关于可视化的一切
本文包括特征图可视化和 Grad-Based 和 Grad-Free CAM 可视化
特征图可视化

MMYOLO 中,将使用 MMEngine 提供的 Visualizer 可视化器进行特征图可视化,其具备如下功能:
- 支持基础绘图接口以及特征图可视化。
- 支持选择模型中的不同层来得到特征图,包含
squeeze_mean,select_max,topk三种显示方式,用户还可以使用arrangement自定义特征图显示的布局方式。
特征图绘制
你可以调用 demo/featmap_vis_demo.py 来简单快捷地得到可视化结果,为了方便理解,将其主要参数的功能梳理如下:
img:选择要用于特征图可视化的图片,支持单张图片或者图片路径列表。config:选择算法的配置文件。checkpoint:选择对应算法的权重文件。--out-file:将得到的特征图保存到本地,并指定路径和文件名。--device:指定用于推理图片的硬件,--device cuda:0表示使用第 1 张 GPU 推理,--device cpu表示用 CPU 推理。--score-thr:设置检测框的置信度阈值,只有置信度高于这个值的框才会显示。--preview-model:可以预览模型,方便用户理解模型的特征层结构。--target-layers:对指定层获取可视化的特征图。- 可以单独输出某个层的特征图,例如:
--target-layers backbone,--target-layers neck,--target-layers backbone.stage4等。 - 参数为列表时,也可以同时输出多个层的特征图,例如:
--target-layers backbone.stage4 neck表示同时输出 backbone 的 stage4 层和 neck 的三层一共四层特征图。
- 可以单独输出某个层的特征图,例如:
--channel-reduction:输入的 Tensor 一般是包括多个通道的,channel_reduction参数可以将多个通道压缩为单通道,然后和图片进行叠加显示,有以下三个参数可以设置:squeeze_mean:将输入的 C 维度采用 mean 函数压缩为一个通道,输出维度变成 (1, H, W)。select_max:将输入先在空间维度 sum,维度变成 (C, ),然后选择值最大的通道。None:表示不需要压缩,此时可以通过topk参数可选择激活度最高的topk个特征图显示。
--topk:只有在channel_reduction参数为None的情况下,topk参数才会生效,其会按照激活度排序选择topk个通道,然后和图片进行叠加显示,并且此时会通过--arrangement参数指定显示的布局,该参数表示为一个数组,两个数字需要以空格分开,例如:--topk 5 --arrangement 2 3表示以2行 3列显示激活度排序最高的 5 张特征图,--topk 7 --arrangement 3 3表示以3行 3列显示激活度排序最高的 7 张特征图。- 如果 topk 不是 -1,则会按照激活度排序选择 topk 个通道显示。
- 如果 topk = -1,此时通道 C 必须是 1 或者 3 表示输入数据是图片,否则报错提示用户应该设置
channel_reduction来压缩通道。
考虑到输入的特征图通常非常小,函数默认将特征图进行上采样后方便进行可视化。
注意:当图片和特征图尺度不一样时候,draw_featmap 函数会自动进行上采样对齐。如果你的图片在推理过程中前处理存在类似 Pad 的操作此时得到的特征图也是 Pad 过的,那么直接上采样就可能会出现不对齐问题。
用法示例
以预训练好的 YOLOv5-s 模型为例:
请提前下载 YOLOv5-s 模型权重到本仓库根路径下:
cd mmyolo
wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
(1) 将多通道特征图采用 select_max 参数压缩为单通道并显示, 通过提取 backbone 层输出进行特征图可视化,将得到 backbone 三个输出层的特征图:
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone \
--channel-reduction select_max

实际上上述代码存在图片和特征图不对齐问题,解决办法有两个:
修改 YOLOv5 配置,让后处理只是简单的 Resize 即可,这对于可视化是没有啥影响的
可视化时候图片应该用前处理后的,而不能用前处理前的
为了简单目前这里采用第一种解决办法,后续会采用第二种方案修复,让大家可以不修改配置即可使用。具体来说是将原先的 test_pipeline 替换为仅仅 Resize 版本。
旧的 test_pipeline 为:
test_pipeline = [
dict(
type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
修改为如下配置:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
正确效果如下:
(2) 将多通道特征图采用 squeeze_mean 参数压缩为单通道并显示, 通过提取 neck 层输出进行特征图可视化,将得到 neck 三个输出层的特征图:
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers neck \
--channel-reduction squeeze_mean
(3) 将多通道特征图采用 squeeze_mean 参数压缩为单通道并显示, 通过提取 backbone.stage4 和 backbone.stage3 层输出进行特征图可视化,将得到两个输出层的特征图:
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone.stage4 backbone.stage3 \
--channel-reduction squeeze_mean

(4) 利用 --topk 3 --arrangement 2 2 参数选择多通道特征图中激活度最高的 3 个通道并采用 2x2 布局显示, 用户可以通过 arrangement 参数选择自己想要的布局,特征图将自动布局,先按每个层中的 top3 特征图按 2x2 的格式布局,再将每个层按 2x2 布局:
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone.stage3 backbone.stage4 \
--channel-reduction None \
--topk 3 \
--arrangement 2 2

(5) 存储绘制后的图片,在绘制完成后,可以选择本地窗口显示,也可以存储到本地,只需要加入参数 --out-file xxx.jpg:
python demo/featmap_vis_demo.py demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--target-layers backbone \
--channel-reduction select_max \
--out-file featmap_backbone.jpg
Grad-Based 和 Grad-Free CAM 可视化
目标检测 CAM 可视化相比于分类 CAM 复杂很多且差异很大。本文只是简要说明用法,后续会单独开文档详细描述实现原理和注意事项。
你可以调用 demo/boxmap_vis_demo.py 来简单快捷地得到 Box 级别的 AM 可视化结果,目前已经支持 YOLOv5/YOLOv6/YOLOX/RTMDet。
以 YOLOv5 为例,和特征图可视化绘制一样,你需要先修改 test_pipeline,否则会出现特征图和原图不对齐问题。
旧的 test_pipeline 为:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
修改为如下配置:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
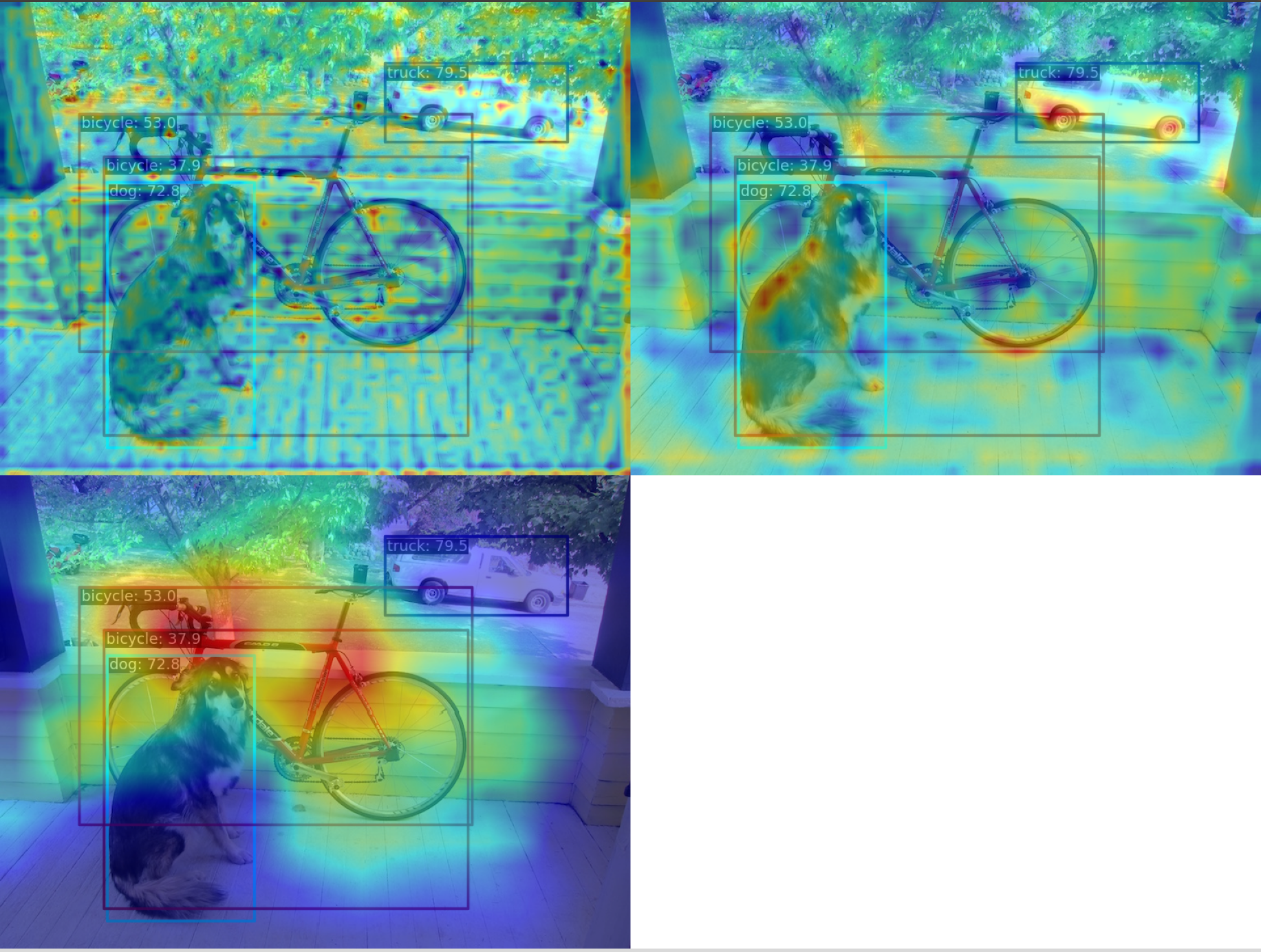
(1) 使用 GradCAM 方法可视化 neck 模块的最后一个输出层的 AM 图
python demo/boxam_vis_demo.py \
demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth

相对应的特征图 AM 图如下:
可以看出 GradCAM 效果可以突出 box 级别的 AM 信息。
你可以通过 --topk 参数选择仅仅可视化预测分值最高的前几个预测框
python demo/boxam_vis_demo.py \
demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--topk 2

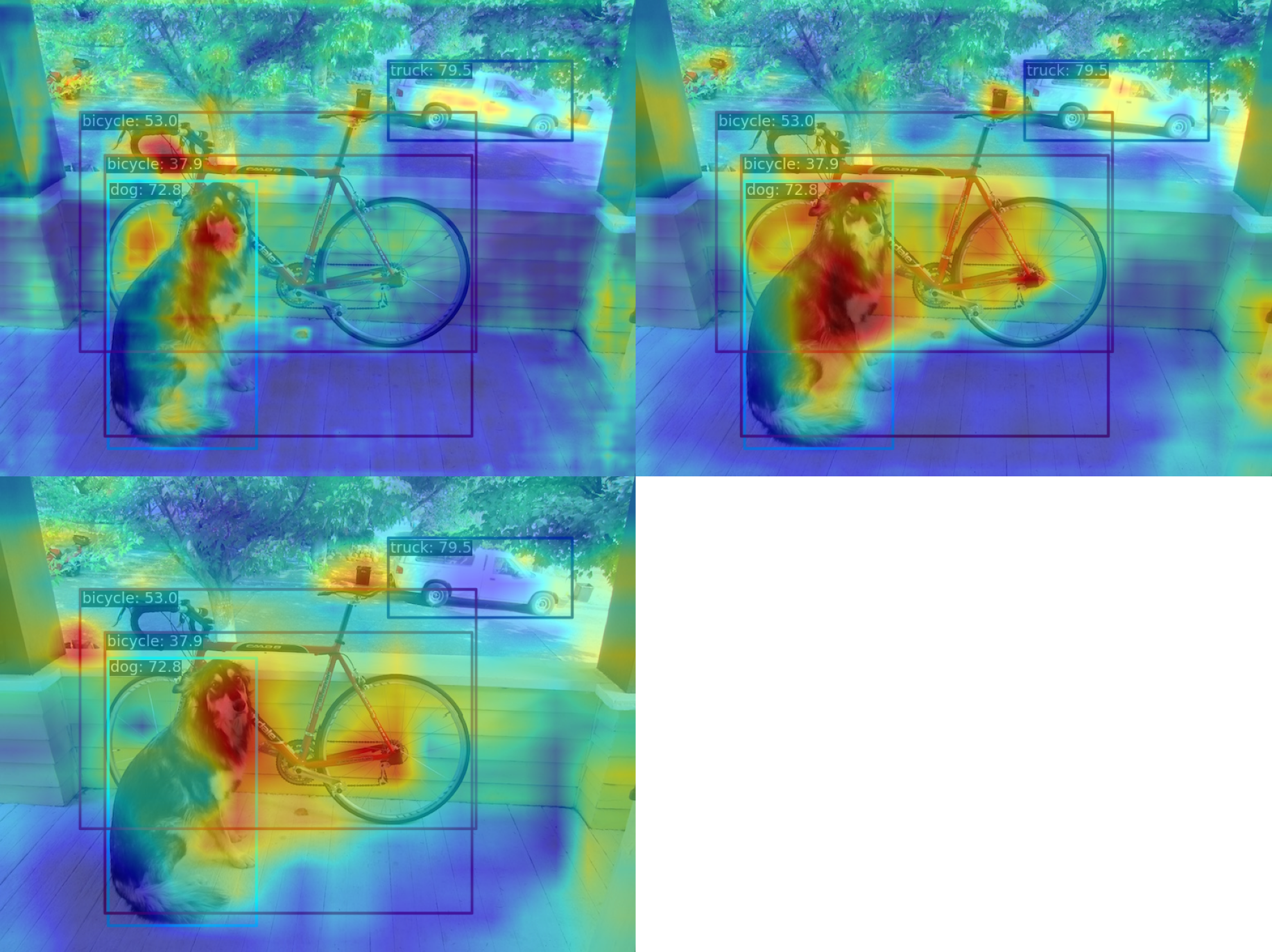
(2) 使用 AblationCAM 方法可视化 neck 模块的最后一个输出层的 AM 图
python demo/boxam_vis_demo.py \
demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--method ablationcam
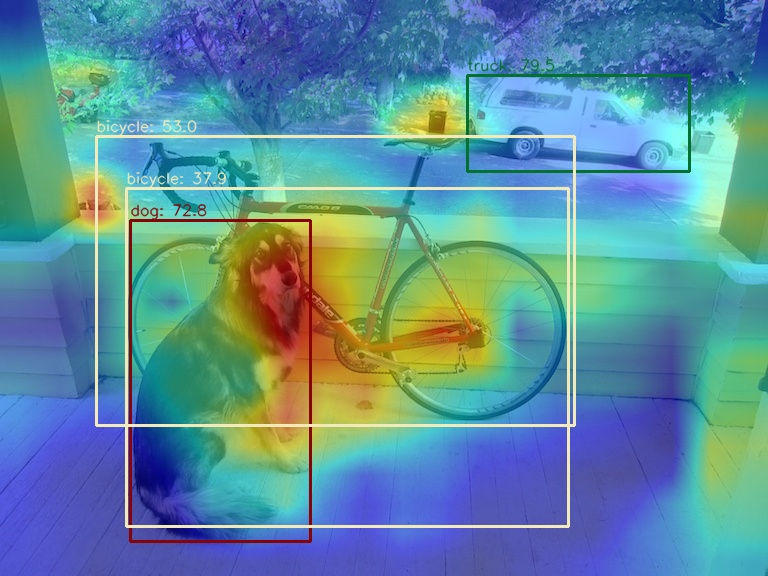
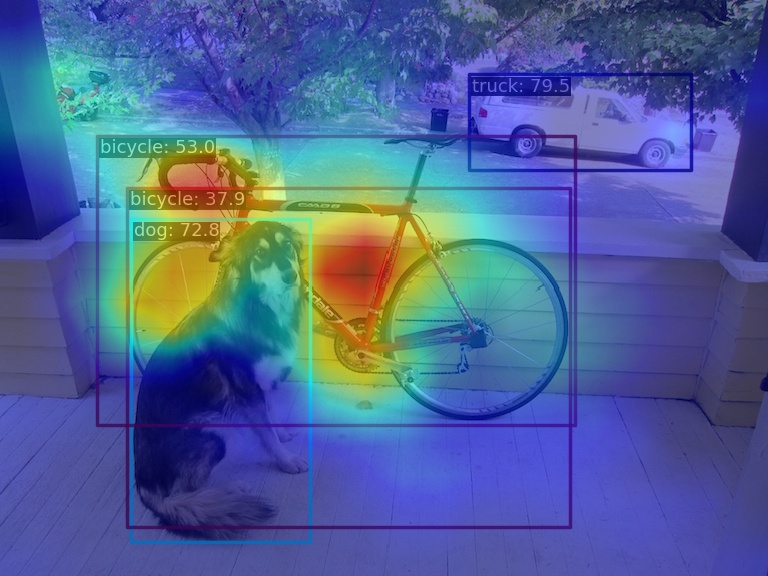
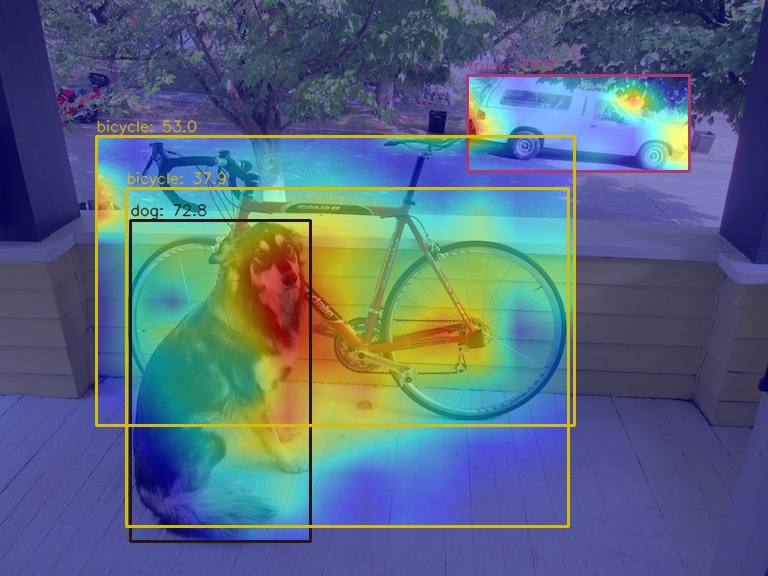
由于 AblationCAM 是通过每个通道对分值的贡献程度来加权,因此无法实现类似 GradCAM 的仅仅可视化 box 级别的 AM 信息, 但是你可以使用 --norm-in-bbox 来仅仅显示 bbox 内部 AM
python demo/boxam_vis_demo.py \
demo/dog.jpg \
configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
--method ablationcam \
--norm-in-bbox
可视化 COCO 标签
脚本 tools/analysis_tools/browse_coco_json.py 能够使用可视化显示 COCO 标签在图片的情况。
python tools/analysis_tools/browse_coco_json.py [--data-root ${DATA_ROOT}] \
[--img-dir ${IMG_DIR}] \
[--ann-file ${ANN_FILE}] \
[--wait-time ${WAIT_TIME}] \
[--disp-all] [--category-names CATEGORY_NAMES [CATEGORY_NAMES ...]] \
[--shuffle]
其中,如果图片、标签都在同一个文件夹下的话,可以指定 --data-root 到该文件夹,然后 --img-dir 和 --ann-file 指定该文件夹的相对路径,代码会自动拼接。
如果图片、标签文件不在同一个文件夹下的话,则无需指定 --data-root ,直接指定绝对路径的 --img-dir 和 --ann-file 即可。
例子:
- 查看
COCO全部类别,同时展示bbox、mask等所有类型的标注:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--disp-all
如果图片、标签不在同一个文件夹下的话,可以使用绝对路径:
python tools/analysis_tools/browse_coco_json.py --img-dir '/dataset/image/coco/train2017' \
--ann-file '/label/instances_train2017.json' \
--disp-all
- 查看
COCO全部类别,同时仅展示bbox类型的标注,并打乱显示:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--shuffle
- 只查看
bicycle和person类别,同时仅展示bbox类型的标注:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--category-names 'bicycle' 'person'
- 查看
COCO全部类别,同时展示bbox、mask等所有类型的标注,并打乱显示:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--disp-all \
--shuffle
可视化数据集
python tools/analysis_tools/browse_dataset.py \
${CONFIG_FILE} \
[-o, --output-dir ${OUTPUT_DIR}] \
[-p, --phase ${DATASET_PHASE}] \
[-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \
[-i, --show-interval ${SHOW_INTERRVAL}] \
[-m, --mode ${DISPLAY_MODE}] \
[--cfg-options ${CFG_OPTIONS}]
所有参数的说明:
config: 模型配置文件的路径。-o, --output-dir: 保存图片文件夹,如果没有指定,默认为'./output'。-p, --phase: 可视化数据集的阶段,只能为['train', 'val', 'test']之一,默认为'train'。-n, --show-number: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。-m, --mode: 可视化的模式,只能为['original', 'transformed', 'pipeline']之一。 默认为'transformed'。--cfg-options: 对配置文件的修改,参考学习配置文件。
`-m, --mode` 用于设置可视化的模式,默认设置为 'transformed'。
- 如果 `--mode` 设置为 'original',则获取原始图片;
- 如果 `--mode` 设置为 'transformed',则获取预处理后的图片;
- 如果 `--mode` 设置为 'pipeline',则获得数据流水线所有中间过程图片。
示例:
- 'original' 模式 :
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py --phase val --output-dir tmp --mode original
--phase val: 可视化验证集, 可简化为-p val;--output-dir tmp: 可视化结果保存在 "tmp" 文件夹, 可简化为-o tmp;--mode original: 可视化原图, 可简化为-m original;--show-number 100: 可视化100张图,可简化为-n 100;
2.'transformed' 模式 :
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py
3.'pipeline' 模式 :
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py -m pipeline
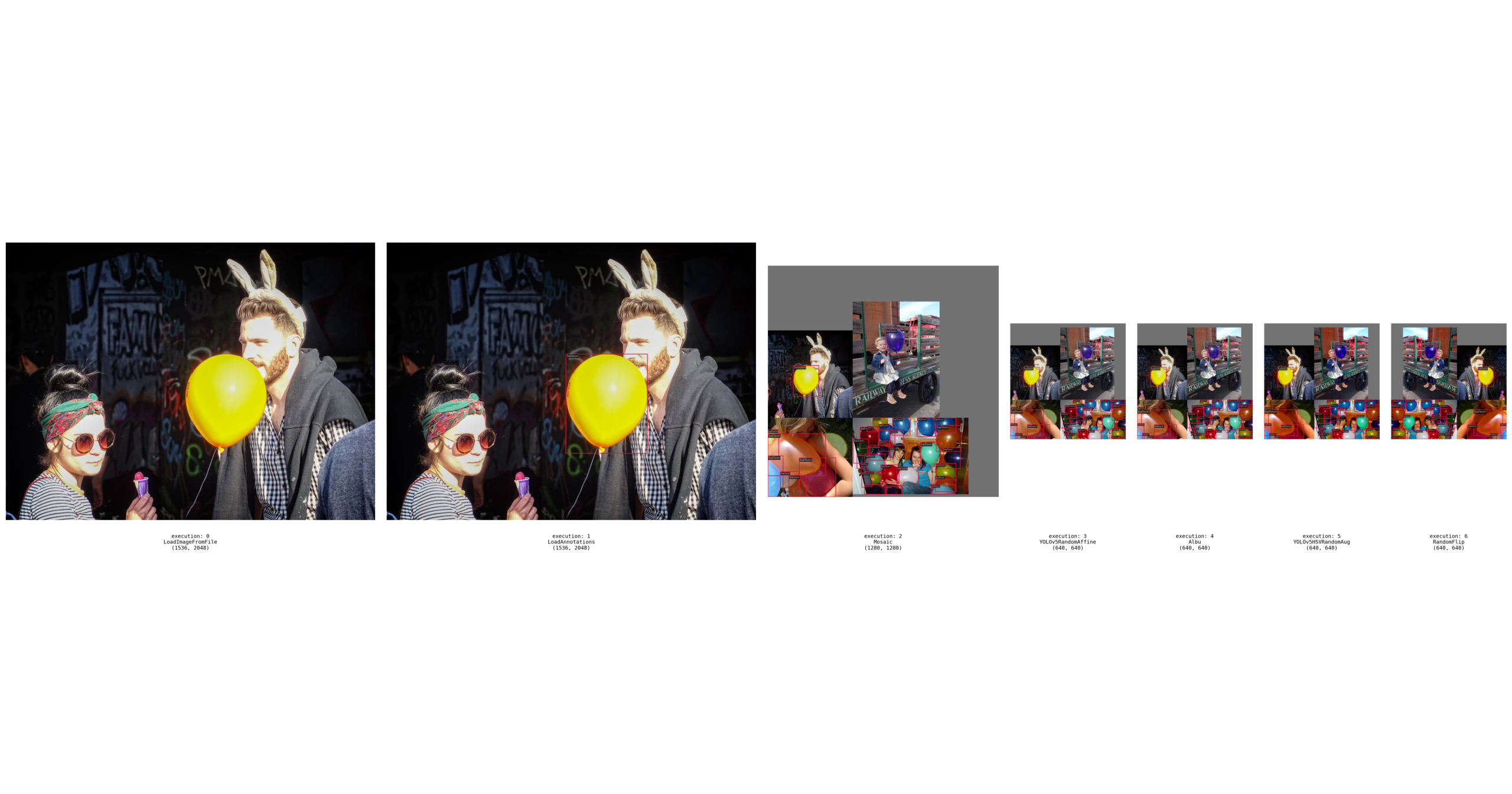
可视化数据集分析
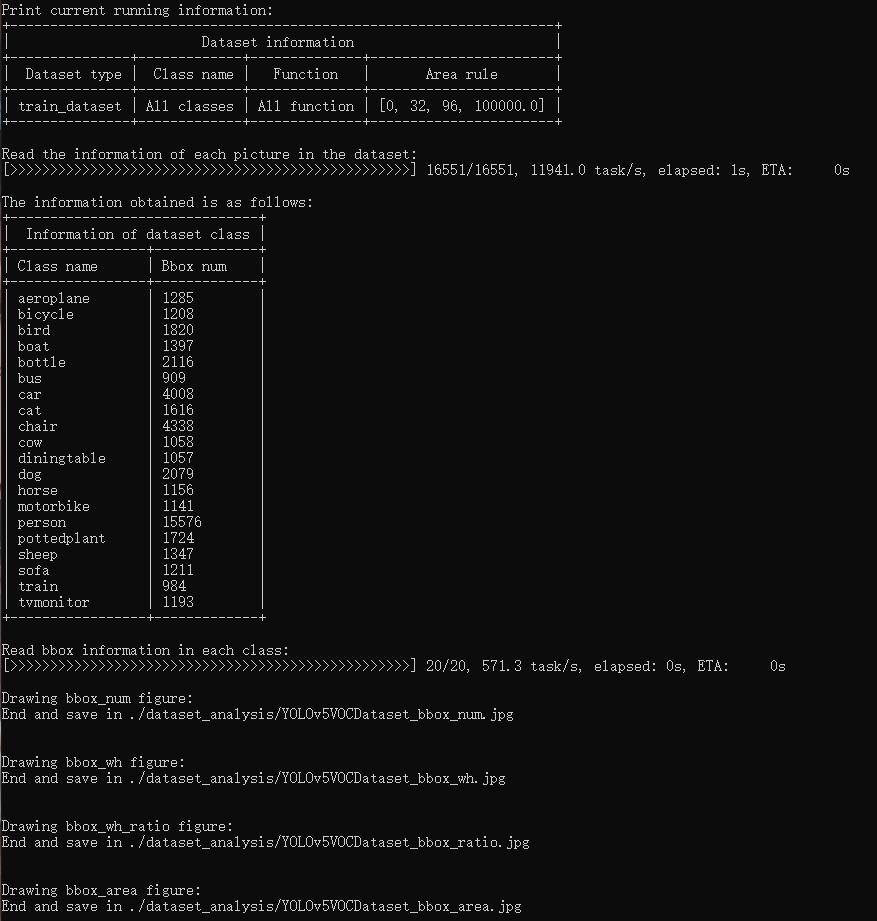
脚本 tools/analysis_tools/dataset_analysis.py 能够帮助用户得到四种功能的结果图,并将图片保存到当前运行目录下的 dataset_analysis 文件夹中。
关于该脚本的功能的说明:
通过 main() 的数据准备,得到每个子函数所需要的数据。
功能一:显示类别和 bbox 实例个数的分布图,通过子函数 show_bbox_num 生成。
功能二:显示类别和 bbox 实例宽、高的分布图,通过子函数 show_bbox_wh 生成。
功能三:显示类别和 bbox 实例宽/高比例的分布图,通过子函数 show_bbox_wh_ratio 生成。
功能四:基于面积规则下,显示类别和 bbox 实例面积的分布图,通过子函数 show_bbox_area 生成。
打印列表显示,通过脚本中子函数 show_class_list 和 show_data_list 生成。
python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
[-h] \
[--val-dataset ${TYPE}] \
[--class-name ${CLASS_NAME}] \
[--area-rule ${AREA_RULE}] \
[--func ${FUNC}] \
[--out-dir ${OUT_DIR}]
例子:
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,其中默认设置:数据加载类型为train_dataset,面积规则设置为[0,32,96,1e5],生成包含所有类的结果图并将图片保存到当前运行目录下./dataset_analysis文件夹中:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--val-dataset设置将数据加载类型由默认的train_dataset改为val_dataset:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--val-dataset
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--class-name设置将生成所有类改为特定类显示,以显示person为例:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--class-name person
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--area-rule重新定义面积规则,以30 70 125为例,面积规则变为[0,30,70,125,1e5]:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--area-rule 30 70 125
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--func设置,将显示四个功能效果图改为只显示功能一为例:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--func show_bbox_num
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--out-dir设置修改图片保存地址,以work_dirs/dataset_analysis地址为例:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--out-dir work_dirs/dataset_analysis
优化器参数策略可视化
tools/analysis_tools/vis_scheduler.py 旨在帮助用户检查优化器的超参数调度器(无需训练),支持学习率(learning rate)、动量(momentum)和权值衰减(weight decay)。
python tools/analysis_tools/vis_scheduler.py \
${CONFIG_FILE} \
[-p, --parameter ${PARAMETER_NAME}] \
[-d, --dataset-size ${DATASET_SIZE}] \
[-n, --ngpus ${NUM_GPUs}] \
[-o, --out-dir ${OUT_DIR}] \
[--title ${TITLE}] \
[--style ${STYLE}] \
[--window-size ${WINDOW_SIZE}] \
[--cfg-options]
所有参数的说明:
config: 模型配置文件的路径。-p, parameter: 可视化参数名,只能为["lr", "momentum", "wd"]之一, 默认为"lr".-d, --dataset-size: 数据集的大小。如果指定,DATASETS.build将被跳过并使用这个数值作为数据集大小,默认使用DATASETS.build所得数据集的大小。-n, --ngpus: 使用 GPU 的数量, 默认为1。-o, --out-dir: 保存的可视化图片的文件夹路径,默认不保存。--title: 可视化图片的标题,默认为配置文件名。--style: 可视化图片的风格,默认为whitegrid。--window-size: 可视化窗口大小,如果没有指定,默认为12*7。如果需要指定,按照格式'W*H'。--cfg-options: 对配置文件的修改,参考学习配置文件。
部分数据集在解析标注阶段比较耗时,推荐直接将 `-d, dataset-size` 指定数据集的大小,以节约时间。
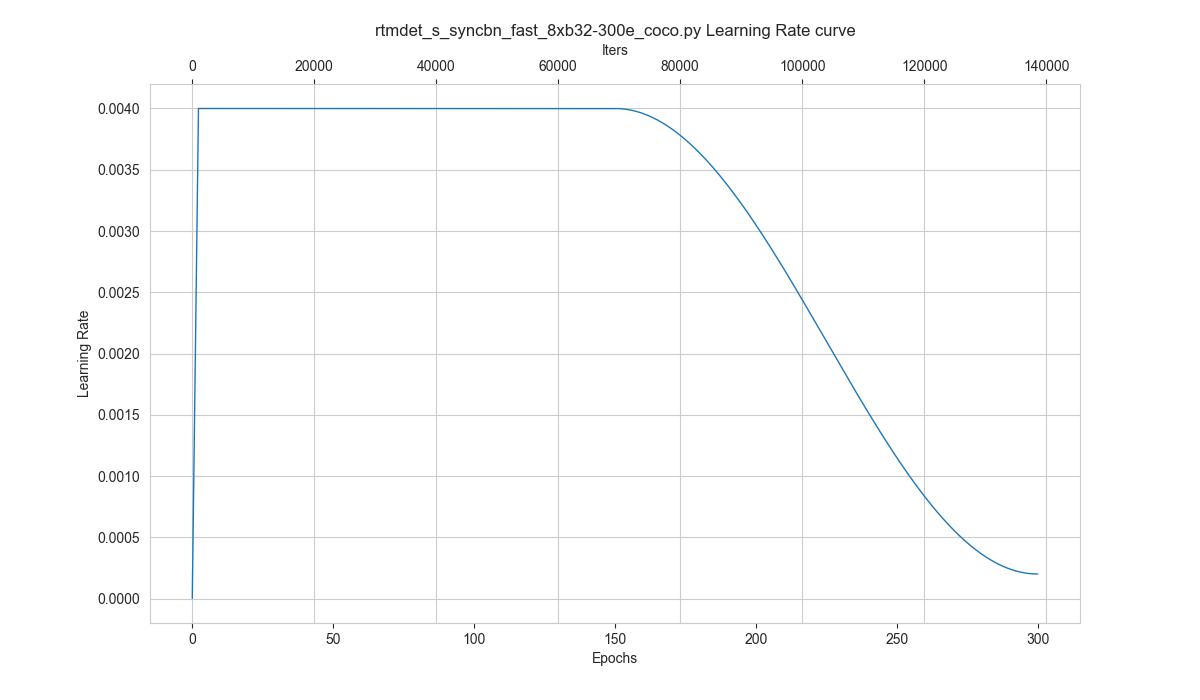
你可以使用如下命令来绘制配置文件 configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py 将会使用的学习率变化曲线:
python tools/analysis_tools/vis_scheduler.py \
configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
--dataset-size 118287 \
--ngpus 8 \
--out-dir ./output