanum_fraction": 0.6392080187797546,
"avg_line_length": 34.364444732666016,
"blob_id": "bc2164ce90dde29a33748acf52cd9f000aa871ea",
"content_id": "ba51a1c0056706d0dcd4197b60115f4ea0ff63d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8182,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 225,
"path": "/graph-performance/des-graph-test/src/test/java/com/trivadis/TestGremlinQueries.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis;\r\n\r\n\r\nimport java.util.ArrayList;\r\nimport java.util.List;\r\nimport java.util.Properties;\r\nimport java.util.concurrent.ExecutionException;\r\n\r\nimport org.apache.commons.lang3.StringUtils;\r\nimport org.apache.commons.math3.stat.StatUtils;\r\nimport org.joda.time.DateTime;\r\nimport org.junit.After;\r\nimport org.junit.Before;\r\nimport org.junit.Test;\r\n\r\nimport com.datastax.driver.core.ConsistencyLevel;\r\nimport com.datastax.driver.dse.DseCluster;\r\nimport com.datastax.driver.dse.DseSession;\r\nimport com.datastax.driver.dse.graph.GraphNode;\r\nimport com.datastax.driver.dse.graph.GraphOptions;\r\nimport com.datastax.driver.dse.graph.GraphResultSet;\r\nimport com.datastax.driver.dse.graph.SimpleGraphStatement;\r\nimport com.google.common.util.concurrent.ListenableFuture;\r\n\r\n\r\npublic class TestGremlinQueries {\r\n\t\r\n\tProperties properties = new Properties();\r\n\t\r\n\tprivate String cassandraHost;\r\n\tprivate String cassandraPort;\r\n\r\n\tprivate static final String GRAPH_NAME = \"sma_graph_22mar_prod_v10\";\r\n\tprivate static final int NOF_RUNS = 20;\r\n\tprivate static final int READ_TIMEOUT = 0;\r\n\t\r\n\tprivate DseSession session = null;\r\n\t\r\n\tprivate DateTime createDate(String dateTime) {\r\n\t\tDateTime result = new DateTime();\r\n\t\treturn result;\r\n\t}\r\n\t\r\n\tprivate void executeStmt(String stmt) {\r\n\t\tsession.executeGraph(stmt);\r\n\t}\r\n\t\r\n\tprivate void reportResult(int currentRun, int nofRuns, int nofTweets, int nofHashtags, long elapsedTime) {\r\n\t\tSystem.out.println(\"[\" + (currentRun+1) + \" out of \" + nofRuns + \"] took \" + elapsedTime + \" ms.\");\r\n\t}\r\n\r\n\tprivate List<String> createHashtags(String... hashtags) {\r\n\t\tList<String> hts = new ArrayList<String>();\r\n\r\n\t\tfor (String hashtag : hashtags) {\r\n\t\t\thts.add(hashtag);\r\n\t\t}\r\n\r\n\t\treturn hts;\r\n\t}\r\n\t\t\r\n\tprivate void reportResult(int currentRun, int nofRuns, int nofResults, double elapsedTime) {\r\n\t\tSystem.out.println(\"[\" + (currentRun+1) + \" out of \" + nofRuns + \"] returned \" + nofResults + \" results and took \" + new Double(elapsedTime).intValue() + \" ms.\");\r\n\t}\r\n\t\r\n\t\r\n\tprivate void executeGremlin(String stmt, String testCase, int nofRuns) throws InterruptedException, ExecutionException {\r\n\t\tdouble[] elapsedTimes = new double[nofRuns];\r\n\r\n\t\tSystem.out.println(\"======================================================\");\r\n\t\tSystem.out.println(\"Executing .... (\" + testCase + \")\"); \r\n\t\tSystem.out.println(stmt);\r\n\t\tlong startTime = 0;\r\n\r\n\t\t// loop nofRuns\r\n\t\tfor (int r = 0; r < nofRuns; r++) {\r\n\t\t\tstartTime = System.currentTimeMillis();\r\n\t\t\t\r\n\t\t\t// loop for each tweet\r\n\t\t\tSimpleGraphStatement sgs = new SimpleGraphStatement(stmt);\r\n\r\n\t\t\tListenableFuture<GraphResultSet> f = session.executeGraphAsync(sgs);\r\n\t\t\tGraphResultSet grs = f.get();\r\n\t\t\tList<GraphNode> l = grs.all();\r\n\t\t\telapsedTimes[r] = System.currentTimeMillis() - startTime;\r\n\t\t\treportResult(r, nofRuns, l.size(), elapsedTimes[r]);\r\n\t\t\t\r\n\t\t}\r\n\t\tSystem.out.println(\"Median: \" + StatUtils.percentile(elapsedTimes, 50) + \", 10th p: \" + StatUtils.percentile(elapsedTimes, 10) + \", 90th p: \" + StatUtils.percentile(elapsedTimes, 90));\r\n\r\n\t}\r\n\t\r\n\t@Before\r\n\tpublic void setup() throws Exception {\r\n\t\tproperties.load(TestGraphIngestStrategies.class.getClassLoader().getResourceAsStream(\"config.properties\"));\r\n\t\tcassandraHost = properties.getProperty(\"cassandra.host\");\r\n\t\tcassandraPort = properties.getProperty(\"cassandra.port\");\r\n\t\tString graphSource = properties.getProperty(\"graph.source\");\r\n\t\t\r\n\t\tSystem.out.println(\"Running Tests against \" + cassandraHost + \"......\");\r\n\r\n\t\tDseCluster dseCluster = DseCluster.builder()\r\n\t\t .addContactPoints(StringUtils.split(cassandraHost,\",\"))\r\n\t\t .withGraphOptions(new GraphOptions().setGraphName(GRAPH_NAME)\r\n\t\t\t\t\t\t.setReadTimeoutMillis(0)\r\n\t\t\t\t\t\t.setGraphSource(graphSource)\r\n\t\t\t\t\t\t.setGraphReadConsistencyLevel(ConsistencyLevel.ONE)\r\n\t\t\t\t\t\t.setGraphWriteConsistencyLevel(ConsistencyLevel.ONE))\r\n\t\t .build();\r\n\t\tsession = dseCluster.connect();\r\n\t}\r\n\t\r\n\t@After\r\n\tpublic void teardown() {\r\n\t\tsession.close();\r\n\t}\r\n\r\n\t@Test\r\n\tpublic void testUseCase_1() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_1\"; \r\n\t\tString stmt = \"g.V().has('tweet', 'id', 712172172748304384).\" + \"\\n\"\r\n\t\t\t\t+ \"in('publishes').\" + \"\\n\"\r\n\t\t\t\t+ \"out('publishes').\" + \"\\n\"\r\n\t\t\t\t+ \"has('id', neq(712172172748304384)).\" + \"\\n\"\r\n\t\t\t\t+ \"in('retweets').\" + \"\\n\"\r\n\t\t\t\t+ \"in('publishes').\" + \"\\n\"\r\n\t\t\t\t+ \"out('publishes').count()\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\r\n\r\n\t//@Test\r\n\tpublic void testUseCase_2() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_2\"; \r\n\t\tString stmt = \"g.V().has('tweet', 'id', '712172172748304384').\" + \"\\n\"\r\n\t\t\t\t\t+ \"repeat(both().\" + \"\\n\"\r\n\t\t\t\t\t+ \"simplePath()).\" + \"\\n\"\r\n\t\t\t\t\t+ \"until(has('id', '712193920411832321')).\" + \"\\n\"\r\n\t\t\t\t\t+ \"path().limit(1)\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\r\n\t\r\n\t@Test\r\n\tpublic void testUseCase_3() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_3\"; \r\n\t\tString stmt = \"g.V().has('twitterUser','name',Search.prefix('cnn'))\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\r\n\t\r\n\t@Test\r\n\tpublic void testUseCase_4() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_4\"; \r\n\t\tString stmt = \"g.V().has('term','name','bomb').in('contains')\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\r\n\r\n\r\n\t@Test\r\n\tpublic void testUseCase_4b() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_4b (returning text only)\"; \r\n\t\tString stmt = \"g.V().has('term','name','bomb').in('contains').values('text')\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\r\n\r\n\t@Test\r\n\tpublic void testUseCase_4c() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_4c (without index)\"; \r\n\t\texecuteStmt(\"schema.vertexLabel('tweet').index('containsType').remove()\");\r\n\r\n\t\tString stmt = \"g.V().has('term','name','bomb').inE('contains').has('type','hashtag').outV()\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\r\n\t}\r\n\t\r\n\t@Test\r\n\tpublic void testUseCase_4d() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_4d - (with Index)\"; \r\n\t\texecuteStmt(\"schema.vertexLabel('tweet').index('containsType').outE('contains').by('type').ifNotExists().add()\");\r\n\r\n\t\tString stmt = \"g.V().has('term','name','bomb').inE('contains').has('type','hashtag').outV()\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\r\n\t\texecuteStmt(\"schema.vertexLabel('tweet').index('containsType').remove()\");\r\n\t}\r\n\t@Test\r\n\tpublic void testUseCase_5() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_5\"; \r\n\t\tString stmt = \"g.V().has('term','name','bomb').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"in('contains').as('t1').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"in('publishes').as('u').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"out('publishes').where(neq('t1')).as('t2').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"out('contains').has('name','shock').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"select('u', 't2').by('name').by('text')\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\r\n\t\r\n\t@Test\r\n\tpublic void testUseCase_6a() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_6\"; \r\n\t\tString stmt = \"g.V().has('term','name','bomb').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"in('contains').as('t1').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"in('publishes').as('u').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"out('publishes').where(neq('t1')).as('t2').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"outE('contains').has('type','hashtag').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"inV().has('name','maga').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"select('u', 't2').by('name').by('text')\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\t}\t\r\n\t\r\n\t@Test\r\n\tpublic void testUseCase_6b() throws InterruptedException, ExecutionException {\r\n\t\tString tc = \"testUseCase_6b\"; \r\n\t\texecuteStmt(\"schema.vertexLabel('tweet').index('containsType').outE('contains').by('type').ifNotExists().add()\");\r\n\t\t\r\n\t\tString stmt = \"g.V().has('term','name','bomb').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"in('contains').as('t1').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"in('publishes').as('u').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"out('publishes').where(neq('t1')).as('t2').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"outE('contains').has('type','hashtag').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"inV().has('name','maga').\" + \"\\n\" + \r\n\t\t\t\t\t\t\"select('u', 't2').by('name').by('text')\";\r\n\t\texecuteGremlin(stmt, tc, NOF_RUNS);\r\n\r\n\t\texecuteStmt(\"schema.vertexLabel('tweet').index('containsType').remove()\");\r\n\t}\t\t\r\n}\r\n"
},
{
"alpha_fraction": 0.5700325965881348,
"alphanum_fraction": 0.6807817816734314,
"avg_line_length": 15.105262756347656,
"blob_id": "20df5b019441a962cf8908d055c2fadef3b45617",
"content_id": "b04a24211f2dfb60b68a5d8337b120c11b90871e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 19,
"path": "/working-with-druid/readme.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Working with Druid\n\n```\ndocker pull druidio/example-cluster\n```\n\n```\ndocker run --rm -i -p 3000:8082 -p 3001:8081 druidio/example-cluster\n```\n\n```\ncurl http://localhost:3000/druid/v2/datasources\n```\n\n<http://localhost:3001/>\n\n```\ndocker run --detach --name superset -p 38088:8088 amancevice/superset\n```\n\n"
},
{
"alpha_fraction": 0.4725011885166168,
"alphanum_fraction": 0.48373982310295105,
"avg_line_length": 40.693878173828125,
"blob_id": "d09cf443c55aa8209d992ca2a85af4f37485c920",
"content_id": "7c4029bf9acb8be8b81b279ffb51182f2e130ed9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 4182,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 98,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/ords/ords-order-orderdetail.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "-- Generated by Oracle SQL Developer REST Data Services 18.3.0.277.2354\r\n-- Exported REST Definitions from ORDS Schema Version 19.1.1.r1081514\r\n-- Schema: ORDER_PROCESSING Date: Sun Sep 29 18:35:41 PDT 2019\r\n--\r\nBEGIN\r\n ORDS.ENABLE_SCHEMA(\r\n p_enabled => TRUE,\r\n p_schema => 'ORDER_PROCESSING',\r\n p_url_mapping_type => 'BASE_PATH',\r\n p_url_mapping_pattern => 'order_processing',\r\n p_auto_rest_auth => FALSE); \r\n\r\n ORDS.DEFINE_MODULE(\r\n p_module_name => 'order_processing',\r\n p_base_path => '/orders/',\r\n p_items_per_page => 25,\r\n p_status => 'PUBLISHED',\r\n p_comments => NULL); \r\n ORDS.DEFINE_TEMPLATE(\r\n p_module_name => 'order_processing',\r\n p_pattern => ':id',\r\n p_priority => 0,\r\n p_etag_type => 'HASH',\r\n p_etag_query => NULL,\r\n p_comments => NULL);\r\n ORDS.DEFINE_HANDLER(\r\n p_module_name => 'order_processing',\r\n p_pattern => ':id',\r\n p_method => 'GET',\r\n p_source_type => 'resource/lob',\r\n p_items_per_page => 25,\r\n p_mimes_allowed => '',\r\n p_comments => NULL,\r\n p_source => \r\n'SELECT ''application/json'', json_object(''orderId'' VALUE po.id,\r\n ''orderDate'' VALUE po.order_date,\r\n ''orderMode'' VALUE po.order_mode,\r\n ''orderStatus'' VALUE DECODE (po.order_status,2,''PROCESSING''),\r\n ''totalPrice'' VALUE po.order_total,\r\n ''customer'' VALUE\r\n json_object(''firstName'' VALUE cu.first_name,\r\n ''lastName'' VALUE cu.last_name,\r\n ''emailAddress'' VALUE cu.email\r\n ),\r\n ''items'' VALUE (SELECT json_arrayagg(\r\n json_object(''itemNumber'' VALUE li.id,\r\n ''product'' VALUE\r\n json_object(''id'' VALUE li.product_id,\r\n ''name'' VALUE li.product_name,\r\n ''unitPrice'' VALUE li.unit_price),\r\n ''quantity'' VALUE li.quantity))\r\n FROM order_item_t li WHERE po.id = li.order_id))\r\n FROM order_t po LEFT JOIN customer_t cu ON (po.customer_id = cu.id)\r\n where po.id = :id'\r\n );\r\n ORDS.DEFINE_TEMPLATE(\r\n p_module_name => 'order_processing',\r\n p_pattern => 'changes/:offset',\r\n p_priority => 0,\r\n p_etag_type => 'HASH',\r\n p_etag_query => NULL,\r\n p_comments => NULL);\r\n ORDS.DEFINE_HANDLER(\r\n p_module_name => 'order_processing',\r\n p_pattern => 'changes/:offset',\r\n p_method => 'GET',\r\n p_source_type => 'resource/lob',\r\n p_items_per_page => 1,\r\n p_mimes_allowed => '',\r\n p_comments => NULL,\r\n p_source => \r\n'SELECT ''application/json'', json_object(''orderId'' VALUE po.id,\r\n ''orderDate'' VALUE po.order_date,\r\n ''orderMode'' VALUE po.order_mode,\r\n ''orderStatus'' VALUE DECODE (po.order_status,2,''PROCESSING''),\r\n ''totalPrice'' VALUE po.order_total,\r\n ''customer'' VALUE\r\n json_object(''firstName'' VALUE cu.first_name,\r\n ''lastName'' VALUE cu.last_name,\r\n ''emailAddress'' VALUE cu.email\r\n ),\r\n ''items'' VALUE (SELECT json_arrayagg(\r\n json_object(''itemNumber'' VALUE li.id,\r\n ''product'' VALUE\r\n json_object(''id'' VALUE li.product_id,\r\n ''name'' VALUE li.product_name,\r\n ''unitPrice'' VALUE li.unit_price),\r\n ''quantity'' VALUE li.quantity))\r\n FROM order_item_t li WHERE po.id = li.order_id),\r\n ''Offset'' VALUE TO_CHAR(po.modified_at, ''YYYYMMDDHH24MISS''))\r\nFROM order_t po LEFT JOIN customer_t cu ON (po.customer_id = cu.id)\r\nWHERE po.modified_at > TO_DATE(:offset, ''YYYYMMDDHH24MISS'')'\r\n );\r\n\r\n\r\n COMMIT; \r\nEND;\r\n/"
},
{
"alpha_fraction": 0.6962060332298279,
"alphanum_fraction": 0.7125449776649475,
"avg_line_length": 25.755556106567383,
"blob_id": "98583bbbd91354adc6b4d6401a141e560b2d5e88",
"content_id": "e6f0fe16e1b39dcd062ac329f66443d65eb59b03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3611,
"license_type": "no_license",
"max_line_length": 505,
"num_lines": 135,
"path": "/atlas/amundsen-atlas/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Apache Atlas & Amundsen Governance Demo\n\nThis demo shows how Apache Atlas can be setup and works and how Amundsen can be setup to work on top of Apache Altas to be used for Big Data Governance. \n\n## Setup\n\nThe environment can be started using docker compose.\n\n```\ndocker-compose up -d\n```\n\nThe Atlas docker images has been forked from <https://github.com/ing-bank/rokku-dev-apache-atlas>.\n\n### Install Example Data\n\nYou can control the installation of sample data by the environment variable `ATLAS_PROVISION_EXAMPLES`. By default it is set to true. \n\n```\n environment:\n - ATLAS_PROVISION_EXAMPLES=true\n```\n\n\n### Hive Integration\n\nAccording to the <https://atlas.apache.org/Hook-Hive.html>\n\nAdd to `hadoop-hive.env`\n\n```\nHIVE_SITE_CONF_hive_exec_post_hooks=org.apache.atlas.hive.hook.HiveHook\nHIVE_AUX_JARS_PATH=/atlas/hook/hive\n```\n\n```\nuntar apache-atlas-${project.version}-hive-hook.tar.gz available in the Atlas container\n```\n\n### Kafka Integration\n\nCreate a topic in Kafka\n\n```\ndocker exec -ti broker-1 kafka-topics --create --bootstrap-server broker-1:9092 --topic truck_position --replication-factor 1 --partitions 8\n```\n\n\n```\ntar -xzf apache-atlas-kafka-hook.tar.gz \n```\n\nmv kafka/ /opt/atlas/hook\n\n\n\n```\nProperties properties = new Properties();\nproperties.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, \"localhost:9092\");\nKafkaAdminClient kafkaAdminClient = (KafkaAdminClient) AdminClient.create(properties);\nListTopicsResult listTopicResult = kafkaAdminClient.listTopics();\nSystem.out.println(listTopicResult.names().get().toString());\n```\n\n### Spark Integration\n\n```\nfrom pyspark.sql import SparkSession\n\nspark = SparkSession.builder.master(\"spark://spark-master:7077\").appName(\"Hello World\").getOrCreate()\n\nl = [('Alice', 1),('Bob', 3)]\n\ndf = spark.createDataFrame(l, ['name', 'age'])\n\ndf.filter(df.age > 1).collect()\n```\n\n\n## ATLAS REST API\n\n```\ncurl -u admin:admin -H 'Content-Type: application/json' -XGET http://analyticsplatform:21000/api/atlas/types\n```\n\ncurl -u admin:admin -H 'Content-Type: application/json' -XGET http://analyticsplatform:21000/api/atlas/v2/types/typedefs\n\n```\ncurl -u admin:admin -H 'Content-Type: application/json' -XGET http://analyticsplatform:21000/api/atlas/types/avro_type \n```\n\n```\ncurl -X POST -H 'Content-Type: application/json' -H 'X-XSRF-HEADER: valid' -H 'Authorization: Basic YWRtaW46YWRtaW4=' -i http://analyticsplatform:21000/api/atlas/v2/entity --data '{ \"entity\":{ \"typeName\":\"kafka_topic\", \"attributes\":{ \"description\":null, \"name\":\"truck_position\", \"owner\":\"Guido\", \"qualifiedName\":\"PRIVATE@${cluster_name}\", \"topic\":\"truck_position\", \"uri\":\"none\" }, \"guid\":-1 }, \"referredEntities\":{ }}'```\n```\n\n\nSearch\n\n```\nhttp://analyticsplatform:5001/search?query_term=product&page_index=0\n```\n\nMetadata\n\nGet Details for a table\n\n```\nhttp://analyticsplatform:5002/table/Table://null.Sales@cl1/time_dim@cl1\n```\n\n### Tips und Tricks\n\n#### What does xxxxNational and xxxxLocal mean in Kafka Typedef\n\nWe have National and Local kafka installations and may have different replication Factors, retention Bytes, partitionCounts, and segmentBytes for National vs Local\n\n#### How to add custom types to the \"create new entity\" type selection dropdown in the Atlas UI?\n\n1. Add the following property in ATLAS_HOME/conf/atlas-application.properties :\n\n```\natlas.ui.editable.entity.types=your_custom_type\n```\n\nor\n\n```\natlas.ui.editable.entity.types=* ( to list all types)\n```\n\n2. Restart Atlas.\n\n3. Refresh browser cache\n\nNow you should be able to see the custom type you created."
},
{
"alpha_fraction": 0.6386687755584717,
"alphanum_fraction": 0.6529318690299988,
"avg_line_length": 27.636363983154297,
"blob_id": "633e93f1acfcb0c18c78e0c40d48c5d9fee2130a",
"content_id": "918053f3df8e7212b522f79806c130874d0a8011",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 631,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 22,
"path": "/streaming-visualization/scripts/start-connect-slack-sink.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"removing Slack Sink Connectors\"\n\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/slack-sink\"\n\necho \"creating Slack Sink Connector\"\n\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n --data '{\n \"name\": \"slack-sink\",\n \"config\": {\n \"connector.class\": \"net.mongey.kafka.connect.SlackSinkConnector\",\n \"tasks.max\": \"1\",\n \"topics\":\"slack-notify\",\n \"slack.token\":\"xxxxxx\",\n \"slack.channel\":\"general\",\n \"message.template\":\"tweet by ${USER_SCREENNAME} with ${TEXT}\",\n \"key.converter\": \"org.apache.kafka.connect.storage.StringConverter\"\n }\n }'\n\n"
},
{
"alpha_fraction": 0.7078740000724792,
"alphanum_fraction": 0.7078740000724792,
"avg_line_length": 22.518518447875977,
"blob_id": "ffbb8789d898e1a949aceeff43886e483aa4cdde",
"content_id": "f68391e5d1e894202c5877dc35b5c0d0efeeca30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1270,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 54,
"path": "/event-sourcing/axon/finance-axon-command/src/main/java/com/trivadis/sample/axon/account/event/AccountCreatedEvent.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.event;\n\nimport java.math.BigDecimal;\n\n\n/**\n * @author gschmutz\n *\n */\npublic class AccountCreatedEvent extends BaseEvent<String> {\n\n\tprivate String forCustomerId;\n\tprivate String accountType;\n\tprivate BigDecimal balance;\n\n\tpublic AccountCreatedEvent(String id, String forCustoemrId, String accountType, BigDecimal balance) {\n\t\tsuper(id);\n\t\tthis.forCustomerId = forCustoemrId;\n\t\tthis.accountType = accountType;\n\t\tthis.balance = balance;\n\t}\n\n\tpublic String getForCustomerId() {\n\t\treturn forCustomerId;\n\t}\n\n\tpublic String getAccountType() {\n\t\treturn accountType;\n\t}\n\n\tpublic BigDecimal getBalance() {\n\t\treturn balance;\n\t}\n\n\tpublic void setForCustomerId(String forCustomerId) {\n\t\tthis.forCustomerId = forCustomerId;\n\t}\n\n\tpublic void setAccountType(String accountType) {\n\t\tthis.accountType = accountType;\n\t}\n\n\tpublic void setBalance(BigDecimal balance) {\n\t\tthis.balance = balance;\n\t}\n\n\t@Override\n\tpublic String toString() {\n\t\treturn \"AccountCreatedEvent [forCustomerId=\" + forCustomerId + \", accountType=\" + accountType + \", balance=\"\n\t\t\t\t+ balance + \", get__eventType()=\" + get__eventType() + \", getId()=\" + getId() + \", getClass()=\"\n\t\t\t\t+ getClass() + \", hashCode()=\" + hashCode() + \", toString()=\" + super.toString() + \"]\";\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.6854327917098999,
"alphanum_fraction": 0.7213230133056641,
"avg_line_length": 30.230770111083984,
"blob_id": "d78cb59be5320b37e4f9a8450873046c84b325b8",
"content_id": "f35460a8d27a5201ca177b4f55a5df4c899e598e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2842,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 91,
"path": "/avro-vs-protobuf/protobuf/java/protobuf-v1/src/test/java/com/trivadis/protobuf/demo/TestProtobufV1.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.protobuf.demo;\n\nimport java.io.FileInputStream;\nimport java.io.FileOutputStream;\nimport java.io.IOException;\nimport java.time.Instant;\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport org.junit.Test;\n\nimport com.google.protobuf.Timestamp;\nimport com.trivadis.protobuf.address.v1.AddressWrapper;\nimport com.trivadis.protobuf.lov.TitleEnumWrapper;\nimport com.trivadis.protobuf.person.v1.PersonWrapper;\n\n\n\npublic class TestProtobufV1 {\n\n\tprivate final static String BIN_FILE_NAME_V1 = \"../../data/person_v1.0.bin\";\n\t\n\t@Test\n\tpublic void testToByteArray() throws IOException {\n\t\tList<AddressWrapper.Addresss> addresses = new ArrayList<>();\n\t\t\n\t\taddresses.add(AddressWrapper.Addresss.newBuilder()\n\t\t\t\t.setId(1)\n\t\t\t\t.setStreetAndNr(\"Somestreet 10\")\n\t\t\t\t.setZipAndCity(\"9332 Somecity\").build());\n\t\t\n\t\tInstant time = Instant.parse(\"1995-11-10T00:00:00.00Z\");\n\t\tTimestamp timestamp = Timestamp.newBuilder().setSeconds(time.getEpochSecond())\n\t\t\t .setNanos(time.getNano()).build();\n\n\t\tPersonWrapper.Person person = PersonWrapper.Person.newBuilder().setId(1)\n\t\t\t\t\t.setFirstName(\"Peter\")\n\t\t\t\t\t.setLastName(\"Sample\")\n\t\t\t\t\t.setEmailAddress(\"peter.sample@somecorp.com\")\n\t\t\t\t\t.setPhoneNumber(\"+41 79 345 34 44\")\n\t\t\t\t\t.setFaxNumber(\"+41 31 322 33 22\")\n\t\t\t\t\t.setTitle(TitleEnumWrapper.Title.MR)\n\t\t\t\t\t.setDateOfBirth(timestamp)\n\t\t\t\t\t.addAllAddresses(addresses).build();\n\n\t\tSystem.out.println(person);\n\t\t\n\t\tbyte[] serialized = person.toByteArray();\n\t\tSystem.out.println(\"Length of byte array:\" + serialized.length);\n\t\t\n\t}\n\t\n\t@Test\n\tpublic void testWriteToBinaryFileV1() throws IOException {\n\t\tList<AddressWrapper.Addresss> addresses = new ArrayList<>();\n\t\t\n\t\taddresses.add(AddressWrapper.Addresss.newBuilder()\n\t\t\t\t.setId(1)\n\t\t\t\t.setStreetAndNr(\"Somestreet 10\")\n\t\t\t\t.setZipAndCity(\"9332 Somecity\").build());\n\t\t\n\t\tInstant time = Instant.parse(\"1995-11-10T00:00:00.00Z\");\n\t\tTimestamp timestamp = Timestamp.newBuilder().setSeconds(time.getEpochSecond())\n\t\t\t .setNanos(time.getNano()).build();\n\n\t\tPersonWrapper.Person person = PersonWrapper.Person.newBuilder().setId(1)\n\t\t\t\t\t.setFirstName(\"Peter\")\n\t\t\t\t\t.setLastName(\"Sample\")\n\t\t\t\t\t.setEmailAddress(\"peter.sample@somecorp.com\")\n\t\t\t\t\t.setPhoneNumber(\"+41 79 345 34 44\")\n\t\t\t\t\t.setFaxNumber(\"+41 31 322 33 22\")\n\t\t\t\t\t.setTitle(TitleEnumWrapper.Title.MR)\n\t\t\t\t\t.setDateOfBirth(timestamp)\n\t\t\t\t\t.addAllAddresses(addresses).build();\n\n\t\tSystem.out.println(person);\n\t\t\n\t\tFileOutputStream output = new FileOutputStream(BIN_FILE_NAME_V1);\n\t\tperson.writeTo(output);\n\t}\n\t\n\t@Test\n\tpublic void testReadFromBinaryFileV1() throws IOException {\n\t\t\n\t\tPersonWrapper.Person person =\n\t\t\t PersonWrapper.Person.parseFrom(new FileInputStream(BIN_FILE_NAME_V1));\n\t\tSystem.out.println(\"Person:\" + person);\n\t\tSystem.out.println(\"FirstName: \" + person.getFirstName());\n\t\tSystem.out.println(\"Unknown fields:\" + person.getUnknownFields());\n\t}\t\n}\n"
},
{
"alpha_fraction": 0.6514360308647156,
"alphanum_fraction": 0.6801566481590271,
"avg_line_length": 29.600000381469727,
"blob_id": "fd40d11ab6929e6e88aaa201fd3a0ee7347a5bb0",
"content_id": "ea8e5f098f29a3f795274e3e64b310e7d5914132",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 766,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 25,
"path": "/streaming-visualization/scripts/start-connect-twitter-source.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"removing Twitter Source Connectors\"\n\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/twitter-source\"\n\necho \"creating Twitter Source Connector\"\n\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n --data '{\n \"name\": \"twitter-source\",\n \"config\": {\n \t\"connector.class\": \"com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector\",\n \t\"twitter.oauth.consumerKey\": \"xxxxx\",\n \t\"twitter.oauth.consumerSecret\": \"xxxxx\",\n \t\"twitter.oauth.accessToken\": \"xxxx\",\n \t\"twitter.oauth.accessTokenSecret\": \"xxxxx\",\n \t\"process.deletes\": \"false\",\n \t\"filter.keywords\": \"#javazone,#javazone2019\",\n \t\"filter.userIds\": \"15148494\",\n \t\"kafka.status.topic\": \"tweet-raw-v1\",\n \t\"tasks.max\": \"1\"\n\t}\n }'\n\n"
},
{
"alpha_fraction": 0.6689705848693848,
"alphanum_fraction": 0.6704326272010803,
"avg_line_length": 41.50564956665039,
"blob_id": "5ab4c6367142ce4d429146b58987375671c3781a",
"content_id": "82dea312663857526bb20fa52d6574bd8b557ea0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 15047,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 354,
"path": "/graph-performance/des-graph-test/src/main/java/com/trivadis/VertexHelper.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis;\n\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\n\nimport org.apache.commons.lang.text.StrSubstitutor;\n\nimport com.datastax.driver.dse.DseSession;\nimport com.datastax.driver.dse.graph.Edge;\nimport com.datastax.driver.dse.graph.GraphNode;\nimport com.datastax.driver.dse.graph.GraphResultSet;\nimport com.datastax.driver.dse.graph.SimpleGraphStatement;\nimport com.datastax.driver.dse.graph.Vertex;\nimport com.google.common.collect.ImmutableMap;\n\npublic class VertexHelper {\n\t\n\t/**\n\t * Remove a property with a NULL value from the Object array\n\t * @param properties\n\t * @return\n\t */\n\tpublic static Object[] removeNULLPropertyValue(Object ... properties) {\n\t\tList<Object> propertiesCopy = new ArrayList<Object>();\n\t\tint x = 0;\n\t\tfor (int i=0; i<properties.length/2 ; i++) {\n\t\t\tString key = (String)properties[x];\n\t\t\tObject value = properties[++x];\n\t\t\tif (value != null) {\n\t\t\t\tpropertiesCopy.add(key);\n\t\t\t\tpropertiesCopy.add(value);\n\t\t\t}\n\t\t\tx++;\n\t\t}\n\t\treturn propertiesCopy.toArray();\n\t}\n\t\n\n\t\n\tpublic static Vertex getVertexByLabelAndPropertyKey(DseSession session, String label, String propertyKey, Object propertyKeyValue) {\n\t\tVertex vertex = null;\n\n\t\tSimpleGraphStatement s = new SimpleGraphStatement(\"g.V().has(vertexLabel, propertyKey ,propertyKeyValue)\")\n\t\t\t\t\t\t\t\t\t\t\t\t.set(\"vertexLabel\", label)\n\t\t\t\t\t\t\t\t\t\t\t\t.set(\"propertyKey\", propertyKey)\n\t\t\t\t\t\t\t\t\t\t\t\t.set(\"propertyKeyValue\", propertyKeyValue);\n\t\tGraphResultSet resultSet = session.executeGraph(s);\n\t\tGraphNode node = resultSet.one();\n\t\t\n\t\tif (node != null) {\n\t\t\tvertex = node.asVertex();\n\t\t}\n\t\t\n\t\treturn vertex;\n\t}\n\n\tpublic static String fmtLoadVertex(String vertexName, String vertexLabel, String propertyKey, String propertyKeyValue) {\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tStrSubstitutor subst = null;\n\t\t\n\t\tMap<String,String> params = new HashMap();\n\t\tparams.put(\"vertexName\", vertexName);\n\t\tparams.put(\"vertexLabel\", vertexLabel);\n\t\tparams.put(\"propertyKey\", propertyKey);\n\t\tparams.put(\"propertyKeyValue\", (String)propertyKeyValue);\n\t\tsubst = new StrSubstitutor(params);\n\t\tstmt.append(subst.replace(\"${vertexName} = g.V().has('${vertexLabel}', '${propertyKey}', '${propertyKeyValue}').next()\"));\n\t\t\n\t\treturn stmt.toString();\n\t}\n\t\n\tpublic static String fmtCreateOrUpdateVertex(String vertexName, String vertexLabel, String propertyKey, String propertyKeyValue, String... propertiesParam) {\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tStrSubstitutor subst = null;\n\t\t\n\t\tMap<String,String> params = new HashMap();\n\t\tparams.put(\"vertexName\", vertexName);\n\t\tparams.put(\"vertexLabel\", vertexLabel);\n\t\tparams.put(\"propertyKey\", propertyKey);\n\t\tparams.put(\"propertyKeyValue\", (String)propertyKeyValue);\n\t\tsubst = new StrSubstitutor(params);\n\t\tstmt.append(subst.replace(\"${vertexName} = g.V().has('${vertexLabel}', '${propertyKey}', ${propertyKeyValue}).tryNext().orElseGet { nofNewV++; g.addV('${vertexLabel}').property('${propertyKey}', ${propertyKeyValue}).next() }\"));\n\t\tparams.clear();\n\t\tfor (int i=0; i<propertiesParam.length/2 ; i++) {\n\t\t\tparams.put(\"vertexName\", vertexName);\n\t\t\tparams.put(\"propertyKey\", propertiesParam[i*2]);\n\t\t\tparams.put(\"propertyValue\", propertiesParam[i*2+1]);\n\n\t\t\tsubst = new StrSubstitutor(params);\n\t\t\tstmt.append(\"\\n\");\n\t\t\tstmt.append(subst.replace(\"${vertexName}.property('${propertyKey}',${propertyValue})\"));\n\t\t}\n\t\t\n\t\treturn stmt.toString();\n\t}\n\t\n\tpublic static String fmtCreateOrUpdateEdge(String edgeName, String fromVertexName, String toVertexName, String edgeLabel, String... propertiesParam) {\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tStrSubstitutor subst = null;\n\t\t\n\t\tMap<String,String> params = new HashMap();\n\t\tparams.put(\"edgeName\", edgeName);\n\t\tparams.put(\"fromVertexName\", fromVertexName);\n\t\tparams.put(\"toVertexName\", toVertexName);\n\t\tparams.put(\"edgeLabel\", edgeLabel);\n\t\tsubst = new StrSubstitutor(params);\n\t\t\n\t\t//if (g.V(tweet).out(\"uses\").hasId(term[2].id()).hasNext()) {\n\t\t//stmt.append(subst.replace(\"${edgeName} = g.V(${fromVertexName}).out('${edgeLabel}').V(${toVertexName}).tryNext().orElseGet { ${fromVertexName}.addEdge('${edgeLabel}', ${toVertexName}) }\"));\t\n\t\tstmt.append(subst.replace(\"if (!g.V(${fromVertexName}).out('${edgeLabel}').hasId(${toVertexName}.id()).hasNext()) {\\n\"));\n\t\tstmt.append(subst.replace(\"\\t\\t${edgeName} = g.V(${fromVertexName}).as('f').V(${toVertexName}).as('t').addE('${edgeLabel}').from('f').next()\\n\"));\n\t\tstmt.append(subst.replace(\"\\t\\tnofE++\\n\"));\n\t\tparams.clear();\n\t\tfor (int i=0; i<propertiesParam.length/2 ; i++) {\n\t\t\tparams.put(\"edgeName\", edgeName);\n\t\t\tparams.put(\"propertyKey\", propertiesParam[i*2]);\n\t\t\tparams.put(\"propertyValue\", propertiesParam[i*2+1]);\n\n\t\t\tsubst = new StrSubstitutor(params);\n\t\t\tstmt.append(\"\\n\");\n\t\t\tstmt.append(subst.replace(\"${edgeName}.property('${propertyKey}','${propertyValue}')\"));\n\t\t}\n\t\tstmt.append(\"\\t}\");\n\t\t//stmt.append(subst.replace(\"${edgeName} = g.V(${fromVertexName}).out('${edgeLabel}').hasId(${toVertexName}.id()).tryNext().orElseGet { g.V(${fromVertexName}.id()).as('fromV').V(${toVertexName}.id()).addE('${edgeLabel}').from('fromV') }\"));\n\t\t//stmt.append(subst.replace(\" ${edgeName} = g.V(${fromVertexName}).as('fromV').V(${toVertexName}).addE('${edgeLabel}').from('fromV') \"));\n\t\t\n\t\t\n\n\t\treturn stmt.toString();\n\t}\n\n\t\t\n\tpublic static Vertex getVertexAndUpdateProperties(DseSession session, String vertexLabel, String propertyKey, Object propertyKeyValue, Object... propertiesParam) {\n\t\tVertex vertex = null;\n\t\t// remove properties with NULL values\n\t\tObject[] properties = removeNULLPropertyValue(propertiesParam);\n\n\t\tvertex = VertexHelper.getVertexByLabelAndPropertyKey(session, vertexLabel, propertyKey, propertyKeyValue);\n/*\t\t\n\t\tint x = 0;\n\t\tfor (int i=0; i<properties.length/2 ; i++) {\n\t\t\tString key = (String)properties[x];\n\t\t\tObject o = properties[++x];\n\t\t\tif (vertex.properties(key) != null) {\n\t\t\t\tvertex.property(key, o);\n\t\t\t} else {\n\t\t\t\tvertex.property(key, o);\n\t\t\t}\n\t\t\tx++;\n\t\t}\n*/\t\t\n\t\treturn vertex;\n\t}\n\t\n\tpublic static Pair<String, Map<String, Object>> formatPropertyStatement(Object[] properties) {\n\t\tMap<String,Object> param = new HashMap<String,Object>();\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tfor (int i = 0; i < properties.length/2; i++) {\n\t\t\tint k = i * 2;\n\t\t\tint v = i * 2 + 1;\n\t\t\tString paramName = \"propertyParam\" + i;\n\t\t\tstmt.append(\"v.property(\\\"\").append(properties[k]).append(\"\\\",b.\").append(paramName).append(\")\" + \"\\n\");\n\t\t\tparam.put(paramName, properties[v]);\n\t\t\t\n\t\t}\n\t\treturn new Pair<String, Map<String,Object>>(stmt.toString(), param);\n\t}\n\n\tpublic static Vertex createVertex(DseSession session, String vertexLabel, String propertyKey, Object propertyKeyValue, Object... propertiesParam) {\n\t\tVertex vertex = null;\n\t\t// remove properties with NULL values\n\t\tObject[] properties = VertexHelper.removeNULLPropertyValue(propertiesParam);\n\t\tPair<String, Map<String,Object>> propertyParams = formatPropertyStatement(properties);\n\t\tString stmt = \"\"\n\t\t\t\t\t\t+ \"Vertex v\" + \"\\n\"\n\t\t\t\t\t\t+ \"v = graph.addVertex(label, b.vertexLabel, b.propertyKey, b.propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ propertyParams.getLeft() + \"\\n\"\n\t\t\t\t\t\t+ \"return v\";\n//\t\tSystem.out.println(stmt);\n\n\t\tMap<String,Object> map = ImmutableMap.<String,Object>of(\"vertexLabel\", vertexLabel, \"propertyKey\", propertyKey, \"propertyKeyValue\", propertyKeyValue);\n\n\t\tvertex = session.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>builder().putAll(map).putAll(propertyParams.getRight()).build()\n\t\t\t\t\t\t\t\t)).one().asVertex();\n\t\treturn vertex;\n\t}\n\n\tpublic static Vertex createOrUpdateVertex(DseSession session, boolean updateOnly, String vertexLabel, String propertyKey, Object propertyKeyValue, Object... propertiesParam) {\n\t\tVertex vertex = null;\n\t\t// remove properties with NULL values\n\t\tObject[] properties = VertexHelper.removeNULLPropertyValue(propertiesParam);\n\t\tif (!updateOnly) {\n\t\t\t Pair<String, Map<String,Object>> propertyParams = formatPropertyStatement(properties);\n\t\t\t\tString stmt = \"\"\n\t\t\t\t\t\t+ \"Vertex v\" + \"\\n\"\n\t\t\t\t\t\t+ \"GraphTraversal gt = g.V().has(b.vertexLabel, b.propertyKey, b.propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \"if (!gt.hasNext()) {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t\tv = graph.addVertex(label, b.vertexLabel, b.propertyKey, b.propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \"} else {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t\tv = gt.next()\" + \"\\n\"\n\t\t\t\t\t\t+ \"}\" + \"\\n\"\n\t\t\t\t\t\t+ propertyParams.getLeft() + \"\\n\"\n\t\t\t\t\t\t+ \"return v\";\n\t\t\t\tSystem.out.println(stmt);\n\n\t\t\t\tMap<String,Object> map = ImmutableMap.<String,Object>of(\"vertexLabel\", vertexLabel, \"propertyKey\", propertyKey, \"propertyKeyValue\", propertyKeyValue);\n\n\t\t\t\tvertex = session.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>builder().putAll(map).putAll(propertyParams.getRight()).build()\n\t\t\t\t\t\t\t\t)).one().asVertex();\n\t\t} else {\n\t\t\tvertex = VertexHelper.getVertexAndUpdateProperties(session, vertexLabel, propertyKey, propertyKeyValue, properties);\n\t\t}\n\t\treturn vertex;\n\t}\n\n\tpublic static void createOrUpdateVertices(DseSession session, String vertexLabel, String propertyKey, List<Object> propertyKeyValues, Object... propertiesParam) {\n\t\tVertex vertex = null;\n\t\t// remove properties with NULL values\n\t\tObject[] properties = VertexHelper.removeNULLPropertyValue(propertiesParam);\n\t\tPair<String, Map<String,Object>> propertyParams = formatPropertyStatement(properties);\n\t\tString stmt = \"\"\n\t\t\t\t\t\t+ \"List<Vertex> l = new ArrayList<Vertex>()\"\n\t\t\t\t\t\t+ \"for (Object propertyKeyValue : b.propertyKeyValues) {\"\n\t\t\t\t\t\t+ \" Vertex v\" + \"\\n\"\n\t\t\t\t\t\t+ \" GraphTraversal gt = g.V().has(b.vertexLabel, b.propertyKey, propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \" if (!gt.hasNext()) {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t \tv = graph.addVertex(label, b.vertexLabel, b.propertyKey, propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \" } else {\" + \"\\n\"\n\t\t\t\t\t\t+ \" \tv = gt.next()\" + \"\\n\"\n\t\t\t\t\t\t+ \" }\" + \"\\n\"\n\t\t\t\t\t\t+ propertyParams.getLeft() + \"\\n\"\n\t\t\t\t\t\t+ \" l.add(v)\" + \"\\n\"\n\t\t\t\t\t\t+ \" }\" + \"\\n\"\n\t\t\t\t\t\t+ \"return l\";\n//\t\tSystem.out.println(stmt);\n\n\t\tMap<String,Object> map = ImmutableMap.<String,Object>of(\"vertexLabel\", vertexLabel, \"propertyKey\", propertyKey, \"propertyKeyValues\", propertyKeyValues);\n\n\t\tsession.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>builder().putAll(map).putAll(propertyParams.getRight()).build()\n\t\t\t\t\t\t\t\t));\n\n\t}\n\n\tpublic static Vertex createOrUpdateVertexAndEdge(DseSession session, String vertexLabel, String propertyKey, \n\t\t\t\t\t\t\t\t\t\tObject propertyKeyValue, String edgeLabel, Vertex toVertex, Object... propertiesParam) {\n\t\tVertex vertex = null;\n\t\t// remove properties with NULL values\n\t\tObject[] properties = VertexHelper.removeNULLPropertyValue(propertiesParam);\n\t\t\n\t\tPair<String, Map<String,Object>> propertyParams = formatPropertyStatement(properties);\n\t\tString stmt = \"\"\n\t\t\t\t\t\t+ \"Vertex v\" + \"\\n\"\n\t\t\t\t\t\t+ \"GraphTraversal gt = g.V().has(b.vertexLabel, b.propertyKey, b.propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \"if (!gt.hasNext()) {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t\tv = graph.addVertex(label, b.vertexLabel, b.propertyKey, b.propertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \"} else {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t\tv = gt.next()\" + \"\\n\"\n\t\t\t\t\t\t+ \"}\" + \"\\n\"\n\t\t\t\t\t\t+ \"Vertex to = g.V(t).next(); v.addEdge(b.edgeLabel, to)\" + \"\\n\"\n\t\t\t\t\t\t+ propertyParams.getLeft() + \"\\n\"\n\t\t\t\t\t\t+ \"return v\";\n//\t\tSystem.out.println(stmt);\n\n\t\tMap<String,Object> map = ImmutableMap.<String,Object>of(\"vertexLabel\", vertexLabel, \"propertyKey\", propertyKey, \"propertyKeyValue\", propertyKeyValue, \"edgeLabel\", edgeLabel);\n\n\t\tvertex = session.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t\t\t.set(\"t\", toVertex)\n\t\t\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>builder().putAll(map).putAll(propertyParams.getRight()).build()\n\t\t\t\t\t\t\t\t)).one().asVertex();\n\t\treturn vertex;\n\t}\n\n\tpublic static Vertex createOrUpdateVertexAndEdges(DseSession session, String fromVertexLabel, String fromPropertyKey,\n\t\t\t\t\t\t\t\tObject fromPropertyKeyValue, String edgeLabel, String toVertexLabel, String toPropertyKey, \n\t\t\t\t\t\t\t\tList<Object> toPropertyKeyValues, Object... propertiesParam) {\n\t\tVertex vertex = null;\n\t\t// remove properties with NULL values\n\t\tObject[] properties = VertexHelper.removeNULLPropertyValue(propertiesParam);\n\n\t\tPair<String, Map<String,Object>> propertyParams = formatPropertyStatement(properties);\n\t\tString stmt = \"\"\n\t\t\t\t\t\t+ \"Vertex from\" + \"\\n\"\n\t\t\t\t\t\t+ \"GraphTraversal gt\" + \"\\n\"\n\t\t\t\t\t\t+ \"gt = g.V().has(b.fromVertexLabel, b.fromPropertyKey, b.fromPropertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \"if (!gt.hasNext()) {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t\tfrom = graph.addVertex(label, b.fromVertexLabel, b.fromPropertyKey, b.fromPropertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \"} else {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t\tfrom = gt.next()\" + \"\\n\"\n\t\t\t\t\t\t+ \"}\" + \"\\n\"\n\t\t\t\t\n\t\t\t\t\t\t+ \"for (Object toPropertyKeyValue : b.toPropertyKeyValues) {\" + \"\\n\"\n\t\t\t\t\t\t+ \" gt = g.V().has(b.toVertexLabel, b.toPropertyKey, toPropertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \" if (!gt.hasNext()) {\" + \"\\n\"\n\t\t\t\t\t\t+ \"\t \tto = graph.addVertex(label, b.toVertexLabel, b.toPropertyKey, toPropertyKeyValue)\" + \"\\n\"\n\t\t\t\t\t\t+ \" } else {\" + \"\\n\"\n\t\t\t\t\t\t+ \" \tto = gt.next()\" + \"\\n\"\n\t\t\t\t\t\t+ \" }\" + \"\\n\"\n//\t\t\t\t\t\t+ propertyParams.getLeft() + \"\\n\"\n\t\t\t\t\t\t+ \"\tfrom.addEdge(b.edgeLabel, to)\" + \"\\n\"\n\t\t\t\t\t\t+ \" }\" + \"\\n\"\n \t\t\t\t\t\t+ \"return from\";\n//\t\tSystem.out.println(stmt);\n\n\t\tvertex = session.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>builder()\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"fromVertexLabel\", fromVertexLabel)\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"fromPropertyKey\", fromPropertyKey)\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"fromPropertyKeyValue\", fromPropertyKeyValue)\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"edgeLabel\", edgeLabel)\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"toVertexLabel\", toVertexLabel)\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"toPropertyKey\", toPropertyKey)\n\t\t\t\t\t\t\t\t\t\t\t\t.put(\"toPropertyKeyValues\", toPropertyKeyValues)\n\t\t\t\t\t\t\t\t\t\t\t\t.build()\n\t\t\t\t\t\t\t\t)).one().asVertex();\n\t\treturn vertex;\n\t}\n\n\tpublic static Edge createOrUpdateEdge(DseSession session, boolean ifNotExists, String edgeLabel, Vertex fromVertex, Vertex toVertex, Object... propertiesParam) {\n\t\tEdge edge = null;\n\t\tString stmt = null;\n\n\t\t// remove properties with NULL values\n\t\tObject[] properties = VertexHelper.removeNULLPropertyValue(propertiesParam);\n\n\t\tif (ifNotExists) {\n\t\t\tstmt = \"Vertex from = g.V(f).next(); Vertex to = g.V(t).next(); if (!g.V(f).out(b.edgeLabel).V(t).hasNext()) { from.addEdge(b.edgeLabel, to) }\";\n\t\t} else { \n\t\t\tstmt = \"Vertex from = g.V(f).next(); Vertex to = g.V(t).next(); from.addEdge(b.edgeLabel, to)\";\n\t\t}\n//\t\tSystem.out.println(stmt);\n\t\t\n\t\tedge = session.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t.set(\"f\", fromVertex)\n\t\t\t\t\t\t.set(\"t\", toVertex)\n\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>of(\"edgeLabel\", edgeLabel, \"propertiesParam\", properties))).one().asEdge();\n\t\treturn edge;\n\t}\n\t\n\tpublic static boolean hasEdge(DseSession session, String edgeLabel, Vertex fromVertex, Vertex toVertex) {\n\t\tboolean result = false;\n\t\tString stmt = \"g.V(f).out(b.edgeLabel).V(t).hasNext()\";\n\t\tresult = session.executeGraph(new SimpleGraphStatement(stmt)\n\t\t\t\t\t\t.set(\"f\", fromVertex)\n\t\t\t\t\t\t.set(\"t\", toVertex)\n\t\t\t\t\t\t.set(\"b\", ImmutableMap.<String,Object>of(\"edgeLabel\", edgeLabel))).one().asBoolean();\n\t\treturn result;\n\t\t\n\t}\n}\n"
},
{
"alpha_fraction": 0.6644020676612854,
"alphanum_fraction": 0.710355281829834,
"avg_line_length": 31.463014602661133,
"blob_id": "cd1c15e64e39084bc23ac7f526833c9d25623dab",
"content_id": "a21db3c8f015d5607a1d4ada9a508f19080254b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23698,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 730,
"path": "/iot-truck-demo/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# IoT Truck Demo\n\nThis project shows how to setup and run the demo used in various talks, such as \"Introduction into Stream Processing\". \n\n## Prepare Environment\n\nThe environment is completley based on docker containers. In order to easily start the multiple containers, we are going to use Docker Compose. You need to have at least 8 GB of RAM available, better is 12 GB or 16 GB. \n\n### Preparing environment\n\nFirst let's export the `SAMPLE_HOME` variable pointing to the local folder of this GitHub project, to simplify navigating below. \n\n```\nexport SAMPLE_HOME=/mnt/hgfs/git/gschmutz/various-demos/iot-truck-demo\n```\n\nFor Kafka to work with this Docker Compose setup, two envrionment variables are necessary, which are configured with the IP address of the docker machine as well as the Public IP of the docker machine. \n\nYou can either add them to `/etc/environment` (without export) to make them persistent:\n\n```\nexport DOCKER_HOST_IP=192.168.25.136\nexport PUBLIC_IP=192.168.25.136\n```\n\nMake sure to adapt the IP address according to your environment. \n\nOptionally you can also create an `.env` file inside the `docker` folder with the following content:\n\n```\nDOCKER_HOST_IP=192.168.25.136\nPUBLIC_IP=192.168.25.136\n```\n\nLast but not least add `streamingplatform` as an alias to the `/etc/hosts` file on the machine you are using to run the demo on.\n\n```\n192.168.25.136\tstreamingplatform\n```\n\n### Installing Kafkacat\n\nTo simplify peeking into a Kafka topic, the kafkacat tool becomes handy. You can optinally install it using the follwing command:\n\n```\nsudo apt-get install kafkacat\n```\n\nTo see that it has been installed successfully, run a `kafkacat -V`\n\n```\n>kafkacat -V\n\nkafkacat - Apache Kafka producer and consumer tool\nhttps://github.com/edenhill/kafkacat\nCopyright (c) 2014-2017, Magnus Edenhill\nVersion 1.4.0 (JSON) (librdkafka 1.0.0 builtin.features=gzip,snappy,ssl,sasl,regex,lz4,sasl_gssapi,sasl_plain,sasl_scram,plugins,zstd)\n```\n\n### Preparing the infrastructure with Docker Compose\n\nFirst create a folder to keep the `docker-compose.yml` file and the necessary artifacts. We are using `streamingfolder` for the folder name here. \n\n```\nmkdir streamingplatform\ncd streamingplatform\n```\n\nNow let's download the `docker-compose.yml` file from the GitHub repository\n\n### Starting the infrastructure using Docker Compose\n\nNow we can start the environment. Navigate to the `docker` sub-folder inside the `SAMPLE_HOME` folder. \n\n```\ncd $SAMPLE_HOME/docker\nmkdir kafka-connect\n```\n\nand start the vaious docker containers \n\n```\ndocker-compose up -d\n```\n\nTo show all logs of all containers use\n\n```\ndocker-compose logs -f\n```\n\nTo show only the logs for some of the containers, for example `connect-1` and `connect-2`, use\n\n```\ndocker-compose logs -f connect-1 connect-2\n```\n\nSome services in the `docker-compose.yml` are optional and can be removed, if you don't have enough resources to start them. \n\n### Available Services \n\nThe following user interfaces are available:\n\n * Confluent Control Center: <http://streamingplatform:9021>\n * Kafka Manager: <http://streamingplatform:9000> \n * KAdmin: <http://streamingplatform:28080>\n * KafkaHQ: <http://streamingplatform:28082>\n * Kafdrop: <http://streamingplatform:29020>\n * Schema Registry UI: <http://streamingplatform:8002>\n * Kafka Connect UI: <http://streamingplatform:8003>\n * StreamSets Data Collector: <http://streamingplatform:18630>\n * Tsujun KSQL UI: <http://streamingplatform:28083>\n * MQTT UI: <http://streamingplatform:29080>\n\n### Creating the necessary Kafka Topics\n\nThe Kafka cluster is configured with `auto.topic.create.enable` set to `false`. Therefore we first have to create all the necessary topics, using the `kafka-topics` command line utility of Apache Kafka. \n\nWe can easily get access to the `kafka-topics` CLI by navigating into one of the containers for the 3 Kafka Borkers. Let's use `broker-1`\n\n```\ndocker exec -ti broker-1 bash\n```\n\nFirst lets see all existing topics\n\n```\nkafka-topics --zookeeper zookeeper-1:2181 --list\n```\n\nAnd now create the topics `truck_position`, `dangerous_driving_and_driver ` and `truck_driver`.\n\n```\nkafka-topics --zookeeper zookeeper-1:2181 --create --topic truck_position --partitions 8 --replication-factor 2\nkafka-topics --zookeeper zookeeper-1:2181 --create --topic dangerous_driving --partitions 8 --replication-factor 2\nkafka-topics --zookeeper zookeeper-1:2181 --create --topic dangerous_driving_and_driver --partitions 8 --replication-factor 2\n\nkafka-topics --zookeeper zookeeper-1:2181 --create --topic truck_driver --partitions 8 --replication-factor 2 --config cleanup.policy=compact --config segment.ms=100 --config delete.retention.ms=100 --config min.cleanable.dirty.ratio=0.001\n```\n\nIf you don't like to work with the CLI, you can also create the Kafka topics using the [Kafka Manager GUI](http://streamingplatform:9000). \n\n### Prepare Database Table\n\nWe also need a database table holding the information of the truck driver. \n\nThe infrastructure we have started above also conains an instance of Postgresql in a separate docker container. \n\nLet's connect to that container \n\n```\ndocker exec -ti postgresql bash\n```\n\nand run the `psql` command line utility. \n\n```\npsql -d sample -U sample\n```\n\n```\nDROP TABLE driver;\nCREATE TABLE driver (id BIGINT, first_name CHARACTER VARYING(45), last_name CHARACTER VARYING(45), available CHARACTER VARYING(1), birthdate DATE, last_update TIMESTAMP);\nALTER TABLE driver ADD CONSTRAINT driver_pk PRIMARY KEY (id);\n```\n\n```\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (10,'Diann', 'Butler', 'Y', '10-JUN-68', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (11,'Micky', 'Isaacson', 'Y', '31-AUG-72' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (12,'Laurence', 'Lindsey', 'Y', '19-MAY-78' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (13,'Pam', 'Harrington', 'Y','10-JUN-68' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (14,'Brooke', 'Ferguson', 'Y','10-DEC-66' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (15,'Clint','Hudson', 'Y','5-JUN-75' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (16,'Ben','Simpson', 'Y','11-SEP-74' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (17,'Frank','Bishop', 'Y','3-OCT-60' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (18,'Trevor','Hines', 'Y','23-FEB-78' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (19,'Christy','Stephens', 'Y','11-JAN-73' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (20,'Clarence','Lamb', 'Y','15-NOV-77' ,CURRENT_TIMESTAMP);\n\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (21,'Lila', 'Page', 'Y', '5-APR-77', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (22,'Patricia', 'Coleman', 'Y', '11-AUG-80' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (23,'Jeremy', 'Olson', 'Y', '13-JUN-82', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (24,'Walter', 'Ward', 'Y', '24-JUL-85', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (25,'Kristen', ' Patterson', 'Y', '14-JUN-73', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (26,'Jacquelyn', 'Fletcher', 'Y', '24-AUG-85', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (27,'Walter', ' Leonard', 'Y', '12-SEP-88', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (28,'Della', ' Mcdonald', 'Y', '24-JUL-79', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (29,'Leah', 'Sutton', 'Y', '12-JUL-75', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (30,'Larry', 'Jensen', 'Y', '14-AUG-83', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (31,'Rosemarie', 'Ruiz', 'Y', '22-SEP-80', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (32,'Shaun', ' Marshall', 'Y', '22-JAN-85', CURRENT_TIMESTAMP);\n```\n## Runnging the Truck Simulator (1)\n\nFor simulating truck data, we are going to use a Java program (adapted from Hortonworks) and maintained in this [GitHub project](https://github.com/TrivadisBDS/various-bigdata-prototypes/tree/master/streaming-sources/iot-truck-simulator/impl).\n\nThe simulator can produce data either to a **Kafka** or **MQTT**. These two options are shown below. \n\n### Producing to Kafka\n\nFirst let's start a consumer on the topic `truck_position` either using the `kafka-console-consumer `or `kafkacat` CLI. \n\n* To start consuming using the kafka console consumer:\n \n```\ndocker exec -ti broker-1 kafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_position\n```\n\n* To start consuming using kafkacat (using the quiet option):\n\n```\nkafkacat -b analyticsplatform:9092 -t truck_position -q\n```\n\nNow let's produce the truck events to the Kafka topic `truck_position `.\n\n```\ndocker run trivadis/iot-truck-simulator '-s' 'KAFKA' '-h' $DOCKER_HOST_IP '-p' '9092' '-f' 'CSV' \"-t\" \"sec\"\n```\n\n### Producing to MQTT\n\nFirst let's start a consumer on the MQTT topics `trucks/+/position`. \n\n * To start consuming using through a command line, perform the following docker command:\n\n```\ndocker run -it --rm efrecon/mqtt-client sub -h $DOCKER_HOST_IP -t \"truck/+/position\" -v\n```\n \n * to start consuming using the MQTT UI (HiveMQ Web Client), navigate to <http://streamingplatform:29080> and connect using `streamingplatform` for the **Host** field, `9001` for the **Port** field and then click on **Connect**: \n\n\t\n\t\n\tWhen successfully connected, click on Add New Topic Subscription and enter `truck/+/position` into **Topic** field and click **Subscribe**:\n\t\n\t\n\t\nNow let's produce the truck events to the MQTT broker running on port 1883:\n\n```\ndocker run trivadis/iot-truck-simulator '-s' 'MQTT' '-h' $DOCKER_HOST_IP '-p' '1883' '-f' 'CSV'\n```\n\nAs soon as messages are produced to MQTT, you should see them either on the CLI or in the MQTT UI (Hive MQ) as shown below.\n\n\n\nAlternatively you can also use the [MQTT.fx](https://mqttfx.jensd.de/) or the [MQTT Explorer](https://mqtt-explorer.com/) applications to browse for the messages on the MQTT broker. They are both available for installation on Mac or Windows. \n\n## Using Kafka Connect to bridge between MQTT and Kafka (2)\n\nIn order to get the messages from MQTT into Kafka, we will be using Kafka Connect. Luckily, there are multiple Kafka Connectors available for MQTT. We will be using the one available from the [Landoop Stream-Reactor Project](https://github.com/Landoop/stream-reactor/tree/master/kafka-connect-mqtt) called `kafka-connect-mqtt`.\n\nAs part of the restart of the `connect` service, the `kafka-connect` folder mapped into the container should have been created on the Docker host. Make sure that it belongs to the `cas` user by executing the following command:\n\n```\nsudo chown bigdata:bigdata -R kafka-connect\n```\n\nThen navigate into the `kafka-connect` folder, create a folder `mqtt` and navigate into this folder.\n\n```\nmkdir mqtt\ncd mqtt\n```\n\nIn here, download the `kafka-connect-mqtt-1.1.1-2.1.0-all.tar.gz` file from the [Landoop Stream-Reactor Project](https://github.com/Landoop/stream-reactor/tree/master/kafka-connect-mqtt).\n\n```\nwget https://github.com/Landoop/stream-reactor/releases/download/1.2.1/kafka-connect-mqtt-1.2.1-2.1.0-all.tar.gz\n```\n\nOnce it is successfully downloaded, untar it using this `tar` command. \n\n```\ntar xvf kafka-connect-mqtt-1.0.0-1.0.0-all.tar.gz\n```\n\nNow let's restart Kafka connect in order to pick up the new connector. \n\n```\ndocker-compose restart connect-1 connect-2\n```\n\n\nFirst let's listen on the topic \n\n```\nkafkacat -b streamingplatform:9092 -t truck_position -q\n```\n\nAdd and start the MQTT connector (make sure that consumer is still running):\n\n```\ncd $SAMPLE_HOME/scripts\n./start-connect-mqtt.sh\n```\n\nNavigate to the [Kafka Connect UI](http://streamingplatform:8003) to see the connector configured and running.\n\nYou can remove the connector using the following command\n\n```\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/mqtt-source\"\n```\n\n## MQTT to Kafa using Confluent MQTT Proxy (3)\n\nMake sure that the MQTT proxy has been started as a service in the `docker-compose.yml`.\n\n```\n mqtt-proxy:\n image: confluentinc/cp-kafka-mqtt:5.2.1\n hostname: mqtt-proxy\n ports:\n - \"1884:1884\"\n environment:\n KAFKA_MQTT_TOPIC_REGEX_LIST: 'truck_position:.*position,truck_engine:.*engine'\n KAFKA_MQTT_LISTENERS: 0.0.0.0:1884\n KAFKA_MQTT_BOOTSTRAP_SERVERS: PLAINTEXT://broker-1:9092,broker-2:9093\n KAFKA_MQTT_CONFLUENT_TOPIC_REPLICATIN_FACTOR: 1\n```\n\nChange the truck simulator to produce on port 1884, which is the one the MQTT proxy listens on.\n\n```\nmvn exec:java -Dexec.args=\"-s MQTT -f CSV -p 1884 -m SPLIT -t millisec\"\n```\n\n## Using KSQL for Stream Analytics (4)\n\n### Connect to KSQL CLI\n\n\nFirst let's connect to the KSQL CLI\n\n```\ndocker run -it --network analyticsplatform_default confluentinc/cp-ksql-cli http://ksql-server-1:8088\n```\n\nShow the available Kafka topics\n\n```\nshow topics;\n```\n\n\n```\nprint 'truck_position';\n```\n\n```\nprint 'truck_position' from beginning;\n```\n\n```\nshow streams;\nshow tables;\nshow queries;\n```\n\n### Basic Streaming Query\n\nCreate a KSQL STREAM object on the `truck_position`\n\n```\nDROP STREAM IF EXISTS truck_position_s;\n\nCREATE STREAM truck_position_s \\\n (ts VARCHAR, \\\n truckId VARCHAR, \\\n driverId BIGINT, \\\n routeId BIGINT, \\\n eventType VARCHAR, \\\n latitude DOUBLE, \\\n longitude DOUBLE, \\\n correlationId VARCHAR) \\\n WITH (kafka_topic='truck_position', \\\n value_format='DELIMITED');\n```\n\nGet info on the stream using the `DESCRIBE` command\n\n```\nDESCRIBE truck_position_s;\nDESCRIBE EXTENDED truck_position_s;\n```\n\n```\nSELECT * FROM truck_position_s;\n```\n\n```\ncd $SAMPLE_HOME/scripts/\n./stop-connect-mqtt.sh\n```\n\n\n```\nksql> SELECT * from truck_position_s;\n\n1539711991642 | truck/24/position | null | 24 | 10 | 1198242881 | Normal | 36.84 | -94.83 | -6187001306629414077\n1539711991691 | truck/26/position | null | 26 | 13 | 1390372503 | Normal | 42.04 | -88.02 | -6187001306629414077\n1539711991882 | truck/66/position | null | 66 | 22 | 1565885487 | Normal | 38.33 | -94.35 | -6187001306629414077\n1539711991902 | truck/22/position | null | 22 | 26 | 1198242881 | Normal | 36.73 | -95.01 | -6187001306629414077\n1539711992051 | truck/97/position | null | 97 | 30 | 1325712174 | Normal | 41.89 | -87.66 | -6187001306629414077\n```\n\n### Streaming Filter with KSQL\n\nNow let's filter on all the info messages, where the `eventType` is not normal:\n\n```\nSELECT * FROM truck_position_s WHERE eventType != 'Normal';\n```\n\n```\n1539712101614 | truck/67/position | null | 67 | 11 | 160405074 | Lane Departure | 38.98 | -92.53 | -6187001306629414077\n1539712116450 | truck/18/position | null | 18 | 25 | 987179512 | Overspeed | 40.76 | -88.77 | -6187001306629414077\n1539712118653 | truck/67/position | null | 67 | 11 | 160405074 | Overspeed | 38.83 | -90.79 | -6187001306629414077\n1539712120102 | truck/31/position | null | 31 | 12 | 927636994 | Unsafe following distance | 38.22 | -91.18 | -6187001306629414077\n```\n\n## Create a new Stream based on the KSQL SELECT (5)\n\nLet's provide the data as a topic:\n\nFirst create a topic where all \"dangerous driving\" events should be sent to\n\t\n```\ndocker exec broker-1 kafka-topics --zookeeper zookeeper-1:2181 --create --topic dangerous_driving --partitions 8 --replication-factor 2\n```\n\nNow create a \"console\" listener on the topic, either using the `kafka-console-consumer`\n\n```\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic dangerous_driving\n```\n\nor the `kafkacat` utility.\n\n```\nkafkacat -b analyticsplatform -t dangerous_driving\n```\n\n```\ndocker run -it --network analyticsplatform_default confluentinc/cp-ksql-cli http://ksql-server-1:8088\n```\n\n```\nDROP STREAM dangerous_driving_s;\n```\n\n```\nCREATE STREAM dangerous_driving_s \\\n WITH (kafka_topic='dangerous_driving', \\\n value_format='JSON', \\\n partitions=8) \\\nAS SELECT * FROM truck_position_s \\\nWHERE eventType != 'Normal';\n```\n\n```\nSELECT * FROM dangerous_driving_s;\n```\n\n## Aggregations using KSQL (6)\n\nDROP TABLE dangerous_driving_count;\n\n```\nCREATE TABLE dangerous_driving_count \\\nAS SELECT eventType, count(*) nof \\\nFROM dangerous_driving_s \\\nWINDOW TUMBLING (SIZE 30 SECONDS) \\\nGROUP BY eventType;\n```\n\n```\nSELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS'), eventType, nof \\\nFROM dangerous_driving_count;\n```\n\n```\nCREATE TABLE dangerous_driving_count\nAS\nSELECT eventType, count(*) nof \\\nFROM dangerous_driving_s \\\nWINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS) \\\nGROUP BY eventType;\n```\n\n## Join with Static Driver Data (7)\n\n### Start the synchronization from the RDBMS table \"truck\"\nFirst start the console consumer on the `truck_driver` topic:\n\n```\ndocker exec -ti broker-1 kafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_driver --from-beginning\n```\n\nPrint the key and value of the truck_driver topic\n\n```\nkafkacat -b analyticsplatform -t truck_driver -f \"%k::%s\\n\" -u -q\n```\n\nthen start the JDBC connector:\n\n```\ncd $SAMPLE_HOME\n./scripts/start-connect-jdbc.sh\n```\n\nTo stop the connector execute the following command\n\n```\ncurl -X \"DELETE\" \"http://$DOCKER_HOST_IP:8083/connectors/jdbc-driver-source\"\n```\n\nPerform an update to see that these will be delivered\n\n```\ndocker exec -ti docker_db_1 bash\n\npsql -d sample -U sample\n```\n\n```\nUPDATE \"driver\" SET \"available\" = 'N', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 21;\n```\n\n```\nUPDATE \"driver\" SET \"available\" = 'N', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 14;\n```\n\nStop the consumer and restart with `--from-beginning` option\n\n```\ndocker exec -ti broker-1 kafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_driver --from-beginning\n```\n\n### Create a KSQL table\n\nIn the KSQL CLI, let's create a table over the `truck_driver` topic. It will hold the latest state of all the drivers:\n\n```\nset 'commit.interval.ms'='5000';\nset 'cache.max.bytes.buffering'='10000000';\nset 'auto.offset.reset'='earliest';\n\nDROP TABLE driver_t;\n\nCREATE TABLE driver_t \\\n (id BIGINT, \\\n first_name VARCHAR, \\\n last_name VARCHAR, \\\n available VARCHAR, \\\n birthdate VARCHAR) \\\n WITH (kafka_topic='truck_driver', \\\n value_format='JSON', \\\n KEY = 'id');\n```\n\nLet's see that we actually have some drivers in the table. \n\n```\nset 'commit.interval.ms'='5000';\nset 'cache.max.bytes.buffering'='10000000';\nset 'auto.offset.reset'='earliest';\n\nSELECT * FROM driver_t;\n```\n\n\n```\ndocker exec -ti postgresql psql -d sample -U sample\n```\n\n```\nUPDATE \"driver\" SET \"available\" = 'N', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 21;\n```\n\n\njoin `dangerous_driving_s` stream to `driver_t` table\n\n```\nset 'commit.interval.ms'='5000';\nset 'cache.max.bytes.buffering'='10000000';\nset 'auto.offset.reset'='latest';\n```\n\n```\nSELECT driverid, first_name, last_name, truckId, routeId, eventType, latitude, longitude \\\nFROM dangerous_driving_s \\\nLEFT JOIN driver_t \\\nON dangerous_driving_s.driverId = driver_t.id;\n```\n\nwith outer join\n\n```\nSELECT driverid, first_name, last_name, truckId, routeId, eventType, latitude, longitude \\\nFROM dangerous_driving_s \\\nLEFT OUTER JOIN driver_t \\\nON dangerous_driving_s.driverId = driver_t.id;\n```\n\nCreate Stream `dangerous_driving_and_driver`\n\n```\nDROP STREAM dangerous_driving_and_driver_s;\nCREATE STREAM dangerous_driving_and_driver_s \\\n WITH (kafka_topic='dangerous_driving_and_driver', \\\n value_format='JSON', partitions=8) \\\nAS SELECT driverid, first_name, last_name, truckId, routeId, eventType, latitude, longitude \\\nFROM dangerous_driving_s \\\nLEFT JOIN driver_t \\\nON dangerous_driving_s.driverId = driver_t.id;\n```\n\n\n```\nSELECT * FROM dangerous_driving_and_driver_s;\n```\n\n```\nSELECT * FROM dangerous_driving_and_driver_s WHERE driverid = 11;\n```\n\nPerform an update on the first_name to see the change in the live stream:\n\n```\ndocker exec -ti docker_db_1 bash\n\npsql -d sample -U sample\n```\n\n```\nUPDATE \"driver\" SET \"first_name\" = 'Slow Down Mickey', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 11;\nUPDATE \"driver\" SET \"first_name\" = 'Slow Down Patricia', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 22;\n```\n\n## GeoHash and Aggregation (8)\n\n```\nSELECT latitude, longitude, geohash(latitude, longitude, 4) \\\nFROM dangerous_driving_s;\n```\n\n```\nksql> SELECT latitude, longitude, geohash(latitude, longitude, 4) \\\n FROM dangerous_driving_s;\n38.31 | -91.07 | 9yz1\n37.7 | -92.61 | 9ywn\n34.78 | -92.31 | 9ynm\n42.23 | -91.78 | 9zw8\n```\n\n```\nDROP STREAM dangerous_driving_and_driver_geohashed_s;\nCREATE STREAM dangerous_driving_and_driver_geohashed_s \\\n WITH (kafka_topic='dangerous_and_position', \\\n value_format='JSON', partitions=8) \\\nAS SELECT driverid, first_name, last_name, truckid, routeid, eventtype, geohash(latitude, longitude, 4) as geohash \\\nFROM dangerous_driving_and_driver_s;\n```\n\n```\nSELECT eventType, geohash, count(*) nof \\\nFROM dangerous_driving_and_driver_geohashed_s \\\nWINDOW TUMBLING (SIZE 120 SECONDS) \\\nGROUP BY eventType, geohash;\n```\n\n\n## Current Positions\n\nCREATE TABLE truck_position_t \\\n WITH (kafka_topic='truck_position_t', \\\n value_format='JSON', \\\n KEY = 'truckid') \\\nAS SELECT truck_id, FROM truck_position_s GROUP BY truckid; \n\n\n\n## More complex analytics in KSQL\n\n```\nCREATE TABLE dangerous_driving_count \\\nAS SELECT eventType, count(*) \\\nFROM dangerous_driving_and_driver_s \\\nWINDOW TUMBLING (SIZE 30 SECONDS) \\\nGROUP BY eventType;\n```\n\n```\nCREATE TABLE dangerous_driving_count\nAS\nSELECT eventType, count(*) \\\nFROM dangerous_driving_and_driver_s \\\nWINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS) \\\nGROUP BY eventType;\n```\n\n```\nSELECT first_name, last_name, eventType, count(*) \\\nFROM dangerous_driving_and_driver_s \\\nWINDOW TUMBLING (SIZE 20 SECONDS) \\\nGROUP BY first_name, last_name, eventType;\n```\n\n\n\n## Using Kafka Streams to detect danagerous driving\n\n```\ndocker exec -ti broker-1 bash\n```\n\n```\nkafka-topics --zookeeper zookeeper-1:2181 --create --topic dangerous_driving --partitions 8 --replication-factor 2\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic dangerous_driving\n```\n\n```\ncd $SAMPLE_HOME/src/kafka-streams-truck\nmvn exec:java\n```\n"
},
{
"alpha_fraction": 0.6440235376358032,
"alphanum_fraction": 0.6564337015151978,
"avg_line_length": 18.413333892822266,
"blob_id": "da7cd1f0c696149aa79955ef8ad24dbe3ca71b3c",
"content_id": "154620f19914d35ea1a2947c3915c713b4e41798",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1531,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 75,
"path": "/graph-performance/des-graph-test/src/main/java/com/trivadis/domain/Tweet.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.domain;\r\n\r\nimport java.io.Serializable;\r\nimport java.util.List;\r\nimport java.util.UUID;\r\n\r\nimport org.joda.time.DateTime;\r\n\r\npublic class Tweet implements Serializable {\r\n\r\n\tprivate static final long serialVersionUID = 7173965502903960812L;\r\n\r\n\tprivate Long id;\r\n\tprivate DateTime createdAt;\r\n\tprivate List<String> hashtags;\r\n\tprivate List<String> mentions;\r\n\tprivate List<String> urls;\r\n\tprivate User user;\r\n\tprivate String language;\r\n\r\n\tpublic Tweet() {\r\n\t}\r\n\r\n\tpublic Tweet(Long id, DateTime createdAt, List<String> hashtags, List<String> mentions,\r\n\t\t\tList<String> urls, User user, String language) {\r\n\t\tthis.id = id;\r\n\t\tthis.createdAt = createdAt;\r\n\t\tthis.hashtags = hashtags;\r\n\t\tthis.mentions = mentions;\r\n\t\tthis.urls = urls;\r\n\t\tthis.user = user;\r\n\t\tthis.language = language;\r\n\t}\r\n\r\n\tpublic static long getSerialversionuid() {\r\n\t\treturn serialVersionUID;\r\n\t}\r\n\r\n\tpublic Long getId() {\r\n\t\treturn id;\r\n\t}\r\n\r\n\tpublic DateTime getCreatedAt() {\r\n\t\treturn createdAt;\r\n\t}\r\n\r\n\tpublic List<String> getHashtags() {\r\n\t\treturn hashtags;\r\n\t}\r\n\r\n\tpublic List<String> getMentions() {\r\n\t\treturn mentions;\r\n\t}\r\n\r\n\tpublic List<String> getUrls() {\r\n\t\treturn urls;\r\n\t}\r\n\r\n\tpublic User getUser() {\r\n\t\treturn user;\r\n\t}\r\n\r\n\tpublic String getLanguage() {\r\n\t\treturn language;\r\n\t}\r\n\r\n\t@Override\r\n\tpublic String toString() {\r\n\t\treturn \"Tweet [id=\" + id + \", createdAt=\" + createdAt + \", hashtags=\" + hashtags\r\n\t\t\t\t+ \", mentions=\" + mentions + \", urls=\" + urls + \", user=\" + user + \", language=\"\r\n\t\t\t\t+ language + \"]\";\r\n\t}\r\n\t\r\n\r\n}\r\n"
},
{
"alpha_fraction": 0.7607282400131226,
"alphanum_fraction": 0.7620286345481873,
"avg_line_length": 20.97142791748047,
"blob_id": "b8e1f25b05ea18a6db06101c265d0e32c29a8029",
"content_id": "d67edc465696cff47078ff0225518aa410f43ea2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 35,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/command/AccountCreateCommand.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.command;\n\n/**\n * @author saikatkar1\n *\n */\npublic class AccountCreateCommand extends BaseCommand<String>{\n\n\tprivate String forCustomerId;\n\tprivate String accountType;\n\t\n\tpublic AccountCreateCommand(String id,String forCustomerId,String accountType) {\n\t\tsuper(id);\n\t\tthis.forCustomerId = forCustomerId;\n\t\tthis.accountType = accountType;\n\t\n\t\t// TODO Auto-generated constructor stub\n\t}\n\tpublic AccountCreateCommand() {}\n\t\n\tpublic String getForCustomerId() {\n\t\treturn forCustomerId;\n\t}\n\tpublic void setForCustomerId(String forCustomerId) {\n\t\tthis.forCustomerId = forCustomerId;\n\t}\n\tpublic String getAccountType() {\n\t\treturn accountType;\n\t}\n\tpublic void setAccountType(String accountType) {\n\t\tthis.accountType = accountType;\n\t}\n\t\n\n}\n"
},
{
"alpha_fraction": 0.7037037014961243,
"alphanum_fraction": 0.7242798209190369,
"avg_line_length": 36.230770111083984,
"blob_id": "ccf46304ffb65468b63349b016b05e8f230df87f",
"content_id": "410d5eaa02f5763ef9117c74cc8c023e0801fa51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 972,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 26,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/table/order_item_t.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nCREATE TABLE order_item_t (\n id NUMBER(3) CONSTRAINT pk_order_item PRIMARY KEY,\n order_id NUMBER(12) NOT NULL CONSTRAINT fk_order REFERENCES order_t,\n product_id NUMBER(6) NOT NULL,\n product_name VARCHAR2(50) NOT NULL,\n unit_price NUMBER(8,2) NOT NULL,\n quantity NUMBER(8) NOT NULL,\n created_at TIMESTAMP(0)\tNOT NULL,\n modified_at TIMESTAMP(0)\tNOT NULL\n);\n\n\n\n\n"
},
{
"alpha_fraction": 0.6774060130119324,
"alphanum_fraction": 0.6988847851753235,
"avg_line_length": 33.33333206176758,
"blob_id": "3c8a19ab20a67ed6c7dd2e203c92cdf398f00ece",
"content_id": "db67dfe2bebd3aea0087f4c2d402f2e312695c8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 4847,
"license_type": "no_license",
"max_line_length": 321,
"num_lines": 141,
"path": "/various-datastores/postgresql.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "DROP SCHEMA IF EXISTS \"order_processing\" CASCADE;\nCREATE SCHEMA \"order_processing\";\n\n/* Foreign Keys */\n\nCREATE TABLE \"order_t\" (\n \"order_id\" serial NOT NULL,\n \"customer_id\" integer NOT NULL,\n \"delivery_address_id\" integer NOT NULL,\n \"billing_address_id\" integer NULL\n);\n\nALTER TABLE \"order_t\"\nADD CONSTRAINT \"order_t_order_id\" PRIMARY KEY (\"order_id\");\n\nCREATE TABLE \"order_line_t\" (\n \"order_line_id\" serial NOT NULL,\n \"order_id\" integer NOT NULL,\n \"product_id\" integer NOT NULL,\n \"quantity\" integer NOT NULL,\n \"item_price\" money NOT NULL\n);\n\nALTER TABLE \"order_line_t\"\nADD CONSTRAINT \"order_line_t_order_line_id\" PRIMARY KEY (\"order_line_id\");\n\nCREATE TABLE \"customer_t\" (\n \"customer_id\" serial NOT NULL,\n \"first_name\" character varying(50) NOT NULL,\n \"last_name\" character varying(50) NOT NULL,\n \"gender\" character(1) NOT NULL\n);\n\nALTER TABLE \"customer_t\"\nADD CONSTRAINT \"customer_t_customer_id\" PRIMARY KEY (\"customer_id\");\n\nCREATE TABLE \"product_t\" (\n \"product_id\" serial NOT NULL,\n \"category_id\" integer NOT NULL,\n \"name\" character varying(100) NOT NULL,\n \"price\" money NOT NULL,\n \"description\" character varying(1000) NOT NULL\n);\n\nALTER TABLE \"product_t\"\nADD CONSTRAINT \"product_t_product_id\" PRIMARY KEY (\"product_id\");\n\nCREATE TABLE \"category_t\" (\n \"category_id\" serial NOT NULL,\n \"name\" character varying(100) NOT NULL\n);\n\nALTER TABLE \"category_t\"\nADD CONSTRAINT \"category_t_category_id\" PRIMARY KEY (\"category_id\");\n\nCREATE TABLE \"address_t\" (\n \"address_id\" serial NOT NULL,\n \"street\" character varying(100) NOT NULL,\n \"nr\" character varying(10) NOT NULL,\n \"zipCode\" character varying(10) NOT NULL,\n \"city\" character varying(100) NOT NULL,\n \"country_id\" integer NULL\n);\n\nALTER TABLE \"address_t\"\nADD CONSTRAINT \"address_t_address_id\" PRIMARY KEY (\"address_id\");\n\nCREATE TABLE \"customer_address_t\" (\n \"customer_address_id\" serial NOT NULL,\n \"customer_id\" integer NOT NULL,\n \"address_id\" integer NOT NULL,\n \"address_type\" character varying(10) NOT NULL\n);\n\nALTER TABLE \"customer_address_t\"\nADD CONSTRAINT \"customer_address_t_customer_address_id\" PRIMARY KEY (\"customer_address_id\");\n\nCREATE TABLE \"country_t\" (\n \"country_id\" serial NOT NULL,\n \"name\" character varying(100) NOT NULL,\n \"code\" character varying(10) NOT NULL\n);\n\nALTER TABLE \"country_t\"\nADD CONSTRAINT \"country_t_country_id\" PRIMARY KEY (\"country_id\");\n\n\n/* Foreign Keys */\n\nALTER TABLE \"order_line_t\"\nADD FOREIGN KEY (\"order_id\") REFERENCES \"order_t\" (\"order_id\") ON DELETE CASCADE ON UPDATE RESTRICT;\n\nALTER TABLE \"order_line_t\"\nADD FOREIGN KEY (\"product_id\") REFERENCES \"product_t\" (\"product_id\") ON DELETE CASCADE ON UPDATE RESTRICT;\n\nALTER TABLE \"order_t\"\nADD FOREIGN KEY (\"customer_id\") REFERENCES \"customer_t\" (\"customer_id\") ON DELETE RESTRICT ON UPDATE RESTRICT;\n\nALTER TABLE \"product_t\"\nADD FOREIGN KEY (\"category_id\") REFERENCES \"category_t\" (\"category_id\") ON DELETE CASCADE ON UPDATE RESTRICT;\n\nALTER TABLE \"customer_address_t\"\nADD FOREIGN KEY (\"customer_id\") REFERENCES \"customer_t\" (\"customer_id\") ON DELETE RESTRICT ON UPDATE RESTRICT;\n\nALTER TABLE \"customer_address_t\"\nADD FOREIGN KEY (\"address_id\") REFERENCES \"address_t\" (\"address_id\") ON DELETE RESTRICT ON UPDATE RESTRICT;\n\nALTER TABLE \"address_t\"\nADD FOREIGN KEY (\"country_id\") REFERENCES \"country_t\" (\"country_id\") ON DELETE RESTRICT ON UPDATE RESTRICT;\n\nINSERT INTO \"country_t\" (\"country_id\", \"name\", \"code\") VALUES\n(1,\t'Switzerland',\t'CH'),\n(2,\t'Germany',\t'GE');\n\nINSERT INTO \"category_t\" (\"category_id\", \"name\") VALUES\n(1,\t'Electronics'),\n(2,\t'Food');\n\nINSERT INTO \"product_t\" (\"product_id\", \"category_id\", \"name\", \"price\", \"description\") VALUES\n(1,\t1,\t'SAMSUNG UE65MU8000',\t1396.90,\t'Samsung TV'),\n(2,\t1,\t'APPLE iPhone X 64 GB Space Grau',\t829.00,\t'Beim iPhone X ist das Gerät das Display. Das Super-Retina-Display füllt die ganze Hand aus und lässt die Augen nicht mehr los. Auf kleinstem Raum arbeiten hier die fortschrittlichen Technologien. Dazu gehören auch die Kameras und Sensoren, die Face ID möglich machen.');\n\nINSERT INTO \"customer_t\" (\"customer_id\", \"first_name\", \"last_name\", \"gender\") VALUES\n(1,\t'Peter',\t'Muster',\t'M'),\n(2,\t'Gaby',\t'Steiner',\t'F');\n\nINSERT INTO \"address_t\" (\"address_id\", \"street\", \"nr\", \"zipCode\", \"city\", \"country_id\") VALUES\n(1,\t'Musterstrasse',\t'5',\t'3001',\t'Bern',\t1);\nINSERT INTO \"address_t\" (\"address_id\", \"street\", \"nr\", \"zipCode\", \"city\", \"country_id\") VALUES\n(2,\t'Seeweg',\t'15',\t'3700',\t'Spiez', 1);\n\nINSERT INTO \"customer_address_t\" (\"customer_address_id\", \"customer_id\", \"address_id\", \"address_type\") VALUES\n(1,\t1,\t1,\t'HOME'),\n(2,\t1,\t2,\t'HOME');\n\nINSERT INTO \"order_t\" (\"order_id\", \"customer_id\", \"delivery_address_id\", \"billing_address_id\") VALUES\n(1,\t1,\t1,\tNULL);\n\nINSERT INTO \"order_line_t\" (\"order_line_id\", \"order_id\", \"product_id\", \"quantity\", \"item_price\") VALUES\n(1,\t1,\t1,\t1,\t1396.90),\n(2,\t1,\t2,\t2,\t829.00);\n\n"
},
{
"alpha_fraction": 0.7994186282157898,
"alphanum_fraction": 0.8284883499145508,
"avg_line_length": 67.80000305175781,
"blob_id": "0014eed70d93a5c399f5b4ab7eda192dd0be97b1",
"content_id": "e40d2fded88c03261d7180e01cd73624b51e24f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 313,
"num_lines": 5,
"path": "/working-with-azure-event-hub/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Azure Event Hub as Kafka\n\n\n\nkafka-avro-console-consumer --bootstrap-server dorstevh001.servicebus.windows.net:9093 --topic test-property security.protocol:SASL_SSL --property sasl.mechanism:PLAIN --property sasl.jaas.config:Endpoint=sb://dorstevh001.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=BZfVUNfTBNmLvmi9X5M7PWXIrkUCcVmCV2hl4dt8OfI=\n"
},
{
"alpha_fraction": 0.5689204335212708,
"alphanum_fraction": 0.5875980854034424,
"avg_line_length": 30.494117736816406,
"blob_id": "93b35c5bca967018c1041e6433f80ac17f2551da",
"content_id": "74489fde0e7bd810f03816acc858def64632367c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2677,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 85,
"path": "/streaming-visualization/consume-json-hashtag.py",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "import json\nimport requests\n\nfrom subprocess import check_output\n\nfrom confluent_kafka import Consumer, KafkaError\n\n# Get your API_KEY from your settings file ('~/.tipboard/settings-local.py').\nAPI_KEY = 'api-key-here'\n# Change '127.0.0.1:7272' to the address of your Tipboard instance.\nAPI_URL = 'http://localhost:80/api/v0.1/{}'.format(API_KEY)\nAPI_URL_PUSH = '/'.join((API_URL, 'push'))\nAPI_URL_TILECONFIG = '/'.join((API_URL, 'tileconfig'))\n\ndef prepare_for_pie_chart(data):\n # Pie chart needs data as a list of lists (whose elements are pairs\n # component-percentage), so we have to prepare it.\n # data={\"title\": \"My title\", \"pie_data\": [[\"Pie 1\", 25], [\"Pie 2\", 25], [\"Pie 3\", 50]]}'\n data_prepared = []\n for k, v in data.items():\n data_prepared.append([k, v[0]])\n data_prepared = {'title': 'my title', 'pie_data': data_prepared}\n return data_prepared\n\ndef prepare_for_listing(data):\n # Listing needs data as a list of lists (whose elements are pairs\n # component-percentage), so we have to prepare it.\n # \"data={\"items\": [\"Leader: 5\", \"Product Owner: 0\", \"Scrum Master: 3\", \"Developer: 0\"]}\"\n data_prepared = []\n for k in data:\n data_prepared.append(k)\n data_prepared = {'items': data_prepared}\n print (data_prepared)\n return data_prepared\n\n\ndef main():\n # Tile 'pie001' (pie chart)\n # (let's say we want to show issues count for project 'Tipboard' grouped by\n # issue status i.e. 'Resolved', 'In Progress', 'Open', 'Closed' etc.)\n TILE_NAME = 'listing'\n TILE_KEY = 'top_hashtags'\n\n c = Consumer({\n 'bootstrap.servers': 'streamingplatform:9092',\n 'group.id': 'test-consumer-group',\n 'default.topic.config': {\n 'auto.offset.reset': 'largest'\n }\n })\n\n c.subscribe(['DASH_HASHTAG_TOP10_5MIN_T'])\n\n while True:\n msg = c.poll(1.0)\n\n if msg is None:\n continue\n if msg.error():\n if msg.error().code() == KafkaError._PARTITION_EOF:\n continue\n else:\n print(msg.error())\n break\n\n data = json.loads(msg.value().decode('utf-8'))\n # print (data)\n top10 = data.get('TOP_10')\n term = data.get('TERM')\n data_selected = [ term + ':' + str(top10) ]\n data_prepared = prepare_for_listing(data_selected)\n data_jsoned = json.dumps(data_prepared)\n data_to_push = {\n 'tile': TILE_NAME,\n 'key': TILE_KEY,\n 'data': data_jsoned,\n }\n resp = requests.post(API_URL_PUSH, data=data_to_push)\n if resp.status_code != 200:\n print(resp.text)\n return\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6962025165557861,
"alphanum_fraction": 0.7364786863327026,
"avg_line_length": 38.40909194946289,
"blob_id": "1739e36805697ce13121ca1bc481791dadac2de8",
"content_id": "9b5000c409b61cd2f523e708c228665e9ad42baf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "SQL",
"length_bytes": 869,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 22,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/testdata/order_item_t.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nINSERT INTO order_item_t (ID,ORDER_ID,PRODUCT_ID,PRODUCT_NAME,UNIT_PRICE,QUANTITY) \n\tvalues (1, 2355, 2289, 'Sportshoe Max', 146, 1);\nINSERT INTO order_item_t (ID,ORDER_ID,PRODUCT_ID,PRODUCT_NAME,UNIT_PRICE,QUANTITY) \n\tvalues (2, 2355, 2264, 'Sony Headphone', 299.1, 1);\n\nCOMMIT;\n\n\n"
},
{
"alpha_fraction": 0.7785235047340393,
"alphanum_fraction": 0.7785235047340393,
"avg_line_length": 15.55555534362793,
"blob_id": "4055e45dc0555422bd7fe60c47669437e341cc8d",
"content_id": "8d4df1bf0f9e9901d768813e7a3b24f04cb10639",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 9,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/query/handler/CountAccountSummariesQuery.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.query.handler;\n\npublic class CountAccountSummariesQuery {\n\t\n\tpublic CountAccountSummariesQuery() {\n\t\t\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7460317611694336,
"avg_line_length": 24,
"blob_id": "08f9fbbdff6ffb65ce0ab64c3278e9c9d2b20c2d",
"content_id": "fea77e5b3f962e6c7cfd670d05fad9e09a29cc94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 5,
"path": "/streaming-visualization/scripts/stop-connect-slack-sink.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"removing MQTT Source Connectors\"\n\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/mqtt-position-source\"\n\n"
},
{
"alpha_fraction": 0.4691597819328308,
"alphanum_fraction": 0.4866439998149872,
"avg_line_length": 20.63157844543457,
"blob_id": "af910d21f95f72cf98f0ade15980373e95c223e0",
"content_id": "8395ec79e786c6e30ec6fd616331940f6e926715",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2059,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 95,
"path": "/streaming-visualization/consume-avro.py",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "from confluent_kafka import avro\n\nrecord_schema = avro.loads(\"\"\"\n{\n \"type\": \"record\",\n \"name\": \"KsqlDataSourceSchema\",\n \"namespace\": \"io.confluent.ksql.avro_schemas\",\n \"fields\": [\n {\n \"name\": \"TYPE\",\n \"type\": [\n \"null\",\n \"string\"\n ],\n \"default\": null\n },\n {\n \"name\": \"TOP_10\",\n \"type\": [\n \"null\",\n {\n \"type\": \"array\",\n \"items\": [\n \"null\",\n \"string\"\n ]\n }\n ],\n \"default\": null\n },\n {\n \"name\": \"TOP_20\",\n \"type\": [\n \"null\",\n {\n \"type\": \"array\",\n \"items\": [\n \"null\",\n \"string\"\n ]\n }\n ],\n \"default\": null\n }\n ]\n}\n\"\"\")\n\n\n\ndef consume(topic, conf):\n \"\"\"\n Consume User records\n \"\"\"\n from confluent_kafka.avro import AvroConsumer\n from confluent_kafka.avro.serializer import SerializerError\n\n print(\"Consuming user records from topic {} with group {}. to exit.\".format(topic, conf[\"group.id\"]))\n\n c = AvroConsumer(conf)\n c.subscribe([topic])\n\n while True:\n try:\n msg = c.poll(1)\n\n # There were no messages on the queue, continue polling\n if msg is None:\n continue\n\n if msg.error():\n print(\"Consumer error: {}\".format(msg.error()))\n continue\n\n record = User(msg.value())\n print(\"type: {}\\n\".format(\n record.TYPE))\n except SerializerError as e:\n # Report malformed record, discard results, continue polling\n print(\"Message deserialization failed {}\".format(msg,e))\n continue\n except KeyboardInterrupt:\n break\n\n print(\"Shutting down consumer..\")\n c.close()\n\n\nif __name__ == '__main__':\n\n # handle common configs\n conf = {'bootstrap.servers': '192.168.73.86:9092',\n\t\t\t'schema.registry.url': 'http://192.168.73.86:8089',\n\t\t\t'group.id': 'consumer'}\n consume ('TWEET_HASHTAG_TOP10_1MIN_T', conf)\n "
},
{
"alpha_fraction": 0.6595237851142883,
"alphanum_fraction": 0.7095237970352173,
"avg_line_length": 13.413793563842773,
"blob_id": "bd9c91051c9d43e6022ffb4d741fdf7c93679a5d",
"content_id": "370314e8897439cb7bb1df267fe2996b0997d20d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 29,
"path": "/rb-dr-case/vmware/scripts/cleanup-dc1.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncd ../data\n\nrm -R kafka-1\nrm -R kafka-2\nrm -R kafka-3\n\nrm -R zookeeper-1 \nrm -R zookeeper-2\nrm -R zookeeper-3 \n\nmkdir kafka-1\nmkdir kafka-2\nmkdir kafka-3\n\nmkdir -p zookeeper-1/data\nmkdir -p zookeeper-2/data\nmkdir -p zookeeper-3/data\n\n\nmkdir -p zookeeper-1/log\nmkdir -p zookeeper-2/log\nmkdir -p zookeeper-3/log\n\n\necho 1 > zookeeper-1/data/myid\necho 2 > zookeeper-2/data/myid\necho 3 > zookeeper-3/data/myid\n\n\n"
},
{
"alpha_fraction": 0.7698113322257996,
"alphanum_fraction": 0.7698113322257996,
"avg_line_length": 19.384614944458008,
"blob_id": "f193f18b1b54b57b3c049a1ed87a060ce9c82126",
"content_id": "eb83dc9c263602f7a29d8c52d5c476f33e4eb0e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 13,
"path": "/event-sourcing/axon/finance-axon-command/src/main/java/com/trivadis/sample/axon/account/aggregate/DepositTransaction.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.aggregate;\n\nimport java.math.BigDecimal;\nimport java.util.UUID;\n\npublic class DepositTransaction extends Transaction {\n\n\tpublic DepositTransaction(UUID id, BigDecimal amount, long when) {\n\t\tsuper(id, amount, when);\n\t\t\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5443891286849976,
"alphanum_fraction": 0.5534720420837402,
"avg_line_length": 33.82653045654297,
"blob_id": "ac328355ba45642ce791a1ad29e8b859f0c10f49",
"content_id": "cb125e34e3c787bd592e82bbea08fc7cf372cbef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Maven POM",
"length_bytes": 6826,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 196,
"path": "/kafka-geofencing/kafka-streams/kafka-streams-position/pom.xml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<project xmlns=\"http://maven.apache.org/POM/4.0.0\"\n xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\n xsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\n <modelVersion>4.0.0</modelVersion>\n\n\t<groupId>com.trivadis.sample.geofencing</groupId>\n <artifactId>kafka-streams-position</artifactId>\n <version>0.0.1-SNAPSHOT</version>\n <packaging>jar</packaging>\n\n <description>\n Kafka Streams which consumes the Position Mecomo and enriches it with the barge info and ETA\n </description>\n\n <repositories>\n <repository>\n <id>confluent</id>\n <url>https://packages.confluent.io/maven/</url>\n </repository>\n <repository>\n \t\t\t<id>dev-azure-com-se-innovationprojects-barge-tracking</id>\n \t\t\t<url>https://pkgs.dev.azure.com/SE-InnovationProjects/_packaging/barge-tracking/maven/v1</url>\n \t\t\t<releases>\n \t\t\t<enabled>true</enabled>\n \t\t\t</releases>\n \t\t\t<snapshots>\n \t\t\t<enabled>true</enabled>\n \t\t\t</snapshots>\n\t\t</repository>\n </repositories>\n\n <pluginRepositories>\n <pluginRepository>\n <id>confluent</id>\n <url>https://packages.confluent.io/maven/</url>\n </pluginRepository>\n </pluginRepositories>\n\n <!-- Other properties such as kafka.version are derived from parent project(s) such as\n https://github.com/confluentinc/common (see common's pom.xml for kafka.version).\n -->\n <properties>\n \t<confluent.version>5.3.0</confluent.version>\n \t<kafka.version>2.3.0</kafka.version>\n <avro.version>1.9.0</avro.version>\n <docker.skip-build>false</docker.skip-build>\n <docker.skip-test>false</docker.skip-test>\n <java.version>1.8</java.version>\n <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>\n </properties>\n\n <dependencies>\n \t<dependency>\n \t\t\t<groupId>com.trivadis.sample.geofencing</groupId>\n \t\t\t<artifactId>avro-schemas</artifactId>\n \t\t\t<version>1.0-SNAPSHOT</version>\n\t\t</dependency>\n\t\t<dependency>\n \t\t \t<groupId>com.trivadis.sample.geofencing</groupId>\n \t\t\t<artifactId>geo-utils</artifactId>\n \t\t\t<version>0.0.1-SNAPSHOT</version>\n\t\t</dependency>\n\t\t\n\t\t<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->\n <dependency>\n <groupId>org.slf4j</groupId>\n <artifactId>slf4j-log4j12</artifactId>\n <version>1.7.26</version>\n </dependency>\n \n <dependency>\n <groupId>io.confluent</groupId>\n <artifactId>kafka-streams-avro-serde</artifactId>\n <version>${confluent.version}</version>\n </dependency>\n <dependency>\n <groupId>io.confluent</groupId>\n <artifactId>kafka-avro-serializer</artifactId>\n <version>${confluent.version}</version>\n </dependency>\n <dependency>\n <groupId>io.confluent</groupId>\n <artifactId>kafka-schema-registry-client</artifactId>\n <version>${confluent.version}</version>\n </dependency>\n <dependency>\n <groupId>org.apache.kafka</groupId>\n <artifactId>kafka-streams</artifactId>\n <version>${kafka.version}</version>\n </dependency>\n\n <dependency>\n <groupId>org.apache.avro</groupId>\n <artifactId>avro</artifactId>\n <version>${avro.version}</version>\n </dependency>\n\t\t\n\t\t<dependency>\n\t\t\t<groupId>commons-cli</groupId>\n\t\t\t<artifactId>commons-cli</artifactId>\n\t\t\t<version>1.4</version>\n\t\t</dependency>\n\t\t\n\n\n <!-- Test dependencies -->\n <dependency>\n <groupId>junit</groupId>\n <artifactId>junit</artifactId>\n <version>4.12</version>\n <scope>test</scope>\n </dependency>\n\n <dependency>\n <groupId>org.apache.kafka</groupId>\n <artifactId>kafka-clients</artifactId>\n <version>${kafka.version}</version>\n <classifier>test</classifier>\n <scope>test</scope>\n </dependency>\n <dependency>\n <groupId>org.apache.kafka</groupId>\n <artifactId>kafka-streams</artifactId>\n <version>${kafka.version}</version>\n <classifier>test</classifier>\n <scope>test</scope>\n </dependency>\n\n <dependency>\n <groupId>io.confluent</groupId>\n <artifactId>kafka-schema-registry</artifactId>\n <version>${confluent.version}</version>\n <scope>test</scope>\n </dependency>\n <dependency>\n <groupId>io.confluent</groupId>\n <artifactId>kafka-schema-registry</artifactId>\n <version>${confluent.version}</version>\n <!-- Required for e.g. schema registry's RestApp -->\n <classifier>tests</classifier>\n <scope>test</scope>\n </dependency>\n\n \n </dependencies>\n\n <build>\n\n <plugins>\n\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-compiler-plugin</artifactId>\n <version>3.3</version>\n <inherited>true</inherited>\n <configuration>\n <source>${java.version}</source>\n <target>${java.version}</target>\n <compilerArgs>\n <arg>-Xlint:all</arg>\n <!--TODO: enable this once we have warnings under control<arg>-Werror</arg>-->\n </compilerArgs>\n </configuration>\n </plugin>\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-assembly-plugin</artifactId>\n <configuration>\n <descriptors>\n <descriptor>src/assembly/development.xml</descriptor>\n <descriptor>src/assembly/package.xml</descriptor>\n <descriptor>src/assembly/standalone.xml</descriptor>\n </descriptors>\n <archive>\n <manifest>\n <mainClass>com.thyssenkrupp.tkse.KafkaStreamsPositionMecomoApp</mainClass>\n </manifest>\n </archive>\n <attach>false</attach>\n </configuration>\n <executions>\n <execution>\n <id>make-assembly</id>\n <phase>package</phase>\n <goals>\n <goal>single</goal>\n </goals>\n </execution>\n </executions>\n </plugin>\n </plugins>\n </build>\n\n\n</project>\n"
},
{
"alpha_fraction": 0.6027550101280212,
"alphanum_fraction": 0.6485480070114136,
"avg_line_length": 15.266666412353516,
"blob_id": "df3b09946af612fa459ed23dbdc7bf5196926736",
"content_id": "3ef1aaf4c2655c55b3440df96a0ee9d917d63ddd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2686,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 165,
"path": "/rb-dr-case/vmware/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Kafka Disaster Recovery Test\n\nIn this project a Kafka HA Setup based on a so-called Streteched Cluster is setup and tested. \n\n## Setup\n\nTwo virtual machines simulating 2 datacenters. Each VM runs 3 Zookeeper Nodes and 3 Kafka brokers.\n\n\n### Setup Kafka-1\n\nConfigure Zookeeper in Supervisor: /etc/supervisor/conf.d/kafka.conf\n\nConfigure Kafka in Supervisor: /etc/supervisor/conf.d/kafka.conf\n\nCheckout the rb-dr-case project\n\n```\ngit clone https://github.com/gschmutz/various-demos.git/ --no-checkout\ncd various-demos\n\ngit config core.sparseCheckout true\necho \"/rb-dr-case/*\" > .git/info/sparse-checkout\ngit checkout master\n```\n\n\n### Configuring /etc/hosts\n\n```\n192.168.73.80 kafka-manager\t\n\n192.168.73.81 broker-1\t\tbroker-2\tbroker-3\n192.168.73.81 zookeeper-1\tzookeeper-2\tzookeeper-3\n\n192.168.73.82 broker-4 \tbroker-5 broker-6\n192.168.73.82 zookeeper-4 \tzookeeper-5 zookeeper-6\n```\n\n## Starting Environment\n\n\n### Starting Zookeeper\n\nIn DC1 perform\n\n```\nsudo supervisorctl start zookeeper-1 zookeeper-2 zookeeper-3\ntail -f /var/log/zookeeper/zookeeper-*.log\n```\n\nIn DC2 platform\n\n```\nsudo supervisorctl start zookeeper-4 zookeeper-5 zookeeper-6\ntail -f /var/log/zookeeper/zookeeper-*.log\n```\n\n### Starting Kafka \n\nIn DC1 perform\n\n```\nsudo supervisorctl start kafka-1 kafka-2 kafka-3\ntail -f /var/log/kafka/kafka-*.log\n```\n\nIn DC2 perform\n\n```\nsudo supervisorctl start kafka-4 kafka-5 kafka-6\ntail -f /var/log/kafka/kafka-*.log\n```\n\n### Starting Kafka Manger\n\nIn MGR perform\n\n```\nsudo supervisorctl start all\n```\n\n<http://kafka-manager:9000>\n\n\n## Use Cluster\n\n### Create a Topic\n\n```\ncd /home/gus/confluent-5.0.1/bin\n```\n\n```\n./kafka-topics --zookeeper zookeeper-1:2181, zookeeper-4:2185 --create --topic sequence --partitions 8 --replication-factor 4\n```\n\n<http://kafka-manager:9000/clusters/rb/topics/sequence>\n\n## Running the test\n\n### Cleanup\n\nRun the following command to cleanup the cluster. \n\n```\n./cleanup.sh\n```\n\n```\ngus@kafka-manager /m/h/g/w/g/g/v/r/v/scripts> tree ../data/\n\n../data/\n|-- kafka-1\n|-- kafka-2\n|-- kafka-3\n|-- kafka-4\n|-- kafka-5\n|-- kafka-6\n|-- zookeeper-1\n| |-- data\n| | `-- myid\n| `-- log\n|-- zookeeper-2\n| |-- data\n| | `-- myid\n| `-- log\n|-- zookeeper-3\n| |-- data\n| | `-- myid\n| `-- log\n|-- zookeeper-4\n| |-- data\n| | `-- myid\n| `-- log\n|-- zookeeper-5\n| |-- data\n| | `-- myid\n| `-- log\n`-- zookeeper-6\n |-- data\n | `-- myid\n `-- log\n```\n\n### Produce to Topic\n\n```\ncd $VARIOUS_DEMOS/rb-dr-case/vmware/scripts/\n./produce.sh\n```\n\n```\necho \"true\" > control.info\n```\n\n```\necho \"false\" > control.info\n```\n\n\n### Consume from Topic\n```\nkafkacat -b broker-1:9092 -t sequence -p 1\n```\n\n\n"
},
{
"alpha_fraction": 0.7463185787200928,
"alphanum_fraction": 0.7483266592025757,
"avg_line_length": 27.730770111083984,
"blob_id": "24a2be7d2eda06d680d6fc1269969e39de569a7a",
"content_id": "6fa0be9c1eb9a2e820f2925854db90c7695b5f46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 52,
"path": "/event-sourcing/kafka-streams/account-ms/src/main/java/com/trivadis/sample/kafkastreams/ms/account/converter/AccountCommandConverter.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.kafkastreams.ms.account.converter;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport com.trivadis.avro.command.account.v1.AccountCreateCommand;\nimport com.trivadis.avro.command.account.v1.AccountTypeEnum;\nimport com.trivadis.avro.command.account.v1.DepositMoneyCommand;\n\npublic class AccountCommandConverter {\n\tpublic static List<String> convertFromCS (List<CharSequence> input) {\n\t\tList<String> value = new ArrayList<String>();\n\t\t\n\t\tif (input != null) {\n\t\t\tfor (CharSequence cs : input) {\n\t\t\t\tvalue.add(input.toString());\n\t\t\t}\n\t\t}\n\t\treturn value;\n\t}\n\t\n\tpublic static List<CharSequence> convertFromString (List<String> input) {\n\t\tList<CharSequence> value = new ArrayList<CharSequence>();\n\t\t\n\t\tif (input != null) {\n\t\t\tfor (String str : input) {\n\t\t\t\tvalue.add(str);\n\t\t\t}\n\t\t}\n\t\treturn value;\n\t}\n\t\n\tpublic static AccountCreateCommand convert (com.trivadis.sample.kafkastreams.ms.account.command.AccountCreateCommand command) {\n\t\tAccountCreateCommand avro = new AccountCreateCommand();\n\t\t\n\t\tavro.setId(command.getId());\n\t\tavro.setCustomerId(command.getForCustomerId());\n\t\tavro.setAccountType(AccountTypeEnum.valueOf(command.getAccountType()));\n\t\t\n\t\treturn avro;\n\t}\n\n\t\n\tpublic static DepositMoneyCommand convert (com.trivadis.sample.kafkastreams.ms.account.command.DepositMoneyCommand command) {\n\t\tDepositMoneyCommand avro = new DepositMoneyCommand();\n\t\t\n\t\tavro.setId(command.getId());\n\t\tavro.setAmount(command.getAmount().doubleValue());\n\t\t\n\t\treturn avro;\n\t}\n}\n"
},
{
"alpha_fraction": 0.7732758522033691,
"alphanum_fraction": 0.7745689749717712,
"avg_line_length": 34.15151596069336,
"blob_id": "765a444c4b4ed3fa19cc91260ab7241017debd47",
"content_id": "c8cb79d2e4a5a23eb19d829dd3b982a6326f6201",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4640,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 132,
"path": "/event-sourcing/axon/finance-axon-command/src/main/java/com/trivadis/sample/axon/account/aggregate/AccountAggregate.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.aggregate;\n\nimport static org.axonframework.commandhandling.model.AggregateLifecycle.apply;\n\nimport java.math.BigDecimal;\nimport java.util.ArrayList;\nimport java.util.Date;\nimport java.util.List;\nimport java.util.UUID;\n\nimport org.axonframework.commandhandling.CommandHandler;\nimport org.axonframework.commandhandling.model.AggregateIdentifier;\nimport org.axonframework.eventsourcing.EventSourcingHandler;\nimport org.axonframework.eventsourcing.EventSourcingRepository;\nimport org.axonframework.spring.stereotype.Aggregate;\nimport org.slf4j.Logger;\nimport org.slf4j.LoggerFactory;\nimport org.springframework.beans.factory.annotation.Autowired;\nimport org.springframework.util.Assert;\n\nimport com.trivadis.sample.axon.account.command.AccountCreateCommand;\nimport com.trivadis.sample.axon.account.command.DepositMoneyCommand;\nimport com.trivadis.sample.axon.account.command.WithdrawMoneyCommand;\nimport com.trivadis.sample.axon.account.event.AccountCreatedEvent;\nimport com.trivadis.sample.axon.account.event.MoneyDepositedEvent;\nimport com.trivadis.sample.axon.account.event.MoneyWithdrawnEvent;\nimport com.trivadis.sample.axon.account.exception.InsufficientBalanceException;\n\n@Aggregate\npublic class AccountAggregate{\n\tprivate static final Logger LOGGER = LoggerFactory.getLogger(AccountAggregate.class);\n\n\t@Autowired\n\tprivate EventSourcingRepository<AccountAggregate> repo;\n\t\n\t@AggregateIdentifier\n\tprivate String id;\n\t\n\tprivate BigDecimal balance;\n\tprivate String forCustomerId;\n\tprivate String accountType;\n\n\tprivate List<Transaction> transactions;\n\t\n\tpublic BigDecimal getBalance() {\n\t\treturn balance;\n\t}\n\n\tpublic void setBalance(BigDecimal balance) {\n\t\tthis.balance = balance;\n\t}\n\n\tpublic String getForCustomerId() {\n\t\treturn forCustomerId;\n\t}\n\n\tpublic void setForCustomerId(String forCustomerId) {\n\t\tthis.forCustomerId = forCustomerId;\n\t}\n\n\tpublic String getAccountType() {\n\t\treturn accountType;\n\t}\n\n\tpublic void setAccountType(String accountType) {\n\t\tthis.accountType = accountType;\n\t}\n\n\tpublic AccountAggregate() {\n\t\t// constructor needed for reconstructing the aggregate\n\t\ttransactions = new ArrayList<Transaction>();\n\t\tLOGGER.info(\"(F) Empty Account Aggregate created\");\n\t}\n\t\n\t@CommandHandler\n\tpublic AccountAggregate(AccountCreateCommand command) {\n\t\tLOGGER.info(\"(C) Handle: \" + command.toString());\n\t\t\n\t\tAssert.hasLength(command.getForCustomerId(), \"CustomerId must have a value\");\n\t\tAssert.hasLength(command.getAccountType(), \"AccountType must have a value\");\n\t\tAssert.hasLength(command.getId(), \"Account id must have length greater than Zero\");\n\t\tapply(new AccountCreatedEvent(command.getId(), command.getForCustomerId(), command.getAccountType(), new BigDecimal(\"0\")));\n\t}\n\t\n\t@EventSourcingHandler\n\tpublic void handle(AccountCreatedEvent event) {\n\t\tLOGGER.info(\"(E) Handle \"+ event.toString());\n\t\t\n\t\tthis.id = event.getId();\n\t\tthis.forCustomerId = event.getForCustomerId();\n\t\tthis.accountType = event.getAccountType();\n\t\tthis.balance = event.getBalance();\n\t}\n\t\n\t@CommandHandler\n\tpublic void on(DepositMoneyCommand command) {\n\t\tLOGGER.info(\"(C) Handle: \" + command.toString());\n\t\tAssert.isTrue(command.getAmount().compareTo(BigDecimal.ZERO) > 0 , \"Amount should be a positive number\");\n\t\tapply(new MoneyDepositedEvent(command.getId(), command.getAmount(), new Date().getTime()));\n\t}\n\t\n\t@EventSourcingHandler\n\tpublic void handle(MoneyDepositedEvent event) {\n\t\tLOGGER.info(\"(E) Handle \"+ event.toString());\n\t\t//AccountAggregate aggregate = repository.load(event.getId()).getWrappedAggregate().getAggregateRoot();\n\t\tthis.balance = this.balance.add(event.getAmount());\n\n\t\t// add the withdrawn transaction\n\t\ttransactions.add(new DepositTransaction(UUID.randomUUID(), event.getAmount(), new Date().getTime()));\n\t\t\n\t}\n\t\n\t@CommandHandler\n\tpublic void on(WithdrawMoneyCommand command) {\n\t\tLOGGER.info(\"(C) Handle: \" + command.toString());\n\t\tAssert.isTrue(command.getAmount().compareTo(BigDecimal.ZERO) > 0 , \"Amount should be a positive number\");\n\t\tif(command.getAmount().compareTo(this.balance) > 0 ) {\n\t\t\tthrow new InsufficientBalanceException(\"Insufficient balance. Trying to withdraw:\" + command.getAmount() + \", but current balance is: \" + this.balance);\n\t\t}\n\t\tapply(new MoneyWithdrawnEvent(command.getId(), command.getAmount(), new Date().getTime()));\n\t}\n\t\n\t@EventSourcingHandler\n\tpublic void handle(MoneyWithdrawnEvent event) {\n\t\tLOGGER.info(\"(E) Handle \"+ event.toString());\n\t\tthis.balance = this.balance.subtract((event.getAmount()));\n\t\t\n\t\t// add the withdrawn transaction\n\t\ttransactions.add(new WithdrawTransaction(UUID.randomUUID(), event.getAmount(), new Date().getTime()));\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6890243887901306,
"alphanum_fraction": 0.6890243887901306,
"avg_line_length": 13.909090995788574,
"blob_id": "46a3e04ae70d661236a555221cd6c3948d7e3f6e",
"content_id": "03498be478d31ca5bc03d671a929cc70075501f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 328,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 22,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/model/Transaction.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.model;\n\npublic class Transaction {\n\tprivate Double amount;\n\tprivate long when;\n\t\n\tpublic Transaction(Double amount, long when) {\n\t\tsuper();\n\t\tthis.amount = amount;\n\t\tthis.when = when;\n\t}\n\n\tpublic Double getAmount() {\n\t\treturn amount;\n\t}\n\n\tpublic long getWhen() {\n\t\treturn when;\n\t}\n\t\n\t\n}\n"
},
{
"alpha_fraction": 0.7285886406898499,
"alphanum_fraction": 0.7382388710975647,
"avg_line_length": 29.703702926635742,
"blob_id": "71e66b0a95c6ab272db7e5962ec00e125c7b991c",
"content_id": "0456921a5495b0a0339c96ba44c41724b9a92ce3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 27,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/trigger/customer_biu_trg.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz\t@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nCREATE OR REPLACE TRIGGER customer_biu_trg\n BEFORE UPDATE OR INSERT ON customer_t\n FOR EACH ROW\nDECLARE\nBEGIN\n\tIF INSERTING THEN\n\t :NEW.created_at := CURRENT_TIMESTAMP;\n\tEND IF;\n \t:NEW.modified_at := CURRENT_TIMESTAMP;\nEND;\n/\n"
},
{
"alpha_fraction": 0.7005758285522461,
"alphanum_fraction": 0.7044146060943604,
"avg_line_length": 19.84000015258789,
"blob_id": "8f5bb622c9d984e92758fa28d31f061759460a5b",
"content_id": "655e3a8f96eace77e084a297ea3bf9e4f242ff1b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 521,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 25,
"path": "/php-kafka/php-rdkafka-3.0.5/travis.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -xe\n\ngit clone --depth 1 --branch \"$LIBRDKAFKA_VERSION\" https://github.com/edenhill/librdkafka.git\n(\n cd librdkafka\n ./configure\n make\n sudo make install\n)\nsudo ldconfig\n\nsudo apt-get update\nsudo apt-get install -qq valgrind\n\necho \"extension = $(pwd)/modules/rdkafka.so\" >> ~/.phpenv/versions/$(phpenv version-name)/etc/php.ini\nphpenv config-rm xdebug.ini || true\n\nphpize\n./configure\nmake\n\nPHP=$(which php)\nREPORT_EXIT_STATUS=1 TEST_PHP_EXECUTABLE=\"$PHP\" \"$PHP\" run-tests.php -q -m --show-diff\n"
},
{
"alpha_fraction": 0.759765625,
"alphanum_fraction": 0.767578125,
"avg_line_length": 24,
"blob_id": "6a7def796b8c5d9baaacde74f05d5425a4779e19",
"content_id": "318e0801c3e4e94cd83bc197ba1cf9741337d67c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1024,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 41,
"path": "/data-lake-platform/cask-cdap/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Cask CDAP\n\n[CDAP](http://cask.co/) is an open source, Apache 2.0 licensed, distributed, application framework for \ndelivering Hadoop solutions. It integrates and abstracts the underlying Hadoop \ntechnologies to provide simple and easy-to-use APIs and a graphical UI to build, deploy, \nand manage complex data analytics applications in the cloud or on-premises.\n\nCDAP provides a container architecture for your data and applications on Hadoop. Simpli\u001fed \nabstractions and deep integrations with diverse Hadoop technologies dramatically increase \nproductivity and quality. This accelerates development and reduces time-to-production to get \nyour Hadoop projects to market faster. \n\n## Setup\n\n```\nexport DOCKER_HOST_IP=nnn.nnn.nnn.nnnn\nexport PUBLIC_HOST_IP=\n```\n\n```\ncd $VARIOUS_DEMOS/data-lake-platform/cask-cdap/docker\n```\n\n```\ndocker-compose up -d\n```\n\nto connect a terminal to the CDAP environment\n\n```\ndocker exec -ti docker_cdap_1 bash\n\ncd /\nmkdir datalake\ncd /datalake\nmkdir poc \n```\n\n\n\n* CDAP UI: <http://cdap:11011>"
},
{
"alpha_fraction": 0.6809045076370239,
"alphanum_fraction": 0.6809045076370239,
"avg_line_length": 26.63888931274414,
"blob_id": "a33009b23273a54a28a70eb0952bf6bdcd8b8dd3",
"content_id": "6a4b291966187d9ca73051a90b57e03adcaf5017",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1990,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 72,
"path": "/jax-2018-kafka-streams-vs-spark-streaming/src/truck-client/src/main/java/com/hortonworks/simulator/impl/domain/transport/MobileEyeEvent.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.hortonworks.simulator.impl.domain.transport;\n\nimport java.sql.Timestamp;\nimport java.util.Date;\n\nimport com.hortonworks.simulator.impl.domain.Event;\nimport com.hortonworks.simulator.impl.domain.gps.Location;\n\npublic class MobileEyeEvent extends Event {\n\tprivate MobileEyeEventTypeEnum eventType;\n\tprivate Truck truck;\n\tprivate Location location;\n\tprivate long correlationId;\n\n\tpublic MobileEyeEvent(long correlationId, Location location, MobileEyeEventTypeEnum eventType,\n\t\t\tTruck truck) {\n\t\tthis.location = location;\n\t\tthis.eventType = eventType;\n\t\tthis.truck = truck;\n\t\tthis.correlationId = correlationId;\n\t}\n\n\tpublic MobileEyeEventTypeEnum getEventType() {\n\t\treturn eventType;\n\t}\n\n\tpublic void setEventType(MobileEyeEventTypeEnum eventType) {\n\t\tthis.eventType = eventType;\n\t}\n\n\tpublic Location getLocation() {\n\t\treturn location;\n\t}\n\t\n\tpublic Truck getTruck() {\n\t\treturn this.truck;\n\t}\n\n\t@Override\n\tpublic String toString() {\n\t\treturn truck.toString() + eventType.toString() + \",\"\n\t\t\t\t+ location.getLatitude() + \",\" + location.getLongitude() + \",\" + correlationId;\n\t}\n\t\n\tpublic String toCSV() {\n\t\treturn truck.toCSV() + eventType.toCSV() + \",\"\n\t\t\t\t+ location.getLatitude() + \",\" + location.getLongitude() + \",\" + correlationId;\n\t}\n\n\tpublic String toJSON() { \n\t\tStringBuffer msg = new StringBuffer();\n\t\tmsg.append(\"{\");\n\t\tmsg.append(\"\\\"timestamp\\\":\" + new Date().getTime());\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"truckId\\\":\" + truck.getTruckId());\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"driverId\\\":\" + truck.getDriver().getDriverId());\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"routeId\\\":\" + truck.getDriver().getRoute().getRouteId());\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"eventType\\\":\\\"\" + eventType + \"\\\"\");\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"latitude\\\":\" + location.getLatitude());\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"longitude\\\":\" + location.getLongitude());\n\t\tmsg.append(\",\");\n\t\tmsg.append(\"\\\"correlationId\\\":\\\"\" + correlationId + \"\\\"\");\n\t\tmsg.append(\"}\");\n\t\treturn msg.toString();\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.6598984599113464,
"alphanum_fraction": 0.6954314708709717,
"avg_line_length": 50.78947448730469,
"blob_id": "d62debec79998ab6aecb7465f798026605143f1b",
"content_id": "9059b06b63b78cd58526cb710663388974a642c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 985,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 19,
"path": "/bidirectional-integration-oracle-kafka/scripts/kafka-connect/start-aqjms-source.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"creating JMS Source Connector\"\n\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n --data '{\n \"name\": \"jms-source\",\n \"config\": {\n \"name\": \"jms-source\",\n \"connector.class\": \"com.datamountaineer.streamreactor.connect.jms.source.JMSSourceConnector\",\n \"connect.jms.initial.context.factory\": \"oracle.jms.AQjmsInitialContextFactory\",\n \"connect.jms.initial.context.extra.params\": \"db_url=jdbc:oracle:thin:@//192.168.73.86:1521/XEPDB1,java.naming.security.principal=order_processing,java.naming.security.credentials=order_processing\",\n \"tasks.max\": \"1\",\n \"connect.jms.connection.factory\": \"ConnectionFactory\",\n \"connect.jms.url\": \"jdbc:oracle:thin:@//192.168.73.86:1521/XEPDB1\",\n \"connect.jms.kcql\": \"INSERT INTO order SELECT * FROM order_aq WITHTYPE QUEUE WITHCONVERTER=`com.datamountaineer.streamreactor.connect.converters.source.JsonSimpleConverter`\"\n }\n}'\n\n"
},
{
"alpha_fraction": 0.7282447218894958,
"alphanum_fraction": 0.734184741973877,
"avg_line_length": 37.151161193847656,
"blob_id": "d2c9402cefa69812d9ef82ee3ab22e88c0c75c03",
"content_id": "2999c8e661c01f3d83bedcda0359278f05503965",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3367,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 86,
"path": "/graph-performance/des-graph-test/src/main/java/com/trivadis/GraphRepositorySingle.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis;\r\n\r\nimport java.io.Serializable;\r\n\r\nimport org.apache.commons.lang3.StringUtils;\r\n\r\nimport com.datastax.driver.core.ConsistencyLevel;\r\nimport com.datastax.driver.dse.DseCluster;\r\nimport com.datastax.driver.dse.DseSession;\r\nimport com.datastax.driver.dse.graph.Edge;\r\nimport com.datastax.driver.dse.graph.GraphOptions;\r\nimport com.datastax.driver.dse.graph.Vertex;\r\nimport com.trivadis.domain.Tweet;\r\n\r\npublic class GraphRepositorySingle implements Serializable, GraphRepository {\r\n\r\n\tprivate static final long serialVersionUID = 4725813855174838651L;\r\n\r\n\tprivate transient DseSession session = null;\r\n\t\r\n\tprivate String cassandraHost;\r\n\tprivate String cassandraPort;\r\n\tprivate String graphName;\r\n\t\r\n\tpublic GraphRepositorySingle(String cassandraHost, String cassandraPort, String graphName) {\r\n\t\tthis.cassandraHost = cassandraHost;\t\t\t\r\n\t\t DseCluster dseCluster = DseCluster.builder()\r\n\t\t .addContactPoints(StringUtils.split(cassandraHost,\",\"))\r\n\t\t .withGraphOptions(new GraphOptions().setGraphName(graphName)\r\n\t\t\t\t\t\t//.setReadTimeoutMillis(readTimeoutMillis)\r\n\t\t\t\t\t\t.setGraphReadConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM)\r\n\t\t\t\t\t\t.setGraphWriteConsistencyLevel(ConsistencyLevel.ONE))\r\n\t\t .build();\r\n\t\tsession = dseCluster.connect();\r\n\r\n\t\tthis.cassandraPort = cassandraPort;\r\n\t\tthis.graphName = graphName;\r\n\r\n\t}\r\n\r\n\tpublic DseSession getDseSession() {\r\n\t\treturn session;\r\n\t}\r\n\r\n\t/* ======================= implementation =================================*/\r\n\r\n\t/* (non-Javadoc)\r\n\t * @see com.trivadis.GraphRepository#createTweetAndUsers(com.trivadis.domain.Tweet, boolean, boolean)\r\n\t */\r\n\t@Override\r\n\tpublic GraphMetrics createTweetAndUsers(Tweet tweetDO) {\r\n\r\n\t\tVertex userVertex = VertexHelper.createOrUpdateVertex(session,\r\n\t\t\t\tfalse,\r\n\t\t\t\tSocialGraphConstants.TWITTER_USER_VERTEX_LABEL, \r\n\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getUser().getId(), \r\n\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, tweetDO.getUser().getScreenName() != null ? tweetDO.getUser().getScreenName().toLowerCase() : null,\r\n\t\t\t\tSocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getUser().getLanguage() != null ? tweetDO.getUser().getLanguage().toLowerCase() : null,\r\n\t\t\t\tSocialGraphConstants.VERIFIED_PROPERTY_KEY, tweetDO.getUser().getVerified() != null ? tweetDO.getUser().getVerified() : false);\r\n\t\t\r\n\t\tVertex tweetVertex = VertexHelper.createOrUpdateVertex(session,\r\n\t\t\t\tfalse,\r\n\t\t\t\tSocialGraphConstants.TWEET_VERTEX_LABEL, \r\n\t\t\t\tSocialGraphConstants.ID_PROPERTY_KEY, tweetDO.getId(), \r\n\t\t\t\tSocialGraphConstants.TIME_PROPERTY_KEY, tweetDO.getCreatedAt().toDate().getTime(), \r\n\t\t\t\tSocialGraphConstants.LANGUAGE_PROPERTY_KEY, tweetDO.getLanguage() != null ? tweetDO.getLanguage().toLowerCase() : null);\r\n\t\t\r\n\t\tEdge publishedBy = VertexHelper.createOrUpdateEdge(session, true, SocialGraphConstants.PUBLISHES_EDGE_LABEL,\r\n\t\t\t\tuserVertex, tweetVertex);\r\n\t\t\r\n\t\tfor (String term : tweetDO.getHashtags()) {\r\n\t\t\tVertex termVertex = VertexHelper.createOrUpdateVertex(session,\r\n\t\t\t\t\tfalse,\r\n\t\t\t\t\tSocialGraphConstants.TERM_VERTEX_LABEL,\r\n\t\t\t\t\tSocialGraphConstants.NAME_PROPERTY_KEY, term.toLowerCase(),\r\n\t\t\t\t\tSocialGraphConstants.TYPE_PROPERTY_KEY, \"hashtag\");\r\n\t\t\r\n\t\t\tEdge replyToEdge = VertexHelper.createOrUpdateEdge(session, true, SocialGraphConstants.USES_EDGE_LABEL,\r\n\t\t\t\t\ttweetVertex, termVertex);\r\n\t\t}\r\n\t\t\r\n\t\treturn null;\r\n\t}\r\n\r\n\r\n}\r\n"
},
{
"alpha_fraction": 0.6481149196624756,
"alphanum_fraction": 0.6642729043960571,
"avg_line_length": 26.850000381469727,
"blob_id": "edd12dd7b028a966eac39fb0a0fb1d16346442b4",
"content_id": "0e6e1d0a3a3f8fee8cfb6da24820900468c3a440",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 557,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 20,
"path": "/iot-truck-demo/scripts/start-connect-cassandra.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"removing Cassandra Sink Connectors\"\n\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/cassandra-sink\"\n\necho \"creating Cassandra Sink Connector\"\n\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n --data '{\n \"name\": \"cassandra-sink\",\n \"config\": {\n \"connector.class\" : \"io.confluent.connect.cassandra.CassandraSinkConnector\",\n \"tasks.max\": \"1\",\n \"topics\" : \"DANGEROUS_DRIVING_COUNT\",\n \"cassandra.contact.points\" : \"cassandra\",\n \"cassandra.keyspace\" : \"iot-truck\"\n }\n }'\n"
},
{
"alpha_fraction": 0.8571428656578064,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 35,
"blob_id": "2e9d596b95855fe7eb52ce6c5c55c34827324ac6",
"content_id": "fca10543480d1d7bdc9a65392a6040f8085d89fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 1,
"path": "/iot-stream-ingestion-demo/src/truck-client/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "Fill out instructions for this part"
},
{
"alpha_fraction": 0.6529666185379028,
"alphanum_fraction": 0.7004695534706116,
"avg_line_length": 28.127885818481445,
"blob_id": "f62502291a7e8337f0d560b734dd42488f2231a4",
"content_id": "96672782a15181062d2527bfbea29a383bae44ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16399,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 563,
"path": "/iot-truck-demo-2nd/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# IoT Truck Demo\n\n## Prepare Environment\n\n### Docker Compose\n\nIn order for Kafka to work in the Docker Compose setup below, two envrionment variables are necessary.\n\nYou can add them to /etc/environment (without export) to make them persistent:\n\n```\nexport DOCKER_HOST_IP=192.168.25.136\nexport PUBLIC_IP=192.168.25.136\n```\n\nAdd streamingplatform alias to /etc/hosts\n\n```\n192.168.25.136\tstreamingplatform\n```\n\nStart the environment using \n\n```\nexport SAMPLE_HOME=/mnt/hgfs/git/gschmutz/various-demos/iot-truck-demo\ncd $SAMPLE_HOME/docker\n```\n\nStart Docker Compose environemnt\n\n```\ndocker-compose up -d\n```\n\nShow logs\n\n```\ndocker-compose logs -f\n```\n\nthe following user interfaces are available:\n\n * Confluent Control Center: <http://streamingplatform:9021>\n * Kafka Manager: <http://streamingplatform:9000> \n * Streamsets: <http://streamingplatform:18630>\n\n\n### Creating Kafka Topics\n\nConnect to docker container (broker-1)\n\n```\ndocker exec -ti docker_broker-1_1 bash\n```\n\nlist topics and create an new topic\n\n```\nkafka-topics --zookeeper zookeeper:2181 --list\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_position --partitions 8 --replication-factor 2\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_driving_info --partitions 8 --replication-factor 2\nkafka-topics --zookeeper zookeeper:2181 --create --topic dangerous_driving_and_driver --partitions 8 --replication-factor 2\n\n\nkafka-topics --zookeeper zookeeper:2181 --create --topic truck_driver --partitions 8 --replication-factor 2 --config cleanup.policy=compact --config segment.ms=100 --config delete.retention.ms=100 --config min.cleanable.dirty.ratio=0.001\n```\n### Prepare Database Table\n\n```\ndocker exec -ti docker_db_1 bash\npsql -d sample -U sample\n```\n\n```\nDROP TABLE driver;\nCREATE TABLE driver (id BIGINT, first_name CHARACTER VARYING(45), last_name CHARACTER VARYING(45), available CHARACTER VARYING(1), birthdate DATE, last_update TIMESTAMP);\nALTER TABLE driver ADD CONSTRAINT driver_pk PRIMARY KEY (id);\n```\n\n```\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (10,'Diann', 'Butler', 'Y', '10-JUN-68', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (11,'Micky', 'Isaacson', 'Y', '31-AUG-72' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (12,'Laurence', 'Lindsey', 'Y', '19-MAY-78' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (13,'Pam', 'Harrington', 'Y','10-JUN-68' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (14,'Brooke', 'Ferguson', 'Y','10-DEC-66' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (15,'Clint','Hudson', 'Y','5-JUN-75' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (16,'Ben','Simpson', 'Y','11-SEP-74' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (17,'Frank','Bishop', 'Y','3-OCT-60' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (18,'Trevor','Hines', 'Y','23-FEB-78' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (19,'Christy','Stephens', 'Y','11-JAN-73' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (20,'Clarence','Lamb', 'Y','15-NOV-77' ,CURRENT_TIMESTAMP);\n\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (21,'Lila', 'Page', 'Y', '5-APR-77', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (22,'Patricia', 'Coleman', 'Y', '11-AUG-80' ,CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (23,'Jeremy', 'Olson', 'Y', '13-JUN-82', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (24,'Walter', 'Ward', 'Y', '24-JUL-85', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (25,'Kristen', ' Patterson', 'Y', '14-JUN-73', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (26,'Jacquelyn', 'Fletcher', 'Y', '24-AUG-85', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (27,'Walter', ' Leonard', 'Y', '12-SEP-88', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (28,'Della', ' Mcdonald', 'Y', '24-JUL-79', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (29,'Leah', 'Sutton', 'Y', '12-JUL-75', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (30,'Larry', 'Jensen', 'Y', '14-AUG-83', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (31,'Rosemarie', 'Ruiz', 'Y', '22-SEP-80', CURRENT_TIMESTAMP);\nINSERT INTO \"driver\" (\"id\", \"first_name\", \"last_name\", \"available\", \"birthdate\", \"last_update\") VALUES (32,'Shaun', ' Marshall', 'Y', '22-JAN-85', CURRENT_TIMESTAMP);\n```\n## Truck Simulator\n\n### Producing to Kafka\n\nStart the kafka console consumer on the Kafka topic `truck_position` and another on `truck_driving_info`:\n \n```\ndocker exec -ti docker_broker-1_1 bash\n```\n\n```\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_position\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_driving_info\n```\n\nor by using kafkacat:\n\n```\nkafkacat -b streamingplatform:9092 -t truck_position\nkafkacat -b streamingplatform:9092 -t truck_driving_info\n```\n\nProduce the IoT Truck events to topic `truck_position` and `truck_driving_info`.\n\n```\ncd $SAMPLE_HOME/../iot-truck-simulator\n```\n\n```\nmvn exec:java -Dexec.args=\"-s KAFKA -f JSON -m SPLIT -t sec -b localhost -p 9092\"\n```\n\n### Producing to MQTT\n\n```\ncd $SAMPLE_HOME/../iot-truck-simulator\n```\n\nTo produce to 2 separate topics in MQTT\n\n```\nmvn exec:java -Dexec.args=\"-s MQTT -f JSON -p 1883 -m SPLIT -t millisec\"\n```\n\nin MQTT.fx suscribe to `truck/+/position` and `truck/+/drving-info`\n\n## MQTT to Kafa using Kafka Connect\n\nFirst let's listen on the two topcis: \n\n```\nkafkacat -b streamingplatform:9092 -t truck_position\nkafkacat -b streamingplatform:9092 -t truck_driving_info\n```\n\nAdd and start the MQTT connector (make sure that consumer is still running):\n\n```\ncd $SAMPLE_HOME/docker\n./configure-connect-mqtt.sh\n```\n\nNavigate to the [Kafka Connect UI](http://streamingplatform:8003) to see the connector configured and running.\n\nYou can remove the connector using the following command\n\n```\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/mqtt-source\"\n```\n\n## MQTT to Kafa using Confluent MQTT Proxy\n\nMake sure that the MQTT proxy has been started as a service in the `docker-compose.yml`.\n\n```\n mqtt-proxy:\n image: confluentinc/cp-kafka-mqtt:5.0.0\n hostname: mqtt-proxy\n ports:\n - \"1884:1884\"\n environment:\n KAFKA_MQTT_TOPIC_REGEX_LIST: 'truck_position:.*position, truck_driving_info:.*driving-info'\n KAFKA_MQTT_LISTENERS: 0.0.0.0:1884\n KAFKA_MQTT_BOOTSTRAP_SERVERS: PLAINTEXT://broker-1:9092,broker-2:9093\n KAFKA_MQTT_CONFLUENT_TOPIC_REPLICATIN_FACTOR: 1\n```\n\nChange the truck simulator to produce on port 1884, which is the one the MQTT proxy listens on.\n\n```\nmvn exec:java -Dexec.args=\"-s MQTT -f JSON -p 1884 -m SPLIT -t millisec\"\n```\n\n## MQTT to Kafa using StreamSets Data Collector (todo)\n\n\n## Using KSQL for Stream Analytics\n\nconnect to KSQL CLI\n\n```\ncd $SAMPLE_HOME/docker\n\ndocker-compose exec ksql-cli ksql http://ksql-server:8088\n```\n\n\n```\nshow topics;\n```\n\n```\nprint 'truck_position';\nprint 'truck_driving_info';\n```\n\n```\nprint 'truck_position' from beginning;\nprint 'truck_driving_info' from beginning;\n```\n\n```\nshow streams;\nshow tables;\nshow queries;\n```\n\n## Streaming Query\n```\nDROP STREAM IF EXISTS truck_driving_info_s;\n\nCREATE STREAM truck_driving_info_s \\\n (timestamp VARCHAR, \\\n truckId VARCHAR, \\\n driverId BIGINT, \\\n routeId BIGINT, \\\n eventType VARCHAR, \\\n correlationId VARCHAR) \\\n WITH (kafka_topic='truck_driving_info', \\\n value_format='JSON');\n```\n\nGet info on the stream\n\n```\nDESCRIBE truck_driving_info_s;\nDESCRIBE EXTENDED truck_driving_info_s;\n```\n\n```\nSELECT * FROM truck_driving_info_s;\n```\n\n```\nksql> SELECT * from truck_driving_info_s;\n1537349668679 | 84 | 1537349668598 | 84 | 11 | 1565885487 | Normal | -6815250318731517092\n1537349668800 | 48 | 1537349668685 | 48 | 14 | 1390372503 | Normal | -6815250318731517092\n1537349668827 | 108 | 1537349668807 | 108 | 28 | 137128276 | Normal | -6815250318731517092\n1537349668846 | 78 | 1537349668834 | 78 | 30 | 1594289134 | Normal | -6815250318731517092\n1537349668895 | 97 | 1537349668854 | 97 | 19 | 927636994 | Normal | -6815250318731517092\n1537349669104 | 19 | 1537349668905 | 19 | 26 | 1090292248 | Normal | -6815250318731517092\n```\n\n## Streaming Filter with KSQL\n\nNow let's filter on all the info messages, where the `eventType` is not normal:\n\n```\nSELECT * FROM truck_driving_info_s WHERE eventType != 'Normal';\n```\n\nLet's provide the data as a topic:\n\ncreate a topic where all \"dangerous driving\" events should be sent to\n\t\n```\ncd $SAMPLE_HOME/docker\ndocker exec -ti docker_broker-1_1 bash\n\nkafka-topics --zookeeper zookeeper:2181 --create --topic dangerous_driving --partitions 8 --replication-factor 2\n```\n\nlisten on the topic\n\n```\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic dangerous_driving\n```\n\n```\nDROP STREAM dangerous_driving_s;\nCREATE STREAM dangerous_driving_s \\\n WITH (kafka_topic='dangerous_driving', \\\n value_format='DELIMITED', \\\n partitions=8) \\\nAS SELECT * FROM truck_driving_info_s \\\nWHERE eventType != 'Normal';\n```\n\n```\nSELECT * FROM dangerous_driving_s;\n```\n\n## Aggregations using KSQL\n\nDROP TABLE dangerous_driving_count;\n\n```\nCREATE TABLE dangerous_driving_count \\\nAS SELECT eventType, count(*) nof \\\nFROM dangerous_driving_s \\\nWINDOW TUMBLING (SIZE 30 SECONDS) \\\nGROUP BY eventType;\n```\n\n```\nSELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS'), eventType, nof \\\nFROM dangerous_driving_count;\n```\n\n```\nCREATE TABLE dangerous_driving_count\nAS\nSELECT eventType, count(*) \\\nFROM dangerous_driving_s \\\nWINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS) \\\nGROUP BY eventType;\n```\n\n## Join with Static Driver Data\n\nfirst start the console consumer on the `trucking_driver` topic:\n\n```\ndocker exec -ti docker_broker-1_1 bash\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic truck_driver --from-beginning\n```\n\nPrint the key and value of the truck_driver topic\n\n```\nkafkacat -b streamingplatform -t truck_driver -f \"%k::%s\\n\" -u -q\n```\n\nthen start the JDBC connector:\n\n```\ncd $SAMPLE_HOME/docker\n./configure-connect-jdbc.sh\n```\n\nTo stop the connector execute the following command\n\n```\ncurl -X \"DELETE\" \"http://$DOCKER_HOST_IP:8083/connectors/jdbc-driver-source\"\n```\n\nPerform an update to see that these will be delivered\n\n```\ndocker exec -ti docker_db_1 bash\n\npsql -d sample -U sample\n```\n\n```\nUPDATE \"driver\" SET \"available\" = 'N', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 21;\n```\n\n```\nUPDATE \"driver\" SET \"available\" = 'N', \"last_update\" = CURRENT_TIMESTAMP WHERE \"id\" = 14;\n```\n\nStop the consumer and restart with `--from-beginning` option\n\n```\ndocker exec -ti docker_broker-1_1 bash\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic trucking_driver --from-beginning\n```\n\n\n### Create a KSQL table\n\n```\ndocker-compose exec ksql-cli ksql http://ksql-server:8088\n```\n\n```\nset 'commit.interval.ms'='5000';\nset 'cache.max.bytes.buffering'='10000000';\nset 'auto.offset.reset'='earliest';\n\nDROP TABLE driver_t;\nCREATE TABLE driver_t \\\n (id BIGINT, \\\n first_name VARCHAR, \\\n last_name VARCHAR, \\\n available VARCHAR, \\\n birthdate VARCHAR) \\\n WITH (kafka_topic='truck_driver', \\\n value_format='JSON', \\\n KEY = 'id');\n```\n\n```\nSELECT * FROM driver_t;\n```\n\njoin `dangerous_driving_s` stream to `driver_t` table\n\n```\nSELECT driverid, first_name, last_name, truckId, routeId, eventType \\\nFROM dangerous_driving_s \\\nLEFT JOIN driver_t \\\nON dangerous_driving_s.driverId = driver_t.id;\n```\n\nwith outer join\n\n```\nSELECT driverid, first_name, last_name, truckId, routeId, eventType \\\nFROM dangerous_driving_s \\\nLEFT OUTER JOIN driver_t \\\nON dangerous_driving_s.driverId = driver_t.id;\n```\n\nCreate a Stream with the joined information\n\n```\ndocker exec -ti docker_broker-1_1 bash\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic dangerous_driving_and_driver --from-beginning\n```\n\ndangerous_driving_and_driver\n\n```\nDROP STREAM dangerous_driving_and_driver_s;\nCREATE STREAM dangerous_driving_and_driver_s \\\n WITH (kafka_topic='dangerous_driving_and_driver', \\\n value_format='JSON', partitions=8) \\\nAS SELECT driverid, first_name, last_name, truckId, routeId ,eventType \\\nFROM dangerous_driving_s \\\nLEFT JOIN driver_t \\\nON dangerous_driving_s.driverId = driver_t.id;\n```\n\n\n```\nSELECT * FROM dangerous_driving_and_driver_s;\n```\n\n```\nSELECT * FROM dangerous_driving_and_driver_s WHERE driverid = 11;\n```\n\n```\nDROP STREAM truck_position_s;\n\nCREATE STREAM truck_position_s \\\n (timestamp VARCHAR, \\\n truckId VARCHAR, \\\n latitude DOUBLE, \\\n longitude DOUBLE) \\\n WITH (kafka_topic='truck_position', \\\n value_format='JSON');\n```\n\n## Stream to Stream Join\n\n```\nSELECT ddad.driverid, ddad.first_name, ddad.last_name, ddad.truckid, ddad.routeid, ddad.eventtype, tp.latitude, tp.longitude \\\nFROM dangerous_driving_and_driver_s ddad \\\nINNER JOIN truck_position_s tp \\\nWITHIN 2 second \\\nON tp.truckid = ddad.truckid;\n```\n\n```\nSELECT ddad.driverid, ddad.first_name, ddad.last_name, ddad.truckid, ddad.routeid, ddad.eventtype, geohash(tp.latitude, tp.longitude, 5) \\\nFROM dangerous_driving_and_driver_s ddad \\\nINNER JOIN truck_position_s tp \\\nWITHIN 2 second \\\nON tp.truckid = ddad.truckid;\n```\n## GeoHash and Aggregation\n\n```\nDROP STREAM dangerous_and_position_s;\nCREATE STREAM dangerous_and_position_s \\\n WITH (kafka_topic='dangerous_and_position', \\\n value_format='JSON', partitions=8) \\\nAS SELECT ddad.driverid, ddad.first_name, ddad.last_name, ddad.truckid, ddad.routeid, ddad.eventtype, geohash(tp.latitude, tp.longitude, 4) as geohash \\\nFROM dangerous_driving_and_driver_s ddad \\\nINNER JOIN truck_position_s tp \\\nWITHIN 2 second \\\nON tp.truckid = ddad.truckid;\n```\n\n```\nSELECT eventType, geohash, count(*) nof \\\nFROM dangerous_and_position_s \\\nWINDOW TUMBLING (SIZE 30 SECONDS) \\\nGROUP BY eventType, geohash;\n```\n\n\n## Current Positions\n\nCREATE TABLE truck_position_t \\\n WITH (kafka_topic='truck_position_t', \\\n value_format='JSON', \\\n KEY = 'truckid') \\\nAS SELECT truck_id, FROM truck_position_s GROUP BY truckid; \n\n\n\n## More complex analytics in KSQL\n\n```\nCREATE TABLE dangerous_driving_count \\\nAS SELECT eventType, count(*) \\\nFROM dangerous_driving_and_driver_s \\\nWINDOW TUMBLING (SIZE 30 SECONDS) \\\nGROUP BY eventType;\n```\n\n```\nCREATE TABLE dangerous_driving_count\nAS\nSELECT eventType, count(*) \\\nFROM dangerous_driving_and_driver_s \\\nWINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS) \\\nGROUP BY eventType;\n```\n\n```\nSELECT first_name, last_name, eventType, count(*) \\\nFROM dangerous_driving_and_driver_s \\\nWINDOW TUMBLING (SIZE 20 SECONDS) \\\nGROUP BY first_name, last_name, eventType;\n```\n\n\n\n## Using Kafka Streams to detect danagerous driving\n\n```\ndocker exec -ti docker_broker-1_1 bash\n```\n\n```\nkafka-topics --zookeeper zookeeper:2181 --create --topic dangerous_driving --partitions 8 --replication-factor 2\nkafka-console-consumer --bootstrap-server broker-1:9092 --topic dangerous_driving\n```\n\n```\ncd $SAMPLE_HOME/src/kafka-streams-truck\nmvn exec:java\n```\n"
},
{
"alpha_fraction": 0.7507692575454712,
"alphanum_fraction": 0.7507692575454712,
"avg_line_length": 18.117647171020508,
"blob_id": "b0759c38a89a087a21cf4d2fc26aa18ac84613ab",
"content_id": "90e2403249ac35ad0d6b654c355630e8d6744f0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 975,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 51,
"path": "/event-sourcing/kafka-streams/account-ms/src/main/java/com/trivadis/sample/kafkastreams/ms/account/event/AccountCreatedEvent.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.kafkastreams.ms.account.event;\n\nimport java.math.BigDecimal;\n\n\n/**\n * @author gschmutz\n *\n */\npublic class AccountCreatedEvent extends BaseEvent<String> {\n\n\tprivate String forCustomerId;\n\tprivate String accountType;\n\tprivate BigDecimal balance;\n\n\tpublic AccountCreatedEvent(String id, String forCustomerId, String accountType, BigDecimal balance) {\n\t\tsuper(id);\n\t\tthis.forCustomerId = forCustomerId;\n\t\tthis.accountType = accountType;\n\t\tthis.balance = balance;\n\t}\n\t\n\tpublic AccountCreatedEvent() {\n\t\t\n\t}\n\n\tpublic String getForCustomerId() {\n\t\treturn forCustomerId;\n\t}\n\n\tpublic String getAccountType() {\n\t\treturn accountType;\n\t}\n\n\tpublic BigDecimal getBalance() {\n\t\treturn balance;\n\t}\n\n\tpublic void setForCustomerId(String forCustomerId) {\n\t\tthis.forCustomerId = forCustomerId;\n\t}\n\n\tpublic void setAccountType(String accountType) {\n\t\tthis.accountType = accountType;\n\t}\n\n\tpublic void setBalance(BigDecimal balance) {\n\t\tthis.balance = balance;\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.7936117649078369,
"alphanum_fraction": 0.7940213084220886,
"avg_line_length": 31.11842155456543,
"blob_id": "6264f0d59b8dcfcc6ac6024c83a57808e45b70d3",
"content_id": "0226198bbc10bcf7036a509fad95937589e5ee40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2442,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 76,
"path": "/event-sourcing/axon/finance-axon-query/src/main/java/com/trivadis/sample/axon/account/controller/AccountQueryController.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.sample.axon.account.controller;\n\nimport java.math.BigDecimal;\nimport java.time.Instant;\nimport java.util.List;\n\nimport org.axonframework.config.ProcessingGroup;\nimport org.axonframework.eventhandling.EventHandler;\nimport org.axonframework.eventhandling.Timestamp;\nimport org.springframework.beans.factory.annotation.Autowired;\nimport org.springframework.web.bind.annotation.GetMapping;\nimport org.springframework.web.bind.annotation.PathVariable;\nimport org.springframework.web.bind.annotation.RequestMapping;\nimport org.springframework.web.bind.annotation.RestController;\n\nimport com.trivadis.sample.axon.account.event.AccountCreatedEvent;\nimport com.trivadis.sample.axon.account.event.MoneyDepositedEvent;\nimport com.trivadis.sample.axon.account.event.MoneyWithdrawnEvent;\nimport com.trivadis.sample.axon.account.model.Account;\nimport com.trivadis.sample.axon.account.model.Transaction;\n\nimport springbootaxon.account.repo.AccountRepository;\n\n\n@RestController\n@ProcessingGroup(\"Accounts\")\n@RequestMapping(\"/accounts\")\npublic class AccountQueryController {\n\t\n\t@Autowired\n\tprivate AccountRepository accRepo;\n\t\n\t@EventHandler\n\tpublic void on(AccountCreatedEvent event,@Timestamp Instant instant) {\n\t\tAccount account = new Account(event.getId(),event.getBalance(),event.getForCustomerId(),event.getAccountType(),instant.toString());\n\t\t\n\t\taccRepo.insert(account);\n\t\t\n\t}\n\t\n\t@EventHandler\n\tpublic void on(MoneyDepositedEvent event,@Timestamp Instant instant) {\n\t\tAccount account = accRepo.findByAccountNo(event.getId());\n\t\taccount.setBalance(account.getBalance().add(event.getAmount()));\n\t\taccount.setLastUpdated(instant.toString());\n\t\t\n\t\taccount.appendTransaction(new Transaction(event.getAmount().doubleValue(), event.getWhen()));\n\n\t\taccRepo.save(account);\n\t}\n\t\n\n\t@EventHandler\n\tpublic void on(MoneyWithdrawnEvent event, @Timestamp Instant instant) {\n\t\tAccount account = accRepo.findByAccountNo(event.getId());\n\t\taccount.setBalance(account.getBalance().subtract(event.getAmount()));\n\t\taccount.setLastUpdated(instant.toString());\n\t\t\n\t\taccount.appendTransaction(new Transaction(event.getAmount().multiply(new BigDecimal(-1)).doubleValue(), event.getWhen()));\n\t\t\n\t\taccRepo.save(account);\n\t}\n\t\n\t@GetMapping(\"/details\")\n\tpublic List<Account> getAccDetails() {\n\t\treturn accRepo.findAll();\n\t}\n\t\n\t@GetMapping(\"/details/{id}\")\n\tpublic Account getAccDetails(@PathVariable String id) {\n\t\treturn accRepo.findByAccountNo(id);\n\t}\n\t\n\n\t\n}\n\n"
},
{
"alpha_fraction": 0.6622920036315918,
"alphanum_fraction": 0.7016639113426208,
"avg_line_length": 18.846511840820312,
"blob_id": "5d01eb0630fc0ccef07899aab9fb0b476d3bfada",
"content_id": "47fa84e9e612f205f91d8f92662fca209fa199fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4267,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 215,
"path": "/oracle-property-graph/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "cd dockerfiles/18.4.0\n\n## Express Edition 18.4.0\n\nBuild the Oracle XE docker container \n\n```\n./buildDockerImage.sh -v 18.4.0 -x -i\n```\n\nRun an instance using the following command\n\n```\ndocker run --name xe \\\n\t\t-p 1521:1521 -p 5500:5500 \\\n\t\t-e ORACLE_PWD=manager \\\n\t\t-e ORACLE_CHARACTERSET=AL32UTF8 \\\n\t\t-v ./work/docker/db_setup_scripts:/opt/oracle/scripts/setup \\\n\t\toracle/database:18.4.0-xe\n```\n\n```\ndocker run --name xe \\\n\t\t-p 1521:1521 -p 5500:5500 \\\n\t\t-e ORACLE_PWD=manager \\\n\t\t-e ORACLE_CHARACTERSET=AL32UTF8 \\\n\t\toracle/database:18.4.0-xe\n```\n\n## Standard Edition 18.3.0\n\n```\n./buildDockerImage.sh -v 18.3.0 -s -i\n```\n\n```\ndocker run --name orcl \\\n-p 1521:1521 -p 5500:5500 \\\n-e ORACLE_SID=ORCLCDB \\\n-e ORACLE_PDB=ORCLPDB1 \\\n-e ORACLE_PWD=manager \\\n-e ORACLE_CHARACTERSET=AL32UTF8 \\\noracle/database:18.3.0-se2\n```\n\n## Enterprise Edition 18.3.0\n\n```\n./buildDockerImage.sh -v 18.3.0 -e -i\n```\n\n```\ndocker run --name orcl \\\n-p 1521:1521 -p 5500:5500 \\\n-e ORACLE_SID=ORCLCDB \\\n-e ORACLE_PDB=ORCLPDB1 \\\n-e ORACLE_PWD=manager \\\n-e ORACLE_CHARACTERSET=AL32UTF8 \\\n-v ${PWD}/db_setup_scripts:/opt/oracle/scripts/setup \\\noracle/database:18.3.0-ee\n```\n\n```\nalter session set container=ORCLPDB1;\n```\n\n```\nCREATE USER scott IDENTIFIED BY tiger DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp;\nGRANT CONNECT, RESOURCE TO scott;\nGRANT UNLIMITED TABLESPACE TO scott;\n```\n\n```\nsqlplus scott/tiger@ORCLPDB1\n```\n\n```\nBEGIN\n OPG_APIS.CREATE_PG('gt', 4, 8, 'users');\nEND;\n/\n```\n\n\n```\ncd /opt/oracle/product/18c/dbhome_1/demo/schema/human_resources\nsqlplus / as sysdba\n```\n\n```\nalter session set container=ORCLPDB1;\n```\n\n```\n@hr_main.sql\n```\n\n\n```\ncd /opt/oracle/product/18c/dbhome_1/demo/schema/human_resources\nsqlplus / as sysdba\n```\n\n```\n@oe_main.sql\n```\n\n\n```\ndeclare\n\tcursor tabs is select table_name from dba_tables where owner ='HR';\n\tsqlstr varchar(100);\nbegin\n\n\tfor tab in tabs\n\tloop\n\t sqlstr:='grant select on hr.'||tab.table_name||' to scott';\n\t execute immediate sqlstr;\n\tend loop;\nend;\n/\n```\n\nCreate a view from HR sample schema employees table that has attributes\n\n```\ncreate or replace view employees \nas \nselect e.employee_id,e.first_name||' '||e.last_name as\n \tfull_name,d.department_name,e.salary,e2.first_name||' '||e2.last_name as \tmanager_name,e.hire_date \n\t,j.job_title,e.manager_id\nfrom hr.employees e\nleft outer join hr.employees e2 on e2.employee_id =e.manager_id\njoin hr.jobs j on j.job_id=e.job_id\njoin hr.departments d on d.department_id=e.department_id\nwhere e.department_id is not null order by e.manager_id;\n```\n\n```\ncreate or replace view employeeRelation as\nselect to_number(to_char(e.manager_id)||to_char(e.employee_id)) as relationID,\ne.manager_id as source,\ne.employee_id as destination,\n'manage' as relationType,\nto_date(e.hire_date) as hire_date,\ne.manager_name\nfrom employees e\nunion all\nselect relationID,\nemp1,\nemp2,\nrelationType,\nto_date(hire_date) as hire_date ,\nmanager_name\nfrom(\nselect to_number(to_char(a.employee_id)||to_char(b.employee_id)) as relationID,a.employee_id as emp1, b.employee_id as emp2,\n'colleague' as relationType,case when a.hire_date>b.hire_date then a.hire_date else b.hire_date end as hire_date \n,a.manager_name\nfrom employees a\njoin hr.employees b on b.manager_id=a.manager_id and a.employee_id<>b.employee_id --and a.employee_id<b.employee_id\norder by a.employee_id);\n```\n\n## Working with Groovy\n\n```\ndocker exec -ti orcl bash\n```\n\nStart the Groovy Shell\n```\ncd /opt/oracle/product/18c/dbhome_1/md/property_graph/dal/groovy\n./gremlin-opg-rdbms.sh\n```\n\nConnect to the database\n\n```\ncfg = GraphConfigBuilder.forPropertyGraphRdbms().\n setJdbcUrl(\"jdbc:oracle:thin:@localhost:1521/ORCLPDB1\").\n setUsername(\"scott\").\n\tsetPassword(\"tiger\").\n\tsetName(\"test\").\n\tsetMaxNumConnections(8).\n\tsetLoadEdgeLabel(false).\n\taddVertexProperty(\"name\", PropertyType.STRING, \"default_name\").\n\taddEdgeProperty(\"cost\", PropertyType.DOUBLE, \"1000000\").\n\tbuild();\n```\n\n```\nopg = OraclePropertyGraph.getInstance(cfg);\n```\n\nStart from scratch\n```\nopg.clearRepository();\nopgdl=OraclePropertyGraphDataLoader.getInstance();\n```\n\n```\nvfile=\"../../data/connections.opv\"\nefile=\"../../data/connections.ope\" \n```\n\n```\nopgdl.loadData(opg, vfile, efile, 2,\n10000, true, null);\n```\n\n## Python\n\n```\npip install JPype1\n```\n"
},
{
"alpha_fraction": 0.7154471278190613,
"alphanum_fraction": 0.7479674816131592,
"avg_line_length": 23.399999618530273,
"blob_id": "9197a90beefd4c42ff2141d81ab2e5f991f18271",
"content_id": "245fcaffa646d763967154fb8aa6d8b05ae36979",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 123,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 5,
"path": "/streaming-visualization/scripts/stop-connect-twitter-source.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"removing Twitter Source Connectors\"\n\ncurl -X \"DELETE\" \"$DOCKER_HOST_IP:8083/connectors/twitter-source\"\n\n"
},
{
"alpha_fraction": 0.3752816319465637,
"alphanum_fraction": 0.738775372505188,
"avg_line_length": 46.83445739746094,
"blob_id": "85de20fd046e5cd6d7ce16b907e831bffbb53567",
"content_id": "b84c40d1c40075e438aa0942bc04d239765cfe4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 49712,
"license_type": "no_license",
"max_line_length": 6613,
"num_lines": 1039,
"path": "/kafka-geofencing/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Kafka GeoFencing Demo\nThis demo shows how to use GeoFencing with Kafka. \n\n## Important Links\n\n * <http://geojson.io/>\n * <http://geohash.gofreerange.com/>\n * <https://www.google.com/maps/d/u/0/>\n\n## Starting the environment\n\nNavigate to the `docker` folder and start the Docker Compose stack\n\n```\ndocker-compose up -d\n```\n\nThe following topics will be created automatically during startup (check the `kafka-setup` service to see how it is done):\n\n* vehicle_position\n* geo_fence\n* geo_fences_keyedby_geohash\n* geo_event\n* vehicle_position_matched_geo_fences\n\n\n## Populating GeoFences\n\nGeoFences can be populated in two ways:\n\n* Command Line using `kafakcat`\n* Python Script inside Apache Zeppelin\n\nCurrently the following geofences will be defined:\n\n### Area of St. Louis\n\n\n\n### Area of Columbia (near St. Louis)\n\n\n\n### Area of Berlin\n\n\n\n### Area of Brighton (UKOUG Techfest)\n\n\n\n\n### Create GeoFences using Command Line (does not work)\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic geo_fence --replication-factor 3 --partitions 8\n```\n\n```\necho '1:{\"id\":1,\"name\":\"Colombia, Missouri\",\"wkt\":\"POLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536))\",\"last_update\":1560632581060}' | kafkacat -b analyticsplatform -t geo_fence -K:1\n```\n\n```\necho '2:{\"id\":2,\"name\":\"St. Louis, Missouri\",\"wkt\":\"POLYGON ((-90.25749206542969 38.71551876930462, -90.31723022460938 38.69301319283493, -90.3247833251953 38.64744452237617, -90.31997680664062 38.58306291549108, -90.27053833007812 38.55460931253295, -90.22109985351562 38.54601733154524, -90.15037536621094 38.55299839430547, -90.11123657226562 38.566421609878674, -90.08583068847656 38.63028174397134, -90.08583068847656 38.66996443163297, -90.0933837890625 38.718197532760165, -90.15243530273436 38.720876195817276, -90.25749206542969 38.71551876930462))\",\"last_update\":1560632392130}' | kafkacat -b analyticsplatform -t geo_fence -K:2\n```\n\n```\necho '3:{\"id\":3,\"name\":\"Berlin, Germany\",\"wkt\":\"POLYGON ((13.297920227050781 52.56195151687443, 13.2440185546875 52.530216577830124, 13.267364501953125 52.45998421679598, 13.35113525390625 52.44826791583386, 13.405036926269531 52.44952338289473, 13.501167297363281 52.47148826410652, 13.509750366210938 52.489261333143126, 13.509063720703125 52.53710835019913, 13.481597900390625 52.554854904263195, 13.41156005859375 52.57217696877135, 13.37207794189453 52.5748894436198, 13.297920227050781 52.56195151687443))\",\"last_update\":1560669937877}' | kafkacat -b analyticsplatform -t geo_fence -K:3\n```\n\nTo delete a geofence, here the one with ID 3, produce a key with a `null` value:\n\n```\necho '3:' | kafkacat -b analyticsplatform -t geo_fence -K:\n```\n\n### Create GeoFences using Zeppelin\n\nNavigate to <http://analyticsplatform:28055>, import the `GeoFence Management.json` notebook from the `zeppelin` folder and run the notebook. \n\n**Note:** make sure to set the default interpreter to `python` before running the notebook. \n\n\n## Simulating Vehicle Position\n\nNavigate to <http://analyticsplatform:28055>, import the `Simulate Route.json` notebook from the `zeppelin` folder and run the notebook. \n\n## GeoFencing using ksqlDB\n\nFirst let's connect to ksqlDB Server\n\n```\ndocker exec -it ksqldb-cli ksql http://ksqldb-server-1:8088\n```\n\n## Create the Vehicle Position KSQL Stream\n\n\nCreate the stream with the vehicle positions\n\n```\nDROP STREAM IF EXISTS vehicle_position_s;\n\nCREATE STREAM vehicle_position_s\n WITH (kafka_topic='vehicle_position',\n value_format='AVRO');\n```\n\n```\nDESCRIBE vehicle_position_s;\n```\n\n```\nSELECT * FROM vehicle_position_s;\n```\n\n```\nINSERT INTO vehicle_position_s (vehicleId, latitude, longitude) VALUES (10, 52.4497, 13.3096);\nINSERT INTO vehicle_position_s (vehicleId, latitude, longitude) VALUES (10, 52.4556, 13.3178);\n```\n\n## GeoFence UDF\n\nThe geo UDFs are implemented here: \n\n```\nCREATE STREAM test_udf_s (id INT, latitude DOUBLE, longitude DOUBLE)\nWITH (kafka_topic='test_udf',\n value_format='JSON', partitions=8); \n```\n\n```\nDESCRIBE FUNCTION geo_fence;\n```\n\n```\nSELECT latitude, \n\t\tlongitude, \n\t\tgeo_fence(latitude, longitude, 'POLYGON ((13.297920227050781 52.56195151687443, 13.2440185546875 52.530216577830124, 13.267364501953125 52.45998421679598, 13.35113525390625 52.44826791583386, 13.405036926269531 52.44952338289473, 13.501167297363281 52.47148826410652, 13.509750366210938 52.489261333143126, 13.509063720703125 52.53710835019913, 13.481597900390625 52.554854904263195, 13.41156005859375 52.57217696877135, 13.37207794189453 52.5748894436198, 13.297920227050781 52.56195151687443))') geo_fence_status\nFROM test_udf_s;\n```\n\nTest with a coordinate which is OUTSIDE the geofence\n\n```\nINSERT INTO test_udf_s (id, latitude, longitude) VALUES (10, 52.4497, 13.3096);\n```\n\nTest with a coordinate which is INSIDE the geofence\n\n```\nINSERT INTO test_udf_s (id, latitude, longitude) VALUES (10, 52.4556, 13.3178);\n```\n\nTest with a LatLong which is OUTSIDE of the geo fence\n\n```\necho '10:{\"id\":\"10\", \"latitude\":\"52.4497\", \"longitude\":\"13.3096\" }' | kafkacat -b analyticsplatform -t test_udf -K:\n```\n\nTest with a LatLong which is INSIDE of the geo fence\n\n```\necho '10:{\"id\":\"10\", \"latitude\":\"52.4556\", \"longitude\":\"13.3178\" }' | kafkacat -b analyticsplatform -t test_udf -K:\n```\n\n\n## Implementing GeoFence Analytics in KSQL\n\n\n### Attempt 1: Perform a Cross-Join (does not work!)\n\n```\nDROP TABLE IF EXISTS geo_fence_t;\n```\n\n```\nCREATE TABLE geo_fence_t \nWITH (KAFKA_TOPIC='geo_fence',\n VALUE_FORMAT='AVRO',\n KEY = 'id');\n```\n\n```\nset 'auto.offset.reset'='earliest';\nSELECT * FROM geo_fence_t;\n```\n\n```\nCREATE STREAM a01_vehp_join_geof_s\r\nWITH (PARTITIONS=8, KAFKA_TOPIC='vehp_join_geof', VALUE_FORMAT='AVRO')\nAS\r\nSELECT vehp.id, vehp.latitude, vehp.longitude, \u000b geof.geometry_wkt\r\nFROM vehicle_position_s vehp\r\nCROSS JOIN geo_fence_t geof;\n```\n\n### Attempt 2: Perform an Inner-Join (does not work!)\n\nWhat if we try with an inner join in KSQL on an artifical single group\n\n```\nSELECT vp.id, vp.latitude, vp.longitude, \u000b gf.geometry_wkt\r\nFROM vehicle_position_s vp\r\nINNER JOIN a02_geo_fence_t gf\nWHERE vp.group = gf.group;\n```\n\nBut both `geo_fence` and `vehicle_position` do not contain this `group` column. But we can use an enrichment KSQL SELECT to add the group \n\n```\nDROP STREAM IF EXISTS a02_geo_fence_s;\n\nCREATE STREAM a02_geo_fence_s \n (id BIGINT, \n name VARCHAR, \n geometry_wkt VARCHAR)\nWITH (KAFKA_TOPIC='geo_fence', \n VALUE_FORMAT='AVRO',\n KEY = 'id');\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic a02_geo_fence --replication-factor 3 --partitions 8\n```\n\n```\nDROP TABLE IF EXISTS a02_geo_fence_t;\n\nCREATE TABLE a02_geo_fence_t \n (group_id BIGINT,\n id BIGINT, \n name VARCHAR,\n geometry_wkt VARCHAR)\nWITH (KAFKA_TOPIC='a02_geo_fence',\n VALUE_FORMAT='AVRO',\n KEY = 'group_id');\n```\n\nset 'auto.offset.reset'='earliest';\n\n```\nINSERT INTO a02_geo_fence_t\nSELECT '1' AS group_id, geof.id, geof.name, geof.geometry_wkt\nFROM a02_geo_fence_s geof;\n```\n\n```\nCREATE TABLE a02a_geo_fence_t\nWITH (PARTITIONS=8, KAFKA_TOPIC='a02a_geo_fence', VALUE_FORMAT='AVRO')\nAS\nSELECT max(1) AS group_id, geof.id, geof.name, geof.geometry_wkt\nFROM a02_geo_fence_s geof\nGROUP BY 1;\n```\n\n### Attempt 3: aggregate geofences by single group\n\n```\nDROP STREAM IF EXISTS a03_geo_fence_s;\n\nCREATE STREAM a03_geo_fence_s \nWITH (KAFKA_TOPIC='geo_fence', \n VALUE_FORMAT='AVRO',\n KEY='id');\n```\n\n```\nDROP STREAM a03_geo_fence_by_group_s DELETE TOPIC;\n\nCREATE STREAM a03_geo_fence_by_group_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='a03_geo_fence_by_group', VALUE_FORMAT='JSON')\nAS\r\nSELECT '1' AS group_id\n, id\n, name\n, wkt\nFROM a03_geo_fence_s geof\nPARTITION BY group_id;\n```\n\n```\nDROP TABLE a03_geo_fence_aggby_group_t DELETE TOPIC;\n\nCREATE TABLE a03_geo_fence_aggby_group_t\nWITH (PARTITIONS=8, KAFKA_TOPIC='a03_geo_fence_aggby_group', VALUE_FORMAT='AVRO')\nAS\nSELECT group_id\n, collect_set(id)\t\t\t\t\tid_list\n, collect_set(CAST(id AS VARCHAR) + ':' + wkt) AS id_wkt_list\nFROM a03_geo_fence_by_group_s\t geof\nGROUP BY group_id;\n```\n\nThe extra step with a stream and then the group by is necessary, to avoid an error later when joining `vehicle_pos_by_group` with `geofence_aggby_group`:\n\n\n```\nksql> SELECT vehp.id, vehp.latitude, vehp.longitude, geofagg.geometry_wkt_list\n>FROM a03_vehicle_position_by_group_s vehp\n>INNER JOIN a03_geo_fence_aggby_group_t geofagg\n>ON vehp.group_id = geofagg.group_id;\nSource table (GEOFAGG) key column ('1') is not the column used in the join criteria (GROUP_ID).\nStatement: SELECT vehp.id, vehp.latitude, vehp.longitude, geofagg.geometry_wkt_list\nFROM a03_vehicle_position_by_group_s vehp\nINNER JOIN a03_geo_fence_aggby_group_t geofagg\nON vehp.group_id = geofagg.group_id;\nCaused by: Source table (GEOFAGG) key column ('1') is not the column used in the\n\tjoin criteria (GROUP_ID).\n```\n\nCreate a new stream `a03_vehicle_position_by_group_s` which enriches the vehicle_position with the \"artificial\" group id\n\n```\nDROP STREAM a03_vehicle_position_by_group_s DELETE TOPIC;\n\nCREATE STREAM a03_vehicle_position_by_group_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='a03_vehicle_position_by_group', VALUE_FORMAT='AVRO')\r\nAS\nSELECT '1' group_id, vehp.vehicleId, vehp.latitude, vehp.longitude\nFROM vehicle_position_s vehp\nPARTITION BY group_id;\n```\n\n```\nDROP STREAM a03_geo_fence_status_s DELETE TOPIC;\n\nCREATE STREAM a03_geo_fence_status_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='vehp_join_geof_aggby_vehp', VALUE_FORMAT='AVRO')\r\nAS\r\nSELECT vehp.vehicleId, vehp.latitude, vehp.longitude, geo_fence_bulk(vehp.latitude, vehp.longitude, geofagg.id_wkt_list) geofence_status\r\nFROM a03_vehicle_position_by_group_s vehp\r\nLEFT JOIN a03_geo_fence_aggby_group_t geofagg\nON vehp.group_id = geofagg.group_id;\n```\n\n```\nINSERT INTO vehicle_position_s (vehicleId, latitude, longitude) VALUES (10, 52.4497, 13.3096);\nINSERT INTO vehicle_position_s (vehicleId, latitude, longitude) VALUES (10, 52.4556, 13.3178);\n```\n\n### Attempt 4: aggregate by geohash\n\nCreate a Stream on the `geo_fence`topic\n\n```\nDROP STREAM a04_geo_fence_s;\n\nCREATE STREAM a04_geo_fence_s \n WITH (kafka_topic='geo_fence', \n value_format='AVRO',\n key='id');\n```\n\nCreate a new stream `a04_geo_fence_by_geohash_s` which enriches the GeoFences with the GeoHashes they belong to (currently using precision of 3, but can be increased or reduced upon use-case). As there can be multiple geo-fences covering the geometry of the geo-fence, we have to \"explode\" it using a first create followed by multiple inserts. Currently we do it for a total of 4 geo hashes (array position 0 to 3).\n\n```\nDROP STREAM IF EXISTS a04_geo_fence_by_geohash_s DELETE TOPIC;\n\nCREATE STREAM a04_geo_fence_by_geohash_s\nWITH (PARTITIONS=8, kafka_topic='a04_geo_fence_by_geohash', value_format='AVRO')\nAS\nSELECT geo_hash(wkt, 3)[0] geo_hash, id, name, wkt\nFROM a04_geo_fence_s\nPARTITION by geo_hash;\n```\n\n```\nINSERT INTO a04_geo_fence_by_geohash_s\nSELECT geo_hash(wkt, 3)[1] geo_hash, id, name, wkt\nFROM a04_geo_fence_s\nWHERE geo_hash(wkt, 3)[1] IS NOT NULL\nPARTITION BY geo_hash;\n```\n\n```\nINSERT INTO a04_geo_fence_by_geohash_s\nSELECT geo_hash(wkt, 3)[2] geo_hash, id, name, wkt\nFROM a04_geo_fence_s\nWHERE geo_hash(wkt, 3)[2] IS NOT NULL\nPARTITION BY geo_hash;\n```\n\n```\nINSERT INTO a04_geo_fence_by_geohash_s\nSELECT geo_hash(wkt, 3)[3] geo_hash, id, name, wkt\nFROM a04_geo_fence_s\nWHERE geo_hash(wkt, 3)[3] IS NOT NULL\nPARTITION BY geo_hash;\n```\n\n\nNow we create a table which groups the geo-fences by geohash and creates a set with all geometries per geohash. Can be 1 to many, depending on how many geo-fence geometries belong to a given geohash. \n\n```\nDROP TABLE IF EXISTS a04_geo_fence_by_geohash_t DELETE TOPIC;\n\nCREATE TABLE a04_geo_fence_by_geohash_t\nWITH (PARTITIONS=8, KAFKA_TOPIC='geo_fence_by_geohash_t', VALUE_FORMAT='AVRO')\nAS\nSELECT geo_hash, COLLECT_SET(CAST (id AS VARCHAR) + ':' + wkt) id_wkt_list, COLLECT_SET(wkt) wkt_list, COLLECT_SET(id) id_list\nFROM a04_geo_fence_by_geohash_s\nGROUP BY geo_hash;\n```\n\nCreate a new stream `a04_vehicle_position_by_geohash_s` which enriches the vehicle positions with the geohash the LatLong belongs to ((currently using precision of 3, but can be increased or reduced upon use-case, but needs to be the same as above for the geo fences).\n\n```\nDROP STREAM IF EXISTS a04_vehicle_position_by_geohash_s DELETE TOPIC;\n\nCREATE STREAM a04_vehicle_position_by_geohash_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='vehicle_position_by_geohash', value_format='AVRO')\nAS\nSELECT vp.vehicleId, vp.latitude, vp.longitude, geo_hash(vp.latitude, vp.longitude, 3) geo_hash\nFROM vehicle_position_s vp\nPARTITION BY geo_hash;\n```\n\nnow call the geo_fence UDF\n\n```\nDROP STREAM a04_geo_fence_status_s DELETE TOPIC;\n\nCREATE STREAM a04_geo_fence_status_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='vehicle_position_by_geohash', value_format='AVRO')\nAS\nSELECT vp.vehicleId, vp.latitude, vp.longitude, vp.geo_hash, gf.wkt_list,\ngeo_fence_bulk (vp.latitude, vp.longitude, gf.id_wkt_list) fence_status\nFROM a04_vehicle_position_by_geohash_s vp \\\nLEFT JOIN a04_geo_fence_by_geohash_t gf \\\nON (vp.geo_hash = gf.geo_hash);\n```\n\n### Attempt 4a: call Kafka from geo_fence UDF\n\n```\nDROP STREAM a04b_geofence_udf_status_s DELETE TOPIC;\n\nCREATE STREAM a04a_geofence_udf_status_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='04a_geofence_udf_status', value_format='AVRO')\nAS\nSELECT vp.vehicleId, vp.latitude, vp.longitude, vp.geo_hash, gf.wkt_list,\ngeo_fence_bulk (vp.latitude, vp.longitude, gf.id_wkt_list, 'broker-1:9092,broker-2:9093') fence_status\nFROM a04_vehicle_position_by_geohash_s vp \\\nLEFT JOIN a04_geo_fence_by_geohash_t gf \\\nON (vp.geo_hash = gf.geo_hash);\n```\n\n### Attempt 4b: Explode geometry_wkt_list before calling geofence\n\n```\nDROP STREAM a04b_geofence_udf_status_s DELETE TOPIC;\n\nCREATE STREAM a04b_geofence_udf_status_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='04b_geofence_udf_status', value_format='AVRO')\nAS \nSELECT vehicleId, latitude, longitude, id_list[0] geofence_id, geo_fence(latitude, longitude, wkt_list[0]) geofence_status\nFROM a04_vehicle_position_by_geohash_s vp \\\nLEFT JOIN a04_geo_fence_by_geohash_t gf \\\nON (vp.geo_hash = gf.geo_hash);\n\nINSERT INTO a04b_geofence_udf_status_s\nSELECT vehicleId, latitude, longitude, id_list[1] geofence_id, geo_fence(latitude, longitude, wkt_list[1]) geofence_status\nFROM a04_vehicle_position_by_geohash_s vp \\\nLEFT JOIN a04_geo_fence_by_geohash_t gf \\\nON (vp.geo_hash = gf.geo_hash)\nWHERE id_list[1] IS NOT NULL;\n\nINSERT INTO a04b_geofence_udf_status_s\nSELECT vehicleId, latitude, longitude, id_list[2] geofence_id, geo_fence(latitude, longitude, wkt_list[2]) geofence_status\nFROM a04_vehicle_position_by_geohash_s vp \\\nLEFT JOIN a04_geo_fence_by_geohash_t gf \\\nON (vp.geo_hash = gf.geo_hash)\nWHERE id_list[2] IS NOT NULL;\n\n```\n\n## Working with Tile 38\n\n```\ndocker exec -ti tile38 tile38-cli\n```\n\n```\nSET city berlin OBJECT {\"type\":\"Polygon\",\"coordinates\": [[[13.297920227050781,52.56195151687443],[13.2440185546875,52.530216577830124],[13.267364501953125,52.45998421679598],[13.35113525390625,52.44826791583386],[13.405036926269531,52.44952338289473],[13.501167297363281,52.47148826410652],[13.509750366210938,52.489261333143126],[13.509063720703125,52.53710835019913],[13.481597900390625,52.554854904263195],[13.41156005859375,52.57217696877135],[13.37207794189453,52.5748894436198],[13.297920227050781,52.56195151687443]]]}\n```\n\n### Geofence CHANNEL\n\n```\nSETCHAN berlin WITHIN vehicle FENCE OBJECT {\"type\":\"Polygon\",\"coordinates\":[[[13.297920227050781,52.56195151687443],[13.2440185546875,52.530216577830124],[13.267364501953125,52.45998421679598],[13.35113525390625,52.44826791583386],[13.405036926269531,52.44952338289473],[13.501167297363281,52.47148826410652],[13.509750366210938,52.489261333143126],[13.509063720703125,52.53710835019913],[13.481597900390625,52.554854904263195],[13.41156005859375,52.57217696877135],[13.37207794189453,52.5748894436198],[13.297920227050781,52.56195151687443]]]}\n```\n\n```\nSUBSCRIBE berlin\n```\n\nPoint OUTSIDE\n\n```\nSET vehicle 10 POINT 52.4497 13.3096\n```\n\nPoint INSIDE\n\n```\nSET vehicle 10 POINT 52.4556 13.3178\n```\n\n\n### geofence HOOK\n\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic tile38_geofence_status --replication-factor 3 --partitions 1\n```\n\n\n```\nSETHOOK berlin_hook kafka://broker-1:9092/tile38_geofence_status WITHIN vehicle FENCE OBJECT {\"type\":\"Polygon\",\"coordinates\":[[[13.297920227050781,52.56195151687443],[13.2440185546875,52.530216577830124],[13.267364501953125,52.45998421679598],[13.35113525390625,52.44826791583386],[13.405036926269531,52.44952338289473],[13.501167297363281,52.47148826410652],[13.509750366210938,52.489261333143126],[13.509063720703125,52.53710835019913],[13.481597900390625,52.554854904263195],[13.41156005859375,52.57217696877135],[13.37207794189453,52.5748894436198],[13.297920227050781,52.56195151687443]]]}\n```\n\nPoint OUTSIDE\n\n```\nSET vehicle 10 POINT 52.4497 13.3096\n```\n\nPoint INSIDE\n\n```\nSET vehicle 10 POINT 52.4556 13.3178\n```\n\n### Integration with KSQL\n\n### Integration with Kafka Connect\n\n```\ncurl -X PUT \\\n /api/kafka-connect-1/connectors/Tile38SinkConnector/config \\\n -H 'Content-Type: application/json' \\\n -H 'Accept: application/json' \\\n -d '{\n \"connector.class\": \"com.trivadis.geofence.kafka.connect.Tile38SinkConnector\",\n \"topics\": \"vehicle_position\",\n \"tasks.max\": \"1\",\n \"tile38.key\": \"vehicle\",\n \"tile38.operation\": \"SET\",\n \"tile38.hosts\": \"tile38:9851\"\n}'\n```\n\n-------\n\n### Geo Fences aggregated\n\n1st approach: Create aggregation of all the geometries\n\n```\nCREATE VIEW geo_fence_gpt_v\nAS\nSELECT '1' AS id\n , string_agg(geometry_wkt, ', ') AS geometry_list\n , max(last_update) AS last_update\nFROM geo_fence\nGROUP BY 1;\n```\n\nand join it to the vehicle table\n\n```\nCREATE VIEW geo_fence_v\nAS\nSELECT ve.id vehicle_id\n, ve.name. vehicle_name\n,\tgeometry_list\n, GREATEST(gf.last_update, ve.last_update) AS last_update\nFROM geo_fence_gpt_v gf\nCROSS JOIN vehicle ve;\n```\n\n2nd approach: Build a cross-join between table `geo_fence` and `vehicle`\n\n```\nDROP VIEW geo_fence_v;\n\nCREATE VIEW geo_fence_v\nAS\nSELECT concat (ve.id, ':', gf.id) AS id \n, ve.id AS vehicle_id\n, ve.name AS vehicle_name\n, gf.name AS geofence_name\n, gf.geometry_wkt\n, GREATEST(gf.last_update, ve.last_update) AS last_update\nFROM geo_fence gf\nCROSS JOIN vehicle ve;\n```\n\n\n## Geo Fence KSQL Table\n\n```\ndocker run -it --network docker_default confluentinc/cp-ksql-cli:5.2.1 http://ksql-server-1:8088\n```\n\n\n```\nDROP TABLE geo_fence_t;\n\nCREATE TABLE geo_fence_t \\\n (id BIGINT, \\\n name VARCHAR, \\\n geometry_wkt VARCHAR) \\\nWITH (KAFKA_TOPIC='geo_fence', \\\n VALUE_FORMAT='JSON', \\\n KEY = 'id');\n```\n\n```\nDROP TABLE geo_fence2_t;\n\nCREATE TABLE geo_fence2_t \\\n (id VARCHAR,\n vehicle_id BIGINT, \\\n vehicle_name VARCHAR, \\\n geofence_name VARCHAR, \\\n geometry_wkt VARCHAR) \\\nWITH (KAFKA_TOPIC='geo_fence_v', \\\n VALUE_FORMAT='JSON', \\\n KEY = 'id');\n```\n\n```\nSELECT vehicle_id, geofence_name FROM geo_fence2_t;\n```\n\n```\n./scripts/start-connect-jdbc.sh\n```\n\n\n## Geo Fence KSQL\n\nCreate the stream with the vehicle positions\n\n```\nDROP STREAM vehicle_position_s;\nCREATE STREAM vehicle_position_s \\\n (id VARCHAR, \\\n truck_id VARCHAR, \\\n latitude DOUBLE, \\\n longitude DOUBLE) \\\n WITH (kafka_topic='vehicle_position', \\\n value_format='DELIMITED');\n```\n\nPublish position outside of geofence #1 (Columbia, Missouri)\n\n```\necho '10:1,1,38.3900,-90.1840' | kafkacat -b streamingplatform -t vehicle_position -K:\n```\n\nPublish position inside geofence #1 (Columbia, Missouri)\n\n```\necho '10:1,1,38.4147,-90.1981' | kafkacat -b streamingplatform -t vehicle_position -K:\n```\n\nCreate the Geo Fence Stream holding status of INSIDE or OUTSIDE\n\n```\nDROP STREAM vehicle_geofence_s;\nCREATE STREAM vehicle_geofence_s \\\nWITH (kafka_topic='vehicle_geofence', \\\n value_format='DELIMITED', \\\n partitions=8) \\ \nAS \\\nSELECT vp.truck_id, geo_fence(vp.latitude, vp.longitude, gf.geometry_wkt) as geofence_status, gf.geometry_wkt \\ \nFROM vehicle_position_s vp \\\nLEFT JOIN geo_fence2_t gf \\\nON (vp.truck_id = gf.vehicle_id)\nPARTITION BY truck_id;\n```\n\nCreate a KSQL Table which keeps the last value of the geofence_status for 20sec by truck_id\n\n```\nDROP TABLE vehicle_geofence_status_t;\n\nCREATE TABLE vehicle_geofence_status_t \\\nWITH (kafka_topic='vehicle_geofence_status', \\\n value_format='DELIMITED', \\\n partitions=8) \\ \nAS \\\nSELECT truck_id, LASTVALUE(geofence_status) last_status \\\nFROM vehicle_geofence_s \\\nWINDOW SESSION (20 SECONDS) \\\nGROUP BY truck_id;\n```\n\nCreate a KSQL Table which keeps the last value of the geofence_status by truck_id\n\n```\nDROP TABLE vehicle_geofence_status_t;\n\nCREATE TABLE vehicle_geofence_status_t \\\nWITH (kafka_topic='vehicle_geofence_status', \\\n value_format='DELIMITED', \\\n partitions=8) \\ \nAS \\\nSELECT truck_id, LASTVALUE(geofence_status) last_status \\\nFROM vehicle_geofence_s \\\nGROUP BY truck_id;\n```\n\nJoin the latest status to the last (previous) status in the table\n\n```\nSELECT vg.truck_id, vg.geofence_status, vgs.last_status\nFROM vehicle_geofence_s vg\nLEFT JOIN vehicle_geofence_status_t vgs\nON (vg.truck_id = vgs.truck_id);\n```\n\n```\nCASE\n WHEN orderunits < 2.0 THEN 'small'\n WHEN orderunits < 4.0 THEN 'medium'\n ELSE 'large'\n END AS case_result\n```\n\n\n```\nSELECT vg.truck_id, geo_fence(vp.latitude, vp.longitude, vgs.last_status, vp.geometry_wkt) status\nFROM vehicle_position_s vp\nLEFT JOIN vehicle_geofence_status_t vgs\nON (vg.truck_id = vgs.truck_id);\n```\n\n\n```\nSELECT LASTVALUE( GEOFENCE(latitude,longitude,'POLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536))') ) \\ \nFROM vehicle_position_s G\nWINDOW SESSION (20 SECONDS)\nGROUP BY truckId;\n```\n\n\n\n## Misc\n\n```\nGEOMETRYCOLLECTION(POINT (-90.21316232463931 38.44383114670336),POLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536)))\n```\n\n```\nGEOMETRYCOLLECTION(POLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536)),\nPOLYGON ((-90.16685485839844 38.39818224865764, -90.16685485839844 38.48476975349254, -90.25886535644531 38.48476975349254, -90.25886535644531 38.39818224865764, -90.16685485839844 38.39818224865764)), \nLINESTRING (-90.15387 38.36086, -90.15398 38.36125, -90.15405 38.36154, -90.15407 38.36165, -90.1541 38.36192, -90.15393 38.36349, -90.15393 38.3636, -90.15392 38.36375, -90.15392 38.3639, -90.15393 38.36405, -90.15397 38.36438, -90.154 38.36456, -90.15403999999999 38.36472, -90.15411 38.36495, -90.15430000000001 38.36539, -90.15434 38.36546, -90.15438 38.36555, -90.15443999999999 38.36566, -90.1545 38.36575, -90.15456 38.36585, -90.15483999999999 38.36627, -90.15586 38.36767, -90.15591000000001 38.36775, -90.15629 38.36829, -90.15640999999999 38.36848, -90.15646 38.36855, -90.15658999999999 38.3688, -90.15657 38.36894, -90.15669 38.36922, -90.1568 38.36955, -90.15688 38.36986, -90.15692 38.37005, -90.15716 38.37141, -90.15724 38.37177, -90.15738 38.37231, -90.15748000000001 38.3726, -90.15755 38.37278, -90.15759 38.3729, -90.15804 38.3739, -90.15942 38.37714, -90.15958999999999 38.37751, -90.16063 38.37995, -90.16083999999999 38.38037, -90.16095 38.38057, -90.16125 38.38105, -90.16333 38.38412, -90.16357000000001 38.38449, -90.16382 38.38491, -90.16388999999999 38.38504, -90.16391 38.38509, -90.16414 38.38552, -90.16591 38.38912, -90.16710999999999 38.3915, -90.16727 38.39188, -90.16735 38.39209, -90.16739 38.39221, -90.16745 38.39242, -90.16757 38.39307, -90.16773000000001 38.39423, -90.16776 38.39437, -90.16784 38.39468, -90.16788 38.39479, -90.16791000000001 38.3949, -90.16817 38.39552, -90.16825 38.39569, -90.16829 38.39576, -90.16829 38.39578, -90.16903000000001 38.3974, -90.16916999999999 38.39774, -90.16924 38.39793, -90.16930000000001 38.39813, -90.16934000000001 38.39824, -90.16943000000001 38.39857, -90.16945 38.39867, -90.16947999999999 38.39878, -90.16952000000001 38.39899, -90.16952999999999 38.39911, -90.16954 38.39914, -90.1696 38.39978, -90.1696 38.40032, -90.16956 38.40077, -90.16951 38.40109, -90.16943999999999 38.40144, -90.16939000000001 38.40164, -90.16763 38.407, -90.16755999999999 38.40725, -90.16745 38.40771, -90.1674 38.40797, -90.16712 38.40982, -90.16705 38.41017, -90.16699 38.41055, -90.16698 38.41059, -90.16696 38.41073, -90.16694 38.41094, -90.16695 38.41127, -90.16697000000001 38.41149, -90.16701 38.41181, -90.16701999999999 38.41182, -90.16719000000001 38.41267, -90.16726 38.41298, -90.16736 38.4133, -90.16746999999999 38.4136, -90.16761 38.41391, -90.16775 38.41417, -90.16798 38.41454, -90.16811 38.41471, -90.16858999999999 38.4153, -90.16864 38.41537, -90.16979000000001 38.41673, -90.17043 38.41746, -90.17112 38.41818, -90.17144999999999 38.4185, -90.17319999999999 38.42032, -90.17359 38.4208, -90.17395999999999 38.42134, -90.17424 38.42183, -90.17435 38.42204, -90.17574999999999 38.42539, -90.17589 38.42568, -90.17626 38.42634, -90.17641 38.42656, -90.17694 38.42722, -90.1772 38.42752, -90.17738 38.4277, -90.17779 38.42808, -90.17825999999999 38.42846, -90.17854 38.42867, -90.17883999999999 38.42887, -90.17945 38.42923, -90.18073 38.42994, -90.18120999999999 38.43022, -90.18165999999999 38.43052, -90.18205 38.43081, -90.18272 38.43136, -90.18312 38.43171, -90.18365 38.43215, -90.18388 38.43231, -90.18409 38.43247, -90.18451 38.43275, -90.18455 38.43277, -90.18495 38.43302, -90.18499 38.43305, -90.18606 38.43362, -90.18879 38.43497, -90.18939 38.43525, -90.18976000000001 38.43544, -90.19078 38.43589, -90.19141999999999 38.43614, -90.19233 38.43643, -90.19286 38.43657, -90.19341 38.43669, -90.19395 38.43679, -90.19761 38.43735, -90.19959 38.43769, -90.2003 38.43784, -90.2038 38.43868, -90.20929 38.44005, -90.20976 38.44018, -90.2102 38.44032, -90.211 38.44062, -90.21172 38.44093, -90.2123 38.44123, -90.21257 38.44138, -90.21352 38.44198, -90.21409 38.4424, -90.21442999999999 38.44268, -90.21496 38.44317, -90.21528000000001 38.4435, -90.21559999999999 38.44386, -90.21568000000001 38.44396, -90.2158 38.44409, -90.21617000000001 38.44457, -90.21626999999999 38.44472, -90.21638 38.44486, -90.21684999999999 38.44554, -90.21723 38.44616, -90.21729999999999 38.4463, -90.21798 38.44747, -90.21847 38.44853, -90.21850000000001 38.44858, -90.21863999999999 38.44891, -90.21905 38.44999, -90.21933 38.45086, -90.21948999999999 38.45144, -90.22051 38.45552, -90.22059 38.4559, -90.22069 38.45632, -90.22078 38.45665, -90.22082 38.45683, -90.22111 38.45794, -90.2214 38.45888, -90.22167 38.45957, -90.22252 38.46163, -90.22264 38.4619, -90.223 38.46278, -90.22302000000001 38.46284, -90.22302999999999 38.46285, -90.22309 38.46301, -90.2231 38.46302, -90.22328 38.46347, -90.22369 38.46443, -90.22410000000001 38.46554, -90.22417 38.46579, -90.22423000000001 38.46595, -90.22432000000001 38.46625, -90.22445999999999 38.46678, -90.22451 38.467, -90.22454999999999 38.46715, -90.22495000000001 38.4692, -90.22499999999999 38.46934, -90.22521999999999 38.47024, -90.22532 38.4706, -90.22537 38.47075, -90.22546 38.47098, -90.22553000000001 38.47111, -90.22557999999999 38.47123, -90.22569 38.47144, -90.22578 38.47159, -90.22598000000001 38.47189, -90.22599 38.47191, -90.22614 38.47211, -90.22635 38.47237, -90.22659 38.47263, -90.22698 38.47296, -90.22709999999999 38.47304, -90.22727999999999 38.47318, -90.22750000000001 38.47334, -90.22759000000001 38.47339, -90.2277 38.47346, -90.22801 38.47364, -90.22845 38.47387, -90.22869 38.47397, -90.22895 38.47406, -90.2291 38.47412, -90.22984 38.47433, -90.22986 38.47434, -90.23025 38.47442, -90.23062 38.47448, -90.2313 38.47455, -90.23157 38.47455, -90.23188 38.47456, -90.23208 38.47456, -90.23263 38.47458, -90.23296999999999 38.47458, -90.23339 38.4746, -90.23414 38.47467, -90.23455 38.47473, -90.23553 38.47492, -90.23554 38.47492, -90.23577 38.47504, -90.23604 38.47511, -90.23618 38.47514, -90.24784 38.47859, -90.24805000000001 38.47866, -90.25381 38.48037, -90.25382999999999 38.48037, -90.25834 38.48172, -90.26107 38.4825, -90.26112000000001 38.48252, -90.265 38.48364, -90.26501 38.48364, -90.2667 38.48412, -90.26814 38.48459, -90.27489 38.48657, -90.27509999999999 38.48664, -90.27618 38.48695, -90.27896 38.48779, -90.27924 38.48789, -90.28066 38.48832, -90.28747 38.49019, -90.2876 38.49022, -90.28968999999999 38.4908, -90.28979 38.49082, -90.29071 38.49107, -90.29174 38.49137, -90.29174999999999 38.49138, -90.29213 38.49149, -90.29331000000001 38.49187, -90.30221 38.49495, -90.30354 38.49549, -90.31444999999999 38.50054, -90.31542 38.50094, -90.31582 38.50108, -90.31583000000001 38.50108, -90.31609 38.50117, -90.31695999999999 38.50141, -90.31753 38.50155, -90.31795 38.50163, -90.31822 38.50169, -90.31870000000001 38.50177, -90.31939 38.50186, -90.31998 38.50191, -90.32001 38.50192, -90.32861 38.50256, -90.33362 38.50298))\n```\n```\nGEOMETRYCOLLECTION(LINESTRING (-90.15387 38.36086, -90.15398 38.36125, -90.15405 38.36154, -90.15407 38.36165, -90.1541 38.36192, -90.15393 38.36349, -90.15393 38.3636, -90.15392 38.36375, -90.15392 38.3639, -90.15393 38.36405, -90.15397 38.36438, -90.154 38.36456, -90.15403999999999 38.36472, -90.15411 38.36495, -90.15430000000001 38.36539, -90.15434 38.36546, -90.15438 38.36555, -90.15443999999999 38.36566, -90.1545 38.36575, -90.15456 38.36585, -90.15483999999999 38.36627, -90.15586 38.36767, -90.15591000000001 38.36775, -90.15629 38.36829, -90.15640999999999 38.36848, -90.15646 38.36855, -90.15658999999999 38.3688, -90.15657 38.36894, -90.15669 38.36922, -90.1568 38.36955, -90.15688 38.36986, -90.15692 38.37005, -90.15716 38.37141, -90.15724 38.37177, -90.15738 38.37231, -90.15748000000001 38.3726, -90.15755 38.37278, -90.15759 38.3729, -90.15804 38.3739, -90.15942 38.37714, -90.15958999999999 38.37751, -90.16063 38.37995, -90.16083999999999 38.38037, -90.16095 38.38057, -90.16125 38.38105, -90.16333 38.38412, -90.16357000000001 38.38449, -90.16382 38.38491, -90.16388999999999 38.38504, -90.16391 38.38509, -90.16414 38.38552, -90.16591 38.38912, -90.16710999999999 38.3915, -90.16727 38.39188, -90.16735 38.39209, -90.16739 38.39221, -90.16745 38.39242, -90.16757 38.39307, -90.16773000000001 38.39423, -90.16776 38.39437, -90.16784 38.39468, -90.16788 38.39479, -90.16791000000001 38.3949, -90.16817 38.39552, -90.16825 38.39569, -90.16829 38.39576, -90.16829 38.39578, -90.16903000000001 38.3974, -90.16916999999999 38.39774, -90.16924 38.39793, -90.16930000000001 38.39813, -90.16934000000001 38.39824, -90.16943000000001 38.39857, -90.16945 38.39867, -90.16947999999999 38.39878, -90.16952000000001 38.39899, -90.16952999999999 38.39911, -90.16954 38.39914, -90.1696 38.39978, -90.1696 38.40032, -90.16956 38.40077, -90.16951 38.40109, -90.16943999999999 38.40144, -90.16939000000001 38.40164, -90.16763 38.407, -90.16755999999999 38.40725, -90.16745 38.40771, -90.1674 38.40797, -90.16712 38.40982, -90.16705 38.41017, -90.16699 38.41055, -90.16698 38.41059, -90.16696 38.41073, -90.16694 38.41094, -90.16695 38.41127, -90.16697000000001 38.41149, -90.16701 38.41181, -90.16701999999999 38.41182, -90.16719000000001 38.41267, -90.16726 38.41298, -90.16736 38.4133, -90.16746999999999 38.4136, -90.16761 38.41391, -90.16775 38.41417, -90.16798 38.41454, -90.16811 38.41471, -90.16858999999999 38.4153, -90.16864 38.41537, -90.16979000000001 38.41673, -90.17043 38.41746, -90.17112 38.41818, -90.17144999999999 38.4185, -90.17319999999999 38.42032, -90.17359 38.4208, -90.17395999999999 38.42134, -90.17424 38.42183, -90.17435 38.42204, -90.17574999999999 38.42539, -90.17589 38.42568, -90.17626 38.42634, -90.17641 38.42656, -90.17694 38.42722, -90.1772 38.42752, -90.17738 38.4277, -90.17779 38.42808, -90.17825999999999 38.42846, -90.17854 38.42867, -90.17883999999999 38.42887, -90.17945 38.42923, -90.18073 38.42994, -90.18120999999999 38.43022, -90.18165999999999 38.43052, -90.18205 38.43081, -90.18272 38.43136, -90.18312 38.43171, -90.18365 38.43215, -90.18388 38.43231, -90.18409 38.43247, -90.18451 38.43275, -90.18455 38.43277, -90.18495 38.43302, -90.18499 38.43305, -90.18606 38.43362, -90.18879 38.43497, -90.18939 38.43525, -90.18976000000001 38.43544, -90.19078 38.43589, -90.19141999999999 38.43614, -90.19233 38.43643, -90.19286 38.43657, -90.19341 38.43669, -90.19395 38.43679, -90.19761 38.43735, -90.19959 38.43769, -90.2003 38.43784, -90.2038 38.43868, -90.20929 38.44005, -90.20976 38.44018, -90.2102 38.44032, -90.211 38.44062, -90.21172 38.44093, -90.2123 38.44123, -90.21257 38.44138, -90.21352 38.44198, -90.21409 38.4424, -90.21442999999999 38.44268, -90.21496 38.44317, -90.21528000000001 38.4435, -90.21559999999999 38.44386, -90.21568000000001 38.44396, -90.2158 38.44409, -90.21617000000001 38.44457, -90.21626999999999 38.44472, -90.21638 38.44486, -90.21684999999999 38.44554, -90.21723 38.44616, -90.21729999999999 38.4463, -90.21798 38.44747, -90.21847 38.44853, -90.21850000000001 38.44858, -90.21863999999999 38.44891, -90.21905 38.44999, -90.21933 38.45086, -90.21948999999999 38.45144, -90.22051 38.45552, -90.22059 38.4559, -90.22069 38.45632, -90.22078 38.45665, -90.22082 38.45683, -90.22111 38.45794, -90.2214 38.45888, -90.22167 38.45957, -90.22252 38.46163, -90.22264 38.4619, -90.223 38.46278, -90.22302000000001 38.46284, -90.22302999999999 38.46285, -90.22309 38.46301, -90.2231 38.46302, -90.22328 38.46347, -90.22369 38.46443, -90.22410000000001 38.46554, -90.22417 38.46579, -90.22423000000001 38.46595, -90.22432000000001 38.46625, -90.22445999999999 38.46678, -90.22451 38.467, -90.22454999999999 38.46715, -90.22495000000001 38.4692, -90.22499999999999 38.46934, -90.22521999999999 38.47024, -90.22532 38.4706, -90.22537 38.47075, -90.22546 38.47098, -90.22553000000001 38.47111, -90.22557999999999 38.47123, -90.22569 38.47144, -90.22578 38.47159, -90.22598000000001 38.47189, -90.22599 38.47191, -90.22614 38.47211, -90.22635 38.47237, -90.22659 38.47263, -90.22698 38.47296, -90.22709999999999 38.47304, -90.22727999999999 38.47318, -90.22750000000001 38.47334, -90.22759000000001 38.47339, -90.2277 38.47346, -90.22801 38.47364, -90.22845 38.47387, -90.22869 38.47397, -90.22895 38.47406, -90.2291 38.47412, -90.22984 38.47433, -90.22986 38.47434, -90.23025 38.47442, -90.23062 38.47448, -90.2313 38.47455, -90.23157 38.47455, -90.23188 38.47456, -90.23208 38.47456, -90.23263 38.47458, -90.23296999999999 38.47458, -90.23339 38.4746, -90.23414 38.47467, -90.23455 38.47473, -90.23553 38.47492, -90.23554 38.47492, -90.23577 38.47504, -90.23604 38.47511, -90.23618 38.47514, -90.24784 38.47859, -90.24805000000001 38.47866, -90.25381 38.48037, -90.25382999999999 38.48037, -90.25834 38.48172, -90.26107 38.4825, -90.26112000000001 38.48252, -90.265 38.48364, -90.26501 38.48364, -90.2667 38.48412, -90.26814 38.48459, -90.27489 38.48657, -90.27509999999999 38.48664, -90.27618 38.48695, -90.27896 38.48779, -90.27924 38.48789, -90.28066 38.48832, -90.28747 38.49019, -90.2876 38.49022, -90.28968999999999 38.4908, -90.28979 38.49082, -90.29071 38.49107, -90.29174 38.49137, -90.29174999999999 38.49138, -90.29213 38.49149, -90.29331000000001 38.49187, -90.30221 38.49495, -90.30354 38.49549, -90.31444999999999 38.50054, -90.31542 38.50094, -90.31582 38.50108, -90.31583000000001 38.50108, -90.31609 38.50117, -90.31695999999999 38.50141, -90.31753 38.50155, -90.31795 38.50163, -90.31822 38.50169, -90.31870000000001 38.50177, -90.31939 38.50186, -90.31998 38.50191, -90.32001 38.50192, -90.32861 38.50256, -90.33362 38.50298),\nPOLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536)),\nPOLYGON ((-90.23081789920012 38.50459453822468, -90.16627322146574 38.49599421747762, -90.1643249060413 38.49563563217073, -90.16242162335251 38.49508605831588, -90.16058204705975 38.49435088794208, -90.15882422578142 38.49343733401984, -90.15716540601365 38.49235435969258, -90.15562186292 38.49111259033661, -90.15420874065097 38.48972420931247, -90.15293990376043 38.48820283843047, -90.15182780117637 38.48656340430311, -90.15088334406093 38.48482199189576, -90.15011579875772 38.48299568671235, -90.14953269587713 38.48110240716457, -90.14913975641119 38.47916072876907, -90.14894083560338 38.47718970189771, -90.14688089907995 38.4368620214741, -90.14688203543342 38.43479947461972, -90.14709558779319 38.43274801265139, -90.14751928497606 38.43072945338423, -90.14814862085569 38.42876526470479, -90.14897690228641 38.42687633625475, -90.14999532028641 38.42508275726427, -90.17402791305985 38.38742325360005, -90.17520415524115 38.38577119597267, -90.17654165464239 38.38424675003237, -90.17802665896077 38.38286559028504, -90.1796438992331 38.38164191795357, -90.18137674683287 38.38058831495945, -90.18320738444747 38.37971561455424, -90.18511698927755 38.37903278993092, -90.18708592657492 38.37854686196069, -90.18909395152905 38.37826282700361, -90.19112041742619 38.37818360553556, -90.19314448794096 38.37831001211962, -90.24052302798 38.38369114306222, -90.24255068209438 38.38402773463947, -90.24453308264155 38.38457065559867, -90.24644929212599 38.38531417177816, -90.24827907214143 38.38625043039224, -90.25000309712276 38.38736954296976, -90.25160315845642 38.38865968979316, -90.25306235679425 38.39010724473452, -90.25436528053905 38.39169691917056, -90.25549816861708 38.39341192345628, -90.27609753385147 38.42837950949905, -90.27707876542273 38.43026829456027, -90.27785371536606 38.43225066107262, -90.27841360674486 38.43430415712761, -90.27875209833522 38.43640552521701, -90.27886535644531 38.438530965643, -90.27886535644531 38.47455675836861, -90.27876733209382 38.4765344755593, -90.27847421991667 38.4784928063055, -90.27798889312699 38.48041255419704, -90.27731610910917 38.48227490102974, -90.27646246278488 38.48406159126952, -90.27543632196688 38.48575511100117, -90.27424774533398 38.48733885960736, -90.27290838383156 38.48879731249509, -90.27143136646387 38.49011617327449, -90.2698311715979 38.49128251389831, -90.26812348504002 38.49228490138822, -90.26632504627699 38.49311350990586, -90.24091916248793 38.50332650502979, -90.23897285459638 38.50399480536716, -90.23696817736069 38.50445957297614, -90.23492635399681 38.50471588743204, -90.23286900098113 38.50476103517233, -90.23081789920012 38.50459453822468)))\n```\n\n## Setup GeoFences\n\n```\n\"Columbia\", \"POLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536))\"\n\"St. Louis\", \"POLYGON ((-90.31997680664062 38.74337300148123, -90.38589477539062 38.66942832560808, -90.35018920898438 38.613651383524335, -90.31448364257812 38.55460931253295, -90.17303466796875 38.55460931253295, -90.07965087890625 38.58359966761715, -90.05905151367186 38.634036452919226, -90.05905151367186 38.68658172716673, -90.0714111328125 38.72730457751627, -90.120849609375 38.74444410121548, -90.31997680664062 38.74337300148123))\"\n```\n\n\n## Demo\n\nDROP STREAM demo_geo_fence_s;\n\nCREATE STREAM demo_geo_fence_s \n (id VARCHAR,\n name VARCHAR,\n geometry_wkt VARCHAR)\n WITH (kafka_topic='geo_fence', \n value_format='JSON',\n key='id');\n\n```\nDROP STREAM IF EXISTS demo_geo_fence_by_geohash_s DELETE TOPIC;\n\nCREATE STREAM demo_geo_fence_by_geohash_s\nWITH (PARTITIONS=8, kafka_topic='a04_geo_fence_by_geohash', value_format='JSON')\nAS\nSELECT geo_hash(geometry_wkt, 3)[0] geo_hash, id, name, geometry_wkt\nFROM demo_geo_fence_s\nPARTITION by geo_hash;\n```\n\n```\nINSERT INTO demo_geo_fence_by_geohash_s\nSELECT geo_hash(geometry_wkt, 3)[1] geo_hash, id, name, geometry_wkt\nFROM demo_geo_fence_s\nWHERE geo_hash(geometry_wkt, 3)[1] IS NOT NULL\nPARTITION BY geo_hash;\n```\n\n```\nINSERT INTO demo_geo_fence_by_geohash_s\nSELECT geo_hash(geometry_wkt, 3)[2] geo_hash, id, name, geometry_wkt\nFROM demo_geo_fence_s\nWHERE geo_hash(geometry_wkt, 3)[2] IS NOT NULL\nPARTITION BY geo_hash;\n```\n\n```\nINSERT INTO a04_geo_fence_by_geohash_s\nSELECT geo_hash(geometry_wkt, 3)[3] geo_hash, id, name, geometry_wkt\nFROM a04_geo_fence_s\nWHERE geo_hash(geometry_wkt, 3)[3] IS NOT NULL\nPARTITION BY geo_hash;\n```\n\n\nNow we create a table which groups the geo-fences by geohash and creates a set with all geometries per geohash. Can be 1 to many, depending on how many geo-fence geometries belong to a given geohash. \n\n```\nDROP TABLE IF EXISTS demo_geo_fence_by_geohash_t DELETE TOPIC;\n\nCREATE TABLE demo_geo_fence_by_geohash_t\nWITH (PARTITIONS=8, KAFKA_TOPIC='geo_fence_by_geohash_t', VALUE_FORMAT='JSON')\nAS\nSELECT geo_hash, COLLECT_SET(id + ':' + geometry_wkt) id_geometry_wkt_list, COLLECT_SET(geometry_wkt) geometry_wkt_list, COLLECT_SET(id) id_list\nFROM demo_geo_fence_by_geohash_s\nGROUP BY geo_hash;\n```\n\nCreate a new stream `a04_vehicle_position_by_geohash_s` which enriches the vehicle positions with the geohash the LatLong belongs to ((currently using precision of 3, but can be increased or reduced upon use-case, but needs to be the same as above for the geo fences).\n\n```\nDROP STREAM IF EXISTS demo_vehicle_position_by_geohash_s DELETE TOPIC;\n\nCREATE STREAM demo_vehicle_position_by_geohash_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='vehicle_position_by_geohash', value_format='AVRO')\nAS\nSELECT vp.id, vp.latitude, vp.longitude, geo_hash(vp.latitude, vp.longitude, 3) geo_hash\nFROM vehicle_position_s vp\nPARTITION BY geo_hash;\n```\n\nnow call the geo_fence UDF\n\n```\nDROP STREAM demo_geo_fence_status_s DELETE TOPIC;\n\nCREATE STREAM demo_geo_fence_status_s\nWITH (PARTITIONS=8, KAFKA_TOPIC='demo_geo_fence_status', value_format='AVRO')\nAS\nSELECT vp.id, vp.latitude, vp.longitude, vp.geo_hash, gf.geometry_wkt_list,\ngeo_fence_bulk (vp.latitude, vp.longitude, gf.id_geometry_wkt_list) fence_status\nFROM demo_vehicle_position_by_geohash_s vp \\\nLEFT JOIN demo_geo_fence_by_geohash_t gf \\\nON (vp.geo_hash = gf.geo_hash);\n```\n\n-----\n\n## Setup Static Data in PostgreSQL (no longer necessary anymore)\n\nThe infrastructure we have started above also contains an instance of Postgresql in a separate docker container.\n\nLet's connect to that container\n\n```\ndocker exec -ti postgresql psql -d sample -U sample\n```\n\n\n### Vehicle Table\n\n```\nDROP TABLE vehicle;\nCREATE TABLE vehicle (id BIGINT\n , name CHARACTER VARYING(45)\n , last_update TIMESTAMP);\nALTER TABLE vehicle ADD CONSTRAINT vehicle_pk PRIMARY KEY (id);\n```\n\n```\nINSERT INTO vehicle (id, name, last_update)\nVALUES (1, 'Vehicle-1', CURRENT_TIMESTAMP);\n\nINSERT INTO vehicle (id, name, last_update)\nVALUES (2, 'Vehicle-2', CURRENT_TIMESTAMP);\n\nINSERT INTO vehicle (id, name, last_update)\nVALUES (3, 'Vehicle-3', CURRENT_TIMESTAMP);\n\nINSERT INTO vehicle (id, name, last_update)\nVALUES (4, 'Vehicle-4', CURRENT_TIMESTAMP);\n\nINSERT INTO vehicle (id, name, last_update)\nVALUES (10, 'Vehicle-10', CURRENT_TIMESTAMP);\n```\n\n### Geo Fence Table\n\n```\nDROP TABLE geo_fence;\nCREATE TABLE geo_fence (id BIGINT\n , name CHARACTER VARYING(45)\n , geometry_wkt CHARACTER VARYING(2000)\n , last_update TIMESTAMP);\nALTER TABLE geo_fence ADD CONSTRAINT geo_fence_pk PRIMARY KEY (id);\n```\n\n```\nINSERT INTO geo_fence (id, name, geometry_wkt, last_update)\nVALUES (1, 'Colombia, Missouri', 'POLYGON ((-90.23345947265625 38.484769753492536, -90.25886535644531 38.47455675836861, -90.25886535644531 38.438530965643004, -90.23826599121092 38.40356337960024, -90.19088745117188 38.39818224865764, -90.16685485839844 38.435841752321856, -90.16891479492188 38.47616943274547, -90.23345947265625 38.484769753492536))', CURRENT_TIMESTAMP);\n\nINSERT INTO geo_fence (id, name, geometry_wkt, last_update)\nVALUES (2, 'St. Louis, Missouri', 'POLYGON ((-90.25749206542969 38.71551876930462, -90.31723022460938 38.69301319283493, -90.3247833251953 38.64744452237617, -90.31997680664062 38.58306291549108, -90.27053833007812 38.55460931253295, -90.22109985351562 38.54601733154524, -90.15037536621094 38.55299839430547, -90.11123657226562 38.566421609878674, -90.08583068847656 38.63028174397134, -90.08583068847656 38.66996443163297, -90.0933837890625 38.718197532760165, -90.15243530273436 38.720876195817276, -90.25749206542969 38.71551876930462))', CURRENT_TIMESTAMP);\n\nINSERT INTO geo_fence (id, name, geometry_wkt, last_update)\nVALUES (3, 'Berlin, Germany', 'POLYGON ((13.297920227050781 52.56195151687443, 13.2440185546875 52.530216577830124, 13.267364501953125 52.45998421679598, 13.35113525390625 52.44826791583386, 13.405036926269531 52.44952338289473, 13.501167297363281 52.47148826410652, 13.509750366210938 52.489261333143126, 13.509063720703125 52.53710835019913, 13.481597900390625 52.554854904263195, 13.41156005859375 52.57217696877135, 13.37207794189453 52.5748894436198, 13.297920227050781 52.56195151687443))', CURRENT_TIMESTAMP);\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic geo_fence --replication-factor 3 --partitions 8\n```\n\nEnrichment of geo_fence by vehicle\n\n```\nALTER TABLE geo_fence RENAME TO geo_fence_t;\n\nCREATE VIEW geo_fence\nAS\nSELECT veh.id AS vehicle_id\n, veh.name AS vehicle_name\n,\tgeof.geometry_wkt\n, GREATEST(geof.last_update, veh.last_update) AS last_update\nFROM geo_fence_t geof\nCROSS JOIN vehicle veh;\n```\n## Using Kafka Connect to integrate with Kafka\n\n### Sync GeoFences\n\nTo sync the `geo_fence` table from PostgreSQL into the Kafka Topic `geo_fence` use the following script\n\n```\n#!/bin/bash\n\necho \"removing JDBC Source Connector\"\n\ncurl -X \"DELETE\" \"http://$DOCKER_HOST_IP:8083/connectors/geo_fence_source\"\n\necho \"creating JDBC Source Connector\"\n\n## Request\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n -d $'{\n \"name\": \"geo_fence_source\",\n \"config\": {\n \"connector.class\": \"io.confluent.connect.jdbc.JdbcSourceConnector\",\n \"tasks.max\": \"1\",\n \"connection.url\":\"jdbc:postgresql://postgresql/sample?user=sample&password=sample\",\n \"mode\": \"timestamp\",\n \"timestamp.column.name\":\"last_update\",\n \"table.whitelist\":\"geo_fence\",\n \"validate.non.null\":\"false\",\n \"topic.prefix\":\"\",\n \"key.converter\":\"org.apache.kafka.connect.storage.StringConverter\",\n \"key.converter.schemas.enable\": \"false\",\n \"value.converter\":\"org.apache.kafka.connect.json.JsonConverter\",\n \"value.converter.schemas.enable\": \"false\",\n \"name\": \"geo_fence_source\",\n \"transforms\":\"createKey,extractInt\",\n \"transforms.createKey.type\":\"org.apache.kafka.connect.transforms.ValueToKey\",\n \"transforms.createKey.fields\":\"id\",\n \"transforms.extractInt.type\":\"org.apache.kafka.connect.transforms.ExtractField$Key\",\n \"transforms.extractInt.field\":\"id\"\n }\n}'\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic geo_fence --replication-factor 3 --partitions 8\n```\n\n\n### Sync Vehicles\n\nTo sync the `vehicle` table from PostgreSQL into the Kafka Topic `vehicle` use the following script\n\n```\n#!/bin/bash\n\necho \"removing JDBC Source Connector\"\n\ncurl -X \"DELETE\" \"http://$DOCKER_HOST_IP:8083/connectors/vehicle_source\"\n\necho \"creating JDBC Source Connector\"\n\n## Request\ncurl -X \"POST\" \"$DOCKER_HOST_IP:8083/connectors\" \\\n -H \"Content-Type: application/json\" \\\n -d $'{\n \"name\": \"vehicle_source\",\n \"config\": {\n \"connector.class\": \"io.confluent.connect.jdbc.JdbcSourceConnector\",\n \"tasks.max\": \"1\",\n \"connection.url\":\"jdbc:postgresql://postgresql/sample?user=sample&password=sample\",\n \"mode\": \"timestamp\",\n \"timestamp.column.name\":\"last_update\",\n \"table.whitelist\":\"vehicle\",\n \"validate.non.null\":\"false\",\n \"topic.prefix\":\"\",\n \"key.converter\":\"org.apache.kafka.connect.storage.StringConverter\",\n \"key.converter.schemas.enable\": \"false\",\n \"value.converter\":\"org.apache.kafka.connect.json.JsonConverter\",\n \"value.converter.schemas.enable\": \"false\",\n \"name\": \"geo_fence_source\",\n \"transforms\":\"createKey,extractInt\",\n \"transforms.createKey.type\":\"org.apache.kafka.connect.transforms.ValueToKey\",\n \"transforms.createKey.fields\":\"id\",\n \"transforms.extractInt.type\":\"org.apache.kafka.connect.transforms.ExtractField$Key\",\n \"transforms.extractInt.field\":\"id\"\n }\n}'\n```\n\n```\ndocker exec -ti broker-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic vehicle --replication-factor 3 --partitions 8\n```\n"
},
{
"alpha_fraction": 0.71875,
"alphanum_fraction": 0.71875,
"avg_line_length": 9.666666984558105,
"blob_id": "10d04d423b47637229273f0f10b26cfe01de2a9f",
"content_id": "292ff0fc717a14b008488a50923cd078d75bafed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 3,
"path": "/rb-dr-case/vmware/scripts/produce.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\npython producer.py\n"
},
{
"alpha_fraction": 0.5344467759132385,
"alphanum_fraction": 0.5741127133369446,
"avg_line_length": 19.7391300201416,
"blob_id": "86a94ace35924de202cf5bef41d5092d79b7bf9e",
"content_id": "8eb753614e218bf2f55b7f1e767f26d5a9114a96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 23,
"path": "/php-kafka/producer.php",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "\n<?php\n\n$conf = new RdKafka\\Conf();\n$conf->setErrorCb(function ($kafka, $err, $reason) {\n printf(\"Kafka error: %s (reason: %s)\\n\", rd_kafka_err2str($err), $reason);\n});\n\n$rk = new RdKafka\\Producer($conf);\n$rk->setLogLevel(LOG_DEBUG);\n$rk->addBrokers(\"192.168.1.141\");\n\n$topic = $rk->newTopic(\"php_test\");\n\nfor ($i = 0; $i < 10; $i++) {\n $topic->produce(RD_KAFKA_PARTITION_UA, 0, \"Message $i\");\n $rk->poll(0);\n}\n\nwhile ($rk->getOutQLen() > 0) {\n $rk->poll(50);\n}\n\n?>\n\n"
},
{
"alpha_fraction": 0.7053701281547546,
"alphanum_fraction": 0.742017388343811,
"avg_line_length": 28.623655319213867,
"blob_id": "34de17a2bb4ff8832f0cb439e96684adade76c37",
"content_id": "e60edd8b1d739da1b859d7087562aea9e33f303c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2760,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 93,
"path": "/kafka-geofencing/docker/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Modern Data Platform Stack für Development beim AWS-ONE Projekt\n\nIm folgenden ist beschrieben, wie der Stack gestartet werden kann und auf was es zu achten gilt. \n\n## Start on Lightsail\n\nThe following script can be used to start the stack on Lightsail\n\n```\n# Install Docker\ncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -\nadd-apt-repository \"deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable edge\"\napt-get install -y docker-ce\nsudo usermod -aG docker ubuntu\n\n# Install Docker Compose\ncurl -L \"https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)\" -o /usr/local/bin/docker-compose\nchmod +x /usr/local/bin/docker-compose\nln -s /usr/local/bin/docker-compose /usr/bin/docker-compose\n\n# Prepare Environment Variables\nexport PUBLIC_IP=$(curl ipinfo.io/ip)\nexport DOCKER_HOST_IP=$(ip addr show eth0 | grep \"inet\\b\" | awk '{print $2}' | cut -d/ -f1)\n\n# needed for elasticsearch\nsudo sysctl -w vm.max_map_count=262144 \n\n# Get the project\ncd /home/ubuntu \ngit clone https://github.com/TrivadisPF/modern-data-analytics-stack.git\nchown -R ubuntu:ubuntu modern-data-analytics-stack\ncd modern-data-analytics-stack/customer-poc/aws-one/docker\n# Startup Environment\nsudo -E docker-compose up -d\n```\n\n## Spark History Server\n\nFür den Spark History Server muss der Folder zurzeit noch manuell erstellt werden:\n\n```\ndocker exec -ti hadoop-client hadoop fs -mkdir -p /spark/logs\n```\n\n## Verfügbare Services\n\nDie wichtigsten Services:\n\n* Zeppelin: <http://analyticsplatform:38081>\n* Minio Browser: <http://analyticsplatform:9000>\n* Hue: <http://analyticsplatform:28888>\n* StreamSets: <http://analyticsplatform:18630>\n* Spark UI: <http://analyticsplatform:8080>\n* Spark History Server: <http://analyticsplatform:18080>\n* Hadoop Namenode: <http://analyticsplatform:9870>\n* Yarn Ressource Manager: <http://analyticsplatform:8088>\n* Kafka Manager: <http://analyticsplatform:29000>\n* Kafka HQ: <http://analyticsplatform:28082>\n\n\n## Spark\n\nTesten von Spark über das CLI\n\n```\ndocker exec -ti spark-master spark-shell spark.version\n\nspark.version\n:quit\n```\n\n## Zeppelin\n\nTo work with Spark, the following dependency is needed on the **Spark** interpreter:\n \n * `org.apache.commons:commons-lang3:3.5` \n\n\nAnd if you want to use S3, the following 7 additional dependencies have to be added:\n\n * `org.apache.httpcomponents:httpclient:4.5.8`\n * `com.amazonaws:aws-java-sdk-core:1.11.524`\n * `com.amazonaws:aws-java-sdk-kms:1.11.524`\n * `com.amazonaws:aws-java-sdk:1.11.524`\n * `com.amazonaws:aws-java-sdk-s3:1.11.524`\n * `joda-time:joda-time:2.9.9`\n * `org.apache.hadoop:hadoop-aws:3.1.1`\t\n\n## ToDo\n\n * Livy richtig konfigurieren\n * Konfiguration auf externes S3 einrichten\n * "
},
{
"alpha_fraction": 0.7351256012916565,
"alphanum_fraction": 0.7377699613571167,
"avg_line_length": 42.63461685180664,
"blob_id": "15f210046db911630fa315da045f4b8a30b58c75",
"content_id": "fd8cf8f9e844dcf23a9f693f2ebd63432686a067",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 9076,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 208,
"path": "/jugs-2018/src/kafka-streams-truck/src/main/java/com/trivadis/kafkastreams/json/KafkaStreamsExampleJSON.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.kafkastreams.json;\nimport java.awt.datatransfer.StringSelection;\nimport java.util.HashMap;\nimport java.util.Map;\nimport java.util.Properties;\nimport java.util.concurrent.TimeUnit;\n\nimport org.apache.commons.lang3.StringUtils;\nimport org.apache.kafka.clients.consumer.ConsumerConfig;\nimport org.apache.kafka.common.serialization.Deserializer;\nimport org.apache.kafka.common.serialization.Serde;\nimport org.apache.kafka.common.serialization.Serdes;\nimport org.apache.kafka.common.serialization.Serializer;\nimport org.apache.kafka.connect.json.JsonDeserializer;\nimport org.apache.kafka.connect.json.JsonSerializer;\nimport org.apache.kafka.streams.Consumed;\nimport org.apache.kafka.streams.KafkaStreams;\nimport org.apache.kafka.streams.KeyValue;\nimport org.apache.kafka.streams.StreamsBuilder;\nimport org.apache.kafka.streams.StreamsConfig;\nimport org.apache.kafka.streams.kstream.GlobalKTable;\nimport org.apache.kafka.streams.kstream.Joined;\nimport org.apache.kafka.streams.kstream.KGroupedStream;\nimport org.apache.kafka.streams.kstream.KStream;\nimport org.apache.kafka.streams.kstream.KTable;\nimport org.apache.kafka.streams.kstream.Materialized;\nimport org.apache.kafka.streams.kstream.Printed;\nimport org.apache.kafka.streams.kstream.Produced;\nimport org.apache.kafka.streams.kstream.Serialized;\nimport org.apache.kafka.streams.kstream.TimeWindows;\nimport org.apache.kafka.streams.kstream.Windowed;\n\nimport com.fasterxml.jackson.databind.JsonNode;\nimport com.trivadis.kafkastreams.Driver;\nimport com.trivadis.kafkastreams.TruckPosition;\n\npublic class KafkaStreamsExampleJSON {\n\t\n\tstatic public class TruckPositionDriver {\n\t\tpublic TruckPosition truckPosition;\n\t\tpublic String driverFirstName;\n\t\tpublic String driverLastname;\n\t\t\n\t\tpublic TruckPositionDriver(TruckPosition truckPosition, String driverFirstName, String driverLastname) {\n\t\t\tthis.truckPosition = truckPosition;\n\t\t\tthis.driverFirstName = driverFirstName;\n\t\t\tthis.driverLastname = driverLastname;\n\t\t}\n\n\t\t@Override\n\t\tpublic String toString() {\n\t\t\treturn \"TruckPositionDriver [truckPosition=\" + truckPosition + \", driverFirstName=\" + driverFirstName\n\t\t\t\t\t+ \", driverLastname=\" + driverLastname + \"]\";\n\t\t}\n\t}\n\t\n\tpublic static void main(String[] args) {\n\t\t// Serializers/deserializers (serde) for String and Long types\n\t\tfinal Serde<String> stringSerde = Serdes.String();\n\t\tfinal Serde<Long> longSerde = Serdes.Long();\n final Serializer<JsonNode> jsonSerializer = new JsonSerializer();\n final Deserializer<JsonNode> jsonDeserializer = new JsonDeserializer();\n final Serde<JsonNode> jsonSerde = Serdes.serdeFrom(jsonSerializer, jsonDeserializer);\n\t\t\n\t final String bootstrapServers = args.length > 0 ? args[0] : \"192.168.69.135:9092\";\n\t final Properties streamsConfiguration = new Properties();\n\t // Give the Streams application a unique name. The name must be unique in the Kafka cluster\n\t // against which the application is run.\n\t streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, \"kafka-streams-trucking\");\n\n\t // Where to find Kafka broker(s).\n\t streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);\n\t streamsConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, \"earliest\");\n\t \n\t // Specify default (de)serializers for record keys and for record values.\n\t streamsConfiguration.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());\n\t streamsConfiguration.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());\t\t\n\t \n\t // specify the TimestampExtrator to use\n\t //streamsConfiguration.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, JsonTimestampExtractor.class);\n\t\t\n\t\t// In the subsequent lines we define the processing topology of the Streams application.\n\t\t// used to be KStreamBuilder ....\n\t final StreamsBuilder builder = new StreamsBuilder();\n\n\t\t/*\n\t\t * Prepare serdes to map to/from Json data to Java objects\n\t\t */\n\n\t\tMap<String, Object> serdeProps = new HashMap<>();\n\t\t \n final Serializer<TruckPosition> truckPositionSerializer = new JsonPOJOSerializer<>();\n serdeProps.put(\"JsonPOJOClass\", TruckPosition.class);\n truckPositionSerializer.configure(serdeProps, false);\n\n final Deserializer<TruckPosition> truckPositionDeserializer = new JsonPOJODeserializer<>();\n serdeProps.put(\"JsonPOJOClass\", TruckPosition.class);\n truckPositionDeserializer.configure(serdeProps, false);\n \n final Serde<TruckPosition> truckPositionSerde = Serdes.serdeFrom(truckPositionSerializer, truckPositionDeserializer);\n\n final Serializer<Driver> driverSerializer = new JsonPOJOSerializer<>();\n serdeProps.put(\"JsonPOJOClass\", Driver.class);\n driverSerializer.configure(serdeProps, false);\n\n final Deserializer<Driver> driverDeserializer = new JsonPOJODeserializer<>();\n serdeProps.put(\"JsonPOJOClass\", Driver.class);\n driverDeserializer.configure(serdeProps, false);\n \n final Serde<Driver> driverSerde = Serdes.serdeFrom(driverSerializer, driverDeserializer);\n\n final Serializer<TruckPositionDriver> truckPositionDriverSerializer = new JsonPOJOSerializer<>();\n serdeProps.put(\"JsonPOJOClass\", Driver.class);\n truckPositionDriverSerializer.configure(serdeProps, false);\n\n final Deserializer<TruckPositionDriver> truckPositionDriverDeserializer = new JsonPOJODeserializer<>();\n serdeProps.put(\"JsonPOJOClass\", Driver.class);\n truckPositionDriverDeserializer.configure(serdeProps, false);\n \n final Serde<TruckPositionDriver> truckPositionDriverSerde = Serdes.serdeFrom(truckPositionDriverSerializer, truckPositionDriverDeserializer);\n \n\t\t/*\n\t\t * Consume TruckPositions data from Kafka topic\n\t\t */\n\t\tKStream<String, TruckPosition> positions = builder.stream(\"truck_position\", Consumed.with(Serdes.String(), truckPositionSerde));\n\n\n\t\t/*\n\t\t * Non stateful transformation => filter out normal behaviour\n\t\t */\n\t\tKStream<String, TruckPosition> filtered = positions.filter(TruckPosition::filterNonNORMAL);\n\t\t\n\t\t// just for debugging\n\t\t// same as: xxx.foreach((key, value) -> System.out.println(key + \", \" + value))\n\t\tfiltered.print(Printed.toSysOut());\n\n\t\t/*\n\t\t * Repartition to prepare for the join\n\t\t */\n\t\tKStream<String, TruckPosition> filteredRekeyed = filtered\n\t\t\t\t.selectKey((key,value) -> value.driverId.toString());\n\t\t\n\t\t/*\n\t\t * Consume Driver data including changes from trucking_driver Kafka topic\n\t\t */\n KTable<String, Driver> driver = builder.table(\"trucking_driver\"\n \t\t\t\t\t\t\t\t\t\t\t, Consumed.with(Serdes.String(), driverSerde)\n \t\t\t\t\t\t\t\t\t\t\t, Materialized.as(\"trucking-driver-store-name\"));\t\n\t\t// just for debugging\n\t\t//driver.toStream().print(Printed.toSysOut());\n\n /*\n\t\t * Join Truck Position Stream with Driver data\n\t\t */\n\t\tKStream<String, TruckPositionDriver> joined = filteredRekeyed\n\t\t\t\t\t\t\t\t\t.leftJoin(driver\n\t\t\t\t\t\t\t\t\t\t\t\t, (left,right) -> new TruckPositionDriver(left\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t, (right != null) ? right.first_name : \"unknown\"\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t, (right != null) ? right.last_name : \"unkown\")\n\t\t\t\t\t\t\t\t\t\t\t\t, Joined.with(Serdes.String(), truckPositionSerde, driverSerde));\n\t\t\n\t\t/*\n\t\t * Write joined data to Kafka topic\n\t\t */\n\t\tjoined.to(\"dangerous_driving_kafka\", Produced.with(Serdes.String(), truckPositionDriverSerde));\n\t\t// just for debugging\n\t\t//joined.print(Printed.toSysOut());\n\n\t\t/*\n\t\t * Group by event type without window, !!!included in the statement below!!!\n\t\t */\n\t\tKGroupedStream<String,TruckPosition> truckPositionByEventType = filtered\n\t\t\t\t.groupBy((key,value) -> value.eventType, Serialized.with(Serdes.String(), truckPositionSerde));\n\t\t\n\t\t/*\n\t\t * Count by Event Type over a window of 1 minutes sliding 30 seconds \n\t\t */\n\t\tlong windowSizeMs = TimeUnit.MINUTES.toMillis(1);\n\t\tlong advanceMs = TimeUnit.SECONDS.toMillis(30); \n\t\tKTable<Windowed<String>, Long> countByEventType = filtered\n\t\t\t\t.groupBy((key,value) -> value.eventType, Serialized.with(Serdes.String(), truckPositionSerde))\n\t\t\t .windowedBy(TimeWindows.of(windowSizeMs).advanceBy(advanceMs))\n\t\t\t\t.count(Materialized.as(\"RollingSevenDaysOfPageViewsByRegion\"));\n\t\t\n\t\t\n\t\t// same as: xxx.foreach((key, value) -> System.out.println(key + \", \" + value))\n\t\t//countByEventType.toStream().print(Printed.toSysOut());\n\t\t\n\t\t// used to be new KafkaStreams(build, streamsConfiguration)\n\t\tfinal KafkaStreams streams = new KafkaStreams(builder.build(), streamsConfiguration);\n\t\t\n\t\t// clean up all local state by application-id\n\t\tstreams.cleanUp();\n\n\t streams.setUncaughtExceptionHandler((Thread thread, Throwable throwable) -> {\n\t \tSystem.out.println(\"Within UncaughtExceptionHandler =======>\");\n\t \tSystem.out.println(throwable);\n\t \t // here you should examine the throwable/exception and perform an appropriate action!\n\t \t});\n\n\t\tstreams.start();\n\n\t // Add shutdown hook to respond to SIGTERM and gracefully close Kafka Streams\n\t Runtime.getRuntime().addShutdownHook(new Thread(streams::close));\n\t \n\t}\n\n}\n"
},
{
"alpha_fraction": 0.7281976938247681,
"alphanum_fraction": 0.7393410801887512,
"avg_line_length": 26.520000457763672,
"blob_id": "60705884bfa61e7851eff7e6e6dd8e3d671d1ef3",
"content_id": "0b978e71baa86419233c22d456fabd004d0e3a8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2064,
"license_type": "no_license",
"max_line_length": 385,
"num_lines": 75,
"path": "/data-lake-platform/kylo/README.md",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Kylo\n\n[Kylo](http://kylo.io) is a data lake platform built on Apache Hadoop and Apache Spark. Kylo provides a business-friendly data lake solution and enables self-service data ingestion, data wrangling, data profiling, data validation, data cleansing/standardization, and data discovery. Its intuitive user interface allows IT professionals to access the data lake (without having to code).\n\n## Setup\nIn order to get a Kylo sandbox environment, eihter a virtual machine can be downloaded from the Kylo website or the Kylo sandbox can be provisioned on AWS: <https://kylo.io/quickstart.html>.\n\nThe following is based on a local virtual machine, downloaded and imported into VMWare Fusion.\n\nYou can login to the sandbox using user `root` and password `kylo`. Be aware that the keyboard is US! See below how to change it. \n\n\n### Change Keyboard to Swiss-German\n\n```\nyum install kbd\n\nlocalectl set-keymap ch-de_mac\n```\n\n### Change /etc/hosts\nAdd the IP address as `kylo` to the `/etc/hosts` file.\n\nYou can get the address using\n\n```\nip addr\n```\n\n### Configure HDFS to allow admin user\n\nConfigure proxy user for user admin\n\nIn Ambari click on **Services** | **HDFS**. Navigate to tab **Configs** and then **Advanced**. \nJump forward to **Custom core-site** and add the following two properties:\n\n```\nhadoop.proxyuser.root.groups=*\nhadoop.proxyuser.root.hosts=*\n```\n \nNow create the folder /user/admin\n\n```\nhadoop fs -mkdir /user/admin\nhadoop fs -chmod +777 /user/admin\n```\n\nand both the File View and Hive view in Abmari should work.\n\n## Using Kylo\n\n* Kylo UI: <http://kylo:8400> login: dladmin/thinkbig\n* Kylo NiFi: <http://kylo:8079/nifi/>\n* API Doc: <http://kylo:8400/api-docs/index.html>\n* Ambari UI: <http://kylo:8080> - login admin/admin\n* ActiveMQ Admin: <http:kylo:8161>\n\n\nCreate a folder ini the dropzone\n\n```\ncd /var/dropzone\nmkdir airplane\n\nchmod nifi:hdfs airplane\n```\n\nDrop the files here\n\n```\nscp flights.csv root@kylo:/var/dropzone/airplane\nscp airports.csv root@kylo:/var/dropzone/airplane\nscp airlines.csv root@kylo:/var/dropzone/airplane\n```\n"
},
{
"alpha_fraction": 0.7565543055534363,
"alphanum_fraction": 0.7565543055534363,
"avg_line_length": 19.615385055541992,
"blob_id": "a6bf928a233bbc171c457b80ec5357771b0011d2",
"content_id": "3d23155bcf2345ad504a6a23819387e0faabd46d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 13,
"path": "/graph-performance/des-graph-test/src/main/java/com/trivadis/GraphRepository.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis;\n\nimport com.trivadis.domain.Tweet;\n\npublic interface GraphRepository {\n\n\t/**\n\t * Creates the graph representation of a Tweet and the User being the author of the tweet \n\t * @param tweetDO\n\t */\n\tGraphMetrics createTweetAndUsers(Tweet tweetDO);\n\n}"
},
{
"alpha_fraction": 0.6211832165718079,
"alphanum_fraction": 0.6652965545654297,
"avg_line_length": 32.559112548828125,
"blob_id": "b3059f360d72501803b86acccf454e9dc42954d9",
"content_id": "7e3f4a9c429ef8e4a7c4f9e111139a18d18bb88a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 13624,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 406,
"path": "/avro-and-schema-registry/docker/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#\n# Docker Compose with the following services:\n# Zookeeper\n# Kafka Broker 1-3\n# Schema Registry\n# Kafka Connect 1 - 2\n# Kafka Rest Proxy\n# KSQL server\n# Schema Registry UI\n# Kafka Connect UI\n# Kafka Manager\n# Zoonavigator\n# Kafdrop\n# Streamsets\n# Apache NiFi\n#\n\nversion: '2'\nservices:\n zookeeper-1:\n image: confluentinc/cp-zookeeper:5.3.1\n hostname: zookeeper-1\n container_name: zookeeper-1\n ports:\n - \"2181:2181\"\n environment:\n ZOOKEEPER_CLIENT_PORT: 2181\n ZOOKEEPER_TICK_TIME: 2000\n restart: always\n\n zoonavigator:\n image: elkozmon/zoonavigator-web:0.5.1\n container_name: zoonavigator\n ports:\n - \"28047:8010\"\n environment:\n WEB_HTTP_PORT: 8010\n API_HOST: \"zoonavigator-api\"\n API_PORT: 9010\n depends_on:\n - zoonavigator-api\n restart: always\n \n zoonavigator-api:\n image: elkozmon/zoonavigator-api:0.5.1\n container_name: zoonavigator-api\n ports:\n - \"28048:9010\"\n environment:\n API_HTTP_PORT: 9010\n\n broker-1:\n image: confluentinc/cp-kafka:5.3.1\n hostname: broker-1\n container_name: broker-1\n depends_on:\n - zookeeper-1\n ports:\n - \"9092:9092\"\n environment:\n KAFKA_BROKER_ID: 1\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${PUBLIC_IP}:9092'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9994\n restart: always\n\n broker-2:\n image: confluentinc/cp-kafka:5.3.1\n hostname: broker-2\n container_name: broker-2\n depends_on:\n - zookeeper-1\n ports:\n - \"9093:9093\"\n environment:\n KAFKA_BROKER_ID: 2\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${PUBLIC_IP}:9093'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9993\n restart: always\n\n broker-3:\n image: confluentinc/cp-kafka:5.3.1\n hostname: broker-3\n container_name: broker-3\n depends_on:\n - zookeeper-1\n ports:\n - \"9094:9094\"\n environment:\n KAFKA_BROKER_ID: 3\n KAFKA_BROKER_RACK: 'r1'\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${PUBLIC_IP}:9094'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3\n KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0\n KAFKA_DELETE_TOPIC_ENABLE: 'true'\n KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'\n KAFKA_JMX_PORT: 9992\n restart: always\n \n schema-registry-1:\n image: confluentinc/cp-schema-registry:5.3.1\n hostname: schema-registry-1\n container_name: schema-registry-1 \n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"28030:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry-1\n SCHEMA_REGISTRY_MASTER_ELIGIBILITY: 'true'\n SCHEMA_REGISTRY_AVRO_COMPATIBILITY_LEVEL: 'full'\n# SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper-1:2181'\n SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker-1:9092,broker-2:9093'\n SCHEMA_REGISTRY_MASTER_ELIGIBILITY: \"true\"\n SCHEMA_REGISTRY_KAFKASTORE_TOPIC_REPLICATION_FACTOR: 3\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always\n\n schema-registry-2:\n image: confluentinc/cp-schema-registry:5.3.1\n hostname: schema-registr-2\n container_name: schema-registry-2 \n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"28031:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry-2\n SCHEMA_REGISTRY_MASTER_ELIGIBILITY: 'true'\n SCHEMA_REGISTRY_AVRO_COMPATIBILITY_LEVEL: 'full'\n# SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper-1:2181'\n SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker-1:9092,broker-2:9093'\n SCHEMA_REGISTRY_MASTER_ELIGIBILITY: \"true\"\n SCHEMA_REGISTRY_KAFKASTORE_TOPIC_REPLICATION_FACTOR: 3\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always \n \n schema-registry-3:\n image: confluentinc/cp-schema-registry:5.3.1\n hostname: schema-registr-3\n container_name: schema-registry-3 \n depends_on:\n - zookeeper-1\n - broker-1\n ports:\n - \"28032:8081\"\n environment:\n SCHEMA_REGISTRY_HOST_NAME: schema-registry-3\n SCHEMA_REGISTRY_MASTER_ELIGIBILITY: 'true'\n SCHEMA_REGISTRY_AVRO_COMPATIBILITY_LEVEL: 'full'\n# SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper-1:2181'\n SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker-1:9092,broker-2:9093'\n SCHEMA_REGISTRY_MASTER_ELIGIBILITY: \"false\"\n SCHEMA_REGISTRY_KAFKASTORE_TOPIC_REPLICATION_FACTOR: 3\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'\n SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,OPTIONS'\n restart: always \n\n connect-1:\n image: confluentinc/cp-kafka-connect:5.3.1\n hostname: connect-1\n container_name: connect-1\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry-1\n ports:\n - \"28013:8083\"\n environment:\n CONNECT_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONNECT_REST_ADVERTISED_HOST_NAME: connect-1\n CONNECT_REST_PORT: 8083\n CONNECT_GROUP_ID: compose-connect-group\n CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs\n CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000\n CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets\n CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status\n CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONNECT_PLUGIN_PATH: \"/usr/share/java,/etc/kafka-connect/custom-plugins\"\n CONNECT_LOG4J_ROOT_LOGLEVEL: INFO\n CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-4.0.0.jar\n AWS_ACCESS_KEY_ID: V42FCGRVMK24JJ8DHUYG\n AWS_SECRET_ACCESS_KEY: bKhWxVF3kQoLY9kFmt91l+tDrEoZjqnWXzY9Eza\n volumes:\n - ./kafka-connect:/etc/kafka-connect/custom-plugins\n restart: always\n\n connect-2:\n image: confluentinc/cp-kafka-connect:5.3.1\n hostname: connect-2\n container_name: connect-2\n depends_on:\n - zookeeper-1\n - broker-1\n - schema-registry-1\n ports:\n - \"28014:8084\"\n environment:\n CONNECT_BOOTSTRAP_SERVERS: 'broker-1:9092'\n CONNECT_REST_ADVERTISED_HOST_NAME: connect-2\n CONNECT_REST_PORT: 8084\n CONNECT_GROUP_ID: compose-connect-group\n CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs\n CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000\n CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets\n CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status\n CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 3\n CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter\n CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry-1:8081'\n CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter\n CONNECT_ZOOKEEPER_CONNECT: 'zookeeper-1:2181'\n CONNECT_PLUGIN_PATH: \"/usr/share/java,/etc/kafka-connect/custom-plugins\"\n CONNECT_LOG4J_ROOT_LOGLEVEL: INFO\n CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-4.0.0.jar\n AWS_ACCESS_KEY_ID: V42FCGRVMK24JJ8DHUYG\n AWS_SECRET_ACCESS_KEY: bKhWxVF3kQoLY9kFmt91l+tDrEoZjqnWXzY9Eza\n volumes:\n - ./kafka-connect:/etc/kafka-connect/custom-plugins\n restart: always\n\n\n ksql-server-1:\n image: confluentinc/cp-ksql-server:5.3.0\n container_name: ksql-server-1\n ports:\n - '28034:8088'\n depends_on:\n - broker-1\n - schema-registry-1\n environment:\n KSQL_CONFIG_DIR: \"/etc/ksql\"\n KSQL_LOG4J_OPTS: \"-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties\"\n KSQL_BOOTSTRAP_SERVERS: \"broker-1:9092,broker-2:9093\"\n KSQL_HOST_NAME: ksql-server-1\n KSQL_APPLICATION_ID: \"kafka-demo\"\n KSQL_LISTENERS: \"http://0.0.0.0:8088\"\n KSQL_CACHE_MAX_BYTES_BUFFERING: 0\n # Schema Registry using HTTPS\n KSQL_KSQL_SCHEMA_REGISTRY_URL: \"http://schema-registry-1:8081\"\n KSQL_KSQL_SERVICE_ID: \"kafka-demo\"\n KSQL_PRODUCER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor\n KSQL_CONSUMER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor\n KSQL_KSQL_SERVER_UI_ENABLED: \"false\"\n volumes:\n - $PWD/ksql:/etc/ksql/ext \n restart: always\n\n ksql-server-2:\n image: confluentinc/cp-ksql-server:5.3.0\n container_name: ksql-server-2\n ports:\n - '28035:8088'\n depends_on:\n - broker-1\n - schema-registry-1\n environment:\n KSQL_CONFIG_DIR: \"/etc/ksql\"\n KSQL_LOG4J_OPTS: \"-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties\"\n KSQL_BOOTSTRAP_SERVERS: \"broker-1:9092,broker-2:9093\"\n KSQL_HOST_NAME: ksql-server-2\n KSQL_APPLICATION_ID: \"kafka-demo\"\n KSQL_LISTENERS: \"http://0.0.0.0:8088\"\n KSQL_CACHE_MAX_BYTES_BUFFERING: 0\n # Schema Registry using HTTPS\n KSQL_KSQL_SCHEMA_REGISTRY_URL: \"http://schema-registry-1:8081\"\n KSQL_KSQL_SERVICE_ID: \"kafka-demo\"\n KSQL_PRODUCER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor\n KSQL_CONSUMER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor\n KSQL_KSQL_SERVER_UI_ENABLED: \"false\"\n volumes:\n - $PWD/ksql:/etc/ksql/ext \n restart: always\n\n schema-registry-ui:\n image: landoop/schema-registry-ui\n hostname: schema-registry-ui\n container_name: schema-registry-ui\n depends_on:\n - broker-1\n - schema-registry-1\n ports:\n - \"28039:8000\"\n environment:\n SCHEMAREGISTRY_URL: 'http://${PUBLIC_IP}:28030'\n restart: always\n\n kafka-connect-ui:\n image: landoop/kafka-connect-ui\n hostname: kafka-connect-ui\n container_name: kafka-connect-ui\n ports:\n - \"28038:8000\"\n environment:\n CONNECT_URL: \"http://${PUBLIC_IP}:28013/,http://${PUBLIC_IP}:28014/\"\n PROXY: \"true\"\n depends_on:\n - connect-1\n restart: always\n\n kafka-manager:\n image: trivadisbds/kafka-manager\n hostname: kafka-manager\n container_name: kafka-manager\n depends_on:\n - zookeeper-1\n - broker-1\n - broker-2\n - broker-3\n ports:\n - \"28044:9000\"\n environment:\n ZK_HOSTS: 'zookeeper-1:2181'\n APPLICATION_SECRET: 'abc123!'\n restart: always\n\n kafkahq:\n image: tchiotludo/kafkahq\n container_name: kafkahq\n ports:\n - '28042:8080'\n environment:\n KAFKAHQ_CONFIGURATION: |\n kafkahq:\n connections:\n docker-kafka-server:\n properties:\n bootstrap.servers: \"broker-1:9092,broker-2:9093\"\n schema-registry:\n url: \"http://schema-registry-1:8081\"\n connect:\n url: \"http://connect-1:8083\"\n depends_on:\n - broker-1\n restart: always\n\n kafka-setup:\n image: confluentinc/cp-kafka:5.3.1\n hostname: kafka-setup\n container_name: kafka-setup\n depends_on:\n - broker-1\n - broker-2\n - broker-3\n - zookeeper-1\n command: \"bash -c 'echo Waiting for Kafka to be ready... && \\\n cub kafka-ready -b broker-1:9092 1 120 && \\\n kafka-topics --create --if-not-exists --zookeeper zookeeper-1:2181 --partitions 8 --replication-factor 3 --topic person-v1 && \\\n kafka-topics --create --if-not-exists --zookeeper zookeeper-1:2181 --partitions 8 --replication-factor 3 --topic person-v2\n '\"\n environment:\n # The following settings are listed here only to satisfy the image's requirements.\n # We override the image's `command` anyways, hence this container will not start a broker.\n KAFKA_BROKER_ID: ignored\n KAFKA_ZOOKEEPER_CONNECT: ignored \n\n streamsets:\n image: trivadisbds/streamsets-kafka-nosql\n hostname: streamsets\n container_name: streamsets\n ports:\n - \"28029:18630\"\n restart: always\n\n # Container UI ===============================================\n \n portainer:\n image: portainer/portainer\n volumes:\n - /var/run/docker.sock:/var/run/docker.sock\n# - data_portainer:/data\n# environment:\n# - VIRTUAL_HOST=monitor.bioatlas.se\n# - VIRTUAL_PORT=9000\n ports:\n - 28071:9000 \n restart: always"
},
{
"alpha_fraction": 0.7319298386573792,
"alphanum_fraction": 0.7761403322219849,
"avg_line_length": 32.92856979370117,
"blob_id": "5b1579488e687de854e0c6464c8146302dcec1ec",
"content_id": "3c1175c550da000d6e6194bc910ba878591f756f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1425,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 42,
"path": "/kafka-geofencing/kafka-streams/geo-utils/src/test/java/com/thyssenkrupp/tkse/DistanceUtilTest.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.thyssenkrupp.tkse;\n\nimport java.util.Locale;\n\nimport org.geotools.geometry.jts.JTSFactoryFinder;\nimport org.junit.Test;\nimport org.locationtech.jts.geom.Coordinate;\nimport org.locationtech.jts.geom.GeometryFactory;\nimport org.locationtech.jts.geom.Point;\n\npublic class DistanceUtilTest {\n\t\n\tprivate static GeometryFactory geometryFactory = JTSFactoryFinder.getGeometryFactory();\n\t\n\t@Test\n\tpublic void near() throws Exception {\n\t\tthis.calculateDistanceToRhine(6.688356399536133, 51.5295183372046);\n\t}\n\t\n\t@Test\n\tpublic void far() throws Exception {\n\t\tthis.calculateDistanceToRhine(6.894950866699219, 51.58282994156007);\n\t}\n\t\n\tpublic double calculateDistanceToRhine(double longitude, double latitude) throws Exception {\n\t\tCoordinate spotCoordinate = new Coordinate(longitude, latitude);\n\t\tPoint spotPoint = geometryFactory.createPoint(spotCoordinate);\n\n\t\tCoordinate closestOnRhine = RhineUtil.calculateClosestPointOnRhine(spotPoint);\n\t\tdouble distanceInMeters = DistanceUtil.calculateDistanceInMeters(spotCoordinate, closestOnRhine);\n\t\t\n\t\tSystem.out.printf(Locale.US,\n\t\t\t\t\"Distance from POINT(%f %f) to POINT(%f %f) [LINESTRING(%f %f, %f %f)] is: %f.%n\", \n\t\t\t\tspotCoordinate.getX(), spotCoordinate.getY(), \n\t\t\t\tclosestOnRhine.getX(), closestOnRhine.getY(), \n\t\t\t\tspotCoordinate.getX(), spotCoordinate.getY(), \n\t\t\t\tclosestOnRhine.getX(), closestOnRhine.getY(), \n\t\t\t\tdistanceInMeters);\n\n\t\treturn distanceInMeters;\n\t}\n}\n"
},
{
"alpha_fraction": 0.643410861492157,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 42,
"blob_id": "5d3284d9ae8b0b35d641cf719dab9f4b5ae9d3bb",
"content_id": "86e540ae55648465ffb00113f55569e9fd628749",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 3,
"path": "/rb-dr-case/vmware/scripts/delete-topic.sh",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n/home/gus/confluent-5.0.1/bin/kafka-topics --zookeeper zookeeper-1:2181, zookeeper-4:2185 --delete --topic sequence\n"
},
{
"alpha_fraction": 0.7188552021980286,
"alphanum_fraction": 0.7297979593276978,
"avg_line_length": 26,
"blob_id": "d1a4aa3b9f71a9d764906e559c2a1cb5cda95212",
"content_id": "7fdb9369c7a14b073f150b8b1828414ac31a39a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 44,
"path": "/avro-vs-protobuf/protobuf/java/protobuf-encoding/src/test/java/com/trivadis/protobuf/demo/TestProtobufV1.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis.protobuf.demo;\n\nimport java.io.FileInputStream;\nimport java.io.FileOutputStream;\nimport java.io.IOException;\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport org.junit.Test;\n\nimport com.trivadis.protobuf.person.v1.PersonWrapper;\n\npublic class TestProtobufV1 {\n\n\tprivate final static String BIN_FILE_NAME_V1 = \"../../data/encoding_v1.0.bin\";\n\t\n\t@Test\n\tpublic void testWriteToBinaryFileV1() throws IOException {\n\t\tList<String> skills = new ArrayList<>();\n\t\t\n\t\tskills.add(\"Avro\");\n\t\tskills.add(\"Protobuf\");\n\t\tskills.add(\"Kafka\");\n\t\t\n\t\tPersonWrapper.Person person = PersonWrapper.Person.newBuilder().setId(1842)\n\t\t\t\t\t.setName(\"Guido Schmutz\")\n\t\t\t\t\t.addAllSkills(skills).build();\n\n\t\tSystem.out.println(person);\n\t\t\n\t\tFileOutputStream output = new FileOutputStream(BIN_FILE_NAME_V1);\n\t\tperson.writeTo(output);\n\t}\n\t\n\t@Test\n\tpublic void testReadFromBinaryFileV1() throws IOException {\n\t\t\n\t\tPersonWrapper.Person person =\n\t\t\t PersonWrapper.Person.parseFrom(new FileInputStream(BIN_FILE_NAME_V1));\n\t\tSystem.out.println(\"Person:\" + person);\n\t\tSystem.out.println(\"FirstName: \" + person.getName());\n\t\tSystem.out.println(\"Unknown fields:\" + person.getUnknownFields());\n\t}\t\n}\n"
},
{
"alpha_fraction": 0.6026344895362854,
"alphanum_fraction": 0.6333699226379395,
"avg_line_length": 30.413793563842773,
"blob_id": "7058d70a35ff5ea613a7aa931b386bb43cb1c7f7",
"content_id": "c9444247fbababb716f8e59dc2d42d86af4808ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 29,
"path": "/rb-dr-case/scripts/producer.py",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "from confluent_kafka import Producer\nimport time\n\np = Producer({'bootstrap.servers': 'broker-1:9092,broker-2:9093'}, retries=999999)\n\ndef delivery_report(err, msg):\n \"\"\" Called once for each message produced to indicate delivery result.\n Triggered by poll() or flush(). \"\"\"\n if err is not None:\n print('Message delivery failed: {}'.format(err))\n else:\n print('Message delivered to {} [{}]'.format(msg.topic(), msg.partition()))\n\nfor data in range(10000):\n for part in range(1,8):\n # Trigger any available delivery report callbacks from previous produce() calls\n p.poll(0)\n\n p.produce('sequence', partition=part,key=str(1),value=str(data), callback=delivery_report)\n p.flush()\n\n while 1==1:\n\t with open(\"control.info\") as f: \n\t\t\tflag = f.read() \n\t\t\tif (\"true\" in flag):\n \t\t\ttime.sleep(1)\n \t\t\tbreak\n \t\telse:\n \t\t\tprint \"producer stopped!\"\n"
},
{
"alpha_fraction": 0.6755205988883972,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 38.51863479614258,
"blob_id": "e8ea793a14b65827265841e44a80fc9316409de3",
"content_id": "6661da3d7f3f0c8ebe1a1dfac143aa290b81f041",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 12725,
"license_type": "no_license",
"max_line_length": 258,
"num_lines": 322,
"path": "/graph-performance/des-graph-test/src/main/java/com/trivadis/DseGraphDynGremlinHelper.java",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "package com.trivadis;\n\n\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\n\nimport org.apache.commons.lang.text.StrSubstitutor;\nimport org.apache.commons.lang3.StringUtils;\n\nimport com.datastax.driver.dse.DseSession;\nimport com.datastax.driver.dse.graph.GraphNode;\nimport com.datastax.driver.dse.graph.GraphResultSet;\nimport com.datastax.driver.dse.graph.SimpleGraphStatement;\n\npublic class DseGraphDynGremlinHelper {\n\n\tprivate GraphMetrics graphMetrics = null;\n\t\n\tprivate Map<String,Map<String,Object>> bindVars = new HashMap();\n\tprivate StringBuffer stmt = new StringBuffer();\n\t\n\tprivate DseSession session;\n\t\n\n\n\tprivate String fmtLoadVertex(String vertexName, String vertexLabel, String propertyKey, Object propertyKeyValue) {\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tStrSubstitutor subst = null;\n\t\t\n\t\tMap<String,Object> params = new HashMap();\n\t\tparams.put(\"vertexName\", vertexName);\n\t\tparams.put(\"vertexLabel\", vertexLabel);\n\t\tparams.put(\"propertyKey\", propertyKey);\n\t\tparams.put(\"propertyKeyValue\", propertyKeyValue);\n\t\tsubst = new StrSubstitutor(params);\n\n\t\tstmt.append(subst.replace(\"${vertexName} = g.V().has('${vertexLabel}', '${propertyKey}', ${propertyKeyValue}).next()\"));\n\t\t\n\t\treturn stmt.toString();\n\t}\n\t\n\tprivate String fmtCreateOrUpdateVertex(String vertexName, String vertexLabel, String propertyKey, String propertyKeyValue, String... propertiesParam) {\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tStrSubstitutor subst = null;\n\t\t\n\t\tMap<String,Object> params = new HashMap();\n\t\tparams.put(\"vertexName\", vertexName);\n\t\tparams.put(\"vertexLabel\", vertexLabel);\n\t\tparams.put(\"propertyKey\", propertyKey);\n\t\tparams.put(\"propertyKeyValue\", propertyKeyValue);\n\t\tsubst = new StrSubstitutor(params);\n\t\tstmt.append(subst.replace(\"if (!nof.containsKey('vertex.lookup.${vertexLabel}')) nof['vertex.lookup.${vertexLabel}'] = 0\")).append(\"\\n\");\n\t\tstmt.append(subst.replace(\"nof['vertex.lookup.${vertexLabel}']++\")).append(\"\\n\");\n\t\tstmt.append(subst.replace(\"if (!nof.containsKey('vertex.create.${vertexLabel}')) nof['vertex.create.${vertexLabel}'] = 0\")).append(\"\\n\");\n\t\tstmt.append(subst.replace(\"${vertexName} = g.V().has('${vertexLabel}', '${propertyKey}', ${propertyKeyValue}).tryNext().orElseGet { nof['vertex.create.${vertexLabel}']++; g.addV('${vertexLabel}').property('${propertyKey}', ${propertyKeyValue}).next() }\"));\n\t\tparams.clear();\n\t\tfor (int i=0; i<propertiesParam.length/2 ; i++) {\n\t\t\tparams.put(\"vertexName\", vertexName);\n\t\t\tparams.put(\"propertyKey\", propertiesParam[i*2]);\n\t\t\tparams.put(\"propertyValue\", propertiesParam[i*2+1]);\n\n\t\t\tsubst = new StrSubstitutor(params);\n\t\t\tstmt.append(\"\\n\");\n\t\t\tstmt.append(subst.replace(\"${vertexName}.property('${propertyKey}',${propertyValue})\"));\n\t\t}\n\t\t\n\t\treturn stmt.toString();\n\t}\n\t\n\tprivate String fmtCreateOrUpdateEdge(String edgeName, String fromVertexName, String toVertexName, String edgeLabel, String... propertiesParam) {\n\t\tStringBuffer stmt = new StringBuffer();\n\t\tStrSubstitutor subst = null;\n\t\t\n\t\tMap<String,String> params = new HashMap();\n\t\tparams.put(\"edgeName\", edgeName);\n\t\tparams.put(\"fromVertexName\", fromVertexName);\n\t\tparams.put(\"toVertexName\", toVertexName);\n\t\tparams.put(\"edgeLabel\", edgeLabel);\n\t\tsubst = new StrSubstitutor(params);\n\t\t\n\t\tstmt.append(subst.replace(\"if (!nof.containsKey('edge.lookup.${edgeLabel}')) nof['edge.lookup.${edgeLabel}'] = 0\")).append(\"\\n\");\n\t\tstmt.append(subst.replace(\"nof['edge.lookup.${edgeLabel}']++\")).append(\"\\n\");\n\t\tstmt.append(subst.replace(\"if (!nof.containsKey('edge.create.${edgeLabel}')) nof['edge.create.${edgeLabel}'] = 0\")).append(\"\\n\");\n\t\tstmt.append(subst.replace(\"if (!g.V(${fromVertexName}).out('${edgeLabel}').hasId(${toVertexName}.id()).hasNext()) {\\n\"));\n\t\tstmt.append(subst.replace(\"\\t\\t${edgeName} = g.V(${fromVertexName}).as('f').V(${toVertexName}).as('t').addE('${edgeLabel}').from('f').next()\\n\"));\n\t\tstmt.append(subst.replace(\"\\t\\tnof['edge.create.${edgeLabel}']++;\\n\"));\n\t\tparams.clear();\n\t\tfor (int i=0; i<propertiesParam.length/2 ; i++) {\n\t\t\tparams.put(\"edgeName\", edgeName);\n\t\t\tparams.put(\"propertyKey\", propertiesParam[i*2]);\n\t\t\tparams.put(\"propertyValue\", propertiesParam[i*2+1]);\n\n\t\t\tsubst = new StrSubstitutor(params);\n\t\t\tstmt.append(\"\\n\");\n\t\t\tstmt.append(subst.replace(\"${edgeName}.property('${propertyKey}','${propertyValue}')\"));\n\t\t}\n\t\tstmt.append(\"\\t}\");\n\t\treturn stmt.toString();\n\t}\n\n\tpublic DseGraphDynGremlinHelper(DseSession session) {\n\t\tthis.session = session;\n\t\tstmt.append(\"nof = [:]\").append(\"\\n\");\n\t\t\n\t\tstmt.append(\"int i = 0\").append(\"\\n\");\n\t}\n\t\n\tpublic void addLoadVertex(String vertexName, String vertexLabel, String propertyKey, Object propertyKeyValue) {\n\t\tfinal String bindVar = \"b\" + StringUtils.capitalize(vertexName);\n\t\tMap<String,Object> bindVarsMap = new HashMap<String,Object>();\n\n\t\tbindVarsMap.put(propertyKey, propertyKeyValue);\n\t\tbindVars.put(bindVar, bindVarsMap);\n\n\t\tstmt.append(fmtLoadVertex(vertexName, vertexLabel, propertyKey, bindVar+\".\"+propertyKey));\n\t\tstmt.append(\"\\n\");\n\t}\n\n\tpublic void addCreateVertex(String vertexName, String vertexLabel, String propertyKey, String propertyKeyValue, Object... propertyParams) {\n\t\tfinal String bindVar = \"b\" + StringUtils.capitalize(vertexName);\n\t\tList<String> params = new ArrayList<String>();\n\t\tMap<String,Object> bindVarsMap = new HashMap<String,Object>();\n\t\t\n\t\tif (propertyParams != null) {\n\t\t\tfor (int i=0; i<propertyParams.length/2 ; i++) {\n\t\t\t\tif (propertyParams[i*2+1] != null) {\n\t\t\t\t\tparams.add((String)propertyParams[i*2]);\n\t\t\t\t\tparams.add(bindVar + \".\" + (String)propertyParams[i*2]);\n\t\t\t\t\t\n\t\t\t\t\tbindVarsMap.put((String)propertyParams[i*2], propertyParams[i*2+1]);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tbindVarsMap.put(propertyKey, propertyKeyValue);\n\t\tbindVars.put(bindVar, bindVarsMap);\n\t\t\n\t\t//stmt.append(\"try {\").append(\"\\n\");\t\t\n\t\tstmt.append(fmtCreateOrUpdateVertex(vertexName, vertexLabel, propertyKey, bindVar+\".\"+propertyKey, params.toArray(new String[0])));\n\t\t//stmt.append(\"} catch(Exception e) { println(\\\"\").append(vertexName).append(\"\\\")\\n throw e}\").append(\"\\n\");\n\t\tstmt.append(\"\\n\");\n\t}\n\t\n\t\n\tpublic void addCreateEdge(String edgeName, String fromVertexName, String toVertexName, String edgeLabel, Object... propertyParams) {\n\t\tfinal String bindVar = \"b\" + StringUtils.capitalize(edgeName);\n\n\t\tList<String> params = new ArrayList<String>();\n\t\tMap<String,Object> bindVarsMap = new HashMap<String,Object>();\n\t\t\n\t\tif (propertyParams != null) {\n\t\t\t\n\t\t\tfor (int i=0; i<propertyParams.length/2 ; i++) {\n\t\t\t\tif (propertyParams[i*2+1] != null) {\n\t\t\t\t\tparams.add((String)propertyParams[i*2]);\n\t\t\t\t\tparams.add(bindVar + \".\" + (String)propertyParams[i*2]);\n\t\t\t\t\n\t\t\t\t\tbindVarsMap.put((String)propertyParams[i*2], propertyParams[i*2+1]);\n\t\t\t\t}\n\t\t\t}\n\t\t\tif (!bindVarsMap.isEmpty())\n\t\t\t\tbindVars.put(bindVar, bindVarsMap);\n\t\t}\n\t\t\n\t\tstmt.append(fmtCreateOrUpdateEdge(edgeName, fromVertexName, toVertexName, edgeLabel, params.toArray(new String[0])));\n\t\tstmt.append(\"\\n\");\n\t\t\n\t}\n\t\n\tpublic void addCreateVertices(String vertexName, String vertexLabel, String propertyKey, List<Object> propertyKeyValues, Object ... propertyParams) {\n\t\tList<Map<String,Object>> params = new ArrayList<Map<String,Object>>();\n\n\t\tif (propertyKeyValues != null && propertyKeyValues.size() > 0) {\n\t\t\n\t\t\tfor (Object o : propertyKeyValues) {\n\t\t\t\tMap<String,Object> map = new HashMap<String,Object>();\n\t\n\t\t\t\tif (propertyParams != null) {\n\t\t\t\t\tfor (int i=0; i<propertyParams.length/2 ; i++) {\n\t\t\t\t\t\tif (propertyParams[i*2+1] != null) {\n\t\t\t\t\t\t\tmap.put((String)propertyParams[i*2], propertyParams[i*2+1]);\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tparams.add(map);\n\t\t\t}\n\t\t\taddCreateVertices(vertexName, vertexLabel, propertyKey, propertyKeyValues, params);\n\t\t}\n\t}\n\n\tpublic void addCreateVertices(String vertexName, String vertexLabel, String propertyKey, List<Object> propertyKeyValues, List<Map<String,Object>> propertyParams) {\n\t\tfinal String bindVar = \"b\" + StringUtils.capitalize(vertexName);\n\t\tMap<String,Object> bindVarsMap = new HashMap<String,Object>();\n\n\t\tif (propertyKeyValues != null && propertyKeyValues.size() > 0) {\n\t\t\tstmt.append(\"i = 0\\n\");\n\t\t\tstmt.append(\"Vertex[] \").append(vertexName).append(\" = new Vertex[\").append(propertyKeyValues.size()).append(\"]\\n\");\n\t\t\tstmt.append(\"for (Object keyValue : \" + bindVar + \".propertyKeyValues) {\");\n\t\t\tstmt.append(\"\\n\");\n\t\n\t\t\tstmt.append(\"\\t\").append(fmtCreateOrUpdateVertex(vertexName + \"[i]\", vertexLabel, propertyKey, \"keyValue\")).append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"Map<String,Object> params = \" + bindVar + \".params[i]\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"if (params != null)\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"for (String key : params.keySet()) {\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\\t\").append(vertexName + \"[i].property(key, params.get(key))\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"}\").append(\"\\n\");\n\t\t\tstmt.append(\"i++\").append(\"\\n\");\n\t\t\tstmt.append(\"}\").append(\"\\n\");\n\t\t\t\n\t\t\tbindVarsMap.put(\"propertyKeyValues\", propertyKeyValues);\n\t\t\tbindVarsMap.put(\"params\", propertyParams);\n\t\t\tbindVars.put(bindVar, bindVarsMap);\n\t\t}\n\t}\n\t\n\tpublic void addCreateEdges(String edgeName, String fromVertexName, int fromVertexSize, String toVertexName, int toVertexSize, String edgeLabel, Object ... propertyParams) {\n\t\tList<Map<String,Object>> params = new ArrayList<Map<String,Object>>();\n\n\t\tif (toVertexSize > 0) {\n\t\t\n\t\t\tfor (int i = 0; i < toVertexSize; i++) {\n\t\t\t\tMap<String,Object> map = new HashMap<String,Object>();\n\t\n\t\t\t\tif (propertyParams != null) {\n\t\t\t\t\tfor (int j=0; j<propertyParams.length/2 ; j++) {\n\t\t\t\t\t\tif (propertyParams[j*2+1] != null) {\n\t\t\t\t\t\t\tmap.put((String)propertyParams[j*2], propertyParams[j*2+1]);\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tparams.add(map);\n\t\t\t}\n\t\t\taddCreateEdges(edgeName, fromVertexName, fromVertexSize, toVertexName, toVertexSize, edgeLabel, params);\n\t\t}\t\n\t}\n\n\tpublic void addCreateEdges(String edgeName, String fromVertexName, int fromVertexSize, String toVertexName, int toVertexSize, String edgeLabel, List<Map<String,Object>> propertyParams) {\n\t\tfinal String bindVar = \"b\" + StringUtils.capitalize(edgeName);\n\t\tMap<String,Object> bindVarsMap = new HashMap<String,Object>();\n\t\t\n\t\tif (toVertexSize > 0) {\n\t\t\tstmt.append(\"Edge[] \").append(edgeName).append(\" = new Edge[\").append(toVertexSize).append(\"]\\n\");\n\t\t\tstmt.append(\"for (i = 0; i < \" + bindVar + \".count; i++) {\");\n\t\t\tstmt.append(\"\\n\");\n\t\n\t\t\tstmt.append(\"\\t\").append(fmtCreateOrUpdateEdge(edgeName + \"[i]\", fromVertexName, toVertexName + \"[i]\", edgeLabel)).append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"Map<String,Object> params = \" + bindVar + \".params[i]\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"if (params != null)\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"for (String key : params.keySet()) {\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\\t\").append(edgeName + \"[i]\" + \".property(key, params.get(key))\").append(\"\\n\");\n\t\t\tstmt.append(\"\\t\").append(\"}\").append(\"\\n\");\n\t\t\tstmt.append(\"}\").append(\"\\n\");\n\t\n\t\t\t//bindVarsMap.put(\"propertyKeyValues\", propertyKeyValues);\n\t\t\tbindVarsMap.put(\"count\", toVertexSize);\n\t\t\tbindVarsMap.put(\"params\", propertyParams);\n\t\t\tbindVars.put(bindVar, bindVarsMap);\n\t\t}\n\t}\t\n\n\tpublic void execute(String name, boolean logIt) {\n\t\t//stmt.append(\"return nofV + ',' + nofE\").append(\"\\n\");\n\n\t\tstmt.append(\"return nof\").append(\"\\n\");\n\t\tSimpleGraphStatement sgs = new SimpleGraphStatement(stmt.toString());\n\t\tfor (String key : bindVars.keySet()) {\n\t\t\tsgs.set(key, bindVars.get(key));\n\t\t}\n\t\ttry {\n\t\t\tif (logIt) {\n\t\t\t\tSystem.out.println(stmt.toString());\n\t\t\t}\n\n\t\t\tgraphMetrics = new GraphMetrics();\n\t\t\t\n\t\t\tLong t = System.currentTimeMillis();\n\t\t\tGraphResultSet rs = session.executeGraph(sgs);\n\t\t\tLong tAfter = System.currentTimeMillis() - t;\n\t\t\t\n\t\t\tfor (GraphNode gn : rs.all()) {\n\t\t\t\tMap<String,Integer> metrics = new HashMap<String,Integer>();\n\t\t\t\tMap<String,Object> m = gn.asMap();\n\t\t\t\tfor (String key : m.keySet()) {\n\t\t\t\t\tmetrics.put(key, (Integer)m.get(key));\n\t\t\t\t}\n\t\t\t\tgraphMetrics.add(metrics);\n\t\t\t}\n\n\t\t} catch (RuntimeException re) {\n\t\t\tSystem.out.println(stmt.toString());\n\t\t\tSystem.out.println(fmtBindVars());\n\t\t\tre.printStackTrace();\n\t\t}\n\t\t\n\t\t//session.close();\n\t}\t\t\n\t\n\tpublic void execute(String name) {\n\t\texecute(name, false);\n\t}\n\t\n\tpublic String fmtBindVars() {\n\t\tStringBuffer result = new StringBuffer();\n\t\tfor (String key : bindVars.keySet()) {\n\t\t\tresult.append(key).append(\"==>\").append(\"(\");\n\t\t\tString sep = \"\";\n\t\t\tfor (String innerKey : bindVars.get(key).keySet()) {\n\t\t\t\tresult.append(sep).append(innerKey).append(\"=\").append(bindVars.get(key).get(innerKey)).append(\"[\").append(bindVars.get(key).get(innerKey).getClass().getCanonicalName()).append(\"]\");\n\t\t\t\tsep = \",\";\n\t\t\t}\n\t\t\tresult.append(\")\").append(\"\\n\");\n\t\t}\n\t\treturn result.toString();\n\t}\n\n\tpublic GraphMetrics getGraphMetrics() {\n\t\treturn graphMetrics;\n\t}\n\n\t\t\t\t\n}\n"
},
{
"alpha_fraction": 0.6825242638587952,
"alphanum_fraction": 0.7106795907020569,
"avg_line_length": 30.212121963500977,
"blob_id": "2489a9cd28d56ab8a8f628f678ad28ee1e103c08",
"content_id": "56275315e20eb4cd38daa6aeb8454e2762b49a6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "SQL",
"length_bytes": 1030,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 33,
"path": "/bidirectional-integration-oracle-kafka/scripts/oracle/order-processing/testdata/create_order.sql",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright 2019 Guido Schmutz <guido.schmutz@trivadis.com>\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing, software\n* distributed under the License is distributed on an \"AS IS\" BASIS,\n* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n* See the License for the specific language governing permissions and\n* limitations under the License.\n*/\n\nDECLARE\n order_id INTEGER := 6;\n\torder_item_obj order_item_objt := order_item_objt((order_id * 10) + 1, 2289, 'AppleIPad', 800, 1);\n\torder_item_coll order_item_collt := order_item_collt(order_item_obj);\n\torder_obj order_objt := order_objt(order_id, SYSDATE, 'direct', 101, 2, 800, null, order_item_coll);\nBEGIN\n order_pck.insert_order(order_obj);\n commit;\nEND; \n/\n\nDECLARE\nBEGIN\n order_pck.update_status(3, 1);\n commit;\nEND;\n/\n"
},
{
"alpha_fraction": 0.6152899265289307,
"alphanum_fraction": 0.6832451224327087,
"avg_line_length": 32.9832649230957,
"blob_id": "b64511b65067a7c625fe18c8e4cd23f3f386b97e",
"content_id": "57b19126a4600ad32342375776a453561f3dbbe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 8123,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 239,
"path": "/rb-dr-case/docker-compose.yml",
"repo_name": "rodrigo-mendes/various-demos",
"src_encoding": "UTF-8",
"text": "# Kafka Disaster Recovery Test\n\nversion: \"2.1\"\n\nservices:\n zookeeper-1:\n image: confluentinc/cp-zookeeper:5.0.1\n hostname: zookeeper-1\n ports:\n - \"2181:2181\"\n environment:\n ZOOKEEPER_SERVER_ID: 1\n ZOOKEEPER_CLIENT_PORT: 2181\n ZOOKEEPER_TICK_TIME: 2000\n ZOOKEEPER_INIT_LIMIT: 5\n ZOOKEEPER_SYNC_LIMIT: 2\n ZOOKEEPER_SERVERS: zookeeper-1:22888:23888;zookeeper-2:32888:33888;zookeeper-3:42888:43888 \n volumes:\n - $PWD/zookeeper-1:/var/lib/zookeeper/data\n restart: always\n\n zookeeper-2:\n image: confluentinc/cp-zookeeper:5.0.1\n hostname: zookeeper-2\n ports:\n - \"2182:2182\"\n environment:\n ZOOKEEPER_SERVER_ID: 2\n ZOOKEEPER_CLIENT_PORT: 2182\n ZOOKEEPER_TICK_TIME: 2000\n ZOOKEEPER_INIT_LIMIT: 5\n ZOOKEEPER_SYNC_LIMIT: 2\n ZOOKEEPER_SERVERS: zookeeper-1:22888:23888;zookeeper-2:32888:33888;zookeeper-3:42888:43888 \n volumes:\n - $PWD/zookeeper-2:/var/lib/zookeeper/data\n restart: always\n\n zookeeper-3:\n image: confluentinc/cp-zookeeper:5.0.1\n hostname: zookeeper-3\n ports:\n - \"2183:2183\"\n environment:\n ZOOKEEPER_SERVER_ID: 3\n ZOOKEEPER_CLIENT_PORT: 2183\n ZOOKEEPER_TICK_TIME: 2000\n ZOOKEEPER_INIT_LIMIT: 5\n ZOOKEEPER_SYNC_LIMIT: 2\n ZOOKEEPER_SERVERS: zookeeper-1:22888:23888;zookeeper-2:32888:33888;zookeeper-3:42888:43888 \n volumes:\n - $PWD/zookeeper-3:/var/lib/zookeeper/data\n restart: always\n\n broker-1:\n image: confluentinc/cp-enterprise-kafka:5.0.1\n hostname: broker-1\n depends_on:\n - zookeeper-1\n - zookeeper-2\n - zookeeper-3\n ports:\n - \"9092:9092\"\n environment:\n KAFKA_BROKER_ID: 1\n KAFKA_BROKER_RACK: rack-a\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9092'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9999\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9999'\n KAFKA_JMX_HOSTNAME: 'broker-1'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-1:9092\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n\n broker-2:\n image: confluentinc/cp-enterprise-kafka:5.0.1\n hostname: broker-2\n depends_on:\n - zookeeper-1\n - zookeeper-2\n - zookeeper-3\n ports:\n - \"9093:9093\"\n environment:\n KAFKA_BROKER_ID: 2\n KAFKA_BROKER_RACK: rack-a\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9093'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9998\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9998'\n KAFKA_JMX_HOSTNAME: 'broker-2'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-2:9093\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n\n broker-3:\n image: confluentinc/cp-enterprise-kafka:5.0.1\n hostname: broker-3\n depends_on:\n - zookeeper-1\n - zookeeper-2\n - zookeeper-3\n ports:\n - \"9094:9094\"\n environment:\n KAFKA_BROKER_ID: 3\n KAFKA_BROKER_RACK: rack-b\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9094'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9997\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9997'\n KAFKA_JMX_HOSTNAME: 'broker-3'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-3:9094\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always\n\n\n broker-4:\n image: confluentinc/cp-enterprise-kafka:5.0.1\n hostname: broker-4\n depends_on:\n - zookeeper-1\n - zookeeper-2\n - zookeeper-3\n ports:\n - \"9095:9095\"\n environment:\n KAFKA_BROKER_ID: 4\n KAFKA_BROKER_RACK: rack-b\n KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183'\n KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}\n KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://${DOCKER_HOST_IP}:9095'\n KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter\n KAFKA_DELETE_TOPIC_ENABLE: \"true\"\n KAFKA_JMX_PORT: 9996\n KAFKA_JMX_OPTS: '-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.rmi.port=9996'\n KAFKA_JMX_HOSTNAME: 'broker-4'\n KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1\n CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker-4:9095\n CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183\n CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1\n CONFLUENT_METRICS_ENABLE: 'true'\n CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'\n restart: always \n\n kafka-manager:\n image: trivadisbds/kafka-manager\n hostname: kafka-manager\n depends_on:\n - zookeeper-1\n ports:\n - \"9000:9000\"\n environment:\n ZK_HOSTS: 'zookeeper-1:2181'\n APPLICATION_SECRET: 'letmein' \n restart: always\n\n web:\n image: elkozmon/zoonavigator-web:0.5.0\n container_name: zoonavigator-web\n ports:\n - \"8010:8010\"\n environment:\n WEB_HTTP_PORT: 8010\n API_HOST: \"api\"\n API_PORT: 9010\n depends_on:\n - api\n restart: always\n api:\n image: elkozmon/zoonavigator-api:0.5.0\n container_name: zoonavigator-api\n environment:\n API_HTTP_PORT: 9010\n restart: always\n\n kafka-offset-monitor:\n image: jpodeszwik/kafka-offset-monitor:0.2.1\n ports:\n - \"8080:8080\"\n environment:\n ZK: zookeeper-1:2181\n restart: always\n\n kafdrop:\n image: thomsch98/kafdrop:latest\n ports:\n - \"9020:9020\" \n environment:\n ZK_HOSTS: zookeeper-1:2181\n LISTEN: 9020\n restart: always\n\n burrow:\n image: toddpalino/burrow\n volumes:\n - ${PWD}/burrow-config:/etc/burrow/\n - ${PWD}/tmp:/var/tmp/burrow\n ports:\n - 8000:8000\n depends_on:\n - zookeeper-1\n - broker-1\n restart: always\n\n burrow-dashboard:\n image: joway/burrow-dashboard:latest\n ports:\n - \"8085:80\"\n environment:\n BURROW_BACKEND: http://burrow:8000\n\n burrowui:\n image: generalmills/burrowui\n ports:\n - 3000:3000\n environment:\n BURROW_HOME: http://${DOCKER_HOST_IP}:8000/v3/kafka\n\n"
}
] | 101 |
ellakcd/week-2 | https://github.com/ellakcd/week-2 | 43ac6971265e941b950dbaed759d9c42dd84f70f | 7d0b814bdacc85e1776a0e45d7a334c565c90f66 | 35596bd24b7b0da10d8f0e925e7d833fb0305d2a | refs/heads/master | 2021-05-13T13:57:33.877538 | 2018-01-08T21:02:42 | 2018-01-08T21:02:42 | 116,723,040 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5340659618377686,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 25.376811981201172,
"blob_id": "62d1016995fc8cb58c2406b01e25592d29fd1233",
"content_id": "8464a7ccce6e4960358d01c7fe687b241906bb3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1820,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 69,
"path": "/wordcount.py",
"repo_name": "ellakcd/week-2",
"src_encoding": "UTF-8",
"text": "# put your code here.\n\"\"\"\ninitialize dictionary\nopen the file\nsplit it on any space\niterate over the list\nuse .get to check if word is in the dictionary\nif it is, we'll increment the current value by 1\n\nprint dictionary with the format, key \" \" value\n\"\"\"\nfrom sys import argv\nfrom collections import Counter\n\n\n# TODO: Fix bug where punctuation in the middle of a word\n# is being stripped from the word\n\n# def get_word_count(file_name):\n# \"\"\"Prints word count of given file\"\"\"\n# word_count = {}\n# # document = open(file_name)\n\n# with open(file_name) as document:\n\n# for line in document:\n# line = line.rstrip()\n# words = line.split()\n# for word in words:\n# word = word.lower()\n# if word.isalnum():\n# word_count[word] = word_count.get(word, 0) + 1\n# else:\n# new_word = \"\"\n# for character in word:\n# if character.isalnum():\n# new_word += character\n# word_count[new_word] = word_count.get(new_word, 0) + 1\n\n# for word, count in word_count.iteritems():\n# print word, count\n\ndef get_word_count(file_name):\n document = open(file_name)\n document_contents = document.read()\n\n words = document_contents.split()\n\n c = Counter()\n\n for word in words:\n word = word.lower()\n if word.isalnum():\n c[word] += 1\n else:\n new_word = \"\"\n for character in word:\n if character.isalnum():\n new_word += character\n c[new_word] += 1\n\n document.close()\n\n sorted_words = sorted(c.keys())\n\n for word in sorted_words:\n print word, c[word]\n\nget_word_count(argv[1])\n"
}
] | 1 |
RoundStarling20/EEBot | https://github.com/RoundStarling20/EEBot | 919e1a826107b66d580f6fea912a8f2c8ca6cc1f | e35625c087aae107c5f6f7b32fc3a11f76d48a56 | 83b9347025290fa0288943cd7576d689d4bb0f65 | refs/heads/main | 2023-08-13T15:05:37.764085 | 2021-10-18T07:16:08 | 2021-10-18T07:16:08 | 418,386,285 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5789793729782104,
"alphanum_fraction": 0.6023693680763245,
"avg_line_length": 47.411766052246094,
"blob_id": "fb08b69147a6740758e57c8832cc495be3c94bf7",
"content_id": "66d6bf57e14bd164991f8dba9b3b9f6311da9a9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3340,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 68,
"path": "/cogs/role.py",
"repo_name": "RoundStarling20/EEBot",
"src_encoding": "UTF-8",
"text": "import discord\nimport custom\nfrom discord.ext import commands\n\n\nclass role(commands.Cog, name=\"RoleAdder\", description=\"Adds roles on reaction\"):\n def __init__(self, client):\n self.client = client\n\n @commands.command(help= \"send a message for people to react to\")\n @commands.check(custom.isItme)\n async def prompt(self, ctx):\n embed = discord.Embed(\n title = 'Add Roles!',\n description=\"React to this message to self-assign roles\",\n color = 0xd8815e\n )\n embed.set_thumbnail(url=ctx.guild.icon_url)\n embed.add_field(name=\"Majors\",value=\"Degrees offered by our school\", inline=False)\n embed.add_field(name=\"🔌\", value=\"Electrical Engineering\", inline=True)\n embed.add_field(name=\"💻\", value=\"Computer Engineering\", inline=True)\n embed.add_field(name=\"Degree Tracks\",value=\"Specialization tracks offered by our school\", inline=False)\n embed.add_field(name=\"🤖\", value=\"Robotics Track\", inline=True)\n embed.add_field(name=\"👾\", value=\"Space Track\", inline=True)\n msg = await ctx.send(embed=embed)\n await msg.add_reaction(emoji='🔌')\n await msg.add_reaction(emoji='💻')\n await msg.add_reaction(emoji='🤖')\n await msg.add_reaction(emoji='👾')\n\n @commands.Cog.listener()\n async def on_raw_reaction_add(self, payload: discord.RawReactionActionEvent):\n if payload.message_id == 899550874051940362:\n guild = self.client.get_guild(id=payload.guild_id)\n role = False\n if not(payload.user_id == 896677611340701726):\n if payload.emoji.name == '🤖':\n role = discord.utils.get(iterable=guild.roles, name=\"Robotics Track\")\n elif payload.emoji.name == '👾':\n role = discord.utils.get(iterable=guild.roles, name=\"Space Track\")\n elif payload.emoji.name == '🔌':\n role = discord.utils.get(iterable=guild.roles, name=\"Electrical Engineering\")\n elif payload.emoji.name == '💻':\n role = discord.utils.get(iterable=guild.roles, name=\"Computer Engineering\")\n if role:\n await payload.member.add_roles(role)\n\n @commands.Cog.listener()\n async def on_raw_reaction_remove(self, payload: discord.RawReactionActionEvent):\n if payload.message_id == 899550874051940362:\n guild = self.client.get_guild(id=payload.guild_id)\n member = guild.get_member(payload.user_id)\n role = False\n if not(payload.user_id == 896677611340701726):\n if payload.emoji.name == '🤖':\n role = discord.utils.get(iterable=guild.roles, name=\"Robotics Track\")\n elif payload.emoji.name == '👾':\n role = discord.utils.get(iterable=guild.roles, name=\"Space Track\")\n elif payload.emoji.name == '🔌':\n role = discord.utils.get(iterable=guild.roles, name=\"Electrical Engineering\")\n elif payload.emoji.name == '💻':\n role = discord.utils.get(iterable=guild.roles, name=\"Computer Engineering\")\n if role:\n await member.remove_roles(role)\n\n\ndef setup(client):\n client.add_cog(role(client))\n"
},
{
"alpha_fraction": 0.6774370074272156,
"alphanum_fraction": 0.6894851922988892,
"avg_line_length": 29.517240524291992,
"blob_id": "dd253bbdb657fe87945f4f185bb941b7cdedbcdc",
"content_id": "74d7e25341e7661666fb56c7ea95e8d973efcf7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1826,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 58,
"path": "/bot.py",
"repo_name": "RoundStarling20/EEBot",
"src_encoding": "UTF-8",
"text": "import os\r\n\r\nimport discord\r\nfrom discord import file\r\nfrom discord.ext import commands\r\nfrom discord.flags import Intents\r\n\r\nimport custom\r\nfrom custom import directoryPath\r\n\r\nclient = commands.Bot(command_prefix = custom.getPrefix, intents=Intents.all(), description=\"A bot programmed by RoundStarling20\")\r\n\r\n@client.event\r\nasync def on_guild_join(guild):\r\n prefixes = custom.get_db(filePath=directoryPath[\"serverPrefixdb\"])\r\n prefixes[str(guild.id)] = '.'\r\n custom.save_db(db=prefixes, filePath=directoryPath[\"serverPrefixdb\"])\r\n\r\n@client.event\r\nasync def on_guild_remove(guild):\r\n prefixes = custom.get_db(filePath=directoryPath[\"serverPrefixdb\"])\r\n prefixes.pop(str(guild.id))\r\n custom.save_db(db=prefixes, filePath=directoryPath[\"serverPrefixdb\"])\r\n\r\n@client.event\r\nasync def on_member_join(member):\r\n await member.guild.system_channel.send(f'Welcome <@{member.id}>, check out <#899548270454513734>!')\r\n\r\n@client.event\r\nasync def on_member_remove(member):\r\n await member.guild.system_channel.send(f'Goodbye DooDoo Head <@{member.id}>!')\r\n\r\n@client.event\r\nasync def on_command_error(ctx, error):\r\n if isinstance(error, discord.ext.commands.CommandNotFound):\r\n await ctx.send(\"Thats not a command\")\r\n\r\n@client.command(help= \"send a member's profile picture\")\r\nasync def av(ctx, member: discord.Member = None):\r\n if member is None:\r\n member = ctx.author\r\n embed = discord.Embed(\r\n title = f'{member.name}',\r\n url = f'{member.avatar_url}'\r\n )\r\n embed.set_image(url=member.avatar_url)\r\n await ctx.send(embed=embed)\r\n\r\n\r\nfor filename in os.listdir(\"./cogs\"):\r\n if filename.endswith(\".py\"):\r\n client.load_extension(f'cogs.{filename[:-3]}')\r\n\r\n\r\nwith open(\"token.txt\", 'r', encoding=\"utf-8\") as fp:\r\n client.run(f\"{fp.read()}\")\r\n\r\n#rotate images"
}
] | 2 |
lvjiaming/CatchDoll | https://github.com/lvjiaming/CatchDoll | 3fd7e8a363176038f257e8395e8ac8d63a90f75d | d5430112da9448ad8977d3d8290a43ebc74816cb | 63a5a935a7fe30d7c3e0655e5307719fd51e994a | refs/heads/master | 2020-04-16T01:03:52.857395 | 2019-01-15T02:53:56 | 2019-01-15T02:53:56 | 165,159,984 | 0 | 0 | null | 2019-01-11T01:45:45 | 2019-01-10T16:20:24 | 2019-01-10T16:20:21 | null | [
{
"alpha_fraction": 0.5896444916725159,
"alphanum_fraction": 0.5919629335403442,
"avg_line_length": 25.428571701049805,
"blob_id": "34b0b4204a3063392d226389e2ac664a702fcece",
"content_id": "26070d65bfa8b8a309bf23e1b5668325cce07cc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1320,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 49,
"path": "/Nodejs/src/JsonParse.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "import { readFileSync } from \"fs\";\n\nexport class JsonParse {\n\n private static readonly PropPath: string = \"resource/table/PropTable.json\"\n\n private static readonly ConfigPath: string = \"resource/config.json\"\n\n public static propData: table.PropTable[];\n\n public static propDataID: string[] = [];\n /* 道具前缀 */\n public static propForm: string = \"propID_\"\n /* 是否调试模式 */\n public static isDebug: boolean = false;\n\n public static SQLHost: string = \"\";\n\n public static SQLPost: number = -1;\n\n constructor() {\n\n }\n\n /**\n * 初始化\n */\n public static init(): void {\n let buffer: Buffer = readFileSync(this.ConfigPath);\n let configData = JSON.parse(buffer.toString());\n this.isDebug = configData[\"isDebug\"];\n if (this.isDebug) {\n this.SQLHost = configData[\"debug\"][\"SQLHost\"];\n this.SQLPost = configData[\"debug\"][\"SQLPost\"];\n }\n else{\n this.SQLHost = configData[\"dev\"][\"SQLHost\"];\n this.SQLPost = configData[\"dev\"][\"SQLPost\"];\n }\n\n let buffer2: Buffer = readFileSync(this.PropPath);\n this.propData = JSON.parse(buffer2.toString());\n for (let item of this.propData) {\n this.propDataID.push(this.propForm + item.id);\n }\n\n }\n\n}"
},
{
"alpha_fraction": 0.5138818621635437,
"alphanum_fraction": 0.5184250473976135,
"avg_line_length": 33.17241287231445,
"blob_id": "801e89f70412a64e981e1947bd4a1846872bb525",
"content_id": "b11d0bb05faee13a1d4637c5e3de1a8b66708630",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2051,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 58,
"path": "/Nodejs/src/MsgHandler.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "import { SQLServe } from \"./SQLServe\";\nimport { Cmd } from \"../protobuf/common\";\nimport { ProtoParse } from \"./ProtoParse\";\nimport { Dictionary } from \"./util/Dictionary\";\nimport { PlayerCenter } from \"./PlayerCenter\";\nimport { TaskMgr } from \"./Task/TaskMgr\";\nexport class MsgHandler {\n private static _handler: MsgHandler = null; // 实例\n private _target: any = null; // 外部应用(MyWebScoket实例)\n private _curWs: any = null; // 当前的连接\n private _taskTimer: any = null;\n /**\n * 获取单例\n * @param target \n */\n public static getInstance(target, ws): MsgHandler {\n if (!this._handler) {\n this._handler = new MsgHandler(target, ws);\n }\n return this._handler;\n };\n /**\n * 构造函数\n */\n constructor(target, ws) {\n this._target = target;\n this._curWs = ws;\n };\n public handler(event, msgData) {\n switch(event) {\n /* 登陆协议 */\n case \"Cmd.Login_C\":{\n console.log(\"玩家登陆\");\n // this.taskTimer();\n let data: Cmd.Login_C = msgData as Cmd.Login_C;\n this._target.connectMap.set(data.uid, this._curWs);\n this._target.heartMap.set(data.uid, 0);\n SQLServe.instance.seekLogin(data)\n }\n break;\n /* 物品变更 */\n case \"Cmd.ItemUpdate_CS\":{\n let data2: Cmd.ItemUpdate_CS = msgData as Cmd.ItemUpdate_CS;\n let itemInfo = data2.itemInfo;\n // data2.uid = data2.uid;\n PlayerCenter.clearUpdateNum(data2.uid);\n for (let item of itemInfo) {\n if (item.itemUpdateNum && item.itemUpdateNum != 0) {\n PlayerCenter.updateProp(data2.uid, item.itemID, item.itemUpdateNum);\n }\n }\n PlayerCenter.sendPlayerData(data2.uid);\n break;\n }\n }\n };\n};\nglobal[\"MsgHandler\"] = MsgHandler;"
},
{
"alpha_fraction": 0.5183817148208618,
"alphanum_fraction": 0.5201564431190491,
"avg_line_length": 34.71669006347656,
"blob_id": "9fb54695237a11d2218eb1eb3077c9e071f7aabd",
"content_id": "98f68087e4550b7dc687402b1a1d989278c1c699",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 27609,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 773,
"path": "/Nodejs/protobuf/common.js",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "/*eslint-disable block-scoped-var, no-redeclare, no-control-regex, no-prototype-builtins*/\n\"use strict\";\n\nvar $protobuf = require(\"protobufjs/minimal\");\n\n// Common aliases\nvar $util = $protobuf.util;\n\n// Exported root namespace\nvar $root = $protobuf.roots[\"default\"] || ($protobuf.roots[\"default\"] = {});\n\n$root.Cmd = (function() {\n\n /**\n * Namespace Cmd.\n * @exports Cmd\n * @namespace\n */\n var Cmd = {};\n\n Cmd.Login_C = (function() {\n\n /**\n * Properties of a Login_C.\n * @memberof Cmd\n * @interface ILogin_C\n * @property {string} account Login_C account\n * @property {string} password Login_C password\n * @property {number|null} [uid] Login_C uid\n */\n\n /**\n * Constructs a new Login_C.\n * @memberof Cmd\n * @classdesc Represents a Login_C.\n * @implements ILogin_C\n * @constructor\n * @param {Cmd.ILogin_C=} [properties] Properties to set\n */\n function Login_C(properties) {\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * Login_C account.\n * @member {string} account\n * @memberof Cmd.Login_C\n * @instance\n */\n Login_C.prototype.account = \"\";\n\n /**\n * Login_C password.\n * @member {string} password\n * @memberof Cmd.Login_C\n * @instance\n */\n Login_C.prototype.password = \"\";\n\n /**\n * Login_C uid.\n * @member {number} uid\n * @memberof Cmd.Login_C\n * @instance\n */\n Login_C.prototype.uid = 0;\n\n /**\n * Creates a Login_C message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.Login_C\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.Login_C} Login_C\n */\n Login_C.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.Login_C)\n return object;\n var message = new $root.Cmd.Login_C();\n if (object.account != null)\n message.account = String(object.account);\n if (object.password != null)\n message.password = String(object.password);\n if (object.uid != null)\n message.uid = object.uid | 0;\n return message;\n };\n\n /**\n * Creates a plain object from a Login_C message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.Login_C\n * @static\n * @param {Cmd.Login_C} message Login_C\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n Login_C.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.defaults) {\n object.account = \"\";\n object.password = \"\";\n object.uid = 0;\n }\n if (message.account != null && message.hasOwnProperty(\"account\"))\n object.account = message.account;\n if (message.password != null && message.hasOwnProperty(\"password\"))\n object.password = message.password;\n if (message.uid != null && message.hasOwnProperty(\"uid\"))\n object.uid = message.uid;\n return object;\n };\n\n /**\n * Converts this Login_C to JSON.\n * @function toJSON\n * @memberof Cmd.Login_C\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n Login_C.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n return Login_C;\n })();\n\n Cmd.ItemInfo_CS = (function() {\n\n /**\n * Properties of an ItemInfo_CS.\n * @memberof Cmd\n * @interface IItemInfo_CS\n * @property {number} itemID ItemInfo_CS itemID\n * @property {number|null} [itemNum] ItemInfo_CS itemNum\n * @property {number|null} [itemUpdateNum] ItemInfo_CS itemUpdateNum\n */\n\n /**\n * Constructs a new ItemInfo_CS.\n * @memberof Cmd\n * @classdesc Represents an ItemInfo_CS.\n * @implements IItemInfo_CS\n * @constructor\n * @param {Cmd.IItemInfo_CS=} [properties] Properties to set\n */\n function ItemInfo_CS(properties) {\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * ItemInfo_CS itemID.\n * @member {number} itemID\n * @memberof Cmd.ItemInfo_CS\n * @instance\n */\n ItemInfo_CS.prototype.itemID = 0;\n\n /**\n * ItemInfo_CS itemNum.\n * @member {number} itemNum\n * @memberof Cmd.ItemInfo_CS\n * @instance\n */\n ItemInfo_CS.prototype.itemNum = 0;\n\n /**\n * ItemInfo_CS itemUpdateNum.\n * @member {number} itemUpdateNum\n * @memberof Cmd.ItemInfo_CS\n * @instance\n */\n ItemInfo_CS.prototype.itemUpdateNum = 0;\n\n /**\n * Creates an ItemInfo_CS message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.ItemInfo_CS\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.ItemInfo_CS} ItemInfo_CS\n */\n ItemInfo_CS.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.ItemInfo_CS)\n return object;\n var message = new $root.Cmd.ItemInfo_CS();\n if (object.itemID != null)\n message.itemID = object.itemID | 0;\n if (object.itemNum != null)\n message.itemNum = object.itemNum | 0;\n if (object.itemUpdateNum != null)\n message.itemUpdateNum = object.itemUpdateNum | 0;\n return message;\n };\n\n /**\n * Creates a plain object from an ItemInfo_CS message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.ItemInfo_CS\n * @static\n * @param {Cmd.ItemInfo_CS} message ItemInfo_CS\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n ItemInfo_CS.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.defaults) {\n object.itemID = 0;\n object.itemNum = 0;\n object.itemUpdateNum = 0;\n }\n if (message.itemID != null && message.hasOwnProperty(\"itemID\"))\n object.itemID = message.itemID;\n if (message.itemNum != null && message.hasOwnProperty(\"itemNum\"))\n object.itemNum = message.itemNum;\n if (message.itemUpdateNum != null && message.hasOwnProperty(\"itemUpdateNum\"))\n object.itemUpdateNum = message.itemUpdateNum;\n return object;\n };\n\n /**\n * Converts this ItemInfo_CS to JSON.\n * @function toJSON\n * @memberof Cmd.ItemInfo_CS\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n ItemInfo_CS.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n return ItemInfo_CS;\n })();\n\n Cmd.PlayerInfo_S = (function() {\n\n /**\n * Properties of a PlayerInfo_S.\n * @memberof Cmd\n * @interface IPlayerInfo_S\n * @property {number} uid PlayerInfo_S uid\n * @property {Array.<Cmd.IItemInfo_CS>|null} [itemInfo] PlayerInfo_S itemInfo\n */\n\n /**\n * Constructs a new PlayerInfo_S.\n * @memberof Cmd\n * @classdesc Represents a PlayerInfo_S.\n * @implements IPlayerInfo_S\n * @constructor\n * @param {Cmd.IPlayerInfo_S=} [properties] Properties to set\n */\n function PlayerInfo_S(properties) {\n this.itemInfo = [];\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * PlayerInfo_S uid.\n * @member {number} uid\n * @memberof Cmd.PlayerInfo_S\n * @instance\n */\n PlayerInfo_S.prototype.uid = 0;\n\n /**\n * PlayerInfo_S itemInfo.\n * @member {Array.<Cmd.IItemInfo_CS>} itemInfo\n * @memberof Cmd.PlayerInfo_S\n * @instance\n */\n PlayerInfo_S.prototype.itemInfo = $util.emptyArray;\n\n /**\n * Creates a PlayerInfo_S message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.PlayerInfo_S\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.PlayerInfo_S} PlayerInfo_S\n */\n PlayerInfo_S.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.PlayerInfo_S)\n return object;\n var message = new $root.Cmd.PlayerInfo_S();\n if (object.uid != null)\n message.uid = object.uid | 0;\n if (object.itemInfo) {\n if (!Array.isArray(object.itemInfo))\n throw TypeError(\".Cmd.PlayerInfo_S.itemInfo: array expected\");\n message.itemInfo = [];\n for (var i = 0; i < object.itemInfo.length; ++i) {\n if (typeof object.itemInfo[i] !== \"object\")\n throw TypeError(\".Cmd.PlayerInfo_S.itemInfo: object expected\");\n message.itemInfo[i] = $root.Cmd.ItemInfo_CS.fromObject(object.itemInfo[i]);\n }\n }\n return message;\n };\n\n /**\n * Creates a plain object from a PlayerInfo_S message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.PlayerInfo_S\n * @static\n * @param {Cmd.PlayerInfo_S} message PlayerInfo_S\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n PlayerInfo_S.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.arrays || options.defaults)\n object.itemInfo = [];\n if (options.defaults)\n object.uid = 0;\n if (message.uid != null && message.hasOwnProperty(\"uid\"))\n object.uid = message.uid;\n if (message.itemInfo && message.itemInfo.length) {\n object.itemInfo = [];\n for (var j = 0; j < message.itemInfo.length; ++j)\n object.itemInfo[j] = $root.Cmd.ItemInfo_CS.toObject(message.itemInfo[j], options);\n }\n return object;\n };\n\n /**\n * Converts this PlayerInfo_S to JSON.\n * @function toJSON\n * @memberof Cmd.PlayerInfo_S\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n PlayerInfo_S.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n return PlayerInfo_S;\n })();\n\n Cmd.ItemUpdate_CS = (function() {\n\n /**\n * Properties of an ItemUpdate_CS.\n * @memberof Cmd\n * @interface IItemUpdate_CS\n * @property {number} uid ItemUpdate_CS uid\n * @property {Array.<Cmd.IItemInfo_CS>|null} [itemInfo] ItemUpdate_CS itemInfo\n */\n\n /**\n * Constructs a new ItemUpdate_CS.\n * @memberof Cmd\n * @classdesc Represents an ItemUpdate_CS.\n * @implements IItemUpdate_CS\n * @constructor\n * @param {Cmd.IItemUpdate_CS=} [properties] Properties to set\n */\n function ItemUpdate_CS(properties) {\n this.itemInfo = [];\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * ItemUpdate_CS uid.\n * @member {number} uid\n * @memberof Cmd.ItemUpdate_CS\n * @instance\n */\n ItemUpdate_CS.prototype.uid = 0;\n\n /**\n * ItemUpdate_CS itemInfo.\n * @member {Array.<Cmd.IItemInfo_CS>} itemInfo\n * @memberof Cmd.ItemUpdate_CS\n * @instance\n */\n ItemUpdate_CS.prototype.itemInfo = $util.emptyArray;\n\n /**\n * Creates an ItemUpdate_CS message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.ItemUpdate_CS\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.ItemUpdate_CS} ItemUpdate_CS\n */\n ItemUpdate_CS.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.ItemUpdate_CS)\n return object;\n var message = new $root.Cmd.ItemUpdate_CS();\n if (object.uid != null)\n message.uid = object.uid | 0;\n if (object.itemInfo) {\n if (!Array.isArray(object.itemInfo))\n throw TypeError(\".Cmd.ItemUpdate_CS.itemInfo: array expected\");\n message.itemInfo = [];\n for (var i = 0; i < object.itemInfo.length; ++i) {\n if (typeof object.itemInfo[i] !== \"object\")\n throw TypeError(\".Cmd.ItemUpdate_CS.itemInfo: object expected\");\n message.itemInfo[i] = $root.Cmd.ItemInfo_CS.fromObject(object.itemInfo[i]);\n }\n }\n return message;\n };\n\n /**\n * Creates a plain object from an ItemUpdate_CS message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.ItemUpdate_CS\n * @static\n * @param {Cmd.ItemUpdate_CS} message ItemUpdate_CS\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n ItemUpdate_CS.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.arrays || options.defaults)\n object.itemInfo = [];\n if (options.defaults)\n object.uid = 0;\n if (message.uid != null && message.hasOwnProperty(\"uid\"))\n object.uid = message.uid;\n if (message.itemInfo && message.itemInfo.length) {\n object.itemInfo = [];\n for (var j = 0; j < message.itemInfo.length; ++j)\n object.itemInfo[j] = $root.Cmd.ItemInfo_CS.toObject(message.itemInfo[j], options);\n }\n return object;\n };\n\n /**\n * Converts this ItemUpdate_CS to JSON.\n * @function toJSON\n * @memberof Cmd.ItemUpdate_CS\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n ItemUpdate_CS.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n return ItemUpdate_CS;\n })();\n\n Cmd.Heartbeat_CS = (function() {\n\n /**\n * Properties of a Heartbeat_CS.\n * @memberof Cmd\n * @interface IHeartbeat_CS\n * @property {number} uid Heartbeat_CS uid\n */\n\n /**\n * Constructs a new Heartbeat_CS.\n * @memberof Cmd\n * @classdesc Represents a Heartbeat_CS.\n * @implements IHeartbeat_CS\n * @constructor\n * @param {Cmd.IHeartbeat_CS=} [properties] Properties to set\n */\n function Heartbeat_CS(properties) {\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * Heartbeat_CS uid.\n * @member {number} uid\n * @memberof Cmd.Heartbeat_CS\n * @instance\n */\n Heartbeat_CS.prototype.uid = 0;\n\n /**\n * Creates a Heartbeat_CS message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.Heartbeat_CS\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.Heartbeat_CS} Heartbeat_CS\n */\n Heartbeat_CS.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.Heartbeat_CS)\n return object;\n var message = new $root.Cmd.Heartbeat_CS();\n if (object.uid != null)\n message.uid = object.uid | 0;\n return message;\n };\n\n /**\n * Creates a plain object from a Heartbeat_CS message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.Heartbeat_CS\n * @static\n * @param {Cmd.Heartbeat_CS} message Heartbeat_CS\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n Heartbeat_CS.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.defaults)\n object.uid = 0;\n if (message.uid != null && message.hasOwnProperty(\"uid\"))\n object.uid = message.uid;\n return object;\n };\n\n /**\n * Converts this Heartbeat_CS to JSON.\n * @function toJSON\n * @memberof Cmd.Heartbeat_CS\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n Heartbeat_CS.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n return Heartbeat_CS;\n })();\n\n Cmd.TaskUpdate_CS = (function() {\n\n /**\n * Properties of a TaskUpdate_CS.\n * @memberof Cmd\n * @interface ITaskUpdate_CS\n * @property {number} uid TaskUpdate_CS uid\n * @property {Array.<Cmd.TaskUpdate_CS.ITaskInfo>|null} [taskInfo] TaskUpdate_CS taskInfo\n */\n\n /**\n * Constructs a new TaskUpdate_CS.\n * @memberof Cmd\n * @classdesc Represents a TaskUpdate_CS.\n * @implements ITaskUpdate_CS\n * @constructor\n * @param {Cmd.ITaskUpdate_CS=} [properties] Properties to set\n */\n function TaskUpdate_CS(properties) {\n this.taskInfo = [];\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * TaskUpdate_CS uid.\n * @member {number} uid\n * @memberof Cmd.TaskUpdate_CS\n * @instance\n */\n TaskUpdate_CS.prototype.uid = 0;\n\n /**\n * TaskUpdate_CS taskInfo.\n * @member {Array.<Cmd.TaskUpdate_CS.ITaskInfo>} taskInfo\n * @memberof Cmd.TaskUpdate_CS\n * @instance\n */\n TaskUpdate_CS.prototype.taskInfo = $util.emptyArray;\n\n /**\n * Creates a TaskUpdate_CS message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.TaskUpdate_CS\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.TaskUpdate_CS} TaskUpdate_CS\n */\n TaskUpdate_CS.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.TaskUpdate_CS)\n return object;\n var message = new $root.Cmd.TaskUpdate_CS();\n if (object.uid != null)\n message.uid = object.uid | 0;\n if (object.taskInfo) {\n if (!Array.isArray(object.taskInfo))\n throw TypeError(\".Cmd.TaskUpdate_CS.taskInfo: array expected\");\n message.taskInfo = [];\n for (var i = 0; i < object.taskInfo.length; ++i) {\n if (typeof object.taskInfo[i] !== \"object\")\n throw TypeError(\".Cmd.TaskUpdate_CS.taskInfo: object expected\");\n message.taskInfo[i] = $root.Cmd.TaskUpdate_CS.TaskInfo.fromObject(object.taskInfo[i]);\n }\n }\n return message;\n };\n\n /**\n * Creates a plain object from a TaskUpdate_CS message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.TaskUpdate_CS\n * @static\n * @param {Cmd.TaskUpdate_CS} message TaskUpdate_CS\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n TaskUpdate_CS.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.arrays || options.defaults)\n object.taskInfo = [];\n if (options.defaults)\n object.uid = 0;\n if (message.uid != null && message.hasOwnProperty(\"uid\"))\n object.uid = message.uid;\n if (message.taskInfo && message.taskInfo.length) {\n object.taskInfo = [];\n for (var j = 0; j < message.taskInfo.length; ++j)\n object.taskInfo[j] = $root.Cmd.TaskUpdate_CS.TaskInfo.toObject(message.taskInfo[j], options);\n }\n return object;\n };\n\n /**\n * Converts this TaskUpdate_CS to JSON.\n * @function toJSON\n * @memberof Cmd.TaskUpdate_CS\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n TaskUpdate_CS.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n TaskUpdate_CS.TaskInfo = (function() {\n\n /**\n * Properties of a TaskInfo.\n * @memberof Cmd.TaskUpdate_CS\n * @interface ITaskInfo\n * @property {number} taskID TaskInfo taskID\n * @property {number} taskState TaskInfo taskState\n */\n\n /**\n * Constructs a new TaskInfo.\n * @memberof Cmd.TaskUpdate_CS\n * @classdesc Represents a TaskInfo.\n * @implements ITaskInfo\n * @constructor\n * @param {Cmd.TaskUpdate_CS.ITaskInfo=} [properties] Properties to set\n */\n function TaskInfo(properties) {\n if (properties)\n for (var keys = Object.keys(properties), i = 0; i < keys.length; ++i)\n if (properties[keys[i]] != null)\n this[keys[i]] = properties[keys[i]];\n }\n\n /**\n * TaskInfo taskID.\n * @member {number} taskID\n * @memberof Cmd.TaskUpdate_CS.TaskInfo\n * @instance\n */\n TaskInfo.prototype.taskID = 0;\n\n /**\n * TaskInfo taskState.\n * @member {number} taskState\n * @memberof Cmd.TaskUpdate_CS.TaskInfo\n * @instance\n */\n TaskInfo.prototype.taskState = 0;\n\n /**\n * Creates a TaskInfo message from a plain object. Also converts values to their respective internal types.\n * @function fromObject\n * @memberof Cmd.TaskUpdate_CS.TaskInfo\n * @static\n * @param {Object.<string,*>} object Plain object\n * @returns {Cmd.TaskUpdate_CS.TaskInfo} TaskInfo\n */\n TaskInfo.fromObject = function fromObject(object) {\n if (object instanceof $root.Cmd.TaskUpdate_CS.TaskInfo)\n return object;\n var message = new $root.Cmd.TaskUpdate_CS.TaskInfo();\n if (object.taskID != null)\n message.taskID = object.taskID | 0;\n if (object.taskState != null)\n message.taskState = object.taskState | 0;\n return message;\n };\n\n /**\n * Creates a plain object from a TaskInfo message. Also converts values to other types if specified.\n * @function toObject\n * @memberof Cmd.TaskUpdate_CS.TaskInfo\n * @static\n * @param {Cmd.TaskUpdate_CS.TaskInfo} message TaskInfo\n * @param {$protobuf.IConversionOptions} [options] Conversion options\n * @returns {Object.<string,*>} Plain object\n */\n TaskInfo.toObject = function toObject(message, options) {\n if (!options)\n options = {};\n var object = {};\n if (options.defaults) {\n object.taskID = 0;\n object.taskState = 0;\n }\n if (message.taskID != null && message.hasOwnProperty(\"taskID\"))\n object.taskID = message.taskID;\n if (message.taskState != null && message.hasOwnProperty(\"taskState\"))\n object.taskState = message.taskState;\n return object;\n };\n\n /**\n * Converts this TaskInfo to JSON.\n * @function toJSON\n * @memberof Cmd.TaskUpdate_CS.TaskInfo\n * @instance\n * @returns {Object.<string,*>} JSON object\n */\n TaskInfo.prototype.toJSON = function toJSON() {\n return this.constructor.toObject(this, $protobuf.util.toJSONOptions);\n };\n\n return TaskInfo;\n })();\n\n return TaskUpdate_CS;\n })();\n\n /**\n * TASK_STATE enum.\n * @name Cmd.TASK_STATE\n * @enum {string}\n * @property {number} undone=0 undone value\n * @property {number} done=1 done value\n */\n Cmd.TASK_STATE = (function() {\n var valuesById = {}, values = Object.create(valuesById);\n values[valuesById[0] = \"undone\"] = 0;\n values[valuesById[1] = \"done\"] = 1;\n return values;\n })();\n\n return Cmd;\n})();\n\nmodule.exports = $root;\n"
},
{
"alpha_fraction": 0.5887640714645386,
"alphanum_fraction": 0.5932584404945374,
"avg_line_length": 17.183673858642578,
"blob_id": "2622b6e2c08db5bab09b1d25be5d8889bd8eb389",
"content_id": "ac025c9145e5a0e50e80b7b1ce254cfa1ce643fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 938,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 49,
"path": "/Egret/src/CatchDoll/Task/TaskItem.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "/**\n * 详细任务面板\n * @author suo \n */\nmodule catchDoll {\n\texport class TaskItem extends eui.Component {\n\n\t\t/**\n\t\t * 任务描述\n\t\t */\n\t\tpublic taskDec: eui.Label;\n\t\t/**\n\t\t * 领取按钮\n\t\t */\n\t\tpublic getBtn: Button;\n\t\t/**\n\t\t * 星级盒子\n\t\t */\n\t\tpublic starBox: eui.Group;\n\n\t\tpublic constructor() {\n\t\t\tsuper();\n\t\t\tthis.skinName = \"TaskItemSkin\"\n\t\t}\n\n\t\t/**\n\t\t * 设置数据\n\t\t */\n\t\tpublic setData(id: number, state?: TASK_STATE): void {\n\t\t\tlet data: table.TaskTable = ConfigParse.getWholeByProperty(TableCenter.instance.TaskTable, \"id\", id.toString());\n\t\t\tfor (let i: number = 0; i < data.taskLevel; i++) {\n\t\t\t\tlet img: eui.Image = new eui.Image();\n\t\t\t\timg.source = \"otherRes2_47\";\n\t\t\t\tthis.starBox.addChild(img);\n\t\t\t}\n\t\t\tthis.taskDec.text = data.taskContent;\n\t\t\tthis.getBtn = new Button(this.skin[\"_getBtn\"]);\n\t\t}\n\n\n\t\t/**\n\t\t * 释放\n\t\t */\n\t\tpublic dispose(): void {\n\t\t\tthis.getBtn.dispose();\n\t\t\tthis.getBtn = null;\n\t\t}\n\t}\n}"
},
{
"alpha_fraction": 0.5942583680152893,
"alphanum_fraction": 0.599043071269989,
"avg_line_length": 27.80555534362793,
"blob_id": "6bb2f378e32b5b936a3a242f00ace77ad6e1df69",
"content_id": "53b5edc9217f2f0eb3cd1f1d6674b1b767ea8ac4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1053,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 36,
"path": "/utils/protoExtendtion.py",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport os,shutil,time\n\ndef writeProtoExtendition(pkg,msgAry):\n\tt = time.strftime('%Y-%m-%d',time.localtime()) \n\tnewfile= r\"..\\resource\\proto\\ProtoExtendtion.ts\"\n\twith open(newfile,'w') as f:\n\t\tf.write(\"declare namespace \"+ pkg +\"{\\n\");\n\t\tfor item in msgAry:\n\t\t\tf.write(\"\\tinterface \"+item+ \" {\\n\")\n\t\t\tf.write(\"\\t\\tGetType(): string;\\n\")\n\t\t\tf.write(\"\\t}\\n\")\n\t\tf.write(\"}\\n\");\n\t\tfor item in msgAry:\n\t\t\tf.write(pkg+ \".\"+item+\".prototype.GetType = function () {\\n\")\n\t\t\tf.write(\"\\treturn \\\"\"+pkg+\".\"+item +\"\\\";\\n\")\n\t\t\tf.write(\"}\\n\")\n\tprint(u\"生成protoExtendition成功\")\n\ndef openProto():\n\twith open(r\"..\\resource\\proto\\common.proto\", 'r') as f:\n\t\tmsgAry = [];\n\t\tpkg = '';\n\t\tlist = f.readlines();\n\t\tfor item in list:\n\t\t\tif item.find('message') == 0:\n\t\t\t\tmsgType = item[len('message'):];\n\t\t\t\tmsgType = msgType.strip();\n\t\t\t\tmsgAry.append(msgType);\n\t\t\telif item.find('package') == 0:\n\t\t\t\tpkgName = item[len('package'):];\n\t\t\t\tpkgName = pkgName.strip()\n\t\t\t\tpkg = pkgName[0:-1]\n\t\twriteProtoExtendition(pkg,msgAry);\n\nopenProto();\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6514341235160828,
"alphanum_fraction": 0.658078134059906,
"avg_line_length": 25.60344886779785,
"blob_id": "8c2b6398c0435d37da880c533105487023cb34ce",
"content_id": "5410b9dba82334126e55113afd22823f04a82842",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 6473,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 232,
"path": "/Egret/src/Center/WebSocket.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "module catchDoll {\n\texport class WebSocket {\n\n\t\t/*单例*/\n\t\tprivate static _instance: WebSocket = null;\n\t\t/*socket*/\n\t\tprivate _webSocket: egret.WebSocket = new egret.WebSocket();\n\t\t/**\n\t\t * 写入字节数组\n\t\t */\n\t\tprivate _writeByteAry: egret.ByteArray = new egret.ByteArray();\n\n\t\t/**\n\t\t * 读取字节数组\n\t\t */\n\t\tprivate _readByteAry: egret.ByteArray = new egret.ByteArray();\n\n\t\tprivate _protoRoot = new protobuf.Root();\n\t\t/**\n\t\t * 当前检测次数\n\t\t */\n\t\tprivate _curHeartCount: number = 0;\n\t\t/**\n\t\t * 最大检测次数\n\t\t **/ \n\t\tprivate readonly MAX_COUNT: number = 3;\n\n\n\n\n\t\tpublic constructor() {\n\t\t\tthis._init();\n\t\t}\n\n\t\t/**\n\t\t * 获得单例\n\t\t */\n\t\tpublic static get instance(): WebSocket {\n\t\t\tif (this._instance == null) {\n\t\t\t\tthis._instance = new WebSocket();\n\t\t\t}\n\t\t\treturn this._instance;\n\t\t}\n\n\t\t/**\n\t\t * 初始化\n\t\t */\n\t\tprivate _init(): void {\n\n\n\t\t\tthis._webSocket.type = egret.WebSocket.TYPE_BINARY;\n\n\t\t\tthis._webSocket.addEventListener(egret.Event.CONNECT, this._onSocketOpen, this)\n\t\t\tthis._webSocket.addEventListener(egret.ProgressEvent.SOCKET_DATA, this._onReceiveMessage, this);\n\t\t\tthis._webSocket.addEventListener(egret.IOErrorEvent.IO_ERROR, this._onSocketError, this);\n\t\t\tthis._webSocket.addEventListener(egret.Event.CLOSE, this._onSocketClose, this);\n\t\t\tthis._webSocket.connect(DataCenter.instance.host, DataCenter.instance.post);\n\t\t\tthis._writeByteAry.endian = egret.EndianConst.BIG_ENDIAN.toString();\n\n\t\t\tprotobuf.parse(RES.getRes(\"common_proto\"), this._protoRoot);\n\t\t}\n\n\t\t/**\n\t\t * 登录\n\t\t */\n\t\tprivate _login(): void {\n\t\t\tlet cmd: Cmd.Login_C = new Cmd.Login_C()\n\t\t\tcmd.account = \"suo\";\n\t\t\tcmd.password = MathUtil.random(0, 10000).toString();\n\n\t\t\tlet index = location.search.indexOf(\"?uid=\")\n\t\t\tif (index != -1) {\n\t\t\t\tlet StrAry = location.search.split(\"?uid=\")\n\t\t\t\tlet uid = StrAry[StrAry.length - 1];\n\t\t\t\tcmd.uid = Number(uid);\n\t\t\t}\n\t\t\telse{\n\t\t\t\tcmd.uid = 9999;\n\t\t\t}\n\t\t\tthis.sendMsg(cmd);\n\n\t\t}\n\t\t/**\n\t\t * socket异常\n\t\t */\n\t\tprivate _onSocketError(e: egret.IOErrorEvent): void {\n\t\t\tconsole.log(\"IO异常\")\n\t\t}\n\n\t\t/**\n\t\t * socket关闭\n\t\t */\n\t\tprivate _onSocketClose(e: egret.Event): void {\n\t\t\tconsole.log(\"服务器断开连接\")\n\t\t}\n\n\t\t/** \n\t\t * socket链接\n\t\t */\n\t\tprivate _onSocketOpen(e: egret.Event): void {\n\t\t\tconsole.log(\"webScoket链接成功\")\n\t\t\tthis._login();\n\n\t\t}\n\t\t/**\n\t\t * 心跳检测\n\t\t */\n\t\tprivate _heartCheck(): void {\n\t\t\tLaya.timer.loop(1000 * 10, this, this._sendHeartMsg);\n\t\t}\n\t\t/**\n\t\t * 发送心跳消息\n\t\t */\n\t\tprivate _sendHeartMsg(): void {\n\t\t\tthis._curHeartCount++;\n\t\t\tif (this._curHeartCount >= this.MAX_COUNT) {\n\t\t\t\tconsole.log(\"连接失败,请检查网络\");\n\t\t\t\tLaya.timer.clear(this, this._sendHeartMsg);\n\t\t\t}\n\t\t\tlet cmd: Cmd.Heartbeat_CS = new Cmd.Heartbeat_CS();\n\t\t\tcmd.uid = Master.instance.uid;\n\t\t\tthis.sendMsg(cmd);\n\t\t}\n\t\t/**\n\t\t * 接受数据\n\t\t */\n\t\tprivate _onReceiveMessage(e: egret.ProgressEvent): void {\n\n\t\t\t//todo 在这里收到心跳协议回复,将_isGetRep置为true\n\t\t\tlet ws: egret.WebSocket = e.target as egret.WebSocket;\n\t\t\tthis._readByteAry.clear();\n\t\t\tws.readBytes(this._readByteAry);\n\t\t\t/*rawData:buffer 组成:协议名字长度+协议名字+协议数据长度+协议数据 */\n\t\t\tlet nameLen: number = this._readByteAry.readUnsignedShort();\n\t\t\tlet cmdTitle = this._readByteAry.readUTFBytes(nameLen);\n\t\t\tlet rawDataLen: number = this._readByteAry.readUnsignedShort();\n\t\t\tlet rawData: Uint8Array = this._readByteAry.bytes.slice(4 + nameLen, 4 + nameLen + rawDataLen);\n\t\t\tconst protoType: protobuf.Type = this._protoRoot.lookupType(cmdTitle);\n\t\t\tlet message: protobuf.Message<{}> = protoType.decode(rawData)\n\n\t\t\tconsole.log(\"[收到服务器数据: \" + cmdTitle + \":\" + JSON.stringify(message) + \"]\");\n\t\t\tlet jsonData = message.toJSON();\n\t\t\t/* 登陆协议 */\n\t\t\tswitch (cmdTitle) {\n\t\t\t\tcase \"Cmd.Login_C\":\n\t\t\t\t\t// let accurateData: Cmd.Login_C = jsonData as Cmd.Login_C;\n\t\t\t\t\tbreak;\n\t\t\t\tcase \"Cmd.PlayerInfo_S\":\n\t\t\t\t\tlet accurateData2: Cmd.PlayerInfo_S = jsonData as Cmd.PlayerInfo_S;\n\t\t\t\t\tMaster.instance.uid = accurateData2.uid;\n\t\t\t\t\tMaster.instance.itemData = accurateData2.itemInfo;\n\t\t\t\t\tEventManager.fireEvent(EVENT_ID.SERVE_COMPLETE);\n\t\t\t\t\tthis._heartCheck();\n\n\t\t\t\t\tbreak;\n\t\t\t\tcase \"Cmd.ItemUpdate_CS\":\n\t\t\t\t\tlet accurateData3: Cmd.ItemUpdate_CS = jsonData as Cmd.ItemUpdate_CS;\n\t\t\t\t\tMaster.instance.itemData = accurateData3.itemInfo;\n\t\t\t\t\tEventManager.fireEvent(EVENT_ID.UPDATE_ITEM_INFO);\n\n\t\t\t\t\tbreak;\n\t\t\t\tcase \"Cmd.Heartbeat_CS\":\n\t\t\t\t\tlet accurateData4: Cmd.Heartbeat_CS = jsonData as Cmd.Heartbeat_CS;\n\t\t\t\t\tif (Master.instance.uid == accurateData4.uid) {\n\t\t\t\t\t\tthis._curHeartCount = 0;\n\t\t\t\t\t}\n\t\t\t\t\telse {\n\t\t\t\t\t\tconsole.assert(false, \"逻辑有误\")\n\t\t\t\t\t}\n\t\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\n\t\t/**\n\t\t * 发送数据\n\t\t */\n\t\tpublic sendString(str: string): void {\n\t\t\tthis._webSocket.writeUTF(str)\n\t\t\tthis._webSocket.flush();\n\t\t}\n\n\t\t/**\n\t\t * 发送字节二进制 \n\t\t */\n\t\tpublic sendMsg(cmd: any): void {\n\t\t\t// let constructor = cmd.constructor\n\t\t\tif (cmd[\"GetType\"] === void 0) {\n\t\t\t\tconsole.assert(false, \"cmd未扩展GetType\")\n\t\t\t\treturn\n\t\t\t}\n\n\t\t\tlet protoName: string = cmd[\"GetType\"]()\n\t\t\tconsole.error(\"协议标题:\" + protoName)\n\t\t\tconst protoType = this._protoRoot.lookupType(protoName)\n\t\t\tlet writer: protobuf.Writer = protoType.encode(cmd);\n\t\t\tlet data: Uint8Array = writer.finish();\n\t\t\tthis._writeByteAry.clear();\n\n\t\t\tthis._writeByteAry.writeUTFBytes(protoName);\n\t\t\tlet len: number = this._writeByteAry.length;\n\t\t\tthis._writeByteAry.position = 0;\n\t\t\tlet len2: number = data.length;\n\t\t\tthis._writeByteAry.position = 0;\n\n\t\t\tthis._writeByteAry.writeUnsignedShort(len);\n\t\t\tthis._writeByteAry.writeUTFBytes(protoName);\n\t\t\tthis._writeByteAry.writeUnsignedShort(len2);\n\t\t\tthis._writeByteAry._writeUint8Array(data);\n\n\n\n\t\t\t// this._writeByteAry.position = 0;\n\t\t\t// let len3: number = this._writeByteAry.readUnsignedShort();\n\t\t\t// let TypeName = this._writeByteAry.readUTFBytes(len3);\n\n\n\t\t\tthis._webSocket.writeBytes(this._writeByteAry);\n\t\t\tthis._webSocket.flush();\n\t\t}\n\n\t\t/**\n\t\t * 释放\n\t\t */\n\t\tpublic dispose(): void {\n\t\t\tLaya.timer.clear(this, this._sendHeartMsg);\n\t\t\tthis._webSocket.removeEventListener(egret.Event.CONNECT, this._onSocketOpen, this)\n\t\t\tthis._webSocket.removeEventListener(egret.ProgressEvent.SOCKET_DATA, this._onReceiveMessage, this);\n\t\t\tthis._webSocket.removeEventListener(egret.IOErrorEvent.IO_ERROR, this._onSocketError, this);\n\t\t\tthis._webSocket.removeEventListener(egret.Event.CLOSE, this._onSocketClose, this);\n\t\t}\n\t}\n}"
},
{
"alpha_fraction": 0.5308998823165894,
"alphanum_fraction": 0.5352367162704468,
"avg_line_length": 25.615385055541992,
"blob_id": "3f13d1a7b73959a2a0253c411382b421952d4d6f",
"content_id": "7a9cba79b4c9585dded7cee9a856bde2e0ed1ac2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2845,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 104,
"path": "/Nodejs/src/PlayerCenter.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "import { Dictionary } from \"./util/Dictionary\";\nimport { Cmd } from \"../protobuf/common\";\nimport { MyWebSocket } from \"./MyWebSocket\";\nimport { JsonParse } from \"./JsonParse\";\n\nexport class PlayerCenter {\n\n public static playerMap: Dictionary = new Dictionary()\n\n public constructor() {\n\n }\n\n\n /**\n\t * 获得玩家道具数量\n\t */\n public static getProp(uid: number, propID: number): number {\n let propData: Cmd.IItemInfo_CS[] = this.playerMap.get(uid)\n for (let item of propData) {\n if (item.itemID == propID) {\n return item.itemNum;\n }\n }\n }\n\n /**\n * 设置玩家道具数量\n */\n public static updateProp(uid: number, propID: number, updateNum: number): number {\n let propData: Cmd.IItemInfo_CS[] = this.playerMap.get(uid)\n for (let item of propData) {\n if (item.itemID == propID) {\n item.itemNum += updateNum;\n item.itemUpdateNum = updateNum;\n return item.itemNum;\n }\n }\n }\n\n public static clearUpdateNum(uid: number): void {\n let propData: Cmd.IItemInfo_CS[] = this.playerMap.get(uid)\n for (let item of propData) {\n item.itemUpdateNum = 0;\n }\n }\n\n\n /**\n * 设置玩家道具数量\n */\n public static setProp(uid: number, propID: number, num: number): void {\n let propData: Cmd.IItemInfo_CS[] = this.playerMap.get(uid)\n for (let item of propData) {\n if (item.itemID == propID) {\n item.itemNum = num;\n break;\n }\n }\n }\n\n /**\n * 发送玩家数据\n * @param uid \n * @param itemInfoAry \n */\n public static sendPlayerData(uid: number, itemInfoAry?: Cmd.ItemInfo_CS[]): void {\n let cmd: Cmd.PlayerInfo_S = new Cmd.PlayerInfo_S();\n cmd.uid = uid;\n if (itemInfoAry === void 0) {\n itemInfoAry = PlayerCenter.playerMap.get(uid);\n }\n cmd.itemInfo = itemInfoAry;\n this.playerMap.set(uid, itemInfoAry);\n MyWebSocket.instance.sendMsg(uid, cmd);\n }\n\n /**\n * 发送初始化玩家数据\n * @param data \n */\n public static sendInitPlayerData(data: Cmd.Login_C): void {\n let itemInfoAry: Cmd.ItemInfo_CS[] = []\n for (let item of JsonParse.propData) {\n let itemInfo: Cmd.ItemInfo_CS = new Cmd.ItemInfo_CS();\n itemInfo.itemID = item.id;\n if (item.id == 1 || item.id == 2 || item.id == 3) {\n itemInfo.itemNum = 100\n }\n else {\n itemInfo.itemNum = 0;\n }\n itemInfoAry.push(itemInfo);\n }\n PlayerCenter.sendPlayerData(data.uid, itemInfoAry);\n }\n\n\n}\nexport enum PROP_ID {\n MONEY = 1,\n DIMOND = 2,\n HONOR = 3,\n}"
},
{
"alpha_fraction": 0.5581837296485901,
"alphanum_fraction": 0.5583736896514893,
"avg_line_length": 29.1633243560791,
"blob_id": "aa492b3a9b6b3f9cdca7a58bdb0679c6309239b8",
"content_id": "ef125fad4bc8e67b2eaac45d73b952fcead509c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "TypeScript",
"length_bytes": 10527,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 349,
"path": "/Nodejs/protobuf/common.d.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "import * as $protobuf from \"protobufjs\";\n\n/** Namespace Cmd. */\nexport namespace Cmd {\n\n /** Properties of a Login_C. */\n interface ILogin_C {\n\n /** Login_C account */\n account: string;\n\n /** Login_C password */\n password: string;\n\n /** Login_C uid */\n uid?: (number|null);\n }\n\n /** Represents a Login_C. */\n class Login_C implements ILogin_C {\n\n /**\n * Constructs a new Login_C.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.ILogin_C);\n\n /** Login_C account. */\n public account: string;\n\n /** Login_C password. */\n public password: string;\n\n /** Login_C uid. */\n public uid: number;\n\n /**\n * Creates a Login_C message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns Login_C\n */\n public static fromObject(object: { [k: string]: any }): Cmd.Login_C;\n\n /**\n * Creates a plain object from a Login_C message. Also converts values to other types if specified.\n * @param message Login_C\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.Login_C, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this Login_C to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n\n /** Properties of an ItemInfo_CS. */\n interface IItemInfo_CS {\n\n /** ItemInfo_CS itemID */\n itemID: number;\n\n /** ItemInfo_CS itemNum */\n itemNum?: (number|null);\n\n /** ItemInfo_CS itemUpdateNum */\n itemUpdateNum?: (number|null);\n }\n\n /** Represents an ItemInfo_CS. */\n class ItemInfo_CS implements IItemInfo_CS {\n\n /**\n * Constructs a new ItemInfo_CS.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.IItemInfo_CS);\n\n /** ItemInfo_CS itemID. */\n public itemID: number;\n\n /** ItemInfo_CS itemNum. */\n public itemNum: number;\n\n /** ItemInfo_CS itemUpdateNum. */\n public itemUpdateNum: number;\n\n /**\n * Creates an ItemInfo_CS message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns ItemInfo_CS\n */\n public static fromObject(object: { [k: string]: any }): Cmd.ItemInfo_CS;\n\n /**\n * Creates a plain object from an ItemInfo_CS message. Also converts values to other types if specified.\n * @param message ItemInfo_CS\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.ItemInfo_CS, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this ItemInfo_CS to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n\n /** Properties of a PlayerInfo_S. */\n interface IPlayerInfo_S {\n\n /** PlayerInfo_S uid */\n uid: number;\n\n /** PlayerInfo_S itemInfo */\n itemInfo?: (Cmd.IItemInfo_CS[]|null);\n }\n\n /** Represents a PlayerInfo_S. */\n class PlayerInfo_S implements IPlayerInfo_S {\n\n /**\n * Constructs a new PlayerInfo_S.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.IPlayerInfo_S);\n\n /** PlayerInfo_S uid. */\n public uid: number;\n\n /** PlayerInfo_S itemInfo. */\n public itemInfo: Cmd.IItemInfo_CS[];\n\n /**\n * Creates a PlayerInfo_S message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns PlayerInfo_S\n */\n public static fromObject(object: { [k: string]: any }): Cmd.PlayerInfo_S;\n\n /**\n * Creates a plain object from a PlayerInfo_S message. Also converts values to other types if specified.\n * @param message PlayerInfo_S\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.PlayerInfo_S, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this PlayerInfo_S to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n\n /** Properties of an ItemUpdate_CS. */\n interface IItemUpdate_CS {\n\n /** ItemUpdate_CS uid */\n uid: number;\n\n /** ItemUpdate_CS itemInfo */\n itemInfo?: (Cmd.IItemInfo_CS[]|null);\n }\n\n /** Represents an ItemUpdate_CS. */\n class ItemUpdate_CS implements IItemUpdate_CS {\n\n /**\n * Constructs a new ItemUpdate_CS.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.IItemUpdate_CS);\n\n /** ItemUpdate_CS uid. */\n public uid: number;\n\n /** ItemUpdate_CS itemInfo. */\n public itemInfo: Cmd.IItemInfo_CS[];\n\n /**\n * Creates an ItemUpdate_CS message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns ItemUpdate_CS\n */\n public static fromObject(object: { [k: string]: any }): Cmd.ItemUpdate_CS;\n\n /**\n * Creates a plain object from an ItemUpdate_CS message. Also converts values to other types if specified.\n * @param message ItemUpdate_CS\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.ItemUpdate_CS, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this ItemUpdate_CS to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n\n /** Properties of a Heartbeat_CS. */\n interface IHeartbeat_CS {\n\n /** Heartbeat_CS uid */\n uid: number;\n }\n\n /** Represents a Heartbeat_CS. */\n class Heartbeat_CS implements IHeartbeat_CS {\n\n /**\n * Constructs a new Heartbeat_CS.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.IHeartbeat_CS);\n\n /** Heartbeat_CS uid. */\n public uid: number;\n\n /**\n * Creates a Heartbeat_CS message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns Heartbeat_CS\n */\n public static fromObject(object: { [k: string]: any }): Cmd.Heartbeat_CS;\n\n /**\n * Creates a plain object from a Heartbeat_CS message. Also converts values to other types if specified.\n * @param message Heartbeat_CS\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.Heartbeat_CS, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this Heartbeat_CS to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n\n /** Properties of a TaskUpdate_CS. */\n interface ITaskUpdate_CS {\n\n /** TaskUpdate_CS uid */\n uid: number;\n\n /** TaskUpdate_CS taskInfo */\n taskInfo?: (Cmd.TaskUpdate_CS.ITaskInfo[]|null);\n }\n\n /** Represents a TaskUpdate_CS. */\n class TaskUpdate_CS implements ITaskUpdate_CS {\n\n /**\n * Constructs a new TaskUpdate_CS.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.ITaskUpdate_CS);\n\n /** TaskUpdate_CS uid. */\n public uid: number;\n\n /** TaskUpdate_CS taskInfo. */\n public taskInfo: Cmd.TaskUpdate_CS.ITaskInfo[];\n\n /**\n * Creates a TaskUpdate_CS message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns TaskUpdate_CS\n */\n public static fromObject(object: { [k: string]: any }): Cmd.TaskUpdate_CS;\n\n /**\n * Creates a plain object from a TaskUpdate_CS message. Also converts values to other types if specified.\n * @param message TaskUpdate_CS\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.TaskUpdate_CS, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this TaskUpdate_CS to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n\n namespace TaskUpdate_CS {\n\n /** Properties of a TaskInfo. */\n interface ITaskInfo {\n\n /** TaskInfo taskID */\n taskID: number;\n\n /** TaskInfo taskState */\n taskState: number;\n }\n\n /** Represents a TaskInfo. */\n class TaskInfo implements ITaskInfo {\n\n /**\n * Constructs a new TaskInfo.\n * @param [properties] Properties to set\n */\n constructor(properties?: Cmd.TaskUpdate_CS.ITaskInfo);\n\n /** TaskInfo taskID. */\n public taskID: number;\n\n /** TaskInfo taskState. */\n public taskState: number;\n\n /**\n * Creates a TaskInfo message from a plain object. Also converts values to their respective internal types.\n * @param object Plain object\n * @returns TaskInfo\n */\n public static fromObject(object: { [k: string]: any }): Cmd.TaskUpdate_CS.TaskInfo;\n\n /**\n * Creates a plain object from a TaskInfo message. Also converts values to other types if specified.\n * @param message TaskInfo\n * @param [options] Conversion options\n * @returns Plain object\n */\n public static toObject(message: Cmd.TaskUpdate_CS.TaskInfo, options?: $protobuf.IConversionOptions): { [k: string]: any };\n\n /**\n * Converts this TaskInfo to JSON.\n * @returns JSON object\n */\n public toJSON(): { [k: string]: any };\n }\n }\n\n /** TASK_STATE enum. */\n enum TASK_STATE {\n undone = 0,\n done = 1\n }\n}\n"
},
{
"alpha_fraction": 0.5495626926422119,
"alphanum_fraction": 0.565597653388977,
"avg_line_length": 14.613636016845703,
"blob_id": "093d45ea4cc7c58768fb63868b3191912d7d4fed",
"content_id": "d4bbac4fddb4d9de9f1038eb37ef726d5dbfd983",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 718,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 44,
"path": "/Egret/src/util/GlobeTool.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "/**\n * 全局工具\n * @author suo\n */\nmodule catchDoll {\n\texport class GlobeTool {\n\n\n\n\t\tpublic constructor() {\n\t\t}\n\n\t\t/**\n\t\t * 在视图内\n\t\t */\n\t\tpublic static inView(x: number, y: number): boolean {\n\t\t\tif (x < -10 || x > catchDoll.GameCenter.stageW + 10) {\n\t\t\t\treturn false\n\t\t\t}\n\t\t\tif (y < -10 || y > catchDoll.GameCenter.stageH + 10) {\n\t\t\t\treturn false;\n\t\t\t}\n\t\t\treturn true;\n\t\t}\n\n\t\t/**\n\t\t * 获得玩家道具数量\n\t\t */\n\t\tpublic static getProp(propID: number): number {\n\t\t\tlet propData: Cmd.IItemInfo_CS[] = Master.instance.itemData;\n\t\t\tfor (let item of propData) {\n\t\t\t\tif (item.itemID == propID) {\n\t\t\t\t\treturn item.itemNum;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\n\texport enum ITEM_ID {\n\t\tMONEY = 1,\n\t\tDIMOND = 2,\n\t\tHONOR = 3,\n\t}\n}"
},
{
"alpha_fraction": 0.4464781582355499,
"alphanum_fraction": 0.4502827823162079,
"avg_line_length": 30.144229888916016,
"blob_id": "1299cc4d832bcfd52d09f076c8332d2da49fdc59",
"content_id": "baf2cc998b937355db156f5e399640e0d13aac33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 9955,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 312,
"path": "/Nodejs/src/SQLServe.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "import { Connection } from \"mysql\";\nimport { Cmd } from \"../protobuf/common\";\nimport { JsonParse } from \"./JsonParse\";\nimport { PlayerCenter } from \"./PlayerCenter\";\nimport { Handler } from \"./util/Handler\";\nvar SQL = require('mysql');\nexport class SQLServe {\n private uidIndex = 100;\n\n /* 单例 */\n private static _instance: SQLServe = null;\n /* 链接 */\n private connection: Connection;\n /* */\n private _isReconnet: boolean = false;\n\n private _reconnetHandler: Handler[] = [];\n\n constructor() {\n }\n\n /* 获取单例 */\n public static get instance(): SQLServe {\n if (this._instance == null) {\n this._instance = new SQLServe();\n }\n return this._instance;\n }\n\n public createConnection() {\n //创建一个connection\n this.connection = SQL.createConnection({\n host: JsonParse.SQLHost, //主机\n user: 'root', //MySQL认证用户名\n password: 'JYM8398337', //MySQL认证用户密码\n port: JsonParse.SQLPost, //端口号\n database: 'test',\n debug: false,\n });\n\n this.connection.connect((err) => {\n if (err) {\n\n console.log('[query] - :' + err);\n setTimeout(SQLServe.instance.createConnection, 2000);\n return;\n }\n this._isReconnet = true;\n this._addCow();\n // this._clearSQL();\n console.log('数据库[connection connect] succeed!');\n });\n\n this.connection.on('error', function (err) {\n console.error('sql error', err);\n if (err.code === 'PROTOCOL_CONNECTION_LOST') {\n this._isReconnet = true;\n console.error('sql error执行重连:' + err.message);\n SQLServe.instance.createConnection();\n } else {\n throw err;\n }\n })\n }\n\n /**\n * 清除数据库\n */\n private _clearSQL(): void {\n var userDelSql = 'delete from Login';\n this.connection.query(userDelSql, this._onSQLDelete);\n\n var userDelSql = 'delete from PropInfo';\n this.connection.query(userDelSql, this._onSQLDelete);\n }\n\n /**\n * 添加列\n */\n private _addCow(): void {\n var sql = 'SELECT * FROM PropInfo'\n this.connection.query(sql, (err, result, fields) => {\n if (err) {\n console.log('[query] - :' + err);\n return;\n }\n let propIDAry: string[] = JsonParse.propDataID.slice();\n\n for (let item of fields) {\n if (propIDAry.indexOf(item.name) != -1) {\n propIDAry.remove(item.name);\n }\n }\n for (let item of propIDAry) {\n let addSqlCow: string = \"alter table PropInfo add \" + item + \" int(20)\"\n this.connection.query(addSqlCow, (err, result, fields) => {\n if (err) {\n console.log('[query] - :' + err);\n return;\n }\n })\n }\n })\n\n }\n\n /**\n * 数据库查找\n * @param data \n */\n public seekLogin(data: Cmd.Login_C) {\n var sql = 'SELECT * FROM Login where uid=' + data.uid;\n this.connection.query(sql, (err, result, fields) => {\n if (err) {\n console.log('数据库[SELsECT ERROR] - ', err.message);\n } else {\n console.log('--------------------------SELECT----------------------------');\n console.log(result);\n if (result.length) {\n this._seekPlayerData(data);\n }\n else {\n this._initPlayerData(data);\n }\n console.log('------------------------------------------------------------\\n\\n');\n }\n })\n }\n\n /**\n * 查询玩家数据\n * @param data \n */\n private _seekPlayerData(data: Cmd.Login_C): void {\n var sql = 'SELECT * FROM PropInfo where uid=' + data.uid;\n this.connection.query(sql, (err, result, fields) => {\n if (err) {\n console.log('[query] - :' + err);\n return;\n }\n let playerData: Object = result[0];\n let itemInfoAry: Cmd.ItemInfo_CS[] = [];\n for (let item in playerData) {\n if (item != \"uid\") {\n let itemInfo: Cmd.ItemInfo_CS = new Cmd.ItemInfo_CS();\n itemInfo.itemID = Number(item.slice(JsonParse.propForm.length));\n itemInfo.itemNum = playerData[item];\n itemInfoAry.push(itemInfo);\n }\n }\n PlayerCenter.sendPlayerData(data.uid, itemInfoAry);\n })\n }\n\n\n /**\n * 初始化玩家数据\n * @param data \n */\n private _initPlayerData(data: Cmd.Login_C): void {\n let ready1: boolean = false;\n let ready2: boolean = false;\n\n var addSql = 'INSERT INTO Login ' + '(account,password,uid)' + ' VALUES(?,?,?)';\n var addSqlParams = [data.account, data.password, data.uid];\n this.connection.query(addSql, addSqlParams, (err, result, fields) => {\n if (err) {\n console.log('数据库[INSERT ERROR] - ', err.message);\n return;\n }\n ready1 = true;\n console.log('--------------------------INSERT----------------------------');\n console.log('insert:', result);\n console.log('-----------------------------------------------------------------\\n\\n');\n if (ready1 && ready2) {\n PlayerCenter.sendInitPlayerData(data)\n }\n })\n\n let rowName = \"uid,\";\n let valueStr = \"?,\";\n var addUserParams: number[] = [data.uid];\n for (let item of JsonParse.propDataID) {\n rowName += item + \",\";\n valueStr += \"?,\"\n if (item == \"propID_1\" || item == \"propID_2\" || item == \"propID_3\") {\n addUserParams.push(100)\n }\n else {\n addUserParams.push(0);\n }\n }\n valueStr = valueStr.slice(0, valueStr.length - 1)\n rowName = rowName.slice(0, rowName.length - 1);\n rowName = \"(\" + rowName + \")\"\n valueStr = \" values(\" + valueStr + \")\"\n var addUser = 'INSERT INTO PropInfo ' + rowName + valueStr;\n this.connection.query(addUser, addUserParams, (err, result, fields) => {\n if (err) {\n console.log('数据库[INSERT ERROR] - ', err.message);\n return;\n }\n ready2 = true;\n console.log('数据库插入:', result);\n if (ready1 && ready2) {\n PlayerCenter.sendInitPlayerData(data);\n }\n })\n\n var addSql = 'INSERT INTO OtherInfo' + '(account,password,uid)' + ' VALUES(?,?,?)';\n var addSqlParams = [data.account, data.password, data.uid];\n this.connection.query(addSql, addSqlParams, (err, result, fields) => {\n if (err) {\n console.log('数据库[INSERT ERROR] - ', err.message);\n return;\n }\n ready1 = true;\n console.log('--------------------------INSERT----------------------------');\n console.log('insert:', result);\n console.log('-----------------------------------------------------------------\\n\\n');\n if (ready1 && ready2) {\n PlayerCenter.sendInitPlayerData(data)\n }\n })\n }\n\n\n\n\n\n\n\n public deleteSQL() {\n var userDelSql = 'DELETE FROM Login';\n this.connection.query(userDelSql, this._onSQLDelete);\n }\n\n /**\n * 数据库删除\n * @param err \n * @param result \n */\n private _onSQLDelete(err, result): void {\n if (err) {\n console.log('[DELETE ERROR] - ', err.message);\n return;\n }\n console.log('数据库删除', result.affectedRows);\n }\n\n\n /**\n * 数据库添加\n */\n private _onSQLInsert(err, result, fields): void {\n if (err) {\n console.log('数据库[INSERT ERROR] - ', err.message);\n return;\n }\n console.log('数据库添加:', result);\n }\n\n public getUidIndex() {\n var sql = 'SELECT * FROM Login where uid';\n //查\n this.connection.query(sql, function (err, result) {\n if (err) {\n console.log('数据库[SELECT ERROR] - ', err.message);\n } else {\n console.log('--------------------------SELECT----------------------------');\n console.log(result);\n console.log('------------------------------------------------------------\\n\\n');\n\n this.uidIndex = result[result.length - 1].uid + 1\n }\n });\n }\n\n public setUserData(uid: number, itemInfo: Cmd.ItemInfo_CS[]): void {\n\n let rowName = \"\";\n var sqlParams = [];\n for (let item of itemInfo) {\n rowName += JsonParse.propForm + item.itemID + \"=?,\"\n sqlParams.push(item.itemNum);\n }\n rowName = rowName.slice(0, rowName.length - 1)\n sqlParams.push(uid);\n\n var sql = 'UPDATE PropInfo SET ' + rowName + ' WHERE uid = ?';\n this.connection.query(sql, sqlParams, (err, result, fields) => {\n if (err) {\n console.log('[query] - :' + err);\n return;\n }\n console.log(\"数据库修改:\" + result);\n\n })\n }\n\n public close() {\n // 关闭connection\n this.connection.end(function (err) {\n if (err) {\n return;\n }\n console.log('数据库[connection end] succeed!');\n });\n }\n}\n\nglobal[\"SQLServe\"] = SQLServe;\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.42081448435783386,
"alphanum_fraction": 0.4270797073841095,
"avg_line_length": 30.58241844177246,
"blob_id": "50ee02f707fa51c1212dd905389744b7cb489781",
"content_id": "d5752103145decfc228a5df8082b38c4f011d3a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 3029,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 91,
"path": "/Nodejs/src/Task/TaskMgr.ts",
"repo_name": "lvjiaming/CatchDoll",
"src_encoding": "UTF-8",
"text": "/**\n * 任务系统管理类,任何任务有关放在这\n */\nimport { Cmd } from \"../../protobuf/common\";\nimport { Utils } from \"../util/Utils\";\nimport { MyWebSocket } from \"../MyWebSocket\";\nexport class TaskMgr {\n private static _taskMgr: TaskMgr = null;\n private _taskTimer: any = null;\n private _ws = null;\n private _taskNum: number = 3;\n /**\n * 获取单例\n */\n public static getInstance(): TaskMgr {\n if (!this._taskMgr) {\n this._taskMgr = new TaskMgr();\n }\n return this._taskMgr;\n };\n constructor() {\n\n };\n /**\n * 任务刷新计时\n */\n public taskTimer(): void {\n this._taskTimer = setInterval(() => {\n var time = new Date();\n var hour = time.getHours();\n var min = time.getMinutes();\n var ys = hour % 2;\n this.pushTaskList(); \n if (ys == 0) {\n if (min < 2 || min > 58) {\n this.pushTaskList(); \n } else {\n // console.log(`还有${60 - min}分钟刷新任务列表`);\n }\n } else {\n // console.log(`还有${ys}小时${60 - min}分钟刷新任务列表`);\n }\n }, 2000);\n };\n /**\n * 清空任务计时\n */\n public clealTsskTimer(): void {\n if (this._taskTimer) {\n clearInterval(this._taskTimer);\n this._taskTimer = null;\n }\n };\n /**\n * 推送任务列表\n */\n public pushTaskList(): void {\n let cmd: Cmd.TaskUpdate_CS = new Cmd.TaskUpdate_CS();\n let taskInfo: Cmd.TaskUpdate_CS.TaskInfo = new Cmd.TaskUpdate_CS.TaskInfo();\n Utils.getInstance().getFile(\"../resource/table/TaskTable.json\", (data) => {\n console.log('任务列表', data);\n const curTaskIndex = [];\n const func = () => {\n if (curTaskIndex.length >= this._taskNum) {\n console.log(\"刷新的任务下表列表:\", curTaskIndex);\n curTaskIndex.forEach((item) => {\n // console.log(\"任务: \", data[item - 1]);\n taskInfo.taskID = data[item - 1].id;\n taskInfo.taskState = Cmd.TASK_STATE.undone;\n cmd.taskInfo.push(taskInfo);\n // MyWebSocket.instance.connectMap\n });\n } else {\n let canAdd = true;\n const curNum = Utils.getInstance().getRandom(1, data.length);\n curTaskIndex.forEach((item) => {\n if (item == curNum) {\n canAdd = false;\n }\n });\n if (canAdd) {\n curTaskIndex.push(curNum);\n }\n func();\n }\n };\n func();\n });\n // this._target.sendMsg(1, data);\n };\n};"
}
] | 11 |
Sourceless/rtf-scraper | https://github.com/Sourceless/rtf-scraper | ac0ccf92f08c3737394afc95b8b2af18b9506624 | 921191691958d68f47cf28ede6976d8e0294bbc0 | fcd5acdcf16e7c5b7d18d6bc3b1487e57b9d2720 | refs/heads/master | 2021-01-21T23:38:09.514183 | 2013-07-03T00:22:30 | 2013-07-03T00:22:30 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6312236189842224,
"alphanum_fraction": 0.6320675015449524,
"avg_line_length": 29.384614944458008,
"blob_id": "954e890c337866d9b0c572f5f3aa8deea25028f0",
"content_id": "7f0f6105fa7ef29c92db0385d80809a19cea7267",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1185,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 39,
"path": "/mapper.py",
"repo_name": "Sourceless/rtf-scraper",
"src_encoding": "UTF-8",
"text": "import requests\nfrom BeautifulSoup import BeautifulSoup\n\n\ndef map_site(url):\n '''Find all the linked-to pages of a site and return a list of them'''\n not_searched = [url]\n searched = []\n\n while len(not_searched):\n # really terrible, O(n^2), but it needs done fast, so...\n search_url = not_searched.pop()\n if search_url not in searched:\n print \"Searching {}\".format(search_url)\n not_searched.extend(scrape_links(url, search_url))\n else:\n continue # skip, already searched\n searched.append(search_url) \n\n return searched\n\n\ndef scrape_links(root, url):\n '''Scrape an url for links, return a list of urls'''\n page = requests.get(url)\n soup = BeautifulSoup(page.text)\n\n anchors = soup.findAll('a', href=True)\n anchors = [dict(anchor.attrs)['href'] for anchor in anchors]\n anchors = [anchor for anchor in anchors if anchor != None]\n anchors = [rootify(root, anchor) for anchor in anchors if anchor.startswith('/')]\n\n return anchors\n\n\ndef rootify(root, url):\n if url.startswith(u'/'): # It's a relative path\n return '/'.join(u.strip('/') for u in (root, url))\n return url\n"
},
{
"alpha_fraction": 0.7721893787384033,
"alphanum_fraction": 0.7751479148864746,
"avg_line_length": 47.28571319580078,
"blob_id": "1c8248727bf9390a9f98bedd9b1a4346a8df979b",
"content_id": "802044da22e349e67543a66283a1f5803edb8eff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Sourceless/rtf-scraper",
"src_encoding": "UTF-8",
"text": "Currently a problem: only works when links are relative paths. Might fix but this project isn't exactly long term.\n\nProblem 2: my rushed attempt at getting them to go into nice files/folders didn't work. Preserved in filename instead.\n\n# To use\n\nGo into the directory you want to scrape the site to and then `python <path-to-scraper.py>`\n"
},
{
"alpha_fraction": 0.5582329034805298,
"alphanum_fraction": 0.5595716238021851,
"avg_line_length": 28.860000610351562,
"blob_id": "7148bb7fecadd58e1f59efc23bf5446baf059dec",
"content_id": "c476bde90d33fa1f8bc2e917d429b56a08ebfe09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 50,
"path": "/scraper.py",
"repo_name": "Sourceless/rtf-scraper",
"src_encoding": "UTF-8",
"text": "import mapper\nimport requests\nimport os\nimport os.path\nimport sys\nimport json\nimport codecs\n\n\ndef scrape_recursively(url, dir_=os.getcwd()):\n print \"Scraping links {}, this could take some time...\".format(url)\n link_list = mapper.map_site(url)\n print \"Done. Scraping pages, this will take a little while...\"\n \n for link in link_list:\n print \"Scraping {}\".format(link)\n page = requests.get(link)\n file_loc = os.path.join(dir_, link[len(url):].strip('/')) + '.html'\n if link == url:\n file_loc = './index.html'\n ensure_dirs(file_loc)\n\n with codecs.open(file_loc, 'w', 'utf-8') as f:\n f.write(page.text)\n\n # dirty, hacky, horrible, please never do this\n try:\n print \"Trying to get page JSON\"\n link_json = link + '.json'\n page_json = json.loads(requests.get(link_json).text)\n file_loc_json = os.path.join(dir_, link_json[len(url):].strip('/'))\n if link == url:\n file_loc_json = './index.json'\n ensure_dirs(file_loc_json)\n\n with codecs.open(file_loc_json, 'w', 'utf-8') as f:\n f.write(json.dumps(page_json))\n print \"Success\"\n except Exception:\n print \"Failed\"\n continue\n\ndef ensure_dirs(f):\n d = os.path.dirname(f)\n if not os.path.exists(d):\n os.makedirs(d)\n\n\nif __name__ == '__main__':\n scrape_recursively(\"http://www.restorethefourth.net/\") \n"
}
] | 3 |
3453-315h/BurpBountyProfiles | https://github.com/3453-315h/BurpBountyProfiles | 37d4b63c14d7f1e42038620aca68b3f58cd75f16 | e20679e1d8bbc82fc391ed5823b1dde3d6069029 | 25b83a0267a8f63d1fd51e645de55fe5d54340b2 | refs/heads/main | 2023-03-03T12:28:42.192006 | 2021-02-08T15:56:10 | 2021-02-08T15:56:10 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7064732313156128,
"alphanum_fraction": 0.7098214030265808,
"avg_line_length": 23.91666603088379,
"blob_id": "210253f919aece9acd7df81f9e6f092a9a7f743c",
"content_id": "88bb66f63c51ec356f8829f1e85eeb2605e7d927",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 896,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 36,
"path": "/convert.py",
"repo_name": "3453-315h/BurpBountyProfiles",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport json\nfrom optparse import OptionParser\nfrom collections import OrderedDict\n\nparser = OptionParser(usage='Imput parameters')\nparser.add_option('-i', dest=\"ifilename\", help='input file')\nparser.add_option('-o', dest=\"ofilename\", help='input file')\nparser.add_option('-d', action='store_true', dest=\"debug\", default=False, help='debug')\n\n(args, ooo ) = parser.parse_args()\n\n\nif not args.ifilename:\n\tprint \"give input file\"\n\texit()\n\n#Read JSON data into the datastore variable\nif args.ifilename:\n with open(str(args.ifilename), 'r') as f:\n datastore = json.load(f,object_pairs_hook=OrderedDict,strict=False)\n f.close()\n\nif args.debug:\n\t\n\tprint json.dumps(datastore,indent=1)\n\nif args.ofilename:\n\twith open(str(args.ofilename), 'w') as f:\n\t\tjson.dump(datastore, f, indent=1)\nelse:\n\twith open(args.ifilename, 'w') as f:\n\t\tjson.dump(datastore, f, indent=1)\n\nexit()"
},
{
"alpha_fraction": 0.5916836857795715,
"alphanum_fraction": 0.6141785979270935,
"avg_line_length": 33.13953399658203,
"blob_id": "d453fad145f9cc5adc3fa6737c599e2f5cb422b0",
"content_id": "98dc734683ba465280206ee6bcc5cb7333bd6b46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1467,
"license_type": "no_license",
"max_line_length": 359,
"num_lines": 43,
"path": "/convert_txt2bb.sh",
"repo_name": "3453-315h/BurpBountyProfiles",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#converting txt file to BurpBounty json bb file\n#ex: for ff in *; do /opt/burp/BurpBounty-Profiles/convert.sh $ff; done\n#outfile=$1'.bb'\nissuename=${1%.*}\noutfile=$issuename'.bb'\n#out Header\necho -n '[{\"Name\":\"' > $outfile\necho -n \"$issuename\" >> $outfile\necho -n '\",\"Active\":true,\"Scanner\":1,\"Payloads\":[' >> $outfile\n\necho \"filename: $1\"\nind=0\nwhile read -r ss \ndo\n\t\n\t#escape & -> \\u0026, \" -> \\\", ' -> \\u0027\n\tssc=$(echo -n \"$ss\" | sed 's/\\\\/\\\\\\\\/g; s/&/\\\\u0026/g; s/\"/\\\\\"/g; s/\\x27/\\\\u0027/g')\n\t\n\n\tif [[ ! -z \"$ssc\" ]]; then \n\t\tif [[ $ind -eq 0 ]]; then\n\t\t\techo -n '\"'\"$ssc\"'\"' >> $outfile\n\t\t\t#echo debug: \"$ssc\"\n\t\telse\n\t\t\techo -n ',\"'\"$ssc\"'\"' >> $outfile\n\t\t\t#echo debug: \"$ssc\"\n\t\tfi\n\tfi\n\tind+=1;\ndone < \"$1\"\n\n#out footer\necho -n '],\"Encoder\":[],\"UrlEncode\":false,\"CharsToUrlEncode\":\"\",\"SearchString\":\"\",\"ReplaceString\":\"\",\"Grep\":[\"error\"],\"PayloadResponse\":false,\"NotResponse\":false,\"NotCookie\":false,\"CaseSensitive\":false,\"ExcludeHTTP\":false,\"OnlyHTTP\":false,\"IsContentType\":false,\"ContentType\":\"\",\"IsResponseCode\":false,\"ResponseCode\":\"\",\"MatchType\":1,\"IssueName\":\"' >> $outfile\n#out issuename\necho -n \"$issuename\" >> $outfile\n\necho -n '\",\"IssueSeverity\":\"Information\",\"IssueConfidence\":\"Certain\",\"IssueDetail\":\"' >> $outfile\necho -n \"$issuename\" >> $outfile\necho -n '\\n\\n\\u003cgrep\\u003e\",\"RemediationDetail\":\"\",\"IssueBackground\":\"\",\"RemediationBackground\":\"\"}]' >> $outfile\n#echo -n '' >> $outfile\n#echo -n '' >> $outfile\n#echo -n '' >> $outfile"
},
{
"alpha_fraction": 0.6346153616905212,
"alphanum_fraction": 0.6346153616905212,
"avg_line_length": 20,
"blob_id": "3e952df71de43b8424a14362bf762f88861be229",
"content_id": "bc4e8f99b969f703136a7cb5e71527803de0aad1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 5,
"path": "/convert_bb2multibb.sh",
"repo_name": "3453-315h/BurpBountyProfiles",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfor file in *.bb\n do \n echo \"Converting File: \" $file; python convert.py -i \"$file\";\ndone"
}
] | 3 |
theofpa/ran | https://github.com/theofpa/ran | ab403e8d11af041fab83fbdc144fa35438546c59 | b7f4cf0517dfcb50856080cdca11c2feb4d3947e | 64c764daa7d54a104815715c70a8b7298f7e08d4 | refs/heads/master | 2021-08-30T07:15:03.598920 | 2017-12-16T16:47:17 | 2017-12-16T16:47:17 | 114,475,790 | 0 | 0 | null | 2017-12-16T16:46:27 | 2017-12-11T14:43:03 | 2017-06-29T15:35:04 | null | [
{
"alpha_fraction": 0.7252328395843506,
"alphanum_fraction": 0.743014395236969,
"avg_line_length": 51.488887786865234,
"blob_id": "1c55f21117d3faf3385d142a0a5baeee92da0f0d",
"content_id": "eca88c1b13b1b190225159d75a941aedc83a06ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2362,
"license_type": "no_license",
"max_line_length": 276,
"num_lines": 45,
"path": "/README.md",
"repo_name": "theofpa/ran",
"src_encoding": "UTF-8",
"text": "## Introduction\n\nThis codebase supports replication of the language modeling results in [Recurrent Additive Networks](https://arxiv.org/abs/1705.07393) ([Kenton Lee](http://www.kentonl.com), [Omer Levy](https://levyomer.wordpress.com), and [Luke Zettlemoyer](https://www.cs.washington.edu/people/faculty/lsz)).\n\n## Recurrent Additive Networks\nThe TensorFlow implementation of Recurrent Additive Networks (RAN) is found in `ran.py` and is used by the experiments in the subdirectories.\n\n## Experiments\n### Penn Treebank:\nThe word-level language modeling for Penn Treebank is found under the `ptb` directory. This code is derived from https://github.com/tensorflow/models/tree/master/tutorials/rnn/ptb.\n\n#### Data preparation\n* ```curl -O http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz```\n* ```mkdir data```\n* ```tar -xzvf simple-examples.tgz -C data```\n\n#### Train and Evaluate\n* `python -m ptb.ptb_word_lm --data_path=data/simple-examples/data --model=tanh_medium`\n\nReplace `tanh_medium` with the desired setting.\n\n### Billion-word Benchmark:\nThe word-level language modeling for the billion-word benchmark is found under the `bwb` directory. This code is derived from https://github.com/rafaljozefowicz/lm.\n\n#### Data preparation\n* ```curl -O http://www.statmt.org/lm-benchmark/1-billion-word-language-modeling-benchmark-r13output.tar.gz```\n* ```mkdir data```\n* ```tar -xzvf 1-billion-word-language-modeling-benchmark-r13output.tar.gz -C data```\n* ```curl -o data/1-billion-word-language-modeling-benchmark-r13output/1b_word_vocab.txt https://raw.githubusercontent.com/rafaljozefowicz/lm/master/1b_word_vocab.txt```\n\n#### Train\n* `CUDA_VISIBLE_DEVICES=0,1 python -m bwb.single_lm_train --logdir logs --num_gpus 2 --hpconfig num_shards=2 --datadir data/1-billion-word-language-modeling-benchmark-r13output`\n#### Evaluate\n* `CUDA_VISIBLE_DEVICES= python -m bwb.single_lm_train --logdir logs --mode eval_test_ave --hpconfig num_shards=2 --datadir data/1-billion-word-language-modeling-benchmark-r13output`\n\n### Text8:\nThe character-level language modeling for Text8 is found under the `text` directory. This code is derived from https://github.com/julian121266/RecurrentHighwayNetworks\n\n#### Data Preparation\n* ```curl -O http://mattmahoney.net/dc/text8.zip```\n* ```mkdir data```\n* ```unzip text8.zip -d data```\n\n#### Train and Evaluate\n* `python -m text8.char_train`\n"
},
{
"alpha_fraction": 0.6372041702270508,
"alphanum_fraction": 0.6554487347602844,
"avg_line_length": 37.26415252685547,
"blob_id": "74f1de84345f3fe8e9e333f854e0e3052b7cacc2",
"content_id": "bcc9d92242ec734e282dc02f671970e9c111c08e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8112,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 212,
"path": "/text8/char_train.py",
"repo_name": "theofpa/ran",
"src_encoding": "UTF-8",
"text": "\"\"\"Word/Symbol level next step prediction using Recurrent Highway Networks.\n\nTo run:\n$ python -m text8.char_train\n\n\"\"\"\nfrom __future__ import absolute_import, division, print_function\n\nimport time\nfrom copy import deepcopy\n\nimport numpy as np\nimport tensorflow as tf\nfrom sacred import Experiment\n\nfrom text8 import reader\nfrom text8.charmod import Model\n\nex = Experiment('ran_prediction')\nlogging = tf.logging\n\nclass Config:\n pass\nC = Config()\n\n\n@ex.config\ndef hyperparameters():\n data_path = 'data'\n dataset = 'text8'\n init_scale = 0.04\n init_bias = -4.0\n hidden_sizes = [128, 1024, 1024, 2048]\n num_layers = len(hidden_sizes) - 1\n depth = 10\n learning_rate = 0.2\n lr_decay = 1.03\n # lr_decay = 1.04\n weight_decay = 1e-7\n max_grad_norm = 10\n # num_steps = 50\n num_steps = 100\n max_epoch = 5\n max_max_epoch = 500\n batch_size = 128\n # batch_size = 64\n drop_x = 0.10\n drop_i = 0.40\n drop_h = 0.10\n drop_o = 0.40\n tied = False\n vocab_size = 27\n\n\n@ex.capture\ndef get_config(_config):\n\n C.__dict__ = dict(_config)\n return C\n\n\ndef get_data(data_path, dataset):\n raw_data = reader.text8_raw_data(data_path)\n return reader, raw_data\n\n\ndef run_epoch(session, m, data, eval_op, config, verbose=False, is_training=False):\n \"\"\"Run the model on the given data.\"\"\"\n epoch_size = ((len(data) // m.batch_size) - 1) // m.num_steps\n start_time = time.time()\n costs = 0.0\n iters = 0\n state = [(x[0].eval(), x[1].eval()) for x in m.initial_state]\n for step, (x, y) in enumerate(reader.data_iterator(data, m.batch_size, m.num_steps)):\n feed_dict = {m.input_data: x, m.targets: y, m.is_training: is_training}\n feed_dict.update({m.initial_state[i]: state[i] for i in range(m.num_layers)})\n cost, state, _ = session.run([m.cost, m.final_state, eval_op], feed_dict)\n costs += cost\n iters += m.num_steps\n\n if verbose and step % (epoch_size // 10) == 10:\n print(\"%.3f perplexity: %.3f speed: %.0f wps\" % (step * 1.0 / epoch_size, np.exp(costs / iters),\n iters * m.batch_size / (time.time() - start_time)))\n\n return np.exp(costs / iters)\n\n\n@ex.command\ndef evaluate(data_path, dataset, load_model):\n \"\"\"Evaluate the model on the given data.\"\"\"\n ex.commands[\"print_config\"]()\n print(\"Evaluating model:\", load_model)\n reader, (train_data, valid_data, test_data, _) = get_data(data_path, dataset)\n\n config = get_config()\n val_config = deepcopy(config)\n test_config = deepcopy(config)\n val_config.drop_x = test_config.drop_x = 0.0\n val_config.drop_i = test_config.drop_i = 0.0\n val_config.drop_h = test_config.drop_h = 0.0\n val_config.drop_o = test_config.drop_o = 0.0\n test_config.batch_size = test_config.num_steps = 1\n\n with tf.Session() as session:\n initializer = tf.random_uniform_initializer(-config.init_scale, config.init_scale)\n with tf.variable_scope(\"model\", reuse=None, initializer=initializer):\n _ = Model(is_training=True, config=config)\n with tf.variable_scope(\"model\", reuse=True, initializer=initializer):\n mvalid = Model(is_training=False, config=val_config)\n mtest = Model(is_training=False, config=test_config)\n tf.global_variables_initializer().run()\n saver = tf.train.Saver()\n saver.restore(session, load_model)\n\n print(\"Testing on batched Valid ...\")\n valid_perplexity = run_epoch(session, mvalid, valid_data, tf.no_op(), config=val_config)\n print(\"Valid Perplexity (batched): %.3f, Bits: %.3f\" % (valid_perplexity, np.log2(valid_perplexity)))\n\n print(\"Testing on non-batched Valid ...\")\n valid_perplexity = run_epoch(session, mtest, valid_data, tf.no_op(), config=test_config, verbose=True)\n print(\"Full Valid Perplexity: %.3f, Bits: %.3f\" % (valid_perplexity, np.log2(valid_perplexity)))\n\n print(\"Testing on non-batched Test ...\")\n test_perplexity = run_epoch(session, mtest, test_data, tf.no_op(), config=test_config, verbose=True)\n print(\"Full Test Perplexity: %.3f, Bits: %.3f\" % (test_perplexity, np.log2(test_perplexity)))\n\n\n@ex.automain\ndef main(data_path, dataset, seed, _run):\n ex.commands['print_config']()\n np.random.seed(seed)\n reader, (train_data, valid_data, test_data, _) = get_data(data_path, dataset)\n\n config = get_config()\n val_config = deepcopy(config)\n test_config = deepcopy(config)\n val_config.drop_x = test_config.drop_x = 0.0\n val_config.drop_i = test_config.drop_i = 0.0\n val_config.drop_h = test_config.drop_h = 0.0\n val_config.drop_o = test_config.drop_o = 0.0\n test_config.batch_size = test_config.num_steps = 1\n\n with tf.Graph().as_default(), tf.Session() as session:\n tf.set_random_seed(seed)\n initializer = tf.random_uniform_initializer(-config.init_scale, config.init_scale)\n with tf.variable_scope(\"model\", reuse=None, initializer=initializer):\n mtrain = Model(is_training=True, config=config)\n with tf.variable_scope(\"model\", reuse=True, initializer=initializer):\n mvalid = Model(is_training=False, config=val_config)\n mtest = Model(is_training=False, config=test_config)\n\n tf.global_variables_initializer().run()\n\n saver = tf.train.Saver()\n trains, vals, tests, best_val = [np.inf], [np.inf], [np.inf], np.inf\n\n for i in range(config.max_max_epoch):\n lr_decay = config.lr_decay ** max(i - config.max_epoch + 1, 0.0)\n mtrain.assign_lr(session, config.learning_rate / lr_decay)\n\n print(\"Epoch: %d Learning rate: %.3f\" % (i + 1, session.run(mtrain.lr)))\n train_perplexity = run_epoch(session, mtrain, train_data, mtrain.train_op, config=config, verbose=True, is_training=True)\n print(\"Epoch: %d Train Perplexity: %.3f, Bits: %.3f\" % (i + 1, train_perplexity, np.log2(train_perplexity)))\n\n valid_perplexity = run_epoch(session, mvalid, valid_data, tf.no_op(), config=val_config)\n print(\"Epoch: %d Valid Perplexity (batched): %.3f, Bits: %.3f\" % (i + 1, valid_perplexity, np.log2(valid_perplexity)))\n\n test_perplexity = run_epoch(session, mvalid, test_data, tf.no_op(), config=val_config)\n print(\"Epoch: %d Test Perplexity (batched): %.3f, Bits: %.3f\" % (i + 1, test_perplexity, np.log2(test_perplexity)))\n\n trains.append(train_perplexity)\n vals.append(valid_perplexity)\n tests.append(test_perplexity)\n\n if valid_perplexity < best_val:\n best_val = valid_perplexity\n print(\"Best Batched Valid Perplexity improved to %.03f\" % best_val)\n save_path = saver.save(session, './' + dataset + \"_\" + str(seed) + \"_best_model.ckpt\")\n print(\"Saved to:\", save_path)\n\n _run.info['epoch_nr'] = i + 1\n _run.info['nr_parameters'] = mtrain.nvars.item()\n _run.info['logs'] = {'train_perplexity': trains, 'valid_perplexity': vals, 'test_perplexity': tests}\n\n\n print(\"Training is over.\")\n best_val_epoch = np.argmin(vals)\n print(\"Best Batched Validation Perplexity %.03f (Bits: %.3f) was at Epoch %d\" %\n (vals[best_val_epoch], np.log2(vals[best_val_epoch]), best_val_epoch))\n print(\"Training Perplexity at this Epoch was %.03f, Bits: %.3f\" %\n (trains[best_val_epoch], np.log2(trains[best_val_epoch])))\n print(\"Batched Test Perplexity at this Epoch was %.03f, Bits: %.3f\" %\n (tests[best_val_epoch], np.log2(tests[best_val_epoch])))\n\n _run.info['best_val_epoch'] = best_val_epoch\n _run.info['best_valid_perplexity'] = vals[best_val_epoch]\n\n with tf.Session() as sess:\n saver.restore(sess, './' + dataset + \"_\" + str(seed) + \"_best_model.ckpt\")\n\n print(\"Testing on non-batched Valid ...\")\n valid_perplexity = run_epoch(sess, mtest, valid_data, tf.no_op(), config=test_config, verbose=True)\n print(\"Full Valid Perplexity: %.3f, Bits: %.3f\" % (valid_perplexity, np.log2(valid_perplexity)))\n\n print(\"Testing on non-batched Test ...\")\n test_perplexity = run_epoch(sess, mtest, test_data, tf.no_op(), config=test_config, verbose=True)\n print(\"Full Test Perplexity: %.3f, Bits: %.3f\" % (test_perplexity, np.log2(test_perplexity)))\n\n _run.info['full_best_valid_perplexity'] = valid_perplexity\n _run.info['full_test_perplexity'] = test_perplexity\n\n return vals[best_val_epoch]\n"
},
{
"alpha_fraction": 0.6485216617584229,
"alphanum_fraction": 0.6559823155403137,
"avg_line_length": 30.74561309814453,
"blob_id": "929cd60424d1fb05d5f2edeeb2346b00a526339e",
"content_id": "81869fc634d5047c3c16af5c1db57d0bf8840715",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3619,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 114,
"path": "/text8/charmod.py",
"repo_name": "theofpa/ran",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, division, print_function\nimport tensorflow as tf\nimport numpy as np\nfrom tensorflow.contrib.rnn.python.ops.core_rnn import static_rnn\n\nfrom ran import RANCell\n\n\nclass Model(object):\n\n def __init__(self, is_training, config):\n self.batch_size = batch_size = config.batch_size\n self.num_steps = num_steps = config.num_steps\n self.num_layers = num_layers = config.num_layers\n vocab_size = config.vocab_size\n self.in_size = in_size = config.hidden_sizes[0]\n self._input_data = tf.placeholder(tf.int32, [batch_size, num_steps])\n self._targets = tf.placeholder(tf.int32, [batch_size, num_steps])\n \n self.is_training = tf.placeholder(dtype=tf.bool, shape=[])\n keep_prob_x = 1 - (tf.to_float(self.is_training) * config.drop_x)\n keep_prob_o = 1 - (tf.to_float(self.is_training) * config.drop_o)\n\n embedding = tf.get_variable(\"embedding\", [vocab_size, in_size])\n embedding = tf.nn.dropout(embedding, keep_prob_x, noise_shape=[vocab_size, 1])\n inputs = tf.nn.embedding_lookup(embedding, self._input_data)\n\n def rancell(size):\n return tf.contrib.rnn.DropoutWrapper(RANCell(size), keep_prob_o)\n cell = tf.contrib.rnn.MultiRNNCell([rancell(s) for s in config.hidden_sizes[1:]])\n \n inputs = tf.unstack(inputs, num=num_steps, axis=1)\n self._initial_state = cell.zero_state(batch_size, tf.float32)\n outputs, self._final_state = static_rnn(cell, inputs, self._initial_state)\n output = tf.reshape(tf.stack(outputs, axis=1), [-1, config.hidden_sizes[-1]])\n \n softmax_w = tf.transpose(embedding) if config.tied else tf.get_variable(\"softmax_w\", [config.hidden_sizes[-1], vocab_size])\n softmax_b = tf.get_variable(\"softmax_b\", [vocab_size])\n logits = tf.matmul(output, softmax_w) + softmax_b\n loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example(\n [logits],\n [tf.reshape(self._targets, [-1])],\n [tf.ones([batch_size * num_steps])])\n pred_loss = tf.reduce_sum(loss) / batch_size\n self._cost = cost = pred_loss\n if not is_training:\n return\n tvars = tf.trainable_variables()\n l2_loss = tf.add_n([tf.nn.l2_loss(v) for v in tvars])\n self._cost = cost = pred_loss + config.weight_decay * l2_loss\n\n self._lr = tf.Variable(0.0, trainable=False)\n self._nvars = np.prod(tvars[0].get_shape().as_list())\n print(tvars[0].name, tvars[0].get_shape().as_list())\n for var in tvars[1:]:\n sh = var.get_shape().as_list()\n print(var.name, sh)\n self._nvars += np.prod(sh)\n print(self._nvars, 'total variables')\n grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),\n config.max_grad_norm)\n optimizer = tf.train.GradientDescentOptimizer(self.lr)\n self._train_op = optimizer.apply_gradients(zip(grads, tvars))\n\n def assign_lr(self, session, lr_value):\n session.run(tf.assign(self.lr, lr_value))\n\n @property\n def input_data(self):\n return self._input_data\n\n @property\n def targets(self):\n return self._targets\n\n @property\n def noise_x(self):\n return self._noise_x\n\n @property\n def noise_i(self):\n return self._noise_i\n\n @property\n def noise_h(self):\n return self._noise_h\n\n @property\n def noise_o(self):\n return self._noise_o\n\n @property\n def initial_state(self):\n return self._initial_state\n\n @property\n def cost(self):\n return self._cost\n\n @property\n def final_state(self):\n return self._final_state\n\n @property\n def lr(self):\n return self._lr\n\n @property\n def train_op(self):\n return self._train_op\n\n @property\n def nvars(self):\n return self._nvars\n"
}
] | 3 |
dougz/tugofwar | https://github.com/dougz/tugofwar | f6b4f114e9fd077f345f89b3b8a466b62e36d4cd | 7a8f1ea186950be651017064d69abcf8f60fb266 | a674c9c284d61dfbf359b84cad9265390633409e | refs/heads/master | 2022-04-04T16:12:39.189365 | 2020-01-14T01:59:06 | 2020-01-14T01:59:06 | 201,809,932 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6406779885292053,
"alphanum_fraction": 0.6732203364372253,
"avg_line_length": 27.365385055541992,
"blob_id": "36c125ea4fc77df510dd173bff7b184a6e0f5a7d",
"content_id": "3b1411d63fd0ace8a96cb9836f868a66f336f78f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1475,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 52,
"path": "/static_puzzle.html",
"repo_name": "dougz/tugofwar",
"src_encoding": "UTF-8",
"text": "<head>\n <style>\n.button {\n background-color: #4CAF50; /* Green */\n border: none;\n color: white;\n padding: 15px 32px;\n text-align: center;\n text-decoration: none;\n display: inline-block;\n border-radius: 8px;\n font-size: 16px;\n width: 180px;\n}\n\n.button:hover {\n box-shadow: 0 12px 16px 0 rgba(0,0,0,0.24), 0 17px 50px 0 rgba(0,0,0,0.19);\n}\n\n.timer {\n color: red;\n font-size: 24px;\n}\n </style>\n <script src=\"static_9098.js\"></script>\n</head>\n<body id=puzz> \n <p class=\"flavor\">\n Outside the Big Top tent is a parade of happy clowns, doing their best to cheer you up.\n The grumpy strong man challenges them to a game of Tug of War.\n </p>\n <div class=fourthwall style=\"background-color: white; border: 2px dotted blue;\">\n <p>\n This was a \"scrum\" puzzle—a puzzle meant to be solved by many teammates\n looking at their computers at the same time.\n The game showed each player a pair of choices with voting buttons.\n And there was a deadline clock.\n Once enough players had voted, the winning choice became the team choice.\n For this after-the-hunt version, we'll let you make all the choices on your own.\n</div>\n\n<center>\n <p>\n <input id=\"button1\" class=\"button\" type = \"button\" value=\"Ready!\" onclick=\"clicked(1);\">\n   \n <input id=\"button2\" class=\"button\" type = \"button\" value=\"Ready!\" onclick=\"clicked(2);\">\n\n <p id=\"demo\">Click either button to start!</p>\n <div id=\"timerText\" class=\"timer\"></div>\n</center>\n\n</body>\n"
},
{
"alpha_fraction": 0.5222005844116211,
"alphanum_fraction": 0.5312973856925964,
"avg_line_length": 29.674419403076172,
"blob_id": "43010273cb17d84bab6c54e364cf9af7a5e28f72",
"content_id": "b19e919cfa3a8893de7bfcbd62a192e1a0222911",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9234,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 301,
"path": "/tugofwar.py",
"repo_name": "dougz/tugofwar",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport argparse\nimport asyncio\nimport collections\nimport html\nimport json\nimport os\nimport time\nimport unicodedata\n\nimport http.client\nimport tornado.web\n\nimport scrum\n\n\nclass GameState:\n BY_TEAM = {}\n\n ROUND_TIME = 12\n\n @classmethod\n def set_globals(cls, options):\n cls.wordpairs = (\n (\"GODOT\", \"DAUB\", 0),\n (\"PESTO\", \"HOG\", 1),\n (\"ROPE\", \"ONCE\", 0),\n (\"GLANCE\", \"MODERN\", 0),\n (\"JOLTS\", \"UNFOLD\", 1),\n (\"TICKER\", \"ROTATE\", 1),\n (\"SHIMS\", \"WITH\", 1),\n (\"PHONE\", \"PARADISE\", 0),\n (\"WRAP\", \"ESCAPE\", 1),\n (\"MOTH\", \"CLOUD\", 0),\n (\"EASY\", \"SON\", 0),\n (\"ROD\", \"IDEA\", 0),\n (\"OVERSEER\", \"CRAWFORD\", 1),\n (\"DRYSTONE\", \"TEACHER\", 1),\n (\"ROMEO\", \"ISLES\", 0),\n (\"SANEST\", \"BIDET\", 0),\n (\"WOUND\", \"PUB\", 1),\n (\"FRUITS\", \"TESLA\", 0),\n (\"TOWN\", \"VENEER\", 0),\n (\"DINAR\", \"WHINES\", 1),\n (\"OINKS\", \"WHIMS\", 1),\n (\"GRASS\", \"HEROICS\", 1),\n (\"VOWEL\", \"WHEAT\", 0),\n (\"RIFLE\", \"THREAD\", 0),\n (\"FLAMES\", \"OUTER\", 1),\n (\"TWIN\", \"SLOPE\", 0),\n (\"FORE\", \"REFINED\", 1),\n (\"MUSING\", \"SLUMP\", 1),\n (\"EROSION\", \"RENTAL\", 0),\n (\"STEWED\", \"EUROS\", 0),\n (\"FASTED\", \"FIREMAN\", 0),\n (\"FLOUR\", \"FLAIR\", 1),\n (\"PHILEBUS\", \"HIPSTER\", 0),\n (\"MISER\", \"FELLA\", 0),\n (\"FACETED\", \"VORACITY\", 1),\n (\"BOULDER\", \"THRONING\", 0),\n (\"FATE\", \"FORCE\", 1),\n (\"MYTHUNGA\", \"NICHE\", 1),\n )\n cls.options = options\n\n @classmethod\n def get_for_team(cls, team):\n if team not in cls.BY_TEAM:\n cls.BY_TEAM[team] = cls(team)\n return cls.BY_TEAM[team]\n\n def __init__(self, team):\n self.team = team\n self.sessions = {}\n self.running = False\n self.cond = asyncio.Condition()\n self.current_pair = None\n\n self.min_size = scrum.default_min_players(self.options, team.size)\n\n async def on_wait(self, session):\n async with self.cond:\n if session not in self.sessions:\n self.sessions[session] = None\n self.cond.notify_all()\n\n async def run_game(self):\n start_text = \"Click either button to start!\"\n while True:\n self.current_choice = -1\n self.votes = (collections.OrderedDict(),\n collections.OrderedDict())\n\n await self.team.send_messages([{\"method\": \"set_buttons\",\n \"left\": \"Ready!\",\n \"right\": \"Ready!\",\n \"message\": start_text,\n \"choice\": -1}],\n sticky=1)\n result, msg = await self.get_selection()\n msg[\"message\"] = \"Here we go!\"\n await self.team.send_messages([msg])\n await asyncio.sleep(1.0)\n\n for ch, (leftword, rightword, correct) in enumerate(self.wordpairs):\n deadline = time.time() + self.ROUND_TIME\n self.current_choice = ch\n self.votes = (collections.OrderedDict(),\n collections.OrderedDict())\n\n await self.team.send_messages([{\"method\": \"set_buttons\",\n \"left\": leftword,\n \"right\": rightword,\n \"message\": \"Think happy thoughts!\",\n \"choice\": ch,\n \"end_time\": deadline}],\n sticky=1)\n\n result, msg = await self.get_selection(deadline)\n if result == correct:\n msg[\"message\"] = \"Correct!\"\n msg[\"matchleft\"] = leftword\n msg[\"matchright\"] = rightword\n msg[\"matchcorrect\"] = correct\n elif result == -1:\n msg[\"message\"] = \"Out of time!\"\n else:\n msg[\"message\"] = \"That's not a happy thought!\"\n msg[\"select\"] = -1\n await self.team.send_messages([msg])\n await asyncio.sleep(1.0)\n\n if result != correct: break\n else:\n await self.team.send_messages([{\"method\": \"finish\",\n \"message\": \"All done!\"}])\n await asyncio.sleep(10.0)\n\n # reached the end\n start_text = \"Click either button to start over!\"\n\n async def set_vote(self, session, name, clicked):\n if clicked not in (0, 1): return\n async with self.cond:\n # Remove old vote from either side.\n self.votes[clicked].pop(session, None)\n self.votes[1-clicked].pop(session, None)\n\n # Add new vote to new side.\n self.votes[clicked][session] = name\n self.cond.notify_all()\n\n async def get_selection(self, deadline=None):\n async with self.cond:\n while True:\n left_count = len(self.votes[0])\n right_count = len(self.votes[1])\n net = right_count - left_count\n await self.team.send_messages([{\"method\": \"tally\",\n \"left\": list(self.votes[0].values()),\n \"right\": list(self.votes[1].values()),\n \"net\": net,\n \"req\": self.min_size}])\n\n if net >= self.min_size:\n result = 1\n net = self.min_size\n break\n if net <= -self.min_size:\n result = 0\n net = -self.min_size\n break\n\n if deadline is None:\n await self.cond.wait()\n else:\n try:\n timeout = deadline - time.time()\n if timeout <= 0: break\n await asyncio.wait_for(self.cond.wait(), timeout)\n except asyncio.TimeoutError:\n # On timeout, take whichever side is ahead.\n if net > 0:\n result = 1\n elif net < 0:\n result = 0\n else:\n result = -1\n break\n\n return (result, {\"method\": \"tally\",\n \"left\": list(self.votes[0].values()),\n \"right\": list(self.votes[1].values()),\n \"net\": net,\n \"req\": self.min_size,\n \"select\": result})\n\n async def set_name(self, session, name):\n self.sessions[session] = name\n\n players = []\n for n in self.sessions.values():\n if n:\n players.append((n.lower(), n))\n else:\n players.append((\"zzzzzzzz\", \"anonymous\"))\n\n players.sort()\n players = \", \".join(p[1] for p in players)\n players = html.escape(players)\n\n await self.team.send_messages([{\"method\": \"players\", \"players\": players}])\n\n\nclass ClickHandler(tornado.web.RequestHandler):\n def prepare(self):\n self.args = json.loads(self.request.body)\n\n async def post(self):\n scrum_app = self.application.settings[\"scrum_app\"]\n team, session = await scrum_app.check_cookie(self)\n gs = GameState.get_for_team(team)\n\n if self.args[\"choice\"] == gs.current_choice:\n clicked = self.args[\"clicked\"]\n who = self.args[\"who\"].strip()\n if not who: who = \"anonymous\"\n\n await gs.set_vote(session, who, clicked)\n\n self.set_status(http.client.NO_CONTENT.value)\n\n\nclass NameHandler(tornado.web.RequestHandler):\n def prepare(self):\n self.args = json.loads(self.request.body)\n\n async def post(self):\n scrum_app = self.application.settings[\"scrum_app\"]\n team, session = await scrum_app.check_cookie(self)\n gs = GameState.get_for_team(team)\n\n await gs.set_name(session, self.args.get(\"who\"))\n self.set_status(http.client.NO_CONTENT.value)\n\n\nclass TugOfWarApp(scrum.ScrumApp):\n async def on_wait(self, team, session, wid):\n gs = GameState.get_for_team(team)\n\n if not gs.running:\n gs.running = True\n self.add_callback(gs.run_game)\n\n await gs.on_wait(session)\n\n\nclass DebugHandler(tornado.web.RequestHandler):\n def get(self, fn):\n if fn.endswith(\".css\"):\n self.set_header(\"Content-Type\", \"text/css\")\n elif fn.endswith(\".js\"):\n self.set_header(\"Content-Type\", \"application/javascript\")\n with open(fn) as f:\n self.write(f.read())\n\n\ndef make_app(options):\n GameState.set_globals(options)\n handlers = [(r\"/tugclick\", ClickHandler),\n (r\"/tugname\", NameHandler)]\n if options.debug:\n handlers.append((r\"/tugdebug/(\\S+)\", DebugHandler))\n return handlers\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Run the tug of war puzzle.\")\n parser.add_argument(\"--debug\", action=\"store_true\",\n help=\"Run in debug mode.\")\n parser.add_argument(\"-c\", \"--cookie_secret\",\n default=\"snellen2020\",\n help=\"Secret used to create session cookies.\")\n parser.add_argument(\"--listen_port\", type=int, default=2003,\n help=\"Port requests from frontend.\")\n parser.add_argument(\"--wait_url\", default=\"tugwait\",\n help=\"Path for wait requests from frontend.\")\n parser.add_argument(\"--main_server_port\", type=int, default=2020,\n help=\"Port to use for requests to main server.\")\n parser.add_argument(\"--min_players\", type=int, default=None,\n help=\"Number of players needed to make a choice.\")\n\n options = parser.parse_args()\n\n app = TugOfWarApp(options, make_app(options))\n app.start()\n\n\nif __name__ == \"__main__\":\n main()\n\n"
},
{
"alpha_fraction": 0.5905511975288391,
"alphanum_fraction": 0.6220472455024719,
"avg_line_length": 38.07692337036133,
"blob_id": "32f2c5f6fa394ebadce7fd4bef41b46aee2dcdce",
"content_id": "63fb938b2613be0d188de3739996f065232cb290",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 508,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 13,
"path": "/recompile.sh",
"repo_name": "dougz/tugofwar",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n\"${HUNT2020_BASE}/snellen/external/closure/bin/calcdeps.py\" \\\n -i \"tugofwar.js\" \\\n -i \"${HUNT2020_BASE}/snellen/src/common.js\" \\\n -p \"${HUNT2020_BASE}/snellen/external/closure/\" \\\n --output_file \"tugofwar-compiled.js\" \\\n -o compiled \\\n -c \"${HUNT2020_BASE}/snellen/external/closure-compiler.jar\" \\\n -f '--compilation_level' -f 'ADVANCED_OPTIMIZATIONS' \\\n -f '--define' -f 'goog.DEBUG=false' \\\n -f '--externs' -f \"externs.js\" \\\n -f '--rename_variable_prefix' -f 'S'\n"
},
{
"alpha_fraction": 0.5860597491264343,
"alphanum_fraction": 0.5903271436691284,
"avg_line_length": 28.893617630004883,
"blob_id": "69c6d3cd23476438128d5b87d7b80bdd53a3ca72",
"content_id": "815bc91bf0afe3c3310bcfdd109c59c33a986213",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1406,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 47,
"path": "/make_puzzle_zip.py",
"repo_name": "dougz/tugofwar",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport argparse\nimport os\nimport zipfile\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\"--debug\", action=\"store_true\")\noptions = parser.parse_args()\n\nwith zipfile.ZipFile(\"tug_of_war.zip\", mode=\"w\") as z:\n with z.open(\"puzzle.html\", \"w\") as f_out:\n with open(\"tugofwar.html\", \"rb\") as f_in:\n\n html = f_in.read()\n\n if options.debug:\n head = ('<link rel=stylesheet href=\"/tugdebug/tugofwar.css\" />'\n '<script src=\"/closure/goog/base.js\"></script>'\n '<script src=\"/tugdebug/tugofwar.js\"></script>')\n else:\n head = ('<link rel=stylesheet href=\"tugofwar.css\" />'\n '<script src=\"tugofwar-compiled.js\"></script>')\n\n html = html.replace(b\"@HEAD@\", head.encode(\"utf-8\"))\n\n f_out.write(html)\n\n with z.open(\"solution.html\", \"w\") as f_out:\n with open(\"solution.html\", \"rb\") as f_in:\n f_out.write(f_in.read())\n\n with z.open(\"metadata.yaml\", \"w\") as f_out:\n with open(\"metadata.yaml\", \"rb\") as f_in:\n f_out.write(f_in.read())\n\n z.write(\"static_puzzle.html\")\n z.write(\"static_9098.js\")\n\n if not options.debug:\n with z.open(\"tugofwar.css\", \"w\") as f_out:\n with open(\"tugofwar.css\", \"rb\") as f_in:\n f_out.write(f_in.read())\n\n with z.open(\"tugofwar-compiled.js\", \"w\") as f_out:\n with open(\"tugofwar-compiled.js\", \"rb\") as f_in:\n f_out.write(f_in.read())\n\n"
},
{
"alpha_fraction": 0.6400189399719238,
"alphanum_fraction": 0.6532639265060425,
"avg_line_length": 20.353534698486328,
"blob_id": "1f30d3adea6e4583d14d1d1e0eb52c8a97a69801",
"content_id": "a36fdecab3e6c66afdbbe593cff00b3000a0158a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2114,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 99,
"path": "/static_9098.js",
"repo_name": "dougz/tugofwar",
"src_encoding": "UTF-8",
"text": "var waitingToStart = true;\nvar listIndex = 0;\n/* SPOILER WARNING:\n if you base64-decode this long string, you'll have the questions ahead of time\n*/\nvar data = JSON.parse(atob('W1siR09ET1QiLCJEQVVCIiwxXSxbIlBFU1RPIiwiSE9HIiwyXSxbIlJPUEUiLCJPTkNFIiwxXSxbIkdMQU5DRSIsIk1PREVSTiIsMV0sWyJKT0xUUyIsIlVORk9MRCIsMl0sWyJUSUNLRVIiLCJST1RBVEUiLDJdLFsiU0hJTVMiLCJXSVRIIiwyXSxbIlBIT05FIiwiUEFSQURJU0UiLDFdLFsiV1JBUCIsIkVTQ0FQRSIsMl0sWyJNT1RIIiwiQ0xPVUQiLDFdLFsiRUFTWSIsIlNPTiIsMV0sWyJST0QiLCJJREVBIiwxXSxbIk9WRVJTRUVSIiwiQ1JBV0ZPUkQiLDJdLFsiRFJZU1RPTkUiLCJURUFDSEVSIiwyXSxbIlJPTUVPIiwiSVNMRVMiLDFdLFsiU0FORVNUIiwiQklERVQiLDFdLFsiV09VTkQiLCJQVUIiLDJdLFsiRlJVSVRTIiwiVEVTTEEiLDFdLFsiVE9XTiIsIlZFTkVFUiIsMV0sWyJESU5BUiIsIldISU5FUyIsMl0sWyJPSU5LUyIsIldISU1TIiwyXSxbIkdSQVNTIiwiSEVST0lDUyIsMl0sWyJWT1dFTCIsIldIRUFUIiwxXSxbIlJJRkxFIiwiVEhSRUFEIiwxXSxbIkZMQU1FUyIsIk9VVEVSIiwyXSxbIlRXSU4iLCJTTE9QRSIsMV0sWyJGT1JFIiwiUkVGSU5FRCIsMl0sWyJNVVNJTkciLCJTTFVNUCIsMl0sWyJFUk9TSU9OIiwiUkVOVEFMIiwxXSxbIlNURVdFRCIsIkVVUk9TIiwxXSxbIkZBU1RFRCIsIkZJUkVNQU4iLDFdLFsiRkxPVVIiLCJGTEFJUiIsMl0sWyJQSElMRUJVUyIsIkhJUFNURVIiLDFdLFsiTUlTRVIiLCJGRUxMQSIsMV0sWyJGQUNFVEVEIiwiVk9SQUNJVFkiLDJdLFsiQk9VTERFUiIsIlRIUk9OSU5HIiwxXSxbIkZBVEUiLCJGT1JDRSIsMl0sWyJNWVRIVU5HQSIsIk5JQ0hFIiwyXV0='));\n\nfunction clicked(num) {\n stopTimer();\n if (waitingToStart) {\n\twaitingToStart = false;\n\tlistIndex = 0\n\tsetText(\"think happy thoughts!\")\n\tshowNewOptions();\n\treturn \n }\n var correct = data[listIndex][2];\n if (correct == num) {\n\tif (document.getElementById(\"demo\").innerHTML == \"correct\") {\n\t setText(\"yes\");\n\t} else {\n\t setText(\"correct\"); \n\t}\n\tlistIndex = listIndex + 1;\n\tif (listIndex == data.length) {\n\t winner()\n\t} else {\n\t showNewOptions();\n\t}\n } else {\n\tsetText(\"That's not a happy thought! Click any button to restart\");\n\twaitingToStart = true;\n\tlistIndex = 0;\n\tresetState();\n }\n}\n\nfunction winner() {\n document.getElementById(\"button1\").value = \"winner\";\n document.getElementById(\"button2\").value = \"winner\";\n var text = \"Winner winner! </br></br>\";\n for (var i = 0; i < data.length; i++) {\n\ttext += data[i][0] + \" \" + data[i][1] + \"</br>\";\n } \n setText(text)\n \n} \n\t\t\t\nfunction showNewOptions() {\n document.getElementById(\"button1\").value = data[listIndex][0];\n document.getElementById(\"button2\").value = data[listIndex][1];\n startTimer();\n}\n\nfunction resetState() {\n stopTimer();\n document.getElementById(\"button1\").value = \"ready\";\n document.getElementById(\"button2\").value = \"ready\";\n}\n\nfunction setText(text) {\n document.getElementById(\"demo\").innerHTML = text;\n}\n\nvar interval;\nvar timeLeft;\n\nfunction startTimer() {\n stopTimer();\n timeLeft = 12\n interval = setInterval(myTimer, 1000);\n}\n\nfunction stopTimer() {\n clearInterval(interval);\n}\n\nfunction myTimer() {\n showTimeLeft()\n timeLeft = timeLeft - 1; \n if (timeLeft < 0) {\n outOfTime()\n }\n} \n\nfunction outOfTime() {\n setText(\"click any button to restart\");\n waitingToStart = true;\n listIndex = 0;\n resetState();\n}\n\nfunction showTimeLeft() {\n if (timeLeft < 0) {\n document.getElementById(\"timerText\").innerHTML = \"out of time\";\n } else { \n document.getElementById(\"timerText\").innerHTML = timeLeft;\n }\n}\n"
},
{
"alpha_fraction": 0.6365354061126709,
"alphanum_fraction": 0.644673764705658,
"avg_line_length": 28.152542114257812,
"blob_id": "8b302703fbc21037003c7328a9cc9a3e3858cfef",
"content_id": "03177a60716d92f76e8643ca89ca76f4d2e85de3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6881,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 236,
"path": "/tugofwar.js",
"repo_name": "dougz/tugofwar",
"src_encoding": "UTF-8",
"text": "goog.require('goog.dom');\ngoog.require(\"goog.dom.classlist\");\ngoog.require('goog.events');\ngoog.require('goog.events.KeyCodes');\ngoog.require('goog.net.XhrIo');\ngoog.require(\"goog.json.Serializer\");\n\nclass TugOfWarCountdown {\n constructor(end_time) {\n\tthis.end_time = end_time;\n\tthis.timer = setInterval(goog.bind(this.update_timer, this), 200);\n }\n\n reset(end_time) {\n\tthis.end_time = end_time;\n\tif (!this.timer) {\n\t this.timer = setInterval(goog.bind(this.update_timer, this), 200);\n\t}\n\tthis.update_timer();\n }\n\n update_timer() {\n\tvar now = (new Date()).getTime() / 1000.0;\n\tvar s = (this.end_time - now) + 1;\n\tif (s < 0) s = 0;\n\tvar min = Math.trunc(s/60);\n\tvar sec = Math.trunc(s%60);\n\tvar text = \"\" + min + \":\" + (\"\"+sec).padStart(2, \"0\");\n\ttugofwar.countdown_text.innerHTML = text;\n }\n\n finish() {\n\tclearInterval(this.timer);\n\tthis.timer = null;\n\ttugofwar.countdown_text.innerHTML = \" \";\n }\n}\n\n\nclass TugOfWarDispatcher {\n constructor() {\n\tthis.methods = {\n\t \"set_buttons\": goog.bind(this.set_buttons, this),\n\t \"tally\": goog.bind(this.tally, this),\n\t \"finish\": goog.bind(this.finish, this),\n \"players\": this.players,\n\t}\n }\n\n /** @param{Message} msg */\n dispatch(msg) {\n\tthis.methods[msg.method](msg);\n }\n\n /** @param{Message} msg */\n players(msg) {\n var el = goog.dom.getElement(\"players\");\n el.innerHTML = \"<b>Players:</b> \" + msg.players;\n }\n\n /** @param{Message} msg */\n set_buttons(msg) {\n\tgoog.dom.classlist.remove(tugofwar.tally, \"unselect\");\n\ttugofwar.left_button.innerHTML = msg.left;\n\ttugofwar.left_button.className = \"choice\";\n\tgoog.dom.classlist.remove(tugofwar.left_button, \"unselect\");\n\ttugofwar.right_button.innerHTML = msg.right;\n\ttugofwar.right_button.className = \"choice\";\n\tgoog.dom.classlist.remove(tugofwar.right_button, \"unselect\");\n\tif (msg.message) {\n\t tugofwar.message.innerHTML = msg.message;\n\t}\n\ttugofwar.current_choice = msg.choice;\n\tif (msg.end_time) {\n\t if (tugofwar.countdown) {\n\t\ttugofwar.countdown.reset(msg.end_time);\n\t } else {\n\t\ttugofwar.countdown = new TugOfWarCountdown(msg.end_time);\n\t }\n\t} else {\n\t if (tugofwar.countdown) {\n\t\ttugofwar.countdown.finish();\n\t\ttugofwar.countdown = null;\n\t }\n\t}\n }\n\n /** @param{Message} msg */\n finish(msg) {\n\tgoog.dom.classlist.add(tugofwar.left_button, \"unselect\");\n\tgoog.dom.classlist.add(tugofwar.right_button, \"unselect\");\n\tgoog.dom.classlist.add(tugofwar.tally, \"unselect\");\n\ttugofwar.target_pos = 0;\n\tif (msg.message) {\n\t tugofwar.message.innerHTML = msg.message;\n\t}\n }\n\n /** @param{Message} msg */\n tally(msg) {\n\tthis.show_voters(tugofwar.left_voters, msg.left);\n\tthis.show_voters(tugofwar.right_voters, msg.right);\n\ttugofwar.target_pos = 225.0 * msg.net / msg.req;\n\tif (msg.message) {\n\t tugofwar.message.innerHTML = msg.message;\n\t}\n\n\tif (!(typeof msg.select === \"undefined\")) {\n\t if (msg.select == 0 || msg.select == -1) {\n\t\tgoog.dom.classlist.add(tugofwar.right_button, \"unselect\");\n\t }\n\t if (msg.select == 1 || msg.select == -1) {\n\t\tgoog.dom.classlist.add(tugofwar.left_button, \"unselect\");\n\t }\n\t if (tugofwar.countdown) {\n\t\ttugofwar.countdown.finish();\n\t }\n\n\t if (msg.matchleft) {\n\t\tif (!goog.dom.getFirstElementChild(tugofwar.matches)) {\n\t\t var th = goog.dom.createDom(\"TH\", {colSpan: 2}, \"Previous matches:\");\n\t\t var tr = goog.dom.createDom(\"TR\", null, th)\n\t\t tugofwar.matches.appendChild(tr);\n\t\t}\n\n\t\tvar tdl = goog.dom.createDom(\"TD\", \"left\" + (msg.matchcorrect == 0 ? \" correct\" : \"\"), msg.matchleft);\n\t\tvar tdr = goog.dom.createDom(\"TD\", \"right\" + (msg.matchcorrect == 1 ? \" correct\" : \"\"), msg.matchright);\n\t\tvar tr = goog.dom.createDom(\"TR\", null, tdl, tdr);\n\t\ttugofwar.matches.appendChild(tr);\n\t } else {\n\t\ttugofwar.matches.innerHTML = \"\";\n\t }\n\t}\n }\n\n show_voters(el, voters) {\n\tgoog.dom.removeChildren(el);\n\tfor (var i = 0; i < voters.length; ++i) {\n\t if (i > 0) {\n\t\tel.appendChild(goog.dom.createElement(\"BR\"));\n\t }\n\t el.appendChild(goog.dom.createTextNode(voters[i]));\n\t}\n }\n}\n\nfunction tugofwar_click(which) {\n if (which) {\n\ttugofwar.left_button.className = \"choice\";\n\ttugofwar.right_button.className = \"selected\";\n } else {\n\ttugofwar.left_button.className = \"selected\";\n\ttugofwar.right_button.className = \"choice\";\n }\n\n var username = tugofwar.who.value;\n localStorage.setItem(\"name\", username);\n var msg = tugofwar.serializer.serialize(\n\t{\"choice\": tugofwar.current_choice,\n\t \"who\": username,\n\t \"clicked\": which});\n goog.net.XhrIo.send(\"/tugclick\", Common_expect_204, \"POST\", msg);\n}\n\nfunction tugofwar_move_ball() {\n if (tugofwar.current_pos == tugofwar.target_pos) return;\n tugofwar.current_pos = 0.4 * tugofwar.target_pos + 0.6 * tugofwar.current_pos;\n if (Math.abs(tugofwar.current_pos - tugofwar.target_pos) < 2) {\n\ttugofwar.current_pos = tugofwar.target_pos;\n }\n tugofwar.target.setAttribute(\"cx\", tugofwar.current_pos);\n}\n\nfunction tugofwar_send_name() {\n var name = tugofwar.who.value;\n if (name != tugofwar.sent_name) {\n tugofwar.sent_name = name;\n var msg = tugofwar.serializer.serialize({\"who\": name});\n goog.net.XhrIo.send(\"/tugname\", Common_expect_204, \"POST\", msg);\n }\n}\n\nvar tugofwar = {\n left_button: null,\n right_button: null,\n left_voters: null,\n right_voters: null,\n message: null,\n countdown: null,\n countdown_text: null,\n who: null,\n tally: null,\n target: null,\n preload: null,\n serializer: null,\n current_choice: null,\n matches: null,\n\n current_pos: 0,\n target_pos: 0,\n mover: null,\n\n sent_name: null,\n}\n\npuzzle_init = function() {\n tugofwar.serializer = new goog.json.Serializer();\n\n tugofwar.body = goog.dom.getElement(\"puzz\");\n tugofwar.left_button = goog.dom.getElement(\"left\");\n tugofwar.right_button = goog.dom.getElement(\"right\");\n tugofwar.left_voters = goog.dom.getElement(\"leftvoters\");\n tugofwar.right_voters = goog.dom.getElement(\"rightvoters\");\n tugofwar.message = goog.dom.getElement(\"message\");\n tugofwar.who = goog.dom.getElement(\"who\");\n tugofwar.who.value = localStorage.getItem(\"name\");\n tugofwar.countdown_text = goog.dom.getElement(\"countdown\");\n tugofwar.tally = goog.dom.getElement(\"tally\");\n tugofwar.target = goog.dom.getElement(\"target\");\n tugofwar.matches = goog.dom.getElement(\"matches\");\n\n goog.events.listen(tugofwar.left_button,\n\t\t goog.events.EventType.CLICK,\n\t\t goog.bind(tugofwar_click, null, 0));\n goog.events.listen(tugofwar.right_button,\n\t\t goog.events.EventType.CLICK,\n\t\t goog.bind(tugofwar_click, null, 1));\n\n\n tugofwar.mover = setInterval(tugofwar_move_ball, 20);\n\n tugofwar.waiter = new Common_Waiter(new TugOfWarDispatcher(), \"/tugwait\", 0, null, null);\n tugofwar.waiter.start();\n\n setInterval(tugofwar_send_name, 1000);\n}\n\n"
}
] | 6 |
rahulbordoloi/Machine-Learning | https://github.com/rahulbordoloi/Machine-Learning | 5a9b90d6fe3788140dead2fc442aaf7553f2035f | 211cb8e87ee40696559ac63f95db49af3f6ddd9e | 3ca03296451e54c32b53ea3ac73fb99c66d2eaea | refs/heads/master | 2022-11-15T23:59:00.029095 | 2020-07-11T15:09:58 | 2020-07-11T15:09:58 | 254,524,702 | 2 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6377759575843811,
"alphanum_fraction": 0.6721177697181702,
"avg_line_length": 34.02941131591797,
"blob_id": "4f0fe62dd4784bc5efb8669041f793d599d03c31",
"content_id": "8d77b1231cde96e5e8bac7f4b01011f993715ed0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1223,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 34,
"path": "/Clustering/hierarchical_clus.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#hierarchical clustering\r\n\r\n#importing the libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n#importing the dataset\r\ndataset=pd.read_csv('Mall_Customers.csv')\r\nx = dataset.iloc[:,[3,4]].values\r\n\r\n#using dendrogram to find the optimal no. of clusters\r\nimport scipy.cluster.hierarchy as sch\r\ndendrogram=sch.dendrogram(sch.linkage(x,method='ward'))\r\nplt.title('Dendrogram')\r\nplt.xlabel('Customers')\r\nplt.ylabel('Euclidean distances')\r\nplt.show()\r\n\r\n#applying hierarchical clustering to the mall dataset\r\nfrom sklearn.cluster import AgglomerativeClustering as ac\r\nhc=ac(n_clusters=5,affinity='euclidean',linkage='ward')\r\ny_hc=hc.fit_predict(x)\r\n\r\n#visualizing the clusters\r\nplt.scatter(x[y_hc==0,0],x[y_hc==0,1],s=100,c='red',label='Careful')\r\nplt.scatter(x[y_hc == 1, 0],x[y_hc == 1, 1], s = 100, c = 'blue', label = 'Standard')\r\nplt.scatter(x[y_hc == 2, 0],x[y_hc == 2, 1], s = 100, c = 'green', label = 'Target')\r\nplt.scatter(x[y_hc == 3, 0],x[y_hc == 3, 1], s = 100, c = 'cyan', label = 'Careless')\r\nplt.scatter(x[y_hc == 4, 0],x[y_hc == 4, 1], s = 100, c = 'magenta', label = 'Sensible')\r\nplt.xlabel('Annual Income (k$)')\r\nplt.ylabel('Spending Score (1-100)')\r\nplt.legend()\r\nplt.show()"
},
{
"alpha_fraction": 0.7164276242256165,
"alphanum_fraction": 0.7307692170143127,
"avg_line_length": 28.719999313354492,
"blob_id": "7f37d2554b885456d04543e9f6aef20f7440ae24",
"content_id": "fda8999ca2bcbe3db9fa7f6e98d5a1a52b65ffd5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1534,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 50,
"path": "/Natural Language Processing/nlp.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#Natural Language Processing\r\n\r\n#importing the libraries\r\nimport pandas as pd\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\n#importing the dataset\r\ndataset=pd.read_csv('Restaurant_Reviews.tsv',delimiter='\\t',quoting=3)\r\n\r\n#cleaning the texts\r\nimport re\r\nimport nltk\r\nnltk.download('all')\r\nfrom nltk.corpus import stopwords\r\nfrom nltk.stem.porter import PorterStemmer\r\ncorpus=[]\r\n\"\"\"stop_words = stopwords.word('english')\r\nstop_words.remove('not')\"\"\"\r\nfor i in range(0,1000):\r\n review=re.sub('[^a-zA-Z]',' ',dataset['Review'][i])\r\n review=review.lower()\r\n review=review.split()\r\n ps=PorterStemmer()\r\n review=[ps.stem(word) for word in review if not word in set(stopwords.words('english'))]\r\n review=' '.join(review)\r\n corpus.append(review)\r\n#creating the bag of words model\r\nfrom sklearn.feature_extraction.text import CountVectorizer\r\ncv=CountVectorizer(max_features=1500)\r\nx=cv.fit_transform(corpus).toarray()\r\ny=dataset.iloc[:,1].values\r\n\r\n#splitting the dataset into training set and test set\r\nfrom sklearn.model_selection import train_test_split\r\nx_train, x_test, y_train, y_test = train_test_split(x, y ,test_size = 0.20, random_state = 0)\r\n\r\n#fitting naive bayes to the training set\r\nfrom sklearn.naive_bayes import GaussianNB\r\nclassifier = GaussianNB()\r\nclassifier.fit(x_train, y_train)\r\n\r\n#predicting the test set results\r\ny_pred=classifier.predict(x_test)\r\n\r\n#making the confusion matrix\r\nfrom sklearn.metrics import confusion_matrix\r\ncm=confusion_matrix(y_test, y_pred)\r\n\r\naccuracy=(55+91)/200"
},
{
"alpha_fraction": 0.8154761791229248,
"alphanum_fraction": 0.8154761791229248,
"avg_line_length": 41,
"blob_id": "f681004aec0f60a1e7e65402434989fec9389e6f",
"content_id": "c181e68db884091b9a3b026f308aac471fc7b75d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 168,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 4,
"path": "/README.md",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "# Machine-Learning\nContains my Glossary for Machine Learning related Stuffs using Python \n\nFor Reference & Datasets - https://www.superdatascience.com/machine-learning\n"
},
{
"alpha_fraction": 0.696004331111908,
"alphanum_fraction": 0.7138229012489319,
"avg_line_length": 29.965517044067383,
"blob_id": "7ded003c89b49a7a677614d33069db1f3935e904",
"content_id": "ca108c37b95355e56633ac5425943a94a9d6dd32",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1852,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 58,
"path": "/Regression/multiple_LR.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#multiple linear regression\r\n\r\n#importing the libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n#importing the dataset\r\ndataset=pd.read_csv('50_Startups.csv')\r\nx = dataset.iloc[:,:-1].values\r\ny = dataset.iloc[:,4].values\r\n\r\n#encoding categorical data\r\nfrom sklearn.preprocessing import LabelEncoder, OneHotEncoder\r\nlabelencoder_x = LabelEncoder()\r\nx[:,3] = labelencoder_x.fit_transform(x[:,3])\r\nonehotencoder = OneHotEncoder(categorical_features = [3])\r\nx= onehotencoder.fit_transform(x).toarray()\r\n\r\n#avoiding dummy variable trap\r\nx=x[:,1:]\r\n \r\n#splitting the dataset into training set and test set\r\nfrom sklearn.model_selection import train_test_split\r\nx_train, x_test, y_train, y_test = train_test_split(x, y ,test_size = 0.2, random_state = 0)\r\n\r\n\"\"\"#feature scaling\r\nfrom sklearn.preprocessing import StandardScaler\r\nsc_x= StandardScaler() \r\nx_train = sc_x.fit_transform(x_train)\r\nx_test = sc_x.transform(x_test)\"\"\"\r\n\r\n#fitting multiple linear regression to the training set\r\nfrom sklearn.linear_model import LinearRegression\r\nregressor=LinearRegression()\r\nregressor.fit(x_train,y_train)\r\n\r\n#predicting the test set results\r\ny_pred=regressor.predict(x_test)\r\n\r\n#bulding the optimal model using Backward Elimination\r\nimport statsmodels.formula.api as sm\r\nx=np.append(arr=np.ones((50,1)).astype(int),values=x,axis=1)\r\nx_opt=x[:,[0,1,2,3,4,5]]\r\nregressor_OLS=sm.OLS(endog = y, exog = x_opt).fit()\r\nregressor_OLS.summary()\r\nx_opt=x[:,[0,3,4,5]]\r\nregressor_OLS=sm.OLS(endog = y, exog = x_opt).fit()\r\nregressor_OLS.summary()\r\nx_opt=x[:,[0,3,5]]\r\nregressor_OLS=sm.OLS(endog = y, exog = x_opt).fit()\r\nregressor_OLS.summary()\r\nx_opt=x[:,[0,3,5]]\r\nregressor_OLS=sm.OLS(endog = y, exog = x_opt).fit()\r\nregressor_OLS.summary()\r\nx_opt=x[:,[0,3]]\r\nregressor_OLS=sm.OLS(endog = y, exog = x_opt).fit()\r\nregressor_OLS.summary()"
},
{
"alpha_fraction": 0.7160377502441406,
"alphanum_fraction": 0.7273585200309753,
"avg_line_length": 30.090909957885742,
"blob_id": "1bdc3286ed5fd4c0d7893a25f6f607a4df8fefec",
"content_id": "952b641266a6656911e64711c2999aa7fa19d8f6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1060,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 33,
"path": "/Regression/randomforest_R.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#random forest regression \r\n\r\n# Importing the libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n# Importing the dataset\r\ndataset = pd.read_csv('Position_Salaries.csv')\r\nx = dataset.iloc[:, 1:2].values\r\ny = dataset.iloc[:, 2].values\r\n\r\n# Splitting the dataset into the Training set and Test set\r\n\"\"\"from sklearn.cross_validation import train_test_split\r\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)\"\"\"\r\n\r\n# Feature Scaling\r\n\"\"\"from sklearn.preprocessing import StandardScaler\r\nsc_X = StandardScaler()\r\nX_train = sc_X.fit_transform(X_train)\r\nX_test = sc_X.transform(X_test)\r\nsc_y = StandardScaler()\r\ny_train = sc_y.fit_transform(y_train)\"\"\"\r\n\r\n# Fitting the Random Forest Regression to the dataset\r\nfrom sklearn.ensemble import RandomForestRegressor as rfr\r\nregressor=rfr(n_estimators=300, random_state=0)\r\nregressor.fit(x,y)\r\n\r\n# Predicting a new result\r\ny_pred = regressor.predict([[6.5]])\r\n\r\n# Visualising the Regression results (for higher resolution and smoother curve)\r\n "
},
{
"alpha_fraction": 0.7246136665344238,
"alphanum_fraction": 0.7345474362373352,
"avg_line_length": 29.20689582824707,
"blob_id": "3b6e95024ed01e576af6ac0dcf4abe93bfee5514",
"content_id": "9dc9178cdd6d45aa320a4ecceee21ee66546a0f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1812,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 58,
"path": "/Regression/polynomial_R.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#Polynomial Regression\r\n\r\n#importing the libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n#importing the dataset\r\ndataset=pd.read_csv('Position_Salaries.csv')\r\nx = dataset.iloc[:, 1:2].values\r\ny = dataset.iloc[:,2].values\r\n\r\n#splitting the dataset into training set and test set\r\n\"\"\"from sklearn.model_selection import train_test_split\r\nx_train, x_test, y_train, y_test = train_test_split(x, y ,test_size = 0.2, random_state = 0)\"\"\"\r\n\r\n\"\"\"#feature scaling\r\nfrom sklearn.preprocessing import StandardScaler\r\nsc_x= StandardScaler() \r\nx_train = sc_x.fit_transform(x_train)\r\nx_test = sc_x.transform(x_test)\"\"\"\r\n\r\n#fitting linear regression to the dataset\r\nfrom sklearn.linear_model import LinearRegression\r\nlin_reg=LinearRegression()\r\nlin_reg.fit(x,y)\r\n\r\n#fitting polynomial regression to the dataset\r\nfrom sklearn.preprocessing import PolynomialFeatures\r\npoly_reg=PolynomialFeatures(degree=4)\r\nx_poly=poly_reg.fit_transform(x)\r\npoly_reg.fit(x_poly,y)\r\nlin_reg_2=LinearRegression()\r\nlin_reg_2.fit(x_poly,y)\r\n\r\n#visualising the linear regression results\r\nplt.scatter(x,y,color='red')\r\nplt.plot(x,lin_reg.predict(x),color='blue')\r\nplt.title('Truth or Bluff (Linear Regression)')\r\nplt.xlabel('Position Level')\r\nplt.ylabel('Salary')\r\nplt.show()\r\n\r\n#visualising the polynomial regression results \r\nx_grid=np.arange(min(x),max(x),0.1)\r\nx_grid=x_grid.reshape((len(x_grid),1))\r\nplt.scatter(x,y,color='red')\r\nplt.plot(x_grid,lin_reg_2.predict(poly_reg.fit_transform(x_grid)),color='blue')\r\nplt.title('Truth or Bluff (Polynomial Regression)')\r\nplt.xlabel('Position Level')\r\nplt.ylabel('Salary')\r\nplt.show()\r\n\r\n#predicting a new result with linear regression\r\n lin_reg.predict(6.5)\r\n\r\n#predicting a new result with polynomial regression \r\nlin_reg_2.predict(poly_reg.fit_transform(6.5))\r\n\r\n"
},
{
"alpha_fraction": 0.4146789014339447,
"alphanum_fraction": 0.46170932054519653,
"avg_line_length": 40.60905456542969,
"blob_id": "030bd07e6af82f8a05ebc4348bc253aec3f90662",
"content_id": "cd5c0255ed0c87d15c4481550e71c58d0fc255e3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20710,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 486,
"path": "/Ensemble Learning/Stacking/stackingClassifier.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "###############################################################################\r\n# Stacking Classifier #\r\n###############################################################################\r\n\r\n# Stacking Classifier Documentation - https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.StackingClassifier.html\r\n# Mlxtend Documentation - http://rasbt.github.io/mlxtend/user_guide/classifier/StackingClassifier\r\n\r\n# Colab Notebook Link - https://colab.research.google.com/drive/1HYZzNPkv1fgJsvOK1fascnxdGzdhbXou?usp=sharing\r\n\r\n\"\"\" ***************************************************************************\r\n# * File Description: *\r\n# * An Example of How to use Stack Classifiers. *\r\n# * *\r\n# * The contents of this script are: *\r\n# * 1. Importing Libraries and Dataset *\r\n# * 2. Feature Engineering and Selection *\r\n# * 3. Data Preprocessing *\r\n# * 4. Splitting the dataset into training set and test set *\r\n# * 5. Random Forest Classifier *\r\n# * 6. Logistic Regression Classifier *\r\n# * 7. Naive Bayes Classifier *\r\n# * 8. Multi-Layer Perceptron Classifier *\r\n# * 9. Stacking Classifier *\r\n# * 10. Tuning the Meta-Classifier *\r\n# * --------------------------------------------------------------------------*\r\n# * AUTHOR: Rahul Bordoloi <rahulbordoloi24@gmail.com> *\r\n# * --------------------------------------------------------------------------*\r\n# * DATE CREATED: 2nd July, 2020 *\r\n# * ************************************************************************\"\"\"\r\n\r\n###############################################################################\r\n# 1. Importing Libraries and Dataset #\r\n###############################################################################\r\n\r\n# Do\r\n'''!pip install category_encoders'''\r\n\r\n## For Data Operations and Visualizations\r\nimport numpy as np\r\nimport pandas as pd\r\nimport matplotlib.pyplot as plt\r\nimport seaborn as sns\r\nfrom sklearn.preprocessing import LabelEncoder, StandardScaler\r\nfrom category_encoders import TargetEncoder\r\nfrom sklearn.model_selection import train_test_split, GridSearchCV\r\nfrom sklearn.metrics import classification_report, roc_auc_score\r\n\r\n## For Classifiers\r\nfrom sklearn.ensemble import RandomForestClassifier as rfc\r\nfrom sklearn.linear_model import LogisticRegression\r\nfrom sklearn.naive_bayes import GaussianNB\r\nfrom sklearn.neural_network import MLPClassifier\r\n\r\nimport warnings\r\nwarnings.filterwarnings('ignore')\r\n\r\n# Importing Dataset\r\ndf = pd.read_csv('Churn_Modelling.csv')\r\n\r\n###############################################################################\r\n# 2. Feature Engineering and Selection #\r\n###############################################################################\r\n\r\ndf.columns\r\n\r\n'''\r\nIndex(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography',\r\n 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard',\r\n 'IsActiveMember', 'EstimatedSalary', 'Exited'],\r\n dtype='object')\r\n'''\r\n\r\n# Dropping off redundant columns\r\ndf.drop(['RowNumber', 'CustomerId', 'Surname'], inplace = True, axis = 1) \r\n\r\ndf.info()\r\n\r\n'''\r\n<class 'pandas.core.frame.DataFrame'>\r\nRangeIndex: 10000 entries, 0 to 9999\r\nData columns (total 11 columns):\r\nCreditScore 10000 non-null int64\r\nGeography 10000 non-null object\r\nGender 10000 non-null object\r\nAge 10000 non-null int64\r\nTenure 10000 non-null int64\r\nBalance 10000 non-null float64\r\nNumOfProducts 10000 non-null int64\r\nHasCrCard 10000 non-null int64\r\nIsActiveMember 10000 non-null int64\r\nEstimatedSalary 10000 non-null float64\r\nExited 10000 non-null int64\r\ndtypes: float64(2), int64(7), object(2)\r\nmemory usage: 859.5+ KB\r\n'''\r\n# Check for Imbalance\r\ndf.groupby('Exited')['Geography'].count()\r\n\r\n'''\r\nExited\r\n0 7963\r\n1 2037\r\nName: Geography, dtype: int64\r\n'''\r\n\r\n###############################################################################\r\n# 3. Data Preprocessing #\r\n###############################################################################\r\n\r\n# Encoding Categorical Variables\r\nl = LabelEncoder()\r\ndf['Gender'] = l.fit_transform(df['Gender'])\r\n\r\nencoder = TargetEncoder()\r\ndf['country'] = encoder.fit_transform(df['Geography'], df['Exited'])\r\n\r\ndf.drop(['Geography'], inplace = True, axis = 1)\r\n\r\n# Spliting into dependent and independent vectors\r\nx = df.drop(['Exited'], axis = 1)\r\ny = df.Exited\r\n\r\n# y = y.values.reshape(-1,1)\r\n\r\n# Standard Scaling\r\nS = StandardScaler()\r\nx = S.fit_transform(x)\r\n\r\n###############################################################################\r\n# 4. Splitting the dataset into training set and test set #\r\n###############################################################################\r\n\r\nx_train, x_test, y_train, y_test = train_test_split(x, y ,test_size = 0.25, \r\n random_state = 0)\r\n\r\n###############################################################################\r\n# 5. Random Forest Classifier #\r\n###############################################################################\r\n\r\n# fitting my model\r\nclassifier = rfc(n_estimators = 100, random_state = 0, criterion = 'entropy')\r\nclassifier.fit(x_train, y_train)\r\n\r\n# predicting the test set results\r\ny_pred = classifier.predict(x_test)\r\n\r\n# Checking Accuracy\r\nprint(classification_report(y_test, y_pred))\r\n\r\n'''\r\n precision recall f1-score support\r\n\r\n 0 0.87 0.96 0.91 1991\r\n 1 0.72 0.45 0.56 509\r\n\r\n accuracy 0.85 2500\r\n macro avg 0.80 0.70 0.73 2500\r\nweighted avg 0.84 0.85 0.84 2500\r\n'''\r\n\r\n###############################################################################\r\n# 6. Logistic Regression Classifier #\r\n###############################################################################\r\n\r\n# fitting my model\r\nclassifier = LogisticRegression(random_state = 0)\r\nclassifier.fit(x_train, y_train)\r\n\r\n# predicting the test set results\r\ny_pred = classifier.predict(x_test)\r\n\r\n# Checking Accuracy\r\nprint(classification_report(y_test, y_pred))\r\n\r\n'''\r\n precision recall f1-score support\r\n\r\n 0 0.82 0.97 0.89 1991\r\n 1 0.60 0.17 0.27 509\r\n\r\n accuracy 0.81 2500\r\n macro avg 0.71 0.57 0.58 2500\r\nweighted avg 0.77 0.81 0.76 2500\r\n'''\r\n\r\n###############################################################################\r\n# 7. Naive Bayes Classifier #\r\n###############################################################################\r\n\r\n# fitting my model\r\nclassifier = GaussianNB()\r\nclassifier.fit(x_train, y_train)\r\n\r\n# predicting the test set results\r\ny_pred = classifier.predict(x_test)\r\n\r\n# Checking Accuracy\r\nprint(classification_report(y_test, y_pred))\r\n\r\n'''\r\n precision recall f1-score support\r\n\r\n 0 0.83 0.97 0.90 1991\r\n 1 0.70 0.24 0.36 509\r\n\r\n accuracy 0.82 2500\r\n macro avg 0.77 0.61 0.63 2500\r\nweighted avg 0.81 0.82 0.79 2500\r\n'''\r\n\r\n###############################################################################\r\n# 8. Multi-Layer Perceptron Classifier #\r\n###############################################################################\r\n\r\n# fitting my model\r\nclassifier = MLPClassifier(activation = \"relu\", alpha = 0.05, random_state = 0)\r\nclassifier.fit(x_train, y_train)\r\n\r\n# predicting the test set results\r\ny_pred = classifier.predict(x_test)\r\n\r\n# Checking Accuracy\r\nprint(classification_report(y_test, y_pred))\r\n\r\n'''\r\n precision recall f1-score support\r\n\r\n 0 0.88 0.96 0.92 1991\r\n 1 0.75 0.47 0.58 509\r\n\r\n accuracy 0.86 2500\r\n macro avg 0.81 0.72 0.75 2500\r\nweighted avg 0.85 0.86 0.85 2500\r\n'''\r\n\r\n###############################################################################\r\n# 9. Stacking Classifier #\r\n###############################################################################\r\n\r\n# Install Dependencies in py-shell\r\n'''!pip install mlxtend'''\r\n\r\n# Importing Necessary Libraries\r\nfrom sklearn.ensemble import StackingClassifier\r\n\r\n# Initialising the Stacking Algorithms\r\nestimators = [\r\n ('naive-bayes', GaussianNB()),\r\n ('random-forest', rfc(n_estimators = 100, random_state = 0)),\r\n ('mlp', MLPClassifier(activation = \"relu\", alpha = 0.05, random_state = 0))\r\n ]\r\n\r\n# Setting up the Meta-Classifier\r\nclf = StackingClassifier(\r\n estimators = estimators, \r\n final_estimator = LogisticRegression(random_state = 0)\r\n )\r\n# fitting my model\r\nclf.fit(x_train, y_train)\r\n\r\n# getting info about the hyperparameters \r\nclf.get_params()\r\n\r\n'''\r\n{'cv': None,\r\n 'estimators': [('naive-bayes', GaussianNB(priors=None, var_smoothing=1e-09)),\r\n ('random-forest',\r\n RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,\r\n criterion='gini', max_depth=None, max_features='auto',\r\n max_leaf_nodes=None, max_samples=None,\r\n min_impurity_decrease=0.0, min_impurity_split=None,\r\n min_samples_leaf=1, min_samples_split=2,\r\n min_weight_fraction_leaf=0.0, n_estimators=100,\r\n n_jobs=None, oob_score=False, random_state=0, verbose=0,\r\n warm_start=False)),\r\n ('mlp',\r\n MLPClassifier(activation='relu', alpha=0.05, batch_size='auto', beta_1=0.9,\r\n beta_2=0.999, early_stopping=False, epsilon=1e-08,\r\n hidden_layer_sizes=(100,), learning_rate='constant',\r\n learning_rate_init=0.001, max_fun=15000, max_iter=200,\r\n momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,\r\n power_t=0.5, random_state=0, shuffle=True, solver='adam',\r\n tol=0.0001, validation_fraction=0.1, verbose=False,\r\n warm_start=False))],\r\n 'final_estimator': LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,\r\n intercept_scaling=1, l1_ratio=None, max_iter=100,\r\n multi_class='auto', n_jobs=None, penalty='l2',\r\n random_state=0, solver='lbfgs', tol=0.0001, verbose=0,\r\n warm_start=False),\r\n 'final_estimator__C': 1.0,\r\n 'final_estimator__class_weight': None,\r\n 'final_estimator__dual': False,\r\n 'final_estimator__fit_intercept': True,\r\n 'final_estimator__intercept_scaling': 1,\r\n 'final_estimator__l1_ratio': None,\r\n 'final_estimator__max_iter': 100,\r\n 'final_estimator__multi_class': 'auto',\r\n 'final_estimator__n_jobs': None,\r\n 'final_estimator__penalty': 'l2',\r\n 'final_estimator__random_state': 0,\r\n 'final_estimator__solver': 'lbfgs',\r\n 'final_estimator__tol': 0.0001,\r\n 'final_estimator__verbose': 0,\r\n 'final_estimator__warm_start': False,\r\n 'mlp': MLPClassifier(activation='relu', alpha=0.05, batch_size='auto', beta_1=0.9,\r\n beta_2=0.999, early_stopping=False, epsilon=1e-08,\r\n hidden_layer_sizes=(100,), learning_rate='constant',\r\n learning_rate_init=0.001, max_fun=15000, max_iter=200,\r\n momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,\r\n power_t=0.5, random_state=0, shuffle=True, solver='adam',\r\n tol=0.0001, validation_fraction=0.1, verbose=False,\r\n warm_start=False),\r\n 'mlp__activation': 'relu',\r\n 'mlp__alpha': 0.05,\r\n 'mlp__batch_size': 'auto',\r\n 'mlp__beta_1': 0.9,\r\n 'mlp__beta_2': 0.999,\r\n 'mlp__early_stopping': False,\r\n 'mlp__epsilon': 1e-08,\r\n 'mlp__hidden_layer_sizes': (100,),\r\n 'mlp__learning_rate': 'constant',\r\n 'mlp__learning_rate_init': 0.001,\r\n 'mlp__max_fun': 15000,\r\n 'mlp__max_iter': 200,\r\n 'mlp__momentum': 0.9,\r\n 'mlp__n_iter_no_change': 10,\r\n 'mlp__nesterovs_momentum': True,\r\n 'mlp__power_t': 0.5,\r\n 'mlp__random_state': 0,\r\n 'mlp__shuffle': True,\r\n 'mlp__solver': 'adam',\r\n 'mlp__tol': 0.0001,\r\n 'mlp__validation_fraction': 0.1,\r\n 'mlp__verbose': False,\r\n 'mlp__warm_start': False,\r\n 'n_jobs': None,\r\n 'naive-bayes': GaussianNB(priors=None, var_smoothing=1e-09),\r\n 'naive-bayes__priors': None,\r\n 'naive-bayes__var_smoothing': 1e-09,\r\n 'passthrough': False,\r\n 'random-forest': RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,\r\n criterion='gini', max_depth=None, max_features='auto',\r\n max_leaf_nodes=None, max_samples=None,\r\n min_impurity_decrease=0.0, min_impurity_split=None,\r\n min_samples_leaf=1, min_samples_split=2,\r\n min_weight_fraction_leaf=0.0, n_estimators=100,\r\n n_jobs=None, oob_score=False, random_state=0, verbose=0,\r\n warm_start=False),\r\n 'random-forest__bootstrap': True,\r\n 'random-forest__ccp_alpha': 0.0,\r\n 'random-forest__class_weight': None,\r\n 'random-forest__criterion': 'gini',\r\n 'random-forest__max_depth': None,\r\n 'random-forest__max_features': 'auto',\r\n 'random-forest__max_leaf_nodes': None,\r\n 'random-forest__max_samples': None,\r\n 'random-forest__min_impurity_decrease': 0.0,\r\n 'random-forest__min_impurity_split': None,\r\n 'random-forest__min_samples_leaf': 1,\r\n 'random-forest__min_samples_split': 2,\r\n 'random-forest__min_weight_fraction_leaf': 0.0,\r\n 'random-forest__n_estimators': 100,\r\n 'random-forest__n_jobs': None,\r\n 'random-forest__oob_score': False,\r\n 'random-forest__random_state': 0,\r\n 'random-forest__verbose': 0,\r\n 'random-forest__warm_start': False,\r\n 'stack_method': 'auto',\r\n 'verbose': 0}\r\n'''\r\n\r\n# predicting the test set results\r\ny_pred = clf.predict(x_test)\r\n\r\n# Checking Accuracy\r\nprint(classification_report(y_test, y_pred))\r\n\r\n'''\r\n precision recall f1-score support\r\n\r\n 0 0.88 0.96 0.92 1991\r\n 1 0.76 0.46 0.58 509\r\n\r\n accuracy 0.86 2500\r\n macro avg 0.82 0.71 0.75 2500\r\nweighted avg 0.85 0.86 0.85 2500\r\n'''\r\n\r\n###############################################################################\r\n# 10. Tuning the Meta-Classifier #\r\n###############################################################################\r\n\r\n# Defining Parameter Grid\r\nparams = {'final_estimator__C': [1.0,1.1,1.5],\r\n 'final_estimator__max_iter': [50,100,150,200],\r\n 'final_estimator__n_jobs': [1,-1,5],\r\n 'final_estimator__penalty': ['l1','l2'],\r\n 'final_estimator__random_state': [0],\r\n }\r\n\r\n# Initialize GridSearchCV\r\ngrid = GridSearchCV(estimator = clf, \r\n param_grid = params, \r\n cv = 5,\r\n scoring = \"roc_auc\",\r\n verbose = 10,\r\n n_jobs = -1)\r\n\r\n# Fit GridSearchCV\r\ngrid.fit(x_train, y_train)\r\n\r\n'''\r\nFitting 5 folds for each of 72 candidates, totalling 360 fits\r\n[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.\r\n[Parallel(n_jobs=-1)]: Done 1 tasks | elapsed: 48.6s\r\n[Parallel(n_jobs=-1)]: Done 4 tasks | elapsed: 1.6min\r\n[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 4.0min\r\n[Parallel(n_jobs=-1)]: Done 14 tasks | elapsed: 5.5min\r\n[Parallel(n_jobs=-1)]: Done 21 tasks | elapsed: 8.7min\r\n[Parallel(n_jobs=-1)]: Done 28 tasks | elapsed: 11.0min\r\n[Parallel(n_jobs=-1)]: Done 37 tasks | elapsed: 15.0min\r\n[Parallel(n_jobs=-1)]: Done 46 tasks | elapsed: 18.2min\r\n[Parallel(n_jobs=-1)]: Done 57 tasks | elapsed: 22.9min\r\n[Parallel(n_jobs=-1)]: Done 68 tasks | elapsed: 27.0min\r\n[Parallel(n_jobs=-1)]: Done 81 tasks | elapsed: 32.5min\r\n[Parallel(n_jobs=-1)]: Done 94 tasks | elapsed: 37.3min\r\n[Parallel(n_jobs=-1)]: Done 109 tasks | elapsed: 43.5min\r\n[Parallel(n_jobs=-1)]: Done 124 tasks | elapsed: 49.2min\r\n[Parallel(n_jobs=-1)]: Done 141 tasks | elapsed: 56.2min\r\n[Parallel(n_jobs=-1)]: Done 158 tasks | elapsed: 62.7min\r\n[Parallel(n_jobs=-1)]: Done 177 tasks | elapsed: 70.6min\r\n[Parallel(n_jobs=-1)]: Done 196 tasks | elapsed: 77.7min\r\n[Parallel(n_jobs=-1)]: Done 217 tasks | elapsed: 86.4min\r\n[Parallel(n_jobs=-1)]: Done 238 tasks | elapsed: 94.4min\r\n[Parallel(n_jobs=-1)]: Done 261 tasks | elapsed: 103.7min\r\n[Parallel(n_jobs=-1)]: Done 284 tasks | elapsed: 112.5min\r\n[Parallel(n_jobs=-1)]: Done 309 tasks | elapsed: 122.6min\r\n[Parallel(n_jobs=-1)]: Done 334 tasks | elapsed: 132.1min\r\n[Parallel(n_jobs=-1)]: Done 360 out of 360 | elapsed: 142.3min finished\r\nGridSearchCV(cv=5, error_score=nan,\r\n estimator=StackingClassifier(cv=None,\r\n estimators=[('naive-bayes',\r\n GaussianNB(priors=None,\r\n var_smoothing=1e-09)),\r\n ('random-forest',\r\n RandomForestClassifier(bootstrap=True,\r\n ccp_alpha=0.0,\r\n class_weight=None,\r\n criterion='gini',\r\n max_depth=None,\r\n max_features='auto',\r\n max_leaf_nodes=None,\r\n max_samples=None,\r\n min_impurity_decrease=0.0,\r\n min_i...\r\n stack_method='auto', verbose=0),\r\n iid='deprecated', n_jobs=-1,\r\n param_grid={'final_estimator__C': [1.0, 1.1, 1.5],\r\n 'final_estimator__max_iter': [50, 100, 150, 200],\r\n 'final_estimator__n_jobs': [1, -1, 5],\r\n 'final_estimator__penalty': ['l1', 'l2'],\r\n 'final_estimator__random_state': [0]},\r\n pre_dispatch='2*n_jobs', refit=True, return_train_score=False,\r\n scoring='roc_auc', verbose=10)\r\n'''\r\n\r\n# predicting the test set results\r\ny_pred = grid.predict(x_test)\r\n\r\n# Checking Accuracy\r\nprint(classification_report(y_test, y_pred))\r\n\r\n'''\r\n precision recall f1-score support\r\n\r\n 0 0.88 0.96 0.92 1991\r\n 1 0.75 0.46 0.57 509\r\n\r\n accuracy 0.86 2500\r\n macro avg 0.81 0.71 0.75 2500\r\nweighted avg 0.85 0.86 0.85 2500\r\n'''\r\n\r\n###############################################################################\r\n# END #\r\n###############################################################################\r\n\r\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.8058608174324036,
"avg_line_length": 67.25,
"blob_id": "4514d16b25c806353f9c1be9c533ad6d82a23eb5",
"content_id": "365c284526690807f5cdb12f2b1860eeca168c7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 273,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 4,
"path": "/Ensemble Learning/Stacking/README.md",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "# Stacking Classifier\n\nFind the Colab Notebook for the same here - [Colab ipynb](https://colab.research.google.com/drive/1HYZzNPkv1fgJsvOK1fascnxdGzdhbXou?usp=sharing) <br>\nOr, Github Gist at - [Gist](https://gist.github.com/rahulbordoloi/8172da0502d4334ac1cc11c6af373836)\n"
},
{
"alpha_fraction": 0.6163934469223022,
"alphanum_fraction": 0.6590163707733154,
"avg_line_length": 35.24390411376953,
"blob_id": "6475f200bc5e72e9be342994425f2f99fde0e29a",
"content_id": "13681dab67584ffac2219506adbe1400df16c810",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1525,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 41,
"path": "/Clustering/k-means.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#k-means clustering\r\n\r\n#importing the libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n#importing the dataset\r\ndataset=pd.read_csv('Mall_Customers.csv')\r\nx = dataset.iloc[:,[3,4]].values\r\n\r\n#using elbow method to find the optimal no. of clusters\r\nfrom sklearn.cluster import KMeans\r\nwcss=[]\r\nfor i in range(1,11):\r\n kmeans=KMeans(n_clusters=i,init='k-means++',max_iter=300,n_init=10,random_state=0)\r\n kmeans.fit(x)\r\n wcss.append(kmeans.inertia_)\r\nplt.plot(range(1,11),wcss)\r\nplt.title(\"The Elbow Method\")\r\nplt.xlabel('No. of clusters')\r\nplt.ylabel('WCSS')\r\nplt.show()\r\n\r\n#%reset -f\r\n#applying k-means to the mall dataset\r\nkmeans=KMeans(n_clusters=5,init='k-means++',max_iter=300,n_init=10,random_state=0)\r\ny_kmeans=kmeans.fit_predict(x)\r\n\r\n#visualizing the clusters\r\nplt.scatter(x[y_kmeans==0,0],x[y_kmeans==0,1],s=100,c='red',label='Careful')\r\nplt.scatter(x[y_kmeans == 1, 0],x[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Standard')\r\nplt.scatter(x[y_kmeans == 2, 0],x[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Target')\r\nplt.scatter(x[y_kmeans == 3, 0],x[y_kmeans == 3, 1], s = 100, c = 'cyan', label = 'Careless')\r\nplt.scatter(x[y_kmeans == 4, 0],x[y_kmeans == 4, 1], s = 100, c = 'magenta', label = 'Sensible')\r\nplt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')\r\nplt.title('Clusters of customers')\r\nplt.xlabel('Annual Income (k$)')\r\nplt.ylabel('Spending Score (1-100)')\r\nplt.legend()\r\nplt.show()"
},
{
"alpha_fraction": 0.6745718121528625,
"alphanum_fraction": 0.7009222507476807,
"avg_line_length": 29.54166603088379,
"blob_id": "f0aba07866e5ece5b18d75d608765f1805c584c0",
"content_id": "f9b3949ee98265a6de18c732856d9a844b824026",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 759,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 24,
"path": "/Association Rule Learning/aprioripy.py",
"repo_name": "rahulbordoloi/Machine-Learning",
"src_encoding": "UTF-8",
"text": "#Apriori\r\n\r\n# Importing the libraries\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n# Importing the dataset\r\ndataset = pd.read_csv('Market_Basket_Optimisation.csv',header=None)\r\ntransactions=list()\r\nfor i in range(0,7501):\r\n transactions.append([str(dataset.values[i,j]) for j in range(0,20)])\r\n \r\n#training apriori on the dataset\r\nfrom apyori import apriori\r\nrules=apriori(transactions,min_support=0.003,min_confidence=0.2,min_lift=3,max_length=2)\r\n\r\n#visualising the results\r\nresults=list(rules)\r\n\r\n#extra part to display the results\r\nresults_list = []\r\nfor i in range(0, len(results)):\r\n results_list.append('RULE:\\t' + str(results[i][0]) + '\\nSUPPORT:\\t' + str(results[i][1]) + '\\nInfo:\\t' + str(results[i][2]))\r\n\r\n"
}
] | 10 |
PetrK1/piskvorky1 | https://github.com/PetrK1/piskvorky1 | 9f958178a39050096abf9b536776bf17a4a8b0bb | c6084319d9aa8efe3dcdddcb64be2b49b14ee093 | 3b079f679c92d73ee556cd56a363dd41f2d7a689 | refs/heads/master | 2023-03-24T19:22:52.005506 | 2021-03-20T19:33:04 | 2021-03-20T19:33:04 | 349,818,342 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.45750898122787476,
"alphanum_fraction": 0.4835881292819977,
"avg_line_length": 31.47445297241211,
"blob_id": "62f3f0df0944f3b0076ea6c385a70acc81538e7e",
"content_id": "83914c20bfd2b99e2c6ec46f30105947692f8b3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4448,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 137,
"path": "/piskvorky.py",
"repo_name": "PetrK1/piskvorky1",
"src_encoding": "UTF-8",
"text": "oddelovac = '=' * 45\n\ndef zdravice() -> None:\n#funkce pozdravi uzivatele a seznami ho s pravidly\n oddelovac1 = '-' * 45\n print('Welcome to Tic Tac Toe')\n print(oddelovac)\n text = ('Each player can place one mark (or stone)', 'per turn on the 3x3 grid. The WINNER is',\n 'who succeeds in placing three of their','marks in a:', '*horizontal,', '*vertical or',\n '*diagonal row')\n print('{0:^40s}'.format('RULE GAMES:'))\n for radek in range(len(text)):\n print('{0:<40s}'.format(text[radek]))\n print(oddelovac)\n print('{0:^40s}'.format('''Let's start the game'''))\n print(oddelovac1)\n\n\ndef tisk(desk) -> None:\n#funkce vytiskne pole\n print('+---+---+---+')\n print('|{0:^3s}|{1:^3s}|{2:^3s}|'.format(desk['1'], desk['2'], desk['3']))\n print('+---+---+---+')\n print('|{0:^3s}|{1:^3s}|{2:^3s}|'.format(desk['4'], desk['5'], desk['6']))\n print('+---+---+---+')\n print('|{0:^3s}|{1:^3s}|{2:^3s}|'.format(desk['7'], desk['8'], desk['9']))\n print('+---+---+---+')\n print(oddelovac)\n\ndef test_vstupu(vstup,desk):\n#test, jestli je vstup validni a jestli pole neni obsazene\n\n if vstup.isdigit() and 0 < int(vstup) < 10:\n if desk[vstup] == ' ':\n print(oddelovac)\n return True\n\n\n else:\n print('The field is already occupied, try again.')\n return False\n\n elif not vstup.isdigit():\n print('You must enter a number between 1 and 9')\n return False\n\n elif vstup.isdigit() and not (0 < int(vstup) < 10):\n print('The number must be between 1 and 9')\n return False\n\n\n\ndef test_vyhry(desk):\n# test vyhry v radcich a sloupcich\n if desk['1'] == 'O' and desk['2'] == 'O' and desk['3'] == 'O':\n return True\n elif desk['4'] == 'O' and desk['5'] == 'O' and desk['6'] == 'O':\n return True\n elif desk['7'] == 'O' and desk['8'] == 'O' and desk['9'] == 'O':\n return True\n elif desk['1'] == 'O' and desk['4'] == 'O' and desk['7'] == 'O':\n return True\n elif desk['2'] == 'O' and desk['5'] == 'O' and desk['8'] == 'O':\n return True\n elif desk['3'] == 'O' and desk['6'] == 'O' and desk['9'] == 'O':\n return True\n elif desk['1'] == 'X' and desk['2'] == 'X' and desk['3'] == 'X':\n return True\n elif desk['4'] == 'X' and desk['5'] == 'X' and desk['6'] == 'X':\n return True\n elif desk['7'] == 'X' and desk['8'] == 'X' and desk['9'] == 'X':\n return True\n elif desk['1'] == 'X' and desk['4'] == 'X' and desk['7'] == 'X':\n return True\n elif desk['2'] == 'X' and desk['5'] == 'X' and desk['8'] == 'X':\n return True\n elif desk['3'] == 'X' and desk['6'] == 'X' and desk['9'] == 'X':\n return True\n# test vyhry na diagonale\n elif desk['1'] == 'X' and desk['5'] == 'X' and desk['9'] == 'X':\n return True\n elif desk['3'] == 'X' and desk['5'] == 'X' and desk['7'] == 'X':\n return True\n\n elif desk['1'] == 'O' and desk['5'] == 'O' and desk['9'] == 'O':\n return True\n elif desk['3'] == 'O' and desk['5'] == 'O' and desk['7'] == 'O':\n return True\n else:\n return False\n\n\ndef main():\n #prazdne hraci pole\n desk = {'1': ' ', '2': ' ', '3': ' ', '4': ' ', '5': ' ', '6': ' ', '7': ' ', '8': ' ', '9': ' '}\n\n zdravice()\n tisk(desk)\n znak = 'O'\n pocet = 1\n vyhra = False\n\n while pocet <= 9 and vyhra == False:\n vstup = input(f'Player {znak} | enter your move number: ')\n\n zadani = test_vstupu(vstup,desk)\n while zadani == False:\n #smycka pro opravu vstupu\n vstup = input(f'Player {znak} | enter your move number: ')\n if test_vstupu(vstup,desk) == True:\n zadani = True\n\n #tisk znaku do prislusneho pole\n desk[vstup] = znak\n #tisk aktualizovaneho hraciho pole\n tisk(desk)\n #test, jestli nekdo nevyhral\n if pocet >= 5:\n vyhra = test_vyhry(desk)\n if vyhra == True:\n print('Congratulations, the player {} WON'.format(znak))\n print(oddelovac)\n #test na remizu\n if pocet == 9 and not vyhra:\n print('The game ended with a tie')\n print(oddelovac)\n\n #dalsi kolo\n pocet += 1\n #zmena soupere\n if znak == 'O':\n znak = 'X'\n else:\n znak = 'O'\n\n\nmain()"
}
] | 1 |
mklarqvist/libflagstats | https://github.com/mklarqvist/libflagstats | 1f0778d4c08271688ca23df2e0c1a9a1b87e14a6 | 93f68238b662add883ead01b717ca176ec9d07f4 | df4116b71aabeff9162db0c7cfa6e34c408f62e7 | refs/heads/master | 2020-05-16T16:55:07.062765 | 2019-12-16T02:00:10 | 2019-12-16T02:00:10 | 183,177,985 | 14 | 3 | Apache-2.0 | 2019-04-24T07:57:38 | 2019-12-12T08:08:47 | 2019-12-12T08:08:57 | C | [
{
"alpha_fraction": 0.4821739196777344,
"alphanum_fraction": 0.5517391562461853,
"avg_line_length": 25.136363983154297,
"blob_id": "21aeede6a26f124bb2d846466b991357a914fa35",
"content_id": "5bddaf7c8f21a780e3dbbcc233173afde482a03e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2300,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 88,
"path": "/paper/scripts/mask_data.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nFLAGSTAT_FPAIRED = 1 # bit 0\nFLAGSTAT_FUNMAP = 4 # bit 2\nFLAGSTAT_FMUNMAP = 8 # bit 3\nFLAGSTAT_FREVERSE = 16 # bit 4\nFLAGSTAT_FMREVERSE = 32 # bit 5\nFLAGSTAT_FREAD1 = 64 # bit 6\nFLAGSTAT_FREAD2 = 128 # bit 7\nFLAGSTAT_FSECONDARY = 256 # bit 8\nFLAGSTAT_FQCFAIL = 512 # bit 9\nFLAGSTAT_FDUP = 1024 # bit 10\nFLAGSTAT_FSUPPLEMENTARY = 2048 # bit 11\n\nFLAGSTAT_BIT12 = 1 << 12\nFLAGSTAT_BIT13 = 1 << 13\nFLAGSTAT_BIT14 = 1 << 14\n\n\"\"\"\n FLAGSTAT_FSUPPLEMENTARY\n | FLAGSTAT_FQCFAIL\n | |FLAGSTAT_FSECONDARY\n | || FLAGSTAT_FPAIRED\n | || |\n[0000|x0yw|0000|000z]\n[0000|0000|0000|xzyw]\n\"\"\"\n\ndef get_mask(FSUPPLEMENTARY, FQCFAIL, FSECONDARY, FPAIRED):\n mask = 0\n mask |= FLAGSTAT_FUNMAP\n mask |= FLAGSTAT_FDUP\n mask |= FLAGSTAT_FQCFAIL\n\n if FSECONDARY:\n mask |= FLAGSTAT_FSECONDARY\n elif FSUPPLEMENTARY:\n mask |= FLAGSTAT_FSUPPLEMENTARY\n elif FPAIRED:\n mask |= FLAGSTAT_BIT12\n mask |= FLAGSTAT_BIT13\n mask |= FLAGSTAT_BIT14\n mask |= FLAGSTAT_FREAD1\n mask |= FLAGSTAT_FREAD2\n\n return mask\n\ndef qcfail(case):\n print(\" # | FSUPPLEMENTARY | FPAIRED | FQCFAIL | FSECONDARY || mask\")\n\n vpshufb_values = []\n for k in range(32):\n FSECONDARY = int(k & 0x01 != 0)\n FQCFAIL = int(k & 0x02 != 0)\n FPAIRED = int(k & 0x04 != 0)\n FSUPPLEMENTARY = int(k & 0x08 != 0)\n\n m = get_mask(FSUPPLEMENTARY, FQCFAIL, FSECONDARY, FPAIRED)\n if FQCFAIL != case:\n m = 0\n\n vpshufb_values.append(m)\n\n print(f\"{k:^3x}|{FSUPPLEMENTARY:^16}|{FPAIRED:^9}|{FQCFAIL:^9}|{FSECONDARY:^12}|| 0x{m:04x}\")\n\n array = []\n for word in vpshufb_values:\n array.append(word & 0xff)\n array.append(word >> 8)\n\n print(avx512_const(array))\n\ndef avx512_const(array):\n assert len(array) == 64\n dwords = []\n for i in range(0, 64, 4):\n b0 = array[i + 0]\n b1 = array[i + 1]\n b2 = array[i + 2]\n b3 = array[i + 3]\n\n dword = (b3 << 24) | (b2 << 16) | (b1 << 8) | b0\n dwords.append(dword)\n\n return \"_mm512_setr_epi32(%s)\" % ', '.join('0x%08x' % v for v in dwords)\n\nqcfail(1)\nqcfail(0)\n"
},
{
"alpha_fraction": 0.6328871846199036,
"alphanum_fraction": 0.6462715268135071,
"avg_line_length": 25.200000762939453,
"blob_id": "d79225f433225ce6dd632c9b23815daa65d0c395",
"content_id": "ef6bb84d5cb9ef896f35c9cc88315c131e0b058b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 523,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 20,
"path": "/benchmark/utility.cpp",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#include <string>\n#include <iostream>\n#include <fstream>\n#include <cstring>\n\n// Utility function accepting data from cin stream and converting\n// text-based FLAG values into uint16_t words.\n// Intended use:\n// samtools view FILE | cut -f 2 | utility > DEST_FILE.bin\nint main(int argc, char** argv) {\n std::string str;\n while (std::getline(std::cin, str)) {\n uint16_t val = std::atoi(str.c_str());\n std::cout.write((char*)&val, sizeof(uint16_t));\n }\n std::cout.flush();\n\n\n return EXIT_SUCCESS;\n}"
},
{
"alpha_fraction": 0.6548856496810913,
"alphanum_fraction": 0.6636174917221069,
"avg_line_length": 31.945205688476562,
"blob_id": "ca06ac8bdd0207a246eba0459ba7d7b11c527688",
"content_id": "d90e3594810201adc0640abc37ad58d842387fb6",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2405,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 73,
"path": "/Makefile",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "###################################################################\n# Copyright (c) 2019\n# Author(s): Marcus D. R. Klarqvist\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n###################################################################\n\nOPTFLAGS := -O3 -march=native\nCFLAGS = -std=c99 $(OPTFLAGS) $(DEBUG_FLAGS)\nCPPFLAGS = -std=c++0x $(OPTFLAGS) $(DEBUG_FLAGS)\nCPP_SOURCE = benchmark/flagstats.cpp benchmark/utility.cpp benchmark/generate.cpp linux/instrumented_benchmark.cpp benchmark/inmemory.cpp\nC_SOURCE = \nOBJECTS = $(CPP_SOURCE:.cpp=.o) $(C_SOURCE:.c=.o)\n\nPOSPOPCNT_PATH := ./libalgebra\nLZ4_PATH :=\nZSTD_PATH :=\nINCLUDE_PATHS := -I$(PWD)\nLIBRARY_PATHS :=\nifneq ($(LZ4_PATH),)\n\tINCLUDE_PATHS += -I$(LZ4_PATH)/include\n\tLIBRARY_PATHS += -L$(LZ4_PATH)/lib\nendif\nifneq ($(ZSTD_PATH),)\n\tINCLUDE_PATHS += -I$(ZSTD_PATH)/include\n\tLIBRARY_PATHS += -L$(ZSTD_PATH)/lib\nendif\n\n# dedup\nINCLUDE_PATHS := $(sort $(INCLUDE_PATHS))\nLIBRARY_PATHS := $(sort $(LIBRARY_PATHS))\n\n# Default target\nall: benchmark utility generate\n\n# Generic rules\nutility: benchmark/utility.cpp\n\t$(CXX) $(CPPFLAGS) -o $@ $<\n\ngenerate: benchmark/generate.cpp\n\t$(CXX) $(CPPFLAGS) -o $@ $<\n\ninmemory: benchmark/inmemory.cpp libflagstats.h\n\t$(CXX) $(CPPFLAGS) -I$(POSPOPCNT_PATH) $(INCLUDE_PATHS) -o $@ $<\n\nbench.o: benchmark/flagstats.cpp\n\t$(CXX) $(CPPFLAGS) -I$(POSPOPCNT_PATH) $(INCLUDE_PATHS) -c -o $@ $<\n\nbenchmark: bench.o\n\t$(CXX) $(CPPFLAGS) bench.o -I$(POSPOPCNT_PATH) $(INCLUDE_PATHS) $(LIBRARY_PATHS) -o bench -llz4 -lzstd\n\ninstrumented_benchmark : linux/instrumented_benchmark.cpp\n\t$(CXX) $(CPPFLAGS) -I. -I$(POSPOPCNT_PATH) -I./linux -o $@ $<\n\ninstrumented_benchmark_align64 : linux/instrumented_benchmark.cpp\n\t$(CXX) $(CPPFLAGS) -DALIGN -I. -I$(POSPOPCNT_PATH) -I./linux -c -o $@ $<\n\nclean:\n\trm -f $(OBJECTS)\n\trm -f bench bench.o utility generate instrumented_benchmark instrumented_benchmark_align64 inmemory\n\n.PHONY: all clean\n"
},
{
"alpha_fraction": 0.4998471736907959,
"alphanum_fraction": 0.5505806803703308,
"avg_line_length": 29.013761520385742,
"blob_id": "58e10f060ae2efd76caafb940e7b92139ff4e6c0",
"content_id": "9fcc8ba0e54765063b886c4eaaa5dddc37e5ab31",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6544,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 218,
"path": "/benchmark/inmemory.cpp",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <iomanip>\n#include <chrono>\n#include <memory>\n#include <cstdint>\n#include <random>\n#include <vector>\n\n// force flagstats to define all implementations\n#define STORM_HAVE_AVX2\n#define STORM_HAVE_AVX512\n#define STORM_HAVE_SSE42\n\n#include \"libalgebra.h\" // pospopcnt\n#include \"../libflagstats.h\" // flagstats\n\nusing Clock = std::chrono::high_resolution_clock;\n\ntemplate <typename UNIT = std::chrono::microseconds>\nClock::time_point::rep elapsed(const Clock::time_point& t1, const Clock::time_point& t2) {\n return std::chrono::duration_cast<UNIT>(t2 - t1).count();\n}\n\nclass Application {\nprivate:\n const size_t size;\n std::unique_ptr<uint16_t[]> flags;\n std::ostream& out;\npublic:\n Application(size_t size)\n : size(size)\n , flags(new uint16_t[size])\n , out(std::cout) {\n\n initialize_input();\n }\n\n void run() {\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n uint32_t scalar[32];\n run(\"scalar\", FLAGSTAT_scalar, scalar);\n\n#if defined(STORM_HAVE_SSE42)\n if (cpuid & STORM_CPUID_runtime_bit_SSE42) {\n uint32_t sse4[32];\n const uint64_t time_sse4 = run(\"SSE4\", FLAGSTAT_sse4, sse4);\n\n uint32_t sse4_improved[32];\n run(\"SSE4 improved\", FLAGSTAT_sse4_improved, sse4_improved, sse4, time_sse4);\n\n uint32_t sse4_improved2[32];\n run(\"SSE4 improved 2\", FLAGSTAT_sse4_improved2, sse4_improved2, sse4, time_sse4);\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if (cpuid & STORM_CPUID_runtime_bit_AVX2) {\n uint32_t avx2[32];\n const uint64_t time_avx2 = run(\"AVX2\", FLAGSTAT_avx2, avx2);\n\n uint32_t avx2_improved[32];\n run(\"AVX2 improved\", FLAGSTAT_avx2_improved, avx2_improved, avx2, time_avx2);\n\n uint32_t avx2_improved2[32];\n run(\"AVX2 improved2\", FLAGSTAT_avx2_improved2, avx2_improved2, avx2, time_avx2);\n }\n#endif\n\n#if defined(STORM_HAVE_AVX512)\n if (cpuid & STORM_CPUID_runtime_bit_AVX512BW) {\n uint32_t avx512[32];\n const uint64_t time_avx512 = run(\"AVX512\", FLAGSTAT_avx512, avx512, scalar);\n\n uint32_t avx512_improved[32];\n const uint64_t time_avx512_improved = run(\"AVX512 improved\", FLAGSTAT_avx512_improved, avx512_improved, scalar, time_avx512);\n\n uint32_t avx512_improved2[32];\n const uint64_t time_avx512_improved2 = run(\"AVX512 improved 2\", FLAGSTAT_avx512_improved2, avx512_improved2, scalar, time_avx512_improved);\n\n uint32_t avx512_improved3[32];\n const uint64_t time_avx512_improved3 = run(\"AVX512 improved 3\", FLAGSTAT_avx512_improved3, avx512_improved3, scalar);\n\n uint32_t avx512_improved4[32];\n const uint64_t time_avx512_improved4 = run(\"AVX512 improved 4\", FLAGSTAT_avx512_improved4, avx512_improved4, scalar);\n }\n#endif\n }\n\nprivate:\n void initialize_input() {\n std::random_device rd;\n std::mt19937 eng(rd());\n eng.seed(0); // make the results repeatable\n\n std::uniform_int_distribution<uint16_t> flag(0, 4096 - 1);\n for (size_t i=0; i < size; i++)\n flags[i] = flag(eng);\n }\n\n template <typename FUN>\n uint64_t run(const char* name,\n FUN function,\n uint32_t* stats,\n uint32_t* stats_ref = nullptr,\n uint64_t time_ref = 0)\n {\n out << \"Running function \" << name << \": \";\n out << std::flush;\n\n for (int i=0; i < 32; i++) stats[i] = 0;\n\n const auto t1 = Clock::now();\n function(flags.get(), size, stats);\n const auto t2 = Clock::now();\n \n const uint16_t time_us = elapsed(t1, t2);\n out << \"time \" << time_us << \" us\";\n if (time_ref != 0)\n out << \" (speedup: \" << double(time_ref)/time_us << \")\";\n out << '\\n';\n dump_stats(stats);\n\n if (stats_ref != nullptr) {\n const bool has_error = compare(stats_ref, stats);\n }\n\n return time_us;\n }\n\n void dump_array(uint32_t* arr, int size) {\n out << '[';\n for (int i=0; i < size; i++) {\n if (i != 0)\n out << \", \";\n\n out << std::setw(6);\n out << arr[i];\n }\n out << ']';\n }\n\n void dump_stats(uint32_t* stats) {\n out << \"statistics are: \";\n out << '\\n';\n for (int i=0; i < 32; i += 8) {\n out << \" \";\n dump_array(stats + i, 8);\n out << '\\n';\n }\n }\n\n bool compare(uint32_t* reference, uint32_t* stats) {\n bool has_error = false;\n // test only the counters actually written by FLAGSTAT_scalar_update\n static const std::vector<int> tested_counters{\n FLAGSTAT_FQCFAIL_OFF,\n FLAGSTAT_FSECONDARY_OFF,\n FLAGSTAT_FSUPPLEMENTARY_OFF,\n FLAGSTAT_BIT12_OFF,\n FLAGSTAT_FREAD1_OFF,\n FLAGSTAT_FREAD2_OFF,\n FLAGSTAT_BIT13_OFF,\n FLAGSTAT_BIT14_OFF,\n FLAGSTAT_FUNMAP_OFF,\n FLAGSTAT_FDUP_OFF,\n FLAGSTAT_FQCFAIL_OFF + 16,\n FLAGSTAT_FSECONDARY_OFF + 16,\n FLAGSTAT_FSUPPLEMENTARY_OFF + 16,\n FLAGSTAT_BIT12_OFF + 16,\n FLAGSTAT_FREAD1_OFF + 16,\n FLAGSTAT_FREAD2_OFF + 16,\n FLAGSTAT_BIT13_OFF + 16,\n FLAGSTAT_BIT14_OFF + 16,\n FLAGSTAT_FUNMAP_OFF + 16,\n FLAGSTAT_FDUP_OFF + 16,\n };\n\n for (const int index: tested_counters) {\n const uint32_t expected = reference[index];\n const uint32_t actual = stats[index];\n if (expected != actual) {\n out << \"Difference at \" << index << \": expected = \" << expected << \", actual = \" << actual << '\\n';\n has_error = true;\n }\n }\n\n return has_error;\n }\n};\n\nint main(int argc, char* argv[]) {\n const size_t default_size = 1024 * 100;\n\n size_t size = default_size;\n if (argc > 1)\n size = atoi(argv[1]);\n\n Application app(size);\n app.run();\n}\n\n"
},
{
"alpha_fraction": 0.4969755709171295,
"alphanum_fraction": 0.5843213200569153,
"avg_line_length": 31.543306350708008,
"blob_id": "dc4487d578f9847cbef0ad4af827f4ab82544e54",
"content_id": "253db729ca234b88ea1953ace7e27e9b95235be7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4133,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 127,
"path": "/paper/scripts/version5.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom avx512 import *\n\nAVX512_BIT12_FQCFAIL_0 = 5\nAVX512_BIT12_FQCFAIL_1 = 13\nAVX512_BIT13_FQCFAIL_0 = 4\nAVX512_BIT13_FQCFAIL_1 = 12\nAVX512_BIT14_FQCFAIL_0 = 3\nAVX512_BIT14_FQCFAIL_1 = 11\nAVX512_FREAD1_FQCFAIL_0 = 7\nAVX512_FREAD2_FQCFAIL_0 = 15\nAVX512_FREAD1_FQCFAIL_1 = 6\nAVX512_FREAD2_FQCFAIL_1 = 14\nAVX512_FSECONDARY_FQCFAIL_0 = 0\nAVX512_FSECONDARY_FQCFAIL_1 = 8\nAVX512_FDUP_FQCFAIL_0 = 1\nAVX512_FDUP_FQCFAIL_1 = 9\nAVX512_FSUPPLEMENTARY_FQCFAIL_0 = 2\nAVX512_FSUPPLEMENTARY_FQCFAIL_1 = 10\nAVX512_FQCFAIL = 15\n\ndef bit12(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & FPROPER_PAIR\n\ndef bit13(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & FMUNMAP\n\ndef bit14(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & (~FMUNMAP)\n\ndef bit(pos):\n return 1 << pos\n\n\ndef complete_bits_lookup():\n vpshufw = []\n for k in range(2**5):\n FPAIRED = int(k & 0x01 != 0)\n FPROPER_PAIR = int(k & 0x02 != 0)\n FUNMAP = int(k & 0x04 != 0)\n FMUNMAP = int(k & 0x08 != 0)\n\n b12 = bit12(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n b13 = bit13(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n b14 = bit14(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n\n word = (b12 << AVX512_BIT12_FQCFAIL_0) \\\n | (b12 << AVX512_BIT12_FQCFAIL_1) \\\n | (b13 << AVX512_BIT13_FQCFAIL_0) \\\n | (b13 << AVX512_BIT13_FQCFAIL_1) \\\n | (b14 << AVX512_BIT14_FQCFAIL_0) \\\n | (b14 << AVX512_BIT14_FQCFAIL_1) \\\n | (FPAIRED << 12)\n\n vpshufw.append(word)\n\n return word2byte_array(vpshufw)\n\n\ndef condition_mask_lookup():\n def get_mask(FSUPPLEMENTARY, FSECONDARY, FPAIRED):\n mask = 0\n mask |= bit(AVX512_FDUP_FQCFAIL_0) | bit(AVX512_FDUP_FQCFAIL_1)\n\n if FSECONDARY:\n mask |= bit(AVX512_FSECONDARY_FQCFAIL_0) | bit(AVX512_FSECONDARY_FQCFAIL_1)\n elif FSUPPLEMENTARY:\n mask |= bit(AVX512_FSUPPLEMENTARY_FQCFAIL_0) | bit(AVX512_FSUPPLEMENTARY_FQCFAIL_1)\n elif FPAIRED:\n mask |= bit(AVX512_BIT12_FQCFAIL_0) | bit(AVX512_BIT12_FQCFAIL_1)\n mask |= bit(AVX512_BIT13_FQCFAIL_0) | bit(AVX512_BIT13_FQCFAIL_1)\n mask |= bit(AVX512_BIT14_FQCFAIL_0) | bit(AVX512_BIT14_FQCFAIL_1)\n mask |= bit(AVX512_FREAD1_FQCFAIL_0) | bit(AVX512_FREAD1_FQCFAIL_1)\n mask |= bit(AVX512_FREAD2_FQCFAIL_0) | bit(AVX512_FREAD2_FQCFAIL_1)\n\n return mask\n\n vpshufw = []\n for k in range(2**5):\n FSECONDARY = int(k & 0x01 != 0)\n FQCFAIL = int(k & 0x02 != 0)\n FDUP = int(k & 0x04 != 0)\n FSUPPLEMENTARY = int(k & 0x08 != 0)\n FPAIRED = int(k & 0x10 != 0)\n\n vpshufw.append(get_mask(FSUPPLEMENTARY, FSECONDARY, FPAIRED))\n\n return word2byte_array(vpshufw)\n\n\ndef reshuffle_bits_lookup():\n def get_word(FSUPPLEMENTARY, FDUP, FSECONDARY, FQCFAIL):\n mask = 0\n\n if FSUPPLEMENTARY:\n mask |= bit(AVX512_FSUPPLEMENTARY_FQCFAIL_0)\n\n if FDUP:\n mask |= bit(AVX512_FDUP_FQCFAIL_0)\n\n if FSECONDARY:\n mask |= bit(AVX512_FSECONDARY_FQCFAIL_0)\n\n if FQCFAIL:\n mask |= bit(AVX512_FQCFAIL)\n\n return mask\n\n vpshufw = []\n for k in range(2**5):\n FSECONDARY = int(k & 0x01 != 0)\n FQCFAIL = int(k & 0x02 != 0)\n FDUP = int(k & 0x04 != 0)\n FSUPPLEMENTARY = int(k & 0x08 != 0)\n FPAIRED = int(k & 0x10 != 0)\n\n vpshufw.append(get_word(FSUPPLEMENTARY, FDUP, FSECONDARY, FQCFAIL))\n\n return word2byte_array(vpshufw)\n\nprint(\" // generated by scripts/version5.py\")\nprint(avx512_var(\"complete_bits_lookup\", complete_bits_lookup()))\nprint()\nprint(avx512_var(\"reshuffle_bits_lookup\", reshuffle_bits_lookup()))\nprint()\nprint(avx512_var(\"condition_mask_lookup\", condition_mask_lookup()))\nprint(\" // end of autogenered content\")\n"
},
{
"alpha_fraction": 0.43286624550819397,
"alphanum_fraction": 0.5294468998908997,
"avg_line_length": 41.43270492553711,
"blob_id": "5a1ab8695e647cfbb11f5f789b6408843c4e4200",
"content_id": "95bb37e070950778abf1af8d6106082978928ac0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 130523,
"license_type": "permissive",
"max_line_length": 217,
"num_lines": 3076,
"path": "/libflagstats.h",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "// License for libflagstats.h\n/*\n* Copyright (c) 2019 Marcus D. R. Klarqvist\n* Author(s): Marcus D. R. Klarqvist\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing,\n* software distributed under the License is distributed on an\n* \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n* KIND, either express or implied. See the License for the\n* specific language governing permissions and limitations\n* under the License.\n*/\n// License for libalgebra.h\n/*\n* Copyright (c) 2019 Marcus D. R. Klarqvist\n* Author(s): Marcus D. R. Klarqvist\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing,\n* software distributed under the License is distributed on an\n* \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n* KIND, either express or implied. See the License for the\n* specific language governing permissions and limitations\n* under the License.\n*/\n// License for pospopcnt.h\n/*\n* Copyright (c) 2019\n* Author(s): Marcus D. R. Klarqvist, Wojciech Muła, and Daniel Lemire\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing,\n* software distributed under the License is distributed on an\n* \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n* KIND, either express or implied. See the License for the\n* specific language governing permissions and limitations\n* under the License.\n*/\n#ifndef LIBFLAGSTATS_H_98345934843\n#define LIBFLAGSTATS_H_98345934843\n\n/* *************************************\n* Includes\n***************************************/\n#include \"libalgebra.h\"\n\n/* *************************************\n* Target SAM fields\n***************************************/\n\n// Modified from sam.h\n/*! @abstract the read is paired in sequencing, no matter whether it is mapped in a pair */\n#define FLAGSTAT_FPAIRED 1\n#define FLAGSTAT_FPAIRED_OFF 0\n/*! @abstract the read is mapped in a proper pair */\n#define FLAGSTAT_FPROPER_PAIR 2\n#define FLAGSTAT_FPROPER_PAIR_OFF 1\n/*! @abstract the read itself is unmapped; conflictive with FLAGSTAT_FPROPER_PAIR */\n#define FLAGSTAT_FUNMAP 4\n#define FLAGSTAT_FUNMAP_OFF 2\n/*! @abstract the mate is unmapped */\n#define FLAGSTAT_FMUNMAP 8\n#define FLAGSTAT_FMUNMAP_OFF 3\n/*! @abstract the read is mapped to the reverse strand */\n#define FLAGSTAT_FREVERSE 16\n#define FLAGSTAT_FREVERSE_OFF 4\n/*! @abstract the mate is mapped to the reverse strand */\n#define FLAGSTAT_FMREVERSE 32\n#define FLAGSTAT_FMREVERSE_OFF 5\n/*! @abstract this is read1 */\n#define FLAGSTAT_FREAD1 64\n#define FLAGSTAT_FREAD1_OFF 6\n/*! @abstract this is read2 */\n#define FLAGSTAT_FREAD2 128\n#define FLAGSTAT_FREAD2_OFF 7\n/*! @abstract not primary alignment */\n#define FLAGSTAT_FSECONDARY 256\n#define FLAGSTAT_FSECONDARY_OFF 8\n/*! @abstract QC failure */\n#define FLAGSTAT_FQCFAIL 512\n#define FLAGSTAT_FQCFAIL_OFF 9\n/*! @abstract optical or PCR duplicate */\n#define FLAGSTAT_FDUP 1024\n#define FLAGSTAT_FDUP_OFF 10\n/*! @abstract supplementary alignment */\n#define FLAGSTAT_FSUPPLEMENTARY 2048\n#define FLAGSTAT_FSUPPLEMENTARY_OFF 11\n/*! @abstract auxilary bit #12 set by SIMD procedures */\n#define FLAGSTAT_BIT12 (1 << 12)\n#define FLAGSTAT_BIT12_OFF 12\n/*! @abstract auxilary bit #13 set by SIMD procedures */\n#define FLAGSTAT_BIT13 (1 << 13)\n#define FLAGSTAT_BIT13_OFF 13\n/*! @abstract auxilary bit #14 set by SIMD procedures */\n#define FLAGSTAT_BIT14 (1 << 14)\n#define FLAGSTAT_BIT14_OFF 14\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nvoid FLAGSTAT_scalar_update(uint16_t val, uint32_t* flags) {\n // If the FLAGSTAT_FQCFAIL is set the data is shift 16 values to\n // the right to distinguish between statistics for data\n // that failed and passed quality control.\n const int offset = ( (val & FLAGSTAT_FQCFAIL) == 0 ) ? 0 : 16;\n uint32_t* f = &flags[offset];\n // Count only reads that with FLAGSTAT_FQCFAIL set. The other\n // reads are implicitly known and computed at the end of\n // FLAGSTAT_* functions.\n if (offset) ++f[FLAGSTAT_FQCFAIL_OFF];\n\n if (val & FLAGSTAT_FSECONDARY) ++f[FLAGSTAT_FSECONDARY_OFF];\n else if (val & FLAGSTAT_FSUPPLEMENTARY) ++f[FLAGSTAT_FSUPPLEMENTARY_OFF];\n else if (val & FLAGSTAT_FPAIRED) {\n // ++(s)->n_pair_all[w]; \n if ( (val & FLAGSTAT_FPROPER_PAIR) && !(val & FLAGSTAT_FUNMAP) ) ++f[FLAGSTAT_BIT12_OFF];\n if (val & FLAGSTAT_FREAD1) ++f[FLAGSTAT_FREAD1_OFF];\n if (val & FLAGSTAT_FREAD2) ++f[FLAGSTAT_FREAD2_OFF];\n if ((val & FLAGSTAT_FMUNMAP) && !(val & FLAGSTAT_FUNMAP)) ++f[FLAGSTAT_BIT13_OFF];\n if (!(val & FLAGSTAT_FUNMAP) && !(val & FLAGSTAT_FMUNMAP)) ++f[FLAGSTAT_BIT14_OFF];\n }\n // Count as is FUNMAP then use arithmetic to compute N - FUNMAP\n if (val & FLAGSTAT_FUNMAP) ++f[FLAGSTAT_FUNMAP_OFF];\n if (val & FLAGSTAT_FDUP) ++f[FLAGSTAT_FDUP_OFF];\n}\n\n// #define SAMTOOLS_flagstat_loop(s, c) do { \\\n// int w = (c & FLAGSTAT_FQCFAIL)? 1 : 0; \\\n// ++(s)->n_reads[w]; \\\n// if (c & FLAGSTAT_FSECONDARY ) { \\\n// ++(s)->n_secondary[w]; \\\n// } else if (c & FLAGSTAT_FSUPPLEMENTARY ) { \\\n// ++(s)->n_supp[w]; \\\n// } else if (c & FLAGSTAT_FPAIRED) { \\\n// ++(s)->n_pair_all[w]; \\\n// if ( (c & FLAGSTAT_FPROPER_PAIR) && !(c & FLAGSTAT_FUNMAP) ) ++(s)->n_pair_good[w]; \\\n// if (c & FLAGSTAT_FREAD1) ++(s)->n_read1[w]; \\\n// if (c & FLAGSTAT_FREAD2) ++(s)->n_read2[w]; \\\n// if ((c & FLAGSTAT_FMUNMAP) && !(c & FLAGSTAT_FUNMAP)) ++(s)->n_sgltn[w]; \\\n// if (!(c & FLAGSTAT_FUNMAP) && !(c & FLAGSTAT_FMUNMAP)) { \\\n// ++(s)->n_pair_map[w]; \\\n// } \\\n// } \\\n// if (!(c & FLAGSTAT_FUNMAP)) ++(s)->n_mapped[w]; \\\n// if (c & FLAGSTAT_FDUP) ++(s)->n_dup[w]; \\\n// } while (0)\n\n// FLAGSTAT_FPROPER_PAIR & !FLAGSTAT_FUNMAP\n// x |= (x & (FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP) == FLAGSTAT_FPROPER_PAIR) & 1 << 13\n// FLAGSTAT_FMUNMAP & !FLAGSTAT_FUNMAP\n// x |= (x & (FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP) == FLAGSTAT_FMUNMAP) & 1 << 14\n\nstatic\nint FLAGSTAT_scalar(const uint16_t* array, uint32_t len, uint32_t* flags) {\n for (uint32_t i = 0; i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n return 0;\n}\n\n#if defined(STORM_HAVE_SSE42)\n\n#include <immintrin.h>\n\nSTORM_TARGET(\"sse4.2\")\nstatic\nint FLAGSTAT_sse4(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n \n for (uint32_t i = len - (len % (16 * 8)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m128i* data = (const __m128i*)array;\n size_t size = len / 8;\n __m128i v1 = _mm_setzero_si128();\n __m128i v2 = _mm_setzero_si128();\n __m128i v4 = _mm_setzero_si128();\n __m128i v8 = _mm_setzero_si128();\n __m128i v16 = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m128i v1U = _mm_setzero_si128();\n __m128i v2U = _mm_setzero_si128();\n __m128i v4U = _mm_setzero_si128();\n __m128i v8U = _mm_setzero_si128();\n __m128i v16U = _mm_setzero_si128();\n __m128i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[8];\n __m128i counter[16];\n __m128i counterU[16];\n \n // Masks and mask selectors.\n const __m128i m1 = _mm_set1_epi16(FLAGSTAT_FSECONDARY);\n const __m128i m1S = _mm_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m128i m2 = _mm_set1_epi16(FLAGSTAT_FSUPPLEMENTARY);\n const __m128i m2S = _mm_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m128i m3 = _mm_set1_epi16(FLAGSTAT_FPAIRED);\n const __m128i m4 = _mm_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m128i one = _mm_set1_epi16(1); // (00...1) vector\n const __m128i zero = _mm_set1_epi16(0); // (00...0) vector\n\n // Main body.\n while (i < limit) { \n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_setzero_si128();\n counterU[i] = _mm_setzero_si128();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n ///////////////////////////////////////////////////////////////////////\n // We load a register of data (data + i + j) and then construct the\n // conditional bits: \n // 12: FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP == FLAGSTAT_FPROPER_PAIR\n // 13: FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP == FLAGSTAT_FMUNMAP\n // 14: FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP == 0\n //\n // These construction of these bits can be described for data x as:\n // x |= (x & LEFT_MASK == RIGHT_MASK) & 1 << TARGET_BIT\n // with the assumption that predicate evaluatons result in the selection\n // masks (00...0) or (11...1) for FALSE and TRUE, respectively. These\n // construction macros are named O1, O2, and O3.\n //\n // The original SAMtools method is also heavily branched with three\n // main branch points:\n // If FLAGSTAT_FSECONDARY then count FLAGSTAT_FSECONDARY\n // If FLAGSTAT_FSUPPLEMENTARY then count FLAGSTAT_FSUPPLEMENTARY\n // Else then count FLAGSTAT_FREAD1, \n // FLAGSTAT_FREAD2,\n // Special bit 12, 13, and 14\n // Always count FLAGSTAT_FUNMAP, \n // FLAGSTAT_FDUP, \n // FLAGSTAT_FQCFAIL\n //\n // These bits can be selected using a mask-select propagate-carry approach:\n // x &= x & ((x == MASK) | CARRY_BITS)\n // with the arguments for MASK and CARRY_BITS as follows:\n // 1. {FLAGSTAT_FSECONDARY, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n // 2. {FLAGSTAT_FSUPPLEMENTARY, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY \n // + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n // 3. {FLAGSTAT_FPAIRED, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY \n // + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n //\n // FLAGSTATS outputs summary statistics separately for reads that pass\n // QC and those that do not. Therefore we need to partition the data\n // into these two classes. For data that pass QC, the L registers, we\n // first bit-select the target FLAGSTAT_FQCFAIL bit using the mask\n // mask3. The resulting data is used to perform another mask-select\n // using VPCMPEQW against the empty vector (00...0). As above, if the\n // data has the FLAGSTAT_FQCFAIL bit set then this register will be\n // zeroed out. The exact process is performed for reads that fail QC,\n // the LU registers, with the difference that mask-selection is based on\n // the one vector (00...1).\n\n#define W(j) __m128i data##j = _mm_loadu_si128(data + i + j);\n#define O1(j) data##j = data##j | _mm_slli_epi16(data##j & _mm_cmpeq_epi16((data##j & _mm_set1_epi16(FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP)), _mm_set1_epi16(FLAGSTAT_FPROPER_PAIR)) & one, 12); \n#define O2(j) data##j = data##j | _mm_slli_epi16(data##j & _mm_cmpeq_epi16((data##j & _mm_set1_epi16(FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP)), _mm_set1_epi16(FLAGSTAT_FMUNMAP)) & one, 13); \n#define O3(j) data##j = data##j | _mm_slli_epi16(data##j & _mm_cmpeq_epi16((data##j & _mm_set1_epi16(FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP)), zero) & one, 14); \n#define L1(j) data##j = data##j & (_mm_cmpeq_epi16((data##j & m1), zero) | m1S);\n#define L2(j) data##j = data##j & (_mm_cmpeq_epi16((data##j & m2), zero) | m2S);\n#define L3(j) data##j = data##j & (_mm_cmpeq_epi16((data##j & m3), m3) | m2S);\n#define LOAD(j) W(j) O1(j) O2(j) O3(j) L1(j) L2(j) L3(j)\n#define L(j) data##j & _mm_cmpeq_epi16( data##j & m4, zero )\n#define LU(j) data##j & _mm_cmpeq_epi16( data##j & m4, m4 )\n \n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm_add_epi16(counter[pos], _mm_and_si128(v16, one)); \\\n v16 = _mm_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm_add_epi16(counterU[pos], _mm_and_si128(v16U, one)); \\\n v16U = _mm_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_sse(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_sse(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_sse(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_sse(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n#undef O3\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_add_epi16(counter[i], _mm_and_si128(v16, one));\n v16 = _mm_srli_epi16(v16, 1);\n counterU[i] = _mm_add_epi16(counterU[i], _mm_and_si128(v16U, one));\n v16U = _mm_srli_epi16(v16U, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm_storeu_si128((__m128i*)buffer, counter[i]);\n for (size_t z = 0; z < 8; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm_storeu_si128((__m128i*)buffer, counterU[i]);\n for (size_t z = 0; z < 8; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v1);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v1U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v2);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v2U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v4);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v4U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v8);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v8U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic\nint FLAGSTAT_sse4_improved(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n \n for (uint32_t i = len - (len % (16 * 8)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m128i* data = (const __m128i*)array;\n size_t size = len / 8;\n __m128i v1 = _mm_setzero_si128();\n __m128i v2 = _mm_setzero_si128();\n __m128i v4 = _mm_setzero_si128();\n __m128i v8 = _mm_setzero_si128();\n __m128i v16 = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m128i v1U = _mm_setzero_si128();\n __m128i v2U = _mm_setzero_si128();\n __m128i v4U = _mm_setzero_si128();\n __m128i v8U = _mm_setzero_si128();\n __m128i v16U = _mm_setzero_si128();\n __m128i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[8];\n __m128i counter[16];\n __m128i counterU[16];\n \n // Masks and mask selectors.\n const __m128i m1 = _mm_set1_epi16(FLAGSTAT_FSECONDARY);\n const __m128i m1S = _mm_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m128i m2 = _mm_set1_epi16(FLAGSTAT_FSUPPLEMENTARY);\n const __m128i m2S = _mm_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m128i m3 = _mm_set1_epi16(FLAGSTAT_FPAIRED);\n const __m128i m4 = _mm_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m128i one = _mm_set1_epi16(1); // (00...1) vector\n const __m128i zero = _mm_set1_epi16(0); // (00...0) vector\n\n const __m128i complete_bits_lookup = _mm_setr_epi8( // generated by expand_data.py\n 0x00, 0x40, 0x00, 0x50, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x30, 0x00, 0x00, 0x00, 0x00);\n\n // Main body.\n while (i < limit) { \n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_setzero_si128();\n counterU[i] = _mm_setzero_si128();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n ///////////////////////////////////////////////////////////////////////\n // We load a register of data (data + i + j) and then construct the\n // conditional bits:\n // 12: FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP == FLAGSTAT_FPROPER_PAIR\n // 13: FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP == FLAGSTAT_FMUNMAP\n // 14: FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP == 0\n /*\n The bits span the lower 4 bits of flag set and this makes that\n suitable for use pshufb to quickly lookup desired bits. The lookup\n must be done only for the higer byte of 16-bit word, the lower\n byte must be zeroed. Such a transformed input must be or-ed with\n the input word.\n FLAGSTAT_FMUNMAP\n |FLAGSTAT_FUNMAP\n ||FLAGSTAT_FPROPER_PAIR\n |||FLAGSTAT_FPAIRED\n ||||\n input word: [0000|0000|0000|xxxx] -- simple bitand to mask higher bits\n\n bit14\n |bit13\n ||bit12\n |||\n output word: [0abc|0000|0000|0000] -- shuffle followed by shift left\n\n Please note that for all the flags equal zero, also bits 12..14 are\n also zero. Thus byte shuffle operation on the zeroed higher byte\n does not alter that byte.\n */\n // The original SAMtools method is also heavily branched with three\n // main branch points:\n // If FLAGSTAT_FSECONDARY then count FLAGSTAT_FSECONDARY\n // If FLAGSTAT_FSUPPLEMENTARY then count FLAGSTAT_FSUPPLEMENTARY\n // Else then count FLAGSTAT_FREAD1, \n // FLAGSTAT_FREAD2,\n // Special bit 12, 13, and 14\n // Always count FLAGSTAT_FUNMAP, \n // FLAGSTAT_FDUP, \n // FLAGSTAT_FQCFAIL\n //\n // These bits can be selected using a mask-select propagate-carry approach:\n // x &= x & ((x == MASK) | CARRY_BITS)\n // with the arguments for MASK and CARRY_BITS as follows:\n // 1. {FLAGSTAT_FSECONDARY, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n // 2. {FLAGSTAT_FSUPPLEMENTARY, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY \n // + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n // 3. {FLAGSTAT_FPAIRED, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY \n // + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n //\n // FLAGSTATS outputs summary statistics separately for reads that pass\n // QC and those that do not. Therefore we need to partition the data\n // into these two classes. For data that pass QC, the L registers, we\n // first bit-select the target FLAGSTAT_FQCFAIL bit using the mask\n // mask3. The resulting data is used to perform another mask-select\n // using VPCMPEQW against the empty vector (00...0). As above, if the\n // data has the FLAGSTAT_FQCFAIL bit set then this register will be\n // zeroed out. The exact process is performed for reads that fail QC,\n // the LU registers, with the difference that mask-selection is based on\n // the one vector (00...1).\n\n#define W(j) __m128i data##j = _mm_loadu_si128(data + i + j);\n#define O1(j) const __m128i complete_index##j = _mm_and_si128(data##j, _mm_set1_epi16(0x000f));\n#define O2(j) data##j = data##j | _mm_slli_epi16(_mm_shuffle_epi8(complete_bits_lookup, complete_index##j), 8);\n#define L1(j) data##j = data##j & (_mm_cmpeq_epi16((data##j & m1), zero) | m1S);\n#define L2(j) data##j = data##j & (_mm_cmpeq_epi16((data##j & m2), zero) | m2S);\n#define L3(j) data##j = data##j & (_mm_cmpeq_epi16((data##j & m3), m3) | m2S);\n#define LOAD(j) W(j) O1(j) O2(j) L1(j) L2(j) L3(j)\n#define L(j) data##j & _mm_cmpeq_epi16( data##j & m4, zero )\n#define LU(j) data##j & _mm_cmpeq_epi16( data##j & m4, m4 )\n \n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm_add_epi16(counter[pos], _mm_and_si128(v16, one)); \\\n v16 = _mm_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm_add_epi16(counterU[pos], _mm_and_si128(v16U, one)); \\\n v16U = _mm_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_sse(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_sse(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_sse(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_sse(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_add_epi16(counter[i], _mm_and_si128(v16, one));\n v16 = _mm_srli_epi16(v16, 1);\n counterU[i] = _mm_add_epi16(counterU[i], _mm_and_si128(v16U, one));\n v16U = _mm_srli_epi16(v16U, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm_storeu_si128((__m128i*)buffer, counter[i]);\n for (size_t z = 0; z < 8; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm_storeu_si128((__m128i*)buffer, counterU[i]);\n for (size_t z = 0; z < 8; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v1);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v1U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v2);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v2U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v4);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v4U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v8);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v8U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic\nint FLAGSTAT_sse4_improved2(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n\n for (uint32_t i = len - (len % (16 * 8)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m128i* data = (const __m128i*)array;\n size_t size = len / 8;\n __m128i v1 = _mm_setzero_si128();\n __m128i v2 = _mm_setzero_si128();\n __m128i v4 = _mm_setzero_si128();\n __m128i v8 = _mm_setzero_si128();\n __m128i v16 = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m128i v1U = _mm_setzero_si128();\n __m128i v2U = _mm_setzero_si128();\n __m128i v4U = _mm_setzero_si128();\n __m128i v8U = _mm_setzero_si128();\n __m128i v16U = _mm_setzero_si128();\n __m128i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[8];\n __m128i counter[16];\n __m128i counterU[16];\n\n // Masks and mask selectors.\n const __m128i m4 = _mm_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m128i one = _mm_set1_epi16(1); // (00...1) vector\n const __m128i zero = _mm_set1_epi16(0); // (00...0) vector\n\n const __m128i complete_bits_lookup = _mm_setr_epi8( // generated by expand_data.py\n 0x00, 0x40, 0x00, 0x50, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x30, 0x00, 0x00, 0x00, 0x00);\n\n const __m128i duplicate_even_bytes = _mm_setr_epi8(0, 0, 2, 2, 4, 4, 6, 6, 8, 8, 10, 10, 12, 12, 14, 14);\n\n // constants generated by paper/scripts/sse4_avx2_mask.py\n const __m128i mask_lookup = _mm_setr_epi8(0x04, 0x04, 0xc4, 0x04, 0x06, 0x07, 0x76, 0x07, 0x04, 0x04, 0x04, 0x04, 0x0e, 0x07, 0x0e, 0x07);\n\n // Main body.\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_setzero_si128();\n counterU[i] = _mm_setzero_si128();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n /*\n The conditional flags (bits #12, #13 and #14) are completed\n in the same way as in FLAGSTAT_sse4_improved.\n\n The later mask generation is done differently.\n\n 0. We're starting with following bit layout, where x denotes\n non-control bits:\n\n FSUPPLEMENTARY\n | FSECONDARY\n | | FPAIRED\n | | |\n in = [xxxx|AxxB|xxxx|xxxC]\n\n 1. We isolate the control bits:\n\n t0 = [0000|B00A|0000|000C] = in & 0x0901 (0b0000'1001'0000'0001)\n\n 2. Then we build a 4-bit word suitable for pshufb in the lower\n byte of each word:\n\n t1 = [0000|0000|0000|B0CA] = pmaddubsw(t2, 0x0102)\n\n 3. And then copy these bits also to the higher byte:\n\n t2 = [0000|B0CA|0000|B0CA] = pshufb(t1, duplicate_even_bytes)\n\n 4. Now we set 3rd bit in the higher word. Thanks to that\n we are able to get separate bytes of mask in **single** pshufb\n invocation.\n\n t3 = [0000|B1CA|0000|B0CA] = t3 | 0x0400 (0b0000'0100'0000'0000)\n\n 5. Finally obtain the mask:\n\n t4 = pshufb(mask_lookup, t3)\n\n Conceptually, we have here something like:\n\n uint16_t word_mask = function(A, B, C)\n if (3rd bit set)\n byte_mask = word_mask >> 8\n else\n byte_mask = word_mask & 0xff\n\n 6. The rest of algorithm is the same...\n */\n\n#define W(j) __m128i data##j = _mm_loadu_si128(data + i + j);\n#define O1(j) const __m128i complete_index##j = _mm_and_si128(data##j, _mm_set1_epi16(0x000f));\n#define O2(j) data##j = data##j | _mm_slli_epi16(_mm_shuffle_epi8(complete_bits_lookup, complete_index##j), 8);\n#define LOAD(j) \\\n W(j) O1(j) O2(j) \\\n const __m128i t0_##j = _mm_and_si128(data##j, _mm_set1_epi16(0x0901)); \\\n const __m128i t1_##j = _mm_maddubs_epi16(t0_##j, _mm_set1_epi16(0x0102)); \\\n const __m128i t2_##j = _mm_shuffle_epi8(t1_##j, duplicate_even_bytes); \\\n const __m128i t3_##j = _mm_or_si128(t2_##j, _mm_set1_epi16(0x0400)); \\\n const __m128i t4_##j = _mm_shuffle_epi8(mask_lookup, t3_##j); \\\n data##j = _mm_and_si128(data##j, t4_##j);\n\n#define L(j) data##j & _mm_cmpeq_epi16( data##j & m4, zero )\n#define LU(j) data##j & _mm_cmpeq_epi16( data##j & m4, m4 )\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm_add_epi16(counter[pos], _mm_and_si128(v16, one)); \\\n v16 = _mm_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm_add_epi16(counterU[pos], _mm_and_si128(v16U, one)); \\\n v16U = _mm_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_sse(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_sse(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_sse(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_sse(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_sse(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_sse(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_sse(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_sse(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_add_epi16(counter[i], _mm_and_si128(v16, one));\n v16 = _mm_srli_epi16(v16, 1);\n counterU[i] = _mm_add_epi16(counterU[i], _mm_and_si128(v16U, one));\n v16U = _mm_srli_epi16(v16U, 1);\n }\n\n for (size_t i = 0; i < 16; ++i) {\n _mm_storeu_si128((__m128i*)buffer, counter[i]);\n for (size_t z = 0; z < 8; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm_storeu_si128((__m128i*)buffer, counterU[i]);\n for (size_t z = 0; z < 8; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v1);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v1U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v2);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v2U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v4);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v4U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v8);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v8U);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n\n#include <immintrin.h>\n\nSTORM_TARGET(\"avx2\")\nstatic\nint FLAGSTAT_avx2(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n \n for (uint32_t i = len - (len % (16 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m256i* data = (const __m256i*)array;\n size_t size = len / 16;\n __m256i v1 = _mm256_setzero_si256();\n __m256i v2 = _mm256_setzero_si256();\n __m256i v4 = _mm256_setzero_si256();\n __m256i v8 = _mm256_setzero_si256();\n __m256i v16 = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m256i v1U = _mm256_setzero_si256();\n __m256i v2U = _mm256_setzero_si256();\n __m256i v4U = _mm256_setzero_si256();\n __m256i v8U = _mm256_setzero_si256();\n __m256i v16U = _mm256_setzero_si256();\n __m256i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[16];\n __m256i counter[16]; \n __m256i counterU[16];\n \n // Masks and mask selectors.\n const __m256i m1 = _mm256_set1_epi16(FLAGSTAT_FSECONDARY);\n const __m256i m1S = _mm256_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m256i m2 = _mm256_set1_epi16(FLAGSTAT_FSUPPLEMENTARY);\n const __m256i m2S = _mm256_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m256i m3 = _mm256_set1_epi16(FLAGSTAT_FPAIRED);\n const __m256i m4 = _mm256_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m256i one = _mm256_set1_epi16(1); // (00...1) vector\n const __m256i zero = _mm256_set1_epi16(0); // (00...0) vector\n\n // Main body.\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_setzero_si256();\n counterU[i] = _mm256_setzero_si256();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n ///////////////////////////////////////////////////////////////////////\n // We load a register of data (data + i + j) and then construct the\n // conditional bits: \n // 12: FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP == FLAGSTAT_FPROPER_PAIR\n // 13: FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP == FLAGSTAT_FMUNMAP\n // 14: FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP == 0\n //\n // These construction of these bits can be described for data x as:\n // x |= (x & LEFT_MASK == RIGHT_MASK) & 1 << TARGET_BIT\n // with the assumption that predicate evaluatons result in the selection\n // masks (00...0) or (11...1) for FALSE and TRUE, respectively. These\n // construction macros are named O1, O2, and O3.\n //\n // The original SAMtools method is also heavily branched with three\n // main branch points:\n // If FLAGSTAT_FSECONDARY then count FLAGSTAT_FSECONDARY\n // If FLAGSTAT_FSUPPLEMENTARY then count FLAGSTAT_FSUPPLEMENTARY\n // Else then count FLAGSTAT_FREAD1, \n // FLAGSTAT_FREAD2,\n // Special bit 12, 13, and 14\n // Always count FLAGSTAT_FUNMAP, \n // FLAGSTAT_FDUP, \n // FLAGSTAT_FQCFAIL\n //\n // These bits can be selected using a mask-select propagate-carry approach:\n // x &= x & ((x == MASK) | CARRY_BITS)\n // with the arguments for MASK and CARRY_BITS as follows:\n // 1. {FLAGSTAT_FSECONDARY, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n // 2. {FLAGSTAT_FSUPPLEMENTARY, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY \n // + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n // 3. {FLAGSTAT_FPAIRED, \n // FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY \n // + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP}\n //\n // FLAGSTATS outputs summary statistics separately for reads that pass\n // QC and those that do not. Therefore we need to partition the data\n // into these two classes. For data that pass QC, the L registers, we\n // first bit-select the target FLAGSTAT_FQCFAIL bit using the mask\n // mask3. The resulting data is used to perform another mask-select\n // using VPCMPEQW against the empty vector (00...0). As above, if the\n // data has the FLAGSTAT_FQCFAIL bit set then this register will be\n // zeroed out. The exact process is performed for reads that fail QC,\n // the LU registers, with the difference that mask-selection is based on\n // the one vector (00...1).\n\n#define W(j) __m256i data##j = _mm256_loadu_si256(data + i + j);\n#define O1(j) data##j = data##j | _mm256_slli_epi16(data##j & _mm256_cmpeq_epi16((data##j & _mm256_set1_epi16(FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP)), _mm256_set1_epi16(FLAGSTAT_FPROPER_PAIR)) & one, 12); \n#define O2(j) data##j = data##j | _mm256_slli_epi16(data##j & _mm256_cmpeq_epi16((data##j & _mm256_set1_epi16(FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP)), _mm256_set1_epi16(FLAGSTAT_FMUNMAP)) & one, 13); \n#define O3(j) data##j = data##j | _mm256_slli_epi16(data##j & _mm256_cmpeq_epi16((data##j & _mm256_set1_epi16(FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP)), zero) & one, 14); \n#define L1(j) data##j = data##j & (_mm256_cmpeq_epi16((data##j & m1), zero) | m1S);\n#define L2(j) data##j = data##j & (_mm256_cmpeq_epi16((data##j & m2), zero) | m2S);\n#define L3(j) data##j = data##j & (_mm256_cmpeq_epi16((data##j & m3), m3) | m2S);\n#define LOAD(j) W(j) O1(j) O2(j) O3(j) L1(j) L2(j) L3(j)\n#define L(j) data##j & _mm256_cmpeq_epi16( data##j & m4, zero )\n#define LU(j) data##j & _mm256_cmpeq_epi16( data##j & m4, m4 )\n \n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm256_add_epi16(counter[pos], _mm256_and_si256(v16, one)); \\\n v16 = _mm256_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm256_add_epi16(counterU[pos], _mm256_and_si256(v16U, one)); \\\n v16U = _mm256_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx2(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx2(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_avx2(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_avx2(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n#undef O3\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_add_epi16(counter[i], _mm256_and_si256(v16, one));\n v16 = _mm256_srli_epi16(v16, 1);\n counterU[i] = _mm256_add_epi16(counterU[i], _mm256_and_si256(v16U, one));\n v16U = _mm256_srli_epi16(v16U, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm256_storeu_si256((__m256i*)buffer, counter[i]);\n for (size_t z = 0; z < 16; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm256_storeu_si256((__m256i*)buffer, counterU[i]);\n for (size_t z = 0; z < 16; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v1);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v1U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v2);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v2U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v4);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v4U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v8);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v8U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\n// Note: this is a 1:1 port of FLAGSTAT_sse4_improved\nSTORM_TARGET(\"avx2\")\nstatic\nint FLAGSTAT_avx2_improved(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n\n for (uint32_t i = len - (len % (16 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m256i* data = (const __m256i*)array;\n size_t size = len / 16;\n __m256i v1 = _mm256_setzero_si256();\n __m256i v2 = _mm256_setzero_si256();\n __m256i v4 = _mm256_setzero_si256();\n __m256i v8 = _mm256_setzero_si256();\n __m256i v16 = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m256i v1U = _mm256_setzero_si256();\n __m256i v2U = _mm256_setzero_si256();\n __m256i v4U = _mm256_setzero_si256();\n __m256i v8U = _mm256_setzero_si256();\n __m256i v16U = _mm256_setzero_si256();\n __m256i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 32;\n uint64_t i = 0;\n uint16_t buffer[16];\n __m256i counter[16];\n __m256i counterU[16];\n\n // Masks and mask selectors.\n const __m256i m1 = _mm256_set1_epi16(FLAGSTAT_FSECONDARY);\n const __m256i m1S = _mm256_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m256i m2 = _mm256_set1_epi16(FLAGSTAT_FSUPPLEMENTARY);\n const __m256i m2S = _mm256_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m256i m3 = _mm256_set1_epi16(FLAGSTAT_FPAIRED);\n const __m256i m4 = _mm256_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m256i one = _mm256_set1_epi16(1); // (00...1) vector\n const __m256i zero = _mm256_set1_epi16(0); // (00...0) vector\n\n const __m256i complete_bits_lookup = _mm256_setr_epi8( // generated by expand_data.py\n 0x00, 0x40, 0x00, 0x50, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x30, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x40, 0x00, 0x50, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x30, 0x00, 0x00, 0x00, 0x00);\n\n // Main body.\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_setzero_si256();\n counterU[i] = _mm256_setzero_si256();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n#define W(j) __m256i data##j = _mm256_loadu_si256(data + i + j);\n#define O1(j) const __m256i complete_index##j = _mm256_and_si256(data##j, _mm256_set1_epi16(0x000f));\n#define O2(j) data##j = data##j | _mm256_slli_epi16(_mm256_shuffle_epi8(complete_bits_lookup, complete_index##j), 8);\n#define L1(j) data##j = data##j & (_mm256_cmpeq_epi16((data##j & m1), zero) | m1S);\n#define L2(j) data##j = data##j & (_mm256_cmpeq_epi16((data##j & m2), zero) | m2S);\n#define L3(j) data##j = data##j & (_mm256_cmpeq_epi16((data##j & m3), m3) | m2S);\n#define LOAD(j) W(j) O1(j) O2(j) L1(j) L2(j) L3(j)\n#define L(j) data##j & _mm256_cmpeq_epi16( data##j & m4, zero )\n#define LU(j) data##j & _mm256_cmpeq_epi16( data##j & m4, m4 )\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm256_add_epi16(counter[pos], _mm256_and_si256(v16, one)); \\\n v16 = _mm256_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm256_add_epi16(counterU[pos], _mm256_and_si256(v16U, one)); \\\n v16U = _mm256_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx2(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx2(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_avx2(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_avx2(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_add_epi16(counter[i], _mm256_and_si256(v16, one));\n v16 = _mm256_srli_epi16(v16, 1);\n counterU[i] = _mm256_add_epi16(counterU[i], _mm256_and_si256(v16U, one));\n v16U = _mm256_srli_epi16(v16U, 1);\n }\n\n for (size_t i = 0; i < 16; ++i) {\n _mm256_storeu_si256((__m256i*)buffer, counter[i]);\n for (size_t z = 0; z < 16; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm256_storeu_si256((__m256i*)buffer, counterU[i]);\n for (size_t z = 0; z < 16; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v1);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v1U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v2);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v2U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v4);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v4U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v8);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v8U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\n// Note: this is a 1:1 port of FLAGSTAT_sse4_improved2\nSTORM_TARGET(\"avx2\")\nstatic\nint FLAGSTAT_avx2_improved2(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n\n for (uint32_t i = len - (len % (16 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m256i* data = (const __m256i*)array;\n size_t size = len / 16;\n __m256i v1 = _mm256_setzero_si256();\n __m256i v2 = _mm256_setzero_si256();\n __m256i v4 = _mm256_setzero_si256();\n __m256i v8 = _mm256_setzero_si256();\n __m256i v16 = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m256i v1U = _mm256_setzero_si256();\n __m256i v2U = _mm256_setzero_si256();\n __m256i v4U = _mm256_setzero_si256();\n __m256i v8U = _mm256_setzero_si256();\n __m256i v16U = _mm256_setzero_si256();\n __m256i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 32;\n uint64_t i = 0;\n uint16_t buffer[16];\n __m256i counter[16];\n __m256i counterU[16];\n\n // Masks and mask selectors.\n const __m256i m4 = _mm256_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m256i one = _mm256_set1_epi16(1); // (00...1) vector\n const __m256i zero = _mm256_set1_epi16(0); // (00...0) vector\n\n const __m256i complete_bits_lookup = _mm256_setr_epi8( // generated by expand_data.py\n 0x00, 0x40, 0x00, 0x50, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x30, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x40, 0x00, 0x50, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x30, 0x00, 0x00, 0x00, 0x00);\n\n const __m256i duplicate_even_bytes = _mm256_setr_epi8(\n 0, 0, 2, 2, 4, 4, 6, 6, 8, 8, 10, 10, 12, 12, 14, 14, // Note: AVX2 vpshufb works on 128-bit lanes\n 0, 0, 2, 2, 4, 4, 6, 6, 8, 8, 10, 10, 12, 12, 14, 14);\n\n // constants generated by paper/scripts/sse4_avx2_mask.py\n const __m256i mask_lookup = _mm256_setr_epi8(\n 0x04, 0x04, 0xc4, 0x04, 0x06, 0x07, 0x76, 0x07, 0x04, 0x04, 0x04, 0x04, 0x0e, 0x07, 0x0e, 0x07,\n 0x04, 0x04, 0xc4, 0x04, 0x06, 0x07, 0x76, 0x07, 0x04, 0x04, 0x04, 0x04, 0x0e, 0x07, 0x0e, 0x07);\n\n // Main body.\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_setzero_si256();\n counterU[i] = _mm256_setzero_si256();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n#define W(j) __m256i data##j = _mm256_loadu_si256(data + i + j);\n#define O1(j) const __m256i complete_index##j = _mm256_and_si256(data##j, _mm256_set1_epi16(0x000f));\n#define O2(j) data##j = data##j | _mm256_slli_epi16(_mm256_shuffle_epi8(complete_bits_lookup, complete_index##j), 8);\n#define LOAD(j) \\\n W(j) O1(j) O2(j) \\\n const __m256i t0_##j = _mm256_and_si256(data##j, _mm256_set1_epi16(0x0901)); \\\n const __m256i t1_##j = _mm256_maddubs_epi16(t0_##j, _mm256_set1_epi16(0x0102)); \\\n const __m256i t2_##j = _mm256_shuffle_epi8(t1_##j, duplicate_even_bytes); \\\n const __m256i t3_##j = _mm256_or_si256(t2_##j, _mm256_set1_epi16(0x0400)); \\\n const __m256i t4_##j = _mm256_shuffle_epi8(mask_lookup, t3_##j); \\\n data##j = _mm256_and_si256(data##j, t4_##j);\n\n#define L(j) data##j & _mm256_cmpeq_epi16( data##j & m4, zero )\n#define LU(j) data##j & _mm256_cmpeq_epi16( data##j & m4, m4 )\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm256_add_epi16(counter[pos], _mm256_and_si256(v16, one)); \\\n v16 = _mm256_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm256_add_epi16(counterU[pos], _mm256_and_si256(v16U, one)); \\\n v16U = _mm256_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx2(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx2(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_avx2(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx2(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx2(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx2(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_avx2(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_avx2(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_add_epi16(counter[i], _mm256_and_si256(v16, one));\n v16 = _mm256_srli_epi16(v16, 1);\n counterU[i] = _mm256_add_epi16(counterU[i], _mm256_and_si256(v16U, one));\n v16U = _mm256_srli_epi16(v16U, 1);\n }\n\n for (size_t i = 0; i < 16; ++i) {\n _mm256_storeu_si256((__m256i*)buffer, counter[i]);\n for (size_t z = 0; z < 16; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm256_storeu_si256((__m256i*)buffer, counterU[i]);\n for (size_t z = 0; z < 16; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v1);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v1U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v2);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v2U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v4);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v4U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v8);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v8U);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n#endif // end avx2\n\n#if defined(STORM_HAVE_AVX512)\n\n#include <immintrin.h>\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint FLAGSTAT_avx512(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n \n for (uint32_t i = len - (len % (32 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m512i* data = (const __m512i*)array;\n size_t size = len / 32;\n __m512i v1 = _mm512_setzero_si512();\n __m512i v2 = _mm512_setzero_si512();\n __m512i v4 = _mm512_setzero_si512();\n __m512i v8 = _mm512_setzero_si512();\n __m512i v16 = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m512i v1U = _mm512_setzero_si512();\n __m512i v2U = _mm512_setzero_si512();\n __m512i v4U = _mm512_setzero_si512();\n __m512i v8U = _mm512_setzero_si512();\n __m512i v16U = _mm512_setzero_si512();\n __m512i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[32];\n __m512i counter[16]; \n __m512i counterU[16];\n \n // Masks and mask selectors.\n const __m512i m1 = _mm512_set1_epi16(FLAGSTAT_FSECONDARY);\n const __m512i m1S = _mm512_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m512i m2 = _mm512_set1_epi16(FLAGSTAT_FSUPPLEMENTARY);\n const __m512i m2S = _mm512_set1_epi16(FLAGSTAT_FQCFAIL + FLAGSTAT_FSUPPLEMENTARY + FLAGSTAT_FSECONDARY + FLAGSTAT_FUNMAP + FLAGSTAT_FDUP);\n const __m512i m3 = _mm512_set1_epi16(FLAGSTAT_FPAIRED);\n const __m512i m4 = _mm512_set1_epi16(FLAGSTAT_FQCFAIL);\n const __m512i one = _mm512_set1_epi16(1); // (00...1) vector\n const __m512i zero = _mm512_set1_epi16(0); // (00...0) vector\n\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_setzero_si512();\n counterU[i] = _mm512_setzero_si512();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n#define W(j) __m512i data##j = _mm512_loadu_si512(data + i + j);\n#define O1(j) data##j = data##j | _mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask(data##j & _mm512_set1_epi16(FLAGSTAT_FPROPER_PAIR + FLAGSTAT_FUNMAP), _mm512_set1_epi16(FLAGSTAT_FPROPER_PAIR)), (uint16_t)1 << 12); \n#define O2(j) data##j = data##j | _mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask(data##j & _mm512_set1_epi16(FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP), _mm512_set1_epi16(FLAGSTAT_FMUNMAP)), (uint16_t)1 << 13);\n#define O3(j) data##j = data##j | _mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask(data##j & _mm512_set1_epi16(FLAGSTAT_FMUNMAP + FLAGSTAT_FUNMAP), zero), (uint16_t)1 << 14);\n#define L1(j) data##j = data##j & (_mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask((data##j & m1), zero),65535) | m1S);\n#define L2(j) data##j = data##j & (_mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask((data##j & m2), zero),65535) | m2S);\n#define L3(j) data##j = data##j & (_mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask((data##j & m3), m3), 65535) | m2S);\n#define LOAD(j) W(j) O1(j) O2(j) O3(j) L1(j) L2(j) L3(j)\n#define L(j) data##j & _mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask( data##j & m4, zero ), 65535)\n#define LU(j) data##j & _mm512_maskz_set1_epi16(_mm512_cmpeq_epi16_mask( data##j & m4, m4 ), 65535)\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm512_add_epi16(counter[pos], _mm512_and_si512(v16, one)); \\\n v16 = _mm512_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm512_add_epi16(counterU[pos], _mm512_and_si512(v16U, one)); \\\n v16U = _mm512_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx512(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx512(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_avx512(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_avx512(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef O2\n#undef O3\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_add_epi16(counter[i], _mm512_and_si512(v16, one));\n v16 = _mm512_srli_epi16(v16, 1);\n counterU[i] = _mm512_add_epi16(counterU[i], _mm512_and_si512(v16U, one));\n v16U = _mm512_srli_epi16(v16U, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)buffer, counter[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm512_storeu_si512((__m512i*)buffer, counterU[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v1);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v1U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v2);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v2U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v4);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v4U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v8);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v8U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint FLAGSTAT_avx512_improved(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n \n for (uint32_t i = len - (len % (32 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m512i* data = (const __m512i*)array;\n size_t size = len / 32;\n __m512i v1 = _mm512_setzero_si512();\n __m512i v2 = _mm512_setzero_si512();\n __m512i v4 = _mm512_setzero_si512();\n __m512i v8 = _mm512_setzero_si512();\n __m512i v16 = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m512i v1U = _mm512_setzero_si512();\n __m512i v2U = _mm512_setzero_si512();\n __m512i v4U = _mm512_setzero_si512();\n __m512i v8U = _mm512_setzero_si512();\n __m512i v16U = _mm512_setzero_si512();\n __m512i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[32];\n __m512i counter[16]; \n __m512i counterU[16];\n \n // Masks and mask selectors.\n const __m512i one = _mm512_set1_epi16(1); // (00...1) vector\n\n // generated by expand_data.py\n const __m512i complete_bits_lookup = _mm512_setr_epi32(\n 0x40000000, 0x50000000, 0x00000000, 0x00000000, 0x20000000, 0x30000000, 0x00000000, 0x00000000,\n 0x40000000, 0x50000000, 0x00000000, 0x00000000, 0x20000000, 0x30000000, 0x00000000, 0x00000000);\n\n // generated by mask_data.py\n const __m512i qcfail_1_lookup = _mm512_setr_epi32(\n 0x00000000, 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04,\n 0x00000000, 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04);\n\n // generated by mask_data.py\n const __m512i qcfail_0_lookup = _mm512_setr_epi32(\n 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04, 0x00000000,\n 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04, 0x00000000);\n\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_setzero_si512();\n counterU[i] = _mm512_setzero_si512();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n\n#define W(j) __m512i data##j = _mm512_loadu_si512(data + i + j);\n#define O1(j) data##j = data##j | _mm512_permutexvar_epi16(data##j, complete_bits_lookup);\n /*\n We're gathering bits that decide about the major control flow.\n The resulting value will be issued to lookup instructions, that\n provide masks for data.\n\n FLAGSTAT_FSUPPLEMENTARY\n | FLAGSTAT_FQCFAIL\n | |FLAGSTAT_FSECONDARY\n | || FLAGSTAT_FPAIRED\n | || |\n [....|x.yw|....|...z] (. = garbage)\n\n This is the layout of words obtained in L1\n\n [0000|0000|0000|xzyw]\n */\n\n// We're using 32-bit shifts, as they're faster than 16-bit shifts.\n#define L1(j) const __m512i mask_index##j = _mm512_maddubs_epi16( \\\n _mm512_and_si512(data##j, _mm512_set1_epi16(0x0b01)), \\\n _mm512_set1_epi16(0x0104));\n#define L2(j) const __m512i mask_qcfail0_##j = _mm512_permutexvar_epi16(mask_index##j, qcfail_0_lookup);\n#define L3(j) const __m512i mask_qcfail1_##j = _mm512_permutexvar_epi16(mask_index##j, qcfail_1_lookup);\n#define LOAD(j) W(j) O1(j) L1(j) L2(j) L3(j)\n#define L(j) _mm512_and_si512(data##j, mask_qcfail0_##j)\n#define LU(j) _mm512_and_si512(data##j, mask_qcfail1_##j)\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm512_add_epi16(counter[pos], _mm512_and_si512(v16, one)); \\\n v16 = _mm512_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm512_add_epi16(counterU[pos], _mm512_and_si512(v16U, one)); \\\n v16U = _mm512_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx512(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx512(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_avx512(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_avx512(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_add_epi16(counter[i], _mm512_and_si512(v16, one));\n v16 = _mm512_srli_epi16(v16, 1);\n counterU[i] = _mm512_add_epi16(counterU[i], _mm512_and_si512(v16U, one));\n v16U = _mm512_srli_epi16(v16U, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)buffer, counter[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm512_storeu_si512((__m512i*)buffer, counterU[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v1);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v1U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v2);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v2U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v4);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v4U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v8);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v8U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint FLAGSTAT_avx512_improved2(const uint16_t* array, uint32_t len, uint32_t* flags) {\n const uint32_t start_qc = flags[FLAGSTAT_FQCFAIL_OFF + 16];\n \n for (uint32_t i = len - (len % (32 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], flags);\n }\n\n const __m512i* data = (const __m512i*)array;\n size_t size = len / 32;\n __m512i v1 = _mm512_setzero_si512();\n __m512i v2 = _mm512_setzero_si512();\n __m512i v4 = _mm512_setzero_si512();\n __m512i v8 = _mm512_setzero_si512();\n __m512i v16 = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n __m512i v1U = _mm512_setzero_si512();\n __m512i v2U = _mm512_setzero_si512();\n __m512i v4U = _mm512_setzero_si512();\n __m512i v8U = _mm512_setzero_si512();\n __m512i v16U = _mm512_setzero_si512();\n __m512i twosAU, twosBU, foursAU, foursBU, eightsAU, eightsBU;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[32];\n __m512i counter[16]; \n __m512i counterU[16];\n \n // Masks and mask selectors.\n const __m512i one = _mm512_set1_epi16(1); // (00...1) vector\n\n /*\n FLAGSTAT_FSUPPLEMENTARY\n | FLAGSTAT_FQCFAIL\n | |FLAGSTAT_FSECONDARY\n | || FLAGSTAT_FMUNMAP\n | || |FLAGSTAT_FUNMAP\n | || ||FLAGSTAT_FPROPER_PAIR\n | || |||FLAGSTAT_FPAIRED\n | || ||||\n [....|e.fg|....|abcd] (. = garbage)\n\n From the marked bits we need two extra masks:\n\n F1 [0ABC|0000|0000|0000] (A, B, C are calculated from a, b, c, d)\n F2 [0000|0000|0000|edfg]\n\n The first mask is produced by VPSHUFW. But at this step we can\n also place bit d at proper position in the 3rd nibble:\n\n F3 [0ABC|0d00|0000|0000]\n\n The mask F1 must be or'ed with the input data, but we can use\n F3 and ternary logic operator to perform merge:\n\n // 0xca defines function (m & F3) | (~m & data)\n data = _mm512_ternarylogic_epi32(m=[0111|0000|0000|0000], F3=[0ABC|0d00|0000|0000], data, 0xca)\n\n The mask F2 can be also obtained from data vector and F3\n\n // F2 = [....|edfg|....|....]\n F2 = _mm512_ternarylogic_epi32(m=[0000|0100|0000|0000], F3=[0ABC|0d00|0000|0000], data, 0xca)\n // F2 = [0000|0000|....|edfg] \n F2 = _mm512_srli_epi32(tmp, 8);\n */\n\n // generated by expand_data.py\n const __m512i complete_bits_lookup = _mm512_setr_epi32(\n 0x44000000, 0x54000000, 0x04000000, 0x04000000, 0x24000000, 0x34000000, 0x04000000, 0x04000000,\n 0x44000000, 0x54000000, 0x04000000, 0x04000000, 0x24000000, 0x34000000, 0x04000000, 0x04000000);\n\n // generated by mask_data.py\n const __m512i qcfail_1_lookup = _mm512_setr_epi32(\n 0x00000000, 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04,\n 0x00000000, 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04);\n\n // generated by mask_data.py\n const __m512i qcfail_0_lookup = _mm512_setr_epi32(\n 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04, 0x00000000,\n 0x07040604, 0x00000000, 0x070476c4, 0x00000000, 0x07040e04, 0x00000000, 0x07040e04, 0x00000000);\n\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_setzero_si512();\n counterU[i] = _mm512_setzero_si512();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n#define W(j) __m512i data##j = _mm512_loadu_si512(data + i + j);\n#define O1(j) const __m512i mask##j = _mm512_permutexvar_epi16(data##j, complete_bits_lookup);\n#define O2(j) data##j = _mm512_ternarylogic_epi32(_mm512_set1_epi16(0x7000), mask##j, data##j, 0xca);\n#define L1(j) const __m512i mask_index##j = _mm512_srli_epi16(_mm512_ternarylogic_epi32(_mm512_set1_epi16(0x0400), mask##j, data##j, 0xca), 8);\n#define L2(j) const __m512i mask_qcfail0_##j = _mm512_permutexvar_epi16(mask_index##j, qcfail_0_lookup);\n#define L3(j) const __m512i mask_qcfail1_##j = _mm512_permutexvar_epi16(mask_index##j, qcfail_1_lookup);\n#define LOAD(j) W(j) O1(j) O2(j) L1(j) L2(j) L3(j)\n#define L(j) _mm512_and_si512(data##j, mask_qcfail0_##j)\n#define LU(j) _mm512_and_si512(data##j, mask_qcfail1_##j)\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm512_add_epi16(counter[pos], _mm512_and_si512(v16, one)); \\\n v16 = _mm512_srli_epi16(v16, 1); \\\n}\n#define UU(pos) { \\\n counterU[pos] = _mm512_add_epi16(counterU[pos], _mm512_and_si512(v16U, one)); \\\n v16U = _mm512_srli_epi16(v16U, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 0), L( 1));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 0), LU( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU( 2), LU( 3));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursAU, &v2U, twosAU, twosBU);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 4), L( 5));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 4), LU( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU( 6), LU( 7));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx512(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&eightsAU,&v4U, foursAU, foursBU);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 8), L( 9));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU( 8), LU( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU(10), LU(11));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursAU, &v2U, twosAU, twosBU);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L(12), L(13));\n STORM_pospopcnt_csa_avx512(&twosAU, &v1U, LU(12), LU(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx512(&twosBU, &v1U, LU(14), LU(15));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&foursBU, &v2U, twosAU, twosBU);\n STORM_pospopcnt_csa_avx512(&eightsB, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&eightsBU,&v4U, foursAU, foursBU);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n UU(0) UU(1) UU(2) UU(3) UU(4) UU(5) UU(6) UU(7) UU(8) UU(9) UU(10) UU(11) UU(12) UU(13) UU(14) UU(15) // Updates\n STORM_pospopcnt_csa_avx512(&v16, &v8, eightsA, eightsB);\n STORM_pospopcnt_csa_avx512(&v16U, &v8U, eightsAU, eightsBU);\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_add_epi16(counter[i], _mm512_and_si512(v16, one));\n v16 = _mm512_srli_epi16(v16, 1);\n counterU[i] = _mm512_add_epi16(counterU[i], _mm512_and_si512(v16U, one));\n v16U = _mm512_srli_epi16(v16U, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)buffer, counter[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n\n _mm512_storeu_si512((__m512i*)buffer, counterU[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[16+i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v1);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v1U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v2);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v2U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v4);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v4U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v8);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm512_storeu_si512((__m512i*)buffer, v8U);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[16+j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // QC\n flags[FLAGSTAT_FQCFAIL_OFF] += len - (flags[FLAGSTAT_FQCFAIL_OFF+16] - start_qc);\n\n return 0;\n}\n\n/*\n Variant 3\n --------------------------------------------------------------\n\n This variant is based on the observation that we're doing two\n full 16-bit positional popcounts (32 counters), while in fact\n we have to count only 19 counters. The FLAGSTAT_FQCFAIL is counted\n unconditionally and then following 8 bits are counted twice for\n FLAGSTAT_FQCFAIL = 0 or 1: FLAGSTAT_FUNMAP, FLAGSTAT_FDUP,\n FLAGSTAT_FSUPPLEMENTARY, FLAGSTAT_FSECONDARY, FLAGSTAT_FREAD1,\n FLAGSTAT_FREAD2, FLAGSTAT_BIT12, FLAGSTAT_BIT13, FLAGSTAT_BIT14.\n\n The idea is to duplicate most of these bits in a 16-bit word\n and then mask them depending on FQCFAIL. The 16-bit word is\n then issued to pospopcnt procedure. The remaining three bits\n are counted separately.\n\n The bits we want to re-shuffle (it's layout from the previous version,\n so bits #12, 13 and 14 are not actually occupied in the input word):\n\n BIT#14\n | BIT#13\n | | BIT#12\n | | | FSUPPLEMENTARY\n | | | | FDUP\n | | | | | FQCFAIL\n | | | | | | FSECONDARY\n | | | | | | | FREAD2\n | | | | | | | | FREAD1 FUNMAP FPAIRED\n | | | | | | | | | | |\n [ . | a | b | c | d | e | f | g | h | i | . | . | . | j | . | p ] = input\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 1. In the first step we need to calculate bits #12, #13 and #14 using\n lookup as in the previous approaches (bits 0..3 are indices for lookup).\n (notation: a0 - bit for case when FQCFAIL=0, a1 - FQCFAIL=1):\n\n [ . | . | . | p | . | . | j | . | . | . | a1| b1| c1| a0| b0| c0] = t0\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 2. In the second step we need to duplicate bits FREAD1 (i) and FREAD2 (h):\n\n [ . | . | . | . | . | . | h1| i1| h0| i0| . | . | . | . | . | . ] = t1\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 3. We marge vector 'input' with 't0' and shift it right to form an\n index for following lookups:\n\n [ . | . | . | p | d | e | j | g | . | . | . | . | . | . | . | . ] --- merged\n [ . | . | . | . | . | . | . | . | . | . | . | p | d | e | j | g ] = idx\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 4. The index 'idx' is now used to build two vectors with:\n a. duplicated FSUPPLEMENTARY (d), FDUP (e) and FSECONDARY (g), and also\n a copy of FUNMAP (j)\n\n [ d1| d0| e1| e0| g1| g0| . | . | . | . | . | . | . | . | . | j ] = t2\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n b. build masks for condition depending on flags: FSUPPLEMENTARY, FSECONDARY\n and FPAIRED: let's call this 'cond_mask'\n\n 5. Build vector with flags depending on 'cond_mask' from intermediate vectors\n t0, t1 and t2.\n\n [ d1| d0| e1| e0| g1| g0| h1| i1| h0| i0| . | . | . | . | . | j ] = t1 | t2\n [ d1| d0| e1| e0| g1| g0| h1| i1| h0| i0| a1| a0| b1| b0| c1| c0] = t3 = bitcond(0x003f, t0, (t1 | t2))\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 6. Populate FQCFAIL (f) [note: as decimal 0 or -1]:\n\n [ f | f | f | f | f | f | f | f | f | f | f | f | f | f | f | f ] = qcfail\n\n 7. Mask out bits from t3 depending on FQCFAIL -- we get mask 'qcfail_mask',\n equals either:\n\n [ 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 ] --- qcfail=0\n [ 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 ] --- qcfail=1\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n qcfail_mask = (qcfail & ~0x54d5) | (~qcfail & 0x54d5) = qcfail ^ 0x54d5\n\n 8. Call pospopcnt(t3 & qcfail_mask)\n\n 7. Separately count FUNMAP (j), which is now present in t2:\n - increment local 16-bit counter: t2 & qcfail & vector(0x0001) # ternary func: 0x80\n - increment local 16-bit counter: t2 & ~qcfail & vector(0x0001) # ternary func: 0x20\n\n 8. add to local 16-bit counter: qcfail\n\n 9. After pospopcnt, update the global counters with these local ones updated in #7 and #8.\n*/\n#define AVX512_BIT12_FQCFAIL_0 0\n#define AVX512_BIT12_FQCFAIL_1 1\n#define AVX512_BIT13_FQCFAIL_0 2\n#define AVX512_BIT13_FQCFAIL_1 3\n#define AVX512_BIT14_FQCFAIL_0 4\n#define AVX512_BIT14_FQCFAIL_1 5\n#define AVX512_FREAD1_FQCFAIL_0 6\n#define AVX512_FREAD2_FQCFAIL_0 7\n#define AVX512_FREAD1_FQCFAIL_1 8\n#define AVX512_FREAD2_FQCFAIL_1 9\n#define AVX512_FSECONDARY_FQCFAIL_0 10\n#define AVX512_FSECONDARY_FQCFAIL_1 11\n#define AVX512_FDUP_FQCFAIL_0 12\n#define AVX512_FDUP_FQCFAIL_1 13\n#define AVX512_FSUPPLEMENTARY_FQCFAIL_0 14\n#define AVX512_FSUPPLEMENTARY_FQCFAIL_1 15\n\n#define avx512_bitcond(condition, true_val, false_val) _mm512_ternarylogic_epi32((condition), (true_val), (false_val), 0xca)\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nuint32_t avx512_sum_epu32(__m512i v) {\n uint32_t tmp[16];\n uint32_t sum = 0;\n\n _mm512_storeu_si512(tmp, v);\n for (int i=0; i < 16; i++)\n sum += tmp[i];\n\n return sum;\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint FLAGSTAT_avx512_improved3(const uint16_t* array, uint32_t len, uint32_t* user_flags) {\n for (uint32_t i = len - (len % (32 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], user_flags);\n }\n\n uint32_t flags[16];\n for (int i=0; i < 16; i++)\n flags[i] = 0;\n\n const __m512i* data = (const __m512i*)array;\n size_t size = len / 32;\n __m512i v1 = _mm512_setzero_si512();\n __m512i v2 = _mm512_setzero_si512();\n __m512i v4 = _mm512_setzero_si512();\n __m512i v8 = _mm512_setzero_si512();\n __m512i v16 = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[32];\n __m512i counter[16];\n\n // Masks and mask selectors.\n const __m512i one = _mm512_set1_epi16(1); // (00...1) vector\n\n // generated by scripts/expand_data3.py\n const __m512i complete_bits_lookup = _mm512_setr_epi32(\n 0x10300000, 0x10330000, 0x12000200, 0x12000200, 0x100c0000, 0x100f0000, 0x12000200, 0x12000200,\n 0x10300000, 0x10330000, 0x12000200, 0x12000200, 0x100c0000, 0x100f0000, 0x12000200, 0x12000200\n );\n\n // generated by scripts/mask_data3.py\n const __m512i duplicate_bits_lookup = _mm512_setr_epi32(\n 0x0c000000, 0x0c010001, 0x3c003000, 0x3c013001, 0xcc00c000, 0xcc01c001, 0xfc00f000, 0xfc01f001,\n 0x0c000000, 0x0c010001, 0x3c003000, 0x3c013001, 0xcc00c000, 0xcc01c001, 0xfc00f000, 0xfc01f001\n );\n\n // generated by scripts/mask_data3.py\n const __m512i condition_mask_lookup = _mm512_setr_epi32(\n 0x3c003000, 0x3c003000, 0x3c003000, 0x3c003000, 0x3c00f000, 0x3c00f000, 0x3c00f000, 0x3c00f000,\n 0x3c0033ff, 0x3c0033ff, 0x3c0033ff, 0x3c0033ff, 0x3c00f000, 0x3c00f000, 0x3c00f000, 0x3c00f000\n );\n\n // 32-bit counters\n __m512i qcfail_global_counter = _mm512_setzero_si512();\n __m512i funmap_global_counter_qcfail_0 = _mm512_setzero_si512();\n __m512i funmap_global_counter_qcfail_1 = _mm512_setzero_si512();\n\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_setzero_si512();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n#define LOAD(j) \\\n __m512i data##j = _mm512_loadu_si512(data + i + j); \\\n const __m512i t0_##j = _mm512_permutexvar_epi16(data##j, complete_bits_lookup); \\\n const __m512i t1a_##j = _mm512_and_si512(data##j, _mm512_set1_epi16(0x00c0)); \\\n const __m512i t1_##j = _mm512_or_si512(t1a_##j, _mm512_slli_epi32(t1a_##j, 2)); \\\n const __m512i idx##j = _mm512_srli_epi32(avx512_bitcond(_mm512_set1_epi16(0x1200), t0_##j, data##j), 8); \\\n const __m512i t2_##j = _mm512_permutexvar_epi16(idx##j, duplicate_bits_lookup); \\\n const __m512i cond_mask##j = _mm512_permutexvar_epi16(idx##j, condition_mask_lookup); \\\n const __m512i t3_##j = avx512_bitcond(_mm512_set1_epi16(0x003f), t0_##j, (t1_##j | t2_##j)); \\\n const __m512i qcfail##j = _mm512_srai_epi16(_mm512_slli_epi32(data##j, 6), 16); \\\n const __m512i qcfail_mask##j = _mm512_xor_si512(qcfail##j, _mm512_set1_epi16(0x54d5)); \\\n qcfail_counter = _mm512_sub_epi16(qcfail_counter, qcfail##j); \\\n funmap_counter_qcfail_0 = _mm512_add_epi16(funmap_counter_qcfail_0, \\\n _mm512_ternarylogic_epi32(t2_##j, qcfail##j, one, 0x20)); \\\n funmap_counter_qcfail_1 = _mm512_add_epi16(funmap_counter_qcfail_1, \\\n _mm512_ternarylogic_epi32(t2_##j, qcfail##j, one, 0x80));\n\n#define L(j) (t3_##j & cond_mask##j & qcfail_mask##j)\n\n for (/**/; i < thislimit; i += 16) {\n\n // 16-bit counters\n __m512i qcfail_counter = _mm512_setzero_si512();\n __m512i funmap_counter_qcfail_0 = _mm512_setzero_si512();\n __m512i funmap_counter_qcfail_1 = _mm512_setzero_si512();\n\n#define U(pos) { \\\n counter[pos] = _mm512_add_epi16(counter[pos], _mm512_and_si512(v16, one)); \\\n v16 = _mm512_srli_epi16(v16, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 0), L( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 4), L( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&eightsA, &v4, foursA, foursB);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 8), L( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L(12), L(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&eightsB, &v4, foursA, foursB);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n STORM_pospopcnt_csa_avx512(&v16, &v8, eightsA, eightsB);\n\n qcfail_global_counter = _mm512_add_epi32(qcfail_global_counter,\n _mm512_madd_epi16(qcfail_counter, one));\n funmap_global_counter_qcfail_0 =\n _mm512_add_epi32(funmap_global_counter_qcfail_0,\n _mm512_madd_epi16(funmap_counter_qcfail_0, one));\n funmap_global_counter_qcfail_1 =\n _mm512_add_epi32(funmap_global_counter_qcfail_1,\n _mm512_madd_epi16(funmap_counter_qcfail_1, one));\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_add_epi16(counter[i], _mm512_and_si512(v16, one));\n v16 = _mm512_srli_epi16(v16, 1);\n }\n\n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)buffer, counter[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v1);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v2);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v4);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v8);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // update flags from our custom flags table\n user_flags[FLAGSTAT_FQCFAIL_OFF + 16] += avx512_sum_epu32(qcfail_global_counter);\n user_flags[FLAGSTAT_FUNMAP_OFF + 0] += avx512_sum_epu32(funmap_global_counter_qcfail_0);\n user_flags[FLAGSTAT_FUNMAP_OFF + 16] += avx512_sum_epu32(funmap_global_counter_qcfail_1);\n user_flags[FLAGSTAT_FDUP_OFF + 0] += flags[AVX512_FDUP_FQCFAIL_0];\n user_flags[FLAGSTAT_FDUP_OFF + 16] += flags[AVX512_FDUP_FQCFAIL_1];\n user_flags[FLAGSTAT_FSECONDARY_OFF + 0] += flags[AVX512_FSECONDARY_FQCFAIL_0];\n user_flags[FLAGSTAT_FSECONDARY_OFF + 16] += flags[AVX512_FSECONDARY_FQCFAIL_1];\n user_flags[FLAGSTAT_FSUPPLEMENTARY_OFF + 0] += flags[AVX512_FSUPPLEMENTARY_FQCFAIL_0];\n user_flags[FLAGSTAT_FSUPPLEMENTARY_OFF + 16] += flags[AVX512_FSUPPLEMENTARY_FQCFAIL_1];\n user_flags[FLAGSTAT_BIT12_OFF + 0] += flags[AVX512_BIT12_FQCFAIL_0];\n user_flags[FLAGSTAT_BIT12_OFF + 16] += flags[AVX512_BIT12_FQCFAIL_1];\n user_flags[FLAGSTAT_BIT13_OFF + 0] += flags[AVX512_BIT13_FQCFAIL_0];\n user_flags[FLAGSTAT_BIT13_OFF + 16] += flags[AVX512_BIT13_FQCFAIL_1];\n user_flags[FLAGSTAT_BIT14_OFF + 0] += flags[AVX512_BIT14_FQCFAIL_0];\n user_flags[FLAGSTAT_BIT14_OFF + 16] += flags[AVX512_BIT14_FQCFAIL_1];\n user_flags[FLAGSTAT_FREAD1_OFF + 0] += flags[AVX512_FREAD1_FQCFAIL_0];\n user_flags[FLAGSTAT_FREAD1_OFF + 16] += flags[AVX512_FREAD1_FQCFAIL_1];\n user_flags[FLAGSTAT_FREAD2_OFF + 0] += flags[AVX512_FREAD2_FQCFAIL_0];\n user_flags[FLAGSTAT_FREAD2_OFF + 16] += flags[AVX512_FREAD2_FQCFAIL_1];\n\n return 0;\n}\n#undef AVX512_BIT12_FQCFAIL_0\n#undef AVX512_BIT12_FQCFAIL_1\n#undef AVX512_BIT13_FQCFAIL_0\n#undef AVX512_BIT13_FQCFAIL_1\n#undef AVX512_BIT14_FQCFAIL_0\n#undef AVX512_BIT14_FQCFAIL_1\n#undef AVX512_FREAD1_FQCFAIL_0\n#undef AVX512_FREAD2_FQCFAIL_0\n#undef AVX512_FREAD1_FQCFAIL_1\n#undef AVX512_FREAD2_FQCFAIL_1\n#undef AVX512_FSECONDARY_FQCFAIL_0\n#undef AVX512_FSECONDARY_FQCFAIL_1\n#undef AVX512_FDUP_FQCFAIL_0\n#undef AVX512_FDUP_FQCFAIL_1\n#undef AVX512_FSUPPLEMENTARY_FQCFAIL_0\n#undef AVX512_FSUPPLEMENTARY_FQCFAIL_1\n\n/*\n Variant 4\n --------------------------------------------------------------\n\n The idea is similar to #3, but we don't scatter the bits of interest\n over the whole 16-bit word, but put them in lower byte and then\n duplicate that byte.\n\n The bits we want to re-shuffle (it's layout from the previous versions,\n so bits #12, 13 and 14 are not actually occupied in the input word):\n\n BIT#14\n | BIT#13\n | | BIT#12\n | | | FSUPPLEMENTARY\n | | | | FDUP\n | | | | | FQCFAIL\n | | | | | | FSECONDARY\n | | | | | | | FREAD2\n | | | | | | | | FREAD1 FUNMAP FPAIRED\n | | | | | | | | | | |\n [ . | a | b | c | d | e | f | g | h | i | . | . | . | j | . | p ] = input\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 1. In the first step we need to calculate bits #12, #13 and #14 using\n lookup as in the previous approaches (bits 0..3 are indices for lookup).\n\n [ . | . | . | p | . | . | . | . | . | . | a | b | c | . | . | . ] = t0\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 2. We marge vector 'input' with 't0' and shift it right to form an\n index for following lookups:\n\n [ . | . | . | p | d | e | f | g | . | . | . | . | . | . | . | . ] --- merged\n [ . | . | . | . | . | . | . | . | . | . | . | p | d | e | f | g ] = idx\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 3. The index 'idx' is now used to build two vectors with:\n a. shuffled FSUPPLEMENTARY (d), FDUP (e), FSECONDARY (g), and FQCFAIL (d).\n\n [ f | . | . | . | . | . | . | . | . | . | . | . | . | d | e | g ] = t1\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n b. masks for condition depending on flags: FSUPPLEMENTARY, FSECONDARY\n and FPAIRED: let's call it 'cond_mask'\n\n 5. Populate FQCFAIL (f) which is now MSB of t1 [note: as decimal 0 or -1]:\n\n [ f | f | f | f | f | f | f | f | f | f | f | f | f | f | f | f ] = qcfail\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 4. Merge t0 and t1. The lower byte has got almost all flags: FREAD1(h),\n FREAD2(i), BIT12(a), BIT13(b), BIT14(c), FSUPPLEMENTARY(d), FDUP(e),\n FSECONDARY(g). Only FUNMAP(j) and FQCFAIL(f) have to be counted separately.\n\n [ 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | h | i | a | b | c | d | e | g ] = t2\n 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0\n\n 5. If FQCFAIL=1 then shift t2 by 8.\n\n 6. Call pospopcnt(t3 & qcfail)\n\n 7. Separately count FUNMAP (j), which is bit #2 of input\n - increment local 16-bit counter: t2 & ~qcfail & vector(0x0004)\n - increment local 16-bit counter: t2 & qcfail & vector(0x0004)\n\n 8. add to local 16-bit counter: qcfail\n\n 9. After pospopcnt, update the global counters with these local ones updated in #7 and #8.\n FUNMAP local counter should be divided by 4, and FQCFAIL's higer byte must be negated.\n*/\n#define AVX512_BIT12_FQCFAIL_0 5\n#define AVX512_BIT12_FQCFAIL_1 13\n#define AVX512_BIT13_FQCFAIL_0 4\n#define AVX512_BIT13_FQCFAIL_1 12\n#define AVX512_BIT14_FQCFAIL_0 3\n#define AVX512_BIT14_FQCFAIL_1 11\n#define AVX512_FREAD1_FQCFAIL_0 7\n#define AVX512_FREAD2_FQCFAIL_0 15\n#define AVX512_FREAD1_FQCFAIL_1 6\n#define AVX512_FREAD2_FQCFAIL_1 14\n#define AVX512_FSECONDARY_FQCFAIL_0 0\n#define AVX512_FSECONDARY_FQCFAIL_1 8\n#define AVX512_FDUP_FQCFAIL_0 1\n#define AVX512_FDUP_FQCFAIL_1 9\n#define AVX512_FSUPPLEMENTARY_FQCFAIL_0 2\n#define AVX512_FSUPPLEMENTARY_FQCFAIL_1 10\n\n#define avx512_bitcond(condition, true_val, false_val) _mm512_ternarylogic_epi32((condition), (true_val), (false_val), 0xca)\n#define epi16 _mm512_set1_epi16\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint FLAGSTAT_avx512_improved4(const uint16_t* array, uint32_t len, uint32_t* user_flags) {\n for (uint32_t i = len - (len % (32 * 16)); i < len; ++i) {\n FLAGSTAT_scalar_update(array[i], user_flags);\n }\n\n uint32_t flags[16];\n for (int i=0; i < 16; i++)\n flags[i] = 0;\n\n const __m512i* data = (const __m512i*)array;\n size_t size = len / 32;\n __m512i v1 = _mm512_setzero_si512();\n __m512i v2 = _mm512_setzero_si512();\n __m512i v4 = _mm512_setzero_si512();\n __m512i v8 = _mm512_setzero_si512();\n __m512i v16 = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[32];\n __m512i counter[16];\n\n // Masks and mask selectors.\n const __m512i one = _mm512_set1_epi16(1); // (00...1) vector\n\n // generated by scripts/version5.py\n const __m512i complete_bits_lookup = _mm512_setr_epi32(\n 0x18080000, 0x38280000, 0x10000000, 0x10000000, 0x10100000, 0x30300000, 0x10000000, 0x10000000,\n 0x18080000, 0x38280000, 0x10000000, 0x10000000, 0x10100000, 0x30300000, 0x10000000, 0x10000000\n );\n\n const __m512i reshuffle_bits_lookup = _mm512_setr_epi32(\n 0x00010000, 0x80018000, 0x00030002, 0x80038002, 0x00050004, 0x80058004, 0x00070006, 0x80078006,\n 0x00010000, 0x80018000, 0x00030002, 0x80038002, 0x00050004, 0x80058004, 0x00070006, 0x80078006\n );\n\n const __m512i condition_mask_lookup = _mm512_setr_epi32(\n 0x03030202, 0x03030202, 0x03030202, 0x03030202, 0x03030606, 0x03030606, 0x03030606, 0x03030606,\n 0x0303fafa, 0x0303fafa, 0x0303fafa, 0x0303fafa, 0x03030606, 0x03030606, 0x03030606, 0x03030606\n );\n // end of autogenered content\n\n // 32-bit counters\n __m512i qcfail_global_counter = _mm512_setzero_si512();\n __m512i funmap_global_counter_qcfail_0 = _mm512_setzero_si512();\n __m512i funmap_global_counter_qcfail_1 = _mm512_setzero_si512();\n\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_setzero_si512();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n#define LOAD(j) \\\n __m512i data##j = _mm512_loadu_si512(data + i + j); \\\n const __m512i t0_##j = _mm512_permutexvar_epi16(data##j, complete_bits_lookup); \\\n const __m512i idx##j = _mm512_srli_epi32(avx512_bitcond(epi16(0x1000), t0_##j, data##j), 8); \\\n const __m512i t1_##j = _mm512_permutexvar_epi16(idx##j, reshuffle_bits_lookup); \\\n const __m512i cond_mask##j = _mm512_permutexvar_epi16(idx##j, condition_mask_lookup); \\\n const __m512i qcfail##j = _mm512_srai_epi16(t1_##j, 16); \\\n const __m512i t2_##j = avx512_bitcond(epi16(0x00c0), data##j, (t0_##j | t1_##j)) & epi16(0x00ff); \\\n const __m512i t3_##j = _mm512_sllv_epi16(t2_##j, qcfail##j & _mm512_set1_epi16(8)); \\\n qcfail_counter = _mm512_sub_epi16(qcfail_counter, qcfail##j); \\\n funmap_counter_qcfail_0 = _mm512_add_epi16(funmap_counter_qcfail_0, \\\n _mm512_ternarylogic_epi32(data##j, qcfail##j, _mm512_set1_epi16(FLAGSTAT_FUNMAP), 0x20)); \\\n funmap_counter_qcfail_1 = _mm512_add_epi16(funmap_counter_qcfail_1, \\\n _mm512_ternarylogic_epi32(data##j, qcfail##j, _mm512_set1_epi16(FLAGSTAT_FUNMAP), 0x80));\n\n#define L(j) (t3_##j & cond_mask##j)\n\n for (/**/; i < thislimit; i += 16) {\n // 16-bit counters\n __m512i qcfail_counter = _mm512_setzero_si512();\n __m512i funmap_counter_qcfail_0 = _mm512_setzero_si512();\n __m512i funmap_counter_qcfail_1 = _mm512_setzero_si512();\n\n#define U(pos) { \\\n counter[pos] = _mm512_add_epi16(counter[pos], _mm512_and_si512(v16, one)); \\\n v16 = _mm512_srli_epi16(v16, 1); \\\n}\n LOAD(0) LOAD(1)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 0), L( 1));\n LOAD(2) LOAD(3)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 2), L( 3));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n LOAD(4) LOAD(5)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 4), L( 5));\n LOAD(6) LOAD(7)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L( 6), L( 7));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&eightsA, &v4, foursA, foursB);\n LOAD(8) LOAD(9)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L( 8), L( 9));\n LOAD(10) LOAD(11)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(10), L(11));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n LOAD(12) LOAD(13)\n STORM_pospopcnt_csa_avx512(&twosA, &v1, L(12), L(13));\n LOAD(14) LOAD(15)\n STORM_pospopcnt_csa_avx512(&twosB, &v1, L(14), L(15));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&eightsB, &v4, foursA, foursB);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n STORM_pospopcnt_csa_avx512(&v16, &v8, eightsA, eightsB);\n\n qcfail_global_counter = _mm512_add_epi32(qcfail_global_counter,\n _mm512_madd_epi16(qcfail_counter, one));\n funmap_global_counter_qcfail_0 =\n _mm512_add_epi32(funmap_global_counter_qcfail_0,\n _mm512_srli_epi16(_mm512_madd_epi16(funmap_counter_qcfail_0, one), 2));\n funmap_global_counter_qcfail_1 =\n _mm512_add_epi32(funmap_global_counter_qcfail_1,\n _mm512_srli_epi16(_mm512_madd_epi16(funmap_counter_qcfail_1, one), 2));\n#undef U\n#undef UU\n#undef LOAD\n#undef L\n#undef LU\n#undef W\n#undef O1\n#undef L1\n#undef L2\n#undef L3\n }\n\n // Update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm512_add_epi16(counter[i], _mm512_and_si512(v16, one));\n v16 = _mm512_srli_epi16(v16, 1);\n }\n\n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)buffer, counter[i]);\n for (size_t z = 0; z < 32; z++) {\n flags[i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v1);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v2);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v4);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v8);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n flags[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n // update flags from our custom flags table\n user_flags[FLAGSTAT_FQCFAIL_OFF + 16] += avx512_sum_epu32(qcfail_global_counter);\n user_flags[FLAGSTAT_FUNMAP_OFF + 0] += avx512_sum_epu32(funmap_global_counter_qcfail_0);\n user_flags[FLAGSTAT_FUNMAP_OFF + 16] += avx512_sum_epu32(funmap_global_counter_qcfail_1);\n user_flags[FLAGSTAT_FDUP_OFF + 0] += flags[AVX512_FDUP_FQCFAIL_0];\n user_flags[FLAGSTAT_FDUP_OFF + 16] += flags[AVX512_FDUP_FQCFAIL_1];\n user_flags[FLAGSTAT_FSECONDARY_OFF + 0] += flags[AVX512_FSECONDARY_FQCFAIL_0];\n user_flags[FLAGSTAT_FSECONDARY_OFF + 16] += flags[AVX512_FSECONDARY_FQCFAIL_1];\n user_flags[FLAGSTAT_FSUPPLEMENTARY_OFF + 0] += flags[AVX512_FSUPPLEMENTARY_FQCFAIL_0];\n user_flags[FLAGSTAT_FSUPPLEMENTARY_OFF + 16] += flags[AVX512_FSUPPLEMENTARY_FQCFAIL_1];\n user_flags[FLAGSTAT_BIT12_OFF + 0] += flags[AVX512_BIT12_FQCFAIL_0];\n user_flags[FLAGSTAT_BIT12_OFF + 16] += flags[AVX512_BIT12_FQCFAIL_1];\n user_flags[FLAGSTAT_BIT13_OFF + 0] += flags[AVX512_BIT13_FQCFAIL_0];\n user_flags[FLAGSTAT_BIT13_OFF + 16] += flags[AVX512_BIT13_FQCFAIL_1];\n user_flags[FLAGSTAT_BIT14_OFF + 0] += flags[AVX512_BIT14_FQCFAIL_0];\n user_flags[FLAGSTAT_BIT14_OFF + 16] += flags[AVX512_BIT14_FQCFAIL_1];\n user_flags[FLAGSTAT_FREAD1_OFF + 0] += flags[AVX512_FREAD1_FQCFAIL_0];\n user_flags[FLAGSTAT_FREAD1_OFF + 16] += flags[AVX512_FREAD1_FQCFAIL_1];\n user_flags[FLAGSTAT_FREAD2_OFF + 0] += flags[AVX512_FREAD2_FQCFAIL_0];\n user_flags[FLAGSTAT_FREAD2_OFF + 16] += flags[AVX512_FREAD2_FQCFAIL_1];\n\n return 0;\n}\n#undef AVX512_BIT12_FQCFAIL_0\n#undef AVX512_BIT12_FQCFAIL_1\n#undef AVX512_BIT13_FQCFAIL_0\n#undef AVX512_BIT13_FQCFAIL_1\n#undef AVX512_BIT14_FQCFAIL_0\n#undef AVX512_BIT14_FQCFAIL_1\n#undef AVX512_FREAD1_FQCFAIL_0\n#undef AVX512_FREAD2_FQCFAIL_0\n#undef AVX512_FREAD1_FQCFAIL_1\n#undef AVX512_FREAD2_FQCFAIL_1\n#undef AVX512_FSECONDARY_FQCFAIL_0\n#undef AVX512_FSECONDARY_FQCFAIL_1\n#undef AVX512_FDUP_FQCFAIL_0\n#undef AVX512_FDUP_FQCFAIL_1\n#undef AVX512_FSUPPLEMENTARY_FQCFAIL_0\n#undef AVX512_FSUPPLEMENTARY_FQCFAIL_1\n#endif // end AVX512\n\n/* *************************************\n* Function pointer definitions.\n***************************************/\ntypedef int (*FLAGSTATS_func)(const uint16_t*, uint32_t, uint32_t*);\n\n/* *************************************\n* Wrapper functions\n***************************************/\n\nstatic\nFLAGSTATS_func FLAGSTATS_get_function(uint32_t n_len)\n{\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_len >= 1024) { // 16*512\n return &FLAGSTAT_avx512;\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 512) { // 16*256\n return &FLAGSTAT_avx2;\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_SSE42) && n_len >= 256) { // 16*128\n return &FLAGSTAT_sse4;\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE42) && n_len >= 256) { // 16*128\n return &FLAGSTAT_sse4;\n }\n#endif\n\n return &FLAGSTAT_scalar;\n}\n\nstatic\nuint64_t FLAGSTATS_u16(const uint16_t* array, uint32_t n_len, uint32_t* flags)\n{\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_len >= 1024) { // 16*512\n return FLAGSTAT_avx512(array, n_len, flags);\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 512) { // 16*256\n return FLAGSTAT_avx2(array, n_len, flags);\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_SSE42) && n_len >= 256) { // 16*128\n return FLAGSTAT_sse4(array, n_len, flags);\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE42) && n_len >= 256) { // 16*128\n return FLAGSTAT_sse4(array, n_len, flags);\n }\n#endif\n\n return FLAGSTAT_scalar(array, n_len, flags);\n}\n\n#ifdef __cplusplus\n} /* extern \"C\" */\n#endif\n\n#endif\n"
},
{
"alpha_fraction": 0.4443186819553375,
"alphanum_fraction": 0.5330523252487183,
"avg_line_length": 32.283103942871094,
"blob_id": "970c71e32a77f80ad48027780c325eed89014d60",
"content_id": "55670f8d4461a742a1e1495ac61991ca771c9b55",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 118396,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 3557,
"path": "/python/libalgebra.h",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "// License for libalgebra.h\n/*\n* Copyright (c) 2019 Marcus D. R. Klarqvist\n* Author(s): Marcus D. R. Klarqvist\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing,\n* software distributed under the License is distributed on an\n* \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n* KIND, either express or implied. See the License for the\n* specific language governing permissions and limitations\n* under the License.\n*/\n// License for pospopcnt.h\n/*\n* Copyright (c) 2019\n* Author(s): Marcus D. R. Klarqvist, Wojciech Muła, and Daniel Lemire\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing,\n* software distributed under the License is distributed on an\n* \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n* KIND, either express or implied. See the License for the\n* specific language governing permissions and limitations\n* under the License.\n*/\n// License for libpopcnt.h\n/*\n * libpopcnt.h - C/C++ library for counting the number of 1 bits (bit\n * population count) in an array as quickly as possible using\n * specialized CPU instructions i.e. POPCNT, AVX2, AVX512, NEON.\n *\n * Copyright (c) 2016 - 2018, Kim Walisch\n * Copyright (c) 2016 - 2018, Wojciech Muła\n *\n * All rights reserved.\n *\n * Redistribution and use in source and binary forms, with or without\n * modification, are permitted provided that the following conditions are met:\n *\n * 1. Redistributions of source code must retain the above copyright notice, this\n * list of conditions and the following disclaimer.\n * 2. Redistributions in binary form must reproduce the above copyright notice,\n * this list of conditions and the following disclaimer in the documentation\n * and/or other materials provided with the distribution.\n *\n * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n * ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n * WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n * DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR\n * ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n * (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n * SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n */\n#ifndef LIBALGEBRA_H_8723467365934\n#define LIBALGEBRA_H_8723467365934\n\n/* *************************************\n* Includes\n***************************************/\n#include <stdint.h>\n#include <assert.h>\n#include <memory.h>\n#include <string.h>\n#include <math.h>\n\n/* *************************************\n* Safety\n***************************************/\n\n#if !(defined(__APPLE__)) && !(defined(__FreeBSD__))\n#include <malloc.h> // this should never be needed but there are some reports that it is needed.\n#endif\n\n#if defined(__SIZEOF_LONG_LONG__) && __SIZEOF_LONG_LONG__ != 8\n#error This code assumes 64-bit long longs (by use of the GCC intrinsics). Your system is not currently supported.\n#endif\n\n/****************************\n* Memory management\n* \n* The subroutines aligned_malloc and aligned_free had to be renamed to\n* STORM_aligned_malloc and STORM_aligned_free to prevent clashing with the\n* same subroutines in Roaring. These subroutines are included here\n* since there is no hard dependency on using Roaring bitmaps.\n*\n* These subroutines and definitions are taken from the CRoaring repo\n* by Daniel Lemire et al. available under the Apache 2.0 License\n* (same as libalgebra.h):\n* https://github.com/RoaringBitmap/CRoaring/ \n****************************/\n// portable version of posix_memalign\n#ifndef _MSC_VER\n#include <x86intrin.h>\n#endif\n\n#ifndef STORM_aligned_malloc\nstatic \nvoid* STORM_aligned_malloc(size_t alignment, size_t size) {\n void *p;\n#ifdef _MSC_VER\n p = _aligned_malloc(size, alignment);\n#elif defined(__MINGW32__) || defined(__MINGW64__)\n p = __mingw_aligned_malloc(size, alignment);\n#else\n // somehow, if this is used before including \"x86intrin.h\", it creates an\n // implicit defined warning.\n if (posix_memalign(&p, alignment, size) != 0) \n return NULL;\n#endif\n return p;\n}\n#endif\n\n#ifndef STORM_aligned_free\nstatic \nvoid STORM_aligned_free(void* memblock) {\n#ifdef _MSC_VER\n _aligned_free(memblock);\n#elif defined(__MINGW32__) || defined(__MINGW64__)\n __mingw_aligned_free(memblock);\n#else\n free(memblock);\n#endif\n}\n#endif\n\n// portable alignment\n#if defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 201112L) /* C11+ */\n# include <stdalign.h>\n# define STORM_ALIGN(n) alignas(n)\n#elif defined(__GNUC__)\n# define STORM_ALIGN(n) __attribute__ ((aligned(n)))\n#elif defined(_MSC_VER)\n# define STORM_ALIGN(n) __declspec(align(n))\n#else\n# define STORM_ALIGN(n) /* disabled */\n#endif\n\n/* *************************************\n* Compiler Specific Options\n***************************************/\n// Taken from XXHASH\n#ifdef _MSC_VER /* Visual Studio */\n# pragma warning(disable : 4127) /* disable: C4127: conditional expression is constant */\n# define STORM_FORCE_INLINE static __forceinline\n# define STORM_NO_INLINE static __declspec(noinline)\n#else\n# if defined (__cplusplus) || defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* C99 */\n# ifdef __GNUC__\n# define STORM_FORCE_INLINE static inline __attribute__((always_inline))\n# define STORM_NO_INLINE static __attribute__((noinline))\n# else\n# define STORM_FORCE_INLINE static inline\n# define STORM_NO_INLINE static\n# endif\n# else\n# define STORM_FORCE_INLINE static\n# define STORM_NO_INLINE static\n# endif /* __STDC_VERSION__ */\n#endif\n\n/****************************\n* General checks\n****************************/\n\n#ifndef __has_builtin\n #define STORM_HAS_BUILTIN(x) 0\n#else\n #define STORM_HAS_BUILTIN(x) __has_builtin(x)\n#endif\n\n#ifndef __has_attribute\n #define STORM_HAS_ATTRIBUTE(x) 0\n#else\n #define STORM_HAS_ATTRIBUTE(x) __has_attribute(x)\n#endif\n\n// disable noise\n#ifdef __GNUC__\n#define STORM_WARN_UNUSED __attribute__((warn_unused_result))\n#else\n#define STORM_WARN_UNUSED\n#endif\n\n#if defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* >= C99 */\n# define STORM_RESTRICT restrict\n#else\n/* note : it might be useful to define __restrict or STORM_RESTRICT for some C++ compilers */\n# define STORM_RESTRICT /* disable */\n#endif\n\n#ifdef __GNUC__\n #define GNUC_PREREQ(x, y) \\\n (__GNUC__ > x || (__GNUC__ == x && __GNUC_MINOR__ >= y))\n#else\n #define GNUC_PREREQ(x, y) 0\n#endif\n\n#ifdef __clang__\n #define CLANG_PREREQ(x, y) \\\n (__clang_major__ > x || (__clang_major__ == x && __clang_minor__ >= y))\n#else\n #define CLANG_PREREQ(x, y) 0\n#endif\n\n#if (defined(__i386__) || \\\n defined(__x86_64__) || \\\n defined(_M_IX86) || \\\n defined(_M_X64))\n #define X86_OR_X64\n#endif\n\n#if defined(X86_OR_X64) && \\\n (defined(__cplusplus) || \\\n defined(_MSC_VER) || \\\n (GNUC_PREREQ(4, 2) || \\\n STORM_HAS_BUILTIN(__sync_val_compare_and_swap)))\n #define STORM_HAVE_CPUID\n#endif\n\n#if GNUC_PREREQ(4, 2) || \\\n STORM_HAS_BUILTIN(__builtin_popcount)\n #define STORM_HAVE_BUILTIN_POPCOUNT\n#endif\n\n#if GNUC_PREREQ(4, 2) || \\\n CLANG_PREREQ(3, 0)\n #define STORM_HAVE_ASM_POPCNT\n#endif\n\n#if defined(STORM_HAVE_CPUID) && \\\n (defined(STORM_HAVE_ASM_POPCNT) || \\\n defined(_MSC_VER))\n #define STORM_HAVE_POPCNT\n#endif\n\n#if defined(STORM_HAVE_CPUID) && \\\n GNUC_PREREQ(4, 9)\n #define STORM_HAVE_SSE42\n #define STORM_HAVE_AVX2\n#endif\n\n#if defined(STORM_HAVE_CPUID) && \\\n GNUC_PREREQ(5, 0)\n #define STORM_HAVE_AVX512\n#endif\n\n#if defined(STORM_HAVE_CPUID) && \\\n defined(_MSC_VER) && \\\n defined(__AVX2__)\n #define STORM_HAVE_SSE42\n #define STORM_HAVE_AVX2\n#endif\n\n#if defined(STORM_HAVE_CPUID) && \\\n defined(_MSC_VER) && \\\n defined(__AVX512__)\n #define STORM_HAVE_AVX512\n#endif\n\n#if defined(STORM_HAVE_CPUID) && \\\n CLANG_PREREQ(3, 8) && \\\n STORM_HAS_ATTRIBUTE(target) && \\\n (!defined(_MSC_VER) || defined(__AVX2__)) && \\\n (!defined(__apple_build_version__) || __apple_build_version__ >= 8000000)\n #define STORM_HAVE_SSE42\n #define STORM_HAVE_AVX2\n #define STORM_HAVE_AVX512\n#endif\n\n// Target attribute\n#if !defined(_MSC_VER)\n #define STORM_TARGET(x) __attribute__ ((target (x)))\n#else\n #define STORM_TARGET(x) 0\n#endif\n\n\n/****************************\n* CPUID and SIMD\n****************************/\n\n#define STORM_SSE_ALIGNMENT 16\n#define STORM_AVX2_ALIGNMENT 32\n#define STORM_AVX512_ALIGNMENT 64\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\n#if defined(STORM_HAVE_CPUID)\n\n#if defined(_MSC_VER)\n #include <intrin.h>\n #include <immintrin.h>\n#endif\n\n// CPUID flags. See https://en.wikipedia.org/wiki/CPUID for more info.\n/* %ecx bit flags */\n#define STORM_CPUID_runtime_bit_POPCNT (1 << 23) // POPCNT instruction \n#define STORM_CPUID_runtime_bit_SSE41 (1 << 19) // CPUID.01H:ECX.SSE41[Bit 19]\n#define STORM_CPUID_runtime_bit_SSE42 (1 << 20) // CPUID.01H:ECX.SSE41[Bit 20]\n\n/* %ebx bit flags */\n#define STORM_CPUID_runtime_bit_AVX2 (1 << 5) // CPUID.(EAX=07H, ECX=0H):EBX.AVX2[bit 5]\n#define STORM_CPUID_runtime_bit_AVX512BW (1 << 30) // AVX-512 Byte and Word Instructions\n\n/* xgetbv bit flags */\n#define STORM_XSTATE_SSE (1 << 1)\n#define STORM_XSTATE_YMM (1 << 2)\n#define STORM_XSTATE_ZMM (7 << 5)\n\nstatic \nvoid STORM_run_cpuid(int eax, int ecx, int* abcd) {\n#if defined(_MSC_VER)\n __cpuidex(abcd, eax, ecx);\n#else\n int ebx = 0;\n int edx = 0;\n\n#if defined(__i386__) && \\\n defined(__PIC__)\n /* in case of PIC under 32-bit EBX cannot be clobbered */\n __asm__ (\"movl %%ebx, %%edi;\"\n \"cpuid;\"\n \"xchgl %%ebx, %%edi;\"\n : \"=D\" (ebx),\n \"+a\" (eax),\n \"+c\" (ecx),\n \"=d\" (edx));\n#else\n __asm__ (\"cpuid;\"\n : \"+b\" (ebx),\n \"+a\" (eax),\n \"+c\" (ecx),\n \"=d\" (edx));\n#endif\n\n abcd[0] = eax;\n abcd[1] = ebx;\n abcd[2] = ecx;\n abcd[3] = edx;\n#endif\n}\n\n#if defined(STORM_HAVE_AVX2) || \\\n defined(STORM_HAVE_AVX512)\n\nstatic \nint STORM_get_xcr0() {\n int xcr0;\n\n#if defined(_MSC_VER)\n xcr0 = (int) _xgetbv(0);\n#else\n __asm__ (\"xgetbv\" : \"=a\" (xcr0) : \"c\" (0) : \"%edx\" );\n#endif\n\n return xcr0;\n}\n\n#endif\n\nstatic \nint STORM_get_cpuid() {\n int flags = 0;\n int abcd[4];\n\n STORM_run_cpuid(1, 0, abcd);\n\n // Check for POPCNT instruction\n if ((abcd[2] & STORM_CPUID_runtime_bit_POPCNT) == STORM_CPUID_runtime_bit_POPCNT)\n flags |= STORM_CPUID_runtime_bit_POPCNT;\n\n // Check for SSE4.1 instruction set\n if ((abcd[2] & STORM_CPUID_runtime_bit_SSE41) == STORM_CPUID_runtime_bit_SSE41)\n flags |= STORM_CPUID_runtime_bit_SSE41;\n\n // Check for SSE4.2 instruction set\n if ((abcd[2] & STORM_CPUID_runtime_bit_SSE42) == STORM_CPUID_runtime_bit_SSE42)\n flags |= STORM_CPUID_runtime_bit_SSE42;\n\n#if defined(STORM_HAVE_AVX2) || \\\n defined(STORM_HAVE_AVX512)\n\n int osxsave_mask = (1 << 27);\n\n /* ensure OS supports extended processor state management */\n if ((abcd[2] & osxsave_mask) != osxsave_mask)\n return 0;\n\n int ymm_mask = STORM_XSTATE_SSE | STORM_XSTATE_YMM;\n int zmm_mask = STORM_XSTATE_SSE | STORM_XSTATE_YMM | STORM_XSTATE_ZMM;\n\n int xcr0 = STORM_get_xcr0();\n\n if ((xcr0 & ymm_mask) == ymm_mask) {\n STORM_run_cpuid(7, 0, abcd);\n\n if ((abcd[1] & STORM_CPUID_runtime_bit_AVX2) == STORM_CPUID_runtime_bit_AVX2)\n flags |= STORM_CPUID_runtime_bit_AVX2;\n\n if ((xcr0 & zmm_mask) == zmm_mask) {\n if ((abcd[1] & STORM_CPUID_runtime_bit_AVX512BW) == STORM_CPUID_runtime_bit_AVX512BW)\n flags |= STORM_CPUID_runtime_bit_AVX512BW;\n }\n }\n\n#endif\n\n return flags;\n}\n#endif // defined(STORM_HAVE_CPUID)\n\n/// Taken from libpopcnt.h\n#if defined(STORM_HAVE_ASM_POPCNT) && \\\n defined(__x86_64__)\n\nSTORM_FORCE_INLINE\nuint64_t STORM_POPCOUNT(uint64_t x)\n{\n __asm__ (\"popcnt %1, %0\" : \"=r\" (x) : \"0\" (x));\n return x;\n}\n\n#elif defined(STORM_HAVE_ASM_POPCNT) && \\\n defined(__i386__)\n\nSTORM_FORCE_INLINE\nuint32_t STORM_popcnt32(uint32_t x)\n{\n __asm__ (\"popcnt %1, %0\" : \"=r\" (x) : \"0\" (x));\n return x;\n}\n\nSTORM_FORCE_INLINE\nuint64_t STORM_POPCOUNT(uint64_t x)\n{\n return STORM_popcnt32((uint32_t) x) +\n STORM_popcnt32((uint32_t)(x >> 32));\n}\n\n#elif defined(_MSC_VER) && \\\n defined(_M_X64)\n\n#include <nmmintrin.h>\n\nSTORM_FORCE_INLINE\nuint64_t STORM_POPCOUNT(uint64_t x) {\n return _mm_popcnt_u64(x);\n}\n\n#elif defined(_MSC_VER) && \\\n defined(_M_IX86)\n\n#include <nmmintrin.h>\n\nSTORM_FORCE_INLINE\nuint64_t STORM_POPCOUNT(uint64_t x)\n{\n return _mm_popcnt_u32((uint32_t) x) + \n _mm_popcnt_u32((uint32_t)(x >> 32));\n}\n\n/* non x86 CPUs */\n#elif defined(STORM_HAVE_BUILTIN_POPCOUNT)\n\nSTORM_FORCE_INLINE\nuint64_t STORM_POPCOUNT(uint64_t x) {\n return __builtin_popcountll(x);\n}\n\n/* no hardware POPCNT,\n * use pure integer algorithm */\n#else\n\nSTORM_FORCE_INLINE\nuint64_t STORM_POPCOUNT(uint64_t x) {\n return STORM_popcount64(x);\n}\n\n#endif\n\n\nstatic \nuint64_t STORM_intersect_count_unrolled(const uint64_t* STORM_RESTRICT data1, \n const uint64_t* STORM_RESTRICT data2, \n size_t size)\n{\n const uint64_t limit = size - size % 4;\n uint64_t cnt = 0;\n uint64_t i = 0;\n\n for (/**/; i < limit; i += 4) {\n cnt += STORM_POPCOUNT(data1[i+0] & data2[i+0]);\n cnt += STORM_POPCOUNT(data1[i+1] & data2[i+1]);\n cnt += STORM_POPCOUNT(data1[i+2] & data2[i+2]);\n cnt += STORM_POPCOUNT(data1[i+3] & data2[i+3]);\n }\n\n for (/**/; i < size; ++i)\n cnt += STORM_POPCOUNT(data1[i] & data2[i]);\n\n return cnt;\n}\n\nstatic \nuint64_t STORM_union_count_unrolled(const uint64_t* STORM_RESTRICT data1, \n const uint64_t* STORM_RESTRICT data2, \n size_t size)\n{\n const uint64_t limit = size - size % 4;\n uint64_t cnt = 0;\n uint64_t i = 0;\n\n for (/**/; i < limit; i += 4) {\n cnt += STORM_POPCOUNT(data1[i+0] | data2[i+0]);\n cnt += STORM_POPCOUNT(data1[i+1] | data2[i+1]);\n cnt += STORM_POPCOUNT(data1[i+2] | data2[i+2]);\n cnt += STORM_POPCOUNT(data1[i+3] | data2[i+3]);\n }\n\n for (/**/; i < size; ++i)\n cnt += STORM_POPCOUNT(data1[i] | data2[i]);\n\n return cnt;\n}\n\nstatic \nuint64_t STORM_diff_count_unrolled(const uint64_t* STORM_RESTRICT data1, \n const uint64_t* STORM_RESTRICT data2, \n size_t size)\n{\n const uint64_t limit = size - size % 4;\n uint64_t cnt = 0;\n uint64_t i = 0;\n\n for (/**/; i < limit; i += 4) {\n cnt += STORM_POPCOUNT(data1[i+0] ^ data2[i+0]);\n cnt += STORM_POPCOUNT(data1[i+1] ^ data2[i+1]);\n cnt += STORM_POPCOUNT(data1[i+2] ^ data2[i+2]);\n cnt += STORM_POPCOUNT(data1[i+3] ^ data2[i+3]);\n }\n\n for (/**/; i < size; ++i)\n cnt += STORM_POPCOUNT(data1[i] ^ data2[i]);\n\n return cnt;\n}\n\nstatic\nint STORM_pospopcnt_u16_scalar_naive(const uint16_t* data, size_t len, uint32_t* out) {\n for (int i = 0; i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((data[i] & (1 << j)) >> j);\n }\n }\n\n return 0;\n}\n\n#ifndef _MSC_VER\n\nSTORM_FORCE_INLINE\nuint64_t STORM_pospopcnt_umul128(uint64_t a, uint64_t b, uint64_t* hi) {\n unsigned __int128 x = (unsigned __int128)a * (unsigned __int128)b;\n *hi = (uint64_t)(x >> 64);\n return (uint64_t)x;\n}\n\nSTORM_FORCE_INLINE\nuint64_t STORM_pospopcnt_loadu_u64(const void* ptr) {\n uint64_t data;\n memcpy(&data, ptr, sizeof(data));\n return data;\n}\n\n// By @aqrit (https://github.com/aqrit)\n// @see: https://gist.github.com/aqrit/c729815b0165c139d0bac642ab7ee104\nstatic\nint STORM_pospopcnt_u16_scalar_umul128_unroll2(const uint16_t* in, size_t n, uint32_t* out) {\n while (n >= 8) {\n uint64_t counter_a = 0; // 4 packed 12-bit counters\n uint64_t counter_b = 0;\n uint64_t counter_c = 0;\n uint64_t counter_d = 0;\n\n // end before overflowing the counters\n uint32_t len = ((n < 0x0FFF) ? n : 0x0FFF) & ~7;\n n -= len;\n for (const uint16_t* end = &in[len]; in != end; in += 8) {\n const uint64_t mask_a = UINT64_C(0x1111111111111111);\n const uint64_t mask_b = mask_a + mask_a;\n const uint64_t mask_c = mask_b + mask_b;\n const uint64_t mask_0001 = UINT64_C(0x0001000100010001);\n const uint64_t mask_cnts = UINT64_C(0x000000F00F00F00F);\n\n uint64_t v0 = STORM_pospopcnt_loadu_u64(&in[0]);\n uint64_t v1 = STORM_pospopcnt_loadu_u64(&in[4]);\n\n uint64_t a = (v0 & mask_a) + (v1 & mask_a);\n uint64_t b = ((v0 & mask_b) + (v1 & mask_b)) >> 1;\n uint64_t c = ((v0 & mask_c) + (v1 & mask_c)) >> 2;\n uint64_t d = ((v0 >> 3) & mask_a) + ((v1 >> 3) & mask_a);\n\n uint64_t hi;\n a = STORM_pospopcnt_umul128(a, mask_0001, &hi);\n a += hi; // broadcast 4-bit counts\n b = STORM_pospopcnt_umul128(b, mask_0001, &hi);\n b += hi;\n c = STORM_pospopcnt_umul128(c, mask_0001, &hi);\n c += hi;\n d = STORM_pospopcnt_umul128(d, mask_0001, &hi);\n d += hi;\n\n counter_a += a & mask_cnts;\n counter_b += b & mask_cnts;\n counter_c += c & mask_cnts;\n counter_d += d & mask_cnts;\n }\n\n out[0] += counter_a & 0x0FFF;\n out[1] += counter_b & 0x0FFF;\n out[2] += counter_c & 0x0FFF;\n out[3] += counter_d & 0x0FFF;\n out[4] += (counter_a >> 36);\n out[5] += (counter_b >> 36);\n out[6] += (counter_c >> 36);\n out[7] += (counter_d >> 36);\n out[8] += (counter_a >> 24) & 0x0FFF;\n out[9] += (counter_b >> 24) & 0x0FFF;\n out[10] += (counter_c >> 24) & 0x0FFF;\n out[11] += (counter_d >> 24) & 0x0FFF;\n out[12] += (counter_a >> 12) & 0x0FFF;\n out[13] += (counter_b >> 12) & 0x0FFF;\n out[14] += (counter_c >> 12) & 0x0FFF;\n out[15] += (counter_d >> 12) & 0x0FFF;\n }\n\n // assert(n < 8)\n if (n != 0) {\n uint64_t tail_counter_a = 0;\n uint64_t tail_counter_b = 0;\n do { // zero-extend a bit to 8-bits (emulate pdep) then accumulate\n const uint64_t mask_01 = UINT64_C(0x0101010101010101);\n const uint64_t magic = UINT64_C(0x0000040010004001); // 1+(1<<14)+(1<<28)+(1<<42)\n uint64_t x = *in++;\n tail_counter_a += ((x & 0x5555) * magic) & mask_01; // 0101010101010101\n tail_counter_b += (((x >> 1) & 0x5555) * magic) & mask_01;\n } while (--n);\n\n out[0] += tail_counter_a & 0xFF;\n out[8] += (tail_counter_a >> 8) & 0xFF;\n out[2] += (tail_counter_a >> 16) & 0xFF;\n out[10] += (tail_counter_a >> 24) & 0xFF;\n out[4] += (tail_counter_a >> 32) & 0xFF;\n out[12] += (tail_counter_a >> 40) & 0xFF;\n out[6] += (tail_counter_a >> 48) & 0xFF;\n out[14] += (tail_counter_a >> 56) & 0xFF;\n out[1] += tail_counter_b & 0xFF;\n out[9] += (tail_counter_b >> 8) & 0xFF;\n out[3] += (tail_counter_b >> 16) & 0xFF;\n out[11] += (tail_counter_b >> 24) & 0xFF;\n out[5] += (tail_counter_b >> 32) & 0xFF;\n out[13] += (tail_counter_b >> 40) & 0xFF;\n out[7] += (tail_counter_b >> 48) & 0xFF;\n out[15] += (tail_counter_b >> 56) & 0xFF;\n }\n\n return 0;\n}\n#endif\n\n/*\n * This uses fewer arithmetic operations than any other known\n * implementation on machines with fast multiplication.\n * It uses 12 arithmetic operations, one of which is a multiply.\n * http://en.wikipedia.org/wiki/Hamming_weight#Efficient_implementation\n */\nSTORM_FORCE_INLINE\nuint64_t STORM_popcount64(uint64_t x)\n{\n uint64_t m1 = UINT64_C(0x5555555555555555);\n uint64_t m2 = UINT64_C(0x3333333333333333);\n uint64_t m4 = UINT64_C(0x0F0F0F0F0F0F0F0F);\n uint64_t h01 = UINT64_C(0x0101010101010101);\n\n x -= (x >> 1) & m1;\n x = (x & m2) + ((x >> 2) & m2);\n x = (x + (x >> 4)) & m4;\n\n return (x * h01) >> 56;\n}\n\n\nstatic\nconst uint8_t STORM_popcnt_lookup8bit[256] = {\n\t/* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n\t/* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n\t/* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n\t/* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4,\n\t/* 10 */ 1, /* 11 */ 2, /* 12 */ 2, /* 13 */ 3,\n\t/* 14 */ 2, /* 15 */ 3, /* 16 */ 3, /* 17 */ 4,\n\t/* 18 */ 2, /* 19 */ 3, /* 1a */ 3, /* 1b */ 4,\n\t/* 1c */ 3, /* 1d */ 4, /* 1e */ 4, /* 1f */ 5,\n\t/* 20 */ 1, /* 21 */ 2, /* 22 */ 2, /* 23 */ 3,\n\t/* 24 */ 2, /* 25 */ 3, /* 26 */ 3, /* 27 */ 4,\n\t/* 28 */ 2, /* 29 */ 3, /* 2a */ 3, /* 2b */ 4,\n\t/* 2c */ 3, /* 2d */ 4, /* 2e */ 4, /* 2f */ 5,\n\t/* 30 */ 2, /* 31 */ 3, /* 32 */ 3, /* 33 */ 4,\n\t/* 34 */ 3, /* 35 */ 4, /* 36 */ 4, /* 37 */ 5,\n\t/* 38 */ 3, /* 39 */ 4, /* 3a */ 4, /* 3b */ 5,\n\t/* 3c */ 4, /* 3d */ 5, /* 3e */ 5, /* 3f */ 6,\n\t/* 40 */ 1, /* 41 */ 2, /* 42 */ 2, /* 43 */ 3,\n\t/* 44 */ 2, /* 45 */ 3, /* 46 */ 3, /* 47 */ 4,\n\t/* 48 */ 2, /* 49 */ 3, /* 4a */ 3, /* 4b */ 4,\n\t/* 4c */ 3, /* 4d */ 4, /* 4e */ 4, /* 4f */ 5,\n\t/* 50 */ 2, /* 51 */ 3, /* 52 */ 3, /* 53 */ 4,\n\t/* 54 */ 3, /* 55 */ 4, /* 56 */ 4, /* 57 */ 5,\n\t/* 58 */ 3, /* 59 */ 4, /* 5a */ 4, /* 5b */ 5,\n\t/* 5c */ 4, /* 5d */ 5, /* 5e */ 5, /* 5f */ 6,\n\t/* 60 */ 2, /* 61 */ 3, /* 62 */ 3, /* 63 */ 4,\n\t/* 64 */ 3, /* 65 */ 4, /* 66 */ 4, /* 67 */ 5,\n\t/* 68 */ 3, /* 69 */ 4, /* 6a */ 4, /* 6b */ 5,\n\t/* 6c */ 4, /* 6d */ 5, /* 6e */ 5, /* 6f */ 6,\n\t/* 70 */ 3, /* 71 */ 4, /* 72 */ 4, /* 73 */ 5,\n\t/* 74 */ 4, /* 75 */ 5, /* 76 */ 5, /* 77 */ 6,\n\t/* 78 */ 4, /* 79 */ 5, /* 7a */ 5, /* 7b */ 6,\n\t/* 7c */ 5, /* 7d */ 6, /* 7e */ 6, /* 7f */ 7,\n\t/* 80 */ 1, /* 81 */ 2, /* 82 */ 2, /* 83 */ 3,\n\t/* 84 */ 2, /* 85 */ 3, /* 86 */ 3, /* 87 */ 4,\n\t/* 88 */ 2, /* 89 */ 3, /* 8a */ 3, /* 8b */ 4,\n\t/* 8c */ 3, /* 8d */ 4, /* 8e */ 4, /* 8f */ 5,\n\t/* 90 */ 2, /* 91 */ 3, /* 92 */ 3, /* 93 */ 4,\n\t/* 94 */ 3, /* 95 */ 4, /* 96 */ 4, /* 97 */ 5,\n\t/* 98 */ 3, /* 99 */ 4, /* 9a */ 4, /* 9b */ 5,\n\t/* 9c */ 4, /* 9d */ 5, /* 9e */ 5, /* 9f */ 6,\n\t/* a0 */ 2, /* a1 */ 3, /* a2 */ 3, /* a3 */ 4,\n\t/* a4 */ 3, /* a5 */ 4, /* a6 */ 4, /* a7 */ 5,\n\t/* a8 */ 3, /* a9 */ 4, /* aa */ 4, /* ab */ 5,\n\t/* ac */ 4, /* ad */ 5, /* ae */ 5, /* af */ 6,\n\t/* b0 */ 3, /* b1 */ 4, /* b2 */ 4, /* b3 */ 5,\n\t/* b4 */ 4, /* b5 */ 5, /* b6 */ 5, /* b7 */ 6,\n\t/* b8 */ 4, /* b9 */ 5, /* ba */ 5, /* bb */ 6,\n\t/* bc */ 5, /* bd */ 6, /* be */ 6, /* bf */ 7,\n\t/* c0 */ 2, /* c1 */ 3, /* c2 */ 3, /* c3 */ 4,\n\t/* c4 */ 3, /* c5 */ 4, /* c6 */ 4, /* c7 */ 5,\n\t/* c8 */ 3, /* c9 */ 4, /* ca */ 4, /* cb */ 5,\n\t/* cc */ 4, /* cd */ 5, /* ce */ 5, /* cf */ 6,\n\t/* d0 */ 3, /* d1 */ 4, /* d2 */ 4, /* d3 */ 5,\n\t/* d4 */ 4, /* d5 */ 5, /* d6 */ 5, /* d7 */ 6,\n\t/* d8 */ 4, /* d9 */ 5, /* da */ 5, /* db */ 6,\n\t/* dc */ 5, /* dd */ 6, /* de */ 6, /* df */ 7,\n\t/* e0 */ 3, /* e1 */ 4, /* e2 */ 4, /* e3 */ 5,\n\t/* e4 */ 4, /* e5 */ 5, /* e6 */ 5, /* e7 */ 6,\n\t/* e8 */ 4, /* e9 */ 5, /* ea */ 5, /* eb */ 6,\n\t/* ec */ 5, /* ed */ 6, /* ee */ 6, /* ef */ 7,\n\t/* f0 */ 4, /* f1 */ 5, /* f2 */ 5, /* f3 */ 6,\n\t/* f4 */ 5, /* f5 */ 6, /* f6 */ 6, /* f7 */ 7,\n\t/* f8 */ 5, /* f9 */ 6, /* fa */ 6, /* fb */ 7,\n\t/* fc */ 6, /* fd */ 7, /* fe */ 7, /* ff */ 8\n};\n\n/****************************\n* SSE4.1 functions\n****************************/\n\n#if defined(STORM_HAVE_SSE42)\n\n#include <immintrin.h>\n\nSTORM_TARGET(\"sse4.2\")\nSTORM_FORCE_INLINE \nuint64_t STORM_POPCOUNT_SSE(const __m128i n) {\n return(STORM_POPCOUNT(_mm_cvtsi128_si64(n)) + \n STORM_POPCOUNT(_mm_cvtsi128_si64(_mm_unpackhi_epi64(n, n))));\n}\n\nSTORM_TARGET(\"sse4.2\")\nSTORM_FORCE_INLINE \nvoid STORM_CSA128(__m128i* h, __m128i* l, __m128i a, __m128i b, __m128i c) {\n __m128i u = _mm_xor_si128(a, b);\n *h = _mm_or_si128(_mm_and_si128(a, b), _mm_and_si128(u, c));\n *l = _mm_xor_si128(u, c);\n}\n\n/**\n * Carry-save adder update step.\n * @see https://en.wikipedia.org/wiki/Carry-save_adder#Technical_details\n * \n * Steps:\n * 1) U = *L ⊕ B\n * 2) *H = (*L ^ B) | (U ^ C)\n * 3) *L = *L ⊕ B ⊕ C = U ⊕ C\n * \n * B and C are 16-bit staggered registers such that &C - &B = 1.\n * \n * Example usage:\n * pospopcnt_csa_sse(&twosA, &v1, _mm_loadu_si128(data + i + 0), _mm_loadu_si128(data + i + 1));\n * \n * @param h \n * @param l \n * @param b \n * @param c \n */\nSTORM_TARGET(\"sse4.2\")\nSTORM_FORCE_INLINE\nvoid STORM_pospopcnt_csa_sse(__m128i* STORM_RESTRICT h, \n __m128i* STORM_RESTRICT l, \n const __m128i b, \n const __m128i c) \n{\n const __m128i u = _mm_xor_si128(*l, b);\n *h = _mm_or_si128(*l & b, u & c); // shift carry (sc_i).\n *l = _mm_xor_si128(u, c); // partial sum (ps).\n}\n\n// By @aqrit (https://github.com/aqrit)\n// @see: https://gist.github.com/aqrit/cb52b2ac5b7d0dfe9319c09d27237bf3\nSTORM_TARGET(\"sse4.2\")\nstatic\nint STORM_pospopcnt_u16_sse_sad(const uint16_t* data, size_t len, uint32_t* flag_counts) {\n const __m128i zero = _mm_setzero_si128();\n const __m128i mask_lo_byte = _mm_srli_epi16(_mm_cmpeq_epi8(zero, zero), 8);\n const __m128i mask_lo_cnt = _mm_srli_epi16(mask_lo_byte, 2);\n const __m128i mask_bits_a = _mm_set1_epi8(0x41); // 01000001\n const __m128i mask_bits_b = _mm_add_epi8(mask_bits_a, mask_bits_a);\n uint32_t buffer[16];\n\n __m128i counterA = zero;\n __m128i counterB = zero;\n __m128i counterC = zero;\n __m128i counterD = zero;\n\n for (const uint16_t* end = &data[(len & ~31)]; data != end; data += 32) {\n __m128i r0 = _mm_loadu_si128((__m128i*)&data[0]);\n __m128i r1 = _mm_loadu_si128((__m128i*)&data[8]);\n __m128i r2 = _mm_loadu_si128((__m128i*)&data[16]);\n __m128i r3 = _mm_loadu_si128((__m128i*)&data[24]);\n __m128i r4, r5, r6, r7;\n\n // seperate LOBYTE and HIBYTE of each WORD\n // (emulate PSHUFB F,D,B,9,7,5,3,1, E,C,A,8,6,4,2,0)\n r4 = _mm_and_si128(mask_lo_byte, r0);\n r5 = _mm_and_si128(mask_lo_byte, r1);\n r6 = _mm_and_si128(mask_lo_byte, r2);\n r7 = _mm_and_si128(mask_lo_byte, r3);\n r0 = _mm_srli_epi16(r0, 8);\n r1 = _mm_srli_epi16(r1, 8);\n r2 = _mm_srli_epi16(r2, 8);\n r3 = _mm_srli_epi16(r3, 8);\n r0 = _mm_packus_epi16(r0, r4);\n r1 = _mm_packus_epi16(r1, r5);\n r2 = _mm_packus_epi16(r2, r6);\n r3 = _mm_packus_epi16(r3, r7);\n\n // isolate bits to count\n r4 = _mm_and_si128(mask_bits_a, r0);\n r5 = _mm_and_si128(mask_bits_a, r1);\n r6 = _mm_and_si128(mask_bits_a, r2);\n r7 = _mm_and_si128(mask_bits_a, r3);\n\n // horizontal sum of qwords\n r4 = _mm_sad_epu8(r4, zero);\n r5 = _mm_sad_epu8(r5, zero);\n r6 = _mm_sad_epu8(r6, zero);\n r7 = _mm_sad_epu8(r7, zero);\n\n // sum 6-bit counts\n r4 = _mm_add_epi16(r4,r5);\n r4 = _mm_add_epi16(r4,r6);\n r4 = _mm_add_epi16(r4,r7);\n\n // unpack 6-bit counts to 32-bits\n r5 = _mm_and_si128(mask_lo_cnt, r4);\n r4 = _mm_srli_epi16(r4, 6);\n r4 = _mm_packs_epi32(r4, r5);\n\n // accumulate\n counterA = _mm_add_epi32(counterA, r4);\n\n // do it again...\n r4 = _mm_and_si128(mask_bits_b, r0);\n r5 = _mm_and_si128(mask_bits_b, r1);\n r6 = _mm_and_si128(mask_bits_b, r2);\n r7 = _mm_and_si128(mask_bits_b, r3);\n\n r4 = _mm_sad_epu8(r4, zero);\n r5 = _mm_sad_epu8(r5, zero);\n r6 = _mm_sad_epu8(r6, zero);\n r7 = _mm_sad_epu8(r7, zero);\n\n r4 = _mm_add_epi16(r4,r5);\n r4 = _mm_add_epi16(r4,r6);\n r4 = _mm_add_epi16(r4,r7);\n\n r5 = _mm_avg_epu8(zero, r4); // shift right 1\n r5 = _mm_and_si128(r5, mask_lo_cnt);\n r4 = _mm_srli_epi16(r4, 7);\n r4 = _mm_packs_epi32(r4, r5);\n\n counterB = _mm_add_epi32(counterB, r4); // accumulate\n\n // rotate right 4\n r4 = _mm_slli_epi16(r0, 12);\n r5 = _mm_slli_epi16(r1, 12);\n r6 = _mm_slli_epi16(r2, 12);\n r7 = _mm_slli_epi16(r3, 12);\n r0 = _mm_srli_epi16(r0, 4);\n r1 = _mm_srli_epi16(r1, 4);\n r2 = _mm_srli_epi16(r2, 4);\n r3 = _mm_srli_epi16(r3, 4);\n r0 = _mm_or_si128(r0, r4);\n r1 = _mm_or_si128(r1, r5);\n r2 = _mm_or_si128(r2, r6);\n r3 = _mm_or_si128(r3, r7);\n\n // do it again...\n r4 = _mm_and_si128(mask_bits_a, r0);\n r5 = _mm_and_si128(mask_bits_a, r1);\n r6 = _mm_and_si128(mask_bits_a, r2);\n r7 = _mm_and_si128(mask_bits_a, r3);\n\n r4 = _mm_sad_epu8(r4, zero);\n r5 = _mm_sad_epu8(r5, zero);\n r6 = _mm_sad_epu8(r6, zero);\n r7 = _mm_sad_epu8(r7, zero);\n\n r4 = _mm_add_epi16(r4,r5);\n r4 = _mm_add_epi16(r4,r6);\n r4 = _mm_add_epi16(r4,r7);\n\n r5 = _mm_and_si128(mask_lo_cnt, r4);\n r4 = _mm_srli_epi16(r4, 6);\n r4 = _mm_packs_epi32(r4, r5);\n\n counterC = _mm_add_epi32(counterC, r4); // accumulate\n\n // do it again...\n r0 = _mm_and_si128(r0, mask_bits_b);\n r1 = _mm_and_si128(r1, mask_bits_b);\n r2 = _mm_and_si128(r2, mask_bits_b);\n r3 = _mm_and_si128(r3, mask_bits_b);\n\n r0 = _mm_sad_epu8(r0, zero);\n r1 = _mm_sad_epu8(r1, zero);\n r2 = _mm_sad_epu8(r2, zero);\n r3 = _mm_sad_epu8(r3, zero);\n\n r0 = _mm_add_epi16(r0,r1);\n r0 = _mm_add_epi16(r0,r2);\n r0 = _mm_add_epi16(r0,r3);\n\n r1 = _mm_avg_epu8(zero, r0);\n r1 = _mm_and_si128(r1, mask_lo_cnt);\n r0 = _mm_srli_epi16(r0, 7);\n r0 = _mm_packs_epi32(r0, r1);\n\n counterD = _mm_add_epi32(counterD, r0); // accumulate\n }\n\n // transpose then store counters\n __m128i counter_1098 = _mm_unpackhi_epi32(counterA, counterB);\n __m128i counter_76FE = _mm_unpacklo_epi32(counterA, counterB);\n __m128i counter_32BA = _mm_unpacklo_epi32(counterC, counterD);\n __m128i counter_54DC = _mm_unpackhi_epi32(counterC, counterD);\n __m128i counter_7654 = _mm_unpackhi_epi64(counter_54DC, counter_76FE);\n __m128i counter_FEDC = _mm_unpacklo_epi64(counter_54DC, counter_76FE);\n __m128i counter_3210 = _mm_unpackhi_epi64(counter_1098, counter_32BA);\n __m128i counter_BA98 = _mm_unpacklo_epi64(counter_1098, counter_32BA);\n\n \n _mm_storeu_si128((__m128i*)&buffer[0], counter_3210);\n _mm_storeu_si128((__m128i*)&buffer[4], counter_7654);\n _mm_storeu_si128((__m128i*)&buffer[8], counter_BA98);\n _mm_storeu_si128((__m128i*)&buffer[12], counter_FEDC);\n for (int i = 0; i < 16; ++i) flag_counts[i] += buffer[i];\n\n // scalar tail loop\n int tail = len & 31;\n if (tail != 0) {\n uint64_t countsA = 0;\n uint64_t countsB = 0;\n do {\n // zero-extend a bit to 8-bits then accumulate\n // (emulate pdep)\n const uint64_t mask_01 = UINT64_C(0x0101010101010101);// 100000001000000010000000100000001000000010000000100000001\n const uint64_t magic = UINT64_C(0x0000040010004001);// 000000000000001000000000000010000000000000100000000000001\n // 1+(1<<14)+(1<<28)+(1<<42)\n uint64_t x = *data++;\n countsA += ((x & 0x5555) * magic) & mask_01; // 0101010101010101\n countsB += (((x >> 1) & 0x5555) * magic) & mask_01;\n } while (--tail);\n\n // transpose then store counters\n flag_counts[0] += countsA & 0xFF;\n flag_counts[8] += (countsA >> 8) & 0xFF;\n flag_counts[2] += (countsA >> 16) & 0xFF;\n flag_counts[10] += (countsA >> 24) & 0xFF;\n flag_counts[4] += (countsA >> 32) & 0xFF;\n flag_counts[12] += (countsA >> 40) & 0xFF;\n flag_counts[6] += (countsA >> 48) & 0xFF;\n flag_counts[14] += (countsA >> 56) & 0xFF;\n flag_counts[1] += countsB & 0xFF;\n flag_counts[9] += (countsB >> 8) & 0xFF;\n flag_counts[3] += (countsB >> 16) & 0xFF;\n flag_counts[11] += (countsB >> 24) & 0xFF;\n flag_counts[5] += (countsB >> 32) & 0xFF;\n flag_counts[13] += (countsB >> 40) & 0xFF;\n flag_counts[7] += (countsB >> 48) & 0xFF;\n flag_counts[15] += (countsB >> 56) & 0xFF;\n }\n\n return 0;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic\nint STORM_pospopcnt_u16_sse_blend_popcnt_unroll8(const uint16_t* array, size_t len, uint32_t* out) {\n const __m128i* data_vectors = (const __m128i*)(array);\n const uint32_t n_cycles = len / 8;\n\n size_t i = 0;\n for (/**/; i + 8 <= n_cycles; i += 8) {\n#define L(p) __m128i v##p = _mm_loadu_si128(data_vectors+i+p);\n L(0) L(1) L(2) L(3)\n L(4) L(5) L(6) L(7)\n\n#define U0(p,k) __m128i input##p = _mm_or_si128(_mm_and_si128(v##p, _mm_set1_epi16(0x00FF)), _mm_slli_epi16(v##k, 8));\n#define U1(p,k) __m128i input##k = _mm_or_si128(_mm_and_si128(v##p, _mm_set1_epi16(0xFF00)), _mm_srli_epi16(v##k, 8));\n#define U(p, k) U0(p,k) U1(p,k)\n\n U(0,1) U(2,3) U(4,5) U(6,7)\n \n for (int i = 0; i < 8; ++i) {\n#define A0(p) out[ 7 - i] += _mm_popcnt_u32(_mm_movemask_epi8(input##p));\n#define A1(k) out[15 - i] += _mm_popcnt_u32(_mm_movemask_epi8(input##k));\n#define A(p, k) A0(p) A1(k)\n A(0,1) A(2, 3) A(4,5) A(6, 7)\n\n#define P0(p) input##p = _mm_add_epi8(input##p, input##p);\n#define P(p, k) input##p = P0(p) P0(k)\n\n P(0,1) P(2, 3) P(4,5) P(6, 7)\n }\n }\n\n for (/**/; i + 4 <= n_cycles; i += 4) {\n L(0) L(1) L(2) L(3)\n U(0,1) U(2,3)\n \n for (int i = 0; i < 8; ++i) {\n A(0,1) A(2, 3)\n P(0,1) P(2, 3)\n }\n }\n\n for (/**/; i + 2 <= n_cycles; i += 2) {\n L(0) L(1)\n U(0,1)\n \n for (int i = 0; i < 8; ++i) {\n A(0,1)\n P(0,1)\n }\n }\n\n i *= 8;\n for (/**/; i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((array[i] & (1 << j)) >> j);\n }\n }\n\n#undef L\n#undef U0\n#undef U1\n#undef U\n#undef A0\n#undef A1\n#undef A\n#undef P0\n#undef P\n return 0;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic\nint STORM_pospopcnt_u16_sse_harvey_seal(const uint16_t* array, size_t len, uint32_t* out) {\n for (uint32_t i = len - (len % (16 * 8)); i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((array[i] & (1 << j)) >> j);\n }\n }\n\n const __m128i* data = (const __m128i*)array;\n size_t size = len / 8;\n __m128i v1 = _mm_setzero_si128();\n __m128i v2 = _mm_setzero_si128();\n __m128i v4 = _mm_setzero_si128();\n __m128i v8 = _mm_setzero_si128();\n __m128i v16 = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[8];\n __m128i counter[16];\n\n while (i < limit) { \n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_setzero_si128();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm_add_epi16(counter[pos], _mm_and_si128(v16, _mm_set1_epi16(1))); \\\n v16 = _mm_srli_epi16(v16, 1); \\\n}\n STORM_pospopcnt_csa_sse(&twosA, &v1, _mm_loadu_si128(data + i + 0), _mm_loadu_si128(data + i + 1));\n STORM_pospopcnt_csa_sse(&twosB, &v1, _mm_loadu_si128(data + i + 2), _mm_loadu_si128(data + i + 3));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&twosA, &v1, _mm_loadu_si128(data + i + 4), _mm_loadu_si128(data + i + 5));\n STORM_pospopcnt_csa_sse(&twosB, &v1, _mm_loadu_si128(data + i + 6), _mm_loadu_si128(data + i + 7));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&eightsA,&v4, foursA, foursB);\n STORM_pospopcnt_csa_sse(&twosA, &v1, _mm_loadu_si128(data + i + 8), _mm_loadu_si128(data + i + 9));\n STORM_pospopcnt_csa_sse(&twosB, &v1, _mm_loadu_si128(data + i + 10), _mm_loadu_si128(data + i + 11));\n STORM_pospopcnt_csa_sse(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&twosA, &v1, _mm_loadu_si128(data + i + 12), _mm_loadu_si128(data + i + 13));\n STORM_pospopcnt_csa_sse(&twosB, &v1, _mm_loadu_si128(data + i + 14), _mm_loadu_si128(data + i + 15));\n STORM_pospopcnt_csa_sse(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_sse(&eightsB,&v4, foursA, foursB);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n STORM_pospopcnt_csa_sse(&v16, &v8, eightsA, eightsB);\n#undef U\n }\n\n // update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm_add_epi16(counter[i], _mm_and_si128(v16, _mm_set1_epi16(1)));\n v16 = _mm_srli_epi16(v16, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm_storeu_si128((__m128i*)buffer, counter[i]);\n for (size_t z = 0; z < 8; z++) {\n out[i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v1);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm_storeu_si128((__m128i*)buffer, v2);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v4);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm_storeu_si128((__m128i*)buffer, v8);\n for (size_t i = 0; i < 8; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n return 0;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_intersect_count_csa_sse4(const __m128i* STORM_RESTRICT data1, \n const __m128i* STORM_RESTRICT data2, \n size_t size)\n{\n __m128i ones = _mm_setzero_si128();\n __m128i twos = _mm_setzero_si128();\n __m128i fours = _mm_setzero_si128();\n __m128i eights = _mm_setzero_si128();\n __m128i sixteens = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t cnt64 = 0;\n\n#define LOAD(a) (_mm_loadu_si128(&data1[i+a]) & _mm_loadu_si128(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA128(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA128(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA128(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA128(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA128(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA128(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt64 += STORM_POPCOUNT_SSE(sixteens);\n }\n#undef LOAD\n\n cnt64 <<= 4;\n cnt64 += STORM_POPCOUNT_SSE(eights) << 3;\n cnt64 += STORM_POPCOUNT_SSE(fours) << 2;\n cnt64 += STORM_POPCOUNT_SSE(twos) << 1;\n cnt64 += STORM_POPCOUNT_SSE(ones) << 0;\n\n for (/**/; i < size; ++i)\n cnt64 = STORM_POPCOUNT_SSE(_mm_loadu_si128(&data1[i]) & _mm_loadu_si128(&data2[i]));\n\n return cnt64;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_union_count_csa_sse4(const __m128i* STORM_RESTRICT data1, \n const __m128i* STORM_RESTRICT data2, \n size_t size)\n{\n __m128i ones = _mm_setzero_si128();\n __m128i twos = _mm_setzero_si128();\n __m128i fours = _mm_setzero_si128();\n __m128i eights = _mm_setzero_si128();\n __m128i sixteens = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t cnt64 = 0;\n\n#define LOAD(a) (_mm_loadu_si128(&data1[i+a]) | _mm_loadu_si128(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA128(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA128(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA128(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA128(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA128(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA128(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt64 += STORM_POPCOUNT_SSE(sixteens);\n }\n#undef LOAD\n\n cnt64 <<= 4;\n cnt64 += STORM_POPCOUNT_SSE(eights) << 3;\n cnt64 += STORM_POPCOUNT_SSE(fours) << 2;\n cnt64 += STORM_POPCOUNT_SSE(twos) << 1;\n cnt64 += STORM_POPCOUNT_SSE(ones) << 0;\n\n for (/**/; i < size; ++i)\n cnt64 = STORM_POPCOUNT_SSE(_mm_loadu_si128(&data1[i]) | _mm_loadu_si128(&data2[i]));\n\n return cnt64;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_diff_count_csa_sse4(const __m128i* STORM_RESTRICT data1, \n const __m128i* STORM_RESTRICT data2, \n size_t size)\n{\n __m128i ones = _mm_setzero_si128();\n __m128i twos = _mm_setzero_si128();\n __m128i fours = _mm_setzero_si128();\n __m128i eights = _mm_setzero_si128();\n __m128i sixteens = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t cnt64 = 0;\n\n#define LOAD(a) (_mm_loadu_si128(&data1[i+a]) ^ _mm_loadu_si128(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA128(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA128(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA128(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA128(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA128(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA128(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt64 += STORM_POPCOUNT_SSE(sixteens);\n }\n#undef LOAD\n\n cnt64 <<= 4;\n cnt64 += STORM_POPCOUNT_SSE(eights) << 3;\n cnt64 += STORM_POPCOUNT_SSE(fours) << 2;\n cnt64 += STORM_POPCOUNT_SSE(twos) << 1;\n cnt64 += STORM_POPCOUNT_SSE(ones) << 0;\n\n for (/**/; i < size; ++i)\n cnt64 = STORM_POPCOUNT_SSE(_mm_loadu_si128(&data1[i]) ^ _mm_loadu_si128(&data2[i]));\n\n return cnt64;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_popcnt_csa_sse4(const __m128i* STORM_RESTRICT data,\n size_t size)\n{\n __m128i ones = _mm_setzero_si128();\n __m128i twos = _mm_setzero_si128();\n __m128i fours = _mm_setzero_si128();\n __m128i eights = _mm_setzero_si128();\n __m128i sixteens = _mm_setzero_si128();\n __m128i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t cnt64 = 0;\n\n#define LOAD(a) (_mm_loadu_si128(&data[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA128(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA128(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA128(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA128(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA128(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA128(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA128(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA128(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA128(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA128(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt64 += STORM_POPCOUNT_SSE(sixteens);\n }\n#undef LOAD\n\n cnt64 <<= 4;\n cnt64 += STORM_POPCOUNT_SSE(eights) << 3;\n cnt64 += STORM_POPCOUNT_SSE(fours) << 2;\n cnt64 += STORM_POPCOUNT_SSE(twos) << 1;\n cnt64 += STORM_POPCOUNT_SSE(ones) << 0;\n\n for (/**/; i < size; ++i)\n cnt64 = STORM_POPCOUNT_SSE(_mm_loadu_si128(&data[i]));\n\n return cnt64;\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_intersect_count_sse4(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m128i* r1 = (__m128i*)b1;\n const __m128i* r2 = (__m128i*)b2;\n const uint32_t n_cycles = n_ints / 2;\n\n count += STORM_intersect_count_csa_sse4(r1, r2, n_cycles);\n\n for (int i = n_cycles*2; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] & b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_union_count_sse4(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m128i* r1 = (__m128i*)b1;\n const __m128i* r2 = (__m128i*)b2;\n const uint32_t n_cycles = n_ints / 2;\n\n count += STORM_union_count_csa_sse4(r1, r2, n_cycles);\n\n for (int i = n_cycles*2; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] | b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_diff_count_sse4(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m128i* r1 = (__m128i*)b1;\n const __m128i* r2 = (__m128i*)b2;\n const uint32_t n_cycles = n_ints / 2;\n\n count += STORM_diff_count_csa_sse4(r1, r2, n_cycles);\n\n for (int i = n_cycles*2; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] ^ b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"sse4.2\")\nstatic \nuint64_t STORM_popcnt_sse4(const uint64_t* STORM_RESTRICT data, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m128i* r1 = (__m128i*)data;\n const uint32_t n_cycles = n_ints / 2;\n\n count += STORM_popcnt_csa_sse4(r1, n_cycles);\n\n for (int i = n_cycles*2; i < n_ints; ++i) {\n count += STORM_POPCOUNT(data[i]);\n }\n\n return(count);\n}\n#endif\n\n/****************************\n* AVX256 functions\n****************************/\n\n#if defined(STORM_HAVE_AVX2)\n\n#include <immintrin.h>\n\nSTORM_TARGET(\"avx2\")\nSTORM_FORCE_INLINE \nvoid STORM_CSA256(__m256i* h, __m256i* l, __m256i a, __m256i b, __m256i c) {\n __m256i u = _mm256_xor_si256(a, b);\n *h = _mm256_or_si256(_mm256_and_si256(a, b), _mm256_and_si256(u, c));\n *l = _mm256_xor_si256(u, c);\n}\n\nSTORM_TARGET(\"avx2\")\nSTORM_FORCE_INLINE\nvoid STORM_pospopcnt_csa_avx2(__m256i* STORM_RESTRICT h, \n __m256i* STORM_RESTRICT l, \n const __m256i b, \n const __m256i c) \n{\n const __m256i u = _mm256_xor_si256(*l, b);\n *h = _mm256_or_si256(*l & b, u & c);\n *l = _mm256_xor_si256(u, c);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic\nint STORM_pospopcnt_u16_avx2_blend_popcnt_unroll8(const uint16_t* array, size_t len, uint32_t* out) {\n const __m256i* data_vectors = (const __m256i*)(array);\n const uint32_t n_cycles = len / 16;\n\n size_t i = 0;\n for (/**/; i + 8 <= n_cycles; i += 8) {\n#define L(p) __m256i v##p = _mm256_loadu_si256(data_vectors+i+p);\n L(0) L(1) L(2) L(3)\n L(4) L(5) L(6) L(7) \n \n#define U0(p,k) __m256i input##p = _mm256_or_si256(_mm256_and_si256(v##p, _mm256_set1_epi16(0x00FF)), _mm256_slli_epi16(v##k, 8));\n#define U1(p,k) __m256i input##k = _mm256_or_si256(_mm256_and_si256(v##p, _mm256_set1_epi16(0xFF00)), _mm256_srli_epi16(v##k, 8));\n#define U(p, k) U0(p,k) U1(p,k)\n U(0,1) U(2, 3) U(4, 5) U(6, 7)\n \n for (int i = 0; i < 8; ++i) {\n#define A0(p) out[ 7 - i] += _mm_popcnt_u32(_mm256_movemask_epi8(input##p));\n#define A1(k) out[15 - i] += _mm_popcnt_u32(_mm256_movemask_epi8(input##k));\n#define A(p, k) A0(p) A1(k)\n A(0,1) A(2, 3) A(4, 5) A(6, 7)\n\n#define P0(p) input##p = _mm256_add_epi8(input##p, input##p);\n#define P(p, k) input##p = P0(p) P0(k)\n P(0,1) P(2, 3) P(4, 5) P(6, 7)\n }\n }\n\n for (/**/; i + 4 <= n_cycles; i += 4) {\n L(0) L(1) L(2) L(3)\n U(0,1) U(2, 3)\n \n for (int i = 0; i < 8; ++i) {\n A(0,1) A( 2, 3)\n P(0,1) P( 2, 3)\n }\n }\n\n for (/**/; i + 2 <= n_cycles; i += 2) {\n L(0) L(1)\n U(0,1)\n \n for (int i = 0; i < 8; ++i) {\n A(0,1)\n P(0,1)\n }\n }\n\n i *= 16;\n for (/**/; i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((array[i] & (1 << j)) >> j);\n }\n }\n\n#undef L\n#undef U0\n#undef U1\n#undef U\n#undef A0\n#undef A1\n#undef A\n#undef P0\n#undef P\n\n return 0;\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nint STORM_pospopcnt_u16_avx2_harvey_seal(const uint16_t* array, size_t len, uint32_t* out) {\n for (uint32_t i = len - (len % (16 * 16)); i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((array[i] & (1 << j)) >> j);\n }\n }\n\n const __m256i* data = (const __m256i*)array;\n size_t size = len / 16;\n __m256i v1 = _mm256_setzero_si256();\n __m256i v2 = _mm256_setzero_si256();\n __m256i v4 = _mm256_setzero_si256();\n __m256i v8 = _mm256_setzero_si256();\n __m256i v16 = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n const uint64_t limit = size - size % 16;\n uint64_t i = 0;\n uint16_t buffer[16];\n __m256i counter[16];\n const __m256i one = _mm256_set1_epi16(1);\n\n while (i < limit) { \n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_setzero_si256();\n }\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm256_add_epi16(counter[pos], _mm256_and_si256(v16, one)); \\\n v16 = _mm256_srli_epi16(v16, 1); \\\n}\n STORM_pospopcnt_csa_avx2(&twosA, &v1, _mm256_loadu_si256(data + i + 0), _mm256_loadu_si256(data + i + 1));\n STORM_pospopcnt_csa_avx2(&twosB, &v1, _mm256_loadu_si256(data + i + 2), _mm256_loadu_si256(data + i + 3));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&twosA, &v1, _mm256_loadu_si256(data + i + 4), _mm256_loadu_si256(data + i + 5));\n STORM_pospopcnt_csa_avx2(&twosB, &v1, _mm256_loadu_si256(data + i + 6), _mm256_loadu_si256(data + i + 7));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&eightsA,&v4, foursA, foursB);\n STORM_pospopcnt_csa_avx2(&twosA, &v1, _mm256_loadu_si256(data + i + 8), _mm256_loadu_si256(data + i + 9));\n STORM_pospopcnt_csa_avx2(&twosB, &v1, _mm256_loadu_si256(data + i + 10), _mm256_loadu_si256(data + i + 11));\n STORM_pospopcnt_csa_avx2(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&twosA, &v1, _mm256_loadu_si256(data + i + 12), _mm256_loadu_si256(data + i + 13));\n STORM_pospopcnt_csa_avx2(&twosB, &v1, _mm256_loadu_si256(data + i + 14), _mm256_loadu_si256(data + i + 15));\n STORM_pospopcnt_csa_avx2(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx2(&eightsB,&v4, foursA, foursB);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n STORM_pospopcnt_csa_avx2(&v16, &v8, eightsA, eightsB);\n#undef U\n }\n\n // update the counters after the last iteration\n for (size_t i = 0; i < 16; ++i) {\n counter[i] = _mm256_add_epi16(counter[i], _mm256_and_si256(v16, one));\n v16 = _mm256_srli_epi16(v16, 1);\n }\n \n for (size_t i = 0; i < 16; ++i) {\n _mm256_storeu_si256((__m256i*)buffer, counter[i]);\n for (size_t z = 0; z < 16; z++) {\n out[i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v1);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm256_storeu_si256((__m256i*)buffer, v2);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v4);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n _mm256_storeu_si256((__m256i*)buffer, v8);\n for (size_t i = 0; i < 16; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n return 0;\n}\n\n\nSTORM_TARGET(\"avx2\")\nstatic \n__m256i STORM_popcnt256(__m256i v) {\n __m256i lookup1 = _mm256_setr_epi8(\n 4, 5, 5, 6, 5, 6, 6, 7,\n 5, 6, 6, 7, 6, 7, 7, 8,\n 4, 5, 5, 6, 5, 6, 6, 7,\n 5, 6, 6, 7, 6, 7, 7, 8\n );\n\n __m256i lookup2 = _mm256_setr_epi8(\n 4, 3, 3, 2, 3, 2, 2, 1,\n 3, 2, 2, 1, 2, 1, 1, 0,\n 4, 3, 3, 2, 3, 2, 2, 1,\n 3, 2, 2, 1, 2, 1, 1, 0\n );\n\n __m256i low_mask = _mm256_set1_epi8(0x0f);\n __m256i lo = _mm256_and_si256(v, low_mask);\n __m256i hi = _mm256_and_si256(_mm256_srli_epi16(v, 4), low_mask);\n __m256i popcnt1 = _mm256_shuffle_epi8(lookup1, lo);\n __m256i popcnt2 = _mm256_shuffle_epi8(lookup2, hi);\n\n return _mm256_sad_epu8(popcnt1, popcnt2);\n}\n\n// modified from https://github.com/WojciechMula/sse-popcount\nSTORM_TARGET(\"avx2\")\nstatic\nuint64_t STORM_intersect_count_lookup_avx2_func(const uint8_t* STORM_RESTRICT data1, \n const uint8_t* STORM_RESTRICT data2, \n const size_t n)\n{\n\n size_t i = 0;\n\n const __m256i lookup = _mm256_setr_epi8(\n /* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n /* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n /* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n /* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4,\n\n /* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n /* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n /* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n /* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4\n );\n\n const __m256i low_mask = _mm256_set1_epi8(0x0f);\n\n __m256i acc = _mm256_setzero_si256();\n\n#define ITER { \\\n const __m256i vec = _mm256_and_si256(_mm256_loadu_si256((const __m256i*)(data1 + i)), \\\n _mm256_loadu_si256((const __m256i*)(data2 + i))); \\\n const __m256i lo = _mm256_and_si256(vec, low_mask); \\\n const __m256i hi = _mm256_and_si256(_mm256_srli_epi16(vec, 4), low_mask); \\\n const __m256i popcnt1 = _mm256_shuffle_epi8(lookup, lo); \\\n const __m256i popcnt2 = _mm256_shuffle_epi8(lookup, hi); \\\n local = _mm256_add_epi8(local, popcnt1); \\\n local = _mm256_add_epi8(local, popcnt2); \\\n i += 32; \\\n }\n\n while (i + 8*32 <= n) {\n __m256i local = _mm256_setzero_si256();\n ITER ITER ITER ITER\n ITER ITER ITER ITER\n acc = _mm256_add_epi64(acc, _mm256_sad_epu8(local, _mm256_setzero_si256()));\n }\n\n __m256i local = _mm256_setzero_si256();\n\n while (i + 32 <= n) {\n ITER;\n }\n\n acc = _mm256_add_epi64(acc, _mm256_sad_epu8(local, _mm256_setzero_si256()));\n\n#undef ITER\n\n uint64_t result = 0;\n\n result += (uint64_t)(_mm256_extract_epi64(acc, 0));\n result += (uint64_t)(_mm256_extract_epi64(acc, 1));\n result += (uint64_t)(_mm256_extract_epi64(acc, 2));\n result += (uint64_t)(_mm256_extract_epi64(acc, 3));\n\n for (/**/; i < n; ++i) {\n result += STORM_popcnt_lookup8bit[data1[i] & data2[i]];\n }\n\n return result;\n}\n\n// modified from https://github.com/WojciechMula/sse-popcount\nSTORM_TARGET(\"avx2\")\nstatic\nuint64_t STORM_union_count_lookup_avx2_func(const uint8_t* STORM_RESTRICT data1, \n const uint8_t* STORM_RESTRICT data2, \n const size_t n)\n {\n\n size_t i = 0;\n\n const __m256i lookup = _mm256_setr_epi8(\n /* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n /* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n /* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n /* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4,\n\n /* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n /* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n /* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n /* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4\n );\n\n const __m256i low_mask = _mm256_set1_epi8(0x0f);\n\n __m256i acc = _mm256_setzero_si256();\n\n#define ITER { \\\n const __m256i vec = _mm256_or_si256(_mm256_loadu_si256((const __m256i*)(data1 + i)), \\\n _mm256_loadu_si256((const __m256i*)(data2 + i))); \\\n const __m256i lo = _mm256_and_si256(vec, low_mask); \\\n const __m256i hi = _mm256_and_si256(_mm256_srli_epi16(vec, 4), low_mask); \\\n const __m256i popcnt1 = _mm256_shuffle_epi8(lookup, lo); \\\n const __m256i popcnt2 = _mm256_shuffle_epi8(lookup, hi); \\\n local = _mm256_add_epi8(local, popcnt1); \\\n local = _mm256_add_epi8(local, popcnt2); \\\n i += 32; \\\n }\n\n while (i + 8*32 <= n) {\n __m256i local = _mm256_setzero_si256();\n ITER ITER ITER ITER\n ITER ITER ITER ITER\n acc = _mm256_add_epi64(acc, _mm256_sad_epu8(local, _mm256_setzero_si256()));\n }\n\n __m256i local = _mm256_setzero_si256();\n\n while (i + 32 <= n) {\n ITER;\n }\n\n acc = _mm256_add_epi64(acc, _mm256_sad_epu8(local, _mm256_setzero_si256()));\n\n#undef ITER\n\n uint64_t result = 0;\n\n result += (uint64_t)(_mm256_extract_epi64(acc, 0));\n result += (uint64_t)(_mm256_extract_epi64(acc, 1));\n result += (uint64_t)(_mm256_extract_epi64(acc, 2));\n result += (uint64_t)(_mm256_extract_epi64(acc, 3));\n\n for (/**/; i < n; ++i) {\n result += STORM_popcnt_lookup8bit[data1[i] | data2[i]];\n }\n\n return result;\n}\n\n// modified from https://github.com/WojciechMula/sse-popcount\nSTORM_TARGET(\"avx2\")\nstatic\nuint64_t STORM_diff_count_lookup_avx2_func(const uint8_t* STORM_RESTRICT data1, \n const uint8_t* STORM_RESTRICT data2, \n const size_t n)\n{\n\n size_t i = 0;\n\n const __m256i lookup = _mm256_setr_epi8(\n /* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n /* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n /* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n /* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4,\n\n /* 0 */ 0, /* 1 */ 1, /* 2 */ 1, /* 3 */ 2,\n /* 4 */ 1, /* 5 */ 2, /* 6 */ 2, /* 7 */ 3,\n /* 8 */ 1, /* 9 */ 2, /* a */ 2, /* b */ 3,\n /* c */ 2, /* d */ 3, /* e */ 3, /* f */ 4\n );\n\n const __m256i low_mask = _mm256_set1_epi8(0x0f);\n\n __m256i acc = _mm256_setzero_si256();\n\n#define ITER { \\\n const __m256i vec = _mm256_xor_si256(_mm256_loadu_si256((const __m256i*)(data1 + i)), \\\n _mm256_loadu_si256((const __m256i*)(data2 + i))); \\\n const __m256i lo = _mm256_and_si256(vec, low_mask); \\\n const __m256i hi = _mm256_and_si256(_mm256_srli_epi16(vec, 4), low_mask); \\\n const __m256i popcnt1 = _mm256_shuffle_epi8(lookup, lo); \\\n const __m256i popcnt2 = _mm256_shuffle_epi8(lookup, hi); \\\n local = _mm256_add_epi8(local, popcnt1); \\\n local = _mm256_add_epi8(local, popcnt2); \\\n i += 32; \\\n }\n\n while (i + 8*32 <= n) {\n __m256i local = _mm256_setzero_si256();\n ITER ITER ITER ITER\n ITER ITER ITER ITER\n acc = _mm256_add_epi64(acc, _mm256_sad_epu8(local, _mm256_setzero_si256()));\n }\n\n __m256i local = _mm256_setzero_si256();\n\n while (i + 32 <= n) {\n ITER;\n }\n\n acc = _mm256_add_epi64(acc, _mm256_sad_epu8(local, _mm256_setzero_si256()));\n\n#undef ITER\n\n uint64_t result = 0;\n\n result += (uint64_t)(_mm256_extract_epi64(acc, 0));\n result += (uint64_t)(_mm256_extract_epi64(acc, 1));\n result += (uint64_t)(_mm256_extract_epi64(acc, 2));\n result += (uint64_t)(_mm256_extract_epi64(acc, 3));\n\n for (/**/; i < n; ++i) {\n result += STORM_popcnt_lookup8bit[data1[i] ^ data2[i]];\n }\n\n return result;\n}\n\nSTORM_TARGET(\"avx2\")\nstatic\nuint64_t STORM_popcnt_csa_avx2(const __m256i* data, uint64_t size)\n{\n __m256i cnt = _mm256_setzero_si256();\n __m256i ones = _mm256_setzero_si256();\n __m256i twos = _mm256_setzero_si256();\n __m256i fours = _mm256_setzero_si256();\n __m256i eights = _mm256_setzero_si256();\n __m256i sixteens = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm256_loadu_si256(&data[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA256(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA256(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA256(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA256(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA256(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA256(&sixteens, &eights, eights, eightsA, eightsB);\n\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(sixteens));\n }\n#undef LOAD\n\n cnt = _mm256_slli_epi64(cnt, 4);\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(eights), 3));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(fours), 2));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(twos), 1));\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(data[i]));\n\n cnt64 = (uint64_t*) &cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3];\n}\n\n\n/*\n * AVX2 Harley-Seal popcount (4th iteration).\n * The algorithm is based on the paper \"Faster Population Counts\n * using AVX2 Instructions\" by Daniel Lemire, Nathan Kurz and\n * Wojciech Mula (23 Nov 2016).\n * @see https://arxiv.org/abs/1611.07612\n */\n// In this version we perform the operation A&B as input into the CSA operator.\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_intersect_count_csa_avx2(const __m256i* STORM_RESTRICT data1, \n const __m256i* STORM_RESTRICT data2, \n size_t size)\n{\n __m256i cnt = _mm256_setzero_si256();\n __m256i ones = _mm256_setzero_si256();\n __m256i twos = _mm256_setzero_si256();\n __m256i fours = _mm256_setzero_si256();\n __m256i eights = _mm256_setzero_si256();\n __m256i sixteens = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm256_loadu_si256(&data1[i+a]) & _mm256_loadu_si256(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA256(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA256(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA256(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA256(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA256(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA256(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(sixteens));\n }\n#undef LOAD\n\n cnt = _mm256_slli_epi64(cnt, 4);\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(eights), 3));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(fours), 2));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(twos), 1));\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(_mm256_loadu_si256(&data1[i]) & _mm256_loadu_si256(&data2[i])));\n\n cnt64 = (uint64_t*) &cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3];\n}\n\n// In this version we perform the operation A|B as input into the CSA operator.\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_union_count_csa_avx2(const __m256i* STORM_RESTRICT data1, \n const __m256i* STORM_RESTRICT data2, \n size_t size)\n{\n __m256i cnt = _mm256_setzero_si256();\n __m256i ones = _mm256_setzero_si256();\n __m256i twos = _mm256_setzero_si256();\n __m256i fours = _mm256_setzero_si256();\n __m256i eights = _mm256_setzero_si256();\n __m256i sixteens = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm256_loadu_si256(&data1[i+a]) | _mm256_loadu_si256(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA256(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA256(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA256(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA256(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA256(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA256(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(sixteens));\n }\n#undef LOAD\n\n cnt = _mm256_slli_epi64(cnt, 4);\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(eights), 3));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(fours), 2));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(twos), 1));\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(_mm256_loadu_si256(&data1[i]) | _mm256_loadu_si256(&data2[i])));\n\n cnt64 = (uint64_t*) &cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3];\n}\n\n// In this version we perform the operation A^B as input into the CSA operator.\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_diff_count_csa_avx2(const __m256i* STORM_RESTRICT data1, \n const __m256i* STORM_RESTRICT data2, \n size_t size)\n{\n __m256i cnt = _mm256_setzero_si256();\n __m256i ones = _mm256_setzero_si256();\n __m256i twos = _mm256_setzero_si256();\n __m256i fours = _mm256_setzero_si256();\n __m256i eights = _mm256_setzero_si256();\n __m256i sixteens = _mm256_setzero_si256();\n __m256i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm256_loadu_si256(&data1[i+a]) ^ _mm256_loadu_si256(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA256(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA256(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA256(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA256(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA256(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA256(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA256(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA256(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA256(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA256(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(sixteens));\n }\n#undef LOAD\n\n cnt = _mm256_slli_epi64(cnt, 4);\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(eights), 3));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(fours), 2));\n cnt = _mm256_add_epi64(cnt, _mm256_slli_epi64(STORM_popcnt256(twos), 1));\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm256_add_epi64(cnt, STORM_popcnt256(_mm256_loadu_si256(&data1[i]) ^ _mm256_loadu_si256(&data2[i])));\n\n cnt64 = (uint64_t*) &cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3];\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_intersect_count_avx2(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n uint64_t count = 0;\n const __m256i* r1 = (__m256i*)b1;\n const __m256i* r2 = (__m256i*)b2;\n const uint32_t n_cycles = n_ints / 4;\n\n count += STORM_intersect_count_csa_avx2(r1, r2, n_cycles);\n\n for (int i = n_cycles*4; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] & b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_union_count_avx2(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n uint64_t count = 0;\n const __m256i* r1 = (__m256i*)b1;\n const __m256i* r2 = (__m256i*)b2;\n const uint32_t n_cycles = n_ints / 4;\n\n count += STORM_union_count_csa_avx2(r1, r2, n_cycles);\n\n for (int i = n_cycles*4; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] | b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_diff_count_avx2(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n uint64_t count = 0;\n const __m256i* r1 = (__m256i*)b1;\n const __m256i* r2 = (__m256i*)b2;\n const uint32_t n_cycles = n_ints / 4;\n\n count += STORM_diff_count_csa_avx2(r1, r2, n_cycles);\n\n for (int i = n_cycles*4; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] ^ b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_intersect_count_lookup_avx2(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n return STORM_intersect_count_lookup_avx2_func((uint8_t*)b1, (uint8_t*)b2, n_ints*8);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_union_count_lookup_avx2(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n return STORM_union_count_lookup_avx2_func((uint8_t*)b1, (uint8_t*)b2, n_ints*8);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_diff_count_lookup_avx2(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n return STORM_diff_count_lookup_avx2_func((uint8_t*)b1, (uint8_t*)b2, n_ints*8);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_popcnt_avx2(const uint64_t* data, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const uint32_t n_cycles = n_ints / 4;\n const uint32_t n_cycles_sse = (n_ints % 4) / 2;\n\n const __m256i* r1 = (__m256i*)&data[0];\n const __m128i* r2 = (__m128i*)&data[n_cycles_sse*4];\n\n count += STORM_popcnt_csa_avx2(r1, n_cycles);\n count += STORM_popcnt_csa_sse4(r2, n_cycles_sse);\n\n for (int i = (4*n_cycles + 2*n_cycles_sse); i < n_ints; ++i) {\n count += STORM_POPCOUNT(data[i]);\n }\n\n return count;\n}\n#endif\n\n/****************************\n* AVX512BW functions\n****************************/\n\n#if defined(STORM_HAVE_AVX512)\n\n#include <immintrin.h>\n\nSTORM_TARGET(\"avx512bw\")\nSTORM_FORCE_INLINE \n__m512i STORM_popcnt512(__m512i v) {\n __m512i m1 = _mm512_set1_epi8(0x55);\n __m512i m2 = _mm512_set1_epi8(0x33);\n __m512i m4 = _mm512_set1_epi8(0x0F);\n __m512i t1 = _mm512_sub_epi8(v, (_mm512_srli_epi16(v, 1) & m1));\n __m512i t2 = _mm512_add_epi8(t1 & m2, (_mm512_srli_epi16(t1, 2) & m2));\n __m512i t3 = _mm512_add_epi8(t2, _mm512_srli_epi16(t2, 4)) & m4;\n\n return _mm512_sad_epu8(t3, _mm512_setzero_si512());\n}\n\nSTORM_TARGET(\"avx512bw\")\nSTORM_FORCE_INLINE \nvoid STORM_CSA512(__m512i* h, __m512i* l, __m512i a, __m512i b, __m512i c) {\n *l = _mm512_ternarylogic_epi32(c, b, a, 0x96);\n *h = _mm512_ternarylogic_epi32(c, b, a, 0xe8);\n}\n\n// By Wojciech Muła\n// @see https://github.com/WojciechMula/sse-popcount/blob/master/popcnt-avx512-harley-seal.cpp#L3\n// @see https://arxiv.org/abs/1611.07612\nSTORM_TARGET(\"avx512bw\")\nSTORM_FORCE_INLINE\n__m512i STORM_avx512_popcount(const __m512i v) {\n const __m512i m1 = _mm512_set1_epi8(0x55); // 01010101\n const __m512i m2 = _mm512_set1_epi8(0x33); // 00110011\n const __m512i m4 = _mm512_set1_epi8(0x0F); // 00001111\n\n const __m512i t1 = _mm512_sub_epi8(v, (_mm512_srli_epi16(v, 1) & m1));\n const __m512i t2 = _mm512_add_epi8(t1 & m2, (_mm512_srli_epi16(t1, 2) & m2));\n const __m512i t3 = _mm512_add_epi8(t2, _mm512_srli_epi16(t2, 4)) & m4;\n return _mm512_sad_epu8(t3, _mm512_setzero_si512());\n}\n\n// 512i-version of carry-save adder subroutine.\nSTORM_TARGET(\"avx512bw\")\nSTORM_FORCE_INLINE\nvoid STORM_pospopcnt_csa_avx512(__m512i* STORM_RESTRICT h, \n __m512i* STORM_RESTRICT l, \n __m512i b, __m512i c) \n{\n *h = _mm512_ternarylogic_epi32(c, b, *l, 0xE8); // 11101000\n *l = _mm512_ternarylogic_epi32(c, b, *l, 0x96); // 10010110\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_popcnt_csa_avx512bw(const __m512i* STORM_RESTRICT data, size_t size)\n{\n __m512i cnt = _mm512_setzero_si512();\n __m512i ones = _mm512_setzero_si512();\n __m512i twos = _mm512_setzero_si512();\n __m512i fours = _mm512_setzero_si512();\n __m512i eights = _mm512_setzero_si512();\n __m512i sixteens = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm512_loadu_si512(&data[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA512(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA512(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA512(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA512(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA512(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA512(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(sixteens));\n }\n#undef LOAD\n\n cnt = _mm512_slli_epi64(cnt, 4);\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(eights), 3));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(fours), 2));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(twos), 1));\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(_mm512_loadu_si512(&data[i])));\n\n cnt64 = (uint64_t*)&cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3] +\n cnt64[4] +\n cnt64[5] +\n cnt64[6] +\n cnt64[7];\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint STORM_pospopcnt_u16_avx512bw_harvey_seal(const uint16_t* array, size_t len, uint32_t* out) {\n for (uint32_t i = len - (len % (32 * 16)); i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((array[i] & (1 << j)) >> j);\n }\n }\n\n const __m512i* data = (const __m512i*)array;\n __m512i v1 = _mm512_setzero_si512();\n __m512i v2 = _mm512_setzero_si512();\n __m512i v4 = _mm512_setzero_si512();\n __m512i v8 = _mm512_setzero_si512();\n __m512i v16 = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n __m512i one = _mm512_set1_epi16(1);\n __m512i counter[16];\n\n const size_t size = len / 32;\n const uint64_t limit = size - size % 16;\n\n uint16_t buffer[32];\n\n uint64_t i = 0;\n while (i < limit) {\n for (size_t i = 0; i < 16; ++i)\n counter[i] = _mm512_setzero_si512();\n\n size_t thislimit = limit;\n if (thislimit - i >= (1 << 16))\n thislimit = i + (1 << 16) - 1;\n\n for (/**/; i < thislimit; i += 16) {\n#define U(pos) { \\\n counter[pos] = _mm512_add_epi16(counter[pos], _mm512_and_si512(v16, _mm512_set1_epi16(1))); \\\n v16 = _mm512_srli_epi16(v16, 1); \\\n}\n STORM_pospopcnt_csa_avx512(&twosA, &v1, _mm512_loadu_si512(data + i + 0), _mm512_loadu_si512(data + i + 1));\n STORM_pospopcnt_csa_avx512(&twosB, &v1, _mm512_loadu_si512(data + i + 2), _mm512_loadu_si512(data + i + 3));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&twosA, &v1, _mm512_loadu_si512(data + i + 4), _mm512_loadu_si512(data + i + 5));\n STORM_pospopcnt_csa_avx512(&twosB, &v1, _mm512_loadu_si512(data + i + 6), _mm512_loadu_si512(data + i + 7));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&eightsA, &v4, foursA, foursB);\n STORM_pospopcnt_csa_avx512(&twosA, &v1, _mm512_loadu_si512(data + i + 8), _mm512_loadu_si512(data + i + 9));\n STORM_pospopcnt_csa_avx512(&twosB, &v1, _mm512_loadu_si512(data + i + 10), _mm512_loadu_si512(data + i + 11));\n STORM_pospopcnt_csa_avx512(&foursA, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&twosA, &v1, _mm512_loadu_si512(data + i + 12), _mm512_loadu_si512(data + i + 13));\n STORM_pospopcnt_csa_avx512(&twosB, &v1, _mm512_loadu_si512(data + i + 14), _mm512_loadu_si512(data + i + 15));\n STORM_pospopcnt_csa_avx512(&foursB, &v2, twosA, twosB);\n STORM_pospopcnt_csa_avx512(&eightsB, &v4, foursA, foursB);\n U(0) U(1) U(2) U(3) U(4) U(5) U(6) U(7) U(8) U(9) U(10) U(11) U(12) U(13) U(14) U(15) // Updates\n STORM_pospopcnt_csa_avx512(&v16, &v8, eightsA, eightsB);\n }\n // Update the counters after the last iteration.\n for (size_t i = 0; i < 16; ++i) U(i)\n#undef U\n \n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)buffer, counter[i]);\n for (size_t z = 0; z < 32; z++) {\n out[i] += 16 * (uint32_t)buffer[z];\n }\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v1);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 1 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v2);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 2 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n \n _mm512_storeu_si512((__m512i*)buffer, v4);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 4 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n _mm512_storeu_si512((__m512i*)buffer, v8);\n for (size_t i = 0; i < 32; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += 8 * ((buffer[i] & (1 << j)) >> j);\n }\n }\n\n return 0;\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic \nint STORM_pospopcnt_u16_avx512bw_blend_popcnt_unroll8(const uint16_t* data, size_t len, uint32_t* out) { \n#define AND_OR 0xea // ternary function: (a & b) | c\n const __m512i* data_vectors = (const __m512i*)(data);\n const uint32_t n_cycles = len / 32;\n\n size_t i = 0;\n for (/**/; i + 8 <= n_cycles; i += 8) {\n#define L(p) __m512i v##p = _mm512_loadu_si512(data_vectors+i+p);\n L(0) L(1) L(2) L(3) \n L(4) L(5) L(6) L(7) \n\n#define U0(p,k) __m512i input##p = _mm512_ternarylogic_epi32(v##p, _mm512_set1_epi16(0x00FF), _mm512_slli_epi16(v##k, 8), AND_OR);\n#define U1(p,k) __m512i input##k = _mm512_ternarylogic_epi32(v##p, _mm512_set1_epi16(0xFF00), _mm512_srli_epi16(v##k, 8), AND_OR);\n#define U(p, k) U0(p,k) U1(p,k)\n\n U(0,1) U( 2, 3) U( 4, 5) U( 6, 7)\n \n for (int i = 0; i < 8; ++i) {\n#define A0(p) out[ 7 - i] += _mm_popcnt_u64(_mm512_movepi8_mask(input##p));\n#define A1(k) out[15 - i] += _mm_popcnt_u64(_mm512_movepi8_mask(input##k));\n#define A(p, k) A0(p) A1(k)\n A(0,1) A(2, 3) A(4,5) A(6, 7)\n\n#define P0(p) input##p = _mm512_add_epi8(input##p, input##p);\n#define P(p, k) input##p = P0(p) P0(k)\n\n P(0,1) P(2, 3) P(4,5) P(6, 7)\n }\n }\n\n for (/**/; i + 4 <= n_cycles; i += 4) {\n L(0) L(1) L(2) L(3)\n U(0,1) U(2,3)\n \n for (int i = 0; i < 8; ++i) {\n A(0,1) A(2, 3)\n P(0,1) P(2, 3)\n }\n }\n\n for (/**/; i + 2 <= n_cycles; i += 2) {\n L(0) L(1)\n U(0,1)\n \n for (int i = 0; i < 8; ++i) {\n A(0,1)\n P(0,1)\n }\n }\n\n i *= 32;\n for (/**/; i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((data[i] & (1 << j)) >> j);\n }\n }\n\n#undef L\n#undef U0\n#undef U1\n#undef U\n#undef A0\n#undef A1\n#undef A\n#undef P0\n#undef P\n#undef AND_OR\n \n return 0;\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic\nint STORM_pospopcnt_u16_avx512bw_adder_forest(const uint16_t* array, size_t len, uint32_t* out) {\n __m512i counters[16];\n\n for (size_t i = 0; i < 16; ++i) {\n counters[i] = _mm512_setzero_si512();\n }\n\n const __m512i mask1bit = _mm512_set1_epi16(0x5555); // 0101010101010101 Pattern: 01\n const __m512i mask2bit = _mm512_set1_epi16(0x3333); // 0011001100110011 Pattern: 0011\n const __m512i mask4bit = _mm512_set1_epi16(0x0F0F); // 0000111100001111 Pattern: 00001111\n const __m512i mask8bit = _mm512_set1_epi16(0x00FF); // 0000000011111111 Pattern: 0000000011111111\n \n const uint32_t n_cycles = len / (2048 * (16*32));\n const uint32_t n_total = len / (16*32);\n uint16_t tmp[32];\n\n/*------ Macros --------*/\n#define LE(i,p,k) const __m512i sum##p##k##_##i##bit_even = _mm512_add_epi8(input##p & mask##i##bit, input##k & mask##i##bit);\n#define LO(i,p,k) const __m512i sum##p##k##_##i##bit_odd = _mm512_add_epi8(_mm512_srli_epi16(input##p, i) & mask##i##bit, _mm512_srli_epi16(input##k, i) & mask##i##bit);\n\n#define LBLOCK(i) \\\n LE(i,0,1) LO(i,0,1) \\\n LE(i,2,3) LO(i,2,3) \\\n LE(i,4,5) LO(i,4,5) \\\n LE(i,6,7) LO(i,6,7) \\\n LE(i,8,9) LO(i,8,9) \\\n LE(i,10,11) LO(i,10,11) \\\n LE(i,12,13) LO(i,12,13) \\\n LE(i,14,15) LO(i,14,15) \\\n\n#define EVEN(b,i,k,p) input##i = sum##k##p##_##b##bit_even;\n#define ODD(b,i,k,p) input##i = sum##k##p##_##b##bit_odd;\n\n#define UPDATE(i) \\\n EVEN(i,0,0,1) EVEN(i,1,2,3) EVEN(i,2,4,5) EVEN(i,3,6,7) \\\n EVEN(i,4,8,9) EVEN(i,5,10,11) EVEN(i,6,12,13) EVEN(i,7,14,15) \\\n ODD(i,8,0,1) ODD(i,9,2,3) ODD(i,10,4,5) ODD(i,11,6,7) \\\n ODD(i,12,8,9) ODD(i,13,10,11) ODD(i,14,12,13) ODD(i,15,14,15) \\\n\n#define UE(i,p,k) counters[i] = _mm512_add_epi16(counters[i], sum##p##k##_8bit_even);\n#define UO(i,p,k) counters[i] = _mm512_add_epi16(counters[i], sum##p##k##_8bit_odd);\n\n/*------ Start --------*/\n#define L(p) __m512i input##p = _mm512_loadu_si512((__m512i*)(array + i*2048*512 + j*512 + p*32));\n size_t i = 0;\n for (/**/; i < n_cycles; ++i) {\n for (int j = 0; j < 2048; ++j) {\n // Load 16 registers.\n L(0) L(1) L(2) L(3) \n L(4) L(5) L(6) L(7) \n L(8) L(9) L(10) L(11) \n L(12) L(13) L(14) L(15)\n\n // Perform updates for bits {1,2,4,8}.\n LBLOCK(1) UPDATE(1)\n LBLOCK(2) UPDATE(2)\n LBLOCK(4) UPDATE(4)\n LBLOCK(8) UPDATE(8)\n\n // Update accumulators.\n UE( 0,0,1) UE( 1, 2, 3) UE( 2, 4, 5) UE( 3, 6, 7) \n UE( 4,8,9) UE( 5,10,11) UE( 6,12,13) UE( 7,14,15) \n UO( 8,0,1) UO( 9, 2, 3) UO(10, 4, 5) UO(11, 6, 7) \n UO(12,8,9) UO(13,10,11) UO(14,12,13) UO(15,14,15)\n }\n\n // Update.\n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)tmp, counters[i]);\n for (int j = 0; j < 32; ++j) out[i] += tmp[j];\n }\n // Reset.\n for (size_t i = 0; i < 16; ++i) {\n counters[i] = _mm512_setzero_si512();\n }\n }\n#undef L\n#define L(p) __m512i input##p = _mm512_loadu_si512((__m512i*)(array + i*512 + p*32));\n i *= 2048;\n for (/**/; i < n_total; ++i) {\n // Load 16 registers.\n L(0) L(1) L(2) L(3) \n L(4) L(5) L(6) L(7) \n L(8) L(9) L(10) L(11) \n L(12) L(13) L(14) L(15)\n\n // Perform updates for bits {1,2,4,8}.\n LBLOCK(1) UPDATE(1)\n LBLOCK(2) UPDATE(2)\n LBLOCK(4) UPDATE(4)\n LBLOCK(8) UPDATE(8)\n\n // Update accumulators.\n UE( 0,0,1) UE( 1, 2, 3) UE( 2, 4, 5) UE( 3, 6, 7) \n UE( 4,8,9) UE( 5,10,11) UE( 6,12,13) UE( 7,14,15) \n UO( 8,0,1) UO( 9, 2, 3) UO(10, 4, 5) UO(11, 6, 7) \n UO(12,8,9) UO(13,10,11) UO(14,12,13) UO(15,14,15)\n }\n\n i *= 512;\n for (/**/; i < len; ++i) {\n for (int j = 0; j < 16; ++j) {\n out[j] += ((array[i] & (1 << j)) >> j);\n }\n }\n\n#undef L\n#undef UPDATE\n#undef ODD\n#undef EVEN\n#undef LBLOCK\n#undef LE\n#undef LO\n#undef UO\n#undef UE\n\n for (size_t i = 0; i < 16; ++i) {\n _mm512_storeu_si512((__m512i*)tmp, counters[i]);\n for (int j = 0; j < 32; ++j) out[i] += tmp[j];\n }\n return 0;\n}\n\n/*\n * AVX512 Harley-Seal popcount (4th iteration).\n * The algorithm is based on the paper \"Faster Population Counts\n * using AVX2 Instructions\" by Daniel Lemire, Nathan Kurz and\n * Wojciech Mula (23 Nov 2016).\n * @see https://arxiv.org/abs/1611.07612\n */\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_intersect_count_csa_avx512(const __m512i* STORM_RESTRICT data1, \n const __m512i* STORM_RESTRICT data2, \n size_t size)\n{\n __m512i cnt = _mm512_setzero_si512();\n __m512i ones = _mm512_setzero_si512();\n __m512i twos = _mm512_setzero_si512();\n __m512i fours = _mm512_setzero_si512();\n __m512i eights = _mm512_setzero_si512();\n __m512i sixteens = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm512_loadu_si512(&data1[i+a]) & _mm512_loadu_si512(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA512(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA512(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA512(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA512(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA512(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA512(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(sixteens));\n }\n#undef LOAD\n\n cnt = _mm512_slli_epi64(cnt, 4);\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(eights), 3));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(fours), 2));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(twos), 1));\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(_mm512_loadu_si512(&data1[i]) & _mm512_loadu_si512(&data2[i])));\n\n cnt64 = (uint64_t*)&cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3] +\n cnt64[4] +\n cnt64[5] +\n cnt64[6] +\n cnt64[7];\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_union_count_csa_avx512(const __m512i* STORM_RESTRICT data1, \n const __m512i* STORM_RESTRICT data2, \n size_t size)\n{\n __m512i cnt = _mm512_setzero_si512();\n __m512i ones = _mm512_setzero_si512();\n __m512i twos = _mm512_setzero_si512();\n __m512i fours = _mm512_setzero_si512();\n __m512i eights = _mm512_setzero_si512();\n __m512i sixteens = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm512_loadu_si512(&data1[i+a]) | _mm512_loadu_si512(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA512(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA512(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA512(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA512(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA512(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA512(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(sixteens));\n }\n#undef LOAD\n\n cnt = _mm512_slli_epi64(cnt, 4);\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(eights), 3));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(fours), 2));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(twos), 1));\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(_mm512_loadu_si512(&data1[i]) | _mm512_loadu_si512(&data2[i])));\n\n cnt64 = (uint64_t*)&cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3] +\n cnt64[4] +\n cnt64[5] +\n cnt64[6] +\n cnt64[7];\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_diff_count_csa_avx512(const __m512i* STORM_RESTRICT data1, \n const __m512i* STORM_RESTRICT data2, \n size_t size)\n{\n __m512i cnt = _mm512_setzero_si512();\n __m512i ones = _mm512_setzero_si512();\n __m512i twos = _mm512_setzero_si512();\n __m512i fours = _mm512_setzero_si512();\n __m512i eights = _mm512_setzero_si512();\n __m512i sixteens = _mm512_setzero_si512();\n __m512i twosA, twosB, foursA, foursB, eightsA, eightsB;\n\n uint64_t i = 0;\n uint64_t limit = size - size % 16;\n uint64_t* cnt64;\n\n#define LOAD(a) (_mm512_loadu_si512(&data1[i+a]) ^ _mm512_loadu_si512(&data2[i+a]))\n\n for (/**/; i < limit; i += 16) {\n STORM_CSA512(&twosA, &ones, ones, LOAD(0), LOAD(1));\n STORM_CSA512(&twosB, &ones, ones, LOAD(2), LOAD(3));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(4), LOAD(5));\n STORM_CSA512(&twosB, &ones, ones, LOAD(6), LOAD(7));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsA, &fours, fours, foursA, foursB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(8), LOAD(9));\n STORM_CSA512(&twosB, &ones, ones, LOAD(10), LOAD(11));\n STORM_CSA512(&foursA, &twos, twos, twosA, twosB);\n STORM_CSA512(&twosA, &ones, ones, LOAD(12), LOAD(13));\n STORM_CSA512(&twosB, &ones, ones, LOAD(14), LOAD(15));\n STORM_CSA512(&foursB, &twos, twos, twosA, twosB);\n STORM_CSA512(&eightsB, &fours, fours, foursA, foursB);\n STORM_CSA512(&sixteens,&eights, eights,eightsA,eightsB);\n\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(sixteens));\n }\n#undef LOAD\n\n cnt = _mm512_slli_epi64(cnt, 4);\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(eights), 3));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(fours), 2));\n cnt = _mm512_add_epi64(cnt, _mm512_slli_epi64(STORM_popcnt512(twos), 1));\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(ones));\n\n for (/**/; i < size; ++i)\n cnt = _mm512_add_epi64(cnt, STORM_popcnt512(_mm512_loadu_si512(&data1[i]) ^ _mm512_loadu_si512(&data2[i])));\n\n cnt64 = (uint64_t*)&cnt;\n\n return cnt64[0] +\n cnt64[1] +\n cnt64[2] +\n cnt64[3] +\n cnt64[4] +\n cnt64[5] +\n cnt64[6] +\n cnt64[7];\n}\n\n// Functions\n// AVX512\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_intersect_count_avx512(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m512i* r1 = (const __m512i*)(b1);\n const __m512i* r2 = (const __m512i*)(b2);\n const uint32_t n_cycles = n_ints / 8;\n\n count += STORM_intersect_count_csa_avx512(r1, r2, n_cycles);\n\n for (int i = n_cycles*8; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] & b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_union_count_avx512(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m512i* r1 = (const __m512i*)(b1);\n const __m512i* r2 = (const __m512i*)(b2);\n const uint32_t n_cycles = n_ints / 8;\n\n count += STORM_union_count_csa_avx512(r1, r2, n_cycles);\n\n for (int i = n_cycles*8; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] | b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"avx512bw\")\nstatic \nuint64_t STORM_diff_count_avx512(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const __m512i* r1 = (const __m512i*)(b1);\n const __m512i* r2 = (const __m512i*)(b2);\n const uint32_t n_cycles = n_ints / 8;\n\n count += STORM_diff_count_csa_avx512(r1, r2, n_cycles);\n\n for (int i = n_cycles*8; i < n_ints; ++i) {\n count += STORM_POPCOUNT(b1[i] ^ b2[i]);\n }\n\n return(count);\n}\n\nSTORM_TARGET(\"avx2\")\nstatic \nuint64_t STORM_popcnt_avx512(const uint64_t* data, \n const size_t n_ints) \n{\n uint64_t count = 0;\n const uint32_t n_cycles = n_ints / 8;\n const uint32_t n_cycles_avx2 = (n_ints % 8) / 4;\n const uint32_t n_cycles_sse = ((n_ints % 8) % 4) / 2;\n\n const __m512i* r1 = (__m512i*)&data[0];\n const __m256i* r2 = (__m256i*)&data[n_cycles*8];\n const __m128i* r3 = (__m128i*)&data[n_cycles*8+n_cycles_avx2*4];\n\n count += STORM_popcnt_csa_avx512bw(r1, n_cycles);\n count += STORM_popcnt_csa_avx2(r2, n_cycles_avx2);\n count += STORM_popcnt_csa_sse4(r3, n_cycles_sse);\n\n for (int i = (8*n_cycles + 4*n_cycles + 2*n_cycles_sse); i < n_ints; ++i) {\n count += STORM_POPCOUNT(data[i]);\n }\n\n return count;\n}\n#endif\n\n/****************************\n* Popcount\n****************************/\n\nSTORM_FORCE_INLINE\nuint64_t STORM_popcount64_unrolled(const uint64_t* data, size_t size) {\n uint64_t i = 0;\n uint64_t limit = size - size % 4;\n uint64_t cnt = 0;\n\n for (/**/; i < limit; i += 4) {\n cnt += STORM_popcount64(data[i+0]);\n cnt += STORM_popcount64(data[i+1]);\n cnt += STORM_popcount64(data[i+2]);\n cnt += STORM_popcount64(data[i+3]);\n }\n\n for (/**/; i < size; ++i)\n cnt += STORM_popcount64(data[i]);\n\n return cnt;\n}\n\n/****************************\n* Scalar functions\n****************************/\n\nSTORM_FORCE_INLINE \nuint64_t STORM_intersect_count_scalar(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n return STORM_intersect_count_unrolled(b1, b2, n_ints);\n}\n\nSTORM_FORCE_INLINE \nuint64_t STORM_union_count_scalar(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n return STORM_union_count_unrolled(b1, b2, n_ints);\n}\n\nSTORM_FORCE_INLINE \nuint64_t STORM_diff_count_scalar(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const size_t n_ints)\n{\n return STORM_diff_count_unrolled(b1, b2, n_ints);\n}\n\nstatic\nuint64_t STORM_intersect_count_scalar_list(const uint64_t* STORM_RESTRICT b1, \n const uint64_t* STORM_RESTRICT b2, \n const uint32_t* STORM_RESTRICT l1, \n const uint32_t* STORM_RESTRICT l2,\n const size_t n1, \n const size_t n2) \n{\n uint64_t count = 0;\n\n#define MOD(x) (( (x) * 64 ) >> 6)\n if (n1 < n2) {\n for (int i = 0; i < n1; ++i)\n count += ((b2[l1[i] >> 6] & (1L << MOD(l1[i]))) != 0);\n } else {\n for (int i = 0; i < n2; ++i)\n count += ((b1[l2[i] >> 6] & (1L << MOD(l2[i]))) != 0);\n }\n#undef MOD\n return(count);\n}\n\n\n/* *************************************\n* Function pointer definitions.\n***************************************/\ntypedef uint64_t (*STORM_compute_func)(const uint64_t*, const uint64_t*, const size_t);\ntypedef int (STORM_pposcnt_func)(const uint16_t*, size_t, uint32_t*);\ntypedef uint64_t (STORM_popcnt_func)(const uint8_t*, size_t);\n\n/* *************************************\n* Alignment \n***************************************/\n// Return the best alignment given the available instruction set at\n// run-time.\nstatic \nuint32_t STORM_get_alignment() {\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n uint32_t alignment = 0;\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW)) { // 16*512\n alignment = STORM_AVX512_ALIGNMENT;\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && alignment == 0) { // 16*256\n alignment = STORM_AVX2_ALIGNMENT;\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && alignment == 0) { // 16*128\n alignment = STORM_SSE_ALIGNMENT;\n }\n#endif\n\n if (alignment == 0) alignment = 8;\n return alignment;\n}\n\n/* *************************************\n* Set algebra functions\n***************************************/\n// Return the optimal intersection function given the range [0, n_bitmaps_vector)\n// and the available instruction set at run-time.\nstatic\nSTORM_compute_func STORM_get_intersect_count_func(const size_t n_bitmaps_vector) {\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_bitmaps_vector >= 128) { // 16*512\n return &STORM_intersect_count_avx512;\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_bitmaps_vector >= 64) { // 16*256\n return &STORM_intersect_count_avx2;\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_bitmaps_vector >= 4) {\n return &STORM_intersect_count_lookup_avx2;\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && n_bitmaps_vector >= 32) { // 16*128\n return &STORM_intersect_count_sse4;\n }\n#endif\n\n return &STORM_intersect_count_scalar;\n}\n\nstatic\nSTORM_compute_func STORM_get_union_count_func(const size_t n_bitmaps_vector) {\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_bitmaps_vector >= 128) { // 16*512\n return &STORM_union_count_avx512;\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_bitmaps_vector >= 64) { // 16*256\n return &STORM_union_count_avx2;\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_bitmaps_vector >= 4) {\n return &STORM_union_count_lookup_avx2;\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && n_bitmaps_vector >= 32) { // 16*128\n return &STORM_union_count_sse4;\n }\n#endif\n\n return &STORM_union_count_scalar;\n}\n\nstatic\nSTORM_compute_func STORM_get_diff_count_func(const size_t n_bitmaps_vector) {\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_bitmaps_vector >= 128) { // 16*512\n return &STORM_diff_count_avx512;\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_bitmaps_vector >= 64) { // 16*256\n return &STORM_diff_count_avx2;\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_bitmaps_vector >= 4) {\n return &STORM_diff_count_lookup_avx2;\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && n_bitmaps_vector >= 32) { // 16*128\n return &STORM_diff_count_sse4;\n }\n#endif\n\n return &STORM_diff_count_scalar;\n}\n\n// real\n// Return the optimal intersection function given the range [0, n_bitmaps_vector)\n// and the available instruction set at run-time.\nstatic\nuint64_t STORM_intersect_count(const uint64_t* STORM_RESTRICT data1, \n const uint64_t* STORM_RESTRICT data2, \n const size_t n_len)\n{\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_len >= 128) { // 16*512\n return STORM_intersect_count_avx512(data1, data2, n_len);\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 64) { // 16*256\n return STORM_intersect_count_avx2(data1, data2, n_len);\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 4) {\n return STORM_intersect_count_lookup_avx2(data1, data2, n_len);\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && n_len >= 32) { // 16*128\n return STORM_intersect_count_sse4(data1, data2, n_len);\n }\n#endif\n\n return STORM_intersect_count_scalar(data1, data2, n_len);\n}\n\nstatic\nuint64_t STORM_union_count(const uint64_t* STORM_RESTRICT data1, \n const uint64_t* STORM_RESTRICT data2, \n const size_t n_len)\n{\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_len >= 128) { // 16*512\n return STORM_union_count_avx512(data1, data2, n_len);\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 64) { // 16*256\n return STORM_union_count_avx2(data1, data2, n_len);\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 4) {\n return STORM_union_count_lookup_avx2(data1, data2, n_len);\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && n_len >= 32) { // 16*128\n return STORM_union_count_sse4(data1, data2, n_len);\n }\n#endif\n\n return STORM_union_count_scalar(data1, data2, n_len);\n}\n\nstatic\nuint64_t STORM_diff_count(const uint64_t* STORM_RESTRICT data1, \n const uint64_t* STORM_RESTRICT data2, \n const size_t n_len)\n{\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) && n_len >= 128) { // 16*512\n return STORM_diff_count_avx512(data1, data2, n_len);\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 64) { // 16*256\n return STORM_diff_count_avx2(data1, data2, n_len);\n }\n \n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) && n_len >= 4) {\n return STORM_diff_count_lookup_avx2(data1, data2, n_len);\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE41) && n_len >= 32) { // 16*128\n return STORM_diff_count_sse4(data1, data2, n_len);\n }\n#endif\n\n return STORM_diff_count_scalar(data1, data2, n_len);\n}\n\n/* *************************************\n* POPCNT and POSPOPCNT functions.\n***************************************/\nstatic\nuint64_t STORM_popcnt(const uint8_t* data, size_t size) {\n uint64_t cnt = 0;\n uint64_t i;\n // size /= 8;\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n#if defined(STORM_HAVE_AVX512)\n\n /* AVX512 requires arrays >= 1024 bytes */\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW) &&\n size >= 1024)\n {\n // cnt += STORM_popcnt_avx512((const __m512i*)data, size / 64);\n // data += size - size % 64;\n // size = size % 64;\n cnt += STORM_popcnt_avx512((uint64_t*)data, size/8);\n data += size - size % 8;\n size = size % 8;\n }\n\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n\n /* AVX2 requires arrays >= 512 bytes */\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2) &&\n size >= 512)\n {\n cnt += STORM_popcnt_avx2((uint64_t*)data, size/8);\n data += size - size % 8;\n size = size % 8;\n // data += size - size % 32;\n // size = size % 32;\n }\n\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n\n /* AVX2 requires arrays >= 512 bytes */\n if ((cpuid & STORM_CPUID_runtime_bit_SSE42) &&\n size >= 256)\n {\n cnt += STORM_popcnt_sse4((uint64_t*)data, size/8);\n data += size - size % 8;\n size = size % 8;\n // data += size - size % 32;\n // size = size % 32;\n }\n\n#endif\n\n#if defined(STORM_HAVE_POPCNT)\n\n if (cpuid & STORM_CPUID_runtime_bit_POPCNT) {\n cnt += STORM_popcount64_unrolled((const uint64_t*)data, size / 8);\n data += size - size % 8;\n size = size % 8;\n for (i = 0; i < size; ++i)\n cnt += STORM_popcount64(data[i]);\n\n return cnt;\n }\n\n#endif\n\n /* pure integer popcount algorithm */\n if (size >= 8) {\n cnt += STORM_popcount64_unrolled((const uint64_t*)data, size / 8);\n data += size - size % 8;\n size = size % 8;\n }\n\n /* pure integer popcount algorithm */\n for (i = 0; i < size; ++i)\n cnt += STORM_popcount64(data[i]);\n\n return cnt;\n}\n\nstatic\nint STORM_pospopcnt_u16(const uint16_t* data, size_t len, uint32_t* out) {\n memset(out, 0, sizeof(uint32_t)*16);\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n#if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW))\n {\n if (len < 32) return(STORM_pospopcnt_u16_sse_sad(data, len, out)); // small\n else if (len < 256) return(STORM_pospopcnt_u16_sse_blend_popcnt_unroll8(data, len, out)); // small\n else if (len < 512) return(STORM_pospopcnt_u16_avx512bw_blend_popcnt_unroll8(data, len, out)); // medium\n else if (len < 4096) return(STORM_pospopcnt_u16_avx512bw_adder_forest(data, len, out)); // medium3\n else return(STORM_pospopcnt_u16_avx512bw_harvey_seal(data, len, out)); // fix\n }\n#endif\n\n#if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2))\n {\n if (len < 128) return(STORM_pospopcnt_u16_sse_sad(data, len, out)); // small\n else if (len < 1024) return(STORM_pospopcnt_u16_avx2_blend_popcnt_unroll8(data, len, out)); // medium\n else return(STORM_pospopcnt_u16_avx2_harvey_seal(data, len, out)); // large\n }\n#endif\n\n#if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE42))\n {\n return(STORM_pospopcnt_u16_sse_harvey_seal(data, len, out));\n }\n#endif\n\n#ifndef _MSC_VER\n return(STORM_pospopcnt_u16_scalar_umul128_unroll2(data, len, out)); // fallback scalar\n#else\n return(STORM_pospopcnt_u16_scalar_naive(data, len, out));\n#endif\n}\n\n#ifdef __cplusplus\n} /* extern \"C\" */\n#endif\n\n#endif /* LIBALGEBRA_H_8723467365934 */\n"
},
{
"alpha_fraction": 0.44218888878822327,
"alphanum_fraction": 0.5083848237991333,
"avg_line_length": 23.630434036254883,
"blob_id": "cc5724d256ca4802fd082979202e2ed4efe58ee4",
"content_id": "472b1b8193ffc2686e00fe38aef8e484212335f1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1133,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 46,
"path": "/paper/scripts/avx512.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "def word2byte_array(array):\n assert len(array) == 32\n res = []\n for word in array:\n assert word >= 0\n assert word <= 0xffff\n res.append(word & 0xff)\n res.append(word >> 8)\n\n return res\n\n\ndef avx512_dwords(array):\n assert len(array) == 64\n dwords = []\n for i in range(0, 64, 4):\n b0 = array[i + 0]\n b1 = array[i + 1]\n b2 = array[i + 2]\n b3 = array[i + 3]\n\n dword = (b3 << 24) | (b2 << 16) | (b1 << 8) | b0\n dwords.append(dword)\n\n return dwords\n\n\nindent = ' ' * 4\n\ndef avx512_const(array):\n dwords = avx512_dwords(array)\n lo = ', '.join('0x%08x' % v for v in dwords[:8])\n hi = ', '.join('0x%08x' % v for v in dwords[8:])\n\n return f\"_mm512_setr_epi32(\\n{indent}{lo},\\n{indent}{hi}\\n);\"\n\n\ndef avx512_var(name, array):\n dwords = avx512_dwords(array)\n lo = ', '.join('0x%08x' % v for v in dwords[:8])\n hi = ', '.join('0x%08x' % v for v in dwords[8:])\n\n return f\"{indent}const __m512i {name} = _mm512_setr_epi32(\\n\" \\\n f\"{indent}{indent}{lo},\\n\" \\\n f\"{indent}{indent}{hi}\\n\" \\\n f\"{indent});\"\n"
},
{
"alpha_fraction": 0.4806157350540161,
"alphanum_fraction": 0.5518814325332642,
"avg_line_length": 32.730770111083984,
"blob_id": "bc726fb4195a4168b82943d6cab4dfb7fdfb279e",
"content_id": "428dfdd5e7c3cdd7afb2ac5c4ba7c0a0c6786c8b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1754,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 52,
"path": "/paper/scripts/expand_data.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\ndef bit12(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & FPROPER_PAIR\n\ndef bit13(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & FMUNMAP\n\ndef bit14(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & (~FMUNMAP)\n\nprint(\" # | MNUNMAP | FUNMAP | FPROPER_PAIR | FPAIRED || bit #12 | bit #13 | bit #14 | pshufb word\")\nprint(\"---+---------+--------+--------------+---------++---------+---------+---------+-------------\")\n\npshufb_values = []\nvpshufb_values = []\nfor k in range(16):\n FPAIRED = int(k & 0x01 != 0)\n FPROPER_PAIR = int(k & 0x02 != 0)\n FUNMAP = int(k & 0x04 != 0)\n FMUNMAP = int(k & 0x08 != 0)\n\n b12 = bit12(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n b13 = bit13(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n b14 = bit14(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n \n pshufb = (b12 << 4) | (b13 << 5) | (b14 << 6)\n pshufb_values.append(pshufb)\n vpshufb_values.append(0)\n vpshufb_values.append(pshufb)\n\n print(f\"{k:^3x}|{FMUNMAP:^9}|{FUNMAP:^8}|{FPROPER_PAIR:^14}|{FPAIRED:^9}||{b12:^9}|{b13:^9}|{b14:^9}| 0x{pshufb:02x}\")\n\nvpshufb_values.extend([0] * 32) # the upper half is 0, as we use only 4 lower bits\n\nprint(\"pshufb: %s\" % (', '.join(f'0x{x:02x}' for x in pshufb_values)),)\n\ndef avx512_const(array):\n assert len(array) == 64\n dwords = []\n for i in range(0, 64, 4):\n b0 = array[i + 0]\n b1 = array[i + 1]\n b2 = array[i + 2]\n b3 = array[i + 3]\n\n dword = (b3 << 24) | (b2 << 16) | (b1 << 8) | b0\n dwords.append(dword)\n\n return \"_mm512_setr_epi32(%s)\" % ', '.join('0x%08x' % v for v in dwords)\n\nprint(avx512_const(vpshufb_values))\n"
},
{
"alpha_fraction": 0.46930232644081116,
"alphanum_fraction": 0.5767441987991333,
"avg_line_length": 35.440677642822266,
"blob_id": "206f90ea131099d896953c5859782be0d04e0eb9",
"content_id": "830be08fe2dcbcf1e98005e223ab9fbb11f5b532",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2150,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 59,
"path": "/paper/scripts/expand_data3.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom avx512 import *\n\nAVX512_BIT12_FQCFAIL_0 = 0\nAVX512_BIT12_FQCFAIL_1 = 1\nAVX512_BIT13_FQCFAIL_0 = 2\nAVX512_BIT13_FQCFAIL_1 = 3\nAVX512_BIT14_FQCFAIL_0 = 4\nAVX512_BIT14_FQCFAIL_1 = 5\nAVX512_FREAD1_FQCFAIL_0 = 6\nAVX512_FREAD1_FQCFAIL_1 = 8\nAVX512_FREAD2_FQCFAIL_0 = 7\nAVX512_FREAD2_FQCFAIL_1 = 9\nAVX512_FSECONDARY_FQCFAIL_0 = 10\nAVX512_FSECONDARY_FQCFAIL_1 = 11\nAVX512_FSUPPLEMENTARY_FQCFAIL_0 = 14\nAVX512_FSUPPLEMENTARY_FQCFAIL_1 = 15\nAVX512_FDUP_FQCFAIL_0 = 12\nAVX512_FDUP_FQCFAIL_1 = 13\n\ndef bit12(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & FPROPER_PAIR\n\ndef bit13(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & FMUNMAP\n\ndef bit14(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP):\n return FPAIRED & (~FUNMAP) & (~FMUNMAP)\n\nprint(\" # | MNUNMAP | FUNMAP | FPROPER_PAIR | FPAIRED || bit #12 | bit #13 | bit #14 | pshufw word\")\nprint(\"---+---------+--------+--------------+---------++---------+---------+---------+-------------\")\n\nvpshufb_values = []\nfor k in range(16):\n FPAIRED = int(k & 0x01 != 0)\n FPROPER_PAIR = int(k & 0x02 != 0)\n FUNMAP = int(k & 0x04 != 0)\n FMUNMAP = int(k & 0x08 != 0)\n\n b12 = bit12(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n b13 = bit13(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n b14 = bit14(FPAIRED, FPROPER_PAIR, FUNMAP, FMUNMAP) & 0x01\n\n word = (b12 << AVX512_BIT12_FQCFAIL_0) \\\n | (b12 << AVX512_BIT12_FQCFAIL_1) \\\n | (b13 << AVX512_BIT13_FQCFAIL_0) \\\n | (b13 << AVX512_BIT13_FQCFAIL_1) \\\n | (b14 << AVX512_BIT14_FQCFAIL_0) \\\n | (b14 << AVX512_BIT14_FQCFAIL_1) \\\n | (FPAIRED << 12) \\\n | (FUNMAP << 9)\n\n vpshufb_values.append(word & 0xff)\n vpshufb_values.append(word >> 8)\n\n print(f\"{k:^3x}|{FMUNMAP:^9}|{FUNMAP:^8}|{FPROPER_PAIR:^14}|{FPAIRED:^9}||{b12:^9}|{b13:^9}|{b14:^9}| 0x{word:04x}\")\n\nvpshufb_values.extend(vpshufb_values[:]) # the upper half must be the same as lower one\nprint(avx512_const(vpshufb_values))\n"
},
{
"alpha_fraction": 0.6217345595359802,
"alphanum_fraction": 0.7439916133880615,
"avg_line_length": 31.457626342773438,
"blob_id": "15b7b71b2cf8b4cd0bfba8227198d728f7ae7a3f",
"content_id": "6cc13b418d883080da472e41cebb7175e7d53773",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1914,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 59,
"path": "/python/README.md",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "# pyflagstats\n\n[](https://badge.fury.io/py/pyflagstats)\n\nGiven a stream of k-bit words, we seek to sum the bit values at indexes 0, 1, 2,\n..., k-1 across multiple words by computing k distinct sums. If the k-bit words\nare one-hot encoded then the sums corresponds to their frequencies.\n\nThis multiple-sum problem is a generalization of the population-count problem\nwhere we count the total number of set bits in independent machine words. We\nrefer to this new problem as the positional population-count problem.\n\nUsing SIMD (Single Instruction, Multiple Data) instructions from recent Intel\nprocessors, we describe algorithms for computing the 16-bit position population\ncount using about one eighth (0.125) of a CPU cycle per 16-bit word. Our best\napproach is about 140-fold faster than competitive code using only non-SIMD\ninstructions in terms of CPU cycles.\n\nThis package contains native Python bindings for the applying the efficient\npositional population count operator to computing summary statistics for the SAM\nFLAG field\n\n## Intallation\n\nInstall with\n```bash\npip3 install .\n```\n\nor locally with\n```bash\npython3 setup.py build_ext --inplace\n```\n\nUninstall with\n```bash\npip3 uninstall pyflagstats\n```\n\n## Example\n\n```python\nimport numpy as np\nimport pyflagstats as fs\n\n# Compute summary statistics for 100 million random FLAG fields.\n# Completes in around 1 second.\nfs.flagstats(np.random.randint(0,8192,100000000,dtype=\"uint16\"))\n```\n\nreturns (for example)\n\n```\n{'passed': array([ 624787, 312748, 2500089, 312384, 312314, 312678, 312045,\n 311845, 2499502, 4999279, 2497500, 1248979, 389744, 156194,\n 156029, 0], dtype=uint32), 'failed': array([ 625143, 312906, 2498840, 312818, 312129, 312802, 311869,\n 312105, 2501477, 5000721, 2499178, 1249105, 390962, 155828,\n 156018, 0], dtype=uint32)}\n```"
},
{
"alpha_fraction": 0.538222074508667,
"alphanum_fraction": 0.5688166618347168,
"avg_line_length": 36.31150817871094,
"blob_id": "39a8f863a4d564c8195d088c8e5bff30120bdd8f",
"content_id": "0a5eebdd37caa47fc0ff8d3d63c9cc551549e388",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 35333,
"license_type": "permissive",
"max_line_length": 215,
"num_lines": 947,
"path": "/benchmark/flagstats.cpp",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "/*\n* Copyright (c) 2019\n* Author(s): Marcus D. R. Klarqvist\n*\n* Licensed under the Apache License, Version 2.0 (the \"License\");\n* you may not use this file except in compliance with the License.\n* You may obtain a copy of the License at\n*\n* http://www.apache.org/licenses/LICENSE-2.0\n*\n* Unless required by applicable law or agreed to in writing,\n* software distributed under the License is distributed on an\n* \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n* KIND, either express or implied. See the License for the\n* specific language governing permissions and limitations\n* under the License.\n*/\n\n#include <cstring> // memcpy\n#include <stdio.h> // For printf()\n#include <string.h> // For memcmp()\n#include <stdlib.h> // For exit()\n#include <getopt.h> // options\n\n#include <string>\n#include <iostream>\n#include <fstream>\n#include <cassert>\n#include <chrono>//timer\n\n#include <unistd.h>//sync\n#include <bitset>\n\n#include \"lz4.h\" // lz4\n#include \"lz4hc.h\"\n#include \"zstd.h\" // zstd\n// #include \"zstd_errors.h\"\n#include \"libalgebra.h\" // pospopcnt\n#include \"libflagstats.h\" // flagstats\n\n// samtools count flagstat different:\n// https://github.com/samtools/samtools/blob/master/bam_stat.c#L47\ntypedef struct {\n long long n_reads[2], n_mapped[2], n_pair_all[2], n_pair_map[2], n_pair_good[2];\n long long n_sgltn[2], n_read1[2], n_read2[2];\n long long n_dup[2];\n long long n_diffchr[2], n_diffhigh[2];\n long long n_secondary[2], n_supp[2];\n} bam_flagstat_t;\n\n#define flagstat_loop(s, c) do { \\\n int w = (c & FLAGSTAT_FQCFAIL)? 1 : 0; \\\n ++(s)->n_reads[w]; \\\n if (c & FLAGSTAT_FSECONDARY ) { \\\n ++(s)->n_secondary[w]; \\\n } else if (c & FLAGSTAT_FSUPPLEMENTARY ) { \\\n ++(s)->n_supp[w]; \\\n } else if (c & FLAGSTAT_FPAIRED) { \\\n ++(s)->n_pair_all[w]; \\\n if ((c & FLAGSTAT_FPROPER_PAIR) && !(c & FLAGSTAT_FUNMAP) ) ++(s)->n_pair_good[w]; \\\n if (c & FLAGSTAT_FREAD1) ++(s)->n_read1[w]; \\\n if (c & FLAGSTAT_FREAD2) ++(s)->n_read2[w]; \\\n if ((c & FLAGSTAT_FMUNMAP) && !(c & FLAGSTAT_FUNMAP)) ++(s)->n_sgltn[w]; \\\n if (!(c & FLAGSTAT_FUNMAP) && !(c & FLAGSTAT_FMUNMAP)) { \\\n ++(s)->n_pair_map[w]; \\\n } \\\n } \\\n if (!(c & FLAGSTAT_FUNMAP)) ++(s)->n_mapped[w]; \\\n if (c & FLAGSTAT_FDUP) ++(s)->n_dup[w]; \\\n} while (0)\n\n\nstatic const char* percent(char* buffer, long long n, long long total)\n{\n if (total != 0) sprintf(buffer, \"%.2f%%\", (float)n / total * 100.0);\n else strcpy(buffer, \"N/A\");\n return buffer;\n}\n\n\n// @see: https://stackoverflow.com/questions/6818606/how-to-programmatically-clear-the-filesystem-memory-cache-in-c-on-a-linux-syst\nvoid clear_cache() {\n#ifdef __linux__ \n sync();\n std::ofstream ofs(\"/proc/sys/vm/drop_caches\");\n ofs << \"3\" << std::endl;\n#endif\n}\n \nint ZstdCompress(const uint8_t* in, uint32_t n_in, uint8_t* out, uint32_t out_capacity, const int32_t c_level = 1) {\n int ret = ZSTD_compress(out, out_capacity, in, n_in, c_level);\n return(ret);\n}\n\nint ZstdDecompress(const uint8_t* in, uint32_t n_in, uint8_t* out, uint32_t out_capacity) {\n int ret = ZSTD_decompress(out, out_capacity, in, n_in);\n return(ret);\n}\n\nstatic const std::string SAM_FLAG_NAME[] = {\"FPAIRED\",\"FPROPER_PAIR\",\"FUNMAP\",\"FMUNMAP\",\"FREVERSE\",\"FMREVERSE\", \"FREAD1\",\"FREAD2\",\"FSECONDARY\",\"FQCFAIL\",\"FDUP\",\"FSUPPLEMENTARY\",\"n_pair_good\",\"n_sgltn\",\"n_pair_map\"};\n\n/*\n * Easy show-error-and-bail function.\n */\nvoid run_screaming(const char* message, const int code) {\n printf(\"%s \\n\", message);\n exit(code);\n}\n\nint lz4f(const std::string& file, const std::string& out_prefix, const int acceleration = 2) {\n std::ifstream f(file, std::ios::in | std::ios::binary);\n if (f.good() == false) return 0;\n\n std::string outfile = out_prefix + \"_fast_a\" + std::to_string(acceleration) + \".lz4\";\n std::cerr << \"Opening=\" << outfile << std::endl;\n std::ofstream of(outfile, std::ios::out | std::ios::binary);\n if (of.good() == false) return 0;\n\n uint8_t buffer[1024000]; // 512k 16-bit ints \n const int max_dst_size = LZ4_compressBound(1024000);\n uint8_t* out_buffer = new uint8_t[max_dst_size];\n\n while (f.good()) {\n f.read((char*)buffer, 1024000);\n int32_t bytes_read = f.gcount();\n\n const int32_t compressed_data_size = LZ4_compress_fast((char*)buffer, (char*)out_buffer, bytes_read, max_dst_size, acceleration);\n // Check return_value to determine what happened.\n \n if (compressed_data_size < 0)\n run_screaming(\"A negative result from LZ4_compress_default indicates a failure trying to compress the data. See exit code (echo $?) for value returned.\", compressed_data_size);\n \n if (compressed_data_size == 0)\n run_screaming(\"A result of 0 means compression worked, but was stopped because the destination buffer couldn't hold all the information.\", 1);\n\n of.write((char*)&bytes_read, sizeof(int32_t));\n of.write((char*)&compressed_data_size, sizeof(int32_t));\n of.write((char*)out_buffer, compressed_data_size);\n \n // std::cerr << \"Compressed \" << bytes_read << \"->\" << compressed_data_size << std::endl;\n }\n\n delete[] out_buffer;\n return 1;\n}\n\nint lz4hc(const std::string& file, const std::string& out_prefix, int clevel = 9) {\n std::ifstream f(file, std::ios::in | std::ios::binary);\n if (f.good() == false) return 0;\n\n std::string outfile = out_prefix + \"_HC_c\" + std::to_string(clevel) + \".lz4\";\n std::cerr << \"Opening=\" << outfile << std::endl;\n std::ofstream of(outfile, std::ios::out | std::ios::binary);\n if (of.good() == false) {\n std::cerr << \"outfile not good\" << std::endl;\n return 0;\n }\n\n std::cerr << \"here1\" << std::endl;\n\n uint8_t buffer[1024000]; // 512k 16-bit ints \n const int max_dst_size = LZ4_compressBound(1024000);\n uint8_t* out_buffer = new uint8_t[max_dst_size];\n\n std::cerr << \"here\" << std::endl;\n\n while (f.good()) {\n f.read((char*)buffer, 1024000);\n int32_t bytes_read = f.gcount();\n std::cerr << \"read=\" << bytes_read << std::endl;\n\n const int32_t compressed_data_size = LZ4_compress_HC((char*)buffer, (char*)out_buffer, bytes_read, max_dst_size, clevel);\n \n // Check return_value to determine what happened.\n if (compressed_data_size < 0)\n run_screaming(\"A negative result from LZ4_compress_default indicates a failure trying to compress the data. See exit code (echo $?) for value returned.\", compressed_data_size);\n \n if (compressed_data_size == 0)\n run_screaming(\"A result of 0 means compression worked, but was stopped because the destination buffer couldn't hold all the information.\", 1);\n\n of.write((char*)&bytes_read, sizeof(int32_t));\n of.write((char*)&compressed_data_size, sizeof(int32_t));\n of.write((char*)out_buffer, compressed_data_size);\n \n // std::cerr << \"Compressed \" << bytes_read << \"->\" << compressed_data_size << std::endl;\n }\n\n delete[] out_buffer;\n return 1;\n}\n\nint zstd(const std::string& file, const std::string& out_prefix, int clevel = 22) {\n std::ifstream f(file, std::ios::in | std::ios::binary);\n if (f.good() == false) return 0;\n\n std::string outfile = out_prefix + \"_c\" + std::to_string(clevel) + \".zst\";\n std::cerr << \"Opening=\" << outfile << std::endl;\n std::ofstream of(outfile, std::ios::out | std::ios::binary);\n if (of.good() == false) return 0;\n\n uint8_t buffer[1024000]; // 512k 16-bit ints \n uint8_t out_buffer[1024000];\n\n while (f.good()) {\n f.read((char*)buffer, 1024000);\n int32_t bytes_read = f.gcount();\n\n const int32_t compressed_data_size = ZstdCompress(buffer, bytes_read, out_buffer, 1024000, clevel);\n // Check return_value to determine what happened.\n \n if (compressed_data_size < 0)\n run_screaming(\"A negative result from LZ4_compress_default indicates a failure trying to compress the data. See exit code (echo $?) for value returned.\", compressed_data_size);\n \n if (compressed_data_size == 0)\n run_screaming(\"A result of 0 means compression worked, but was stopped because the destination buffer couldn't hold all the information.\", 1);\n \n of.write((char*)&bytes_read, sizeof(int32_t));\n of.write((char*)&compressed_data_size, sizeof(int32_t));\n of.write((char*)out_buffer, compressed_data_size);\n\n // std::cerr << \"Compressed \" << bytes_read << \"->\" << compressed_data_size << std::endl;\n }\n of.close();\n\n return 1;\n}\n\nint lz4_decompress_only(const std::string& file) {\n std::ifstream f(file, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) return 0;\n int64_t filesize = f.tellg();\n f.seekg(0);\n // uint8_t buffer[1024000]; // 512k 16-bit ints \n // uint8_t out_buffer[1024000];\n uint8_t* buffer = new uint8_t[1024000+65536];\n // uint8_t* out_buffer;\n // assert(!posix_memalign((void**)&out_buffer, SIMD_ALIGNMENT, 1024000));\n // out_buffer = new uint8_t[1024000];\n uint8_t* out_buffer = (uint8_t*)STORM_aligned_malloc(STORM_get_alignment(), 1024000+65536);\n\n int32_t uncompresed_size, compressed_size;\n\n uint32_t counters[16] = {0}; // flags\n uint64_t tot_flags = 0;\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n // std::cerr << \"here\" << std::endl;\n f.read((char*)&uncompresed_size, sizeof(int32_t));\n f.read((char*)&compressed_size, sizeof(int32_t));\n f.read((char*)buffer, compressed_size);\n\n const int32_t decompressed_size = LZ4_decompress_safe((char*)buffer, (char*)out_buffer, compressed_size, uncompresed_size);\n // Check return_value to determine what happened.\n if (decompressed_size < 0)\n run_screaming(\"A negative result from LZ4_decompress_safe indicates a failure trying to decompress the data. See exit code (echo $?) for value returned.\", decompressed_size);\n if (decompressed_size == 0)\n run_screaming(\"I'm not sure this function can ever return 0. Documentation in lz4.h doesn't indicate so.\", 1);\n\n // assert(decompressed_size == uncompresed_size);\n\n const uint32_t N = uncompresed_size >> 1;\n tot_flags += N;\n // pospopcnt_u16((uint16_t*)out_buffer,N,counters);\n\n // std::cerr << \"Decompressed \" << compressed_size << \"->\" << uncompresed_size << std::endl;\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[LZ4 \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n // std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // for (int i = 0; i < 12; ++i) {\n // std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << std::endl;\n // }\n\n delete[] buffer;\n // delete[] out_buffer;\n // free(buffer);\n // free(out_buffer);\n STORM_aligned_free(out_buffer);\n return 1;\n}\n\nint lz4_decompress(const std::string& file) {\n std::ifstream f(file, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) return 0;\n int64_t filesize = f.tellg();\n f.seekg(0);\n // uint8_t buffer[1024000]; // 512k 16-bit ints \n // uint8_t out_buffer[1024000];\n \n uint8_t* buffer = new uint8_t[1024000+65536];\n // uint8_t* out_buffer;\n // assert(!posix_memalign((void**)&out_buffer, SIMD_ALIGNMENT, 1024000));\n // out_buffer = new uint8_t[1024000];\n uint8_t* out_buffer = (uint8_t*)STORM_aligned_malloc(STORM_get_alignment(), 1024000+65536);\n\n int32_t uncompresed_size, compressed_size;\n\n uint32_t counters[16*2] = {0}; // flags\n uint64_t tot_flags = 0;\n\n FLAGSTATS_func func;\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)&uncompresed_size, sizeof(int32_t));\n f.read((char*)&compressed_size, sizeof(int32_t));\n f.read((char*)buffer, compressed_size);\n\n const int32_t decompressed_size = LZ4_decompress_safe((char*)buffer, (char*)out_buffer, compressed_size, uncompresed_size);\n // Check return_value to determine what happened.\n if (decompressed_size < 0)\n run_screaming(\"A negative result from LZ4_decompress_safe indicates a failure trying to decompress the data. See exit code (echo $?) for value returned.\", decompressed_size);\n if (decompressed_size == 0)\n run_screaming(\"I'm not sure this function can ever return 0. Documentation in lz4.h doesn't indicate so.\", 1);\n\n const uint32_t N = uncompresed_size >> 1;\n tot_flags += N;\n // pospopcnt_u16((uint16_t*)out_buffer,N,counters);\n // FLAGSTAT_avx512((uint16_t*)out_buffer,N,counters);\n // STORM_pospopcnt_u16_avx2_harvey_seal((uint16_t*)out_buffer,N,counters);\n func = FLAGSTATS_get_function(N);\n (*func)((uint16_t*)out_buffer,N,counters);\n // std::cerr << \"Decompressed \" << compressed_size << \"->\" << uncompresed_size << std::endl;\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[LZ4 \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // std::cerr << \"Pass QC\" << std::endl;\n for (int i = 0; i < 15; ++i) {\n std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << \"\\t\" << counters[16+i] << std::endl;\n }\n // for (int i = 12; i < 15; ++i) {\n // std::cerr << \"special-\" << i << \"\\t\" << counters[i] << \"\\t\" << counters[16+i] << std::endl;\n // }\n\n // std::cerr << \"Fail QC\" << std::endl;\n // for (int i = 0; i < 12; ++i) {\n // std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[16+i] << std::endl;\n // }\n\n delete[] buffer;\n // delete[] out_buffer;\n // free(buffer);\n // free(out_buffer);\n STORM_aligned_free(out_buffer);\n return 1;\n}\n\nint flagstat_raw_read(const std::string& file) {\n std::size_t found = file.find(\".bin\");\n std::string file2;\n if (found != std::string::npos) {\n // std::cerr << \"first 'needle' found at: \" << found << '\\n';\n std::cerr << \"file new=\" << file.substr(0, found + 4) << std::endl;\n file2 = file.substr(0, found + 4);\n } else {\n return -1;\n }\n \n std::ifstream f(file2, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) {\n std::cerr << \"file not good\" << std::endl;\n return 0;\n }\n int64_t filesize = f.tellg();\n f.seekg(0);\n // std::cerr << \"filesize=\" << filesize << std::endl;\n \n // uint8_t* buffer = new uint8_t[1024000];\n uint8_t* out_buffer = (uint8_t*)STORM_aligned_malloc(STORM_get_alignment(), 1024000);\n uint32_t counters[16*2] = {0}; // flags\n uint64_t tot_flags = 0;\n\n // FLAGSTATS_func func;\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)out_buffer, 1024000);\n size_t read = f.gcount();\n // std::cerr << \"Read \" << read << std::endl;\n\n // FLAGSTAT_avx512((uint16_t*)out_buffer, read/2, counters);\n // func = FLAGSTATS_get_function(read >> 1);\n // (*func)((uint16_t*)out_buffer,read >> 1,counters);\n\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[RAW READ \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n // std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // std::cerr << \"Pass QC\" << std::endl;\n // for (int i = 0; i < 15; ++i) {\n // std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << \"\\t\" << counters[16+i] << std::endl;\n // }\n\n STORM_aligned_free(out_buffer);\n return 1;\n}\n\nint flagstat_raw(const std::string& file) {\n std::size_t found = file.find(\".bin\");\n std::string file2;\n if (found != std::string::npos) {\n // std::cerr << \"first 'needle' found at: \" << found << '\\n';\n std::cerr << \"file new=\" << file.substr(0, found + 4) << std::endl;\n file2 = file.substr(0, found + 4);\n } else {\n return -1;\n }\n \n std::ifstream f(file2, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) {\n std::cerr << \"file not good\" << std::endl;\n return 0;\n }\n int64_t filesize = f.tellg();\n f.seekg(0);\n // std::cerr << \"filesize=\" << filesize << std::endl;\n \n // uint8_t* buffer = new uint8_t[1024000];\n uint8_t* out_buffer = (uint8_t*)STORM_aligned_malloc(STORM_get_alignment(), 1024000);\n uint32_t counters[16*2] = {0}; // flags\n uint64_t tot_flags = 0;\n\n FLAGSTATS_func func;\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)out_buffer, 1024000);\n size_t read = f.gcount();\n // std::cerr << \"Read \" << read << std::endl;\n\n // FLAGSTAT_avx512((uint16_t*)out_buffer, read/2, counters);\n func = FLAGSTATS_get_function(read >> 1);\n (*func)((uint16_t*)out_buffer,read >> 1,counters);\n\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[RAW \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // std::cerr << \"Pass QC\" << std::endl;\n for (int i = 0; i < 15; ++i) {\n std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << \"\\t\" << counters[16+i] << std::endl;\n }\n\n STORM_aligned_free(out_buffer);\n return 1;\n}\n\nint flagstat_raw_samtools(const std::string& file) {\n std::size_t found = file.find(\".bin\");\n std::string file2;\n if (found != std::string::npos) {\n // std::cerr << \"first 'needle' found at: \" << found << '\\n';\n std::cerr << \"file new=\" << file.substr(0, found + 4) << std::endl;\n file2 = file.substr(0, found + 4);\n } else {\n return -1;\n }\n \n std::ifstream f(file2, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) {\n std::cerr << \"file not good\" << std::endl;\n return 0;\n }\n int64_t filesize = f.tellg();\n f.seekg(0);\n // std::cerr << \"filesize=\" << filesize << std::endl;\n \n // uint8_t* buffer = new uint8_t[1024000];\n uint8_t* out_buffer = (uint8_t*)STORM_aligned_malloc(STORM_get_alignment(), 1024000);\n uint32_t counters[16*2] = {0}; // flags\n uint64_t tot_flags = 0;\n\n // FLAGSTATS_func func;\n bam_flagstat_t* s;\n s = (bam_flagstat_t*)calloc(1, sizeof(bam_flagstat_t));\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)out_buffer, 1024000);\n size_t read = f.gcount();\n // std::cerr << \"Read \" << read << std::endl;\n\n // FLAGSTAT_avx512((uint16_t*)out_buffer, read/2, counters);\n // func = FLAGSTATS_get_function(read >> 1);\n // (*func)((uint16_t*)out_buffer,read >> 1,counters);\n uint16_t* inflags = (uint16_t*)out_buffer;\n for (int i = 0; i < ((uint32_t)read >> 1); ++i) {\n flagstat_loop(s, inflags[i]);\n }\n\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[RAW SAMTOOLS \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // std::cerr << \"Pass QC\" << std::endl;\n for (int i = 0; i < 15; ++i) {\n std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << \"\\t\" << counters[16+i] << std::endl;\n }\n\n STORM_aligned_free(out_buffer);\n free(s);\n return 1;\n}\n\nint lz4_decompress_samtools(const std::string& file) {\n std::ifstream f(file, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) return 0;\n int64_t filesize = f.tellg();\n f.seekg(0);\n uint8_t buffer[1024000+65536]; // 512k 16-bit ints \n uint8_t out_buffer[1024000+65536];\n\n int32_t uncompresed_size, compressed_size;\n\n // uint32_t counters[16] = {0}; // flags\n uint64_t tot_flags = 0;\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n \n bam_flagstat_t* s;\n s = (bam_flagstat_t*)calloc(1, sizeof(bam_flagstat_t));\n\n while (f.good()) {\n f.read((char*)&uncompresed_size, sizeof(int32_t));\n f.read((char*)&compressed_size, sizeof(int32_t));\n f.read((char*)buffer, compressed_size);\n\n const int32_t decompressed_size = LZ4_decompress_safe((char*)buffer, (char*)out_buffer, compressed_size, uncompresed_size);\n // Check return_value to determine what happened.\n if (decompressed_size < 0)\n run_screaming(\"A negative result from LZ4_decompress_safe indicates a failure trying to decompress the data. See exit code (echo $?) for value returned.\", decompressed_size);\n if (decompressed_size == 0)\n run_screaming(\"I'm not sure this function can ever return 0. Documentation in lz4.h doesn't indicate so.\", 1);\n\n const uint32_t N = uncompresed_size >> 1;\n tot_flags += N;\n\n uint16_t* inflags = (uint16_t*)out_buffer;\n for (int i = 0; i < N; ++i) {\n flagstat_loop(s, inflags[i]);\n }\n\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[LZ4 samtools \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n char b0[16], b1[16];\n printf(\"%lld + %lld in total (QC-passed reads + QC-failed reads)\\n\", s->n_reads[0], s->n_reads[1]);\n printf(\"%lld + %lld secondary\\n\", s->n_secondary[0], s->n_secondary[1]);\n printf(\"%lld + %lld supplementary\\n\", s->n_supp[0], s->n_supp[1]);\n printf(\"%lld + %lld duplicates\\n\", s->n_dup[0], s->n_dup[1]);\n printf(\"%lld + %lld mapped (%s : %s)\\n\", s->n_mapped[0], s->n_mapped[1], percent(b0, s->n_mapped[0], s->n_reads[0]), percent(b1, s->n_mapped[1], s->n_reads[1]));\n printf(\"%lld + %lld paired in sequencing\\n\", s->n_pair_all[0], s->n_pair_all[1]);\n printf(\"%lld + %lld read1\\n\", s->n_read1[0], s->n_read1[1]);\n printf(\"%lld + %lld read2\\n\", s->n_read2[0], s->n_read2[1]);\n printf(\"%lld + %lld properly paired (%s : %s)\\n\", s->n_pair_good[0], s->n_pair_good[1], percent(b0, s->n_pair_good[0], s->n_pair_all[0]), percent(b1, s->n_pair_good[1], s->n_pair_all[1]));\n printf(\"%lld + %lld with itself and mate mapped\\n\", s->n_pair_map[0], s->n_pair_map[1]);\n printf(\"%lld + %lld singletons (%s : %s)\\n\", s->n_sgltn[0], s->n_sgltn[1], percent(b0, s->n_sgltn[0], s->n_pair_all[0]), percent(b1, s->n_sgltn[1], s->n_pair_all[1]));\n // printf(\"%lld + %lld with mate mapped to a different chr\\n\", s->n_diffchr[0], s->n_diffchr[1]);\n // printf(\"%lld + %lld with mate mapped to a different chr (mapQ>=5)\\n\", s->n_diffhigh[0], s->n_diffhigh[1]);\n free(s);\n\n return 1;\n}\n\nint zstd_decompress_only(const std::string& file) {\n std::ifstream f(file, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) return 0;\n int64_t filesize = f.tellg();\n f.seekg(0);\n uint8_t buffer[1024000]; // 512k 16-bit ints \n uint8_t out_buffer[1024000];\n\n int32_t uncompresed_size, compressed_size;\n uint64_t tot_flags = 0; \n \n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)&uncompresed_size, sizeof(int32_t));\n f.read((char*)&compressed_size, sizeof(int32_t));\n f.read((char*)buffer, compressed_size);\n\n const int32_t decompressed_size = ZstdDecompress(buffer, 1024000, out_buffer, uncompresed_size);\n // assert(decompressed_size == uncompresed_size);\n\n const uint32_t N = uncompresed_size >> 1;\n tot_flags += N;\n\n // std::cerr << \"Decompressed \" << compressed_size << \"->\" << uncompresed_size << std::endl;\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[ZSTD \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n // std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // for (int i = 0; i < 12; ++i) {\n // std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << std::endl;\n // }\n\n return 1;\n}\n\nint zstd_decompress(const std::string& file) {\n std::ifstream f(file, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) return 0;\n int64_t filesize = f.tellg();\n f.seekg(0);\n uint8_t buffer[1024000]; // 512k 16-bit ints \n uint8_t out_buffer[1024000];\n\n int32_t uncompresed_size, compressed_size;\n\n uint32_t counters[16*2] = {0}; // flags\n uint64_t tot_flags = 0;\n\n\n FLAGSTATS_func func;\n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)&uncompresed_size, sizeof(int32_t));\n f.read((char*)&compressed_size, sizeof(int32_t));\n f.read((char*)buffer, compressed_size);\n\n const int32_t decompressed_size = ZstdDecompress(buffer, 1024000, out_buffer, uncompresed_size);\n // assert(decompressed_size == uncompresed_size);\n\n const uint32_t N = uncompresed_size >> 1;\n tot_flags += N;\n // pospopcnt_u16((uint16_t*)out_buffer,N,counters);\n func = FLAGSTATS_get_function(N);\n (*func)((uint16_t*)out_buffer,N,counters);\n\n // std::cerr << \"Decompressed \" << compressed_size << \"->\" << uncompresed_size << std::endl;\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[ZSTD \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n // std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // for (int i = 0; i < 12; ++i) {\n // std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << std::endl;\n // }\n\n return 1;\n}\n\nint zstd_decompress_samtools(const std::string& file) {\n std::ifstream f(file, std::ios::in | std::ios::binary | std::ios::ate);\n if (f.good() == false) return 0;\n int64_t filesize = f.tellg();\n f.seekg(0);\n uint8_t buffer[1024000]; // 512k 16-bit ints \n uint8_t out_buffer[1024000];\n\n int32_t uncompresed_size, compressed_size;\n\n uint32_t counters[16] = {0}; // flags\n uint64_t tot_flags = 0;\n\n bam_flagstat_t *s;\n s = (bam_flagstat_t*)calloc(1, sizeof(bam_flagstat_t)); \n\n std::chrono::high_resolution_clock::time_point t1 = std::chrono::high_resolution_clock::now();\n\n while (f.good()) {\n f.read((char*)&uncompresed_size, sizeof(int32_t));\n f.read((char*)&compressed_size, sizeof(int32_t));\n f.read((char*)buffer, compressed_size);\n\n const int32_t decompressed_size = ZstdDecompress(buffer, 1024000, out_buffer, uncompresed_size);\n // assert(decompressed_size == uncompresed_size);\n\n const uint32_t N = uncompresed_size >> 1;\n tot_flags += N;\n // pospopcnt_u16((uint16_t*)out_buffer,N,counters);\n uint16_t* inflags = (uint16_t*)out_buffer;\n for (int i = 0; i < N; ++i) {\n // flagstat_loop(s, c);\n flagstat_loop(s, inflags[i]);\n // flagstat_loop_branchless(s, inflags, i);\n }\n\n // std::cerr << \"Decompressed \" << compressed_size << \"->\" << uncompresed_size << std::endl;\n if (f.tellg() == filesize) break;\n }\n\n std::chrono::high_resolution_clock::time_point t2 = std::chrono::high_resolution_clock::now();\n auto time_span = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);\n std::cerr << \"[ZSTD samtools \" << file << \"] Time elapsed \" << time_span.count() << \" ms \" << tot_flags << std::endl;\n\n // std::cerr << \"Tot flags=\" << tot_flags << std::endl;\n // for (int i = 0; i < 12; ++i) {\n // std::cerr << SAM_FLAG_NAME[i] << \"\\t\" << counters[i] << std::endl;\n // }\n\n free(s);\n\n return 1;\n}\n\nint compress(int argc, char** argv) {\n int c;\n\tif(argc < 3){\n\t\tstd::cerr << \"usage\" << std::endl;\n return(EXIT_FAILURE);\n\t}\n\n\tint option_index = 0;\n\tstatic struct option long_options[] = {\n\t\t{\"input\", required_argument, 0, 'i' },\n\t\t{\"output\", optional_argument, 0, 'o' },\n\t\t{\"compression-level\", required_argument, 0, 'c' },\n {\"lz4\", optional_argument, 0, 'l' },\n {\"zstd\", optional_argument, 0, 'z' },\n {\"fast\", optional_argument, 0, 'f' },\n\t\t{0,0,0,0}\n\t};\n\t\n std::string input, output;\n int clevel = 1;\n bool lz4_fast = false;\n bool lz4 = false;\n bool mzstd = false;\n\n\twhile ((c = getopt_long(argc, argv, \"i:o:c:lzf?\", long_options, &option_index)) != -1){\n\t\tswitch (c){\n\t\tcase 0:\n\t\t\tstd::cerr << \"Case 0: \" << option_index << '\\t' << long_options[option_index].name << std::endl;\n\t\t\tbreak;\n\t\tcase 'i':\n\t\t\tinput = std::string(optarg);\n\t\t\tbreak;\n\t\tcase 'o':\n\t\t\toutput = std::string(optarg);\n\t\t\tbreak;\n\t\tcase 'c':\n\t\t\tclevel = atoi(optarg);\n\t\t\tif(clevel < 0){\n\t\t\t\tstd::cerr << \"illegal clevel=\" << clevel << std::endl;\n\t\t\t\treturn(EXIT_FAILURE);\n\t\t\t}\n\t\t\tbreak;\n\t\tcase 'f':\n\t\t\tlz4_fast = true;\n\t\t\tbreak;\n\t\tcase 'z':\n\t\t\tmzstd = true;\n\t\t\tbreak;\n\t\tcase 'l':\n\t\t\tlz4 = true;\n\t\t\tbreak;\n\n\t\tdefault:\n\t\t\tstd::cerr << \"Unrecognized option: \" << (char)c << std::endl;\n\t\t\treturn(EXIT_FAILURE);\n\t\t}\n\t}\n\n if (lz4 == false && mzstd == false) {\n std::cerr << \"must pick a compression algorithm (lz4 or zstd)\" << std::endl;\n return EXIT_FAILURE;\n }\n\n if (mzstd && lz4_fast) {\n std::cerr << \"fast mode is only used with LZ4. Ignoring...\" << std::endl;\n }\n\n if (input.size() == 0) {\n std::cerr << \"No input file given\" << std::endl;\n return EXIT_FAILURE; \n }\n\n if (mzstd) {\n if (output.size() == 0) {\n output = input;\n }\n zstd(input,output, clevel);\n }\n \n if (lz4) {\n if (output.size() == 0) {\n output = input;\n }\n if (lz4_fast) lz4f(input, output, clevel);\n else lz4hc(input, output, clevel);\n }\n\n return EXIT_SUCCESS;\n}\n\nint check_file_extension(const std::string& filename) {\n size_t pos = filename.rfind('.');\n if (pos == std::string::npos)\n return 0;\n\n std::string ext = filename.substr(pos + 1);\n\n if (ext == \"zst\") return 1;\n if (ext == \"lz4\") return 2;\n\n return 0;\n}\n\nint decompress(int argc, char** argv) {\n int c;\n\tif(argc < 3){\n\t\tstd::cerr << \"usage decompress\" << std::endl;\n return(EXIT_FAILURE);\n\t}\n\n\tint option_index = 0;\n\tstatic struct option long_options[] = {\n\t\t{\"input\", required_argument, 0, 'i' },\n\n {\"raw-read\", optional_argument, 0, 'R' },\n {\"raw-flagstats\", optional_argument, 0, 'D' },\n {\"raw-samtools\", optional_argument, 0, 'S' },\n\n {\"read\", optional_argument, 0, 'r' },\n {\"flagstats\", optional_argument, 0, 'd' },\n {\"samtools\", optional_argument, 0, 's' },\n\n\t\t{0,0,0,0}\n\t};\n\t\n std::string input;\n bool lz4 = false;\n bool mzstd = false;\n int step = 0;\n\n\twhile ((c = getopt_long(argc, argv, \"i:RDSrds?\", long_options, &option_index)) != -1){\n\t\tswitch (c){\n\t\tcase 0:\n\t\t\tstd::cerr << \"Case 0: \" << option_index << '\\t' << long_options[option_index].name << std::endl;\n\t\t\tbreak;\n\t\tcase 'i':\n\t\t\tinput = std::string(optarg);\n\t\t\tbreak;\n case 'R': step = 0; break;\n case 'D': step = 1; break;\n case 'S': step = 2; break;\n case 'r': step = 3; break;\n case 'd': step = 4; break;\n case 's': step = 5; break;\n\t\tdefault:\n\t\t\tstd::cerr << \"Unrecognized option: \" << (char)c << std::endl;\n\t\t\treturn(EXIT_FAILURE);\n\t\t}\n\t}\n\n if (input.size() == 0) {\n std::cerr << \"No input file given\" << std::endl;\n return EXIT_FAILURE; \n }\n\n // determine suffix\n int method = check_file_extension(input);\n if (method == 0) {\n std::cerr << \"unknown file extension\" << std::endl;\n return EXIT_FAILURE;\n }\n\n if (method == 1) {\n // std::cerr << \"method1\" << std::endl;\n switch(step) {\n case 0: flagstat_raw_read(input); break; // -R\n case 1: flagstat_raw(input); break;// -D\n case 2: flagstat_raw_samtools(input); break;// -S\n case 3: zstd_decompress_only(input); break;// warmup, -r\n case 4: zstd_decompress(input); break;// -d\n case 5: zstd_decompress_samtools(input); break;// -s\n }\n }\n \n if (method == 2) {\n switch(step) {\n case 0: flagstat_raw_read(input); break;\n case 1: flagstat_raw(input); break;\n case 2: flagstat_raw_samtools(input); break;\n case 3: lz4_decompress_only(input); break; // warmup\n case 4: lz4_decompress(input); break;\n case 5: lz4_decompress_samtools(input); break;\n }\n }\n\n return EXIT_SUCCESS;\n}\n\nint main(int argc, char** argv) {\n if (argc == 1) {\n std::cerr << \"usage\" << std::endl;\n return EXIT_SUCCESS;\n }\n\n if(strcmp(&argv[1][0], \"compress\") == 0){\n\t\t// return(compress(argc, argv));\n std::cerr << \"compress\" << std::endl;\n return(compress(argc,argv));\n\t} else if(strcmp(&argv[1][0], \"decompress\") == 0){\n\t\t// return(compress(argc, argv));\n std::cerr << \"decompress\" << std::endl;\n return(decompress(argc,argv));\n\t}\n else {\n std::cerr << \"unknown\" << std::endl;\n return EXIT_FAILURE;\n }\n\n return EXIT_SUCCESS;\n}"
},
{
"alpha_fraction": 0.5154394507408142,
"alphanum_fraction": 0.5441495180130005,
"avg_line_length": 36.628238677978516,
"blob_id": "fe8a76987715867f6238d7fbaf9b26b127cda77d",
"content_id": "832116ad782f57d1511682fa4d835f2bd51702cc",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 29049,
"license_type": "permissive",
"max_line_length": 166,
"num_lines": 772,
"path": "/linux/instrumented_benchmark.cpp",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#ifdef __linux__\n\n/* ****************************\n* Definitions\n******************************/\n#include <memory>\n#include <cassert>\n#include <cinttypes>\n#include <cstdio>\n#include <cstdlib>\n#include <cstring>\n#include <iostream>\n#include <libgen.h>\n#include <random>\n#include <string>\n#include <vector>\n#include <chrono>\n\n#include \"libflagstats.h\"\n#include \"linux-perf-events.h\"\n#include \"aligned_alloc.h\"\n\n#ifdef ALIGN\n#include \"memalloc.h\"\n# define memory_allocate(size) aligned_alloc(64, (size))\n#else\n# define memory_allocate(size) malloc(size)\n#endif\n\n// Definition for microsecond timer.\ntypedef std::chrono::high_resolution_clock::time_point clockdef;\n\n// FLAGSTATS_func methods[] = {FLAGSTAT_sse4, FLAGSTAT_avx2, FLAGSTAT_avx512};\n\ntypedef struct {\n long long n_reads[2], n_mapped[2], n_pair_all[2], n_pair_map[2], n_pair_good[2];\n long long n_sgltn[2], n_read1[2], n_read2[2];\n long long n_dup[2];\n long long n_diffchr[2], n_diffhigh[2];\n long long n_secondary[2], n_supp[2];\n} bam_flagstat_t;\n\n#define SAMTOOLS_flagstat_loop(s, c) do { \\\n int w = (c & FLAGSTAT_FQCFAIL)? 1 : 0; \\\n ++(s)->n_reads[w]; \\\n if (c & FLAGSTAT_FSECONDARY ) { \\\n ++(s)->n_secondary[w]; \\\n } else if (c & FLAGSTAT_FSUPPLEMENTARY ) { \\\n ++(s)->n_supp[w]; \\\n } else if (c & FLAGSTAT_FPAIRED) { \\\n ++(s)->n_pair_all[w]; \\\n if ( (c & FLAGSTAT_FPROPER_PAIR) && !(c & FLAGSTAT_FUNMAP) ) ++(s)->n_pair_good[w]; \\\n if (c & FLAGSTAT_FREAD1) ++(s)->n_read1[w]; \\\n if (c & FLAGSTAT_FREAD2) ++(s)->n_read2[w]; \\\n if ((c & FLAGSTAT_FMUNMAP) && !(c & FLAGSTAT_FUNMAP)) ++(s)->n_sgltn[w]; \\\n if (!(c & FLAGSTAT_FUNMAP) && !(c & FLAGSTAT_FMUNMAP)) { \\\n ++(s)->n_pair_map[w]; \\\n } \\\n } \\\n if (!(c & FLAGSTAT_FUNMAP)) ++(s)->n_mapped[w]; \\\n if (c & FLAGSTAT_FDUP) ++(s)->n_dup[w]; \\\n} while (0)\n\nvoid SAMTOOLS_func(bam_flagstat_t* s, const uint16_t c) {\n int w = (c & FLAGSTAT_FQCFAIL) ? 1 : 0; \n ++(s)->n_reads[w];\n if (c & FLAGSTAT_FSECONDARY ) {\n ++(s)->n_secondary[w];\n } else if (c & FLAGSTAT_FSUPPLEMENTARY ) {\n ++(s)->n_supp[w];\n } else if (c & FLAGSTAT_FPAIRED) {\n ++(s)->n_pair_all[w];\n if ( (c & FLAGSTAT_FPROPER_PAIR) && !(c & FLAGSTAT_FUNMAP) ) ++(s)->n_pair_good[w];\n if (c & FLAGSTAT_FREAD1) ++(s)->n_read1[w];\n if (c & FLAGSTAT_FREAD2) ++(s)->n_read2[w];\n if ((c & FLAGSTAT_FMUNMAP) && !(c & FLAGSTAT_FUNMAP)) ++(s)->n_sgltn[w];\n if (!(c & FLAGSTAT_FUNMAP) && !(c & FLAGSTAT_FMUNMAP)) {\n ++(s)->n_pair_map[w];\n }\n }\n if (!(c & FLAGSTAT_FUNMAP)) ++(s)->n_mapped[w];\n if (c & FLAGSTAT_FDUP) ++(s)->n_dup[w];\n}\n\n#ifdef __GNUC__\n__attribute__((optimize(\"no-tree-vectorize\")))\n#endif\nint samtools_flagstats(const uint16_t* array, uint32_t len, uint32_t* flags) {\n bam_flagstat_t* s = (bam_flagstat_t*)calloc(1, sizeof(bam_flagstat_t));\n for (int i = 0; i < len; ++i) {\n // SAMTOOLS_flagstat_loop(s, array[i]);\n SAMTOOLS_func(s, array[i]);\n }\n flags[0] = s->n_read1[0]; // prevent optimzie away\n flags[1] += flags[0];\n free(s);\n return 0;\n}\n\n\nvoid print16(uint32_t *flags) {\n for (int k = 0; k < 16; k++)\n printf(\" %8u \", flags[k]);\n printf(\"\\n\");\n}\n\nstd::vector<unsigned long long>\ncompute_mins(std::vector< std::vector<unsigned long long> > allresults) {\n if (allresults.size() == 0)\n return std::vector<unsigned long long>();\n \n std::vector<unsigned long long> answer = allresults[0];\n \n for (size_t k = 1; k < allresults.size(); k++) {\n assert(allresults[k].size() == answer.size());\n for (size_t z = 0; z < answer.size(); z++) {\n if (allresults[k][z] < answer[z])\n answer[z] = allresults[k][z];\n }\n }\n return answer;\n}\n\nstd::vector<double>\ncompute_averages(std::vector< std::vector<unsigned long long> > allresults) {\n if (allresults.size() == 0)\n return std::vector<double>();\n \n std::vector<double> answer(allresults[0].size());\n \n for (size_t k = 0; k < allresults.size(); k++) {\n assert(allresults[k].size() == answer.size());\n for (size_t z = 0; z < answer.size(); z++) {\n answer[z] += allresults[k][z];\n }\n }\n\n for (size_t z = 0; z < answer.size(); z++) {\n answer[z] /= allresults.size();\n }\n return answer;\n}\n\n/**\n * @brief \n * \n * @param n Number of integers.\n * @param iterations Number of iterations.\n * @param fn Target function pointer.\n * @param verbose Flag enabling verbose output.\n * @return Returns true if the results are correct. Returns false if the results\n * are either incorrect or the target function is not supported.\n */\nbool benchmark(uint32_t n, uint32_t iterations, FLAGSTATS_func fn, bool verbose, bool test) {\n std::vector<int> evts;\n uint16_t* vdata = (uint16_t*)memory_allocate(n * sizeof(uint16_t));\n std::unique_ptr<uint16_t, decltype(&free)> dataholder(vdata, free);\n if(verbose) {\n printf(\"alignment: %d\\n\", get_alignment(vdata));\n }\n evts.push_back(PERF_COUNT_HW_CPU_CYCLES);\n evts.push_back(PERF_COUNT_HW_INSTRUCTIONS);\n evts.push_back(PERF_COUNT_HW_BRANCH_MISSES);\n evts.push_back(PERF_COUNT_HW_CACHE_REFERENCES);\n evts.push_back(PERF_COUNT_HW_CACHE_MISSES);\n evts.push_back(PERF_COUNT_HW_REF_CPU_CYCLES);\n LinuxEvents<PERF_TYPE_HARDWARE> unified(evts);\n std::vector<unsigned long long> results; // tmp buffer\n std::vector< std::vector<unsigned long long> > allresults;\n results.resize(evts.size());\n \n std::random_device rd;\n std::mt19937 gen(rd());\n std::uniform_int_distribution<> dis(0, 0xFFFF);\n\n bool isok = true;\n for (uint32_t i = 0; i < iterations; i++) {\n for (size_t k = 0; k < n; k++) {\n vdata[k] = dis(gen); // random init.\n }\n uint32_t correctflags[16] = {0};\n FLAGSTAT_scalar(vdata, n, correctflags); // this is our gold standard\n uint32_t flags[16] = {0};\n \n unified.start();\n fn(vdata, n, flags);\n unified.end(results);\n\n uint64_t tot_obs = 0;\n for (size_t k = 0; k < 16; ++k) tot_obs += flags[k];\n if (tot_obs == 0) { // when a method is not supported it returns all zero\n return false;\n }\n\n for (size_t k = 0; k < 16; k++) {\n if (correctflags[k] != flags[k]) {\n if (test) {\n printf(\"bug:\\n\");\n printf(\"expected : \");\n print16(correctflags);\n printf(\"got : \");\n print16(flags);\n return false;\n } else {\n isok = false;\n }\n }\n }\n allresults.push_back(results);\n }\n\n std::vector<unsigned long long> mins = compute_mins(allresults);\n std::vector<double> avg = compute_averages(allresults);\n \n if (verbose) {\n printf(\"instructions per cycle %4.2f, cycles per 16-bit word: %4.3f, \"\n \"instructions per 16-bit word %4.3f \\n\",\n double(mins[1]) / mins[0], double(mins[0]) / n, double(mins[1]) / n);\n // first we display mins\n printf(\"min: %8llu cycles, %8llu instructions, \\t%8llu branch mis., %8llu \"\n \"cache ref., %8llu cache mis.\\n\",\n mins[0], mins[1], mins[2], mins[3], mins[4]);\n printf(\"avg: %8.1f cycles, %8.1f instructions, \\t%8.1f branch mis., %8.1f \"\n \"cache ref., %8.1f cache mis.\\n\",\n avg[0], avg[1], avg[2], avg[3], avg[4]);\n } else {\n printf(\"cycles per 16-bit word: %4.3f; ref cycles per 16-bit word: %4.3f \\n\", double(mins[0]) / n, double(mins[5]) / n);\n }\n\n return isok;\n}\n\n/**\n * @brief \n * \n * @param n Number of integers.\n * @param m Number of arrays.\n * @param iterations Number of iterations.\n * @param fn Target function pointer.\n * @param verbose Flag enabling verbose output.\n * @return Returns true if the results are correct. Returns false if the results\n * are either incorrect or the target function is not supported.\n */\nbool benchmarkMany(const std::string& fn_name, uint32_t n, uint32_t m, uint32_t iterations, FLAGSTATS_func fn, bool verbose, bool test, bool tabular) {\n std::vector<int> evts;\n#ifdef ALIGN\n std::vector<std::vector<uint16_t,AlignedSTLAllocator<uint16_t,64>>> vdata(m, std::vector<uint16_t,AlignedSTLAllocator<uint16_t,64>>(n));\n#else\n std::vector<std::vector<uint16_t>> vdata(m, std::vector<uint16_t>(n));\n#endif\n#ifdef ALIGN\n for(auto & x : vdata) {\n assert(get_alignment(x.data()) == 64);\n }\n#endif\n if(verbose && !tabular) {\n printf(\"alignments: \");\n for(auto & x : vdata) {\n printf(\"%d \", get_alignment(x.data()));\n }\n printf(\"\\n\");\n } \n evts.push_back(PERF_COUNT_HW_CPU_CYCLES);\n evts.push_back(PERF_COUNT_HW_INSTRUCTIONS);\n evts.push_back(PERF_COUNT_HW_BRANCH_MISSES);\n evts.push_back(PERF_COUNT_HW_CACHE_REFERENCES);\n evts.push_back(PERF_COUNT_HW_CACHE_MISSES);\n evts.push_back(PERF_COUNT_HW_REF_CPU_CYCLES);\n LinuxEvents<PERF_TYPE_HARDWARE> unified(evts);\n std::vector<unsigned long long> results; // tmp buffer\n std::vector< std::vector<unsigned long long> > allresults;\n std::vector<uint32_t> times;\n results.resize(evts.size());\n \n std::random_device rd;\n std::mt19937 gen(rd());\n std::uniform_int_distribution<> dis(0, 0xFFFF);\n\n bool isok = true;\n for (uint32_t i = 0; i < iterations; i++) {\n for (size_t k = 0; k < vdata.size(); k++) {\n for(size_t k2 = 0; k2 < vdata[k].size() ; k2++) { \n vdata[k][k2] = dis(gen); // random init.\n }\n }\n\n std::vector<std::vector<uint32_t>> flags(m,std::vector<uint32_t>(16*2));\n\n const clockdef t1 = std::chrono::high_resolution_clock::now();\n unified.start();\n for (size_t k = 0; k < m ; k++) {\n fn(vdata[k].data(), vdata[k].size(), flags[k].data());\n }\n unified.end(results);\n const clockdef t2 = std::chrono::high_resolution_clock::now();\n allresults.push_back(results);\n\n const auto time_span = std::chrono::duration_cast<std::chrono::nanoseconds>(t2 - t1);\n times.push_back(time_span.count());\n }\n\n uint32_t tot_time = std::accumulate(times.begin(), times.end(), 0);\n double mean_time = tot_time / times.size();\n\n std::vector<unsigned long long> mins = compute_mins(allresults);\n std::vector<double> avg = compute_averages(allresults);\n\n double throughput = ((2*n) / (1024*1024.0)) / (mean_time / 1000000000.0);\n \n if (tabular) {\n for (int i = 0; i < iterations; ++i) {\n throughput = ((2*n) / (1024*1024.0)) / (times[i] / 1000000000.0);\n printf(\"%s\\t%u\\t%d\\t\", fn_name.c_str(), n, i);\n printf(\"%4.2f\\t%4.3f\\t%4.3f\\t\",\n double(allresults[i][1]) / allresults[i][0], double(allresults[i][0]) / (n*m), double(allresults[i][1]) / (n*m));\n printf(\"%llu\\t%llu\\t%llu\\t%llu\\t%llu\\t\",\n allresults[i][0], allresults[i][1], allresults[i][2], allresults[i][3], allresults[i][4]);\n printf(\"%u\\t%4.2f\\n\", times[i], throughput);\n }\n } else if (verbose) {\n printf(\"instructions per cycle %4.2f, cycles per 16-bit word: %4.3f, \"\n \"instructions per 16-bit word %4.3f \\n\",\n double(mins[1]) / mins[0], double(mins[0]) / (n*m), double(mins[1]) / (n*m));\n // first we display mins\n printf(\"min: %8llu cycles, %8llu instructions, \\t%8llu branch mis., %8llu \"\n \"cache ref., %8llu cache mis.\\n\",\n mins[0], mins[1], mins[2], mins[3], mins[4]);\n printf(\"avg: %8.1f cycles, %8.1f instructions, \\t%8.1f branch mis., %8.1f \"\n \"cache ref., %8.1f cache mis.\\n\",\n avg[0], avg[1], avg[2], avg[3], avg[4]);\n printf(\"avg time: %f ns, %4.2f mb/s\\n\", mean_time, throughput);\n } else {\n printf(\"cycles per 16-bit word: %4.3f; ref cycles per 16-bit word: %4.3f \\n\", double(mins[0]) / (n*m), double(mins[5]) / (n*m));\n }\n\n return isok;\n}\n\nbool benchmarkManyMemoryOptimized(const std::string& fn_name, uint32_t n, uint32_t m, uint32_t iterations, FLAGSTATS_func fn, bool verbose, bool test, bool tabular) {\n std::vector<int> evts;\n\n const uint32_t best_alignment = STORM_get_alignment();\n STORM_ALIGN(64) uint16_t** vdata = (uint16_t**)STORM_aligned_malloc(best_alignment, m*sizeof(uint16_t*));\n for (int i = 0; i < m; ++i)\n vdata[i] = (uint16_t*)STORM_aligned_malloc(best_alignment, n*sizeof(uint16_t));\n\n if (!tabular) printf(\"alignments: %d\\n\", best_alignment);\n\n evts.push_back(PERF_COUNT_HW_CPU_CYCLES);\n evts.push_back(PERF_COUNT_HW_INSTRUCTIONS);\n evts.push_back(PERF_COUNT_HW_BRANCH_MISSES);\n evts.push_back(PERF_COUNT_HW_CACHE_REFERENCES);\n evts.push_back(PERF_COUNT_HW_CACHE_MISSES);\n evts.push_back(PERF_COUNT_HW_REF_CPU_CYCLES);\n LinuxEvents<PERF_TYPE_HARDWARE> unified(evts);\n std::vector<unsigned long long> results; // tmp buffer\n std::vector< std::vector<unsigned long long> > allresults;\n results.resize(evts.size());\n \n std::random_device rd;\n std::mt19937 gen(rd());\n std::uniform_int_distribution<> dis(0, 0xFFFF);\n\n bool isok = true;\n for (uint32_t i = 0; i < iterations; i++) {\n for (size_t k = 0; k < m; k++) {\n for(size_t k2 = 0; k2 < n ; k2++) { \n vdata[k][k2] = dis(gen); // random init.\n }\n }\n\n std::vector<std::vector<uint32_t>> flags(m, std::vector<uint32_t>(16*2));\n \n unified.start();\n for (size_t k = 0; k < m ; k++) {\n fn(vdata[k], n, flags[k].data());\n }\n unified.end(results);\n allresults.push_back(results);\n }\n\n std::vector<unsigned long long> mins = compute_mins(allresults);\n std::vector<double> avg = compute_averages(allresults);\n \n if (verbose) {\n printf(\"instructions per cycle %4.2f, cycles per 16-bit word: %4.3f, \"\n \"instructions per 16-bit word %4.3f \\n\",\n double(mins[1]) / mins[0], double(mins[0]) / (n*m), double(mins[1]) / (n*m));\n // first we display mins\n printf(\"min: %8llu cycles, %8llu instructions, \\t%8llu branch mis., %8llu \"\n \"cache ref., %8llu cache mis.\\n\",\n mins[0], mins[1], mins[2], mins[3], mins[4]);\n printf(\"avg: %8.1f cycles, %8.1f instructions, \\t%8.1f branch mis., %8.1f \"\n \"cache ref., %8.1f cache mis.\\n\",\n avg[0], avg[1], avg[2], avg[3], avg[4]);\n } else {\n printf(\"cycles per 16-bit word: %4.3f; ref cycles per 16-bit word: %4.3f \\n\", double(mins[0]) / (n*m), double(mins[5]) / (n*m));\n }\n\n if (tabular) {\n for (int i = 0; i < iterations; ++i) {\n printf(\"%s\\t%d\\t\", fn_name.c_str(), i);\n printf(\"%4.2f\\t%4.3f\\t%4.3f\\t\",\n double(allresults[i][1]) / allresults[i][0], double(allresults[i][0]) / (n*m), double(allresults[i][1]) / (n*m));\n printf(\"%llu\\t%llu\\t%llu\\t%llu\\t%llu\\n\",\n allresults[i][0], allresults[i][1], allresults[i][2], allresults[i][3], allresults[i][4]);\n }\n }\n\n for (int i = 0; i < m; ++i)\n STORM_aligned_free(vdata[i]);\n STORM_aligned_free(vdata);\n\n return isok;\n}\n\nvoid measureoverhead(uint32_t n, uint32_t iterations, bool verbose) {\n std::vector<int> evts;\n evts.push_back(PERF_COUNT_HW_CPU_CYCLES);\n evts.push_back(PERF_COUNT_HW_INSTRUCTIONS);\n evts.push_back(PERF_COUNT_HW_BRANCH_MISSES);\n evts.push_back(PERF_COUNT_HW_CACHE_REFERENCES);\n evts.push_back(PERF_COUNT_HW_CACHE_MISSES);\n evts.push_back(PERF_COUNT_HW_REF_CPU_CYCLES);\n LinuxEvents<PERF_TYPE_HARDWARE> unified(evts);\n std::vector<unsigned long long> results; // tmp buffer\n std::vector< std::vector<unsigned long long> > allresults;\n results.resize(evts.size());\n \n for (uint32_t i = 0; i < iterations; i++) {\n unified.start();\n unified.end(results);\n allresults.push_back(results);\n }\n\n std::vector<unsigned long long> mins = compute_mins(allresults);\n std::vector<double> avg = compute_averages(allresults);\n printf(\"%-40s\\t\",\"nothing\"); \n \n if (verbose) {\n printf(\"instructions per cycle %4.2f, cycles per 16-bit word: %4.3f, \"\n \"instructions per 16-bit word %4.3f \\n\",\n double(mins[1]) / mins[0], double(mins[0]) / n, double(mins[1]) / n);\n // first we display mins\n printf(\"min: %8llu cycles, %8llu instructions, \\t%8llu branch mis., %8llu \"\n \"cache ref., %8llu cache mis.\\n\",\n mins[0], mins[1], mins[2], mins[3], mins[4]);\n printf(\"avg: %8.1f cycles, %8.1f instructions, \\t%8.1f branch mis., %8.1f \"\n \"cache ref., %8.1f cache mis.\\n\",\n avg[0], avg[1], avg[2], avg[3], avg[4]);\n } else {\n printf(\"cycles per 16-bit word: %4.3f; ref cycles per 16-bit word: %4.3f \\n\", double(mins[0]) / n, double(mins[5]) / n);\n }\n}\n\nbool benchmarkMemoryCopy(const std::string& fn_name, uint32_t n, uint32_t m, uint32_t iterations, bool verbose, bool tabular) {\n std::vector<int> evts;\n const uint32_t best_alignment = STORM_get_alignment();\n STORM_ALIGN(64) uint16_t** vdata = (uint16_t**)STORM_aligned_malloc(best_alignment, m*sizeof(uint16_t*));\n for (int i = 0; i < m; ++i)\n vdata[i] = (uint16_t*)STORM_aligned_malloc(best_alignment, n*sizeof(uint16_t));\n STORM_ALIGN(64) uint16_t* dst = (uint16_t*)STORM_aligned_malloc(best_alignment, n*sizeof(uint16_t*));\n \n if (!tabular) printf(\"alignments: %d\\n\", best_alignment);\n\n evts.push_back(PERF_COUNT_HW_CPU_CYCLES);\n evts.push_back(PERF_COUNT_HW_INSTRUCTIONS);\n evts.push_back(PERF_COUNT_HW_BRANCH_MISSES);\n evts.push_back(PERF_COUNT_HW_CACHE_REFERENCES);\n evts.push_back(PERF_COUNT_HW_CACHE_MISSES);\n evts.push_back(PERF_COUNT_HW_REF_CPU_CYCLES);\n LinuxEvents<PERF_TYPE_HARDWARE> unified(evts);\n std::vector<unsigned long long> results; // tmp buffer\n std::vector< std::vector<unsigned long long> > allresults;\n std::vector<uint32_t> times;\n results.resize(evts.size());\n \n std::random_device rd;\n std::mt19937 gen(rd());\n std::uniform_int_distribution<> dis(0, 0xFFFF);\n\n bool isok = true;\n for (uint32_t i = 0; i < iterations; i++) {\n for (size_t k = 0; k < m; k++) {\n for(size_t k2 = 0; k2 < n ; k2++) {\n vdata[k][k2] = dis(gen); // random init.\n }\n }\n\n const clockdef t1 = std::chrono::high_resolution_clock::now();\n unified.start();\n for (size_t k = 0; k < m ; k++) {\n memcpy(dst, vdata[k], n*sizeof(uint16_t));\n }\n unified.end(results);\n const clockdef t2 = std::chrono::high_resolution_clock::now();\n allresults.push_back(results);\n\n const auto time_span = std::chrono::duration_cast<std::chrono::nanoseconds>(t2 - t1);\n times.push_back(time_span.count());\n }\n \n uint32_t tot_time = std::accumulate(times.begin(), times.end(), 0);\n double mean_time = tot_time / times.size();\n\n std::vector<unsigned long long> mins = compute_mins(allresults);\n std::vector<double> avg = compute_averages(allresults);\n\n double throughput = ((2*n) / (1024*1024.0)) / (mean_time / 1000000000.0);\n \n if (tabular) {\n for (int i = 0; i < iterations; ++i) {\n throughput = ((2*n) / (1024*1024.0)) / (times[i] / 1000000000.0);\n printf(\"%s\\t%u\\t%d\\t\", fn_name.c_str(), n, i);\n printf(\"%4.2f\\t%4.3f\\t%4.3f\\t\",\n double(allresults[i][1]) / allresults[i][0], double(allresults[i][0]) / (n*m), double(allresults[i][1]) / (n*m));\n printf(\"%llu\\t%llu\\t%llu\\t%llu\\t%llu\\t\",\n allresults[i][0], allresults[i][1], allresults[i][2], allresults[i][3], allresults[i][4]);\n printf(\"%u\\t%4.2f\\n\", times[i], throughput);\n }\n } else if (verbose) {\n printf(\"instructions per cycle %4.2f, cycles per 16-bit word: %4.3f, \"\n \"instructions per 16-bit word %4.3f \\n\",\n double(mins[1]) / mins[0], double(mins[0]) / (n*m), double(mins[1]) / (n*m));\n // first we display mins\n printf(\"min: %8llu cycles, %8llu instructions, \\t%8llu branch mis., %8llu \"\n \"cache ref., %8llu cache mis.\\n\",\n mins[0], mins[1], mins[2], mins[3], mins[4]);\n printf(\"avg: %8.1f cycles, %8.1f instructions, \\t%8.1f branch mis., %8.1f \"\n \"cache ref., %8.1f cache mis.\\n\",\n avg[0], avg[1], avg[2], avg[3], avg[4]);\n printf(\"avg time: %f ns, %4.2f mb/s\\n\", mean_time, throughput);\n } else {\n printf(\"cycles per 16-bit word: %4.3f; ref cycles per 16-bit word: %4.3f \\n\", double(mins[0]) / (n*m), double(mins[5]) / (n*m));\n }\n\n return isok;\n\n for (int i = 0; i < m; ++i) STORM_aligned_free(vdata[i]);\n STORM_aligned_free(vdata);\n STORM_aligned_free(dst);\n\n return isok;\n}\n\nstatic void print_usage(char *command) {\n printf(\" Try %s -n 100000 -i 15 -v \\n\", command);\n printf(\"-n is the number of 16-bit words \\n\");\n printf(\"-i is the number of tests or iterations \\n\");\n printf(\"-v makes things verbose\\n\");\n}\n\nint main(int argc, char **argv) {\n size_t n = 100000;\n size_t m = 1;\n size_t iterations = 0; \n bool verbose = false;\n bool tabular = false;\n int c;\n\n while ((c = getopt(argc, argv, \"vthm:n:i:\")) != -1) {\n switch (c) {\n case 'n':\n n = atoll(optarg);\n break;\n case 'm':\n m = atoll(optarg);\n break;\n case 'v':\n verbose = true;\n break;\n case 't':\n tabular = true;\n break;\n case 'h':\n print_usage(argv[0]);\n return EXIT_SUCCESS;\n case 'i':\n iterations = atoi(optarg);\n break;\n default:\n abort();\n }\n }\n\n if(n > UINT32_MAX) {\n printf(\"setting n to %u \\n\", UINT32_MAX);\n n = UINT32_MAX;\n }\n\n if(iterations > UINT32_MAX) {\n printf(\"setting iterations to %u \\n\", UINT32_MAX);\n iterations = UINT32_MAX;\n }\n\n if(iterations == 0) {\n if(m*n < 1000000) iterations = 100;\n else iterations = 10;\n }\n \n if (!tabular) {\n printf(\"n = %zu m = %zu \\n\", n, m);\n printf(\"iterations = %zu \\n\", iterations);\n }\n if(n == 0) {\n printf(\"n cannot be zero.\\n\");\n return EXIT_FAILURE;\n }\n\n if (!tabular) {\n size_t array_in_bytes = sizeof(uint16_t) * n * m;\n if(array_in_bytes < 1024) {\n printf(\"array size: %zu B\\n\", array_in_bytes);\n } else if (array_in_bytes < 1024 * 1024) {\n printf(\"array size: %.3f kB\\n\", array_in_bytes / 1024.);\n } else {\n printf(\"array size: %.3f MB\\n\", array_in_bytes / (1024 * 1024.));\n }\n }\n\n if (!tabular) measureoverhead(n*m, iterations, verbose);\n\n#if defined(STORM_HAVE_CPUID)\n #if defined(__cplusplus)\n /* C++11 thread-safe singleton */\n static const int cpuid = STORM_get_cpuid();\n #else\n static int cpuid_ = -1;\n int cpuid = cpuid_;\n if (cpuid == -1) {\n cpuid = STORM_get_cpuid();\n\n #if defined(_MSC_VER)\n _InterlockedCompareExchange(&cpuid_, cpuid, -1);\n #else\n __sync_val_compare_and_swap(&cpuid_, -1, cpuid);\n #endif\n }\n #endif\n#endif\n\n if (!tabular) printf(\"libflagstats-scalar\\t\");\n fflush(NULL);\n bool isok = benchmarkMany(\"libflagstats-scalar\", n, m, iterations, FLAGSTAT_scalar, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 0);\n }\n if (verbose && !tabular)\n printf(\"\\n\");\n\n if (!tabular) printf(\"samtools\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"samtools\", n, m, iterations, samtools_flagstats, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 0);\n }\n if (verbose && !tabular)\n printf(\"\\n\");\n\n if (!tabular) printf(\"memcpy\\t\");\n fflush(NULL);\n isok = benchmarkMemoryCopy(\"memcpy\", n, m, iterations, verbose, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 0);\n }\n if (verbose && !tabular)\n printf(\"\\n\");\n \n\n #if defined(STORM_HAVE_SSE42)\n if ((cpuid & STORM_CPUID_runtime_bit_SSE42)) {\n if (!tabular) printf(\"libflagstats-sse4.2\\t\");\n fflush(NULL);\n bool isok = benchmarkMany(\"libflagstats-sse4.2\", n, m, iterations, FLAGSTAT_sse4, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 0);\n }\n if (verbose && !tabular) printf(\"\\n\");\n\n if (!tabular) printf(\"libflagstats-sse4.2-optimized\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"libflagstats-sse4.2-optimized\", n, m, iterations, FLAGSTAT_sse4_improved, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 0);\n }\n if (verbose && !tabular) printf(\"\\n\");\n\n if (!tabular) printf(\"libflagstats-sse4.2-optimized2\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"libflagstats-sse4.2-optimized2\", n, m, iterations, FLAGSTAT_sse4_improved2, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 0);\n }\n if (verbose && !tabular) printf(\"\\n\");\n }\n // }\n #endif\n\n #if defined(STORM_HAVE_AVX2)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX2)) {\n if (!tabular) printf(\"libflagstats-avx2\\t\");\n fflush(NULL);\n bool isok = benchmarkMany(\"libflagstats-avx2\", n, m, iterations, FLAGSTAT_avx2, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 1);\n }\n if (verbose && !tabular) printf(\"\\n\");\n\n if (!tabular) printf(\"libflagstats-avx2-improved\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"libflagstats-avx2-improved\", n, m, iterations, FLAGSTAT_avx2_improved, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 1);\n }\n if (verbose && !tabular) printf(\"\\n\");\n\n if (!tabular) printf(\"libflagstats-avx2-improved2\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"libflagstats-avx2-improved2\", n, m, iterations, FLAGSTAT_avx2_improved2, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 1);\n }\n if (verbose && !tabular) printf(\"\\n\");\n }\n // }\n #endif\n\n #if defined(STORM_HAVE_AVX512)\n if ((cpuid & STORM_CPUID_runtime_bit_AVX512BW)) {\n if (!tabular) printf(\"libflagstats-avx512bw\\t\");\n fflush(NULL);\n bool isok = benchmarkMany(\"libflagstats-avx512bw\", n, m, iterations, FLAGSTAT_avx512, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 2);\n }\n if (verbose && !tabular) printf(\"\\n\");\n\n if (!tabular) printf(\"libflagstats-avx512bw-improved\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"libflagstats-avx512bw-improved\", n, m, iterations, FLAGSTAT_avx512_improved, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 2);\n }\n if (verbose && !tabular) printf(\"\\n\");\n\n if (!tabular) printf(\"libflagstats-avx512bw-improved2\\t\");\n fflush(NULL);\n isok = benchmarkMany(\"libflagstats-avx512bw-improved2\", n, m, iterations, FLAGSTAT_avx512_improved2, verbose, true, tabular);\n if (isok == false) {\n printf(\"Problem detected with %u.\\n\", 2);\n }\n if (verbose && !tabular) printf(\"\\n\");\n // }\n }\n #endif\n\n if (!verbose && !tabular)\n printf(\"Try -v to get more details.\\n\");\n\n return EXIT_SUCCESS;\n}\n#else // __linux__\n\n#include <stdio.h>\n#include <stdlib.h>\n\nint main() {\n printf(\"This is a linux-specific benchmark\\n\");\n return EXIT_SUCCESS;\n}\n\n#endif\n"
},
{
"alpha_fraction": 0.6639785170555115,
"alphanum_fraction": 0.6693548560142517,
"avg_line_length": 31.34782600402832,
"blob_id": "e72df9525511a33d790f9013fcf3a1e06951c320",
"content_id": "55c87e7057ffbce5076e00d16874e964b9a5bae3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1488,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 46,
"path": "/python/setup.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "try:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nfrom distutils.command.sdist import sdist as _sdist\nfrom Cython.Distutils import build_ext\nfrom Cython.Build import cythonize\nfrom distutils.extension import Extension\n\nimport numpy as np\n\n# Read contents of README markdown file and store\n# in the long_description parameter\nfrom os import path\nthis_directory = path.abspath(path.dirname(__file__))\nwith open(path.join(this_directory, 'README.md'), encoding='UTF-8') as f:\n long_description = f.read()\n\nsetup(\n name='pyflagstats',\n version='0.1.4',\n description=\"Efficient subroutines for computing summary statistics for the SAM FLAG field\",\n long_description=long_description,\n long_description_content_type='text/markdown',\n author=\"Marcus D. R. Klarqvist\",\n author_email=\"mk819@cam.ac.uk\",\n platforms=\"Linux, MacOSX, Windows\",\n url=\"https://github.com/mklarqvist/libflagstats\",\n ext_modules=cythonize(\n Extension(\n \"pyflagstats\",\n sources=[\"libflagstats.pyx\"],\n include_dirs=[np.get_include()]\n )\n ),\n install_requires=[\"numpy\", \"cython\"],\n license=\"Apache 2.0\",\n keywords = ['simd', 'popcount', 'popcnt', 'pospopcnt', 'hts', 'ngs', 'flags'],\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3',\n ],\n)\n"
},
{
"alpha_fraction": 0.44174888730049133,
"alphanum_fraction": 0.5696569085121155,
"avg_line_length": 45.03333282470703,
"blob_id": "069780242d8f2bb048294f2bbe5a3a65aeca3256",
"content_id": "4f49ca973bb0b70e9a0adb25c5b31f7bb90e4ce3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11051,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 240,
"path": "/README.md",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "# libflagstats\n\n[](https://badge.fury.io/py/pyflagstats)\n[](https://colab.research.google.com/github/mklarqvist/libflagstats/blob/master/python/pyflagstats.ipynb)\n\n\nThese functions compute the summary statistics for the SAM FLAG field (flagstat)\nusing fast SIMD instructions. They are based on the\n[positional-popcount](https://github.com/mklarqvist/positional-popcount)\n(`pospopcnt`) subroutines implemented in\n[libalgebra](https://github.com/mklarqvist/libalgebra) and assumes that the data\nis available as contiguous streams (e.g. [column projection](https://en.wikipedia.org/wiki/Projection_(relational_algebra))). The heavily\nbranched and bit-dependent [SAMtools](https://github.com/samtools/samtools/) code can be rewritten using a mask-select\npropagate-carry approach that feeds into bit-transposed Harley-Seal-based carry-save adder\nnetworks.\n\nThe positional population count is described in the paper:\n* [Efficient Computation of Positional Population Counts Using SIMD Instructions](https://arxiv.org/abs/1911.02696) by Marcus D. R. Klarqvist and Wojciech Muła and Daniel Lemire\n\n## Speedup\n\nThis benchmark shows the speedup of the pospopcnt algorithms compared to\n[samtools](https://github.com/samtools/samtools) using a human HiSeqX readset\nwith 824,541,892 reads. See [Results](#results) for additional information. On\nthis readset, the pospopcnt-based functions are >3802-fold faster compared to\nBAM and 402.6-fold faster compared to CRAM. Note that the BAM format does not\nhave column projection capabilities. Around 80% of the CPU time is spent\nretrieving data from disk for the `pospopcnt`-functions. In this example, we\ncompress data blocks of 512k records (1 MB) using LZ4. \n\n| Approach | Time | Speedup |\n|-----------------|------------|---------|\n| Samtools – BAM | 30m 50.06s | 1 |\n| Samtools – CRAM | 4m 50.68s | 6.36 |\n| libflagstats-LZ9 | 0.72s | 2569.53 |\n| libflagstats-raw | 0.48s | 3802.90 |\n\nWe also directly compared the potential speed of the naive flagstat subroutine\nin samtools againt these functions if samtools would be rewritten with efficient\ncolumn projection and the compression method changed to LZ4. In this context,\nthese functions are still 6.58-fold faster.\n\n| Approach | Time | Speedup |\n|----------------------|--------|---------|\n| samtools-rewrite+LZ4 | 4.74 s | 1 |\n| libflagstats | 0.72s | 6.58 |\n\n### Usage\n\nFor Linux/Mac: Compile the test suite with: `make`. LZ4 and Zstd needs to be\ninstalled on the target machine or pass the `LZ4_PATH` and `ZSTD_PATH` flags to\nmake for non-standard locations.\n\nFirst, import 2-byte FLAG words from a SAM file:\n```bash\nsamtools view NA12878D_HiSeqX_R12_GRCh37.bam | cut -f 2 | ./utility > NA12878D_HiSeqX_R12_GRCh37_flags.bin\n```\n\nCompress the binary file using 512k blocks:\n```bash\nfor i in {1..10}; do ./bench compress -i NA12878D_HiSeqX_R12_GRCh37_flags.bin -l -c $i; done\nfor i in {1..10}; do ./bench compress -i NA12878D_HiSeqX_R12_GRCh37_flags.bin -l -f -c $i; done\nfor i in {1..20}; do ./bench compress -i NA12878D_HiSeqX_R12_GRCh37_flags.bin -z -c $i; done\n```\n\nEvaluate the flagstat subroutines by first decompressing the file twice while\nclearing cache and then computing samtools and pospopcnt.\n```bash\nfor i in {1..10}; do ./bench decompress -i NA12878D_HiSeqX_R12_GRCh37_flags.bin_HC_c${i}.lz4; done\nfor i in {1..10}; do ./bench decompress -i NA12878D_HiSeqX_R12_GRCh37_flags.bin_fast_a${i}.lz4; done\nfor i in {1..20}; do ./bench decompress -i NA12878D_HiSeqX_R12_GRCh37_flags.bin_c${i}.zst; done\n```\n\n### History\n\nThese functions were developed for [pil](https://github.com/mklarqvist/pil).\n\n## Problem statement\n\nThe FLAG field in the [SAM interchange\nformat](https://github.com/samtools/hts-specs) is defined as the union of\n[1-hot](https://en.wikipedia.org/wiki/One-hot) encoded states for a given read.\nFor example, the following three states evaluating to true\n\n```\n00000001: read paired\n01000000: first in pair\n00001000: mate unmapped\n--------\n01001001: Decimal (73)\n```\n\nare stored in a packed 16-bit value (only the LSB is shown here). There are 12\nstates described in the SAM format:\n\n| One-hot | Description |\n|-------------------|-------------------------------------------|\n| 00000000 00000001 | Read paired |\n| 00000000 00000010 | Read mapped in proper pair |\n| 00000000 00000100 | Read unmapped |\n| 00000000 00001000 | Mate unmapped |\n| 00000000 00010000 | Read reverse strand |\n| 00000000 00100000 | Mate reverse strand |\n| 00000000 01000000 | First in pair |\n| 00000000 10000000 | Second in pair |\n| 00000001 00000000 | Not primary alignment |\n| 00000010 00000000 | Read fails platform/vendor quality checks |\n| 00000100 00000000 | Read is PCR or optical duplicate |\n| 00001000 00000000 | Supplementary alignment |\n\nComputing FLAG statistics from readsets involves iteratively incrementing up to\n16 counters. The native properties of a column-oriented storage, specifically\ncolumn projection, already deliver good performance because of data locality\n(memory contiguity) and value typing. We want to maximize compute on large\narrays of values by exploiting vectorized instructions, if available.\n\n## Goals\n\n* Achieve high-performance on large arrays of values.\n* Support machines without SIMD (scalar).\n* Specialized algorithms for SSE4 up to AVX512.\n\n## Technical approach\n\n### Results\n### Datasets\nAligned data:\n* https://dnanexus-rnd.s3.amazonaws.com/NA12878-xten/mappings/NA12878D_HiSeqX_R1.bam\n\nUnaligned data:\n* https://dnanexus-rnd.s3.amazonaws.com/NA12878-xten/reads/NA12878D_HiSeqX_R1.fastq.gz\n* https://dnanexus-rnd.s3.amazonaws.com/NA12878-xten/reads/NA12878D_HiSeqX_R2.fastq.gz\n\n### Speed\n\n| Comp. Method | Decomp. | Sam-branchless | sam | flagstat |\n|--------------|---------|----------------|------|----------|\n| LZ4-HC-c1 | 988 | 8924 | 4991 | 1107 |\n| LZ4-HC-c2 | 993 | 8848 | 5076 | 1132 |\n| LZ4-HC-c3 | 938 | 8686 | 4930 | 1049 |\n| LZ4-HC-c4 | 846 | 8803 | 4876 | 933 |\n| LZ4-HC-c5 | 824 | 8525 | 5117 | 974 |\n| LZ4-HC-c6 | 770 | 8536 | 4774 | 851 |\n| LZ4-HC-c7 | 680 | 8404 | 4748 | 837 |\n| LZ4-HC-c8 | 644 | 8453 | 4662 | 755 |\n| LZ4-HC-c9 | **580** | 8434 | 4740 | **722** |\n| LZ4-fast-c2 | 814 | 8658 | 4886 | 990 |\n| LZ4-fast-c3 | 837 | 8576 | 4840 | 941 |\n| LZ4-fast-c4 | 889 | 8627 | 4861 | 1026 |\n| LZ4-fast-c5 | 826 | 8590 | 4885 | 1037 |\n| LZ4-fast-c6 | 823 | 8629 | 5034 | 951 |\n| LZ4-fast-c7 | 837 | 8606 | 4999 | 985 |\n| LZ4-fast-c8 | 834 | 8604 | 4920 | 962 |\n| LZ4-fast-c9 | 853 | 8615 | 4944 | 951 |\n| LZ4-fast-c10 | 853 | 8648 | 5024 | 950 |\n| Zstd-c1 | 3435 | 11438 | 7798 | 3630 |\n| Zstd-c2 | 3577 | 11231 | 8110 | 3767 |\n| Zstd-c3 | 3403 | 11250 | 7922 | 3553 |\n| Zstd-c4 | 3562 | 11223 | 7949 | 3649 |\n| Zstd-c5 | 2919 | 10584 | 7263 | 2986 |\n| Zstd-c6 | 2964 | 10680 | 7545 | 3015 |\n| Zstd-c7 | 2681 | 10591 | 7067 | 2715 |\n| Zstd-c8 | 2641 | 10523 | 7103 | 2850 |\n| Zstd-c9 | 2352 | 10453 | 6669 | 2463 |\n| Zstd-c10 | 2309 | 10094 | 6756 | 2509 |\n| Zstd-c11 | 2344 | 10018 | 6430 | 2467 |\n| Zstd-c12 | 2116 | 9916 | 6242 | 2252 |\n| Zstd-c13 | 2107 | 9844 | 6183 | 2236 |\n| Zstd-c14 | 1955 | 9616 | 5969 | 2044 |\n| Zstd-c15 | 1716 | 9562 | 5807 | 1808 |\n| Zstd-c16 | 1286 | 9208 | 5592 | 1448 |\n| Zstd-c17 | 1278 | 8996 | 5592 | 1396 |\n| Zstd-c18 | 1192 | 8907 | 5294 | 1306 |\n| Zstd-c19 | 1181 | 8931 | 5362 | 1293 |\n| Zstd-c20 | 1175 | 8982 | 5369 | 1303 |\n\n```bash\n$ time samtools flagstat NA12878D_HiSeqX_R12_GRCh37.bam\n824541892 + 0 in total (QC-passed reads + QC-failed reads)\n0 + 0 secondary\n5393628 + 0 supplementary\n0 + 0 duplicates\n805383403 + 0 mapped (97.68% : N/A)\n819148264 + 0 paired in sequencing\n409574132 + 0 read1\n409574132 + 0 read2\n781085884 + 0 properly paired (95.35% : N/A)\n797950890 + 0 with itself and mate mapped\n2038885 + 0 singletons (0.25% : N/A)\n9537902 + 0 with mate mapped to a different chr\n4425946 + 0 with mate mapped to a different chr (mapQ>=5)\n\nreal 30m50.059s\nuser 30m10.638s\nsys 0m38.440s\n```\n\n```bash\n$ time samtools flagstat NA12878D_HiSeqX_R12_GRCh37.cram\n824541892 + 0 in total (QC-passed reads + QC-failed reads)\n0 + 0 secondary\n5393628 + 0 supplementary\n0 + 0 duplicates\n805383403 + 0 mapped (97.68% : N/A)\n819148264 + 0 paired in sequencing\n409574132 + 0 read1\n409574132 + 0 read2\n781085884 + 0 properly paired (95.35% : N/A)\n797950890 + 0 with itself and mate mapped\n2038885 + 0 singletons (0.25% : N/A)\n9537902 + 0 with mate mapped to a different chr\n4425946 + 0 with mate mapped to a different chr (mapQ>=5)\n\nreal 4m50.684s\nuser 3m37.394s\nsys 1m12.396s\n```\n\n```c\n#define flagstat_loop(s, c) do { \\\n int w = (c & BAM_FQCFAIL)? 1 : 0; \\\n ++(s)->n_reads[w]; \\\n if (c & BAM_FSECONDARY ) { \\\n ++(s)->n_secondary[w]; \\\n } else if (c & BAM_FSUPPLEMENTARY ) { \\\n ++(s)->n_supp[w]; \\\n } else if (c & BAM_FPAIRED) { \\\n ++(s)->n_pair_all[w]; \\\n if ((c & BAM_FPROPER_PAIR) && !(c & BAM_FUNMAP) ) ++(s)->n_pair_good[w]; \\\n if (c & BAM_FREAD1) ++(s)->n_read1[w]; \\\n if (c & BAM_FREAD2) ++(s)->n_read2[w]; \\\n if ((c & BAM_FMUNMAP) && !(c & BAM_FUNMAP)) ++(s)->n_sgltn[w]; \\\n if (!(c & BAM_FUNMAP) && !(c & BAM_FMUNMAP)) { \\\n ++(s)->n_pair_map[w]; \\\n } \\\n } \\\n if (!(c & BAM_FUNMAP)) ++(s)->n_mapped[w]; \\\n if (c & BAM_FDUP) ++(s)->n_dup[w]; \\\n} while (0)\n```"
},
{
"alpha_fraction": 0.5444148182868958,
"alphanum_fraction": 0.6408692598342896,
"avg_line_length": 29.858823776245117,
"blob_id": "2b2c621c75fb3656021bc253453feb187bbcc4ae",
"content_id": "7fc006287e3479936c976937b1d70509062fa726",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2623,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 85,
"path": "/paper/scripts/mask_data3.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom avx512 import *\n\nAVX512_BIT12_FQCFAIL_0 = 0\nAVX512_BIT12_FQCFAIL_1 = 1\nAVX512_BIT13_FQCFAIL_0 = 2\nAVX512_BIT13_FQCFAIL_1 = 3\nAVX512_BIT14_FQCFAIL_0 = 4\nAVX512_BIT14_FQCFAIL_1 = 5\nAVX512_FREAD1_FQCFAIL_0 = 6\nAVX512_FREAD1_FQCFAIL_1 = 8\nAVX512_FREAD2_FQCFAIL_0 = 7\nAVX512_FREAD2_FQCFAIL_1 = 9\nAVX512_FSECONDARY_FQCFAIL_0 = 10\nAVX512_FSECONDARY_FQCFAIL_1 = 11\nAVX512_FSUPPLEMENTARY_FQCFAIL_0 = 14\nAVX512_FSUPPLEMENTARY_FQCFAIL_1 = 15\nAVX512_FDUP_FQCFAIL_0 = 12\nAVX512_FDUP_FQCFAIL_1 = 13\nAVX512_FUNMAP = 0\n\ndef bit(pos):\n return 1 << pos\n\n\ndef get_condition_mask(FSUPPLEMENTARY, FSECONDARY, FPAIRED):\n mask = 0\n mask |= bit(AVX512_FDUP_FQCFAIL_0) | bit(AVX512_FDUP_FQCFAIL_1)\n\n if FSECONDARY:\n mask |= bit(AVX512_FSECONDARY_FQCFAIL_0) | bit(AVX512_FSECONDARY_FQCFAIL_1)\n elif FSUPPLEMENTARY:\n mask |= bit(AVX512_FSUPPLEMENTARY_FQCFAIL_0) | bit(AVX512_FSUPPLEMENTARY_FQCFAIL_1)\n elif FPAIRED:\n mask |= bit(AVX512_BIT12_FQCFAIL_0) | bit(AVX512_BIT12_FQCFAIL_1)\n mask |= bit(AVX512_BIT13_FQCFAIL_0) | bit(AVX512_BIT13_FQCFAIL_1)\n mask |= bit(AVX512_BIT14_FQCFAIL_0) | bit(AVX512_BIT14_FQCFAIL_1)\n mask |= bit(AVX512_FREAD1_FQCFAIL_0) | bit(AVX512_FREAD1_FQCFAIL_1)\n mask |= bit(AVX512_FREAD2_FQCFAIL_0) | bit(AVX512_FREAD2_FQCFAIL_1)\n\n print(\"{:d} {:d} {:d} {:016b}\".format(FSECONDARY, FSUPPLEMENTARY, FPAIRED, mask))\n\n return mask\n\n\ndef get_duplication_word(FSUPPLEMENTARY, FDUP, FSECONDARY, FUNMAP):\n mask = 0\n\n if FSUPPLEMENTARY:\n mask |= bit(AVX512_FSUPPLEMENTARY_FQCFAIL_0)\n mask |= bit(AVX512_FSUPPLEMENTARY_FQCFAIL_1)\n\n if FDUP:\n mask |= bit(AVX512_FDUP_FQCFAIL_0)\n mask |= bit(AVX512_FDUP_FQCFAIL_1)\n\n if FSECONDARY:\n mask |= bit(AVX512_FSECONDARY_FQCFAIL_0)\n mask |= bit(AVX512_FSECONDARY_FQCFAIL_1)\n\n if FUNMAP:\n mask |= bit(AVX512_FUNMAP)\n\n return mask\n\n\ncondition = []\nduplication = []\nfor k in range(2**5):\n FSECONDARY = int(k & 0x01 != 0)\n FUNMAP = int(k & 0x02 != 0)\n FDUP = int(k & 0x04 != 0)\n FSUPPLEMENTARY = int(k & 0x08 != 0)\n FPAIRED = int(k & 0x10 != 0)\n\n condition.append(get_condition_mask(FSUPPLEMENTARY, FSECONDARY, FPAIRED))\n duplication.append(get_duplication_word(FSUPPLEMENTARY, FDUP, FSECONDARY, FUNMAP))\n\nprint(\"Duplication lookup\")\nprint(avx512_const(word2byte_array(duplication)))\n\nprint()\n\nprint(\"Condition mask\")\nprint(avx512_const(word2byte_array(condition)))\n"
},
{
"alpha_fraction": 0.5247018933296204,
"alphanum_fraction": 0.5837592482566833,
"avg_line_length": 26.952381134033203,
"blob_id": "f477e8691ef6e2fdf8e8b74a270c65f7758fb83c",
"content_id": "ce6f9a87b0d49c54c2d4482dbfb898b89375d463",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1761,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 63,
"path": "/paper/scripts/sse4_avx2_mask.py",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nFLAGSTAT_FPAIRED = 1 # bit 0\nFLAGSTAT_FUNMAP = 4 # bit 2\nFLAGSTAT_FMUNMAP = 8 # bit 3\nFLAGSTAT_FREVERSE = 16 # bit 4\nFLAGSTAT_FMREVERSE = 32 # bit 5\nFLAGSTAT_FREAD1 = 64 # bit 6\nFLAGSTAT_FREAD2 = 128 # bit 7\nFLAGSTAT_FSECONDARY = 256 # bit 8\nFLAGSTAT_FQCFAIL = 512 # bit 9\nFLAGSTAT_FDUP = 1024 # bit 10\nFLAGSTAT_FSUPPLEMENTARY = 2048 # bit 11\n\nFLAGSTAT_BIT12 = 1 << 12\nFLAGSTAT_BIT13 = 1 << 13\nFLAGSTAT_BIT14 = 1 << 14\n\ndef get_mask16(FSECONDARY, FSUPPLEMENTARY, FPAIRED):\n mask = 0\n mask |= FLAGSTAT_FUNMAP\n mask |= FLAGSTAT_FDUP\n mask |= FLAGSTAT_FQCFAIL\n\n if FSECONDARY:\n mask |= FLAGSTAT_FSECONDARY\n elif FSUPPLEMENTARY:\n mask |= FLAGSTAT_FSUPPLEMENTARY\n elif FPAIRED:\n mask |= FLAGSTAT_BIT12\n mask |= FLAGSTAT_BIT13\n mask |= FLAGSTAT_BIT14\n mask |= FLAGSTAT_FREAD1\n mask |= FLAGSTAT_FREAD2\n\n return mask\n\n\ndef get_mask(FSUPPLEMENTARY, HIGH_BYTE, FPAIRED, FSECONDARY):\n mask = get_mask16(FSECONDARY, FSUPPLEMENTARY, FPAIRED)\n\n if HIGH_BYTE:\n return mask >> 8\n else:\n return mask & 0xff\n\n\ndef main():\n values = []\n for k in range(2**4):\n FSECONDARY = int(k & 0x01 != 0)\n FPAIRED = int(k & 0x02 != 0)\n HIGH_BYTE = int(k & 0x04 != 0)\n FSUPPLEMENTARY = int(k & 0x08 != 0)\n\n values.append(get_mask(FSUPPLEMENTARY, HIGH_BYTE, FPAIRED, FSECONDARY))\n\n hexstr = ', '.join(f\"0x{byte:02x}\" for byte in values)\n print(f\"const __m128i mask_lookup = _mm_setr_epi8({hexstr});\")\n print(f\"const __m256i mask_lookup = _mm256_setr_epi8({hexstr}, {hexstr});\")\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.58890700340271,
"alphanum_fraction": 0.6378466486930847,
"avg_line_length": 33.11111068725586,
"blob_id": "d9241f851de192493ce242843e4e02b76550ae9d",
"content_id": "6632ebe1a0fdccf189a636b0cf9a93654c67a9cd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 613,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 18,
"path": "/benchmark/generate.cpp",
"repo_name": "mklarqvist/libflagstats",
"src_encoding": "UTF-8",
"text": "#include <iostream>//out streams\n#include <random>//random generator (c++11)\n#include <chrono>//time (c++11)\n\n// Generates N random numbers in U(0, 4096) given the first provided\n// input argument.\nint main(int argc, char** argv) {\n std::random_device rd; // obtain a random number from hardware\n std::mt19937 eng(rd()); // seed the generator\n\n std::uniform_int_distribution<uint16_t> distr(0, 4096-1); // right inclusive\n for (int i = 0; i < strtoull( argv[1], NULL, 10 ); ++i) {\n uint16_t x = distr(eng);\n std::cout.write((char*)&x, sizeof(uint16_t));\n }\n\n return EXIT_SUCCESS;\n}"
}
] | 18 |
chandan114/Programming_Questions | https://github.com/chandan114/Programming_Questions | 174ae3027b939d2cd75128b504d59d9324b38b07 | b430708176a955af5003db53672ea4f1537ed9f3 | c3719a8dca90866201036fd4704dceaba55e8bd4 | refs/heads/master | 2023-01-15T10:54:47.043242 | 2020-11-22T10:34:19 | 2020-11-22T10:34:19 | 274,869,053 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4730113744735718,
"alphanum_fraction": 0.5355113744735718,
"avg_line_length": 20.580644607543945,
"blob_id": "5a3e7d9ac8cd817c3463a3b8fb72845f6d94f37e",
"content_id": "b120916363b1fda381bd869af7426e77de901327",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 31,
"path": "/Life_Bord.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "import math\r\nfrom decimal import getcontext, Decimal\r\ngetcontext().prec = 7\r\ndef dist(x , y , x1 ,y1):\r\n return Decimal((math.sqrt( ((x1-x)*(x1-x)) + ((y1-y)*(y1-y)))))\r\n\r\nx1 = Decimal(float(input()))\r\nx2 = Decimal(float(input()))\r\ny1 = Decimal(float(input()))\r\ny2 = Decimal(float(input()))\r\nf = Decimal(float(input()))\r\n\r\nif(x1 > x2):\r\n ub,lb = x1 , x2\r\nelse:\r\n ub,lb = x2 , x1\r\n\r\nwhile lb<ub:\r\n mid = lb+ub/Decimal(2)\r\n mid1 = lb+mid/Decimal(2)\r\n mid2 = ub+mid/Decimal(2)\r\n\r\n t1 = dist(x1,y1,mid1,0)/f + dist(mid1,0,x2,y2)\r\n t2 = dist(x1,y1,mid2,0)/f + dist(mid2,0,x2,y2)\r\n\r\n if(t1 < t2):\r\n ub = mid\r\n else:\r\n lb = mid\r\n\r\nprint(\"{0:.6f}\".format(ub))\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.47162023186683655,
"alphanum_fraction": 0.49432405829429626,
"avg_line_length": 11.676055908203125,
"blob_id": "664601715357feac8aa1dc074bf9fa502a711571",
"content_id": "b96fdadfabba575ffcd693506cc962d95b4a449d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 969,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 71,
"path": "/Search_rotated_array.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Search_rotated_array{\r\n\r\n\tstatic int binary(int array[] , int low , int high , int key){\r\n\r\n\t\twhile(low<high){\r\n\r\n\t\t\tint mid = (low + high)/2 ;\r\n\r\n\t\t\tif(array[mid] == key ) {\r\n\r\n\t\t\t\treturn 1 ;\r\n\t\t\t\t\r\n\r\n\r\n\t\t\t}\r\n\t\t\telse if(key>array[mid]){\r\n\r\n\t\t\t\tlow = mid+1;\r\n\t\t\t}\r\n\t\t\telse{\r\n\r\n\t\t\t\thigh = mid;\r\n\t\t\t}\r\n\r\n\t\t}\r\n\r\n\t\treturn 0;\r\n\t}\r\n\r\n\tstatic int findpivot(int array[]){\r\n\r\n\t\tfor (int i=0; i<array.length-1;i++ ) {\r\n\t\t\t\r\n\t\t\tif(array[i] > array[i+1]){\r\n\r\n\t\t\t\treturn i+1 ;\r\n\t\t\t}\r\n\t\t}\r\n\r\n\t\treturn 0 ;\r\n\t}\r\n\r\n\r\n\tstatic int rotatedarray(int array[] , int key){\r\n\r\n\t\tint pivot = findpivot(array) ;\r\n\r\n\t\tif(binary(array , 0 , pivot , key)==1){\r\n\r\n\t\t\tSystem.out.println(\"yes\") ;\r\n\t\t}\r\n\t\telse if (binary(array , pivot , array.length , key)==1) {\r\n\t\t\t\t\r\n\t\t\t\tSystem.out.println(\"yes\") ;\r\n\t\t}\r\n\t\telse{\r\n\r\n\t\t\tSystem.out.println(\"NO\") ;\r\n\t\t}\r\n\r\n\t\treturn 0;\r\n\r\n\t}\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\t\tint array[] = {4,5,6,7,8,1,2} ;\r\n\r\n\t\trotatedarray(array , 61);\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.4623376727104187,
"alphanum_fraction": 0.5116882920265198,
"avg_line_length": 20.764705657958984,
"blob_id": "ba50da100f53e73db90d26b2fe5fced7272a1b2a",
"content_id": "088df7fdc9f54914dab398f791b99edcf4f91af3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 17,
"path": "/Subarray_with_given_Sum_Efficient.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "array = [1, 20 ,20 , 3 ,10 , 5]\r\nrequireSum = 23\r\n# maxval = array[0] \r\nsumval = array[0]\r\nstart = 0\r\n\r\nfor i in range(1 , len(array)+1):\r\n \r\n while(sumval>requireSum and start < i-1):\r\n sumval -= array[start]\r\n start+=1\r\n \r\n if(sumval == requireSum):\r\n print(\"start :{} End:{}\".format(start, i-1)) ;\r\n\r\n if(i<len(array)):\r\n sumval+=array[i]"
},
{
"alpha_fraction": 0.41327914595603943,
"alphanum_fraction": 0.424119234085083,
"avg_line_length": 20.1875,
"blob_id": "f1c62bf715aec9b127d654a330722fb448d212b9",
"content_id": "394abc8fd451633e200382411dbc2272a93d12de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 32,
"path": "/Wordbreak_recursion.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "dicnry = [\"mobile\",\"samsung\",\"sam\",\"sung\", \r\n \"man\",\"mango\", \"icecream\",\"and\", \r\n \"go\",\"i\",\"love\",\"ice\",\"cream\" ]\r\n\r\n\r\n\r\ndef wordbreak(arr , str , n , dicnry, result):\r\n\r\n \r\n\r\n if(str in dicnry):\r\n\r\n result+=str+' '\r\n\r\n if(n==len(arr)-1):\r\n print(result)\r\n return True\r\n\r\n str = arr[n:]\r\n return wordbreak(arr , arr[n+1] , n+1 , dicnry , result)\r\n \r\n else:\r\n if(n==len(arr)-1):\r\n return False\r\n\r\n return wordbreak(arr , str + arr[n+1] , n+1 , dicnry , result)\r\n\r\n\r\n # return False\r\n\r\narr = 'ilovesamsungmobile'\r\nprint(wordbreak(arr , arr[0] , 0 , dicnry, ''))\r\n\r\n\r\n \r\n\r\n \r\n \r\n"
},
{
"alpha_fraction": 0.40444016456604004,
"alphanum_fraction": 0.4160231649875641,
"avg_line_length": 9.795454978942871,
"blob_id": "bf206cd9aca4b7250567932c18da238fcb09ce08",
"content_id": "326a58fb189987d69ad548fc9daeca62cc010fa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 88,
"path": "/KMP_ALO.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Kmp{\r\n\r\n\tpublic static void main(String[] args) {\r\n\r\n\r\n\t\tString text = \"ABABDABACDABABCABAB\" ;\r\n\t\tString find = \"ABABCABAB\" ;\r\n\r\n\r\n\r\n\r\n\r\n\t\tint lenfind = find.length();\r\n\r\n\t\tint pre[] = new int[lenfind];\r\n\t\tint index = 0 ;\r\n\t\tpre[index] = 0 ;\r\n\t\tint i = 1 ;\r\n\r\n\t\twhile(i<lenfind){\r\n\r\n\t\t\tif(find.charAt(i) == find.charAt(index)){\r\n\r\n\t\t\t\tindex++ ;\r\n\t\t\t\tpre[i] = index ;\r\n\t\t\t\ti++ ;\r\n\r\n\t\t\t}\r\n\r\n\t\t\telse{\r\n\r\n\t\t\t\tif(index!=0){\r\n\r\n\t\t\t\t\tindex = pre[index-1] ;\r\n\r\n\t\t\t\t}\r\n\t\t\t\telse{\r\n\r\n\t\t\t\t\tpre[i] = index ;\r\n\t\t\t\t\ti++ ;\r\n\t\t\t\t}\r\n\t\t\t}\r\n\t\t}\r\n\r\n\t// \tfor( int l : pre)\r\n\r\n\t// System.out.print(l) ;\r\n\t\t\r\n\t// }\r\n\r\n\t\tint k = 0 ;\r\n\t\tint f= -1 ;\r\n\t\tint textlen = text.length() ;\r\n\t\twhile(k<textlen){\r\n\r\n\r\n\t\t\tif( text.charAt(k) == find.charAt(f+1)){\r\n\r\n\t\t\t\tf++ ;\r\n\t\t\t\tk++ ;\r\n\t\t\t}\r\n\r\n\t\t\tif ( f == (lenfind-1) ){\r\n\r\n\t\t\t\tSystem.out.println(k - lenfind) ;\r\n\t\t\t\tf = pre[f] ;\r\n\t\t\t}\r\n\r\n\t\t\t\r\n\t\t\telse if(k<textlen && text.charAt(k) != find.charAt(f+1)){\r\n\r\n\t\t\t\tif(f == 0){\r\n\r\n\t\t\t\t\tk++ ;\r\n\t\t\t\t}\r\n\t\t\t\telse{\r\n\r\n\t\t\t\t\tf = pre[f-1] ;\r\n\t\t\t\t}\r\n\t\t\t}\r\n\t\t}\r\n\r\n\r\n\r\n}\r\n\t\r\n\r\n}"
},
{
"alpha_fraction": 0.3952205777168274,
"alphanum_fraction": 0.40257352590560913,
"avg_line_length": 13.54285717010498,
"blob_id": "ffd0becc9bbe7d835373a4c9ef314774c0763f1a",
"content_id": "8e50aa5140d00e36f7f7b87abc0984d07480f974",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 35,
"path": "/limitobject.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Exx extends Exception{\r\n \r\n public Exx(){\r\n }\r\n \r\n}\r\n\r\nclass Callme{\r\n static int count = 0; \r\n Callme(){\r\n count++;\r\n if(count==3){\r\n try{\r\n throw new Exx() ;\r\n }\r\n catch(Exx e){\r\n System.out.println(\"out bond\") ; \r\n }\r\n \r\n }\r\n }\r\n}\r\n\r\n\r\n\r\npublic class Main\r\n{\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\t\tCallme a = new Callme() ;\r\n\t\tCallme a1 = new Callme() ;\r\n\t\tCallme a2 = new Callme() ;\r\n\t\t\r\n\t}\r\n}\r\n"
},
{
"alpha_fraction": 0.5124555230140686,
"alphanum_fraction": 0.527876615524292,
"avg_line_length": 25.19354820251465,
"blob_id": "d184bf3c7a99786b125a0d9b3f8f7b8f4a299103",
"content_id": "460f987bd9eabd5d60d1e5d38e184d7d7babd88e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 843,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 31,
"path": "/CodeChef July 2020/Reverse_gear.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "Testcase = int(input())\r\nfor i in range(Testcase):\r\n forward_count =0\r\n backward_count =0\r\n forward_time =0\r\n backward_time = 0\r\n rem = 0\r\n val = True\r\n x= list(map(int,input().split()))\r\n forward , backward , time , distance = x\r\n while(val):\r\n distance = distance - backward\r\n if(distance<0):\r\n rem = distance+backward\r\n break\r\n if(distance==0):\r\n backward_count+=1\r\n break\r\n backward_count +=1\r\n\r\n distance = distance + forward\r\n if(distance<0):\r\n break\r\n if(distance==0):\r\n forward_count+=1\r\n break\r\n forward_count +=1\r\n\r\n forward_time = forward*time\r\n backward_time = backward*time\r\n print( (forward_count*forward_time) + (backward_count*backward_time) + (rem*time) )\r\n"
},
{
"alpha_fraction": 0.4035608172416687,
"alphanum_fraction": 0.459940642118454,
"avg_line_length": 17.117647171020508,
"blob_id": "e3fa0a947ec374bac650cd2d7584e5787fc07bf0",
"content_id": "faa1b66b23c800837e0b7f21981d6a3ba109d419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 17,
"path": "/Length_of_Largest_Subarray_sum_0.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "array = [ 1 , 20 , 3 , 5 , 10 , 5 , 3 , 4] \r\nreq = 23\r\nsum = array[0]\r\nstart = 0\r\nmaxlen = 0\r\n\r\nfor i in range(1 ,len(array)):\r\n\r\n sum = sum+array[i]\r\n while(sum > req and start<i-1):\r\n sum-= array[start]\r\n start+=1\r\n\r\n if(sum==req):\r\n maxlen = max(maxlen , (i+1) - start)\r\n \r\nprint(maxlen)\r\n \r\n\r\n"
},
{
"alpha_fraction": 0.432314395904541,
"alphanum_fraction": 0.4890829622745514,
"avg_line_length": 15.461538314819336,
"blob_id": "708af5ad3cec029a9fd9bf4cad52608e9fe89b73",
"content_id": "c964b7184bf4f00398814e81036602ebdfb6b688",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 13,
"path": "/Kadane_Algo.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "array = [-2, -3, 4, -1, -2, 1, 5, -3]\r\nmaxval = array[0]\r\nsumval = 0\r\n\r\nfor i in range(1 ,len(array)):\r\n\r\n sumval+=array[i]\r\n maxval = max(sumval , maxval)\r\n\r\n if(sumval<0):\r\n sumval = 0 ;\r\n \r\nprint(maxval)\r\n\r\n"
},
{
"alpha_fraction": 0.33940398693084717,
"alphanum_fraction": 0.37251654267311096,
"avg_line_length": 16.75,
"blob_id": "f8ffb9b3b34a4e7b0060a8b8f9e9ead4811b413f",
"content_id": "e39f750369040aa27be57c48ef976cb6bc28683c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 32,
"path": "/CodeChef July 2020/codechef August 3.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "for l in range( int(input()) ):\r\n chef , rick = map(int , input().split())\r\n\r\n if(chef<10 and rick<10):\r\n print(\"{} {}\".format(1,1))\r\n continue\r\n\r\n \r\n\r\n if(chef%9!=0):\r\n c = (chef//9) +1\r\n else:\r\n c = chef//9\r\n\r\n \r\n if(rick%9!=0):\r\n r = (rick//9) +1\r\n else:\r\n r = rick//9\r\n\r\n if(chef==rick):\r\n print(\"{} {}\".format(1,r))\r\n continue \r\n \r\n if(c>r):\r\n print( \"{} {}\".format(1 , r ))\r\n continue\r\n else:\r\n print( \"{} {}\".format(0 , c ))\r\n continue\r\n\r\n print(\"{} {}\".format(1,r))\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.37197232246398926,
"alphanum_fraction": 0.39100345969200134,
"avg_line_length": 10.859259605407715,
"blob_id": "acf6b5823e054bc60ecac9ec1d28e3be9a34e228",
"content_id": "9d4d3908153808832905274b7b7380d75f92cecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1734,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 135,
"path": "/ReversePairs.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class ReversePairs{\r\n\r\n\r\n\t\tint sort(int low , int high , int array[]){\r\n\r\n\t\tint c = 0;\r\n\r\n\t\tif(low<high){\r\n\r\n\t\t\tint mid = (low+high)/2 ;\r\n\r\n\t\t\tc+=sort(low , mid , array);\r\n\t\t\tc+=sort(mid+1 , high , array) ;\r\n\t\t\tc+=merge(low , mid , high , array);\r\n\t\t}\r\n\r\n\t\treturn c;\r\n\t}\r\n\r\n\tint merge(int low , int mid ,int high , int array[]){\r\n\r\n\t\tint n1 = mid - low + 1;\r\n\t\tint n2 = high - mid;\r\n\r\n\t\tint l[] = new int[n1];\r\n\t\tint r[] = new int[n2];\r\n\r\n\r\n\r\n\t\tfor(int i=0 ; i<n1 ; ++i){\r\n\r\n\t\t\tl[i] = array[low+i] ;\r\n\t\t}\r\n\r\n\t\tfor(int j=0 ; j<n2 ; ++j){\r\n\r\n\t\t\tr[j] = array[mid + 1 + j];\r\n\t\t}\r\n\r\n\t\tint p = 0 ;\r\n\t\tint c= 0 ;\r\n\r\n\t\t for(int i = 0 ; i < n1 ; i++){\r\n\r\n\t\t \twhile(p<n2){\r\n\r\n\t\t \t\tif(l[i] > 2*r[p]){\r\n\t\t \t\t\tp++ ;\r\n\t\t \t\t}\r\n\t\t \t\telse{\r\n\r\n\t\t \t\t\tbreak;\r\n\t\t \t\t}\r\n\r\n\t\t \t\t\r\n\t\t \t}\r\n\r\n\t\t \tc+=p;\r\n\r\n\r\n\r\n\t\t }\r\n\r\n\r\n\t\tint i = 0 , j = 0 , k = low ;\r\n\t\t\r\n\r\n\t\twhile(i<n1 && j<n2){\r\n\r\n\r\n\r\n\r\n\t\t\tif(l[i]<=r[j]){\r\n\r\n\t\t\t\tarray[k] = l[i] ;\r\n\t\t\t\ti++ ;\r\n\r\n\r\n\t\t\t}else {\r\n\t\t\t\t\r\n\t\t\t\tarray[k] = r[j] ;\r\n\t\t\t\tj++ ;\r\n\t\t\t\t\r\n\t\t\t}\r\n\r\n\t\t\tk++ ;\r\n\t\t}\r\n\r\n\t\twhile(i<n1){\r\n\r\n\t\t\tarray[k] = l[i] ;\r\n\t\t\ti++ ;\r\n\t\t\tk++ ;\r\n\r\n\r\n\t\t}\r\n\r\n\t\twhile(j<n2){\r\n\r\n\t\t\tarray[k] = r[j] ;\r\n\t\t\tj++ ;\r\n\t\t\tk++ ;\r\n\r\n\r\n\t\t}\r\n\r\n\t\treturn(c);\r\n\t}\r\n\r\n\tstatic void printArray(int arr[]) \r\n { \r\n int n = arr.length; \r\n for (int i = 0; i < n; ++i) \r\n System.out.print(arr[i] + \" \"); \r\n System.out.println(); \r\n } \r\n\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\t\r\n\r\n\t\t\tint arr[] = {1,3,2,3,1}; \r\n \r\n System.out.println(\"Given Array\"); \r\n printArray(arr); \r\n \r\n ReversePairs ob = new ReversePairs(); \r\n System.out.println(ob.sort(0, arr.length - 1 ,arr)); \r\n \r\n System.out.println(\"\\nSorted array\"); \r\n printArray(arr); \r\n\r\n\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.5102880597114563,
"alphanum_fraction": 0.5267489552497864,
"avg_line_length": 18.69565200805664,
"blob_id": "96b1376e7dd594d90d7bb0f77b6fd88998d06248",
"content_id": "88183bfdbbc9b86edb9619814a3170460fb9d86c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 486,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 23,
"path": "/Collusion_course.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "\r\ncollusions= {}\r\ncount = 0\r\ndef dist(x,y , velocity):\r\n return ( (x**2 + y**2) / velocity**2 )\r\n\r\ndef comb(val):\r\n return ((val*(val-1))//2)\r\n\r\n\r\ncars = int(input())\r\nfor _ in range(cars):\r\n l = list(map(int , input().split()))\r\n x,y,velocity = l\r\n time = dist(x,y,velocity)\r\n try:\r\n collusions[time] = collusions[time] + 1\r\n except:\r\n collusions[time] = 1\r\n\r\nfor i in collusions:\r\n count = count + comb(collusions[i])\r\n\r\nprint(count)\r\n \r\n\r\n"
},
{
"alpha_fraction": 0.47351351380348206,
"alphanum_fraction": 0.4816216230392456,
"avg_line_length": 13.956896781921387,
"blob_id": "f0756609c44f195c223f0d34b82c06a68cadef88",
"content_id": "53a7b9b377d40fbf8ddd7ac47d0ae1ed5e166834",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1850,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 116,
"path": "/Max_number_in_each_level_Bst.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": " import java.util.*;\r\n\r\n class Max_number_in_each_level_Bst{\r\n\r\n \tpublic static Node root = null;\r\n\r\n \tclass Node{\r\n\r\n \t\tint val ;\r\n\r\n \t\tNode left , right ;\r\n\r\n \t\tNode(int val){\r\n\r\n \t\t\tthis.val =val ;\r\n \t\t\tright = left = null ;\r\n\r\n \t\t}\r\n \t}\r\n\r\n\r\n \tNode insert(Node node , int val){\r\n\r\n \t\tif(root==null){\r\n\r\n \t\t\troot = new Node(val);\r\n \t\t}\r\n\r\n \t\tif(root!=null){\r\n\r\n\r\n \t\t\tif(node==null){\r\n\r\n \t\t\t\tnode = new Node(val);\r\n \t\t\t\treturn node ;\r\n \t\t\t\t\r\n \t\t\t}\r\n\r\n \t\t\tif(val < node.val){\r\n\r\n \t\t\t\tnode.left = insert( node.left , val) ;\r\n \t\t\t}\r\n \t\t\telse{\r\n\r\n \t\t\t\tnode.right = insert(node.right , val) ;\r\n \t\t\t}\r\n\r\n \t\t}\r\n\r\n \t\treturn node ;\r\n \t}\r\n\r\n \tvoid inorder() { \r\n inorderRec(root); \r\n } \r\n \r\n // A utility function to do inorder traversal of BST \r\n void inorderRec(Node root) { \r\n if (root != null) { \r\n \tSystem.out.println(root.val); \r\n inorderRec(root.left); \r\n \r\n inorderRec(root.right);\r\n }\r\n }\r\n\r\n void level( Hashtable<Integer , Integer> dic , int d , Node node){\r\n\r\n\r\n \tif(node!=null){\r\n\r\n \t\ttry{\r\n\r\n \t\tdic.put(d , Math.max(dic.get(d) , node.val));\r\n \t}\r\n \tcatch(Exception e){\r\n\r\n \t\tdic.put(d , node.val);\r\n \t}\r\n \t\r\n\r\n \tlevel(dic , d+1 , node.right) ;\r\n \tlevel(dic ,d+1 ,node.left ) ;\r\n\r\n \t}\r\n\r\n \t\r\n\r\n }\r\n\r\n\r\n \tpublic static void main(String[] args) {\r\n\r\n \t\tMax_number_in_each_level_Bst ob = new Max_number_in_each_level_Bst() ;\r\n \t\tob.insert(root , 50) ;\r\n \t\tob.insert(root , 40) ;\r\n \t\tob.insert(root , 10) ;\r\n \t\tob.insert(root , 60) ;\r\n \t\tob.insert(root , 78) ;\r\n \t\tob.insert(root , 42) ;\r\n\r\n\r\n \t\tob.inorder();\r\n\r\n \t\tHashtable< Integer , Integer > dic = new Hashtable<Integer , Integer>() ;\r\n \t\tob.level(dic , 0 , root);\r\n\r\n\r\n \t\tdic.forEach ( (k , v) ->\r\n\r\n \t\t\tSystem.out.println(\"level:\"+k+\" max val :\"+v) ) ;\r\n \t\t\r\n \t\t\r\n \t\t\r\n \t}\r\n }"
},
{
"alpha_fraction": 0.4161490797996521,
"alphanum_fraction": 0.4316770136356354,
"avg_line_length": 19.600000381469727,
"blob_id": "af04165b73091003a82ef39d38ede12a7c35164f",
"content_id": "2f4f172f9f6fc22ea032986c677b51ad0ce1ad2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 15,
"path": "/CodeChef July 2020/codechef August 1.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "for _ in range(int(input())):\r\n Health , power = map(int , input().split())\r\n strike = power\r\n val = power\r\n while(True):\r\n if( power <= 0 ):\r\n break\r\n strike += power//2\r\n power = power//2\r\n \r\n \r\n if(strike>=Health):\r\n print(1)\r\n else:\r\n print(0)"
},
{
"alpha_fraction": 0.3813953399658203,
"alphanum_fraction": 0.4775193929672241,
"avg_line_length": 15.026315689086914,
"blob_id": "9ff7737902f9b5d988de9bf954b80f6d7cbe09d8",
"content_id": "ca4b3f1aa584df3b0a510bf6ee0782acd32d80ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 645,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 38,
"path": "/Board_game.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "n = int(input())\r\nmatrix = []\r\nfor i in range(n):\r\n a = list(map(int , input().split()))\r\n matrix.append(a)\r\n\r\n\r\ndef check(matrix ,cr,cc,pr,pc,n,sum,l):\r\n if(cc>=n or cr>=n or pr<0 or pc<0 or cc <0 or cr < 0):\r\n return\r\n \r\n sum = (sum//2) + matrix[cr][cc]\r\n \r\n\r\n if(cc== n-1 and cr== n-1):\r\n l.append(sum)\r\n\r\n check(matrix ,cc,cr+1,pr,pc,n,sum,l) #Right\r\n check(matrix , cc+1,cr,pr,pc,n,sum,l) #Down\r\nl = []\r\ncheck(matrix,0,0,0,0,n,0,l)\r\nprint(\"DONE\")\r\n# print(min(l))\r\n\r\n\r\n# 5\r\n# 0 82 2 6 7\r\n# 4 3 1 5 21 \r\n# 6 4 20 2 8\r\n# 6 6 64 1 8\r\n# 1 65 1 6 4 \r\n\r\n\r\n# 4\r\n# 0 3 9 6\r\n# 1 4 4 5\r\n# 8 2 5 4\r\n# 1 8 5 9"
},
{
"alpha_fraction": 0.3974025845527649,
"alphanum_fraction": 0.44155845046043396,
"avg_line_length": 19.5,
"blob_id": "c7116069040a1bce540e96ec737c14db089726c5",
"content_id": "90969033a97ca746e3d79117efdfda8d267a3e7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 18,
"path": "/Subarray_with_given_Sum.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "array = [1, 20 ,20 , 3 ,10 , 5]\r\nrequireSum = 33\r\nmaxval = array[0] \r\nsumval = 0\r\nc = 0\r\n\r\nfor i in range(len(array)):\r\n sumval = 0 \r\n if(c == 1):\r\n break\r\n for j in range(i ,len(array)):\r\n sumval += array[j]\r\n # maxval = max(sum , maxval)\r\n\r\n if(sumval == requireSum):\r\n print(\"{} {}\".format(i, j))\r\n c = 1\r\n break"
},
{
"alpha_fraction": 0.4362744987010956,
"alphanum_fraction": 0.45588234066963196,
"avg_line_length": 16,
"blob_id": "630e3be759d78c82d6e9368c7c38f670394c50e4",
"content_id": "708e2fd68bdbd575702b765c413e5773425429dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 11,
"path": "/sumprime.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "sum=0\r\nl=[int(x) for x in input().split()]\r\nprint(l)\r\nfor i in range(len(l)):\r\n if l[i]==1:\r\n continue\r\n if l[i]%2 != 0:\r\n sum=sum+l[i]\r\n else:\r\n continue\r\nprint(sum)\r\n \r\n"
},
{
"alpha_fraction": 0.49163180589675903,
"alphanum_fraction": 0.5230125784873962,
"avg_line_length": 27.9375,
"blob_id": "67ad89249be179e565fd90e3a90b9eeb6a92ede3",
"content_id": "06af07e2f0ea05a4b6c6e9b703f9950765a84d92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 956,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 32,
"path": "/Board_game_Dynamic.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "n = int(input())\r\nmatrix = []\r\nfor i in range(n):\r\n a = list(map(int , input().split()))\r\n matrix.append(a)\r\n \r\ndef minCost(cost, m, n): \r\n \r\n # Instead of following line, we can use int tc[m+1][n+1] or \r\n # dynamically allocate memoery to save space. The following \r\n # line is used to keep te program simple and make it working \r\n # on all compilers. \r\n tc = [[0 for x in range(n+1)] for x in range(m+1)] \r\n \r\n tc[0][0] = cost[0][0] \r\n \r\n # Initialize first column of total cost(tc) array \r\n for i in range(1, m+1): \r\n tc[i][0] = tc[i-1][0] + cost[i][0] \r\n \r\n # Initialize first row of tc array \r\n for j in range(1, n+1): \r\n tc[0][j] = tc[0][j-1] + cost[0][j] \r\n \r\n # Construct rest of the tc array \r\n for i in range(1, m+1): \r\n for j in range(1, n+1): \r\n tc[i][j] = (min(tc[i-1][j], tc[i][j-1])//2) + cost[i][j] \r\n return tc[m][n]\r\n \r\n\r\nprint(minCost(matrix, n-1, n-1))"
},
{
"alpha_fraction": 0.2737939953804016,
"alphanum_fraction": 0.3076923191547394,
"avg_line_length": 16.7560977935791,
"blob_id": "0606d3bf809a133404e4080cdbf2008b9362fddc",
"content_id": "1cff0a5d0fb135d9c2d549e4059ba5cbd29baefc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 767,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 41,
"path": "/CodeChef July 2020/codechef August 2.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "import sys\r\nmaxval = sys.maxsize\r\nd = {}\r\nfor _ in range(int(input())):\r\n pval = 0\r\n c = 0\r\n n , k = map(int , input().split())\r\n p = list(map(int , input().split()))\r\n p.sort(reverse = True)\r\n # for i in p:\r\n # m = i\r\n # if( k%i == 0):\r\n # c = 1\r\n # # if( ((k//i)-1) <maxval):\r\n # # maxval = ((k//i)-1)\r\n # # pval = i\r\n \r\n # d[( ( (k//i)-1 )) ] = i\r\n\r\n # if(c>0):\r\n # minval = min(d)\r\n # print(d[minval])\r\n # else:\r\n # print(-1)\r\n\r\n for i in p:\r\n if(k%i==0):\r\n c = 1\r\n print(i)\r\n break\r\n \r\n if(c!=1):\r\n print(-1)\r\n \r\n\r\n\r\n# 2\r\n# 4 6\r\n# 4 3 2 8\r\n# 4 7\r\n# 4 3 2 8"
},
{
"alpha_fraction": 0.2926829159259796,
"alphanum_fraction": 0.34688347578048706,
"avg_line_length": 10.793103218078613,
"blob_id": "bfb42b8d95155b0019073b34b8550360dab9a33b",
"content_id": "d47b3582d042946810052aea84b14f8c94ce9cc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 29,
"path": "/Overlapping_subInterval.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "arr = [[6, 8], [1, 9], [2, 4], [4, 7] , [9 , 15]] \r\nd= []\r\n\r\narr.sort()\r\n\r\n# print(arr)\r\n\r\na = arr[0][0]\r\nb=arr[0][1]\r\n\r\nfor i in range(0,len(arr)):\r\n\r\n\r\n # a,b = interval\r\n\r\n if( b >= arr[i][0]):\r\n\r\n b = max(b , arr[i][1])\r\n\r\n \r\n else:\r\n\r\n d.append( [a,b] )\r\n a = arr[i][0]\r\n b = arr[i][1]\r\n \r\nd.append([a,b])\r\n\r\nprint(d)"
},
{
"alpha_fraction": 0.4320809245109558,
"alphanum_fraction": 0.48121386766433716,
"avg_line_length": 20.064516067504883,
"blob_id": "316ed9742f70226de8cbbec7483774e1e827bdba",
"content_id": "252aa86ebe1f45c2393e72c1ddad1528db230c12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 31,
"path": "/BFS.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "import sys\r\ng = [[0,1,0,0,1],\r\n [1,0,1,1,1],\r\n [0,1,0,1,0],\r\n [0,1,1,0,1],\r\n [1,1,0,1,0]]\r\nVisitedVertex = [False]*(len(g)+1)\r\nVertexQue=[]\r\nVertexQue.append(1)\r\n\r\n\r\n\r\ndef bfs(g , VisitedVertex , VertexQue):\r\n count = 0\r\n result = []\r\n while(len(VertexQue) != 0):\r\n vertex = VertexQue.pop()\r\n VisitedVertex[vertex]=True\r\n count += 1\r\n result.append(vertex)\r\n if(count==len(g)):\r\n break\r\n \r\n for i in range(len(g)):\r\n if(g[vertex-1][i]==1 and VisitedVertex[i+1]==False):\r\n VertexQue.append(i+1)\r\n \r\n return(result)\r\n\r\n\r\nprint(bfs(g,VisitedVertex,VertexQue))\r\n\r\n \r\n"
},
{
"alpha_fraction": 0.3966480493545532,
"alphanum_fraction": 0.4450651705265045,
"avg_line_length": 17.962963104248047,
"blob_id": "709a6868ab17412029f9863ffeb777b76987cccc",
"content_id": "92e4a21d2b7b5cb423cad38e1b42dde333ea2d10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 27,
"path": "/Subarray_with_given_Sum_having_k_size.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "array = [1, 10 ,20 , 3 ,10 , 5]\r\nrequireSum = 33\r\n# maxval = array[0] \r\nsumval = array[0]\r\nstart = 0\r\nk = 3\r\nc = 0\r\n\r\nfor i in range(1 , len(array)+1):\r\n\r\n \r\n c+=1\r\n if (c%k!=0):\r\n\r\n # sumval -= array[start]\r\n # start+=1\r\n while(sumval>=requireSum and c%k!=0):\r\n sumval -= array[start]\r\n start+=1\r\n c-=1\r\n \r\n if(sumval == requireSum and c%k==0):\r\n print(\"start :{} End:{}\".format(start, i-1)) ;\r\n break\r\n\r\n if(i<len(array)):\r\n sumval+=array[i]"
},
{
"alpha_fraction": 0.38723403215408325,
"alphanum_fraction": 0.43191489577293396,
"avg_line_length": 21.600000381469727,
"blob_id": "466b473f8b655e5cf83ba0d628a5d859715d2d1b",
"content_id": "97c297b6f98716adcf1cdd1456cf0661e275d67a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 20,
"path": "/LCS.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "def lcs(str , str2 , n , m , dp):\r\n\r\n if(n==0 or m==0):\r\n return 0\r\n if(dp[n][m]!=-1):\r\n return dp[n][m]\r\n if(str[n-1]==str2[m-1]):\r\n\r\n dp[n][m] = (1+lcs(str , str2 , n-1 , m-1,dp))\r\n return dp[n][m]\r\n else:\r\n\r\n dp[n][m] = max(lcs(str , str2 , n , m-1,dp) ,lcs(str , str2 , n , m-1,dp) )\r\n return dp[n][m]\r\n\r\ndp = [[-1 for x in range(8)] for y in range(7)]\r\n\r\n\r\nprint(lcs(\"AGGTAB\" , \"GXTXAYB\" , 6 , 7 , dp))\r\nprint(dp)"
},
{
"alpha_fraction": 0.3264462947845459,
"alphanum_fraction": 0.40909090638160706,
"avg_line_length": 12.235294342041016,
"blob_id": "aee1a076d5200432ab03f55fa0ed0ed4b5a01e79",
"content_id": "88b8d163f438ba9ec0543ef6e385cbf0ed16459c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/max_length_of_subarray_all_have_same_element.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "array = [1, 2, 3, 4, 5, 5, 5, 5, 5, 2, 2, 1, 1]\r\nmaxlen = 1 ;\r\nc= 1\r\nx =0\r\n\r\nfor i in range(1 , len(array)):\r\n if( array[i]==array[i-1]):\r\n\r\n c+=1\r\n else:\r\n\r\n c = 1\r\n \r\n\r\n maxlen = max (maxlen , c)\r\n\r\nprint(maxlen)\r\n"
},
{
"alpha_fraction": 0.45472636818885803,
"alphanum_fraction": 0.45771142840385437,
"avg_line_length": 8.38144302368164,
"blob_id": "d2038478dc3ac9b136e23f1818159981f04e7be2",
"content_id": "9dd19d07c1efb2175e4f6ab5dfcdb3c2f057f3d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1005,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 97,
"path": "/LinkList_loop.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class LinkList_loop{\r\n\r\n\tstatic Node head = null;\r\n\r\n\tclass Node{\r\n\r\n\t\t\r\n\r\n\t\tint val ;\r\n\t\tNode next ;\r\n\r\n\t\tNode(int val){\r\n\r\n\t\t\tthis.val = val ;\r\n\t\t\tthis.next = null ;\r\n\r\n\t\t}\r\n\r\n\t}\r\n\r\n\tpublic void insert(int val){\r\n\r\n\t\tNode node = new Node(val);\r\n\r\n\t\tif(head==null){\r\n\r\n\t\t\thead = node ;\r\n\t\t}\r\n\t\telse{\r\n\r\n\t\t\tNode curr = head ;\r\n\t\t\twhile(curr.next!=null){\r\n\r\n\t\t\t\tcurr = curr.next ;\r\n\t\t\t}\r\n\r\n\t\t\tcurr.next = node ;\r\n\r\n\t\t}\r\n\r\n\t}\r\n\r\n\r\n\tNode detectloop(){\r\n\r\n\t\tNode p = head ;\r\n\t\t\tNode q = head ;\r\n\r\n\t\tif(head!=null){\r\n\r\n\t\t\t\r\n\r\n\t\t\twhile(p!=null){\r\n\r\n\t\t\t\tp = p.next.next ;\r\n\t\t\t\tq = q.next ;\r\n\r\n\t\t\t\tif(q==p){\r\n\r\n\t\t\t\t\tbreak;\r\n\t\t\t\t}\r\n\t\t\t}\r\n\r\n\t\t\tp = head ;\r\n\t\t\twhile(p!=q){\r\n\r\n\t\t\t\tp = p.next ;\r\n\t\t\t\tq = q.next ;\r\n\r\n\t\t\t}\r\n\r\n\r\n\r\n\r\n\t\t}\r\n\r\n\t\treturn p ;\r\n\t}\r\n\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\r\n\t\tLinkList_loop ob = new LinkList_loop() ;\r\n\t\tob.insert(1) ;\r\n\t\tob.insert(2) ;\r\n\t\tob.insert(3) ;\r\n\t\thead.next.next.next = head.next ;\r\n\r\n\t\tNode v = ob.detectloop() ;\r\n\r\n\r\n\r\n\t\tSystem.out.println(v.val);\r\n\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.4345991611480713,
"alphanum_fraction": 0.4641350209712982,
"avg_line_length": 14.413793563842773,
"blob_id": "46ccd742c36533dcf20a3cb4fa352569658d9c33",
"content_id": "2ea0176566f09eafa862019ed49db3312dc94202",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 29,
"path": "/Set_matrix_zero.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "matrix = [[1,0,1],[1,1,0],[1,1,1]]\r\n\r\nrow = [False]*3\r\n\r\ncol = [False]*3\r\n\r\nfor i in range(len(matrix)):\r\n\r\n for j in range(len(matrix)):\r\n\r\n if(matrix[i][j] == 0):\r\n row[i] = True\r\n col[j] = True\r\n\r\nfor i in range(len(matrix)):\r\n\r\n for j in range(len(matrix)):\r\n\r\n if(row[i] or col[j]):\r\n\r\n matrix[i][j] = 0\r\n else:\r\n\r\n continue\r\n\r\nprint(matrix)\r\n\r\n#time Complexity = o(2mn)\r\n#space Complexity = O(m+n)"
},
{
"alpha_fraction": 0.4218240976333618,
"alphanum_fraction": 0.447882741689682,
"avg_line_length": 13.79487133026123,
"blob_id": "01fd4e7680376ff761a23de932672cdd933d93f8",
"content_id": "888ba18760805bf5a75ff04dafeebd8c6eacc019",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 614,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 39,
"path": "/sum_3.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "import java.util.HashSet ;\r\n\r\nclass Sum_3{\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\t\tint array[] = { 1 , 4 , 8 , 3 , 12 , 2 , 6} ;\r\n\t\tint target = 12;\r\n\t\tint c = 0 ;\r\n\t\t\r\n\r\n\t\tfor(int i = 0 ; i < array.length ; i++){\r\n\r\n\t\t\tif(c == 1){\r\n\t\t\t\tbreak ;\r\n\t\t\t}\r\n\t\t\tHashSet<Integer> s = new HashSet<Integer>() ;\r\n\t\t\tint sum = target - array[i] ;\r\n\r\n\r\n\t\t\tfor(int j=i+1 ; j < array.length ; j++){\r\n\r\n\t\t\t\tint res = sum - array[j] ;\r\n\r\n\t\t\t\tif(s.contains(res)){\r\n\r\n\t\t\t\t\tSystem.out.println(\"\"+array[i]+\" \"+array[j]+\" \"+res) ;\r\n\t\t\t\t\tc = 1;\r\n\t\t\t\t\tbreak ;\r\n\r\n\r\n\t\t\t\t}else{\r\n\r\n\t\t\t\t\ts.add(array[j]);\r\n\t\t\t\t}\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.3469387888908386,
"alphanum_fraction": 0.362811803817749,
"avg_line_length": 18.511627197265625,
"blob_id": "b7021d9ae8fe0a64e8565e7fc67a17d9e964a241",
"content_id": "bd72b3f09e530c9229aa16b40b28f9979500ff76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 882,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 43,
"path": "/fact_recursion.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "# n = int(input())\r\nstr = input()\r\n\r\n\r\n# def fact(n):\r\n# if(n<=1):\r\n# return 1\r\n# res = n*fact(n-1) \r\n# return res\r\n\r\n# print(fact(n))\r\n\r\n# __________________________Sum of N Natural Numbers_________________________\r\n\r\n# def n_natural(n):\r\n# if(n<=1):\r\n# return 1\r\n# res = n + n_natural(n-1)\r\n# return res\r\n\r\n# print(n_natural(n))\r\n\r\n#____________________________String Reverse____________________________________\r\n\r\n# def Rev_string(str,n):\r\n# if(n<=0):\r\n# return(str[0])\r\n# res = str[n]+Rev_string(str,n-1)\r\n# return res\r\n\r\n# print(Rev_string(str,len(str)-1))\r\n\r\n#_____________________________string Length_____________________________________\r\n\r\ndef len_str(str , n):\r\n if(str[n] =='\\0'):\r\n return n\r\n res = len_str(str,n+1)\r\n return res\r\n\r\nprint(len_str(str+'\\0',0))\r\n\r\n#_____________________________\r\n"
},
{
"alpha_fraction": 0.5031847357749939,
"alphanum_fraction": 0.5286624431610107,
"avg_line_length": 13.800000190734863,
"blob_id": "5b4c3fd01dc42c70c4e81960bbdd3e7a69e60445",
"content_id": "4ef9ef0cb54fd33d64f5c35dea7ca7a866306c18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 20,
"path": "/Stock_buy_sell.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "import java.util.* ;\r\n\r\nclass Stock_buy_sell{\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\t\tint arr[] = {7,1,5,3,6,4} ;\r\n\t\tint minval = arr[0] ;\r\n\t\tint diff = 0 ;\r\n\r\n\t\tfor(int a : arr){\r\n\r\n\t\t\tminval = Math.min(a , minval);\r\n\r\n\t\t\tdiff = Math.max((a-minval) , diff);\r\n\t\t}\r\n\r\n\t\tSystem.out.println(diff) ;\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.4528301954269409,
"alphanum_fraction": 0.4558093249797821,
"avg_line_length": 7.99009895324707,
"blob_id": "b85d2cceecfadf89626da7816349317946cb98f5",
"content_id": "463ac589169570267077625342fcc598c9ad2e00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1007,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 101,
"path": "/Reverse_linklist.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Reverse_linklist{\r\n\r\n\tstatic Node head = null;\r\n\r\n\tclass Node{\r\n\r\n\t\t\r\n\r\n\t\tint val ;\r\n\t\tNode next ;\r\n\r\n\t\tNode(int val){\r\n\r\n\t\t\tthis.val = val ;\r\n\t\t\tthis.next = null ;\r\n\r\n\t\t}\r\n\r\n\t}\r\n\r\n\tpublic void insert(int val){\r\n\r\n\t\tNode node = new Node(val);\r\n\r\n\t\tif(head==null){\r\n\r\n\t\t\thead = node ;\r\n\t\t}\r\n\t\telse{\r\n\r\n\t\t\tNode curr = head ;\r\n\t\t\twhile(curr.next!=null){\r\n\r\n\t\t\t\tcurr = curr.next ;\r\n\t\t\t}\r\n\r\n\t\t\tcurr.next = node ;\r\n\r\n\t\t}\r\n\r\n\t}\r\n\r\n\r\n\tvoid reverse(){\r\n\r\n\t\tif(head!=null){\r\n\r\n\t\t\tif(head.next!=null){\r\n\r\n\t\t\t\tNode q = null ;\r\n\t\t\t\tNode p = head.next ;\r\n\r\n\r\n\t\t\t\twhile(p!=null){\r\n\r\n\t\t\t\t\thead.next = q ;\r\n\t\t\t\t\tq = head ;\r\n\t\t\t\t\thead = p ;\r\n\t\t\t\t\tp = p.next ;\r\n\r\n\r\n\t\t\t\t}\r\n\r\n\t\t\t\thead.next = q;\r\n\r\n\r\n\r\n\t\t\t}\r\n\t\t}\r\n\r\n\t}\r\n\r\n\t\r\n\r\n\r\n\t\r\n\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\r\n\t\tReverse_linklist ob = new Reverse_linklist() ;\r\n\t\tob.insert(1) ;\r\n\t\tob.insert(2) ;\r\n\r\n\r\n\t\t// ob.reverse(4) ;\r\n\r\n\t\tob.reverse() ;\r\n\r\n\t\twhile(head!=null){\r\n\r\n\t\t\tSystem.out.println(head.val) ;\r\n\t\t\thead = head.next ;\r\n\t\t}\r\n\t\t\r\n\r\n\r\n\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.49572649598121643,
"alphanum_fraction": 0.5071225166320801,
"avg_line_length": 20.0625,
"blob_id": "3e3af34fd8d1ad777f32e5c23bbe7b87156745a1",
"content_id": "f5a1db8fb0762be069ffc5027193dc68174830b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 16,
"path": "/Recursion_palindrome.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "#palindrome Recursion\r\n\r\ndef palindrome_recursion( strR , i , j ):\r\n if(i>j):\r\n return\r\n if(strR[i]!=strR[j]):\r\n print(\"NOT Palindrome\")\r\n return\r\n else:\r\n if(i==j):\r\n print(\"Palindrom\")\r\n \r\n palindrome_recursion( strR , i+1 , j-1)\r\n \r\ns = \"MALAYALAM\"\r\npalindrome_recursion(s , 0, len(s)-1)"
},
{
"alpha_fraction": 0.2786885201931,
"alphanum_fraction": 0.2991803288459778,
"avg_line_length": 20,
"blob_id": "d7c51d6c940e1d86630af72d14bcd4b17005449f",
"content_id": "b97c9474d2327cd03dd98746e2fcef3557325372",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 22,
"path": "/CodeChef July 2020/Missing Point.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "a = {}\r\nb = {}\r\nfor _ in range(int(input())):\r\n for __ in range( (4*(int(input())) )-1):\r\n x,y = map(int, input().split())\r\n try:\r\n a[x] = a[x]+1\r\n except:\r\n a[x]=1\r\n try:\r\n b[y] = b[y]+1\r\n except:\r\n b[y]=1\r\n \r\n for k in a:\r\n if(a[k]%2!=0):\r\n print(k , end = \" \")\r\n break\r\n for k in b:\r\n if(b[k]%2!=0):\r\n print(k , end = \" \")\r\n break\r\n "
},
{
"alpha_fraction": 0.471766859292984,
"alphanum_fraction": 0.506375253200531,
"avg_line_length": 20.040000915527344,
"blob_id": "cc5d646983ddd28217477d1680e484531d980524",
"content_id": "e55eded5525a00059a0ad36561dd56ea7f9a4463",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 25,
"path": "/Spiral Matrix Number.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "def spiral( n , matrix , i , j , rangeval):\r\n if(i>rangeval-1 or j>rangeval-1 or j < 0 or i < 0 ):\r\n \r\n return\r\n \r\n if(matrix[i][j]!=0):\r\n return\r\n \r\n matrix[i][j] = n\r\n spiral(n+1 , matrix , i , j+1 , rangeval)\r\n spiral(n+1 , matrix , i+1 , j , rangeval)\r\n spiral(n+1 , matrix , i , j-1 , rangeval)\r\n spiral(n+1 , matrix , i-1 , j , rangeval)\r\n\r\n\r\nmatrix=[]\r\nrangeval=5\r\nfor _ in range(rangeval):\r\n matrix.append([0]*5)\r\n\r\nspiral(1 , matrix , 0 , 0 , rangeval)\r\n\r\n\r\nfor i in matrix:\r\n print(i)"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.36477985978126526,
"avg_line_length": 12.636363983154297,
"blob_id": "6c90bd55d4eb5b232c4ca0d674eae7a9943183f0",
"content_id": "7fa3ecd2db0c6b4c9df48f13b5f6c518f39ba2aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 11,
"path": "/pascalstriangle.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "n = int(input())\r\n\r\nfor i in range(1,n+1):\r\n c = 1\r\n for j in range(1 ,n+1):\r\n\r\n print( c, end=\" \")\r\n\r\n c = c * (i - j)//j\r\n\r\n print('')"
},
{
"alpha_fraction": 0.3677419424057007,
"alphanum_fraction": 0.38064515590667725,
"avg_line_length": 15.333333015441895,
"blob_id": "e57e488f94bef48b7b0d9c47e49f59917a058918",
"content_id": "f828e1830f4888b73985e9f35b51c3b5dde4983e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 18,
"path": "/whithousubtraction.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "x = int(input(\"Enter the divisor \\n\"))\r\ny = int(input(\"Enter the Dividend \\n\"))\r\n\r\n\r\ndef sub(x , y , ):\r\n c = 0\r\n rem = 0\r\n while(True):\r\n x-=y\r\n if(x>=0):\r\n c+=1\r\n else:\r\n rem = x+y\r\n return [c , rem]\r\n break\r\n\r\nr = sub(x,y)\r\nprint(r)"
},
{
"alpha_fraction": 0.3308080732822418,
"alphanum_fraction": 0.35185185074806213,
"avg_line_length": 12.512195587158203,
"blob_id": "a443ae8c07af88e8cd48150db6327bc73baae6ca",
"content_id": "c6d00cddc5cb4b901d7095d5d01a0d4b353d4eb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 82,
"path": "/Matrix_spiral_patter.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "import java.util.Scanner ;\r\n\r\nclass Matrix_spiral_patter{\r\n\r\n\t// int print( int arr[][] , int n , int col , int row){\r\n\r\n\t// \tif(col>n-1){\r\n\r\n\t// \t\treturn 0;\r\n\t// \t}\r\n\r\n\t// \tif( row == 0){\r\n\t// \t\trow = n-3\r\n\t// \t\tprint(arr , n , col , row)\r\n\t// \t}\r\n\r\n\t// \tif(col != (n-1) ){\r\n\r\n\t// \t\twhile(true) {\r\n\t\t\t\t\r\n\t// \t\t\tarr[row][col] = \r\n\r\n\t// \t}\r\n\r\n\t// \t}\r\n\r\n\t// \tif(col == n-1){\r\n\r\n\t// \t\tfor ( int i = n-2 ; i >= 0 ; i-- ) {\r\n\t\t\t\t\r\n\r\n\r\n\t// \t}\r\n\t// \t}\r\n\t\t\r\n\t// }\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\r\n\t\tScanner sc = new Scanner(System.in) ;\r\n\t\tint n = sc.nextInt() ;\r\n\t\tint[][] arr = new int[n][n];\r\n\t\tint count = 0 ;\r\n\r\n\t\tint row = n-2 ;\r\n\t\tint num = 1 ;\r\n\t\tfor(int i = 0 ; i < n-2 ; i++){\r\n\r\n\t\t\tfor(int j = 0 ; j < n-1 ; j++){\r\n\r\n\t\t\t\tif(count == n-2){\r\n\r\n\t\t\t\t\tnum++ ;\r\n\t\t\t\t\tcount = 0 ;\r\n\r\n\t\t\t\t}\r\n\t\t\t\tarr[row][i] = num ;\r\n\t\t\t\trow-- ;\r\n\t\t\t\tcount++ ;\r\n\t\t\t}\r\n\r\n\t\t\trow = n-2 ;\r\n\r\n\t\t}\r\n\r\n\t\tint col = n-2;\r\n\t\tfor ( int i = 0; i<n-1 ; i++ ) {\r\n\t\t\t\r\n\t\t\tarr[i][col] = n;\r\n\t\t}\r\n\r\n\r\n\t\tfor (int i = 0; i < n-1; i++) { \r\n for (int j = 0; j < n-1; j++) { \r\n System.out.print(arr[i][j] + \" \"); \r\n } \r\n \r\n System.out.println(); \r\n } \r\n\t}\r\n}"
},
{
"alpha_fraction": 0.3769230842590332,
"alphanum_fraction": 0.4307692348957062,
"avg_line_length": 13.680000305175781,
"blob_id": "900746b637797c314d12ff6b8ae03070f8915674",
"content_id": "3622c2c0b55c84f2a74203aca3a83a7e55d83b84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 25,
"path": "/Longest_common_string.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "def lcs(str , str2 , n , m , dp):\r\n\r\n if(n==0 or m==0):\r\n return dp\r\n\r\n if(str[n-1]==str2[m-1]):\r\n\r\n \r\n dp = lcs(str , str2 , n-1 , m-1,dp+1)\r\n\r\n else:\r\n\r\n\r\n dp = max( dp , max(lcs(str , str2 , n-1 , m,0) , lcs(str , str2 , n , m-1,0)))\r\n\r\n\r\n return dp \r\n\r\n \r\n\r\n\r\n\r\ndp = 0\r\nprint(lcs(\"geeksforxgeekss\" , \"geekssforgeeks\" , 15 , 14 , dp))\r\nprint(dp)"
},
{
"alpha_fraction": 0.2581574022769928,
"alphanum_fraction": 0.3896353244781494,
"avg_line_length": 22.186046600341797,
"blob_id": "b6806b87ef1f0ed293d7bae13e9d6051e6fbf5e3",
"content_id": "8da727a7d7141125f5e96393b2fcfd26e9b65a2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1042,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 43,
"path": "/subset_sum_dp.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "\r\ndef subset(array , target , n , c):\r\n\r\n print(n)\r\n\r\n if(n==len(array)):\r\n return False ;\r\n\r\n if(target==0):\r\n \r\n return True ;\r\n \r\n\r\n for i in range(len(array)):\r\n\r\n if(target>=array[n]):\r\n\r\n\r\n dp[n][target] = (subset(array , target - array[n] , n+1 , c) or subset(array , target , n+1 , c))\r\n return dp[n][target]\r\n \r\n else:\r\n\r\n dp[n][target] = subset(array , target , n+1 , c)\r\n return dp[n][target]\r\n \r\n\r\n \r\n return dp[n][target]\r\n\r\narray = [8,4,2,8,6,8,4]\r\ntarget = 15\r\ndp = [[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1],\r\n[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1]]\r\n\r\n\r\nprint(subset(array , 13 , 0 , 0 ) );\r\n# print(dp)\r\n"
},
{
"alpha_fraction": 0.2777777910232544,
"alphanum_fraction": 0.3298611044883728,
"avg_line_length": 14.11111068725586,
"blob_id": "24701682d43a7c0a78404e56eb0006a698e87945",
"content_id": "f99f9864e91859346c2e773cce75ade0e6a0fa9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 18,
"path": "/matrixnumber.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "arr = [[1,2,3],\r\n [4,5,6],\r\n [7,8,9]]\r\n\r\n\r\nc=1\r\n\r\nfor i in range(len(arr)):\r\n k = len(arr)-1\r\n for j in range(len(arr)):\r\n\r\n if(c%2!=0):\r\n print(arr[i][j] , end =\" \")\r\n else:\r\n\r\n print(arr[i][k] , end =\" \")\r\n k-=1\r\n c+=1"
},
{
"alpha_fraction": 0.3252279758453369,
"alphanum_fraction": 0.36474165320396423,
"avg_line_length": 13.7619047164917,
"blob_id": "4df0fafd966ed6474f92cd3948da27b5c7496470",
"content_id": "7893d8bd22ce19326d81ecd774a139b62324c838",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 329,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 21,
"path": "/matrix_rotate.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "arr = [[1,2,3],\r\n [4,5,6],\r\n [7,8,9]]\r\nn = len(arr)\r\n\r\nfor i in range(n):\r\n for j in range(i,n):\r\n\r\n arr[i][j],arr[j][i] = arr[j][i],arr[i][j]\r\n \r\nfor i in range(n):\r\n j = 0 \r\n k = n-1\r\n while(j<k):\r\n arr[i][j],arr[i][k] = arr[i][k],arr[i][j]\r\n j+=1\r\n k-=1\r\n\r\n\r\n\r\nprint(arr)"
},
{
"alpha_fraction": 0.5247747898101807,
"alphanum_fraction": 0.5307807922363281,
"avg_line_length": 9.296609878540039,
"blob_id": "cc81595a4641ae936aba5516097c0ab92bc258e5",
"content_id": "c5ff707ec7d9f555a97a60673ea4a037ee8e6599",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 118,
"path": "/insertinsortedlinklist.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Node{\r\n\r\n\tint data ;\r\n\tNode Next;\r\n\tNode head;\r\n\r\n\tNode(int data){\r\n\r\n\t\tthis.data = data ;\r\n\t\tthis.Next = null;\r\n\t}\r\n\r\n\tvoid insert(int elemnet){\r\n\r\n\t\t\r\n\t\tNode newnode = new Node(elemnet) ;\r\n\t\tnewnode.Next = null ;\r\n\r\n\t\tif(head == null){\r\n\t\t\thead = newnode ;\r\n\t\t}\r\n\t\telse {\r\n\r\n\r\n\t\t\tNode current = head ;\r\n\t\t\twhile(current.Next!= null){\r\n\r\n\t\t\t\tcurrent = current.Next ;\r\n\t\t\t}\r\n\r\n\t\t\tcurrent.Next = newnode ;\r\n\r\n\r\n\r\n\t\t}\r\n\r\n\r\n\r\n\t}\r\n\r\n\r\nvoid sortinsert(int val){\r\n\r\n\tNode newnode = new Node(val) ;\r\n\tnewnode.Next = null ;\r\n\t\r\n\r\n\tNode temp = head ;\r\n\r\n\tif(temp.Next==null){\r\n\r\n\t\tif(newnode.data>temp.data){\r\n\t\t\ttemp.Next = newnode ;\r\n\r\n\t\t}\r\n\t\telse{\r\n\r\n\t\t\thead = newnode ;\r\n\t\t\thead.Next = temp ;\r\n\t\t\t\r\n\t\t}\r\n\r\n\t}\r\n\r\n\telse\r\n\t{\r\n\twhile(temp.Next !=null){\r\n\r\n\t\tif(newnode.data < temp.Next.data){\r\n\r\n\t\t\tnewnode.Next = temp.Next ;\r\n\t\t\ttemp.Next = newnode ;\r\n\t\t\t\r\n\t\t\tbreak ;\r\n\r\n\t\t}\r\n\r\n\t\ttemp = temp.Next ;\r\n\r\n\t}\r\n}\r\n}\r\n\r\n}\r\n\r\n\r\nclass insertinsortedlinklist{\r\n\r\n\r\n\r\n\tpublic static void main(String[] args) {\r\n\r\n\r\n\r\n\tNode node = new Node(0) ;\r\n\tnode.insert(1) ;\r\n\tnode.insert(2) ;\r\n\tnode.insert(3) ;\r\n\tnode.insert(4) ;\r\n\tnode.insert(5);\r\n\tnode.insert(6);\r\n\tnode.sortinsert(2) ;\r\n\t\r\nNode headdata = node.head ;\r\n\twhile(headdata!=null){\r\n\t\t\r\n\t\tSystem.out.println(\"val:\"+headdata.data);\r\n\t\theaddata = headdata.Next ;\r\n\r\n\t}\r\n\r\n\r\n\r\n\r\n\r\n\t}\r\n\r\n} "
},
{
"alpha_fraction": 0.488095223903656,
"alphanum_fraction": 0.4985119104385376,
"avg_line_length": 20.33333396911621,
"blob_id": "ac612a733b97b3332f29ddace44a10e2e35baeec",
"content_id": "57139e6a1f03ceba7a936082382febf71f3a783a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 30,
"path": "/Monkey Groving.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "# testcase = int(input())\r\n\r\n# def Monkey(pattern , n , count , pattern_sort):\r\n# if(pattern_sort==pattern):\r\n# return count\r\n# count+=1\r\n# for i in range(len(pattern)):\r\n \r\n# Monkey()\r\n\r\n\r\n\r\n\r\n# for _ in range(testcase):\r\n# n = int(input())\r\n# count = 0\r\n# pattern = list(map(int,input().split()))\r\n# pattern_sort = pattern.copy()\r\n# pattern_sort.sort()\r\n# Monkey(pattern , n , count , pattern_sort)\r\n\r\nrem = 0\r\nfor _ in range(int(input())):\r\n rem=0\r\n n = int(input())\r\n x = list(map(int , input().split()))\r\n for i in range(n-1):\r\n rem = rem + abs(abs((x[i]-x[i+1]))-1)\r\n \r\n print(rem)\r\n\r\n"
},
{
"alpha_fraction": 0.4532966911792755,
"alphanum_fraction": 0.4793955981731415,
"avg_line_length": 19.02941131591797,
"blob_id": "a9d66d6e02dc3cfe27fd1ac0373066a75a93bec4",
"content_id": "195911d2ab09524586c2f559438a4fc0cbdc5258",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 34,
"path": "/Marathon.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "n = int(input())\r\ntime = int(input())\r\ntime = time-1\r\nWinner = [0]*(n+1)\r\nsum_list = [0]*(n)\r\nsteps = []\r\n\r\nif(time%2==0):\r\n pass\r\nelse:\r\n time = time-1\r\n\r\nfor _ in range(n):\r\n l = list(map(int,input().split()))\r\n steps.append(l)\r\n\r\n\r\nfor i in range( 0, time , 2):\r\n sum = 0\r\n sum2=0\r\n inc = 0\r\n for j in range(n):\r\n sum_list[j] += ( (steps[j][i])+(steps[j][i+1]) )*(steps[j][-1])\r\n maxval = max(sum_list)\r\n if(sum_list.count(maxval)>1):\r\n for x in range(n):\r\n if(sum_list[x]==maxval):\r\n Winner[x] +=1\r\n else:\r\n indx = sum_list.index(maxval)\r\n Winner[indx] +=1\r\nWinneris = max(Winner)\r\n\r\nprint(Winner.index(Winneris)+1,end='') \r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.35849055647850037,
"alphanum_fraction": 0.3836477994918823,
"avg_line_length": 15.13513469696045,
"blob_id": "abf0b7f161aa3db321697b69aeaa4140592458a0",
"content_id": "96ff887e41fba649a3bca2dac26f6933c92ae204",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 37,
"path": "/Next_permutation.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "num = input()\r\nnum = list(map(int , num.split()))\r\n# num = [1,3,5,4,2]\r\n\r\ndef reversenum(l , k , num):\r\n while(k<l):\r\n num[l],num[k] = num[k],num[l]\r\n k+=1\r\n l-=1\r\n\r\n\r\n\r\n\r\n\r\nfor i in range(len(num)-2, -1 , -1):\r\n \r\n if(num[i]<num[i+1]):\r\n k = i ;\r\n # print(k)\r\n \r\n break;\r\n \r\nif(k<0):\r\n print(num.reverse())\r\nelse:\r\n for j in range(len(num)-1 , k , -1):\r\n if(num[j] > num[k]):\r\n l = j\r\n break\r\n num[l],num[k] = num[k],num[l]\r\n print(k)\r\n print(l)\r\n reversenum(len(num)-1 , k+1 , num)\r\n \r\n\r\n\r\nprint(num)\r\n\r\n"
},
{
"alpha_fraction": 0.42189282178878784,
"alphanum_fraction": 0.44355759024620056,
"avg_line_length": 23.114286422729492,
"blob_id": "1c5d9c9c891401a268d7871b139aa3d0e91faedf",
"content_id": "bfe379f8f4c458c499f0d99dd28bca34c6cb5716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 877,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 35,
"path": "/CodeChef July 2020/chef and card.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "# def digitsum(n):\r\n# while (True):\r\n# if(n<10):\r\n# break\r\n# else:\r\n# n = n%10\r\n\r\ndef digitsum( n ): \r\n if n == 0: \r\n return 0\r\n return (n % 10 + digitsum(int(n / 10))) \r\n\r\nfor _ in range(int(input())):\r\n chef_points = 0 \r\n monty_points = 0\r\n for __ in range(int(input())):\r\n x , y = map(int,input().split())\r\n chef = digitsum(x)\r\n monty = digitsum(y)\r\n if(chef>monty):\r\n chef_points+=1 \r\n elif(monty>chef):\r\n monty_points+=1\r\n else:\r\n chef_points+=1\r\n monty_points+=1\r\n if(chef_points>monty_points):\r\n print(0 , end=\" \")\r\n print(chef_points)\r\n elif(monty_points>chef_points):\r\n print(1 , end = ' ')\r\n print(monty_points)\r\n else:\r\n print(2 , end = \" \")\r\n print(monty_points)"
},
{
"alpha_fraction": 0.4197819232940674,
"alphanum_fraction": 0.4267912805080414,
"avg_line_length": 10.233333587646484,
"blob_id": "819c70418131fbdbbc3d9139aa4d2263fa41ca39",
"content_id": "fe4515ddd1fa8f18d6005b3dd934387fbb756957",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2568,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 210,
"path": "/LinkList.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Node{\r\n\r\n\tint data ;\r\n\tNode Next;\r\n\tNode head;\r\n\r\n\tNode(int data){\r\n\r\n\t\tthis.data = data ;\r\n\t\tthis.Next = null;\r\n\t}\r\n\r\n\r\n// Delete the head ------------------------------------------------------------------\r\n\r\n\tvoid delhead(){\r\n\t\t\r\n\r\n\t\thead = head.Next ;\r\n\t}\r\n\r\n\t\r\n\r\n// Insert at start-------------------------------\r\n\r\n\tvoid start(int elemnet){\r\n\r\n\t\tNode newnode = new Node(elemnet) ;\r\n\t\tnewnode.Next = null ;\r\n\r\n\t\tNode temp = head ;\r\n\t\thead = newnode ;\r\n\t\thead.Next = temp ;\r\n\r\n\r\n\t}\r\n\r\n\r\n// insert at end-------------------------------------------------------------------------------\r\n\r\n\tvoid insert(int elemnet){\r\n\r\n\t\t\r\n\t\tNode newnode = new Node(elemnet) ;\r\n\t\tnewnode.Next = null ;\r\n\r\n\t\tif(head == null){\r\n\t\t\thead = newnode ;\r\n\t\t}\r\n\t\telse {\r\n\r\n\r\n\t\t\tNode current = head ;\r\n\t\t\twhile(current.Next!= null){\r\n\r\n\t\t\t\tcurrent = current.Next ;\r\n\t\t\t}\r\n\r\n\t\t\tcurrent.Next = newnode ;\r\n\r\n\r\n\r\n\t\t}\r\n\r\n\r\n\r\n\t}\r\n\r\n\t// delete eery kth Node---------------------------------------------------------------------------------\r\n\r\n\tvoid kthnode(int kval){\r\n\r\n\t\tint count = 1 ;\r\n\r\n\t\tNode temp ;\r\n\t\ttemp = head ;\r\n\t\twhile(temp.Next != null){\r\n\r\n\t\t\t\r\n\t\t\tcount++;\r\n\r\n\t\t\tif(count == kval){\r\n\r\n\t\t\t\tif(temp.Next.Next == null){\r\n\t\t\t\t\ttemp.Next = null ;\r\n\t\t\t\t\tcontinue ;\r\n\t\t\t\t}\r\n\r\n\t\t\t\ttemp.Next = temp.Next.Next ;\r\n\t\t\t\tcount = 1;\r\n\r\n\t\t\t}\r\n\r\n\r\n\t\t\ttemp = temp.Next ;\r\n\t\t}\r\n\r\n\t\t\r\n\r\n\r\n\t}\r\n\r\n\r\n\t// delete dup val in link list sorted--------------------------------------------------\r\n\r\n\tvoid duplicateval(){\r\n\r\n\t\t\r\n\r\n\t\tNode temp ;\r\n\t\ttemp = head ;\r\n\t\twhile( temp.Next != null){\r\n\t\t\t\t\r\n\r\n\t\t\t\tNode d = temp ;\r\n\t\t\t\twhile(d.data == temp.Next.data){\r\n\r\n\t\t\t\t\ttemp = temp.Next ;\r\n\r\n\r\n\t\t\t\t}\r\n\r\n\t\t\t\t\r\n\r\n\t\t\td.Next = temp.Next ;\r\n\r\n\t\t\t\t\r\n\r\n\t\t\ttemp = temp.Next ;\r\n\r\n\r\n\t\t\t}\r\n\r\n\r\n\r\n\t\r\n\r\n\t\t\t\r\n\r\n\t\t\r\n\r\n\r\n\t}\r\n\r\n// Get nth element from link list -------------------------------------------------------------\r\n\r\n\tint getmyel(int position) {\r\n\r\n\r\n\tNode temp = head ;\r\n\tint count = 1 ;\r\n\twhile(temp != null){\r\n\r\n\r\n\t\tSystem.out.println(count) ;\r\n\r\n\t\tif( count == position ){\r\n\r\n\t\t\treturn temp.data ;\r\n\r\n\t\t}\r\n\r\n\t\tcount++ ;\r\n\r\n\t\ttemp = temp.Next ;\r\n\r\n\t\r\n\r\n\t}\r\n\r\nreturn 0 ;\r\n\r\n}\r\n\r\n\r\n}\r\n\r\nclass LinkList{\r\n\r\n\r\n\r\n\tpublic static void main(String[] args) {\r\n\r\n\r\n\r\n\tNode node = new Node(0) ;\r\n\tnode.insert(4) ;\r\n\tnode.insert(10) ;\r\n\tnode.insert(100) ;\r\n\tnode.insert(88) ;\r\n\tnode.insert(100);\r\n\tnode.insert(9);\r\n\t\r\n\tSystem.out.println(\"data : \"+node.getmyel(4) ) ;\r\n\t\r\nNode headdata = node.head ;\r\n\twhile(headdata!=null){\r\n\t\t\r\n\t\tSystem.out.println(\"val:\"+headdata.data);\r\n\t\theaddata = headdata.Next ;\r\n\r\n\t}\r\n\r\n\r\n\r\n\r\n\r\n\t}\r\n\r\n} "
},
{
"alpha_fraction": 0.3053571283817291,
"alphanum_fraction": 0.3321428596973419,
"avg_line_length": 21.41666603088379,
"blob_id": "c1922f73ddc13cef66b9688422ee6524abd04467",
"content_id": "34c8f39b6903fe00a327e08d22191732e7a46753",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 560,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 24,
"path": "/selection_sort.py",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "a = [5, 2, 6, 7, 2, 1, 0, 3]\r\n\r\n# -----------------------Selection Sort------------------------------\r\n\r\n# for i in range(0 , len(a)):\r\n# min = i\r\n# for j in range(i+1 , len(a)):\r\n# if(a[min]>a[j]):\r\n# min = j\r\n# a[min],a[i] = a[i],a[min]\r\n\r\n# print(a)\r\n\r\n# ------------------------insertion sort---------------------------------\r\n\r\n# for i in range(1 , len(a)):\r\n# value = a[i]\r\n# hole = i\r\n# while(a[hole-1]>value and hole>0):\r\n# a[hole] = a[hole-1]\r\n# hole-=1\r\n# a[hole] = value\r\n\r\n# print(a)"
},
{
"alpha_fraction": 0.38288289308547974,
"alphanum_fraction": 0.44294294714927673,
"avg_line_length": 11.359999656677246,
"blob_id": "83977a1b10f76229b6a89eff9987af068b92c20e",
"content_id": "508b562360b0d62bbf6560d09ec9bd3d947eb67a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 666,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 50,
"path": "/Merge_two_sorted_array.java",
"repo_name": "chandan114/Programming_Questions",
"src_encoding": "UTF-8",
"text": "class Merge_two_sorted_array{\r\n\r\n\tpublic static void main(String[] args) {\r\n\t\t\r\n\t\tint arr1[] = { 2 , 10 , 18} ;\r\n\t\tint arr2[] = { 3 , 5 , 12,16};\r\n\r\n\t\tint arr1len = arr1.length ;\r\n\t\tint arr2len = arr2.length ;\r\n\r\n\t\tint i =0 ;\r\n\t\t\r\n\r\n\t\twhile(i < arr1len){\r\n\r\n\t\t\tif(arr1[i]>arr2[0]){\r\n\r\n\t\t\t\tint temp = arr1[i] ;\r\n\t\t\t\tarr1[i] = arr2[0] ;\r\n\t\t\t\tarr2[0]=temp ;\r\n\r\n\r\n\t\t\t\tint key = arr2[0] ;\r\n\t\t\t\tint j = 1 ;\r\n\t\t\t\twhile(j<arr2len && arr2[j]<key){\r\n\r\n\t\t\t\t\tarr2[j-1] = arr2[j] ;\r\n\t\t\t\t\tj++ ;\r\n\t\t\t\t}\r\n\r\n\t\t\t\tarr2[j-1] = key ;\r\n\r\n\t\t\t}\r\n\r\n\t\t\ti++ ;\r\n\r\n\t\t}\r\n\t\tfor(int n: arr1){\r\n\r\n\t\t\tSystem.out.println(n) ;\r\n\t\t}\r\n\r\n\t\tfor(int n: arr2){\r\n\r\n\t\t\tSystem.out.println(n) ;\r\n\t\t}\r\n\r\n\r\n\t}\r\n}"
}
] | 48 |
AdritoPramanik/tabbedBrowser | https://github.com/AdritoPramanik/tabbedBrowser | 221dcf4d1598a75ddc125c88c911c9afed783a90 | 1ed7ec84090586d72e5f86c9f2b3ab8272052d71 | 2d1aec7826c40279c765807ee1bb99213fbd4a7c | refs/heads/main | 2023-07-09T14:28:08.293506 | 2021-08-16T04:14:44 | 2021-08-16T04:14:44 | 396,612,581 | 3 | 5 | null | null | null | null | null | [
{
"alpha_fraction": 0.6920731663703918,
"alphanum_fraction": 0.6942904591560364,
"avg_line_length": 28.218486785888672,
"blob_id": "f44b7be8db1bf9d8feb4178c8d42d90a26b44250",
"content_id": "73bfdc76b0dbd6a62857aeb88be6708e605dc92a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3608,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 119,
"path": "/tabbedBrowser.py",
"repo_name": "AdritoPramanik/tabbedBrowser",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtWidgets import *\r\nfrom PyQt5.QtCore import *\r\nfrom PyQt5.QtGui import *\r\nfrom PyQt5.QtWebEngineWidgets import *\r\nfrom PyQt5.QtPrintSupport import *\r\nimport os\r\nimport sys\r\n\r\nclass MainWindow(QMainWindow):\r\n\tdef __init__(self, *args, **kwargs):\r\n\t\tsuper(MainWindow, self).__init__(*args, **kwargs)\r\n\t\tself.tabs = QTabWidget()\r\n\t\tself.tabs.setDocumentMode(True)\r\n\t\tself.tabs.tabBarDoubleClicked.connect(self.tab_open_doubleclick)\r\n\t\tself.tabs.currentChanged.connect(self.current_tab_changed)\r\n\t\tself.tabs.setTabsClosable(True)\r\n\t\tself.tabs.tabCloseRequested.connect(self.close_current_tab)\r\n\t\tself.setCentralWidget(self.tabs)\r\n\t\tself.status = QStatusBar()\r\n\t\tself.setStatusBar(self.status)\r\n\t\tnavtb = QToolBar(\"Navigation\")\r\n\t\tself.addToolBar(navtb)\r\n\r\n\t\tback_btn = QAction(QIcon('back.png'), 'back',self)\r\n\t\tback_btn.setStatusTip(\"Back to previous page\")\r\n\t\tback_btn.triggered.connect(lambda:self.tabs.currentWidget().back())\r\n\t\tnavtb.addAction(back_btn)\r\n\r\n\t\tforward_btn = QAction(QIcon('forward.png'),'Forward', self)\r\n\t\tforward_btn.setStatusTip(\"Forward to next page\")\r\n\t\tforward_btn.triggered.connect(lambda:self.tabs.currentWidget().forward())\r\n\t\tnavtb.addAction(forward_btn)\r\n\r\n\t\treload_btn = QAction(QIcon('reload.png'),'reload', self)\r\n\t\treload_btn.setStatusTip(\"Reload page\")\r\n\t\treload_btn.triggered.connect(lambda:self.tabs.currentWidget().reload())\r\n\t\tnavtb.addAction(reload_btn)\r\n\r\n\t\thome_btn = QAction(QIcon('home.png'),'home', self)\r\n\t\thome_btn.setStatusTip(\"Go home\")\r\n\t\thome_btn.triggered.connect(self.navigate_home)\r\n\t\tnavtb.addAction(home_btn)\r\n\r\n\t\tnavtb.addSeparator()\r\n\r\n\t\tself.urlBar = QLineEdit()\r\n\t\tself.urlBar.returnPressed.connect(self.navigate_to_url)\r\n\t\tnavtb.addWidget(self.urlBar)\r\n\r\n\t\tstop_btn = QAction('Stop', self)\r\n\t\tstop_btn.setStatusTip(\"Stop loading current page\")\r\n\t\tstop_btn.triggered.connect(lambda:self.tabs.currentWidget().stop())\r\n\t\tnavtb.addAction(stop_btn)\r\n\r\n\t\tself.add_new_tab(QUrl('http://www.google.com'), 'homepage')\r\n\t\tself.show()\r\n\t\tself.setWindowTitle('Browser')\r\n\r\n\tdef add_new_tab(self, qurl=None, label = \"Blank\"):\r\n\t\tif qurl is None:\r\n\t\t\tqurl = QUrl('http://www.google.com')\r\n\r\n\t\tbrowser = QWebEngineView()\r\n\t\tbrowser.setUrl(qurl)\r\n\r\n\t\ti= self.tabs.addTab(browser, label)\r\n\t\tself.tabs.setCurrentIndex(i)\r\n\r\n\t\tbrowser.urlChanged.connect(lambda qurl, browser = browser : self.update_urlbar(qurl, browser))\r\n\r\n\t\tbrowser.loadFinished.connect(lambda _, i= i, browser = browser : self.tabs.setTabText(i, browser.page().title()))\r\n\r\n\tdef tab_open_doubleclick(self, i):\r\n\r\n\t\tif i == -1:\r\n\t\t\tself.add_new_tab()\r\n\r\n\tdef current_tab_changed(self, i):\r\n\t\tqurl = self.tabs.currentWidget().url()\r\n\t\tself.update_urlbar(qurl, self.tabs.currentWidget())\r\n\t\tself.update_title(self.tabs.currentWidget())\r\n\r\n\tdef close_current_tab(self, i):\r\n\t\tif self.tabs.count() <2:\r\n\t\t\treturn\r\n\r\n\t\tself.tabs.removeTab(i)\r\n\r\n\tdef update_title(self, browser):\r\n\t\tif browser != self.tabs.currentWidget():\r\n\t\t\treturn\r\n\r\n\t\ttitle = self.tabs.currentWidget().page().title()\r\n\t\tself.setWindowTitle(\"% s - Browser\" % title)\r\n\r\n\tdef navigate_home(self):\r\n\t\tself.tabs.currentWidget().setUrl(QUrl(\"http://www.google.com\"))\r\n\r\n\tdef navigate_to_url(self):\r\n\t\tq = QUrl(self.urlBar.text())\r\n\t\tif q.scheme()== \"\":\r\n\t\t\tq.setScheme(\"http\")\r\n\r\n\t\tself.tabs.currentWidget().setUrl(q)\r\n\r\n\tdef update_urlbar(self, q, browser = None):\r\n\t\tif browser != self.tabs.currentWidget():\r\n\t\t\treturn\r\n\t\t\r\n\t\tself.urlBar.setText(q.toString())\r\n\t\tself.urlBar.setCursorPosition(0)\r\n\r\n\t\r\n\r\n\r\napp = QApplication(sys.argv)\r\napp.setApplicationName(\"Adi's Browser\")\r\nwindow = MainWindow()\r\napp.exec_()\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 1 |
TobyF/CERN_AT_SEA_utils | https://github.com/TobyF/CERN_AT_SEA_utils | 8277c381f0fdb71600f4da30898416988fc99e34 | c3343a533a5715aae2e2e7dcebb70a8a25bd2102 | 2bfbc6ab5b14be47f98f41ef18e21876c7396765 | refs/heads/master | 2021-01-20T20:14:34.861036 | 2016-11-23T14:03:06 | 2016-11-23T14:03:06 | 63,189,965 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5987988114356995,
"alphanum_fraction": 0.6138138175010681,
"avg_line_length": 30.433961868286133,
"blob_id": "5c0693502564d6d6b3951702a893709b01465a43",
"content_id": "bc00dcde78f732c56e9bb16c765c9b2064f09869",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1665,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 53,
"path": "/Archive/dataFormats.py",
"repo_name": "TobyF/CERN_AT_SEA_utils",
"src_encoding": "UTF-8",
"text": "#XYC is 1 file per frame with X (x coordinate) Y (y coordinate) and C (charge/ToT) per line\n#NC is 1 file per frame with N (pixel number) and C (charge/ToT) per line\n#MNC is a multi frame version of NC and is a series of NC files separated by a single \"#\" <-- This is the default output of a RasPix\n#import matplotlib.pyplot as plt\nimport numpy as np\n\ndef MNC2XYC(mncFile):\n output = []\n #print(mncFile)\n for frame in mncFile:\n outputFrame = []\n #print(\"Frame:\"+str(frame))\n for pixel in frame:\n #print(outputFrame)\n #print(pixel)\n Y = pixel[0]//255\n X = pixel[0]%255\n outputFrame.append([X,Y,pixel[1]])\n output.append(outputFrame)\n return output\n\n\ndef MNCtoNCs(mncFile, outputFileNamePrefix = \"NC\"):\n i = 0\n for line in mncFile.readlines():\n if line.strip() == \"#\": i+=1\n else:\n with open(outputFileNamePrefix + str(i), \"a\") as output: output.write(line)\n\n\ndef isMNC(potentialFile):\n for line in potentialFile.readlines():\n if line.strip() == \"#\": return True\n return False\n\ndef importMNC(mncFile):\n #Output is a 3D array. output[FrameNumber][Pixel(NotNumbered)][0=PixelNumber,1=ToT]\n currentFrame = []\n outputMNClist = []\n for line in mncFile.readlines():\n if line.strip() == \"#\":\n outputMNClist.append(currentFrame)\n currentFrame = []\n elif line.split()[1] not in [\"1\",\"11810\"]:\n currentFrame.append(list(map(int,line.split())))\n return outputMNClist\n\n\nwith open(\"DataFiles\\mnc_test\") as file:\n mnc = importMNC(file)\n\n #print(mnc)\n #print(MNC2XYC(mnc))"
},
{
"alpha_fraction": 0.5442873239517212,
"alphanum_fraction": 0.5550138354301453,
"avg_line_length": 34.988304138183594,
"blob_id": "c2e21af9fcbcda0b34cc7b62d58743f27fea7e26",
"content_id": "9b78fcf1fb6b6f2dd68f234abb334b2028b0eeae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6153,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 171,
"path": "/Archive/datasetreader.py",
"repo_name": "TobyF/CERN_AT_SEA_utils",
"src_encoding": "UTF-8",
"text": "import os\nimport datetime\nimport json\nimport numpy as np\nimport math\n#import magic\nimport time\nimport sys\n\ndef neighbourGen(pixelNo):\n neighbours = []\n for xChange in range(-1,2,2):\n for yChange in range(-1,2,2):\n neighbours.append(pixelNo+xChange+256*yChange)\n return neighbours\n\ndef surrogateFunction(tot, a, b, c, t):\n e = (t * a + tot - b + math.sqrt((b + t * a - tot) ** 2 + 4 * a * c)) / (2 * a)\n return e\n\nclass CASfile():\n def __init__(self,inputLoc, calibDataLoc=\"NOT IMPLEMENTED\", outputLoc=None):\n print(\"New CAS File: Looking for Frame files! \")\n self.frames = []\n\n calibrationMatrixA = np.loadtxt(r\"calibs\\H05-W0240\\caliba.txt\").flatten()\n calibrationMatrixB = np.loadtxt(r\"calibs\\H05-W0240\\calibb.txt\").flatten()\n calibrationMatrixC = np.loadtxt(r\"calibs\\H05-W0240\\calibc.txt\").flatten()\n calibrationMatrixT = np.loadtxt(r\"calibs\\H05-W0240\\calibt.txt\").flatten()\n\n calibMatricies = {\"a\":calibrationMatrixA, \"b\":calibrationMatrixB,\n \"c\":calibrationMatrixC, \"t\":calibrationMatrixT}\n\n for filename in os.listdir(inputLoc):\n extension = os.path.splitext(filename)[-1].lower()\n if extension == \"\" and os.path.isfile(os.path.join(inputLoc, filename+\".dsc\")): #A DSC file and mnt\n\n print(\"\\tFound a NT file: \"+filename+\" with its .dsc file. Now processing...\")\n\n with open(os.path.join(inputLoc, filename),\"r\") as ntFile: #Opens the file with all the frames in set\n ntFileString = ntFile.read().split(\"#\") #Splitting the file into frames\n\n with open(os.path.join(inputLoc, filename+\".dsc\"),\"r\") as dscFile: #Opens .dsc file\n dscData = dscFile.read().split(\"[F\") #Splits it at every Frame marker - [F1] = 2nd Frame\n\n frameNumber = 0\n\n for importedFrameString in ntFileString: #Go through all the frames\n pixels = []\n\n #Get the pixels\n for importedPixelString in importedFrameString.split(\"\\n\"):\n if importedPixelString.split(\"\\t\") != ['']: #Avoiding Blank Space Errors\n pixels.append(importedPixelString.split(\"\\t\"))\n\n\n for dscEntry in dscData:\n #print(dscEntry)\n if dscEntry.startswith(str(frameNumber)+\"]\"): #Checks if the correct entry has been found\n\n dscEntry = dscEntry.split('\\n')\n\n for lineCounter in range(len(dscEntry)):\n if dscEntry[lineCounter].startswith('\"Acq time\"'):\n acqTimeTemp = dscEntry[lineCounter+2]\n\n if dscEntry[lineCounter].startswith('\"Start time\"'):\n startTimeTemp = dscEntry[lineCounter + 2]\n #print(pixels)\n self.frames.append(Frame(pixels, filename,\n frameNumber, calibMatricies,\n acqTimeTemp, startTimeTemp)) #Make the new frame with all its pixels\n\n frameNumber+=1\n\n\n print(\"\\tProcessed \\n\")\n\n if filename.endswith(\".gps\"):\n pass\n\n print(\"New File Initialised: Found \"+str(len(self.frames))+\" frames:\")\n print(str(self.frames))\n\n def histogram(self):\n pass\n\n def map(self):\n pass\n\n def countrate(self,timeRange):\n pass\n\n def getFrame(self,frameNo):\n pass\n\n\n\nclass Frame():\n def __init__(self, nt, ntFileName, frameNumber, calibMatricies, acqTime=None, startTime=None):\n #print(nt)\n self.nt = [[int(string) for string in inner] for inner in nt]\n self.ntFileName = ntFileName\n self.frameNumber = frameNumber\n self.acqTime = acqTime\n self.startTimeRaw = startTime\n self.startTime = datetime.datetime.fromtimestamp(float(startTime))\n\n self.gammaEnergyList = []\n\n print(\"\\t \\tNew Frame Instance: Calibrating Data\",end=\" \")\n #print(self.nt)\n self.i = 0\n for pixel in self.nt:\n self.i+=1\n\n inCluster = False\n for neighbour in neighbourGen(int(pixel[0])):\n if neighbour in [pixel[0] for pixel in self.nt]:\n inCluster = True\n\n if not inCluster and pixel[1] not in [1, 11810]: # Max and Min values for chip - taking out background data\n #print(type(pixel[0]))\n e = surrogateFunction(pixel[1],\n calibMatricies[\"a\"][int(pixel[0])],\n calibMatricies[\"b\"][int(pixel[0])],\n calibMatricies[\"c\"][int(pixel[0])],\n calibMatricies[\"t\"][int(pixel[0])])\n self.gammaEnergyList.append(e)\n\n print(\"Done.\")\n\n def __repr__(self):\n return \"Frame with: \"+str(len(self.nt))+' pixels'\n\n\n def description(self):\n print(\"Frame Instance:\")\n print(\"\\tFrom the \"+self.ntFileName+\" file.\")\n print(\"\\tIt contains \"+str(len(self.nt))+' activated pixels.')\n print(\"\\tIt was started at time: \"+self.startTime.isoformat()+\".\")\n print(\"\\tIt was acquiring data for: \"+self.acqTime+\" second(s).\")\n\n\n def get_xyc(self):\n if self.xyc == None:\n pass\n return self.xyc\n\n def get_array(self):\n if self.array ==None:\n pass\n return self.array\n\n def calibrateData(self):\n if not self.calibrated:\n pass\n def get_xye(self):\n pass\n\n def get_arraye(self):\n pass\n\ntestFile = CASfile(r\"C:\\Users\\Toby\\PycharmProjects\\CERN@SEA_utils_\\CAStest1\")\n#testFile.frames[0].description()\n#testFile.frames[1].description()\n#testFile.frames[2].description()\n#testFile.frames[3].description()\n\n#with open(r\"C:\\Users\\Toby\\PycharmProjects\\CERN@SEA_utils_\\CAStest1\\FIRST YEAH.dsc\", \"r\") as dscFILE:\n #jsonFile = json.load(dscFILE)"
},
{
"alpha_fraction": 0.6498873233795166,
"alphanum_fraction": 0.6551464796066284,
"avg_line_length": 30.714284896850586,
"blob_id": "1fb4cde6ffa9355aae3cb23802283c889240a03b",
"content_id": "0def90ce381b822598359bcac50f823290def69e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1331,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 42,
"path": "/PixelCount.py",
"repo_name": "TobyF/CERN_AT_SEA_utils",
"src_encoding": "UTF-8",
"text": "import os\nimport Tkinter as tk\nimport tkFileDialog\n\nroot = tk.Tk() #Opens the main window\nroot.wm_title(\"hey\")\n\nthreshFreqFrame = tk.Frame(root)\nthreshFreqFrame.pack()\n\nthreshFreqEntry = tk.Entry(threshFreqFrame)\nthreshFreqEntry.pack()\n\n\ninputLoc = tkFileDialog.askdirectory(parent = root) #Asks for a directory to look for RasPix data\ndirectoryData = {\"FileCount\":0,\"FrameCount\":0,\"PixelCount\":0}\n\nfor filename in os.listdir(inputLoc): #For all of the files (regardless of type in the directory)\n\n extension = os.path.splitext(filename)[-1].lower() #Find tis extension\n\n if extension == \"\": #If it dosnt have one (the RasPix data files dont :( )\n #XT refers to type of file that raspix outputs, X is the position, T is the TimeOverThreshold.\n\n print(\"Found a XT file: \" + filename + \". Now processing...\")\n directoryData[\"FileCount\"] += 1\n\n with open(os.path.join(inputLoc, filename), \"r\") as ntFile: # Opens the file with all the frames in set\n xtList = ntFile.read().split(\"#\") # Splitting the file into frames (which have # between them)\n\n for frame in xtList:\n directoryData[\"FrameCount\"] += 1\n\n for pixel in frame:\n directoryData[\"PixelCount\"] += 1\n\n\n\n\nprint(directoryData)\n\nroot.mainloop()"
},
{
"alpha_fraction": 0.6004862189292908,
"alphanum_fraction": 0.635737419128418,
"avg_line_length": 34.78260803222656,
"blob_id": "ada90a37d62ac2fd31139607f43e9dbdf640424e",
"content_id": "c0523331a8c67c21b4da8c95992352e64888b016",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2468,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 69,
"path": "/CalibrationFunctions.py",
"repo_name": "TobyF/CERN_AT_SEA_utils",
"src_encoding": "UTF-8",
"text": "import math\nimport numpy as np\nimport os\nimport matplotlib.pyplot as plt\nimport glob\n\n#CERN@SEA1 = H\n#CERN@SEA2 = G\ndef neighbourGen(pixelNo):\n neighbours = []\n for xChange in range(-1,2,2):\n for yChange in range(-1,2,2):\n neighbours.append(pixelNo+xChange+256*yChange)\n print(neighbours)\n return neighbours\n\ndef NC2E(MNC,calibA,calibB,calibC,calibT):\n #Takes each pixel activation, converts the ToT value to Energy\n #by using the surrogate function\n energyList = []\n i = 0\n for NC in MNC:\n i+=1\n print(\"I am in frame:\"+str(i))\n for pixel in NC:\n inCluster = False\n for neighbour in neighbourGen(pixel[0]):\n if neighbour in [pixel[0] for pixel in NC]:\n inCluster = True\n\n if not inCluster and pixel[1] not in [1,11810]: #Max and Min values for chip - taking out background data\n e = surrogateFunction(pixel[1],\n calibA[int(pixel[0])],\n calibB[int(pixel[0])],\n calibC[int(pixel[0])],\n calibT[int(pixel[0])])\n energyList.append(e)\n return energyList\n\ndef surrogateFunction(tot, a, b, c, t):\n e = (t * a + tot - b + math.sqrt((b + t * a - tot) ** 2 + 4 * a * c)) / (2 * a)\n return e\n\ncalibrationMatrixA = np.loadtxt(r\"calibs\\H05-W0240\\caliba.txt\").flatten()\ncalibrationMatrixB = np.loadtxt(r\"calibs\\H05-W0240\\calibb.txt\").flatten()\ncalibrationMatrixC = np.loadtxt(r\"calibs\\H05-W0240\\calibc.txt\").flatten()\ncalibrationMatrixT = np.loadtxt(r\"calibs\\H05-W0240\\calibt.txt\").flatten()\n\npath = r\"C:\\Users\\Toby\\PycharmProjects\\CERN@SEA_utils_\\DataFiles1\"\n\ndataNC = []# np.loadtxt(r\"C:\\Users\\Toby\\PycharmProjects\\CERN@SEA_utils_\\DataFiles\\NC1\")\nfor filename in os.listdir(path):\n dataNC.append(list(np.loadtxt(os.path.join(path,filename))))\n\n#dataNC = np.loadtxt(r\"DataFiles\\FIRST YEAH\")\n#print(dataNC)\n#print(calibrationMatrixA[0:2])\nenergyList = NC2E(dataNC,calibrationMatrixA,calibrationMatrixB,calibrationMatrixC,calibrationMatrixT)\nprint(len(energyList))\nbins = 42\n\ny,binEdges=np.histogram(energyList,bins=bins)\nbincenters = 0.5*(binEdges[1:]+binEdges[:-1])\n#plt.plot(bincenters,y,'-',)\nplt.hist(energyList,bins,log=True,range=[0,3500], normed=True)#,log=True)\nplt.xlabel(\"Energy of Gamma (keV)\")\nplt.ylabel(\"Intensity\")\nplt.vlines([600,1450,2600],0,0.001)\nplt.show()"
},
{
"alpha_fraction": 0.6387096643447876,
"alphanum_fraction": 0.6741935610771179,
"avg_line_length": 30.100000381469727,
"blob_id": "c9b3f905a43b0d22a7a0218e0a9158db925e270a",
"content_id": "f2b0a762e48c18a222d5f2e8f8eccb4dd704399d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 10,
"path": "/Archive/dataTest.py",
"repo_name": "TobyF/CERN_AT_SEA_utils",
"src_encoding": "UTF-8",
"text": "import datasetreader\n\n#dataset = datasetreader.CASfile(r\"C:\\Users\\Toby\\PycharmProjects\\CERN@SEA_utils_\\CAStest1\")\n\nwith open(r\"C:\\Users\\Toby\\PycharmProjects\\CERN@SEA_utils_\\DataFiles1\\mnc_test\") as file:\n i = 0\n for line in file.readlines():\n print(line)\n i += 1\n print((100*i)/(255**2))"
}
] | 5 |